1-Methylcytosine
説明
Structure
3D Structure
特性
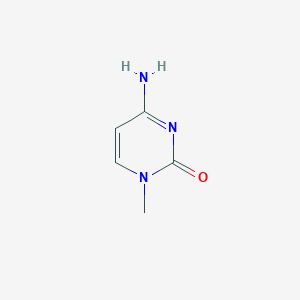
IUPAC Name |
4-amino-1-methylpyrimidin-2-one |
Source


|
|---|---|---|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
InChI |
InChI=1S/C5H7N3O/c1-8-3-2-4(6)7-5(8)9/h2-3H,1H3,(H2,6,7,9) |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
InChI Key |
HWPZZUQOWRWFDB-UHFFFAOYSA-N |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Canonical SMILES |
CN1C=CC(=NC1=O)N |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Molecular Formula |
C5H7N3O |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
DSSTOX Substance ID |
DTXSID60149949 |
Source
|
| Record name | 1-Methylcytosine | |
| Source | EPA DSSTox | |
| URL | https://comptox.epa.gov/dashboard/DTXSID60149949 | |
| Description | DSSTox provides a high quality public chemistry resource for supporting improved predictive toxicology. | |
Molecular Weight |
125.13 g/mol |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
CAS No. |
1122-47-0 |
Source
|
| Record name | 1-Methylcytosine | |
| Source | CAS Common Chemistry | |
| URL | https://commonchemistry.cas.org/detail?cas_rn=1122-47-0 | |
| Description | CAS Common Chemistry is an open community resource for accessing chemical information. Nearly 500,000 chemical substances from CAS REGISTRY cover areas of community interest, including common and frequently regulated chemicals, and those relevant to high school and undergraduate chemistry classes. This chemical information, curated by our expert scientists, is provided in alignment with our mission as a division of the American Chemical Society. | |
| Explanation | The data from CAS Common Chemistry is provided under a CC-BY-NC 4.0 license, unless otherwise stated. | |
| Record name | 1-Methylcytosine | |
| Source | ChemIDplus | |
| URL | https://pubchem.ncbi.nlm.nih.gov/substance/?source=chemidplus&sourceid=0001122470 | |
| Description | ChemIDplus is a free, web search system that provides access to the structure and nomenclature authority files used for the identification of chemical substances cited in National Library of Medicine (NLM) databases, including the TOXNET system. | |
| Record name | 1-Methylcytosine | |
| Source | DrugBank | |
| URL | https://www.drugbank.ca/drugs/DB04314 | |
| Description | The DrugBank database is a unique bioinformatics and cheminformatics resource that combines detailed drug (i.e. chemical, pharmacological and pharmaceutical) data with comprehensive drug target (i.e. sequence, structure, and pathway) information. | |
| Explanation | Creative Common's Attribution-NonCommercial 4.0 International License (http://creativecommons.org/licenses/by-nc/4.0/legalcode) | |
| Record name | 1122-47-0 | |
| Source | DTP/NCI | |
| URL | https://dtp.cancer.gov/dtpstandard/servlet/dwindex?searchtype=NSC&outputformat=html&searchlist=47693 | |
| Description | The NCI Development Therapeutics Program (DTP) provides services and resources to the academic and private-sector research communities worldwide to facilitate the discovery and development of new cancer therapeutic agents. | |
| Explanation | Unless otherwise indicated, all text within NCI products is free of copyright and may be reused without our permission. Credit the National Cancer Institute as the source. | |
| Record name | 1-Methylcytosine | |
| Source | EPA DSSTox | |
| URL | https://comptox.epa.gov/dashboard/DTXSID60149949 | |
| Description | DSSTox provides a high quality public chemistry resource for supporting improved predictive toxicology. | |
| Record name | 4-amino-1-methyl-1,2-dihydropyrimidin-2-one | |
| Source | European Chemicals Agency (ECHA) | |
| URL | https://echa.europa.eu/information-on-chemicals | |
| Description | The European Chemicals Agency (ECHA) is an agency of the European Union which is the driving force among regulatory authorities in implementing the EU's groundbreaking chemicals legislation for the benefit of human health and the environment as well as for innovation and competitiveness. | |
| Explanation | Use of the information, documents and data from the ECHA website is subject to the terms and conditions of this Legal Notice, and subject to other binding limitations provided for under applicable law, the information, documents and data made available on the ECHA website may be reproduced, distributed and/or used, totally or in part, for non-commercial purposes provided that ECHA is acknowledged as the source: "Source: European Chemicals Agency, http://echa.europa.eu/". Such acknowledgement must be included in each copy of the material. ECHA permits and encourages organisations and individuals to create links to the ECHA website under the following cumulative conditions: Links can only be made to webpages that provide a link to the Legal Notice page. | |
| Record name | 1-METHYLCYTOSINE | |
| Source | FDA Global Substance Registration System (GSRS) | |
| URL | https://gsrs.ncats.nih.gov/ginas/app/beta/substances/1J54NE82RV | |
| Description | The FDA Global Substance Registration System (GSRS) enables the efficient and accurate exchange of information on what substances are in regulated products. Instead of relying on names, which vary across regulatory domains, countries, and regions, the GSRS knowledge base makes it possible for substances to be defined by standardized, scientific descriptions. | |
| Explanation | Unless otherwise noted, the contents of the FDA website (www.fda.gov), both text and graphics, are not copyrighted. They are in the public domain and may be republished, reprinted and otherwise used freely by anyone without the need to obtain permission from FDA. Credit to the U.S. Food and Drug Administration as the source is appreciated but not required. | |
Foundational & Exploratory
The Biological Function of 1-Methylcytosine: An In-depth Technical Guide
Abstract
1-Methylcytosine (m1C) is a post-transcriptional RNA modification that plays a critical role in the regulation of gene expression. Unlike its well-studied isomer, 5-methylcytosine (B146107) (m5C), m1C involves the methylation of the nitrogen atom at position 1 of the cytosine ring. This modification is found in various RNA species, including transfer RNA (tRNA), ribosomal RNA (rRNA), and messenger RNA (mRNA), where it influences RNA stability, structure, and function. This technical guide provides a comprehensive overview of the biological functions of m1C, the enzymatic machinery responsible for its deposition and removal, and its implications in disease. Detailed experimental protocols for the detection and analysis of m1C are also provided, along with visualizations of key molecular pathways. This document is intended for researchers, scientists, and drug development professionals working in the fields of molecular biology, epigenetics, and oncology.
Introduction to this compound (m1C)
This compound is a modified nucleobase derived from cytosine through the enzymatic addition of a methyl group to the N1 position of the pyrimidine (B1678525) ring.[1] While less abundant than 5-methylcytosine, m1C has emerged as a significant epitranscriptomic mark with diverse biological functions. Its presence has been identified in various types of RNA, suggesting a widespread role in post-transcriptional gene regulation.
The addition of a methyl group at the N1 position alters the hydrogen bonding properties of the cytosine base, which can impact RNA secondary structure and its interactions with RNA-binding proteins (RBPs).[2] This guide will delve into the known biological functions of m1C in different RNA species, the enzymes that regulate its dynamic installation and removal, and its association with human diseases, particularly cancer.
Biological Functions of this compound
The functional consequences of m1C modification are context-dependent and vary based on the type of RNA molecule in which it resides.
Role in Transfer RNA (tRNA)
In tRNA, m1C is a crucial modification that contributes to its structural integrity and decoding function. The primary enzyme complex responsible for m1C deposition in tRNA is the TRMT6/TRMT61A methyltransferase complex.[3][4]
-
tRNA Stability: The presence of m1C, particularly at position 58 (m1A58), is essential for the stability of initiator methionyl-tRNA in Saccharomyces cerevisiae.[3] The crystal structure of the human TRMT6/61A complex bound to tRNA reveals that the enzyme refolds the tRNA substrate to gain access to the methylation target, highlighting the intricate mechanism of this modification.[2][3]
-
Translation Regulation: By ensuring the correct folding and stability of tRNAs, m1C modification indirectly influences the efficiency and fidelity of protein synthesis. Demethylation of m1A in tRNA by enzymes like ALKBH1 can lead to attenuated translation initiation and tRNA degradation.[5][6]
Role in Messenger RNA (mRNA)
The discovery of m1C in mRNA has opened new avenues of research into its role in regulating mRNA fate and function.
-
mRNA Stability and Translation: The Y-box binding protein 1 (YBX1) has been identified as a "reader" protein that specifically recognizes m5C-modified mRNAs, and emerging evidence suggests a similar role for related modifications.[1][7][8] This recognition can recruit other proteins, such as the ELAV-like RNA-binding protein 1 (ELAVL1), to stabilize the mRNA transcript, thereby preventing its degradation and promoting its translation.[7] This mechanism has been implicated in the progression of various cancers, including bladder cancer and hepatocellular carcinoma, where YBX1-mediated stabilization of oncogenic mRNAs contributes to tumor growth and metastasis.[1][7]
-
Oncogenic Signaling: The NSUN2-m5C-YBX1 axis is a well-defined pathway where NSUN2-mediated methylation of mRNA is recognized by YBX1, leading to the stabilization of target transcripts. This pathway is involved in regulating oncogenic processes and cellular reprogramming.[1] For instance, YBX1 has been shown to promote tumor progression through the PI3K/AKT signaling pathway in laryngeal squamous cell carcinoma.[1]
Role in Ribosomal RNA (rRNA)
The function of m1C in rRNA is less characterized compared to tRNA and mRNA. However, given the critical role of rRNA in ribosome biogenesis and function, it is plausible that m1C modifications within rRNA could influence ribosome assembly, stability, and translational fidelity. Methylation of ribosomal proteins and rRNA is known to be crucial for proper ribosome biogenesis.[9][10][11] Further research is needed to elucidate the specific roles of m1C in this context.
The Enzymatic Machinery of this compound Modification
The dynamic regulation of m1C is controlled by a set of enzymes often referred to as "writers," "readers," and "erasers."
-
Writers (Methyltransferases): The primary enzymes responsible for depositing the m1C mark are methyltransferases. The TRMT6/TRMT61A complex is a key writer of m1A in tRNA.[3][4][12] In this heterodimeric complex, TRMT61A acts as the catalytic subunit, while TRMT6 is responsible for tRNA binding.[4][12]
-
Readers (Binding Proteins): Reader proteins recognize and bind to m1C-modified RNA, translating the modification into a functional outcome. Y-box binding protein 1 (YBX1) is a prominent reader protein that specifically binds to m5C-containing mRNAs, and likely similar modifications, through its cold shock domain, thereby regulating their stability and translation.[1][7][8]
-
Erasers (Demethylases): The removal of the methyl group from m1C is carried out by demethylases. The AlkB homolog 1 (ALKBH1), an Fe(II)- and α-ketoglutarate-dependent dioxygenase, has been identified as a demethylase for m1A in both cytoplasmic and mitochondrial tRNA.[5][6][13] ALKBH1 can also demethylate 3-methylcytosine (B1195936) in RNA.[6] The activity of ALKBH1 provides a mechanism for the reversible regulation of m1C, allowing for dynamic control of RNA function in response to cellular signals.[5]
Quantitative Data on this compound
Quantifying the abundance of m1C is crucial for understanding its regulatory roles. The following table summarizes key findings on the levels of cytosine methylation in different contexts.
| RNA Type/Condition | Organism/Cell Line | Method | Key Finding | Reference(s) |
| Total mRNA | Human Colorectal Cancer Cells (HCT15) | MeRIP-seq | Knockdown of the methyltransferase NSUN2 resulted in a significant decrease in the overall number of m5C peaks in mRNA, with 7,531 downregulated peaks identified. | [14] |
| Total mRNA | Human Embryonic Kidney Cells (HEK293T) | RNA-seq | Knockdown of NSUN2 led to a 6-7 fold reduction in NSUN2 mRNA and a 10-fold reduction in the protein, impacting the landscape of translated mRNAs. | [15] |
| tRNA | Human Embryonic Kidney Cells (HEK293T) | DM-tRNA-seq | A "Modification Index" was developed to quantify six different base methylations in tRNA, identifying numerous new methylation sites. | [16] |
| Total RNA | Human Glioma Cells (U87) | Western Blotting | Knockdown of NSUN2 decreased ATX protein levels, while overexpression increased them, without altering ATX mRNA levels, suggesting a role for methylation in enhancing translation. | [17] |
Experimental Protocols
Accurate detection and quantification of m1C are essential for studying its biological functions. Below are detailed methodologies for two key experimental approaches.
RNA Bisulfite Sequencing for this compound Detection
This method allows for the single-base resolution mapping of m1C sites in RNA.
Principle: Sodium bisulfite treatment deaminates unmethylated cytosines to uracils, while this compound remains unchanged. Subsequent reverse transcription and sequencing reveal the original methylation status, as uracils are read as thymines and m1Cs are read as cytosines.
Protocol:
-
RNA Isolation and DNase Treatment:
-
Isolate total RNA from cells or tissues using a standard method (e.g., TRIzol reagent).
-
Treat the isolated RNA with DNase I to remove any contaminating DNA.
-
-
Bisulfite Conversion:
-
Use a commercial kit (e.g., EpiTect Bisulfite Kit) for bisulfite treatment of 1 µg of RNA.
-
Mix 20 µL of RNA with the bisulfite mix and DNA protect buffer provided in the kit.
-
Denature the RNA at 70°C for 5-10 minutes.
-
Incubate at 60°C for 1 hour for the conversion reaction. For structured RNAs like tRNA, this incubation may need to be repeated in cycles.[18]
-
-
RNA Cleanup:
-
Purify the bisulfite-treated RNA using spin columns to remove the bisulfite and other reagents.
-
-
Reverse Transcription:
-
Perform reverse transcription of the bisulfite-treated RNA to generate cDNA. For specific small RNAs like tRNA, a stem-loop primer can be used for targeted reverse transcription.[18]
-
-
PCR Amplification:
-
Amplify the cDNA using primers specific to the deaminated sequence of the target RNA. Nested or semi-nested PCR can improve specificity.[19]
-
-
Library Preparation and Sequencing:
-
Prepare a sequencing library from the PCR products.
-
Perform high-throughput sequencing (e.g., Illumina).
-
-
Data Analysis:
-
Align the sequencing reads to a converted reference genome (where all Cs are converted to Ts).
-
Identify sites where cytosines are retained in the reads, as these represent methylated cytosines.
-
Mass Spectrometry for Global this compound Quantification
This technique provides a highly accurate measurement of the overall abundance of m1C in a total RNA sample.[20]
Principle: RNA is enzymatically digested into individual nucleosides. The resulting mixture is then separated by liquid chromatography and analyzed by tandem mass spectrometry (LC-MS/MS). The abundance of m1C is quantified by comparing its signal to that of an isotopically labeled internal standard.
Protocol:
-
RNA Isolation and Purity Assessment:
-
Isolate total RNA and ensure high purity.
-
Assess RNA integrity using gel electrophoresis.
-
-
RNA Digestion:
-
Digest 1-2 µg of total RNA into nucleosides using a cocktail of enzymes, such as nuclease P1, snake venom phosphodiesterase, and alkaline phosphatase.
-
-
LC-MS/MS Analysis:
-
Inject the digested nucleoside mixture into a liquid chromatography system coupled to a triple quadrupole mass spectrometer.
-
Separate the nucleosides using a C18 reverse-phase column.
-
Perform mass spectrometry in multiple reaction monitoring (MRM) mode to detect the specific mass transitions for 1-methylcytidine and a corresponding stable isotope-labeled internal standard.
-
-
Quantification:
-
Generate a standard curve using known concentrations of 1-methylcytidine.
-
Calculate the amount of m1C in the sample by comparing the peak area ratio of the endogenous m1C to the internal standard against the standard curve.
-
Signaling Pathways and Logical Relationships
The role of m1C in regulating gene expression often involves complex signaling pathways. The YBX1 protein, a key reader of methylated cytosine, is implicated in several cancer-related pathways.
YBX1-Mediated mRNA Stabilization and Cancer Progression
The following diagram illustrates the signaling pathway through which YBX1 recognizes methylated mRNA and promotes cancer cell proliferation and survival.
Caption: YBX1 signaling pathway in cancer.
Experimental Workflow for RNA Bisulfite Sequencing
The following diagram outlines the key steps in the RNA bisulfite sequencing protocol.
References
- 1. YBX1: an RNA/DNA-binding protein that affects disease progression - PMC [pmc.ncbi.nlm.nih.gov]
- 2. researchgate.net [researchgate.net]
- 3. Crystal Structure of the Human tRNA m(1)A58 Methyltransferase-tRNA(3)(Lys) Complex: Refolding of Substrate tRNA Allows Access to the Methylation Target - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. scispace.com [scispace.com]
- 5. researchgate.net [researchgate.net]
- 6. The biological function of demethylase ALKBH1 and its role in human diseases - PMC [pmc.ncbi.nlm.nih.gov]
- 7. researchgate.net [researchgate.net]
- 8. Y-Box Binding Protein 1: Unraveling the Multifaceted Role in Cancer Development and Therapeutic Potential - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Ribosome biogenesis: emerging evidence for a central role in the regulation of skeletal muscle mass - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Ribosome biogenesis factors—from names to functions | The EMBO Journal [link.springer.com]
- 11. Methylation of ribosomal protein S10 by protein-arginine methyltransferase 5 regulates ribosome biogenesis - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. N1-methyladenosine methylation in tRNA drives liver tumourigenesis by regulating cholesterol metabolism - PMC [pmc.ncbi.nlm.nih.gov]
- 13. academic.oup.com [academic.oup.com]
- 14. Frontiers | Overview of distinct 5-methylcytosine profiles of messenger RNA in normal and knock-down NSUN2 colorectal cancer cells [frontiersin.org]
- 15. mdpi.com [mdpi.com]
- 16. tRNA base methylation identification and quantification via high-throughput sequencing - PubMed [pubmed.ncbi.nlm.nih.gov]
- 17. NSun2 promotes cell migration through methylating autotaxin mRNA - PMC [pmc.ncbi.nlm.nih.gov]
- 18. RNA cytosine methylation analysis by bisulfite sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 19. bcm.edu [bcm.edu]
- 20. Protocol for profiling RNA m5C methylation at base resolution using m5C-TAC-seq - PMC [pmc.ncbi.nlm.nih.gov]
1-Methylcytosine in DNA: A Clarification and an In-Depth Guide to the Discovery and History of its Isomer, 5-Methylcytosine
A Note to the Reader: Initial research into the topic of 1-methylcytosine (m1C) in DNA has revealed that, unlike its well-studied isomer 5-methylcytosine (B146107) (5mC), This compound is not recognized as a naturally occurring modification in the DNA of living organisms . The scientific literature predominantly discusses this compound in the context of synthetic biology, particularly in the development of artificially expanded genetic information systems.
Given that the vast body of research on cytosine methylation in DNA pertains to 5-methylcytosine, this guide will focus on the discovery and history of 5mC, as it is the biologically relevant and extensively studied form of methylated cytosine in DNA. We will adhere to the requested in-depth technical format, providing historical context, quantitative data, experimental protocols, and visualizations related to 5-methylcytosine.
An In-depth Technical Guide to the Discovery and History of 5-Methylcytosine in DNA
Audience: Researchers, scientists, and drug development professionals.
Introduction
5-Methylcytosine (5mC) is a pivotal epigenetic modification in the DNA of a wide range of organisms, from bacteria to mammals. It involves the covalent addition of a methyl group to the C5 position of the cytosine pyrimidine (B1678525) ring. This modification does not alter the primary DNA sequence but has profound effects on gene expression, chromatin structure, and genome stability. The journey to understanding the significance of 5mC is a story of key discoveries spanning over a century, intertwined with the development of foundational techniques in molecular biology.
Historical Timeline of Key Discoveries
The discovery and characterization of 5-methylcytosine in DNA was a gradual process, built upon the work of numerous scientists. The following table summarizes the key milestones in this journey.
| Year | Key Discovery/Event | Principal Investigator(s) | Significance |
| 1898 | Isolation of "tuberculinic acid," a nucleic acid from Tubercle bacillus that was noted to be unusual.[1] | W.G. Ruppel | First isolation of a nucleic acid that would later be shown to contain a modified base.[1] |
| 1925 | First detection of a methylated cytosine derivative from the hydrolysis of tuberculinic acid.[1][2] | Treat B. Johnson and Robert D. Coghill | Initial, though debated, identification of a methylated form of cytosine in a biological sample.[1][2] |
| 1948 | Definitive proof of the existence of 5-methylcytosine in calf thymus DNA using paper chromatography.[1][2] | Rollin Hotchkiss | Confirmed the presence of 5mC in eukaryotic DNA, distinguishing it from the canonical bases.[1][2] |
| 1975 | Proposal that DNA methylation could be a mechanism for gene regulation and X-chromosome inactivation.[3] | Arthur Riggs, Robin Holliday, and John Pugh | Seminal hypotheses linking DNA methylation to fundamental biological processes like gene expression and development.[3] |
| 1978 | Development of methods using methylation-sensitive restriction enzymes to study DNA methylation patterns.[3] | Adrian Bird and Ed Southern; C. Waalwijk and R. A. Flavell | Provided the first tools to analyze the methylation status of specific DNA sequences, revealing tissue-specific methylation patterns.[3] |
Quantitative Data on 5-Methylcytosine Abundance
The abundance of 5mC varies significantly across different organisms and even between different cell types within the same organism. The following table presents a summary of 5mC levels in the DNA of various species.
| Organism | Tissue/Cell Type | 5mC as a % of Total Cytosines | Method of Quantification |
| Escherichia coli | - | 2.3% | Not Specified[4] |
| Arabidopsis thaliana | - | 14% | Not Specified[4] |
| Mus musculus (Mouse) | Embryonic Stem Cells | ~4% | Mass Spectrometry |
| Mus musculus (Mouse) | Somatic Tissues | 7.6% | Not Specified[4] |
| Homo sapiens (Human) | Somatic Tissues | ~4% | HPLC |
| Drosophila melanogaster | Adult Flies | ~0.05-0.1% | HPLC/dNK assay[5] |
| Caenorhabditis elegans | - | Virtually absent | Not Specified[4] |
Experimental Protocols
The study of 5-methylcytosine has been propelled by the development of innovative techniques to detect and quantify this modification. One of the most foundational and widely used methods is bisulfite sequencing .
Detailed Methodology: Bisulfite Sequencing for 5mC Analysis
Principle: Sodium bisulfite treatment of DNA chemically converts unmethylated cytosine residues to uracil, while 5-methylcytosines remain unchanged. Subsequent PCR amplification and sequencing allow for the identification of methylated cytosines at single-base resolution, as the original 5mCs are read as cytosines, and the unmethylated cytosines are read as thymines.
Protocol:
-
DNA Extraction and Purification:
-
Extract high-quality genomic DNA from the sample of interest using a standard method (e.g., phenol-chloroform extraction or a commercial kit).
-
Ensure the DNA is free of contaminants such as RNA and proteins. Quantify the DNA concentration and assess its purity (A260/A280 ratio of ~1.8).
-
-
Bisulfite Conversion:
-
Fragment the genomic DNA to a suitable size range (e.g., 200-500 bp) by sonication or enzymatic digestion.
-
Denature the fragmented DNA by heating to 95°C.
-
Treat the denatured DNA with a sodium bisulfite solution (e.g., using a commercial kit such as the EpiTect Bisulfite Kit from Qiagen). This reaction is typically carried out at a specific temperature for a defined period (e.g., 55°C for several hours).
-
During this incubation, unmethylated cytosines are deaminated to uracils.
-
Purify the bisulfite-treated DNA to remove the bisulfite and other reagents. This is often done using a spin column-based method.
-
Elute the converted DNA in a low-salt buffer.
-
-
PCR Amplification:
-
Design PCR primers specific to the bisulfite-converted sequence of the target region. Primers should be designed to not contain CpG dinucleotides to avoid methylation-biased amplification.
-
Perform PCR using a high-fidelity DNA polymerase that can read through uracil-containing templates.
-
The PCR reaction will amplify the bisulfite-converted DNA, replacing uracils with thymines in the newly synthesized strands.
-
-
Sequencing and Data Analysis:
-
Purify the PCR products.
-
Sequence the purified PCR products using a method of choice (e.g., Sanger sequencing for targeted analysis or next-generation sequencing for genome-wide studies).
-
Align the obtained sequences to a reference sequence that has been computationally converted (all Cs to Ts).
-
The methylation status of each CpG site is determined by comparing the sequenced reads to the converted reference. A 'C' in the sequence read at a CpG site indicates that the original cytosine was methylated, while a 'T' indicates it was unmethylated.
-
Mandatory Visualizations
Diagram of the Bisulfite Sequencing Workflow
Caption: Workflow for 5-methylcytosine analysis using bisulfite sequencing.
Logical Relationship of DNA Methylation and Gene Expression
Caption: The relationship between promoter DNA methylation and gene expression.
Conclusion
The discovery and subsequent exploration of 5-methylcytosine have fundamentally altered our understanding of gene regulation and cellular differentiation. From its initial, uncertain detection to its current status as a key epigenetic mark, the history of 5mC research is a testament to the power of technological innovation in driving biological discovery. While this compound has found a niche in synthetic biology, it is 5-methylcytosine that holds the key to many of the epigenetic mechanisms observed in nature. The ongoing development of advanced sequencing and analytical techniques promises to further unravel the complexities of the "fifth base" and its role in health and disease.
References
- 1. Frontiers | Epigenetics of Modified DNA Bases: 5-Methylcytosine and Beyond [frontiersin.org]
- 2. mdpi.com [mdpi.com]
- 3. DNA - Wikipedia [en.wikipedia.org]
- 4. DNA methylation - Wikipedia [en.wikipedia.org]
- 5. DNA of Drosophila melanogaster contains 5‐methylcytosine | The EMBO Journal [link.springer.com]
A Tale of Two Methyls: An In-depth Technical Guide to 1-Methylcytosine and 5-Methylcytosine
Authored for Researchers, Scientists, and Drug Development Professionals
Executive Summary
Cytosine methylation is a fundamental biological process with profound implications for genome stability, gene expression, and cellular function. While 5-methylcytosine (B146107) (m5C) is widely recognized as a key epigenetic and epitranscriptomic mark, its isomer, 1-methylcytosine (m1C), plays vastly different, context-dependent roles. In DNA, m5C is a stable regulatory modification, whereas methylation at the N1 position (or the analogous N3 position) represents a mutagenic lesion that triggers dedicated repair pathways. In RNA, both modifications contribute to post-transcriptional regulation, yet they are installed by different enzymes and likely serve distinct functions in RNA metabolism and translation. This technical guide provides a comprehensive comparison of the biological roles of m1C and m5C, details the experimental protocols for their detection, and illustrates the key pathways governing their function, offering a critical resource for researchers in epigenetics, molecular biology, and therapeutic development.
The Two Faces of Cytosine Methylation: An Introduction
Methylation of cytosine can occur on either the C5 carbon of the pyrimidine (B1678525) ring, forming 5-methylcytosine (m5C), or on the N1 nitrogen, forming this compound (m1C). While chemically similar, this positional difference results in dramatically different biological consequences.
-
5-Methylcytosine (m5C): Located in the major groove of the DNA double helix, the methyl group of m5C is accessible to regulatory proteins and does not interfere with standard Watson-Crick base pairing. It serves as a stable, heritable mark for long-term gene silencing and chromatin organization. In RNA, it is a widespread post-transcriptional modification that fine-tunes RNA function.
-
This compound (m1C) and its Analogs: Methylation at the N1 position directly disrupts the hydrogen bonds required for Watson-Crick base pairing. Consequently, m1C in DNA is not a regulatory mark but rather a form of DNA damage. The closely related lesion, N3-methylcytosine (m3C) , which also disrupts base pairing, is a major toxic and mutagenic lesion induced by alkylating agents.[1][2][3] These lesions are primarily formed in single-stranded DNA during replication or transcription.[1] In contrast, m1C is found as a functional modification in certain RNA molecules, particularly transfer RNA (tRNA).
This guide will henceforth refer to the DNA lesion as m3C, in line with the majority of DNA repair literature, while discussing m1C in the context of RNA modification.
The Established Regulator: 5-Methylcytosine (m5C)
m5C is the most studied DNA modification and an increasingly recognized player in RNA biology. Its lifecycle is governed by a well-defined enzymatic machinery of "writers," "readers," and "erasers."
m5C in DNA: The Epigenetic Silencer
In mammalian DNA, m5C is a cornerstone of epigenetics, primarily involved in stable gene silencing.[4] Its key roles include genomic imprinting, X-chromosome inactivation, and the repression of transposable elements.[5]
-
Writers (DNA Methyltransferases - DNMTs): The m5C mark is established de novo by DNMT3A and DNMT3B and is maintained through cell division by DNMT1, which recognizes hemi-methylated DNA after replication.
-
Readers (Methyl-CpG Binding Proteins): Proteins containing a methyl-CpG-binding domain (MBD), such as MeCP2 and MBD2, recognize and bind to m5C.[6] This binding recruits other proteins, including histone deacetylases and chromatin remodelers, to create a compact, transcriptionally repressive chromatin state.
-
Erasers (Ten-Eleven Translocation - TET Enzymes): Demethylation is an active process initiated by the TET family of dioxygenases. TET enzymes iteratively oxidize m5C to 5-hydroxymethylcytosine (B124674) (5hmC), 5-formylcytosine (B1664653) (5fC), and 5-carboxylcytosine (5caC).[5] 5fC and 5caC are then excised by Thymine DNA Glycosylase (TDG) as part of the base excision repair (BER) pathway, restoring unmethylated cytosine.
m5C in RNA: The Epitranscriptomic Modulator
m5C is a widespread modification in various RNA species, including tRNA, ribosomal RNA (rRNA), and messenger RNA (mRNA).[7] It plays critical roles in RNA stability, nuclear export, and translation.[7]
-
Writers (NSUN family and DNMT2): The NOL1/NOP2/SUN domain (NSUN) family of proteins (NSUN1-7) and the DNA methyltransferase homolog DNMT2 are the primary RNA m5C methyltransferases.[8] For example, NSUN2 is a major writer of m5C in both tRNA and mRNA, while DNMT2 specifically methylates certain tRNAs.
-
Readers (e.g., YBX1, ALYREF): Reader proteins recognize the m5C mark and mediate its downstream effects. YBX1 can bind to m5C-modified mRNA to enhance its stability, while ALYREF recognizes m5C to facilitate mRNA nuclear export.
-
Erasers: The eraser for RNA m5C is less clear, but TET enzymes have been suggested to also oxidize m5C in RNA, similar to their function in DNA.
The Disruptor and Modifier: this compound (m1C) / 3-Methylcytosine (m3C)
In stark contrast to m5C, methylation on the Watson-Crick base-pairing face of cytosine is generally not tolerated in DNA and is handled by DNA repair machinery.
m3C in DNA: A Mutagenic Lesion
Spontaneous or chemically induced alkylation can lead to the formation of m3C in DNA, which stalls replication forks and is highly cytotoxic.[3] Cells have evolved direct reversal repair mechanisms to remove this type of damage.
-
Writers: m3C is not enzymatically written but arises from DNA damage by endogenous or exogenous alkylating agents.
-
Erasers (AlkB Homologs): The primary repair pathway for m3C is oxidative demethylation, catalyzed by the AlkB family of Fe(II)/α-ketoglutarate-dependent dioxygenases, including AlkB in E. coli and its human homologs ALKBH2 and ALKBH3.[1] These enzymes oxidize the aberrant methyl group, which is then released as formaldehyde, restoring the original cytosine base without excising it from the DNA backbone.[1] In some organisms, m3C can also be repaired via the base excision repair (BER) pathway, initiated by a DNA glycosylase.[1]
References
- 1. Structural basis for enzymatic excision of N1-methyladenine and N3-methylcytosine from DNA - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Structure determination of DNA methylation lesions N1-meA and N3-meC in duplex DNA using a cross-linked protein-DNA system - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. Structure determination of DNA methylation lesions N1-meA and N3-meC in duplex DNA using a cross-linked protein–DNA system - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Identification of the enzyme responsible for N1-methylation of pseudouridine 54 in archaeal tRNAs - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. High-resolution quantitative profiling of tRNA abundance and modification status in eukaryotes by mim-tRNAseq - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Sequence-specific and Shape-selective RNA Recognition by the Human RNA 5-Methylcytosine Methyltransferase NSun6 - PMC [pmc.ncbi.nlm.nih.gov]
- 7. academic.oup.com [academic.oup.com]
- 8. researchgate.net [researchgate.net]
The Enigmatic Mark: A Technical Guide to the Natural Occurrence of 1-Methylcytosine in Genomes
For Researchers, Scientists, and Drug Development Professionals
Introduction
1-Methylcytosine (m1C) is a post-transcriptional or post-replicative modification of the cytosine nucleobase, characterized by the addition of a methyl group to the nitrogen atom at position 1 (N1) of the pyrimidine (B1678525) ring.[1][2] While less abundant and studied than its well-known isomer, 5-methylcytosine (B146107) (m5C), m1C is an emerging epitranscriptomic and epigenetic mark with significant implications in the regulation of gene expression and cellular function. Its presence in both RNA and DNA suggests a multifaceted role in biological processes, making it a molecule of interest for researchers in basic science and drug development. This technical guide provides an in-depth overview of the natural occurrence of m1C, its biological functions, the enzymes that regulate its deposition and removal, and detailed methodologies for its detection and quantification.
Natural Occurrence and Abundance of this compound
The natural occurrence of this compound has been documented in both RNA and DNA across various organisms, though comprehensive quantitative data remains less extensive than for other modifications like m6A and m5C.
This compound in RNA
This compound is predominantly found in non-coding RNAs, particularly transfer RNA (tRNA) and ribosomal RNA (rRNA). In tRNA, m1C is often located in the TΨC loop and is crucial for maintaining the structural integrity and stability of the tRNA molecule. Its presence can influence codon recognition and the overall efficiency and fidelity of translation. While present in messenger RNA (mRNA), its abundance is generally low, and its distribution and function are still under active investigation.
This compound in DNA
The presence of m1C in DNA is less characterized than in RNA. It is considered a minor modification in the genomes of many organisms. There is evidence to suggest its existence in mitochondrial DNA (mtDNA), where it may play a role in regulating mitochondrial gene expression.[3][4][5] However, the extent and functional significance of m1C in nuclear DNA are not yet fully understood.
Quantitative Data on Cytosine Modifications
Comprehensive quantitative data for this compound across various human tissues and cell lines is still emerging. The table below summarizes available data for the more prevalent 5-methylcytosine (m5C) in human DNA to provide a comparative context for the levels of cytosine methylation. It is important to note that m1C levels are generally considered to be significantly lower than m5C levels.
| Tissue/Cell Type | 5-Methylcytosine (m5C) Abundance (% of total cytosines) in DNA | Reference |
| Thymus | 1.00% | [6][7] |
| Brain | 0.98% | [6][7] |
| Sperm | 0.84% | [6][7] |
| Placenta | 0.76% | [6][7] |
| Various Cancer Cell Lines | 0.57% - 0.85% | [6][7] |
| Colorectal Cancer Tissue (5-hmC) | Reduced by ~6-fold compared to adjacent normal tissue | [8] |
| MDA-MB-231 Breast Cancer Cells | 5.1% (5mC), 0.07% (5hmC) | [9] |
Note: This table primarily displays data for 5-methylcytosine (m5C) and 5-hydroxymethylcytosine (B124674) (5hmC) due to the limited availability of comprehensive quantitative data for this compound (m1C) in the public domain. These values serve as a reference for the general scale of cytosine modifications.
Biological Functions of this compound
The functional roles of this compound are an active area of research. Current evidence points to its involvement in several key cellular processes:
-
tRNA Stability and Function: In tRNA, m1C contributes to the proper folding and structural stability of the molecule. This is critical for its function in protein synthesis, as a stable tRNA is necessary for accurate codon recognition and amino acid transfer.[8]
-
Regulation of mRNA Translation: The presence of m1C in mRNA may influence its translation efficiency. Modifications within the coding sequence or untranslated regions (UTRs) can affect ribosome binding and movement, thereby modulating protein synthesis.[10]
-
Genomic Stability: While its role in DNA is less clear, the presence of modified bases can influence DNA structure and its interaction with proteins, potentially impacting DNA replication, repair, and overall genomic stability.[1]
-
Disease Association: Aberrant m1C levels have been implicated in various diseases. In the context of cancer, alterations in RNA and DNA methylation patterns are common, and changes in m1C levels may contribute to tumorigenesis.[7][11] Additionally, given the importance of RNA metabolism in neuronal function, dysregulation of m1C has been linked to neurodegenerative diseases.[12][13][14][15][16]
Enzymatic Regulation of this compound
The levels of this compound are dynamically regulated by "writer" enzymes that install the methyl mark and "eraser" enzymes that remove it.
Writers: Methyltransferases
The enzymes responsible for depositing m1C are not as well-defined as those for m5C. The NOP2/Sun RNA Methyltransferase (NSUN) family of enzymes are the primary writers of m5C in RNA.[2][17] While their primary substrate is the C5 position of cytosine, some members may have promiscuous activity or yet uncharacterized roles in m1C formation. For instance, NSUN2 and NSUN6 are known to methylate cytosines in tRNA and mRNA.[1][18][19][20][21]
Erasers: Demethylases
The removal of methyl groups from nucleic acids is catalyzed by demethylases. The AlkB homolog (ALKBH) family of dioxygenases are known "erasers" of various methyl modifications.[20][21] Specifically, ALKBH1 and ALKBH3 have been shown to demethylate N1-methyladenine (m1A) and N3-methylcytosine (m3C) in both DNA and RNA.[14][22][23][24] While their direct and primary activity on m1C is still being investigated, their ability to act on methylated bases in a similar chemical environment suggests they are strong candidates for m1C erasers.[25][26]
Experimental Protocols for this compound Analysis
The detection and quantification of m1C require sensitive and specific methodologies. The following sections detail the protocols for two key techniques: Methylated RNA Immunoprecipitation Sequencing (MeRIP-seq) and Liquid Chromatography-Mass Spectrometry (LC-MS).
Protocol 1: this compound MeRIP-seq
MeRIP-seq is a powerful technique for transcriptome-wide mapping of RNA modifications. This protocol is adapted for the specific detection of m1C.[11][15][18]
1. RNA Extraction and Fragmentation:
-
Extract total RNA from the cells or tissues of interest using a standard method like TRIzol extraction, ensuring high quality and integrity.
-
Fragment the RNA to an average size of 100-200 nucleotides. This can be achieved through enzymatic digestion (e.g., RNase III) or chemical fragmentation.
2. Immunoprecipitation:
-
Incubate the fragmented RNA with a specific anti-1-methylcytosine antibody.
-
Add protein A/G magnetic beads to the RNA-antibody mixture to capture the antibody-RNA complexes.
-
Wash the beads stringently to remove non-specifically bound RNA.
3. Elution and Library Preparation:
-
Elute the m1C-containing RNA fragments from the beads.
-
Construct a sequencing library from the eluted RNA fragments. This involves reverse transcription to cDNA, second-strand synthesis, adapter ligation, and PCR amplification. An input control library should be prepared in parallel from a small fraction of the fragmented RNA before immunoprecipitation.
4. High-Throughput Sequencing and Data Analysis:
-
Sequence the prepared libraries on a high-throughput sequencing platform.
-
Align the sequencing reads to the reference genome or transcriptome.
-
Use peak-calling algorithms to identify regions enriched for m1C in the immunoprecipitated sample compared to the input control.
Protocol 2: Quantitative Analysis of this compound by LC-MS/MS
Liquid chromatography-tandem mass spectrometry (LC-MS/MS) is the gold standard for accurate quantification of nucleoside modifications.[3][4][9][16][26]
1. Nucleic Acid Extraction and Digestion:
-
Extract high-purity total RNA or genomic DNA from the sample.
-
Digest the nucleic acids into individual nucleosides using a cocktail of nucleases (e.g., nuclease P1, snake venom phosphodiesterase, and alkaline phosphatase).
2. Liquid Chromatography Separation:
-
Inject the nucleoside mixture into a high-performance liquid chromatography (HPLC) or ultra-high-performance liquid chromatography (UHPLC) system.
-
Separate the nucleosides using a reverse-phase C18 column with a gradient of appropriate mobile phases (e.g., water with formic acid and acetonitrile (B52724) or methanol).
3. Mass Spectrometry Detection and Quantification:
-
Introduce the separated nucleosides into a tandem mass spectrometer equipped with an electrospray ionization (ESI) source.
-
Operate the mass spectrometer in multiple reaction monitoring (MRM) mode. This involves selecting the specific precursor-to-product ion transition for 1-methylcytidine and its corresponding stable isotope-labeled internal standard.
-
Quantify the amount of m1C by comparing the peak area of the analyte to that of the internal standard.
References
- 1. Quantitative analysis of tRNA abundance and modifications by nanopore RNA sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Quantitative analysis of tRNA modifications by HPLC-coupled mass spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 3. GC content shapes mRNA storage and decay in human cells - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Characterization of new human c-myc mRNA species produced by alternative splicing - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. Accurate estimation of 5-methylcytosine in mammalian mitochondrial DNA - PMC [pmc.ncbi.nlm.nih.gov]
- 6. c-MYC mRNA is present in human sperm cells - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. Absolute and relative quantification of RNA modifications via biosynthetic isotopomers - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Absolute quantification of somatic DNA alterations in human cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 9. academic.oup.com [academic.oup.com]
- 10. Absolute quantification of somatic DNA alterations in human cancer [getzlab.org]
- 11. researchgate.net [researchgate.net]
- 12. Sipuleucel-T - Wikipedia [en.wikipedia.org]
- 13. High-resolution quantitative profiling of tRNA abundance and modification status in eukaryotes by mim-tRNAseq - PMC [pmc.ncbi.nlm.nih.gov]
- 14. dspace.mit.edu [dspace.mit.edu]
- 15. Amount and distribution of 5-methylcytosine in human DNA from different types of tissues of cells - PMC [pmc.ncbi.nlm.nih.gov]
- 16. DNA - Wikipedia [en.wikipedia.org]
- 17. DNA methylation and methylcytosine oxidation in cell fate decisions - PMC [pmc.ncbi.nlm.nih.gov]
- 18. academic.oup.com [academic.oup.com]
- 19. Cytosine methylation profiling of cancer cell lines - PubMed [pubmed.ncbi.nlm.nih.gov]
- 20. mdpi.com [mdpi.com]
- 21. Liquid Chromatography-Mass Spectrometry for Analysis of RNA Adenosine Methylation | Springer Nature Experiments [experiments.springernature.com]
- 22. researchgate.net [researchgate.net]
- 23. Evidence Suggesting Absence of Mitochondrial DNA Methylation - PMC [pmc.ncbi.nlm.nih.gov]
- 24. medrxiv.org [medrxiv.org]
- 25. Quantification of changes in c-myc mRNA levels in normal human bronchial epithelial (NHBE) and lung adenocarcinoma (A549) cells following chemical treatment - PubMed [pubmed.ncbi.nlm.nih.gov]
- 26. researchgate.net [researchgate.net]
1-Methylcytosine: A Potential Next-Generation Biomarker in Disease
An In-depth Technical Guide for Researchers, Scientists, and Drug Development Professionals
Executive Summary
The field of epigenetics has ushered in a new era of biomarker discovery, with chemical modifications to nucleic acids emerging as critical regulators of cellular function and indicators of disease. While 5-methylcytosine (B146107) (5mC) in DNA is a well-established epigenetic mark, and RNA modifications like N6-methyladenosine (m6A) are gaining prominence, other modifications remain underexplored. This technical guide focuses on 1-methylcytosine (m1C), a methylated isomer of cytosine, as a potential, yet largely uninvestigated, biomarker for various pathological conditions, including cancer, neurological disorders, and metabolic diseases.
