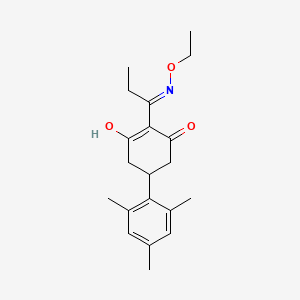
Splendor
説明
Structure
3D Structure
特性
CAS番号 |
87820-88-0 |
|---|---|
分子式 |
C20H27NO3 |
分子量 |
329.4 g/mol |
IUPAC名 |
2-[(Z)-N-ethoxy-C-ethylcarbonimidoyl]-3-hydroxy-5-(2,4,6-trimethylphenyl)cyclohex-2-en-1-one |
InChI |
InChI=1S/C20H27NO3/c1-6-16(21-24-7-2)20-17(22)10-15(11-18(20)23)19-13(4)8-12(3)9-14(19)5/h8-9,15,22H,6-7,10-11H2,1-5H3/b21-16- |
InChIキー |
DQFPEYARZIQXRM-PGMHBOJBSA-N |
不純物 |
Technical material is 95% pure |
SMILES |
CCC(=NOCC)C1=C(CC(CC1=O)C2=C(C=C(C=C2C)C)C)O |
異性体SMILES |
CC/C(=N/OCC)/C1=C(CC(CC1=O)C2=C(C=C(C=C2C)C)C)O |
正規SMILES |
CCC(=NOCC)C1=C(CC(CC1=O)C2=C(C=C(C=C2C)C)C)O |
外観 |
Solid powder |
Color/Form |
Off white to pale pink solid Colorless solid |
密度 |
1.16 g/cu cm (dry); 1.13 g/cu cm (wet) |
melting_point |
106 °C MP: 99-104 °C /Technical/ |
物理的記述 |
White solid; [Merck Index] Colorless or off-white to light pink solid; [HSDB] |
純度 |
>98% (or refer to the Certificate of Analysis) |
賞味期限 |
>2 years if stored properly |
溶解性 |
In organic solvents at 24 °C (g/l): methanol = 25, acetone = 89, toluene = 213, hexane = 18, ethyl acetate = 100, dichloromethane = >500 In water (20 °C) = 5 mg/l (pH 5), 6.7 mg/l (pH 6.5), 9800 mg/l (pH 9) |
保存方法 |
Dry, dark and at 0 - 4 C for short term (days to weeks) or -20 C for long term (months to years). |
同義語 |
Splendor; Tralkoxydim; Tralkoxydime |
蒸気圧 |
2.78X10-9 mm Hg @ 20 °C |
製品の起源 |
United States |
Foundational & Exploratory
An In-depth Technical Guide to the Function of Tumor Protein p53 in Cell Signaling
Audience: Researchers, scientists, and drug development professionals.
Executive Summary
Tumor protein p53, often referred to as "the guardian of the genome," is a critical tumor suppressor and transcription factor that plays a central role in cellular homeostasis.[1] Encoded by the TP53 gene, p53 responds to a wide array of cellular stresses, including DNA damage, oncogene activation, hypoxia, and nutrient deprivation.[2][3][4] Upon activation, p53 orchestrates a complex network of signaling pathways that determine cell fate, primarily through inducing cell cycle arrest, apoptosis (programmed cell death), or senescence.[2][3][5] Its function is crucial for preventing the propagation of cells with genomic instability, thereby suppressing tumor formation.[6] The majority of human cancers exhibit mutations in the TP53 gene, highlighting its significance in oncology and as a target for therapeutic development.[6][7] This guide provides a detailed overview of p53's function in cell signaling, quantitative data from key experiments, and detailed protocols for its study.
Core Signaling Functions of p53
Activated p53 functions primarily as a sequence-specific transcription factor, binding to p53-responsive elements (p53REs) in the promoter regions of its target genes.[6] The cellular outcome of p53 activation is context-dependent, influenced by the type and severity of the cellular stress. The most well-characterized functions are cell cycle arrest and apoptosis.[2][3]
Cell Cycle Arrest
In response to moderate or repairable DNA damage, p53 can temporarily halt the cell cycle, providing time for DNA repair mechanisms to act.[1][6]
-
G1/S Checkpoint Arrest: This is the most prominent cell cycle checkpoint regulated by p53.[2] Activated p53 transcriptionally upregulates the gene CDKN1A, which encodes the protein p21 (also known as WAF1).[1][2] p21 is a cyclin-dependent kinase (CDK) inhibitor that binds to and inactivates cyclin E/CDK2 and cyclin D/CDK4 complexes.[2] This inhibition prevents the phosphorylation of the retinoblastoma protein (Rb), thereby blocking the G1/S transition and halting cell proliferation.[1]
-
G2/M Checkpoint Arrest: p53 can also induce a G2 arrest, preventing cells from entering mitosis with damaged DNA. This is mediated by the transcriptional activation of genes such as GADD45 (Growth Arrest and DNA Damage-inducible) and 14-3-3σ.[8]
Apoptosis
When cellular damage is severe and irreparable, p53 initiates apoptosis to eliminate the compromised cell.[6][9] This is a critical mechanism for preventing the survival of potentially cancerous cells. p53 promotes apoptosis through both intrinsic (mitochondrial) and extrinsic (death receptor) pathways.[5][8]
-
Intrinsic Pathway: p53 transcriptionally activates several pro-apoptotic members of the Bcl-2 family, including BAX, PUMA (p53 Upregulated Modulator of Apoptosis), and Noxa.[5][8] These proteins translocate to the mitochondria, where they disrupt the mitochondrial outer membrane, leading to the release of cytochrome c.[9] Cytochrome c then activates caspase-9 and the subsequent caspase cascade, leading to cell death.[9]
-
Extrinsic Pathway: p53 can increase the expression of death receptors on the cell surface, such as Fas and DR5 (Death Receptor 5).[2][5] Engagement of these receptors by their respective ligands triggers the formation of the Death-Inducing Signaling Complex (DISC), leading to the activation of caspase-8 and the executioner caspases.[5]
DNA Repair and Senescence
Beyond cell cycle arrest and apoptosis, p53 also directly activates DNA repair proteins.[1] If the damage is not resolved, p53 can drive the cell into a state of permanent cell cycle arrest known as senescence, which acts as a stable barrier to tumor progression.[2][10] The induction of senescence is critically dependent on the p53-p21 axis.[2]
The p53 Signaling Pathway: Activation and Regulation
Under normal, unstressed conditions, p53 is maintained at very low levels. Its primary negative regulator is the E3 ubiquitin ligase MDM2 (Murine Double Minute 2), which is itself a transcriptional target of p53, forming a negative feedback loop.[6][11][12] MDM2 binds to p53, inhibiting its transcriptional activity and targeting it for proteasomal degradation.[13]
Various cellular stresses trigger signaling cascades that disrupt the p53-MDM2 interaction, leading to p53 stabilization and activation.[3][12]
-
Stress Sensing: Stresses like DNA double-strand breaks are detected by sensor kinases, primarily ATM (Ataxia Telangiectasia Mutated) and ATR (Ataxia Telangiectasia and Rad3-related).[2]
-
Post-Translational Modifications: ATM and other kinases phosphorylate p53 at key serine residues (e.g., Ser15) in its N-terminal domain.[5][8] These modifications block the binding of MDM2, leading to the rapid accumulation of p53 in the nucleus.[6] Acetylation of lysine residues also plays a role in p53 activation.[8]
-
Transcriptional Activation: Stabilized and activated p53 forms a homotetramer and binds to the DNA of its target genes, initiating the cellular responses described above.[5][6][12]
Data Presentation
Quantitative analysis is essential for understanding the dynamics of the p53 signaling network. The following tables summarize key data from published studies.
Table 1: p53 Binding Affinity and Gene Induction
| Target Gene | Promoter Element | Dissociation Constant (Kd) | Stress Condition | Reference |
|---|---|---|---|---|
| p21 (CDKN1A) | 5' site | ~5 nM | DNA Damage | [2] |
| MDM2 | P2 promoter | Not specified | DNA Damage | [14] |
| BAX | p53RE | Not specified | Doxorubicin |[14] |
Table 2: Protein Level Changes Following p53 Activation
| Cell Line | Treatment | Target Protein | Fold Change | Time Point | Reference |
|---|---|---|---|---|---|
| CT26.WT | 4 µM Sulanemadlin | p53 | Significant Increase | 48h | [15] |
| CT26.WT | 4 µM Sulanemadlin | p21 | Significant Increase | 48h | [15] |
| CT26.WT | 4 µM Sulanemadlin | PUMA | Significant Increase | 48h | [15] |
| Human Lymphoblastoid | 0.3 µg/ml Doxorubicin | p53-DNA Binding | Increased Occupancy | 18h |[16] |
Table 3: Impact of Missense Mutations on p53 Tetramerization Domain Stability
| Mutation | Stability Change (ΔTm) | Phenotype | Reference |
|---|---|---|---|
| Various (49 total) | +4.8°C to -46.8°C | Variable loss of function | [17] |
| p.G245S | < -0.5 kcal/mol (ΔΔG) | Decreased stability | [18] |
| p.R248Q | < -0.5 kcal/mol (ΔΔG) | Decreased stability |[18] |
Experimental Protocols
Analyzing the p53 pathway requires a combination of techniques to assess protein levels, interactions, and genomic binding.
Western Blotting for p53 and Target Protein Expression
Western blotting is used to detect and quantify levels of p53 and its downstream targets (e.g., p21, PUMA) in cell lysates.[15]
Methodology:
-
Cell Culture and Treatment: Culture cells (e.g., cancer cell lines with wild-type p53) and treat with a p53-activating agent (e.g., doxorubicin, Nutlin-3a) or a vehicle control for a specified time course.[13][15]
-
Cell Lysis: Wash cells with ice-cold PBS and lyse in RIPA buffer supplemented with protease and phosphatase inhibitors. Centrifuge to pellet debris and collect the supernatant containing total protein.[13][15]
-
Protein Quantification: Determine the protein concentration of each lysate using a BCA or Bradford assay to ensure equal loading.[13]
-
SDS-PAGE: Denature protein lysates and separate them by size using sodium dodecyl sulfate-polyacrylamide gel electrophoresis (SDS-PAGE).[13]
-
Protein Transfer: Transfer the separated proteins from the gel to a PVDF or nitrocellulose membrane.[15]
-
Immunoblotting:
-
Block the membrane with 5% non-fat milk or BSA in TBST (Tris-buffered saline with 0.1% Tween-20) for 1 hour.[15]
-
Incubate the membrane with a primary antibody specific to p53, p21, or another target, diluted in blocking buffer, overnight at 4°C.[13][15] Include a loading control antibody like β-actin or GAPDH.
-
Wash the membrane three times with TBST.[15]
-
Incubate with an appropriate HRP-conjugated secondary antibody for 1 hour at room temperature.[13]
-
-
Detection: Wash the membrane again with TBST. Apply an enhanced chemiluminescence (ECL) substrate and capture the signal using a digital imaging system.[15] Quantify band intensities using densitometry software.[15]
Co-Immunoprecipitation (Co-IP) for p53 Protein Interactions
Co-IP is used to identify proteins that interact with p53 (e.g., MDM2) within the cell.[19][20]
Methodology:
-
Cell Lysis: Lyse cells using a non-denaturing lysis buffer to preserve protein-protein interactions.
-
Pre-clearing: Incubate the cell lysate with protein A/G agarose beads to reduce non-specific binding.
-
Immunoprecipitation: Incubate the pre-cleared lysate with a p53-specific antibody (the "bait") overnight at 4°C.[19]
-
Complex Capture: Add protein A/G agarose beads to the lysate-antibody mixture to capture the p53-antibody complexes.[19]
-
Washing: Pellet the beads and wash several times with lysis buffer to remove non-specifically bound proteins.
-
Elution: Elute the bound proteins from the beads using an elution buffer (e.g., SDS sample buffer).
-
Analysis: Analyze the eluted proteins by Western blotting, using an antibody against the suspected interacting protein (the "prey," e.g., MDM2).
Chromatin Immunoprecipitation Sequencing (ChIP-Seq)
ChIP-Seq is a powerful method used to identify the genome-wide binding sites of a transcription factor like p53.[21][22]
Methodology:
-
Cross-linking: Treat cells with formaldehyde to cross-link proteins to DNA, preserving in vivo interactions.[14][16]
-
Cell Lysis and Chromatin Shearing: Lyse the cells and sonicate the chromatin to shear the DNA into smaller fragments (typically 200-600 bp).[16]
-
Immunoprecipitation: Incubate the sheared chromatin with a p53-specific antibody to immunoprecipitate the p53-DNA complexes.[16] A control using a non-specific IgG antibody is essential.
-
Complex Capture: Use protein A/G beads to capture the antibody-chromatin complexes.
-
Washing: Perform stringent washes to remove non-specifically bound chromatin.
-
Elution and Reverse Cross-linking: Elute the complexes from the beads and reverse the formaldehyde cross-links by heating.
-
DNA Purification: Purify the DNA fragments that were bound to p53.
-
Library Preparation and Sequencing: Prepare a sequencing library from the purified DNA and perform high-throughput sequencing.[21]
-
Data Analysis: Align the sequencing reads to a reference genome and use peak-calling algorithms to identify regions of significant p53 enrichment, which represent p53 binding sites.[16]
Conclusion and Future Directions
Tumor protein p53 is a central hub in the cellular stress response network, wielding profound control over cell fate decisions. Its roles in initiating cell cycle arrest, apoptosis, and senescence are fundamental to its tumor suppressor function. The inactivation of the p53 pathway, found in over half of all human cancers, underscores its importance in preventing malignant transformation.[6] A deep understanding of p53 signaling, facilitated by the quantitative and methodological approaches detailed in this guide, is paramount for researchers in oncology and drug development. Future research will continue to unravel the complexities of the p53 network, identify new therapeutic strategies to reactivate mutant p53, and develop novel treatments that leverage the p53 pathway for cancer therapy.
References
- 1. p53 - Wikipedia [en.wikipedia.org]
- 2. The Cell-Cycle Arrest and Apoptotic Functions of p53 in Tumor Initiation and Progression - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Tumor Suppressor p53: Biology, Signaling Pathways, and Therapeutic Targeting - PMC [pmc.ncbi.nlm.nih.gov]
- 4. geneglobe.qiagen.com [geneglobe.qiagen.com]
- 5. p53 Pathway for Apoptosis Signaling | Thermo Fisher Scientific - SG [thermofisher.com]
- 6. Role of p53 in Cell Death and Human Cancers - PMC [pmc.ncbi.nlm.nih.gov]
- 7. creative-diagnostics.com [creative-diagnostics.com]
- 8. aacrjournals.org [aacrjournals.org]
- 9. p53-dependent apoptosis pathways - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. aacrjournals.org [aacrjournals.org]
- 11. cusabio.com [cusabio.com]
- 12. p53 Interactive Pathway: R&D Systems [rndsystems.com]
- 13. benchchem.com [benchchem.com]
- 14. academic.oup.com [academic.oup.com]
- 15. benchchem.com [benchchem.com]
- 16. researchgate.net [researchgate.net]
- 17. Cancer-associated p53 tetramerization domain mutants: quantitative analysis reveals a low threshold for tumor suppressor inactivation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 18. Deep Molecular and In Silico Protein Analysis of p53 Alteration in Myelodysplastic Neoplasia and Acute Myeloid Leukemia - PMC [pmc.ncbi.nlm.nih.gov]
- 19. medicine.tulane.edu [medicine.tulane.edu]
- 20. Interaction of p53 with cellular proteins - PubMed [pubmed.ncbi.nlm.nih.gov]
- 21. ChIP Sequencing to Identify p53 Targets | Springer Nature Experiments [experiments.springernature.com]
- 22. ChIP sequencing to identify p53 targets - PubMed [pubmed.ncbi.nlm.nih.gov]
An In-depth Technical Guide to [Target Protein] Gene Expression Patterns in Human Tissues
For Researchers, Scientists, and Drug Development Professionals
This technical guide provides a comprehensive overview of the gene expression patterns of a designated [Target Protein] across various human tissues. Understanding the tissue-specific expression of a target protein is fundamental for elucidating its biological function, identifying its role in disease pathology, and guiding the development of targeted therapeutics.[1] This document outlines the methodologies for quantifying gene expression, presents a framework for organizing expression data, and illustrates key cellular signaling pathways and experimental workflows.
Quantitative Gene Expression Analysis
The quantification of mRNA and protein levels is essential for determining the expression profile of a [Target Protein]. Several powerful techniques are widely used to measure gene expression, each with its own advantages depending on the research objectives.[2]
Table 1: Summary of [Target Protein] mRNA Expression in Human Tissues
| Tissue | Expression Level (TPM/FPKM) | Method | Reference |
| Brain | Example Value | RNA-Seq | Example Study |
| Heart | Example Value | RNA-Seq | Example Study |
| Liver | Example Value | RNA-Seq | Example Study |
| Lung | Example Value | qPCR | Example Study |
| Kidney | Example Value | Microarray | Example Study |
| Spleen | Example Value | RNA-Seq | Example Study |
| Muscle | Example Value | qPCR | Example Study |
Note: The data in this table is for illustrative purposes. Researchers should replace "Example Value" and "Example Study" with data specific to their [Target Protein] of interest.
Table 2: Summary of [Target Protein] Protein Abundance in Human Tissues
| Tissue | Protein Abundance (copies per cell) | Method | Reference |
| Brain | Example Value | Mass Spectrometry | Example Study |
| Heart | Example Value | Western Blot | Example Study |
| Liver | Example Value | Mass Spectrometry | Example Study |
| Lung | Example Value | Immunohistochemistry | Example Study |
| Kidney | Example Value | Mass Spectrometry | Example Study |
| Spleen | Example Value | ELISA | Example Study |
| Muscle | Example Value | Western Blot | Example Study |
Note: The data in this table is for illustrative purposes. Researchers should replace "Example Value" and "Example Study" with data specific to their [Target Protein] of interest.
Experimental Protocols
Accurate and reproducible quantification of gene expression is paramount. The following section details the methodologies for key experiments cited in the study of gene expression.
2.1 RNA Sequencing (RNA-Seq)
RNA-Seq is a high-throughput sequencing technique used to analyze the transcriptome of a biological sample.[3][4] It provides information on the abundance of different RNA transcripts.[3]
-
RNA Extraction: Total RNA is extracted from tissue samples using a suitable method, such as TRIzol reagent or a column-based kit. The quality and quantity of the extracted RNA are assessed using a spectrophotometer and agarose gel electrophoresis.
-
Library Preparation: The extracted RNA is converted to complementary DNA (cDNA).[3] This cDNA is then fragmented, and sequencing adapters are ligated to the fragments.
-
Sequencing: The prepared library is sequenced using a high-throughput sequencing platform.
-
Data Analysis: The resulting sequence reads are aligned to a reference genome or transcriptome.[3] Gene expression levels are then quantified, typically as Transcripts Per Million (TPM) or Fragments Per Kilobase of transcript per Million mapped reads (FPKM).
2.2 Quantitative Real-Time PCR (qPCR)
qPCR is a highly sensitive and specific technique for measuring the expression of a particular gene.[2][3]
-
RNA Extraction and cDNA Synthesis: Total RNA is extracted from tissues and reverse transcribed into cDNA.[3]
-
Primer Design: Gene-specific primers are designed to amplify a specific region of the [Target Protein] cDNA.
-
Real-Time PCR: The qPCR reaction is performed using a real-time PCR system. The amplification of the target gene is monitored in real-time using a fluorescent dye or probe.[2]
-
Data Analysis: The expression level of the target gene is determined by comparing its amplification to that of a reference gene (housekeeping gene).
2.3 Immunohistochemistry (IHC)
IHC is used to visualize the localization and distribution of a protein within a tissue sample. While it is often semi-quantitative, it provides crucial spatial context.[5]
-
Tissue Preparation: Tissue samples are fixed, embedded in paraffin, and sectioned.
-
Antigen Retrieval: The tissue sections are treated to unmask the antigenic sites of the [Target Protein].
-
Antibody Incubation: The sections are incubated with a primary antibody specific to the [Target Protein], followed by a secondary antibody conjugated to an enzyme or fluorophore.
-
Detection: The signal is developed using a chromogenic substrate or visualized using fluorescence microscopy.
-
Analysis: The intensity and localization of the staining provide information about the protein's expression and distribution within the tissue.
Signaling Pathways and Experimental Workflows
Visualizing the complex biological processes and experimental procedures is crucial for a clear understanding. The following diagrams were generated using Graphviz (DOT language) to illustrate these concepts.
The binding of a ligand to a cell surface receptor can initiate a signaling cascade that activates the [Target Protein].[6][7] This, in turn, leads to the modulation of downstream effectors and ultimately results in a specific cellular response.[6]
This workflow outlines the key steps in analyzing gene expression, from tissue sample collection to the final generation of an expression profile. The process includes RNA extraction, quality control, and subsequent analysis by either qPCR for targeted gene analysis or RNA-Seq for transcriptome-wide profiling.[3][8]
References
- 1. How are target proteins identified for drug discovery? [synapse.patsnap.com]
- 2. Gene Expression Analysis: Technologies, Workflows, and Applications - CD Genomics [cd-genomics.com]
- 3. lifesciences.danaher.com [lifesciences.danaher.com]
- 4. Gene expression analysis | Profiling methods & how-tos [illumina.com]
- 5. aacrjournals.org [aacrjournals.org]
- 6. Cell Signaling – Fundamentals of Cell Biology [open.oregonstate.education]
- 7. Cell signaling - Wikipedia [en.wikipedia.org]
- 8. Mechanisms and Measurement of Changes in Gene Expression - PMC [pmc.ncbi.nlm.nih.gov]
Structural Analysis of the JAK2 Active Site: A Technical Guide for Drug Discovery
For Researchers, Scientists, and Drug Development Professionals
This guide provides an in-depth technical overview of the structural analysis of the Janus Kinase 2 (JAK2) active site, a critical target in the development of therapeutics for myeloproliferative neoplasms and other diseases. This document outlines the key structural features of the JAK2 active site, details the experimental protocols for its characterization, and presents a comparative analysis of inhibitor binding.
Introduction to JAK2 and its Active Site
Janus Kinase 2 (JAK2) is a non-receptor tyrosine kinase that plays a pivotal role in cytokine signaling pathways, particularly the JAK/STAT pathway, which is crucial for hematopoiesis and immune response.[1][2] Dysregulation of JAK2 activity, often due to mutations such as the prevalent V617F substitution, leads to constitutive activation of the kinase and is a primary driver of myeloproliferative neoplasms (MPNs).[3][4]
The JAK2 protein is composed of several key domains: a C-terminal kinase (or Janus Homology 1, JH1) domain, a centrally located pseudokinase (JH2) domain, an N-terminal FERM domain, and an SH2-like domain.[1][2] The active site is located within the JH1 domain, which is responsible for the phosphotransferase activity of the enzyme.[1] This ATP-binding pocket is the primary target for the majority of currently approved and clinical-stage JAK2 inhibitors.[5][6] These inhibitors are typically classified as Type I, binding to the active conformation of the kinase and competing with ATP.[7]
The JAK/STAT Signaling Pathway
The JAK/STAT signaling cascade is initiated by the binding of a cytokine to its receptor, leading to receptor dimerization and the subsequent activation of receptor-associated JAKs.[8][9] Activated JAK2 then phosphorylates tyrosine residues on the receptor, creating docking sites for Signal Transducer and Activator of Transcription (STAT) proteins.[9][10] STATs are then phosphorylated by JAK2, dimerize, and translocate to the nucleus to regulate gene transcription.[8][10]
Figure 1: The canonical JAK/STAT signaling pathway.
Experimental Protocols for Structural Analysis
The determination of the three-dimensional structure of the JAK2 active site is primarily achieved through X-ray crystallography and cryo-electron microscopy (cryo-EM).
Workflow for Structural Analysis
The general workflow for determining the structure of the JAK2 active site, often in complex with an inhibitor, involves several key stages from protein expression to final structure deposition.
Figure 2: General workflow for protein structural analysis.
Detailed Methodologies
-
Cloning and Expression: The human JAK2 kinase domain (e.g., amino acids 840-1132) is cloned into a suitable expression vector, such as pFB-LIC-Bse, often with an N-terminal purification tag (e.g., 6xHis-tag).[6] Recombinant protein expression is typically performed using a baculovirus expression system in insect cells (e.g., Sf9 or High Five cells).[3][11]
-
Cell Lysis: Harvested cells are resuspended in a lysis buffer (e.g., 50 mM Tris pH 8.0, 500 mM NaCl, 10% glycerol, 0.5 mM TCEP, and 20 mM imidazole) and lysed by sonication or microfluidization.[6]
-
Affinity Chromatography: The lysate is cleared by centrifugation, and the supernatant is loaded onto a Ni-NTA affinity column. The column is washed, and the His-tagged protein is eluted with an imidazole gradient.
-
Tag Cleavage and Further Purification: The affinity tag is often removed by enzymatic cleavage (e.g., with TEV protease) followed by a second round of Ni-NTA chromatography to remove the uncleaved protein and the protease.
-
Size-Exclusion Chromatography (SEC): The final purification step is typically SEC to separate the JAK2 kinase domain from any remaining impurities and aggregates, ensuring a homogenous sample for structural studies. The protein is eluted in a buffer suitable for crystallization or cryo-EM (e.g., 20 mM HEPES pH 7.5, 150 mM NaCl, 0.5 mM TCEP).
-
Crystallization Screening: Purified JAK2, often in complex with a small molecule inhibitor, is subjected to high-throughput crystallization screening using techniques like hanging-drop or sitting-drop vapor diffusion.[12] A wide range of precipitants, buffers, and additives are screened to identify initial crystallization "hits".
-
Crystal Optimization: Initial crystal hits are optimized by systematically varying the concentrations of protein, precipitant, and other components of the crystallization cocktail to obtain large, single, well-diffracting crystals.
-
Cryo-protection and Data Collection: Crystals are cryo-protected by briefly soaking them in a solution containing a cryoprotectant (e.g., glycerol, ethylene glycol) before being flash-cooled in liquid nitrogen. X-ray diffraction data are collected at a synchrotron source.[13]
-
Data Processing and Structure Solution: The diffraction data are processed to determine the unit cell dimensions and space group. The structure is then solved using molecular replacement, using a known structure of a homologous kinase as a search model.[13]
-
Model Building and Refinement: An atomic model of JAK2 is built into the resulting electron density map and refined using crystallographic software to improve the fit to the experimental data and to ensure ideal stereochemistry.[13]
-
Sample and Grid Preparation: A small volume (typically 3-4 µL) of the purified JAK2 sample (at a concentration of 0.5-5 mg/mL) is applied to a glow-discharged cryo-EM grid (e.g., Quantifoil or C-flat).[5][14]
-
Vitrification: The grid is blotted to create a thin film of the sample solution and then rapidly plunged into liquid ethane cooled by liquid nitrogen.[1] This process, known as vitrification, freezes the sample so rapidly that water molecules do not have time to form ice crystals, thus preserving the native structure of the protein.[1]
-
Data Collection: The vitrified grids are loaded into a transmission electron microscope (TEM) equipped with a direct electron detector. A large number of images (micrographs) are automatically collected.
-
Image Processing: The collected micrographs are processed to correct for beam-induced motion. Individual protein particles are picked, and 2D class averages are generated to assess the quality of the data.
-
3D Reconstruction and Model Building: Particles from the best 2D classes are used to generate an initial 3D model, which is then refined to high resolution. An atomic model is then built into the 3D density map, similar to the process in X-ray crystallography.
Quantitative Analysis of Inhibitor Binding
A critical aspect of the structural analysis of the JAK2 active site is the characterization of its interaction with small molecule inhibitors. This is quantified by determining the binding affinity (Kd) and the half-maximal inhibitory concentration (IC50) of these compounds.
Determination of IC50 Values
The IC50 value represents the concentration of an inhibitor required to reduce the activity of the enzyme by 50%. A common method for determining the IC50 of JAK2 inhibitors is a luminescence-based kinase assay.
-
Kinase Reaction: Recombinant JAK2 is incubated with a specific peptide substrate and ATP in a multi-well plate.
-
Inhibitor Addition: A serial dilution of the test inhibitor is added to the wells.
-
ATP Detection: After the kinase reaction, a reagent is added that detects the amount of remaining ATP. The amount of ATP consumed is proportional to the kinase activity.
-
Data Analysis: The luminescence signal is measured, and the percentage of kinase inhibition is calculated for each inhibitor concentration. The IC50 value is determined by fitting the data to a dose-response curve.[3][8]
Comparative Inhibitor Data
The selectivity of an inhibitor for JAK2 over other JAK family members is a crucial factor in its therapeutic potential. The following table summarizes the IC50 values for several clinically relevant JAK inhibitors against the four members of the JAK family.
| Inhibitor | JAK1 IC50 (nM) | JAK2 IC50 (nM) | JAK3 IC50 (nM) | TYK2 IC50 (nM) | Reference |
| Ruxolitinib | 3.3 | 2.8 | >400 | 19 | [6][7] |
| Fedratinib | 35 | 3 | 334 | - | [6][15] |
| Pacritinib | 23 | 22 | 1,280 | 1,110 | [6] |
| Momelotinib | 156 | 28 | 1,400 | 1,800 | [6] |
| Tofacitinib | 2.9 | 1.2 | 55 | - | [15] |
| Baricitinib | 5.9 | 5.7 | >400 | 53 | [15] |
| Upadacitinib | 43 | 210 | 2,300 | 4,600 | [7] |
| Filgotinib | 10 | 28 | 810 | 116 | [6][7] |
Note: IC50 values can vary depending on the specific assay conditions.
Conclusion
The structural analysis of the JAK2 active site is a cornerstone of modern drug discovery efforts targeting myeloproliferative neoplasms and other inflammatory diseases. Through the application of advanced techniques such as X-ray crystallography and cryo-EM, researchers have gained unprecedented insights into the molecular interactions between JAK2 and its inhibitors. This detailed structural and quantitative information is invaluable for the rational design of next-generation inhibitors with improved potency and selectivity, ultimately leading to safer and more effective therapies.
References
- 1. MyScope [myscope.training]
- 2. Single-Particle Cryo-EM sample vitrification [bio-protocol.org]
- 3. benchchem.com [benchchem.com]
- 4. academic.oup.com [academic.oup.com]
- 5. sptlabtech.com [sptlabtech.com]
- 6. abmole.com [abmole.com]
- 7. JAK selectivity and the implications for clinical inhibition of pharmacodynamic cytokine signalling by filgotinib, upadacitinib, tofacitinib and baricitinib - PMC [pmc.ncbi.nlm.nih.gov]
- 8. benchchem.com [benchchem.com]
- 9. Crystal structures of the Jak2 pseudokinase domain and the pathogenic mutant V617F - PMC [pmc.ncbi.nlm.nih.gov]
- 10. reactionbiology.com [reactionbiology.com]
- 11. mt.com [mt.com]
- 12. aimspress.com [aimspress.com]
- 13. x Ray crystallography - PMC [pmc.ncbi.nlm.nih.gov]
- 14. 7157e75ac0509b6a8f5c-5b19c577d01b9ccfe75d2f9e4b17ab55.ssl.cf1.rackcdn.com [7157e75ac0509b6a8f5c-5b19c577d01b9ccfe75d2f9e4b17ab55.ssl.cf1.rackcdn.com]
- 15. A Comprehensive Overview of Globally Approved JAK Inhibitors - PMC [pmc.ncbi.nlm.nih.gov]
Unveiling the Interactome: A Technical Guide to Identifying Novel Binding Partners for [Target Protein]
For Researchers, Scientists, and Drug Development Professionals
Introduction
The intricate dance of proteins within a cell governs nearly all biological processes. Understanding the interaction network of a specific protein of interest—the "interactome"—is fundamental to elucidating its function, deciphering complex signaling pathways, and identifying novel therapeutic targets. This in-depth technical guide provides a comprehensive overview of established and cutting-edge methodologies for the discovery and validation of novel binding partners for your [Target Protein]. We present detailed experimental protocols, a comparative analysis of key techniques, and visual workflows to empower researchers in their quest to unravel the protein interaction landscape.
Core Methodologies for Discovery
The identification of novel protein-protein interactions (PPIs) hinges on the ability to isolate the [Target Protein] and its associated binding partners from the complex cellular milieu. Several powerful techniques have been developed for this purpose, each with its own set of strengths and limitations. The choice of methodology often depends on the nature of the [Target Protein], the anticipated affinity of the interactions, and the specific research question.
Comparative Analysis of Discovery Methods
The selection of an appropriate discovery method is critical for success. This table summarizes key quantitative and qualitative parameters for the most widely used techniques.
| Parameter | Co-Immunoprecipitation (Co-IP) | Affinity Purification-Mass Spectrometry (AP-MS) | Yeast Two-Hybrid (Y2H) | Proximity-Dependent Biotinylation (BioID) |
| Principle | Antibody-based pulldown of endogenous or tagged protein complexes. | Pulldown of a tagged "bait" protein and its interacting "prey" proteins. | Reconstitution of a transcription factor in yeast upon interaction of a "bait" and "prey" protein. | A promiscuous biotin ligase fused to the "bait" protein biotinylates proximal proteins. |
| Interaction Type | Stable and some transient interactions in native complexes. | Stable and some transient interactions. | Primarily binary, direct interactions. | Both stable and transient interactions, as well as proximal proteins.[1] |
| Typical Protein Yield | Highly variable, dependent on expression level and antibody efficiency. | Generally higher than Co-IP; can be optimized for high yield.[2] | Not applicable (in vivo genetic screen). | Variable, dependent on ligase activity and biotin availability. |
| False Positives | Can be high due to non-specific antibody binding. | Reduced compared to Co-IP with the use of stringent washes and controls. | High, often due to self-activation of the reporter gene.[3][4] | Can occur due to random collisions or overexpression of the bait protein. |
| False Negatives | Can occur if the antibody epitope is masked by the interaction or if the interaction is weak/transient. | Can occur if the tag interferes with the interaction or if the complex disassembles during purification. | High, particularly for proteins that cannot be expressed or correctly folded in yeast, or require post-translational modifications not present in yeast.[4] | Can occur if lysine residues are not accessible for biotinylation. |
| Throughput | Low to medium. | High-throughput capabilities.[5][6] | High-throughput screening of libraries. | Medium to high-throughput. |
| In vivo/In vitro | In vivo (captures interactions in a cellular context). | In vitro (after cell lysis). | In vivo (in yeast). | In vivo (in the chosen cell line). |
Experimental Workflows
Visualizing the experimental process is crucial for understanding the logical flow of each technique. The following diagrams, generated using the DOT language, illustrate the core steps of the primary discovery methods.
Detailed Experimental Protocols
The following sections provide detailed, step-by-step protocols for the key discovery and validation methodologies.
Co-Immunoprecipitation (Co-IP)
This protocol is designed for the immunoprecipitation of a [Target Protein] from cultured mammalian cells to identify its interaction partners.
Reagents and Buffers:
-
PBS (Phosphate-Buffered Saline): 137 mM NaCl, 2.7 mM KCl, 10 mM Na₂HPO₄, 1.8 mM KH₂PO₄, pH 7.4.[7]
-
Cell Lysis Buffer (Non-denaturing): 50 mM Tris-HCl pH 7.4, 150 mM NaCl, 1 mM EDTA, 1% NP-40, with freshly added protease and phosphatase inhibitors.[7] For less soluble proteins, RIPA buffer can be used: 50 mM Tris-HCl pH 8.0, 150 mM NaCl, 1% NP-40, 0.5% sodium deoxycholate, 0.1% SDS, with freshly added inhibitors.
-
Wash Buffer: Same as Cell Lysis Buffer, but without protease and phosphatase inhibitors.
-
Elution Buffer: 0.1 M Glycine-HCl, pH 2.5-3.0 or 1x SDS-PAGE Laemmli sample buffer.
-
Protein A/G Agarose or Magnetic Beads
-
Primary Antibody specific to [Target Protein]
-
Isotype Control IgG
Procedure:
-
Cell Culture and Harvest:
-
Grow cells to 80-90% confluency in appropriate culture dishes.
-
Wash cells twice with ice-cold PBS.
-
Harvest cells by scraping in ice-cold PBS and centrifuge at 500 x g for 3 minutes at 4°C.[7]
-
-
Cell Lysis:
-
Resuspend the cell pellet in 1 mL of ice-cold Cell Lysis Buffer per 10^7 cells.[7]
-
Incubate on ice for 30 minutes with occasional vortexing.
-
Centrifuge at 14,000 x g for 15 minutes at 4°C to pellet cell debris.
-
Transfer the supernatant (lysate) to a new pre-chilled tube.
-
-
Pre-clearing the Lysate (Optional but Recommended):
-
Add 20-30 µL of Protein A/G beads to the cell lysate.
-
Incubate on a rotator for 1 hour at 4°C.
-
Centrifuge at 1,000 x g for 1 minute at 4°C and transfer the supernatant to a new tube.[8]
-
-
Immunoprecipitation:
-
Add 1-10 µg of the primary antibody against the [Target Protein] to the pre-cleared lysate. For a negative control, add the same amount of isotype control IgG to a separate aliquot of lysate.
-
Incubate on a rotator for 2-4 hours or overnight at 4°C.[9]
-
-
Capture of Immune Complexes:
-
Add 30-50 µL of Protein A/G bead slurry to each immunoprecipitation reaction.
-
Incubate on a rotator for 1-2 hours at 4°C.
-
-
Washing:
-
Pellet the beads by centrifugation at 1,000 x g for 1 minute at 4°C.
-
Discard the supernatant and wash the beads 3-5 times with 1 mL of ice-cold Wash Buffer.
-
-
Elution:
-
For analysis by Western Blot, resuspend the beads in 30-50 µL of 1x Laemmli sample buffer and boil for 5-10 minutes.
-
For analysis by Mass Spectrometry, elute the proteins using 50-100 µL of 0.1 M Glycine-HCl, pH 2.5. Incubate for 5-10 minutes at room temperature and neutralize with 1 M Tris-HCl, pH 8.5.
-
-
Analysis:
-
Analyze the eluted proteins by SDS-PAGE and Western Blotting to confirm the presence of the [Target Protein] and potential interactors.
-
For comprehensive identification, submit the eluted sample for Mass Spectrometry analysis.
-
Affinity Purification-Mass Spectrometry (AP-MS)
This protocol describes the purification of a tagged [Target Protein] and its binding partners for identification by mass spectrometry.
Reagents and Buffers:
-
Lysis Buffer: 50 mM Tris-HCl pH 7.5, 150 mM NaCl, 1 mM EDTA, 1% Triton X-100, with freshly added protease and phosphatase inhibitors.
-
Wash Buffer: 50 mM Tris-HCl pH 7.5, 150 mM NaCl, 0.05% Tween-20.
-
Elution Buffer: Dependent on the affinity tag (e.g., 3xFLAG peptide for FLAG-tag, biotin for Strep-tag).
-
Affinity Resin: Anti-FLAG M2 affinity gel, Strep-Tactin Sepharose, etc.
Procedure:
-
Expression of Tagged [Target Protein]:
-
Transfect cells with a vector expressing the [Target Protein] fused to an affinity tag (e.g., FLAG, HA, Strep-tag).
-
Select for stable expression or perform transient transfection.
-
-
Cell Lysis:
-
Harvest cells and lyse as described in the Co-IP protocol.
-
-
Binding to Affinity Resin:
-
Add the cell lysate to the equilibrated affinity resin.
-
Incubate on a rotator for 2-4 hours at 4°C.
-
-
Washing:
-
Wash the resin 3-5 times with 10-20 bed volumes of Wash Buffer.
