tDHU, acid
Beschreibung
BenchChem offers high-quality this compound suitable for many research applications. Different packaging options are available to accommodate customers' requirements. Please inquire for more information about this compound including the price, delivery time, and more detailed information at info@benchchem.com.
Structure
3D Structure
Eigenschaften
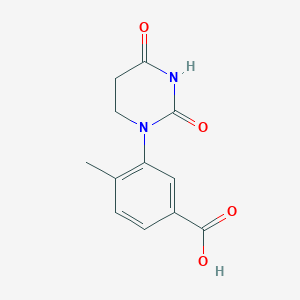
Molekularformel |
C12H12N2O4 |
|---|---|
Molekulargewicht |
248.23 g/mol |
IUPAC-Name |
3-(2,4-dioxo-1,3-diazinan-1-yl)-4-methylbenzoic acid |
InChI |
InChI=1S/C12H12N2O4/c1-7-2-3-8(11(16)17)6-9(7)14-5-4-10(15)13-12(14)18/h2-3,6H,4-5H2,1H3,(H,16,17)(H,13,15,18) |
InChI-Schlüssel |
NXRZIUASGSMTJJ-UHFFFAOYSA-N |
Kanonische SMILES |
CC1=C(C=C(C=C1)C(=O)O)N2CCC(=O)NC2=O |
Herkunft des Produkts |
United States |
Foundational & Exploratory
The Role of Dihydrouridine in tRNA Structure: A Technical Guide
Authored for Researchers, Scientists, and Drug Development Professionals
December 2025
Abstract
Dihydrouridine (D), a post-transcriptionally modified nucleoside, is one of the most abundant modifications in transfer RNA (tRNA) across bacteria and eukaryotes.[1][2][3][4] Synthesized by the reduction of uridine (B1682114), dihydrouridine introduces significant structural alterations to the tRNA molecule, primarily by increasing its conformational flexibility.[3][4][5][6] This guide provides an in-depth technical overview of the pivotal role of dihydrouridine in tRNA structure and function. It details the biosynthesis of dihydrouridine, its impact on tRNA conformation, and its functional implications in cellular processes such as thermal adaptation and stress response. Furthermore, this document outlines key experimental protocols for the analysis of dihydrouridine and presents quantitative data in a structured format to facilitate comparative analysis.
Introduction: The Significance of Dihydrouridine in tRNA
Transfer RNA molecules are central to protein synthesis and are subject to extensive post-transcriptional modifications that are crucial for their proper folding, stability, and function.[7][8][9] Among the more than 150 known RNA modifications, dihydrouridine is unique due to the saturation of the C5-C6 double bond of the uracil (B121893) ring, resulting in a non-planar, non-aromatic nucleobase.[2] This modification is predominantly found in the "D-loop" of tRNAs, a region named after this modified nucleoside.[2][3][6] The presence of dihydrouridine residues imparts localized flexibility to the tRNA structure, which is thought to be essential for the correct folding of the D-arm and the overall tertiary structure of the tRNA molecule.[3][4][7][10]
Biosynthesis of Dihydrouridine
Dihydrouridine is synthesized from uridine residues within a tRNA molecule by a family of flavin-dependent enzymes known as dihydrouridine synthases (Dus).[2][3][11] These enzymes utilize NADPH as a cofactor to reduce the C5-C6 double bond of uridine.[2][11] The Dus enzyme family exhibits specificity for different uridine positions within the tRNA molecule. For instance, in Saccharomyces cerevisiae, Dus1p, Dus2p, Dus3p, and Dus4p are responsible for dihydrouridine formation at distinct sites.[6]
The catalytic mechanism of Dus enzymes involves a reductive half-reaction where NADPH transfers a hydride to the enzyme-bound flavin mononucleotide (FMN), followed by an oxidative half-reaction where the reduced FMN reduces the target uridine on the tRNA.[2] Structural studies of Dus enzymes in complex with tRNA have revealed that the enzyme recognizes the elbow region of the L-shaped tRNA, pulling the target uridine into the catalytic center for reduction.[3]
Structural Impact of Dihydrouridine on tRNA
The conversion of uridine to dihydrouridine has profound consequences for the local structure of the tRNA molecule. The saturation of the pyrimidine (B1678525) ring disrupts the planarity of the base, which in turn destabilizes the C3'-endo ribose pucker conformation typically associated with A-form helical structures in RNA.[3][4] Instead, dihydrouridine favors the more flexible C2'-endo conformation.[4][10] This increased flexibility is crucial for the proper folding of the D-loop and its interaction with the T-loop, which helps to establish the characteristic L-shaped tertiary structure of tRNA.[2]
An NMR study on a D-arm fragment of tRNAiMet from S. pombe demonstrated that the presence of dihydrouridine is essential for the oligonucleotide to fold into a stable hairpin structure, whereas the unmodified counterpart exists in multiple undefined conformations.[7]
Quantitative Analysis of Dihydrouridine
The quantification of dihydrouridine in tRNA is essential for understanding its abundance and potential regulatory roles. Various methods have been developed for this purpose, with liquid chromatography-mass spectrometry (LC-MS) being a widely used and highly sensitive technique.[1][12][13][14]
| Sample Type | Organism | Method | Dihydrouridine Content (residues/tRNA) | Reference |
| tRNASerVGA | Escherichia coli | LC-MS | 2.03 | [1] |
| tRNAThrGGU | Escherichia coli | LC-MS | 2.84 | [1] |
| Unfractionated tRNA | Escherichia coli | LC-MS | 1.4 | [1] |
| 23S rRNA | Escherichia coli | LC-MS | 1.1 | [1] |
Table 1: Quantitative Measurement of Dihydrouridine in RNA from E. coli
| Parameter | Uridine (Up) | Dihydrouridine (Dp) | Reference |
| % C2'-endo at 25°C | 46% | 68% | [4] |
| Keq ([C2'-endo]/[C3'-endo]) at 25°C | 0.85 | 2.08 | [4] |
| ΔH (kcal/mol) for C2'-endo stabilization | - | 1.5 | [4] |
Table 2: Impact of Dihydrouridine on Ribose Conformation
Functional Roles of Dihydrouridine
The structural flexibility imparted by dihydrouridine has several functional implications:
-
tRNA Stability and Folding: Dihydrouridine contributes to the correct folding and stability of the D-arm of tRNA, which is a key element of its tertiary structure.[7]
-
Thermal Adaptation: Psychrophilic (cold-adapted) organisms have been found to have a higher content of dihydrouridine in their tRNAs compared to mesophilic organisms.[2][10] The increased flexibility provided by dihydrouridine may help to maintain tRNA function at low temperatures.[2]
-
Cellular Stress Response: The synthesis of dihydrouridine can be influenced by cellular stress conditions.[5][15][16][17] For example, oxidative stress can affect the activity of dihydrouridine synthases, suggesting a role for this modification in the regulation of translation during stress.[5][15][17]
-
Aminoacylation: While not universally observed for all tRNAs, dihydrouridine modification can enhance the charging of specific tRNA species with their cognate amino acids.[10]
Experimental Protocols
Isolation of tRNA
The purification of tRNA is a prerequisite for its analysis. The following is a generalized protocol for the isolation of total tRNA from bacterial cells.
-
Cell Lysis: Resuspend bacterial cell pellets in a lysis buffer (e.g., 10 mM Tris-HCl, pH 7.5, 10 mM MgCl2).
-
Phenol (B47542) Extraction: Add an equal volume of buffer-saturated phenol and mix vigorously. Separate the phases by centrifugation. The aqueous phase contains the total RNA.
-
Ethanol (B145695) Precipitation: Precipitate the RNA from the aqueous phase by adding 2.5 volumes of cold absolute ethanol and incubating at -20°C.
-
High Salt Precipitation: To separate tRNA from larger RNA species (rRNA, mRNA), resuspend the RNA pellet in a high-salt buffer and selectively precipitate the high molecular weight RNA. The tRNA remains in the supernatant.
-
Isopropanol Precipitation: Precipitate the tRNA from the supernatant with isopropanol.
-
Quality Control: Assess the purity and integrity of the isolated tRNA using denaturing polyacrylamide gel electrophoresis (PAGE).
Quantification of Dihydrouridine by LC-MS
This protocol outlines the general steps for the quantitative analysis of dihydrouridine in a purified tRNA sample.[12][13][14][][19]
-
Enzymatic Digestion: Digest the purified tRNA (typically a few micrograms) to its constituent nucleosides using a mixture of enzymes such as nuclease P1 and alkaline phosphatase.
-
Stable Isotope Internal Standards: Add known amounts of stable isotope-labeled internal standards for dihydrouridine ([15N2]dihydrouridine) and uridine ([15N2]uridine) to the digested sample for accurate quantification.[1]
-
Reversed-Phase HPLC Separation: Separate the nucleosides using a reversed-phase high-performance liquid chromatography (HPLC) column.
-
Mass Spectrometry Detection: Analyze the eluate by tandem mass spectrometry (MS/MS) using dynamic multiple reaction monitoring (DMRM) to specifically detect and quantify the parent and fragment ions of both the native and isotope-labeled nucleosides.[12][14]
-
Data Analysis: Calculate the amount of dihydrouridine in the original sample by comparing the peak areas of the native nucleoside to its corresponding stable isotope-labeled internal standard.
Structural Analysis by X-ray Crystallography
Determining the high-resolution structure of tRNA provides direct insight into the conformational effects of dihydrouridine.
-
RNA Production: Synthesize the desired tRNA molecule, either through in vitro transcription or by purification from a biological source.
-
Crystallization: Screen a wide range of crystallization conditions (e.g., pH, temperature, precipitant concentration) to obtain diffraction-quality crystals of the tRNA.
-
Heavy Atom Derivatization: For de novo structure determination, prepare heavy-atom derivatives of the crystals by soaking them in solutions containing heavy atoms (e.g., lanthanides).[20]
-
X-ray Diffraction Data Collection: Expose the crystals to a high-intensity X-ray beam and collect the diffraction data.
-
Structure Determination and Refinement: Process the diffraction data to determine the electron density map and build an atomic model of the tRNA molecule. Refine the model to best fit the experimental data.
Conclusion and Future Perspectives
Dihydrouridine is a fundamental and widespread modification of tRNA that plays a critical role in defining its structure and function. Its unique ability to increase the conformational flexibility of the RNA backbone is essential for the proper folding of the tRNA molecule and its adaptation to different cellular conditions. While significant progress has been made in understanding the biosynthesis and structural impact of dihydrouridine, its precise roles in the fine-tuning of translation and in cellular stress responses are still being actively investigated. The development of novel high-throughput sequencing methods for the detection of dihydrouridine will undoubtedly accelerate research in this area, potentially uncovering new functions for this intriguing RNA modification.[21][22]
References
- 1. academic.oup.com [academic.oup.com]
- 2. tandfonline.com [tandfonline.com]
- 3. Molecular basis of dihydrouridine formation on tRNA - PMC [pmc.ncbi.nlm.nih.gov]
- 4. academic.oup.com [academic.oup.com]
- 5. openscience.ub.uni-mainz.de [openscience.ub.uni-mainz.de]
- 6. tRNA-dihydrouridine synthase - Wikipedia [en.wikipedia.org]
- 7. Contribution of dihydrouridine in folding of the D-arm in tRNA - Organic & Biomolecular Chemistry (RSC Publishing) [pubs.rsc.org]
- 8. tRNA modifications regulate translation during cellular stress - PMC [pmc.ncbi.nlm.nih.gov]
- 9. mdpi.com [mdpi.com]
- 10. biorxiv.org [biorxiv.org]
- 11. Mechanism of Dihydrouridine Synthase 2 from Yeast and the Importance of Modifications for Efficient tRNA Reduction - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Quantitative analysis of tRNA modifications by HPLC-coupled mass spectrometry [dspace.mit.edu]
- 13. Quantitative analysis of tRNA modifications by HPLC-coupled mass spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Quantitative analysis of ribonucleoside modifications in tRNA by HPLC-coupled mass spectrometry - PubMed [pubmed.ncbi.nlm.nih.gov]
- 15. Differential redox sensitivity of tRNA dihydrouridylation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 16. grantome.com [grantome.com]
- 17. academic.oup.com [academic.oup.com]
- 19. tRNA Modification Analysis by MS - CD Genomics [rna.cd-genomics.com]
- 20. doudnalab.org [doudnalab.org]
- 21. Quantitative CRACI reveals transcriptome-wide distribution of RNA dihydrouridine at base resolution - PMC [pmc.ncbi.nlm.nih.gov]
- 22. Frontiers | DPred_3S: identifying dihydrouridine (D) modification on three species epitranscriptome based on multiple sequence-derived features [frontiersin.org]
The Epitranscriptome: A Historical and Technical Guide to Modified Nucleosides in RNA
For Researchers, Scientists, and Drug Development Professionals
Introduction
The central dogma of molecular biology, in its simplest form, describes a linear flow of genetic information from DNA to RNA to protein. However, this view has been significantly expanded by the discovery of a complex layer of regulation at the RNA level, known as the epitranscriptome. This refers to the diverse array of post-transcriptional chemical modifications to RNA nucleosides, which play a pivotal role in regulating every aspect of RNA metabolism, from splicing and nuclear export to stability and translation. With over 170 distinct RNA modifications identified to date, the epitranscriptome represents a vast and dynamic landscape of biological control.[1] This in-depth technical guide provides a comprehensive overview of the discovery and history of modified nucleosides in RNA, detailed experimental protocols for their detection, and a summary of their impact on cellular signaling pathways, with a focus on applications for researchers and professionals in drug development.
I. A Historical Journey: The Discovery of a New Layer of Genetic Information
The story of modified nucleosides began in the mid-20th century, challenging the notion of RNA as a simple messenger. This timeline highlights the key milestones in the discovery of this fascinating field.
Table 1: A Timeline of Key Discoveries in Modified RNA Nucleosides
| Year | Discovery | Key Contributor(s) | Significance |
| 1951 | Discovery of pseudouridine (B1679824) (Ψ), the "fifth nucleoside," in calf liver RNA.[2] | Cohn and Volkin | First identification of a modified nucleoside in RNA, revealing that the composition of RNA is more complex than the four canonical bases.[3] |
| 1970s | Discovery of N6-methyladenosine (m6A) in mRNA. | Multiple researchers | Identification of the most abundant internal modification in eukaryotic mRNA, hinting at a widespread regulatory mechanism. |
| 1993 | Development of a method to map the position of pseudouridine with single-nucleotide resolution using CMC chemistry.[2] | Bakin and Ofengand | Enabled the precise localization of pseudouridine, paving the way for understanding its site-specific functions. |
| 2011 | Discovery of the first RNA demethylase, FTO, which removes m6A. | Chuan He and colleagues | Revealed that RNA methylation is a reversible and dynamic process, akin to DNA and histone modifications. |
| 2012 | Development of m6A-seq (MeRIP-seq), a high-throughput method to map m6A across the transcriptome.[4] | Two independent groups | Enabled the first transcriptome-wide maps of an RNA modification, revolutionizing the study of the epitranscriptome. |
| 2014 | First transcriptome-wide mapping of pseudouridine in mRNA using Pseudo-seq.[5][6] | Multiple research groups | Confirmed the presence of pseudouridine in mRNA and revealed its dynamic regulation.[5][6] |
II. The Landscape of RNA Modifications: Quantitative Insights
The abundance and stoichiometry of modified nucleosides vary significantly across different RNA species and cellular conditions. This quantitative data is crucial for understanding their functional significance.
Table 2: Abundance of Pseudouridine (Ψ) in Human and Mouse mRNA
| Cell Line/Tissue | Number of Ψ Sites Identified | Median Modification Level/Fraction | Key Findings |
| Human Cell Lines (A549, HeLa, HEK293T) | Hundreds of confident sites | 10-40% for most sites, with some exceeding 50%[7] | Ψ sites are distributed in CDS and 3'-UTR and can be cell-line specific or shared.[7] |
| Mouse Tissues (12 different tissues) | Thousands of frequently modified sites | >10% stoichiometry in most tissues, with thousands of highly modified sites (>50%)[7] | Mouse tissues exhibit a much higher abundance of mRNA pseudouridylation compared to cultured cells.[8] |
| Human HEK293T Cells | 2,714 confident Ψ sites | ~10% median modification level[3] | Provides a quantitative landscape of Ψ in the human transcriptome.[3] |
Table 3: Stoichiometry of N6-methyladenosine (m6A) in Mammalian Cells
| Cell Line/Condition | Method | Key Findings on Stoichiometry |
| Mammalian Cells | MAZTER-seq | Most methylated sites exhibit low stoichiometry, often less than 20%.[4] |
| Human Cell Lines (HEK293, HepG2, A549) | m6A-SAC-seq | The majority of m6A sites display considerably different stoichiometries across different cell lines.[9] |
| Human Hematopoietic Stem and Progenitor Cells (HSPCs) | m6A-SAC-seq | m6A stoichiometry is highly dynamic during cell differentiation.[9] |
Table 4: 5-methylcytosine (B146107) (m5C) in Eukaryotic tRNA
| Location in tRNA | Function | Key Enzymes |
| Variable regions and anticodon loops | Stabilizes tRNA secondary structure, regulates codon identification and tRNA aminoacylation.[10] | NSUN2, DNMT2 |
| Cytoplasmic tRNAs | tRNA stability | DNMT2, NSUN2, NSUN6[11] |
| Mitochondrial tRNAs | NSUN2, NSUN3, NSUN4[11] |
III. Experimental Protocols for the Detection and Analysis of Modified Nucleosides
The study of the epitranscriptome relies on a diverse toolkit of experimental techniques. This section provides detailed methodologies for key experiments.
A. Global Analysis of Modified Nucleosides
1. Two-Dimensional Thin-Layer Chromatography (2D-TLC)
This classical method is used for the separation and semi-quantitative analysis of radiolabeled nucleosides.
Methodology:
-
RNA Isolation and Radiolabeling: Isolate total RNA or specific RNA species of interest. The RNA can be radiolabeled in vivo by growing cells in the presence of [³²P]-orthophosphate or in vitro by post-labeling with [γ-³²P]ATP and T4 polynucleotide kinase.
-
RNA Digestion: Digest the radiolabeled RNA to single nucleosides using a mixture of nucleases, such as Nuclease P1 and bacterial alkaline phosphatase.
-
2D-TLC Separation:
-
Spot the digested nucleoside mixture onto a cellulose (B213188) TLC plate.
-
Develop the chromatogram in the first dimension using a solvent system such as isobutyric acid/0.5 M NH₄OH (5:3, v/v).
-
After drying, rotate the plate 90 degrees and develop in the second dimension using a different solvent system, for example, isopropanol/HCl/water (70:15:15, v/v/v).
-
-
Detection and Quantification:
-
Expose the TLC plate to a phosphor screen or X-ray film to visualize the separated radiolabeled nucleosides.
-
Identify the spots by comparing their positions to a standard map of known modified nucleosides.
-
Quantify the radioactivity of each spot using a phosphorimager to determine the relative abundance of each modified nucleoside.
-
2. Liquid Chromatography-Mass Spectrometry (LC-MS/MS)
LC-MS/MS is the gold standard for the accurate identification and quantification of a wide range of modified nucleosides.[12][13]
Methodology:
-
RNA Isolation and Purification: Isolate total RNA or purify specific RNA species (e.g., mRNA using oligo(dT) beads). Ensure high purity and integrity of the RNA sample.
-
Enzymatic Hydrolysis:
-
Digest the RNA into single nucleosides using a cocktail of enzymes. A common combination includes nuclease P1, snake venom phosphodiesterase, and alkaline phosphatase to ensure complete digestion to nucleosides.
-
The reaction is typically carried out in a buffer such as ammonium (B1175870) acetate (B1210297) or ammonium bicarbonate at 37°C for several hours to overnight.
-
-
LC Separation:
-
Inject the nucleoside mixture onto a reverse-phase C18 column.
-
Separate the nucleosides using a gradient of a polar mobile phase (e.g., water with a small amount of formic acid or ammonium acetate) and a non-polar mobile phase (e.g., acetonitrile (B52724) or methanol).
-
-
MS/MS Detection and Quantification:
-
The eluent from the LC is introduced into a tandem mass spectrometer.
-
The mass spectrometer is operated in positive ion mode using electrospray ionization (ESI).
-
For quantification, use multiple reaction monitoring (MRM) mode. This involves selecting the precursor ion (the protonated nucleoside) and a specific fragment ion (typically the protonated base) for each nucleoside.
-
Create a standard curve using known concentrations of authentic modified and unmodified nucleoside standards to achieve absolute quantification.[14]
-
B. Transcriptome-Wide Mapping of Modified Nucleosides
1. Methylated RNA Immunoprecipitation Sequencing (MeRIP-seq or m6A-seq)
MeRIP-seq is a widely used antibody-based method to map the locations of m6A across the transcriptome.[15][16][17]
Methodology:
-
RNA Isolation and Fragmentation:
-
Isolate total RNA from cells or tissues.
-
Purify mRNA using oligo(dT) magnetic beads.
-
Fragment the mRNA to an average size of ~100-200 nucleotides using chemical or enzymatic methods.
-
-
Immunoprecipitation (IP):
-
Incubate the fragmented RNA with an antibody specific to m6A.
-
Capture the antibody-RNA complexes using protein A/G magnetic beads.
-
Wash the beads extensively to remove non-specifically bound RNA.
-
-
RNA Elution and Library Preparation:
-
Elute the m6A-containing RNA fragments from the antibody-bead complexes.
-
Prepare a sequencing library from the eluted RNA fragments (IP sample) and an input control sample (a fraction of the fragmented RNA that did not undergo IP).
-
-
High-Throughput Sequencing and Data Analysis:
-
Sequence the IP and input libraries on a high-throughput sequencing platform.
-
Align the sequencing reads to the reference genome/transcriptome.
-
Identify m6A peaks by identifying regions with a significant enrichment of reads in the IP sample compared to the input control.
-
2. Pseudouridine Sequencing (Pseudo-seq)
Pseudo-seq utilizes the chemical reactivity of pseudouridine with CMC (N-cyclohexyl-N'-(2-morpholinoethyl)carbodiimide metho-p-toluenesulfonate) to identify its location.[18][19]
Methodology:
-
RNA Isolation and CMC Treatment:
-
Isolate total RNA or poly(A)+ RNA.
-
Treat the RNA with CMC, which forms a bulky adduct on pseudouridine residues.
-
-
Alkaline Treatment:
-
Subject the CMC-treated RNA to alkaline conditions (e.g., sodium carbonate buffer, pH 10.4). This removes the CMC adducts from uridine (B1682114) and guanosine (B1672433) but not from pseudouridine.
-
-
RNA Fragmentation and Library Preparation:
-
Fragment the RNA to the desired size.
-
Perform reverse transcription. The CMC adduct on pseudouridine blocks the reverse transcriptase, leading to truncation of the cDNA one nucleotide 3' to the modified base.
-
Ligate adapters and prepare a sequencing library from the truncated cDNA fragments. A control library is prepared from untreated RNA.
-
-
High-Throughput Sequencing and Data Analysis:
-
Sequence both the CMC-treated and control libraries.
-
Align the reads to the reference genome/transcriptome.
-
Identify pseudouridine sites by locating positions with a significant accumulation of reverse transcription stops in the CMC-treated sample compared to the control.
-
IV. Functional Consequences: Modified Nucleosides in Cellular Signaling
RNA modifications are not merely static decorations; they are key players in the dynamic regulation of cellular signaling pathways.
A. N6-methyladenosine (m6A) in Signal Transduction
m6A has emerged as a critical regulator of major signaling pathways implicated in development, cancer, and other diseases.
1. TGF-β Signaling Pathway
The Transforming Growth Factor-β (TGF-β) pathway plays a crucial role in cell growth, differentiation, and apoptosis. m6A modification has been shown to be intricately linked to this pathway. For example, upon TGF-β stimulation, the m6A methyltransferase complex can be recruited to specific transcripts, leading to their methylation and subsequent degradation, thereby influencing cell fate decisions.
2. PI3K/Akt/mTOR Signaling Pathway
The PI3K/Akt/mTOR pathway is a central regulator of cell growth, proliferation, and survival. Several studies have demonstrated that m6A regulators can be downstream targets of this pathway, and in turn, m6A modifications can modulate the expression of key components of this pathway, creating a complex regulatory feedback loop.[20][21]
B. Pseudouridylation and its Molecular Consequences
Pseudouridylation can alter the structural and functional properties of RNA, impacting processes like translation and mRNA stability.
Molecular Consequences of Pseudouridylation:
-
Enhanced RNA Stability: The additional hydrogen bond donor in pseudouridine can increase the rigidity of the sugar-phosphate backbone, leading to enhanced base stacking and increased stability of RNA secondary structures.[22]
-
Altered Protein-RNA Interactions: The presence of pseudouridine can either enhance or weaken the binding of RNA-binding proteins (RBPs), thereby modulating various aspects of RNA metabolism.
-
Modulation of Translation: Pseudouridylation within the coding sequence of an mRNA can affect the speed and accuracy of translation by the ribosome. It has been shown to cause translational readthrough of stop codons.[7]
V. Experimental and Logical Workflows
Visualizing the workflows of key experimental techniques and logical relationships helps in understanding the complex processes involved in studying RNA modifications.
Workflow for MeRIP-seq:
Logical Relationship of m6A "Writers," "Erasers," and "Readers":
VI. Conclusion and Future Perspectives
The discovery of modified nucleosides has unveiled a new dimension of gene regulation, transforming our understanding of RNA biology. The epitranscriptome is no longer a niche field but a central area of research with profound implications for human health and disease. For drug development professionals, the enzymes that write, erase, and read these modifications represent a promising new class of therapeutic targets. As technologies for detecting and quantifying RNA modifications continue to advance, we can expect to uncover even more intricate layers of this regulatory code. The future of epitranscriptomics holds the promise of novel diagnostic markers, therapeutic strategies, and a deeper understanding of the fundamental principles of life.
References
- 1. youtube.com [youtube.com]
- 2. Function and detection of 5-methylcytosine in eukaryotic RNA - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. biorxiv.org [biorxiv.org]
- 4. Hidden codes in mRNA: Control of gene expression by m6A - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Pseudouridine profiling reveals regulated mRNA pseudouridylation in yeast and human cells - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Unraveling the timeline of gene expression: A pseudotemporal trajectory analysis of single-cell RNA sequencing data - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Quantitative sequencing using BID-seq uncovers abundant pseudouridines in mammalian mRNA at base resolution - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Recent developments, opportunities, and challenges in the study of mRNA pseudouridylation - PMC [pmc.ncbi.nlm.nih.gov]
- 9. m6A RNA modifications are measured at single-base resolution across the mammalian transcriptome - PMC [pmc.ncbi.nlm.nih.gov]
- 10. academic.oup.com [academic.oup.com]
- 11. tandfonline.com [tandfonline.com]
- 12. pubs.acs.org [pubs.acs.org]
- 13. researchgate.net [researchgate.net]
- 14. Quantitative analysis of m6A RNA modification by LC-MS - PMC [pmc.ncbi.nlm.nih.gov]
- 15. researchgate.net [researchgate.net]
- 16. pdfs.semanticscholar.org [pdfs.semanticscholar.org]
- 17. MeRIP-seq for Detecting RNA methylation: An Overview - CD Genomics [cd-genomics.com]
- 18. Updated Pseudo-seq Protocol for Transcriptome-Wide Detection of Pseudouridines - PMC [pmc.ncbi.nlm.nih.gov]
- 19. MODOMICS - Database Commons [ngdc.cncb.ac.cn]
- 20. m6A RNA modification modulates PI3K/Akt/mTOR signal pathway in Gastrointestinal Cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 21. m6A RNA modification modulates PI3K/Akt/mTOR signal pathway in Gastrointestinal Cancer - PubMed [pubmed.ncbi.nlm.nih.gov]
- 22. bioweb.supagro.inrae.fr [bioweb.supagro.inrae.fr]
A Technical Guide to the Function of Dihydrouridine in Translational Fidelity
Audience: Researchers, scientists, and drug development professionals.
Executive Summary: Dihydrouridine (D), a universally conserved post-transcriptional modification of tRNA, plays a critical, albeit complex, role in protein synthesis. Formed by the reduction of uridine (B1682114) by NADPH-dependent Dihydrouridine Synthases (Dus), this modification is predominantly found in the D-loop of tRNAs.[1][2][3] Unlike most other modifications that stabilize RNA structure, dihydrouridine's unique non-planar, non-aromatic nucleobase introduces local flexibility into the tRNA molecule.[3][4] It achieves this by destabilizing the rigid C3'-endo ribose conformation typical of A-form helices and promoting a more flexible C2'-endo state.[5] This increased conformational dynamism is crucial for the correct folding of the tRNA's L-shaped tertiary structure and its subsequent interactions within the ribosome.[6] While not directly involved in codon-anticodon pairing at the wobble position, dihydrouridine's influence on the overall tRNA structure indirectly impacts translational fidelity by modulating translation speed, ensuring proper tRNA binding in the ribosomal A and P sites, and contributing to the maintenance of the correct reading frame.[7] Recent evidence also points to its presence and functional roles in mRNA, further expanding its regulatory significance in gene expression.[8][9][10] This guide provides an in-depth analysis of the molecular mechanisms, quantitative effects, and experimental methodologies related to dihydrouridine's function in translation.
The Enzymatic Synthesis of Dihydrouridine
Dihydrouridine is synthesized from uridine through the enzymatic reduction of the C5-C6 double bond of the uracil (B121893) base.[2] This reaction is catalyzed by a conserved family of flavoenzymes known as dihydrouridine synthases (Dus).[1][11] The process is dependent on NADPH as a hydride source, which first reduces the enzyme-bound flavin mononucleotide (FMN) cofactor to FMNH⁻.[3][12] The reduced flavin then transfers a hydride to the uridine base to form dihydrouridine.[3][11] Different Dus enzymes exhibit specificity for different uridine positions within the tRNA molecule, such as positions 16, 17, 20, 20a, and 47.[2][13][14]
Structural Impact of Dihydrouridine on tRNA
The primary role of dihydrouridine is to modulate the structural and dynamic properties of the tRNA molecule. Its impact is a direct consequence of the saturation of the C5-C6 bond in the uracil ring.
Enhanced Conformational Flexibility
The reduction of the uracil ring results in a non-planar, puckered conformation that disrupts the base-stacking interactions that stabilize helical RNA structures. This disruption has a profound effect on the sugar-phosphate backbone. Nuclear Magnetic Resonance (NMR) studies have shown that dihydrouridine significantly destabilizes the C3'-endo sugar pucker, which is characteristic of stable A-form helices, and instead promotes the more flexible C2'-endo conformation.[15][5] This shift increases the local flexibility of the tRNA backbone, particularly within the D-loop.[4][5] This inherent flexibility is thought to be an evolutionary adaptation, with tRNAs from psychrophilic (cold-loving) organisms containing higher levels of dihydrouridine to maintain functional tRNA structure at low temperatures.[2][3]
Contribution to tRNA Tertiary Structure
While seemingly destabilizing, the flexibility imparted by dihydrouridine is essential for the tRNA to achieve its proper three-dimensional L-shaped structure.[6] The D-loop, named for its high content of dihydrouridine, engages in crucial tertiary interactions with the T-loop (TΨC loop).[2][14] The flexibility within the D-loop facilitates this "kissing loop" interaction, which is fundamental to stabilizing the overall tRNA fold.[1][16] Dus enzymes recognize the complete L-shaped structure of tRNAs, suggesting that dihydrouridylation is a key step in tRNA maturation that monitors and reinforces the correct global architecture.[1][2]
Role of Dihydrouridine in Translational Fidelity
Dihydrouridine's influence on translational fidelity is indirect, stemming from its structural effects on the tRNA molecule and its interactions with the ribosome.
Influence on Ribosome Interaction and Translation Speed
The flexibility of the D-modified tRNA is thought to be critical for its proper accommodation and movement through the ribosome's A (aminoacyl), P (peptidyl), and E (exit) sites. While modifications in the anticodon loop directly influence codon recognition, modifications in the tRNA core, like dihydrouridine, ensure the entire molecule is correctly positioned for each step of the elongation cycle.[16][17]
Recent studies using ribosome profiling have revealed that dihydrouridylation can affect the speed of translation.[7] The presence of dihydrouridine on certain mRNAs in fission yeast was shown to slow down ribosome translocation.[7] This modulation of translation speed can be a mechanism for regulating protein expression levels and ensuring proper co-translational folding. For example, the absence of dihydrouridylation on tubulin-encoding mRNA leads to dysregulated protein synthesis and severe defects in meiotic chromosome segregation.[7][10]
Context-Dependent Effects on Translation
The precise effect of dihydrouridine appears to be context-dependent. Early in vitro experiments using synthetic polymers suggested that the presence of dihydrouridine within a codon leads to a significant loss of coding ability and represses translation.[3] However, more recent cellular studies show a more nuanced role. In E. coli, the DusA enzyme, which forms D20, selectively improves translation at several specific codons, suggesting a direct contribution to the function of certain tRNAs on the ribosome.[18] This indicates that rather than being a general inhibitor, dihydrouridine may act to fine-tune protein synthesis for specific transcripts or under particular cellular conditions, such as oxidative stress.[12][19]
Quantitative Data on Dihydrouridine's Function
The functional impact of dihydrouridine has been quantified through various biophysical and genetic experiments. The data below summarizes key findings.
Table 1: Effect of Dihydrouridine Synthase (Dus) Deletion on Total Dihydrouridine Levels in E. coli
| Knockout Strain | Dus Enzyme Specificity | Reduction in Total D Content (%) | Reference |
|---|---|---|---|
| ΔdusA | Modifies U20 and U20a | 55% | [12] |
| ΔdusB | Modifies U17 | 23% | [12] |
| ΔdusC | Modifies U16 | 23% |[12] |
Table 2: Biophysical and Translational Effects of Dihydrouridine
| Parameter | Observation | Quantitative Value | Reference |
|---|---|---|---|
| Ribose Conformation | Equilibrium constant (Keq = [C2'-endo]/[C3'-endo]) for Dp vs. Up at 25°C. | Keq increases from 0.85 (Up) to 2.08 (Dp). | [15] |
| Thermodynamic Stability | Stabilization of C2'-endo conformation in Dp compared to Up. | ΔH = 1.5 kcal/mol. | [5] |
| In Vitro Translation | Loss of Phenylalanine incorporation from a UUU-containing ribopolymer. | Up to 60% loss with 4.2% D content. | [3] |
| Cellular D Levels | Decrease in total tRNA D content in E. coli treated with paraquat (B189505) (0.3 mM). | 28% reduction. | [12] |
| Mapping Efficiency | T→C mutation rate at reduced D sites using the CRACI method. | ~96% |[20] |
Key Experimental Protocols
The study of dihydrouridine relies on a combination of biochemical, genetic, and sequencing-based approaches.
Protocol: Transcriptome-Wide Mapping of Dihydrouridine (D-Seq)
This method identifies dihydrouridine sites at single-nucleotide resolution based on the chemical reactivity of the modified base.[9][10]
-
RNA Isolation: Isolate total RNA or specific RNA fractions (e.g., poly(A)+ mRNA) from both wild-type (WT) cells and a DUS knockout (KO) strain.
-
Chemical Treatment: Treat the RNA with sodium borohydride (B1222165) (NaBH₄). This chemical reduces dihydrouridine (D) to tetrahydrouridine (B1681287).[10]
-
Reverse Transcription (RT): Perform reverse transcription on the treated RNA. The resulting tetrahydrouridine adduct acts as a block, causing the reverse transcriptase to terminate prematurely at the position +1 relative to the modification site.[9][10]
-
Library Preparation & Sequencing: Prepare cDNA libraries from the RT products and perform high-throughput sequencing to map the 3' ends of the cDNA fragments.
