SA-PA
Description
BenchChem offers high-quality this compound suitable for many research applications. Different packaging options are available to accommodate customers' requirements. Please inquire for more information about this compound including the price, delivery time, and more detailed information at info@benchchem.com.
Propriétés
Formule moléculaire |
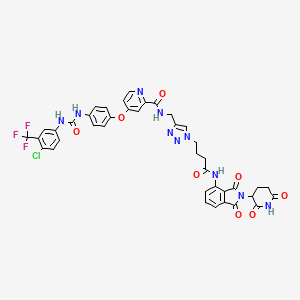
C40H32ClF3N10O8 |
|---|---|
Poids moléculaire |
873.2 g/mol |
Nom IUPAC |
4-[4-[[4-chloro-3-(trifluoromethyl)phenyl]carbamoylamino]phenoxy]-N-[[1-[4-[[2-(2,6-dioxopiperidin-3-yl)-1,3-dioxoisoindol-4-yl]amino]-4-oxobutyl]triazol-4-yl]methyl]pyridine-2-carboxamide |
InChI |
InChI=1S/C40H32ClF3N10O8/c41-28-11-8-22(17-27(28)40(42,43)44)48-39(61)47-21-6-9-24(10-7-21)62-25-14-15-45-30(18-25)35(57)46-19-23-20-53(52-51-23)16-2-5-32(55)49-29-4-1-3-26-34(29)38(60)54(37(26)59)31-12-13-33(56)50-36(31)58/h1,3-4,6-11,14-15,17-18,20,31H,2,5,12-13,16,19H2,(H,46,57)(H,49,55)(H2,47,48,61)(H,50,56,58) |
Clé InChI |
YUHFKRLPSTYTKB-UHFFFAOYSA-N |
SMILES canonique |
C1CC(=O)NC(=O)C1N2C(=O)C3=C(C2=O)C(=CC=C3)NC(=O)CCCN4C=C(N=N4)CNC(=O)C5=NC=CC(=C5)OC6=CC=C(C=C6)NC(=O)NC7=CC(=C(C=C7)Cl)C(F)(F)F |
Origine du produit |
United States |
Foundational & Exploratory
The SAPA Tool: An In-depth Technical Guide to Uncovering Protein Function
For Researchers, Scientists, and Drug Development Professionals
Introduction
In the complex world of protein analysis, identifying functionally significant regions within vast protein sequences is a critical challenge. The SAPA (Sequence Analysis and Pattern Association) tool is a powerful web-based application designed to address this challenge by enabling researchers to identify and analyze protein regions based on a combination of amino acid composition, scaled profiles of amino acid properties, and sequence patterns. This multifaceted approach allows for the discovery of functional modules that may not be identifiable by sequence homology or simple pattern matching alone.[1][2]
The SAPA tool is particularly valuable when only a limited number of experimentally confirmed protein examples are available. By leveraging the combined features of these known examples, researchers can extrapolate and identify similar regions in other proteins, paving the way for further experimental investigation and a deeper understanding of protein function. This guide provides a comprehensive technical overview of the SAPA tool, its core functionalities, detailed experimental protocols, and the interpretation of its quantitative outputs, making it an essential resource for professionals in protein research and drug development.
Core Functionalities
The SAPA tool integrates three key search strategies to provide a flexible and powerful platform for protein sequence analysis:
-
Amino Acid Composition: Users can define a specific amino acid composition to search for within protein sequences. This is particularly useful for identifying regions with a biased composition, which can be indicative of certain structural or functional properties, such as intrinsically disordered regions or regions prone to specific post-translational modifications.[1]
-
Scaled Amino Acid Profiles: The tool allows for the use of scaled profiles from the AAindex database. These profiles assign a numerical value to each amino acid based on a specific physicochemical property (e.g., hydrophobicity, alpha-helical propensity). Users can search for regions that have an average profile score above or below a defined threshold, enabling the identification of regions with desired biophysical characteristics.
-
Sequence Patterns and Rules: The SAPA tool supports searching for specific sequence motifs using an extended PROSITE pattern syntax. This allows for the identification of known functional sites, such as enzyme active sites, binding motifs, or post-translational modification sites. Furthermore, multiple patterns can be combined using logical operators (AND, OR, NOT) to create complex search queries.
A key feature of the SAPA tool is its integrated scoring system. The tool calculates a score for each identified target region based on the specified search parameters. This allows for the ranking of potential hits and the prioritization of candidates for further analysis. Additionally, the tool provides an estimation of the False Discovery Rate (FDR), giving users a statistical measure of the reliability of the identified targets.[1][2]
Data Presentation: Quantitative Outputs
The SAPA tool presents its results in a clear and organized manner, with all quantitative data summarized in downloadable tables. This facilitates easy comparison and further analysis of the identified protein regions.
Scoring Scheme
The scoring of identified target regions is a crucial aspect of the SAPA tool, allowing for a quantitative assessment of the confidence in each hit. The final score for a target is a weighted sum of the scores from the three search components: amino acid composition, scaled profiles, and pattern matching.
Table 1: SAPA Tool Scoring Parameters
| Parameter | Description | Default Weight |
| Composition Score | Based on the frequency of specified amino acids within the target region. | 1.0 |
| Profile Score | Calculated from the average of the selected AAindex profile values over the target region. | 1.0 |
| Pattern Score | A score assigned upon a successful match to a defined PROSITE pattern. | 1.0 |
Note: The weights for each scoring component can be adjusted by the user to tailor the search to their specific needs.
False Discovery Rate (FDR)
To provide a statistical measure of the likelihood of false positives, the SAPA tool calculates the False Discovery Rate (FDR). This is achieved by searching the user's query against a set of decoy sequences, which are generated by randomizing the original input sequences. The FDR is then estimated by comparing the number of hits in the decoy dataset to the number of hits in the original dataset.
Table 2: Example of FDR Calculation Output
| Score Threshold | Hits in Original Dataset | Hits in Decoy Dataset | Estimated FDR (%) |
| 10 | 150 | 5 | 3.33 |
| 15 | 80 | 1 | 1.25 |
| 20 | 45 | 0 | 0.00 |
Experimental Protocols: A Case Study
A key application of the SAPA tool is the identification of post-translationally modified regions in proteins. The following protocol details a published example of using the SAPA tool to identify potentially O-glycosylated regions in the proteome of Mycobacterium tuberculosis.[1][2]
Objective
To identify protein regions in the Mycobacterium tuberculosis H37Rv proteome that have a similar amino acid composition to known O-glycosylated peptides.
Materials
-
FASTA formatted protein sequences of the Mycobacterium tuberculosis H37Rv proteome.
-
A set of 21 known O-glycosylated peptide sequences from M. tuberculosis to be used as a training set.
-
Access to the SAPA tool web server.
Methodology
-
Training Set Analysis:
-
The initial step involves analyzing the amino acid composition of the 21 known O-glycosylated peptides. This analysis reveals a high content of Alanine (A), Proline (P), Serine (S), and Threonine (T).
-
-
SAPA Tool Parameter Configuration:
-
Input Sequences: Upload the FASTA file containing the M. tuberculosis H37Rv proteome.
-
Amino Acid Composition:
-
Define a search for regions with a high percentage of the amino acids Alanine, Proline, Serine, and Threonine. For this study, a threshold of at least 40% for the combination of these residues was used.
-
-
Scaled Profiles:
-
Select an AAindex profile that correlates with O-glycosylation potential. A relevant choice would be a scale related to "O-glycosylation sites" or "surface accessibility." Set the threshold to enrich for regions with scores indicative of glycosylation sites.
-
-
Sequence Patterns:
-
While not explicitly detailed in the original study for this specific example, one could optionally include PROSITE patterns known to be associated with glycosylation, such as [ST]-X-[V] or other relevant motifs.
-
-
Scoring and FDR:
-
Utilize the default weighting for the scoring parameters.
-
Enable the calculation of the False Discovery Rate to assess the statistical significance of the results.
-
-
-
Execution and Results Analysis:
-
Run the SAPA tool with the configured parameters.
-
The output will be a list of protein regions from the M. tuberculosis proteome that match the defined criteria, ranked by their scores.
-
The results table will include the protein identifier, the start and end positions of the identified region, the calculated score, and the estimated FDR.
-
The identified candidate regions can then be prioritized for experimental validation, such as mass spectrometry, to confirm the presence of O-glycosylation.
-
Mandatory Visualizations
SAPA Tool Workflow
The following diagram illustrates the logical workflow of the SAPA tool, from user input to the final output of candidate protein regions.
References
The SAPA Tool: A Technical Guide to Linear Motif Discovery
For Researchers, Scientists, and Drug Development Professionals
Introduction
In the intricate world of molecular biology, the identification of functional regions within proteins is a cornerstone of understanding cellular processes and developing targeted therapeutics. While well-defined protein domains are readily identifiable, a significant portion of protein functionality is mediated by short, linear motifs (SLiMs). These motifs, typically 3 to 10 amino acids in length, are crucial for a vast array of protein-protein interactions, post-translational modifications, and localization signals. However, their short and often degenerate nature makes them challenging to identify using conventional sequence alignment methods. The SAPA (Sequence Analysis and Pattern Association) tool emerges as a powerful web-based application designed to address this challenge by enabling the discovery of protein regions based on a flexible combination of amino acid composition, scaled physicochemical profiles, and user-defined sequence patterns.[1][2] This technical guide provides an in-depth exploration of the SAPA tool's core functionalities, underlying principles, and practical applications in research and drug development.
Core Functionalities of the SAPA Tool
The SAPA tool provides a unique and powerful approach to linear motif discovery by integrating three distinct but complementary search strategies.[1][3] This multifaceted methodology allows researchers to define and identify protein regions of interest with a high degree of specificity, moving beyond simple consensus sequence matching.
At its core, the SAPA tool allows users to search a given set of protein sequences for regions that simultaneously satisfy user-defined criteria across three key parameters:
-
Amino Acid Composition: Users can specify the desired percentage of certain amino acids or groups of amino acids within a target region. This is particularly useful for identifying regions with specific compositional biases, such as proline-rich or acidic regions, which are often associated with functional sites.
-
Scaled Amino Acid Profiles: The tool enables searching based on the physicochemical properties of amino acids. It utilizes a variety of scales from the AAindex database, which numerically represent properties like hydrophobicity, charge, and secondary structure propensity. Users can define a desired range for the average score of a region based on a selected profile.
-
Sequence Patterns (Motifs): SAPA allows for the inclusion of specific sequence patterns using a syntax similar to PROSITE patterns. This enables the search for known or hypothetical motifs, including those with ambiguous or variable positions. These patterns can be combined using logical operators such as AND, OR, and NOT, providing a high level of flexibility in defining the search query.
Once the search is executed, the SAPA tool ranks the identified target regions using an integrated scoring system and estimates the False Discovery Rate (FDR) to provide a statistical measure of confidence in the results. The output is presented in a user-friendly format, including sequence files and spreadsheets, for further analysis.[1][2]
The SAPA Tool Workflow
The logical workflow of the SAPA tool is designed to be intuitive and iterative, allowing researchers to refine their search parameters based on initial findings. The process can be broken down into several key stages, from inputting protein sequences to analyzing the scored and ranked results.
References
An In-depth Technical Guide to SAPA Protein Sequence Analysis
For Researchers, Scientists, and Drug Development Professionals
This technical guide provides a comprehensive overview of the Sensitivity to Antimicrobial Peptides (Sap) A protein, hereafter referred to as SAPA. It delves into its sequence analysis, structural characteristics, function, and its role as a potential target for drug development. This document summarizes key quantitative data, details relevant experimental protocols, and provides visual diagrams of associated signaling pathways and workflows.
Introduction to SAPA Protein
SAPA is the periplasmic component of the Sap (Sensitivity to antimicrobial peptides) ABC (ATP-binding cassette) transporter system, an essential machinery for the survival and persistence of various Gram-negative pathogens, including nontypeable Haemophilus influenzae (NTHi) and Actinobacillus pleuropneumoniae[1][2][3]. This protein plays a crucial role in the resistance of these bacteria to host-derived antimicrobial peptides (AMPs), which are a fundamental part of the innate immune system[1][2]. The Sap system, and particularly SAPA, allows bacteria to evade the host's first line of defense, contributing to their virulence and colonization[2].
From a structural standpoint, SAPA is classified as a Substrate Binding Protein (SBP) of the SBP superfamily, specifically a Class II SBP belonging to Cluster C[1]. Its primary function involves binding to specific substrates in the periplasm and delivering them to the inner membrane permease components of the Sap transporter for translocation into the cytoplasm[1][2]. While initially thought to directly transport AMPs, recent structural and phylogenetic analyses suggest that SAPA's binding cavity is more suited for small, hydrophobic di- or tri-peptides[1][3].
SAPA Protein Sequence and Structural Analysis
Sequence analysis of the sapA gene and its corresponding protein has been instrumental in understanding its function and evolutionary relationships. The amino acid sequence of SAPA from A. pleuropneumoniae shares significant identity with its homologs in H. ducreyi (71.1%) and nontypeable H. influenzae (44.4%)[2]. A conserved signature sequence motif for the SBP family 5, which includes peptide and nickel-binding proteins, is present in NTHi SAPA[1].
The crystal structure of NTHi SAPA has been solved in both open and closed conformations, revealing a two-lobed structure with a central ligand-binding cavity[1][3][4]. The protein consists of two main domains (Domain I and Domain II), with Domain I further divided into subdomains Ia and Ib[1]. The binding cavity is relatively small (approximately 400 ų) and predominantly hydrophobic, which supports the hypothesis of it binding small peptides rather than large, folded AMPs[1].
Quantitative Data Summary
The following tables summarize key quantitative data related to SAPA protein analysis.
Table 1: Structural and Molecular Properties of NTHi SAPA
| Property | Value | Source |
| Molecular Weight | ~60 kDa | [1] |
| Resolution of Crystal Structure | 2.6 Å | [1] |
| Ligand-Binding Cavity Volume | ~400 ų | [1] |
| Total Structure Weight (in complex) | 131.44 kDa | [5] |
| Atom Count (in complex) | 8,917 | [5] |
| Modeled Residue Count (in complex) | 1,029 | [5] |
Table 2: Binding Affinities of NTHi SAPA for Various Ligands
| Ligand | Binding Affinity (Kd) | Method | Source |
| Heme | 282 μM | Not Specified | [1][3] |
| dsRNA | 4.4 μM (estimated) | Not Specified | [1][3] |
| hBD-3 | High Affinity | Surface Plasmon Resonance | [6] |
| hBD-2 | High Affinity | Surface Plasmon Resonance | [6] |
| hNP-1 | High Affinity | Surface Plasmon Resonance | [6] |
The SAPA Signaling Pathway: The Sap ABC Transporter System
SAPA is a key component of the larger Sap ABC transporter system, which is responsible for importing substrates across the bacterial inner membrane. This system is a critical virulence factor in several pathogens.
The Sap system is comprised of five proteins:
-
SapA: A periplasmic solute-binding protein that captures the substrate.
-
SapB and SapC: These are the permease subunits that form the channel through the inner membrane.
-
SapD and SapF: These two proteins are ATPases that provide the energy for the transport process by hydrolyzing ATP.
The currently accepted model of the Sap ABC transporter system's function is depicted in the following diagram.
References
- 1. The structure of nontypeable Haemophilus influenzae SapA in a closed conformation reveals a constricted ligand-binding cavity and a novel RNA binding motif - PMC [pmc.ncbi.nlm.nih.gov]
- 2. The SapA Protein Is Involved in Resistance to Antimicrobial Peptide PR-39 and Virulence of Actinobacillus pleuropneumoniae - PMC [pmc.ncbi.nlm.nih.gov]
- 3. The structure of nontypeable Haemophilus influenzae SapA in a closed conformation reveals a constricted ligand-binding cavity and a novel RNA binding motif | PLOS One [journals.plos.org]
- 4. researchgate.net [researchgate.net]
- 5. rcsb.org [rcsb.org]
- 6. pubs.acs.org [pubs.acs.org]
The SAPA Tool: An In-depth Technical Guide to Identifying Functional Protein Regions
For Immediate Release
A Comprehensive Technical Overview for Researchers, Scientists, and Drug Development Professionals
This technical guide provides a detailed exploration of the SAPA bioinformatics tool, a web-based application designed for the identification of functional regions within protein sequences. The SAPA tool distinguishes itself by integrating three key search strategies: amino acid composition, scaled amino acid profiles, and sequence pattern motifs. This combined approach allows for the nuanced identification of functional modules that may not be discernible by sequence homology alone, making it a valuable asset in proteomics, drug discovery, and molecular biology research.
Core Features of the SAPA Tool
The SAPA (Sequence Analysis and Pattern Annotation) tool offers a flexible and powerful platform for researchers to analyze protein sequences by identifying regions with specific biochemical and structural properties. Unlike tools that rely on a single methodology, SAPA's strength lies in its ability to combine multiple analytical dimensions.[1]
Key functionalities include:
-
Combined Search Strategies: The tool simultaneously analyzes amino acid composition, searches for matches to scaled amino acid property profiles from the AAINDEX database, and scans for user-defined sequence motifs using an extended PROSITE pattern syntax.[1][2] This multi-pronged approach enhances the specificity and sensitivity of the search for functional protein regions.
-
Flexible Input: Researchers can input protein sequences in multiple formats, including FASTA files, NCBI protein database identifiers, or by pasting raw sequence data.[1]
-
Customizable Search Parameters: Users can define specific criteria for their search, including the minimum and maximum length of the target region, and can specify the required amino acid composition by setting minimum occurrence percentages for up to six single amino acids or three groups of related amino acids.[1]
-
Scoring and Ranking: The SAPA tool employs an integrated scoring system that ranks the identified target regions. This allows researchers to prioritize candidates for further investigation. The scoring considers the information content of the amino acids matching the composition criteria, the scores from the scaled profiles, and the presence of defined motifs.[2]
-
False Discovery Rate (FDR) Estimation: To ensure the statistical significance of the results, the tool estimates the false discovery rate by using decoy sequences, providing a measure of confidence in the identified target regions.[2][3]
-
User-Friendly Output: The results are presented in a clear and interactive format. A summary table lists all identified targets sorted by their scores, with visual representations of the target regions within the protein sequences.[1] The results, including settings and target sequences, can be downloaded in Excel and FASTA formats for further analysis.[1]
Experimental Protocol: Identifying O-Glycosylated Peptides in Mycobacterium tuberculosis
This protocol provides a detailed methodology for utilizing the SAPA tool to identify putative O-glycosylated protein regions, using the example of analyzing the proteome of Mycobacterium tuberculosis H37Rv. This protocol is based on the application described in the original publication by Maier et al. (2013).[1]
Objective: To identify protein regions in the M. tuberculosis proteome that share characteristics with known O-glycosylated peptides.
Materials:
-
A list of known O-glycosylated protein sequences from M. tuberculosis (or a closely related organism) to serve as a training set.
-
The complete proteome of M. tuberculosis H37Rv in FASTA format.
-
Access to the SAPA tool web server.
Methodology:
-
Training Set Analysis:
-
Analyze the amino acid composition of the known O-glycosylated peptides to identify biased compositions. For instance, a higher prevalence of proline, alanine, serine, and threonine might be observed.
-
Identify any recurring short sequence motifs within the training set.
-
-
SAPA Tool Configuration:
-
Input Data: Upload the M. tuberculosis H37Rv proteome FASTA file as the target sequence set.
-
Amino Acid Composition: Based on the analysis of the training set, define the compositional criteria. For example, set minimum percentage requirements for Proline (P), Alanine (A), Serine (S), and Threonine (T).
-
Scaled Profiles: Select relevant amino acid scales from the AAINDEX database that may correspond to properties of glycosylated regions, such as hydrophilicity or surface accessibility. Set the desired score thresholds.
-
Motif Definition: Define any identified sequence motifs using the extended PROSITE syntax. For example, a simple motif could be P-x-S-x-T, where 'x' can be any amino acid. Motifs can be combined using 'AND', 'OR', or 'NOT' operators.[2]
-
Scoring and FDR: Configure the scoring weights for each of the three search strategies to reflect their relative importance for the specific search. Enable the estimation of the False Discovery Rate.
-
-
Execution and Analysis:
-
Run the SAPA tool with the configured parameters.
-
The tool will scan the entire proteome and identify regions that satisfy the defined criteria.
-
The output will be a ranked list of target sequences.
-
-
Result Interpretation and Validation:
-
Examine the high-scoring target sequences. The interactive results page allows for the visualization of the identified regions within the context of the full-length proteins.
-
Download the results in Excel format for further analysis and comparison with experimental data.
-
The identified candidate proteins can then be prioritized for experimental validation of O-glycosylation through techniques such as mass spectrometry.
-
Quantitative Data Presentation
The following table is a representative example illustrating the typical quantitative output from the SAPA tool for the identification of putative O-glycosylated regions in Mycobacterium tuberculosis.
| Protein ID (UniProt) | Target Sequence | Start Position | End Position | Score | False Discovery Rate (FDR) |
| P9WJ87 | APSTATPAPSTATP | 123 | 136 | 85.6 | 0.01 |
| P9WIX0 | PTSAPTSAPTSA | 45 | 56 | 79.2 | 0.02 |
| O53508 | APTPAPTPAPTP | 211 | 222 | 75.4 | 0.03 |
| P9WJ90 | PSTPSTPST | 88 | 96 | 68.1 | 0.05 |
| P9WJ89 | APAPAPAPA | 301 | 309 | 62.5 | 0.07 |
Note: This table presents hypothetical data for illustrative purposes, as the original quantitative data from the Maier et al. (2013) study is not publicly available.
SAPA Tool Workflow
The following diagram illustrates the logical workflow of the SAPA bioinformatics tool, from data input to the final output of ranked target sequences.
Caption: Workflow of the SAPA bioinformatics tool.
Conclusion
The SAPA tool provides a unique and valuable approach to identifying functional regions in protein sequences by combining information on amino acid composition, physicochemical properties, and sequence motifs. This integrated strategy enables the discovery of functional modules that might be missed by conventional homology-based search methods. Its user-friendly web interface and flexible search parameters make it an accessible and powerful tool for researchers in various fields of life sciences and drug development. The ability to customize searches and obtain ranked lists with statistical confidence empowers researchers to generate novel hypotheses and guide experimental validation.
References
An In-depth Technical Guide to Identifying Functional Protein Regions
This guide provides a comprehensive overview of computational methods for identifying functional regions in proteins, with a focus on the SAPA tool, Spatial Aggregation Propensity (SAP), and Solvent Accessible Surface Area (SASA) analysis. It is intended for researchers, scientists, and drug development professionals.
The SAPA Tool: A Multi-faceted Approach to Functional Region Identification
The SAPA (Sequence Analysis and Pattern Arrangement) tool, developed by Maier et al., is a web-based application designed to identify functional protein regions by combining three key sequence features: amino acid composition, scaled profiles of amino acid properties, and the presence of specific sequence motifs.[1][2] This approach is particularly useful when only a small number of experimentally confirmed protein sequences are available to define a functional region.[1][3]
Core Methodology
The SAPA tool operates on the principle that many functional regions, while not always defined by a strict consensus sequence, share common biochemical and sequential characteristics.[1] The tool allows users to define these characteristics and then search a protein dataset for regions that match the defined criteria.
The core of the SAPA tool's methodology is a scoring scheme that combines information from:
-
Amino Acid Composition: Users can specify the minimum percentage of certain amino acids or groups of related amino acids that should be present in a potential functional region.[3]
-
Scaled Amino Acid Profiles: The tool utilizes the AAINDEX database, which contains a wide range of amino acid indices representing various physicochemical properties (e.g., hydrophobicity, polarity).[3] Users can select up to three of these profiles to score sequences, specifying whether a high or low score is indicative of the functional region.[3]
-
Sequence Motifs: The SAPA tool supports the use of PROSITE patterns to define specific sequence motifs.[1][3] These motifs can be combined using logical operators (AND, OR, NOT) to create complex search criteria.[1][3]
Each potential target sequence is assigned a score based on how well it matches the user-defined parameters.[3] To estimate the reliability of the predictions, the tool calculates a False Discovery Rate (FDR) by comparing the scores of the target sequences to those of decoy sequences generated by shuffling or reversing the original sequences.[3]
Experimental Protocol: Identifying O-Glycosylated Regions in Mycobacterium tuberculosis
A practical application of the SAPA tool was demonstrated in the identification of putative O-glycosylated regions in the proteome of Mycobacterium tuberculosis.[1] The following protocol outlines the general steps a researcher would take, based on this example.
Objective: To identify novel protein regions with characteristics similar to known O-glycosylated peptides.
Materials:
-
A set of known O-glycosylated peptide sequences from the organism of interest.
-
The proteome of the organism in FASTA format.
-
Access to the SAPA tool web server.
Methodology:
-
Define Search Parameters based on Known Examples:
-
Amino Acid Composition: Analyze the amino acid composition of the known O-glycosylated peptides. For example, determine the average percentage of proline, alanine, serine, and threonine. These values will be used to set the minimum occurrence percentages in the SAPA tool.
-
Scaled Profiles: Based on the known properties of glycosylated regions (e.g., often located in disordered regions), select relevant AAINDEX profiles. For instance, a profile related to protein flexibility or polarity might be chosen.
-
Motifs: Identify any recurring short sequence motifs in the known examples. These can be defined using PROSITE syntax.
-
-
Perform the Search using the SAPA Tool:
-
Upload the target proteome sequence file.
-
Enter the defined parameters for amino acid composition, scaled profiles, and motifs.
-
Select a decoy method (e.g., riffled) to enable FDR calculation.
-
Initiate the search.
-
-
Analyze the Results:
-
The SAPA tool will return a list of putative functional regions, ranked by their scores.
-
Examine the top-scoring hits and their associated FDR values. A lower FDR indicates a higher confidence prediction.
-
The tool provides a visual representation of the identified regions within the protein sequences.
-
-
Experimental Validation (Downstream):
-
The list of high-confidence candidate proteins can then be used to guide experimental validation.
-
Mass Spectrometry: A common method for validating glycosylation is mass spectrometry. Peptides from the candidate proteins can be analyzed to detect the mass shift corresponding to the glycan moiety.[4]
-
Site-directed Mutagenesis: Mutating the predicted glycosylation sites (e.g., serine or threonine residues) and observing the functional consequences can also provide evidence for their importance.
-
Quantitative Data
The performance of the SAPA tool is dependent on the quality of the initial set of known functional regions and the specificity of the defined search parameters. The primary quantitative output of the tool is the False Discovery Rate (FDR), which provides a statistical measure of the likelihood that a prediction is a false positive.
| Parameter | Description | Example Value/Range |
| Score | A composite score reflecting the match to the defined amino acid composition, scaled profiles, and motifs. | Varies depending on the search |
| False Discovery Rate (FDR) | The estimated percentage of false positives among the results with a score equal to or greater than the given score. | 0.0 - 1.0 (lower is better) |
Logical Workflow for the SAPA Tool
Spatial Aggregation Propensity (SAP): Identifying Regions Prone to Aggregation
The Spatial Aggregation Propensity (SAP) technology is a computational method used to identify regions on the surface of a protein that are prone to aggregation.[5][6] Protein aggregation is a critical factor in drug development, as it can lead to reduced efficacy and potential immunogenicity of therapeutic proteins.[7] Therefore, identifying and engineering these regions is crucial for developing stable and effective biotherapeutics.
Core Methodology
SAP is calculated based on the dynamic exposure of hydrophobic amino acid residues on the protein surface.[5] The core idea is that patches of hydrophobic residues that are accessible to the solvent are more likely to interact with each other and initiate aggregation.
The calculation of SAP involves:
-
Molecular Dynamics (MD) Simulations: A full-atomistic MD simulation of the protein is performed to capture its dynamic behavior in solution.[6]
-
Calculation of Solvent Accessible Area (SAA): For each snapshot of the simulation, the SAA of the side chain atoms for each residue is calculated.[5]
-
Hydrophobicity Scale: A hydrophobicity value is assigned to each amino acid residue.[5]
-
SAP Calculation: For each residue, the SAP is calculated by summing the hydrophobicities of neighboring residues within a defined radius, weighted by their solvent accessible area.[8]
The resulting SAP values are then mapped onto the 3D structure of the protein, with regions of high SAP (typically colored red) indicating "hot spots" for aggregation.[7]
Experimental Protocol: Validation of SAP Predictions for a Monoclonal Antibody
This protocol describes the experimental steps to validate the aggregation-prone regions predicted by the SAP technology on a monoclonal antibody (mAb).
Objective: To confirm that mutating residues in high-SAP regions leads to increased protein stability and reduced aggregation.