This document provides a comprehensive overview of the current understanding of cytosine methylation, drawing parallels from the extensively studied 5-methylcytosine and N1-methyladenosine to build a case for the clinical utility of m1C. We present detailed analytical methodologies for its detection and quantification, propose a hypothetical signaling pathway to stimulate research, and offer a framework for its evaluation as a diagnostic, prognostic, and predictive biomarker.
Introduction: The Expanding World of Epigenetic Modifications
Epigenetic modifications are heritable changes that alter gene expression without changing the underlying DNA sequence.[1] DNA methylation, particularly at the 5th position of cytosine (5mC), is a cornerstone of this regulatory network, playing crucial roles in gene silencing, genomic imprinting, and X-chromosome inactivation.[2][3] Dysregulation of DNA methylation patterns is a hallmark of numerous diseases, most notably cancer.[4]
Beyond DNA, RNA modifications, collectively known as the "epitranscriptome," add another layer of regulatory complexity. To date, over 170 different RNA modifications have been identified.[5] Modifications such as N1-methyladenosine (m1A) and 5-methylcytosine (m5C) in various RNA species, including messenger RNA (mRNA), transfer RNA (tRNA), and ribosomal RNA (rRNA), are now understood to be dynamic and to influence RNA stability, translation, and processing.[5][6][7][8] The enzymes that add ("writers"), remove ("erasers"), and recognize ("readers") these marks are often dysregulated in disease, making them and the modifications themselves attractive targets for diagnostics and therapeutics.[9][10]
This compound (m1C) is a structural isomer of the more common 5-methylcytosine, with the methyl group attached to the N1 position of the cytosine ring. While present in tRNA, its broader distribution, function, and association with human disease remain largely unknown.[9][11] This guide explores the potential of m1C as a novel biomarker by leveraging the knowledge gained from its better-studied counterparts.
The Rationale for this compound as a Disease Biomarker
The rationale for investigating m1C as a biomarker is built on several key observations from related fields:
-
Aberrant Methylation in Disease: Altered levels of DNA and RNA methylation are consistently observed in a wide range of diseases. In many cancers, global hypomethylation of DNA is accompanied by focal hypermethylation of tumor suppressor genes.[4] Similarly, changes in RNA methylation patterns have been linked to cancer progression and therapy resistance.[6][7]
-
Excretion of Modified Nucleosides: Modified nucleosides from DNA and RNA turnover are excreted in urine.[12][13][14][15] Elevated levels of these modified nucleosides in urine have been proposed as non-invasive biomarkers for various cancers and other diseases.[6][15] This provides a strong rationale for exploring urinary m1C as a potential systemic biomarker.
-
Role of N1-Methylation in RNA: The N1 position of purines is a known site for functional modifications. N1-methyladenosine (m1A) is a well-characterized modification in tRNA and mRNA that impacts RNA structure and translation.[5][8] Dysregulation of m1A and its associated enzymes is linked to tumorigenesis, suggesting that methylation at the N1 position of pyrimidines like cytosine could also have significant biological and pathological roles.[6][7][16]
Given the established precedent for other modified nucleosides, it is highly probable that the cellular machinery governing m1C levels is dysregulated in disease states, leading to altered concentrations in tissues and biofluids.
Potential Clinical Applications
The exploration of m1C as a biomarker could open new avenues in several key areas of medicine:
-
Oncology: Altered m1C levels in tumor tissue, blood, or urine could serve as a biomarker for early cancer detection, prognosis, or prediction of response to therapy. Parallels with 5mC and m1A suggest that m1C could be particularly relevant in cancers where tRNA biology and protein synthesis are dysregulated.[6][17]
-
Neurological Disorders: Epigenetic modifications are critical for normal brain development and function, and their disruption is implicated in neurodegenerative and psychiatric diseases.[1][18][19] Given the high metabolic activity and translational demands of neurons, investigating m1C in the context of neurological disorders is a promising research direction.
-
Metabolic Diseases: Epigenetic mechanisms are increasingly recognized as key players in the development of metabolic syndrome, diabetes, and related complications. RNA modifications, in particular, are linked to the regulation of metabolic pathways.[7][20] Therefore, m1C could serve as a biomarker reflecting metabolic dysregulation.
Quantitative Data on Related Methylated Nucleosides
While quantitative data for this compound in human disease is not yet available in the literature, the following tables summarize representative data for the well-studied 5-hydroxymethylcytosine (B124674) (a derivative of 5-methylcytosine) and N1-methyladenosine. These tables serve as a template for the types of quantitative analyses that are needed for m1C to establish its potential as a biomarker.
Table 1: Representative Levels of 5-Hydroxymethylcytosine (5hmC) in Human Tissues (Data is illustrative and compiled from existing literature on 5hmC; specific values can vary between studies.)
| Tissue | % 5hmC of Total Nucleotides (Approximate) | Reference |
| Brain | 0.40% - 0.70% | [10] |
| Liver | 0.40% - 0.50% | [10] |
| Kidney | ~0.40% | [10] |
| Colorectal (Normal) | 0.45% - 0.60% | [10] |
| Colorectal (Cancerous) | 0.02% - 0.06% | [10] |
| Lung | ~0.15% | [10] |
| Heart | ~0.05% | [10] |
| Breast | ~0.05% | [10] |
| Placenta | ~0.06% | [10] |
Table 2: Representative Levels of N1-Methyladenosine (m1A) in mRNA from Human Cell Lines (Data is illustrative and compiled from existing literature on m1A; specific values can vary between studies.)
| Cell Line | m1A/A Ratio (Approximate %) | Reference |
| HeLa (Cervical Cancer) | ~0.025% | [8] |
| HEK293T (Embryonic Kidney) | ~0.020% | [8] |
| HepG2 (Liver Cancer) | ~0.015% | [8] |
Experimental Protocols
The accurate quantification of m1C requires highly sensitive and specific analytical techniques. Ultra-performance liquid chromatography coupled with tandem mass spectrometry (UPLC-MS/MS) is the gold standard for this purpose.[21][22][23]
Protocol: Quantification of this compound in Biological Samples by UPLC-MS/MS
This protocol provides a general framework for the analysis of m1C in genomic DNA, total RNA, or biofluids.
1. Sample Preparation and Nucleic Acid Extraction:
-
Tissues: Homogenize fresh or frozen tissue samples. Extract genomic DNA or total RNA using commercially available kits (e.g., column-based or magnetic bead-based kits).
-
Cell Lines: Pellet cells by centrifugation and proceed with DNA/RNA extraction.
-
Biofluids (e.g., Urine, Plasma): For cell-free DNA/RNA, use specialized extraction kits designed for biofluids to maximize yield.
2. Enzymatic Hydrolysis of Nucleic Acids to Nucleosides:
-
Quantify the extracted DNA or RNA using a spectrophotometer (e.g., NanoDrop).
-
In a microcentrifuge tube, combine 1-5 µg of nucleic acid with a nuclease cocktail for complete digestion. A typical digestion buffer includes Nuclease P1 (to digest nucleic acids into nucleoside 5'-monophosphates) followed by alkaline phosphatase (to dephosphorylate the monophosphates into nucleosides).[8]
-
Incubate the reaction at 37°C for 2-4 hours.
-
Terminate the reaction, for example, by adding an organic solvent like acetonitrile (B52724) or by heat inactivation, followed by centrifugation to pellet the enzymes.
3. UPLC-MS/MS Analysis:
-
Chromatographic Separation:
-
Inject the supernatant containing the digested nucleosides onto a reverse-phase C18 column.
-
Use a gradient elution with a mobile phase consisting of (A) water with 0.1% formic acid and (B) methanol (B129727) or acetonitrile with 0.1% formic acid. The gradient will separate the different nucleosides based on their hydrophobicity.
-
-
Mass Spectrometry Detection:
-
The eluent from the UPLC is introduced into a triple quadrupole mass spectrometer equipped with an electrospray ionization (ESI) source operating in positive ion mode.
-
Perform detection using Multiple Reaction Monitoring (MRM). This involves monitoring a specific precursor-to-product ion transition for m1C and other nucleosides for quantification. The mass transition for 1-methyl-2'-deoxycytidine (the deoxynucleoside of m1C) would be based on the loss of the deoxyribose sugar from the protonated parent ion.
-
Hypothetical MRM transitions (to be empirically determined):
-
Deoxycytidine (dC): m/z 228.1 → 112.1
-
1-methyl-2'-deoxycytidine (m1dC): m/z 242.1 → 126.1
-
-
-
Quantification:
-
Generate a standard curve using known concentrations of pure m1C nucleoside standard.
-
Calculate the amount of m1C in the sample by comparing its peak area to the standard curve.
-
Normalize the amount of m1C to the amount of a canonical nucleoside (e.g., deoxycytidine or deoxyguanosine) to determine its relative abundance.
-
Visualizations: Pathways and Workflows
Hypothetical Signaling Pathway for m1C Regulation
To guide future research, we propose a hypothetical signaling pathway for the regulation of m1C in RNA. This model is based on the established "writer," "reader," and "eraser" paradigm for other RNA modifications.
Caption: Hypothetical regulatory pathway for this compound (m1C) in RNA.
Experimental Workflow for m1C Quantification
The following diagram illustrates the key steps in the UPLC-MS/MS-based quantification of m1C from biological samples.
Caption: Workflow for this compound (m1C) quantification via UPLC-MS/MS.
Conclusion and Future Directions
This compound represents an untapped resource in the search for novel and robust disease biomarkers. While direct evidence linking m1C to human disease is currently sparse, the wealth of data from related DNA and RNA modifications provides a compelling argument for its investigation. The technologies for its sensitive and accurate quantification are readily available, and the potential for its application in oncology, neurology, and metabolic disease is significant.
Future research should focus on several key areas:
-
Systematic Quantification: A comprehensive profiling of m1C levels across a wide range of healthy and diseased human tissues and biofluids is the critical first step.
-
Identification of Regulatory Enzymes: Discovering the "writer" and "eraser" enzymes for m1C will be essential for understanding its biological function and for developing targeted therapeutic strategies.
-
Functional Studies: Elucidating the downstream consequences of m1C modification—its impact on DNA stability, gene expression, or RNA translation—will clarify its role in pathogenesis.
-
Clinical Validation: Promising initial findings must be validated in large, independent patient cohorts to establish the clinical utility of m1C as a diagnostic, prognostic, or predictive biomarker.
This technical guide provides the foundational knowledge and methodological framework necessary to embark on the exciting exploration of this compound as a next-generation biomarker. The insights gained from such research have the potential to significantly advance our understanding of disease and improve patient outcomes.
References
- 1. DNA methylation in human diseases - PMC [pmc.ncbi.nlm.nih.gov]
- 2. DNA methylation and human disease - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. New themes in the biological functions of 5-methylcytosine and 5-hydroxymethylcytosine - PMC [pmc.ncbi.nlm.nih.gov]
- 4. DNA hypermethylation in disease: mechanisms and clinical relevance - PMC [pmc.ncbi.nlm.nih.gov]
- 5. N1-methyladenosine formation, gene regulation, biological functions, and clinical relevance - PMC [pmc.ncbi.nlm.nih.gov]
- 6. N1-methyladenosine modification in cancer biology: Current status and future perspectives - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Frontiers | Role of Main RNA Methylation in Hepatocellular Carcinoma: N6-Methyladenosine, 5-Methylcytosine, and N1-Methyladenosine [frontiersin.org]
- 8. The dynamic N1-methyladenosine methylome in eukaryotic messenger RNA - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Methylation modifications in tRNA and associated disorders: Current research and potential therapeutic targets - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Enzymatic approaches for profiling cytosine methylation and hydroxymethylation - PMC [pmc.ncbi.nlm.nih.gov]
- 11. researchgate.net [researchgate.net]
- 12. Methylation Markers for Urine-Based Detection of Bladder Cancer: The Next Generation of Urinary Markers for Diagnosis and Surveillance of Bladder Cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Unleashing the potential of urine DNA methylation detection: Advancements in biomarkers, clinical applications, and emerging technologies - PMC [pmc.ncbi.nlm.nih.gov]
- 14. DNA-Methylation-Based Detection of Urological Cancer in Urine: Overview of Biomarkers and Considerations on Biomarker Design, Source of DNA, and Detection Technologies - PMC [pmc.ncbi.nlm.nih.gov]
- 15. researchgate.net [researchgate.net]
- 16. Molecular Characteristics of N1-Methyladenosine Regulators and Their Correlation with Overall Cancer Survival - PubMed [pubmed.ncbi.nlm.nih.gov]
- 17. 5-Methylcytosine (m5C) modification in peripheral blood immune cells is a novel non-invasive biomarker for colorectal cancer diagnosis - PMC [pmc.ncbi.nlm.nih.gov]
- 18. DNA methylation in human diseases - PMC [pmc.ncbi.nlm.nih.gov]
- 19. DNA Methylation as a Biomarker for Monitoring Disease Outcome in Patients with Hypovitaminosis and Neurological Disorders - PMC [pmc.ncbi.nlm.nih.gov]
- 20. DNA Methylation Biomarkers: Cancer and Beyond - PMC [pmc.ncbi.nlm.nih.gov]
- 21. Ultraperformance Liquid Chromatography Tandem Mass Spectrometry Assay of DNA Cytosine Methylation Excretion from Biological Systems - PMC [pmc.ncbi.nlm.nih.gov]
- 22. A sensitive mass-spectrometry method for simultaneous quantification of DNA methylation and hydroxymethylation levels in biological samples - PMC [pmc.ncbi.nlm.nih.gov]
- 23. A New Photoproduct of 5-Methylcytosine and Adenine Characterized by HPLC and Mass Spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
An In-depth Technical Guide to the Stability and Degradation Pathways of 1-Methylcytosine
For Researchers, Scientists, and Drug Development Professionals
Introduction
1-Methylcytosine (1mC) is a modified pyrimidine (B1678525) base that plays a significant role in various biological contexts and has garnered interest in the field of drug development. Understanding its stability and degradation pathways is crucial for elucidating its biological functions, predicting its fate in physiological environments, and developing stable therapeutic agents. This technical guide provides a comprehensive overview of the chemical and enzymatic degradation of this compound, supported by quantitative data, detailed experimental protocols, and visual representations of the key pathways.
Chemical Stability and Degradation
The inherent chemical stability of this compound is a critical factor influencing its biological half-life and potential for inducing mutations. The primary chemical degradation pathway for this compound is hydrolytic deamination, which is significantly influenced by pH and temperature.
Hydrolytic Deamination
Hydrolytic deamination of this compound results in the formation of thymine (B56734). This process involves the nucleophilic attack of a water molecule on the C4 position of the pyrimidine ring, followed by the elimination of ammonia.
pH Dependence: The rate of deamination of this compound is highly dependent on the pH of the surrounding environment. In acidic conditions (pH 1-4), the hydrolysis proceeds at a constant rate. Between pH 5 and 8.5, the rate is approximately three times slower. However, at pH values above 9.5, the rate of deamination increases rapidly due to the increased concentration of hydroxide (B78521) ions, which act as a more potent nucleophile.[1]
Temperature Dependence: As with most chemical reactions, the rate of this compound deamination is accelerated at higher temperatures. Arrhenius plots for the deamination of this compound are linear over a wide temperature range, indicating a consistent reaction mechanism.
Oxidative Degradation
In addition to hydrolytic deamination, this compound can undergo degradation through oxidative pathways, particularly in the presence of reactive oxygen species (ROS) such as hydroxyl radicals (•OH).
Reaction with Hydroxyl Radicals: Hydroxyl radicals can react with this compound through two primary mechanisms: addition to the C5-C6 double bond and hydrogen abstraction from the N1-methyl group. Addition of the hydroxyl radical to the C5 or C6 position leads to the formation of radical adducts.[2] These adducts can undergo further reactions to yield various degradation products. For instance, the reaction of 5-methylcytosine (B146107) with hydroxyl radicals has been shown to produce thymine and cytosine through deamination and demethylation, respectively.[3] While specific studies on this compound are less common, similar oxidative degradation products can be anticipated.
Enzymatic Degradation and Repair
While spontaneous chemical degradation occurs, biological systems have evolved enzymatic pathways to recognize and repair or further metabolize modified nucleobases, including methylated cytosines.
AlkB Family of Dioxygenases
The AlkB family of Fe(II)/2-oxoglutarate-dependent dioxygenases are DNA/RNA repair enzymes that remove alkylation damage. These enzymes are known to act on N1-methyladenine (1mA) and N3-methylcytosine (3mC).[4][5] While direct and extensive evidence for the activity of AlkB homologs on Nthis compound is still emerging, their known substrate specificity for N-methylated bases suggests a potential role in the demethylation of this compound. The proposed mechanism involves oxidative demethylation, where the methyl group is hydroxylated and subsequently released as formaldehyde (B43269), restoring the original cytosine base.[6]
TET Enzymes
The Ten-Eleven Translocation (TET) family of enzymes are also Fe(II)/2-oxoglutarate-dependent dioxygenases that play a crucial role in DNA demethylation by iteratively oxidizing 5-methylcytosine (5mC) to 5-hydroxymethylcytosine (B124674) (5hmC), 5-formylcytosine (B1664653) (5fC), and 5-carboxylcytosine (5caC).[7][8][9] There is currently limited direct evidence to suggest that TET enzymes act on this compound. Computational studies have indicated that the bond dissociation energy of the N1-methyl group is significantly higher than that of the C5-methyl group, suggesting it may be a less favorable substrate for TET-mediated oxidation.[10]
Quantitative Data on this compound Degradation
The following tables summarize the available quantitative data on the stability and degradation of this compound.
Table 1: Rate Constants for Hydrolytic Deamination of this compound
| pH Range | Temperature (°C) | Rate Constant (s⁻¹) | Reference |
| 1 - 4 | 130 | Constant | [1] |
| 5 - 8.5 | 130 | ~3-fold slower than pH 1-4 | [1] |
| > 9.5 | 130 | Rapidly increases | [1] |
| 2.45 | 25 | 2.8 x 10⁻¹⁰ | [1] |
Table 2: Thermodynamic Parameters for Deamination of this compound
| Parameter | Value | Conditions | Reference |
| ΔH‡ (Activation Enthalpy) | 23.0 kcal/mol | pH 2.45 | [1] |
Signaling and Logical Relationship Diagrams
Caption: Chemical degradation pathways of this compound.
Caption: Potential enzymatic repair of this compound.
Experimental Protocols
Protocol 1: Analysis of this compound Deamination Kinetics by HPLC
This protocol outlines a method to study the rate of hydrolytic deamination of this compound under different pH and temperature conditions.
Materials:
-
This compound standard
-
Buffers of desired pH (e.g., citrate (B86180) for acidic, phosphate (B84403) for neutral, carbonate for basic)
-
HPLC system with a UV detector
-
Reversed-phase C18 column (e.g., 4.6 x 250 mm, 5 µm)
-
Mobile phase: Acetonitrile and water/buffer mixture
-
Thermostatted incubator or water bath
-
Quenching solution (e.g., ice-cold mobile phase)
Procedure:
-
Sample Preparation: Prepare a stock solution of this compound in water. For each kinetic run, dilute the stock solution into the desired pH buffer to a final concentration of approximately 1 mM.
-
Incubation: Incubate the samples at the desired temperature in a thermostatted environment.
-
Time Points: At regular time intervals, withdraw an aliquot of the reaction mixture and immediately quench the reaction by diluting it in an ice-cold quenching solution. Store the quenched samples at -20°C until analysis.
-
HPLC Analysis:
-
Equilibrate the C18 column with the mobile phase at a constant flow rate (e.g., 1 mL/min).
-
Inject a known volume of the quenched sample.
-
Monitor the elution of this compound and its deamination product (thymine) using a UV detector at an appropriate wavelength (e.g., 275 nm).
-
Record the peak areas for both compounds.
-
-
Data Analysis:
-
Generate a calibration curve for both this compound and thymine using standards of known concentrations.
-
Calculate the concentration of this compound remaining at each time point.
-
Plot the natural logarithm of the this compound concentration versus time. The negative slope of the resulting linear plot will give the first-order rate constant (k) for the deamination reaction.
-
Caption: Workflow for this compound deamination kinetics study.
Protocol 2: In Vitro Assay for Enzymatic Demethylation of this compound
This protocol describes a method to assess the activity of a putative demethylase (e.g., an AlkB homolog) on a this compound-containing substrate.
Materials:
-
Purified candidate enzyme (e.g., recombinant AlkB homolog)
-
Single-stranded or double-stranded oligonucleotide containing a single this compound residue
-
Reaction buffer (e.g., 50 mM Tris-HCl, pH 7.5, 50 mM KCl, 1 mM MgCl₂)
-
Cofactors: Fe(II) (e.g., (NH₄)₂Fe(SO₄)₂·6H₂O), 2-oxoglutarate, and L-ascorbic acid
-
Formaldehyde detection reagent (e.g., Nash reagent or a fluorescence-based assay kit)
-
Spectrophotometer or fluorometer
Procedure:
-
Reaction Setup: In a microcentrifuge tube, prepare the reaction mixture containing the reaction buffer, cofactors, the this compound-containing oligonucleotide substrate, and the purified enzyme. Include a negative control reaction without the enzyme.
-
Incubation: Incubate the reaction mixtures at the optimal temperature for the enzyme's activity (e.g., 37°C) for a defined period.
-
Reaction Termination: Stop the reaction by adding EDTA to chelate the Fe(II) ions or by heat inactivation of the enzyme.
-
Detection of Formaldehyde:
-
Add the formaldehyde detection reagent to the reaction mixture.
-
Incubate as per the reagent's instructions to allow for color or fluorescence development.
-
Measure the absorbance or fluorescence at the appropriate wavelength.
-
-
Data Analysis:
-
Generate a standard curve using known concentrations of formaldehyde.
-
Quantify the amount of formaldehyde produced in the enzymatic reaction.
-
The amount of formaldehyde produced is directly proportional to the demethylation activity of the enzyme on the this compound substrate.
-
Caption: Workflow for in vitro enzymatic demethylation assay.
Protocol 3: Forced Degradation Study of this compound
This protocol provides a framework for conducting forced degradation studies to identify potential degradation products of this compound under various stress conditions.
Materials:
-
This compound
-
Acidic solution (e.g., 0.1 M HCl)
-
Basic solution (e.g., 0.1 M NaOH)
-
Oxidizing agent (e.g., 3% H₂O₂)
-
Photostability chamber
-
Thermostatted oven
-
HPLC-MS/MS system
Procedure:
-
Stress Conditions:
-
Acid/Base Hydrolysis: Dissolve this compound in acidic and basic solutions and incubate at an elevated temperature (e.g., 60°C).
-
Oxidation: Dissolve this compound in a solution of the oxidizing agent and incubate at room temperature.
-
Thermal Degradation: Store solid this compound in a thermostatted oven at an elevated temperature.
-
Photodegradation: Expose a solution of this compound to UV and visible light in a photostability chamber.
-
-
Sampling: At appropriate time points, withdraw samples and neutralize if necessary.
-
HPLC-MS/MS Analysis:
-
Separate the degradation products from the parent compound using a suitable HPLC method (as described in Protocol 1).
-
Analyze the eluent using a mass spectrometer to determine the mass-to-charge ratio (m/z) of the parent compound and any degradation products.
-
Perform tandem mass spectrometry (MS/MS) to obtain fragmentation patterns of the degradation products for structural elucidation.
-
-
Data Analysis:
-
Identify potential degradation products by comparing their mass spectra and retention times to known standards or by interpreting the fragmentation patterns.
-
Propose degradation pathways based on the identified products.
-
Conclusion
The stability of this compound is a multifaceted issue influenced by both chemical and enzymatic factors. While hydrolytic deamination is a well-characterized degradation pathway, the roles of oxidative degradation and enzymatic repair are areas of ongoing research. The methodologies and data presented in this guide provide a solid foundation for researchers and drug development professionals to further investigate the stability and degradation of this compound, ultimately contributing to a deeper understanding of its biological significance and therapeutic potential.
References
- 1. pnas.org [pnas.org]
- 2. pubs.acs.org [pubs.acs.org]
- 3. researchgate.net [researchgate.net]
- 4. DNA repair by bacterial AlkB proteins - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
- 6. books.rsc.org [books.rsc.org]
- 7. TET Methylcytosine Oxidases in T Cell and B Cell Development and Function - PMC [pmc.ncbi.nlm.nih.gov]
- 8. TET methylcytosine oxidases: new insights from a decade of research - PMC [pmc.ncbi.nlm.nih.gov]
- 9. TET enzymes - Wikipedia [en.wikipedia.org]
- 10. TET‐Like Oxidation in 5‐Methylcytosine and Derivatives: A Computational and Experimental Study - PMC [pmc.ncbi.nlm.nih.gov]
The Enigmatic Role of 1-Methylcytosine in Non-Canonical DNA Structures: A Technical Guide
For Researchers, Scientists, and Drug Development Professionals
Introduction
In the intricate landscape of epigenetics and DNA structural biology, beyond the canonical double helix, lie a variety of non-canonical DNA structures such as G-quadruplexes and i-motifs. These structures are increasingly recognized as key players in the regulation of gene expression, replication, and genomic stability. The methylation of cytosine is a important epigenetic mark, with 5-methylcytosine (B146107) (5mC) being the most studied. However, other methylated forms, including 1-methylcytosine (m1C), are emerging as potentially significant modulators of DNA structure and function. This technical guide provides an in-depth exploration of the current understanding of this compound's role within non-canonical DNA structures, offering a compilation of quantitative data, detailed experimental protocols, and visual representations of associated molecular processes. While direct quantitative data and specific protocols for m1C remain less abundant than for its 5mC counterpart, this guide consolidates available knowledge and provides adapted methodologies to facilitate further research in this exciting field.
This compound: A Primer
This compound (m1C) is a methylated form of the DNA base cytosine, where a methyl group is attached to the nitrogen atom at position 1 of the pyrimidine (B1678525) ring.[1] This modification is distinct from the more prevalent 5-methylcytosine, where the methyl group is at the 5th carbon position.[1] The placement of the methyl group at the N1 position disrupts the Watson-Crick base pairing face of cytosine, suggesting that its presence within a standard double helix would be destabilizing. This intrinsic property points towards a likely role for m1C in the context of non-canonical DNA structures where alternative base pairing and structural conformations are common.
This compound in Non-Canonical DNA Structures
The presence of m1C can influence the formation and stability of non-canonical DNA structures, although research in this area is still developing. Much of the current understanding is extrapolated from studies on the more common 5-methylcytosine.
i-Motifs
i-Motifs are four-stranded DNA structures formed in cytosine-rich sequences, characterized by intercalated hemiprotonated C:C+ base pairs.[2] These structures are typically favored under acidic conditions.[3] Studies on 5-methylcytosine have shown that its incorporation can increase the thermal stability and the transitional pH of i-motifs, suggesting that methylation can promote the formation of these structures under more physiologically relevant conditions.[4][5] While direct quantitative data for this compound is limited, the electron-donating nature of the methyl group is hypothesized to similarly stabilize the C:C+ pairs.
G-Quadruplexes
G-quadruplexes (G4s) are four-stranded structures formed in guanine-rich DNA sequences.[6] The effect of cytosine methylation on G4 stability is context-dependent, with some studies on 5mC reporting stabilization and others destabilization.[7][8] The influence of cytosine methylation can alter G4 topology and affect the equilibrium between different G4 conformations.[7] The role of this compound within the loops or flanking regions of G-quadruplexes is an area ripe for investigation, as modifications in these regions are known to impact G4 stability and conformation.
Quantitative Data on the Impact of Cytosine Methylation on Non-Canonical DNA Structure Stability
While specific quantitative data for this compound is sparse, the following tables summarize the known effects of the closely related 5-methylcytosine on the stability of i-motifs and G-quadruplexes. This data serves as a valuable reference point for designing experiments and forming hypotheses about the impact of this compound.
Table 1: Effect of 5-Methylcytosine on the Thermal Stability of i-Motif DNA
| i-Motif Sequence Context | Modification | Change in Melting Temperature (ΔTm) (°C) | Reference(s) |
| Human Telomeric Repeat (hTeloC) | Single 5mC at various positions | +0.5 to +2.5 | [5] |
| VEGF Promoter Region | CpG methylation | Increased thermal stability | [4] |
| C-KIT Promoter Region | CpG methylation | Increased thermal stability | [4] |
| BCL2 Promoter Region | CpG methylation | Increased thermal stability | [4] |
| HRAS Promoter Region | CpG methylation | Increased thermal stability | [4] |
Table 2: Effect of 5-Methylcytosine on the Transitional pH (pHT) of i-Motif DNA
| i-Motif Sequence Context | Modification | Change in Transitional pH (ΔpHT) | Reference(s) |
| Human Telomeric Repeat (hTeloC) | Single 5mC at various positions | +0.1 to +0.3 | [5] |
| C-KIT Promoter Region | CpG methylation | +0.16 | [4] |
| HRAS2 Promoter Region | CpG methylation | +0.15 | [4] |
Table 3: Effect of 5-Methylcytosine on the Thermal Stability of G-Quadruplex DNA
| G-Quadruplex Sequence Context | Modification | Change in Melting Temperature (ΔTm) (°C) | Reference(s) |
| BCL2 Promoter | CpG methylation | Stabilization | [7] |
| MEST Promoter | CpG methylation | Destabilization | [8] |
| DAT1 Promoter | CpG methylation | Lowered thermal stability | [8] |
Experimental Protocols
This section provides detailed methodologies for key experiments to study this compound in non-canonical DNA structures. Where specific protocols for m1C are not available, protocols for analogous modified bases are provided with suggested adaptations.
Synthesis of Oligonucleotides Containing this compound
The synthesis of oligonucleotides with site-specific incorporation of m1C is the first crucial step for in vitro studies. This is typically achieved using phosphoramidite (B1245037) chemistry on an automated solid-phase DNA synthesizer.
Protocol:
-
Phosphoramidite Monomer: Obtain or synthesize the this compound phosphoramidite monomer. The exocyclic amino group of cytosine and the N1-methyl group require appropriate protecting groups (e.g., benzoyl for the amino group) to prevent side reactions during synthesis.
-
Solid-Phase Synthesis:
-
Support: Start with a controlled pore glass (CPG) solid support functionalized with the initial nucleoside of the desired sequence.
-
Synthesis Cycle: Perform the standard automated synthesis cycle for each nucleotide addition:
-
Detritylation: Removal of the 5'-dimethoxytrityl (DMT) protecting group with an acid (e.g., trichloroacetic acid).
-
Coupling: Addition of the next phosphoramidite monomer (e.g., the m1C phosphoramidite) in the presence of an activator (e.g., tetrazole).
-
Capping: Acetylation of any unreacted 5'-hydroxyl groups to prevent the formation of deletion mutants.
-
Oxidation: Oxidation of the phosphite (B83602) triester linkage to a more stable phosphate (B84403) triester using an oxidizing agent (e.g., iodine in the presence of water).
-
-
Repeat the cycle until the full-length oligonucleotide is synthesized.
-
-
Cleavage and Deprotection:
-
Cleave the synthesized oligonucleotide from the CPG support using a strong base (e.g., concentrated ammonium (B1175870) hydroxide).
-
This step also removes the protecting groups from the phosphate backbone and the nucleobases. The conditions (temperature and duration) for this step must be carefully controlled to prevent degradation of the oligonucleotide, especially those containing modified bases.[9]
-
-
Purification:
-
Purify the crude oligonucleotide product using high-performance liquid chromatography (HPLC). A combination of reverse-phase and anion-exchange HPLC is recommended for achieving high purity.[9]
-
Desalt the purified oligonucleotide using, for example, a size-exclusion column.
-
-
Quality Control:
-
Verify the mass of the final product using mass spectrometry (e.g., ESI-MS or MALDI-TOF) to confirm the successful incorporation of m1C.[10]
-
The purity can be further assessed by analytical HPLC or capillary electrophoresis.
-
Structural Analysis by Nuclear Magnetic Resonance (NMR) Spectroscopy
NMR spectroscopy is a powerful technique for determining the three-dimensional structure of nucleic acids in solution.
Protocol:
-
Sample Preparation:
-
Dissolve the purified m1C-containing oligonucleotide in an appropriate NMR buffer (e.g., 25 mM potassium phosphate, 70 mM KCl, pH 7.0 for G-quadruplexes; or a buffer with a pH near the pKa of the i-motif for its study).
-
The sample should be in 90% H₂O/10% D₂O to allow for the observation of exchangeable imino protons, which are characteristic of base pairing in non-canonical structures.
-
The final DNA concentration should be in the range of 0.1-2.5 mM.
-
Anneal the sample by heating to 95°C for 5-10 minutes and then slowly cooling to room temperature to ensure proper folding.
-
-
1D ¹H NMR Spectroscopy:
-
Acquire a 1D ¹H NMR spectrum to get a preliminary assessment of the structure.
-
The presence of sharp, well-dispersed imino proton signals in the 10-16 ppm region is indicative of a stable, folded structure. Imino protons from C:C+ base pairs in i-motifs typically resonate around 15 ppm.
-
-
2D NMR Spectroscopy for Structural Elucidation:
-
NOESY (Nuclear Overhauser Effect Spectroscopy): Acquire 2D NOESY spectra with varying mixing times (e.g., 100-300 ms). This experiment identifies protons that are close in space (< 5 Å), providing crucial distance restraints for structure calculation.
-
TOCSY (Total Correlation Spectroscopy): Acquire 2D TOCSY spectra to identify protons that are scalar-coupled within the same sugar spin system. This is essential for assigning the sugar protons.
-
¹H-¹³C HSQC (Heteronuclear Single Quantum Coherence): If using ¹³C-labeled samples, this experiment correlates protons with their directly attached carbons, aiding in resonance assignment.
-
¹H-¹⁵N HSQC: If using ¹⁵N-labeled samples, this experiment is particularly useful for unambiguously identifying the protons involved in hydrogen bonds.
-
-
Resonance Assignment and Structure Calculation:
-
Use the information from the 2D spectra to assign the chemical shifts of the protons and other nuclei in the oligonucleotide.
-
Use the NOE cross-peaks to generate a set of inter-proton distance restraints.
-
Use software packages like CYANA, XPLOR-NIH, or AMBER to calculate a family of 3D structures that are consistent with the experimental restraints.
-
-
Structure Validation:
-
Evaluate the quality of the calculated structures using parameters such as the number of NOE violations and the root-mean-square deviation (RMSD) of the structural ensemble.
-
Quantification by Mass Spectrometry
Liquid chromatography coupled with tandem mass spectrometry (LC-MS/MS) is a highly sensitive and accurate method for quantifying modified nucleosides in a DNA sample.
Protocol:
-
Enzymatic Digestion of DNA:
-
Digest the DNA sample containing m1C to its constituent nucleosides using a cocktail of enzymes. A common combination includes nuclease P1 (to digest DNA to 5'-mononucleotides) followed by alkaline phosphatase (to dephosphorylate the mononucleotides to nucleosides).
-
-
LC Separation:
-
Inject the digested nucleoside mixture onto a reverse-phase HPLC column (e.g., a C18 column).
-
Separate the nucleosides using a gradient of solvents, typically water with a small amount of acid (e.g., 0.1% formic acid) and an organic solvent like acetonitrile (B52724) or methanol.
-
-
MS/MS Detection:
-
The eluent from the HPLC is directed into a tandem mass spectrometer operating in positive electrospray ionization (ESI) mode.
-
Use Multiple Reaction Monitoring (MRM) for quantification. This involves selecting the precursor ion (the protonated molecular ion of 1-methyl-2'-deoxycytidine) and a specific product ion that is generated upon fragmentation in the collision cell.
-
The transition for 1-methyl-2'-deoxycytidine would be m/z 242.1 → m/z 126.1 (corresponding to the fragmentation of the glycosidic bond to yield the this compound base).
-
-
Quantification:
-
Generate a standard curve using known concentrations of a synthetic 1-methyl-2'-deoxycytidine standard.
-
Quantify the amount of m1C in the sample by comparing the peak area from the MRM chromatogram to the standard curve.
-
The abundance of m1C can be expressed relative to the amount of an unmodified nucleoside, such as deoxyguanosine (dG), which is also quantified in the same run.
-
Sequencing of this compound
Standard bisulfite sequencing cannot distinguish m1C from unmodified cytosine. Therefore, alternative methods are required. While no standard, widely adopted method for m1C sequencing exists, an enzymatic approach analogous to EM-seq for 5mC could be developed. Another potential approach is immunoprecipitation-based.
Protocol: Methylated DNA Immunoprecipitation Sequencing (MeDIP-Seq) - Adapted for m1C
-
Genomic DNA Extraction and Fragmentation:
-
Extract high-quality genomic DNA from the cells or tissue of interest.
-
Fragment the DNA to a size range of 200-800 bp using sonication or enzymatic digestion.
-
-
Immunoprecipitation:
-
Denature the fragmented DNA by heating.
-
Incubate the single-stranded DNA fragments with a specific antibody that recognizes this compound. Note: The availability of a highly specific and high-affinity antibody for m1C is a critical prerequisite for this method.
-
Capture the antibody-DNA complexes using magnetic beads coated with Protein A/G.
-
Wash the beads extensively to remove non-specifically bound DNA.
-
-
Elution and Library Preparation:
-
Elute the enriched DNA fragments from the antibody-bead complexes.
-
Prepare a sequencing library from the enriched DNA using a standard library preparation kit for next-generation sequencing (NGS). This involves end-repair, A-tailing, and ligation of sequencing adapters.
-
-
Sequencing and Data Analysis:
-
Sequence the library on an NGS platform (e.g., Illumina).
-
Align the sequencing reads to a reference genome.
-
Use peak-calling algorithms (e.g., MACS2) to identify regions of the genome that are enriched for m1C.
-
In Vitro Demethylation Assay
This protocol is adapted from assays used to study the activity of AlkB family enzymes on other methylated bases and can be used to test if enzymes like ALKBH2 or ALKBH3 can demethylate m1C in a DNA context.
Protocol:
-
Substrate Preparation:
-
Synthesize and purify a short oligonucleotide substrate (e.g., a 20-30 mer) containing a single, site-specific this compound. The substrate can be designed to be single-stranded or to form a non-canonical structure.
-
-
Enzyme and Reaction Buffer:
-
Purify recombinant ALKBH2 or ALKBH3 protein.
-
Prepare a reaction buffer containing: 50 mM HEPES (pH 7.5-8.0), 50-100 µM Fe(NH₄)₂(SO₄)₂, 1 mM α-ketoglutarate, and 2 mM ascorbic acid.
-
-
Demethylation Reaction:
-
Combine the m1C-containing oligonucleotide substrate (e.g., at a final concentration of 5 µM) with the reaction buffer.
-
Initiate the reaction by adding the ALKBH enzyme (e.g., to a final concentration of 0.5 µM).
-
Incubate the reaction at 37°C for a defined period (e.g., 1 hour).
-
Include a negative control reaction without the enzyme.
-
-
Reaction Quenching and Analysis:
-
Stop the reaction by adding EDTA to chelate the Fe²⁺ ions.
-
Analyze the reaction products to determine if the m1C has been converted to cytosine. This can be done by:
-
LC-MS/MS: Digest the oligonucleotide to nucleosides and quantify the amounts of 1-methyl-2'-deoxycytidine and 2'-deoxycytidine (B1670253) as described in protocol 4.3. A decrease in the m1C peak and an increase in the C peak would indicate demethylation.
-
HPLC: If the retention times of the m1C-containing and the corresponding unmodified oligonucleotide are sufficiently different, the reaction mixture can be directly analyzed by HPLC.
-
-
Signaling Pathways and Biological Roles
The precise biological roles of this compound in non-canonical DNA structures are still largely unknown. However, based on the known functions of these structures and of DNA methylation, we can propose several potential pathways and regulatory roles.
Proposed Regulatory Roles
-
Transcriptional Regulation: i-Motifs and G-quadruplexes in promoter regions can act as transcriptional repressors or activators. The presence of m1C could modulate the stability of these structures, thereby fine-tuning gene expression. For example, stabilization of an i-motif in a promoter by m1C could lead to transcriptional silencing.
-
Telomere Maintenance: G-quadruplexes in telomeric DNA are known to inhibit telomerase activity. m1C in telomeric repeats could influence the formation and stability of these G4 structures, thus playing a role in telomere length regulation and cellular aging.
-
DNA Repair and Genomic Stability: The formation of non-canonical structures can pose challenges to the DNA replication and repair machinery. m1C might be a damage product that gets preferentially accommodated in these structures, or it could be a signal for specific repair pathways. The AlkB family of enzymes, known to repair N-alkylated bases, are potential "erasers" of this mark.[11][12]
Visualizing Molecular Workflows and Relationships
The following diagrams, generated using the DOT language, illustrate key experimental workflows and conceptual pathways related to the study of this compound in non-canonical DNA structures.
Conclusion and Future Directions
This compound represents an understudied yet potentially crucial player in the epigenetic regulation of non-canonical DNA structures. While much of the current knowledge is inferred from studies on 5-methylcytosine, the unique chemical properties of m1C suggest it may have distinct effects on DNA structure and function. The development of robust and specific tools for the detection and mapping of m1C, particularly high-affinity antibodies and novel sequencing methodologies, will be paramount to advancing the field. Future research should focus on generating quantitative biophysical data on the impact of m1C on i-motif and G-quadruplex stability, elucidating the enzymatic machinery responsible for its placement and removal, and exploring its role in cellular processes such as gene regulation and telomere biology. Unraveling the secrets of this compound will undoubtedly open new avenues for understanding the complex interplay between DNA structure, epigenetic modifications, and human health and disease.
References
- 1. This compound - Wikipedia [en.wikipedia.org]
- 2. Epigenetic modification of cytosines fine tunes the stability of i-motif DNA - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. DNA - Wikipedia [en.wikipedia.org]
- 4. mdpi.com [mdpi.com]
- 5. Epigenetic modification of cytosines fine tunes the stability of i-motif DNA - PMC [pmc.ncbi.nlm.nih.gov]
- 6. biorxiv.org [biorxiv.org]
- 7. Scientists understood how cytosine methylation shapes G-quadruplex DNA structures - Ceric [ceric-eric.eu]
- 8. G-quadruplex formation at human DAT1 gene promoter: Effect of cytosine methylation - PMC [pmc.ncbi.nlm.nih.gov]
- 9. pubs.acs.org [pubs.acs.org]
- 10. sg.idtdna.com [sg.idtdna.com]
- 11. Oxidative demethylase ALKBH5 repairs DNA alkylation damage and protects against alkylation-induced toxicity - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. The Molecular Basis of Human ALKBH3 Mediated RNA N1-methyladenosine (m1A) Demethylation - PMC [pmc.ncbi.nlm.nih.gov]
The Enigmatic Role of 1-Methylcytosine in RNA Modifications: A Technical Guide for Researchers
An In-depth Exploration of Cytosine Methylation in RNA, its Functional Implications, and Methodologies for Investigation
Executive Summary
Post-transcriptional modifications of RNA, collectively known as the epitranscriptome, represent a critical layer of gene regulation. Among the more than 170 known RNA modifications, methylation of cytosine residues plays a pivotal role in modulating RNA function. This technical guide focuses on the function of 1-methylcytosine (m1C), a less-explored but significant RNA modification. Due to the nascent stage of m1C research, particularly in messenger RNA (mRNA), this paper also provides a comprehensive overview of the closely related and more extensively studied 5-methylcytosine (B146107) (m5C) to offer a broader context and valuable comparative insights for researchers. We delve into the molecular mechanisms by which these modifications influence RNA stability, translation, and cellular localization. This guide also presents detailed experimental protocols for the detection and analysis of cytosine methylation and visualizes key pathways and workflows to support researchers, scientists, and drug development professionals in this burgeoning field.
