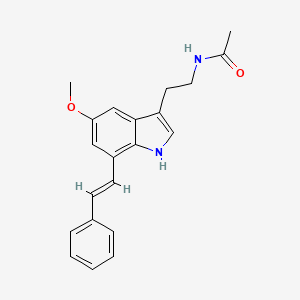
MD6a
説明
BenchChem offers high-quality this compound suitable for many research applications. Different packaging options are available to accommodate customers' requirements. Please inquire for more information about this compound including the price, delivery time, and more detailed information at info@benchchem.com.
特性
分子式 |
C21H22N2O2 |
|---|---|
分子量 |
334.4 g/mol |
IUPAC名 |
N-[2-[5-methoxy-7-[(E)-2-phenylethenyl]-1H-indol-3-yl]ethyl]acetamide |
InChI |
InChI=1S/C21H22N2O2/c1-15(24)22-11-10-18-14-23-21-17(12-19(25-2)13-20(18)21)9-8-16-6-4-3-5-7-16/h3-9,12-14,23H,10-11H2,1-2H3,(H,22,24)/b9-8+ |
InChIキー |
KSFLVIWGTBWZHL-CMDGGOBGSA-N |
異性体SMILES |
CC(=O)NCCC1=CNC2=C(C=C(C=C12)OC)/C=C/C3=CC=CC=C3 |
正規SMILES |
CC(=O)NCCC1=CNC2=C(C=C(C=C12)OC)C=CC3=CC=CC=C3 |
製品の起源 |
United States |
Foundational & Exploratory
The Role of N6-methyladenosine (m6A) in Gene Expression Regulation: An In-depth Technical Guide
For Researchers, Scientists, and Drug Development Professionals
Executive Summary
N6-methyladenosine (m6A) is the most abundant internal modification in eukaryotic messenger RNA (mRNA) and has emerged as a critical regulator of gene expression. This dynamic and reversible epitranscriptomic mark influences every stage of the mRNA lifecycle, from splicing and nuclear export to translation and decay. The m6A landscape is dynamically controlled by a set of proteins: "writers" that install the mark, "erasers" that remove it, and "readers" that interpret its functional consequences. Dysregulation of m6A has been implicated in a wide range of human diseases, including cancer, neurodevelopmental disorders, and metabolic diseases, making the m6A pathway a promising area for therapeutic intervention. This technical guide provides a comprehensive overview of the molecular mechanisms underlying m6A-mediated gene expression regulation, detailed experimental protocols for its study, and quantitative data to illustrate its impact.
The m6A Machinery: Writers, Erasers, and Readers
The m6A modification is a dynamic process orchestrated by three classes of proteins that act in concert to regulate the epitranscriptomic landscape.
1.1. Writers: The Methyltransferase Complex
The deposition of m6A is catalyzed by a nuclear multiprotein methyltransferase complex. The core components of this complex are METTL3 (Methyltransferase-like 3) and METTL14 (Methyltransferase-like 14), which form a stable heterodimer. METTL3 is the catalytic subunit, while METTL14 serves as an RNA-binding platform that enhances the complex's activity. Other essential components of the writer complex include WTAP (Wilms' tumor 1-associating protein), which facilitates the localization of the METTL3-METTL14 heterodimer to the nuclear speckles, and other regulatory subunits such as KIAA1429 (VIRMA), RBM15/15B, and ZC3H13 that guide the complex to specific RNA targets.
1.2. Erasers: The Demethylases
The m6A modification is reversible, thanks to the action of demethylases known as "erasers." The two primary m6A erasers identified to date are FTO (fat mass and obesity-associated protein) and ALKBH5 (alkB homolog 5). Both are Fe(II)- and α-ketoglutarate-dependent dioxygenases. FTO, the first identified m6A demethylase, has been shown to have a preference for demethylating m6Am, a related modification at the 5' cap of mRNA, although it can also demethylate internal m6A. ALKBH5, on the other hand, is considered the primary demethylase for internal m6A residues in mRNA. The activity of these erasers allows for dynamic regulation of m6A levels in response to various cellular signals.
1.3. Readers: The Effector Proteins
The functional consequences of m6A modification are mediated by "reader" proteins that specifically recognize and bind to m6A-containing transcripts. These readers then recruit other protein complexes to influence the fate of the modified mRNA. The most well-characterized family of m6A readers is the YTH (YT521-B homology) domain-containing family, which includes YTHDF1, YTHDF2, YTHDF3, YTHDC1, and YTHDC2.
-
YTHDF1: Primarily located in the cytoplasm, YTHDF1 promotes the translation of m6A-modified mRNAs by interacting with translation initiation factors.
-
YTHDF2: Also cytoplasmic, YTHDF2 is a key player in mRNA stability. It recognizes m6A-modified transcripts and recruits the CCR4-NOT deadenylase complex to promote their degradation.
-
YTHDF3: This reader appears to act as a facilitator for both YTHDF1-mediated translation and YTHDF2-mediated decay.
-
YTHDC1: A nuclear reader, YTHDC1 regulates the splicing of m6A-modified pre-mRNAs by recruiting splicing factors.
-
YTHDC2: This reader has been implicated in both enhancing translation efficiency and decreasing mRNA abundance.
Beyond the YTH family, other proteins, including members of the HNRNP (heterogeneous nuclear ribonucleoprotein) family and IGF2BP (insulin-like growth factor 2 mRNA-binding protein) family, have also been identified as m6A readers, expanding the known repertoire of m6A-mediated regulatory functions.
Mechanisms of m6A-Mediated Gene Expression Regulation
The m6A modification exerts its regulatory effects at multiple levels of gene expression, influencing mRNA processing, translation, and stability.
2.1. mRNA Stability and Decay
One of the most well-established roles of m6A is the regulation of mRNA stability. The binding of the reader protein YTHDF2 to m6A-modified transcripts is a key step in initiating their degradation. YTHDF2 recruits the CCR4-NOT deadenylase complex, which removes the poly(A) tail of the mRNA, leading to its subsequent decay. This process allows for the rapid turnover of specific transcripts, enabling cells to dynamically adjust their gene expression programs. For instance, knockdown of METTL3 has been shown to increase the stability of certain mRNAs by reducing their m6A levels.
2.2. mRNA Splicing
The m6A modification also plays a significant role in regulating pre-mRNA splicing. The nuclear m6A reader YTHDC1 can bind to m6A marks within pre-mRNAs and recruit splicing factors, such as SRSF3 and SRSF10, to influence exon inclusion or exclusion. This mechanism adds another layer of control to the production of different protein isoforms from a single gene. For example, the m6A reader hnRNPG has been shown to interact with the phosphorylated C-terminal domain of RNA polymerase II and regulate co-transcriptional alternative splicing.
2.3. mRNA Translation
The m6A modification can either enhance or repress translation depending on the context and the specific reader proteins involved. The
The Discovery and Elucidation of N6-methyladenosine (m6A) in mRNA: A Technical Guide
For Researchers, Scientists, and Drug Development Professionals
Introduction
N6-methyladenosine (m6A) is the most abundant and prevalent internal chemical modification in eukaryotic messenger RNA (mRNA).[1][2][3][4][5] First identified in the 1970s, its profound role in regulating gene expression remained largely enigmatic for decades due to technical limitations.[1][3][6][7][8][9] The discovery of its dynamic and reversible nature, orchestrated by a dedicated set of proteins, has revitalized the field, establishing m6A as a critical player in the "epitranscriptome."[10][11][12] This modification influences nearly every aspect of the mRNA lifecycle, including splicing, nuclear export, stability, and translation, thereby impacting a vast array of biological processes, from cellular differentiation to disease pathogenesis.[2][10][13][14] This guide provides a comprehensive technical overview of the core discoveries, experimental methodologies, and functional implications of m6A in mRNA.
The m6A Machinery: Writers, Erasers, and Readers
The regulation of m6A is a dynamic process controlled by three classes of proteins: "writers" that install the mark, "erasers" that remove it, and "readers" that recognize the mark and execute its downstream effects.[10][12][15][16]
-
Writers (Methyltransferases): The primary m6A methyltransferase complex is a heterodimer of METTL3 (Methyltransferase-like 3) and METTL14.[1] METTL3 is the catalytic subunit responsible for transferring a methyl group from S-adenosylmethionine (SAM) to the N6 position of adenosine (B11128).[4] This core complex is stabilized and guided by other proteins, including WTAP (Wilms' tumor 1-associating protein).
-
Erasers (Demethylases): The discovery of m6A demethylases confirmed the reversible nature of this RNA mark.[11] The first identified eraser was the fat mass and obesity-associated protein (FTO), which oxidatively removes the methyl group.[1][3][11][17] Another key demethylase is ALKBH5 (alkB homolog 5).[3]
-
Readers (Effector Proteins): Reader proteins selectively bind to m6A-containing transcripts to mediate their functional consequences.[10][15] The most prominent family of readers contains the YT521-B homology (YTH) domain. This family includes:
-
YTHDF1: Primarily promotes the translation of m6A-modified mRNAs by interacting with translation initiation factors.[6][15]
-
YTHDF2: The first characterized m6A reader, it primarily targets m6A-modified transcripts for degradation.[15][18]
-
YTHDF3: Works in concert with YTHDF1 to promote translation.[6]
-
YTHDC1: A nuclear reader that influences mRNA splicing.[13]
-
YTHDC2: Functions in both the nucleus and cytoplasm, affecting mRNA stability and translation efficiency.[13]
-
Quantitative Data and Distribution
The m6A modification is widespread, with distinct patterns of abundance and distribution across the transcriptome. This quantitative information is crucial for understanding its regulatory scope.
| Parameter | Value / Description | Citations |
| Abundance | 0.1% - 0.6% of all adenosine residues in total cellular RNA. | [1][3][5] |
| Frequency | Approximately 3-5 m6A sites per mRNA molecule on average. | |
| Consensus Motif | RRACH (where R = A or G; H = A, C, or U). | [13][19] |
| Transcriptome Presence | Found in over 25% of mammalian mRNAs. | [20] |
| Distribution | Enriched in specific regions: near stop codons, in 3' untranslated regions (3' UTRs), and within long internal exons. | [1][13][21][22] |
Key Experimental Protocol: m6A-Seq (MeRIP-Seq)
The development of methylated RNA immunoprecipitation followed by sequencing (MeRIP-Seq or m6A-Seq) was a watershed moment, enabling the first transcriptome-wide mapping of m6A.[9][23][24][25] The technique relies on the specific capture of m6A-containing RNA fragments using an anti-m6A antibody.[23][24][26]
Detailed Methodology
-
RNA Isolation and Preparation:
-
Isolate total RNA from cells or tissues of interest. For mRNA-focused studies, perform poly(A) selection to enrich for mRNA.[24]
-
Assess RNA quality and quantity using spectrophotometry and capillary electrophoresis.
-
-
RNA Fragmentation:
-
Immunoprecipitation (IP):
-
Save a small fraction of the fragmented RNA as the "input" control, which represents the total transcriptome.[24][26][28]
-
Incubate the remaining fragmented RNA with a highly specific anti-m6A antibody.
-
Capture the antibody-RNA complexes using protein A/G magnetic beads.[26][29]
-
Wash the beads to remove non-specifically bound RNA fragments.
-
Elute the m6A-containing RNA fragments from the antibody-bead complex.
-
-
Library Preparation and Sequencing:
-
Bioinformatic Analysis:
-
Align sequencing reads from both IP and input samples to a reference genome or transcriptome.[25][30]
-
Use peak-calling algorithms (e.g., MACS) to identify regions that are significantly enriched for m6A in the IP sample compared to the input control.[31] These enriched "peaks" represent m6A sites.
-
Perform motif analysis on the identified peaks to confirm the presence of the RRACH consensus sequence.[25]
-
Functional Consequences and Signaling Pathways
The discovery of m6A and its regulatory machinery has unveiled a new layer of post-transcriptional gene regulation. The fate of an m6A-modified mRNA is largely determined by the reader proteins that bind to it.
-
mRNA Stability and Decay: The most well-established function of m6A is the regulation of mRNA stability.[2][32] The reader protein YTHDF2 recognizes m6A-marked transcripts and recruits decay machinery, leading to their degradation.[15] Conversely, in some contexts, m6A can also stabilize certain mRNAs.[32][33]
-
mRNA Translation: m6A modification has a dual role in translation.[32][34] When located in the 3' UTR, m6A can be bound by YTHDF1, which interacts with translation initiation factors to promote ribosome loading and enhance translation efficiency.[6][13] However, m6A marks within the coding sequence (CDS) or 5' UTR can sometimes impede translation elongation.[6][34]
-
Splicing and Nuclear Export: Nuclear m6A readers, such as YTHDC1, can influence pre-mRNA splicing by recruiting splicing factors to m6A sites.[13] The modification has also been implicated in facilitating the nuclear export of mRNAs.[1][14]
The m6A pathway is deeply integrated with cellular signaling networks. Key signaling pathways like TGF-β, ERK, mTORC1, and p53 have been shown to regulate, or be regulated by, the m6A machinery, linking extracellular signals to post-transcriptional responses.[35][36][37] For example, ERK signaling can phosphorylate METTL3, affecting its ability to methylate specific transcripts involved in cell differentiation.[35]
References
- 1. m6A RNA methylation: from mechanisms to therapeutic potential - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Frontiers | The N6-Methyladenosine Modification and Its Role in mRNA Metabolism and Gastrointestinal Tract Disease [frontiersin.org]
- 3. Emerging Roles of N6-Methyladenosine (m6A) Epitranscriptomics in Toxicology - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Ghost authors revealed: The structure and function of human N6 -methyladenosine RNA methyltransferases - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. A Review in Research Progress Concerning m6A Methylation and Immunoregulation - PMC [pmc.ncbi.nlm.nih.gov]
- 6. m6A-Mediated Translation Regulation - PMC [pmc.ncbi.nlm.nih.gov]
- 7. researchgate.net [researchgate.net]
- 8. Functional Dissection of the m6A RNA Modification - PMC [pmc.ncbi.nlm.nih.gov]
- 9. m.youtube.com [m.youtube.com]
- 10. N6-methyladenosine modification in mRNA: machinery, function and implications for health and diseases - PubMed [pubmed.ncbi.nlm.nih.gov]
- 11. N6-Methyladenosine - Wikipedia [en.wikipedia.org]
- 12. N6-Methyladenosine in RNA and DNA: An Epitranscriptomic and Epigenetic Player Implicated in Determination of Stem Cell Fate - PMC [pmc.ncbi.nlm.nih.gov]
- 13. m6A RNA Regulatory Diagram | Cell Signaling Technology [cellsignal.com]
- 14. The functions of N6-methyladenosine modification in lncRNAs - PMC [pmc.ncbi.nlm.nih.gov]
- 15. Effects of m6A modifications on signaling pathways in human cance...: Ingenta Connect [ingentaconnect.com]
- 16. researchgate.net [researchgate.net]
- 17. Epigenetics - Wikipedia [en.wikipedia.org]
- 18. sciencedaily.com [sciencedaily.com]
- 19. N6-methyladenosine (m6A): Revisiting the Old with Focus on New, an Arabidopsis thaliana Centered Review - PMC [pmc.ncbi.nlm.nih.gov]
- 20. researchgate.net [researchgate.net]
- 21. academic.oup.com [academic.oup.com]
- 22. researchgate.net [researchgate.net]
- 23. An experimental workflow for identifying RNA m6A alterations in cellular senescence by methylated RNA immunoprecipitation sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 24. Genome-Wide Location Analyses of N6-Methyladenosine Modifications (m6A-seq) - PMC [pmc.ncbi.nlm.nih.gov]
- 25. rna-seqblog.com [rna-seqblog.com]
- 26. researchgate.net [researchgate.net]
- 27. labinsights.nl [labinsights.nl]
- 28. academic.oup.com [academic.oup.com]
- 29. Protocol for antibody-based m6A sequencing of human postmortem brain tissues - PMC [pmc.ncbi.nlm.nih.gov]
- 30. How MeRIP-seq Works: Principles, Workflow, and Applications Explained - CD Genomics [rna.cd-genomics.com]
- 31. Comprehensive Overview of m6A Detection Methods - CD Genomics [cd-genomics.com]
- 32. m6A modification plays an integral role in mRNA stability and translation during pattern-triggered immunity - PubMed [pubmed.ncbi.nlm.nih.gov]
- 33. pnas.org [pnas.org]
- 34. Frontiers | Transcriptome-wide analyses of RNA m6A methylation in hexaploid wheat reveal its roles in mRNA translation regulation [frontiersin.org]
- 35. m6A in the Signal Transduction Network - PMC [pmc.ncbi.nlm.nih.gov]
- 36. m6A in the Signal Transduction Network - PubMed [pubmed.ncbi.nlm.nih.gov]
- 37. academic.oup.com [academic.oup.com]
function of m6A writers METTL3 and METTL14
An In-depth Technical Guide to the Core Functions of m6A Writers METTL3 and METTL14
Introduction
N6-methyladenosine (m6A) is the most abundant internal modification on messenger RNA (mRNA) and non-coding RNAs in most eukaryotes.[1] This dynamic and reversible epitranscriptomic mark plays a pivotal role in regulating RNA metabolism, including splicing, nuclear export, stability, and translation.[2] The deposition of m6A is primarily catalyzed by a multi-subunit methyltransferase complex, often referred to as the "writer" complex. At the heart of this complex are two key proteins: Methyltransferase-like 3 (METTL3) and Methyltransferase-like 14 (METTL14).[3]
Dysregulation of m6A modification has been implicated in a wide array of human diseases, including various cancers and developmental disorders, making the m6A writer complex a subject of intense research and a promising target for therapeutic intervention.[4][5] This technical guide provides a comprehensive overview of the core functions of METTL3 and METTL14, detailing their molecular mechanisms, roles in cellular processes, and the experimental protocols used to study them.
Core Functions of the METTL3-METTL14 Heterodimer
METTL3 and METTL14 form a stable and obligate heterodimer that constitutes the catalytic core of the m6A methyltransferase complex.[6][7] While both proteins possess a methyltransferase domain (MTD), they serve distinct and complementary roles.[8][9]
-
METTL3: The Catalytic Subunit METTL3 is the sole catalytically active enzyme within the complex.[1][9] It contains a highly conserved S-adenosylmethionine (SAM)-binding pocket, enabling it to bind the methyl donor SAM.[10][11] METTL3 is responsible for transferring the methyl group from SAM to the N6 position of a target adenosine (B11128) residue on the RNA substrate.[12] The catalytic activity of METTL3 is significantly enhanced through its interaction with METTL14.[13]
-
METTL14: The Structural Scaffold and Substrate Recognizer In contrast to METTL3, METTL14 is catalytically inactive.[9][12] Its primary function is structural; it acts as a scaffold to stabilize the entire complex and correctly orient METTL3 for efficient catalysis.[8][14] Crucially, METTL14 possesses a deep RNA-binding groove that is essential for recognizing and binding to the target RNA substrate, thereby conferring substrate specificity to the complex.[8][10] This interaction ensures that methylation occurs at the correct consensus sequence, typically RRACH (where R = A/G, H = A/C/U).[1]
The formation of the METTL3-METTL14 heterodimer is essential for m6A deposition. Knockout or depletion of either component leads to a dramatic reduction in global m6A levels and often results in the degradation of the other partner protein, highlighting their interdependence.[15]
Beyond the core heterodimer, other regulatory proteins associate to form the full m6A-METTL associated complex (MACOM). These include Wilms' tumor 1-associating protein (WTAP), which facilitates the nuclear localization of the METTL3-METTL14 complex, and other factors like VIRMA, RBM15, and ZC3H13 that help guide the complex to specific RNA targets.[2][16]
Figure 1. The N6-methyladenosine (m6A) Writer Complex.
Molecular Mechanism and Downstream Consequences
The process of m6A deposition and its subsequent effects on RNA fate is a multi-step pathway involving "writers," "erasers," and "readers."
-
Writing the Mark: The METTL3-METTL14 complex identifies the target adenosine within the RRACH consensus motif on a nascent RNA transcript. METTL3, using SAM as a methyl donor, catalyzes the methylation.
-
Reading the Mark: Once deposited, the m6A mark is recognized by a family of m6A-binding proteins known as "readers." The most well-characterized readers belong to the YTH domain-containing family (YTHDF1, YTHDF2, YTHDF3, YTHDC1/2).
-
Executing the Function: The binding of a specific reader protein determines the downstream fate of the methylated RNA. For example, YTHDF2 binding often leads to mRNA degradation, while YTHDF1 binding can promote translation. YTHDC1 is involved in regulating splicing and nuclear export.
This writer-reader axis allows for precise post-transcriptional control of gene expression, impacting a vast range of cellular functions.
Figure 2. The m6A methylation pathway and its functional outcomes.
Roles in Health and Disease
The METTL3-METTL14 complex is integral to numerous biological processes, and its dysregulation is a hallmark of several diseases.
-
Cancer: The role of METTL3 and METTL14 in cancer is context-dependent, acting as either oncogenes or tumor suppressors.[17] In acute myeloid leukemia (AML), METTL3 is overexpressed and promotes leukemogenesis by methylating key oncogenic transcripts like MYC and BCL2.[6] Similarly, in lung and liver cancer, elevated METTL3 expression is associated with tumor progression and poor prognosis.[1][2] Conversely, in some contexts like glioblastoma, METTL14 can act as a tumor suppressor.[6]
-
Stem Cell Biology: m6A methylation is critical for maintaining the balance between stem cell self-renewal and differentiation.[[“]] Depletion of METTL3 or METTL14 in embryonic stem cells (ESCs) can block their differentiation, trapping them in a pluripotent state.[15] In hematopoietic stem cells, proper m6A levels are required for normal differentiation into various blood lineages.[19]
Quantitative Data on METTL3/METTL14 Function
The following tables summarize quantitative data from various studies, illustrating the impact of METTL3/METTL14 modulation and the efficacy of small molecule inhibitors.
Table 1: Effects of METTL3/METTL14 Modulation on Cellular Phenotypes
| Cell Type | Modulation | Effect on Global m6A | Key Target mRNA(s) | Phenotypic Outcome | Reference(s) |
|---|---|---|---|---|---|
| Hepatoblastoma (HB) | METTL3 Knockdown | Significantly Decreased | CTNNB1 | Suppressed proliferation, migration, and invasion. | [1] |
| Non-Small Cell Lung Cancer (NSCLC) | METTL3 Knockdown | Decreased | JUNB | Decreased mRNA stability of JUNB; inhibited EMT. | [1] |
| Uveal Melanoma (UM) | METTL3 Knockdown | Decreased | c-Met | Decreased proliferation, colony formation, migration, and invasion. | [2] |
| Skeletal Muscle Cells | METTL3/METTL14 Overexpression | Increased | MNK2 | Blocked myotube formation. | [20] |
| Skeletal Muscle Cells | METTL3/METTL14 Knockdown | Decreased | MNK2 | Accelerated differentiation. | [20] |
| Acute Myeloid Leukemia (AML) | METTL14 Overexpression | Increased | MYB, MYC | Blocked differentiation; promoted leukemogenesis. |[6][21] |
Table 2: Characterized Small Molecule Inhibitors of METTL3
| Inhibitor | Target | IC₅₀ (in vitro) | Cell-Based IC₅₀ | Validated Cancer Type(s) | Reference(s) |
|---|---|---|---|---|---|
| STM2457 | METTL3-METTL14 | 16.8 nM | 1.6 µM (MOLM13 cells) | Acute Myeloid Leukemia (AML) | [5] |
| UZH1a | METTL3-METTL14 | 320 nM | ~20 µM (HEK293T cells) | General research tool | [13] |
| Quercetin | METTL3-METTL14 | ~20 µM | >50% inhibition at 100 µM | Pancreatic Cancer, Lung Cancer | [11][16] |
| Eltrombopag | METTL3-METTL14 | ~15 µM | Not specified | Acute Myeloid Leukemia (AML) |[16] |
Key Experimental Methodologies
Studying m6A modifications requires specialized techniques to quantify levels and map their locations across the transcriptome.
Figure 3. Workflow for Methylated RNA Immunoprecipitation Sequencing.
Protocol 1: Global m6A Quantification by LC-MS/MS
Liquid chromatography-tandem mass spectrometry (LC-MS/MS) is the gold standard for accurately quantifying the absolute or relative levels of m6A in a total RNA or mRNA sample.[22][23]
-
RNA Isolation: Isolate high-quality total RNA from cells or tissues. Purify mRNA using oligo(dT) magnetic beads to remove ribosomal RNA contamination.
-
RNA Digestion: Digest the purified mRNA into single nucleosides. This is typically a two-step enzymatic process:
-
LC Separation: Separate the resulting nucleosides (adenosine, guanosine, cytidine, uridine, and m6A) using reverse-phase liquid chromatography.
-
MS/MS Quantification: Introduce the separated nucleosides into a triple quadrupole mass spectrometer. Quantify the amount of adenosine and N6-methyladenosine by monitoring specific parent-to-daughter ion transitions (Multiple Reaction Monitoring - MRM).[23]
-
Data Analysis: Calculate the m6A/A ratio by comparing the area under the curve for the m6A and adenosine signals against a standard curve generated from known concentrations of pure nucleosides.
Protocol 2: Transcriptome-Wide m6A Mapping by MeRIP-Seq
Methylated RNA Immunoprecipitation followed by Sequencing (MeRIP-Seq or m6A-Seq) is the most widely used technique to map the location of m6A modifications across the entire transcriptome.[25][26]
-
RNA Preparation: Isolate total RNA and deplete ribosomal RNA. Chemically or enzymatically fragment the RNA into ~100-nucleotide-long fragments.[27]
-
Immunoprecipitation (IP): Incubate the fragmented RNA with a highly specific anti-m6A antibody.[25] Capture the antibody-RNA complexes using Protein A/G magnetic beads. A parallel sample (Input) that does not undergo IP is saved as a control.
-
Washing: Perform stringent washes to remove non-specifically bound RNA fragments.
-
Elution and Purification: Elute the m6A-containing RNA fragments from the beads and purify them.
-
Library Preparation: Construct next-generation sequencing (NGS) libraries from both the immunoprecipitated (IP) RNA and the Input RNA.
-
Sequencing: Sequence the libraries using a high-throughput platform.
-
Bioinformatic Analysis: Align the sequencing reads to a reference genome/transcriptome. Use peak-calling algorithms (e.g., MACS, exomePeak) to identify regions enriched for m6A in the IP sample relative to the Input control.[26][28] These peaks represent m6A-modified regions.
Protocol 3: Single-Nucleotide Resolution Mapping by miCLIP
m6A individual-nucleotide-resolution crosslinking and immunoprecipitation (miCLIP) is an advanced technique that refines m6A mapping to single-nucleotide precision.[29][30]
-
UV Crosslinking: Incubate fragmented cellular RNA with an anti-m6A antibody and expose to UV light to induce covalent crosslinks between the antibody and the RNA at the m6A site.[29]
-
Immunoprecipitation and Ligation: Perform immunoprecipitation as in MeRIP-Seq. Ligate a 3' adapter to the captured RNA fragments.
-
Reverse Transcription (RT): Perform reverse transcription. The crosslinked antibody often causes the reverse transcriptase to terminate or introduce a mutation (e.g., a C-to-T transition) at the site immediately adjacent to the m6A residue.[29][30]
-
Library Preparation and Sequencing: Circularize the resulting cDNA, re-linearize, amplify by PCR, and sequence.
-
Data Analysis: Analyze the sequencing data to identify the specific truncation sites or mutational signatures. These signatures pinpoint the precise location of the m6A modification at nucleotide resolution.[29]
Conclusion and Future Directions
METTL3 and METTL14 are the foundational components of the m6A writer complex, working in a synergistic partnership to deposit epitranscriptomic marks that are critical for gene expression regulation. METTL3 provides the catalytic activity, while METTL14 ensures structural integrity and substrate specificity. The discovery of their central roles in cancer and stem cell biology has opened new avenues for therapeutic development. The recent development of potent and selective small-molecule inhibitors against METTL3 offers a promising strategy for treating diseases like AML.[5] Future research will focus on further elucidating the context-specific functions of the writer complex, understanding its m6A-independent roles, and advancing METTL3-targeted therapies into clinical applications.
References
- 1. Roles of METTL3 in cancer: mechanisms and therapeutic targeting - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Multifaceted Roles of the N6-Methyladenosine RNA Methyltransferase METTL3 in Cancer and Immune Microenvironment - PMC [pmc.ncbi.nlm.nih.gov]
- 3. tandfonline.com [tandfonline.com]
- 4. Roles and drug development of METTL3 (methyltransferase-like 3) in anti-tumor therapy - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. Mining for METTL3 inhibitors to suppress cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Functions, mechanisms, and therapeutic implications of METTL14 in human cancer | springermedizin.de [springermedizin.de]
- 7. Novel insights into the METTL3-METTL14 complex in musculoskeletal diseases - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Structural basis for cooperative function of Mettl3 and Mettl14 methyltransferases - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Human m6A writers: Two subunits, 2 roles - PMC [pmc.ncbi.nlm.nih.gov]
- 10. researchgate.net [researchgate.net]
- 11. Frontiers | Discovery of METTL3 Small Molecule Inhibitors by Virtual Screening of Natural Products [frontiersin.org]
- 12. Functions, mechanisms, and therapeutic implications of METTL14 in human cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 13. METTL3 from Target Validation to the First Small-Molecule Inhibitors: A Medicinal Chemistry Journey - PMC [pmc.ncbi.nlm.nih.gov]
- 14. librarysearch.colby.edu [librarysearch.colby.edu]
- 15. mdpi.com [mdpi.com]
- 16. researchgate.net [researchgate.net]
- 17. academic.oup.com [academic.oup.com]
- 18. consensus.app [consensus.app]
- 19. Meddling with METTLs in Normal and Leukemia Stem Cells - PubMed [pubmed.ncbi.nlm.nih.gov]
- 20. Dynamic m6A mRNA Methylation Reveals the Role of METTL3/14-m6A-MNK2-ERK Signaling Axis in Skeletal Muscle Differentiation and Regeneration - PMC [pmc.ncbi.nlm.nih.gov]
- 21. METTL14 Inhibits Hematopoietic Stem/Progenitor Differentiation and Promotes Leukemogenesis via mRNA m6A Modification - PMC [pmc.ncbi.nlm.nih.gov]
- 22. bpb-us-e2.wpmucdn.com [bpb-us-e2.wpmucdn.com]
- 23. m6A RNA Methylation Analysis by MS - CD Genomics [rna.cd-genomics.com]
- 24. Frontiers | Current progress in strategies to profile transcriptomic m6A modifications [frontiersin.org]
- 25. MeRIP-seq Protocol - CD Genomics [rna.cd-genomics.com]
- 26. rna-seqblog.com [rna-seqblog.com]
- 27. RNA-Seq and m6A-RNA Immunoprecipitation (MeRIP-seq) Seq [bio-protocol.org]
- 28. Comprehensive Overview of m6A Detection Methods - CD Genomics [cd-genomics.com]
- 29. Mapping m6A at individual-nucleotide resolution using crosslinking and immunoprecipitation (miCLIP) - PMC [pmc.ncbi.nlm.nih.gov]
- 30. Mapping m6A at Individual-Nucleotide Resolution Using Crosslinking and Immunoprecipitation (miCLIP) - PubMed [pubmed.ncbi.nlm.nih.gov]
mechanism of m6A erasers FTO and ALKBH5
An In-depth Technical Guide on the Core Mechanisms of m6A Erasers FTO and ALKBH5
For Researchers, Scientists, and Drug Development Professionals
Abstract
N6-methyladenosine (m6A) is the most abundant internal modification in eukaryotic messenger RNA (mRNA), playing a pivotal role in RNA metabolism and function. The reversibility of this modification is controlled by m6A methyltransferases ("writers") and demethylases ("erasers"). This technical guide provides a comprehensive overview of the core mechanisms of the two principal m6A erasers, the fat mass and obesity-associated protein (FTO) and the AlkB homolog 5 (ALKBH5). We delve into their enzymatic mechanisms, substrate specificities, roles in key signaling pathways, and the methodologies used to study their function. This guide is intended to serve as a valuable resource for researchers, scientists, and drug development professionals working in the field of epitranscriptomics and related areas.
Introduction to m6A Erasers: FTO and ALKBH5
FTO was the first identified m6A demethylase, initially linked to obesity through genome-wide association studies.[1] Subsequent research revealed its broader role in various cellular processes.[2][3][4] ALKBH5 was later identified as the second m6A demethylase, also playing critical roles in diverse biological processes, including spermatogenesis and cancer.[5][6] Both FTO and ALKBH5 belong to the Fe(II)/α-ketoglutarate (α-KG)-dependent dioxygenase superfamily.[6][7] Despite their shared function in removing the methyl group from N6-methyladenosine, they exhibit distinct catalytic mechanisms, substrate preferences, and biological roles.
Enzymatic Mechanism and Substrate Specificity
FTO and ALKBH5 catalyze the demethylation of m6A through an oxidative process that requires Fe(II) as a cofactor and α-KG as a co-substrate. However, their catalytic pathways diverge significantly.
2.1. FTO: A Stepwise Oxidation Pathway
FTO removes the methyl group from m6A in a two-step oxidative process.[8][9] It first hydroxylates m6A to N6-hydroxymethyladenosine (hm6A), which is a relatively stable intermediate.[8][10] FTO can then further oxidize hm6A to N6-formyladenosine (f6A).[9] Both hm6A and f6A are subsequently hydrolyzed to adenosine (B11128), releasing formaldehyde (B43269).[7][10] This stepwise mechanism suggests potential regulatory roles for the hydroxylated intermediates.
FTO exhibits a broader substrate specificity compared to ALKBH5. While its primary substrate is m6A in single-stranded RNA (ssRNA), it can also demethylate N6,2'-O-dimethyladenosine (m6Am) at the 5' cap of mRNA, as well as 3-methylthymidine (B1204310) (m3T) and 3-methyluracil (B189468) (3-meU) in single-stranded DNA (ssDNA) and RNA (ssRNA) respectively.[11][12]
2.2. ALKBH5: Direct Demethylation
In contrast to FTO, ALKBH5 catalyzes the direct removal of the methyl group from m6A to yield adenosine and formaldehyde in a single step.[7][8][10] This direct reversal mechanism is more efficient in producing the demethylated product without the generation of stable intermediates.[10]
ALKBH5 demonstrates a stricter substrate specificity, primarily targeting m6A in ssRNA.[6][13][14] It shows a preference for a consensus sequence of Pu[G>A]m6AC[A/C/U] (where Pu is a purine).[6] Unlike FTO, ALKBH5 does not efficiently demethylate m6Am at the 5' cap.[12]
2.3. Structural Basis for Mechanistic Differences
The structural differences between FTO and ALKBH5 contribute to their distinct catalytic mechanisms and substrate specificities. Both enzymes possess a conserved double-stranded β-helix (DSBH) fold, which forms the catalytic core.[7] However, variations in the loops and surrounding residues within the active site create unique environments for substrate recognition and catalysis. For instance, FTO has a specific loop that helps in recognizing the 5' cap structure, which is absent in ALKBH5.[11] The orientation of the RNA substrate within the active site also differs between the two enzymes.[15]
Quantitative Data
Table 1: Kinetic Parameters of FTO and ALKBH5
| Enzyme | Substrate | Km (μM) | kcat (min-1) | Reference |
| Human FTO | m6A in ssRNA | 791 | - | [12] |
| Human FTO | m6A in ssRNA | - | - | [16] |
| Human ALKBH5 | m6A in ssRNA | - | - | [17] |
Note: Direct comparison of kinetic parameters can be challenging due to variations in experimental conditions and FTO/ALKBH5 constructs used in different studies.[18]
Table 2: IC50 Values of Selected FTO Inhibitors
| Inhibitor | IC50 (μM) | Cell Line/Assay | Reference |
| Rhein | 3.2 (at 0.5% DMSO) | In vitro assay | [19] |
| Meclofenamic acid (MA) | - | - | [20] |
| FB23-2 | - | - | [21] |
| Compound 14a | 1.5 | In vitro LC-based assay | [1] |
| Compound C6 | 0.78 | Enzymatic inhibition assay | [22] |
| 18097 | 0.64 | In vitro demethylation assay | [6] |
| FTO-11N | 0.11 | In vitro inhibition assay | [21] |
| FTO-43N | 10-50 (antiproliferative) | Gastric cancer cell lines | [23] |
Table 3: IC50 Values of Selected ALKBH5 Inhibitors
| Inhibitor | IC50 (μM) | Cell Line/Assay | Reference |
| Citrate | 488 | In vitro assay | [24] |
| Compound 3 | 0.84 | ELISA-based enzyme inhibition assay | [13][15] |
| Compound 6 | 1.79 | ELISA-based enzyme inhibition assay | [13][15] |
| Inhibitor A | 0.84 | - | [25] |
| Inhibitor B | 1.79 | - | [25] |
Signaling Pathways and Biological Roles
FTO and ALKBH5 are implicated in a multitude of signaling pathways, thereby regulating a wide array of biological processes and contributing to various diseases.
4.1. FTO-Regulated Signaling Pathways
-
WNT Signaling: FTO has been shown to regulate both canonical and non-canonical WNT signaling pathways.[23][26] FTO depletion can lead to the upregulation of the WNT inhibitor DKK1, thereby attenuating the canonical WNT/β-Catenin pathway.[27]
-
PI3K/AKT/mTOR Pathway: FTO can influence the PI3K/AKT/mTOR pathway, which is crucial for cell growth, proliferation, and metabolism.[28] For instance, FTO can regulate adipogenesis and lipid metabolism through this pathway.[9]
-
FOXO Signaling: FTO has been linked to the regulation of the FOXO signaling pathway, which is involved in stress resistance, metabolism, and longevity.[29]
4.2. ALKBH5-Regulated Signaling Pathways
-
FAK Signaling: ALKBH5 can activate the Focal Adhesion Kinase (FAK) signaling pathway by demethylating the mRNA of integrin subunit beta 1 (ITGB1), thereby promoting tumor-associated lymphangiogenesis and metastasis in ovarian cancer.[10]
-
TGF-β/SMAD Pathway: In non-small cell lung cancer, ALKBH5 has been found to inhibit the TGF-β-induced epithelial-mesenchymal transition (EMT) by regulating the TGF-β/SMAD signaling pathway.[30]
-
Notch Signaling: ALKBH5 plays a role in T-cell development by regulating the stability of key components of the Notch signaling pathway.[18]
-
PI3K/AKT Pathway: ALKBH5 can enhance the PI3K/AKT signaling pathway to promote dentin matrix formation.[18]
Experimental Protocols
5.1. In Vitro m6A Demethylation Assay
This assay is used to determine the enzymatic activity of FTO and ALKBH5 on an m6A-containing RNA substrate.
Materials:
-
Recombinant FTO or ALKBH5 protein
-
m6A-containing synthetic RNA oligonucleotide
-
5X FTO/ALKBH5 Reaction Buffer (e.g., 250 mM HEPES, pH 7.0)
-
α-ketoglutarate (α-KG)
-
Ammonium iron(II) sulfate (B86663) ((NH₄)₂Fe(SO₄)₂)
-
L-ascorbic acid
-
Nuclease-free water
-
EDTA (for quenching the reaction)
-
LC-MS/MS system for analysis
Protocol:
-
Prepare the reaction mixture in a final volume of 50 µL containing 1X reaction buffer, 100 µM α-KG, 100 µM (NH₄)₂Fe(SO₄)₂, 2 mM L-ascorbic acid, and 1 µM m6A-containing RNA substrate.
-
Initiate the reaction by adding a specific concentration of recombinant FTO or ALKBH5 protein (e.g., 0.1-1 µM).
-
Incubate the reaction at 37°C for a specified time (e.g., 1 hour).
-
Quench the reaction by adding EDTA to a final concentration of 5 mM.
-
Digest the RNA substrate to nucleosides using nuclease P1 and alkaline phosphatase.
-
Analyze the ratio of m6A to adenosine (A) using LC-MS/MS to determine the extent of demethylation.[31]
5.2. Methylated RNA Immunoprecipitation Sequencing (MeRIP-seq)
MeRIP-seq is a widely used technique to map the transcriptome-wide distribution of m6A.
Materials:
-
Total RNA from cells or tissues
-
Anti-m6A antibody
-
Protein A/G magnetic beads
-
IP buffer (e.g., 50 mM Tris-HCl pH 7.4, 150 mM NaCl, 0.1% NP-40)
-
Wash buffers
-
Elution buffer
-
RNA fragmentation buffer
-
RNA purification kit
-
Library preparation kit for next-generation sequencing
Protocol:
-
RNA Fragmentation: Fragment the purified mRNA into ~100-nucleotide fragments using fragmentation buffer or enzymatic methods.
-
Immunoprecipitation: Incubate the fragmented RNA with an anti-m6A antibody in IP buffer at 4°C for 2 hours.
-
Bead Binding: Add pre-washed protein A/G magnetic beads and incubate for another 2 hours at 4°C to capture the antibody-RNA complexes.
-
Washing: Wash the beads several times with wash buffers to remove non-specifically bound RNA.
-
Elution: Elute the m6A-containing RNA fragments from the beads using an elution buffer.
-
RNA Purification: Purify the eluted RNA using an RNA purification kit.
-
Library Preparation and Sequencing: Construct a sequencing library from the immunoprecipitated RNA and an input control (fragmented RNA that did not undergo immunoprecipitation). Sequence the libraries on a high-throughput sequencing platform.[3][11][32][33]
5.3. Quantification of Cellular m6A Levels
Several methods can be used to quantify the overall m6A levels in a cell or tissue.
-
LC-MS/MS: This is the gold standard for accurate quantification. Total mRNA is isolated, digested into single nucleosides, and the ratio of m6A to A is determined by liquid chromatography-tandem mass spectrometry.[4]
-
m6A Dot Blot: This is a semi-quantitative method where serially diluted RNA is spotted onto a membrane and probed with an anti-m6A antibody.
-
ELISA-based assays: Commercially available kits allow for the colorimetric or fluorometric quantification of m6A in RNA samples.[2][5]
Visualizations
Signaling Pathways
Caption: FTO's involvement in key signaling pathways.
Caption: ALKBH5's regulatory roles in cellular signaling.
Experimental Workflows
Caption: Workflow for an in vitro demethylation assay.
Caption: The experimental workflow for MeRIP-seq.
Conclusion and Future Directions
The m6A erasers FTO and ALKBH5 are critical regulators of gene expression, and their dysregulation is implicated in a wide range of human diseases, including obesity, cancer, and cardiovascular disorders.[2][4][5] Understanding their core mechanisms is essential for the development of novel therapeutic strategies. The distinct catalytic mechanisms and substrate specificities of FTO and ALKBH5 suggest that they have non-redundant roles in cellular physiology and pathology, making them attractive targets for the development of selective inhibitors.[20][21]
Future research should focus on further elucidating the specific cellular contexts and downstream effectors through which FTO and ALKBH5 exert their functions. The development of more potent and selective inhibitors will be crucial for dissecting their individual roles and for their potential translation into clinical applications. The methodologies described in this guide provide a robust framework for advancing our understanding of these important epitranscriptomic regulators.
References
- 1. Structure-Based Design of Selective Fat Mass and Obesity Associated Protein (FTO) Inhibitors - PMC [pmc.ncbi.nlm.nih.gov]
- 2. m6A-ELISA, a simple method for quantifying N6-methyladenosine from mRNA populations - PMC [pmc.ncbi.nlm.nih.gov]
- 3. MeRIP-seq and Its Principle, Protocol, Bioinformatics, Applications in Diseases - CD Genomics [cd-genomics.com]
- 4. Comprehensive Overview of m6A Detection Methods - CD Genomics [cd-genomics.com]
- 5. researchgate.net [researchgate.net]
- 6. researchgate.net [researchgate.net]
- 7. Scm6A: A Fast and Low-cost Method for Quantifying m6A Modifications at the Single-cell Level - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. pubs.acs.org [pubs.acs.org]
- 9. researchgate.net [researchgate.net]
- 10. Distinct RNA N-demethylation pathways catalyzed by nonheme iron ALKBH5 and FTO enzymes enable regulation of formaldehyde release rates - PMC [pmc.ncbi.nlm.nih.gov]
- 11. researchgate.net [researchgate.net]
- 12. repo.lib.jfn.ac.lk [repo.lib.jfn.ac.lk]
- 13. pubs.acs.org [pubs.acs.org]
- 14. Frontiers | ALKBH5 in development: decoding the multifaceted roles of m6A demethylation in biological processes [frontiersin.org]
- 15. Rational Design of Novel Anticancer Small-Molecule RNA m6A Demethylase ALKBH5 Inhibitors - PMC [pmc.ncbi.nlm.nih.gov]
- 16. Item - Kinetic constants for FTO demethylation of m6A in ssRNA and 5mdC in DNA. - figshare - Figshare [figshare.com]
- 17. ALKBH5 Is a Mammalian RNA Demethylase that Impacts RNA Metabolism and Mouse Fertility - PMC [pmc.ncbi.nlm.nih.gov]
- 18. researchgate.net [researchgate.net]
- 19. benchchem.com [benchchem.com]
- 20. Meclofenamic acid selectively inhibits FTO demethylation of m6A over ALKBH5 - PMC [pmc.ncbi.nlm.nih.gov]
- 21. biorxiv.org [biorxiv.org]
- 22. Discovery of novel mRNA demethylase FTO inhibitors against esophageal cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 23. Rational Design and Optimization of m6A-RNA Demethylase FTO Inhibitors as Anticancer Agents - PMC [pmc.ncbi.nlm.nih.gov]
- 24. Insights into the m6A demethylases FTO and ALKBH5 : structural, biological function, and inhibitor development - PMC [pmc.ncbi.nlm.nih.gov]
- 25. RNA demethylase ALKBH5 in cancer: from mechanisms to therapeutic potential - PMC [pmc.ncbi.nlm.nih.gov]
- 26. academic.oup.com [academic.oup.com]
- 27. Post-translational modification of RNA m6A demethylase ALKBH5 regulates ROS-induced DNA damage response - PMC [pmc.ncbi.nlm.nih.gov]
- 28. Deregulation of N6-Methyladenosine RNA Modification and Its Erasers FTO/ALKBH5 among the Main Renal Cell Tumor Subtypes - PMC [pmc.ncbi.nlm.nih.gov]
- 29. Down-regulated FTO and ALKBH5 co-operatively activates FOXO signaling through m6A methylation modification in HK2 mRNA mediated by IGF2BP2 to enhance glycolysis in colorectal cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 30. METTL3 and ALKBH5 oppositely regulate m6A modification of TFEB mRNA, which dictates the fate of hypoxia/reoxygenation-treated cardiomyocytes - PMC [pmc.ncbi.nlm.nih.gov]
- 31. researchgate.net [researchgate.net]
- 32. MeRIP-seq Protocol - CD Genomics [rna.cd-genomics.com]
- 33. sysy.com [sysy.com]
The m6A Pathway in Neurological Disorders: A Technical Guide for Researchers and Drug Development Professionals
An In-depth Exploration of N6-methyladenosine's Role in Neurodegeneration and Neurological Dysfunction
The field of epitranscriptomics has unveiled a critical layer of gene regulation, with N6-methyladenosine (m6A) emerging as the most abundant internal modification of mRNA in eukaryotes. This dynamic and reversible methylation plays a pivotal role in various aspects of RNA metabolism, including splicing, stability, translation, and localization. The enrichment of m6A in the brain underscores its significance in neuronal function and development. Consequently, dysregulation of the m6A pathway is increasingly implicated in the pathogenesis of a wide range of neurological disorders. This technical guide provides a comprehensive overview of the core components of the m6A pathway, its pathological role in key neurological diseases, detailed experimental protocols for its study, and a summary of quantitative data to facilitate comparative analysis.
The Core m6A Regulatory Machinery
The m6A modification is a dynamically regulated process orchestrated by a trio of protein families: "writers" that install the methyl mark, "erasers" that remove it, and "readers" that recognize and bind to m6A-modified transcripts to elicit downstream effects.
-
Writers (Methyltransferases): The primary m6A writer complex is a multicomponent machinery. The catalytic core is a heterodimer of Methyltransferase-like 3 (METTL3) and METTL14. METTL3 is the catalytically active subunit, while METTL14 serves as a structural scaffold, enhancing the complex's stability and substrate recognition. Other essential components include Wilms' tumor 1-associating protein (WTAP), which facilitates the localization of the METTL3-METTL14 heterodimer to the nuclear speckles, and other regulatory subunits like RBM15/15B and KIAA1429 (VIRMA).
-
Erasers (Demethylases): The reversibility of m6A methylation is mediated by two key demethylases belonging to the AlkB homolog (ALKBH) family of dioxygenases. Fat mass and obesity-associated protein (FTO) was the first identified m6A demethylase, followed by AlkB homolog 5 (ALKBH5). These enzymes oxidatively remove the methyl group from adenosine (B11128) residues, thereby erasing the m6A mark.
-
Readers (m6A-Binding Proteins): The functional consequences of m6A modification are determined by a diverse set of "reader" proteins that specifically recognize and bind to the m6A motif. The most well-characterized family of m6A readers is the YTH domain-containing family, which includes YTHDF1, YTHDF2, YTHDF3, YTHDC1, and YTHDC2. These proteins mediate distinct downstream effects. For instance, YTHDF1 is known to promote the translation of m6A-modified mRNAs, while YTHDF2 typically facilitates their degradation. YTHDC1 is primarily located in the nucleus and is involved in splicing regulation and nuclear export of methylated transcripts.
Below is a diagram illustrating the core m6A pathway.
Dysregulation of the m6A Pathway in Neurological Disorders
Aberrant m6A modification has been identified as a significant contributor to the pathophysiology of several neurological disorders. The following sections summarize the key findings in Alzheimer's disease, Parkinson's disease, ischemic stroke, epilepsy, and Huntington's disease.
Alzheimer's Disease (AD)
In AD, the role of m6A is complex, with conflicting reports on the direction of change in global m6A levels.[1] However, specific changes in the expression of m6A regulators and the methylation of particular transcripts are more consistently observed.
Quantitative Data Summary: m6A Pathway in Alzheimer's Disease
| Component | Change in AD | Brain Region | Model | Reference |
| Global m6A | Decreased | Brain | 5XFAD mice | [1] |
| Increased | Hippocampus | 5xFAD mice | [2] | |
| METTL3 | Decreased (mRNA, soluble protein) | Hippocampus | Human postmortem | [3][4] |
| Increased (insoluble fraction) | Hippocampus | Human postmortem | [3] | |
| Increased (mRNA) | Cortex, Hippocampus | AD mice | [5] | |
| Increased | Hippocampus | 5xFAD mice, Human postmortem | [2] | |
| FTO | Decreased | Hippocampus | AD mice | [5] |
| RBM15B | Upregulated | Hippocampus | Human postmortem | [3] |
A key finding is the altered expression and localization of METTL3.[3][4][6] Decreased soluble METTL3 in the hippocampus may contribute to cognitive deficits, while its accumulation in insoluble fractions correlates with Tau pathology.[3] Dysregulated m6A modification has been linked to abnormal processing of amyloid precursor protein (APP) and Tau, as well as synaptic dysfunction.[1][5]
Below is a diagram illustrating the proposed role of m6A dysregulation in Alzheimer's Disease.
Parkinson's Disease (PD)
In PD, the loss of dopaminergic neurons in the substantia nigra is a hallmark of the disease. Emerging evidence points to the involvement of m6A dysregulation in this process, particularly through the demethylase FTO.
Quantitative Data Summary: m6A Pathway in Parkinson's Disease
| Component | Change in PD | Brain Region/Cell Model | Model | Reference |
| Global m6A | Decreased | Dopaminergic neurons | 6-OHDA-exposed PC12 cells, Striatum of PD rats | [7] |
| FTO | Increased | Dopaminergic neurons | MPTP-treated mice, MPP+-induced MN9D cells | [7][8] |
| Increased | PD models | - | [9] |
Studies have shown that global m6A levels are decreased in PD models, while FTO expression is significantly increased.[7][9] FTO has been shown to regulate the stability of mRNAs encoding proteins involved in neuronal death and survival, such as ataxia telangiectasia mutated (ATM) and nuclear factor erythroid 2-related factor-2 (NRF2).[7][9][10] Knockdown of FTO has been demonstrated to alleviate dopaminergic neuronal death in PD models, suggesting that targeting FTO could be a potential therapeutic strategy.[7][10]
Below is a diagram of the FTO-mediated signaling pathway in Parkinson's Disease.
Ischemic Stroke
Following an ischemic stroke, the brain undergoes a complex cascade of events leading to neuronal cell death. The m6A pathway is dynamically regulated in response to ischemic injury and plays a crucial role in post-stroke pathophysiology.
Quantitative Data Summary: m6A Pathway in Ischemic Stroke
| Component | Change Post-Stroke | Brain Region/Model | Time Point | Reference |
| Global m6A | Increased (3.3- to 4.1-fold) | Peri-infarct cortex (male mice) | 12h, 24h reperfusion | [11] |
| Increased (3.2-fold) | Peri-infarct cortex (female mice) | 24h reperfusion | [11] | |
| Increased | Peripheral blood (human) | - | [12] | |
| FTO | Decreased | Ischemic brain | - | [11] |
| YTHDF1 | Increased (~1.5-fold) | Peri-infarct cortex | 24h reperfusion | [11] |
| YTHDF3 | Increased (~1.5-fold) | Peri-infarct cortex | 24h reperfusion | [11] |
Global m6A levels are significantly increased in the peri-infarct cortex following transient focal ischemia.[11] This hypermethylation is associated with a decrease in the m6A eraser FTO.[11] The differentially methylated transcripts are enriched in pathways related to inflammation, apoptosis, and transcriptional regulation.[11] The upregulation of m6A readers YTHDF1 and YTHDF3 suggests altered translation of specific mRNAs in the post-stroke brain.[11]
Epilepsy
Epilepsy is characterized by recurrent seizures resulting from abnormal neuronal excitability. Dysregulation of the m6A pathway has been identified as a contributor to the hyperexcitable networks underlying epilepsy.