Materials:
-
Wild-type monoclonal antibody.
-
Mutant monoclonal antibodies with single amino acid substitutions in high-SAP regions (e.g., replacing a hydrophobic residue with a charged one).
-
Size-Exclusion High-Performance Liquid Chromatography (SEC-HPLC) system.
-
Spectrophotometer for turbidity measurements.
-
Differential Scanning Calorimeter (DSC).
-
Heat block or incubator.
Methodology:
-
Protein Expression and Purification: Express and purify both the wild-type and mutant mAbs.
-
Heat Stress-Induced Aggregation:
-
Prepare solutions of both wild-type and mutant mAbs at a high concentration (e.g., 10 mg/mL).
-
Incubate the samples at an elevated temperature (e.g., 50°C) for a defined period (e.g., 24 hours) to induce aggregation.
-
-
Size-Exclusion High-Performance Liquid Chromatography (SEC-HPLC):
-
Analyze the heat-stressed samples using SEC-HPLC.
-
This technique separates proteins based on their size. Monomeric (non-aggregated) protein will elute at a specific time, while aggregated forms will elute earlier.
-
Quantify the percentage of monomer and aggregate in each sample. A lower percentage of aggregate in the mutant compared to the wild-type indicates increased stability.
-
-
Turbidity Measurement:
-
Measure the turbidity (optical density at a wavelength like 350 nm) of the heat-stressed samples.
-
An increase in turbidity is indicative of protein aggregation. A lower turbidity value for the mutant compared to the wild-type suggests reduced aggregation.
-
-
Differential Scanning Calorimetry (DSC):
-
Perform DSC analysis on both wild-type and mutant mAbs.
-
DSC measures the heat required to unfold a protein as the temperature is increased.
-
The melting temperature (Tm) is the temperature at which 50% of the protein is unfolded. A higher Tm for the mutant compared to the wild-type indicates increased thermal stability.
-
Quantitative Data
The following table summarizes typical quantitative data obtained from the experimental validation of SAP predictions.
| Method | Metric | Wild-Type mAb | Mutant mAb | Interpretation |
| SEC-HPLC | % Monomer (after heat stress) | 85% | 95% | Mutant has a lower propensity to aggregate. |
| Turbidity | OD350 (after heat stress) | 0.2 | 0.05 | Mutant forms fewer large aggregates. |
| DSC | Melting Temperature (Tm) | 70°C | 72°C | Mutant is more thermally stable. |
Experimental Workflow for SAP-guided Antibody Engineering
Solvent Accessible Surface Area (SASA): A Fundamental Predictor of Function
Solvent Accessible Surface Area (SASA) is a measure of the surface area of a protein that is accessible to a solvent.[9] It is a fundamental property that is widely used to understand and predict protein structure and function.[3][10] Residues with high SASA values are on the exterior of the protein and are more likely to be involved in interactions with other molecules, such as ligands, substrates, or other proteins.[11][12]
Core Methodology
The most common method for calculating SASA is the "rolling ball" algorithm.[10] This algorithm simulates a spherical probe (typically with a radius of 1.4 Å, the approximate radius of a water molecule) rolling over the van der Waals surface of the protein. The surface traced by the center of this probe defines the solvent-accessible surface.[10][13]
The total SASA of a protein can provide insights into its folding and stability, while the SASA of individual residues can be used to predict functional sites.[9][13]
Experimental Protocol: Computational Prediction of Ligand Binding Sites using SASA
This protocol outlines a computational workflow for predicting ligand binding sites on a protein of known structure using SASA.
Objective: To identify potential ligand binding pockets on the surface of a protein.
Materials:
-
The 3D structure of the protein in PDB format.
-
Software for calculating SASA (e.g., VMD, GROMACS, or various web servers).[10][14]
-
Software for visualizing protein structures (e.g., PyMOL, Chimera).
Methodology:
-
Obtain Protein Structure: Download the PDB file for the protein of interest from a database like the Protein Data Bank.
-
Calculate Per-Residue SASA:
-
Use a computational tool to calculate the SASA for each residue in the protein.
-
It is also useful to calculate the relative solvent accessibility (RSA) by normalizing the SASA of each residue by its maximum possible SASA.
-
-
Identify Surface-Exposed Residues:
-
Filter the residues to identify those with high RSA values (e.g., > 25%), as these are located on the protein surface.
-
-
Cluster Exposed Residues to Identify Pockets:
-
Binding sites are typically formed by a cluster of surface-exposed residues that create a pocket or cleft on the protein surface.
-
Visualize the protein structure and color the residues by their SASA values.
-
Identify clusters of residues with high SASA that form concave surfaces. These are putative ligand binding sites.
-
-
Analyze Physicochemical Properties of Pockets:
-
Examine the amino acid composition of the predicted pockets. The presence of hydrophobic or charged residues can provide clues about the types of ligands that might bind there.
-
-
Comparison with Known Binding Sites (if available):
-
If the protein has a known ligand, compare the predicted binding site with the experimentally determined one to validate the prediction.
-
Quantitative Data
The performance of SASA-based prediction methods can be evaluated by comparing their predictions to known functional sites. The following table shows typical performance metrics for SASA prediction algorithms.
| Prediction Method | Pearson Correlation Coefficient (PCC) | Mean Absolute Error (MAE) | Reference |
| Method A (e.g., based on sequence) | 0.75 | 0.15 | - |
| Method B (e.g., using structural information) | 0.85 | 0.10 | - |
| Method C (e.g., deep learning-based) | 0.90 | 0.08 | - |
PCC measures the linear correlation between predicted and actual SASA values. MAE is the average of the absolute differences between predicted and actual values.
Signaling Pathway Diagram: Glycosylation and the MAPK Signaling Pathway
The SAPA tool's ability to identify regions with specific amino acid compositions and motifs makes it suitable for predicting post-translational modification sites, such as glycosylation sites. Glycosylation plays a crucial role in regulating many cellular signaling pathways, including the Mitogen-Activated Protein Kinase (MAPK) pathway.[11][15]
Proper glycosylation of receptors like the Epidermal Growth Factor Receptor (EGFR) is essential for their stability, ligand binding, and subsequent activation of the MAPK cascade.[15] Tools like SAPA can be used to predict potential N-glycosylation sites (which have a consensus motif of N-X-S/T, where X is not proline) in receptor sequences, thereby identifying regions critical for signal transduction.[16]
References
- 1. researchgate.net [researchgate.net]
- 2. SAPA tool: finding protein regions by combination of amino acid composition, scaled profiles, patterns and rules - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. academic.oup.com [academic.oup.com]
- 4. Beginners Guide To Glycosylation Of Proteins | Peak Proteins [peakproteins.com]
- 5. Predictive tools for stabilization of therapeutic proteins - PMC [pmc.ncbi.nlm.nih.gov]
- 6. pnas.org [pnas.org]
- 7. tandfonline.com [tandfonline.com]
- 8. Which Frailty Evaluation Method Can Better Improve the Predictive Ability of the SASA for Postoperative Complications of Patients Undergoing Elective Abdominal Surgery? - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Solvent Accessible Surface Area (SASA) Analysis Services - CD ComputaBio [computabio.com]
- 10. youtube.com [youtube.com]
- 11. Proper protein glycosylation promotes MAPK signal fidelity - PMC [pmc.ncbi.nlm.nih.gov]
- 12. CAT-Site: Predicting Protein Binding Sites Using a Convolutional Neural Network - PMC [pmc.ncbi.nlm.nih.gov]
- 13. m.youtube.com [m.youtube.com]
- 14. compchems.com [compchems.com]
- 15. mdpi.com [mdpi.com]
- 16. Determination of Glycosylation Sites and Site-specific Heterogeneity in Glycoproteins - PMC [pmc.ncbi.nlm.nih.gov]
A Technical Guide to Amino Acid Composition Analysis and the SAPA Tool for Protein Region Identification
For researchers, scientists, and professionals in drug development, understanding the amino acid composition of proteins is a foundational aspect of characterizing biologics. This guide provides an in-depth overview of standard amino acid analysis techniques and introduces the SAPA (Sequence Analysis and Pattern Annotation) tool, a specialized bioinformatics application that utilizes amino acid composition to identify specific protein regions.
Part 1: Core Principles of Amino Acid Composition Analysis
Amino acid composition analysis (AACA) is a technique used to determine the relative abundance of each amino acid in a protein or peptide. This information is critical for confirming protein identity, assessing purity, and understanding its physicochemical properties.[] The general workflow for AACA involves two primary stages: hydrolysis of the protein into its constituent amino acids, followed by the separation and quantification of these amino acids.[2]
A standard experimental workflow for amino acid analysis typically involves the following steps:
-
Sample Preparation : The protein or peptide sample must be pure and free of contaminants that could interfere with the analysis. Techniques such as dialysis, precipitation, or chromatography are often used for sample cleanup.[3]
-
Hydrolysis : The peptide bonds of the protein are broken to release individual amino acids. The most common method is acid hydrolysis using 6M hydrochloric acid at high temperatures (e.g., 110°C for 24 hours).[4]
-
Derivatization : The free amino acids are chemically modified (derivatized) to enhance their detection by chromatography. A common derivatizing agent is phenylisothiocyanate (PITC).[2][3]
-
Chromatographic Separation : The derivatized amino acids are separated using techniques like reverse-phase high-performance liquid chromatography (RP-HPLC).[3][5]
-
Detection and Quantification : As the amino acids elute from the chromatography column, they are detected, typically by UV absorbance.[5] The area under each peak in the chromatogram is proportional to the amount of that amino acid in the sample.
The following diagram illustrates a typical workflow for amino acid composition analysis.
The output of an amino acid analysis experiment is typically presented in a table showing the number of moles or the mole percentage of each amino acid in the sample. This can be compared to the theoretical composition based on the protein's sequence.
| Amino Acid | Theoretical Composition (Mole %) | Experimental Composition (Mole %) |
| Alanine (Ala) | 8.5 | 8.3 |
| Arginine (Arg) | 5.1 | 5.0 |
| Asparagine (Asn) | 4.4 | 4.5 |
| Aspartic acid (Asp) | 5.5 | 5.6 |
| Cysteine (Cys) | 1.8 | 1.5 |
| Glutamic acid (Glu) | 6.2 | 6.3 |
| Glutamine (Gln) | 4.0 | 4.1 |
| Glycine (Gly) | 7.5 | 7.6 |
| Histidine (His) | 2.3 | 2.2 |
| Isoleucine (Ile) | 5.3 | 5.2 |
| Leucine (Leu) | 9.5 | 9.4 |
| Lysine (Lys) | 5.9 | 5.8 |
| Methionine (Met) | 2.3 | 2.1 |
| Phenylalanine (Phe) | 3.9 | 3.8 |
| Proline (Pro) | 4.9 | 5.0 |
| Serine (Ser) | 7.2 | 7.0 |
| Threonine (Thr) | 5.8 | 5.7 |
| Tryptophan (Trp) | 1.4 | 1.2 |
| Tyrosine (Tyr) | 3.2 | 3.1 |
| Valine (Val) | 6.6 | 6.5 |
Part 2: The SAPA Tool for Identifying Protein Regions
The SAPA tool is a web-based bioinformatics application designed to find specific regions within protein sequences that exhibit a combination of desired features.[6][7] It is not a tool for determining the overall amino acid composition of a protein, but rather uses amino acid composition as one of the criteria for its search.[7]
The SAPA tool allows users to search for protein regions based on a combination of three main properties:
-
Amino Acid Composition : Users can specify the minimum percentage of certain amino acids or groups of amino acids within a defined sequence window.[7]
-
Scaled Profiles of Amino Acid Properties : The tool can search for regions that have a high or low score for specific physicochemical properties, such as hydrophobicity or charge, based on established amino acid scales (e.g., AAINDEX).[7]
-
Sequence Patterns (Motifs) : Users can define specific sequence motifs using an extended PROSITE pattern syntax.[7]
The tool then scores the identified target regions based on the user-defined criteria and provides an estimation of the false discovery rate.[6]
The following steps outline the general workflow for using the SAPA tool to identify protein regions of interest:
-
Input Protein Sequences : The user uploads a list of protein sequences in FASTA format.[7]
-
Define Search Parameters :
-
Amino Acid Composition : Specify the desired amino acid composition bias (e.g., minimum percentage of specific amino acids).[7]
-
Amino Acid Property Profiles : Select relevant amino acid scales and define the scoring thresholds.[7]
-
Sequence Motifs : Input any known sequence patterns using PROSITE syntax.[7]
-
-
Run the Search : The SAPA tool searches the input sequences for regions that match the defined parameters.
-
Review and Analyze Results : The tool presents the results in a table, with target regions highlighted and scored.[7] The results can be downloaded as a spreadsheet or a FASTA file of the identified regions.[7]
-
Iterative Refinement : The initial results can be used to refine the search parameters for a more targeted analysis in subsequent runs.[7]
The logical workflow of the SAPA tool is depicted in the following diagram.
The SAPA tool presents its findings in a structured table, allowing for easy comparison of the identified target regions.
| Target ID | Protein ID | Start Position | End Position | Score | Amino Acid Composition Match | Profile Score | Motif Match |
| T001 | P12345 | 101 | 120 | 85.2 | Yes | 0.87 | Yes |
| T002 | P12345 | 250 | 265 | 76.5 | Yes | 0.65 | No |
| T003 | Q67890 | 55 | 72 | 92.1 | Yes | 0.95 | Yes |
References
- 2. Amino Acid Composition Analysis - Creative Biolabs [creative-biolabs.com]
- 3. perso.univ-rennes1.fr [perso.univ-rennes1.fr]
- 4. Determination of Amino Acid Composition | MtoZ Biolabs [mtoz-biolabs.com]
- 5. Protein Amino Acid Analysis-Techniques, Instruments, and Applications - Creative Proteomics [creative-proteomics.com]
- 6. researchgate.net [researchgate.net]
- 7. academic.oup.com [academic.oup.com]
Initial Exploration of Protein Sequences: A Technical Guide to the SapA System for Antimicrobial Resistance
This technical guide provides an in-depth exploration of the SapA (Sensitivity to Antimicrobial Peptides A) protein and its associated system, a critical mechanism in bacterial resistance to host-derived antimicrobial peptides (AMPs). This document is intended for researchers, scientists, and drug development professionals engaged in the discovery of novel antimicrobial targets. We will delve into the core functionalities of the SapA system, present detailed experimental protocols for its study, and summarize key quantitative data to facilitate comparative analysis.
Introduction to the SapA System
The SapA protein is a key component of the Sap (Sensitivity to Antimicrobial Peptides) transporter system, which plays a crucial role in the survival and virulence of various pathogenic bacteria.[1] This system provides a defense mechanism against host innate immunity by binding and transporting antimicrobial peptides, thereby preventing them from reaching their cellular targets and causing membrane disruption.[2] The Sap transporter generally consists of five proteins: SapA, a periplasmic solute-binding protein; SapB and SapC, which form the permease; and SapD and SapF, which are ATPases that power the transport process.[1] Understanding the structure, function, and regulation of the SapA system is paramount for the development of novel therapeutics that can overcome bacterial resistance.
Experimental Protocols
The following section details the methodologies for key experiments used to investigate the SapA system.
Quantitative Real-Time PCR (qRT-PCR) for sapA Gene Expression Analysis
This protocol is designed to quantify the expression levels of the sapA gene in response to antimicrobial peptide exposure.
Methodology:
-
Bacterial Culture and Treatment: Cultivate the bacterial strain of interest (e.g., Actinobacillus pleuropneumoniae) to mid-logarithmic phase. Expose the culture to a sub-lethal concentration of the antimicrobial peptide (e.g., PR-39). An untreated culture should be maintained as a control.
-
RNA Extraction: Harvest bacterial cells from both treated and untreated cultures. Extract total RNA using a commercially available RNA purification kit, following the manufacturer's instructions.
-
cDNA Synthesis: Synthesize complementary DNA (cDNA) from the extracted RNA using a reverse transcription kit.
-
qRT-PCR: Perform qRT-PCR using a suitable real-time PCR system. The reaction mixture should contain the synthesized cDNA, SYBR Green I master mix, and primers specific for the sapA gene.[1] Use housekeeping genes (e.g., recF, glyA, rho) for normalization.[1]
-
Data Analysis: Calculate the relative expression of the sapA gene in the treated sample compared to the untreated control using the ΔΔCt method.
Bactericidal Assay
This assay determines the susceptibility of bacterial strains with and without a functional SapA protein to antimicrobial peptides.
Methodology:
-
Bacterial Strains: Use the wild-type strain, a ΔsapA mutant strain, and a complemented strain (PΔsapA).
-
Peptide Preparation: Prepare serial dilutions of the antimicrobial peptide (e.g., PR-39, hBD-3, LL-37) in a suitable buffer.[1][3]
-
Incubation: Incubate a standardized suspension of each bacterial strain with the different concentrations of the antimicrobial peptide for a defined period (e.g., 3 hours).[1]
-
Viability Assessment: Determine the number of viable bacteria after incubation by plating serial dilutions on appropriate agar plates and counting the colony-forming units (CFU).
-
Data Analysis: Compare the survival rates of the ΔsapA mutant to the wild-type and complemented strains at each peptide concentration.
Surface Plasmon Resonance (SPR) for Binding Affinity Analysis
SPR is employed to measure the binding affinity between the SapA protein and various antimicrobial peptides.
Methodology:
-
Protein and Peptide Preparation: Purify the recombinant SapA protein. Synthesize or obtain the desired antimicrobial peptides (e.g., hBD-3, hBD-2, hNP-1, LL-37).
-
Chip Immobilization: Immobilize the antimicrobial peptides onto a sensor chip surface using standard amine coupling chemistry.
-
Binding Analysis: Inject different concentrations of the purified SapA protein over the sensor chip surface. Measure the association and dissociation rates.
-
Data Analysis: Fit the sensorgram data to a suitable binding model (e.g., two-state model) to determine the equilibrium dissociation constant (KD), which reflects the binding affinity.[2][3]
Quantitative Data Summary
The following tables summarize key quantitative findings from studies on the SapA protein.
| Antimicrobial Peptide | Bacterial Strain | Fold Change in sapA Expression (vs. Untreated) | Reference |
| PR-39 | Actinobacillus pleuropneumoniae | Upregulated | [1] |
Table 1: Relative Expression of the sapA Gene in Response to Antimicrobial Peptide Exposure.
| Antimicrobial Peptide | Wild-Type Strain (Survival) | ΔsapA Mutant Strain (Survival) | Reference |
| PR-39 (0.5–4 μM) | Higher | Significantly Lower | [1] |
| hBD-3 | Higher | More Susceptible | [3] |
| LL-37 | Higher | More Susceptible | [3] |
| hNP-1 | Highly Resistant | Highly Resistant | [3] |
Table 2: Susceptibility of Bacterial Strains to Antimicrobial Peptides.
| Antimicrobial Peptide | Binding Affinity (KD) | Reference |
| hBD-3 | 4 - 17.5 nM | [2][3] |
| hBD-2 | 4 - 17.5 nM | [2][3] |
| hNP-1 | 4 - 17.5 nM | [2][3] |
Table 3: Binding Affinities of SapA to Human Defensins.
Visualizing Workflows and Pathways
The following diagrams illustrate key processes related to the study of the SapA system.
Caption: The Sap Transporter System for Antimicrobial Peptide Resistance.
Caption: Experimental Workflow for Investigating the SapA System.
References
- 1. The SapA Protein Is Involved in Resistance to Antimicrobial Peptide PR-39 and Virulence of Actinobacillus pleuropneumoniae - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Antimicrobial Peptide Recognition Motif of the Substrate Binding Protein SapA from Nontypeable Haemophilus influenzae - PMC [pmc.ncbi.nlm.nih.gov]
- 3. pubs.acs.org [pubs.acs.org]
Discovering Novel Protein Motifs with SAPA: A Technical Guide
For Researchers, Scientists, and Drug Development Professionals
This in-depth technical guide explores the application of the SAPA (Sequence Analysis and Profile Alignment) tool for the discovery of novel protein motifs. The SAPA tool is a powerful web-based application designed to identify functional regions in protein sequences by combining three distinct search strategies: amino acid composition, scaled profiles of amino acid properties, and sequence patterns.[1][2] This integrated approach allows for the identification of complex and degenerate motifs that may be missed by methods relying on sequence consensus alone.
This guide provides a comprehensive overview of the SAPA methodology, detailed experimental protocols for its application, and a summary of its core functionalities.
Core Concepts of the SAPA Tool
The SAPA tool was developed to address the challenge of identifying functional protein regions that are not defined by a strict consensus sequence.[1][2] Many functional modules, such as sites of post-translational modification or protein-protein interaction domains, are characterized by a combination of features including a biased amino acid composition, specific physicochemical properties, and degenerate sequence patterns.[1] The SAPA tool uniquely integrates these three search modalities into a single, flexible platform.
The tool was named after a frequently observed "SAPA" motif in bacterial glycopeptides of Neisseria gonorrhoeae, for which it was originally developed.[1]
The Three Pillars of SAPA Search Strategy:
-
Amino Acid Composition: The tool allows users to define a target amino acid composition by specifying the minimum percentage of up to six individual amino acids or three groups of related amino acids. This is particularly useful for identifying regions with a specific compositional bias, such as proline-rich or acidic regions.
-
Scaled Amino Acid Profiles: SAPA can utilize up to three scaled amino acid profiles from the AAINDEX database.[1] These profiles assign a numerical value to each amino acid based on a specific physicochemical property (e.g., hydrophobicity, flexibility). Users can then search for sequence regions that have a mean profile score above or below a defined threshold.
-
Sequence Patterns and Rules: The tool employs an extended PROSITE pattern syntax to define sequence motifs.[1][2] This allows for the definition of complex patterns, including ambiguous residues, variable spacing, and logical operators (AND, OR, NOT) to combine multiple pattern elements.
The SAPA Workflow: A Visual Representation
The general workflow for utilizing the SAPA tool involves a series of steps from input sequence submission to the analysis of scored and ranked target regions.
Experimental Protocol: Identifying O-glycosylated Peptides in Mycobacterium tuberculosis
A key application of the SAPA tool, as detailed in the supplementary information of the original publication, is the identification of potentially O-glycosylated sequence regions in the proteome of Mycobacterium tuberculosis H37Rv.[1] This example showcases the power of SAPA to enrich for post-translationally modified peptides based on a set of known examples.
Methodological Steps:
-
Preparation of Input Data:
-
Defining the SAPA Search Parameters:
-
Amino Acid Composition: The compositional analysis of the 21 known O-glycosylated peptides revealed a high content of Alanine (A), Proline (P), and Threonine (T). The search parameters were set to enrich for peptides with a similar compositional bias.
-
Scaled Amino Acid Profiles: Specific AAINDEX profiles related to glycosylation propensity or surface accessibility were likely selected to further refine the search.
-
Sequence Patterns: While not explicitly detailed for this specific example in the main text, patterns characteristic of O-glycosylation sites (e.g., proximity of serines and threonines) could be incorporated.
-
-
Execution of the SAPA Search: The defined search parameters were applied to the M. tuberculosis H37Rv proteome to identify and score potential O-glycosylated regions.
-
Analysis of Results and False Discovery Rate (FDR) Estimation:
-
The SAPA tool ranks the identified target regions based on an integrated score.
-
To estimate the False Discovery Rate (FDR), a set of decoy sequences is generated and searched with the same parameters. The number of hits in the decoy database is used to calculate the FDR for the hits in the target proteome.
-
Data Presentation:
While the original publication does not provide a specific table of quantitative results for this experiment, a typical output from a SAPA search can be summarized as follows:
| Target Protein ID | Target Sequence | Score | FDR (%) |
| RvXXXX | APTAPATAPTAP... | 150.5 | 0.1 |
| RvYYYY | GATPGATPGATP... | 125.2 | 0.5 |
| ... | ... | ... | ... |
This table is a representative example of how SAPA output can be structured. The actual scores and FDR would be generated by the tool.
Experimental Workflow Diagram:
Core Functionalities in Detail
Scoring Algorithm
The scoring scheme of the SAPA tool is a key aspect of its functionality. Each identified target sequence is assigned a score based on the cumulative contribution of the three search components:
-
Amino Acid Composition Score: This score is based on the information content of each amino acid that matches the defined compositional criteria.
-
Scaled Profile Score: The scores from the selected AAINDEX scales are appropriately re-scaled and weighted to contribute to the total score.
-
Motif Score: The information content of the defined sequence patterns that are present in the target sequence is also factored into the final score.
The total score for a protein is the sum of the scores of all its identified target regions.[1]
False Discovery Rate (FDR)
To assess the statistical significance of the identified motifs, the SAPA tool provides an estimation of the False Discovery Rate (FDR). This is achieved by searching against a set of decoy sequences, which are typically generated by shuffling the original input sequences. The FDR is calculated as the ratio of the number of hits found in the decoy database to the number of hits in the original database at a given score threshold. This allows researchers to set a confidence level for their findings.
Applications in Signaling Pathway Analysis
While the primary publication of the SAPA tool does not explicitly detail its use in dissecting signaling pathways, its core functionality lends itself to such applications. The discovery of novel motifs within signaling proteins can uncover previously unknown phosphorylation sites, docking sites for other proteins, or localization signals.
For instance, a researcher could use a set of known substrates for a particular kinase as a training set in the SAPA tool. By analyzing the amino acid composition, physicochemical profiles, and degenerate patterns within these known substrates, SAPA could identify a more comprehensive and nuanced motif for that kinase. This new motif could then be used to scan a proteome for novel, putative substrates, thereby expanding our understanding of the signaling network.
Logical Relationship for Signaling Motif Discovery:
Conclusion
The SAPA tool provides a versatile and powerful platform for the discovery of novel protein motifs that are not easily identifiable through conventional sequence alignment methods. By integrating searches based on amino acid composition, scaled profiles, and degenerate patterns, SAPA enables researchers to uncover complex functional regions within proteins. Its application in identifying post-translational modification sites, as demonstrated by the M. tuberculosis O-glycosylation example, highlights its potential for generating novel hypotheses for experimental validation. Furthermore, the logical framework of the SAPA tool makes it a promising approach for exploring the intricacies of signaling pathways and expanding our knowledge of protein function and regulation.
References
Methodological & Application
SAPA Tool: A Guide to Identifying Novel Protein Regions
Application Notes and Protocols for Researchers, Scientists, and Drug Development Professionals
The SAPA (Sequence Analysis and Pattern Annotation) tool is a powerful bioinformatics web application designed to identify and characterize specific regions within protein sequences. This tool stands out by enabling researchers to search for protein regions that are defined not by a single consensus sequence, but by a combination of features. This is particularly useful for identifying functional protein regions that are characterized by more subtle patterns, such as a particular amino acid composition, specific physicochemical properties, or the presence of multiple, degenerate sequence motifs.
The SAPA tool integrates three primary search strategies:
-
Amino Acid Composition: Identifying regions enriched or depleted in certain amino acids.
-
Scaled Amino Acid Profiles: Utilizing physicochemical properties of amino acids from the AAINDEX database to find regions with particular characteristics (e.g., hydrophobicity, flexibility).
-
Sequence Motifs: Searching for the presence or absence of specific sequence patterns using the PROSITE syntax.
By combining these search parameters, the SAPA tool provides a flexible and powerful platform for hypothesis-driven protein sequence analysis. It scores the identified target regions, providing a ranked list for further investigation, and estimates a false discovery rate (FDR) to help assess the statistical significance of the findings.[1][2]
One of the key applications of the SAPA tool is in the identification of post-translationally modified regions, such as glycosylation sites, which often lack a strict consensus sequence.
Key Applications in Protein Research
-
Identification of Post-Translational Modification Sites: As demonstrated in the seminal paper by Maier et al. (2013), the SAPA tool can be effectively used to identify regions of O-glycosylation, which are often characterized by an enrichment of proline, serine, and alanine.
-
Characterization of Functional Domains: Researchers can define the known characteristics of a protein domain (e.g., high content of acidic residues, specific flexibility profile) to search for novel proteins that may contain similar functional regions.
-
Drug Target Discovery: By identifying unique protein regions in pathogens or disease-related proteins, the SAPA tool can aid in the discovery of novel targets for therapeutic intervention.
-
Analysis of Protein-Protein Interaction Sites: Some interaction sites are characterized by specific amino acid compositions and structural propensities that can be modeled and searched for using the SAPA tool.
Experimental Protocols
While the original SAPA tool web server is not consistently accessible, the following protocols are based on the published functionalities and are intended to guide researchers in designing their search strategies.