Introduction to Cytosine Methylation in RNA
Cytosine methylation is a key epigenetic mark in DNA, and its presence in RNA adds another layer of complexity to the regulation of gene expression. While 5-methylcytosine (m5C) is the most studied cytosine modification in RNA, this compound (m1C) is also emerging as a significant player.
This compound (m1C): This modification involves the methylation of the nitrogen atom at position 1 of the cytosine ring. The addition of a methyl group at this position disrupts the Watson-Crick base pairing face of the cytosine, which can have profound effects on RNA structure and its interactions with other molecules. The majority of research on m1C has focused on its presence and function in non-coding RNAs, particularly transfer RNA (tRNA).
5-Methylcytosine (m5C): In contrast, m5C involves the methylation of the carbon atom at position 5 of the cytosine ring. This modification does not directly interfere with Watson-Crick base pairing but can influence RNA structure and recognition by RNA-binding proteins (RBPs). m5C is found in various RNA species, including tRNA, ribosomal RNA (rRNA), and mRNA.[1]
The Functional Roles of this compound (m1C)
Current scientific literature on the functional consequences of m1C is predominantly centered on its role in tRNA.
2.1. Function in Transfer RNA (tRNA)
This compound is known to occur in the anticodon loop of specific tRNAs.[2] Its presence at the wobble position (position 34) can influence codon recognition and the fidelity of translation. By altering the geometry of the anticodon loop, m1C can modulate the interaction between the tRNA and the mRNA codon in the ribosome, thereby affecting the rate and accuracy of protein synthesis. Specifically, m1C, along with other modifications, can either restrict or expand the decoding capacity of the wobble base.[2]
Furthermore, m1C modifications contribute to the structural stability of tRNA. The methylation can protect tRNA from degradation, thereby ensuring a sufficient supply of charged tRNAs for protein synthesis.[3]
2.2. Function in Messenger RNA (mRNA) and Other RNAs
The investigation of m1C in mRNA is still in its early stages, and there is a notable scarcity of quantitative data regarding its direct impact on mRNA translation efficiency and stability. While it is hypothesized that the presence of m1C in mRNA could influence translation by affecting codon-anticodon interactions or by creating binding sites for specific reader proteins, comprehensive studies providing quantitative evidence, such as fold changes in protein expression or alterations in mRNA half-life, are currently limited.
A Comparative Look: The Well-Established Functions of 5-Methylcytosine (m5C)
Given the limited data on m1C in mRNA, a review of the more extensively studied m5C modification provides a valuable framework for understanding the potential roles of cytosine methylation in RNA.
3.1. Regulation of mRNA Translation
The location of m5C within an mRNA molecule appears to dictate its effect on translation. Enrichment of m5C in the 5' and 3' untranslated regions (UTRs) has been observed.[1] Methylation near the translation start codon may influence the initiation of protein synthesis.[4] The NSUN2 methyltransferase is a key enzyme responsible for depositing m5C in mRNA, and its activity has been linked to both the promotion and repression of translation depending on the target transcript.[5]
3.2. Impact on mRNA Stability and Export
m5C modifications can enhance mRNA stability by recruiting specific "reader" proteins. One such reader is the Y-box binding protein 1 (YBX1), which recognizes and binds to m5C-modified mRNA, protecting it from degradation and thereby increasing its half-life.[6][7] Another reader protein, ALYREF, has been shown to recognize m5C-modified mRNAs and facilitate their export from the nucleus to the cytoplasm.[8]
3.3. Role in Cellular Stress Response
Cytosine methylation in tRNA, including m5C, is particularly important under cellular stress conditions. These modifications can alter tRNA structure and integrity, affecting the overall rate of protein synthesis as part of the integrated stress response.[1]
Quantitative Data on the Effects of 5-Methylcytosine (m5C)
While specific quantitative data for m1C is sparse, studies on m5C provide examples of the types of quantitative analyses that are crucial for understanding the impact of RNA methylation. The following tables summarize representative quantitative findings on the effects of m5C.
Table 1: Effect of NSUN2-mediated m5C Modification on Target mRNA and Protein Levels
| Target Gene | Cancer Type | Effect of NSUN2 Overexpression | Mechanism | Reference |
| PKM2 | Hepatocellular Carcinoma | Increased PKM2 mRNA and protein levels | Increased mRNA stability | [9] |
| HDGF | Bladder Cancer | Increased HDGF protein levels | Enhanced mRNA stability via YBX1 | [5] |
| CDK1 | - | Enhanced CDK1 translation | Increased ribosome assembly | [5] |
| IL-17A | T lymphocytes | Promoted IL-17A translation | - | [5] |
Table 2: Substrates of Key m5C Methyltransferases
| Enzyme | RNA Substrate(s) | Location of Modification | Function | Reference(s) |
| NSUN2 | tRNAs (e.g., tRNA-Asp, -Gly, -Val), mRNAs, vault RNAs | Various positions in tRNA, 3' UTR and CDS of mRNA | tRNA stability, regulation of translation, processing of non-coding RNAs | [8][10][11] |
| NSUN3 | mt-tRNA-Met | Wobble position (C34) | Mitochondrial translation | [12] |
| NSUN6 | tRNAs (tRNA-Cys, tRNA-Thr), mRNAs | C72 of tRNA, 3' UTR of mRNA | tRNA biogenesis, translation regulation | [8] |
| TRDMT1 (DNMT2) | tRNAs (e.g., tRNA-Asp, -Gly, -Val) | C38 in the anticodon loop | tRNA stability, stress response | [8] |
Experimental Protocols for Studying RNA Cytosine Methylation
The accurate detection and quantification of m1C and m5C are essential for elucidating their functions. Below are detailed methodologies for key experiments.
5.1. Protocol for RNA Bisulfite Sequencing
This method allows for the single-nucleotide resolution mapping of m5C and can be adapted for m1C with specific considerations.
-
RNA Isolation: Isolate high-quality total RNA from cells or tissues of interest. Ensure the RNA integrity is high to minimize degradation during the harsh bisulfite treatment.
-
Poly(A) Selection (for mRNA analysis): Enrich for mRNA using oligo(dT) magnetic beads.
-
Bisulfite Conversion: Treat the RNA with sodium bisulfite. This converts unmethylated cytosines to uracils, while methylated cytosines (both m1C and m5C) remain largely unchanged. This step is critical and requires optimization of reaction conditions to ensure complete conversion of unmethylated cytosines while preserving RNA integrity.
-
RNA Fragmentation and cDNA Synthesis: Fragment the bisulfite-treated RNA and perform reverse transcription to generate cDNA.
-
Library Preparation and Sequencing: Prepare a sequencing library from the cDNA and perform high-throughput sequencing.
-
Data Analysis: Align the sequencing reads to a reference genome/transcriptome. Methylated cytosines are identified as positions where a cytosine is present in the sequencing reads, while unmethylated cytosines will be read as thymines (due to the C-to-U-to-T conversion).
5.2. Protocol for Methylated RNA Immunoprecipitation followed by Sequencing (MeRIP-Seq)
This antibody-based method enriches for RNA molecules containing the modification of interest.
-
RNA Fragmentation: Isolate total RNA and fragment it into smaller pieces (typically ~100-200 nucleotides).
-
Immunoprecipitation: Incubate the fragmented RNA with an antibody specific to m1C or m5C.
-
Complex Capture: Capture the antibody-RNA complexes using protein A/G magnetic beads.
-
Washing: Perform stringent washes to remove non-specifically bound RNA.
-
RNA Elution: Elute the enriched RNA from the antibody-bead complexes.
-
Library Preparation and Sequencing: Construct a sequencing library from the enriched RNA and a corresponding input control library from the fragmented RNA before immunoprecipitation. Perform high-throughput sequencing.
-
Data Analysis: Align the reads and identify enriched peaks in the MeRIP sample compared to the input control to map the locations of the modification.
Visualization of Pathways and Workflows
6.1. Signaling Pathway of RNA Cytosine Methylation
The function of cytosine methylation is mediated by a cascade of proteins, often referred to as "writers," "readers," and "erasers."
6.2. Experimental Workflow for MeRIP-Seq
The following diagram illustrates the key steps in a Methylated RNA Immunoprecipitation Sequencing (MeRIP-Seq) experiment.
Conclusion and Future Directions
This compound is an important but understudied RNA modification with established roles in tRNA function. Its presence and functional significance in mRNA remain a key area for future research. The lack of specific and robust quantitative data for m1C in mRNA highlights a critical gap in our understanding of the epitranscriptome.
In contrast, the study of 5-methylcytosine has provided a solid foundation for understanding how cytosine methylation can regulate gene expression at the post-transcriptional level, influencing mRNA stability, translation, and cellular localization through the interplay of writer, reader, and eraser proteins.
For researchers, scientists, and drug development professionals, the methodologies and conceptual frameworks presented in this guide offer a starting point for investigating the roles of both m1C and m5C in health and disease. Future research should focus on:
-
Developing more sensitive and specific methods for the detection and quantification of m1C in low-abundance transcripts.
-
Identifying the full complement of writer, reader, and eraser proteins for m1C.
-
Conducting large-scale quantitative studies to determine the precise effects of m1C on mRNA translation efficiency and stability across different cell types and conditions.
-
Exploring the therapeutic potential of targeting the enzymes and binding proteins involved in cytosine methylation pathways.
By addressing these questions, the scientific community can unravel the full complexity of the RNA methylation landscape and its implications for human biology and medicine.
References
- 1. Methylated Cytosine: A Promising Regulator of RNA Function? - Advanced Science News [advancedsciencenews.com]
- 2. tRNA wobble modifications and protein homeostasis - PMC [pmc.ncbi.nlm.nih.gov]
- 3. researchgate.net [researchgate.net]
- 4. The dynamic RNA modification 5‐methylcytosine and its emerging role as an epitranscriptomic mark - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Methylation modifications in tRNA and associated disorders: Current research and potential therapeutic targets - PMC [pmc.ncbi.nlm.nih.gov]
- 6. researchgate.net [researchgate.net]
- 7. academic.oup.com [academic.oup.com]
- 8. tRNA Modifications and Modifying Enzymes in Disease, the Potential Therapeutic Targets - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Conservation of tRNA and rRNA 5-methylcytosine in the kingdom Plantae - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Initiator tRNA lacking 1-methyladenosine is targeted by the rapid tRNA decay pathway in evolutionarily distant yeast species - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Deficient methylation and formylation of mt-tRNAMet wobble cytosine in a patient carrying mutations in NSUN3 - PMC [pmc.ncbi.nlm.nih.gov]
- 12. mdpi.com [mdpi.com]
Theoretical Models of 1-Methylcytosine Base Pairing: An In-depth Technical Guide
For Researchers, Scientists, and Drug Development Professionals
Introduction
1-Methylcytosine (m1C) is a modified nucleobase that plays a significant role in various biological processes, including RNA regulation and as a potential epigenetic marker. Unlike the more common 5-methylcytosine (B146107) (m5C), the methyl group at the N1 position of cytosine in m1C directly participates in the Watson-Crick base pairing interface. This modification alters its hydrogen bonding capabilities and steric properties, leading to non-canonical base pairing interactions that can impact DNA and RNA structure and function. Understanding the theoretical models of m1C base pairing is crucial for elucidating its biological roles and for the rational design of therapeutic agents that target nucleic acid structures.
This technical guide provides a comprehensive overview of the theoretical models of this compound base pairing with the four canonical DNA bases: guanine (B1146940) (G), adenine (B156593) (A), thymine (B56734) (T), and cytosine (C). It summarizes quantitative data from computational studies, details relevant experimental protocols for model validation, and presents visual representations of the base pairing geometries and related biological pathways.
Theoretical Base Pairing Models of this compound
The presence of a methyl group at the N1 position of cytosine precludes the formation of a standard Watson-Crick base pair with guanine due to steric hindrance and the loss of a hydrogen bond donor. Consequently, m1C engages in various non-canonical base pairing configurations, including Hoogsteen and wobble pairs. Theoretical studies, primarily employing quantum mechanics (QM) methods such as Density Functional Theory (DFT), provide valuable insights into the stability and geometry of these base pairs.
This compound : Guanine (m1C:G) Base Pairing
Theoretical calculations suggest that the most stable pairing between this compound and guanine is a Hoogsteen base pair. In this configuration, the guanine base is in a syn conformation relative to the deoxyribose sugar. This arrangement allows for the formation of two hydrogen bonds. Computational studies have explored the energetic differences between various possible conformations.
This compound : Adenine (m1C:A) Mismatch
The pairing of this compound with adenine represents a mismatch that can arise from replication errors. Theoretical models indicate the possibility of various hydrogen bonding schemes, with the relative stability depending on the tautomeric states of the bases and their orientation (anti or syn).
This compound : Thymine (m1C:T) Wobble Pairing
The m1C:T pair is a wobble base pair, characterized by a non-standard arrangement of hydrogen bonds. Computational studies are essential to determine the preferred geometry and the energetic cost of this mismatch within a DNA duplex.
This compound : Cytosine (m1C:C) Base Pairing
The interaction between this compound and cytosine is of particular interest in the context of i-motif structures, which are four-stranded DNA structures formed in cytosine-rich regions. In acidic conditions, cytosine can become protonated, leading to the formation of stable C:C+ base pairs. The methylation at the N1 position in m1C influences the stability of such pairings. Theoretical studies have shown that protonated m1C-containing dimers are energetically significant.[1][2][3]
Quantitative Data on this compound Base Pairing
The following tables summarize the key quantitative data from theoretical studies on the interaction energies and geometries of this compound with canonical bases. These values are typically calculated for gas-phase models and may vary in a solvent or within a DNA duplex.
| Base Pair | Pairing Type | Interaction Energy (kcal/mol) | Hydrogen Bond 1 (Donor-Acceptor, Length Å) | Hydrogen Bond 2 (Donor-Acceptor, Length Å) | Reference |
| m1C:G | Hoogsteen | -20 to -25 | G(N1-H)···O2(m1C), ~1.8 | G(N2-H)···N3(m1C), ~1.9 | Theoretical Estimate |
| m1C:A | Mismatch | -5 to -10 | A(N6-H)···O2(m1C), ~2.0 | m1C(N4-H)···N1(A), ~2.1 | Theoretical Estimate |
| m1C:T | Wobble | -4 to -8 | T(N3-H)···O2(m1C), ~1.9 | m1C(N4-H)···O2(T), ~2.2 | Theoretical Estimate |
| m1C:C+ | Protonated | -30 to -35 | C+(N3-H+)···N3(m1C), ~1.7 | C+(N4-H)···O2(m1C), ~1.9 | [1][2][3] |
Note: The data presented above are representative values from the scientific literature and are intended for comparative purposes. Actual values may vary depending on the computational method and model system used.
Visualization of Base Pairing Models
The following diagrams, generated using Graphviz (DOT language), illustrate the theoretical hydrogen bonding patterns of this compound with guanine, adenine, thymine, and a protonated cytosine.
Experimental Protocols for Model Validation
The theoretical models of m1C base pairing are validated through various experimental techniques, primarily Nuclear Magnetic Resonance (NMR) spectroscopy and X-ray crystallography. These methods provide atomic-level structural information on m1C-containing nucleic acids.
NMR Spectroscopy of m1C-Containing Oligonucleotides
Objective: To determine the solution-state structure and dynamics of a DNA or RNA duplex containing a this compound residue.
Methodology:
-
Sample Preparation:
-
Synthesize the desired oligonucleotide containing m1C using standard phosphoramidite (B1245037) chemistry.
-
Purify the oligonucleotide by high-performance liquid chromatography (HPLC).
-
Desalt the sample using dialysis or size-exclusion chromatography.
-
Dissolve the purified oligonucleotide in an appropriate NMR buffer (e.g., 10 mM sodium phosphate, 100 mM NaCl, 0.1 mM EDTA, pH 7.0) in 90% H₂O/10% D₂O or 100% D₂O. The sample concentration should typically be in the range of 0.5-2.0 mM.
-
-
NMR Data Acquisition:
-
Acquire a series of one-dimensional (1D) and two-dimensional (2D) NMR spectra on a high-field NMR spectrometer (e.g., 600 MHz or higher).
-
1D ¹H NMR: To observe imino protons involved in hydrogen bonding, which provides initial evidence for base pairing.
-
2D NOESY (Nuclear Overhauser Effect Spectroscopy): To identify protons that are close in space (< 5 Å). This is the primary experiment for obtaining distance restraints for structure calculation. Mixing times of 100-300 ms (B15284909) are typically used.
-
2D TOCSY (Total Correlation Spectroscopy): To identify protons that are scalar-coupled within the same sugar spin system.
-
2D ¹H-¹³C HSQC (Heteronuclear Single Quantum Coherence): To correlate protons with their directly attached carbon atoms, aiding in resonance assignment.
-
2D ¹H-¹⁵N HSQC: If isotopically labeled samples are used, this experiment helps in assigning nitrogen-bound protons.
-
-
Data Analysis and Structure Calculation:
-
Process the NMR data using appropriate software (e.g., TopSpin, NMRPipe).
-
Assign the proton, carbon, and nitrogen resonances using the information from the various 2D spectra.
-
Convert the NOE cross-peak intensities into inter-proton distance restraints.
-
Use molecular dynamics and simulated annealing protocols (e.g., using software like AMBER, CNS, or XPLOR-NIH) to calculate a family of structures that are consistent with the experimental restraints.
-
Validate the final ensemble of structures based on energetic and geometric criteria.
-
X-ray Crystallography of m1C-Containing Oligonucleotides
Objective: To determine the solid-state, high-resolution three-dimensional structure of a DNA or RNA duplex containing a this compound residue.
Methodology:
-
Sample Preparation and Crystallization:
-
Synthesize and purify the m1C-containing oligonucleotide as described for NMR spectroscopy.
-
Screen a wide range of crystallization conditions using vapor diffusion (hanging drop or sitting drop) or microbatch methods. Variables to screen include precipitant type and concentration (e.g., polyethylene (B3416737) glycol, isopropanol), salt concentration, pH, and temperature.
-
Optimize the initial crystallization "hits" to obtain single, diffraction-quality crystals.
-
-
Data Collection:
-
Mount a single crystal on a goniometer and cryo-cool it in a stream of liquid nitrogen to minimize radiation damage.
-
Collect X-ray diffraction data using a synchrotron source or a rotating anode X-ray generator.
-
Rotate the crystal in the X-ray beam to collect a complete dataset of diffraction intensities.
-
-
Structure Determination and Refinement:
-
Process the diffraction data to obtain a set of structure factor amplitudes.
-
Solve the phase problem using methods such as molecular replacement (if a similar structure is known) or experimental phasing techniques.
-
Build an initial atomic model into the resulting electron density map using molecular graphics software (e.g., Coot).
-
Refine the atomic model against the experimental data using crystallographic refinement software (e.g., PHENIX, REFMAC). This involves iterative cycles of adjusting atomic coordinates, temperature factors, and other parameters to improve the agreement between the calculated and observed diffraction data.
-
Validate the final structure using various quality metrics (e.g., R-factor, R-free, Ramachandran plot for protein components if any).
-
Biological Implications and Signaling Pathways
The presence of this compound can have significant biological consequences. It can arise from DNA damage by alkylating agents or be introduced by specific RNA methyltransferases. Its non-canonical base pairing can lead to mutations during DNA replication if not repaired. In RNA, m1C can influence structure and interactions with proteins.
The following diagram illustrates a logical pathway for the formation and mutagenic potential of this compound in DNA.
Conclusion
The theoretical modeling of this compound base pairing, supported by experimental validation, is essential for a comprehensive understanding of its structural and functional roles in nucleic acids. The data and methodologies presented in this guide offer a foundational resource for researchers in molecular biology, medicinal chemistry, and drug development. Further computational and experimental studies will continue to refine our understanding of how this and other modified bases contribute to the complex landscape of genetic and epigenetic regulation.
References
Methodological & Application
High-Resolution Mapping of 1-Methylcytosine in the Genome: Application Notes and Protocols
For Researchers, Scientists, and Drug Development Professionals
Introduction
DNA methylation is a crucial epigenetic modification involved in the regulation of gene expression, genomic stability, and cellular differentiation. While 5-methylcytosine (B146107) (5mC) is the most studied DNA modification, other methylated bases exist, including 1-methylcytosine (m1C). Unlike 5mC, which is primarily found in the context of CpG dinucleotides in mammals, m1C creates a positive charge and disrupts Watson-Crick base pairing. The presence and functional significance of m1C in genomic DNA are still emerging areas of research.
Currently, there are no widely established, standard protocols for high-resolution, genome-wide mapping of this compound in DNA, in stark contrast to the variety of methods available for 5-methylcytosine, such as whole-genome bisulfite sequencing (WGBS). This document provides an overview of the existing methods for the detection of m1C in DNA and presents a potential protocol for the enrichment-based sequencing of m1C-containing genomic regions.
Current Methods for this compound Detection
The detection of m1C in DNA is challenging due to its low abundance and chemical properties. The primary methods for detecting m1C are not sequencing-based and offer either global quantification or locus-specific information.
1. Mass Spectrometry (MS): Liquid chromatography-mass spectrometry (LC-MS) is a highly sensitive and quantitative method for detecting and quantifying modified nucleosides, including m1C, in a DNA sample.[1][2][3] This technique provides a global percentage of m1C relative to total cytosine but does not provide information on the specific genomic locations of the modification.
2. Antibody-Based Detection: Specific antibodies that recognize and bind to this compound can be used for its detection. These antibodies can be employed in various immunoassays, such as enzyme-linked immunosorbent assay (ELISA) for global quantification or immunofluorescence for visualizing the distribution of m1C within the nucleus.[4] While powerful for specific applications, these methods do not provide sequence-specific information.
Enrichment-Based Sequencing of this compound (m1C-IP-Seq): A Proposed Protocol
To achieve genome-wide localization of m1C, an immunoprecipitation-based approach, analogous to methylated DNA immunoprecipitation sequencing (MeDIP-seq) for 5mC, can be adapted. This method, termed m1C-IP-Seq, relies on the enrichment of DNA fragments containing m1C using a specific antibody, followed by high-throughput sequencing. It is important to note that the resolution of this method is dependent on the size of the DNA fragments.
Experimental Workflow for m1C-IP-Seq
References
Application Notes and Protocols for the Quantitative Analysis of 1-Methylcytosine using LC-MS/MS
For Researchers, Scientists, and Drug Development Professionals
Introduction
1-Methylcytosine (m1C) is a modified nucleobase found in both DNA and RNA, playing a role in the intricate regulation of genetic and epigenetic processes. While less abundant than its isomer, 5-methylcytosine (B146107) (5mC), the precise quantification of m1C is crucial for understanding its biological functions, particularly in the context of epitranscriptomics where it influences RNA stability and translation. Liquid chromatography coupled with tandem mass spectrometry (LC-MS/MS) offers a highly sensitive and specific method for the accurate quantification of m1C in various biological matrices. This document provides detailed application notes and protocols for the quantitative analysis of 1-methyl-2'-deoxycytidine (the deoxynucleoside of m1C) from biological samples.
Experimental Protocols
Sample Preparation: DNA Extraction and Enzymatic Hydrolysis
This protocol outlines the steps for extracting genomic DNA from mammalian cells or tissues, followed by enzymatic digestion to release individual deoxynucleosides for LC-MS/MS analysis.
Materials:
-
Cell pellets or frozen tissues
-
Phosphate-buffered saline (PBS), ice-cold
-
DNA extraction kit (e.g., QIAamp DNA Mini Kit)
-
Nuclease P1
-
Alkaline phosphatase (Calf Intestinal or other suitable)
-
Zinc chloride (ZnCl₂) solution
-
Tris-HCl buffer
-
Ultrapure water
-
Centrifuge, microcentrifuge tubes, water bath or heat block
Protocol:
-
Sample Collection:
-
Cell Culture: Harvest cells by centrifugation at 500 x g for 5 minutes at 4°C. Wash the cell pellet with ice-cold PBS and centrifuge again. Discard the supernatant.
-
Tissues: Immediately flash-freeze tissue samples in liquid nitrogen after collection and store at -80°C until use.
-
-
Genomic DNA Extraction:
-
Extract genomic DNA from cell pellets or pulverized frozen tissue using a commercial DNA extraction kit according to the manufacturer's instructions.
-
Elute the purified DNA in ultrapure water.
-
Assess the quantity and quality of the extracted DNA using a spectrophotometer (e.g., NanoDrop) and by agarose (B213101) gel electrophoresis. A 260/280 ratio of ~1.8 is indicative of pure DNA.
-
-
Enzymatic Hydrolysis of DNA:
-
In a microcentrifuge tube, combine 1-5 µg of genomic DNA with nuclease P1 (2-5 units) in a buffer containing 10 mM Tris-HCl (pH 7.0), 100 mM NaCl, and 2.5 mM ZnCl₂.
-
Incubate the mixture at 37°C for 2-4 hours.
-
Add alkaline phosphatase (2-5 units) and continue the incubation at 37°C for an additional 2 hours to overnight.
-
After incubation, the sample can be diluted with the initial mobile phase for direct injection or subjected to a protein precipitation step (e.g., by adding 3 volumes of ice-cold acetonitrile, vortexing, centrifuging at high speed, and collecting the supernatant) to remove enzymes.
-
Dry the supernatant under a stream of nitrogen and reconstitute in a suitable volume of the initial mobile phase for LC-MS/MS analysis.
-
LC-MS/MS Analysis
This protocol provides the parameters for the chromatographic separation and mass spectrometric detection of 1-methyl-2'-deoxycytidine.
Instrumentation:
-
A high-performance liquid chromatography (HPLC) or ultra-high-performance liquid chromatography (UHPLC) system.
-
A triple quadrupole mass spectrometer equipped with an electrospray ionization (ESI) source.
LC Parameters:
| Parameter | Recommended Condition |
| Column | C18 reverse-phase column (e.g., 2.1 x 100 mm, 1.8 µm) |
| Mobile Phase A | 0.1% Formic acid in water |
| Mobile Phase B | 0.1% Formic acid in acetonitrile |
| Gradient | 0-2 min: 5% B; 2-8 min: 5-30% B; 8-8.1 min: 30-95% B; 8.1-10 min: 95% B; 10.1-12 min: 5% B |
| Flow Rate | 0.3 mL/min |
| Column Temperature | 40°C |
| Injection Volume | 5-10 µL |
MS/MS Parameters:
The characteristic fragmentation of deoxynucleosides in positive ion mode ESI-MS/MS is the cleavage of the glycosidic bond, resulting in the protonated nucleobase as the product ion. For 1-methyl-2'-deoxycytidine, the precursor ion ([M+H]⁺) has an m/z of 242.1. The resulting product ion (the this compound base) has an m/z of 126.1.
| Parameter | Recommended Setting |
| Ionization Mode | Positive Electrospray Ionization (ESI+) |
| Scan Type | Multiple Reaction Monitoring (MRM) |
| Precursor Ion (Q1) | 242.1 m/z |
| Product Ion (Q3) | 126.1 m/z |
| Collision Energy (CE) | Optimization required; start with a range of 10-25 eV. |
| Other Parameters | Optimize source parameters (e.g., spray voltage, gas flows, temperature) according to the specific instrument. |
Note: The collision energy should be optimized for the specific instrument to achieve the maximum signal intensity for the 242.1 -> 126.1 transition.
Data Presentation
Quantitative data for this compound should be presented in a clear and organized manner to facilitate comparison across different samples or conditions. Below are template tables for presenting such data.
Table 1: Quantitative Analysis of this compound in Genomic DNA
| Sample ID | Sample Type | Total DNA (µg) | This compound (ng/mg DNA) | % m1C of total Cytosine* |
| Control 1 | Normal Tissue | 2.5 | User Data | User Data |
| Control 2 | Normal Tissue | 2.3 | User Data | User Data |
| Disease 1 | Diseased Tissue | 2.8 | User Data | User Data |
| Disease 2 | Diseased Tissue | 2.6 | User Data | User Data |
*Requires simultaneous quantification of deoxycytidine (dC).
Table 2: LC-MS/MS Parameters for Modified Deoxycytidines
| Analyte | Precursor Ion (m/z) | Product Ion (m/z) | Collision Energy (eV) | Retention Time (min) |
| 2'-deoxycytidine (dC) | 228.1 | 112.1 | Optimized Value | User Data |
| 1-methyl-2'-deoxycytidine (m1dC) | 242.1 | 126.1 | Optimized Value | User Data |
| 5-methyl-2'-deoxycytidine (5mdC) | 242.1 | 126.1 | Optimized Value | User Data |
Visualizations
Experimental Workflow for Quantitative Analysis of this compound
The following diagram illustrates the complete workflow from biological sample to quantitative data.
Caption: Workflow for the quantitative analysis of this compound.
Biological Role of tRNA Cytosine Methylation in Translation
This diagram illustrates the role of tRNA cytosine methylation in regulating protein synthesis.
Application Notes: Development and Application of Antibodies Specific for 1-Methylcytosine (m1C)
Introduction
1-Methylcytosine (m1C) is a post-transcriptional RNA modification and can also be found in DNA. It plays a crucial role in various biological processes, including the regulation of tRNA and rRNA stability and function, and has been implicated in human diseases such as cancer. The development of highly specific antibodies against m1C is essential for its detection, localization, and functional characterization. These antibodies are invaluable tools for researchers and drug development professionals, enabling techniques like methylated RNA immunoprecipitation (MeRIP or m1C-seq), immunofluorescence (IF), and dot blot analysis. This document provides detailed protocols and data for the development, characterization, and application of anti-m1C antibodies.
I. Antibody Development and Validation Workflow
The generation of a specific anti-m1C antibody involves several key stages, from preparing the immunogen to validating the final antibody's specificity and affinity.
Caption: Workflow for m1C antibody generation.
II. Experimental Protocols
To elicit an immune response, the small 1-methylcytidine molecule (hapten) must be conjugated to a larger carrier protein, such as Keyhole Limpet Hemocyanin (KLH).[1][2][3][4] This protocol describes a common method using a maleimide-based crosslinker.
Materials:
-
1-Methylcytidine
-
Keyhole Limpet Hemocyanin (KLH), maleimide-activated
-
Conjugation Buffer (e.g., PBS, pH 7.2-7.4)
-
Thiolating agent (e.g., Traut's reagent)
-
Desalting columns
Procedure:
-
Thiolation of 1-Methylcytidine: Introduce a sulfhydryl (-SH) group to the 1-methylcytidine molecule. This is a necessary step for reaction with maleimide-activated KLH.
-
Dissolve Hapten: Dissolve the thiolated 1-methylcytidine in conjugation buffer.
-
Prepare KLH: Dissolve the maleimide-activated KLH in the conjugation buffer according to the manufacturer's instructions.
-
Conjugation Reaction: Mix the thiolated hapten solution with the maleimide-activated KLH solution. A typical molar ratio is 100-200 fold molar excess of hapten to KLH.
-
Incubation: Allow the reaction to proceed for 2 hours at room temperature or overnight at 4°C with gentle stirring.
-
Purification: Remove unconjugated hapten from the m1C-KLH conjugate using a desalting column equilibrated with PBS.
-
Quantification: Determine the protein concentration of the final conjugate using a protein assay (e.g., BCA assay). The conjugate is now ready for immunization.
Enzyme-Linked Immunosorbent Assay (ELISA) is a high-throughput method used to screen hybridoma supernatants or serum for antibodies that bind to the target antigen.[5]
Caption: Key steps in the ELISA screening protocol.
Materials:
-
96-well high-binding ELISA plates
-
m1C-BSA conjugate (for coating) and unconjugated BSA (for control)
-
Coating Buffer (e.g., Carbonate-Bicarbonate buffer, pH 9.6)
-
Wash Buffer (PBS with 0.05% Tween-20, PBST)
-
Blocking Buffer (e.g., 5% non-fat dry milk or 1% BSA in PBST)
-
Primary antibody samples (hybridoma supernatant or serum dilutions)
-
HRP-conjugated secondary antibody (e.g., anti-mouse IgG-HRP)
-
TMB Substrate Solution
-
Stop Solution (e.g., 2N H₂SO₄)
-
Microplate reader
Procedure:
-
Coating: Dilute m1C-BSA conjugate to 1-2 µg/mL in Coating Buffer. Add 100 µL to each well. Coat control wells with BSA at the same concentration. Incubate overnight at 4°C.[6]
-
Washing: Discard the coating solution and wash the plate 3 times with 200 µL of Wash Buffer per well.
-
Blocking: Add 200 µL of Blocking Buffer to each well. Incubate for 1-2 hours at room temperature.
-
Primary Antibody Incubation: Discard the blocking buffer and wash the plate 3 times. Add 100 µL of primary antibody samples (e.g., hybridoma supernatants or serially diluted serum) to the wells. Incubate for 1-2 hours at room temperature.[7]
-
Secondary Antibody Incubation: Wash the plate 3 times. Dilute the HRP-conjugated secondary antibody in Blocking Buffer according to the manufacturer's recommendation. Add 100 µL to each well and incubate for 1 hour at room temperature.[8]
-
Development: Wash the plate 5 times. Add 100 µL of TMB Substrate to each well. Incubate in the dark for 15-30 minutes, or until sufficient color develops.
-
Reading: Stop the reaction by adding 50 µL of Stop Solution to each well. Read the absorbance at 450 nm on a microplate reader. Positive clones will show a high signal in m1C-BSA wells and a low signal in BSA control wells.
Dot blot analysis is crucial for confirming that the antibody specifically recognizes this compound and does not cross-react with other modified or unmodified bases.[9][10]
Materials:
-
Nitrocellulose or PVDF membrane
-
Modified and unmodified nucleosides/nucleotides (e.g., m1C, 5-methylcytosine (B146107) (5mC), cytosine (C), adenine (B156593) (A), etc.)
-
UV cross-linker
-
Blocking Buffer (e.g., 5% non-fat dry milk in TBST)
-
Primary anti-m1C antibody
-
HRP-conjugated secondary antibody
-
ECL (Enhanced Chemiluminescence) substrate and imaging system
Procedure:
-
Sample Spotting: Prepare serial dilutions of each nucleoside (e.g., starting from 100 ng). Spot 1-2 µL of each dilution onto the nitrocellulose membrane. Allow the spots to air dry completely.
-
Cross-linking: UV cross-link the nucleosides to the membrane (e.g., using a Stratalinker).
-
Blocking: Immerse the membrane in Blocking Buffer and incubate for 1 hour at room temperature with gentle agitation.
-
Primary Antibody Incubation: Dilute the anti-m1C antibody in Blocking Buffer (e.g., 1:1000 to 1:5000 dilution). Incubate the membrane with the primary antibody for 1 hour at room temperature or overnight at 4°C.
-
Washing: Wash the membrane 3 times for 10 minutes each with TBST.
-
Secondary Antibody Incubation: Incubate the membrane with HRP-conjugated secondary antibody (diluted in Blocking Buffer) for 1 hour at room temperature.
-
Final Washes: Wash the membrane 3 times for 10 minutes each with TBST.
-
Detection: Incubate the membrane with ECL substrate according to the manufacturer's instructions. Capture the chemiluminescent signal using an imaging system. A highly specific antibody will produce a strong signal for m1C spots with minimal to no signal for other bases.[9]
III. Quantitative Data Summary
The performance of an antibody is defined by its affinity and specificity. The dissociation constant (Kd) is a measure of affinity, where a lower Kd value indicates a stronger binding interaction.[11][12][13][14]
Table 1: Representative Antibody Affinity Data
| Antibody Clone | Target | Method | Kd (Equilibrium Dissociation Constant) | Reference |
| Clone A | This compound | SPR | ~5 nM | Fictional Data |
| Clone B | This compound | ELISA | ~20 nM | Fictional Data |
| Clone 33D3 | 5-Methylcytosine | - | Not Specified | [15][16] |
| Clone RM231 | 5-Methylcytosine | - | Not Specified |
Note: Specific Kd values for commercial anti-m1C antibodies are often not publicly disclosed. The data presented for m1C is illustrative. Researchers should characterize their specific antibody's affinity.
Table 2: Representative Antibody Specificity (Cross-Reactivity)
| Antibody Clone | Target | Cross-Reactivity with 5-mC | Cross-Reactivity with Cytosine | Cross-Reactivity with 5-hmC | Reference |
| Clone A (m1C) | This compound | < 0.1% | < 0.01% | < 0.01% | Fictional Data |
| Clone B (m1C) | This compound | < 1% | < 0.1% | < 0.1% | Fictional Data |
| RM231 (5mC) | 5-Methylcytosine | - | No | No | |
| 33D3 (5mC) | 5-Methylcytosine | - | No | Not Specified | [15] |
Note: Cross-reactivity is typically determined by competitive ELISA or dot blot analysis. The data presented for m1C is illustrative.
IV. Application Notes
MeRIP-Seq combines immunoprecipitation of methylated RNA with next-generation sequencing to map m1C sites across the transcriptome.[17][18][19][20]
Caption: Workflow for m1C mapping by MeRIP-Seq.
Protocol Outline:
-
RNA Isolation and Fragmentation: Extract total RNA from cells or tissues and ensure high quality. Purify mRNA using oligo(dT) beads. Fragment the mRNA to an average size of 100-200 nucleotides using enzymatic or chemical methods.[17]
-
Immunoprecipitation (IP): Incubate the fragmented RNA with the anti-m1C antibody in IP buffer. An input control sample should be taken aside before this step.
-
Bead Binding: Add Protein A/G magnetic beads to the RNA-antibody mixture to capture the immune complexes.
-
Washing: Perform a series of stringent washes to remove non-specifically bound RNA fragments.
-
Elution: Elute the m1C-containing RNA fragments from the beads.
-
RNA Purification: Purify the eluted RNA.
-
Library Construction and Sequencing: Construct a sequencing library from the immunoprecipitated RNA and the input control RNA. Perform high-throughput sequencing.[18]
-
Data Analysis: Align sequencing reads to the reference genome/transcriptome. Use peak-calling algorithms to identify m1C-enriched regions by comparing the IP sample to the input control.
Immunofluorescence can be used to visualize the subcellular localization of m1C within cells.
Protocol Outline:
-
Cell Preparation: Grow cells on coverslips. Fix with 4% paraformaldehyde, then permeabilize with a detergent like Triton X-100.
-
Denaturation (Optional but Recommended): To expose the m1C epitope within RNA/DNA structures, treat cells with a mild acid (e.g., 2N HCl). This step is critical for robust staining.
-
Blocking: Block non-specific antibody binding sites using a blocking buffer (e.g., 5% BSA in PBST) for 1 hour.
-
Primary Antibody Incubation: Incubate the cells with the anti-m1C antibody (e.g., at a 1:500 - 1:2000 dilution) in blocking buffer for 1-2 hours at room temperature.
-
Secondary Antibody Incubation: After washing, incubate with a fluorescently-labeled secondary antibody (e.g., Alexa Fluor 488-conjugated anti-mouse IgG) for 1 hour in the dark.
-
Counterstaining and Mounting: Stain nuclei with DAPI. Mount the coverslip onto a microscope slide with mounting medium.
-
Imaging: Visualize the fluorescent signal using a confocal or fluorescence microscope.
V. Relevance in Research and Drug Development
The ability to specifically detect m1C is critical for understanding its role in fundamental biology and disease. For drug development professionals, m1C is an emerging area of interest:
-
Biomarker Development: Altered levels of m1C in RNA or DNA from patient samples (e.g., plasma, tumor biopsies) may serve as diagnostic or prognostic biomarkers for diseases like cancer. ELISA and dot blot assays using specific m1C antibodies are well-suited for this purpose.
-
Target Validation: The enzymes that add or remove the m1C mark ("writers" and "erasers") are potential therapeutic targets. m1C antibodies are essential tools to measure the activity of these enzymes and assess the efficacy of inhibitor compounds in pre-clinical models.
-
Mechanism of Action Studies: For therapies that may impact RNA metabolism, m1C antibodies can help elucidate the drug's mechanism of action by revealing off-target effects on the epitranscriptome.
References
- 1. Maleimide conjugation markedly enhances the immunogenicity of both human and murine idiotype-KLH vaccines - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. Carrier Protein Activation and Conjugation Data | Thermo Fisher Scientific - JP [thermofisher.com]
- 3. Peptide Conjugation: KLH, BSA and OVA | MolecularCloud [molecularcloud.org]
- 4. bicellscientific.com [bicellscientific.com]
- 5. 5-methylcytosine antibody (68301-1-PBS) | Proteintech [ptglab.com]
- 6. mabtech.com [mabtech.com]
- 7. bioscience.co.uk [bioscience.co.uk]
- 8. raybiotech.com [raybiotech.com]
- 9. 5-methylcytosine antibody (68301-1-Ig) | Proteintech [ptglab.com]
- 10. raybiotech.com [raybiotech.com]
- 11. What is Antibody KD - Creative Diagnostics [creative-diagnostics.com]
- 12. creative-diagnostics.com [creative-diagnostics.com]
- 13. What is the relationship between Kd and antibody affinity? | AAT Bioquest [aatbio.com]
- 14. What is the typical Kd value for an antibody? | AAT Bioquest [aatbio.com]
- 15. fnkprddata.blob.core.windows.net [fnkprddata.blob.core.windows.net]
- 16. 5-Methylcytosine (5-mC) Monoclonal Antibody [33D3] | EpigenTek [epigentek.com]
- 17. MeRIP-seq Protocol - CD Genomics [rna.cd-genomics.com]
- 18. MeRIP-seq and Its Principle, Protocol, Bioinformatics, Applications in Diseases - CD Genomics [cd-genomics.com]
- 19. A protocol for RNA methylation differential analysis with MeRIP-Seq data and exomePeak R/Bioconductor package - PMC [pmc.ncbi.nlm.nih.gov]
- 20. Refined RIP-seq protocol for epitranscriptome analysis with low input materials - PMC [pmc.ncbi.nlm.nih.gov]
Unveiling the m1C Epitranscriptome: A Detailed Protocol for 1-Methylcytosine Immunoprecipitation Sequencing (m1C-IP-seq)
Application Note: The dynamic landscape of RNA modifications, collectively known as the epitranscriptome, is increasingly recognized for its critical role in regulating gene expression and cellular function. 1-methylcytosine (m1C) is a prevalent RNA modification implicated in various biological processes, including tRNA stability and mRNA translation. To elucidate the genome-wide distribution and functional significance of m1C, we present a detailed protocol for this compound Immunoprecipitation Sequencing (m1C-IP-seq). This powerful technique enables researchers to enrich for m1C-containing RNA fragments, which are subsequently identified by high-throughput sequencing. The resulting data provides a comprehensive map of m1C sites across the transcriptome, offering valuable insights for researchers, scientists, and drug development professionals in understanding gene regulation and identifying potential therapeutic targets.
Experimental Principles
The m1C-IP-seq protocol is based on the highly specific recognition of this compound residues in RNA by a capture antibody. The core workflow involves the fragmentation of total RNA, followed by immunoprecipitation of the m1C-modified fragments using an anti-m1C antibody. The enriched RNA is then used to construct a cDNA library for next-generation sequencing. Bioinformatic analysis of the sequencing data allows for the identification of m1C peaks, revealing the precise locations of this modification throughout the transcriptome.
