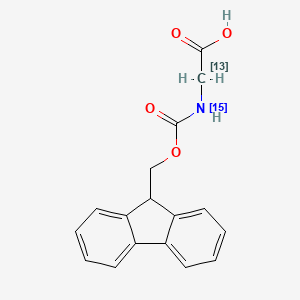
Fmoc-Gly-OH-2-13C,15N
説明
BenchChem offers high-quality this compound suitable for many research applications. Different packaging options are available to accommodate customers' requirements. Please inquire for more information about this compound including the price, delivery time, and more detailed information at info@benchchem.com.
Structure
3D Structure
特性
分子式 |
C17H15NO4 |
|---|---|
分子量 |
299.29 g/mol |
IUPAC名 |
2-(9H-fluoren-9-ylmethoxycarbonyl(15N)amino)acetic acid |
InChI |
InChI=1S/C17H15NO4/c19-16(20)9-18-17(21)22-10-15-13-7-3-1-5-11(13)12-6-2-4-8-14(12)15/h1-8,15H,9-10H2,(H,18,21)(H,19,20)/i9+1,18+1 |
InChIキー |
NDKDFTQNXLHCGO-PHHLUUBBSA-N |
異性体SMILES |
C1=CC=C2C(=C1)C(C3=CC=CC=C32)COC(=O)[15NH][13CH2]C(=O)O |
正規SMILES |
C1=CC=C2C(=C1)C(C3=CC=CC=C32)COC(=O)NCC(=O)O |
製品の起源 |
United States |
Foundational & Exploratory
An In-depth Technical Guide to Fmoc-Gly-OH-2-¹³C,¹⁵N: Properties, Synthesis, and Applications
For Researchers, Scientists, and Drug Development Professionals
This technical guide provides a comprehensive overview of the chemical properties, synthesis, and applications of Fmoc-Gly-OH-2-¹³C,¹⁵N, an isotopically labeled amino acid crucial for modern biochemical and biomedical research. This document details its physical and chemical characteristics, provides protocols for its use in solid-phase peptide synthesis (SPPS), and explores its application in studying protein-protein interactions.
Chemical Properties of Fmoc-Gly-OH-2-¹³C,¹⁵N
Fmoc-Gly-OH-2-¹³C,¹⁵N, also known as N-(9-Fluorenylmethoxycarbonyl)-glycine-2-¹³C,¹⁵N, is a stable isotope-labeled derivative of glycine (B1666218). The incorporation of a carbon-13 (¹³C) isotope at the alpha-carbon (the "2" position) and a nitrogen-15 (B135050) (¹⁵N) isotope in the amino group provides a distinct mass shift, making it an invaluable tool for nuclear magnetic resonance (NMR) spectroscopy and mass spectrometry (MS)-based applications.[1] The isotopic labels do not alter the chemical reactivity of the molecule compared to its unlabeled counterpart.[2]
Table 1: Summary of Chemical and Physical Properties
| Property | Value | Reference(s) |
| Chemical Name | N-(9-Fluorenylmethoxycarbonyl)-glycine-2-¹³C,¹⁵N | |
| Synonyms | Fmoc-glycine-2-¹³C,¹⁵N, Glycine-2-¹³C,¹⁵N N-Fmoc | [1] |
| CAS Number | 285978-12-3 | [1] |
| Linear Formula | (H¹⁵N-Fmoc)¹³CH₂CO₂H | |
| Molecular Weight | 299.29 g/mol | |
| Appearance | White to off-white solid/powder | [3] |
| Melting Point | 174-175 °C (lit.) | |
| Isotopic Purity | 99 atom % ¹³C, 98 atom % ¹⁵N | |
| Mass Shift | M+2 | |
| Storage Temperature | 2-8°C, desiccated and protected from light | |
| Solubility | Soluble in organic solvents such as DMF and DMSO | [1][4] |
Experimental Protocols
The primary application of Fmoc-Gly-OH-2-¹³C,¹⁵N is in solid-phase peptide synthesis (SPPS) to introduce a site-specific isotopic label into a peptide sequence.[2]
This protocol outlines the manual Fmoc-based synthesis of a peptide incorporating Fmoc-Gly-OH-2-¹³C,¹⁵N. This can be adapted for automated peptide synthesizers.
Materials and Reagents:
-
Fmoc-Gly-OH-2-¹³C,¹⁵N
-
Standard Fmoc-protected amino acids
-
Appropriate resin (e.g., Rink Amide resin for C-terminal amides, Wang resin for C-terminal carboxylic acids)
-
N,N-Dimethylformamide (DMF)
-
Dichloromethane (DCM)
-
Piperidine (B6355638) solution (20% in DMF) for Fmoc deprotection
-
Coupling reagents: e.g., N,N'-Diisopropylcarbodiimide (DIC) and Oxyma Pure, or HBTU and DIPEA
-
Cleavage cocktail (e.g., 95% Trifluoroacetic acid (TFA), 2.5% water, 2.5% Triisopropylsilane (TIS))
-
Diethyl ether
Procedure:
-
Resin Swelling: Swell the resin in DMF in a reaction vessel for 30-60 minutes.
-
Fmoc Deprotection: Drain the DMF and add the 20% piperidine in DMF solution to the resin. Agitate for 5-10 minutes. Drain and repeat this step for another 15-20 minutes.
-
Washing: Thoroughly wash the resin with DMF (5-7 times) to remove all traces of piperidine.
-
Amino Acid Coupling (for standard amino acids):
-
In a separate vessel, dissolve the Fmoc-amino acid (3-5 equivalents relative to resin loading) and an activating agent (e.g., HBTU, 3-5 equivalents) in DMF.
-
Add a base (e.g., DIPEA, 6-10 equivalents) to the amino acid solution and pre-activate for 1-2 minutes.
-
Add the activated amino acid solution to the deprotected resin and agitate for 1-2 hours.
-
-
Incorporation of Fmoc-Gly-OH-2-¹³C,¹⁵N:
-
Due to its higher cost, it is advisable to use a smaller excess of the labeled amino acid.
-
Dissolve Fmoc-Gly-OH-2-¹³C,¹⁵N (1.5-2 equivalents) and an activating agent (e.g., HBTU, 1.5-2 equivalents) in DMF.
-
Add a base (e.g., DIPEA, 3-4 equivalents) and allow for pre-activation.
-
Add the solution to the resin and allow the coupling reaction to proceed for 2-4 hours, or until a completion test (e.g., Kaiser test) is negative.
-
-
Washing: Wash the resin with DMF (5-7 times) to remove excess reagents.
-
Chain Elongation: Repeat steps 2 through 6 for each subsequent amino acid in the peptide sequence.
-
Final Deprotection: After the final amino acid has been coupled, perform a final Fmoc deprotection (Step 2).
-
Cleavage and Global Deprotection:
-
Wash the resin with DCM and dry it under a stream of nitrogen.
-
Add the cleavage cocktail to the resin and agitate for 2-3 hours at room temperature.
-
Filter the resin and collect the filtrate containing the peptide.
-
-
Peptide Precipitation and Purification:
-
Precipitate the crude peptide by adding the filtrate to cold diethyl ether.
-
Centrifuge to pellet the peptide and decant the ether.
-
Wash the peptide pellet with cold ether.
-
Purify the peptide using reverse-phase high-performance liquid chromatography (RP-HPLC).
-
-
Analysis: Confirm the identity and purity of the final peptide by mass spectrometry and analytical HPLC.
Caption: General workflow for Fmoc solid-phase peptide synthesis.
Applications in Research
Peptides synthesized with Fmoc-Gly-OH-2-¹³C,¹⁵N are powerful tools for investigating biological systems, particularly for studying protein-protein interactions, enzyme mechanisms, and protein structure and dynamics.[2]
A common application is to use the isotopically labeled peptide as a probe in NMR titration experiments to identify the binding interface with a target protein. By monitoring the chemical shift perturbations (CSPs) in the NMR spectra of the target protein upon addition of the labeled peptide, researchers can map the interaction site at the residue level.
Experimental Protocol Outline: NMR Titration
-
Protein Expression and Purification: Express and purify the target protein, typically with ¹⁵N labeling for heteronuclear single quantum coherence (HSQC) experiments.
-
Peptide Synthesis: Synthesize the peptide of interest with Fmoc-Gly-OH-2-¹³C,¹⁵N incorporated at a specific position using the SPPS protocol described above.
-
NMR Sample Preparation: Prepare a series of NMR samples with a constant concentration of the ¹⁵N-labeled target protein and increasing concentrations of the ¹³C,¹⁵N-labeled peptide.
-
NMR Data Acquisition: Acquire a series of ¹H-¹⁵N HSQC spectra for each titration point.
-
Data Analysis:
-
Overlay the spectra and identify protein amide peaks that shift or broaden upon addition of the peptide.
-
Calculate the chemical shift perturbations for each residue.
-
Map the residues with significant CSPs onto the three-dimensional structure of the target protein to visualize the binding interface.
-
The signals from the labeled glycine in the peptide can also be monitored to confirm its involvement in the interaction.
-
While a specific signaling pathway elucidated using Fmoc-Gly-OH-2-¹³C,¹⁵N is not detailed in the available literature, this methodology is broadly applicable to studying components of various signaling cascades. For instance, a labeled peptide substrate could be used to study the interaction with a specific kinase in the MAPK signaling pathway.
References
Fmoc-Gly-OH-2-13C,15N molecular structure and weight.
For Researchers, Scientists, and Drug Development Professionals
This technical guide provides a comprehensive overview of the molecular structure and weight of Fmoc-Gly-OH isotopically labeled with Carbon-13 at the alpha-carbon and Nitrogen-15 (B135050). This information is critical for a variety of research applications, including peptide synthesis, metabolic labeling, and mass spectrometry-based proteomics.
Molecular Structure and Weight
Fmoc-Gly-OH, or N-(9-Fluorenylmethoxycarbonyl)glycine, is a derivative of the amino acid glycine, where the amino group is protected by a fluorenylmethoxycarbonyl (Fmoc) group.[1][2][3] The specific isotopic labeling in Fmoc-Gly-OH-2-13C,15N involves the substitution of the naturally abundant isotopes with heavier, stable isotopes at defined positions.
The molecular formula for the unlabeled Fmoc-Gly-OH is C₁₇H₁₅NO₄.[1][4] The labeling introduces one Carbon-13 (¹³C) atom and one Nitrogen-15 (¹⁵N) atom.
Quantitative Data Summary
| Property | Value |
| Molecular Formula (Unlabeled) | C₁₇H₁₅NO₄ |
| Molecular Formula (Labeled) | C₁₆¹³CH₁₅¹⁵NO₄ |
| Molecular Weight (Unlabeled) | 297.31 g/mol |
| Isotopic Mass of Carbon-13 | 13.003354835 Da[5] |
| Isotopic Mass of Nitrogen-15 | 15.0001088983 Da[6][7] |
| Calculated Molecular Weight (Labeled) | 299.29 g/mol |
Calculation of Labeled Molecular Weight:
The molecular weight of the isotopically labeled compound is calculated by summing the masses of its constituent atoms, taking into account the specific isotopes. The standard atomic weights for Carbon, Hydrogen, and Oxygen are 12.011 u, 1.008 u, and 15.999 u, respectively. For the labeled molecule, the mass of one carbon atom is substituted with the mass of ¹³C, and the mass of the nitrogen atom is substituted with the mass of ¹⁵N.
Molecular Structure Visualization
The following diagram illustrates the molecular structure of this compound, highlighting the positions of the isotopic labels.
Caption: Molecular structure of this compound.
Experimental Protocols
The determination of the molecular structure and weight of isotopically labeled compounds like this compound relies on several key experimental techniques.
1. Mass Spectrometry (MS)
-
Objective: To determine the precise molecular weight of the labeled compound and confirm the incorporation of the stable isotopes.
-
Methodology:
-
A sample of this compound is ionized using a suitable technique, such as Electrospray Ionization (ESI) or Matrix-Assisted Laser Desorption/Ionization (MALDI).
-
The resulting ions are separated based on their mass-to-charge ratio (m/z) in a mass analyzer (e.g., Time-of-Flight, Quadrupole, or Orbitrap).
-
The detector records the abundance of ions at each m/z value, generating a mass spectrum.
-
The molecular weight is determined from the peak corresponding to the molecular ion. The observed molecular weight should correspond to the calculated value for the labeled compound.
-
2. Nuclear Magnetic Resonance (NMR) Spectroscopy
-
Objective: To confirm the position of the isotopic labels within the molecule.
-
Methodology:
-
A solution of the labeled compound is prepared in a suitable deuterated solvent.
-
¹³C NMR and ¹⁵N NMR spectra are acquired.
-
The chemical shifts and coupling constants in the spectra provide information about the chemical environment of the labeled atoms, confirming their position at the alpha-carbon and the amine group, respectively.
-
Logical Workflow for Characterization
The following diagram outlines the logical workflow for the characterization of this compound.
Caption: Workflow for the synthesis and characterization of labeled Fmoc-Gly-OH.
References
- 1. Fmoc-Gly-OH | C17H15NO4 | CID 93124 - PubChem [pubchem.ncbi.nlm.nih.gov]
- 2. medchemexpress.com [medchemexpress.com]
- 3. Fmoc-Gly-OH ≥98.0% (T) | Sigma-Aldrich [sigmaaldrich.com]
- 4. raybiotech.com [raybiotech.com]
- 5. Carbon-13 - Wikipedia [en.wikipedia.org]
- 6. Nitrogen-15 - isotopic data and properties [chemlin.org]
- 7. Isotope data for nitrogen-15 in the Periodic Table [periodictable.com]
In-Depth Technical Guide to Fmoc-Gly-OH-2-13C,15N
For Researchers, Scientists, and Drug Development Professionals
This technical guide provides comprehensive information on the isotopically labeled amino acid derivative, Fmoc-Gly-OH-2-13C,15N. This compound is a crucial tool in various scientific disciplines, particularly in peptide synthesis, proteomics, and drug development, where isotopic labeling is essential for analytical tracking and quantification.
Chemical Identity and Properties
N-(9-Fluorenylmethoxycarbonyl)-glycine-2-13C,15N, commonly referred to as this compound, is a stable isotope-labeled form of Fmoc-glycine. The isotopic enrichment with Carbon-13 at the alpha-carbon and Nitrogen-15 at the amino group provides a distinct mass shift, making it an invaluable tracer in mass spectrometry and a sensitive probe in NMR spectroscopy.
The CAS number for this compound is 285978-12-3 [1][2]. It is important to distinguish this from the dually carbon-labeled version, Fmoc-Gly-OH-13C2,15N, which has a different CAS number (285978-13-4)[3][4][5][6].
Table 1: Physicochemical Properties of this compound
| Property | Value | Source |
| CAS Number | 285978-12-3 | [1][2] |
| Molecular Formula | C₁₆¹³CH₁₅¹⁵NO₄ | [2] |
| Molecular Weight | 299.29 g/mol | [1][2] |
| Appearance | White to off-white solid | [2] |
| Melting Point | 174-175 °C | [1][4] |
| Storage Temperature | 2-8°C | [1][4] |
| Isotopic Purity | 99 atom % ¹³C, 98 atom % ¹⁵N | [1] |
Analytical Data
The isotopic labels in this compound result in characteristic spectral data that are essential for its identification and for tracking its incorporation into larger molecules.
Table 2: Key Analytical Data for this compound
| Analytical Technique | Observed Data |
| Mass Spectrometry (MS) | Mass shift of M+2 compared to the unlabeled analog. |
| Nuclear Magnetic Resonance (NMR) | Distinct chemical shifts for the ¹³C-labeled alpha-carbon and the ¹⁵N-labeled nitrogen, providing enhanced sensitivity and resolution.[3] |
Applications in Research and Drug Development
The unique properties of this compound make it a versatile tool in several research areas:
-
Peptide Synthesis : It serves as a building block in Solid Phase Peptide Synthesis (SPPS) for creating isotopically labeled peptides.[3] These labeled peptides are critical for a variety of studies.
-
Quantitative Proteomics : Labeled peptides are used as internal standards for the accurate quantification of proteins in complex biological samples using mass spectrometry-based techniques.[7]
-
Structural Biology : NMR studies of proteins and peptides incorporating this labeled amino acid can provide detailed insights into their structure, dynamics, and interactions.[3] The isotopic labels act as specific probes for monitoring molecular behavior.
-
Metabolic Studies : It can be used as a tracer to follow the metabolic fate of glycine (B1666218) or glycine-containing molecules in biological systems.[2][7]
-
Drug Development : In pharmaceutical research, it aids in studying the metabolism and pharmacokinetics of peptide-based drugs.[3]
Experimental Protocols
Protocol 1: Incorporation of this compound into a Peptide via Solid Phase Peptide Synthesis (SPPS)
This protocol outlines the general steps for coupling this compound to a growing peptide chain on a solid support.
-
Resin Preparation : The peptide synthesis resin with the N-terminal Fmoc group removed is swollen in a suitable solvent like dimethylformamide (DMF).
-
Fmoc Deprotection : The Fmoc protecting group of the resin-bound peptide is removed by treating it with a solution of 20-25% piperidine (B6355638) in DMF.[8] This exposes the free amino group for the next coupling step.
-
Washing : The resin is thoroughly washed with DMF to remove residual piperidine and by-products.
-
Coupling Reaction :
-
A solution of this compound (typically 1.5-4 equivalents over the resin loading) and a coupling agent (e.g., HBTU, HOBt) is prepared in DMF.[8]
-
A base, such as N,N-diisopropylethylamine (DIPEA), is added to the activation mixture.[8]
-
The activated amino acid solution is added to the washed resin.
-
The reaction is allowed to proceed for a specified time (e.g., 60 minutes) to ensure complete coupling.[8]
-
-
Washing : The resin is washed extensively with DMF, methanol (B129727) (MeOH), and dichloromethane (B109758) (DCM) to remove excess reagents and by-products.[8]
-
Confirmation of Coupling : A small sample of the resin can be tested (e.g., using the Kaiser test) to confirm the completion of the coupling reaction.
-
Chain Elongation : The cycle of deprotection, washing, and coupling is repeated for subsequent amino acids in the peptide sequence.
Visualizations
Diagram 1: Solid Phase Peptide Synthesis (SPPS) Workflow
Caption: Workflow for the incorporation of an Fmoc-amino acid in SPPS.
Diagram 2: Application Logic for Labeled Peptides
Caption: Key applications stemming from the synthesis of labeled peptides.
References
- 1. This compound 99 atom % 13C, 98 atom % 15N | 285978-12-3 [sigmaaldrich.com]
- 2. medchemexpress.com [medchemexpress.com]
- 3. Fmoc-Gly-OH-13C2,15N | 285978-13-4 | Benchchem [benchchem.com]
- 4. Fmoc-Gly-OH-13C2,15N 99 atom % 13C, 98 atom % 15N | 285978-13-4 [sigmaaldrich.com]
- 5. chempep.com [chempep.com]
- 6. Glycine-ð-Fmoc (¹³Câ, 99%; ¹âµN, 99%) | Cambridge Isotope Laboratories, Inc. [isotope.com]
- 7. medchemexpress.com [medchemexpress.com]
- 8. pubs.rsc.org [pubs.rsc.org]
A Technical Guide to 13C and 15N Labeled Glycine for Peptide Synthesis
For Researchers, Scientists, and Drug Development Professionals
This in-depth guide explores the pivotal role of glycine (B1666218) labeled with stable isotopes of carbon (¹³C) and nitrogen (¹⁵N) in the realm of peptide synthesis. The strategic incorporation of these non-radioactive isotopes into peptide chains provides a powerful tool for a myriad of applications, from elucidating protein structure and function to advancing drug discovery and development. This document provides a comprehensive overview of the synthesis, analysis, and application of these invaluable research tools, complete with detailed experimental protocols and quantitative data.
Introduction to Isotopic Labeling in Peptide Synthesis
Stable isotope labeling involves the substitution of an atom in a molecule with its heavier, non-radioactive isotope. In the context of peptide synthesis, amino acids, such as glycine, can be chemically synthesized to contain ¹³C instead of the naturally more abundant ¹²C, and ¹⁵N in place of ¹⁴N.[1] These "heavy" amino acids are chemically identical to their "light" counterparts, meaning they participate in the same biochemical reactions and form peptides with the same three-dimensional structures.[2] The key difference lies in their mass, a property that can be precisely detected by analytical techniques like mass spectrometry (MS) and nuclear magnetic resonance (NMR) spectroscopy.[3]
Glycine, the simplest amino acid, is a frequent target for isotopic labeling due to its conformational flexibility and common occurrence in protein motifs. Peptides synthesized with ¹³C and ¹⁵N labeled glycine serve as powerful probes in a variety of research areas.
Core Applications
The use of peptides incorporating ¹³C and ¹⁵N labeled glycine is widespread across several scientific disciplines:
-
Structural Biology (NMR): Isotopic labeling is fundamental to modern NMR spectroscopy for the determination of peptide and protein structures in solution and in the solid state. The presence of ¹³C and ¹⁵N, both of which have a nuclear spin of 1/2, allows for the use of multidimensional heteronuclear NMR experiments that are not possible with the natural abundance of these isotopes.[4] This enables the precise assignment of atomic resonances and the determination of three-dimensional structures.
-
Quantitative Proteomics (Mass Spectrometry): In proteomics, the study of the entire set of proteins in a biological system, stable isotope labeling is a cornerstone of quantitative analysis. Techniques like Stable Isotope Labeling by Amino Acids in Cell Culture (SILAC) utilize cells grown in media containing "heavy" amino acids to differentiate and quantify proteins between different cell populations.[5] Peptides containing ¹³C and ¹⁵N labeled glycine can also be synthesized and used as internal standards for the absolute quantification of specific proteins in complex biological samples.[6]
-
Metabolic Studies: Labeled peptides can be introduced into biological systems to trace metabolic pathways and study the fate of specific molecules in vivo.[6]
-
Drug Development: The synthesis of isotopically labeled versions of peptide-based drugs or their targets is crucial for studying their stability, metabolism, and interaction with other molecules.[3] This information is vital for optimizing drug design and formulation.
Quantitative Data for Labeled Glycine and Peptide Synthesis
The success of experiments utilizing isotopically labeled peptides hinges on the quality of the labeled amino acids and the efficiency of the peptide synthesis process. The following tables summarize key quantitative data.
| Parameter | Typical Value(s) | Reference(s) |
| Isotopic Purity of ¹³C | >99% | [1] |
| Isotopic Purity of ¹⁵N | >98% | [1] |
| Chemical Purity | >98% | [7] |
Table 1: Typical Purity of Commercially Available ¹³C and ¹⁵N Labeled Glycine.
| Parameter | Typical Value(s) | Reference(s) |
| Coupling Efficiency per Cycle | >99% | [2] |
| Crude Yield (for a pentapeptide) | ~50 mg (from ~100 mg resin scale) | [2] |
| Final Purified Yield (for a pentapeptide) | 30-40% (15-25 mg) | [2] |
| Mass Shift per ¹³C atom | +1.00335 Da | [2] |
| Mass Shift per ¹⁵N atom | +0.99703 Da | |
| Total Mass Shift for Glycine-¹³C₂,¹⁵N | +3.00373 Da |
Table 2: Quantitative Parameters in Solid-Phase Peptide Synthesis (SPPS) with Labeled Glycine.
Experimental Protocols
The primary method for producing synthetic peptides is Solid-Phase Peptide Synthesis (SPPS).[3] The following is a detailed protocol for the manual Fmoc (9-fluorenylmethyloxycarbonyl) SPPS cycle for incorporating a ¹³C and ¹⁵N labeled glycine residue into a peptide chain.
Protocol 1: Manual Fmoc SPPS Cycle for ¹³C, ¹⁵N-Glycine Incorporation
Materials:
-
Peptide synthesis vessel with a fritted disc
-
Resin with N-terminal Fmoc-deprotected peptide
-
Fmoc-Gly-¹³C₂,¹⁵N-OH
-
Coupling reagent (e.g., HBTU - 2-(1H-benzotriazol-1-yl)-1,1,3,3-tetramethyluronium hexafluorophosphate)
-
Base (e.g., N,N-Diisopropylethylamine - DIPEA)
-
Dimethylformamide (DMF), peptide synthesis grade
-
20% (v/v) piperidine (B6355638) in DMF
-
Dichloromethane (DCM)
-
Methanol (MeOH)
-
Kaiser test kit (optional, for monitoring coupling completion)
Procedure:
-
Resin Swelling: Swell the resin in DMF for at least 30 minutes in the reaction vessel.
-
Fmoc Deprotection:
-
Drain the DMF.
-
Add the 20% piperidine in DMF solution to the resin.
-
Agitate the mixture for 5-10 minutes at room temperature to remove the Fmoc protecting group from the N-terminus of the growing peptide chain.
-
Drain the piperidine solution and wash the resin thoroughly with DMF (3-5 times).
-
-
Coupling of Fmoc-Gly-¹³C₂,¹⁵N-OH:
-
In a separate vial, dissolve 3-5 equivalents of Fmoc-Gly-¹³C₂,¹⁵N-OH and a slightly lower molar equivalent of the coupling reagent (e.g., HBTU) in DMF.
-
Add 6-10 equivalents of DIPEA to the activation mixture and vortex for 1-2 minutes. This pre-activates the labeled amino acid.
-
Add the activated amino acid solution to the resin in the reaction vessel.
-
Agitate the reaction vessel for 1-2 hours at room temperature to allow for the coupling of the labeled glycine to the deprotected N-terminus of the peptide chain.
-
-
Washing:
-
Drain the coupling solution.
-
Wash the resin extensively with DMF (3-5 times), DCM (3 times), and MeOH (3 times) to remove any unreacted reagents and byproducts.
-
-
Kaiser Test (Optional):
-
Take a small sample of the resin beads.
-
Perform the Kaiser test to confirm the absence of free primary amines, which indicates a complete coupling reaction. A negative result (yellow beads) is desired.
-
-
Repeat Cycle: The deprotection and coupling steps are repeated for each subsequent amino acid in the peptide sequence.
-
Final Cleavage and Deprotection: Once the peptide synthesis is complete, the peptide is cleaved from the resin, and the side-chain protecting groups are removed using a cleavage cocktail, typically containing trifluoroacetic acid (TFA).
-
Purification and Analysis: The crude peptide is then purified, typically by reverse-phase high-performance liquid chromatography (RP-HPLC), and its identity and purity are confirmed by mass spectrometry.[2]
Visualizing Workflows and Signaling Pathways
Visual representations of experimental workflows and biological pathways are invaluable for understanding complex processes. The following diagrams were generated using the Graphviz DOT language.
Application in a Signaling Pathway: Protein Kinase A
Protein Kinase A (PKA) is a key enzyme in many signal transduction pathways, regulating processes such as metabolism, gene expression, and cell growth. PKA recognizes and phosphorylates specific substrate proteins containing a consensus sequence. A well-known synthetic peptide substrate for PKA is "Kemptide," with the sequence Leu-Arg-Arg-Ala-Ser-Leu-Gly. By synthesizing Kemptide with a ¹³C and ¹⁵N labeled glycine at the C-terminus, researchers can use mass spectrometry to accurately quantify PKA activity by measuring the mass shift upon phosphorylation of the serine residue.
Conclusion
The incorporation of ¹³C and ¹⁵N labeled glycine into synthetic peptides is a cornerstone of modern biochemical and biomedical research. This technique provides an unparalleled level of insight into the intricate workings of biological systems, from the atomic-level detail of protein structure to the dynamic changes of the proteome. The ability to synthesize high-purity peptides with defined isotopic labeling patterns, primarily through SPPS, has empowered researchers to address fundamental questions in biology and to accelerate the development of new therapeutics. As analytical technologies continue to advance, the applications for peptides synthesized with stable isotopes are poised to expand even further, promising new discoveries in science and medicine.
References
- 1. Isotope-labeled peptides – ProteoGenix [proteogenix.science]
- 2. benchchem.com [benchchem.com]
- 3. Solid Phase Peptide Synthesis with Isotope Labeling | Silantes [silantes.com]
- 4. chempep.com [chempep.com]
- 5. Synthesis of 13C-methyl-labeled amino acids and their incorporation into proteins in mammalian cells - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Metabolic Pathway Confirmation and Discovery Through 13C-labeling of Proteinogenic Amino Acids - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Peptide Synthesis â Cambridge Isotope Laboratories, Inc. [isotope.com]
The fundamental principles of stable isotope labeling in proteomics.
An In-depth Technical Guide to the Fundamental Principles of Stable Isotope Labeling in Proteomics
Introduction
Quantitative proteomics is a critical discipline in modern biological research and drug development, aiming to measure the absolute or relative abundance of proteins in a sample. Among the various techniques available, stable isotope labeling has become a cornerstone for its accuracy and robustness.[1][2] This methodology involves the incorporation of stable, non-radioactive heavy isotopes (such as ¹³C, ¹⁵N, ²H, or ¹⁸O) into proteins or peptides.[3][4] By creating "heavy" and "light" versions of molecules that are chemically identical but distinguishable by mass spectrometry, researchers can precisely quantify changes in protein expression levels between different biological samples.[1][5]
This guide provides a comprehensive overview of the core principles, experimental protocols, and comparative analysis of the most prominent stable isotope labeling techniques used in proteomics today: SILAC, ICAT, iTRAQ, and TMT.
General Principle of Stable Isotope Labeling
The fundamental concept behind stable isotope labeling is to introduce a known mass difference between proteins from different samples. A control ("light") sample is compared to an experimental ("heavy") sample. After labeling, the samples are combined, processed, and analyzed in a single mass spectrometry run.[6][7] This co-analysis minimizes experimental variability that can arise from separate sample preparations and analyses.[6][7] The relative protein abundance is then determined by comparing the signal intensities of the light and heavy isotopic peptide pairs in the mass spectrometer.
Figure 1: Core logic of stable isotope labeling for quantitative proteomics.
Labeling strategies are broadly divided into two categories: metabolic labeling, where isotopes are incorporated in vivo, and chemical labeling, where isotopes are attached in vitro.[4][8]
Metabolic Labeling: SILAC (Stable Isotope Labeling by Amino Acids in Cell Culture)
SILAC is a powerful and accurate in vivo metabolic labeling technique first introduced in 2002.[9][10] It involves growing two populations of cells in media that are identical except for specific amino acids, which are either in their natural "light" form or a "heavy" stable isotope-labeled form.[1][9] Typically, labeled versions of arginine (Arg) and lysine (B10760008) (Lys) are used, as trypsin digestion cleaves proteins after these residues, ensuring that nearly every resulting peptide contains a label for quantification.[2][11] After several cell divisions, the heavy amino acids are fully incorporated into the entire proteome of one cell population.[9][11]
Experimental Workflow and Protocol
The SILAC experiment is conducted in two main phases: an adaptation phase to ensure complete labeling and an experimental phase for the biological investigation.[12][13]
Figure 2: Experimental workflow for a typical SILAC experiment.
Generalized Experimental Protocol:
-
Adaptation Phase : Two cell populations are cultured in specialized SILAC media deficient in certain amino acids (e.g., lysine and arginine).[13] One culture is supplemented with normal "light" amino acids, while the other receives "heavy" isotope-labeled amino acids (e.g., ¹³C₆-Lys, ¹³C₆¹⁵N₄-Arg).[12] Cells are grown for at least five generations to ensure near-complete incorporation (>95%) of the labeled amino acids into their proteomes.[10][14] Label incorporation efficiency should be confirmed via mass spectrometry on a small sample.[12][15]
-
Experimental Phase : Once fully labeled, the cells are subjected to the desired experimental conditions (e.g., one population is treated with a drug while the other serves as a control).[14]
-
Sample Combination and Preparation : The "light" and "heavy" cell populations are combined in a 1:1 ratio.[15] This early-stage mixing is a key advantage of SILAC, as it minimizes downstream processing errors. The combined cells are then lysed to extract the proteins.