Protocol 1: Identification of Putative O-Glycosylated Regions
This protocol is adapted from the example of identifying O-glycosylated peptides in Mycobacterium tuberculosis.[1]
1. Data Preparation:
-
Prepare a FASTA file containing the protein sequences to be analyzed. This could be a single protein, a curated list of proteins, or a whole proteome.
-
If available, create a separate FASTA file of known O-glycosylated proteins from the same or a related organism to serve as a positive control set.
2. Defining the Search Parameters in the SAPA Tool:
-
Amino Acid Composition:
-
Based on known O-glycosylated proteins, define the expected amino acid composition. For example, specify a high percentage of Alanine (A), Proline (P), Serine (S), and Threonine (T).
-
Set the minimum occurrence percentages for these amino acids within a defined window size.
-
-
Scaled Amino Acid Profiles:
-
Select relevant profiles from the AAINDEX database. For instance, a profile related to "surface accessibility" or "flexibility" might be relevant for glycosylation sites.
-
Set a threshold for the mean score of the profile within the search window.
-
-
Sequence Motifs:
-
Define motifs that are known to be associated with O-glycosylation in the organism of interest. Use the PROSITE syntax. For example, a simple motif could be P-x-S or P-x-T.
-
Combine multiple motifs using "OR" to increase sensitivity.
-
3. Execution and Analysis:
-
Upload the FASTA file of target proteins.
-
Input the defined search parameters.
-
Run the SAPA tool.
-
The output will be a list of proteins containing regions that match the search criteria, ranked by a composite score.
-
Analyze the results table, which will indicate the location of the identified regions within each protein.
-
The results can be downloaded as an Excel file for further analysis and as a FASTA file of the identified target sequences.[1]
Table 1: Example of Quantitative Data Output for O-Glycosylation Search
| Protein ID | Target Region | Score | Amino Acid Composition (%) | Motif Hits |
| Rv0001 | 45-65 | 85.2 | A:25, P:20, S:15, T:10 | P-x-S |
| Rv0023 | 112-130 | 78.9 | A:22, P:18, S:18, T:12 | P-x-T |
| Rv0147 | 88-105 | 72.5 | A:20, P:22, S:16, T:11 | P-x-S, P-x-T |
Protocol 2: Searching for Novel Acidic Domains
This protocol describes a hypothetical use case for identifying proteins with domains characterized by a high content of acidic residues and a specific secondary structure propensity.
1. Data Preparation:
-
Prepare a FASTA file of the proteome of interest.
2. Defining the Search Parameters in the SAPA Tool:
-
Amino Acid Composition:
-
Specify a high percentage of Aspartic Acid (D) and Glutamic Acid (E).
-
Optionally, specify a low percentage of basic residues like Lysine (K) and Arginine (R).
-
-
Scaled Amino Acid Profiles:
-
Select a profile from the AAINDEX database that corresponds to "alpha-helical propensity" and set a high mean score threshold if you hypothesize the domain to be helical.
-
Alternatively, select a profile for "beta-sheet propensity" or "coil propensity" based on your hypothesis.
-
-
Sequence Motifs:
-
If there are any known short motifs within acidic domains, define them using PROSITE syntax. For example, D-E-x-D.
-
3. Execution and Analysis:
-
Upload the proteome FASTA file.
-
Input the defined parameters for acidic composition and structural propensity.
-
Run the analysis.
-
Examine the ranked list of proteins and the specific regions identified.
-
Download the results for further characterization and comparison with known protein domain databases.
Visualization of Workflows
SAPA Tool General Workflow
General workflow for using the SAPA tool.
Logical Relationship of SAPA Search Components
Logical combination of search parameters in SAPA.
References
Application Notes and Protocols for the SAPA Tool: A Beginner's Guide
For researchers, scientists, and drug development professionals, identifying specific protein regions with desired characteristics is a crucial step in understanding disease mechanisms and discovering novel therapeutic targets. The SAPA (S-adenosyl-L-homocysteine-P-aminobenzoyl-L-glutamate) tool is a powerful bioinformatics web application designed for this purpose. It allows for the identification of protein regions by combining searches based on amino acid composition, scaled profiles, patterns, and rules.[1][2] This tutorial provides a comprehensive guide for beginners on how to effectively use the SAPA tool.
Application Notes
The SAPA tool is particularly useful for identifying functional modules within protein sequences that may not be defined by a strict consensus sequence but rather by a combination of features.[2][3] This makes it a versatile instrument for a variety of research applications, including:
-
Identifying post-translationally modified regions: As demonstrated in the original publication, the SAPA tool can be used to retrieve protein regions with characteristics similar to known O-glycosylated peptides.[1]
-
Discovering linear motifs: The tool can identify short, continuous stretches of amino acid residues that are involved in protein folding, protein-protein interactions, and ligand binding.[1]
-
Characterizing protein families: By defining a set of rules based on known members of a protein family, the SAPA tool can be used to identify new, uncharacterized members in a given proteome.
-
Drug Target Identification: Researchers can use the SAPA tool to find specific protein regions that could serve as potential binding sites for small molecules, aiding in the initial stages of drug discovery.
The strength of the SAPA tool lies in its ability to combine multiple search strategies, rank the identified target regions with an integrated score, and estimate the false discovery rate to enhance the reliability of the predictions.[1][2]
Experimental Protocols
This section provides a detailed protocol for using the SAPA tool to identify protein regions with specific characteristics. We will use a hypothetical scenario of identifying potential kinase phosphorylation sites as an example.
Objective: To identify protein regions in a list of human kinases that are rich in serine (S) and threonine (T) residues and contain a specific phosphorylation motif.
Materials:
-
A list of protein sequences in FASTA format. For this example, we will use a hypothetical list of human kinase sequences.
-
A web browser and internet access.
Protocol:
-
Accessing the SAPA tool: The web application is freely available at --INVALID-LINK--.[2]
-
Uploading Protein Sequences:
-
On the SAPA tool homepage, locate the "Upload your protein sequences" section.
-
You can either paste your sequences in FASTA format directly into the text box or upload a FASTA file from your local computer.
-
-
Defining the Search Strategy: The SAPA tool allows for a combination of search criteria. For our example, we will define the following:
-
Amino Acid Composition:
-
In the "Composition" section, specify the desired amino acid composition.
-
For our example, we are looking for regions rich in Serine and Threonine. We can set a condition for the combined percentage of S+T to be above a certain threshold (e.g., > 30%).
-
-
Sequence Motif/Pattern:
-
In the "Pattern" section, define the consensus sequence for a kinase phosphorylation site. A common, though simplified, motif is [R/K]x[S/T].
-
Enter this pattern into the pattern search box.
-
-
Scaled Profiles:
-
The tool allows searching based on amino acid properties using scaled profiles from the AAINDEX database.[1] For this beginner's tutorial, we will not use this feature to keep the example straightforward.
-
-
-
Setting Parameters and Running the Search:
-
Define the window size for the sliding window search (e.g., 20 amino acids). This is the length of the protein region that will be analyzed at each step.
-
Give your job a descriptive name.
-
Click the "Submit" button to start the analysis.
-
-
Interpreting the Results:
-
The results page will display a table of protein regions that match your search criteria, sorted by a calculated score.[1]
-
The table will include:
-
The protein identifier.
-
The start and end positions of the identified region.
-
The sequence of the region.
-
The calculated score, indicating the strength of the match.
-
A visual representation of the protein with the highlighted target region.[1]
-
-
Data Presentation
The quantitative data from a SAPA tool analysis is best summarized in a table for easy comparison. Below is an example of how the results for our hypothetical kinase phosphorylation site search might be presented.
| Protein ID | Start Position | End Position | Sequence | S+T Content (%) | Motif Hits | Score |
| Kinase_A | 120 | 139 | ...RGS T V... | 35 | 2 | 8.5 |
| Kinase_B | 250 | 269 | ...K T S P... | 40 | 3 | 9.2 |
| Kinase_C | 85 | 104 | ...R T S I... | 30 | 1 | 7.8 |
Visualization of Experimental Workflow
The following diagram illustrates the general workflow for using the SAPA tool.
Signaling Pathway Context
The identification of phosphorylation sites is critical for understanding signaling pathways. For instance, the identified kinase target regions could be involved in a well-known pathway like the MAPK/ERK pathway, which is crucial for cell proliferation, differentiation, and survival. Dysregulation of this pathway is often implicated in cancer.
The diagram below illustrates a simplified MAPK/ERK signaling pathway. The proteins analyzed with the SAPA tool could be kinases within this pathway, and the identified regions could be the sites of their activation or their interaction with downstream substrates.
By using the SAPA tool to identify key functional regions in proteins within such pathways, researchers can gain valuable insights for designing experiments to probe pathway function and for developing targeted therapies.
References
Unlocking Functional Insights: A Guide to the SAPA Tool for Functional Module Extraction
For Immediate Release
Oberndorf, Germany – November 21, 2025 – For researchers, scientists, and drug development professionals navigating the complexities of protein analysis, the identification of functional modules within protein sequences is a critical step. The SAPA (Scaled Amino acid Profile and Pattern) tool offers a powerful web-based application for this purpose, enabling the extraction of protein regions based on a combination of amino acid composition, scaled profiles, patterns, and rules. This document provides detailed application notes and protocols for utilizing the SAPA tool in functional module extraction, a key process in understanding protein function and advancing drug discovery efforts.
The SAPA tool is particularly valuable when only a limited number of functionally characterized protein examples are available, allowing researchers to identify similar sequences for further investigation[1][2]. By integrating multiple search strategies, SAPA provides a flexible and comprehensive approach to defining and discovering functional regions that may not be identifiable by simple consensus sequence patterns alone[1][3].
Core Concepts of the SAPA Tool
The SAPA tool's methodology is founded on the principle that functional modules in proteins can be described by a combination of features beyond linear motifs. These include:
-
Amino Acid Composition: The tool allows users to specify the required percentage of up to six individual amino acids or three groups of related amino acids within a target sequence[3].
-
Scaled Amino Acid Profiles: Users can leverage up to three scaled profiles from the AAINDEX database. These profiles assign a weight to each amino acid based on specific properties (e.g., hydrophobicity, alpha-helix propensity), and target sequences can be selected based on a mean score threshold[3].
-
Sequence Patterns and Rules: The SAPA tool employs an extended PROSITE pattern syntax to define motifs. These motifs can be combined using logical operators such as 'AND', 'OR', and 'NOT' to create complex search criteria[2][3].
A key feature of the SAPA tool is its scoring system, which ranks the extracted target regions based on an integrated score derived from the specified search parameters. Furthermore, the tool estimates a false discovery rate (FDR) to assess the statistical significance of the results[1][2].
Application Notes
The SAPA tool is a versatile instrument for a range of applications in molecular biology and drug development:
-
Functional Annotation of Uncharacterized Proteins: By defining search parameters based on known functional modules, researchers can scan proteomes for proteins containing similar regions, thus inferring potential functions.
-
Identification of Post-Translational Modification Sites: As demonstrated in the tool's proof-of-concept, SAPA can be used to identify regions likely to undergo post-translational modifications, such as O-glycosylation[3].
-
Drug Target Identification and Validation: The identification of novel functional modules within proteins can reveal potential binding sites for small molecules or biologics. By understanding the key amino acid features of a functional site, researchers can better design targeted therapies.
-
Biomarker Discovery: Proteins with specific functional modules that are differentially present in disease states can serve as potential biomarkers. The SAPA tool can be used to systematically search for such proteins in relevant datasets.
Experimental Protocols
The following protocols provide a step-by-step guide to using the SAPA tool for functional module extraction.
Protocol 1: Basic Functional Module Extraction
This protocol outlines the fundamental steps for identifying protein regions based on a combination of amino acid composition and sequence patterns.
-
Input Protein Sequences:
-
Navigate to the SAPA tool web server.
-
Upload a FASTA file containing the protein sequences to be analyzed. Alternatively, paste the sequences directly into the input box.
-
-
Define Amino Acid Composition:
-
In the "Amino Acid Composition" section, specify the minimum percentage for up to six individual amino acids or three groups of amino acids that should be present in the target regions.
-
-
Define Sequence Patterns:
-
In the "Patterns and Rules" section, define the sequence motifs of interest using the extended PROSITE syntax.
-
Combine multiple patterns using the 'AND', 'OR', and 'NOT' operators to refine the search.
-
-
Set Scoring and Output Options:
-
Review the default scoring weights or adjust them based on the relative importance of each search criterion.
-
Select the desired output format (e.g., Excel spreadsheet, FASTA file of target sequences).
-
-
Execute the Search and Analyze Results:
-
Submit the job and wait for the analysis to complete.
-
The results page will display a table of identified target regions, sorted by their integrated score. The output will also include the estimated false discovery rate.
-
The results can be downloaded for further analysis.
-
Protocol 2: Advanced Search Using Scaled Amino Acid Profiles
This protocol describes how to incorporate physicochemical properties into the search for functional modules.
-
Input Protein Sequences:
-
Follow step 1 of Protocol 1.
-
-
Select Scaled Amino Acid Profiles:
-
In the "Scaled Profiles" section, choose up to three profiles from the AAINDEX database that represent relevant physicochemical properties.
-
For each selected profile, specify a threshold for the mean score (either above or below).
-
-
Combine with Composition and Pattern Searches (Optional):
-
Optionally, define amino acid composition and sequence patterns as described in Protocol 1 to create a more specific search.
-
-
Set Scoring and Output Options:
-
Follow step 4 of Protocol 1.
-
-
Execute and Analyze:
-
Follow step 5 of Protocol 1 to run the analysis and interpret the results.
-
Quantitative Data Presentation
The output of the SAPA tool is readily amenable to quantitative analysis. The primary data to be summarized are the integrated scores and false discovery rates for the identified target regions. An example of how to structure this data is provided below, based on the proof-of-concept study of identifying O-glycosylated regions in Mycobacterium tuberculosis proteins[3].
| Target Protein | Target Region | Integrated Score | False Discovery Rate (FDR) |
| Protein A | 45-65 | 15.8 | 0.01 |
| Protein B | 112-130 | 12.5 | 0.03 |
| Protein C | 210-225 | 10.1 | 0.05 |
| ... | ... | ... | ... |
Visualizing Workflows and Pathways
To effectively integrate the SAPA tool into a research pipeline, it is helpful to visualize the experimental and logical workflows.
The output from the SAPA tool can be a crucial starting point for broader drug discovery and development efforts. The identified functional modules can inform target validation, lead discovery, and the design of subsequent experiments.
References
Unveiling Protein Function: A Protocol for Sequence Analysis with SAPA
For Immediate Release
OBERNDORF, Germany – November 21, 2025 – In the intricate world of proteomics and drug discovery, identifying functional regions within protein sequences is a critical step. The SAPA (Sequence Analysis and Pattern Alignment) tool offers researchers a powerful web-based application to pinpoint these regions by combining amino acid composition, scaled physicochemical profiles, and sequence motifs. This application note provides a detailed protocol for utilizing the SAPA tool for protein sequence analysis, with a specific application in identifying O-glycosylated peptides from Mycobacterium tuberculosis. Additionally, we describe the distinct signaling pathway of the SapA protein, a key component in bacterial resistance to antimicrobial peptides.
Application Note: Identifying Functional Protein Regions with the SAPA Tool
The SAPA tool is a versatile bioinformatics application designed to identify functional modules in protein sequences that may not be defined by simple consensus patterns.[1][2] It allows for a multi-faceted search strategy, integrating three key features:
-
Amino Acid Composition: Users can define the minimum percentage of up to six individual amino acids or three groups of related amino acids.[1]
-
Scaled Amino Acid Profiles: The tool utilizes up to three scaled profiles from the AAINDEX database to score and select target sequences based on specific physicochemical properties.[1]
-
Sequence Motifs: It employs an extended PROSITE pattern syntax to search for specific motifs, which can be combined using logical operators (AND, OR, NOT).[1]
The SAPA tool scores the identified target regions, allows for the estimation of a false discovery rate (FDR) using decoy sequences, and provides results in downloadable formats, including Excel spreadsheets and FASTA files.[1]
Experimental Protocol: Identification of O-Glycosylated Peptides in Mycobacterium tuberculosis using the SAPA Tool
This protocol outlines the steps to identify potentially O-glycosylated protein regions from the proteome of Mycobacterium tuberculosis H37Rv, based on the characteristics of known O-glycosylated peptides.
1. Data Preparation:
-
Input Protein Sequences: A FASTA file containing the protein sequences from the Mycobacterium tuberculosis H37Rv proteome is required.
-
Training Set: A list of known O-glycosylated peptides from M. tuberculosis is necessary to define the search parameters.
2. SAPA Tool Workflow:
The overall workflow for the SAPA tool is depicted below.
References
Unlocking the Proteome: Practical Applications of Sequential Affinity Purification and Analysis (SAPA)
For Researchers, Scientists, and Drug Development Professionals
Sequential Affinity Purification and Analysis (SAPA), a powerful proteomic tool synonymous with Tandem Affinity Purification (TAP), has revolutionized our ability to elucidate the intricate networks of protein-protein interactions within the cell. By enabling the isolation of protein complexes with high purity, SAPA coupled with mass spectrometry (SAPA-MS) provides a window into the dynamic machinery of cellular processes. This application note details the practical applications of SAPA in proteomics, providing detailed protocols and showcasing its utility in deciphering signaling pathways and its emerging role in drug discovery.
Application 1: Elucidating the Strigolactone Signaling Pathway in Plants
Objective: To identify protein interactors of key components in the strigolactone (SL) signaling pathway in Arabidopsis thaliana and to quantify changes in these interactions upon SL treatment. Strigolactones are a class of phytohormones that regulate various aspects of plant development.
Methodology: A quantitative TAP-MS (qTAP-MS) approach was employed. The bait protein, a central regulator in the SL pathway, was fused with a tandem affinity tag (e.g., GS-tag, composed of Protein G and a Streptavidin-binding peptide). This tagged protein was expressed in Arabidopsis cell cultures. The protein complex was then purified through two sequential affinity chromatography steps. The purified proteins were identified and quantified using label-free quantification (LFQ) mass spectrometry.
Data Presentation:
The following table summarizes the key interacting proteins identified and their relative abundance changes upon treatment with the synthetic strigolactone analog rac-GR24. The data is presented as LFQ intensity ratios (treated/untreated).
| Interacting Protein | Gene ID | Function | LFQ Intensity Ratio (GR24/Control) |
| DWARF14 (D14) | AT3G03990 | SL Receptor | 2.5 |
| MORE AXILLARY GROWTH 2 (MAX2) | AT2G42620 | F-box protein | 2.1 |
| SUPPRESSOR OF MAX2 1-LIKE 7 (SMXL7) | AT2G29970 | Transcriptional repressor | 0.4 |
| TOPLESS-RELATED PROTEIN 2 (TPR2) | AT1G79940 | Transcriptional co-repressor | 0.5 |
Signaling Pathway Visualization:
The qTAP-MS results suggest a model where, in the absence of SL, the receptor D14 and the F-box protein MAX2 have a basal level of interaction. Upon SL perception, the interaction between D14 and MAX2 is enhanced, leading to the recruitment and subsequent degradation of the transcriptional repressor SMXL7. This degradation relieves the repression of downstream target genes.
Strigolactone signaling pathway elucidated by SAPA-MS.
Application 2: Mapping the mTOR Signaling Network in Mammalian Cells
Objective: To identify the components of the mechanistic target of rapamycin (mTOR) complexes (mTORC1 and mTORC2) and to understand their protein-protein interaction networks. The mTOR pathway is a central regulator of cell growth, proliferation, and metabolism and is frequently dysregulated in diseases like cancer.
Methodology: Key components of the mTOR complexes, such as Raptor (for mTORC1) and Rictor (for mTORC2), were individually tagged with a tandem affinity tag (e.g., FLAG-HA) and expressed in mammalian cell lines (e.g., HEK293T). The complexes were purified using sequential immunoprecipitation against the two tags. The interacting proteins were then identified by mass spectrometry.
Data Presentation:
The following table shows a partial list of proteins identified in the Raptor and Rictor purifications, highlighting the core components of mTORC1 and mTORC2.
| Bait Protein | Interacting Protein | Complex Association | Function |
| Raptor | mTOR | mTORC1 | Serine/threonine kinase |
| Raptor | MLST8 (GβL) | mTORC1 | Subunit of mTOR complexes |
| Raptor | PRAS40 (AKT1S1) | mTORC1 | Inhibitory subunit |
| Raptor | DEPTOR | mTORC1/mTORC2 | Inhibitory subunit |
| Rictor | mTOR | mTORC2 | Serine/threonine kinase |
| Rictor | MLST8 (GβL) | mTORC2 | Subunit of mTOR complexes |
| Rictor | mSIN1 (MAPKAP1) | mTORC2 | Essential subunit for kinase activity |
| Rictor | Protor-1/2 | mTORC2 | Substrate-recruiting subunit |
Experimental Workflow Visualization:
The general workflow for SAPA-MS analysis of mTOR complexes involves several key steps from construct design to data analysis.
SAPA-MS workflow for mTOR complex analysis.
Application 3: Drug Target Identification and Mechanism of Action Studies
Objective: To identify the cellular targets of a novel drug candidate and to understand its mechanism of action by analyzing changes in protein-protein interactions.
Methodology: A common approach is "pull-down" proteomics. The drug of interest is immobilized on a solid support (e.g., beads) and incubated with a cell lysate. Proteins that bind to the drug are then eluted and identified by mass spectrometry. A more advanced application of SAPA in this context involves using a known protein target of a drug as the bait in a SAPA-MS experiment. The experiment is then performed in the presence and absence of the drug. Changes in the protein interaction profile of the bait protein can reveal the drug's mechanism of action.
Logical Relationship Visualization:
This diagram illustrates the logical flow of using SAPA-MS for drug target deconvolution and mechanism of action studies.
Logic diagram for SAPA-MS in drug discovery.
Experimental Protocols
Protocol 1: Tandem Affinity Purification (TAP) from Mammalian Cells
This protocol is a generalized procedure for the purification of a FLAG-HA tagged protein complex from a mammalian cell line.
1. Generation of Stable Cell Lines: 1.1. Clone the cDNA of the protein of interest into a mammalian expression vector containing a C-terminal or N-terminal tandem FLAG-HA tag. 1.2. Transfect the construct into a suitable mammalian cell line (e.g., HEK293T, HeLa). 1.3. Select for stably expressing cells using an appropriate selection marker (e.g., puromycin, G418). 1.4. Expand a clonal population of cells expressing the tagged protein at near-endogenous levels.
2. Cell Lysis and Lysate Preparation: 2.1. Harvest approximately 1-5 x 10^8 cells by centrifugation. 2.2. Wash the cell pellet with ice-cold PBS. 2.3. Resuspend the pellet in a suitable lysis buffer (e.g., 50 mM Tris-HCl pH 7.4, 150 mM NaCl, 1 mM EDTA, 1% Triton X-100, supplemented with protease and phosphatase inhibitors). 2.4. Incubate on ice for 30 minutes with occasional vortexing. 2.5. Clarify the lysate by centrifugation at 14,000 x g for 15 minutes at 4°C.
3. First Affinity Purification (Anti-FLAG): 3.1. Add anti-FLAG affinity resin (e.g., anti-FLAG M2 agarose) to the clarified lysate. 3.2. Incubate for 2-4 hours at 4°C with gentle rotation. 3.3. Pellet the resin by centrifugation and discard the supernatant. 3.4. Wash the resin three times with lysis buffer. 3.5. Elute the bound proteins by competing with a 3xFLAG peptide solution (e.g., 100-200 µg/mL in TBS) for 1 hour at 4°C.
4. Second Affinity Purification (Anti-HA): 4.1. Add anti-HA affinity resin to the eluate from the first purification. 4.2. Incubate for 2 hours at 4°C with gentle rotation. 4.3. Pellet the resin and discard the supernatant. 4.4. Wash the resin three times with a wash buffer (e.g., TBS with 0.05% Tween-20). 4.5. Elute the final protein complex with a low pH buffer (e.g., 0.1 M glycine, pH 2.5) or by peptide competition with an HA peptide. Immediately neutralize the eluate with a high pH buffer (e.g., 1 M Tris-HCl, pH 8.5).
5. Sample Preparation for Mass Spectrometry: 5.1. Precipitate the eluted proteins using a method such as trichloroacetic acid (TCA) precipitation. 5.2. Resuspend the protein pellet in a denaturing buffer (e.g., 8 M urea in 100 mM Tris-HCl, pH 8.5). 5.3. Reduce the proteins with dithiothreitol (DTT) and alkylate with iodoacetamide. 5.4. Digest the proteins with trypsin overnight at 37°C. 5.5. Desalt the resulting peptides using a C18 StageTip before LC-MS/MS analysis.
Protocol 2: Label-Free Quantification (LFQ) Data Analysis Workflow
This protocol outlines the general steps for analyzing SAPA-MS data using a label-free quantification approach.
1. LC-MS/MS Analysis: 1.1. Analyze the tryptic digests from the control and experimental samples (e.g., untreated vs. drug-treated) by nano-liquid chromatography coupled to a high-resolution mass spectrometer (e.g., Orbitrap).
2. Database Searching and Protein Identification: 2.1. Process the raw mass spectrometry data using a software platform like MaxQuant. 2.2. Search the MS/MS spectra against a relevant protein database (e.g., UniProt) to identify peptides and proteins.
3. Label-Free Quantification: 3.1. Enable the "LFQ" option in the data processing software. The software will calculate LFQ intensities for each identified protein based on the extracted ion chromatograms of its corresponding peptides. 3.2. The software performs normalization across different LC-MS runs to account for variations in sample loading and instrument performance.
4. Statistical Analysis: 4.1. Import the protein LFQ intensity data into a statistical analysis environment (e.g., Perseus, R). 4.2. Perform data filtering to remove contaminants and proteins with too many missing values. 4.3. Impute missing values if necessary. 4.4. Perform statistical tests (e.g., t-test, ANOVA) to identify proteins that are significantly enriched or depleted in the experimental condition compared to the control. 4.5. Visualize the results using volcano plots and heatmaps.
5. Biological Interpretation: 5.1. Perform functional enrichment analysis (e.g., Gene Ontology, pathway analysis) on the list of significantly changing proteins to gain insights into the biological processes affected by the experimental perturbation.
Unveiling the SAPA Tool: A Guide for Protein Sequence Analysis
For researchers, scientists, and drug development professionals engaged in the intricate world of protein analysis, the SAPA (Sequence Analysis and Profiling Application) tool offers a powerful web-based platform for identifying and characterizing functional regions within protein sequences.[1][2][3] This guide provides a detailed overview of the SAPA tool, its functionalities, and step-by-step protocols for its effective utilization.
The SAPA tool distinguishes itself by integrating three key search strategies—amino acid composition, scaled profiles of amino acid properties, and sequence patterns or motifs—into a single, flexible interface.[1] This combined approach allows for a more nuanced and comprehensive analysis of protein sequences, enabling the identification of functional regions that may be missed by methods relying on a single type of feature.[2][3]
Core Functionalities
The SAPA tool is designed to assist researchers in subsetting protein lists based on a combination of compositional, profile, and motif data.[1] It scores the identified target regions and estimates their False Discovery Rate (FDR) to ensure statistical rigor.[1]
| Feature | Description |
| Data Input | Protein sequences can be uploaded in FASTA format, imported from the NCBI protein database, or pasted directly into the application.[1] |
| Combined Search Strategies | Users can simultaneously search for regions with specific amino acid compositions, profiles based on various amino acid scales, and defined sequence patterns or motifs.[1] |
| Target Scoring | The application ranks the extracted target regions using an integrated scoring system.[3] |
| False Discovery Rate (FDR) Estimation | To assess the statistical significance of the findings, the SAPA tool can generate and scan decoy sequences to estimate the FDR.[1][3] |
| Data Output | Results are presented in a table format, with target regions highlighted on protein sequence icons.[1] The complete results, including settings and sequences, can be downloaded as a multi-sheet Excel file or a FASTA-formatted sequence file.[1][3] |
Experimental Protocols: A Step-by-Step Guide to Using the SAPA Tool
This section provides a detailed protocol for utilizing the SAPA web application for protein sequence analysis.
Data Input
The initial step involves providing the protein sequences for analysis. The SAPA tool offers three methods for data input:
-
File Upload: Upload a file containing protein sequences in the standard FASTA format.
-
NCBI Import: Directly import sequences from the NCBI protein database by providing the accession numbers.
-
Pasted Sequences: Copy and paste protein sequences directly into the designated text box.
Defining Search Parameters
This is the most critical step, where the user defines the criteria for identifying the target regions.
-
Amino Acid Composition: Specify the desired percentage of certain amino acids or groups of amino acids within a defined sequence window.