-
Data Analysis: Align sequencing reads to the reference transcriptome. Identify sites with a significant pileup of RT stops in the WT sample that are absent or greatly reduced in the DUS KO sample. These differential stop signals correspond to the locations of dihydrouridine.[10]
Protocol: Quantification by Liquid Chromatography-Mass Spectrometry (LC-MS/MS)
This is the gold standard for quantifying the absolute levels of modified nucleosides in an RNA sample.[12]
-
RNA Isolation and Digestion: Isolate total tRNA from cells. Digest the purified tRNA down to single nucleosides using a cocktail of enzymes (e.g., nuclease P1 followed by phosphodiesterase I and alkaline phosphatase).
-
Chromatographic Separation: Separate the resulting nucleosides using high-performance liquid chromatography (HPLC), typically with a reverse-phase C18 column. Dihydrouridine is less hydrophobic than uridine and will have a shorter retention time.[12]
-
Mass Spectrometry: Couple the HPLC to a tandem mass spectrometer (MS/MS). Monitor the specific mass-to-charge (m/z) transitions for dihydrouridine and canonical nucleosides (e.g., adenosine, guanosine, cytidine, uridine) for accurate identification and quantification.
-
Quantification: Calculate the amount of dihydrouridine relative to the amount of one or more canonical nucleosides by integrating the areas under the respective chromatographic peaks.
Protocol: Polysome Profiling
This technique is used to analyze tRNAs that are actively engaged in translation.[12][21]
-
Cell Lysis: Lyse cells under conditions that preserve ribosome-mRNA complexes, typically in the presence of a translation inhibitor like cycloheximide.
-
Sucrose (B13894) Gradient Ultracentrifugation: Layer the cell lysate onto a continuous sucrose gradient (e.g., 10-50%) and centrifuge at high speed. This separates cellular components by size and density.
-
Fractionation: Collect fractions from the gradient while monitoring absorbance at 260 nm. The resulting profile will show peaks corresponding to free ribosomal subunits, monosomes, and polysomes (multiple ribosomes on a single mRNA).
-
RNA Extraction: Isolate RNA from the polysome-containing fractions. This RNA population is enriched for mRNAs and tRNAs that were actively participating in translation at the time of cell lysis.
-
Downstream Analysis: Analyze the extracted tRNA for dihydrouridine content using LC-MS/MS or sequencing methods to determine the modification status of the translationally active tRNA pool.[12]
Conclusion and Future Directions
Dihydrouridine is a fundamental RNA modification that exerts its influence on translational fidelity primarily by imparting structural flexibility to the tRNA molecule. This flexibility is not a defect but a crucial feature that ensures correct tRNA folding, facilitates essential tertiary interactions, and allows for proper accommodation within the dynamic ribosomal machinery. While its direct impact on codon reading is minimal, its role in modulating translation speed and efficiency for specific transcripts highlights a sophisticated layer of gene expression regulation. The recent discovery of dihydrouridine in mRNA opens up new avenues of research into its potential roles in splicing, mRNA stability, and translational control beyond the realm of tRNA.[9][10] Future work for researchers and drug development professionals should focus on elucidating the specific "readers" that may recognize D-modified RNA, understanding how Dus enzyme activity is regulated in response to cellular stress and disease states, and exploring the therapeutic potential of targeting Dus enzymes in pathologies like cancer where dihydrouridine levels are often elevated.[2][20]
References
- 1. pnas.org [pnas.org]
- 2. Molecular basis of dihydrouridine formation on tRNA - PMC [pmc.ncbi.nlm.nih.gov]
- 3. The Dihydrouridine landscape from tRNA to mRNA: a perspective on synthesis, structural impact and function - PMC [pmc.ncbi.nlm.nih.gov]
- 4. biorxiv.org [biorxiv.org]
- 5. Conformational flexibility in RNA: the role of dihydrouridine - PMC [pmc.ncbi.nlm.nih.gov]
- 6. fiveable.me [fiveable.me]
- 7. lafontainelab.com [lafontainelab.com]
- 8. Dihydrouridine in the Transcriptome: New Life for This Ancient RNA Chemical Modification - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. Expanding the epitranscriptome: Dihydrouridine in mRNA | PLOS Biology [journals.plos.org]
- 10. Expanding the epitranscriptome: Dihydrouridine in mRNA - PMC [pmc.ncbi.nlm.nih.gov]
- 11. academic.oup.com [academic.oup.com]
- 12. academic.oup.com [academic.oup.com]
- 13. Dihydrouridine synthesis in tRNAs is under reductive evolution in Mollicutes - PMC [pmc.ncbi.nlm.nih.gov]
- 14. tandfonline.com [tandfonline.com]
- 15. academic.oup.com [academic.oup.com]
- 16. Metabolism Meets Translation: Dietary and Metabolic Influences on tRNA Modifications and Codon Biased Translation - PMC [pmc.ncbi.nlm.nih.gov]
- 17. researchgate.net [researchgate.net]
- 18. The tRNA dihydrouridine synthase DusA has a distinct mechanism in optimizing tRNAs for translation | Sciety Labs (Experimental) [sciety-labs.elifesciences.org]
- 19. openscience.ub.uni-mainz.de [openscience.ub.uni-mainz.de]
- 20. Quantitative CRACI reveals transcriptome-wide distribution of RNA dihydrouridine at base resolution - PMC [pmc.ncbi.nlm.nih.gov]
- 21. Differential redox sensitivity of tRNA dihydrouridylation - PMC [pmc.ncbi.nlm.nih.gov]
Dihydrouridine Synthase (Dus) Enzyme Families and Their Evolution: A Technical Guide
For Researchers, Scientists, and Drug Development Professionals
Abstract
Dihydrouridine (D), a ubiquitous modified nucleoside in transfer RNA (tRNA), plays a crucial role in maintaining tRNA structure and function. The synthesis of dihydrouridine from uridine (B1682114) is catalyzed by a conserved family of flavoenzymes known as dihydrouridine synthases (Dus). These enzymes are found across all domains of life and are classified into distinct families based on their sequence and substrate specificity. Dysregulation of Dus enzyme activity and altered dihydrouridine levels have been implicated in various human diseases, including cancer and neurodegenerative disorders, making them promising targets for therapeutic intervention. This technical guide provides a comprehensive overview of the Dus enzyme families, their evolutionary relationships, catalytic mechanisms, and roles in cellular processes. Furthermore, it offers detailed experimental protocols for the characterization of Dus enzymes and a summary of available quantitative data to facilitate further research and drug development in this field.
Introduction to Dihydouridine and Dus Enzymes
Dihydrouridine is a post-transcriptional modification formed by the reduction of the C5-C6 double bond of uridine residues in RNA, primarily tRNA.[1][2] This modification disrupts the planarity of the uracil (B121893) base, leading to increased conformational flexibility of the RNA backbone.[3][4] This flexibility is thought to be important for the proper folding and function of tRNA molecules.[4] The enzymes responsible for this modification are the dihydrouridine synthases (Dus), a family of NADPH-dependent flavoproteins that utilize a flavin mononucleotide (FMN) cofactor to catalyze the reduction of uridine.[5][6]
Dus Enzyme Families: Classification and Distribution
Phylogenetic analyses have classified Dus enzymes into several distinct families, each with characteristic substrate specificities.[6] These families are broadly distributed across the three domains of life: Bacteria, Archaea, and Eukarya.
Table 1: Major Dihydrouridine Synthase (Dus) Enzyme Families and their Characteristics
| Family | Domain | Primary Substrate Position(s) in tRNA | Key Features |
| DusA | Bacteria | U20, U20a | One of the three major bacterial Dus families.[7] |
| DusB | Bacteria | U17 | Considered the ancestral bacterial Dus enzyme.[8] |
| DusC | Bacteria | U16 | Exhibits specificity for a single uridine position.[8] |
| Dus1 | Eukarya | U16, U17 | A dual-specific eukaryotic Dus.[9] |
| Dus2 | Eukarya | U20 | Implicated in cancer and neurodegenerative diseases.[1][10] |
| Dus3 | Eukarya | U47 (variable loop) | Considered the ancestral eukaryotic Dus enzyme. |
| Dus4 | Eukarya | U20a, U20b | Another dual-specific eukaryotic Dus.[9] |
| Archaeal Dus | Archaea | Various | A distinct family of Dus enzymes found in Archaea. |
Evolution of Dihydrouridine Synthases
The evolutionary history of Dus enzymes suggests a complex pattern of gene duplication and divergence. It is proposed that an ancestral Dus enzyme existed in the Last Universal Common Ancestor (LUCA). In bacteria, DusB is considered the ancestral enzyme from which DusA and DusC likely arose through gene duplication events.[8] Similarly, in eukaryotes, Dus3 is thought to be the ancestral enzyme that gave rise to the other eukaryotic Dus families. The diversification of Dus enzymes has led to the evolution of distinct substrate specificities, allowing for precise modification of different uridine residues within the tRNA molecule.
References
- 1. Interaction of human tRNA-dihydrouridine synthase-2 with interferon-induced protein kinase PKR - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Functional redundancy in tRNA dihydrouridylation - PMC [pmc.ncbi.nlm.nih.gov]
- 3. researchgate.net [researchgate.net]
- 4. researchgate.net [researchgate.net]
- 5. medchemexpress.com [medchemexpress.com]
- 6. academic.oup.com [academic.oup.com]
- 7. biorxiv.org [biorxiv.org]
- 8. tandfonline.com [tandfonline.com]
- 9. Sequence- and Structure-Specific tRNA Dihydrouridylation by hDUS2 - PMC [pmc.ncbi.nlm.nih.gov]
- 10. researchgate.net [researchgate.net]
The Impact of Dihydrouridine on tRNA D-Loop Flexibility: A Technical Guide
For Researchers, Scientists, and Drug Development Professionals
Abstract
Dihydrouridine (D), a post-transcriptionally modified uridine (B1682114), is a prevalent modification in the D-loop of transfer RNA (tRNA) across all domains of life. Its unique non-aromatic and non-planar structure imparts significant conformational flexibility to the tRNA molecule. This technical guide provides an in-depth analysis of the structural impact of dihydrouridine on the tRNA D-loop, summarizing key quantitative data, detailing experimental methodologies for its study, and visualizing the associated molecular pathways and workflows. Understanding the nuanced effects of this modification is critical for research into tRNA function, protein synthesis fidelity, and the development of novel therapeutics targeting these processes.
Introduction: The Significance of Dihydrouridine in tRNA Structure
Transfer RNA molecules are central to protein synthesis, acting as adaptors between mRNA codons and their corresponding amino acids. The precise three-dimensional structure of tRNA is crucial for its function, and this structure is fine-tuned by a variety of post-transcriptional modifications. Among these, dihydrouridine (D) is one of the most common, particularly within the D-loop, a region critical for the correct folding and stability of the entire tRNA molecule.[1][2]
The conversion of uridine to dihydrouridine involves the enzymatic reduction of the C5-C6 double bond in the uracil (B121893) ring, a reaction catalyzed by a family of enzymes known as dihydrouridine synthases (Dus).[2] This seemingly simple modification has profound structural consequences. The saturation of the uracil ring disrupts its planarity, preventing the base from participating in the stabilizing base-stacking interactions that are fundamental to the rigidity of nucleic acid helices.[3] This disruption introduces a localized increase in the flexibility of the polynucleotide chain, particularly within the D-loop.[4]
Furthermore, the ribose sugar of dihydrouridine preferentially adopts a C2'-endo conformation, in contrast to the C3'-endo pucker typically associated with A-form helical RNA.[3] This conformational preference further contributes to the destabilization of the rigid helical structure and enhances the dynamic nature of the D-loop.[3] The increased flexibility imparted by dihydrouridine is thought to be essential for the proper folding of the tRNA into its functional L-shaped tertiary structure and for its interactions with other components of the translational machinery.
Quantitative Analysis of Dihydrouridine's Impact
While the qualitative effects of dihydrouridine on tRNA structure are well-established, quantitative data providing a direct comparison between dihydrouridine-containing and unmodified tRNAs are not extensively compiled in the literature. However, studies on dihydrouridine monophosphate (Dp) and short oligonucleotides containing dihydrouridine offer valuable insights into the thermodynamic consequences of this modification.
One study reported that the lack of dihydrouridine at position 20a in E. coli tRNASer led to a decrease in the melting temperature (Tm), suggesting that in some contexts, the increased flexibility can paradoxically contribute to the overall stability of the tertiary structure.[5] However, specific Tm values for a direct comparison are not consistently reported in a tabular format across the literature. Similarly, while molecular dynamics simulations have been employed to study tRNA flexibility, readily available tables comparing root-mean-square deviation (RMSD) values for the D-loop with and without dihydrouridine are scarce.
The most direct quantitative data comes from NMR studies on the conformational equilibrium of the ribose sugar.
Table 1: Thermodynamic Parameters for Ribose Conformer Interconversion at 25°C [3]
| Compound | Keq ([C2'-endo]/[C3'-endo]) | ΔH (kcal/mol) for C2'-endo Stabilization (relative to Up) |
| Uridine monophosphate (Up) | 0.85 | - |
| Dihydrouridine monophosphate (Dp) | 2.08 | 1.5 |
| ApUpA (U residue) | - | - |
| ApDpA (D residue) | 10.8 | 5.3 |
| ApDpA (5'-terminal A) | 1.35 | 3.6 |
Note: A higher Keq indicates a greater preference for the more flexible C2'-endo conformation. A positive ΔH indicates that the C2'-endo form is thermodynamically favored.
Experimental Protocols
Investigating the structural and functional impact of dihydrouridine on tRNA requires a combination of biochemical and biophysical techniques. Below are detailed methodologies for key experiments.
Preparation of Unmodified and Dihydrouridine-Containing tRNA
3.1.1. In Vitro Transcription of Unmodified tRNA
This protocol allows for the production of tRNA transcripts that lack any post-transcriptional modifications.
-
Template Preparation: A DNA template encoding the tRNA of interest under the control of a T7 promoter is generated by PCR or synthesized as a double-stranded DNA fragment.
-
Transcription Reaction: The transcription reaction is assembled in a total volume of 50 µL containing:
-
1 µg of DNA template
-
1X Transcription Buffer (40 mM Tris-HCl pH 8.0, 22 mM MgCl2, 1 mM spermidine, 5 mM DTT)
-
4 mM each of ATP, GTP, CTP, and UTP
-
10 units of RNase inhibitor
-
50 units of T7 RNA polymerase
-
-
Incubation: The reaction mixture is incubated at 37°C for 2-4 hours.
-
DNase Treatment: To remove the DNA template, 1 µL of RNase-free DNase I is added, and the mixture is incubated at 37°C for 15 minutes.
-
Purification: The transcribed tRNA is purified by phenol:chloroform extraction followed by ethanol (B145695) precipitation or by using a commercial RNA purification kit. The purified tRNA is then resolved on a denaturing polyacrylamide gel, the corresponding band is excised, and the tRNA is eluted from the gel.
3.1.2. Isolation of Dihydrouridine-Containing tRNA from Cells
This protocol allows for the purification of mature, fully modified tRNA from cellular sources.
-
Cell Lysis: Harvested cells (e.g., E. coli or yeast) are resuspended in a lysis buffer (e.g., 50 mM sodium acetate (B1210297) pH 5.0, 10 mM MgCl2) and lysed by methods such as sonication or French press.
-
Phenol Extraction: An equal volume of acid phenol:chloroform (pH 4.5) is added to the cell lysate. The mixture is vortexed vigorously and centrifuged to separate the phases. The aqueous phase containing the RNA is collected.
-
Ethanol Precipitation: The RNA is precipitated from the aqueous phase by adding 0.1 volumes of 3 M sodium acetate (pH 5.2) and 2.5 volumes of cold 100% ethanol. The mixture is incubated at -20°C overnight and then centrifuged to pellet the RNA.
-
tRNA Enrichment: The total RNA pellet is resuspended in a high-salt buffer (e.g., 1 M NaCl) to selectively precipitate high molecular weight RNA, leaving the smaller tRNAs in solution. The supernatant is collected, and the tRNA is precipitated with ethanol.
-
Purification: The crude tRNA can be further purified by anion-exchange chromatography (e.g., DEAE-cellulose column) or size-exclusion chromatography to obtain a highly pure tRNA fraction.
Biophysical Characterization
3.2.1. NMR Spectroscopy for Structural Analysis
NMR spectroscopy is a powerful technique to probe the structure and dynamics of tRNA in solution.
-
Sample Preparation: Purified tRNA (unmodified or modified) is dissolved in NMR buffer (e.g., 10 mM sodium phosphate (B84403) pH 6.5, 50 mM NaCl, 0.1 mM EDTA) in 90% H2O/10% D2O to a final concentration of 0.5-1.0 mM.
-
Data Acquisition: 1D and 2D NMR spectra (e.g., 1H-1H NOESY, 1H-15N HSQC for labeled samples) are acquired on a high-field NMR spectrometer (e.g., 600 MHz or higher).
-
Spectral Analysis: Imino proton signals in the 1D 1H spectrum provide information on base pairing and tertiary structure. NOESY spectra are used to assign proton resonances and identify through-space interactions to determine the three-dimensional structure. Chemical shift perturbations between the unmodified and dihydrouridine-containing tRNA can reveal localized conformational changes.
3.2.2. UV-Melting for Thermodynamic Stability
UV-melting experiments are used to determine the melting temperature (Tm) and thermodynamic parameters of tRNA folding.
-
Sample Preparation: Purified tRNA is diluted to a concentration of 1-5 µM in a buffer of choice (e.g., 10 mM sodium cacodylate, 100 mM NaCl, 5 mM MgCl2, pH 7.0).
-
Data Collection: The absorbance of the tRNA solution at 260 nm is monitored as a function of temperature using a spectrophotometer equipped with a temperature controller. The temperature is typically ramped from 20°C to 95°C at a rate of 1°C/minute.
-
Data Analysis: The melting temperature (Tm) is determined as the temperature at which 50% of the tRNA is unfolded, which corresponds to the midpoint of the sigmoidal melting curve. Thermodynamic parameters (ΔH°, ΔS°, and ΔG°) can be derived from the shape of the melting curve.
3.2.3. Molecular Dynamics Simulations
Molecular dynamics (MD) simulations provide atomic-level insights into the conformational dynamics of tRNA.
-
System Setup: An initial atomic model of the tRNA (with and without dihydrouridine) is generated based on crystal structures or homology modeling. The tRNA is placed in a simulation box filled with an explicit solvent model (e.g., TIP3P water) and counterions to neutralize the system.
-
Force Field: An appropriate force field for nucleic acids (e.g., AMBER, CHARMM) is chosen. Parameters for the dihydrouridine residue may need to be specifically developed or validated.
-
Simulation Protocol: The system is first energy-minimized to remove steric clashes. This is followed by a gradual heating of the system to the desired temperature (e.g., 300 K) and an equilibration phase. Finally, a production simulation is run for an extended period (nanoseconds to microseconds).
-
Trajectory Analysis: The resulting trajectory is analyzed to calculate structural and dynamic properties, including root-mean-square deviation (RMSD) to assess structural stability, root-mean-square fluctuation (RMSF) to identify flexible regions, and analysis of sugar pucker conformations and base stacking interactions.
Visualizing the Impact of Dihydrouridine
The following diagrams, generated using the DOT language for Graphviz, illustrate key aspects of dihydrouridine's role in tRNA.
Caption: Enzymatic synthesis of dihydrouridine in tRNA by Dus enzymes.
Caption: Workflow for studying the impact of dihydrouridine on tRNA.
Caption: Structural and functional consequences of dihydrouridine modification.
Conclusion and Future Directions
The presence of dihydrouridine in the D-loop of tRNA is a key determinant of its structural flexibility and, consequently, its biological function. The non-planar nature of the modified base and its preference for the C2'-endo sugar conformation disrupt the canonical A-form helical structure, leading to a more dynamic D-loop. This localized flexibility is crucial for the proper tertiary folding of tRNA and its interactions with the ribosome and other proteins involved in translation.
While the qualitative impact of dihydrouridine is well-understood, there is a need for more comprehensive quantitative studies that directly compare the biophysical properties of dihydrouridine-containing tRNAs with their unmodified counterparts. Such studies, providing detailed thermodynamic and structural data, will be invaluable for refining our models of tRNA function and for informing the design of novel therapeutic strategies that target tRNA-mediated processes. Future research should also focus on elucidating the specific roles of dihydrouridine in different tRNA species and under various cellular conditions to fully appreciate the regulatory complexity imparted by this subtle yet significant RNA modification.
References
dihydrouridine levels in different organisms and tissues
An In-depth Technical Guide to Dihydrouridine Levels in Diverse Biological Systems
For Researchers, Scientists, and Drug Development Professionals
Executive Summary
Dihydrouridine (D) is a structurally unique, post-transcriptionally modified nucleoside found in transfer RNA (tRNA) across all domains of life and, as recent evidence suggests, in messenger RNA (mRNA) and other non-coding RNAs in eukaryotes.[1][2][3][4] Formed by the enzymatic reduction of uridine (B1682114), its non-planar and non-aromatic ring structure imparts significant conformational flexibility to the RNA backbone, disrupting canonical base stacking and influencing RNA folding.[5][6][7][8] This guide provides a comprehensive overview of dihydrouridine levels across various organisms and tissues, details the precise experimental protocols for its quantification and mapping, and explores its emerging roles in cellular processes and disease, including carcinogenesis.[2][9]
Quantitative Dihydrouridine Levels Across Organisms and Tissues
The abundance of dihydrouridine varies significantly across different species and RNA types. It is one of the most prevalent modifications in tRNA, second only to pseudouridine.[1][6] In contrast, its presence in mRNA is rare and occurs at a very low stoichiometry.[1] Environmental factors, such as temperature, also influence D levels, with psychrophilic (cold-adapted) organisms exhibiting significantly higher concentrations in their tRNAs compared to their mesophilic and thermophilic counterparts, likely as a mechanism to maintain RNA flexibility at low temperatures.[6][9][10][11]
Dihydrouridine Levels in Prokaryotes
The tables below summarize the mole percent and number of dihydrouridine residues per RNA molecule in various bacterial species. Data is primarily derived from studies on Escherichia coli and Mycoplasma capricolum.
Table 1: Dihydrouridine (D) Quantification in E. coli
| RNA Type | Mole % D | Residues per Molecule | Reference |
|---|---|---|---|
| Unfractionated tRNA | 1.79% | 1.4 | [12][13] |
| 23S rRNA | 0.0396% | 1.1 | [12][13] |
| tRNASer(VGA) | Not Reported | 2.03 | [12][13] |
| tRNAThr(GGU) | Not Reported | 2.84 |[12][13] |
Table 2: Dihydrouridine (D) Content in E. coli Dihydrouridine Synthase (Dus) Mutants
| Strain | D Residues per tRNA | Reference |
|---|---|---|
| Wild Type | ~1.5 | [11] |
| ΔdusA Mutant | 0.6 | [11] |
| ΔdusB Mutant | 0.9 | [11] |
| ΔdusC Mutant | 1.3 |[11] |
Table 3: Dihydrouridine (D) Site Distribution in Mycoplasma capricolum tRNAs
| D-site Position | Number of tRNAs Modified | Reference |
|---|---|---|
| D20 | 17 | [11] |
| D17 | 13 | [11] |
| D20a | 11 |[11] |
Dihydrouridine Levels in Eukaryotes
In eukaryotes, dihydrouridine is ubiquitous in tRNA and has been identified in mRNA, although at much lower levels. Elevated D levels have been consistently observed in cancerous tissues.[2][9]
Table 4: Dihydrouridine (D) Distribution in Eukaryotic Organisms
| Organism/Tissue | RNA Type | Finding | Reference |
|---|---|---|---|
| Yeast (S. cerevisiae) | tRNA | At least one D modification in every sequenced tRNA; most have ≥2. | [14] |
| Yeast (S. cerevisiae) | mRNA | ~130 distinct D sites identified. | [7] |
| Mouse (Embryonic Stem Cells) | Cytoplasmic tRNA | D modifications located at positions 16, 17, 20, 20a, 20b, and 47. | [1] |
| Human | mRNA | Present but rare and at very low stoichiometry; 112 sites identified. | [1][7] |
| Human (Malignant Tissues) | tRNAPhe | Increased levels compared to normal tissues. | [15] |
| Human (Cancerous Tissues) | General | Generally increased D levels. |[2][9] |
Dihydrouridine in Archaea
Dihydrouridine is characteristically absent from the RNA of most archaea.[12] When present, it is found only in trace amounts.[12] However, similar to bacteria, psychrophilic archaea contain higher levels of D in their tRNA compared to their thermophilic counterparts.[10]
Experimental Protocols
The accurate quantification and mapping of dihydrouridine require specialized techniques capable of distinguishing it from the canonical uridine. Isotope-dilution mass spectrometry provides precise quantification, while next-generation sequencing-based methods enable transcriptome-wide mapping.
Quantification by Liquid Chromatography-Mass Spectrometry (LC-MS/MS)
LC-MS/MS is the gold standard for accurate quantification of nucleoside modifications.[12][13] The method relies on stable isotope dilution for high precision and sensitivity, requiring less than 1 µg of tRNA for analysis.[12]
Protocol Steps:
-
RNA Hydrolysis: Total RNA is enzymatically digested to its constituent nucleosides. This is typically achieved using a combination of nuclease P1, followed by snake venom phosphodiesterase and/or alkaline phosphatase.[13][16][17]
-
Isotope Dilution: A known quantity of isotopically labeled internal standards, specifically [1,3-¹⁵N₂]dihydrouridine and [1,3-¹⁵N₂]uridine, is added to the nucleoside mixture.[12][13][16]
-
HPLC Separation: The nucleoside mixture is separated using reverse-phase high-performance liquid chromatography (HPLC), typically on a C18 column.[18] A gradient of a buffered aqueous solution (e.g., ammonium (B1175870) acetate) and an organic solvent (e.g., acetonitrile) is used for elution.[16][18] Dihydrouridine elutes earlier than uridine due to its altered hydrophobicity.[18]
-
MS/MS Detection: The eluate is directed into a tandem mass spectrometer. Quantification is performed using selected ion monitoring (SIM) to measure the signal intensity of the protonated molecular ions for the analyte and its corresponding stable isotope-labeled internal standard.[12][16]
-
Data Analysis: The concentration of dihydrouridine in the original sample is calculated by comparing the peak area ratio of the unlabeled (endogenous) nucleoside to the labeled internal standard against a pre-established calibration curve.[16][19]
Transcriptome-Wide Mapping by D-Seq and Rho-Seq
Methods like D-Seq and Rho-Seq have been developed to map dihydrouridine sites across the transcriptome.[5][6][7] Both rely on the chemical reactivity of the dihydrouridine ring.
General Protocol:
-
Chemical Modification: RNA is treated with sodium borohydride (B1222165) (NaBH₄).[5][7] This reduces the dihydrouridine ring, creating a structure that can be detected during reverse transcription.
-
Detection via Reverse Transcription:
-
In D-Seq , the reduced base (tetrahydrouridine) causes the reverse transcriptase enzyme to stall and dissociate, leaving a truncated cDNA product.[5][7]
-
In Rho-Seq , a bulky rhodamine molecule is covalently attached to the reduced base, which serves as a robust block to the reverse transcriptase.[6][7]
-
-
Library Preparation and Sequencing: The resulting cDNA fragments are converted into a library for next-generation sequencing.
-
Data Analysis: The sequencing reads are mapped back to the reference transcriptome. An accumulation of cDNA 3'-ends at a specific nucleotide position, which is absent in control samples (e.g., from DUS knockout cells), indicates a dihydrouridine site.[7]
Cellular Synthesis and Functional Implications
Dihydrouridine is not incorporated during transcription but is synthesized post-transcriptionally by a conserved family of flavoenzymes known as dihydrouridine synthases (DUS).[1][2][20] These enzymes utilize NADPH as a hydride source to reduce a flavin mononucleotide (FMN) cofactor, which in turn reduces a specific uridine residue on the target RNA.[2][21][22]
Dihydrouridine Synthases (DUS)
Distinct DUS enzymes are responsible for modifying specific uridine sites.
-
Bacteria: Possess three main enzymes, DusA, DusB, and DusC, with non-overlapping specificities for different positions in the D-loop.[1][11][23]
-
Eukaryotes: Contain four homologs (DUS1-4).[1] In yeast, Dus1 modifies U16/17, Dus2 modifies U20, Dus3 modifies U47 (in the variable loop), and Dus4 modifies U20a/20b.[1][23] Mammalian DUS enzymes have similar site specificities.[1] DUS2L has been identified as the writer protein for human mitochondrial tRNAs.[1]
Functional Roles and Signaling
The structural impact of dihydrouridine—imparting local flexibility—underpins its diverse cellular functions.
-
RNA Structure and Stability: By disrupting base stacking, D modification introduces flexibility into the RNA structure.[8] This is crucial for the proper folding and stability of tRNAs, and tRNAs lacking D can be subject to rapid degradation.[11]
-
mRNA Processing and Translation: The discovery of D in mRNA has opened new avenues of investigation. Evidence suggests D is required for the proper splicing of certain introns.[5][7] Its role in translation appears to be transcript-specific, with some reports indicating it can suppress protein synthesis from specific mRNAs, while other studies show no effect.[5][7]
-
Role in Disease: Overexpression of the human DUS2 enzyme (hDUS2) and elevated dihydrouridine levels are associated with pulmonary carcinogenesis and worse patient outcomes.[2][6][15] Furthermore, hDUS2 has been shown to interact with and inhibit the interferon-induced protein kinase R (PKR), a critical component of cellular stress and antiviral signaling pathways.[24] This interaction suggests a role for dihydrouridine metabolism in modulating cellular responses to stress and viral infection.
Conclusion and Future Directions
Dihydrouridine is a widespread and functionally significant RNA modification. While its role in providing tRNA flexibility is well-established, its presence on mRNA and its implications for splicing, translation, and human diseases like cancer represent an exciting frontier in epitranscriptomics. The continued application of high-sensitivity analytical methods like LC-MS/MS and advanced sequencing techniques will be critical for fully elucidating the dihydrouridine landscape and deciphering its complex regulatory roles in gene expression. This knowledge is paramount for drug development professionals, as DUS enzymes and the pathways they regulate may represent novel therapeutic targets.
References
- 1. Quantitative CRACI reveals transcriptome-wide distribution of RNA dihydrouridine at base resolution - PMC [pmc.ncbi.nlm.nih.gov]
- 2. pnas.org [pnas.org]
- 3. Molecular evolution of dihydrouridine synthases - PMC [pmc.ncbi.nlm.nih.gov]
- 4. mdpi.com [mdpi.com]
- 5. Expanding the epitranscriptome: Dihydrouridine in mRNA | PLOS Biology [journals.plos.org]
- 6. The Dihydrouridine landscape from tRNA to mRNA: a perspective on synthesis, structural impact and function - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Expanding the epitranscriptome: Dihydrouridine in mRNA - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Mechanism of Dihydrouridine Synthase 2 from Yeast and the Importance of Modifications for Efficient tRNA Reduction - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Molecular basis of dihydrouridine formation on tRNA - PMC [pmc.ncbi.nlm.nih.gov]
- 10. researchgate.net [researchgate.net]
- 11. Dihydrouridine synthesis in tRNAs is under reductive evolution in Mollicutes - PMC [pmc.ncbi.nlm.nih.gov]
- 12. academic.oup.com [academic.oup.com]
- 13. Quantitative measurement of dihydrouridine in RNA using isotope dilution liquid chromatography-mass spectrometry (LC/MS) - PubMed [pubmed.ncbi.nlm.nih.gov]
- 14. Modomics - A Database of RNA Modifications [genesilico.pl]
- 15. researchgate.net [researchgate.net]
- 16. academic.oup.com [academic.oup.com]
- 17. academic.oup.com [academic.oup.com]
- 18. academic.oup.com [academic.oup.com]
- 19. researchgate.net [researchgate.net]
- 20. tRNA-dihydrouridine synthase - Wikipedia [en.wikipedia.org]
- 21. tandfonline.com [tandfonline.com]
- 22. DihydrouridinE RNA modification marks: written and erased by the same enzyme | ANR [anr.fr]
- 23. biorxiv.org [biorxiv.org]
- 24. Interaction of human tRNA-dihydrouridine synthase-2 with interferon-induced protein kinase PKR - PMC [pmc.ncbi.nlm.nih.gov]
The Enzymatic Synthesis of Dihydrouridine by Dus Enzymes: A Technical Guide
For Researchers, Scientists, and Drug Development Professionals
Abstract
Dihydrouridine (D), a ubiquitous modified nucleoside found in transfer RNA (tRNA), is synthesized by the evolutionarily conserved family of dihydrouridine synthases (Dus). These flavin-dependent enzymes catalyze the NADPH-dependent reduction of specific uridine (B1682114) residues, playing a crucial role in maintaining tRNA structure and function. Dysregulation of dihydrouridine levels has been implicated in various pathological conditions, including cancer, making Dus enzymes a potential therapeutic target. This technical guide provides an in-depth overview of the enzymatic synthesis of dihydrouridine by Dus enzymes, including their classification, catalytic mechanism, and substrate specificity. Furthermore, it offers detailed experimental protocols for the expression, purification, and functional characterization of Dus enzymes, along with methods for the detection and quantification of dihydrouridine.
Introduction to Dihydrouridine and Dus Enzymes
Dihydrouridine is one of the most common post-transcriptional modifications in tRNA, primarily located in the D-loop, a region named after this modified nucleoside.[1] The reduction of the C5-C6 double bond of uridine by dihydrouridine synthases (Dus) results in a non-planar, flexible structure that disrupts base stacking and increases the conformational flexibility of the tRNA backbone.[2] This flexibility is thought to be important for the proper folding and stability of tRNA, as well as for its interactions with other components of the translational machinery.
Dus enzymes are flavin-dependent oxidoreductases that utilize flavin mononucleotide (FMN) as a cofactor and NADPH as a hydride source.[1][3] They are found in all domains of life and are classified into distinct families based on their sequence homology and substrate specificity.
Classification and Substrate Specificity of Dus Enzymes
Dus enzymes exhibit remarkable specificity for the uridine residues they modify within a tRNA molecule. This specificity is crucial for the precise regulation of tRNA structure and function.
Prokaryotic Dus Enzymes
In bacteria, three main families of Dus enzymes have been identified: DusA, DusB, and DusC.[4] These enzymes have non-overlapping specificities for different uridine positions within the D-loop of tRNA.
-
DusA: Modifies uridine at positions 20 and 20a.[4]
-
DusB: Modifies uridine at position 17.[4]
-
DusC: Modifies uridine at position 16.[4]
Interestingly, some bacteria, like Mycoplasma capricolum, possess a single DusB enzyme that can modify positions 17, 20, and 20a, suggesting an evolutionary consolidation of activities.[4]
Eukaryotic Dus Enzymes
Eukaryotes have four distinct families of Dus enzymes, designated Dus1 through Dus4, which also display specificities for different uridine residues in tRNA.
-
Dus1: Modifies uridines at positions 16 and 17.[5]
-
Dus2: Modifies uridine at position 20.[5]
-
Dus3: Modifies uridine at position 47 in the variable loop.[5]
-
Dus4: Modifies uridines at positions 20a and 20b.[6]
The substrate recognition mechanisms of Dus enzymes are complex and can involve major reorientations of the tRNA substrate to present the target uridine to the active site.[7]
Catalytic Mechanism of Dus Enzymes
The synthesis of dihydrouridine by Dus enzymes proceeds through a two-step mechanism involving a reductive and an oxidative half-reaction.
Reductive Half-Reaction:
-
NADPH binds to the FMN-bound Dus enzyme.
-
A hydride ion is transferred from NADPH to the N5 position of the isoalloxazine ring of FMN, reducing it to FMNH₂.