Quantitative Data Summary: m6A Pathway in Epilepsy
| Component | Change in Epilepsy | Brain Region/Model | Reference |
| Global m6A | Increased | Epileptic mice and human TLE tissue | [13] |
| WTAP | Overexpressed | Patients with epilepsy | [14][15] |
| YTHDC1 | Overexpressed | Patients with epilepsy | [14][15] |
| RBM15 | Underexpressed | Patients with epilepsy | [14] |
| CBLL1 | Underexpressed | Patients with epilepsy | [14] |
| YTHDC2 | Underexpressed | Patients with epilepsy | [14] |
| HNRNPC | Underexpressed | Patients with epilepsy | [14][15] |
| RBMX | Underexpressed | Patients with epilepsy | [14] |
Studies have shown that epileptic brain tissue has higher global m6A levels compared to control tissue.[13] The expression of several m6A regulators is altered in patients with epilepsy, with WTAP and YTHDC1 being overexpressed, while others like HNRNPC are underexpressed.[14][15] This dysregulation is thought to alter the translation of proteins involved in neuronal excitability and metabolism, contributing to the epileptic phenotype.[13][16]
Huntington's Disease (HD)
Huntington's disease is a progressive neurodegenerative disorder caused by a CAG repeat expansion in the huntingtin (HTT) gene. Recent studies have begun to unravel the role of m6A modification in HD pathogenesis.
Quantitative Data Summary: m6A Pathway in Huntington's Disease
| Component | Change in HD | Brain Region/Model | Finding | Reference |
| Global m6A | Hypermethylation of synaptic & HD-related genes | Hippocampus (Hdh+/Q111 mice) | - | [17][18] |
| m6A on HTT mRNA | Increased methylation in intron 1 | Striatum (Hdh+/Q111 mice), Human HD fibroblasts | Promotes biogenesis of pathogenic HTT1a transcripts | [19] |
| METTL14 & FTO | Altered nuclear distribution | Hippocampus (Hdh+/Q111 mice) | Impaired synaptic gene expression & memory | [20] |
In HD mouse models, there is evidence of m6A hypermethylation of genes related to synaptic function.[17][18] A key finding is the increased m6A methylation within the first intron of the mutant HTT RNA, which promotes the production of a pathogenic, truncated form of the huntingtin protein (HTT1a).[19] Furthermore, altered nuclear distribution of METTL14 and FTO has been observed, which may contribute to cognitive deficits by disrupting synaptic gene expression.[20] Inhibition of the m6A demethylase FTO has been shown to improve memory in HD mice, highlighting a potential therapeutic avenue.[21]
Key Experimental Protocols
Studying the m6A epitranscriptome requires specialized techniques. This section provides detailed methodologies for two key experiments: transcriptome-wide m6A profiling using MeRIP-seq and global m6A quantification by LC-MS/MS.
Methylated RNA Immunoprecipitation Sequencing (MeRIP-seq)
MeRIP-seq is a powerful technique to map the transcriptome-wide distribution of m6A. It involves immunoprecipitation of m6A-containing RNA fragments followed by high-throughput sequencing.
Detailed Methodology for MeRIP-seq from Brain Tissue
-
RNA Extraction and Fragmentation:
-
Extract total RNA from brain tissue using a TRIzol-based method, ensuring high quality and integrity (RIN > 7).
-
Fragment the total RNA to an average size of 100-200 nucleotides using enzymatic or chemical fragmentation methods.[22]
-
-
Immunoprecipitation (IP):
-
Take an aliquot of the fragmented RNA as the "input" control.
-
Incubate the remaining fragmented RNA with an m6A-specific antibody overnight at 4°C with gentle rotation.
-
Add protein A/G magnetic beads to the RNA-antibody mixture and incubate for 2 hours at 4°C to capture the antibody-RNA complexes.
-
Wash the beads multiple times with IP buffer to remove non-specifically bound RNA.
-
-
RNA Elution and Purification:
-
Elute the m6A-containing RNA fragments from the antibody-bead complexes.
-
Purify the eluted RNA and the input control RNA using a suitable RNA cleanup kit.
-
-
Library Preparation and Sequencing:
-
Construct sequencing libraries from the m6A-immunoprecipitated RNA and the input RNA. This typically involves reverse transcription, second-strand synthesis, adapter ligation, and PCR amplification.
-
Perform high-throughput sequencing of the prepared libraries on a platform such as Illumina.
-
-
Data Analysis:
-
Align the sequencing reads to the reference genome.
-
Perform peak calling to identify m6A-enriched regions in the IP samples relative to the input samples.
-
Annotate the identified m6A peaks to specific genes and genomic features.
-
Perform differential methylation analysis between different experimental conditions.
-
Conduct motif analysis to identify conserved sequences within the m6A peaks.
-
Perform functional enrichment analysis (e.g., GO and KEGG) of the genes with differential m6A methylation.
-
Below is a diagram illustrating the MeRIP-seq workflow.
Quantification of Global m6A Levels by LC-MS/MS
Liquid chromatography-tandem mass spectrometry (LC-MS/MS) is the gold standard for accurate quantification of global m6A levels in a given RNA sample.
Detailed Methodology for LC-MS/MS m6A Quantification
-
RNA Isolation and Purification:
-
Isolate total RNA from cells or tissues.
-
Purify mRNA from the total RNA using oligo(dT) magnetic beads to minimize contamination from ribosomal RNA.
-
-
RNA Digestion to Nucleosides:
-
Digest the purified mRNA into individual nucleosides using a cocktail of enzymes. This typically involves treatment with nuclease P1 followed by phosphodiesterase I and alkaline phosphatase.[23]
-
-
LC-MS/MS Analysis:
-
Inject the digested nucleoside mixture into a liquid chromatography system coupled to a triple quadrupole mass spectrometer.
-
Separate the nucleosides by reverse-phase chromatography.
-
Perform quantitative analysis using multiple reaction monitoring (MRM) mode. This involves monitoring specific precursor-to-product ion transitions for adenosine (A) and N6-methyladenosine (m6A).
-
-
Data Quantification:
-
Generate standard curves for both adenosine and m6A using known concentrations of pure standards.
-
Quantify the amounts of adenosine and m6A in the samples by comparing their peak areas to the standard curves.
-
Calculate the global m6A level as the ratio of m6A to total adenosine (m6A/A ratio).
-
Conclusion and Future Directions
The study of m6A modification in the nervous system is a rapidly evolving field. The evidence presented in this guide strongly indicates that dysregulation of the m6A pathway is a significant contributor to the pathogenesis of a range of neurological disorders. The development of advanced techniques for m6A detection and quantification, coupled with in-depth functional studies, will continue to unravel the complex roles of this epitranscriptomic mark in neuronal health and disease.
For researchers and drug development professionals, the m6A pathway presents a novel and promising landscape for therapeutic intervention. Targeting the writers, erasers, or readers of m6A could offer new strategies to combat neurodegenerative diseases and other neurological conditions. Future research should focus on elucidating the cell-type-specific roles of m6A, identifying the precise mRNA targets of dysregulated m6A in different disease contexts, and developing specific and potent modulators of m6A regulatory proteins. This will pave the way for the development of novel epitranscriptomic-based diagnostics and therapeutics for neurological disorders.
References
- 1. A new perspective on Alzheimer’s disease: m6A modification - PMC [pmc.ncbi.nlm.nih.gov]
- 2. researchgate.net [researchgate.net]
- 3. Altered Expression of the m6A Methyltransferase METTL3 in Alzheimer’s Disease - PMC [pmc.ncbi.nlm.nih.gov]
- 4. eneuro.org [eneuro.org]
- 5. Frontiers | Abnormality of m6A mRNA Methylation Is Involved in Alzheimer’s Disease [frontiersin.org]
- 6. Frontiers | A new perspective on Alzheimer’s disease: m6A modification [frontiersin.org]
- 7. FTO-targeted siRNA delivery by MSC-derived exosomes synergistically alleviates dopaminergic neuronal death in Parkinson's disease via m6A-dependent regulation of ATM mRNA - PMC [pmc.ncbi.nlm.nih.gov]
- 8. researchgate.net [researchgate.net]
- 9. Knockdown of fat mass and obesity alleviates the ferroptosis in Parkinson's disease through m6A-NRF2-dependent manner - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. FTO-targeted siRNA delivery by MSC-derived exosomes synergistically alleviates dopaminergic neuronal death in Parkinson's disease via m6A-dependent regulation of ATM mRNA - PubMed [pubmed.ncbi.nlm.nih.gov]
- 11. ahajournals.org [ahajournals.org]
- 12. researchgate.net [researchgate.net]
- 13. N6-methyladenosine (m6A) dysregulation contributes to network excitability in temporal lobe epilepsy – FutureNeuro [futureneurocentre.ie]
- 14. Frontiers | Identification of RNA N6-methyladenosine regulation in epilepsy: Significance of the cell death mode, glycometabolism, and drug reactivity [frontiersin.org]
- 15. Identification of RNA N6-methyladenosine regulation in epilepsy: Significance of the cell death mode, glycometabolism, and drug reactivity - PMC [pmc.ncbi.nlm.nih.gov]
- 16. N6-methyladenosine (m6A) dysregulation contributes to network excitability in temporal lobe epilepsy - PMC [pmc.ncbi.nlm.nih.gov]
- 17. Altered m6A RNA methylation contributes to hippocampal memory deficits in Huntington’s disease mice - PMC [pmc.ncbi.nlm.nih.gov]
- 18. researchgate.net [researchgate.net]
- 19. m6A modification of mutant huntingtin RNA promotes the biogenesis of pathogenic huntingtin transcripts - PMC [pmc.ncbi.nlm.nih.gov]
- 20. mdpi.com [mdpi.com]
- 21. oaepublish.com [oaepublish.com]
- 22. MeRIP-seq Protocol - CD Genomics [rna.cd-genomics.com]
- 23. Quantification of global m6A RNA methylation levels by LC-MS/MS [visikol.com]
The Cellular Landscape of N6-methyladenosine (m6A) Modification: A Technical Guide
For Researchers, Scientists, and Drug Development Professionals
Abstract
N6-methyladenosine (m6A) is the most abundant internal modification on eukaryotic messenger RNA (mRNA) and has emerged as a critical regulator of gene expression. The cellular localization of m6A-modified RNA and the machinery that governs this modification are intricately linked to its diverse functions, including the control of RNA splicing, stability, nuclear export, and translation. Understanding the spatial dynamics of m6A is paramount for elucidating its role in cellular homeostasis and disease pathogenesis. This technical guide provides an in-depth overview of the cellular localization of m6A modification, its regulatory proteins, and the experimental methodologies used to investigate its subcellular distribution.
Introduction to m6A Modification and its Cellular Importance
N6-methyladenosine (m6A) is a dynamic and reversible post-transcriptional modification that plays a pivotal role in almost every aspect of RNA biology.[1][2][3] The addition and removal of the methyl group on adenosine (B11128) residues are tightly controlled by a set of proteins known as "writers" (methyltransferases) and "erasers" (demethylases), respectively. The functional consequences of m6A are mediated by "reader" proteins that specifically recognize and bind to m6A-containing transcripts.[1][4] The subcellular compartmentalization of these regulators and their target RNAs dictates the ultimate fate of the modified transcripts, thereby influencing a myriad of cellular processes, from cell differentiation and development to stress responses and the progression of diseases like cancer.[3][5][6]
The m6A Machinery: Subcellular Localization and Function
The precise localization of the m6A writers, erasers, and readers within the cell is crucial for their function. The dynamic interplay between these proteins in different cellular compartments ensures the proper regulation of m6A-modified RNAs.
m6A Writers
The m6A methyltransferase complex, responsible for installing the m6A mark, is predominantly localized in the nucleus.[7][8] This nuclear localization is consistent with its primary function of co-transcriptionally modifying nascent pre-mRNAs.[8][9]
| Component | Primary Localization | Key Functions |
| METTL3 | Nucleus (predominantly), Cytoplasm | Catalytic subunit of the methyltransferase complex.[1][4] Can also promote translation in the cytoplasm independent of its catalytic activity.[10] |
| METTL14 | Nucleus | RNA-binding platform that enhances METTL3's catalytic activity.[1][4][10] |
| WTAP | Nucleus (Nuclear Speckles) | Interacts with the METTL3-METTL14 complex to facilitate its localization and recruitment to target mRNAs.[11][12] |
| VIRMA (KIAA1429) | Nucleus | Component of the writer complex.[11] |
| RBM15/15B | Nucleus | Component of the writer complex.[4] |
| ZC3H13 | Nucleus | Component of the writer complex.[4] |
m6A Erasers
The demethylases that remove m6A marks are also primarily found in the nucleus, underscoring the dynamic nature of this modification within the nuclear compartment.[7][13]
| Eraser | Primary Localization | Key Functions |
| FTO | Nucleus, Cytoplasm | Removes m6A marks from nuclear RNA, with a preference for m6Am.[4][14] Also found at the synapse, suggesting local demethylation.[8] |
| ALKBH5 | Nucleus | Removes m6A marks on nuclear RNA, thereby regulating mRNA export.[1][15] Considered a major m6A demethylase.[4] |
m6A Readers
m6A reader proteins are distributed throughout the cell, in both the nucleus and the cytoplasm, where they mediate the diverse downstream effects of the m6A mark.[5][7]
| Reader | Primary Localization | Key Functions |
| YTHDC1 | Nucleus | Regulates pre-mRNA splicing, promotes exon inclusion, and facilitates the nuclear export of m6A-modified mRNA.[3][5][16] |
| YTHDC2 | Nucleus, Cytoplasm | Plays a role in the switch from mitosis to meiosis.[3] |
| YTHDF1 | Cytoplasm | Promotes the translation of m6A-modified mRNAs by interacting with translation initiation factors.[3][5][8] |
| YTHDF2 | Cytoplasm | Promotes the degradation of m6A-modified mRNAs.[3][5] |
| YTHDF3 | Cytoplasm | Works with YTHDF1 to promote translation and with YTHDF2 to mediate mRNA decay.[3][5] |
| HNRNPA2B1 | Nucleus | Influences pre-mRNA splicing and miRNA processing.[8][11] |
| HNRNPC/G | Nucleus | Regulates the processing and abundance of m6A-containing transcripts.[8][11] |
| IGF2BP1/2/3 | Cytoplasm | Promotes the stability and storage of target mRNAs in an m6A-dependent manner.[4][7] |
| eIF3 | Cytoplasm | Promotes cap-independent translation of m6A-modified mRNAs.[5] |
Cellular Compartments and the Role of m6A
The functional consequences of m6A modification are highly dependent on the cellular compartment in which the modified RNA resides.
The Nucleus
The nucleus is the primary site for the writing and erasing of m6A marks.[7][8] Nuclear m6A plays a crucial role in:
-
RNA Splicing : Nuclear reader proteins like YTHDC1 and HNRNPs recognize m6A sites and influence alternative splicing decisions.[3][7]
-
Nuclear Export : YTHDC1 facilitates the export of methylated mRNAs to the cytoplasm.[16] Conversely, some studies suggest that m6A can also lead to the nuclear retention of certain transcripts as a quality control mechanism.[17]
-
Chromatin Organization and Transcription : Emerging evidence suggests a role for m6A in modulating chromatin structure and transcription.[18]
The Cytoplasm
Once exported to the cytoplasm, m6A-modified RNAs are subject to regulation by cytoplasmic reader proteins, which determine their fate.[7][8] Key cytoplasmic functions include:
-
mRNA Translation : Readers like YTHDF1 and eIF3 can enhance the translation efficiency of m6A-modified transcripts.[3][5][8]
-
mRNA Stability and Decay : YTHDF2 is a major player in promoting the degradation of methylated mRNAs, while IGF2BP proteins can enhance their stability.[3][4][8]
-
Subcellular Localization : m6A modifications can act as signals for the localization of mRNAs to specific subcellular regions, such as neuronal dendrites, for localized translation.[19]
Mitochondria
Recent studies have revealed the presence of m6A modifications on mitochondrial transcripts, suggesting a role for this mark in regulating mitochondrial gene expression and function.[1][20] m6A modification has been shown to be enriched in nuclear-encoded mitochondrial-related RNAs and to promote their translation, thereby regulating mitochondrial respiration and ATP production.[2][21]
Signaling Pathways and Experimental Workflows
Visualizing the complex interplay of the m6A machinery and the experimental approaches to study its localization is essential for a comprehensive understanding.
Experimental Protocols for Studying m6A Localization
A variety of techniques are employed to investigate the subcellular distribution of m6A-modified RNAs and their associated proteins.
Immunofluorescence (IF) for m6A and Associated Proteins
Immunofluorescence is a powerful technique to visualize the localization of m6A itself or the writer, eraser, and reader proteins within cells.
Protocol Outline:
-
Cell Culture and Fixation:
-
Grow cells on coverslips to the desired confluency.
-
Wash cells with phosphate-buffered saline (PBS).
-
Fix cells with 4% paraformaldehyde in PBS for 10 minutes at room temperature.[22] For m6A staining, methanol (B129727) fixation at -20°C for 10 minutes is often used.[23][24]
-
-
Permeabilization:
-
If using paraformaldehyde fixation, permeabilize cells with a solution of 0.2% Triton X-100 in PBS for 10 minutes.[25]
-
-
Blocking:
-
Block non-specific antibody binding by incubating coverslips in a blocking buffer (e.g., 1-3% bovine serum albumin in PBS) for at least 30 minutes.[22]
-
-
Primary Antibody Incubation:
-
Secondary Antibody Incubation:
-
Wash cells three times with PBS.
-
Incubate with a fluorescently labeled secondary antibody (e.g., anti-rabbit IgG conjugated to a fluorophore) and a nuclear counterstain like DAPI for 45-60 minutes at room temperature, protected from light.[22]
-
-
Mounting and Imaging:
-
Wash cells three times with PBS.
-
Mount coverslips onto microscope slides using an anti-fade mounting medium.
-
Visualize and capture images using a fluorescence or confocal microscope.
-
Cellular Fractionation followed by m6A-Seq (MeRIP-Seq)
This method allows for the transcriptome-wide profiling of m6A-modified RNAs in different cellular compartments, such as the nucleus and cytoplasm.
Protocol Outline:
-
Cellular Fractionation:
-
Harvest cells and perform subcellular fractionation to separate the nuclear and cytoplasmic components using a commercially available kit or a standard biochemical protocol. The purity of the fractions should be validated by Western blotting for compartment-specific protein markers.
-
-
RNA Extraction and Fragmentation:
-
Extract total RNA from the nuclear and cytoplasmic fractions using a standard RNA extraction method.
-
Fragment the RNA to a size of approximately 100-200 nucleotides using RNA fragmentation buffer or enzymatic methods.[26]
-
-
Methylated RNA Immunoprecipitation (MeRIP):
-
Incubate the fragmented RNA with an anti-m6A antibody that has been pre-bound to magnetic beads.
-
Wash the beads to remove non-specifically bound RNA.
-
Elute the m6A-containing RNA fragments.
-
-
Library Preparation and Sequencing:
-
Prepare sequencing libraries from the immunoprecipitated RNA and an input control (a portion of the fragmented RNA that did not undergo immunoprecipitation).
-
Perform high-throughput sequencing of the libraries.[27]
-
-
Bioinformatic Analysis:
-
Align the sequencing reads to a reference genome.
-
Identify m6A peaks by comparing the read distribution in the immunoprecipitated sample to the input control.
-
Analyze the distribution and enrichment of m6A peaks in different cellular compartments and on different transcripts.
-
In Situ Visualization of m6A-Modified Transcripts
Advanced techniques like DART-FISH (Deamination-Assisted Ribonucleic acid Targeting Fluorescence In Situ Hybridization) allow for the visualization of specific m6A sites on individual RNA molecules within cells, providing high-resolution spatial information.[22][28][29] This method can distinguish between methylated and unmethylated transcripts of the same gene.[30]
Conclusion and Future Perspectives
The cellular localization of m6A modification is a key determinant of its regulatory function. The spatial segregation of m6A writers, erasers, and readers, along with their target RNAs, provides a sophisticated layer of gene expression control. While significant progress has been made in mapping the m6A landscape within different cellular compartments, many questions remain. Future research will likely focus on developing and applying single-cell and spatially resolved m6A profiling techniques to unravel the cell-type-specific and context-dependent roles of m6A localization in health and disease. A deeper understanding of these processes will undoubtedly open new avenues for therapeutic intervention in a wide range of pathologies.
References
- 1. The Role of N6-Methyladenosine in Mitochondrial Dysfunction and Pathology [mdpi.com]
- 2. m6A RNA methylation regulates mitochondrial function - PMC [pmc.ncbi.nlm.nih.gov]
- 3. The role of m6A modification in the biological functions and diseases - PMC [pmc.ncbi.nlm.nih.gov]
- 4. m6A writers, erasers, readers and their functions | Abcam [abcam.com]
- 5. Reading m6A in the transcriptome: m6A-binding proteins - PMC [pmc.ncbi.nlm.nih.gov]
- 6. researchgate.net [researchgate.net]
- 7. researchgate.net [researchgate.net]
- 8. RNA N6-methyladenosine and the regulation of RNA localisation and function in the brain - PMC [pmc.ncbi.nlm.nih.gov]
- 9. youtube.com [youtube.com]
- 10. Interconnections between m6A RNA modification, RNA structure, and protein–RNA complex assembly | Life Science Alliance [life-science-alliance.org]
- 11. m6A reader proteins: the executive factors in modulating viral replication and host immune response - PMC [pmc.ncbi.nlm.nih.gov]
- 12. m6A modification in RNA: biogenesis, functions and roles in gliomas - PMC [pmc.ncbi.nlm.nih.gov]
- 13. researchgate.net [researchgate.net]
- 14. jme.bioscientifica.com [jme.bioscientifica.com]
- 15. Structural Insights Into m6A-Erasers: A Step Toward Understanding Molecule Specificity and Potential Antiviral Targeting - PMC [pmc.ncbi.nlm.nih.gov]
- 16. Dynamic regulation and functions of mRNA m6A modification - PMC [pmc.ncbi.nlm.nih.gov]
- 17. life-science-alliance.org [life-science-alliance.org]
- 18. The Functions of N6-Methyladenosine in Nuclear RNAs - PubMed [pubmed.ncbi.nlm.nih.gov]
- 19. cd-genomics.com [cd-genomics.com]
- 20. biorxiv.org [biorxiv.org]
- 21. researchgate.net [researchgate.net]
- 22. academic.oup.com [academic.oup.com]
- 23. m6A visualization/immunofluorescence of DamID [protocols.io]
- 24. biorxiv.org [biorxiv.org]
- 25. Immunofluorescence (IF) Protocol | EpigenTek [epigentek.com]
- 26. N6-Methyladenosine (M6A) in Fetal Offspring Modifies Mitochondrial Gene Expression following Gestational Nano-TiO2 Inhalation Exposure - PMC [pmc.ncbi.nlm.nih.gov]
- 27. An experimental workflow for identifying RNA m6A alterations in cellular senescence by methylated RNA immunoprecipitation sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 28. In situ visualization of m6A sites in cellular mRNAs - PubMed [pubmed.ncbi.nlm.nih.gov]
- 29. researchgate.net [researchgate.net]
- 30. public-pages-files-2025.frontiersin.org [public-pages-files-2025.frontiersin.org]
The Epitranscriptomic Undercurrent: A Technical Guide to the Consequences of m6A Dysregulation in Disease
For Researchers, Scientists, and Drug Development Professionals
Abstract
N6-methyladenosine (m6A) is the most abundant internal modification of messenger RNA in eukaryotes, playing a pivotal role in RNA metabolism, including splicing, nuclear export, stability, and translation. The dynamic and reversible nature of m6A modification, governed by a complex interplay of "writer," "eraser," and "reader" proteins, is crucial for maintaining cellular homeostasis. Consequently, dysregulation of the m6A machinery has been increasingly implicated in the pathogenesis of a wide array of human diseases. This technical guide provides an in-depth exploration of the consequences of m6A dysregulation in cancer, neurological disorders, metabolic diseases, and cardiovascular diseases. We present a comprehensive summary of quantitative data on the altered expression of m6A regulators, detail the signaling pathways affected by these perturbations, and provide meticulous experimental protocols for key m6A analysis techniques. This guide is intended to serve as a valuable resource for researchers and professionals in drug development seeking to understand and target the epitranscriptomic landscape in disease.
Introduction to N6-methyladenosine (m6A) Modification
The m6A modification is a post-transcriptional epigenetic mark that profoundly influences gene expression. This dynamic process is orchestrated by a set of proteins:
-
Writers: These are methyltransferase complexes that install the m6A mark. The primary writer complex consists of METTL3 (Methyltransferase-like 3) and METTL14, along with other regulatory subunits like WTAP.
-
Erasers: These are demethylases that remove the m6A modification. The two known erasers are FTO (Fat mass and obesity-associated protein) and ALKBH5.
-
Readers: These proteins recognize and bind to m6A-modified RNA, mediating the downstream effects. The YTH domain-containing family of proteins (YTHDF1, YTHDF2, YTHDF3, YTHDC1, and YTHDC2) are the most well-characterized m6A readers.
Dysregulation in the expression or activity of these proteins can lead to aberrant m6A patterns on target transcripts, contributing to the initiation and progression of various diseases.
Figure 1: The dynamic regulation of m6A modification.
Dysregulation of m6A in Cancer
Aberrant m6A modification is a hallmark of many cancers, where it can function as either an oncogenic driver or a tumor suppressor depending on the cellular context.
Quantitative Data on m6A Regulator Expression in Cancer
The expression levels of m6A writers, erasers, and readers are frequently altered in various malignancies, and these changes often correlate with patient prognosis.
| Gene | Cancer Type | Expression Change (Tumor vs. Normal) | Patient Cohort Size | Key Finding | Reference |
| METTL3 | Esophageal Carcinoma | Upregulated | 184 | High expression associated with unfavorable prognosis. | [1] |
| METTL14 | Pancreatic Cancer | Downregulated | 930 | Low expression correlated with higher immune cell infiltration and better survival. | [2] |
| FTO | Breast Cancer | Upregulated | N/A | Promotes proliferation and metastasis. | [3] |
| YTHDF1 | Colorectal Cancer | Upregulated | N/A | Promotes tumor growth. | [3] |
| ALKBH5 | Glioblastoma | Downregulated | N/A | Acts as a tumor suppressor. | |
| ZC3H13 | Esophageal Carcinoma | Mutated in 12.5% of cases | 184 | Highest frequency of mutations among m6A regulators. | [1] |
Impact on Signaling Pathways
m6A dysregulation perturbs key signaling pathways that are fundamental to cancer biology.
-
PI3K/Akt/mTOR Pathway: This pathway is crucial for cell growth, proliferation, and survival. m6A modification can regulate the stability and translation of key components of this pathway. For instance, aberrant m6A modification has been shown to affect the expression of PTEN, AKT1, and PIK3CA, leading to the overactivation of this signaling cascade in gastrointestinal cancers.[4][5]
Figure 2: m6A-mediated regulation of the PI3K/Akt/mTOR pathway.
-
Wnt/β-catenin Pathway: Dysregulation of this pathway is a common event in many cancers. m6A modification can influence the expression of key components of the Wnt pathway, such as β-catenin, thereby promoting tumorigenesis.
-
Hedgehog Pathway: In medulloblastoma, the m6A writer METTL3 has been shown to promote tumor progression by regulating the m6A modification and expression of GLI1, a key transcription factor in the Hedgehog pathway.[6]
Consequences in Neurological Disorders
The brain exhibits the highest abundance of m6A modifications, highlighting its critical role in neuronal function. Dysregulation of m6A is increasingly linked to the pathogenesis of neurodegenerative diseases.
Quantitative Data on m6A Dysregulation in Neurological Disorders
| Gene | Disease | Expression Change (Disease vs. Control) | Brain Region | Key Finding | Reference |
| METTL3 | Alzheimer's Disease | Downregulated | Hippocampus | Aberrant expression may contribute to neuronal dysfunction. | [7] |
| METTL14 | Alzheimer's Disease | Upregulated | N/A | Associated with subtype classification and immune infiltration. | [8] |
| FTO | Alzheimer's Disease | Downregulated | N/A | Reduced expression may activate the Notch1 pathway.[9][10] | [9][10] |
| YTHDF2 | Alzheimer's Disease | Downregulated | N/A | Identified as a key regulator in AD. | [8] |
| FTO | Parkinson's Disease | Upregulated | Striatum | Elevated expression observed in PD patients. | [11] |
| YTHDF3 | Parkinson's Disease | Upregulated | Striatum | Significantly elevated in PD patients. | [11] |
Impact on Signaling Pathways
-
Notch Signaling Pathway: In Alzheimer's disease, the downregulation of FTO has been linked to the activation of the Notch1 signaling pathway. This may occur through increased m6A methylation of Notch1 mRNA, leading to its upregulation and subsequent neuroinflammation.[9][10]
Figure 3: FTO and Notch1 signaling in Alzheimer's disease.
Role in Metabolic Diseases
m6A modification plays a significant role in regulating metabolic processes, and its dysregulation is implicated in obesity and type 2 diabetes (T2D).
Quantitative Data in Metabolic Diseases
| Gene | Disease | Expression Change (Disease vs. Control) | Tissue/Cell Type | Key Finding | Reference |
| FTO | Type 2 Diabetes | 1.27-fold higher | White blood cells | Positively correlated with serum glucose. | [12] |
| METTL3 | Type 2 Diabetes | 1.45-fold higher | White blood cells | Negatively correlated with m6A content. | [12] |
| METTL14 | Type 2 Diabetes | 1.30-fold higher | White blood cells | Negatively correlated with m6A content. | [12] |
| ALKBH5 | Obesity | Higher expression | Adipose tissue | Correlates with obesity and clinical variables. | [13] |
| WTAP | Obesity | Correlates with obesity | Adipose tissue | Correlates with clinical variables. | [13] |
Impact on Adipogenesis and Glucose Metabolism
The m6A eraser FTO has been strongly linked to obesity and T2D.[3] FTO influences adipogenesis, the process of fat cell formation, and regulates glucose metabolism.[14] In T2D, high glucose levels can increase FTO expression, leading to a decrease in global m6A levels.[12] This can affect the expression of genes involved in glucose and lipid metabolism.
Involvement in Cardiovascular Diseases
Emerging evidence highlights the critical role of m6A modification in cardiovascular health and disease.
Quantitative Data in Cardiovascular Diseases
| Gene/Modification | Disease | Expression/Level Change (Disease vs. Control) | Tissue | Key Finding | Reference |
| Global m6A | Heart Failure | Significantly higher | Left ventricular tissue | Associated with heart failure progression. | |
| METTL3 | Heart Failure with Preserved Ejection Fraction | Upregulated | Peripheral blood mononuclear cells | Part of an altered m6A regulator expression pattern. | |
| FTO | Heart Failure with Preserved Ejection Fraction | Upregulated | Peripheral blood mononuclear cells | Elevated expression in HFpEF patients. | |
| METTL14 | Coronary Heart Disease | Significantly increased | Serum | Positively associated with inflammatory markers. | |
| m6A peaks | Atherosclerosis | 16,825 in model vs. 20,957 in control | Human coronary artery smooth muscle cells | Altered m6A landscape in atherosclerosis model. |
Impact on Cardiac Function and Signaling
-
TGF-β Signaling: In the context of cardiac fibrosis, a common feature of many heart diseases, the TGF-β signaling pathway can enhance m6A levels. This can lead to the stabilization of pro-fibrotic gene transcripts, contributing to disease progression.
Figure 4: m6A and TGF-β signaling in cardiac fibrosis.
-
MAPK Signaling: The MAPK pathway is involved in various cellular processes in the heart, including hypertrophy and apoptosis. Dysregulation of m6A has been shown to affect the expression of components of the MAPK pathway, thereby contributing to cardiac pathology.
-
NF-κB Signaling: In the context of inflammation, which plays a significant role in many cardiovascular diseases, m6A modification can regulate the NF-κB signaling pathway. For example, METTL3 can modulate the m6A levels of transcripts encoding components of the NF-κB pathway, thereby influencing the inflammatory response.
Experimental Protocols
Accurate and reproducible methods are essential for studying m6A modification. Below are detailed protocols for key techniques.
MeRIP-seq (m6A-seq) Protocol
This is the most widely used technique for transcriptome-wide mapping of m6A.
Figure 5: Workflow of the MeRIP-seq experiment.
Materials:
-
Total RNA of high quality (RIN > 7.0)
-
m6A antibody
-
Protein A/G magnetic beads
-
RNA fragmentation buffer
-
IP buffer (50 mM Tris-HCl, 750 mM NaCl, 0.5% Igepal CA-630)
-
Wash buffers
-
Elution buffer
-
RNase inhibitors
-
Library preparation kit for sequencing
Procedure:
-
RNA Fragmentation:
-
Start with 5-10 µg of mRNA or 100-200 µg of total RNA.
-
Fragment the RNA to an average size of ~100 nucleotides by incubating with fragmentation buffer at 94°C for 5-15 minutes. The exact time should be optimized.
-
Immediately stop the reaction by adding a stop solution and placing it on ice.
-
Purify the fragmented RNA.
-
-
Immunoprecipitation:
-
Incubate the fragmented RNA with an m6A-specific antibody in IP buffer for 2 hours at 4°C with rotation.
-
Add pre-washed Protein A/G magnetic beads and incubate for another 2 hours at 4°C with rotation to capture the antibody-RNA complexes.
-
Wash the beads multiple times with wash buffers to remove non-specific binding.
-
-
Elution and RNA Purification:
-
Elute the m6A-containing RNA fragments from the beads using an elution buffer.
-
Purify the eluted RNA using a suitable RNA purification kit.
-
-
Library Preparation and Sequencing:
-
Construct a sequencing library from the immunoprecipitated RNA and an input control (a small fraction of the fragmented RNA before IP).
-
Perform high-throughput sequencing.
-
-
Data Analysis:
-
Align the sequencing reads to the reference genome.
-
Use peak-calling algorithms (e.g., MACS2) to identify m6A-enriched regions (peaks) by comparing the IP sample to the input control.
-
Perform differential methylation analysis between different conditions.
-
Motif analysis can be used to confirm the enrichment of the m6A consensus sequence (RRACH).
-
m6A-CLIP-seq (miCLIP) Protocol
m6A-CLIP-seq provides single-nucleotide resolution mapping of m6A sites.
Procedure Outline:
-
UV Crosslinking: UV irradiate cells or tissues to covalently crosslink RNA-binding proteins (including the anti-m6A antibody) to RNA.
-
Immunoprecipitation: Lyse the cells and immunoprecipitate the m6A-antibody-RNA complexes.
-
RNase Digestion: Partially digest the RNA to leave only the RNA fragments protected by the crosslinked antibody.
-
Adapter Ligation and Radiolabeling: Ligate adapters to the RNA fragments and radioactively label the 5' end.
-
SDS-PAGE and Transfer: Run the protein-RNA complexes on an SDS-PAGE gel and transfer them to a nitrocellulose membrane.
-
RNA Isolation: Excise the membrane region corresponding to the correct size and isolate the RNA.
-
Reverse Transcription and Library Preparation: Reverse transcribe the RNA into cDNA. During this step, the crosslinking site often causes a mutation or truncation in the cDNA, which marks the m6A site. Prepare the library for sequencing.
-
Data Analysis: Analyze the sequencing data to identify the specific mutation or truncation sites, which correspond to the m6A locations at single-nucleotide resolution.[6]
Therapeutic Perspectives and Future Directions
The growing understanding of the role of m6A dysregulation in disease has opened up new avenues for therapeutic intervention. Small molecule inhibitors targeting m6A writers and erasers are being developed and are in various stages of preclinical and clinical investigation.[4][5] For example, inhibitors of FTO have shown promise in preclinical models of cancer.
However, challenges remain. The ubiquitous nature of m6A modification means that systemic inhibition of m6A regulators could have significant off-target effects. Therefore, developing strategies for targeted delivery of these inhibitors to diseased tissues is a key area of future research.
References
- 1. miCLIP-m6A - Enseqlopedia [enseqlopedia.com]
- 2. Global mapping of RNA N6-methyladenosine (m6A) in human subcutaneous and visceral adipose tissue reveals novel targets that correlate with clinical variables of obesity - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Screening of key genes related to M6A methylation in patients with heart failure - PMC [pmc.ncbi.nlm.nih.gov]
- 4. MeRIP-seq: Comprehensive Guide to m6A RNA Modification Analysis - CD Genomics [rna.cd-genomics.com]
- 5. researchgate.net [researchgate.net]
- 6. researchgate.net [researchgate.net]
- 7. High-Resolution N6-Methyladenosine (m6A) Map Using Photo-Crosslinking-Assisted m6A Sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 8. N6-methyladenosine (m6A) RNA modification in the pathophysiology of heart failure: a narrative review - PMC [pmc.ncbi.nlm.nih.gov]
- 9. researchgate.net [researchgate.net]
- 10. researchgate.net [researchgate.net]
- 11. mdpi.com [mdpi.com]
- 12. Frontiers | m6A Regulators in Human Adipose Tissue - Depot-Specificity and Correlation With Obesity [frontiersin.org]
- 13. Mapping m6A at individual-nucleotide resolution using crosslinking and immunoprecipitation (miCLIP) - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Deep and accurate detection of m6A RNA modifications using miCLIP2 and m6Aboost machine learning - PMC [pmc.ncbi.nlm.nih.gov]
Methodological & Application
Application Notes and Protocols for Methylated RNA Immunoprecipitation Sequencing (MeRIP-seq)
For Researchers, Scientists, and Drug Development Professionals
These application notes provide a comprehensive overview and detailed protocol for performing Methylated RNA Immunoprecipitation Sequencing (MeRIP-seq), a powerful technique for transcriptome-wide profiling of RNA modifications, particularly N6-methyladenosine (m6A).
Introduction
Methylated RNA Immunoprecipitation Sequencing (MeRIP-seq), also known as m6A-seq, is a cutting-edge method that combines the principles of immunoprecipitation of methylated RNA fragments with high-throughput sequencing.[1][2] This technique allows for the identification and quantification of RNA modifications across the entire transcriptome, providing valuable insights into the roles of RNA methylation in various biological processes, including gene expression regulation, cell differentiation, and disease pathogenesis.[3][4] The workflow involves immunoprecipitating RNA fragments containing the modification of interest using a specific antibody, followed by sequencing of the enriched fragments.[5]
Principle of MeRIP-seq
The core principle of MeRIP-seq lies in the specific recognition and capture of methylated RNA species.[4] The process begins with the fragmentation of total RNA into smaller, manageable pieces. These fragments are then incubated with an antibody that specifically binds to the methylation mark of interest, most commonly m6A.[6] The resulting antibody-RNA complexes are then captured, typically using protein A/G magnetic beads.[7] After stringent washing steps to remove non-specifically bound RNA, the enriched methylated RNA fragments are eluted and used to construct a cDNA library for next-generation sequencing.[1] A parallel "input" library is typically prepared from a portion of the fragmented RNA that has not undergone immunoprecipitation to serve as a control for background and to normalize the data.[8][9]
Experimental Workflow Diagram
Caption: A schematic of the MeRIP-seq experimental workflow.
Detailed Experimental Protocol
This protocol provides a step-by-step guide for performing MeRIP-seq, from sample preparation to library construction.
Material Preparation
It is crucial to maintain an RNase-free environment throughout the experiment. Use RNase-free water, tubes, and tips.[6]
| Reagent/Material | Specifications |
| Cell or Tissue Samples | Rapidly frozen to preserve RNA integrity.[1] |
| m6A Antibody | Select a highly specific and validated antibody. |
| Protein A/G Magnetic Beads | For capturing antibody-RNA complexes.[7] |
| RNA Extraction Kit | e.g., TRIzol or other column-based kits.[1] |
| RNA Fragmentation Buffer | To shear RNA to the desired size.[6] |
| Immunoprecipitation (IP) Buffer | For antibody-RNA binding.[6] |
| Wash Buffers | Stringent buffers to remove non-specific binding. |
| Elution Buffer | To release the enriched RNA from the beads.[6] |
| RNase Inhibitors | To prevent RNA degradation.[1] |
RNA Extraction and Quality Control
High-quality total RNA is a prerequisite for a successful MeRIP-seq experiment.
-
Extract total RNA from your cells or tissues of interest using a standard protocol or a commercial kit.[1][2]
-
Assess the quality and quantity of the extracted RNA.
-
Purity: Measure the A260/A280 and A260/A230 ratios using a spectrophotometer. The ideal A260/A280 ratio is ~2.0.
-
Integrity: Evaluate the RNA integrity number (RIN) using an Agilent Bioanalyzer or similar instrument. A RIN value > 7 is generally recommended.
-
RNA Fragmentation
-
Fragment the total RNA to an average size of 100-300 nucleotides.[1][9] This can be achieved through enzymatic digestion or metal-ion-catalyzed hydrolysis.[1]
-
Verify the size distribution of the fragmented RNA using a Bioanalyzer.
Immunoprecipitation (IP)
-
Input Control: Set aside a small fraction (e.g., 5-10%) of the fragmented RNA to serve as the input control. This sample will not be subjected to immunoprecipitation and will be used for library construction directly.[6]
-
Antibody Incubation: Incubate the remaining fragmented RNA with the m6A-specific antibody in IP buffer. The incubation is typically performed at 4°C for 2 hours to overnight with gentle rotation.[6]
-
Bead Capture: Add pre-washed protein A/G magnetic beads to the RNA-antibody mixture and incubate for another 1-2 hours at 4°C to capture the complexes.[1]
-
Washing: Pellet the beads using a magnetic stand and discard the supernatant. Wash the beads multiple times with a series of stringent wash buffers to remove non-specifically bound RNA.
-
Elution: Elute the enriched methylated RNA from the beads using an appropriate elution buffer.[6]
Library Construction and Sequencing
-
Purify the eluted RNA and the input control RNA.
-
Construct sequencing libraries from both the IP and input RNA samples using a strand-specific RNA library preparation kit.[1] This process typically involves reverse transcription, second-strand synthesis, adapter ligation, and PCR amplification.[7]
-
Assess the quality and quantity of the constructed libraries.
-
Perform high-throughput sequencing on a suitable platform (e.g., Illumina).[10]
Data Analysis Pipeline
The analysis of MeRIP-seq data is a multi-step bioinformatic process.[11]
Quality Control and Pre-processing
-
Perform quality control of the raw sequencing reads using tools like FastQC to assess read quality, GC content, and adapter contamination.[10][12]
-
Trim adapter sequences and remove low-quality reads.[12]
Read Alignment
-
Align the processed reads to a reference genome or transcriptome using a splice-aware aligner such as STAR or HISAT2.[11][12]
Peak Calling
-
Identify regions of the transcriptome that are significantly enriched for methylation in the IP sample compared to the input control. This is known as peak calling.[12]
-
Several software tools are available for peak calling, including MACS2 and exomePeak.[12][13][14]
Differential Methylation Analysis
-
To identify changes in RNA methylation between different conditions, perform differential methylation analysis. Tools like DESeq2 and edgeR can be adapted for this purpose.[7]
Functional Annotation
-
Annotate the identified methylation peaks to specific genes and genomic features (e.g., 5' UTR, CDS, 3' UTR).
-
Perform Gene Ontology (GO) and pathway enrichment (e.g., KEGG) analysis to understand the biological functions of the genes with altered methylation.[7][12]
Data Presentation: Quantitative Parameters
| Parameter | Recommended Value/Range | Notes |
| Total RNA Input | 10 - 100 µg | Dependent on the abundance of the target modification. |
| RNA Fragmentation Size | 100 - 300 nt | Optimal for immunoprecipitation and sequencing.[9] |
| m6A Antibody Amount | 5 - 10 µg per IP | Should be optimized for each antibody and sample type. |
| Sequencing Depth | > 30 million reads per sample | Higher depth provides better resolution and sensitivity.[3] |
| Read Length | 50 - 150 bp | Single-end or paired-end sequencing can be used. |
Applications in Research and Drug Development
MeRIP-seq is a versatile technique with broad applications:
-
Disease Mechanism Research: Investigating the role of RNA methylation in the pathogenesis of diseases such as cancer and neurological disorders.[7]
-
Drug Discovery and Development: Identifying novel therapeutic targets by understanding how drug candidates affect the RNA methylome.[7]
-
Biomarker Discovery: Identifying RNA methylation patterns that can serve as diagnostic or prognostic biomarkers for various diseases.[4]
-
Fundamental Biology: Elucidating the fundamental roles of RNA modifications in gene regulation and cellular processes.[4]
References
- 1. MeRIP-seq Protocol - CD Genomics [rna.cd-genomics.com]
- 2. MeRIP-seq: Comprehensive Guide to m6A RNA Modification Analysis - CD Genomics [rna.cd-genomics.com]
- 3. An experimental workflow for identifying RNA m6A alterations in cellular senescence by methylated RNA immunoprecipitation sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 4. How MeRIP-seq Works: Principles, Workflow, and Applications Explained - CD Genomics [rna.cd-genomics.com]
- 5. MeRIP-Seq/m6A-seq [illumina.com]
- 6. sysy.com [sysy.com]
- 7. MeRIP-seq and Its Principle, Protocol, Bioinformatics, Applications in Diseases - CD Genomics [cd-genomics.com]
- 8. MeRIP-PF: An Easy-to-use Pipeline for High-resolution Peak-finding in MeRIP-Seq Data - PMC [pmc.ncbi.nlm.nih.gov]
- 9. researchgate.net [researchgate.net]
- 10. MeRIP-seq for Detecting RNA methylation: An Overview - CD Genomics [cd-genomics.com]
- 11. academic.oup.com [academic.oup.com]
- 12. Master MeRIP-seq Data Analysis: Step-by-Step Process for RNA Methylation Studies - CD Genomics [rna.cd-genomics.com]
- 13. GitHub - canceromics/MeRIPseqPipe: MeRIPseqPipe:An integrated analysis pipeline for MeRIP-seq data based on Nextflow. [github.com]
- 14. A protocol for RNA methylation differential analysis with MeRIP-Seq data and exomePeak R/Bioconductor package - PMC [pmc.ncbi.nlm.nih.gov]
Application Notes and Protocols for m6A qPCR Analysis
For Researchers, Scientists, and Drug Development Professionals
Introduction
N6-methyladenosine (m6A) is the most abundant internal modification in eukaryotic messenger RNA (mRNA) and plays a critical role in various biological processes, including RNA stability, splicing, translation, and cellular localization. The dynamic nature of m6a modification, regulated by "writer," "eraser," and "reader" proteins, implicates it in numerous physiological and pathological conditions, making it a key area of investigation in molecular biology and a potential target for therapeutic development.
Methylated RNA Immunoprecipitation followed by quantitative PCR (MeRIP-qPCR) is a powerful and widely used technique to investigate the m6A modification status of specific RNA transcripts.[1][2] This method combines the specificity of immunoprecipitation using an anti-m6A antibody with the sensitivity of quantitative real-time PCR (qPCR) to determine the relative abundance of m6A on a target RNA. This document provides a detailed, step-by-step guide for performing and analyzing m6A qPCR experiments.
Principle of MeRIP-qPCR
The MeRIP-qPCR workflow begins with the isolation of total RNA from cells or tissues. The RNA is then fragmented to an appropriate size. A small fraction of the fragmented RNA is saved as the "input" control, representing the total amount of the target transcript. The remaining RNA is incubated with an anti-m6A antibody to specifically capture m6A-containing RNA fragments. These antibody-RNA complexes are then pulled down using protein A/G magnetic beads. After stringent washing steps to remove non-specifically bound RNA, the m6A-enriched RNA is eluted. Finally, both the immunoprecipitated (IP) RNA and the input RNA are reverse transcribed into cDNA and quantified by qPCR using gene-specific primers. The relative abundance of m6A on the target transcript is then calculated by normalizing the amount of immunoprecipitated RNA to the amount of input RNA.
Experimental Workflow
Caption: Experimental workflow for m6A qPCR (MeRIP-qPCR).
Biological Context of m6A Modification
Caption: Regulation and function of m6A RNA modification.
Detailed Experimental Protocol
This protocol is a generalized workflow and may require optimization for specific cell types or tissues.
Materials and Reagents:
-
RNA Extraction: Your preferred kit for total RNA isolation (e.g., TRIzol, RNeasy Kit).
-
RNA Fragmentation: RNA Fragmentation Reagents (e.g., Ambion, AM8740).
-
Immunoprecipitation:
-
Anti-m6A antibody (e.g., Synaptic Systems, 202003).
-
Normal Rabbit or Mouse IgG (as a negative control).
-
Protein A/G Magnetic Beads (e.g., Thermo Fisher, 10001D).
-
IPP Buffer (150 mM NaCl, 10 mM Tris-HCl pH 7.4, 0.5% NP-40 in DEPC-treated water).
-
Wash Buffers (Low salt, High salt).
-
Elution Buffer.
-
-
RNA Purification: RNA purification kit (e.g., RNeasy MinElute Cleanup Kit).
-
Reverse Transcription: Your preferred reverse transcription kit.
-
qPCR: SYBR Green or probe-based qPCR master mix and gene-specific primers.
Step 1: Total RNA Extraction and Quality Control
-
Extract total RNA from your samples using a standard protocol.
-
Assess RNA integrity using a Bioanalyzer or gel electrophoresis. The RNA Integrity Number (RIN) should be > 7.
-
Quantify the RNA concentration using a spectrophotometer (e.g., NanoDrop). Ensure high purity (A260/280 ratio of ~2.0).
Step 2: RNA Fragmentation
-
For each sample, take 50-100 µg of total RNA.
-
Fragment the RNA to an average size of ~100 nucleotides using an RNA fragmentation kit or magnesium-based fragmentation buffer.[1] Follow the manufacturer's instructions, typically involving incubation at an elevated temperature for a specific time.
-
Immediately stop the reaction by placing the tubes on ice and adding a stop buffer.
-
Purify the fragmented RNA using an RNA cleanup kit.
Step 3: Immunoprecipitation (MeRIP)
-
Input Sample: Save 10% of the fragmented RNA from each sample to serve as the input control. Store at -80°C.
-
Antibody-Bead Conjugation:
-
Resuspend the Protein A/G magnetic beads.
-
For each IP reaction, wash an appropriate amount of beads with IPP buffer.
-
Add the anti-m6A antibody (or IgG control) to the beads and incubate with rotation for 1-2 hours at 4°C to allow for antibody conjugation.
-
-
Immunoprecipitation Reaction:
-
Add the remaining 90% of fragmented RNA to the antibody-conjugated beads.
-
Add IPP buffer to the final reaction volume.
-
Incubate with rotation for 2-4 hours or overnight at 4°C.
-
-
Washing:
-
Pellet the beads on a magnetic stand and discard the supernatant.
-
Perform a series of stringent washes to remove non-specifically bound RNA. This typically includes washes with low-salt buffer, high-salt buffer, and a final wash with IPP buffer.[3]
-
-
Elution:
-
Elute the m6A-containing RNA from the beads using an appropriate elution buffer (e.g., containing Proteinase K or a competitive eluent).
-
Incubate at a suitable temperature to release the RNA.
-
-
RNA Purification:
-
Purify the eluted RNA using an RNA cleanup kit. Elute in a small volume of RNase-free water.
-
Step 4: Reverse Transcription
-
Perform reverse transcription on both the immunoprecipitated (IP) RNA and the input RNA samples to synthesize cDNA. Use a consistent amount of RNA for all reactions where possible.
Step 5: Quantitative PCR (qPCR)
-
Design and validate qPCR primers for your target gene(s). Primers should amplify a region of interest where m6A modification is expected.
-
Perform qPCR using a SYBR Green or probe-based master mix with the cDNA from the IP and input samples.
-
Include a no-template control (NTC) for each primer set to check for contamination.
-
Run all reactions in triplicate.
Data Presentation and Analysis
The primary method for quantifying m6A levels with MeRIP-qPCR is the "percent input" method.[1] This approach normalizes the amount of m6A-immunoprecipitated RNA to the total amount of the transcript present in the input sample.
Calculation:
-
Determine the Ct values for your gene of interest in both the Input and IP samples.
-
Calculate the relative expression of the IP and Input samples. A common method is to use the 2-Ct formula.
-
Normalize the IP signal to the Input signal. The formula is: % Input = (2-Ct(IP) / 2-Ct(Input)) * 100%
Note: Some protocols may include a dilution factor in this calculation if the input sample was diluted prior to reverse transcription or qPCR.
Data Summary Table:
| Sample Name | Target Gene | Replicate | Ct (Input) | Ct (IP) | Ct (IgG) | % Input (m6A) | % Input (IgG) | Fold Enrichment (m6A/IgG) |
| Control 1 | GENE_A | 1 | 22.5 | 28.0 | 33.5 | |||
| Control 1 | GENE_A | 2 | 22.6 | 28.1 | 33.6 | |||
| Control 1 | GENE_A | 3 | 22.4 | 27.9 | 33.4 | |||
| Treatment 1 | GENE_A | 1 | 22.7 | 26.5 | 33.8 | |||
| Treatment 1 | GENE_A | 2 | 22.8 | 26.6 | 33.7 | |||
| Treatment 1 | GENE_A | 3 | 22.6 | 26.4 | 33.9 |
-
% Input (m6A): Calculated using the formula above for the anti-m6A IP.
