1-Methylcytosine
Description
Structure
3D Structure
Propriétés
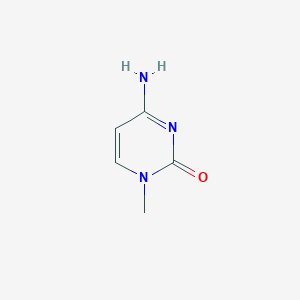
IUPAC Name |
4-amino-1-methylpyrimidin-2-one |
Source


|
|---|---|---|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
InChI |
InChI=1S/C5H7N3O/c1-8-3-2-4(6)7-5(8)9/h2-3H,1H3,(H2,6,7,9) |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
InChI Key |
HWPZZUQOWRWFDB-UHFFFAOYSA-N |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Canonical SMILES |
CN1C=CC(=NC1=O)N |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Molecular Formula |
C5H7N3O |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
DSSTOX Substance ID |
DTXSID60149949 |
Source
|
| Record name | 1-Methylcytosine | |
| Source | EPA DSSTox | |
| URL | https://comptox.epa.gov/dashboard/DTXSID60149949 | |
| Description | DSSTox provides a high quality public chemistry resource for supporting improved predictive toxicology. | |
Molecular Weight |
125.13 g/mol |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
CAS No. |
1122-47-0 |
Source
|
| Record name | 1-Methylcytosine | |
| Source | CAS Common Chemistry | |
| URL | https://commonchemistry.cas.org/detail?cas_rn=1122-47-0 | |
| Description | CAS Common Chemistry is an open community resource for accessing chemical information. Nearly 500,000 chemical substances from CAS REGISTRY cover areas of community interest, including common and frequently regulated chemicals, and those relevant to high school and undergraduate chemistry classes. This chemical information, curated by our expert scientists, is provided in alignment with our mission as a division of the American Chemical Society. | |
| Explanation | The data from CAS Common Chemistry is provided under a CC-BY-NC 4.0 license, unless otherwise stated. | |
| Record name | 1-Methylcytosine | |
| Source | ChemIDplus | |
| URL | https://pubchem.ncbi.nlm.nih.gov/substance/?source=chemidplus&sourceid=0001122470 | |
| Description | ChemIDplus is a free, web search system that provides access to the structure and nomenclature authority files used for the identification of chemical substances cited in National Library of Medicine (NLM) databases, including the TOXNET system. | |
| Record name | 1-Methylcytosine | |
| Source | DrugBank | |
| URL | https://www.drugbank.ca/drugs/DB04314 | |
| Description | The DrugBank database is a unique bioinformatics and cheminformatics resource that combines detailed drug (i.e. chemical, pharmacological and pharmaceutical) data with comprehensive drug target (i.e. sequence, structure, and pathway) information. | |
| Explanation | Creative Common's Attribution-NonCommercial 4.0 International License (http://creativecommons.org/licenses/by-nc/4.0/legalcode) | |
| Record name | 1122-47-0 | |
| Source | DTP/NCI | |
| URL | https://dtp.cancer.gov/dtpstandard/servlet/dwindex?searchtype=NSC&outputformat=html&searchlist=47693 | |
| Description | The NCI Development Therapeutics Program (DTP) provides services and resources to the academic and private-sector research communities worldwide to facilitate the discovery and development of new cancer therapeutic agents. | |
| Explanation | Unless otherwise indicated, all text within NCI products is free of copyright and may be reused without our permission. Credit the National Cancer Institute as the source. | |
| Record name | 1-Methylcytosine | |
| Source | EPA DSSTox | |
| URL | https://comptox.epa.gov/dashboard/DTXSID60149949 | |
| Description | DSSTox provides a high quality public chemistry resource for supporting improved predictive toxicology. | |
| Record name | 4-amino-1-methyl-1,2-dihydropyrimidin-2-one | |
| Source | European Chemicals Agency (ECHA) | |
| URL | https://echa.europa.eu/information-on-chemicals | |
| Description | The European Chemicals Agency (ECHA) is an agency of the European Union which is the driving force among regulatory authorities in implementing the EU's groundbreaking chemicals legislation for the benefit of human health and the environment as well as for innovation and competitiveness. | |
| Explanation | Use of the information, documents and data from the ECHA website is subject to the terms and conditions of this Legal Notice, and subject to other binding limitations provided for under applicable law, the information, documents and data made available on the ECHA website may be reproduced, distributed and/or used, totally or in part, for non-commercial purposes provided that ECHA is acknowledged as the source: "Source: European Chemicals Agency, http://echa.europa.eu/". Such acknowledgement must be included in each copy of the material. ECHA permits and encourages organisations and individuals to create links to the ECHA website under the following cumulative conditions: Links can only be made to webpages that provide a link to the Legal Notice page. | |
| Record name | 1-METHYLCYTOSINE | |
| Source | FDA Global Substance Registration System (GSRS) | |
| URL | https://gsrs.ncats.nih.gov/ginas/app/beta/substances/1J54NE82RV | |
| Description | The FDA Global Substance Registration System (GSRS) enables the efficient and accurate exchange of information on what substances are in regulated products. Instead of relying on names, which vary across regulatory domains, countries, and regions, the GSRS knowledge base makes it possible for substances to be defined by standardized, scientific descriptions. | |
| Explanation | Unless otherwise noted, the contents of the FDA website (www.fda.gov), both text and graphics, are not copyrighted. They are in the public domain and may be republished, reprinted and otherwise used freely by anyone without the need to obtain permission from FDA. Credit to the U.S. Food and Drug Administration as the source is appreciated but not required. | |
Foundational & Exploratory
role of 1-Methylcytosine in epigenetic regulation
An In-Depth Technical Guide to 1-Methylcytosine (B60703) in Epitranscriptomic Regulation
Abstract
This compound (m1C) is a post-transcriptional RNA modification where a methyl group is added to the nitrogen-1 position of the cytosine base. Distinct from the well-known epigenetic DNA mark 5-methylcytosine (B146107) (m5C), m1C is a key player in the burgeoning field of epitranscriptomics. This modification is found in various RNA species, particularly transfer RNA (tRNA) and ribosomal RNA (rRNA), where it influences RNA stability, structure, and the process of translation. The regulatory machinery governing m1C—the "writers" (methyltransferases), "erasers" (demethylases), and "readers" (binding proteins)—is still being actively investigated. The enzyme ALKBH1 has been identified as a potential eraser, while specific writers and readers for m1C remain to be fully characterized. Dysregulation of RNA methylation is increasingly linked to human diseases, including cancer, positioning the m1C pathway as a potential area for future therapeutic development. This guide provides a comprehensive overview of the molecular biology of m1C, details methodologies for its detection and analysis, and explores its functional significance and future research directions.
Introduction to this compound (m1C)
This compound is a modified nucleobase derived from cytosine. The modification consists of the addition of a methyl group to the nitrogen atom at the N1 position of the pyrimidine (B1678525) ring. This seemingly subtle change distinguishes it fundamentally from 5-methylcytosine (m5C), the canonical epigenetic mark in DNA, where the methyl group is on the C5 carbon position. While m5C is a cornerstone of epigenetic regulation affecting gene expression through chromatin structure, m1C's role is primarily at the post-transcriptional level, regulating the fate and function of RNA molecules. This has led to its study under the umbrella of "epitranscriptomics," which encompasses all post-transcriptional modifications to RNA.
The m1C Regulatory Machinery: Writers, Readers, and Erasers
Like other epigenetic and epitranscriptomic marks, the lifecycle of m1C is dynamically controlled by a set of specialized proteins. These are categorized as writers, which install the mark; erasers, which remove it; and readers, which recognize the mark and mediate its downstream biological effects.
-
Writers (Methyltransferases): The specific enzymes that catalyze the formation of m1C in RNA have not yet been definitively identified. However, by analogy to other N1-position modifications, such as N1-methyladenosine (m1A), the writer is likely a complex enzyme. The primary methyltransferase complex for m1A in tRNA is a heterodimer of TRMT6 and TRMT61A, where TRMT61A is the catalytic subunit and TRMT6 facilitates tRNA binding.[1][2][3] The discovery of a dedicated m1C writer remains a key area of future research.
-
Erasers (Demethylases): Evidence points to the AlkB homolog family of dioxygenases as potential erasers of m1C. Specifically, ALKBH1 has been shown to be a multifaceted enzyme with demethylase activity against various substrates, including N1-methyladenosine (m1A) in tRNA.[4][5][6] Its ability to act on the N1 position of purines suggests it may also be capable of removing the methyl group from the N1 position of pyrimidines like cytosine, although this is yet to be conclusively demonstrated for m1C.
-
Readers (Binding Proteins): Reader proteins are crucial effectors that recognize specific modifications and translate them into functional outcomes.[7] To date, no proteins have been identified that specifically bind to m1C in RNA. For the related m5C mark, reader proteins like ALYREF and YBX1 have been shown to recognize the modification and mediate functions such as mRNA nuclear export and stability.[8][9] Identifying the reader proteins for m1C is critical to fully understanding its biological role.
Biological Functions of m1C
m1C modifications have been detected in several classes of RNA and are implicated in fundamental cellular processes.
-
Role in tRNA and rRNA: The most well-documented roles for m1C are in non-coding RNAs. In tRNA, modifications like m1C are crucial for maintaining structural stability and ensuring correct folding. This, in turn, affects the efficiency and fidelity of protein translation. Similar roles in structural integrity are proposed for m1C in rRNA, a core component of the ribosome.
-
Role in mRNA: The function of m1C in messenger RNA is less understood. By analogy with other mRNA modifications, it could potentially influence mRNA stability, alternative splicing, nuclear export, and the initiation or elongation phases of translation.
-
Role in Mitochondrial RNA: While the presence of m5C in mitochondrial RNA (mtRNA) has been established and is regulated by the methyltransferase NSUN4 to flag transcripts for degradation, a specific role for m1C in mitochondria has not yet been described.[10][11][12] Given that RNA modifications are present and functional within mitochondria, this represents an important area for future investigation.
-
Association with Disease: Dysregulation of RNA methylation is a known driver in various cancers.[13][14] For instance, the overexpression of m1A writers (TRMT6/TRMT61A) has been linked to liver and bladder cancers by promoting proliferation.[1][3] While the direct involvement of m1C is still under investigation, it is plausible that its misregulation could contribute to pathogenesis by altering the translation of key oncogenes or tumor suppressors.
Comparative Analysis of Cytosine and Adenosine (B11128) Methylation
To provide context, it is useful to compare m1C with other well-studied RNA modifications.
| Feature | This compound (m1C) | 5-Methylcytosine (m5C) | N6-Methyladenosine (m6A) | N1-Methyladenosine (m1A) |
| Molecule | RNA | DNA, RNA | RNA | RNA |
| Position | N1 of Cytosine | C5 of Cytosine | N6 of Adenosine | N1 of Adenosine |
| Known Writers | Uncharacterized | DNMTs, NSUN family | METTL3/14 complex | TRMT6/61A complex |
| Known Erasers | ALKBH1 (putative) | TET enzymes | FTO, ALKBH5 | ALKBH1, ALKBH3 |
| Primary Role | RNA structure, translation | DNA: Gene silencing; RNA: Stability, translation | mRNA stability, splicing, translation | tRNA structure, translation initiation |
Methodologies for m1C Detection and Mapping
The study of m1C requires specialized and sensitive analytical techniques.
Liquid Chromatography-Mass Spectrometry (LC-MS/MS)
LC-MS/MS is the gold standard for the absolute quantification of the global m1C levels in a total RNA sample. It offers high sensitivity and specificity.
-
RNA Isolation: Extract total RNA from cells or tissues using a high-purity extraction method (e.g., Trizol or column-based kits). Ensure RNA integrity is high.
-
RNA Digestion: Digest 1-5 µg of total RNA into individual nucleosides. This is typically a two-step enzymatic process:
-
Incubate RNA with Nuclease P1 at 37°C for 2-4 hours to digest RNA into 5'-mononucleotides.
-
Add Bacterial Alkaline Phosphatase and incubate at 37°C for an additional 2-4 hours to dephosphorylate the nucleotides into nucleosides.
-
-
Liquid Chromatography (LC) Separation: Inject the digested nucleoside mixture into a reverse-phase HPLC column (e.g., C18). Separate the nucleosides using a gradient of two mobile phases (e.g., water with 0.1% formic acid and methanol (B129727) or acetonitrile).
-
Mass Spectrometry (MS) Analysis: Eluted nucleosides are ionized (typically by electrospray ionization, ESI) and enter the mass spectrometer.
-
Operate the MS in Multiple Reaction Monitoring (MRM) mode.
-
Monitor the specific mass transition of the parent ion (protonated m1C) to a characteristic fragment ion (the m1C base).
-
-
Quantification: Create a standard curve using known concentrations of pure m1C and other canonical nucleosides. Calculate the amount of m1C in the sample relative to a canonical nucleoside (e.g., cytidine (B196190) or adenosine).
m1C Individual-Nucleotide Resolution Crosslinking and Immunoprecipitation (m1C-miCLIP)
To map the specific locations of m1C across the transcriptome, a sequencing-based approach is required. The miCLIP method, adapted from its use for m6A, could provide single-nucleotide resolution. Note: This method is contingent upon the availability of a highly specific and efficient anti-m1C antibody validated for immunoprecipitation of RNA.
-
Cell Culture and UV Crosslinking: Grow cells of interest and irradiate them with UV light (254 nm) to induce covalent crosslinks between RNA and interacting proteins.
-
Lysis and RNA Fragmentation: Lyse the cells and fragment the RNA to a desired size range (e.g., 100-200 nucleotides) using RNase or enzymatic fragmentation.
-
Immunoprecipitation (IP): Incubate the fragmented RNA-protein lysate with magnetic beads conjugated to an anti-m1C antibody. The antibody will bind to the m1C-containing RNA fragments.
-
Washes and Adapter Ligation: Perform stringent washes to remove non-specifically bound RNA. Ligate a 3' adapter to the captured RNA fragments while they are still on the beads.
-
Radiolabeling and Gel Electrophoresis: Dephosphorylate the 5' end of the RNA and then radiolabel with ³²P. Elute the RNA-protein complexes and separate them by SDS-PAGE.
-
Membrane Transfer and RNA Isolation: Transfer the separated complexes to a nitrocellulose membrane. Excise the region corresponding to the crosslinked complexes and recover the RNA by proteinase K digestion.
-
Reverse Transcription (RT): Perform reverse transcription on the isolated RNA fragments. The crosslink site often causes the reverse transcriptase to terminate or introduce a mutation in the resulting cDNA, marking the modification site.
-
Library Preparation and Sequencing: Circularize the cDNA, re-linearize, PCR amplify, and perform high-throughput sequencing.
-
Bioinformatic Analysis: Align reads to the reference transcriptome. Identify the precise location of m1C sites by analyzing the truncation and mutation patterns at crosslink sites.
Inapplicability of Bisulfite Sequencing
Bisulfite sequencing is a cornerstone technique for mapping m5C in DNA. The method relies on the chemical deamination of cytosine to uracil, while the methyl group at the C5 position protects 5-methylcytosine from this conversion.[15][16][17] However, the methyl group at the N1 position in this compound does not offer this protection. Therefore, standard bisulfite treatment will convert both cytosine and this compound to uracil , making the method unsuitable for distinguishing m1C from unmodified cytosine.
Future Perspectives and Drug Development
The study of this compound is a rapidly evolving frontier in molecular biology. The discovery and characterization of its dedicated writers, erasers, and readers will be a major breakthrough, enabling a much deeper understanding of its regulatory networks. Key unanswered questions include:
-
What are the specific methyltransferases that install the m1C mark?
-
Which reader proteins recognize m1C and what are their downstream effector functions?
-
What is the full extent of the m1C epitranscriptome across different cell types and developmental stages?
-
How does the dysregulation of m1C deposition or removal contribute to diseases like cancer and neurodevelopmental disorders?
From a therapeutic perspective, the enzymes that regulate RNA modifications are emerging as promising drug targets.[18] Once the m1C writers and erasers are identified, they will represent a new class of potential targets for small molecule inhibitors. Modulating the m1C status of key cancer-related transcripts could offer a novel strategy for controlling tumor growth and progression. The development of this field holds significant promise for both fundamental science and clinical applications.
References
- 1. N1-methyladenosine methylation in tRNA drives liver tumourigenesis by regulating cholesterol metabolism - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Reactome | TRMT6:TRMT61A methylate adenosine yielding 1-methyladenosine at nucleotide 58 of tRNA(Met) [reactome.org]
- 3. Depletion of the m1A writer TRMT6/TRMT61A reduces proliferation and resistance against cellular stress in bladder cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 4. ALKBH1 alkB homolog 1, histone H2A dioxygenase [Homo sapiens (human)] - Gene - NCBI [ncbi.nlm.nih.gov]
- 5. The biological function of demethylase ALKBH1 and its role in human diseases - PMC [pmc.ncbi.nlm.nih.gov]
- 6. researchgate.net [researchgate.net]
- 7. Reading RNA methylation codes through methyl-specific binding proteins - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Transcriptome-wide identification of 5-methylcytosine by deaminase and reader protein-assisted sequencing [elifesciences.org]
- 9. Identification of putative reader proteins of 5-methylcytosine and its derivatives in Caenorhabditis elegans RNA - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Cytosine methylation flags mitochondrial RNA for degradation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 11. RNA 5-methylcytosine marks mitochondrial double-stranded RNAs for degradation and cytosolic release - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. RNA 5-methylcytosine marks mitochondrial double-stranded RNAs for degradation and cytosolic release - PMC [pmc.ncbi.nlm.nih.gov]
- 13. The Role of DNA Methylation in Cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Significant roles of RNA 5-methylcytosine methylation in cancer - PubMed [pubmed.ncbi.nlm.nih.gov]
- 15. Bisulfite sequencing - Wikipedia [en.wikipedia.org]
- 16. DNA methylation detection: Bisulfite genomic sequencing analysis - PMC [pmc.ncbi.nlm.nih.gov]
- 17. academic.oup.com [academic.oup.com]
- 18. Methylation Landscape: Targeting Writer or Eraser to Discover Anti-Cancer Drug - PMC [pmc.ncbi.nlm.nih.gov]
An In-depth Technical Guide on 1-Methylcytosine: Discovery, History, and Core Methodologies
For Researchers, Scientists, and Drug Development Professionals
Abstract
1-Methylcytosine (B60703) (1mC) is a methylated derivative of the canonical nucleobase cytosine, distinguished by the addition of a methyl group at the first nitrogen atom of the pyrimidine (B1678525) ring. While less prevalent than its well-studied isomer, 5-methylcytosine (B146107) (5mC), 1mC has garnered increasing interest for its unique chemical properties and its role in expanding the genetic alphabet. This technical guide provides a comprehensive overview of the discovery, history, and key experimental methodologies associated with this compound. It is designed to serve as a core resource for researchers, scientists, and drug development professionals, offering detailed data, experimental protocols, and visualizations of relevant biological and chemical processes.
Introduction
Epigenetic modifications of nucleic acids play a pivotal role in regulating a vast array of cellular processes. Among these, the methylation of cytosine is a key mechanism for controlling gene expression and maintaining genome stability. While 5-methylcytosine (5mC) has been the subject of extensive research, other methylated forms of cytosine, such as this compound, are emerging as important molecules in both natural and synthetic biological systems.
This compound is a pyrimidone in which the hydrogen attached to the nitrogen at position 1 is substituted by a methyl group[1][2]. This structural alteration distinguishes it from the more common 5-methylcytosine and has significant implications for its chemical behavior and biological function[3]. This guide delves into the historical context of 1mC's discovery, its physicochemical properties, and the experimental techniques used for its synthesis, detection, and characterization.
Discovery and History
The history of this compound is marked by early crystallographic studies and a more recent resurgence of interest due to its application in synthetic biology.
-
Early Structural Elucidation (1960s-1970s): The foundational work on the structure of this compound was laid in the mid-20th century. In 1964, the crystal and molecular structure of N-methyl cytosine was first described[4]. Later, in 1977, Miriam Rossi and her colleagues further refined the crystallographic structure of this compound, providing precise data on its molecular geometry[3]. These early studies were crucial in understanding the fundamental chemical nature of this modified base.
-
A Stable Analogue in Synthetic Genetics (2009): A significant milestone in the history of this compound was its identification as a stable replacement for 2'-deoxy-5-methylisocytidine in 2009[3]. This discovery highlighted its potential for use in creating novel, stable nucleic acid structures.
-
Component of the Hachimoji DNA System (2019): The prominence of this compound in the field of synthetic biology was solidified with its inclusion as a key component of the "hachimoji" DNA and RNA system[3]. In this expanded genetic alphabet, this compound pairs with isoguanine, demonstrating the potential to create life with an eight-letter genetic code[3].
Physicochemical Properties
The distinct physicochemical properties of this compound are central to its unique role in nucleic acid chemistry.
| Property | Value | Reference |
| Molecular Formula | C₅H₇N₃O | [1][2] |
| Molecular Weight | 125.13 g/mol | [5] |
| IUPAC Name | 4-amino-1-methylpyrimidin-2(1H)-one | [1][2] |
| CAS Number | 1122-47-0 | [6] |
| Appearance | White to off-white powder | |
| Melting Point | 296-300 °C | |
| Solubility | Soluble in DMSO (1.26 mg/mL with sonication) | [7] |
Experimental Protocols
This section provides detailed methodologies for the synthesis and detection of this compound, crucial for researchers working with this modified nucleobase.
Synthesis of this compound
While several synthetic routes exist, a common approach involves the reaction of a methylated urea (B33335) derivative with a suitable precursor to form the pyrimidine ring. A general, multi-step synthesis starting from ethyl cyanoacetate (B8463686) is outlined below.
Protocol: Synthesis of 4-amino-1-methylpyrimidin-2(1H)-one
This protocol is a generalized representation and may require optimization based on specific laboratory conditions and available reagents.
Step 1: Synthesis of Ethyl Cyano-2-ureidoacrylate
-
React ethyl cyanoacetate with triethyl orthoformate in the presence of a catalyst (e.g., acetic anhydride) to form an intermediate.
-
React the intermediate with urea to yield ethyl cyano-2-ureidoacrylate.
Step 2: Cyclization to 5-ethoxycarbonylcytosine
-
Treat the ethyl cyano-2-ureidoacrylate with a strong base (e.g., sodium ethoxide) to induce cyclization, forming 5-ethoxycarbonylcytosine.
Step 3: Hydrolysis to 5-carboxycytosine
-
Hydrolyze the ester group of 5-ethoxycarbonylcytosine using aqueous sodium hydroxide.
-
Neutralize the reaction mixture with an acid (e.g., hydrochloric acid) to precipitate 5-carboxycytosine.
Step 4: Decarboxylation to Cytosine
-
Heat the 5-carboxycytosine in a high-boiling point solvent to induce decarboxylation, yielding cytosine.
Step 5: Methylation to this compound
-
React cytosine with a methylating agent, such as dimethyl sulfate (B86663) or methyl iodide, in the presence of a base to introduce the methyl group at the N1 position.
-
Purify the resulting this compound using recrystallization or column chromatography.
Detection and Quantification of this compound
Accurate detection and quantification of this compound in biological samples are essential for understanding its potential roles. Ultra-high performance liquid chromatography-tandem mass spectrometry (UHPLC-MS/MS) is a highly sensitive and specific method for this purpose.
Protocol: UHPLC-MS/MS for this compound Quantification in Genomic DNA
This protocol is adapted from a general method for detecting methylated nucleosides in genomic DNA[3][8][9][10].
1. DNA Digestion to Nucleosides:
-
To 1-2 µg of genomic DNA, add 10 U of DNA Degradase Plus enzyme mix in 1X DNA Degradase Plus buffer to a final volume of 25-30 µL.
-
Incubate the reaction at 37 °C for 2-3 hours.
-
Add 70-75 µL of ultra-pure water to bring the total volume to 100 µL and mix thoroughly.
-
Filter the sample through a 0.22 µm syringe filter directly into an HPLC vial.
2. UHPLC-MS/MS Analysis:
-
Chromatographic Separation:
-
Column: C18 reversed-phase column.
-
Mobile Phase A: Water with 0.1% (v/v) formic acid.
-
Mobile Phase B: Methanol with 0.1% (v/v) formic acid.
-
Gradient: A suitable gradient from low to high organic phase to separate the nucleosides.
-
-
Mass Spectrometry Detection:
-
Ionization Mode: Positive electrospray ionization (ESI).
-
Detection Mode: Dynamic Multiple Reaction Monitoring (dMRM).
-
Monitor the specific mass transition from the precursor ion of this compound to its characteristic product ion.
-
3. Quantification:
-
Prepare a calibration curve using serial dilutions of a pure this compound standard.
-
Quantify the amount of this compound in the sample by comparing its peak area to the standard curve.
Biological Role and Signaling Pathways
Currently, the known biological role of this compound is primarily in the context of synthetic biological systems. There is limited evidence for its widespread presence or a defined signaling function in natural biological processes in mammals.
-
Hachimoji DNA: The most well-documented role of this compound is as a component of the expanded genetic alphabet in hachimoji DNA, where it forms a stable base pair with isoguanine[3]. This demonstrates its capacity to function within a nucleic acid duplex, expanding the possibilities for information storage in synthetic life forms.
-
Enzymatic Recognition: While the enzymes that specifically recognize and process this compound in vivo are not well-characterized, some DNA repair enzymes have been shown to act on other N-methylated purines and pyrimidines. For instance, the AfAlkA base excision repair glycosylase from Archaeoglobus fulgidus can excise N1-methyladenine and N3-methylcytosine from DNA[6][9]. Further research is needed to determine if similar enzymes can recognize and process this compound in other organisms.
The lack of extensive data on the natural occurrence and function of this compound presents an exciting frontier for future research. Investigating its potential role in gene regulation, DNA repair, and other cellular processes could unveil novel biological mechanisms.
Visualizations
To aid in the understanding of the concepts discussed, the following diagrams have been generated using the DOT language.
Synthesis and Detection Workflow
Relationship of this compound to Other Cytosine Modifications
Conclusion
This compound, while historically less studied than 5-methylcytosine, is a molecule of growing importance, particularly in the realm of synthetic biology. Its unique structural properties and ability to form stable, non-canonical base pairs have opened up new avenues for the design of novel genetic systems. This technical guide has provided a comprehensive overview of the discovery, properties, and key experimental methodologies related to this compound. As research continues, a deeper understanding of its potential biological roles and the development of more refined analytical techniques will undoubtedly emerge, further solidifying its place in the landscape of nucleic acid research and drug development.
References
- 1. spectrabase.com [spectrabase.com]
- 2. This compound | C5H7N3O | CID 79143 - PubChem [pubchem.ncbi.nlm.nih.gov]
- 3. Human Metabolome Database: 1H NMR Spectrum (1D, 200 MHz, D2O, predicted) (HMDB0247144) [hmdb.ca]
- 4. neb.com [neb.com]
- 5. Enzymatic approaches for profiling cytosine methylation and hydroxymethylation - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Structural basis for enzymatic excision of N1-methyladenine and N3-methylcytosine from DNA - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Effects of ionization on stability of this compound — DFT and PCM studies - PMC [pmc.ncbi.nlm.nih.gov]
- 8. TAUTOMERISM AND SITE OF PROTONATION OF this compound: PROOF BY NUCLEAR MAGNETIC RESONANCE SPIN-SPIN COUPLING - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. Structural basis for enzymatic excision of N1‐methyladenine and N3‐methylcytosine from DNA | The EMBO Journal [link.springer.com]
- 10. Is this compound a faithful model compound for ultrafast deactivation dynamics of cytosine nucleosides in solution? - Physical Chemistry Chemical Physics (RSC Publishing) [pubs.rsc.org]
An In-depth Technical Guide to 1-Methylcytosine: Chemical Structure, Properties, and Biological Significance
For Researchers, Scientists, and Drug Development Professionals
Abstract
1-Methylcytosine (B60703) (1mC) is a modified pyrimidine (B1678525) nucleobase derived from cytosine through methylation at the nitrogen-1 (N1) position. While less common than its isomer 5-methylcytosine (B146107) (5mC), 1mC plays a significant role in various biological contexts, including the expanded genetic alphabet of hachimoji DNA, and is of growing interest in the fields of epigenetics and drug development. This technical guide provides a comprehensive overview of the chemical structure, physicochemical properties, and biological implications of this compound, along with methodologies for its synthesis and detection.
Chemical Structure and Identification
This compound is structurally distinguished from cytosine by the presence of a methyl group on the nitrogen atom at the first position of the pyrimidine ring.[1][2][3] This modification alters its hydrogen bonding capabilities and steric profile compared to canonical cytosine.
Table 1: Chemical Identifiers for this compound
| Identifier | Value |
| IUPAC Name | 4-amino-1-methylpyrimidin-2(1H)-one |
| CAS Number | 1122-47-0 |
| Molecular Formula | C₅H₇N₃O |
| Molecular Weight | 125.13 g/mol |
| SMILES | CN1C=CC(=NC1=O)N |
| InChI | InChI=1S/C5H7N3O/c1-8-3-2-4(6)7-5(8)9/h2-3H,1H3,(H2,6,7,9) |
Physicochemical Properties
The physicochemical properties of this compound are crucial for understanding its behavior in biological systems and for developing analytical methods.
Table 2: Physicochemical Properties of this compound
| Property | Value | Reference |
| Melting Point | 300-303 °C | [1] |
| Density | 1.448 g/cm³ | [1] |
| pKa | 4.53 ± 0.10 (Predicted) | [1] |
| Solubility | Slightly soluble in water and methanol | [1] |
Spectroscopic Data
Spectroscopic analysis is essential for the identification and characterization of this compound.