-
Protein Digestion : The extracted protein mixture is digested into peptides, typically using the enzyme trypsin.[13]
-
LC-MS/MS Analysis : The resulting peptide mixture is separated by liquid chromatography (LC) and analyzed by tandem mass spectrometry (MS/MS).[13]
-
Quantification : In the MS1 scan, peptides appear in pairs (light and heavy). The relative abundance of a protein is determined by calculating the ratio of the signal intensities of these corresponding peptide pairs.[1]
Chemical Labeling Methods
Chemical labeling is an in vitro approach where stable isotopes are covalently attached to proteins or peptides after extraction from the cell or tissue. This method is highly versatile as it is not limited to cultured cells and can be applied to virtually any sample type, including tissues and biofluids.[16][17]
Isotope-Coded Affinity Tag (ICAT)
The ICAT method, one of the earliest chemical labeling techniques, specifically targets the sulfhydryl group of cysteine residues.[18][19] The ICAT reagent consists of three parts: a reactive group that binds to cysteines, an isotopically coded linker (e.g., containing eight deuterium (B1214612) atoms in the "heavy" version and none in the "light" version), and a biotin (B1667282) affinity tag.[20] The biotin tag allows for the specific isolation of the labeled (cysteine-containing) peptides, which significantly reduces sample complexity before MS analysis.[18][19]
Figure 3: Experimental workflow for the ICAT technique.
Generalized Experimental Protocol:
-
Protein Extraction and Labeling : Proteins are extracted from two separate samples (e.g., control and treated). The cysteine residues in one sample are labeled with the "light" ICAT reagent, and the other with the "heavy" reagent.[21][22]
-
Sample Combination and Digestion : The two labeled protein samples are combined and then digested with a protease like trypsin.[22]
-
Affinity Purification : The combined peptide mixture is passed through an avidin (B1170675) affinity column. Only the biotin-tagged peptides (those containing cysteine) are retained, while all other peptides are washed away.[19][22]
-
LC-MS/MS Analysis : The enriched, labeled peptides are eluted from the column and analyzed by LC-MS/MS.
-
Quantification : Similar to SILAC, quantification is based on the ratio of signal intensities of the light and heavy peptide pairs at the MS1 level.[18]
A major limitation of ICAT is that it only quantifies proteins containing cysteine residues, and proteins without cysteines will not be detected.[18]
Isobaric Labeling: iTRAQ and TMT
Isobaric labeling, which includes popular techniques like iTRAQ (isobaric Tags for Relative and Absolute Quantitation) and TMT (Tandem Mass Tags), is a powerful chemical labeling method that allows for multiplexing—the simultaneous analysis of multiple samples.[23][24]
The core principle is that the tags are isobaric, meaning they have the same total mass.[23][25] Peptides from different samples labeled with different isobaric tags (e.g., a 4-plex experiment) will appear as a single, combined peak in the initial MS1 scan.[17] Upon fragmentation during the MS/MS scan, the tag breaks apart, releasing unique reporter ions of different masses. The intensity of these reporter ions is then used to quantify the relative abundance of the peptide in each of the original samples.[23][26]
The tags are composed of three parts: a reporter group (with a unique isotopic composition for each tag), a balance group (which ensures the total mass of the tag remains constant), and a peptide-reactive group that binds to the N-terminus and lysine side chains of peptides.[17][24][25]
Figure 4: General workflow for isobaric labeling (iTRAQ/TMT).
Generalized Experimental Protocol (iTRAQ/TMT):
-
Protein Extraction and Digestion : Proteins are extracted from each sample (up to 18 with TMTpro) and digested into peptides, usually with trypsin.[24][27]
-
Peptide Labeling : Each peptide digest is individually labeled with a different isobaric tag from the multiplex kit.[27][28] The reaction targets the primary amines on the peptide N-terminus and lysine residues.[29][30]
-
Sample Pooling : After labeling, all samples are combined into a single mixture.[25][27]
-
Fractionation (Optional but Recommended) : To reduce the complexity of the peptide mixture and increase proteome coverage, the pooled sample is often fractionated using techniques like high-pH reversed-phase liquid chromatography.[24]
-
LC-MS/MS Analysis : Each fraction is then analyzed by tandem mass spectrometry.[24] In the MS/MS scan, a specific precursor ion (the combined peak from all samples) is isolated and fragmented.[31]
-
Quantification and Data Analysis : The fragmentation pattern provides the peptide's sequence for identification, while the intensities of the low-mass reporter ions provide the relative quantification across the different samples.[28][31] Specialized software is used to process the data, identify the proteins, and perform statistical analysis.[27]
Quantitative Data and Method Comparison
Choosing the right stable isotope labeling method depends on the experimental design, sample type, and desired depth of analysis. The table below summarizes and compares the key features of each technique.
| Feature | SILAC | ICAT | iTRAQ | TMT |
| Labeling Type | Metabolic (in vivo) | Chemical (in vitro) | Chemical (in vitro) | Chemical (in vitro) |
| Principle | Mass shift at MS1 | Mass shift at MS1 | Isobaric; Reporter ions at MS2 | Isobaric; Reporter ions at MS2 |
| Target Residues | Specific amino acids (e.g., Arg, Lys) | Cysteine | N-terminus, Lysine | N-terminus, Lysine |
| Multiplexing | Typically 2-3 plex | 2 plex | 4-plex, 8-plex | 6, 10, 11, 16, 18-plex |
| Sample Type | Proliferating cells in culture | Any protein sample | Any protein sample | Any protein sample |
| Advantages | - High accuracy and reproducibility[2][9]- Labeling at protein level minimizes error[6]- Can study protein turnover (dynamic SILAC)[32] | - Reduces sample complexity[18]- Gel-free approach | - High throughput[25][31]- Broad applicability[17][31]- Good precision[17] | - Highest multiplexing capability[24]- Fewer missing values compared to label-free[33]- High throughput |
| Limitations | - Limited to metabolically active, cultured cells[9]- Long adaptation time[9]- Arginine-to-proline conversion can occur[2]- Lower multiplexing | - Only quantifies cysteine-containing proteins[18]- May miss PTM information[18]- Lower proteome coverage | - Quantification at MS2 can be affected by co-isolation interference[34]- Reagents can be costly[6][7] | - Co-isolation interference can affect accuracy (MS3 methods can mitigate this)[33][34]- Higher cost of reagents[7] |
Conclusion
Stable isotope labeling is a fundamental and powerful approach in quantitative proteomics, offering high precision and accuracy for dissecting complex biological systems. Metabolic labeling with SILAC provides exceptional quantitative accuracy for cell culture-based experiments. Chemical labeling methods have broader applicability; ICAT offers a unique way to reduce sample complexity by focusing on cysteine-containing peptides, while isobaric tagging with iTRAQ and TMT provides high-throughput capabilities essential for comparing multiple samples simultaneously, a common need in clinical research and drug development. The choice of method should be carefully aligned with the specific research question, sample availability, and experimental goals. As mass spectrometry technology continues to advance, these labeling strategies will undoubtedly evolve, further enhancing our ability to understand the dynamic nature of the proteome.
References
- 1. Stable isotope labeling by amino acids in cell culture - Wikipedia [en.wikipedia.org]
- 2. biocev.lf1.cuni.cz [biocev.lf1.cuni.cz]
- 3. academic.oup.com [academic.oup.com]
- 4. Stable isotopic labeling in proteomics - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. ckisotopes.com [ckisotopes.com]
- 6. Comparing SILAC- and Stable Isotope Dimethyl-Labeling Approaches for Quantitative Proteomics - PMC [pmc.ncbi.nlm.nih.gov]
- 7. pubs.acs.org [pubs.acs.org]
- 8. academic.oup.com [academic.oup.com]
- 9. SILAC: Principles, Workflow & Applications in Proteomics - Creative Proteomics Blog [creative-proteomics.com]
- 10. info.gbiosciences.com [info.gbiosciences.com]
- 11. SILAC - Based Proteomics Analysis - Creative Proteomics [creative-proteomics.com]
- 12. researchgate.net [researchgate.net]
- 13. info.gbiosciences.com [info.gbiosciences.com]
- 14. researchgate.net [researchgate.net]
- 15. SILAC Quantitation | UT Southwestern Proteomics Core [proteomics.swmed.edu]
- 16. Advances in stable isotope labeling: dynamic labeling for spatial and temporal proteomic analysis - PMC [pmc.ncbi.nlm.nih.gov]
- 17. iTRAQ-based Quantitative Proteomics Analysis - Creative Proteomics [creative-proteomics.com]
- 18. ICAT (Isotope-coded affinity-tag-based protein profiling) | Proteomics [medicine.yale.edu]
- 19. ICAT -- A New Method for Quantitative Proteome Analysis [bioprocessonline.com]
- 20. Isotope-coded affinity tag - Wikipedia [en.wikipedia.org]
- 21. researchgate.net [researchgate.net]
- 22. researchgate.net [researchgate.net]
- 23. iTRAQ in Proteomics: Principles, Differences, and Applications - Creative Proteomics [creative-proteomics.com]
- 24. TMT Quantitative Proteomics: A Comprehensive Guide to Labeled Protein Analysis - MetwareBio [metwarebio.com]
- 25. iTRAQ Introduction and Applications in Quantitative Proteomics - Creative Proteomics Blog [creative-proteomics.com]
- 26. Isobaric tag for relative and absolute quantitation - Wikipedia [en.wikipedia.org]
- 27. A Detailed Workflow of TMT-Based Quantitative Proteomics | MtoZ Biolabs [mtoz-biolabs.com]
- 28. TMT Based Proteomics Service - Creative Proteomics [creative-proteomics.com]
- 29. Isobaric Tag for Relative and Absolute Quantitation (iTRAQ)-Based Protein Profiling in Plants - PubMed [pubmed.ncbi.nlm.nih.gov]
- 30. Quantification of Proteins by iTRAQ | Springer Nature Experiments [experiments.springernature.com]
- 31. iTRAQ Quantification Technology: Principles, Advantages, and Applications | MtoZ Biolabs [mtoz-biolabs.com]
- 32. SILAC Metabolic Labeling Systems | Thermo Fisher Scientific - US [thermofisher.com]
- 33. Protein Quantification Technology-TMT Labeling Quantitation - Creative Proteomics [creative-proteomics.com]
- 34. researchgate.net [researchgate.net]
Dual Isotopic Labeling in NMR Studies: A Technical Guide to Unlocking Complex Biological Systems
For Researchers, Scientists, and Drug Development Professionals
In the intricate world of molecular biology and drug discovery, understanding the structure, dynamics, and interactions of proteins is paramount. Nuclear Magnetic Resonance (NMR) spectroscopy stands as a powerful technique for elucidating these molecular details in solution, mimicking the native cellular environment. However, the inherent complexity and size of many biological macromolecules often lead to crowded and poorly resolved NMR spectra, hindering detailed analysis. Dual isotopic labeling, the strategic incorporation of two different stable isotopes, typically Carbon-13 (¹³C) and Nitrogen-15 (¹⁵N), into a protein of interest, has emerged as a transformative approach to overcome these limitations. This technical guide delves into the core advantages of dual isotopic labeling in NMR studies, providing a comprehensive overview for researchers, scientists, and drug development professionals.
Core Advantages of Dual Isotopic Labeling
The primary benefit of employing dual isotopic labeling lies in the significant simplification and enhanced information content of NMR spectra. By enriching proteins with ¹³C and ¹⁵N, researchers can exploit the distinct magnetic properties of these nuclei to perform a suite of multidimensional heteronuclear NMR experiments. These experiments disperse the otherwise overlapping proton signals into higher dimensions, dramatically improving spectral resolution.
The advantages of this approach are multifaceted and quantitatively significant. The combination of ¹³C and ¹⁵N labeling, often coupled with deuteration (²H labeling), leads to a substantial reduction in signal linewidths and a corresponding increase in sensitivity. For instance, the use of deuteration in concert with ¹³C and ¹⁵N labeling can significantly improve the relaxation properties of the observed nuclei, leading to sharper signals and enabling the study of larger proteins and protein complexes.[1] While ¹⁵N labeling alone provides a "fingerprint" of a protein via the ¹H-¹⁵N HSQC spectrum, the addition of ¹³C labeling unlocks the ability to perform triple-resonance experiments, which are crucial for the sequential assignment of the protein backbone and side chains. This comprehensive assignment is the foundation for detailed structural and dynamic studies.
Quantitative Impact of Isotopic Labeling on NMR Parameters
To illustrate the profound impact of isotopic labeling, the following table summarizes the typical quantitative improvements observed in key NMR parameters. These values are representative and can vary depending on the specific protein and experimental conditions.
| Parameter | Unlabeled Protein | ¹⁵N Labeled Protein | ¹³C/¹⁵N Dual Labeled Protein | ¹³C/¹⁵N/²H Triple Labeled Protein |
| Spectral Resolution | Low (severe overlap in ¹H dimension) | Moderate (dispersed in 2D ¹H-¹⁵N) | High (dispersed in 3D/4D) | Very High (reduced ¹H-¹H couplings) |
| Typical ¹H Linewidth (Hz) for a 25 kDa Protein | > 30 | ~25-30 | ~20-25 | < 15 |
| Relative Sensitivity | 1x | ~10x (for ¹H-¹⁵N correlation) | ~100x (for triple resonance) | Up to 1000x (with TROSY) |
| Feasible Protein Size for Detailed Study | < 15 kDa | < 25 kDa | < 40 kDa | > 50 kDa |
This table presents generalized data compiled from various sources to illustrate the progressive advantages of different labeling schemes.
Elucidating Signaling Pathways: The β2-Adrenergic Receptor Activation
A prime example of the power of isotopic labeling in unraveling complex biological processes is the study of G-protein coupled receptor (GPCR) signaling. The β2-adrenergic receptor (β2AR), a prototypical GPCR, is a critical drug target, and understanding its activation mechanism is of immense therapeutic interest.[2][3] Dual isotopic labeling, in combination with advanced NMR techniques, has provided unprecedented insights into the conformational changes that accompany β2AR activation.
By selectively labeling methionine residues with ¹³CH₃ in the β2AR, researchers have been able to monitor conformational changes in the transmembrane core of the receptor upon binding to different ligands (inverse agonists, agonists) and a G-protein-mimetic nanobody.[2] These studies have revealed the existence of multiple conformational states that are not observable in static crystal structures, highlighting the dynamic nature of receptor activation.[2] The ability to track specific residues provides a powerful tool to map the allosteric communication network within the receptor that links ligand binding to G-protein coupling.[4]
Below is a diagram illustrating the logical workflow of how dual isotopic labeling is employed to study the β2-adrenergic receptor activation pathway.
Experimental Protocols
The successful application of dual isotopic labeling in NMR studies hinges on robust and reproducible experimental protocols. Below are detailed methodologies for key experiments.
Uniform ¹³C/¹⁵N Dual Labeling of a Target Protein in E. coli
This protocol is a standard method for producing uniformly dual-labeled proteins for NMR analysis.
1. Plasmid Transformation:
- Transform an E. coli expression strain (e.g., BL21(DE3)) with a plasmid containing the gene of interest under the control of an inducible promoter (e.g., T7).
- Plate the transformed cells on an LB agar (B569324) plate containing the appropriate antibiotic and incubate overnight at 37°C.
2. Starter Culture:
- Inoculate a single colony into 50 mL of LB medium with the corresponding antibiotic.
- Grow the culture overnight at 37°C with shaking (220 rpm).
3. M9 Minimal Medium Preparation (per liter):
- Autoclave separately:
- 900 mL of water with 6 g Na₂HPO₄, 3 g KH₂PO₄, and 0.5 g NaCl.
- 1 M MgSO₄ solution.
- 1 M CaCl₂ solution.
- 20% (w/v) glucose solution.
- 10 mg/mL thiamine (B1217682) solution.
- After cooling, aseptically combine the solutions. Add 2 mL of 1 M MgSO₄, 100 µL of 1 M CaCl₂, and 1 mL of 10 mg/mL thiamine.
- For isotopic labeling, use ¹³C₆-glucose as the sole carbon source and ¹⁵NH₄Cl (1 g/L) as the sole nitrogen source.
4. Main Culture and Induction:
- Inoculate 1 L of the prepared M9 minimal medium with the 50 mL overnight starter culture.
- Grow the cells at 37°C with shaking until the optical density at 600 nm (OD₆₀₀) reaches 0.6-0.8.
- Induce protein expression by adding isopropyl β-D-1-thiogalactopyranoside (IPTG) to a final concentration of 0.5-1 mM.
- Continue to grow the culture for 4-6 hours at 30°C or overnight at 18-20°C.
5. Cell Harvesting and Protein Purification:
- Harvest the cells by centrifugation (e.g., 6000 x g for 15 minutes at 4°C).
- Resuspend the cell pellet in a suitable lysis buffer and lyse the cells (e.g., by sonication or high-pressure homogenization).
- Purify the labeled protein using standard chromatography techniques (e.g., affinity chromatography followed by size-exclusion chromatography).
6. NMR Sample Preparation:
- Concentrate the purified protein to the desired concentration (typically 0.1-1 mM).
- Exchange the buffer to an NMR-compatible buffer (e.g., 20 mM sodium phosphate, 50 mM NaCl, pH 6.5) containing 5-10% D₂O for the lock signal.
NMR Data Acquisition for a Dual-Labeled Protein
This protocol outlines the general steps for acquiring a standard 2D ¹H-¹⁵N HSQC spectrum, which is a cornerstone experiment for studying labeled proteins.[5][6]
1. Spectrometer Setup:
- Insert the NMR sample into the spectrometer.
- Tune and match the probe for the ¹H and ¹⁵N frequencies.
- Lock the spectrometer on the D₂O signal.
- Shim the magnetic field to achieve optimal homogeneity.
2. Experiment Setup:
- Load a standard ¹H-¹⁵N HSQC pulse program (e.g., hsqcfpf3gpph on a Bruker spectrometer).
- Set the appropriate spectral widths in both the ¹H and ¹⁵N dimensions to cover all expected signals.
- Set the carrier frequencies for ¹H (typically at the water resonance) and ¹⁵N (center of the amide region, ~118 ppm).
- Set the number of scans (NS), number of increments in the indirect dimension (TD1), and the acquisition time.
3. Data Acquisition:
- Start the acquisition. The experiment time will depend on the sample concentration and the desired signal-to-noise ratio.
4. Data Processing:
- Apply appropriate window functions (e.g., squared sine bell) in both dimensions.
- Perform Fourier transformation.
- Phase the spectrum.
- Reference the spectrum using an internal or external standard.
The logical relationship for this experimental workflow is depicted below.
References
- 1. pound.med.utoronto.ca [pound.med.utoronto.ca]
- 2. The dynamic process of β2-adrenergic receptor activation - PMC [pmc.ncbi.nlm.nih.gov]
- 3. The Dynamic Process of β2-Adrenergic Receptor Activation [escholarship.org]
- 4. Illuminating GPCR Signaling Mechanisms by NMR Spectroscopy with Stable-Isotope Labeled Receptors - PMC [pmc.ncbi.nlm.nih.gov]
- 5. NMR data collection and analysis protocol for high-throughput protein structure determination - PMC [pmc.ncbi.nlm.nih.gov]
- 6. static1.squarespace.com [static1.squarespace.com]
Basic concepts of using labeled amino acids in biological research.
An In-depth Technical Guide to the Use of Labeled Amino Acids in Biological Research
For Researchers, Scientists, and Drug Development Professionals
This guide provides a comprehensive overview of the fundamental concepts and applications of labeled amino acids in biological research. It is designed to serve as a technical resource for professionals in the fields of life sciences and drug development, offering detailed methodologies and data interpretation principles.
Core Concepts of Amino Acid Labeling
The use of labeled amino acids is a cornerstone of modern biological research, enabling the precise tracking and quantification of proteins and metabolic pathways.[] This technique involves replacing atoms in an amino acid molecule with their heavier, non-radioactive stable isotopes.[] These isotopes are chemically identical to their natural counterparts but have a different mass, which allows them to be detected and distinguished by analytical methods like mass spectrometry (MS) and nuclear magnetic resonance (NMR).[]
Common Stable Isotopes
The most frequently used stable isotopes in amino acid labeling are Carbon-13 (¹³C), Nitrogen-15 (¹⁵N), Deuterium (²H), and Oxygen-18 (¹⁸O).[3][4] Unlike radioactive isotopes, these are non-decaying, ensuring safety and stability in long-term experiments.[] The choice of isotope depends on the specific research question and the analytical method employed.
Labeling Strategies
There are two primary strategies for introducing labeled amino acids into proteins:
-
Metabolic Labeling: In this in vivo approach, cells are cultured in a medium where a standard essential amino acid is replaced with its heavy isotope-labeled counterpart.[5] As cells grow and synthesize new proteins, they incorporate these labeled amino acids.[5] This method is highly efficient and provides excellent quantitative accuracy as the label is introduced early in the experimental workflow.[][6]
-
Chemical Labeling: This in vitro method involves chemically modifying proteins or peptides with isotope-containing tags after they have been extracted from the cell. While useful for samples that cannot be metabolically labeled, it can be more prone to experimental variation.[4]
Key Applications and Techniques
Labeled amino acids are versatile tools with a wide range of applications, from quantifying protein synthesis to mapping complex metabolic fluxes.[3][7]
Quantitative Proteomics: SILAC
Stable Isotope Labeling by Amino Acids in Cell Culture (SILAC) is a powerful mass spectrometry-based technique for the accurate relative quantification of protein abundance between different cell populations.[8][9] In a typical SILAC experiment, two cell populations are grown in media containing either "light" (natural) or "heavy" (isotope-labeled) forms of an essential amino acid, typically arginine and lysine (B10760008).[10]
After a specific treatment or perturbation, the cell populations are combined, proteins are extracted and digested (usually with trypsin), and the resulting peptides are analyzed by LC-MS/MS.[9][11] Since peptides from the "heavy" and "light" samples are chemically identical but differ in mass, they appear as distinct peaks in the mass spectrum.[8] The ratio of the intensities of these peaks directly reflects the relative abundance of the protein in the two samples.[8]
Measuring Protein Synthesis: SUnSET
Surface Sensing of Translation (SUnSET) is a non-radioactive method to monitor global protein synthesis rates.[12][13] This technique utilizes puromycin (B1679871), an antibiotic that is a structural analog of aminoacyl-tRNA.[13] When added to cells, puromycin is incorporated into nascent polypeptide chains, leading to the termination of translation.[14] These puromycylated peptides can then be detected and quantified by western blotting using an anti-puromycin antibody.[14] The intensity of the resulting signal is directly proportional to the rate of protein synthesis.[14] SUnSET is considered a valid and accurate alternative to traditional methods that use radioactive tracers.[15]
Visualizing Protein Synthesis: BONCAT
Bio-Orthogonal Non-Canonical Amino Acid Tagging (BONCAT) is a technique that enables the visualization and identification of newly synthesized proteins.[16][17] BONCAT relies on the incorporation of a non-canonical amino acid, such as azidohomoalanine (AHA) or homopropargylglycine (HPG), in place of methionine during translation.[18][19] These amino acids contain a "bio-orthogonal" chemical handle (an azide (B81097) or alkyne group) that can be selectively tagged with a fluorescent probe or affinity tag via "click chemistry".[20] This allows for the specific detection or enrichment of proteins synthesized within a defined time window.[20]
Metabolic Flux Analysis (MFA)
Metabolic Flux Analysis (MFA) is a technique used to quantify the rates (fluxes) of metabolic reactions within a cell.[21] By supplying cells with a substrate labeled with a stable isotope (e.g., ¹³C-glucose or ¹⁵N-glutamine), researchers can trace the path of the labeled atoms through various metabolic pathways.[22][23] The pattern of isotope incorporation into downstream metabolites, including amino acids, is measured by mass spectrometry or NMR.[24] This labeling pattern provides crucial information for calculating the intracellular metabolic fluxes, revealing how cells reroute their metabolism in response to different conditions or disease states.[24][25]
Data Presentation
Quantitative data from experiments using labeled amino acids should be presented in a clear and structured manner to facilitate comparison and interpretation.
Table 1: Common Stable Isotopes for Amino Acid Labeling
| Isotope | Natural Abundance (%) | Key Applications |
| Carbon-13 (¹³C) | ~1.1%[3] | Metabolic Flux Analysis (MFA), Proteomics (SILAC)[][25] |
| Nitrogen-15 (¹⁵N) | ~0.4%[3] | Quantitative Proteomics (SILAC), NMR structural studies[][26] |
| Deuterium (²H) | ~0.02%[3] | NMR structural studies, Metabolic tracing[26] |
| Oxygen-18 (¹⁸O) | ~0.2%[4] | Proteomics (labeling during proteolysis)[4] |
Table 2: Example SILAC Data - Protein Abundance Changes
| Protein ID | Gene Name | H/L Ratio | Log₂(H/L) | Regulation |
| P02768 | ALB | 0.98 | -0.03 | Unchanged |
| P60709 | ACTB | 1.05 | 0.07 | Unchanged |
| P12345 | XYZ | 4.20 | 2.07 | Up-regulated |
| Q67890 | ABC | 0.45 | -1.15 | Down-regulated |
| (H/L Ratio: Ratio of heavy-labeled (treated) to light-labeled (control) peptide intensities) |
Experimental Protocols
Protocol for SILAC-based Quantitative Proteomics
This protocol outlines the key steps for a typical two-plex SILAC experiment.
Phase 1: Adaptation (Metabolic Labeling)
-
Cell Culture Preparation: Culture two populations of cells. One population is grown in "light" medium (containing normal L-arginine and L-lysine). The second population is grown in "heavy" medium, identical to the light medium but with normal arginine and lysine replaced by heavy isotope-labeled counterparts (e.g., ¹³C₆,¹⁵N₄-Arginine and ¹³C₆,¹⁵N₂-Lysine).[27]
-
Achieving Full Incorporation: Grow the cells in their respective SILAC media for at least five to six cell divisions to ensure >99% incorporation of the labeled amino acids.[5][10]
-
Verification (Optional but Recommended): Before starting the experiment, verify the incorporation efficiency by analyzing a small sample of the "heavy" cell lysate via mass spectrometry.[28]
Phase 2: Experimentation and Analysis
-
Experimental Treatment: Apply the desired experimental treatment to one cell population (e.g., the "heavy" labeled cells) while maintaining the other population as a control ("light").
-
Cell Harvesting and Mixing: After treatment, harvest the cells. Count the cells from each population and combine them in a 1:1 ratio.[29]
-
Protein Extraction and Digestion: Lyse the combined cell mixture and extract the total protein. Digest the proteins into peptides using trypsin.[11]
-
LC-MS/MS Analysis: Analyze the resulting peptide mixture using high-resolution liquid chromatography-tandem mass spectrometry (LC-MS/MS).[28]
-
Data Analysis: Use specialized software (e.g., MaxQuant) to identify peptides and quantify the intensity ratios of heavy to light peptide pairs.[28] This ratio indicates the relative abundance of each identified protein between the two conditions.
Protocol for SUnSET Assay
This protocol describes how to measure global protein synthesis rates in cultured cells.
-
Cell Culture and Treatment: Plate cells and allow them to adhere. Apply any desired experimental treatments for the specified duration.
-
Puromycin Incubation: Shortly before harvesting (e.g., 15-30 minutes), add puromycin directly to the culture medium at a final concentration of 1-10 µg/mL.[14][30] The optimal concentration and incubation time should be determined empirically for each cell type.
-
Cell Lysis: After puromycin incubation, immediately place the culture plate on ice. Remove the medium, wash the cells once with ice-cold PBS, and add lysis buffer (e.g., RIPA buffer) containing protease and phosphatase inhibitors.[30]
-
Protein Quantification: Scrape the cells, collect the lysate, and clear it by centrifugation.[30] Determine the protein concentration of the supernatant using a standard protein assay (e.g., BCA or Bradford).
-
Western Blotting:
-
Load equal amounts of protein (e.g., 20 µg) per lane on an SDS-PAGE gel.[30]
-
Transfer the separated proteins to a nitrocellulose or PVDF membrane.
-
Block the membrane and then incubate it with a primary antibody specific for puromycin.
-
Wash the membrane and incubate with a suitable HRP-conjugated secondary antibody.
-
Detect the signal using a chemiluminescence substrate.[14]
-
-
Data Analysis: Quantify the intensity of the puromycin signal in each lane. The signal intensity, which often appears as a smear, represents the global rate of protein synthesis. Normalize this signal to a loading control like tubulin or actin.[14]
Visualizations
Diagrams created using Graphviz to illustrate key workflows.
Caption: Workflow for a SILAC quantitative proteomics experiment.
Caption: Experimental workflow for the SUnSET protein synthesis assay.
Caption: Conceptual overview of Metabolic Flux Analysis (MFA).
References
- 3. chempep.com [chempep.com]
- 4. academic.oup.com [academic.oup.com]
- 5. Stable isotope labeling by amino acids in cell culture, SILAC, as a simple and accurate approach to expression proteomics - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. youtube.com [youtube.com]
- 7. pharmiweb.com [pharmiweb.com]
- 8. Stable isotope labeling by amino acids in cell culture - Wikipedia [en.wikipedia.org]
- 9. SILAC: Principles, Workflow & Applications in Proteomics - Creative Proteomics Blog [creative-proteomics.com]
- 10. grokipedia.com [grokipedia.com]
- 11. info.gbiosciences.com [info.gbiosciences.com]
- 12. agscientific.com [agscientific.com]
- 13. SUrface SEnsing of Translation (SUnSET), a Method Based on Western Blot Assessing Protein Synthesis Rates in vitro [en.bio-protocol.org]
- 14. SUrface SEnsing of Translation (SUnSET), a Method Based on Western Blot Assessing Protein Synthesis Rates in vitro [bio-protocol.org]
- 15. Measuring protein synthesis with SUnSET: a valid alternative to traditional techniques? - PubMed [pubmed.ncbi.nlm.nih.gov]
- 16. Bioorthogonal Noncanonical Amino Acid Tagging (BONCAT) Enables Time-Resolved Analysis of Protein Synthesis in Native Plant Tissue - PubMed [pubmed.ncbi.nlm.nih.gov]
- 17. info.gbiosciences.com [info.gbiosciences.com]
- 18. Bioorthogonal Non-Canonical Amino Acid Tagging (BONCAT) to detect newly synthesized proteins in cells and their secretome | PLOS One [journals.plos.org]
- 19. quora.com [quora.com]
- 20. academic.oup.com [academic.oup.com]
- 21. Amino Acid Metabolic Flux Analysis - Creative Proteomics MFA [creative-proteomics.com]
- 22. Metabolic flux analysis using ¹³C peptide label measurements - PubMed [pubmed.ncbi.nlm.nih.gov]
- 23. Applications of Stable Isotope Labeling in Metabolic Flux Analysis - Creative Proteomics [creative-proteomics.com]
- 24. mdpi.com [mdpi.com]
- 25. Isotope-Assisted Metabolic Flux Analysis: A Powerful Technique to Gain New Insights into the Human Metabolome in Health and Disease - PMC [pmc.ncbi.nlm.nih.gov]
- 26. Isotopic Labeling for NMR Spectroscopy of Biological Solids [sigmaaldrich.com]
- 27. researchgate.net [researchgate.net]
- 28. researchgate.net [researchgate.net]
- 29. researchgate.net [researchgate.net]
- 30. researchgate.net [researchgate.net]
Methodological & Application
Application Notes and Protocols for Solid-Phase Peptide Synthesis (SPPS) using Fmoc-Gly-OH-2-¹³C,¹⁵N
For Researchers, Scientists, and Drug Development Professionals
This document provides a detailed, step-by-step protocol for solid-phase peptide synthesis (SPPS) utilizing the isotopically labeled amino acid Fmoc-Gly-OH-2-¹³C,¹⁵N. The incorporation of stable isotopes is a critical technique for advanced analytical studies in proteomics, structural biology, and drug development, enabling precise quantification and structural elucidation of peptides and proteins.