-
% Input (IgG): Calculated using the formula above for the IgG control IP.
-
Fold Enrichment (m6A/IgG): Calculated as (% Input (m6A)) / (% Input (IgG)). This value indicates the specificity of the m6A enrichment over the background.
Quality Control and Troubleshooting
| Issue | Possible Cause | Solution |
| No or low signal in IP samples | Inefficient immunoprecipitation | - Check the quality and concentration of the anti-m6A antibody. - Ensure proper antibody-bead conjugation. - Optimize the amount of starting RNA. |
| Low abundance of m6A on the target transcript | - Confirm the presence of the m6A consensus motif (DRACH) in the target region. | |
| High signal in IgG control | Non-specific binding of RNA to beads or IgG | - Increase the stringency and number of washes. - Pre-clear the RNA sample with beads alone before adding the antibody. |
| High variability between replicates | Pipetting errors or inconsistent sample handling | - Ensure accurate and consistent pipetting. - Homogenize samples thoroughly. |
| Poor RNA quality | - Use high-quality, intact RNA for the experiment. |
By following this comprehensive guide, researchers can confidently perform m6A qPCR analysis to investigate the role of this critical RNA modification in their biological systems of interest.
References
Application Notes and Protocols for Targeted m6A Editing Using CRISPR-Cas9
For Researchers, Scientists, and Drug Development Professionals
Introduction
N6-methyladenosine (m6A) is the most abundant internal modification in eukaryotic messenger RNA (mRNA) and plays a critical role in various aspects of RNA metabolism, including splicing, nuclear export, stability, and translation.[1][2] The reversible nature of m6A, dynamically regulated by methyltransferases ("writers") and demethylases ("erasers"), has implicated it in a wide range of physiological and pathological processes, such as cell differentiation, immunity, and cancer.[1][3] The ability to manipulate m6A at specific RNA sites is crucial for elucidating the functional consequences of individual m6A modifications and for developing potential therapeutic strategies.[4]
The advent of CRISPR-Cas9 technology has provided a powerful tool for targeted genome editing. This system has been adapted for epitranscriptome engineering by fusing a catalytically inactive Cas9 (dCas9) protein to m6A modifying enzymes.[1][5] These engineered CRISPR-Cas9 conjugates can be programmed with a single guide RNA (sgRNA) to install or remove m6A at specific locations on target RNAs without altering the underlying nucleotide sequence.[2][6][7] This technology offers unprecedented precision for studying the functional role of m6A in gene expression and cellular processes.
This document provides detailed application notes and protocols for utilizing CRISPR-Cas9 systems for targeted m6A editing. It is intended for researchers, scientists, and drug development professionals who are interested in applying this technology in their work.
Principle of CRISPR-Cas9 Mediated m6A Editing
The core of the CRISPR-Cas9 system for m6A editing consists of two main components:
-
dCas9-Effector Fusion Protein: A catalytically inactive Cas9 (dCas9) protein is fused to an m6A "writer" or "eraser" enzyme.
-
Single Guide RNA (sgRNA): A short RNA molecule that directs the dCas9-effector fusion protein to a specific target sequence on an RNA molecule.
-
Protospacer Adjacent Motif (PAM)mer: Since Cas9 requires a PAM sequence (typically NGG) for binding to its target, and RNA molecules lack this motif, a short DNA oligonucleotide called a PAMmer is used to provide the PAM sequence in trans.[1]
The sgRNA guides the dCas9-effector complex to the target RNA, and the PAMmer facilitates the binding of the complex. Once bound, the fused effector enzyme catalyzes the addition or removal of the methyl group at the targeted adenosine (B11128) residue.
Visualization of the m6A Editing Workflow
Caption: General workflow for CRISPR-Cas9 mediated m6A editing.
Quantitative Data Summary
The following tables summarize quantitative data from key experiments demonstrating the efficiency and specificity of CRISPR-Cas9 based m6A editing.
Table 1: On-Target m6A Editing Efficiency
| Target Gene & Region | Editing System | sgRNA | On-Target m6A Increase (%) | Reference |
| Hsp70 5' UTR | M3M14-dCas9 | sgRNA(b) | >50 | [5] |
| Hsp70 5' UTR | M3M14-dCas9 | sgRNA(c) | >50 | [5] |
| ACTB 3' UTR | dCasRx-METTL3 | sgRNA | Significant Increase | [8] |
| CYB5A CDS | dCas13b-ALKBH5 | gRNA2 | 80.2 ± 3.6 (demethylation) | [9][10] |
Table 2: Effects of Targeted m6A Editing on mRNA Stability
| Target Gene | Editing System | Effect on mRNA Half-life | Reference |
| Actb | MTase-dCas9 | Significantly Reduced | [5] |
| SQLE | dCasRx-METTL3 | Significantly Decreased | [8] |
| CYB5A | dCas13b-ALKBH5 | Significantly Increased | [10] |
Experimental Protocols
Protocol 1: Design of sgRNA and PAMmer
-
Target Site Selection: Identify the target adenosine residue for m6A editing within a DRACH motif (D=A, G, or U; R=A or G; H=A, C, or U).
-
sgRNA Design: Design a 20-nucleotide sgRNA sequence that is complementary to the target RNA sequence adjacent to the target adenosine. Several online tools can be used for sgRNA design, although they are primarily for DNA targeting, the principles of on-target scoring can be adapted. Ensure the sgRNA sequence is unique to the target transcript to minimize off-target effects.
-
PAMmer Design: Design a DNA oligonucleotide (PAMmer) that is antisense to the target RNA and contains a PAM sequence (5'-NGG-3'). The PAMmer should be designed to bind to the target RNA in close proximity to the sgRNA binding site.
Protocol 2: Plasmid Construction and Cell Transfection
-
Plasmid Construction:
-
Clone the designed sgRNA sequence into a suitable expression vector, typically under the control of a U6 promoter.
-
Obtain or construct plasmids expressing the dCas9-effector fusion proteins (e.g., M3M14-dCas9 for writing, ALKBH5-dCas9 for erasing). These are often available from plasmid repositories like Addgene.
-
-
Cell Culture: Culture the desired cell line (e.g., HEK293T, HeLa) under standard conditions.
-
Transfection: Co-transfect the cells with the sgRNA expression plasmid, the dCas9-effector plasmid, and the chemically synthesized PAMmer. Use a suitable transfection reagent according to the manufacturer's protocol.
Caption: Workflow for cell transfection with CRISPR-m6A editing components.
Protocol 3: Quantification of m6A Editing by m6A-RIP-qPCR
This protocol allows for the quantification of m6A levels at a specific site.
-
Total RNA Extraction: At 48-72 hours post-transfection, harvest the cells and extract total RNA using a suitable kit (e.g., Trizol).
-
mRNA Fragmentation: Fragment the total RNA to an average size of ~100 nucleotides.
-
Immunoprecipitation (IP):
-
Incubate the fragmented RNA with an anti-m6A antibody to capture m6A-containing RNA fragments.
-
Use protein A/G magnetic beads to pull down the antibody-RNA complexes.
-
Wash the beads to remove non-specifically bound RNA.
-
-
RNA Elution: Elute the m6A-containing RNA fragments from the beads.
-
Reverse Transcription and qPCR (RT-qPCR):
-
Perform reverse transcription on the eluted RNA and an input control (a fraction of the fragmented RNA before IP).
-
Perform qPCR using primers that specifically amplify the target region containing the edited m6A site.
-
-
Data Analysis: Calculate the enrichment of m6A at the target site in the edited sample relative to a control sample (e.g., cells transfected with a non-targeting sgRNA).
Protocol 4: Global m6A Quantification by LC-MS/MS
This protocol provides a global quantification of the m6A/A ratio in the total mRNA population.[11][12][13]
-
mRNA Isolation: Isolate mRNA from the total RNA using oligo(dT) magnetic beads.[14]
-
mRNA Digestion: Digest the purified mRNA into single nucleosides using nuclease P1 and alkaline phosphatase.[11][12]
-
LC-MS/MS Analysis:
-
Data Analysis: Calculate the m6A/A ratio by dividing the amount of m6A by the amount of A.
Signaling Pathways and Logical Relationships
The targeted modulation of m6A can influence various signaling pathways by altering the stability and translation of key transcripts.
References
- 1. whatisepigenetics.com [whatisepigenetics.com]
- 2. Targeted RNA m6A Editing Using Engineered CRISPR-Cas9 Conjugates - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. CRISPR-based m6A modification and its potential applications in telomerase regulation - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Targeted manipulation of m6A RNA modification through CRISPR-Cas-based strategies - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. Programmable RNA N6-methyladenosine editing by CRISPR-Cas9 conjugates - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Targeted RNA m6A Editing Using Engineered CRISPR-Cas9 Conjugates | Springer Nature Experiments [experiments.springernature.com]
- 7. researchgate.net [researchgate.net]
- 8. Epitranscriptomic editing of the RNA N6-methyladenosine modification by dCasRx conjugated methyltransferase and demethylase - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Targeted mRNA demethylation using an engineered dCas13b-ALKBH5 fusion protein - PMC [pmc.ncbi.nlm.nih.gov]
- 10. biorxiv.org [biorxiv.org]
- 11. bpb-us-e2.wpmucdn.com [bpb-us-e2.wpmucdn.com]
- 12. Quantitative analysis of m6A RNA modification by LC-MS - PubMed [pubmed.ncbi.nlm.nih.gov]
- 13. Quantitative analysis of m6A RNA modification by LC-MS [escholarship.org]
- 14. researchgate.net [researchgate.net]
Revolutionizing Epitranscriptomics: A Guide to Single-Nucleotide m6A Mapping
For Researchers, Scientists, and Drug Development Professionals
The dynamic landscape of RNA modifications, known as the epitranscriptome, is rapidly emerging as a critical layer of gene regulation. Among the more than 170 known RNA modifications, N6-methyladenosine (m6A) is the most abundant internal modification in eukaryotic messenger RNA (mRNA) and plays a pivotal role in nearly every aspect of RNA metabolism, from splicing and nuclear export to translation and decay. Dysregulation of m6A has been implicated in a wide range of human diseases, including cancer, neurodevelopmental disorders, and metabolic diseases, making it a prime target for novel therapeutic interventions.
Accurate and precise mapping of m6A sites is crucial for unraveling its biological functions and therapeutic potential. While early methods could only identify m6A-containing regions, recent technological advancements have enabled the mapping of this critical modification at single-nucleotide resolution. This level of precision is essential for understanding how m6A fine-tunes gene expression and for the development of targeted therapies.
These application notes provide a detailed overview and experimental protocols for four cutting-edge techniques for single-nucleotide resolution m6A mapping:
-
miCLIP (m6A individual-Nucleotide Resolution Cross-Linking and Immunoprecipitation): An antibody-based method that induces mutations at m6A sites upon UV cross-linking.
-
DART-seq (Deamination Adjacent to RNA Modification Targets sequencing): An enzyme-based, antibody-free method that utilizes a cytidine (B196190) deaminase fused to an m6A-binding protein to induce C-to-U edits near m6A sites.
-
MAZTER-seq (MazF-assisted m6A-sensitive endoribonuclease sequencing): An enzyme-based, antibody-independent technique that employs a methylation-sensitive RNase to specifically cleave unmethylated RNA.
-
m6A-SEAL-seq (m6A-Selective chemical Labeling and sequencing): A chemical-based, antibody-free approach that uses an FTO-like enzyme to oxidize m6A, enabling subsequent chemical labeling and identification.
This document offers detailed experimental protocols, a comparative analysis of their quantitative performance, and visual workflows to guide researchers in selecting and implementing the most suitable method for their specific research needs.
Quantitative Comparison of m6A Mapping Techniques
The selection of an appropriate m6A mapping method depends on various factors, including the required resolution, sensitivity, specificity, and the amount of available starting material. The following table summarizes the key quantitative parameters of the four highlighted techniques to facilitate an informed decision.
| Feature | miCLIP (m6A individual-Nucleotide Resolution Cross-Linking and Immunoprecipitation) | DART-seq (Deamination Adjacent to RNA Modification Targets sequencing) | MAZTER-seq (MazF-assisted m6A-sensitive endoribonuclease sequencing) | m6A-SEAL-seq (m6A-Selective chemical Labeling and sequencing) |
| Principle | Antibody-based, UV cross-linking induces mutations at m6A sites.[1] | Enzyme-based (APOBEC1-YTH fusion), C-to-U editing adjacent to m6A.[2][3] | Enzyme-based (MazF RNase), cleavage of unmethylated 'ACA' motifs.[4][5] | Chemical-based (FTO-assisted), selective chemical labeling of m6A.[6] |
| Resolution | Single nucleotide.[1] | Single nucleotide.[7] | Single nucleotide.[5] | Single nucleotide. |
| Input RNA | Typically requires micrograms of poly(A)+ RNA.[8] | Low input, as little as 10-50 ng of total RNA.[2][3] | Can be performed with as little as 25-50 ng of mRNA for qPCR validation.[9] | Low input requirements. |
| Sensitivity | High, can be enhanced with machine learning (m6Aboost).[8] | High, with improved sensitivity using engineered YTH domains.[10] | Interrogates 16-25% of m6A sites within the 'ACA' sequence context.[4][6] | Good sensitivity and specificity.[11] |
| Specificity | Can be affected by antibody cross-reactivity, but computational filtering improves accuracy.[8] | High, as it is an antibody-free method. Off-target edits can be filtered using controls.[12] | High within the 'ACA' context, antibody-independent.[5] | High, antibody-free chemical labeling.[11] |
| Advantages | Well-established, provides direct evidence of antibody-RNA interaction at the modification site. | Antibody-free, low input requirement, compatible with in vivo and in vitro applications.[7] | Antibody-independent, provides stoichiometric information.[5] | Antibody-free, overcomes sequence context bias of MAZTER-seq.[6] |
| Limitations | Technically challenging, potential for UV-induced biases, relies on antibody specificity.[9] | Requires expression of a fusion protein in cells (for in vivo approach), potential for off-target deamination. | Limited to the 'ACA' sequence motif, potentially missing a significant fraction of m6A sites.[4] | Multi-step chemical and enzymatic reactions can be complex. |
Experimental Protocols
miCLIP (m6A individual-Nucleotide Resolution Cross-Linking and Immunoprecipitation)
This protocol is adapted from the original miCLIP and the improved miCLIP2 methodologies.[8][13] It relies on the UV-induced cross-linking of an m6A-specific antibody to RNA, which causes specific mutations (substitutions and deletions) during reverse transcription, thereby marking the precise location of the m6A modification.
-
Poly(A)+ RNA
-
Anti-m6A antibody (e.g., Synaptic Systems, Cat. No. 202 003)
-
Protein A/G magnetic beads
-
UV cross-linker (254 nm)
-
Nuclease-free water
-
IP buffer (50 mM Tris-HCl pH 7.4, 150 mM NaCl, 0.5% NP-40)
-
Wash buffers (high salt, low salt)
-
3' RNA adapter
-
T4 RNA ligase
-
[γ-³²P]ATP for radiolabeling (optional, for visualization)
-
T4 Polynucleotide Kinase (PNK)
-
Proteinase K
-
Reverse transcriptase
-
PCR amplification reagents
-
Agencourt AMPure XP beads
-
RNA Fragmentation: Fragment 1-5 µg of poly(A)+ RNA to an average size of ~100 nucleotides by chemical or enzymatic methods.
-
Immunoprecipitation:
-
Incubate the fragmented RNA with 2-5 µg of anti-m6A antibody in IP buffer for 2 hours at 4°C with rotation.
-
Add pre-washed Protein A/G magnetic beads and incubate for another 1 hour at 4°C.
-
-
UV Cross-linking: Transfer the bead-RNA-antibody complexes to a petri dish on ice and expose to 254 nm UV light (e.g., 400 mJ/cm²).
-
Washes: Wash the beads sequentially with high-salt and low-salt wash buffers to remove non-specific binding.
-
3' Adapter Ligation: Ligate a 3' RNA adapter to the RNA fragments on the beads using T4 RNA ligase.
-
(Optional) 5' End Radiolabeling: For visualization, dephosphorylate the 5' ends with alkaline phosphatase and then radiolabel with [γ-³²P]ATP using T4 PNK.
-
Proteinase K Digestion: Elute the RNA-protein complexes from the beads and digest the antibody with Proteinase K, leaving a small peptide adduct at the cross-link site.
-
Reverse Transcription: Perform reverse transcription using a primer complementary to the 3' adapter. The peptide adduct will cause the reverse transcriptase to stall or misincorporate nucleotides, creating deletions or substitutions in the cDNA.
-
Library Preparation: Circularize the resulting cDNA, followed by linearization and PCR amplification to generate the sequencing library.
-
Sequencing and Data Analysis: Sequence the library on a high-throughput sequencing platform. Analyze the data to identify characteristic mutation patterns (C-to-T transitions, deletions) at m6A sites.
DART-seq (Deamination Adjacent to RNA Modification Targets sequencing)
DART-seq is an antibody-free method that offers high sensitivity with low RNA input.[2][7] This protocol describes the in vitro DART-seq procedure.
-
Total RNA or poly(A)+ RNA (as little as 50 ng)
-
Purified APOBEC1-YTH fusion protein
-
Purified APOBEC1-YTHmut (m6A-binding deficient mutant for control)
-
DART reaction buffer (e.g., 20 mM HEPES pH 7.5, 100 mM KCl, 10% glycerol, 1 mM DTT)
-
RNase inhibitors
-
RNA purification kit (e.g., Zymo RNA Clean & Concentrator)
-
Reagents for reverse transcription and library preparation
-
DART Reaction Setup:
-
In separate tubes, combine 50 ng of RNA with either the APOBEC1-YTH fusion protein or the APOBEC1-YTHmut control protein in DART reaction buffer.
-
Incubate the reactions at 37°C for 1 hour.
-
-
RNA Purification: Purify the RNA from the DART reaction using an RNA purification kit to remove the proteins and buffer components.
-
Reverse Transcription and Library Preparation:
-
Perform reverse transcription on the purified RNA.
-
Prepare a sequencing library from the resulting cDNA using a standard RNA-seq library preparation kit.
-
-
Sequencing and Data Analysis:
-
Sequence the libraries on a high-throughput sequencing platform.
-
Align the sequencing reads to the reference transcriptome.
-
Identify C-to-U edits (read as C-to-T changes) that are significantly enriched in the APOBEC1-YTH sample compared to the APOBEC1-YTHmut control. The position adjacent to the edit is inferred as the m6A site.
-
MAZTER-seq (MazF-assisted m6A-sensitive endoribonuclease sequencing)
MAZTER-seq leverages the property of the MazF endoribonuclease to cleave RNA at unmethylated 'ACA' motifs while leaving methylated 'm6ACA' sites intact.[4][5]
-
Poly(A)+ RNA
-
MazF RNase
-
MazF reaction buffer (e.g., 20 mM Tris-HCl pH 7.5, 50 mM NaCl, 1 mM DTT)
-
RNA fragmentation reagents (optional, if starting with full-length RNA)
-
Reagents for end-repair, adapter ligation, reverse transcription, and PCR amplification
-
RNA Preparation: Start with poly(A)+ selected RNA. If necessary, fragment the RNA to the desired size range.
-
MazF Digestion:
-
Incubate the RNA with MazF RNase in the appropriate reaction buffer. The incubation time and enzyme concentration should be optimized to achieve efficient cleavage of unmethylated 'ACA' sites.
-
-
Library Preparation:
-
The resulting RNA fragments will have 5'-hydroxyl and 3'-phosphate ends. Perform end-repair to generate 5'-phosphate and 3'-hydroxyl ends suitable for adapter ligation.
-
Ligate adapters to both ends of the RNA fragments.
-
Perform reverse transcription and PCR amplification to generate the sequencing library.
-
-
Sequencing and Data Analysis:
-
Sequence the library on a high-throughput sequencing platform.
-
Align the reads to the reference transcriptome.
-
Analyze the read start and end positions. A decrease in reads starting or ending at a specific 'ACA' motif, coupled with an increase in reads spanning that motif, indicates the presence of m6A. The ratio of spanning reads to cleaved reads provides a quantitative measure of m6A stoichiometry.
-
References
- 1. Comprehensive Overview of m6A Detection Methods - CD Genomics [cd-genomics.com]
- 2. Detecting m6A with In Vitro DART-Seq - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. Scholars@Duke publication: Detecting m6A with In Vitro DART-Seq. [scholars.duke.edu]
- 4. Counting the Cuts: MAZTER-Seq Quantifies m6A Levels Using a Methylation-Sensitive Ribonuclease - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. Deciphering the "m6A Code" via Antibody-Independent Quantitative Profiling - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. Current progress in strategies to profile transcriptomic m6A modifications - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Resources — The Meyer Lab [themeyerlab.com]
- 8. Comparison of m6A Sequencing Methods - CD Genomics [cd-genomics.com]
- 9. Identification of m6A residues at single-nucleotide resolution using eCLIP and an accessible custom analysis pipeline - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Frontiers | Improved Methods for Deamination-Based m6A Detection [frontiersin.org]
- 11. biorxiv.org [biorxiv.org]
- 12. scDART-seq reveals distinct m6A signatures and mRNA methylation heterogeneity in single cells - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Deep and accurate detection of m6A RNA modifications using miCLIP2 and m6Aboost machine learning - PMC [pmc.ncbi.nlm.nih.gov]
Application Notes and Protocols for m6A Antibody Selection in Immunoprecipitation
Audience: Researchers, scientists, and drug development professionals.
Introduction
N6-methyladenosine (m6A) is the most abundant internal modification in eukaryotic messenger RNA (mRNA) and plays a critical role in various biological processes, including RNA stability, splicing, translation, and cellular localization.[1][2] The accurate mapping of m6A sites across the transcriptome is crucial for understanding its regulatory functions in gene expression, cellular senescence, and disease.[2] Methylated RNA Immunoprecipitation followed by sequencing (MeRIP-seq or m6A-seq) is the most widely used technique for transcriptome-wide m6A profiling.[1][2][3][4] This method relies on the specific enrichment of m6A-containing RNA fragments using an anti-m6A antibody.[3][5] Consequently, the selection of a high-quality antibody is a pivotal determinant for the success and reliability of MeRIP-seq experiments.[1][6]
These application notes provide a comprehensive guide for selecting the optimal anti-m6A antibody for immunoprecipitation, complete with a detailed experimental protocol and key considerations for successful MeRIP-seq.
m6A Antibody Selection Criteria
The quality of MeRIP-seq data is highly dependent on the specificity and efficiency of the anti-m6A antibody used.[6] A suboptimal antibody can lead to high background noise, low signal, and inaccurate m6A peak identification.[7] Key factors to consider when selecting an m6A antibody include:
-
Specificity: The antibody should exhibit high affinity for m6A while showing minimal cross-reactivity to unmodified adenosine (B11128) (A) or other methylated bases like N1-methyladenosine (m1A).[8] Validation data, such as dot blots and competition assays, are essential to confirm specificity.
-
Sensitivity: The antibody must be able to efficiently capture m6A-modified RNA fragments, even from low-input samples.[1][6]
-
Clonality: Both monoclonal and polyclonal antibodies are available. Polyclonal antibodies can sometimes offer better precipitation efficiency due to their ability to recognize multiple epitopes, while monoclonal antibodies may provide higher batch-to-batch consistency.
-
Validation in Application: It is crucial to choose an antibody that has been validated for immunoprecipitation (IP) or RNA immunoprecipitation (RIP) by the manufacturer or in peer-reviewed publications.[9]
-
Reproducibility: The chosen antibody should yield consistent results across different experiments and sample types.[7]
Comparison of Commercially Available m6A Antibodies
Several commercial anti-m6A antibodies have been widely used and validated in the literature. The following table summarizes the key features and recommended usage for some of the most common options.
| Antibody (Supplier) | Catalog No. | Clonality | Host | Validated Applications | Recommended Amount for IP | Key Findings/Notes |
| Millipore | ABE572 | Polyclonal | Rabbit | IP, RIP | 5 µg for 15 µg total RNA | Performs well with high RNA input.[1][6] This antibody has been widely used and is considered efficient, though it may be discontinued.[10] |
| Millipore | MABE1006 | Monoclonal | Rabbit | IP, RIP | 5 µg for 15 µg total RNA | Another well-performing antibody from Millipore for high RNA input.[1][6] |
| Cell Signaling Technology (CST) | #56593 | Monoclonal | Rabbit | IP, RIP | 1.25 µg for low-input total RNA (0.1-1 µg) | Suitable and effective for experiments with low RNA input.[1][6][10] It is considered a good alternative to the Millipore antibodies.[10] |
| Synaptic Systems | 202 003 | Polyclonal | Rabbit | IP, ELISA, DB | 12.5 µg per reaction (as per one protocol)[11] | Considered one of the best commercially available m6A antibodies.[12] It shows good enrichment for fragmented mRNA, making it ideal for sequencing sample preparation.[12] |
| Diagenode | C15200082 | Monoclonal | Mouse | IP, RIP, DB | 1-10 µg per IP (user-determined) | Shows high specificity for m6A-modified oligonucleotides.[13] |
Logical Workflow for m6A Antibody Selection
The following diagram illustrates the decision-making process for selecting a suitable anti-m6A antibody for your MeRIP-seq experiment.
Caption: Decision-making workflow for m6A antibody selection.
Detailed Experimental Protocol: Methylated RNA Immunoprecipitation (MeRIP)
This protocol provides a generalized procedure for m6A immunoprecipitation from total RNA, which is a critical step in the MeRIP-seq workflow.
Materials and Reagents:
-
Total RNA or purified mRNA
-
RNase-free water, tubes, and tips
-
RNA Fragmentation Buffer (e.g., 10x: 100 mM Tris-HCl pH 7.0, 100 mM ZnCl₂)[14]
-
0.5 M EDTA
-
IP Buffer (e.g., 5x: 50 mM Tris-HCl pH 7.4, 750 mM NaCl, 0.5% Igepal CA-630)[11][14]
-
RNase Inhibitor (e.g., RNasin)
-
Anti-m6A antibody
-
Protein A/G magnetic beads
-
Washing Buffer
-
Elution Buffer (e.g., IP buffer containing free m6A)[11][14]
-
RNA purification kit or reagents (e.g., TRIzol, ethanol)
Procedure:
-
RNA Preparation and Quality Control:
-
RNA Fragmentation:
-
Fragment the RNA to an average size of 100-200 nucleotides.[10][15] This is typically achieved by incubating the RNA with a fragmentation buffer at a high temperature (e.g., 94°C for 5 minutes).[14]
-
Immediately stop the fragmentation reaction by adding EDTA and placing the tubes on ice.[14]
-
Purify the fragmented RNA. A small aliquot should be saved as the "input" control.[11]
-
-
Immunoprecipitation (IP):
-
Dilute the fragmented RNA in IP buffer supplemented with RNase inhibitors.[11]
-
Add the anti-m6A antibody to the RNA solution and incubate for 2 hours to overnight at 4°C with gentle rotation.[12]
-
While the antibody-RNA incubation is in progress, wash the Protein A/G magnetic beads with IP buffer.
-
Add the washed beads to the RNA-antibody mixture and incubate for another 1-2 hours at 4°C to capture the immune complexes.
-
-
Washing:
-
Elution:
-
RNA Purification:
-
Purify the eluted RNA using an appropriate RNA clean-up kit or ethanol (B145695) precipitation to prepare it for downstream applications.[11][15]
-
-
Library Preparation and Sequencing:
MeRIP-Seq Experimental Workflow
The following diagram provides a visual overview of the entire MeRIP-seq experimental process, from sample collection to data analysis.
Caption: Overview of the MeRIP-seq experimental workflow.
Conclusion
The selection of a high-quality, well-validated anti-m6A antibody is paramount for the success of MeRIP-seq experiments. Researchers should carefully consider the amount of starting material and consult validation data to choose the most appropriate antibody. The protocols and workflows provided here serve as a detailed guide for performing m6A immunoprecipitation and contribute to generating reliable and reproducible data for advancing our understanding of the epitranscriptome.
References
- 1. rna-seqblog.com [rna-seqblog.com]
- 2. An experimental workflow for identifying RNA m6A alterations in cellular senescence by methylated RNA immunoprecipitation sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 3. MeRIP-seq: Comprehensive Guide to m6A RNA Modification Analysis - CD Genomics [rna.cd-genomics.com]
- 4. MeRIP Sequencing - CD Genomics [cd-genomics.com]
- 5. researchgate.net [researchgate.net]
- 6. Comparative analysis of improved m6A sequencing based on antibody optimization for low-input samples - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. researchgate.net [researchgate.net]
- 8. Development and validation of monoclonal antibodies against N6-methyladenosine for the detection of RNA modifications - PMC [pmc.ncbi.nlm.nih.gov]
- 9. biocompare.com [biocompare.com]
- 10. portlandpress.com [portlandpress.com]
- 11. sysy.com [sysy.com]
- 12. biocompare.com [biocompare.com]
- 13. N6-methyladenosine (m6A) antibody - RIP Grade (C15200082) | Diagenode [diagenode.com]
- 14. sysy.com [sysy.com]
- 15. MeRIP-seq Protocol - CD Genomics [rna.cd-genomics.com]
experimental workflow for m6A dot blot assay
Application Notes for m6A Dot Blot Assay
Introduction
N6-methyladenosine (m6A) is the most abundant internal modification in eukaryotic messenger RNA (mRNA) and is also found in other RNA species.[1][2][3] This reversible epigenetic mark plays a crucial role in regulating various aspects of RNA metabolism, including splicing, nuclear export, stability, and translation, thereby influencing numerous biological processes.[4][5] The m6A modification is installed by methyltransferases ("writers"), removed by demethylases ("erasers"), and recognized by specific binding proteins ("readers") that mediate its downstream effects.[4][5][6][7] Dysregulation of m6A modification has been implicated in various diseases, including cancer.[6][8] The m6A dot blot assay is a straightforward and efficient method for detecting and quantifying global m6A levels in RNA samples.[1][2][9] This semi-quantitative technique is particularly useful for initial screening of changes in m6A levels across different conditions or in mutant organisms before proceeding with more complex and quantitative methods like LC-MS/MS.[1]
Principle of the Assay
The m6A dot blot assay is a simple and rapid method for quantifying global m6A levels in various nucleic acid samples, including RNA, DNA, urine, serum, and plasma.[8][9] The assay involves spotting denatured RNA samples directly onto a nitrocellulose or nylon membrane. The immobilized RNA is then crosslinked to the membrane, which is subsequently probed with a specific anti-m6A antibody. An enzyme-conjugated secondary antibody is then used to detect the primary antibody, and the signal is visualized using a chemiluminescent substrate. The intensity of the dots is proportional to the amount of m6A in the sample. To ensure equal loading of RNA, a methylene (B1212753) blue staining of a replicate lane can be performed as an internal control.[9]
Experimental Workflow Diagram
Caption: Experimental workflow for the m6A dot blot assay.
m6A Regulatory Pathway
Caption: The m6A RNA modification pathway.
Detailed Experimental Protocol
This protocol provides a step-by-step guide for performing an m6A dot blot assay.
Materials and Reagents
-
Total RNA or mRNA samples
-
Nitrocellulose or nylon membrane
-
Anti-m6A antibody
-
HRP-conjugated secondary antibody
-
Blocking buffer (e.g., 5% non-fat milk in TBST)
-
Wash buffer (e.g., TBST: Tris-buffered saline with 0.1% Tween-20)
-
Antibody dilution buffer (e.g., 5% non-fat milk in TBST)[1]
-
Methylene blue solution (0.02% methylene blue in 0.3 M sodium acetate, pH 5.2)
-
Enhanced chemiluminescent (ECL) substrate
-
RNase-free water
-
UV crosslinker
-
Bio-Dot apparatus (optional)[10]
Procedure
-
RNA Preparation and Denaturation:
-
Isolate total RNA or purify mRNA from your samples. For a standard dot blot, it is recommended to start with at least 20 µg of total RNA.[1]
-
Quantify the RNA concentration using a spectrophotometer (e.g., NanoDrop).
-
Prepare serial dilutions of your RNA samples (e.g., 500 ng, 250 ng, 125 ng) in RNase-free water.[11]
-
Denature the RNA samples by heating at 95°C for 3-5 minutes, then immediately chill on ice to prevent renaturation.[1][11]
-
-
Dot Blotting:
-
Carefully spot 1-2 µL of each denatured RNA sample onto a dry nitrocellulose or nylon membrane. Mark the positions of the spots.
-
Allow the membrane to air dry completely at room temperature for 5-15 minutes.[12]
-
Crosslink the RNA to the membrane using a UV crosslinker. This is typically done at 254 nm.
-
-
Methylene Blue Staining (Loading Control):
-
To verify equal loading of RNA, a replicate membrane or a separate lane can be stained with methylene blue.
-
Immerse the membrane in methylene blue solution and incubate for 5-10 minutes at room temperature.
-
Destain the membrane with RNase-free water until the background is clear and the RNA spots are visible.
-
-
Immunodetection:
-
Block the membrane with blocking buffer for 1 hour at room temperature with gentle agitation.[1]
-
Incubate the membrane with the primary anti-m6A antibody diluted in antibody dilution buffer. The incubation is typically performed overnight at 4°C with gentle shaking.[1]
-
Wash the membrane three times for 5-10 minutes each with wash buffer.[1]
-
Incubate the membrane with the HRP-conjugated secondary antibody diluted in antibody dilution buffer for 1 hour at room temperature with gentle agitation.[1]
-
Wash the membrane four times for 10 minutes each with wash buffer.[1]
-
-
Signal Detection and Analysis:
-
Incubate the membrane with ECL substrate for 5 minutes in the dark.[1]
-
Capture the chemiluminescent signal using a digital imaging system or X-ray film.
-
Quantify the dot intensities using image analysis software such as ImageJ.[1] The signal intensity of the m6A dots should be normalized to the corresponding methylene blue staining intensity to account for any loading variations.
-
Quantitative Data Summary
The following table provides a summary of typical quantitative parameters used in an m6A dot blot assay. These values may require optimization depending on the specific experimental conditions and reagents used.
| Parameter | Typical Range/Value | Reference |
| RNA Sample Amount | 100 ng - 2 µg per dot | [12][13] |
| Primary Antibody (anti-m6A) Dilution | 1:250 - 1:2000 | [1][10][14][15] |
| Secondary Antibody (HRP-conjugated) Dilution | 1:2,000 - 1:10,000 | [1][14] |
| Blocking Time | 1 hour | [1][14] |
| Primary Antibody Incubation | Overnight at 4°C | [1][14] |
| Secondary Antibody Incubation | 1 hour at room temperature | [1][14] |
Note: It is crucial to perform serial dilutions of the RNA samples to ensure that the signal intensity falls within the linear range of detection. As the m6A dot blot is a semi-quantitative method, results should be confirmed with at least three biological replicates.[1] For more sensitive and quantitative analysis, especially when the fraction of m6A-modified RNA is low, an immunoprecipitation step to enrich for m6A-modified RNA prior to the dot blot can be employed.[2][16]
References
- 1. Dot Blot Analysis of N6-methyladenosine RNA Modification Levels - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Dot Blot Analysis for Measuring Global N6-Methyladenosine Modification of RNA | Springer Nature Experiments [experiments.springernature.com]
- 3. M6a dot blot protocol - jrnery [jrnery.weebly.com]
- 4. m6A RNA Regulatory Diagram | Cell Signaling Technology [cellsignal.com]
- 5. blog.cellsignal.com [blog.cellsignal.com]
- 6. researchgate.net [researchgate.net]
- 7. researchgate.net [researchgate.net]
- 8. biocat.com [biocat.com]
- 9. raybiotech.com [raybiotech.com]
- 10. 2.8. Analysis of m6A Level Using Dot-Blot Assay [bio-protocol.org]
- 11. researchgate.net [researchgate.net]
- 12. ptglab.com [ptglab.com]
- 13. Detecting RNA Methylation by Dot Blotting | Proteintech Group [ptglab.com]
- 14. A Method for Measuring RNA N6-methyladenosine Modifications in Cells and Tissues - PMC [pmc.ncbi.nlm.nih.gov]
- 15. merckmillipore.com [merckmillipore.com]
- 16. Dot Blot Analysis for Measuring Global N6-Methyladenosine Modification of RNA - PubMed [pubmed.ncbi.nlm.nih.gov]
Application Notes and Protocols for m6A Detection Using Nanopore Direct RNA Sequencing
For Researchers, Scientists, and Drug Development Professionals
Introduction
N6-methyladenosine (m6A) is the most abundant internal modification in eukaryotic messenger RNA (mRNA) and plays a critical role in various biological processes, including gene expression regulation, cellular differentiation, and disease pathogenesis.[1][2] Traditional methods for m6A detection, such as those based on immunoprecipitation, often suffer from low resolution and antibody specificity issues.[3][4] Oxford Nanopore Technologies' direct RNA sequencing (dRNA-seq) offers a revolutionary approach to epitranscriptomics by enabling the direct sequencing of native RNA molecules.[5][6] This technology allows for the detection of RNA modifications, including m6A, at single-nucleotide resolution by analyzing characteristic disruptions in the ionic current as an RNA strand passes through a nanopore.[7]
These application notes provide a comprehensive overview and detailed protocols for the detection of m6A modifications using nanopore dRNA-seq, from sample preparation to data analysis and validation.
Principle of m6A Detection
Nanopore sequencing identifies nucleic acid bases by measuring the changes in electrical current as a single strand of RNA passes through a protein nanopore. The presence of a modified base, such as m6A, alters the chemical structure and, consequently, the ionic current signal in a distinct manner compared to its unmodified counterpart.[7][8] Computational tools are trained to recognize these specific signal alterations, allowing for the identification and quantification of m6A modifications directly from the raw sequencing data.[9][10] This method provides several advantages, including single-molecule resolution, the ability to identify modifications on specific transcript isoforms, and the avoidance of biases associated with antibody-based enrichment or chemical labeling.[11][12]
Experimental and Data Analysis Workflow
The overall workflow for m6A detection using nanopore dRNA-seq involves several key stages, from RNA extraction to the final identification of modified sites.
Caption: A high-level overview of the experimental and bioinformatic workflow for m6A detection using nanopore direct RNA sequencing.
Detailed Experimental Protocols
This section provides a detailed protocol for preparing a direct RNA sequencing library. This protocol is based on the Oxford Nanopore Direct RNA Sequencing Kit (SQK-RNA002).
1. Poly(A) RNA Isolation
-
Objective: To enrich for mRNA from total RNA.
-
Procedure:
-
Start with high-quality total RNA. The amount of starting material will depend on the poly(A) enrichment method used.
-
Use a commercially available poly(A) RNA enrichment kit (e.g., magnetic bead-based selection) and follow the manufacturer's instructions.
-
Elute the poly(A) RNA in nuclease-free water.
-
Quantify the enriched RNA using a Qubit fluorometer or similar.
-
2. Direct RNA Library Preparation
-
Materials:
-
Protocol Steps:
-
Adapter Ligation:
-
Reverse Transcription:
-
Cleanup:
-
Transfer the reaction to a 1.5 mL LoBind tube.
-
Resuspend Agencourt RNAClean XP beads and add them to the reaction. Mix well.[14]
-
Incubate for 5 minutes at room temperature.
-
Pellet the beads on a magnetic rack and discard the supernatant.[14]
-
Wash the beads twice with 150 µL of fresh 70% ethanol (B145695) without disturbing the pellet.[14]
-
Air-dry the beads for approximately 2 minutes.
-
Resuspend the pellet in nuclease-free water and incubate for 5 minutes at room temperature.[14]
-
Pellet the beads on the magnet and transfer the eluate (containing the library) to a new LoBind tube.[14]
-
-
Sequencing Adapter Ligation and Final Cleanup:
-
To the purified library, add the RNA Adapter (RMX) and T4 DNA Ligase.
-
Mix by pipetting and incubate for 10 minutes at room temperature.
-
Perform another cleanup step using Agencourt RNAClean XP beads as described above, but using the Wash Buffer (WSB) provided in the kit.[13][14]
-
Elute the final library in the Elution Buffer (ELB).[13]
-
-
3. Nanopore Sequencing
-
Procedure:
-
Prime the Nanopore flow cell according to the manufacturer's instructions.
-
Prepare the final library for loading by mixing it with the Sequencing Buffer (SQB) and Loading Beads (LB).
-
Load the library onto the primed flow cell and start the sequencing run using the MinKNOW software.
-
Bioinformatic Analysis for m6A Detection
Accurate identification of m6A from dRNA-seq data relies on sophisticated bioinformatic tools that can interpret the subtle changes in the nanopore current signal.
Caption: A flowchart detailing the key steps in the bioinformatic analysis of nanopore direct RNA sequencing data for m6A detection.
1. Basecalling and Modification Calling
-
The raw electrical signal data, stored in FAST5 or POD5 files, must be translated into RNA sequences (basecalling).
-
Modern basecallers, such as Oxford Nanopore's Dorado , can perform simultaneous basecalling and modification detection, outputting the results in a BAM file format that includes modification tags.[3]
2. Read Alignment
-
The basecalled reads (in FASTQ or BAM format) are aligned to a reference genome or transcriptome.
-
Minimap2 is a widely used aligner for long-read sequencing data and is well-suited for this purpose.[15]
3. m6A Site Identification with Specialized Tools
-
Several computational tools have been developed to identify m6A modifications from dRNA-seq data. These tools often use different machine learning models and features from the raw signal or basecalling errors.[1][5]
-
Key Features for Detection:
-
Current Signal Deviations: Changes in the mean, standard deviation, and duration of the electrical current.[9]
-
Basecalling Errors: Increased mismatch, deletion, and insertion rates at and around modified sites.[9][10]
-
Base Quality Scores: Lower quality scores are often associated with modified bases.[10]
-
Comparison of m6A Detection Tools
The performance of different tools can vary depending on the dataset and the specific biological context.[1][5] Integrating results from multiple tools can often improve performance.[1]
| Tool | Approach | Key Features Utilized | Notes |
| m6Anet | Multiple Instance Learning (MIL) framework.[16] | Signal intensity-based features from a single sample.[16] Outperforms many existing methods and generalizes well across cell lines.[16] | |
| MINES | Random Forest classifier.[12] | Trained on experimentally validated m6A sites within DRACH motifs.[12][17] Can identify previously unannotated m6A sites.[12] | |
| EpiNano | Support Vector Machine (SVM) model.[6][18] | Basecalling errors (mismatch, deletion) and base quality scores.[10][18] Can be trained on synthetic or in vivo datasets.[6][10] | |
| Xron | Hybrid encoder-decoder framework.[7][8] | Raw sequencing signal.[7] Delivers a direct methylation-distinguishing basecaller.[7][8] | |
| RedNano | Deep neural networks.[9] | Utilizes both raw electrical signals and basecalling errors.[9] Shows high performance in various datasets.[9] |
4. Validation of m6A Sites
-
To validate the predictions from computational tools, it is recommended to use orthogonal methods or control experiments.
-
Common Validation Strategies:
-
Knockout/Knockdown Experiments: Compare sequencing data from wild-type cells with data from cells where an m6A "writer" enzyme (like METTL3) has been knocked out or an m6A "eraser" (like ALKBH5) has been overexpressed.[12] A true m6A site should show a significantly reduced modification signal in the knockout/overexpression line.
-
Synthetic RNA Controls: Sequence in vitro transcribed RNA with and without m6A at known positions to train and validate the detection models.[9][10]
-
Comparison with Orthogonal Methods: Compare identified sites with established m6A databases or results from methods like miCLIP or m6ACE-seq.[7][9]
-
Conclusion
Nanopore direct RNA sequencing provides a powerful and direct method for transcriptome-wide m6A detection at single-nucleotide resolution.[11] By leveraging the characteristic changes in ionic current caused by modified bases, this technology overcomes many limitations of previous methods. The combination of optimized library preparation protocols and advanced bioinformatic analysis tools enables researchers to explore the dynamics of the epitranscriptome with unprecedented detail, offering new insights into gene regulation in health and disease.
References
- 1. Systematic comparison of tools used for m6A mapping from nanopore direct RNA sequencing - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. Benchmarking of computational methods for m6A profiling with Nanopore direct RNA sequencing - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. A comparative evaluation of computational models for RNA modification detection using nanopore sequencing with RNA004 chemistry - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Direct Analysis of HIV mRNA m6A Methylation by Nanopore Sequencing | Springer Nature Experiments [experiments.springernature.com]
- 5. academic.oup.com [academic.oup.com]
- 6. EpiNano: Detection of m6A RNA Modifications Using Oxford Nanopore Direct RNA Sequencing | Springer Nature Experiments [experiments.springernature.com]
- 7. Detecting m6A RNA modification from nanopore sequencing using a semisupervised learning framework - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Detecting m6A RNA modification from nanopore sequencing using a semisupervised learning framework - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. academic.oup.com [academic.oup.com]
- 10. nanoporetech.com [nanoporetech.com]
- 11. Comparison of m6A Sequencing Methods - CD Genomics [cd-genomics.com]
- 12. Direct RNA sequencing enables m6A detection in endogenous transcript isoforms at base-specific resolution - PMC [pmc.ncbi.nlm.nih.gov]
- 13. DSpace [repositori.upf.edu]
- 14. Identification of m6A RNA Modifications by Nanopore Sequencing Protocol - CD Genomics [cd-genomics.com]
- 15. m.youtube.com [m.youtube.com]
- 16. nanoporetech.com [nanoporetech.com]
- 17. nanoporetech.com [nanoporetech.com]
- 18. researchgate.net [researchgate.net]
Application Notes and Protocols for m6A individual-nucleotide resolution cross-linking and immunoprecipitation (miCLIP)
For Researchers, Scientists, and Drug Development Professionals
Introduction
N6-methyladenosine (m6A) is the most abundant internal modification in eukaryotic messenger RNA (mRNA), playing a crucial role in various aspects of RNA metabolism, including splicing, stability, and translation.[1][2] Dysregulation of m6A has been implicated in numerous diseases, making it a significant area of interest for therapeutic development. The m6A individual-nucleotide resolution cross-linking and immunoprecipitation (miCLIP) technique offers a powerful method to map m6A modifications transcriptome-wide at single-nucleotide resolution.[3][4][5] This is achieved by using anti-m6A antibodies to induce specific mutational signatures at m6A sites following UV cross-linking and reverse transcription.[1][2] These mutational signatures are then identified through high-throughput sequencing to pinpoint the precise location of m6A residues.[1][6]
These application notes provide a detailed protocol for performing miCLIP, from sample preparation to data analysis, intended to guide researchers in the successful implementation of this high-resolution m6A mapping technique.
Experimental Workflow
The miCLIP protocol involves several key stages, beginning with the isolation and fragmentation of cellular RNA, followed by immunoprecipitation of m6A-containing fragments, library preparation, and high-throughput sequencing. The bioinformatic analysis then identifies the precise m6A locations based on characteristic mutations introduced during the process.
Caption: A schematic overview of the miCLIP experimental and computational workflow.
Quantitative Data Summary
Successful miCLIP experiments rely on precise quantification of reagents. The following tables provide recommended starting amounts and concentrations.
Table 1: Key Reagent Concentrations
| Reagent | Stock Concentration | Recommended Working Concentration/Amount |
| Anti-m6A antibody | 1 mg/mL | 5 µL per 1 µg of poly(A)-enriched mRNA |
| RNase-free DNase I | 1 U/µL | As per manufacturer's instructions for DNase treatment |
| Proteinase K | 10 mg/mL | Final concentration of 2 mg/mL for elution |
| T4 Polynucleotide Kinase | 1000 U/µL | As per standard radiolabeling protocols |
| T4 RNA Ligase I | 1000 U/µL | As per manufacturer's instructions for 3' adapter ligation |
| [γ-³²P]ATP | 3000 Ci/mmol | For radiolabeling 5' ends |
Table 2: Typical Input Material and Yields
| Parameter | Recommended Amount | Expected Yield/Outcome |
| Starting Cellular RNA | Variable (e.g., from one confluent 10 cm plate of HeLa cells) | ~100 µg of total RNA |
| Poly(A)-selected mRNA | 1-20 µg | Sufficient for library generation |
| PCR Amplification Cycles | 15-25 cycles | Optimized based on test PCR to avoid over-amplification |
Detailed Experimental Protocols
The following protocols are adapted from established miCLIP methodologies.[1][6]
RNA Preparation and Fragmentation
-
RNA Isolation: Isolate total RNA from cultured cells or tissues using a standard RNA extraction method.
-
mRNA Enrichment: Enrich for mRNA from the total RNA pool using oligo(dT) magnetic beads. A starting amount of at least 1 µg of poly(A)-selected mRNA is required.[7]
-
RNA Fragmentation:
-
Resuspend 5–20 µg of DNase-treated, poly(A)-selected RNA in 20 µl of nuclease-free water.[6]
-
Add RNA fragmentation reagent and incubate according to the manufacturer's instructions to obtain RNA fragments of approximately 100-200 nucleotides.[1][2]
-
Immediately stop the reaction by adding the provided stop solution.
-
Immunoprecipitation and Cross-linking
-
Antibody Binding: For each 1 µg of fragmented poly(A)-enriched mRNA, prepare an IP mixture containing 5 µL of anti-m6A antibody (0.5 mg/mL) in a total volume of 200 µL with 5x IP buffer and a SUPERase inhibitor.[7]
-
Incubation: Incubate the IP mixture on a rotator at 4°C for 2 hours.[7]
-
UV Cross-linking: Transfer the IP mixture to a 96-well plate on ice and irradiate three times with 0.15 J/cm² of 254 nm UV light.[7][8]
-
Immunoprecipitation:
Library Preparation
-
3' Adapter Ligation:
-
5' End Radiolabeling:
-
Dephosphorylate the 3' ends of the RNA fragments.
-
Radiolabel the 5' ends of the RNA fragments using T4 polynucleotide kinase and [γ-³²P]ATP.[1]
-
-
SDS-PAGE Purification:
-
RNA Elution and Proteinase K Digestion:
-
Reverse Transcription:
-
Perform reverse transcription using a primer that is complementary to the 3' adapter. The reverse transcriptase will often stall or introduce mutations at the site of the peptide adduct.[1]
-
-
cDNA Purification and Circularization:
-
Purify the resulting cDNA.
-
Circularize the single-stranded cDNA to preserve the information at the 3' end, which corresponds to the cross-link site.[1]
-
-
PCR Amplification:
-
Re-linearize the circularized cDNA.
-
Perform PCR to amplify the cDNA library. The optimal number of cycles should be determined by a test PCR to avoid over-amplification.[1]
-
Data Analysis Protocol
The computational analysis of miCLIP data is crucial for identifying m6A sites with high confidence.
Caption: A flowchart detailing the key steps in the miCLIP bioinformatic analysis pipeline.
-
Preprocessing of Sequencing Reads:
-
Alignment: The preprocessed reads are aligned to a reference genome.[6]
-
Calling of m6A Sites:
-
The core of miCLIP data analysis involves identifying the specific mutational signatures—substitutions and truncations—that arise from the cross-linking event at m6A sites.[6]
-
Specialized tools, such as the CIMS (cross-linking-induced mutation sites) pipeline, are used to call these mutations.[1]
-
A common substitution observed is a C-to-T transition.[6]
-
Identified sites are often filtered to retain those within the known m6A consensus motif (DRACH, where D=A/G/U, R=A/G, H=A/C/U) to increase confidence in the called m6A sites.[6]
-
Troubleshooting
Table 3: Common Issues and Solutions in miCLIP
| Issue | Potential Cause | Suggested Solution |
| Low Library Yield | - Degraded input RNA- Inefficient antibody binding- Suboptimal enzyme activity | - Verify RNA integrity using a Bioanalyzer.- Increase antibody concentration.- Ensure all buffers and enzymes are fresh and stored correctly. |
| High PCR Duplication Rate | - Low amount of starting material- Over-amplification during PCR | - Start with a sufficient amount of poly(A)-selected RNA.- Optimize the number of PCR cycles using a test PCR. |
| Background Signal/Non-specific Binding | - Insufficient washing stringency- Antibody cross-reactivity | - Ensure stringent washing steps are performed after immunoprecipitation.- Use a well-validated anti-m6A antibody. |
| Adapter Dimers | - Suboptimal adapter-to-insert ratio | - Optimize the concentration of adapters during the ligation steps. |
References
- 1. Mapping m6A at individual-nucleotide resolution using crosslinking and immunoprecipitation (miCLIP) - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Mapping m6A at Individual-Nucleotide Resolution Using Crosslinking and Immunoprecipitation (miCLIP) | Springer Nature Experiments [experiments.springernature.com]
- 3. miCLIP-m6A - Enseqlopedia [enseqlopedia.com]
- 4. miCLIP-m6A [illumina.com]
- 5. miCLIP-m6A [emea.illumina.com]
- 6. Transcriptome-wide mapping of m6A and m6Am at single-nucleotide resolution using miCLIP - PMC [pmc.ncbi.nlm.nih.gov]
- 7. High-Resolution Mapping of N6-Methyladenosine Using m6A Crosslinking Immunoprecipitation Sequencing (m6A-CLIP-Seq) - PMC [pmc.ncbi.nlm.nih.gov]
- 8. youtube.com [youtube.com]
- 9. academic.oup.com [academic.oup.com]
- 10. researchgate.net [researchgate.net]
Application Note: Quantitative Analysis of N6-methyladenosine (m6A) in mRNA by LC-MS/MS
Audience: Researchers, scientists, and drug development professionals.