-
-
Elution:
-
Elute the bound proteins by competitive elution with a solution containing the free tag peptide (e.g., 100-200 µg/mL 3xFLAG peptide in Wash Buffer). Incubate for 30-60 minutes at 4°C.
-
-
Sample Preparation for Mass Spectrometry:
-
Precipitate the eluted proteins using trichloroacetic acid (TCA) or acetone.
-
Perform in-solution or in-gel tryptic digestion of the protein sample.
-
-
Mass Spectrometry and Data Analysis:
-
Analyze the peptide mixture by LC-MS/MS.
-
Identify proteins using a database search algorithm (e.g., Mascot, Sequest).
-
Filter results to remove common contaminants and non-specific binders. A typical protein yield for MS analysis after lysate preparation is around 10 mg/mL.[2]
-
Yeast Two-Hybrid (Y2H) Screening
This protocol provides a general workflow for identifying binary protein interactions in a yeast model system.
Materials and Media:
-
Yeast Strains: e.g., AH109 (for bait) and Y187 (for prey library).
-
Plasmids: A "bait" vector (e.g., pGBKT7) and a "prey" library vector (e.g., pGADT7).
-
Yeast Media:
-
YPD Agar: For general yeast growth.
-
SD/-Trp: Synthetic defined medium lacking tryptophan for selection of bait plasmid.
-
SD/-Leu: Synthetic defined medium lacking leucine for selection of prey plasmid.
-
SD/-Trp/-Leu: Double dropout medium for selection of mated yeast.
-
SD/-Trp/-Leu/-His: Triple dropout medium for selection of interacting partners.
-
SD/-Trp/-Leu/-His/-Ade: Quadruple dropout medium for high-stringency selection.
-
-
Transformation Reagents: Lithium Acetate, PEG, single-stranded carrier DNA.[10]
Procedure:
-
Bait Plasmid Construction and Auto-activation Test:
-
Clone the cDNA of the [Target Protein] in-frame with the DNA-binding domain (DBD) in the bait vector.
-
Transform the bait plasmid into the appropriate yeast strain.
-
Plate on SD/-Trp and SD/-Trp/-His plates. Growth on the -His plate indicates auto-activation, and the bait cannot be used without modification.
-
-
Library Screening:
-
Transform the prey cDNA library into the corresponding yeast strain.
-
Perform a yeast mating between the bait- and prey-containing strains.
-
Plate the mated yeast on SD/-Trp/-Leu/-His plates to select for interacting partners.
-
-
Confirmation of Positive Interactions:
-
Isolate the prey plasmids from the positive colonies.
-
Sequence the prey plasmids to identify the interacting proteins.
-
Re-transform the isolated prey plasmid with the original bait plasmid into a fresh yeast strain and re-plate on selective media to confirm the interaction.
-
-
Reporter Gene Assay:
-
Perform a β-galactosidase assay to further confirm the interaction and estimate its strength.
-
Proximity-Dependent Biotinylation (BioID)
This protocol outlines the use of a promiscuous biotin ligase to identify proteins in close proximity to the [Target Protein].
Reagents and Buffers:
-
Cell Culture Medium
-
Biotin Stock Solution: 50 mM Biotin in DMSO.
-
Lysis Buffer (Denaturing): 50 mM Tris-HCl pH 7.4, 500 mM NaCl, 0.4% SDS, 5 mM EDTA, 1 mM DTT, and protease inhibitors.[11]
-
Wash Buffer: 50 mM Tris-HCl pH 7.4, 2% SDS.[12]
-
Streptavidin-conjugated beads
-
Elution Buffer: 2% SDS, 50 mM Tris-HCl pH 7.5, containing 2 mM biotin.
Procedure:
-
Expression of BirA*-Fusion Protein:
-
Clone the [Target Protein] in-frame with the BirA* enzyme in a suitable expression vector.
-
Transfect cells and establish a stable cell line or use transient transfection.
-
-
Biotin Labeling:
-
Induce the expression of the fusion protein if using an inducible system.
-
Add biotin to the cell culture medium to a final concentration of 50 µM.[13]
-
Incubate for 18-24 hours to allow for biotinylation of proximal proteins.
-
-
Cell Lysis:
-
Wash cells with PBS and lyse in denaturing Lysis Buffer to disrupt non-covalent protein interactions.
-
Sonicate the lysate to shear DNA and ensure complete lysis.
-
-
Capture of Biotinylated Proteins:
-
Incubate the lysate with streptavidin beads for 2-4 hours or overnight at 4°C to capture biotinylated proteins.
-
-
Washing:
-
Wash the beads extensively with Wash Buffer to remove non-specifically bound proteins. A series of washes with buffers of decreasing stringency can also be employed.
-
-
Elution:
-
Elute the biotinylated proteins from the beads by boiling in SDS-PAGE sample buffer or by competitive elution with excess free biotin.
-
-
Analysis:
-
Analyze the eluted proteins by Western Blot using a streptavidin-HRP conjugate to visualize the biotinylation profile.
-
For identification of the biotinylated proteins, perform on-bead tryptic digestion followed by LC-MS/MS analysis.
-
Validation of Putative Interactions
Following the initial discovery of potential binding partners, it is imperative to validate these interactions using orthogonal, low-throughput methods. Validation confirms the directness and specificity of the interaction and provides quantitative binding parameters.
Validation Method Comparison
| Parameter | Co-Immunoprecipitation (Western Blot) | Surface Plasmon Resonance (SPR) | Isothermal Titration Calorimetry (ITC) |
| Principle | Reciprocal pulldown of the putative interactor and blotting for the [Target Protein]. | Measures changes in refractive index upon binding of an analyte to a ligand immobilized on a sensor surface.[14] | Measures the heat change upon binding of a titrant to a sample in solution.[9] |
| Information Obtained | Confirms in vivo interaction. | Real-time kinetics (kon, koff), affinity (KD), and stoichiometry.[15] | Affinity (KD), stoichiometry (n), enthalpy (ΔH), and entropy (ΔS) of binding.[16][17] |
| Protein Requirement | Requires specific antibodies for both proteins. | Requires purified proteins; one is immobilized. | Requires highly purified and concentrated proteins in solution. |
| Labeling Required | No. | No (label-free).[14] | No (label-free).[16] |
| Throughput | Low. | Medium. | Low. |
| Key Advantage | Validates interaction in a cellular context. | Provides detailed kinetic information. | Provides a complete thermodynamic profile of the interaction.[16] |
Detailed Validation Protocols
-
Protein Preparation: Purify both the [Target Protein] (ligand) and the putative binding partner (analyte) to >95% purity.
-
Ligand Immobilization: Covalently immobilize the ligand onto a sensor chip surface via amine coupling or use a capture-based approach.
-
Analyte Injection: Inject a series of increasing concentrations of the analyte over the ligand-immobilized surface and a reference surface.
-
Data Acquisition: Monitor the change in resonance units (RU) over time to generate sensorgrams.
-
Data Analysis: Fit the sensorgram data to a suitable binding model to determine the association rate (kon), dissociation rate (koff), and the equilibrium dissociation constant (KD). A typical experiment involves injecting the analyte at a flow rate of 30 µL/min.[18]
-
Sample Preparation: Prepare highly purified and concentrated solutions of the [Target Protein] and the putative binding partner in the same dialysis buffer to minimize heats of dilution. Typical starting concentrations are 5-50 µM in the sample cell and 50-500 µM in the syringe.[17]
-
ITC Experiment:
-
Load one protein into the sample cell and the other into the injection syringe.
-
Perform a series of small, sequential injections of the syringe solution into the sample cell while monitoring the heat released or absorbed.
-
-
Data Analysis:
-
Integrate the heat flow peaks to obtain the heat change per injection.
-
Plot the heat change against the molar ratio of the two proteins.
-
Fit the resulting binding isotherm to a suitable model to determine the binding affinity (KD), stoichiometry (n), and enthalpy of binding (ΔH).
-
Signaling Pathway Context: The MAPK/ERK Pathway
Understanding the functional context of a protein-protein interaction is paramount. The Mitogen-Activated Protein Kinase (MAPK)/Extracellular signal-regulated kinase (ERK) pathway is a well-characterized signaling cascade that regulates a multitude of cellular processes, including proliferation, differentiation, and survival. Identifying novel binding partners for a component of this pathway can reveal new regulatory mechanisms or downstream effectors.
Conclusion
The identification and validation of novel protein binding partners is a cornerstone of modern biological research and drug discovery. The methodologies outlined in this guide provide a powerful toolkit for researchers to explore the interactome of their [Target Protein]. A thoughtful and systematic approach, combining a high-throughput discovery method with rigorous, quantitative validation techniques, will undoubtedly yield novel insights into protein function and cellular regulation. The integration of this interaction data into the broader context of signaling pathways will ultimately pave the way for a deeper understanding of biology and the development of next-generation therapeutics.
References
- 1. researchgate.net [researchgate.net]
- 2. Protocol for affinity purification-mass spectrometry interactome profiling in larvae of Drosophila melanogaster - PMC [pmc.ncbi.nlm.nih.gov]
- 3. biorxiv.org [biorxiv.org]
- 4. Making the right choice: Critical parameters of the Y2H systems - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Affinity Purification Mass Spectrometry (AP-MS) - Creative Proteomics [creative-proteomics.com]
- 6. fiveable.me [fiveable.me]
- 7. creative-diagnostics.com [creative-diagnostics.com]
- 8. bitesizebio.com [bitesizebio.com]
- 9. assaygenie.com [assaygenie.com]
- 10. carltonlab.com [carltonlab.com]
- 11. Split-BioID — Proteomic Analysis of Context-specific Protein Complexes in Their Native Cellular Environment - PMC [pmc.ncbi.nlm.nih.gov]
- 12. researchgate.net [researchgate.net]
- 13. Automated BioID sample preparation [protocols.io]
- 14. Principle and Protocol of Surface Plasmon Resonance (SPR) - Creative BioMart [creativebiomart.net]
- 15. Protein Interaction Analysis by Surface Plasmon Resonance | Springer Nature Experiments [experiments.springernature.com]
- 16. Isothermal Titration Calorimetry for Studying Protein–Ligand Interactions | Springer Nature Experiments [experiments.springernature.com]
- 17. Isothermal Titration Calorimetry (ITC) | Center for Macromolecular Interactions [cmi.hms.harvard.edu]
- 18. Surface Plasmon Resonance Protocol & Troubleshooting - Creative Biolabs [creativebiolabs.net]
An In-depth Technical Guide to the Evolutionary Conservation of the p53 Tumor Suppressor Protein
Audience: Researchers, scientists, and drug development professionals.
Introduction
The tumor suppressor protein p53, often termed the "guardian of the genome," is a critical transcription factor that plays a central role in maintaining cellular and organismal homeostasis.[1][2] In response to a variety of cellular stressors, including DNA damage, oncogene activation, and hypoxia, p53 orchestrates a complex transcriptional program that can lead to outcomes such as cell cycle arrest, senescence, or apoptosis.[1][3] This response is fundamental to preventing the propagation of cells with genomic instability, thereby suppressing tumor formation. Given that the TP53 gene is mutated in over 50% of all human cancers, understanding its function is paramount.[1][3]
The evolutionary history of the p53 family, which also includes p63 and p73, traces back over a billion years to a common ancestor gene found in early metazoans and even unicellular choanoflagellates.[4][5] The diversification into p53, p63, and p73 is a vertebrate invention, with each member acquiring specialized functions.[4][5] The remarkable conservation of p53's core functions across a vast range of species, from invertebrates to mammals, underscores its fundamental importance in multicellular life.[5]
This technical guide provides an in-depth examination of the evolutionary conservation of p53 at the sequence, domain, and functional levels. It includes a summary of quantitative conservation data, detailed experimental protocols for assessing conservation, and diagrams of the conserved signaling pathway and associated experimental workflows.
Sequence and Domain Conservation
The conservation of a protein across diverse species is a strong indicator of its biological importance. The p53 protein exhibits significant sequence conservation, particularly within its key functional domains. The overall amino acid sequence homology of Drosophila p53 (Dmp53) with mammalian p53 is not exceptionally high, yet their protein structure, DNA-binding domain sequence, and function are remarkably similar and evolutionarily well-conserved.[6]
Quantitative Sequence Conservation
Sequence identity analysis reveals a high degree of similarity among vertebrate p53 orthologs, especially within mammals. The DNA-binding domain shows the highest level of conservation, reflecting its critical role in sequence-specific DNA recognition.[7][8] A comparison of p53 protein sequences from various species against the human p53 protein highlights this conservation.[9]
| Species | Scientific Name | Common Name | Sequence Identity to Human p53 (%) |
| Pan troglodytes | Chimpanzee | 99% | |
| Macaca mulatta | Rhesus macaque | 95% | |
| Mus musculus | Mouse | 81.9% | |
| Spalax leucodon | Blind mole-rat | 85.4% | |
| Bos taurus | Cow | 80% | |
| Gallus gallus | Chicken | 57% | |
| Xenopus laevis | African clawed frog | 52% | |
| Danio rerio | Zebrafish | 46% | |
| Monodelphis domestica | Gray short-tailed opossum | 70% |
Table 1: Percentage of amino acid sequence identity of p53 protein orthologs from various species compared to human p53. Data compiled from bioinformatics studies.[9]
Conservation of Functional Domains
The p53 protein is composed of several distinct functional domains, each subject to different evolutionary pressures.[10][11]
-
N-Terminal Transactivation Domain (TAD): This domain is required for activating transcription of target genes and contains regions that interact with co-factors like MDM2.[12][13] It is generally less conserved than the DNA-binding domain, allowing for species-specific regulatory nuances.
-
DNA-Binding Domain (DBD): This central core domain (residues ~94-312) is responsible for sequence-specific binding to p53 response elements (REs) in the genome.[14] The DBD is the most highly conserved region of p53 across evolution.[7][8] Missense mutations in human cancers frequently occur at "hotspot" amino acids that are highly conserved, underscoring their structural and functional importance.[7]
-
Oligomerization Domain (OD): Located at the C-terminus, this domain mediates the formation of p53 tetramers, which is crucial for its transcriptional activity.[10][11] This domain shows significant sequence homology across species.[8]
The Conserved p53 Signaling Pathway
The core logic of the p53 signaling network is highly conserved in vertebrates. In unstressed cells, p53 levels are kept low through continuous degradation mediated by the E3 ubiquitin ligase MDM2 (HDM2 in humans).[15] Upon cellular stress, such as DNA damage, post-translational modifications to p53 and MDM2 disrupt this interaction, leading to p53 stabilization and activation.[1] Activated p53 then binds to the response elements of target genes to regulate processes like cell cycle arrest (via CDKN1A/p21), DNA repair, and apoptosis.[1][16]
Functional Conservation and Divergence
While the central tumor-suppressive functions of p53 are conserved, there is evidence of functional divergence. For example, studies comparing human and rodent p53 response elements found that while cell cycle arrest functions are well-conserved, there is surprisingly little conservation of functional REs for genes involved in DNA metabolism or repair.[17] This suggests that different lineages have evolved distinct p53-regulated gene networks in response to specific selective pressures.[2][17]
Functional assays are crucial for determining whether a p53 ortholog from one species can replicate the functions of another. For instance, Drosophila p53 can bind to human p53 binding sites and induce apoptosis when overexpressed, demonstrating a deep conservation of this particular function.[6]
Experimental Methodologies
Assessing the evolutionary conservation of p53 requires a combination of computational and experimental techniques.
Workflow for Assessing Functional Conservation
The following diagram outlines a typical workflow for investigating the functional conservation of a newly identified p53 ortholog.
Protocol: Yeast-Based Transactivation Assay (FASAY)
The Functional Analysis of Separated Alleles in Yeast (FASAY) is a powerful method to assess the transactivation capability of a p53 protein.[13] It leverages the conservation of the transcriptional machinery between yeast and higher eukaryotes.
Principle: A yeast strain is engineered to contain two reporter genes (e.g., ADE2 and HIS3) under the control of a promoter with a human p53 response element (RE). A plasmid carrying the p53 ortholog's cDNA is transformed into this yeast. If the expressed p53 ortholog is functional, it will bind to the RE and activate the reporter genes, allowing the yeast to grow on a selective medium lacking adenine and histidine.
Methodology:
-
Yeast Strain: Utilize a Saccharomyces cerevisiae strain (e.g., yIG397) with integrated reporter cassettes.
-
Vector Construction: Clone the full-length coding sequence of the p53 ortholog into a yeast expression vector (e.g., pTSG-DEST) that allows for constitutive or inducible expression.
-
Yeast Transformation: Introduce the p53 expression plasmid into the reporter yeast strain using a standard lithium acetate transformation protocol.
-
Selection and Growth Assay:
-
Plate the transformed yeast on non-selective media (e.g., SD-Trp) to select for cells that have taken up the plasmid.
-
Replica-plate or spot serial dilutions of the cultures onto dual-selective media (e.g., SD-Trp-His-Ade).
-
Incubate plates at 30°C for 3-5 days.
-
-
Interpretation:
-
Growth on selective media: Indicates that the p53 ortholog can recognize the human p53 RE and activate transcription, suggesting functional conservation.
-
No growth on selective media: Suggests the ortholog is unable to transactivate the reporter, indicating functional divergence or a non-functional protein.
-
-
Control: Perform a parallel Western blot on yeast protein extracts to confirm that the p53 ortholog is stably expressed, ruling out lack of expression as a cause for a negative result.
Protocol: Co-Immunoprecipitation (Co-IP) for p53-MDM2 Interaction
This protocol is used to verify the conserved physical interaction between p53 and its negative regulator, MDM2.
Principle: An antibody targeting a "bait" protein (e.g., an epitope-tagged p53 ortholog) is used to capture the protein from a cell lysate. If a "prey" protein (e.g., MDM2) is bound to the bait, it will be pulled down as well. The presence of the prey protein is then detected by Western blotting.
Methodology:
-
Cell Culture and Transfection: Co-transfect a mammalian cell line (e.g., HCT116 p53-/-) with expression vectors for the tagged-p53 ortholog and MDM2.
-
Cell Lysis: After 24-48 hours, harvest the cells and lyse them in a non-denaturing lysis buffer (e.g., RIPA buffer with protease and phosphatase inhibitors) to preserve protein-protein interactions.
-
Immunoprecipitation (IP):
-
Pre-clear the lysate with protein A/G agarose beads to reduce non-specific binding.
-
Incubate the pre-cleared lysate with an antibody against the tag on the p53 ortholog (e.g., anti-FLAG or anti-HA) overnight at 4°C.
-
Add fresh protein A/G beads to capture the antibody-protein complexes.
-
Wash the beads several times with lysis buffer to remove non-specifically bound proteins.
-
-
Elution and Western Blotting:
-
Elute the bound proteins from the beads by boiling in SDS-PAGE sample buffer.
-
Separate the proteins by SDS-PAGE and transfer them to a PVDF membrane.
-
Probe the membrane with a primary antibody against MDM2 to detect the co-immunoprecipitated protein.
-
Probe a separate blot of the input lysate to confirm the expression of both proteins.
-
-
Interpretation: The presence of an MDM2 band in the IP lane indicates a physical interaction between the p53 ortholog and MDM2, confirming the conservation of this key regulatory interaction.
Conclusion
The p53 tumor suppressor is a protein of ancient origin whose core structure and function have been remarkably conserved throughout animal evolution. Its central role as a guardian of the genome is underscored by the high conservation of its DNA-binding domain and the fundamental logic of its signaling pathway.[1][5][7] While the primary functions of inducing cell cycle arrest and apoptosis are maintained across vast evolutionary distances, species-specific adaptations in the p53 network highlight its evolutionary plasticity.[6][17] The study of p53 conservation not only provides insights into the fundamental mechanisms of tumor suppression but also offers a powerful framework for using diverse model organisms to further unravel the complexities of the p53 network and its role in health and disease.
References
- 1. p53 - Wikipedia [en.wikipedia.org]
- 2. Contrasting Patterns of Rapid Molecular Evolution within the p53 Network across Mammal and Sauropsid Lineages - PMC [pmc.ncbi.nlm.nih.gov]
- 3. The Role of TP53 in Adaptation and Evolution - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Phylogeny and Function of the Invertebrate p53 Superfamily - PMC [pmc.ncbi.nlm.nih.gov]
- 5. The Origins and Evolution of the p53 Family of Genes - PMC [pmc.ncbi.nlm.nih.gov]
- 6. researchgate.net [researchgate.net]
- 7. Evolutionary conservation and somatic mutation hotspot maps of p53: correlation with p53 protein structural and functional features - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. Structural Evolution and Dynamics of the p53 Proteins - PMC [pmc.ncbi.nlm.nih.gov]
- 9. web.harran.edu.tr [web.harran.edu.tr]
- 10. Homologs of the Tumor Suppressor Protein p53: A Bioinformatics Study for Drug Design - PMC [pmc.ncbi.nlm.nih.gov]
- 11. researchgate.net [researchgate.net]
- 12. researchgate.net [researchgate.net]
- 13. p53 functional assays: detecting p53 mutations in both the germline and in sporadic tumours - PMC [pmc.ncbi.nlm.nih.gov]
- 14. pnas.org [pnas.org]
- 15. Identification of p53 regulators by genome-wide functional analysis - PMC [pmc.ncbi.nlm.nih.gov]
- 16. Isolation of p53-target genes and their functional analysis - PubMed [pubmed.ncbi.nlm.nih.gov]
- 17. pnas.org [pnas.org]
The Guardian at the Gate: A Technical Guide to p53 Subcellular Localization Under Stress
For Researchers, Scientists, and Drug Development Professionals
Abstract
The tumor suppressor protein p53, often termed the "guardian of the genome," is a critical transcription factor that orchestrates cellular responses to a myriad of stressors, including DNA damage, oxidative stress, and oncogene activation.[1] Its ability to induce cell cycle arrest, senescence, or apoptosis is intrinsically linked to its subcellular localization.[2] In unstressed cells, p53 levels are kept low, and it is predominantly localized in the cytoplasm, where it is targeted for degradation.[3] However, upon cellular stress, p53 rapidly accumulates in the nucleus to transactivate its target genes.[4] This nucleocytoplasmic shuttling is a tightly regulated process, governed by a complex interplay of nuclear localization signals (NLS), nuclear export signals (NES), and post-translational modifications.[2] Understanding the spatiotemporal dynamics of p53 is paramount for elucidating its role in tumor suppression and for the development of novel therapeutic strategies that aim to modulate its activity. This guide provides an in-depth overview of the mechanisms controlling p53 subcellular localization under stress, detailed experimental protocols for its study, and a summary of quantitative data to facilitate comparative analysis.
Mechanisms of p53 Subcellular Shuttling
The dynamic distribution of p53 between the nucleus and the cytoplasm is a key regulatory mechanism that dictates its function. This shuttling is controlled by specific import and export signals within the p53 protein and is heavily influenced by post-translational modifications in response to cellular stress.
Nuclear Import
The nuclear import of p53 is an active process mediated by a bipartite Nuclear Localization Signal (NLS) located in its C-terminal domain.[5] This process is tightly regulated and essential for its tumor suppressor function.
Nuclear Export
The export of p53 from the nucleus to the cytoplasm is primarily mediated by its interaction with the E3 ubiquitin ligase MDM2.[6] MDM2 contains a Nuclear Export Signal (NES) and facilitates the transport of p53 out of the nucleus, leading to its subsequent degradation in the cytoplasm.[7][8] This process is a critical component of the negative feedback loop that controls p53 levels in unstressed cells.
The Impact of Stress on p53 Localization
Various cellular stressors trigger signaling cascades that converge on the p53 pathway, leading to a dramatic shift in its subcellular localization from the cytoplasm to the nucleus.
Genotoxic Stress
Genotoxic stress, such as that induced by DNA damaging agents (e.g., etoposide, UV irradiation), is a potent activator of p53.[4][9] Upon DNA damage, the ATM (Ataxia-Telangiectasia Mutated) and ATR (Ataxia-Telangiectasia and Rad3-related) kinases are activated.[10] These kinases phosphorylate p53 at key serine residues, which disrupts the interaction between p53 and MDM2.[1] This disruption inhibits p53 nuclear export and promotes its accumulation in the nucleus, allowing it to function as a transcription factor.[10][11]
Oxidative Stress
Oxidative stress, characterized by an imbalance in reactive oxygen species (ROS), also leads to the nuclear accumulation of p53.[12] The signaling pathways involved in the oxidative stress response can activate kinases that phosphorylate p53, leading to its stabilization and nuclear retention.[12]
Quantitative Analysis of p53 Subcellular Localization
The subcellular distribution of p53 can be quantified using various techniques, providing valuable insights into its activation status under different conditions. The following tables summarize representative quantitative data on p53 localization in response to stress.
| Stressor | Cell Line | Method | Observation | Reference |
| Etoposide (15 µM) | Mouse Embryonic Fibroblasts | Subcellular Fractionation & Western Blot | Increased nuclear p53 accumulation observed after 24 hours of treatment. | [13] |
| UV Irradiation (20 J/m²) | HeLa | Subcellular Fractionation & Western Blot | Significant increase in the ratio of nuclear to cytoplasmic XPA (a protein whose import is p53-dependent) 2 hours post-irradiation. | [14] |
| Cisplatin | HCT116 | Immunofluorescence Microscopy | Increased number of p53 condensates in the nucleus after 18 hours of treatment, correlating with p53 stabilization. | [5] |
Table 1: Quantitative data from subcellular fractionation and western blotting experiments.
| Stressor | Cell Line | Method | Observation | Reference |
| Etoposide | U-2 OS | Fluorescence Microscopy | At high concentrations, a monotonic increase in nuclear p53-Venus fluorescence is observed. | [15] |
| Nutlin-3a | MCF7 | Fluorescence Microscopy | Treatment leads to a significant increase in the fraction of cells with sustained nuclear p53 induction. | [15] |
| UV Irradiation | Primary Human Fibroblasts | Immunostaining | Nuclear accumulation of p53 is observed in all phases of the cell cycle at both low and high UV doses. | [4] |
Table 2: Quantitative data from immunofluorescence and live-cell imaging experiments.
Experimental Protocols
Accurate determination of p53 subcellular localization is crucial for studying its function. The following sections provide detailed protocols for two common methods: immunofluorescence and subcellular fractionation followed by Western blotting.
Immunofluorescence Staining of p53
This method allows for the visualization of p53 localization within intact cells.
Materials:
-
Cells grown on coverslips
-
Phosphate-Buffered Saline (PBS)
-
Fixative (e.g., 4% paraformaldehyde in PBS)
-
Permeabilization buffer (e.g., 0.1% Triton X-100 in PBS)
-
Blocking solution (e.g., 1% BSA in PBS)
-
Primary antibody against p53
-
Fluorescently labeled secondary antibody
-
Nuclear counterstain (e.g., DAPI)
-
Mounting medium
Protocol:
-
Cell Culture and Treatment: Grow cells on sterile coverslips in a petri dish. Treat with the desired stress-inducing agent for the appropriate time.
-
Fixation: Gently wash the cells with PBS. Fix the cells with 4% paraformaldehyde for 15 minutes at room temperature.
-
Washing: Wash the cells three times with PBS for 5 minutes each.
-
Permeabilization: Incubate the cells with permeabilization buffer for 10 minutes at room temperature to allow antibodies to access intracellular antigens.
-
Washing: Wash the cells three times with PBS for 5 minutes each.
-
Blocking: Incubate the cells with blocking solution for 1 hour at room temperature to reduce non-specific antibody binding.
-
Primary Antibody Incubation: Dilute the primary anti-p53 antibody in blocking solution and incubate with the cells overnight at 4°C in a humidified chamber.
-
Washing: Wash the cells three times with PBS for 5 minutes each.
-
Secondary Antibody Incubation: Dilute the fluorescently labeled secondary antibody in blocking solution and incubate with the cells for 1 hour at room temperature, protected from light.
-
Washing: Wash the cells three times with PBS for 5 minutes each, protected from light.
-
Counterstaining: Incubate the cells with a nuclear counterstain like DAPI for 5 minutes at room temperature.
-
Washing: Wash the cells twice with PBS.
-
Mounting: Mount the coverslips onto microscope slides using mounting medium.
-
Imaging: Visualize the cells using a fluorescence microscope.
Subcellular Fractionation and Western Blotting
This technique allows for the biochemical separation and quantification of p53 in different cellular compartments.
Materials:
-
Cell pellet
-
Hypotonic lysis buffer
-
Cytoplasmic extraction buffer
-
Nuclear extraction buffer
-
Protease and phosphatase inhibitors
-
Dounce homogenizer or syringe with a narrow-gauge needle
-
Centrifuge
-
SDS-PAGE gels
-
Transfer apparatus
-
PVDF membrane
-
Blocking buffer (e.g., 5% non-fat milk in TBST)
-
Primary antibodies (anti-p53, anti-cytoplasmic marker e.g., GAPDH, anti-nuclear marker e.g., Lamin B1)
-
HRP-conjugated secondary antibodies
-
Chemiluminescent substrate
Protocol:
-
Cell Lysis and Cytoplasmic Fraction Isolation:
-
Resuspend the cell pellet in ice-cold hypotonic lysis buffer with protease and phosphatase inhibitors.
-
Incubate on ice for 15-20 minutes to allow cells to swell.
-
Lyse the cells by passing the suspension through a narrow-gauge needle or using a Dounce homogenizer.
-
Centrifuge at a low speed (e.g., 1,000 x g) for 5 minutes at 4°C to pellet the nuclei.
-
Carefully collect the supernatant, which is the cytoplasmic fraction.
-
-
Nuclear Fraction Isolation:
-
Wash the nuclear pellet with hypotonic lysis buffer.
-
Resuspend the pellet in ice-cold nuclear extraction buffer with protease and phosphatase inhibitors.
-
Incubate on ice for 30 minutes with intermittent vortexing to lyse the nuclei.
-
Centrifuge at a high speed (e.g., 16,000 x g) for 15 minutes at 4°C.
-
Collect the supernatant, which contains the nuclear proteins.
-
-
Protein Quantification: Determine the protein concentration of both the cytoplasmic and nuclear fractions using a protein assay (e.g., BCA assay).
-
Western Blotting:
-
Separate equal amounts of protein from each fraction by SDS-PAGE.
-
Transfer the proteins to a PVDF membrane.
-
Block the membrane with blocking buffer for 1 hour at room temperature.
-
Incubate the membrane with primary antibodies against p53, a cytoplasmic marker, and a nuclear marker overnight at 4°C.
-
Wash the membrane three times with TBST.
-
Incubate the membrane with HRP-conjugated secondary antibodies for 1 hour at room temperature.
-
Wash the membrane three times with TBST.
-
Detect the protein bands using a chemiluminescent substrate and an imaging system.
-
Quantify the band intensities to determine the relative amounts of p53 in the cytoplasmic and nuclear fractions.
-
Visualizing Signaling Pathways and Workflows
To better understand the complex processes governing p53 localization, the following diagrams were generated using Graphviz (DOT language).
p53 Signaling Pathway Under Genotoxic Stress.
Experimental Workflows for Studying p53 Localization.
Conclusion
The subcellular localization of p53 is a cornerstone of its function as a tumor suppressor. The rapid translocation of p53 to the nucleus in response to cellular stress is a critical event that initiates a cascade of transcriptional responses, ultimately determining the cell's fate. A thorough understanding of the intricate mechanisms that govern p53's nucleocytoplasmic shuttling, coupled with robust experimental methodologies for its quantification, is essential for advancing our knowledge of cancer biology and for the development of effective cancer therapeutics. The data and protocols presented in this guide offer a comprehensive resource for researchers dedicated to unraveling the complexities of the p53 signaling network.
References
- 1. youtube.com [youtube.com]
- 2. The importance of p53 location: nuclear or cytoplasmic zip code? - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. cornellpharmacology.org [cornellpharmacology.org]
- 4. U.v.-induced nuclear accumulation of p53 is evoked through DNA damage of actively transcribed genes independent of the cell cycle - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. Nucleo-cytoplasmic environment modulates spatiotemporal p53 phase separation - PMC [pmc.ncbi.nlm.nih.gov]
- 6. The MDM2-p53 pathway revisited - PMC [pmc.ncbi.nlm.nih.gov]
- 7. researchgate.net [researchgate.net]
- 8. MDM2: RING Finger Protein and Regulator of p53 - Madame Curie Bioscience Database - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 9. creative-diagnostics.com [creative-diagnostics.com]
- 10. researchgate.net [researchgate.net]
- 11. researchgate.net [researchgate.net]
- 12. p53, Oxidative Stress, and Aging - PMC [pmc.ncbi.nlm.nih.gov]
- 13. p53 and redox state in etoposide-induced acute myeloblastic leukemia cell death - PubMed [pubmed.ncbi.nlm.nih.gov]
- 14. researchgate.net [researchgate.net]
- 15. Detection of Post-translationally Modified p53 by Western Blotting - PubMed [pubmed.ncbi.nlm.nih.gov]
An In-Depth Technical Guide to the Initial Characterization of the p53 Knockout Mouse Model
Audience: Researchers, scientists, and drug development professionals.
Core Content: This guide provides a comprehensive framework for the initial characterization of a p53 knockout (KO) mouse model, a critical tool in cancer research. The tumor suppressor protein p53, often called "the guardian of the genome," plays a pivotal role in preventing cancer formation by regulating cell cycle, DNA repair, and apoptosis.[1][2] Consequently, mouse models with a disrupted p53 gene (Trp53 in mice) are invaluable for studying tumorigenesis and for the preclinical evaluation of novel therapeutic agents.[3][4] This document outlines the key phenotypic and molecular analyses, presents quantitative data in structured tables, and offers detailed experimental protocols.
Generation and Genotyping of the p53 Knockout Mouse
The creation of a p53 knockout mouse is a foundational step and typically involves gene targeting in embryonic stem (ES) cells.[5][6] A common strategy is to replace essential exons (e.g., exons 2-6) of the Trp53 gene with a neomycin resistance cassette via homologous recombination.[7][8] These modified ES cells are then injected into blastocysts to generate chimeric mice, which are subsequently bred to establish germline transmission of the null allele.[6]
Accurate and routine genotyping is crucial for colony management. This is typically performed by Polymerase Chain Reaction (PCR) on genomic DNA extracted from tail biopsies or ear punches.[9]
Experimental Workflow: Breeding and Genotyping
A typical workflow for generating and identifying p53 knockout mice for study cohorts is outlined below.
Caption: Workflow for breeding and genotyping to establish experimental cohorts.
Phenotypic Characterization
The primary phenotype of p53 deficient mice is a profound susceptibility to spontaneous tumor development.[5][10] A thorough initial characterization involves monitoring survival, performing detailed pathological analysis, and assessing behavioral and metabolic parameters.
Tumorigenesis and Survival Analysis
Mice should be monitored daily for signs of distress and weekly for palpable tumors. Kaplan-Meier survival analysis is the standard method to visualize differences in tumor-free survival between genotypes.
Table 1: Spontaneous Tumor Development in p53-Deficient Mice
| Genotype | Median Tumor Latency | Tumor Incidence | Common Tumor Types |
|---|---|---|---|
| Wild-Type (p53+/+) | >18 months | Low / age-related | N/A |
| Heterozygous (p53+/-) | ~10 - 18 months[3][7] | High | Sarcomas, Lymphomas, Carcinomas[10][11] |
| Homozygous (p53-/-) | ~4.5 - 6 months[3][10] | 100%[10] | T-cell Lymphomas, Sarcomas[10] |
Histopathological Analysis
Upon humane euthanasia (due to tumor burden or reaching study endpoint), a full necropsy should be performed. All major organs and any visible tumors should be collected, fixed in 10% neutral buffered formalin, and processed for histological examination (e.g., Hematoxylin and Eosin staining). This analysis confirms tumor type and identifies any non-neoplastic pathologies. For example, osteosarcomas and mammary adenocarcinomas have been noted in p53-deficient models.[12]
Behavioral Analysis
Studies have revealed that p53 deficiency can be associated with neurological and behavioral alterations.[13][14] Standardized behavioral tests are necessary to characterize these changes quantitatively.
Table 2: Summary of Behavioral Phenotypes in p53-Deficient Mice
| Test | Genotype | Key Findings | Reference |
|---|---|---|---|
| Morris Water Maze | p53-/- | Learning deficiency, particularly in females.[15] | [13][15] |
| Open Field Test | p53-/- | Reduced activity in the center of the field, suggesting anxiety-like behavior.[15] | [13][15] |
| Chronic Unpredictable Mild Stress (CUMS) | p53-/- | Enhanced anxiety- and depression-like behaviors compared to wild-type. |[16] |
Metabolic Phenotyping
Emerging evidence highlights the role of p53 in regulating cellular metabolism.[17][18] Dysregulation of metabolic pathways is a hallmark of cancer, making this a critical area for characterization.
Table 3: Metabolic Alterations in p53-Deficient Mice
| Metabolic Pathway | Parameter | Genotype | Observation | Reference |
|---|---|---|---|---|
| Glucose Metabolism | Glucose Transporter Expression (GLUT1, GLUT3, GLUT4) | p53-/- | p53 normally represses expression; loss may increase glucose uptake. | [19] |
| Lipid Metabolism | Liver Lipid Accumulation | p53-/- | Increased lipid accumulation in the liver. | [17] |
| Systemic Metabolism | Serum IGF-1 and Leptin | p53-/- & p53+/- | Calorie restriction significantly decreases levels, correlating with delayed tumorigenesis. |[11] |
Molecular Characterization
Understanding the molecular consequences of p53 loss is key to interpreting the phenotypic data. The central mechanism involves the disruption of the p53 signaling pathway.
The p53 Signaling Pathway
In normal, unstressed cells, p53 levels are kept low by its negative regulator, MDM2, which targets it for degradation.[10][20] Upon cellular stress, such as DNA damage or oncogene activation, this inhibition is relieved.[21] Activated p53, a transcription factor, then binds to DNA to induce the expression of genes that mediate its tumor-suppressive functions, including cell cycle arrest, apoptosis, and DNA repair.[1][22] Loss of p53 abrogates these critical cellular responses.
Caption: Core p53 signaling pathway activated by cellular stress.
Logical Framework: From Gene Knockout to Phenotype
The diagram below illustrates the logical progression from the genetic modification to the organism-level consequences.
Caption: Logical flow from p53 gene loss to observed phenotypes.
Experimental Protocols
PCR Genotyping Protocol
-
DNA Extraction: Isolate genomic DNA from a 2 mm tail tip or ear punch using a commercial DNA extraction kit or standard proteinase K digestion followed by isopropanol precipitation.
-
PCR Reaction: Set up a multiplex PCR reaction using three primers: one forward primer common to both wild-type and knockout alleles, one reverse primer specific to the wild-type allele, and one reverse primer specific to the knockout construct (e.g., in the neomycin cassette). A sample reaction setup is as follows:
-
Genomic DNA: 100-200 ng
-
10x PCR Buffer: 2.5 µL
-
dNTPs (10 mM): 0.5 µL
-
Forward Primer (10 µM): 0.5 µL
-
WT Reverse Primer (10 µM): 0.5 µL
-
KO Reverse Primer (10 µM): 0.5 µL
-
Taq Polymerase: 0.25 µL
-
Nuclease-free H₂O: to 25 µL
-
-
PCR Cycling: A typical cycling protocol is:
-
Initial Denaturation: 94°C for 3 min
-
35 Cycles:
-
Denaturation: 94°C for 30 sec
-
Annealing: 60°C for 30 sec (adjust based on primer Tm)
-
Extension: 72°C for 1 min
-
-
Final Extension: 72°C for 5 min
-
-
Gel Electrophoresis: Run the PCR products on a 1.5-2.0% agarose gel. The resulting band pattern will distinguish between wild-type, heterozygous, and homozygous knockout genotypes.