-
NADP⁺ is released from the enzyme.
Oxidative Half-Reaction:
-
The tRNA substrate binds to the reduced enzyme-FMNH₂ complex.
-
The target uridine residue is positioned in the active site.
-
A hydride is transferred from the N5 of FMNH₂ to the C6 of the uridine base.
-
A proton is transferred from a conserved active site cysteine residue to the C5 of the uridine, completing the reduction of the double bond.
-
The dihydrouridine-modified tRNA is released, and the enzyme-FMN complex is regenerated.
The crystal structure of Thermus thermophilus Dus in complex with tRNA has provided valuable insights into the catalytic mechanism, revealing a covalent intermediate between a conserved cysteine residue and the C5 of the target uridine.[8]
Quantitative Data on Dus Enzyme Activity
The following tables summarize the available quantitative data on the kinetic parameters of Dus enzymes. It is important to note that comprehensive kinetic data for all Dus enzymes across different species and with various tRNA substrates is still an active area of research.
| Enzyme | Organism | Substrate(s) | KM (NADPH) (µM) | kcat (s⁻¹) | Catalytic Efficiency (kcat/KM) (M⁻¹s⁻¹) | Reference(s) |
| Prokaryotic Dus Enzymes | ||||||
| DusA | Escherichia coli | tRNAPhe | N/A | N/A | N/A | [6] |
| DusB | Mycoplasma capricolum | Bulk tRNA | >15-fold higher than hDus2 | N/A | N/A | [9] |
| DusC | Escherichia coli | Bulk tRNA | N/A | N/A | Low activity, KM difficult to determine | [2] |
| Eukaryotic Dus Enzymes | ||||||
| hDUS2 | Homo sapiens | tRNAVal-CAC | N/A | N/A | N/A | [10] |
N/A: Data not available in the reviewed literature.
Experimental Protocols
This section provides detailed methodologies for the key experiments involved in the study of Dus enzymes.
Recombinant Dus Enzyme Expression and Purification
This protocol describes a general method for the expression and purification of His-tagged Dus enzymes in E. coli.
Materials:
-
pET expression vector containing the Dus gene with an N-terminal His-tag
-
E. coli BL21(DE3) competent cells
-
LB medium and agar (B569324) plates with appropriate antibiotic
-
Isopropyl β-D-1-thiogalactopyranoside (IPTG)
-
Lysis buffer (50 mM Tris-HCl pH 7.5, 300 mM NaCl, 10 mM imidazole, 1 mM DTT, 10% glycerol)
-
Wash buffer (50 mM Tris-HCl pH 7.5, 300 mM NaCl, 20 mM imidazole, 1 mM DTT, 10% glycerol)
-
Elution buffer (50 mM Tris-HCl pH 7.5, 300 mM NaCl, 250 mM imidazole, 1 mM DTT, 10% glycerol)
-
Ni-NTA affinity chromatography column
-
Size-exclusion chromatography column (e.g., Superdex 75)
-
SDS-PAGE analysis reagents
Protocol:
-
Transform the pET-Dus plasmid into E. coli BL21(DE3) cells and plate on selective agar plates.
-
Inoculate a single colony into a starter culture and grow overnight at 37°C.
-
Inoculate a larger volume of LB medium with the starter culture and grow at 37°C to an OD₆₀₀ of 0.6-0.8.
-
Induce protein expression by adding IPTG to a final concentration of 0.5-1 mM and continue to grow at 18-25°C for 16-20 hours.
-
Harvest the cells by centrifugation and resuspend the pellet in lysis buffer.
-
Lyse the cells by sonication or high-pressure homogenization.
-
Clarify the lysate by centrifugation.
-
Load the supernatant onto a pre-equilibrated Ni-NTA column.
-
Wash the column with wash buffer to remove unbound proteins.
-
Elute the His-tagged Dus enzyme with elution buffer.
-
Further purify the protein by size-exclusion chromatography to remove aggregates and impurities.
-
Analyze the purity of the enzyme by SDS-PAGE.
-
Concentrate the purified protein, flash-freeze in liquid nitrogen, and store at -80°C.[6]
Dus Enzyme Activity Assay (NADPH Oxidation)
This spectrophotometric assay measures the activity of Dus enzymes by monitoring the decrease in absorbance at 340 nm due to the oxidation of NADPH.[6]
Materials:
-
Purified Dus enzyme
-
FMN
-
NADPH
-
In vitro transcribed or purified tRNA substrate
-
Reaction buffer (e.g., 50 mM Tris-HCl pH 7.5, 70 mM NH₄Cl, 30 mM KCl, 1 mM EDTA, 4 mM MgCl₂)
-
UV-Vis spectrophotometer
Protocol:
-
Prepare a reaction mixture containing the reaction buffer, FMN (e.g., 2 µM), and tRNA substrate (e.g., 50 µM).
-
Add the purified Dus enzyme to the reaction mixture to a final concentration of e.g., 2 µM.
-
Initiate the reaction by adding NADPH to a final concentration of e.g., 500 µM.
-
Immediately monitor the decrease in absorbance at 340 nm over time.
-
Calculate the initial rate of NADPH oxidation using the molar extinction coefficient of NADPH (ε₃₄₀ = 6220 M⁻¹cm⁻¹).
-
To determine kinetic parameters (KM and kcat), vary the concentration of one substrate (e.g., tRNA) while keeping the other (NADPH) at a saturating concentration, and fit the initial rate data to the Michaelis-Menten equation.
Detection and Quantification of Dihydrouridine
5.3.1. HPLC-based Quantification
This method allows for the quantification of dihydrouridine at the nucleoside level.
Materials:
-
tRNA sample
-
Nuclease P1
-
Bacterial alkaline phosphatase
-
HPLC system with a C18 reverse-phase column and a UV detector
-
Mobile phase buffers (e.g., ammonium (B1175870) acetate (B1210297) buffer with a methanol (B129727) gradient)
-
Dihydrouridine standard
Protocol:
-
Digest the tRNA sample to nucleosides by sequential treatment with Nuclease P1 and bacterial alkaline phosphatase.
-
Filter the digested sample to remove enzymes.
-
Inject the sample onto the HPLC column.
-
Separate the nucleosides using an appropriate gradient of the mobile phase.
-
Detect the nucleosides by monitoring the absorbance at 210 nm or 230 nm, as dihydrouridine has a weak chromophore at 254 nm.[11]
-
Quantify the amount of dihydrouridine by comparing the peak area to a standard curve generated with a known concentration of the dihydrouridine standard.
5.3.2. LC-MS/MS-based Quantification
This highly sensitive and specific method can quantify dihydrouridine at both the nucleoside and oligonucleotide level.
Materials:
-
tRNA sample
-
Enzymes for digestion (Nuclease P1, alkaline phosphatase for nucleoside analysis; RNase T1, RNase A for oligonucleotide analysis)
-
LC-MS/MS system with a triple quadrupole mass spectrometer
-
Appropriate columns and mobile phases for separation
Protocol (Nucleoside Level):
-
Digest the tRNA to nucleosides as described for the HPLC method.
-
Inject the sample into the LC-MS/MS system.
-
Separate the nucleosides by liquid chromatography.
-
Detect and quantify dihydrouridine using selected reaction monitoring (SRM) by monitoring the specific parent-to-daughter ion transition for dihydrouridine.[12]
Protocol (Oligonucleotide Level):
-
Digest the tRNA with specific RNases (e.g., RNase T1) to generate oligonucleotides.
-
Analyze the resulting fragments by LC-MS/MS to identify and quantify the dihydrouridine-containing fragments.[10]
Visualizations
Diagrams of Pathways and Workflows
Caption: Enzymatic mechanism of dihydrouridine synthesis by Dus enzymes.
Caption: Experimental workflow for studying Dus enzymes.
Caption: Logical flow of the functional consequences of tRNA dihydrouridylation.
Conclusion
The enzymatic synthesis of dihydrouridine by Dus enzymes is a fundamental process in tRNA maturation with significant implications for cellular function. The exquisite specificity of these enzymes and their role in modulating tRNA structure highlight their importance in the fine-tuning of translation. While significant progress has been made in understanding the mechanism and structure of Dus enzymes, further research is needed to fully elucidate the kinetic parameters of all enzyme families and their precise roles in cellular signaling pathways. The experimental protocols and information provided in this guide serve as a valuable resource for researchers aiming to further unravel the complexities of dihydrouridine synthesis and its impact on human health and disease.
References
- 1. Kinetic Analysis of tRNA Methylfransferases - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Kinetic analysis and substrate specificity of Escherichia coli dimethyl sulfoxide reductase - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. Functional redundancy in tRNA dihydrouridylation - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Sequence- and Structure-Specific tRNA Dihydrouridylation by hDUS2 - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Initial kinetic and mechanistic characterization of Escherichia coli fumarase A - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. Kinetic analysis of the mechanism of Escherichia coli dihydrofolate reductase - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. RNA modifying enzymes shape tRNA biogenesis and function [ouci.dntb.gov.ua]
- 8. Cell type-specific translational regulation by human DUS enzymes - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. Enzyme - Wikipedia [en.wikipedia.org]
- 10. openscience.ub.uni-mainz.de [openscience.ub.uni-mainz.de]
- 11. researchgate.net [researchgate.net]
- 12. biorxiv.org [biorxiv.org]
Methodological & Application
Detecting Dihydrouridine in tRNA: A Guide to Current Methodologies
Application Note & Protocol Guide
Audience: Researchers, scientists, and drug development professionals.
Introduction: Dihydrouridine (D) is a highly conserved and abundant modified nucleoside found in transfer RNA (tRNA) across all domains of life. Unlike the planar structure of its precursor, uridine, the saturation of the C5-C6 double bond in dihydrouridine introduces a non-planar conformation to the nucleobase. This structural alteration imparts significant flexibility to the RNA backbone, influencing tRNA folding, stability, and interaction with other components of the translational machinery. The accurate detection and quantification of dihydrouridine are crucial for understanding its role in tRNA function, gene expression regulation, and its implication in various diseases, including cancer. This document provides a detailed overview of current methods for detecting dihydrouridine in tRNA, complete with quantitative comparisons and step-by-step experimental protocols.
Methods for Dihydrouridine Detection: A Comparative Overview
Several techniques have been developed to identify and quantify dihydrouridine in tRNA. These methods can be broadly categorized into two groups: quantitative analysis of total dihydrouridine content and high-throughput sequencing approaches for mapping the precise location of dihydrouridine within tRNA molecules.
Quantitative Analysis
Liquid Chromatography-Mass Spectrometry (LC-MS): This is a highly sensitive and accurate method for quantifying the total amount of dihydrouridine in an RNA sample.[1][2] The method involves the enzymatic digestion of tRNA into its constituent nucleosides, followed by separation using liquid chromatography and detection by mass spectrometry. Isotope dilution is often employed for precise quantification, where a known amount of a stable isotope-labeled dihydrouridine standard is added to the sample.
High-Throughput Sequencing Methods
Recent advances in sequencing technology have enabled the transcriptome-wide mapping of RNA modifications at single-nucleotide resolution. Several methods have been adapted or specifically developed for dihydrouridine detection.
-
D-seq (Dihydrouridine Sequencing): This method relies on the chemical reduction of dihydrouridine with sodium borohydride (B1222165) (NaBH₄) to tetrahydrouridine (B1681287). This chemical conversion induces stalling of the reverse transcriptase during cDNA synthesis, and the resulting termination sites are identified by high-throughput sequencing.[3][4][5]
-
Rho-seq (Rhodamine Sequencing): Similar to D-seq, Rho-seq utilizes sodium borohydride treatment. However, it includes an additional step where a bulky rhodamine molecule is attached to the reduced dihydrouridine.[6][7] This large adduct leads to more efficient and robust reverse transcriptase stalling.[7]
-
AlkAniline-Seq: This technique exploits the chemical instability of the N-glycosidic bond in dihydrouridine under alkaline conditions.[2][8] Heat and alkaline treatment lead to the removal of the dihydrouracil (B119008) base, creating an abasic site. Subsequent treatment with aniline (B41778) cleaves the RNA backbone at this site, generating fragments that can be specifically ligated to sequencing adapters.[2]
-
CRACI-seq (Chemical Reduction Assisted Cytosine Incorporation sequencing): This method also begins with the chemical reduction of dihydrouridine. However, instead of causing a hard stop for the reverse transcriptase, the modification leads to the misincorporation of a cytosine (C) nucleotide opposite the modified base during reverse transcription.[9][10] This "mutation signature" is then identified through sequencing.
Quantitative Data Summary
The following table summarizes the key quantitative parameters of the different methods for dihydrouridine detection.
| Method | Principle | Resolution | Sensitivity | Throughput | Key Advantage | Limitations |
| LC-MS | Isotope dilution mass spectrometry | Not applicable (total quantification) | High (<1 µg of tRNA)[1] | Low | High accuracy (95-98%) and direct quantification[2] | Does not provide positional information. |
| D-seq | NaBH₄ reduction followed by RT stop | Single nucleotide | Moderate | High | Relatively straightforward protocol. | RT stops can be variable; potential for missed sites. |
| Rho-seq | NaBH₄ reduction, rhodamine labeling, and RT stop | Single nucleotide | High | High | Bulky adduct enhances RT stalling efficiency.[7] | Requires an additional labeling step. |
| AlkAniline-Seq | Alkaline hydrolysis and aniline cleavage | Single nucleotide | High | High | Very low background signal.[2] | Signal strength for D may be lower than for other modifications like m⁷G.[8] |
| CRACI-seq | NaBH₄ reduction followed by RT misincorporation | Single nucleotide | High | High | Avoids issues with RT drop-off, potentially allowing for better quantification of modification stoichiometry.[10] | Misincorporation rates can be influenced by sequence context. |
Experimental Protocols
This section provides detailed methodologies for the key experiments discussed.
Protocol 1: Quantification of Dihydrouridine by LC-MS
This protocol is based on the principle of stable isotope dilution liquid chromatography-mass spectrometry.[1][2]
Materials:
-
tRNA sample
-
[1,3-¹⁵N₂]dihydrouridine and [1,3-¹⁵N₂]uridine internal standards
-
Nuclease P1
-
Bacterial alkaline phosphatase
-
LC-MS system
Procedure:
-
Enzymatic Digestion:
-
To 1 µg of tRNA, add a known amount of [¹⁵N₂]dihydrouridine and [¹⁵N₂]uridine internal standards.
-
Digest the RNA to nucleosides by incubating with nuclease P1 followed by bacterial alkaline phosphatase.
-
-
LC-MS Analysis:
-
Inject the digested sample into the LC-MS system.
-
Separate the nucleosides using a suitable C18 reverse-phase column.
-
Perform mass spectrometry in selected ion monitoring (SIM) mode to monitor the protonated molecular ions of the labeled and unlabeled nucleosides. The mass-to-charge ratios (m/z) to monitor are: Uridine (245), Dihydrouridine (247), [¹⁵N₂]uridine (247), and [¹⁵N₂]dihydrouridine (249).[1]
-
-
Data Analysis:
-
Quantify the amount of dihydrouridine by comparing the peak area of the unlabeled dihydrouridine to that of the labeled internal standard.
-
Protocol 2: Dihydrouridine Mapping by D-seq
This protocol outlines the key steps for performing D-seq to map dihydrouridine sites in tRNA.[4]
Materials:
-
Total RNA or purified tRNA
-
Sodium borohydride (NaBH₄)
-
Reverse transcriptase (e.g., SuperScript III)
-
Reagents for library preparation for high-throughput sequencing
Procedure:
-
RNA Fragmentation (Optional, depending on starting material):
-
Fragment the RNA to a suitable size range (e.g., 100-200 nucleotides) using chemical or enzymatic methods.
-
-
Sodium Borohydride Reduction:
-
Prepare a fresh solution of 100 mg/mL NaBH₄ in 10 mM KOH.
-
To the RNA sample, add the NaBH₄ solution and incubate on ice for 1 hour.
-
Neutralize the reaction with acetic acid.
-
Purify the RNA by ethanol (B145695) precipitation.
-
-
Reverse Transcription:
-
Perform reverse transcription using a reverse transcriptase that is sensitive to the reduced dihydrouridine. The sites of tetrahydrouridine will cause the enzyme to stall, resulting in truncated cDNA fragments.
-
-
Library Preparation and Sequencing:
-
Ligate adapters to the 3' and 5' ends of the cDNA fragments.
-
Amplify the library by PCR.
-
Perform high-throughput sequencing of the library.
-
-
Data Analysis:
-
Map the sequencing reads to the reference tRNA sequences.
-
Identify dihydrouridine sites by looking for positions with a significant enrichment of read start sites (corresponding to the 3' ends of the cDNA) in the NaBH₄-treated sample compared to an untreated control.
-
Protocol 3: Dihydrouridine Mapping by Rho-seq
This protocol provides a general workflow for Rho-seq.[1][11]
Materials:
-
Total RNA or purified tRNA
-
Sodium borohydride (NaBH₄)
-
Rhodamine-110
-
Reverse transcriptase
-
Reagents for library preparation
Procedure:
-
Sodium Borohydride Reduction:
-
Treat the RNA with NaBH₄ as described in the D-seq protocol.
-
-
Rhodamine Labeling:
-
After the reduction step, add rhodamine-110 under acidic conditions and incubate in the dark.
-
Adjust the pH to neutral and purify the rhodamine-labeled RNA.
-
-
Reverse Transcription:
-
Perform reverse transcription. The bulky rhodamine adduct will cause a strong termination of the reverse transcriptase one nucleotide 3' to the dihydrouridine site.
-
-
Library Preparation and Sequencing:
-
Prepare sequencing libraries from the resulting truncated cDNA fragments as described for D-seq.
-
-
Data Analysis:
-
Analyze the sequencing data to identify positions with an increased frequency of reverse transcriptase stops in the rhodamine-labeled sample compared to a mock-treated control.
-
Protocol 4: Dihydrouridine Mapping by AlkAniline-Seq
The following is a generalized protocol for AlkAniline-Seq.[2][8]
Materials:
-
Total RNA or purified tRNA
-
Alkaline buffer
-
Aniline solution
-
Reagents for library preparation
Procedure:
-
Alkaline Hydrolysis:
-
Incubate the RNA in an alkaline buffer at an elevated temperature. This treatment will lead to the specific removal of the dihydrouracil base.
-
-
Aniline Cleavage:
-
Treat the RNA with an aniline solution. Aniline will catalyze the cleavage of the phosphodiester backbone at the abasic site.
-
-
Library Preparation and Sequencing:
-
The resulting RNA fragments will have a 5'-phosphate group at the cleavage site, which can be specifically ligated to sequencing adapters.
-
Prepare and sequence the library.
-
-
Data Analysis:
-
Map the reads to the reference tRNA sequences. Dihydrouridine sites are identified as the 5' ends of the mapped reads.
-
Protocol 5: Dihydrouridine Mapping by CRACI-seq
This protocol describes the principle of CRACI-seq.[9][10]
Materials:
-
Total RNA or purified tRNA
-
Potassium borohydride (KBH₄)
-
Reverse transcriptase (e.g., HIV RT)
-
Reagents for library preparation
Procedure:
-
Chemical Reduction:
-
Treat the RNA with KBH₄ to reduce dihydrouridine.
-
-
Reverse Transcription with Misincorporation:
-
Perform reverse transcription using a reverse transcriptase and reaction conditions that promote the misincorporation of cytosine opposite the reduced dihydrouridine.
-
-
Library Preparation and Sequencing:
-
Generate full-length cDNA, prepare sequencing libraries, and perform high-throughput sequencing.
-
-
Data Analysis:
-
Align the sequencing reads to the reference transcriptome.
-
Identify dihydrouridine sites by looking for positions with a high frequency of T-to-C mutations in the KBH₄-treated sample compared to an untreated control.
-
Visualizations
The following diagrams illustrate the experimental workflows for the different dihydrouridine detection methods.
References
- 1. researchgate.net [researchgate.net]
- 2. Mapping of 7-methylguanosine (m7G), 3-methylcytidine (m3C), dihydrouridine (D) and 5-hydroxycytidine (ho5C) RNA modifications by AlkAniline-Seq - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. D-Seq: Genome-wide detection of dihydrouridine modifications in RNA - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. austindraycott.com [austindraycott.com]
- 5. Transcriptome-wide mapping reveals a diverse dihydrouridine landscape including mRNA - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Transcription-wide mapping of dihydrouridine reveals that mRNA dihydrouridylation is required for meiotic chromosome segregation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. Expanding the epitranscriptome: Dihydrouridine in mRNA - PMC [pmc.ncbi.nlm.nih.gov]
- 8. The Dihydrouridine landscape from tRNA to mRNA: a perspective on synthesis, structural impact and function - PMC [pmc.ncbi.nlm.nih.gov]
- 9. researchgate.net [researchgate.net]
- 10. researchgate.net [researchgate.net]
- 11. Transcription-wide mapping of dihydrouridine reveals that mRNA dihydrouridylation is required for meiotic chromosome segregation - PMC [pmc.ncbi.nlm.nih.gov]
Application Note: Quantitative Analysis of Dihydrouridine in Biological Matrices using LC-MS/MS
For Researchers, Scientists, and Drug Development Professionals
Abstract
Dihydrouridine (D) is a post-transcriptionally modified nucleoside integral to the structure and function of transfer RNA (tRNA) and has been increasingly recognized for its regulatory roles in messenger RNA (mRNA).[1][2][3] Accurate quantification of dihydrouridine is crucial for understanding its biological significance in various physiological and pathological processes, including cancer.[3] This application note provides a detailed protocol for the sensitive and accurate quantification of dihydrouridine in RNA samples using Liquid Chromatography with tandem Mass Spectrometry (LC-MS/MS). The described method, which utilizes a stable isotope-labeled internal standard, is suitable for high-throughput analysis in academic and industrial research settings.
Introduction
5,6-dihydrouridine (D) is one of the most common modified nucleosides found in tRNA across all domains of life.[3] It is synthesized from uridine (B1682114) through the reduction of the C5-C6 double bond by a class of enzymes known as dihydrouridine synthases (Dus).[3] The non-planar and non-aromatic nature of the dihydrouracil (B119008) base disrupts standard base stacking, thereby increasing the conformational flexibility of the RNA backbone.[1][3] This property is critical for the formation of the D-loop in tRNAs, which contributes to the proper folding and stability of the molecule.[2]
Recent studies have revealed the presence of dihydrouridine in mRNA, where it is implicated in the regulation of mRNA stability and translation.[1][4] For instance, dihydrouridylation of specific mRNAs has been shown to be required for critical cellular processes like meiotic chromosome segregation.[5] Given its emerging roles in gene expression and its association with diseases such as cancer, robust analytical methods for the precise quantification of dihydrouridine are essential.[3]
LC-MS/MS has become the gold standard for the analysis of modified nucleosides due to its high sensitivity, selectivity, and accuracy.[3][6][7] This application note details a validated LC-MS/MS method for the quantitative analysis of dihydrouridine in RNA samples, providing researchers with a reliable tool to investigate its biological functions.
Experimental Protocols
Sample Preparation: Enzymatic Hydrolysis of RNA
The initial and critical step in the quantitative analysis of dihydrouridine is the complete enzymatic digestion of RNA into its constituent nucleosides.[6][7]
Materials:
-
Purified RNA sample (e.g., total RNA, mRNA, or tRNA)
-
Nuclease P1 (from Penicillium citrinum)
-
Bacterial Alkaline Phosphatase (BAP)
-
Ammonium (B1175870) acetate (B1210297) buffer (pH 5.3)
-
Stable isotope-labeled internal standard: [1,3-¹⁵N₂]dihydrouridine
-
Ultrapure water
Protocol:
-
To 1-5 µg of purified RNA, add 2 Units of Nuclease P1 in a final volume of 20 µL of 10 mM ammonium acetate (pH 5.3).
-
Incubate the mixture at 37°C for 2 hours to digest the RNA into 5'-mononucleotides.
-
Add 1 µL of 1 M ammonium bicarbonate and 2 Units of Bacterial Alkaline Phosphatase.
-
Incubate at 37°C for an additional 2 hours to dephosphorylate the mononucleotides into nucleosides.
-
Spike the sample with a known concentration of the [1,3-¹⁵N₂]dihydrouridine internal standard.
-
Centrifuge the sample at 10,000 x g for 5 minutes to pellet the enzymes.
-
Transfer the supernatant containing the nucleosides for LC-MS/MS analysis. For small sample volumes, enzyme removal can also be achieved using molecular-weight-cutoff filters.[6][7]
LC-MS/MS Analysis
Instrumentation:
-
A high-performance liquid chromatography (HPLC) or ultra-high-performance liquid chromatography (UHPLC) system.
-
A triple quadrupole mass spectrometer equipped with an electrospray ionization (ESI) source.
LC Parameters:
| Parameter | Value |
| Column | Reversed-phase C18 column (e.g., 2.1 x 100 mm, 1.8 µm) |
| Mobile Phase A | 0.1% Formic acid in water |
| Mobile Phase B | Acetonitrile |
| Flow Rate | 0.3 mL/min |
| Injection Volume | 5-10 µL |
| Gradient | 0-2 min, 2% B; 2-5 min, 2-55% B; 5-15 min, 55-100% B; 15-20 min, 100% B; 20.1-29 min, 2% B |
MS/MS Parameters:
The mass spectrometer should be operated in positive ion mode using Multiple Reaction Monitoring (MRM).
| Parameter | Dihydrouridine | [1,3-¹⁵N₂]dihydrouridine (IS) |
| Precursor Ion (m/z) | 247.1 | 249.1 |
| Product Ion (m/z) | 115.0 | 117.0 |
| Collision Energy (eV) | Optimized for the specific instrument (typically 10-20 eV) | Optimized for the specific instrument |
| Dwell Time (ms) | 100 | 100 |
Note: The specific MRM transition for dihydrouridine is from its protonated molecule [M+H]⁺ to the fragment corresponding to the ribose moiety.[8]
Quantitative Data Summary
The performance of the LC-MS/MS method for dihydrouridine quantification is summarized in the table below, based on previously published data.[9][10]
| Parameter | Result | Reference |
| Linearity (r²) | > 0.99 | [11] |
| Accuracy | 95-98% | [10] |
| Precision (%RSD) | 0.43 - 2.4% | [10] |
| Lower Limit of Quantification (LLOQ) | pmol range | [10] |
Visualizations
Dihydrouridine Synthesis and Role in mRNA Regulation
Dihydrouridine is synthesized from uridine by Dihydrouridine Synthase (Dus) enzymes. In mRNA, the presence of dihydrouridine can influence its stability and translation, thereby regulating protein expression. This has implications for cellular processes such as cell division.
Caption: Enzymatic synthesis of dihydrouridine and its impact on mRNA fate.
Experimental Workflow for Dihydrouridine Quantification
The overall experimental workflow for the quantitative analysis of dihydrouridine from biological samples is depicted below.
Caption: Workflow for dihydrouridine analysis by LC-MS/MS.
Conclusion
The LC-MS/MS method detailed in this application note provides a robust and reliable approach for the quantitative analysis of dihydrouridine in RNA samples. This protocol, combined with the use of a stable isotope-labeled internal standard, ensures high accuracy and precision, making it an invaluable tool for researchers investigating the role of this important RNA modification in health and disease. The growing understanding of dihydrouridine's function beyond tRNA structure underscores the need for such precise analytical methods in the expanding field of epitranscriptomics.
References
- 1. Expanding the epitranscriptome: Dihydrouridine in mRNA - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Expanding the epitranscriptome: Dihydrouridine in mRNA | PLOS Biology [journals.plos.org]
- 3. The Dihydrouridine landscape from tRNA to mRNA: a perspective on synthesis, structural impact and function - PMC [pmc.ncbi.nlm.nih.gov]
- 4. biorxiv.org [biorxiv.org]
- 5. Transcription-wide mapping of dihydrouridine reveals that mRNA dihydrouridylation is required for meiotic chromosome segregation [dspace.mit.edu]
- 6. pubs.acs.org [pubs.acs.org]
- 7. Pitfalls in RNA Modification Quantification Using Nucleoside Mass Spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Differential redox sensitivity of tRNA dihydrouridylation - PMC [pmc.ncbi.nlm.nih.gov]
- 9. academic.oup.com [academic.oup.com]
- 10. Quantitative measurement of dihydrouridine in RNA using isotope dilution liquid chromatography-mass spectrometry (LC/MS) - PubMed [pubmed.ncbi.nlm.nih.gov]
- 11. researchgate.net [researchgate.net]
Application Notes and Protocols for the Separation of Modified Ribonucleosides by HPLC
For researchers, scientists, and drug development professionals, the accurate separation and quantification of modified ribonucleosides are critical for understanding the epitranscriptome and its role in various biological processes and disease states. High-Performance Liquid Chromatography (HPLC), particularly when coupled with mass spectrometry, stands as a gold-standard technique for this purpose.[1][2][3] This document provides detailed application notes and protocols for two principal HPLC-based methodologies: Reverse-Phase HPLC (RP-HPLC) and Hydrophilic Interaction Liquid Chromatography (HILIC).
Introduction to HPLC Techniques for Ribonucleoside Analysis
The separation of the diverse array of modified ribonucleosides, which can be quite similar in structure, presents a significant analytical challenge.[4] The choice between RP-HPLC and HILIC often depends on the specific ribonucleosides of interest and their polarity.
-
Reverse-Phase HPLC (RP-HPLC) is a widely used technique that separates molecules based on their hydrophobicity.[5] It is particularly effective for a broad range of modified ribonucleosides. Common stationary phases include C18 and C30 columns.[6]
-
Hydrophilic Interaction Liquid Chromatography (HILIC) is an alternative approach well-suited for the retention and separation of highly polar compounds that are not well-retained by reverse-phase columns.[7][8] HILIC utilizes a polar stationary phase and a mobile phase with a high concentration of organic solvent.[8][9]
Experimental Workflow for Ribonucleoside Analysis
The overall experimental workflow for the analysis of modified ribonucleosides from an RNA sample involves several key steps, from sample preparation to data analysis.
Caption: A generalized experimental workflow for the analysis of modified ribonucleosides using HPLC.
Detailed Experimental Protocols
Protocol 1: Sample Preparation from RNA
This protocol outlines the necessary steps to digest RNA into its constituent ribonucleosides for subsequent HPLC analysis.
Materials:
-
Purified RNA sample
-
Nuclease P1
-
Snake Venom Phosphodiesterase (SVP)
-
Bacterial Alkaline Phosphatase (BAP)
-
Tris buffer
Procedure:
-
RNA Denaturation: Dissolve 2-100 µg of RNA in nuclease-free water. Heat at 95°C for 5 minutes and then cool on ice.
-
Nuclease P1 Digestion: Add ammonium acetate to a final concentration of 10 mM and zinc chloride to a final concentration of 1 mM. Add 1-2 units of Nuclease P1 and incubate at 37°C for 2 hours or overnight.[10]
-
Dephosphorylation: Add Tris buffer to a final concentration of 50 mM and magnesium acetate to a final concentration of 10 mM. Add 0.5 units of SVP and 1 unit of BAP. Incubate at 37°C for 2 hours.[6]
-
Sample Cleanup: After digestion, centrifuge the sample at high speed (e.g., 12,000 x g) for 10 minutes to pellet any undigested material or enzymes.[6] The supernatant containing the ribonucleosides is then ready for HPLC analysis.
Protocol 2: Reverse-Phase HPLC (RP-HPLC) Separation
This protocol provides a general method for the separation of a broad range of modified ribonucleosides.
Instrumentation and Columns:
-
HPLC System: A standard HPLC system with a UV detector or coupled to a mass spectrometer.
-
Column: A C18 or C30 reverse-phase column (e.g., 25 cm x 4.6 mm, 5 µm particle size) is commonly used.[6][10]
Mobile Phases:
-
Mobile Phase A: 5 mM ammonium acetate, pH 6.0.[10]
-
Mobile Phase B: 40% (v/v) acetonitrile (B52724) in water.[10]
Gradient Program:
| Time (min) | % Mobile Phase B |
| 0 | 0 |
| 50 | 25 |
| 55 | 100 |
| 60 | 100 |
| 65 | 0 |
| 75 | 0 |
Flow Rate: 1.0 mL/min Column Temperature: 21°C[10] Detection: UV at 254 nm or by mass spectrometry.
Protocol 3: Hydrophilic Interaction Liquid Chromatography (HILIC) Separation
This protocol is optimized for the separation of more polar modified ribonucleosides.[7]
Instrumentation and Columns:
-
HPLC System: An HPLC or UHPLC system coupled to a mass spectrometer is highly recommended for sensitive detection.
-
Column: A zwitterionic HILIC column (e.g., Atlantis Premier BEH Z-HILIC) is a suitable choice.
Mobile Phases:
-
Mobile Phase A: Water with 0.1% formic acid.[11]
-
Mobile Phase B: Acetonitrile with 0.1% formic acid.[11]
Gradient Program:
| Time (min) | % Mobile Phase B |
| 0 | 95 |
| 10 | 60 |
| 12 | 5 |
| 15 | 5 |
| 16 | 95 |
| 20 | 95 |
Flow Rate: 0.3 mL/min Column Temperature: 35°C[11] Detection: Mass spectrometry (e.g., triple quadrupole in MRM mode).
Data Presentation: Retention Times of Common Modified Ribonucleosides
The following table summarizes typical retention times for a selection of modified ribonucleosides obtained using RP-HPLC. Note that these values can vary depending on the specific HPLC system, column, and exact mobile phase conditions.
| Modified Ribonucleoside | Abbreviation | RP-HPLC Retention Time (min) - Approximate |
| Pseudouridine | Ψ | ~8 |
| 5-Methylcytidine | m⁵C | ~12 |
| N⁶-Methyladenosine | m⁶A | ~26 |
| N¹-Methyladenosine | m¹A | ~15 |
| N⁷-Methylguanosine | m⁷G | ~10 |
| 2'-O-Methylguanosine | Gm | ~18 |
| Inosine | I | ~9 |
| Wybutosine | YW | >30 |
Signaling Pathways and Logical Relationships in HPLC-MS Analysis
The process of identifying and quantifying modified ribonucleosides by LC-MS/MS involves a logical sequence of events within the mass spectrometer.
Caption: Logical workflow of modified ribonucleoside analysis by HPLC-MS/MS.
In this workflow, the HPLC separates the ribonucleosides, which are then ionized. The first stage of the mass spectrometer (MS1) selects the precursor ion (the intact modified ribonucleoside). This ion is then fragmented through collision-induced dissociation (CID), and the resulting product ions (typically the nucleobase) are detected in the second stage (MS2). This highly specific process allows for accurate identification and quantification.[2]
References
- 1. researchgate.net [researchgate.net]
- 2. Detection of ribonucleoside modifications by liquid chromatography coupled with mass spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Detection of ribonucleoside modifications by liquid chromatography coupled with mass spectrometry - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. mdpi.com [mdpi.com]
- 5. Ribonucleoside analysis by reversed-phase high-performance liquid chromatography - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. HPLC Analysis of tRNA‐Derived Nucleosides [bio-protocol.org]
- 7. Nucleoside Analysis by Hydrophilic Interaction Liquid Chromatography Coupled with Mass Spectrometry - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. chromatographyonline.com [chromatographyonline.com]
- 9. Hydrophilic interaction liquid chromatography (HILIC)—a powerful separation technique - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Detection of RNA Modifications by HPLC Analysis and Competitive ELISA - PMC [pmc.ncbi.nlm.nih.gov]
- 11. researchgate.net [researchgate.net]
Application Notes and Protocols: Developing a DUS-Complementation Assay in E. coli
For Researchers, Scientists, and Drug Development Professionals.