Abstract: N6-methyladenosine (m6A) is the most abundant internal modification on messenger RNA (mRNA) in most eukaryotes and plays a critical regulatory role in gene expression.[1][2][3] Accurate measurement of m6A levels is crucial for understanding its dynamic changes in various biological and pathological processes.[1][3][4] This document provides a detailed protocol for the global quantification of m6A in mRNA using Liquid Chromatography with tandem Mass Spectrometry (LC-MS/MS), the gold standard for accurate and sensitive detection.[5][6][7] The protocol covers all steps from mRNA isolation to data analysis and includes an example of how m6A regulation can impact cellular signaling pathways.
Principle of the Method
The quantitative analysis of m6A by LC-MS/MS relies on a multi-step process. First, high-purity messenger RNA (mRNA) is isolated from total RNA using poly(A) enrichment to minimize contamination from ribosomal RNA (rRNA), which also contains m6A.[8] The purified mRNA is then enzymatically digested into its constituent single nucleosides.[1][9][10]
These nucleosides are separated using Ultra-High-Performance Liquid Chromatography (UHPLC). The separated nucleosides then enter a tandem mass spectrometer, typically a triple quadrupole (QQQ) instrument, operating in Multiple Reaction Monitoring (MRM) mode.[11] This allows for highly specific and sensitive detection and quantification of N6-methyladenosine (m6A) and the unmodified adenosine (B11128) (A). An isotopically labeled internal standard is often used to ensure the highest accuracy.[12][13][14] By comparing the signal intensity of m6A to that of adenosine, the relative abundance of m6A (m6A/A ratio) in the initial mRNA sample can be precisely calculated.[11]
Experimental Workflow
The overall experimental workflow is depicted below, outlining the process from sample collection to final data analysis.
Detailed Experimental Protocols
This protocol is adapted for cells grown in culture but can be modified for tissue samples.[1][4] Ensure all surfaces and equipment are treated with RNase-inactivating agents.[9]
Part 1: Total RNA Isolation and mRNA Purification
-
Cell Harvest: Harvest approximately 5-10 million cells by centrifugation. Wash the cell pellet with cold 1X PBS.
-
Total RNA Isolation: Isolate total RNA using a commercial kit (e.g., PureLink RNA Mini Kit) or TRIzol-based method according to the manufacturer's instructions.[1]
-
RNA Quality Control: Assess the quantity and purity of the total RNA using a spectrophotometer (e.g., NanoDrop). An A260/A280 ratio of ~2.0 is indicative of pure RNA. Check RNA integrity on an agarose (B213101) gel or using a bioanalyzer.
-
mRNA Purification: a. Enrich for mRNA from at least 50 µg of total RNA using oligo(dT) magnetic beads according to the manufacturer's protocol. b. To minimize rRNA contamination, perform a second round of poly(A) purification. c. Elute the purified mRNA in RNase-free water. Quantify the mRNA concentration. Typically, 1-2% of the total RNA is recovered as mRNA.
Part 2: Enzymatic Digestion of mRNA to Nucleosides
-
Digestion Reaction Setup: In a sterile microcentrifuge tube, combine the following:
-
Purified mRNA: 200 ng - 1 µg
-
Nuclease P1: 2 Units
-
10X Nuclease P1 Buffer: 2 µL
-
RNase-free Water: to a final volume of 18 µL
-
-
First Incubation: Incubate the reaction at 45°C for 2 hours.[11]
-
Second Digestion Step: Add the following to the reaction tube:
-
Bacterial Alkaline Phosphatase (BAP): 0.5 Units
-
10X BAP Buffer: 2 µL
-
-
Second Incubation: Incubate at 37°C for an additional 2 hours. The sample is now fully digested into single nucleosides.[15][16]
-
Note: Alternatively, a commercial one-step Nucleoside Digestion Mix can be used following the manufacturer's protocol.[17]
-
-
Sample Cleanup: Centrifuge the digested sample through a 3K molecular weight cutoff filter to remove the enzymes.[11] The flow-through contains the nucleosides.
Part 3: LC-MS/MS Analysis
-
Instrument Setup: Use a UHPLC system coupled to a triple quadrupole mass spectrometer.[4]
-
Gradient Elution: A typical gradient might be:
Time (min) % Mobile Phase B 0.0 10 5.0 10 7.5 90 10.0 90 10.1 10 | 15.0 | 10 |
-
Mass Spectrometer Settings:
-
Ionization Mode: Positive Electrospray Ionization (ESI+).
-
Analysis Mode: Multiple Reaction Monitoring (MRM).
-
MRM Transitions:
-
Adenosine (A): Precursor ion (m/z) 268 -> Product ion (m/z) 136.
-
N6-methyladenosine (m6A): Precursor ion (m/z) 282 -> Product ion (m/z) 150.[11]
-
-
-
Standard Curve: Prepare a series of calibration standards with known concentrations of pure adenosine and m6A (e.g., 0.5 to 50 µg/L) to generate a standard curve for absolute quantification.[1][4]
Data Presentation and Analysis
The primary output of the analysis is the quantification of the m6A to Adenosine ratio.
-
Peak Integration: Integrate the area under the curve for the chromatographic peaks corresponding to the m6A and Adenosine MRM transitions.
-
Concentration Calculation: Use the standard curves to calculate the absolute amount (e.g., in nanograms) of m6A and Adenosine in the injected sample.
-
Ratio Calculation: Calculate the percentage of m6A relative to total adenosine using the following formula: % m6A = [Amount of m6A / (Amount of m6A + Amount of Adenosine)] * 100
Example Quantitative Data
The following table shows example data from an experiment comparing m6A levels in a control cell line versus a cell line with a knockout (KO) of the m6A methyltransferase, METTL3.
| Sample ID | Biological Replicate | Adenosine (ng) | m6A (ng) | % m6A/A |
| Control | 1 | 150.2 | 0.15 | 0.100% |
| Control | 2 | 145.8 | 0.14 | 0.096% |
| Control | 3 | 155.1 | 0.16 | 0.103% |
| Control Avg. | 150.4 | 0.15 | 0.100% | |
| METTL3 KO | 1 | 160.5 | 0.02 | 0.012% |
| METTL3 KO | 2 | 158.2 | 0.01 | 0.006% |
| METTL3 KO | 3 | 162.9 | 0.02 | 0.012% |
| METTL3 KO Avg. | 160.5 | 0.017 | 0.010% |
Application Example: m6A in the Wnt/β-catenin Signaling Pathway
The m6A modification is a key regulator of various signaling pathways that control cell fate, proliferation, and differentiation.[2][18] The Wnt/β-catenin pathway is a classic example where m6A has been shown to exert significant influence. The m6A "writer" complex, primarily composed of METTL3 and METTL14, can methylate the mRNA of key pathway components. For instance, increased m6A modification on the mRNA of β-catenin (CTNNB1) can enhance its translation, leading to an accumulation of β-catenin protein. This promotes its translocation to the nucleus, where it activates the transcription of Wnt target genes, ultimately driving processes like cell proliferation in certain cancers.
References
- 1. bpb-us-e2.wpmucdn.com [bpb-us-e2.wpmucdn.com]
- 2. m6A in the Signal Transduction Network - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Quantitative analysis of m6A RNA modification by LC-MS - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. Quantitative analysis of m6A RNA modification by LC-MS - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Frontiers | Current progress in strategies to profile transcriptomic m6A modifications [frontiersin.org]
- 6. biorxiv.org [biorxiv.org]
- 7. An Improved m6A-ELISA for Quantifying N6 -methyladenosine in Poly(A)-purified mRNAs - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Global analysis by LC-MS/MS of N6-methyladenosine and inosine in mRNA reveal complex incidence - PMC [pmc.ncbi.nlm.nih.gov]
- 9. researchgate.net [researchgate.net]
- 10. escholarship.org [escholarship.org]
- 11. Quantification of global m6A RNA methylation levels by LC-MS/MS [visikol.com]
- 12. Production and Application of Stable Isotope-Labeled Internal Standards for RNA Modification Analysis - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Stable isotopically labeled internal standards in quantitative bioanalysis using liquid chromatography/mass spectrometry: necessity or not? - PubMed [pubmed.ncbi.nlm.nih.gov]
- 14. scispace.com [scispace.com]
- 15. Protocol for preparation and measurement of intracellular and extracellular modified RNA using liquid chromatography-mass spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 16. neb.com [neb.com]
- 17. neb.com [neb.com]
- 18. m6A in the Signal Transduction Network [escholarship.org]
Application Notes and Protocols: Modulation of m6A Writer Activity
These application notes provide detailed protocols for researchers, scientists, and drug development professionals to induce or inhibit the activity of N6-methyladenosine (m6A) writer complexes. The methods described include small molecule inhibition, genetic knockdown and knockout, and targeted induction using CRISPR-based systems.
Introduction to m6A Writers
N6-methyladenosine (m6A) is the most abundant internal modification on eukaryotic messenger RNA (mRNA), profoundly influencing RNA metabolism, including splicing, nuclear export, stability, and translation.[1][2][3][4] This dynamic and reversible modification is installed by a multi-protein methyltransferase complex, commonly referred to as the "m6A writer" complex.[4][5][6][7] The core components of this complex include the catalytic subunit Methyltransferase-like 3 (METTL3) and its partner Methyltransferase-like 14 (METTL14), which forms a stable heterodimer.[1][2][3][4] Other associated proteins, such as Wilms' tumor 1-associated protein (WTAP), recruit the complex to target mRNAs in the nucleus.[4]
Given the critical role of m6A in regulating gene expression, dysregulation of the writer complex is implicated in numerous diseases, including various cancers.[5][6][8] Consequently, the ability to precisely control the activity of m6A writers is a powerful tool for both basic research and therapeutic development. These notes detail established methods for the targeted inhibition and induction of m6A writer activity.
Section 1: Methods for Inhibiting m6A Writers
Inhibition of m6A writers, primarily targeting the catalytic subunit METTL3, can be achieved through small molecule inhibitors or genetic approaches. These methods are crucial for studying the functional consequences of reduced m6A levels and for validating the writer complex as a therapeutic target.
Small Molecule Inhibitors
The development of small molecule inhibitors against m6A writers has rapidly advanced, with most compounds designed to be competitive with the S-adenosylmethionine (SAM) cofactor.[1][2][3] These inhibitors allow for acute, reversible, and dose-dependent suppression of methyltransferase activity.
Quantitative Data: Small Molecule Inhibitors of METTL3
| Inhibitor | Target | Mechanism | IC₅₀ | Cell-based Potency | Reference |
| STM2457 | METTL3 | SAM-competitive | 17.5 nM (Biochemical) | ~10 µM (m6A/A reduction) | [6] |
| UZH1a | METTL3 | SAM-competitive | 30 nM (Biochemical) | 4.6 µM (m6A/A reduction in MOLM-13 cells) | [2][6] |
| Compound 54 | METTL3 | SAM-competitive | 2.2 nM (HTRF Assay) | Not Reported | [1][3] |
| SAH | METTL3/METTL14 | Product Inhibition | 520 ± 90 nM (Radiometric) | Not Applicable | [9] |
| 3-Deazaadenosine | Pan-methyltransferase inhibitor | SAM-competitive | Broad | Micromolar range | [9] |
| Eltrombopag | METTL3-METTL14 | Not specified | Micromolar range | Not Reported | [9] |
| Quercetin | METTL3 | Not specified | Micromolar range | Not Reported | [8] |
Workflow for Small Molecule Inhibitor Screening and Validation
Caption: Workflow for inhibitor discovery and validation.
Protocol 1.1: In Vitro METTL3 Inhibition Assay (HTRF)
This protocol is adapted from previously reported Homogeneous Time-Resolved Fluorescence (HTRF) assays used to measure METTL3/METTL14 activity.[2][3]
Materials:
-
Recombinant human METTL3/METTL14 complex
-
S-adenosylmethionine (SAM)
-
Biotinylated RNA oligonucleotide substrate (containing a consensus RRACH motif)
-
S-adenosyl-L-homocysteine (SAH)
-
Europium cryptate-labeled anti-m6A antibody
-
Streptavidin-XL665
-
Assay buffer (e.g., 50 mM Tris-HCl pH 8.0, 50 mM NaCl, 1 mM DTT, 0.01% BSA)
-
384-well low-volume plates
-
HTRF-compatible plate reader
Procedure:
-
Prepare serial dilutions of the test compound in DMSO, then dilute further in assay buffer.
-
In a 384-well plate, add 2 µL of the diluted compound. For controls, add 2 µL of DMSO (negative control) or a known inhibitor like SAH (positive control).
-
Add 4 µL of the METTL3/METTL14 enzyme solution (e.g., final concentration 1 nM) to each well.
-
Incubate for 15 minutes at room temperature to allow compound binding.
-
Initiate the reaction by adding 4 µL of a substrate mix containing SAM (e.g., 100 nM final concentration) and biotinylated RNA oligo (e.g., 50 nM final concentration).
-
Incubate the reaction for 1 hour at room temperature.
-
Stop the reaction and proceed with detection by adding 10 µL of a detection mix containing the Europium-labeled anti-m6A antibody and Streptavidin-XL665.
-
Incubate for 1 hour at room temperature, protected from light.
-
Read the plate on an HTRF-compatible reader (excitation at 320 nm, emission at 620 nm and 665 nm).
-
Calculate the HTRF ratio (665 nm / 620 nm * 10,000) and plot the results against compound concentration to determine the IC₅₀ value using non-linear regression.
Protocol 1.2: Cell Culture Treatment with m6A Writer Inhibitor
Materials:
-
Mammalian cell line of interest
-
Complete cell culture medium
-
Small molecule inhibitor stock solution (e.g., 10 mM in DMSO)
-
DMSO (vehicle control)
-
Multi-well culture plates
Procedure:
-
Seed cells in multi-well plates at a density that will ensure they are in the exponential growth phase (e.g., 70-80% confluency) at the time of harvest.
-
Allow cells to attach and grow overnight.
-
Prepare working concentrations of the inhibitor by diluting the stock solution in complete culture medium. Also, prepare a vehicle control medium containing the same final concentration of DMSO (typically ≤ 0.1%).
-
Aspirate the old medium from the cells and replace it with the medium containing the inhibitor or vehicle control.
-
Incubate the cells for the desired treatment duration (e.g., 24, 48, or 72 hours).
-
After incubation, harvest the cells for downstream analysis, such as RNA extraction (for m6A quantification), protein extraction (for Western blotting), or phenotypic assays (e.g., proliferation, apoptosis).
Genetic Inhibition
Genetic methods provide a highly specific means to ablate m6A writer function by targeting the mRNA or the genomic locus of a core component, typically METTL3.
Workflow for Genetic Inhibition of m6A Writers
References
- 1. semanticscholar.org [semanticscholar.org]
- 2. pubs.acs.org [pubs.acs.org]
- 3. Structure-Based Design of Inhibitors of the m6A-RNA Writer Enzyme METTL3 - PMC [pmc.ncbi.nlm.nih.gov]
- 4. m6A RNA Regulatory Diagram | Cell Signaling Technology [cellsignal.com]
- 5. Frontiers | Small-molecule and peptide inhibitors of m6A regulators [frontiersin.org]
- 6. Small-molecule and peptide inhibitors of m6A regulators - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Exploring m6A RNA Methylation: Writers, Erasers, Readers | EpigenTek [epigentek.com]
- 8. Small molecule inhibitors targeting m6A regulators - PMC [pmc.ncbi.nlm.nih.gov]
- 9. researchgate.net [researchgate.net]
Small Molecule Inhibitors of m6A Demethylases: Application Notes and Protocols for Researchers
For Researchers, Scientists, and Drug Development Professionals
These application notes provide a comprehensive overview of small molecule inhibitors targeting the N6-methyladenosine (m6A) demethylases FTO and ALKBH5. This document includes detailed protocols for key experimental assays, quantitative data for inhibitor comparison, and visualizations of relevant signaling pathways to guide research and drug development efforts in this burgeoning field of epitranscriptomics.
Introduction to m6A Demethylase Inhibitors
N6-methyladenosine (m6A) is the most abundant internal modification in eukaryotic messenger RNA (mRNA), playing a crucial role in various cellular processes, including mRNA stability, splicing, and translation.[1] The reversible nature of this modification is controlled by methyltransferases ("writers") and demethylases ("erasers"). The two known m6A demethylases in mammals are the fat mass and obesity-associated protein (FTO) and the alkB homolog 5 (ALKBH5).[2] Dysregulation of these enzymes has been implicated in a range of diseases, most notably cancer, making them attractive therapeutic targets.[3][4] Small molecule inhibitors of FTO and ALKBH5 offer a promising avenue for therapeutic intervention by modulating the m6A landscape of cellular RNA.[5][6]
Quantitative Data for m6A Demethylase Inhibitors
The following tables summarize the in vitro and in-cell potency of selected small molecule inhibitors for FTO and ALKBH5. This data is essential for comparing the efficacy and selectivity of different compounds.
Table 1: FTO Inhibitor Potency
| Inhibitor | Target | Assay Type | IC50 (µM) | Cell Line | Reference |
| FB23-2 | FTO | Biochemical (HPLC, ssRNA) | 2.6 | - | [1][7][8] |
| FB23-2 | FTO | Cell-based (proliferation) | 0.8 | NB4 | [7] |
| FB23-2 | FTO | Cell-based (proliferation) | 1.5 | MONOMAC6 | [7] |
| CS1 (Bisantrene) | FTO | Cell-based (viability) | Low nanomolar range | AML cell lines | [9] |
| CS2 (Brequinar) | FTO | Cell-based (viability) | Low nanomolar range | AML cell lines | [9] |
| MO-I-500 | FTO | Not Specified | - | - | [9] |
| Rhein | FTO | Biochemical | - | - | [10] |
| Meclofenamic Acid | FTO | Biochemical | - | - | [5] |
Table 2: ALKBH5 Inhibitor Potency
| Inhibitor | Target | Assay Type | IC50 (µM) | Cell Line | Reference |
| Compound 3 | ALKBH5 | Biochemical (ELISA) | 0.84 | - | [6][11] |
| Compound 3 | ALKBH5 | Cell-based (proliferation) | 1.38 ± 0.30 | CCRF-CEM | [11] |
| Compound 3 | ALKBH5 | Cell-based (proliferation) | 11.9 ± 2.3 | HL-60 | [11] |
| Compound 3 | ALKBH5 | Cell-based (proliferation) | 16.5 ± 2.1 | K562 | [11] |
| Compound 6 | ALKBH5 | Biochemical (ELISA) | 1.79 | - | [6][11] |
| Compound 6 | ALKBH5 | Cell-based (proliferation) | 7.62 ± 2.61 | CCRF-CEM | [11] |
| Compound 6 | ALKBH5 | Cell-based (proliferation) | 11.0 ± 2.7 | HL-60 | [11] |
| Compound 6 | ALKBH5 | Cell-based (proliferation) | 1.41 ± 0.12 | K562 | [11] |
| 20m | ALKBH5 | Fluorescence Polarization | 0.021 | - | [12] |
| MV1035 | ALKBH5 | Not Specified | - | U87-MG | [11] |
| TD19 | ALKBH5 | Cell-based (viability) | 15.1 ± 1.4 | NB4 | [10] |
| TD19 | ALKBH5 | Cell-based (viability) | 9.5 ± 3.0 | MOLM13 | [10] |
| TD19 | ALKBH5 | Cell-based (viability) | 7.2 ± 0.4 | U87 | [10] |
| TD19 | ALKBH5 | Cell-based (viability) | 22.3 ± 1.7 | A172 | [10] |
Experimental Protocols
This section provides detailed, step-by-step protocols for essential assays used to characterize m6A demethylase inhibitors.
Protocol 1: In Vitro FTO/ALKBH5 Demethylase Activity Assay (Fluorescence-Based)
This protocol describes a fluorescence-based assay to measure the enzymatic activity of FTO or ALKBH5 and the inhibitory effect of small molecules.
Materials:
-
Recombinant human FTO or ALKBH5 protein
-
Fluorescently labeled m6A-containing single-stranded RNA (ssRNA) or DNA (ssDNA) oligonucleotide substrate
-
Assay Buffer: 50 mM HEPES (pH 7.0), 75 µM (NH4)2Fe(SO4)2·6H2O, 300 µM α-ketoglutarate, 2 mM L-ascorbic acid in RNase-free water
-
Test compounds dissolved in DMSO
-
Black 384-well plates
-
Fluorescence plate reader
Procedure:
-
Reagent Preparation:
-
Warm the Assay Buffer to room temperature before use.
-
Dilute the recombinant FTO or ALKBH5 enzyme to the desired concentration (e.g., 0.25 µM) in Assay Buffer.
-
Dilute the fluorescently labeled m6A substrate to the desired concentration (e.g., 7.5 µM) in Assay Buffer.
-
Prepare serial dilutions of the test compounds in DMSO. The final DMSO concentration in the assay should not exceed 1%.
-
-
Assay Reaction:
-
Add 1 µL of the test compound dilution or DMSO (for vehicle control) to the wells of a black 384-well plate.
-
Add 20 µL of the diluted enzyme solution to each well.
-
Add 20 µL of the diluted m6A substrate to each well to initiate the reaction.
-
Include a "no enzyme" control with Assay Buffer instead of the enzyme solution.
-
-
Incubation:
-
Incubate the plate at room temperature for the desired time (e.g., 60-120 minutes), protected from light.
-
-
Data Acquisition:
-
Read the fluorescence intensity using a plate reader with the appropriate excitation and emission wavelengths for the fluorophore used on the substrate.
-
-
Data Analysis:
-
Subtract the background fluorescence (from the "no enzyme" control wells) from all other readings.
-
Calculate the percent inhibition for each compound concentration relative to the DMSO control.
-
Plot the percent inhibition against the compound concentration and fit the data to a dose-response curve to determine the IC50 value.
-
Protocol 2: Cell Viability Assay (MTT/MTS)
This protocol details the use of MTT or MTS assays to assess the effect of m6A demethylase inhibitors on cell proliferation and viability.
Materials:
-
Adherent or suspension cells of interest
-
Complete cell culture medium
-
Test compounds dissolved in DMSO
-
MTT (3-(4,5-dimethylthiazol-2-yl)-2,5-diphenyltetrazolium bromide) or MTS (3-(4,5-dimethylthiazol-2-yl)-5-(3-carboxymethoxyphenyl)-2-(4-sulfophenyl)-2H-tetrazolium) reagent
-
Solubilization solution (for MTT assay, e.g., DMSO or a solution of SDS in HCl)
-
96-well clear flat-bottom plates
-
Microplate reader
Procedure:
-
Cell Seeding:
-
Seed cells in a 96-well plate at a predetermined optimal density (e.g., 5,000-20,000 cells/well for adherent cells) in 100 µL of complete culture medium.
-
Incubate the plate overnight at 37°C in a humidified incubator with 5% CO2 to allow for cell attachment (for adherent cells).
-
-
Compound Treatment:
-
Prepare serial dilutions of the test compounds in culture medium.
-
Add the desired concentrations of the compounds to the wells. Include a vehicle control (DMSO) and a no-treatment control.
-
Incubate the plate for the desired treatment period (e.g., 24, 48, or 72 hours).
-
-
MTT/MTS Addition and Incubation:
-
For MTT assay: Add 10 µL of MTT solution (5 mg/mL in PBS) to each well and incubate for 2-4 hours at 37°C until a purple precipitate is visible. Then, add 100 µL of solubilization solution and incubate for at least 2 hours at room temperature in the dark, with shaking, to dissolve the formazan (B1609692) crystals.[13]
-
For MTS assay: Add 20 µL of MTS solution to each well and incubate for 1-4 hours at 37°C.[13][14]
-
-
Data Acquisition:
-
Measure the absorbance at the appropriate wavelength (e.g., 570 nm for MTT, 490 nm for MTS) using a microplate reader.[14]
-
-
Data Analysis:
-
Subtract the absorbance of the background control (medium only) from all readings.
-
Calculate the percentage of cell viability for each treatment condition relative to the vehicle control.
-
Plot the percentage of cell viability against the compound concentration to determine the IC50 value.
-
Protocol 3: m6A Dot Blot Assay
This protocol provides a semi-quantitative method to assess global m6A levels in mRNA following treatment with demethylase inhibitors.
Materials:
-
Total RNA or purified mRNA from treated and control cells
-
Amersham Hybond-N+ membrane
-
UV crosslinker
-
Blocking buffer (e.g., 5% non-fat milk in 1x PBS with 0.02% Tween-20)
-
Primary anti-m6A antibody
-
HRP-conjugated secondary antibody
-
ECL Western Blotting Substrate
-
Chemiluminescence detection system
Procedure:
-
RNA Preparation and Denaturation:
-
Isolate total RNA or purify mRNA from cells treated with the inhibitor or vehicle control.
-
Prepare serial dilutions of the RNA samples (e.g., 400 ng, 200 ng, 100 ng) in RNase-free water.
-
Denature the RNA by heating at 95°C for 3-5 minutes, followed by immediate chilling on ice.[15]
-
-
Dot Blotting:
-
Spot the denatured RNA samples onto the Hybond-N+ membrane.
-
UV-crosslink the RNA to the membrane.
-
-
Immunoblotting:
-
Block the membrane with blocking buffer for 1 hour at room temperature.
-
Incubate the membrane with the primary anti-m6A antibody (e.g., 1:1000 dilution) overnight at 4°C.[15]
-
Wash the membrane three times with wash buffer (1x PBS with 0.02% Tween-20).
-
Incubate the membrane with the HRP-conjugated secondary antibody (e.g., 1:5000 dilution) for 1 hour at room temperature.[15]
-
Wash the membrane four times with wash buffer.
-
-
Detection:
-
Incubate the membrane with ECL substrate and detect the chemiluminescent signal using an appropriate imaging system.
-
-
Data Analysis:
-
Quantify the dot intensities using image analysis software (e.g., ImageJ).
-
To normalize for the amount of RNA spotted, the membrane can be stained with methylene (B1212753) blue.
-
Protocol 4: LC-MS/MS for m6A Quantification
This protocol offers a highly accurate and quantitative method for determining the m6A/A ratio in mRNA.
Materials:
-
Purified mRNA from treated and control cells
-
Nuclease P1
-
Bacterial alkaline phosphatase
-
LC-MS/MS system
Procedure:
-
mRNA Digestion:
-
Digest 100-200 ng of purified mRNA with nuclease P1 at 42°C overnight.
-
Further digest with bacterial alkaline phosphatase for at least 3 hours at 37°C to dephosphorylate the nucleoside 5'-monophosphates.
-
-
LC-MS/MS Analysis:
-
Separate the resulting nucleosides using liquid chromatography.
-
Quantify the amounts of adenosine (B11128) (A) and N6-methyladenosine (m6A) using tandem mass spectrometry.
-
-
Data Analysis:
-
Calculate the ratio of m6A to A to determine the overall level of m6A modification in the mRNA population.
-
Signaling Pathways and Experimental Workflows
The following diagrams, generated using the DOT language for Graphviz, illustrate key signaling pathways involving FTO and ALKBH5, as well as a typical experimental workflow for inhibitor screening.
FTO Signaling in Acute Myeloid Leukemia (AML)
FTO plays a significant oncogenic role in certain subtypes of acute myeloid leukemia (AML).[16][17] It promotes leukemogenesis by demethylating the mRNA of key target genes, thereby altering their expression.[2]
Caption: FTO's role in AML involves the regulation of key target mRNAs.
ALKBH5-FOXM1 Signaling in Glioblastoma
In glioblastoma stem-like cells (GSCs), ALKBH5 is highly expressed and sustains tumorigenicity by regulating the expression of the transcription factor FOXM1.[4][18]
Caption: ALKBH5 regulates GSC tumorigenicity through the FOXM1 axis.
FTO and the PI3K/AKT/mTOR Pathway
FTO has been shown to influence cancer cell energy metabolism through the PI3K/AKT/mTOR signaling pathway.[19][20]
References
- 1. Targeting the RNA demethylase FTO for cancer therapy - PMC [pmc.ncbi.nlm.nih.gov]
- 2. FTO Plays an Oncogenic Role in Acute Myeloid Leukemia as a N6-Methyladenosine RNA Demethylase - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. FTO degrader impairs ribosome biogenesis and protein translation in acute myeloid leukemia - PMC [pmc.ncbi.nlm.nih.gov]
- 4. The m6A Demethylase ALKBH5 Maintains Tumorigenicity of Glioblastoma Stem-Like Cells by Sustaining FOXM1 Expression and Cell Proliferation Program - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Small-molecule targeting of oncogenic FTO demethylase in acute myeloid leukemia - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Rational Design of Novel Anticancer Small-Molecule RNA m6A Demethylase ALKBH5 Inhibitors - PMC [pmc.ncbi.nlm.nih.gov]
- 7. medchemexpress.com [medchemexpress.com]
- 8. selleckchem.com [selleckchem.com]
- 9. ashpublications.org [ashpublications.org]
- 10. A covalent compound selectively inhibits RNA demethylase ALKBH5 rather than FTO - PMC [pmc.ncbi.nlm.nih.gov]
- 11. pubs.acs.org [pubs.acs.org]
- 12. Discovery of a potent, selective and cell active inhibitor of m6A demethylase ALKBH5 - PubMed [pubmed.ncbi.nlm.nih.gov]
- 13. Cell Viability Assays - Assay Guidance Manual - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 14. broadpharm.com [broadpharm.com]
- 15. Dot Blot Analysis of N6-methyladenosine RNA Modification Levels - PMC [pmc.ncbi.nlm.nih.gov]
- 16. FTO plays an oncogenic role in acute myeloid leukemia as a N6-methyladenosine RNA demethylase - PMC [pmc.ncbi.nlm.nih.gov]
- 17. cityofhope.org [cityofhope.org]
- 18. m6A Demethylase ALKBH5 Maintains Tumorigenicity of Glioblastoma Stem-like Cells by Sustaining FOXM1 Expression and Cell Proliferation Program - PubMed [pubmed.ncbi.nlm.nih.gov]
- 19. PI3K/AKT/mTOR pathway - Wikipedia [en.wikipedia.org]
- 20. The PI3K/AKT/mTOR interactive pathway - PubMed [pubmed.ncbi.nlm.nih.gov]
Application Notes and Protocols for MeRIP-seq Data Analysis
Audience: Researchers, scientists, and drug development professionals.
Introduction
Methylated RNA Immunoprecipitation Sequencing (MeRIP-seq or m6A-seq) is a powerful technique used to profile the transcriptome-wide distribution of N6-methyladenosine (m6A), the most abundant internal modification in eukaryotic messenger RNA (mRNA).[1][2][3] This modification plays a crucial role in various biological processes, including RNA stability, splicing, and translation, and its dysregulation has been implicated in numerous diseases, making it a key area of investigation in drug development.[4][5]
This document provides a detailed bioinformatics pipeline for the analysis of MeRIP-seq data, from raw sequencing reads to the identification of differentially methylated regions and downstream functional analysis. The protocols and application notes are intended to guide researchers through the complex data analysis workflow.
Overall Experimental and Analytical Workflow
The MeRIP-seq procedure involves immunoprecipitation of m6A-containing RNA fragments using an m6A-specific antibody, followed by high-throughput sequencing.[3][6] The resulting data consists of reads from the immunoprecipitated (IP) sample and a corresponding input control sample, which represents the total transcriptome.[4] The bioinformatics analysis pipeline is a multi-step process designed to identify and quantify m6A methylation peaks across the transcriptome.
I. Data Pre-processing and Quality Control
The initial step in the bioinformatics pipeline is to assess the quality of the raw sequencing data and pre-process it to remove low-quality reads and adapter sequences.
Protocol:
-
Quality Assessment: Utilize tools like FastQC to generate a comprehensive report on the quality of the raw FASTQ files.[7] Key metrics to evaluate include per-base sequence quality, GC content, and adapter content.[7]
-
Adapter and Quality Trimming: Employ tools such as fastp , Trimmomatic , or Cutadapt to remove adapter sequences and trim low-quality bases from the reads.[7][8]
-
Ribosomal RNA (rRNA) Removal: It is crucial to assess and potentially remove rRNA contamination, as it can otherwise consume a significant portion of sequencing reads, reducing the effective sequencing depth for the target mRNA.[7]
Table 1: Tools for Data Pre-processing and Quality Control
| Tool | Key Function | Reference |
| FastQC | Generates quality control reports for high-throughput sequence data. | [8] |
| fastp | An all-in-one FASTQ preprocessor for trimming, quality filtering, and adapter removal. | [1][8] |
| Trimmomatic | A flexible read trimming tool for Illumina sequence data. | [7] |
| Cutadapt | Finds and removes adapter sequences, primers, poly-A tails, and other types of unwanted sequence from high-throughput sequencing reads. | [7] |
| RSeQC | Provides a number of useful modules that can comprehensively evaluate RNA-seq data quality.[1][9] |
II. Read Alignment
After pre-processing, the high-quality reads are aligned to a reference genome.
Protocol:
-
Genome Indexing: Before alignment, the reference genome must be indexed using the chosen alignment software.
-
Alignment: Align the cleaned reads from both the IP and input samples to the reference genome using a splice-aware aligner. STAR and HISAT2 are widely used for this purpose.[8][10]
-
Post-alignment Processing: The resulting SAM/BAM files should be sorted, and duplicate reads, which can arise from PCR amplification during library preparation, should be removed using tools like SAMtools .
Table 2: Tools for Read Alignment
| Tool | Description | Reference |
| STAR | Spliced Transcripts Alignment to a Reference; an ultrafast universal RNA-seq aligner. | [8][10] |
| HISAT2 | A fast and sensitive alignment program for mapping next-generation sequencing reads to a population of human genomes as well as to a single reference genome. | [1][10] |
| SAMtools | A suite of programs for interacting with high-throughput sequencing data in SAM/BAM format. | [2] |
III. Peak Calling
Peak calling is the process of identifying regions in the genome with a significant enrichment of reads in the IP sample compared to the input control, which correspond to m6A-modified regions.[10]
Protocol:
-
Peak Calling: Use a peak calling algorithm to identify enriched regions. Several tools are available, each with its own statistical model. It is often beneficial to use multiple peak callers and identify consensus peaks.
-
Consensus Peak Identification: To obtain a high-confidence set of peaks, the results from multiple peak callers can be combined.[1]
Table 3: Tools for Peak Calling
| Tool | Description | Reference |
| MACS2 | Model-based Analysis of ChIP-Seq; a widely used tool for identifying transcript factor binding sites, it can also be applied to MeRIP-seq data. | [1][8][10] |
| MeTPeak | A graphical model-based peak-calling method specifically designed for MeRIP-seq data.[1][8][11] | |
| exomePeak | An R/Bioconductor package for detecting RNA methylation sites from MeRIP-Seq data.[12][13] | |
| MeRIP-PF | A user-friendly analysis pipeline for signal identification in MeRIP-Seq data.[2] |
IV. Peak Annotation and Motif Analysis
Once peaks are identified, they need to be annotated to determine their genomic context and associated genes.
Protocol:
-
Peak Annotation: Annotate the identified peaks with genomic features (e.g., 5' UTR, CDS, 3' UTR, introns) using tools like bedtools , Homer , or the R package ChIPseeker .[7][10] This step links the m6A modifications to specific genes.
-
Motif Analysis: Perform motif analysis on the peak regions to identify the consensus sequence motif for m6A methylation, which is typically RRACH (where R is G or A; H is A, C, or U).[3] This serves as a quality control step to confirm the specificity of the immunoprecipitation.
Table 4: Tools for Peak Annotation and Motif Analysis
| Tool | Key Function | Reference |
| bedtools | A suite of utilities for comparing genomic features. | [7][10] |
| Homer | A suite of tools for motif discovery and next-gen sequencing analysis. | [7] |
| ChIPseeker | An R/Bioconductor package for annotating and visualizing genomic peaks. | [7] |
V. Differential Methylation Analysis
A key objective of many MeRIP-seq studies is to identify regions that are differentially methylated between different experimental conditions.[4]
Protocol:
-
Quantification: Quantify the read counts within the identified peaks for both IP and input samples across all replicates and conditions.
-
Statistical Analysis: Use statistical methods to identify differentially methylated regions (DMRs). Tools like edgeR , DESeq2 , and specialized packages such as TRESS can be used for this purpose.[10][14] These methods typically model the count data and perform statistical tests to assess the significance of methylation changes while accounting for variations in gene expression.[4][14]
Table 5: Tools for Differential Methylation Analysis
| Tool | Description | Reference |
| edgeR | An R/Bioconductor package for the analysis of differential expression of replicated count data. | [10] |
| DESeq2 | An R/Bioconductor package for differential gene expression analysis based on the negative binomial distribution. | [1][10] |
| TRESS | An R/Bioconductor package that develops a novel statistical method to detect differentially methylated mRNA regions from MeRIP-seq data.[14] | |
| RADAR | An R/Bioconductor package for differential RNA methylation analysis. | [12] |
VI. Downstream Functional Analysis
The final step is to interpret the biological significance of the identified differentially methylated regions and their associated genes.
Protocol:
-
Functional Enrichment Analysis: Perform Gene Ontology (GO) and pathway analysis (e.g., KEGG, Reactome) on the list of genes with differentially methylated peaks to identify enriched biological processes and pathways.[3][10]
-
Integration with Gene Expression Data: Correlate the differential methylation data with differential gene expression data (from RNA-seq) from the same samples to understand the functional impact of m6A modification on gene expression.[1][10]
-
Data Visualization: Use visualization tools like the Integrative Genomics Viewer (IGV) to manually inspect the peaks and their genomic context.[3][7] Heatmaps and volcano plots can be used to visualize the results of the differential methylation analysis.
Conclusion
The bioinformatics analysis of MeRIP-seq data is a complex but powerful approach to unravel the roles of m6A RNA methylation in health and disease. The pipeline described here provides a comprehensive framework for researchers to analyze their data robustly. Several integrated pipelines, such as MeRIPseqPipe , are also available to automate many of these steps, making the analysis more accessible to researchers with limited bioinformatics expertise.[1][8][15] Careful consideration of the experimental design and appropriate application of the bioinformatics tools outlined in these protocols will lead to reliable and insightful discoveries in the field of epitranscriptomics.
References
- 1. academic.oup.com [academic.oup.com]
- 2. MeRIP-PF: An Easy-to-use Pipeline for High-resolution Peak-finding in MeRIP-Seq Data - PMC [pmc.ncbi.nlm.nih.gov]
- 3. MeRIP-seq: Comprehensive Guide to m6A RNA Modification Analysis - CD Genomics [rna.cd-genomics.com]
- 4. academic.oup.com [academic.oup.com]
- 5. researchgate.net [researchgate.net]
- 6. MeRIP-seq Analysis - CD Genomics [bioinfo.cd-genomics.com]
- 7. Master MeRIP-seq Data Analysis: Step-by-Step Process for RNA Methylation Studies - CD Genomics [rna.cd-genomics.com]
- 8. GitHub - canceromics/MeRIPseqPipe: MeRIPseqPipe:An integrated analysis pipeline for MeRIP-seq data based on Nextflow. [github.com]
- 9. trumpet: transcriptome-guided quality assessment of m6A-seq data - PMC [pmc.ncbi.nlm.nih.gov]
- 10. MeRIP-seq and Its Principle, Protocol, Bioinformatics, Applications in Diseases - CD Genomics [cd-genomics.com]
- 11. academic.oup.com [academic.oup.com]
- 12. Detecting m6A methylation regions from Methylated RNA Immunoprecipitation Sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 13. gccri.uthscsa.edu [gccri.uthscsa.edu]
- 14. Differential RNA methylation analysis for MeRIP-seq data under general experimental design - PubMed [pubmed.ncbi.nlm.nih.gov]
- 15. GitHub - lazyky/meripseqpipe: MeRIP-seq analysis pipeline arranged multiple alignment tools, peakCalling tools, Merge Peaks' methods and methylation analysis methods. [github.com]
Application Notes and Protocols for Site-Specific Installation of m6A using CRISPR
For Researchers, Scientists, and Drug Development Professionals
Introduction
N6-methyladenosine (m6A) is the most abundant internal modification in eukaryotic messenger RNA (mRNA) and plays a pivotal role in various biological processes, including mRNA stability, splicing, translation, and cellular differentiation.[1][2] The ability to manipulate m6A at specific sites is crucial for elucidating its precise functions and for developing novel therapeutic strategies targeting epitranscriptomic pathways.[3][4] This document provides a comprehensive guide to the site-specific installation of m6A using CRISPR-based technologies. By fusing a catalytically inactive Cas protein (dCas9 or dCas13) to an m6A methyltransferase ("writer"), researchers can achieve programmable and targeted methylation of specific RNA transcripts.[5][6][7][8][9]
These application notes detail the principles, experimental workflows, and protocols for utilizing CRISPR-dCas-writer fusion proteins to install m6A modifications. We provide quantitative data on editing efficiency and off-target effects, along with detailed methodologies for key experiments. The included diagrams and protocols are intended to serve as a practical resource for researchers in academia and industry.
Principle of Site-Specific m6A Installation
The core of this technology lies in the fusion of a programmable RNA-targeting protein with an m6A writer enzyme.
-
CRISPR-dCas System: A catalytically inactive Cas9 (dCas9) or Cas13 (dCas13) protein is used as a programmable RNA-binding domain.[2][9] It is guided to a specific target RNA sequence by a single guide RNA (sgRNA).
-
m6A Writer: The catalytic domain of an m6A methyltransferase, typically a fusion of METTL3 and METTL14 domains, is fused to the dCas protein.[8][10] This "writer" domain is responsible for transferring a methyl group to the N6 position of adenosine (B11128).
-
Targeted Methylation: The sgRNA directs the dCas-writer fusion protein to the desired RNA locus, where the writer domain installs the m6A modification on a nearby adenosine residue within a specific consensus motif (e.g., DRACH; D=A, G, or U; R=A or G; H=A, C, or U).[6][8]
Experimental Workflow
A typical workflow for site-specific m6A installation involves several key steps, from the design of the CRISPR-based tool to the validation of the targeted modification.
Caption: A generalized workflow for targeted m6A installation using CRISPR.
Data Presentation: Quantitative Analysis of m6A Editing
The efficiency and specificity of CRISPR-mediated m6A installation are critical parameters. The following tables summarize quantitative data from various studies.
Table 1: On-Target m6A Editing Efficiency
| CRISPR System | Target Gene/Region | Cell Line | Method of Quantification | On-Target m6A Installation Efficiency | Reference |
| dCas9-METTL3/14 | Hsp70 5' UTR | HeLa | MeRIP-qPCR | >50% increase in m6A signal for effective sgRNAs | --INVALID-LINK-- |
| dCas13-METTL3 | Reporter transcript | HEK293T | MeRIP-RT-qPCR | 1.8- to 3-fold increase in m6A incorporation | --INVALID-LINK-- |
| dCasRx-METTL3 | ACTB 3' UTR | HEK293T | MeRIP-qPCR | Significant increase in m6A levels at the targeted site | --INVALID-LINK-- |
| TME (dCas13Rx-GhMTA) | GhECA1 | Cotton | SELECT-qPCR | 1.37- to 2.51-fold increase in m6A enrichment | --INVALID-LINK-- |
Table 2: Off-Target Effects of CRISPR-m6A Editors
| CRISPR System | Method of Off-Target Analysis | Key Findings | Reference |
| dCas9-DNMT3A | Whole Genome Bisulfite Seq. | Over 1000 off-target differentially methylated regions (DMRs) identified. | --INVALID-LINK-- |
| dCas13-METTL3 | MeRIP-seq | Low off-target activity, with only a small number of off-target peaks detected. | --INVALID-LINK-- |
| dCasRx-METTL3 | MeRIP-seq | Minimal off-target alterations observed at non-targeted adenine (B156593) sites. | --INVALID-LINK-- |
| dCas9-MTase | Bisulfite sequencing | Mild methylation increase (9-11%) at two out of four predicted off-target sites. | --INVALID-LINK-- |
Experimental Protocols
Protocol 1: Construction of dCas-Writer Fusion Protein Expression Vector
This protocol describes the cloning of a dCas13-METTL3 fusion protein into a mammalian expression vector. A similar strategy can be used for dCas9-based constructs.
Caption: Workflow for constructing the dCas-writer expression vector.
Materials:
-
DNA template for dCas13 and METTL3
-
Restriction enzymes and T4 DNA ligase
-
Competent E. coli
-
Plasmid purification kit
Procedure:
-
Amplification of Inserts:
-
Amplify the coding sequence of dCas13 (with nuclease-inactivating mutations) and the catalytic domain of METTL3 using PCR with primers containing appropriate restriction sites and a linker sequence between the two domains.
-
-
Vector Preparation:
-
Digest the mammalian expression vector with the corresponding restriction enzymes.
-
Purify the linearized vector by gel electrophoresis.
-
-
Ligation:
-
Ligate the amplified dCas13 and METTL3 fragments into the digested vector using T4 DNA ligase.
-
-
Transformation:
-
Transform the ligation product into competent E. coli cells.
-
Plate on selective agar (B569324) plates and incubate overnight.
-
-
Verification:
-
Perform colony PCR on selected colonies to screen for the correct insert size.
-
Purify plasmid DNA from positive colonies and verify the sequence by Sanger sequencing.
-
Protocol 2: sgRNA Design and Cloning
Principles of sgRNA Design:
-
The sgRNA contains a 20-24 nucleotide guide sequence that is complementary to the target RNA.
-
For dCas9 systems, a Protospacer Adjacent Motif (PAM) sequence (typically NGG) is required on the target DNA, which is supplied by a "PAMmer" oligonucleotide for RNA targeting.[13] dCas13 systems do not require a PAM.
-
Online design tools can be used to identify suitable sgRNA target sites and predict potential off-target effects.
Procedure:
-
Identify the target adenosine for methylation within the desired RNA transcript.
-
Select a 20-24 nucleotide target sequence adjacent to the target adenosine.
-
Synthesize DNA oligonucleotides encoding the sgRNA sequence with appropriate overhangs for cloning.
-
Anneal the complementary oligonucleotides.
-
Ligate the annealed duplex into a linearized sgRNA expression vector (e.g., U6 promoter-driven).
-
Transform into E. coli and verify the sequence.
Protocol 3: Validation of Site-Specific m6A Installation by MeRIP-qPCR
Methylated RNA Immunoprecipitation (MeRIP) followed by quantitative PCR (qPCR) is a common method to validate targeted m6A installation.[1][6][14][15]
Caption: Workflow for MeRIP-qPCR to validate m6A editing.
Materials:
-
Total RNA extraction kit
-
RNA fragmentation buffer
-
Anti-m6A antibody
-
Protein A/G magnetic beads
-
RNA purification kit
-
RT-qPCR reagents and primers flanking the target site
Procedure:
-
RNA Extraction and Fragmentation:
-
Immunoprecipitation:
-
Incubate the fragmented RNA with an anti-m6A antibody.
-
Capture the antibody-RNA complexes using Protein A/G magnetic beads.
-
Wash the beads to remove non-specific binding.
-
-
Elution and Purification:
-
Elute the m6A-containing RNA fragments from the beads.
-
Purify the eluted RNA.
-
-
RT-qPCR:
-
Perform reverse transcription followed by qPCR using primers specific to the target region.
-
Quantify the enrichment of the target RNA in the m6A-immunoprecipitated fraction relative to an input control.
-
Protocol 4: Absolute Quantification of m6A by LC-MS/MS
Liquid chromatography-tandem mass spectrometry (LC-MS/MS) provides a highly accurate method for the absolute quantification of m6A levels.[2][5][6][9]
Procedure:
-
mRNA Isolation and Digestion:
-
LC-MS/MS Analysis:
-
Separate the nucleosides by liquid chromatography.
-
Detect and quantify adenosine and m6A using tandem mass spectrometry in multiple reaction monitoring (MRM) mode.[5]
-
-
Data Analysis:
-
Generate a standard curve using known concentrations of adenosine and m6A.
-
Calculate the ratio of m6A to total adenosine in the sample.
-
Signaling Pathways and Logical Relationships
The targeted installation of m6A can influence various downstream pathways by affecting the fate of the target mRNA.
Caption: Downstream consequences of targeted m6A installation.
Applications in Research and Drug Development
The ability to precisely install m6A modifications opens up numerous avenues for research and therapeutic development.
-
Functional Genomics: Elucidate the causal role of specific m6A sites in regulating gene expression and cellular phenotypes.
-
Disease Modeling: Investigate the involvement of aberrant m6A modifications in diseases such as cancer and neurological disorders.[4]
-
Therapeutic Targeting: Develop novel therapies that modulate m6A levels on specific disease-related transcripts.
-
Drug Discovery: Screen for small molecules that can inhibit or enhance the activity of m6A writer enzymes.[4]
Conclusion
The CRISPR-based site-specific installation of m6A is a powerful tool for epitranscriptome engineering. The protocols and data presented here provide a foundation for researchers to implement this technology in their own studies. As the field continues to evolve, further refinements in the efficiency and specificity of these tools are anticipated, promising deeper insights into the biological roles of m6A and new opportunities for therapeutic intervention.
References
- 1. m6A Modification LC-MS Analysis Service - Creative Proteomics [creative-proteomics.com]
- 2. Global analysis by LC-MS/MS of N6-methyladenosine and inosine in mRNA reveal complex incidence - PMC [pmc.ncbi.nlm.nih.gov]
- 3. mdpi.com [mdpi.com]
- 4. epigenie.com [epigenie.com]
- 5. m6A RNA Methylation Analysis by MS - CD Genomics [rna.cd-genomics.com]
- 6. Quantitative analysis of m6A RNA modification by LC-MS - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Genome-wide determination of on-target and off-target characteristics for RNA-guided DNA methylation by dCas9 methyltransferases [dash.harvard.edu]
- 8. Genome-wide determination of on-target and off-target characteristics for RNA-guided DNA methylation by dCas9 methyltransferases - PMC [pmc.ncbi.nlm.nih.gov]
- 9. bpb-us-e2.wpmucdn.com [bpb-us-e2.wpmucdn.com]
- 10. Programmable m6A modification of cellular RNAs with a Cas13-directed methyltransferase - PMC [pmc.ncbi.nlm.nih.gov]
- 11. addgene.org [addgene.org]
- 12. addgene.org [addgene.org]
- 13. Site-Specific m6A Erasing via Conditionally Stabilized CRISPR-Cas13b Editor - PMC [pmc.ncbi.nlm.nih.gov]
- 14. An experimental workflow for identifying RNA m6A alterations in cellular senescence by methylated RNA immunoprecipitation sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 15. merckmillipore.com [merckmillipore.com]
Troubleshooting & Optimization
troubleshooting common problems in MeRIP-seq experiments
This technical support center provides troubleshooting guidance and frequently asked questions (FAQs) for researchers, scientists, and drug development professionals working with Methylated RNA Immunoprecipitation Sequencing (MeRIP-seq).
Frequently Asked Questions (FAQs)
Q1: What are the most critical quality control checkpoints in a MeRIP-seq experiment?
A1: The success of a MeRIP-seq experiment hinges on several key quality control steps. Initially, it is crucial to assess the integrity and purity of your starting RNA. An RNA Integrity Number (RIN) of 7.0 or higher is generally recommended to ensure that the RNA is not degraded.[1] Following immunoprecipitation (IP), it is important to validate the enrichment of methylated RNA. This can be done by performing RT-qPCR on known methylated and unmethylated transcripts. After sequencing, bioinformatic quality control using tools like FastQC is essential to check for sequencing quality, adapter contamination, and other potential issues.[1][2]
Q2: How much starting material (total RNA) is required for a MeRIP-seq experiment?
A2: Traditionally, MeRIP-seq protocols required a substantial amount of total RNA, often around 300 μg.[3][4] However, recent optimizations have made it possible to perform MeRIP-seq with as little as 500 ng of total RNA.[3][4] For low-input protocols, it is crucial to adjust and optimize experimental parameters such as antibody concentration and library preparation kits.[5] Some studies have successfully performed MeRIP-seq with 1-2 μg of total RNA.[6] The optimal amount can also depend on the expression level of the target transcripts and the efficiency of the m6A antibody.
Q3: How do I choose the right anti-m6A antibody?
A3: The choice of anti-m6A antibody is a critical factor for a successful MeRIP-seq experiment, as antibody performance can vary significantly.[3][7] It is essential to use a well-validated antibody with high specificity and efficiency. Some studies have compared the performance of commercially available anti-m6A antibodies.[8][9] When starting with a new antibody, it is highly recommended to perform validation experiments, such as dot blots or western blots with m6A-containing and non-methylated RNA controls, to confirm its specificity.
Q4: What are some common pitfalls in MeRIP-seq data analysis?
A4: Common challenges in MeRIP-seq data analysis include proper peak calling, differential methylation analysis, and distinguishing true methylation signals from background noise.[10] It is important to use a suitable peak calling algorithm, such as MACS2, and to optimize its parameters for MeRIP-seq data.[11][12] For differential methylation analysis, it is crucial to account for variations in gene expression levels between samples.[13][14] Normalization of the data is another critical step to address biases introduced during the experimental workflow.