-
Scaled Profiles: Select from a variety of amino acid scales (e.g., hydrophobicity, polarity) from the AAINDEX database to search for regions with specific physicochemical properties.[1]
-
Patterns and Rules: Define specific sequence motifs or patterns using standard Prosite syntax. This allows for the identification of known functional sites or domains.
Execution of the Analysis
Once the input data and search parameters are set, initiate the analysis. The SAPA tool will scan the provided sequences for regions that match the combined criteria. The application will also generate and analyze decoy sequences (using methods like riffling, shuffling, or reversing) to calculate the FDR for the identified targets.[1]
Interpretation of Results
The results are displayed in a comprehensive table.[1]
-
Scored and Sorted Targets: The identified target regions are listed and sorted by their calculated scores.[1]
-
Visual Representation: Each target is visualized on a protein sequence icon, with the intensity of the color indicating the score.[1]
-
Detailed View: Clicking on an icon opens a pop-up window showing the sequence with the highlighted regions.[1]
-
Data Export: The entire dataset, including the search parameters and results, can be downloaded for further analysis and record-keeping.[1][3]
Visualizing the SAPA Workflow
To better understand the logical flow of the SAPA tool, the following diagrams illustrate the key steps in the process.
Caption: The general workflow of the SAPA web application.
Caption: Logical relationship of the combined search strategy in SAPA.
References
Application Notes and Protocols for Integrating SAPA Tool with Other Bioinformatics Software
Audience: Researchers, scientists, and drug development professionals.
Introduction
The SAPA (Structure-Aided-Phylogenetic-Analysis) tool is a web-based application designed to identify functional regions within protein sequences by combining searches based on amino acid composition, scaled profiles of amino acid properties, and sequence patterns.[1][2][3] This powerful tool is particularly useful when only a small number of functional protein examples are known, allowing researchers to identify and investigate similar sequences. The SAPA tool is available as a web application, and its source code, written in Perl, can be downloaded for local installation on an Apache server.[1][2][3] This allows for its integration into larger bioinformatics pipelines.
This document provides detailed application notes and protocols for integrating the SAPA tool with other common bioinformatics software, enabling a more streamlined and powerful analysis workflow.
Data Input and Output
A key aspect of integrating any bioinformatics tool is understanding its data formats. The SAPA tool utilizes standard and accessible formats, facilitating its use in conjunction with other software.
| Data Type | Format | Description | Integration Potential |
| Input | FASTA | Protein sequences can be uploaded as a multi-FASTA file.[2] | Compatible with virtually all sequence analysis tools. |
| NCBI Accession IDs | Protein sequences can be directly retrieved from the NCBI database using their accession IDs. | Allows for direct analysis of publicly available data. | |
| Plain Text | Sequences can be pasted directly into the web interface. | Useful for quick, single-sequence analyses. | |
| Output | Excel (.xls) | A comprehensive summary of the results, including scores and identified regions, is provided in a multi-sheet Excel file.[1][2] | Easily parsed by scripts (e.g., using Python with the pandas library) for downstream analysis and data aggregation. |
| FASTA | The identified target protein sequences or regions can be downloaded in FASTA format.[2] | The FASTA output can be directly used as input for other sequence analysis tools like BLAST, ClustalOmega, or motif finders. |
Integration Strategies
Integration of the SAPA tool into a bioinformatics workflow can be achieved through two primary methods:
-
Web-based, Manual Integration: This approach involves using the public SAPA web server and manually transferring the output files to other tools. This is suitable for smaller-scale analyses or for users without access to a local server.
-
Local, Automated Integration: For high-throughput analysis and integration into automated pipelines, it is recommended to install the SAPA tool on a local server. This allows for scripted execution and seamless data transfer between different tools.
Experimental Protocol: Identifying Novel O-Glycosylated Peptides
This protocol provides a detailed methodology for identifying putative O-glycosylated sequence regions in a proteome, based on the example of analyzing Mycobacterium tuberculosis H37Rv as described in the original SAPA tool publication.[2]
Objective: To identify novel protein regions with characteristics similar to known O-glycosylated peptides.
Materials:
-
A set of known O-glycosylated protein sequences from the target organism (in FASTA format).
-
The proteome of the target organism (in FASTA format).
-
Access to the SAPA tool (web server or local installation).
-
Access to the NCBI BLASTp suite for downstream analysis.
Methodology:
-
Preparation of Input Data:
-
Create a multi-FASTA file containing the sequences of known O-glycosylated proteins. This will serve as the training set to define the search parameters.
-
Obtain the complete proteome of the organism of interest in FASTA format.
-
-
SAPA Tool Analysis:
-
Navigate to the SAPA tool web interface or your local installation.
-
Sequence Input: Upload the proteome FASTA file in the "Protein sequences" section.
-
Defining Search Parameters based on Known Examples:
-
In a separate browser tab or using the SAPA tool's features, analyze the known O-glycosylated sequences to determine their characteristic amino acid composition, relevant AAINDEX profiles, and any conserved motifs. For the M. tuberculosis example, this would involve identifying compositions enriched in Alanine, Proline, and Serine.
-
Composition: In the "Composition" section of the SAPA tool, set the minimum percentage for amino acids that are overrepresented in the known examples.
-
Scaled Profiles: In the "Scaled Profiles" section, select relevant amino acid indices from the AAINDEX database that might correlate with glycosylation.
-
Patterns/Motifs: In the "Patterns" section, define any known short sequence motifs associated with O-glycosylation in the target organism using PROSITE pattern syntax.[1]
-
-
Execution: Run the SAPA tool analysis.
-
-
Analysis of SAPA Tool Output:
-
Download the results as both an Excel file and a FASTA file of the identified target regions.
-
The Excel file will provide a ranked list of potential target regions based on the calculated score.
-
The FASTA file will contain the sequences of these high-scoring regions.
-
-
Downstream Analysis with BLASTp:
-
Take the FASTA file of the high-scoring target regions generated by the SAPA tool.
-
Perform a BLASTp search against a relevant protein database (e.g., NCBI non-redundant (nr) database) to identify homologous proteins. This can help in assigning potential functions to the newly identified regions.
-
Analyze the BLASTp results to see if the identified regions are conserved across different species and if they are found in proteins with known functions related to post-translational modifications or cell surface localization.
-
Experimental Workflow Diagram:
Protocol for Local Installation and Automated Integration
For researchers requiring high-throughput analysis, a local installation of the SAPA tool is recommended.
Prerequisites:
-
A web server with Perl CGI support (e.g., Apache).
-
Perl interpreter.
-
The SAPA tool source code, which is freely available for download.[1][2][3]
Installation Steps:
-
Download the SAPA tool source code package.
-
Follow the instructions in the user manual to install the tool on your local server. This will typically involve placing the Perl scripts in the server's cgi-bin directory and ensuring the necessary file permissions are set.
-
Verify the installation by accessing the tool through a web browser via its local URL.
Automated Workflow:
With a local installation, you can create scripts (e.g., in Python or Bash) to automate the submission of jobs to the SAPA tool and the parsing of its results. While the SAPA tool does not have a formal command-line interface, its Perl scripts can be executed from the command line with appropriate parameters.
Automated Integration Workflow Diagram:
Signaling Pathway and Logical Relationship Visualization
The SAPA tool itself does not analyze signaling pathways. However, the proteins identified by SAPA may be components of such pathways. The following diagram illustrates the logical relationship of how SAPA can be a starting point for pathway analysis.
Logical Relationship Diagram:
Conclusion
The SAPA tool offers a flexible and powerful method for identifying protein regions with specific characteristics. By understanding its input and output formats, and by leveraging a local installation, researchers can effectively integrate SAPA into both manual and automated bioinformatics workflows. This integration enables more complex and comprehensive analyses, ultimately accelerating research and discovery in proteomics and drug development.
References
Troubleshooting & Optimization
improving SAPA tool search specificity
This technical support center provides troubleshooting guidance and answers to frequently asked questions for the SAPA (Sequence Analysis and Protein Annotation) tool. The SAPA tool is designed for researchers, scientists, and drug development professionals to identify functional regions in protein sequences by combining searches based on amino acid composition, scaled profiles, and sequence patterns.[1][2][3]
Frequently Asked Questions (FAQs)
Q1: What is the primary function of the SAPA tool?
A1: The SAPA tool is a web application that allows users to search for specific protein regions by combining three distinct search strategies: analysis of amino acid composition, application of scaled amino acid profiles, and scanning for sequence motifs or patterns.[1][2] It is particularly useful when only a few functional examples of a protein region are known, and researchers need to identify similar sequences for further investigation.[2][3]
Q2: What kind of input does the SAPA tool accept?
A2: The SAPA tool accepts a list of protein sequences for analysis. Users can upload their sequences to the web application to begin the search process.[1]
Q3: How does the SAPA tool rank the identified target regions?
A3: The tool ranks the extracted target regions using an integrated score. The results are presented in a table sorted by these scores, allowing users to quickly identify the most relevant findings.[1][3]
Q4: How can I interpret the results from the SAPA tool?
A4: The results are displayed in a table that includes protein sequence icons with the identified target regions highlighted. The intensity of the color in the highlight corresponds to the score of the region. Clicking on an icon will open a pop-up window showing the sequence with the highlighted areas.[1]
Q5: Can I download the results from my analysis?
A5: Yes, all settings and result tables can be downloaded as a multiple Excel spreadsheet file. The protein sequences that are identified can be downloaded in a FASTA-formatted sequence file.[1]
Troubleshooting Guides
This section addresses specific issues users might encounter during their experiments with the SAPA tool.
Issue 1: No significant target regions are identified in my submitted sequences.
Possible Causes and Solutions:
-
Search parameters may be too stringent. The combination of amino acid composition, profile scaling, and pattern matching might be too specific for your dataset.
-
Solution: Try to broaden your search criteria. You can start by using only one or two of the search strategies and then gradually add more constraints. For example, begin with a search based only on amino acid composition and then layer on a scaled profile.
-
-
The input sequences may not contain the regions of interest.
-
Solution: It is crucial to have a positive control if possible—a sequence that is known to contain the functional region you are looking for. This will help validate that your search parameters are appropriate. For instance, when searching for putative O-glycosylated sequence regions in Mycobacterium tuberculosis proteins, starting with known examples helps in refining the search for novel targets.[1]
-
-
Incorrect format of uploaded sequence file.
-
Solution: Ensure your protein sequences are in a compatible format, such as a simple list or a standard FASTA format. Refer to the tool's documentation or help section for specific formatting requirements.
-
Experimental Protocol for Parameter Optimization:
-
Baseline Search: Begin with your full set of query sequences and use the most general search parameters you hypothesize might be relevant.
-
Positive Control Test: Upload a known positive control sequence and adjust the amino acid composition, scaled profiles, and pattern rules until the tool successfully identifies the target region.
-
Iterative Broadening: If your initial search on the full dataset yielded no results, systematically relax the parameters. For instance, widen the allowed percentage range for specific amino acids.
-
Component Analysis: Run separate searches for each component (composition, profile, pattern) to see if any single component yields results. This can help identify which parameters are overly restrictive.
-
Result Evaluation: For each set of results, download the Excel spreadsheet and FASTA file to analyze the identified regions and scores.[1]
Issue 2: The tool returns too many non-specific target regions.
Possible Causes and Solutions:
-
Search parameters are too broad. If your criteria are not specific enough, the tool may identify many regions that are not functionally relevant.
-
Solution: Gradually make your search parameters more stringent. You can narrow the amino acid composition ranges, select a more specific scaled profile from a database like AAINDEX, or define a more conserved sequence pattern.[1]
-
-
Lack of a negative control set. Without a set of sequences known to lack the target region, it is difficult to assess the false discovery rate.
Data Presentation: Refining Search Parameters
To systematically refine your search, you can create a table to track your parameter adjustments and the corresponding number of hits.
| Experiment ID | Amino Acid Composition | Scaled Profile (AAINDEX ID) | Sequence Pattern | Number of Hits | False Discovery Rate (FDR) |
| 001 | Broad | General Hydrophobicity | None | 542 | 0.35 |
| 002 | Narrowed (e.g., high Pro, low Cys) | Specific (e.g., Beta-turn propensity) | None | 112 | 0.12 |
| 003 | Narrowed | Specific | [AP]-x-G | 23 | 0.04 |
Visualizing Workflows and Logic
The following diagrams illustrate the experimental workflow and the logical relationships within the SAPA tool.
References
Technical Support Center: Troubleshooting Common Errors in Automated Patch Clamp (APC) Analysis
Welcome to the Technical Support Center for Automated Patch Clamp (APC) systems. This guide is designed for researchers, scientists, and drug development professionals to troubleshoot common issues encountered during their experiments. Below you will find troubleshooting guides and Frequently Asked Questions (FAQs) in a question-and-answer format to help you resolve specific problems and improve the quality and success rate of your APC experiments.
Frequently Asked Questions (FAQs)
Q1: What are the most critical quality control parameters I should monitor during an APC experiment?
A1: To ensure high-quality, reproducible data, you should closely monitor several key parameters throughout your experiment. These include:
-
Seal Resistance (Rseal): This is a measure of the electrical tightness of the seal between the cell membrane and the patch aperture. A high seal resistance (typically >500 MΩ, ideally >1 GΩ) is crucial for low-noise recordings.
-
Access Resistance (Ra) or Series Resistance (Rs): This represents the electrical resistance between the recording electrode and the cell interior. Low and stable access resistance (typically <20 MΩ) is essential for accurate voltage clamp and rapid recording of ion channel kinetics.
-
Cell Capacitance (Cm): This is proportional to the cell surface area and can be used to normalize current amplitudes to current densities. It also serves as an indicator of cell size and health.
-
Holding Current (Ihold): A stable holding current at a given holding potential indicates a stable recording and healthy cell. Drifting holding currents can suggest seal instability or changes in cell health.
Q2: My experiment success rate is low. What are the most common factors that could be causing this?
A2: A low success rate in APC experiments can be attributed to several factors, often related to the quality of the cells and solutions. The most common culprits include:
-
Poor Cell Health: Unhealthy or dying cells will not form stable, high-resistance seals.
-
Improper Cell Suspension: Clumped cells or the presence of excessive cellular debris can clog the microfluidic channels of the APC chip.
-
Suboptimal Solutions: Incorrect osmolarity, pH, or ion concentrations in either the internal or external solutions can negatively impact cell health and seal formation.
-
Instrumental Issues: Problems with the pressure control system, clogged fluidics, or faulty electronics can all lead to experiment failure.
Troubleshooting Guides
This section provides detailed troubleshooting for specific, common errors encountered during APC analysis.
Issue 1: Low Seal Resistance (Failure to achieve "Gigaseal")
A high-resistance "gigaseal" is the foundation of a successful patch clamp recording. Failure to achieve an adequate seal resistance will result in noisy data that is unusable for analysis.
Q: I am consistently observing low seal resistance (<500 MΩ) across my experiments. What steps can I take to troubleshoot this?
A: Low seal resistance is a frequent issue in automated patch clamp experiments. A systematic approach to troubleshooting is often the most effective way to identify and resolve the underlying cause.
Experimental Protocol: Optimizing Seal Formation
-
Cell Preparation:
-
Health and Viability: Ensure cells are in a logarithmic growth phase and have a viability of >95%. Avoid using cells that are over-confluent or have been passaged too many times.
-
Dissociation: Use a gentle dissociation protocol (e.g., Accutase) to obtain a single-cell suspension. Avoid harsh enzymatic treatments like trypsin, which can damage the cell membrane.
-
Washing and Resuspension: Wash the cells thoroughly to remove all traces of dissociation enzymes and resuspend them in the appropriate external solution at the optimal density for your specific APC platform.
-
-
Solution Quality Control:
-
Filtration: Filter all solutions (internal, external, and wash solutions) through a 0.22 µm filter to remove any particulate matter.
-
Osmolarity and pH: Verify that the osmolarity and pH of your internal and external solutions are within the recommended range for the cell type you are using. Typically, the internal solution should be slightly hypo-osmotic compared to the external solution.
-
Freshness: Prepare fresh solutions regularly and store them appropriately to prevent degradation or contamination.
-
-
Instrument and Chip Inspection:
-
Chip Inspection: Before starting an experiment, visually inspect the patch chip for any defects, debris, or clogs.
-
Pressure System Check: Ensure that the pressure system of the instrument is functioning correctly and that there are no leaks in the tubing.
-
Quantitative Data Summary: Typical Parameters for Successful Seal Formation
| Parameter | Recommended Value | Common Error Indication |
| Cell Viability | > 95% | Low viability leads to fragile membranes that do not seal well. |
| Pipette/Aperture Resistance | 2 - 5 MΩ | Resistance outside this range can make sealing difficult.[1] |
| Seal Resistance (Rseal) | > 500 MΩ (ideally > 1 GΩ) | Values below this threshold indicate a "leaky" seal, resulting in noisy recordings. |
| Internal Solution Osmolarity | 280-300 mOsm | Incorrect osmolarity can cause cells to swell or shrink, preventing proper seal formation. |
| External Solution Osmolarity | 310-330 mOsm | Mismatch with internal solution can lead to osmotic stress on the cells. |
Troubleshooting Workflow: Low Seal Resistance
Caption: Troubleshooting workflow for low seal resistance.
Issue 2: High or Unstable Access Resistance
After achieving a good seal, the cell membrane patch must be ruptured to gain electrical access to the cell's interior (whole-cell configuration). High or unstable access resistance can distort the recorded currents and lead to inaccurate voltage clamp.
Q: My recordings show slow capacitive transients and the current amplitudes seem to be drifting. How can I troubleshoot high or unstable access resistance?
A: High or unstable access resistance (Ra) is a common problem that can significantly impact data quality. Here’s how you can address it.
Experimental Protocol: Minimizing and Stabilizing Access Resistance
-
Membrane Rupture:
-
Rupture Pulse: Apply brief, sharp suction pulses to rupture the membrane. Some APC systems also allow for the application of an electrical "zap" to facilitate membrane rupture.
-
Monitoring: Continuously monitor the access resistance after the rupture attempt. A successful whole-cell configuration is indicated by a sudden drop in resistance and the appearance of capacitive transients.
-
-
Pipette/Aperture Properties:
-
Size: As a general rule, larger pipette or aperture openings will result in lower access resistance. However, this may make achieving a gigaseal more challenging. An optimal balance must be found for your specific cell type.
-
-
Recording Stability:
-
Monitor Over Time: After establishing a whole-cell recording, monitor the access resistance for several minutes before adding any compounds. If it is unstable, the recording should be discarded.
-
Compensation: Use the amplifier's series resistance compensation circuitry to electrically compensate for the access resistance. This is particularly important for accurately recording fast-activating and inactivating currents.
-
Quantitative Data Summary: Access Resistance and its Impact
| Parameter | Ideal Value | Consequence of High Value |
| Access Resistance (Ra) | < 20 MΩ | - Voltage-clamp errors- Slowing of current kinetics- Attenuation of current amplitude |
| Ra Stability | < 10% change | Drifting Ra can lead to run-down or run-up of currents, complicating pharmacological analysis. |
Troubleshooting Workflow: High Access Resistance
Caption: Troubleshooting workflow for high access resistance.
Issue 3: Common Data Artifacts
Data artifacts can obscure the true physiological signals and lead to misinterpretation of results. It is important to be able to identify and mitigate common artifacts.
Q: I am seeing a lot of noise and strange waveforms in my recordings. How can I identify and remove common artifacts?
A: Several types of artifacts can contaminate patch clamp recordings. Here are some of the most common ones and how to address them.
Types of Artifacts and Their Solutions:
-
50/60 Hz Line Noise: This appears as a sinusoidal wave at the frequency of the electrical mains.
-
Solution: Ensure proper grounding of the APC system and any nearby electrical equipment. Use a Faraday cage to shield the instrument from external electrical fields. Some amplifiers also have built-in noise cancellation features.
-
-
Capacitive Transients: These are large, brief currents that occur at the beginning and end of a voltage step.
-
Solution: While these are a normal feature of patch clamp recordings, they can be minimized by using the amplifier's capacitance compensation circuits. For analysis, these transient periods are typically excluded.
-
-
Drift: This is a slow, steady change in the baseline current over time.
-
Solution: Drift can be caused by unstable seal resistance, changes in cell health, or temperature fluctuations. If the drift is minor, it can sometimes be corrected for during data analysis by subtracting a baseline trend. However, significant drift usually indicates an unstable recording that should be discarded.
-
Experimental Protocol: Minimizing Artifacts
-
Proper Grounding: Ensure all components of the patch clamp rig are connected to a common ground.
-
Environmental Isolation: Place the APC system on a vibration isolation table and within a Faraday cage.
-
Regular Maintenance: Keep the instrument clean and perform regular maintenance as recommended by the manufacturer.
Logical Relationship: Identifying Artifact Sources
References
optimizing search parameters in the SAPA tool
Welcome to the technical support center for the SAPA (Sequence Alignment and Protein Analysis) tool. This resource is designed to assist researchers, scientists, and drug development professionals in optimizing their search parameters and troubleshooting common issues encountered during their experiments.
Frequently Asked Questions (FAQs)
Q1: What is the primary function of the SAPA tool?
A1: The SAPA tool is a web-based application designed to identify and analyze specific regions within protein sequences. It uniquely combines three distinct search strategies: analysis of amino acid composition, application of scaled amino acid property profiles (from the AAINDEX database), and motif searching using an extended PROSITE pattern syntax.[1][2][3] This integrated approach allows for the nuanced identification of functional protein regions that may not be detectable by standard sequence alignment methods alone.
Q2: What are the main input formats supported by the SAPA tool?
A2: The SAPA tool is designed to be flexible with input data. Users can provide protein sequences in the widely-used FASTA format. Additionally, sequences can be pasted directly into the input field or retrieved from the NCBI protein database.
Q3: How does the SAPA tool score and rank the identified target regions?
A3: The SAPA tool employs a comprehensive scoring scheme to rank the identified target regions. The final score for a target is an aggregation of scores derived from its amino acid composition, the applied AAINDEX profiles, and the presence of defined motifs.[1][3] This multi-faceted scoring allows for a more robust and biologically relevant ranking of potential regions of interest.
Q4: How can I estimate the false discovery rate (FDR) of my results?
A4: The SAPA tool includes a feature to estimate the False Discovery Rate (FDR) by using decoy sequences. This is a crucial step in validating the statistical significance of your findings and minimizing the impact of false positives.
Q5: Can I download the results from the SAPA tool?
A5: Yes, the SAPA tool provides options to download your results for further analysis. You can export the data as a formatted Excel file or as a FASTA file containing the sequences of the identified target regions.
Troubleshooting Guides
Optimizing Amino Acid Composition Searches
Issue: Your search for proteins with a specific amino acid composition is returning too many or too few results.
Solution: The specificity of your amino acid composition search is determined by the defined percentages of single amino acids or related amino acid groups. To optimize your search, consider the following:
-
Refining Percentages: If you are getting too many results, try increasing the minimum occurrence percentages for the specified amino acids. Conversely, if your search is too restrictive, cautiously decrease the percentage thresholds.
-
Grouping Amino Acids: Instead of specifying individual amino acids, group them based on their physicochemical properties (e.g., hydrophobic, polar, charged). This can broaden your search to include functionally similar residues.
-
Iterative Approach: Start with a broader search and progressively narrow down the parameters based on the initial results. This iterative process can help you pinpoint the optimal settings for your specific research question.
| Parameter | Recommendation for Too Many Results | Recommendation for Too Few Results |
| Minimum Occurrence % | Increase the percentage | Decrease the percentage |
| Number of Amino Acids | Increase the number of specified residues | Decrease the number of specified residues |
| Amino Acid Grouping | Use more specific groups | Use broader physicochemical groups |
Fine-tuning AAINDEX Profile Searches
Issue: The use of scaled AAINDEX profiles is not effectively discriminating between your target and background sequences.
Solution: The AAINDEX database contains a vast collection of amino acid indices representing various physicochemical and biochemical properties. Effective use of these profiles in SAPA requires careful selection and weighting.
-
Profile Selection: Choose AAINDEX profiles that are most relevant to the biological function or property you are investigating. For example, if you are searching for transmembrane domains, hydrophobicity scales would be a logical choice.
-
Weighting and Scaling: The SAPA tool allows for the re-scaling and weighting of AAINDEX profiles.[1][3] If a particular property is more critical to your search, assign it a higher weight. Experiment with different scaling options to enhance the signal from your property of interest.
-
Combining Profiles: The tool allows the use of up to three scaled AAINDEX profiles.[3] Combining orthogonal properties can significantly improve the specificity of your search. For instance, you could combine a hydrophobicity scale with a profile related to secondary structure propensity.
| Parameter | Optimization Strategy | Example |
| AAINDEX Profile Selection | Choose profiles relevant to the target function. | For DNA-binding regions, select profiles related to positive charge and alpha-helix propensity. |
| Profile Weighting | Increase the weight of more important profiles. | If hydrophobicity is the key feature, assign it a higher weight compared to other profiles. |
| Profile Scaling | Adjust the scaling factor to enhance signal. | Normalize scales to a common range to prevent dominance by profiles with larger value ranges. |
Troubleshooting Motif Searches with PROSITE Patterns
Issue: Your motif search using PROSITE pattern syntax is not identifying known motifs or is returning too many false positives.
Solution: The extended PROSITE pattern syntax used by the SAPA tool is a powerful feature for identifying conserved motifs. However, the syntax needs to be precise.
-
Syntax Check: Carefully review your PROSITE pattern for any syntax errors. Even a small mistake can lead to incorrect results. Refer to the official PROSITE documentation for the correct syntax.
-
Specificity of the Pattern: A very general pattern will result in many hits, while a highly specific one might miss valid variations. If your pattern is too broad, add more conserved residues. If it is too restrictive, consider using ambiguities (e.g., [AG] for Alanine or Glycine) or variable spacing (x(2,4) for 2 to 4 of any amino acid).
-
Logical Operators: The SAPA tool allows for the combination of motifs using 'AND', 'NOT', or 'OR' operators.[3] Use these to build more complex and specific search queries. For example, you could search for sequences that contain MotifA AND MotifB but NOT MotifC.
Experimental Protocols & Workflows
Protocol: Identifying Novel O-glycosylated Peptides using SAPA
This protocol outlines a general workflow for identifying potentially O-glycosylated peptide regions from a protein dataset, a demonstrated application of the SAPA tool.[3]
-
Data Preparation:
-
Compile a list of known O-glycosylated proteins to serve as a positive control and training set.
-
Prepare your target protein dataset in FASTA format.
-
-
SAPA Tool - Amino Acid Composition:
-
Based on your training set, determine the common amino acid composition of O-glycosylated regions. These are often rich in Serine (S) and Threonine (T).
-
In the SAPA tool, set the minimum occurrence percentages for S and T. Start with a moderate threshold and refine iteratively.
-
-
SAPA Tool - AAINDEX Profile:
-
Select an AAINDEX profile that reflects the propensity for O-glycosylation. Profiles related to surface accessibility and intrinsic disorder can be relevant.
-
Apply and potentially weight this profile in your search.
-
-
SAPA Tool - Motif Search:
-
If there are known short motifs associated with O-glycosylation in your organism of interest, define them using the PROSITE pattern syntax.
-
Combine these motifs with your composition and profile searches.
-
-
Execution and Analysis:
-
Run the SAPA search with your defined parameters.
-
Analyze the results table, paying close attention to the scores.
-
Use the FDR estimation with decoy sequences to assess the significance of your findings.
-
Download the high-scoring candidates for further experimental validation.
-
Visualizations
Caption: Workflow for identifying O-glycosylated peptides using the SAPA tool.
Caption: Logical relationships for combining search parameters in the SAPA tool.
References
troubleshooting false positives in SAPA tool results
This technical support center provides troubleshooting guidance and frequently asked questions (FAQs) to help researchers, scientists, and drug development professionals resolve issues with false positives in Sandwich Proximity Assay (SAPA) tool results.
Frequently Asked Questions (FAQs)
Q1: What are the most common causes of false-positive signals in a SAPA experiment?
False-positive signals in a SAPA experiment can arise from several factors:
-
Non-specific binding of antibodies: Primary or secondary antibodies may bind to unintended targets or surfaces in the assay.[1][2][3]
-
Cross-reactivity of antibodies: One or both of the primary antibodies may recognize other proteins with similar epitopes.
-
High antibody concentrations: Excessive concentrations of primary or detection antibodies can lead to increased background signal.[3][4]
-
Insufficient blocking: Incomplete blocking of non-specific binding sites on the assay surface can cause antibodies or other reagents to adhere randomly.[3][5]
-
Inadequate washing: Failure to remove unbound reagents during wash steps is a frequent cause of high background.[5]
-
Sample-related issues: Autofluorescence from the sample or the presence of interfering substances can be misinterpreted as a positive signal.[6]
-
Reagent contamination: Contamination of buffers or reagents can introduce artifacts that generate a signal.