Introduction
Genetic complementation assays are powerful tools in molecular biology to determine the function of genes and the effect of specific DNA sequences. This document details the development and protocol for a DNA Uptake Sequence (DUS) complementation assay in Escherichia coli. While DUS are naturally found in species like Neisseria and Haemophilus influenzae to facilitate preferential uptake of their own DNA, this assay repurposes the concept to study the efficiency of various DUS sequences in mediating DNA uptake and functional complementation in an E. coli model system.[1] This can be particularly useful in drug development for screening compounds that may inhibit or enhance DNA uptake processes in pathogenic bacteria.
The principle of this assay is based on the transformation of a specially engineered E. coli strain, deficient in a key metabolic or resistance gene, with a plasmid carrying that gene under the control of a DUS. The successful uptake of the plasmid and expression of the gene "complements" the deficiency, allowing the bacteria to grow under selective conditions. The efficiency of complementation can then be quantified to assess the functionality of the tested DUS.
Principle of the DUS-Complementation Assay
The DUS-complementation assay leverages a genetically modified E. coli strain with a specific gene deletion (e.g., an antibiotic resistance gene or a gene essential for metabolizing a specific sugar). This strain is then transformed with a plasmid containing the corresponding wild-type gene. The key feature of this plasmid is the inclusion of a DUS upstream of the gene. The rate and success of transformation, and therefore complementation, are hypothesized to be influenced by the presence and sequence of the DUS. By measuring the number of transformed colonies (colony-forming units or CFUs), one can infer the efficiency of the DUS in promoting DNA uptake and subsequent gene expression.
Logical Workflow of the DUS-Complementation Assay
Caption: Logical workflow of the DUS-complementation assay.
Materials and Methods
Bacterial Strains and Plasmids
A suitable E. coli strain deficient in a selectable marker is required. For this protocol, we will use E. coli DH5α ΔlacZ, which is incapable of metabolizing lactose. The complementing plasmid, pDUS-lacZ, will carry the lacZ gene and a specific DUS variant. A control plasmid without a DUS (pControl-lacZ) is also necessary.
Table 1: Bacterial Strains and Plasmids
| Name | Relevant Characteristics | Purpose |
| E. coli DH5α ΔlacZ | F- φ80lacZΔM15 Δ(lacZYA-argF) U169 recA1 endA1 hsdR17(rk-, mk+) phoA supE44 λ- thi-1 gyrA96 relA1 | Host strain for complementation, unable to metabolize lactose. |
| pDUS-lacZ | pUC19 backbone, Ampicillin (B1664943) resistance, lacZ gene, DUS variant sequence | Experimental plasmid to test DUS functionality. |
| pControl-lacZ | pUC19 backbone, Ampicillin resistance, lacZ gene, no DUS | Negative control plasmid. |
Experimental Protocol
-
Preparation of Competent Cells:
-
Inoculate a single colony of E. coli DH5α ΔlacZ into 5 mL of LB broth and grow overnight at 37°C with shaking.
-
The next day, inoculate 1 mL of the overnight culture into 100 mL of fresh LB broth and grow to an OD600 of 0.4-0.6.
-
Chill the culture on ice for 20-30 minutes.
-
Centrifuge the cells at 4,000 x g for 15 minutes at 4°C.
-
Discard the supernatant and resuspend the cell pellet in 50 mL of ice-cold, sterile 100 mM CaCl2.
-
Incubate on ice for 30 minutes.
-
Centrifuge again at 4,000 x g for 15 minutes at 4°C.
-
Discard the supernatant and resuspend the pellet in 2 mL of ice-cold, sterile 100 mM CaCl2 with 15% glycerol.
-
Aliquot 50 µL of the competent cells into pre-chilled microcentrifuge tubes and store at -80°C.
-
-
Transformation:
-
Thaw aliquots of competent E. coli DH5α ΔlacZ cells on ice.
-
Add 10 ng of either pDUS-lacZ or pControl-lacZ plasmid DNA to the cells.
-
Incubate on ice for 30 minutes.
-
Heat-shock the cells at 42°C for 45 seconds.
-
Immediately place the tubes back on ice for 2 minutes.
-
Add 950 µL of SOC medium and incubate at 37°C for 1 hour with gentle shaking.
-
-
Plating and Selection:
-
Plate 100 µL of the transformed cells onto M9 minimal media agar (B569324) plates containing lactose as the sole carbon source and ampicillin (100 µg/mL).
-
Also, plate a 1:100 dilution of the transformation mix onto LB agar plates with ampicillin to determine the total number of transformants.
-
Incubate all plates at 37°C for 24-48 hours.
-
-
Data Analysis:
-
Count the number of colonies on both the M9-lactose and LB-ampicillin plates.
-
Calculate the complementation efficiency as the ratio of CFUs on M9-lactose plates to the CFUs on LB-ampicillin plates.
-
Experimental Workflow Diagram
Caption: Detailed experimental workflow for the DUS-complementation assay.
Expected Results and Data Presentation
The number of colonies on the M9-lactose plates will be indicative of successful complementation. A higher number of colonies for the pDUS-lacZ transformation compared to the pControl-lacZ transformation would suggest that the DUS enhances DNA uptake and/or subsequent gene expression leading to complementation.
Table 2: Hypothetical Complementation Efficiency Data
| Plasmid | DUS Sequence | CFUs on LB-Amp (Total Transformants) | CFUs on M9-Lactose-Amp (Complemented) | Complementation Efficiency (%) |
| pControl-lacZ | None | 1.5 x 10^4 | 150 | 1.0 |
| pDUS-lacZ_Var1 | ATGCCGTCTGAA | 1.6 x 10^4 | 780 | 4.9 |
| pDUS-lacZ_Var2 | GCCGTCTGAA | 1.4 x 10^4 | 630 | 4.5 |
| pDUS-lacZ_Var3 | AAGTGCGGT | 1.5 x 10^4 | 450 | 3.0 |
Applications in Drug Development
This DUS-complementation assay can be adapted for high-throughput screening of small molecules that modulate DNA uptake in bacteria.[2][3][4][5] By performing the assay in the presence of test compounds, researchers can identify potential inhibitors of bacterial transformation, which could be developed as novel antimicrobial agents. Conversely, compounds that enhance transformation could be investigated for their potential in biotechnology and synthetic biology applications.
Signaling Pathway for DUS-Mediated Uptake (Hypothetical in E. coli)
Caption: Hypothetical signaling pathway for DUS-mediated DNA uptake.
Troubleshooting
Table 3: Troubleshooting Guide
| Issue | Possible Cause | Solution |
| No colonies on any plates | Inefficient competent cells | Prepare fresh competent cells and test their efficiency with a control plasmid. |
| Poor quality plasmid DNA | Purify plasmid DNA and verify its concentration and integrity. | |
| Incorrect antibiotic concentration | Prepare fresh antibiotic stocks and plates. | |
| Low number of colonies on M9-lactose plates for all samples | Inefficient complementation | Increase the amount of plasmid DNA used for transformation. |
| Increase the recovery time after heat shock. | ||
| High background on control plates (pControl-lacZ) | Contamination of the E. coli strain | Streak out the strain for single colonies and verify the ΔlacZ phenotype. |
| Reversion of the lacZ mutation | Use a freshly prepared stock of the E. coli strain. |
Conclusion
The DUS-complementation assay in E. coli provides a versatile and quantitative method to study the function of DNA uptake sequences. Its application can be extended to screen for modulators of bacterial transformation, offering a valuable tool for both basic research and drug discovery. The detailed protocol and guidelines presented here should enable researchers to successfully implement and adapt this assay for their specific needs.
References
- 1. Uptake signal sequence - Wikipedia [en.wikipedia.org]
- 2. lifesciences.danaher.com [lifesciences.danaher.com]
- 3. bioagilytix.com [bioagilytix.com]
- 4. Cell-based assays are a key component in drug development process [thermofisher.com]
- 5. Role of Cell-Based Assays in Drug Discovery and Development - Creative Bioarray | Creative Bioarray [creative-bioarray.com]
Application Notes and Protocols for In Vitro Dihydrouridylation Assay Using Recombinant hDUS2
For Researchers, Scientists, and Drug Development Professionals
These application notes provide a detailed protocol for an in vitro dihydrouridylation assay using recombinant human Dihydrouridine Synthase 2 (hDUS2). This assay is crucial for studying the enzymatic activity of hDUS2, screening for potential inhibitors, and investigating its role in various cellular processes, including tRNA maturation and its implications in diseases like non-small cell lung cancer.[1][2][3][4]
Introduction
Dihydrouridine (D) is a common modified nucleoside found in transfer RNA (tRNA), synthesized by the reduction of uridine (B1682114).[5][6] This modification is catalyzed by a family of enzymes known as dihydrouridine synthases (DUS). In humans, hDUS2 is a key enzyme that has been shown to exclusively modify uridine at position 20 (U20) within the D-loop of various tRNA substrates.[1][3][7][8] Dysregulation of hDUS2 has been linked to pulmonary carcinogenesis, making it a potential therapeutic target.[2][9]
The following protocol details the expression and purification of recombinant hDUS2, the setup of the in vitro dihydrouridylation reaction, and the analysis of the results using LC-MS/MS.
Key Experimental Workflow
The overall workflow for the in vitro dihydrouridylation assay is depicted below.
hDUS2 Signaling and Interaction Pathway
hDUS2 is involved in cellular processes beyond tRNA modification, including interactions with proteins involved in translation and antiviral responses.
Experimental Protocols
Recombinant hDUS2 Expression and Purification
Recombinant hDUS2 can be expressed in E. coli and purified using affinity chromatography.[1][10]
Materials:
-
hDUS2 expression vector (e.g., pET-based with His-tag)
-
E. coli expression strain (e.g., BL21(DE3))
-
LB Broth and appropriate antibiotic
-
Isopropyl β-D-1-thiogalactopyranoside (IPTG)
-
Lysis Buffer (e.g., 50 mM Tris-HCl pH 8.0, 300 mM NaCl, 10 mM imidazole, 1 mM DTT, protease inhibitors)
-
Wash Buffer (e.g., 50 mM Tris-HCl pH 8.0, 300 mM NaCl, 20-40 mM imidazole, 1 mM DTT)
-
Elution Buffer (e.g., 50 mM Tris-HCl pH 8.0, 300 mM NaCl, 250-500 mM imidazole, 1 mM DTT)
-
Ni-NTA affinity resin
-
Dialysis buffer (e.g., 50 mM HEPES pH 7.5, 150 mM NaCl, 10% glycerol, 1 mM DTT)
Protocol:
-
Transform the hDUS2 expression vector into the E. coli expression strain.
-
Inoculate a starter culture and grow overnight.
-
Inoculate a larger culture with the starter culture and grow at 37°C to an OD600 of 0.6-0.8.
-
Induce protein expression with IPTG (e.g., 0.5 mM) and continue to grow at a lower temperature (e.g., 18°C) overnight.
-
Harvest the cells by centrifugation and resuspend the pellet in Lysis Buffer.
-
Lyse the cells (e.g., by sonication) and clarify the lysate by centrifugation.
-
Apply the supernatant to a pre-equilibrated Ni-NTA column.
-
Wash the column with Wash Buffer to remove non-specifically bound proteins.
-
Elute the recombinant hDUS2 with Elution Buffer.
-
Analyze the fractions by SDS-PAGE for purity.
-
Pool the pure fractions and dialyze against a suitable storage buffer.
-
Determine the protein concentration, aliquot, and store at -80°C.
In Vitro Dihydrouridylation Assay
This assay measures the conversion of uridine to dihydrouridine in an in vitro transcribed tRNA substrate.[1][3]
Materials:
-
Purified recombinant hDUS2
-
In vitro transcribed (IVT) tRNA substrate (e.g., human tRNA-Val-CAC)
-
Reaction Buffer (see Table 1 for composition)
-
NADPH solution
-
Nuclease P1
-
Zinc sulfate (B86663)
-
LC-MS/MS system
Reaction Conditions Summary
| Component | Final Concentration |
| Recombinant hDUS2 | 1-5 µM |
| IVT tRNA | 1-5 µM |
| Tris-HCl (pH 8.0) | 100 mM |
| Ammonium Acetate | 150 mM |
| MgCl₂ | 10 mM |
| DTT | 2 mM |
| NADPH | 1 mM |
| FMN | 250 µM |
| Table 1: Recommended reaction conditions for the in vitro dihydrouridylation assay.[11] |
Protocol:
-
Assemble the reaction mixture in a microcentrifuge tube, including all components except the enzyme.
-
Pre-incubate the mixture at 37°C for 5 minutes.
-
Initiate the reaction by adding the recombinant hDUS2 enzyme.
-
Incubate at 37°C for a specified time course (e.g., 0, 5, 15, 30, 60 minutes).
-
Stop the reaction by adding an equal volume of acidic phenol (B47542) or by heat inactivation.[12]
-
Purify the RNA from the reaction mixture (e.g., by ethanol (B145695) precipitation or using a suitable clean-up kit).
-
Digest the purified RNA to nucleosides by incubating with Nuclease P1 in ammonium acetate and zinc sulfate overnight at 37°C.[9]
-
Analyze the resulting nucleosides by LC-MS/MS to quantify the levels of uridine and dihydrouridine.
Data Presentation and Analysis
The quantitative data from the LC-MS/MS analysis can be summarized to show the efficiency of the dihydrouridylation reaction over time.
Example Data Table
| Time (minutes) | % Dihydrouridine (D/U+D) | Standard Deviation |
| 0 | 0.5 | ± 0.1 |
| 5 | 15.2 | ± 1.5 |
| 15 | 45.8 | ± 3.2 |
| 30 | 62.5 | ± 4.1 |
| 60 | 63.1 | ± 3.9 |
| Table 2: Example time course of dihydrouridine formation on IVT tRNA-Val-CAC catalyzed by recombinant hDUS2. |
Troubleshooting
| Issue | Possible Cause | Suggested Solution |
| Low or no enzyme activity | Inactive recombinant protein | Verify protein purity and folding. Perform a new purification. |
| Incorrect buffer composition | Check pH and concentrations of all buffer components, especially cofactors like NADPH and FMN. | |
| Degraded tRNA substrate | Use freshly prepared IVT tRNA and verify its integrity on a gel. | |
| High background signal | Contamination in reagents | Use nuclease-free water and high-purity reagents. |
| Non-specific RNA degradation | Add RNase inhibitors to the reaction. | |
| Inconsistent results | Pipetting errors | Use calibrated pipettes and prepare a master mix for the reaction setup. |
| Incomplete RNA digestion | Optimize Nuclease P1 concentration and incubation time. | |
| Table 3: Common troubleshooting tips for the in vitro dihydrouridylation assay. |
References
- 1. pubs.acs.org [pubs.acs.org]
- 2. researchgate.net [researchgate.net]
- 3. Sequence- and Structure-Specific tRNA Dihydrouridylation by hDUS2 - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Interaction of human tRNA-dihydrouridine synthase-2 with interferon-induced protein kinase PKR - PMC [pmc.ncbi.nlm.nih.gov]
- 5. tandfonline.com [tandfonline.com]
- 6. The Dihydrouridine landscape from tRNA to mRNA: a perspective on synthesis, structural impact and function - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Sequence- and Structure-Specific tRNA Dihydrouridylation by hDUS2 - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. Collection - Sequence- and Structure-Specific tRNA Dihydrouridylation by hDUS2 - ACS Central Science - Figshare [acs.figshare.com]
- 9. biorxiv.org [biorxiv.org]
- 10. avantorsciences.com [avantorsciences.com]
- 11. academic.oup.com [academic.oup.com]
- 12. tandfonline.com [tandfonline.com]
using CRISPR/Cas9 to create DUS knockout cell lines for functional studies
Application Note & Protocols
Topic: Using CRISPR/Cas9 to Create DUS Knockout Cell Lines for Functional Studies
Audience: Researchers, scientists, and drug development professionals.
Introduction
Dihydrouridine synthases (DUS) are a conserved family of enzymes responsible for catalyzing the formation of dihydrouridine (D), a modified nucleoside, in transfer RNA (tRNA).[1][2] This modification, found in the "D-loop" of tRNAs, is thought to increase the conformational flexibility of the tRNA molecule.[1][2] While eukaryotes possess multiple DUS enzymes with specificities for different uridine (B1682114) sites on various tRNAs, their precise physiological roles are still under investigation.[3][4][5] Emerging evidence suggests that DUS enzymes and the dihydrouridine modification play important roles in tRNA stability, cellular proliferation, and protein translation, with links to human diseases such as pulmonary carcinogenesis.[3][6][7]
To elucidate the specific functions of individual DUS enzymes, loss-of-function studies are essential. The CRISPR/Cas9 system offers a powerful and precise tool for generating gene knockouts by introducing targeted double-strand breaks (DSBs) in the DNA.[8] These breaks are primarily repaired by the cell's non-homologous end joining (NHEJ) pathway, which often results in small insertions or deletions (indels) that can cause a frameshift mutation, leading to a premature stop codon and functional gene knockout.[8]
This document provides a detailed methodology for creating and validating DUS knockout (KO) cell lines using CRISPR/Cas9 technology, as well as protocols for subsequent functional analysis.
Principle of the Method
The CRISPR/Cas9 system requires two key components to be delivered into a cell: the Cas9 nuclease and a single guide RNA (sgRNA).[9][10] The sgRNA contains a user-defined ~20 nucleotide spacer sequence that is complementary to the target DNA sequence within a DUS gene.[11] This spacer sequence directs the Cas9 nuclease to the specific genomic locus, where it induces a DSB, typically 3-4 base pairs upstream of a protospacer adjacent motif (PAM).[11] The subsequent error-prone repair by the NHEJ machinery leads to the creation of a functional gene knockout.[8] This protocol focuses on the delivery of the Cas9 protein and sgRNA as a ribonucleoprotein (RNP) complex, which has advantages including high editing efficiency and reduced off-target effects.[12]
Experimental Workflow Overview
The process begins with the design of sgRNAs targeting an early exon of the DUS gene of interest. The CRISPR/Cas9 components are then delivered into the target cell line. Following delivery, single cells are isolated to grow clonal populations. These clones are screened to identify those with the desired knockout, which are then validated at both the genomic and proteomic levels before being used in functional assays.
Caption: Overall experimental workflow for generating and validating DUS knockout cell lines.
Detailed Protocols
Protocol 1: sgRNA Design for Human DUS Genes
-
Identify Target Gene and Exon: Select the human DUS gene of interest (e.g., DUS1L, DUS2L, DUS3L). To maximize the chance of creating a loss-of-function mutation, target an early coding exon (e.g., exon 1 or 2).[13][14]
-
Use a Design Tool: Utilize an online sgRNA design tool (e.g., IDT Custom Alt-R® CRISPR-Cas9 Guide RNA Design Tool, CHOPCHOP).[11][14] Input the target exon sequence to generate a list of potential sgRNA sequences.
-
Select sgRNAs: Choose 2-3 sgRNAs based on high predicted on-target scores and low off-target scores.[11] The tool will evaluate potential off-target sites across the genome.[13]
-
Order or Synthesize: Order synthetic sgRNAs (e.g., from Integrated DNA Technologies or Synthego). Chemically synthesized guides are highly pure and effective.
Table 1: Example sgRNA Designs for Human DUS2L
| Target Gene | Target Exon | sgRNA Sequence (5' to 3') | PAM | Predicted On-Target Score |
|---|---|---|---|---|
| DUS2L | 2 | GAACAUCAAGACGCACCGCA | GGG | 95 |
| DUS2L | 2 | UCUACUGGCUCCGCAAGCAC | AGG | 92 |
| DUS2L | 2 | GCAUGCUGGUGUCCGAGAAG | AGG | 89 |
Note: Scores are hypothetical and depend on the algorithm used. Sequences do not include the PAM.
Protocol 2: CRISPR RNP Delivery via Electroporation
This protocol is optimized for electroporation of a ribonucleoprotein (RNP) complex, a highly efficient method for many cell types.[12][15]
Materials:
-
HEK293T or other target cell line
-
Cas9 Nuclease (e.g., S.p. Cas9 Nuclease V3, IDT)
-
Custom synthesized sgRNA
-
Electroporation system (e.g., Lonza 4D-Nucleofector™, Neon™ Transfection System)
-
Appropriate electroporation buffer/kit for the cell line
-
Nuclease-Free Duplex Buffer
-
Cell culture medium (e.g., DMEM + 10% FBS)
Method:
-
Cell Preparation: Culture cells to ~80% confluency. On the day of electroporation, harvest and count the cells. For each reaction, you will typically need 2x10^5 to 1x10^6 cells.
-
sgRNA and tracrRNA Annealing (if using a two-part system): If using a crRNA:tracrRNA system, anneal the two components by mixing equal molar amounts, heating to 95°C for 5 minutes, and allowing to cool to room temperature. If using a single-molecule sgRNA, this step is not necessary.
-
RNP Complex Formation:
-
In a sterile microcentrifuge tube, dilute Cas9 protein and the sgRNA in an appropriate buffer (e.g., Opti-MEM or the electroporation buffer). A common molar ratio is 1:1.2 (Cas9:sgRNA).
-
Incubate the mixture at room temperature for 10-20 minutes to allow the RNP complex to form.[12]
-
-
Electroporation:
-
Wash the required number of cells once with PBS.
-
Resuspend the cell pellet in the recommended electroporation buffer for your system.
-
Gently mix the resuspended cells with the pre-formed RNP complex.
-
Transfer the mixture to the electroporation cuvette or tip.
-
Apply the electric pulse using a pre-optimized program for your specific cell line.
-
-
Post-Electroporation Culture:
-
Immediately after electroporation, transfer the cells into a culture plate containing pre-warmed complete medium.
-
Incubate at 37°C and 5% CO2. Allow cells to recover for 24-48 hours before proceeding to the next step.
-
Protocol 3: Isolation of Single-Cell Clones
To generate a pure knockout cell line, it is essential to isolate and expand single cells.[9]
Method 1: Limiting Dilution
-
After 48 hours of recovery, trypsinize and count the transfected cells.
-
Perform a serial dilution of the cell suspension in complete medium to a final concentration of approximately 0.5-1 cell per 100 µL.
-
Dispense 100 µL of the diluted cell suspension into each well of a 96-well plate.
-
Incubate the plate for 7-14 days, monitoring for the growth of single colonies. Wells with more than one colony should be excluded.
-
Once colonies are visible and large enough, expand them by transferring them to larger plates (24-well, then 6-well).
Method 2: Fluorescence-Activated Cell Sorting (FACS) If using a plasmid that co-expresses Cas9 and a fluorescent marker like GFP, FACS is a more efficient method.
-
48 hours post-transfection, harvest the cells.
-
Use a cell sorter to deposit single GFP-positive cells into individual wells of a 96-well plate containing complete medium.
-
Incubate and expand clones as described above.
Protocol 4: Validation of DUS Knockout Clones
Validation is a critical step to confirm the knockout at both the genomic and protein levels.
A. Genomic Validation (PCR and Sanger Sequencing)
-
Genomic DNA Extraction: Once a clonal population is sufficiently expanded (e.g., one well of a 24-well plate), harvest a portion of the cells and extract genomic DNA using a commercial kit.
-
PCR Amplification: Design PCR primers that flank the sgRNA target site, amplifying a 400-600 bp region.
-
PCR Reaction: Perform PCR using the extracted genomic DNA as a template. Include a sample from wild-type (WT) cells as a control.
-
Sanger Sequencing: Purify the PCR products and send them for Sanger sequencing using both the forward and reverse PCR primers.
-
Sequence Analysis: Align the sequencing results from the clonal lines to the WT reference sequence. Use a tool like TIDE (Tracking of Indels by Decomposition) or ICE (Inference of CRISPR Edits) to analyze the sequencing chromatograms. A successful biallelic knockout will show two different indel mutations or the same homozygous indel, resulting in a frameshift.[16]
B. Proteomic Validation (Western Blot)
-
Protein Lysate Preparation: Harvest protein lysates from the expanded clones identified as potential knockouts by sequencing, alongside a WT control.
-
Protein Quantification: Determine the protein concentration of each lysate using a BCA or Bradford assay.
-
SDS-PAGE and Transfer: Separate equal amounts of protein (e.g., 20-30 µg) on an SDS-PAGE gel and transfer to a PVDF or nitrocellulose membrane.
-
Immunoblotting:
-
Block the membrane (e.g., with 5% non-fat milk or BSA in TBST).
-
Incubate with a primary antibody specific to the target DUS protein.
-
Wash and incubate with an appropriate HRP-conjugated secondary antibody.
-
Use a loading control antibody (e.g., GAPDH, β-actin) to ensure equal protein loading.
-
-
Detection: Visualize the bands using an ECL substrate. The absence of a band at the correct molecular weight in the knockout clones, compared to a clear band in the WT control, confirms the knockout at the protein level.[17][18]
Table 2: Summary of Validation Results for DUS2L Clones
| Clone ID | Genotyping Result (Indel) | Protein Expression (Western Blot) | Conclusion |
|---|---|---|---|
| WT | Wild-Type Sequence | +++ | Wild-Type |
| Clone A3 | +1 bp / -4 bp | - | Biallelic KO |
| Clone B7 | -2 bp / -2 bp | - | Biallelic KO (Homozygous) |
| Clone C1 | Wild-Type / +5 bp | ++ | Monoallelic KO |
| Clone D5 | Wild-Type / Wild-Type | +++ | No Edit (WT) |
Protocol 5: Functional Characterization of DUS KO Cell Lines
After validation, functional assays can be performed to investigate the phenotype of the DUS knockout.
A. Cell Proliferation Assay
-
Seed equal numbers of WT and validated DUS KO cells (e.g., 2,000 cells/well) in multiple 96-well plates.
-
At various time points (e.g., 0, 24, 48, 72, 96 hours), measure cell viability using an appropriate assay (e.g., CellTiter-Glo® Luminescent Cell Viability Assay, MTS assay).
-
Plot cell viability against time to compare the proliferation rates of KO and WT cells. Knockout of some human DUS proteins has been shown to reduce cell proliferation.[3][7]
B. Protein Synthesis Assay This assay measures the rate of new protein synthesis.
-
Seed WT and DUS KO cells in a 96-well plate and culture overnight.
-
Use a non-radioactive method, such as O-propargyl-puromycin (OPP) incorporation (e.g., Click-iT® HPG Alexa Fluor® Protein Synthesis Assay). OPP is an amino acid analog that gets incorporated into newly synthesized proteins.
-
Incubate cells with OPP for a short period (e.g., 30-60 minutes).
-
Fix, permeabilize, and perform a click chemistry reaction to attach a fluorescent dye to the incorporated OPP.
-
Quantify the fluorescence intensity per cell using a high-content imager or flow cytometer. A decrease in fluorescence in KO cells would indicate impaired protein translation.[7]
Table 3: Example Data from a Cell Proliferation Assay (MTS)
| Cell Line | 24h (Absorbance) | 48h (Absorbance) | 72h (Absorbance) |
|---|---|---|---|
| Wild-Type | 0.45 ± 0.03 | 0.88 ± 0.05 | 1.65 ± 0.09 |
| DUS2L KO Clone A3 | 0.42 ± 0.04 | 0.71 ± 0.06* | 1.21 ± 0.08** |
Data are represented as mean ± SD. *p < 0.05, **p < 0.01 compared to Wild-Type.
DUS-Mediated tRNA Modification Pathway
DUS enzymes catalyze the reduction of a uridine base in tRNA to dihydrouridine. This reaction is flavin-dependent and uses NADPH as a reducing agent.[19][20] The knockout of a DUS gene eliminates its ability to perform this modification at its specific target sites.
Caption: Simplified pathway of DUS-catalyzed dihydrouridine synthesis in tRNA.
References
- 1. tRNA-dihydrouridine synthase - Wikipedia [en.wikipedia.org]
- 2. pnas.org [pnas.org]
- 3. biorxiv.org [biorxiv.org]
- 4. tandfonline.com [tandfonline.com]
- 5. Molecular evolution of dihydrouridine synthases - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Mechanism of Dihydrouridine Synthase 2 from Yeast and the Importance of Modifications for Efficient tRNA Reduction - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Activity-based RNA modifying enzyme probing reveals DUS3L-mediated dihydrouridylation - PMC [pmc.ncbi.nlm.nih.gov]
- 8. CRISPR/Cas9-mediated Gene Knockout - Protocol - OneLab [onelab.andrewalliance.com]
- 9. genemedi.net [genemedi.net]
- 10. Optimizing sgRNA to Improve CRISPR/Cas9 Knockout Efficiency: Special Focus on Human and Animal Cell - PMC [pmc.ncbi.nlm.nih.gov]
- 11. sg.idtdna.com [sg.idtdna.com]
- 12. idtdna.com [idtdna.com]
- 13. Tips to optimize sgRNA design - Life in the Lab [thermofisher.com]
- 14. Generation of knock-in and knock-out CRISPR/Cas9 editing in mammalian cells [protocols.io]
- 15. synthego.com [synthego.com]
- 16. cyagen.com [cyagen.com]
- 17. 5 ways to validate and extend your research with Knockout Cell Lines [horizondiscovery.com]
- 18. Overcoming the pitfalls of validating knockout cell lines by western blot [horizondiscovery.com]
- 19. tandfonline.com [tandfonline.com]
- 20. The Dihydrouridine landscape from tRNA to mRNA: a perspective on synthesis, structural impact and function - PMC [pmc.ncbi.nlm.nih.gov]
Application Notes and Protocols for Chemical Labeling and Identification of Dihydrouridine (D) Sites in RNA
For Researchers, Scientists, and Drug Development Professionals
Introduction
Dihydrouridine (D) is a widespread and evolutionarily conserved RNA modification found in various RNA species, including transfer RNA (tRNA), ribosomal RNA (rRNA), and messenger RNA (mRNA).[1] Unlike the planar structure of its precursor, uridine (B1682114), the saturated C5-C6 bond in dihydrouridine introduces a non-planar conformation to the nucleobase. This structural alteration imparts increased flexibility to the RNA backbone and can influence RNA folding, stability, and interactions with proteins. Given its impact on RNA function, the accurate identification and quantification of dihydrouridine sites are crucial for understanding its role in biological processes and its potential as a therapeutic target.
These application notes provide detailed protocols and a comparative analysis of key chemical labeling techniques for the transcriptome-wide mapping of dihydrouridine at single-nucleotide resolution. The methods covered include sequencing-based approaches such as D-Seq, AlkAniline-Seq, and CRACI-seq, as well as a fluorescent labeling method for bulk quantification.
Comparative Analysis of Dihydrouridine Detection Methods
The selection of an appropriate method for dihydrouridine analysis depends on the specific research question, including the desired resolution, sensitivity, and whether quantitative information is required. Below is a summary of the key quantitative and qualitative parameters for the discussed techniques.
| Feature | D-Seq | AlkAniline-Seq | CRACI-seq | Fluorescent Labeling |
| Principle | NaBH₄ reduction to tetrahydrouridine, inducing reverse transcriptase (RT) stalling one nucleotide 3' to the D site.[2][3] | Alkaline hydrolysis-induced ring opening and subsequent aniline-mediated cleavage of the RNA backbone at the D site.[4][5] | Chemical reduction followed by a specific reverse transcriptase-induced T-to-C misincorporation at the D site.[6][7] | NaBH₄ reduction and subsequent covalent attachment of a fluorophore.[8][9] |
| Output | Sequencing reads indicating RT stop positions. | Sequencing reads from RNA fragments cleaved at D sites. | Sequencing reads with T-to-C mutations at D sites. | Fluorescence intensity. |
| Resolution | Single nucleotide. | Single nucleotide. | Single nucleotide. | Bulk RNA (no positional information). |
| Quantitative | Semi-quantitative, based on RT stop frequency.[2] | Semi-quantitative, based on cleavage efficiency. Signal strength for D can be lower than for other modifications like m⁷G.[5][10] | Highly quantitative, allowing for the determination of modification stoichiometry.[6][7] | Quantitative for total D content. |
| Sensitivity | Moderate. RT stop-based methods can be limited in sensitivity.[11] | High sensitivity with low background signal.[4][8] | High sensitivity, capable of detecting sites with low stoichiometry.[6][7] | Dependent on labeling efficiency and detection instrumentation. |
| Specificity | Good. Relies on the specific reduction of D by NaBH₄. | Good. Based on the chemical lability of the D ring under alkaline conditions. | High. The T-to-C misincorporation is a specific signature. | Good. Relies on the specific reduction of D. |
| Key Advantages | Relatively straightforward chemistry. | Simultaneous detection of other alkali-labile modifications (e.g., m⁷G, m³C). Very low background.[4][8] | Provides accurate stoichiometry of modification. Avoids issues with RT stops in densely modified regions.[6][12] | Rapid and suitable for high-throughput screening of total D levels. |
| Limitations | RT stops can also be caused by other factors (e.g., stable RNA structures). May have biases in detecting sites in highly structured or modified regions.[11] | Signal strength for D can be variable and lower than for other modifications.[10] | Requires specific reverse transcriptase and optimized reaction conditions. | Does not provide positional information. |
| False Discovery Rate | Estimated at <5% for mRNA D sites with appropriate controls.[13] | Not explicitly quantified in the provided results, but reported to have very low noise levels.[5] | Minimized through the use of in vitro transcribed unmodified controls.[2] | Not applicable. |
Experimental Protocols and Workflows
D-Seq: Dihydrouridine Sequencing
D-Seq is a method for the transcriptome-wide mapping of dihydrouridine sites based on the principle that sodium borohydride (B1222165) (NaBH₄) reduces dihydrouridine to tetrahydrouridine, which subsequently leads to the stalling of reverse transcriptase during cDNA synthesis.[2] The resulting 3' ends of the cDNA fragments correspond to the position +1 nucleotide relative to the dihydrouridine site.
Protocol for D-Seq Library Preparation:
-
RNA Preparation:
-
Isolate total RNA from the biological sample of interest using a standard method (e.g., Trizol extraction).
-
Fragment the RNA to a desired size range (e.g., 100-200 nucleotides) using chemical (e.g., ZnCl₂) or enzymatic methods. Purify the fragmented RNA.
-
-
Borohydride Reduction:
-
Prepare a fresh solution of 100 mg/mL sodium borohydride (NaBH₄) in 10 mM KOH.
-
To the fragmented RNA, add the NaBH₄ solution and a buffering agent (e.g., Tris-HCl, pH 7.5).
-
Incubate the reaction on ice for 1 hour.
-
Quench the reaction by adding acetic acid.
-
Purify the RNA by ethanol (B145695) precipitation.
-
-
3' End Healing and Adapter Ligation:
-
Heal the 3' ends of the RNA fragments using T4 Polynucleotide Kinase (PNK) to ensure they have a 3'-hydroxyl group.
-
Ligate a 3' adapter to the RNA fragments using T4 RNA Ligase.
-
-
Reverse Transcription:
-
Perform reverse transcription using a reverse transcriptase that is sensitive to the reduced dihydrouridine (e.g., SuperScript III). Use a primer that is complementary to the 3' adapter. The reverse transcriptase will stall one nucleotide downstream of the tetrahydrouridine.
-
-
cDNA Purification and 5' Adapter Ligation:
-
Purify the resulting cDNA fragments, selecting for the truncated products.
-
Ligate a 5' adapter to the purified cDNA. This can be done through various methods, including single-stranded DNA ligation or circularization followed by linearization.
-
-
PCR Amplification and Sequencing:
-
Amplify the adapter-ligated cDNA library by PCR.
-
Sequence the library using a high-throughput sequencing platform.
-
-
Data Analysis:
-
Trim adapter sequences from the raw sequencing reads.
-
Map the reads to the reference transcriptome.
-
Identify the 5' ends of the mapped reads, which correspond to the reverse transcription stop sites.
-
The dihydrouridine site is located at the position immediately upstream (-1) of the identified stop site. Compare the stop signals between the NaBH₄-treated sample and a mock-treated control to identify D-specific stops.