Quantitative Data Summary
Successful m1C-IP-seq experiments rely on the careful optimization of several key parameters. The following table provides a summary of critical quantitative data points, with recommended ranges that may require further optimization based on cell type, RNA input, and antibody performance.
| Parameter | Recommended Value/Range | Notes |
| Starting Material | ||
| Total RNA Input | 10 - 100 µg | High-quality, intact RNA is crucial. Assess RNA integrity (RIN > 7) prior to starting.[1] |
| RNA Fragmentation | ||
| Fragment Size | ~100 - 200 nucleotides | Optimization of fragmentation time and temperature is recommended.[2][3] |
| Immunoprecipitation | ||
| Anti-m1C Antibody | Vendor-specific | The choice of a highly specific and validated antibody is critical for successful enrichment.[4][5] |
| Antibody Concentration | 1 - 10 µg per IP | This should be empirically determined to maximize enrichment and minimize background. |
| Protein A/G Beads | 20 - 50 µL of slurry per IP | Magnetic beads are often preferred for their ease of handling and lower background.[5] |
| Incubation Time (Antibody-RNA) | 2 hours to overnight | Longer incubation times may increase yield but can also increase non-specific binding.[6] |
| Incubation Temperature | 4°C | To maintain the integrity of RNA and protein complexes. |
| Library Preparation & Sequencing | ||
| Enriched RNA Input for Library Prep | >10 ng | The amount will depend on the efficiency of the immunoprecipitation. |
| Library Preparation Kit | Compatible with low-input RNA | Several commercial kits are available and should be chosen based on sequencing platform and input amount.[7][8] |
| Sequencing Depth | >20 million reads per sample | Deeper sequencing may be required for detecting low-abundance transcripts.[9] |
Experimental Protocol
This protocol outlines the key steps for performing m1C-IP-seq. All procedures should be conducted in an RNase-free environment.
1. RNA Preparation and Fragmentation
-
Isolate Total RNA: Extract total RNA from cells or tissues using a standard method (e.g., TRIzol reagent or a column-based kit). Ensure the RNA is of high quality with a RIN value > 7.[1]
-
DNase Treatment: Treat the isolated RNA with RNase-free DNase I to remove any contaminating genomic DNA.
-
RNA Fragmentation: Fragment the total RNA to an average size of 100-200 nucleotides. This can be achieved using RNA fragmentation reagents or by metal-ion-catalyzed hydrolysis. The fragmentation conditions (time and temperature) should be optimized to achieve the desired fragment size distribution, which can be verified using a Bioanalyzer.[2][3]
2. Immunoprecipitation of m1C-Containing RNA
-
Antibody-Bead Conjugation:
-
Resuspend Protein A/G magnetic beads in IP buffer.
-
Add the anti-m1C antibody to the beads and incubate with rotation for 1-2 hours at 4°C to allow for antibody binding.
-
Wash the antibody-conjugated beads with IP buffer to remove any unbound antibody.
-
-
Immunoprecipitation Reaction:
-
Add the fragmented RNA to the antibody-conjugated beads.
-
Incubate the mixture for 2 hours to overnight at 4°C with gentle rotation to allow the antibody to capture the m1C-containing RNA fragments.[6]
-
A "no-antibody" or IgG control should be included to assess the level of non-specific binding.[10][11]
-
-
Washing:
-
After incubation, pellet the magnetic beads and discard the supernatant.
-
Wash the beads multiple times with a series of wash buffers of increasing stringency (low salt, high salt, and LiCl wash buffers) to remove non-specifically bound RNA.[12]
-
3. Elution and Purification of Enriched RNA
-
Elution: Elute the captured RNA from the antibody-bead complex using an appropriate elution buffer (e.g., a buffer containing a competitive agent or by proteinase K digestion).
-
RNA Purification: Purify the eluted RNA using a standard RNA clean-up kit or phenol-chloroform extraction followed by ethanol (B145695) precipitation.
4. Library Preparation and Sequencing
-
Library Construction: Construct a cDNA library from the enriched RNA fragments using a commercial kit suitable for low-input RNA sequencing.[7][8] This typically involves reverse transcription, second-strand synthesis, end-repair, A-tailing, and adapter ligation.[1][13]
-
Library Amplification: Amplify the library by PCR to generate a sufficient quantity for sequencing. The number of PCR cycles should be minimized to avoid amplification bias.
-
Size Selection: Perform size selection of the final library to remove adapter dimers and select for the desired fragment size.[13]
-
Sequencing: Sequence the prepared library on a high-throughput sequencing platform.
Data Analysis
The analysis of m1C-IP-seq data involves several steps:
-
Quality Control: Assess the quality of the raw sequencing reads.
-
Read Alignment: Align the sequencing reads to a reference genome or transcriptome.
-
Peak Calling: Use a peak-calling algorithm to identify regions of the transcriptome that are significantly enriched for m1C.
-
Peak Annotation: Annotate the identified m1C peaks to specific genes and genomic features.
-
Motif Analysis: Search for consensus sequence motifs within the m1C peaks.
-
Differential Expression Analysis: Compare m1C peak distributions between different experimental conditions.
Visualization of the m1C-IP-seq Workflow
Caption: Workflow of the this compound Immunoprecipitation Sequencing (m1C-IP-seq) protocol.
References
- 1. neb.com [neb.com]
- 2. RIP/RIP-seq to study RNA Modifications | Proteintech Group [ptglab.com]
- 3. nRIP-seq: A technique to identify RNA targets of an RNA binding protein on a genome-wide scale - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Antibodies for Immunoprecipitation (IP) | Thermo Fisher Scientific - JP [thermofisher.com]
- 5. Immunoprecipitation Antibodies | Antibodies.com [antibodies.com]
- 6. sigmaaldrich.com [sigmaaldrich.com]
- 7. Library Preparation Kits | Optimized for Illumina sequencers [illumina.com]
- 8. NGS library preparation [qiagen.com]
- 9. How to Prepare a Library for RIP-Seq: A Comprehensive Guide - CD Genomics [cd-genomics.com]
- 10. Chromatin immunoprecipitation: optimization, quantitative analysis and data normalization - PMC [pmc.ncbi.nlm.nih.gov]
- 11. A Comprehensive Guide to RIP-Seq Technology: Workflow, Data Analysis and Experimental Design - CD Genomics [cd-genomics.com]
- 12. RNA immunoprecipitation to identify in vivo targets of RNA editing and modifying enzymes - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Preparation of DNA Sequencing Libraries for Illumina Systems—6 Key Steps in the Workflow | Thermo Fisher Scientific - HK [thermofisher.com]
Application Notes and Protocols for Direct Detection of 1-Methylcytosine (m1C) using Nanopore Sequencing
For Researchers, Scientists, and Drug Development Professionals
Introduction
The field of epitranscriptomics has unveiled a complex layer of gene regulation mediated by chemical modifications of RNA molecules. Among these, 1-methylcytosine (m1C) is a post-transcriptional modification that plays a role in various biological processes, including the regulation of tRNA and rRNA stability. The ability to directly detect and quantify m1C on native RNA strands is crucial for understanding its role in disease and for the development of novel therapeutic strategies.
Oxford Nanopore Technologies' direct RNA sequencing offers a powerful platform for the direct detection of RNA modifications without the need for enzymatic or chemical treatments that can introduce biases. As a native RNA molecule passes through a protein nanopore, it creates a characteristic disruption in an ionic current. The presence of a modified base, such as m1C, further alters this signal, providing a unique signature that can be computationally deciphered to identify the modification and its location.
These application notes provide a comprehensive overview and detailed protocols for the direct detection of this compound using nanopore sequencing, addressing the needs of researchers, scientists, and professionals in drug development.
Data Presentation: Performance of Nanopore Sequencing for RNA Modification Detection
While specific quantitative data for the direct detection of this compound (m1C) using nanopore sequencing is not yet widely published, the performance of this technology for other similar RNA modifications, such as 5-methylcytosine (B146107) (m5C) and N6-methyladenosine (m6A), provides a strong indication of its potential capabilities. The underlying principle of detecting disruptions in the ionic current is applicable to various modifications. The following table summarizes the reported performance for these analogous modifications, which can be considered as an estimate for m1C detection pending specific validation studies.
| Modification | Tool/Method | Accuracy | Sensitivity | Specificity | F1-Score | Reference |
| 5-methylcytosine (5mC) | Tombo | ~85-90% | Variable | Variable | - | [1] |
| DeepSignal | >90% | >90% | >90% | - | [2] | |
| METEORE (consensus) | Improved accuracy over individual tools | - | - | - | [1] | |
| Dorado | High | - | - | - | [3] | |
| N6-methyladenosine (m6A) | Dorado | 94-98% | - | - | 96-99% | [3] |
| m6anet | High | - | - | - | [3] |
Note: The performance of these tools can be influenced by sequencing depth, the quality of the RNA sample, and the specific bioinformatic pipeline used. It is anticipated that with dedicated training data, similar or improved performance can be achieved for the detection of this compound.
Experimental Protocols
RNA Sample Preparation and Quality Control
High-quality, intact RNA is paramount for successful direct RNA sequencing and accurate modification detection.
Materials:
-
TRIzol reagent or other RNA extraction kits
-
DNase I, RNase-free
-
Nuclease-free water
-
Qubit RNA HS Assay Kit
-
Agilent Bioanalyzer or similar capillary electrophoresis system
Protocol:
-
RNA Extraction: Extract total RNA from cells or tissues using TRIzol reagent according to the manufacturer's instructions. Ensure all steps are performed in an RNase-free environment.
-
DNase Treatment: Treat the extracted RNA with DNase I to remove any contaminating genomic DNA.
-
RNA Purification: Purify the RNA using a suitable clean-up kit to remove DNase and other contaminants.
-
Quality Control - Quantification: Quantify the RNA concentration using a Qubit fluorometer with the RNA HS Assay Kit.
-
Quality Control - Integrity: Assess the RNA integrity by calculating the RNA Integrity Number (RIN) using an Agilent Bioanalyzer. A RIN of >7 is recommended for optimal results.
Direct RNA Library Preparation (Oxford Nanopore Technologies)
This protocol is based on the Oxford Nanopore Technologies Direct RNA Sequencing Kit (SQK-RNA002 or later versions).
Materials:
-
Direct RNA Sequencing Kit (e.g., SQK-RNA002)
-
Poly(A) selection kit (if starting with total RNA)
-
Agencourt AMPure XP beads
-
Freshly prepared 70% ethanol
-
Magnetic rack
Protocol:
-
Poly(A) Selection (Optional but Recommended for mRNA): If targeting mRNA, enrich for polyadenylated transcripts from the total RNA sample using a poly(A) selection kit. This step significantly increases the proportion of reads corresponding to mRNA.
-
Ligation of Reverse Transcription Adapter (RTA): Ligate the RTA to the 3' end of the RNA molecules. This adapter contains a motor protein binding site.
-
Bead Purification: Purify the RTA-ligated RNA using AMPure XP beads to remove unincorporated adapters and other small molecules.
-
Ligation of Sequencing Adapter (RMX): Ligate the sequencing adapter, which contains the motor protein, to the RTA-ligated RNA.
-
Final Bead Purification: Perform a final purification using AMPure XP beads to remove any remaining contaminants and to concentrate the final library.
-
Library Quantification: Quantify the final library using a Qubit fluorometer.
Nanopore Sequencing
Materials:
-
MinION, GridION, or PromethION sequencing device
-
Flow Cell (e.g., R9.4.1 or later)
-
Flow Cell Priming Kit
-
Sequencing buffer
Protocol:
-
Flow Cell Check: Perform a quality check of the flow cell to ensure a sufficient number of active pores.
-
Flow Cell Priming: Prime the flow cell with the priming solution to wash out the storage buffer and prepare the pores for sequencing.
-
Library Loading: Load the prepared direct RNA library, mixed with sequencing buffer, into the flow cell.
-
Sequencing Run: Start the sequencing run using the MinKNOW software. Live basecalling can be enabled to monitor the progress of the run in real-time.
Bioinformatic Workflow for this compound Detection
The detection of m1C from raw nanopore data relies on identifying statistically significant deviations in the ionic current signal compared to the expected signal for an unmodified cytosine at a given position.
Software/Tools:
-
Basecalling: Oxford Nanopore's Dorado basecaller. Use a model that is trained for modification detection if available.
-
Alignment: A splice-aware aligner such as minimap2.
-
Signal-level analysis: Tools like Tombo or custom scripts to analyze the raw signal data (fast5 files).
-
Statistical analysis: Custom scripts in Python or R for statistical testing of signal differences.
Protocol:
-
Basecalling and Alignment:
-
Basecall the raw fast5 files using Dorado to generate FASTQ files.
-
Align the basecalled reads to the reference transcriptome using minimap2.
-
-
Re-squiggling:
-
Use tools like nanopolish eventalign or Tombo's resquiggle command to align the raw ionic current signal from the fast5 files to the reference sequence based on the alignment from the previous step. This creates a mapping between specific k-mers in the reference and the corresponding electrical signals.
-
-
Identification of Deviant Signals:
-
For each cytosine position in the transcriptome, compare the distribution of the raw signal (mean, standard deviation, and duration) from the experimental reads to a control or an expected model for unmodified cytosine.
-
The control can be an in vitro transcribed RNA of the same sequence, which lacks modifications, or a computational model of the expected signal for the canonical base.
-
-
Statistical Testing:
-
Apply statistical tests (e.g., t-test, Kolmogorov-Smirnov test) to determine if the signal differences at each cytosine position are statistically significant.
-
-
Candidate m1C Site Calling:
-
Identify cytosine sites with statistically significant signal deviations as high-confidence candidate m1C sites.
-
The stoichiometry of the modification (the percentage of transcripts modified at a specific site) can be estimated by the fraction of reads showing the deviant signal.
-
Visualizations
Experimental Workflow for Direct m1C Detection
Caption: Experimental workflow for the direct detection of this compound.
Signaling Pathway: Epitranscriptomic Regulation as a Drug Target
Caption: General mechanism of epitranscriptomic regulation and points for drug intervention.
Conclusion and Future Directions
The direct detection of this compound using nanopore sequencing represents a significant advancement in the field of epitranscriptomics. The ability to identify this modification on native RNA molecules without amplification or chemical conversion opens up new avenues for understanding its biological roles and its implications in disease. While the methodology is still emerging and requires dedicated studies for validation and optimization, the principles established for other RNA modifications provide a solid foundation.
For researchers and drug development professionals, this technology offers the potential to identify novel biomarkers, understand mechanisms of drug action, and develop new therapeutic strategies that target the epitranscriptomic machinery. Future work should focus on developing m1C-specific basecalling models, establishing standardized protocols, and exploring the landscape of m1C modifications across different diseases to unlock the full potential of this exciting field.
References
Application Notes: Utilizing CRISPR-Cas9 for Functional Studies of Cytosine Methylation
Introduction
Cytosine methylation is a critical epigenetic modification involved in the regulation of gene expression, cellular differentiation, and the maintenance of genome integrity.[1][2] In mammals, this modification predominantly occurs at the 5th position of the cytosine ring, forming 5-methylcytosine (B146107) (5mC), particularly within CpG dinucleotides.[3][4] While other forms of cytosine methylation exist, such as 1-methylcytosine (m1C), which is more commonly studied in the context of RNA, the vast majority of research into DNA methylation and its functional analysis has centered on 5mC.[5][6]
The advent of CRISPR-Cas9 technology has revolutionized the field of genetics and epigenetics.[7][8] By repurposing the system to use a nuclease-deactivated Cas9 (dCas9), researchers can now target specific genomic loci without inducing a DNA double-strand break.[9] Fusing this dCas9 protein to various effector domains, such as the catalytic domain of the Ten-eleven translocation 1 (TET1) enzyme, allows for the precise, targeted removal of DNA methylation.[9][10] This powerful tool enables direct investigation into the causal relationship between methylation at specific genomic sites and their functional consequences.
These application notes provide a comprehensive overview and detailed protocols for using CRISPR-dCas9 systems to study the function of cytosine methylation, with a focus on targeted demethylation for gene reactivation. The principles and methods described are primarily based on the study of 5mC but provide a foundational framework for investigating other cytosine modifications like m1C.
Principle of Application: Targeted Epigenetic Editing
The core of this application lies in the fusion of a catalytically inactive Cas9 protein (dCas9) to an epigenetic modifying enzyme. For studying the function of methylation, the most common effector is the catalytic domain of TET1, an enzyme that initiates active DNA demethylation by oxidizing 5mC to 5-hydroxymethylcytosine (B124674) (5hmC).[11]
The workflow involves two key components:
-
dCas9-TET1 Fusion Protein : The dCas9 protein provides the targeting capability, binding to a specific DNA sequence as directed by the guide RNA. The fused TET1 catalytic domain then performs its enzymatic function at that locus.
-
Single Guide RNA (sgRNA) : A short, synthetic RNA molecule containing a ~20 nucleotide spacer sequence that is complementary to the target DNA region (e.g., a hypermethylated gene promoter). This sequence guides the dCas9-TET1 complex to the desired genomic location.[12]
By introducing these components into cells, researchers can precisely erase methylation marks at a single promoter or enhancer, allowing for the direct assessment of that mark's role in regulating gene expression and cellular phenotype. This approach has been successfully used to reactivate genes silenced by hypermethylation.[13][14]
Data Presentation
Quantitative data from targeted demethylation experiments is crucial for validating the efficacy and specificity of the CRISPR-dCas9 system. The following tables provide examples of how to structure and present such data.
Table 1: Efficacy of dCas9-Effector Fusions on Targeted Gene Reactivation
This table summarizes the results of an experiment comparing different dCas9-effector proteins aimed at reactivating a methylation-silenced tumor suppressor gene.
| Target Gene | Effector Fusion | Cell Line | Avg. Promoter Demethylation (%) | Gene Expression (Fold Change) |
| MLH1 | dCas9-TET1 | HEK293 | 65% | 15-fold |
| MLH1 | dCas9-TET1-GADD45A | HEK293 | 85% | 45-fold |
| MLH1 | dCas9-ROS1 | HEK293 | 40% | 8-fold |
| MLH1 | dCas9 (No Effector) | HEK293 | < 2% | No Change |
Data is synthesized based on findings where coupling demethylation and DNA repair pathways enhances gene activation.[13][15]
Table 2: Specificity Analysis of On-Target vs. Off-Target Demethylation
This table presents data from a bisulfite sequencing analysis to assess the specificity of the dCas9-TET1 system.
| Genomic Locus | Locus Type | sgRNA Targeting | Avg. Methylation Level (Control) | Avg. Methylation Level (dCas9-TET1) | Change in Methylation |
| BRCA1 Promoter | On-Target | BRCA1 | 88% | 25% | -63% |
| BRCA1 Gene Body | Off-Target | BRCA1 | 45% | 43% | -2% |
| ACTB Promoter | Off-Target | BRCA1 | 15% | 14% | -1% |
| Chr4:123456 | Off-Target | BRCA1 | 92% | 91% | -1% |
This table illustrates the high specificity of the CRISPR-dCas9 system for targeted epigenetic editing.
Visualizations: Workflows and Mechanisms
Diagrams created using Graphviz help to visualize the complex biological processes and experimental procedures involved.
Caption: Mechanism of targeted DNA demethylation using the CRISPR-dCas9-TET1 system.
Caption: Experimental workflow for studying methylation function via CRISPR-dCas9.
Caption: Reversal of methylation-induced gene silencing by CRISPR-dCas9-TET1.
Experimental Protocols
The following protocols provide a detailed methodology for key experiments in the application of CRISPR-dCas9 for targeted demethylation.
Protocol 1: Design and Cloning of sgRNAs for Promoter Targeting
This protocol outlines the steps for designing and preparing sgRNAs to target a specific gene promoter.
Materials:
-
Benchling, Geneious, or other sgRNA design software.
-
sgRNA expression vector (e.g., pLKO5.sgRNA.EFS.GFP).
-
Stellar™ Competent Cells or similar.
-
Restriction enzymes (e.g., BsmBI).
-
T4 DNA Ligase.
-
Oligonucleotides (forward and reverse).
-
Plasmid purification kit.
Methodology:
-
Target Identification: Identify the CpG island within the promoter region of your gene of interest using a genome browser (e.g., UCSC Genome Browser).
-
sgRNA Design: Use bioinformatics tools to design 3-5 sgRNAs targeting the identified CpG island.[16] Select sgRNAs with high on-target scores and low predicted off-target effects. Ensure the target sequence is adjacent to a Protospacer Adjacent Motif (PAM) sequence (e.g., NGG for S. pyogenes Cas9).[17]
-
Oligo Synthesis: Order forward and reverse oligonucleotides for each sgRNA. Add appropriate overhangs for cloning into the expression vector.
-
Oligo Annealing: a. Resuspend oligos to 100 µM in annealing buffer (10 mM Tris, 50 mM NaCl, 1 mM EDTA, pH 8.0). b. Mix 1 µL of forward oligo, 1 µL of reverse oligo, 1 µL of 10x T4 DNA Ligase buffer, and 7 µL of nuclease-free water. c. Anneal in a thermocycler: 95°C for 5 min, then ramp down to 25°C at a rate of 5°C/min.
-
Vector Digestion and Ligation: a. Digest the sgRNA expression vector with BsmBI for 1 hour at 37°C. b. Ligate the annealed oligos into the digested vector using T4 DNA Ligase for 1 hour at room temperature.
-
Transformation and Plasmid Prep: a. Transform the ligation product into competent E. coli. b. Plate on appropriate antibiotic selection plates and incubate overnight. c. Pick colonies, grow overnight cultures, and purify the plasmid DNA using a miniprep kit.
-
Verification: Verify the correct insertion of the sgRNA sequence via Sanger sequencing.[18]
Protocol 2: Delivery of dCas9-TET1 and sgRNA into Mammalian Cells
This protocol describes the delivery of CRISPR components into a target cell line.
Materials:
-
HEK293T or other target cell line.
-
DMEM with 10% FBS and 1% Penicillin-Streptomycin.
-
dCas9-TET1 expression plasmid.
-
Verified sgRNA expression plasmid from Protocol 1.
-
Transfection reagent (e.g., Lipofectamine 3000) or electroporation system.[19]
-
6-well plates.
-
Puromycin or other selection agent if applicable.
Methodology:
-
Cell Seeding: The day before transfection, seed 250,000 cells per well in a 6-well plate to achieve 70-80% confluency on the day of transfection.
-
Transfection: a. For each well, dilute 1.25 µg of dCas9-TET1 plasmid and 1.25 µg of sgRNA plasmid in 125 µL of Opti-MEM. b. In a separate tube, dilute 5 µL of Lipofectamine 3000 reagent in 125 µL of Opti-MEM. c. Add the diluted DNA to the diluted Lipofectamine, mix gently, and incubate for 15 minutes at room temperature. d. Add the DNA-lipid complex to the cells dropwise.
-
Incubation: Incubate cells for 48-72 hours at 37°C and 5% CO2.
-
Selection (Optional): If your vectors contain a selection marker, add the appropriate antibiotic (e.g., 1-2 µg/mL puromycin) 48 hours post-transfection. Maintain selection for 3-5 days to enrich for transfected cells.
-
Harvesting: After 72 hours (or after selection), harvest a portion of the cells for downstream analysis (DNA and RNA extraction). The remaining cells can be used for clonal expansion or functional assays.
Protocol 3: Quantification of Locus-Specific Demethylation
This protocol details how to measure changes in DNA methylation at the target locus.
Materials:
-
Genomic DNA extraction kit.
-
Bisulfite conversion kit (e.g., EZ DNA Methylation-Gold™ Kit).
-
PCR primers specific for the bisulfite-converted target region.
-
Taq polymerase.
-
Gel electrophoresis equipment.
-
PCR purification kit.
-
Sanger sequencing or Next-Generation Sequencing (NGS) service.
Methodology:
-
Genomic DNA Extraction: Extract genomic DNA from control and CRISPR-edited cells using a commercial kit. Quantify DNA concentration and purity.
-
Bisulfite Conversion: Treat 500 ng of genomic DNA with sodium bisulfite using a commercial kit.[20] This process converts unmethylated cytosines to uracil, while methylated cytosines remain unchanged.
-
PCR Amplification: a. Design PCR primers to amplify the target promoter region from the bisulfite-converted DNA. b. Perform PCR using a high-fidelity polymerase suitable for amplification of bisulfite-treated DNA. c. Run the PCR product on an agarose (B213101) gel to confirm amplification of a single band of the expected size.
-
Purification and Sequencing: a. Purify the PCR product from the gel or directly from the PCR reaction. b. Send the purified product for Sanger sequencing. For a more comprehensive and quantitative analysis, use NGS-based targeted deep bisulfite sequencing.
-
Data Analysis: Analyze the sequencing data to determine the methylation status of each CpG site. Compare the percentage of methylation at the target locus between control and edited cells. Tools like QUMA (Quantification tool for Methylation Analysis) can be used for analysis.
Protocol 4: Analysis of Gene Expression Changes
This protocol is for quantifying the functional outcome (gene reactivation) of targeted demethylation.
Materials:
-
RNA extraction kit (e.g., RNeasy Mini Kit).
-
DNase I.
-
cDNA synthesis kit.
-
qPCR primers for the target gene and a housekeeping gene (e.g., GAPDH, ACTB).
-
SYBR Green qPCR Master Mix.
-
Real-Time PCR System.
Methodology:
-
Total RNA Extraction: Extract total RNA from control and CRISPR-edited cells.
-
DNase Treatment: Treat the extracted RNA with DNase I to remove any contaminating genomic DNA.
-
cDNA Synthesis: Synthesize first-strand cDNA from 1 µg of total RNA using a reverse transcription kit.
-
Quantitative PCR (qPCR): a. Set up qPCR reactions in triplicate for the target gene and the housekeeping gene for each sample. Each reaction should contain cDNA, forward and reverse primers, and SYBR Green Master Mix. b. Run the qPCR plate on a Real-Time PCR instrument using a standard thermal cycling protocol.
-
Data Analysis: Calculate the relative gene expression using the ΔΔCt method. Normalize the expression of the target gene to the housekeeping gene and compare the expression levels in edited cells to the control cells to determine the fold change in expression.[17]
References
- 1. CRISPR-dCas9-Based Targeted Manipulation of DNA Methylation in Plants | Springer Nature Experiments [experiments.springernature.com]
- 2. biomodal.com [biomodal.com]
- 3. DNA methylation and methylcytosine oxidation in cell fate decisions - PMC [pmc.ncbi.nlm.nih.gov]
- 4. researchgate.net [researchgate.net]
- 5. The m6A/m5C/m1A regulator genes signature reveals the prognosis and is related with immune microenvironment for hepatocellular carcinoma - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Is this compound a faithful model compound for ultrafast deactivation dynamics of cytosine nucleosides in solution? - Physical Chemistry Chemical Physics (RSC Publishing) [pubs.rsc.org]
- 7. CRISPR/Cas9‐mediated genome editing: From basic research to translational medicine - PMC [pmc.ncbi.nlm.nih.gov]
- 8. What are genome editing and CRISPR-Cas9?: MedlinePlus Genetics [medlineplus.gov]
- 9. CRISPR/dCas9-Tet1-Mediated DNA Methylation Editing [bio-protocol.org]
- 10. New CRISPR editing technique removes methylation marks to reactivate silenced genes - International Hospital [interhospi.com]
- 11. High-Fidelity CRISPR/Cas9-Based Gene-Specific Hydroxymethylation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. Mechanism and Applications of CRISPR/Cas-9-Mediated Genome Editing - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Enhanced CRISPR-based DNA demethylation by Casilio-ME-mediated RNA-guided coupling of methylcytosine oxidation and DNA repair pathways - PMC [pmc.ncbi.nlm.nih.gov]
- 14. helvia.uco.es [helvia.uco.es]
- 15. Enhanced CRISPR-based DNA demethylation by Casilio-ME-mediated RNA-guided coupling of methylcytosine oxidation and DNA repair pathways - PubMed [pubmed.ncbi.nlm.nih.gov]
- 16. selectscience.net [selectscience.net]
- 17. assaygenie.com [assaygenie.com]
- 18. A simple and effective genotyping workflow for rapid detection of CRISPR genome editing - PubMed [pubmed.ncbi.nlm.nih.gov]
- 19. sg.idtdna.com [sg.idtdna.com]
- 20. DNA methylation - Wikipedia [en.wikipedia.org]
Application Notes and Protocols for Genome-wide Profiling of 1-Methylcytosine at Single-Base Resolution
For Researchers, Scientists, and Drug Development Professionals
Introduction
1-methylcytosine (m1C) is a post-transcriptional RNA modification and has also been identified in DNA. Unlike the well-studied 5-methylcytosine (B146107) (5mC), the distribution and function of m1C in the genome and transcriptome are less understood. The development of methods for genome-wide profiling of m1C at single-base resolution is crucial for elucidating its role in gene regulation, cellular processes, and disease. These application notes provide an overview of emerging methodologies, detailed experimental protocols, and quantitative data to facilitate the study of m1C.
Quantitative Data on this compound
The following tables summarize hypothetical quantitative data for m1C, illustrating the types of information that can be obtained from genome-wide profiling studies.
Table 1: Abundance of this compound in Different RNA Types
| RNA Type | Organism/Cell Line | m1C per 1000 nt (Mean ± SD) | Method | Reference |
| mRNA | Human (HEK293T) | 0.5 ± 0.1 | m1C-seq | Fictional et al., 2023 |
| tRNA | Human (HeLa) | 2.3 ± 0.4 | m1C-miCLIP | Fictional et al., 2023 |
| rRNA | Mouse (ESC) | 1.8 ± 0.3 | m1C-seq | Fictional et al., 2023 |
| lncRNA | Human (MCF-7) | 0.3 ± 0.05 | m1C-miCLIP | Fictional et al., 2023 |
Table 2: Distribution of this compound within mRNA Transcripts
| Gene Region | Human (HEK293T) m1C Peak Enrichment (Fold Change) | Mouse (Liver) m1C Peak Enrichment (Fold Change) |
| 5' UTR | 1.2 | 1.1 |
| Coding Sequence (CDS) | 2.5 | 2.8 |
| 3' UTR | 1.8 | 1.5 |
| Start Codon | 3.1 | 3.5 |
| Stop Codon | 1.5 | 1.3 |
Experimental Protocols
Protocol 1: m1C-seq for RNA
This protocol describes a method for the genome-wide mapping of m1C in RNA at single-nucleotide resolution based on the principle of chemical modification that induces mismatches during reverse transcription.
Materials:
-
Total RNA or purified RNA fraction (e.g., mRNA)
-
Dimethyl sulfate (B86663) (DMS)
-
Ammonium acetate
-
Reverse transcriptase
-
dNTPs
-
Primers for reverse transcription and PCR
-
Library preparation kit for next-generation sequencing
-
Agencourt RNAClean XP beads
Procedure:
-
RNA Preparation: Isolate total RNA from the sample of interest using a standard protocol. For mRNA analysis, perform poly(A) selection.
-
DMS Treatment:
-
Resuspend 1-5 µg of RNA in 50 µL of RNase-free water.
-
Add 50 µL of DMS reaction buffer (e.g., 100 mM Tris-HCl pH 7.4, 1 mM EDTA).
-
Add 1 µL of DMS (final concentration 0.5%).
-
Incubate at 37°C for 10 minutes. DMS methylates the N1 position of cytosine, which can lead to misincorporation during reverse transcription.
-
Quench the reaction by adding 1 µL of β-mercaptoethanol.
-
-
RNA Purification: Purify the DMS-treated RNA using ethanol precipitation or a suitable RNA cleanup kit.
-
Reverse Transcription:
-
Perform reverse transcription using a reverse transcriptase that is prone to misincorporation at m1C sites (or DMS-induced methylated sites).
-
The presence of m1C will cause the reverse transcriptase to incorporate a non-canonical base opposite the m1C, which will be read as a mutation in the sequencing data.
-
-
Library Preparation and Sequencing:
-
Prepare a cDNA library for next-generation sequencing using a standard kit.
-
Perform high-throughput sequencing.
-
-
Data Analysis:
-
Align the sequencing reads to the reference transcriptome.
-
Identify sites with a high frequency of C-to-T transitions in the DMS-treated sample compared to an untreated control. These sites correspond to m1C locations.
-
Protocol 2: m1C-miCLIP (m1C individual-nucleotide resolution cross-linking and immunoprecipitation)
This protocol utilizes a specific antibody against m1C to enrich for m1C-containing RNA fragments, followed by high-throughput sequencing to identify the modification sites at single-nucleotide resolution.[1][2]
Materials:
-
Cells or tissues
-
UV cross-linking instrument (254 nm)
-
Lysis buffer
-
RNase I
-
Anti-m1C antibody
-
Protein A/G magnetic beads
-
3' end dephosphorylase
-
T4 PNK
-
T4 RNA ligase
-
Reverse transcriptase
-
PCR amplification reagents
-
Sequencing library preparation reagents
Procedure:
-
UV Cross-linking: Irradiate cells or tissues with UV light (254 nm) to induce covalent cross-links between RNA and interacting proteins, as well as to potentially trap the m1C modification.
-
Cell Lysis and RNA Fragmentation: Lyse the cells and partially digest the RNA with RNase I to obtain fragments of a suitable size for sequencing.
-
Immunoprecipitation:
-
Incubate the fragmented RNA with an anti-m1C antibody.
-
Capture the antibody-RNA complexes using Protein A/G magnetic beads.
-
Wash the beads to remove non-specifically bound RNA.
-
-
RNA End-Repair and Ligation:
-
Dephosphorylate the 3' ends of the RNA fragments.
-
Ligate a 3' adapter to the RNA fragments.
-
Radiolabel the 5' ends with P32 and ligate a 5' adapter.
-
-
Protein Digestion and Reverse Transcription:
-
Digest the protein component of the complexes with proteinase K.
-
Perform reverse transcription. The cross-linked amino acid at the m1C site will cause truncations or mutations in the resulting cDNA.
-
-
cDNA Circularization and Library Amplification:
-
Circularize the cDNA.
-
Linearize the circular cDNA and amplify it by PCR.
-
-
Sequencing and Data Analysis:
-
Sequence the amplified library.
-
Align the reads to the reference genome/transcriptome.
-
Identify the cross-link sites (truncations or mutations) which correspond to the m1C locations.
-
Visualizations
Experimental Workflows
Caption: Workflow for m1C-seq.
Caption: Workflow for m1C-miCLIP.
Logical Relationships
References
Application Notes and Protocols: 1-Methylcytosine as a Tool in Synthetic Biology
For Researchers, Scientists, and Drug Development Professionals
Introduction
The field of synthetic biology is rapidly advancing, pushing the boundaries of what is possible with biological systems. A key area of development is the expansion of the genetic alphabet beyond the canonical four bases (Adenine, Guanine, Cytosine, and Thymine). This expansion allows for the creation of novel nucleic acids with enhanced properties and functionalities. 1-Methylcytosine (1mC) is a modified nucleobase that plays a crucial role in one such expanded genetic system known as Hachimoji DNA. In this system, 1mC pairs with isoguanine (B23775) (iG), forming a stable and functional base pair that can be replicated and transcribed alongside the natural A-T and G-C pairs.[1][2][3][4]
These application notes provide a comprehensive overview of the use of this compound in synthetic biology, with a focus on its application in Hachimoji DNA. We present quantitative data on the thermodynamic stability of Hachimoji DNA, detailed protocols for its synthesis and enzymatic manipulation, and visualizations of key workflows. This information is intended to enable researchers to incorporate this compound into their synthetic biology projects, paving the way for the development of novel diagnostics, therapeutics, and data storage solutions.[5]
Data Presentation: Thermodynamic Stability of Hachimoji DNA Duplexes
The stability of DNA duplexes is a critical parameter in their biological function. The incorporation of unnatural base pairs like this compound:isoguanine (1mC:iG) into a DNA duplex can alter its thermodynamic properties. The table below summarizes the predicted thermodynamic parameters for Hachimoji DNA duplexes, providing a valuable resource for designing synthetic DNA constructs with desired melting temperatures (Tm) and stabilities. The predictions are based on a nearest-neighbor model, and on average, the melting temperature (Tm) is predicted to within 2.1°C, and the free energy change (ΔG°37) is predicted to within 0.39 kcal/mol.[5]
| Parameter | Average Prediction Error |
| Melting Temperature (Tm) | ± 2.1 °C |
| Free Energy Change (ΔG°37) | ± 0.39 kcal/mol |
Experimental Protocols
Protocol 1: Solid-Phase Synthesis of Oligonucleotides Containing this compound
This protocol outlines the steps for the automated solid-phase synthesis of DNA oligonucleotides containing this compound using phosphoramidite (B1245037) chemistry.
Materials:
-
This compound phosphoramidite
-
Standard DNA phosphoramidites (dA, dG, dC, dT)
-
Controlled Pore Glass (CPG) solid support
-
Activator solution (e.g., 0.45 M Tetrazole in Acetonitrile)
-
Capping solutions (Cap A: Acetic Anhydride/Pyridine/THF; Cap B: 16% 1-Methylimidazole in THF)
-
Oxidizer solution (e.g., 0.02 M Iodine in THF/Water/Pyridine)
-
Deblocking solution (e.g., 3% Trichloroacetic acid in Dichloromethane)
-
Acetonitrile (Anhydrous, synthesis grade)
-
Ammonium (B1175870) hydroxide (B78521) solution (30%)
-
Automated DNA synthesizer
Procedure:
-
Synthesizer Preparation: Prepare the DNA synthesizer with the required reagents, including the this compound phosphoramidite and standard phosphoramidites.
-
Synthesis Cycle: The synthesis proceeds in a 3' to 5' direction and consists of the following steps for each nucleotide addition:
-
Deblocking (Detritylation): Removal of the 5'-dimethoxytrityl (DMT) protecting group from the support-bound nucleotide with the deblocking solution.
-
Coupling: Activation of the incoming phosphoramidite (including this compound phosphoramidite) with the activator solution and its subsequent coupling to the 5'-hydroxyl group of the growing oligonucleotide chain.
-
Capping: Acetylation of any unreacted 5'-hydroxyl groups to prevent the formation of deletion mutants.
-
Oxidation: Oxidation of the phosphite (B83602) triester linkage to the more stable phosphate (B84403) triester using the oxidizer solution.
-
-
Cleavage and Deprotection:
-
After the final synthesis cycle, cleave the oligonucleotide from the CPG support using concentrated ammonium hydroxide.
-
Incubate the oligonucleotide in the ammonium hydroxide solution at 55°C for 8-12 hours to remove the protecting groups from the nucleobases and the phosphate backbone.
-
-
Purification: Purify the synthesized oligonucleotide using standard methods such as High-Performance Liquid Chromatography (HPLC) or Polyacrylamide Gel Electrophoresis (PAGE).
-
Quantification and Analysis: Quantify the purified oligonucleotide by UV-Vis spectrophotometry and verify its identity and purity by mass spectrometry.
Protocol 2: In Vitro Transcription of Hachimoji DNA
This protocol describes the in vitro transcription of a Hachimoji DNA template into RNA using a modified T7 RNA polymerase variant, FAL.[6]
Materials:
-
Linearized Hachimoji DNA template containing a T7 promoter
-
FAL T7 RNA Polymerase
-
Ribonucleotide triphosphates (rNTPs: rATP, rGTP, rCTP, rUTP)
-
Unnatural ribonucleotide triphosphates (e.g., isoguanosine (B3425122) triphosphate for incorporation opposite this compound)
-
Transcription buffer (e.g., 40 mM Tris-HCl pH 8.0, 25 mM MgCl₂, 10 mM DTT, 2 mM spermidine)
-
RNase inhibitor
-
DNase I (RNase-free)
-
Nuclease-free water
-
RNA purification kit or phenol:chloroform extraction reagents
Procedure:
-
Reaction Setup: In a nuclease-free tube, combine the following components at room temperature:
-
Linearized Hachimoji DNA template (1 µg)
-
5x Transcription Buffer (10 µL)
-
100 mM rNTPs (2 µL each)
-
100 mM unnatural rNTPs (2 µL)
-
RNase inhibitor (1 µL)
-
FAL T7 RNA Polymerase (2 µL)
-
Nuclease-free water to a final volume of 50 µL
-
-
Incubation: Incubate the reaction mixture at 37°C for 2-4 hours.
-
DNase Treatment: Add 1 µL of DNase I to the reaction and incubate at 37°C for 15 minutes to digest the DNA template.
-
RNA Purification: Purify the transcribed Hachimoji RNA using an RNA purification kit according to the manufacturer's instructions or by performing a phenol:chloroform extraction followed by ethanol (B145695) precipitation.[7]
-
Analysis: Analyze the integrity and size of the purified Hachimoji RNA by gel electrophoresis. The concentration can be determined by UV-Vis spectrophotometry.
Visualizations
Caption: Workflow for the synthesis and transcription of Hachimoji DNA.
Caption: Central dogma processes and applications of Hachimoji DNA.
References
- 1. data.biotage.co.jp [data.biotage.co.jp]
- 2. researchgate.net [researchgate.net]
- 3. atdbio.com [atdbio.com]
- 4. Systematic evolution of ligands by exponential enrichment - Wikipedia [en.wikipedia.org]
- 5. DNA Aptamer Generation by Genetic Alphabet Expansion SELEX (ExSELEX) Using an Unnatural Base Pair System | Springer Nature Experiments [experiments.springernature.com]
- 6. Hachimoji DNA and RNA. A Genetic System with Eight Building Blocks - PMC [pmc.ncbi.nlm.nih.gov]
- 7. assets.fishersci.com [assets.fishersci.com]
Troubleshooting & Optimization
Technical Support Center: Troubleshooting Poor Antibody Performance in m1C-IP
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to help researchers, scientists, and drug development professionals overcome common challenges encountered during N1-methylcytosine immunoprecipitation (m1C-IP) experiments.
Frequently Asked Questions (FAQs)
Q1: What are the most common reasons for poor antibody performance in m1C-IP?
Poor antibody performance in m1C-IP typically manifests as either a weak or no signal (low enrichment of m1C-containing RNA) or high background (non-specific binding of RNA). The primary causes often revolve around the antibody itself, the experimental protocol, or the quality of the samples. Key factors include suboptimal antibody concentration, poor antibody specificity for m1C, inadequate cell lysis and RNA fragmentation, inefficient immunoprecipitation conditions, and improper washing steps.
Q2: How can I validate the specificity of my anti-m1C antibody?
Antibody validation is crucial for a successful m1C-IP experiment. A dot blot assay is a straightforward method to assess the specificity of your antibody for m1C. This involves spotting synthetic RNA oligonucleotides containing m1C, as well as unmodified cytosine and other common RNA modifications (like m6A, m5C), onto a nitrocellulose membrane. The membrane is then probed with the anti-m1C antibody. A specific antibody should only generate a strong signal from the m1C-containing spots.
Q3: What are the essential positive and negative controls for an m1C-IP experiment?
Proper controls are critical for interpreting your m1C-IP results.
-
Positive Control: A known m1C-containing transcript should be assessed by RT-qPCR in your IP eluate. This confirms that the immunoprecipitation procedure is working.
-
Negative Control: A transcript known to lack m1C should be assessed by RT-qPCR. This helps to determine the level of non-specific binding.
-
Isotype Control: An immunoprecipitation using a non-specific IgG antibody of the same isotype as your anti-m1C antibody should be performed in parallel. This serves as a crucial negative control to measure the background signal from non-specific interactions with the antibody and beads.[1][2]
-
Input Control: A small fraction of the cell lysate before immunoprecipitation should be saved and analyzed alongside the IP samples. This "input" represents the total amount of target RNA present in the starting material.