Q2: How can I determine if my primary antibodies are specific to the target protein?
Antibody specificity is crucial for reliable SAPA results. It is highly recommended to validate your primary antibodies using multiple approaches before using them in a SAPA experiment:
-
Western Blotting: Confirm that the antibody detects a single band at the correct molecular weight in a lysate from a cell line or tissue known to express the target protein.
-
Knockout/Knockdown Validation: Use cell lines where the target protein has been knocked out or knocked down. A specific antibody should show a significantly reduced or absent signal in these cells compared to the wild-type control.
-
Immunofluorescence/Immunohistochemistry (IF/IHC): Ensure the antibody shows the expected subcellular localization and staining pattern.[6][7] Antibodies that perform well in IF are often suitable for proximity ligation assays.[6]
-
Use of multiple antibodies: Employ two or more antibodies that recognize different, non-overlapping epitopes on the same target protein to confirm localization and expression.
Q3: What are the appropriate negative controls to include in my SAPA experiment?
Including proper negative controls is essential to identify and troubleshoot false positives. Key negative controls include:
-
No primary antibody control: Omitting one or both primary antibodies helps to identify non-specific binding of the detection reagents.[8]
-
Isotype control: Replacing the primary antibody with an isotype-matched control antibody that does not target the protein of interest can help assess non-specific binding of the primary antibody.
-
Biologically negative sample: Use a sample from a cell line or tissue that does not express the target protein (e.g., a knockout cell line). This is the most stringent negative control.
-
Buffer alone control: Wells containing only the assay buffer can help determine the baseline noise of the instrument.
Q4: How can I optimize the concentration of my primary antibodies to reduce background?
Optimizing the concentration of primary antibodies is a critical step to maximize the signal-to-noise ratio.
-
Titration experiment: Perform a titration of each primary antibody to find the concentration that gives the best signal with the lowest background. This can be done using a single-plex version of your assay or by immunofluorescence.[2][4]
-
Start with manufacturer's recommendations: Use the antibody datasheet as a starting point for the dilution range to be tested.
-
Lower concentrations for high-abundance targets: For highly expressed proteins, lower antibody concentrations are often sufficient and can help reduce non-specific binding.
Q5: What should I consider when preparing my wash buffers to minimize false positives?
Proper washing is critical to remove unbound reagents.
-
Detergent concentration: Including a non-ionic detergent like Tween-20 (typically at 0.05-0.1%) in your wash buffer can help reduce non-specific binding.[5]
-
Salt concentration: Increasing the salt concentration (e.g., with NaCl) in the wash buffer can disrupt ionic interactions that may contribute to non-specific binding.[5][9][10]
-
Number of washes: Increasing the number of wash steps or the duration of each wash can improve the removal of unbound reagents.[5]
Troubleshooting Guides
High Background Signal
A high background signal can mask true positive results and lead to false positives.
| Potential Cause | Recommended Solution |
| Antibody Concentration Too High | Titrate primary and secondary antibody concentrations to find the optimal balance between signal and background.[3][4] A 1:750 dilution for the primary antibody may provide a good starting point for optimization. |
| Insufficient Blocking | Increase the concentration of the blocking agent (e.g., BSA from 1% to 3%) or extend the blocking incubation time.[5] Consider using a different blocking agent. |
| Inadequate Washing | Increase the number of wash steps (e.g., from 3 to 5) and ensure complete aspiration of the wash buffer between steps.[5] Add a soaking step of a few minutes during washes.[5] |
| Non-specific Antibody Binding | Include an isotype control to assess the level of non-specific binding from the primary antibody. Validate antibody specificity using orthogonal methods. |
| Sample Autofluorescence | Image an unstained sample to assess the level of autofluorescence.[6] If significant, consider using a quenching agent like Sudan Black B for tissue samples.[6] |
Experimental Protocols
Antibody Validation Protocol for SAPA
This protocol outlines the key steps for validating primary antibodies prior to their use in a SAPA experiment.
-
Initial Screen by Western Blot:
-
Prepare lysates from cells or tissues known to express (positive control) and not express (negative control) the target protein.
-
Separate the proteins by SDS-PAGE and transfer to a membrane.
-
Probe the membrane with the primary antibody at the manufacturer's recommended dilution.
-
A specific antibody should detect a single band at the expected molecular weight in the positive control lysate and no band in the negative control.
-
-
Immunofluorescence (IF) Staining for Subcellular Localization:
-
Culture cells on coverslips and fix them using a method appropriate for the target antigen (e.g., 4% paraformaldehyde).[11]
-
Permeabilize the cells if the target is intracellular (e.g., with 0.1% Triton X-100).[11]
-
Block non-specific binding sites with a suitable blocking buffer.
-
Incubate with the primary antibody, followed by a fluorescently labeled secondary antibody.
-
Image the cells using a fluorescence microscope and confirm that the staining pattern matches the known subcellular localization of the protein.
-
-
Antibody Titration for Optimal Concentration:
-
Using the IF protocol, test a range of primary antibody dilutions (e.g., from 1:100 to 1:2000).
-
Identify the lowest concentration that provides a clear, specific signal with minimal background. This concentration will serve as a good starting point for your SAPA experiment.[2]
-
Visualizations
Caption: Troubleshooting workflow for false positives in SAPA.
Caption: Example of a signaling pathway with potential for cross-reactivity.
References
- 1. researchgate.net [researchgate.net]
- 2. Proximity Ligation Assay for Detecting Protein-Protein Interactions and Protein Modifications in Cells and Tissues In Situ - PMC [pmc.ncbi.nlm.nih.gov]
- 3. 5 Tips for Reducing Non-specific Signal on Western Blots - Nordic Biosite [nordicbiosite.com]
- 4. sigmaaldrich.com [sigmaaldrich.com]
- 5. biocompare.com [biocompare.com]
- 6. blog.benchsci.com [blog.benchsci.com]
- 7. merckmillipore.com [merckmillipore.com]
- 8. Optimizing In Situ Proximity Ligation Assays for Mitochondria, ER, or MERC Markers in Skeletal Muscle Tissue and Cells - PMC [pmc.ncbi.nlm.nih.gov]
- 9. 4 Ways To Reduce Non-specific Binding in Surface Plasmon Resonance Experiments | Technology Networks [technologynetworks.com]
- 10. nicoyalife.com [nicoyalife.com]
- 11. clyte.tech [clyte.tech]
SAPA Tool Server: Technical Support Center
This technical support center provides troubleshooting guidance and answers to frequently asked questions for users of the SAPA (Structure-Activity-guided Protein Alignment) tool server. Our aim is to help researchers, scientists, and drug development professionals resolve common issues encountered during their experiments.
Frequently Asked Questions (FAQs)
Q1: What is the SAPA tool?
A1: The SAPA tool is a web application designed to identify specific regions within protein sequences by combining searches based on amino acid composition, scaled profiles of amino acid properties, and sequence patterns. It is particularly useful when only a small number of functional examples are well-characterized, allowing researchers to find similar sequences for further investigation.[1][2]
Q2: Where can I find the SAPA tool and its documentation?
A2: The SAPA tool web application, along with its source code and user manual, is freely available at 31][2]
Q3: What is the correct input format for the SAPA tool?
A3: The SAPA tool accepts protein sequences in FASTA format. You can upload a file containing your sequences or paste them directly into the input form on the web server.[4] It is crucial to ensure your input file strictly adheres to the FASTA format to avoid processing errors.
Q4: How does the SAPA tool score and rank target regions?
A4: The SAPA tool ranks the identified target regions using an integrated score. This score is calculated based on the combined properties you define in your search, including amino acid composition, profile scores, and motif content.[1][2][4]
Q5: How can I interpret the results from the SAPA tool?
A5: The results are presented in a table, with targets sorted by their scores. The output also includes protein sequence icons with the identified regions highlighted, where the color intensity corresponds to the score. Clicking on an icon will display the sequence with the highlighted regions. You can download the complete results as a Microsoft Excel file and the protein sequences as a FASTA-formatted file.[4]
Troubleshooting Guide
This guide addresses specific issues users might encounter while using the SAPA tool server.
Issue 1: Server Accessibility and Timeouts
Symptom: The SAPA tool website is unreachable, or the connection times out during a job submission or analysis.
Possible Causes & Solutions:
| Cause | Solution |
| Server is down for maintenance. | Check the SAPA tool website for any announcements regarding scheduled maintenance. It is also possible that the server is temporarily unavailable due to unforeseen issues.[5] |
| Network connectivity issues. | Verify your own internet connection. Try accessing other websites to ensure the problem is not on your end. |
| Large dataset submission. | Submitting a very large number of sequences or very long sequences can lead to timeouts. Try breaking down your dataset into smaller batches for submission. |
| Proxy server timeouts. | If you are accessing the internet through a proxy server, it may have timeout settings that are shorter than the time required for your analysis to complete. If possible, try submitting your job from a direct internet connection. |
Issue 2: Data Submission and Input Errors
Symptom: The SAPA tool returns an error immediately after submitting your data, or the job fails to start.
Possible Causes & Solutions:
| Cause | Solution |
| Incorrect file format. | Ensure your input sequences are in the correct FASTA format. Common errors include missing ">" symbols before the header line or invalid characters in the sequence. |
| Invalid characters in sequence data. | Protein sequences should only contain standard amino acid one-letter codes. Remove any non-standard characters from your input. |
| Inconsistent data formatting. | If pasting sequences, ensure there are no extra spaces or hidden characters that could disrupt parsing. |
A common workflow for troubleshooting data input errors is as follows:
Issue 3: Unexpected or No Results
Symptom: The analysis completes, but the results are not what you expected, or no target regions are identified.
Possible Causes & Solutions:
| Cause | Solution |
| Search parameters are too stringent. | The combination of amino acid composition, profile scores, and motif patterns may be too specific, resulting in no matches. Try relaxing your search criteria. |
| Incorrect motif syntax. | The SAPA tool uses an extended PROSITE pattern syntax.[4] Double-check your motif definitions for any errors. |
| Misinterpretation of scoring. | A low score does not necessarily mean the result is incorrect, but rather that it is a weaker match to your defined properties. Review the distribution of scores to identify potentially interesting hits. |
| Reference dataset issues. | The quality and relevance of the protein sequences you are analyzing will directly impact the results. Ensure your dataset is appropriate for your research question.[6] |
Experimental Protocols
While the SAPA tool publication does not provide detailed, step-by-step experimental protocols, it describes the general methodology for using the tool. The following is a generalized workflow based on the available information.[1][2][4]
General Workflow for using the SAPA Tool:
-
Prepare Input Data: Collect protein sequences of interest and format them in a FASTA file.
-
Access the SAPA Tool: Navigate to the SAPA web server at --INVALID-LINK--.
-
Submit Sequences: Upload the FASTA file or paste the sequences into the provided text box.
-
Define Search Parameters:
-
Amino Acid Composition: Specify the minimum occurrence percentages for up to six single amino acids or three groups of related amino acids.
-
Scaled Profiles: Select up to three scaled AAINDEX amino acid profiles and set the desired mean score thresholds.
-
Motif Search: Define sequence motifs using the extended PROSITE pattern syntax and combine them using logical operators (AND, NOT, OR).
-
-
Run Analysis: Initiate the search.
-
Analyze Results:
-
Examine the output table, which ranks target regions by score.
-
Visualize the highlighted target regions on the protein sequences.
-
Download the results in Excel and FASTA formats for further analysis.
-
The logical flow of a typical SAPA tool experiment can be visualized as follows:
References
- 1. SAPA tool: finding protein regions by combination of amino acid composition, scaled profiles, patterns and rules - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. researchgate.net [researchgate.net]
- 3. sapa-tool.uio.no [sapa-tool.uio.no]
- 4. academic.oup.com [academic.oup.com]
- 5. Reddit - The heart of the internet [reddit.com]
- 6. Ten common issues with reference sequence databases and how to mitigate them - PMC [pmc.ncbi.nlm.nih.gov]
Navigating Ambiguity: A Technical Support Guide for the SAPA Tool
For Immediate Release
Researchers and drug development professionals now have a dedicated resource for interpreting complex and ambiguous results from the SAPA (Sequence Analysis and Profile Alignment) tool. This new technical support center provides in-depth troubleshooting guides and frequently asked questions (FAQs) to empower users in their protein analysis workflows. By offering clear, actionable guidance, this resource aims to accelerate research and development by minimizing time spent on deciphering uncertain findings.
The SAPA tool is a powerful bioinformatics web application designed to identify functionally significant regions within protein sequences. It uniquely integrates three distinct analytical approaches: amino acid composition, scaled amino acid profiles, and sequence pattern motifs. While this multi-faceted approach provides a comprehensive analysis, it can sometimes generate results that are not immediately straightforward to interpret. This support center directly addresses these challenges.
Troubleshooting Ambiguous Results
Ambiguous results from the SAPA tool can manifest in several ways: a high False Discovery Rate (FDR), low-scoring hits, or conflicting outputs from the different analysis modules. Below are guides to troubleshoot these common issues.
Issue 1: High False Discovery Rate (FDR)
A high FDR suggests that a significant proportion of the identified protein regions could be false positives.
Question: My SAPA tool results show a high False Discovery Rate (FDR). How should I interpret this and what are my next steps?
Answer:
A high FDR indicates that the current search parameters may be too lenient, leading to the identification of many regions that are not biologically significant. An acceptable FDR is typically low, often below 5% (or 0.05), meaning that you would expect less than 5% of the significant results to be false positives.[1]
Troubleshooting Steps:
-
Refine Search Parameters: The most effective way to reduce a high FDR is to make your search criteria more stringent.
-
Increase Score Thresholds: If you have set a low threshold for the overall score, raise it to filter out weaker, potentially random matches.
-
Narrow Amino Acid Composition: If using the amino acid composition filter, tighten the percentage ranges for the specified residues.
-
Adjust Profile Scores: When using scaled amino acid profiles, increase the minimum required mean score.
-
Specify More Complex Motifs: If using pattern motifs, a more specific and longer pattern will reduce the likelihood of random matches.
-
-
Utilize Decoy Methods: The SAPA tool offers three methods for generating decoy sequences (riffled, shuffled, and reversed) to estimate the FDR.[2] The "riffled" method is generally recommended as it largely preserves sequence redundancy while disrupting local amino acid composition.[2] If you are getting a high FDR, ensure you are using an appropriate decoy method for your dataset.
-
Iterative Refinement: As stated in the original publication, the SAPA tool is designed for an iterative approach.[3] Start with a broader search to identify a set of potential candidates. Experimentally validate a few of the top-scoring hits. Use the information from these validated hits to perform a new, more informed, and stringent search.
| Parameter | Initial Broad Search (Example) | Refined Stringent Search (Example) |
| Min. Target Score | 10 | 25 |
| Amino Acid Composition | Proline: 15-30% | Proline: 20-25% |
| AAINDEX Profile Score | > 1.5 | > 2.0 |
| Motif | P-x(2)-P | [ST]-P-x-P-[KR] |
This table provides illustrative examples of how to adjust parameters from a broad to a more stringent search to reduce the False Discovery Rate.
Issue 2: Low-Scoring Target Regions
It can be challenging to determine the biological relevance of identified regions with low scores.
Question: The SAPA tool has identified a potential region of interest, but its score is very low. How do I know if this is a significant finding or just background noise?
Answer:
A low score does not automatically negate the potential significance of a hit, but it does warrant a more critical evaluation. The score in the SAPA tool is a composite value derived from the information content of the amino acid composition, the scaled AAINDEX profiles, and the defined motifs.[4]
Troubleshooting Steps:
-
Examine the Contribution of Each Component: Analyze the score breakdown if available in the output. Did the score come primarily from one feature (e.g., a weak motif match) while the other features were not significant? A region that scores moderately across all three criteria (composition, profile, and motif) may be more promising than one with a low score derived from a single, weak match.
-
Compare with Negative Controls: If you have a set of proteins that are known not to contain the functional region of interest, run them through the SAPA tool with the same parameters. If your low-scoring hit has a score that is significantly higher than any hits in your negative control set, it may be worth further investigation.
-
Look for Corroborating Evidence:
-
Literature Review: Is there any existing literature that suggests the identified region or similar sequences might be functionally important?
-
Structural Analysis: If a 3D structure of the protein is available, is the identified region located on the surface of the protein where it might be involved in interactions?[5][6] Tools like RasMol or PyMOL can be used for this visualization.
-
Conservation Analysis: Is the low-scoring region conserved across homologous proteins in other species? High conservation can be an indicator of functional importance.
-
Issue 3: Conflicting Results Between Search Strategies
Ambiguity can arise when the different search methods within the SAPA tool provide conflicting information.
Question: A protein region was identified by its amino acid composition, but it does not contain the expected sequence motif. How should I proceed?
Answer:
This scenario highlights the strength of the SAPA tool in identifying functional regions that may not conform to a strict consensus pattern. Functional modules in proteins are not always defined by a linear motif.[4][7]
Troubleshooting Steps:
-
Re-evaluate Your Motif: Is it possible that the defined motif is too stringent or based on a limited number of examples? The true functional motif may be more degenerate than initially assumed. Try searching with a less strict pattern.
-
Consider a Composition-Dominant Region: Some functional regions are primarily defined by their physical properties, which are a direct result of their amino acid composition (e.g., intrinsically disordered regions rich in polar and charged residues). The absence of a conserved motif does not preclude function.
-
Prioritize Experimental Validation: In cases of conflicting computational evidence, experimental validation is paramount. The SAPA tool is intended to generate hypotheses and guide experimental work.[3]
Experimental Protocols for Validation
The ultimate confirmation of a computationally predicted functional region lies in experimental validation. Below are generalized protocols for common validation experiments.
Protocol 1: Site-Directed Mutagenesis and Functional Assay
This is a cornerstone technique to probe the function of specific amino acid residues within a protein.
Methodology:
-
Hypothesis: Formulate a hypothesis about the function of the identified protein region (e.g., "This proline-rich region is essential for protein-protein interaction with Protein X").
-
Mutagenesis:
-
Obtain the cDNA of your protein of interest cloned into an appropriate expression vector.
-
Use a commercial site-directed mutagenesis kit to introduce point mutations or deletions within the predicted functional region. A common strategy is to mutate key residues to Alanine (Alanine scanning) to disrupt function without causing major structural changes.
-
Positive Control: Wild-type (unmutated) protein.
-
Negative Control: A mutation in a region of the protein not expected to be functional.
-
-
Protein Expression and Purification: Express the wild-type and mutant proteins in a suitable system (e.g., E. coli, mammalian cells) and purify them.
-
Functional Assay: Perform an assay relevant to the hypothesized function.
-
Enzyme Kinetics: If an enzymatic function is predicted, measure the kinetic parameters (Km, kcat) of the wild-type and mutant proteins. A significant change in these parameters for the mutant would support the prediction.
-
Binding Assays: To test for interactions with other proteins, DNA, or ligands, use techniques like co-immunoprecipitation, pull-down assays, surface plasmon resonance (SPR), or isothermal titration calorimetry (ITC).
-
-
Data Analysis: Compare the activity or binding affinity of the mutant proteins to the wild-type. A significant reduction or loss of function in the mutant provides strong evidence for the importance of the mutated region.
Protocol 2: Peptide Binding Assay
If the identified region is predicted to be a binding motif, synthetic peptides can be used to validate the interaction.
Methodology:
-
Peptide Synthesis: Synthesize a short peptide (typically 15-25 amino acids) corresponding to the sequence of the predicted functional region. Also, synthesize a scrambled version of the peptide to serve as a negative control.
-
Binding Partner Immobilization: Immobilize the purified, full-length binding partner protein onto a solid support (e.g., ELISA plate, SPR chip).
-
Binding Assay:
-
Incubate the immobilized protein with varying concentrations of the synthesized peptide (and the scrambled control).
-
Use a detection method to quantify the amount of bound peptide. For example, if the peptide is biotinylated, you can use a streptavidin-HRP conjugate for colorimetric detection in an ELISA.
-
-
Data Analysis: A specific binding signal for the target peptide that is significantly higher than the scrambled peptide confirms the interaction.
Visualizing Workflows and Logic
Diagrams can clarify complex experimental and logical workflows.
Caption: Troubleshooting workflow for ambiguous SAPA tool results.
Caption: Logical pathway for the experimental validation of a predicted functional protein region.
Frequently Asked Questions (FAQs)
Q1: What is the main advantage of using the SAPA tool over other motif-finding tools?
A1: The SAPA tool's primary advantage is its integrated, multi-faceted approach. While many tools rely solely on sequence motifs, SAPA combines this with analysis of amino acid composition and scaled profiles. This allows for the identification of functional regions that may not have a well-defined, conserved motif but are characterized by their overall biochemical properties.
Q2: Can I use the SAPA tool to analyze a whole proteome?
A2: Yes, the SAPA tool is designed to handle large sets of protein sequences, such as an entire proteome. For instance, it was successfully used to extract putative target regions from the proteome of M. tuberculosis H37Rv.[3] When analyzing large datasets, it is particularly important to pay close attention to the False Discovery Rate to manage the number of potential false positives.
Q3: Where can I find the user manual and supplementary data for the SAPA tool?
A3: The original publication in Bioinformatics mentions that the user manual, source code, and supplementary data, including a detailed example, are available at the tool's website.[3][4][7] While the original hosting link (--INVALID-LINK--) may no longer be active, searching for the publication (Maier et al., 2013, Bioinformatics) should provide access to the supplementary materials through the journal's website.
Q4: How does the "riffling" method for decoy generation work?
A4: The riffling method shuffles the sequence in a manner analogous to riffling a deck of cards. This process largely maintains the natural redundancy of amino acids in the sequence but effectively destroys the local amino acid composition, making it a robust way to generate decoy sequences for an accurate estimation of the False Discovery Rate.[2]
Q5: What if I have very few experimentally confirmed examples to start my search?
A5: The SAPA tool is particularly useful in scenarios where only a small number of functional examples are known.[3][7] With a limited starting set, you may need to begin with broader search parameters. The initial results, even with a higher FDR, can provide a larger pool of candidates for a first round of experimental validation. The validated hits from this pool can then be used to build a more refined and stringent set of search parameters for subsequent rounds of analysis.[3]
References
- 1. In Silico Identification and Characterization of a Hypothetical Protein From Rhodobacter capsulatus Revealing S-Adenosylmethionine-Dependent Methyltransferase Activity - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Prediction and experimental validation of enzyme substrate specificity in protein structures - PMC [pmc.ncbi.nlm.nih.gov]
- 3. academic.oup.com [academic.oup.com]
- 4. researchgate.net [researchgate.net]
- 5. In silico identification of functional regions in proteins - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. researchgate.net [researchgate.net]
- 7. SAPA tool: finding protein regions by combination of amino acid composition, scaled profiles, patterns and rules - PubMed [pubmed.ncbi.nlm.nih.gov]
Technical Support Center: Optimizing SAPA Protein Analysis
This technical support center provides researchers, scientists, and drug development professionals with comprehensive troubleshooting guides and frequently asked questions (FAQs) to minimize noise and enhance the reliability of Sequential Affinity Purification and Analysis (SAPA) experiments.
Frequently Asked Questions (FAQs)
Q1: What is the primary goal of Sequential Affinity Purification and Analysis (SAPA)?
SAPA, often referred to as Tandem Affinity Purification (TAP), is a technique designed to isolate protein complexes from a cellular environment with high purity. The use of two successive affinity purification steps significantly reduces the presence of non-specific protein contaminants, making it a powerful tool for identifying bona fide protein-protein interactions.[1][2]
Q2: What are the most common sources of noise in a SAPA experiment?
Noise in SAPA experiments primarily originates from proteins that co-purify with the bait protein but are not true interaction partners. These can be broadly categorized as:
-
Non-specific binding proteins: Highly abundant or "sticky" proteins that bind to the affinity resin, the tags, or the bait protein itself.
-
Environmental contaminants: Primarily keratin from skin and hair, which can be introduced during sample handling.[3]
-
Contaminants from reagents and equipment: Detergents like polyethylene glycol (PEG), residual proteins from previous runs, and impurities in buffers can all contribute to background noise.[3]
Q3: How can I distinguish true interaction partners from background contaminants?
Distinguishing true interactors from noise is a critical challenge. A multi-pronged approach is recommended:
-
Use of negative controls: The most crucial step is to perform parallel purifications with a control, such as cells expressing only the affinity tag or an unrelated bait protein. Proteins that appear in your experimental sample but not in the control are more likely to be true interactors.[1][4]
-
Quantitative comparison: Utilize quantitative mass spectrometry techniques to compare the abundance of co-purifying proteins between your bait and control purifications. True interactors should be significantly enriched in the bait sample.[5]
-
Consulting contaminant databases: Resources like the CRAPome database are repositories of proteins frequently identified in negative control AP-MS experiments. Checking your results against this database can help flag common contaminants.[6][7][8]
Troubleshooting Guides
Issue 1: High Background of Non-Specific Proteins
High background is the most common issue in SAPA experiments, obscuring the identification of true interactors.
Possible Causes and Solutions:
| Cause | Solution | Rationale |
| Insufficiently Stringent Wash Steps | Optimize wash buffer composition by increasing salt concentration (e.g., up to 500 mM NaCl) or including detergents (e.g., 0.1-0.5% NP-40 or Triton X-100). Increase the number and volume of washes.[9][10] | Harsher wash conditions disrupt weak, non-specific interactions, thereby reducing the amount of background proteins that remain bound to the resin. |
| Inappropriate Lysis Buffer | The choice of detergent in the lysis buffer is critical. Mild detergents (e.g., NP-40, Triton X-100) are often used to preserve protein complex integrity, but stronger detergents (e.g., RIPA buffer components) may be necessary to reduce background, albeit with a risk to weaker interactions.[11][12][13] | The lysis buffer must effectively solubilize proteins while minimizing the disruption of specific protein-protein interactions. The optimal buffer is a balance between these two factors. |
| Overexpression of the Bait Protein | Aim for near-endogenous expression levels of your tagged bait protein. Overexpression can lead to aggregation and non-physiological, spurious interactions.[6] | Expressing the bait protein at physiological levels is more likely to preserve the natural stoichiometry and composition of the protein complex. |
| Excessive Amount of Affinity Resin | Use the minimum amount of affinity resin necessary to capture the bait protein. Beads are a major source of non-specific binding.[4] | Minimizing the surface area of the affinity matrix reduces the potential for non-specific protein adsorption. |
| Contamination During Sample Handling | Always wear gloves and change them frequently. Work in a laminar flow hood if possible. Use filtered pipette tips and high-purity reagents. Pre-clear the lysate by centrifugation at high speed before the first purification step.[3] | Strict aseptic techniques are crucial to prevent the introduction of environmental contaminants like keratin. |
Issue 2: Low Yield of the Bait Protein and its Interactors
Low recovery of the target complex can lead to the inability to detect true, low-abundance interactors.
Possible Causes and Solutions:
| Cause | Solution | Rationale |
| Inefficient Lysis | Ensure complete cell disruption. This may require testing different lysis buffers or mechanical disruption methods (e.g., sonication, douncing), while being mindful of potentially disrupting protein complexes.[11] | Incomplete lysis will result in a lower starting concentration of your protein complex. |
| Disruption of Protein Interactions | Lysis and wash buffers may be too harsh. If yield is low and background is not an issue, consider reducing the stringency of the buffers (e.g., lower salt or detergent concentrations).[14] | Maintaining the integrity of the protein complex is essential for co-purifying interacting partners. |
| Inefficient Elution | Optimize the elution conditions for both affinity steps. For tag-cleavage elution (e.g., with TEV protease), ensure the protease is active and incubation time is sufficient. For competitive elution, ensure the concentration of the competing peptide is adequate. | Incomplete elution leaves the target complex bound to the resin, leading to poor recovery. |
| Poor Expression or Instability of the Bait Protein | Confirm the expression of the full-length tagged protein by Western blot before starting the purification. The affinity tag may interfere with protein folding and stability. | If the bait protein is not expressed or is degraded, the purification will fail. |
| Tag Accessibility Issues | The affinity tag may be buried within the protein structure, preventing its binding to the resin. Consider moving the tag to the other terminus (N- or C-terminus) of the protein.[15] | The tag must be accessible for efficient capture by the affinity matrix. |
Experimental Protocols
Optimized Tandem Affinity Purification (TAP) Protocol
This protocol provides a general framework for a TAP experiment designed to minimize noise. It is based on a common TAP tag system (e.g., Protein A and Calmodulin Binding Peptide).