-
AlkAniline-Seq: Alkaline Hydrolysis and Aniline (B41778) Cleavage Sequencing
AlkAniline-Seq takes advantage of the chemical instability of the dihydrouridine ring under alkaline conditions.[4] The treatment leads to the opening of the ring, creating an abasic site that is then cleaved by aniline, leaving a 5'-phosphate group on the adjacent nucleotide. This 5'-phosphate serves as a specific entry point for adapter ligation during library preparation, resulting in a low background signal.[4][8]
Protocol for AlkAniline-Seq Library Preparation:
-
RNA Isolation:
-
Isolate total RNA from the sample of interest.
-
-
Alkaline Hydrolysis:
-
Incubate the RNA in a basic buffer (e.g., sodium carbonate/bicarbonate buffer, pH ~9.0) at an elevated temperature (e.g., 50-60°C) for a defined period. This step induces the opening of the dihydrouridine ring.
-
-
Aniline Cleavage:
-
Add aniline to the reaction to induce β-elimination at the abasic site, resulting in the cleavage of the RNA backbone and the formation of a 5'-phosphate on the nucleotide downstream of the original D site.
-
Purify the cleaved RNA fragments.
-
-
5' Adapter Ligation:
-
Ligate a 5' sequencing adapter specifically to the 5'-phosphate of the cleaved RNA fragments using T4 RNA Ligase. This step provides the specificity of the method.
-
-
Reverse Transcription and Library Amplification:
-
Perform reverse transcription using a random primer or a gene-specific primer.
-
Amplify the resulting cDNA library by PCR.
-
-
Sequencing and Data Analysis:
-
Sequence the library on a high-throughput sequencing platform.
-
Map the sequencing reads to the reference transcriptome.
-
The 5' ends of the mapped reads correspond to the cleavage sites. The dihydrouridine is located at the position immediately upstream (-1) of the cleavage site.
-
CRACI-seq: Chemical Reduction Assisted Cytosine Incorporation Sequencing
CRACI-seq is a quantitative method that identifies dihydrouridine sites by inducing a specific T-to-C misincorporation during reverse transcription.[6][7] The RNA is first treated with a reducing agent, and then a specific reverse transcriptase (such as HIV-RT) is used under conditions that promote the misincorporation of a cytosine opposite the modified dihydrouridine.[6]
Protocol for CRACI-seq Library Preparation:
-
RNA Preparation:
-
Isolate and fragment the RNA as described for D-Seq.
-
-
Chemical Reduction:
-
Reduce the dihydrouridine residues in the RNA using a reducing agent such as potassium borohydride (KBH₄).
-
-
Reverse Transcription with Misincorporation:
-
Perform reverse transcription using a reverse transcriptase that promotes misincorporation at the reduced dihydrouridine site (e.g., HIV reverse transcriptase).
-
The reaction conditions are optimized to favor the incorporation of a cytosine opposite the modified base.
-
-
Library Construction and Sequencing:
-
Construct a standard next-generation sequencing library from the resulting cDNA.
-
Sequence the library on a high-throughput platform.
-
-
Data Analysis:
-
Map the sequencing reads to the reference transcriptome.
-
Analyze the mapped reads for T-to-C mutations.
-
The frequency of the T-to-C mutation at a specific uridine position in the treated sample, compared to a control (untreated or in vitro transcribed unmodified RNA), provides a quantitative measure of the dihydrouridine stoichiometry at that site.
-
Fluorescent Labeling of Dihydrouridine
This method allows for the bulk quantification of dihydrouridine in an RNA sample. It is based on the same initial chemical reduction as D-Seq, followed by the covalent attachment of a fluorescent dye.
Protocol for Fluorescent Labeling:
-
RNA Isolation:
-
Isolate the RNA of interest.
-
-
Sodium Borohydride Reduction:
-
Reduce the dihydrouridine residues in the RNA with NaBH₄ as described in the D-Seq protocol.
-
-
Fluorescent Dye Coupling:
-
Couple a hydrazine- or amine-containing fluorescent dye (e.g., Cy3-hydrazide, rhodamine) to the reduced dihydrouridine. The reaction mechanism involves the formation of a stable covalent bond.[8]
-
-
Purification:
-
Remove the unreacted fluorescent dye from the labeled RNA using methods such as size-exclusion chromatography or ethanol precipitation.
-
-
Quantification:
-
Measure the fluorescence intensity of the labeled RNA sample using a fluorometer or a fluorescence plate reader.
-
The fluorescence intensity is proportional to the amount of dihydrouridine in the sample. A standard curve can be generated using RNA with a known dihydrouridine content for absolute quantification.
-
Conclusion
The chemical labeling techniques described provide a powerful toolkit for the investigation of dihydrouridine in RNA. Sequencing-based methods like D-Seq, AlkAniline-Seq, and CRACI-seq enable the precise mapping of D sites across the transcriptome, with CRACI-seq offering the added advantage of accurate stoichiometry determination. Fluorescent labeling, while not providing positional information, offers a rapid and quantitative method for assessing global dihydrouridine levels. The choice of method will depend on the specific biological question, available resources, and the desired level of detail. As our understanding of the epitranscriptome expands, these techniques will be instrumental in elucidating the functional significance of dihydrouridine in health and disease.
References
- 1. researchgate.net [researchgate.net]
- 2. researchgate.net [researchgate.net]
- 3. researchgate.net [researchgate.net]
- 4. Quantitative measurement of dihydrouridine in RNA using isotope dilution liquid chromatography-mass spectrometry (LC/MS) - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. Quantification of substoichiometric modification reveals global tsRNA hypomodification, preferences for angiogenin-mediated tRNA cleavage, and idiosyncratic epitranscriptomes of human neuronal cell-lines - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Quantitative CRACI reveals transcriptome-wide distribution of RNA dihydrouridine at base resolution - PMC [pmc.ncbi.nlm.nih.gov]
- 7. researchgate.net [researchgate.net]
- 8. Mapping of 7-methylguanosine (m7G), 3-methylcytidine (m3C), dihydrouridine (D) and 5-hydroxycytidine (ho5C) RNA modifications by AlkAniline-Seq - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. Differential redox sensitivity of tRNA dihydrouridylation - PMC [pmc.ncbi.nlm.nih.gov]
- 10. The Dihydrouridine landscape from tRNA to mRNA: a perspective on synthesis, structural impact and function - PMC [pmc.ncbi.nlm.nih.gov]
- 11. researchgate.net [researchgate.net]
- 12. austindraycott.com [austindraycott.com]
- 13. Transcriptome-wide mapping reveals a diverse dihydrouridine landscape including mRNA - PMC [pmc.ncbi.nlm.nih.gov]
Application Note and Protocol: Isotope Dilution Mass Spectrometry for Dihydrouridine Quantification
For Researchers, Scientists, and Drug Development Professionals
Introduction
Dihydrouridine (D) is a post-transcriptionally modified nucleoside found in transfer RNA (tRNA) and, to a lesser extent, in ribosomal RNA (rRNA) across all domains of life.[1][2] Unlike other nucleosides, dihydrouridine lacks a significant UV chromophore, making its detection and quantification by traditional HPLC with UV detection challenging. Isotope Dilution Mass Spectrometry (IDMS) offers a highly sensitive and accurate method for the quantification of dihydrouridine in biological samples. This application note provides a detailed protocol for the quantification of dihydrouridine in RNA samples using Liquid Chromatography-Mass Spectrometry (LC-MS) with a stable isotope-labeled internal standard.
The principle of this method is based on the addition of a known amount of an isotopically labeled internal standard, [1,3-¹⁵N₂]dihydrouridine, to a sample containing the analyte, dihydrouridine.[1] The sample is then enzymatically digested to release the individual nucleosides. The ratio of the unlabeled dihydrouridine to the labeled internal standard is measured by mass spectrometry. Since the analyte and the internal standard have nearly identical chemical and physical properties, they co-elute during chromatography and experience similar ionization efficiencies, leading to highly accurate and precise quantification.
Experimental Protocols
Synthesis of [1,3-¹⁵N₂]dihydrouridine Internal Standard
The synthesis of the [1,3-¹⁵N₂]dihydrouridine internal standard is a critical step for this protocol. While [1,3-¹⁵N₂]uridine can be purchased from commercial suppliers like Cambridge Isotope Laboratories, the dihydrouridine analog requires an additional synthesis step.[1]
Materials:
-
[1,3-¹⁵N₂]Uridine
-
5% Rhodium on alumina (B75360) catalyst
-
Water (HPLC grade)
-
Ammonium (B1175870) bicarbonate
-
Acetonitrile
Procedure:
-
Dissolve 10 mg of [1,3-¹⁵N₂]uridine in 1 ml of water.[1]
-
Add 7 mg of 5% rhodium on alumina catalyst to the solution.[1]
-
Hydrogenate the mixture at atmospheric pressure for 4 hours.[1]
-
After hydrogenation, remove the catalyst by filtration.[1]
-
Purify the filtrate by reversed-phase HPLC using 25 mM ammonium bicarbonate containing 1% acetonitrile, pH 6.5, at a flow rate of 1 ml/min.[1]
-
Verify the identity of the collected fraction as [1,3-¹⁵N₂]dihydrouridine by LC-MS, monitoring for the protonated molecular ion [M+H]⁺ at m/z 249.[1]
Sample Preparation: Enzymatic Digestion of RNA
This protocol describes the enzymatic digestion of RNA to release individual nucleosides for LC-MS analysis.
Materials:
-
RNA sample (e.g., tRNA, rRNA)
-
Nuclease P1
-
Bacterial Alkaline Phosphatase (BAP)
-
HEPES buffer (200 mM, pH 7.0)
-
Ultrapure water
Procedure:
-
In a microcentrifuge tube, combine up to 2.5 µg of the RNA sample with 2 µL of Nuclease P1 solution (0.5 U/µL) and 0.5 µL of BAP.
-
Add 2.5 µL of 200 mM HEPES buffer (pH 7.0).
-
Bring the total volume to 25 µL with ultrapure water.
-
Incubate the reaction mixture at 37°C for 3 hours. For nucleosides that are more resistant to digestion, the incubation time can be extended up to 24 hours.
-
Following digestion, add a known amount of the [1,3-¹⁵N₂]dihydrouridine internal standard to the sample.
-
The digested sample is now ready for LC-MS analysis.
LC-MS/MS Analysis
The following are general parameters for the LC-MS/MS analysis of dihydrouridine. These may need to be optimized for specific instruments.
Liquid Chromatography (LC) Parameters:
| Parameter | Recommended Setting |
| Column | C18 reversed-phase column (e.g., 2.1 x 150 mm, 1.8 µm) |
| Mobile Phase A | 0.1% Formic acid in water |
| Mobile Phase B | 0.1% Formic acid in acetonitrile |
| Flow Rate | 0.2 mL/min |
| Gradient | 0-5 min, 2% B; 5-10 min, 2-50% B; 10-12 min, 50% B; 12-15 min, 2% B |
| Column Temp. | 40°C |
| Injection Vol. | 5 µL |
Mass Spectrometry (MS) Parameters:
| Parameter | Recommended Setting |
| Ionization Mode | Positive Electrospray Ionization (ESI+) |
| Scan Mode | Selected Ion Monitoring (SIM) or Multiple Reaction Monitoring (MRM) |
| Monitored Ions (SIM) | Dihydrouridine (D): m/z 247 [M+H]⁺[1,3-¹⁵N₂]dihydrouridine: m/z 249 [M+H]⁺ |
| Capillary Voltage | 3.5 kV |
| Source Temperature | 120°C |
| Desolvation Temp. | 350°C |
Data Presentation
The quantification of dihydrouridine is achieved by constructing a calibration curve using known concentrations of unlabeled dihydrouridine and a fixed concentration of the [1,3-¹⁵N₂]dihydrouridine internal standard. The peak area ratio of the analyte to the internal standard is then used to determine the concentration of dihydrouridine in the unknown sample.
Table 1: Quantitative Data for Dihydrouridine in E. coli RNA
| RNA Sample | Mole % Dihydrouridine | Residues per Molecule | Accuracy (%) | Precision (RSD, %) |
| E. coli tRNASer(VGA) | - | 2.03 | 98 | 0.43 - 2.4 |
| E. coli tRNAThr(GGU) | - | 2.84 | 95 | 0.43 - 2.4 |
| Unfractionated E. coli tRNA | 1.79 | 1.4 | - | 0.43 - 2.4 |
| E. coli 23S rRNA | 0.0396 | 1.1 | - | 0.43 - 2.4 |
Data sourced from Dalluge et al., Nucleic Acids Research, 1996.[3]
Visualizations
Experimental Workflow
Caption: Experimental workflow for dihydrouridine quantification.
Isotope Dilution Principle
Caption: Principle of isotope dilution mass spectrometry.
References
- 1. academic.oup.com [academic.oup.com]
- 2. The Dihydrouridine landscape from tRNA to mRNA: a perspective on synthesis, structural impact and function - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Quantitative measurement of dihydrouridine in RNA using isotope dilution liquid chromatography-mass spectrometry (LC/MS) - PubMed [pubmed.ncbi.nlm.nih.gov]
Application Notes and Protocols for Transcriptome-wide Dihydrouridine Profiling using Rho-seq
For Researchers, Scientists, and Drug Development Professionals
Introduction
The epitranscriptome, the collection of chemical modifications to RNA, adds a critical layer of gene regulation beyond the primary sequence. Dihydrouridine (D), a universally conserved modification, has been identified not only in tRNAs but also in mRNAs, where it influences processes such as translation and meiotic chromosome segregation.[1][2] Rho-seq is a recently developed, powerful technique for the transcriptome-wide mapping of dihydrouridine at single-nucleotide resolution.[1] This method relies on the specific chemical labeling of dihydrouridine with a bulky rhodamine molecule, which causes reverse transcriptase to stall, allowing for the precise identification of modified sites through next-generation sequencing.[3]
These application notes provide a comprehensive overview of Rho-seq, including detailed experimental protocols and data analysis pipelines, to enable researchers to successfully implement this technique in their own studies.
Principle of Rho-seq
Rho-seq leverages a two-step chemical process to identify dihydrouridine sites. First, the dihydrouridine base is reduced using sodium borohydride (B1222165) (NaBH4). Subsequently, a rhodamine derivative is specifically attached to the reduced dihydrouridine. This bulky adduct effectively blocks the progression of reverse transcriptase during cDNA synthesis. By comparing the reverse transcription termination sites in treated versus untreated samples, dihydrouridine locations can be mapped across the transcriptome.[3]
Applications in Research and Drug Development
-
Epitranscriptome Mapping: Rho-seq allows for the global identification and quantification of dihydrouridine sites in various RNA species, including mRNA, tRNA, and rRNA.[1][2][3] This can reveal novel regulatory roles for this modification.
-
Understanding Disease Mechanisms: Dysregulation of RNA modifications has been implicated in numerous diseases, including cancer. Rho-seq can be used to investigate the role of dihydrouridine in disease pathogenesis and identify potential therapeutic targets.
-
Drug Discovery and Development: By understanding how dihydrouridine modifications affect the translation of specific mRNAs, researchers can explore the development of drugs that target dihydrouridine synthases (DUS) or the recognition of dihydrouridylated transcripts.
-
Investigating Fundamental Biological Processes: The discovery that dihydrouridylation of specific mRNAs, such as those encoding tubulin, is crucial for processes like meiotic chromosome segregation highlights the importance of this modification in fundamental cellular functions.[1][2][4]
Experimental Workflow
The Rho-seq workflow can be summarized in the following key steps:
References
- 1. Transcription-wide mapping of dihydrouridine reveals that mRNA dihydrouridylation is required for meiotic chromosome segregation [dspace.mit.edu]
- 2. Transcription-wide mapping of dihydrouridine reveals that mRNA dihydrouridylation is required for meiotic chromosome segregation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. Epitranscriptomic mapping of RNA modifications at single-nucleotide resolution using rhodamine sequencing (Rho-seq) - PMC [pmc.ncbi.nlm.nih.gov]
- 4. lafontainelab.com [lafontainelab.com]
Troubleshooting & Optimization
Technical Support Center: Sequencing tRNA for Dihydrouridine Detection
This technical support center provides troubleshooting guidance and frequently asked questions (FAQs) for researchers, scientists, and drug development professionals working on sequencing tRNA for the detection of dihydrouridine (D).
Troubleshooting Guides
This section addresses specific issues that may arise during tRNA sequencing experiments for dihydrouridine detection.
| Problem | Possible Cause(s) | Suggested Solution(s) |
| Low Library Yield | 1. Poor quality of input RNA: Degraded or impure RNA can lead to inefficient library preparation.[1][2] 2. Inefficient adapter ligation: Suboptimal reaction conditions or low-quality reagents can reduce ligation efficiency.[1][3] 3. Suboptimal PCR amplification: Incorrect number of PCR cycles can lead to low yield or PCR artifacts.[3] | 1. Assess RNA quality: Before starting, check RNA integrity using a Bioanalyzer or similar instrument. Ensure high purity with appropriate 260/280 and 260/230 ratios.[1] 2. Optimize ligation: Use fresh, high-quality reagents and consider optimizing the adapter-to-insert ratio.[1][3] 3. Optimize PCR cycles: Perform a qPCR to determine the optimal number of cycles to avoid over- or under-amplification.[3] |
| Adapter-Dimer Contamination | 1. High adapter concentration: Using an excess of adapters increases the likelihood of dimer formation.[3] 2. Low amount of input RNA: Insufficient template allows for increased adapter self-ligation.[3] | 1. Titrate adapter concentration: Perform a titration to find the optimal adapter concentration for your input amount. 2. Perform a double size selection: Use paramagnetic beads to perform a two-sided size selection to remove small fragments like adapter-dimers.[4] |
| High Background Noise or False Positives in D-detection | 1. Incomplete chemical modification: Incomplete reduction of dihydrouridine can lead to a weak signal and high background.[5] 2. Non-specific reverse transcriptase stops: Other RNA modifications or secondary structures can cause RT to stall, mimicking a dihydrouridine signal.[6][7] 3. Contamination with other RNA species: Preparations of tRNA may be contaminated with other RNAs like rRNA or mRNA, which can contain dihydrouridine.[8] | 1. Optimize reaction conditions: Ensure optimal concentration of chemical reagents (e.g., NaBH4) and reaction time.[5][9] 2. Use a control without chemical treatment: Comparing treated and untreated samples can help differentiate D-specific stops from other RT pausing events. 3. Use a dihydrouridine synthase (DUS) knockout/knockdown control: Comparing wild-type with DUS-deficient samples can confirm that the signal is dependent on dihydrouridine.[5][8] 4. Stringent purification of tRNA: Employ robust methods to isolate pure tRNA fractions. |
| Difficulty in Detecting Dihydrouridine in Heavily Modified Regions (e.g., D-loop) | 1. Reverse transcriptase (RT) drop-off: The high density of modifications in regions like the D-loop can cause the RT to dissociate from the template, leading to a loss of signal.[6][7][10] 2. Methodological limitations: Some methods relying solely on RT stops are less sensitive for detecting D in regions already prone to RT pausing.[6][7] | 1. Use a processive reverse transcriptase: Employ enzymes engineered for higher processivity and the ability to read through modified bases. 2. Consider alternative methods: Techniques like CRACI (Chemical Reduction Assisted Cytosine Incorporation) sequencing, which introduces a misincorporation signature rather than an RT stop, can be more effective in these regions.[6][11] |
| Bias in tRNA Abundance Quantification | 1. Differential modification status: The presence or absence of certain modifications can affect reverse transcription efficiency, leading to biased representation of tRNA isoacceptors. 2. Codon usage bias: The relative abundance of tRNAs can be influenced by the codon usage of highly expressed genes in the source organism.[12][13][14] | 1. Use sequencing methods less prone to RT drop-off: Methods that do not rely on RT stalling can provide more accurate quantification. 2. Incorporate spike-in controls: Use synthetic tRNAs with known modifications and concentrations to normalize the data. 3. Be aware of biological context: When comparing samples, consider that changes in tRNA modification levels can be a biological response and not necessarily a technical artifact.[15] |
Frequently Asked Questions (FAQs)
1. What are the main challenges in sequencing tRNA for dihydrouridine detection?
The primary challenges stem from the chemical nature of dihydrouridine and the structural properties of tRNA. Dihydrouridine itself does not cause a distinct signature during standard reverse transcription. Therefore, chemical modification is required to induce a detectable signal, typically a reverse transcriptase (RT) stop or a misincorporation.[6][7] However, tRNAs are heavily modified, particularly in the D-loop where dihydrouridine is commonly found.[9][16] This high density of modifications can lead to premature RT drop-off, making it difficult to sequence through these regions and accurately identify dihydrouridine sites.[6][7][10]
2. Which are the most common methods for dihydrouridine detection by sequencing?
Several methods have been developed, each with its own advantages and limitations:
-
D-seq (Dihydrouridine Sequencing): This method uses sodium borohydride (B1222165) (NaBH₄) to reduce dihydrouridine to tetrahydrouridine, which then causes the reverse transcriptase to stall one nucleotide 3' to the modification.[5][8][17]
-
Rho-seq: Similar to D-seq, Rho-seq involves NaBH₄ reduction followed by the addition of a bulky rhodamine molecule to the modified base, which enhances the RT stop signal.[8][9]
-
AlkAniline-Seq: This method relies on alkaline treatment to open the dihydrouridine ring, followed by aniline (B41778) cleavage of the RNA backbone at the modified site.[9][18]
-
CRACI (Chemical Reduction Assisted Cytosine Incorporation) Sequencing: This highly sensitive and quantitative method uses a chemical reduction approach that leads to the incorporation of a cytosine opposite the modified dihydrouridine during reverse transcription, creating a specific misincorporation signature.[6][11]
3. How can I quantify the stoichiometry of dihydrouridine at a specific site?
Quantitative analysis of dihydrouridine modification can be challenging. Methods like CRACI are designed to be quantitative, allowing for the estimation of modification stoichiometry at single-base resolution.[6][11] Another approach is liquid chromatography-mass spectrometry (LC/MS), which is highly accurate and sensitive for quantifying modified nucleosides in a bulk RNA sample.[19] For sequencing-based methods, comparing the signal (e.g., RT stop or misincorporation rate) in your sample to a fully modified synthetic standard or a sample from a DUS knockout organism can provide an estimate of stoichiometry.
4. What are dihydrouridine synthases (DUS), and why are they important for D detection?
Dihydrouridine synthases (DUS) are the enzymes responsible for converting uridine (B1682114) to dihydrouridine in RNA.[9] They are crucial in the context of D detection as genetic knockout or knockdown of DUS enzymes can be used as a negative control to validate that the detected signals are indeed dihydrouridine-dependent.[5][8]
Quantitative Data Summary
The following table summarizes key quantitative data related to dihydrouridine detection.
| Parameter | Value | RNA Source | Method | Reference |
| Sensitivity of D Detection | <1 µg tRNA (~1 pmol D) | E. coli tRNA | LC/MS | [19] |
| Accuracy of D Quantification | 95-98% | E. coli tRNA | LC/MS | [19] |
| Dihydrouridine Content | 1.79 mole% (1.4 residues/molecule) | Unfractionated E. coli tRNA | LC/MS | [19] |
| Dihydrouridine Content | 0.0396 mole% (1.1 residues/molecule) | E. coli 23S rRNA | LC/MS | [19] |
Experimental Protocols
Key Experiment: D-seq Library Preparation
This protocol provides a generalized workflow for D-seq, a common method for dihydrouridine detection.
-
RNA Isolation: Isolate total RNA or small RNA fractions from your cells or tissue of interest. Ensure high quality and purity of the RNA.
-
Dihydrouridine Reduction:
-
RNA Fragmentation: Fragment the RNA to the desired size range for sequencing.
-
Library Preparation:
-
Sequencing and Data Analysis:
-
Sequence the library on a high-throughput sequencing platform.
-
Align the reads to the reference transcriptome.
-
Identify sites of RT termination by analyzing the 3' ends of the sequencing reads. An enrichment of read ends at a specific location in the NaBH₄-treated sample compared to a control indicates a dihydrouridine site.[5][8]
-
Visualizations
References
- 1. How to Troubleshoot Sequencing Preparation Errors (NGS Guide) - CD Genomics [cd-genomics.com]
- 2. biocompare.com [biocompare.com]
- 3. neb.com [neb.com]
- 4. theseus.fi [theseus.fi]
- 5. Expanding the epitranscriptome: Dihydrouridine in mRNA - PMC [pmc.ncbi.nlm.nih.gov]
- 6. researchgate.net [researchgate.net]
- 7. researchgate.net [researchgate.net]
- 8. Expanding the epitranscriptome: Dihydrouridine in mRNA | PLOS Biology [journals.plos.org]
- 9. The Dihydrouridine landscape from tRNA to mRNA: a perspective on synthesis, structural impact and function - PMC [pmc.ncbi.nlm.nih.gov]
- 10. researchgate.net [researchgate.net]
- 11. Quantitative CRACI reveals transcriptome-wide distribution of RNA dihydrouridine at base resolution - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Codon usage bias from tRNA's point of view: Redundancy, specialization, and efficient decoding for translation optimization - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Codon usage bias - Wikipedia [en.wikipedia.org]
- 14. Codon-biased translation can be regulated by wobble-base tRNA modification systems during cellular stress responses - PMC [pmc.ncbi.nlm.nih.gov]
- 15. mdpi.com [mdpi.com]
- 16. tandfonline.com [tandfonline.com]
- 17. Transcriptome-wide mapping reveals a diverse dihydrouridine landscape including mRNA - PMC [pmc.ncbi.nlm.nih.gov]
- 18. researchgate.net [researchgate.net]
- 19. academic.oup.com [academic.oup.com]
overcoming low sensitivity in modified nucleoside detection
Welcome to the technical support center for modified nucleoside analysis. This resource is designed for researchers, scientists, and drug development professionals to troubleshoot and overcome common challenges related to low sensitivity in the detection and quantification of modified nucleosides.
Section 1: Troubleshooting Guide
This guide addresses specific issues encountered during experimental workflows, providing potential causes and actionable solutions in a direct question-and-answer format.
Q1: My signal intensity is extremely low or absent for my target modified nucleoside. What are the initial troubleshooting steps?
A: Low or no signal is a common issue stemming from multiple stages of the workflow. Begin by systematically checking the most likely causes:
-
Mass Spectrometer (MS) Optimization: Ensure the MS interface settings are optimized for your specific analyte and mobile phase. Key parameters include desolvation temperature, nebulizing gas flow, and capillary voltage. A suboptimal desolvation temperature can lead to a complete signal loss for thermally labile compounds.
-
Analyte Instability: Certain modified nucleosides are chemically unstable under specific pH conditions. For example, m1A can undergo a Dimroth rearrangement to m6A at a mild alkaline pH, leading to under-quantification. Similarly, m3C can convert to m3U. We recommend carefully considering solvent pH throughout the entire sample handling process.
-
Sample Preparation Loss: Hydrophobic nucleosides can adsorb to filtration materials like polyethersulfone (PES), significantly reducing the amount of analyte reaching the instrument. Consider pre-washing filters or using alternative materials like composite regenerate cellulose (B213188) (CRC).
-
LC Method: Ensure your analyte is eluting correctly from the column. Highly polar nucleosides may elute in the void volume with standard reversed-phase chromatography, while non-polar analytes may be retained too strongly.
Q2: I'm observing poor reproducibility and high variability in quantification between my sample replicates. What could be the cause?
A: Poor reproducibility often points to inconsistencies in sample preparation or chromatographic separation.
-
Inconsistent Hydrolysis: Incomplete or variable enzymatic hydrolysis of RNA can lead to inconsistent yields of nucleosides. Ensure your enzyme-to-substrate ratio is optimized and that all samples are incubated for the same duration and temperature. Contaminations in hydrolysis reagents can also lead to misquantification.
-
Internal Standard Issues: The absence or improper use of a stable-isotope labeled internal standard (SILIS) can cause significant quantification errors. A SILIS should be added early in the sample preparation process to account for analyte loss during extraction and handling.
-
Chromatographic Shifts: Residual solvents, such as ethanol (B145695) from RNA precipitation, can cause retention time shifts and peak splitting, which will affect integration and quantification. Even a 1% residual ethanol concentration can impact the peak shape of polar nucleosides like pseudouridine.
-
Matrix Effects: Co-eluting compounds from the sample matrix can suppress or enhance the ionization of the target analyte, leading to variability. Improving chromatographic resolution to separate the analyte from interfering matrix components is crucial.
Q3: My chromatographic peaks are broad, tailing, or splitting. How can I improve peak shape?
A: Poor peak shape compromises both resolution and sensitivity.
-
Column Contamination: Buildup of contaminants from the sample matrix on the column can distort peak profiles. Use a guard column and ensure adequate sample cleanup to protect the analytical column.
-
Suboptimal Mobile Phase: The sample solvent should be as similar as possible to the mobile phase. Injecting a sample in a solvent much stronger than the mobile phase can cause peak distortion. Also, ensure the mobile phase pH is appropriate for the analyte and column type.
-
Secondary Interactions: The analyte may be interacting with active sites on the column packing material. Consider adding a small amount of a competing agent to the mobile phase or switching to a different column chemistry.
-
System Issues: Extraneous tubing between the column and detector can increase dead volume and contribute to peak broadening. Check all fittings for leaks, as this can also impact peak shape.
Q4: How can I differentiate between structural isomers that have the same mass-to-charge ratio?
A: Distinguishing isomers is a significant challenge for low-resolution mass spectrometers like triple quadrupoles (TQ-MS).
-
Chromatographic Separation: The most effective strategy is to separate the isomers chromatographically. This requires optimizing the HPLC method. Different column chemistries can be employed; for example, a PFP (pentafluorophenyl) column can be effective for separating uridine (B1682114) and cytidine (B196190) derivatives, while a HILIC (hydrophilic interaction chromatography) column may better separate adenosine (B11128) and guanosine (B1672433) derivatives.
-
High-Resolution Mass Spectrometry (HRAM): HRAM instruments can differentiate molecules with very small mass differences, which can sometimes distinguish isomers if their elemental composition differs slightly or if they exhibit different fragmentation patterns.
-
Tandem MS (MS/MS): Even if precursor ions are identical, isomers may produce different product ions upon fragmentation. Developing an MS/MS method with unique transitions for each isomer is key. Positional isomers are more readily differentiated using HRAM with varying collision energies, which generates more fragments than just the dissociation of the glycosidic bond.
Section 2: Frequently Asked Questions (FAQs)
Q1: What are the primary strategies to enhance overall assay sensitivity for low-abundance modified nucleosides?
A: Improving sensitivity requires a multi-faceted approach focusing on sample preparation, chromatography, and mass spectrometry.
-
**En
Technical Support Center: Dihydrouridine Synthase (DUS) Enzymatic Assays
This guide provides troubleshooting advice and frequently asked questions for researchers working with dihydrouridine synthase (DUS) enzymatic assays.
Troubleshooting Guide
This section addresses specific problems you may encounter during your experiments in a question-and-answer format.
Question: Why am I observing very low or no enzyme activity?
Possible Cause 1: Sub-optimal tRNA Substrate
Many dihydrouridine synthases exhibit significantly higher activity on tRNA that already contains other post-transcriptional modifications.[1][2] Using in vitro transcribed tRNA that lacks these modifications can result in very slow reaction rates.[1]
-
Solution: If possible, use tRNA purified from a relevant biological source (e.g., a DUS knockout strain of yeast or bacteria) as a substrate.[1] This will ensure the presence of other modifications that may be required for optimal enzyme activity.
Possible Cause 2: Improper tRNA Folding
The three-dimensional structure of the tRNA substrate is critical for enzyme recognition and activity.
-
Solution: Before starting the assay, ensure your tRNA is properly folded by heating it to 65°C for 10 minutes and then cooling it on ice for 5 minutes.[1]
Possible Cause 3: Incorrect Assay Conditions
Enzyme activity is highly sensitive to buffer composition, pH, temperature, and the presence of necessary cofactors.
-
Solution: Verify that your reaction buffer composition, pH, and incubation temperature are optimal for the specific DUS enzyme you are studying.[3][4] Ensure that the cofactor NADPH is present at a sufficient concentration (typically in the millimolar range).[3][4]
Possible Cause 4: Enzyme Instability
Dihydrouridine synthases, like many enzymes, can lose activity if not handled or stored properly.
-
Solution: Keep the enzyme on ice at all times before adding it to the reaction mixture.[5] Avoid repeated freeze-thaw cycles by storing the enzyme in aliquots at the recommended temperature.[6]
Question: My standard curve is not linear. What could be the issue?
Possible Cause 1: Pipetting Errors
Inaccurate pipetting, especially of small volumes, can lead to non-linear standard curves.
-
Solution: Use calibrated pipettes and avoid pipetting very small volumes.[7] Whenever possible, prepare a master mix for your reaction components to ensure consistency across all wells.[7]
Possible Cause 2: Reagent Issues
Partially thawed or improperly mixed components can lead to inconsistent results.
-
Solution: Ensure all kit components are completely thawed and mixed gently but thoroughly before use.[7]
Question: I'm seeing inconsistent readings between replicate samples. Why?
Possible Cause 1: Incomplete Mixing
Failure to properly mix the reaction components after adding the enzyme can lead to variability.
-
Solution: Gently pipette the reaction mixture up and down a few times after adding the enzyme to ensure a homogenous solution. Be careful not to introduce air bubbles.[5][7]
Possible Cause 2: "Edge Effects" in Microplates
Evaporation from the wells at the edges of a microplate can concentrate the reactants and lead to higher or lower readings.
-
Solution: If using a microplate, consider not using the outermost wells. Alternatively, ensure the plate is well-sealed and incubated in a humidified chamber to minimize evaporation.[6]
Troubleshooting Workflow
The following diagram illustrates a logical workflow for troubleshooting common issues in DUS enzymatic assays.
Caption: A flowchart for troubleshooting DUS enzymatic assays.
Frequently Asked Questions (FAQs)
What are dihydrouridine synthases (DUS)?
Dihydrouridine synthases are a conserved family of enzymes that catalyze the reduction of uridine (B1682114) to dihydrouridine in RNA molecules, most notably in transfer RNA (tRNA).[8] This modification is important for the proper folding and flexibility of tRNA.[2]
What are the different types of DUS enzymes?
Bacteria typically have three main families of DUS enzymes: DusA, DusB, and DusC, each with specificities for different uridine positions within the tRNA molecule.[2][9] Eukaryotes have four families, named Dus1 through Dus4, which also exhibit non-overlapping specificities.[2]
What cofactors are required for DUS activity?
DUS enzymes are flavin-dependent, utilizing either flavin mononucleotide (FMN) or flavin adenine (B156593) dinucleotide (FAD) as a prosthetic group.[3][10] They require NADPH as a reducing agent to regenerate the reduced flavin cofactor.[1][3]
What are the common methods for assaying DUS activity?
Several methods can be used to measure DUS activity:
-
Monitoring NADPH Oxidation: The consumption of NADPH can be monitored by the decrease in absorbance at 340 nm.[2][3] This is a continuous assay that measures the reductive half-reaction of the enzyme.
-
Colorimetric Assay: Dihydrouridine can be detected using a colorimetric method that involves chemical hydrolysis of the dihydrouridine ring followed by a reaction that produces a colored product, which can be measured by absorbance at 550 nm.[1]
-
LC-MS/MS Analysis: Liquid chromatography coupled with tandem mass spectrometry (LC-MS/MS) can be used to directly quantify the amount of dihydrouridine in the tRNA substrate after the enzymatic reaction.[2] This is a highly sensitive and specific method.