Table 3: Spectroscopic Data for this compound
| Spectrum | Data |
| ¹H NMR | Predicted peaks in D₂O. |
| ¹³C NMR | Predicted peaks in D₂O. |
| FT-IR | Characteristic peaks for C=O, N-H, and C-N stretching and bending vibrations. |
| UV-Vis | Absorption maxima are observed in the UV region. |
Note: Specific, experimentally validated peak lists with assignments are not consistently available across public databases. The provided information is based on predicted spectra and general characteristics of similar compounds.
Biological Significance
Hachimoji DNA
A significant role for this compound has been demonstrated in the synthetic biology concept of "hachimoji DNA." In this expanded genetic alphabet, this compound is designed to form a stable base pair with isoguanine.[1][2] This pairing is a key component of an eight-letter genetic system that can store and transmit information, expanding the possibilities for synthetic biological systems and data storage.
Epigenetics and Gene Regulation
While 5-methylcytosine is the primary epigenetic mark in mammals, the role of other methylated cytosine isomers like this compound is an area of active investigation. DNA methylation, in general, is a crucial mechanism for regulating gene expression.[4][5] The methylation of cytosine residues, particularly in CpG islands, can lead to gene silencing by preventing the binding of transcription factors and recruiting proteins that promote a condensed chromatin state.[5][6] The presence of this compound in DNA or RNA could potentially influence these regulatory processes, although its natural occurrence and specific enzymatic pathways in mammals are not as well-characterized as those for 5-methylcytosine.
The general pathway of DNA methylation and demethylation provides a framework for understanding how methylated cytosines, including potentially this compound, could be involved in gene regulation.
Experimental Protocols
Synthesis of this compound
A general approach for the synthesis of this compound involves the methylation of cytosine. While specific, detailed protocols can vary, a common strategy is the direct methylation of cytosine using a methylating agent. An alternative approach involves the synthesis of a pyrimidine ring with the methyl group already in place.
General Protocol for Methylation of Genomic DNA (as a proxy for cytosine methylation): [1]
-
Reaction Setup: In a microcentrifuge tube, combine nuclease-free water, a 10X methyltransferase reaction buffer, and S-adenosylmethionine (SAM) as the methyl donor.
-
Addition of DNA and Enzyme: Add the DNA substrate (containing cytosine residues) and the appropriate DNA methyltransferase enzyme.
-
Incubation: Incubate the reaction mixture at the optimal temperature for the enzyme (typically 37°C) for a sufficient duration to allow for methylation.
-
Reaction Termination: Stop the reaction by heat inactivation of the enzyme (e.g., 65°C for 20 minutes).
-
Purification: The methylated DNA can then be purified using standard DNA purification methods.
Note: The synthesis of pure this compound for use as a standard or in further reactions would require a more specialized organic synthesis approach, the details of which are beyond the scope of this general guide.
Detection and Quantification of this compound
Several advanced analytical techniques can be employed for the detection and quantification of this compound in biological samples.
HPLC-MS is a powerful method for the sensitive and specific detection of modified nucleosides.
General Workflow for HPLC-MS Analysis:
Methodology Outline: [7][8][9][10][11]
-
Sample Preparation: Isolate DNA or RNA from the biological sample of interest.
-
Enzymatic Digestion: Digest the nucleic acids into individual nucleosides using a cocktail of enzymes such as nuclease P1 and alkaline phosphatase.
-
Chromatographic Separation: Separate the resulting nucleoside mixture using reverse-phase HPLC. A C18 column is commonly used with a gradient of an aqueous buffer and an organic solvent (e.g., acetonitrile (B52724) or methanol).
-
Mass Spectrometric Detection: The eluent from the HPLC is introduced into a tandem mass spectrometer. This compound is ionized (typically by electrospray ionization, ESI) and detected using multiple reaction monitoring (MRM) or selected reaction monitoring (SRM) for high specificity and sensitivity. A specific precursor ion to product ion transition for this compound is monitored.
-
Quantification: The amount of this compound is quantified by comparing its peak area to that of a known concentration of a stable isotope-labeled internal standard.
Nanopore sequencing offers a direct method for identifying base modifications, including methylation, in native DNA or RNA without the need for amplification or chemical conversion.[12][13][14][15][16]
General Workflow for Nanopore Sequencing-Based Detection:
Methodology Outline: [12][13][14][15][16]
-
DNA/RNA Extraction: Isolate high-molecular-weight DNA or RNA from the sample.
-
Library Preparation: Prepare a sequencing library by ligating sequencing adapters to the ends of the nucleic acid fragments.
-
Nanopore Sequencing: Load the library onto a nanopore flow cell. As individual DNA or RNA strands pass through a protein nanopore, they cause characteristic disruptions in an ionic current.
-
Data Analysis: The raw electrical signal is basecalled to determine the nucleotide sequence. Specialized algorithms are then used to analyze the raw signal to detect deviations from the expected signal for canonical bases, allowing for the identification of modified bases like this compound at single-molecule resolution.
Conclusion
This compound, while not as extensively studied as 5-methylcytosine, represents an important modified nucleobase with established roles in synthetic biology and potential implications in epigenetic regulation. The continued development of sensitive analytical techniques will further elucidate its presence and function in biological systems. This guide provides a foundational understanding for researchers and professionals in drug development and related scientific fields to explore the multifaceted nature of this compound.
References
- 1. neb.com [neb.com]
- 2. This compound - Wikipedia [en.wikipedia.org]
- 3. DNAmod: this compound [dnamod.hoffmanlab.org]
- 4. DNA methylation and methylcytosine oxidation in cell fate decisions - PMC [pmc.ncbi.nlm.nih.gov]
- 5. DNA methylation and the regulation of gene transcription - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Cytosine methylation of an Sp1 site contributes to organ-specific and cell-specific regulation of expression of the lung epithelial gene t1alpha - PMC [pmc.ncbi.nlm.nih.gov]
- 7. pubs.acs.org [pubs.acs.org]
- 8. Ultraperformance Liquid Chromatography Tandem Mass Spectrometry Assay of DNA Cytosine Methylation Excretion from Biological Systems - PMC [pmc.ncbi.nlm.nih.gov]
- 9. A New Photoproduct of 5-Methylcytosine and Adenine Characterized by HPLC and Mass Spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 10. pubs.acs.org [pubs.acs.org]
- 11. rsc.org [rsc.org]
- 12. Analysis of DNA 5-methylcytosine Using Nanopore Sequencing [bio-protocol.org]
- 13. Detecting DNA cytosine methylation using nanopore sequencing - PubMed [pubmed.ncbi.nlm.nih.gov]
- 14. Nanopore Single-Molecule Sequencing for Mitochondrial DNA Methylation Analysis: Investigating Parkin-Associated Parkinsonism as a Proof of Concept - PMC [pmc.ncbi.nlm.nih.gov]
- 15. researchgate.net [researchgate.net]
- 16. youtube.com [youtube.com]
1-Methylcytosine: A Key Regulator in the Epitranscriptome
An In-depth Technical Guide for Researchers, Scientists, and Drug Development Professionals
Introduction
1-Methylcytosine (B60703) (m1C) is a modified nucleobase, a derivative of cytosine where a methyl group is attached to the nitrogen atom at the first position of the pyrimidine (B1678525) ring.[1][2][3] This modification distinguishes it from the more extensively studied 5-methylcytosine (B146107) (m5C), where the methyl group is at the fifth carbon position.[1] While m1C is found in both DNA and RNA, its role as an epitranscriptomic mark in RNA is gaining significant attention for its influence on various biological processes, including gene expression regulation and the maintenance of genomic stability.[2][4] This technical guide provides a comprehensive overview of the core aspects of m1C, including its biogenesis, functional roles, detection methodologies, and implications in disease, with a focus on providing actionable data and protocols for the scientific community.
The Lifecycle of this compound: Writers, Erasers, and Readers
The dynamic regulation of m1C modification is orchestrated by a coordinated interplay of three key protein families: "writers" that install the mark, "erasers" that remove it, and "readers" that recognize and interpret its functional consequences.
Writers: The Methyltransferases
The primary enzymes responsible for depositing the m1C mark on RNA are members of the NOL1/NOP2/SUN domain (NSUN) family of methyltransferases.[3][5][6] Specifically, NSUN2 and NSUN6 have been identified as major m1C writers in mRNA.[3][5][6][7] These enzymes catalyze the transfer of a methyl group from S-adenosyl-L-methionine (SAM) to the N1 position of cytosine within specific RNA sequences.[8] Another enzyme family, the tRNA methyltransferases TRMT6 and TRMT61A, are known to catalyze N1-methyladenosine (m1A) formation, a modification structurally similar to m1C, suggesting a potential for broader substrate specificity that may include cytosine.[9][10][11][12][13]
Erasers: The Demethylases
The removal of m1C is less well-characterized compared to its deposition. However, members of the AlkB homolog (ALKBH) family of dioxygenases are known to act as demethylases for various RNA modifications.[14][15] ALKBH1 has been shown to remove methyl groups from 1-methyladenine (B1486985) and 3-methylcytosine (B1195936) in RNA and may play a role in m1C demethylation, although its primary substrates appear to be other modifications.[14][15][16][17] The potential for a dedicated m1C eraser remains an active area of research.
Readers: The Effector Proteins
The functional consequences of m1C modification are mediated by "reader" proteins that specifically recognize and bind to this mark. The Y-box binding protein 1 (YBX1) has been identified as a key m1C reader.[1][2][4][18][19] YBX1 contains a cold shock domain that directly interacts with the m1C-modified base, influencing the stability and translation of the target mRNA.[1][2] This interaction often involves the recruitment of other proteins, such as the ELAV-like RNA-binding protein 1 (ELAVL1), which further contributes to the stabilization of the mRNA transcript.[2] Another identified reader is the Aly/REF export factor (ALYREF), which has been shown to mediate the nuclear export of m5C-modified mRNA, and may have a similar role for m1C.[20]
Functional Implications of this compound
The presence of m1C in RNA has profound effects on its metabolism and function, impacting processes from translation to degradation.
In RNA:
-
mRNA Stability: One of the most well-documented roles of m1C is the enhancement of mRNA stability. By recruiting reader proteins like YBX1, m1C protects the mRNA transcript from degradation, thereby increasing its half-life and leading to elevated protein expression.[2][8][20]
-
Translation Regulation: m1C modification can directly influence the efficiency of protein translation. The presence of m1C within the coding sequence or untranslated regions of an mRNA can modulate ribosome binding and translocation.[8]
-
mRNA Export: The recognition of m1C by reader proteins like ALYREF can facilitate the transport of mRNA from the nucleus to the cytoplasm, a critical step in gene expression.[20]
In DNA:
While the role of m1C in DNA is less understood compared to its function in RNA, it is considered a form of DNA damage that can arise from exposure to certain alkylating agents. If not repaired, m1C in DNA can lead to mutations. The base excision repair (BER) pathway is responsible for recognizing and removing such modified bases from the genome.
Quantitative Analysis of Cytosine Methylation
The abundance of methylated cytosine varies across different tissues and disease states. While specific quantitative data for this compound is still emerging, data for the related 5-methylcytosine provides a valuable reference for understanding the landscape of cytosine methylation.
| Tissue/Cell Type | 5-Methylcytosine (m5C) Abundance (mole percent) | Reference |
| Human Thymus | 1.00 | [21] |
| Human Brain | 0.98 | [21] |
| Human Sperm | 0.84 | [21] |
| Human Placenta | 0.76 | [21] |
| Human Cell Lines | 0.57 - 0.85 | [21] |
| Human Brain (Cerebellum) - 5-Hydroxymethylcytosine (5hmC) | 1550 modifications per 10^6 nucleosides | [22] |
| Human Brain (Cerebellum) - 5-Formylcytosine (5fC) | 1.7 modifications per 10^6 nucleosides | [22] |
| Human Brain (Cerebellum) - 5-Carboxylcytosine (5caC) | 0.15 modifications per 10^6 nucleosides | [22] |
| Human Brain, Liver, Kidney, Colorectal Tissues - 5-hmC | 0.40–0.65% | [23] |
| Human Lung - 5-hmC | 0.18% | [23] |
| Human Heart, Breast, Placenta - 5-hmC | 0.05-0.06% | [23] |
| Cancerous Colorectal Tissues - 5-hmC | 0.02–0.06% | [23] |
| Normal Colorectal Tissues - 5-hmC | 0.46–0.57% | [23] |
Experimental Protocols for this compound Detection
Several techniques are available for the detection and quantification of m1C in DNA and RNA. Below are detailed methodologies for two key approaches.
RNA Bisulfite Sequencing (m1C-BS-Seq)
This method allows for the single-nucleotide resolution mapping of m1C sites in RNA.
Protocol:
-
RNA Isolation: Isolate total RNA from the sample of interest using a standard RNA extraction protocol. Assess RNA quality and quantity using a spectrophotometer and agarose (B213101) gel electrophoresis.[24]
-
mRNA Enrichment (Optional): If focusing on mRNA, enrich for polyadenylated transcripts using oligo(dT) magnetic beads.[24]
-
Bisulfite Conversion: Treat the RNA with sodium bisulfite. This chemical treatment converts unmethylated cytosines to uracil, while this compound remains unchanged.[24][25]
-
Denature 100 ng to 2 µg of RNA by heating at 70°C for 10 minutes.
-
Prepare a fresh solution of sodium bisulfite and hydroquinone.
-
Add the bisulfite solution to the denatured RNA and incubate at 55-65°C for 4-16 hours.
-
-
RNA Cleanup: Purify the bisulfite-converted RNA using a spin column-based method to remove excess bisulfite and other reagents.[24]
-
Reverse Transcription: Synthesize first-strand cDNA from the bisulfite-treated RNA using a reverse transcriptase and random primers or gene-specific primers.[24]
-
PCR Amplification: Amplify the cDNA using primers specific to the target region of interest. The forward primer should be designed to the converted sequence (with U's instead of C's), while the reverse primer is designed to the original sequence.
-
Library Preparation and Sequencing: Prepare a sequencing library from the PCR products and perform high-throughput sequencing.[26][27]
-
Data Analysis: Align the sequencing reads to a reference genome or transcriptome. Unmethylated cytosines will be read as thymines (due to the U to T conversion during PCR), while 1-methylcytosines will be read as cytosines.
Liquid Chromatography-Mass Spectrometry (LC-MS/MS)
LC-MS/MS provides a highly sensitive and quantitative method for measuring the global levels of m1C.
Protocol:
-
Nucleic Acid Extraction and Digestion:
-
Extract DNA or RNA from the sample.
-
Digest the nucleic acids into individual nucleosides using a cocktail of enzymes such as nuclease P1 and alkaline phosphatase.
-
-
Chromatographic Separation:
-
Inject the nucleoside mixture onto a reverse-phase high-performance liquid chromatography (HPLC) column.
-
Separate the nucleosides using a gradient of solvents (e.g., water with formic acid and methanol).[28]
-
-
Mass Spectrometry Analysis:
-
Elute the separated nucleosides from the HPLC column directly into the electrospray ionization (ESI) source of a tandem mass spectrometer.
-
Perform selected reaction monitoring (SRM) or multiple reaction monitoring (MRM) to specifically detect and quantify this compound based on its unique mass-to-charge ratio (m/z) and fragmentation pattern.[28][29]
-
-
Quantification:
-
Generate a standard curve using known concentrations of a pure this compound standard.
-
Calculate the absolute or relative amount of m1C in the sample by comparing its peak area to the standard curve.
-
This compound in Disease
Aberrant m1C modification has been implicated in the pathogenesis of various diseases, particularly cancer.
-
Cancer: The dysregulation of m1C writers, erasers, and readers is frequently observed in cancer.[30][31][32] For instance, the overexpression of the m1C writer NSUN2 and the reader YBX1 has been linked to increased stability of oncogenic mRNAs, promoting tumor growth and metastasis in various cancers, including bladder, cervical, and colorectal cancer.[8]
-
Neurological Disorders: Emerging evidence suggests a role for RNA methylation in neurodevelopment and neurological diseases.[6] The precise involvement of m1C in these conditions is an area of active investigation.
-
Cellular Aging: Recent studies have linked the m1C methyltransferases NSUN2 and NSUN6 to cellular aging processes.[3][5][6][33]
Signaling and Experimental Workflow Diagrams
DOT Language Scripts and Diagrams
Caption: The lifecycle of this compound (m1C) modification in RNA.
Caption: The YBX1-mediated mRNA stability pathway initiated by m1C.
Caption: Experimental workflow for this compound detection by bisulfite sequencing.
Conclusion
This compound is emerging as a critical player in the epitranscriptomic regulation of gene expression. The identification of its writers, erasers, and readers has provided a framework for understanding its functional roles in mRNA stability, translation, and export. The dysregulation of the m1C lifecycle has significant implications for human health, particularly in the context of cancer. The continued development of sensitive and specific detection methods will be crucial for further elucidating the biological functions of m1C and for exploring its potential as a biomarker and therapeutic target in various diseases. This guide provides a foundational resource for researchers to delve into the exciting and rapidly evolving field of this compound biology.
References
- 1. researchgate.net [researchgate.net]
- 2. researchgate.net [researchgate.net]
- 3. Frontiers | Unveiling the potential impact of RNA m5C methyltransferases NSUN2 and NSUN6 on cellular aging [frontiersin.org]
- 4. Multifaceted functions of Y-box binding protein 1 in RNA methylated modifications (Review) - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Unveiling the potential impact of RNA m5C methyltransferases NSUN2 and NSUN6 on cellular aging - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. Unveiling the potential impact of RNA m5C methyltransferases NSUN2 and NSUN6 on cellular aging - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Substrate diversity of NSUN enzymes and links of 5-methylcytosine to mRNA translation and turnover | Life Science Alliance [life-science-alliance.org]
- 8. mdpi.com [mdpi.com]
- 9. TRMT6/61A-dependent base methylation of tRNA-derived fragments regulates gene-silencing activity and the unfolded protein response in bladder cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 10. researchgate.net [researchgate.net]
- 11. researchgate.net [researchgate.net]
- 12. Depletion of the m1A writer TRMT6/TRMT61A reduces proliferation and resistance against cellular stress in bladder cancer - PubMed [pubmed.ncbi.nlm.nih.gov]
- 13. Frontiers | Depletion of the m1A writer TRMT6/TRMT61A reduces proliferation and resistance against cellular stress in bladder cancer [frontiersin.org]
- 14. ALKBH1 alkB homolog 1, histone H2A dioxygenase [Homo sapiens (human)] - Gene - NCBI [ncbi.nlm.nih.gov]
- 15. UChicago scientists identify enzyme that removes molecular - UChicago Medicine [uchicagomedicine.org]
- 16. The biological function of demethylase ALKBH1 and its role in human diseases - PMC [pmc.ncbi.nlm.nih.gov]
- 17. academic.oup.com [academic.oup.com]
- 18. journals.biologists.com [journals.biologists.com]
- 19. mdpi.com [mdpi.com]
- 20. tandfonline.com [tandfonline.com]
- 21. Amount and distribution of 5-methylcytosine in human DNA from different types of tissues of cells - PMC [pmc.ncbi.nlm.nih.gov]
- 22. Quantitative assessment of Tet-induced oxidation products of 5-methylcytosine in cellular and tissue DNA - PMC [pmc.ncbi.nlm.nih.gov]
- 23. Distribution of 5-Hydroxymethylcytosine in Different Human Tissues - PMC [pmc.ncbi.nlm.nih.gov]
- 24. A Guide to RNA Bisulfite Sequencing (m5C Sequencing) - CD Genomics [rna.cd-genomics.com]
- 25. Bisulfite Protocol | Stupar Lab [stuparlab.cfans.umn.edu]
- 26. bcm.edu [bcm.edu]
- 27. epigenie.com [epigenie.com]
- 28. Ultraperformance Liquid Chromatography Tandem Mass Spectrometry Assay of DNA Cytosine Methylation Excretion from Biological Systems - PMC [pmc.ncbi.nlm.nih.gov]
- 29. pubs.acs.org [pubs.acs.org]
- 30. RNA modifications in cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 31. dovepress.com [dovepress.com]
- 32. RNA modifications in cancer - PubMed [pubmed.ncbi.nlm.nih.gov]
- 33. researchgate.net [researchgate.net]
The Enigmatic Presence of 1-Methylcytosine in Genomes: A Technical Guide
For Researchers, Scientists, and Drug Development Professionals
Introduction
In the landscape of epigenetics, cytosine methylation has long been a cornerstone of gene regulation research. The vast majority of this focus has been on 5-methylcytosine (B146107) (5mC), the so-called "fifth base" of DNA, which plays a critical role in transcriptional silencing, genomic imprinting, and X-chromosome inactivation in mammals.[1][2] However, the cytosine ring can be methylated at different positions, leading to isomers with potentially distinct biological implications. This technical guide delves into the natural occurrence, detection, and functional significance of one such isomer: 1-methylcytosine (B60703) (1mC).
Unlike the well-established role of 5mC as a key epigenetic marker, current scientific evidence suggests that this compound in DNA is not a common, intentionally placed regulatory modification. Instead, its presence in the genome is primarily considered a form of DNA damage arising from exposure to alkylating agents. This guide will provide a comprehensive overview of 1mC, focusing on its formation as a DNA lesion, the cellular mechanisms for its repair, and the advanced methodologies used for its detection and quantification.
This compound: A DNA Lesion Requiring Repair
This compound is a methylated form of the DNA base cytosine where a methyl group is attached to the nitrogen atom at the first position of the pyrimidine (B1678525) ring.[3] This modification is distinct from the more prevalent 5-methylcytosine, where the methyl group is at the fifth carbon position.[3] While 5mC is enzymatically deposited by DNA methyltransferases (DNMTs) to regulate gene expression, 1mC is typically formed by the action of endogenous or exogenous alkylating agents.
Formation of this compound
The formation of 1mC is a consequence of DNA alkylation, a process where alkyl groups are transferred to the DNA molecule. This can be induced by various environmental and cellular agents. While specific quantitative data on the natural abundance of 1mC in genomic DNA is scarce, its presence is generally associated with exposure to methylating agents.
Repair of this compound
The cellular defense against alkylating DNA damage involves a class of enzymes known as AlkB homologs. In humans, the primary enzymes responsible for the repair of such lesions are ALKBH2 and ALKBH3.[4][5] These enzymes function as dioxygenases that catalyze the oxidative demethylation of alkylated bases, directly reversing the damage.
The primary substrates for ALKBH2 and ALKBH3 are 1-methyladenine (B1486985) (1meA) and 3-methylcytosine (B1195936) (3meC).[4][5] While direct evidence for the repair of 1mC by these enzymes is still emerging, their known substrate specificity suggests they are the most likely candidates for its removal. Mice lacking mABH2 have been shown to accumulate significant levels of 1meA in their genome, highlighting the importance of this repair pathway in handling endogenous methylation damage.[5]
dot
References
- 1. DNA - Wikipedia [en.wikipedia.org]
- 2. Genome-wide detection of cytosine methylation by single molecule real-time sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 3. researchgate.net [researchgate.net]
- 4. Lack of mismatch repair enhances resistance to methylating agents for cells deficient in oxidative demethylation - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Repair deficient mice reveal mABH2 as the primary oxidative demethylase for repairing 1meA and 3meC lesions in DNA | The EMBO Journal [link.springer.com]
In Vitro Enzymatic Synthesis of 1-Methylcytosine: A Technical Guide
An In-depth Technical Guide for Researchers, Scientists, and Drug Development Professionals
December 4, 2025
Executive Summary
The precise control of cellular processes through epigenetic and epitranscriptomic modifications is a burgeoning field of study, offering novel avenues for therapeutic intervention. Among these modifications, the methylation of cytosine residues in nucleic acids plays a critical role. This technical guide addresses the enzymatic synthesis of 1-methylcytosine (B60703) (1mC) in vitro. However, it is crucial to note that the scientific literature extensively details the enzymatic synthesis of the isomeric 5-methylcytosine (B146107) (m5C) in RNA, while information on the enzymatic production of this compound is notably scarce. The primary enzymes responsible for RNA cytosine methylation, the NSUN family and DNMT2, are known to catalyze the formation of m5C.
This guide, therefore, provides a comprehensive overview of the well-established in vitro enzymatic synthesis of 5-methylcytosine in RNA, which serves as a robust framework for researchers interested in cytosine methylation. We will detail the key enzymes involved, provide established experimental protocols, and present quantitative data to facilitate the design and execution of in vitro methylation studies. Additionally, we will discuss what is known about this compound and suggest alternative methods for its incorporation into RNA.
Introduction to Cytosine Methylation in RNA
Cytosine methylation is a post-transcriptional modification that plays a significant role in various aspects of RNA metabolism, including stability, translation, and nuclear export. The most prevalent and well-studied form of cytosine methylation in RNA is 5-methylcytosine (m5C). This modification is catalyzed by a family of enzymes known as RNA methyltransferases. In contrast, this compound (1mC) is a structural isomer of m5C where the methyl group is attached to the N1 position of the cytosine ring. While 1mC has been utilized in synthetic biological systems, such as hachimoji DNA, its natural occurrence and enzymatic synthesis pathways in biological systems are not well-documented.
Key Enzymes in 5-Methylcytosine (m5C) RNA Synthesis
The primary enzymes responsible for catalyzing the formation of m5C in RNA are members of the NOL1/NOP2/Sun domain (NSUN) family and the DNA methyltransferase homolog DNMT2 (also known as TRDMT1).
-
NSUN2: A major m5C methyltransferase in mammals, NSUN2 targets a wide range of RNAs, including transfer RNAs (tRNAs) and messenger RNAs (mRNAs).
-
NSUN6: This enzyme is another key tRNA m5C methyltransferase, specifically targeting cytosine 72 in the acceptor stem of certain tRNAs, such as tRNA-Cys and tRNA-Thr.
-
DNMT2 (TRDMT1): Despite its homology to DNA methyltransferases, DNMT2 is a highly conserved RNA methyltransferase that specifically methylates cytosine 38 in the anticodon loop of tRNA-Asp, tRNA-Gly, and tRNA-Val.
These enzymes utilize S-adenosylmethionine (SAM) as the methyl group donor in a reaction that results in the formation of 5-methylcytosine in the target RNA and S-adenosylhomocysteine (SAH) as a byproduct.
Quantitative Data for In Vitro m5C Methylation
The following table summarizes key quantitative parameters for the enzymatic activity of m5C RNA methyltransferases. This data is essential for designing kinetic studies and optimizing reaction conditions.
| Enzyme | Substrate | K_m (µM) | k_cat (min⁻¹) | Optimal Temperature (°C) | Optimal pH |
| Human DNMT2 | tRNA-Asp | ~1.0 | ~0.05 | 37 | 7.5 - 8.0 |
| Human NSUN2 | tRNA | Not widely reported | Not widely reported | 37 | 7.5 - 8.0 |
| Human NSUN6 | tRNA-Cys | ~0.5 | ~0.1 | 37 | 7.0 - 7.5 |
Note: Kinetic parameters for RNA methyltransferases can vary significantly depending on the specific RNA substrate, its folding state, and the assay conditions. The values presented here are approximate and collated from various studies for guidance.
Experimental Protocols for In Vitro m5C RNA Methylation
This section provides a generalized yet detailed methodology for the in vitro methylation of RNA using recombinant m5C methyltransferases.
Preparation of Recombinant Methyltransferases
The expression and purification of active recombinant NSUN2, NSUN6, or DNMT2 are critical for successful in vitro methylation. A common approach involves the following steps:
-
Cloning: The cDNA of the desired methyltransferase is cloned into an expression vector (e.g., pGEX, pET, or pMAL series) containing an affinity tag (e.g., GST, His6, or MBP) for purification.
-
Expression: The expression vector is transformed into a suitable host, typically E. coli (e.g., BL21(DE3) strain). Protein expression is induced under optimized conditions of temperature and inducer concentration (e.g., IPTG).
-
Lysis: Bacterial cells are harvested and lysed using sonication or high-pressure homogenization in a lysis buffer containing protease inhibitors.
-
Purification: The soluble lysate is cleared by centrifugation, and the recombinant protein is purified using affinity chromatography (e.g., Glutathione Sepharose for GST-tags, Ni-NTA agarose (B213101) for His6-tags, or amylose (B160209) resin for MBP-tags)[1][2][3].
-
Quality Control: The purity and concentration of the purified enzyme are assessed by SDS-PAGE with Coomassie blue staining and a protein concentration assay (e.g., Bradford or BCA).
In Vitro RNA Transcription
The RNA substrate for the methylation reaction is typically generated by in vitro transcription.
-
Template Generation: A DNA template containing a T7, T3, or SP6 promoter upstream of the target RNA sequence is prepared. This can be a linearized plasmid or a PCR product.
-
Transcription Reaction: The in vitro transcription reaction is set up using a commercially available kit or individual components, including the DNA template, RNA polymerase (e.g., T7 RNA polymerase), and ribonucleoside triphosphates (NTPs).
-
Purification: The transcribed RNA is purified, typically by denaturing polyacrylamide gel electrophoresis (PAGE) followed by elution, or by using specialized RNA purification columns.
In Vitro Methylation Reaction
The following is a general protocol for an in vitro RNA methylation assay. The optimal conditions may need to be determined empirically for each enzyme-substrate pair.