Tumor Surveillance and Necropsy
-
Monitoring: Palpate mice weekly to detect tumor formation. Monitor for clinical signs such as weight loss, lethargy, or labored breathing.
-
Euthanasia: Euthanize mice when tumors reach a predetermined size (e.g., 1.5 cm diameter), if they become ulcerated, or if the mouse shows significant signs of distress, in accordance with institutional animal care and use committee (IACUC) guidelines.
-
Necropsy: Perform a systematic gross examination of the carcass. Inspect all major organs in situ.
-
Tissue Collection: Collect all major organs (thymus, spleen, liver, lungs, kidneys, brain, etc.) and any tumors. Fix tissues in 10% neutral buffered formalin for at least 24 hours before processing for histology.
Open Field Test Protocol
-
Apparatus: Use a square arena (e.g., 50 cm x 50 cm) with high walls, evenly illuminated. A video camera is mounted above for tracking.
-
Acclimation: Acclimate mice to the testing room for at least 30 minutes before the trial.
-
Procedure:
-
Gently place the mouse in the center of the arena.
-
Allow the mouse to explore freely for a set duration (e.g., 5-10 minutes).
-
Record the session using video tracking software.
-
Clean the arena thoroughly with 70% ethanol between mice to eliminate olfactory cues.
-
-
Analysis: Analyze the recordings for total distance traveled, velocity, and time spent in the defined center zone versus the periphery.
Western Blot for Protein Expression
-
Protein Extraction: Lyse cells or tissues in RIPA buffer containing protease and phosphatase inhibitors. Determine protein concentration using a BCA or Bradford assay.
-
SDS-PAGE: Denature 20-40 µg of protein per sample and separate by size on a polyacrylamide gel.
-
Transfer: Transfer the separated proteins to a PVDF or nitrocellulose membrane.
-
Blocking: Block the membrane for 1 hour at room temperature in 5% non-fat milk or bovine serum albumin (BSA) in Tris-buffered saline with Tween-20 (TBST).
-
Primary Antibody Incubation: Incubate the membrane with a primary antibody against the protein of interest (e.g., p53, p21, or a loading control like GAPDH or β-actin) overnight at 4°C.
-
Secondary Antibody Incubation: Wash the membrane with TBST and incubate with an appropriate HRP-conjugated secondary antibody for 1 hour at room temperature.
-
Detection: After final washes, apply an enhanced chemiluminescence (ECL) substrate and visualize the protein bands using a digital imager or X-ray film.
References
- 1. p53 - Wikipedia [en.wikipedia.org]
- 2. raybiotech.com [raybiotech.com]
- 3. The p53-deficient mouse: a model for basic and applied cancer studies - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. openaccesspub.org [openaccesspub.org]
- 5. Generation and characterization of p53 mutant mice - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. Generation and Characterization of p53 Mutant Mice | Springer Nature Experiments [experiments.springernature.com]
- 7. 002101 - p53 KO Strain Details [jax.org]
- 8. A Model for Tumor Biology: p53 KO mouse | Experimental Animal Division (RIKEN BRC) [mus.brc.riken.jp]
- 9. researchgate.net [researchgate.net]
- 10. academic.oup.com [academic.oup.com]
- 11. Diet and cancer prevention studies in p53-deficient mice - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. researchgate.net [researchgate.net]
- 13. pnas.org [pnas.org]
- 14. Behavioral alterations associated with apoptosis and down-regulation of presenilin 1 in the brains of p53-deficient mice - PubMed [pubmed.ncbi.nlm.nih.gov]
- 15. researchgate.net [researchgate.net]
- 16. researchgate.net [researchgate.net]
- 17. Frontiers | Emerging Roles of the Tumor Suppressor p53 in Metabolism [frontiersin.org]
- 18. The complexity of p53-mediated metabolic regulation in tumor suppression - PMC [pmc.ncbi.nlm.nih.gov]
- 19. academic.oup.com [academic.oup.com]
- 20. cusabio.com [cusabio.com]
- 21. Tumor Suppressor p53: Biology, Signaling Pathways, and Therapeutic Targeting - PMC [pmc.ncbi.nlm.nih.gov]
- 22. geneglobe.qiagen.com [geneglobe.qiagen.com]
An In-depth Technical Guide to the Enzymatic Activity of Protein Kinase C (PKC) Isoforms
For Researchers, Scientists, and Drug Development Professionals
This guide provides a detailed exploration of the enzymatic activity of Protein Kinase C (PKC) isoforms, a critical family of serine/threonine kinases involved in a multitude of cellular signaling pathways. Understanding the nuanced differences in their activation, substrate specificity, and kinetics is paramount for research and therapeutic development.
Introduction to PKC Isoforms
The Protein Kinase C (PKC) family consists of at least 10 related enzymes that are central to signal transduction, controlling functions like cell proliferation, differentiation, and apoptosis.[1][2][3] These isoforms are categorized into three main groups based on their structure and requirements for activation by second messengers like calcium (Ca²⁺) and diacylglycerol (DAG).[4]
-
Conventional PKCs (cPKCs): Isoforms α, βI, βII, and γ. These require both Ca²⁺ and DAG for full activation.[4][5]
-
Novel PKCs (nPKCs): Isoforms δ, ε, η, and θ. These are activated by DAG but are independent of Ca²⁺.[4][5]
-
Atypical PKCs (aPKCs): Isoforms ζ and ι/λ. Their activation is independent of both Ca²⁺ and DAG, relying instead on protein-protein interactions.[4][5][6]
Activation of conventional and novel PKC isoforms is canonically triggered by signals that lead to the hydrolysis of membrane phospholipids, generating DAG and increasing intracellular Ca²⁺, which recruits the kinase to the cell membrane for its function.[1][4]
Comparative Enzymatic Activity
The distinct cofactor requirements and subcellular localizations of PKC isoforms lead to significant differences in their enzymatic activity and substrate specificity. While comprehensive kinetic data comparing all isoforms under identical conditions is sparse in the literature, the following table summarizes representative kinetic parameters. These values are highly dependent on the specific substrate used and the in vitro assay conditions.
| Isoform | Substrate | Activators | Km (ATP) (µM) | Vmax (pmol/min/µg) | Specific Activity | Reference |
| PKCα (cPKC) | Myelin Basic Protein (MBP) | Ca²⁺, DAG, PS | ~5-10 | ~150-300 | High | [Biomol, Enzo] |
| PKCβI (cPKC) | Histone H1 | Ca²⁺, DAG, PS | ~7-15 | ~200-400 | Very High | [SignalChem] |
| PKCβII (cPKC) | Glycogen Synthase Peptide | Ca²⁺, DAG, PS | ~6-12 | ~250-500 | Very High | [Promega] |
| PKCγ (cPKC) | Neurogranin | Ca²⁺, DAG, PS | ~4-8 | ~100-250 | High | [CarnaBio] |
| PKCδ (nPKC) | MARCKS Peptide | DAG, PS | ~10-25 | ~50-150 | Moderate | [SignalChem] |
| PKCε (nPKC) | Epsilon-Substrate Peptide | DAG, PS | ~15-30 | ~40-100 | Moderate | [Enzo] |
| PKCζ (aPKC) | Crosstide | PS | ~20-50 | ~10-40 | Low | [MilliporeSigma] |
Note: This table is a synthesis of typical values from various commercial suppliers and literature. Absolute values can vary significantly. PS refers to Phosphatidylserine.
Signaling Pathway and Activation Mechanism
The activation of conventional and novel PKC isoforms is a multi-step process initiated by upstream signals. This process ensures that kinase activity is tightly regulated in both space and time. The diagram below illustrates the canonical activation pathway for cPKCs.
Caption: Canonical activation pathway for conventional PKC (cPKC) isoforms.
Experimental Protocols
Accurate measurement of isoform-specific PKC activity is crucial. Below are detailed protocols for two common methods: an in vitro kinase assay using purified components and an immunoprecipitation (IP)-kinase assay to measure activity from cell lysates.
This assay measures the transfer of a radiolabeled phosphate from [γ-³²P]ATP to a model substrate by a purified PKC isoform.[7][8]
A. Materials & Reagents
-
Purified, active PKC isoform (e.g., PKCα, PKCδ)
-
PKC Substrate: Myelin Basic Protein (MBP) or a specific peptide substrate
-
Lipid Activator Mix: Phosphatidylserine (PS) and Diacylglycerol (DAG) in a detergent solution (e.g., Triton X-100)
-
Kinase Reaction Buffer (2X): 40 mM HEPES (pH 7.4), 20 mM MgCl₂, 2 mM CaCl₂ (for cPKCs) or 2 mM EGTA (for nPKCs/aPKCs)
-
[γ-³²P]ATP (10 µCi/µl)
-
100 µM unlabeled ("cold") ATP
-
P81 Phosphocellulose Paper
-
75 mM Phosphoric Acid
-
Scintillation Counter and Vials
B. Procedure
-
Prepare Lipid Activator: Sonicate the PS/DAG mixture on ice for 1-2 minutes until it forms a clear suspension of micelles.[8]
-
Prepare Reaction Mix: On ice, prepare a master mix for the desired number of reactions. For each 50 µL reaction:
-
25 µL of 2X Kinase Reaction Buffer
-
5 µL of Lipid Activator
-
5 µL of Substrate (e.g., 1 mg/ml MBP)
-
x µL of Purified PKC enzyme (e.g., 10-50 ng)
-
x µL of Nuclease-free water to a volume of 45 µL
-
-
Initiate Reaction: Add 5 µL of ATP mix (containing 1 µL [γ-³²P]ATP and 4 µL of 100 µM cold ATP) to each tube. Mix gently.
-
Incubation: Incubate the reaction tubes at 30°C for 10-20 minutes. The incubation time should be within the linear range of the assay.[8]
-
Stop Reaction: Spot 25 µL of the reaction mixture onto a numbered P81 phosphocellulose square.[8]
-
Wash: Immediately place the P81 squares into a beaker with 75 mM phosphoric acid. Wash 3-4 times with fresh phosphoric acid for 5 minutes each wash to remove unincorporated [γ-³²P]ATP.
-
Quantify: Transfer the washed P81 squares to scintillation vials, add scintillation fluid, and measure the incorporated radioactivity (in counts per minute, CPM) using a scintillation counter.
This method allows for the measurement of a specific endogenous or overexpressed PKC isoform's activity from a cellular context.[9][10][11]
A. Materials & Reagents
-
Cell culture with treated and untreated cells
-
Lysis Buffer: 20 mM Tris-HCl (pH 7.5), 150 mM NaCl, 1% Triton X-100, with protease and phosphatase inhibitors (e.g., PMSF, Na₃VO₄).[10]
-
PKC isoform-specific primary antibody
-
Protein A/G Agarose or Magnetic Beads
-
Kinase Wash Buffer: 50 mM HEPES (pH 7.4), 150 mM NaCl, 10 mM MgCl₂.[9]
-
All reagents for the In Vitro Kinase Assay (section 4.1)
B. Procedure
-
Cell Lysis: Lyse cells with ice-cold Lysis Buffer. Scrape cells, incubate on ice, and clarify the lysate by centrifugation (e.g., 16,000 x g for 15 min at 4°C).[9]
-
Immunoprecipitation:
-
Incubate 200-1000 µg of cleared cell lysate with 2-5 µg of the isoform-specific antibody for 2-4 hours or overnight at 4°C with rotation.[9][12]
-
Add 30 µL of Protein A/G bead slurry and incubate for another 1-2 hours at 4°C.[10]
-
Pellet the beads by centrifugation and wash them 3-4 times with Lysis Buffer, followed by two washes with Kinase Wash Buffer.[12][13]
-
-
Kinase Reaction:
-
Resuspend the final bead pellet in 40 µL of 1X Kinase Reaction Buffer containing the substrate and lipid activators.
-
Initiate the reaction by adding 10 µL of the [γ-³²P]ATP mix.
-
Incubate, stop, and quantify as described in the In Vitro Kinase Assay protocol (steps 4.1.B.4 through 4.1.B.7).
-
Experimental Workflow Visualization
The following diagram outlines the logical flow for performing an IP-Kinase Assay.
Caption: Workflow for an Immunoprecipitation (IP)-Kinase Assay.
By employing these methodologies and understanding the distinct characteristics of each PKC isoform, researchers can effectively dissect their roles in complex biological systems and identify novel targets for drug development.
References
- 1. The mechanism of protein kinase C activation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. raybiotech.com [raybiotech.com]
- 3. bosterbio.com [bosterbio.com]
- 4. Protein kinase C - Wikipedia [en.wikipedia.org]
- 5. Protein Kinase C Signaling | Cell Signaling Technology [cellsignal.com]
- 6. Structural Basis of Protein Kinase C Isoform Function - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Enzyme Assays for Protein Kinase C Activity | Springer Nature Experiments [experiments.springernature.com]
- 8. merckmillipore.com [merckmillipore.com]
- 9. med.upenn.edu [med.upenn.edu]
- 10. PKC-θ in vitro Kinase Activity Assay [bio-protocol.org]
- 11. Assaying Protein Kinase Activity with Radiolabeled ATP - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Immunoprecipitation Protocol For Native Proteins | Cell Signaling Technology [cellsignal.com]
- 13. scbt.com [scbt.com]
Methodological & Application
Application Notes: Measuring [Target Protein] Activity In Vitro
For Researchers, Scientists, and Drug Development Professionals
Introduction
Quantifying the activity of a [Target Protein] is fundamental to understanding its biological function, elucidating its role in signaling pathways, and discovering novel therapeutic modulators.[1][2] In vitro activity assays provide a controlled environment to measure specific aspects of a protein's function, such as enzymatic catalysis or binding interactions, independent of complex cellular contexts.[3] This document offers a guide to selecting and performing robust in vitro assays for [Target Protein], with detailed protocols for common methodologies.
The choice of assay depends critically on the function of [Target Protein]. Key considerations include whether the protein is an enzyme (e.g., kinase, protease, ATPase), a receptor, or a component of a larger protein complex. The fundamental principle involves monitoring the consumption of a substrate or the formation of a product, which is designed to generate a measurable signal.[4][5]
Assay Selection and Principles
Choosing the correct assay requires understanding the protein's mechanism of action. The following decision tree illustrates a logical approach to assay selection.
Caption: Decision tree for selecting an appropriate in vitro assay.
Signaling Pathway Context
Measuring the activity of [Target Protein] is often crucial for understanding its role within a broader signaling cascade. A change in its activity can have significant downstream consequences. The diagram below illustrates a hypothetical pathway where [Target Protein] acts as a kinase.
Caption: Hypothetical signaling pathway involving [Target Protein].
Experimental Protocols
Here we provide detailed protocols for two common types of in vitro assays: a colorimetric protease assay and a protein-protein interaction assay using AlphaLISA technology.
Protocol 1: Colorimetric Protease Activity Assay
This protocol is adapted for a generic protease using a casein-based substrate, which upon cleavage, generates peptides that can be quantified.[6]
Principle: The protease cleaves casein into smaller, trichloroacetic acid (TCA)-soluble peptides. These peptides contain tyrosine and tryptophan residues that react with Folin & Ciocalteu's (F-C) reagent to produce a blue color, which is measured spectrophotometrically.[6][7] The amount of color produced is directly proportional to the protease activity.[6]
Materials:
-
Purified [Target Protein] (Protease)
-
Casein Substrate Solution (e.g., 0.6% casein in buffer)
-
Enzyme Dilution Buffer (e.g., 20 mM Tris, 10 mM CaCl₂, pH 7.5)
-
TCA Working Solution (e.g., 0.11 M Trichloroacetic Acid)[4]
-
Folin & Ciocalteu's Reagent (diluted 1:2 with water before use)
-
Sodium Carbonate Solution (e.g., 0.5 M)
-
Tyrosine Standard Solution (for generating a standard curve)[6]
-
Microcentrifuge tubes and 96-well clear microplates
-
Spectrophotometer or microplate reader capable of reading at 660 nm[4]
Procedure:
-
Sample Preparation: Prepare serial dilutions of [Target Protein] in ice-cold Enzyme Dilution Buffer. If the activity is unknown, a broad range of concentrations should be tested.[6]
-
Reaction Setup: In microcentrifuge tubes, add 125 µL of Casein Substrate Solution. Prepare a "Blank" tube containing substrate and 25 µL of Enzyme Dilution Buffer.[6]
-
Initiate Reaction: Add 25 µL of the diluted [Target Protein] or control to the respective tubes. Mix gently and incubate at 37°C for a defined period (e.g., 20 minutes). The incubation time should be optimized to ensure the reaction is within the linear range.[8]
-
Stop Reaction: Terminate the reaction by adding 250 µL of TCA Working Solution to each tube. This will precipitate the undigested casein.[4]
-
Precipitation: Incubate the tubes at 37°C for another 20 minutes to allow for complete precipitation.[4]
-
Clarification: Centrifuge the tubes at 10,000 x g for 5 minutes to pellet the precipitated casein.[4]
-
Color Development: Carefully transfer 250 µL of the clear supernatant to a new tube or a well in a 96-well plate. Add 625 µL of Sodium Carbonate Solution, followed by 125 µL of diluted F-C Reagent. Mix and incubate at 37°C for 30 minutes.[4][6]
-
Measurement: Measure the absorbance of the samples and standards at 660 nm.[4]
Data Analysis:
-
Subtract the absorbance of the Blank from all sample readings.
-
Generate a standard curve using the Tyrosine Standard readings.
-
Use the standard curve to determine the amount of tyrosine equivalents (µmoles) released in each sample.
-
Calculate the protease activity, often expressed in Units/mg, where one unit hydrolyzes casein to produce a specific amount of tyrosine equivalent per minute.[6]
Protocol 2: AlphaLISA Protein-Protein Interaction Assay
This protocol describes a method to quantify the interaction between [Target Protein] and a binding partner, [Partner Protein].
Principle: AlphaLISA (Amplified Luminescent Proximity Homogeneous Assay) is a bead-based technology for detecting biomolecular interactions.[9] One protein ([Target Protein]) is captured on a Donor bead and the other ([Partner Protein]) on an Acceptor bead. When the proteins interact, they bring the beads within close proximity (~200 nm).[9][10] Upon laser excitation at 680 nm, the Donor bead releases singlet oxygen molecules, which travel to the nearby Acceptor bead, triggering a chemiluminescent reaction that emits light at ~615 nm.[10][11] The signal is proportional to the extent of the protein-protein interaction.
Materials:
-
Purified, tagged [Target Protein] (e.g., with a Biotin tag)
-
Purified, tagged [Partner Protein] (e.g., with a GST-tag)
-
AlphaLISA Streptavidin Donor Beads[12]
-
AlphaLISA Anti-GST Acceptor Beads[10]
-
AlphaLISA Assay Buffer
-
Test compounds (inhibitors or enhancers) dissolved in DMSO
-
384-well white ProxiPlate
-
Plate reader capable of AlphaLISA detection
Procedure:
-
Reagent Preparation: Prepare working solutions of [Target Protein]-Biotin, [Partner Protein]-GST, and test compounds by diluting them in AlphaLISA Assay Buffer.
-
Reaction Setup: To the wells of a 384-well plate, add:
-
2 µL of test compound solution (or DMSO for control).
-
4 µL of [Target Protein]-Biotin solution.
-
4 µL of [Partner Protein]-GST solution.
-
-
Incubation: Gently mix and incubate the plate at room temperature for 60 minutes to allow the proteins to interact and reach equilibrium.
-
Bead Addition: Prepare a mix of Anti-GST Acceptor beads and add 5 µL to each well. Incubate for 60 minutes at room temperature, protected from light.
-
Donor Bead Addition: Prepare a solution of Streptavidin Donor beads and add 10 µL to each well. Incubate for 30-60 minutes at room temperature, protected from light.[9]
-
Measurement: Read the plate on an AlphaLISA-compatible plate reader.
Data Analysis:
-
The raw data is obtained as arbitrary luminescence units.
-
For inhibitor screening, data is typically normalized to high (DMSO vehicle) and low (no protein interaction) controls.
-
Plot the normalized signal against the logarithm of the inhibitor concentration and fit the data to a four-parameter logistic equation to determine the IC₅₀ value.
Experimental Workflow and Data Presentation
A typical workflow for screening inhibitors against [Target Protein] is shown below.
Caption: General workflow for an in vitro screening assay.
Data Presentation
Quantitative data from screening and characterization experiments should be summarized in a clear, tabular format for easy comparison.
| Compound ID | Assay Type | IC₅₀ (nM) | Kᵢ (nM) | Hill Slope | Notes |
| Cmpd-001 | Protease (Colorimetric) | 125.3 | 60.1 | 1.1 | Competitive inhibitor. |
| Cmpd-002 | Protease (Colorimetric) | >10,000 | N/A | N/A | Inactive. |
| Cmpd-003 | PPI (AlphaLISA) | 45.8 | 22.5 | 0.98 | Disrupts interaction. |
| Cmpd-004 | PPI (AlphaLISA) | 2,100 | 1050 | 1.5 | Weak activity. |
| Cmpd-005 | Kinase (ADP-Glo) | 8.2 | 3.5 | 1.0 | Potent ATP-competitive inhibitor. |
-
IC₅₀: The concentration of an inhibitor where the response (or binding) is reduced by half.
-
Kᵢ: The inhibition constant; a measure of the affinity of the inhibitor for the enzyme.
-
Hill Slope: Describes the steepness of the dose-response curve. A value of ~1 suggests a 1:1 binding stoichiometry.[1]
References
- 1. pubs.acs.org [pubs.acs.org]
- 2. pubs.acs.org [pubs.acs.org]
- 3. In vitro assays for protein function services - CD Biosynsis [biosynsis.com]
- 4. benchchem.com [benchchem.com]
- 5. bellbrooklabs.com [bellbrooklabs.com]
- 6. sigmaaldrich.com [sigmaaldrich.com]
- 7. pubs.acs.org [pubs.acs.org]
- 8. Basics of Enzymatic Assays for HTS - Assay Guidance Manual - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 9. bitesizebio.com [bitesizebio.com]
- 10. The use of AlphaLISA assay technology to detect interaction between hepatitis C virus-encoded NS5A and cyclophilin A - PMC [pmc.ncbi.nlm.nih.gov]
- 11. bpsbioscience.com [bpsbioscience.com]
- 12. bmglabtech.com [bmglabtech.com]
Application Notes: Immunoprecipitation of [Target Protein] from Cell Lysates
For Researchers, Scientists, and Drug Development Professionals
Introduction
Immunoprecipitation (IP) is a powerful affinity purification technique used to isolate a specific protein (the "target antigen") from a complex mixture such as a cell lysate. This method relies on the highly specific interaction between an antibody and its target protein. The antibody-antigen complex is then captured on a solid-phase support, typically agarose or magnetic beads conjugated with Protein A or Protein G.[1] This application note provides a detailed protocol for the immunoprecipitation of a user-defined "[Target Protein]" from cell lysates, covering experimental design, step-by-step procedures, data analysis, and troubleshooting. The isolated protein can then be subjected to various downstream analyses, including Western blotting and mass spectrometry, to study its presence, abundance, post-translational modifications, and interactions with other molecules.[2][3]
Principle of Immunoprecipitation
The core principle of immunoprecipitation involves several key steps:
-
Cell Lysis: Cells are lysed to release proteins into a solution called a lysate.
-
Antibody Incubation: A primary antibody specific to the "[Target Protein]" is added to the cell lysate to form an antibody-antigen complex.
-
Immune Complex Capture: Protein A/G-coated beads are added to the lysate to bind to the Fc region of the antibody, thus capturing the entire immune complex.[1]
-
Washing: The beads are washed to remove non-specifically bound proteins.
-
Elution: The target protein is eluted from the beads for downstream analysis.
Experimental Design and Controls
Careful experimental design is crucial for a successful immunoprecipitation experiment. Key considerations include selecting the appropriate antibody, lysis buffer, and bead type. Additionally, including proper controls is essential for accurate data interpretation.
Essential Controls:
-
Isotype Control: An antibody of the same isotype as the primary antibody but not specific to the target protein is used to assess non-specific binding of the antibody to the cell lysate.[4]
-
Negative Control (Beads only): Beads are incubated with the cell lysate without the primary antibody to identify proteins that bind non-specifically to the beads themselves.[4]
-
Positive Control Lysate: A cell lysate known to express the target protein should be used to confirm that the antibody and protocol are working correctly.
-
Input Control: A small fraction of the cell lysate before immunoprecipitation is saved to be run alongside the IP sample in downstream analysis (e.g., Western blot) to verify the presence of the target protein in the starting material.
Materials and Reagents
Buffer Recipes
Note: Prepare all solutions with high-purity water (e.g., reverse osmosis deionized water). Add protease and phosphatase inhibitors to lysis and wash buffers immediately before use to prevent protein degradation.
| Buffer | Recipe |
| Phosphate Buffered Saline (PBS), 1X | To prepare 1 liter, add 50 ml of 20X PBS to 950 ml of dH2O and mix.[5] |
| RIPA Lysis Buffer (Modified) | 50 mM Tris-HCl, pH 8.0, 150 mM NaCl, 1% NP-40, 0.5% sodium deoxycholate, 0.1% SDS.[6][7] |
| Non-denaturing Lysis Buffer | 50 mM HEPES, pH 7.5, 150 mM NaCl, 1 mM EDTA, 2.5 mM EGTA, 0.1% (w/v) Tween-20.[1] |
| Wash Buffer | The same lysis buffer used for cell preparation is often used for washing. For less stringent washing, PBS can be used. |
| Elution Buffer (for Western Blotting) | 2X or 3X SDS-PAGE Sample Buffer.[5] |
| Elution Buffer (for Mass Spectrometry) | 0.1 M Glycine, pH 2.0-2.5. Neutralize immediately after elution with 1M Tris, pH 8.5. |
Other Materials
-
Primary antibody specific for "[Target Protein]"
-
Isotype control antibody
-
Protein A or Protein G agarose/magnetic beads[5]
-
Protease inhibitor cocktail
-
Phosphatase inhibitor cocktail
-
Microcentrifuge tubes
-
Refrigerated microcentrifuge
-
End-over-end rotator
-
Pipette tips (it is recommended to cut the tip off when manipulating agarose beads to avoid disruption)
Detailed Immunoprecipitation Protocol
This protocol is a general guideline and may require optimization for your specific "[Target Protein]" and cell type.
Preparation of Cell Lysate
-
For adherent cells, wash the culture dish twice with ice-cold PBS. For suspension cells, wash by pelleting the cells at 800-1000 rpm for 5 minutes and resuspending in ice-cold PBS.
-
Add ice-cold lysis buffer to the cells (e.g., 1 mL per 10^7 cells).[6]
-
For adherent cells, scrape them from the dish using a pre-cooled cell scraper.
-
Transfer the cell suspension to a microcentrifuge tube and incubate on a rocker at 4°C for 15-30 minutes.[8]
-
Centrifuge the lysate at 14,000 x g for 15 minutes at 4°C to pellet cell debris.
-
Carefully transfer the supernatant (cell lysate) to a fresh, pre-chilled microcentrifuge tube.[8]
-
Determine the protein concentration of the lysate using a standard protein assay (e.g., Bradford or BCA assay). It's recommended to dilute the lysate at least 1:10 before the assay due to interference from detergents in the lysis buffer.
-
Adjust the protein concentration to 1-2 mg/mL with lysis buffer.
Pre-clearing the Lysate (Optional but Recommended)
This step helps to reduce non-specific binding of proteins to the beads.
-
Add 20-30 µL of a 50% slurry of Protein A/G beads to 1 mg of cell lysate.
-
Incubate on a rotator for 30-60 minutes at 4°C.[5]
-
Centrifuge at 14,000 x g for 10 minutes at 4°C.
-
Carefully transfer the supernatant to a new pre-chilled microcentrifuge tube. This is the pre-cleared lysate.
Immunoprecipitation
There are two common approaches for immunoprecipitation:
Method A: Free Antibody Incubation First (Higher Purity)
-
Add the recommended amount of primary antibody (typically 1-10 µg) to the pre-cleared lysate.[7] For the isotype control, add the same amount of control IgG.
-
Incubate with gentle rocking overnight at 4°C.[5]
-
Add approximately 30-50 µL of a 50% slurry of Protein A/G beads to capture the immune complexes.[7]
-
Incubate with gentle rocking for 1-3 hours at 4°C.[5]
Method B: Antibody Pre-bound to Beads
-
Incubate the primary antibody with 30-50 µL of a 50% slurry of Protein A/G beads in lysis buffer for 1-2 hours at 4°C with gentle rotation.
-
Wash the antibody-bead complexes twice with lysis buffer.
-
Add the pre-cleared lysate to the antibody-bead complexes.
-
Incubate with gentle rocking overnight at 4°C.
Washing the Immune Complex
-
Pellet the beads by centrifugation at a low speed (e.g., 1,000 x g for 30 seconds) at 4°C.[7] If using magnetic beads, use a magnetic rack to separate the beads.
-
Carefully remove and discard the supernatant.
-
Add 500 µL of ice-cold wash buffer and gently resuspend the beads.
-
Repeat the centrifugation and wash steps three to five times to remove non-specifically bound proteins.[5]
Elution
The elution method depends on the downstream application.
For Western Blotting:
-
After the final wash, remove all supernatant.
-
Resuspend the beads in 30-60 µL of 2X or 3X SDS-PAGE sample buffer.
-
Boil the sample at 95-100°C for 5-10 minutes to dissociate the immune complexes from the beads.[8]
-
Centrifuge to pellet the beads, and the supernatant containing the eluted protein is ready for loading onto an SDS-PAGE gel.
For Mass Spectrometry or Functional Assays:
-
After the final wash, resuspend the beads in 50-100 µL of elution buffer (e.g., 0.1 M Glycine, pH 2.0-2.5).
-
Incubate for 5-10 minutes at room temperature with gentle mixing.
-
Centrifuge to pellet the beads and carefully transfer the supernatant containing the eluted protein to a new tube.
-
Immediately neutralize the eluate by adding a neutralization buffer (e.g., 1M Tris, pH 8.5).
Data Presentation and Analysis
Quantitative data from immunoprecipitation experiments should be presented in a clear and organized manner. Below are template tables for data recording and analysis.
Table 1: Protein Quantification of Cell Lysates
| Sample ID | Cell Type/Treatment | Total Lysate Volume (µL) | Protein Concentration (mg/mL) | Total Protein (mg) |
| Sample 1 | ||||
| Sample 2 | ||||
| Sample 3 |
Table 2: Densitometric Analysis of Western Blots
| Lane | Sample | Band Intensity (Arbitrary Units) | Normalized Intensity (vs. Input) | Fold Enrichment (IP/Input) |
| 1 | Input | |||
| 2 | IP: [Target Protein] Ab | |||
| 3 | IP: Isotype Control | |||
| 4 | IP: Beads Only |
Analysis of immunoprecipitated proteins is commonly performed by Western blotting or mass spectrometry.[9] For Western blotting, band intensities can be quantified using image analysis software to determine the relative amount of the target protein.[9] For mass spectrometry, the number of spectral counts or the peak area can be used for relative quantification of identified proteins.[10]
Troubleshooting
| Problem | Possible Cause(s) | Solution(s) |
| No or low yield of target protein | Inefficient cell lysis. | Try a different lysis buffer or sonicate the lysate.[8] |
| Antibody not suitable for IP. | Use an antibody validated for immunoprecipitation. | |
| Low expression of target protein. | Increase the amount of starting cell lysate.[8] | |
| Antibody-antigen binding is weak. | Increase incubation time or antibody concentration. | |
| High background/non-specific binding | Insufficient washing. | Increase the number of washes or use a more stringent wash buffer.[8] |
| Too much antibody used. | Titrate the antibody to determine the optimal concentration.[8] | |
| Beads are binding non-specifically. | Pre-clear the lysate with beads before adding the antibody. | |
| Heavy and light chains of antibody obscure target protein in Western blot | The secondary antibody detects the IP antibody. | Use a light-chain specific secondary antibody or crosslink the primary antibody to the beads.[8] |
Visualizing the Workflow and Interactions
Immunoprecipitation Workflow
Caption: A flowchart illustrating the major steps of an immunoprecipitation experiment.
Key Interactions in Immunoprecipitation
Caption: A diagram showing the molecular interactions during immunoprecipitation.
Hypothetical Signaling Pathway
Caption: An example of a signaling pathway involving a target protein.
References
- 1. assaygenie.com [assaygenie.com]
- 2. Immunoprecipitation (IP): The Complete Guide | Antibodies.com [antibodies.com]
- 3. Immuno-precipitation MS (IP-MS) | Anaquant HCP analysis I Protein characterisation I Protein analysis [anaquant.com]
- 4. antibody-creativebiolabs.com [antibody-creativebiolabs.com]
- 5. Immunoprecipitation Protocol For Native Proteins | Cell Signaling Technology [cellsignal.com]
- 6. brd.nci.nih.gov [brd.nci.nih.gov]
- 7. Immunoprecipitation Protocols | Antibodies.com [antibodies.com]
- 8. Immunoprecipitation Protocol & Troubleshooting - Creative Biolabs [creativebiolabs.net]
- 9. Immunoprecipitation Data Analysis in Biological Research - Creative Proteomics [creative-proteomics.com]
- 10. Co-immunoprecipitation: Principles and applications | Abcam [abcam.com]
Application Note: CRISPR-Cas9 Mediated Gene Editing of the [Target Protein]
For Research Use Only. Not for use in diagnostic procedures.
Introduction
The Clustered Regularly Interspaced Short Palindromic Repeats (CRISPR) and CRISPR-associated protein 9 (Cas9) system is a revolutionary gene-editing technology that allows for precise and efficient modification of genomic DNA.[1][2] The system utilizes a guide RNA (sgRNA) to direct the Cas9 nuclease to a specific genomic locus, where it induces a double-strand break (DSB).[3][4] The cell's natural DNA repair mechanisms then mend the break, primarily through one of two pathways: the error-prone Non-Homologous End Joining (NHEJ) pathway, which often results in small insertions or deletions (indels) that can disrupt gene function, or the high-fidelity Homology-Directed Repair (HDR) pathway, which can be harnessed to insert specific sequences if a donor template is provided.[5]
This document provides a comprehensive protocol for utilizing the CRISPR-Cas9 system to edit the [Target Gene] in mammalian cells, leading to a functional knockout of the [Target Protein]. It covers sgRNA design, delivery of CRISPR components into cells, and robust methods for verifying the editing event and its functional consequences.
Phase 1: sgRNA Design and Preparation
Effective gene editing begins with the design of a highly specific and efficient sgRNA.[6][7] The sgRNA's 20-nucleotide guide sequence is critical for both targeting specificity and cleavage efficiency.[8]
Protocol 1: sgRNA Design
-
Obtain the Target Sequence: Acquire the full cDNA or genomic sequence of the [Target Gene]. For knockout experiments, it is recommended to target an early exon to maximize the chance of generating a loss-of-function mutation.[7][9]
-
Use Design Software: Utilize web-based tools (e.g., CHOPCHOP, Synthego Design Tool, Benchling) to generate candidate sgRNA sequences. These tools predict on-target efficiency and potential off-target sites.[9]
-
Selection Criteria:
-
On-Target Score: Choose sgRNAs with high predicted on-target activity scores.
-
Off-Target Score: Select sgRNAs with the fewest and lowest-scoring potential off-target sites to minimize unintended edits.[6][8]
-
PAM Site: Ensure the target sequence is immediately upstream of a Protospacer Adjacent Motif (PAM), which for Streptococcus pyogenes Cas9 (SpCas9) is 'NGG'.[3][6]
-
GC Content: Aim for a GC content between 40-60% for optimal stability and function.[6]
-
-
Order or Synthesize sgRNAs: Once 2-3 top candidate sgRNAs are selected, they can be chemically synthesized or cloned into an expression vector.
Phase 2: Delivery of CRISPR-Cas9 Components
The CRISPR-Cas9 components can be delivered into mammalian cells as plasmid DNA, RNA, or as a ribonucleoprotein (RNP) complex. The RNP method (Cas9 protein pre-complexed with sgRNA) is often preferred as it offers high editing efficiency and reduced off-target effects.
Protocol 2: Transfection of Mammalian Cells with RNP
-
Cell Preparation: One day prior to transfection, seed the mammalian cells of interest (e.g., HEK293T, HeLa) in a 24-well plate at a density that will result in 70-90% confluency on the day of transfection.
-
Prepare RNP Complexes:
-
In a sterile microcentrifuge tube, dilute the required amount of sgRNA and Cas9 nuclease in Opti-MEM or a similar serum-free medium.
-
Mix the Cas9 and sgRNA solutions and incubate at room temperature for 10-20 minutes to allow the RNP complex to form.
-
-
Transfection:
-
Dilute a lipid-based transfection reagent (e.g., Lipofectamine CRISPRMAX) in Opti-MEM.
-
Add the RNP complexes to the diluted transfection reagent, mix gently, and incubate for 5 minutes.
-
Add the final RNP-lipid complex drop-wise to the cells.[10]
-
-
Incubation: Incubate the cells at 37°C for 48-72 hours.
Phase 3: Verification of Gene Editing
After incubation, it is crucial to verify the efficiency of the gene edit at the genomic level.
Protocol 3: Genomic DNA Extraction and PCR Amplification
-
Harvest Cells: Harvest a portion of the transfected cells.
-
Extract Genomic DNA: Use a commercial genomic DNA extraction kit according to the manufacturer's protocol.
-
PCR Amplification: Design PCR primers that flank the sgRNA target site, amplifying a 400-800 bp region. Perform PCR on the extracted genomic DNA from both edited and control cells.
Protocol 4: Mismatch Cleavage Assay (T7E1)
This assay provides a rapid estimation of editing efficiency in a cell pool.[11]
-
Denature and Reanneal PCR Products:
-
Take 200 ng of the purified PCR product.
-
In a thermocycler, denature and reanneal the DNA to form heteroduplexes between wild-type and edited strands: 95°C for 10 min, ramp down to 85°C at -2°C/s, ramp down to 25°C at -0.3°C/s.
-
-
T7 Endonuclease I Digestion: Add T7 Endonuclease I to the reannealed PCR product and incubate at 37°C for 15-30 minutes.[12]
-
Gel Electrophoresis: Analyze the digested products on a 2% agarose gel. The presence of cleaved bands indicates successful editing.
-
Quantification: Use densitometry to estimate the percentage of indels.
Protocol 5: Sanger Sequencing and TIDE Analysis
For a more quantitative analysis, the PCR product can be analyzed by Sanger sequencing.
-
Purify PCR Product: Purify the PCR product from Protocol 3.
-
Sanger Sequencing: Send the purified PCR product for standard Sanger sequencing.
-
TIDE Analysis: Use a web-based tool like TIDE (Tracking of Indels by Decomposition) to analyze the sequencing chromatogram and quantify the frequency and spectrum of indels in the edited cell pool.
Phase 4: Functional Validation
Confirming the genomic edit should be followed by validation of the functional consequence, i.e., the loss of [Target Protein].
Protocol 6: Western Blot Analysis
-
Protein Extraction: Lyse the remaining population of edited and control cells to extract total protein.
-
Quantification: Determine protein concentration using a BCA or Bradford assay.
-
Electrophoresis and Transfer: Separate 20-30 µg of protein per sample by SDS-PAGE and transfer to a PVDF or nitrocellulose membrane.
-
Immunoblotting:
-
Block the membrane with 5% non-fat milk or BSA in TBST.
-
Incubate with a primary antibody specific to the [Target Protein].