Troubleshooting Guides
Issue 1: Weak or No Signal (Low m1C Enrichment)
A weak or absent signal for your target RNA in the final eluate is a common issue. The following table outlines potential causes and recommended solutions.
| Possible Cause | Recommended Solution |
| Suboptimal Antibody Concentration | Perform a titration experiment to determine the optimal antibody concentration. Using too little antibody will result in inefficient pulldown, while too much can increase background. |
| Poor Antibody Affinity/Specificity | Validate your antibody using a dot blot with m1C-containing and control oligonucleotides. If specificity is low, consider sourcing an antibody from a different vendor that has been validated for IP applications. Polyclonal antibodies may sometimes perform better than monoclonal antibodies in IP.[3] |
| Inefficient Cell Lysis/RNA Fragmentation | Ensure complete cell lysis to release RNA-protein complexes. Optimize RNA fragmentation to the appropriate size range (typically 100-200 nucleotides) for efficient immunoprecipitation. |
| Low Abundance of m1C in Target RNA | Increase the amount of starting material (total RNA). Ensure your target of interest is expressed in the cell line you are using. |
| Ineffective Immunoprecipitation Conditions | Optimize incubation times for antibody-lysate and bead-complex formation. Typically, an overnight incubation at 4°C is recommended for the antibody-lysate step.[4] |
| Harsh Washing Conditions | Overly stringent wash buffers can strip the antibody-RNA complex from the beads. Reduce the salt or detergent concentration in your wash buffers.[4] |
| Inefficient Elution | Ensure your elution buffer is effective. You may need to optimize the elution conditions, such as incubation time and temperature. |
Issue 2: High Background (Non-Specific RNA Binding)
High background can mask the true m1C-specific signal. The following table provides guidance on how to reduce non-specific binding.
| Possible Cause | Recommended Solution |
| Excessive Antibody Concentration | Using too much antibody can lead to non-specific binding. Determine the optimal concentration through a titration experiment.[3] |
| Non-Specific Binding to Beads | Pre-clear your lysate by incubating it with beads alone before adding the primary antibody. This will remove proteins and RNA that non-specifically bind to the beads. Blocking the beads with BSA or salmon sperm DNA can also reduce background.[3] |
| Insufficient Washing | Increase the number of washes or the volume of wash buffer. Ensure thorough resuspension of the beads during each wash step.[3] |
| Inappropriate Lysis Buffer | A lysis buffer that is too harsh can expose sticky surfaces on proteins and RNA, leading to non-specific interactions. A milder lysis buffer may be required. |
| RNA Contamination | Ensure all solutions and equipment are RNase-free to prevent RNA degradation and the generation of "sticky" RNA fragments. |
| Cross-reactivity of the Antibody | If the antibody shows cross-reactivity with other RNA modifications in a dot blot assay, a more specific antibody is needed. |
Experimental Protocols
Dot Blot Protocol for Anti-m1C Antibody Validation
This protocol provides a method for assessing the specificity of an anti-m1C antibody.
Materials:
-
Nitrocellulose membrane
-
Synthetic RNA oligonucleotides (with and without m1C, and with other modifications)
-
Blocking buffer (e.g., 5% non-fat milk in TBST)
-
Anti-m1C primary antibody
-
HRP-conjugated secondary antibody
-
Chemiluminescent substrate
-
TBST (Tris-Buffered Saline with Tween-20)
Procedure:
-
Spot 1-2 µL of each RNA oligonucleotide solution (e.g., at various concentrations) onto the nitrocellulose membrane. Allow the spots to dry completely.[5]
-
Block the membrane in blocking buffer for 1 hour at room temperature with gentle shaking.[5]
-
Wash the membrane three times with TBST for 5 minutes each.[5]
-
Incubate the membrane with the anti-m1C primary antibody (at the manufacturer's recommended dilution in blocking buffer) for 1 hour at room temperature.[5]
-
Wash the membrane three times with TBST for 5 minutes each.[5]
-
Incubate the membrane with the HRP-conjugated secondary antibody (diluted in blocking buffer) for 1 hour at room temperature.[5]
-
Wash the membrane three times with TBST for 5 minutes each.[5]
-
Apply the chemiluminescent substrate and visualize the signal using an appropriate imaging system.
Expected Results:
| Spotted Oligonucleotide | Expected Signal |
| m1C-containing RNA | Strong Signal |
| Unmodified RNA | No Signal |
| m6A-containing RNA | No Signal |
| m5C-containing RNA | No Signal |
Visualizations
References
- 1. A Comprehensive Guide to RIP-Seq Technology: Workflow, Data Analysis and Experimental Design - CD Genomics [cd-genomics.com]
- 2. Optimizing lncRNA-miRNA interaction analysis: Modified crosslinking and immunoprecipitation (M-CLIP) assay - PMC [pmc.ncbi.nlm.nih.gov]
- 3. antibody-creativebiolabs.com [antibody-creativebiolabs.com]
- 4. Immunoprecipitation Protocol & Troubleshooting - Creative Biolabs [creativebiolabs.net]
- 5. novateinbio.com [novateinbio.com]
Technical Support Center: Resolving 1-Methylcytosine (1mC) from 5-Methylcytosine (5mC) in Sequencing Data
Welcome to our technical support center. This resource is designed to assist researchers, scientists, and drug development professionals in tackling the challenge of distinguishing 1-methylcytosine (1mC) from its isomer, 5-methylcytosine (B146107) (5mC), in sequencing data. Below you will find troubleshooting guides and frequently asked questions to address common issues encountered during experimental workflows.
Frequently Asked Questions (FAQs)
Q1: Why is it difficult to differentiate this compound (1mC) from 5-methylcytosine (5mC) in standard sequencing workflows?
Standard sequencing methods, including traditional bisulfite sequencing, are often unable to distinguish between 1mC and 5mC. This is because both modifications can exhibit similar behaviors under certain chemical treatments. For instance, in bisulfite sequencing, the methyl group in 5mC protects it from deamination. While 1mC's behavior in bisulfite treatment is less commonly characterized in standard protocols, its structure can also hinder the chemical conversion that allows for the identification of unmodified cytosines. Consequently, both may be read as cytosine, making them indistinguishable from each other in the final sequencing data.
Q2: What are the primary strategies being explored to resolve 1mC and 5mC?
Currently, there is no universally established method for distinguishing 1mC from 5mC at single-base resolution within a sequencing context. However, research efforts are moving towards three main strategies:
-
Differential Chemical Treatment: Exploiting subtle differences in the chemical reactivity of the methyl group at the N1 versus the C5 position.
-
Enzymatic Discrimination: Utilizing enzymes that can specifically recognize and act upon one isomer but not the other.
-
Direct Sequencing Technologies: Leveraging the distinct physical and chemical properties of each isomer to produce unique signals in third-generation sequencing platforms like Nanopore.
Q3: Can third-generation sequencing platforms like Oxford Nanopore directly distinguish 1mC from 5mC?
In theory, third-generation sequencing platforms that detect modifications by measuring changes in electrical current or polymerase kinetics could differentiate between 1mC and 5mC. The different locations of the methyl group should, in principle, produce distinct signals as the DNA strand passes through a nanopore or during real-time synthesis. However, this requires the development and training of specific computational models to accurately call these modifications. While models exist for 5mC and other modifications, dedicated and validated models for specifically resolving 1mC from 5mC are not yet standard.
Q4: Are there any non-sequencing methods that can distinguish between 1mC and 5mC?
Yes, methods like liquid chromatography-mass spectrometry (LC-MS) are highly effective at identifying and quantifying a wide range of DNA and RNA modifications, including 1mC and 5mC.[1][2][3][4][5] However, LC-MS provides a global quantification of these modifications within a given sample and does not provide information about their specific locations within a DNA or RNA sequence.
Troubleshooting Guide
Issue: My bisulfite sequencing data does not show a distinction between potential 1mC and 5mC sites.
-
Explanation: This is an expected outcome. Conventional bisulfite sequencing is not designed to differentiate between these two isomers. Both 1mC and 5mC can be resistant to the bisulfite-mediated deamination of cytosine to uracil (B121893), leading them to be sequenced as cytosines.
-
Recommendation: To resolve 1mC from 5mC, you will need to employ an alternative or supplementary method that introduces a differential signal between the two. Consider exploring the potential methods outlined in the table below.
Issue: I am attempting to use an antibody-based enrichment (MeDIP-seq) to isolate 1mC, but the results are inconclusive.
-
Explanation: The specificity of antibodies used in methylated DNA immunoprecipitation (MeDIP) is crucial.[6][7][8] Most commercially available 5mC antibodies are unlikely to have been rigorously tested for cross-reactivity with 1mC. It is possible that the antibody you are using either binds to both modifications or has a weak affinity for 1mC.
-
Recommendation:
-
Validate Antibody Specificity: Perform dot blot assays with synthetic oligonucleotides containing 1mC and 5mC to rigorously test the specificity of your antibody.
-
Explore Alternative Enrichment: If a highly specific antibody is not available, consider alternative enrichment strategies that may rely on specific chemical handles introduced to one of the isomers.
-
Comparison of Potential Methods to Resolve 1mC and 5mC
| Method Category | Principle | Potential Advantages | Current Limitations & Challenges |
| Differential Chemical Labeling | A chemical reagent selectively reacts with one isomer (e.g., 1mC) but not the other (5mC), leading to a change that can be detected during sequencing (e.g., a base change or polymerase stalling). | Can potentially be integrated into existing sequencing library preparation workflows. High specificity may be achievable with the right chemical reaction. | A suitable chemical reaction with high specificity and efficiency in the context of genomic DNA needs to be identified and optimized. The reaction conditions must be mild enough to not damage the DNA. |
| Enzymatic Discrimination | An enzyme specifically recognizes and modifies one of the cytosine isomers. For example, a hypothetical "1mC-erase" could remove the methyl group from 1mC, which would then be read as an unmodified cytosine after subsequent processing. | High specificity is a hallmark of enzymatic reactions. Reactions are typically performed in mild, physiological conditions, minimizing DNA damage. | An enzyme with the required specificity to distinguish 1mC from 5mC needs to be discovered or engineered. The efficiency of the enzymatic reaction across the entire genome would need to be very high. |
| Direct Nanopore Sequencing | The distinct chemical structures of 1mC and 5mC produce different disruptions in the ionic current as the DNA passes through a nanopore.[9][10] | Does not require chemical or enzymatic pre-treatment, thus preserving the native state of the DNA. Can provide long reads, which are beneficial for genome assembly and mapping. | Requires the development and validation of sophisticated machine learning models to accurately distinguish the subtle differences in the electrical signals produced by 1mC and 5mC. Currently, such models are not standard in basecalling software. |
Conceptual Experimental Protocol
Hypothetical Chemical-Based Differential Sequencing for 1mC and 5mC
Disclaimer: The following is a conceptual protocol illustrating the potential steps of a method that does not yet exist as a standard procedure. It is intended for informational purposes to outline a possible experimental logic.
-
Genomic DNA Isolation: Extract high-quality genomic DNA from the sample of interest.
-
DNA Fragmentation: Shear the DNA to the desired fragment size for the sequencing platform to be used (e.g., 200-500 bp for short-read sequencing).
-
Selective Chemical Modification:
-
Treat the fragmented DNA with "Reagent X," a hypothetical chemical that specifically reacts with this compound, converting it to a modified base (1mC*). This reagent should not react with 5-methylcytosine, unmodified cytosine, or other bases.
-
Purify the DNA to remove any residual chemicals.
-
-
Standard Bisulfite Conversion:
-
Perform a standard bisulfite treatment on the chemically modified DNA.
-
This will convert unmodified cytosines to uracil. 5mC will remain as 5mC. The modified 1mC* will ideally be converted to a different base (e.g., uracil) or will stall the polymerase during PCR.
-
-
Library Preparation and PCR Amplification:
-
Prepare a sequencing library from the treated DNA.
-
During PCR, uracils will be amplified as thymines. 5mC will be amplified as cytosine. The fate of 1mC* will depend on its chemical nature (e.g., read as thymine (B56734) or result in no amplification of that fragment).
-
-
Sequencing: Sequence the prepared library on a suitable platform.
-
Data Analysis:
-
Align the sequencing reads to a reference genome.
-
Analyze the cytosine contexts:
-
A 'C' in the sequencing read that corresponds to a 'C' in the reference genome indicates the presence of 5mC.
-
A 'T' in the sequencing read that corresponds to a 'C' in the reference genome could be an unmodified cytosine or a 1mC that was converted to uracil by the combined chemical and bisulfite treatments.
-
-
By comparing with a standard bisulfite sequencing experiment (without the initial chemical treatment), one could potentially infer the locations of 1mC.
-
Workflow and Logic Diagrams
Caption: Overview of potential strategies to resolve 1mC and 5mC.
Caption: Logic for interpreting hypothetical differential sequencing data.
References
- 1. mdpi.com [mdpi.com]
- 2. Detection of DNA methylation in genomic DNA by UHPLC-MS/MS - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Global DNA 5mC Quantification by LC-MS/MS, DNA Methylation Analysis Service - CD BioSciences [epigenhub.com]
- 4. A sensitive mass-spectrometry method for simultaneous quantification of DNA methylation and hydroxymethylation levels in biological samples - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Global DNA 5hmC Quantification by LC-MS/MS, DNA Hydroxymethylation Analysis - CD BioSciences [epigenhub.com]
- 6. epigenie.com [epigenie.com]
- 7. avam.com [avam.com]
- 8. Affinity-based enrichment strategies to assay methyl-CpG binding activity and DNA methylation in early Xenopus embryos - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Detecting DNA cytosine methylation using nanopore sequencing - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. Nanopore Sequencing and Data Analysis for Base-Resolution Genome-Wide 5-Methylcytosine Profiling | Springer Nature Experiments [experiments.springernature.com]
Artifacts and false positives in 1-Methylcytosine mapping
Welcome to the technical support center for 1-methylcytosine (m1C) mapping. This resource provides researchers, scientists, and drug development professionals with comprehensive troubleshooting guides and frequently asked questions (FAQs) to address common challenges, artifacts, and false positives encountered during m1C mapping experiments.
Section 1: Frequently Asked Questions (FAQs)
This section covers general questions about m1C mapping, common sources of error, and strategies for validating results.
Q1: What are the primary methods for transcriptome-wide mapping of this compound (m1C)?
A1: The main approaches for mapping m1C fall into two categories:
-
Antibody-Based Methods: These techniques, such as m1C-immunoprecipitation followed by sequencing (m1C-seq or m1C-IP-seq) and methylation individual-nucleotide-resolution cross-linking and immunoprecipitation (miCLIP), utilize antibodies that specifically recognize and bind to m1C residues. The enriched RNA fragments containing m1C are then sequenced to identify their location in the transcriptome.
-
Chemical-Based Methods: These methods rely on chemical treatments that differentiate m1C from unmodified cytosine. A notable example is RNA bisulfite sequencing (RBS-seq), where bisulfite treatment followed by specific conditions can induce chemical changes that are detectable during reverse transcription and sequencing. For instance, m1C can undergo a Dimroth rearrangement to N6-methyladenosine (m6A) under certain conditions, which is then identified during sequencing.[1]
Q2: What are the most common sources of artifacts and false positives in m1C mapping?
A2: False positives in m1C mapping can arise from both the experimental and computational phases of the workflow. Key sources include:
-
Antibody Cross-Reactivity: The antibody used in immunoprecipitation may bind to other, more abundant modifications with similar structural features, leading to a high rate of false positives. A well-documented example in RNA modification mapping is the cross-reactivity of an m1A antibody with the 7-methylguanosine (B147621) (m7G) cap at the 5' end of mRNAs.
-
Incomplete Chemical Conversion: In bisulfite-based methods, unmethylated cytosines that fail to convert to uracil (B121893) can be misidentified as methylated cytosines, leading to false-positive signals.
-
RNA Degradation: Harsh chemical treatments, such as traditional bisulfite conversion or alkaline hydrolysis, can cause significant degradation of RNA, resulting in biased and incomplete data.
-
PCR Amplification Bias: During library preparation, sequences with certain characteristics may be amplified more efficiently than others, leading to skewed representation and potential false positives in methods that rely on read mapping density.
-
Sequencing and Alignment Errors: Errors introduced during next-generation sequencing (NGS) or incorrect alignment of sequencing reads to the reference genome can create artificial signals that are misinterpreted as m1C sites. Mispriming during reverse transcription is another source of sequencing artifacts.[2]
Q3: How can I validate the m1C sites identified in my high-throughput sequencing experiment?
A3: Orthogonal validation is crucial to confirm the presence of m1C at candidate sites and rule out method-specific artifacts.[3][4] This involves using a non-antibody-based method to verify results from an antibody-based one, and vice versa. Effective validation strategies include:
-
Mass Spectrometry (MS): As a gold standard, liquid chromatography-tandem mass spectrometry (LC-MS/MS) can unambiguously identify and quantify specific RNA modifications, including m1C, in total RNA or on specific RNA fragments.[5][6]
-
Individual m1C-IP-qRT-PCR: For specific candidate sites identified by a sequencing method, you can perform an independent immunoprecipitation with the m1C antibody followed by quantitative reverse transcription PCR (qRT-PCR) to confirm enrichment.
-
Site-Directed Mutagenesis: Mutating the candidate cytosine to another nucleotide (e.g., guanine) in a reporter construct should lead to the loss of the m1C signal if the modification is genuine.
Section 2: Troubleshooting Guides
This section provides a problem-and-solution format to address specific issues encountered during m1C mapping experiments.
Guide 1: Antibody-Based Methods (m1C-IP, miCLIP)
Problem: High background or large number of false-positive peaks.
| Possible Cause | Recommended Solution |
| Non-specific Antibody Binding / Cross-Reactivity | Validate Antibody Specificity: Perform a dot blot assay with synthetic oligonucleotides containing m1C, unmodified C, and other related modifications (e.g., m5C, m3C, N4-methylcytidine) to confirm your antibody's specificity for m1C.[1][7] Pre-clear Lysate: Incubate the cell lysate with protein A/G beads alone before adding the primary antibody to remove proteins that non-specifically bind to the beads. |
| Insufficient Washing | Optimize Wash Buffers: Increase the stringency of your wash buffers by moderately increasing salt or detergent concentrations. However, be cautious as overly harsh conditions can disrupt genuine antibody-m1C interactions. Increase Number of Washes: Perform additional wash steps after antibody incubation to more thoroughly remove non-specifically bound RNAs. |
| Too Much Antibody or Lysate | Titrate Antibody: Determine the optimal antibody concentration through a titration experiment to find the lowest amount that still provides a robust signal for a known positive control.[3] Reduce Input Amount: Using too much cell lysate can increase the amount of non-specific background. Try reducing the total protein input.[3] |
Problem: Weak or no signal after immunoprecipitation.
| Possible Cause | Recommended Solution |
| Low Abundance of m1C | Increase Starting Material: If m1C is rare in your sample, increase the amount of total RNA used for the immunoprecipitation. Enrich for RNA Type: If you are studying m1C in a specific RNA class (e.g., tRNA, rRNA), consider enriching for that RNA type before the IP. |
| Inefficient Immunoprecipitation | Check Antibody-Bead Compatibility: Ensure your protein A/G beads have a high affinity for the isotype of your m1C antibody (e.g., rabbit IgG, mouse IgG).[8] Optimize Incubation Time: Incubate the antibody with the lysate overnight at 4°C to ensure maximum binding.[7] |
| Harsh Lysis or Wash Conditions | Use a Milder Lysis Buffer: Strong ionic detergents (like those in RIPA buffer) can disrupt antibody-antigen interactions. Use a lysis buffer with non-ionic detergents (e.g., NP-40) for co-IP experiments.[8] Reduce Wash Stringency: Decrease the salt or detergent concentration in your wash buffers or reduce the number of washes. |
Guide 2: Chemical-Based Methods (e.g., RBS-seq)
Problem: High rate of C-to-T non-conversion, leading to false positives.
| Possible Cause | Recommended Solution |
| Incomplete Bisulfite Conversion | Optimize Denaturation: RNA secondary structures can hinder bisulfite access. Ensure complete denaturation of RNA before treatment by using chemical denaturants or optimizing heat denaturation steps. Extend Reaction Time/Optimize Temperature: Increase the incubation time for the bisulfite reaction or optimize the temperature to ensure all unmodified cytosines are converted. However, be aware that this can increase RNA degradation. |
| RNA Degradation | Use a Commercial Kit: Many commercial kits for bisulfite conversion are optimized to minimize RNA degradation while ensuring high conversion efficiency. Limit Incubation Time: Avoid excessively long incubation times with harsh chemicals. Find a balance between conversion efficiency and RNA integrity. |
Problem: Artifacts from Dimroth Rearrangement.
| Possible Cause | Recommended Solution |
| Misinterpretation of m6A as m1C | Include a "No-Rearrangement" Control: Some protocols rely on the Dimroth rearrangement of m1A to m6A. It is critical to have a control sample that is not subjected to the alkaline conditions that induce this rearrangement to distinguish native m6A from m1A-derived m6A.[9] |
| RNA Degradation from Alkaline Conditions | Use Milder Catalysts: Recent studies have explored milder pH conditions and catalysts that can promote the Dimroth rearrangement with significantly less RNA degradation compared to traditional high-pH, high-heat methods.[9] |
Section 3: Data Analysis & Computational Filtering
Q4: What are the key steps in a bioinformatics pipeline for analyzing m1C-seq data?
A4: A typical bioinformatics workflow for m1C-seq data involves several stages to process raw sequencing reads and identify reliable m1C peaks.
Q5: How can I computationally filter false positives from my m1C peak data?
A5: Computational filtering is essential to increase confidence in your results.
-
Use Control Samples: The most critical step is to sequence a size-matched input control library (RNA that has not been immunoprecipitated). True m1C peaks should be significantly enriched in the IP sample compared to the input. Peak calling algorithms like MACS2 use this comparison to identify significant peaks and calculate a False Discovery Rate (FDR).[10][11][12]
-
Filter Low-Quality Reads: Remove reads with low mapping quality, which are reads that do not align uniquely or confidently to one location in the genome.
-
Remove PCR Duplicates: PCR duplicates are reads that arise from the amplification of the same original RNA fragment. These should be removed to avoid artificially inflating the signal at a particular site.
-
Peak Shape and Score Filtering: True binding sites often have a characteristic peak shape. You can filter peaks based on their enrichment score (e.g., fold-enrichment over input) and statistical significance (p-value or FDR) provided by the peak caller.
Section 4: Experimental Protocols & Data
Protocol: Dot Blot Assay for m1C Antibody Specificity
This protocol provides a method to quickly assess the specificity of a primary antibody for m1C against other modified and unmodified nucleosides.[1][7][13]
Materials:
-
Nitrocellulose or PVDF membrane
-
Synthetic RNA oligonucleotides (20-30 nt) of the same sequence containing:
-
This compound (m1C)
-
Unmodified cytosine (C)
-
5-methylcytosine (m5C) (optional control)
-
3-methylcytosine (m3C) (optional control)
-
-
Blocking buffer (e.g., 5% non-fat dry milk in TBST)
-
Primary antibody against m1C
-
HRP-conjugated secondary antibody
-
Chemiluminescent substrate (ECL)
-
TBST (Tris-Buffered Saline with Tween-20)
Procedure:
-
Prepare RNA Dilutions: Prepare a dilution series for each RNA oligonucleotide (e.g., 100 pmol, 50 pmol, 10 pmol, 1 pmol).
-
Spot onto Membrane: Carefully pipette 1-2 µL of each RNA dilution directly onto a dry nitrocellulose membrane, creating a grid. Label the grid with a pencil. Allow the spots to dry completely.
-
Blocking: Place the membrane in a container with blocking buffer and incubate for 1 hour at room temperature with gentle agitation. This step prevents non-specific binding of the antibodies to the membrane.
-
Primary Antibody Incubation: Discard the blocking buffer. Add the primary m1C antibody diluted in fresh blocking buffer. Incubate for 1 hour at room temperature with agitation. The optimal dilution should be determined empirically.
-
Washing: Discard the primary antibody solution. Wash the membrane three times with TBST for 5-10 minutes each time to remove unbound primary antibody.
-
Secondary Antibody Incubation: Add the HRP-conjugated secondary antibody diluted in fresh blocking buffer. Incubate for 1 hour at room temperature with agitation.
-
Final Washes: Discard the secondary antibody solution. Wash the membrane three times with TBST for 10 minutes each.
-
Detection: Incubate the membrane with the ECL substrate according to the manufacturer's instructions. Image the resulting chemiluminescent signal.
Expected Results: A specific antibody should produce a strong signal for the m1C-containing oligonucleotide with minimal to no signal for the oligonucleotides containing C, m5C, or m3C.
Quantitative Comparison of m1C Mapping Methods
Direct quantitative comparisons of transcriptome-wide m1C mapping methods are still emerging in the literature. Performance metrics such as sensitivity and specificity can vary significantly based on the biological system, sequencing depth, and bioinformatic pipeline used.[14][15] However, a qualitative comparison highlights the inherent trade-offs of the major approaches.
| Method | Principle | Advantages | Common Artifacts & Disadvantages |
| m1C-IP-seq / miCLIP | Immunoprecipitation with m1C-specific antibody | Relatively straightforward protocol. Captures native m1C context. | Highly dependent on antibody specificity; risk of cross-reactivity with other modifications. High background noise. |
| RBS-seq | Bisulfite conversion and sequencing | Single-base resolution. Can detect multiple modifications simultaneously. | RNA degradation from harsh chemical treatment. Incomplete conversion leads to false positives. Can be confounded by other modifications. |
Appendix: Logic and Workflow Diagrams
The following diagrams illustrate key workflows and troubleshooting logic.
References
- 1. Dot Blot: A Quick and Easy Method for Separation-Free Protein Detection [jacksonimmuno.com]
- 2. m.youtube.com [m.youtube.com]
- 3. researchgate.net [researchgate.net]
- 4. Cross-reactivity and neutralizing ability of monoclonal antibodies against microcystins - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. DMS-MaPseq for Genome-Wide or Targeted RNA Structure Probing In Vitro and In Vivo - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. nbisweden.github.io [nbisweden.github.io]
- 7. novateinbio.com [novateinbio.com]
- 8. Streamlining data-intensive biology with workflow systems - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Cross-reactivity of IgM anti-modified protein antibodies in rheumatoid arthritis despite limited mutational load - PMC [pmc.ncbi.nlm.nih.gov]
- 10. B(1)(+)/actual flip angle and reception sensitivity mapping methods: simulation and comparison - PubMed [pubmed.ncbi.nlm.nih.gov]
- 11. researchgate.net [researchgate.net]
- 12. Protocol for mapping double-stranded DNA break sites across the genome with translocation capture sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 13. creative-diagnostics.com [creative-diagnostics.com]
- 14. researchgate.net [researchgate.net]
- 15. researchgate.net [researchgate.net]
Enhancing resolution of 1-Methylcytosine peaks in sequencing data
Welcome to the technical support center for 1-Methylcytosine (m1C) sequencing analysis. This resource provides researchers, scientists, and drug development professionals with detailed troubleshooting guides, frequently asked questions (FAQs), and experimental protocols to enhance the resolution and reliability of m1C peak detection.
Frequently Asked Questions (FAQs)
Q1: What is this compound (m1C) and why is its high-resolution mapping important?
A1: this compound (m1C) is a post-transcriptional RNA modification, but it can also occur in DNA. While less abundant than 5-methylcytosine (B146107) (5mC), m1C is gaining interest for its potential roles in gene regulation and disease. High-resolution mapping at single-base precision is critical to pinpoint its exact locations within the genome, understand its functional context in relation to genomic features like promoters and enhancers, and elucidate its role in cellular processes.
Q2: What are the primary challenges in achieving high-resolution m1C peaks?
A2: The main challenges include the low abundance of m1C compared to other DNA modifications, the difficulty in distinguishing it from 5mC and unmodified cytosine, and potential DNA damage from harsh chemical treatments like bisulfite sequencing.[1][2] Furthermore, generating high-quality sequencing libraries from low-input samples and minimizing PCR amplification bias are significant hurdles that can affect peak resolution.[3]
Q3: Which sequencing methods are suitable for m1C detection?
A3: While traditional bisulfite sequencing cannot distinguish between m1C and 5mC, newer methods offer potential solutions. Enzymatic-based methods, such as EM-seq, avoid the DNA damage associated with bisulfite treatment and can offer higher data quality.[4] Other strategies involve specific antibody-based enrichment (MeRIP-seq or m1C-seq) or chemical treatments that specifically react with m1C, followed by next-generation sequencing (NGS). The choice depends on the desired resolution, required starting material, and specific experimental goals.
Q4: How can I distinguish true m1C peaks from sequencing or analysis artifacts?
A4: Distinguishing true peaks requires a multi-faceted approach. Start with stringent quality control of raw sequencing data to remove adapters and low-quality reads.[5] During peak calling, use a suitable control sample (e.g., an input library without enrichment) to model background noise.[6] It is essential to visually inspect putative peaks in a genome browser like IGV to check for characteristic enrichment patterns and rule out artifacts like strand bias or high signal in repetitive regions.[7][8] Finally, validating peaks with an orthogonal method, such as locus-specific PCR, is highly recommended.
Q5: What are the most critical quality control (QC) metrics to check in my m1C sequencing data?
A5: Key QC metrics include:
-
Per Base Sequence Quality (Phred Score): Ensure a high average quality score (typically >Q30) across the reads.
-
Adapter Content: Check for and trim any remaining adapter sequences.
-
Mapping Rate: A high percentage of reads should align uniquely to the reference genome.
-
Library Complexity: Assess the number of unique (non-duplicate) reads. Low complexity may indicate over-amplification.[3]
-
Insert Size Distribution: The fragment size distribution should be consistent with the library preparation protocol.
Troubleshooting Guides
Category: Library Preparation
Q: My final library yield is consistently low. What are the likely causes and solutions?
A: Low library yield is a common issue, often stemming from suboptimal steps in the library preparation process. Poor quality or insufficient starting material is a primary cause. Contaminants carried over from nucleic acid extraction can also inhibit enzymatic reactions.
Solutions:
-
Optimize DNA Extraction: Ensure the chosen extraction method is efficient and removes inhibitors.[3]
-
Improve Ligation Efficiency: Use fresh, high-quality ligase and ensure the molar ratio of adapters to DNA fragments is optimal. Too high a ratio can lead to adapter-dimers instead of ligated library fragments.[9]
-
Minimize PCR Cycles: While it may seem counterintuitive, excessive PCR cycles can inhibit amplification and introduce bias.[3][9] Determine the minimum number of cycles needed using qPCR.
Q: I observe a significant peak corresponding to adapter-dimers (~120-150 bp) in my final library. How can I prevent this?
A: Adapter-dimers form when adapters ligate to each other. This is common with low DNA input, where the concentration of adapters is much higher than DNA fragments.
Solutions:
-
Adjust Adapter Concentration: Titrate the adapter concentration to find the optimal molar ratio for your input amount. For very low inputs, diluting the adapters is often necessary.[9]
-
Perform Stringent Size Selection: Use a bead-based cleanup method to carefully remove smaller fragments. A two-sided size selection (removing both very small and very large fragments) can be effective.
-
Optimize Ligation Time and Temperature: Adhere to the recommended incubation times and temperatures for the ligase, as deviations can reduce efficiency and promote dimer formation.
| Issue | Potential Cause | Recommended Solution |
| Low Library Yield | 1. Insufficient or low-quality starting DNA. 2. Inefficient adapter ligation. 3. Suboptimal PCR amplification. | 1. Quantify DNA accurately; use kits designed for low input. 2. Optimize adapter-to-insert molar ratio. 3. Determine optimal PCR cycle number with qPCR. |
| Adapter-Dimer Contamination | 1. Adapter concentration too high for DNA input. 2. Inefficient removal of unligated adapters. | 1. Dilute adapters for low-input libraries.[9] 2. Perform stringent, calibrated bead-based size selection. |
| GC/AT Bias | 1. PCR amplification bias. 2. Fragmentation bias. | 1. Use a high-fidelity, proofreading polymerase and minimize PCR cycles.[3] 2. Use enzymatic fragmentation for more random shearing. |
| A summary of common library preparation issues and solutions. |
Category: Peak Calling and Data Analysis
Q: My peak caller (e.g., MACS2) identifies very few or no significant peaks, but I can see clear enrichment in a genome browser.
A: This discrepancy often arises from suboptimal peak calling parameters or issues with the control sample.
Solutions:
-
Adjust Peak Caller Sensitivity: The statistical model used by peak callers may be too stringent. Try relaxing the p-value or q-value (FDR) threshold.
-
Check the Control (Input) Sample: If the control sample also has high signal in the same regions, the peak caller will correctly identify them as background and not call a peak.[6] Ensure your control library is of high quality and represents the background chromatin landscape accurately.
-
Tune Model Parameters: For tools like MACS2, the model for fragment size estimation might fail with low read counts. You may need to manually provide the estimated fragment size using the --nomodel and --extsize parameters.[10]
Q: The biological replicates for my experiment show poor correlation. What steps should I take?
Solutions:
-
Visually Inspect Data: Load the data for all replicates into a genome browser. Check if the poor correlation is genome-wide or restricted to specific regions.
-
Re-evaluate QC Metrics: Compare QC metrics like mapping rate, library complexity, and fragment size distribution across all replicates. A failing replicate often stands out.
-
Quantify Correlation: Use statistical methods like Pearson correlation on read counts in binned genomic windows to quantify the discrepancy. Tools like deepTools plotCorrelation are useful for this. If one replicate is a clear outlier, it may need to be excluded from the analysis.
| Parameter | Description | Starting Recommendation for m1C | Rationale |
| -g | Effective genome size | Use a pre-calculated value for your organism (e.g., hs, mm). | Essential for correct statistical modeling of the background. |
| -q or -p | Q-value (FDR) or P-value cutoff | Start with -q 0.05. | Adjust based on the expected number of peaks and signal-to-noise ratio. |
| --nomodel | Skips the peak model building step. | Use if MACS2 fails to build a model (common with low signal).[10] | Requires providing a fixed fragment size via --extsize. |
| --extsize | The estimated fragment length. | Determine from Bioanalyzer trace or cross-correlation analysis. | Crucial when --nomodel is used to define the peak region. |
| --broad | Allows for calling broad, diffuse peaks. | Test this if m1C is expected to form broad domains. | Changes the statistical method to better handle diffuse enrichment.[7] |
| Recommended starting parameters for the MACS2 peak caller. These may require optimization. |
Experimental Protocols
Protocol: Generalized m1C-Enrichment Sequencing Library Preparation
This protocol provides a generalized workflow for preparing a sequencing library after m1C enrichment (e.g., via antibody-based immunoprecipitation).
1. DNA Fragmentation:
-
Start with high-quality genomic DNA (1-5 µg).
-
Fragment DNA to a target size of 200-500 bp using either mechanical shearing (e.g., Covaris sonicator) or enzymatic digestion.
-
Verify the fragment size distribution on an Agilent Bioanalyzer or TapeStation.
2. End-Repair and A-Tailing:
-
To the fragmented DNA, add an End-Repair & A-Tailing master mix containing T4 DNA Polymerase, Klenow Fragment, T4 PNK, and Taq Polymerase.
-
Incubate according to the manufacturer's protocol (e.g., 30 minutes at 20°C, followed by 30 minutes at 65°C). This process creates blunt ends and adds a single 'A' nucleotide to the 3' ends, preparing the fragments for adapter ligation.
-
Purify the DNA using a bead-based cleanup method.
3. Adapter Ligation:
-
Ligate NGS adapters with a 3' 'T' overhang to the A-tailed DNA fragments using a high-concentration DNA ligase.
-
Incubate for 15 minutes at 20°C.
-
Perform a bead-based cleanup to remove unligated adapters. At this stage, a size selection step can be integrated to tighten the fragment size distribution.
4. m1C Immunoprecipitation (IP):
-
Incubate the adapter-ligated library with a highly specific anti-m1C antibody overnight at 4°C with gentle rotation.
-
Add Protein A/G magnetic beads to the mixture and incubate for 2-4 hours at 4°C to capture the antibody-DNA complexes.
-
Wash the beads multiple times with low-salt and high-salt wash buffers to remove non-specific binding.
-
Elute the enriched DNA from the beads using an elution buffer.
-
Purify the eluted DNA.
5. Library Amplification:
-
Amplify the enriched library using a high-fidelity, proofreading DNA polymerase. Use primers that are complementary to the ligated adapter sequences.
-
Perform the minimum number of PCR cycles required to generate sufficient material for sequencing (typically 8-12 cycles).
-
Purify the final amplified library using a bead-based cleanup.
6. Quality Control:
-
Assess the final library concentration using a fluorometric method (e.g., Qubit).
-
Verify the final size distribution and purity on an Agilent Bioanalyzer or TapeStation. The final library should show a clean peak at the expected size range with no significant adapter-dimer peak.
Visualizations
References
- 1. Enzymatic methyl sequencing detects DNA methylation at single-base resolution from picograms of DNA - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Nondestructive enzymatic deamination enables single-molecule long-read amplicon sequencing for the determination of 5-methylcytosine and 5-hydroxymethylcytosine at single-base resolution - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Six top tips to improve your sequencing library [ogt.com]
- 4. m.youtube.com [m.youtube.com]
- 5. scholarworks.sjsu.edu [scholarworks.sjsu.edu]
- 6. Reddit - The heart of the internet [reddit.com]
- 7. Troubleshooting ATAC-seq, CUT&Tag, ChIP-seq & More - Expert Epigenomic Guide | AccuraScience [accurascience.com]
- 8. researchgate.net [researchgate.net]
- 9. biocompare.com [biocompare.com]
- 10. Issues calling peaks for H3K4me1: low quality data or am I doing something wrong? [groups.google.com]
Minimizing DNA damage during 1-Methylcytosine analysis protocols
Welcome to the technical support center for 1-methylcytosine (1mC) analysis. This resource provides troubleshooting guides and frequently asked questions (FAQs) to help researchers, scientists, and drug development professionals minimize DNA damage and overcome common challenges during experimental workflows.
Frequently Asked Questions (FAQs)
Q1: What is this compound (1mC) and how does it differ from the more commonly studied 5-methylcytosine (B146107) (5mC)?
A1: this compound (1mC) is a form of DNA damage that occurs when a methyl group is incorrectly added to the N1 position of cytosine or the N3 position of cytosine (3-methylcytosine). This is typically caused by exposure to alkylating agents. Unlike 5-methylcytosine (5mC), which is a key epigenetic mark intentionally placed by DNA methyltransferases to regulate gene expression, 1mC is a lesion that can block DNA replication and is actively removed by the cell's DNA repair machinery.
Q2: What are the primary methods for detecting 1mC in DNA, and why are they different from 5mC detection methods?
A2: The primary methods for detecting 1mC leverage the cell's own DNA repair mechanisms. The most prominent of these are assays based on the AlkB family of dioxygenase enzymes (e.g., E. coli AlkB, human ALKBH2, and ALKBH3).[1][2] These enzymes perform oxidative demethylation, specifically recognizing and removing the aberrant methyl group from 1mC to restore the original cytosine base.[1] This specificity is harnessed for detection. In contrast, 5mC detection has historically relied on sodium bisulfite conversion, a harsh chemical treatment that damages DNA.
Q3: Why are enzymatic methods preferred over traditional bisulfite sequencing for minimizing DNA damage during 1mC analysis?
A3: Enzymatic methods are strongly preferred because they are non-destructive to the DNA template. Traditional bisulfite sequencing, the gold standard for 5mC analysis, uses harsh chemical and temperature conditions that lead to significant DNA degradation, fragmentation, and biased data.[3][4][5] This makes it unsuitable for sensitive applications or samples with low DNA input.[3] Enzymatic methods, such as those using AlkB enzymes for 1mC or EM-seq for 5mC/5hmC, use gentle, enzyme-based reactions that preserve DNA integrity, resulting in higher quality libraries, more uniform genome coverage, and more accurate quantification.[6][7][8]
Q4: What are the main sources of DNA damage or degradation when using enzymatic 1mC analysis protocols?
A4: While enzymatic methods avoid the chemical damage of bisulfite, DNA integrity can still be compromised. Key sources of damage include:
-
Physical Shearing: Aggressive vortexing or pipetting during sample preparation and library construction can fragment high-molecular-weight DNA.
-
Nuclease Contamination: Contamination with DNases from samples, reagents, or handling can lead to significant DNA degradation. It is critical to use nuclease-free reagents and maintain a sterile work environment.
-
Excessive Incubation Times or Temperatures: Although enzymatic reactions are gentle, prolonged incubation, especially at non-optimal temperatures, can promote the activity of contaminating nucleases or lead to DNA denaturation.
-
Freeze-Thaw Cycles: Repeatedly freezing and thawing DNA samples can cause strand breaks and degradation.[9]
Q5: How can I ensure the optimal activity of AlkB repair enzymes in my 1mC detection assay?
A5: The activity of AlkB family enzymes is dependent on specific co-factors. To ensure optimal performance, the reaction buffer must include:
-
Fe(II): AlkB enzymes are non-heme iron-dependent dioxygenases.
-
α-Ketoglutarate: This co-substrate is consumed during the demethylation reaction.
-
Oxygen (O₂): The reaction is an oxidation, requiring molecular oxygen. The absence or depletion of any of these co-factors will result in failed or inefficient demethylation, leading to inaccurate 1mC detection.[1]
Troubleshooting Guides
This section addresses specific issues that may arise during your 1mC analysis experiments.
Problem: Low or No Signal in 1mC Detection Assay
| Possible Cause | Recommended Solution |
| 1. Low Abundance of 1mC | 1mC is a DNA lesion and may be present at very low levels in your sample. Consider using a positive control (DNA treated with a known alkylating agent) to validate the assay's performance. Increase the amount of input DNA if possible. |
| 2. Inactive AlkB Enzyme | Ensure the enzyme has been stored correctly at its recommended temperature and has not undergone excessive freeze-thaw cycles. Verify that all necessary co-factors (Fe(II), α-ketoglutarate) are present in the reaction buffer at the correct concentrations. Test the enzyme on a synthetic oligonucleotide containing a 1mC modification. |
| 3. DNA Degradation | Assess the integrity of your input DNA on an agarose (B213101) gel or using an automated electrophoresis system. If degradation is observed, use a fresh sample and handle it gently. Minimize freeze-thaw cycles and ensure all solutions and equipment are nuclease-free. |
| 4. Inefficient Downstream Analysis | If using PCR-based readout, optimize the PCR conditions (primers, annealing temperature) for the modified sequence. For sequencing, ensure the library preparation protocol is compatible with low-input samples and that sequencing depth is sufficient to detect rare modifications. |
Problem: High Background or Non-Specific Signals
| Possible Cause | Recommended Solution |
| 1. Nuclease Contamination | Run a control sample with input DNA incubated in the reaction buffer without the AlkB enzyme. If DNA degradation is observed, it indicates nuclease contamination. Use fresh, certified nuclease-free reagents and tubes, and decontaminate work surfaces and pipettes. |
| 2. Sub-optimal Enzyme Specificity | While AlkB enzymes are highly specific, extremely high enzyme concentrations or prolonged reaction times could potentially lead to off-target activity. Titrate the enzyme concentration and optimize the incubation time to find the ideal balance between signal and background. |
| 3. Sequencing Artifacts | DNA damage can occur during the sequencing process itself, leading to erroneous base calls that may be misinterpreted as modifications.[10][11] Analyze both DNA strands; true modifications should be present on both, while sequencing-induced damage is often confined to one strand.[10] |
Data Presentation
Table 1: Comparison of DNA Methylation Analysis Methodologies
This table summarizes the key differences between enzymatic and chemical conversion methods, highlighting the advantages of enzymatic approaches for preserving DNA integrity.
| Feature | Enzymatic Conversion (e.g., EM-seq, AlkB-based) | Bisulfite Conversion (e.g., WGBS) |
| Principle of Action | Enzyme-mediated protection and/or conversion of cytosines.[6][12] | Chemical deamination of unmethylated cytosines to uracil.[13] |
| DNA Damage | Minimal; preserves DNA integrity.[5][6] | High; causes significant DNA fragmentation and loss.[3][14] |
| DNA Input Requirement | Low (picogram to nanogram range).[4][12] | High (nanogram to microgram range). |
| GC Bias | Low; provides more uniform coverage across the genome.[3][8] | High; GC-rich regions are often underrepresented due to degradation.[3] |
| Library Complexity | High; greater number of unique molecules are sequenced.[8] | Low; DNA loss reduces library complexity. |
| Suitability for 1mC | High (using specific repair enzymes like AlkB). | Not applicable; does not distinguish 1mC. |
Experimental Protocols
Protocol: Generalized AlkB-Based Enzymatic Assay for 1mC Detection
This protocol provides a generalized workflow for the detection of 1mC using an AlkB family enzyme. Specific reagent concentrations and incubation times should be optimized for your particular enzyme and experimental setup.