Reaction Components:
| Component | Stock Concentration | Final Concentration |
| Recombinant Methyltransferase (NSUN2, NSUN6, or DNMT2) | 10 µM | 0.5 - 1.0 µM |
| RNA Substrate | 10 µM | 0.5 - 2.0 µM |
| Methylation Buffer (10X) | See below | 1X |
| S-Adenosylmethionine (SAM) | 10 mM | 100 - 200 µM |
| RNase Inhibitor | 40 U/µL | 0.5 U/µL |
| Nuclease-free Water | - | To final volume |
10X Methylation Buffer Composition (General):
-
200-500 mM Tris-HCl or HEPES-KOH (pH 7.5-8.0)
-
500-1000 mM NaCl or KCl
-
50 mM MgCl₂
-
10 mM DTT
Protocol:
-
In a nuclease-free microcentrifuge tube, combine the RNA substrate, 10X methylation buffer, RNase inhibitor, and nuclease-free water.
-
Heat the mixture at 65-70°C for 5 minutes and then allow it to cool to room temperature to ensure proper RNA folding.
-
Add the recombinant methyltransferase and SAM to the reaction mixture.
-
To stop the reaction, add EDTA to a final concentration of 20 mM or heat-inactivate the enzyme (if appropriate).
-
The methylated RNA can then be purified by phenol:chloroform extraction and ethanol (B145695) precipitation or by using an RNA cleanup kit.
For detection and quantification of methylation, radiolabeled [³H]-SAM can be used, and the incorporation of the radiolabel into the RNA can be measured by scintillation counting or visualized by autoradiography after gel electrophoresis[4][5].
Analysis of RNA Methylation
Several techniques can be employed to detect and quantify m5C in RNA following the in vitro reaction.
-
High-Performance Liquid Chromatography (HPLC): The RNA is enzymatically hydrolyzed to nucleosides, and the resulting mixture is separated by reverse-phase HPLC. The m5C peak can be identified and quantified by comparing its retention time and peak area to a known standard[7].
-
Liquid Chromatography-Mass Spectrometry (LC-MS): This highly sensitive method allows for the definitive identification and quantification of m5C and other modified nucleosides based on their mass-to-charge ratio[8][9][10].
-
Bisulfite Sequencing: This technique can be adapted for RNA to map the precise location of m5C residues at single-nucleotide resolution. Unmethylated cytosines are converted to uracil (B121893) upon bisulfite treatment, while m5C remains unchanged.
The Case of this compound (1mC)
As previously stated, there is a significant lack of information regarding the enzymatic synthesis of this compound in RNA. Its primary mention in the literature is in the context of synthetic biology, where it is used as a component of an expanded genetic alphabet[11].
For researchers seeking to incorporate 1mC into RNA for functional or structural studies, the most viable and established approach is through chemical synthesis . This involves:
-
Synthesis of 1-methylcytidine phosphoramidite (B1245037): The 1-methylcytidine nucleoside is chemically synthesized and then converted into a phosphoramidite building block suitable for solid-phase RNA synthesis.
-
Solid-phase RNA synthesis: The 1-methylcytidine phosphoramidite is incorporated at the desired position(s) in an RNA oligonucleotide using an automated RNA synthesizer.
This chemical synthesis route offers precise control over the location of the modification.
Visualizing the In Vitro RNA Methylation Workflow
The following diagrams illustrate the key processes described in this guide.
Caption: Workflow for the in vitro enzymatic synthesis of m5C-modified RNA.
Caption: The enzymatic reaction for 5-methylcytosine (m5C) formation in RNA.
Conclusion
While the direct enzymatic synthesis of this compound in vitro remains an underexplored area, the methodologies for the in vitro synthesis of 5-methylcytosine are well-established and provide a valuable blueprint for research in RNA methylation. This guide has provided a detailed overview of the key enzymes, quantitative data, experimental protocols, and analytical techniques pertinent to the study of m5C in RNA. For researchers specifically interested in this compound, chemical synthesis stands as the most reliable method for its incorporation into RNA. As the field of epitranscriptomics continues to evolve, further research may yet uncover the enzymatic machinery and biological significance of this compound.
References
- 1. academic.oup.com [academic.oup.com]
- 2. mdanderson.org [mdanderson.org]
- 3. Purification Strategy for Recombinant Forms of the Human Mitochondrial DNA Helicase - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Human DNMT2 methylates tRNAAsp molecules using a DNA methyltransferase-like catalytic mechanism - PMC [pmc.ncbi.nlm.nih.gov]
- 5. NSUN6 is a human RNA methyltransferase that catalyzes formation of m5C72 in specific tRNAs - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Mammalian NSUN2 introduces 5-methylcytidines into mitochondrial tRNAs - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Detection of RNA Modifications by HPLC Analysis and Competitive ELISA - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Formation and determination of the oxidation products of 5-methylcytosine in RNA - Chemical Science (RSC Publishing) DOI:10.1039/C6SC01589A [pubs.rsc.org]
- 9. Liquid Chromatography-Mass Spectrometry for Analysis of RNA Adenosine Methylation | Springer Nature Experiments [experiments.springernature.com]
- 10. tandfonline.com [tandfonline.com]
- 11. biorxiv.org [biorxiv.org]
1-Methylcytosine in Hachimoji DNA Systems: A Technical Guide
For Researchers, Scientists, and Drug Development Professionals
This technical guide provides an in-depth overview of 1-Methylcytosine (1mC) within the framework of hachimoji DNA, an artificially expanded genetic information system. It covers the core concepts, quantitative structural and thermodynamic data, detailed experimental protocols, and potential applications relevant to research and drug development.
Introduction to this compound and Hachimoji DNA
The expansion of the genetic alphabet beyond the canonical four bases (A, T, C, G) is a cornerstone of synthetic biology, offering unprecedented opportunities for data storage, nanotechnology, and the creation of novel biologics.[1] Hachimoji DNA stands as a landmark achievement in this field, creating a stable eight-letter genetic system that can store and transmit information.[2] This system incorporates four synthetic nucleotides to form two additional, non-natural base pairs alongside the native A:T and G:C pairs.[3]
A key component in this expanded alphabet is This compound (1mC) . Unlike the more common epigenetic marker 5-methylcytosine, 1mC features a methyl group on the N1 position of the pyrimidine (B1678525) ring. In the context of hachimoji DNA, 1mC (designated as S ) serves as a synthetic pyrimidine analog that forms a stable, three-hydrogen-bond pair with the purine (B94841) analog isoguanine (B23775) (B) .[4][5] This guide explores the structural and functional integration of 1mC into the hachimoji system, providing the technical details necessary for its study and application.
Core Concepts of the Hachimoji System
The hachimoji system is built on the principle of size and hydrogen-bonding complementarity, ensuring that the synthetic base pairs integrate seamlessly into the double helix without distorting its structure.[6] The system comprises four orthogonal base pairs:
-
Natural Purine:Pyrimidine Pairs:
-
Adenine (A) : Thymine (T)
-
Guanine (G) : Cytosine (C)
-
-
Synthetic Purine:Pyrimidine Pairs:
The B:S pair, featuring this compound, is critical to the system's stability and informational capacity. High-order quantum-mechanical analysis confirms that the non-natural B:S and P:Z pairs exhibit stronger interaction energies than their natural counterparts, contributing to the overall stability of the hachimoji duplex.[4]
Quantitative Data and Structural Properties
The integration of 1mC and other synthetic bases into hachimoji DNA results in a predictable and robust biopolymer. Extensive biophysical studies have quantified its structural and thermodynamic properties.[6]
Table 1: Structural Parameters of Hachimoji DNA vs. Natural B-DNA
| Parameter | Hachimoji DNA | Natural B-DNA | Reference |
|---|---|---|---|
| Helical Form | B-form | B-form | [6][7] |
| Base Pairs per Turn | 10.2 – 10.4 | ~10.5 | [7] |
| Groove Geometry | Major and minor groove widths similar to GC-rich DNA | Varies with AT/GC content | [7] |
| Pair Parameters | Buckle and propeller angles fall within ranges for natural DNA | Standard ranges |[7] |
Table 2: Thermodynamic Stability of Hachimoji DNA Duplexes
| Parameter | Value | Description | Reference |
|---|---|---|---|
| Number of Duplexes Studied | 94 | A diverse set of sequences containing all eight bases was analyzed. | [6] |
| Average Tm Prediction Error | ± 2.1 °C | Melting temperature (Tm) predictions based on a nearest-neighbor model show high accuracy. | [6][7] |
| Average ΔG°37 Prediction Error | ± 0.39 kcal/mol | Gibbs free energy change predictions also demonstrate the system's thermodynamic predictability. |[6][8] |
Experimental Protocols & Workflows
The study and application of hachimoji DNA involves several key experimental procedures, from synthesis to functional analysis.
Hachimoji DNA strands, including those containing this compound, are synthesized using standard solid-phase phosphoramidite (B1245037) chemistry on an automated synthesizer.[6][7] This cyclic process builds the DNA strand one base at a time.
Methodology:
-
Deblocking/Detritylation: The 5'-dimethoxytrityl (DMT) protecting group is removed from the support-bound nucleoside using an acid (e.g., trichloroacetic acid), exposing a free 5'-hydroxyl group.[9]
-
Coupling: The next phosphoramidite monomer (e.g., the 1mC phosphoramidite), activated by a catalyst like tetrazole, is added. Its 3'-phosphoramidite group reacts with the free 5'-hydroxyl of the growing chain.[9]
-
Capping: Any unreacted 5'-hydroxyl groups are acetylated ("capped") using reagents like acetic anhydride (B1165640) to prevent the formation of deletion-mutant sequences.[10]
-
Oxidation: The unstable phosphite (B83602) triester linkage formed during coupling is oxidized to a stable phosphate (B84403) triester using an iodine solution, completing the cycle for that nucleotide addition.[11]
-
Final Cleavage and Deprotection: After the final cycle, the completed oligonucleotide is cleaved from the solid support, and all remaining protecting groups on the bases and phosphate backbone are removed, typically with aqueous ammonia.[11][12]
The stability of hachimoji duplexes is determined by measuring their melting temperature (Tm) using UV-Vis spectrophotometry.
Methodology:
-
Sample Preparation: Synthesize complementary hachimoji DNA oligonucleotides. Anneal them in a buffer solution (e.g., 0.25M NaCl, 20mM Sodium Phosphate, pH 7.0).[13]
-
UV Absorbance Measurement: Place the duplex solution in a cuvette in a spectrophotometer with a temperature controller. Monitor the UV absorbance at 260 nm as the temperature is slowly increased (e.g., 1°C/min).[13]
-
Data Acquisition: As the DNA duplex "melts" into single strands, the absorbance increases due to the hyperchromic effect. A melting curve of absorbance vs. temperature is generated.[14]
-
Tm Calculation: The Tm is the temperature at which 50% of the DNA is in the duplex state, corresponding to the midpoint of the transition on the melting curve. This is often calculated from the peak of the first derivative of the curve.[14][15]
-
Thermodynamic Parameter Derivation: The raw melting data from multiple duplexes and concentrations are processed with specialized software (e.g., Meltwin v.3.5) to derive nearest-neighbor thermodynamic parameters like Gibbs Free Energy (ΔG°37) and Enthalpy (ΔH°).[6]
High-resolution structural data for hachimoji DNA was obtained via X-ray crystallography using a host-guest complex method.[6][16]
Methodology:
-
Complex Formation: A self-complementary 16-mer hachimoji DNA duplex (the "guest") is mixed with a protein, such as the N-terminal fragment of Moloney murine leukemia virus reverse transcriptase (the "host"). The protein binds to the ends of the duplex, creating a stable complex that facilitates crystallization.[7][16]
-
Crystallization: The protein-DNA complex is subjected to sparse matrix screening, where it is mixed with a wide array of precipitants, buffers, and salts to find conditions that promote the growth of single, well-ordered crystals.[17][18]
-
X-ray Diffraction: A suitable crystal is cryo-protected and exposed to a high-intensity X-ray beam. The crystal diffracts the X-rays into a specific pattern of spots, which is recorded by a detector.[19]
-
Structure Solution and Refinement: The diffraction pattern is processed to determine the electron density map of the molecule. A 3D model of the hachimoji duplex is then built into this map and refined to produce a final, high-resolution atomic structure.[19]
A key functional test of hachimoji DNA is its ability to be transcribed into RNA. This requires an engineered RNA polymerase capable of recognizing all eight bases.[6]
Methodology:
-
Template Preparation: A linear DNA template is prepared, typically by PCR or plasmid linearization. The template must contain a double-stranded T7 promoter sequence upstream of the hachimoji sequence to be transcribed.[20]
-
Reaction Assembly: The transcription reaction is assembled at room temperature and includes the DNA template, all eight ribonucleoside triphosphates (NTPs for A, U, G, C, and the synthetic bases), a transcription buffer, and an engineered T7 RNA polymerase variant (e.g., the "FAL" variant).[7][21]
-
Incubation: The reaction is incubated at 37°C for several hours to allow the polymerase to synthesize the hachimoji RNA transcript.[22]
-
Template Removal and Purification: The DNA template is removed by treatment with DNase. The resulting RNA is then purified, for example by ethanol (B145695) precipitation or gel electrophoresis.[21][23]
-
Analysis: The integrity and composition of the hachimoji RNA product are confirmed using methods like thin-layer chromatography (TLC) or HPLC.[7]
Applications in Drug Discovery and Development
The ability to expand the genetic alphabet with components like this compound opens new frontiers in drug discovery and therapeutic development.[24]
-
Novel Biotherapeutics: An expanded genetic code allows for the site-specific incorporation of non-canonical amino acids (ncAAs) into proteins.[25] This can be used to create next-generation antibody-drug conjugates (ADCs) with precisely controlled drug-to-antibody ratios, engineer proteins with enhanced stability and half-life, or develop novel immunotherapies.[26]
-
Aptamer-Based Diagnostics and Therapeutics: Hachimoji DNA and RNA can be used to generate aptamers—nucleic acid molecules that bind to specific targets with high affinity. The increased chemical diversity of an eight-letter system can lead to aptamers with superior binding properties for diagnostic reagents or as therapeutic agents themselves.[6]
-
Advanced Information Storage: The information density of hachimoji DNA is double that of natural DNA, making it a candidate for advanced, long-term molecular data storage.[2]
-
Elucidation of Drug Mechanisms: The ability to introduce unique chemical functionalities into proteins can help elucidate complex biological mechanisms and map interactions between drug targets and their ligands or antibodies.[25][27]
Conclusion
This compound is an integral component of the hachimoji expanded genetic alphabet, serving as the stable pyrimidine analog 'S' that pairs with isoguanine 'B'. Its successful incorporation underscores the power of synthetic chemistry to create a robust, eight-letter genetic system that adheres to the fundamental structural and thermodynamic principles of natural DNA. For researchers and drug development professionals, the hachimoji system, enabled by synthetic bases like 1mC, provides a powerful toolkit for creating novel biologics, diagnostics, and materials, pushing the boundaries of what is possible in biotechnology and medicine.
References
- 1. Vision of expanded genetic code for making novel biologics comes closer to realization | Scripps Research [scripps.edu]
- 2. Hachimoji DNA and RNA: A genetic system with eight building blocks - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. Hachimoji DNA: The Eight-letter Genetic Code | Center for Genetically Encoded Materials [gem-net.net]
- 4. High-Order Quantum-Mechanical Analysis of Hydrogen Bonding in Hachimoji and Natural DNA Base Pairs - PMC [pmc.ncbi.nlm.nih.gov]
- 5. File:Hachimoji DNA base pairs.png - Wikimedia Commons [commons.wikimedia.org]
- 6. Hachimoji DNA and RNA. A Genetic System with Eight Building Blocks - PMC [pmc.ncbi.nlm.nih.gov]
- 7. trilinkbiotech.com [trilinkbiotech.com]
- 8. researchgate.net [researchgate.net]
- 9. DNA寡核苷酸合成 [sigmaaldrich.com]
- 10. Synthesis of DNA/RNA and Their Analogs via Phosphoramidite and H-Phosphonate Chemistries - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Standard Protocol for Solid-Phase Oligonucleotide Synthesis using Unmodified Phosphoramidites | LGC, Biosearch Technologies [biosearchtech.com]
- 12. Manual Oligonucleotide Synthesis Using the Phosphoramidite Method | Springer Nature Experiments [experiments.springernature.com]
- 13. chem.sites.mtu.edu [chem.sites.mtu.edu]
- 14. ocw.mit.edu [ocw.mit.edu]
- 15. sigmaaldrich.com [sigmaaldrich.com]
- 16. berstructuralbioportal.org [berstructuralbioportal.org]
- 17. bitesizebio.com [bitesizebio.com]
- 18. home.ccr.cancer.gov [home.ccr.cancer.gov]
- 19. x Ray crystallography - PMC [pmc.ncbi.nlm.nih.gov]
- 20. RNAT7 < Lab < TWiki [barricklab.org]
- 21. josephgroup.ucsd.edu [josephgroup.ucsd.edu]
- 22. tools.thermofisher.com [tools.thermofisher.com]
- 23. researchgate.net [researchgate.net]
- 24. pubs.acs.org [pubs.acs.org]
- 25. researchgate.net [researchgate.net]
- 26. Therapeutic applications of genetic code expansion - PMC [pmc.ncbi.nlm.nih.gov]
- 27. walshmedicalmedia.com [walshmedicalmedia.com]
understanding the significance of N1-methylation of cytosine
An In-depth Technical Guide to N1-methylcytosine (m1C)
For Researchers, Scientists, and Drug Development Professionals
Abstract
Nthis compound (m1C) is a modification of the cytosine base where a methyl group is attached to the nitrogen atom at position 1. Unlike the well-studied 5-methylcytosine (B146107) (m5C), which is a key epigenetic mark in many organisms, Nthis compound is not considered a common, programmed epigenetic modification. Instead, the current body of scientific literature predominantly characterizes m1C as a form of nucleic acid damage induced by alkylating agents. This guide provides a comprehensive overview of the current understanding of m1C, focusing on its formation, its recognition and repair as a DNA lesion, and the potential methodologies for its detection and analysis. Given the limited research specifically on m1C, this guide also draws analogies from the study of other alkylated base modifications, such as N1-methyladenine (m1A) and N3-methylcytosine (m3C).
Introduction: The Landscape of Cytosine Methylation
Cytosine methylation is a critical modification in nucleic acids, playing pivotal roles in the regulation of gene expression, genomic stability, and development. The most prevalent and extensively studied form is 5-methylcytosine (m5C), where a methyl group is added to the 5th carbon of the cytosine ring.[1][2] This modification is a cornerstone of epigenetics.[2]
In contrast, methylation at other positions on the cytosine ring, such as N1, N3, and N4, is less common and often associated with different biological consequences. N3-methylcytosine (m3C) is primarily recognized as a mutagenic DNA lesion arising from exposure to alkylating agents.[1] This guide focuses on Nthis compound, a modification that, like m3C, is largely understood as a product of DNA damage rather than a functional epigenetic mark.
Biochemical Formation and Chemical Properties of Nthis compound
The formation of Nthis compound in DNA and RNA is not believed to be a common enzymatic process for regulatory purposes in mammalian cells. Instead, it is primarily the result of exposure to endogenous or exogenous alkylating agents. These agents are electrophilic compounds that can react with nucleophilic centers in DNA and RNA, leading to the addition of alkyl groups. The N1 position of cytosine is a nucleophilic center susceptible to such attacks.[1]
Key points regarding the formation of m1C:
-
Source of Alkylating Agents: These can be environmental mutagens (e.g., industrial chemicals, tobacco smoke) or endogenous byproducts of cellular metabolism.
-
Chemical Instability: N1-methylation of cytosine can disrupt the Watson-Crick base pairing with guanine, as the N1 position is involved in hydrogen bonding. This disruption can lead to helix destabilization and create a lesion that stalls replication and transcription.[3]
Nthis compound as a DNA Lesion and Its Repair
The presence of m1C in DNA is considered a form of damage that can be cytotoxic and mutagenic if not repaired. Cells have evolved sophisticated DNA repair mechanisms to remove such lesions and restore the integrity of the genome. The primary pathway responsible for the repair of alkylated bases is Base Excision Repair (BER) .
While direct experimental evidence for the repair of m1C is limited, the process can be inferred from the well-established mechanisms for other similar lesions like N1-methyladenine (m1A) and N3-methylcytosine (m3C).[1][4]
The Base Excision Repair Pathway for Alkylated Bases
The BER pathway involves a series of enzymatic steps:
-
Recognition and Excision: An enzyme called a DNA glycosylase recognizes the damaged base. For alkylated bases, specific glycosylases such as AlkA in bacteria and its mammalian homolog, AlkB, can remove the damaged base by cleaving the N-glycosidic bond that links the base to the sugar-phosphate backbone.[1] This creates an apurinic/apyrimidinic (AP) site.
-
AP Site Incision: An AP endonuclease cleaves the phosphodiester backbone at the AP site.
-
DNA Synthesis: A DNA polymerase fills the gap with the correct nucleotide.
-
Ligation: DNA ligase seals the nick in the DNA backbone.
dot
Caption: Inferred Base Excision Repair Pathway for Nthis compound.
Potential Regulatory Roles and Significance in Disease
Due to the scarcity of research, there is currently no substantial evidence to suggest a programmed regulatory role for m1C in cellular processes like gene expression. Its significance in disease is primarily linked to its nature as a DNA lesion.
-
Cancer: The accumulation of DNA damage, including alkylated bases, is a hallmark of cancer. If the repair mechanisms for m1C are deficient, it could contribute to genomic instability and mutagenesis, potentially driving tumorigenesis.
-
Neurological Disorders: The brain has a high metabolic rate, which can lead to the production of endogenous alkylating agents. Inefficient repair of DNA lesions in post-mitotic neurons could contribute to neurodegenerative processes.
Methodologies for the Study of Nthis compound
Direct experimental protocols for the detection and quantification of m1C are not well-established. However, methodologies used for other rare DNA and RNA modifications can be adapted.
Quantitative Analysis
Table 1: Potential Quantitative Methods for Nthis compound
| Method | Principle | Advantages | Disadvantages |
| Liquid Chromatography-Mass Spectrometry (LC-MS) | Separates nucleosides by chromatography and identifies them by their mass-to-charge ratio. | Highly sensitive and specific. Can quantify absolute levels of modification. | Requires specialized equipment and expertise. |
| Immunoblotting (Dot Blot) | Uses an antibody specific to m1C to detect its presence in a sample of DNA or RNA. | Relatively simple and can provide a semi-quantitative estimate. | Depends on the availability and specificity of a high-quality antibody. |
Locus-Specific and Genome-Wide Mapping
Mapping the location of m1C in the genome or transcriptome would be challenging but crucial for understanding its distribution and potential hotspots.
Table 2: Potential Mapping Methods for Nthis compound
| Method | Principle | Advantages | Disadvantages |
| Immunoprecipitation followed by Sequencing (m1C-IP-seq) | Uses an m1C-specific antibody to enrich for DNA or RNA fragments containing the modification, which are then sequenced. | Can provide genome-wide or transcriptome-wide maps. | Relies on a specific and high-affinity antibody. |
| Chemical Derivatization and Sequencing | A chemical treatment could potentially be developed to specifically modify m1C, leading to a signature (e.g., a mutation or a stop) during reverse transcription or PCR, which can be detected by sequencing. | Can provide single-base resolution. | Requires the development of a specific and efficient chemical reaction. |
Experimental Protocols
Detailed protocols for the above methods would need to be adapted from existing protocols for other modifications. Below are generalized workflows.
Workflow 1: LC-MS for m1C Quantification
dot
Caption: Generalized LC-MS Workflow for m1C Quantification.
Workflow 2: m1C-IP-seq for Locus Mapping
dot
Caption: Generalized m1C-IP-seq Workflow.
Future Directions and Conclusions
The study of Nthis compound is still in its infancy. Future research is needed to:
-
Develop specific tools: The development of high-affinity antibodies and specific chemical methods for m1C detection is crucial for advancing the field.
-
Investigate its presence in different contexts: Systematic studies are needed to determine the prevalence of m1C in different organisms, tissues, and disease states.
-
Elucidate its biological impact: Further research is required to fully understand the consequences of m1C on DNA replication, transcription, and translation, and its role in mutagenesis.
References
- 1. Structural basis for enzymatic excision of N1-methyladenine and N3-methylcytosine from DNA - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Nucleic acid - Methylation, DNA, RNA | Britannica [britannica.com]
- 3. Structure determination of DNA methylation lesions N1-meA and N3-meC in duplex DNA using a cross-linked protein-DNA system - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. The Mechanisms of Generation, Recognition, and Erasure of DNA 5-Methylcytosine and Thymine Oxidations - PMC [pmc.ncbi.nlm.nih.gov]
Unraveling the Photochemistry of 1-Methylcytosine: A Theoretical Deep Dive into its Excited States
For Researchers, Scientists, and Drug Development Professionals
This technical guide provides a comprehensive overview of the theoretical studies on the excited states of 1-methylcytosine (B60703) (1mCyt), a crucial analog of the DNA base cytosine. Understanding the photophysical and photochemical behavior of 1mCyt is paramount for elucidating the mechanisms of UV-induced DNA damage and for the rational design of photosensitizers and photoprotective agents. This document summarizes key quantitative data from high-level computational studies, details the methodologies employed, and visualizes the complex deactivation pathways of photoexcited this compound.
Core Findings: A Tale of Ultrafast Deactivation
Theoretical investigations, primarily employing sophisticated quantum chemical methods, have revealed that this compound, much like its parent molecule cytosine, possesses a remarkable degree of photostability. This intrinsic property is attributed to highly efficient non-radiative decay channels that rapidly dissipate the energy absorbed from UV radiation, returning the molecule to its electronic ground state on a picosecond or even sub-picosecond timescale. These ultrafast deactivation pathways are critical in preventing potentially harmful photochemical reactions.
The photodynamics of this compound are governed by a complex interplay of different electronic excited states, primarily of ¹ππ* and ¹nπ* character. The initial photoexcitation typically populates a bright ¹ππ* state. From there, the molecule can navigate through a landscape of potential energy surfaces, leading to conical intersections (CIs) with the ground state or other excited states. These CIs act as efficient funnels for rapid internal conversion.
Furthermore, studies have highlighted the role of different tautomers, such as the canonical amino-oxo (AO) form and the less stable imino-oxo (IO) form, in the photochemistry of this compound. UV irradiation can induce tautomerization from the AO to the IO form, which itself has distinct photochemical properties.[1][2][3] The solvent environment has also been shown to play a significant role in modulating the excited-state dynamics and fluorescence properties of 1mCyt.[4][5]
Quantitative Data Summary
The following tables summarize the key quantitative data from various theoretical studies on the excited states of the canonical amino-keto tautomer of this compound. These values provide a comparative look at the energies of different electronic states and their transition probabilities.
Table 1: Calculated Vertical and Adiabatic Transition Energies (in cm⁻¹) and Oscillator Strengths (fₑₗ)
| State | Computational Method | Vertical Transition Energy (cm⁻¹) | Oscillator Strength (fₑₗ) | Adiabatic Transition Energy (cm⁻¹) |
| S₁ (¹ππ) | SCS-CC2/aug-cc-pVDZ | - | - | 31,899 |
| S₁ (¹ππ) | MS-CASPT2/ANO-L | - | - | 31,429 |
| S₂ (¹nπ) | SCS-CC2/aug-cc-pVDZ | ~42,500 | - | - |
| S₂ (¹nπ) | MS-CASPT2/ANO-L | ~42,500 | - | - |
| S₃/S₄ | MS-CASPT2/ANO-L | ~46,000 | - | - |
Data sourced from high-level ab initio calculations.[6]
Table 2: Excited State Lifetimes and Intersystem Crossing Rates
| Parameter | Condition/Method | Value |
| S₁ State Lifetime | Experimental (aqueous) | ~1 ps |
| Dark ¹nπ* State Lifetime | Experimental (aqueous) | ~5.7 ps |
| S₁⇝S₀ Internal Conversion Rate (k_IC) | Near S₁(v=0) | 2 x 10⁹ s⁻¹ |
| S₁⇝S₀ Internal Conversion Rate (k_IC) | E_exc = 516 cm⁻¹ | 1 x 10¹¹ s⁻¹ |
| S₁⇝T₁ Intersystem Crossing Rate (k_ISC) | Near S₁(v=0) | 2 x 10⁸ s⁻¹ |
| S₁⇝T₁ Intersystem Crossing Rate (k_ISC) | E_exc = 516 cm⁻¹ | 2 x 10⁹ s⁻¹ |
Experimental and computational data indicate that the internal conversion rate increases significantly with vibrational excess energy in the S₁ state.[4][5][7]
Methodologies and Protocols
The theoretical investigation of the excited states of this compound relies on a variety of high-level quantum chemical methods. A general workflow for these computational studies is outlined below.
Computational Workflow
References
- 1. Photochemistry and photophysics of the amino and imino tautomers of this compound: tautomerisation as a side product of the radiationless decay - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. Photochemistry and photophysics of the amino and imino tautomers of this compound: tautomerisation as a side product of the radiationless decay - Photochemical & Photobiological Sciences (RSC Publishing) [pubs.rsc.org]
- 3. researchgate.net [researchgate.net]
- 4. Is this compound a faithful model compound for ultrafast deactivation dynamics of cytosine nucleosides in solution? - Physical Chemistry Chemical Physics (RSC Publishing) [pubs.rsc.org]
- 5. pubs.rsc.org [pubs.rsc.org]
- 6. pubs.aip.org [pubs.aip.org]
- 7. The excited-state structure, vibrations, lifetimes, and nonradiative dynamics of jet-cooled this compound: AGOSR [agosr.com]
1-Methylcytosine's impact on DNA stability and structure
An In-depth Technical Guide to the Impact of 1-Methylcytosine (B60703) on DNA Stability and Structure
For: Researchers, Scientists, and Drug Development Professionals
Abstract
This compound (1mC) is a methylated derivative of the DNA base cytosine, where a methyl group is attached at the N1 position of the pyrimidine (B1678525) ring.[1] Unlike the well-studied epigenetic mark 5-methylcytosine (B146107) (5mC), 1mC is not a standard epigenetic modification and is typically considered a form of DNA damage. Its presence in the DNA duplex significantly alters the molecule's structural integrity and thermodynamic stability. This guide provides a comprehensive technical overview of the impact of this compound on DNA, summarizing key quantitative data, detailing relevant experimental protocols, and illustrating the biological pathways involved in its recognition and repair.