1. Cell Lysis: a. Harvest cells and wash with ice-cold PBS. b. Resuspend the cell pellet in a pre-chilled, appropriate lysis buffer (e.g., containing 150 mM NaCl, 50 mM Tris-HCl pH 7.5, 0.5% NP-40, and protease/phosphatase inhibitors).[11][12] c. Incubate on ice to facilitate lysis. d. Centrifuge the lysate at high speed (e.g., >15,000 x g) to pellet cell debris. e. Carefully transfer the supernatant to a new pre-chilled tube.
2. First Affinity Purification: a. Equilibrate the first affinity resin (e.g., IgG Sepharose for Protein A tag) with lysis buffer. b. Add the equilibrated resin to the cleared lysate and incubate with gentle rotation at 4°C. c. Pellet the resin by gentle centrifugation and discard the supernatant. d. Wash the resin extensively with increasingly stringent wash buffers. For example:
- Wash 1: Lysis buffer.
- Wash 2: Lysis buffer with 500 mM NaCl.
- Wash 3: Lysis buffer. e. Elute the protein complex. If using a TEV protease cleavage site between the tags, incubate the resin with TEV protease in an appropriate buffer.
3. Second Affinity Purification: a. Add binding buffer and calcium to the eluate from the first step to facilitate binding to the second affinity resin (e.g., Calmodulin resin). b. Add equilibrated Calmodulin resin and incubate with gentle rotation at 4°C. c. Pellet the resin and wash with Calmodulin binding buffer. d. Elute the final, purified protein complex using a calcium-chelating agent like EGTA.
4. Sample Preparation for Mass Spectrometry: a. Concentrate the eluted sample. b. Perform in-solution or in-gel trypsin digestion. c. Analyze the resulting peptides by LC-MS/MS.
Visualizations
Experimental and Logical Workflows
Caption: General workflow for a Sequential Affinity Purification and Analysis (SAPA) experiment.
Caption: Troubleshooting decision tree for addressing high background noise in SAPA experiments.
Caption: Simplified diagram of the core Hippo signaling pathway, a common subject of SAPA studies.[16][17][18]
References
- 1. Tandem Affinity Purification Combined with Mass Spectrometry to Identify Components of Protein Complexes - PMC [pmc.ncbi.nlm.nih.gov]
- 2. researchgate.net [researchgate.net]
- 3. The CRAPome: a contaminant reposit ... | Article | H1 Connect [archive.connect.h1.co]
- 4. Protocol for the purification of Wnt proteins | The WNT Homepage [wnt.stanford.edu]
- 5. Quantitative Tandem Affinity Purification, an Effective Tool to Investigate Protein Complex Composition in Plant Hormone Signaling: Strigolactones in the Spotlight - PMC [pmc.ncbi.nlm.nih.gov]
- 6. The CRAPome: a Contaminant Repository for Affinity Purification Mass Spectrometry Data - PMC [pmc.ncbi.nlm.nih.gov]
- 7. [PDF] The CRAPome: a Contaminant Repository for Affinity Purification Mass Spectrometry Data | Semantic Scholar [semanticscholar.org]
- 8. collaborate.princeton.edu [collaborate.princeton.edu]
- 9. Immunoprecipitation Data Analysis in Biological Research - Creative Proteomics [creative-proteomics.com]
- 10. researchgate.net [researchgate.net]
- 11. Choosing The Right Lysis Buffer | Proteintech Group [ptglab.com]
- 12. Lysis buffer - Wikipedia [en.wikipedia.org]
- 13. Lysis buffer composition dramatically affects extraction of phosphotyrosine-containing proteins - PubMed [pubmed.ncbi.nlm.nih.gov]
- 14. reddit.com [reddit.com]
- 15. Tandem Affinity Purification Combined with Mass Spectrometry to Identify Components of Protein Complexes | Springer Nature Experiments [experiments.springernature.com]
- 16. The Hippo signaling pathway interactome - PubMed [pubmed.ncbi.nlm.nih.gov]
- 17. The Hippo Signaling Pathway Interactome - PMC [pmc.ncbi.nlm.nih.gov]
- 18. researchgate.net [researchgate.net]
SAPA Tool Optimization: Technical Support Center
Welcome to the technical support center for the SAPA (Sequence Analysis and Prediction Application) tool. This resource is designed for researchers, scientists, and drug development professionals to provide guidance on advanced settings, troubleshooting, and frequently asked questions to optimize your protein analysis experiments.
Troubleshooting Guides
This section provides solutions to specific issues you may encounter while using the SAPA tool.
Issue: No significant target regions found
If your search yields no significant results, consider the following troubleshooting steps:
-
Broaden Search Parameters: Your initial search criteria may be too stringent. Try relaxing the parameters for amino acid composition, scaled profiles, and motif definitions.
-
Check Input Sequence Format: Ensure your protein sequences are in a valid FASTA format. Incorrect formatting can lead to input errors.
-
Review Motif Syntax: A common source of error is incorrect syntax in the motif definition. The SAPA tool uses an extended PROSITE pattern syntax. Refer to the PROSITE user manual for detailed syntax rules.[1][2][3][4]
-
Adjust Scoring Threshold: The significance of a find is determined by a scoring threshold. If this threshold is too high, potentially relevant regions may be filtered out. Try lowering the threshold to see if any targets appear.
Issue: Too many non-specific target regions identified
When your search returns a large number of what appear to be non-specific or irrelevant target regions, use these strategies to refine your results:
-
Refine Search Parameters: Make your search criteria more specific. This could involve defining a more conserved motif, narrowing the allowed range for amino acid composition, or selecting a more specific AAINDEX profile.
-
Increase Scoring Threshold: By raising the scoring threshold, you can filter out less significant hits that are more likely to be random occurrences.
-
Utilize Boolean Operators in Motifs: The SAPA tool's extended PROSITE syntax allows for the use of 'AND', 'NOT', and 'OR' operators to create more complex and specific search patterns.[5]
-
Implement a False Discovery Rate (FDR): The SAPA tool can estimate an FDR by using decoy sequences.[5] A lower FDR will result in a more stringent selection of target regions.
Experimental Protocol: Identifying O-glycosylated Peptides
This protocol outlines a general methodology for identifying potentially O-glycosylated sequence regions, as demonstrated in the original SAPA tool publication.[5]
-
Input Data: A set of known O-glycosylated peptide sequences in FASTA format.
-
Parameter Settings:
-
Amino Acid Composition: Define the expected amino acid composition based on the known examples. For instance, you might set a minimum percentage for proline, serine, and threonine.
-
Scaled Profiles: Select an appropriate AAINDEX profile that represents properties of O-glycosylated regions, such as polarity or hydrophilicity.
-
Motif Definition: If a consensus motif for O-glycosylation is known for your organism of interest, define it using the extended PROSITE syntax.
-
-
Execution: Run the SAPA tool with the defined parameters.
-
Analysis of Results:
-
Examine the list of identified target regions, sorted by score.
-
Review the graphical representation of the target regions on the protein sequences.
-
Consider the estimated False Discovery Rate (FDR) to assess the statistical significance of the findings.
-
Parameter Optimization Workflow
Caption: Iterative workflow for optimizing SAPA tool search parameters.
Frequently Asked Questions (FAQs)
General
Q1: What is the SAPA tool?
A1: The SAPA tool is a web application designed to find and analyze functional regions within protein sequences. It does this by combining three search strategies: amino acid composition, scaled profiles of amino acid properties, and sequence motifs.[5]
Q2: What is the "extended PROSITE pattern syntax"?
Input and Output
Q3: What format should my input sequences be in?
A3: Your input protein sequences should be in the standard FASTA format.
Q4: How are the results presented?
A4: The results are summarized in a table that lists the identified target regions, their scores, and other relevant information. The tool also provides a graphical representation showing the location of the target regions within the input protein sequences.[5]
Advanced Settings
Q5: How does the scoring system in the SAPA tool work?
A5: The scoring scheme is detailed in the tool's user manual.[5] Generally, the score for a target sequence is calculated based on the information content of the amino acids that match the composition settings, the scores from the selected AAINDEX scales, and the information content of the defined motifs.
Q6: What are AAINDEX profiles and how do I choose one?
A6: AAINDEX is a database of numerical indices representing various physicochemical and biochemical properties of amino acids. When using the SAPA tool, you can select up to three of these profiles to score or select target sequences. The choice of profile depends on the properties of the functional region you are searching for (e.g., hydrophobicity, polarity, secondary structure propensity).
Q7: How is the False Discovery Rate (FDR) calculated?
A7: The SAPA tool estimates the FDR by generating and scanning a set of decoy sequences alongside your input sequences.[5] The FDR for a given score is calculated based on the number of hits in the decoy sequences versus the number of hits in the real sequences at or above that score.
SAPA Tool Search Logic
Caption: Logical flow of a search query within the SAPA tool.
Data Interpretation
Q8: What does a high score for a target region signify?
A8: A high score indicates that the identified region is a strong match to the combined search parameters you defined (amino acid composition, scaled profiles, and motif). This suggests a higher likelihood that the region is a true positive.
Q9: How should I interpret the False Discovery Rate (FDR)?
A9: The FDR provides a measure of the statistical significance of your results. A low FDR (e.g., <0.05) indicates that a small proportion of the identified target regions are likely to be false positives.
Quantitative Data Summary: Example Output
| Target ID | Protein ID | Start Position | End Position | Score | FDR |
| 1 | P12345 | 112 | 135 | 25.8 | 0.01 |
| 2 | P12345 | 240 | 263 | 22.1 | 0.03 |
| 3 | Q98765 | 56 | 78 | 19.5 | 0.04 |
| 4 | P54321 | 189 | 211 | 15.2 | 0.08 |
References
Validation & Comparative
Navigating the Labyrinth of Alternative Splicing: A Guide to Validating Pathway Analysis Tool Results
For researchers, scientists, and drug development professionals venturing into the intricate world of alternative splicing, bioinformatics tools offer a powerful lens to uncover novel disease mechanisms and therapeutic targets. However, the computational predictions of these tools are just the first step; rigorous experimental validation is paramount to ensure their biological relevance. This guide provides a framework for validating the results of alternative splicing pathway analysis tools, comparing common methodologies and presenting the data in a clear, comparative format.
It is important to note that the "SAPA tool" as a "Splicing-based ASsociated Pathway" analysis tool could not be identified in publicly available literature. The SAPA tool referenced in publications is a tool for finding protein regions based on amino acid composition and other properties.[1][2][3] This guide, therefore, will focus on the general principles and workflows for validating predictions from established alternative splicing analysis and pathway enrichment tools.
The Path from Prediction to Validation: An Overview
The journey from a computationally predicted alternative splicing event impacting a biological pathway to a validated finding involves several key stages. Initially, bioinformatics tools analyze RNA sequencing (RNA-seq) data to identify and quantify alternative splicing events between different experimental conditions. Subsequent pathway analysis can then implicate these events in specific signaling or metabolic pathways. The crucial next step is to experimentally validate these predictions in the laboratory.
A typical workflow for this process is illustrated below. This involves identifying differentially spliced events, performing pathway analysis on the affected genes, and then proceeding with experimental validation of both the splicing event and its functional consequence on the pathway.
Comparing the Tools of the Trade: Alternative Splicing Analysis Platforms
A variety of bioinformatics tools are available to identify and quantify alternative splicing events from RNA-seq data. The choice of tool can influence the outcome of the analysis, and thus it is crucial to understand their underlying algorithms and outputs. Below is a comparison of some widely used tools.
| Tool | Method | Key Features | Output |
| rMATS | Utilizes a statistical model to calculate the p-value and false discovery rate of differential splicing events from junction and exon reads.[4] | Detects all major types of alternative splicing events and provides a statistical framework for differential analysis. | Percent Spliced In (PSI) values, p-values, FDR. |
| SUPPA | Calculates PSI values from transcript isoform abundance.[5][6] It can generate events from a given annotation.[5][7] | Very fast and suitable for large datasets.[6][8] Flexible and can be integrated with various transcript quantification methods.[7] | PSI values for various event types (e.g., exon skipping, intron retention).[7] |
| AS-Quant | Calculates read coverage of potential spliced exons and the corresponding gene to identify and categorize alternative splicing events.[9] | Outperforms some other tools in simulated and real datasets and includes visualization of splicing events.[9] | Categorized alternative splicing events with significance scores. |
| SpliceWiz | Quantifies alternative splicing using junction reads and intronic coverage, with a focus on interactive analysis and visualization.[10] | User-friendly interactive interface and fast processing of BAM files.[10] | Interactive plots and tables of differential splicing analysis. |
Experimental Protocols for Validation
Once a high-confidence prediction is made, the next step is experimental validation. The specific protocols will depend on the nature of the splicing event and the affected pathway.
Validation of the Alternative Splicing Event: Reverse Transcription PCR (RT-PCR)
This is the gold standard for validating predicted alternative splicing events.
-
Objective: To confirm the existence of the predicted splice isoforms and to quantify their relative abundance.
-
Methodology:
-
RNA Isolation: Extract total RNA from the same cell lines or tissues used for the initial RNA-seq experiment.
-
cDNA Synthesis: Synthesize complementary DNA (cDNA) from the extracted RNA using reverse transcriptase.
-
Primer Design: Design PCR primers that flank the alternative splicing event. One forward and one reverse primer should bind to constitutive exons flanking the alternatively spliced region.
-
PCR Amplification: Perform PCR to amplify the cDNA. The different splice isoforms will produce PCR products of different lengths.
-
Gel Electrophoresis: Separate the PCR products on an agarose gel. The presence of bands of the expected sizes confirms the predicted isoforms. The intensity of the bands provides a semi-quantitative measure of their relative abundance.[9]
-
Quantitative PCR (qPCR): For more precise quantification, isoform-specific primers can be designed for use in a quantitative real-time PCR assay.
-
Validation of Protein Isoform Expression
A change in mRNA splicing should ideally lead to a detectable change at the protein level.
-
Objective: To confirm that the alternative splicing event results in the production of distinct protein isoforms.
-
Methodology:
-
Western Blotting: If the alternative splicing event leads to a change in protein size (e.g., due to exon skipping) or affects an epitope for which an antibody is available, Western blotting can be used to detect the different protein isoforms.
-
Mass Spectrometry (MS): For more definitive identification and quantification of protein isoforms, mass spectrometry-based proteomics can be employed. This can identify peptides that are unique to each predicted isoform.[1]
-
Validation of Functional Impact on the Pathway
This is the most critical step to establish the biological significance of the alternative splicing event.
-
Objective: To demonstrate that the change in isoform expression has a measurable effect on the activity of the predicted downstream pathway.
-
Methodology: The specific assay will depend on the pathway .
-
Cell-based Assays:
-
Reporter Assays: If the pathway regulates the expression of a specific gene, a reporter construct (e.g., luciferase) driven by the promoter of that gene can be used to measure pathway activity.
-
Phosphorylation Status: For signaling pathways, the phosphorylation status of key downstream proteins can be assessed by Western blotting using phospho-specific antibodies.
-
Cell Proliferation/Apoptosis Assays: If the pathway is involved in cell growth or death, assays measuring these phenotypes can be performed.
-
-
In Vitro Assays: For metabolic pathways, the activity of key enzymes can be measured in vitro using purified proteins or cell lysates.
-
Visualizing the Logic: From Splicing to Pathway Dysregulation
The logical flow from a splicing event to a change in pathway function can be visualized to clarify the experimental hypothesis. For instance, if a tool predicts that the skipping of an exon in a kinase gene leads to a constitutively active protein, this would be expected to increase the phosphorylation of its downstream targets.
References
- 1. academic.oup.com [academic.oup.com]
- 2. SAPA tool: finding protein regions by combination of amino acid composition, scaled profiles, patterns and rules - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. researchgate.net [researchgate.net]
- 4. A survey of computational methods in transcriptome-wide alternative splicing analysis - PMC [pmc.ncbi.nlm.nih.gov]
- 5. GitHub - comprna/SUPPA: SUPPA: Fast quantification of splicing and differential splicing [github.com]
- 6. biorxiv.org [biorxiv.org]
- 7. researchgate.net [researchgate.net]
- 8. rna-seqblog.com [rna-seqblog.com]
- 9. par.nsf.gov [par.nsf.gov]
- 10. academic.oup.com [academic.oup.com]
comparing SAPA tool with other motif-finding software
A Comparative Guide to de novo DNA Motif Discovery Software For researchers, scientists, and drug development professionals, identifying DNA sequence motifs—short, recurring patterns that are presumed to have a biological function—is a critical step in understanding gene regulation and disease pathways. The discovery of these motifs, often corresponding to transcription factor binding sites, is powered by a variety of computational tools. This guide provides an objective comparison of several widely-used de novo motif discovery software: STREME, MEME, DREME, and HOMER, with a focus on their performance in analyzing ChIP-seq data.
Performance Comparison
The following table summarizes the performance of the selected motif discovery tools based on a comprehensive benchmark study. The metrics include accuracy, sensitivity, thoroughness, and computational speed.
| Software | Primary Strengths | Optimal Use Case | Accuracy (vs. Reference Motifs) | Sensitivity (Motif Detection Rate) | Speed |
| STREME | High accuracy, speed, and versatility; handles large datasets and various motif widths. | General purpose de novo motif discovery from large sequence datasets (e.g., ChIP-seq). | High | High (82.5% in a benchmark study)[1] | Very Fast (Order of magnitude faster than DREME)[1][2] |
| MEME | Highly flexible, can find long motifs, part of the comprehensive MEME Suite. | In-depth analysis of a smaller number of sequences for various motif models. | High | High (Over 70% in a benchmark study)[1] | Slow (Impractical for more than ~10,000 sequences)[3] |
| DREME | Very fast, excels at finding short motifs. | Rapid discovery of short, core motifs from large datasets. | Good | Good | Fast (Suited for ChIP-seq scale data)[3] |
| HOMER | Specialized for differential motif discovery, integrates well with genomics workflows. | Identifying motifs enriched in one set of sequences compared to another (e.g., ChIP-seq peaks vs. background). | Good | Good | Fast |
Experimental Protocols
The performance data presented above is largely based on studies employing a common experimental workflow for benchmarking motif discovery tools using Chromatin Immunoprecipitation followed by sequencing (ChIP-seq) data. A typical protocol is as follows:
-
Dataset Selection : A large collection of ChIP-seq datasets for various transcription factors is used. For instance, a benchmark might use 40 ENCODE Transcription Factor (TF) ChIP-seq datasets.[1]
-
Sequence Preparation : For each ChIP-seq dataset, the sequences corresponding to the top 500 peaks (regions of transcription factor binding) are extracted. These sequences constitute the "primary" dataset.
-
Control Dataset Generation : A "control" dataset is generated by shuffling the primary sequences. This preserves the nucleotide composition while scrambling any existing motifs.
-
Motif Discovery : Each motif discovery tool is run on the primary and control datasets to identify enriched motifs.
-
Validation : The motifs discovered by the tools are compared against a reference database of known motifs for the corresponding transcription factors, often derived from in vitro experiments like SELEX. The similarity between the discovered and reference motifs is quantified to assess accuracy.
-
Performance Metrics :
-
Accuracy : Measured by the similarity score between the best-discovered motif and the known reference motif.
-
Sensitivity : The percentage of datasets in which a tool successfully identifies a motif with a similarity score above a certain threshold.
-
Thoroughness : The ability of a tool to discover multiple distinct motifs in a dataset, which is important for identifying co-binding factors.
-
Speed : The computational runtime of each tool on the same dataset.
-
Visualizing Key Concepts
To better illustrate the context and application of these tools, the following diagrams are provided.
Conclusion
The choice of a motif discovery tool depends on the specific research question and the nature of the dataset. For rapid and accurate analysis of large datasets like those from ChIP-seq, STREME emerges as a top performer, offering a balance of speed, sensitivity, and accuracy. MEME remains a powerful tool for in-depth analysis of smaller datasets where flexibility is key. DREME is an excellent choice for the quick identification of short, core motifs. HOMER is particularly well-suited for comparative genomics, where the goal is to find motifs that are differentially enriched between two sets of sequences. As the field of genomics continues to evolve, these tools provide researchers with the essential capabilities to uncover the regulatory logic encoded in DNA.
References
A Head-to-Head Comparison: SAPA Tool vs. MEME Suite for Protein Analysis
In the dynamic landscape of protein analysis, researchers, scientists, and drug development professionals are constantly seeking robust computational tools to decipher the intricate language of protein sequences. Two prominent platforms, the SAPA tool and the MEME Suite, offer distinct approaches to identifying and characterizing functional protein regions. This guide provides an objective comparison of their capabilities, supported by a breakdown of their methodologies, to aid researchers in selecting the most appropriate tool for their specific needs.
Core Functionalities at a Glance
The fundamental difference between the SAPA tool and the MEME Suite lies in their core philosophies. The MEME Suite is a comprehensive toolkit primarily focused on the discovery and analysis of short, conserved sequence patterns, or motifs.[1][2][3][4][5] In contrast, the SAPA tool adopts a multi-faceted approach, integrating amino acid composition, physicochemical properties, and sequence patterns to identify functional protein regions that may not be defined by a single, highly conserved motif.[6][7][8]
| Feature | SAPA Tool | MEME Suite |
| Primary Function | Identification of protein regions based on a combination of amino acid composition, scaled profiles, and patterns.[6][7] | Discovery, analysis, and searching of sequence motifs.[1][2][5] |
| Input | Protein sequences in FASTA format.[6] | DNA, RNA, or protein sequences in FASTA format.[2][5] |
| Core Algorithms | Combines user-defined rules for amino acid composition, physicochemical property profiles, and regular expression patterns.[6][8] | Primarily utilizes expectation-maximization (MEME) and other probabilistic or discrete models for motif discovery.[2][3] |
| Output | A list of protein regions that match the combined search criteria, with an integrated score and false discovery rate.[8] | A set of discovered motifs, their sequence logos, position-specific probability matrices, and statistical significance.[9] |
| Key Strength | Flexibility in defining complex and less-conserved functional regions.[7] | A comprehensive and widely-used toolkit for rigorous motif-based sequence analysis.[10] |
| Gapped Motifs | Can identify regions with variable spacing between patterns through its rule-based system. | Includes the GLAM2 tool specifically for the discovery of gapped motifs.[1][3] |
Delving into the Methodologies
The power of these tools stems from their distinct algorithmic foundations. Understanding these methodologies is crucial for interpreting their results and applying them effectively.
The SAPA Tool: A Rule-Based, Multi-Property Approach
The SAPA tool operates on a user-driven, combinatorial search strategy. Researchers can define a set of rules based on:
-
Amino Acid Composition: Specifying the desired percentage of certain amino acids or groups of amino acids within a defined sequence window.[6]
-
Scaled Profiles: Utilizing various amino acid scales (e.g., hydrophobicity, polarity) to search for regions with specific physicochemical property profiles.[6]
-
Patterns and Rules: Employing regular expressions to identify specific sequence patterns.[6]
This allows for the identification of functional regions that may be characterized by a combination of these features rather than a single, conserved motif. For instance, it can be used to find regions with a high content of proline and specific flanking patterns, a common feature of certain protein-protein interaction domains.
Experimental Protocol: Identifying O-glycosylated Peptides with the SAPA Tool
A notable application of the SAPA tool was in the identification of putative O-glycosylated sequence regions from the proteome of Mycobacterium tuberculosis.[6] The experimental workflow involved the following steps:
-
Initial Seed Data: A set of 21 known O-glycosylated peptides was used as the starting point.
-
Feature Analysis: The amino acid composition and other properties of these known peptides were analyzed to derive a set of search criteria for the SAPA tool.
-
SAPA Tool Configuration: The tool was configured with rules reflecting the observed properties of the known glycopeptides.
-
Proteome-wide Search: The configured SAPA tool was used to scan the entire proteome of M. tuberculosis H37Rv.
-
Candidate Ranking and Selection: The tool returned a list of putative glycopeptide regions, ranked by a score that reflects how well they match the defined criteria.
-
Experimental Validation: The top-ranking candidates could then be prioritized for experimental validation to confirm their O-glycosylation status.
The MEME Suite: A Probabilistic Motif-Finding Powerhouse
The MEME (Multiple Em for Motif Elicitation) algorithm, the cornerstone of the suite, employs a probabilistic approach to discover motifs in a set of unaligned sequences.[3] It represents motifs as position-specific probability matrices (PSPMs), which capture the likelihood of each amino acid (or nucleotide) appearing at each position within the motif.[2]
The MEME Suite encompasses a collection of specialized tools that work in concert:[2][5]
-
MEME: Discovers ungapped motifs.[3]
-
STREME: A faster alternative for finding short, ungapped motifs.[2]
-
GLAM2: Identifies gapped motifs.[1]
-
Tomtom: Compares discovered motifs against a database of known motifs.[9]
-
FIMO & MAST: Scan sequence databases for occurrences of a given motif.[1]
-
GOMO: Identifies potential biological roles of DNA-binding motifs by associating them with Gene Ontology (GO) terms.[9]
Experimental Protocol: De Novo Motif Discovery with the MEME Suite
A typical workflow for discovering novel protein motifs using the MEME Suite involves the following steps:
-
Input Sequence Preparation: A set of related protein sequences, often obtained from experiments like co-immunoprecipitation or identified as having a shared function, is compiled in FASTA format.
-
Motif Discovery with MEME: The sequences are submitted to the MEME tool. The user can specify parameters such as the expected number of motifs and their potential widths. MEME then identifies statistically overrepresented, ungapped patterns.
-
Motif Visualization and Analysis: MEME outputs the discovered motifs as sequence logos and PSPMs, along with their statistical significance (E-value).
-
Motif Comparison with Tomtom: The discovered motifs can be compared against databases of known motifs using Tomtom to identify potential similarities to characterized functional patterns.
-
Database Searching with FIMO/MAST: The identified motifs can be used to search for additional occurrences in larger protein sequence databases using FIMO or MAST.
Head-to-Head Performance Comparison
Due to the absence of direct comparative studies in the literature, a quantitative performance comparison is not feasible. However, a qualitative assessment based on their intended applications and underlying methodologies can guide the user's choice.
| Aspect | SAPA Tool | MEME Suite |
| Discovery of Novel, Conserved Motifs | Less suited for de novo discovery of highly conserved, short motifs. | Superior. This is the core strength of the MEME algorithm and the suite's primary purpose. |
| Identification of Functionally Related but Sequence-Diverse Regions | Superior. Its ability to combine compositional and physicochemical properties makes it ideal for this task. | May fail to identify regions that lack a clear, conserved sequence pattern. |
| User-Friendliness | The web interface is relatively straightforward for defining search rules.[6] | The comprehensive suite has a steeper learning curve, but the web server provides a user-friendly interface for individual tools.[9] |
| Computational Resources | As a web application, it does not require local computational resources.[7] | Can be run on a public web server or installed locally for more intensive analyses.[3] |
| Post-Discovery Analysis | Provides a ranked list of targets for further investigation.[8] | Offers a rich set of tools for motif comparison, database searching, and functional annotation.[2][5] |
Conclusion: Choosing the Right Tool for the Job
The choice between the SAPA tool and the MEME Suite is not a matter of one being definitively better than the other, but rather which is more appropriate for the research question at hand.
-
Choose the MEME Suite when: Your primary goal is to discover and analyze short, conserved sequence motifs within a set of related proteins. It is the gold standard for de novo motif discovery and provides a wealth of tools for downstream analysis.
-
Choose the SAPA Tool when: You are searching for functional protein regions that are not necessarily defined by a single, highly conserved motif. Its strength lies in its ability to identify regions based on a combination of amino acid composition, physicochemical properties, and degenerate patterns. This makes it particularly useful for exploring less-characterized protein families or functional sites with higher sequence variability.
Ultimately, for a comprehensive protein analysis strategy, these tools can be viewed as complementary. A researcher might use the MEME Suite to identify core conserved motifs and then employ the SAPA tool to explore the broader sequence context and identify related but more divergent functional regions. By understanding their respective strengths and methodologies, researchers can leverage both platforms to unlock deeper insights into the complex world of protein function.