Introduction
Solid-phase peptide synthesis (SPPS) is the cornerstone of modern peptide synthesis, allowing for the efficient and controlled assembly of amino acids into a desired peptide sequence on an insoluble resin support.[1][2][3][4] The most widely adopted method is the Fmoc/tBu strategy, which employs the base-labile 9-fluorenylmethoxycarbonyl (Fmoc) group for temporary Nα-amino protection and acid-labile groups for side-chain protection.[2][5][6] This orthogonal protection scheme ensures the stepwise and specific formation of peptide bonds.[5]
The use of isotopically labeled amino acids, such as Fmoc-Gly-OH-2-¹³C,¹⁵N, allows for the introduction of heavy isotopes at specific sites within a peptide sequence.[7] This labeling is invaluable for a range of applications, including:
-
Quantitative Proteomics: Labeled peptides serve as internal standards for accurate quantification of proteins in complex biological samples by mass spectrometry.
-
Structural Biology: NMR studies utilize the distinct signals from ¹³C and ¹⁵N to determine the three-dimensional structure and dynamics of peptides and proteins.[7]
-
Metabolic Labeling: Tracing the metabolic fate of peptides and proteins in vivo.[8][9]
Quantitative Data Summary
The efficiency of each step in SPPS is crucial for the overall yield and purity of the final peptide. The following table summarizes key quantitative parameters for a typical Fmoc-SPPS cycle on a 0.1 mmol scale.
| Parameter | Value | Unit | Notes |
| Resin | |||
| Type | Wang Resin or Rink Amide Resin | - | Choice depends on desired C-terminus (acid or amide).[10] |
| Substitution | 0.3 - 0.8 | mmol/g | |
| Amount | 125 - 333 | mg | Based on a 0.1 mmol scale. |
| Fmoc Deprotection | |||
| Reagent | 20% Piperidine (B6355638) in DMF | v/v | A 5% piperidine solution can also be used, though deprotection times may increase.[11] |
| Treatment Time | 5 + 15 | minutes | Two treatments are recommended for complete deprotection. |
| Amino Acid Coupling | |||
| Fmoc-Amino Acid | 3 - 5 | equivalents | Relative to resin loading.[5] |
| Coupling Reagent (e.g., HBTU/HATU) | 3 - 5 | equivalents | HATU is recommended for isotopically labeled or sterically hindered amino acids to ensure high efficiency. |
| Base (e.g., DIPEA) | 6 - 10 | equivalents | |
| Coupling Time | 1 - 2 | hours | Can be extended for challenging couplings. |
| Cleavage | |||
| Reagent Cocktail | 95% TFA, 2.5% TIS, 2.5% Water | v/v | A common cocktail for cleavage and side-chain deprotection.[2] |
| Treatment Time | 2 - 3 | hours | |
| Yield | |||
| Crude Peptide | Variable | mg | Dependent on peptide length and sequence. A pentapeptide could yield ~50 mg of crude product from 100 mg of resin.[12] |
| Purified Peptide | 10 - 40 | % | Typical yield after purification.[12] |
Experimental Workflow Diagram
Caption: Workflow for Fmoc-based solid-phase peptide synthesis.
Detailed Experimental Protocol
This protocol details the manual synthesis of a peptide incorporating Fmoc-Gly-OH-2-¹³C,¹⁵N. All steps should be performed in a fume hood with appropriate personal protective equipment.[12]
1. Resin Preparation and Swelling
-
Weigh the appropriate amount of resin (e.g., Wang or Rink Amide resin) for a 0.1 mmol scale synthesis and place it into a fritted reaction vessel.[10][12]
-
Add N,N-dimethylformamide (DMF) to the resin (approximately 10 mL per gram of resin).
-
Allow the resin to swell for at least 30-60 minutes at room temperature with gentle agitation.[10]
-
After swelling, drain the DMF.[5]
2. First Amino Acid Loading (if not using pre-loaded resin)
-
If using a resin that is not pre-loaded, the first Fmoc-amino acid must be attached. This procedure varies depending on the resin type (e.g., loading onto 2-chlorotrityl chloride resin or Wang resin).[10][13] This is a critical step and should be performed carefully to ensure optimal loading.[14]
3. Synthesis Cycle: Fmoc Deprotection
-
Add a solution of 20% piperidine in DMF to the swollen resin.[5]
-
Agitate the mixture for 5 minutes, then drain the solution.
-
Add a fresh solution of 20% piperidine in DMF and agitate for an additional 15 minutes to ensure complete removal of the Fmoc group.[15]
-
Drain the deprotection solution and wash the resin thoroughly with DMF (5-7 times) to remove all traces of piperidine.[5]
4. Synthesis Cycle: Amino Acid Coupling (Incorporation of Fmoc-Gly-OH-2-¹³C,¹⁵N)
-
Activation: In a separate vial, dissolve Fmoc-Gly-OH-2-¹³C,¹⁵N (3-5 equivalents), a coupling reagent such as HATU (3-5 equivalents), in DMF.[5] For isotopically labeled amino acids, using a more potent coupling reagent like HATU is recommended to ensure high coupling efficiency.
-
Add a base, such as N,N-diisopropylethylamine (DIPEA) (6-10 equivalents), to the amino acid solution and allow it to pre-activate for 1-2 minutes.[5]
-
Coupling: Add the activated amino acid solution to the deprotected resin in the reaction vessel.
-
Agitate the mixture for 1-2 hours at room temperature. A longer coupling time (up to 4 hours) may be beneficial for labeled amino acids.
-
Monitoring (Optional): Perform a Kaiser test (ninhydrin test) to check for the presence of free primary amines.[5] A blue color indicates an incomplete reaction, and the coupling step should be repeated.[5]
-
After complete coupling, drain the coupling solution and wash the resin thoroughly with DMF (3-5 times).[5]
5. Subsequent Synthesis Cycles
-
Repeat steps 3 and 4 for each subsequent amino acid in the peptide sequence.
6. Final Fmoc Deprotection
-
After the final amino acid has been coupled, perform a final Fmoc deprotection as described in step 3.
7. Resin Washing and Drying
-
Following the final deprotection, wash the peptide-resin with DMF, followed by a less polar solvent like dichloromethane (B109758) (DCM) (3-5 times) to prepare for cleavage.[5]
-
Dry the resin under a stream of nitrogen or in a vacuum desiccator for at least 1 hour.[2][5]
8. Peptide Cleavage and Side-Chain Deprotection
-
Prepare a fresh cleavage cocktail (e.g., 95% TFA, 2.5% triisopropylsilane (B1312306) (TIS), 2.5% water).[2][15] Caution: TFA is highly corrosive.
-
Add the cleavage cocktail to the dry peptide-resin (approximately 10 mL per gram of resin) in a fume hood.[5][16]
-
Gently agitate the mixture at room temperature for 2-3 hours.[15]
9. Peptide Precipitation and Isolation
-
Filter the cleavage mixture to separate the resin, collecting the filtrate which contains the peptide.
-
Add the filtrate dropwise to a large volume of cold diethyl ether (approximately 10 times the volume of the filtrate) to precipitate the peptide as a white solid.[5][16]
-
Centrifuge the ether suspension to pellet the precipitated peptide.[5]
-
Decant the ether and wash the peptide pellet with cold ether two more times.[5][16]
-
Dry the crude peptide pellet under vacuum.[5]
10. Purification and Analysis
-
Purify the crude peptide using reverse-phase high-performance liquid chromatography (RP-HPLC).[2]
-
Analyze the purified peptide by mass spectrometry to confirm its identity and isotopic incorporation.
References
- 1. jpt.com [jpt.com]
- 2. benchchem.com [benchchem.com]
- 3. bachem.com [bachem.com]
- 4. csbio.com [csbio.com]
- 5. benchchem.com [benchchem.com]
- 6. Fmoc Amino Acids for SPPS - AltaBioscience [altabioscience.com]
- 7. Fmoc-Gly-OH-13C2,15N | 285978-13-4 | Benchchem [benchchem.com]
- 8. medchemexpress.com [medchemexpress.com]
- 9. medchemexpress.com [medchemexpress.com]
- 10. chem.uci.edu [chem.uci.edu]
- 11. peptide.com [peptide.com]
- 12. americanpeptidesociety.org [americanpeptidesociety.org]
- 13. chemistry.du.ac.in [chemistry.du.ac.in]
- 14. academic.oup.com [academic.oup.com]
- 15. Fmoc Solid Phase Peptide Synthesis: Mechanism and Protocol - Creative Peptides [creative-peptides.com]
- 16. rsc.org [rsc.org]
Application Notes and Protocols for Biomolecular NMR Analysis Using Fmoc-Gly-OH-2-¹³C,¹⁵N
For Researchers, Scientists, and Drug Development Professionals
Introduction
Stable isotope labeling is an indispensable tool in modern biomolecular Nuclear Magnetic Resonance (NMR) spectroscopy, enabling detailed structural and dynamic studies of peptides and proteins.[1] Fmoc-Gly-OH-2-¹³C,¹⁵N is a specialized, isotopically labeled amino acid designed for incorporation into synthetic peptides via Solid-Phase Peptide Synthesis (SPPS). The specific labeling at the alpha-carbon (¹³C) and the amide nitrogen (¹⁵N) provides unique probes for a variety of advanced NMR experiments. These labels facilitate resonance assignment, structure determination, and the characterization of molecular interactions and dynamics, which are critical aspects of drug discovery and development.[2][3]
This document provides detailed application notes and experimental protocols for the effective use of Fmoc-Gly-OH-2-¹³C,¹⁵N in biomolecular NMR analysis.
Key Applications in Biomolecular Research
The incorporation of ¹³C,¹⁵N-labeled glycine (B1666218) residues into a peptide or protein allows for a range of NMR-based applications:
-
Structural Determination: The unique chemical shifts of the ¹³Cα and ¹⁵N nuclei are critical for sequential backbone resonance assignment using a suite of triple-resonance NMR experiments.[4][5] This forms the foundation for determining the three-dimensional structure of the biomolecule.
-
Protein-Ligand Interaction Studies: Changes in the chemical environment upon ligand binding can be monitored by observing the chemical shift perturbations of the labeled glycine residue in 2D ¹H-¹⁵N HSQC spectra.[2] This allows for the identification of binding sites and the quantification of binding affinities.
-
Dynamics and Flexibility Analysis: Glycine residues often confer local flexibility to the polypeptide chain. NMR relaxation experiments (T₁, T₂, and {¹H}-¹⁵N NOE) on the labeled glycine can provide quantitative insights into the pico- to nanosecond timescale dynamics of the peptide backbone.[6][7]
-
Folding and Stability Studies: The labeled glycine can serve as a sensitive probe to monitor conformational changes during protein folding or unfolding processes.
Experimental Protocols
Peptide Synthesis using Fmoc-Gly-OH-2-¹³C,¹⁵N
The following protocol outlines the manual incorporation of Fmoc-Gly-OH-2-¹³C,¹⁵N into a peptide using Fmoc-based Solid-Phase Peptide Synthesis (SPPS). This can be adapted for automated synthesizers.
Materials and Reagents:
-
Fmoc-Gly-OH-2-¹³C,¹⁵N
-
Rink Amide resin (or other suitable solid support)
-
Standard Fmoc-protected amino acids
-
N,N-Dimethylformamide (DMF)
-
Dichloromethane (DCM)
-
20% (v/v) Piperidine (B6355638) in DMF
-
Coupling reagents: HCTU (or HBTU/HATU)
-
N,N-Diisopropylethylamine (DIPEA)
-
Cleavage cocktail (e.g., 95% Trifluoroacetic acid (TFA), 2.5% Triisopropylsilane (TIS), 2.5% H₂O)
-
Cold diethyl ether
Protocol:
-
Resin Swelling: Swell the resin in DMF for at least 1 hour in a reaction vessel.
-
Fmoc Deprotection:
-
Drain the DMF.
-
Add the 20% piperidine in DMF solution to the resin and agitate for 5 minutes.
-
Drain the solution.
-
Repeat the piperidine treatment for an additional 15 minutes.
-
Wash the resin thoroughly with DMF (5 times) to remove all traces of piperidine.
-
-
Coupling of Fmoc-Gly-OH-2-¹³C,¹⁵N:
-
In a separate vial, dissolve Fmoc-Gly-OH-2-¹³C,¹⁵N (2-5 equivalents relative to resin loading) and HCTU (2-5 equivalents) in DMF.
-
Add DIPEA (2-5 equivalents) to the amino acid solution and pre-activate for 1-2 minutes.
-
Add the activated amino acid solution to the deprotected resin.
-
Agitate the reaction mixture for 1-2 hours at room temperature.
-
Perform a ninhydrin (B49086) test to confirm complete coupling. A negative result (colorless beads) indicates success.
-
-
Washing: Wash the resin with DMF (5 times) to remove excess reagents.
-
Chain Elongation: Repeat steps 2-4 for each subsequent amino acid in the peptide sequence.
-
Final Deprotection and Cleavage:
-
After the final coupling, perform a final Fmoc deprotection (step 2).
-
Wash the resin with DMF and then DCM, and dry under vacuum.
-
Add the cleavage cocktail to the resin and react for 2-3 hours at room temperature.
-
Filter the resin and collect the filtrate.
-
Precipitate the peptide by adding the filtrate to cold diethyl ether.
-
Centrifuge to pellet the peptide, wash with cold ether, and dry.
-
-
Purification: Purify the crude peptide using reverse-phase high-performance liquid chromatography (RP-HPLC).
-
Characterization: Confirm the mass of the final labeled peptide using mass spectrometry.
References
- 1. benchchem.com [benchchem.com]
- 2. protein-nmr.org.uk [protein-nmr.org.uk]
- 3. Peptides in Therapeutic Applications | BroadPharm [broadpharm.com]
- 4. Triple-resonance nuclear magnetic resonance spectroscopy - Wikipedia [en.wikipedia.org]
- 5. Triple resonance three-dimensional protein NMR: Before it became a black box - PMC [pmc.ncbi.nlm.nih.gov]
- 6. 3D NMR experiments for measuring 15N relaxation data of large proteins: application to the 44 kDa ectodomain of SIV gp41 - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. NMR Structure Determinations of Small Proteins Using Only One Fractionally 20% 13C- and Uniformly 100% 15N-Labeled Sample - PMC [pmc.ncbi.nlm.nih.gov]
A Guide to Absolute Protein Quantification by Mass Spectrometry with Fmoc-Gly-OH-2-¹³C,¹⁵N
For Researchers, Scientists, and Drug Development Professionals
Application Notes
The precise quantification of proteins is paramount in understanding cellular processes, identifying disease biomarkers, and developing novel therapeutics. Absolute quantification, which determines the exact molar amount of a protein in a sample, offers a higher level of accuracy compared to relative quantification methods. This is often achieved by using stable isotope-labeled synthetic peptides as internal standards in mass spectrometry-based workflows.
This guide details the use of Fmoc-Gly-OH-2-¹³C,¹⁵N, a stable isotope-labeled glycine (B1666218) derivative, for the synthesis of heavy-labeled peptides for absolute protein quantification. The incorporation of ¹³C and ¹⁵N isotopes into the glycine residue of a synthetic peptide creates a mass shift that allows it to be distinguished from its endogenous, unlabeled ("light") counterpart by the mass spectrometer. Because the labeled and unlabeled peptides have nearly identical physicochemical properties, they exhibit similar ionization efficiency and fragmentation patterns. This allows for the accurate determination of the endogenous peptide concentration by comparing its signal intensity to that of the known concentration of the spiked-in heavy-labeled peptide standard.
A common application of this technique is in the study of signaling pathways, where precise changes in protein abundance can indicate pathway activation or inhibition. The Epidermal Growth Factor Receptor (EGFR) signaling pathway, which is crucial in cell proliferation and is often dysregulated in cancer, serves as an excellent model system to demonstrate this application. By synthesizing a heavy-labeled peptide corresponding to a tryptic peptide of a key protein in the EGFR pathway, researchers can accurately quantify its absolute abundance in cancer cells under different conditions, such as before and after drug treatment.
Experimental Protocols
This section provides a detailed methodology for the absolute quantification of a target protein using a synthetic peptide incorporating Fmoc-Gly-OH-2-¹³C,¹⁵N.
Synthesis of the Heavy-Labeled Peptide
The first step is to synthesize a proteotypic peptide (a peptide unique to the target protein and readily detectable by mass spectrometry) incorporating the Fmoc-Gly-OH-2-¹³C,¹⁵N label. This is typically achieved through solid-phase peptide synthesis (SPPS).
Materials:
-
Fmoc-Gly-OH-2-¹³C,¹⁵N
-
Other standard Fmoc-protected amino acids
-
Rink Amide resin
-
Coupling reagents (e.g., HBTU, HOBt)
-
N,N-Diisopropylethylamine (DIPEA)
-
Piperidine (B6355638) solution (20% in DMF)
-
N,N-Dimethylformamide (DMF)
-
Dichloromethane (DCM)
-
Trifluoroacetic acid (TFA) cleavage cocktail (e.g., 95% TFA, 2.5% water, 2.5% triisopropylsilane)
-
Peptide synthesizer
Protocol:
-
Resin Preparation: Swell the Rink Amide resin in DMF.
-
Fmoc Deprotection: Remove the Fmoc protecting group from the resin using 20% piperidine in DMF.
-
Amino Acid Coupling: Couple the C-terminal amino acid to the resin using a coupling agent and DIPEA in DMF.
-
Iterative Coupling and Deprotection: Repeat the deprotection and coupling steps for each subsequent amino acid in the peptide sequence. When the glycine position is reached, use Fmoc-Gly-OH-2-¹³C,¹⁵N for the coupling reaction.
-
Cleavage and Deprotection: Once the synthesis is complete, cleave the peptide from the resin and remove the side-chain protecting groups using a TFA cleavage cocktail.
-
Purification: Purify the crude peptide using reverse-phase high-performance liquid chromatography (RP-HPLC).
-
Characterization: Confirm the mass and purity of the synthesized heavy-labeled peptide using mass spectrometry.
-
Quantification of the Standard: Accurately determine the concentration of the purified heavy-labeled peptide stock solution, for example, by amino acid analysis.
Sample Preparation from Cell Culture
This protocol outlines the preparation of a protein digest from cultured cells for mass spectrometry analysis.
Materials:
-
Cultured cells (e.g., A431 human epidermoid carcinoma cells)
-
Lysis buffer (e.g., RIPA buffer with protease and phosphatase inhibitors)
-
BCA protein assay kit
-
Dithiothreitol (DTT)
-
Iodoacetamide (IAA)
-
Trypsin (sequencing grade)
-
Ammonium (B1175870) bicarbonate buffer (50 mM, pH 8.0)
-
Formic acid
-
C18 solid-phase extraction (SPE) cartridges
Protocol:
-
Cell Lysis: Harvest cells and lyse them in lysis buffer.
-
Protein Quantification: Determine the total protein concentration of the lysate using a BCA assay.
-
Reduction and Alkylation: Take a known amount of total protein (e.g., 50 µg). Reduce the disulfide bonds by adding DTT and incubating at 60°C. Alkylate the free cysteine residues by adding IAA and incubating in the dark.
-
Protein Digestion: Dilute the sample with ammonium bicarbonate buffer to reduce the concentration of detergents. Add trypsin at an appropriate enzyme-to-protein ratio (e.g., 1:50) and incubate overnight at 37°C.
-
Spiking of Internal Standard: Add a known amount of the purified heavy-labeled peptide to the digested sample.
-
Desalting: Acidify the sample with formic acid and desalt the peptides using a C18 SPE cartridge.
-
Drying and Reconstitution: Dry the desalted peptides and reconstitute them in a suitable buffer for LC-MS/MS analysis (e.g., 0.1% formic acid in water).
LC-MS/MS Analysis
The following are general parameters for a targeted proteomics experiment using a triple quadrupole or a high-resolution mass spectrometer capable of selected reaction monitoring (SRM) or parallel reaction monitoring (PRM).
Instrumentation:
-
High-performance liquid chromatograph (HPLC) coupled to a mass spectrometer
LC Parameters:
-
Column: C18 reverse-phase column (e.g., 2.1 mm ID, 100 mm length, 1.8 µm particle size)
-
Mobile Phase A: 0.1% formic acid in water
-
Mobile Phase B: 0.1% formic acid in acetonitrile
-
Gradient: A linear gradient from low to high percentage of mobile phase B over a suitable time to ensure good separation of the target peptide.
-
Flow Rate: Appropriate for the column dimensions (e.g., 0.3 mL/min)
-
Column Temperature: 40°C
MS Parameters (SRM/PRM):
-
Ionization Mode: Positive electrospray ionization (ESI)
-
Precursor Ion Selection: Set the mass spectrometer to specifically select the m/z of both the light (endogenous) and heavy (labeled) precursor peptides.
-
Collision Energy: Optimize the collision energy for each precursor to generate specific and intense fragment ions.
-
Fragment Ion Selection: Monitor at least three to five specific fragment ions (transitions) for both the light and heavy peptides to ensure specificity and accurate quantification.
-
Dwell Time: Set an appropriate dwell time for each transition to ensure a sufficient number of data points across the chromatographic peak.
Data Analysis
Data analysis is performed using specialized software such as Skyline to integrate the peak areas of the selected transitions for both the light and heavy peptides.
Software:
-
Skyline (or similar quantitative proteomics software)
Protocol:
-
Import Data: Import the raw mass spectrometry data files into Skyline.
-
Define Targets: Set up the Skyline document with the precursor and product ion m/z values for both the light and heavy peptides.
-
Peak Integration: Manually inspect and, if necessary, adjust the peak integration boundaries for all transitions to ensure accuracy.
-
Calculate Peak Area Ratios: The software will automatically calculate the ratio of the peak areas of the light peptide to the heavy peptide.
-
Generate Calibration Curve (Optional but Recommended): For absolute quantification, a calibration curve should be generated by analyzing a series of samples containing a fixed amount of the heavy peptide and varying known concentrations of the light synthetic peptide.
-
Calculate Endogenous Peptide Concentration: Use the peak area ratio from the biological sample and the calibration curve to determine the absolute concentration of the endogenous peptide. The concentration of the protein can then be calculated based on its molecular weight and the amount of total protein analyzed.
Data Presentation
The following table provides a hypothetical example of quantitative data for a protein in the EGFR signaling pathway, Protein X, in A431 cells with and without treatment with an EGFR inhibitor.
| Sample Condition | Replicate | Peak Area (Light Peptide) | Peak Area (Heavy Peptide) | Light/Heavy Ratio | Calculated Concentration of Protein X (fmol/µg total protein) |
| Untreated | 1 | 1,250,000 | 2,500,000 | 0.50 | 5.2 |
| Untreated | 2 | 1,300,000 | 2,550,000 | 0.51 | 5.3 |
| Untreated | 3 | 1,280,000 | 2,520,000 | 0.51 | 5.3 |
| Average Untreated | 0.51 | 5.3 | |||
| EGFR Inhibitor | 1 | 630,000 | 2,510,000 | 0.25 | 2.6 |
| EGFR Inhibitor | 2 | 650,000 | 2,530,000 | 0.26 | 2.7 |
| EGFR Inhibitor | 3 | 640,000 | 2,500,000 | 0.26 | 2.7 |
| Average EGFR Inhibitor | 0.26 | 2.7 |
Mandatory Visualization
Experimental Workflow for Absolute Protein Quantification
Application Notes and Protocols for Incorporating ¹³C and ¹⁵N Labeled Amino Acids into Synthetic Peptides
For Researchers, Scientists, and Drug Development Professionals
Introduction
Stable isotope labeling of peptides with Carbon-13 (¹³C) and Nitrogen-15 (¹⁵N) is a powerful and indispensable tool in modern research and drug development. By replacing naturally abundant ¹²C and ¹⁴N atoms with their heavier, non-radioactive isotopes, researchers can precisely trace and quantify peptides and proteins in complex biological systems. This enables a deeper understanding of protein structure and function, protein-protein interactions, post-translational modifications, and metabolic pathways. The primary analytical techniques benefiting from this approach are Mass Spectrometry (MS) and Nuclear Magnetic Resonance (NMR) spectroscopy. These application notes provide an overview of the most common techniques for incorporating ¹³C and ¹⁵N labeled amino acids into synthetic peptides, along with detailed experimental protocols and comparative data to guide researchers in selecting the most appropriate method for their specific needs.
Techniques for Isotopic Labeling of Synthetic Peptides
There are three primary methodologies for generating peptides labeled with ¹³C and ¹⁵N:
-
Solid-Phase Peptide Synthesis (SPPS): A chemical synthesis method that offers precise control over the peptide sequence and the exact position of isotopic labels.
-
Cell-Free Protein Synthesis (CFPS): An in vitro biological synthesis method that utilizes cellular machinery to produce peptides from a DNA template, allowing for efficient incorporation of labeled amino acids.
-
In Vivo Labeling: A biological method where living cells are cultured in media containing stable isotope-labeled amino acids, leading to the incorporation of these labels into the entire proteome. Stable Isotope Labeling by Amino Acids in Cell Culture (SILAC) is a prominent example of this approach.
Data Presentation: Comparison of Labeling Techniques
The choice of labeling technique depends on several factors, including the desired peptide length, required yield and purity, cost considerations, and the specific experimental application. The following table summarizes key quantitative parameters for each method.
| Parameter | Solid-Phase Peptide Synthesis (SPPS) | Cell-Free Protein Synthesis (CFPS) | In Vivo Labeling (e.g., SILAC) |
| Typical Yield | Milligrams to grams | Micrograms to milligrams[1] | Not directly applicable for specific peptide yield; focuses on relative protein quantification. |
| Purity (after purification) | High (>95-98%)[2] | High (>90%) | Not applicable for isolating a single pure labeled peptide. |
| Incorporation Efficiency | 100% at specified positions | High (>90%)[3] | High (>95-97%)[4][5] |
| Peptide Length | Typically up to ~50 amino acids[6] | Can produce longer peptides and small proteins | Applicable to the entire proteome. |
| Cost | Can be high, dependent on the cost of labeled Fmoc-amino acids. | Moderate, efficient use of labeled amino acids reduces cost.[5] | Can be high due to the cost of labeled media for cell culture. |
| Control over Label Position | Precise, site-specific labeling is straightforward. | Uniform or selective labeling of specific amino acid types. | Uniform labeling of specific amino acid types throughout the proteome. |
| Post-Translational Modifications | Can be incorporated chemically. | Can incorporate some PTMs depending on the cell extract used. | Naturally occurring PTMs are present. |
Experimental Protocols
Solid-Phase Peptide Synthesis (SPPS) of a ¹³C/¹⁵N Labeled Peptide
This protocol describes the manual Fmoc-based solid-phase synthesis of a peptide with a single ¹³C/¹⁵N-labeled amino acid.
Materials:
-
Fmoc-Rink Amide resin
-
Unlabeled Fmoc-protected amino acids
-
¹³C/¹⁵N-labeled Fmoc-amino acid (e.g., Fmoc-L-Leucine-¹³C₆,¹⁵N)
-
Coupling reagents: HBTU (2-(1H-benzotriazol-1-yl)-1,1,3,3-tetramethyluronium hexafluorophosphate), HOBt (Hydroxybenzotriazole)
-
N,N-Diisopropylethylamine (DIPEA)
-
Deprotection solution: 20% piperidine (B6355638) in N,N-Dimethylformamide (DMF)
-
Solvents: DMF, Dichloromethane (DCM), Diethyl ether
-
Cleavage cocktail: Trifluoroacetic acid (TFA) / Triisopropylsilane (TIS) / Water (95:2.5:2.5)
-
SPPS reaction vessel
Procedure:
-
Resin Swelling: Swell the Fmoc-Rink Amide resin in DMF for 30 minutes in the reaction vessel.
-
Fmoc Deprotection:
-
Drain the DMF.
-
Add the 20% piperidine/DMF solution to the resin and agitate for 5 minutes.
-
Drain the solution and repeat the piperidine treatment for another 15 minutes.
-
Wash the resin thoroughly with DMF (5 times) and DCM (3 times).
-
-
Amino Acid Coupling (for each amino acid in the sequence):
-
Dissolve the Fmoc-amino acid (3 equivalents relative to resin substitution) and HOBt (3 equivalents) in DMF.
-
Add HBTU (3 equivalents) and DIPEA (6 equivalents) to the amino acid solution and pre-activate for 2 minutes.
-
Add the activated amino acid solution to the deprotected resin and agitate for 1-2 hours.
-
Monitor the coupling reaction using a qualitative test (e.g., Kaiser test). If the reaction is incomplete, repeat the coupling step.
-
Wash the resin with DMF (3 times) and DCM (3 times).
-
-
Incorporation of the Labeled Amino Acid: Follow the same coupling procedure as in step 3, using the ¹³C/¹⁵N-labeled Fmoc-amino acid.
-
Final Fmoc Deprotection: After the final amino acid has been coupled, perform the deprotection step as described in step 2.
-
Cleavage and Deprotection:
-
Wash the resin with DCM and dry under vacuum.
-
Add the cleavage cocktail to the resin and incubate for 2-3 hours at room temperature with occasional agitation.
-
Filter the resin and collect the filtrate containing the cleaved peptide.
-
Precipitate the peptide by adding cold diethyl ether.
-
Centrifuge to pellet the peptide, decant the ether, and repeat the ether wash twice. . Dry the peptide pellet under vacuum.
-
-
Purification: Purify the crude peptide using reverse-phase high-performance liquid chromatography (RP-HPLC).
-
Analysis: Confirm the identity and isotopic incorporation of the peptide by mass spectrometry.
Cell-Free Synthesis of a ¹³C/¹⁵N Labeled Peptide
This protocol outlines the general steps for producing a labeled peptide using a commercially available E. coli-based cell-free protein synthesis kit.
Materials:
-
Cell-free protein synthesis kit (containing E. coli lysate, reaction mix, and energy source)
-
DNA template (plasmid or linear PCR product) encoding the peptide of interest
-
Amino acid mixture lacking the amino acid(s) to be labeled
-
¹³C/¹⁵N-labeled amino acid(s)
-
Nuclease-free water
Procedure:
-
Template Preparation: Prepare a high-purity DNA template encoding the target peptide. The template should contain the necessary promoter and terminator sequences for transcription and translation.
-
Reaction Setup:
-
On ice, combine the cell-free extract, reaction mix, and energy source in a microcentrifuge tube according to the manufacturer's instructions.
-
Add the amino acid mixture lacking the amino acid to be labeled.
-
Add the ¹³C/¹⁵N-labeled amino acid(s) to the desired final concentration.
-
Add the DNA template to the reaction mixture.
-
Adjust the final volume with nuclease-free water.
-
-
Incubation: Incubate the reaction mixture at the recommended temperature (typically 30-37°C) for several hours (e.g., 2-8 hours).
-
Purification: Purify the expressed peptide using an appropriate method based on the peptide's properties (e.g., affinity chromatography if a tag is included, RP-HPLC).
-
Analysis: Analyze the purified peptide by SDS-PAGE and mass spectrometry to confirm expression, purity, and isotopic incorporation.
In Vivo Labeling using SILAC
This protocol provides a general workflow for SILAC labeling of a cell line for relative quantification of proteins.
Materials:
-
Cell line of interest
-
SILAC-specific cell culture medium (deficient in arginine and lysine)
-
"Light" amino acids: L-Arginine and L-Lysine
-
"Heavy" amino acids: L-Arginine (¹³C₆, ¹⁵N₄) and L-Lysine (¹³C₆, ¹⁵N₂)
-
Dialyzed fetal bovine serum (FBS)
-
Standard cell culture reagents and equipment
Procedure:
-
Cell Adaptation:
-
Culture the cells in the SILAC medium supplemented with "light" arginine and lysine (B10760008) and dialyzed FBS for at least five cell doublings to ensure complete incorporation of the light amino acids.