Experimental Protocols
Protocol 1: Colorimetric Assay for Dihydrouridine Detection
This protocol is adapted from established methods for the colorimetric quantification of dihydrouridine.[1]
-
Enzymatic Reaction:
-
Set up your enzymatic reaction in a suitable buffer (e.g., 100 mM Tris-HCl, pH 8) containing your DUS enzyme, tRNA substrate, and NADPH (e.g., 2 mM).[3]
-
Incubate at the optimal temperature for your enzyme (e.g., 37°C) for a defined period (e.g., 60 minutes).[3]
-
Stop the reaction, for example, by adding acidic phenol.[3]
-
-
Hydrolysis of Dihydrouridine:
-
To a 0.3 mL sample of the reaction mixture, add 0.03 mL of 1 M KOH.
-
Incubate for 30 minutes at 37°C to hydrolyze the dihydrouridine ring.
-
-
Color Development:
-
Acidify the sample by adding 0.15 mL of 1 M H₂SO₄.
-
Add 0.3 mL of a solution containing 10 mM 2,3-butanedione-2-oxime and 5 mM N-phenyl-p-phenylenediamine.
-
Heat the sample for 5 minutes at 95°C.
-
Cool to 50°C for 5 minutes.
-
Add 0.3 mL of 10 mM FeCl₃.
-
-
Measurement:
-
Read the absorbance at 550 nm.
-
Protocol 2: Monitoring NADPH Oxidation
This protocol allows for the continuous monitoring of DUS activity by measuring the consumption of NADPH.[3]
-
Reaction Setup:
-
Initiate the Reaction:
-
Add the DUS enzyme to the cuvette to start the reaction.
-
-
Measurement:
Quantitative Data Summary
Table 1: Typical Reaction Conditions for In Vitro DUS Assays
| Component | Typical Concentration Range | Reference(s) |
| DUS Enzyme | 1 - 5 µM | [3] |
| tRNA Substrate | 10 - 125 µM | [1][3] |
| NADPH | 0.5 - 2 mM | [2][3] |
| Buffer | 50-100 mM Tris-HCl or HEPES | [3] |
| pH | 7.5 - 8.0 | [3] |
| MgCl₂ | 2 - 10 mM | [3] |
| Dithiothreitol (DTT) | 1 - 5 mM | [3][11] |
| Incubation Temperature | 30 - 37°C | [3][4] |
Table 2: Common Interfering Substances in Enzymatic Assays
| Substance | Inhibitory Concentration | Reference(s) |
| EDTA | > 0.5 mM | [7] |
| SDS | > 0.2% | [7] |
| Sodium Azide | > 0.2% | [7] |
| NP-40 | > 1% | [7] |
| Tween-20 | > 1% | [7] |
DUS Assay Workflow
The following diagram outlines the general workflow for performing a DUS enzymatic assay followed by product detection.
Caption: General workflow for a DUS enzymatic assay.
References
- 1. Mechanism of Dihydrouridine Synthase 2 from Yeast and the Importance of Modifications for Efficient tRNA Reduction - PMC [pmc.ncbi.nlm.nih.gov]
- 2. biorxiv.org [biorxiv.org]
- 3. academic.oup.com [academic.oup.com]
- 4. tandfonline.com [tandfonline.com]
- 5. home.sandiego.edu [home.sandiego.edu]
- 6. youtube.com [youtube.com]
- 7. docs.abcam.com [docs.abcam.com]
- 8. Molecular evolution of dihydrouridine synthases - PMC [pmc.ncbi.nlm.nih.gov]
- 9. tandfonline.com [tandfonline.com]
- 10. Exploring a unique class of flavoenzymes: Identification and biochemical characterization of ribosomal RNA dihydrouridine synthase - PMC [pmc.ncbi.nlm.nih.gov]
- 11. pnas.org [pnas.org]
Technical Support Center: Accurate Dihydrouridine Quantification in Complex Samples
This technical support center provides troubleshooting guidance and frequently asked questions (FAQs) to assist researchers, scientists, and drug development professionals in improving the accuracy of dihydrouridine (D) quantification in complex biological samples.
Section 1: Frequently Asked Questions (FAQs) & Troubleshooting
This section addresses common issues encountered during dihydrouridine quantification experiments, particularly those utilizing liquid chromatography-mass spectrometry (LC-MS).
Q1: Why is dihydrouridine difficult to quantify accurately using traditional methods?
A1: Dihydrouridine presents unique challenges for quantification due to its molecular structure. Unlike canonical nucleosides, it lacks a significant chromophore, making traditional UV-based detection methods like HPLC with UV detection impractical due to poor sensitivity. This has led to the development of more sensitive and specific techniques, primarily based on mass spectrometry.
Q2: What is the recommended method for the most accurate quantification of dihydrouridine?
A2: The gold standard for accurate dihydrouridine quantification is stable isotope dilution liquid chromatography-mass spectrometry (LC-MS). This method involves spiking the sample with a known amount of a stable isotope-labeled internal standard, such as [1,3-¹⁵N₂]dihydrouridine, prior to analysis. The ratio of the endogenous dihydrouridine to the labeled internal standard allows for highly accurate and precise quantification, correcting for variations in sample preparation and instrument response.
Q3: I'm observing poor peak shape (tailing, fronting, or splitting) for my dihydrouridine peak in LC-MS analysis. What are the possible causes and solutions?
A3: Poor peak shape can arise from several factors related to the mobile phase, column, or sample preparation. Here’s a breakdown of common causes and their solutions:
| Problem | Potential Cause | Solution |
| Peak Tailing | Secondary interactions with the column stationary phase (e.g., silanol (B1196071) interactions). | Optimize mobile phase pH to be at least 2 units away from the analyte's pKa. Use a high-purity, well-endcapped column. |
| Column contamination or degradation. | Flush the column with a strong solvent. If the problem persists, replace the column. | |
| Peak Fronting | Column overload. | Reduce the sample concentration or injection volume. |
| Sample solvent is stronger than the mobile phase. | Ensure the sample is dissolved in a solvent that is weaker than or equal in strength to the initial mobile phase. | |
| Split Peaks | Partially blocked column frit. | Backflush the column. If this doesn't resolve the issue, the frit may need replacement, or the entire column may need to be replaced. |
| Sample solvent incompatibility with the mobile phase. | Ensure the sample solvent is miscible with the mobile phase to prevent precipitation on the column. |
**Q4: My dihydrouridine signal is weak or has a low signal-to
addressing matrix effects in mass spectrometry of RNA modifications
Welcome to the technical support center for addressing matrix effects in the mass spectrometry of RNA modifications. This resource is designed for researchers, scientists, and drug development professionals to troubleshoot and resolve common issues encountered during their experiments.
Frequently Asked Questions (FAQs)
Q1: What are matrix effects in the context of RNA modification analysis by mass spectrometry?
A1: Matrix effects are the alteration of ionization efficiency for a target analyte (a modified nucleoside) due to the presence of co-eluting compounds from the sample matrix.[1] These effects can either suppress or enhance the signal of the analyte, leading to inaccurate quantification.[1][2] In RNA analysis, the matrix can include residual salts, solvents, and cellular components like proteins and lipids that were not completely removed during sample preparation.[3][4]
Q2: How can I know if my experiment is being affected by matrix effects?
A2: Signs of matrix effects include poor signal intensity, inconsistent quantification between runs, peak shape distortion (splitting or broadening), and shifts in retention time.[1][5] A common method to assess matrix effects is the post-extraction spike method, where the signal response of an analyte in a clean solvent is compared to the response of the same amount of analyte spiked into a blank matrix sample after extraction.[6] A significant difference in signal indicates the presence of matrix effects.
Q3: What is the most effective way to counteract matrix effects?
A3: The most widely recognized and effective method to correct for matrix effects is the use of stable isotope-labeled internal standards (SILIS).[3][7][8] These standards are chemically identical to the analyte but have a different mass due to the incorporation of heavy isotopes (e.g., ¹³C, ¹⁵N).[7][9] Because SILIS co-elute with the analyte and experience the same ionization suppression or enhancement, the ratio of the analyte signal to the SILIS signal provides accurate quantification.[2]
Q4: Can my sample preparation method contribute to matrix effects?
A4: Absolutely. Inadequate sample preparation is a primary cause of matrix effects.[4] For example, protein precipitation is a common technique but can leave behind a significant amount of phospholipids, which are known to cause ion suppression.[4] More rigorous cleanup methods like solid-phase extraction (SPE) or liquid-liquid extraction (LLE) are generally more effective at removing interfering matrix components.[4][10]
Q5: Are there any specific RNA modifications that are more susceptible to issues during analysis?
A5: Yes, certain modifications can be problematic. For instance, hydrophobic modifications like N⁶,N⁶-dimethyladenosine (m⁶₂A) and N⁶-isopentenyladenosine (i⁶A) can be lost due to adsorption to filtration materials like polyethersulfone (PES).[3] Additionally, some modifications are chemically unstable under certain pH conditions, such as the Dimroth rearrangement of m¹A to m⁶A in alkaline conditions.[3]
Troubleshooting Guide
This guide provides solutions to specific problems you might encounter during your LC-MS analysis of RNA modifications.
| Problem | Potential Cause | Suggested Solution |
| Poor or No Signal | Ion Suppression: Co-eluting matrix components are interfering with the ionization of your target analyte.[5] | - Optimize Sample Cleanup: Employ more effective sample preparation techniques like solid-phase extraction (SPE) or liquid-liquid extraction (LLE) to remove interfering compounds.[4][10] - Use a Stable Isotope-Labeled Internal Standard (SILIS): This will help to accurately quantify the analyte despite signal suppression.[3][7] - Dilute the Sample: Reducing the concentration of matrix components by diluting the sample can alleviate suppression, provided the analyte concentration remains within the detection limits.[11] |
| Sample Concentration Issues: The sample may be too dilute to detect or too concentrated, causing suppression.[5] | - Adjust Sample Concentration: Concentrate dilute samples or dilute overly concentrated ones.[5] | |
| Inefficient Ionization: The chosen ionization method may not be optimal for your analyte.[5] | - Experiment with Ionization Techniques: Test different ionization methods (e.g., ESI, APCI) and optimize source parameters.[5] | |
| Inaccurate or Irreproducible Quantification | Matrix Effects: Ion suppression or enhancement is altering the analyte signal inconsistently.[1] | - Implement SILIS: Use a stable isotope-labeled internal standard for each analyte to normalize the signal.[7][9] - Matrix-Matched Calibration: Prepare calibration standards in a blank matrix extract that is similar to your samples to compensate for matrix effects.[12][13] |
| Enzyme Contaminations: Contaminating enzymes (e.g., deaminases) in hydrolysis reagents can alter modifications.[3] | - Use Enzyme Inhibitors: Add deaminase inhibitors like pentostatin (B1679546) and tetrahydrouridine (B1681287) during RNA hydrolysis.[3] | |
| Chemical Instability: The pH during sample preparation or storage may be causing degradation or rearrangement of modifications.[3] | - Control pH: Carefully consider and control the pH throughout the entire workflow, from RNA isolation to injection.[3] | |
| Peak Splitting or Broadening | Column Contamination: Buildup of matrix components on the analytical column.[5] | - Column Washing: Implement a robust column washing protocol between samples.[14] - Use a Guard Column: Protect the analytical column from strongly retained matrix components.[14] |
| Co-elution with Interfering Substances: A matrix component is eluting at the same time as the analyte.[1] | - Optimize Chromatography: Adjust the mobile phase gradient, temperature, or change the column chemistry to improve separation.[6] | |
| Retention Time Shifts | Matrix-Induced Chromatographic Effects: Components in the matrix can interact with the stationary phase and alter the retention of the analyte.[1] | - Improve Sample Cleanup: Reduce the amount of matrix components injected onto the column.[4][10] - Use SILIS: The internal standard will experience the same shift, allowing for correct identification and quantification.[7] |
Experimental Protocols
Protocol 1: General Workflow for RNA Analysis with Matrix Effect Mitigation
This protocol outlines the key steps from RNA isolation to LC-MS/MS analysis, incorporating strategies to minimize matrix effects.
-
RNA Isolation: Isolate total RNA from cells or tissues using a method that minimizes contamination from proteins, lipids, and other cellular components. Phenol-chloroform extraction followed by ethanol (B145695) precipitation is a standard method.[3]
-
RNA Purification: Purify the RNA of interest (e.g., mRNA, tRNA) to remove other RNA species and potential contaminants. For mRNA, oligo(dT) purification can be used.[15] For specific RNA types, size-exclusion chromatography can be effective.[16]
-
Enzymatic Hydrolysis:
-
Digest the purified RNA into single nucleosides using a combination of nucleases (e.g., nuclease P1) and phosphatases (e.g., bacterial alkaline phosphatase).[15]
-
Crucial Step: Add deaminase inhibitors such as pentostatin and tetrahydrouridine to the digestion mixture to prevent unwanted conversion of adenosine (B11128) and cytidine (B196190) modifications.[3]
-
-
Internal Standard Spiking:
-
Best Practice: Before any cleanup steps, spike the digested sample with a known concentration of a stable isotope-labeled internal standard (SILIS) mix.[3] This allows for the correction of analyte loss during cleanup and for matrix effects during LC-MS analysis.
-
-
Sample Cleanup (Post-Hydrolysis):
-
Remove enzymes and other high-molecular-weight components using molecular weight cutoff (MWCO) filters. Caution: Be aware that some hydrophobic modifications can adsorb to certain filter materials like PES. Consider using alternative materials like regenerated cellulose.[3]
-
Alternatively, for more complex matrices, use solid-phase extraction (SPE) to purify the nucleosides.
-
-
LC-MS/MS Analysis:
-
Separate the nucleosides using reversed-phase liquid chromatography.
-
Detect and quantify the nucleosides using a mass spectrometer operating in multiple reaction monitoring (MRM) mode.[17]
-
Quantify the endogenous modified nucleosides by calculating the ratio of their peak area to that of the corresponding SILIS.[7]
-
Protocol 2: Preparation of Stable Isotope-Labeled Internal Standards (SILIS)
Metabolic labeling is a common method for producing a comprehensive mix of SILIS for RNA modification analysis.[9][18]
-
Cell Culture: Culture microorganisms (e.g., E. coli or S. cerevisiae) in a defined minimal medium where standard nitrogen and carbon sources are replaced with heavy isotope-labeled counterparts (e.g., ¹⁵N-ammonium chloride and ¹³C-glucose).[9][16]
-
RNA Isolation: After sufficient growth to ensure incorporation of the heavy isotopes, harvest the cells and isolate the total RNA.[16]
-
RNA Digestion: Digest the heavy-labeled RNA into single nucleosides using the same enzymatic hydrolysis protocol as for the experimental samples.
-
Characterization and Quantification: Analyze the resulting heavy-labeled nucleosides by mass spectrometry to confirm complete labeling and to determine their concentration.
-
Use as Internal Standard: This characterized SILIS mixture can then be spiked into experimental samples for accurate quantification.[9]
Visualizations
Caption: Workflow for RNA modification analysis incorporating steps to mitigate matrix effects.
Caption: Decision tree for troubleshooting suspected matrix effects in LC-MS experiments.
References
- 1. Matrix effects break the LC behavior rule for analytes in LC-MS/MS analysis of biological samples - PMC [pmc.ncbi.nlm.nih.gov]
- 2. chromatographyonline.com [chromatographyonline.com]
- 3. pubs.acs.org [pubs.acs.org]
- 4. chromatographyonline.com [chromatographyonline.com]
- 5. gmi-inc.com [gmi-inc.com]
- 6. chromatographyonline.com [chromatographyonline.com]
- 7. researchgate.net [researchgate.net]
- 8. espace.library.uq.edu.au [espace.library.uq.edu.au]
- 9. Production and Application of Stable Isotope-Labeled Internal Standards for RNA Modification Analysis - PMC [pmc.ncbi.nlm.nih.gov]
- 10. researchgate.net [researchgate.net]
- 11. Compensate for or Minimize Matrix Effects? Strategies for Overcoming Matrix Effects in Liquid Chromatography-Mass Spectrometry Technique: A Tutorial Review - PMC [pmc.ncbi.nlm.nih.gov]
- 12. m.youtube.com [m.youtube.com]
- 13. Matrix-Matched Calibration Curves for Assessing Analytical Figures of Merit in Quantitative Proteomics - PMC [pmc.ncbi.nlm.nih.gov]
- 14. agilent.com [agilent.com]
- 15. Protocol for preparation and measurement of intracellular and extracellular modified RNA using liquid chromatography-mass spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 16. researchgate.net [researchgate.net]
- 17. Analysis of RNA and its Modifications - PMC [pmc.ncbi.nlm.nih.gov]
- 18. mdpi.com [mdpi.com]
common pitfalls in the interpretation of tRNA sequencing data
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to help researchers, scientists, and drug development professionals navigate the common pitfalls encountered during the interpretation of tRNA sequencing (tRNA-seq) data.
Frequently Asked Questions (FAQs)
Q1: Why is my tRNA sequencing read alignment so low?
A1: Low read alignment in tRNA-seq is a common issue stemming from the unique characteristics of tRNA molecules. Several factors can contribute to this problem:
-
tRNA Modifications: tRNAs are heavily modified post-transcriptionally. These modifications can interfere with reverse transcriptase activity during library preparation, leading to mismatches, deletions, or premature termination of cDNA synthesis.[1][2][3] This results in sequencing reads that do not perfectly match the reference genome.
-
Complex Secondary and Tertiary Structures: The highly structured nature of tRNAs, including their characteristic cloverleaf secondary structure, can impede the sequencing process and affect the efficiency of reverse transcription and adapter ligation.[1][4]
-
Short Sequence Length: tRNAs are small (typically 70-90 nucleotides), which can make unambiguous alignment challenging, especially when dealing with short sequencing reads.[1][5]
-
Presence of Isoacceptors and Isodecoders: The existence of multiple tRNA genes with identical or nearly identical sequences (isoacceptors and isodecoders) complicates the unique mapping of reads to a single genomic locus.[1][6][7]
Troubleshooting Steps:
-
Use Specialized Alignment Tools: Standard RNA-seq alignment tools may not be suitable for tRNA-seq data. Utilize aligners specifically designed for or optimized for tRNA analysis, such as tRNAscan-SE or specialized pipelines like MINTmap.[1][6]
-
Employ Demodification Treatments: Chemical or enzymatic treatments can be applied to remove certain tRNA modifications prior to library preparation, which can improve reverse transcription efficiency and sequencing accuracy.[1]
-
Optimize Library Preparation: Use library preparation kits and protocols specifically designed for small RNAs and tRNAs. Some methods, like DM-tRNA-seq, utilize thermostable reverse transcriptases to better handle the complex structures of tRNA.[1]
-
Consider Nanopore Sequencing: Direct RNA sequencing technologies, such as nanopore sequencing, can sequence native tRNA molecules without the need for reverse transcription and amplification, thus bypassing biases associated with these steps and allowing for the direct detection of modifications.[8][9][10]
Q2: How can I accurately quantify tRNA expression levels from my sequencing data?
A2: Accurate quantification of tRNA expression is challenging due to several biases introduced during the experimental and analytical workflow.
-
Library Preparation Biases: Biases can be introduced during RNA fragmentation, adapter ligation, and PCR amplification, leading to uneven representation of different tRNA species in the final sequencing library.[11][12][13] For example, some tRNA species may ligate to adapters more efficiently than others.[4][14]
-
Multimapping Reads: Due to the high sequence similarity between tRNA genes, a significant portion of reads may map to multiple locations in the genome (multimapping), making it difficult to assign them to a specific tRNA gene.[7]
-
Normalization Methods: The choice of normalization method can profoundly impact the results of differential expression analysis.[15][16] Standard RNA-seq normalization methods may not be appropriate for tRNA-seq data.
Troubleshooting and Best Practices:
-
Consistent Library Preparation: Use the same library preparation method for all samples within a study to minimize batch effects.[11]
-
Handle Multimapping Reads Appropriately: Employ bioinformatic strategies that can account for multimapping reads. Some approaches distribute multimapped reads among the possible locations based on unique read counts or other statistical models.[7]
-
Choose Appropriate Normalization Methods: For tRNA-seq, normalization methods that account for the unique characteristics of tRNA data should be considered. While methods like Total Counts, Upper Quartile (UQ), and Trimmed Mean of M-values (TMM) are used, their performance should be evaluated for your specific dataset.[17] Using spike-in controls can also aid in normalization.
-
Simulate Data for Benchmarking: Realistic tRNA-seq data simulation can help benchmark different quantification approaches and identify the most accurate one for your experimental setup.[7][18]
Table 1: Comparison of Common Normalization Methods in RNA-Seq
| Normalization Method | Principle | Advantages | Disadvantages |
| Total Counts (TC) | Divides gene counts by the total number of mapped reads per sample.[17] | Simple to implement. | Sensitive to highly expressed, differentially expressed genes. |
| Upper Quartile (UQ) | Uses the upper quartile of the counts for scaling. | More robust to outliers than Total Counts. | May not perform well with very low library sizes. |
| Trimmed Mean of M-values (TMM) | Calculates a scaling factor based on the weighted trimmed mean of the log-fold changes.[17] | Robust to the presence of a high proportion of differentially expressed genes. | Assumes that the majority of genes are not differentially expressed. |
| Quantile Normalization (Q) | Normalizes the counts to have the same quantiles across samples.[17] | Can effectively remove technical variation. | Can obscure true biological variation. |
Q3: My data shows a high abundance of tRNA fragments. How do I interpret this?
A3: The presence of tRNA-derived fragments (tRFs) and tRNA halves (tiRNAs) is a biological phenomenon and not necessarily a result of random degradation.[19][20] These fragments are generated through specific enzymatic cleavage of precursor or mature tRNAs and have been implicated in various biological processes, including gene expression regulation.[19][21][22]
Key Considerations for Interpretation:
-
Fragment Type: tRFs can be categorized based on their origin from the parent tRNA (e.g., 5'-tRFs, 3'-tRFs, internal-tRFs). The type of fragment can provide clues about its biogenesis and potential function.[20]
-
Cellular Condition: The abundance and composition of tRFs can vary significantly depending on the cell type, disease state, or environmental stress.[3][21]
-
Bioinformatic Analysis: Accurate identification and quantification of tRFs require specialized bioinformatic pipelines that can distinguish them from random degradation products and map them correctly to their parent tRNAs.[3][6][22]
Experimental Workflow for tRNA Fragment Analysis:
Caption: Workflow for the analysis of tRNA-derived fragments from small RNA sequencing data.
Troubleshooting Guide
Issue: Inconsistent results between biological replicates.
Potential Causes & Solutions:
| Cause | Solution |
| Variations in Sample Preparation | Ensure standardized protocols for RNA extraction and library preparation are used across all samples.[23] Minimize variations in handling time and conditions. |
| Batch Effects | If samples are processed in different batches, batch effects can be introduced.[24] Process all samples for a given comparison in the same batch if possible. If not, use statistical methods to correct for batch effects during data analysis. |
| Insufficient Sequencing Depth | Low sequencing depth can lead to high variability in the detection of low-abundance tRNAs and tRFs.[23] Determine the optimal sequencing depth for your research question. |
| Biological Variability | True biological variability between samples can be high. Ensure a sufficient number of biological replicates are included in the experimental design to achieve statistical power.[23] |
Issue: Difficulty in detecting tRNA modifications.
Challenges & Approaches:
-
Limitations of Standard NGS: Conventional next-generation sequencing (NGS) methods that rely on reverse transcription often lose information about RNA modifications.[10]
-
Specialized Sequencing Methods:
-
Methods based on RT signatures: Some techniques can predict modification sites by detecting reverse transcription-derived signatures, such as mismatched bases or premature termination.[2]
-
Nanopore Direct RNA Sequencing: This technology allows for the direct sequencing of RNA molecules, and modifications can be detected as characteristic changes in the ionic current signal.[8][10] This approach can potentially detect all tRNA modifications.[10]
-
-
Combined Approaches: Coupling tRNA-seq with methods like RNA mass spectrometry can provide comprehensive identification and quantification of tRNA modifications.[2]
Logical Diagram of tRNA Modification Detection Challenges:
Caption: Challenges in detecting tRNA modifications using standard vs. direct RNA sequencing.
References
- 1. tRNA Sequencing: Methods, Applications and Challenges - CD Genomics [rna.cd-genomics.com]
- 2. Comparative tRNA sequencing and RNA mass spectrometry for surveying tRNA modifications - PMC [pmc.ncbi.nlm.nih.gov]
- 3. tDRmapper: challenges and solutions to mapping, naming, and quantifying tRNA-derived RNAs from human small RNA-sequencing data - PMC [pmc.ncbi.nlm.nih.gov]
- 4. m.youtube.com [m.youtube.com]
- 5. Single-read tRNA-seq analysis reveals coordination of tRNA modification and aminoacylation and fragmentation - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Accurate Profiling and Quantification of tRNA Fragments from RNA-Seq Data: A Vade Mecum for MINTmap - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. Benchmarking tRNA-Seq quantification approaches by realistic tRNA-Seq data simulation identifies two novel approaches with higher accuracy [elifesciences.org]
- 8. Quantitative analysis of tRNA abundance and modifications by nanopore RNA sequencing [immaginabiotech.com]
- 9. rna-seqblog.com [rna-seqblog.com]
- 10. youtube.com [youtube.com]
- 11. blog.genohub.com [blog.genohub.com]
- 12. Bias in RNA-seq Library Preparation: Current Challenges and Solutions - PMC [pmc.ncbi.nlm.nih.gov]
- 13. rna-seqblog.com [rna-seqblog.com]
- 14. Frontiers | Addressing Bias in Small RNA Library Preparation for Sequencing: A New Protocol Recovers MicroRNAs that Evade Capture by Current Methods [frontiersin.org]
- 15. rna-seqblog.com [rna-seqblog.com]
- 16. The Impact of Normalization Methods on RNA-Seq Data Analysis - PMC [pmc.ncbi.nlm.nih.gov]
- 17. Frontiers | Comparison of Normalization Methods for Analysis of TempO-Seq Targeted RNA Sequencing Data [frontiersin.org]
- 18. biorxiv.org [biorxiv.org]
- 19. tRF&tiRNA Sequencing - CD Genomics [rna.cd-genomics.com]
- 20. Frontiers | tRNA Fragments Populations Analysis in Mutants Affecting tRNAs Processing and tRNA Methylation [frontiersin.org]
- 21. Profiling of tRNA fragments (small RNA sequencing) | omiics.com [omiics.com]
- 22. academic.oup.com [academic.oup.com]
- 23. What are common pitfalls in RNA-seq data analysis? [synapse.patsnap.com]
- 24. dromicsedu.com [dromicsedu.com]
Technical Support Center: Enhancing HPLC Resolution of Isomeric Nucleosides
Welcome to the technical support center for enhancing the resolution of isomeric nucleosides by High-Performance Liquid Chromatography (HPLC). This resource provides troubleshooting guides and frequently asked questions (FAQs) to help researchers, scientists, and drug development professionals overcome common challenges in separating these structurally similar compounds.
Frequently Asked Questions (FAQs)
Q1: What are the key factors influencing the resolution of isomeric nucleosides in HPLC?
A1: The resolution of isomeric nucleosides is governed by the fundamental principles of chromatography, encapsulated in the resolution equation:
-
Efficiency (N): This relates to the sharpness of the peaks. It can be improved by using columns with smaller particle sizes (sub-2 µm for UHPLC), increasing the column length, and optimizing the flow rate.[1][2] Minimizing system dead volume also helps prevent band broadening.[2]
-
Selectivity (α): This is the most critical factor for separating closely related isomers and refers to the ability of the chromatographic system to distinguish between them.[1][3] Selectivity can be significantly altered by changing the stationary phase chemistry, mobile phase composition (organic solvent type, pH, and buffer), and column temperature.[1][3][4]
-
Retention Factor (k'): Also known as the capacity factor, this represents the retention of an analyte on the column. Optimal retention (typically k' between 2 and 10) is necessary to achieve good resolution. It is primarily controlled by the strength of the mobile phase.[1][4]
Q2: Which type of HPLC column is best suited for separating nucleoside isomers?
A2: The choice of column is critical and depends on the nature of the isomers (e.g., enantiomers, diastereomers, or structural isomers).
-
Chiral Stationary Phases (CSPs): For enantiomeric and diastereomeric nucleosides, chiral columns are often essential. Polysaccharide-based CSPs, such as those derived from cellulose (B213188) (e.g., Chiralcel® OD-H) and amylose (B160209) (e.g., Chiralpak® AD), have proven effective for separating various nucleoside analogues.[5] Cyclodextrin-based columns (e.g., Cyclobond I 2000) are another viable option, particularly in reversed-phase or polar organic modes.[6][7]
-
Reversed-Phase Columns (C18, Phenyl): For non-chiral structural isomers, traditional reversed-phase columns like C18 can be effective. However, achieving separation may require careful optimization of the mobile phase. Phenyl columns can offer alternative selectivity due to π-π interactions with the nucleobases.[2][8]
-
Hydrophilic Interaction Liquid Chromatography (HILIC): HILIC columns are suitable for separating polar compounds like nucleosides and can provide different selectivity compared to reversed-phase chromatography.[9][10] Zwitterionic and diol-based HILIC phases are commonly used.[9]
Q3: How does the mobile phase composition affect the separation of isomeric nucleosides?
A3: Mobile phase composition is a powerful tool for optimizing selectivity (α) and retention (k').
-
Organic Modifier: In reversed-phase HPLC, changing the organic solvent (e.g., from acetonitrile (B52724) to methanol) can alter selectivity due to different interactions with the analyte and stationary phase.[1]
-
pH: The pH of the mobile phase can influence the ionization state of nucleosides, which in turn affects their retention and peak shape.[2][11] For basic molecules, higher pH can lead to better resolution, while acidic compounds are often better resolved at lower pH.[2]
-
Buffers: Using a buffer system helps maintain a stable pH and can improve peak shape and reproducibility.[2][11] The buffer concentration can also impact resolution.[2]
-
Ion-Pairing Reagents: For charged or highly polar nucleosides, adding an ion-pairing reagent to the mobile phase in reversed-phase HPLC can significantly improve retention and resolution.[12]
Q4: Can temperature be used to enhance the resolution of isomeric nucleosides?
A4: Yes, adjusting the column temperature can be an effective strategy.
-
Improved Efficiency: Increasing the temperature reduces the viscosity of the mobile phase, which can lead to sharper peaks (higher efficiency) and shorter analysis times.[13][14]
-
Altered Selectivity: Temperature can also change the selectivity of the separation, especially for ionizable compounds, as it affects the equilibrium between the analytes, mobile phase, and stationary phase.[14][15] Even small changes in temperature can be enough to resolve closely eluting peaks.[15] For some DNA fragments, an optimal temperature between 40 and 50 °C has been observed for HPLC separation.[16][17]
Troubleshooting Guide
This guide addresses common issues encountered during the HPLC separation of isomeric nucleosides.
// Nodes start [label="Start:\nPoor Resolution of\nIsomeric Nucleosides", shape=ellipse, style=filled, fillcolor="#EA4335", fontcolor="#FFFFFF"];
// Peak Shape Issues peak_shape [label="Assess Peak Shape", style=filled, fillcolor="#FBBC05", fontcolor="#202124"]; broad_peaks [label="Issue:\nBroad or Tailing Peaks", shape=Mdiamond, style=filled, fillcolor="#F1F3F4", fontcolor="#202124"]; cause_broad [label="Potential Causes:\n- Column Contamination\n- Mismatched Sample Solvent\n- Suboptimal pH\n- High Dead Volume", style=filled, fillcolor="#F1F3F4", fontcolor="#202124"]; solution_broad [label="Solutions:\n1. Flush column with strong solvent.\n2. Dissolve sample in mobile phase.\n3. Adjust mobile phase pH.\n4. Check system for leaks and minimize tubing length.", style=filled, fillcolor="#34A853", fontcolor="#FFFFFF"];
// Retention Time Issues retention [label="Evaluate Retention Time (k')", style=filled, fillcolor="#FBBC05", fontcolor="#202124"]; k_issue [label="Issue:\nPoor Retention (k' < 2)\nor Excessive Retention (k' > 10)", shape=Mdiamond, style=filled, fillcolor="#F1F3F4", fontcolor="#202124"]; cause_k [label="Potential Causes:\n- Mobile phase too strong/weak\n- Incorrect column choice", style=filled, fillcolor="#F1F3F4", fontcolor="#202124"]; solution_k [label="Solutions:\n1. Adjust organic solvent percentage.\n2. For reversed-phase, decrease %B to increase retention.\n3. Consider a more/less retentive stationary phase.", style=filled, fillcolor="#34A853", fontcolor="#FFFFFF"];
// Selectivity Issues selectivity [label="Optimize Selectivity (α)", style=filled, fillcolor="#FBBC05", fontcolor="#202124"]; alpha_issue [label="Issue:\nCo-eluting or\nPoorly Separated Peaks (α ≈ 1)", shape=Mdiamond, style=filled, fillcolor="#F1F3F4", fontcolor="#202124"]; cause_alpha [label="Potential Causes:\n- Insufficient chemical difference in interactions", style=filled, fillcolor="#F1F3F4", fontcolor="#202124"]; solution_alpha [label="Solutions:\n1. Change stationary phase (e.g., C18 to Phenyl or Chiral).\n2. Change organic modifier (e.g., ACN to MeOH).\n3. Adjust mobile phase pH.\n4. Vary column temperature.", style=filled, fillcolor="#34A853", fontcolor="#FFFFFF"];
// Edges start -> peak_shape; peak_shape -> broad_peaks; broad_peaks -> cause_broad [label="Yes"]; cause_broad -> solution_broad; broad_peaks -> retention [label="No"];
retention -> k_issue; k_issue -> cause_k [label="Yes"]; cause_k -> solution_k; k_issue -> selectivity [label="No"];
selectivity -> alpha_issue; alpha_issue -> cause_alpha [label="Yes"]; cause_alpha -> solution_alpha; }
Caption: Troubleshooting workflow for poor resolution of isomeric nucleosides.
Experimental Protocols
Protocol 1: Chiral Separation of Nucleoside Diastereomers using a Polysaccharide-Based CSP
This protocol is adapted from methodologies for separating diastereomeric nucleoside analogues.[5]
-
HPLC System: A standard HPLC system with a UV detector.
-
Column: Chiralcel OD-H (cellulose tris-3,5-dimethylphenylcarbamate), 250 x 4.6 mm, 5 µm.
-
Mobile Phase: A mixture of n-hexane and an alcohol (e.g., ethanol (B145695) or 2-propanol). The ratio is critical and should be optimized. Start with a ratio of 90:10 (n-hexane:alcohol) and adjust as needed.
-
Flow Rate: 1.0 mL/min.
-
Temperature: Ambient (e.g., 25 °C).
-
Detection: UV at 254 nm.
-
Sample Preparation: Dissolve the nucleoside isomer mixture in the mobile phase at a concentration of approximately 1 mg/mL.
-
Injection Volume: 10 µL.
-
Procedure: a. Equilibrate the column with the mobile phase for at least 30 minutes or until a stable baseline is achieved. b. Inject the sample. c. Monitor the chromatogram for the separation of the diastereomers. d. If resolution is insufficient, systematically vary the percentage of alcohol in the mobile phase. Increasing the alcohol content will generally decrease retention times.
Protocol 2: Reversed-Phase Separation of Nucleoside Isomers
This protocol provides a general starting point for separating structural isomers of nucleosides on a C18 column.
-
HPLC System: A standard HPLC system with a UV detector.
-
Column: C18 column, 150 x 4.6 mm, 5 µm.
-
Mobile Phase:
-
Solvent A: 20 mM phosphate (B84403) buffer, pH adjusted to 4.5.
-
Solvent B: Acetonitrile.
-
-
Gradient Program:
-
Start with 5% B for 5 minutes.
-
Linear gradient from 5% to 40% B over 20 minutes.
-
Hold at 40% B for 5 minutes.
-
Return to 5% B and re-equilibrate for 10 minutes.
-
-
Flow Rate: 1.0 mL/min.