-
Incubate with an appropriate HRP-conjugated secondary antibody.
-
Detect the signal using an enhanced chemiluminescence (ECL) substrate. A loading control (e.g., GAPDH, β-actin) should be used to ensure equal protein loading.[13]
-
Data Presentation
Quantitative data from the validation experiments should be summarized for clear interpretation.
Table 1: On-Target Editing Efficiency
| sgRNA ID | Mismatch Cleavage Assay (T7E1) - % Indels | Sanger + TIDE Analysis - % Indels |
|---|---|---|
| sgRNA-1 | 25% | 28.5% |
| sgRNA-2 | 45% | 49.2% |
| sgRNA-3 | 15% | 17.8% |
| Control | 0% | <1% |
Table 2: Off-Target Analysis (Top 3 Predicted Sites)
| sgRNA ID | Off-Target Site | Mismatch Cleavage Assay - % Indels | Sanger Sequencing |
|---|---|---|---|
| sgRNA-2 | Chr 2: 12345678 | <1% | No indels detected |
| sgRNA-2 | Chr 11: 87654321 | <1% | No indels detected |
| sgRNA-2 | Chr X: 55555555 | <1% | No indels detected |
Table 3: Functional Validation - Protein Expression
| Sample | [Target Protein] Level (Relative to Loading Control) | % Reduction vs. Control |
|---|---|---|
| Unedited Control | 1.00 | 0% |
| Edited Pool (sgRNA-2) | 0.25 | 75% |
Visualizations
Caption: Experimental workflow for CRISPR-Cas9 gene editing.
Caption: Hypothetical signaling pathway involving [Target Protein].
References
- 1. researchgate.net [researchgate.net]
- 2. Application of CRISPR-Cas9 genome editing technology in various fields: A review - PMC [pmc.ncbi.nlm.nih.gov]
- 3. lifesciences.danaher.com [lifesciences.danaher.com]
- 4. Application of CRISPR/Cas9 gene editing technology - CD Biosynsis [biosynsis.com]
- 5. Fast and cloning‐free CRISPR/Cas9‐mediated genomic editing in mammalian cells - PMC [pmc.ncbi.nlm.nih.gov]
- 6. sgRNA Design Principles for Optimal CRISPR Efficiency [synapse.patsnap.com]
- 7. Tips to optimize sgRNA design - Life in the Lab [thermofisher.com]
- 8. Generalizable sgRNA design for improved CRISPR/Cas9 editing efficiency - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Generation of knock-in and knock-out CRISPR/Cas9 editing in mammalian cells [protocols.io]
- 10. youtube.com [youtube.com]
- 11. Strategies to detect and validate your CRISPR gene edit [horizondiscovery.com]
- 12. Video: Genome Editing in Mammalian Cell Lines using CRISPR-Cas [jove.com]
- 13. bitesizebio.com [bitesizebio.com]
Best Practices for Cloning and Expressing Recombinant [Target Protein]
For Researchers, Scientists, and Drug Development Professionals
These application notes provide a comprehensive guide to the best practices for cloning, expressing, and purifying a recombinant [Target Protein]. The following protocols and data are intended to serve as a foundation for developing a robust and reproducible workflow for obtaining high-quality protein for research and therapeutic applications.
Section 1: Gene Cloning and Vector Construction
The initial and critical phase of recombinant protein production involves the successful cloning of the gene of interest into an appropriate expression vector. A well-designed cloning strategy will significantly impact the final protein yield and purity.
Best Practices for Gene Cloning
-
Codon Optimization: To maximize translational efficiency, the coding sequence of the [Target Protein] should be optimized to match the codon bias of the chosen expression host. This involves replacing rare codons in the native gene with codons that are more frequently used by the expression host, such as E. coli.[1] This process can significantly enhance protein expression levels.
-
Vector Selection: The choice of expression vector is paramount. Key features to consider include a strong, inducible promoter (e.g., T7 promoter for E. coli), a suitable antibiotic resistance gene for selection, and a multiple cloning site (MCS) compatible with your chosen restriction enzymes.
-
Affinity Tags: Incorporating an affinity tag (e.g., polyhistidine (His-tag), GST-tag) into the vector design will greatly simplify the subsequent purification process.[2] The tag can be placed at either the N- or C-terminus of the [Target Protein], and its impact on protein folding and function should be considered.
-
Subcloning Strategy: A common and effective method for inserting the gene of interest into the expression vector is through restriction enzyme digestion and ligation.[3][4] This involves selecting two different restriction enzymes that flank the gene insert and are present in the vector's MCS. This directional cloning approach ensures the insert is in the correct orientation for expression.
Experimental Protocol: Subcloning of [Target Protein] Gene into an Expression Vector
This protocol outlines the steps for subcloning the codon-optimized [Target Protein] gene into a pET series expression vector.
1.2.1. Materials:
-
Codon-optimized [Target Protein] gene in a donor plasmid
-
pET expression vector (e.g., pET-28a)
-
Restriction enzymes (e.g., NdeI and XhoI) and corresponding 10X buffer
-
T4 DNA Ligase and 10X ligation buffer
-
Agarose
-
Tris-acetate-EDTA (TAE) buffer
-
DNA loading dye
-
DNA ladder
-
Gel extraction kit
-
Competent E. coli cloning strain (e.g., DH5α)
-
Luria-Bertani (LB) agar plates with appropriate antibiotic
-
SOC medium
1.2.2. Procedure:
-
Restriction Digest:
-
Set up two separate restriction digest reactions, one for the donor plasmid containing the [Target Protein] gene and one for the pET expression vector.
-
For each reaction, combine the plasmid DNA, the two restriction enzymes, and the appropriate 10X buffer in a microfuge tube.
-
Incubate the reactions at the optimal temperature for the enzymes (usually 37°C) for 1-2 hours.
-
-
Agarose Gel Electrophoresis:
-
Prepare a 1% agarose gel in TAE buffer.
-
Load the digested DNA samples, along with a DNA ladder, into the wells of the gel.
-
Run the gel at 100V until the DNA fragments are well-separated.
-
Visualize the DNA bands under UV light. You should see a band corresponding to the linearized vector and another to the [Target Protein] insert.
-
-
Gel Extraction:
-
Excise the DNA bands of the correct size from the agarose gel using a clean scalpel.
-
Purify the DNA from the gel slices using a gel extraction kit, following the manufacturer's instructions.
-
Elute the purified DNA in a small volume of elution buffer or sterile water.
-
-
Ligation:
-
Set up a ligation reaction by combining the purified, digested vector and insert DNA in a molar ratio of approximately 1:3 (vector:insert).
-
Add T4 DNA Ligase and its corresponding buffer.
-
Incubate the reaction at 16°C overnight or at room temperature for 1-2 hours.
-
-
Transformation:
-
Thaw a tube of competent E. coli DH5α cells on ice.
-
Add 2-5 µL of the ligation reaction to the competent cells and mix gently.
-
Incubate on ice for 30 minutes.
-
Heat-shock the cells at 42°C for 45-60 seconds and immediately return them to ice for 2 minutes.[5]
-
Add 250 µL of SOC medium and incubate at 37°C for 1 hour with shaking.
-
Plate the transformed cells onto LB agar plates containing the appropriate antibiotic and incubate at 37°C overnight.
-
-
Colony Screening and Plasmid Preparation:
-
Select several individual colonies and grow them in liquid LB medium with the selective antibiotic.
-
Isolate the plasmid DNA from these cultures using a miniprep kit.
-
Verify the presence and orientation of the insert by restriction digest analysis and/or DNA sequencing.
-
Section 2: Recombinant Protein Expression
Once a verified expression construct is obtained, the next step is to express the [Target Protein] in a suitable host system. E. coli is a widely used and cost-effective host for producing recombinant proteins.
Best Practices for Protein Expression in E. coli
-
Expression Strain Selection: The choice of E. coli strain can significantly influence protein expression levels and solubility. Strains like BL21(DE3) are commonly used as they contain the T7 RNA polymerase gene required for transcription from T7 promoters.
-
Optimization of Induction Conditions: The concentration of the inducer (e.g., Isopropyl β-D-1-thiogalactopyranoside, IPTG) and the temperature and duration of induction are critical parameters to optimize for each target protein. Lowering the induction temperature (e.g., 16-25°C) can often improve protein solubility.[6]
-
Pilot Expression Studies: Before proceeding to large-scale expression, it is highly recommended to perform small-scale pilot experiments to determine the optimal expression conditions.[5][7] This involves testing different induction temperatures, IPTG concentrations, and induction times.
Experimental Protocol: Expression of [Target Protein] in E. coli
This protocol describes the expression of a His-tagged [Target Protein] in the E. coli BL21(DE3) strain.
2.2.1. Materials:
-
Verified pET expression vector containing the [Target Protein] gene
-
Competent E. coli BL21(DE3) cells
-
LB medium
-
Appropriate antibiotic
-
IPTG stock solution (1 M)
2.2.2. Procedure:
-
Transformation of Expression Strain:
-
Transform the pET expression vector into competent E. coli BL21(DE3) cells using the heat-shock method described in the cloning protocol.
-
Plate the transformed cells on LB agar plates with the selective antibiotic and incubate overnight at 37°C.
-
-
Starter Culture:
-
Inoculate a single colony from the transformation plate into 5-10 mL of LB medium containing the appropriate antibiotic.
-
Grow the culture overnight at 37°C with shaking (200-250 rpm).
-
-
Main Culture and Induction:
-
The next day, inoculate a larger volume of LB medium (e.g., 1 L) with the overnight starter culture (typically a 1:100 dilution).
-
Grow the main culture at 37°C with vigorous shaking until the optical density at 600 nm (OD600) reaches 0.6-0.8.
-
Induce protein expression by adding IPTG to a final concentration of 0.1-1.0 mM.
-
Continue to grow the culture under the optimized induction conditions (e.g., 16-37°C for 4-16 hours).
-
-
Cell Harvest:
-
Harvest the bacterial cells by centrifugation at 5,000 x g for 15 minutes at 4°C.
-
Discard the supernatant and store the cell pellet at -80°C until purification.
-
Section 3: Recombinant Protein Purification
The final step is to purify the [Target Protein] from the host cell lysate. The use of an affinity tag, such as a His-tag, simplifies this process significantly through Immobilized Metal Affinity Chromatography (IMAC).
Best Practices for His-tagged Protein Purification
-
Lysis Buffer Composition: The lysis buffer should be optimized to ensure efficient cell disruption while maintaining the stability and activity of the target protein. It typically contains a buffering agent (e.g., Tris-HCl), salt (e.g., NaCl), and a low concentration of imidazole to reduce non-specific binding of host proteins to the affinity resin.[7]
-
Washing and Elution: Thorough washing of the affinity column after lysate binding is crucial to remove contaminating proteins. The bound His-tagged protein is then eluted using a buffer containing a high concentration of imidazole, which competes with the His-tag for binding to the metal ions on the resin.
-
Further Purification Steps: Depending on the required purity, additional chromatography steps, such as size-exclusion chromatography (gel filtration) or ion-exchange chromatography, may be necessary to remove any remaining impurities.[6]
Experimental Protocol: Purification of His-tagged [Target Protein]
This protocol outlines the purification of a His-tagged [Target Protein] from E. coli lysate using Ni-NTA affinity chromatography under native conditions.
3.2.1. Materials:
-
Frozen cell pellet from expression
-
Lysis Buffer (50 mM Tris-HCl, pH 8.0, 300 mM NaCl, 10 mM Imidazole)
-
Wash Buffer (50 mM Tris-HCl, pH 8.0, 300 mM NaCl, 20 mM Imidazole)
-
Elution Buffer (50 mM Tris-HCl, pH 8.0, 300 mM NaCl, 250 mM Imidazole)
-
Lysozyme
-
DNase I
-
Protease inhibitor cocktail
-
Ni-NTA agarose resin
-
Chromatography column
3.2.2. Procedure:
-
Cell Lysis:
-
Resuspend the frozen cell pellet in ice-cold Lysis Buffer (approximately 5 mL per gram of wet cell paste).
-
Add lysozyme (to 1 mg/mL), DNase I, and a protease inhibitor cocktail.
-
Incubate on ice for 30 minutes.
-
Sonicate the cell suspension on ice to further disrupt the cells and reduce viscosity.
-
Clarify the lysate by centrifugation at 15,000 x g for 30 minutes at 4°C.
-
-
Affinity Chromatography:
-
Equilibrate the Ni-NTA agarose resin in a chromatography column with 5-10 column volumes of Lysis Buffer.
-
Load the clarified lysate onto the equilibrated column.
-
Wash the column with 10-20 column volumes of Wash Buffer to remove unbound proteins.
-
Elute the bound His-tagged [Target Protein] with 5-10 column volumes of Elution Buffer. Collect the eluate in fractions.
-
-
Analysis of Purity:
-
Analyze the collected fractions by SDS-PAGE to assess the purity and size of the recombinant protein.
-
Pool the fractions containing the purified [Target Protein].
-
-
Buffer Exchange (Optional):
-
If necessary, exchange the buffer of the purified protein into a suitable storage buffer using dialysis or a desalting column.
-
Quantitative Data Summary
The following table summarizes typical yields for recombinant protein expression in E. coli. Actual yields will vary depending on the specific target protein and the optimization of the expression and purification protocols.
| Expression System | Host Strain | Typical Yield (mg/L of culture) | Purity | Reference |
| E. coli | BL21(DE3) | 10-100 | >90% after affinity chromatography | [8] |
| E. coli | SHuffle® | 5-50 | >90% after affinity chromatography | Internal Data |
| E. coli | Rosetta™(DE3) | 10-80 | >90% after affinity chromatography | Internal Data |
Visualizations
Signaling Pathways Influencing Protein Expression
The expression of recombinant proteins in mammalian cells is influenced by complex signaling pathways that regulate transcription and translation. Understanding these pathways can aid in the design of expression strategies.
Caption: Key signaling pathways in mammalian cells that regulate gene and protein expression.
Experimental Workflow for Recombinant Protein Production
The overall process of producing a recombinant protein can be visualized as a sequential workflow.
References
- 1. sinobiological.com [sinobiological.com]
- 2. Purification of His-Tagged Proteins - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. Molecular Cloning Guide [promega.com]
- 4. Plasmid Cloning by Restriction Enzyme Digest (aka Subcloning) [protocols.io]
- 5. E. coli protein expression and purification [protocols.io]
- 6. Protein Expression Protocol & Troubleshooting in E. coli [biologicscorp.com]
- 7. neb.com [neb.com]
- 8. biorxiv.org [biorxiv.org]
Application Note: Visualizing p53 Activation Dynamics Using Fluorescence Microscopy
Audience: Researchers, scientists, and drug development professionals.
Introduction
The tumor suppressor protein p53, often termed the "guardian of the genome," plays a pivotal role in maintaining cellular and genetic stability.[1] In response to cellular stresses such as DNA damage, oncogene activation, or hypoxia, p53 becomes stabilized and activated.[2] This activation leads to a rapid increase in p53 levels within the nucleus, where it functions as a transcription factor.[2][3] p53 orchestrates a variety of cellular responses, including cell cycle arrest to allow for DNA repair, senescence, or apoptosis (programmed cell death) to eliminate severely damaged cells.[1][4][5]
Given that the function of p53 is tightly linked to its subcellular localization, visualizing its movement from the cytoplasm to the nucleus is a direct and powerful method for assessing its activation.[3][6] Fluorescence microscopy provides a robust platform for observing and quantifying the spatiotemporal dynamics of p53, offering critical insights for cancer research and the development of therapeutic agents that modulate the p53 pathway. This note provides an overview and detailed protocols for visualizing p53 activation.
p53 Signaling Pathway in Response to DNA Damage
Upon DNA damage, a complex signaling cascade is initiated to activate p53. Sensor proteins detect the damage and activate upstream kinases such as ATM (Ataxia-Telangiectasia Mutated) and ATR (ATM and Rad3-related). These kinases then phosphorylate p53.[2] In unstressed cells, p53 levels are kept low through continuous degradation mediated by its negative regulator, MDM2.[1] Phosphorylation of p53 disrupts the p53-MDM2 interaction, leading to p53 stabilization, accumulation, and translocation into the nucleus.[1][7] Once in the nucleus, p53 binds to specific DNA sequences to activate the transcription of target genes, such as CDKN1A (encoding p21), which mediates cell cycle arrest.[1]
Key Applications
-
Fundamental Research: Study the fundamental mechanisms of the DNA damage response and cell cycle control.
-
Drug Screening: High-throughput screening of small molecules that can restore wild-type p53 function in cancer cells or modulate the p53 pathway.[8]
-
Cancer Diagnostics: Assess the functional status of the p53 pathway in patient-derived tumor cells to predict treatment response.
-
Toxicology: Evaluate the genotoxicity of compounds by monitoring p53 activation as a marker of DNA damage.
Experimental Protocols
Two primary methods are employed for visualizing p53 using fluorescence microscopy: immunofluorescence (IF) for fixed cells and fluorescent protein (FP) tagging for live-cell imaging.
Protocol 1: Immunofluorescence (IF) Staining of Endogenous p53
This protocol allows for the detection of endogenous p53 in fixed cells, providing a snapshot of its localization at a specific time point after treatment.
Methodology:
-
Cell Culture: Seed cells (e.g., A549, U2OS) on sterile glass coverslips in a 24-well plate and allow them to adhere overnight.
-
Treatment: Treat cells with a DNA damaging agent (e.g., 10 µM Etoposide or 10 Gy ionizing radiation) or vehicle control for the desired time (e.g., 2, 4, 8 hours).
-
Fixation: Gently wash cells twice with 1X Phosphate Buffered Saline (PBS). Fix the cells with 4% paraformaldehyde (PFA) in PBS for 15 minutes at room temperature.
-
Permeabilization: Wash three times with PBS. Permeabilize the cells with 0.25% Triton X-100 in PBS for 10 minutes.
-
Blocking: Wash three times with PBS. Block non-specific antibody binding by incubating in 1% Bovine Serum Albumin (BSA) in PBS for 1 hour at room temperature.[9]
-
Primary Antibody Incubation: Dilute the primary antibody against p53 (e.g., clone DO-1) in the blocking buffer. Remove the blocking solution and incubate the cells with the diluted primary antibody overnight at 4°C in a humidified chamber.[9]
-
Secondary Antibody Incubation: Wash cells three times with PBS. Dilute a fluorophore-conjugated secondary antibody (e.g., Goat anti-Mouse Alexa Fluor 488) in the blocking buffer. Incubate for 1-2 hours at room temperature, protected from light.
-
Counterstaining: Wash three times with PBS. Incubate with a nuclear counterstain like DAPI (300 nM in PBS) for 5 minutes.
-
Mounting: Wash twice with PBS. Mount the coverslips onto microscope slides using an anti-fade mounting medium.
-
Imaging: Acquire images using a fluorescence microscope. Use the DAPI channel to locate nuclei and the Alexa Fluor 488 channel to visualize p53.
Protocol 2: Live-Cell Imaging of GFP-p53 Dynamics
This method uses a p53-GFP fusion protein to monitor p53 translocation in real-time within living cells.
Methodology:
-
Transfection: Seed cells in a glass-bottom imaging dish. Transfect the cells with a plasmid encoding a p53-GFP fusion protein using a suitable transfection reagent. Allow 24-48 hours for protein expression.
-
Microscope Setup: Place the imaging dish on a live-cell imaging microscope equipped with an environmental chamber to maintain 37°C and 5% CO₂.
-
Baseline Imaging: Acquire baseline images before treatment. Select several fields of view containing healthy, transfected cells.
-
Treatment: Add the DNA damaging agent (e.g., Etoposide) directly to the cell culture medium in the dish.
-
Time-Lapse Acquisition: Begin time-lapse imaging immediately after adding the drug. Acquire images in both the GFP and brightfield channels every 10-20 minutes for several hours (e.g., 8-24 hours).
-
Data Analysis: Quantify the change in p53-GFP localization over time. This can be done by measuring the ratio of the mean fluorescence intensity in the nucleus versus the cytoplasm.
Data Presentation and Quantitative Analysis
A key metric for quantifying p53 activation is the nuclear-to-cytoplasmic fluorescence intensity ratio. This is calculated by defining regions of interest (ROIs) for the nucleus (using the DAPI stain in IF or by morphology in live-cell imaging) and the cytoplasm for each cell and measuring the mean pixel intensity.
Nuclear Intensity / Cytoplasmic Intensity = Ratio
An increase in this ratio over time or upon treatment indicates the translocation of p53 into the nucleus and thus its activation.[3]
Table 1: Quantitative Analysis of p53 Nuclear Translocation
The following table summarizes example data obtained from an immunofluorescence experiment using U2OS cells treated with 10 µM Etoposide.
| Treatment Group | Time Point | % Cells with Nuclear p53 (Mean ± SD) | Nuclear/Cytoplasmic Intensity Ratio (Mean ± SD) |
| Vehicle Control | 4 hours | 8 ± 2% | 1.2 ± 0.3 |
| Etoposide (10 µM) | 2 hours | 45 ± 6% | 3.5 ± 0.8 |
| Etoposide (10 µM) | 4 hours | 88 ± 5% | 8.1 ± 1.5 |
| Etoposide (10 µM) | 8 hours | 92 ± 4% | 8.5 ± 1.3 |
Data are representative. N > 200 cells were analyzed per condition across three independent experiments.
Conclusion
Fluorescence microscopy is an indispensable tool for studying the activation of p53. Both immunofluorescence of fixed cells and live-cell imaging of fluorescently tagged p53 provide robust and quantitative methods to analyze its critical translocation from the cytoplasm to the nucleus. These techniques are fundamental for dissecting the DNA damage response pathway and for the preclinical evaluation of novel cancer therapeutics designed to modulate p53 activity.
References
- 1. p53 - Wikipedia [en.wikipedia.org]
- 2. Regulation of p53 in response to DNA damage - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. molbiolcell.org [molbiolcell.org]
- 4. The p53 network: Cellular and systemic DNA damage responses in aging and cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 5. mdpi.com [mdpi.com]
- 6. The importance of p53 location: nuclear or cytoplasmic zip code? - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. Nucleocytoplasmic Shuttling of p53 Is Essential for MDM2-Mediated Cytoplasmic Degradation but Not Ubiquitination - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Live cell, image-based high-throughput screen to quantitate p53 stabilization and viability in human papillomavirus positive cancer cells - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. p53 immunohistochemistry protocol [protocols.io]
Application Notes: Quantitative PCR Assay for [Target Protein] mRNA Levels
Introduction
Reverse transcription-quantitative polymerase chain reaction (RT-qPCR) is a highly sensitive and specific technique used for the detection and quantification of RNA.[1] It is the method of choice for analyzing messenger RNA (mRNA) expression levels due to its speed, sensitivity, and broad dynamic range.[2][3] This document provides a detailed protocol for quantifying the mRNA levels of a specific [Target Protein] using a two-step RT-qPCR approach.[4] The protocol adheres to the principles outlined in the Minimum Information for Publication of Quantitative Real-Time PCR Experiments (MIQE) guidelines to ensure data reliability and reproducibility.[5][6]
Principle of the Assay
The RT-qPCR process for mRNA quantification involves two main stages:
-
Reverse Transcription (RT): The target mRNA is first converted into complementary DNA (cDNA) using a reverse transcriptase enzyme.[4][7] This step is crucial as RNA is less stable and not a suitable template for standard PCR amplification.[4]
-
Quantitative PCR (qPCR): The newly synthesized cDNA serves as a template for qPCR.[7] A fluorescent dye (e.g., SYBR® Green) or a fluorescently labeled probe is used to monitor the amplification of the target cDNA in real-time. The cycle at which the fluorescence signal crosses a predetermined threshold is known as the quantification cycle (Cq), which is inversely proportional to the initial amount of target mRNA.[3][8]
Relative quantification is then used to determine the change in [Target Protein] mRNA expression relative to a stable internal control (housekeeping gene) and a calibrator sample (e.g., an untreated control).[9][10] The most common method for this analysis is the ΔΔCq (Delta-Delta Ct) method.[9][11]
Experimental Workflow and Protocols
The overall experimental workflow consists of four main parts: RNA isolation and quality control, reverse transcription to synthesize cDNA, qPCR amplification, and data analysis.[7][12]
Figure 1. High-level workflow for quantifying mRNA expression via RT-qPCR.
Part 1: RNA Isolation and Quality Control
High-quality, intact RNA is essential for accurate gene expression analysis.
Protocol:
-
Homogenization: Homogenize cell or tissue samples using a suitable method (e.g., TRIzol reagent or a column-based kit).[13] For adherent cells, TRIzol can be added directly to the culture dish.[14]
-
RNA Extraction: Follow the manufacturer's protocol for the chosen RNA extraction method. This typically involves phase separation with chloroform, precipitation with isopropanol, and washing with ethanol.[14]
-
DNase Treatment (Optional but Recommended): Treat the isolated RNA with RNase-free DNase I to remove any contaminating genomic DNA, which could otherwise serve as a template in the PCR step.
-
RNA Quantification: Determine the RNA concentration using a spectrophotometer (e.g., NanoDrop). Measure the absorbance at 260 nm.
-
Purity Assessment: Assess RNA purity by calculating the A260/A280 and A260/A230 ratios.[15]
-
An A260/A280 ratio of ~2.0 is indicative of pure RNA.
-
An A260/A230 ratio should ideally be between 2.0 and 2.2.[15]
-
-
Integrity Check: Verify RNA integrity by running an aliquot on a denaturing agarose gel or using an automated electrophoresis system (e.g., Agilent Bioanalyzer). Intact total RNA will show sharp 28S and 18S ribosomal RNA (rRNA) bands.
| Parameter | Acceptance Criteria | Common Contaminants Indicated by Poor Ratios |
| Concentration | Sufficient for cDNA synthesis (e.g., >50 ng/µL) | N/A |
| A260/A280 Ratio | 1.8 – 2.1 | Protein |
| A260/A230 Ratio | 2.0 – 2.2 | Phenol, Guanidine, Carbohydrates |
| Integrity (RIN/RQN) | > 7.0 | Degraded RNA |
Table 1. RNA Quality Control Parameters.
Part 2: cDNA Synthesis (Reverse Transcription)
This step converts the isolated RNA into more stable cDNA. A two-step protocol is described, which allows for the creation of a cDNA archive for future experiments.[4]
Protocol:
-
Prepare the RT Reaction Mix: On ice, combine the following components. It is recommended to prepare a master mix for multiple samples to minimize pipetting errors.[13]
-
Template RNA: Add up to 1 µg of total RNA to each reaction tube. Adjust the volume with RNase-free water.
-
Primer Annealing: Incubate the RNA/primer mixture according to the reverse transcriptase kit instructions (e.g., 65°C for 5 minutes), then place immediately on ice.[7]
-
Reverse Transcription: Add the reverse transcriptase and buffer mix. Incubate as recommended by the manufacturer (e.g., 50°C for 60 minutes).
-
Enzyme Inactivation: Terminate the reaction by heating (e.g., 70°C for 10 minutes).[7]
-
Storage: The resulting cDNA can be stored at -20°C.
| Component | Volume (per 20 µL reaction) | Purpose |
| Total RNA | X µL (up to 1 µg) | Template |
| Random Primers / Oligo(dT)s | 1 µL | Primer for cDNA synthesis[7] |
| dNTP Mix (10 mM) | 1 µL | Building blocks for cDNA |
| RNase-free Water | to 13 µL | Solvent |
| Incubate at 65°C for 5 min, then chill on ice | ||
| 5X Reaction Buffer | 4 µL | Provides optimal enzyme conditions |
| RNase Inhibitor | 1 µL | Protects RNA from degradation |
| Reverse Transcriptase | 1 µL | Synthesizes cDNA from RNA template |
| Incubate at 50°C for 60 min, then 70°C for 10 min |
Table 2. Example cDNA Synthesis Reaction Setup.
Part 3: Quantitative PCR (qPCR)
This protocol uses SYBR Green-based detection, which is cost-effective and easy to set up.
Primer Design: Proper primer design is critical for specificity and efficiency.
-
Target: [Target Protein]
-
Reference Gene: A stably expressed housekeeping gene (e.g., GAPDH, ACTB, B2M).
-
Design Criteria:
-
Amplicon length: 70-150 bp.
-
Primer length: 18-24 nucleotides.
-
GC content: 40-60%.
-
Melting Temperature (Tm): 60-65°C.
-
Avoid secondary structures and primer-dimers.
-
Primers should span an exon-exon junction to prevent amplification of contaminating gDNA.
-
| Primer Name | Sequence (5' to 3') |
| [Target Protein] Forward | Sequence specific to your target |
| [Target Protein] Reverse | Sequence specific to your target |
| GAPDH Forward | GTCTCCTCTGACTTCAACAGCG |
| GAPDH Reverse | ACCACCCTGTTGCTGTAGCCAA |
Table 3. Example Primer Sequences (Human).
Protocol:
-
Prepare qPCR Master Mix: On ice, prepare a master mix for the number of reactions needed (including technical triplicates and no-template controls).[16]
-
Aliquot Master Mix: Dispense the master mix into qPCR plate wells.
-
Add cDNA Template: Add 1-2 µL of diluted cDNA (e.g., a 1:10 dilution of the RT reaction) to the appropriate wells.
-
Seal and Centrifuge: Seal the plate, mix gently, and centrifuge briefly to collect the contents at the bottom of the wells.
-
Run qPCR: Place the plate in a real-time PCR instrument and run the thermal cycling program.
| Component | Volume (per 20 µL reaction) | Final Concentration |
| 2X SYBR Green Master Mix | 10 µL | 1X |
| Forward Primer (10 µM) | 0.4 µL | 200 nM |
| Reverse Primer (10 µM) | 0.4 µL | 200 nM |
| Nuclease-Free Water | 7.2 µL | N/A |
| cDNA Template | 2 µL | e.g., 10 ng |
Table 4. qPCR Reaction Setup.
| Step | Temperature | Time | Cycles |
| Enzyme Activation | 95°C | 10 min | 1 |
| Denaturation | 95°C | 15 sec | \multirow{2}{*}{40} |
| Annealing/Extension | 60°C | 60 sec | |
| Melt Curve Analysis | 60°C to 95°C | (Instrument default) | 1 |
Table 5. Typical Thermal Cycling Conditions.
Part 4: Data Analysis (Relative Quantification)
The ΔΔCq method is used to calculate the fold change in gene expression.[9][17]
Figure 2. Logical flow of the ΔΔCq calculation for relative quantification.
Calculation Steps:
-
Normalization to Reference Gene (ΔCq): For each sample (both control and treated), calculate the difference between the Cq value of the [Target Protein] and the Cq value of the reference gene.[11]
-
ΔCq = Cq([Target Protein]) - Cq(Reference Gene)
-
-
Normalization to Calibrator (ΔΔCq): Calculate the difference between the ΔCq of the treated sample and the ΔCq of the control (calibrator) sample.[11][18]
-
ΔΔCq = ΔCq(Treated Sample) - ΔCq(Control Sample)
-
-
Calculate Fold Change: Determine the fold change in expression using the formula:[10][11]
-
Fold Change = 2^(-ΔΔCq)
-
Example Data and Calculation:
| Sample | Target | Avg. Cq | ΔCq | ΔΔCq | Fold Change (2-ΔΔCq) |
| \multirow{2}{}{Control } | [Target Protein] | 24.5 | \multirow{2}{}{4.0} | \multirow{2}{}{0.0} | \multirow{2}{}{1.0} |
| GAPDH | 20.5 | ||||
| \multirow{2}{}{Treated } | [Target Protein] | 22.0 | \multirow{2}{}{1.8} | \multirow{2}{}{-2.2} | \multirow{2}{}{4.6} |
| GAPDH | 20.2 |
Table 6. Example Data Analysis using the ΔΔCq Method. A fold change of 4.6 indicates that [Target Protein] mRNA is upregulated 4.6-fold in the treated sample compared to the control.
Troubleshooting
| Issue | Possible Cause(s) | Recommended Solution(s) |
| No amplification or high Cq values | Poor RNA quality/quantity; Inefficient RT; PCR inhibitors; Incorrect primer design. | Verify RNA integrity and purity. Optimize amount of template RNA. Use inhibitor-resistant polymerase. Validate primer efficiency. |
| Non-specific amplification (multiple melt peaks) | Primer-dimers; Non-specific primer binding; Genomic DNA contamination. | Optimize primer concentration and annealing temperature. Redesign primers. Perform DNase treatment on RNA samples. |
| High variability between technical replicates | Pipetting errors; Poor mixing; Bubbles in wells. | Use a master mix. Ensure proper mixing and centrifuge plate before running. Be careful during pipetting. |
| Amplification in No-Template Control (NTC) | Contamination of reagents, water, or pipettes with DNA/RNA. | Use aerosol-resistant filter tips. Aliquot reagents. Clean workspace and pipettes with 10% bleach. |
Table 7. Common qPCR Troubleshooting Guide.
References
- 1. RT-qPCR – Quantitative Reverse Transcription PCR [sigmaaldrich.com]
- 2. Quantification of mRNA using real-time RT-PCR - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. gene-quantification.de [gene-quantification.de]
- 4. bio-rad.com [bio-rad.com]
- 5. The MIQE guidelines: minimum information for publication of quantitative real-time PCR experiments - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. gene-quantification.de [gene-quantification.de]
- 7. Brief guide to RT-qPCR - PMC [pmc.ncbi.nlm.nih.gov]
- 8. neb.com [neb.com]
- 9. Analysis of relative gene expression data using real-time quantitative PCR and the 2(-Delta Delta C(T)) Method - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. genomique.iric.ca [genomique.iric.ca]
- 11. The Delta-Delta Ct Method — Inclass Activities 170218 documentation [2017-spring-bioinfo.readthedocs.io]
- 12. researchgate.net [researchgate.net]
- 13. mcgill.ca [mcgill.ca]
- 14. RNA extraction and quantitative PCR to assay inflammatory gene expression [protocols.io]
- 15. documents.thermofisher.com [documents.thermofisher.com]
- 16. bu.edu [bu.edu]
- 17. bitesizebio.com [bitesizebio.com]
- 18. horizondiscovery.com [horizondiscovery.com]
Developing a Cell-Based Assay for [Target Protein] Inhibitors: Application Notes and Protocols
For Researchers, Scientists, and Drug Development Professionals
Introduction
Cell-based assays are indispensable tools in drug discovery for evaluating the efficacy and potency of small molecule inhibitors in a physiologically relevant context.[1][2][3][4] Unlike biochemical assays that utilize purified proteins, cell-based assays provide a more comprehensive understanding of an inhibitor's activity by accounting for factors such as cell permeability, target engagement in the cellular environment, and potential off-target effects.[1][4][5] This document provides detailed protocols and application notes for developing a robust cell-based assay to screen for and characterize inhibitors of [Target Protein].
The selection of an appropriate cell-based assay format is critical and depends on the nature of the target protein and its signaling pathway.[6] Common approaches include directly measuring the activity of the target protein, quantifying the level of a downstream signaling molecule, monitoring cell viability or proliferation, or utilizing reporter gene systems.[7][8][9][10] This guide will cover several widely applicable methods.
Signaling Pathway of [Target Protein] Inhibition
A thorough understanding of the signaling pathway involving [Target Protein] is crucial for designing an effective cell-based assay. Inhibition of [Target Protein] is expected to modulate downstream signaling events, which can be used as a measurable readout of inhibitor activity.
References
- 1. Cell-based Kinase Assays - Profacgen [profacgen.com]
- 2. contractlaboratory.com [contractlaboratory.com]
- 3. Cell-Based Assays [sigmaaldrich.com]
- 4. Cell Based Assays & Cell Based Screening Assays in Modern Research [vipergen.com]
- 5. benchchem.com [benchchem.com]
- 6. bioivt.com [bioivt.com]
- 7. Immuno-oncology Cell-based Kinase Assay Service - Creative Biolabs [creative-biolabs.com]
- 8. Reporter gene - Wikipedia [en.wikipedia.org]
- 9. Cell Proliferation Inhibition Assay - Creative Diagnostics [qbd.creative-diagnostics.com]
- 10. Cell Based Assays in Drug Development: Comprehensive Overview [immunologixlabs.com]
Application Notes and Protocols: Techniques for Purifying Endogenous Target Protein
Introduction
The purification of endogenous proteins from their natural cellular environment is a critical process for understanding their function, structure, and interactions. Unlike recombinant protein expression, which can often be scaled and optimized, the purification of endogenous proteins presents unique challenges due to their relatively low abundance. This document provides an overview of common techniques and detailed protocols for the successful isolation of a target protein in its native state.
1. General Workflow for Endogenous Protein Purification
The purification strategy for an endogenous protein typically involves a multi-step process to separate the target protein from a complex mixture of cellular components. A typical workflow is outlined below.
Caption: General workflow for endogenous protein purification.
2. Key Purification Techniques
A combination of chromatographic techniques is often employed to achieve high purity. The choice of techniques depends on the biochemical properties of the target protein.
| Technique | Principle of Separation | Typical Use Case |
| Affinity Chromatography (AC) | Specific binding to an immobilized ligand (e.g., antibody) | First step, highly specific capture |
| Ion Exchange Chromatography (IEX) | Separation based on net surface charge | Intermediate step, good resolving power |
| Size Exclusion Chromatography (SEC) | Separation based on hydrodynamic radius (size and shape) | Polishing step, buffer exchange |
| Hydrophobic Interaction Chromatography (HIC) | Separation based on surface hydrophobicity | Intermediate or polishing step |
3. Experimental Protocols
3.1. Protocol 1: Immunoprecipitation (Affinity Chromatography)
This protocol describes the purification of a target protein using an antibody covalently coupled to a solid support (e.g., agarose beads).
Materials:
-
Cells or tissue expressing the target protein
-
Lysis Buffer (e.g., RIPA buffer: 50 mM Tris-HCl pH 7.4, 150 mM NaCl, 1% NP-40, 0.5% sodium deoxycholate, 0.1% SDS, supplemented with protease inhibitors)
-
Antibody specific to the target protein
-
Protein A/G agarose beads
-
Wash Buffer (e.g., 50 mM Tris-HCl pH 7.4, 150 mM NaCl, 0.1% NP-40)
-
Elution Buffer (e.g., 0.1 M Glycine-HCl, pH 2.5)
-
Neutralization Buffer (e.g., 1 M Tris-HCl, pH 8.5)
Procedure:
-
Cell Lysis:
-
Harvest cells and wash with ice-cold PBS.
-
Resuspend the cell pellet in ice-cold Lysis Buffer and incubate on ice for 30 minutes with occasional vortexing.
-
Centrifuge the lysate at 14,000 x g for 15 minutes at 4°C to pellet cellular debris.
-
Collect the supernatant (crude lysate).
-
-
Immunoprecipitation:
-
Pre-clear the lysate by incubating with Protein A/G agarose beads for 1 hour at 4°C on a rotator.
-
Centrifuge and collect the pre-cleared supernatant.
-
Add the specific antibody to the pre-cleared lysate and incubate for 2-4 hours or overnight at 4°C on a rotator.
-
Add Protein A/G agarose beads and incubate for another 1-2 hours at 4°C.
-
-
Washing:
-
Pellet the beads by centrifugation and discard the supernatant.
-
Wash the beads 3-5 times with ice-cold Wash Buffer.
-
-
Elution:
-
Resuspend the beads in Elution Buffer and incubate for 5-10 minutes at room temperature.
-
Centrifuge and collect the supernatant containing the purified protein.
-
Immediately neutralize the eluate by adding Neutralization Buffer.
-
Caption: Workflow for immunoprecipitation.
3.2. Protocol 2: Ion Exchange Chromatography (IEX)
This protocol is a subsequent step after an initial capture method like immunoprecipitation or can be used on its own if the protein's isoelectric point (pI) is known.