Introduction: this compound vs. 5-Methylcytosine
It is critical to distinguish this compound (1mC) from its isomer, 5-methylcytosine (5mC).
-
5-Methylcytosine (5mC): This is the most common DNA methylation mark in mammals, occurring at the C5 position of cytosine, primarily in CpG dinucleotides.[2][3] The methyl group extends into the major groove of the DNA helix without disrupting the Watson-Crick hydrogen bonds with guanine.[2] 5mC plays a crucial role in epigenetic regulation, including gene silencing and chromatin structuring.[4][5]
-
This compound (1mC): In 1mC, the methyl group is located at the N1 position.[1] This position is directly involved in the hydrogen bonding that forms the standard C-G base pair. Consequently, the presence of 1mC prevents canonical Watson-Crick pairing, leading to significant structural distortion and duplex destabilization. It is often formed by exposure to certain alkylating agents and is considered a mutagenic lesion.[6]
Due to its nature as a DNA lesion, quantitative biophysical data for 1mC is sparse compared to the extensive research on 5mC. This guide will present the available information on 1mC and, where direct data is lacking, will provide comparative data from 5mC studies to highlight their distinct effects.
Impact on DNA Stability
The methylation at the N1 position fundamentally disrupts the hydrogen bonding capacity of cytosine, preventing a stable Watson-Crick pair with guanine. This disruption is the primary driver of DNA destabilization.
Thermodynamic Destabilization
While extensive quantitative data exists for the stabilizing effect of 5mC, the effect of 1mC is the opposite. The inability to form a proper base pair introduces a "mismatch-like" character at the 1mC site, lowering the energy required to separate the DNA strands.
For comparative purposes, the thermodynamic data for 5-methylcytosine shows a consistent stabilizing effect. Methylation at the C5 position generally increases the DNA duplex melting temperature (Tm) and results in a more favorable free energy of duplex formation (ΔG°).[7][8] This stabilization is attributed to enhanced base stacking interactions and favorable hydrophobic effects of the methyl group.[7][8]
Table 1: Comparative Thermodynamic Parameters for DNA Duplexes with 5-Methylcytosine (5mC) (Note: This data is for 5mC and illustrates the typical stabilizing effect of C5 methylation, which contrasts with the destabilizing effect of N1 methylation in 1mC.)
| Oligonucleotide System | Number of 5mC Modifications | Melting Temp (Tm) (°C) | ΔG°37 (kcal/mol) | ΔH° (kcal/mol) | -TΔS°37 (kcal/mol) | Reference |
| 10-mer duplex (dilute) | 0 | 51.4 | -8.5 | -68.8 | 60.3 | [7] |
| 10-mer duplex (dilute) | 8 | 59.5 | -10.9 | -81.7 | 70.8 | [7] |
| 12-mer duplex (C3/C9) | 0 | 59.8 | -9.61 | -80.9 | 71.3 | [9] |
| 12-mer duplex (mC3/C9) | 1 | 59.9 | -9.56 | -78.4 | 68.8 | [9] |
The average increase in melting temperature (ΔTm) per 5mC modification is reported to be between 0.5°C and 1.5°C.[7][8] In contrast, a 1mC lesion would be expected to significantly lower the Tm, similar to a canonical base mismatch.
Impact on DNA Structure
The structural consequences of N1-methylation are profound, preventing the formation of a canonical B-form DNA helix at the lesion site.
-
Disruption of Watson-Crick Pairing: The methyl group at the N1 position physically blocks the hydrogen bond donor site required to pair with guanine. This forces the bases at that position to be unpaired or to adopt a non-canonical conformation, creating a significant bulge or distortion in the DNA backbone.
-
Analogy to Pseudouridine: The N1-methylated deoxyribonucleoside, N¹-methyl-2'-deoxy-pseudocytidine, has a C-glycosidic bond, where the base is attached at the C5 position instead of the usual N1 position. This is analogous to the difference between uridine (B1682114) and pseudouridine.[1]
-
Role in Synthetic Genetic Systems: The unique pairing properties of 1mC have been exploited in synthetic biology. In the "hachimoji" Artificially Expanded Genetic Information System, 1mC (designated as 'S') is used to form a stable base pair with isoguanine (B23775) (designated as 'B').[1] This demonstrates its capacity for non-canonical, yet specific, hydrogen bonding when a suitable partner is provided.
Caption: Logical impact of this compound on DNA base pairing and its consequences.
Cellular Response: DNA Repair
Because 1mC is a mutagenic lesion that stalls replication and transcription, cells have evolved mechanisms to remove it. The primary pathway for repairing such N-alkylated bases is direct reversal by the AlkB family of dioxygenases.[6][10]
The AlkB enzyme, along with its human homologs (hABH2 and hABH3), catalyzes the oxidative demethylation of N1-methyladenine and N3-methylcytosine.[6] It is highly probable that 1mC is also a substrate for this repair system. The reaction requires cofactors α-ketoglutarate, non-heme iron (Fe(II)), and molecular oxygen.[10] The process removes the methyl group, converting it to formaldehyde, and restores the original cytosine base without excising it from the DNA backbone.[6][10]
Caption: The AlkB-mediated direct reversal repair pathway for this compound.
Experimental Protocols
Studying the effects of 1mC requires specialized methodologies for its detection and for the characterization of 1mC-containing DNA.
Detection of this compound in DNA
Standard epigenetic methods like bisulfite sequencing are not suitable for 1mC detection, as they are designed for 5mC.[11] Methods for detecting DNA adducts and lesions are more appropriate.
Protocol: High-Performance Liquid Chromatography with Mass Spectrometry (HPLC-MS)
This is a gold-standard method for the sensitive and quantitative detection of modified nucleosides.[11]
-
DNA Isolation: Extract high-purity genomic DNA from the sample using a standard phenol-chloroform extraction or a commercial kit.
-
DNA Digestion: Enzymatically digest the DNA to single nucleosides. This typically involves a cocktail of enzymes such as DNAse I, nuclease P1, and alkaline phosphatase.
-
Chromatographic Separation: Inject the nucleoside mixture into an HPLC system equipped with a C18 reverse-phase column. Use a gradient of solvents (e.g., aqueous ammonium (B1175870) acetate (B1210297) and methanol) to separate the canonical nucleosides from modified ones like N¹-methyl-2'-deoxycytidine.
-
Mass Spectrometry Detection: Couple the HPLC eluent to a tandem mass spectrometer (MS/MS). Monitor for the specific mass-to-charge (m/z) ratio transition corresponding to N¹-methyl-2'-deoxycytidine.
-
Quantification: Use a stable isotope-labeled internal standard to accurately quantify the amount of 1mC relative to the amount of canonical deoxycytidine.
Caption: Experimental workflow for the detection of this compound via HPLC-MS.
Analysis of DNA Stability
Protocol: UV Thermal Denaturation Analysis (Melting Curve Analysis)
This technique is used to determine the melting temperature (Tm) and other thermodynamic parameters of a DNA duplex.
-
Oligonucleotide Synthesis: Synthesize complementary DNA oligonucleotides, one of which contains a 1mC modification at a defined position. Also synthesize an unmodified control duplex of the same sequence.
-
Sample Preparation: Dissolve the annealed duplex DNA in a buffered solution (e.g., 10 mM sodium phosphate, 100 mM NaCl, 0.1 mM EDTA, pH 7.0) to a known concentration (e.g., 2 µM).[7][9]
-
Spectrophotometer Setup: Use a UV-Vis spectrophotometer equipped with a temperature controller. Set the wavelength to 260 nm.
-
Melting Process: Slowly increase the temperature of the sample at a constant rate (e.g., 0.5°C/minute) from a low temperature (e.g., 20°C) to a high temperature (e.g., 95°C), recording the absorbance at 260 nm throughout.
-
Data Analysis: Plot absorbance versus temperature. The resulting sigmoidal curve is the melting profile. The Tm is the temperature at which 50% of the DNA is denatured, corresponding to the midpoint of the transition.
-
Thermodynamic Calculation: Repeat the melting experiment at several different DNA concentrations. A van't Hoff plot (1/Tm vs. ln(CT), where CT is the total strand concentration) can then be used to extract thermodynamic parameters such as enthalpy (ΔH°) and entropy (ΔS°).[9]
Analysis of DNA Structure
Protocol: X-ray Crystallography
This method provides high-resolution, three-dimensional structural information.
-
Oligonucleotide Synthesis and Purification: Synthesize and purify a short, self-complementary DNA sequence containing 1mC.
-
Crystallization: Screen a wide range of crystallization conditions (precipitants, buffers, salts, temperature) using techniques like hanging-drop or sitting-drop vapor diffusion to obtain diffraction-quality crystals.
-
Data Collection: Expose the crystal to a high-intensity X-ray beam (often from a synchrotron source) and collect the resulting diffraction pattern on a detector.
-
Structure Solution and Refinement: Process the diffraction data to determine the unit cell dimensions and space group. Solve the phase problem using methods like molecular replacement with a standard B-DNA model.[9] Build the 1mC-containing DNA model into the electron density map and refine it to achieve the best fit with the experimental data. The final refined structure will reveal atomic-level details of the helix, including bond angles, distances, and local distortions caused by the 1mC lesion.[9]
Conclusion
This compound is a significant DNA lesion whose impact on DNA structure and stability is diametrically opposed to that of the epigenetic mark 5-methylcytosine. By physically blocking Watson-Crick hydrogen bonding, 1mC introduces a major structural distortion and destabilizes the DNA duplex. This damage is recognized and corrected by the cell's direct reversal repair machinery, primarily the AlkB family of enzymes. Understanding the biophysical properties of 1mC and its repair pathways is crucial for research into DNA damage, mutagenesis, and the development of therapeutics that target these processes. The methodologies detailed herein provide a framework for the continued investigation of this and other forms of DNA alkylation damage.
References
- 1. This compound - Wikipedia [en.wikipedia.org]
- 2. Cytosine methylation alters DNA mechanical properties - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Impact of Methylation on the Physical Properties of DNA - PMC [pmc.ncbi.nlm.nih.gov]
- 4. DNA methylation and methylcytosine oxidation in cell fate decisions - PMC [pmc.ncbi.nlm.nih.gov]
- 5. taylorandfrancis.com [taylorandfrancis.com]
- 6. Mutagenesis, genotoxicity, and repair of 1-methyladenine, 3-alkylcytosines, 1-methylguanine, and 3-methylthymine in alkB Escherichia coli - PMC [pmc.ncbi.nlm.nih.gov]
- 7. mdpi.com [mdpi.com]
- 8. Combined Effects of Methylated Cytosine and Molecular Crowding on the Thermodynamic Stability of DNA Duplexes - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Comparison of the structural and dynamic effects of 5-methylcytosine and 5-chlorocytosine in a CpG dinucleotide sequence - PMC [pmc.ncbi.nlm.nih.gov]
- 10. researchgate.net [researchgate.net]
- 11. mdpi.com [mdpi.com]
1-Methylcytosine: An In-depth Technical Guide for Molecular Biologists
An extensive examination of 1-methylcytosine (B60703), from its fundamental biochemistry to its emerging role in disease and therapeutic development.
Introduction to this compound (m1C)
This compound (m1C) is a modified nucleobase derived from cytosine through the addition of a methyl group at the nitrogen-1 (N1) position of the pyrimidine (B1678525) ring.[1][2] This post-transcriptional and post-replicative modification is found in both DNA and various RNA species, where it plays a crucial role in the epigenetic and epitranscriptomic regulation of gene expression. Unlike its more extensively studied isomer, 5-methylcytosine (B146107) (5mC), which has a well-established role in transcriptional silencing, the functions of m1C are more diverse and are the subject of ongoing research. The unique chemical properties of m1C, particularly the methylation at a site involved in Watson-Crick base pairing, lead to significant alterations in the structural and functional characteristics of nucleic acids. This guide provides a comprehensive overview of m1C for researchers, scientists, and drug development professionals, covering its biosynthesis, biological functions, detection methodologies, and implications in disease and therapeutics.
Chemical and Structural Properties of this compound
This compound is a pyrimidone where the hydrogen attached to the nitrogen at position 1 of cytosine is substituted by a methyl group.[3][4] This seemingly minor modification has profound implications for the molecule's behavior.
Table 1: Chemical and Physical Properties of this compound
| Property | Value | Reference(s) |
| IUPAC Name | 4-amino-1-methylpyrimidin-2(1H)-one | [1] |
| Molecular Formula | C5H7N3O | [1] |
| Molar Mass | 125.13 g/mol | [1] |
| CAS Number | 1122-47-0 | [1] |
The presence of the methyl group at the N1 position disrupts the canonical Watson-Crick hydrogen bonding with guanine. This can lead to altered DNA and RNA secondary structures, influencing protein-nucleic acid interactions and the overall stability of the duplex.[2]
Biosynthesis of this compound
The methylation of cytosine to form m1C is a highly regulated enzymatic process carried out by specific methyltransferases. These enzymes utilize S-adenosylmethionine (SAM) as the methyl donor.
In DNA:
In mammals, DNA methylation is primarily carried out by a family of DNA methyltransferases (DNMTs).[3] While DNMT1 is the maintenance methyltransferase that copies existing methylation patterns onto newly synthesized DNA strands, DNMT3A and DNMT3B are responsible for de novo methylation.[5][6] Although primarily known for generating 5-methylcytosine, under certain conditions, these enzymes may also be responsible for the formation of this compound in DNA.
In RNA:
A distinct set of enzymes, the NOL1/NOP2/SUN domain (NSUN) family of RNA methyltransferases, is responsible for the majority of m5C RNA methylation.[7] Specifically, enzymes like NSUN2 have been shown to catalyze the formation of 5-methylcytosine in various RNA molecules, including transfer RNAs (tRNAs) and messenger RNAs (mRNAs).[8] While the focus has been on m5C, it is plausible that members of this family or other yet-to-be-identified enzymes are responsible for m1C formation in RNA.
Biological Functions of this compound
The functional consequences of m1C modification are context-dependent, varying between DNA and RNA and even within different regions of the same molecule.
Impact on DNA Structure and Function
The presence of m1C in DNA can significantly alter its local structure and flexibility.[9] This can, in turn, influence the binding of transcription factors and other DNA-binding proteins. Some proteins may be sterically hindered from binding to their target sequences by the methyl group, while others may exhibit enhanced binding through hydrophobic interactions.[1][3] This modulation of protein-DNA interactions provides a mechanism for m1C to participate in the regulation of gene expression.
Table 2: Quantitative Impact of Cytosine Methylation on Transcription Factor Binding
| Transcription Factor | Effect of Methylation on Binding Affinity | Fold Change in Binding | Reference(s) |
| c-Myc | Decreased | ~2-fold | [10] |
| Egr1 | Position-dependent increase or decrease | Variable | [11] |
| ZFP57 | Increased | Position-dependent | [12] |
| CTCF | Position-dependent decrease | Variable | [12] |
Note: Much of the available quantitative data is for 5-methylcytosine, which serves as a model for how methylation can affect transcription factor binding.
Impact on RNA Metabolism and Function
In RNA, m1C modifications can have a profound impact on various aspects of RNA metabolism, including splicing, nuclear export, stability, and translation. The altered secondary structure induced by m1C can affect the accessibility of RNA to processing enzymes and the ribosome.[8] For instance, m1C within the coding sequence of an mRNA can lead to ribosomal stalling and decreased translation efficiency.[13]
This compound in Disease and as a Therapeutic Target
Aberrant m1C methylation patterns have been implicated in various diseases, most notably cancer. The dysregulation of DNMTs and NSUN enzymes can lead to global changes in the m1C landscape, contributing to the silencing of tumor suppressor genes or the activation of oncogenes.[14]
Table 3: 5-Methylcytosine Levels in Normal vs. Cancer Tissues
| Tissue Type | Normal Tissue (% 5mC) | Cancer Tissue (% 5mC) | Reference(s) |
| Lung | ~4.0% | ~2.5-3.5% | [14][15] |
| Colorectal | ~4.5% | ~3.0-4.0% | [9] |
| Breast | ~4.2% | ~3.5-4.0% | [9] |
| Brain | ~1.0% | Depleted | [14] |
Note: This table presents data for the related 5-methylcytosine modification, as directly comparable quantitative data for this compound across a wide range of tissues is still emerging. These values highlight the general trend of global hypomethylation in cancer.
The critical role of m1C in cancer biology has made the enzymes responsible for its deposition attractive targets for therapeutic intervention. The development of small molecule inhibitors that specifically target DNMTs and NSUNs is an active area of research.
Small Molecule Inhibitors
Several small molecule inhibitors targeting DNMTs and NSUNs are in various stages of development. These inhibitors aim to reverse the aberrant methylation patterns observed in cancer and restore normal gene expression.
-
DNMT Inhibitors: Nucleoside analogs such as 5-azacytidine (B1684299) and decitabine (B1684300) are FDA-approved drugs that incorporate into DNA and trap DNMTs, leading to their degradation and a reduction in DNA methylation.[6][16] Non-nucleoside inhibitors that target the catalytic site of DNMT1 are also being developed.[2]
-
NSUN2 Inhibitors: Recently, covalent inhibitors of NSUN2 have been discovered through chemical proteomic approaches.[3][7][17] These compounds show promise for selectively targeting RNA methylation in cancer cells.
Experimental Protocols for this compound Detection
A variety of techniques are available for the detection and quantification of m1C in DNA and RNA. These methods range from global quantification to base-resolution mapping.
Liquid Chromatography-Mass Spectrometry (LC-MS/MS)
LC-MS/MS is the gold standard for the accurate quantification of modified nucleosides. This method involves the enzymatic digestion of nucleic acids into individual nucleosides, followed by their separation by liquid chromatography and detection by mass spectrometry.
Detailed Protocol for LC-MS/MS Quantification of m1C:
-
Nucleic Acid Isolation: Isolate high-quality DNA or RNA from cells or tissues using a standard protocol.
-
Enzymatic Digestion:
-
Digest 1-5 µg of nucleic acid with a cocktail of nucleases (e.g., nuclease P1, snake venom phosphodiesterase, and alkaline phosphatase) to hydrolyze the nucleic acid into individual nucleosides.
-
Incubate the reaction at 37°C for 2-4 hours.
-
-
Sample Cleanup: Remove proteins and other contaminants by filtration or solid-phase extraction.
-
LC-MS/MS Analysis:
-
Inject the digested nucleoside mixture onto a reverse-phase C18 column.
-
Separate the nucleosides using a gradient of an appropriate mobile phase (e.g., water with 0.1% formic acid and methanol (B129727) with 0.1% formic acid).
-
Detect and quantify the nucleosides using a triple quadrupole mass spectrometer operating in multiple reaction monitoring (MRM) mode. The specific mass transitions for cytosine and this compound are monitored.
-
-
Data Analysis: Calculate the absolute or relative amount of m1C by comparing the peak area of m1C to that of a known amount of an isotopically labeled internal standard and/or to the peak area of unmodified cytosine.[18][19]
m1C Immunoprecipitation and Sequencing (m1C-Seq)
m1C-Seq is a powerful technique for the transcriptome-wide mapping of m1C sites at high resolution. This method utilizes an antibody specific for m1C to enrich for RNA fragments containing this modification, which are then sequenced.
Detailed Protocol for m1C-Seq:
-
RNA Fragmentation: Fragment total RNA or poly(A)-selected RNA to an appropriate size (e.g., 100-200 nucleotides).
-
Immunoprecipitation (IP):
-
Incubate the fragmented RNA with an m1C-specific antibody.
-
Capture the antibody-RNA complexes using protein A/G magnetic beads.
-
Wash the beads extensively to remove non-specifically bound RNA.
-
-
RNA Elution and Library Preparation:
-
Elute the enriched RNA from the beads.
-
Prepare a sequencing library from the enriched RNA fragments and an input control (a sample of the fragmented RNA that did not undergo IP). This typically involves reverse transcription, second-strand synthesis, adapter ligation, and PCR amplification.
-
-
Sequencing: Sequence the libraries on a high-throughput sequencing platform.
-
Data Analysis:
Role of this compound in Signaling Pathways
Emerging evidence suggests that epigenetic modifications, including DNA and RNA methylation, can play a significant role in regulating key cellular signaling pathways.
Wnt Signaling Pathway
The Wnt signaling pathway is crucial for embryonic development and adult tissue homeostasis. Aberrant Wnt signaling is a hallmark of many cancers. The expression of several key components of the Wnt pathway, including antagonists like SFRPs and DKKs, can be regulated by promoter methylation.[22] While direct evidence for the role of m1C is still being gathered, it is plausible that m1C in the promoter regions of these genes could contribute to their silencing and the subsequent activation of the Wnt pathway.
Conclusion and Future Perspectives
This compound is emerging from the shadow of its more famous cousin, 5-methylcytosine, as a critical player in the epigenetic and epitranscriptomic landscape. Its unique chemical properties and diverse biological functions in both DNA and RNA underscore its importance in gene regulation. The continued development of sensitive detection methods and specific inhibitors will undoubtedly accelerate our understanding of m1C's role in health and disease. For molecular biologists, researchers, and drug development professionals, this compound represents a promising new frontier with the potential for novel diagnostic and therapeutic strategies. As research in this area progresses, a more detailed picture of the m1C methylome and its dynamic regulation will provide invaluable insights into the complex interplay between the genome, the environment, and disease.
References
- 1. scbt.com [scbt.com]
- 2. Specific inhibition of one DNMT1-including complex influences tumor initiation and progression - PMC [pmc.ncbi.nlm.nih.gov]
- 3. researchgate.net [researchgate.net]
- 4. NF-κB: regulation by methylation - PMC [pmc.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
- 6. longdom.org [longdom.org]
- 7. researchgate.net [researchgate.net]
- 8. researchgate.net [researchgate.net]
- 9. Tissue Sample Preparation for LC-MS Analysis [protocols.io]
- 10. researchgate.net [researchgate.net]
- 11. Posttranslational modifications of NF-κB: another layer of regulation for NF-κB signaling pathway - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Discovery of a first-in-class reversible DNMT1-selective inhibitor with improved tolerability and efficacy in acute myeloid leukemia - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Wnt signalosomes: What we know that we do not know - PMC [pmc.ncbi.nlm.nih.gov]
- 14. 5-hydroxymethylcytosine is strongly depleted in human cancers but its levels do not correlate with IDH1 mutations - PMC [pmc.ncbi.nlm.nih.gov]
- 15. DNA methylation topology differentiates between normal and malignant in cell models, resected human tissues, and exfoliated sputum cells of lung epithelium - PMC [pmc.ncbi.nlm.nih.gov]
- 16. Chemical Proteomic Discovery of Isotype-Selective Covalent Inhibitors of the RNA Methyltransferase NSUN2 - PMC [pmc.ncbi.nlm.nih.gov]
- 17. researchgate.net [researchgate.net]
- 18. pubs.acs.org [pubs.acs.org]
- 19. researchgate.net [researchgate.net]
- 20. Master MeRIP-seq Data Analysis: Step-by-Step Process for RNA Methylation Studies - CD Genomics [rna.cd-genomics.com]
- 21. rna-seqblog.com [rna-seqblog.com]
- 22. NF-κB Signaling | Cell Signaling Technology [cellsignal.com]
Methodological & Application
Application Notes and Protocols for the Detection of 1-Methylcytosine in Genomic DNA
For Researchers, Scientists, and Drug Development Professionals
Introduction
1-Methylcytosine (B60703) (m1C) is a modified DNA base where a methyl group is attached to the first nitrogen atom of the cytosine ring. While less abundant and studied than its isomer, 5-methylcytosine (B146107) (5mC), emerging research suggests that m1C may play a role in various biological processes and disease states. Accurate detection and quantification of m1C in genomic DNA are crucial for elucidating its function and exploring its potential as a biomarker or therapeutic target.
These application notes provide an overview and detailed protocols for the current and potential methods for detecting m1C in genomic DNA. The methodologies are categorized into three main approaches: mass spectrometry for global quantification, antibody-based enrichment for regional analysis, and sequencing-based methods for precise localization.
Methods for this compound Detection
Several techniques can be employed or adapted to detect and quantify m1C in genomic DNA. The choice of method depends on the specific research question, including the need for quantitative accuracy, single-base resolution, and genome-wide coverage.
1. Liquid Chromatography-Tandem Mass Spectrometry (LC-MS/MS): The Gold Standard for Quantification
Liquid chromatography-tandem mass spectrometry (LC-MS/MS) is the most reliable and accurate method for the global quantification of this compound in a DNA sample.[1][2][3] This technique offers high sensitivity and specificity, allowing for the precise measurement of the m1C content relative to the total cytosine content.
Workflow for LC-MS/MS Detection of m1C:
Caption: Workflow for the quantification of this compound using LC-MS/MS.
2. Antibody-Based Methods: Enrichment of m1C-Containing DNA Fragments
Antibody-based methods, such as methylated DNA immunoprecipitation (MeDIP), utilize antibodies that specifically recognize and bind to the modified base of interest. While a highly specific and validated monoclonal antibody for this compound is not as commercially available as for 5mC, the principles of antibody development and MeDIP-seq can be applied to m1C detection.[4][5] The development of a specific anti-m1C antibody would enable the enrichment of DNA fragments containing this modification. These enriched fragments can then be analyzed by quantitative PCR (qPCR) for locus-specific analysis or by next-generation sequencing (m1C-IP-seq) for genome-wide mapping.
Conceptual Workflow for m1C-IP-seq:
Caption: Conceptual workflow for genome-wide mapping of this compound using m1C-IP-seq.
3. Sequencing-Based Methods: Towards Single-Base Resolution
Currently, there is no widely established chemical or enzymatic method analogous to bisulfite sequencing for 5mC that specifically targets and allows for the single-base resolution mapping of this compound. The development of such a method would be a significant advancement in the field. Potential strategies could involve:
-
Chemical Modification: Investigating chemical reagents that selectively react with m1C, leading to a base change that can be detected by sequencing.
-
Enzymatic Approaches: Identifying or engineering enzymes that specifically recognize and modify m1C, creating a substrate for a subsequent reaction that alters the base-pairing properties.
The development of such methods would enable the creation of genome-wide, single-nucleotide resolution maps of m1C, providing unprecedented insights into its genomic context and potential regulatory functions.
Quantitative Data Summary
The following table summarizes the key quantitative parameters for the discussed m1C detection methods. It is important to note that while LC-MS/MS is a well-established quantitative technique, the data for antibody-based and sequencing methods for m1C are largely theoretical and depend on the development of specific reagents and protocols.
| Method | Principle | Resolution | Sensitivity | Throughput | Quantitative Accuracy |
| LC-MS/MS | Chromatographic separation and mass-to-charge ratio detection of nucleosides. | Global | High (fmol range)[6][7] | Low to Medium | High |
| m1C-IP-seq (Hypothetical) | Immunoprecipitation with a specific anti-m1C antibody followed by sequencing. | ~150-200 bp | Dependent on antibody affinity and m1C density. | High | Semi-quantitative |
| m1C Sequencing (Future) | Chemical or enzymatic conversion of m1C followed by sequencing. | Single-base | Potentially high | High | Quantitative |
Experimental Protocols
Protocol 1: Global Quantification of this compound by LC-MS/MS
This protocol outlines the general steps for the quantification of m1C in genomic DNA using LC-MS/MS.[1][3][8]
Materials:
-
Genomic DNA sample
-
Nuclease P1
-
Alkaline Phosphatase
-
1-methyl-2'-deoxycytidine (m1dC) standard
-
LC-MS/MS system
Procedure:
-
Genomic DNA Digestion: a. Digest 1-2 µg of genomic DNA to single nucleosides using a cocktail of DNase I, Nuclease P1, and phosphodiesterase, followed by dephosphorylation with alkaline phosphatase.
-
Sample Preparation: a. Prepare a calibration curve using a serial dilution of the m1dC standard. b. Prepare the digested DNA sample for injection.
-
LC-MS/MS Analysis: a. Inject the prepared sample and standards onto a C18 reversed-phase column for chromatographic separation. b. Perform mass spectrometry in positive electrospray ionization mode. c. Use multiple reaction monitoring (MRM) to detect the specific mass transitions for deoxycytidine and 1-methyl-2'-deoxycytidine.
-
Data Analysis: a. Quantify the amount of m1C in the sample by comparing the peak area to the calibration curve. b. Express the m1C content as a percentage of total cytosine or total nucleosides.
Protocol 2: Conceptual Protocol for m1C Immunoprecipitation (m1C-IP)
This protocol is a conceptual outline for the enrichment of m1C-containing DNA fragments, assuming the availability of a specific anti-m1C antibody.
Materials:
-
Genomic DNA
-
Sonicator or restriction enzymes for DNA fragmentation
-
Anti-m1C monoclonal antibody
-
Protein A/G magnetic beads
-
Buffers (IP buffer, wash buffers, elution buffer)
Procedure:
-
DNA Fragmentation: a. Fragment genomic DNA to an average size of 200-500 bp by sonication or enzymatic digestion.
-
Immunoprecipitation: a. Incubate the fragmented DNA with the anti-m1C antibody to allow for the formation of DNA-antibody complexes. b. Add Protein A/G magnetic beads to the mixture to capture the DNA-antibody complexes.