-
Temperature: 30 °C.
-
Detection: UV at 260 nm.
-
Sample Preparation: Dissolve the sample in a mixture of water and acetonitrile (e.g., 95:5 v/v) to a concentration of 0.5 mg/mL.
-
Injection Volume: 10 µL.
-
Procedure: a. Equilibrate the column with the initial mobile phase composition (95% A, 5% B) until a stable baseline is observed. b. Inject the sample and run the gradient program. c. If separation is not optimal, adjust the gradient slope, pH of the mobile phase, or change the organic modifier to methanol.
Data Presentation
The following tables summarize quantitative data from studies on the separation of nucleoside isomers, illustrating the impact of different chromatographic conditions on resolution (Rs).
Table 1: Separation of Nucleoside Analogue Enantiomers on a Chiral Stationary Phase
| Compound | Chiral Stationary Phase | Mobile Phase (v/v) | Retention Factor (k') | Selectivity (α) | Resolution (Rs) |
| Enantiomer Pair 1 | Cyclobond I 2000 RSP | Acetonitrile/Water (40/60) | k'1 = 2.5, k'2 = 3.1 | 1.24 | 1.8 |
| Enantiomer Pair 2 | Cyclobond I 2000 RSP | Acetonitrile/Water (40/60) | k'1 = 4.2, k'2 = 4.9 | 1.17 | 1.5 |
Data is illustrative and based on typical performance for such separations.[7]
Table 2: Effect of Temperature on the Resolution of Oligonucleotides
| Column | Temperature (°C) | Sample | Observation |
| Polymeric PLRP-S | 35 | 29/30 mer oligonucleotides | Good separation |
| Polymeric PLRP-S | 80 | 29/30 mer oligonucleotides | Significantly improved resolution and selectivity |
| Thermally Stable Silica C18 | 35 | poly(dT) 19-24 mer ladder | Best separation at this temperature |
| Thermally Stable Silica C18 | 80 | poly(dT) 19-24 mer ladder | Improved resolution |
This table demonstrates that increasing temperature generally improves resolution due to enhanced mass transfer.[13]
Logical Workflow for Method Development
The following diagram outlines a logical workflow for developing a method to enhance the resolution of isomeric nucleosides.
// Nodes start [label="Start:\nSeparate Isomeric Nucleosides", shape=ellipse, style=filled, fillcolor="#4285F4", fontcolor="#FFFFFF"];
// Column Selection col_select [label="1. Column Selection", style=filled, fillcolor="#FBBC05", fontcolor="#202124"]; is_chiral [label="Are isomers\nenantiomers or\ndiastereomers?", shape=diamond, style=filled, fillcolor="#F1F3F4", fontcolor="#202124"]; chiral_col [label="Select Chiral Stationary Phase\n(e.g., Polysaccharide, Cyclodextrin)", style=filled, fillcolor="#F1F3F4", fontcolor="#202124"]; rp_col [label="Select Reversed-Phase (C18, Phenyl)\nor HILIC Column", style=filled, fillcolor="#F1F3F4", fontcolor="#202124"];
// Mobile Phase Optimization mp_opt [label="2. Mobile Phase Optimization", style=filled, fillcolor="#FBBC05", fontcolor="#202124"]; mp_params [label="Adjust:\n- Organic solvent type (ACN, MeOH)\n- Solvent strength (%B)\n- pH and buffer", style=filled, fillcolor="#F1F3F4", fontcolor="#202124"];
// Parameter Tuning param_tune [label="3. Parameter Tuning", style=filled, fillcolor="#FBBC05", fontcolor="#202124"]; param_list [label="Optimize:\n- Flow Rate\n- Column Temperature", style=filled, fillcolor="#F1F3F4", fontcolor="#202124"];
// Evaluation eval [label="4. Evaluate Resolution (Rs)", style=filled, fillcolor="#FBBC05", fontcolor="#202124"]; is_resolved [label="Resolution > 1.5?", shape=diamond, style=filled, fillcolor="#F1F3F4", fontcolor="#202124"];
// End end [label="Method Optimized", shape=ellipse, style=filled, fillcolor="#34A853", fontcolor="#FFFFFF"];
// Edges start -> col_select; col_select -> is_chiral; is_chiral -> chiral_col [label="Yes"]; is_chiral -> rp_col [label="No"]; chiral_col -> mp_opt; rp_col -> mp_opt; mp_opt -> mp_params; mp_params -> param_tune; param_tune -> param_list; param_list -> eval; eval -> is_resolved; is_resolved -> end [label="Yes"]; is_resolved -> col_select [label="No, try different column/mobile phase"]; }
Caption: A systematic approach to HPLC method development for isomeric nucleosides.
References
- 1. chromatographyonline.com [chromatographyonline.com]
- 2. pharmaguru.co [pharmaguru.co]
- 3. Factors Affecting Resolution in HPLC [sigmaaldrich.com]
- 4. mastelf.com [mastelf.com]
- 5. Diastereomeric resolution of nucleoside analogues, new potential antiviral agents, using high-performance liquid chromatography on polysaccharide-type chiral stationary phases - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. tandfonline.com [tandfonline.com]
- 7. tandfonline.com [tandfonline.com]
- 8. Effect of mobile phase pH on the retention of nucleotides on different stationary phases for high-performance liquid chromatography - PMC [pmc.ncbi.nlm.nih.gov]
- 9. researchgate.net [researchgate.net]
- 10. pdfs.semanticscholar.org [pdfs.semanticscholar.org]
- 11. Mobile Phase Optimization: A Critical Factor in HPLC | Phenomenex [phenomenex.com]
- 12. phenomenex.blob.core.windows.net [phenomenex.blob.core.windows.net]
- 13. agilent.com [agilent.com]
- 14. chromatographytoday.com [chromatographytoday.com]
- 15. chromtech.com [chromtech.com]
- 16. Effect of temperature on the separation of DNA fragments by high-performance liquid chromatography and capillary electrophoresis: a comparative study - PubMed [pubmed.ncbi.nlm.nih.gov]
- 17. researchgate.net [researchgate.net]
Technical Support Center: Strategies to Minimize RNA Degradation
Welcome to our technical support center. This resource is designed for researchers, scientists, and drug development professionals to provide troubleshooting guidance and answer frequently asked questions regarding the minimization of RNA degradation during sample preparation.
Troubleshooting Guides
This section provides solutions to common problems encountered during RNA extraction and analysis.
Issue 1: Low RNA Yield
Symptoms:
-
Low RNA concentration as determined by spectrophotometry (e.g., NanoDrop) or fluorometry (e.g., Qubit).
-
Insufficient material for downstream applications.
Possible Causes & Solutions:
| Possible Cause | Recommended Solution |
| Incomplete Sample Lysis/Homogenization | Ensure the sample is thoroughly disrupted. For tissues, consider using a bead beater or rotor-stator homogenizer. For cells that are difficult to lyse, an enzymatic digestion step (e.g., with proteinase K or lysozyme) prior to lysis can be beneficial.[1][2] Increase the time for sample digestion or homogenization.[2][3] |
| Incorrect Amount of Starting Material | Using too much starting material can overload the purification system (e.g., silica (B1680970) column), leading to inefficient lysis and RNA binding, which reduces yield.[4] Conversely, too little starting material will naturally result in a low yield. Refer to your kit's recommendations for the optimal amount of input material.[4] |
| Inefficient RNA Elution | When using silica spin columns, ensure the elution buffer (RNase-free water or elution buffer) is applied directly to the center of the membrane. For maximal recovery, you can increase the elution volume or perform a second elution.[2][5] Incubating the column with the elution buffer for 5-10 minutes at room temperature before centrifugation can also improve yield.[2] |
| RNA Degradation | If the RNA is degraded, the yield of intact RNA will be low. See the "RNA is Degraded" section below for troubleshooting steps. |
Issue 2: RNA is Degraded
Symptoms:
-
Smeared bands on a denaturing agarose (B213101) gel with indistinct or absent 28S and 18S rRNA bands.[1]
-
A 28S:18S rRNA ratio significantly less than 2:1 for eukaryotic samples.[1][5]
-
Low RNA Integrity Number (RIN) value (typically < 7).
Possible Causes & Solutions:
| Possible Cause | Recommended Solution |
| RNase Contamination | RNases are ubiquitous and can be introduced from various sources.[6][7] See the FAQ section on "How can I prevent RNase contamination?" for detailed prevention strategies. |
| Improper Sample Storage/Handling | Samples should be processed immediately after collection. If immediate processing is not possible, snap-freeze the sample in liquid nitrogen and store it at -80°C, or use an RNA stabilization reagent like RNAlater™.[1][8] Avoid repeated freeze-thaw cycles.[9] When thawing samples, do so on ice.[10] |
| Excessive Homogenization | Over-homogenizing can generate heat, leading to RNA degradation. Homogenize in short bursts of 30-45 seconds, with rest periods on ice in between to prevent overheating.[2][5] |
| Delayed Lysis | For fresh tissues, add a cold guanidine-based lysis buffer (like TRIzol) immediately after harvesting to inactivate endogenous RNases.[2][5] |
Issue 3: Low A260/A280 Ratio (<1.8)
Symptoms:
-
The ratio of absorbance at 260 nm to 280 nm is below the optimal range of 1.8-2.1, as measured by a UV spectrophotometer.[11]
Possible Causes & Solutions:
| Possible Cause | Recommended Solution |
| Protein Contamination | This is a common cause, often resulting from incomplete phase separation in TRIzol-based extractions or overloading a silica column.[6] When using TRIzol, be careful not to transfer any of the interphase or organic phase along with the aqueous phase. For column-based methods, ensure you are using the recommended amount of starting material.[6] |
| Phenol (B47542) Carryover | Residual phenol from TRIzol or phenol-chloroform extractions can lead to a low A260/A280 ratio.[4][12] Ensure no phenol is carried over with the aqueous phase. An additional chloroform (B151607) extraction can help remove residual phenol. |
| Incorrect Blank Measurement | The solution used to blank the spectrophotometer should have the same pH and ionic strength as the solution your RNA is dissolved in. Using water to blank samples dissolved in a buffer like TE can skew the ratio.[12] |
| Acidic pH of the Solution | If the RNA is dissolved in water, which can be slightly acidic, it can lower the A260/A280 ratio. Using a slightly basic buffer, such as TE buffer (pH 7.5-8.0), can help maintain an optimal ratio.[4][12] |
Issue 4: Genomic DNA (gDNA) Contamination
Symptoms:
-
High molecular weight smearing or a distinct band above the 28S rRNA band on an agarose gel.[1]
-
Amplification in no-reverse transcriptase (-RT) controls in a subsequent RT-PCR experiment.[6]
Possible Causes & Solutions:
| Possible Cause | Recommended Solution |
| Incomplete Homogenization | Insufficient shearing of gDNA during homogenization can lead to its carryover.[6] Use methods that effectively break up DNA, such as a bead beater or a rotor-stator homogenizer.[6] |
| Improper Phase Separation (TRIzol) | The pH of the phenol in TRIzol is acidic, which helps retain DNA in the interphase and organic layers.[6] Carefully pipette only the upper aqueous phase to avoid gDNA contamination.[6] |
| Column Overloading | Using too much starting material can exceed the binding capacity of the silica membrane for RNA, potentially allowing gDNA to bind and co-elute.[13][14] |
| Omission of DNase Treatment | The most effective way to remove gDNA is to perform a DNase treatment. This can be done "on-column" for silica-based kits or in-solution after RNA elution.[3][14] Ensure the DNase is subsequently removed or inactivated to prevent it from degrading DNA in downstream applications.[14] |
Frequently Asked Questions (FAQs)
Q1: What are the primary sources of RNase contamination?
RNases are enzymes that degrade RNA and are ubiquitous in the laboratory environment. Key sources include:
-
Human sources: Skin, hair, and saliva are rich in RNases. Always wear gloves and change them frequently, especially after touching non-sterile surfaces like your face or hair.[7][15][16]
-
Environment: Dust particles can carry bacteria and mold, which are sources of RNases.[7] Lab surfaces, pipettors, and other equipment can become contaminated if left exposed.[17][18]
-
Reagents and Solutions: Water and buffers can be a common source of contamination if not certified RNase-free or properly treated (e.g., with DEPC).[6][17]
-
Samples: The cells or tissues themselves contain endogenous RNases that are released upon lysis.[7]
Q2: How can I create and maintain an RNase-free work environment?
-
Designated Area: Set aside a specific area of the lab exclusively for RNA work.[4][19]
-
Surface Decontamination: Regularly clean your workbench, pipettes, and equipment with RNase decontamination solutions (e.g., RNaseZap™).[15][19][20]
-
Use Certified Consumables: Use disposable plasticware (tubes, pipette tips) that are certified RNase-free.[7][17] Filter tips are highly recommended to prevent cross-contamination.[10]
-
Proper Personal Protective Equipment (PPE): Always wear a clean lab coat and sterile gloves. Change gloves often.[7][15]
-
Treat Non-disposable Items: Bake glassware at 180°C or higher for several hours.[6] Treat non-disposable plasticware with solutions like 0.1 M NaOH/1 mM EDTA, followed by a rinse with RNase-free water.[6][19]
Q3: What is the role of an RNase inhibitor?
RNase inhibitors are proteins that bind to and inactivate a broad spectrum of RNases.[21][22][23] They act as a safeguard to protect RNA from degradation by any residual RNases that may be present during enzymatic manipulations like reverse transcription, in vitro transcription, or cDNA synthesis.[21][22] Adding an RNase inhibitor to your reactions is a highly recommended precautionary step.[24]
Q4: What are the best practices for storing samples and purified RNA?
Proper storage is critical for maintaining RNA integrity.
| Sample Type | Short-Term Storage | Long-Term Storage |
| Tissue/Cell Samples | Process immediately or use a stabilization reagent (e.g., RNAlater™) and store at 4°C for a few days or -20°C for longer periods.[5] | Snap-freeze in liquid nitrogen and store at -80°C.[1][2] |
| Purified RNA | Store at -20°C for up to a year.[7][8] | Store at -80°C. For very long-term storage, RNA can be stored as an ethanol (B145695) precipitate at -20°C.[7][11][14] |
To avoid degradation from multiple freeze-thaw cycles, it is best to aliquot purified RNA into single-use tubes.[8][9]
Q5: How does storage temperature and duration affect RNA quality?
RNA integrity is sensitive to both storage temperature and duration. The RNA Integrity Number (RIN) is a common metric for quality, with values above 8 being ideal for most downstream applications.[25]
| Storage Condition | Impact on RNA Integrity (RIN) |
| -80°C | Generally stable for several years. One study found that blood samples stored for up to 3 years maintained a median RIN above 6, which is considered high-quality.[25] Another study showed no significant degradation after 5 years.[25] |
| -20°C | Suitable for short-term storage of purified RNA.[8][15] |
| 4°C | Blood samples stored at 4°C for up to 7 days with RIN values above 5.3 were found to be suitable for RNA-seq.[26] |
| Room Temperature | RNA in water can degrade within hours. However, in a stabilizing buffer, it can remain largely intact for several weeks.[15] |
| Temperature Fluctuation (e.g., freezer failure) | RNA integrity in frozen tissues is not significantly affected until the temperature rises to 0°C. However, if the temperature reaches room temperature for even a few hours, the RNA can be almost completely destroyed. |
Experimental Protocols
Protocol 1: Total RNA Extraction using TRIzol™ Reagent
This protocol is a common method for isolating RNA from cells and tissues.
-
Homogenization:
-
Tissues: Add 1 ml of TRIzol™ reagent per 50-100 mg of tissue and homogenize using a power homogenizer.[15]
-
Cells: For cells grown in a monolayer, add 1 ml of TRIzol™ to a 3.5 cm diameter dish and pass the cell lysate through a pipette several times.[15] For cell suspensions, pellet the cells and add 1 ml of TRIzol™ per 5-10 x 10^6 cells.[2]
-
-
Phase Separation:
-
Incubate the homogenate for 5 minutes at room temperature.[15]
-
Add 0.2 ml of chloroform per 1 ml of TRIzol™ used. Cap the tube securely and shake vigorously by hand for 15 seconds.[15][21]
-
Incubate at room temperature for 2-3 minutes.[19]
-
Centrifuge at 12,000 x g for 15 minutes at 4°C. The mixture will separate into a lower red organic phase, an interphase, and an upper colorless aqueous phase containing the RNA.[15][19]
-
-
RNA Precipitation:
-
Carefully transfer the upper aqueous phase to a fresh tube without disturbing the interphase.[15]
-
Add 0.5 ml of isopropanol (B130326) per 1 ml of TRIzol™ used. Mix by inverting the tube and incubate at room temperature for 10 minutes.[2]
-
Centrifuge at 12,000 x g for 10 minutes at 4°C. The RNA will form a gel-like pellet on the side or bottom of the tube.[19]
-
-
RNA Wash:
-
Resuspension:
-
Discard the supernatant and briefly air-dry the pellet for 5-10 minutes. Do not over-dry, as this will make the RNA difficult to dissolve.[15]
-
Resuspend the RNA in an appropriate volume (e.g., 20-50 µl) of RNase-free water or buffer by pipetting up and down. Incubate at 55-60°C for 10 minutes to aid dissolution.[15]
-
Protocol 2: RNA Quality Assessment by Denaturing Agarose Gel Electrophoresis
This method assesses the integrity of a total RNA sample.
-
Gel Preparation:
-
Prepare a 1% agarose gel with 1X MOPS buffer. Heat to dissolve the agarose, then cool to about 60°C.
-
In a fume hood, add formaldehyde (B43269) to a final concentration of 2.2 M and ethidium (B1194527) bromide to 10 µg/ml. Pour the gel and allow it to solidify.[1]
-
-
Sample Preparation:
-
In a fresh tube, mix 1-3 µg of your RNA sample with 3 parts of formaldehyde load dye.
-
Heat the mixture at 65°C for 15 minutes to denature the RNA, then immediately place on ice.[1]
-
-
Electrophoresis:
-
Load the denatured RNA samples and an RNA ladder into the wells of the gel.
-
Run the gel at 5-6 V/cm in 1X MOPS running buffer until the bromophenol blue dye has migrated approximately two-thirds of the way down the gel.[1]
-
-
Visualization and Interpretation:
-
Visualize the gel on a UV transilluminator.
-
Intact total eukaryotic RNA will show two sharp bands corresponding to the 28S and 18S ribosomal RNA (rRNA). The 28S band should be approximately twice as intense as the 18S band.[1][5]
-
Degraded RNA will appear as a smear down the lane, with the rRNA bands being faint or absent.[1]
-
Protocol 3: RNA Quantification using UV Spectrophotometry
This is a common method for determining RNA concentration and purity.
-
Prepare the Spectrophotometer:
-
Turn on the spectrophotometer and allow the lamp to warm up. Select the nucleic acid quantification setting.
-
-
Blank the Instrument:
-
Use the same RNase-free buffer or water that your RNA is dissolved in as the blank. Pipette 1-2 µl onto the pedestal (for microvolume spectrophotometers) or into a quartz cuvette and take a blank reading.[26]
-
-
Measure the RNA Sample:
-
Wipe the pedestal clean. Pipette 1-2 µl of your RNA sample and take a reading.
-
-
Calculate Concentration and Purity:
-
The instrument will typically calculate the concentration automatically based on the absorbance at 260 nm (A260). An A260 of 1.0 is equivalent to approximately 40 µg/ml of single-stranded RNA.[11][26]
-
The purity is assessed by the A260/A280 and A260/A230 ratios. For pure RNA, the A260/A280 ratio should be ~2.0.[4] The A260/A230 ratio should ideally be between 2.0 and 2.2.[12]
-
Visualizations
Caption: General workflow for RNA extraction, from sample collection to storage.
References
- 1. Agarose Gel Electrophoresis of RNA | Thermo Fisher Scientific - JP [thermofisher.com]
- 2. zymoresearch.com [zymoresearch.com]
- 3. mpbio.com [mpbio.com]
- 4. documents.thermofisher.com [documents.thermofisher.com]
- 5. Protocols · Benchling [benchling.com]
- 6. bitesizebio.com [bitesizebio.com]
- 7. wellcomeopenresearch.org [wellcomeopenresearch.org]
- 8. merckmillipore.com [merckmillipore.com]
- 9. Troubleshooting Guide: RNA Extraction for Sequencing - CD Genomics [rna.cd-genomics.com]
- 10. Quantitating RNA | Thermo Fisher Scientific - US [thermofisher.com]
- 11. documents.thermofisher.com [documents.thermofisher.com]
- 12. m.youtube.com [m.youtube.com]
- 13. RNA Preparation Troubleshooting [sigmaaldrich.com]
- 14. animal.ifas.ufl.edu [animal.ifas.ufl.edu]
- 15. DNA and RNA Quantification [sigmaaldrich.com]
- 16. RNA Extraction using Trizol [protocols.io]
- 17. Troubleshooting – Low OD Ratios [qiagen.com]
- 18. TRIzol RNA Extraction Protocol - CD Genomics [rna.cd-genomics.com]
- 19. apps.weber.edu [apps.weber.edu]
- 20. rnaseqcore.vet.cornell.edu [rnaseqcore.vet.cornell.edu]
- 21. researchgate.net [researchgate.net]
- 22. researchgate.net [researchgate.net]
- 23. Protocol: high throughput silica-based purification of RNA from Arabidopsis seedlings in a 96-well format - PMC [pmc.ncbi.nlm.nih.gov]
- 24. mpbio.com [mpbio.com]
- 25. The Best Techniques for RNA Quantification [denovix.com]
- 26. A cost-effective RNA extraction technique from animal cells and tissue using silica columns [polscientific.com]
Validation & Comparative
A Researcher's Guide to Validating Dihydrouridine Sites Identified by High-Throughput Sequencing
For researchers, scientists, and drug development professionals, the accurate identification and validation of dihydrouridine (D) sites in RNA is crucial for understanding its role in biological processes and its potential as a therapeutic target. The advent of high-throughput sequencing has enabled transcriptome-wide mapping of this modification. This guide provides a comprehensive comparison of current high-throughput sequencing methods and traditional validation techniques for dihydrouridine sites, complete with experimental protocols and performance data to aid in the selection of the most appropriate methods for your research needs.
Dihydrouridine, a non-canonical RNA modification, is increasingly recognized for its significant impact on RNA structure and function. Its accurate detection is paramount. High-throughput sequencing methods such as D-seq, Rho-seq, and the more recent CRACI-seq have revolutionized the field by enabling genome-wide screens for D sites. However, the validation of these identified sites remains a critical step to ensure data accuracy and biological relevance. This guide will delve into the principles, protocols, and comparative performance of these cutting-edge sequencing technologies and the gold-standard validation methods.
High-Throughput Sequencing Methods for Dihydrouridine Detection: A Comparative Overview
The landscape of dihydrouridine detection has rapidly evolved, with each new method aiming to improve upon the sensitivity, specificity, and quantitative accuracy of its predecessors. The primary methods currently in use are D-seq, Rho-seq, CRACI-seq, and AlkAniline-Seq. A key differentiator among these techniques is their reliance on either reverse transcriptase (RT) stalling or misincorporation signatures to identify D sites.
| Method | Principle | Signal Type | Key Advantages | Key Limitations |
| D-seq | Sodium borohydride (B1222165) (NaBH₄) reduction of dihydrouridine to tetrahydrouridine (B1681287), which induces a stall in reverse transcription.[1][2] | RT stop 1 nucleotide 3' to the D site.[1] | Relatively straightforward protocol. | Relies on RT stops, which can be inefficient and difficult to distinguish from other RT-pausing events. Not inherently quantitative. |
| Rho-seq | Two-step chemical modification: NaBH₄ reduction followed by covalent labeling with rhodamine. The bulky rhodamine adduct strongly blocks reverse transcriptase.[3] | Strong RT stop 1 nucleotide 3' to the D site.[3] | The bulky adduct provides a more robust RT stop signal compared to D-seq. | Also reliant on RT stops with similar limitations to D-seq. Not inherently quantitative. |
| CRACI-seq | Chemical reduction of dihydrouridine followed by the use of a specific reverse transcriptase that reads the modified base as a cytosine.[4] | T-to-C misincorporation at the D site.[4] | Highly sensitive and quantitative, as it relies on a positive signal (misincorporation) rather than a lack of signal (RT stop).[4] Can determine the stoichiometry of the modification.[4] | Requires a specific reverse transcriptase and more complex bioinformatic analysis to call misincorporations. |
| AlkAniline-Seq | Exploits the chemical fragility of the N-glycosidic bond in dihydrouridine under alkaline conditions, leading to RNA cleavage at the modification site.[5] | RNA fragments starting 1 nucleotide downstream of the D site. | Can simultaneously map other modifications like m⁷G and m³C.[5] | Signal for dihydrouridine is reported to be weaker compared to other modifications it detects.[3][6] |
Validating Putative Dihydrouridine Sites: Established Methodologies
The validation of dihydrouridine sites identified through high-throughput sequencing is a critical step to confirm their authenticity. The use of dihydrouridine synthase (DUS) knockout (KO) organisms as a negative control is a fundamental validation strategy for all sequencing-based methods. A true dihydrouridine site should be absent in DUS KO samples.[2] Beyond this genetic approach, two biochemical methods are widely used for site-specific validation: primer extension analysis and mass spectrometry.
Primer Extension Analysis
This classic technique can be adapted to validate specific dihydrouridine sites. The principle relies on the chemical modification of dihydrouridine to induce a premature stop during reverse transcription, which can be visualized on a gel.
Mass Spectrometry
Mass spectrometry (MS) is a powerful tool for the unambiguous identification and quantification of modified nucleosides. While it is the gold standard for detecting the presence of dihydrouridine in a total RNA sample, its application for validating specific sites identified by sequencing is more complex. It typically requires the purification of the specific RNA species or fragments containing the putative D site, which can be challenging. The common approach involves the enzymatic digestion of RNA into individual nucleosides, followed by liquid chromatography-mass spectrometry (LC-MS) to quantify the amount of dihydrouridine relative to other nucleosides.[7]
Experimental Protocols
D-seq Library Preparation (Simplified)
-
RNA Fragmentation: Fragment total RNA to the desired size range.
-
Borohydride Reduction: Treat the fragmented RNA with sodium borohydride (NaBH₄) to reduce dihydrouridine to tetrahydrouridine.
-
3' End Repair and Adapter Ligation: Perform enzymatic end-repair and ligate a 3' adapter.
-
Reverse Transcription: Use a reverse transcriptase to synthesize cDNA. The enzyme will stall at the tetrahydrouridine sites.
-
Circularization and PCR: Ligate a 5' adapter, followed by PCR amplification to generate the sequencing library.
Primer Extension Assay for Dihydouridine Validation
-
Primer Labeling: End-label a DNA oligonucleotide primer complementary to the target RNA sequence downstream of the putative D site with ³²P.
-
Annealing: Anneal the radiolabeled primer to the total RNA sample.
-
Chemical Treatment: Treat the RNA-primer hybrids with either an alkaline solution or NaBH₄ to modify the dihydrouridine.
-
Reverse Transcription: Perform a primer extension reaction using a reverse transcriptase.
-
Gel Electrophoresis: Separate the cDNA products on a denaturing polyacrylamide gel.
-
Autoradiography: Visualize the radiolabeled cDNA products. A band corresponding to a truncated product at the expected size validates the presence of a modification that induces an RT stop after chemical treatment.[8]
Mass Spectrometry for Bulk Dihydrouridine Quantification
-
RNA Isolation: Purify the RNA of interest (e.g., mRNA, tRNA).
-
Enzymatic Digestion: Digest the RNA to single nucleosides using a cocktail of nucleases (e.g., nuclease P1, snake venom phosphodiesterase, and alkaline phosphatase).
-
LC-MS/MS Analysis: Separate the nucleosides by liquid chromatography and detect and quantify them using tandem mass spectrometry. Stable isotope-labeled dihydrouridine is often used as an internal standard for accurate quantification.[7]
Logical Framework for Validation
Conclusion
The accurate mapping and validation of dihydrouridine sites are essential for advancing our understanding of the epitranscriptome. While high-throughput methods provide a powerful tool for discovery, orthogonal validation is indispensable for confirming these findings. CRACI-seq currently represents the most sensitive and quantitative high-throughput method. For site-specific validation, primer extension analysis remains a robust and accessible technique. The choice of methods will ultimately depend on the specific research question, available resources, and the desired level of quantitative accuracy. By combining high-throughput screening with rigorous validation, researchers can confidently delineate the dihydrouridine landscape and unravel its functional significance in health and disease.
References
- 1. Transcriptome-wide mapping reveals a diverse dihydrouridine landscape including mRNA - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Expanding the epitranscriptome: Dihydrouridine in mRNA - PMC [pmc.ncbi.nlm.nih.gov]
- 3. The Dihydrouridine landscape from tRNA to mRNA: a perspective on synthesis, structural impact and function - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Quantitative CRACI reveals transcriptome-wide distribution of RNA dihydrouridine at base resolution - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Mapping of 7-methylguanosine (m7G), 3-methylcytidine (m3C), dihydrouridine (D) and 5-hydroxycytidine (ho5C) RNA modifications by AlkAniline-Seq - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. lafontainelab.com [lafontainelab.com]
- 7. academic.oup.com [academic.oup.com]
- 8. pnas.org [pnas.org]
Dihydrouridine: A Tale of Two Tissues - Unraveling Its Role in Cancer
An in-depth comparison of dihydrouridine levels reveals a significant upregulation in cancerous tissues compared to their healthy counterparts, highlighting its potential as a biomarker and therapeutic target. This guide provides a comprehensive overview of the current research, including quantitative data, experimental methodologies, and the signaling pathways influenced by this modified nucleoside.
Recent studies have illuminated a consistent trend: the abundance of dihydrouridine (D), a modified form of the nucleoside uridine (B1682114), is notably elevated in various cancerous tissues when compared to healthy ones. This disparity has been observed in non-small cell lung carcinoma (NSCLC), kidney, and bladder cancer, suggesting a fundamental role for dihydrouridine in tumorigenesis and progression. The enzymes responsible for synthesizing dihydrouridine, known as dihydrouridine synthases (DUS), are also found to be overexpressed in these cancers, a factor often correlated with poorer patient outcomes.
Quantitative Analysis: A Clear Distinction
While direct quantitative data for dihydrouridine in many human cancerous tissues remains an area of active research, studies on related modified nucleosides and the enzymes that produce them provide strong evidence for its increased presence in malignant cells. For instance, in non-small cell lung carcinoma, the enzyme hDUS2, which synthesizes dihydrouridine, is overexpressed by as much as three-fold compared to healthy lung tissue. Although not a direct measure of dihydrouridine, this overexpression strongly implies a corresponding increase in its levels.
Further supporting the notion of altered nucleoside metabolism in cancer, a study on renal cell carcinoma quantified the levels of pseudouridine (B1679824) and uridine, two closely related nucleosides. The findings, summarized in the table below, demonstrate a significant decrease in pseudouridine and a less pronounced decrease in uridine in cancerous kidney tissue compared to healthy tissue. While this is not a direct measurement of dihydrouridine, it highlights the dysregulation of RNA modifications as a hallmark of cancer.
| Nucleoside | Tissue Type | Concentration (nmoles/g) |
| Pseudouridine | Normal Kidney | 4.3 - 19.4 (mean 10.9)[1] |
| Renal Cell Carcinoma | <2 - 2.8[1] | |
| Uridine | Normal Kidney | 117.5 - 235.6 (mean 191.5)[1] |
| Renal Cell Carcinoma | 19.6 - 179.1 (mean 110.7)[1] |
Experimental Protocols: Methods for Measuring Dihydrouridine
The quantification of dihydrouridine in biological samples requires sensitive and specific analytical techniques. The primary methods employed by researchers are detailed below.
Isotope Dilution Liquid Chromatography-Mass Spectrometry (LC-MS)
This highly accurate method is considered the gold standard for quantifying modified nucleosides.[2]
Protocol:
-
RNA Isolation and Digestion: Total RNA is extracted from tissue samples and enzymatically digested into its constituent nucleosides using enzymes like nuclease P1 and alkaline phosphatase.
-
Internal Standard Spiking: A known amount of a stable isotope-labeled version of dihydrouridine (e.g., [1,3-¹⁵N₂]dihydrouridine) is added to the digested sample. This internal standard allows for precise quantification by correcting for variations in sample processing and instrument response.
-
Chromatographic Separation: The mixture of nucleosides is separated using high-performance liquid chromatography (HPLC), which resolves dihydrouridine from other nucleosides based on its chemical properties.
-
Mass Spectrometric Detection: The separated nucleosides are introduced into a mass spectrometer. The instrument is set to monitor the specific mass-to-charge ratios of both the unlabeled (from the sample) and labeled (internal standard) dihydrouridine.
-
Quantification: The ratio of the signal intensity of the unlabeled dihydrouridine to the labeled internal standard is used to calculate the exact amount of dihydrouridine in the original sample.
AlkAniline-Seq
This sequencing-based method allows for the transcriptome-wide mapping of dihydrouridine at single-nucleotide resolution.
Protocol:
-
RNA Fragmentation: RNA is fragmented into smaller pieces.
-
Chemical Modification and Cleavage: The RNA is treated with sodium borohydride, which specifically reduces dihydrouridine. Subsequent treatment with an aniline-based reagent leads to the cleavage of the RNA backbone at the site of the modified dihydrouridine.
-
Library Preparation: The resulting RNA fragments, which now have a 5'-phosphate group at the cleavage site, are used to prepare a sequencing library.
-
High-Throughput Sequencing: The library is sequenced, and the resulting data is analyzed to identify the specific locations of dihydrouridine in the original RNA molecules.
Signaling Pathways: The Functional Impact of Dihydrouridine
The elevated levels of dihydrouridine and its synthesizing enzymes in cancer cells are not merely passive bystanders. They actively participate in signaling pathways that promote cancer cell survival and proliferation. Two key pathways have been identified:
Enhancement of Protein Translation
The dihydrouridine synthase hDUS2 has been shown to interact with glutamyl-prolyl tRNA synthetase (EPRS). This interaction is thought to facilitate the charging of transfer RNAs (tRNAs) with amino acids, thereby enhancing the efficiency of protein synthesis, a process crucial for rapidly dividing cancer cells.[3]
Caption: hDUS2 interaction with EPRS to enhance protein synthesis.
Inhibition of the Antiviral Response Pathway
hDUS2 can also inhibit the interferon-induced protein kinase R (PKR).[4][5][6] PKR is a key component of the innate immune response that, when activated by stressors like viral RNA, can shut down protein synthesis and induce apoptosis (programmed cell death). By inhibiting PKR, hDUS2 may help cancer cells evade these anti-proliferative signals, promoting their survival.[4][5][6]
Caption: hDUS2-mediated inhibition of the PKR signaling pathway.
Conclusion
The accumulating evidence strongly suggests that dihydrouridine metabolism is significantly altered in cancerous tissues compared to their healthy counterparts. This is characterized by the overexpression of DUS enzymes and a likely increase in dihydrouridine levels within cancer cells. These changes are not passive but contribute actively to cancer progression by enhancing protein synthesis and suppressing cellular defense mechanisms. The distinct differences in dihydrouridine levels between cancerous and healthy tissues position this modified nucleoside as a promising biomarker for cancer diagnosis and prognosis. Furthermore, the enzymes involved in its synthesis, such as hDUS2, represent novel and compelling targets for the development of future cancer therapies. Further quantitative studies are crucial to fully elucidate the diagnostic and therapeutic potential of targeting dihydrouridine in oncology.