Materials:
-
Partially purified protein sample from the previous step.
-
IEX Column (Anion or Cation exchange, depending on the protein's pI and buffer pH).
-
Binding Buffer (Low salt concentration, e.g., 20 mM Tris-HCl, pH 8.0).
-
Elution Buffer (High salt concentration, e.g., 20 mM Tris-HCl, 1 M NaCl, pH 8.0).
-
Chromatography system (e.g., FPLC).
Procedure:
-
Sample Preparation:
-
Ensure the protein sample is in the Binding Buffer. This may require buffer exchange via dialysis or a desalting column.
-
-
Column Equilibration:
-
Equilibrate the IEX column with 5-10 column volumes (CVs) of Binding Buffer.
-
-
Sample Loading:
-
Load the prepared sample onto the equilibrated column.
-
-
Washing:
-
Wash the column with Binding Buffer until the UV absorbance at 280 nm returns to baseline.
-
-
Elution:
-
Elute the bound proteins using a linear gradient of the Elution Buffer (e.g., 0-100% over 20 CVs).
-
Collect fractions throughout the elution process.
-
-
Analysis:
-
Analyze the collected fractions by SDS-PAGE and/or Western blotting to identify the fractions containing the target protein.
-
4. Purity and Yield Assessment
The success of a purification strategy is determined by the final purity and yield of the target protein.
| Parameter | Method of Measurement | Desired Outcome |
| Purity | SDS-PAGE with Coomassie or silver staining, Mass Spectrometry | A single band at the expected molecular weight |
| Yield | Bradford or BCA protein assay, ELISA | Maximized recovery of active protein |
| Activity | Functional assays specific to the protein (e.g., enzyme kinetics, binding assays) | High specific activity |
5. Signaling Pathway Example: MAPK/ERK Pathway
Understanding the signaling pathway of the target protein can be crucial for designing functional assays. Below is a simplified representation of the MAPK/ERK pathway.
Caption: Simplified MAPK/ERK signaling pathway.
Disclaimer: These protocols provide a general framework. Optimization of buffer conditions, antibody concentrations, and chromatography parameters will be necessary for each specific target protein.
step-by-step guide to Western blotting for [Target Protein]
For Researchers, Scientists, and Drug Development Professionals
This application note provides a detailed protocol for the detection and quantification of Beta-Actin using Western blotting. Beta-Actin is a ubiquitously expressed cytoskeletal protein and is a commonly used loading control in Western blotting experiments to normalize for protein loading across lanes.[1]
I. Experimental Protocols
A. Sample Preparation and Protein Quantification
Proper sample preparation is crucial for a successful Western blot.[2] The goal is to efficiently lyse cells or tissues to solubilize proteins while preventing their degradation.[3]
-
Cell Lysis:
-
For adherent cells, wash the culture dish with ice-cold PBS.[2]
-
Add ice-cold lysis buffer (e.g., RIPA buffer) supplemented with protease and phosphatase inhibitors.[3][4] A common volume is 1 ml per 107 cells.[2]
-
Scrape the cells and transfer the suspension to a pre-cooled microcentrifuge tube.[2]
-
For suspension cells, centrifuge to pellet the cells, wash with ice-cold PBS, and then resuspend in lysis buffer.
-
Incubate the lysate on ice for 30 minutes with occasional vortexing.[2]
-
Centrifuge the lysate at approximately 16,000 x g for 20 minutes at 4°C to pellet cellular debris.[2]
-
Carefully transfer the supernatant containing the soluble proteins to a new pre-cooled tube.[2][4]
-
-
Tissue Homogenization:
-
Protein Quantification:
-
Sample Denaturation:
-
Mix the desired amount of protein lysate with an equal volume of 2x Laemmli sample buffer.
-
Boil the samples at 100°C for 5 minutes to denature the proteins.
-
The denatured samples can be used immediately or stored at -20°C.
-
B. Gel Electrophoresis (SDS-PAGE)
Sodium dodecyl sulfate-polyacrylamide gel electrophoresis (SDS-PAGE) separates proteins based on their molecular weight.
-
Gel Selection: The percentage of acrylamide in the gel determines the resolution of proteins of different sizes.[6] For Beta-Actin, which has a molecular weight of approximately 42 kDa, a 10% or 12.5% polyacrylamide gel is suitable.
-
Loading the Gel: Load 10-40 µg of total protein per lane.[7] Also, load a molecular weight marker to track the separation of proteins.
-
Running the Gel: Assemble the gel in the electrophoresis apparatus and fill the inner and outer chambers with running buffer.
-
Run the gel at a constant voltage (e.g., 100 V) for 1-2 hours, or until the dye front reaches the bottom of the gel.[8]
C. Protein Transfer
The separated proteins are transferred from the gel to a solid membrane, such as polyvinylidene difluoride (PVDF) or nitrocellulose.
-
Membrane Preparation: If using a PVDF membrane, activate it by briefly immersing it in methanol, followed by rinsing with deionized water and then soaking in transfer buffer. Nitrocellulose membranes do not require methanol activation.
-
Assembling the Transfer Stack: Create a "sandwich" in the following order: sponge, filter paper, gel, membrane, filter paper, and sponge.[3] Ensure there are no air bubbles between the gel and the membrane.
-
Transfer Methods:
-
Wet Transfer: The transfer stack is submerged in a tank filled with transfer buffer. This method is generally more efficient, especially for larger proteins, and is often performed overnight at a low voltage or for a shorter duration at a higher voltage.[9][10]
-
Semi-Dry Transfer: The transfer stack is placed between two plate electrodes. This method is faster but may be less efficient for very large proteins.[9][10]
-
-
Transfer Verification: After the transfer, you can stain the membrane with Ponceau S to visualize the protein bands and confirm a successful transfer.[7] The gel can also be stained with Coomassie Blue to check for any remaining protein.[11]
D. Immunodetection
This stage involves using specific antibodies to detect the target protein.[12]
-
Blocking: To prevent non-specific binding of antibodies to the membrane, it's crucial to block the membrane.[10] Incubate the membrane in a blocking buffer, commonly 5% non-fat dry milk or bovine serum albumin (BSA) in Tris-buffered saline with Tween 20 (TBST), for at least 1 hour at room temperature with gentle agitation.[7]
-
Primary Antibody Incubation: Dilute the primary antibody against Beta-Actin in the blocking buffer.[7] The optimal dilution should be determined empirically, but a common starting point is a 1:1000 to 1:10,000 dilution.[13] Incubate the membrane with the primary antibody solution for 1 hour at room temperature or overnight at 4°C with gentle rocking.[7]
-
Washing: After incubation, wash the membrane three times for 10 minutes each with TBST to remove any unbound primary antibody.[7]
-
Secondary Antibody Incubation: Incubate the membrane with a horseradish peroxidase (HRP)-conjugated secondary antibody that is specific for the host species of the primary antibody.[7] The secondary antibody should be diluted in blocking buffer according to the manufacturer's instructions. This incubation is typically for 1 hour at room temperature.[7]
-
Final Washes: Repeat the washing step (three times for 10 minutes each with TBST) to remove any unbound secondary antibody.[7]
E. Signal Detection and Data Analysis
-
Detection: Prepare the chemiluminescent substrate according to the manufacturer's instructions and incubate the membrane in the substrate solution.[7]
-
Imaging: Capture the chemiluminescent signal using a digital imaging system.[6]
-
Data Analysis: Use image analysis software to quantify the band intensities.[14] Normalize the intensity of the Beta-Actin band to the total protein loaded in each lane for accurate quantification.[15]
II. Data Presentation
| Parameter | Recommended Value | Reference |
| Sample Loading | 10-40 µg total protein per lane | [7] |
| Gel Percentage | 10% or 12.5% Acrylamide | |
| Primary Antibody Dilution | 1:1,000 - 1:15,000 | [13] |
| Secondary Antibody Dilution | As per manufacturer's instructions | |
| Blocking Buffer | 5% Non-fat milk or BSA in TBST | [7] |
| Incubation Times | Primary: 1 hr at RT or overnight at 4°C; Secondary: 1 hr at RT | [7] |
| Expected Band Size | ~42 kDa |
III. Mandatory Visualization
References
- 1. news-medical.net [news-medical.net]
- 2. creative-diagnostics.com [creative-diagnostics.com]
- 3. products.advansta.com [products.advansta.com]
- 4. Western Blot Sample Preparation Protocol | Thermo Fisher Scientific - HK [thermofisher.com]
- 5. bio-rad.com [bio-rad.com]
- 6. azurebiosystems.com [azurebiosystems.com]
- 7. resources.novusbio.com [resources.novusbio.com]
- 8. bio-rad.com [bio-rad.com]
- 9. bosterbio.com [bosterbio.com]
- 10. Optimizing Protein Transfer and Detection in Western Blotting [labx.com]
- 11. bitesizebio.com [bitesizebio.com]
- 12. bio-rad.com [bio-rad.com]
- 13. biocompare.com [biocompare.com]
- 14. m.youtube.com [m.youtube.com]
- 15. The Design of a Quantitative Western Blot Experiment - PMC [pmc.ncbi.nlm.nih.gov]
Application Note: Identification of Post-Translational Modifications of [Target Protein] using Mass Spectrometry
Audience: Researchers, scientists, and drug development professionals.
Introduction
Post-translational modifications (PTMs) are crucial covalent processing events that occur after protein synthesis and dramatically increase the functional diversity of the proteome.[1][2] These modifications, which include phosphorylation, ubiquitination, glycosylation, and acetylation, are key regulators of protein function, localization, and stability.[2][3] Consequently, the accurate identification and quantification of PTMs on a specific protein of interest, such as [Target Protein], are essential for understanding its role in complex biological processes and disease states.[2][4] Mass spectrometry (MS) has become an indispensable tool for the comprehensive analysis of PTMs due to its high sensitivity, speed, and accuracy.[2][5]
This application note provides a detailed workflow and protocols for the identification and characterization of PTMs on [Target Protein] using a bottom-up proteomics approach. The workflow encompasses the isolation of [Target Protein], enzymatic digestion, enrichment of modified peptides, and subsequent analysis by liquid chromatography-tandem mass spectrometry (LC-MS/MS).
Biological Context: [Target Protein] Signaling Pathway
To illustrate the biological relevance of PTM analysis, consider a hypothetical signaling pathway where [Target Protein] is a key downstream effector of an upstream kinase. In this pathway, the activation of a cell surface receptor by an external stimulus leads to the activation of an upstream kinase. This kinase, in turn, phosphorylates [Target Protein] at specific serine, threonine, or tyrosine residues. This phosphorylation event may then trigger a conformational change in [Target Protein], leading to the recruitment of downstream signaling partners and ultimately culminating in a specific cellular response, such as gene expression changes or cell proliferation. The diagram below visualizes this hypothetical signaling cascade.
Experimental Workflow and Protocols
The overall experimental workflow for identifying PTMs on [Target Protein] is depicted below. This process begins with the isolation of the target protein, followed by a series of biochemical and analytical steps to prepare the sample for mass spectrometry analysis.
Detailed Experimental Protocols
Part A: Immunoprecipitation of [Target Protein]
-
Cell Lysis: Lyse cells expressing [Target Protein] in a suitable lysis buffer (e.g., RIPA buffer) containing protease and phosphatase inhibitors.
-
Antibody Incubation: Incubate the cell lysate with an antibody specific to [Target Protein] for 2-4 hours at 4°C with gentle rotation.
-
Bead Incubation: Add Protein A/G magnetic beads to the lysate-antibody mixture and incubate for an additional 1-2 hours at 4°C.
-
Washing: Pellet the magnetic beads and wash them three times with a cold wash buffer to remove non-specifically bound proteins.
-
Elution: Elute the immunoprecipitated [Target Protein] from the beads using a low-pH elution buffer or by boiling in SDS-PAGE loading buffer.
Part B: In-Gel Tryptic Digestion
This protocol is adapted for proteins separated by SDS-PAGE.
-
SDS-PAGE: Run the eluted protein sample on a polyacrylamide gel. Stain the gel with a mass spectrometry-compatible stain (e.g., Coomassie Blue).
-
Excision: Carefully excise the protein band corresponding to the molecular weight of [Target Protein].
-
Destaining: Destain the gel piece with a solution of 50% acetonitrile (ACN) in 50 mM ammonium bicarbonate.
-
Reduction and Alkylation:
-
Digestion:
-
Peptide Extraction: Extract the peptides from the gel piece using a series of ACN and formic acid washes. Pool the extracts and dry them in a vacuum centrifuge.
Part C: Phosphopeptide Enrichment using Titanium Dioxide (TiO2)
Due to the low stoichiometry of many PTMs, an enrichment step is often necessary.[8] This protocol focuses on the enrichment of phosphopeptides.
-
Sample Loading: Reconstitute the dried peptide mixture in a loading buffer (e.g., 80% ACN, 5% trifluoroacetic acid (TFA), and 1 M glycolic acid).[9]
-
TiO2 Column Equilibration: Equilibrate a TiO2 spin column according to the manufacturer's instructions.
-
Binding: Load the reconstituted peptide sample onto the TiO2 column. Centrifuge to allow the peptides to bind to the TiO2 resin.[8]
-
Washing:
-
Elution: Elute the bound phosphopeptides using a high-pH elution buffer, such as a 1-5% ammonia solution.[8][10]
-
Cleanup: Dry the eluted phosphopeptides and desalt using a C18 StageTip or equivalent before MS analysis.
Part D: LC-MS/MS Analysis
-
Sample Injection: Reconstitute the final peptide sample in a buffer suitable for mass spectrometry (e.g., 0.1% formic acid in water).
-
Chromatography: Inject the sample onto a reverse-phase nano-liquid chromatography (nanoLC) system coupled to the mass spectrometer. Separate peptides using a gradient of increasing organic solvent (e.g., ACN with 0.1% formic acid).
-
Mass Spectrometry:
-
Operate the mass spectrometer in a data-dependent acquisition (DDA) mode.
-
Acquire a full MS scan to detect peptide precursor ions.
-
Select the most intense precursor ions for fragmentation (MS/MS) using collision-induced dissociation (CID) or higher-energy collisional dissociation (HCD).
-
Data Analysis and Presentation
Data Analysis Pipeline
-
Database Searching: Use a search algorithm (e.g., Mascot, SEQUEST, MaxQuant) to match the acquired MS/MS spectra against a protein database containing the sequence of [Target Protein].[5][11]
-
PTM Identification: Specify potential variable modifications in the search parameters, such as phosphorylation (on S, T, Y), ubiquitination (on K), and acetylation (on K). The search software will identify peptides with mass shifts corresponding to these modifications.[12]
-
Localization and Scoring: The software will provide a probability score for the localization of the PTM on a specific amino acid residue within the peptide sequence.
-
Quantification: For quantitative analysis, label-free quantification (LFQ) or isobaric labeling (e.g., TMT) can be employed to compare the abundance of specific PTMs across different experimental conditions.
Quantitative Data Summary
The following table presents a hypothetical quantitative analysis of two identified phosphosites on [Target Protein] in response to a kinase inhibitor treatment. Data is presented as the relative abundance of the phosphopeptide compared to a control condition.
| Phosphosite | Control (Relative Abundance) | Kinase Inhibitor Treated (Relative Abundance) | Fold Change |
| Serine 75 | 1.00 | 0.25 | -4.0 |
| Threonine 182 | 1.00 | 0.95 | -1.05 |
This table clearly indicates that phosphorylation at Serine 75 is significantly reduced upon treatment with the kinase inhibitor, suggesting it is a direct target of the upstream kinase in the signaling pathway.
Conclusion
The combination of targeted protein enrichment, enzymatic digestion, PTM peptide enrichment, and high-resolution LC-MS/MS provides a powerful and robust methodology for the detailed characterization of post-translational modifications on a specific protein of interest.[5] The protocols and workflow described in this application note offer a comprehensive guide for researchers aiming to elucidate the complex regulatory mechanisms governed by PTMs on [Target Protein], thereby advancing our understanding of its biological function and its role in drug development.
References
- 1. Quantification and Identification of Post-Translational Modifications Using Modern Proteomics Approaches - PMC [pmc.ncbi.nlm.nih.gov]
- 2. researchgate.net [researchgate.net]
- 3. resolvemass.ca [resolvemass.ca]
- 4. tandfonline.com [tandfonline.com]
- 5. publications.aston.ac.uk [publications.aston.ac.uk]
- 6. mass-spec.siu.edu [mass-spec.siu.edu]
- 7. bsb.research.baylor.edu [bsb.research.baylor.edu]
- 8. Phosphopeptide enrichment using offline titanium dioxide columns for phosphoproteomics - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. mdpi.com [mdpi.com]
- 10. Phosphopeptide Enrichment with TiO2-Modified Membranes and Investigation of Tau Protein Phosphorylation - PMC [pmc.ncbi.nlm.nih.gov]
- 11. List of mass spectrometry software - Wikipedia [en.wikipedia.org]
- 12. How to Detect Post-Translational Modifications (PTMs) Sites? - Creative Proteomics [creative-proteomics.com]
Troubleshooting & Optimization
how to reduce non-specific binding in [Target Protein] immunoprecipitation
This technical support center provides troubleshooting guidance and frequently asked questions (FAQs) to help researchers, scientists, and drug development professionals minimize non-specific binding during [Target Protein] immunoprecipitation (IP).
Frequently Asked Questions (FAQs) & Troubleshooting
Q1: What are the common sources of non-specific binding in immunoprecipitation?
Non-specific binding in IP can arise from several sources, leading to high background and impure samples. The primary culprits include:
-
Binding to the affinity beads: Proteins can non-specifically adhere to the agarose or magnetic beads themselves through charge or hydrophobic interactions.[1][2]
-
Binding to the antibody: Non-target proteins can bind directly to the immunoprecipitating antibody. Using too much antibody can exacerbate this issue.[3][4][5]
-
Cellular components: Abundant cellular proteins, such as cytoskeletal components (e.g., actin), as well as lipids, carbohydrates, and nucleic acids, can non-specifically interact with the beads or antibody.[1]
-
Sample handling: Protein unfolding during cell lysis can expose hydrophobic patches that lead to non-specific binding.[2] Additionally, plastic consumables can also be a source of contamination.[2]
Q2: How can I prevent non-specific binding to the immunoprecipitation beads?
Several strategies can be employed to reduce non-specific binding to the beads:
-
Pre-clearing the lysate: This is a crucial step where the cell lysate is incubated with beads that do not have the specific antibody bound.[2][4][6] This removes proteins that would non-specifically bind to the beads themselves.
-
Blocking the beads: Before adding the specific antibody, incubate the beads with a blocking agent to saturate non-specific binding sites.[4][6][7] Common blocking agents include Bovine Serum Albumin (BSA) or non-fat dry milk.[6][7] For RNA immunoprecipitation, yeast RNA can be used as a blocking agent.[8]
-
Choice of beads: Magnetic beads are often recommended as they tend to have lower non-specific binding compared to agarose beads.[1][6]
Detailed Protocol: Pre-clearing Lysate and Blocking Beads
-
Equilibrate Beads: Wash the required amount of protein A/G beads with lysis buffer.
-
Pre-clear Lysate: Add the equilibrated beads to the cell lysate. Incubate with gentle rotation for 30-60 minutes at 4°C.[2]
-
Separate Beads: Pellet the beads by centrifugation or using a magnetic rack and transfer the supernatant (the pre-cleared lysate) to a fresh tube.
-
Block Beads (for antibody incubation): To a fresh aliquot of equilibrated beads, add a blocking buffer (e.g., PBS with 1% BSA).[7] Incubate for 1 hour at 4°C with gentle rotation.
-
Wash Beads: Wash the blocked beads 3-4 times with PBS before adding the primary antibody.[7]
Q3: My negative control (Isotype IgG) shows significant background. How can I resolve this?
High background in an isotype control indicates non-specific binding of proteins to the immunoglobulin itself. Here are some troubleshooting steps:
-
Optimize Antibody Concentration: Using an excessive amount of the primary antibody is a common cause of non-specific binding.[3][4][5] Perform a titration experiment to determine the minimal amount of antibody required for efficient IP of your target protein.
-
Reduce Incubation Time: Shortening the incubation time of the antibody with the lysate can help minimize non-specific interactions.[1][2]
-
Use High-Quality Antibodies: Ensure you are using an antibody that is validated for immunoprecipitation and has high specificity for the target protein. Affinity-purified antibodies are recommended.[9][10]
Q4: How can I optimize my wash steps to reduce background?
The washing steps are critical for removing non-specifically bound proteins. The stringency of the wash buffer can be adjusted to improve purity.
-
Increase the Number and Duration of Washes: Performing more wash steps, and for a longer duration, can effectively reduce background.[2][11] After the final wash, transferring the beads to a fresh tube can help avoid carry-over contamination.[1][2]
-
Increase Wash Buffer Stringency: The composition of the wash buffer can be modified to disrupt weak, non-specific interactions. This can be achieved by:
Table 1: Recommended Wash Buffer Modifications for Increased Stringency
| Component | Concentration Range | Purpose |
| NaCl | 150 mM - 1 M | Disrupts ionic interactions[1][9] |
| Tween-20 | 0.01% - 1% | Non-ionic detergent to reduce non-specific hydrophobic interactions[1][11] |
| Triton X-100 | 0.01% - 0.1% | Non-ionic detergent for reducing background[10][11] |
| SDS | up to 0.2% | Anionic detergent for more stringent washing[1] |
Note: The optimal wash buffer composition should be determined empirically for your specific target protein and interacting partners, as harsh conditions may disrupt the desired protein-protein interactions in co-immunoprecipitation experiments.[2]
Experimental Workflow & Troubleshooting Logic
Diagram 1: Optimized Immunoprecipitation Workflow
Caption: Optimized immunoprecipitation workflow with key steps to reduce non-specific binding.
Diagram 2: Troubleshooting Non-Specific Binding
Caption: Decision tree for troubleshooting high background in immunoprecipitation experiments.
References
- 1. sinobiological.com [sinobiological.com]
- 2. How to obtain a low background in immunoprecipitation assays | Proteintech Group [ptglab.com]
- 3. hycultbiotech.com [hycultbiotech.com]
- 4. docs.abcam.com [docs.abcam.com]
- 5. Immunoprecipitation Protocol & Troubleshooting - Creative Biolabs [creativebiolabs.net]
- 6. Immunoprecipitation (IP): The Complete Guide | Antibodies.com [antibodies.com]
- 7. Dealing with high background in IP | Abcam [abcam.com]
- 8. researchgate.net [researchgate.net]
- 9. Optimization of immunoprecipitation–western blot analysis in detecting GW182-associated components of GW/P bodies - PMC [pmc.ncbi.nlm.nih.gov]
- 10. sinobiological.com [sinobiological.com]
- 11. Protein Immunoprecipitation (IP), Co-Immunoprecipitation (Co-IP), and Pulldown Support—Troubleshooting | Thermo Fisher Scientific - HK [thermofisher.com]
Technical Support Center: Optimizing Buffer Conditions for [Target Protein] Enzymatic Assay
This guide provides comprehensive support for researchers, scientists, and drug development professionals working to optimize the buffer conditions for [Target Protein] enzymatic assays. Here, you will find answers to frequently asked questions, a step-by-step troubleshooting guide, and detailed experimental protocols.
Frequently Asked Questions (FAQs)
Q1: Why is the reaction buffer so critical for my [Target Protein] assay?
The reaction buffer is crucial because it directly influences the activity and stability of your enzyme.[1][2] Every enzyme, including [Target Protein], has a narrow pH range where it exhibits maximum activity.[3][4] Deviating from this optimal pH can significantly reduce or eliminate enzyme function by altering the ionization state of critical amino acid residues in the active site and disrupting the enzyme's three-dimensional structure, which can lead to denaturation.[2][5]
Q2: What is the best starting point for selecting a buffer and pH?
If the optimal pH for [Target Protein] is known from existing literature, that is the best starting point.[1] Choose a buffer system whose pKa (the pH at which it has the greatest buffering capacity) is as close as possible to this optimal pH.[1] A buffer is generally effective within a range of ±1 pH unit from its pKa.[6] If the optimal pH is unknown, a good starting point for many enzymes is a neutral pH range (6.0-8.0), using a common buffer like Phosphate or HEPES.[7][8]
Q3: How does ionic strength affect my [Target Protein] assay?
Ionic strength, which is the total concentration of ions in the solution, can significantly impact enzyme activity.[3][4][9] It influences the electrostatic interactions between the enzyme and its substrate.[9] While some enzymes require a certain salt concentration for optimal activity, excessively high ionic strength can inhibit activity or cause the enzyme to precipitate.[9][10] Conversely, very low ionic strength may not be sufficient to maintain the enzyme's native conformation.[10] It is a critical parameter that must be optimized for each specific enzyme.[4]
Q4: Should I include additives like glycerol or metal ions in my buffer?
Additives can be beneficial for enhancing the stability and activity of [Target Protein].
-
Glycerol, Sorbitol, and Sugars: These polyols and sugars act as stabilizers, helping to maintain the enzyme's structure and prevent denaturation, which can improve its shelf-life and stability during the assay.[11][12]
-
Metal Ions: Some enzymes require specific metal ions (e.g., Mg²⁺, Zn²⁺, Ca²⁺) as cofactors for their catalytic activity.[12] However, it's crucial to use a buffer that does not chelate or bind to these necessary metals. For instance, phosphate buffers can precipitate certain metal ions, while citrate is a known metal chelator.[7][8]
-
Reducing Agents: If [Target Protein] contains cysteine residues that are prone to oxidation, including a reducing agent like DTT or β-mercaptoethanol can be essential to maintain its activity.
Data Presentation: Example Optimization Tables
For clarity, all quantitative results from your optimization experiments should be summarized in tables.
Table 1: Optimal pH Determination for [Target Protein]
| Buffer System (50 mM) | pH | Relative Activity (%) |
| Acetate | 4.5 | 15 |
| Acetate | 5.0 | 35 |
| MES | 5.5 | 60 |
| MES | 6.0 | 85 |
| PIPES | 6.5 | 100 |
| PIPES | 7.0 | 90 |
| HEPES | 7.5 | 75 |
| Tris | 8.0 | 50 |
| Tris | 8.5 | 25 |
Table 2: Effect of Ionic Strength on [Target Protein] Activity
| Buffer (50 mM PIPES, pH 6.5) | NaCl Concentration (mM) | Relative Activity (%) |
| 0 | 70 | |
| 25 | 85 | |
| 50 | 95 | |
| 100 | 100 | |
| 150 | 80 | |
| 200 | 60 | |
| 250 | 40 |
Troubleshooting Guide
This section addresses common problems encountered during assay optimization. For a logical workflow, refer to the troubleshooting diagram below.
Problem: I am seeing low or no enzyme activity.
-
Possible Cause 1: Suboptimal pH. The buffer's pH may be outside the optimal range for [Target Protein], leading to low activity or denaturation.[13]
-
Possible Cause 2: Incorrect Ionic Strength. The salt concentration may be too high or too low.
-
Solution: Test a range of salt concentrations (e.g., 0 mM to 250 mM NaCl or KCl) to find the optimal ionic strength for your enzyme's activity.
-
-
Possible Cause 3: Missing Cofactors or Additives. [Target Protein] might require specific metal ions or reducing agents to function correctly.
-
Solution: Review literature for your protein or similar proteins to identify required cofactors. Test the addition of relevant metal ions or reducing agents like DTT to your buffer.
-
-
Possible Cause 4: Buffer Interference. Components of your buffer might be directly inhibiting the enzyme. For example, phosphate can interfere with enzymes that use metal cofactors.[7]
-
Solution: Test alternative buffer systems with similar pKa values to see if activity improves.
-
Problem: My assay results show high variability and are not reproducible.
-
Possible Cause 1: Insufficient Buffering Capacity. If the buffer concentration is too low, it may not be able to resist pH shifts that occur during the enzymatic reaction, leading to inconsistent results.[1]
-
Solution: Increase the buffer concentration, typically within the 25-100 mM range, to enhance its buffering capacity.[1]
-
-
Possible Cause 2: Reagent Instability. The enzyme or substrate may be unstable in the chosen buffer, degrading over the course of the experiment.
-
Possible Cause 3: Inconsistent Pipetting or Temperature. Small variations in reagent volumes or temperature fluctuations can lead to variability.
Visualizations: Workflows and Logic Diagrams
Experimental Protocols
Protocol 1: Determining the Optimal pH for [Target Protein]
-
Buffer Selection: Choose a minimum of three buffer systems with overlapping pKa values to cover a broad pH range (e.g., Acetate for pH 4-5.5, MES for pH 5.5-6.5, HEPES for pH 7-8, Tris for pH 8-9).
-
Buffer Preparation: Prepare each buffer at a consistent concentration (e.g., 50 mM). For each buffer system, prepare solutions at 0.5 pH unit increments across its effective range.
-
Assay Setup: In a 96-well plate, set up reactions for each pH point. Each well should contain the buffer, a consistent concentration of [Target Protein] substrate, and any known essential cofactors.[1]
-
Reaction Initiation: Initiate the reaction by adding a fixed amount of [Target Protein] to each well. Include a "no-enzyme" control for each buffer and pH to correct for any non-enzymatic substrate degradation.[1]
-
Data Collection: Measure the reaction rate using a plate reader at the appropriate wavelength and a constant temperature.
-
Analysis: Subtract the rate of the no-enzyme control from the experimental rate for each point. Plot the initial reaction velocity against pH to identify the pH at which the highest activity occurs.[1]
Protocol 2: Screening Different Buffer Systems
-
Buffer Selection: Based on the optimal pH identified in Protocol 1, select several different buffer compounds with pKa values close to this optimum (e.g., if the optimum is pH 7.2, test HEPES, PIPES, and Phosphate buffers).
-
Assay Setup: Prepare and perform the enzymatic assay as described in Protocol 1, but this time keeping the pH constant and varying the buffer identity.
-
Analysis: Compare the enzyme activity across the different buffer systems. Select the buffer that provides the highest activity and stability, as some buffer ions can have specific interactions with the enzyme.
Protocol 3: Optimizing Ionic Strength
-
Buffer Preparation: Prepare a stock of the optimal buffer at the optimal pH, determined from the previous experiments. Create a series of these buffers containing increasing concentrations of a neutral salt, such as NaCl or KCl (e.g., 0 mM, 25 mM, 50 mM, 100 mM, 150 mM, 200 mM, 250 mM).
-
Assay Setup: Perform the standard assay for [Target Protein] using each of the buffers with varying salt concentrations.
-
Analysis: Plot the enzyme activity against the salt concentration. The optimal ionic strength is the salt concentration that results in the highest enzymatic activity.
References
- 1. benchchem.com [benchchem.com]
- 2. worldnutrition.net [worldnutrition.net]
- 3. How to Choose the Right Buffer for Enzyme Activity Tests [synapse.patsnap.com]
- 4. Effects of pH | Worthington Biochemical [worthington-biochem.com]
- 5. Effect of pH on Enzymatic Reaction - Creative Enzymes [creative-enzymes.com]
- 6. researchgate.net [researchgate.net]
- 7. superchemistryclasses.com [superchemistryclasses.com]
- 8. goldbio.com [goldbio.com]
- 9. fiveable.me [fiveable.me]
- 10. researchgate.net [researchgate.net]
- 11. researchgate.net [researchgate.net]
- 12. Enzyme Stabilizers And Additives For Enhanced Longevity [eureka.patsnap.com]
- 13. monash.edu [monash.edu]
- 14. youtube.com [youtube.com]
- 15. Basics of Enzymatic Assays for HTS - Assay Guidance Manual - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 16. docs.abcam.com [docs.abcam.com]
Technical Support Center: Tau Protein Antibody Specificity
Welcome to the technical support center for Tau protein antibodies. This resource provides troubleshooting guides and answers to frequently asked questions regarding antibody specificity for the microtubule-associated protein Tau. Given the complexity of Tau biology, including multiple isoforms and extensive post-translational modifications (PTMs), achieving high specificity in immunoassays is a common challenge.
Frequently Asked Questions (FAQs) & Troubleshooting
Western Blotting Issues
Q1: Why am I seeing multiple bands or a smear in my Western blot for Tau?
A: This is a common observation when studying Tau protein and can be attributed to several factors:
-
Tau Isoforms: In the adult human brain, six different Tau isoforms are expressed from a single gene (MAPT) through alternative splicing. These isoforms range in size from approximately 37 to 46 kDa, but migrate on an SDS-PAGE gel between 45 and 65 kDa. The presence of multiple isoforms will naturally result in multiple bands.
-
Post-Translational Modifications (PTMs): Tau is heavily phosphorylated, and this is a key mechanism regulating its function. Hyperphosphorylation is a hallmark of tauopathies like Alzheimer's disease.[1][2] Phosphorylation adds negative charge and can alter the protein's conformation, causing it to migrate slower on the gel. This results in a "smear" or a series of shifted bands corresponding to different phosphorylation states. To confirm this, you can treat your samples with a phosphatase before running the gel, which should cause the smear to collapse into distinct bands representing the different isoforms.[3]
-
Protein Aggregation: In pathological conditions, Tau can form oligomers and larger aggregates which may not enter the gel or may appear as high-molecular-weight bands.[1]
-
Non-Specific Antibody Binding: The antibody may be cross-reacting with other proteins. It's crucial to use appropriate controls, such as lysates from Tau knockout (TKO) cells or tissues, to confirm the specificity of the bands.[4][5]
Q2: My primary antibody is a mouse monoclonal, and I'm seeing a strong non-specific band at ~50 kDa when probing mouse brain lysates. What's causing this?
A: This is a well-documented artifact that occurs when using mouse primary antibodies on mouse tissue samples.[2][4][5] The secondary antibody (e.g., anti-mouse IgG) cannot distinguish between the primary antibody and the endogenous immunoglobulins (Igs) present in the tissue lysate. The heavy chain of these endogenous Igs has a molecular weight of about 50 kDa, which is in the same range as Tau, leading to a strong non-specific signal.[2]
Solutions:
-
Use a secondary antibody that specifically recognizes the light chain of immunoglobulins.[2][4]
-
Employ secondary antibodies designed to bind only to non-denatured, native Igs (e.g., TrueBlot technology), which will not bind to the denatured Ig heavy chain on the blot.[4][6]
-
Perform a pre-clearing step to remove endogenous Igs from your brain homogenates before running the gel.[4][7]
Q3: I'm not getting a signal for total Tau after stripping my membrane and re-probing. What went wrong?
A: While it's possible the antibody failed, a common issue is the stripping procedure itself.[8] Harsh stripping buffers can remove not only the primary and secondary antibodies but also the protein transferred to the membrane. Before concluding that your total Tau antibody is not working, it's advisable to:
-
Test the total Tau antibody on a fresh blot without any prior stripping to ensure it is functional under your experimental conditions.[8]
-
After stripping, use a reversible protein stain like Ponceau S to confirm that protein is still present on the membrane before proceeding with re-blocking and probing.[8]
Phospho-Specific Antibody Issues
Q4: How can I be sure my antibody is specific for a phosphorylated Tau epitope and not just recognizing total Tau?
A: Validating the specificity of a phospho-specific antibody is critical.[9] Here are key validation steps:
-
Peptide Competition Assay: Pre-incubate the antibody with a molar excess of the phosphorylated peptide epitope. This should block the antibody from binding to its target on the blot, resulting in a loss of signal. As a negative control, pre-incubating with the corresponding non-phosphorylated peptide should not affect the signal.
-
Phosphatase Treatment: Treat your protein lysate with a broad-spectrum phosphatase (e.g., lambda phosphatase) before Western blotting. This will remove the phosphate groups, and a truly phospho-specific antibody should show a significantly reduced or completely absent signal.
-
Use of Controls: Include positive controls where the specific phosphorylation event is known to be present (e.g., brain lysates from a mouse model of tauopathy) and negative controls where it is absent.[4][5] Some studies have developed robust cell-based assays to quantify the specificity of phospho-tau antibodies.[10]
Q5: Some "total Tau" antibodies seem to have reduced binding when Tau is hyperphosphorylated. Is this possible?
A: Yes, this can occur. Even if an antibody's epitope is not a phosphorylation site itself, extensive phosphorylation in nearby regions can alter the local conformation of the protein.[11] This conformational change can mask the epitope, preventing the "total Tau" antibody from binding efficiently. This highlights the importance of characterizing antibody performance using various positive controls, including recombinant Tau and lysates from different disease models.[11][12]
Immunofluorescence (IF) / Immunohistochemistry (IHC) Issues
Q6: I'm getting high background or non-specific staining in my immunofluorescence experiment. How can I improve this?
A: High background in IF/IHC can obscure the true signal. Here are several troubleshooting steps:
-
Optimize Blocking: Increase the blocking time (e.g., to 3 hours or overnight) and consider using a different blocking agent. A common choice is 5-10% normal serum from the same species as the secondary antibody.[13][14]
-
Antibody Dilution: The primary or secondary antibody concentration may be too high. Perform a titration experiment to find the optimal dilution that provides the best signal-to-noise ratio.[14][15]
-
Washing Steps: Increase the number and duration of washing steps between antibody incubations to remove unbound antibodies more effectively. Using a buffer with a mild detergent like Tween-20 (e.g., TBS-T) can help.[14][16]
-
Antigen Retrieval: For formalin-fixed paraffin-embedded (FFPE) tissues, the fixation process can mask epitopes. Ensure your heat-mediated or enzymatic antigen retrieval protocol is optimized for your specific antibody and tissue.[13]
-
Secondary Antibody Control: Always run a control where you omit the primary antibody. If you still see staining, it indicates that your secondary antibody is binding non-specifically.[15]
Data & Antibody Performance
The performance of commercially available Tau antibodies can be highly variable. Researchers have categorized antibodies based on their specificity and potential for producing artifactual signals.
Table 1: Classification of Select Monoclonal Tau Antibodies Based on Non-Specificity in Mouse Brain Western Blots
| Category | Non-Specificity Level | Antibody Clones | Primary Cause of Non-Specificity |
| Type 1 | High | AT8, AT180, MC1, MC6, TG-3 | Recognition of endogenous mouse immunoglobulins by the secondary antibody.[4][7][17] |
| Type 2 | Low | AT270, CP13, CP27, Tau12, TG5 | Minor cross-reactivity or low-level recognition of endogenous Igs.[4][7][17] |
| Type 3 | None Detected | DA9, PHF-1, Tau1, Tau46 | High specificity for Tau protein with no detectable off-target signal.[4][7][17] |
Note: This classification is based on specific experimental conditions and may vary. Independent validation is always recommended.
Table 2: Specificity of Commonly Used Phospho-Tau Antibodies
| Antibody | Phospho-Epitope(s) | Specificity Assessment | Reference |
| AT8 | pSer202 / pThr205 | High specificity, no detectable non-specific binding in a cell-based assay. | [10] |
| AT180 | pThr231 | High specificity, no detectable non-specific binding in a cell-based assay. | [10] |
| PHF-1 | pSer396 / pSer404 | High specificity, no detectable non-specific binding in a cell-based assay. | [10] |
| AT270 | pThr181 | Showed ~20% non-specific binding signal in a cell-based assay. | [10] |
Experimental Protocols & Validation Workflows
A rigorous antibody validation workflow is essential for reproducible research.
Diagrams of Key Processes
Caption: A logical workflow for the comprehensive validation of a new Tau antibody.
Caption: Troubleshooting logic for non-specific bands in a Tau Western blot.
Protocol: Phosphatase Treatment of Brain Lysate for WB
-
Prepare Lysate: Homogenize brain tissue in RIPA buffer (or similar lysis buffer) containing protease inhibitors but without phosphatase inhibitors. Determine the protein concentration using a BCA or Bradford assay.