-
Washing: a. Wash the beads several times with wash buffers of increasing stringency to remove non-specifically bound DNA.
-
Elution: a. Elute the enriched m1C-containing DNA from the beads using an elution buffer.
-
Downstream Analysis: a. The enriched DNA can be analyzed by qPCR to assess m1C levels at specific loci or used for library preparation for next-generation sequencing (m1C-IP-seq).
Conclusion
The detection and characterization of this compound in genomic DNA is an emerging area of epigenetic research. While robust methods for the global quantification of m1C using LC-MS/MS exist, the development of specific antibodies and novel sequencing technologies will be instrumental in advancing our understanding of the distribution and function of this rare DNA modification. The protocols and workflows presented here provide a framework for researchers to begin exploring the presence and potential significance of this compound in their biological systems of interest.
References
- 1. Genomics Sequencing Services | Next-Generation Sequencing | Novogene [novogene.com]
- 2. Enzymatic methyl-seq - Wikipedia [en.wikipedia.org]
- 3. Liquid Chromatography-Mass Spectrometry Analysis of Cytosine Modifications - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. Enzymatic approaches for profiling cytosine methylation and hydroxymethylation - PMC [pmc.ncbi.nlm.nih.gov]
- 5. The Development of Monoclonal Antibodies - PMC [pmc.ncbi.nlm.nih.gov]
- 6. pubs.acs.org [pubs.acs.org]
- 7. Quantification of 5-Methylcytosine and 5-Hydroxymethylcytosine in Genomic DNA from Hepatocellular Carcinoma Tissues by Capillary Hydrophilic-Interaction Liquid Chromatography/Quadrupole TOF Mass Spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 8. 5-Methylcytosine Recombinant Monoclonal Antibody (10S5V10) (MA5-42759) [thermofisher.com]
protocol for mapping 1-Methylcytosine using bisulfite sequencing
For Researchers, Scientists, and Drug Development Professionals
Introduction: The Challenge of Mapping 1-Methylcytosine (B60703) (1mC)
This compound (1mC) is a modified DNA base where a methyl group is attached to the nitrogen atom at position 1 of the cytosine ring. This modification is chemically distinct from the more extensively studied 5-methylcytosine (B146107) (5mC), where the methyl group is at the carbon-5 position. While 5mC plays a well-established role in epigenetic regulation, the functions of 1mC in DNA are still being elucidated. Accurate mapping of 1mC is crucial for understanding its biological significance.
A common misconception is that bisulfite sequencing, the gold standard for 5mC mapping, can be used to map 1mC. However, this is not the case. The chemical mechanism of sodium bisulfite treatment is specific to the C5 and C6 positions of the cytosine ring, leading to the deamination of unmodified cytosine to uracil. Methylation at the C5 position protects the cytosine from this conversion.[1][2][3][4] The methyl group at the N1 position in this compound does not prevent this deamination. Therefore, standard bisulfite sequencing cannot distinguish this compound from unmodified cytosine.
This document provides an overview of the established methodologies for the detection and mapping of this compound, moving beyond the limitations of bisulfite sequencing.
Alternative Methodologies for this compound Mapping
Several advanced techniques have been developed to accurately map 1mC and other modified bases. These methods can be broadly categorized into antibody-based enrichment, third-generation sequencing, and mass spectrometry.
Antibody-Based Enrichment Sequencing (m1C-IP-seq)
This approach, analogous to m1A-MAP for N1-methyladenosine, utilizes an antibody that specifically recognizes and binds to this compound.[5][6][7][8][9] The DNA is fragmented, and the antibody is used to immunoprecipitate the DNA fragments containing 1mC. These enriched fragments are then sequenced to identify the genomic locations of the modification.
Experimental Protocol: m1C-IP-seq
-
Genomic DNA Isolation and Fragmentation:
-
Isolate high-quality genomic DNA from the sample of interest.
-
Fragment the DNA to a desired size range (e.g., 100-500 bp) using sonication or enzymatic digestion.
-
-
Immunoprecipitation (IP):
-
Denature the fragmented DNA to single strands.
-
Incubate the single-stranded DNA fragments with a specific anti-1-methylcytosine antibody.
-
Add protein A/G magnetic beads to the mixture to capture the antibody-DNA complexes.
-
Wash the beads to remove non-specifically bound DNA.
-
-
Elution and Library Preparation:
-
Elute the enriched DNA fragments from the beads.
-
Prepare a sequencing library from the eluted DNA. This includes end-repair, A-tailing, and ligation of sequencing adapters.
-
-
Sequencing and Data Analysis:
-
Sequence the library on a high-throughput sequencing platform.
-
Align the sequencing reads to a reference genome.
-
Identify peaks of enriched reads, which correspond to the locations of 1mC.
-
Third-Generation Sequencing
Third-generation sequencing technologies, such as Single-Molecule Real-Time (SMRT) sequencing and Nanopore sequencing, offer a direct way to detect DNA modifications without the need for chemical conversion or amplification.[10][11][12][13][14][15][16][17][18][19]
a) Single-Molecule Real-Time (SMRT) Sequencing
SMRT sequencing by Pacific Biosciences (PacBio) detects modifications by monitoring the kinetics of a DNA polymerase as it synthesizes a complementary strand. The presence of a modified base can cause a delay in the incorporation of the next nucleotide, which is detected as a change in the interpulse duration (IPD).
Experimental Protocol: SMRT Sequencing for 1mC Detection
-
Library Preparation:
-
Ligate hairpin adapters to both ends of double-stranded DNA fragments to create a circular template (SMRTbell).
-
Anneal a sequencing primer and bind a DNA polymerase to the adapter.
-
-
Sequencing:
-
Load the SMRTbell library onto a SMRT Cell, which contains thousands of Zero-Mode Waveguides (ZMWs).
-
Perform real-time sequencing, where the incorporation of fluorescently labeled nucleotides is recorded.
-
-
Data Analysis:
-
The sequencing instrument software records the sequence of bases and the IPD for each position.
-
Analyze the IPD data to identify positions with significantly longer delays, which indicate the presence of modified bases like 1mC.
-
b) Nanopore Sequencing
Nanopore sequencing from Oxford Nanopore Technologies detects modifications by measuring changes in the ionic current as a single strand of DNA passes through a protein nanopore. Each base has a characteristic current signal, and modified bases produce a distinct signal that can be identified.
Experimental Protocol: Nanopore Sequencing for 1mC Detection
-
Library Preparation:
-
Ligate sequencing adapters to the ends of DNA fragments. These adapters facilitate the entry of the DNA into the nanopore.
-
-
Sequencing:
-
Load the library onto a flow cell containing an array of nanopores.
-
Apply a voltage across the membrane to drive the DNA through the pores.
-
The instrument records the changes in ionic current as the DNA passes through the pore.
-
-
Data Analysis:
-
Use basecalling algorithms to convert the raw current signal into a DNA sequence.
-
Employ specialized software to analyze the raw signal and identify deviations that correspond to modified bases like 1mC.
-
Mass Spectrometry
Liquid chromatography-tandem mass spectrometry (LC-MS/MS) is a highly sensitive and accurate method for the global quantification of modified bases.[20][21][22][23][24] It can determine the overall percentage of 1mC in a DNA sample but does not provide information about the specific genomic locations of the modification.
Experimental Protocol: LC-MS/MS for 1mC Quantification
-
DNA Digestion:
-
Digest the genomic DNA to individual nucleosides using a cocktail of enzymes (e.g., DNase I, nuclease P1, and alkaline phosphatase).
-
-
Chromatographic Separation:
-
Separate the nucleosides using high-performance liquid chromatography (HPLC).
-
-
Mass Spectrometry Analysis:
-
Introduce the separated nucleosides into a tandem mass spectrometer.
-
Identify and quantify the different nucleosides (including 1-methyl-2'-deoxycytidine) based on their specific mass-to-charge ratios.
-
Data Presentation: Comparison of 1mC Mapping Methodologies
| Methodology | Principle | Resolution | Quantitative | Advantages | Limitations |
| m1C-IP-seq | Antibody-based enrichment of 1mC-containing DNA fragments. | ~100-500 bp | Semi-quantitative | High specificity for 1mC. | Resolution is limited by fragment size; antibody availability and specificity are critical. |
| SMRT Sequencing | Detection of altered DNA polymerase kinetics at modified bases. | Single-base | Yes | Direct detection without chemical conversion; provides long reads. | Requires specialized equipment and bioinformatics expertise. |
| Nanopore Sequencing | Detection of altered ionic current as modified DNA passes through a nanopore. | Single-base | Yes | Direct detection; provides long reads; portable sequencing options. | Basecalling accuracy for modifications is an active area of development. |
| LC-MS/MS | Separation and quantification of nucleosides by mass. | N/A (Global) | Yes | Highly accurate and sensitive for quantification. | Does not provide sequence-specific location information. |
Visualizations
Workflow for this compound Mapping using m1C-IP-seq.
Workflows for Direct 1mC Detection via Third-Generation Sequencing.
References
- 1. researchgate.net [researchgate.net]
- 2. researchgate.net [researchgate.net]
- 3. Discovery of bisulfite-mediated cytosine conversion to uracil, the key reaction for DNA methylation analysis — A personal account - PMC [pmc.ncbi.nlm.nih.gov]
- 4. researchgate.net [researchgate.net]
- 5. weizmann.elsevierpure.com [weizmann.elsevierpure.com]
- 6. Evolution of a Reverse Transcriptase to Map N1-Methyladenosine in Human mRNA - PMC [pmc.ncbi.nlm.nih.gov]
- 7. m1A RNA Methylation Analysis - CD Genomics [cd-genomics.com]
- 8. qian.human.cornell.edu [qian.human.cornell.edu]
- 9. Base-resolution mapping reveals distinct m1A methylome in nuclear- and mitochondrial-encoded transcripts - PMC [pmc.ncbi.nlm.nih.gov]
- 10. 5-base sequencing - Wikipedia [en.wikipedia.org]
- 11. The advantages of SMRT sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Single-molecule real-time sequencing - Wikipedia [en.wikipedia.org]
- 13. Detecting DNA cytosine methylation using nanopore sequencing - PubMed [pubmed.ncbi.nlm.nih.gov]
- 14. nanoporetech.com [nanoporetech.com]
- 15. Single-Molecule Real-Time Sequencing in cfDNA Analysis - CD Genomics [cd-genomics.com]
- 16. biorxiv.org [biorxiv.org]
- 17. m.youtube.com [m.youtube.com]
- 18. ivanchen-47612.medium.com [ivanchen-47612.medium.com]
- 19. What is PacBio SMRT sequencing? [yourgenome.org]
- 20. researchgate.net [researchgate.net]
- 21. mdpi.com [mdpi.com]
- 22. Detection of DNA methylation in genomic DNA by UHPLC-MS/MS - PMC [pmc.ncbi.nlm.nih.gov]
- 23. Quantification of Global DNA Methylation Levels by Mass Spectrometry - PubMed [pubmed.ncbi.nlm.nih.gov]
- 24. fan.genetics.ucla.edu [fan.genetics.ucla.edu]
Application of Mass Spectrometry for 1-Methylcytosine Quantification
Application Note and Protocol
Introduction
1-Methylcytosine (B60703) (m1C) is a post-transcriptional RNA modification and a rare DNA modification where a methyl group is added to the N1 position of the cytosine base. Unlike the well-studied 5-methylcytosine (B146107) (5mC), the precise biological functions and regulatory pathways of m1C are still under investigation. Accurate quantification of m1C is crucial for understanding its role in various biological processes, including gene expression regulation, and for the development of novel therapeutic agents targeting epitranscriptomic and epigenetic pathways. Liquid chromatography-tandem mass spectrometry (LC-MS/MS) has emerged as the gold standard for the sensitive and specific quantification of modified nucleosides due to its high accuracy and reproducibility.[1][2] This document provides a detailed protocol for the quantification of this compound in RNA and DNA samples using a stable isotope dilution LC-MS/MS method.
Principle
The method is based on the stable isotope dilution technique, which is a highly accurate method for quantitative analysis.[3][4] The workflow involves the enzymatic hydrolysis of nucleic acids (RNA or DNA) into individual nucleosides. A known amount of a stable isotope-labeled internal standard for this compound is added to the sample prior to processing. This internal standard behaves identically to the endogenous analyte during sample preparation and LC-MS/MS analysis, thus correcting for any sample loss or ionization suppression. The nucleosides are then separated by liquid chromatography and detected by a triple quadrupole mass spectrometer operating in multiple reaction monitoring (MRM) mode. The ratio of the signal intensity of the endogenous this compound to that of the internal standard is used to calculate the exact amount of this compound in the original sample.
Experimental Workflow
The overall experimental workflow for the quantification of this compound by LC-MS/MS is depicted below.
References
- 1. Liquid Chromatography–Mass Spectrometry Analysis of Cytosine Modifications | Springer Nature Experiments [experiments.springernature.com]
- 2. Quantification of Global DNA Methylation Levels by Mass Spectrometry - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. Measurement of DNA methylation using stable isotope dilution and gas chromatography-mass spectrometry - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. Isotope-dilution mass spectrometry for exact quantification of noncanonical DNA nucleosides [pubmed.ncbi.nlm.nih.gov]
Application Notes and Protocols for Methylated DNA Immunoprecipitation (MeDIP) of N1-methyladenosine (1mC)
For Researchers, Scientists, and Drug Development Professionals
Introduction
N1-methyladenosine (1mC) is a modification of the adenine (B156593) base in DNA. Unlike the well-studied 5-methylcytosine (B146107) (5mC), 1mC is not considered a canonical epigenetic mark in mammals. Instead, it is primarily recognized as a form of DNA damage that can arise from exposure to certain alkylating agents. The presence of a methyl group at the N1 position of adenine disrupts the Watson-Crick base pairing, which can stall DNA replication and transcription. Consequently, cells have evolved specific repair mechanisms to remove this lesion and maintain genomic integrity. The study of 1mC in DNA is crucial for understanding the impacts of environmental mutagens, the efficacy of certain chemotherapeutic drugs, and the cellular DNA damage response.
Methylated DNA immunoprecipitation (MeDIP) is a powerful immunocapturing technique that can be adapted to enrich for DNA fragments containing 1mC. This method utilizes a specific antibody that recognizes and binds to 1mC within single-stranded DNA. The enriched DNA can then be analyzed by various downstream applications, such as quantitative PCR (qPCR) for locus-specific analysis or next-generation sequencing (MeDIP-seq) for genome-wide profiling. These analyses can provide valuable insights into the distribution and frequency of 1mC lesions under different experimental conditions.
Biological Significance of 1mC in DNA
In mammalian cells, 1mC is primarily considered a cytotoxic lesion that can block DNA replication. Its repair is crucial for maintaining genome stability. The primary pathway for repairing 1mC lesions in DNA is through the action of AlkB homolog (ALKBH) enzymes, specifically ALKBH2 and ALKBH3 in humans. These enzymes are Fe(II)/α-ketoglutarate-dependent dioxygenases that oxidatively demethylate 1mC, restoring it to an unmodified adenine base. This direct reversal repair mechanism is a critical component of the cell's defense against alkylating DNA damage. Dysregulation of these repair pathways can have implications in various diseases, including cancer.
Experimental Protocols
Methylated DNA Immunoprecipitation (MeDIP) for 1mC
This protocol provides a detailed methodology for the enrichment of 1mC-containing DNA fragments from purified genomic DNA.
Materials and Reagents:
-
Genomic DNA (gDNA)
-
N1-methyladenosine (1mC) specific antibody
-
Protein A/G magnetic beads
-
TE Buffer (10 mM Tris-HCl, pH 8.0; 1 mM EDTA)
-
IP Buffer (10 mM Sodium Phosphate, pH 7.0; 140 mM NaCl; 0.05% Triton X-100)
-
Wash Buffer 1 (IP Buffer with 250 mM NaCl)
-
Wash Buffer 2 (IP Buffer with 500 mM NaCl)
-
Wash Buffer 3 (IP Buffer)
-
Elution Buffer (1% SDS, 0.1 M NaHCO3)
-
Proteinase K
-
Phenol:Chloroform:Isoamyl Alcohol (25:24:1)
-
3 M Sodium Acetate, pH 5.2
-
100% Ethanol (B145695)
-
80% Ethanol
-
Nuclease-free water
-
Glycogen (B147801) (molecular biology grade)
Equipment:
-
Sonicator (e.g., Bioruptor)
-
Heating blocks or water baths
-
Microcentrifuge
-
Vortexer
-
Magnetic rack
-
Spectrophotometer (e.g., NanoDrop)
-
Fluorometer and dsDNA quantification kit (e.g., Qubit)
-
Real-time PCR system
Protocol:
-
DNA Fragmentation:
-
Resuspend 1-5 µg of gDNA in 100 µL of TE Buffer.
-
Shear the DNA to an average size of 200-800 bp using a sonicator. Optimization of sonication conditions is critical and will depend on the instrument used.
-
Verify the fragment size by running an aliquot on a 1.5% agarose (B213101) gel.
-
-
DNA Denaturation:
-
Heat the fragmented DNA at 95°C for 10 minutes to denature it into single-stranded DNA (ssDNA).
-
Immediately place the tube on ice for 5 minutes to prevent re-annealing.
-
-
Immunoprecipitation:
-
To the denatured DNA, add 400 µL of IP Buffer and 1-5 µg of the anti-1mC antibody. The optimal antibody concentration should be determined empirically.
-
Incubate overnight at 4°C on a rotating platform.
-
On the following day, wash the required amount of Protein A/G magnetic beads three times with IP Buffer.
-
Add the washed beads to the DNA-antibody mixture and incubate for 2-4 hours at 4°C on a rotating platform.
-
-
Washing:
-
Place the tube on a magnetic rack to capture the beads. Carefully remove and discard the supernatant.
-
Wash the beads sequentially with 1 mL of the following buffers, incubating for 5 minutes on a rotator for each wash:
-
Wash Buffer 1
-
Wash Buffer 2
-
Wash Buffer 3 (perform this wash twice)
-
-
-
Elution:
-
After the final wash, resuspend the beads in 250 µL of Elution Buffer.
-
Incubate at 65°C for 30 minutes with occasional vortexing.
-
Place the tube on the magnetic rack and carefully transfer the supernatant (containing the enriched DNA) to a new tube.
-
-
Reverse Cross-linking and DNA Purification:
-
Add 10 µL of 5 M NaCl and 2 µL of Proteinase K (20 mg/mL) to the eluate.
-
Incubate at 65°C for 2 hours.
-
Purify the DNA using phenol:chloroform extraction followed by ethanol precipitation. Add 1 µL of glycogen as a carrier.
-
Resuspend the purified DNA pellet in 20-50 µL of nuclease-free water.
-
-
Quantification:
-
Quantify the yield of the enriched DNA using a fluorometric method (e.g., Qubit).
-
Quantitative Analysis: MeDIP-qPCR
To validate the enrichment of 1mC-containing DNA, quantitative PCR can be performed on the MeDIP-enriched DNA and the input DNA (a small fraction of the fragmented DNA saved before immunoprecipitation).
-
Primer Design: Design qPCR primers for genomic regions suspected to contain 1mC (positive loci) and regions expected to be devoid of 1mC (negative control loci).
-
qPCR Reaction: Set up qPCR reactions for both the MeDIP DNA and the input DNA using a SYBR Green-based master mix.
-
Data Analysis: Calculate the percent input enrichment for each target region using the following formula:
-
% Input = 2^((Ct(Input) - log2(Input Dilution Factor)) - Ct(MeDIP)) * 100
-
Data Presentation
Quantitative data on the abundance of 1mC in genomic DNA is currently limited in the scientific literature, as this is an emerging area of research. The table below serves as a template for presenting results from MeDIP-qPCR experiments designed to quantify the relative enrichment of 1mC at specific genomic loci under different conditions. Researchers are encouraged to populate this table with their own experimental data.
| Genomic Locus | Cell Type/Condition | Mean % Input Enrichment (± SD) | p-value |
| Gene X Promoter | Control | Data to be generated | N/A |
| Gene X Promoter | Treatment A | Data to be generated | |
| Gene Y Intron | Control | Data to be generated | N/A |
| Gene Y Intron | Treatment A | Data to be generated | |
| Negative Control Region | Control | Data to be generated | N/A |
| Negative Control Region | Treatment A | Data to be generated |
Visualizations
Caption: Workflow for Methylated DNA Immunoprecipitation of 1mC (MeDIP-1mC).
Caption: N1-methyladenosine (1mC) DNA Damage Repair Pathway.
Application Notes and Protocols for the Immunodetection of Methylated Cytosine
For Researchers, Scientists, and Drug Development Professionals
Introduction
Cytosine methylation is a critical epigenetic modification that plays a pivotal role in regulating gene expression, genomic stability, and cellular differentiation. While 5-methylcytosine (B146107) (5mC) is the most well-characterized and abundant form of DNA methylation in mammals, other methylated cytosine isomers, such as 1-methylcytosine (B60703) (m1C), also exist. These modifications can be present in both DNA and various RNA species, influencing their structure and function.[1] The study of these modifications is crucial for understanding normal biological processes and the pathogenesis of various diseases, including cancer.[1]
This document provides detailed application notes and protocols for the use of antibodies in the detection and analysis of methylated cytosine.
Important Note on Antibody Specificity:
Commercially available and well-characterized antibodies for the specific detection of This compound (m1C) are not readily found in the market. The vast majority of available antibodies are designed to recognize 5-methylcytosine (5mC) . Therefore, the following protocols and data are based on the use of anti-5-methylcytosine antibodies . Researchers interested in studying m1C should exercise caution and thoroughly validate the specificity of any antibody claimed to recognize this modification. The experimental workflows and principles described herein are, however, broadly applicable to immunodetection techniques for nucleic acid modifications.
Biological Significance of Cytosine Methylation
5-Methylcytosine (5mC): In mammals, 5mC is a key epigenetic mark predominantly found in the context of CpG dinucleotides.[2] It is established by DNA methyltransferases (DNMTs) and is generally associated with transcriptional repression when located in promoter regions.[3][4] Aberrant DNA methylation patterns are a hallmark of many cancers and developmental disorders.[3] In RNA, 5mC is also present and is involved in regulating RNA stability, nuclear export, and translation, a field of study known as epitranscriptomics.[5]
This compound (m1C): this compound is a methylated form of the DNA base cytosine where a methyl group is attached to the nitrogen atom at the 1-position of the cytosine ring.[1] Its biological role in mammals is less understood compared to 5mC.
Antibody Specifications and Quantitative Data
The selection of a highly specific and sensitive antibody is critical for the successful immunodetection of 5-methylcytosine. Below is a summary of typical specifications and recommended working concentrations for commercially available anti-5mC monoclonal antibodies.
| Application | Recommended Dilution Range | Typical Incubation Time and Temperature | Notes |
| Methylated DNA Immunoprecipitation (MeDIP) | 1 - 5 µg per 1 µg of DNA | 2 hours to overnight at 4°C | Antibody amount may need optimization based on the abundance of 5mC in the sample. |
| Immunofluorescence (IF) / Immunocytochemistry (ICC) | 1:100 - 1:1000 | 1 hour at room temperature or overnight at 4°C | Optimal dilution should be determined by titration for specific cell/tissue types and fixation methods. |
| Western Blot (for proteins interacting with 5mC) | 1:500 - 1:2000 | 1 hour at room temperature or overnight at 4°C | This application is indirect, detecting proteins that bind to 5mC-containing DNA/RNA. |
| Dot Blot | 1:1000 - 1:5000 | 1 hour at room temperature | Useful for assessing antibody specificity against various methylated and unmethylated DNA/RNA species. |
Specificity of Anti-5mC Antibodies:
High-quality monoclonal antibodies for 5mC exhibit high specificity with minimal to no cross-reactivity with unmodified cytosine or other modified bases like 5-hydroxymethylcytosine (B124674) (5hmC).[6][7] It is crucial to consult the manufacturer's datasheet for specificity data, which is often demonstrated through dot blot analysis against a panel of modified oligonucleotides.[8]
Experimental Protocols
Methylated DNA Immunoprecipitation (MeDIP-Seq) Protocol
MeDIP followed by high-throughput sequencing (MeDIP-Seq) is a powerful technique for genome-wide profiling of DNA methylation.[3]
1. DNA Preparation and Fragmentation:
-
Isolate high-quality genomic DNA from cells or tissues.
-
Fragment the DNA to a size range of 200-800 bp using sonication or enzymatic digestion.
-
Verify the fragment size by agarose (B213101) gel electrophoresis.
2. DNA Denaturation:
-
Denature the fragmented DNA by heating at 95°C for 10 minutes, followed by immediate cooling on ice for 5 minutes. This is crucial for exposing the 5mC for antibody binding.
3. Immunoprecipitation:
-
Incubate the denatured DNA with an anti-5mC antibody (typically 1-5 µg) overnight at 4°C with gentle rotation.
-
Add Protein A/G magnetic beads to the DNA-antibody mixture and incubate for 2 hours at 4°C to capture the immune complexes.
-
Wash the beads three times with a low-salt wash buffer and once with a high-salt wash buffer to remove non-specifically bound DNA.
4. Elution and DNA Purification:
-
Elute the methylated DNA from the beads using an elution buffer (e.g., containing Proteinase K) and incubate at 55°C for 2-3 hours.
-
Purify the eluted DNA using phenol-chloroform extraction or a DNA purification kit.
5. Library Preparation and Sequencing:
-
Prepare a sequencing library from the immunoprecipitated DNA and an input control DNA (fragmented genomic DNA that has not undergone immunoprecipitation).
-
Perform high-throughput sequencing.
6. Data Analysis:
-
Align the sequencing reads to a reference genome.
-
Identify enriched regions (peaks) of methylation by comparing the MeDIP sample to the input control.
Workflow for MeDIP-Seq
References
- 1. api.repository.cam.ac.uk [api.repository.cam.ac.uk]
- 2. CpG site - Wikipedia [en.wikipedia.org]
- 3. Cytosine methylation and mammalian development - PMC [pmc.ncbi.nlm.nih.gov]
- 4. 5-Methylcytosine (5-mC) Monoclonal Antibody [33D3] | EpigenTek [epigentek.com]
- 5. mdpi.com [mdpi.com]
- 6. Examination of the specificity of DNA methylation profiling techniques towards 5-methylcytosine and 5-hydroxymethylcytosine - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Examination of the specificity of DNA methylation profiling techniques towards 5-methylcytosine and 5-hydroxymethylcytosine - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. biocompare.com [biocompare.com]
Application Notes and Protocols for Single-Nucleotide Resolution Mapping of 1-Methylcytosine (m1C)
For Researchers, Scientists, and Drug Development Professionals
Introduction to 1-Methylcytosine (m1C)
This compound (m1C) is a post-transcriptional RNA modification where a methyl group is added to the N1 position of the cytosine base. This modification is found in various RNA species, including transfer RNA (tRNA) and ribosomal RNA (rRNA). The presence of m1C can influence RNA structure and function by altering Watson-Crick base pairing and introducing a positive charge at physiological pH. Emerging evidence suggests that m1C plays a role in regulating translation and may be involved in cellular stress responses and disease processes. Accurate mapping of m1C sites at single-nucleotide resolution is crucial for understanding its biological significance and its potential as a therapeutic target.
While well-established methods exist for mapping other RNA modifications like 5-methylcytosine (B146107) (5mC) and N6-methyladenosine (m6A), techniques for the precise localization of m1C across the transcriptome are still in development. This document provides an overview of potential methodologies for single-nucleotide resolution mapping of m1C, drawing from established principles for other RNA modifications.
Quantitative Analysis of this compound
Currently, the most common method for quantifying the overall abundance of m1C in RNA is liquid chromatography-mass spectrometry (LC-MS/MS). This technique provides a highly accurate measurement of the m1C/C ratio in total RNA or isolated RNA species. However, it does not provide information about the specific location of the modification. Below is a summary of representative quantitative data for m1C abundance in various human cell lines.
| Cell Line | RNA Type | m1C Abundance (per 1000 nucleotides) | Reference Method |
| HEK293T | Total RNA | ~0.5 - 1.0 | LC-MS/MS |
| HeLa | Total RNA | ~0.4 - 0.8 | LC-MS/MS |
| A549 | Total RNA | ~0.3 - 0.7 | LC-MS/MS |
Note: The abundance of m1C can vary depending on cell type, growth conditions, and the specific RNA species being analyzed. The data presented here are approximate values based on published literature and should be considered as a general guide.
Proposed Methodologies for Single-Nucleotide Resolution Mapping of m1C
Given the lack of a standardized, widely adopted protocol for high-resolution m1C mapping, this section outlines two potential approaches based on established techniques for other RNA modifications: m1C-MaP-seq (this compound Mutational Profiling sequencing) , which relies on the reverse transcription signature of m1C, and m1C-IP-seq (this compound Immunoprecipitation sequencing) , an antibody-based enrichment method.
Protocol 1: m1C-MaP-seq (this compound Mutational Profiling sequencing)
This proposed method leverages the principle that the methyl group at the N1 position of cytosine can interfere with reverse transcriptase (RT) processivity, leading to truncations and misincorporations at and near the modification site. This "RT signature" can be used to identify m1C residues at single-nucleotide resolution.[1][2][3][4]
Experimental Workflow
References
- 1. The reverse transcription signature of N-1-methyladenosine in RNA-Seq is sequence dependent - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. epublications.marquette.edu [epublications.marquette.edu]
- 3. The reverse transcription signature of N-1-methyladenosine in RNA-Seq is sequence dependent - PMC [pmc.ncbi.nlm.nih.gov]
- 4. researchgate.net [researchgate.net]
Application Notes and Protocols for the Analysis of 1-Methylcytosine (m1C) in RNA
For Researchers, Scientists, and Drug Development Professionals
Introduction to 1-Methylcytosine (m1C) in RNA
This compound (m1C) is a post-transcriptional RNA modification that plays a crucial role in various biological processes, including RNA stability, translation, and the regulation of gene expression. The dynamic nature of m1C modification, installed by "writer" enzymes (e.g., NSUN2, NSUN6, DNMT2) and potentially removed by "erasers," positions it as a key player in the epitranscriptome. Dysregulation of m1C levels has been implicated in several human diseases, including cancer and neurological disorders, making the accurate analysis of m1C in RNA a critical area of research for both basic science and therapeutic development.[1][2][3][4][5][6] This document provides detailed application notes and protocols for the principal techniques used to analyze m1C in RNA.