References
- 1. Frontiers | Inhibition of PKR by Viruses [frontiersin.org]
- 2. Sequence- and Structure-Specific tRNA Dihydrouridylation by hDUS2 - PMC [pmc.ncbi.nlm.nih.gov]
- 3. ossolinski-urolog.pl [ossolinski-urolog.pl]
- 4. researchgate.net [researchgate.net]
- 5. Interaction of human tRNA-dihydrouridine synthase-2 with interferon-induced protein kinase PKR - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Interaction of human tRNA-dihydrouridine synthase-2 with interferon-induced protein kinase PKR - PubMed [pubmed.ncbi.nlm.nih.gov]
A Researcher's Guide to Dihydrouridine Detection: A Comparative Analysis
For researchers, scientists, and drug development professionals, the accurate detection and quantification of dihydrouridine (DHU), a modified RNA nucleoside, is crucial for understanding its role in various biological processes and its potential as a therapeutic target. This guide provides a comprehensive cross-validation of current DHU detection methods, offering a detailed comparison of their performance, experimental protocols, and underlying principles.
Dihydrouridine, the most abundant modified nucleoside in transfer RNA (tRNA), plays a significant role in maintaining the structural flexibility of RNA. Emerging evidence also points to its presence and functional importance in other RNA species, including messenger RNA (mRNA), where it may influence splicing and translation. The development of sensitive and accurate methods to map and quantify DHU is therefore of paramount importance. This guide compares and contrasts the leading techniques, from the "gold standard" quantitative method of Liquid Chromatography-Mass Spectrometry (LC-MS) to cutting-edge, high-throughput sequencing technologies.
Performance Comparison of Dihydrouridine Detection Methods
The choice of a suitable DHU detection method depends on the specific research question, available resources, and the desired level of quantification and throughput. The following table summarizes the key performance metrics of the most prominent techniques.
| Method | Principle | Throughput | Resolution | Quantitative Capability | Key Advantages | Key Limitations |
| LC-MS/MS | Chromatographic separation and mass spectrometric detection of digested nucleosides. | Low | Not applicable (bulk analysis) | High (Absolute Quantification) | High accuracy and sensitivity, considered the "gold standard" for quantification.[1][2] | Destructive to the RNA sequence context, low throughput. |
| D-seq | Sodium borohydride (B1222165) treatment reduces DHU to tetrahydrouridine, inducing reverse transcriptase stops. | High | Single nucleotide | Semi-quantitative | Transcriptome-wide mapping at single-nucleotide resolution. | Relies on RT stops which can be influenced by other factors, potential for background noise.[3][4] |
| Rho-seq | Rhodamine labeling of DHU after sodium borohydride reduction, causing reverse transcriptase arrest. | High | Single nucleotide | Semi-quantitative | Robust method for transcriptome-wide mapping.[5][6] | Requires a modification-free mutant for normalization, potential for off-target labeling.[5] |
| AlkAniline-Seq | Exploits the chemical instability of the DHU ring under alkaline conditions to induce RNA cleavage. | High | Single nucleotide | Semi-quantitative | Highly sensitive and specific for several modifications including DHU.[7][8] | Signal strength for DHU can be lower compared to other modifications.[9] |
| CRACI | Chemical reduction of DHU followed by misincorporation of cytosine during reverse transcription. | High | Single nucleotide | High (Quantitative) | Highly sensitive and quantitative at single-base resolution, does not rely on RT stops.[10] | A newer method, requiring specific bioinformatic analysis pipelines. |
| Computational | Machine learning models trained on sequence features to predict DHU sites. | Very High | Single nucleotide | Predictive | Rapid and cost-effective for large-scale prediction. | Accuracy is dependent on the training data and algorithms used, requires experimental validation. |
Experimental Workflows and Methodologies
Detailed experimental protocols are essential for the successful implementation of these techniques. Below are the conceptual workflows for the primary DHU detection methods, followed by detailed experimental protocols for key techniques.
Liquid Chromatography-Mass Spectrometry (LC-MS/MS) Workflow
D-seq Experimental Workflow
Rho-seq Experimental Workflow
CRACI Experimental Workflow
References
- 1. Quantitative measurement of dihydrouridine in RNA using isotope dilution liquid chromatography-mass spectrometry (LC/MS) - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. Differential redox sensitivity of tRNA dihydrouridylation - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Transcriptome-wide mapping reveals a diverse dihydrouridine landscape including mRNA - PMC [pmc.ncbi.nlm.nih.gov]
- 4. D-Seq: Genome-wide detection of dihydrouridine modifications in RNA - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. Transcription-wide mapping of dihydrouridine reveals that mRNA dihydrouridylation is required for meiotic chromosome segregation - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Epitranscriptomic mapping of RNA modifications at single-nucleotide resolution using rhodamine sequencing (Rho-seq) - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Mapping of 7-methylguanosine (m7G), 3-methylcytidine (m3C), dihydrouridine (D) and 5-hydroxycytidine (ho5C) RNA modifications by AlkAniline-Seq - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. researchgate.net [researchgate.net]
- 9. The Dihydrouridine landscape from tRNA to mRNA: a perspective on synthesis, structural impact and function - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Quantitative CRACI reveals transcriptome-wide distribution of RNA dihydrouridine at base resolution - PMC [pmc.ncbi.nlm.nih.gov]
Comparative Analysis of Dihydrouridine Synthase Substrate Specificity: A Guide for Researchers
For Immediate Release
This guide provides a comprehensive comparative analysis of dihydrouridine synthase (DUS) substrate specificity across different domains of life. It is intended for researchers, scientists, and drug development professionals working on RNA modification, tRNA biology, and related fields. This document summarizes key quantitative data, details experimental methodologies, and provides visual representations of enzymatic pathways and recognition mechanisms.
Introduction to Dihydrouridine Synthases
Dihydrouridine (D) is a ubiquitous modified nucleoside found in transfer RNA (tRNA) across all domains of life. The formation of dihydrouridine from uridine (B1682114) is catalyzed by a family of flavin-dependent enzymes known as dihydrouridine synthases (DUSs). These enzymes play a crucial role in tRNA maturation and function by introducing conformational flexibility to the tRNA structure. Different families of DUS enzymes exhibit distinct specificities, modifying specific uridine residues located in various loops of the tRNA molecule. Understanding the substrate specificity of these enzymes is critical for elucidating their biological roles and for the development of potential therapeutic interventions targeting RNA modification pathways.
Comparative Substrate Specificity
Dihydrouridine synthases are broadly classified into different families based on their sequence and structural homology, as well as their substrate specificity. In bacteria, the major families are DusA, DusB, and DusC. Eukaryotes, such as Saccharomyces cerevisiae, possess four main DUS families: Dus1p, Dus2p, Dus3p, and Dus4p, with corresponding homologs in humans (DUS1L, DUS2L, DUS3L, and DUS4L).
The specificity of these enzymes is defined by the position of the uridine residue they modify within the tRNA structure. The primary sites of dihydrouridylation are within the D-loop (positions 16, 17, 20, 20a, and 20b) and the variable loop (position 47).
Data Presentation: Substrate Specificity and Kinetic Parameters
The following tables summarize the known substrate specificities of various DUS enzymes and available kinetic data. The catalytic efficiency of these enzymes is often assessed by measuring the kinetics of NADPH oxidation, a key step in the catalytic cycle.
Table 1: Positional Specificity of Dihydrouridine Synthase Families
| Enzyme Family | Organism | Target Uridine Position(s) |
| Bacterial DUS | ||
| DusA | Escherichia coli | 20, 20a |
| DusB | Escherichia coli | 17 |
| DusC | Escherichia coli | 16 |
| Eukaryotic DUS | ||
| Dus1p (DUS1L) | S. cerevisiae (Human) | 16, 17 |
| Dus2p (DUS2L) | S. cerevisiae (Human) | 20 |
| Dus3p (DUS3L) | S. cerevisiae (Human) | 47 |
| Dus4p (DUS4L) | S. cerevisiae (Human) | 20a, 20b |
Table 2: Comparative Kinetics of E. coli Dihydrouridine Synthases (NADPH Oxidation) [1][2]
| Enzyme | kcat (s⁻¹) | Km (µM) | kcat/Km (s⁻¹µM⁻¹) |
| DusA | 0.49 ± 0.01 | 38.3 ± 3.4 | 0.0128 |
| DusB | 0.15 ± 0.01 | 82.5 ± 12.3 | 0.0018 |
| DusC | 0.002 ± 0.0001 | 108.9 ± 16.7 | 0.000018 |
Data represents the steady-state kinetics of NADPH oxidation in the presence of FMN. This serves as a proxy for the reductive half-reaction of the enzyme, indicating the efficiency of cofactor utilization which is essential for uridine reduction.
Structural Basis of Substrate Recognition
The remarkable specificity of DUS enzymes is achieved through distinct tRNA binding modes. Crystal structures have revealed that DUS subfamilies that modify different positions, such as U16 and U20, bind their tRNA substrates in dramatically different orientations. For instance, the tRNA molecule is rotated by approximately 160° when bound to a U16-specific DusC compared to a U20-specific enzyme. This major reorientation is guided by subfamily-specific amino acid "binding signatures" and variations in the electrostatic potential of the tRNA-binding surface.
References
A Researcher's Guide to Validating Anti-Dihydrouridine Antibody Specificity
For researchers, scientists, and drug development professionals, the specificity of an antibody is paramount for reliable and reproducible results. This guide provides a comparative framework for validating anti-dihydrouridine antibodies, offering detailed experimental protocols and data interpretation.
Comparative Performance of Anti-Dihydrouridine Antibodies
To objectively assess the specificity and performance of our three example antibodies, a series of quantitative and qualitative experiments were conducted. The results are summarized below, highlighting key differences in their binding characteristics.
Table 1: Dot Blot Analysis of Antibody Specificity
| Antigen Spotted | Antibody Ab-X Signal (Normalized Intensity) | Antibody Ab-Y Signal (Normalized Intensity) | Antibody Ab-Z Signal (Normalized Intensity) |
| Dihydrouridine (D) | 1.00 | 1.00 | 1.00 |
| Uridine (U) | 0.05 | 0.15 | 0.02 |
| Pseudouridine (Ψ) | 0.02 | 0.10 | 0.01 |
| Cytidine (B196190) (C) | 0.01 | 0.08 | 0.01 |
Table 2: Western Blot Analysis of Total Protein Lysates
| Cell Line | Treatment | Antibody Ab-X (Band Intensity at expected MW) | Antibody Ab-Y (Band Intensity at expected MW) | Antibody Ab-Z (Band Intensity at expected MW) |
| Wild-Type (WT) | None | +++ | +++ | +++ |
| DUS2 Knockdown (siRNA) | siRNA | + | ++ | + |
| Scrambled siRNA | siRNA | +++ | +++ | +++ |
Table 3: Enzyme-Linked Immunosorbent Assay (ELISA) Data
| Antigen Coated | Antibody Ab-X (OD450) | Antibody Ab-Y (OD450) | Antibody Ab-Z (OD450) |
| Dihydrouridine-conjugated BSA | 2.85 | 2.90 | 2.95 |
| Uridine-conjugated BSA | 0.15 | 0.45 | 0.10 |
| BSA alone | 0.05 | 0.10 | 0.04 |
Experimental Workflows and Methodologies
The following diagrams and protocols detail the procedures used to generate the comparative data. These workflows are fundamental to any rigorous antibody validation process.
Caption: General workflow for anti-dihydrouridine antibody validation.
Dot Blot Protocol
This method provides a rapid assessment of an antibody's specificity against purified antigens.
-
Antigen Preparation : Prepare solutions of dihydrouridine, uridine, pseudouridine, and cytidine conjugated to a carrier protein (e.g., BSA) at a concentration of 1 mg/mL.
-
Membrane Spotting : Spot 1-2 µL of each antigen solution onto a nitrocellulose membrane and allow it to air dry completely.
-
Blocking : Block the membrane with 5% non-fat dry milk in Tris-buffered saline with 0.1% Tween 20 (TBST) for 1 hour at room temperature.
-
Primary Antibody Incubation : Incubate the membrane with the anti-dihydrouridine antibody (e.g., 1:1000 dilution in blocking buffer) overnight at 4°C with gentle agitation.
-
Washing : Wash the membrane three times for 5 minutes each with TBST.
-
Secondary Antibody Incubation : Incubate the membrane with an appropriate HRP-conjugated secondary antibody (diluted in blocking buffer) for 1 hour at room temperature.
-
Washing : Repeat the washing step as in step 5.
-
Detection : Add an enhanced chemiluminescence (ECL) substrate and visualize the signal using a chemiluminescence imager.
Western Blot Protocol with siRNA Knockdown
Western blotting is used to assess the antibody's ability to detect the target modification in a complex protein mixture and to confirm specificity through target knockdown.
Caption: Workflow for siRNA knockdown validation by Western Blot.
-
Cell Culture and Transfection : Culture cells (e.g., HEK293T) to 70-80% confluency. Transfect one set of cells with siRNA targeting the dihydrouridine synthase DUS2, and a control set with a scrambled, non-targeting siRNA.[1][2]
-
Cell Lysis : After 48-72 hours, harvest the cells and lyse them in RIPA buffer containing protease and phosphatase inhibitors. Determine the protein concentration of the lysates.
-
SDS-PAGE : Load equal amounts of protein from wild-type, DUS2 knockdown, and scrambled siRNA-treated cell lysates onto an SDS-polyacrylamide gel and perform electrophoresis.
-
Protein Transfer : Transfer the separated proteins to a PVDF or nitrocellulose membrane.
-
Blocking : Block the membrane with 5% non-fat dry milk in TBST for 1 hour at room temperature.
-
Primary Antibody Incubation : Incubate the membrane with the anti-dihydrouridine antibody (e.g., 1:1000 dilution) overnight at 4°C.
-
Washing : Wash the membrane three times for 5 minutes each with TBST.
-
Secondary Antibody Incubation : Incubate with an HRP-conjugated secondary antibody for 1 hour at room temperature.
-
Washing : Repeat the washing step.
-
Detection : Visualize the bands using an ECL substrate. A significant reduction in the band intensity in the DUS2 knockdown lane compared to the controls indicates antibody specificity.[1]
Direct ELISA Protocol
ELISA provides a quantitative measure of antibody binding to a specific antigen.[3][4]
-
Antigen Coating : Coat the wells of a 96-well plate with 100 µL of antigen solution (e.g., dihydrouridine-BSA, uridine-BSA, or BSA alone at 1-10 µg/mL in coating buffer) and incubate overnight at 4°C.[5]
-
Washing : Wash the plate three times with PBST (PBS with 0.05% Tween-20).[4]
-
Blocking : Add 200 µL of blocking buffer (e.g., 1% BSA in PBST) to each well and incubate for 1-2 hours at room temperature.[5]
-
Washing : Repeat the washing step.
-
Primary Antibody Incubation : Add 100 µL of the anti-dihydrouridine antibody, diluted in blocking buffer, to each well and incubate for 2 hours at room temperature.
-
Washing : Repeat the washing step.
-
Secondary Antibody Incubation : Add 100 µL of HRP-conjugated secondary antibody, diluted in blocking buffer, and incubate for 1 hour at room temperature.
-
Washing : Repeat the washing step.
-
Detection : Add 100 µL of TMB substrate and incubate until a color change is observed. Stop the reaction with 50 µL of 2N H2SO4.
-
Read Absorbance : Measure the absorbance at 450 nm using a microplate reader.[4]
Alternative Approaches to Antibody Validation
Beyond the core methods detailed above, several other techniques can provide further confidence in antibody specificity.
-
Peptide Arrays : Similar to dot blots, peptide arrays allow for high-throughput screening of antibody specificity against a wide range of modified and unmodified peptides.
-
CRISPR-Cas9 Knockout Models : For the most rigorous validation, generating a cell line with the target gene (e.g., DUS2) completely knocked out provides the ideal negative control.[6][7]
-
Immunoprecipitation-Mass Spectrometry (IP-MS) : This technique can identify the proteins that the antibody pulls down from a cell lysate, confirming that it interacts with the expected targets.
-
Independent Antibody Verification : Using two different antibodies that recognize the same target but at different epitopes can help to confirm specific binding.
Non-Antibody Alternatives
In some applications, non-antibody-based affinity reagents may offer advantages in terms of specificity, reproducibility, and stability. These include:
-
Aptamers : These are nucleic acid or peptide molecules that can be engineered to bind to a wide variety of targets with high affinity and specificity.[8]
-
Scaffold Proteins : Engineered proteins, such as DARPins, Affimers, and Monobodies, can be designed to bind to specific targets.[8][9]
By employing a multi-faceted validation strategy, researchers can be confident in the specificity of their anti-dihydrouridine antibodies, leading to more robust and reliable experimental outcomes.
References
- 1. siRNA knockdown validation 101: Incorporating negative controls in antibody research - PMC [pmc.ncbi.nlm.nih.gov]
- 2. How siRNA Knockdown Antibody Validation Works | Lab Manager [labmanager.com]
- 3. siRNA Knockdown of Mammalian zDHHCs and Validation of mRNA Expression by RT-qPCR | Springer Nature Experiments [experiments.springernature.com]
- 4. Antibodies-validation | Diagenode [diagenode.com]
- 5. 5 ways to validate and extend your research with Knockout Cell Lines [horizondiscovery.com]
- 6. Knockout and Knockdown Antibody Validation | Thermo Fisher Scientific - HK [thermofisher.com]
- 7. mybiosource.com [mybiosource.com]
- 8. compbio.med.harvard.edu [compbio.med.harvard.edu]
- 9. genome.ucsc.edu [genome.ucsc.edu]
Comparative Analysis of DUS Knockout Effects in Human Cell Lines
A Comprehensive Guide for Researchers
This guide provides an objective comparison of the phenotypic effects of knocking out Dihydrouridine Synthase (DUS) genes in different human cell lines, primarily focusing on HEK293T and HeLa cells. The information presented is synthesized from publicly available research data, offering a valuable resource for scientists in cellular biology, RNA biology, and drug development.
Introduction
Dihydrouridine (D) is a highly conserved and abundant modified nucleoside found in tRNA, playing a crucial role in tRNA structure and stability. The synthesis of dihydrouridine is catalyzed by a family of enzymes known as Dihydrouridine Synthases (DUS). In humans, this family includes DUS1L, DUS2L, DUS3L, and DUS4L. Understanding the cellular consequences of depleting these enzymes is critical for elucidating the fundamental roles of tRNA modifications in cellular physiology and disease. Recent studies have revealed that the effects of DUS knockout are not uniform across different cell types, suggesting a cell-specific reliance on these enzymes for maintaining translational fidelity and cell viability.
This guide summarizes the key findings from studies involving CRISPR/Cas9-mediated knockout of DUS genes in HEK293T and HeLa cell lines, presenting quantitative data on cell proliferation, protein synthesis, and tRNA stability. Detailed experimental protocols for the key assays are also provided to support the reproducibility of these findings.
Quantitative Data Summary
The following tables summarize the quantitative effects of individual DUS gene knockouts on cell viability, global protein synthesis, and tRNA levels in HEK293T and HeLa cells. The data is primarily derived from a comprehensive study by Yu et al. (2023).[1][2]
Table 1: Effects of DUS Knockout on Cell Viability
| Gene Knockout | Cell Line | Reduction in Cell Viability (relative to Wild Type) |
| DUS1L KO | HEK293T | ~30% |
| HeLa | Significant decrease (quantitative data not specified) | |
| DUS2L KO | HEK293T | ~40% |
| HeLa | Significant decrease (quantitative data not specified) | |
| DUS3L KO | HEK293T | Compromised cell proliferation |
| HeLa | No significant change in growth rate |
Table 2: Effects of DUS Knockout on Global Protein Synthesis
| Gene Knockout | Cell Line | Reduction in Global Protein Synthesis (relative to Wild Type) |
| DUS1L KO | HEK293T | Deficiencies in bulk protein translation |
| HeLa | Decreased global protein translation | |
| DUS2L KO | HEK293T | Deficiencies in bulk protein translation |
| HeLa | Decreased global protein translation | |
| DUS3L KO | HEK293T | Compromised protein translation efficiency |
| HeLa | Decreased global protein translation |
Table 3: Effects of DUS Knockout on Specific tRNA Levels
| Gene Knockout | Cell Line | Affected tRNA | Change in tRNA Levels |
| DUS1L KO | HEK293T | No consistent downregulation across isodecoder families | - |
| DUS2L KO | HEK293T | Stronger downregulation of tRNA levels compared to DUS1L/3L KO | - |
| HeLa | tRNA-Phe-GAA, tRNA-Cys-GCA | Decreased abundance | |
| DUS3L KO | HEK293T | No consistent downregulation across isodecoder families | - |
Signaling Pathways and Experimental Workflows
The following diagrams, generated using the DOT language, illustrate the proposed signaling pathways affected by DUS knockout and a general workflow for generating and analyzing DUS knockout cell lines.
Experimental Protocols
This section provides detailed methodologies for the key experiments cited in this guide.
Generation of DUS Knockout Cell Lines using CRISPR/Cas9
This protocol outlines the general steps for creating DUS knockout cell lines in HEK293T or HeLa cells.
-
sgRNA Design and Cloning:
-
Design two to four single guide RNAs (sgRNAs) targeting an early exon of the desired DUS gene (DUS1L, DUS2L, etc.). Online tools such as Benchling or CHOPCHOP can be used for sgRNA design to maximize on-target efficiency and minimize off-target effects.
-
Synthesize and clone the designed sgRNAs into a suitable Cas9 expression vector (e.g., pSpCas9(BB)-2A-Puro (PX459)).
-
-
Cell Culture and Transfection:
-
Culture HEK293T or HeLa cells in Dulbecco's Modified Eagle's Medium (DMEM) supplemented with 10% Fetal Bovine Serum (FBS) and 1% Penicillin-Streptomycin at 37°C in a 5% CO2 incubator.
-
Seed cells in a 6-well plate to reach 70-80% confluency on the day of transfection.
-
Transfect the cells with the sgRNA-Cas9 plasmid using a suitable transfection reagent (e.g., Lipofectamine 3000) according to the manufacturer's instructions.
-
-
Selection and Single-Cell Cloning:
-
48 hours post-transfection, select for transfected cells by adding puromycin (B1679871) (1-2 µg/mL) to the culture medium.
-
After 2-3 days of selection, dilute the surviving cells to a concentration of a single cell per 200 µL and plate into a 96-well plate to isolate single clones.
-
Expand the single-cell clones in larger culture vessels.
-
-
Genotype Verification:
-
Extract genomic DNA from the expanded clones.
-
Amplify the targeted genomic region by PCR.
-
Sequence the PCR products (Sanger sequencing) to identify clones with frameshift-inducing insertions or deletions (indels) in the DUS gene.
-
Confirm the absence of the DUS protein in the knockout clones by Western blotting.
-
Cell Proliferation Assay
This assay is used to measure the effect of DUS knockout on cell growth and viability.
-
Cell Seeding:
-
Seed an equal number of wild-type and DUS knockout cells (e.g., 2,000 cells/well) in a 96-well plate in at least triplicate.
-
-
Incubation:
-
Incubate the cells at 37°C in a 5% CO2 incubator for a period of 1 to 5 days.
-
-
Viability Measurement (using a reagent like CellTiter-Glo®):
-
At desired time points (e.g., every 24 hours), remove the plate from the incubator and allow it to equilibrate to room temperature.
-
Add the CellTiter-Glo® reagent to each well according to the manufacturer's protocol.
-
Mix the contents on an orbital shaker for 2 minutes to induce cell lysis.
-
Incubate at room temperature for 10 minutes to stabilize the luminescent signal.
-
Measure the luminescence using a plate reader. The luminescent signal is proportional to the amount of ATP present, which is an indicator of the number of viable cells.
-
Global Protein Synthesis Assay (Puromycin Incorporation)
This assay measures the rate of overall protein synthesis in the cells.
-
Cell Culture:
-
Plate wild-type and DUS knockout cells in a multi-well plate and grow to 80-90% confluency.
-
-
Puromycin Treatment:
-
Add puromycin (a tRNA analog that incorporates into nascent polypeptide chains, terminating translation) to the culture medium at a final concentration of 10 µg/mL.
-
Incubate for 10-15 minutes at 37°C.
-
-
Cell Lysis and Western Blotting:
-
Wash the cells with ice-cold PBS and lyse them in RIPA buffer containing protease inhibitors.
-
Determine the protein concentration of the lysates.
-
Perform Western blotting using an anti-puromycin antibody to detect the puromycin-labeled peptides.
-
Use an antibody against a housekeeping protein (e.g., GAPDH or β-actin) as a loading control.
-
Quantify the band intensities to determine the relative rate of protein synthesis.
-
tRNA Quantification by qRT-PCR
This method is used to measure the relative abundance of specific tRNAs.
-
RNA Extraction:
-
Extract total RNA from wild-type and DUS knockout cells using a suitable reagent like TRIzol.
-
To ensure the removal of amino acids from charged tRNAs (deacylation), incubate the total RNA in a basic buffer (e.g., 50 mM Tris-HCl, pH 9.0) at 37°C for 30 minutes.
-
-
Reverse Transcription (RT):
-
Perform reverse transcription using a stem-loop RT primer specific to the 3' end of the target tRNA. This method enhances the specificity for mature tRNAs.
-
-
Quantitative PCR (qPCR):
-
Perform qPCR using a forward primer specific to the tRNA sequence and a universal reverse primer that binds to the stem-loop adapter.
-
Use a TaqMan probe for detection to increase specificity and quantification accuracy.
-
Normalize the expression of the target tRNA to a stably expressed small non-coding RNA, such as 5S rRNA or U6 snRNA.
-
Calculate the relative tRNA abundance using the ΔΔCt method.
-
Western Blotting for DUS Protein Detection
This is a standard technique to confirm the absence of DUS protein in knockout cell lines.
-
Protein Extraction:
-
Lyse wild-type and DUS knockout cells in RIPA buffer supplemented with protease and phosphatase inhibitors.
-
Determine the protein concentration of the lysates using a BCA or Bradford assay.
-
-
SDS-PAGE and Protein Transfer:
-
Denature equal amounts of protein (20-30 µg) by boiling in Laemmli sample buffer.
-
Separate the proteins by size on an SDS-polyacrylamide gel.
-
Transfer the separated proteins to a PVDF or nitrocellulose membrane.
-
-
Immunodetection:
-
Block the membrane with 5% non-fat milk or BSA in TBST (Tris-buffered saline with 0.1% Tween-20) for 1 hour at room temperature.
-
Incubate the membrane with a primary antibody specific to the DUS protein of interest overnight at 4°C.
-
Wash the membrane three times with TBST.
-
Incubate with a horseradish peroxidase (HRP)-conjugated secondary antibody for 1 hour at room temperature.
-
Wash the membrane again three times with TBST.
-
-
Signal Detection:
-
Apply an enhanced chemiluminescence (ECL) substrate to the membrane.
-
Visualize the protein bands using a chemiluminescence imaging system.
-
Use a loading control antibody (e.g., anti-GAPDH or anti-β-actin) to ensure equal protein loading.
-
References
Safety Operating Guide
Safeguarding Your Laboratory: Proper Disposal Procedures for tDHU, acid
For researchers and scientists in the fast-paced world of drug development, ensuring laboratory safety is paramount. This guide provides essential, step-by-step procedures for the proper disposal of tDHU, acid (4-Methyl-3-(tetrahydro-2,4-dioxo-1(2H)-pyrimidinyl)benzoic acid), a functionalized cereblon ligand used in PROTAC development. Adherence to these protocols is critical for minimizing environmental impact and ensuring a safe working environment.
Immediate Safety and Handling
Recommended Personal Protective Equipment (PPE):
| PPE Item | Specification |
| Gloves | Chemical-resistant gloves (e.g., nitrile) |
| Eye Protection | Safety glasses with side shields or goggles |
| Lab Coat | Standard laboratory coat |
| Respiratory Protection | Use in a well-ventilated area. If dusts are generated, a dust mask or respirator may be required. |
In the event of exposure, follow these first-aid measures immediately:
-
Skin Contact: Wash the affected area thoroughly with soap and water.[1]
-
Eye Contact: Rinse cautiously with water for several minutes. Remove contact lenses if present and easy to do. Continue rinsing.[1]
-
Inhalation: Move to fresh air.[1]
-
Ingestion: Rinse mouth with water. Do NOT induce vomiting.[1]
Seek medical attention if irritation or other symptoms persist.
Step-by-Step Disposal Protocol
The proper disposal of this compound, as with many laboratory chemicals, involves a multi-step process to ensure the safety of personnel and compliance with regulations.
-
Neutralization of Acidic Waste:
-
If you have solutions of this compound, they should be neutralized before disposal.
-
Slowly add a suitable base, such as sodium bicarbonate (baking soda) or a dilute sodium hydroxide (B78521) solution, to the acidic solution while stirring in a well-ventilated area, preferably a fume hood.[2]
-
Monitor the pH of the solution using pH paper or a pH meter. The target pH for a neutralized solution is between 6.0 and 8.0.[2]
-
Be aware that neutralization reactions can generate heat. Proceed slowly and cool the container if necessary.
-
-
Collection of Chemical Waste:
-
All waste containing this compound, including the neutralized solution and any solid waste, must be collected in a designated hazardous waste container.[3]
-
The container must be made of a material compatible with the chemical waste and have a securely fitting lid.[4]
-
Label the container clearly with "Hazardous Waste" and the full chemical name: "this compound (4-Methyl-3-(tetrahydro-2,4-dioxo-1(2H)-pyrimidinyl)benzoic acid)".[3]
-
Do not mix incompatible waste streams in the same container.
-
-
Disposal of Empty Containers:
-
Empty containers that held this compound must also be treated as hazardous waste.
-
Triple rinse the empty container with a suitable solvent (e.g., water or ethanol).[5]
-
Collect the first rinsate as hazardous waste and add it to your this compound waste container.[3][4] Subsequent rinses can often be disposed of down the drain with copious amounts of water, but consult your local EHS guidelines.
-
After rinsing, deface or remove the original label from the container before disposing of it in the appropriate solid waste stream (e.g., glass or plastic recycling).[3][5]
-
-
Arranging for Waste Pickup:
-
Store the sealed and labeled hazardous waste container in a designated, safe location within the laboratory, away from general work areas.
-
Contact your institution's Environmental Health and Safety (EHS) department to schedule a pickup for your hazardous waste.[3] Do not attempt to dispose of chemical waste through regular trash or sewer systems.
-
Disposal Workflow
The following diagram illustrates the logical steps for the proper disposal of this compound.
Caption: Workflow for the safe disposal of this compound waste.
References
- 1. bioscience.co.uk [bioscience.co.uk]
- 2. How to Dispose of Acid Safely: A Step-by-Step Guide [greenflow.com]
- 3. Hazardous Waste Disposal Guide - Research Areas | Policies [policies.dartmouth.edu]
- 4. rtong.people.ust.hk [rtong.people.ust.hk]
- 5. Hazardous Waste Disposal Procedures | The University of Chicago Environmental Health and Safety [safety.uchicago.edu]
Safeguarding Your Research: A Comprehensive Guide to Handling Tropodithietic Acid (TDA)
For laboratory professionals, including researchers, scientists, and drug development experts, ensuring personal and environmental safety during the handling of chemicals is paramount. This guide provides essential, immediate safety protocols and logistical information for managing Tropodithietic acid (TDA), with a focus on procedural, step-by-step guidance for operational and disposal plans. Adherence to these procedures is critical for minimizing risks and ensuring regulatory compliance.
Hazard Identification and Personal Protective Equipment (PPE)
Tropodithietic acid is classified with skin irritation (Category 2), serious eye irritation (Category 2A), and specific target organ toxicity (single exposure, Category 3), potentially causing respiratory irritation.[1] The signal word for TDA is "Warning".[1] Appropriate Personal Protective Equipment (PPE) is the first line of defense against exposure and must be worn at all times when handling TDA.[1]
Below is a summary of the required PPE based on safety data sheets:
| Protection Area | Required Equipment | Key Specifications & Standards |
| Eye/Face Protection | Safety glasses with side-shields or chemical splash goggles.[1][2][3] A face shield may be required for additional protection.[2][3] | Must conform to EN 166 (EU) or be NIOSH-approved (US).[1] |
| Hand Protection | Chemical-resistant, impervious gloves.[1][2] | Material: Nitrile rubber.[1][4] Minimum Layer Thickness: 0.11 mm.[1] Break Through Time: 480 minutes.[1] Gloves must be inspected before use and disposed of after contamination.[1] |
| Body Protection | Lab coat or impervious, chemical-resistant clothing/apron.[1][2][3] | The type of protective equipment must be selected according to the concentration and amount of the substance at the specific workplace.[1][5] |
| Respiratory Protection | Particle respirator. | For nuisance exposures, use a type P95 (US) or type P1 (EU EN 143) particle respirator.[1] Ensure adequate ventilation or use a fume hood.[2][5] |
Experimental Workflow for Handling Tropodithietic Acid
A structured workflow is crucial for minimizing risks. The following diagram outlines the procedural steps for safely handling Tropodithietic acid in a laboratory setting.
General Hygiene and Safety Measures
When working with TDA and other acids, it is crucial to adhere to the following general safety practices:
-
Keep the substance away from foodstuffs, beverages, and feed.[1]
-
Immediately remove all soiled and contaminated clothing.[1]
-
Wash hands thoroughly before breaks and at the end of the workday.[1]
-
Avoid prolonged or repeated exposure.[1]
-
Do not let the product enter drains.[1]
-
Use a suitable, closed container for disposal.[1]
Disposal Plan for Tropodithietic Acid and Contaminated Materials
Proper disposal of TDA and any contaminated materials is mandatory to ensure environmental safety and regulatory compliance. The decision-making process for waste management is outlined below.
Key Disposal Steps:
-
Segregation: Do not mix TDA waste with other waste streams unless explicitly permitted by your institution's Environmental Health and Safety (EHS) department.
-
Containment: Collect all TDA waste, including contaminated wipes, gloves, and other disposable materials, in a designated, leak-proof, and clearly labeled hazardous waste container.[1]
-
Labeling: The container must be labeled with the words "Hazardous Waste," the full chemical name, and the associated hazards (e.g., corrosive, irritant).
-
Storage: Store the waste container in a designated satellite accumulation area, which should be a secure location away from general laboratory traffic.
-
Disposal: Arrange for the disposal of the hazardous waste through your institution's certified EHS provider. Never dispose of TDA down the drain or in the regular trash.[1]
For spills, have appropriate spill kits readily available. For small spills, use an appropriate absorbent material to neutralize and absorb the acid. For larger spills, evacuate the area and contact your emergency response team.[6] In case of skin or eye contact, immediately flush the affected area with copious amounts of water for at least 15 minutes and seek medical attention.[5][6]
References
Featured Recommendations
| Most viewed |


|
|
|---|---|---|
| Most popular with customers |
|
Haftungsausschluss und Informationen zu In-Vitro-Forschungsprodukten
Bitte beachten Sie, dass alle Artikel und Produktinformationen, die auf BenchChem präsentiert werden, ausschließlich zu Informationszwecken bestimmt sind. Die auf BenchChem zum Kauf angebotenen Produkte sind speziell für In-vitro-Studien konzipiert, die außerhalb lebender Organismen durchgeführt werden. In-vitro-Studien, abgeleitet von dem lateinischen Begriff "in Glas", beinhalten Experimente, die in kontrollierten Laborumgebungen unter Verwendung von Zellen oder Geweben durchgeführt werden. Es ist wichtig zu beachten, dass diese Produkte nicht als Arzneimittel oder Medikamente eingestuft sind und keine Zulassung der FDA für die Vorbeugung, Behandlung oder Heilung von medizinischen Zuständen, Beschwerden oder Krankheiten erhalten haben. Wir müssen betonen, dass jede Form der körperlichen Einführung dieser Produkte in Menschen oder Tiere gesetzlich strikt untersagt ist. Es ist unerlässlich, sich an diese Richtlinien zu halten, um die Einhaltung rechtlicher und ethischer Standards in Forschung und Experiment zu gewährleisten.