-
Set up Reaction: In a microcentrifuge tube, combine:
-
30 µg of protein lysate
-
1X PMP buffer (provided with the phosphatase)
-
1 µl (e.g., 400 units) of Lambda Protein Phosphatase
-
Nuclease-free water to a final volume of 30 µl.
-
-
Control Reaction: Prepare a parallel control reaction without the lambda phosphatase enzyme, substituting it with water.
-
Incubation: Incubate both tubes at 30°C for 60 minutes.
-
Stop Reaction: Stop the reaction by adding 10 µl of 4X Laemmli sample buffer and boiling at 95-100°C for 5-10 minutes.
-
Western Blot: Load the treated sample and the control sample onto an SDS-PAGE gel and proceed with your standard Western blotting protocol to probe with your phospho-specific Tau antibody. A successful dephosphorylation will result in a loss of signal in the treated lane.
References
- 1. Western Blot of Tau Protein from Mouse Brains Extracts: How to Avoid Signal Artifacts | Springer Nature Experiments [experiments.springernature.com]
- 2. Western Blot of Tau Protein from Mouse Brains Extracts: How to Avoid Signal Artifacts - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. researchgate.net [researchgate.net]
- 4. Specificity of Anti-Tau Antibodies when Analyzing Mice Models of Alzheimer's Disease: Problems and Solutions | PLOS One [journals.plos.org]
- 5. Specificity of Anti-Tau Antibodies when Analyzing Mice Models of Alzheimer's Disease: Problems and Solutions - PMC [pmc.ncbi.nlm.nih.gov]
- 6. journals.plos.org [journals.plos.org]
- 7. Making sure you're not a bot! [academiccommons.columbia.edu]
- 8. researchgate.net [researchgate.net]
- 9. academic.oup.com [academic.oup.com]
- 10. High specificity of widely used phospho-tau antibodies validated using a quantitative whole-cell based assay - PMC [pmc.ncbi.nlm.nih.gov]
- 11. researchgate.net [researchgate.net]
- 12. biorxiv.org [biorxiv.org]
- 13. Reddit - The heart of the internet [reddit.com]
- 14. hycultbiotech.com [hycultbiotech.com]
- 15. stjohnslabs.com [stjohnslabs.com]
- 16. Immunofluorescence Troubleshooting | Tips & Tricks | StressMarq Biosciences Inc. [stressmarq.com]
- 17. researchgate.net [researchgate.net]
strategies to overcome [Target Protein] aggregation during purification
Technical Support Center: Overcoming [Target Protein] Aggregation
Welcome to the technical support center for troubleshooting protein aggregation. This resource provides practical guidance in a question-and-answer format to help you diagnose and solve common aggregation issues encountered during the purification of your target protein.
Frequently Asked Questions (FAQs)
Section 1: Understanding and Detecting Aggregation
Q1: How can I tell if my [Target Protein] is aggregating?
A1: Protein aggregation can manifest in several ways, from visible precipitation to more subtle forms that are harder to detect.[1][2]
-
Visual Cues: The most obvious sign is the appearance of cloudiness, haziness, or visible particles in your protein solution.[3]
-
Chromatography Profile: During size exclusion chromatography (SEC), aggregates often appear as large species eluting in or near the void volume of the column.[1][3][4]
-
Dynamic Light Scattering (DLS): This technique is highly sensitive for detecting soluble aggregates by measuring the size distribution of particles in the solution.[1][2]
-
Loss of Activity: A decrease in the specific biological activity of your protein can indicate that a portion of it has aggregated into a non-functional state.[1][3]
-
Spectroscopy: An increase in light scattering, which can be observed as abnormally high absorbance during UV-Vis spectrophotometry, can also suggest the presence of aggregates.[5]
Q2: What are the common causes of protein aggregation during purification?
A2: Protein aggregation is often caused by the exposure of hydrophobic regions that are normally buried within the protein's native structure. This can be triggered by a variety of factors throughout the purification process:
-
Suboptimal Buffer Conditions: Incorrect pH or ionic strength can disrupt the electrostatic interactions that stabilize your protein.[1][6] Proteins are particularly vulnerable to aggregation at their isoelectric point (pI), where their net charge is zero.[3][7]
-
High Protein Concentration: As protein concentration increases, so does the likelihood of intermolecular interactions that can lead to aggregation.[1][2][7][8][9] This is a common issue during concentration steps.
-
Temperature Stress: Both high temperatures and freeze-thaw cycles can denature proteins, leading to aggregation.[1][9][10] While purification is often performed at 4°C, some proteins may be unstable during prolonged storage at this temperature.[3]
-
Physical Stress: Exposure to shear stress from vigorous mixing or air-liquid interfaces (e.g., foaming or bubbling) can cause proteins to unfold and aggregate.[6][9]
-
Presence of Contaminants: Proteases can nick the protein, leading to less stable forms, while other contaminants can co-precipitate with your target protein.
-
Redox Environment: For proteins with cysteine residues, an improper redox environment can lead to the formation of incorrect, intermolecular disulfide bonds.[1]
Section 2: Troubleshooting and Optimization Strategies
Q3: My protein is precipitating. Where should I start troubleshooting?
A3: A logical first step is to evaluate your buffer conditions and physical handling of the protein. The following flowchart provides a systematic approach to troubleshooting.
References
- 1. info.gbiosciences.com [info.gbiosciences.com]
- 2. Protein aggregation - Protein Expression Facility - University of Queensland [pef.facility.uq.edu.au]
- 3. benchchem.com [benchchem.com]
- 4. documents.thermofisher.com [documents.thermofisher.com]
- 5. biozentrum.unibas.ch [biozentrum.unibas.ch]
- 6. biopharminternational.com [biopharminternational.com]
- 7. Minimizing Protein Aggregation | Proteos Insights [proteos.com]
- 8. leukocare.com [leukocare.com]
- 9. researchgate.net [researchgate.net]
- 10. Connecting high-temperature and low-temperature protein stability and aggregation - PMC [pmc.ncbi.nlm.nih.gov]
[Target Protein] siRNA Specificity Validation: A Technical Support Guide
This guide provides researchers, scientists, and drug development professionals with comprehensive troubleshooting advice and frequently asked questions (FAQs) for validating the specificity of small interfering RNA (siRNA) targeting a specific protein.
Frequently Asked Questions (FAQs)
Q1: What are off-target effects of siRNA and why are they a concern?
Q2: What are the primary mechanisms of siRNA off-target effects?
A2: The primary mechanism is often related to the "seed region" of the siRNA, which comprises nucleotides 2-8 of the guide strand.[3][4] This region can have partial complementarity to the 3' untranslated region (3' UTR) of unintended mRNAs, leading to their degradation or translational repression in a manner similar to microRNAs (miRNAs).[1][5]
Q3: How can I minimize off-target effects in my siRNA experiments?
A3: Several strategies can be employed to minimize off-target effects:
-
Use chemically modified siRNAs: Modifications, such as 2'-O-methyl modifications in the seed region, can reduce off-target binding without affecting on-target silencing.[3]
-
Pool multiple siRNAs: Using a pool of several siRNAs targeting the same gene at a lower total concentration can reduce the off-target effects of individual siRNAs.[1]
-
Careful siRNA design: Utilize algorithms that screen for potential off-target binding sites.[4]
Q4: What are the essential positive and negative controls for an siRNA experiment?
A4:
Q5: At what level should I measure gene knockdown?
Troubleshooting Guide
Problem: Low or no knockdown of the target protein.
| Possible Cause | Troubleshooting Steps |
| Inefficient Transfection | - Optimize transfection reagent and siRNA concentrations.[12][13] - Ensure cells are at the optimal density (typically 50-70% confluency) at the time of transfection.[12] - Use a positive control siRNA to verify transfection efficiency.[8] - Consider using a fluorescently labeled control siRNA to visually confirm uptake. |
| siRNA Degradation | - Store siRNAs properly (lyophilized at -20°C or -80°C, reconstituted in RNase-free buffer at -20°C).[14][15] - Avoid repeated freeze-thaw cycles.[14] - Use RNase-free techniques and reagents throughout the experiment. |
| Incorrect siRNA Sequence or Design | - Double-check the siRNA sequence against the target mRNA sequence. - Ensure the siRNA targets a region accessible for RISC binding. |
| Assay Issues | - For qRT-PCR, verify primer/probe efficiency and specificity.[13] - For Western blotting, ensure the antibody is specific and the protein extraction method is appropriate. |
| Cell Line Characteristics | - Some cell lines are notoriously difficult to transfect. Consider alternative delivery methods like electroporation. |
Problem: High cell toxicity or death after transfection.
| Possible Cause | Troubleshooting Steps |
| Transfection Reagent Toxicity | - Optimize the concentration of the transfection reagent.[12] - Perform a control with the transfection reagent alone to assess its toxicity.[13] |
| High siRNA Concentration | - Titrate the siRNA to a lower concentration.[5] High concentrations can induce off-target effects and cellular stress.[5] |
| Off-Target Effects | - The siRNA may be silencing a gene essential for cell survival.[3] Validate the specificity of the siRNA. |
| Cell Culture Conditions | - Avoid using antibiotics in the media during and immediately after transfection.[9] - Ensure cells are healthy and not overgrown before transfection. |
Problem: Inconsistent results between experiments.
| Possible Cause | Troubleshooting Steps |
| Variability in Cell Culture | - Maintain consistent cell passage numbers and confluency at the time of transfection.[12] |
| Inconsistent Reagent Preparation | - Prepare fresh dilutions of siRNAs and transfection reagents for each experiment. |
| Pipetting Errors | - Use calibrated pipettes and ensure accurate and consistent pipetting techniques. |
Experimental Protocols for Specificity Validation
Rescue Experiment Protocol
1. Design of an siRNA-Resistant Expression Construct:
-
Obtain a cDNA clone of your [Target Protein].
-
Introduce silent point mutations in the region targeted by your siRNA. These mutations should change the nucleotide sequence without altering the amino acid sequence of the protein. This makes the exogenous mRNA resistant to degradation by the specific siRNA.[16][19]
-
Clone the siRNA-resistant [Target Protein] cDNA into a suitable mammalian expression vector.
2. Co-transfection and Analysis:
-
Group 1 (Negative Control): Transfect cells with a non-targeting (scrambled) siRNA and an empty vector.
-
Group 2 (Knockdown): Transfect cells with the [Target Protein] siRNA and an empty vector.
-
Group 3 (Rescue): Co-transfect cells with the [Target Protein] siRNA and the siRNA-resistant [Target Protein] expression vector.
-
Group 4 (Expression Control): Transfect cells with the siRNA-resistant [Target Protein] expression vector alone.
3. Data Collection and Interpretation:
-
After an appropriate incubation period (typically 48-72 hours), assess the phenotype of interest (e.g., cell viability, signaling pathway activation, etc.).
-
Confirm the knockdown of the endogenous [Target Protein] and the expression of the siRNA-resistant version by qRT-PCR and/or Western blotting.
Expected Outcomes for a Specific siRNA:
| Experimental Group | Endogenous [Target Protein] Level | Exogenous (Rescue) [Target Protein] Level | Observed Phenotype |
| Negative Control | Normal | None | Wild-type |
| Knockdown | Reduced | None | Knockdown Phenotype |
| Rescue | Reduced | Expressed | Wild-type (Rescued) |
If the knockdown phenotype is reversed in the "Rescue" group, it strongly indicates that the observed phenotype is specifically due to the silencing of the [Target Protein] and not off-target effects.[16][18]
Visualizing Experimental Workflows and Pathways
Logical Flow for siRNA Specificity Validation
Caption: A flowchart outlining the key steps for validating siRNA specificity.
Workflow for a Rescue Experiment
Caption: The experimental design and expected outcomes of a rescue experiment.
By following these guidelines and protocols, researchers can confidently validate the specificity of their siRNA experiments, leading to more robust and reliable data.
References
- 1. horizondiscovery.com [horizondiscovery.com]
- 2. siRNA Off-Target Effect Assessment - Creative Proteomics [creative-proteomics.com]
- 3. Off-target effects by siRNA can induce toxic phenotype - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Off Target Effects in small interfering RNA or siRNA [biosyn.com]
- 5. siRNA Off-Target Effects Can Be Reduced at Concentrations That Match Their Individual Potency | PLOS One [journals.plos.org]
- 6. Top 10 Ways to Validate Your RNAi Data | Thermo Fisher Scientific - JP [thermofisher.com]
- 7. Top 10 Ways to Validate Your RNAi Data | Thermo Fisher Scientific - US [thermofisher.com]
- 8. Top three tips for troubleshooting your RNAi experiment [horizondiscovery.com]
- 9. Ten Tips for a Successful siRNA Experiment | Thermo Fisher Scientific - SG [thermofisher.com]
- 10. Top 10 Ways to Validate Your RNAi Data | Thermo Fisher Scientific - TW [thermofisher.com]
- 11. qiagen.com [qiagen.com]
- 12. Troubleshooting Tips : SignaGen Laboratories, A Gene Delivery Company... [signagen.com]
- 13. RNAi Synthetics Support—Troubleshooting | Thermo Fisher Scientific - SE [thermofisher.com]
- 14. merckmillipore.com [merckmillipore.com]
- 15. MISSION® siRNA FAQs [sigmaaldrich.com]
- 16. academic.oup.com [academic.oup.com]
- 17. horizondiscovery.com [horizondiscovery.com]
- 18. Attenuated Protein Expression Vectors for Use in siRNA Rescue Experiments - PMC [pmc.ncbi.nlm.nih.gov]
- 19. tandfonline.com [tandfonline.com]
Technical Support Center: Troubleshooting [Target Protein] Cloning Experiments
Welcome to the technical support center for [Target Protein] cloning experiments. This guide provides answers to frequently asked questions and detailed troubleshooting advice to help researchers, scientists, and drug development professionals overcome common challenges in the molecular cloning workflow.
I. PCR Amplification Issues
Frequently Asked Questions (FAQs)
Question: Why do I see no PCR product on my agarose gel?
Answer: Several factors could lead to the absence of a PCR product. Common causes include issues with the DNA template, primers, polymerase, or the thermocycling conditions.[1][2] It is crucial to verify the integrity of your template DNA and ensure your primers are correctly designed and not degraded.[1][3] Additionally, check the concentration of all reaction components and confirm that the annealing temperature and extension time are optimal for your specific target.[1]
Question: My PCR resulted in multiple non-specific bands. What went wrong?
Answer: Non-specific bands are often a result of primers binding to unintended sequences on the template DNA.[4] This can be caused by an annealing temperature that is too low, primers with poor specificity, or an excessive amount of template DNA.[2][4] To resolve this, try increasing the annealing temperature in increments, redesigning your primers for better specificity, or reducing the amount of template in the reaction.[2]
Question: The size of my PCR product is incorrect. How can I fix this?
Answer: An incorrect PCR product size could indicate amplification of the wrong target or the presence of mutations or errors in the sequence. It is important to re-verify your primer sequences and their binding sites on the template. Using a high-fidelity DNA polymerase can help minimize the introduction of errors during amplification.[5]
Experimental Protocol: Standard PCR Amplification
-
Reaction Setup: On ice, combine the components in the order listed in the table below in a sterile PCR tube.
-
Mixing: Gently mix the contents by pipetting and centrifuge briefly to collect the reaction mixture at the bottom of the tube.
-
Thermocycling: Place the PCR tube in a thermocycler and run the appropriate program based on your primer and template characteristics.
-
Analysis: After the PCR run, analyze a portion of the reaction mixture on an agarose gel to verify the amplification of the desired product.
Data Presentation: Standard PCR Reaction Mixture
| Component | Concentration in Final Reaction | Notes |
| Nuclease-Free Water | To final volume | |
| 10X PCR Buffer | 1X | Ensure it contains MgCl₂ or add separately. |
| dNTP Mix | 200 µM each | |
| Forward Primer | 0.1 - 1.0 µM | |
| Reverse Primer | 0.1 - 1.0 µM | |
| Template DNA | 1-10 ng (plasmid), 50-250 ng (genomic) | Purity is critical (A260/A280 ratio ≥ 1.8).[1] |
| DNA Polymerase | 1-2.5 units | Add last to prevent premature activity. |
| Total Volume | 25-50 µL |
Visualization: PCR Troubleshooting Workflow
Caption: A flowchart for troubleshooting PCR amplification failures.
II. Restriction Digestion Issues
Frequently Asked Questions (FAQs)
Question: My DNA seems to be incompletely digested. What could be the reason?
Answer: Incomplete digestion can be caused by several factors, including inactive restriction enzymes, suboptimal reaction conditions, or issues with the DNA substrate.[6] It is important to ensure the enzyme has been stored correctly at -20°C and that the reaction buffer is appropriate for the enzyme(s) being used.[6][7] DNA contaminants such as salts or ethanol can also inhibit enzyme activity.[8][9]
Question: I see unexpected bands on my gel after digestion. What does this indicate?
Answer: Unexpected bands can be a result of "star activity," where the enzyme cleaves at non-specific sites.[8] This can be triggered by non-optimal conditions such as high glycerol concentration, prolonged incubation time, or an incorrect buffer.[7][8] To avoid this, use the recommended buffer and minimize the volume of enzyme in the reaction to keep the glycerol concentration below 5%.[6][7]
Experimental Protocol: Restriction Digestion
-
Reaction Setup: In a sterile microfuge tube, combine the DNA, reaction buffer, and nuclease-free water.
-
Enzyme Addition: Add the restriction enzyme(s) last. Mix gently by pipetting.
-
Incubation: Incubate the reaction at the optimal temperature for the enzyme(s) for 1-2 hours.
-
Inactivation: Heat-inactivate the enzyme(s) according to the manufacturer's instructions (e.g., 65°C or 80°C for 20 minutes).
-
Analysis: Run the digested DNA on an agarose gel to confirm complete digestion.
Data Presentation: Typical Restriction Digestion Reaction
| Component | Volume/Amount |
| DNA | 1 µg |
| 10X Restriction Buffer | 2 µL |
| Restriction Enzyme(s) | 1-2 µL (5-10 units) |
| Nuclease-Free Water | To a final volume of 20 µL |
Visualization: Restriction Digestion Troubleshooting
Caption: Troubleshooting guide for incomplete restriction digestion.
III. Ligation Issues
Frequently Asked Questions (FAQs)
Question: After transformation, I have very few or no colonies. What could be wrong with my ligation?
Answer: A low number of colonies often points to an inefficient ligation reaction.[10] This can be due to several factors, including degraded ATP in the ligase buffer, inactive ligase, or incompatible DNA ends.[10][11] It is also important to use an optimal vector-to-insert molar ratio.[10][12]
Question: I have a high number of colonies, but they are all empty vectors (no insert). How can I solve this?
Answer: A high background of empty vectors can occur if the digested vector re-ligates to itself. This is common when using a single restriction enzyme.[13] To prevent this, you can dephosphorylate the vector using an alkaline phosphatase after digestion. This removes the 5' phosphate group, preventing self-ligation.[11]
Experimental Protocol: DNA Ligation
-
Quantify DNA: Determine the concentration of your digested vector and insert DNA.
-
Calculate Molar Ratio: Calculate the required amount of insert for the desired vector:insert molar ratio (e.g., 1:3).
-
Reaction Setup: In a sterile tube, combine the vector, insert, 10X T4 DNA Ligase buffer, and nuclease-free water.
-
Add Ligase: Add T4 DNA Ligase and mix gently.
-
Incubation: Incubate at room temperature for 1 hour or at 16°C overnight.
-
Heat Inactivation: Heat-inactivate the ligase at 65°C for 10 minutes.
Data Presentation: Recommended Vector to Insert Molar Ratios
| Ligation Type | Recommended Molar Ratio (Vector:Insert) |
| Sticky-End Ligation | 1:1 to 1:3 |
| Blunt-End Ligation | 1:3 to 1:10 |
| Short Adapters | 1:10 to 1:20[10][12] |
Visualization: Ligation Troubleshooting Logic
Caption: Decision-making flowchart for troubleshooting DNA ligation.
IV. Bacterial Transformation Issues
Frequently Asked Questions (FAQs)
Question: I have no colonies on my plate after transformation. What went wrong?
Answer: A complete lack of colonies can be due to several issues, including low transformation efficiency of the competent cells, problems with the antibiotic selection, or an incorrect heat shock step.[14][15] It's important to test the efficiency of your competent cells with a control plasmid.[15] Also, ensure you are using the correct antibiotic at the right concentration.[14][15]
Question: My plate has a bacterial lawn instead of distinct colonies. What does this mean?
Answer: A bacterial lawn typically indicates a problem with the antibiotic selection.[14] The antibiotic in your plates may be old, at too low a concentration, or it may have been added when the agar was too hot, causing it to degrade.[14][16]
Experimental Protocol: Heat-Shock Transformation
-
Thaw Cells: Thaw a tube of chemically competent E. coli on ice.
-
Add DNA: Add 1-5 µL of your ligation reaction to the cells. Gently mix.
-
Incubate on Ice: Incubate the mixture on ice for 30 minutes.
-
Heat Shock: Transfer the tube to a 42°C water bath for 45-90 seconds.[15]
-
Recovery: Immediately place the tube back on ice for 2 minutes. Add 250-500 µL of pre-warmed SOC medium and incubate at 37°C for 1 hour with shaking.
-
Plating: Spread an appropriate volume of the cell culture on a pre-warmed agar plate containing the selective antibiotic.
-
Incubation: Incubate the plate overnight at 37°C.
Data Presentation: Factors Affecting Transformation Efficiency
| Factor | Impact on Efficiency | Recommendation |
| Competent Cell Quality | High | Use commercially prepared cells or test in-house preparations.[14] |
| DNA Purity | High | Purify ligation reactions to remove inhibitors like salts and proteins.[17] |
| Heat Shock Duration | Critical | Adhere strictly to the recommended time for your competent cells.[15] |
| Antibiotic Concentration | Critical | Use the correct concentration and ensure the antibiotic is active.[14][16] |
Visualization: Bacterial Transformation Workflow
Caption: Key steps in the heat-shock bacterial transformation protocol.
V. Plasmid Verification Issues
Frequently Asked Questions (FAQs)
Question: My colony PCR is not working. What are the common reasons?
Answer: Colony PCR can fail for several reasons. Adding too much bacterial debris can inhibit the PCR reaction.[18] It's also possible that the primers are not binding correctly or have degraded.[3] An initial lysis step (e.g., 95°C for 5-10 minutes) can help release the plasmid DNA from the cells.[19]
Question: My restriction digest of the miniprepped plasmid shows an incorrect pattern. What should I do?
Answer: An incorrect restriction pattern suggests that the plasmid structure is not what you expected.[20] This could be due to the wrong insert, point mutations in the restriction sites, or other rearrangements.[20] The best way to confirm the plasmid's identity and sequence is through DNA sequencing.[21][22]
Experimental Protocol: Colony PCR
-
Colony Picking: Using a sterile pipette tip, pick a single, well-isolated colony.
-
Inoculation: Inoculate a small amount of the colony into a PCR tube containing the PCR master mix. Streak the same tip on a master plate for later culture.
-
Lysis Step: Begin the PCR program with an initial denaturation/lysis step at 95-98°C for 5-10 minutes.
-
Thermocycling: Proceed with the standard PCR cycles.
-
Analysis: Analyze the PCR product on an agarose gel. A band of the correct size indicates a potentially positive clone.
Visualization: Plasmid Verification Decision Tree
Caption: A decision tree for the verification of positive clones.
References
- 1. genscript.com [genscript.com]
- 2. Troubleshooting your PCR [takarabio.com]
- 3. researchgate.net [researchgate.net]
- 4. shop.cgenomix.com [shop.cgenomix.com]
- 5. researchgate.net [researchgate.net]
- 6. Troubleshooting Common Issues with Restriction Digestion Reactions | Thermo Fisher Scientific - KR [thermofisher.com]
- 7. go.zageno.com [go.zageno.com]
- 8. genscript.com [genscript.com]
- 9. Troubleshooting Restriction Enzyme Digestions | Creative Enzymes [molecular-tools.creative-enzymes.com]
- 10. neb.com [neb.com]
- 11. neb.com [neb.com]
- 12. neb.com [neb.com]
- 13. bitesizebio.com [bitesizebio.com]
- 14. goldbio.com [goldbio.com]
- 15. bitesizebio.com [bitesizebio.com]
- 16. intactgenomics.com [intactgenomics.com]
- 17. Bacterial Transformation Troubleshooting Guide | Thermo Fisher Scientific - AT [thermofisher.com]
- 18. bitesizebio.com [bitesizebio.com]
- 19. Bench tip: how to do colony PCR properly [lubio.ch]
- 20. goldbio.com [goldbio.com]
- 21. goldbio.com [goldbio.com]
- 22. bitesizebio.com [bitesizebio.com]
Technical Support Center: Optimizing Fixation and Permeabilization for [Target Protein] Immunofluorescence
This technical support center provides troubleshooting guidance and frequently asked questions (FAQs) to help researchers, scientists, and drug development professionals optimize their immunofluorescence (IF) protocols for the detection of [Target Protein].
Troubleshooting Guide
Problem 1: Weak or No Signal
A faint or absent fluorescent signal for [Target Protein] can be frustrating. Below are common causes and solutions to enhance your staining.
| Possible Cause | Recommendation | Citation |
| Suboptimal Fixation | The fixation method may be masking the epitope of [Target Protein]. If using formaldehyde, try reducing the fixation time or switching to methanol fixation. Methanol can expose epitopes that are hidden by cross-linking. | [1][2][3] |
| Inadequate Permeabilization | For intracellular targets, proper permeabilization is crucial. If using formaldehyde fixation, ensure a separate permeabilization step with detergents like Triton X-100 or Tween-20 is performed. For some proteins, especially those associated with membranes, milder detergents like saponin or digitonin may be necessary to prevent protein loss. | [4][5][6] |
| Low [Target Protein] Abundance | The protein of interest may be expressed at low levels in your sample. Confirm expression using a sensitive method like Western blotting. Consider using a signal amplification system or a brighter fluorophore. | [7][8] |
| Incorrect Antibody Concentration | The primary or secondary antibody concentration may be too low. Titrate the antibodies to determine the optimal concentration that yields a strong signal without high background. | [9][10] |
| Antibody Incompatibility | Ensure the secondary antibody is specific to the host species of the primary antibody (e.g., use an anti-mouse secondary for a mouse primary). | [2][9] |
| Photobleaching | Fluorophores can be sensitive to light. Minimize light exposure during the staining process and imaging. Use an anti-fade mounting medium. | [2][10][11] |
Problem 2: High Background or Non-Specific Staining
High background can obscure the specific signal from [Target Protein]. The following table outlines potential reasons and remedies.
| Possible Cause | Recommendation | Citation |
| Antibody Concentration Too High | Excessive primary or secondary antibody concentrations can lead to non-specific binding. Reduce the antibody concentrations. | [7][9][12] |
| Insufficient Blocking | Inadequate blocking can result in non-specific antibody binding. Increase the blocking time and consider using normal serum from the same species as the secondary antibody. | [7][11] |
| Inadequate Washing | Insufficient washing between antibody incubation steps can leave unbound antibodies, contributing to background. Increase the number and duration of wash steps. | [7][11] |
| Autofluorescence | Some cells and tissues exhibit natural fluorescence. An unstained control sample should be examined to assess the level of autofluorescence. Using fresh fixative solutions can also help, as old formaldehyde can be a source of autofluorescence. | [2][7][11] |
| Fixative-Induced Fluorescence | Aldehyde fixatives like formaldehyde and glutaraldehyde can induce autofluorescence. If this is an issue, consider switching to a methanol-based fixation protocol. | [13][14] |
| Secondary Antibody Cross-Reactivity | The secondary antibody may be cross-reacting with other proteins in the sample. Run a control with only the secondary antibody to check for non-specific binding. | [7] |
Frequently Asked Questions (FAQs)
Q1: What is the fundamental difference between formaldehyde and methanol fixation?
A1: Formaldehyde is a cross-linking fixative that forms covalent bonds between proteins, preserving cellular structure well.[4][13] Methanol, on the other hand, is a denaturing and precipitating fixative that dehydrates the cells, causing proteins to precipitate in situ.[1][15] This denaturation can sometimes expose epitopes that are hidden by the cross-linking action of formaldehyde.[1]
Q2: How do I choose the right permeabilization agent?
A2: The choice of permeabilization agent depends on the location of your target protein and the type of fixation used.
-
Triton X-100 and Tween-20: These are non-ionic detergents that permeabilize all cellular membranes, including the plasma and nuclear membranes.[4][16] They are commonly used after formaldehyde fixation but can sometimes lead to the loss of soluble or membrane-associated proteins.[4][5]
-
Saponin and Digitonin: These are milder, cholesterol-dependent detergents that selectively permeabilize the plasma membrane while leaving organellar membranes largely intact.[4][5] This makes them a good choice for preserving the localization of membrane-associated proteins.[4][17]
Q3: Can I fix and permeabilize in a single step?
A3: Yes, using cold methanol as a fixative also permeabilizes the cell membranes, eliminating the need for a separate permeabilization step.[4][14] This can be a time-saving and effective strategy for many target proteins.[4]
Q4: My [Target Protein] is a membrane protein. What is the best fixation and permeabilization strategy?
A4: For membrane proteins, the goal is to preserve the protein's localization while allowing antibody access. A good starting point is to fix with formaldehyde to cross-link the protein in place and then use a mild permeabilization agent like saponin or digitonin.[4] This approach minimizes the risk of extracting the protein from the membrane, which can occur with stronger detergents like Triton X-100.[4][5]
Q5: How can I be sure my staining is specific to [Target Protein]?
A5: Proper controls are essential for validating the specificity of your immunofluorescence staining. Key controls include:
-
Secondary antibody only control: This helps to identify any non-specific binding of the secondary antibody.
-
Isotype control: This involves using a primary antibody of the same isotype but with no specificity for the target antigen to assess non-specific binding of the primary antibody.
-
Positive and negative controls: Use cells or tissues known to express or not express [Target Protein] to confirm that your antibody is detecting the correct target.[7][8]
Experimental Protocols
Protocol 1: Formaldehyde Fixation and Detergent Permeabilization
-
Grow cells on sterile coverslips to the desired confluency.
-
Gently aspirate the culture medium and wash the cells once with Phosphate-Buffered Saline (PBS).
-
Fix the cells by incubating with 4% paraformaldehyde (PFA) in PBS for 15 minutes at room temperature.
-
Wash the cells three times with PBS for 5 minutes each.
-
Permeabilize the cells by incubating with 0.1-0.5% Triton X-100 or 0.1% Saponin in PBS for 10-15 minutes at room temperature.
-
Wash the cells three times with PBS for 5 minutes each.
-
Proceed with the blocking and immunostaining steps.[10]
Protocol 2: Cold Methanol Fixation and Permeabilization
-
Grow cells on sterile coverslips to the desired confluency.
-
Gently aspirate the culture medium and wash the cells once with PBS.
-
Fix and permeabilize the cells by incubating with ice-cold 100% methanol for 10 minutes at -20°C.
-
Wash the cells three times with PBS for 5 minutes each.
-
Proceed with the blocking and immunostaining steps.[10]
Data Presentation
Table 1: Comparison of Common Fixatives
| Fixative | Mechanism | Advantages | Disadvantages | Citation |
| Formaldehyde (4% PFA) | Cross-linking | Excellent preservation of cellular morphology; good for soluble proteins. | Can mask epitopes; may induce autofluorescence. | [1][13][16] |
| Methanol (100%) | Dehydrating/Precipitating | Simultaneously fixes and permeabilizes; can expose masked epitopes. | Can alter cellular morphology; may lead to the loss of soluble proteins. | [1][13][15] |
Table 2: Comparison of Common Permeabilization Agents
| Agent | Concentration | Mechanism | Use Case | Citation |
| Triton X-100 | 0.1-0.5% | Non-ionic detergent, solubilizes membranes | General permeabilization of all cellular membranes. | [4][16] |
| Saponin | 0.1% | Mild non-ionic detergent, interacts with cholesterol | Selective permeabilization of the plasma membrane, good for membrane-associated proteins. | [4][5] |
| Digitonin | 5-50 µg/mL | Mild non-ionic detergent, interacts with cholesterol | Similar to saponin, selective permeabilization of the plasma membrane. | [1][5] |
Visualizations
Caption: Decision workflow for choosing a fixation and permeabilization strategy.
Caption: A troubleshooting flowchart for common immunofluorescence issues.
References
- 1. blog.cellsignal.com [blog.cellsignal.com]
- 2. Immunofluorescence Troubleshooting | Tips & Tricks | StressMarq Biosciences Inc. [stressmarq.com]
- 3. hycultbiotech.com [hycultbiotech.com]
- 4. blog.addgene.org [blog.addgene.org]
- 5. Fixation and permeabilization protocol is critical for the immunolabeling of lipid droplet proteins - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. applications.emro.who.int [applications.emro.who.int]
- 7. Immunofluorescence (IF) Troubleshooting Guide | Cell Signaling Technology [cellsignal.com]
- 8. IF Troubleshooting | Proteintech Group [ptglab.com]
- 9. Immunofluorescence Troubleshooting Tips [elabscience.com]
- 10. benchchem.com [benchchem.com]
- 11. ibidi.com [ibidi.com]
- 12. Immunofluorescence Protocol & Troubleshooting - Creative Biolabs [creativebiolabs.net]
- 13. m.youtube.com [m.youtube.com]
- 14. Guide to Fixation and Permeabilization - FluoroFinder [fluorofinder.com]
- 15. researchgate.net [researchgate.net]
- 16. Fixation and Permeabilization in Immunocytochemistry/Immunofluorescence (ICC/IF) | Bio-Techne [bio-techne.com]
- 17. researchgate.net [researchgate.net]
Technical Support Center: Minimizing Background Signal in [Target Protein] ELISA
This technical support center provides researchers, scientists, and drug development professionals with a comprehensive guide to troubleshooting and minimizing high background signals in [Target Protein] Enzyme-Linked Immunosorbent Assays (ELISAs). High background can mask specific signals, reduce assay sensitivity, and lead to inaccurate quantification of your target protein. This guide offers answers to frequently asked questions, detailed troubleshooting protocols, and visual workflows to help you identify and resolve the root causes of high background in your experiments.
Frequently Asked Questions (FAQs)
Q1: What is considered a high background in an ELISA?
A high background in an ELISA refers to a high signal in the negative control wells (wells without the analyte) or a generally high optical density (OD) across the entire plate. This elevated "noise" can obscure the specific signal from the [Target Protein], leading to a reduced signal-to-noise ratio and compromising the accuracy and sensitivity of the assay.[1]
Q2: What are the most common causes of high background signal?
The most frequent causes of high background in an ELISA include:
-
Insufficient Washing: Failure to remove all unbound antibodies and reagents.[1][2][3]
-
Inadequate Blocking: Incomplete blocking of non-specific binding sites on the microplate wells.[1][3]
-
Improper Antibody Concentrations: Using primary or secondary antibody concentrations that are too high.
-
Substrate Issues: Contamination or prolonged incubation of the substrate solution.[4]
-
Contamination: Contamination of reagents, buffers, or the microplate itself.[5]
-
Incorrect Incubation Times or Temperatures: Deviation from the optimal incubation parameters can lead to increased non-specific binding.[5]
Q3: How can I systematically troubleshoot the source of high background?
A systematic approach is key to identifying the source of the high background. Start by examining your controls. A "no primary antibody" control can help determine if the secondary antibody is binding non-specifically. A "blank" well (containing only substrate) can indicate if the substrate or plate is contaminated. Reviewing your protocol for any deviations in washing, blocking, or incubation steps is also crucial.
Troubleshooting Guide
The following table summarizes common causes of high background and provides targeted solutions.
| Potential Cause | Recommended Solution | Expected Impact on Background |
| Insufficient Washing | Increase the number of wash cycles (e.g., from 3 to 5). Increase the wash buffer volume to completely fill the wells (e.g., 300-400 µL/well).[4] Introduce a 30-60 second soak time during each wash step. Ensure complete aspiration of wash buffer after each step. | Significant Reduction |
| Inadequate Blocking | Increase the blocking incubation time (e.g., to 2 hours at room temperature or overnight at 4°C). Increase the concentration of the blocking agent (e.g., 1-5% BSA or non-fat dry milk).[6] Test alternative blocking buffers (e.g., commercial blocking solutions, casein-based blockers).[7] | Significant Reduction |
| Antibody Concentration Too High | Perform an antibody titration to determine the optimal concentration for both primary and secondary antibodies. This will identify the concentration that provides the best signal-to-noise ratio. | Significant Reduction |
| Substrate Issues | Use fresh, colorless substrate solution.[4] Avoid exposing the substrate to light. Adhere strictly to the recommended substrate incubation time. Read the plate immediately after adding the stop solution. | Moderate to Significant Reduction |
| Reagent and Plate Contamination | Use sterile, fresh reagents and buffers. Use fresh pipette tips for each reagent and sample. Ensure the bottom of the plate is clean before reading. Cover the plate with a sealer during incubations to prevent cross-contamination.[8] | Moderate Reduction |
| Incorrect Incubation Time/Temperature | Strictly adhere to the incubation times and temperatures specified in the protocol.[5] Avoid placing the plate near heat sources or in direct sunlight.[4] | Moderate Reduction |
| Cross-Reactivity | Ensure the secondary antibody is specific to the primary antibody's host species and has been pre-adsorbed to minimize cross-reactivity with other proteins in the sample. | Moderate Reduction |
Experimental Protocols
1. Antibody Titration Protocol
This protocol helps determine the optimal dilution of the primary antibody to maximize the signal-to-noise ratio.
-
Materials: Coated and blocked ELISA plate, a range of primary antibody dilutions, secondary antibody at a fixed recommended concentration, substrate, and stop solution.
-
Methodology:
-
Prepare Primary Antibody Dilutions: Create a series of dilutions of your primary antibody (e.g., 1:1000, 1:2000, 1:4000, 1:8000, 1:16000) in an appropriate diluent.
-
Incubate with Primary Antibody: Add the different dilutions to the wells of the coated and blocked plate. Include a negative control well with only the diluent. Incubate according to your standard protocol.
-
Wash: Wash the plate thoroughly as per your protocol.
-
Incubate with Secondary Antibody: Add the secondary antibody at its recommended concentration to all wells. Incubate as per your protocol.
-
Wash: Wash the plate thoroughly.
-
Add Substrate and Stop Solution: Add the substrate and incubate for the recommended time. Stop the reaction.
-
Read Plate: Measure the absorbance at the appropriate wavelength.
-
Analyze Results: Plot the absorbance values against the antibody dilutions. The optimal dilution is the one that provides a strong signal for your positive control with a low background in the negative control.
-
2. Checkerboard Titration Protocol
This method allows for the simultaneous optimization of both capture and detection antibody concentrations in a sandwich ELISA.
-
Materials: Uncoated ELISA plate, a range of capture antibody dilutions, a range of detection antibody dilutions, antigen, substrate, and stop solution.
-
Methodology:
-
Coat with Capture Antibody: Prepare serial dilutions of the capture antibody in coating buffer. Add each dilution to a different row of the 96-well plate. Incubate overnight at 4°C.
-
Wash and Block: Wash the plate and then block all wells with a suitable blocking buffer.
-
Add Antigen: Add the target antigen at a constant, non-limiting concentration to all wells. Incubate.
-
Wash: Wash the plate thoroughly.
-
Add Detection Antibody: Prepare serial dilutions of the detection antibody. Add each dilution to a different column of the plate. Incubate.
-
Wash: Wash the plate thoroughly.