Troubleshooting Guides
Problem 1: Low Yield of Immunoprecipitated RNA
Possible Causes & Solutions
| Cause | Recommended Solution |
| Poor RNA Quality | Ensure your starting total RNA has a high RIN value (≥7.0) and is free of contaminants.[1] |
| Inefficient Immunoprecipitation | - Optimize the amount of antibody used. Titrate the antibody to find the optimal concentration for your specific conditions. - Ensure proper binding of the antibody to the beads. Pre-incubate the antibody with protein A/G beads. - Optimize incubation times for antibody-RNA binding. |
| Suboptimal RNA Fragmentation | Ensure RNA is fragmented to the desired size range (typically around 100 nucleotides).[15] Over- or under-fragmentation can reduce IP efficiency. Verify fragment size using a Bioanalyzer or similar instrument. |
| Inefficient Elution | Ensure the elution buffer and conditions are optimal for releasing the RNA from the antibody-bead complex. |
Problem 2: High Background Signal / Low Signal-to-Noise Ratio
Possible Causes & Solutions
| Cause | Recommended Solution |
| Non-specific Antibody Binding | - Use a highly specific and validated anti-m6A antibody. - Include a negative control IP with a non-specific IgG antibody to assess background levels.[16] - Increase the stringency of the wash buffers (e.g., by increasing salt concentration) to reduce non-specific interactions.[8] |
| Insufficient Washing | Increase the number and duration of wash steps after immunoprecipitation to remove unbound RNA. |
| High Input RNA Amount | While sufficient input is necessary, excessively high amounts of starting RNA can sometimes lead to increased non-specific binding.[1] |
| Contamination | Ensure all reagents and labware are RNase-free to prevent RNA degradation, which can contribute to background. |
Problem 3: Inconsistent Results Between Replicates
Possible Causes & Solutions
| Cause | Recommended Solution |
| Technical Variability | - Standardize all steps of the protocol, including RNA fragmentation, antibody incubation, and washing. - Prepare master mixes for reagents to minimize pipetting errors. |
| Biological Variability | Ensure that biological replicates are processed in parallel and under identical conditions. |
| Low Library Complexity | This can be caused by low input RNA or issues during library preparation. Consider using a library preparation kit optimized for low-input samples. |
| Batch Effects | If processing a large number of samples, process them in smaller, manageable batches to minimize technical variation between batches. |
Problem 4: Issues with Peak Calling and Data Analysis
Possible Causes & Solutions
| Cause | Recommended Solution |
| Inappropriate Peak Caller | Use a peak caller suitable for MeRIP-seq data, such as MACS2. While originally designed for ChIP-seq, it is commonly used for MeRIP-seq.[11][12] |
| Suboptimal Peak Calling Parameters | Adjust the parameters of the peak caller (e.g., p-value or q-value threshold, genome size) to fit the characteristics of your data. For human transcriptome, a genome size (--gsize) of ~1e8 can be used as an approximation.[11] |
| Lack of Input Control | Always include an input control sample (RNA that has not been immunoprecipitated) for each biological condition. The input sample is crucial for normalizing the IP signal and identifying true enrichment peaks.[2] |
| Ignoring Gene Expression Differences | When performing differential methylation analysis, it is essential to normalize for differences in gene expression between samples, as these can affect the number of reads in both the IP and input samples.[13][14] |
Experimental Protocols
Detailed MeRIP-seq Immunoprecipitation Protocol
This protocol is adapted from optimized low-input MeRIP-seq procedures.[3][5]
-
RNA Fragmentation:
-
Start with 1-15 µg of total RNA.
-
Fragment the RNA to an average size of ~100-200 nucleotides using an RNA fragmentation buffer or enzymatic methods.
-
Incubate at 70-94°C for a defined period (e.g., 5 minutes), then immediately stop the reaction on ice.
-
Purify the fragmented RNA.
-
-
Antibody-Bead Conjugation:
-
Use a mixture of Protein A and Protein G magnetic beads.
-
Wash the beads twice with IP buffer (e.g., 150 mM NaCl, 10 mM Tris-HCl pH 7.5, 0.1% IGEPAL CA-630).
-
Resuspend the beads in IP buffer and add the anti-m6A antibody (e.g., 1.25-5 µg, depending on the antibody and input amount).
-
Incubate with rotation at 4°C for at least 4-6 hours or overnight.
-
-
Immunoprecipitation:
-
Wash the antibody-conjugated beads twice with IP buffer.
-
Resuspend the beads and add the fragmented RNA.
-
Incubate with rotation at 4°C for 4 hours to overnight.
-
-
Washing:
-
Wash the beads to remove non-specifically bound RNA. A series of washes with buffers of increasing stringency is recommended:
-
Two washes with low-salt buffer.
-
Two washes with high-salt buffer.
-
One wash with IP buffer.
-
-
-
Elution and RNA Purification:
-
Elute the methylated RNA from the beads using an appropriate elution buffer.
-
Purify the eluted RNA using a suitable RNA clean-up kit.
-
Library Preparation for MeRIP-seq
For library preparation, especially with low-input RNA, it is recommended to use a commercial kit specifically designed for this purpose, such as the SMARTer Stranded Total RNA-Seq Kit.
-
Input and IP RNA: Use the purified, immunoprecipitated RNA and a corresponding amount of the input fragmented RNA.
-
Library Construction: Follow the manufacturer's instructions for the chosen library preparation kit. This typically involves reverse transcription, second-strand synthesis, adapter ligation, and PCR amplification.
-
PCR Cycles: The number of PCR cycles should be optimized to avoid over-amplification, which can lead to PCR duplicates and biased library representation. For IP samples, a slightly higher number of cycles (e.g., 16 cycles) may be needed compared to input samples (e.g., 14 cycles).[5]
-
Quality Control: After library construction, assess the library quality and quantity using a Bioanalyzer and qPCR.
Quantitative Data Summary
Table 1: Comparison of Anti-m6A Antibodies
This table summarizes a comparison of three different anti-m6A antibodies based on their MeRIP efficiency and the number of m6A peaks identified. Data is adapted from a study by Cui et al., 2018.[8]
| Antibody | MeRIP Efficiency (S/N Ratio) | Number of m6A Peaks Identified | Overlap with Other Antibodies |
| Synaptic Systems (SySy) | High | Highest | High |
| NEB | Moderate | Moderate | Moderate |
| Millipore | Moderate | Moderate | Moderate |
S/N ratio was determined by the enrichment of a known m6A-containing spike-in control over a non-methylated control.
Table 2: Effect of Starting RNA Amount on MeRIP-seq Efficiency and Peak Calling
This table illustrates how the amount of starting total RNA affects the efficiency of the MeRIP and the number of identified m6A peaks. Data is adapted from a study by Cui et al., 2018.[6][8]
| Starting Total RNA Amount | MeRIP Efficiency | Total Number of m6A Peaks Identified |
| 32 µg | Highest | Highest |
| 8 µg | High | High |
| 2 µg | Moderate | Moderate |
| 0.5 µg | Low | Lowest |
Visualizations
References
- 1. MeRIP-seq for Detecting RNA methylation: An Overview - CD Genomics [cd-genomics.com]
- 2. Master MeRIP-seq Data Analysis: Step-by-Step Process for RNA Methylation Studies - CD Genomics [rna.cd-genomics.com]
- 3. Refined RIP-seq protocol for epitranscriptome analysis with low input materials - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Refined RIP-seq protocol for epitranscriptome analysis with low input materials - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. portlandpress.com [portlandpress.com]
- 6. researchgate.net [researchgate.net]
- 7. rna-seqblog.com [rna-seqblog.com]
- 8. Refined RIP-seq protocol for epitranscriptome analysis with low input materials | PLOS Biology [journals.plos.org]
- 9. researchgate.net [researchgate.net]
- 10. m.youtube.com [m.youtube.com]
- 11. how did you decide the --gsize of human when using macs2 call m6A peaks · Issue #1 · al-mcintyre/merip_reanalysis_scripts · GitHub [github.com]
- 12. Peak calling with MACS2 | Introduction to ChIP-Seq using high-performance computing [hbctraining.github.io]
- 13. academic.oup.com [academic.oup.com]
- 14. Differential RNA methylation analysis for MeRIP-seq data under general experimental design - PMC [pmc.ncbi.nlm.nih.gov]
- 15. MeRIP-seq Protocol - CD Genomics [rna.cd-genomics.com]
- 16. RNA-Seq and m6A-RNA Immunoprecipitation (MeRIP-seq) Seq [bio-protocol.org]
optimizing antibody concentration for m6A immunoprecipitation
This technical support center provides troubleshooting guidance and frequently asked questions to help researchers, scientists, and drug development professionals optimize antibody concentration for N6-methyladenosine (m6A) immunoprecipitation (IP) experiments.
Frequently Asked Questions (FAQs)
Q1: How do I select the right anti-m6A antibody for my experiment?
A1: The choice of an anti-m6A antibody is a critical determinant for successful m6A immunoprecipitation.[1][2] Selection should be based on the amount of starting material (total RNA) and the specific tissue or cell type. Different antibodies exhibit varying performance with high-input versus low-input RNA samples.[1][3] It is recommended to consult studies that have performed comparative analyses of commercially available antibodies.[1][2]
Q2: What is a good starting concentration for my anti-m6A antibody?
A2: The optimal antibody concentration depends on the specific antibody used and the amount of input RNA. For standard RNA inputs (around 15 µg), 5 µg of antibodies from Millipore (such as ABE572 and MABE1006) have been shown to perform well.[1][3] For low-input RNA, as little as 1.25 µg of a Cell Signaling Technology (CST) antibody (#56593) has proven effective.[1][3] It is crucial to perform an antibody titration to determine the most effective concentration for your specific experimental conditions.[4]
Q3: Should I use polyclonal or monoclonal antibodies for m6A IP?
A3: Both polyclonal and monoclonal antibodies are used for m6A IP.[2] While monoclonal antibodies offer high specificity and batch-to-batch consistency, the development of highly specific monoclonal antibodies against m6A has been challenging.[5][6][7] The most important factor is the validation of the antibody's specificity and performance in your experimental setup.[5][6]
Q4: What are the essential controls for an m6A IP experiment?
A4: To ensure the specificity of your m6A IP, it is crucial to include proper controls. An "input" control, which is a sample of the fragmented RNA before immunoprecipitation, is essential to assess the initial abundance of transcripts.[8] Additionally, a negative control reaction using a non-specific IgG of the same isotype as your primary antibody is highly recommended to determine the level of non-specific binding.[4][9]
Troubleshooting Guide
Issue 1: Low Yield of Immunoprecipitated RNA
| Possible Cause | Recommended Solution |
| Suboptimal Antibody Concentration | Titrate the antibody to find the optimal concentration for your input RNA amount. Using too little antibody will result in inefficient pulldown, while too much can increase non-specific binding and decrease enrichment.[10][11] |
| Inefficient Antibody-Bead Coupling | Ensure proper mixing and incubation of the antibody with the protein A/G magnetic beads. The ratio of antibody to beads may need optimization.[12][13] |
| Inefficient Elution | Ensure the elution buffer is correctly prepared and that the incubation time is sufficient to release the m6A-containing RNA from the antibody-bead complex.[4] |
| Performing two rounds of IP | One round of IP is often sufficient for enriching m6A-containing RNA and may increase the final yield.[10][11] |
Issue 2: High Background or Non-Specific Binding
| Possible Cause | Recommended Solution |
| Excessive Antibody Concentration | Using too much antibody can lead to the pulldown of unmodified RNA fragments. Reduce the antibody amount in your IP reaction.[10][11] |
| Insufficient Washing | Increase the number or stringency of wash steps after the immunoprecipitation to remove non-specifically bound RNA.[2] |
| Non-specific binding to beads | Pre-clear your fragmented RNA by incubating it with beads alone before adding the anti-m6A antibody. This will reduce background binding to the beads.[14] |
| Contamination | Ensure that all reagents and equipment are RNase-free to prevent RNA degradation, which can contribute to background.[15] |
Issue 3: Inconsistent Results Between Replicates
| Possible Cause | Recommended Solution |
| Variable RNA Fragmentation | Ensure consistent and uniform fragmentation of your RNA samples. Inconsistent fragment sizes can lead to variability in IP efficiency.[4] |
| Pipetting Errors | Use precise pipetting techniques, especially when dealing with small volumes of antibody and beads. |
| Inconsistent Incubation Times | Adhere strictly to the optimized incubation times for antibody-bead binding and RNA immunoprecipitation. |
Quantitative Data Summary
Table 1: Recommended Anti-m6A Antibody Concentrations for MeRIP-seq
| Antibody | Starting Total RNA | Recommended Antibody Amount | Reference |
| Millipore (ABE572, MABE1006) | 15 µg | 5 µg | [1][3] |
| Cell Signaling Technology (CST, #56593) | Low-input | 1.25 µg | [1][3] |
| Cell Signaling Technology (CST) | 1 µg | 2.5 µg | [16] |
| Cell Signaling Technology (CST) | 0.5 µg | 1.25 µg | [16] |
| Cell Signaling Technology (CST) | 0.1 µg | 1.25 µg | [16] |
| Synaptic Systems | Not specified | 1 µg | [12] |
| Synaptic Systems | Not specified | 12.5 µg | [15] |
Experimental Protocols & Visualizations
Experimental Workflow: m6A Immunoprecipitation
The following diagram outlines the key steps in a typical m6A immunoprecipitation (MeRIP-seq) experiment.
Caption: Workflow for m6A RNA Immunoprecipitation (MeRIP-seq).
Troubleshooting Logic: Low IP Yield
This diagram illustrates a logical approach to troubleshooting low yield in your m6A IP experiment.
Caption: Troubleshooting flowchart for low m6A IP yield.
Detailed Protocol: Antibody Titration for m6A IP
This protocol provides a general framework for optimizing antibody concentration. Specific volumes and incubation times may need to be adjusted based on the antibody manufacturer's recommendations and your specific experimental conditions.
-
Prepare Fragmented RNA : Start with a consistent amount of high-quality, fragmented total RNA for each IP reaction.
-
Set up Titration Reactions : Prepare a series of IP reactions with varying amounts of the anti-m6A antibody (e.g., 0.5 µg, 1 µg, 2.5 µg, 5 µg, and 10 µg). Include a negative control with non-specific IgG.
-
Antibody-Bead Complex Formation :
-
For each reaction, wash an appropriate amount of Protein A/G magnetic beads with IP buffer.
-
Resuspend the beads in IP buffer and add the designated amount of antibody.
-
Incubate for at least 1 hour at 4°C with gentle rotation to allow the antibody to bind to the beads.[17]
-
-
Immunoprecipitation :
-
Washing :
-
After incubation, wash the beads multiple times with IP buffer and salt-containing wash buffers to remove non-specifically bound RNA.
-
-
Elution :
-
Elute the captured RNA from the antibody-bead complex using an appropriate elution buffer.
-
-
Quantification and Analysis :
-
Quantify the amount of RNA recovered from each IP reaction.
-
Analyze the enrichment of known m6A-containing transcripts (positive controls) and the lack of enrichment of transcripts known to be unmethylated (negative controls) using RT-qPCR. The optimal antibody concentration will be the one that gives the highest signal-to-noise ratio (enrichment of positive controls over negative controls).
-
References
- 1. Comparative analysis of improved m6A sequencing based on antibody optimization for low-input samples - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. researchgate.net [researchgate.net]
- 3. rna-seqblog.com [rna-seqblog.com]
- 4. sigmaaldrich.com [sigmaaldrich.com]
- 5. Development and validation of monoclonal antibodies against N6-methyladenosine for the detection of RNA modifications - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Development and validation of monoclonal antibodies against N6-methyladenosine for the detection of RNA modifications | PLOS One [journals.plos.org]
- 7. researchgate.net [researchgate.net]
- 8. researchgate.net [researchgate.net]
- 9. An optimized co-immunoprecipitation protocol for the analysis of endogenous protein-protein interactions in cell lines using mass spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 10. neb.com [neb.com]
- 11. neb.com [neb.com]
- 12. Protocol for antibody-based m6A sequencing of human postmortem brain tissues - PMC [pmc.ncbi.nlm.nih.gov]
- 13. researchgate.net [researchgate.net]
- 14. Immunoprecipitation Troubleshooting Guide | Cell Signaling Technology [cellsignal.com]
- 15. sysy.com [sysy.com]
- 16. portlandpress.com [portlandpress.com]
- 17. pdfs.semanticscholar.org [pdfs.semanticscholar.org]
Technical Support Center: Navigating Low-Input m6A Sequencing
Welcome to the technical support center for N6-methyladenosine (m6A) sequencing with low RNA input. This resource is designed for researchers, scientists, and drug development professionals to provide troubleshooting guidance and answer frequently asked questions related to the challenges of working with limited starting material.
Frequently Asked Questions (FAQs)
Q1: What is the minimum amount of total RNA required for m6A sequencing?
A1: Traditionally, m6A RNA immunoprecipitation sequencing (MeRIP-seq) required substantial amounts of total RNA, often around 300 µg.[1][2][3] However, recent advancements and protocol optimizations have significantly lowered this requirement. Several methods now allow for successful m6A profiling with as little as 500 ng of total RNA, and some specialized protocols can even accommodate input in the picogram range, particularly for single-cell applications.[1][2][3]
Q2: Which are the most common methods for low-input m6A sequencing?
A2: Several methods have been developed or adapted for low-input m6A sequencing. The most prominent include:
-
Refined MeRIP-seq: Optimized versions of the traditional methylated RNA immunoprecipitation sequencing that can work with as little as 500 ng of total RNA.[1][2][3]
-
CUT&RUN RNA m6A-Seq: This method combines Cleavage Under Targets and Release Using Nuclease (CUT&RUN) technology with m6A immunoprecipitation, enabling high-resolution mapping with input as low as 500 ng of total RNA.[4][5][6]
-
scDART-seq: Single-cell Deamination Adjacent to RNA Modification Target sequencing is a technique designed for single-cell m6A profiling, revealing heterogeneity in RNA methylation between individual cells.[7][8][9]
-
m6A-seq2: A multiplexed version of m6A-seq that reduces technical variability and the amount of input material required.[10][11]
Q3: How do I choose the right low-input m6A sequencing method for my experiment?
A3: The choice of method depends on several factors, including the amount of starting material, the desired resolution, and the specific research question.
-
For moderate low inputs (µg to high ng range) , refined MeRIP-seq or m6A-seq2 are robust options.
-
For very low inputs (as low as 500 ng) and a need for reduced background and higher resolution, CUT&RUN RNA m6A-Seq is a strong candidate.[4]
-
For single-cell analysis and studying methylation heterogeneity, scDART-seq is the appropriate choice.[7][9]
Q4: What are the critical quality control steps for low-input m6A sequencing?
A4: With low input, stringent quality control is paramount. Key QC steps include:
-
RNA Integrity: Assess RNA quality using a Bioanalyzer or similar instrument. A high RNA Integrity Number (RIN) is crucial.
-
Antibody Validation: The specificity of the m6A antibody is critical. Validate its performance using dot blots with known methylated and unmethylated RNA oligonucleotides.[12]
-
Library Quantification and Size Distribution: After library preparation, quantify the library using a Qubit or qPCR and check the size distribution on a Bioanalyzer.
Troubleshooting Guide
This guide addresses common issues encountered during low-input m6A sequencing experiments.
| Problem | Possible Cause | Suggested Solution |
| Low yield of immunoprecipitated (IP) RNA | Insufficient starting RNA. | Increase the amount of input RNA if possible. For very limited samples, ensure the chosen protocol is appropriate for the input amount.[13] |
| Inefficient immunoprecipitation. | Optimize the antibody concentration. Different antibodies and sample types may require different concentrations.[14][15][16] Ensure proper binding of the antibody to the beads. | |
| Significant loss of material during washing steps. | Minimize the number of washes or use a more streamlined protocol like CUT&RUN, which involves fewer washing steps.[4] | |
| High background signal | Non-specific binding of RNA to the antibody or beads. | Pre-clear the fragmented RNA with beads before adding the antibody-bead complex.[12] Optimize the stringency of the wash buffers. |
| Low signal-to-noise ratio. | This is a common challenge with low-input samples.[17] Methods like CUT&RUN are designed to minimize background by cleaving away unbound RNA.[5][6] | |
| Inconsistent results between replicates | Technical variability. | Use a multiplexed approach like m6A-seq2 to reduce batch effects.[10][11] Standardize all steps of the protocol and handle all replicates identically. |
| Variability in RNA quality or quantity between samples. | Perform rigorous QC on the input RNA for all replicates to ensure consistency. | |
| No or very few m6A peaks identified | Poor antibody performance. | Validate the m6A antibody to ensure it is specifically pulling down methylated RNA. |
| Insufficient sequencing depth. | For low-input samples, a higher sequencing depth may be required to confidently call peaks.[12] | |
| RNA degradation. | Ensure proper sample handling and storage to prevent RNA degradation. |
Quantitative Data Summary
The following tables provide a summary of quantitative parameters for different low-input m6A sequencing methods and antibody concentrations.
Table 1: Comparison of Low-Input m6A Sequencing Methods
| Method | Typical RNA Input | Key Advantages | Key Disadvantages |
| Refined MeRIP-seq | 500 ng - 2 µg | Well-established principle, optimized protocols available.[1][2][3][14] | Can have higher background compared to newer methods. |
| CUT&RUN RNA m6A-Seq | 500 ng - 10 µg | Low input requirement, reduced background, high resolution.[4][5][6] | A newer technique that may require more initial optimization. |
| m6A-seq2 | Double polyA-enriched RNA | Reduced technical variability, increased throughput.[10][11] | Requires barcoded samples and a specific computational pipeline. |
| scDART-seq | Single cells | Enables single-cell resolution of the m6A methylome.[7][8][9] | Technically challenging and requires specialized data analysis. |
Table 2: Recommended Anti-m6A Antibody Concentrations for Low-Input MeRIP-seq
| Antibody | Starting Total RNA | Recommended Antibody Amount | Reference |
| Cell Signaling Technology (#56593) | 1 µg | 2.5 µg | [15][16] |
| Cell Signaling Technology (#56593) | 0.5 µg | 1.25 µg | [15][16] |
| Cell Signaling Technology (#56593) | 0.1 µg | 1.25 µg | [15][16] |
Experimental Protocols
Refined MeRIP-seq Protocol for Low-Input RNA
This protocol is adapted from studies that have optimized MeRIP-seq for low RNA inputs.[1][15]
-
RNA Fragmentation: Fragment 0.5-2 µg of total RNA into ~100-200 nucleotide-long fragments using RNA fragmentation reagents.
-
Immunoprecipitation:
-
Prepare anti-m6A antibody-bead complexes by incubating the antibody (e.g., 1.25-2.5 µg of CST #56593) with protein A/G magnetic beads.
-
Add the fragmented RNA to the antibody-bead mixture and incubate at 4°C to allow for the binding of methylated RNA fragments.
-
-
Washing: Perform a series of washes with low-salt and high-salt IP buffers to remove non-specifically bound RNA.
-
Elution: Elute the m6A-containing RNA fragments from the beads.
-
RNA Purification: Purify the eluted RNA using an appropriate RNA clean-up kit.
-
Library Preparation: Construct the sequencing library from the immunoprecipitated RNA and an input control sample using a low-input RNA library preparation kit.
CUT&RUN RNA m6A-Seq Workflow
This protocol is based on the principles of the EpiNext CUT&RUN RNA m6A-Seq Kit.[4][5]
-
RNA Binding: Bind 0.5-10 µg of total RNA to magnetic beads.
-
Antibody Incubation: Add the anti-m6A antibody to the RNA-bound beads and incubate to allow for specific binding to m6A sites.
-
Enzymatic Cleavage: Introduce a cleavage enzyme mix that simultaneously fragments the RNA and removes unbound RNA sequences from the ends of the target m6A-containing regions.
-
Elution and Purification: Elute the enriched m6A-containing RNA fragments and purify them.
-
Library Preparation: Proceed with cDNA synthesis and library preparation for next-generation sequencing.
Visualizations
Caption: Key workflows for low-input m6A sequencing.
Caption: Troubleshooting logic for low-input m6A sequencing.
References
- 1. Refined RIP-seq protocol for epitranscriptome analysis with low input materials - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. Refined RIP-seq protocol for epitranscriptome analysis with low input materials - PMC [pmc.ncbi.nlm.nih.gov]
- 3. pdfs.semanticscholar.org [pdfs.semanticscholar.org]
- 4. EpiNext CUT&RUN RNA m6A-Seq Kit | EpigenTek [epigentek.com]
- 5. Improving MeRIP with CUT&RUN Technology | EpigenTek [epigentek.com]
- 6. How CUT&RUN Helps Improve Methylated RNA Immunoprecipitation | EpigenTek [epigentek.com]
- 7. rna-seqblog.com [rna-seqblog.com]
- 8. Single-cell m6A Sequencing - Unlock the New Traffic Password! [www-en.yingzigene.com]
- 9. researchgate.net [researchgate.net]
- 10. researchgate.net [researchgate.net]
- 11. rna-seqblog.com [rna-seqblog.com]
- 12. benchchem.com [benchchem.com]
- 13. An experimental workflow for identifying RNA m6A alterations in cellular senescence by methylated RNA immunoprecipitation sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 14. researchgate.net [researchgate.net]
- 15. A low-cost, low-input method establishment for m6A MeRIP-seq - PMC [pmc.ncbi.nlm.nih.gov]
- 16. A low-cost, low-input method establishment for m6A MeRIP-seq - PubMed [pubmed.ncbi.nlm.nih.gov]
- 17. Studying m6A in the brain: a perspective on current methods, challenges, and future directions - PMC [pmc.ncbi.nlm.nih.gov]
Technical Support Center: MeRIP-Seq Data Analysis
This technical support center provides troubleshooting guidance and answers to frequently asked questions (FAQs) to help researchers, scientists, and drug development professionals overcome common challenges in MeRIP-seq data analysis, with a specific focus on improving peak calling.
Troubleshooting Guides
This section addresses specific issues that can arise during MeRIP-seq data analysis and offers potential solutions.
Issue 1: Low number of identified peaks or weak enrichment signals.
Question: After running my peak calling software, I've identified a very low number of peaks, or the enrichment signal appears weak. What could be the cause, and how can I troubleshoot this?
Answer:
Several factors, from experimental procedures to data analysis parameters, can contribute to a low number of identified peaks or weak enrichment signals. Here’s a step-by-step guide to troubleshoot this issue:
-
Assess RNA Quality and Quantity: High-quality starting material is crucial for a successful MeRIP-seq experiment.
-
RNA Integrity: Ensure that the RNA Integrity Number (RIN) is high (typically ≥ 7.0) to minimize the impact of RNA degradation.
-
Starting Amount: An insufficient amount of starting total RNA can lead to a low yield of immunoprecipitated RNA. A minimum of 10μg of total RNA is generally recommended.
-
-
Evaluate Immunoprecipitation (IP) Efficiency: The efficiency of the IP step is critical for enriching methylated RNA fragments.
-
Antibody Specificity: Use a highly specific and validated antibody for the RNA modification of interest (e.g., m6A). Antibody quality can significantly impact the experiment's success.
-
Spike-in Controls: Consider using spike-in controls with known modifications to assess IP efficiency.
-
-
Review Sequencing Depth: Inadequate sequencing depth can lead to poor peak calling.
-
Recommended Depth: Aim for sufficient sequencing depth for both IP and input samples to capture the complexity of the transcriptome and provide statistical power for peak calling. While specific numbers can vary, deeper sequencing is generally better.
-
-
Optimize Peak Calling Parameters: The choice of peak calling software and its parameters can dramatically affect the results.
-
Software Selection: Different peak callers use different statistical models. Tools like MACS2, exomePeak, MeTPeak, and TRES are commonly used for MeRIP-seq data. It may be beneficial to try more than one peak caller to compare the results.
-
P-value/FDR Threshold: A stringent p-value or False Discovery Rate (FDR) cutoff might filter out weaker but potentially real peaks. Try relaxing the threshold to see if more peaks are identified, but be mindful of increasing the false positive rate.
-
Read Extension Size: For single-end sequencing data, accurately estimating the fragment size and setting the appropriate read extension size is important for defining the peak region correctly.
-
Issue 2: High number of false-positive peaks.
Question: My analysis has identified a large number of peaks, but many of them seem to be false positives upon manual inspection in a genome browser. How can I reduce the number of false positives?
Answer:
A high number of false-positive peaks can obscure true biological signals. Here are several strategies to refine your peak calling and reduce false positives:
-
Importance of the Input Control: The input sample is a critical control for distinguishing true enrichment from background noise and non-specific antibody binding.
-
Proper Normalization: Ensure that the IP signal is properly normalized against the input signal. Peak callers designed for ChIP-seq or MeRIP-seq inherently use the input to model the background read distribution.
-
Input Quality: The quality of the input library should be comparable to the IP library.
-
-
Replication is Key: Biological replicates are essential for robust peak calling and for estimating the biological variance.
-
Consistent Peaks: True peaks should be consistently present across biological replicates. Using software that can incorporate replicate information will significantly increase the reliability of your results.
-
Small Replicates: Even with a small number of replicates (e.g., 2-3), some peak callers can provide more robust results than analyzing single samples.
-
-
Stringent Statistical Cutoffs: Use appropriate statistical thresholds to filter out less significant peaks.
-
FDR Correction: Always use an FDR-corrected p-value (q-value) to control for multiple testing. A common starting point is an FDR of < 0.05.
-
Fold Enrichment: Filter peaks based on a minimum fold enrichment of the IP signal over the input signal. This helps to remove regions with low levels of enrichment that may be statistically significant but not biologically meaningful.
-
-
Peak Annotation and Motif Analysis: Biological context can help validate your peaks.
-
Genomic Feature Distribution: Analyze the distribution of your peaks across genomic features (5'UTR, CDS, 3'UTR, introns). For m6A, peaks are often enriched in the 3'UTR and near stop codons.
-
Motif Discovery: Search for known consensus motifs for the RNA modification of interest (e.g., RRACH for m6A) within your peak regions. A high percentage of peaks containing the expected motif increases confidence in the results.
-
Frequently Asked Questions (FAQs)
This section provides answers to common questions about MeRIP-seq data analysis and peak calling.
Q1: What is the purpose of the "input" sample in MeRIP-seq?
The "input" sample, which is total RNA fragmented in the same way as the IP sample but not subjected to immunoprecipitation, is a crucial control. It serves to:
-
Account for background noise: It helps to distinguish true methylation signals from non-specific antibody binding and other experimental artifacts.
-
Correct for RNA expression levels: Highly expressed genes will naturally have more reads in the IP sample. The input sample allows for normalization, ensuring that identified peaks represent true enrichment of the modification rather than just high gene expression.
-
Identify biases: It can help identify biases in RNA fragmentation and library preparation.
Q2: Can I use ChIP-seq peak calling software for MeRIP-seq data?
While MeRIP-seq data shares similarities with ChIP-seq data, there are key differences to consider. Software designed for ChIP-seq, such as MACS2, is often used for MeRIP-seq analysis. However, there are important distinctions:
-
Nature of the "Input": In ChIP-seq, the input represents genomic DNA, which has relatively uniform distribution. In MeRIP-seq, the input represents the transcriptome, where read counts can vary dramatically between genes due to differences in expression levels. This high variance in the input needs to be properly handled by the peak calling algorithm.
-
Splicing: MeRIP-seq data comes from RNA, so reads can span exon-exon junctions. Using a splice-aware aligner is necessary for mapping the reads to the genome.
Several peak calling tools have been specifically developed or adapted for MeRIP-seq data to account for these differences, including exomePeak, MeTPeak, and TRES.
Q3: How many biological replicates do I need for a robust MeRIP-seq experiment?
While it is possible to call peaks from a single replicate, using biological replicates is highly recommended to ensure the reproducibility and reliability of the results.
-
Improved Statistical Power: Replicates provide the statistical power to distinguish true biological signals from experimental noise.
-
Robustness with Small Numbers: Even with as few as two biological replicates, peak calling algorithms that model biological variance can perform significantly better than single-replicate analysis.
-
Differential Analysis: For differential methylation analysis between different conditions, having biological replicates is essential.
Q4: What are the key quality control (QC) metrics I should check for my MeRIP-seq data?
Thorough quality control is essential at various stages of the MeRIP-seq workflow. Key QC checks include:
-
Raw Sequencing Reads: Use tools like FastQC to assess the quality of your raw sequencing data. Look at per-base sequence quality, GC content, and adapter contamination.
-
Alignment Quality: After mapping reads to the reference genome, check the alignment statistics, such as the percentage of uniquely mapped reads.
-
Library Complexity: Low library complexity can indicate a problem with the initial RNA amount or the IP step.
-
rRNA Contamination: High levels of ribosomal RNA (rRNA) can reduce the effective sequencing depth for your transcripts of interest.
Peak Calling Software Comparison
The choice of peak calling software can influence the outcome of a MeRIP-seq analysis. Below is a summary of some commonly used tools.
| Software | Statistical Model | Key Features | Reference |
| MACS2 | Poisson distribution | Widely used for ChIP-seq, often adapted for MeRIP-seq. | |
| exomePeak | Conditional test (C-test) | One of the first tools specifically for MeRIP-seq. Can perform differential methylation analysis. | |
| MeTPeak | Hierarchical Beta-Binomial model | Models read count variance and dependency of neighboring sites using a Hidden Markov Model. |
m6A Antibody Specificity: Technical Support Center
This technical support center provides troubleshooting guidance and answers to frequently asked questions regarding the validation of N6-methyladenosine (m6A) antibody specificity.
Frequently Asked Questions (FAQs)
Q1: What are the primary challenges in validating m6A antibody specificity?
Validating the specificity of m6A antibodies is critical for reliable experimental outcomes, yet it presents several challenges. The foremost issue is the potential for cross-reactivity with unmodified adenosine (B11128) (A) or other methylated adenosine variants like N1-methyladenosine (m1A) and N6,2'-O-dimethyladenosine (m6Am).[1][2][3] Many commercially available antibodies show poor selectivity, which can lead to nonspecific signal and artifactual data, particularly when quantifying low-abundance m6A modifications.[4] Furthermore, the sequence context surrounding the m6A modification can influence antibody binding, meaning an antibody might recognize the m6A epitope in one sequence but not another. Finally, there is a lack of standardized validation protocols across the field, leading to variability in reported results.[5]
Q2: Can I rely solely on a dot blot assay to validate my m6A antibody?
While the dot blot is a straightforward and common method for initial antibody screening, it is not sufficient on its own for comprehensive validation.[6][7] A dot blot can assess if an antibody binds to synthetic oligonucleotides containing m6A, but it does not fully replicate the complex cellular environment where the antibody will be used.[1][4] Issues like nonspecific binding to other RNA modifications or recognition of secondary structures are not adequately addressed by this method alone.[4] Therefore, dot blot results should always be confirmed with additional, more rigorous validation assays.
Q3: What are the essential positive and negative controls for m6A validation experiments?
Proper controls are fundamental for interpreting m6A validation data.
-
Positive Controls:
-
Negative Controls:
-
In vitro transcribed RNA with no m6A modification (unmodified adenosine).[8]
-
Total RNA from cells where an m6A methyltransferase (e.g., METTL3) or the entire writer complex has been knocked out or knocked down.[8]
-
Synthetic oligonucleotides containing unmodified adenosine or other modifications like m1A.[1][2]
-
An isotype control IgG antibody should be used in immunoprecipitation experiments to control for non-specific binding to the antibody or beads.[4]
-
Q4: How does the sequence context surrounding the m6A modification affect antibody binding?
The nucleotides flanking the m6A modification can significantly impact antibody recognition. Most m6A modifications occur within a specific consensus motif (RRACH), but the antibody's binding affinity can vary even within this context. This variability can lead to underrepresentation of m6A sites in certain sequence contexts during immunoprecipitation-based methods like MeRIP-Seq. It is a key reason why antibody-based methods may produce results that differ from antibody-independent detection techniques.
Troubleshooting Guide
Problem 1: High background or non-specific bands in Immuno-Northern or MeRIP-Western blots.
| Potential Cause | Troubleshooting Step |
| Antibody concentration too high | Titrate the primary antibody to determine the optimal concentration that maximizes specific signal while minimizing background. |
| Insufficient blocking | Increase the blocking time or try a different blocking agent (e.g., 5% nonfat dry milk vs. BSA). Ensure the blocking buffer is fresh. |
| Inadequate washing | Increase the number or duration of wash steps after primary and secondary antibody incubations. Add a mild detergent like Tween-20 to the wash buffer. |
| Cross-reactivity | Validate the antibody with a competitive inhibition assay. Pre-incubate the antibody with free m6A nucleosides before adding it to the membrane/sample. A specific antibody's signal should be significantly reduced. |
| RNA/DNA Contamination | For MeRIP-Western, ensure samples are thoroughly treated with RNase-free DNase or DNase-free RNase, respectively, to remove contaminating nucleic acids. |
Problem 2: Low signal or no enrichment in Methylated RNA Immunoprecipitation (MeRIP-qPCR/MeRIP-Seq).
| Potential Cause | Troubleshooting Step |
| Poor antibody performance | Not all antibodies are suitable for MeRIP.[10] Test multiple validated antibodies. Ensure the antibody has been validated specifically for immunoprecipitation.[3] |
| Low m6A abundance | Confirm the presence of m6A in your input sample using a dot blot or mass spectrometry. Use a positive control cell line or tissue known to have high m6A levels. |
| Inefficient immunoprecipitation | Optimize the amount of antibody and input RNA.[10] Ensure proper binding conditions (incubation time, temperature, rotation). |
| RNA degradation | Check RNA integrity (e.g., using a Bioanalyzer) before starting the experiment.[11] Use RNase inhibitors throughout the protocol. |
| Inefficient elution | Ensure the elution buffer is effective. A competitive elution with a high concentration of free m6A nucleoside can improve specificity. |
Validation Workflows and Protocols
A multi-step approach is crucial for robustly validating m6A antibody specificity.
Caption: A comprehensive workflow for m6A antibody validation.
Protocol 1: Dot Blot Assay for m6A Antibody Specificity
This protocol is for the initial assessment of an antibody's ability to recognize m6A.
-
Sample Preparation : Prepare serial dilutions of synthetic RNA oligonucleotides (e.g., 40-mer) containing either a central m6A or an unmodified A. Recommended amounts range from 200 ng down to ~10 ng.
-
Membrane Application : Spot 1-2 µL of each RNA dilution directly onto a nitrocellulose or nylon membrane.[6] Mark the positions clearly.
-
Crosslinking : Air dry the membrane, then UV-crosslink the RNA to the membrane (typically 120 mJ/cm²).[1]
-
Blocking : Block the membrane for 1 hour at room temperature in a blocking buffer (e.g., 5% nonfat dry milk or 3% BSA in TBST).
-
Primary Antibody Incubation : Incubate the membrane with the primary m6A antibody (e.g., at a 1:1000 to 1:5000 dilution in blocking buffer) overnight at 4°C with gentle agitation.
-
Washing : Wash the membrane 3-4 times for 5-10 minutes each with wash buffer (e.g., TBST).
-
Secondary Antibody Incubation : Incubate with an HRP-conjugated secondary antibody for 1 hour at room temperature.
-
Detection : Wash the membrane again as in step 6. Apply an ECL substrate and visualize the signal using a chemiluminescence imager. A specific antibody should show a strong signal for the m6A-containing RNA and minimal to no signal for the unmodified RNA.
Protocol 2: Competitive Inhibition ELISA
This assay provides quantitative data on antibody specificity.
Caption: Principle of the competitive inhibition ELISA for specificity.
-
Plate Coating : Coat streptavidin-coated 96-well plates with 5 pmol of a biotinylated m6A-containing oligonucleotide per well.[1] Incubate overnight at 4°C. Wash wells with PBS.
-
Competitive Incubation : In separate tubes, pre-incubate a fixed, dilute amount of the primary m6A antibody with increasing concentrations of free competitor nucleosides (m6A, A, m1A, etc.) for 1-2 hours at room temperature.[9]
-
Binding : Add the antibody-competitor mixtures to the coated wells and incubate for 2-3 hours at room temperature.[1]
-
Detection : Wash the wells thoroughly. Add an HRP-conjugated secondary antibody and incubate for 1 hour. Wash again, then add a colorimetric substrate (e.g., TMB).
-
Analysis : Stop the reaction and read the absorbance at the appropriate wavelength. Plot the signal against the log of the competitor concentration. A specific antibody will show a dose-dependent decrease in signal only when competed with free m6A.[9]
Comparison of Validation Methods
| Method | Information Provided | Pros | Cons |
| Dot Blot | Qualitative assessment of binding to modified vs. unmodified nucleic acids. | Simple, fast, requires minimal sample.[12][13] | Lacks physiological context; prone to artifacts; not quantitative.[4] |
| Competitive ELISA | Quantitative measure of specificity against various modified nucleosides. | Highly specific; quantitative data on binding affinity and cross-reactivity.[9] | Requires specific reagents (biotinylated oligos, free nucleosides). |
| MeRIP in KO/KD Cells | Confirms that the signal is dependent on the m6A-writing machinery. | High physiological relevance; confirms biological target.[8] | Requires generation and validation of knockout/knockdown cell lines. |
| MeRIP with Spike-ins | Quantitative assessment of antibody recovery and efficiency in an IP context. | Allows for normalization across experiments; measures efficiency. | Requires synthesis of specific m6A-containing and control spike-in RNAs. |
| Mass Spectrometry | Absolute quantification of m6A levels in input and IP fractions. | Gold standard for quantification; antibody-independent. | Requires specialized equipment and expertise; expensive.[4][14] |
References
- 1. Development and validation of monoclonal antibodies against N6-methyladenosine for the detection of RNA modifications - PMC [pmc.ncbi.nlm.nih.gov]
- 2. N6-Methyladenosine (m6A) (D9D9W) Rabbit Monoclonal Antibody | Cell Signaling Technology [cellsignal.com]
- 3. sysy.com [sysy.com]
- 4. Evaluation of N6-methyldeoxyadenosine antibody-based genomic profiling in eukaryotes - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Validation strategies for antibodies targeting modified ribonucleotides - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Detecting RNA Methylation by Dot Blotting | Proteintech Group [ptglab.com]
- 7. Dot Blot Analysis for Measuring Global N6-Methyladenosine Modification of RNA | Springer Nature Experiments [experiments.springernature.com]
- 8. m6A-ELISA, a simple method for quantifying N6-methyladenosine from mRNA populations - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Hallmarks of Antibody Validation: Complementary Strategies | Cell Signaling Technology [cellsignal.com]
- 10. rna-seqblog.com [rna-seqblog.com]
- 11. MeRIP-seq for Detecting RNA methylation: An Overview - CD Genomics [cd-genomics.com]
- 12. raybiotech.com [raybiotech.com]
- 13. researchgate.net [researchgate.net]
- 14. Comprehensive Overview of m6A Detection Methods - CD Genomics [cd-genomics.com]
Technical Support Center: m6A RNA Immunoprecipitation (IP)
This technical support center provides troubleshooting guidance and answers to frequently asked questions to help researchers minimize RNA degradation and overcome common challenges during the N6-methyladenosine (m6A) RNA immunoprecipitation (IP) protocol.
Troubleshooting Guide
This guide addresses specific issues that may arise during the m6A IP experiment, leading to RNA degradation or suboptimal results.
Problem 1: Low Yield of Immunoprecipitated (IP) RNA
Low recovery of m6A-enriched RNA is a frequent issue that can compromise downstream applications like sequencing or RT-qPCR.
| Possible Cause | Recommended Solution |
| Insufficient Starting Material | While protocols for low-input RNA exist, starting with a higher amount of total RNA (e.g., 15 µg) can significantly increase the yield of IP RNA.[1] For experiments with limited material, optimized protocols for as little as 1-2 µg of total RNA are available.[1][2] |
| Inefficient Immunoprecipitation | Optimize the concentration of the anti-m6A antibody. Different antibodies have optimal performance at varying concentrations.[1] Ensure the antibody is properly coupled to the magnetic beads. |
| Suboptimal Elution | If using a competitive elution method with N6-methyladenosine, ensure the concentration is sufficient (e.g., 6.7 mM) to effectively displace the antibody-RNA interaction.[3] Alternatively, consider a high-salt washing method, which may outperform competitive elution in some cases. |
| RNA Degradation | Incorporate RNase inhibitors throughout the entire protocol.[4] It is crucial to assess the integrity of both your input and IP RNA using a Bioanalyzer or a similar instrument.[1] |
| Inefficient Single Round of IP | Consider performing a single, optimized round of immunoprecipitation, as this is often sufficient for enriching m6A-containing RNA and can improve recovery.[5] |
Problem 2: High Background Signal in Control Samples (No-Antibody or IgG)
High background can obscure true m6A signals, leading to false positives and difficulty in data interpretation.
| Possible Cause | Recommended Solution |
| Non-specific Binding of RNA to Beads | Pre-clear the fragmented RNA by incubating it with protein A/G beads alone before introducing the antibody-coupled beads. This step will help remove molecules that non-specifically adhere to the beads.[1][6] |
| Ineffective Washing Steps | Increase the number and/or stringency of the wash steps following immunoprecipitation. Employing a series of washes with low-salt and high-salt buffers can effectively reduce non-specific binding.[4] |
| Contamination with Genomic DNA | Ensure complete removal of genomic DNA by treating the initial RNA sample with DNase I.[3][7] |
| Excessive Antibody Usage | Using too much antibody can lead to non-specific binding. Titrate the antibody to find the optimal concentration for your specific experimental conditions.[6] |
Problem 3: Evidence of RNA Degradation in Quality Control Analysis
RNA is highly susceptible to degradation by RNases, which are ubiquitous in the laboratory environment.[8][9] Maintaining RNA integrity is paramount for a successful m6A IP experiment.[10]
| Symptom | Possible Cause | Recommended Solution |
| Low RNA Integrity Number (RIN) < 7 | The starting RNA material was of poor quality, or degradation occurred during sample handling and extraction. | Always assess the quality of your total RNA before starting the experiment. Aim for a RIN value of 7 or higher.[11] Use fresh samples or samples properly stored with RNase inhibitors.[8][12] |
| Smearing on a Gel or Bioanalyzer Trace | RNase contamination was introduced at some point during the protocol. | Use certified RNase-free tubes, tips, and reagents.[13] Wear gloves at all times and change them frequently.[14] Use a dedicated workspace for RNA work and decontaminate surfaces and equipment with RNase-deactivating solutions.[14] |
| Disappearance of 28S and 18S rRNA Peaks | Severe RNA degradation has occurred. | Add RNase inhibitors to all buffers used in the protocol, including lysis, wash, and elution buffers.[4] The recommended final concentration is typically 1-2 units per microliter of reaction mixture.[14] |
Frequently Asked Questions (FAQs)
Q1: What is the optimal RNA Integrity Number (RIN) for starting an m6A IP experiment?
A1: For reliable and reproducible m6A IP results, it is highly recommended to start with high-quality total RNA with a RIN value of 7 or greater.[11] Lower RIN values are indicative of RNA degradation, which can significantly impact the efficiency of the immunoprecipitation and the accuracy of the results.
Q2: How much starting RNA material is required for a successful MeRIP-Seq experiment?
A2: Traditionally, MeRIP-Seq protocols recommended using a substantial amount of total RNA, often around 300 µg.[1] However, with protocol optimizations, it is now possible to perform successful experiments with as little as 1-2 µg of total RNA, and in some specialized protocols, even down to 50 ng.[1] The optimal amount can depend on the antibody used and the abundance of m6A in the target RNAs.[1]
Q3: What are the critical steps in the m6A IP protocol where RNA degradation is most likely to occur?
A3: Several steps are particularly sensitive to RNA degradation:
-
Cell/Tissue Lysis: Incomplete lysis or harsh homogenization can release endogenous RNases.
-
RNA Fragmentation: While necessary, this step can introduce damage if not properly controlled.
-
Immunoprecipitation: Long incubation times can increase the risk of degradation if RNase inhibitors are not present.
-
Washing and Elution: Multiple handling steps increase the chances of introducing RNases.
Q4: How can I validate the results of my m6A IP experiment?
A4: MeRIP-qPCR is a common method to validate the enrichment of m6A in specific transcripts identified from MeRIP-Seq data.[4][15] This involves designing qPCR primers for genes identified as having m6A peaks and for negative control genes that do not show m6A enrichment. The fold enrichment of the target in the IP sample relative to the input is then calculated.[4]
Experimental Protocols
1. RNA Quality Assessment using Agilent Bioanalyzer
This protocol outlines the general steps for assessing RNA integrity. Refer to the manufacturer's specific instructions for the RNA 6000 Nano/Pico kit.
-
Prepare the Bioanalyzer: Allow the gel-dye mix to equilibrate to room temperature for 30 minutes. Vortex the dye and spin it down.
-
Load the Chip: Pipette the gel-dye mix into the appropriate well of the RNA chip. Pressurize the chip using the provided syringe.
-
Load Samples: Load the marker, ladder, and RNA samples into their designated wells.
-
Run the Chip: Place the chip in the Agilent 2100 Bioanalyzer and start the run.
-
Analyze the Results: The software will generate an electropherogram and a gel-like image. Assess the RIN value and the 28S:18S rRNA ratio. Intact total RNA will show two distinct ribosomal peaks (28S and 18S for eukaryotes) and a RIN value ≥ 7.[16][17] Degraded RNA will show a shift towards smaller fragments and a lower RIN value.[16][17]
2. Detailed m6A Immunoprecipitation (MeRIP-Seq) Protocol
This is a generalized workflow and may require optimization for specific cell types or tissues.
-
RNA Preparation and Fragmentation:
-
Start with high-quality total RNA (RIN ≥ 7).
-
Fragment the RNA to an average size of ~100 nucleotides. This can be achieved using a fragmentation buffer (e.g., 100 mM Tris-HCl pH 7.0, 100 mM ZnCl2) and incubating at 94°C for a specific time (e.g., 5 minutes), followed by stopping the reaction with EDTA.[13][18] The fragmentation time may need to be optimized.[4]
-
Purify the fragmented RNA using ethanol (B145695) precipitation.[1]
-
-
Immunoprecipitation:
-
Washing:
-
Wash the beads multiple times with IP buffer to remove non-specifically bound RNA. A series of low-salt and high-salt washes can improve specificity.[4]
-
-
Elution:
-
Elute the m6A-containing RNA fragments from the beads. This can be done competitively using a solution of N6-methyladenosine (e.g., 6.7 mM).[3]
-
-
RNA Purification and Library Preparation:
-
Purify the eluted RNA (IP sample) and the input RNA (a fraction of the fragmented RNA saved before IP).
-
Construct sequencing libraries from both the IP and input samples using a strand-specific RNA library preparation kit.[1]
-
3. Validation of m6A Enrichment by RT-qPCR
-
Perform MeRIP: Follow steps 1-4 of the MeRIP-Seq protocol.
-
Reverse Transcription: Reverse transcribe the eluted IP RNA and an equivalent amount of input RNA into cDNA using random hexamer primers.[4]
-
Quantitative PCR (qPCR):
-
Design qPCR primers for target genes identified as potentially methylated in your MeRIP-Seq data, as well as for negative control genes that do not show m6A peaks.
-
Perform qPCR on the IP and input cDNA samples.
-
Calculate the fold enrichment of m6A for each target gene in the IP sample relative to the input sample.
-
Visualizations
Caption: Workflow of the m6A Immunoprecipitation (MeRIP-Seq) protocol.
Caption: A decision tree for troubleshooting common m6A IP issues.
References
- 1. benchchem.com [benchchem.com]
- 2. researchgate.net [researchgate.net]
- 3. A low-cost, low-input method establishment for m6A MeRIP-seq - PMC [pmc.ncbi.nlm.nih.gov]
- 4. An experimental workflow for identifying RNA m6A alterations in cellular senescence by methylated RNA immunoprecipitation sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 5. neb.com [neb.com]
- 6. Dealing with high background in IP | Abcam [abcam.com]
- 7. Deep and accurate detection of m6A RNA modifications using miCLIP2 and m6Aboost machine learning - PMC [pmc.ncbi.nlm.nih.gov]
- 8. RNA Sample Collection, Protection, and Isolation Support—Troubleshooting | Thermo Fisher Scientific - US [thermofisher.com]
- 9. zymoresearch.com [zymoresearch.com]
- 10. MeRIP-seq: Comprehensive Guide to m6A RNA Modification Analysis - CD Genomics [rna.cd-genomics.com]
- 11. Sequencing Degraded RNA Addressed by 3' Tag Counting - PMC [pmc.ncbi.nlm.nih.gov]
- 12. bitesizebio.com [bitesizebio.com]
- 13. sysy.com [sysy.com]
- 14. biotechrabbit.com [biotechrabbit.com]
- 15. sigmaaldrich.com [sigmaaldrich.com]
- 16. urmc.rochester.edu [urmc.rochester.edu]
- 17. umassmed.edu [umassmed.edu]
- 18. sysy.com [sysy.com]
Technical Support Center: Optimizing RNA Fragmentation for m6A Sequencing
Welcome to the technical support center for m6A sequencing. This guide provides troubleshooting advice and frequently asked questions (FAQs) to help researchers, scientists, and drug development professionals optimize the critical RNA fragmentation step of their experiments.
Frequently Asked Questions (FAQs)
Q1: Why is RNA fragmentation a critical step in m6A sequencing?
A1: RNA fragmentation is essential for accurately mapping N6-methyladenosine (m6A) sites across the transcriptome. The goal is to break down long RNA molecules into smaller, manageable fragments, typically around 100-200 nucleotides (nt) in length.[1][2] This optimal fragment size is crucial for several reasons:
-
Resolution: The size of the RNA fragments directly determines the resolution of m6A peak mapping. Smaller fragments allow for more precise localization of the m6A modification.[2][3]
-
Immunoprecipitation (IP) Efficiency: The anti-m6A antibody used in MeRIP-seq (Methylated RNA Immunoprecipitation sequencing) works more effectively on smaller RNA fragments, leading to better enrichment of m6A-containing sequences.
-
Library Construction: Standard next-generation sequencing (NGS) platforms have optimal input fragment sizes for efficient library preparation and sequencing.
Q2: What are the common methods for RNA fragmentation in m6A-seq protocols?
A2: There are two primary methods for RNA fragmentation: chemical fragmentation and enzymatic fragmentation.