References
- 1. academic.oup.com [academic.oup.com]
- 2. Introduction - MEME Suite [meme-suite.org]
- 3. MEME suite - Wikipedia [en.wikipedia.org]
- 4. Overview - MEME Suite [web.mit.edu]
- 5. Overview - MEME Suite [meme-suite.org]
- 6. academic.oup.com [academic.oup.com]
- 7. SAPA tool: finding protein regions by combination of amino acid composition, scaled profiles, patterns and rules - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. researchgate.net [researchgate.net]
- 9. MEME SUITE: tools for motif discovery and searching - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. The MEME Suite: Motif-Based Sequence Analysis Tools - Available technology for licensing from the University of California, San Diego [techtransfer.universityofcalifornia.edu]
Principle of SAH-Based Methyltransferase Assays
A Comprehensive Guide to S-Adenosyl-L-Homocysteine (SAH)-Based Methyltransferase Assays: Accuracy, Limitations, and Alternatives
For researchers, scientists, and drug development professionals engaged in the study of methyltransferases (MTases), the selection of an appropriate assay system is paramount. Methyltransferases, which catalyze the transfer of a methyl group from S-adenosyl-L-methionine (SAM) to a substrate, are a critical class of enzymes implicated in numerous cellular processes and disease states, making them attractive therapeutic targets.[1] Assays designed to measure their activity are fundamental for basic research and for high-throughput screening (HTS) of potential inhibitors.[2][3]
A prevalent and versatile method for quantifying MTase activity is the detection of the universal reaction by-product, S-adenosyl-L-homocysteine (SAH).[1] This guide provides a detailed comparison of the accuracy and limitations of various SAH-based assays, often referred to generically as SAPA (S-adenosyl-L-homocysteine-based protein assay) tools, and contrasts them with alternative methods.
The core principle of SAH-based assays is the quantification of MTase activity by measuring the amount of SAH produced, which is directly proportional to the enzyme's activity. These assays are considered "universal" because SAH is a common product of all SAM-dependent methyltransferases, regardless of the substrate being methylated (e.g., protein, DNA, RNA, or small molecules).[1][4][5] This universality is a significant advantage, as it allows for the use of a single detection platform for a wide variety of MTases.[1]
The detection of SAH can be achieved through several approaches, broadly categorized as direct and coupled-enzyme assays.
-
Coupled-Enzyme Assays: These are the most common methods and involve a series of enzymatic reactions that convert SAH into a readily detectable molecule, which can be measured using absorbance, fluorescence, or luminescence.[6]
-
Direct Detection Assays: These methods utilize molecules that can directly and selectively bind to SAH, such as specific antibodies or RNA aptamers (riboswitches), to generate a signal.[1][6]
Workflow of a Homogeneous SAH-Based Assay
The following diagram illustrates the general workflow for a typical homogeneous, two-step SAH-based methyltransferase assay, such as the AptaFluor™ assay.
Quantitative Comparison of Methyltransferase Assays
The choice of an MTase assay often depends on the specific application, such as the scale of the experiment (low-throughput kinetic studies vs. high-throughput screening), the nature of the enzyme and substrate, and budget constraints. Below is a comparison of common SAH-based assays and their alternatives.
| Assay Type | Principle | Limit of Detection (LOD) / Sensitivity | Dynamic Range | Throughput | Advantages | Limitations |
| SAH-Based Assays | ||||||
| Luminescence (e.g., MTase-Glo™) | Coupled-enzyme reaction converts SAH to ATP, which drives a luciferase reaction.[5][7] | 20–30 nM of SAH[8] | ~3-4 logs | High (compatible with 1536-well format)[2][9] | High sensitivity, low background, robust (Z' > 0.7), less interference from fluorescent compounds.[5][9] | Multi-step enzymatic cascade can be prone to interference from compounds in screening libraries.[2] |
| TR-FRET (e.g., AptaFluor™) | SAH binding to a split RNA aptamer (riboswitch) induces a conformational change, leading to a TR-FRET signal.[1][6] | < 10 nM of SAH[6] | ~2-3 logs | High | Very high sensitivity, direct SAH detection, robust (Z' > 0.7), stable signal.[6][10] | Can be more expensive than other methods. |
| Fluorescence Polarization (FP) (e.g., Transcreener® EPIGEN) | Coupled-enzyme reaction converts SAH to AMP, which is detected in a competitive FP immunoassay.[4] | Nanomolar sensitivity for AMP.[11] | ~2 logs | High | Homogeneous format, robust (Z' > 0.7), stable signal.[4] | Indirect detection, potential for interference with coupling enzymes. |
| Colorimetric | Coupled-enzyme cascade generates a colored product. | L.O.Q: 296 µU/ml[12] | ~2 logs | Medium | Inexpensive, uses standard lab equipment (spectrophotometer). | Lower sensitivity compared to fluorescence or luminescence-based assays. |
| Alternative Assays | ||||||
| Radiometric (Filter-Binding) | Measures the transfer of a radiolabeled methyl group ([³H]-SAM) to a substrate.[13][14] | High (can detect low levels of methylation).[15] | Wide | Low to Medium | "Gold standard", direct measurement of methylation, no substrate modification needed.[13][16] | Use of radioactive materials, low throughput, higher cost, multi-step protocol.[17][18] |
| Antibody-Based (ELISA, AlphaLISA) | Uses an antibody specific to the methylated substrate to generate a signal.[17][18] | High | Varies | Medium to High | High specificity for the methylated product. | Antibody availability and specificity can be a limitation, often expensive, can be low-throughput (ELISA).[18] |
| Mass Spectrometry (MS) | Directly measures the mass change of the substrate upon methylation. | Very High | Wide | Low to Medium | Highly sensitive and specific, provides direct evidence of methylation. | Low throughput, requires expensive specialized equipment, labor-intensive.[18] |
Accuracy and Limitations of SAH-Based Assays
While SAH-based assays offer many advantages, particularly for HTS, it is crucial to be aware of their potential limitations to ensure data accuracy.
Accuracy and Sensitivity
Modern commercial SAH-based assays, such as luminescence and TR-FRET formats, are highly sensitive and can detect SAH in the low nanomolar range.[6][8] This is a critical feature, as many MTases are slow enzymes with low Kₘ values for SAM, often in the sub-micromolar range.[6] High sensitivity allows for the use of physiologically relevant SAM concentrations and reduces the amount of enzyme needed per reaction, which can be a significant cost-saving factor. The robustness of these assays is often demonstrated by Z' factors greater than 0.7, indicating a large signal window and high reproducibility, which is essential for HTS.[2][6][9]
Limitations and Sources of Error
A primary limitation of coupled-enzyme SAH assays is the potential for interference from compounds in screening libraries. These compounds can inhibit one of the coupling enzymes rather than the target MTase, leading to false-positive results.[2] For instance, in a study comparing a fluorescence-based SAH assay with the luminescence-based MTase-Glo™, the MTase-Glo™ assay produced a lower false-positive rate.[2][3]
To mitigate this, it is standard practice to perform counter-screens. A common approach is to run the assay in the absence of the MTase but with the addition of SAH. Compounds that still show a signal change in this setup are likely interfering with the detection system and can be eliminated.[7]
Another consideration is the purity of the SAM cofactor, as commercial preparations can contain contaminating SAH, leading to high background signals.[8]
The following diagram illustrates the logical relationship between potential inhibitor effects in a coupled-enzyme assay.
Experimental Protocols
General Protocol for a Luminescence-Based Coupled-Enzyme Assay (e.g., MTase-Glo™)
This protocol is a generalized representation based on commercially available kits.[9][19]
Materials:
-
MTase-Glo™ Reagent and Detection Solution
-
Purified methyltransferase enzyme
-
Substrate (e.g., peptide, protein, or DNA)
-
SAM cofactor
-
Assay buffer (e.g., 80mM Tris pH 8.0, 200mM NaCl, 4mM EDTA, 12mM MgCl₂, 0.4mg/ml BSA, 4mM DTT)[9]
-
White, opaque 384-well plates
-
Luminometer
Procedure:
-
Prepare MTase Reaction: In a 384-well plate, set up the methyltransferase reaction in a small volume (e.g., 5 µL). This includes the assay buffer, the MTase enzyme, the substrate, and the compound to be tested (or DMSO for control).
-
Initiate Reaction: Start the reaction by adding SAM.
-
Incubate: Incubate the plate at the optimal temperature for the enzyme (e.g., 37°C) for a predetermined time (e.g., 90 minutes).[19]
-
Stop Reaction & Detect SAH:
-
Add an equal volume (5 µL) of MTase-Glo™ Reagent to each well. This reagent stops the MTase reaction and converts SAH to ADP.
-
Incubate at room temperature for 30 minutes.[8]
-
-
Generate Luminescent Signal:
-
Add an equal volume (10 µL) of MTase-Glo™ Detection Solution to each well. This solution converts ADP to ATP and contains luciferase/luciferin to generate light.
-
Incubate at room temperature for 30 minutes.[8]
-
-
Measure Luminescence: Read the plate on a luminometer. The light output is proportional to the amount of SAH produced.
General Protocol for a Radiometric Filter-Binding Assay
This protocol is based on standard methods for radiometric MTase assays.[13][14][15]
Materials:
-
Purified methyltransferase enzyme
-
Substrate (e.g., histone protein)
-
[³H]-labeled SAM (tritiated SAM)
-
Assay buffer (e.g., 50 mM Tris-HCl pH 7.8, 50 mM KCl, 5 mM MgCl₂)[14]
-
Filter paper (e.g., phosphocellulose)
-
Trichloroacetic acid (TCA)
-
Scintillation fluid
-
Scintillation counter
Procedure:
-
Set up MTase Reaction: In a microcentrifuge tube, combine the assay buffer, MTase enzyme, substrate, and any test compounds.
-
Initiate Reaction: Start the reaction by adding [³H]-SAM.
-
Incubate: Incubate at the optimal temperature (e.g., 37°C) for the desired time (e.g., 1 hour).[14]
-
Stop Reaction and Spot: Stop the reaction by spotting the reaction mixture onto a sheet of filter paper.
-
Wash Filter Paper: Wash the filter paper multiple times (e.g., with 10% TCA) to remove unincorporated [³H]-SAM.[14] The methylated substrate, being a larger molecule, will remain bound to the filter paper.
-
Dry Filter Paper: Allow the filter paper to dry completely.
-
Measure Radioactivity: Place the filter paper spots into vials with scintillation fluid and measure the incorporated radioactivity using a scintillation counter. The counts per minute (CPM) are proportional to the MTase activity.
Conclusion
SAH-based assays represent a powerful, versatile, and high-throughput-compatible platform for measuring the activity of methyltransferases. Modern iterations using luminescence and TR-FRET detection offer excellent sensitivity and robustness, making them well-suited for drug discovery screening campaigns.[2][6] However, like all methods, they have limitations, primarily the potential for interference in coupled-enzyme systems.
The traditional radiometric assay remains a valuable "gold standard" for its directness and reliability, especially in smaller-scale studies and for orthogonal validation of hits from HTS campaigns.[13][16] The choice of assay should be guided by a thorough understanding of the experimental goals, the specific MTase system under investigation, and the strengths and weaknesses of each method. By carefully selecting the assay and incorporating appropriate controls and counter-screens, researchers can generate accurate and reliable data to advance our understanding of methyltransferase biology and accelerate the development of novel therapeutics.
References
- 1. bellbrooklabs.com [bellbrooklabs.com]
- 2. Optimization of High-Throughput Methyltransferase Assays for the Discovery of Small Molecule Inhibitors - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Optimization of High-Throughput Methyltransferase Assays for the Discovery of Small Molecule Inhibitors - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. bellbrooklabs.com [bellbrooklabs.com]
- 5. MTase-Glo™ Methyltransferase Assay [promega.com]
- 6. Development and validation of a generic methyltransferase enzymatic assay based on an SAH riboswitch - PMC [pmc.ncbi.nlm.nih.gov]
- 7. biorxiv.org [biorxiv.org]
- 8. 2024.sci-hub.se [2024.sci-hub.se]
- 9. promega.com [promega.com]
- 10. bellbrooklabs.com [bellbrooklabs.com]
- 11. Development and validation of a generic fluorescent methyltransferase activity assay based on the Transcreener® AMP/GMP Assay - PMC [pmc.ncbi.nlm.nih.gov]
- 12. abcam.com [abcam.com]
- 13. reactionbiology.com [reactionbiology.com]
- 14. pubcompare.ai [pubcompare.ai]
- 15. researchgate.net [researchgate.net]
- 16. Assay Development for Histone Methyltransferases - PMC [pmc.ncbi.nlm.nih.gov]
- 17. DNA Methyltransferase Activity Assays: Advances and Challenges - PMC [pmc.ncbi.nlm.nih.gov]
- 18. A novel screening strategy to identify histone methyltransferase inhibitors reveals a crosstalk between DOT1L and CARM1 - PMC [pmc.ncbi.nlm.nih.gov]
- 19. High throughput bioluminescent assay to characterize and monitor the activity of SARS-CoV-2 methyltransferases | PLOS One [journals.plos.org]
Benchmarking the SAPA Tool: A Comparative Guide for Protein Functional Region Identification
In the landscape of bioinformatics, a vast array of tools is available for the identification of functional regions within protein sequences. Among these is the SAPA tool, a web application designed to identify protein regions through a unique combination of amino acid composition, scaled profiles, patterns, and rules.[1][2] This guide provides a comparative overview of the SAPA tool against other established bioinformatics resources, offering a framework for researchers, scientists, and drug development professionals to select the most appropriate tool for their specific needs. Due to a lack of published direct benchmarking studies involving the SAPA tool, this guide presents a hypothetical comparative experiment to illustrate its potential performance against alternatives.
Introduction to the SAPA Tool
The SAPA tool distinguishes itself by allowing users to search for protein regions using a combination of properties rather than relying on a single method like sequence homology or motif matching alone.[1][2][3] This multi-faceted approach can be particularly advantageous when searching for functional regions that are not well-defined by a consensus sequence but rather by a collection of broader characteristics.[1][2] The tool ranks the identified regions using an integrated score and can estimate false discovery rates, providing a measure of confidence in the results.[2][3]
Alternative Tools for Protein Analysis
For a comprehensive evaluation, the SAPA tool is benchmarked against three widely-used bioinformatics tools that offer related functionalities:
-
MEME Suite : A powerful collection of tools for discovering and analyzing sequence motifs in DNA and protein sequences.[4][5][6][7] It excels at identifying conserved, ungapped or gapped motifs within a set of unaligned sequences.[4][6]
-
HMMER : Utilizes profile hidden Markov models (profile HMMs) to perform sensitive database searches for homologous protein sequences.[8][9] It is highly effective at detecting distant evolutionary relationships based on sequence similarity.[8]
-
InterProScan : A tool that scans protein sequences against the InterPro database, which integrates signatures from multiple member databases to classify proteins into families and predict the presence of important domains and sites.[10][11][12]
Hypothetical Benchmarking Experiment
To objectively compare the performance of these tools, a hypothetical experiment was designed to identify a set of known, functionally related protein regions that are characterized by a combination of a loose sequence motif and a distinct amino acid composition.
Experimental Protocol
-
Dataset Preparation : A dataset of 100 protein sequences known to contain a specific functional domain (e.g., a kinase catalytic domain) was compiled from the UniProt database.[13] A negative control set of 1000 protein sequences lacking this domain was also prepared.
-
Tool Configuration :
-
SAPA : Configured to search for regions with a high content of specific amino acids (e.g., glycine, serine, and threonine), a defined hydrophobicity profile, and a degenerate sequence pattern representing the core functional site.
-
MEME : Used to discover motifs in the positive dataset. The discovered motif was then used with FIMO (Find Individual Motif Occurrences) to scan both the positive and negative datasets.
-
HMMER : A profile HMM was built from a multiple sequence alignment of the known functional domains. hmmsearch was then used to search this profile against the combined dataset.[14]
-
InterProScan : The entire dataset was scanned against the InterPro database to identify the target domain.[15]
-
-
Performance Metrics : The performance of each tool was evaluated based on the following metrics:
-
Sensitivity : The proportion of true positive regions correctly identified.
-
Specificity : The proportion of true negative sequences correctly identified as not containing the region.
-
Precision : The proportion of identified regions that are true positives.
-
F1-Score : The harmonic mean of precision and sensitivity.
-
Processing Time : The computational time required to complete the analysis.
-
Experimental Workflow Diagram
Caption: Hypothetical workflow for benchmarking SAPA against other bioinformatics tools.
Comparative Performance Data
The following table summarizes the hypothetical quantitative results from the benchmarking experiment.
| Tool | Sensitivity | Specificity | Precision | F1-Score | Processing Time (minutes) |
| SAPA Tool | 0.88 | 0.95 | 0.92 | 0.90 | 15 |
| MEME Suite | 0.92 | 0.98 | 0.96 | 0.94 | 30 |
| HMMER | 0.95 | 0.99 | 0.98 | 0.96 | 10 |
| InterProScan | 0.98 | 0.99 | 0.99 | 0.98 | 60 |
Discussion of Hypothetical Results
Based on the hypothetical data, InterProScan demonstrates the highest accuracy, which is expected as it leverages curated databases of protein signatures.[11] HMMER also performs exceptionally well, showcasing the power of profile HMMs for detecting homologous domains.[9] The MEME Suite shows strong performance in identifying the conserved motif.[4]
The SAPA tool, in this hypothetical scenario, exhibits slightly lower, yet still robust, sensitivity and precision. Its key advantage would lie in its unique ability to identify regions based on a combination of features that may not be captured by strict motif or homology searches. This makes it a valuable tool for exploring less conserved functional regions or for cases where only a few examples of a functional region are known.[1][2] The processing time for SAPA is competitive, making it a viable option for initial exploratory analyses.
Conclusion
While established tools like InterProScan and HMMER provide high accuracy for well-characterized domains, the SAPA tool offers a unique and flexible approach for identifying protein regions based on a combination of sequence and compositional properties.[1][2][3] This makes it a potentially powerful tool for researchers investigating novel protein functions or for identifying functional regions that are not defined by strong sequence conservation. The choice of tool will ultimately depend on the specific research question and the nature of the protein sequences being analyzed. For well-defined domain identification, InterProScan and HMMER are excellent choices. For discovering novel or less-conserved functional regions, the SAPA tool presents a compelling alternative.
References
- 1. SAPA tool: finding protein regions by combination of amino acid composition, scaled profiles, patterns and rules - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. researchgate.net [researchgate.net]
- 3. academic.oup.com [academic.oup.com]
- 4. academic.oup.com [academic.oup.com]
- 5. Introduction - MEME Suite [meme-suite.org]
- 6. MEME SUITE: tools for motif discovery and searching - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. Overview - MEME Suite [web.mit.edu]
- 8. HMMER [hmmer.org]
- 9. HMMER - Wikipedia [en.wikipedia.org]
- 10. academic.oup.com [academic.oup.com]
- 11. InterPro and InterProScan: tools for protein sequence classification and comparison - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. InterProScan 5: genome-scale protein function classification - PubMed [pubmed.ncbi.nlm.nih.gov]
- 13. uniprot.org [uniprot.org]
- 14. HMMER Manual | i5k - App [i5k.nal.usda.gov]
- 15. InterPro [ebi.ac.uk]
Cross-Validation of the SAPA Tool: A Comparative Guide for Researchers
For researchers, scientists, and drug development professionals, the rigorous assessment of personality and cognitive traits is paramount. The Synthetic Aperture Personality Assessment (SAPA) tool presents a novel, web-based methodology for collecting vast amounts of data on individual differences. This guide provides a comprehensive comparison of the SAPA tool's findings with established personality inventories, supported by psychometric data and detailed experimental protocols.
The SAPA tool is a unique data collection method that utilizes a large pool of public-domain items and a planned missing data design. This allows for the efficient assessment of a wide range of personality and cognitive constructs from a large and diverse sample of online participants. The resulting SAPA Personality Inventory (SPI) provides scores on the well-established "Big Five" personality domains as well as 27 more specific lower-order factors.
Comparative Analysis of Psychometric Properties
One crucial indicator of validity is the agreement between self-reports and reports from knowledgeable informants. A study on the SAPA tool found that the self-informant agreement for the Big Five domains ranged from .63 to .72, indicating a strong level of convergent validity.
For internal consistency, a measure of how well the items on a scale measure the same underlying construct, the SPI demonstrates robust reliability. The table below summarizes the internal consistency (Cronbach's alpha) for the Big Five domains of the SPI, based on the development sample.
| Big Five Domain | Cronbach's Alpha (α) |
| Agreeableness | .86 |
| Conscientiousness | .89 |
| Extraversion | .88 |
| Neuroticism | .90 |
| Openness | .84 |
These reliability coefficients are comparable to those of well-established personality inventories, suggesting that the SPI provides a reliable measure of the Big Five personality traits.
Experimental Protocols
SAPA Data Collection Protocol
The SAPA project employs a unique and efficient online data collection methodology. Understanding this protocol is crucial for interpreting the findings.
-
Participant Recruitment : Participants are typically volunteers who access the assessment through the SAPA project website. This results in a large and diverse, though not necessarily representative, sample.
-
Item Administration : Each participant is administered a random subset of items from a very large item pool (over 6,000 items). This "synthetic aperture" approach allows for the collection of data on a vast number of items without overburdening any single participant.
-
Planned Missing Data Design : The random administration of item subsets creates a dataset with a large amount of planned missing data. This is a deliberate feature of the design.
-
Data Analysis : Sophisticated statistical techniques, such as those based on item response theory (IRT), are used to analyze the incomplete data and estimate the underlying personality and cognitive traits of the participants. This allows for the calculation of scores on the various SPI scales even though no single individual answers all the items for any given scale.
-
Feedback : Participants receive personalized feedback on their personality profile, which includes their scores on the Big Five and the 27 lower-order factors.
Concurrent Validity Study Protocol (Hypothetical)
To provide a direct comparison with an established tool like the NEO PI-R, a concurrent validity study would be necessary. The following protocol outlines the typical methodology for such a study.
-
Participant Sample : A sufficiently large and diverse sample of participants would be recruited.
-
Test Administration : Each participant would complete both the SAPA Personality Inventory (a version with a fixed set of items for all participants) and the NEO PI-R. The order of administration would be counterbalanced to control for order effects.
-
Data Analysis : The scores on the corresponding scales of the SPI and the NEO PI-R would be correlated. For example, the Agreeableness scale of the SPI would be correlated with the Agreeableness domain score of the NEO PI-R.
-
Statistical Analysis : Pearson correlation coefficients (r) would be calculated to determine the strength and direction of the relationships between the scales of the two instruments.
Visualizing the SAPA Methodology and Personality Structure
To further clarify the processes and models discussed, the following diagrams, generated using the DOT language, illustrate the SAPA workflow and the hierarchical structure of the SAPA Personality Inventory.
Choosing the Right Tool for the Job: A Comparative Guide to SAPA and BLAST for Protein Sequence Analysis
In the realm of bioinformatics and drug development, the analysis of protein sequences is a fundamental task. Researchers often need to understand a protein's function, identify related proteins, or pinpoint specific regions of interest. Two powerful tools available for these tasks are the SAPA tool and the Basic Local Alignment Search Tool (BLAST). While both operate on protein sequences, they are designed for fundamentally different purposes and are not direct competitors. This guide provides a comparative analysis of the SAPA tool and BLAST, helping researchers, scientists, and drug development professionals to choose the appropriate tool for their specific research needs.
Core Functionality: Finding What You're Looking For
At its core, the distinction between the SAPA tool and BLAST lies in the nature of the questions they help answer.
BLAST is a sequence similarity search tool.[1][2][3] Its primary function is to find regions of local similarity between a query sequence and a database of sequences.[2][4][5] This is invaluable for identifying homologous sequences, which can provide clues about the function and evolutionary relationships of a newly discovered protein.[1] In essence, BLAST answers the question: "Are there any sequences in this database that look like my protein?"
The SAPA tool , on the other hand, is designed to identify protein regions that share a combination of specific features, which may not be captured by simple sequence similarity.[6][7][8] These features can include amino acid composition, physicochemical properties (scaled profiles), and the presence of specific sequence patterns or motifs.[6][7] The SAPA tool is particularly useful for finding functional regions that are not defined by a conserved linear sequence but rather by a collection of properties. It answers the question: "Are there any proteins in this set that have regions with a similar combination of features to a known functional region?"
Algorithmic Approach: A Tale of Two Strategies
The different functionalities of BLAST and the SAPA tool stem from their distinct algorithmic underpinnings.
BLAST employs a heuristic algorithm to find "local alignments". It breaks down the query sequence into small "words" and searches for matches in a sequence database.[4][5] These initial matches, or "seeds," are then extended in both directions to create a high-scoring segment pair (HSP).[2][4] This approach allows BLAST to rapidly search vast databases and identify regions of similarity, even if the overall sequences are quite different.
The SAPA tool utilizes a multi-faceted approach. It allows users to define a set of criteria to search for specific protein regions. These criteria can include:
-
Amino Acid Composition: Specifying the required percentage of certain amino acids or groups of amino acids.[8]
-
Scaled Profiles: Using profiles of amino acid properties (e.g., hydrophobicity, charge) to find regions with similar physicochemical characteristics.[8]
-
Sequence Patterns and Motifs: Searching for the presence of specific short sequence motifs that may be randomly distributed within the region of interest.[6][7]
The tool then scores protein regions based on how well they match the combined user-defined properties and can estimate a false discovery rate to assess the significance of the findings.[8]
A Head-to-Head Comparison
For a clear overview, the following table summarizes the key differences between the SAPA tool and BLAST.
| Feature | SAPA tool | BLAST (Basic Local Alignment Search Tool) |
| Primary Function | Identification of protein regions based on a combination of features (amino acid composition, profiles, motifs).[6][7][8] | Sequence similarity searching to find homologous sequences.[1][2][3] |
| Core Question | "Does this protein have a region with a specific set of combined properties?" | "Are there sequences in the database that are similar to my query sequence?" |
| Algorithmic Basis | Combined search based on user-defined parameters for amino acid composition, scaled profiles, and patterns.[8] | Heuristic local alignment based on a word-match and extension strategy.[4][5] |
| Input | A set of protein sequences and user-defined search criteria. | A query sequence (protein or nucleotide) and a target sequence database.[2] |
| Output | A ranked list of protein regions that match the defined criteria, with scores and false discovery rates.[8] | A list of sequences from the database with significant local alignments to the query, including alignment scores and statistical significance (E-values).[4] |
| Typical Use Case | Identifying proteins with specific functional domains that are not defined by a simple consensus sequence (e.g., regions prone to certain post-translational modifications). | Inferring the function of a newly sequenced protein by finding its homologs, identifying members of a protein family.[1] |
Experimental Protocols and Use Cases in Drug Development
To illustrate the practical applications of each tool, we present two hypothetical experimental workflows relevant to drug development.
Experimental Workflow 1: Target Identification using BLAST
Objective: To identify potential drug targets in a pathogenic organism by finding homologs of a known drug target in a related, well-characterized organism.
Methodology:
-
Obtain the sequence: Start with the amino acid sequence of a known drug target protein from a well-studied organism (e.g., a human enzyme).
-
Perform a BLASTp search: Use the protein sequence as a query in a BLASTp (protein-protein BLAST) search against the proteome of the pathogenic organism.
-
Analyze the results: Examine the BLAST output for sequences with high similarity scores and low E-values. These represent potential homologs of the drug target in the pathogen.
-
Further characterization: The identified homologous proteins can then be further investigated as potential drug targets for the pathogen.
Experimental Workflow 2: Identifying Novel Glycosylated Proteins using the SAPA tool
Objective: To identify novel proteins in a bacterial proteome that are likely to be O-glycosylated, a post-translational modification that can be important for virulence but is not defined by a simple consensus sequence.
Methodology:
-
Define search parameters: Based on a set of known O-glycosylated proteins, define the search criteria in the SAPA tool. This could include an overrepresentation of serine and threonine residues, a specific amino acid composition in the flanking regions of glycosylation sites, and the absence of transmembrane domains.
-
Run the SAPA tool: Input the entire proteome of the bacterium of interest into the SAPA tool along with the defined search parameters.
-
Analyze the output: The SAPA tool will provide a list of protein regions that match the defined criteria, ranked by a score.
-
Experimental validation: The top-ranking candidate proteins can then be experimentally tested for O-glycosylation to validate the in silico prediction.
Conclusion: Complementary Tools for Comprehensive Analysis
References
- 1. researchgate.net [researchgate.net]
- 2. SAPS/SSPA 20110801 – Statistical Analysis of Protein Sequences & Significant Segment Pair Alignment – My Biosoftware – Bioinformatics Softwares Blog [mybiosoftware.com]
- 3. pubs.acs.org [pubs.acs.org]
- 4. academic.oup.com [academic.oup.com]
- 5. SAPA tool: finding protein regions by combination of amino acid composition, scaled profiles, patterns and rules - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. List of sequence alignment software - Wikipedia [en.wikipedia.org]
- 7. cs.brown.edu [cs.brown.edu]
- 8. groups.molbiosci.northwestern.edu [groups.molbiosci.northwestern.edu]
Unveiling a Deeper Specificity: The SAPA Tool for Non-Consensus Sequence Pattern Analysis
For researchers, scientists, and drug development professionals navigating the complexities of protein analysis, the identification of functional sequence patterns is paramount. While many tools excel at recognizing well-defined, consensus motifs, a significant challenge lies in identifying functional regions characterized by more subtle, non-consensus patterns. The Statistical Algorithm for Pattern Analysis (SAPA) tool emerges as a powerful solution, offering a unique, multi-faceted approach to uncover these elusive protein features. This guide provides a comprehensive comparison of SAPA with alternative tools, supported by experimental insights, to aid researchers in selecting the optimal approach for their specific needs.