-
In parallel, culture another population of cells in SILAC medium supplemented with "heavy" arginine and lysine and dialyzed FBS for the same duration.
-
-
Incorporation Check: After at least five doublings, harvest a small number of cells from the "heavy" culture. Extract proteins, digest them with trypsin, and analyze by mass spectrometry to confirm >97% incorporation of the heavy amino acids.[4]
-
Experimental Treatment: Apply the experimental condition to one cell population (e.g., drug treatment to the "heavy" labeled cells) while keeping the other as a control ("light" labeled cells).
-
Cell Harvesting and Lysis: Harvest both cell populations and lyse them using a suitable lysis buffer.
-
Protein Quantification and Mixing: Determine the protein concentration of each lysate and mix equal amounts of protein from the "light" and "heavy" samples.
-
Protein Digestion: Digest the mixed protein sample into peptides using trypsin.
-
Mass Spectrometry Analysis: Analyze the resulting peptide mixture by LC-MS/MS.
-
Data Analysis: Use specialized software to identify peptides and quantify the intensity ratios of "heavy" to "light" peptide pairs. This ratio reflects the relative abundance of the corresponding protein between the two experimental conditions.
Visualizations
Experimental Workflows
Caption: Workflow for Solid-Phase Peptide Synthesis (SPPS).
Caption: Workflow for Cell-Free Protein Synthesis (CFPS).
Signaling Pathway Example: MAPK/ERK Pathway
Labeled synthetic peptides are frequently used as substrates in kinase assays to study signaling pathways. The MAPK/ERK pathway is a central signaling cascade that regulates cell proliferation, differentiation, and survival. A ¹³C/¹⁵N labeled peptide corresponding to a known substrate of a kinase in this pathway (e.g., MEK or ERK) can be used to quantify kinase activity in cell lysates or purified systems.
Caption: MAPK/ERK Signaling Pathway and Kinase Assay.
References
- 1. [PDF] Quantitative monitoring of solid-phase peptide synthesis by the ninhydrin reaction. | Semantic Scholar [semanticscholar.org]
- 2. researchgate.net [researchgate.net]
- 3. Cell-Free Protein Expression for Generating Stable Isotope-Labeled Proteins | Thermo Fisher Scientific - HK [thermofisher.com]
- 4. researchgate.net [researchgate.net]
- 5. Quantitative analysis of SILAC data sets using spectral counting - PMC [pmc.ncbi.nlm.nih.gov]
- 6. info.gbiosciences.com [info.gbiosciences.com]
Application Notes and Protocols for Metabolic Flux Analysis using Fmoc-Gly-OH-2-13C,15N
Application Notes
Introduction
Metabolic Flux Analysis (MFA) is a critical technique for quantifying the rates (fluxes) of metabolic reactions within a biological system. Stable isotope tracers, such as those labeled with Carbon-13 (¹³C) and Nitrogen-15 (¹⁵N), are indispensable tools in MFA, allowing researchers to trace the flow of atoms through metabolic pathways.[1][2][3][4] Fmoc-Gly-OH-2-¹³C,¹⁵N is a stable isotope-labeled derivative of glycine (B1666218), a key amino acid involved in numerous essential metabolic processes. While the Fmoc protecting group is primarily utilized for peptide synthesis, the underlying ¹³C and ¹⁵N labeled glycine is a powerful tracer for elucidating the dynamics of cellular metabolism, particularly in the context of one-carbon (1C) metabolism, serine biosynthesis, and the glycine cleavage system.[5][6][7]
The Role of Labeled Glycine in Metabolic Flux Analysis
Glycine is a central node in cellular metabolism, connecting pathways for the synthesis of proteins, nucleotides (purines), and glutathione (B108866).[5][7][8][9] By introducing glycine labeled with ¹³C at the C2 position and ¹⁵N at the amino group, researchers can track the fate of these atoms as they are incorporated into various downstream metabolites. This dual labeling provides a more comprehensive picture of metabolic fluxes compared to single-isotope labeling.[10]
Key metabolic pathways that can be investigated using ¹³C,¹⁵N-labeled glycine include:
-
Serine-Glycine One-Carbon (SGOC) Metabolism: This network is crucial for the biosynthesis of nucleotides, amino acids, and for methylation reactions. Labeled glycine can be used to quantify its conversion to serine and the transfer of one-carbon units to the folate cycle.[5][11][12]
-
Glycine Cleavage System (GCS): This mitochondrial enzyme complex is a major route for glycine catabolism, producing a one-carbon unit in the form of 5,10-methylenetetrahydrofolate, which is vital for nucleotide synthesis and other biosynthetic reactions.[7][9][13][14]
-
Glutathione Synthesis: Glycine is one of the three amino acids required for the synthesis of the antioxidant glutathione. Tracing labeled glycine into the glutathione pool provides insights into cellular redox homeostasis.
-
Purine (B94841) Synthesis: The entire glycine molecule (C1, C2, and N) is incorporated into the purine ring structure. Therefore, labeled glycine is an excellent tracer for quantifying de novo purine biosynthesis.
Applications in Research and Drug Development
The study of metabolic fluxes through these pathways is particularly relevant in:
-
Cancer Research: Cancer cells often exhibit altered serine and glycine metabolism to support rapid proliferation.[5][15][16] Quantifying these metabolic shifts can identify novel therapeutic targets.
-
Neuroscience: Glycine acts as a neurotransmitter in the central nervous system. MFA can be used to study glycine metabolism in neurological disorders.
-
Metabolic Diseases: Dysregulation of one-carbon metabolism is implicated in various metabolic diseases. Labeled glycine can be used to probe these alterations.
Experimental Protocols
Protocol 1: Preparation of Labeled Glycine Tracer from Fmoc-Gly-OH-2-¹³C,¹⁵N
While Fmoc-Gly-OH-2-¹³C,¹⁵N is supplied with the Fmoc protecting group, for cell culture-based metabolic flux analysis, the free amino acid is required. The Fmoc group can be removed using a standard deprotection protocol.
Materials:
-
Fmoc-Gly-OH-2-¹³C,¹⁵N
-
20% piperidine (B6355638) in dimethylformamide (DMF)
-
Diethyl ether
-
Dichloromethane (DCM)
-
Rotary evaporator
-
High-purity water for cell culture
Procedure:
-
Dissolve Fmoc-Gly-OH-2-¹³C,¹⁵N in a minimal amount of DMF.
-
Add 20% piperidine in DMF to the solution.
-
Stir the reaction at room temperature for 1-2 hours.
-
Monitor the reaction by thin-layer chromatography (TLC) until the starting material is consumed.
-
Remove the solvent under reduced pressure using a rotary evaporator.
-
Dissolve the residue in a small amount of water and wash with diethyl ether to remove the dibenzofulvene-piperidine adduct.
-
Lyophilize the aqueous layer to obtain the deprotected ¹³C,¹⁵N-glycine.
-
Dissolve the labeled glycine in high-purity water, sterile-filter, and determine the concentration accurately. This stock solution can be used to supplement cell culture media.
Protocol 2: ¹³C,¹⁵N Metabolic Flux Analysis in Mammalian Cells using Labeled Glycine
This protocol outlines a general workflow for a steady-state MFA experiment in cultured mammalian cells.
Materials:
-
Mammalian cell line of interest (e.g., HeLa, A549)
-
Cell culture medium deficient in glycine
-
Fetal Bovine Serum (dialyzed)
-
Sterile-filtered ¹³C,¹⁵N-glycine stock solution
-
Cell culture flasks or plates
-
Methanol, Chloroform, and Water (for metabolite extraction)
-
Liquid chromatography-mass spectrometry (LC-MS) system
Procedure:
-
Cell Culture and Labeling:
-
Culture cells in standard medium to the desired confluency.
-
For the experiment, switch the cells to a glycine-free medium supplemented with a known concentration of ¹³C,¹⁵N-glycine and dialyzed FBS.
-
Culture the cells for a sufficient period to achieve isotopic steady state (typically 24 hours or several cell doubling times).
-
-
Metabolite Extraction:
-
Aspirate the culture medium and quickly wash the cells with ice-cold saline.
-
Quench metabolism by adding a cold extraction solvent (e.g., 80% methanol).
-
Scrape the cells and collect the cell lysate.
-
Perform a liquid-liquid extraction (e.g., using a methanol/chloroform/water system) to separate polar metabolites from lipids and proteins.
-
Collect the polar metabolite fraction and dry it under a stream of nitrogen or using a vacuum concentrator.
-
-
Mass Spectrometry Analysis:
-
Reconstitute the dried metabolite extract in a suitable solvent for LC-MS analysis.
-
Analyze the samples using an LC-MS method optimized for the separation and detection of amino acids and other central carbon metabolites.
-
Collect mass isotopomer distribution (MID) data for glycine, serine, and other relevant downstream metabolites.
-
-
Data Analysis and Flux Calculation:
-
Correct the raw MS data for the natural abundance of isotopes.
-
Use a computational flux modeling software (e.g., INCA, OpenFlux) to estimate intracellular metabolic fluxes by fitting the measured MIDs to a metabolic network model.[1]
-
Data Presentation
Table 1: Example of Relative Metabolic Flux Data in Cancer Cells
This table illustrates the type of quantitative data that can be obtained from a metabolic flux analysis experiment. The values are for illustrative purposes and represent the relative contribution of different pathways to serine and glycine metabolism in a hypothetical cancer cell line.
| Metabolic Flux | Relative Flux Value |
| Serine Inputs | |
| Serine Uptake | 70% |
| De Novo Synthesis from Glucose | 25% |
| Protein Degradation & Other | 5% |
| Glycine Inputs | |
| Glycine Uptake | 45% |
| Conversion from Serine | 45% |
| Protein Degradation & Other | 10% |
| Serine Outputs | |
| Protein Synthesis | 50% |
| Phospholipid & Sphingolipid Synthesis | 40% |
| Conversion to Glycine & 1C Units | 10% |
| Glycine Outputs | |
| Protein Synthesis | 60% |
| Nucleotide Synthesis | 40% |
Data adapted from a study on HeLa cells for illustrative purposes.[15]
Visualizations
Diagram 1: Serine-Glycine One-Carbon Metabolism
Caption: Key pathways in serine and glycine one-carbon metabolism.
Diagram 2: Experimental Workflow for Metabolic Flux Analysis
Caption: General workflow for a stable isotope-assisted metabolic flux analysis experiment.
References
- 1. Understanding metabolism with flux analysis: from theory to application - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Metabolic Flux Analysis and In Vivo Isotope Tracing - Creative Proteomics [creative-proteomics.com]
- 3. Isotope-Assisted Metabolic Flux Analysis: A Powerful Technique to Gain New Insights into the Human Metabolome in Health and Disease - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Overview of 13c Metabolic Flux Analysis - Creative Proteomics [creative-proteomics.com]
- 5. Reprogramming of Serine, Glycine and One-Carbon Metabolism in Cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 6. One-Carbon Metabolic Flux Analysis - Creative Proteomics MFA [creative-proteomics.com]
- 7. Glycine Metabolism Overview - Creative Proteomics [creative-proteomics.com]
- 8. researchgate.net [researchgate.net]
- 9. Glycine and Serine Metabolism | Pathway - PubChem [pubchem.ncbi.nlm.nih.gov]
- 10. One‐shot 13C15N‐metabolic flux analysis for simultaneous quantification of carbon and nitrogen flux - PMC [pmc.ncbi.nlm.nih.gov]
- 11. researchgate.net [researchgate.net]
- 12. Serine Metabolic Network: Gene Expression & Flux in Cancer [thermofisher.com]
- 13. Production of 1-Carbon Units from Glycine Is Extensive in Healthy Men and Women - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Tracing Metabolic Fate of Mitochondrial Glycine Cleavage System Derived Formate In Vitro and In Vivo - PMC [pmc.ncbi.nlm.nih.gov]
- 15. Quantification of the inputs and outputs of serine and glycine metabolism in cancer cells - PubMed [pubmed.ncbi.nlm.nih.gov]
- 16. researchgate.net [researchgate.net]
Application Notes and Protocols for Fmoc Deprotection of Labeled Amino Acids
Audience: Researchers, scientists, and drug development professionals.
Introduction:
The 9-fluorenylmethyloxycarbonyl (Fmoc) protecting group is a cornerstone of modern solid-phase peptide synthesis (SPPS).[1] Its base-lability allows for the selective deprotection of the Nα-amino group under mild conditions, which is crucial for the stepwise elongation of the peptide chain.[2] This orthogonality, where the Fmoc group is removed by a base while side-chain protecting groups are typically acid-labile, is a key advantage of the Fmoc/tBu strategy.[2] The deprotection reaction proceeds via a β-elimination mechanism, initiated by a base, most commonly a secondary amine like piperidine (B6355638).[3] This process results in the formation of a dibenzofulvene (DBF) intermediate, which is subsequently scavenged by the amine to form a stable adduct.[2] This document provides a detailed standard operating procedure for the Fmoc deprotection of labeled amino acids, including experimental protocols, data tables for quick reference, and troubleshooting guidelines.
Experimental Protocols
This section details the standard manual protocol for Fmoc deprotection on a solid support. The procedure may require optimization based on the specific amino acid, the solid support, and the scale of the synthesis.
Materials and Reagents:
-
Fmoc-protected amino acid loaded resin
-
N,N-Dimethylformamide (DMF)
-
Piperidine
-
Deprotection Solution: 20% (v/v) piperidine in DMF.[4][5] Prepare fresh daily.
-
Washing Solvents: DMF, Dichloromethane (DCM), Methanol (MeOH)
-
Reaction vessel (e.g., solid-phase synthesis vessel, fritted syringe)
-
Inert gas (Nitrogen or Argon)
Safety Precautions:
-
Always work in a well-ventilated fume hood.
-
Wear appropriate personal protective equipment (PPE), including safety glasses, chemical-resistant gloves, and a lab coat.
-
Piperidine is toxic and flammable. Consult the Safety Data Sheet (SDS) before use and handle with care.
-
Dispose of all chemical waste according to institutional guidelines.
Detailed Protocol:
-
Resin Swelling:
-
Place the Fmoc-amino acid-loaded resin in the reaction vessel.
-
Add sufficient DMF to cover the resin (approximately 10 mL/g of resin).
-
Allow the resin to swell for 30-60 minutes at room temperature with gentle agitation.[1]
-
-
Initial Solvent Wash:
-
After swelling, drain the DMF from the reaction vessel.
-
Wash the resin with DMF (3 x resin volume) for 1 minute per wash to remove any impurities.[1]
-
-
Fmoc Deprotection:
-
Drain the final DMF wash.
-
Add the 20% piperidine in DMF deprotection solution to the resin, ensuring the resin is fully submerged.
-
Agitate the mixture for an initial 3 minutes.[1]
-
Drain the deprotection solution.
-
Add a fresh aliquot of the deprotection solution.
-
Continue to agitate the mixture for an additional 10-15 minutes.[1][2]
-
-
Washing:
-
Confirmation of Deprotection (Optional but Recommended):
Data Presentation
The following tables summarize key quantitative data for the Fmoc deprotection protocol.
Table 1: Standard Reagent Concentrations and Volumes
| Reagent | Concentration | Volume |
| Piperidine in DMF | 20% (v/v) | ~10 mL per gram of resin |
| DMF (for swelling) | - | ~10 mL per gram of resin |
| DMF (for washing) | - | 3 x resin volume per wash |
Table 2: Standard Reaction Times and Conditions
| Step | Duration | Temperature | Agitation |
| Resin Swelling | 30 - 60 minutes | Room Temperature | Gentle |
| Initial Deprotection | 3 minutes | Room Temperature | Gentle |
| Main Deprotection | 10 - 15 minutes | Room Temperature | Gentle |
| Washing | ~1 minute per wash | Room Temperature | Gentle |
Table 3: Alternative Deprotection Reagents and Conditions
| Reagent | Concentration | Conditions | Notes |
| Piperazine | 20% in DMF | Similar to piperidine | May reduce aspartimide formation.[8] |
| 1,8-Diazabicyclo[5.4.0]undec-7-ene (DBU) | 1-2% in DMF (often with piperidine as a scavenger) | Shorter reaction times | Potent, non-nucleophilic base; can accelerate deprotection for difficult sequences.[9] |
| Morpholine | 3 equivalents in Acetonitrile | 24 hours at room temperature | A milder base, may require longer reaction times.[3] |
Mandatory Visualizations
Caption: A flowchart of the standard Fmoc deprotection workflow.
Caption: The chemical mechanism of Fmoc deprotection by piperidine.
Troubleshooting
Problem: Incomplete Fmoc deprotection, leading to deletion sequences.[6]
-
Potential Causes:
-
Solutions:
-
Optimize Protocol: Increase deprotection time or use a stronger base cocktail (e.g., with DBU).
-
Verify Reagents: Use fresh, high-quality reagents.
-
Improve Swelling: Ensure the resin is fully swelled before deprotection.
-
Problem: Significant loss of peptide from the resin, especially with C-terminal Proline.
-
Potential Cause:
-
Solution:
References
Troubleshooting & Optimization
Technical Support Center: Optimizing Fmoc-Gly-OH-2-13C,15N Coupling in SPPS
This guide provides troubleshooting advice and frequently asked questions for researchers encountering challenges during Solid-Phase Peptide Synthesis (SPPS), with a specific focus on the coupling of Fmoc-Gly-OH-2-¹³C,¹⁵N.
Frequently Asked Questions (FAQs) & Troubleshooting
Q1: I am observing low coupling efficiency for Fmoc-Gly-OH-2-¹³C,¹⁵N in my peptide sequence. What are the potential causes?
Low coupling efficiency for Fmoc-Gly-OH-2-¹³C,¹⁵N, while seemingly straightforward due to glycine's lack of a side chain, can be influenced by several factors:
-
Peptide Aggregation: As the peptide chain elongates, it can fold into secondary structures (e.g., beta-sheets) or aggregate on the resin. This can physically obstruct the N-terminal amine, making it less accessible for the incoming activated amino acid.[1][2] Glycine-rich sequences can sometimes be prone to aggregation.
-
Steric Hindrance from the Fmoc Group: While glycine (B1666218) itself is small, the bulky Fmoc protecting group can sometimes hinder the coupling reaction, especially in sterically crowded environments on the resin.[2]
-
Suboptimal Activation: The pre-activation of the Fmoc-Gly-OH-2-¹³C,¹⁵N carboxylic acid may be incomplete, or the lifetime of the activated species might be too short, leading to inefficient coupling.
-
Incomplete Deprotection: If the Fmoc group from the previously coupled amino acid is not completely removed, the N-terminal amine will not be available for the subsequent coupling reaction, leading to a deletion sequence.
-
Reagent Solubility: Poor solubility of the Fmoc-Gly-OH-2-¹³C,¹⁵N or coupling reagents in the reaction solvent (e.g., DMF) can lead to lower effective concentrations and reduced reaction rates.[1]
Q2: Does the isotopic labeling of Fmoc-Gly-OH-2-¹³C,¹⁵N affect its coupling efficiency?
The isotopic labeling (¹³C and ¹⁵N) at the alpha-carbon and nitrogen does not significantly alter the chemical reactivity of the amino acid. The electronic structure and, therefore, the reaction kinetics are virtually identical to the unlabeled counterpart. Any observed coupling issues are likely attributable to the factors mentioned in Q1.
Q3: What strategies can I employ to improve the coupling efficiency of Fmoc-Gly-OH-2-¹³C,¹⁵N?
Several strategies can be implemented to overcome low coupling efficiency:
-
Optimize Coupling Reagents: For challenging couplings, switching to more potent activating reagents can significantly improve yields.[1]
-
Perform a Double Coupling: If a single coupling reaction is insufficient, a second coupling with a fresh solution of activated Fmoc-Gly-OH-2-¹³C,¹⁵N can be performed.[1]
-
Increase Reaction Time and Temperature: Extending the coupling time or moderately increasing the temperature can help drive the reaction to completion.[1]
-
Incorporate Chaotropic Agents: In cases of suspected peptide aggregation, the addition of chaotropic salts can help disrupt secondary structures and improve resin swelling.
-
Use Structure-Disrupting Amino Acid Derivatives: For known difficult sequences, incorporating pseudoproline dipeptides or N-substituted derivatives like Hmb or Dmb in preceding residues can disrupt aggregation.[3]
Quantitative Data Summary
The following tables provide a summary of coupling conditions and their impact on efficiency. While specific data for Fmoc-Gly-OH-2-¹³C,¹⁵N is not available, the data for standard Fmoc-Gly-OH and other challenging couplings offer valuable guidance.
Table 1: Comparison of Common Coupling Reagents for Difficult Couplings
| Coupling Reagent | Typical Concentration | Activation Time (min) | Key Advantages |
| HBTU/HOBt | 0.45 M | 2-5 | Standard, cost-effective |
| HATU/HOAt | 0.45 M | 2-5 | Highly effective for hindered couplings, reduced racemization.[1] |
| HCTU | 0.45 M | 2-5 | Good coupling efficiency and racemization suppression.[4] |
| PyBOP | 0.45 M | 2-5 | Excellent for difficult couplings.[1] |
| DIC/Oxyma | 0.5 M | 2-5 | Reported to outperform HOBt-based methods.[1] |
Table 2: Troubleshooting Low Coupling Efficiency
| Symptom | Potential Cause | Recommended Action |
| Positive Kaiser test after coupling | Incomplete coupling reaction | Perform a double coupling; switch to a more potent coupling reagent; increase reaction time.[1] |
| Low yield of final peptide | Peptide aggregation | Incorporate chaotropic agents; use structure-disrupting amino acid derivatives.[3] |
| Deletion sequences in final product | Incomplete deprotection or coupling | Ensure complete Fmoc deprotection; optimize coupling conditions. |
Experimental Protocols
Protocol 1: Double Coupling for Fmoc-Gly-OH-2-¹³C,¹⁵N
-
First Coupling: Perform the initial coupling of Fmoc-Gly-OH-2-¹³C,¹⁵N using your standard protocol (e.g., with HATU activation) for 1-2 hours.
-
Washing: After the first coupling, drain the reaction vessel and wash the resin thoroughly with DMF (3-5 times) to remove soluble reagents and byproducts.
-
Second Coupling: Prepare a fresh solution of activated Fmoc-Gly-OH-2-¹³C,¹⁵N using the same protocol as the first coupling. Add this solution to the washed resin and allow the reaction to proceed for another 1-2 hours.[1]
-
Final Wash and Monitoring: After the second coupling, wash the resin thoroughly with DMF. Perform a Kaiser test (Protocol 2) to confirm the absence of free amines before proceeding with the Fmoc deprotection of the newly added residue.[1]
Protocol 2: Kaiser Test (Ninhydrin Test) for Free Primary Amines
-
Sample Collection: After the coupling reaction, remove a small sample of the resin (approximately 5-10 beads) and place it in a small glass test tube.
-
Washing: Wash the resin beads thoroughly with DMF (3x) and then with ethanol (B145695) (3x) to remove any residual reagents.[1]
-
Reagent Addition: Add the following three solutions to the test tube:[1]
-
2-3 drops of potassium cyanide in pyridine (B92270) (e.g., 65 mg KCN in 100 mL pyridine).
-
2-3 drops of ninhydrin (B49086) in ethanol (e.g., 5 g ninhydrin in 100 mL ethanol).
-
2-3 drops of phenol (B47542) in ethanol (e.g., 80 g phenol in 20 mL ethanol).
-
-
Heating: Heat the test tube at 100-120°C for 3-5 minutes.
-
Observation:
-
Positive Result (Incomplete Coupling): The resin beads will turn a deep blue, indicating the presence of free primary amines.
-
Negative Result (Complete Coupling): The resin beads will remain colorless or turn a yellowish color.
-
Visual Guides
Caption: Troubleshooting workflow for low coupling efficiency.
Caption: Experimental workflow for monitoring and improving coupling.
References
Identifying and minimizing common side reactions in Fmoc SPPS with labeled amino acids.
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to assist researchers, scientists, and drug development professionals in identifying and minimizing common side reactions during Fmoc solid-phase peptide synthesis (SPPS) with labeled amino acids.
Frequently Asked Questions (FAQs)
Q1: Do isotopically labeled amino acids (e.g., ¹³C, ¹⁵N) behave differently from their unlabeled counterparts in Fmoc SPPS?
In general, the chemical reactivity of isotopically labeled amino acids is nearly identical to that of their unlabeled counterparts. The fundamental principles of Fmoc SPPS, including coupling and deprotection steps, remain the same. However, it is important to be aware of the potential for a kinetic isotope effect (KIE), where the difference in mass between isotopes can lead to minor differences in reaction rates. While significant alterations to standard protocols are not typically necessary, careful monitoring of coupling and deprotection steps is always recommended.
Q2: What are the most common side reactions encountered when using labeled amino acids in Fmoc SPPS?
The side reactions observed with labeled amino acids are the same as those for unlabeled amino acids. The most prevalent include:
-
Diketopiperazine (DKP) formation: Cyclization of the N-terminal dipeptide, leading to chain termination.[1][2][3]
-
Aspartimide formation: Intramolecular cyclization of aspartic acid residues, which can lead to racemization and the formation of β- and α-peptides.[4][5][6]
-
Racemization: Loss of stereochemical integrity at the α-carbon, particularly during the activation step of the amino acid.[7][8]
-
Aggregation: Interchain association of the growing peptide, which can hinder reagent access and lead to incomplete reactions.
-
Incomplete Deprotection/Coupling: Failure to completely remove the Fmoc group or to couple the next amino acid, resulting in deletion sequences.
Q3: How can I detect and quantify side reactions in my peptide synthesis?
The primary methods for detecting and quantifying side reactions are High-Performance Liquid Chromatography (HPLC) and Mass Spectrometry (MS).
-
HPLC: Provides a profile of the crude peptide product, allowing for the visualization and quantification of impurities based on their retention times.
-
Mass Spectrometry: Enables the identification of side products by their mass-to-charge ratio. For example, DKP formation can be inferred from the presence of truncated sequences, while aspartimide formation can be detected by a neutral mass change, though it can be identified through tandem MS fragmentation patterns.[4][5][9]
Troubleshooting Guides
Issue 1: Low Yield and Presence of Truncated Peptides
Possible Cause: Diketopiperazine (DKP) Formation
Troubleshooting Workflow:
Caption: Troubleshooting workflow for diketopiperazine formation.
Quantitative Data on DKP Formation:
| Condition | DKP Formation (%) | Reference |
| Fmoc-Pro-Pro-Ser-resin in DMF (no mixing) | 0.2 - 0.4 %/hour | [1] |
| Fmoc-Ala-Pro-Pro-Pro-Ser-resin in DMF (650h) | ~25% | [1] |
| Fmoc-Pro-Pro-Pro-Ser-resin in DMF (650h) | ~80% | [1] |
Issue 2: Presence of Isomeric Impurities with the Same Mass
Possible Cause: Aspartimide Formation or Racemization
Troubleshooting Workflow:
References
- 1. pubs.acs.org [pubs.acs.org]
- 2. Mechanistic Study of Diketopiperazine Formation during Solid-Phase Peptide Synthesis of Tirzepatide - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. researchgate.net [researchgate.net]
- 4. biotage.com [biotage.com]
- 5. Side Reaction Analysis in Solid-Phase Peptide Synthesis: A Case Study in the Glu-Asp-Tyr Motif - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. The aspartimide problem persists: Fluorenylmethyloxycarbonyl‐solid‐phase peptide synthesis (Fmoc‐SPPS) chain termination due to formation of N‐terminal piperazine‐2,5‐diones - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Racemization of amino acids in solid-phase peptide synthesis investigated by capillary electrophoresis - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. Suppression of alpha-carbon racemization in peptide synthesis based on a thiol-labile amino protecting group - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. Side reactions in the SPPS of Cys-containing peptides - PubMed [pubmed.ncbi.nlm.nih.gov]
Technical Support Center: Strategies to Prevent Racemization During Fmoc-Protected Amino Acid Coupling
Welcome to the Technical Support Center for preventing racemization during the coupling of Fmoc-protected amino acids. This resource is designed for researchers, scientists, and drug development professionals to troubleshoot and resolve issues related to the loss of stereochemical integrity during solid-phase peptide synthesis (SPPS).
Troubleshooting Guide
This section provides solutions to specific problems you may encounter during your experiments.
Problem 1: High levels of racemization detected in the final peptide, especially with sensitive residues like Cys and His.
-
Potential Cause: Inappropriate choice of coupling reagent.
-
Solution: Certain coupling reagents are more prone to inducing racemization. For carbodiimide-based couplings (e.g., DCC, DIC), it is highly recommended to use them in combination with racemization-suppressing additives like 1-hydroxybenzotriazole (B26582) (HOBt), 1-hydroxy-7-aza-benzotriazole (HOAt), or ethyl 2-cyano-2-(hydroxyimino)acetate (Oxyma).[1][2][3] These additives convert the highly reactive O-acylisourea intermediate into a more stable active ester, which is less susceptible to racemization.[3] Phosphonium and aminium-based reagents like HBTU, HATU, and PyBOP are also excellent choices for minimizing racemization.[3] For particularly racemization-prone residues like Fmoc-His(Trt)-OH, DEPBT has been shown to be a reagent of choice due to its remarkable resistance to racemization.[2]
-
-
Potential Cause: Strong or sterically unhindered base.
-
Solution: The base used during coupling can abstract the α-proton of the activated amino acid, leading to racemization.[4] Using a weaker or more sterically hindered base can mitigate this issue. N-methylmorpholine (NMM) or 2,4,6-collidine (TMP) are generally preferred over N,N-diisopropylethylamine (DIPEA) or triethylamine (B128534) (TEA).[3][4] For cysteine coupling, substituting N-methylmorpholine with 2,4,6-collidine has been shown to suppress racemization.[5]
-
-
Potential Cause: Prolonged pre-activation time.
-
Solution: Extended pre-activation of the Fmoc-amino acid before addition to the resin can increase the risk of racemization, especially for sensitive residues like histidine.[6][7] It is advisable to minimize the pre-activation time or to perform in situ activation where the coupling reagent is added to the mixture of the amino acid and the resin.[3][4]
-
-
Potential Cause: Elevated reaction temperature.
-
Solution: Higher temperatures, particularly in microwave-assisted peptide synthesis, can accelerate the rate of racemization.[8][9][10] If you are using a microwave synthesizer, consider lowering the coupling temperature for sensitive amino acids like histidine and cysteine to around 50°C.[7][9][11] Alternatively, the coupling of these specific residues can be performed at room temperature, even if the rest of the synthesis is conducted at a higher temperature.[7][9][11]
-
Problem 2: Significant racemization specifically observed when coupling Fmoc-Cys-OH.
-
Potential Cause: Base-catalyzed elimination and side reactions.
-
Solution: Cysteine is particularly susceptible to racemization.[1] Base-catalyzed elimination of the protected sulfhydryl group can form a dehydroalanine (B155165) intermediate, which can lead to side products.[1] Utilizing a sterically bulky protecting group like trityl (Trt) can help minimize this side reaction.[1] For coupling Fmoc-Cys(Trt)-OH, the combination of DIC with HOBt or Oxyma Pure under base-free conditions is a recommended method to minimize racemization.[2] Copper(II) chloride (CuCl2) in conjunction with HOBt has also been used to suppress racemization during cysteine coupling.[1]
-
Problem 3: Racemization is occurring with Fmoc-His-OH.
-
Potential Cause: Intramolecular base catalysis by the imidazole (B134444) ring.
-
Solution: The primary cause of histidine racemization is intramolecular base catalysis by the π-nitrogen of the imidazole side chain.[7][12] This nitrogen can abstract the α-proton of the activated histidine, leading to racemization.[7] Protecting the imidazole nitrogen is crucial. The trityl (Trt) protecting group is commonly used. Protecting the pi imidazole nitrogen with a methoxybenzyl group has been shown to greatly reduce racemization.[1] As mentioned previously, using a coupling reagent like DEPBT is highly recommended for histidine incorporation.[2]
-
Frequently Asked Questions (FAQs)
Q1: What are the primary mechanisms of racemization for Fmoc-protected amino acids?