-
Chemical Fragmentation: This is the most widely used method for m6A-seq.[4] It typically involves incubation with divalent metal ions (like Mg²⁺ or Zn²⁺) at high temperatures (e.g., 94°C).[5] This process randomly cleaves the RNA phosphodiester backbone. The duration and temperature of the incubation are critical parameters that control the final fragment size.
-
Enzymatic Fragmentation: This method uses RNases, such as RNase III, to digest the RNA. While it can be effective, it may introduce sequence bias as the enzyme can have cleavage preferences. For m6A sequencing, chemical fragmentation is generally preferred to ensure random cleavage and minimize bias.[6]
Q3: What is the ideal fragment size for m6A sequencing and how do I check it?
A3: The target fragment size for most m6A-seq and MeRIP-seq protocols is between 100 and 200 nucleotides.[1][7]
To verify the size distribution of your fragmented RNA, it is highly recommended to use a microfluidics-based capillary electrophoresis system.[8]
-
Recommended Tool: Agilent Bioanalyzer or a similar instrument.
-
Procedure: Run a small aliquot of your fragmented RNA on an RNA Pico or Nano chip.[8] The resulting electropherogram will show the size distribution and allow you to confirm whether your fragmentation was successful.
Q4: How much starting RNA material do I need for a successful fragmentation and subsequent MeRIP-Seq?
A4: The required amount of starting total RNA has been a significant variable in MeRIP-Seq protocols. While traditional protocols often required large amounts (e.g., 300-400 µg), recent optimizations have significantly lowered this requirement.[3][9] The optimal amount can depend on the specific protocol, the antibody used, and the abundance of m6A in your samples.[9][10]
| Protocol Type | Typical Starting Total RNA Amount | Reference |
| Traditional MeRIP-Seq | 300 - 400 µg | [3][9] |
| Optimized MeRIP-Seq | 2 - 5 µg | [11] |
| Low-Input/Pico-MeRIP-Seq | 50 ng - 500 ng | [1][10] |
| m6A-SAC-seq (Antibody-free) | ~30 ng | [12] |
Troubleshooting Guide
This section addresses specific issues that may arise during RNA fragmentation and subsequent steps.
Problem 1: My RNA is over-fragmented (fragments are <100 nt) or under-fragmented (fragments are >200 nt).
-
Potential Cause: Incorrect incubation time or temperature during chemical fragmentation.
-
Solution:
-
Optimize Fragmentation Conditions: Perform a time-course experiment to determine the optimal fragmentation time for your specific RNA samples and equipment. Test a range of incubation times (e.g., 30 seconds to 15 minutes) at the recommended temperature (e.g., 70°C or 94°C) and analyze the fragment sizes on a Bioanalyzer.[5][6][7]
-
Ensure Temperature Accuracy: Verify that your heat block or thermocycler is accurately calibrated to the target temperature. Temperature fluctuations can lead to inconsistent fragmentation.
-
Check Reagent Concentrations: Ensure that the fragmentation buffer, particularly the concentration of divalent metal ions, is correct as per the protocol.
-
| Parameter | To Decrease Fragment Size | To Increase Fragment Size |
| Incubation Time | Increase | Decrease |
| Temperature | Increase | Decrease |
| ZnCl₂/MgCl₂ Conc. | Increase | Decrease |
Problem 2: I have a low yield of m6A-enriched RNA after immunoprecipitation.
-
Potential Cause 1: Suboptimal RNA Fragmentation. If RNA is under-fragmented, the IP efficiency may be reduced. If it is over-fragmented, very short fragments may be lost during the cleanup steps.
-
Solution 1: Confirm that your RNA fragments are within the optimal 100-200 nt range using a Bioanalyzer before proceeding to the immunoprecipitation step.[8]
-
Potential Cause 2: Poor RNA Quality or Low Input. Starting with degraded RNA (low RNA Integrity Number, RIN) or an insufficient amount of total RNA can lead to low yields.[9][13]
-
Solution 2: Always assess the quality of your starting RNA. A RIN value of 7.0 or higher is generally recommended.[13] If your yield is low, consider increasing the starting amount of RNA if possible.[7]
-
Potential Cause 3: Inefficient Immunoprecipitation. Issues with the antibody, beads, or washing steps can lead to poor enrichment.
-
Solution 3: Ensure the anti-m6A antibody is validated and used at its optimal concentration.[9] Pre-clearing the fragmented RNA with beads before adding the antibody can help reduce non-specific binding.[9]
Problem 3: I see high background noise or inconsistent results between replicates.
-
Potential Cause: Inconsistent RNA fragmentation between samples. Variability in the fragmentation step is a major source of technical noise.[9]
-
Solution:
-
Standardize the Protocol: Ensure every sample is treated identically. Perform the fragmentation for all samples in the same batch on the same calibrated heat block.
-
Assess Fragmentation for Each Sample: Do not assume fragmentation is consistent. Run an aliquot of each fragmented sample on a Bioanalyzer to confirm that all samples have a similar size distribution before pooling or proceeding with IP.
-
Optimize Washing Steps: If fragmentation is consistent, high background may be due to insufficient washing during the IP. Consider increasing the number or stringency of the wash steps.[7][9]
-
Experimental Protocols
Protocol: Chemical RNA Fragmentation and Quality Control
This protocol provides a general workflow for the chemical fragmentation of poly(A)-selected RNA for a standard MeRIP-seq experiment.
1. Materials:
- Purified poly(A)+ RNA (or rRNA-depleted RNA)
- RNA Fragmentation Reagent/Buffer (e.g., containing ZnCl₂ or MgCl₂)[5][12]
- Nuclease-free water
- RNA purification kit (e.g., column-based or beads)
- Ethanol (B145695) (100% and 70%)
- Glycogen (optional, as a co-precipitant)
- 3 M Sodium Acetate (pH 5.5)
2. Fragmentation Procedure:
- Start with 2-10 µg of poly(A)+ RNA in a nuclease-free tube.[3][13]
- Add the RNA Fragmentation Buffer to the RNA sample. The final volume and concentration will depend on the specific kit or protocol being used.
- Incubate the mixture at the optimized temperature and time. For example, incubate at 90°C for 50 seconds to obtain fragments of 100-200 nt.[7] Note: This step requires rigorous optimization.
- Immediately stop the reaction by placing the tube on ice and adding a stop solution (e.g., EDTA) if included in your kit, or proceed directly to purification.
3. Purification of Fragmented RNA:
- Purify the fragmented RNA to remove fragmentation reagents. This can be done using a column-based RNA cleanup kit according to the manufacturer's instructions.
- Alternatively, perform an ethanol precipitation:
- Add 2 µL of glycogen, 0.1 volumes of 3 M NaOAc (pH 5.5), and 2.5-3 volumes of 100% ethanol to the fragmented RNA.[7]
- Incubate at -80°C for at least 1 hour.[7]
- Centrifuge at high speed (e.g., >14,000 rpm) at 4°C for 40-50 minutes.[7]
- Carefully discard the supernatant. Wash the pellet once with 70% ethanol.
- Air-dry the pellet and resuspend it in nuclease-free water.
4. Quality Control:
- Quantify the yield of the purified, fragmented RNA using a fluorometric method (e.g., Qubit).
- Take 1 µL of the sample to analyze the fragment size distribution using an Agilent Bioanalyzer with an RNA Pico chip.[8]
- Confirm that the peak of the fragment distribution lies between 100 and 200 nt before proceeding to the immunoprecipitation step.
Visualizations
Workflow and Logic Diagrams
Caption: Overview of the m6A-Seq (MeRIP-Seq) experimental workflow.
Caption: Troubleshooting flowchart for RNA fragmentation size optimization.
References
- 1. mdpi.com [mdpi.com]
- 2. How CUT&RUN Helps Improve Methylated RNA Immunoprecipitation | EpigenTek [epigentek.com]
- 3. Genome-Wide Location Analyses of N6-Methyladenosine Modifications (m6A-seq) - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Current progress in strategies to profile transcriptomic m6A modifications - PMC [pmc.ncbi.nlm.nih.gov]
- 5. academic.oup.com [academic.oup.com]
- 6. pubs.rsc.org [pubs.rsc.org]
- 7. An experimental workflow for identifying RNA m6A alterations in cellular senescence by methylated RNA immunoprecipitation sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 8. neb.com [neb.com]
- 9. benchchem.com [benchchem.com]
- 10. Refined RIP-seq protocol for epitranscriptome analysis with low input materials - PMC [pmc.ncbi.nlm.nih.gov]
- 11. researchgate.net [researchgate.net]
- 12. Detection of m6A RNA modifications at single-nucleotide resolution using m6A-selective allyl chemical labeling and sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 13. MeRIP-seq for Detecting RNA methylation: An Overview - CD Genomics [cd-genomics.com]
issues with nonspecific binding in m6A antibody-based methods
Welcome to the technical support center for m6A antibody-based methods. This resource provides troubleshooting guides and frequently asked questions (FAQs) to help researchers, scientists, and drug development professionals overcome common challenges, particularly nonspecific binding, encountered during m6A immunoprecipitation sequencing (MeRIP-seq) and related techniques.
Frequently Asked Questions (FAQs)
Q1: What are the common causes of high background and nonspecific binding in MeRIP-seq experiments?
High background in MeRIP-seq can stem from several factors, primarily related to the specificity of the anti-m6A antibody and the stringency of the experimental conditions. Key causes include:
-
Poor Antibody Specificity: The accuracy of MeRIP-seq is highly dependent on the specificity and affinity of the m6A antibody. Suboptimal antibodies may cross-react with unmodified RNA or other similar modifications, leading to nonspecific enrichment.[1]
-
Insufficient Washing: Inadequate washing of the immunoprecipitated complexes can leave behind nonspecifically bound RNA and protein contaminants.
-
Suboptimal Blocking: Incomplete blocking of the protein A/G beads can result in RNA or protein binding directly to the beads.
-
High Input Amount: Using an excessive amount of input RNA can lead to increased nonspecific binding.[1]
-
RNA Secondary Structures: Complex secondary structures in RNA fragments can sometimes be nonspecifically captured during immunoprecipitation.
Q2: How can I validate the specificity of my anti-m6A antibody?
Antibody validation is a critical step to ensure reliable MeRIP-seq results. A dot blot assay is a common and effective method for this purpose. This technique involves spotting known amounts of m6A-containing and unmodified RNA onto a membrane and probing it with the anti-m6A antibody to assess its specificity.
Q3: What are the key quality control metrics I should assess in my MeRIP-seq data?
Assessing the quality of your sequencing data is crucial for interpreting the results accurately. Key quality control metrics to evaluate include:
-
Read Quality: Tools like FastQC can be used to assess the base quality scores, GC content, and sequence length distribution of your raw sequencing reads.[1][2]
-
Alignment Rate: A high percentage of reads should align to the reference genome or transcriptome.
-
Peak Enrichment: A successful MeRIP-seq experiment should show a clear enrichment of reads in the immunoprecipitated (IP) sample compared to the input control. Peak calling algorithms like MACS2 are used to identify these enriched regions.[3]
-
Motif Enrichment: m6A modifications typically occur within a specific consensus motif (e.g., RRACH). A high enrichment of this motif within the identified peaks is a good indicator of a successful experiment.[2][3]
-
Reproducibility: Biological replicates should show a high correlation in their m6A profiles.
Troubleshooting Guides
Issue 1: High Background in Negative Control (IgG) Sample
Problem: You observe a significant number of peaks or high read counts in your negative control immunoprecipitation (e.g., using a non-specific IgG antibody), indicating a high level of nonspecific binding.
Possible Causes and Solutions:
| Cause | Recommended Solution |
| Insufficient pre-clearing of the lysate | Incubate the cell lysate with protein A/G beads alone before adding the specific antibody. This step removes molecules that nonspecifically bind to the beads. |
| Inadequate bead blocking | Before adding the antibody, block the protein A/G beads with a blocking agent like BSA or yeast RNA to prevent nonspecific binding of proteins and RNA to the beads. |
| Ineffective washing steps | Increase the number and/or duration of washes. Use more stringent wash buffers containing detergents (e.g., Tween-20 or Triton X-100) and varying salt concentrations to disrupt weaker, nonspecific interactions. |
Issue 2: Low Signal-to-Noise Ratio
Problem: The enrichment of m6A-containing transcripts in your IP sample is low compared to the input or IgG control, resulting in a poor signal-to-noise (S/N) ratio.
Possible Causes and Solutions:
| Cause | Recommended Solution |
| Suboptimal anti-m6A antibody | The choice of antibody is critical. Different antibodies exhibit varying performance. It is advisable to test multiple commercially available antibodies to find one with high specificity and efficiency for your experimental system. |
| Low abundance of m6A in the sample | Ensure you are starting with a sufficient amount of high-quality total RNA. For samples with inherently low m6A levels, you may need to increase the input amount, though this should be balanced against the risk of increased nonspecific binding. |
| Inefficient immunoprecipitation | Optimize the antibody-to-bead ratio and the incubation times for antibody-RNA binding and bead capture. |
Quantitative Data Summary
The selection of a highly specific and efficient anti-m6A antibody is paramount for a successful MeRIP-seq experiment. The following table summarizes a comparison of three commercially available anti-m6A antibodies, highlighting key performance metrics.
| Antibody | Signal-to-Noise (S/N) Ratio | Number of m6A Peaks Identified | Overlap of m6A Peaks with Other Antibodies |
| Synaptic Systems (SySy) | High | High | Good |
| New England Biolabs (NEB) | Moderate | Moderate | Moderate |
| Millipore | High | High | Good |
Data adapted from a comparative study. The S/N ratio was determined using spike-in controls. The number of peaks and overlap were assessed from MeRIP-seq data.[3]
Experimental Protocols
Protocol 1: Pre-clearing Cell Lysate for RNA Immunoprecipitation
This protocol describes the steps to pre-clear your cell or tissue lysate to reduce nonspecific binding to the immunoprecipitation beads.
-
Prepare Beads: For each 1 mL of cell lysate, wash 20-30 µL of Protein A/G magnetic beads twice with 1 mL of ice-cold IP Lysis Buffer.
-
Incubate Lysate with Beads: Add the washed beads to the cell lysate.
-
Rotate: Incubate the lysate-bead mixture on a rotator for 1-2 hours at 4°C.
-
Separate Beads: Place the tube on a magnetic stand and carefully transfer the supernatant (the pre-cleared lysate) to a new, pre-chilled tube. Discard the beads.
-
Proceed to Immunoprecipitation: Your lysate is now pre-cleared and ready for the addition of the specific anti-m6A antibody.
Protocol 2: Stringent Wash Buffers for MeRIP
Using a series of wash buffers with increasing stringency can effectively remove nonspecifically bound molecules.
-
Low-Salt Wash Buffer: 50 mM Tris-HCl (pH 7.4), 150 mM NaCl, 1 mM EDTA, 0.1% SDS, 1% Triton X-100.
-
High-Salt Wash Buffer: 50 mM Tris-HCl (pH 7.4), 500 mM NaCl, 1 mM EDTA, 0.1% SDS, 1% Triton X-100.
-
LiCl Wash Buffer: 10 mM Tris-HCl (pH 8.0), 250 mM LiCl, 1 mM EDTA, 1% NP-40, 1% Deoxycholic acid.
-
TE Buffer: 10 mM Tris-HCl (pH 8.0), 1 mM EDTA.
Washing Procedure:
-
After the immunoprecipitation step, wash the beads sequentially with 1 mL of each of the following buffers for 5 minutes each on a rotator at 4°C:
-
Low-Salt Wash Buffer (2 washes)
-
High-Salt Wash Buffer (1 wash)
-
LiCl Wash Buffer (1 wash)
-
TE Buffer (2 washes)
-
-
After the final wash, proceed to the elution step.
Protocol 3: Dot Blot Assay for m6A Antibody Validation
This protocol provides a method to assess the specificity of your anti-m6A antibody.
-
Prepare RNA Samples: Prepare serial dilutions of a positive control (e.g., in vitro transcribed RNA with m6A) and a negative control (unmodified RNA) in RNase-free water.
-
Spot onto Membrane: Carefully spot 1-2 µL of each RNA dilution onto a nitrocellulose or nylon membrane. Allow the spots to air dry completely.
-
UV Crosslinking: Crosslink the RNA to the membrane using a UV crosslinker.
-
Blocking: Block the membrane with a suitable blocking buffer (e.g., 5% non-fat milk or BSA in TBST) for 1 hour at room temperature.
-
Primary Antibody Incubation: Incubate the membrane with your anti-m6A antibody (at the manufacturer's recommended dilution) overnight at 4°C.
-
Washing: Wash the membrane three times with TBST for 10 minutes each.
-
Secondary Antibody Incubation: Incubate the membrane with a horseradish peroxidase (HRP)-conjugated secondary antibody for 1 hour at room temperature.
-
Detection: Wash the membrane again as in step 6 and then detect the signal using an enhanced chemiluminescence (ECL) substrate and an imaging system. A specific antibody will show a strong signal for the m6A-containing RNA and minimal to no signal for the unmodified RNA.[4][5][6]
Visualizations
Caption: Overview of the Methylated RNA Immunoprecipitation Sequencing (MeRIP-seq) workflow.
Caption: Logical workflow for troubleshooting high background in MeRIP-seq experiments.
References
- 1. Master MeRIP-seq Data Analysis: Step-by-Step Process for RNA Methylation Studies - CD Genomics [rna.cd-genomics.com]
- 2. MeRIP-seq: Comprehensive Guide to m6A RNA Modification Analysis - CD Genomics [rna.cd-genomics.com]
- 3. researchgate.net [researchgate.net]
- 4. Development and validation of monoclonal antibodies against N6-methyladenosine for the detection of RNA modifications - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Detecting RNA Methylation by Dot Blotting | Proteintech Group [ptglab.com]
- 6. Analysis of N 6 -methyladenosine RNA Modification Levels by Dot Blotting - PMC [pmc.ncbi.nlm.nih.gov]
how to normalize m6A levels across different samples
This guide provides researchers, scientists, and drug development professionals with detailed information on how to normalize N6-methyladenosine (m6A) levels across different samples. It includes troubleshooting advice, frequently asked questions, experimental protocols, and comparative data to ensure accurate and reproducible quantification of m6A modifications.
Troubleshooting Guides and FAQs
This section addresses common issues encountered during the normalization of m6A levels.
Frequently Asked Questions
Q1: Why is normalization of m6A levels necessary?
A1: Normalization is crucial to account for variations in sample input, RNA quality and quantity, and experimental efficiency.[1][2] Without proper normalization, it is difficult to determine whether observed differences in m6A levels are true biological effects or technical artifacts. This is especially important when comparing m6A levels across different conditions, tissues, or treatments.[2]
Q2: What are the primary methods for quantifying and normalizing global m6A levels?
A2: The main techniques for global m6A quantification include LC-MS/MS, m6A dot blot, and m6A-ELISA.[3][4][5]
-
LC-MS/MS: Considered the gold standard for its accuracy and sensitivity, it quantifies the m6A/A ratio by measuring the absolute amounts of m6A and adenosine (B11128) nucleosides.[5][6][7][8] Normalization is achieved by calculating this molar ratio.[6]
-
m6A Dot Blot: A semi-quantitative method that uses an m6A-specific antibody to detect total m6A levels in serially diluted RNA samples spotted on a membrane.[9][10][11] Normalization is typically performed against a loading control, such as methylene (B1212753) blue staining of the membrane.[12]
-
m6A-ELISA: A quantitative method based on an enzyme-linked immunosorbent assay that measures relative m6A levels.[3][4][13][14] Normalization relies on a standard curve generated from RNA with known m6A content.[3]
Q3: How do I normalize for gene-specific m6A changes, for example, in MeRIP-qPCR?
A3: In Methylated RNA Immunoprecipitation (MeRIP)-qPCR, m6A enrichment for a specific gene is calculated relative to the input RNA amount. The normalization is expressed as "fold enrichment" or "percentage of input." This is calculated by comparing the qPCR signal from the immunoprecipitated (IP) RNA to the signal from the input RNA control for the same gene.[15] To compare across different samples, the fold enrichment of a target gene is often normalized to a negative control region (a transcript segment without m6A) or a housekeeping gene assumed to have stable m6A levels.[15]
Q4: What are the challenges in normalizing MeRIP-Seq data?
A4: Normalizing MeRIP-Seq data is complex due to biases from several sources, including antibody specificity, immunoprecipitation efficiency, sequencing depth, and differences in gene expression levels between samples.[16][17][18] A common approach is to normalize the IP sample read counts to the corresponding input sample read counts to identify enriched regions (peaks).[16][19] Statistical models and computational pipelines like MeRIP-PF and exomePeak are used to call differential methylation peaks while accounting for these variables.[19][20]
Troubleshooting Common Issues
| Problem | Potential Cause | Recommended Solution |
| High variability in m6A dot blot results between replicates. | 1. Uneven RNA loading. 2. Inconsistent antibody incubation. 3. Variable secondary structure in RNA. | 1. Carefully quantify RNA before loading and use a loading control (e.g., methylene blue stain). 2. Ensure consistent antibody concentration, incubation time, and temperature for all membranes. 3. Denature RNA samples at 95°C for 3-5 minutes and immediately chill on ice before spotting to disrupt secondary structures.[9][10] |
| LC-MS/MS shows inconsistent m6A/A ratios for the same sample. | 1. Incomplete RNA digestion. 2. Contamination of mRNA preps with rRNA. 3. Instrument calibration drift. | 1. Ensure complete enzymatic digestion of RNA to nucleosides by optimizing enzyme concentrations and incubation times.[7][8] 2. Perform two rounds of poly(A) purification to minimize rRNA contamination.[21] 3. Run standard curves for m6A and adenosine with each batch of samples to ensure accurate quantification.[7][8] |
| MeRIP-qPCR shows high background in negative control genes. | 1. Non-specific antibody binding. 2. Insufficient washing during IP. 3. Antibody cross-reactivity. | 1. Pre-clear the cell lysate with protein A/G beads before adding the m6A antibody.[17] 2. Increase the number and stringency of wash steps after immunoprecipitation.[17] 3. Validate antibody specificity using dot blots with synthetic m6A-containing and unmodified RNA oligos.[17] |
| Difficulty identifying differential m6A peaks in MeRIP-Seq data. | 1. Low sequencing depth. 2. Confounding effects of gene expression changes. 3. Inadequate number of biological replicates. | 1. Increase sequencing depth to ensure sufficient coverage for both IP and input samples. 2. Use analysis pipelines that normalize for gene expression by incorporating input library data into the statistical model for peak calling.[16][20] 3. Use at least three biological replicates per condition to achieve sufficient statistical power for differential analysis.[18] |
Data Presentation: Comparison of m6A Quantification Methods
| Method | Principle | Type | Normalization Strategy | Pros | Cons |
| LC-MS/MS | Chromatographic separation and mass spectrometry of nucleosides.[6][7][8] | Absolute Quantitative | Molar ratio of m6A to Adenosine (m6A/A).[6] | Gold standard; highly accurate and sensitive; provides absolute quantification.[5] | Requires specialized equipment and expertise; relatively low throughput.[4] |
| m6A Dot Blot | Immunodetection with an anti-m6A antibody on membrane-spotted RNA.[9][10] | Semi-Quantitative | Loading control (e.g., methylene blue staining). | Simple, fast, and cost-effective for detecting global changes.[9][10] | Semi-quantitative; prone to variability; low sensitivity for subtle changes.[22] |
| m6A-ELISA | Antibody-based detection in a 96-well plate format.[3][4] | Relative Quantitative | Standard curve with known m6A concentrations.[3] | High throughput, cost-effective, requires small amounts of RNA (as little as 25 ng).[3][14] | Provides relative quantification; susceptible to antibody non-specific binding.[4] |
| MeRIP-Seq | Immunoprecipitation of m6A-containing RNA fragments followed by sequencing.[19][23] | Transcriptome-wide | Normalization of IP read counts to input read counts.[16][19] | Provides transcriptome-wide map of m6A sites. | Technically complex; data analysis requires specialized bioinformatics pipelines.[20] |
Experimental Protocols
Protocol 1: Global m6A Quantification by Dot Blot
This protocol provides a method for the semi-quantitative analysis of total m6A in mRNA.[9][10]
1. mRNA Purification:
- Isolate total RNA from cells or tissues using a standard method (e.g., TRIzol).
- Purify mRNA from at least 20 µg of total RNA using an oligo(dT) bead-based kit (e.g., Dynabeads mRNA Purification Kit) according to the manufacturer's instructions.[9]
- Elute mRNA in RNase-free water and determine its concentration using a NanoDrop spectrophotometer.
2. RNA Sample Preparation:
- Prepare serial dilutions of each mRNA sample (e.g., 500 ng, 250 ng, 125 ng) in RNase-free water.
- Denature the diluted mRNA at 95°C for 3 minutes to disrupt secondary structures.[11]
- Immediately place the tubes on ice to prevent re-annealing.
3. Dot Blotting:
- Spot 1-2 µL of each denatured RNA dilution onto a positively charged nylon or nitrocellulose membrane.
- Allow the membrane to air dry for 5-15 minutes.
- Crosslink the RNA to the membrane using a UV crosslinker (254 nm wavelength) for 5 minutes.[10]
4. Immunoblotting:
- Block the membrane with a blocking buffer (e.g., 5% non-fat milk or 1% BSA in PBST) for 1 hour at room temperature.[10][24]
- Incubate the membrane with an anti-m6A primary antibody (e.g., 1:1000 to 1:2500 dilution) overnight at 4°C with gentle shaking.[9][10]
- Wash the membrane three times with wash buffer (e.g., PBST) for 5 minutes each.[10]
- Incubate with an HRP-conjugated secondary antibody (e.g., 1:10,000 dilution) for 1 hour at room temperature.[9][10]
- Wash the membrane four times with wash buffer for 10 minutes each.
- Detect the signal using an ECL substrate and image the blot.[9]
5. Normalization:
- After imaging, wash the membrane and stain with 0.02% methylene blue in 0.3 M sodium acetate (B1210297) (pH 5.2) to visualize the total RNA spots, which serve as the loading control.
- Quantify the dot intensities using software like ImageJ.
- Normalize the m6A signal intensity to the corresponding methylene blue signal intensity for each spot.
Protocol 2: Normalization of MeRIP-Seq Data
This section outlines the key computational steps for normalizing MeRIP-Seq data to identify differential m6A peaks.
1. Data Preprocessing:
- Perform quality control on raw sequencing reads (IP and Input samples) using tools like FastQC.
- Trim adapters and low-quality bases.
2. Alignment:
- Align trimmed reads to the reference genome using a splice-aware aligner like STAR.[25]
3. Peak Calling:
- Use a peak calling algorithm such as MACS2 or exomePeak to identify regions of m6A enrichment (peaks) in the IP samples relative to the input samples.[15][20] The input sample serves as the background control, normalizing for local chromatin and transcription biases.
4. Differential Methylation Analysis:
- To compare m6A levels between different conditions, use specialized tools like exomePeak or DESeq2.[20][25]
- These tools model read counts in peaks for both IP and input samples across replicates to identify statistically significant changes in m6A levels, while accounting for changes in overall gene expression.
5. Normalization for IP Efficiency (Optional but Recommended):
- Spike-in controls, consisting of synthetic RNA with known m6A modifications, can be added to the RNA samples before immunoprecipitation.[26][27]
- The recovery of these spike-ins can be used to calculate a normalization factor to adjust for variations in IP efficiency between samples.[27][28]
Mandatory Visualizations
Diagram 1: General Workflow for m6A Normalization
Caption: A generalized workflow for normalizing m6A levels.
Diagram 2: MeRIP-Seq Data Normalization Logic
Caption: Logical flow for normalizing MeRIP-Seq data against an input control.
References
- 1. gene-quantification.de [gene-quantification.de]
- 2. Accurate normalization of real-time quantitative RT-PCR data by geometric averaging of multiple internal control genes - PMC [pmc.ncbi.nlm.nih.gov]
- 3. m6A-ELISA, a simple method for quantifying N6-methyladenosine from mRNA populations - PMC [pmc.ncbi.nlm.nih.gov]
- 4. biorxiv.org [biorxiv.org]
- 5. m6A RNA Methylation Analysis by MS - CD Genomics [rna.cd-genomics.com]
- 6. Quantification of global m6A RNA methylation levels by LC-MS/MS [visikol.com]
- 7. bpb-us-e2.wpmucdn.com [bpb-us-e2.wpmucdn.com]
- 8. Quantitative analysis of m6A RNA modification by LC-MS - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Dot Blot Analysis of N6-methyladenosine RNA Modification Levels - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Analysis of N 6 -methyladenosine RNA Modification Levels by Dot Blotting - PMC [pmc.ncbi.nlm.nih.gov]
- 11. researchgate.net [researchgate.net]
- 12. m6A RNA methylation orchestrates transcriptional dormancy during paused pluripotency - PMC [pmc.ncbi.nlm.nih.gov]
- 13. researchgate.net [researchgate.net]
- 14. m6A-ELISA, a simple method for quantifying N6-methyladenosine from mRNA populations - PubMed [pubmed.ncbi.nlm.nih.gov]
- 15. An experimental workflow for identifying RNA m6A alterations in cellular senescence by methylated RNA immunoprecipitation sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 16. academic.oup.com [academic.oup.com]
- 17. benchchem.com [benchchem.com]
- 18. Limits in the detection of m6A changes using MeRIP/m6A-seq - PMC [pmc.ncbi.nlm.nih.gov]
- 19. MeRIP-PF: An Easy-to-use Pipeline for High-resolution Peak-finding in MeRIP-Seq Data - PMC [pmc.ncbi.nlm.nih.gov]
- 20. rna-seqblog.com [rna-seqblog.com]
- 21. An Improved m6A-ELISA for Quantifying N6 -methyladenosine in Poly(A)-purified mRNAs - PMC [pmc.ncbi.nlm.nih.gov]
- 22. Dot Blot Analysis for Measuring Global N6-Methyladenosine Modification of RNA | Springer Nature Experiments [experiments.springernature.com]
- 23. MeRIP-seq Analysis - CD Genomics [bioinfo.cd-genomics.com]
- 24. Detecting RNA Methylation by Dot Blotting | Proteintech Group [ptglab.com]
- 25. researchgate.net [researchgate.net]
- 26. biorxiv.org [biorxiv.org]
- 27. m6A level and isoform characterization sequencing (m6A-LAIC-seq) reveals the census and complexity of the m6A epitranscriptome - PMC [pmc.ncbi.nlm.nih.gov]
- 28. m6A-dependent regulation of messenger RNA stability - PMC [pmc.ncbi.nlm.nih.gov]
Technical Support Center: Avoiding Bias in m6A Library Preparation
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to help researchers, scientists, and drug development professionals identify and mitigate bias during N6-methyladenosine (m6A) library preparation for sequencing.
Frequently Asked Questions (FAQs)
Q1: What are the primary sources of bias in antibody-based m6A-seq (MeRIP-seq)?
Several steps in the m6A-seq workflow can introduce bias, leading to inaccurate quantification and identification of m6A sites. The main sources include:
-
Antibody Specificity and Affinity: The anti-m6A antibody is a critical source of bias. It may exhibit sequence context preferences, meaning it binds more readily to certain sequences around the m6A site than others. Additionally, there can be cross-reactivity with other modifications like N6,2'-O-dimethyladenosine (m6Am), which is often found at the 5' cap of mRNAs.[1]
-
RNA Fragmentation: The method used to fragment RNA before immunoprecipitation can introduce bias. Both enzymatic and mechanical (sonication) methods can have sequence-specific preferences, leading to non-random fragmentation and subsequent skewed representation of RNA fragments in the library.[2][3][4][5]
-
PCR Amplification: During the library amplification step, certain fragments may be amplified more efficiently than others due to their GC content or other sequence features. This can lead to an overrepresentation of these fragments in the final sequencing library.[4][6][7][8]
-
Adapter Ligation: The efficiency of adapter ligation to the RNA or cDNA fragments can be influenced by the sequence and secondary structure of the fragment ends. This can result in a biased representation of the original RNA population.[2][9][10][11][12]
Troubleshooting Guides
Issue 1: Inconsistent or low enrichment of m6A-containing fragments.
Possible Cause: Suboptimal antibody performance or inefficient immunoprecipitation.
Troubleshooting Steps:
-
Antibody Validation:
-
Dot Blot: Perform a dot blot with synthetic RNA oligonucleotides containing known m6A modifications and unmodified controls to verify antibody specificity.
-
Western Blot: If applicable to the antibody, perform a western blot on cell lysates to check for antibody reactivity.
-
-
Optimize IP Conditions:
-
Antibody Concentration: Titrate the amount of antibody used for immunoprecipitation to find the optimal concentration that maximizes signal-to-noise ratio.
-
Incubation Time and Temperature: Optimize the incubation time and temperature for the antibody-RNA binding step.
-
Washing Steps: Ensure washing steps are stringent enough to remove non-specific binding but not too harsh to elute specifically bound fragments.
-
-
Use of Controls:
-
Spike-in Controls: Include synthetic RNA spike-ins with known m6A modifications at various concentrations. This can help assess the efficiency of immunoprecipitation and normalize data across different samples.
-
Negative Control IP: Perform a mock IP with a non-specific IgG antibody to assess the level of background binding.
-
Issue 2: Suspected sequence bias in m6A peak calling.
Possible Cause: Bias introduced during fragmentation, PCR amplification, or by the antibody itself.
Troubleshooting Steps:
-
Fragmentation Method Evaluation:
-
PCR Cycle Optimization:
-
Consider Antibody-Free Methods:
-
If sequence bias from the antibody is a major concern, explore antibody-free m6A profiling methods. These methods often rely on chemical or enzymatic treatment to distinguish m6A from unmodified adenosine (B11128).[1][13]
-
Alternative Antibody-Free m6A Profiling Methods
To circumvent biases associated with anti-m6A antibodies, several alternative methods have been developed.
| Method | Principle | Advantages | Disadvantages |
| m6A-SEAL-seq | FTO-assisted chemical labeling of m6A, followed by biotin (B1667282) pulldown.[1][13] | Overcomes antibody-related sequence bias. | Involves multiple enzymatic and chemical steps which may introduce other biases. |
| DART-seq | Deamination of adenosine adjacent to m6A sites using a fusion protein of an m6A reader and an RNA editing enzyme.[13][14] | Antibody-free, provides single-nucleotide resolution. | Relies on the binding preference of the m6A reader protein. |
| eTAM-seq | TadA-assisted enzymatic deamination of A-to-I at non-m6A sites, leaving m6A sites intact for identification.[1][13] | No sequence bias, provides stoichiometric information at single-nucleotide resolution.[1] | The efficiency of the TadA enzyme can be a factor.[1] |
| Mazter-seq | Utilizes the m6A-sensitive RNA endonuclease MazF, which cleaves at unmethylated ACA motifs.[15] | Provides stoichiometric information. | Limited to ACA motifs, and enzyme activity can be influenced by RNA secondary structure.[1][15] |
Experimental Workflow Diagrams
Standard m6A-seq (MeRIP-seq) Workflow
Caption: Standard workflow for m6A-seq (MeRIP-seq).
Logical Flow for Troubleshooting m6A-seq Bias
Caption: Troubleshooting logic for identifying and mitigating bias in m6A-seq.
Detailed Experimental Protocols
Protocol: RNA Fragmentation Optimization
Objective: To determine the optimal conditions for RNA fragmentation to achieve a target size range (e.g., 100-200 nucleotides) with minimal bias.
Materials:
-
Purified mRNA
-
RNA Fragmentation Buffer (e.g., Tris-HCl, MgCl2) or commercial fragmentation enzyme mix
-
Nuclease-free water
-
RNA loading dye
-
Agarose (B213101) gel or Bioanalyzer
Methodology (Enzymatic Fragmentation):
-
Prepare Reactions: Set up a series of reactions with a fixed amount of mRNA and varying concentrations of the fragmentation enzyme or varying incubation times. Include a no-enzyme control.
-
Example Time Course: 0, 1, 2, 5, 10, 15 minutes at the recommended temperature.
-
Example Enzyme Titration: 1:100, 1:50, 1:25, 1:10 dilutions of the enzyme for a fixed time.
-
-
Incubation: Incubate the reactions at the recommended temperature for the specified times.
-
Stop Reaction: Stop the fragmentation by adding a stop solution (e.g., EDTA) and placing the tubes on ice.
-
Purification: Purify the fragmented RNA using a suitable RNA cleanup kit.
-
Size Analysis: Analyze the size distribution of the fragmented RNA on an agarose gel or using a Bioanalyzer.
-
Selection: Choose the condition that yields the tightest distribution of fragments within the desired size range.
Protocol: PCR Cycle Optimization for Library Amplification
Objective: To determine the minimum number of PCR cycles needed to generate sufficient library material for sequencing, thereby minimizing amplification bias.
Materials:
-
Adapter-ligated cDNA library
-
PCR master mix with a fluorescent dye (e.g., SYBR Green)
-
PCR primers
-
qPCR instrument
Methodology:
-
Prepare qPCR Reaction: Set up a qPCR reaction using a small aliquot of your adapter-ligated cDNA library as the template.
-
Run qPCR: Run the qPCR with the same thermal cycling conditions that will be used for the full library amplification.
-
Analyze Amplification Plot: Examine the amplification plot (fluorescence vs. cycle number).
-
Determine Optimal Cycle Number: Identify the cycle number that corresponds to the end of the exponential phase of amplification (the "elbow" of the curve). To minimize bias, subtract 1-2 cycles from this number for your final library amplification. For example, if the elbow is at 12 cycles, perform 10-11 cycles for the bulk amplification.
-
Amplify Library: Amplify the remaining library using the determined optimal number of cycles.
-
Verify Library: After amplification, run the library on a Bioanalyzer to confirm the size distribution and quantify the yield.
References
- 1. Frontiers | Current progress in strategies to profile transcriptomic m6A modifications [frontiersin.org]
- 2. blog.genohub.com [blog.genohub.com]
- 3. Characterization and mitigation of fragmentation enzyme-induced dual stranded artifacts - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Bias in RNA-seq Library Preparation: Current Challenges and Solutions - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Optimization of enzymatic fragmentation is crucial to maximize genome coverage: a comparison of library preparation methods for Illumina sequencing - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. Detection and measurement of PCR bias in quantitative methylation analysis of bisulphite-treated DNA - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Identifying and Mitigating Bias in Next-Generation Sequencing Methods for Chromatin Biology - PMC [pmc.ncbi.nlm.nih.gov]
- 8. PCR bias in methylation experiments - Methyldetect.com [methyldetect.com]
- 9. A low-bias and sensitive small RNA library preparation method using randomized splint ligation - PMC [pmc.ncbi.nlm.nih.gov]
- 10. rna-seqblog.com [rna-seqblog.com]
- 11. Bias in ligation-based small RNA sequencing library construction is determined by adaptor and RNA structure - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. Frontiers | Addressing Bias in Small RNA Library Preparation for Sequencing: A New Protocol Recovers MicroRNAs that Evade Capture by Current Methods [frontiersin.org]
- 13. Current progress in strategies to profile transcriptomic m6A modifications - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Detecting m6A RNA modification from nanopore sequencing using a semisupervised learning framework - PMC [pmc.ncbi.nlm.nih.gov]
- 15. tandfonline.com [tandfonline.com]
Technical Support Center: Troubleshooting m6A qPCR Variability
Welcome to our technical support center. This guide provides answers to frequently asked questions and troubleshooting advice for researchers encountering variability in their N6-methyladenosine (m6A) qPCR experiments.
Frequently Asked Questions (FAQs)
Q1: What are the most common sources of variability in MeRIP-qPCR experiments?
High variability in Methylated RNA Immunoprecipitation (MeRIP)-qPCR can stem from several factors throughout the experimental workflow. The most significant sources include the quality and quantity of the starting RNA material, the specificity and batch-to-batch consistency of the anti-m6A antibody, the efficiency of RNA fragmentation, and the stringency of the immunoprecipitation washing steps.[1] Reproducibility of m6A peak detection can be low, sometimes between 30-60%, even within the same cell type, underscoring the impact of these variables.[2]
Q2: How can I assess the quality of my starting RNA?
High-quality RNA is crucial for the success of MeRIP-qPCR.[3] You should assess RNA integrity using a method like capillary electrophoresis (e.g., Agilent Bioanalyzer or TapeStation) to determine the RNA Integrity Number (RIN). A RIN value of 7.0 or higher is generally recommended. Additionally, ensure your RNA is free of contaminants like genomic DNA and proteins by measuring absorbance ratios (A260/A280 of ~2.0 and A260/A230 of 2.0-2.2).
Q3: My technical replicates for qPCR show high Cq value variance. What could be the cause?
High variance in Cq values between technical replicates often points to issues in qPCR setup.[4] Common causes include:
-
Pipetting errors: Inaccurate or inconsistent pipetting, especially of small volumes, can introduce significant variability. Ensure your pipettes are calibrated and use proper pipetting techniques.
-
Poor mixing: Inadequate mixing of the reaction components (master mix, primers, cDNA) before loading the plate can lead to uneven distribution.
-
Low template concentration: When the target is present in very low amounts, stochastic effects during the initial amplification cycles can lead to greater Cq variability.[4]
-
Primer-dimer formation: The presence of primer-dimers can compete with the amplification of the target sequence, leading to inconsistent results.
Troubleshooting Guides
Issue 1: Inconsistent Fold Enrichment Between Biological Replicates
| Potential Cause | Recommended Solution |
| Variability in RNA Quality | Ensure consistent RNA isolation methods across all samples. Assess RNA integrity and purity for each sample before starting the experiment. |
| Antibody Performance | Use a validated, high-specificity anti-m6A antibody. If using a new lot, perform validation experiments such as dot blots with known methylated and unmethylated RNA oligos to confirm specificity.[1] |
| Inconsistent Fragmentation | Optimize and standardize the RNA fragmentation protocol. Over-fragmentation can lead to loss of antibody binding sites, while under-fragmentation can result in high background. |
| Insufficient Washing | Optimize the number and stringency of wash steps after immunoprecipitation to reduce non-specific binding. |
| Normalization Issues | Ensure that you are normalizing the IP signal to the input for each sample. This accounts for variations in the initial amount of the target transcript.[5] |
Issue 2: High Background Signal in IgG/Negative Control Samples
| Potential Cause | Recommended Solution |
| Non-specific Antibody Binding | The IgG isotype control may be binding non-specifically to the beads or RNA. Try a different IgG control or pre-clear the fragmented RNA with beads before the IP step. |
| Contamination | Ensure all reagents and consumables are nuclease-free to prevent RNA degradation, which can expose non-specific binding sites. |
| Insufficient Blocking | Block the magnetic beads with a blocking agent like BSA or yeast tRNA before adding the antibody to reduce non-specific binding surfaces. |
Experimental Protocols
Generalized MeRIP-qPCR Protocol
This protocol provides a general workflow. Optimization for specific experimental conditions is recommended.
-
RNA Preparation and Fragmentation:
-
Start with high-quality total RNA (RIN > 7.0).
-
Fragment the RNA to an average size of 100-200 nucleotides using chemical or enzymatic methods.
-
Purify the fragmented RNA.
-
-
Immunoprecipitation (IP):
-
Couple an anti-m6A antibody and a non-specific IgG control to protein A/G magnetic beads.
-
Incubate the fragmented RNA with the antibody-coupled beads for 2-4 hours at 4°C.
-
Reserve a portion of the fragmented RNA as "input" control.
-
Wash the beads multiple times with IP buffer of increasing stringency to remove non-specifically bound RNA.
-
Elute the bound RNA from the beads.
-
-
Reverse Transcription (RT):
-
Perform reverse transcription on the eluted RNA (IP and IgG samples) and the input RNA to generate cDNA. Use random hexamers for priming.
-
-
Quantitative PCR (qPCR):
-
Design qPCR primers flanking the putative m6A site of interest. Also, design primers for a negative control region on the same transcript that is not expected to be methylated.
-
Perform qPCR using a SYBR Green or probe-based master mix.
-
Include technical replicates for each sample.
-
-
Data Analysis (Fold Enrichment Calculation):
-
Calculate the average Cq value for each set of technical replicates.
-
Normalize the Cq value of the IP sample to the input sample: ΔCq = Cq(IP) - [Cq(Input) - log₂(Input Dilution Factor)]
-
Calculate the fold enrichment of the m6A IP relative to the IgG control: ΔΔCq = ΔCq(m6A IP) - ΔCq(IgG IP)
-
Calculate the final fold enrichment: Fold Enrichment = 2^(-ΔΔCq)[3]
-
Visualizations
Caption: Workflow for m6A quantification using MeRIP-qPCR.
Caption: Decision tree for troubleshooting m6A qPCR variability.
References
- 1. benchchem.com [benchchem.com]
- 2. researchgate.net [researchgate.net]
- 3. An experimental workflow for identifying RNA m6A alterations in cellular senescence by methylated RNA immunoprecipitation sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 4. reddit.com [reddit.com]
- 5. Deep and accurate detection of m6A RNA modifications using miCLIP2 and m6Aboost machine learning - PMC [pmc.ncbi.nlm.nih.gov]
Technical Support Center: Navigating m6A Sequencing Data Analysis
Welcome to the technical support center for m6A sequencing data analysis. This resource is designed for researchers, scientists, and drug development professionals to provide troubleshooting guidance and answer frequently asked questions related to the complexities of m6A-seq data analysis.
Section 1: Experimental Design and Quality Control
FAQ: What are the crucial considerations when designing an m6A sequencing experiment?
A well-designed experiment is fundamental to obtaining reliable and interpretable results. Key considerations include:
-
Sufficient biological replicates: It is highly recommended to have at least three biological replicates per condition to ensure statistical power for differential methylation analysis.
-
Input controls: For each sample, a corresponding input control (without immunoprecipitation) is essential to account for biases in RNA fragmentation, library preparation, and sequencing, and to normalize the m6A-specific enrichment.
-
Batch effects: Minimize batch effects by processing all samples in the same batch whenever possible. If experiments are conducted in multiple batches, ensure that each batch contains a balanced representation of the different experimental conditions.[1][2]
-
Sequencing depth: The required sequencing depth depends on the size and complexity of the transcriptome. Generally, a higher sequencing depth allows for the detection of less abundant m6A peaks. Saturation of peak detection is often observed as transcript coverage approaches 10–50X.
-
RNA quality: Start with high-quality, intact RNA. RNA degradation can lead to a loss of methylation site information and result in false negatives.
Troubleshooting: My raw sequencing reads have low-quality scores. What should I do?
Low-quality sequencing reads can significantly impact the accuracy of downstream analysis. It is crucial to perform quality control (QC) on your raw FASTQ files.
Experimental Protocol: Quality Control using FastQC
FastQC is a widely used tool for sequencing data QC.[3][4][5]
-
Installation: Ensure FastQC is installed and accessible in your environment.
-
Run FastQC: Execute the following command in your terminal for each FASTQ file:
-
Review the report: FastQC generates an HTML report with several modules. Pay close attention to:
-
Per base sequence quality: This plot shows the quality scores across all bases at each position. A drop in quality towards the 3' end is common.
-
Per sequence quality scores: This shows the distribution of average quality scores per read.
-
Adapter Content: This module identifies the presence of adapter sequences that need to be removed.
-
-
Trimming: If the report indicates low-quality bases or adapter contamination, use a trimming tool like Trimmomatic or Cutadapt to remove them.
Section 2: m6A Peak Calling
FAQ: What is "peak calling" and why is it a critical step?
Peak calling is the computational process of identifying regions in the genome or transcriptome that are significantly enriched with sequencing reads in the immunoprecipitation (IP) sample compared to the input control.[6] These enriched regions, or "peaks," represent putative m6A modification sites. The accuracy of peak calling directly impacts all subsequent analyses, including the identification of methylated genes and differential methylation analysis.
Troubleshooting: I am getting a low number of peaks or many false positives. What could be the issue?
Several factors can lead to suboptimal peak calling results:
-
Poor antibody efficiency/specificity: The quality of the anti-m6A antibody is paramount. Poor antibody performance can lead to low signal-to-noise ratios and the identification of non-specific peaks.
-
Inadequate sequencing depth: Insufficient sequencing depth may not provide enough coverage to detect less abundant m6A sites.
-
Inappropriate peak calling software or parameters: Different peak callers use different statistical models, and their performance can vary depending on the dataset.[7][8] It's crucial to choose a suitable tool and optimize its parameters.
-
High biological variance: High variability between replicates can make it difficult to consistently identify true peaks.[8]
Experimental Protocol: m6A Peak Calling with MACS2
MACS2 (Model-based Analysis of ChIP-Seq) is a popular peak caller that can be adapted for m6A-seq data.[6][9][10]
-
Installation: Install MACS2.
-
Run MACS2: Use the following command, providing your IP and input BAM files:
-
-t: IP sample BAM file.
-
-c: Input control BAM file.
-
-f BAM: Specifies the input file format.
-
-g hs: Effective genome size for human (replace with mm for mouse or provide a custom value).
-
-n: Prefix for output file names.
-
--outdir: Output directory.
-
Experimental Protocol: m6A Peak Calling with exomePeak2
exomePeak2 is an R package specifically designed for MeRIP-Seq data, which can account for GC content bias.[11][12][13]
-
Installation in R:
-
Run exomePeak2 in R:
-
bam_ip: A character vector of IP BAM file paths.
-
bam_input: A character vector of input BAM file paths.
-
genome: The reference genome (e.g., "hg38" for human).
-
Data Presentation: Comparison of Peak Caller Reproducibility
The choice of peak caller can significantly impact the results. The reproducibility between different tools can be moderate.
| Peak Caller Combination | Jaccard Similarity |
| MACS2 vs. exomePeak | Low (<0.5) |
| MACS2 vs. MeTPeak | Low (<0.5) |
| exomePeak vs. MeTPeak | Moderate |
This table summarizes the general observation that different peak callers can produce substantially different sets of peaks from the same dataset, highlighting the importance of careful tool selection and validation.[7]
Section 3: Differential m6A Methylation Analysis
FAQ: How do I identify genes with changes in m6A methylation between different conditions?
Differential m6A methylation analysis aims to identify genomic regions where the level of m6A modification changes significantly between experimental conditions.[14] This typically involves quantifying the read counts within identified peaks for both IP and input samples across all replicates and conditions, followed by statistical testing.
Troubleshooting: My differential methylation analysis yields very few significant results or results that don't make biological sense. What are common issues?
-
High variability between replicates: As with peak calling, high biological variance can obscure true differential signals.
-
Inadequate normalization: Proper normalization to account for differences in library size and composition between IP and input samples is crucial.
-
Ignoring gene expression changes: Changes in m6A peak enrichment can be confounded by changes in the overall expression level of the host gene. It's important to use statistical models that can distinguish between changes in methylation and changes in transcription.
-
Incorrect statistical model: The choice of statistical method is critical. Methods developed for RNA-seq differential expression, like DESeq2 and edgeR, can be adapted for differential m6A analysis but require careful implementation.
Experimental Protocol: Differential m6A Methylation Analysis with DESeq2
DESeq2 is a popular R package for differential expression analysis of count data that can be adapted for differential m6A analysis.[10][15][16]
-
Count reads in peaks: Use a tool like featureCounts to count the number of reads from each IP and input BAM file that map to a consensus set of m6A peaks.
-
Prepare the count matrix and metadata in R.
-
Run DESeq2 in R:
The interaction term (sample_type:condition) tests for the differential enrichment of IP over input between conditions.
Section 4: Batch Effects
FAQ: What are batch effects and how can they impact my m6A sequencing data?
Batch effects are technical variations that arise when samples are processed in different batches.[1][2][17] These can be introduced by factors such as different reagent lots, different experimenters, or processing on different days. Batch effects can introduce systematic biases that can be mistaken for true biological differences, leading to false positives in differential analysis.[1]
Troubleshooting: I suspect batch effects are confounding my results. How can I diagnose and correct for them?
-
Diagnosis: Principal Component Analysis (PCA) is a useful tool to visualize the clustering of samples. If samples cluster by batch rather than by biological condition, it is a strong indication of batch effects.
-
Correction: Computational methods can be used to adjust the data to remove the influence of batch effects. ComBat-seq is a tool specifically designed for batch effect correction in sequencing count data.[18][19][20]
Experimental Protocol: Batch Effect Correction with ComBat-seq
ComBat-seq is an R package that can be used to adjust for batch effects in count data.[18][19]
-
Installation in R:
-
Run ComBat-seq in R:
The adjusted_counts can then be used for downstream differential analysis.
Visualizing Workflows
Caption: Overview of the m6A-seq experimental and data analysis workflow.
Caption: A logical diagram for troubleshooting common issues in m6A-seq analysis.