The SAPA tool distinguishes itself by its ability to integrate three key search strategies to identify protein regions of interest: amino acid composition, scaled profiles of amino acid properties, and sequence patterns. This combined methodology allows for a more flexible and nuanced analysis, which is particularly advantageous when dealing with functional modules that are not defined by a strict linear consensus sequence.[1][2]
At a Glance: SAPA vs. The Alternatives
| Feature | SAPA Tool | GLAM2 (Gapped Local Alignment of Motifs) | TEIRESIAS (Combinatorial Pattern Discovery) |
| Primary Function | Identifies protein regions based on a combination of amino acid composition, scaled profiles, and sequence patterns. | Discovers gapped motifs (patterns with insertions and deletions) in protein and DNA sequences.[3] | Discovers rigid and degenerate patterns (motifs) in biological sequences using a combinatorial approach.[4] |
| Handling of Non-Consensus Patterns | Explicitly designed for non-consensus patterns by not relying solely on linear motifs. | Excellent for patterns with variable spacing (gaps), a hallmark of many non-consensus motifs. | Can identify degenerate patterns where specific positions can be occupied by a group of amino acids. |
| Key Advantage | Flexible combination of three distinct search strategies in a single, integrated platform.[1] | Robust detection of motifs with insertions and deletions. | Exhaustive discovery of all patterns that meet user-defined criteria. |
| Typical Use Case | Identifying functional regions with subtle sequence features when only a few examples are known. | Finding variable-length motifs, such as those in intrinsically disordered proteins or protein-protein interaction sites. | Discovering novel, complex patterns in a set of related protein sequences. |
Delving Deeper: A Comparative Analysis
The SAPA tool's core strength lies in its holistic approach. For instance, a researcher investigating a novel protein family with limited characterized members can leverage SAPA to search for regions that share a similar, yet not identical, amino acid composition (e.g., a high prevalence of hydrophobic residues) and a specific physicochemical profile (e.g., a propensity for alpha-helical structures), in addition to any loosely defined sequence patterns. This multifaceted search is a significant advantage over tools that rely on a single principle for pattern discovery.
GLAM2 , from the widely-used MEME suite, offers a powerful alternative for identifying "gapped" motifs.[3] This is particularly relevant for non-consensus patterns where the key functional residues may be separated by variable-length linkers. For example, in many protein interaction domains, the critical binding residues are interspersed with non-conserved sequences. GLAM2's algorithm is specifically designed to uncover such patterns, which might be missed by tools that assume a fixed spacing between motif elements.
TEIRESIAS employs a combinatorial algorithm to exhaustively identify all patterns that appear in a minimum number of user-provided sequences.[4] This makes it a valuable tool for discovering novel and unexpected motifs, including those with degenerate positions (e.g., a position that can be occupied by any aromatic amino acid). For researchers exploring uncharted territory in protein families, TEIRESIAS can reveal previously unknown patterns that may have functional significance.
Experimental Protocols: A Glimpse into the SAPA Workflow
While a detailed, step-by-step experimental protocol for every possible application of the SAPA tool is beyond the scope of this guide, the general workflow can be outlined based on the information available from the tool's publication and user interface. The process typically involves defining the search parameters for each of the three modules and then combining them to refine the search for target protein regions.
A detailed example of using the SAPA tool for retrieving possibly O-glycosylated sequence regions from proteins of Mycobacterium tuberculosis is provided in the supplementary information of the original publication by Maier et al. (2013) in the journal Bioinformatics.[1] This supplementary material serves as a valuable resource for new users to understand the practical application of the tool.
The following diagram illustrates the logical workflow of a typical SAPA analysis:
Logical Relationships in Non-Consensus Pattern Discovery
The decision to use SAPA, GLAM2, or TEIRESIAS often depends on the specific characteristics of the non-consensus pattern being investigated. The following diagram illustrates the logical relationship between the type of pattern and the most suitable tool.
References
- 1. academic.oup.com [academic.oup.com]
- 2. SAPA tool: finding protein regions by combination of amino acid composition, scaled profiles, patterns and rules - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. Discovering Sequence Motifs with Arbitrary Insertions and Deletions - PMC [pmc.ncbi.nlm.nih.gov]
- 4. help.intedashboard.com [help.intedashboard.com]
independent verification of SAPA tool predictions
An independent verification of the SAPA (Synergistic Action of Pathway Activity) tool's predictions is crucial for its adoption by researchers, scientists, and drug development professionals. However, a comprehensive search of publicly available literature did not yield specific independent studies that have verified or validated the predictions of a tool explicitly named "SAPA (Synergistic Action of Pathway Activity)".
The field of computational drug synergy prediction is active, with numerous models being developed.[1][2] These models leverage various data types and algorithms, from traditional machine learning to deep learning, to navigate the vast combinatorial space of potential drug pairings.[3][4] The ultimate goal is to identify effective combination therapies that can overcome drug resistance and improve treatment outcomes, particularly in cancer.[1]
This guide provides an overview of the methods used to evaluate and validate drug synergy prediction tools, summarizes the performance of common model types based on available data, and details the experimental protocols required for empirical validation.
Performance of Drug Synergy Prediction Models
The validation of drug synergy prediction models is a significant challenge due to the lack of standardized datasets and metrics.[5] Models are often trained and tested on different benchmarks, making direct comparisons difficult. However, general performance trends can be summarized. Early machine learning approaches have been supplemented by deep learning models that can integrate complex, high-dimensional data like gene expression and molecular fingerprints to improve accuracy.[4]
Performance is typically measured by comparing the model's predicted synergy scores against experimentally determined scores. A common metric is the Pearson correlation coefficient, which assesses the linear relationship between predicted and experimental values.[3] For reference, replicate experiments in large-scale drug screens achieve an average weighted Pearson correlation of around 0.4, setting a benchmark for computational models.[3]
Table 1: Comparison of Synergy Prediction Model Architectures
| Model Type | Common Algorithms | Input Data Types | Performance Characteristics | Challenges |
| Traditional Machine Learning | Random Forest, Support Vector Machine (SVM), Gradient Boosting[2][4] | Chemical structures, drug targets, gene expression, copy number variations[4] | - Good performance on specific datasets.- Can be prone to overfitting, especially with high-dimensional data.[2] | - May not capture complex biological relationships.- Performance can be poor when predicting on new cell lines or drugs.[5] |
| Deep Learning | Deep Neural Networks (DNNs), Graph Neural Networks | Multi-omics data (genomics, transcriptomics), molecular graphs, pharmacological data[3][4] | - Can learn intricate patterns from high-dimensional data.[4]- Often shows improved accuracy and generalization across different datasets.[4] | - Requires large, high-quality training datasets.- Models can be "black boxes," making interpretation difficult. |
| Systems Biology / Mechanistic | Pathway analysis, network topology models | Gene expression profiles, protein-protein interaction networks, signaling pathways[2] | - Provides insights into the biological mechanisms of synergy.- Can identify novel combinations by targeting specific pathways. | - Performance is dependent on the completeness and accuracy of biological pathway information.[2] |
Experimental Protocols for Verifying Synergy Predictions
The in vitro validation of a predicted synergistic drug combination is a critical step to confirm the computational result. The general workflow involves treating cancer cell lines with the drugs individually and in combination across a range of doses.
Key Experimental Steps:
-
Cell Line Selection: Choose cancer cell lines relevant to the disease context for which the drug combination is intended. The genomic and transcriptomic characteristics of these cell lines are often used as input for the prediction models.
-
Dose-Response Matrix Assay:
-
Cells are seeded in multi-well plates and allowed to attach overnight.
-
A dose-response matrix is prepared where one drug is titrated along the x-axis and the second drug is titrated along the y-axis. This typically involves a 6x6 to 10x10 matrix of concentrations.
-
The drugs, both individually and in combination, are added to the cells. Control wells receive a vehicle (e.g., DMSO).
-
The plates are incubated for a standard period, typically 72 hours.
-
-
Cell Viability Measurement: After incubation, cell viability is measured using assays such as CellTiter-Glo® (which measures ATP levels) or colorimetric assays like MTT or resazurin.
-
Synergy Score Calculation: The resulting dose-response data is used to calculate a synergy score. Several reference models exist for this calculation, and they can sometimes produce different results.[6] Commonly used models include:
-
Loewe Additivity: Assumes the two drugs are the same compound and evaluates deviations from this expectation.[6][7]
-
Bliss Independence: Assumes the two drugs act independently, and the expected combination effect is calculated based on the probability of each drug having an effect.[6][7]
-
Zero Interaction Potency (ZIP): A more recent model that combines features of both Loewe and Bliss models.[6][7]
-
Highest Single Agent (HSA): A simple model where the combination effect is compared to the effect of the more potent of the two single drugs.[6][7]
-
-
Comparison: The experimentally derived synergy score is then compared to the score predicted by the computational model to validate the prediction.
Visualizing Workflows and Pathways
Diagrams are essential for understanding the complex workflows and biological pathways involved in drug synergy prediction and validation.
Caption: A generalized workflow for the prediction and experimental validation of synergistic drug combinations.
Many synergistic drug combinations, particularly in oncology, target key signaling pathways involved in cell growth, proliferation, and survival. The PI3K/Akt/mTOR pathway is a frequently studied example.
References
- 1. researchgate.net [researchgate.net]
- 2. mdpi.com [mdpi.com]
- 3. academic.oup.com [academic.oup.com]
- 4. Accurate prediction of synergistic drug combination using a multi-source information fusion framework - PMC [pmc.ncbi.nlm.nih.gov]
- 5. alliedacademies.org [alliedacademies.org]
- 6. SynergyFinder: a web application for analyzing drug combination dose–response matrix data - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Drug Synergy Scoring Models: Bliss vs. Loewe vs. ZIP [kyinno.com]
A Researcher's Guide to the Statistical Interpretation of Protein Functional Region Analysis: A Comparative Look at the SAPA Tool and Its Alternatives
For researchers, scientists, and professionals in drug development, identifying and characterizing functional regions within proteins is a critical step in understanding disease mechanisms and designing targeted therapies. A variety of computational tools are available to predict these regions from protein sequence data. This guide provides a comparative overview of the Statistical Analysis of Pathway Activation (SAPA) tool, a lesser-known but specific tool for this purpose, and contrasts it with more established alternatives. We will delve into their methodologies, the statistical significance of their outputs, and provide a framework for their application.
Understanding the SAPA Tool for Protein Region Analysis
The SAPA (Statistical Analysis of Protein Attributes) tool is a web-based application designed to identify functional regions in protein sequences by combining several features, including amino acid composition, profiles of amino acid properties, and the presence of short sequence motifs[1][2][3]. A key aspect of the SAPA tool is its integrated scoring system, which ranks the identified target regions, and its estimation of the false discovery rate (FDR) to assess the statistical significance of the findings[1][2].
The core strength of the SAPA tool lies in its ability to combine multiple, disparate sequence features into a single predictive framework. This can be particularly useful for identifying functional regions that are not defined by a simple consensus sequence but rather by a more complex combination of properties[2][3].
Statistical Significance in the SAPA Tool
The primary statistical output of the SAPA tool is the False Discovery Rate (FDR). The FDR is a statistical method used to correct for multiple comparisons, which is essential when scanning entire proteomes for regions of interest. An FDR value represents the expected proportion of false positives among the results deemed significant. For example, an FDR cutoff of 0.05 implies that, on average, 5% of the identified protein regions with scores at or above the threshold are expected to be false discoveries[4][5]. The SAPA tool calculates the FDR by comparing the scores of the target sequences to the scores obtained from a set of decoy sequences (e.g., shuffled or reversed versions of the original sequences)[1][2].
Comparative Analysis of Protein Functional Region Prediction Tools
While the SAPA tool offers a unique combination of features, several other well-established tools are widely used for similar purposes. These can be broadly categorized into motif discovery tools and protein domain/family databases.
Data Presentation: A Comparative Table
| Feature | SAPA Tool | MEME Suite | HOMER | Pfam | PROSITE | InterPro |
| Primary Function | Identifies protein regions by combined properties (composition, profile, motif) | Discovers novel, ungapped or gapped motifs in unaligned sequences[6][7] | Discovers motifs in large-scale genomic/proteomic data[8][9] | Database of protein families represented by hidden Markov models (HMMs)[10][11] | Database of protein domains, families, and functional sites using patterns and profiles[12][13][14] | Integrated database of protein families, domains, and functional sites from multiple databases[15][16][17][18] |
| Input | Protein sequences in FASTA format[1] | Protein or DNA sequences in FASTA format[6] | DNA or protein sequences (often from ChIP-seq or similar experiments)[9] | Protein sequence | Protein sequence | Protein sequence |
| Statistical Output | Integrated score, False Discovery Rate (FDR)[1][2] | E-value, p-value, q-value for each motif[19] | p-value for motif enrichment | E-value for domain matches | Profile score, p-value | E-value from member databases |
| Key Advantage | Combines diverse sequence features for prediction[2] | High sensitivity for discovering novel motifs[20] | Optimized for high-throughput sequencing data analysis[8] | Comprehensive database of well-curated protein families[21] | High-quality, manually curated entries with detailed functional information[22] | A comprehensive, one-stop resource integrating multiple signature databases[23] |
| Availability | Web application[1] | Web server and downloadable command-line tools[6][24] | Downloadable command-line software[8] | Web server[10] | Web server[25] | Web server[18] |
Experimental Protocols: Methodologies for In Silico Protein Region Analysis
The following outlines a generalized workflow for identifying and statistically validating functional regions in a set of protein sequences using tools like SAPA, MEME, or by searching databases like Pfam and PROSITE.
Objective: To identify statistically significant functional regions or motifs in a given set of protein sequences.
Materials:
-
A set of protein sequences of interest in FASTA format.
-
Access to the web server or local installation of the chosen analysis tool (e.g., SAPA, MEME Suite).
-
A background set of protein sequences (optional, but recommended for some analyses).
Methodology:
-
Sequence Preparation:
-
Collect the protein sequences of interest into a single FASTA file.
-
If a background set is required, prepare a separate FASTA file containing a relevant set of background proteins (e.g., all proteins from the same organism).
-
-
Analysis with the SAPA Tool:
-
Navigate to the SAPA tool web interface.
-
Upload the FASTA file containing the protein sequences.
-
Define the parameters for the search, including amino acid composition constraints, amino acid property profiles, and any known sequence patterns.
-
Select the method for generating decoy sequences for FDR calculation.
-
Submit the job and await the results.
-
-
Analysis with MEME Suite (for novel motif discovery):
-
Access the MEME Suite web server.
-
Upload the FASTA file.
-
Specify the desired motif width and the expected number of motifs.
-
Run the MEME algorithm.
-
The output will provide a list of discovered motifs, each with a statistical measure of significance (E-value).
-
-
Analysis with Pfam/PROSITE/InterPro (for known domain/motif identification):
-
Go to the respective database's web portal.
-
Paste the protein sequence(s) into the search box or upload the FASTA file.
-
Initiate the search.
-
The results will show significant matches to known protein families, domains, or motifs, along with an E-value or score for each match.
-
-
Interpretation of Statistical Outputs:
-
SAPA Tool: Examine the list of identified regions ranked by their integrated score. Use the provided FDR to set a threshold for significance. For example, you might consider all regions with an FDR < 0.05 as statistically significant.
-
MEME Suite: The E-value of a motif represents the number of times you would expect to find a motif with a similar or better quality by chance in a random set of sequences of the same size. Motifs with low E-values (e.g., < 0.05) are generally considered statistically significant.
-
Pfam/PROSITE/InterPro: The E-value for a domain match indicates the number of times you would expect to see a match with that score or better by chance in the database. A low E-value (typically << 1.0) suggests a true homologous relationship.
-
Visualizing the Workflow and Concepts
To better illustrate the processes and relationships discussed, the following diagrams are provided in the DOT language for Graphviz.
References
- 1. academic.oup.com [academic.oup.com]
- 2. researchgate.net [researchgate.net]
- 3. SAPA tool: finding protein regions by combination of amino acid composition, scaled profiles, patterns and rules - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. m.youtube.com [m.youtube.com]
- 5. False Discovery Rate (FDR), adjusted p-value, and Q-values | by Nivedita Bhadra | Medium [medium.com]
- 6. Introduction - MEME Suite [meme-suite.org]
- 7. Overview - MEME Suite [meme-suite.org]
- 8. homer.ucsd.edu [homer.ucsd.edu]
- 9. Homer Software and Data Download [homer.ucsd.edu]
- 10. Pfam is now hosted by InterPro [pfam.xfam.org]
- 11. Pfam - Wikipedia [en.wikipedia.org]
- 12. PROSITE database of protein families and domains [pdg.cnb.uam.es]
- 13. PROSITE, a protein domain database for functional characterization and annotation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 14. PROSITE - Wikipedia [en.wikipedia.org]
- 15. InterPro: the integrative protein signature database - PubMed [pubmed.ncbi.nlm.nih.gov]
- 16. InterPro - Wikipedia [en.wikipedia.org]
- 17. academic.oup.com [academic.oup.com]
- 18. InterPro [ebi.ac.uk]
- 19. Overview - MEME Suite [web.mit.edu]
- 20. MEME SUITE: tools for motif discovery and searching - PubMed [pubmed.ncbi.nlm.nih.gov]
- 21. FAIRsharing [fairsharing.org]
- 22. scispace.com [scispace.com]
- 23. research-information.bris.ac.uk [research-information.bris.ac.uk]
- 24. academic.oup.com [academic.oup.com]
- 25. Expasy - PROSITE [prosite.expasy.org]
Safety Operating Guide
Navigating the Disposal of "SA-PA": A Procedural Guide for Laboratory Professionals
Proper chemical waste disposal is a critical component of laboratory safety and environmental responsibility. This guide provides a comprehensive framework for the safe handling and disposal of a substance identified as "SA-PA." Given that "this compound" is not a standard chemical name and could represent a mixture of substances, this document outlines a systematic approach to its identification and subsequent disposal, ensuring the safety of laboratory personnel and compliance with regulations.
The first and most crucial step before proceeding with any disposal protocol is to definitively identify the constituents of "this compound." The abbreviation could potentially stand for a variety of chemical combinations, each with distinct hazard profiles and disposal requirements. Two plausible interpretations in a laboratory context are a mixture of Salicylic Acid and Phosphoric Acid, or Salicylic Acid and Picric Acid. The disposal procedures for these two mixtures are significantly different.
Immediate Safety Protocols for Unknown Substances
Before positive identification, treat "this compound" as a hazardous unknown. Adhere to the following preliminary safety measures:
-
Consult the Safety Data Sheet (SDS): If "this compound" was a purchased product, the SDS is the primary source of information for handling and disposal.
-
Assume Hazardous Properties: Until identified, assume the substance is flammable, corrosive, reactive, and toxic.
-
Wear Appropriate Personal Protective Equipment (PPE): This includes, at a minimum, chemical splash goggles, a lab coat, and chemical-resistant gloves.
-
Work in a Ventilated Area: Handle the substance within a certified chemical fume hood.
-
Avoid Incompatible Mixtures: Do not mix "this compound" with any other waste.[1]
Logical Workflow for Identification and Disposal
The following diagram illustrates the critical decision-making process for the safe disposal of "this compound."
Procedure A: Disposal of Salicylic Acid and Phosphoric Acid Mixture
This procedure applies if "this compound" is identified as a mixture of salicylic acid and phosphoric acid. This combination is often used in laboratory syntheses, such as in the preparation of aspirin.[2]
Hazard Profile:
| Chemical Component | Key Hazards |
| Salicylic Acid | Harmful if swallowed, causes serious eye damage.[3][4] |
| Phosphoric Acid | Causes severe skin burns and eye damage, may be corrosive to metals. |
Disposal Protocol:
-
Segregation: Collect the salicylic acid and phosphoric acid waste mixture in a dedicated, properly labeled, and sealed container. The container must be compatible with acidic waste; high-density polyethylene (HDPE) is a suitable choice. Do not mix with other waste streams, especially bases or oxidizers.[1][5]
-
Neutralization (for dilute aqueous solutions only): If the waste is a dilute aqueous solution and institutional policy allows for the neutralization of non-toxic corrosive waste, this step may be performed.[6]
-
Work in a fume hood and wear appropriate PPE.
-
Slowly add a weak base, such as sodium bicarbonate (baking soda) or sodium carbonate (soda ash), to the acidic solution while stirring.
-
Monitor the pH of the solution. The target pH should be between 5.5 and 9.5.[6]
-
Be aware that neutralization is an exothermic reaction and may produce gas; proceed slowly to avoid splashing and excessive heat generation.
-
-
Final Disposal:
-
Neutralized Solution: If the neutralized solution contains no other hazardous components, it may be permissible to dispose of it down the drain with a copious amount of water, in accordance with local wastewater regulations.[6]
-
Concentrated or Non-Neutralized Waste: For concentrated mixtures or if neutralization is not performed, the waste must be disposed of as hazardous chemical waste.[5]
-
Ensure the waste container is clearly labeled with "Hazardous Waste," the full chemical names of the components (Salicylic Acid, Phosphoric Acid), and the associated hazards (Corrosive, Irritant).[5]
-
Arrange for pickup by your institution's environmental health and safety (EHS) department or a licensed hazardous waste disposal company.
-
-
Procedure B: Disposal of Salicylic Acid and Picric Acid Mixture
This procedure applies if "this compound" is identified as a mixture of salicylic acid and picric acid. Picric acid is a high-hazard material that requires special handling.
Hazard Profile:
| Chemical Component | Key Hazards |
| Salicylic Acid | Harmful if swallowed, causes serious eye damage.[3][4] |
| Picric Acid | Flammable solid, explosive when dry, forms shock-sensitive salts with metals, toxic.[7][8] It is crucial to keep picric acid wet with at least 10% water.[7] |
Disposal Protocol:
-
Extreme Caution: Picric acid is explosive in its dry state.[7] Never attempt to handle picric acid that has dried out or shows signs of crystallization around the container cap. If you encounter a container of picric acid in this condition, do not move it. Contact your institution's EHS department immediately.
-
Segregation and Storage:
-
The waste mixture must be kept wet. If the solution is evaporating, add water to maintain a minimum of 10% water content.
-
Store the waste in a dedicated, labeled, and sealed plastic container. Do not use metal containers, as picric acid can form explosive picrate salts with many metals.[8]
-
The storage location should be a cool, well-ventilated area away from heat, shock, friction, and incompatible materials such as bases and metals.[7]
-
-
Final Disposal:
-
Do Not Neutralize: Do not attempt to neutralize picric acid waste with a base, as this can form highly unstable picrate salts.
-
Hazardous Waste Disposal: This waste stream must be disposed of as reactive hazardous waste.
-
Label the container clearly with "Hazardous Waste," the full chemical names (Salicylic Acid, Picric Acid), and all associated hazards (Explosive Hazard when Dry, Flammable, Toxic).
-
Arrange for immediate pickup by your institution's EHS department or a specialized hazardous waste disposal service. Inform them of the presence of picric acid in the waste.
-
-
Procedure C: Disposal of Unknown Hazardous Waste
If the identity of "this compound" cannot be determined, it must be handled as unknown hazardous waste.
Disposal Protocol:
-
Labeling: Label the container clearly with "Hazardous Waste - Unknown Composition." Include any information you do have, such as the process that generated the waste and any suspected components.
-
Segregation: Keep the unknown waste isolated from all other waste streams.
-
Contact EHS: Your institution's EHS department will have a specific protocol for handling unknown waste, which may involve analysis to identify the components before disposal. Do not attempt to dispose of unknown waste through standard channels.
By following this structured approach, researchers and laboratory professionals can ensure the safe and compliant disposal of "this compound," regardless of its specific chemical identity, thereby protecting themselves, their colleagues, and the environment.
References
- 1. pharmacy.kku.edu.sa [pharmacy.kku.edu.sa]
- 2. chem.libretexts.org [chem.libretexts.org]
- 3. geneseo.edu [geneseo.edu]
- 4. sds.metasci.ca [sds.metasci.ca]
- 5. Central Washington University | Laboratory Hazardous Waste Disposal Guidelines [cwu.edu]
- 6. Chapter 7 - Management Procedures For Specific Waste Types [ehs.cornell.edu]
- 7. concordia.ca [concordia.ca]
- 8. uthsc.edu [uthsc.edu]
Essential Safety and Handling Guidelines for Laboratory Chemicals: A Focus on Palmitoylethanolamide (PEA)
Disclaimer: The term "SA-PA" is not a standard chemical identifier. This guide provides safety information for Palmitoylethanolamide (PEA), a potential interpretation of the provided term, and also briefly addresses Salicylic Acid as another possibility. Researchers, scientists, and drug development professionals are strongly advised to confirm the precise identity of any chemical with their supplier and consult the substance-specific Safety Data Sheet (SDS) before handling.
This document provides essential safety protocols, personal protective equipment (PPE) recommendations, and disposal plans for Palmitoylethanolamide (PEA) in a laboratory setting.
Personal Protective Equipment (PPE) for Handling Palmitoylethanolamide (PEA)
When working with Palmitoylethanolamide (PEA), it is crucial to use appropriate personal protective equipment to minimize exposure and ensure personal safety. The recommended PPE includes:
-
Eye Protection: Wear appropriate protective eyeglasses or chemical safety goggles. Standard EN166 or OSHA's eye and face protection regulations in 29 CFR 1910.133 should be followed[1].
-
Hand Protection: Protective gloves must be worn. Always inspect gloves prior to use and use proper glove removal technique to avoid skin contact. Dispose of contaminated gloves after use in accordance with laboratory best practices and applicable laws.
-
Skin and Body Protection: Wear appropriate protective gloves and clothing to prevent skin exposure[1]. A lab coat should be worn and buttoned to its full length.
-
Respiratory Protection: Under normal use conditions with adequate ventilation, no protective equipment is typically needed[1]. However, if dust formation is likely, a particle filter respirator is recommended[1].
Operational and Disposal Plans for Palmitoylethanolamide (PEA)
Handling and Storage:
-
Ventilation: Handle in a well-ventilated place.
-
Safe Handling Practices: Avoid contact with skin, eyes, and clothing. Avoid dust formation. Wash hands and face thoroughly after handling.
-
Storage: Store under an inert atmosphere. Keep the container tightly closed in a dry and well-ventilated place[1].
Accidental Release Measures:
-
Personal Precautions: Use personal protective equipment. Keep people away from and upwind of the spill/leak. Ensure adequate ventilation[1].
-
Containment and Cleaning: Sweep up and shovel into suitable containers for disposal. Avoid dust formation[1].
Disposal:
-
Dispose of contents and container to an approved waste disposal plant. Follow all federal, state, and local environmental regulations.
Quantitative Data for Palmitoylethanolamide (PEA)
| Property | Value | Source |
| CAS Number | 544-31-0 | [1][2][3][4][5] |
| Molecular Formula | C18H37NO2 | [2] |
| Molecular Weight | 299.49 g/mol | [2] |
| Appearance | Fine white to yellow powder | [2] |
| Solubility | Soluble in DMSO and ethanol | [2] |
| Melting Point | 99°C |
Experimental Workflow for Handling Palmitoylethanolamide (PEA)
References
Featured Recommendations
| Most viewed |


|
|
|---|---|---|
| Most popular with customers |
|
Avertissement et informations sur les produits de recherche in vitro
Veuillez noter que tous les articles et informations sur les produits présentés sur BenchChem sont destinés uniquement à des fins informatives. Les produits disponibles à l'achat sur BenchChem sont spécifiquement conçus pour des études in vitro, qui sont réalisées en dehors des organismes vivants. Les études in vitro, dérivées du terme latin "in verre", impliquent des expériences réalisées dans des environnements de laboratoire contrôlés à l'aide de cellules ou de tissus. Il est important de noter que ces produits ne sont pas classés comme médicaments et n'ont pas reçu l'approbation de la FDA pour la prévention, le traitement ou la guérison de toute condition médicale, affection ou maladie. Nous devons souligner que toute forme d'introduction corporelle de ces produits chez les humains ou les animaux est strictement interdite par la loi. Il est essentiel de respecter ces directives pour assurer la conformité aux normes légales et éthiques en matière de recherche et d'expérimentation.