A1: There are two main pathways for racemization during peptide coupling:
-
Oxazolone Formation: The activated carboxylic acid of the Fmoc-amino acid can cyclize to form a 5(4H)-oxazolone intermediate. The α-proton of this intermediate is highly acidic and can be easily removed by a base, leading to racemization. The subsequent reaction with the amine on the resin opens the ring to form the peptide bond, but with a mixture of L- and D-isomers.[4]
-
Direct Enolization (α-Proton Abstraction): A base in the reaction mixture can directly abstract the α-proton of the activated amino acid, forming a planar enolate intermediate. Reprotonation of this intermediate can occur from either side, resulting in racemization.[4]
Q2: Why are some amino acids more prone to racemization than others?
A2: The susceptibility of an amino acid to racemization is influenced by its side chain.[3] Histidine and cysteine are particularly prone to racemization.[1][3] The imidazole ring in histidine can act as an internal base, catalyzing the abstraction of the α-proton.[7][13] For cysteine, the sulfur-containing side chain can also promote racemization. Amino acids with electron-withdrawing groups on their side chains can also be more susceptible as they increase the acidity of the α-proton.[4]
Q3: How do additives like HOBt and Oxyma prevent racemization?
A3: Additives like HOBt, HOAt, and Oxyma act as racemization suppressants.[1][3] When a coupling reagent such as a carbodiimide (B86325) is used, it reacts with the carboxylic acid to form a highly reactive intermediate that is prone to racemization. The additive rapidly converts this unstable intermediate into a less reactive, but still effective, active ester. This active ester is more stable towards racemization and reacts cleanly with the amine to form the desired peptide bond.[3]
Q4: What is the impact of the solvent on racemization?
A4: The polarity of the solvent can influence the rate of racemization. In some cases, using less polar solvents may help to reduce the rate of racemization.[8] Common solvents used in SPPS include DMF and NMP. If aggregation is an issue, which can lead to incomplete reactions and effectively increase the time the activated amino acid is susceptible to racemization, adding DMSO to the solvent or switching to NMP can be beneficial.[1]
Q5: Are there any specific considerations for microwave-assisted peptide synthesis (MAPS)?
A5: Yes, while microwave energy can accelerate both deprotection and coupling steps, the associated higher temperatures can increase the risk of racemization, especially for sensitive amino acids like cysteine and histidine.[9][10][11] It is often recommended to lower the coupling temperature to 50°C for these residues during microwave synthesis to minimize racemization.[9][11]
Quantitative Data on Racemization
The extent of racemization is highly dependent on the specific reaction conditions. The following tables summarize some reported data on the percentage of D-isomer formation under various conditions.
Table 1: Effect of Coupling Reagents and Additives on Racemization of Fmoc-Ser(tBu)-OH
| Coupling Reagent | Additive | % D-Isomer |
| DIC | - | High |
| DIC | HOBt | Low |
| DIC | Oxyma Pure | Low |
| HBTU | - | Moderate |
| HATU | - | Low |
Data is qualitative based on literature and serves for comparative purposes.[8]
Table 2: Racemization of Fmoc-Cys(Trt)-OH with Different Coupling Methods
| Coupling Method | Base | % Racemization (D-isomer) |
| Uronium activation | DIPEA | 8.0 |
| DIC/HOBt | None | <1.0 |
Data adapted from studies on model peptides.[14]
Table 3: Influence of Base on Cysteine Racemization
| Base | % Racemization |
| N-methylmorpholine (NMM) | ~50 |
| 2,4,6-collidine (TMP) | Suppressed |
Data from the synthesis of protoxin II.[5]
Experimental Protocols
Protocol 1: General Coupling Procedure to Minimize Racemization
This protocol provides a starting point for minimizing racemization during a standard coupling cycle in solid-phase peptide synthesis (SPPS).
-
Deprotection: Remove the N-terminal Fmoc protecting group from the resin-bound peptide using a 20% piperidine (B6355638) solution in DMF for 20 minutes.[15]
-
Washing: Thoroughly wash the resin with DMF to remove residual piperidine.
-
Amino Acid Activation and Coupling:
-
In a separate vessel, dissolve 3-5 equivalents of the N-protected amino acid in DMF.
-
Add 3-5 equivalents of a racemization suppressant additive (e.g., Oxyma Pure or HOBt).[8]
-
Add 3-5 equivalents of a coupling reagent (e.g., DIC).
-
Allow the mixture to pre-activate for 1-5 minutes.[8]
-
Add the activation mixture to the washed resin.
-
Allow the coupling reaction to proceed for 1-2 hours at room temperature.[8]
-
-
Washing: Wash the resin with DMF to remove excess reagents and byproducts.
-
Monitoring: Perform a Kaiser test or another appropriate method to confirm the completion of the coupling reaction.[8]
Protocol 2: Protocol for Coupling Racemization-Prone Fmoc-His(Trt)-OH
This protocol is specifically designed for the coupling of histidine to minimize racemization.
-
Resin Preparation: Swell the peptide-resin in DMF and perform the N-terminal Fmoc deprotection as described in Protocol 1.
-
Coupling Reaction:
-
In a separate vessel, pre-dissolve Fmoc-His(Trt)-OH (3 equivalents) and HATU (2.9 equivalents) in DMF.[7]
-
Add DIPEA (6 equivalents) to the solution and vortex briefly.
-
Immediately add the mixture to the deprotected peptide-resin.
-
Allow the coupling to proceed for 2 hours at room temperature.
-
-
Washing and Monitoring: Wash the resin thoroughly and check for reaction completion as described in Protocol 1.
Protocol 3: Chiral HPLC Analysis for Racemization Detection
This protocol outlines a general method for quantifying the extent of racemization.
-
Sample Preparation (Peptide Hydrolysis):
-
Chiral HPLC Analysis:
-
Inject the sample onto a chiral HPLC column (e.g., a cyclodextrin-based or crown ether-based column).[16]
-
Separate the D- and L-amino acid enantiomers using an appropriate mobile phase.
-
Quantify the amount of D-isomer by integrating the peak areas. The percentage of racemization can be calculated from the ratio of the D-isomer peak area to the total peak area (D + L).
-
Visualizations
Caption: Primary pathways for racemization during peptide coupling.
Caption: Decision workflow for selecting coupling conditions to prevent racemization.
References
- 1. peptide.com [peptide.com]
- 2. bachem.com [bachem.com]
- 3. benchchem.com [benchchem.com]
- 4. benchchem.com [benchchem.com]
- 5. pure.johnshopkins.edu [pure.johnshopkins.edu]
- 6. pubs.acs.org [pubs.acs.org]
- 7. benchchem.com [benchchem.com]
- 8. benchchem.com [benchchem.com]
- 9. Limiting racemization and aspartimide formation in microwave-enhanced Fmoc solid phase peptide synthesis - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. pubs.acs.org [pubs.acs.org]
- 11. researchgate.net [researchgate.net]
- 12. ouci.dntb.gov.ua [ouci.dntb.gov.ua]
- 13. Mechanism of racemisation of histidine derivatives in peptide synthesis - PubMed [pubmed.ncbi.nlm.nih.gov]
- 14. researchgate.net [researchgate.net]
- 15. chemistry.du.ac.in [chemistry.du.ac.in]
- 16. benchchem.com [benchchem.com]
Troubleshooting guide for low incorporation of labeled glycine in peptide synthesis.
This guide provides troubleshooting advice for researchers encountering low incorporation of labeled glycine (B1666218) during solid-phase peptide synthesis (SPPS).
Frequently Asked Questions (FAQs)
Q1: What are the primary reasons for low incorporation of labeled glycine in my peptide synthesis?
Low incorporation of labeled glycine can stem from several factors, often related to the unique properties of glycine and the isotopic label. Key reasons include:
-
Steric Hindrance: Although glycine is the smallest amino acid, the isotopic label (e.g., 13C, 15N, 2H) can introduce steric bulk, hindering the coupling reaction. This is particularly relevant when the label is on the alpha-carbon.
-
Peptide Aggregation: The growing peptide chain can fold into secondary structures like β-sheets on the solid support, which physically blocks the N-terminus and prevents the incoming labeled glycine from coupling efficiently.[1] Glycine itself can sometimes contribute to aggregation, especially in longer sequences.[2]
-
Inefficient Coupling Conditions: The choice of coupling reagents, solvents, and reaction time is critical. Standard coupling protocols may not be sufficient for the potentially more demanding coupling of a labeled amino acid.
-
Suboptimal Deprotection: Incomplete removal of the Fmoc protecting group from the N-terminus of the growing peptide chain will prevent the subsequent coupling of the labeled glycine, leading to deletion sequences.[3]
-
Degraded Reagents: The quality of the labeled glycine, coupling reagents, and solvents is crucial. Degradation of these reagents can significantly reduce coupling efficiency.[3]
Q2: How can I confirm that the low yield is due to poor incorporation of labeled glycine?
To pinpoint the issue, a systematic analysis of the crude peptide product is necessary. The following analytical techniques are recommended:
-
Mass Spectrometry (MS): This is the most direct method to identify deletion sequences. A peak corresponding to the mass of the peptide without the labeled glycine will confirm its failed incorporation.[4]
-
High-Performance Liquid Chromatography (HPLC): A complex HPLC chromatogram with multiple peaks suggests the presence of impurities, including deletion sequences. Comparing the chromatogram of your crude product with a standard of the correct peptide can help identify the peak corresponding to the desired product and quantify its purity.[3]
Q3: Can the isotopic label itself affect the reactivity of the glycine molecule?
Yes, the presence of a heavier isotope can lead to a kinetic isotope effect, where the rate of reaction is slightly altered due to the difference in mass between the isotopes (e.g., 1H vs. 2H).[5] This effect is generally small for 13C and 15N but can be more pronounced with deuterium (B1214612) (2H) labeling.[5] This may necessitate longer coupling times or more potent coupling reagents to achieve complete incorporation.
Troubleshooting Guide
Problem: Mass spectrometry and HPLC analysis confirm low incorporation of labeled glycine.
Below are potential causes and recommended solutions to improve the coupling efficiency of your labeled glycine.
| Possible Cause | Suggested Solution |
| Steric Hindrance from the Isotopic Label | 1. Switch to a more powerful coupling reagent: For sterically hindered amino acids, stronger coupling reagents are often required. Consider using aminium/uronium salts like HATU, HCTU, or COMU, or phosphonium (B103445) salts like PyBOP.[6][7] 2. Increase reaction time and/or temperature: Allowing the coupling reaction to proceed for a longer duration (e.g., 2-4 hours or even overnight) can help drive the reaction to completion.[8] Microwave-assisted synthesis can also be beneficial by increasing the reaction temperature and shortening the required time.[7] 3. Perform a double coupling: After the initial coupling reaction, repeat the coupling step with a fresh solution of the labeled glycine and coupling reagents to ensure maximum incorporation.[6] |
| Peptide Chain Aggregation | 1. Use a high-swelling resin: Resins like PEG-based or low-crosslinked polystyrene resins provide more space for the growing peptide chain, reducing the likelihood of aggregation.[9] 2. Incorporate structure-disrupting elements: If the sequence is known to be difficult, consider incorporating pseudoproline dipeptides or Dmb-protected amino acids to disrupt the formation of secondary structures.[1] 3. Use chaotropic salts: Adding chaotropic salts like LiCl or KSCN to the coupling mixture can help to break up secondary structures and improve reagent accessibility.[1] |
| Inefficient Coupling Chemistry | 1. Optimize reagent concentrations: Increasing the concentration of the labeled amino acid and coupling reagents can enhance the reaction kinetics.[8] 2. Choose an appropriate solvent: N,N-Dimethylformamide (DMF) is a standard solvent, but for difficult couplings, consider using N-methyl-2-pyrrolidone (NMP) or a mixture of solvents.[1] |
| Incomplete Fmoc-Deprotection | 1. Monitor deprotection completion: Use a qualitative test like the Kaiser test to ensure complete removal of the Fmoc group before the coupling step. A positive test (blue beads) indicates incomplete deprotection.[3] 2. Increase deprotection time or use a stronger base: For difficult sequences, you may need to extend the piperidine (B6355638) treatment time or use a stronger deprotection agent like DBU. |
Quantitative Data on Coupling Reagent Performance
The choice of coupling reagent significantly impacts the incorporation efficiency, especially for sterically hindered amino acids. The following table summarizes the performance of various coupling reagents in the synthesis of a challenging peptide containing a sterically hindered residue (Aib, α-aminoisobutyric acid, which serves as a model for hindered couplings).
| Coupling Reagent | Additive | Base | Reaction Time (h) | Yield (%) | Epimerization (%) |
| DIC | HOBt | DIPEA | 2 | 75 | 5.2 |
| HBTU | - | DIPEA | 2 | 92 | 1.8 |
| HATU | - | DIPEA | 1 | 98 | <1 |
| COMU | - | DIPEA | 1 | 97 | <1 |
| PyBOP | - | DIPEA | 2 | 90 | 2.5 |
Data synthesized from multiple sources comparing coupling efficiencies for hindered amino acids. Conditions are generalized and may vary between studies.[6]
Experimental Protocols
Protocol 1: Monitoring Coupling Efficiency using the Kaiser Test
The Kaiser test is a colorimetric assay used to detect free primary amines on the resin. A positive result after a coupling step indicates that the coupling was incomplete.[3]
Reagents:
-
Solution A: 5 g ninhydrin (B49086) in 100 mL ethanol.
-
Solution B: 80 g phenol (B47542) in 20 mL ethanol.
-
Solution C: 2 mL of 0.001 M KCN in 98 mL pyridine.
Procedure:
-
After the coupling reaction, wash the resin beads thoroughly with DMF.
-
Take a small sample of resin beads (approx. 5-10 mg) and place them in a small glass test tube.
-
Add 2-3 drops of each of Solution A, Solution B, and Solution C to the test tube.
-
Heat the tube at 100°C for 5 minutes.
-
Observe the color of the beads.
-
Blue beads: Indicate the presence of free amines (incomplete coupling).
-
Yellow/Orange beads: Indicate the absence of free amines (complete coupling).
-
Protocol 2: Cleavage from Resin and Sample Preparation for MS and HPLC Analysis
This protocol describes the cleavage of the peptide from the resin and its preparation for analysis.
Reagents:
-
Cleavage Cocktail: 95% Trifluoroacetic acid (TFA), 2.5% Triisopropylsilane (TIS), 2.5% Water. Caution: TFA is highly corrosive. Handle in a fume hood with appropriate personal protective equipment.
-
Cold diethyl ether.
Procedure:
-
Wash the peptide-resin with dichloromethane (B109758) (DCM) and dry it under a stream of nitrogen.
-
Place the dried resin in a reaction vessel.
-
Add the cleavage cocktail to the resin (approximately 10 mL per gram of resin).
-
Gently agitate the mixture at room temperature for 2-3 hours.
-
Filter the resin and collect the filtrate containing the cleaved peptide.
-
Precipitate the peptide by adding the filtrate to a 50 mL centrifuge tube containing cold diethyl ether (approximately 40 mL).
-
Centrifuge the tube to pellet the peptide.
-
Decant the ether and wash the peptide pellet with cold ether two more times.
-
Dry the peptide pellet under vacuum.
-
Dissolve the crude peptide in a suitable solvent (e.g., a water/acetonitrile mixture with 0.1% TFA) for HPLC and MS analysis.
Troubleshooting Workflow
The following diagram illustrates a logical workflow for troubleshooting low incorporation of labeled glycine.
Caption: Troubleshooting workflow for low labeled glycine incorporation.
References
- 1. researchgate.net [researchgate.net]
- 2. peptide.com [peptide.com]
- 3. hx2.med.upenn.edu [hx2.med.upenn.edu]
- 4. A Mass Spectrometry-Based Method to Screen for α-Amidated Peptides - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Deuterium: Slowing Metabolism One C–H Bond At A Time - Ingenza [ingenza.com]
- 6. benchchem.com [benchchem.com]
- 7. bachem.com [bachem.com]
- 8. Comparative study of methods to couple hindered peptides - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. Recent Advances in Labeling‐Based Quantitative Glycomics: From High‐Throughput Quantification to Structural Elucidation - PMC [pmc.ncbi.nlm.nih.gov]
Optimizing the cleavage of peptides containing 13C, 15N labels from resin supports.
This technical support center provides researchers, scientists, and drug development professionals with comprehensive guidance on optimizing the cleavage of peptides containing ¹³C and ¹⁵N labels from solid-phase synthesis resins. This resource offers troubleshooting guides and frequently asked questions (FAQs) to address common challenges and ensure the integrity and purity of your isotopically labeled peptides for downstream applications such as quantitative proteomics and metabolic flux analysis.
Frequently Asked Questions (FAQs)
Q1: Do ¹³C and ¹⁵N labels affect the peptide cleavage process from the resin?
Stable isotopes such as ¹³C and ¹⁵N are non-radioactive and have a negligible effect on the chemical reactivity of the peptide.[] Therefore, standard cleavage protocols used for unlabeled peptides are generally applicable to their isotopically labeled counterparts. The primary focus should remain on optimizing cleavage conditions to maximize yield and purity while minimizing side reactions.
Q2: How can I be sure that the isotopic labels remain stable during cleavage?
The carbon-13 and nitrogen-15 (B135050) isotopes are incorporated into the peptide backbone and amino acid side chains via strong covalent bonds. These bonds are stable under the acidic conditions of standard cleavage protocols, such as those using trifluoroacetic acid (TFA).[] Post-cleavage analysis by high-resolution mass spectrometry is the most definitive method to confirm the integrity and enrichment of the isotopic labels.[2][3]
Q3: What are the most common side reactions during peptide cleavage, and can they affect my labeled peptide?
During the TFA-mediated cleavage, highly reactive carbocations are generated from the protecting groups and the resin linker. These can react with sensitive amino acid residues.[4][5] While these side reactions are not specific to labeled peptides, they can lead to impurities that complicate the analysis of your labeled compound. Common side reactions include:
-
Alkylation of Tryptophan and Cysteine: Tryptophan and cysteine residues are susceptible to modification by carbocations.[4][6]
-
Oxidation of Methionine: Methionine can be oxidized to methionine sulfoxide.
-
Aspartimide Formation: Peptides containing aspartic acid, particularly Asp-Gly or Asp-Ser sequences, can form a cyclic aspartimide intermediate, which can then reopen to form a mixture of α- and β-aspartyl peptides.[5]
-
Re-attachment of the peptide to the resin. [4]
These side products will appear as unexpected masses in your mass spectrometry analysis and can interfere with the quantification of your target labeled peptide.
Q4: What are scavengers and why are they critical for cleaving labeled peptides?
Scavengers are nucleophilic reagents added to the cleavage cocktail to "trap" the reactive carbocations generated during the cleavage process.[4] By quenching these reactive species, scavengers prevent them from modifying sensitive amino acid residues in your peptide. The use of an appropriate scavenger cocktail is crucial for obtaining a pure labeled peptide, which is essential for accurate quantification in mass spectrometry-based assays.
Troubleshooting Guide
This guide addresses common issues encountered during the cleavage of ¹³C and ¹⁵N labeled peptides from resin supports.
| Problem | Potential Cause(s) | Recommended Solution(s) |
| Low Peptide Yield | Incomplete Cleavage: The cleavage reaction may not have gone to completion. | - Extend the cleavage reaction time (e.g., from 2 hours to 3-4 hours).- Increase the volume of the cleavage cocktail to ensure the resin is fully swollen.[7]- Perform a small-scale test cleavage to optimize the cleavage time. |
| Peptide Precipitation Issues: The peptide may be too soluble in the precipitation solvent (e.g., cold ether). | - Concentrate the TFA solution under a stream of nitrogen before adding to cold ether.[8]- Try a different precipitation solvent, such as methyl tert-butyl ether (MTBE).- If the peptide is highly hydrophobic, it may "oil out" instead of precipitating. In such cases, alternative purification strategies like direct HPLC purification may be necessary.[9] | |
| Incomplete Deprotection of Side Chains: Certain protecting groups may require longer cleavage times or specific scavengers for complete removal. | - For peptides containing Arg(Pmc/Pbf), extend the cleavage time to at least 2-3 hours.[10]- Use a cleavage cocktail specifically designed for peptides with sensitive residues (see Table 1). | |
| Unexpected Peaks in Mass Spectrum | Side-Product Formation: Alkylation, oxidation, or other modifications may have occurred during cleavage. | - Ensure the use of an appropriate scavenger cocktail for your peptide sequence (see Table 1).- For peptides containing Cys, Met, or Trp, the addition of scavengers like triisopropylsilane (B1312306) (TIS), 1,2-ethanedithiol (B43112) (EDT), and/or thioanisole (B89551) is critical.[4][8]- Use fresh, high-quality TFA and scavengers.[7] |
| Aspartimide Formation: The peptide sequence contains an Asp residue prone to this side reaction. | - Add HOBt to the piperidine (B6355638) solution during Fmoc deprotection to reduce aspartimide formation.[5]- Use protecting groups on the Asp side chain, such as 2-hydroxy-4-methoxybenzyl (Hmb), which are removed during the final cleavage.[5] | |
| Incomplete Removal of Protecting Groups: Residual protecting groups will result in adducts with corresponding mass shifts. | - Increase the cleavage time or use a stronger cleavage cocktail.- Confirm the complete removal of protecting groups by mass spectrometry. | |
| Loss of Isotopic Label | Label Scrambling (Metabolic): This is more of a concern during peptide synthesis in biological systems rather than during chemical cleavage. | - Not applicable to the cleavage step itself. The stability of ¹³C and ¹⁵N labels is very high under standard cleavage conditions. |
| Incorrect Mass Spectrometry Analysis: Misinterpretation of the mass spectrum. | - Use high-resolution mass spectrometry to accurately determine the isotopic distribution and confirm label incorporation.[2][3] |
Experimental Protocols
Standard TFA Cleavage Protocol for ¹³C, ¹⁵N Labeled Peptides
This protocol is a general guideline and should be optimized for your specific peptide and resin.
Materials:
-
Peptide-resin (fully protected, N-terminal Fmoc group removed)
-
Trifluoroacetic acid (TFA), reagent grade
-
Scavengers (e.g., Triisopropylsilane (TIS), Water (H₂O), 1,2-Ethanedithiol (EDT), Thioanisole)
-
Dichloromethane (DCM)
-
Cold diethyl ether or methyl tert-butyl ether (MTBE)
-
Reaction vessel (e.g., fritted syringe or round-bottom flask)
-
Shaker or rotator
-
Centrifuge
Procedure:
-
Resin Preparation:
-
Cleavage Cocktail Preparation:
-
Cleavage Reaction:
-
Add the cleavage cocktail to the resin (approximately 10 mL per gram of resin).
-
Gently agitate the mixture at room temperature for 2-3 hours. For sensitive peptides, performing the cleavage at 4°C can help minimize side reactions.
-
-
Peptide Isolation:
-
Filter the resin and collect the filtrate containing the cleaved peptide.
-
Wash the resin twice with a small volume of fresh TFA, and combine the filtrates.
-
-
Peptide Precipitation:
-
Add the TFA solution dropwise to a 10-fold volume of cold diethyl ether or MTBE in a centrifuge tube. A white precipitate of the crude peptide should form.
-
If no precipitate forms immediately, store the mixture at -20°C for 1-2 hours to facilitate precipitation.
-
-
Washing and Drying:
-
Centrifuge the suspension to pellet the peptide.
-
Carefully decant the ether.
-
Wash the peptide pellet with cold ether two more times to remove residual scavengers and TFA.
-
Dry the peptide pellet under a stream of nitrogen or in a vacuum desiccator.
-
Data Presentation
Table 1: Common Cleavage Cocktails for Peptides with Sensitive Residues
| Reagent Name | Composition (v/v or w/v) | Recommended Use | Cautions |
| Reagent K | 82.5% TFA, 5% Phenol, 5% Water, 5% Thioanisole, 2.5% EDT | General-purpose cocktail for peptides containing multiple sensitive residues (Cys, Met, Trp, Tyr, Arg).[4][8] | Phenol and thioanisole are toxic and have strong odors. |
| Reagent B | 88% TFA, 5% Phenol, 5% Water, 2% TIS | "Odorless" alternative for scavenging trityl groups. | Does not adequately protect Methionine from oxidation.[8] |
| Reagent H | 81% TFA, 5% Phenol, 5% Thioanisole, 2.5% EDT, 3% Water, 2% Dimethylsulfide, 1.5% Ammonium Iodide (w/w) | Specifically designed to prevent methionine oxidation.[6][8] | Can lead to disulfide bond formation in Cys-containing peptides with extended reaction times.[6] |
| TFA/TIS/H₂O | 95% TFA, 2.5% TIS, 2.5% Water | Suitable for many sequences, especially when Fmoc-Trp(Boc) and Fmoc-Arg(Pbf) are used.[4] | May not be sufficient for peptides with multiple Cys residues. |
| TFA/TIS/EDT/H₂O | 92.5% TFA, 2.5% TIS, 2.5% EDT, 2.5% H₂O | Recommended for peptides containing Cysteine to prevent S-alkylation. | EDT has a strong, unpleasant odor. |
Visualizations
Caption: Standard workflow for the cleavage of isotopically labeled peptides from resin.
References
- 2. Measuring 15N and 13C Enrichment Levels in Sparsely Labeled Proteins Using High-Resolution and Tandem Mass Spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 3. pubs.acs.org [pubs.acs.org]
- 4. Fmoc Resin Cleavage and Deprotection [sigmaaldrich.com]
- 5. peptide.com [peptide.com]
- 6. Side reactions in the SPPS of Cys-containing peptides - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. pubs.acs.org [pubs.acs.org]
- 8. peptide.com [peptide.com]
- 9. tools.thermofisher.com [tools.thermofisher.com]
- 10. merckmillipore.com [merckmillipore.com]
- 11. peptide.com [peptide.com]
Best practices for the purification of isotope-labeled peptides using high-performance liquid chromatography (HPLC).
Technical Support Center: HPLC Purification of Isotope-Labeled Peptides
This technical support center provides researchers, scientists, and drug development professionals with best practices, troubleshooting guidance, and frequently asked questions for the purification of isotope-labeled peptides using high-performance liquid chromatography (HPLC).
Frequently Asked Questions (FAQs)
Q1: What is the impact of isotope labeling on peptide retention time in reversed-phase HPLC?
Stable isotope-labeled peptides are chemically and physically very similar to their endogenous counterparts. However, minor differences in retention time can occur, especially with deuterium (B1214612) (²H) labeling. Deuterated peptides often elute slightly earlier than their non-deuterated equivalents in reversed-phase chromatography.[1] This is due to subtle changes in the peptide's polarity and interaction with the stationary phase.[1] For peptides labeled with heavy carbon (¹³C) or nitrogen (¹⁵N), the effect on retention time is generally negligible.[2]
Q2: Which type of HPLC column is best suited for purifying isotope-labeled peptides?
Reversed-phase (RP) HPLC is the most common and effective method for peptide purification.[3][4] C18 columns are the primary choice for most peptides, offering a good balance of retention and resolution.[3][5] For very hydrophobic peptides, a C8 or a phenyl-based column might provide better selectivity.[5] The choice of pore size is also critical; wide-pore columns (e.g., 300 Å) are recommended for larger peptides to ensure they can access the bonded phase within the pores.[6]
Q3: What are the recommended mobile phases and additives for peptide purification?
The standard mobile phases for reversed-phase peptide chromatography are:
-
Mobile Phase A: 0.1% Trifluoroacetic acid (TFA) in water.
-
Mobile Phase B: 0.1% Trifluoroacetic acid (TFA) in acetonitrile (B52724) (ACN).[3][7]
TFA acts as an ion-pairing agent, which improves peak shape and resolution, particularly for basic peptides.[4][7] Formic acid (0.1%) is a common alternative, especially when the purified peptide is intended for mass spectrometry (MS) analysis, as TFA can cause signal suppression.[8]
Q4: How should I prepare my crude isotope-labeled peptide for HPLC purification?
Proper sample preparation is crucial for a successful purification.
-
Dissolution: Dissolve the crude peptide in a minimal amount of a strong solvent like acetonitrile, methanol, or dimethylformamide (DMF) before diluting it with the initial mobile phase (e.g., high aqueous content).[3] For hydrophobic peptides that are difficult to dissolve, starting with a small amount of organic solvent is often necessary.[9]
-
Filtration: Always filter your sample through a 0.22 µm or 0.45 µm syringe filter to remove any particulate matter that could clog the column or HPLC system.[3]
-
Injection Solvent: The injection solvent should ideally match the initial mobile phase conditions to avoid peak distortion. Injecting a sample dissolved in a much stronger solvent than the mobile phase can cause the peptide to elute in the void volume.[9]
Troubleshooting Guide
| Problem | Potential Cause(s) | Suggested Solution(s) |
| Poor Resolution / Co-eluting Peaks | - Inappropriate gradient slope.- Incorrect mobile phase or pH.- Unsuitable column chemistry. | - Optimize the gradient. A shallower gradient (e.g., 0.5-1% B per minute) often improves resolution.[5]- Screen different mobile phase modifiers (TFA vs. formic acid) and pH levels.- Try a column with a different selectivity (e.g., C8, Phenyl).[5] |
| Peak Tailing | - Secondary interactions with residual silanols on the column.- Column overload.- Low concentration of ion-pairing agent. | - Ensure an adequate concentration of TFA (typically 0.1%) in the mobile phases.[6]- Reduce the sample load on the column.- Use a high-purity silica (B1680970) column designed for peptide separations.[6] |
| Peak Broadening | - Large injection volume.- Extra-column dead volume.- Slow gradient. | - Reduce the injection volume.- Check and minimize the length and diameter of tubing between the injector, column, and detector.- While shallow gradients improve resolution, excessively long runs can lead to broader peaks due to diffusion. Balance resolution with peak width.[10] |
| High Backpressure | - Clogged column frit or tubing.- Sample precipitation.- High flow rate. | - Filter the sample before injection.[3]- Systematically loosen fittings to identify the source of the blockage.- Wash the column with a strong solvent or a dedicated cleaning solution.- Reduce the flow rate. |
| Peptide Elutes in the Void Volume | - The peptide is too hydrophilic for the column.- The injection solvent is too strong (high organic content).[9]- The peptide did not retain on the column. | - For very hydrophilic peptides, consider Hydrophilic Interaction Liquid Chromatography (HILIC).[3]- Ensure the sample is dissolved in a solvent with a similar or weaker elution strength than the initial mobile phase.[9]- Start the gradient at a very low percentage of organic solvent (e.g., 0-5%).[5] |
| Low Recovery | - Peptide precipitation on the column.- Irreversible adsorption to the column.- Peptide instability in the mobile phase. | - For hydrophobic peptides, a small percentage of organic solvent in the initial mobile phase might be necessary to prevent precipitation.- Try a different column chemistry or mobile phase.- Collect and analyze fractions immediately to prevent degradation.[7] |
Experimental Protocols
General Analytical RP-HPLC Method for Peptides
This protocol provides a starting point for analyzing the purity of a crude isotope-labeled peptide.
-
Column: C18, 4.6 x 150 mm, 5 µm particle size, 100-300 Å pore size.
-
Mobile Phase A: 0.1% TFA in Water.
-
Mobile Phase B: 0.1% TFA in Acetonitrile.
-
Flow Rate: 1.0 mL/min.
-
Detection: UV at 214 nm and 280 nm.[10]
-
Column Temperature: 30-40 °C.
-
Injection Volume: 10-20 µL (of a ~1 mg/mL solution).