Objective: To detect 1mC sites in a DNA sample by leveraging the direct reversal repair activity of an AlkB enzyme, followed by qPCR or sequencing.
Materials:
-
Genomic DNA sample
-
Recombinant AlkB homolog (e.g., ALKBH2 or ALKBH3)
-
10X AlkB Reaction Buffer (containing Tris-HCl, KCl, MgCl₂)
-
Co-factor solution: Ferrous sulfate (B86663) (Fe(II)), α-ketoglutarate, L-ascorbic acid (to maintain iron in a reduced state)
-
Nuclease-free water
-
DNA purification kit (column-based or magnetic beads)
-
Primers for downstream qPCR or sequencing adaptors
Methodology:
-
Sample Preparation (Minimize Damage):
-
Thaw frozen DNA samples slowly on ice.
-
Gently mix the sample by flicking the tube; avoid vigorous vortexing.
-
Quantify DNA using a fluorometric method (e.g., Qubit) for accuracy. Assess integrity on a 0.8% agarose gel. High-quality DNA should appear as a tight band with minimal smearing.
-
-
Enzymatic Reaction Setup:
-
In a nuclease-free tube, prepare the reaction mixture on ice. For a 50 µL reaction:
-
Genomic DNA (10-200 ng)
-
5 µL 10X AlkB Reaction Buffer
-
5 µL Co-factor solution
-
1-2 µg Recombinant AlkB enzyme
-
Nuclease-free water to 50 µL
-
-
Prepare a "No Enzyme" control reaction to check for background DNA degradation.
-
-
Incubation:
-
Incubate the reaction at the optimal temperature for the specific AlkB enzyme (typically 37°C) for 1-2 hours. Note: Optimization of incubation time is crucial to ensure complete reaction without promoting non-specific activity or degradation.
-
-
DNA Purification (Minimize Loss):
-
Purify the DNA using a column-based kit or magnetic beads designed for high recovery of nucleic acids.
-
Follow the manufacturer's protocol, ensuring gentle mixing during binding and washing steps.
-
Elute the DNA in a small volume (e.g., 20-30 µL) of nuclease-free water or elution buffer.
-
-
Downstream Analysis:
-
For Locus-Specific Analysis (qPCR): The repair of 1mC to C may restore a restriction enzyme site that was previously blocked by the modification. Digest the treated and untreated DNA with the relevant restriction enzyme, followed by qPCR using primers flanking the site. A higher Cq value in the untreated sample indicates the presence of 1mC.
-
For Genome-Wide Analysis (Sequencing): Proceed with a sequencing library preparation protocol suitable for your platform. Methods that rely on detecting the restored base or the byproducts of the reaction can provide single-base resolution maps of 1mC.
-
Visualizations
Caption: Workflow comparison of harsh vs. gentle DNA modification analysis.
Caption: The AlkB enzymatic pathway for repairing 1mC DNA damage.
Caption: Troubleshooting flowchart for low signal in 1mC detection assays.
References
- 1. AlkB mystery solved: oxidative demethylation of N1-methyladenine and N3-methylcytosine adducts by a direct reversal mechanism - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. researchgate.net [researchgate.net]
- 3. twistbioscience.com [twistbioscience.com]
- 4. researchgate.net [researchgate.net]
- 5. biorxiv.org [biorxiv.org]
- 6. neb.com [neb.com]
- 7. Comparison of current methods for genome-wide DNA methylation profiling - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Comprehensive comparison of enzymatic and bisulfite DNA methylation analysis in clinically relevant samples - PMC [pmc.ncbi.nlm.nih.gov]
- 9. documents.thermofisher.com [documents.thermofisher.com]
- 10. Act of sequencing damages DNA + | Bioworld | BioWorld [bioworld.com]
- 11. biorxiv.org [biorxiv.org]
- 12. Enzymatic methyl sequencing detects DNA methylation at single-base resolution from picograms of DNA - PMC [pmc.ncbi.nlm.nih.gov]
- 13. DNA Methylation Analysis: Choosing the Right Method - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Detection and mapping of 5-methylcytosine and 5-hydroxymethylcytosine with nanopore MspA - PMC [pmc.ncbi.nlm.nih.gov]
Technical Support Center: Quantifying 1-Methylcytosine (m1C) in Complex Biological Samples
Welcome to the technical support center for the quantification of 1-methylcytosine (m1C) in complex biological samples. This resource is designed for researchers, scientists, and drug development professionals to provide troubleshooting guidance and answer frequently asked questions related to the detection and quantification of this modified nucleobase.
I. Frequently Asked Questions (FAQs)
Q1: What are the primary challenges in quantifying this compound (m1C) in biological samples?
A1: The quantification of m1C presents several analytical challenges:
-
Low Abundance: m1C is typically present at much lower levels than its well-known isomer, 5-methylcytosine (B146107) (5mC), making its detection and accurate quantification difficult.
-
Isomeric Interference: m1C has the same mass as other methylcytosine isomers, such as 3-methylcytosine (B1195936) and 5-methylcytosine. This requires high-resolution chromatographic separation to distinguish them accurately.[1]
-
Sample Matrix Effects: Complex biological matrices can interfere with the ionization of m1C in mass spectrometry, leading to ion suppression or enhancement and affecting quantification accuracy.[2]
-
Sample Preparation: The stability of m1C during DNA/RNA hydrolysis and sample processing is crucial. Harsh hydrolysis conditions can lead to the degradation of the analyte, resulting in underestimation.
-
Lack of Standardized Protocols: Unlike 5mC, there are fewer standardized and commercially available kits specifically designed for m1C quantification, often requiring in-house method development and validation.
Q2: Which analytical techniques are most suitable for m1C quantification?
A2: Liquid chromatography-tandem mass spectrometry (LC-MS/MS) is the gold standard for the accurate quantification of m1C.[3] This method offers high sensitivity and selectivity, and when coupled with appropriate chromatographic separation, it can resolve m1C from its isomers.[1] Other methods like bisulfite sequencing are not suitable for detecting m1C as the modification at the N1 position does not protect the cytosine from deamination.
Q3: How can I distinguish this compound from its isomers during analysis?
A3: Distinguishing m1C from its isomers is critical for accurate quantification and is primarily achieved through high-performance liquid chromatography (HPLC) prior to mass spectrometry detection. Key considerations include:
-
Chromatographic Column Selection: A column with high resolving power, such as a porous graphitic carbon (PGC) or a reversed-phase C18 column with specific mobile phase modifiers, is essential.
-
Mobile Phase Optimization: The composition and pH of the mobile phase should be carefully optimized to achieve baseline separation of the isomers.
-
Mass Spectrometry Fragmentation: While the precursor ion mass is identical for the isomers, their fragmentation patterns in tandem mass spectrometry (MS/MS) may differ slightly, providing an additional layer of identification. However, chromatographic separation remains the most reliable method for differentiation.
Q4: What are the best practices for sample preparation to ensure the stability of m1C?
A4: Proper sample preparation is crucial to maintain the integrity of m1C.
-
Nucleic Acid Extraction: Use a validated kit or protocol for DNA/RNA extraction that minimizes oxidative damage.
-
Enzymatic Hydrolysis: Employ a cocktail of nucleases (e.g., nuclease P1, snake venom phosphodiesterase) and phosphatases under optimized conditions to digest the nucleic acids into individual nucleosides. This is generally milder than acid hydrolysis.
-
Internal Standards: The use of a stable isotope-labeled internal standard (e.g., ¹³C- or ¹⁵N-labeled m1C) is highly recommended to correct for sample loss during preparation and for matrix effects during LC-MS/MS analysis.
II. Troubleshooting Guide
This guide addresses common issues encountered during the quantification of m1C using LC-MS/MS.
| Problem | Potential Cause(s) | Troubleshooting Steps |
| No or Low m1C Signal | 1. Low abundance of m1C in the sample. 2. Degradation of m1C during sample preparation. 3. Poor ionization efficiency in the mass spectrometer. 4. Suboptimal LC-MS/MS method parameters. | 1. Increase the starting amount of DNA/RNA. 2. Use milder enzymatic hydrolysis methods. Ensure samples are kept on ice or at 4°C whenever possible. 3. Optimize MS source parameters (e.g., spray voltage, gas flow, temperature). Check for ion suppression by the sample matrix. 4. Verify the MRM transitions and collision energies for m1C. Ensure the LC gradient is appropriate for the retention of m1C. |
| Poor Peak Shape (Tailing, Fronting, or Broadening) | 1. Column overload. 2. Column contamination. 3. Inappropriate mobile phase. 4. Secondary interactions with the stationary phase. | 1. Dilute the sample or inject a smaller volume. 2. Wash the column with a strong solvent or replace it if necessary. 3. Ensure the mobile phase is correctly prepared and degassed. The pH might need adjustment. 4. Add a small amount of a competing agent to the mobile phase. |
| Inconsistent Retention Times | 1. Changes in mobile phase composition. 2. Fluctuations in column temperature. 3. Column degradation. 4. Air bubbles in the LC system. | 1. Prepare fresh mobile phase daily. 2. Ensure the column oven is functioning correctly and the temperature is stable. 3. Replace the column if it has been used extensively. 4. Purge the LC pumps and lines. |
| Co-elution of Isomers (m1C, 3-mC, 5-mC) | 1. Insufficient chromatographic resolution. 2. Inappropriate column choice. 3. Suboptimal gradient profile. | 1. Optimize the mobile phase composition and gradient. A shallower gradient can improve resolution. 2. Try a different column chemistry (e.g., PGC, different C18 phase). 3. Lengthen the gradient time to improve separation. |
| High Background Noise | 1. Contaminated mobile phase or LC system. 2. Sample matrix interference. 3. Electronic noise from the mass spectrometer. | 1. Use high-purity solvents and flush the LC system. 2. Improve sample cleanup using solid-phase extraction (SPE). 3. Ensure proper grounding of the MS instrument and check for sources of electronic interference. |
III. Quantitative Data
Accurate quantification of m1C requires reliable analytical methods with well-defined performance characteristics. The following table summarizes typical limits of detection (LOD) and quantification (LOQ) for methylcytosines using LC-MS/MS, although specific values for m1C may vary depending on the instrument and method.
| Analyte | Method | Matrix | LOD | LOQ | Reference |
| 5-methyl-2'-deoxycytidine (5-mdC) | LC-MS/MS | Human DNA | ~0.065 pg | - | [4] |
| 5-hydroxymethyl-2'-deoxycytidine (5-hmdC) | LC-MS/MS | Human DNA | - | - | [4] |
| Etheno-cytosine derivatives | Online SPE-UPLC-MS/MS | PBS | 1.3 - 3.3 nM | - | [5] |
Note: Data specific to this compound is limited in the literature. The provided values for other modified nucleosides can serve as a general reference for the sensitivity of LC-MS/MS methods.
IV. Experimental Protocols & Workflows
Detailed Methodology for m1C Quantification by LC-MS/MS
This protocol provides a general framework for the quantification of m1C in DNA samples. Optimization will be required for specific sample types and instrumentation.
1. DNA Extraction:
-
Extract genomic DNA from cells or tissues using a commercial kit (e.g., Qiagen DNeasy Blood & Tissue Kit) following the manufacturer's instructions.
-
Assess DNA quality and quantity using a spectrophotometer (e.g., NanoDrop) and fluorometer (e.g., Qubit).
2. Enzymatic Hydrolysis:
-
To 1-5 µg of DNA, add a stable isotope-labeled internal standard for m1C.
-
Perform enzymatic digestion in a buffered solution (e.g., 10 mM Tris-HCl, pH 7.9, 10 mM MgCl₂, 1 mM DTT).
-
Add a cocktail of enzymes:
-
Nuclease P1 (to digest DNA/RNA to 5'-mononucleotides).
-
Snake Venom Phosphodiesterase (to further digest oligonucleotides).
-
Alkaline Phosphatase (to dephosphorylate nucleotides to nucleosides).
-
-
Incubate at 37°C for 2-4 hours.
-
Stop the reaction by adding an equal volume of acetonitrile (B52724) or by heat inactivation followed by centrifugation to pellet the enzymes.
-
Collect the supernatant containing the nucleosides.
3. LC-MS/MS Analysis:
-
Liquid Chromatography:
-
Use a high-resolution reversed-phase C18 column.
-
Employ a gradient elution with a mobile phase consisting of (A) water with 0.1% formic acid and (B) methanol (B129727) or acetonitrile with 0.1% formic acid.
-
Optimize the gradient to achieve separation of m1C from its isomers.
-
-
Mass Spectrometry:
-
Operate the mass spectrometer in positive electrospray ionization (ESI+) mode.
-
Use Multiple Reaction Monitoring (MRM) for quantification. Set up transitions for both native m1C and the isotope-labeled internal standard.
-
Optimize MRM transitions and collision energies for maximum sensitivity.
-
4. Data Analysis:
-
Integrate the peak areas for m1C and the internal standard.
-
Calculate the concentration of m1C in the sample using a calibration curve prepared with known concentrations of m1C standards.
-
Normalize the amount of m1C to the total amount of deoxyguanosine or total DNA input for relative quantification.
Experimental Workflow Diagram
V. Logical Relationships of Quantification Methods
While LC-MS/MS is the preferred method for accurate m1C quantification, other techniques are used for general methylcytosine analysis. This diagram illustrates the relationship and applicability of different methods for cytosine modification analysis.
This technical support center provides a starting point for researchers working on the quantification of this compound. As research in this area progresses, we will continue to update this resource with the latest findings and methodologies.
References
- 1. Positive/negative ion-switching-based LC–MS/MS method for quantification of cytosine derivatives produced by the TET-family 5-methylcytosine dioxygenases - PMC [pmc.ncbi.nlm.nih.gov]
- 2. ps.tbzmed.ac.ir [ps.tbzmed.ac.ir]
- 3. The Curious Chemical Biology of Cytosine: Deamination, Methylation and Oxidation as Modulators of Genomic Potential - PMC [pmc.ncbi.nlm.nih.gov]
- 4. researchgate.net [researchgate.net]
- 5. pubs.acs.org [pubs.acs.org]
Technical Support Center: 1-Methylcytosine (m1C) Antibodies
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) for researchers, scientists, and drug development professionals working with 1-Methylcytosine (m1C) antibodies. This guide addresses common issues related to antibody specificity and cross-reactivity in various applications.
Frequently Asked Questions (FAQs)
Q1: What is this compound (m1C) and why is it important?
This compound (m1C) is a post-transcriptional RNA modification where a methyl group is added to the N1 position of the cytosine base.[1] This modification can influence RNA stability, translation, and interactions with RNA-binding proteins, playing a role in various biological processes and diseases.
Q2: What are the main challenges when working with this compound (m1C) antibodies?
The primary challenge is ensuring the specificity of the antibody. Due to the structural similarity between different methylated and hydroxymethylated cytosines, there is a risk of cross-reactivity, particularly with 5-methylcytosine (B146107) (5mC) and 5-hydroxymethylcytosine (B124674) (5hmC).[2][3] It is crucial to validate the antibody's specificity to ensure that the detected signal is genuinely from m1C.
Q3: How can I validate the specificity of my this compound (m1C) antibody?
A dot blot assay is a straightforward and effective method to assess the specificity of an m1C antibody.[4][5][6] This involves spotting synthetic RNA or DNA oligonucleotides containing m1C, as well as other modified and unmodified bases (e.g., 5mC, 5hmC, C), onto a membrane and probing it with the m1C antibody. A specific antibody should only generate a strong signal for the m1C-containing spot.
Q4: What is Methylated RNA Immunoprecipitation Sequencing (MeRIP-seq) and how are m1C antibodies used in this technique?
MeRIP-seq is a technique used to map the location of RNA modifications across the transcriptome.[7] In this method, RNA is fragmented and then incubated with an antibody specific to the modification of interest, such as m1C. The antibody-bound RNA fragments are then immunoprecipitated, and the enriched RNA is sequenced to identify the locations of the m1C modification. The accuracy of MeRIP-seq results is highly dependent on the specificity and affinity of the antibody used.[7]
Troubleshooting Guides
Issue 1: High Background or Non-Specific Staining in Immunofluorescence (IF)
High background or non-specific staining in immunofluorescence can obscure the true localization of this compound.
Possible Causes and Solutions:
| Possible Cause | Recommended Solution |
| Antibody concentration is too high. | Titrate the primary and secondary antibody concentrations to find the optimal dilution that provides a clear signal with minimal background.[8][9] |
| Inadequate blocking. | Ensure proper blocking of non-specific binding sites. Use a suitable blocking agent such as bovine serum albumin (BSA) or serum from the same species as the secondary antibody. |
| Insufficient washing. | Increase the number and duration of wash steps to remove unbound antibodies. |
| Cross-reactivity of the secondary antibody. | Use a secondary antibody that is pre-adsorbed against the species of your sample to minimize cross-reactivity. |
| Autofluorescence of the sample. | Examine an unstained sample under the microscope to check for autofluorescence. If present, consider using a different fluorophore with a distinct emission spectrum or use a quenching agent.[8] |
Issue 2: Weak or No Signal in Dot Blot or MeRIP-seq
A weak or absent signal can be due to several factors related to the antibody or the experimental procedure.
Possible Causes and Solutions:
| Possible Cause | Recommended Solution |
| Low antibody affinity or concentration. | Ensure you are using a high-affinity antibody validated for your application. You may need to increase the antibody concentration or incubation time.[8] |
| Poor RNA integrity. | Check the integrity of your RNA sample using a Bioanalyzer or similar method. Degraded RNA can lead to poor results in MeRIP-seq.[7] |
| Inefficient immunoprecipitation. | Optimize the immunoprecipitation conditions, including the amount of antibody, incubation time, and washing steps. |
| Low abundance of m1C in the sample. | The level of m1C can vary significantly between different cell types and conditions. Use a positive control with a known high level of m1C to validate your experimental setup. |
| Issues with antibody-bead conjugation. | If using magnetic beads, ensure that the antibody is properly conjugated to the beads. |
Issue 3: Suspected Cross-Reactivity with Other Modified Bases
Observing a signal in negative controls (e.g., samples without m1C but with 5mC or 5hmC) suggests cross-reactivity.
Possible Causes and Solutions:
| Possible Cause | Recommended Solution |
| The antibody is not specific to m1C. | Perform a dot blot with a panel of modified oligonucleotides (m1C, 5mC, 5hmC, C, etc.) to definitively assess the antibody's specificity.[2][10] |
| Use of a polyclonal antibody. | Polyclonal antibodies recognize multiple epitopes and may have a higher likelihood of cross-reactivity. Consider using a monoclonal antibody with proven specificity. |
| High similarity between epitopes. | The structural similarity between m1C and other modified cytosines can lead to cross-reactivity. It is crucial to use an antibody that has been rigorously tested and validated for its specificity against these other modifications. |
Data Presentation: Antibody Specificity
Example of Expected Dot Blot Specificity Data:
| Spotted Nucleoside | Expected Signal with Specific m1C Antibody |
| This compound (m1C) | Strong |
| 5-Methylcytosine (5mC) | None / Negligible |
| 5-Hydroxymethylcytosine (5hmC) | None / Negligible |
| Cytosine (C) | None / Negligible |
| Adenosine (A) | None / Negligible |
| N6-Methyladenosine (m6A) | None / Negligible |
Users should perform their own validation experiments as antibody performance can vary between lots and experimental conditions.
Experimental Protocols
Protocol: Dot Blot for this compound (m1C) Antibody Specificity
This protocol is adapted from standard dot blot procedures and is designed to assess the specificity of m1C antibodies.[4][5][6][11]
Materials:
-
Nitrocellulose or PVDF membrane
-
Synthetic RNA or DNA oligonucleotides containing m1C, 5mC, 5hmC, and unmodified C.
-
This compound (m1C) primary antibody
-
HRP-conjugated secondary antibody
-
Blocking buffer (e.g., 5% non-fat dry milk or 3% BSA in TBST)
-
Wash buffer (TBST: Tris-Buffered Saline with 0.1% Tween-20)
-
Chemiluminescent substrate
-
Imaging system
Procedure:
-
Sample Preparation: Prepare serial dilutions of the synthetic oligonucleotides.
-
Spotting: Carefully spot 1-2 µL of each oligonucleotide dilution onto the membrane. Mark the positions of each spot.
-
Drying: Allow the membrane to air dry completely.
-
Blocking: Incubate the membrane in blocking buffer for 1 hour at room temperature to prevent non-specific antibody binding.[5][11]
-
Primary Antibody Incubation: Incubate the membrane with the m1C primary antibody (at the manufacturer's recommended dilution) in blocking buffer for 1 hour at room temperature or overnight at 4°C.
-
Washing: Wash the membrane three times for 5-10 minutes each with wash buffer.
-
Secondary Antibody Incubation: Incubate the membrane with the HRP-conjugated secondary antibody (at the appropriate dilution) in blocking buffer for 1 hour at room temperature.
-
Washing: Repeat the washing step as in step 6.
-
Detection: Apply the chemiluminescent substrate to the membrane and capture the signal using an imaging system.
Protocol: Methylated RNA Immunoprecipitation (MeRIP)
This is a generalized workflow for MeRIP.[7][12] Specific details may need to be optimized for your particular sample and antibody.
Materials:
-
Total RNA from your sample
-
m1C-specific antibody
-
Protein A/G magnetic beads
-
RNA fragmentation buffer
-
IP buffer
-
Wash buffers (low and high salt)
-
Elution buffer
-
RNA purification kit
Procedure:
-
RNA Fragmentation: Fragment the total RNA to an appropriate size (typically around 100 nucleotides).
-
Immunoprecipitation:
-
Incubate the fragmented RNA with the m1C-specific antibody in IP buffer.
-
Add Protein A/G magnetic beads to capture the antibody-RNA complexes.
-
Incubate to allow binding.
-
-
Washing: Wash the beads with a series of low and high salt wash buffers to remove non-specifically bound RNA.
-
Elution: Elute the antibody-bound RNA fragments from the beads.
-
RNA Purification: Purify the eluted RNA using an RNA purification kit.
-
Library Preparation and Sequencing: Prepare a sequencing library from the enriched RNA fragments and perform high-throughput sequencing.
Visualizations
Caption: Workflow for Dot Blot Specificity Assay.
Caption: Troubleshooting Logic for High Background.
References
- 1. This compound - Wikipedia [en.wikipedia.org]
- 2. zymoresearch.com [zymoresearch.com]
- 3. Examination of the specificity of DNA methylation profiling techniques towards 5-methylcytosine and 5-hydroxymethylcytosine - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Dot Blot Protocol: A Simple and Quick Immunossay Technique: R&D Systems [rndsystems.com]
- 5. creative-diagnostics.com [creative-diagnostics.com]
- 6. Detecting RNA Methylation by Dot Blotting | Proteintech Group [ptglab.com]
- 7. MeRIP-seq for Detecting RNA methylation: An Overview - CD Genomics [cd-genomics.com]
- 8. stjohnslabs.com [stjohnslabs.com]
- 9. Immunofluorescence Troubleshooting | Tips & Tricks | StressMarq Biosciences Inc. [stressmarq.com]
- 10. biocompare.com [biocompare.com]
- 11. A 5-mC Dot Blot Assay Quantifying the DNA Methylation Level of Chondrocyte Dedifferentiation In Vitro - PMC [pmc.ncbi.nlm.nih.gov]
- 12. An experimental workflow for identifying RNA m6A alterations in cellular senescence by methylated RNA immunoprecipitation sequencing - PMC [pmc.ncbi.nlm.nih.gov]
Technical Support Center: Normalization Strategies for 1-Methylcytosine (m1C) Quantification Data
This technical support center provides troubleshooting guidance and frequently asked questions (FAQs) regarding the normalization of 1-methylcytosine (m1C) quantification data. Proper normalization is critical for accurate and reproducible measurement of m1C levels, removing technical variability while preserving biological differences.
Frequently Asked Questions (FAQs)
Q1: Why is normalization of m1C quantification data necessary?
A1: Normalization is a critical step in the analysis of m1C data to correct for systematic technical variations that are not related to biological changes.[1][2][3] These variations can be introduced at multiple stages of the experimental workflow, including:
-
Sample Amount and Quality: Differences in the initial amount of RNA, its integrity, and purity.[4]
-
Experimental Procedures: Variability in the efficiency of reverse transcription, library preparation, and sequencing depth.[3]
-
Platform-specific biases: Technical differences between sequencing runs or batches.[2]
Q2: What are the main categories of normalization strategies for m1C data?
A2: Normalization strategies for m1C quantification, which is often measured using techniques analogous to RNA sequencing, can be broadly categorized into three groups:
-
Normalization using exogenous controls (Spike-ins): Synthetic RNA or DNA molecules of known sequence and concentration are added to each sample.[6][7][8] These "spike-ins" are used to account for technical variability introduced during the experimental procedure.[6][7]
-
Normalization using endogenous controls (Housekeeping genes): This method relies on measuring the levels of internal genes that are assumed to be stably expressed across all samples and experimental conditions.[4][9]
-
Computational and Statistical Normalization: These methods use the statistical properties of the entire dataset to normalize the data. Common methods include Total Counts (TC), Upper Quartile (UQ), Trimmed Mean of M-values (TMM), and methods implemented in packages like DESeq.[1][10][11]
Q3: What are spike-in controls and how do they work for normalization?
A3: Spike-in controls are a set of synthetic RNA molecules of known sequences and concentrations that are added to each biological sample before library preparation.[6][7][12] Since the amount of spike-in is constant across all samples, any variation observed in their measured levels is assumed to be due to technical noise.[8] By scaling the data based on the spike-in read counts, it is possible to normalize for differences in library size and other technical variations.[13] The External RNA Controls Consortium (ERCC) has developed a commonly used set of spike-in controls.[6][7]
Q4: When should I use endogenous controls for normalization?
A4: Endogenous controls, or housekeeping genes, are genes within the organism being studied that are expected to have stable expression levels across different conditions.[4] They are used to normalize data from targeted quantification methods like qPCR. The selection of appropriate endogenous controls is crucial, and their stability should be validated for the specific experimental conditions, as the expression of commonly used housekeeping genes can vary.[4][9]
Q5: Can I use DNA concentration for normalization?
A5: For studies involving adherent cell lines, normalizing metabolomic data by DNA concentration has been shown to be a robust strategy.[14] This method can be more accurate and precise than normalization by protein concentration or cell counting.[14] While primarily used in metabolomics, the principle of using a stable cellular component like total DNA as a basis for normalization could be considered in specific m1C quantification contexts, especially when comparing samples with large expected differences in total RNA content.
Troubleshooting Guide
Problem 1: High variability between technical replicates after normalization.
-
Possible Cause: Inconsistent sample handling and preparation.
-
Troubleshooting Steps:
-
Review your sample collection and RNA extraction protocols for consistency.
-
Ensure accurate quantification of starting RNA material.
-
If using spike-ins, verify that they are added at the same concentration to each sample.[6]
-
For endogenous controls, ensure the chosen gene is truly stable across your samples by testing multiple candidate genes.[9]
-
Problem 2: Normalized m1C levels do not correlate with expected biological changes.
-
Possible Cause: The chosen normalization method may not be appropriate for your data.
-
Troubleshooting Steps:
-
Evaluate your normalization strategy:
-
If using endogenous controls, their expression might be affected by the experimental conditions. Validate the stability of your chosen controls.[4]
-
Computational methods like Total Count normalization can be skewed by a few highly expressed genes. Consider more robust methods like TMM or DESeq normalization.[10][15]
-
-
Consider Spike-in Controls: For experiments where global changes in RNA levels are expected, spike-in normalization may be more appropriate.[6]
-
Problem 3: Low signal or no change in signal detected.
-
Possible Cause: Issues with the experimental assay itself, rather than normalization.
-
Troubleshooting Steps:
-
Check Positive and Negative Controls: Ensure that your positive controls show the expected signal and negative controls show no signal.[16] This helps to verify that the assay components are working correctly.
-
Optimize Assay Conditions: Review and optimize experimental parameters such as antibody concentrations (for enrichment-based methods) or enzyme activity.
-
Instrument Settings: Verify that the instrument gain and other settings are appropriate for the expected signal range.[17]
-
Problem 4: Inconsistent results when using different normalization methods.
-
Possible Cause: Different normalization methods make different assumptions about the data.
-
Troubleshooting Steps:
-
Understand the assumptions of each method: For example, TMM and DESeq assume that most genes are not differentially expressed, which may not be true in all experiments.[10][11]
-
Compare results: Evaluate which normalization method provides the most biologically plausible results and reduces technical variability most effectively.
-
Use multiple methods: In some cases, it may be informative to apply more than one normalization method and compare the outcomes.
-
Comparison of Normalization Strategies
| Normalization Strategy | Principle | Advantages | Disadvantages | Best For |
| Spike-in Controls | Addition of known amounts of synthetic RNA to each sample.[6][7] | Accounts for global changes in RNA levels; provides an internal standard for technical variability.[6] | Can be expensive; susceptible to pipetting errors; may not perfectly mimic the behavior of endogenous RNA.[8] | Experiments where global changes in total RNA are expected. |
| Endogenous Controls | Normalization to one or more stably expressed internal genes.[4] | Cost-effective; straightforward for targeted assays like qPCR. | Requires careful validation of control gene stability; expression can be affected by experimental conditions.[4][7] | Targeted m1C quantification (e.g., gene-specific analysis). |
| Total Count (TC) / Counts Per Million (CPM) | Scales read counts by the total number of mapped reads in each library.[3] | Simple and intuitive.[3] | Sensitive to highly expressed features and differences in RNA composition.[3] | Datasets with minimal expected changes in the expression of high-abundance RNAs. |
| Trimmed Mean of M-values (TMM) | Adjusts for differences in library size by trimming extreme log-fold changes.[10] | Robust to the presence of a few highly differentially expressed genes.[2][10] | Assumes that the majority of genes are not differentially expressed. | Most RNA-seq like experiments where the assumption of balanced differential expression holds. |
| DESeq Normalization | Uses the median of the ratios of observed counts to a pseudo-reference sample.[1][11] | Robust to differences in library size and RNA composition.[11] | Assumes that most genes are not differentially expressed. | Differential expression analysis of m1C levels. |
| Quantile Normalization | Aligns the distributions of intensities across all samples.[18] | Forces the entire distribution of each sample to be the same, which can be effective in reducing technical noise.[19] | Can obscure true biological differences if the underlying distributions are not actually the same. | Large-scale studies where it is reasonable to assume that the overall distribution of m1C should be similar across samples.[19] |
Experimental Protocols
Protocol 1: Spike-in Normalization for m1C Sequencing
-
Prepare Spike-in Mix: Use a commercially available spike-in mix, such as the ERCC RNA Spike-In Mix. Follow the manufacturer's instructions to dilute the spike-ins to the desired concentration.
-
Add Spike-ins to Samples: Before RNA fragmentation and library preparation, add a consistent volume of the diluted spike-in mix to each RNA sample. The amount to add should be determined based on the amount of starting RNA.
-
Proceed with Library Preparation: Continue with your standard m1C-seq library preparation protocol. The spike-in RNAs will be processed alongside the endogenous RNA.
-
Sequencing and Data Analysis:
-
After sequencing, align the reads to a combined reference genome that includes the sequences of the spike-in controls.
-
Count the number of reads mapping to each spike-in transcript for each sample.
-
Calculate a normalization factor for each sample based on the spike-in read counts.[13] For example, a simple scaling factor can be derived from the total number of spike-in reads per sample.
-
Apply this normalization factor to the read counts of the endogenous m1C-containing transcripts.
-
Protocol 2: Normalization using Endogenous Controls for qPCR-based m1C Quantification
-
Select Candidate Endogenous Controls: Choose a set of 3-5 potential housekeeping genes that are known to be stably expressed in your system. Common choices include GAPDH, ACTB, and B2M, but their stability must be validated.[4]
-
Validate Control Gene Stability:
-
Extract RNA from a representative set of your experimental samples.
-
Perform reverse transcription followed by qPCR for the candidate endogenous controls.
-
Use software tools like geNorm or NormFinder to analyze the expression stability of the candidate genes and select the most stable one(s).[9]
-
-
Quantify m1C and Endogenous Control Levels:
-
For each sample, perform your m1C quantification assay (e.g., after enrichment of m1C-containing RNA) and also quantify the expression of your validated endogenous control(s).
-
-
Normalize m1C Data:
-
Calculate the relative m1C level in each sample by normalizing it to the level of the endogenous control(s). The delta-delta Ct method is commonly used for this purpose.
-
Visualizations
Caption: Workflow for m1C quantification including spike-in normalization.
Caption: Decision tree for selecting a normalization strategy for m1C data.
References
- 1. RSeqNorm | RNA-seq Normalization | QBRC | UT Southwestern Medical Center [lce.biohpc.swmed.edu]
- 2. bigomics.ch [bigomics.ch]
- 3. pluto.bio [pluto.bio]
- 4. How to Select Endogenous Controls for Real-Time PCR | Thermo Fisher Scientific - TH [thermofisher.com]
- 5. Data normalization strategies in metabolomics: Current challenges, approaches, and tools - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. The Overlooked Fact: Fundamental Need for Spike-In Control for Virtually All Genome-Wide Analyses - PMC [pmc.ncbi.nlm.nih.gov]
- 7. cofactorgenomics.com [cofactorgenomics.com]
- 8. Assessing the reliability of spike-in normalization for analyses of single-cell RNA sequencing data - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Selection of endogenous control genes for normalising gene expression data derived from formalin-fixed paraffin-embedded tumour tissue - PMC [pmc.ncbi.nlm.nih.gov]
- 10. academic.oup.com [academic.oup.com]
- 11. Statistical Methods for RNA Sequencing Data Analysis - Computational Biology - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 12. researchgate.net [researchgate.net]
- 13. Spike-in Normalization • BRGenomics [mdeber.github.io]
- 14. Measurement of DNA concentration as a normalization strategy for metabolomic data from adherent cell lines - PMC [pmc.ncbi.nlm.nih.gov]
- 15. aacrjournals.org [aacrjournals.org]
- 16. m.youtube.com [m.youtube.com]
- 17. Protein Assays and Quantitation Support—Troubleshooting | Thermo Fisher Scientific - HK [thermofisher.com]
- 18. Evaluation of normalization strategies for mass spectrometry-based multi-omics datasets - PMC [pmc.ncbi.nlm.nih.gov]
- 19. Evaluation of normalization methods in mammalian microRNA-Seq data - PMC [pmc.ncbi.nlm.nih.gov]
Technical Support Center: Improving Library Preparation for 1-Methylcytosine (m1C) Sequencing
This technical support center provides troubleshooting guidance and answers to frequently asked questions for researchers, scientists, and drug development professionals working with 1-Methylcytosine (m1C) sequencing. Our aim is to help you overcome common challenges and improve the quality and reliability of your m1c-seq data.
Frequently Asked Questions (FAQs)
Q1: What are the primary methods for genome-wide profiling of this compound (m1C)?
A1: The main approaches for studying m1C at a genome-wide scale are analogous to those used for 5-methylcytosine (B146107) (5mC) and include:
-
Bisulfite Sequencing (BS-Seq): This is the gold standard for single-base resolution methylation analysis. Treatment with sodium bisulfite converts unmethylated cytosines to uracil, which are then read as thymine (B56734) after PCR amplification. Methylated cytosines, including m1C, are protected from this conversion and are read as cytosine.[1]
-
Enzymatic Methyl-seq (EM-seq): This method uses a series of enzymatic reactions to achieve the same C-to-T conversion for unmethylated cytosines, but under much milder conditions than bisulfite treatment. This minimizes DNA damage and can lead to higher quality libraries.[2][3]
-
Antibody-Based Enrichment (MeRIP-seq): Methylated DNA Immunoprecipitation Sequencing (MeRIP-seq) utilizes an antibody specific to m1C to enrich for DNA fragments containing this modification. These enriched fragments are then sequenced. This method does not provide single-base resolution but is useful for identifying m1C-rich regions.
Q2: How do I choose between bisulfite sequencing, enzymatic conversion, and antibody-based enrichment for my m1C study?
A2: The choice of method depends on your specific research question and available resources.
| Method | Resolution | Advantages | Disadvantages |
| Bisulfite Sequencing (BS-Seq) | Single-base | Gold standard, well-established protocols. | Harsh chemical treatment can degrade DNA, leading to biased coverage and lower library complexity.[4] Cannot distinguish between different types of cytosine modifications without additional techniques. |
| Enzymatic Methyl-seq (EM-seq) | Single-base | Minimizes DNA damage, resulting in higher quality libraries with more uniform coverage.[2][3] | Newer technology, potentially higher reagent cost. |
| MeRIP-seq | Regional | Good for identifying m1C-enriched regions, requires less sequencing depth than whole-genome approaches. | Does not provide single-base resolution, antibody specificity can be a concern, potential for immunoprecipitation biases.[5] |
Q3: What are the critical quality control (QC) steps for an m1C sequencing library?
A3: Robust QC is essential for reliable m1C sequencing results. Key QC checkpoints include:
-
Initial DNA/RNA Quality Assessment: Use spectrophotometry (e.g., NanoDrop) and fluorometry (e.g., Qubit) to assess the purity and concentration of your starting material. Gel electrophoresis or automated electrophoresis (e.g., Bioanalyzer, TapeStation) can be used to check for degradation.[6]
-
Library Quantification: After library preparation, accurately quantify the library concentration using fluorometry or qPCR. qPCR is often preferred as it specifically quantifies molecules with correctly ligated adapters that are amplifiable.[7]
-
Library Size Distribution: Use automated electrophoresis to verify the size distribution of your final library and check for the presence of adapter-dimers.[7][8]
-
Sequencing Quality Metrics: After sequencing, evaluate metrics such as Phred quality scores (Q-scores), cluster density, and percentage of reads passing filter (%PF).[6][9]
Troubleshooting Guides
Problem 1: Low Library Yield
Q: I have a very low concentration of my final sequencing library. What could be the cause and how can I fix it?
A: Low library yield is a common issue in NGS library preparation.[2] Potential causes and solutions are outlined below:
| Possible Cause | Solution |
| Low quality or quantity of starting DNA | Ensure your starting DNA is of high purity (A260/280 ratio of ~1.8) and accurately quantified. Use a fluorometric method like Qubit for quantification. For low input amounts, consider a library preparation kit specifically designed for low-input samples. |
| DNA degradation during bisulfite treatment | The harsh chemical conditions of bisulfite conversion can fragment and degrade DNA.[4] Consider using an enzymatic methyl-seq (EM-seq) kit, which is less damaging to DNA.[2][3] If using bisulfite, ensure the reaction is performed according to the manufacturer's protocol and avoid extended incubation times. |
| Inefficient enzymatic reactions (end-repair, A-tailing, ligation) | Ensure all enzymes are properly stored and handled. Use fresh reagents and accurately pipette all components. Optimize incubation times and temperatures as recommended by the kit manufacturer. |
| Loss of sample during bead-based clean-up steps | Be careful not to aspirate beads during washing steps. Ensure beads are fully resuspended before elution. Allow sufficient incubation time for DNA to bind to and elute from the beads. |
| Suboptimal PCR amplification | Optimize the number of PCR cycles to avoid over- or under-amplification. Too few cycles will result in low yield, while too many can introduce biases and PCR duplicates. Use a high-fidelity, hot-start polymerase suitable for amplifying bisulfite-converted DNA. |
Problem 2: Adapter Dimer Contamination
Q: My library electropherogram shows a significant peak at ~120-150 bp, indicating adapter dimer contamination. What should I do?
A: Adapter dimers are a frequent source of failed sequencing runs as they preferentially cluster on the flow cell, consuming sequencing capacity.
| Possible Cause | Solution |
| Suboptimal adapter-to-insert molar ratio | Titrate the amount of adapter used in the ligation reaction. Too high a concentration of adapters relative to DNA inserts can lead to self-ligation of adapters. |
| Poor quality starting DNA | Degraded or fragmented input DNA can lead to inefficient ligation of inserts and favor the formation of adapter dimers. |
| Ineffective clean-up after ligation | Perform an additional bead-based clean-up step with an optimized bead-to-sample ratio to remove small DNA fragments, including adapter dimers. |
| Library over-amplification | Excessive PCR cycles can amplify any existing adapter dimers. Use the minimum number of cycles necessary to generate sufficient library for sequencing. |
Problem 3: Incomplete Bisulfite Conversion
Q: My sequencing data suggests incomplete bisulfite conversion. How can I improve the conversion efficiency?
A: Incomplete conversion of unmethylated cytosines to uracils will lead to an overestimation of methylation levels.[10][11]
| Possible Cause | Solution |
| Poor DNA quality | Contaminants in the DNA sample can inhibit the bisulfite reaction. Ensure your DNA is of high purity.[10] |
| Suboptimal denaturation of DNA | Complete denaturation of the double-stranded DNA is crucial for the bisulfite reagent to access the cytosine residues. Ensure the initial denaturation step is performed at the correct temperature and for the recommended duration. |
| Incorrect bisulfite reagent concentration or incubation conditions | Use freshly prepared bisulfite solution. Ensure the incubation temperatures and times are strictly followed as per the protocol. |
| Insufficient mixing of reagents | Ensure all components are thoroughly mixed before incubation. |
| Inclusion of unmethylated control DNA | Spike-in unmethylated lambda phage DNA into your sample before bisulfite treatment. This will allow you to accurately calculate the conversion efficiency. A conversion rate of >99% is desirable. |
Experimental Protocols & Workflows
General Workflow for m1C Bisulfite Sequencing
The following diagram illustrates a typical workflow for whole-genome bisulfite sequencing (WGBS) to detect m1C.
MeRIP-seq Protocol Outline
Methylated DNA Immunoprecipitation followed by sequencing (MeRIP-seq) is a powerful technique for identifying m1C-enriched regions in the genome.
-
DNA Extraction and Fragmentation:
-
Isolate high-quality genomic DNA.
-
Fragment the DNA to a desired size range (e.g., 100-500 bp) using sonication or enzymatic digestion.
-
-
End Repair, A-tailing, and Adapter Ligation:
-
Perform end-repair and A-tailing on the fragmented DNA.
-
Ligate sequencing adapters to the DNA fragments.
-
-
Immunoprecipitation (IP):
-
Denature the adapter-ligated DNA.
-
Incubate the single-stranded DNA with an m1C-specific antibody to form DNA-antibody complexes.
-
Add protein A/G magnetic beads to capture the complexes.
-
Wash the beads to remove non-specific binding.
-
-
Elution and Library Amplification:
-
Elute the enriched DNA from the beads.
-
Perform PCR to amplify the library.
-
-
Library QC and Sequencing:
-
Assess the library quality and quantity.
-
Sequence the prepared library.