References
- 1. Assessing and mitigating batch effects in large-scale omics studies - PMC [pmc.ncbi.nlm.nih.gov]
- 2. biorxiv.org [biorxiv.org]
- 3. john-quensen.com [john-quensen.com]
- 4. mugenomicscore.missouri.edu [mugenomicscore.missouri.edu]
- 5. Quality control using FastQC | Training-modules [hbctraining.github.io]
- 6. Peak calling with MACS2 | Introduction to ChIP-Seq using high-performance computing [hbctraining.github.io]
- 7. academic.oup.com [academic.oup.com]
- 8. Comparative analysis of commonly used peak calling programs for ChIP-Seq analysis - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. meRIP-seq peak-calling [bio-protocol.org]
- 10. academic.oup.com [academic.oup.com]
- 11. rnamd.com [rnamd.com]
- 12. The exomePeak2 Guide [bioconductor.statistik.tu-dortmund.de]
- 13. bioconductor.posit.co [bioconductor.posit.co]
- 14. academic.oup.com [academic.oup.com]
- 15. A Beginner’s Guide to Differential Expression Analysis with DESeq2 in R on Open OnDemand — TTS Research Technology Guides [rtguides.it.tufts.edu]
- 16. Differential expression with DEseq2 | Griffith Lab [genviz.org]
- 17. Statistical strategies for microRNAseq batch effect reduction - PMC [pmc.ncbi.nlm.nih.gov]
- 18. ComBat-seq: batch effect adjustment for RNA-seq count data - PMC [pmc.ncbi.nlm.nih.gov]
- 19. GitHub - zhangyuqing/ComBat-seq: Batch effect adjustment based on negative binomial regression for RNA sequencing count data [github.com]
- 20. Highly effective batch effect correction method for RNA-seq count data - PMC [pmc.ncbi.nlm.nih.gov]
CRISPR-Mediated m6A Editing: A Technical Support Center
Welcome to the technical support center for CRISPR-mediated N6-methyladenosine (m6A) editing. This resource is designed for researchers, scientists, and drug development professionals to provide troubleshooting guidance and answer frequently asked questions related to this powerful epitranscriptome engineering technology.
Troubleshooting Guide
This guide addresses common issues encountered during m6A editing experiments in a direct question-and-answer format.
Issue 1: Low or No Detectable m6A Editing Efficiency
Question: My experiments are showing very low or no change in m6A levels at the target site. What are the potential causes and how can I fix this?
Potential Causes and Recommended Solutions:
| Potential Cause | Recommended Solution |
| Suboptimal sgRNA Design | The design of the single-guide RNA (sgRNA) is critical for efficiency.[1] Ensure your sgRNA targets a unique sequence close to the adenosine (B11128) of interest.[2] Use computational tools that predict on-target activity based on factors like GC content and secondary structure.[3] It is recommended to test 2-3 different sgRNAs for your target to identify the most effective one.[4] |
| Inefficient Delivery of Editing Components | The delivery of Cas protein and sgRNA into the target cells is a common bottleneck.[1][5][6] Different cell types require different delivery strategies.[2] Optimize your method (e.g., electroporation, lipofection, viral vectors) for your specific cells.[2][7] For hard-to-transfect cells, consider using viral vectors like lentivirus or AAV, especially with smaller editors like dCasRx.[8][9] |
| Incorrect Subcellular Localization | Physiological m6A modification often occurs in the nucleus.[10] Ensure your Cas-editor fusion protein has the appropriate nuclear localization signal (NLS) to direct it to the nucleus.[9][11] Conversely, if targeting cytoplasmic RNA, a nuclear export signal (NES) may be required.[9][11] |
| Choice of Cas Protein and Effector | The choice of Cas protein (e.g., dCas9, dCas13) and the fused enzyme (e.g., METTL3, ALKBH5) impacts efficiency. dCas13-based editors may offer higher specificity as they naturally target RNA.[9][12] The fusion of METTL3 and METTL14 catalytic domains can create an efficient m6A 'writer'.[10][13][14] |
| Cell State and Culture Conditions | The cell cycle stage can influence editing efficiency.[7] Consider synchronizing cells before transfection.[7] Ensure cells are healthy and cultured under optimal conditions to maximize uptake and protein expression.[7] |
Issue 2: High Off-Target Editing
Question: I'm observing m6A changes at unintended sites across the transcriptome. How can I improve the specificity of my experiment?
Potential Causes and Recommended Solutions:
| Potential Cause | Recommended Solution |
| Poor sgRNA Specificity | The sgRNA may have sequence similarity to other transcripts, leading to off-target binding.[15] Use sgRNA design tools that perform whole-genome off-target searches, accounting for mismatches.[3] |
| Promiscuous Cas Nuclease Activity | Standard Cas9 can tolerate some mismatches between the sgRNA and the target sequence.[16] Consider using high-fidelity Cas9 variants (e.g., SpCas9-HF1) which are engineered to reduce off-target cleavage.[17] |
| sgRNA-Independent DNA/RNA Editing | Some base editors can exhibit deaminase activity on single-stranded nucleic acids that are not targeted by the sgRNA.[16] While this is more of a concern for DNA base editors, ensuring optimal expression levels of the editing construct can help minimize unintended activity. |
| Choice of Editing Platform | dCas13-based systems are often preferred for RNA editing as they do not require a PAM sequence via a "PAMmer" and naturally target RNA, which can reduce off-target effects compared to dCas9-based systems.[9][12] |
| Excessive Expression of Editing Components | High concentrations of Cas protein and sgRNA can increase the likelihood of off-target events.[2] Titrate the amount of plasmid, RNA, or ribonucleoprotein (RNP) complex delivered to find the lowest effective concentration. |
Frequently Asked Questions (FAQs)
Q1: What is the fundamental difference between dCas9- and dCas13-based m6A editors?
A: The primary difference lies in their native targets. dCas9 (catalytically "dead" Cas9) is derived from a DNA-targeting protein and requires a short oligonucleotide called a "PAMmer" to direct it to an RNA molecule.[10][18] In contrast, dCas13 (e.g., dCas13b, dCasRx) is derived from an RNA-targeting protein, so it binds directly to the target RNA without needing a PAMmer, potentially increasing its specificity and expanding its target range.[9][12] Additionally, Cas13 variants like CasRx are smaller, which is advantageous for packaging into viral vectors for efficient delivery.[8][9]
Q2: How do I construct an m6A "writer" or "eraser"?
A: An m6A "writer" is typically created by genetically fusing a catalytically inactive Cas protein (like dCas9 or dCas13) to an m6A methyltransferase, such as the catalytic domain of METTL3 or a fusion of METTL3 and METTL14 domains.[10][13] An m6A "eraser" is constructed by fusing the dCas protein to an m6A demethylase, such as ALKBH5 or FTO.[8][10][13] These fusion proteins can then be programmed with an sgRNA to add or remove m6A at a specific site.[14]
Q3: What are the best methods to quantify and validate m6A editing events?
A: Several methods can be used to validate site-specific m6A editing:
-
m6A-Specific Antibody-Based Methods (meRIP-qPCR): This is a common technique where an m6A-specific antibody is used to immunoprecipitate methylated RNA fragments, followed by RT-qPCR to quantify the enrichment of the target transcript.[19]
-
Enzyme- and Ligation-Based Methods (SELECT): The SELECT method leverages the fact that m6A can impede the activity of DNA polymerases and ligases. This allows for quantitative, antibody-free detection of m6A at a specific site.[14]
-
Liquid Chromatography-Mass Spectrometry (LC-MS/MS): This highly sensitive method can quantify the overall m6A abundance in a population of RNA molecules but is not ideal for assessing site-specific changes without prior enrichment.[20][21]
Q4: Can I edit m6A in a specific subcellular compartment?
A: Yes. You can control the localization of the m6A editor by adding specific peptide tags. A Nuclear Localization Signal (NLS) will direct the fusion protein to the nucleus, while a Nuclear Export Signal (NES) will target it to the cytoplasm.[9][11] This allows you to study the distinct roles of nuclear versus cytoplasmic m6A modifications.
Quantitative Data Summary
Table 1: Comparison of CRISPR-based m6A Editor Platforms
| Feature | dCas9-Based Editors | dCas13-Based Editors (dCas13b, dCasRx) |
| Native Target | DNA | RNA |
| RNA Targeting | Requires sgRNA and a separate PAMmer oligonucleotide.[10][18] | Requires sgRNA only.[9] |
| Off-Target Effects | Can have higher off-target rates; specificity is dependent on both sgRNA and PAMmer binding.[10] | Generally lower off-target methylation rates observed.[12] |
| Subcellular Targeting | Primarily cytoplasmic unless an NLS is added.[9][10] | Can be engineered with NLS or NES for nuclear or cytoplasmic targeting.[9][11] |
| Size & Delivery | Larger protein, which can be challenging for AAV packaging.[22] | Smaller variants like dCasRx are more amenable to AAV delivery.[8][9] |
Table 2: Overview of m6A Quantification Methods
| Method | Principle | Throughput | Resolution | Key Advantage |
| meRIP-seq/qPCR | Immunoprecipitation with an anti-m6A antibody followed by sequencing or qPCR.[23][24] | High (Sequencing) | Region-specific (~100-200 nt) | Widely used for transcriptome-wide mapping. |
| SELECT | m6A-induced inhibition of DNA polymerase and ligase activity, quantified by qPCR.[14] | Low to Medium | Single nucleotide | Antibody-independent, quantitative. |
| LC-MS/MS | Liquid chromatography separation and mass spectrometry detection of m6A nucleosides.[20][21] | Low | Global (Total RNA) | Highly accurate for global m6A quantification. |
Diagrams: Workflows and Mechanisms
Caption: Mechanism of CRISPR-mediated m6A writing and erasing.
Caption: High-level experimental workflow for m6A editing.
Caption: Troubleshooting decision tree for low m6A editing efficiency.
Experimental Protocols
Protocol: Site-Specific m6A Installation using dCas13b-METTL3 and Validation by meRIP-qPCR
This protocol provides a generalized framework. Researchers must optimize conditions, particularly transfection, for their specific cell line.
Part 1: Preparation of Experimental Components
-
sgRNA Design: Design at least two sgRNAs targeting the region flanking the adenosine of interest using a validated design tool. Order synthetic sgRNAs or clone them into an expression vector.
-
Editor Plasmid: Obtain a mammalian expression plasmid encoding your chosen m6A writer (e.g., dCas13b fused to the METTL3 catalytic domain, tagged with an NLS).
-
Cell Culture: Culture your target cells (e.g., HEK293T, HeLa) in the appropriate medium under standard conditions (37°C, 5% CO2). Ensure cells are healthy and sub-confluent on the day of transfection.
Part 2: Transfection of m6A Editing Components
-
Plating: Seed cells in 6-well plates to be 70-80% confluent at the time of transfection.
-
Transfection: Co-transfect the dCas13b-METTL3 plasmid and the sgRNA expression plasmid (or synthetic sgRNA) using a suitable transfection reagent (e.g., Lipofectamine). Include the following controls:
-
Negative Control: Transfect with a non-targeting sgRNA.[2]
-
Mock Control: Transfect with empty vectors or transfection reagent only.
-
-
Incubation: Incubate the cells for 48-72 hours to allow for expression of the editing machinery and modification of the target RNA.
Part 3: RNA Extraction and Fragmentation
-
Harvesting: Harvest the cells and extract total RNA using a standard protocol (e.g., TRIzol). Ensure high purity and integrity of the RNA.
-
mRNA Isolation (Optional but Recommended): Isolate mRNA from total RNA using oligo(dT) magnetic beads to reduce background from rRNA.
-
Fragmentation: Fragment the RNA to an average size of ~100-200 nucleotides using chemical or enzymatic methods.
Part 4: Methylated RNA Immunoprecipitation (meRIP)
This procedure is based on established meRIP-seq protocols.[23][25]
-
Antibody Binding: Incubate the fragmented RNA with an anti-m6A antibody in immunoprecipitation (IP) buffer for 2 hours at 4°C.
-
Bead Capture: Add Protein A/G magnetic beads to the RNA-antibody mixture and incubate for another 2 hours at 4°C to capture the antibody-RNA complexes.
-
Washing: Wash the beads multiple times with wash buffers to remove non-specifically bound RNA.
-
Elution: Elute the methylated RNA from the beads using an elution buffer.
-
RNA Purification: Purify the eluted RNA. A small fraction of the fragmented RNA before IP should be saved as an "Input" control.
Part 5: Validation by RT-qPCR
-
Reverse Transcription: Perform reverse transcription on the eluted RNA (IP sample) and the saved Input RNA to generate cDNA.
-
qPCR: Perform quantitative PCR using primers that specifically amplify the target region containing the m6A site.
-
Analysis: Calculate the enrichment of your target transcript in the IP sample relative to the Input. Compare the enrichment in cells treated with the targeting sgRNA to the non-targeting control. A significant increase in enrichment indicates successful site-specific m6A installation.
References
- 1. Troubleshooting Low Knockout Efficiency in CRISPR Experiments - CD Biosynsis [biosynsis.com]
- 2. Troubleshooting Guide for Common CRISPR-Cas9 Editing Problems [synapse.patsnap.com]
- 3. Tips to optimize sgRNA design - Life in the Lab [thermofisher.com]
- 4. sg.idtdna.com [sg.idtdna.com]
- 5. What are current challenges in CRISPR-based gene editing? [synapse.patsnap.com]
- 6. Applications and challenges of CRISPR-Cas gene-editing to disease treatment in clinics - PMC [pmc.ncbi.nlm.nih.gov]
- 7. How to Improve CRISPR Editing Efficiency: A Step-by-Step Guide [synapse.patsnap.com]
- 8. Epitranscriptomic editing of the RNA N6-methyladenosine modification by dCasRx conjugated methyltransferase and demethylase - PMC [pmc.ncbi.nlm.nih.gov]
- 9. whatisepigenetics.com [whatisepigenetics.com]
- 10. Programmable RNA N6-methyladenosine editing by CRISPR-Cas9 conjugates - PMC [pmc.ncbi.nlm.nih.gov]
- 11. CRISPR-based m6A modification and its potential applications in telomerase regulation - PMC [pmc.ncbi.nlm.nih.gov]
- 12. researchgate.net [researchgate.net]
- 13. epigenie.com [epigenie.com]
- 14. qian.human.cornell.edu [qian.human.cornell.edu]
- 15. blog.addgene.org [blog.addgene.org]
- 16. Off-target effects in CRISPR/Cas9 gene editing - PMC [pmc.ncbi.nlm.nih.gov]
- 17. dovepress.com [dovepress.com]
- 18. qian.human.cornell.edu [qian.human.cornell.edu]
- 19. academic.oup.com [academic.oup.com]
- 20. m6A-ELISA, a simple method for quantifying N6-methyladenosine from mRNA populations - PMC [pmc.ncbi.nlm.nih.gov]
- 21. researchgate.net [researchgate.net]
- 22. karger.com [karger.com]
- 23. An experimental workflow for identifying RNA m6A alterations in cellular senescence by methylated RNA immunoprecipitation sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 24. An experimental workflow for identifying RNA m6A alterations in cellular senescence by methylated RNA immunoprecipitation sequencing - PubMed [pubmed.ncbi.nlm.nih.gov]
- 25. An experimental workflow for identifying RNA m6A alterations in cellular senescence by methylated RNA immunoprecipitation sequencing [polscientific.com]
Validation & Comparative
A Researcher's Guide to Validating Anti-m6A Antibody Specificity for Western Blot Applications
For researchers, scientists, and drug development professionals, ensuring the specificity of antibodies is paramount for the integrity of experimental results. This guide provides an objective comparison of methods to validate antibodies against N6-methyladenosine (m6A), with a particular focus on clarifying their application in blotting techniques.
While Western blotting is a cornerstone technique for protein detection, its application for the direct detection of m6A modifications in RNA is a common point of confusion. A standard Western blot protocol is designed to separate and identify proteins. Therefore, it cannot be used to directly detect the m6A modification on an RNA molecule. The validation of an anti-m6A antibody's specificity relies on techniques that directly assess its ability to bind to m6A-modified nucleic acids.
This guide details the established and reliable methods for this validation: the Dot Blot Assay, the Competitive ELISA, and the use of genetic models with altered m6A levels. We also present a comparison of commercially available anti-m6A antibodies, summarizing the validation data provided by their manufacturers.
Key Validation Methods for Anti-m6A Antibody Specificity
The gold-standard methods for validating the specificity of an anti-m6A antibody involve demonstrating its preferential binding to m6A-containing nucleic acids over their unmodified counterparts.
Dot Blot Assay
The dot blot is a simple, rapid, and cost-effective method to assess the global m6A levels in an RNA sample and is a primary method for validating an anti-m6A antibody.[1][2][3] The principle involves spotting RNA directly onto a membrane and detecting the m6A modification using a specific primary antibody.
Competitive ELISA
A competitive Enzyme-Linked Immunosorbent Assay (ELISA) is a powerful quantitative method to determine antibody specificity. In this assay, free m6A nucleosides or m6A-containing oligonucleotides compete with immobilized m6A for binding to the antibody. A highly specific antibody will show a significant decrease in signal in the presence of the m6A competitor.
Validation Using Genetic Models
The most rigorous validation of an anti-m6A antibody involves using biological negative controls. This is achieved by analyzing RNA from cells in which a key m6A methyltransferase, such as METTL3, has been knocked out or knocked down.[4][5] A specific anti-m6A antibody should show a dramatically reduced signal in RNA from these genetically modified cells compared to wild-type cells. This approach confirms that the antibody recognizes the enzymatic product of the m6A machinery.
Commercial Antibody Comparison
Several companies offer anti-m6A antibodies. Below is a comparison of some popular options and the validation methods they report. Researchers should always consult the latest datasheets from the manufacturer for the most up-to-date information.
| Antibody (Clone/Catalog No.) | Supplier | Type | Reported Validation Methods | Notes |
| Anti-m6A (202 003) | Synaptic Systems | Rabbit Polyclonal | Dot Blot, ELISA, IP, MeRIP | Widely cited in literature for MeRIP-seq.[1][2] |
| N6-Methyladenosine (m6A) (D9D9W) | Cell Signaling Technology | Rabbit Monoclonal | Dot Blot, ELISA | Validated to not cross-react with adenosine, N6-dimethyladenosine, N1-methyladenosine, or 2'-O-methyladenosine.[6] |
| Anti-N6-methyladenosine (ab151230) | Abcam | Rabbit Polyclonal | Dot Blot, Nucleotide Array, IP, WB | WB validation is shown on m6A-conjugated BSA, not on RNA.[7] |
| Anti-N6-methyladenosine [EPR23561-164] (ab284130) | Abcam | Rabbit Monoclonal | Dot Blot, FRET | Recombinant antibody for high consistency.[8] |
| m6A Monoclonal Antibody (68055-1-Ig) | Proteintech | Mouse Monoclonal | Dot Blot, ELISA, RIP, IHC | Competitive ELISA data shows high specificity for m6A.[5] |
| AbFlex N6-Methyladenosine (rAb) | Proteintech | Rabbit Recombinant | Dot Blot, RIP | Recombinant antibody tested on synthetic oligonucleotides and cellular RNA.[4] |
Detailed Experimental Protocols
Protocol 1: Dot Blot for m6A Detection in mRNA
This protocol is adapted from established methods for the detection of m6A in purified mRNA.[1][9]
Materials:
-
mRNA Purification Kit (e.g., Dynabeads mRNA Purification Kit)
-
Hybond-N+ or Nitrocellulose membrane
-
UV Crosslinker (e.g., Stratalinker)
-
Blocking Buffer (e.g., 5% non-fat milk in PBST)
-
Wash Buffer (PBST: PBS with 0.1% Tween-20)
-
Anti-m6A Primary Antibody
-
HRP-conjugated Secondary Antibody
-
ECL Western Blotting Substrate
-
RNase-free water, tubes, and tips
Procedure:
-
mRNA Purification: Isolate total RNA from cells or tissues. Purify mRNA from at least 20 µg of total RNA using an oligo(dT)-based purification kit according to the manufacturer's instructions.
-
Quantification and Dilution: Determine the concentration of the purified mRNA. Prepare serial dilutions of the mRNA (e.g., 100 ng, 50 ng, 25 ng) in RNase-free water.
-
Denaturation: Denature the mRNA dilutions at 95°C for 3-5 minutes, then immediately chill on ice.
-
Spotting: Carefully spot 2 µL of each denatured mRNA dilution onto a dry nitrocellulose or nylon membrane. Mark the positions of the spots.
-
Crosslinking: Allow the membrane to air dry completely. Crosslink the RNA to the membrane using a UV crosslinker (e.g., 120 mJ/cm²).
-
Blocking: Incubate the membrane in blocking buffer for 1 hour at room temperature with gentle shaking.
-
Primary Antibody Incubation: Incubate the membrane with the anti-m6A antibody (diluted in blocking buffer as recommended by the manufacturer) overnight at 4°C with gentle shaking.
-
Washing: Wash the membrane three times for 5 minutes each with wash buffer.
-
Secondary Antibody Incubation: Incubate the membrane with an HRP-conjugated secondary antibody (diluted in blocking buffer) for 1 hour at room temperature.
-
Washing: Wash the membrane four times for 10 minutes each with wash buffer.
-
Detection: Incubate the membrane with ECL substrate according to the manufacturer's instructions and capture the chemiluminescent signal using an imaging system.
-
(Optional) Loading Control: To ensure equal loading of RNA, a parallel membrane can be stained with Methylene Blue (0.02% Methylene Blue in 0.3 M Sodium Acetate, pH 5.2).
Protocol 2: Competitive ELISA for Antibody Specificity
This protocol outlines a competitive ELISA to test the specificity of an anti-m6A antibody.[5][10][11]
Materials:
-
High-binding 96-well ELISA plate
-
m6A-conjugated BSA (for coating)
-
Coating Buffer (e.g., carbonate-bicarbonate buffer, pH 9.6)
-
Free N6-methyladenosine (competitor)
-
Free Adenosine (negative control competitor)
-
Blocking Buffer (e.g., 1% BSA in PBST)
-
Wash Buffer (PBST)
-
Anti-m6A Primary Antibody
-
HRP-conjugated Secondary Antibody
-
TMB Substrate
-
Stop Solution (e.g., 2N H₂SO₄)
-
Plate reader
Procedure:
-
Coating: Coat the wells of a 96-well plate with 100 µL of m6A-BSA (e.g., 20 ng/well in coating buffer). Incubate overnight at 4°C.
-
Washing: Wash the plate three times with wash buffer.
-
Blocking: Block the wells with 200 µL of blocking buffer for 1-2 hours at room temperature.
-
Washing: Wash the plate three times with wash buffer.
-
Competition: In separate tubes, pre-incubate the anti-m6A antibody (at a fixed, optimized concentration) with serial dilutions of the competitor (free m6A) or the negative control (free adenosine) for 1 hour at 37°C.
-
Incubation: Add 100 µL of the antibody-competitor mixtures to the coated wells. Incubate for 1-2 hours at room temperature.
-
Washing: Wash the plate five times with wash buffer.
-
Secondary Antibody Incubation: Add 100 µL of diluted HRP-conjugated secondary antibody to each well and incubate for 1 hour at room temperature.
-
Washing: Wash the plate five times with wash buffer.
-
Detection: Add 100 µL of TMB substrate to each well. Incubate in the dark until sufficient color develops (15-30 minutes).
-
Stopping the Reaction: Add 100 µL of stop solution to each well.
-
Reading: Read the absorbance at 450 nm. A decrease in absorbance with increasing concentrations of the free m6A competitor indicates specific binding.
References
- 1. biocompare.com [biocompare.com]
- 2. biocompare.com [biocompare.com]
- 3. biocompare.com [biocompare.com]
- 4. AbFlex N6-Methyladenosine (m6A) antibody (rAb) | Proteintech [ptglab.com]
- 5. m6A antibody (68055-1-Ig) | Proteintech [ptglab.com]
- 6. N6-Methyladenosine (m6A) (D9D9W) Rabbit Monoclonal Antibody | Cell Signaling Technology [cellsignal.com]
- 7. citeab.com [citeab.com]
- 8. Anti-N6-methyladenosine (m6A) antibody [EPR23561-164] (ab284130) | Abcam [abcam.com]
- 9. m6A-ELISA, a simple method for quantifying N6-methyladenosine from mRNA populations - PMC [pmc.ncbi.nlm.nih.gov]
- 10. stjohnslabs.com [stjohnslabs.com]
- 11. creative-diagnostics.com [creative-diagnostics.com]
Nanopore Sequencing for m6A Detection: A Superior Alternative to Antibody-Based Methods
For researchers, scientists, and drug development professionals navigating the complexities of epitranscriptomics, the accurate detection of N6-methyladenosine (m6A) is paramount. While antibody-based methods like methylated RNA immunoprecipitation sequencing (MeRIP-Seq) have been foundational, direct RNA sequencing using nanopore technology presents a paradigm shift, offering unprecedented resolution and overcoming key limitations of its predecessors.
This guide provides a comprehensive comparison of nanopore sequencing and antibody-based methods for m6A detection, supported by experimental data and detailed protocols. We will explore the inherent advantages of nanopore sequencing in providing single-molecule, single-nucleotide resolution, and eliminating the biases associated with antibody enrichment.
At a Glance: Nanopore vs. Antibody-Based m6A Detection
| Feature | Nanopore Sequencing (Direct RNA Sequencing) | Antibody-Based Methods (e.g., MeRIP-Seq) |
| Detection Principle | Direct detection of electrical signal disruption caused by modified bases as native RNA passes through a nanopore.[1][2][3] | Immunoprecipitation of RNA fragments containing m6A using a specific antibody, followed by sequencing.[4][5][6] |
| Resolution | Single-nucleotide and single-molecule resolution.[4][7][8] | Low resolution (typically 100-200 nucleotides) due to RNA fragmentation.[9] |
| Antibody Requirement | No antibody required, eliminating antibody-related bias and specificity issues.[4][9] | Relies on m6A-specific antibodies, which can introduce bias and artifacts.[4][6] |
| Isoform Specificity | Can distinguish m6A modifications on different RNA isoforms due to long reads.[7][10] | Isoform ambiguity is a significant limitation.[8] |
| Stoichiometry | Can potentially quantify the stoichiometry of m6A at specific sites.[11][12] | Does not provide stoichiometric information.[9] |
| Input RNA Requirement | Can be performed with low input RNA samples.[4] | Typically requires higher amounts of input RNA. |
| Workflow Complexity | Simpler workflow with no immunoprecipitation step.[2] | More complex, multi-step protocol involving fragmentation, immunoprecipitation, and library preparation.[5][8] |
| Data Analysis | Requires specialized bioinformatic tools to interpret raw signal data and identify modifications.[8][13][14] | Relies on peak calling algorithms to identify enriched regions.[15] |
| Coverage | May have lower coverage for lowly expressed transcripts compared to enrichment-based methods.[16][17] | Higher sensitivity for initial screening of m6A sites due to enrichment.[16][17] |
Delving Deeper: The Advantages of Nanopore Sequencing
Nanopore direct RNA sequencing (dRNA-seq) offers a revolutionary approach to m6A detection by directly reading the sequence of native RNA molecules.[2] As an RNA strand passes through a protein nanopore, it creates a characteristic disruption in an ionic current. The presence of a modified base like m6A causes a distinct alteration in this signal, allowing for its direct identification without the need for antibodies or reverse transcription.[1][2]
This direct approach confers several key advantages over traditional antibody-based methods:
-
Single-Nucleotide and Single-Molecule Resolution: Nanopore sequencing can pinpoint the exact location of an m6A modification on a single RNA molecule.[4][7] This is a significant improvement over MeRIP-Seq, which identifies enriched regions of approximately 100-200 nucleotides.[9] This high resolution is critical for understanding the precise functional roles of m6A in processes like splicing and translation.
-
Elimination of Antibody Bias: Antibody-based methods are susceptible to biases related to antibody specificity and efficiency.[4][6] Nanopore sequencing circumvents these issues entirely, providing a more accurate and unbiased view of the m6A landscape.
-
Isoform-Specific m6A Mapping: The long reads generated by nanopore sequencers make it possible to identify m6A modifications within the context of full-length transcript isoforms.[7][10] This is a crucial capability that is lacking in antibody-based methods, which rely on fragmented RNA.[8]
-
Quantitative Potential: Nanopore sequencing has the potential to determine the stoichiometry of m6A at a given site, meaning it can estimate the proportion of transcripts that are methylated.[11][12] This quantitative aspect is essential for studying the dynamics of RNA methylation.
-
Simplified Workflow: By eliminating the immunoprecipitation step, the workflow for nanopore-based m6A detection is simpler and less prone to experimental variability compared to MeRIP-Seq.[2]
While MeRIP-Seq can be more sensitive for the initial discovery of m6A sites in lowly expressed transcripts due to the enrichment step, recent studies have demonstrated the robust performance of nanopore sequencing in identifying thousands of m6A sites with high confidence.[7][10] For researchers interested in the precise location, isoform context, and potential stoichiometry of m6A, nanopore sequencing is the superior method.
Experimental Workflows: A Visual Comparison
The following diagrams illustrate the key steps in both nanopore-based and antibody-based m6A detection workflows.
References
- 1. Detecting m6A RNA modification from nanopore sequencing using a semisupervised learning framework - PMC [pmc.ncbi.nlm.nih.gov]
- 2. m.youtube.com [m.youtube.com]
- 3. Identification and comparison of m6A modifications in glioblastoma non-coding RNAs with MeRIP-seq and Nanopore dRNA-seq - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Comparison of m6A Sequencing Methods - CD Genomics [cd-genomics.com]
- 5. MeRIP-seq for Detecting RNA methylation: An Overview - CD Genomics [cd-genomics.com]
- 6. MeRIP-Seq/m6A-seq [emea.illumina.com]
- 7. Direct RNA sequencing enables m6A detection in endogenous transcript isoforms at base-specific resolution - PMC [pmc.ncbi.nlm.nih.gov]
- 8. academic.oup.com [academic.oup.com]
- 9. A comparative evaluation of computational models for RNA modification detection using nanopore sequencing with RNA004 chemistry - PMC [pmc.ncbi.nlm.nih.gov]
- 10. nanoporetech.com [nanoporetech.com]
- 11. biorxiv.org [biorxiv.org]
- 12. academic.oup.com [academic.oup.com]
- 13. EpiNano: Detection of m6A RNA Modifications Using Oxford Nanopore Direct RNA Sequencing | Springer Nature Experiments [experiments.springernature.com]
- 14. researchgate.net [researchgate.net]
- 15. MeRIP-seq Protocol - CD Genomics [rna.cd-genomics.com]
- 16. tandfonline.com [tandfonline.com]
- 17. Identification and comparison of m6A modifications in glioblastoma non-coding RNAs with MeRIP-seq and Nanopore dRNA-seq - PubMed [pubmed.ncbi.nlm.nih.gov]
A Researcher's Guide to Cross-Validation of m6A Sites Identified by Different Techniques
For researchers, scientists, and drug development professionals, the accurate identification of N6-methyladenosine (m6A) sites in RNA is crucial for understanding its role in gene regulation and disease. With a variety of techniques available, each with its own strengths and limitations, cross-validation of findings is paramount. This guide provides an objective comparison of popular m6A detection methods, supported by experimental data, detailed protocols for key techniques, and visual workflows to aid in experimental design.
The landscape of m6A detection is rapidly evolving, with methodologies broadly categorized into antibody-based enrichment, antibody-based single-nucleotide resolution, and direct sequencing approaches. This guide focuses on a comparative analysis of three prominent techniques: Methylated RNA Immunoprecipitation followed by Sequencing (MeRIP-Seq), m6A individual-nucleotide resolution cross-linking and immunoprecipitation (miCLIP-Seq), and Nanopore Direct RNA Sequencing (dRNA-seq).
Comparative Performance of m6A Detection Techniques
The choice of an m6A detection method significantly impacts the number, resolution, and potential biases of the identified methylation sites. Below is a summary of quantitative data from a study comparing MeRIP-Seq and Nanopore dRNA-seq for the identification of m6A in long non-coding RNAs (lncRNAs) in the U87-MG glioblastoma cell line.[1]
| Feature | MeRIP-Seq | Nanopore dRNA-seq |
| Total LncRNA Transcripts Identified | 5,086 | 336 |
| m6A Modified LncRNA Transcripts | 556 (~10.9%) | 198 (~58.9%) |
| Overlapping m6A Modified LncRNAs | \multicolumn{2}{c | }{24} |
This data highlights that MeRIP-Seq identifies a larger number of total and m6A-modified lncRNA transcripts, suggesting it may be more suitable for initial screening studies due to its higher coverage.[1] In contrast, Nanopore dRNA-seq, while identifying fewer transcripts, provides the significant advantage of direct, single-molecule detection without the need for antibodies or PCR amplification, potentially offering more precise localization and quantification of m6A sites.[1] The relatively small overlap of 24 lncRNAs underscores the importance of using orthogonal methods for validating m6A sites.
Further studies have shown that the overlap between different MeRIP-Seq datasets can be as low as 30-60%, highlighting issues with reproducibility and the influence of experimental and analytical variables.[2][3] miCLIP-Seq, while more technically demanding, offers single-nucleotide resolution by inducing mutations at the cross-linking site, which can help to pinpoint the exact location of the m6A modification.[2] However, like MeRIP-Seq, it is reliant on the specificity of the anti-m6A antibody.[4]
Experimental Workflows and Logical Relationships
Understanding the workflow of each technique is essential for experimental planning and data interpretation. The following diagrams, generated using the DOT language, illustrate the key steps in cross-validating m6A sites identified by different techniques.
Caption: Workflow for discovery and validation of m6A sites.
This diagram illustrates a typical cross-validation strategy where candidate m6A sites are first identified using one or more high-throughput sequencing methods. These candidates are then subjected to a targeted validation method like SELECT-qPCR to confirm the presence of the modification.
Experimental Protocols
Detailed and robust experimental protocols are the foundation of reproducible research. Below are methodologies for key experiments in m6A detection and validation.
Methylated RNA Immunoprecipitation followed by Sequencing (MeRIP-Seq) Protocol
This protocol outlines the major steps for performing MeRIP-Seq.
-
RNA Preparation:
-
Isolate total RNA from cells or tissues using a standard method like TRIzol extraction.
-
Assess RNA quality and quantity using a spectrophotometer and agarose (B213101) gel electrophoresis.
-
Enrich for poly(A)+ RNA using oligo(dT) magnetic beads.
-
-
RNA Fragmentation:
-
Fragment the enriched poly(A)+ RNA to an average size of ~100 nucleotides using RNA fragmentation buffer or enzymatic methods.
-
Purify the fragmented RNA using a spin column or ethanol (B145695) precipitation.
-
-
Immunoprecipitation (IP):
-
Incubate the fragmented RNA with an anti-m6A antibody.
-
Add protein A/G magnetic beads to the RNA-antibody mixture to capture the antibody-RNA complexes.
-
Wash the beads multiple times with low and high salt buffers to remove non-specifically bound RNA.
-
-
RNA Elution and Library Preparation:
-
Elute the m6A-containing RNA fragments from the beads.
-
Prepare sequencing libraries from the eluted RNA (IP sample) and a portion of the fragmented RNA that was not subjected to immunoprecipitation (input control). This typically involves reverse transcription, second-strand synthesis, adapter ligation, and PCR amplification.
-
-
Sequencing and Data Analysis:
-
Sequence the IP and input libraries on a high-throughput sequencing platform.
-
Align the sequencing reads to a reference genome or transcriptome.
-
Use peak-calling algorithms to identify regions enriched for m6A in the IP sample relative to the input control.
-
m6A individual-nucleotide resolution cross-linking and immunoprecipitation (miCLIP-Seq) Protocol
This protocol provides a more detailed, single-nucleotide resolution view of m6A sites.
-
UV Cross-linking and RNA Fragmentation:
-
Expose cells to UV light to cross-link RNA-binding proteins (including the anti-m6A antibody) to RNA.
-
Isolate total RNA and fragment it to the desired size.
-
-
Immunoprecipitation:
-
Incubate the fragmented RNA with an anti-m6A antibody.
-
Capture the antibody-RNA complexes using protein A/G magnetic beads.
-
Perform stringent washes to remove non-specific interactions.
-
-
On-bead Enzymatic Reactions:
-
While the RNA is bound to the beads, perform enzymatic reactions such as 3' end dephosphorylation and 3' adapter ligation.
-
-
Proteinase K Digestion and RNA Elution:
-
Digest the antibody with proteinase K, leaving a small peptide adduct at the cross-link site.
-
Elute the RNA.
-
-
Reverse Transcription and cDNA Library Preparation:
-
Perform reverse transcription. The peptide adduct at the cross-link site often causes the reverse transcriptase to stall or introduce a mutation (deletion or substitution) in the resulting cDNA.
-
Circularize the cDNA and perform PCR amplification to prepare the sequencing library.
-
-
Sequencing and Data Analysis:
-
Sequence the cDNA library.
-
Align the reads to the reference genome.
-
Identify m6A sites by looking for the characteristic mutations or truncations at the cross-link sites.
-
Nanopore Direct RNA Sequencing (dRNA-seq) for m6A Detection Protocol
This method allows for the direct detection of RNA modifications without the need for antibodies or amplification.
-
RNA Isolation and Quality Control:
-
Isolate total RNA or poly(A)+ RNA. High-quality, intact RNA is crucial for long reads.
-
Assess RNA integrity using a Bioanalyzer or equivalent.
-
-
Library Preparation:
-
Ligate a motor protein-attached adapter to the 3' end of the RNA molecules. This adapter facilitates the entry of the RNA into the nanopore.
-
No reverse transcription or PCR amplification is performed.
-
-
Sequencing:
-
Load the prepared library onto a Nanopore flow cell.
-
As each RNA molecule passes through a nanopore, it creates a characteristic disruption in the ionic current. This "squiggles" of current data are recorded.
-
-
Data Analysis:
-
Basecall the raw signal data to determine the nucleotide sequence.
-
Specialized algorithms are used to analyze the raw signal data. The presence of an m6A modification alters the ionic current in a predictable way compared to an unmodified adenosine, allowing for its direct detection.
-
Various computational tools can be used to identify m6A sites from the raw signal data.
-
SELECT-qPCR for m6A Site Validation Protocol
SELECT (single-base elongation- and ligation-based qPCR) is a method for validating specific m6A sites identified by high-throughput methods.
-
Primer Design:
-
Design a reverse transcription (RT) primer that anneals immediately downstream of the putative m6A site.
-
Design a forward and reverse qPCR primer pair that will amplify a region upstream of the m6A site.
-
Design a "splint" oligonucleotide that is complementary to the sequence spanning the m6A site and the beginning of the qPCR amplicon.
-
-
Reverse Transcription and Single-Base Elongation:
-
Perform reverse transcription using the specific RT primer.
-
In separate reactions, perform a single-base elongation step using a DNA polymerase and either dATP (for the unmodified control) or a mixture of dNTPs. The presence of m6A will hinder the incorporation of the nucleotide opposite it.
-
-
Ligation:
-
Anneal the splint oligonucleotide to the cDNA product.
-
Use a ligase to ligate the elongated cDNA to the splint. The efficiency of ligation will be lower if the m6A modification is present due to the conformational change it induces.
-
-
qPCR Amplification:
-
Use the ligation product as a template for qPCR with the designed forward and reverse primers.
-
A lower Cq value (earlier amplification) in the control reaction (unmodified) compared to the sample suspected of containing m6A indicates the presence of the modification. The difference in Cq values can be used to estimate the relative abundance of m6A at that site.
-
Conclusion
The accurate identification of m6A sites is a complex task that benefits from a multi-pronged approach. While high-throughput methods like MeRIP-Seq, miCLIP-Seq, and Nanopore dRNA-seq are invaluable for discovery, their findings should be interpreted with an understanding of their inherent biases and limitations. Cross-validation of m6A sites using orthogonal techniques and targeted validation methods like SELECT-qPCR is essential for building a robust and reliable map of the m6A epitranscriptome. This guide provides a framework for researchers to critically evaluate and compare different m6A detection methods, enabling more informed experimental design and a deeper understanding of the functional roles of this critical RNA modification.
References
- 1. Identification and comparison of m6A modifications in glioblastoma non-coding RNAs with MeRIP-seq and Nanopore dRNA-seq - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Limits in the detection of m6A changes using MeRIP/m6A-seq - PMC [pmc.ncbi.nlm.nih.gov]
- 3. researchgate.net [researchgate.net]
- 4. Three Methods Comparison: GLORI-seq, miCLIP and Mazter-seq - CD Genomics [cd-genomics.com]
Validating m6A Methylation Sites: A Comparative Guide to Using m6A Writer Knockdown
For researchers, scientists, and drug development professionals, confirming the precise locations of N6-methyladenosine (m6A) modifications on RNA is crucial for understanding its role in gene regulation and disease. The knockdown of m6A "writer" enzymes—the methyltransferases responsible for installing this modification—serves as a powerful and widely used validation strategy. This guide provides a comprehensive comparison of this approach with alternative methods, supported by experimental data and detailed protocols.
The m6A modification is a dynamic and reversible process orchestrated by writer, eraser, and reader proteins.[1][2] The writer complex, primarily composed of METTL3, METTL14, and WTAP, is responsible for catalyzing the methylation of adenosine (B11128) residues.[3][4] Consequently, depleting these essential components provides a direct method to observe the corresponding impact on m6A levels, thereby validating bona fide methylation sites.
The Logic of Validation via Writer Knockdown
The fundamental principle behind this validation method is straightforward: if a specific adenosine site is indeed methylated by the canonical m6A writer complex, the knockdown of a core component of this complex should lead to a significant reduction in m6A levels at that site. This cause-and-effect relationship provides strong evidence for the authenticity of the methylation event.
References
- 1. spandidos-publications.com [spandidos-publications.com]
- 2. researchgate.net [researchgate.net]
- 3. academic.oup.com [academic.oup.com]
- 4. Development and validation of a N6 methylation regulator-related gene signature for prognostic and immune response prediction in non-small cell lung cancer - PMC [pmc.ncbi.nlm.nih.gov]
Validating m6A Sequencing Data: A Comparative Guide to qPCR and Alternative Methods
For researchers, scientists, and drug development professionals navigating the complexities of epitranscriptomics, robust validation of N6-methyladenosine (m6A) sequencing data is paramount. This guide provides an objective comparison of quantitative PCR (qPCR) as a validation tool against other techniques, supported by experimental data and detailed protocols. By understanding the strengths and limitations of each method, researchers can ensure the accuracy and reliability of their m6A profiling studies.
N6-methyladenosine (m6A) is the most abundant internal modification in eukaryotic messenger RNA (mRNA), playing a crucial role in regulating gene expression and various biological processes.[1][2][3] High-throughput sequencing methods, such as methylated RNA immunoprecipitation sequencing (meRIP-seq or m6A-seq), have become instrumental in mapping the m6A landscape across the transcriptome.[1][2][3] However, the results from these sequencing approaches necessitate orthogonal validation to confirm the identified m6A modifications. Quantitative PCR (qPCR) has emerged as a widely adopted method for this purpose.
The Role of qPCR in m6A Sequencing Validation
Following transcriptome-wide identification of m6A peaks by sequencing, qPCR is employed to verify the enrichment of m6A in specific gene transcripts. This method, often referred to as meRIP-qPCR, provides a targeted and quantitative assessment of the m6A levels of selected genes of interest.[1][4] The consistency between meRIP-seq data and meRIP-qPCR results serves to validate the reliability of the high-throughput sequencing findings.[4]
The general workflow involves performing an m6A immunoprecipitation on fragmented RNA, followed by reverse transcription and qPCR to quantify the abundance of specific transcripts in both the immunoprecipitated (IP) and input samples. The enrichment of a particular transcript in the IP sample relative to the input is indicative of m6A modification.
Comparative Analysis of Validation Methods
While qPCR is a staple for validation, other methods can also be employed. The choice of method often depends on the specific research question, available resources, and the desired level of resolution.
| Method | Principle | Advantages | Disadvantages | Typical Application |
| meRIP-qPCR | Quantifies the enrichment of m6A-containing RNA fragments for specific genes after immunoprecipitation. | - Cost-effective and rapid for validating a moderate number of targets.- High sensitivity and specificity for targeted validation.- Widely accessible instrumentation. | - Does not provide single-nucleotide resolution.- Limited to a small number of pre-selected targets.- Relies on the specificity of the m6A antibody.[1] | Confirmation of m6A enrichment in specific genes identified by m6A-seq. |
| SELECT (Single-Base Elongation- and Ligation-based qPCR) | A qPCR-based method that can detect m6A at a single-base resolution by exploiting the inhibitory effect of m6A on DNA polymerase elongation and ligation.[5][6] | - Provides single-nucleotide resolution.- Quantitative assessment of methylation at specific sites. | - Can be influenced by other adenosine (B11128) modifications.[6]- Requires careful primer and probe design.- May require optimization for different sequence contexts. | Validation of specific m6A sites identified by high-resolution sequencing methods. |
| Nanopore Direct RNA Sequencing | Directly sequences native RNA molecules, allowing for the detection of modified bases, including m6A, without the need for immunoprecipitation. | - Provides single-molecule and single-nucleotide resolution.- Can determine the stoichiometry of m6A modification.- Avoids biases associated with antibodies and reverse transcription. | - Higher error rates compared to second-generation sequencing.- Data analysis for modification detection is computationally intensive.- Lower throughput for whole-transcriptome analysis compared to some methods. | Independent validation of m6A sites and their stoichiometry. |
| LC-MS/MS (Liquid Chromatography-Tandem Mass Spectrometry) | Separates and identifies modified nucleosides based on their mass-to-charge ratio. | - Provides absolute quantification of m6A levels.- Considered a "gold standard" for global m6A quantification. | - Does not provide sequence-specific information.- Requires specialized equipment and expertise.- Not suitable for validating m6A on specific transcripts. | Measuring global m6A levels to confirm overall changes observed in sequencing data. |
Experimental Protocols
MeRIP-qPCR Protocol for m6A Validation
This protocol outlines the key steps for validating m6A sequencing data using meRIP-qPCR.
1. RNA Preparation and Fragmentation:
-
Isolate total RNA from cells or tissues of interest, ensuring high quality.
-
Purify mRNA from the total RNA.
-
Fragment the mRNA to an average size of ~100 nucleotides using RNA fragmentation buffer.
2. m6A Immunoprecipitation (meRIP):
-
Take an aliquot of the fragmented mRNA as the "input" control.
-
Incubate the remaining fragmented mRNA with an anti-m6A antibody coupled to magnetic beads.
-
Wash the beads to remove non-specifically bound RNA.
-
Elute the m6A-containing RNA fragments from the beads. This is the "IP" sample.
3. RNA Purification and Reverse Transcription:
-
Purify the RNA from both the "IP" and "input" samples.
-
Perform reverse transcription on equal amounts of RNA from both samples to synthesize cDNA.
4. qPCR Analysis:
-
Design qPCR primers flanking the putative m6A peak region within the genes of interest identified from the m6A-seq data.
-
Perform qPCR using the cDNA from the "IP" and "input" samples.
-
Calculate the enrichment of m6A for each target gene. The fold enrichment is typically calculated as 2^-(Ct(IP) - Ct(Input)).
Data Presentation
The results of meRIP-qPCR validation are often presented as fold enrichment of the IP sample over the input control. Below is a template table for summarizing such data.
| Gene | Condition 1 (Fold Enrichment IP/Input) | Condition 2 (Fold Enrichment IP/Input) | p-value | m6A-seq Result |
| Gene A | 5.2 ± 0.6 | 2.1 ± 0.3 | <0.01 | Hypermethylated |
| Gene B | 1.8 ± 0.2 | 4.5 ± 0.5 | <0.05 | Hypomethylated |
| Gene C | 1.1 ± 0.1 | 1.2 ± 0.2 | >0.05 | No significant change |
Visualizing the Workflow and Logic
To better understand the process, the following diagrams illustrate the experimental workflow and the logical relationship of how qPCR validates m6A sequencing data.
Caption: Experimental workflow for meRIP-qPCR validation of m6A sequencing data.
Caption: Logical flow from m6A sequencing to qPCR validation.
References
- 1. An experimental workflow for identifying RNA m6A alterations in cellular senescence by methylated RNA immunoprecipitation sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 2. An experimental workflow for identifying RNA m6A alterations in cellular senescence by methylated RNA immunoprecipitation sequencing - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. An experimental workflow for identifying RNA m6A alterations in cellular senescence by methylated RNA immunoprecipitation sequencing [polscientific.com]
- 4. researchgate.net [researchgate.net]
- 5. researchgate.net [researchgate.net]
- 6. Current progress in strategies to profile transcriptomic m6A modifications - PMC [pmc.ncbi.nlm.nih.gov]
Confirming the Specificity of m6A Inhibitors: A Comparative Guide
For Researchers, Scientists, and Drug Development Professionals
The burgeoning field of epitranscriptomics has identified N6-methyladenosine (m6A) as a critical regulator of gene expression, with its dysregulation implicated in numerous diseases, including cancer. This has spurred the development of small molecule inhibitors targeting the proteins that write (methyltransferases like METTL3), erase (demethylases like FTO and ALKBH5), and read this modification. However, ensuring the specificity of these inhibitors is paramount to accurately interpreting experimental results and advancing their therapeutic potential. This guide provides a comparative overview of methods to validate the on-target effects of m6A inhibitors, supported by experimental data and detailed protocols.
Data Presentation: Comparative Efficacy of m6A Inhibitors
The following tables summarize the half-maximal inhibitory concentrations (IC50) of selected inhibitors against their primary m6A-related targets. This data, compiled from various studies, offers a snapshot of their biochemical potency.
Table 1: Comparative Potency of METTL3 Inhibitors
| Inhibitor | Type | Assay Type | Potency (IC50/Kd) |
| STM2457 | SAM-Competitive | Biochemical | 16.9 nM[1] |
| Cellular (m6A reduction) | 2.2 µM[1] | ||
| UZH2 | SAM-Competitive | Biochemical | 5 nM[1] |
| Quercetin | Natural Product | Biochemical (LC-MS/MS) | 2.73 µM[2] |
| Cellular (m6A reduction) | Dose-dependent[2] | ||
| Luteolin | Natural Product | Biochemical | 6.23 µM[2] |
| Scutellarin | Natural Product | Biochemical | 19.93 µM[2] |
| SAH | Product | Biochemical (Radiometric) | 520 nM[3] |
| Sinefungin | SAM-Analog | Biochemical (Radiometric) | 1320 nM[3] |
Table 2: Comparative Potency of FTO Inhibitors
| Inhibitor | Type | Assay Type | FTO IC50 | ALKBH5 IC50 | Selectivity (ALKBH5/FTO) |
| FB23-2 | Substrate-Competitive | In vitro | Specific to FTO | >400 other proteins tested | High[4] |
| Meclofenamic Acid (MA) | Substrate-Competitive | FP Assay | 17.4 µM[5] | - | Selective over ALKBH5[6] |
| Rhein | Substrate-Competitive | In vitro | - | - | Poor selectivity[7] |
| Compound 18097 | - | HPLC-MS/MS | 0.64 µM[8] | 179 µM[7] | ~280-fold |
| Compound 14a | 2OG-Competitive | LC-based | 1.5 µM[9] | >100 µM (for some KDMs) | High |
| IOX3 | 2OG-Competitive | In vitro | 2.8 µM[10] | - | Broad-spectrum 2OG oxygenase inhibitor |
Table 3: Comparative Potency of ALKBH5 Inhibitors
| Inhibitor | Assay Type | ALKBH5 IC50 | FTO IC50 | Selectivity (FTO/ALKBH5) |
| Compound 3 | ELISA | 0.84 µM[11] | - | - |
| Compound 6 | ELISA | 1.79 µM[11] | - | - |
| TD19 | Covalent | - | >50 µM[5] | High |
| Compound 20m | Fluorescence Polarization | 0.021 µM[12] | - | High |
| Compound 18l | - | 0.62 µM[12] | No binding observed | High |
Experimental Protocols: Key Assays for Specificity Confirmation
A multi-faceted approach is essential to rigorously confirm the specificity of an m6A inhibitor. This involves a combination of biochemical, cellular, and broader selectivity profiling assays.
Biochemical Assays: Direct Enzyme Inhibition
These assays directly measure the inhibitor's effect on the purified target enzyme.
a) In Vitro Methyltransferase/Demethylase Assay
-
Principle: This assay quantifies the enzymatic activity of a methyltransferase (e.g., METTL3/14) or a demethylase (e.g., FTO, ALKBH5) in the presence of varying inhibitor concentrations.
-
Methodology (Example: Radiometric Methyltransferase Assay for METTL3): [13]
-
Reaction Setup: In a 96-well plate, combine recombinant METTL3/METTL14 enzyme complex, a specific RNA substrate, and S-adenosyl-L-[methyl-³H]methionine ([³H]-SAM) in an appropriate assay buffer.
-
Inhibitor Addition: Add serial dilutions of the test inhibitor or a vehicle control (e.g., DMSO).
-
Incubation: Incubate the reaction mixture at a controlled temperature (e.g., 30°C) for a defined period (e.g., 2 hours).[14]
-
Stopping the Reaction: Terminate the reaction by adding a stop solution, such as trichloroacetic acid (TCA), to precipitate the RNA.[13]
-
Quantification: Transfer the reaction mixture to a filter plate to capture the radiolabeled RNA. Wash the plate to remove unincorporated [³H]-SAM. Add scintillation fluid and measure the radioactivity using a scintillation counter.
-
Data Analysis: Plot the percentage of inhibition against the inhibitor concentration and fit the data to a dose-response curve to determine the IC50 value.
-
Cellular Assays: On-Target Engagement in a Biological Context
These assays confirm that the inhibitor engages its target within a cellular environment and elicits the expected biological response.
a) Cellular m6A Quantification
-
Principle: To determine if the inhibitor affects the overall m6A levels in cellular RNA.
-
Methodology 1: LC-MS/MS (Liquid Chromatography-Tandem Mass Spectrometry): [15]
-
Cell Treatment: Treat cultured cells with the inhibitor at various concentrations for a specified duration.
-
RNA Extraction: Isolate total RNA from the treated and untreated cells, followed by purification of mRNA.
-
RNA Digestion: Digest the purified mRNA into single nucleosides using a cocktail of nucleases and phosphatases.
-
LC-MS/MS Analysis: Separate and quantify the nucleosides (adenosine and m6A) using LC-MS/MS.
-
Data Analysis: Calculate the ratio of m6A to adenosine (B11128) (A) to determine the relative m6A abundance. A dose-dependent reduction in this ratio indicates on-target activity.