-
Gradient:
-
Scouting Gradient: 5% to 65% B over 60 minutes.[3]
-
Optimized Gradient: Based on the scouting run, create a shallower gradient around the elution time of the target peptide. For example, if the peptide elutes at 30% B, a gradient of 20% to 40% B over 20-30 minutes can be used.
-
Preparative RP-HPLC for Peptide Purification
This protocol is for scaling up the analytical method to purify larger quantities of the peptide.
-
Column: C18, 21.2 x 250 mm (or appropriate preparative size).
-
Mobile Phase A: 0.1% TFA in Water.
-
Mobile Phase B: 0.1% TFA in Acetonitrile.
-
Flow Rate: Adjust based on the column diameter (e.g., 15-20 mL/min for a 21.2 mm ID column).
-
Detection: UV at 214 nm and 280 nm.
-
Sample Preparation: Dissolve the crude peptide at a concentration of 10-20 mg/mL in a suitable solvent.
-
Gradient: Use the optimized gradient from the analytical run, adjusting the segment times based on the preparative system's delay volume.
-
Fraction Collection: Collect fractions based on the UV chromatogram peaks.
-
Post-Purification: Analyze the purity of each fraction using analytical HPLC and confirm the identity by mass spectrometry. Pool the fractions with the desired purity and lyophilize to obtain the final product.[3][7]
Visualizations
Caption: Workflow for HPLC purification of isotope-labeled peptides.
References
- 1. Minimal deuterium isotope effects in quantitation of dimethyl‐labeled complex proteomes analyzed with capillary zone electrophoresis/mass spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 2. cpcscientific.com [cpcscientific.com]
- 3. benchchem.com [benchchem.com]
- 4. researchgate.net [researchgate.net]
- 5. HPLC Tech Tip: Approach to Peptide Analysis | Phenomenex [phenomenex.com]
- 6. hplc.eu [hplc.eu]
- 7. peptide.com [peptide.com]
- 8. agilent.com [agilent.com]
- 9. reddit.com [reddit.com]
- 10. protocols.io [protocols.io]
Tips for optimizing NMR data acquisition parameters for 13C and 15N labeled protein samples.
Technical Support Center: Optimizing NMR Data Acquisition for Labeled Proteins
This guide provides troubleshooting advice and frequently asked questions (FAQs) to help researchers, scientists, and drug development professionals optimize NMR data acquisition parameters for 13C and 15N labeled protein samples.
Frequently Asked Questions (FAQs)
Q1: What are the ideal sample conditions for a 13C/15N labeled protein NMR experiment?
A1: The quality of your NMR data is critically dependent on the sample conditions. For optimal results, protein concentration should be between 0.1 and 2.5 mM, with a typical concentration of about 1 mM.[1] For many proteins, a concentration of 0.3-0.5 mM is a good starting point.[2][3] The sample should be stable for at least a week at the measurement temperature.[2] It is also crucial that the protein is pure (>95%), monodisperse, and free of paramagnetic impurities or solid particles.[1]
Q2: How does protein size affect the choice of NMR experiment?
A2: High-resolution NMR is most effective for proteins under 30-50 kDa.[2] For proteins larger than 30 kDa, transverse relaxation optimized spectroscopy (TROSY)-based techniques are often necessary, usually in combination with side-chain deuteration to reduce line broadening.[4] For proteins over 20 kDa, 2H labeling can significantly enhance the signal-to-noise ratio.[2] For very large proteins or protein complexes, specific labeling of methyl groups can improve resolution.[2][5]
Q3: When should I consider using Non-Uniform Sampling (NUS)?
A3: Non-Uniform Sampling (NUS) is an acquisition method that saves time by skipping a fraction of the data points in multidimensional experiments.[6][7] It is particularly useful for 3D and 4D experiments in biomolecular NMR, where it can lead to time savings of up to a factor of 10 or more.[6][8] NUS is most beneficial when the experiment time is limited by the sampling of indirect dimensions rather than by sensitivity.[9] While it can significantly speed up measurements, it's important to choose an appropriate sampling schedule and reconstruction method to avoid artifacts.[7][9]
Q4: What are the key considerations for setting the recycle delay (D1)?
A4: The recycle delay (D1) is crucial for allowing longitudinal (T1) relaxation of the nuclei before the next scan, which is essential for maximizing signal intensity. A common starting point for D1 is 1-2 seconds.[3] For more rapid data acquisition, especially in 13C experiments, paramagnetic relaxation agents can be added to reduce T1 relaxation times, allowing for much shorter recycle delays.[3]
Q5: Why is 13C direct detection beneficial for some protein samples?
A5: 13C direct-detect NMR spectroscopy is particularly advantageous for studying intrinsically disordered proteins (IDPs) or other systems with poor spectral dispersion in the proton dimension.[10][11] The larger chemical shift range of 13C helps to resolve spectral overlap.[11] This technique overcomes challenges associated with traditional 1H-detected NMR for non-aggregating disordered proteins.[10]
Troubleshooting Guides
Issue 1: Low Signal-to-Noise (S/N) Ratio
A low signal-to-noise (S/N) ratio is a common problem, especially in 13C NMR due to its lower gyromagnetic ratio compared to 1H.[3]
| Potential Cause | Solution |
| Insufficient Sample Concentration | The NMR signal is directly proportional to concentration.[3] Increase the protein concentration if possible, aiming for the 0.3-0.5 mM range or higher.[3] Ensure the sample is not aggregated, which reduces the effective concentration of soluble protein.[3] |
| Suboptimal Acquisition Parameters | Incorrectly set relaxation delays or number of scans can severely impact the signal. Optimize the recycle delay (D1) to allow for adequate T1 relaxation (a common starting point is 1-2 seconds).[3] The S/N ratio increases with the square root of the number of scans (NS), so increasing NS can improve the signal.[3] |
| Poor Shimming | An inhomogeneous magnetic field leads to broad lines and reduced peak height. Ensure the sample is properly positioned and perform shimming carefully. For difficult samples, gradient shimming may be required.[12][13] |
| High Salt Concentration | High ionic strength can degrade probe performance, especially for cryogenic probes where the ionic strength should be kept below 100 mM.[1][14] Use the lowest salt concentration possible that maintains protein stability. |
Issue 2: Broad or Distorted Peaks
| Potential Cause | Solution |
| Protein Aggregation | Aggregation leads to very broad signals due to the large effective molecular weight. Check for aggregation using techniques like dynamic light scattering (DLS). Optimize buffer conditions (pH, salt, additives) to improve solubility. |
| Slow Molecular Tumbling | Larger proteins tumble more slowly, leading to broader lines. For proteins >25-30 kDa, consider using TROSY-based experiments and deuteration to sharpen signals.[4][15] |
| Incorrect Processing Parameters | Improper window function application during processing can distort peak shapes. An exponential decay function is common for 13C signals; using a line broadening (LB) factor of around 1.0 Hz can be a good compromise between noise reduction and maintaining sharpness.[16] |
| Sample Viscosity | Highly concentrated samples can be viscous, which broadens NMR signals. If possible, dilute the sample.[13] |
Issue 3: Spectral Artifacts
| Potential Cause | Solution |
| Detector Saturation (ADC Overflow) | Very high sample concentration can lead to a signal that is too strong for the detector, causing artifacts.[17] Reduce the receiver gain (RG) or use a smaller tip angle for the excitation pulse.[12][17][18] |
| Incorrectly Set Spectral Width | If the spectral width is too narrow, peaks outside this range will be "folded" or "aliased" into the spectrum. Set the spectral width to encompass all expected signals for the given nucleus (1H, 13C, or 15N).[19] |
| NUS Reconstruction Issues | The choice of sampling schedule and reconstruction algorithm in NUS can introduce artifacts if not chosen carefully.[9] Ensure the number of samples is greater than the number of expected peaks.[7] |
Quantitative Data Summary
Table 1: Recommended Sample Conditions for Protein NMR
| Parameter | Recommended Range | Notes |
| Protein Concentration | 0.3 - 0.5 mM (typical)[2][3] | Can be as low as 0.1 mM for interaction studies[2] or up to 2.5 mM.[1] |
| Sample Volume | 260 - 300 µL (Shigemi tubes)[1] | 500 - 550 µL for standard 5 mm tubes.[1] |
| pH | 4.0 - 7.0[14] | Should be away from the protein's isoelectric point (pI).[1] |
| Ionic Strength | < 100 mM (Cryoprobes)[1][14] | < 500 mM (Conventional probes).[1] |
| D₂O Content | 5 - 10% | Required for the field-frequency lock.[1][14] |
| Additives | 0.02-0.05% Sodium Azide[1][14] | To prevent bacterial growth. |
| Protease Inhibitors[1] | To prevent protein degradation. | |
| 1-10 mM DTT or TCEP[14] | To keep sulfhydryl groups reduced.[1] |
Table 2: Typical Acquisition Parameters for a Standard ¹H-¹⁵N HSQC Experiment
| Parameter | Typical Value | Purpose |
| Pulse Program | hsqcetf3gpsi[19][20] | Sensitivity-enhanced HSQC with water flip-back. |
| Number of Points (Direct) | 2048 (2k)[19] | Determines digital resolution in the ¹H dimension. |
| Number of Points (Indirect) | ≥ 128[19] | Determines digital resolution in the ¹⁵N dimension. |
| Spectral Width (¹H) | ~14 ppm[21] | Should cover all proton signals, typically centered on the water resonance. |
| Spectral Width (¹⁵N) | ~35 ppm[21] | Should cover all amide nitrogen signals. |
| ¹⁵N Carrier Frequency (Offset) | 115 - 120 ppm[19] | Centered in the amide region of the ¹⁵N spectrum. |
| Number of Scans (NS) | 8 - 16 | Depends on sample concentration; increase for dilute samples. |
| Recycle Delay (D1) | 1.0 - 1.5 s | Allows for T1 relaxation between scans. |
| Dummy Scans (DS) | ≥ 16[19] | To reach a steady state before acquisition begins. |
Experimental Protocols
Protocol: Acquiring a Standard 2D ¹H-¹⁵N HSQC Spectrum
The ¹H-¹⁵N HSQC is a fundamental experiment for labeled proteins, often used to check sample quality and optimize conditions.[22]
1. Sample Preparation and Loading:
-
Prepare the protein sample in a suitable buffer containing 5-10% D₂O.[1]
-
Transfer the sample to a high-quality NMR tube (e.g., Shigemi tube for low volumes).[1][19]
-
Insert the sample into the spectrometer magnet.[19]
2. Spectrometer Setup:
-
Locking: Lock the spectrometer on the D₂O signal.[19]
-
Tuning and Matching: Tune and match the probe for the ¹H and ¹⁵N frequencies.[19]
-
Shimming: Optimize the magnetic field homogeneity using either manual or automated (e.g., topshim) procedures.[12][19]
3. Parameter Calibration and Setup:
-
Calibrate Pulses: Calibrate the 90° pulse widths for ¹H and ¹⁵N. This is crucial for efficient magnetization transfer.
-
Load Experiment: Create a new dataset and load a standard HSQC parameter set (e.g., hsqcetf3gpsi).[20]
-
Set Spectral Widths and Offsets:
-
For the direct ¹H dimension (F2), set the spectral width (SW) to cover all expected proton signals (e.g., 12-16 ppm) and center the transmitter offset (O1P) on the water resonance (~4.7 ppm).
-
For the indirect ¹⁵N dimension (F1), set the spectral width to cover the amide region (e.g., 30-40 ppm) and center the offset (O3P) around 118 ppm.[19]
-
-
Set Acquisition Parameters:
-
Set the number of points in the direct (TD2) and indirect (TD1) dimensions (e.g., 2048 and 256, respectively).[19]
-
Set the number of scans (NS) based on the sample concentration (e.g., 8 for a ~0.5 mM sample).[19]
-
Set the recycle delay (D1) to ~1.5 seconds.
-
If the sample is also ¹³C labeled, ensure ¹³C decoupling is enabled during the experiment.[19]
-
4. Acquisition and Processing:
-
Start Acquisition: Start the experiment by typing zg.[19]
-
Processing: After acquisition is complete, process the data. This typically involves Fourier transformation (xfb), phase correction, and baseline correction.[19]
Visualizations
Caption: General workflow for a protein NMR experiment.
Caption: Troubleshooting logic for low signal-to-noise.
Caption: Relationship between NMR parameters and protein properties.
References
- 1. Sample Requirements - Max T. Rogers NMR [nmr.natsci.msu.edu]
- 2. nmr-bio.com [nmr-bio.com]
- 3. benchchem.com [benchchem.com]
- 4. pubs.acs.org [pubs.acs.org]
- 5. Protein structure and dynamics by NMR: synergy between biochemistry and pulse sequence design | News articles | University of Groningen [rug.nl]
- 6. Non-Uniform Sampling (NUS) | Bruker [bruker.com]
- 7. americanpharmaceuticalreview.com [americanpharmaceuticalreview.com]
- 8. Nonuniform Sampling for NMR Spectroscopy - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. Extreme Non-Uniform Sampling for Protein NMR Dynamics Studies in Minimal Time - PMC [pmc.ncbi.nlm.nih.gov]
- 10. researchgate.net [researchgate.net]
- 11. pubs.acs.org [pubs.acs.org]
- 12. Troubleshooting | Department of Chemistry and Biochemistry | University of Maryland [chem.umd.edu]
- 13. nmr.natsci.msu.edu [nmr.natsci.msu.edu]
- 14. facilities.bioc.cam.ac.uk [facilities.bioc.cam.ac.uk]
- 15. renafobis.fr [renafobis.fr]
- 16. Optimized Default 13C Parameters | NMR Facility - Chemistry Department [chemnmrlab.uchicago.edu]
- 17. 5) Common Problems | SDSU NMR Facility – Department of Chemistry [nmr.sdsu.edu]
- 18. nmr.ucdavis.edu [nmr.ucdavis.edu]
- 19. Collecting a 15N Edited HSQC - Powers Wiki [bionmr.unl.edu]
- 20. 1H-15N HSQC | Department of Chemistry and Biochemistry | University of Maryland [chem.umd.edu]
- 21. TUTORIAL:3D 1H-15N NOESY-HSQC EXPERIMENT [imserc.northwestern.edu]
- 22. Nuclear magnetic resonance spectroscopy of proteins - Wikipedia [en.wikipedia.org]
Refinement of protocols for the synthesis of complex isotope-labeled peptides.
This technical support center provides troubleshooting guidance and answers to frequently asked questions for researchers, scientists, and drug development professionals engaged in the synthesis of complex isotope-labeled peptides.
Frequently Asked Questions (FAQs)
Q1: What are the primary causes of low yield in the synthesis of complex isotope-labeled peptides?
A1: Low yields in complex peptide synthesis can stem from several factors. Key among them are incomplete coupling reactions and peptide aggregation.[1] Difficult or hydrophobic sequences are particularly prone to aggregation, which hinders reaction kinetics.[2][3] Additionally, steric hindrance in longer peptide chains can impede the efficient coupling of amino acids.[4] For isotope-labeled peptides specifically, the quality and handling of expensive labeled amino acids are crucial, as any loss during the process directly impacts the final yield.
Q2: How can I minimize racemization during peptide synthesis, especially when incorporating sensitive amino acids?
A2: Racemization, the conversion of an L-amino acid to a D-amino acid, is a critical issue affecting the purity and biological activity of the final peptide. It is particularly prevalent with amino acids like histidine and cysteine.[5][6] To minimize racemization, consider the following strategies:
-
Choice of Coupling Reagents: Utilize modern onium-type coupling reagents like HATU, HBTU, or COMU, which are known to suppress racemization.[7]
-
Use of Additives: Incorporating additives such as HOBt or Oxyma Pure can further reduce the risk of racemization.
-
Temperature Control: Perform coupling reactions at lower temperatures (e.g., 0°C) as higher temperatures can increase the rate of racemization.[8]
-
Base Selection: Use a hindered base like N,N-diisopropylethylamine (DIPEA) to minimize base-catalyzed racemization.
Q3: What are the best practices for purifying complex isotope-labeled peptides?
A3: The standard and most effective method for purifying synthetic peptides is Reversed-Phase High-Performance Liquid Chromatography (RP-HPLC).[9][10] Key considerations for successful purification include:
-
Column Selection: C18-modified silica (B1680970) is the most common stationary phase for peptide purification.[10]
-
Mobile Phase: A gradient of water and acetonitrile (B52724) (ACN) with an ion-pairing agent like trifluoroacetic acid (TFA) is typically used.[9]
-
Method Development: Optimize the gradient and flow rate on an analytical column before scaling up to a preparative column to ensure efficient separation.[9]
-
Fraction Analysis: Collect fractions and analyze them using mass spectrometry to identify those containing the pure target peptide.[11][12]
Q4: When should I choose Boc vs. Fmoc solid-phase peptide synthesis (SPPS) for my complex peptide?
A4: The choice between Boc and Fmoc chemistry depends on the specific characteristics of your peptide.
-
Boc Strategy: This method uses a strong acid (like HF) for the final cleavage, which can be advantageous for long and difficult sequences prone to aggregation, as the acidic conditions help to break up secondary structures.[13][]
-
Fmoc Strategy: This approach employs milder basic conditions for deprotection, making it more suitable for peptides with sensitive modifications.[13][] It is also more amenable to automated synthesis.
Troubleshooting Guide
Issue 1: Peptide Aggregation
Symptoms:
-
Resin shrinking or failing to swell properly.[3]
-
Slow or incomplete coupling and deprotection reactions.[3]
-
False negatives in amine tests like the Kaiser test.[2]
Solutions:
| Strategy | Description | Quantitative Impact (Example) |
| Chaotropic Salts | Wash the resin with solutions of chaotropic salts like 0.8 M NaClO₄ or LiCl in DMF before coupling to disrupt secondary structures.[15] | Can significantly improve coupling efficiency in aggregated sequences. |
| Elevated Temperature / Microwave Synthesis | Increasing the reaction temperature can disrupt hydrogen bonds causing aggregation. Microwave-assisted synthesis can rapidly heat the reaction.[5][6][16] | Synthesis of a difficult 24-mer peptide at 86°C showed excellent purity compared to poor quality at room temperature.[5][6] |
| "Magic Mixture" Solvents | Use a solvent mixture like DCM/DMF/NMP (1:1:1) to improve solvation of the peptide-resin complex. | A study on a hydrophobic transmembrane peptide showed a crude yield increase from 4% in 100% DMF to 12% in 80% NMP / 20% DMSO.[15] |
| Pseudoproline Dipeptides | Incorporate pseudoproline dipeptides at specific intervals (e.g., every sixth residue) to disrupt the formation of secondary structures. | Can increase product yields by up to 10-fold in highly aggregated sequences.[15] |
Experimental Protocols & Workflows
Standard Solid-Phase Peptide Synthesis (SPPS) Workflow
This diagram outlines the fundamental steps of a standard Fmoc-based solid-phase peptide synthesis cycle.
Caption: General workflow for Fmoc-based Solid-Phase Peptide Synthesis (SPPS).
Troubleshooting Logic for Low Peptide Purity
This decision tree provides a logical workflow for troubleshooting common causes of low peptide purity after synthesis.
Caption: Troubleshooting workflow for identifying and addressing causes of low peptide purity.
Quantitative Data Summary
Comparison of Common Coupling Reagents
The selection of a coupling reagent significantly impacts the yield and purity of the synthesized peptide. The following table provides a comparative overview of commonly used reagents.
| Coupling Reagent | Additive | Base | Solvent | Reaction Time (min) | Yield (%) |
| HATU | HOAt | DIPEA | DMF | 30 | ~99 |
| HBTU | HOBt | DIPEA | DMF | 30 | ~95-98 |
| TBTU | HOBt | DIPEA | DMF | 30 | ~95-98 |
| PyBOP | HOBt | DIPEA | DMF | 30 | ~95 |
| COMU | - | DIPEA | DMF | 15-30 | >99 |
Data synthesized from multiple studies to provide a comparative overview. Yields can vary based on the specific peptide sequence and reaction conditions.[7]
Effect of Temperature on Peptide Synthesis
Temperature is a critical parameter that can be adjusted to improve synthesis efficiency, particularly for difficult sequences.
| Peptide | Coupling Chemistry | Temperature (°C) | Coupling Time (min) | Crude Purity (%) |
| Model Peptide 1 | HBTU | 25 | 60 | 75 |
| Model Peptide 1 | HBTU | 50 | 30 | 85 |
| Model Peptide 1 | HBTU | 75 | 15 | 90 |
| Model Peptide 2 | DIC | 25 | 120 | 60 |
| Model Peptide 2 | DIC | 50 | 60 | 78 |
| Model Peptide 2 | DIC | 75 | 30 | 82 |
This table illustrates the general trend that increasing temperature can allow for reduced coupling times while maintaining or improving crude purity.
Detailed Experimental Methodologies
Protocol 1: Microwave-Assisted Solid-Phase Peptide Synthesis (MW-SPPS)
This protocol provides a general procedure for using a microwave peptide synthesizer to mitigate aggregation and accelerate synthesis.
-
Resin Preparation: Swell the appropriate resin in DMF within the reaction vessel of the microwave synthesizer.
-
Programming: Program the synthesizer with the desired peptide sequence and select a method that utilizes microwave energy for both deprotection and coupling steps. A typical setting is 75-90°C.
-
Fmoc Deprotection: The synthesizer will deliver 20% piperidine in DMF and apply microwave energy for a short duration (e.g., 30 seconds to 3 minutes) to remove the Fmoc group. This is followed by a series of DMF washes.
-
Amino Acid Coupling: A solution of the Fmoc-protected amino acid, coupling reagent (e.g., DIC/Oxyma Pure), and base in DMF is added to the resin.[4] Microwave energy is applied for 2-10 minutes to drive the coupling reaction to completion.[5][6]
-
Washing: The resin is thoroughly washed with DMF to remove excess reagents.
-
Cycle Repetition: Steps 3-5 are repeated for each amino acid in the sequence.
-
Final Cleavage and Deprotection: After synthesis is complete, the peptide is cleaved from the resin using a standard TFA cocktail.
Protocol 2: RP-HPLC Purification of a Crude Peptide
This protocol outlines the steps for purifying a crude synthetic peptide.
-
Sample Preparation: Dissolve the lyophilized crude peptide in a minimal amount of a suitable solvent (e.g., 50% H₂O / 50% ACN with 0.1% TFA).[11][12] Filter the sample through a 0.22 µm filter to remove particulates.[11]
-
Column Equilibration: Equilibrate the preparative RP-HPLC column (e.g., C18) with the initial mobile phase conditions (e.g., 95% Solvent A: 0.1% TFA in water, 5% Solvent B: 0.1% TFA in ACN).
-
Injection and Gradient Elution: Inject the filtered sample onto the column. Elute the peptide using a linear gradient of increasing Solvent B concentration. A typical gradient might be from 5% to 65% Solvent B over 30-60 minutes.[9]
-
Fraction Collection: Collect fractions based on the UV absorbance profile (typically monitored at 210-220 nm).[10]
-
Analysis of Fractions: Analyze the collected fractions by analytical HPLC and mass spectrometry to identify the fractions containing the pure peptide of the correct mass.
-
Pooling and Lyophilization: Pool the pure fractions and freeze-dry (lyophilize) to obtain the purified peptide as a white powder.[9][10]
References
- 1. researchgate.net [researchgate.net]
- 2. luxembourg-bio.com [luxembourg-bio.com]
- 3. peptide.com [peptide.com]
- 4. pubs.acs.org [pubs.acs.org]
- 5. pubs.acs.org [pubs.acs.org]
- 6. researchgate.net [researchgate.net]
- 7. benchchem.com [benchchem.com]
- 8. researchgate.net [researchgate.net]
- 9. peptide.com [peptide.com]
- 10. bachem.com [bachem.com]
- 11. researchgate.net [researchgate.net]
- 12. protocols.io [protocols.io]
- 13. benchchem.com [benchchem.com]
- 15. benchchem.com [benchchem.com]
- 16. gyrosproteintechnologies.com [gyrosproteintechnologies.com]
Validation & Comparative
A Comparative Guide to Confirming Isotopic Enrichment of Fmoc-Gly-OH-2-13C,15N
For researchers in drug development and peptide synthesis, precise confirmation of isotopic enrichment is critical for the validation of experimental results. This guide provides a comprehensive comparison of Liquid Chromatography-Mass Spectrometry (LC-MS) and Nuclear Magnetic Resonance (NMR) spectroscopy for determining the isotopic enrichment of Fmoc-Gly-OH-2-13C,15N. Detailed experimental protocols and supporting data are presented to assist in selecting the most suitable method.
Introduction
Fmoc-Gly-OH is a fundamental building block in solid-phase peptide synthesis. Its isotopically labeled counterpart, this compound, incorporates a stable isotope at the alpha-carbon and the nitrogen atom. This labeling is invaluable for a range of applications, including quantitative proteomics and metabolic studies. The precise degree of isotopic enrichment must be verified to ensure data accuracy. LC-MS and NMR spectroscopy are the two primary analytical techniques for this purpose.
Fmoc-Gly-OH
This compound
Comparison of Analytical Methods
| Feature | LC-MS | NMR Spectroscopy |
| Principle | Separates molecules by chromatography and measures the mass-to-charge ratio of ions. Isotopic enrichment is determined by analyzing the relative abundance of different isotopologues. | Measures the magnetic properties of atomic nuclei. Isotopic enrichment is determined by comparing the integrals of signals from the labeled and unlabeled isotopes. |
| Sensitivity | High (picomole to femtomole range) | Lower (micromole to nanomole range) |
| Sample Requirement | Low (micrograms or less) | Higher (milligrams) |
| Information Provided | Provides the overall isotopic distribution of the molecule. | Provides site-specific information about the location of the isotopic label.[6] |
| Quantitative Accuracy | High, with proper calibration and data analysis. | High, direct comparison of signal integrals. |
| Throughput | High, suitable for automated analysis of many samples. | Lower, longer acquisition times per sample. |
| Instrumentation | Widely available in analytical laboratories. | Requires access to an NMR spectrometer, which may be less common. |
| Data Analysis | Requires deconvolution of mass spectra and comparison with theoretical isotopic distributions. | Involves integration of spectral peaks. |
Experimental Protocols
LC-MS Method for Isotopic Enrichment Analysis
This protocol outlines the steps to determine the isotopic enrichment of this compound using a standard high-performance liquid chromatography (HPLC) system coupled to a high-resolution mass spectrometer (HRMS), such as a Q-Exactive or a time-of-flight (TOF) instrument.
1. Sample Preparation:
-
Prepare a stock solution of the unlabeled Fmoc-Gly-OH standard at a concentration of 1 mg/mL in a 50:50 mixture of acetonitrile (B52724) and water.
-
Prepare a stock solution of the labeled this compound at a concentration of 1 mg/mL in the same solvent.
-
Prepare a series of dilutions from the stock solutions to create working standards ranging from 1 µg/mL to 100 µg/mL.
2. LC Conditions:
-
Column: C18 reversed-phase column (e.g., 2.1 mm x 100 mm, 1.8 µm particle size).
-
Mobile Phase A: 0.1% formic acid in water.
-
Mobile Phase B: 0.1% formic acid in acetonitrile.
-
Gradient: Start with 5% B, ramp to 95% B over 10 minutes, hold for 2 minutes, and then return to initial conditions and equilibrate for 3 minutes.
-
Flow Rate: 0.3 mL/min.
-
Injection Volume: 5 µL.
-
Column Temperature: 40 °C.
3. MS Parameters:
-
Ionization Mode: Electrospray Ionization (ESI) in positive ion mode.
-
Scan Range: m/z 100-500.
-
Resolution: 60,000 or higher.
-
Capillary Voltage: 3.5 kV.
-
Source Temperature: 120 °C.
-
Desolvation Temperature: 350 °C.
4. Data Analysis Workflow:
The isotopic enrichment is calculated by comparing the experimentally observed isotopic distribution with the theoretical distribution.
-
Acquire Data: Analyze both the unlabeled and labeled Fmoc-Gly-OH samples using the defined LC-MS method.
-
Extract Ion Chromatograms (XICs): Extract the XICs for the [M+H]⁺ ions of both the unlabeled (m/z 298.1079) and the labeled (m/z 300.1050) compounds.
-
Obtain Mass Spectra: Generate the mass spectrum for the chromatographic peak of each compound.
-
Determine Isotopic Distribution: From the mass spectrum of the labeled compound, determine the relative intensities of the M+0, M+1, and M+2 peaks. The M+0 peak corresponds to the unlabeled species, the M+1 peak to the species with one ¹³C or ¹⁵N, and the M+2 peak to the Fmoc-Gly-OH-2-¹³C,¹⁵N.
-
Calculate Isotopic Enrichment: The isotopic enrichment can be calculated using the following formula:
Isotopic Enrichment (%) = [Intensity(M+2) / (Intensity(M+0) + Intensity(M+1) + Intensity(M+2))] x 100
This calculation should be corrected for the natural abundance of ¹³C and ¹⁵N present in the unlabeled standard.
A general method for determining the enrichment of isotopically labelled molecules by mass spectrometry involves comparing the measured isotope distributions with calculated theoretical distributions for different enrichment levels using linear regression.[1]
NMR Spectroscopy as an Alternative Method
NMR spectroscopy provides a direct and highly accurate method for determining isotopic enrichment by analyzing the coupling patterns and signal intensities. Both ¹³C and ¹⁵N NMR can be utilized.
1. Sample Preparation:
-
Dissolve 5-10 mg of the labeled this compound in a suitable deuterated solvent (e.g., DMSO-d₆ or CDCl₃).
2. NMR Acquisition:
-
¹³C NMR: Acquire a proton-decoupled ¹³C NMR spectrum. The signal corresponding to the alpha-carbon of glycine (B1666218) will be a doublet due to coupling with the adjacent ¹⁵N. The presence of a singlet at the same chemical shift would indicate the presence of the ¹³C, ¹⁴N isotopologue.
-
¹⁵N NMR: Acquire a proton-decoupled ¹⁵N NMR spectrum. The signal for the glycine nitrogen will be a doublet due to coupling with the adjacent ¹³C.
3. Data Analysis:
-
The isotopic enrichment can be determined by integrating the signals corresponding to the labeled and unlabeled species in the respective spectra. For instance, in the ¹³C NMR spectrum, the ratio of the integral of the doublet to the total integral (doublet + singlet) at that chemical shift gives the ¹³C enrichment at that position.
Workflow Diagram
Caption: Workflow for confirming isotopic enrichment using LC-MS.
Conclusion
Both LC-MS and NMR spectroscopy are powerful techniques for confirming the isotopic enrichment of this compound. LC-MS offers higher throughput and sensitivity, making it ideal for routine analysis of multiple samples. NMR, while requiring more sample and having a lower throughput, provides unambiguous, site-specific information and can be considered a gold standard for accuracy. The choice of method will depend on the specific requirements of the research, including the number of samples, the required level of detail, and the availability of instrumentation. For many applications, LC-MS provides a robust and efficient solution for the reliable determination of isotopic enrichment.
References
- 1. Determination of the enrichment of isotopically labelled molecules by mass spectrometry - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. GitHub - meijaj/isotopic-enrichment-calculator: Isotopic enrichment calculator from mass spectra [github.com]
- 3. pubs.acs.org [pubs.acs.org]
- 4. researchgate.net [researchgate.net]
- 5. sigmaaldrich.com [sigmaaldrich.com]
- 6. benchchem.com [benchchem.com]
Analysis of the 13C NMR spectrum of Fmoc-Gly-OH for structural validation.
A definitive guide to the structural verification of Fmoc-Gly-OH using 13C Nuclear Magnetic Resonance (NMR) spectroscopy. This guide provides a comparative analysis of expected and experimental spectral data, outlines a detailed experimental protocol, and discusses potential impurities, offering researchers, scientists, and drug development professionals a comprehensive resource for quality assessment.