Key Techniques for m1C Analysis
Several methodologies are available for the detection and quantification of m1C in RNA, each with its own set of advantages and limitations. These techniques can be broadly categorized into three groups: sequencing-based methods for transcriptome-wide mapping, immunoprecipitation-based approaches, and chromatography-based quantitative methods.
Sequencing-Based Methods
These methods provide single-nucleotide resolution mapping of m1C across the transcriptome.
-
RNA Bisulfite Sequencing (BS-Seq): Considered the gold standard for m1C detection at single-base resolution.[7] This technique relies on the chemical deamination of unmethylated cytosine to uracil (B121893) by sodium bisulfite, while 5-methylcytosine (B146107) remains unchanged.[8][9] Subsequent reverse transcription and sequencing allow for the identification of methylated cytosines.
-
Methylation-Individual Nucleotide Resolution Crosslinking and Immunoprecipitation (miCLIP): This antibody-based method maps m1C sites with single-nucleotide resolution.[10][11][12] It involves UV crosslinking of an m1C-specific antibody to the RNA, followed by immunoprecipitation and library preparation. The analysis of cDNA truncations and mutations introduced at the crosslinking site allows for the precise identification of the modified nucleotide.
-
5-Azacytidine-Mediated RNA Immunoprecipitation (Aza-IP): A mechanism-based approach that traps m1C methyltransferases covalently to their RNA substrates using the cytidine (B196190) analog 5-azacytidine.[13][14][15][16] Immunoprecipitation of the enzyme-RNA complex enriches for direct targets of the methyltransferase. A characteristic C-to-G transversion at the target cytosine during reverse transcription facilitates the precise identification of the m1C site.[13][14][16]
Immunoprecipitation-Based Methods
These methods enrich for RNA molecules containing m1C but typically provide region-specific rather than single-nucleotide resolution information.
-
m1C-Specific RNA Immunoprecipitation followed by Sequencing (m1C-RIP-Seq): This technique utilizes an antibody specific to m1C to enrich for RNA fragments containing the modification. The enriched RNA is then sequenced to identify the transcripts that are methylated. While it doesn't provide single-nucleotide resolution, it is a powerful tool for identifying m1C-containing transcripts, especially those with low abundance.[2]
Chromatography-Based Methods
These techniques are highly quantitative and are used to determine the overall abundance of m1C in a total RNA sample.
-
Liquid Chromatography-Mass Spectrometry (LC-MS): This method involves the enzymatic digestion of RNA into individual nucleosides, which are then separated by liquid chromatography and detected by mass spectrometry.[17][18][19][20] LC-MS provides highly accurate quantification of the absolute amount of m1C relative to other nucleosides.[17][21]
Quantitative Data Summary
The choice of technique for m1C analysis often depends on the specific research question, balancing factors like resolution, sensitivity, and the amount of starting material. The following table summarizes the key quantitative features of the described methods.
| Technique | Resolution | Sensitivity | Starting RNA Amount | Throughput | Key Advantage | Key Limitation |
| RNA Bisulfite Sequencing | Single nucleotide | High | 1-10 µg total RNA | High | Gold standard for precise localization.[7][8] | RNA degradation due to harsh chemical treatment.[22] |
| miCLIP | Single nucleotide | High | 10-50 µg total RNA | High | Identifies direct antibody-RNA interaction sites.[10][11] | Potential for antibody cross-reactivity and background signal.[23] |
| Aza-IP | Single nucleotide | Moderate to High | 50-100 µg total RNA | High | Identifies direct targets of specific methyltransferases.[13][14] | Requires cell treatment with 5-azacytidine, which can be toxic.[16] |
| m1C-RIP-Seq | ~100-200 nucleotides | Moderate | 10-100 µg total RNA | High | Effective for identifying m1C-containing transcripts.[2] | Does not provide single-nucleotide resolution.[2] |
| LC-MS | Not applicable (global) | Very High | 100 ng - 1 µg total RNA | Low | Highly accurate and quantitative for global m1C levels.[17][19] | Does not provide sequence-specific information.[18] |
Experimental Protocols
Protocol 1: RNA Bisulfite Sequencing (BS-Seq)
This protocol is adapted from established methods for the single-nucleotide resolution analysis of m1C in RNA.[7][24][25]
Materials:
-
Total RNA or poly(A)-selected RNA
-
DNA-free™ DNase Treatment & Removal Reagents
-
RNA Clean & Concentrator™ kit
-
EZ RNA Methylation™ Kit
-
NEBNext® Ultra™ II Directional RNA Library Prep Kit for Illumina®
-
Agilent 2100 Bioanalyzer
Procedure:
-
RNA Preparation:
-
Start with 1-10 µg of high-quality total RNA.
-
Perform DNase treatment to remove any contaminating genomic DNA.
-
Purify the RNA using an RNA Clean & Concentrator™ kit.
-
-
Bisulfite Conversion:
-
Perform bisulfite conversion of the RNA using the EZ RNA Methylation™ Kit according to the manufacturer's instructions. This step converts unmethylated cytosines to uracils.
-
-
RNA Fragmentation and Priming:
-
Fragment the bisulfite-converted RNA to the desired size range (typically 150-200 nucleotides) by incubating at elevated temperature in a fragmentation buffer.
-
Prime the fragmented RNA with random hexamers.
-
-
First and Second Strand cDNA Synthesis:
-
Synthesize the first strand of cDNA using reverse transcriptase.
-
Synthesize the second strand of cDNA, incorporating dUTP to achieve strand specificity.
-
-
Library Preparation:
-
Perform end repair, adenylation of the 3' ends, and ligation of sequencing adapters to the cDNA fragments using the NEBNext® Ultra™ II Directional RNA Library Prep Kit.
-
Digest the dUTP-containing second strand using Uracil-DNA Glycosylase (UDG).
-
Amplify the library by PCR.
-
-
Quality Control and Sequencing:
-
Assess the library quality and size distribution using an Agilent Bioanalyzer.
-
Quantify the library using qPCR.
-
Perform high-throughput sequencing on an Illumina platform.
-
-
Data Analysis:
-
Perform quality control of raw sequencing reads and trim adapter sequences.
-
Align the reads to a reference genome and transcriptome, accounting for the C-to-T conversion.
-
Identify methylated cytosines based on the frequency of C reads at cytosine positions in the reference.
-
Protocol 2: m1C-Specific RNA Immunoprecipitation followed by Sequencing (m1C-RIP-Seq)
This protocol outlines the general steps for enriching m1C-containing RNA fragments for subsequent sequencing.[26][27][28][29]
Materials:
-
10-100 µg of total RNA
-
m1C-specific antibody
-
Protein A/G magnetic beads
-
RIP buffer (50 mM Tris-HCl pH 7.4, 150 mM NaCl, 1 mM MgCl2, 0.1% IGEPAL CA-630)
-
RNase inhibitors
-
Proteinase K
-
RNA extraction kit
-
Library preparation kit for sequencing
Procedure:
-
RNA Fragmentation:
-
Fragment the total RNA to an average size of 100-200 nucleotides using enzymatic or chemical fragmentation methods.
-
-
Immunoprecipitation:
-
Incubate the fragmented RNA with an m1C-specific antibody in RIP buffer supplemented with RNase inhibitors for 2-4 hours at 4°C.
-
Add Protein A/G magnetic beads and incubate for another 1-2 hours at 4°C to capture the antibody-RNA complexes.
-
-
Washing:
-
Wash the beads several times with cold RIP buffer to remove non-specifically bound RNA.
-
-
Elution and RNA Purification:
-
Elute the RNA from the beads using an elution buffer containing Proteinase K to digest the antibody.
-
Purify the enriched RNA using an RNA extraction kit.
-
-
Library Preparation and Sequencing:
-
Prepare a sequencing library from the immunoprecipitated RNA and an input control (fragmented RNA that has not undergone immunoprecipitation).
-
Perform high-throughput sequencing.
-
-
Data Analysis:
-
Align the sequencing reads from both the IP and input samples to the reference genome.
-
Identify enriched peaks in the IP sample compared to the input control to determine the locations of m1C-containing regions.
-
Protocol 3: Liquid Chromatography-Mass Spectrometry (LC-MS) for Global m1C Quantification
This protocol provides a method for the accurate quantification of the total m1C content in an RNA sample.[17][18][19][20][21]
Materials:
-
100 ng - 1 µg of total RNA
-
Nuclease P1
-
Bacterial alkaline phosphatase
-
LC-MS grade water, acetonitrile (B52724), and formic acid
-
C18 reverse-phase HPLC column
-
Triple quadrupole mass spectrometer
Procedure:
-
RNA Digestion:
-
Digest the RNA sample to single nucleosides by incubating with Nuclease P1 and bacterial alkaline phosphatase.
-
-
Liquid Chromatography Separation:
-
Inject the digested sample onto a C18 reverse-phase HPLC column.
-
Separate the nucleosides using a gradient of mobile phases (e.g., water with 0.1% formic acid and acetonitrile with 0.1% formic acid).
-
-
Mass Spectrometry Detection:
-
Analyze the eluting nucleosides using a triple quadrupole mass spectrometer operating in multiple reaction monitoring (MRM) mode.
-
Use pre-established MRM transitions for canonical nucleosides (A, C, G, U) and m1C.
-
-
Quantification:
-
Generate standard curves for each nucleoside using known concentrations of pure standards.
-
Quantify the amount of m1C and canonical nucleosides in the sample by comparing their peak areas to the standard curves.
-
Express the m1C level as a ratio to a canonical nucleoside (e.g., m1C/G).
-
Visualizations
Experimental Workflow: m1C-RIP-Seq
Caption: Workflow for m1C-RIP-Seq from RNA isolation to data analysis.
Signaling Pathway: m1C Regulation of the Innate Immune Response
References
- 1. academic.oup.com [academic.oup.com]
- 2. RNA 5-methylcytosine modification and its emerging role as an epitranscriptomic mark - PMC [pmc.ncbi.nlm.nih.gov]
- 3. 5-Methylcytosine RNA modification and its roles in cancer and cancer chemotherapy resistance - PMC [pmc.ncbi.nlm.nih.gov]
- 4. mdpi.com [mdpi.com]
- 5. mdpi.com [mdpi.com]
- 6. RNA 5-methylcytosine modification and its emerging role as an epitranscriptomic mark - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. researchgate.net [researchgate.net]
- 8. RNA Bisulfite Sequencing (BS RNA-seq) - CD Genomics [rna.cd-genomics.com]
- 9. RNA 5-Methylcytosine Analysis by Bisulfite Sequencing - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. miCLIP-m6A [illumina.com]
- 11. miCLIP-m6A - Enseqlopedia [enseqlopedia.com]
- 12. academic.oup.com [academic.oup.com]
- 13. Transcriptome-wide target profiling of RNA cytosine methyltransferases using the mechanism-based enrichment procedure Aza-IP - PubMed [pubmed.ncbi.nlm.nih.gov]
- 14. Transcriptome-wide target profiling of RNA cytosine methyltransferases using the mechanism-based enrichment procedure Aza-IP | Springer Nature Experiments [experiments.springernature.com]
- 15. researchgate.net [researchgate.net]
- 16. Identification of direct targets and modified bases of RNA cytosine methyltransferases - PMC [pmc.ncbi.nlm.nih.gov]
- 17. Protocol for preparation and measurement of intracellular and extracellular modified RNA using liquid chromatography-mass spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 18. A general LC-MS-based RNA sequencing method for direct analysis of multiple-base modifications in RNA mixtures - PMC [pmc.ncbi.nlm.nih.gov]
- 19. rsc.org [rsc.org]
- 20. researchgate.net [researchgate.net]
- 21. chromatographyonline.com [chromatographyonline.com]
- 22. epigenie.com [epigenie.com]
- 23. academic.oup.com [academic.oup.com]
- 24. Bisulfite Sequencing of RNA for Transcriptome-Wide Detection of 5-Methylcytosine - PubMed [pubmed.ncbi.nlm.nih.gov]
- 25. Bisulfite Sequencing of RNA for Transcriptome-Wide Detection of 5-Methylcytosine | Springer Nature Experiments [experiments.springernature.com]
- 26. How to Prepare a Library for RIP-Seq: A Comprehensive Guide - CD Genomics [cd-genomics.com]
- 27. RIP-Seq Sample Preparation Protocol - CD Genomics [cd-genomics.com]
- 28. A Comprehensive Guide to RIP-Seq Technology: Workflow, Data Analysis and Experimental Design - CD Genomics [cd-genomics.com]
- 29. Ribonucleoprotein Immunoprecipitation (RIP) Analysis - PMC [pmc.ncbi.nlm.nih.gov]
Application Notes and Protocols for 1-Methylcytosine-Sensitive Analysis
For Researchers, Scientists, and Drug Development Professionals
Introduction
1-Methylcytosine (B60703) (m1C) is a modified DNA base, distinct from the more extensively studied 5-methylcytosine (B146107) (5mC). While the biological functions of m1C in mammals are still under investigation, the ability to accurately detect and quantify this modification is crucial for understanding its potential role in gene regulation, disease pathogenesis, and as a possible biomarker in drug development. Unlike 5mC, for which numerous PCR-based detection methods exist, the development of a specific this compound-sensitive PCR (m1C-PCR) is hampered by the unknown reactivity of m1C to standard DNA modification reagents like sodium bisulfite and a lack of m1C-sensitive restriction enzymes.
These application notes provide a robust protocol for the absolute quantification of m1C using Liquid Chromatography-Tandem Mass Spectrometry (LC-MS/MS), which serves as a gold-standard method. Additionally, a conceptual framework and workflow for a future, hypothetical m1C-sensitive PCR are presented, outlining the necessary steps for its development and validation.
Section 1: Absolute Quantification of this compound by LC-MS/MS
Liquid Chromatography-Tandem Mass Spectrometry is a highly sensitive and specific method for the direct detection and quantification of modified nucleosides in a DNA sample without the need for amplification. This method provides an absolute measure of the m1C content relative to the total cytosine content.
Experimental Protocol: LC-MS/MS for m1C Quantification
-
Genomic DNA Extraction and Purification:
-
Extract genomic DNA from cells or tissues using a standard phenol-chloroform extraction method or a commercial DNA extraction kit.
-
Treat the extracted DNA with RNase A to remove any RNA contamination.
-
Assess the purity and concentration of the DNA using UV spectrophotometry (A260/A280 ratio).
-
-
DNA Hydrolysis to Nucleosides:
-
To 50 µg of purified genomic DNA, add nuclease P1 (10 units) in a buffer containing 30 mM sodium acetate (B1210297) (pH 5.3) and 1 mM ZnCl2.
-
Incubate at 37°C for 16 hours to digest the DNA into individual nucleotides.
-
Add alkaline phosphatase (10 units) and continue incubation at 37°C for an additional 2 hours to dephosphorylate the nucleotides into nucleosides.
-
Terminate the reaction by heating at 95°C for 5 minutes.
-
Centrifuge the sample at 10,000 x g for 5 minutes and collect the supernatant containing the nucleosides.
-
-
Liquid Chromatography Separation:
-
Use a C18 reverse-phase HPLC column for the separation of the nucleosides.
-
Employ a gradient elution with a mobile phase consisting of (A) 0.1% formic acid in water and (B) 0.1% formic acid in methanol.
-
A typical gradient could be: 0-5 min, 5% B; 5-15 min, 5-30% B; 15-20 min, 30-95% B; 20-25 min, 95% B; 25-30 min, 95-5% B. The flow rate should be maintained at 0.2 mL/min.
-
-
Tandem Mass Spectrometry Detection:
-
The eluent from the HPLC is directed to a triple quadrupole mass spectrometer equipped with an electrospray ionization (ESI) source operating in positive ion mode.
-
Use Multiple Reaction Monitoring (MRM) for the sensitive and specific detection of 1-methyl-2'-deoxycytidine (the nucleoside of m1C) and 2'-deoxycytidine (B1670253) (for cytosine).
-
The MRM transitions to monitor are:
-
1-methyl-2'-deoxycytidine: Precursor ion (m/z) -> Product ion (m/z) - Specific values would need to be determined empirically based on the instrument and standards.
-
2'-deoxycytidine: Precursor ion (m/z) -> Product ion (m/z) - Specific values would need to be determined empirically based on the instrument and standards.
-
-
Generate a standard curve using known concentrations of pure 1-methyl-2'-deoxycytidine and 2'-deoxycytidine to enable absolute quantification.
-
Data Presentation
The quantitative data obtained from the LC-MS/MS analysis can be summarized in a table to compare the levels of m1C across different samples.
| Sample ID | Total DNA (µg) | This compound (ng) | Total Cytosine (ng) | % m1C (m1C/Total C) |
| Control Cells | 50 | 0.5 | 10,000 | 0.005% |
| Treated Cells - 24h | 50 | 2.5 | 9,950 | 0.025% |
| Treated Cells - 48h | 50 | 5.1 | 9,800 | 0.052% |
| Diseased Tissue | 50 | 10.2 | 9,500 | 0.107% |
| Normal Tissue | 50 | 0.6 | 10,100 | 0.006% |
Workflow for LC-MS/MS Quantification of this compound
Caption: Workflow for the quantification of this compound using LC-MS/MS.
Section 2: Conceptual Framework for a this compound-Sensitive PCR (m1C-PCR)
The development of a PCR-based method for m1C detection would offer a more accessible and high-throughput alternative to LC-MS/MS. Such a method would likely rely on a chemical or enzymatic treatment that differentially modifies m1C compared to unmodified cytosine, allowing for discrimination by PCR.
Hypothetical Signaling Pathway Involving m1C
While no specific signaling pathways directly involving m1C have been fully elucidated in mammals, a hypothetical pathway could involve the enzymatic writing and erasing of this mark, which in turn could be recognized by specific "reader" proteins to influence gene expression.
Caption: A hypothetical signaling pathway involving this compound dynamics.
Conceptual Workflow for a Future m1C-Sensitive PCR
The following workflow outlines the logical steps required to develop and validate a hypothetical m1C-sensitive PCR. The central challenge lies in identifying a suitable treatment that distinguishes m1C from C.
Caption: Conceptual workflow for the development of a this compound-sensitive PCR.
Methodology for Developing an m1C-Sensitive PCR
-
Identification of a Differentiating Treatment:
-
Chemical Approach: Investigate the reactivity of this compound with various chemical modifying agents to identify one that either exclusively modifies m1C or leaves it unmodified while altering cytosine. This would be analogous to the use of sodium bisulfite for 5mC.
-
Enzymatic Approach: Screen a panel of DNA modifying enzymes (e.g., glycosylases, deaminases, restriction enzymes) for activity that is either dependent on or inhibited by the presence of m1C in their recognition sequence.
-
-
Primer Design and PCR Optimization:
-
Once a differential treatment is established, design PCR primers that can distinguish between the treated and untreated sequences. For example, if m1C is resistant to a treatment that converts C to another base (e.g., U), primers can be designed to specifically amplify the m1C-containing sequence.
-
Optimize PCR conditions (annealing temperature, primer concentration, etc.) for specific and efficient amplification.
-
-
Quantitative Analysis:
-
Employ a real-time PCR platform to quantify the amount of m1C in a sample. This could involve using a fluorescent dye like SYBR Green or a probe-based system for enhanced specificity.
-
-
Validation and Calibration:
-
The results from the newly developed m1C-PCR must be validated against the "gold standard" LC-MS/MS method.
-
A series of samples with known m1C content (as determined by LC-MS/MS) should be analyzed by the m1C-PCR to generate a standard curve and establish the accuracy, sensitivity, and specificity of the new assay.
-
While a direct and validated PCR-based protocol for this compound detection is not yet established due to fundamental knowledge gaps, the LC-MS/MS method presented here provides a reliable and sensitive means for its absolute quantification. The conceptual framework for an m1C-sensitive PCR outlines a clear path for future research and development in this area. The ability to accurately measure m1C will be instrumental in uncovering its biological significance and exploring its potential as a novel epigenetic biomarker.
Application Note and Protocols for the Quantitative Analysis of 5-Methylcytosine in Cellular RNA
Topic: Quantitative Analysis of 5-Methylcytosine (B146107) in Cell Lines
Audience: Researchers, scientists, and drug development professionals.
Introduction
While the user's request specified 1-Methylcytosine (m1C), it is important to clarify that in the context of mammalian cell lines, the predominant and extensively studied methylated form of cytosine is 5-Methylcytosine (m5C). This modification, found in both DNA and various RNA species, plays a crucial role in regulating gene expression and other cellular processes. Quantitative analysis of m5C in RNA, a key aspect of the emerging field of epitranscriptomics, is critical for understanding its biological functions and its implications in disease states, including cancer. This document provides detailed application notes and protocols for the quantitative analysis of m5C in RNA from cell lines, focusing on established and reliable methodologies.
1. Overview of Experimental Workflow
The quantitative analysis of 5-methylcytosine in RNA from cell lines involves several key steps, from sample preparation to data analysis. The specific workflow can vary depending on the chosen quantification method.
2. Biological Significance and Signaling Pathways
5-Methylcytosine in RNA is a dynamic modification involved in various aspects of RNA metabolism, including stability, nuclear export, and translation. The enzymes responsible for adding the methyl group are RNA methyltransferases, such as those from the NSUN family, and this process can be influenced by various cellular signaling pathways.
3. Experimental Protocols
3.1. Cell Culture and RNA Extraction
-
Cell Lines: A variety of human cell lines can be used, such as HeLa, HEK293T, and A549.
-
Culture Conditions: Culture cells under standard conditions (e.g., 37°C, 5% CO2) in the appropriate medium supplemented with fetal bovine serum and antibiotics.
-
RNA Extraction:
-
Harvest cells by trypsinization or scraping.
-
Extract total RNA using a commercial kit (e.g., RNeasy Mini Kit, Qiagen) or a TRIzol-based method, following the manufacturer's instructions.
-
Treat the extracted RNA with DNase I to remove any contaminating genomic DNA.
-
Assess RNA quality and quantity using a spectrophotometer (e.g., NanoDrop) and verify integrity with a bioanalyzer (e.g., Agilent 2100 Bioanalyzer).
-
3.2. Quantification of Global 5-Methylcytosine in RNA
3.2.1. Liquid Chromatography-Tandem Mass Spectrometry (LC-MS/MS)
LC-MS/MS is considered the gold standard for the absolute quantification of modified nucleosides due to its high sensitivity and specificity.[1][2]
-
Protocol:
-
RNA Hydrolysis:
-
To 1-5 µg of total RNA, add nuclease P1 (2U) in a buffer containing 10 mM ammonium (B1175870) acetate (B1210297) (pH 5.3).[3]
-
Incubate at 42°C for 2 hours.
-
Add bacterial alkaline phosphatase (1U) and incubate at 37°C for an additional 2 hours to dephosphorylate the nucleotides to nucleosides.[3]
-
-
LC-MS/MS Analysis:
-
Inject the hydrolyzed sample into an LC-MS/MS system.
-
Separate the nucleosides using a C18 reverse-phase column with a gradient of mobile phases (e.g., water with 0.1% formic acid and acetonitrile (B52724) with 0.1% formic acid).
-
Detect and quantify the nucleosides using a triple quadrupole mass spectrometer in multiple reaction monitoring (MRM) mode. The transitions for cytosine and 5-methylcytosine should be optimized.
-
-
Data Analysis:
-
Generate a standard curve using known concentrations of pure cytosine and 5-methylcytosine nucleosides.
-
Calculate the amount of m5C relative to the total amount of cytosine in the sample.
-
-
3.2.2. Enzyme-Linked Immunosorbent Assay (ELISA)
ELISA provides a high-throughput and cost-effective method for the relative quantification of global RNA methylation. Several commercial kits are available for this purpose.
-
General Protocol (based on commercially available kits):
-
RNA Binding: Bind a specific amount of total RNA (e.g., 100-200 ng) to the wells of a microplate.
-
Blocking: Block the remaining protein-binding sites in the wells.
-
Primary Antibody Incubation: Add a primary antibody specific to 5-methylcytosine and incubate.
-
Secondary Antibody Incubation: Add a horseradish peroxidase (HRP)-conjugated secondary antibody and incubate.
-
Detection: Add a colorimetric HRP substrate and measure the absorbance using a microplate reader.
-
Data Analysis: Calculate the relative amount of m5C by comparing the absorbance of the samples to a standard curve generated with a positive control provided in the kit.
-
4. Data Presentation
The quantitative data obtained from different cell lines and methods should be summarized in a clear and structured format for easy comparison.
Table 1: Global 5-Methylcytosine Levels in RNA of Human Cell Lines Determined by LC-MS/MS
| Cell Line | % m5C of Total Cytosine (Mean ± SD) |
| HeLa | Data to be experimentally determined |
| HEK293T | Data to be experimentally determined |
| A549 | Data to be experimentally determined |
Table 2: Relative Global 5-Methylcytosine Levels in RNA of Human Cell Lines Determined by ELISA
| Cell Line | Relative Absorbance (OD450) (Mean ± SD) |
| HeLa | Data to be experimentally determined |
| HEK293T | Data to be experimentally determined |
| A549 | Data to be experimentally determined |
5. Comparison of Quantification Techniques
The choice of quantification method depends on the specific research question, available resources, and desired level of accuracy.
The quantitative analysis of 5-methylcytosine in RNA is a rapidly evolving field with significant implications for understanding gene regulation and disease. The choice of analytical method, whether LC-MS/MS for absolute quantification or ELISA for high-throughput screening, should be guided by the specific research objectives. The protocols and information provided in this application note offer a comprehensive guide for researchers, scientists, and drug development professionals to accurately quantify this important RNA modification in cell lines.
References
- 1. LC-MS-MS quantitative analysis reveals the association between FTO and DNA methylation - PMC [pmc.ncbi.nlm.nih.gov]
- 2. An Overview of Current Detection Methods for RNA Methylation - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Quantitative analysis of tRNA abundance and modifications by nanopore RNA sequencing - PMC [pmc.ncbi.nlm.nih.gov]
Application Notes and Protocols for 1-Methylcytosine (m1C) Immunoprecipitation
For Researchers, Scientists, and Drug Development Professionals
Introduction
1-Methylcytosine (m1C) is a post-transcriptional RNA modification that has been identified in various RNA species, including transfer RNA (tRNA), ribosomal RNA (rRNA), and messenger RNA (mRNA). The precise biological functions of m1C in mRNA are an active area of research, with emerging evidence suggesting its role in regulating RNA stability, translation, and other cellular processes. The ability to specifically isolate and analyze m1C-containing RNA fragments is crucial for elucidating its role in health and disease.
Methylated RNA immunoprecipitation (MeRIP) is a powerful technique used to enrich for RNA molecules containing a specific modification, followed by downstream analysis such as quantitative PCR (qPCR) or next-generation sequencing (MeRIP-seq) to identify and quantify the modified transcripts. While commercial kits are readily available for other RNA modifications like N6-methyladenosine (m6A) and 5-methylcytosine (B146107) (5mC), dedicated commercial kits specifically for this compound (m1C) immunoprecipitation are not currently on the market.
This document provides a comprehensive guide for performing m1C immunoprecipitation by combining a specific anti-1-Methylcytosine antibody with a general RNA immunoprecipitation kit. The following sections detail the necessary components, a step-by-step experimental protocol, and data presentation guidelines.
Required Materials and Reagents
Successful m1C immunoprecipitation requires a highly specific antibody and a robust RNA immunoprecipitation workflow. The following table summarizes the key components needed.
| Component | Recommended Product(s) | Vendor | Catalog Number | Key Features |
| Anti-1-Methylcytosine (m1C) Antibody | Anti-1-methylcytosine Antibody | MBL International | MC-031-100 | Rabbit polyclonal antibody validated for immunoprecipitation of m1C-containing RNA. |
| RNA Immunoprecipitation Kit | Magna MeRIP™ m6A Kit | MilliporeSigma | 17-10499 | Provides optimized buffers, magnetic beads, and a validated protocol for methylated RNA immunoprecipitation that can be adapted for m1C.[1][2] |
| Imprint® RNA Immunoprecipitation Kit | Sigma-Aldrich | RIPA | A comprehensive kit with lysis buffers, magnetic beads, and control antibodies suitable for RIP experiments.[3][4] | |
| RNase Inhibitor | RNasin® Ribonuclease Inhibitors | Promega | N2511 | Essential for preventing RNA degradation throughout the procedure. |
| Protein A/G Magnetic Beads | Dynabeads™ Protein A/G | Thermo Fisher Scientific | 10001D / 10003D | High-quality magnetic beads for efficient immunoprecipitation. |
Experimental Workflow
The overall workflow for this compound (m1C) immunoprecipitation followed by sequencing (MeRIP-seq) is depicted in the diagram below. The process begins with the isolation and fragmentation of total RNA, followed by immunoprecipitation of m1C-containing fragments, and finally, library preparation for sequencing.
Detailed Experimental Protocol
This protocol is adapted from standard MeRIP procedures and should be optimized for your specific cell type or tissue. Always work in an RNase-free environment.