-
-
Methodology 2: Dot Blot: [16]
-
RNA Extraction and Denaturation: Isolate and purify mRNA from treated and untreated cells. Denature the RNA by heating to disrupt secondary structures.
-
Membrane Application: Spot serial dilutions of the denatured mRNA onto a nitrocellulose or nylon membrane.
-
Cross-linking: UV cross-link the RNA to the membrane.
-
Immunoblotting: Block the membrane and then incubate with a primary antibody specific for m6A, followed by a horseradish peroxidase (HRP)-conjugated secondary antibody.
-
Detection: Visualize the dots using an enhanced chemiluminescence (ECL) substrate.
-
Analysis: Quantify the dot intensity using software like ImageJ. A decrease in signal intensity with increasing inhibitor concentration suggests on-target activity.
-
b) Target-Specific Phenotypic Assays
-
Principle: To assess whether the inhibitor induces a biological phenotype consistent with the known function of the target protein.
-
Methodology (Example: Cell Viability/Apoptosis Assay):
-
Cell Treatment: Seed cells in a multi-well plate and treat with a range of inhibitor concentrations.
-
Incubation: Incubate the cells for a period relevant to the expected phenotype (e.g., 48-72 hours).
-
Viability/Apoptosis Measurement:
-
Cell Viability: Use assays like MTS or CCK-8, which measure metabolic activity.
-
Apoptosis: Use flow cytometry with Annexin V and propidium (B1200493) iodide (PI) staining to quantify apoptotic and necrotic cells.
-
-
Data Analysis: A dose-dependent decrease in cell viability or an increase in apoptosis that aligns with genetic knockdown/knockout of the target protein supports on-target activity.
-
Selectivity Profiling: Assessing Off-Target Effects
-
Principle: To evaluate the inhibitor's activity against a panel of related proteins (e.g., other methyltransferases or dioxygenases) to determine its selectivity.
-
Methodology (Example: Thermal Shift Assay): [17]
-
Protein and Dye Preparation: Prepare a solution of the purified off-target enzyme (e.g., METTL1, METTL16) and a fluorescent dye (e.g., SYPRO Orange) that binds to unfolded proteins.
-
Inhibitor Addition: Add the test inhibitor at various concentrations.
-
Thermal Denaturation: Gradually increase the temperature of the solution in a real-time PCR instrument.
-
Fluorescence Measurement: Monitor the fluorescence intensity as the protein unfolds.
-
Data Analysis: The melting temperature (Tm) is the temperature at which 50% of the protein is unfolded. A significant shift in the Tm in the presence of the inhibitor indicates binding. Comparing the Tm shift for the primary target versus other proteins provides a measure of selectivity.
-
Mandatory Visualization: Signaling Pathways and Experimental Workflows
Caption: METTL3-mediated m6A methylation pathway and its inhibition.
Caption: FTO/ALKBH5-mediated m6A demethylation and its role in cancer.
Caption: Workflow for confirming the specificity of m6A inhibitors.
By employing a combination of these robust biochemical and cellular assays, researchers can confidently validate the specificity of m6A inhibitors. This rigorous approach is essential for generating reliable data, accurately interpreting biological functions, and ultimately advancing the development of novel therapeutics targeting the epitranscriptome.
References
- 1. benchchem.com [benchchem.com]
- 2. Discovery of METTL3 Small Molecule Inhibitors by Virtual Screening of Natural Products - PMC [pmc.ncbi.nlm.nih.gov]
- 3. researchgate.net [researchgate.net]
- 4. mdpi.com [mdpi.com]
- 5. A covalent compound selectively inhibits RNA demethylase ALKBH5 rather than FTO - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Recent Advances of m6A Demethylases Inhibitors and Their Biological Functions in Human Diseases - PMC [pmc.ncbi.nlm.nih.gov]
- 7. researchgate.net [researchgate.net]
- 8. A novel inhibitor of N6-methyladenosine demethylase FTO induces mRNA methylation and shows anti-cancer activities - PMC [pmc.ncbi.nlm.nih.gov]
- 9. pubs.acs.org [pubs.acs.org]
- 10. researchgate.net [researchgate.net]
- 11. Rational Design of Novel Anticancer Small-Molecule RNA m6A Demethylase ALKBH5 Inhibitors - PMC [pmc.ncbi.nlm.nih.gov]
- 12. researchgate.net [researchgate.net]
- 13. benchchem.com [benchchem.com]
- 14. researchgate.net [researchgate.net]
- 15. Pan-Cancer Analysis Shows That ALKBH5 Is a Potential Prognostic and Immunotherapeutic Biomarker for Multiple Cancer Types Including Gliomas - PMC [pmc.ncbi.nlm.nih.gov]
- 16. Mechanistic insights into the role of RNA demethylase ALKBH5 in malignant tumor therapy - PMC [pmc.ncbi.nlm.nih.gov]
- 17. Structure-Based Design of Inhibitors of the m6A-RNA Writer Enzyme METTL3 - PMC [pmc.ncbi.nlm.nih.gov]
comparative analysis of m6A computational prediction tools
A Comprehensive Guide to m6A Computational Prediction Tools
The field of epitranscriptomics has been significantly advanced by the development of computational tools capable of predicting N6-methyladenosine (m6A) modifications in RNA. These tools are indispensable for researchers, scientists, and drug development professionals in identifying potential m6A sites for further experimental validation. This guide provides a comparative analysis of prominent m6A computational prediction tools, supported by performance data and detailed experimental methodologies.
Comparative Performance of m6A Prediction Tools
The performance of m6A prediction tools is typically evaluated using several key metrics, including Accuracy (Acc), Area Under the Receiver Operating Characteristic Curve (AUC), Sensitivity (Sn), and Specificity (Sp). The following tables summarize the performance of various tools on independent datasets as reported in benchmark studies. It is important to note that the performance of these tools can vary depending on the dataset and the specific biological context.[1][2][3]
Table 1: Performance Comparison of m6A Prediction Tools on Human Datasets
| Tool | Accuracy (Acc) | AUC | Sensitivity (Sn) | Specificity (Sp) |
| WHISTLE | - | 0.948 (full transcript) | - | - |
| - | 0.880 (mature mRNA) | - | - | |
| SRAMP | - | - | - | High Confidence (95% Sp) |
| DeepM6ASeq | - | Best Performing | - | - |
| MASS | - | Second Best | - | - |
| MultiRM | Stable Performance | Stable Performance | - | - |
| HSM6AP | Surpasses existing tools | - | - | - |
| CLSM6A | - | 0.8040 (average) | - | - |
Note: A direct numerical comparison is challenging as different studies use varied datasets and cross-validation strategies. The table reflects the reported performance in the respective studies.[1][4][5]
Table 2: Performance of m6A Prediction Tools on Saccharomyces cerevisiae Datasets
| Tool | Accuracy (Acc) | AUC | Sensitivity (Sn) | Specificity (Sp) |
| RAM-ESVM | Best Performance | - | - | - |
| m6Apred | Considerable Accuracy | - | - | - |
| iRNA-Methyl | Considerable Accuracy | - | - | - |
Note: Performance of these tools on a common independent dataset (M6Atest6540) showed that RAM-ESVM performed the best, although most models performed worse than originally reported.[2][6]
Methodologies of Key Experimental Protocols
The accuracy of m6A prediction tools is fundamentally dependent on the quality of the training data, which is generated by experimental techniques that map m6A sites at single-nucleotide or high resolution. Below are the detailed methodologies for key experimental protocols.
m6A-seq (methylated RNA immunoprecipitation sequencing)
m6A-seq is a widely used antibody-based method to map the transcriptome-wide distribution of m6A.[7][8][9][10][11]
Experimental Workflow:
-
RNA Isolation and Fragmentation: Total RNA is isolated from cells or tissues and fragmented into smaller pieces (typically around 100 nucleotides).
-
Immunoprecipitation: The fragmented RNA is incubated with an anti-m6A antibody, which specifically binds to RNA fragments containing m6A modifications.
-
Enrichment: The antibody-RNA complexes are captured, usually with protein A/G magnetic beads.
-
RNA Elution and Library Preparation: The m6A-enriched RNA fragments are eluted and used to construct a sequencing library. A parallel "input" library is prepared from the fragmented RNA before immunoprecipitation to serve as a control.
-
High-Throughput Sequencing: Both the m6A-immunoprecipitated and input libraries are sequenced using next-generation sequencing platforms.
-
Data Analysis: The sequencing reads are aligned to a reference genome or transcriptome. Peaks of enrichment in the m6A-IP sample relative to the input control indicate the locations of m6A modifications.
miCLIP (m6A individual-nucleotide-resolution cross-linking and immunoprecipitation)
miCLIP is a technique that provides single-nucleotide resolution mapping of m6A sites by inducing mutations or truncations at the cross-linked m6A sites during reverse transcription.[12][13]
Experimental Workflow:
-
UV Cross-linking: Cells are irradiated with UV light to induce covalent cross-links between m6A-binding proteins (or directly to the anti-m6A antibody) and the RNA.
-
RNA Fragmentation and Immunoprecipitation: RNA is fragmented, and an anti-m6A antibody is used to immunoprecipitate the cross-linked RNA-protein complexes.
-
Adapter Ligation and Radiolabeling: A 3' adapter is ligated to the RNA fragments, and the 5' end is radiolabeled.
-
Protein-RNA Complex Purification: The complexes are run on an SDS-PAGE gel, and the RNA-protein complexes are transferred to a nitrocellulose membrane and purified.
-
Reverse Transcription: The purified RNA is reverse transcribed into cDNA. The cross-linked site often causes the reverse transcriptase to introduce a mutation (substitution or deletion) or terminate, thus marking the precise location of the m6A.
-
cDNA Circularization and PCR Amplification: The resulting cDNA is circularized and then amplified by PCR.
-
Sequencing and Data Analysis: The amplified cDNA library is sequenced, and the reads are analyzed to identify the specific mutation or truncation sites, which correspond to the m6A locations.
Logical Relationships of Prediction Tools
m6A computational prediction tools can be broadly categorized based on their underlying algorithms and the features they utilize. Most modern tools employ machine learning or deep learning approaches.
The general workflow for developing these prediction tools involves:
-
Data Collection: Gathering experimentally verified m6A sites (positive dataset) and non-m6A sites (negative dataset).
-
Feature Extraction: Converting RNA sequences into numerical features. Common features include sequence-based properties (k-mer frequencies, nucleotide composition) and sometimes structural information.[6][14]
-
Model Training: Using the extracted features and the labeled datasets to train a machine learning or deep learning model (e.g., Support Vector Machine, Random Forest, Convolutional Neural Network).
-
Performance Evaluation: Assessing the model's predictive power on an independent test dataset.
Conclusion
The landscape of m6A computational prediction tools is diverse and continually evolving. While sequence-based features remain fundamental, the integration of genomic and structural information, coupled with advanced machine learning and deep learning architectures, is paving the way for more accurate and context-specific predictions.[1][3][15] The choice of tool should be guided by the specific research question, the organism of interest, and the type of available input data. As experimental techniques for m6A detection improve in resolution and accuracy, we can expect a corresponding improvement in the predictive power of computational tools.
References
- 1. From Detection to Prediction: Advances in m6A Methylation Analysis Through Machine Learning and Deep Learning with Implications in Cancer | MDPI [mdpi.com]
- 2. A comprehensive comparison and analysis of computational predictors for RNA N6-methyladenosine sites of Saccharomyces cerevisiae - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. mdpi.com [mdpi.com]
- 4. WHISTLE: A Functionally Annotated High-Accuracy Map of Human m6A Epitranscriptome - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. academic.oup.com [academic.oup.com]
- 6. SRAMP: prediction of mammalian N6-methyladenosine (m6A) sites based on sequence-derived features - PMC [pmc.ncbi.nlm.nih.gov]
- 7. An experimental workflow for identifying RNA m6A alterations in cellular senescence by methylated RNA immunoprecipitation sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Genome-Wide Location Analyses of N6-Methyladenosine Modifications (m6A-seq) - PMC [pmc.ncbi.nlm.nih.gov]
- 9. MeRIP-seq: Comprehensive Guide to m6A RNA Modification Analysis - CD Genomics [rna.cd-genomics.com]
- 10. Current progress in strategies to profile transcriptomic m6A modifications - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Epitranscriptome Mapping of N6-Methyladenosine Using m6A Immunoprecipitation with High Throughput Sequencing in Skeletal Muscle Stem Cells | Springer Nature Experiments [experiments.springernature.com]
- 12. Mapping m6A at individual-nucleotide resolution using crosslinking and immunoprecipitation (miCLIP) - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Comprehensive Overview of m6A Detection Methods - CD Genomics [cd-genomics.com]
- 14. Welcome to SRAMP, an online m6A site predictor [cuilab.cn]
- 15. rejuvenomicslab.com [rejuvenomicslab.com]
Navigating the Epitranscriptome: A Guide to the Reproducibility of m6A Profiling Experiments
For researchers, scientists, and drug development professionals venturing into the dynamic field of epitranscriptomics, the accurate and reproducible profiling of N6-methyladenosine (m6A) is paramount. This guide provides a comprehensive comparison of commonly used m6A profiling techniques, focusing on their reproducibility and performance. We delve into the experimental nuances of each method, present quantitative data to support our comparisons, and offer detailed protocols to aid in experimental design and execution.
The m6A modification, the most abundant internal modification in eukaryotic mRNA, plays a critical role in various biological processes, including RNA stability, splicing, and translation. Dysregulation of m6A has been implicated in numerous diseases, making it a key area of investigation for therapeutic development. The ability to reliably map m6A sites across the transcriptome is therefore essential. However, the reproducibility of m6A profiling experiments can be influenced by the chosen methodology, experimental variability, and data analysis pipelines. This guide aims to equip researchers with the knowledge to critically assess and select the most appropriate method for their research goals.
Comparative Analysis of m6A Profiling Techniques
The landscape of m6A profiling is dominated by several key techniques, each with its own set of strengths and limitations. These can be broadly categorized into antibody-based enrichment, chemical-based labeling, and direct sequencing methods. Below, we compare the performance and reproducibility of four major techniques: MeRIP-seq/m6A-seq, miCLIP, m6A-SEAL, and Nanopore Direct RNA Sequencing.
Quantitative Performance Metrics
The following table summarizes key performance and reproducibility metrics for popular m6A profiling methods. It is important to note that these values are compiled from various studies and can be influenced by specific experimental conditions, cell types, and data analysis approaches.
| Method | Principle | Resolution | Sensitivity | Specificity | Concordance/Reproducibility | Key Advantages | Key Limitations |
| MeRIP-seq/m6A-seq | Antibody-based enrichment of m6A-containing RNA fragments followed by sequencing. | ~100-200 nt | Moderate | Moderate | Peak overlap between studies can vary from 30-60%[1][2]. Biological replicate correlations are generally high. | Widely used, relatively straightforward, cost-effective. | Low resolution, potential for antibody-related bias and off-target binding, variability in peak calling. |
| miCLIP | UV cross-linking of m6A antibody to RNA, enabling precise identification of modification sites through reverse transcription-induced mutations or truncations. | Single nucleotide | High | High | High intra-lab reproducibility. | High resolution, provides single-nucleotide precision. | Technically challenging, requires more input material, potential for UV-induced biases. |
| m6A-SEAL | Chemical labeling of m6A residues, allowing for their enrichment and identification without the use of antibodies. | ~200 nt | High | High | High reproducibility reported in initial studies. | Antibody-free, high specificity. | Multi-step chemical process can be complex. |
| Nanopore Direct RNA Sequencing | Direct sequencing of native RNA molecules, where m6A modifications are detected as alterations in the electrical current signal. | Single nucleotide | Varies by caller | Varies by caller | High reproducibility of raw signal; precision and recall of m6A calling depend on the bioinformatic tool used[3][4][5]. | Direct detection without amplification or chemical labeling, provides long reads, enables isoform-specific methylation analysis. | Higher error rate in base calling compared to short-read sequencing, computational challenges in accurately calling modifications. |
Experimental Protocols
Detailed and consistent experimental protocols are crucial for ensuring the reproducibility of m6A profiling experiments. Below are generalized methodologies for the key techniques discussed.
MeRIP-seq (Methylated RNA Immunoprecipitation Sequencing) Protocol
-
RNA Isolation and Fragmentation: Isolate total RNA from the biological sample of interest. Purify mRNA using oligo(dT) magnetic beads. Fragment the mRNA to an average size of 100-200 nucleotides using chemical or enzymatic methods.
-
Immunoprecipitation: Incubate the fragmented mRNA with an anti-m6A antibody to capture m6A-containing fragments. A portion of the fragmented RNA should be set aside as an input control.
-
Washing and Elution: Wash the antibody-RNA complexes to remove non-specifically bound fragments. Elute the m6A-enriched RNA fragments from the antibody.
-
Library Preparation and Sequencing: Prepare sequencing libraries from both the immunoprecipitated (IP) and input RNA samples. Perform high-throughput sequencing.
-
Data Analysis: Align sequencing reads to a reference genome/transcriptome. Use peak-calling algorithms (e.g., MACS2) to identify enriched regions in the IP sample compared to the input. Perform differential methylation analysis between conditions.
miCLIP (m6A individual-Nucleotide-Resolution Crosslinking and Immunoprecipitation) Protocol
-
RNA-Antibody Cross-linking: Isolate total RNA and incubate with an anti-m6A antibody. Expose the mixture to UV light to induce covalent cross-links between the antibody and the RNA at the m6A site.
-
Immunoprecipitation and RNA Fragmentation: Immunoprecipitate the RNA-antibody complexes. Perform partial RNase digestion to trim the RNA fragments bound to the antibody.
-
Ligation and Labeling: Ligate adapters to the 3' ends of the RNA fragments. Radioactively label the 5' ends of the RNA fragments.
-
Protein-RNA Complex Separation and RNA Isolation: Separate the protein-RNA complexes by SDS-PAGE and transfer to a nitrocellulose membrane. Excise the region corresponding to the antibody-RNA complexes and isolate the RNA.
-
Reverse Transcription and Library Preparation: Perform reverse transcription, which will introduce mutations or truncations at the cross-linked nucleotide. Ligate an adapter to the 3' end of the cDNA, followed by PCR amplification to generate the sequencing library.
-
Sequencing and Data Analysis: Sequence the library and analyze the data to identify the specific nucleotide positions with mutations or truncations, which correspond to the m6A sites.
m6A-SEAL (m6A-Selective Chemical Labeling) Protocol
-
RNA Isolation: Isolate total RNA from the sample.
-
FTO-mediated Oxidation: Treat the RNA with the FTO protein to oxidize m6A to hm6A (N6-hydroxymethyladenosine) and subsequently to f6A (N6-formyladenosine).
-
Biotinylation: Chemically label the f6A residues with a biotin-containing probe.
-
Enrichment: Use streptavidin-coated magnetic beads to enrich the biotin-labeled RNA fragments.
-
Library Preparation and Sequencing: Prepare a sequencing library from the enriched RNA fragments.
-
Data Analysis: Sequence the library and map the reads to identify the locations of m6A.
Nanopore Direct RNA Sequencing for m6A Detection Protocol
-
RNA Isolation and Poly(A) Tailing (optional): Isolate total RNA. For non-polyadenylated RNAs, an in vitro polyadenylation step may be necessary.
-
Library Preparation: Ligate a motor protein-adapter complex to the 3' end of the RNA molecules. This adapter facilitates the entry of the RNA into the nanopore.
-
Sequencing: Load the prepared library onto a Nanopore flow cell. As the RNA molecules pass through the nanopores, the changes in electrical current are measured.
-
Data Analysis: Use specialized basecalling software that can interpret the raw electrical signal to identify not only the nucleotide sequence but also the presence of modifications like m6A. Various computational tools (e.g., Tombo, Epinano, m6Anet) are available for this purpose, each with different performance characteristics in terms of precision and recall[3][4][5].
Visualizing m6A Biology and Experimental Workflows
To further clarify the concepts discussed, the following diagrams illustrate the m6A signaling pathway and the general workflows of the compared profiling techniques.
Caption: The m6A signaling pathway is regulated by writers, erasers, and readers.
Caption: Simplified workflows of four major m6A profiling techniques.
Conclusion
The choice of an m6A profiling method should be guided by the specific research question, available resources, and the desired level of resolution. For transcriptome-wide screening and studies where single-nucleotide resolution is not a primary requirement, MeRIP-seq remains a valuable and widely used technique. However, researchers should be mindful of its limitations in reproducibility and potential for bias. For studies demanding precise localization of m6A sites and investigation of their functional consequences at the nucleotide level, miCLIP offers unparalleled resolution, albeit at the cost of increased technical complexity.
Antibody-free methods like m6A-SEAL provide a promising alternative, mitigating the concerns associated with antibody specificity. The advent of Nanopore direct RNA sequencing is revolutionizing the field by enabling the direct detection of m6A on native RNA molecules, offering the potential for isoform-specific methylation analysis and a more direct view of the epitranscriptome. However, the bioinformatic analysis of Nanopore data for modification detection is still an active area of development.
Ultimately, a thorough understanding of the principles, advantages, and limitations of each method, coupled with rigorous experimental design and data analysis, is essential for generating reproducible and reliable m6A profiling data. As the field continues to evolve, the development of new and improved techniques will undoubtedly provide deeper insights into the complex world of RNA modifications.
References
- 1. Scholars@Duke publication: Limits in the detection of m6A changes using MeRIP/m6A-seq. [scholars.duke.edu]
- 2. researchgate.net [researchgate.net]
- 3. researchgate.net [researchgate.net]
- 4. academic.oup.com [academic.oup.com]
- 5. Benchmarking of computational methods for m6A profiling with Nanopore direct RNA sequencing - PubMed [pubmed.ncbi.nlm.nih.gov]
A Researcher's Guide to Quantifying N6-methyladenosine (m6A) Stoichiometry: m6A-LAIC-seq and its Alternatives
For researchers, scientists, and drug development professionals navigating the complex world of epitranscriptomics, the precise quantification of N6-methyladenosine (m6A) methylation stoichiometry is paramount. This guide provides an objective comparison of m6A-LAIC-seq against other key methods, supported by experimental data and detailed protocols to inform your selection of the most suitable technique for your research needs.
N6-methyladenosine (m6A) is the most abundant internal modification in eukaryotic messenger RNA (mRNA) and plays a critical role in regulating mRNA metabolism, including splicing, nuclear export, stability, and translation. The stoichiometry of m6A—the proportion of transcripts of a specific gene that are methylated at a given site—is a crucial parameter for understanding the functional impact of this modification. Unlike qualitative methods that merely identify the presence of m6A, quantitative approaches provide a deeper understanding of the dynamic nature of RNA methylation.
This guide focuses on m6A-LAIC-seq (m6A-level and isoform-characterization sequencing), a technique designed for the transcriptome-wide quantification of m6A stoichiometry, and compares it with other widely used and emerging methods.
Comparison of m6A Quantification Methods
The choice of method for quantifying m6A stoichiometry depends on several factors, including the desired scale of analysis (gene-specific vs. transcriptome-wide), resolution (gene-level vs. single-nucleotide), required input material, and whether an antibody-based approach is suitable. Below is a summary of key techniques and their performance characteristics.
| Method | Principle | Scale | Resolution | Quantitative | Antibody-Free | Input Material | Key Advantages | Key Limitations |
| m6A-LAIC-seq | Immunoprecipitation of full-length RNA followed by sequencing of methylated and unmethylated fractions. | Transcriptome-wide | Gene/Isoform | Yes | No | ~2 µg poly(A)+ RNA | Quantifies stoichiometry at the gene/isoform level; preserves full-length transcript information. | Relies on antibody specificity; does not provide single-nucleotide resolution. |
| m6A-seq/MeRIP-seq | Immunoprecipitation of fragmented RNA followed by sequencing. | Transcriptome-wide | ~100-200 nt | No (semi-quantitative) | No | High (µg of mRNA) | Widely used for identifying m6A-enriched regions. | Not truly quantitative for stoichiometry; low resolution; potential antibody bias.[1] |
| SCARLET | Site-specific cleavage, radioisotope labeling, and thin-layer chromatography. | Locus-specific | Single-nucleotide | Yes | Yes | ~1 µg poly(A)+ RNA | "Gold standard" for quantifying stoichiometry at specific sites; highly accurate.[2] | Laborious; requires radioisotopes; not high-throughput.[2] |
| DART-seq | Fused APOBEC1-YTH protein induces C-to-U edits near m6A sites, detected by RNA-seq. | Transcriptome-wide | Single-nucleotide | Indirectly | Yes | Low (as little as 10 ng total RNA) | Antibody-free; low input requirement; single-nucleotide resolution.[3][4] | Relies on cellular expression of a fusion protein or in vitro protein activity; indirect quantification based on editing efficiency. |
| m6A-SAC-seq | Chemical conversion of m6A to a detectable analog for sequencing. | Transcriptome-wide | Single-nucleotide | Yes | Yes | Low (as little as 2-50 ng mRNA) | Antibody-free; quantitative at single-base resolution; high sensitivity and specificity.[3][5] | Requires chemical synthesis of a cofactor and enzymatic reactions. |
Experimental Workflows and Logical Relationships
The following diagrams illustrate the experimental workflows of m6A-LAIC-seq and its alternatives, as well as a key signaling pathway influenced by m6A modification.
Caption: Workflow of m6A-LAIC-seq.
Caption: Workflows of alternative m6A quantification methods.
References
- 1. The detection and functions of RNA modification m6A based on m6A writers and erasers - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Current progress in strategies to profile transcriptomic m6A modifications - PMC [pmc.ncbi.nlm.nih.gov]
- 3. m6A-SAC-seq for quantitative whole transcriptome m6A profiling - PMC [pmc.ncbi.nlm.nih.gov]
- 4. sacseq.yech.science [sacseq.yech.science]
- 5. m6A level and isoform characterization sequencing (m6A-LAIC-seq) reveals the census and complexity of the m6A epitranscriptome - PMC [pmc.ncbi.nlm.nih.gov]
A Comparative Guide to the Inhibition of FTO and ALKBH5: Effects, Pathways, and Methodologies
For Researchers, Scientists, and Drug Development Professionals
The field of epitranscriptomics has identified N6-methyladenosine (m6A) as the most abundant internal modification in eukaryotic mRNA, playing a pivotal role in regulating gene expression.[1][2][3] The reversibility of this modification is controlled by methyltransferases ("writers") and demethylases ("erasers"). The two primary m6A erasers in mammals are the fat mass and obesity-associated protein (FTO) and AlkB homolog 5 (ALKBH5).[4][5] While both are Fe(II)/α-ketoglutarate-dependent dioxygenases that remove methyl groups from RNA, they exhibit distinct substrate preferences, catalytic mechanisms, and biological functions.[5] Understanding the differential consequences of inhibiting FTO versus ALKBH5 is critical for developing targeted therapeutic strategies for a range of diseases, including cancer and metabolic disorders.[6][7]
This guide provides an objective comparison of the effects of FTO and ALKBH5 inhibition, supported by experimental data. It details the impact on cellular phenotypes and signaling pathways, provides methodologies for key experiments, and visualizes complex relationships to aid in experimental design and data interpretation.
Section 1: Comparative Effects on Cellular Phenotypes
Inhibition of FTO and ALKBH5 leads to a global increase in m6A levels, yet the resulting cellular phenotypes are often distinct, reflecting their different target transcripts and contexts.[8] While their roles can sometimes overlap, they frequently govern separate biological processes.
Table 1: Comparison of Cellular Phenotypes upon FTO vs. ALKBH5 Inhibition
| Cellular Process | Effect of FTO Inhibition | Effect of ALKBH5 Inhibition | Key Target Genes/Notes |
| Cancer Proliferation | Suppression. Induces cell cycle arrest (G1 phase) and impairs proliferation in AML, glioblastoma, and breast cancer.[3][6] | Suppression (Context-Dependent). Inhibits growth in glioblastoma, multiple myeloma, and bladder cancer, but can have varied roles in other cancers.[9][10] | FTO targets include CCNA2, CDK2, MYC, and CEBPA.[6] ALKBH5 targets include FOXM1, NANOG, and TRAF1.[9][10][11] |
| Apoptosis | Induction. Promotes apoptosis in various cancer cell lines. | Induction. Triggers apoptosis in osteosarcoma and multiple myeloma cells.[9][10] | ALKBH5 inhibition can inactivate the STAT3 signaling pathway.[10] |
| Cell Migration & Invasion | Suppression. FTO downregulation is associated with increased invasion and metastasis in epithelial cancers.[12] | Suppression. Knockdown of ALKBH5 suppresses migration and invasion in lung adenocarcinoma cell lines.[13] | FTO depletion promotes an EMT-like phenotype.[12] |
| Adipogenesis | Strong Suppression. FTO is required for preadipocyte differentiation. Inhibition impairs adipogenesis and lipid accumulation.[6][14] | Minimal to No Direct Role Reported. Less evidence for a direct, primary role in adipogenesis compared to FTO. | FTO regulates key adipogenic factors like CEBPB.[14] |
| DNA Damage Response (DDR) | Limited direct evidence compared to ALKBH5. | Modulation. ALKBH5 knockdown can upregulate key DNA repair factors like BRCA1 and RAD51, facilitating DNA repair and G2/M arrest.[15] | Inhibition of ALKBH5 increases the stability of mRNAs encoding cyclin-dependent kinase inhibitors like CDKN1A.[15] |
| Stem Cell Phenotype | Plays a role in maintaining cellular senescence.[3] | Suppression of Cancer Stem Cells. Hypoxia induces a breast cancer stem cell phenotype via ALKBH5-mediated demethylation of NANOG mRNA. Inhibition reverses this.[11] | ALKBH5 is a key link between the hypoxic tumor microenvironment and the cancer stem cell state.[11] |
Section 2: Differential Impact on Signaling Pathways
The distinct cellular outcomes of FTO and ALKBH5 inhibition are driven by their differential regulation of key signaling pathways. By altering the m6A status of specific transcripts, these erasers can fine-tune the expression of kinases, transcription factors, and other signaling components.
Table 2: Comparison of Affected Signaling Pathways upon FTO vs. ALKBH5 Inhibition
| Signaling Pathway | Role of FTO Inhibition | Role of ALKBH5 Inhibition | Mechanism and Downstream Effects |
| Wnt/β-Catenin | Modulation. FTO depletion can inhibit canonical Wnt signaling via upregulation of DKK1.[16] Conversely, FTO downregulation can also sensitize tumors to Wnt inhibitors.[12] | Limited direct evidence. | FTO sits (B43327) at a branching point of Wnt signaling, affecting both canonical and non-canonical pathways.[16] |
| PI3K/AKT | Modulation. FTO can regulate AKT phosphorylation in adipocytes.[14] | Activation. ALKBH5 overexpression can activate the PI3K/Akt/mTOR pathway in pancreatic neuroendocrine neoplasms.[17] | FTO affects cardiac fibrosis via the PI3K/AKT/GLUT2 pathway.[1] |
| MAPK (ERK/JNK) | Limited direct evidence. | Activation. ALKBH5 can promote tumorigenesis in multiple myeloma via TRAF1-mediated activation of the MAPK pathway.[9] ROS can also activate ERK/JNK signaling, which in turn phosphorylates and inhibits ALKBH5.[18] | This creates a feedback loop where stress signaling (ROS) can regulate m6A levels via ALKBH5.[18] |
| FOXO Signaling | Activation. Co-inhibition of FTO and ALKBH5 activates FOXO signaling in colorectal cancer by increasing HK2 expression.[8] | Activation. Works cooperatively with FTO to regulate the FOXO pathway.[8] | The FTO-ALKBH5/IGF2BP2/HK2/FOXO1 axis has been identified as a key mechanism in colorectal cancer.[8] |
| Leptin/STAT3 | Modulation. A regulatory loop exists where FTO expression is regulated by leptin-STAT3 signaling, and FTO in turn controls this pathway.[19] | Modulation. ALKBH5 can inactivate the STAT3 pathway in osteosarcoma cells by destabilizing SOCS3 mRNA.[10] | FTO is implicated in hepatic glucose metabolism through its interaction with the leptin-STAT3 pathway.[19] |
| Hypoxia (HIF-1α/2α) | Limited direct evidence. | Key Mediator. Hypoxia-inducible factors (HIFs) activate ALKBH5 transcription, which then demethylates target mRNAs like NANOG to promote the cancer stem cell phenotype.[11] | ALKBH5 is a crucial effector of the hypoxia response pathway in breast cancer.[11] |
Section 3: Visualizing Key Concepts and Workflows
Diagrams are essential for conceptualizing the m6A regulatory network, experimental procedures, and the divergent effects of FTO and ALKBH5 inhibition.
References
- 1. mdpi.com [mdpi.com]
- 2. An Improved m6A-ELISA for Quantifying N6-methyladenosine in Poly(A)-purified mRNAs [en.bio-protocol.org]
- 3. researchgate.net [researchgate.net]
- 4. FTO Gene Polymorphisms at the Crossroads of Metabolic Pathways of Obesity and Epigenetic Influences - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Insights into the m6A demethylases FTO and ALKBH5 : structural, biological function, and inhibitor development - PMC [pmc.ncbi.nlm.nih.gov]
- 6. mdpi.com [mdpi.com]
- 7. What are FTO inhibitors and how do they work? [synapse.patsnap.com]
- 8. Down-regulated FTO and ALKBH5 co-operatively activates FOXO signaling through m6A methylation modification in HK2 mRNA mediated by IGF2BP2 to enhance glycolysis in colorectal cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 9. RNA demethylase ALKBH5 promotes tumorigenesis in multiple myeloma via TRAF1-mediated activation of NF-κB and MAPK signaling pathways - PMC [pmc.ncbi.nlm.nih.gov]
- 10. M6A Demethylase ALKBH5 in Human Diseases: From Structure to Mechanisms - PMC [pmc.ncbi.nlm.nih.gov]
- 11. pnas.org [pnas.org]
- 12. Downregulation of the FTO m6A RNA demethylase promotes EMT-mediated progression of epithelial tumors and sensitivity to Wnt inhibitors - PMC [pmc.ncbi.nlm.nih.gov]
- 13. RNA demethylase ALKBH5 in cancer: from mechanisms to therapeutic potential - PMC [pmc.ncbi.nlm.nih.gov]
- 14. FTO mediates cell-autonomous effects on adipogenesis and adipocyte lipid content by regulating gene expression via 6mA DNA modifications - PMC [pmc.ncbi.nlm.nih.gov]
- 15. RNA demethylase ALKBH5 regulates cell cycle progression in DNA damage response - PMC [pmc.ncbi.nlm.nih.gov]
- 16. biorxiv.org [biorxiv.org]
- 17. mdpi.com [mdpi.com]
- 18. academic.oup.com [academic.oup.com]
- 19. FTO contributes to hepatic metabolism regulation through regulation of leptin action and STAT3 signalling in liver - PMC [pmc.ncbi.nlm.nih.gov]
A Researcher's Guide to Monoclonal Antibodies for m6A Detection: A Comparative Analysis
For researchers, scientists, and drug development professionals navigating the burgeoning field of epitranscriptomics, the precise detection of N6-methyladenosine (m6A) is paramount. The choice of a monoclonal antibody is a critical determinant for the success of m6A-based studies. This guide provides an objective comparison of commercially available monoclonal antibodies, supported by experimental data, to aid in the selection of the most suitable antibody for your research needs.
The most prevalent internal modification in eukaryotic messenger RNA (mRNA), m6A, plays a pivotal role in regulating various cellular processes.[1] Immunological methods, such as methylated RNA immunoprecipitation followed by sequencing (MeRIP-seq), are central to mapping and quantifying this modification.[2][3] However, the accuracy and reproducibility of these techniques are highly dependent on the specificity and affinity of the anti-m6A antibody used.[1][4] Monoclonal antibodies, with their inherent homogeneity and consistent performance, are generally preferred over polyclonal antibodies to ensure reproducible results.[1]
Comparative Performance of Leading m6A Monoclonal Antibodies
Several companies offer monoclonal antibodies validated for m6A detection. This guide focuses on a comparative analysis of some of the most frequently cited options based on available performance data in key applications.
| Antibody (Clone) | Supplier | Applications | Key Validation Data | Recommended For |
| Anti-m6A (D9D9W) | Cell Signaling Technology | DB, ELISA | High specificity for m6A; no cross-reactivity with unmodified adenosine, N6-dimethyladenosine, N1-methyladenosine, or 2'-O-methyladenosine.[5] | Low-input MeRIP-seq, Dot Blot, ELISA |
| Anti-m6A (Clone 17-3-4-1) | Millipore (Magna MeRIP™ m6A Kit) | MeRIP-seq | High signal-to-noise ratios in MeRIP assays.[6] | Standard MeRIP-seq protocols |
| Anti-m6A | Diagenode | RIP, DB | High specificity for m6A-containing RNA and DNA oligonucleotides demonstrated by dot blot.[7] | RNA Immunoprecipitation (RIP) |
| Anti-m6A (#B1-3) | MBL International | ELISA, DB, IHC, miCLIP | High sensitivity and specificity with a KD of 6.5 nM for m6A-containing oligoribonucleotides.[1] | Multiple applications including in-situ detection |
| Anti-m6A | Synaptic Systems | MeRIP-seq, DB, IF | Good performance in MeRIP-seq with distinct peak enrichment.[8] | MeRIP-seq and Immunofluorescence |
DB : Dot Blot, ELISA : Enzyme-Linked Immunosorbent Assay, IHC : Immunohistochemistry, IF : Immunofluorescence, miCLIP : m6A individual-nucleotide resolution cross-linking and immunoprecipitation, RIP : RNA Immunoprecipitation, MeRIP-seq : Methylated RNA Immunoprecipitation sequencing.
A recent study highlighted that for MeRIP-seq with low-input total RNA, the Cell Signaling Technology antibody (#56593) was suitable at a concentration of 1.25 µg.[4][9] For larger RNA inputs (15 µg), Millipore antibodies (ABE572 and MABE1006) performed well at a concentration of 5 µg.[4][9]
Experimental Workflow & Methodologies
The validation of anti-m6A antibodies is a multi-step process involving rigorous testing for specificity and sensitivity across various applications.
Figure 1. A generalized workflow for the production and validation of anti-m6A monoclonal antibodies.
Key Experimental Protocols
1. Dot Blot Assay for Specificity Testing
This method provides a rapid and straightforward assessment of an antibody's specificity for m6A over other modifications and unmodified adenosine.
-
RNA/DNA Spotting: Serially dilute synthetic RNA or DNA oligonucleotides containing m6A, as well as unmodified controls (e.g., adenosine, N1-methyladenosine), and spot them onto a nylon membrane.
-
UV Cross-linking: Cross-link the nucleic acids to the membrane using a UV cross-linker.
-
Blocking: Block the membrane with a suitable blocking buffer (e.g., 5% non-fat dry milk in TBST) for 1 hour at room temperature.
-
Antibody Incubation: Incubate the membrane with the primary anti-m6A antibody at the recommended dilution overnight at 4°C.
-
Washing: Wash the membrane three times with TBST.
-
Secondary Antibody Incubation: Incubate with an appropriate HRP-conjugated secondary antibody for 1 hour at room temperature.
-
Detection: Detect the signal using an enhanced chemiluminescence (ECL) substrate.
2. MeRIP-qPCR for Enrichment Validation
This protocol validates the antibody's ability to specifically enrich for m6A-containing RNA transcripts.
-
RNA Fragmentation: Fragment total RNA to an average size of 100-200 nucleotides.
-
Immunoprecipitation: Incubate the fragmented RNA with the anti-m6A antibody pre-coupled to protein A/G magnetic beads. An IgG control should be run in parallel.
-
Washing: Perform stringent washes to remove non-specifically bound RNA.
-
Elution: Elute the immunoprecipitated RNA from the beads.
-
RNA Purification: Purify the eluted RNA.
-
Reverse Transcription and qPCR: Perform reverse transcription followed by quantitative PCR (qPCR) using primers for known m6A-containing and non-m6A-containing transcripts. Enrichment is calculated relative to the input and IgG controls.
3. Immunofluorescence for In-situ m6A Detection
This protocol allows for the visualization of m6A within cells.
-
Cell Fixation and Permeabilization: Fix cells with 4% paraformaldehyde and permeabilize with 0.25% Triton X-100.
-
Blocking: Block with a suitable blocking buffer (e.g., 1% BSA in PBST) for 1 hour.
-
Primary Antibody Incubation: Incubate with the anti-m6A antibody overnight at 4°C.
-
Secondary Antibody Incubation: Incubate with a fluorescently labeled secondary antibody for 1 hour at room temperature in the dark.
-
Staining and Mounting: Counterstain nuclei with DAPI and mount the coverslips.
-
Imaging: Visualize the localization of m6A using a fluorescence microscope. A protocol for visualizing m6A modified DNA by immunofluorescence while preserving other epitopes has been described.[10]
Logical Pathway for Antibody Selection
The selection of an appropriate anti-m6A antibody is contingent on the specific experimental application and the amount of starting material.
Figure 2. A decision pathway for selecting an anti-m6A monoclonal antibody based on application and sample input.
Conclusion
The validation and careful selection of monoclonal antibodies are critical for the generation of reliable and reproducible data in m6A research. While several commercial antibodies demonstrate high specificity and utility in various applications, their performance can be context-dependent. Researchers are encouraged to consult primary literature and manufacturer's validation data when selecting an antibody. For novel or low-input applications, in-house validation using the protocols outlined in this guide is strongly recommended to ensure optimal performance and data integrity. The continued development of highly specific and rigorously validated monoclonal antibodies will be instrumental in advancing our understanding of the epitranscriptome.[1]
References
- 1. Development and validation of monoclonal antibodies against N6-methyladenosine for the detection of RNA modifications - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Comprehensive Overview of m6A Detection Methods - CD Genomics [cd-genomics.com]
- 3. MeRIP-Seq/m6A-seq [illumina.com]
- 4. Comparative analysis of improved m6A sequencing based on antibody optimization for low-input samples - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. N6-Methyladenosine (m6A) (D9D9W) Rabbit Monoclonal Antibody | Cell Signaling Technology [cellsignal.com]
- 6. merckmillipore.com [merckmillipore.com]
- 7. N6-methyladenosine (m6A) antibody - RIP Grade (C15200082) | Diagenode [diagenode.com]
- 8. researchgate.net [researchgate.net]
- 9. rna-seqblog.com [rna-seqblog.com]
- 10. m6A visualization/immunofluorescence of DamID [protocols.io]
Navigating the Nanopore Maze: A Comparative Guide to m6A Mapping Tools
For researchers, scientists, and drug development professionals venturing into the dynamic field of epitranscriptomics, the ability to accurately map N6-methyladenosine (m6A) modifications using nanopore direct RNA sequencing is a significant advantage. This guide provides a systematic comparison of currently available computational tools, offering a clear overview of their performance, methodologies, and underlying principles to aid in the selection of the most suitable tool for your research needs.
The advent of Oxford Nanopore Technologies' (ONT) direct RNA sequencing (DRS) has revolutionized the study of RNA modifications, allowing for the direct detection of m6A without the need for antibodies or chemical treatments.[1][2][3][4] This has led to the development of a diverse ecosystem of bioinformatics tools, each employing unique strategies to identify m6A from the raw nanopore signal. However, the performance of these tools can vary, presenting a trade-off between precision and recall.[1][2]
Performance Snapshot: A Head-to-Head Comparison
Recent comprehensive benchmarking studies have systematically evaluated the performance of numerous m6A detection tools.[1][5][6] These studies utilize datasets from various species, including human, mouse, and yeast, as well as synthetic RNA oligos with known m6A positions, to assess key performance metrics such as precision, recall, and F1-score.[5][6] The performance of these tools often depends on whether they operate in "single-mode" (analyzing a single sample) or "compare-mode" (comparing a sample against a negative control).[1] The use of a negative control has been shown to improve precision by accounting for intrinsic biases.[1][2]
Below is a summary of the performance of several prominent tools based on published benchmarking data. It is important to note that performance can be influenced by factors such as sequencing depth and m6A stoichiometry.[1][2]
Single-Mode m6A Detection Tools
| Tool | Primary Algorithm | Key Features | Precision | Recall | F1-Score |
| m6Anet | CNN/RNN | Utilizes a convolutional and recurrent neural network to detect m6A from raw signal. | Moderate | High | Moderate-High |
| EpiNano | Random Forest | Employs a random forest classifier based on features derived from basecalling errors and signal intensity.[7][8] | High | Low-Moderate | Moderate |
| Tombo | Custom Model | Detects modifications by comparing the raw signal of a native RNA sample to a canonical RNA model. | Moderate | Moderate | Moderate |
| MINES | Random Forest | A random forest classifier trained on experimentally validated m6A sites within the DRACH motif.[9][10] | High | Low | Moderate |
| Dorado | Neural Network | ONT's official basecaller with integrated models for detecting modified bases, including m6A.[11][12][13] | High | Moderate-High | High |
Compare-Mode m6A Detection Tools
| Tool | Primary Algorithm | Key Features | Precision | Recall | F1-Score |
| xPore | Statistical Test | Identifies differential RNA modifications between two conditions using a statistical framework. | High | Moderate | Moderate-High |
| nanocompore | Statistical Test | Compares signal distributions between a sample and a control to detect modifications. | High | Moderate | Moderate-High |
| DRUMMER | GMM/Statistical Test | Uses a Gaussian Mixture Model to compare signal levels between conditions. | Moderate | Moderate | Moderate |
| ELIGOS | Machine Learning | Employs a machine learning approach to identify sites with differential modification levels. | High | Low-Moderate | Moderate |
Note: The precision, recall, and F1-score values are qualitative summaries derived from multiple benchmarking studies.[1][5] Actual performance may vary depending on the dataset and experimental conditions.
The Method Behind the Mapping: Experimental Protocols
The accurate identification of m6A sites is critically dependent on robust experimental design and data generation. The following provides a generalized experimental protocol based on methodologies cited in benchmarking studies.
Cell Culture and RNA Extraction
-
Cell Lines: Commonly used cell lines for m6A analysis include human HEK293T, HeLa, and primary human dermal fibroblasts (NHDFs).[11][13][14]
-
Perturbations: To validate m6A detection, studies often employ genetic knockouts (e.g., METTL3 KO) or chemical inhibition (e.g., STM2457 treatment) of m6A writers to generate negative control samples.[11]
-
RNA Isolation: Total RNA is extracted from cell pellets using standard methods such as TRIzol reagent, followed by poly(A) selection to enrich for mRNA.
Nanopore Direct RNA Sequencing
-
Library Preparation: Direct RNA sequencing libraries are prepared using the Oxford Nanopore DRS Kit (SQK-RNA002 or newer versions like RNA004).[13]
-
Sequencing: Sequencing is performed on a Nanopore device (e.g., MinION, GridION) running the MinKNOW software.[12] The sequencing run should be of sufficient duration to achieve adequate sequencing depth for reliable m6A detection.
Data Preprocessing and Basecalling
-
Basecalling: Raw electrical signal data stored in POD5 or legacy FAST5 format is converted into RNA sequences (FASTQ format) using a basecaller.[12] Oxford Nanopore's Dorado is the current production basecaller, which can also perform modified base calling simultaneously.[11][12][13]
-
Alignment: The basecalled reads are then aligned to a reference genome or transcriptome using a long-read aligner such as minimap2.[12]
m6A Detection and Validation
-
Tool Application: The aligned data is then processed by one of the m6A detection tools listed in the tables above. Each tool has its own specific input requirements and parameters.
-
Validation: The identified m6A sites are often validated against orthogonal methods such as miCLIP, m6ACE-seq, GLORI, or eTAM-seq, which are considered ground truth datasets.[11][13][14]
Visualizing the Workflow
The general process for identifying m6A modifications from nanopore direct RNA sequencing data can be visualized as a multi-step workflow.
Caption: A generalized workflow for m6A mapping from nanopore direct RNA sequencing data.
Logical Framework for Tool Selection
Choosing the right tool depends on the specific research question and experimental design. The following logical diagram illustrates a decision-making process for selecting an appropriate m6A detection tool.
Caption: A decision tree for selecting an m6A mapping tool based on experimental design and research goals.
References
- 1. researchgate.net [researchgate.net]
- 2. Systematic comparison of tools used for m6A mapping from nanopore direct RNA sequencing - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. torontomu.primo.exlibrisgroup.com [torontomu.primo.exlibrisgroup.com]
- 4. Systematic comparison of tools used for m6A mapping from nanopore direct RNA sequencing [ideas.repec.org]
- 5. academic.oup.com [academic.oup.com]
- 6. Benchmarking of computational methods for m6A profiling with Nanopore direct RNA sequencing - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. repositori.upf.edu [repositori.upf.edu]
- 8. EpiNano: Detection of m6A RNA Modifications Using Oxford Nanopore Direct RNA Sequencing | Springer Nature Experiments [experiments.springernature.com]
- 9. Direct RNA sequencing enables m6A detection in endogenous transcript isoforms at base-specific resolution - PMC [pmc.ncbi.nlm.nih.gov]
- 10. nanoporetech.com [nanoporetech.com]
- 11. biorxiv.org [biorxiv.org]
- 12. nanoporetech.com [nanoporetech.com]
- 13. A comparative evaluation of computational models for RNA modification detection using nanopore sequencing with RNA004 chemistry - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Detecting m6A RNA modification from nanopore sequencing using a semisupervised learning framework - PMC [pmc.ncbi.nlm.nih.gov]
Safety Operating Guide
Critical Safety Notice: Identification of "MD6a" Required
Before proceeding, it is essential to definitively identify the chemical you are working with. "MD6a" is not a standard chemical identifier, and the molecular formula C₇H₁₄N₂O₄ corresponds to several different substances with distinct safety profiles. The information provided below is a general guide for handling a low-toxicity solid chemical in a laboratory setting and is not a substitute for the official Safety Data Sheet (SDS) for your specific compound. You must obtain and review the SDS for the exact chemical, identified by its full name or CAS number, before any handling, use, or disposal.
General Safety and Personal Protective Equipment (PPE)
When handling a solid chemical of unknown specific hazards, a cautious approach is necessary. The following personal protective equipment is recommended as a baseline.
Recommended Personal Protective Equipment
| PPE Category | Specification | Purpose |
| Eye/Face Protection | Chemical safety goggles or safety glasses with side shields meeting EN166 (EU) or ANSI Z87.1 (US) standards. A face shield may be required if there is a splash hazard. | Protects eyes from dust particles and potential splashes. |
| Skin Protection | 100% Nitrile gloves (check manufacturer's chemical compatibility chart for specific breakthrough times if available). A standard lab coat. Closed-toe shoes. | Prevents skin contact with the chemical. |
| Respiratory Protection | Generally not required for non-volatile solids under normal use with adequate ventilation. If dust is generated, a particulate filter respirator (e.g., N95, P1/FFP1) may be necessary. | Prevents inhalation of fine dust particles. |
| Hand Protection | Nitrile gloves. | Provides a barrier against direct contact during handling. |
Operational and Disposal Plans
This section provides procedural guidance for the safe handling and disposal of a solid chemical, assuming it is non-reactive and non-hazardous. This plan must be adapted based on the specific hazards identified in the substance's official SDS.
Step-by-Step Handling Protocol
-
Preparation :
-
Read and understand the specific Safety Data Sheet (SDS) for your compound.
-
Ensure a clean and organized workspace. An area with good ventilation, such as a fume hood or a benchtop with local exhaust ventilation, is recommended, especially when weighing or transferring powder.
-
Assemble all necessary equipment (spatulas, weigh boats, containers, etc.) before handling the chemical.
-
Put on all required PPE as specified in the table above.
-
-
Handling :
-
When weighing or transferring the solid, perform the task carefully to minimize the creation of dust.
-
Use a spatula or other appropriate tool to handle the material. Avoid pouring directly from large containers if it is likely to generate dust.
-
Keep containers with the chemical closed when not in use.
-
In case of a spill, follow the procedures outlined in the SDS. For a small, non-hazardous powder spill, you can typically gently sweep it up with a brush and dustpan (or use a wet paper towel for fine dust) and place it in a sealed container for disposal.
-
-
Storage :
-
Store the chemical in a tightly sealed, clearly labeled container.
-
Follow any specific storage conditions mentioned in the SDS, such as temperature (e.g., refrigeration) or protection from light and moisture.
-
Store in a cool, dry, and well-ventilated area away from incompatible materials.
-
Disposal Plan
-
All waste material, including contaminated consumables (e.g., weigh boats, gloves, paper towels), must be disposed of in accordance with local, state, and federal regulations.
-
Place all solid waste contaminated with the chemical into a designated, sealed, and clearly labeled hazardous waste container.
-
Do not dispose of the chemical down the drain or in the regular trash unless explicitly permitted by your institution's environmental health and safety office and the SDS.
Experimental Workflow Visualization
The following diagram illustrates a general workflow for safely handling a solid chemical in a laboratory environment.
Caption: General laboratory workflow for handling solid chemicals.
Featured Recommendations
| Most viewed |


|
|
|---|---|---|
| Most popular with customers |
|
試験管内研究製品の免責事項と情報
BenchChemで提示されるすべての記事および製品情報は、情報提供を目的としています。BenchChemで購入可能な製品は、生体外研究のために特別に設計されています。生体外研究は、ラテン語の "in glass" に由来し、生物体の外で行われる実験を指します。これらの製品は医薬品または薬として分類されておらず、FDAから任何の医療状態、病気、または疾患の予防、治療、または治癒のために承認されていません。これらの製品を人間または動物に体内に導入する形態は、法律により厳格に禁止されています。これらのガイドラインに従うことは、研究と実験において法的および倫理的な基準の遵守を確実にするために重要です。