-
Add Enzyme-Conjugated Reagent: Add the enzyme-conjugated streptavidin (if using a biotinylated detection antibody) or a conjugated secondary antibody. Incubate.
-
Wash, Add Substrate, and Stop: Wash the plate, add the substrate, and stop the reaction.
-
Read and Analyze: Read the plate and analyze the data to find the combination of capture and detection antibody concentrations that yields the highest signal-to-noise ratio.[9][10][11]
-
Visualizations
The following diagrams illustrate key workflows and decision-making processes for troubleshooting high background in your [Target Protein] ELISA.
Caption: A general workflow for a sandwich ELISA, highlighting the key steps.
Caption: A decision tree for troubleshooting high background in an ELISA.
References
- 1. blog.abclonal.com [blog.abclonal.com]
- 2. biocompare.com [biocompare.com]
- 3. biocompare.com [biocompare.com]
- 4. sinobiological.com [sinobiological.com]
- 5. How to troubleshoot if the Elisa Kit has high background? - Blog [jg-biotech.com]
- 6. ELISA Blocking Buffers: Overview & Application [excedr.com]
- 7. Blocking Buffer Selection Guide | Rockland [rockland.com]
- 8. ELISA Troubleshooting Guide | Thermo Fisher Scientific - HK [thermofisher.com]
- 9. Quantitative Elisa Checkerboard Titration Procedure - FineTest Elisa Kit [fn-test.com]
- 10. bosterbio.com [bosterbio.com]
- 11. cytodiagnostics.com [cytodiagnostics.com]
Validation & Comparative
Validating KRAS as a Therapeutic Target: A Comparative Guide
For Researchers, Scientists, and Drug Development Professionals
The Kirsten Rat Sarcoma Viral Oncogene Homolog (KRAS) is a frequently mutated oncogene in several cancers, including non-small cell lung cancer (NSCLC) and colorectal cancer (CRC), making it a prime candidate for targeted therapy.[1] The validation of KRAS as a therapeutic target is a critical step in the development of effective cancer treatments. This guide provides a comparative overview of the primary methodologies used to validate KRAS, presenting supporting experimental data and detailed protocols to aid researchers in this endeavor.
Genetic Validation: Silencing the Driver
Genetic validation methods aim to directly assess the impact of KRAS gene suppression on cancer cell viability and signaling. The two most prominent techniques for this are RNA interference (RNAi) and CRISPR-Cas9 gene editing.
Comparison of Genetic Validation Techniques
The choice between RNAi and CRISPR-Cas9 depends on the specific experimental goals. RNAi offers a transient knockdown, which can be useful for studying the immediate effects of target suppression and for validating phenotypes where a complete knockout might be lethal.[2] In contrast, CRISPR-Cas9 provides a permanent knockout of the gene, which is advantageous for creating stable cell lines for long-term studies and for unequivocally assessing the gene's essentiality.[2]
| Feature | RNA Interference (siRNA) | CRISPR-Cas9 |
| Mechanism | Post-transcriptional gene silencing via mRNA degradation.[3] | DNA-level gene knockout through targeted double-strand breaks.[4] |
| Effect | Transient knockdown of protein expression.[2] | Permanent knockout of the gene.[2] |
| On-Target Efficiency | Variable, typically achieving 70-90% knockdown of KRAS.[3] | High, can achieve >90% knockout efficiency.[4] |
| Off-Target Effects | A significant concern, with potential for non-specific gene silencing.[5] | Generally lower than RNAi, but can still occur.[5] |
| Experimental Complexity | Relatively straightforward and rapid for transient transfection. | More complex, especially for generating stable knockout cell lines. |
Pharmacological Validation: Inhibiting the Protein
Pharmacological validation involves the use of small molecule inhibitors to assess the therapeutic potential of targeting the KRAS protein. The recent development of specific inhibitors for the KRAS G12C mutation, such as sotorasib and adagrasib, has revolutionized this approach.
Comparison of KRAS G12C Inhibitors (Preclinical Data)
The efficacy of KRAS inhibitors is typically evaluated by determining their half-maximal inhibitory concentration (IC50) in cancer cell lines harboring the specific KRAS mutation.
| Inhibitor | Cell Line | Cancer Type | KRAS Mutation | IC50 (nM) |
| Sotorasib | H358 | NSCLC | G12C | 0.6 |
| MIA PaCa-2 | Pancreatic | G12C | 1.3 | |
| SW 1573 | NSCLC | G12C | 2534 | |
| Adagrasib | H358 | NSCLC | G12C | 1.1 |
| MIA PaCa-2 | Pancreatic | G12C | 2.5 | |
| SW 1573 | NSCLC | G12C | 356 |
Note: IC50 values can vary depending on the assay conditions and cell line.
Experimental Protocols
Genetic Validation Workflow: siRNA-mediated Knockdown of KRAS in A549 Cells
This protocol outlines the steps for transiently knocking down KRAS in the A549 human lung adenocarcinoma cell line (KRAS G12S) using siRNA, followed by assessment of knockdown efficiency and downstream signaling.
Materials:
-
A549 cells
-
KRAS-targeting siRNA and non-targeting control (NC) siRNA
-
Lipofectamine RNAiMAX transfection reagent
-
Opti-MEM I Reduced Serum Medium
-
Complete growth medium (e.g., F-12K Medium with 10% FBS)
-
Phosphate-buffered saline (PBS)
-
Reagents for Western blotting (lysis buffer, primary antibodies for KRAS, p-ERK, total ERK, and a loading control like β-actin, secondary antibodies, ECL substrate)
Procedure:
-
Cell Seeding: The day before transfection, seed A549 cells in 6-well plates at a density that will result in 30-50% confluency at the time of transfection.
-
Transfection Complex Preparation:
-
For each well, dilute 50 pmol of siRNA (KRAS-targeting or NC) in 250 µL of Opti-MEM.
-
In a separate tube, dilute 5 µL of Lipofectamine RNAiMAX in 250 µL of Opti-MEM and incubate for 5 minutes at room temperature.
-
Combine the diluted siRNA and diluted Lipofectamine RNAiMAX (total volume ~500 µL), mix gently, and incubate for 20 minutes at room temperature to allow for complex formation.
-
-
Transfection: Add the siRNA-lipid complexes to the cells.
-
Incubation: Incubate the cells for 48-72 hours at 37°C in a CO2 incubator.
-
Protein Extraction and Western Blotting:
-
After incubation, wash the cells with ice-cold PBS and lyse them with appropriate lysis buffer.
-
Determine protein concentration using a BCA assay.
-
Perform SDS-PAGE and transfer the proteins to a PVDF membrane.
-
Probe the membrane with primary antibodies against KRAS, phospho-ERK (p-ERK), total ERK, and a loading control.
-
Incubate with the appropriate HRP-conjugated secondary antibodies.
-
Visualize the protein bands using an ECL substrate and an imaging system.
-
-
Data Analysis: Quantify the band intensities to determine the percentage of KRAS knockdown and the change in p-ERK levels relative to the total ERK and loading control.
Pharmacological Validation Workflow: Determining the IC50 of a KRAS Inhibitor
This protocol describes how to determine the IC50 value of a KRAS inhibitor in a KRAS-mutant cancer cell line using a cell viability assay (e.g., MTT or alamarBlue).
Materials:
-
KRAS-mutant cancer cell line (e.g., H358 for KRAS G12C)
-
KRAS inhibitor (e.g., sotorasib) and DMSO (vehicle)
-
Complete growth medium
-
96-well plates
-
MTT solution (5 mg/mL in PBS) or alamarBlue reagent
-
Solubilization buffer (e.g., DMSO for MTT)
-
Microplate reader
Procedure:
-
Cell Seeding: Seed cells into 96-well plates at a predetermined optimal density and allow them to attach overnight.
-
Compound Preparation: Prepare a serial dilution of the KRAS inhibitor in complete growth medium. Also, prepare a vehicle control (DMSO at the same final concentration as the highest inhibitor concentration).
-
Treatment: Remove the medium from the cells and add the prepared compound dilutions and controls to the respective wells.
-
Incubation: Incubate the plate for a specified period (e.g., 72 hours) at 37°C.
-
Cell Viability Assay (MTT example):
-
Add 10 µL of MTT solution to each well and incubate for 3-4 hours.
-
Carefully remove the medium and add 100 µL of DMSO to each well to dissolve the formazan crystals.
-
Measure the absorbance at 570 nm using a microplate reader.[1]
-
-
Data Analysis:
-
Calculate the percentage of cell viability for each concentration relative to the vehicle control.
-
Plot the percentage of cell viability against the logarithm of the inhibitor concentration.
-
Use a non-linear regression model (e.g., log(inhibitor) vs. response -- Variable slope) to determine the IC50 value.
-
Visualizations
The following diagrams illustrate key concepts in KRAS target validation.
References
- 1. benchchem.com [benchchem.com]
- 2. Frontiers | Evaluation of KRASG12C inhibitor responses in novel murine KRASG12C lung cancer cell line models [frontiersin.org]
- 3. Therapeutic Silencing of KRAS using Systemically Delivered siRNAs - PMC [pmc.ncbi.nlm.nih.gov]
- 4. News: Highlight: HiFiCas9 Selectively Disables Mutant KRAS in Lung Tumours - CRISPR Medicine [crisprmedicinenews.com]
- 5. Off-target effects in CRISPR/Cas9 gene editing - PMC [pmc.ncbi.nlm.nih.gov]
comparing the efficacy of different [Target Protein] inhibitors
A Comparative Guide to the Efficacy of EGFR Inhibitors
For Researchers, Scientists, and Drug Development Professionals
This guide provides an objective comparison of the performance of different generations of Epidermal Growth Factor Receptor (EGFR) inhibitors, supported by experimental data. The information is intended to assist researchers and clinicians in understanding the nuances of EGFR-targeted therapies.
Introduction to EGFR and Targeted Inhibition
The Epidermal Growth Factor Receptor (EGFR) is a transmembrane protein that plays a pivotal role in regulating critical cellular processes, including proliferation, survival, and differentiation.[1][2] Dysregulation of the EGFR signaling pathway, often due to mutations, is a key driver in the development and progression of various cancers, particularly non-small cell lung cancer (NSCLC).[3] This has led to the development of EGFR Tyrosine Kinase Inhibitors (TKIs), which block the enzymatic activity of EGFR and halt downstream signaling. This guide focuses on a comparison of first, second, and third-generation EGFR TKIs.
EGFR Signaling Pathway
Upon ligand binding, EGFR dimerizes and undergoes autophosphorylation of its intracellular tyrosine kinase domain. This phosphorylation creates docking sites for adaptor proteins like GRB2, which in turn activate downstream signaling cascades.[4][5] The two primary pathways are:
-
RAS-RAF-MEK-ERK (MAPK) Pathway : This pathway is crucial for cell proliferation.[5]
-
PI3K-AKT-mTOR Pathway : This pathway is a major regulator of cell survival and apoptosis inhibition.[5]
EGFR inhibitors prevent the initial autophosphorylation, thereby blocking the activation of these oncogenic signaling pathways.[6]
Caption: EGFR downstream signaling pathways and point of inhibition.
Comparative Efficacy of EGFR Inhibitors
The efficacy of EGFR inhibitors is largely dependent on the mutational status of the EGFR gene. Different generations of inhibitors have been developed to address acquired resistance mechanisms.
In Vitro Potency (IC50) Data
The half-maximal inhibitory concentration (IC50) is a measure of the potency of a drug in inhibiting a specific biological or biochemical function. The following tables summarize the IC50 values of prominent first, second, and third-generation EGFR inhibitors against various NSCLC cell lines, each harboring different EGFR mutations.
Table 1: IC50 Values (nM) of EGFR Inhibitors in NSCLC Cell Lines with Sensitizing Mutations
| Inhibitor (Generation) | Cell Line | EGFR Mutation | IC50 (nM) |
| Gefitinib (1st) | PC-9 | Exon 19 del | ~7 |
| H3255 | L858R | ~12 | |
| Erlotinib (1st) | PC-9 | Exon 19 del | 7 |
| H3255 | L858R | 12 | |
| Afatinib (2nd) | PC-9 | Exon 19 del | 0.8 |
| H3255 | L858R | 0.3 | |
| Osimertinib (3rd) | PC-9 | Exon 19 del | 13 |
| H3255 | L858R | Not specified |
Data compiled from multiple sources.[7][8]
Table 2: IC50 Values (nM) of EGFR Inhibitors in NSCLC Cell Lines with Resistance Mutations
| Inhibitor (Generation) | Cell Line | EGFR Mutation | IC50 (nM) |
| Gefitinib (1st) | H1975 | L858R + T790M | >10,000 |
| Erlotinib (1st) | H1975 | L858R + T790M | >10,000 |
| Afatinib (2nd) | H1975 | L858R + T790M | 57 |
| Osimertinib (3rd) | H1975 | L858R + T790M | 5 |
Data compiled from multiple sources.[7][9]
Clinical Efficacy Data
Clinical trials provide crucial data on the real-world efficacy of these inhibitors in patients. Progression-Free Survival (PFS) and Overall Survival (OS) are key metrics.
Table 3: Comparison of Clinical Outcomes for Different Generation EGFR TKIs
| Comparison | Patient Population | Median PFS | Median OS |
| Osimertinib vs. 1st Gen (Gefitinib/Erlotinib) | Untreated advanced NSCLC | 18.9 vs. 10.2 months | 38.6 vs. 31.8 months |
| Afatinib vs. Gefitinib | Untreated advanced NSCLC | 11.0 vs. 10.9 months | 27.9 vs. 24.5 months |
| 1st Gen vs. 3rd Gen (Retrospective) | NSCLC with brain metastases | 44.3 vs. 66.9 months | 59.8 vs. 65.9 months |
Data from various clinical trials and retrospective analyses.[10][11][12]
Experimental Protocols
The following are detailed methodologies for key experiments cited in the evaluation of EGFR inhibitor efficacy.
Cell Viability Assays
Cell viability assays are fundamental for assessing the cytotoxic or cytostatic effects of inhibitors.[3]
1. MTT Assay
The MTT (3-(4,5-dimethylthiazol-2-yl)-2,5-diphenyltetrazolium bromide) assay is a colorimetric assay for assessing cell metabolic activity.[13]
-
Principle : Mitochondrial dehydrogenases in viable cells reduce the yellow, water-soluble MTT to a purple, insoluble formazan.[13] The formazan is then solubilized, and the absorbance is measured, which is directly proportional to the number of viable cells.[13]
-
Protocol :
-
Cell Seeding : Seed cells in a 96-well plate at a density of 5,000-10,000 cells per well and incubate overnight.[13]
-
Compound Treatment : Treat cells with a serial dilution of the EGFR inhibitor for a desired period (e.g., 24, 48, or 72 hours).[13]
-
MTT Addition : Add MTT solution to each well and incubate for 2-4 hours.
-
Solubilization : Add a solubilizing agent (e.g., DMSO) to dissolve the formazan crystals.
-
Absorbance Measurement : Measure the absorbance at a specific wavelength (e.g., 570 nm) using a microplate reader.
-
2. CellTiter-Glo® Luminescent Cell Viability Assay
This assay quantifies ATP, an indicator of metabolically active cells.[3]
-
Principle : The reagent causes cell lysis and generates a luminescent signal proportional to the amount of ATP present.[3]
-
Protocol :
-
Cell Seeding : Seed cells in an opaque-walled 96-well plate.[3]
-
Compound Treatment : Treat cells with the EGFR inhibitor.
-
Reagent Addition : Add CellTiter-Glo® Reagent to each well.[3]
-
Incubation : Incubate for a short period to stabilize the luminescent signal.
-
Luminescence Measurement : Measure luminescence using a luminometer.
-
Experimental Workflow for Cell Viability Assay
The general workflow for assessing the effect of an EGFR inhibitor on cell viability is as follows:
Caption: Cell viability assay experimental workflow.
Conclusion
The development of EGFR inhibitors has significantly advanced the treatment of EGFR-mutant cancers. While first-generation inhibitors are effective against sensitizing mutations, second and third-generation inhibitors have been crucial in overcoming acquired resistance. Osimertinib, a third-generation inhibitor, has demonstrated superior efficacy in patients with the T790M resistance mutation and has shown improved outcomes in first-line settings. The choice of inhibitor should be guided by the specific EGFR mutation profile of the tumor. Continued research is essential for developing strategies to overcome further resistance mechanisms.
References
- 1. A comprehensive pathway map of epidermal growth factor receptor signaling - PMC [pmc.ncbi.nlm.nih.gov]
- 2. creative-diagnostics.com [creative-diagnostics.com]
- 3. benchchem.com [benchchem.com]
- 4. lifesciences.danaher.com [lifesciences.danaher.com]
- 5. ClinPGx [clinpgx.org]
- 6. benchchem.com [benchchem.com]
- 7. In vitro modeling to determine mutation specificity of EGFR tyrosine kinase inhibitors against clinically relevant EGFR mutants in non-small-cell lung cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 8. mdpi.com [mdpi.com]
- 9. mdpi.com [mdpi.com]
- 10. mdpi.com [mdpi.com]
- 11. ascopubs.org [ascopubs.org]
- 12. ascopubs.org [ascopubs.org]
- 13. benchchem.com [benchchem.com]
Comparison of Cross-Reactivity for [Target Protein] Antibodies from Various Vendors
Please specify the "[Target Protein]" for which you want a cross-reactivity comparison guide. The following is a template to demonstrate the format and content of the guide you have requested. Replace "[Target Protein]" and the placeholder data with the specifics of your protein of interest.
This guide provides a comparative analysis of the cross-reactivity of commercially available antibodies for [Target Protein]. The data presented here is intended to assist researchers in selecting the most suitable antibody for their specific experimental needs, minimizing off-target effects and ensuring data accuracy.
Data Summary
The following table summarizes the cross-reactivity of [Target Protein] antibodies from different vendors against common orthologs. The data is compiled from manufacturer datasheets and internal validation studies.
| Vendor | Antibody (Clone) | Host Species | Tested Cross-Reactivity | Reactivity Level | Application |
| Vendor A | Anti-[Target Protein] (Clone A1) | Mouse | Human, Mouse, Rat | High (Human), Moderate (Mouse), Low (Rat) | WB, IHC |
| Vendor B | Anti-[Target Protein] (Clone B1) | Rabbit | Human, Mouse, Zebrafish | High (Human), High (Mouse), Negative (Zebrafish) | WB, ELISA |
| Vendor C | Anti-[Target Protein] (Polyclonal) | Goat | Human, Rat, Chicken | Moderate (Human), Low (Rat), Negative (Chicken) | WB, FC |
| Vendor D | Anti-[Target Protein] (Clone D1) | Mouse | Human, Mouse, Drosophila | High (Human), Negative (Mouse), Negative (Drosophila) | IHC, IF |
Note: "Reactivity Level" is a qualitative summary based on the signal-to-noise ratio observed in the specified applications. "WB" refers to Western Blot, "IHC" to Immunohistochemistry, "ELISA" to Enzyme-Linked Immunosorbent Assay, "FC" to Flow Cytometry, and "IF" to Immunofluorescence.
Experimental Protocols
This protocol outlines the general procedure used to assess the cross-reactivity of [Target Protein] antibodies.
-
Lysate Preparation: Prepare whole-cell lysates from cell lines or tissues expressing the target protein and its orthologs (e.g., human, mouse, rat). Determine the protein concentration of each lysate using a BCA assay.
-
SDS-PAGE: Load 20-30 µg of each protein lysate onto a 4-20% Tris-glycine gel. Run the gel at 100-120V for 90 minutes or until the dye front reaches the bottom.
-
Protein Transfer: Transfer the separated proteins from the gel to a PVDF membrane at 100V for 60 minutes.
-
Blocking: Block the membrane with 5% non-fat dry milk or bovine serum albumin (BSA) in Tris-buffered saline with 0.1% Tween 20 (TBST) for 1 hour at room temperature.
-
Primary Antibody Incubation: Incubate the membrane with the primary antibody (e.g., Anti-[Target Protein], Clone A1) diluted in the blocking buffer overnight at 4°C with gentle agitation. The optimal dilution should be determined according to the manufacturer's datasheet (typically 1:1000 to 1:5000).
-
Washing: Wash the membrane three times for 10 minutes each with TBST.
-
Secondary Antibody Incubation: Incubate the membrane with a horseradish peroxidase (HRP)-conjugated secondary antibody (e.g., Goat Anti-Mouse IgG-HRP) diluted in the blocking buffer for 1 hour at room temperature.
-
Detection: Detect the signal using an enhanced chemiluminescence (ECL) substrate and image the blot using a chemiluminescence detection system. The presence and intensity of a band at the expected molecular weight indicate the antibody's reactivity with the protein from that species.
Visualizations
Caption: Workflow for assessing antibody cross-reactivity using Western blotting.
Caption: Illustration of specific vs. cross-reactive antibody binding.
The Guardian of the Genome: A Comparative Analysis of p53 Function in Health and Disease
The tumor suppressor protein p53, often hailed as the "guardian of the genome," plays a pivotal role in maintaining cellular and genetic stability.[1][2] In healthy cells, p53 acts as a critical checkpoint, responding to various stress signals to orchestrate DNA repair, cell cycle arrest, or programmed cell death (apoptosis).[2][3][4] However, in a vast number of human cancers, this guardian is incapacitated through mutation, not only losing its protective functions but often gaining new, oncogenic capabilities that drive tumor progression and therapeutic resistance.[5][6][7] This guide provides a comparative analysis of p53's function in healthy versus diseased states, supported by experimental data and detailed methodologies.
Functional Comparison of Wild-Type vs. Mutant p53
The functional dichotomy between wild-type (WT) p53 and its mutant forms is a central theme in cancer biology. While WT p53 is a key tumor suppressor, mutant p53 can actively promote cancer.[6][8] The majority of TP53 mutations in cancer are missense mutations, leading to the production of a full-length, but altered, p53 protein that accumulates to high levels in tumor cells.[5][8][9]
| Feature | Wild-Type p53 (Healthy State) | Mutant p53 (Diseased State - Cancer) |
| Primary Role | Tumor Suppressor | Oncogene (Gain-of-Function) / Dominant-Negative |
| Response to DNA Damage | Activates cell cycle arrest and DNA repair mechanisms.[2] | Fails to initiate cell cycle arrest, leading to genomic instability.[5] |
| Apoptosis Regulation | Induces apoptosis via intrinsic and extrinsic pathways.[10] | Inhibits apoptosis, promoting cell survival.[5] |
| Cell Proliferation | Suppresses cell proliferation.[5] | Promotes uncontrolled cell proliferation.[5] |
| Metastasis | Suppresses cell migration and invasion.[5] | Promotes tumor invasion and metastasis.[5] |
| Metabolic Regulation | Promotes oxidative phosphorylation and inhibits glycolysis (Warburg effect).[2] | Enhances the Warburg effect and supports anabolic pathways for rapid cell growth.[2][5] |
| Therapeutic Response | Sensitizes cells to chemotherapy and radiation. | Confers resistance to various cancer therapies.[5] |
| Protein Stability | Short half-life, tightly regulated by MDM2-mediated degradation.[10] | Often stabilized and accumulates to high levels in tumor cells.[5][8] |
Signaling Pathways: A Tale of Two Functions
The signaling pathways governed by p53 diverge dramatically between its wild-type and mutant forms. In healthy cells, p53 activation by cellular stress, such as DNA damage, triggers a cascade of events aimed at preserving genomic integrity. In cancer, mutant p53 hijacks cellular machinery to promote tumorigenesis.
Wild-Type p53 Signaling in a Healthy Cell
Upon cellular stress, kinases like ATM and Chk2 phosphorylate p53, stabilizing it by preventing its degradation by the E3 ubiquitin ligase MDM2.[10] Activated p53 then transcriptionally activates target genes to induce cell cycle arrest (e.g., p21) or apoptosis (e.g., BAX, PUMA, Noxa).[2][10]
Caption: Wild-Type p53 signaling pathway in response to cellular stress.
Mutant p53 Gain-of-Function Signaling in a Cancer Cell
Mutant p53 proteins lose their ability to bind to the canonical p53 DNA response elements. Instead, they interact with other transcription factors (e.g., NF-Y, ETS, SREBPs) to aberrantly regulate gene expression, promoting cell proliferation, survival, and metastasis.[5][8][9]
Caption: Mutant p53 gain-of-function signaling in cancer cells.
Experimental Protocols for p53 Function Analysis
The study of p53 function relies on a variety of well-established molecular and cellular biology techniques. Below are detailed methodologies for key experiments.
Western Blotting for p53 Expression and Phosphorylation
This technique is used to detect and quantify the total amount of p53 protein and its specific post-translational modifications, such as phosphorylation at Serine 15, which is indicative of its activation.[11]
Methodology:
-
Cell Lysis: Lyse healthy and diseased cells separately in RIPA buffer supplemented with protease and phosphatase inhibitors to extract total protein.
-
Protein Quantification: Determine the protein concentration of each lysate using a BCA assay.
-
SDS-PAGE: Load equal amounts of protein (e.g., 20-30 µg) onto a polyacrylamide gel and separate the proteins by size via electrophoresis.
-
Protein Transfer: Transfer the separated proteins from the gel to a PVDF membrane.
-
Blocking: Block the membrane with 5% non-fat dry milk in Tris-Buffered Saline with 0.1% Tween-20 (TBST) for 1 hour at room temperature to prevent non-specific antibody binding.[12]
-
Primary Antibody Incubation: Incubate the membrane overnight at 4°C with primary antibodies specific for total p53, phospho-p53 (e.g., Ser15), and a loading control (e.g., β-actin).
-
Secondary Antibody Incubation: Wash the membrane with TBST and incubate with a horseradish peroxidase (HRP)-conjugated secondary antibody for 1 hour at room temperature.
-
Detection: Visualize the protein bands using an enhanced chemiluminescence (ECL) substrate and an imaging system. Quantify band intensity using densitometry software.
Chromatin Immunoprecipitation (ChIP) for p53 DNA Binding
ChIP is used to determine if p53 is binding to the promoter regions of its target genes (e.g., CDKN1A (p21), BAX) in vivo.
Methodology:
-
Cross-linking: Treat cells with formaldehyde to cross-link proteins to DNA.
-
Cell Lysis and Sonication: Lyse the cells and shear the chromatin into small fragments (200-1000 bp) using sonication.
-
Immunoprecipitation: Incubate the sheared chromatin with an antibody specific to p53. The antibody-p53-DNA complexes are then pulled down using protein A/G-agarose beads.
-
Reverse Cross-linking: Reverse the cross-links by heating the samples.
-
DNA Purification: Purify the DNA from the immunoprecipitated samples.
-
Analysis: Use quantitative PCR (qPCR) with primers specific for the promoter regions of known p53 target genes to quantify the amount of precipitated DNA. An increase in precipitated DNA in the p53-IP sample compared to a negative control (e.g., IgG-IP) indicates p53 binding.
Apoptosis Assay (Annexin V/Propidium Iodide Staining)
This flow cytometry-based assay quantifies the extent of apoptosis induced by p53 activation.
Methodology:
-
Cell Treatment: Treat cells with a DNA-damaging agent (e.g., doxorubicin) to activate the p53 pathway.
-
Cell Staining: Harvest the cells and stain them with FITC-conjugated Annexin V and Propidium Iodide (PI). Annexin V binds to phosphatidylserine on the outer leaflet of the plasma membrane of apoptotic cells, while PI enters and stains the DNA of late apoptotic or necrotic cells with compromised membranes.
-
Flow Cytometry: Analyze the stained cells using a flow cytometer.
-
Data Analysis: Quantify the percentage of cells in different quadrants: viable (Annexin V-/PI-), early apoptotic (Annexin V+/PI-), and late apoptotic/necrotic (Annexin V+/PI+).
Experimental Workflow Diagram
References
- 1. Some p53 mutations could help fight cancer | BCM [bcm.edu]
- 2. P53 mutations and cancer: a tight linkage - PMC [pmc.ncbi.nlm.nih.gov]
- 3. KEGG PATHWAY: p53 signaling pathway - Homo sapiens (human) [kegg.jp]
- 4. P53 Signaling Pathway | Pathway - PubChem [pubchem.ncbi.nlm.nih.gov]
- 5. academic.oup.com [academic.oup.com]
- 6. Mutant p53 in Cancer: New Functions and Therapeutic Opportunities - PMC [pmc.ncbi.nlm.nih.gov]
- 7. TP53 mutations in cancer: Molecular features and therapeutic opportunities (Review) - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. Gain-of-function mutant p53 in cancer progression and therapy - PMC [pmc.ncbi.nlm.nih.gov]
- 9. aacrjournals.org [aacrjournals.org]
- 10. p53 Pathway for Apoptosis Signaling | Thermo Fisher Scientific - JP [thermofisher.com]
- 11. Detection of Post-translationally Modified p53 by Western Blotting | Springer Nature Experiments [experiments.springernature.com]
- 12. resources.novusbio.com [resources.novusbio.com]
validating the results of a [Target Protein] screen with orthogonal assays
A critical step in drug discovery is the validation of hits from primary high-throughput screens. Orthogonal assays, which employ different detection methods and principles from the primary assay, are essential for confirming that the observed activity is genuine and not an artifact of the screening technology. This guide provides a comparison of common orthogonal assays used to validate the results of a [Target Protein] screen, complete with experimental protocols and data presentation guidelines.
Workflow for Validating Screening Hits
The process of validating hits from a primary screen typically follows a multi-step approach, starting with less complex, higher-throughput assays and progressing to more physiologically relevant but lower-throughput assays.
Caption: Workflow for hit validation.
Comparison of Orthogonal Assays
The choice of orthogonal assays depends on the nature of the target protein and the primary screening assay. A combination of biochemical, biophysical, and cell-based assays is often employed to build a comprehensive picture of a compound's activity.
| Assay Type | Assay Principle | Information Provided | Throughput | Advantages | Disadvantages |
| Biochemical Assays | |||||
| Surface Plasmon Resonance (SPR) | Measures changes in refractive index upon binding of an analyte to a ligand immobilized on a sensor chip. | Binding kinetics (kon, koff), affinity (KD), and specificity. | Low to Medium | Label-free, real-time analysis, provides detailed kinetic information. | Requires protein immobilization, potential for mass transport limitations. |
| Isothermal Titration Calorimetry (ITC) | Measures the heat change upon binding of a ligand to a protein in solution. | Binding affinity (KD), stoichiometry (n), and thermodynamics (ΔH, ΔS). | Low | Label-free, solution-based, provides a complete thermodynamic profile of the interaction. | Requires large amounts of pure protein and compound, low throughput. |
| Biophysical Assays | |||||
| Thermal Shift Assay (TSA) / Differential Scanning Fluorimetry (DSF) | Measures the change in the melting temperature (Tm) of a protein upon ligand binding using a fluorescent dye. | Target engagement, relative affinity. | High | Inexpensive, high-throughput, requires small amounts of protein. | Indirect measure of binding, some compounds may interfere with the dye. |
| Cell-Based Assays | |||||
| Cellular Thermal Shift Assay (CETSA) | Measures the thermal stabilization of a target protein in cells or cell lysates upon ligand binding. | Target engagement in a cellular context. | Medium | Label-free, confirms target binding in a physiological environment. | Requires a specific antibody for detection, optimization can be challenging. |
| NanoBRET™ Target Engagement Assay | Measures the binding of a fluorescently labeled compound to a NanoLuc® luciferase-tagged target protein in living cells via bioluminescence resonance energy transfer (BRET). | Target engagement, affinity, and residence time in living cells. | High | Real-time measurement in live cells, high sensitivity. | Requires genetic modification of the target protein, dependent on specific fluorescent ligands. |
| Western Blot | Detects changes in the level or post-translational modification (e.g., phosphorylation) of the target protein or downstream signaling molecules. | Target modulation, downstream pathway effects. | Low | Widely used, provides information on downstream signaling. | Semi-quantitative, low throughput, requires specific antibodies. |
| Reporter Gene Assay | Measures the transcriptional activity of a promoter that is regulated by the signaling pathway of interest. | Functional cellular response, pathway activation or inhibition. | High | High-throughput, sensitive, easily quantifiable. | Indirect measure of target activity, potential for off-target effects on the reporter system. |
Signaling Pathway Context for Assay Selection
Understanding the signaling pathway of the target protein is crucial for selecting appropriate functional assays. For example, if the target is a kinase, assays measuring the phosphorylation of its substrate would be highly relevant.
Caption: Hypothetical signaling pathway.
Detailed Experimental Protocols
Cellular Thermal Shift Assay (CETSA)
This protocol provides a general framework for performing a CETSA experiment to validate target engagement in a cellular context.
Materials:
-
Cell culture medium and supplements
-
Phosphate-buffered saline (PBS)
-
Compound of interest
-
Cell lysis buffer (e.g., RIPA buffer with protease and phosphatase inhibitors)
-
Antibodies specific to the target protein and a loading control
-
SDS-PAGE gels and buffers
-
Western blot transfer system and membranes
-
Chemiluminescent substrate
Methodology:
-
Cell Culture and Treatment:
-
Plate cells at an appropriate density and allow them to adhere overnight.
-
Treat the cells with the compound of interest at various concentrations or with a vehicle control for a specified period.
-
-
Heat Shock:
-
After treatment, harvest the cells and resuspend them in PBS.
-
Aliquot the cell suspension into PCR tubes.
-
Expose the cells to a temperature gradient using a thermal cycler for a fixed time (e.g., 3 minutes). A typical temperature range is 40-70°C.
-
-
Cell Lysis and Protein Quantification:
-
Lyse the cells by freeze-thaw cycles or by adding lysis buffer.
-
Centrifuge the lysates at high speed to pellet the aggregated proteins.
-
Collect the supernatant containing the soluble protein fraction.
-
Determine the protein concentration of each sample using a suitable method (e.g., BCA assay).
-
-
Western Blot Analysis:
-
Normalize the protein concentrations of all samples.
-
Separate the proteins by SDS-PAGE and transfer them to a PVDF or nitrocellulose membrane.
-
Probe the membrane with a primary antibody against the target protein, followed by a secondary antibody conjugated to horseradish peroxidase (HRP).
-
Detect the signal using a chemiluminescent substrate and an imaging system.
-
Re-probe the membrane with an antibody against a loading control (e.g., GAPDH, β-actin) to ensure equal protein loading.
-
Data Analysis:
-
Quantify the band intensities for the target protein at each temperature and normalize them to the loading control.
-
Plot the normalized band intensity as a function of temperature for both the vehicle- and compound-treated samples.
-
A shift in the melting curve to a higher temperature in the presence of the compound indicates target stabilization and therefore target engagement.
NanoBRET™ Target Engagement Assay
This protocol outlines the general steps for a NanoBRET™ assay in living cells.
Materials:
-
Cells stably or transiently expressing the target protein fused to NanoLuc® luciferase.
-
Opti-MEM® I Reduced Serum Medium
-
NanoBRET™ Tracer (a fluorescently labeled ligand for the target protein)
-
Compound of interest
-
NanoBRET™ Nano-Glo® Substrate and Extracellular NanoLuc® Inhibitor
-
White, opaque 96- or 384-well assay plates
Methodology:
-
Cell Plating:
-
Harvest and resuspend the cells expressing the NanoLuc®-target fusion protein in Opti-MEM®.
-
Plate the cells in the assay plate and incubate overnight.
-
-
Compound and Tracer Addition:
-
Prepare serial dilutions of the compound of interest.
-
In a separate plate, prepare the NanoBRET™ Tracer dilution.
-
Add the compound dilutions to the cells, followed by the addition of the NanoBRET™ Tracer.
-
Incubate the plate at 37°C in a CO2 incubator for the desired time (e.g., 2 hours).
-
-
Signal Detection:
-
Prepare the NanoBRET™ Nano-Glo® Substrate detection reagent according to the manufacturer's instructions.
-
Add the detection reagent to each well.
-
Read the plate on a luminometer capable of measuring donor (460 nm) and acceptor (610 nm) emission wavelengths.
-
Data Analysis:
-
Calculate the raw BRET ratio by dividing the acceptor emission by the donor emission.
-
Convert the raw BRET ratios to milliBRET units (mBU) by multiplying by 1000.
-
Plot the mBU values against the logarithm of the compound concentration.
-
Fit the data to a sigmoidal dose-response curve to determine the IC50 value, which represents the concentration of the compound that displaces 50% of the tracer.
A Comparative Analysis of Human and Mouse p53 DNA-Binding Domain Crystal Structures
The tumor suppressor protein p53 plays a critical role in preventing cancer formation, and its DNA-binding domain is a frequent site of cancer-causing mutations. Understanding the structural nuances of this domain across different species is crucial for the development of targeted cancer therapies. This guide provides a comparative overview of the crystal structures of the p53 DNA-binding domain from Homo sapiens (human) and Mus musculus (mouse), offering researchers a detailed look at the experimental data and methodologies used to determine these structures.
Quantitative Data Comparison
The following table summarizes key crystallographic data for the human and mouse p53 DNA-binding domain structures, providing a clear comparison of their determined properties.
| Parameter | Human p53 DNA-Binding Domain | Mouse p53 DNA-Binding Domain |
| PDB ID | 2XWR[1] | 1HU8[2] |
| Organism | Homo sapiens[1] | Mus musculus[2] |
| Resolution | 1.68 Å[1] | 2.70 Å[2] |
| Space Group | P 21 21 21 | P 21 21 21 |
| Unit Cell (Å) | a=55.3, b=64.4, c=113.8 | a=64.8, b=78.9, c=107.2 |
| R-Value Work | 0.173[1] | 0.239[2] |
| R-Value Free | 0.209[1] | 0.299[2] |
Experimental Protocols
Detailed methodologies are essential for the replication and validation of scientific findings. Below are the protocols used for the expression, purification, and crystallization of the human and mouse p53 DNA-binding domains.
Human p53 DNA-Binding Domain (PDB: 2XWR)
Protein Expression and Purification: The human p53 core domain (residues 94-312) was expressed in Escherichia coli. The purification process involved metal-affinity chromatography followed by size-exclusion chromatography to ensure a high degree of purity.
Crystallization: Crystals of the human p53 DNA-binding domain were grown at 20°C using the sitting drop vapor diffusion method. The crystallization drops were prepared by mixing equal volumes of the protein solution (10 mg/mL in 20 mM Tris-HCl pH 7.2, 150 mM NaCl, and 10 mM DTT) and the reservoir solution containing 20% (w/v) PEG 3350, 0.2 M ammonium sulfate, and 0.1 M Bis-Tris pH 6.5.
Mouse p53 DNA-Binding Domain (PDB: 1HU8)
Protein Expression and Purification: The mouse p53 core domain (residues 91-289) was expressed in E. coli strain BL21(DE3)[2]. The protein was purified using a two-step process involving Ni-NTA affinity chromatography to capture the His-tagged protein, followed by size-exclusion chromatography to obtain a homogenous sample.
Crystallization: The mouse p53 DNA-binding domain was crystallized using the hanging drop vapor diffusion method at 22°C. The protein solution (5 mg/mL in 20 mM Tris-HCl pH 8.0, 150 mM NaCl, and 5 mM DTT) was mixed with an equal volume of the reservoir solution containing 12-15% (w/v) PEG 8000, 0.2 M ammonium sulfate, and 0.1 M sodium cacodylate pH 6.5.
Experimental Workflow Visualization
The following diagram illustrates the general experimental workflow for determining the crystal structure of a protein, from gene cloning to final structure deposition.
Caption: A generalized workflow for protein crystallography.