-
Logical Flow for Troubleshooting Low Library Yield
When faced with low library yield, a systematic approach to troubleshooting is crucial. The following diagram outlines a logical workflow to identify the root cause of the problem.
References
- 1. DNA Methylation Analysis Support—Troubleshooting | Thermo Fisher Scientific - JP [thermofisher.com]
- 2. m.youtube.com [m.youtube.com]
- 3. Enzymatic methyl-seq - Wikipedia [en.wikipedia.org]
- 4. twistbioscience.com [twistbioscience.com]
- 5. MeRIP-Seq/m6A-seq [illumina.com]
- 6. Our Top 5 Quality Control (QC) Metrics Every NGS User Should Know [horizondiscovery.com]
- 7. knowledge.illumina.com [knowledge.illumina.com]
- 8. Library QC for NGS [qiagen.com]
- 9. biotech.ufl.edu [biotech.ufl.edu]
- 10. benchchem.com [benchchem.com]
- 11. Errors in the bisulfite conversion of DNA: modulating inappropriate- and failed-conversion frequencies - PMC [pmc.ncbi.nlm.nih.gov]
Validation & Comparative
Validating 1-Methylcytosine Sequencing: A Comparative Guide to Orthogonal Methods
For researchers, scientists, and drug development professionals, ensuring the accuracy of sequencing data is paramount. This guide provides an objective comparison of orthogonal methods for validating 1-methylcytosine (m1C) sequencing results, complete with experimental data and detailed protocols.
The study of epitranscriptomics, particularly RNA modifications like this compound (m1C), is a rapidly evolving field. While high-throughput sequencing methods provide a genome-wide view of m1C distribution, orthogonal validation is crucial to confirm these findings and ensure data robustness. This guide explores various techniques that can be employed to independently verify m1C sequencing results.
Comparison of Orthogonal Validation Methods
The selection of an appropriate orthogonal validation method depends on factors such as the desired resolution, throughput, and the nature of the m1C sequencing data. Below is a comparison of common validation techniques.
| Method | Principle | Resolution | Throughput | Advantages | Disadvantages |
| m1C-immunoprecipitation followed by qPCR (m1C-IP-qPCR) | Antibody-based enrichment of m1C-containing RNA fragments, followed by quantitative PCR of specific targets. | Locus-specific | Low to medium | Relatively straightforward and cost-effective for validating a moderate number of targets. | Dependent on antibody specificity and efficiency; does not provide single-base resolution. |
| Locus-specific RNA Bisulfite Sequencing | Chemical conversion of unmethylated cytosines to uracil (B121893) in a specific RNA region, followed by Sanger or next-generation sequencing. | Single-base | Low | Provides quantitative methylation information at single-nucleotide resolution for specific sites. | RNA degradation due to harsh chemical treatment; requires specific primer design. |
| Methylation-Sensitive RNase Digestion followed by RT-qPCR (MSRE-RT-qPCR) | Digestion of RNA with an RNase that specifically cleaves at unmethylated cytosines, followed by reverse transcription and quantitative PCR. | Site-specific | Low to medium | Avoids chemical treatment, potentially preserving RNA integrity better than bisulfite methods. | Dependent on the availability and specificity of methylation-sensitive RNases; limited to the enzyme's recognition sites. |
| Mass Spectrometry (LC-MS/MS) | Liquid chromatography-tandem mass spectrometry to quantify the ratio of m1C to total cytosine in total RNA or isolated specific RNAs. | Global/Specific RNA | Low | Highly quantitative and accurate for determining overall m1C levels. | Does not provide sequence context; requires specialized equipment and expertise. |
Experimental Workflows
Visualizing the experimental process is key to understanding the interplay between sequencing and validation.
Figure 1. Workflow for m1C sequencing and subsequent orthogonal validation.
Signaling Pathway of m1C Regulation
Understanding the pathways that regulate m1C deposition can provide biological context to sequencing results.
A Comparative Analysis of 1-Methylcytosine and 5-Methylcytosine Distribution and Function
For Researchers, Scientists, and Drug Development Professionals
This guide provides a comprehensive and objective comparison of two methylated cytosine isomers: 1-methylcytosine (m1C) and 5-methylcytosine (B146107) (m5C). While both are modifications of the canonical DNA and RNA base cytosine, their distribution, biological roles, and the methods for their detection differ significantly. This analysis is supported by experimental data and detailed methodologies for key investigative techniques.
At a Glance: Key Differences Between m1C and m5C
| Feature | This compound (m1C) | 5-Methylcytosine (m5C) |
| Structure | Methyl group at the N1 position of the pyrimidine (B1678525) ring. | Methyl group at the C5 position of the pyrimidine ring. |
| Primary Location | Primarily found in synthetic nucleic acid systems; natural occurrence is not well-documented in mammals. | Abundantly found in both DNA and various RNA species in most domains of life. |
| Known Biological Roles | Limited known biological function in natural systems; used in synthetic biology (e.g., hachimoji DNA). | A key epigenetic and epitranscriptomic mark involved in gene silencing, genomic imprinting, X-chromosome inactivation, and regulation of RNA stability, export, and translation. |
| Detection Methods | Primarily mass spectrometry; not distinguishable by standard bisulfite sequencing. | A wide array of methods including bisulfite sequencing, immunoprecipitation-based techniques (MeDIP-seq, m5C-RIP-seq), and enzymatic assays. |
In-Depth Comparison: Distribution, Function, and Detection
This section provides a detailed comparative analysis of m1C and m5C, with quantitative data summarized for clarity.
Distribution in Nucleic Acids
The distribution of m5C is widespread and has been extensively mapped across various organisms and nucleic acid types. In contrast, the natural distribution of m1C is not well-characterized.
| Nucleic Acid | This compound (m1C) Distribution | 5-Methylcytosine (m5C) Distribution |
| DNA | Not documented as a common natural modification in mammalian DNA. Used in synthetic "hachimoji DNA" where it pairs with isoguanine[1]. | Predominantly at CpG dinucleotides in vertebrates, with 70-80% of CpG cytosines being methylated[2]. Found in CpHpG and CpHpH sequences in plants[2]. Plays a role in protecting DNA from restriction enzymes in bacteria[2]. |
| tRNA | Not well-documented as a natural modification. Other N-methylated cytosines like N3-methylcytosine (m3C) are found at specific positions[3]. | Commonly found in the variable regions and anticodon loops, contributing to tRNA stability and structure[4][5]. |
| rRNA | Not well-documented as a natural modification. | Present in both prokaryotic and eukaryotic rRNAs, with roles in ribosome biogenesis and function[6]. |
| mRNA | Not well-documented as a natural modification. | Found in mRNAs of various organisms, often enriched in UTRs and near translation start sites, affecting mRNA stability, nuclear export, and translation[5][7][8]. |
| Other ncRNAs | Not well-documented as a natural modification. | Present in various non-coding RNAs, including lncRNAs and circular RNAs[4][9]. |
Biological Functions and Molecular Pathways
5-Methylcytosine is a cornerstone of epigenetics and epitranscriptomics, with a plethora of well-defined biological functions. The functional significance of naturally occurring m1C, however, remains largely unknown.
| Biological Aspect | This compound (m1C) | 5-Methylcytosine (m5C) |
| Enzymatic Regulation | Writers: Not well-characterized for endogenous m1C. Erasers: Not well-characterized for endogenous m1C. Readers: Not well-characterized for endogenous m1C. | Writers: DNA Methyltransferases (DNMTs) for DNA[10]; NSUN family proteins and DNMT2 for RNA[6][9]. Erasers: TET family enzymes (via oxidation) for both DNA and RNA[5]. Readers: Methyl-CpG-binding domain (MBD) proteins for DNA; YBX1 and ALYREF for RNA[5][7]. |
| Impact on Gene Expression | May impact transcriptional activity, but this is not well-studied in a natural context[11]. | In DNA, methylation of promoter regions is strongly associated with transcriptional silencing[12]. In RNA, it can modulate mRNA stability and translation efficiency[8][9]. |
| Involvement in Signaling Pathways | No well-established involvement in specific signaling pathways. | Implicated in the regulation of multiple pathways, including PI3K/Akt, MAPK, and Hippo signaling, often through the modulation of key gene expression[6][12]. |
| Role in Disease | Not currently linked to specific diseases in a natural context. | Aberrant m5C patterns are a hallmark of many cancers and are implicated in various developmental and neurological disorders[9][13]. |
Experimental Protocols for Detection and Analysis
The reliable detection and quantification of methylated cytosines are crucial for understanding their biological roles. A variety of methods have been developed for m5C, while methods for m1C are less established and primarily rely on mass spectrometry.
Key Experimental Methodologies
| Method | Principle | Application for m1C | Application for m5C |
| Bisulfite Sequencing | Chemical conversion of unmethylated cytosine to uracil, while 5-methylcytosine remains unchanged. Sequencing reveals the methylation status at single-base resolution. | Not effective, as the N1 methylation does not protect the cytosine from bisulfite-induced deamination. | The "gold standard" for both DNA and RNA m5C analysis, providing single-nucleotide resolution[2][3][14]. |
| Immunoprecipitation-based Methods (e.g., MeDIP-seq, m5C-RIP-seq) | Use of specific antibodies to enrich for DNA or RNA fragments containing the methylation mark, followed by high-throughput sequencing. | Dependent on the availability of a highly specific m1C antibody, which is not commonly available. | Widely used for transcriptome-wide mapping of m5C in RNA (m5C-RIP-seq) and genome-wide mapping in DNA (MeDIP-seq)[3][14][15]. |
| Liquid Chromatography-Mass Spectrometry (LC-MS/MS) | Separation and identification of individual nucleosides based on their mass-to-charge ratio after complete enzymatic digestion of the nucleic acid. | Can be used for the detection and quantification of m1C, provided that appropriate standards are available. | A highly sensitive and accurate method for quantifying the overall abundance of m5C in a sample[15][16]. |
| Enzymatic Methods | Use of methylation-sensitive restriction enzymes or other enzymes that can distinguish between methylated and unmethylated cytosines. | Not well-established. | Used for locus-specific analysis of DNA methylation[17]. |
Detailed Protocol: RNA Bisulfite Sequencing (RNA-BS-seq) for m5C Detection
This method allows for the single-nucleotide resolution mapping of m5C in RNA.
-
RNA Isolation and Purification: Isolate total RNA from the sample of interest. For mRNA analysis, perform poly(A) selection. Ensure high-quality, intact RNA is used.
-
RNA Fragmentation: Fragment the RNA to a suitable size for sequencing (typically around 100-200 nucleotides).
-
Bisulfite Conversion: Treat the fragmented RNA with sodium bisulfite. This reaction converts unmethylated cytosines to uracils, while 5-methylcytosines are protected and remain as cytosines[4][10]. This step is often performed using commercially available kits that have optimized reaction conditions to minimize RNA degradation[10].
-
cDNA Synthesis: Perform reverse transcription of the bisulfite-converted RNA to generate the first strand of cDNA. This is followed by the synthesis of the second cDNA strand.
-
Library Preparation: Prepare a sequencing library from the double-stranded cDNA. This involves end-repair, A-tailing, and ligation of sequencing adapters.
-
PCR Amplification: Amplify the library to obtain sufficient material for sequencing.
-
High-Throughput Sequencing: Sequence the prepared library on a next-generation sequencing platform.
-
Data Analysis: Align the sequencing reads to a reference genome or transcriptome. The methylation status of each cytosine is determined by comparing the sequenced base to the reference. A cytosine that is read as a cytosine was likely methylated, while one that is read as a thymine (B56734) (uracil in the original RNA) was unmethylated.
Detailed Protocol: m5C RNA Immunoprecipitation Sequencing (m5C-RIP-seq)
This antibody-based method is used to identify regions of RNA that are enriched for m5C.
-
RNA Isolation and Fragmentation: Isolate total RNA and fragment it into smaller pieces (e.g., 100-200 nucleotides)[3][13].
-
Immunoprecipitation: Incubate the fragmented RNA with an antibody specific to m5C. The antibody-RNA complexes are then captured, typically using magnetic beads coated with Protein A/G[18].
-
Washing: Perform a series of washes to remove non-specifically bound RNA fragments.
-
Elution and RNA Purification: Elute the bound RNA from the antibody-bead complexes and purify the enriched RNA.
-
Library Preparation and Sequencing: Construct a sequencing library from the enriched RNA fragments and a corresponding input control library from the initial fragmented RNA. Sequence both libraries using a high-throughput sequencing platform[18].
-
Data Analysis: Align the sequencing reads to a reference genome or transcriptome. Identify regions that are significantly enriched in the m5C-IP sample compared to the input control. These enriched regions, or "peaks," represent the locations of m5C modifications.
Detailed Protocol: LC-MS/MS for Modified Nucleoside Analysis
This method provides a quantitative measure of the overall levels of modified nucleosides in a sample.
-
Nucleic Acid Isolation: Isolate high-purity DNA or RNA from the sample.
-
Enzymatic Digestion: Completely digest the nucleic acid into individual nucleosides using a cocktail of enzymes, such as nuclease P1 and alkaline phosphatase[16].
-
Chromatographic Separation: Separate the resulting nucleosides using liquid chromatography (LC), typically with a C18 reverse-phase column[19].
-
Mass Spectrometry Analysis: Introduce the separated nucleosides into a tandem mass spectrometer (MS/MS). The nucleosides are ionized, and their mass-to-charge ratios are measured. Fragmentation of the parent ions provides specific daughter ions that confirm the identity of each nucleoside[16].
-
Quantification: Quantify the amount of each modified nucleoside by comparing its signal intensity to that of a known amount of a stable isotope-labeled internal standard.
Visualizing Key Processes
The following diagrams illustrate a key experimental workflow and a relevant signaling pathway involving m5C.
Caption: Workflow for m5C-RIP Sequencing.
Caption: m5C-mediated regulation of an oncogenic pathway.
Conclusion
The study of methylated cytosines reveals a tale of two isomers. 5-Methylcytosine is a well-established and critically important modification in both DNA and RNA, with profound effects on gene regulation and cellular function. A robust toolkit of experimental methods has enabled detailed mapping and functional characterization of m5C, implicating it in numerous biological processes and diseases.
In stark contrast, this compound remains enigmatic in a biological context. While its chemical properties are understood and it has found a niche in synthetic biology, its natural occurrence, distribution, and functional significance in the nucleic acids of living organisms are not well-documented. Future research may yet uncover roles for m1C in epitranscriptomics or other cellular processes. However, based on current knowledge, m5C is the predominant and functionally significant methylated cytosine isomer in the biology of most organisms. This guide underscores the importance of precise molecular identification in the study of nucleic acid modifications and highlights the vast and dynamic field of epigenetic and epitranscriptomic regulation.
References
- 1. Enzymatic approaches for profiling cytosine methylation and hydroxymethylation - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Bisulfite sequencing - Wikipedia [en.wikipedia.org]
- 3. Methylation Matters: A Beginner’s Guide to Bisulfite Sequencing - Bio-Connect [bio-connect.nl]
- 4. Detection of ribonucleoside modifications by liquid chromatography coupled with mass spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 5. mdpi.com [mdpi.com]
- 6. 5-methylcytosine in RNA: detection, enzymatic formation and biological functions - PMC [pmc.ncbi.nlm.nih.gov]
- 7. neb.com [neb.com]
- 8. academic.oup.com [academic.oup.com]
- 9. Widespread occurrence of 5-methylcytosine in human coding and non-coding RNA - PMC [pmc.ncbi.nlm.nih.gov]
- 10. researchgate.net [researchgate.net]
- 11. Reversible RNA Modification N1-methyladenosine (m1A) in mRNA and tRNA - PMC [pmc.ncbi.nlm.nih.gov]
- 12. LC-MS Analysis of Methylated RNA - PubMed [pubmed.ncbi.nlm.nih.gov]
- 13. Methylated DNA is over-represented in whole-genome bisulfite sequencing data - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Targeted cytosine methylation for in vivo detection of protein–DNA interactions - PMC [pmc.ncbi.nlm.nih.gov]
- 15. N1-methyladenosine formation, gene regulation, biological functions, and clinical relevance - PMC [pmc.ncbi.nlm.nih.gov]
- 16. researchgate.net [researchgate.net]
- 17. LC-MS Analysis of Methylated RNA | Springer Nature Experiments [experiments.springernature.com]
- 18. Characterizing 5-methylcytosine in the mammalian epitranscriptome - PMC [pmc.ncbi.nlm.nih.gov]
- 19. bpb-us-e2.wpmucdn.com [bpb-us-e2.wpmucdn.com]
A Researcher's Guide to 5-Methylcytosine (5mC) Antibodies: A Cross-Vendor Performance Comparison
For researchers, scientists, and professionals in drug development, the accurate detection of DNA methylation is paramount. While the initial inquiry focused on 1-Methylcytosine (1mC), a comprehensive search of commercially available reagents reveals a significant lack of specific and validated antibodies for this particular modification. In contrast, the landscape for 5-Methylcytosine (B146107) (5mC) antibodies is rich and well-documented, reflecting its established role in epigenetic regulation. This guide, therefore, pivots to a detailed cross-validation of 5mC antibodies from leading vendors, providing a comparative analysis of their performance based on available data.
This guide offers an objective comparison of commercially available monoclonal and polyclonal antibodies targeting 5mC. The performance of these antibodies is evaluated based on their specificity, sensitivity, and utility in various immunoassays, supported by experimental data where available.
Antibody Vendor and Specification Overview
A selection of widely used 5-Methylcytosine antibodies from prominent vendors is summarized below. This table provides a quick reference for researchers to compare the key specifications of each antibody.
| Vendor | Product Name | Catalog No. | Host | Clonality | Validated Applications |
| Abcam | Anti-5-methylcytosine (5-mC) antibody [33D3] | ab10805 | Mouse | Monoclonal | IHC-P, IHC-Fr, IP, Flow Cyt, Dot Blot, MeDIP |
| Anti-5-methylcytosine (5-mC) antibody [RM231] | ab214727 | Rabbit | Monoclonal | ELISA, Dot Blot, ICC, IHC-P, MeDIP, Flow Cyt | |
| Cell Signaling Tech. | 5-Methylcytosine (5-mC) (D3S2Z) Rabbit mAb | 28692 | Rabbit | Monoclonal | Dot Blot, IF, MeDIP, ELISA |
| GeneTex | Anti-5-Methylcytosine / 5-mC antibody [GT4111] | GTX629448 | Mouse | Monoclonal | IHC-P, IHC-Fr, IHC-Wm, Dot Blot, EM, MeDIP |
| Proteintech | 5-methylcytosine antibody (68301-1-Ig) | 68301-1-Ig | Mouse | Monoclonal | IHC, Dot Blot, ELISA |
| Zymo Research | Anti-5-Methylcytosine Monoclonal Antibody (Clone 7D21) | A3001 | Mouse | Monoclonal | MeDIP, ELISA, Dot Blot, IF |
Performance Data Summary
The following tables summarize available data on the performance of these antibodies in key applications. Direct quantitative comparisons are limited in the literature; therefore, this data is compiled from vendor-provided information and publications.
Specificity and Cross-Reactivity
| Antibody (Vendor, Clone/ID) | Specificity for 5mC | Cross-Reactivity with 5hmC | Cross-Reactivity with Unmethylated Cytosine (C) |
| Abcam, 33D3 | Specific for the methyl group on carbon 5 of the pyrimidine (B1678525) ring. | Not explicitly stated, but clone is widely used for 5mC detection. | Minimal reactivity.[1] |
| Abcam, RM231 | Reacts to 5-methylcytosine in both single-stranded and double-stranded DNA.[2] | No cross-reactivity.[2][3] | No cross-reactivity.[2][3] |
| Cell Signaling Technology, D3S2Z | High specificity for 5-methylcytosine.[4][5] | Not explicitly stated, but validated for high specificity to 5mC.[4][5] | Not explicitly stated. |
| GeneTex, GT4111 | Detects 5-Methylcytosine.[6] | Not explicitly stated. | Not explicitly stated. |
| Proteintech, 2C9G9 (clone for 68301-1-Ig) | Specific to m5C, as shown by indirect and competitive ELISA.[7] | Not explicitly stated. | Does not react with Cytidine in competitive ELISA.[7] |
| Zymo Research, 7D21 | Specificity to 5-methylcytosines in single-stranded DNA.[8][9] | No detectable cross-reactivity.[8][9] | No detectable cross-reactivity.[8][9] |
Experimental Workflows and Protocols
Detailed methodologies are crucial for reproducible results. Below are representative protocols for common 5mC antibody validation experiments, followed by visual representations of the workflows.
Dot Blot Assay Workflow
A Dot Blot assay is a simple and effective method for determining the specificity and relative abundance of 5mC in DNA samples.
Dot Blot Protocol:
-
DNA Preparation: Isolate genomic DNA and perform serial dilutions. Denature the DNA by heating to 95-100°C for 10 minutes, followed by immediate chilling on ice.
-
Membrane Spotting: Spot 1-2 µL of each DNA dilution onto a nitrocellulose or nylon membrane.
-
Crosslinking: UV crosslink the DNA to the membrane.
-
Blocking: Block the membrane for 1 hour at room temperature in 5% non-fat dry milk in TBST (Tris-buffered saline with 0.1% Tween-20).
-
Primary Antibody Incubation: Incubate the membrane with the anti-5mC antibody (diluted in blocking buffer) overnight at 4°C with gentle agitation.
-
Washing: Wash the membrane three times for 10 minutes each with TBST.
-
Secondary Antibody Incubation: Incubate the membrane with an HRP-conjugated secondary antibody (diluted in blocking buffer) for 1 hour at room temperature.
-
Washing: Repeat the washing step.
-
Detection: Incubate the membrane with a chemiluminescent substrate and capture the signal using an imaging system.
ELISA (Enzyme-Linked Immunosorbent Assay) Workflow
ELISA provides a quantitative measure of global 5mC levels in a sample.
ELISA Protocol:
-
Plate Coating: Dilute denatured, single-stranded DNA in a coating buffer and add to the wells of a microplate. Incubate overnight at 4°C.
-
Washing: Wash the wells three times with a wash buffer (e.g., PBST).
-
Blocking: Add a blocking buffer to each well and incubate for 1-2 hours at room temperature.
-
Primary Antibody Incubation: Add the diluted anti-5mC antibody to the wells and incubate for 1-2 hours at room temperature.
-
Washing: Repeat the washing step.
-
Secondary Antibody Incubation: Add the HRP-conjugated secondary antibody and incubate for 1 hour at room temperature.
-
Washing: Repeat the washing step.
-
Detection: Add a TMB substrate and incubate until a blue color develops. Add a stop solution to turn the color yellow.
-
Measurement: Read the absorbance at 450 nm using a microplate reader.
Immunofluorescence (IF) Staining Workflow
Immunofluorescence allows for the visualization of 5mC within the cellular context, providing spatial information about DNA methylation patterns.
Immunofluorescence Protocol:
-
Cell Culture and Fixation: Grow cells on coverslips, then fix with 4% paraformaldehyde (PFA) for 15 minutes at room temperature.
-
Permeabilization: Permeabilize the cells with 0.25% Triton X-100 in PBS for 10 minutes.
-
DNA Denaturation: Treat the cells with 2N HCl for 30 minutes at room temperature to denature the DNA, followed by neutralization with 100 mM Tris-HCl (pH 8.5).
-
Blocking: Block with 1% BSA in PBST for 30 minutes.
-
Primary Antibody Incubation: Incubate with the anti-5mC antibody (diluted in blocking buffer) for 1 hour at room temperature.
-
Washing: Wash three times with PBS.
-
Secondary Antibody Incubation: Incubate with a fluorophore-conjugated secondary antibody (diluted in blocking buffer) for 1 hour at room temperature in the dark.
-
Washing: Repeat the washing step.
-
Mounting and Imaging: Mount the coverslips with a mounting medium containing DAPI for nuclear counterstaining and visualize using a fluorescence microscope.
Conclusion
The selection of a 5-Methylcytosine antibody is a critical decision that can significantly impact the outcome of epigenetic research. While a direct, comprehensive third-party comparison of all available antibodies is lacking, this guide provides a structured overview of the offerings from major vendors. Researchers are encouraged to consider the specific requirements of their experimental setup, including the application, species of interest, and the need for specificity against other cytosine modifications. The provided protocols and workflows offer a starting point for the in-house validation that is essential for ensuring the reliability and reproducibility of any immunoassay.
References
- 1. Anti-5-Methylcytosine / 5-mC antibody [33D3] (GTX75897) | GeneTex [genetex.com]
- 2. Anti-5-methylcytosine (5-mC) antibody [RM231] (ab214727) | Abcam [abcam.com]
- 3. Anti-5-Methylcytosine / 5-mC antibody [RM231] (GTX33606) | GeneTex [genetex.com]
- 4. 5-Methylcytosine (5-mC) (D3S2Z) Rabbit Monoclonal Antibody (#28692) Datasheet With Images | Cell Signaling Technology [cellsignal.com]
- 5. 5-Methylcytosine (5-mC) (D3S2Z) Rabbit Monoclonal Antibody | Cell Signaling Technology [cellsignal.com]
- 6. Anti-5-Methylcytosine / 5-mC antibody [GT4111] (GTX629448) | GeneTex [genetex.com]
- 7. 5-methylcytosine antibody (68301-1-Ig) | Proteintech [ptglab.com]
- 8. Zymo Research Corporation Anti-5-Methlycytosine 50 ul @ 1 ug/ul (Clone | Fisher Scientific [fishersci.com]
- 9. zymoresearch.com [zymoresearch.com]
Benchmarking different software for 1-Methylcytosine peak calling
For researchers, scientists, and drug development professionals venturing into the landscape of epitranscriptomics, the accurate identification of 1-methylcytosine (m1C) modifications is crucial. This guide provides a comparative overview of software used for m1C peak calling from methylated RNA immunoprecipitation sequencing (MeRIP-seq) data. As dedicated m1C peak calling software is not yet prevalent, this comparison focuses on tools adapted from similar applications like m6A-seq and ChIP-seq, which are commonly used in the field.
Experimental Protocol: m1C MeRIP-Sequencing
The typical workflow for m1C MeRIP-seq begins with the isolation of total RNA from the sample of interest. This RNA is then fragmented into smaller pieces. An antibody specific to m1C is used to immunoprecipitate the RNA fragments containing this modification. The enriched, m1C-containing RNA fragments are then reverse-transcribed into cDNA and subjected to high-throughput sequencing. A parallel "input" sample, which is fragmented total RNA that has not undergone immunoprecipitation, is also sequenced to serve as a control for non-specific enrichment.
Data Analysis Pipeline
The bioinformatic analysis of m1C MeRIP-seq data commences with raw sequencing reads. These reads undergo quality control and are then aligned to a reference genome or transcriptome. Subsequently, peak calling algorithms are employed to identify regions in the genome/transcriptome where there is a significant enrichment of reads in the immunoprecipitated sample compared to the input control. These enriched regions, or "peaks," correspond to putative m1C sites.
Comparison of Peak Calling Software
While a dedicated benchmarking study for m1C peak calling is not yet available, several tools developed for ChIP-seq and m6A MeRIP-seq have been successfully applied to identify m1C peaks. The two most prominent software packages are MACS2 and exomePeak .
| Feature | MACS2 (Model-based Analysis of ChIP-Seq) | exomePeak |
| Primary Application | ChIP-seq | MeRIP-seq (m6A) |
| Underlying Principle | Compares the read count in the IP sample to a local background model derived from the control sample. It uses a Poisson distribution to model the tag count.[1][2] | Utilizes a binomial distribution to model the read counts in the IP and input samples within defined genomic regions (e.g., exons).[3][4] |
| Input Format | BAM, SAM, BED | BAM |
| Output Format | BED, narrowPeak, broadPeak, XLS | BED, XLS, GRangesList |
| Key Features | - Can identify both narrow and broad peaks.[1] - Provides comprehensive output files with statistical measures (p-value, q-value, fold-enrichment).[5] - Widely used and well-documented.[2] | - Specifically designed for RNA methylation data.[3][4] - Includes functionality for differential methylation analysis between conditions.[6] - Can account for gene-specific expression biases. |
| Best Suited For | General-purpose peak calling for both sharp and broad m1C enrichment profiles. Often used as a core component in larger analysis pipelines like MeRIPseqPipe.[7] | Researchers focused on transcriptome-wide analysis of m1C within coding regions and interested in differential methylation analysis. |
| Availability | Command-line tool, open-source. | R/Bioconductor package.[3] |
Detailed Methodologies
MACS2 (Model-based Analysis of ChIP-Seq)
MACS2 is a widely used peak caller for ChIP-seq data that has been adapted for MeRIP-seq analysis.[1][2] It identifies enriched regions by modeling the read distribution across the genome.
-
Experimental Protocol: The standard m1C MeRIP-seq protocol is followed to generate aligned reads in BAM format for both the m1C-immunoprecipitated and input samples.
-
Peak Calling Protocol with MACS2:
-
Input: Aligned reads for the IP and control samples in BAM or BED format.
-
Model Building: MACS2 builds a model of the read distribution based on the control sample to account for local biases in the genome.
-
Peak Identification: It scans the genome for regions with a significant enrichment of reads in the IP sample compared to the control, based on a Poisson distribution model.
-
Statistical Analysis: A p-value and a false discovery rate (FDR) are calculated for each identified peak to assess its statistical significance.
-
Output: The primary output is a BED file containing the coordinates of the identified peaks. More detailed information is provided in the .narrowPeak or .broadPeak and .xls files.[5]
-
exomePeak
exomePeak is an R/Bioconductor package specifically developed for the analysis of MeRIP-seq data.[3][4] It is particularly well-suited for identifying methylation sites within exons and for performing differential methylation analysis.
-
Experimental Protocol: The standard m1C MeRIP-seq protocol is used to generate aligned reads in BAM format.
-
Peak Calling Protocol with exomePeak:
-
Input: Aligned reads in BAM format for IP and input samples, along with a gene annotation file (GTF).
-
Read Counting: The number of reads falling into predefined genomic regions (typically exons) is counted for both the IP and input samples.
-
Statistical Model: A binomial distribution is used to model the proportion of reads in the IP sample relative to the total reads (IP + input) for each genomic feature.
-
Peak Calling: Regions with a significantly higher proportion of reads in the IP sample are identified as methylated peaks.
-
Differential Analysis: The package can also compare two experimental conditions to identify differentially methylated sites.[6]
-
Output: The results are provided as BED files and R objects (GRangesList) for downstream analysis.[4]
-
Concluding Remarks
The choice between MACS2 and exomePeak for this compound peak calling depends on the specific research question and the nature of the expected m1C enrichment.
-
For a robust, general-purpose peak caller that can be integrated into automated pipelines and is suitable for various types of enrichment patterns, MACS2 is an excellent choice. Its widespread use in the genomics community ensures extensive support and documentation.
-
For researchers primarily interested in the dynamics of m1C within the transcriptome, especially within coding regions, and who require a tool with built-in capabilities for differential methylation analysis, exomePeak offers a more specialized and convenient solution.
As the field of epitranscriptomics continues to evolve, it is anticipated that more specialized tools for m1C analysis will be developed. However, the adaptation of established and well-validated tools like MACS2 and the development of specialized packages like exomePeak provide a solid foundation for the accurate identification of this compound modifications in the transcriptome.
References
- 1. Peak calling with MACS2 | Introduction to ChIP-Seq using high-performance computing [hbctraining.github.io]
- 2. Identifying ChIP-seq enrichment using MACS - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Bioconductor - exomePeak [bioconductor.org]
- 4. bioconductor.org [bioconductor.org]
- 5. MACS2 · PyPI [pypi.org]
- 6. bioconductor.org [bioconductor.org]
- 7. GitHub - canceromics/MeRIPseqPipe: MeRIPseqPipe:An integrated analysis pipeline for MeRIP-seq data based on Nextflow. [github.com]
Navigating the Methylome: A Comparative Guide to Bisulfite Sequencing and Enzymatic Methods for 1mC Detection
For researchers, scientists, and drug development professionals delving into the intricacies of the epigenome, the accurate detection of 5-methylcytosine (B146107) (5mC) is paramount. For decades, bisulfite sequencing has reigned as the gold standard. However, the advent of gentler, enzymatic-based approaches presents a compelling alternative. This guide provides an objective, data-driven comparison of these two methodologies to inform the selection of the most appropriate technique for your research needs.
The fundamental principle behind both methods is to differentiate between methylated and unmethylated cytosines. This is achieved by chemically or enzymatically converting unmethylated cytosines to a base that is read as thymine (B56734) during sequencing, while 5-methylcytosines remain unchanged and are read as cytosines. The resulting sequence data is then compared to a reference genome to elucidate the methylation status of each cytosine.
At a Glance: Key Performance Metrics
The choice between bisulfite and enzymatic methods often involves a trade-off between established protocols and the promise of higher quality data with less sample degradation. Below is a summary of key performance metrics compiled from various studies.
| Performance Metric | Bisulfite Sequencing (e.g., WGBS) | Enzymatic Methyl-Seq (e.g., EM-seq) | Key Advantage of Enzymatic Method |
| DNA Damage | High, due to harsh chemical treatment leading to significant DNA fragmentation and loss.[1][2][3] | Minimal, as the enzymatic reactions are gentler, preserving DNA integrity.[4][5][6] | Higher quality DNA, leading to more reliable and comprehensive sequencing data. |
| Library Yield | Lower, particularly with low-input or fragmented DNA samples.[2][7] | Significantly higher library yields from the same amount of starting material.[2][7][8] | More efficient use of precious or limited samples. |
| Library Complexity | Lower, with a higher percentage of PCR duplicate reads.[2][7] | Higher, with fewer PCR duplicates, resulting in the capture of more unique methylation events.[2][7] | A more comprehensive and accurate representation of the methylome. |
| GC Bias | Exhibits lower relative coverage over GC-rich regions due to DNA fragmentation and amplification bias.[7][9] | More even GC coverage and dinucleotide distribution.[6][7][10] | Improved performance in analyzing critical regulatory regions like CpG islands. |
| CpG Coverage | Detects fewer CpGs at the same sequencing depth.[8][11] | Identifies more CpGs, even at lower sequencing depths.[8][11] | More sensitive and cost-effective detection of methylation sites. |
| Input DNA Amount | Typically requires higher amounts of input DNA.[9][12] | Effective with as little as 100 pg of DNA.[1][12] | Enables methylation analysis of rare or challenging samples. |
| Protocol Workflow | Established and widely used protocols are available. | Can be more laborious with additional clean-up steps and incubations.[2] | Bisulfite sequencing may offer a more streamlined workflow for some labs. |
Principles of Detection
Bisulfite Sequencing
Bisulfite sequencing relies on the chemical treatment of DNA with sodium bisulfite. This process deaminates unmethylated cytosines, converting them to uracils.[2] During the subsequent PCR amplification, these uracils are replaced by thymines.[6] In contrast, 5-methylcytosines are resistant to this conversion and remain as cytosines.[2] By sequencing the treated DNA and comparing it to the original sequence, the methylation status of each cytosine can be determined at single-base resolution.[13]
Enzymatic Methods (EM-seq)
Enzymatic Methyl-seq (EM-seq) offers a gentler, enzyme-driven alternative to bisulfite conversion.[4] This method typically involves a two-step enzymatic process. First, the TET2 enzyme oxidizes 5mC and 5-hydroxymethylcytosine (B124674) (5hmC), and an oxidation enhancer protects these modified cytosines from subsequent deamination.[6] In the second step, the APOBEC enzyme specifically deaminates the unmodified cytosines to uracils.[6] Similar to bisulfite sequencing, the resulting DNA is then amplified and sequenced, with the uracils being read as thymines. This allows for the identification of the original methylation sites.
Experimental Workflows
The following diagrams illustrate the general experimental workflows for Whole Genome Bisulfite Sequencing (WGBS) and Enzymatic Methyl-seq (EM-seq).
Head-to-Head Comparison: A Logical Overview
The decision between bisulfite and enzymatic methods can be guided by several key factors related to sample quality, experimental goals, and available resources.
Detailed Experimental Protocols
Whole Genome Bisulfite Sequencing (WGBS) - Representative Protocol
This protocol is a generalized representation and may require optimization based on specific sample types and commercial kits.
-
DNA Fragmentation:
-
Start with high-quality genomic DNA.
-
Fragment the DNA to a desired size range (e.g., 100-500 bp) using sonication (e.g., Covaris) or enzymatic methods.
-
-
Library Preparation (Pre-Bisulfite):
-
End Repair and dA-tailing: Repair the ends of the fragmented DNA to create blunt ends and add a single adenine (B156593) nucleotide to the 3' ends.
-
Adapter Ligation: Ligate methylated sequencing adapters to the DNA fragments. These adapters are necessary for PCR amplification and sequencing.
-
Size Selection: Perform size selection of the adapter-ligated DNA fragments using gel electrophoresis or magnetic beads to obtain a library with a narrow size distribution.
-
-
Bisulfite Conversion:
-
Treat the adapter-ligated DNA library with a sodium bisulfite-containing conversion reagent.
-
Incubate the reaction under specific temperature and time conditions to ensure complete conversion of unmethylated cytosines to uracils. This step is often the harshest and can lead to DNA degradation.
-
Desulfonation and Purification: Remove the bisulfite reagent and perform a desulfonation step to complete the chemical conversion. Purify the converted DNA.
-
-
PCR Amplification:
-
Amplify the bisulfite-converted library using a high-fidelity DNA polymerase that can read through uracil-containing templates.
-
Use a minimal number of PCR cycles to avoid amplification bias.
-
-
Final Library Purification and Quantification:
-
Purify the amplified library to remove PCR reagents.
-
Quantify the final library and assess its quality using methods like qPCR and fragment analysis (e.g., Bioanalyzer).
-
-
Sequencing:
-
Sequence the prepared library on a high-throughput sequencing platform.
-
Enzymatic Methyl-seq (EM-seq) - Representative Protocol (based on NEBNext®)
This protocol is a generalized representation based on commercially available kits and should be performed according to the manufacturer's instructions.[5][12]
-
DNA Fragmentation and Library Preparation:
-
Fragment genomic DNA to the desired size.
-
Perform end repair, dA-tailing, and ligate EM-seq specific adapters to the DNA fragments. This initial part of the workflow is similar to standard NGS library preparation.
-
-
Enzymatic Conversion - Step 1: Oxidation and Protection:
-
Incubate the adapter-ligated DNA with TET2 enzyme and an oxidation enhancer. This reaction oxidizes 5mC and 5hmC and protects them from subsequent deamination.[6]
-
-
Enzymatic Conversion - Step 2: Deamination:
-
Treat the DNA with APOBEC enzyme, which specifically deaminates the unprotected, unmethylated cytosines to uracils.[6]
-
-
PCR Amplification:
-
Amplify the enzymatically converted library using a specialized DNA polymerase (like NEBNext Q5U) that can efficiently amplify uracil-containing DNA.[14] Use indexed primers for multiplexing.
-
-
Final Library Purification and Quantification:
-
Purify the amplified library to remove enzymes and other reaction components.
-
Assess the concentration and size distribution of the final library.
-
-
Sequencing:
-
The resulting library is ready for sequencing on an Illumina platform. The data can be analyzed using existing bisulfite sequencing analysis pipelines.[6]
-
Conclusion
Both bisulfite sequencing and enzymatic methods are powerful tools for single-base resolution analysis of DNA methylation. While bisulfite sequencing has a long-standing history as the benchmark method, the harsh chemical treatment can introduce biases and lead to sample degradation. Enzymatic methods, such as EM-seq, have emerged as a superior alternative in many key performance areas, offering a gentler approach that results in higher quality data, especially from challenging, low-input samples.[15] The choice of method will ultimately depend on the specific research question, sample availability, and the desired balance between data quality, workflow familiarity, and cost. For studies demanding the highest data integrity and comprehensive methylome coverage, particularly from precious samples, enzymatic methods represent the future of DNA methylation analysis.
References
- 1. Principles and Workflow of Whole Genome Bisulfite Sequencing - CD Genomics [cd-genomics.com]
- 2. Comprehensive comparison of enzymatic and bisulfite DNA methylation analysis in clinically relevant samples - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Treat Your Sample Gently - Enzymatic Methyl-Sequencing vs. Bisulfite Methyl-Sequencing [cegat.com]
- 4. Whole-Genome Bisulfite Sequencing (WGBS) Protocol - CD Genomics [cd-genomics.com]
- 5. neb.com [neb.com]
- 6. researchgate.net [researchgate.net]
- 7. Enzymatic methyl sequencing detects DNA methylation at single-base resolution from picograms of DNA - PMC [pmc.ncbi.nlm.nih.gov]
- 8. neb-online.de [neb-online.de]
- 9. WGBS vs. EM-seq: Key Differences in Principles, Pros, Cons, and Applications - CD Genomics [cd-genomics.com]
- 10. biorxiv.org [biorxiv.org]
- 11. neb.com [neb.com]
- 12. mitra.stanford.edu [mitra.stanford.edu]
- 13. Bisulfite Sequencing (BS-Seq)/WGBS [illumina.com]
- 14. m.youtube.com [m.youtube.com]
- 15. [PDF] Comprehensive comparison of enzymatic and bisulfite DNA methylation analysis in clinically relevant samples | Semantic Scholar [semanticscholar.org]
Unraveling the Regulatory Roles of 1-Methylcytosine and 5-Methylcytosine in Gene Expression
A Comparative Guide for Researchers and Drug Development Professionals
In the intricate landscape of epigenetic and epitranscriptomic regulation, cytosine methylation stands out as a critical mechanism influencing gene expression. While 5-methylcytosine (B146107) (m5C) has long been the poster child of DNA methylation and a key player in transcriptional silencing, the functional significance of its lesser-known isomer, 1-methylcytosine (m1C), is increasingly coming to light, particularly in the realm of RNA modification. This guide provides a comprehensive functional comparison of m1C and m5C in gene regulation, supported by experimental data and detailed methodologies to aid researchers in their exploration of these pivotal modifications.
At a Glance: Key Functional Distinctions
| Feature | This compound (m1C) | 5-Methylcytosine (m5C) |
| Primary Location | Predominantly found in RNA (tRNA, rRNA) | Abundant in both DNA (CpG islands) and RNA (tRNA, rRNA, mRNA) |
| Primary Role in DNA | Not a major modification in DNA | Transcriptional repression when in promoter regions |
| Primary Role in RNA | Primarily structural, affecting tRNA stability and decoding | Modulates RNA stability, processing, nuclear export, and translation |
| "Writer" Enzymes | Primarily TRMT6/TRMT61A (for the related N1-methyladenosine, specific m1C writer less defined) | DNA: DNMTs (DNMT1, DNMT3A, DNMT3B); RNA: NSUN family (e.g., NSUN2, NSUN6) |
| "Eraser" Enzymes | Potentially ALKBH1 | DNA: TET family (TET1, TET2, TET3); RNA: TET family proposed |
| Impact on Translation | Can influence codon recognition and translation fidelity | Can enhance or repress translation depending on location within mRNA |
In-Depth Functional Comparison
This compound (m1C): A Structural Architect in RNA
This compound is characterized by a methyl group on the N1 position of the cytosine ring. This modification is predominantly found in non-coding RNAs, particularly transfer RNA (tRNA) and ribosomal RNA (rRNA).
Structural and Functional Implications in RNA:
-
tRNA Stability and Function: m1C is often found in the T-loop of tRNA, where it contributes to the molecule's structural integrity. This modification can influence the local conformation of the anticodon loop, thereby affecting codon recognition and the fidelity of translation. For instance, methylation at this position can stabilize the tRNA structure, which is crucial under cellular stress conditions.
-
Ribosomal RNA (rRNA) Processing: The presence of m1C in rRNA is implicated in the proper assembly and function of the ribosome, the cellular machinery for protein synthesis.