The structural integrity of raw materials is a cornerstone of reliable and reproducible research in the chemical and pharmaceutical sciences. For peptide synthesis, the purity of protected amino acids like Nα-Fmoc-glycine (Fmoc-Gly-OH) is paramount. 13C NMR spectroscopy offers a powerful, non-destructive technique to confirm the chemical structure of such compounds. This guide presents an in-depth analysis of the 13C NMR spectrum of Fmoc-Gly-OH for structural validation.
Comparative Analysis of 13C NMR Data
The validation of Fmoc-Gly-OH's structure via 13C NMR relies on comparing the experimentally observed chemical shifts with established reference values. Below is a summary of the expected chemical shifts for each carbon atom in the Fmoc-Gly-OH molecule, alongside typical experimental values.
| Carbon Atom | Chemical Group | Expected Chemical Shift (ppm) | Observed Chemical Shift (ppm) |
| C=O (Carboxyl) | Glycine (B1666218) | ~171 | 171.2 |
| Cα | Glycine | ~44 | 43.8 |
| C=O (Carbamate) | Fmoc | ~156 | 156.3 |
| CH (Fmoc) | Fluorenyl | ~47 | 47.1 |
| CH2 (Fmoc) | Fluorenyl | ~67 | 66.8 |
| C (quaternary) | Fluorenyl | ~144 | 143.9 |
| C (quaternary) | Fluorenyl | ~141 | 141.3 |
| CH (aromatic) | Fluorenyl | ~128 | 127.8 |
| CH (aromatic) | Fluorenyl | ~127 | 127.2 |
| CH (aromatic) | Fluorenyl | ~125 | 125.2 |
| CH (aromatic) | Fluorenyl | ~120 | 120.1 |
Note: Observed chemical shifts can vary slightly depending on the solvent and concentration.
The presence of signals corresponding to each of these carbons, within the expected ranges, provides strong evidence for the correct structure of Fmoc-Gly-OH.
Comparison with Potential Impurities
A crucial aspect of structural validation is the identification of potential impurities. The 13C NMR spectrum of a pure sample of Fmoc-Gly-OH should be free from signals corresponding to common contaminants. Here, we compare the expected chemical shifts of Fmoc-Gly-OH with those of potential impurities such as residual free glycine and the dipeptide Fmoc-Gly-Gly-OH.
| Compound | Key Discriminating Signals (ppm) |
| Fmoc-Gly-OH | 171.2 (Gly COOH), 43.8 (Gly Cα) |
| Glycine | ~176 (COOH), ~42 (Cα) |
| Fmoc-Gly-Gly-OH | ~172 (second Gly COOH), ~41 (second Gly Cα), additional amide carbonyl ~169 |
The absence of significant peaks in the regions characteristic of these impurities in the 13C NMR spectrum of the analyzed sample confirms its high purity.
Experimental Protocol
The following is a standard operating procedure for the acquisition of a 13C NMR spectrum of Fmoc-Gly-OH.
1. Sample Preparation:
-
Weigh approximately 20-30 mg of the Fmoc-Gly-OH sample.
-
Dissolve the sample in 0.6-0.8 mL of a suitable deuterated solvent (e.g., DMSO-d6 or CDCl3).
-
Transfer the solution to a 5 mm NMR tube.
2. NMR Spectrometer Setup:
-
The 13C NMR spectrum is typically acquired on a 400 MHz or 500 MHz NMR spectrometer.
-
The spectrometer should be equipped with a broadband probe.
3. Acquisition Parameters:
-
Pulse Program: A standard proton-decoupled 13C experiment (e.g., zgpg30 on Bruker instruments).
-
Solvent: DMSO-d6 (with its central peak at ~39.5 ppm as a reference).
-
Temperature: 298 K.
-
Spectral Width: 0 to 200 ppm.
-
Number of Scans: 1024 to 4096 scans, depending on the sample concentration and desired signal-to-noise ratio.
-
Relaxation Delay (d1): 2 seconds.
4. Data Processing:
-
Apply an exponential window function with a line broadening factor of 1-2 Hz.
-
Perform a Fourier transform.
-
Phase the spectrum manually.
-
Calibrate the chemical shift scale using the solvent peak as a reference.
-
Integrate the signals and pick the peaks.
Visualizing the Molecular Structure and Experimental Workflow
To further aid in the understanding of the structural analysis, the following diagrams have been generated.
Caption: Structure of Fmoc-Gly-OH with key carbon atoms for NMR analysis.
Caption: A streamlined workflow for the 13C NMR analysis of Fmoc-Gly-OH.
A comparative study of Fmoc-Gly-OH-2-13C,15N versus its unlabeled counterpart.
A Comparative Analysis of Fmoc-Gly-OH-2-13C,15N and its Unlabeled Counterpart, Fmoc-Gly-OH
This guide provides a detailed comparison between the stable isotope-labeled this compound and its unlabeled form, Fmoc-Gly-OH. The information presented is intended for researchers, scientists, and professionals in drug development to facilitate an informed decision on which compound is best suited for their specific experimental needs. The comparison covers physical and chemical properties, primary applications, and performance in key analytical techniques, supported by experimental protocols and data.
Data Presentation: A Head-to-Head Comparison
The fundamental difference between this compound and Fmoc-Gly-OH lies in the isotopic enrichment of the former. This substitution of ¹²C with ¹³C and ¹⁴N with ¹⁵N results in a mass shift without altering the chemical reactivity, making the labeled compound an invaluable tool in quantitative studies.[1][2]
| Property | This compound | Fmoc-Gly-OH (Unlabeled) | Key Differences & Implications |
| Molecular Formula | (¹³C)₂C₁₅H₁₅(¹⁵N)O₄[3] | C₁₇H₁₅NO₄[4] | The presence of stable isotopes is the defining difference. |
| Molecular Weight | ~300.3 g/mol [3] | ~297.3 g/mol [4] | A predictable mass shift is crucial for mass spectrometry-based quantification.[5] |
| Isotopic Purity | Typically >98% for both ¹³C and ¹⁵N[5][6] | Natural abundance (~1.1% ¹³C, ~0.37% ¹⁵N)[7] | High isotopic purity is essential for minimizing interference in sensitive analytical methods.[6][8] |
| Mass Shift | M+3[5] | Not Applicable | This distinct mass difference allows for the differentiation of labeled and unlabeled peptides in a mass spectrometer.[9] |
| Melting Point | 174-175 °C[5][10] | ~176 °C[4] | The physical properties remain largely identical, ensuring similar behavior in chemical reactions.[2] |
| Storage Temperature | 2-8°C[5][10] | 2-8°C[4] | Both compounds require similar storage conditions to maintain stability. |
| Primary Applications | Quantitative proteomics, NMR-based structural biology, metabolic flux analysis.[1][6][] | General solid-phase peptide synthesis, building block for peptide libraries and peptide-based drugs.[12][13][14] | The choice is dictated by the need for quantitative data or structural elucidation at the atomic level. |
Performance in Key Analytical Techniques
The true value of this compound becomes apparent in its application in advanced analytical methodologies such as Nuclear Magnetic Resonance (NMR) spectroscopy and Mass Spectrometry (MS).
Nuclear Magnetic Resonance (NMR) Spectroscopy
In NMR studies, the incorporation of ¹³C and ¹⁵N isotopes, which are NMR-active, provides a significant advantage.[] These labels allow for enhanced sensitivity and resolution, which is critical for the structural characterization of peptides and proteins.[6][15] Multidimensional heteronuclear NMR experiments, such as ¹H-¹⁵N HSQC, can be performed on proteins synthesized with labeled amino acids to provide a unique "fingerprint" spectrum, where each amino acid residue in the protein backbone gives a characteristic signal.[] This level of detail is unattainable with the unlabeled counterpart and is fundamental for studying protein structure, folding, and dynamics.[][15]
Mass Spectrometry (MS)
In the field of proteomics, stable isotope labeling is a cornerstone of quantitative analysis.[16][17] Peptides synthesized with this compound serve as ideal internal standards.[18][19] When mixed with a complex biological sample, the labeled peptide and its natural, unlabeled counterpart co-elute during liquid chromatography and are detected by the mass spectrometer.[9] Due to their identical physicochemical properties, they exhibit the same ionization efficiency.[2] However, they are distinguishable by their mass-to-charge (m/z) ratio.[16] The relative signal intensities of the labeled and unlabeled peptide peaks allow for precise and accurate quantification of the target peptide in the sample.[1][16] This method is widely used in biomarker discovery, drug metabolism studies, and pharmacokinetic analyses.[1][9]
Experimental Protocols
The following is a generalized protocol for the incorporation of either this compound or its unlabeled counterpart into a peptide sequence via solid-phase peptide synthesis (SPPS).
Solid-Phase Peptide Synthesis (SPPS) Cycle
This protocol outlines a single coupling cycle in an Fmoc-based solid-phase peptide synthesis strategy.
1. Resin Preparation:
-
Start with a suitable resin (e.g., Wang or Rink Amide resin) pre-loaded with the C-terminal amino acid of the target peptide.
-
Swell the resin in N,N-dimethylformamide (DMF) for 1-2 hours in a reaction vessel.[20]
2. Fmoc Deprotection:
-
Remove the Fmoc protecting group from the N-terminus of the resin-bound amino acid by treating it with a 20% solution of piperidine (B6355638) in DMF for 20 minutes.[20]
-
Wash the resin thoroughly with DMF to remove the piperidine and the cleaved Fmoc group.
3. Amino Acid Coupling:
-
In a separate vial, dissolve the Fmoc-Gly-OH (either labeled or unlabeled) (3 equivalents relative to the resin substitution), a coupling agent such as HBTU (2.9 equivalents), and a base like N,N-Diisopropylethylamine (DIPEA) (6 equivalents) in DMF.[21]
-
Allow the mixture to pre-activate for 5-10 minutes.[21]
-
Add the activated amino acid solution to the deprotected resin.
-
Agitate the reaction mixture for 1-2 hours at room temperature to ensure complete coupling.[21]
-
Drain the coupling solution and wash the resin extensively with DMF.
4. Capping (Optional):
-
To block any unreacted amino groups and prevent the formation of deletion sequences, the resin can be treated with a capping solution (e.g., acetic anhydride (B1165640) and DIPEA in DMF).
This cycle is repeated for each subsequent amino acid in the peptide sequence. Upon completion of the synthesis, the peptide is cleaved from the resin, and all side-chain protecting groups are removed simultaneously. The crude peptide is then purified, typically by reverse-phase high-performance liquid chromatography (RP-HPLC).[20][21]
Visualizations
The following diagrams illustrate the experimental workflow and the logical relationship in quantitative proteomics.
Caption: A simplified workflow of a single cycle in Fmoc-based solid-phase peptide synthesis.
Caption: Logical workflow for quantitative proteomics using a stable isotope-labeled peptide standard.
Conclusion
The choice between this compound and its unlabeled counterpart is fundamentally driven by the experimental objective. For routine peptide synthesis where quantification or detailed structural analysis is not the primary goal, the unlabeled Fmoc-Gly-OH is a cost-effective and suitable choice.[12][14] However, for advanced applications in quantitative proteomics and NMR-based structural biology, the stable isotope-labeled this compound is an indispensable tool.[1][6] Its ability to serve as a high-purity internal standard for mass spectrometry and to enhance NMR signal resolution provides researchers with the capability to obtain precise quantitative data and detailed molecular insights that are not possible with the unlabeled version.[6][][16]
References
- 1. jpt.com [jpt.com]
- 2. Stable Isotope Labeled peptides - SB-PEPTIDE - Peptide catalog [sb-peptide.com]
- 3. chempep.com [chempep.com]
- 4. Fmoc-Gly-OH | 29022-11-5 | FF15873 | Biosynth [biosynth.com]
- 5. Fmoc-Gly-OH-13C2,15N 99 atom % 13C, 98 atom % 15N | Sigma-Aldrich [sigmaaldrich.com]
- 6. Fmoc-Gly-OH-13C2,15N | 285978-13-4 | Benchchem [benchchem.com]
- 7. benchchem.com [benchchem.com]
- 8. Peptides labelled with stable isotopes 13C or 15N. [innovagen.com]
- 9. qyaobio.com [qyaobio.com]
- 10. This compound 99 atom % 13C, 98 atom % 15N | 285978-12-3 [sigmaaldrich.com]
- 12. chemimpex.com [chemimpex.com]
- 13. peptide.com [peptide.com]
- 14. advancedchemtech.com [advancedchemtech.com]
- 15. Solid state NMR structural characterization of self-assembled peptides with selective 13C and 15N isotopic labels - PMC [pmc.ncbi.nlm.nih.gov]
- 16. Relative Quantification of Stable Isotope Labeled Peptides Using a Linear Ion Trap-Orbitrap Hybrid Mass Spectrometer - PMC [pmc.ncbi.nlm.nih.gov]
- 17. pubs.acs.org [pubs.acs.org]
- 18. medchemexpress.com [medchemexpress.com]
- 19. medchemexpress.com [medchemexpress.com]
- 20. benchchem.com [benchchem.com]
- 21. benchchem.com [benchchem.com]
Validating quantitative analysis results using Fmoc-Gly-OH-2-13C,15N as an internal standard.
For researchers, scientists, and drug development professionals seeking the highest accuracy and precision in quantitative analysis, the choice of an appropriate internal standard is paramount. This guide provides an objective comparison of Fmoc-Gly-OH-2-13C,15N as a stable isotope-labeled internal standard (SIL-IS) against other alternatives, supported by experimental data and detailed methodologies.
Stable isotope-labeled internal standards are widely recognized as the gold standard in quantitative mass spectrometry-based assays.[1] Their near-identical physicochemical properties to the analyte of interest ensure they co-elute and experience similar ionization and matrix effects, leading to superior accuracy and precision compared to structural analogs.[2][3] this compound, a derivative of glycine (B1666218) with isotopic enrichment, serves as a valuable tool in peptide synthesis and quantitative proteomics.[2][4][5]
Performance Comparison: Stable Isotope vs. Structural Analog Internal Standards
The primary advantage of using a stable isotope-labeled internal standard like this compound lies in its ability to mimic the analyte throughout the entire analytical process, from sample preparation to detection. This minimizes variability and leads to more reliable quantitative results.
A study comparing a stable isotope-labeled (SIL) peptide with an extended SIL peptide as internal standards for quantifying human osteopontin (B1167477) in plasma demonstrated the superiority of the extended SIL peptide in accounting for digestion variability.[6] While both internal standards showed inherent digestion variability within ±20%, the extended SIL peptide limited the variability to within ±30% when trypsin activity was intentionally varied, whereas the standard SIL peptide showed a much wider range of -67.4% to 50.6%.[6] This highlights the importance of selecting an internal standard that closely mimics the analyte's behavior, a key characteristic of SIL-ISs.
In another study evaluating peptide internal standards for protein quantification, stable isotope-labeled standards (SIS) were shown to be superior to structural analogs.[2] The study found that structural analog standards can exhibit differences in reversed-phase HPLC retention times compared to the endogenous peptide, which can lead to variations in ion suppression from the sample matrix and compromise accuracy.[2]
| Parameter | This compound (SIL-IS) | Structural Analog IS | Key Considerations |
| Accuracy & Precision | High | Moderate to High | SIL-IS co-elutes with the analyte, providing better correction for matrix effects and variability.[2][3] |
| Matrix Effect Compensation | Excellent | Variable | Differences in chemical properties can lead to differential matrix effects. |
| Retention Time | Co-elutes with unlabeled analyte | May have a slight shift | Deuterated analogs, in particular, can show retention time differences.[2] |
| Cost | Higher | Lower | Synthesis of isotopically labeled compounds is more expensive. |
| Availability | Commercially available | Generally available | Availability can vary depending on the specific analog. |
Experimental Protocols
A robust and validated bioanalytical method is crucial for obtaining reliable quantitative data. Below is a representative experimental protocol for the quantification of a therapeutic peptide in human plasma using this compound as an internal standard.
Sample Preparation: Solid-Phase Extraction (SPE)
-
Conditioning: Condition a mixed-mode SPE plate with methanol (B129727) followed by water.
-
Loading: Load 100 µL of human plasma sample, previously spiked with this compound internal standard solution.
-
Washing: Wash the plate with 5% ammonium (B1175870) hydroxide (B78521) in water, followed by 20% acetonitrile (B52724) in water to remove interferences.
-
Elution: Elute the analyte and internal standard with an appropriate solvent mixture, such as 1% trifluoroacetic acid in 75:25 acetonitrile-water.
-
Evaporation and Reconstitution: Evaporate the eluate to dryness under a stream of nitrogen and reconstitute in the mobile phase for LC-MS/MS analysis.
LC-MS/MS Analysis
-
Liquid Chromatography (LC):
-
Column: A C18 reversed-phase column suitable for peptide separations (e.g., 2.1 mm x 50 mm, 1.7 µm).
-
Mobile Phase A: 0.1% formic acid in water.
-
Mobile Phase B: 0.1% formic acid in acetonitrile.
-
Gradient: A linear gradient from 5% to 40% mobile phase B over 5 minutes.
-
Flow Rate: 0.4 mL/min.
-
Column Temperature: 40 °C.
-
-
Mass Spectrometry (MS):
-
Ionization Mode: Positive Ion Electrospray (ESI+).
-
Analysis Mode: Multiple Reaction Monitoring (MRM).
-
MRM Transitions: Monitor specific precursor-to-product ion transitions for both the analyte and this compound.
-
Method Validation
The bioanalytical method should be validated according to regulatory guidelines (e.g., FDA, EMA) for the following parameters:
-
Selectivity and Specificity: Assessed by analyzing blank matrix samples from at least six different sources to check for interferences at the retention times of the analyte and internal standard.
-
Accuracy and Precision: Determined by analyzing quality control (QC) samples at low, medium, and high concentrations in at least five replicates over three separate analytical runs. Acceptance criteria are typically within ±15% (±20% for the Lower Limit of Quantification, LLOQ) for both accuracy and precision.[1]
-
Calibration Curve: A calibration curve should be prepared with at least six non-zero standards, and the correlation coefficient (r²) should be ≥ 0.99.[1]
-
Matrix Effect: Evaluated by comparing the response of the analyte in post-extraction spiked blank matrix with the response in a neat solution.
-
Recovery: Determined by comparing the analyte response in pre-extraction spiked samples to that in post-extraction spiked samples.
-
Stability: Assessed under various conditions, including freeze-thaw cycles, short-term bench-top storage, and long-term storage.
Visualizing the Workflow
A clear understanding of the experimental workflow is essential for successful implementation.
References
- 1. shoko-sc.co.jp [shoko-sc.co.jp]
- 2. Fmoc-Gly-OH-13C2,15N | 285978-13-4 | Benchchem [benchchem.com]
- 3. youtube.com [youtube.com]
- 4. medchemexpress.com [medchemexpress.com]
- 5. medchemexpress.com [medchemexpress.com]
- 6. Comparison of a stable isotope labeled (SIL) peptide and an extended SIL peptide as internal standards to track digestion variability of an unstable signature peptide during quantification of a cancer biomarker, human osteopontin, from plasma using capillary microflow LC-MS/MS - PubMed [pubmed.ncbi.nlm.nih.gov]
A Researcher's Guide to Cross-Validation of Protein Quantification: The Power of SILAC Internal Standards
In the dynamic fields of proteomics, drug discovery, and biomedical research, the accurate quantification of protein expression is paramount. Stable Isotope Labeling by Amino Acids in Cell Culture (SILAC) has emerged as a robust and reliable method for quantitative proteomics. This guide provides a comprehensive comparison of SILAC with other common protein quantification techniques, supported by experimental data, detailed protocols, and visual workflows to aid researchers in making informed decisions for their experimental designs.
Unveiling the Strengths of SILAC: A Comparative Analysis
SILAC offers a distinct advantage by integrating stable isotopes into proteins metabolically, providing an in-vivo labeling approach that minimizes experimental variability.[1] This contrasts with chemical labeling methods like iTRAQ and TMT, where labeling occurs after protein extraction and digestion, potentially introducing errors.
To illustrate the performance of SILAC in a real-world research context, we will refer to a study that systematically compared Label-Free, SILAC, and Tandem Mass Tag (TMT) techniques to investigate the early adaptation of the colorectal cancer cell line DiFi to EGFR signaling inhibition.[2]
Quantitative Performance Metrics
The following tables summarize the key performance metrics from the comparative study, highlighting the strengths of each method.
Table 1: Comparison of Protein and Phosphosite Identification
| Quantification Strategy | Identified Proteins | Identified Phosphosites |
| Label-Free | ~6,500 | ~12,000 |
| SILAC | ~5,500 | ~18,000 |
| TMT | ~4,500 | ~10,000 |
Data adapted from a comparative study on EGFR signaling in a colorectal cancer cell line.[2]
Table 2: Quantitative Precision and Variability
| Quantification Strategy | Median Coefficient of Variation (CV) for Proteins | Median Coefficient of Variation (CV) for Phosphosites |
| Label-Free | ~15% | ~25% |
| SILAC | ~10% | ~15% |
| TMT | ~20% | ~30% |
Lower CV indicates higher precision. Data adapted from a comparative study on EGFR signaling in a colorectal cancer cell line.[2]
As the data indicates, while Label-Free quantification identified the highest number of proteins, SILAC demonstrated superior precision (lower CV) and excelled in the identification of phosphosites, making it the preferred method for studying cellular signaling pathways.[2] TMT, while offering high-throughput capabilities, showed lower coverage and higher variability in this specific study.[2]
The SILAC Experimental Workflow: A Step-by-Step Protocol
The SILAC method is composed of two main phases: an adaptation phase and an experimental phase.[3]
Phase 1: Adaptation - Incorporating the Isotopic Label
-
Cell Culture Preparation: Begin by culturing two populations of the same cell line. One population is grown in a "light" medium containing normal amino acids (e.g., L-Arginine and L-Lysine), while the other is cultured in a "heavy" medium where these amino acids are replaced with their stable isotope-labeled counterparts (e.g., 13C6-L-Arginine and 13C6-L-Lysine).[1]
-
Metabolic Labeling: Allow the cells to grow for at least five to six cell divisions in their respective media to ensure near-complete incorporation of the labeled amino acids into the proteome.[3]
-
Verification of Incorporation: Before proceeding to the experimental phase, it is crucial to verify the labeling efficiency. This is typically done by analyzing a small sample of the "heavy" labeled cells by mass spectrometry to confirm that over 95% of the target amino acids are the heavy variants.[3]
Phase 2: Experimentation and Analysis
-
Experimental Treatment: Once complete labeling is confirmed, introduce the experimental variable to one of the cell populations. For example, the "heavy" labeled cells could be treated with a drug, while the "light" labeled cells serve as the untreated control.
-
Cell Lysis and Protein Extraction: After the treatment period, harvest both cell populations and lyse them to extract the proteins.
-
Sample Mixing: Combine equal amounts of protein from the "light" and "heavy" cell lysates. This early-stage mixing is a key advantage of SILAC as it minimizes downstream quantitative errors.[4]
-
Protein Digestion: Digest the combined protein mixture into smaller peptides using a protease, most commonly trypsin. Trypsin cleaves after lysine (B10760008) and arginine residues, ensuring that the vast majority of peptides will contain a labeled amino acid.[1]
-
Mass Spectrometry (MS) Analysis: Analyze the resulting peptide mixture using liquid chromatography-tandem mass spectrometry (LC-MS/MS). The mass spectrometer will detect pairs of chemically identical peptides that differ only in the mass of the incorporated stable isotopes.
-
Data Analysis: The relative quantification of proteins is determined by comparing the signal intensities of the "light" and "heavy" peptide pairs. A ratio of 1:1 indicates no change in protein abundance, while a deviation from this ratio signifies up- or down-regulation in response to the experimental treatment.
SILAC Experimental Workflow
Case Study: Investigating the EGFR Signaling Pathway
The Epidermal Growth Factor Receptor (EGFR) signaling pathway is a critical regulator of cell proliferation, differentiation, and survival, and its dysregulation is frequently implicated in cancer.[5] SILAC-based proteomics is an ideal tool for dissecting the complexities of this pathway by providing accurate quantification of changes in protein and phosphosite abundance upon EGFR inhibition.
The following diagram illustrates a simplified EGFR signaling cascade, highlighting key proteins that can be quantified using SILAC to understand the cellular response to targeted therapies.
Simplified EGFR Signaling Pathway
In the context of the comparative study, SILAC was instrumental in revealing that while overall protein levels showed minimal changes upon treatment with an EGFR-blocking antibody, a significant number of phosphorylation sites were dynamically regulated.[2] This highlights SILAC's power in uncovering the nuanced regulatory mechanisms within signaling networks.
Conclusion: Choosing the Right Tool for the Job
The choice of a protein quantification strategy is a critical decision in proteomics research. While Label-Free and TMT methods have their merits, SILAC stands out for its exceptional accuracy and precision, particularly in the context of cell culture-based experiments aimed at elucidating complex cellular processes like signal transduction. By providing a reliable internal standard at the very beginning of the experimental workflow, SILAC minimizes variability and delivers high-confidence quantitative data. For researchers, scientists, and drug development professionals seeking to unravel the intricacies of protein dynamics, SILAC represents a powerful and indispensable tool.
References
A comparative analysis of different coupling reagents for the efficient synthesis of labeled peptides.
For researchers, scientists, and drug development professionals, the selection of a coupling reagent is a pivotal decision in the synthesis of peptides, particularly when incorporating isotopic labels or reporter groups. The efficiency of the coupling reaction directly influences the final yield, purity, and overall success of the synthesis. This guide provides an objective comparison of commonly used coupling reagents, supported by experimental data and detailed protocols, to facilitate an informed choice for your specific research needs.
The fundamental goal in peptide synthesis is the formation of an amide bond between the carboxyl group of one amino acid and the amino group of another. Coupling reagents are activators that facilitate this reaction, ideally with high efficiency and minimal side reactions, most notably racemization. This analysis delves into the performance of several classes of coupling reagents, from the classic carbodiimides to the more advanced onium salts.
Performance Comparison of Common Coupling Reagents
The choice of a coupling reagent often involves a trade-off between reactivity, cost, and the potential for side reactions. For routine syntheses, a cost-effective reagent may be sufficient. However, for "difficult" sequences, such as those containing sterically hindered amino acids or those prone to aggregation, a more potent reagent is often necessary to achieve a high yield of the desired labeled peptide.
Quantitative Data Summary
The following table summarizes the performance of several widely used coupling reagents. The data is a synthesis of results from multiple studies to provide a comparative overview. It is important to note that yields and purity can vary based on the specific peptide sequence and reaction conditions.
| Coupling Reagent | Class | Additive | Typical Yield (%) | Relative Reaction Rate | Racemization Risk | Key Characteristics |
| HATU | Aminium/Uronium Salt | HOAt | ~99 | Very Fast | Low | Highly efficient, especially for hindered couplings and reducing racemization.[1][2][3] Considered a gold standard for difficult sequences.[4] |
| HBTU | Aminium/Uronium Salt | HOBt | ~95-98 | Fast | Low | A reliable and cost-effective option for routine couplings, though generally less reactive than HATU.[1][2][3][5] |
| HCTU | Aminium/Uronium Salt | 6-Cl-HOBt | ~95-99 | High | Very Good | The electron-withdrawing chlorine atom enhances reactivity compared to HBTU.[2] Often a more cost-effective alternative to HATU with comparable performance.[2] |
| TBTU | Aminium/Uronium Salt | HOBt | ~95-98 | Fast | Low | Performance is generally considered very similar to HBTU.[2][6] It is noted for rapid reaction kinetics.[7] |
| COMU | Aminium/Uronium Salt | OxymaPure | >99 | Excellent | Low | A safer and highly efficient reagent, not based on potentially explosive benzotriazoles.[8][9][10] Requires only one equivalent of base.[8][9] |
| PyBOP | Phosphonium Salt | HOBt | ~95 | Fast | Low | A good alternative to BOP reagent, avoiding carcinogenic byproducts.[11] Efficient for both solid-phase and solution-phase synthesis.[12][13] |
| DCC/DIC | Carbodiimide | HOBt/OxymaPure | Variable | Moderate | Moderate | Cost-effective reagents. DCC use in SPPS is limited due to the insoluble dicyclohexylurea (DCU) byproduct.[14][15] DIC is preferred for SPPS as the byproduct is soluble.[14] |
Experimental Protocols
Detailed and consistent experimental protocols are crucial for the reproducible synthesis of labeled peptides. The following provides a generalized protocol for solid-phase peptide synthesis (SPPS) using the Fmoc/tBu strategy, which can be adapted for the specific coupling reagents discussed.
General Solid-Phase Peptide Synthesis (SPPS) Protocol
This protocol outlines a single coupling cycle. The entire peptide is assembled by repeating these steps.
1. Resin Preparation and Swelling:
-
Place the appropriate resin (e.g., Rink Amide resin for C-terminal amides) in a reaction vessel.
-
Swell the resin in N,N-dimethylformamide (DMF) for at least 30 minutes.[16]
2. Fmoc Deprotection:
-
Treat the resin with a solution of 20% piperidine (B6355638) in DMF for 5-20 minutes to remove the Fmoc protecting group from the N-terminal amino acid.[16][17]
-
Wash the resin thoroughly with DMF to remove the piperidine and cleaved Fmoc-adduct.
3. Amino Acid Coupling (Activation and Reaction):
-
Pre-activation: In a separate vial, dissolve the Fmoc-protected amino acid (3-5 equivalents relative to the resin loading), the coupling reagent (e.g., HATU, 3-5 equivalents), and a base such as N,N-diisopropylethylamine (DIPEA) (6-10 equivalents) in DMF.[6][12] For COMU, only one equivalent of base may be sufficient.[10] Allow the mixture to stand for a few minutes to pre-activate the amino acid.
-
Coupling: Add the activated amino acid solution to the deprotected resin.
-
Agitate the mixture at room temperature for 30-120 minutes. Reaction times may need to be extended for sterically hindered amino acids.[12]
-
Monitor the completion of the coupling reaction using a qualitative test such as the Kaiser test.
4. Washing:
-
After the coupling is complete, drain the reaction solution.
-
Wash the resin thoroughly with DMF to remove excess reagents and byproducts.
5. Repetition:
-
Repeat the deprotection, coupling, and washing steps for each subsequent amino acid in the peptide sequence.
6. Cleavage and Deprotection:
-
Once the peptide chain is fully assembled, wash the resin with dichloromethane (B109758) (DCM).
-
Treat the resin with a cleavage cocktail (e.g., a mixture of trifluoroacetic acid (TFA), water, and scavengers like triisopropylsilane (B1312306) (TIS)) to cleave the peptide from the resin and remove the side-chain protecting groups.[18]
7. Peptide Precipitation and Purification:
-
Precipitate the cleaved peptide by adding cold diethyl ether.[12]
-
Collect the crude peptide by centrifugation and wash with cold ether.
-
Purify the peptide using reverse-phase high-performance liquid chromatography (RP-HPLC).[19]
-
Characterize the purified labeled peptide by mass spectrometry.[1]
Visualizing the Workflow and Mechanisms
Diagrams illustrating the experimental workflow and the activation mechanisms of the coupling reagents provide a clearer understanding of the processes involved.
Caption: General workflow for a single cycle of Solid-Phase Peptide Synthesis (SPPS).
The efficacy of a coupling reagent is determined by its mechanism of activating the carboxylic acid of the incoming amino acid, making it susceptible to nucleophilic attack by the N-terminal amine of the growing peptide chain.[19][20]
Caption: Activation mechanisms for Uronium/Aminium and Phosphonium salt coupling reagents.
Conclusion
The selection of a peptide coupling reagent is a critical step that should be made based on the specific requirements of the synthesis. For routine and non-challenging sequences, cost-effective options like carbodiimides with additives or HBTU/TBTU may be adequate.[2][20] However, for the synthesis of complex labeled peptides, particularly those that are long or contain difficult sequences, the use of more advanced and potent reagents such as HATU or the safer alternative COMU is often justified to ensure high yield and purity.[6][10][20] It is always recommended to perform small-scale pilot experiments to determine the optimal coupling conditions for a particular peptide synthesis.
