



|
REACTION_CXSMILES
|
[O:1]=[C:2]([CH2:6][CH2:7][CH2:8][CH2:9][C:10]([O-:12])=[O:11])[C:3]([O-:5])=[O:4].C(CC[NH2:21])CCC(O)=O.[NH2:22][CH2:23][CH2:24][CH2:25][CH2:26][CH2:27][CH:28]=O.C([C@H]([NH3+:37])C([O-])=O)C=O>N[C@H](C(O)=O)CCCCN>[NH2:21][CH:2]([CH2:6][CH2:7][CH2:8][CH2:9][C:10]([O-:12])=[O:11])[C:3]([O-:5])=[O:4].[O:1]=[C:2]([CH2:6][CH2:7][CH2:8][CH2:9][C:10]([O-:12])=[O:11])[C:3]([O-:5])=[O:4].[NH2:22][CH2:23][CH2:24][CH2:25][CH2:26][CH2:27][CH2:28][NH2:37]
|
|
Name
|
amino
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
|
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
C(C=O)[C@@H](C(=O)[O-])[NH3+]
|
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
solvent
|
|
Smiles
|
N[C@@H](CCCCN)C(=O)O
|
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
O=C(C(=O)[O-])CCCCC(=O)[O-]
|
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
C(CCC(=O)O)CCN
|
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
C(CCC(=O)O)CCN
|
|
Name
|
aldehyde
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
|
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
C(CCC(=O)O)CCN
|
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
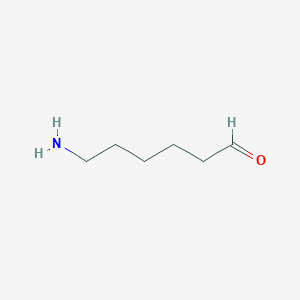
NCCCCCC=O
|
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
NCCCCCC=O
|
|
Conditions are dynamic
|
1
|
|
Details
|
See reaction.notes.procedure_details.
|
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
NC(C(=O)[O-])CCCCC(=O)[O-]
|
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
O=C(C(=O)[O-])CCCCC(=O)[O-]
|
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
NCCCCCCN
|
|
Source
|
Open Reaction Database (ORD) |
|
Description
|
The Open Reaction Database (ORD) is an open-access schema and infrastructure for structuring and sharing organic reaction data, including a centralized data repository. The ORD schema supports conventional and emerging technologies, from benchtop reactions to automated high-throughput experiments and flow chemistry. Our vision is that a consistent data representation and infrastructure to support data sharing will enable downstream applications that will greatly improve the state of the art with respect to computer-aided synthesis planning, reaction prediction, and other predictive chemistry tasks. |
|
REACTION_CXSMILES
|
[O:1]=[C:2]([CH2:6][CH2:7][CH2:8][CH2:9][C:10]([O-:12])=[O:11])[C:3]([O-:5])=[O:4].C(CC[NH2:21])CCC(O)=O.[NH2:22][CH2:23][CH2:24][CH2:25][CH2:26][CH2:27][CH:28]=O.C([C@H]([NH3+:37])C([O-])=O)C=O>N[C@H](C(O)=O)CCCCN>[NH2:21][CH:2]([CH2:6][CH2:7][CH2:8][CH2:9][C:10]([O-:12])=[O:11])[C:3]([O-:5])=[O:4].[O:1]=[C:2]([CH2:6][CH2:7][CH2:8][CH2:9][C:10]([O-:12])=[O:11])[C:3]([O-:5])=[O:4].[NH2:22][CH2:23][CH2:24][CH2:25][CH2:26][CH2:27][CH2:28][NH2:37]
|
|
Name
|
amino
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
|
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
C(C=O)[C@@H](C(=O)[O-])[NH3+]
|
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
solvent
|
|
Smiles
|
N[C@@H](CCCCN)C(=O)O
|
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
O=C(C(=O)[O-])CCCCC(=O)[O-]
|
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
C(CCC(=O)O)CCN
|
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
C(CCC(=O)O)CCN
|
|
Name
|
aldehyde
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
|
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
C(CCC(=O)O)CCN
|
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
NCCCCCC=O
|
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
NCCCCCC=O
|
|
Conditions are dynamic
|
1
|
|
Details
|
See reaction.notes.procedure_details.
|
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
NC(C(=O)[O-])CCCCC(=O)[O-]
|
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
O=C(C(=O)[O-])CCCCC(=O)[O-]
|
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
NCCCCCCN
|
|
Source
|
Open Reaction Database (ORD) |
|
Description
|
The Open Reaction Database (ORD) is an open-access schema and infrastructure for structuring and sharing organic reaction data, including a centralized data repository. The ORD schema supports conventional and emerging technologies, from benchtop reactions to automated high-throughput experiments and flow chemistry. Our vision is that a consistent data representation and infrastructure to support data sharing will enable downstream applications that will greatly improve the state of the art with respect to computer-aided synthesis planning, reaction prediction, and other predictive chemistry tasks. |
|
REACTION_CXSMILES
|
[O:1]=[C:2]([CH2:6][CH2:7][CH2:8][CH2:9][C:10]([O-:12])=[O:11])[C:3]([O-:5])=[O:4].C(CC[NH2:21])CCC(O)=O.[NH2:22][CH2:23][CH2:24][CH2:25][CH2:26][CH2:27][CH:28]=O.C([C@H]([NH3+:37])C([O-])=O)C=O>N[C@H](C(O)=O)CCCCN>[NH2:21][CH:2]([CH2:6][CH2:7][CH2:8][CH2:9][C:10]([O-:12])=[O:11])[C:3]([O-:5])=[O:4].[O:1]=[C:2]([CH2:6][CH2:7][CH2:8][CH2:9][C:10]([O-:12])=[O:11])[C:3]([O-:5])=[O:4].[NH2:22][CH2:23][CH2:24][CH2:25][CH2:26][CH2:27][CH2:28][NH2:37]
|
|
Name
|
amino
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
|
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
C(C=O)[C@@H](C(=O)[O-])[NH3+]
|
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
solvent
|
|
Smiles
|
N[C@@H](CCCCN)C(=O)O
|
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
O=C(C(=O)[O-])CCCCC(=O)[O-]
|
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
C(CCC(=O)O)CCN
|
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
C(CCC(=O)O)CCN
|
|
Name
|
aldehyde
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
|
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
C(CCC(=O)O)CCN
|
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
NCCCCCC=O
|
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
NCCCCCC=O
|
|
Conditions are dynamic
|
1
|
|
Details
|
See reaction.notes.procedure_details.
|
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
NC(C(=O)[O-])CCCCC(=O)[O-]
|
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
O=C(C(=O)[O-])CCCCC(=O)[O-]
|
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
NCCCCCCN
|
|
Source
|
Open Reaction Database (ORD) |
|
Description
|
The Open Reaction Database (ORD) is an open-access schema and infrastructure for structuring and sharing organic reaction data, including a centralized data repository. The ORD schema supports conventional and emerging technologies, from benchtop reactions to automated high-throughput experiments and flow chemistry. Our vision is that a consistent data representation and infrastructure to support data sharing will enable downstream applications that will greatly improve the state of the art with respect to computer-aided synthesis planning, reaction prediction, and other predictive chemistry tasks. |