1. RNA Preparation and Fragmentation
-
Isolate total RNA from your samples using a standard method (e.g., TRIzol extraction). Ensure high-quality RNA with a RIN score > 7.0.
-
Quantify the total RNA using a spectrophotometer (e.g., NanoDrop) and assess its integrity on a Bioanalyzer.
-
For each immunoprecipitation reaction, use 10-50 µg of total RNA.
-
Fragment the RNA to an average size of 100-200 nucleotides. This can be achieved using an RNA fragmentation buffer (e.g., from the Magna MeRIP™ m6A Kit) and incubating at 94°C for 5-15 minutes, followed by immediate cooling on ice. The optimal fragmentation time should be determined empirically.
-
Reserve 5-10% of the fragmented RNA as an "input" control for downstream analysis (qPCR or sequencing).
2. Immunoprecipitation of m1C-Containing RNA
-
Prepare the antibody-bead complexes. For each IP reaction, resuspend the required amount of Protein A/G magnetic beads in IP buffer.
-
Add 2-5 µg of the anti-1-Methylcytosine antibody to the bead suspension.
-
Incubate the antibody-bead mixture for 30-60 minutes at 4°C with gentle rotation to allow for antibody binding.
-
After incubation, wash the beads twice with IP buffer to remove any unbound antibody.
-
Add the fragmented RNA to the antibody-bead complexes.
-
Add RNase inhibitor to the mixture.
-
Incubate the mixture overnight at 4°C with gentle rotation to allow for the immunoprecipitation of m1C-containing RNA fragments.
3. Washing and Elution
-
Following the overnight incubation, pellet the magnetic beads using a magnetic stand and discard the supernatant.
-
Perform a series of washes to remove non-specifically bound RNA. This typically involves sequential washes with low-salt and high-salt wash buffers. Refer to the manual of your chosen RNA immunoprecipitation kit for specific wash buffer compositions and volumes.[1][2][3]
-
After the final wash, resuspend the beads in an elution buffer containing a competitive inhibitor (e.g., free this compound, if available) or by using a high-salt elution buffer followed by proteinase K treatment to release the RNA.
-
Incubate at the recommended temperature and time to elute the enriched RNA from the beads.
-
Separate the beads on a magnetic stand and carefully transfer the supernatant containing the eluted m1C-enriched RNA to a new RNase-free tube.
4. RNA Purification and Quantification
-
Purify the eluted RNA using a standard RNA clean-up kit (e.g., Zymo Research RNA Clean & Concentrator).
-
Elute the purified RNA in a small volume of RNase-free water.
-
Quantify the enriched RNA using a highly sensitive method such as the Qubit RNA HS Assay Kit. The expected yield will be in the nanogram range.
5. Downstream Analysis
-
Validation by RT-qPCR: To validate the enrichment of specific transcripts, perform RT-qPCR on both the immunoprecipitated RNA and the input control RNA. Use primers specific to known or suspected m1C-modified transcripts and a negative control transcript. The enrichment can be calculated as a percentage of the input.
-
MeRIP-Seq Library Preparation and Sequencing: For transcriptome-wide analysis, prepare sequencing libraries from the m1C-enriched RNA and the input control RNA using a low-input RNA library preparation kit suitable for Illumina sequencing. Sequence the libraries on a high-throughput sequencing platform.
Data Analysis Pipeline
The bioinformatic analysis of m1C-MeRIP-seq data is crucial for identifying m1C peaks and understanding their distribution.
Conclusion
While dedicated commercial kits for this compound immunoprecipitation are not yet available, researchers can successfully perform this technique by combining a specific anti-m1C antibody with a general RNA immunoprecipitation kit. The protocol provided here offers a robust framework for the enrichment and subsequent analysis of m1C-containing RNA. Careful optimization of RNA fragmentation, antibody concentration, and washing conditions will be critical for achieving high-quality, specific enrichment. The ability to map m1C across the transcriptome will undoubtedly accelerate our understanding of its regulatory roles in gene expression and its implications for human health and disease.
References
Application Notes and Protocols for the Enzymatic Identification of 1-Methylcytosine (m1C)
Audience: Researchers, scientists, and drug development professionals.
Introduction:
1-Methylcytosine (B60703) (m1C) is a post-transcriptional RNA modification that, like other epigenetic and epitranscriptomic marks, plays a role in various biological processes. Unlike its more studied isomer, 5-methylcytosine (B146107) (5mC), the precise functions and enzymatic regulation of m1C are still being elucidated. The identification and quantification of m1C are crucial for understanding its biological significance and its potential as a biomarker or therapeutic target. Enzymatic methods offer a highly specific and sensitive approach for the detection of such modifications.
This document provides detailed protocols for the enzymatic identification of this compound, primarily focusing on the use of the ALKBH (AlkB homolog) family of dioxygenases. These enzymes catalyze the oxidative demethylation of various methylated nucleobases. While ALKBH3 has well-documented activity against 1-methyladenine (B1486985) (m1A) and 3-methylcytosine (B1195936) (3mC), its potential application for m1C detection provides a strong basis for a targeted enzymatic assay.[1][2] The protocols described herein are foundational and may require optimization for specific applications.
Method 1: In Vitro Demethylation Assay with Formaldehyde (B43269) Detection
This method relies on the enzymatic removal of the methyl group from m1C by an ALKBH family enzyme, which releases formaldehyde as a byproduct. The formaldehyde is then quantified using a sensitive fluorescent assay.
Logical Workflow
Caption: Workflow for m1C detection via enzymatic demethylation and formaldehyde quantification.
Experimental Protocols
Protocol 1.1: Preparation of m1C-Containing RNA Substrate
This protocol describes the synthesis of an RNA molecule containing this compound at specific positions using in vitro transcription (IVT).
Materials:
-
Linearized plasmid DNA or PCR product with a T7 promoter upstream of the target sequence.
-
NTPs (ATP, GTP, UTP).
-
1-methylcytidine-5'-triphosphate (m1C-TP).
-
T7 RNA Polymerase.
-
Transcription Buffer (5X).[3]
-
RNase Inhibitor.
-
DNase I (RNase-free).
-
RNA Purification Kit.
Methodology:
-
Assemble the Transcription Reaction: In a sterile, RNase-free tube, combine the following at room temperature:
-
Nuclease-free water to a final volume of 20 µL.
-
4 µL of 5X Transcription Buffer.
-
2 µL of ATP, GTP, UTP mix (10 mM each).
-
2 µL of m1C-TP (10 mM).
-
1 µg of linear DNA template.
-
1 µL of RNase Inhibitor.
-
2 µL of T7 RNA Polymerase.
-
-
Incubation: Mix gently and incubate at 37°C for 2-4 hours.[3]
-
DNase Treatment: Add 1 µL of DNase I and incubate at 37°C for 15 minutes to remove the DNA template.
-
Purification: Purify the m1C-containing RNA using an RNA purification kit according to the manufacturer's instructions.
-
Quantification: Determine the concentration and purity of the RNA using a spectrophotometer (e.g., NanoDrop).
Protocol 1.2: ALKBH3-Mediated Demethylation Reaction
Materials:
-
Purified m1C-containing RNA substrate (from Protocol 1.1).
-
Recombinant human ALKBH3 protein.
-
Demethylation Buffer (10X): 500 mM Tris-HCl (pH 8.0).
-
Cofactor Mix:
-
Ascorbic acid (20 mM stock).
-
2-oxoglutarate (1 mM stock).
-
Fe(II)SO₄·7H₂O (400 µM stock).
-
Methodology:
-
Prepare Reaction Mix: In a microcentrifuge tube on ice, prepare a master mix for the number of reactions. For a single 50 µL reaction, combine:
-
Initiate Reaction: Add 100-200 ng of recombinant ALKBH3 protein to the reaction mix. For a negative control, add an equivalent volume of storage buffer or use heat-inactivated enzyme.
-
Incubation: Incubate the reaction at 37°C for 60 minutes.[1]
-
Stop Reaction (Optional): The reaction can be stopped by adding EDTA to a final concentration of 5 mM or by proceeding immediately to the detection step.
Protocol 1.3: Quantification of Released Formaldehyde
This protocol uses a commercial fluorescent formaldehyde detection kit as an example. Follow the manufacturer's instructions for the specific kit used.
Materials:
-
Completed demethylation reaction from Protocol 1.2.
-
Formaldehyde Assay Kit (e.g., from Cayman Chemical, Sigma-Aldrich, or BioAssay Systems).[4][5]
-
Formaldehyde Standard (provided in the kit).
-
96-well black plate with a clear bottom.
-
Fluorometric plate reader.
Methodology:
-
Prepare Standards: Prepare a formaldehyde standard curve (e.g., 0-100 µM) in 1X Demethylation Buffer as per the kit's instructions.
-
Plate Setup:
-
Pipette 50 µL of each standard into duplicate wells of the 96-well plate.
-
Pipette 50 µL of each demethylation reaction sample into duplicate wells.
-
Pipette 50 µL of the negative control reaction into duplicate wells.
-
-
Add Detection Reagent: Add the formaldehyde detector reagent from the kit (e.g., 50 µL of a mix containing acetoacetanilide (B1666496) and ammonia) to all standard and sample wells.[6]
-
Incubation: Incubate the plate at room temperature for 15-30 minutes, protected from light.
-
Measure Fluorescence: Read the fluorescence on a plate reader at the recommended wavelengths (typically Ex/Em = 370/470 nm).[5]
-
Data Analysis:
-
Subtract the average fluorescence of the blank (no formaldehyde) from all readings.
-
Plot the standard curve (fluorescence vs. formaldehyde concentration).
-
Determine the concentration of formaldehyde in the samples by interpolating their fluorescence values from the standard curve. The amount of formaldehyde is proportional to the amount of m1C in the original substrate.
-
Method 2: Semi-Quantitative Dot Blot Assay
This method can be used to assess changes in global m1C levels after enzymatic treatment. An m1C-specific antibody is used to detect the modification on a membrane. A decrease in signal after ALKBH3 treatment indicates demethylation.
Experimental Workflow
Caption: Workflow for semi-quantitative analysis of m1C using a demethylation-coupled dot blot assay.
Protocol 2.1: Dot Blot for m1C Detection
Materials:
-
Total RNA samples (treated with ALKBH3 and mock-treated as per Protocol 1.2).
-
Nitrocellulose or Nylon membrane.[7]
-
UV Stratalinker or similar crosslinking device.
-
Blocking Buffer (e.g., 5% non-fat milk in TBST).
-
Primary antibody: Anti-1-methylcytosine (m1C).
-
Secondary antibody: HRP-conjugated anti-rabbit/mouse IgG.
-
TBST Buffer (Tris-Buffered Saline with 0.1% Tween-20).
-
Enhanced Chemiluminescence (ECL) substrate.
-
Imaging system (e.g., ChemiDoc).
Methodology:
-
Sample Preparation: Serially dilute the control and ALKBH3-treated RNA samples in nuclease-free water (e.g., from 500 ng down to 50 ng).
-
Membrane Spotting: Carefully spot 1-2 µL of each RNA dilution onto the dry nitrocellulose membrane. Allow the spots to air dry completely.[7][8]
-
Crosslinking: Place the membrane face-up in a UV crosslinker and irradiate twice with the optimal energy setting (e.g., 120 mJ/cm²).
-
Methylene Blue Staining (Optional Loading Control): To confirm equal loading, a parallel membrane can be stained with 0.02% Methylene Blue in 0.3 M sodium acetate (B1210297) (pH 5.2).
-
Blocking: Incubate the membrane in Blocking Buffer for 1 hour at room temperature with gentle agitation.
-
Primary Antibody Incubation: Dilute the anti-m1C antibody in Blocking Buffer (follow manufacturer's recommendation for dilution). Incubate the membrane with the primary antibody overnight at 4°C with agitation.
-
Washing: Wash the membrane 3 times for 10 minutes each with TBST.
-
Secondary Antibody Incubation: Dilute the HRP-conjugated secondary antibody in Blocking Buffer. Incubate the membrane for 1 hour at room temperature.
-
Final Washes: Wash the membrane 3 times for 10 minutes each with TBST.
-
Detection: Incubate the membrane with ECL substrate according to the manufacturer's protocol. Immediately capture the chemiluminescent signal using an imaging system.
-
Analysis: Quantify the intensity of each dot using software like ImageJ. A reduction in signal intensity in the ALKBH3-treated samples compared to the mock-treated controls indicates the presence and enzymatic removal of m1C.[9]
Data Presentation: Quantitative Comparison of ALKBH Enzymes
| Enzyme | Substrate | K_m (µM) | k_cat (min⁻¹) | Catalytic Efficiency (k_cat/K_m) (µM⁻¹min⁻¹) | Reference(s) |
| E. coli AlkB | ssDNA (1-meA) | 5.6 ± 0.9 | 3.5 ± 0.2 | 0.63 | [10] |
| ssDNA (3-meC) | 7.0 ± 1.6 | 3.3 ± 0.3 | 0.47 | [10] | |
| Human ALKBH2 | ssDNA (1-meA) | N/A | ~1.1 - 2.5 | N/A | [11] |
| Human ALKBH3 | ssDNA (3-meC) | N/A | ~1.7 | N/A | [11] |
| RNA (1-meA) | 1.16 ± 0.11 | 0.13 ± 0.01 | 0.11 | [12] | |
| ssDNA (1-meA) | 1.10 ± 0.14 | 0.13 ± 0.01 | 0.12 | [12] | |
| ssDNA (3-meC) | 1.25 ± 0.15 | 0.12 ± 0.01 | 0.10 | [12] | |
| Human ALKBH6 | 1-me-AMP | 0.96 | 10.8 | 11.25 | [11] |
| 7-me-GMP | 1.03 | 10.0 | 9.71 | [11] |
N/A: Not available from the cited sources. Data illustrates that enzyme efficiencies vary significantly based on the specific substrate and its nucleic acid context (ssDNA, RNA, etc.).
Substrate Specificity of ALKBH Family
The ALKBH family of enzymes exhibits diverse and sometimes overlapping substrate specificities, which is a critical consideration for assay design.
Caption: Substrate specificities of selected human ALKBH enzymes, highlighting ALKBH3's role.
References
- 1. A real-time PCR-based quantitative assay for 3-methylcytosine demethylase activity of ALKBH3 - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Transfer RNA demethylase ALKBH3 promotes cancer progression via induction of tRNA-derived small RNAs - PMC [pmc.ncbi.nlm.nih.gov]
- 3. themoonlab.org [themoonlab.org]
- 4. fnkprddata.blob.core.windows.net [fnkprddata.blob.core.windows.net]
- 5. bioassaysys.com [bioassaysys.com]
- 6. cdn.caymanchem.com [cdn.caymanchem.com]
- 7. A 5-mC Dot Blot Assay Quantifying the DNA Methylation Level of Chondrocyte Dedifferentiation In Vitro - PMC [pmc.ncbi.nlm.nih.gov]
- 8. raybiotech.com [raybiotech.com]
- 9. biorxiv.org [biorxiv.org]
- 10. Kinetic studies of Escherichia coli AlkB using a new fluorescence-based assay for DNA demethylation - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Identification of ALKBH6 as a nucleotide demethylase with a distinct substrate preference - PMC [pmc.ncbi.nlm.nih.gov]
- 12. The Molecular Basis of Human ALKBH3 Mediated RNA N1-methyladenosine (m1A) Demethylation - PMC [pmc.ncbi.nlm.nih.gov]
Application Notes and Protocols for Sensitive 1-Methylcytosine (1mC) Detection
For Researchers, Scientists, and Drug Development Professionals
Introduction to 1-Methylcytosine (B60703) (1mC)
This compound (1mC) is a modified DNA and RNA base where a methyl group is attached to the nitrogen atom at position 1 of the cytosine ring.[1] Unlike the more extensively studied 5-methylcytosine (B146107) (5mC), 1mC disrupts the Watson-Crick base pairing face of cytosine. This modification can impact DNA replication and transcription, and its presence in DNA and RNA is of growing interest in various biological processes, including disease pathogenesis. Accurate and sensitive detection of 1mC at single-base resolution is crucial for understanding its functional roles.
This document provides detailed application notes and protocols for two key techniques for the sensitive detection of 1mC: a chemical labeling method for sequencing (DMS-MaPseq) and an analytical method for global quantification (UHPLC-MS/MS).
I. Chemical Labeling for Single-Base Resolution of 1mC: DMS-MaPseq
Dimethyl sulfate (B86663) (DMS) mutational profiling with sequencing (DMS-MaPseq) is a powerful technique for identifying 1mC in nucleic acids.[1][2] DMS methylates the N3 position of cytosine and the N1 position of adenine (B156593) in single-stranded regions.[3][4] Critically, the presence of a methyl group at the N1 position in 1mC alters its chemical reactivity. While DMS does not directly modify 1mC, the conditions of the DMS treatment can lead to a chemical conversion that results in misincorporation during reverse transcription or PCR, creating a "mutational signature" at the 1mC site that can be identified by high-throughput sequencing.[2]
Experimental Workflow: 1mC-MaPseq
The overall workflow for DMS-MaPseq for 1mC detection in DNA is as follows:
Detailed Experimental Protocol: 1mC-MaPseq for DNA
This protocol is adapted from DMS-MaPseq methods for RNA structure analysis and tailored for DNA.[3][5][6] Optimization may be required for specific cell types or DNA sources.
1. DNA Preparation
1.1. Extract genomic DNA using a standard kit that yields high-purity DNA. 1.2. Fragment the DNA to a desired size range (e.g., 150-300 bp) using sonication or enzymatic digestion. 1.3. Purify the fragmented DNA using a DNA cleanup kit. 1.4. Quantify the DNA concentration using a fluorometric method (e.g., Qubit).
2. DMS Treatment
Caution: Dimethyl sulfate (DMS) is a potent carcinogen and must be handled with extreme care in a certified chemical fume hood with appropriate personal protective equipment.
2.1. For each sample, prepare a DMS reaction mix. For a 50 µL reaction, combine:
- Up to 1 µg of fragmented DNA
- 5 µL of 10x DMS Reaction Buffer (500 mM HEPES pH 7.5, 1 M KCl)
- Nuclease-free water to 49 µL 2.2. Denature the DNA by heating the reaction mix at 95°C for 5 minutes, followed by immediate placement on ice. 2.3. In the chemical fume hood, add 1 µL of DMS (diluted 1:10 in ethanol (B145695) for a final concentration of approximately 1%) to the reaction mix. Mix gently by flicking the tube. 2.4. Incubate at 37°C for 10 minutes. The incubation time may need optimization. 2.5. Quench the reaction by adding 12.5 µL of 3 M sodium acetate (B1210297) (pH 5.2) and 5 µL of β-mercaptoethanol. 2.6. Purify the DMS-treated DNA using a DNA cleanup kit or ethanol precipitation. Elute in nuclease-free water.
3. Library Preparation and Sequencing
3.1. Prepare sequencing libraries from the single-stranded, DMS-treated DNA. It is crucial to use a library preparation kit specifically designed for single-stranded or damaged DNA to ensure the capture of DMS-induced lesions. 3.2. During library amplification, use a high-fidelity polymerase that can read through DMS-induced modifications and introduce mismatches. 3.3. Quantify the final library and perform quality control. 3.4. Sequence the libraries on an Illumina platform, generating paired-end reads.
4. Data Analysis
4.1. Quality Control: Trim adapters and low-quality bases from the raw sequencing reads. 4.2. Alignment: Align the trimmed reads to the appropriate reference genome. 4.3. Mutation Calling: Use a variant caller to identify single nucleotide polymorphisms (SNPs) and mismatches compared to the reference genome. 4.4. 1mC Identification: Filter the called variants to identify C-to-T transitions that are significantly enriched in the DMS-treated samples compared to untreated controls. These positions represent putative 1mC sites.
II. Enzymatic Digestion and UHPLC-MS/MS for Global 1mC Quantification
For a quantitative assessment of the total 1mC content in a DNA sample, Ultra-High Performance Liquid Chromatography coupled with tandem Mass Spectrometry (UHPLC-MS/MS) is the gold standard.[7][8] This method involves the enzymatic digestion of DNA into individual nucleosides, followed by their separation and quantification by mass spectrometry.
Experimental Workflow: UHPLC-MS/MS for 1mC
Detailed Experimental Protocol: UHPLC-MS/MS
1. DNA Digestion
1.1. To 1-5 µg of purified genomic DNA, add nuclease-free water to a final volume of 25 µL. 1.2. Add 5 µL of 10x Nuclease P1 Buffer and 1 µL of Nuclease P1 (100 U/µL). 1.3. Incubate at 37°C for 2 hours. 1.4. Add 5 µL of 10x Alkaline Phosphatase Buffer and 1 µL of Calf Intestinal Alkaline Phosphatase (10 U/µL). 1.5. Incubate at 37°C for an additional 2 hours. 1.6. Filter the reaction mixture through a 0.22 µm filter to remove enzymes.
2. UHPLC-MS/MS Analysis
2.1. Separate the nucleosides using a reversed-phase UHPLC column. 2.2. Perform mass spectrometry analysis in positive ion mode using multiple reaction monitoring (MRM) to detect the specific parent-to-daughter ion transitions for 1-methyl-2'-deoxycytidine and other standard nucleosides (dC, dG, dA, dT, and 5-methyl-2'-deoxycytidine). 2.3. Prepare a standard curve using known concentrations of pure 1-methyl-2'-deoxycytidine and other nucleoside standards.
3. Quantification
3.1. Calculate the amount of 1mC in the sample by comparing the peak area from the sample to the standard curve. 3.2. Express the level of 1mC as a ratio to total cytosine or total guanine.
III. Data Presentation and Comparison of Techniques
The choice of method for 1mC detection depends on the research question. DMS-MaPseq provides single-base resolution information on the location of 1mC, while UHPLC-MS/MS offers a highly accurate global quantification.
| Parameter | DMS-MaPseq | UHPLC-MS/MS |
| Principle | Chemical modification (DMS) inducing mutations at 1mC sites, detected by NGS. | Enzymatic digestion to nucleosides, separation by UHPLC, and quantification by mass spectrometry.[8] |
| Resolution | Single-base. | Global (no positional information). |
| Sensitivity | High, dependent on sequencing depth. Can theoretically detect single modified bases. | High, can detect low femtomole amounts of nucleosides. |
| Specificity | Relies on the differential reactivity of 1mC and subsequent misincorporation. Specificity for 1mC versus other modifications needs further validation in DNA. | High, based on chromatographic retention time and specific mass-to-charge ratio transitions.[7] |
| Input DNA | Nanogram to microgram quantities. | Microgram quantities. |
| Quantitative? | Semi-quantitative (mutation frequency can be correlated with modification level). | Fully quantitative. |
| Advantages | Provides genome-wide, single-base resolution maps of 1mC. | Gold standard for accurate quantification of global 1mC levels. |
| Limitations | Indirect detection method; potential for off-target DMS reactions; requires bioinformatics expertise for data analysis. | Provides no information on the genomic location of 1mC. |
IV. Signaling Pathways and Logical Relationships
The precise biological roles of 1mC are still under investigation. However, its position at the Watson-Crick face suggests a direct impact on DNA-protein interactions and DNA replication/transcription machinery. The following diagram illustrates the potential consequences of 1mC in a DNA signaling context.
Conclusion
The detection of this compound is an emerging area in epigenetics. The methods described here provide powerful tools for researchers to investigate the presence, location, and abundance of this important DNA modification. DMS-MaPseq offers the potential for genome-wide, single-base resolution mapping, while UHPLC-MS/MS provides accurate global quantification. The application of these techniques will be instrumental in elucidating the biological functions of 1mC in health and disease. Currently, there are no established direct enzymatic labeling methods for the sequencing of 1mC, making chemical labeling approaches like DMS-MaPseq the primary method for high-resolution mapping.
References
- 1. escholarship.org [escholarship.org]
- 2. the-dna-universe.com [the-dna-universe.com]
- 3. Enzymatic Methylation of DNA in Cultured Human Cells Studied by Stable Isotope Incorporation and Mass Spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 4. integra-biosciences.com [integra-biosciences.com]
- 5. Sequencing of N6-methyl-deoxyadenosine at single-base resolution across the mammalian genome - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Single-base resolution analysis of active DNA demethylation using methylase-assisted bisulfite sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Detection of DNA Methylation in Genomic DNA by UHPLC-MS/MS | Springer Nature Experiments [experiments.springernature.com]
- 8. researchgate.net [researchgate.net]
Troubleshooting & Optimization
troubleshooting incomplete bisulfite conversion for 1-Methylcytosine
Technical Support Center: 1-Methylcytosine (B60703) (1mC) Analysis
This guide provides troubleshooting strategies for researchers, scientists, and drug development professionals encountering issues with the analysis of this compound (1mC).
Frequently Asked Questions (FAQs)
Q1: Why are my results showing incomplete bisulfite conversion for this compound (1mC)?
This is a common point of confusion. Standard bisulfite sequencing is designed for the detection of 5-methylcytosine (B146107) (5mC), not this compound (1mC). The chemistry of the bisulfite reaction efficiently deaminates unmethylated cytosine to uracil, while 5mC is largely resistant to this conversion. However, 1mC is also resistant to standard bisulfite treatment. Consequently, both 5mC and 1mC will be read as cytosine after sequencing, making them indistinguishable from each other and from genuinely incomplete conversion of unmodified cytosine. Therefore, what appears as "incomplete conversion" is actually the expected chemical behavior of 1mC with bisulfite, highlighting that this method is unsuitable for specific 1mC detection.
Q2: If standard bisulfite sequencing doesn't work for 1mC, what methods should I use?
Several advanced methods have been developed to specifically detect 1mC. These techniques often rely on enzymatic or chemical reactions that differentiate 1mC from other cytosine modifications. Some of these methods include:
-
Enzymatic Deamination-based Methods: Techniques like EM-seq (Enzymatic Methyl-seq) use a combination of enzymes, such as TET2 and APOBEC, to convert unmethylated and 5-methylated cytosines while protecting other modifications.[1][2] This allows for the specific identification of different cytosine variants.
-
Chemical Derivatization: Specific chemical reactions can be used to modify 1mC, making it behave differently during sequencing.
-
Single-Molecule Real-Time (SMRT) Sequencing: This technology can sometimes detect modified bases by observing the kinetics of DNA polymerase as it incorporates nucleotides.[3][4] The presence of a modification like 1mC can cause a detectable pause in the polymerase activity.
-
Nanopore Sequencing: This method detects changes in electrical current as a DNA strand passes through a nanopore.[5][6] Different DNA bases and their modifications create distinct electrical signals, allowing for direct detection.
Q3: What is the difference between 1mC and 5mC?
This compound (1mC) and 5-methylcytosine (5mC) are both methylated forms of the DNA base cytosine, but the position of the methyl group is different. In 5mC, the methyl group is attached to the 5th carbon of the pyrimidine (B1678525) ring. In 1mC, the methyl group is attached to the nitrogen atom at position 1. This structural difference leads to different chemical properties and biological functions, and it is the reason they require different detection methods.
Troubleshooting Guide for Enzymatic 1mC Detection
This guide focuses on troubleshooting a hypothetical enzymatic method for 1mC detection, which often involves a series of reactions including oxidation and deamination steps.
| Problem | Potential Cause | Recommended Solution |
| Low library yield after PCR amplification | DNA Degradation: The multiple enzymatic steps and incubations can lead to DNA fragmentation. | - Start with high-quality, intact genomic DNA. - Minimize freeze-thaw cycles of DNA samples. - Handle DNA gently; avoid vigorous vortexing. - Ensure all buffers are nuclease-free. |
| Inefficient Adapter Ligation: Poor ligation of sequencing adapters will result in fewer molecules being available for PCR. | - Use fresh, high-quality adapters. - Optimize the molar ratio of adapters to DNA fragments. - Ensure the ligase enzyme is active and used at the correct concentration. | |
| High non-conversion rate of unmodified cytosines | Incomplete Deamination: The deaminase enzyme (e.g., APOBEC) may not have worked efficiently. | - Ensure the enzyme is not expired and has been stored correctly. - Verify the reaction buffer composition and pH are optimal for the enzyme. - Optimize the incubation time and temperature for the deamination step. - Ensure the DNA was properly denatured to a single-stranded form before deamination.[7][8] |
| Poor DNA Quality: Contaminants in the DNA sample can inhibit enzyme activity.[9] | - Re-purify the DNA sample using a column-based kit or phenol-chloroform extraction followed by ethanol (B145695) precipitation. | |
| Inaccurate quantification of 1mC levels | Inefficient Protection of 1mC: The initial enzymatic or chemical step designed to protect 1mC from subsequent reactions may be incomplete. | - Optimize the concentration of the protective enzyme/reagent. - Increase the incubation time for the protection step. - Include a known control DNA with 1mC to assess protection efficiency. |
| PCR Bias: During amplification, fragments containing converted (Uracil) bases may amplify differently than those with non-converted (Cytosine) bases. | - Use a polymerase specifically designed for amplifying bisulfite-converted or uracil-containing DNA (e.g., a high-fidelity uracil-tolerant polymerase). - Minimize the number of PCR cycles to avoid introducing bias. |
Experimental Protocol: Conceptual Enzymatic 1mC Detection Workflow
This protocol outlines the key steps in a conceptual enzyme-based method for distinguishing 1mC from C and 5mC.
-
DNA Preparation: Start with 100-500 ng of high-quality, purified genomic DNA fragmented to a desired size (e.g., 200-500 bp).
-
End Repair and A-tailing: Repair the ends of the fragmented DNA to make them blunt and add a single 'A' nucleotide to the 3' ends. This prepares the fragments for adapter ligation.