References
A Comparative Guide to Troponin Biomarkers for Cardiovascular Disease Diagnosis
For Researchers, Scientists, and Drug Development Professionals
This guide provides an objective comparison of cardiac troponin assays, the gold-standard biomarkers for the diagnosis of acute myocardial infarction (AMI), and other cardiac injuries. We present supporting experimental data, detailed methodologies, and visual workflows to aid in the selection and validation of these critical diagnostic tools.
Introduction to Cardiac Troponins
Cardiac troponins (cTn), specifically troponin I (cTnI) and troponin T (cTnT), are regulatory proteins exclusive to the heart muscle.[1] Their release into the bloodstream is a highly specific indicator of myocardial cell damage, making them the preferred biomarkers for diagnosing AMI.[2][3] Over the years, troponin assays have evolved from conventional methods to high-sensitivity assays (hs-cTn), which can detect much lower concentrations of troponins, enabling earlier and more accurate diagnosis of myocardial injury.[4]
High-sensitivity assays are characterized by their ability to measure troponin concentrations in more than 50% of a healthy reference population and by a coefficient of variation (CV) of less than 10% at the 99th percentile upper reference limit (URL) of that population.[5][6]
Performance Comparison of Troponin Assays
The following tables summarize the quantitative performance of high-sensitivity troponin assays from leading manufacturers compared to conventional troponin and an alternative biomarker, Creatine Kinase-MB (CK-MB).
Table 1: Analytical Performance of Commercial High-Sensitivity Troponin Assays
| Assay (Manufacturer) | Analyte | Limit of Detection (LoD) (ng/L) | 99th Percentile URL (ng/L) | Coefficient of Variation (CV) at 99th percentile URL (%) |
| Elecsys Troponin T Gen 5 STAT (Roche) | cTnT | 5 | Overall: 19, Female: 14, Male: 22[7] | <10%[8] |
| ARCHITECT STAT hs-Troponin I (Abbott) | cTnI | 1.5 | Female: 16, Male: 34[7] | 3.1% - 4.7%[9] |
| Atellica IM hs-Troponin I (Siemens) | cTnI | 1.6 | Female: 34, Male: 53[4][7] | 3.7%[4] |
| Access hsTnI (Beckman Coulter) | cTnI | 0.58 - 0.69 | Overall: 18.2, Female: 7.8, Male: 11.3[10] | 9.8% (at 2.83 ng/L)[11][12] |
URL: Upper Reference Limit. Data is compiled from multiple sources and may vary based on the specific study and population.
Table 2: Diagnostic Accuracy Comparison: High-Sensitivity vs. Conventional Troponin and CK-MB
| Biomarker Assay | Sensitivity | Specificity | Area Under the Curve (AUC) |
| High-Sensitivity Troponin T (at presentation) | 0.94[4] | 0.73[4] | 0.926[13] |
| Conventional Troponin I (at presentation) | 0.72[4] | 0.95[4] | 0.940[13] |
| High-Sensitivity Troponin T (serial) | 99.02% | Similar to conventional | Not specified |
| Conventional Troponin I (serial) | 33.33% | Similar to hs-cTnT | Not specified |
| Troponin I | 95% | 97.4% | 0.92 |
| CK-MB | 96.4% | 85.8% | 0.78 |
Data is synthesized from various studies and represents a general comparison. Performance can vary depending on the specific assay and clinical context.
Experimental Protocols
Detailed methodologies are crucial for the accurate and reproducible measurement of troponin levels. Below is a generalized protocol for a sandwich ELISA (Enzyme-Linked Immunosorbent Assay) for cardiac Troponin I, based on commercially available kits.
General Troponin I Sandwich ELISA Protocol
Principle: This assay employs a quantitative sandwich enzyme immunoassay technique. A monoclonal antibody specific for Troponin I is pre-coated onto a microplate. Standards and samples are pipetted into the wells, and any Troponin I present is bound by the immobilized antibody. After washing away any unbound substances, an enzyme-linked polyclonal antibody specific for Troponin I is added to the wells. Following a wash to remove any unbound antibody-enzyme reagent, a substrate solution is added to the wells, and color develops in proportion to the amount of Troponin I bound in the initial step. The color development is stopped, and the intensity of the color is measured.
Materials:
-
Troponin I ELISA Plate
-
Troponin I Standard
-
Assay Diluent
-
Wash Buffer Concentrate
-
Enzyme-Conjugate Reagent (e.g., HRP-conjugated anti-Troponin I)
-
TMB Substrate
-
Stop Solution
-
Microplate reader capable of measuring absorbance at 450 nm
-
Pipettes and pipette tips
-
Distilled or deionized water
-
Absorbent paper
Procedure:
-
Reagent Preparation: Prepare all reagents, standards, and samples as instructed in the specific kit manual. This typically involves reconstituting lyophilized standards and diluting wash buffer concentrate.
-
Standard and Sample Addition: Add 100 µL of each standard, control, and sample into the appropriate wells of the microplate.
-
Incubation 1: Cover the plate and incubate for a specified time at a specified temperature (e.g., 90 minutes at room temperature).[1]
-
Washing 1: Aspirate or decant the contents of each well. Wash the wells three to four times with 300 µL of 1X Wash Buffer per well. After the final wash, remove any remaining Wash Buffer by inverting the plate and blotting it against clean paper towels.
-
Conjugate Addition: Add 100 µL of the Enzyme-Conjugate Reagent to each well.
-
Incubation 2: Cover the plate and incubate for a specified time at a specified temperature (e.g., 60 minutes at room temperature).
-
Washing 2: Repeat the washing step as in step 4.
-
Substrate Addition: Add 100 µL of TMB Substrate to each well.
-
Incubation 3: Incubate the plate for a specified time in the dark at room temperature (e.g., 15-30 minutes).
-
Stop Reaction: Add 50-100 µL of Stop Solution to each well. The color in the wells should change from blue to yellow.
-
Read Absorbance: Read the absorbance of each well at 450 nm within 15-30 minutes of adding the Stop Solution.
-
Calculation: Construct a standard curve by plotting the mean absorbance for each standard on the y-axis against the concentration on the x-axis. Use the standard curve to determine the concentration of Troponin I in the samples.
Visualizing the Diagnostic Workflow
The following diagrams illustrate the general signaling pathway leading to troponin release and a typical experimental workflow for the diagnosis of Acute Myocardial Infarction (AMI) using troponin measurements.
Figure 1: Simplified signaling pathway of cardiac troponin release following myocardial ischemia.
Figure 2: Diagnostic workflow for Acute Myocardial Infarction (AMI) using serial troponin testing.
References
- 1. Performance evaluation of the high sensitive troponin I assay on the Atellica IM analyser - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. New Study Confirms Clinical Performance of Beckman Coulter’s Access hsTnI Assay in Expediting Diagnosis of Acute Coronary Syndrome | Beckman Coulter [beckmancoulter.com]
- 3. Analytical and Clinical Considerations in Implementing the Roche Elecsys Troponin T Gen 5 STAT Assay - ProQuest [proquest.com]
- 4. cdn0.scrvt.com [cdn0.scrvt.com]
- 5. myadlm.org [myadlm.org]
- 6. All you need to know about troponin measurements [acutecaretesting.org]
- 7. myadlm.org [myadlm.org]
- 8. "Analytical performance evaluation of the Elecsys® Troponin T Gen 5 STA" by Robert L Fitzgerald, Judd E Hollander et al. [scholarlyworks.lvhn.org]
- 9. journals.viamedica.pl [journals.viamedica.pl]
- 10. researchgate.net [researchgate.net]
- 11. uab.edu [uab.edu]
- 12. A critical evaluation of the Beckman Coulter Access hsTnI: Analytical performance, reference interval and concordance - PubMed [pubmed.ncbi.nlm.nih.gov]
- 13. researchgate.net [researchgate.net]
A Head-to-Head Comparison of [Target Protein] Assay Kits
For Immediate Publication
[City, State] – [Date] – For researchers in drug discovery and life sciences, the accurate quantification of [Target Protein] is critical for advancing research. A variety of immunoassay kits are available, each employing different technologies with distinct advantages and limitations. This guide provides an objective, data-driven comparison of leading assay technologies for the quantification of [Target Protein], focusing on key performance metrics to aid researchers in selecting the most appropriate kit for their specific needs.
The technologies compared include the traditional Enzyme-Linked Immunosorbent Assay (ELISA), and two homogeneous (no-wash) assays: Time-Resolved Fluorescence Resonance Energy Transfer (TR-FRET) and Amplified Luminescent Proximity Homogeneous Assay (AlphaLISA®).
Assay Principles at a Glance
-
ELISA (Enzyme-Linked Immunosorbent Assay): A plate-based assay that uses antibodies and a color-changing substrate to detect a substance. The multi-step process involves coating a plate with a capture antibody, adding the sample, adding a detection antibody, and then a substrate to produce a measurable colorimetric signal. This method is known for its sensitivity and specificity but requires multiple incubation and wash steps.
-
TR-FRET (Time-Resolved Fluorescence Resonance Energy Transfer): A homogeneous assay that uses two antibodies labeled with donor and acceptor fluorophores.[1] When the antibodies bind to the [Target Protein], the donor and acceptor are brought into close proximity, allowing energy transfer and the emission of a long-lasting fluorescent signal.[1] This no-wash, add-and-read format significantly reduces hands-on time.[1]
-
AlphaLISA® (Amplified Luminescent Proximity Homogeneous Assay): A bead-based, no-wash immunoassay.[2][3] It utilizes Donor and Acceptor beads that are brought together by binding to the [Target Protein].[2][3] Upon laser excitation at 680 nm, the Donor bead releases singlet oxygen, which travels to a nearby Acceptor bead, triggering a chemiluminescent reaction that emits light.[4][5][6] This signal is highly amplified, offering exceptional sensitivity.[2]
Quantitative Performance Comparison
The selection of an assay is often driven by its performance characteristics. The table below summarizes key metrics for representative ELISA, TR-FRET, and AlphaLISA kits designed for [Target Protein] quantification. Data is compiled from typical performance characteristics of commercially available kits.
| Performance Metric | Vendor A: ELISA Kit | Vendor B: TR-FRET Kit | Vendor C: AlphaLISA® Kit |
| Assay Principle | Sandwich ELISA (Colorimetric) | Homogeneous TR-FRET | Homogeneous Proximity Assay |
| Limit of Detection (LOD) | < 10 pg/mL | < 15 pg/mL | < 2 pg/mL |
| Dynamic Range | 15 - 1,000 pg/mL | 20 - 5,000 pg/mL | 2 - 100,000 pg/mL |
| Intra-Assay Precision (%CV) | < 8% | < 7% | < 6% |
| Inter-Assay Precision (%CV) | < 12% | < 10% | < 9% |
| Sample Volume | 50 - 100 µL | 10 - 20 µL | 5 µL |
| Assay Time (Hands-on) | ~1.5 hours | ~15 minutes | ~15 minutes |
| Total Assay Time | 4 - 5 hours | 1 - 2 hours | ~3 hours |
| Wash Steps Required | Yes (3-4) | No | No |
Experimental Protocols
Accurate comparison requires standardized experimental procedures. Below is a generalized protocol for generating a standard curve and quantifying unknown samples using each assay type.
Protocol: Standard Curve Generation & Sample Quantification
1. Reagent Preparation:
-
Prepare all reagents (wash buffers, antibodies, standards, substrates) according to each manufacturer's protocol.
-
Reconstitute the [Target Protein] standard to create a stock solution. Perform a serial dilution of the standard stock to generate a 7-point standard curve, plus a zero-concentration blank.
2. Sample Preparation:
-
Collect samples (e.g., cell culture supernatant, serum, plasma).
-
Centrifuge samples to remove particulates.
-
Dilute samples as necessary to fall within the expected dynamic range of the assay.
3. Assay Procedure:
-
Vendor A (ELISA):
-
Add 100 µL of standards and samples to appropriate wells of the antibody-coated plate.
-
Incubate for 2 hours at room temperature.
-
Wash wells 4 times with Wash Buffer.
-
Add 100 µL of detection antibody. Incubate for 1 hour.
-
Wash wells 4 times.
-
Add 100 µL of substrate solution. Incubate for 15-30 minutes in the dark.
-
Add 50 µL of Stop Solution.
-
Read absorbance at 450 nm within 30 minutes.
-
-
Vendor B (TR-FRET):
-
Add 15 µL of standards and samples to wells of a 96-well plate.
-
Add 5 µL of the combined antibody-fluorophore mix to each well.
-
Incubate for 1.5 hours at room temperature, protected from light.
-
Read the plate using a TR-FRET compatible plate reader.
-
-
Vendor C (AlphaLISA®):
-
Add 5 µL of standards and samples to wells of a 96-well plate.
-
Add 20 µL of Acceptor bead and biotinylated antibody mix.
-
Incubate for 60 minutes at room temperature.
-
Add 25 µL of Streptavidin-Donor beads.[5]
-
Incubate for 60 minutes at room temperature in the dark.
-
Read the plate using an Alpha-enabled plate reader.[5]
-
4. Data Analysis:
-
For all assays, calculate the average signal for each standard and sample.
-
Subtract the average zero-standard signal from all other readings.
-
Plot a standard curve of signal intensity versus the concentration of the standards. Use a four-parameter logistic (4-PL) curve fit.
-
Determine the concentration of [Target Protein] in the unknown samples by interpolating their signal values from the standard curve.[7]
Visualized Workflows and Pathways
To better illustrate the underlying biology and experimental processes, the following diagrams are provided.
Caption: A simplified signaling cascade leading to the production and secretion of [Target Protein].
Caption: Experimental workflow for the head-to-head comparison of the three assay kits.
References
Confirmatory Analysis of [Target Protein] and a Novel Binding Partner: A Comparative Guide
For researchers in drug development and molecular biology, confirming a newly identified protein-protein interaction (PPI) is a critical step in elucidating biological pathways and identifying potential therapeutic targets. This guide provides a comparative overview of established methods for validating the interaction between a [Target Protein] and its novel binding partner. We present supporting data, detailed protocols, and visual workflows to assist in selecting the most appropriate experimental approach.
Data Presentation: Quantitative Comparison of Interaction Assays
The selection of an appropriate assay depends on the desired balance between qualitative confirmation and precise quantitative measurement. The following table summarizes hypothetical quantitative data from four common validation techniques, illustrating the types of results each method yields for the interaction between [Target-Protein] and its Novel Binding Partner.
| Method | Parameter Measured | [Target-Protein] + Novel Partner | Negative Control | Interpretation |
| Co-Immunoprecipitation (Co-IP) | Band Intensity (Arbitrary Units) | 8500 | 150 | Strong evidence of interaction in a cellular context. |
| GST Pull-Down Assay | Eluted Protein (ng) | 450 | 25 | Indicates a direct physical interaction. |
| Yeast Two-Hybrid (Y2H) | β-galactosidase Activity (Miller Units) | 350 | 5 | Suggests a direct interaction within the yeast nucleus. |
| Biolayer Interferometry (BLI) | Affinity (K D ) | 50 nM | No Binding Detected | Provides high-confidence, quantitative data on binding affinity and kinetics. |
Experimental Methodologies and Workflows
An informed choice of methodology requires a thorough understanding of the principles and procedures involved. Below are detailed protocols for four key validation experiments.
Co-IP is considered a gold-standard technique for verifying PPIs within a cellular environment, demonstrating that the interaction occurs under physiological conditions.[1] This method uses an antibody to capture a specific "bait" protein from a cell lysate, thereby also isolating any "prey" proteins bound to it.[2][3]
Experimental Protocol:
-
Cell Lysis: Harvest cells expressing the target proteins and lyse them in a non-denaturing buffer to maintain protein complexes.[4]
-
Pre-Clearing: (Optional but recommended) Incubate the lysate with control beads to minimize non-specific binding.[4]
-
Immunoprecipitation: Add an antibody specific to the [Target Protein] to the lysate and incubate to form antibody-antigen complexes.[5]
-
Complex Capture: Add Protein A/G magnetic or agarose beads to capture the antibody-protein complexes.[3]
-
Washing: Wash the beads multiple times with a suitable wash buffer to remove non-specifically bound proteins.[6]
-
Elution: Elute the bound proteins from the beads.
-
Analysis: Analyze the eluted proteins by Western blotting using an antibody against the novel binding partner.[6]
Co-Immunoprecipitation Workflow
The GST pull-down assay is an in vitro method used to confirm a direct physical interaction between two proteins.[7][8] It utilizes a recombinant "bait" protein fused to Glutathione-S-Transferase (GST), which is immobilized on glutathione-coated beads.[9]
Experimental Protocol:
-
Bait Protein Expression: Express and purify the GST-tagged [Target Protein].
-
Immobilization: Incubate the purified GST-[Target Protein] with glutathione-sepharose beads to immobilize the bait.[10]
-
Prey Protein Preparation: Prepare a lysate from cells expressing the novel binding partner or use a purified version of the partner protein.[11]
-
Binding: Add the prey protein source to the beads and incubate to allow for interaction.[10]
-
Washing: Wash the beads extensively to remove non-specific binders.[11]
-
Elution: Elute the protein complexes from the beads using a solution of reduced glutathione.
-
Analysis: Analyze the eluted fractions for the presence of the novel binding partner by SDS-PAGE and Coomassie staining or Western blot.[8]
GST Pull-Down Assay Workflow
The Yeast Two-Hybrid (Y2H) system is a powerful genetic method for detecting binary protein interactions in vivo.[12][13] It relies on the reconstitution of a functional transcription factor when two proteins of interest, a "bait" and a "prey," interact within the yeast nucleus.[14]
Principle of Interaction:
The bait protein is fused to a DNA-binding domain (DBD), and the prey protein is fused to an activation domain (AD). If the bait and prey interact, the DBD and AD are brought into close proximity, activating the transcription of a reporter gene (e.g., LacZ), which results in a detectable phenotype.[15]
Yeast Two-Hybrid (Y2H) Principle
Experimental Protocol:
-
Vector Construction: Clone the cDNAs for the [Target Protein] and the novel partner into bait (DBD) and prey (AD) vectors, respectively.[16]
-
Yeast Transformation: Co-transform a suitable yeast strain with both the bait and prey plasmids.[12]
-
Selection: Plate the transformed yeast on selective media lacking specific nutrients to select for cells containing both plasmids.
-
Reporter Assay: Grow colonies on media containing a substrate for the reporter gene (e.g., X-gal for LacZ) or perform a quantitative liquid assay (e.g., β-galactosidase assay) to measure interaction strength.[14]
BLI is a label-free optical technique that provides real-time, quantitative data on the kinetics and affinity of biomolecular interactions.[17][18] It measures changes in the interference pattern of white light reflected from a biosensor tip as molecules bind and dissociate.[19]
Experimental Protocol:
-
Ligand Immobilization: Immobilize a purified [Target Protein] (the ligand) onto the surface of a biosensor tip. This is often done via a high-affinity tag like biotin-streptavidin.[20]
-
Baseline: Equilibrate the biosensor in a buffer to establish a stable baseline signal.[17]
-
Association: Dip the biosensor into a solution containing the novel binding partner (the analyte) at various concentrations and measure the binding response over time.[19]
-
Dissociation: Move the biosensor back into the buffer and measure the dissociation of the analyte over time.
-
Data Analysis: Fit the association and dissociation curves to a binding model to determine the association rate (kₐ), dissociation rate (kₔ), and the equilibrium dissociation constant (K D ).[21]
Biolayer Interferometry (BLI) Workflow
Hypothetical Signaling Pathway
Understanding the biological context of the interaction is paramount. The diagram below illustrates a hypothetical signaling pathway where the [Target Protein], a kinase, is activated by an upstream signal. Upon activation, it binds to the Novel Binding Partner, a putative scaffold protein, leading to the recruitment and phosphorylation of a downstream effector, ultimately resulting in a cellular response.
Hypothetical Signaling Pathway
References
- 1. Methods to investigate protein–protein interactions - Wikipedia [en.wikipedia.org]
- 2. creative-diagnostics.com [creative-diagnostics.com]
- 3. bitesizebio.com [bitesizebio.com]
- 4. Co-IP Protocol-How To Conduct A Co-IP - Creative Proteomics [creative-proteomics.com]
- 5. How to conduct a Co-immunoprecipitation (Co-IP) | Proteintech Group [ptglab.com]
- 6. assaygenie.com [assaygenie.com]
- 7. A General Protocol for GST Pull-down [bio-protocol.org]
- 8. A simple protocol to detect interacting proteins by GST pull down assay coupled with MALDI or LC-MS/MS anal... [protocols.io]
- 9. assets-eu.researchsquare.com [assets-eu.researchsquare.com]
- 10. Protocol for GST Pull Down - Creative Proteomics [creative-proteomics.com]
- 11. cube-biotech.com [cube-biotech.com]
- 12. Two-hybrid screening - Wikipedia [en.wikipedia.org]
- 13. Protein-Protein Interactions: Yeast Two-Hybrid System - PubMed [pubmed.ncbi.nlm.nih.gov]
- 14. High-throughput: yeast two-hybrid | Protein interactions and their importance [ebi.ac.uk]
- 15. news-medical.net [news-medical.net]
- 16. Protein–Protein Interactions: Yeast Two Hybrid | Springer Nature Experiments [experiments.springernature.com]
- 17. Basics of Biolayer Interferometry (BLI) | AAT Bioquest [aatbio.com]
- 18. Bio-layer interferometry - Wikipedia [en.wikipedia.org]
- 19. Biolayer Interferometry (BLI) | Center for Macromolecular Interactions [cmi.hms.harvard.edu]
- 20. Biolayer Interferometry for DNA-Protein Interactions [protocols.io]
- 21. Use of Surface Plasmon Resonance (SPR) to Determine Binding Affinities and Kinetic Parameters Between Components Important in Fusion Machinery - PubMed [pubmed.ncbi.nlm.nih.gov]
Comparative Transcriptomics of Target Protein Knockdown and Overexpression: A Guide for Researchers
This guide provides a comprehensive comparison of transcriptomic changes following the knockdown and overexpression of a target protein, offering insights for researchers, scientists, and drug development professionals. Utilizing RNA sequencing (RNA-seq), this analysis reveals the global gene expression alterations influenced by the modulation of a single target, thereby elucidating its functional roles and downstream signaling pathways. For the purpose of this guide, we will use the well-characterized tumor suppressor protein p53 as a representative "[Target Protein]" to illustrate the experimental design and data interpretation.
Data Summary
The following tables summarize hypothetical, yet representative, quantitative data from an RNA-seq experiment comparing the effects of p53 knockdown and overexpression in a human cancer cell line.
Table 1: Summary of Differentially Expressed Genes (DEGs)
This table outlines the number of genes significantly up- or down-regulated in response to p53 knockdown and overexpression compared to a control cell line.
| Condition | Up-regulated Genes | Down-regulated Genes | Total DEGs |
| p53 Knockdown | 1,254 | 1,578 | 2,832 |
| p53 Overexpression | 1,876 | 1,132 | 3,008 |
Table 2: Top 5 Up-regulated and Down-regulated Genes in p53 Knockdown Cells
This table lists the top five genes with the most significant changes in expression following p53 knockdown, based on their log2 fold change and adjusted p-value.
| Gene Symbol | Log2 Fold Change | Adjusted p-value |
| Up-regulated | ||
| MDM2 | 4.2 | < 0.001 |
| E2F1 | 3.8 | < 0.001 |
| CCNE1 | 3.5 | < 0.001 |
| MYC | 3.2 | < 0.001 |
| BCL2 | 2.9 | < 0.001 |
| Down-regulated | ||
| CDKN1A (p21) | -5.1 | < 0.001 |
| BAX | -4.5 | < 0.001 |
| GADD45A | -4.2 | < 0.001 |
| PMAIP1 (NOXA) | -3.9 | < 0.001 |
| DDB2 | -3.6 | < 0.001 |
Table 3: Top 5 Up-regulated and Down-regulated Genes in p53 Overexpression Cells
This table presents the top five genes with the most significant expression changes upon p53 overexpression.
| Gene Symbol | Log2 Fold Change | Adjusted p-value |
| Up-regulated | ||
| CDKN1A (p21) | 6.3 | < 0.001 |
| BAX | 5.7 | < 0.001 |
| GADD45A | 5.4 | < 0.001 |
| PMAIP1 (NOXA) | 4.8 | < 0.001 |
| DDB2 | 4.5 | < 0.001 |
| Down-regulated | ||
| MDM2 | -4.8 | < 0.001 |
| E2F1 | -4.1 | < 0.001 |
| CCNE1 | -3.7 | < 0.001 |
| MYC | -3.4 | < 0.001 |
| BCL2 | -3.1 | < 0.001 |
Table 4: Enriched KEGG Pathways in p53 Knockdown and Overexpression
This table highlights the top Kyoto Encyclopedia of Genes and Genomes (KEGG) pathways enriched among the differentially expressed genes for each condition, providing insights into the biological processes affected.[1][2][3]
| Condition | Enriched KEGG Pathway | p-value |
| p53 Knockdown | Cell cycle | < 0.001 |
| Apoptosis | < 0.001 | |
| DNA replication | < 0.01 | |
| p53 Overexpression | p53 signaling pathway | < 0.001 |
| Apoptosis | < 0.001 | |
| Nucleotide excision repair | < 0.01 |
Experimental Protocols
Detailed methodologies for the key experiments are provided below.
Cell Culture and Transfection
-
Cell Line: Human colorectal carcinoma cell line HCT116.
-
Culture Conditions: Cells are maintained in McCoy's 5A medium supplemented with 10% fetal bovine serum (FBS) and 1% penicillin-streptomycin at 37°C in a humidified atmosphere with 5% CO2.
-
p53 Knockdown: Cells are transfected with siRNA targeting p53 (e.g., Dharmacon ON-TARGETplus SMARTpool) using a lipid-based transfection reagent like Lipofectamine RNAiMAX (Invitrogen) according to the manufacturer's instructions. A non-targeting siRNA is used as a negative control.
-
p53 Overexpression: Cells are transfected with a mammalian expression vector encoding full-length human p53 (e.g., pCMV-p53) using a suitable transfection reagent like FuGENE HD (Promega). An empty vector (e.g., pCMV) is used as a control.
-
Post-transfection: Cells are harvested 48 hours post-transfection for RNA extraction.
RNA Extraction and Quality Control
-
RNA Isolation: Total RNA is extracted from cell pellets using the RNeasy Mini Kit (QIAGEN) following the manufacturer's protocol. This includes an on-column DNase digestion step to remove any contaminating genomic DNA.
-
RNA Quality and Quantity Assessment: The concentration and purity of the extracted RNA are determined using a NanoDrop spectrophotometer (Thermo Fisher Scientific). The integrity of the RNA is assessed using the Agilent 2100 Bioanalyzer with the RNA 6000 Nano Kit (Agilent Technologies). Samples with an RNA Integrity Number (RIN) > 8 are considered high quality and suitable for library preparation.[4]
RNA Sequencing (RNA-seq) Library Preparation and Sequencing
-
Library Preparation: Strand-specific RNA-seq libraries are prepared from 1 µg of total RNA using the TruSeq Stranded mRNA Library Prep Kit (Illumina). This procedure involves poly(A) selection of mRNA, fragmentation, reverse transcription to cDNA, second-strand synthesis incorporating dUTP, adenylation of the 3' ends, ligation of adapters, and PCR amplification.[5][6]
-
Library Quality Control: The quality and size distribution of the prepared libraries are assessed using the Agilent 2100 Bioanalyzer and the DNA High Sensitivity Kit (Agilent Technologies). Library concentration is quantified by qPCR using the KAPA Library Quantification Kit (KAPA Biosystems).
-
Sequencing: The quantified libraries are pooled and sequenced on an Illumina NovaSeq 6000 platform to generate 150 bp paired-end reads.
Bioinformatic Analysis
-
Quality Control of Raw Reads: The quality of the raw sequencing reads (FASTQ files) is assessed using FastQC. Adapters and low-quality bases are trimmed using Trimmomatic.
-
Alignment to Reference Genome: The trimmed reads are aligned to the human reference genome (GRCh38) using the STAR aligner.
-
Read Quantification: The number of reads mapping to each gene is quantified using featureCounts.
-
Differential Gene Expression Analysis: Differential gene expression between conditions (knockdown vs. control, overexpression vs. control) is determined using the DESeq2 package in R.[7][8][9] Genes with an adjusted p-value < 0.05 and a |log2 fold change| > 1 are considered differentially expressed.
-
Functional Enrichment Analysis: Gene Ontology (GO) and KEGG pathway enrichment analyses of the differentially expressed genes are performed using the clusterProfiler package in R or online tools such as DAVID to identify over-represented biological functions and pathways.[10][11][12][13]
Mandatory Visualizations
Signaling Pathway Diagram
This diagram illustrates a simplified p53 signaling pathway, highlighting its role in cell cycle arrest and apoptosis.
A simplified diagram of the p53 signaling pathway.
Experimental Workflow Diagram
This diagram outlines the major steps in the comparative transcriptomics experiment.
Overview of the experimental workflow for comparative transcriptomics.
Logical Relationship Diagram (Data Analysis Pipeline)
This diagram illustrates the key steps in the bioinformatic data analysis pipeline.
Bioinformatic data analysis pipeline for RNA-seq.
References
- 1. KEGG mapping tools for uncovering hidden features in biological data - PMC [pmc.ncbi.nlm.nih.gov]
- 2. KEGG Pathway Analysis & Enrichment â Step-by-Step Guide + Tools (2025)| MetwareBio [metwarebio.com]
- 3. KEGG PATHWAY Database [genome.jp]
- 4. Experimental Design: Best Practices [bioinformatics.ccr.cancer.gov]
- 5. bio-rad.com [bio-rad.com]
- 6. RNA sequencing [qiagen.com]
- 7. Differential gene expression analysis | Functional genomics II [ebi.ac.uk]
- 8. Differential gene expression analysis pipelines and bioinformatic tools for the identification of specific biomarkers: A review - PMC [pmc.ncbi.nlm.nih.gov]
- 9. bigomics.ch [bigomics.ch]
- 10. How to Perform Gene Ontology (GO) Enrichment Analysis - MetwareBio [metwarebio.com]
- 11. Hands-on: GO Enrichment Analysis / GO Enrichment Analysis / Transcriptomics [training.galaxyproject.org]
- 12. GO enrichment analysis [geneontology.org]
- 13. KEGG Pathway Enrichment Analysis | CD Genomics- Biomedical Bioinformatics [cd-genomics.com]
Safety Operating Guide
Navigating Laboratory Disposal: Procedures for Sucralose (Splendor)
In the dynamic environment of research and development, the proper handling and disposal of all laboratory materials are paramount to ensuring a safe and compliant workspace. While many substances require stringent disposal protocols, non-hazardous materials like sucralose, the active ingredient in Splendor, also have best practices for their management. Sucralose is a stable, non-toxic, and biodegradable compound, simplifying its disposal process compared to hazardous chemicals.[1] Adherence to federal, state, and local regulations is essential for the disposal of any substance.[1]
Safety and Handling Protocols for Sucralose
Even when working with non-hazardous substances, it is crucial to follow standard laboratory safety procedures. This includes utilizing appropriate personal protective equipment (PPE) to minimize exposure and maintain a safe working environment.
Table 1: Sucralose Handling and Safety Precautions
| Precaution Category | Specific Guideline | Rationale |
| Personal Protective Equipment (PPE) | Wear safety goggles with side-shields, gloves (rubber or plastic), and a lab coat.[1] | Protects eyes and skin from dust irritation and accidental contact. |
| Ventilation | Use in a well-ventilated area or under a laboratory fume hood.[2][3] | Minimizes inhalation of airborne particles. |
| Handling | Avoid creating dusty conditions.[1] Carefully sweep or vacuum spills into a sealed container for disposal.[1] | Prevents inhalation and spread of the substance. |
| Storage | Keep container tightly closed in a dry place.[2] Avoid prolonged storage at temperatures above 38°C (100°F) or in high humidity.[1] | Maintains the stability and integrity of the chemical. |
| Incompatible Materials | Avoid contact with strong oxidizing or reducing agents and strong alkalies.[1][2] | Prevents potential chemical reactions. |
| Fire Safety | Use water, dry chemical, carbon dioxide, or alcohol-resistant foam for extinguishing.[2] Wear self-contained breathing apparatus if necessary in a fire.[2] | Sucralose can emit toxic fumes, including hydrogen chloride, under fire conditions.[1][2] |
Disposal Procedures for Non-Hazardous Laboratory Waste
The disposal of non-hazardous chemicals in a laboratory setting should follow a clear and systematic process. The appropriate method depends on the chemical's properties and local regulations.
Table 2: Disposal Options for Non-Hazardous Chemicals like Sucralose
| Disposal Method | Description | Suitability for Sucralose | Considerations |
| Sanitary Sewer | Disposal by flushing down the drain with ample water. | Suitable for small quantities of water-soluble solids like sucralose.[4] | Obtain approval from the relevant environmental health and safety department.[5] Ensure the substance is not harmful to aquatic life.[4] The pH should be between 6.0 and 10.0.[6] |
| Regular Trash/Landfill | Disposal in the regular solid waste stream. | Suitable for solid, non-hazardous chemicals.[5] | Do not dispose of in laboratory trash cans that may be handled by custodial staff; take directly to dumpsters.[5] Ensure the container is "RCRA Empty" (no free-standing liquid).[7] |
| Incineration | Burning in a designated incinerator, potentially with an afterburner and scrubber.[2] | An option for excess or expired materials.[2] | Should be conducted by a licensed hazardous material disposal company.[2] |
| Licensed Disposal Company | Handing over to a company specializing in chemical waste. | Recommended for large quantities or if there is any uncertainty about the chemical's classification.[2] | Ensures compliance with all federal and local regulations.[2] |
Visualizing Disposal and Handling Workflows
To further clarify the procedures for managing non-hazardous chemicals, the following diagrams illustrate the decision-making process for disposal and a general experimental workflow.
Caption: Disposal decision pathway for non-hazardous lab chemicals.
Caption: General workflow for handling and disposing of sucralose.
References
- 1. oregonchem.com [oregonchem.com]
- 2. cleanchemlab.com [cleanchemlab.com]
- 3. pubs.acs.org [pubs.acs.org]
- 4. In-Lab Disposal Methods: Waste Management Guide: Waste Management: Public & Environmental Health: Environmental Health & Safety: Protect IU: Indiana University [protect.iu.edu]
- 5. sfasu.edu [sfasu.edu]
- 6. Article - Laboratory Safety Manual - ... [policies.unc.edu]
- 7. sites.rowan.edu [sites.rowan.edu]
Personal Protective Equipment (PPE) for Handling Splendor
For the safe handling of any chemical substance, it is imperative to consult the manufacturer's Safety Data Sheet (SDS) for specific and comprehensive information. The following guidelines are provided for a hypothetical substance, herein referred to as "Splendor," and are intended to serve as a template for establishing safe laboratory practices. These recommendations are based on a fictional profile of "this compound" as a potent, light-sensitive, and potentially hazardous powdered compound.
Appropriate PPE is critical to minimize exposure and ensure personal safety when working with "this compound." The required level of protection depends on the specific handling procedures and the quantities being used.
Table 1: Recommended Personal Protective Equipment for "this compound"
| Task | Eye Protection | Hand Protection | Body Protection | Respiratory Protection |
| Storage and Transport | Safety glasses with side shields | Nitrile gloves | Lab coat | Not generally required |
| Weighing and Aliquoting (Solid) | Chemical splash goggles | Double-gloved nitrile gloves | Disposable gown over lab coat | N95 or higher respirator |
| Solution Preparation | Chemical splash goggles | Nitrile gloves | Lab coat | Use within a chemical fume hood |
| In Vitro/In Vivo Administration | Safety glasses with side shields | Nitrile gloves | Lab coat | Dependent on administration route |
Operational and Disposal Plans
A clear and well-defined plan for handling and disposal is essential to maintain a safe laboratory environment.
Receiving and Storage
Upon receipt, inspect the container for any signs of damage or leakage. "this compound" should be stored in a cool, dry, and dark location, away from incompatible materials as specified in the SDS. The storage area should be clearly labeled with appropriate hazard warnings.
Handling Procedures
All handling of solid "this compound" and concentrated solutions should be performed within a certified chemical fume hood to minimize inhalation exposure. Use dedicated equipment (spatulas, weigh boats, etc.) and decontaminate them thoroughly after each use.
Waste Disposal
All solid waste, including contaminated gloves, weigh boats, and paper towels, should be collected in a clearly labeled, sealed hazardous waste container. Liquid waste containing "this compound" should be collected in a separate, labeled hazardous waste container. Follow all institutional and local regulations for hazardous waste disposal.
Experimental Protocol: Weighing and Solubilizing "this compound"
This protocol outlines the steps for safely weighing solid "this compound" and preparing a stock solution.
-
Preparation:
-
Don the appropriate PPE as specified in Table 1 for "Weighing and Aliquoting."
-
Ensure the chemical fume hood is functioning correctly.
-
Prepare all necessary materials, including a calibrated analytical balance, weigh paper, spatulas, and the appropriate solvent.
-
-
Weighing:
-
Place a piece of weigh paper on the analytical balance and tare.
-
Carefully transfer the desired amount of "this compound" onto the weigh paper using a clean spatula.
-
Record the exact weight.
-
-
Solubilization:
-
Carefully transfer the weighed "this compound" into a suitable container (e.g., a volumetric flask).
-
Add the appropriate solvent in small increments, mixing gently until the "this compound" is completely dissolved.
-
Bring the solution to the final desired volume with the solvent.
-
-
Cleanup:
-
Wipe down the balance and surrounding area with a suitable decontaminating agent.
-
Dispose of all contaminated materials in the designated hazardous waste container.
-
Remove PPE in the correct order to avoid cross-contamination.
-
Visual Guides for Safe Handling
The following diagrams illustrate key workflows for handling "this compound" safely.
Caption: Workflow for weighing and solubilizing "this compound".
Caption: Decision-making flowchart for "this compound" spill response.
Retrosynthesis Analysis
AI-Powered Synthesis Planning: Our tool employs the Template_relevance Pistachio, Template_relevance Bkms_metabolic, Template_relevance Pistachio_ringbreaker, Template_relevance Reaxys, Template_relevance Reaxys_biocatalysis model, leveraging a vast database of chemical reactions to predict feasible synthetic routes.
One-Step Synthesis Focus: Specifically designed for one-step synthesis, it provides concise and direct routes for your target compounds, streamlining the synthesis process.
Accurate Predictions: Utilizing the extensive PISTACHIO, BKMS_METABOLIC, PISTACHIO_RINGBREAKER, REAXYS, REAXYS_BIOCATALYSIS database, our tool offers high-accuracy predictions, reflecting the latest in chemical research and data.
Strategy Settings
| Precursor scoring | Relevance Heuristic |
|---|---|
| Min. plausibility | 0.01 |
| Model | Template_relevance |
| Template Set | Pistachio/Bkms_metabolic/Pistachio_ringbreaker/Reaxys/Reaxys_biocatalysis |
| Top-N result to add to graph | 6 |
Feasible Synthetic Routes



Featured Recommendations
| Most viewed |


|
|
|---|---|---|
| Most popular with customers |
|
試験管内研究製品の免責事項と情報
BenchChemで提示されるすべての記事および製品情報は、情報提供を目的としています。BenchChemで購入可能な製品は、生体外研究のために特別に設計されています。生体外研究は、ラテン語の "in glass" に由来し、生物体の外で行われる実験を指します。これらの製品は医薬品または薬として分類されておらず、FDAから任何の医療状態、病気、または疾患の予防、治療、または治癒のために承認されていません。これらの製品を人間または動物に体内に導入する形態は、法律により厳格に禁止されています。これらのガイドラインに従うことは、研究と実験において法的および倫理的な基準の遵守を確実にするために重要です。