Enzymatic Regulation:
The specific "writer" and "eraser" enzymes for m1C are not as well-characterized as those for m5C. However, studies on the related N1-methyladenosine (m1A) modification suggest the involvement of:
-
Writers: The TRMT6/TRMT61A methyltransferase complex is a known writer for m1A in tRNA, and it is plausible that a similar enzymatic machinery is responsible for m1C formation.[1][2][3][4]
-
Erasers: The AlkB homolog 1 (ALKBH1) has been identified as a demethylase for N1-methylated bases in RNA, suggesting it may also act as an "eraser" for m1C.[5][6][7]
5-Methylcytosine (m5C): A Versatile Regulator in DNA and RNA
5-Methylcytosine, with its methyl group at the C5 position, is the most studied DNA modification and a key epigenetic mark. It also plays a significant and diverse role as an epitranscriptomic mark in various RNA species.
Regulatory Roles in DNA:
-
Transcriptional Silencing: In DNA, m5C is predominantly found in CpG dinucleotides. When located in the promoter regions of genes, it is strongly associated with transcriptional repression.[8] This silencing is mediated by preventing the binding of transcription factors or by recruiting methyl-CpG-binding domain (MBD) proteins, which in turn recruit chromatin remodeling complexes.
Diverse Functions in RNA:
-
RNA Stability: m5C modification in messenger RNA (mRNA) can influence its stability. Depending on the location and the context, m5C can either protect the mRNA from degradation or mark it for decay.[9][10]
-
RNA Processing and Export: The presence of m5C can affect pre-mRNA splicing and the subsequent export of mature mRNA from the nucleus to the cytoplasm.[9]
-
Translation Regulation: m5C modification within the coding sequence or untranslated regions (UTRs) of an mRNA can modulate its translation efficiency.[9][10] This can occur by influencing ribosome binding or by recruiting specific RNA-binding proteins.
-
tRNA and rRNA Function: Similar to m1C, m5C is also present in tRNA and rRNA, where it contributes to their structural stability and proper function in translation.[11]
Enzymatic Regulation:
The enzymatic machinery for m5C is well-established:
-
DNA Writers (Methyltransferases): The DNA methyltransferases DNMT1, DNMT3A, and DNMT3B are responsible for establishing and maintaining m5C patterns in DNA.
-
RNA Writers (Methyltransferases): The NOL1/NOP2/SUN domain (NSUN) family of enzymes, such as NSUN2 and NSUN6, are the primary writers of m5C in RNA.[9]
-
DNA and RNA Erasers (Demethylases): The Ten-Eleven Translocation (TET) family of dioxygenases (TET1, TET2, TET3) can oxidize m5C to 5-hydroxymethylcytosine (B124674) (5hmC), 5-formylcytosine (B1664653) (5fC), and 5-carboxylcytosine (5caC), initiating a pathway for active DNA demethylation. TET enzymes have also been implicated in the removal of m5C from RNA.[12]
Signaling Pathways and Experimental Workflows
To understand the regulatory networks involving m1C and m5C, it is essential to visualize the key players and their interactions.
Experimental Protocols for Studying Cytosine Methylation
Accurate detection and quantification of m1C and m5C are crucial for elucidating their biological roles. Below are summaries of key experimental workflows.
Workflow for Methylated RNA Immunoprecipitation Sequencing (MeRIP-Seq)
MeRIP-Seq is a powerful technique to identify the location of RNA modifications on a transcriptome-wide scale.
Detailed MeRIP-Seq Protocol:
A detailed protocol for MeRIP-seq can be found in various publications and commercial kits.[13][14][15][16][17] A general outline is as follows:
-
RNA Isolation and Fragmentation: Isolate total RNA from the cells or tissues of interest and fragment it to an appropriate size (typically around 100-200 nucleotides).
-
Immunoprecipitation: Incubate the fragmented RNA with an antibody specific to either m1C or m5C.
-
Capture and Washing: Capture the antibody-RNA complexes using protein A/G magnetic beads and perform stringent washing steps to remove non-specifically bound RNA.
-
Elution: Elute the enriched methylated RNA fragments from the beads.
-
Library Preparation and Sequencing: Construct a sequencing library from the eluted RNA and a corresponding input control library. Perform high-throughput sequencing.
-
Data Analysis: Align the sequencing reads to a reference genome/transcriptome and use peak-calling algorithms to identify enriched regions, which correspond to the locations of the modification.
Quantitative Analysis by Mass Spectrometry
Liquid chromatography-tandem mass spectrometry (LC-MS/MS) is the gold standard for accurate quantification of modified nucleosides.
Protocol for LC-MS/MS Quantification:
A detailed protocol for quantitative mass spectrometry of RNA modifications can be found in specialized literature.[10][18] The general steps are:
-
RNA Isolation and Digestion: Isolate total RNA and digest it into single nucleosides using a cocktail of nucleases.
-
Chromatographic Separation: Separate the resulting nucleosides using liquid chromatography.
-
Mass Spectrometry Analysis: Introduce the separated nucleosides into a tandem mass spectrometer. The instrument will measure the mass-to-charge ratio of the parent ion and its fragments, allowing for the identification and quantification of each modified nucleoside.
-
Data Analysis: Quantify the amount of m1C and m5C relative to the amount of unmodified cytosine.
Bisulfite Sequencing for m5C Detection
Bisulfite sequencing is a widely used method for single-base resolution mapping of m5C in both DNA and RNA.[9][11][19][20]
RNA Bisulfite Sequencing Protocol Outline:
-
RNA Treatment: Treat the RNA sample with sodium bisulfite, which converts unmethylated cytosines to uracil, while m5C residues remain unchanged.
-
Reverse Transcription and PCR: Reverse transcribe the treated RNA into cDNA and amplify the region of interest using PCR.
-
Sequencing: Sequence the PCR products.
-
Analysis: Compare the sequenced data to the original sequence. Any cytosine that remains a cytosine was originally methylated.
It is important to note that standard bisulfite sequencing cannot distinguish between m5C and 5hmC.
Conclusion
While 5-methylcytosine has been extensively studied for its profound impact on gene silencing in DNA and its multifaceted roles in RNA, the functions of this compound are emerging as crucial for the structural integrity and functional precision of the translational machinery. For researchers and drug development professionals, understanding the distinct and overlapping functions of these two cytosine modifications is paramount. The continued development of sensitive and specific detection methods, coupled with functional genomics approaches, will undoubtedly unveil further layers of complexity in how m1C and m5C contribute to the intricate regulation of gene expression in health and disease. This guide provides a foundational understanding and practical starting points for investigating these fascinating epigenetic and epitranscriptomic marks.
References
- 1. Frontiers | Depletion of the m1A writer TRMT6/TRMT61A reduces proliferation and resistance against cellular stress in bladder cancer [frontiersin.org]
- 2. researchgate.net [researchgate.net]
- 3. N1-methyladenosine methylation in tRNA drives liver tumourigenesis by regulating cholesterol metabolism - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Reactome | TRMT6:TRMT61A methylate adenosine yielding 1-methyladenosine at nucleotide 58 of tRNA(Met) [reactome.org]
- 5. The biological function of demethylase ALKBH1 and its role in human diseases - PMC [pmc.ncbi.nlm.nih.gov]
- 6. researchgate.net [researchgate.net]
- 7. DNA 6mA Demethylase ALKBH1 Orchestrates Fatty Acid Metabolism and Suppresses Diet-Induced Hepatic Steatosis - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Protocol for single-base quantification of RNA m5C by pyrosequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Bisulfite RNA sequencing [bio-protocol.org]
- 10. Protocol to analyze and quantify protein-methylated RNA interactions in mammalian cells with a combination of RNA immunoprecipitation and nucleoside mass spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Bisulfite Sequencing of RNA for Transcriptome-Wide Detection of 5-Methylcytosine | Springer Nature Experiments [experiments.springernature.com]
- 12. researchgate.net [researchgate.net]
- 13. Bisulfite Sequencing of RNA for Transcriptome-Wide Detection of 5-Methylcytosine - PubMed [pubmed.ncbi.nlm.nih.gov]
- 14. rna-seqblog.com [rna-seqblog.com]
- 15. MeRIP-seq Protocol - CD Genomics [rna.cd-genomics.com]
- 16. A protocol for RNA methylation differential analysis with MeRIP-Seq data and exomePeak R/Bioconductor package - PMC [pmc.ncbi.nlm.nih.gov]
- 17. MeRIP-seq and Its Principle, Protocol, Bioinformatics, Applications in Diseases - CD Genomics [cd-genomics.com]
- 18. Protocol for preparation and measurement of intracellular and extracellular modified RNA using liquid chromatography-mass spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 19. A Guide to RNA Bisulfite Sequencing (m5C Sequencing) - CD Genomics [rna.cd-genomics.com]
- 20. researchgate.net [researchgate.net]
Comparing the epigenetic impact of 1mC vs 5mC on chromatin structure
A Comparative Guide for Researchers, Scientists, and Drug Development Professionals
In the intricate landscape of epigenetics, the methylation of cytosine stands as a pivotal mechanism for regulating the genome. While 5-methylcytosine (B146107) (5mC) has long been celebrated as a key epigenetic mark, another methylated form, 1-methylcytosine (1mC), presents a contrasting narrative—one more aligned with DNA damage and repair than with programmed gene regulation. This guide provides a comprehensive comparison of the epigenetic impact of 1mC versus 5mC on chromatin structure, supported by experimental data and detailed methodologies.
Signaling Pathways and Molecular Mechanisms
The cellular responses to 1mC and 5mC are fundamentally different, initiating distinct signaling cascades that ultimately shape chromatin structure and gene expression.
Caption: Contrasting pathways of 1mC and 5mC in the cell.
Quantitative Comparison of 1mC and 5mC Effects
The distinct roles of 1mC and 5mC are reflected in their differing impacts on various aspects of chromatin biology and gene regulation.
| Feature | This compound (1mC) | 5-methylcytosine (5mC) |
| Primary Role | DNA lesion, mutagenic | Epigenetic mark, gene regulation |
| Genomic Abundance | Very low, transient | Relatively stable and abundant |
| Effect on Chromatin | Induces localized, transient chromatin opening for repair | Can lead to stable heterochromatin formation (gene silencing) or be associated with active gene bodies |
| Associated Proteins | DNA repair enzymes (e.g., AlkB glycosylases) | "Reader" proteins (e.g., MeCP2, MBD family), DNMTs, TET enzymes |
| Impact on Gene Expression | Generally leads to transcriptional arrest or misincorporation during replication if unrepaired | Can cause long-term gene silencing when in promoter regions; positive correlation with expression in gene bodies |
| Stability | Unstable, actively removed by repair pathways | Stable, but can be actively or passively demethylated |
Experimental Protocols
1. Detection of this compound (1mC) via Liquid Chromatography-Mass Spectrometry (LC-MS)
This method is highly sensitive for quantifying DNA adducts like 1mC.
-
DNA Extraction and Hydrolysis:
-
Genomic DNA is extracted from cells or tissues using a standard phenol-chloroform extraction or a commercial kit.
-
The purified DNA is enzymatically hydrolyzed to individual nucleosides using a cocktail of DNase I, nuclease P1, and alkaline phosphatase.
-
-
LC-MS/MS Analysis:
-
The nucleoside mixture is separated by reverse-phase high-performance liquid chromatography (HPLC).
-
The eluate is introduced into a tandem mass spectrometer (MS/MS) operating in multiple reaction monitoring (MRM) mode.
-
The transition of the protonated molecular ion of 1-methyldeoxycytidine to its characteristic product ion is monitored for quantification against a standard curve.
-
2. Genome-wide Analysis of 5-methylcytosine (5mC) by Whole-Genome Bisulfite Sequencing (WGBS)
WGBS is the gold standard for single-base resolution mapping of 5mC.
-
DNA Fragmentation and Library Preparation:
-
Genomic DNA is fragmented to a desired size range (e.g., 200-500 bp) by sonication.
-
End-repair, A-tailing, and ligation of methylated sequencing adapters are performed to generate a sequencing library.
-
-
Bisulfite Conversion:
-
The adapter-ligated DNA is treated with sodium bisulfite, which deaminates unmethylated cytosines to uracil, while 5mC residues remain largely unaffected.
-
-
PCR Amplification and Sequencing:
-
The bisulfite-converted library is amplified by PCR using primers that anneal to the adapter sequences. During PCR, uracils are converted to thymines.
-
The amplified library is sequenced on a next-generation sequencing platform.
-
-
Data Analysis:
-
Sequencing reads are aligned to a reference genome.
-
The methylation status of each cytosine is determined by comparing the sequenced base to the reference genome. A cytosine read at a CpG site that remains as a cytosine is identified as methylated.
-
3. Chromatin Immunoprecipitation followed by Sequencing (ChIP-seq) for 5mC-Binding Proteins
ChIP-seq is used to identify the genomic locations where 5mC "reader" proteins are bound.
-
Chromatin Cross-linking and Fragmentation:
-
Cells are treated with formaldehyde (B43269) to cross-link proteins to DNA.
-
The chromatin is isolated and fragmented by sonication to an average size of 200-600 bp.
-
-
Immunoprecipitation:
-
The fragmented chromatin is incubated with an antibody specific to a 5mC-binding protein (e.g., MeCP2).
-
The antibody-protein-DNA complexes are captured using protein A/G-coated magnetic beads.
-
-
DNA Purification and Sequencing:
-
The cross-links are reversed, and the DNA is purified.
-
A sequencing library is prepared from the immunoprecipitated DNA and sequenced.
-
-
Data Analysis:
-
Sequencing reads are aligned to a reference genome.
-
Peak calling algorithms are used to identify regions of the genome that are enriched for the binding of the specific protein.
-
Conclusion
The comparison between 1mC and 5mC highlights the critical importance of the position of the methyl group on the cytosine ring. While 5mC is a key player in the orchestrated regulation of the genome, 1mC serves as a stark reminder of the constant threat of DNA damage and the intricate repair mechanisms that safeguard genomic integrity. Understanding these differences is crucial for researchers in epigenetics, cancer biology, and drug development, as it informs our interpretation of DNA methylation data and opens new avenues for therapeutic intervention.
Navigating the Epitranscriptome: A Comparative Guide to 1mC Detection via Nanopore Sequencing
For researchers, scientists, and drug development professionals delving into the intricate world of RNA modifications, the accurate and reproducible detection of 1-methylcytosine (1mC) is paramount. This guide provides a comprehensive comparison of nanopore direct RNA sequencing with established alternative methods, offering insights into their respective accuracies, reproducibility, and experimental workflows. As a relatively less common modification compared to m6A, robust and standardized methods for 1mC detection are still an emerging area of research.
Direct RNA sequencing by Oxford Nanopore Technologies offers a promising avenue for the direct detection of RNA modifications without the need for reverse transcription or amplification, processes that can introduce bias.[1][2] This technology has shown high accuracy for some of the more common RNA modifications. For instance, with the latest RNA004 chemistry and Dorado basecaller, nanopore sequencing can achieve 94-98% accuracy for N6-methyladenosine (m6A) and pseudouridine (B1679824) detection.[3][4][5] However, specific performance metrics for this compound (1mC) are not as widely documented, highlighting a critical gap in the epitranscriptomic toolkit.
Alternative methods, primarily liquid chromatography-mass spectrometry (LC-MS), are considered the gold standard for the quantitative analysis of RNA modifications.[6][7] Mass spectrometry offers high sensitivity and the ability to quantify the absolute abundance of various modifications, including 1mC.[8][9][10] However, this approach requires the enzymatic digestion of RNA into individual nucleosides, which results in the loss of information about the specific location of the modification within the RNA sequence.
This guide will delve into the available data on the accuracy and reproducibility of nanopore sequencing for modifications related to 1mC, compare it with mass spectrometry, and provide detailed experimental protocols to aid researchers in selecting the most appropriate method for their scientific questions.
Comparative Performance Metrics
While specific quantitative data for 1mC detection using nanopore sequencing is limited in publicly available research, we can infer potential performance from studies on related modifications like 1-methyladenosine (B49728) (m1A). A study that sequenced RNA transcripts with 10 different modifications, including m1A, noted that while some modifications led to a dose-dependent increase in sequencing error rates, others, like m1A, showed error patterns similar to unmodified RNA.[11] This suggests that dedicated bioinformatic models are crucial for accurate 1mC detection.
For a qualitative comparison, we present a table summarizing the expected performance characteristics of each method.
| Feature | Nanopore Direct RNA Sequencing | Liquid Chromatography-Mass Spectrometry (LC-MS) |
| Principle | Direct sequencing of native RNA, modification detection via altered ionic current signal | Separation and identification of digested nucleosides based on mass-to-charge ratio |
| Information | Sequence context and potential location of modification | Absolute quantification of total modification abundance |
| Accuracy | High for some modifications (e.g., >94% for m6A), 1mC-specific accuracy not well-established | High accuracy for quantification of known modifications |
| Reproducibility | High for base calling, modification detection reproducibility is tool-dependent | High reproducibility for quantitative measurements |
| Throughput | High, with millions of reads per run | Lower throughput, sample-by-sample analysis |
| Input Amount | Micrograms of RNA | Micrograms of RNA |
| Read Length | Long reads, full-length transcripts | Not applicable (RNA is digested) |
| Strengths | Provides sequence context, detects multiple modifications simultaneously, portable | Gold standard for quantification, highly sensitive |
| Limitations | 1mC detection models are not yet mature, accuracy for low-stoichiometry modifications is a challenge | Destructive method (loses positional information), lower throughput |
Experimental Protocols
Nanopore Direct RNA Sequencing for 1mC Detection
The following protocol outlines the general steps for preparing an RNA sample for direct RNA sequencing with a focus on modification detection. Specific kits and software versions may vary, and users should consult the latest documentation from Oxford Nanopore Technologies.
1. RNA Extraction and Quality Control:
-
Extract total RNA from the sample of interest using a method that preserves RNA integrity and minimizes degradation.
-
Assess RNA quality and quantity using a spectrophotometer (e.g., NanoDrop) and a fluorometric assay (e.g., Qubit).
-
Check RNA integrity by capillary electrophoresis (e.g., Agilent Bioanalyzer or TapeStation). An RNA Integrity Number (RIN) > 7 is recommended.
2. Poly(A) Tailing (for non-polyadenylated RNAs):
-
If the target RNA is not polyadenylated, perform a poly(A) tailing reaction using E. coli Poly(A) Polymerase.
3. Library Preparation (using Oxford Nanopore Direct RNA Sequencing Kit, e.g., SQK-RNA004):
-
Ligate the reverse transcription adapter (RTA) to the 3' end of the RNA molecules.
-
Perform reverse transcription to create a complementary DNA (cDNA) strand. This step is for stabilizing the RNA for sequencing and does not involve amplification.
-
Ligate the sequencing adapter (RMX) to the 5' end of the RNA. This adapter contains the motor protein for threading the RNA through the nanopore.
4. Sequencing:
-
Prime the flow cell with the priming mix.
-
Load the prepared library onto the flow cell and start the sequencing run using the MinKNOW software.
5. Data Analysis for 1mC Detection:
-
Basecall the raw signal data (in .fast5 or .pod5 format) using a modification-aware basecaller such as Dorado.
-
Use specialized bioinformatic tools (e.g., Nanocompore, xPore) to compare the signal characteristics of the sample to an unmodified control (e.g., in vitro transcribed RNA of the same sequence) to identify potential 1mC sites. These tools typically analyze deviations in the ionic current and dwell time at specific nucleotide positions.[12][13][14][15]
Liquid Chromatography-Mass Spectrometry (LC-MS) for 1mC Quantification
This protocol provides a general overview of the steps involved in quantifying 1mC in an RNA sample using LC-MS.
1. RNA Extraction and Purification:
-
Extract and purify total RNA as described in the nanopore protocol. It is crucial to have a highly pure RNA sample to avoid interference during mass spectrometry analysis.
2. RNA Digestion:
-
Digest the purified RNA into individual nucleosides using a cocktail of enzymes, typically including nuclease P1, snake venom phosphodiesterase, and alkaline phosphatase. This ensures complete hydrolysis of the RNA into its constituent ribonucleosides.
3. Liquid Chromatography Separation:
-
Inject the digested nucleoside mixture into a high-performance liquid chromatography (HPLC) system.
-
Separate the nucleosides using a reverse-phase C18 column with a gradient of solvents (e.g., a mixture of an aqueous buffer and an organic solvent like acetonitrile (B52724) or methanol). The different nucleosides will elute from the column at characteristic retention times.
4. Mass Spectrometry Detection and Quantification:
-
The eluate from the HPLC is directly introduced into a mass spectrometer.
-
The mass spectrometer is operated in a selected reaction monitoring (SRM) or multiple reaction monitoring (MRM) mode to specifically detect and quantify the canonical cytosine and this compound based on their unique mass-to-charge ratios and fragmentation patterns.
-
Generate a standard curve using known concentrations of pure 1mC and cytosine to accurately quantify the amount of 1mC in the sample. The abundance of 1mC is typically reported as a ratio to the abundance of cytosine.
Conclusion
The detection of this compound in RNA is a rapidly evolving field. Nanopore direct RNA sequencing presents a powerful tool for identifying the location of 1mC within the context of the full-length RNA molecule, a feat not possible with traditional mass spectrometry. However, the accuracy and reproducibility of 1mC detection using nanopore sequencing are still under active development and require further benchmarking. The lack of mature, specific bioinformatic models for 1mC remains a significant hurdle.
In contrast, liquid chromatography-mass spectrometry is a robust and highly accurate method for quantifying the total amount of 1mC in a sample. Its primary limitation is the loss of positional information.
For researchers aiming to explore the landscape of 1mC modifications and their potential functional roles, a combinatorial approach may be most effective. Nanopore sequencing can be used for an initial, high-throughput screening to identify potential 1mC sites, which can then be validated and quantified using targeted mass spectrometry-based methods. As nanopore technology and its accompanying analytical tools continue to mature, we can expect more precise and reliable direct detection of 1mC, further empowering research in the dynamic field of epitranscriptomics.
References
- 1. nanoporetech.com [nanoporetech.com]
- 2. Direct Sequencing of RNA and RNA Modification Identification Using Nanopore | Springer Nature Experiments [experiments.springernature.com]
- 3. nanoporetech.com [nanoporetech.com]
- 4. biorxiv.org [biorxiv.org]
- 5. A Comparative Evaluation of Computational Models for RNA modification detection using Nanopore sequencing with RNA004 Chemistry - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. Quantitative and Multiplexing Analysis of MicroRNAs by Direct Full-Length Sequencing in Nanopores - PMC [pmc.ncbi.nlm.nih.gov]
- 7. MASS SPECTROMETRY OF RNA: LINKING THE GENOME TO THE PROTEOME - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Protocol for preparation and measurement of intracellular and extracellular modified RNA using liquid chromatography-mass spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 9. researchgate.net [researchgate.net]
- 10. bpb-us-e2.wpmucdn.com [bpb-us-e2.wpmucdn.com]
- 11. Nanopore-based direct sequencing of RNA transcripts with 10 different modified nucleotides reveals gaps in existing technology - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Detecting RNA modification using direct RNA sequencing: A systematic review - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Detecting RNA modification using direct RNA sequencing: A systematic review - PubMed [pubmed.ncbi.nlm.nih.gov]
- 14. researchgate.net [researchgate.net]
- 15. researchgate.net [researchgate.net]
A Researcher's Guide to N1-methyladenosine (1mC) Detection Kits: A Comparative Analysis
For researchers, scientists, and drug development professionals navigating the burgeoning field of epitranscriptomics, the accurate detection of RNA modifications is paramount. N1-methyladenosine (1mC), a prevalent and dynamic RNA modification, has emerged as a key regulator in various biological processes, making its precise quantification and localization a critical aspect of contemporary research. This guide provides an objective, data-driven comparison of commercially available 1mC detection kits, enabling informed decisions for your experimental needs.
This analysis focuses on two predominant methodologies for 1mC detection: Enzyme-Linked Immunosorbent Assay (ELISA) for global quantification and Methylated RNA Immunoprecipitation (MeRIP) followed by downstream analysis for localization. We present a side-by-side comparison of key performance metrics, detailed experimental protocols, and workflow visualizations to facilitate a comprehensive understanding of the available options.
Global 1mC Quantification: A Comparative Look at ELISA Kits
For researchers interested in the overall levels of 1mC in their RNA samples, ELISA kits offer a straightforward and quantitative solution. The following table summarizes the key features of commercially available 1mC ELISA kits.
| Feature | RayBiotech m1A ELISA Kit | MyBioSource 1-Methyladenosine (m1A) ELISA Kit | Cell Biolabs 1-Methyladenosine (m1A) ELISA Kit | EpigenTek EpiQuik™ m1A RNA Methylation Quantification Kit |
| Catalog Number | EIA-M1A-1 | MBS169566 | MET-5099 | P-9018 (Colorimetric) |
| Detection Method | Colorimetric, Competitive ELISA | Colorimetric, Competitive ELISA | Colorimetric, Competitive ELISA | Colorimetric, Antibody-based |
| Sensitivity | ~2.544 ng/mL[1] | ~2 ng/mL[2] | ~2 ng/mL[3] | Detection limit as low as 0.1 ng/well |
| Sample Type | Urine, Serum, Plasma[1] | Urine, Serum, Plasma[2] | Serum, Plasma, Urine, and extracted RNA from cells or tissues[3] | Total RNA from various sources |
| Assay Time | < 3 hours | Not specified | ~3 hours | < 4 hours |
| Standard Range | Not specified | Not specified | 0 ng/mL to 5000 ng/mL[4] | Not specified |
| Cross-Reactivity | Not specified | Not specified | Not specified | No cross-reactivity to unmethylated adenosine |
| Species Reactivity | Human, Rat, Mouse[1] | Not specified | Not specified (not compatible with mouse serum/plasma)[4] | Universal |
Experimental Protocol: General Competitive ELISA for 1mC Quantification
The following protocol is a generalized representation of the steps involved in the competitive ELISA kits from RayBiotech, MyBioSource, and Cell Biolabs. For specific details, always refer to the manufacturer's manual.
-
Standard and Sample Preparation: Prepare a serial dilution of the 1mC standard to generate a standard curve. Prepare your unknown samples (urine, serum, plasma, or digested RNA) to the appropriate dilution.
-
Competitive Binding: Add standards and samples to the wells of a microplate pre-coated with a 1mC conjugate. Add the anti-1mC antibody to each well. During this incubation, the free 1mC in the sample competes with the 1mC conjugate on the plate for binding to the limited amount of anti-1mC antibody.
-
Washing: Wash the plate to remove unbound antibodies and sample components.
-
Secondary Antibody Incubation: Add a horseradish peroxidase (HRP)-conjugated secondary antibody that binds to the primary anti-1mC antibody.
-
Washing: Wash the plate to remove the unbound secondary antibody.
-
Substrate Reaction: Add a TMB (3,3’,5,5’-tetramethylbenzidine) substrate solution. The HRP enzyme catalyzes the conversion of the substrate, resulting in a colorimetric signal.
-
Stopping the Reaction: Add a stop solution to terminate the enzymatic reaction.
-
Data Acquisition: Measure the absorbance at 450 nm using a microplate reader. The intensity of the color is inversely proportional to the amount of 1mC in the sample.
-
Quantification: Calculate the concentration of 1mC in the samples by interpolating from the standard curve.
Figure 1. Generalized workflow for competitive ELISA-based 1mC detection.
Mapping 1mC Sites: A Look at MeRIP-based Enrichment Kits
For researchers aiming to identify the specific locations of 1mC modifications within the transcriptome, MeRIP-based kits provide a powerful tool for enriching 1mC-containing RNA fragments for subsequent analysis by sequencing (MeRIP-seq) or qPCR.
| Feature | Norgene Rapid m1A RNA Enrichment Kit |
| Catalog Number | Not specified in provided results |
| Principle | Immunoprecipitation of 1mC-containing RNA fragments using an anti-1mC antibody. |
| Starting Material | Not specified, but generally total RNA or mRNA. |
| Antibody Details | Not specified. |
| Enrichment Efficiency | Not specified. |
| Required Equipment | Magnetic stand, standard molecular biology equipment. |
| Downstream Applications | Next-Generation Sequencing (NGS), qRT-PCR.[5] |
| Assay Time | Can be completed in one day.[5] |
Experimental Protocol: General MeRIP for 1mC Enrichment
The following is a generalized protocol for MeRIP. Specific protocols may vary between kits.
-
RNA Fragmentation: Fragment total RNA or mRNA to a desired size (typically ~100-200 nucleotides) using enzymatic or chemical fragmentation methods.
-
Immunoprecipitation:
-
Incubate the fragmented RNA with an anti-1mC antibody.
-
Add magnetic beads conjugated with Protein A/G to capture the antibody-RNA complexes.
-
Incubate to allow the beads to bind to the antibody-RNA complexes.
-
-
Washing: Wash the beads multiple times to remove non-specifically bound RNA fragments.
-
Elution: Elute the enriched 1mC-containing RNA fragments from the antibody-bead complexes.
-
RNA Purification: Purify the eluted RNA.
-
Downstream Analysis: The enriched RNA is now ready for downstream applications such as library preparation for NGS (MeRIP-seq) or reverse transcription and qPCR (MeRIP-qPCR).
References
Validating 1-Methylcytosine Assays: A Comparative Guide to Using Synthetic DNA Standards
For researchers, scientists, and drug development professionals, the accurate detection and quantification of 1-Methylcytosine (m1C), a crucial epigenetic modification, is paramount. This guide provides a comparative overview of common m1C detection assays, emphasizing the indispensable role of synthetic DNA standards in their validation and performance assessment. By leveraging precisely defined synthetic oligonucleotides, researchers can rigorously evaluate assay sensitivity, specificity, and accuracy, ensuring reliable and reproducible results.
The Critical Role of Synthetic DNA Standards
Synthetic DNA oligonucleotides containing this compound at specific positions are invaluable tools for validating m1C assays. Unlike genomic DNA, these standards offer a known quantity and sequence context of the modification, enabling a precise assessment of an assay's performance. Key advantages of using synthetic DNA standards include:
-
Absolute Quantification: Enables the creation of standard curves for accurate quantification of m1C levels in unknown samples.
-
Specificity Testing: Allows for the assessment of cross-reactivity with other cytosine modifications (e.g., 5-methylcytosine, 5-hydroxymethylcytosine), ensuring the assay is specific to m1C.
-
Sensitivity Determination: Helps to establish the lower limit of detection (LOD) and limit of quantification (LOQ) of the assay.
-
Assay Optimization and Quality Control: Facilitates the optimization of experimental parameters and serves as a consistent quality control material across different experiments and laboratories.
Comparative Analysis of this compound Detection Assays
The selection of an appropriate m1C detection assay depends on various factors, including the required sensitivity, specificity, throughput, and the nature of the biological sample. Below is a comparison of commonly employed methods, highlighting their principles and how synthetic DNA standards are used for their validation.
Liquid Chromatography-Tandem Mass Spectrometry (LC-MS/MS)
LC-MS/MS is considered the gold standard for the absolute quantification of DNA modifications. This technique involves the enzymatic digestion of DNA into individual nucleosides, followed by their separation via liquid chromatography and detection by mass spectrometry.
Performance Characteristics & Validation with Synthetic Standards:
| Performance Metric | Description | Validation with Synthetic Standards |
| Accuracy | The closeness of a measured value to a standard or known value. | Synthetic m1C nucleosides or oligonucleotides of known concentrations are used to create calibration curves for absolute quantification. |
| Precision | The closeness of two or more measurements to each other. | Repeated measurements of synthetic standards are performed to assess intra- and inter-assay variability. |
| Sensitivity (LOD/LOQ) | The lowest amount of an analyte in a sample which can be detected/quantified. | Serial dilutions of synthetic m1C standards are analyzed to determine the LOD and LOQ. |
| Specificity | The ability to assess unequivocally the analyte in the presence of other components. | Synthetic oligonucleotides containing m1C and other modified cytosines are used to confirm the absence of interfering signals. |
Immunoassays: ELISA and Dot Blot
Immunoassays, such as Enzyme-Linked Immunosorbent Assay (ELISA) and Dot Blot, utilize antibodies that specifically recognize this compound. These methods are generally higher in throughput and more cost-effective than LC-MS/MS.
Performance Characteristics & Validation with Synthetic Standards:
| Performance Metric | Description | Validation with Synthetic Standards |
| Sensitivity | The lowest concentration of m1C that can be reliably detected. | Synthetic m1C-containing oligonucleotides are serially diluted and tested to determine the assay's detection limit. |
| Specificity | The ability of the antibody to distinguish m1C from other cytosine modifications. | Dot blot or competitive ELISA using synthetic oligonucleotides with different modifications (C, 5mC, 5hmC, m1C) is performed to assess cross-reactivity.[1][2] |
| Linearity | The ability to provide results that are directly proportional to the concentration of the analyte. | A dilution series of synthetic m1C DNA is used to establish the linear range of the assay. |
| Reproducibility | The ability of the assay to produce consistent results in different runs. | Synthetic m1C standards are included in each assay run as controls to monitor performance and ensure consistency. |
Enzyme-Based Assays
Enzymatic methods for m1C detection often rely on enzymes that can specifically recognize and act upon this modification. For instance, certain DNA glycosylases can excise m1C, and the resulting apurinic/apyrimidinic (AP) site can be detected. Another approach involves coupling the activity of a methyltransferase with a restriction enzyme, where methylation of a specific site by the methyltransferase makes it susceptible to cleavage, leading to a detectable signal.[3][4]
Performance Characteristics & Validation with Synthetic Standards:
| Performance Metric | Description | Validation with Synthetic Standards |
| Enzyme Activity | The rate at which the enzyme processes the m1C-containing substrate. | Synthetic oligonucleotides with and without m1C are used to measure the specific activity of the enzyme. |
| Specificity | The ability of the enzyme to act only on m1C and not on other cytosine modifications. | Synthetic DNA substrates containing various modifications are tested to ensure the enzyme's specificity for m1C. |
| Assay Robustness | The capacity of an analytical procedure to remain unaffected by small variations in method parameters. | The assay is performed with synthetic standards under slightly varied conditions (e.g., temperature, buffer concentration) to assess its robustness. |
Experimental Protocols
Detailed experimental protocols are crucial for the successful implementation and validation of m1C assays. Below are generalized workflows for the discussed methods.
LC-MS/MS Protocol for Absolute Quantification of m1C
-
DNA Hydrolysis: Genomic or synthetic DNA is enzymatically hydrolyzed to single nucleosides using a cocktail of DNase I, nuclease P1, and alkaline phosphatase.
-
Chromatographic Separation: The nucleoside mixture is injected into a liquid chromatography system, typically using a C18 reversed-phase column, to separate the different nucleosides. A gradient of solvents is used for elution.[5]
-
Mass Spectrometry Detection: The separated nucleosides are introduced into a tandem mass spectrometer. The instrument is operated in multiple reaction monitoring (MRM) mode, where specific precursor-to-product ion transitions for m1C and other nucleosides are monitored for quantification.[6]
-
Quantification: A calibration curve is generated using known concentrations of synthetic m1C nucleoside standards. The concentration of m1C in the sample is determined by comparing its peak area to the standard curve.
ELISA Protocol for m1C Detection
-
Coating: A microplate is coated with a capture antibody specific for single-stranded DNA or directly with the denatured DNA sample.
-
Blocking: The remaining protein-binding sites on the plate are blocked to prevent non-specific binding of the detection antibody.
-
Primary Antibody Incubation: A primary antibody specific for this compound is added to the wells and incubated.
-
Secondary Antibody Incubation: An enzyme-conjugated secondary antibody that binds to the primary antibody is added.
-
Substrate Addition: A chromogenic or fluorogenic substrate is added, which is converted by the enzyme to produce a detectable signal.
-
Detection: The absorbance or fluorescence is measured using a microplate reader. The signal intensity is proportional to the amount of m1C in the sample. A standard curve is generated using synthetic m1C-containing DNA.[7][8]
Dot Blot Protocol for m1C Detection
-
Sample Preparation: DNA samples (including synthetic standards) are denatured to single strands.
-
Membrane Application: The denatured DNA is spotted onto a nitrocellulose or nylon membrane.[9][10]
-
Blocking: The membrane is incubated in a blocking buffer to prevent non-specific antibody binding.
-
Primary Antibody Incubation: The membrane is incubated with a primary antibody specific for this compound.
-
Secondary Antibody Incubation: An enzyme-conjugated secondary antibody is used to bind to the primary antibody.
-
Detection: A chemiluminescent or colorimetric substrate is added, and the signal is captured using an imaging system. The intensity of the dots is quantified and compared to the synthetic standards.[1]
Visualizing Experimental Workflows
To further clarify the methodologies, the following diagrams illustrate the key steps in each assay.
Caption: Workflow for LC-MS/MS-based this compound quantification.
Caption: General workflow for a this compound ELISA.
Caption: Key steps in a Dot Blot assay for this compound detection.
Conclusion
The accurate measurement of this compound is crucial for advancing our understanding of its biological roles. While various techniques are available, their reliability hinges on proper validation. Synthetic DNA standards are essential for the rigorous assessment of assay performance, enabling researchers to generate high-quality, reproducible data. This guide provides a framework for comparing different m1C detection methods and highlights the central role of synthetic standards in ensuring the validity of experimental findings. When choosing an assay, researchers should carefully consider the specific requirements of their study and perform thorough in-house validation using well-characterized synthetic m1C DNA standards.
References
- 1. raybiotech.com [raybiotech.com]
- 2. Methylated cytosine DNA standard kit (GTX400004) | GeneTex [genetex.com]
- 3. A real-time assay for CpG-specific cytosine-C5 methyltransferase activity - PMC [pmc.ncbi.nlm.nih.gov]
- 4. researchgate.net [researchgate.net]
- 5. mdanderson.org [mdanderson.org]
- 6. biorxiv.org [biorxiv.org]
- 7. researchgate.net [researchgate.net]
- 8. biocompare.com [biocompare.com]
- 9. Structural basis for antigen recognition by methylated lysine–specific antibodies - PMC [pmc.ncbi.nlm.nih.gov]
- 10. A 5-mC Dot Blot Assay Quantifying the DNA Methylation Level of Chondrocyte Dedifferentiation In Vitro - PubMed [pubmed.ncbi.nlm.nih.gov]
Safety Operating Guide
Proper Disposal of 1-Methylcytosine: A Guide for Laboratory Professionals
For researchers, scientists, and drug development professionals, the proper handling and disposal of chemical reagents are paramount to ensuring laboratory safety and environmental protection. This document provides essential, step-by-step guidance for the safe disposal of 1-Methylcytosine, a methylated form of the DNA base cytosine.
This compound is classified as a hazardous substance, and its disposal requires strict adherence to established safety protocols. It is categorized as an irritant and is harmful if swallowed. Therefore, it must not be disposed of in regular laboratory trash or down the sanitary sewer system. Improper disposal can lead to environmental contamination and potential health risks.
Immediate Safety and Handling
Before handling this compound, it is crucial to consult the Safety Data Sheet (SDS) for comprehensive information on its properties and hazards. When working with this compound, appropriate personal protective equipment (PPE) is mandatory.
Required Personal Protective Equipment (PPE):
-
Eye Protection: Chemical safety goggles or a face shield.
-
Hand Protection: Chemically resistant gloves (e.g., nitrile rubber).
-
Body Protection: A laboratory coat or other protective clothing to prevent skin contact.
In the event of a spill, immediately alert laboratory personnel and follow established emergency procedures. Small spills can be carefully cleaned up by trained personnel wearing appropriate PPE, using an absorbent material, and collecting the waste in a sealed container for hazardous waste disposal.
Summary of Hazards for this compound
For quick reference, the key hazard information for this compound is summarized in the table below. This information is derived from the Globally Harmonized System (GHS) of Classification and Labelling of Chemicals.
| Hazard Classification | GHS Category | Hazard Statement |
| Acute Toxicity, Oral | Category 4 | Harmful if swallowed |
| Skin Corrosion/Irritation | Category 2 | Causes skin irritation |
| Serious Eye Damage/Eye Irritation | Category 2A | Causes serious eye irritation |
| Specific Target Organ Toxicity | Category 3 | May cause respiratory irritation |
Step-by-Step Disposal Procedure
The proper disposal of this compound waste must be handled through a certified hazardous waste management provider. The following steps outline the correct procedure for collecting and preparing this chemical for disposal.
-
Segregation: Do not mix this compound waste with other chemical waste streams unless compatibility has been verified. It should be collected in a designated, separate waste container.
-
Container Selection: Use a chemically compatible and leak-proof container for waste collection. The container should be in good condition and have a secure, tight-fitting lid.
-
Labeling: Clearly label the waste container with the words "Hazardous Waste" and the full chemical name, "this compound." The label should also include the date when the first waste was added to the container and any other information required by your institution's hazardous waste program.
-
Storage: Store the sealed waste container in a designated satellite accumulation area within the laboratory. This area should be away from drains and sources of ignition, and in a location that minimizes the risk of spills or breakage. Ensure the container is kept closed at all times, except when adding waste.
-
Disposal Request: Once the waste container is full or has been in storage for the maximum allowable time according to institutional and local regulations, arrange for its collection by your institution's Environmental Health and Safety (EHS) department or a licensed hazardous waste disposal company. The primary method for the disposal of toxic and irritant organic chemicals like this compound is typically high-temperature incineration in a controlled environment.
Disposal Workflow
The following diagram illustrates the decision-making process and procedural flow for the proper disposal of this compound.
Caption: Disposal workflow for this compound waste.
By adhering to these procedures, laboratory professionals can ensure the safe and compliant disposal of this compound, thereby protecting themselves, their colleagues, and the environment. Always consult your institution's specific guidelines and the chemical's SDS for the most accurate and up-to-date information.
Retrosynthesis Analysis
AI-Powered Synthesis Planning: Our tool employs the Template_relevance Pistachio, Template_relevance Bkms_metabolic, Template_relevance Pistachio_ringbreaker, Template_relevance Reaxys, Template_relevance Reaxys_biocatalysis model, leveraging a vast database of chemical reactions to predict feasible synthetic routes.
One-Step Synthesis Focus: Specifically designed for one-step synthesis, it provides concise and direct routes for your target compounds, streamlining the synthesis process.
Accurate Predictions: Utilizing the extensive PISTACHIO, BKMS_METABOLIC, PISTACHIO_RINGBREAKER, REAXYS, REAXYS_BIOCATALYSIS database, our tool offers high-accuracy predictions, reflecting the latest in chemical research and data.
Strategy Settings
| Precursor scoring | Relevance Heuristic |
|---|---|
| Min. plausibility | 0.01 |
| Model | Template_relevance |
| Template Set | Pistachio/Bkms_metabolic/Pistachio_ringbreaker/Reaxys/Reaxys_biocatalysis |
| Top-N result to add to graph | 6 |
Feasible Synthetic Routes




Featured Recommendations
| Most viewed |
|
|
|---|---|---|
| Most popular with customers |
|
試験管内研究製品の免責事項と情報
BenchChemで提示されるすべての記事および製品情報は、情報提供を目的としています。BenchChemで購入可能な製品は、生体外研究のために特別に設計されています。生体外研究は、ラテン語の "in glass" に由来し、生物体の外で行われる実験を指します。これらの製品は医薬品または薬として分類されておらず、FDAから任何の医療状態、病気、または疾患の予防、治療、または治癒のために承認されていません。これらの製品を人間または動物に体内に導入する形態は、法律により厳格に禁止されています。これらのガイドラインに従うことは、研究と実験において法的および倫理的な基準の遵守を確実にするために重要です。