References
- 1. benchchem.com [benchchem.com]
- 2. benchchem.com [benchchem.com]
- 3. benchchem.com [benchchem.com]
- 4. luxembourg-bio.com [luxembourg-bio.com]
- 5. The Role of HOBt and HBTU in Peptide Coupling Reactions - Creative Peptides [creative-peptides.com]
- 6. benchchem.com [benchchem.com]
- 7. benchchem.com [benchchem.com]
- 8. peptide.com [peptide.com]
- 9. pubs.acs.org [pubs.acs.org]
- 10. benchchem.com [benchchem.com]
- 11. PyBOP - Wikipedia [en.wikipedia.org]
- 12. benchchem.com [benchchem.com]
- 13. benchchem.com [benchchem.com]
- 14. globalresearchonline.net [globalresearchonline.net]
- 15. bachem.com [bachem.com]
- 16. chemistry.du.ac.in [chemistry.du.ac.in]
- 17. chem.uci.edu [chem.uci.edu]
- 18. Unveiling and tackling guanidinium peptide coupling reagent side reactions towards the development of peptide-drug conjugates - RSC Advances (RSC Publishing) DOI:10.1039/C7RA06655D [pubs.rsc.org]
- 19. benchchem.com [benchchem.com]
- 20. benchchem.com [benchchem.com]
A Comparative Guide to Methods for Assessing the Purity and Structural Integrity of Synthesized ¹³C, ¹⁵N Peptides
For Researchers, Scientists, and Drug Development Professionals
The synthesis of peptides labeled with stable isotopes, such as Carbon-13 (¹³C) and Nitrogen-15 (¹⁵N), is a cornerstone of modern proteomics, structural biology, and drug development. These labeled peptides are invaluable as internal standards for mass spectrometry-based quantification, for elucidating protein structure and dynamics via nuclear magnetic resonance (NMR) spectroscopy, and in metabolic flux analysis. Ensuring the purity and structural fidelity of these synthesized peptides is paramount for the accuracy and reproducibility of experimental results.
This guide provides an objective comparison of the primary analytical techniques used to assess the quality of synthesized ¹³C, ¹⁵N peptides: High-Performance Liquid Chromatography (HPLC), Mass Spectrometry (MS), Nuclear Magnetic Resonance (NMR) Spectroscopy, and Amino Acid Analysis (AAA). We present supporting experimental data, detailed methodologies for key experiments, and visualizations to aid in the selection of the most appropriate quality control strategy.
Comparison of Key Performance Metrics
The choice of an analytical method depends on the specific information required, the desired level of sensitivity and accuracy, and the available instrumentation. The following table summarizes the key performance metrics for the four principal methods for peptide quality control.
| Performance Metric | High-Performance Liquid Chromatography (HPLC) | Mass Spectrometry (MS) | Nuclear Magnetic Resonance (NMR) Spectroscopy | Amino Acid Analysis (AAA) |
| Primary Application | Purity assessment, quantification of impurities | Molecular weight confirmation, sequence verification, impurity identification | Structural integrity, conformational analysis, purity assessment | Net peptide content, amino acid composition |
| Principle of Separation/Detection | Differential partitioning between a stationary and mobile phase based on hydrophobicity, charge, or size. | Measurement of the mass-to-charge ratio of ionized molecules. | Nuclear spin properties of atomic nuclei in a magnetic field. | Quantification of individual amino acids after peptide hydrolysis. |
| Limit of Detection (LOD) | ~0.1% for UV detection of impurities[1]. | Femtomole to attomole range. | Millimolar to micromolar concentration range. | Picomole to nanomole range. |
| Limit of Quantitation (LOQ) | Typically 0.02% to 0.03% of the main peptide[2]. | Varies with instrumentation and ionization method. | Analyte and internal standard dependent. | Method-dependent, can be in the sub-picomole range with derivatization[3]. |
| Accuracy | High for quantification with appropriate standards. | High for mass determination (<5 ppm with HRMS). Quantitative accuracy depends on the use of isotopic standards. | High for quantification (qNMR) with an internal standard; CV of 0.36% has been reported for peptides[4]. | Considered a reliable quantitative approach[5]. |
| Precision | High, with low relative standard deviation (RSD) for retention time and peak area. | High for mass measurement. Quantitative precision can be affected by ion suppression. | High; intraday CV of 0.052% for small molecules and 0.36% for peptides has been achieved with qNMR[4]. | Good, but can be affected by hydrolysis efficiency. |
| Structural Information | Limited to retention behavior. | Provides molecular weight and fragmentation patterns for sequence information. | Detailed atomic-level 3D structure and dynamics. | Provides amino acid composition but no sequence or structural information. |
| Key Advantages | Robust, reproducible, high-resolution separation of impurities.[1][6] | High sensitivity and specificity for mass determination.[7] | Non-destructive, provides detailed structural information in solution.[8] | Gold standard for determining net peptide content.[9][10] |
| Key Disadvantages | Co-eluting impurities can be difficult to resolve and quantify accurately without MS. | Quantification can be challenging without isotopically labeled internal standards.[11] | Lower sensitivity compared to MS, requires higher sample concentrations. | Destructive to the peptide, does not provide information on sequence or structural integrity.[9] |
High-Performance Liquid Chromatography (HPLC)
HPLC, particularly Reversed-Phase HPLC (RP-HPLC), is the most widely used technique for assessing the purity of synthetic peptides.[6] It separates the target peptide from impurities based on differences in their hydrophobicity.
Experimental Protocol: RP-HPLC for Peptide Purity Analysis
This protocol outlines a general procedure for the analytical RP-HPLC of a synthesized ¹³C, ¹⁵N peptide.
1. Sample Preparation:
-
Accurately weigh a small amount of the lyophilized peptide (e.g., 1 mg).
-
Dissolve the peptide in a suitable solvent, typically the initial mobile phase (e.g., 0.1% Trifluoroacetic Acid (TFA) in water), to a final concentration of 1 mg/mL.[12]
-
Vortex gently to ensure complete dissolution.
-
Filter the sample through a 0.22 µm syringe filter to remove any particulate matter.[12]
2. HPLC System and Conditions:
-
HPLC System: An analytical HPLC system equipped with a UV detector.
-
Column: A C18 reversed-phase column is most common for a wide range of peptides.[13]
-
Mobile Phase A: 0.1% TFA in HPLC-grade water.
-
Mobile Phase B: 0.1% TFA in HPLC-grade acetonitrile (B52724) (ACN).
-
Gradient: A linear gradient from 5% to 60% Mobile Phase B over 20-30 minutes is a good starting point.[12]
-
Flow Rate: Typically 1.0 mL/min for a standard 4.6 mm ID analytical column.
-
Detection: UV absorbance at 214 nm (for the peptide backbone) and 280 nm (for aromatic residues like Trp and Tyr).[12]
-
Injection Volume: 10-20 µL.
3. Data Analysis:
-
Integrate the peak areas of all detected peaks in the chromatogram.
-
Calculate the purity of the peptide as the percentage of the main peak area relative to the total area of all peaks.[1]
-
Formula: % Purity = (Area of Main Peak / Total Area of All Peaks) x 100
-
Workflow for peptide purity analysis by RP-HPLC.
Mass Spectrometry (MS)
Mass spectrometry is an indispensable tool for confirming the molecular weight of the synthesized ¹³C, ¹⁵N peptide and for identifying impurities. When coupled with a separation technique like HPLC (LC-MS), it provides a powerful platform for both qualitative and quantitative analysis.
Experimental Protocol: MALDI-TOF MS for Molecular Weight Confirmation
This protocol describes a general procedure for Matrix-Assisted Laser Desorption/Ionization Time-of-Flight (MALDI-TOF) MS.
1. Sample and Matrix Preparation:
-
Sample: Prepare a 1 mg/mL stock solution of the peptide in 0.1% TFA in water. Dilute this stock to approximately 1-10 pmol/µL.
-
Matrix: Prepare a saturated solution of a suitable matrix, such as α-cyano-4-hydroxycinnamic acid (CHCA), in a solvent mixture (e.g., 50% acetonitrile, 49.9% water, 0.1% TFA).
2. Sample Spotting (Dried-Droplet Method):
-
Mix 1 µL of the diluted peptide sample with 1 µL of the matrix solution directly on the MALDI target plate.
-
Allow the mixture to air-dry completely at room temperature, forming a crystalline spot.
3. Data Acquisition:
-
Load the MALDI target plate into the mass spectrometer.
-
Calibrate the instrument using a standard peptide mixture with known molecular weights.
-
Acquire the mass spectrum in the appropriate mass range for the expected peptide mass. The instrument should be operated in positive ion reflectron mode for optimal resolution and accuracy.
4. Data Analysis:
-
Determine the monoisotopic mass of the most abundant peak in the spectrum.
-
Compare the observed mass with the theoretical mass of the ¹³C, ¹⁵N-labeled peptide to confirm its identity. The mass accuracy should ideally be within 5 ppm for high-resolution instruments.
Workflow for molecular weight confirmation by MALDI-TOF MS.
Nuclear Magnetic Resonance (NMR) Spectroscopy
NMR spectroscopy is a powerful, non-destructive technique for the detailed structural characterization of peptides in solution. For ¹³C, ¹⁵N-labeled peptides, 2D heteronuclear NMR experiments are particularly informative for confirming the correct incorporation of the isotopes and assessing the three-dimensional structure.
Experimental Protocol: 2D ¹H-¹⁵N HSQC for Structural Integrity
This protocol provides a general outline for acquiring a 2D ¹H-¹⁵N Heteronuclear Single Quantum Coherence (HSQC) spectrum, often referred to as a "fingerprint" of a labeled peptide.
1. Sample Preparation:
-
Dissolve the ¹³C, ¹⁵N-labeled peptide in a suitable buffer (e.g., 20 mM phosphate (B84403) buffer, pH 6.0) to a final concentration of 0.5-1.0 mM.[14]
-
The buffer should be prepared in 90% H₂O / 10% D₂O. The D₂O provides a lock signal for the spectrometer, while the H₂O allows for the observation of exchangeable amide protons.[14]
-
Add a chemical shift reference standard, such as DSS or TSP.[14]
-
Transfer the sample to a high-quality NMR tube.
2. NMR Data Acquisition:
-
Place the sample in the NMR spectrometer and lock onto the D₂O signal.
-
Tune and match the probe for both ¹H and ¹⁵N frequencies.
-
Optimize the magnetic field homogeneity by shimming.
-
Acquire a 1D ¹H spectrum to check the sample quality and determine the spectral width.
-
Set up a 2D ¹H-¹⁵N HSQC experiment. Typical parameters on a 600 MHz spectrometer would include:
-
Spectral widths: ~12 ppm for ¹H and ~30 ppm for ¹⁵N.
-
Number of points: 2048 in the direct dimension (¹H) and 256-512 in the indirect dimension (¹⁵N).
-
A sufficient number of scans per increment to achieve a good signal-to-noise ratio.
-
3. Data Processing and Analysis:
-
Process the 2D data using appropriate software (e.g., TopSpin, NMRPipe). This involves Fourier transformation, phase correction, and baseline correction.
-
Analyze the resulting ¹H-¹⁵N HSQC spectrum. Each cross-peak corresponds to a specific backbone or side-chain amide group. The dispersion of these peaks is an excellent indicator of whether the peptide is well-folded.
Logical relationship for 2D NMR analysis.
Amino Acid Analysis (AAA)
Amino acid analysis is the gold standard for determining the net peptide content of a lyophilized peptide sample.[9][10] This is crucial for accurately preparing stock solutions of known molar concentration.
Experimental Protocol: Amino Acid Analysis for Net Peptide Content
This protocol outlines the general steps for AAA.
1. Peptide Hydrolysis:
-
Accurately weigh a precise amount of the peptide (e.g., 0.5-1 mg).
-
Place the peptide in a hydrolysis tube and add 6 M HCl.
-
Seal the tube under vacuum and heat at 110°C for 24 hours to hydrolyze the peptide bonds.
2. Amino Acid Derivatization and Separation:
-
After hydrolysis, evaporate the HCl under vacuum.
-
Reconstitute the amino acid hydrolysate in a suitable buffer.
-
Derivatize the amino acids with a reagent that allows for sensitive detection (e.g., AccQ-Tag, phenylisothiocyanate). The Waters AccQ•Tag™ System is a pre-column derivatization method followed by reversed-phase analysis.[3]
-
Separate the derivatized amino acids using UPLC or HPLC.
3. Quantification:
-
A known concentration of an amino acid standard mixture is derivatized and analyzed in the same way as the sample.
-
Compare the peak areas of the amino acids in the peptide sample to those in the standard to determine the molar amount of each amino acid.
-
The net peptide content is calculated by comparing the quantified amount of peptide to the initial weight of the lyophilized powder. The net peptide content is typically in the range of 60-90%.[10][15]
Experimental workflow for Amino Acid Analysis.
Conclusion
A comprehensive assessment of the purity and structural integrity of synthesized ¹³C, ¹⁵N-labeled peptides requires a multi-faceted approach. While HPLC is the workhorse for routine purity assessment, it should be complemented by mass spectrometry to confirm the molecular identity and identify any impurities. For applications where the three-dimensional structure is critical, such as in NMR studies or drug development, 2D NMR spectroscopy is essential to verify the correct fold and structural integrity. Finally, amino acid analysis provides an accurate measure of the net peptide content, which is crucial for quantitative applications. By employing a combination of these orthogonal techniques, researchers can ensure the quality of their synthesized peptides, leading to more reliable and reproducible scientific outcomes.
References
- 1. peptidesuk.com [peptidesuk.com]
- 2. Validation of a liquid chromatography-high-resolution mass spectrometry method to quantify peptide-related impurities in teriparatide - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. Analytical methods and Quality Control for peptide products [biosynth.com]
- 4. Precise measurement for the purity of amino acid and peptide using quantitative nuclear magnetic resonance - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. pharmacy.nmims.edu [pharmacy.nmims.edu]
- 6. Principle of Peptide Purity Analysis Using HPLC | MtoZ Biolabs [mtoz-biolabs.com]
- 7. apexpeptidesupply.com [apexpeptidesupply.com]
- 8. books.rsc.org [books.rsc.org]
- 9. bachem.com [bachem.com]
- 10. Net peptide content, amino acid analysis and elemental analysis [innovagen.com]
- 11. researchgate.net [researchgate.net]
- 12. resolvemass.ca [resolvemass.ca]
- 13. benchchem.com [benchchem.com]
- 14. benchchem.com [benchchem.com]
- 15. chem.uzh.ch [chem.uzh.ch]
Benchmarking Fmoc-Gly-OH-2-13C,15N performance in different research applications.
Benchmarking Fmoc-Gly-OH-2-13C,15N: A Comparative Guide for Research Applications
For Researchers, Scientists, and Drug Development Professionals
This guide provides a comprehensive comparison of this compound, a dual isotopically labeled amino acid, against its common alternatives in key research applications. The inclusion of stable isotopes, ¹³C and ¹⁵N, at the second carbon and the nitrogen atom of glycine (B1666218), respectively, makes this reagent a powerful tool for nuclear magnetic resonance (NMR) spectroscopy and mass spectrometry (MS)-based quantitative proteomics. This document outlines its performance, provides detailed experimental protocols, and presents visual workflows to aid in experimental design and execution.
Section 1: Performance in Solid-Phase Peptide Synthesis (SPPS)
This compound is primarily utilized as a building block in solid-phase peptide synthesis (SPPS) to introduce a specific isotopic label into a peptide sequence. Its performance in this application is comparable to its unlabeled counterpart, Fmoc-Gly-OH, with the key differentiator being the introduction of a +2 Da mass shift.
Comparison with Alternatives in SPPS
While direct head-to-head quantitative data on coupling efficiency between labeled and unlabeled glycine is not extensively published in comparative tables, the chemical reactivity is considered virtually identical. The primary alternatives in the context of isotopic labeling are singly labeled glycine derivatives.
Table 1: Comparison of Fmoc-Glycine Derivatives in SPPS
| Feature | This compound | Unlabeled Fmoc-Gly-OH | Singly Labeled Fmoc-Gly-OH (e.g., ¹⁵N or ¹³C) |
| Primary Use | Introduction of a dual isotopic label for NMR and MS analysis. | Standard peptide synthesis. | Introduction of a single isotopic label. |
| Coupling Efficiency | Expected to be comparable to unlabeled Fmoc-Gly-OH. | Standard reference for glycine coupling. | Expected to be comparable to unlabeled Fmoc-Gly-OH. |
| Cleavage and Deprotection | Standard Fmoc deprotection protocols (e.g., 20% piperidine (B6355638) in DMF) are effective. | Standard Fmoc deprotection protocols are effective. | Standard Fmoc deprotection protocols are effective. |
| Key Advantage | Provides a distinct +2 Da mass shift for mass spectrometry and enables advanced NMR experiments. | Cost-effective for routine peptide synthesis. | Provides a +1 Da mass shift. |
| Considerations | Higher cost due to isotopic enrichment. | Not suitable for isotopic labeling studies. | May provide insufficient mass shift for complex mass spectra. |
Experimental Protocol: Solid-Phase Peptide Synthesis (SPPS) of a Labeled Peptide
This protocol outlines the manual synthesis of a short peptide incorporating this compound using a Rink Amide resin.
Materials:
-
Rink Amide MBHA resin
-
Fmoc-amino acids (including this compound)
-
Coupling reagents: HBTU (2-(1H-benzotriazol-1-yl)-1,1,3,3-tetramethyluronium hexafluorophosphate), HOBt (Hydroxybenzotriazole)
-
N,N-Diisopropylethylamine (DIPEA)
-
Deprotection solution: 20% (v/v) piperidine in N,N-Dimethylformamide (DMF)
-
Solvents: DMF, Dichloromethane (DCM), Diethyl ether
-
Cleavage cocktail: 95% Trifluoroacetic acid (TFA), 2.5% Triisopropylsilane (TIS), 2.5% water
Procedure:
-
Resin Swelling: Swell the Rink Amide resin in DMF in a reaction vessel for 30-60 minutes.
-
Fmoc Deprotection: Remove the Fmoc protecting group by treating the resin with 20% piperidine in DMF for 5-10 minutes, drain, and repeat for another 10-15 minutes. Wash the resin thoroughly with DMF.
-
Amino Acid Coupling:
-
In a separate vial, dissolve the Fmoc-amino acid (e.g., this compound) (3 eq.), HBTU (2.9 eq.), and HOBt (3 eq.) in DMF.
-
Add DIPEA (6 eq.) to the amino acid solution and pre-activate for 1-2 minutes.
-
Add the activated amino acid solution to the resin and agitate for 1-2 hours.
-
Monitor coupling completion with a Kaiser test.
-
-
Washing: Wash the resin with DMF to remove excess reagents.
-
Repeat Cycle: Repeat steps 2-4 for each amino acid in the peptide sequence.
-
Final Deprotection: After the final coupling, remove the N-terminal Fmoc group as described in step 2.
-
Cleavage and Deprotection: Wash the resin with DCM and dry. Treat the resin with the cleavage cocktail for 2-3 hours.
-
Peptide Precipitation: Precipitate the peptide by adding the cleavage mixture to cold diethyl ether. Centrifuge to pellet the peptide and wash with cold ether.
-
Purification: Purify the crude peptide using reverse-phase high-performance liquid chromatography (RP-HPLC).
-
Analysis: Confirm the mass of the purified peptide using mass spectrometry.
SPPS Workflow Diagram
Section 2: Performance in Nuclear Magnetic Resonance (NMR) Spectroscopy
The dual labeling of this compound provides significant advantages for NMR-based structural and interaction studies of peptides and proteins. The ¹⁵N label allows for the acquisition of ¹H-¹⁵N heteronuclear single quantum coherence (HSQC) spectra, which provides a unique signal for each backbone amide proton, serving as a "fingerprint" of the protein. The additional ¹³C label enables more advanced multi-dimensional experiments for resonance assignment and structural elucidation.
Comparison of Labeling Strategies for NMR
While quantitative data on signal-to-noise enhancement is highly dependent on the specific peptide and experimental conditions, the qualitative benefits of dual labeling are well-established.
Table 2: Comparison of Isotopic Labeling for Peptide NMR
| Feature | ¹³C,¹⁵N Dual Labeling (from this compound) | ¹⁵N Single Labeling | Unlabeled |
| Primary NMR Experiment | ¹H-¹⁵N HSQC, ¹H-¹³C HSQC, 3D experiments (e.g., HNCA, HN(CO)CA) | ¹H-¹⁵N HSQC | 1D ¹H, 2D TOCSY, NOESY |
| Signal Dispersion | Excellent in both ¹⁵N and ¹³C dimensions. | Good in the ¹⁵N dimension. | Often poor, leading to signal overlap. |
| Resonance Assignment | Facilitates sequential backbone and sidechain assignment. | Enables backbone amide assignment. | Difficult for peptides larger than ~10 residues. |
| Structural Information | Enables high-resolution 3D structure determination. | Provides information on backbone conformation and dynamics. | Limited structural information from NOEs. |
| Interaction Studies | Allows for detailed chemical shift perturbation mapping in multiple dimensions.[1] | Enables chemical shift perturbation mapping of the backbone.[1] | Difficult to resolve binding-induced shifts. |
| Key Advantage | Provides the most comprehensive structural and dynamic information. | Cost-effective method for initial structural assessment and interaction screening. | No special synthesis required. |
| Considerations | Highest cost. | Limited to backbone information. | Limited applicability for larger peptides. |
Experimental Protocol: ¹H-¹⁵N HSQC for a Labeled Peptide
This protocol describes the acquisition of a basic 2D ¹H-¹⁵N HSQC spectrum.
Materials:
-
Lyophilized ¹⁵N-labeled (or ¹³C,¹⁵N-labeled) peptide
-
NMR buffer (e.g., 20 mM sodium phosphate, 50 mM NaCl, pH 6.5)
-
D₂O
-
NMR tube
Procedure:
-
Sample Preparation: Dissolve the lyophilized peptide in the NMR buffer to the desired concentration (typically 0.1-1 mM). Add 5-10% D₂O for the lock signal.
-
NMR Spectrometer Setup:
-
Tune and match the probe for ¹H and ¹⁵N frequencies.
-
Lock the spectrometer on the D₂O signal.
-
Shim the magnetic field to achieve good resolution.
-
-
Acquisition of ¹H-¹⁵N HSQC Spectrum:
-
Load a standard ¹H-¹⁵N HSQC pulse sequence.
-
Set the spectral widths for both ¹H and ¹⁵N dimensions to cover all expected amide signals.
-
Set the number of scans and increments to achieve the desired signal-to-noise ratio.
-
Acquire the data.
-
-
Data Processing:
-
Process the raw data using appropriate software (e.g., TopSpin, NMRPipe). This typically involves Fourier transformation, phase correction, and baseline correction.
-
-
Data Analysis:
-
Analyze the resulting 2D spectrum to identify cross-peaks corresponding to each backbone amide.
-
Workflow for NMR-based Peptide-Ligand Interaction Study
Section 3: Performance in Quantitative Proteomics
In quantitative proteomics, this compound can be used to synthesize stable isotope-labeled (SIL) peptides, which serve as internal standards for the absolute quantification of target proteins (AQUA method). Alternatively, metabolic labeling with [2-¹³C, ¹⁵N]glycine can be employed in cell culture (SILAC), although this is less common than using labeled arginine or lysine (B10760008).
Comparison with Alternatives in Quantitative Proteomics
The standard in SILAC is to use labeled arginine and lysine because trypsin, the most common enzyme used for protein digestion, cleaves after these residues, ensuring that most tryptic peptides will contain a label.[2] Using labeled glycine is a viable alternative for quantifying glycine-containing peptides.
Table 3: Comparison of Labeled Amino Acids for SILAC-based Quantitative Proteomics
| Feature | ¹³C,¹⁵N-Glycine Labeling | ¹³C,¹⁵N-Arginine/Lysine Labeling |
| Applicability | Quantifies glycine-containing peptides. | Quantifies the majority of tryptic peptides. |
| Quantification Accuracy | High, as the labeled peptide is chemically identical to the endogenous peptide. | High, considered the gold standard for SILAC. |
| Proteome Coverage | Limited to glycine-containing peptides. | Broad proteome coverage. |
| Mass Shift | +2 Da (for this compound). | +8 Da (for ¹³C₆,¹⁵N₂-Lys) or +10 Da (for ¹³C₆,¹⁵N₄-Arg). |
| Key Advantage | Useful for targeted quantification of specific glycine-containing peptides or proteins where Arg/Lys are absent. | Provides comprehensive quantitative data for a large portion of the proteome. |
| Considerations | Not suitable for global proteomic quantification. | Potential for metabolic conversion of arginine to proline in some cell lines.[3] |
Experimental Protocol: SILAC Workflow for Quantitative Proteomics
This protocol provides a general workflow for a two-plex SILAC experiment.[4][5]
Materials:
-
Cell culture medium deficient in a specific amino acid (e.g., glycine)
-
"Light" (unlabeled) amino acid
-
"Heavy" ([2-¹³C, ¹⁵N]glycine) amino acid
-
Dialyzed fetal bovine serum (FBS)
-
Cell lysis buffer
-
Trypsin
-
LC-MS/MS system
Procedure:
-
Cell Culture and Labeling:
-
Culture two populations of cells. One in "light" medium supplemented with unlabeled glycine, and the other in "heavy" medium with [2-¹³C, ¹⁵N]glycine.
-
Grow cells for at least five passages to ensure complete incorporation of the labeled amino acid.
-
-
Experimental Treatment: Apply the experimental condition to one of the cell populations.
-
Cell Harvesting and Mixing: Harvest both cell populations and mix them in a 1:1 ratio.
-
Protein Extraction and Digestion: Lyse the mixed cells and extract the proteins. Digest the proteins into peptides using trypsin.
-
LC-MS/MS Analysis: Analyze the peptide mixture using a high-resolution mass spectrometer.
-
Data Analysis:
-
Identify peptides and proteins using database search algorithms.
-
Quantify the relative abundance of proteins by comparing the signal intensities of the "light" and "heavy" peptide pairs.
-
References
- 1. protein-nmr.org.uk [protein-nmr.org.uk]
- 2. researchgate.net [researchgate.net]
- 3. Glycine receptor | PDF [slideshare.net]
- 4. Analysis of Isotopic Labeling in Peptide Fragments by Tandem Mass Spectrometry | PLOS One [journals.plos.org]
- 5. Frontiers | Glycine receptors and brain development [frontiersin.org]
Safety Operating Guide
Proper Disposal Procedures for Fmoc-Gly-OH-2-13C,15N
The following guide provides detailed procedures for the safe and compliant disposal of Fmoc-Gly-OH-2-13C,15N, a stable isotope-labeled amino acid derivative used in peptide synthesis and other research applications. While this compound is not classified as hazardous under the Globally Harmonized System (GHS), it is imperative to follow institutional and regulatory guidelines for chemical waste disposal to ensure laboratory safety and environmental protection.[1][2][3]
The stable, non-radioactive isotopes ¹³C and ¹⁵N do not alter the chemical properties or confer any additional hazards compared to the parent compound, Fmoc-Gly-OH.[4][5] Therefore, the disposal procedures are based on the properties of the Fmoc-glycine molecule.
Data Presentation: Chemical Safety and Disposal Overview
This table summarizes the key identification and safety information for this compound.
| Property | Information |
| Chemical Name | N-(9-Fluorenylmethoxycarbonyl)-glycine-2-¹³C,¹⁵N |
| CAS Number | 285978-12-3 |
| Physical State | Solid, white powder |
| GHS Hazard Classification | Not classified as a hazardous substance.[1][2][3] |
| Primary Disposal Route | Collection as solid chemical waste for disposal by the institution's Environmental Health & Safety (EHS) department or a licensed waste contractor. |
| Personal Protective Equipment (PPE) | Standard laboratory attire including safety goggles, chemical-resistant gloves (e.g., nitrile), and a lab coat should be worn when handling the chemical and its waste.[1][6] |
| Environmental Precautions | Do not allow the product to be disposed of with household garbage or to enter the sewage system.[7] Discharge into the environment should be avoided.[1][2] |
Experimental Protocol: Step-by-Step Disposal Methodology
The overriding principle for laboratory waste is that an activity should not begin until a clear disposal plan is in place.[8] The following protocol details the standard procedure for disposing of solid this compound and associated contaminated materials.
Objective: To safely collect, label, and store this compound waste for proper disposal in accordance with institutional policies.
Materials:
-
Designated solid chemical waste container (sealable, durable plastic or glass)
-
Waste label
-
Personal Protective Equipment (PPE): safety goggles, gloves, lab coat
Procedure:
-
Waste Segregation:
-
Collect unused or expired solid this compound directly into a designated solid chemical waste container.
-
Segregate contaminated consumables such as weighing papers, pipette tips, and gloves into the same container.
-
Do not mix this waste stream with incompatible chemicals. It is prudent practice to collect different types of waste in separate containers.[8]
-
-
Container Packaging:
-
Place the solid waste into a container that can be securely sealed. The original product container, if empty and in good condition, can be used, but it should be placed inside a larger, labeled waste container.
-
Ensure the container is clean on the outside and free of contamination before moving it to the designated waste accumulation area.
-
-
Waste Labeling:
-
Label the waste container clearly. The label must include:
-
The words "Chemical Waste" or "Hazardous Waste" (as required by your institution, which often treats all chemical waste as hazardous for collection purposes).
-
The full chemical name: "this compound".
-
An approximate amount of the waste.
-
The date the container was first used for waste accumulation.
-
-
-
Waste Storage:
-
Store the sealed and labeled waste container in a designated, secure waste accumulation area within the laboratory.
-
This area should be away from general traffic and incompatible materials.[6] The container should be kept closed except when adding waste.
-
-
Arranging for Disposal:
-
Once the container is full or ready for pickup, contact your institution's Environmental Health & Safety (EHS) department or the designated chemical waste officer.
-
Follow their specific procedures for requesting a waste pickup. Do not move the waste outside of the laboratory yourself unless explicitly instructed to do so by EHS personnel.
-
Mandatory Visualization: Disposal Workflow
The following diagram illustrates the decision-making process and procedural flow for the proper disposal of this compound waste.
Caption: Workflow for the compliant disposal of solid this compound waste.
References
- 1. cemcontenttype.s3.amazonaws.com [cemcontenttype.s3.amazonaws.com]
- 2. echemi.com [echemi.com]
- 3. Fmoc-Gly-OH | C17H15NO4 | CID 93124 - PubChem [pubchem.ncbi.nlm.nih.gov]
- 4. medchemexpress.com [medchemexpress.com]
- 5. Fmoc-Gly-OH-13C2,15N | 285978-13-4 | Benchchem [benchchem.com]
- 6. benchchem.com [benchchem.com]
- 7. severnbiotech.com [severnbiotech.com]
- 8. Management of Waste - Prudent Practices in the Laboratory - NCBI Bookshelf [ncbi.nlm.nih.gov]
Featured Recommendations
| Most viewed |


|
|
|---|---|---|
| Most popular with customers |
|
試験管内研究製品の免責事項と情報
BenchChemで提示されるすべての記事および製品情報は、情報提供を目的としています。BenchChemで購入可能な製品は、生体外研究のために特別に設計されています。生体外研究は、ラテン語の "in glass" に由来し、生物体の外で行われる実験を指します。これらの製品は医薬品または薬として分類されておらず、FDAから任何の医療状態、病気、または疾患の予防、治療、または治癒のために承認されていません。これらの製品を人間または動物に体内に導入する形態は、法律により厳格に禁止されています。これらのガイドラインに従うことは、研究と実験において法的および倫理的な基準の遵守を確実にするために重要です。