-
Adapter Ligation: Ligate sequencing adapters to the DNA fragments. These adapters contain the necessary sequences for library amplification and sequencing.
-
First Enzymatic Reaction (Protection of 5mC): Treat the DNA with an enzyme like TET2 dioxygenase. In the presence of specific cofactors, TET2 can oxidize 5mC to 5-hydroxymethylcytosine (B124674) (5hmC), 5-formylcytosine (B1664653) (5fC), and 5-carboxylcytosine (5caC).[10] This modification protects the original 5mC from subsequent deamination. 1mC and unmodified C are not affected by TET2.
-
Second Enzymatic Reaction (Deamination): After heat-inactivating the first enzyme, add a deaminase enzyme (e.g., an APOBEC family enzyme). This enzyme will deaminate unmodified cytosine to uracil. The modified 5mC (now 5caC) and the original 1mC are resistant to this deamination.
-
PCR Amplification: Amplify the resulting library using a uracil-tolerant DNA polymerase. During PCR, the uracils will be read as thymines.
-
Sequencing and Data Analysis: Sequence the amplified library. During data analysis:
-
Reads that appear as 'T' correspond to original unmethylated 'C'.
-
Reads that appear as 'C' can be either original 5mC or 1mC. By comparing with a standard bisulfite sequencing dataset (where both 5mC and 1mC also read as 'C'), and using orthogonal validation methods, one can begin to infer the locations of 1mC. More advanced chemistries are often needed for direct, unambiguous detection.
-
Visualizations
Caption: A logical workflow for troubleshooting 1mC detection issues.
References
- 1. youtube.com [youtube.com]
- 2. biorxiv.org [biorxiv.org]
- 3. pubs.acs.org [pubs.acs.org]
- 4. researchgate.net [researchgate.net]
- 5. Research Portal [laro.lanl.gov]
- 6. Selective and Sensitive Detection of Methylcytosine by Aerolysin Nanopore under Serum Condition - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. DNA Methylation: Bisulphite Modification and Analysis - PMC [pmc.ncbi.nlm.nih.gov]
- 8. epigenie.com [epigenie.com]
- 9. benchchem.com [benchchem.com]
- 10. Enzymatic approaches for profiling cytosine methylation and hydroxymethylation - PMC [pmc.ncbi.nlm.nih.gov]
Technical Support Center: Amplifying 1-methylcytosine (1mC) DNA
This technical support center provides researchers, scientists, and drug development professionals with comprehensive troubleshooting guides, frequently asked questions (FAQs), and detailed protocols for optimizing the Polymerase Chain Reaction (PCR) amplification of DNA containing 1-methylcytosine (B60703) (1mC).
Frequently Asked Questions (FAQs)
Q1: Why is it challenging to amplify DNA containing this compound (1mC)?
A1: this compound (1mC) is a modified base that can interfere with the function of standard DNA polymerases. The methyl group in the N1 position of cytosine disrupts the canonical Watson-Crick base pairing with guanine, which can cause the DNA polymerase to stall or dissociate from the DNA template. This leads to incomplete extension, low PCR yield, or complete amplification failure. High-fidelity polymerases with strong 3'-to-5' exonuclease (proofreading) activity may also be inhibited or may attempt to "correct" the modified base, further complicating amplification.[1]
Q2: Which type of DNA polymerase is best suited for amplifying 1mC-containing DNA?
A2: High-fidelity DNA polymerases engineered for high processivity and tolerance to DNA damage or modified bases are generally recommended.[1][2] Look for enzymes with features like strong strand-displacement activity and enhanced thermostability. While standard Taq polymerase can sometimes work, it is more prone to stalling and has a lower fidelity.[1] Hot-start polymerases are also highly recommended as they reduce non-specific amplification and primer-dimer formation, which is crucial when working with challenging templates.[1][3][4]
Q3: What are PCR additives and can they help amplify 1mC-containing templates?
A3: PCR additives are chemicals that can be included in the reaction mix to improve amplification efficiency, specificity, and yield, especially for difficult templates like those that are GC-rich or contain modified bases.[5][6] Additives like Betaine and Dimethyl Sulfoxide (DMSO) are particularly useful as they help to reduce DNA secondary structures that can inhibit polymerase activity.[7][] Bovine Serum Albumin (BSA) can be used to overcome inhibitors present in the DNA sample.[5][6]
Q4: How does annealing temperature affect the amplification of 1mC templates?
A4: The annealing temperature is a critical parameter for PCR specificity.[9] For 1mC-containing DNA, optimizing the annealing temperature is crucial. A temperature that is too low can lead to non-specific primer binding and amplification of unwanted products, while a temperature that is too high can prevent primers from annealing efficiently to the template, resulting in low or no yield.[10] A gradient PCR is the most effective method to empirically determine the optimal annealing temperature for your specific primers and template.[9][11]
PCR Optimization & Troubleshooting Workflow
The following diagram illustrates a logical workflow for optimizing and troubleshooting PCR for 1mC-containing DNA.
Caption: A workflow for systematic PCR optimization and troubleshooting.
Troubleshooting Guide
This guide addresses common issues encountered when amplifying 1mC-containing DNA.
| Problem | Possible Cause | Recommended Solution |
| No Amplification or Low Yield | Polymerase Stalling: The 1mC modification is inhibiting the DNA polymerase.[1] | • Switch to a high-fidelity polymerase known for high processivity and tolerance to modified bases.[2]• Increase the extension time to give the polymerase more time to bypass the 1mC site.[10]• Add PCR enhancers like Betaine (1.0-1.7 M) or DMSO (2-8%) to resolve secondary structures.[6][7][] |
| Suboptimal Annealing Temperature: Primers are not binding efficiently or specifically.[12] | • Run a gradient PCR to determine the optimal annealing temperature (typically 3–5°C below the lowest primer Tₘ).[9][10] | |
| Incorrect Magnesium Concentration: Mg²⁺ is a critical cofactor for DNA polymerase; concentration can be too high or too low.[5][9] | • Titrate MgCl₂ concentration, typically in a range of 1.5 mM to 3.5 mM.[9] | |
| Poor Template Quality: DNA template may be degraded or contain PCR inhibitors. | • Check template integrity on an agarose (B213101) gel. • Re-purify the DNA template.• Add BSA (up to 0.8 µg/µl) to the reaction to neutralize inhibitors.[6] | |
| Non-Specific Bands or Smearing | Low Annealing Temperature: Primers are binding to off-target sites.[13] | • Increase the annealing temperature in 1–2°C increments.[10] |
| Excessive Template or Primers: Too much starting material can lead to artifacts.[11] | • Reduce the amount of template DNA. • Titrate primer concentration, typically between 0.1 µM and 0.5 µM.[11] | |
| Contamination: Contaminating DNA is being amplified.[14] | • Run a negative control (no template) to check for contamination.• Use fresh reagents and dedicated PCR workstations.[14] | |
| Primer-Dimers | Primer Design: Primers have complementarity, especially at the 3' ends. | • Design new primers using primer design software to avoid self-complementarity.[11]• Use a hot-start polymerase to prevent primer extension at low temperatures during reaction setup.[3][4] |
Experimental Protocols
Protocol 1: Standard PCR Setup for 1mC DNA
This protocol provides a starting point for amplification. Components should be optimized as needed.
-
Thaw Reagents: Thaw all reaction components (polymerase buffer, dNTPs, primers, DNA template) on ice.
-
Prepare Master Mix: On ice, prepare a master mix for the desired number of reactions (plus 10% extra volume). For a single 50 µL reaction, combine the following:
-
Mix and Aliquot: Gently vortex the master mix and briefly centrifuge. Aliquot the appropriate volume into PCR tubes.
-
Add Template DNA: Add the DNA template to each respective tube.
-
Thermocycling: Transfer tubes to a thermocycler preheated to the initial denaturation temperature and begin cycling.[15]
Protocol 2: Thermal Cycling Conditions
These are general cycling parameters that should be adapted based on the polymerase manufacturer's recommendations and the specific template/primers.
| Step | Temperature | Time | Cycles |
| Initial Denaturation | 98°C | 30 seconds | 1 |
| Denaturation | 98°C | 10-15 seconds | |
| Annealing | 55-68°C* | 15-30 seconds | 30-35 |
| Extension | 72°C | 1 minute/kb | |
| Final Extension | 72°C | 5-10 minutes | 1 |
| Hold | 4°C | Indefinite | 1 |
*Optimize using a gradient thermocycler. A good starting point is 3-5°C below the calculated Tₘ of the primers.[10]
Data and Reagent Comparison
Table 1: Common PCR Additives for Difficult Templates
| Additive | Recommended Final Concentration | Mechanism of Action |
| Betaine | 1.0 M - 1.7 M | Reduces the formation of DNA secondary structures and eliminates the base-pair composition dependence of DNA melting.[6][] |
| DMSO | 2% - 8% (v/v) | Reduces secondary DNA structures, particularly in GC-rich regions. Note: Can inhibit Taq polymerase activity at higher concentrations (>10%).[5][7] |
| Formamide | 1% - 5% (v/v) | Lowers the DNA melting temperature by destabilizing the template double-helix.[5][6] |
| BSA | 0.1 - 0.8 µg/µl | Prevents reaction components from adhering to tube walls and suppresses the effect of PCR inhibitors (e.g., phenolic compounds).[5][6] |
| Non-ionic Detergents (Tween® 20, Triton™ X-100) | 0.1% - 1% (v/v) | Reduce secondary structures and can help neutralize SDS contamination. May increase non-specific amplification.[5][6][] |
Table 2: Key Features of High-Performance DNA Polymerases
| Feature | Description | Importance for 1mC DNA Amplification |
| Fidelity | The accuracy of DNA replication, measured by the error rate per base incorporated. High-fidelity enzymes have low error rates.[2] | High. Essential for applications like sequencing or cloning where the amplified sequence must be accurate.[1] |
| Processivity | The number of nucleotides incorporated by the polymerase in a single binding event before dissociating from the template.[2] | Very High. A highly processive enzyme is less likely to stall and dissociate at a modified base like 1mC, increasing the chance of amplifying the full-length product.[1] |
| Thermostability | The ability of the enzyme to withstand high temperatures during the denaturation step without losing significant activity.[1] | High. Important for templates that require high denaturation temperatures (e.g., GC-rich regions) to fully separate the DNA strands.[16] |
| Hot-Start Formulation | The polymerase is kept inactive until the initial high-temperature denaturation step. This is often achieved with antibodies or chemical modification.[1][4] | Highly Recommended. Prevents non-specific amplification and primer-dimer formation that can occur at lower temperatures during reaction setup.[3] |
| 3'→5' Exonuclease Activity | The "proofreading" ability of the polymerase to remove incorrectly incorporated nucleotides.[3] | Double-edged sword. While crucial for fidelity, this activity can sometimes be inhibited by or attempt to excise modified bases, potentially hindering amplification. The performance of a specific proofreading polymerase on 1mC templates should be empirically tested. |
Visualization of PCR Logic
Diagram: Troubleshooting Non-Specific Amplification
This diagram outlines the decision-making process when dealing with multiple or smeared bands on an agarose gel.
Caption: A logical guide for troubleshooting non-specific PCR products.
References
- 1. biocompare.com [biocompare.com]
- 2. Choosing the Right DNA Polymerase for Your PCR Application [synapse.patsnap.com]
- 3. bioline.com [bioline.com]
- 4. PCR Amplification | An Introduction to PCR Methods [promega.com]
- 5. What are the common PCR additives? | AAT Bioquest [aatbio.com]
- 6. bitesizebio.com [bitesizebio.com]
- 7. genelink.com [genelink.com]
- 9. Some Optimizing Strategies for PCR Amplification Success [creative-biogene.com]
- 10. PCRに関するトラブルシューティングガイド | Thermo Fisher Scientific - JP [thermofisher.com]
- 11. PCR Basic Troubleshooting Guide [creative-biogene.com]
- 12. bio-rad.com [bio-rad.com]
- 13. mybiosource.com [mybiosource.com]
- 14. theory.labster.com [theory.labster.com]
- 15. neb.com [neb.com]
- 16. Optimizing your PCR [takarabio.com]
challenges in distinguishing 1-Methylcytosine from other modifications
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) for researchers, scientists, and drug development professionals working on the detection and differentiation of 1-methylcytosine (B60703) (m1C) from other nucleic acid modifications.
Frequently Asked Questions (FAQs)
Q1: What are the primary challenges in distinguishing this compound (m1C) from other cytosine modifications?
The primary challenges in distinguishing this compound (m1C) from other cytosine modifications, particularly its isomers 5-methylcytosine (B146107) (5mC) and 3-methylcytosine (B1195936) (3mC), as well as 5-hydroxymethylcytosine (B124674) (5hmC), stem from their subtle structural similarities. These include:
-
Identical Mass: m1C, 5mC, and 3mC are isomers, meaning they have the same molecular weight. This makes them indistinguishable by standard mass spectrometry without fragmentation analysis.
-
Antibody Cross-Reactivity: Antibodies raised against one methylcytosine variant may exhibit cross-reactivity with others due to the small size and similar chemical nature of the methyl group. This can lead to false-positive signals in antibody-based detection methods like MeDIP-seq.
-
Chemical and Enzymatic Methods: Many traditional methods for studying DNA methylation, such as bisulfite sequencing, are designed to detect 5mC and cannot differentiate it from other modifications like m1C.[1] Similarly, enzymatic approaches may lack the specificity to act on only one type of modification.
Q2: Which methods are best suited for unambiguously identifying this compound (m1C)?
Liquid chromatography-tandem mass spectrometry (LC-MS/MS) is considered the gold standard for the unambiguous identification and quantification of m1C. This is due to its ability to separate different methylated nucleosides based on their unique fragmentation patterns upon collision-induced dissociation.[2][3]
Q3: Can standard bisulfite sequencing detect this compound (m1C)?
No, standard bisulfite sequencing is not a reliable method for detecting m1C. Bisulfite treatment deaminates unmethylated cytosine to uracil, while 5mC is largely protected. The behavior of m1C under bisulfite treatment is not well-characterized to provide a distinct and reliable signal for its identification. Newer enzymatic and chemical sequencing methods are being developed to address the limitations of bisulfite sequencing for various modifications.[4]
Troubleshooting Guides
Guide 1: Poor Specificity in Antibody-Based m1C Detection (e.g., MeDIP)
Problem: Suspected cross-reactivity of the anti-m1C antibody with other methylated cytosines (e.g., 5mC) or other modified bases, leading to high background or false-positive results.
| Potential Cause | Troubleshooting Steps |
| Antibody Specificity | - Validate Antibody Specificity: Before use in immunoprecipitation, validate the antibody's specificity using dot blot or ELISA with DNA/RNA standards containing m1C, 5mC, 3mC, 5hmC, and unmodified cytosine. - Check Manufacturer's Datasheet: Review the manufacturer's data on antibody specificity and cross-reactivity. - Test Different Clones: If available, test monoclonal antibodies from different clones as they may have varying specificity profiles. |
| Insufficient Washing | - Increase Wash Stringency: Increase the salt concentration (e.g., higher NaCl) or include mild detergents (e.g., Tween-20) in your wash buffers to disrupt non-specific binding. - Increase Number of Washes: Perform additional wash steps to reduce background signal. |
| Inappropriate Blocking | - Optimize Blocking Conditions: Ensure adequate blocking of the beads and the membrane (for dot blots) to prevent non-specific antibody binding. Test different blocking agents (e.g., BSA, non-fat dry milk). |
Guide 2: Inconclusive Results from Mass Spectrometry Analysis
Problem: Difficulty in distinguishing the m1C peak from other isomeric modifications (5mC, 3mC) or from background noise.
| Potential Cause | Troubleshooting Steps |
| Co-elution of Isomers | - Optimize Chromatographic Separation: Adjust the gradient of the mobile phase, change the column chemistry (e.g., different C18 phase, HILIC), or modify the flow rate to improve the separation of m1C, 5mC, and 3mC.[3] - Use High-Resolution Mass Spectrometry: Employ a high-resolution mass spectrometer to achieve better mass accuracy, which can aid in distinguishing closely eluting compounds. |
| Low Abundance of m1C | - Enrich for m1C: If the abundance of m1C is low, consider an enrichment step prior to LC-MS/MS, such as immunoprecipitation with a validated m1C-specific antibody. - Increase Sample Input: If possible, increase the amount of starting material (DNA/RNA) to enhance the signal of low-abundance modifications. |
| Suboptimal Fragmentation | - Optimize Collision Energy: In tandem MS (MS/MS), optimize the collision energy to generate unique and reproducible fragmentation patterns for m1C that can be distinguished from its isomers. |
Quantitative Data Summary
The following table summarizes the performance of different methods for the detection of methylcytosines. Note that data specifically for m1C is limited, and much of the available information is for the more common 5mC.
| Method | Modification Detected | Quantitative? | Resolution | Sensitivity | Specificity |
| LC-MS/MS | m1C, 5mC, 3mC, 5hmC, etc. | Yes | Global | High (fmol range)[5] | High (Isomer differentiation) |
| MeDIP-Seq | Primarily 5mC (m1C depends on antibody) | Semi-quantitative | Genome-wide (low-res) | Moderate | Variable (Antibody dependent)[6][7] |
| Bisulfite Sequencing | 5mC (does not reliably detect m1C) | Yes | Single-base | High | Poor for non-5mC modifications[1] |
| Nanopore Sequencing | 5mC, 5hmC (potential for m1C) | Yes | Single-base | High | Good (based on distinct electrical signals)[8] |
Experimental Protocols
Protocol 1: Methylated DNA Immunoprecipitation (MeDIP) for m1C
This protocol provides a general framework for m1C-MeDIP. Optimization of antibody concentration and washing conditions is crucial.
1. DNA Preparation and Fragmentation:
- Isolate genomic DNA using a standard kit.
- Fragment DNA to a size range of 200-800 bp by sonication or enzymatic digestion.
- Purify the fragmented DNA.
2. Immunoprecipitation:
- Denature the fragmented DNA by heating at 95°C for 10 minutes, followed by rapid cooling on ice.
- Incubate the denatured DNA with a validated anti-m1C antibody overnight at 4°C with gentle rotation.
- Add Protein A/G magnetic beads to the DNA-antibody mixture and incubate for 2-4 hours at 4°C to capture the immunocomplexes.
3. Washing:
- Wash the beads multiple times with low and high salt wash buffers to remove non-specifically bound DNA.
4. Elution and DNA Recovery:
- Elute the immunoprecipitated DNA from the beads using an elution buffer.
- Reverse cross-links (if applicable) and treat with Proteinase K.
- Purify the enriched DNA.
5. Analysis:
- The enriched DNA can be analyzed by qPCR for specific loci or by high-throughput sequencing (MeDIP-seq).
Protocol 2: LC-MS/MS for Global m1C Quantification
1. DNA/RNA Hydrolysis:
- Digest purified DNA/RNA to single nucleosides using a cocktail of DNase I, nuclease P1, and alkaline phosphatase.[9]
2. Chromatographic Separation:
- Inject the nucleoside mixture into a reverse-phase C18 column on a UPLC or HPLC system.
- Separate the nucleosides using a gradient of aqueous mobile phase (e.g., water with 0.1% formic acid) and organic mobile phase (e.g., acetonitrile (B52724) or methanol (B129727) with 0.1% formic acid).[2][3]
3. Mass Spectrometry Detection:
- Couple the LC system to a triple quadrupole mass spectrometer operating in positive electrospray ionization (ESI) mode.
- Use Multiple Reaction Monitoring (MRM) to detect the specific precursor-to-product ion transitions for m1C and other nucleosides of interest.
4. Quantification:
- Quantify the amount of m1C by comparing its peak area to a standard curve generated from known concentrations of m1C standard.
Visualizations
References
- 1. mdpi.com [mdpi.com]
- 2. Quantification of Global DNA Methylation Status by LC-MS/MS [visikol.com]
- 3. Ultraperformance Liquid Chromatography Tandem Mass Spectrometry Assay of DNA Cytosine Methylation Excretion from Biological Systems - PMC [pmc.ncbi.nlm.nih.gov]
- 4. US20240294967A1 - Methods of detecting methylcytosine and hydroxymethylcytosine by sequencing - Google Patents [patents.google.com]
- 5. Quantification of 5-Methylcytosine and 5-Hydroxymethylcytosine in Genomic DNA from Hepatocellular Carcinoma Tissues by Capillary Hydrophilic-Interaction Liquid Chromatography/Quadrupole TOF Mass Spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Sensitivity and specificity of immunoprecipitation of DNA containing 5-Methylcytosine - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Sensitivity and specificity of immunoprecipitation of DNA containing 5-Methylcytosine - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. scilit.com [scilit.com]
- 9. LC-MS-MS quantitative analysis reveals the association between FTO and DNA methylation | PLOS One [journals.plos.org]
Technical Support Center: Enhancing 1-Methylcytosine (m1C) Detection
Welcome to the technical support center for 1-methylcytosine (B60703) (m1C) detection. This resource is designed for researchers, scientists, and drug development professionals to provide expert guidance on improving the sensitivity and accuracy of m1C detection experiments. Here you will find troubleshooting guides, frequently asked questions (FAQs), detailed experimental protocols, and comparative data to help you overcome common challenges.
Section 1: Frequently Asked Questions (FAQs)
Q1: What is this compound (m1C) and how does it differ from 5-methylcytosine (B146107) (5mC)?
A1: this compound (m1C) is a methylated form of the DNA and RNA base cytosine, where a methyl group is attached to the nitrogen atom at position 1 of the cytosine ring.[1][2] This distinguishes it from the more extensively studied 5-methylcytosine (5mC), where the methyl group is at the 5th carbon position.[3] This structural difference means that detection methods must be specifically validated for m1C, as techniques optimized for 5mC may not be effective.
Q2: Why is the sensitive detection of m1C important?
A2: Sensitive and specific detection of m1C is crucial for understanding its role in epigenetic regulation, gene expression, and various cellular processes. Aberrant methylation patterns are linked to numerous human diseases.[4] Accurate detection allows researchers to map m1C sites across the genome or transcriptome, quantify its abundance, and elucidate its function in both healthy and diseased states.
Q3: What are the primary methods for detecting m1C?
A3: The main strategies for m1C detection include:
-
Antibody-Based Enrichment: Techniques like Methylated RNA Immunoprecipitation Sequencing (MeRIP-seq) use antibodies specific to m1C to enrich for RNA or DNA fragments containing the modification, which are then sequenced.[5][6]
-
Bisulfite Sequencing: This method involves treating DNA with sodium bisulfite, which converts unmethylated cytosines to uracil (B121893) while methylated cytosines (like 5mC) remain unchanged.[4] The applicability and efficiency of this method for m1C require specific validation, as the chemical stability of m1C to bisulfite may differ from that of 5mC.
-
Nanopore Sequencing: This third-generation sequencing technology offers a direct detection approach by measuring changes in the ionic current as a DNA or RNA strand passes through a nanopore.[7][8] This method can distinguish modified bases from canonical ones without chemical conversion or amplification, offering single-molecule resolution.[8]
Q4: What are the main challenges in achieving high sensitivity for m1C detection?
A4: Key challenges include:
-
Low Abundance: m1C can be a low-abundance modification, making it difficult to distinguish its signal from background noise.
-
Antibody Specificity: The sensitivity and specificity of antibody-based methods are highly dependent on the quality of the antibody, with off-target binding being a common issue.[9][10][11]
-
DNA/RNA Degradation: Chemical treatments, such as bisulfite conversion, can lead to significant degradation of the nucleic acid sample, reducing library complexity and sensitivity, especially with low-input samples.[12]
-
PCR Bias: Amplification steps in many sequencing workflows can introduce bias, where fragments are not amplified with equal efficiency, potentially skewing quantification.[13]
Section 2: Method-Specific Troubleshooting Guides
Guide 1: Antibody-Based Enrichment (m1C-IP/MeRIP-seq)
Q: I am experiencing low yield after immunoprecipitation (IP). What are the possible causes and solutions?
A: Low IP yield is a common problem that can stem from several factors.
-
Cause 1: Inefficient Antibody Binding. The antibody may have low affinity or may not be validated for the specific application.
-
Solution: Ensure the antibody is validated for IP. Perform a titration experiment to determine the optimal antibody concentration. Always include a positive control with a known m1C-containing sequence.
-
-
Cause 2: Low Abundance of m1C. The target modification may be rare in your sample.
-
Solution: Increase the amount of starting material (total RNA or fragmented DNA). If possible, enrich for cell types or tissues where m1C is expected to be more abundant.
-
-
Cause 3: Inefficient Nucleic Acid Fragmentation. Improperly sized fragments can hinder IP efficiency.
-
Solution: Optimize fragmentation to the recommended size range (typically 100-200 nt for MeRIP-seq).[6] Verify fragment size using a Bioanalyzer or similar instrument before proceeding to IP.
-
-
Cause 4: Suboptimal IP Conditions. Incubation times, temperatures, and washing stringency can all affect yield.
-
Solution: Optimize incubation time and temperature. Ensure wash buffers are fresh and used at the correct stringency to reduce non-specific binding without eluting specifically bound fragments.
-
Q: My sequencing data shows high background noise and non-specific peaks. How can I improve signal-to-noise?
A: High background often points to issues with non-specific binding or contamination.
-
Cause 1: Antibody Cross-Reactivity. The antibody may be binding to other modifications or sequence motifs.[9]
-
Solution: Validate antibody specificity using dot blot assays with various modified and unmodified oligonucleotides. If cross-reactivity is confirmed, test an antibody from a different vendor. Always use an IgG isotype control in a parallel experiment to estimate the level of non-specific binding.[6]
-
-
Cause 2: Insufficient Washing. Inadequate washing after IP fails to remove non-specifically bound nucleic acids.
-
Solution: Increase the number of wash steps or the stringency of the wash buffers (e.g., by increasing salt concentration). Be cautious, as overly stringent washes can reduce specific signal.
-
-
Cause 3: rRNA Contamination (for MeRIP-seq). Ribosomal RNA is highly abundant and can contribute significantly to background if not removed.[14]
-
Solution: Ensure your RNA isolation protocol includes a robust rRNA removal step. High rRNA contamination can be detected during the initial quality control of sequencing data.[14]
-
Guide 2: Bisulfite Sequencing-Based Methods
Q: How can I troubleshoot incomplete bisulfite conversion?
A: Incomplete conversion of unmethylated cytosines is a critical issue that leads to false-positive methylation calls.
-
Cause 1: Poor DNA Quality. Contaminants in the DNA sample can inhibit the conversion reaction.
-
Solution: Ensure the input genomic DNA is high-purity, with appropriate 260/280 and 260/230 ratios. If necessary, re-purify the DNA.[15]
-
-
Cause 2: Suboptimal Reaction Conditions. Incorrect incubation times, temperatures, or reagent concentrations can lead to failure.
Q: I'm observing significant DNA degradation and low library yields. What can be done?
A: The harsh chemical conditions of bisulfite treatment can fragment DNA, reducing the amount of usable material for library preparation.[12]
-
Solution 1: Use a Commercial Kit. Many commercial kits are optimized to balance conversion efficiency with DNA protection.
-
Solution 2: Enzymatic Conversion. Consider using newer enzymatic conversion methods (e.g., APOBEC-based) that are less harsh on DNA than chemical treatment and result in higher yields and more uniform coverage.[12]
-
Solution 3: Start with High-Quality DNA. Begin with high-molecular-weight genomic DNA that is free of nicks. The less damaged the DNA is initially, the more likely it is to survive the process.
Section 3: Quantitative Comparison of m1C Detection Methods
The choice of method depends on the specific research question, available resources, and required resolution. The table below summarizes the key features of major m1C detection strategies.
| Feature | Antibody-Enrichment (MeRIP-seq) | Bisulfite Sequencing | Nanopore Direct Sequencing |
| Principle | Immunoprecipitation of m1C-containing fragments using a specific antibody.[5] | Chemical conversion of unmethylated C to U; m1C remains C.[4] | Direct detection of modified bases via characteristic changes in ionic current.[8] |
| Resolution | Low (~100-200 nt). Identifies enriched regions, not precise sites.[17] | Single-base.[18] | Single-base. |
| Sensitivity | Moderate to High. Dependent on m1C abundance and antibody affinity. | High, but can be limited by DNA degradation and PCR bias.[12] | Moderate to High. Can detect modifications on single molecules.[7] |
| Specificity | Variable. Highly dependent on antibody quality; risk of off-target binding.[9] | High, assuming complete conversion. Cannot distinguish 5mC from 5hmC without oxidative steps.[4][8] | High. Distinguishes different modifications based on unique electrical signals. |
| Input Amount | ~1-5 µg of total RNA or fragmented DNA. | 1 ng - 1 µg of DNA. Newer methods require less input.[19] | ~1 µg of high-molecular-weight DNA/RNA. |
| Key Advantage | Good for transcriptome-wide screening of m1C in RNA. | "Gold standard" for quantitative, single-base resolution methylation analysis.[3] | No PCR bias, allows for direct detection of modifications on native strands. |
| Key Limitation | Low resolution; antibody validation is critical.[17] | DNA degradation; cannot distinguish 5mC/5hmC without modification.[8][12] | Higher error rate for base calling compared to short-read sequencing; requires specialized analysis pipelines. |
Section 4: Key Experimental Protocols
Protocol 1: Generalized Workflow for m1C Immunoprecipitation (m1C-IP/MeRIP-seq)
-
Nucleic Acid Isolation & QC: Isolate total RNA or genomic DNA from samples. Assess quality and quantity using a spectrophotometer and Bioanalyzer. For RNA, perform rRNA depletion.
-
Fragmentation: Fragment nucleic acids to an average size of 100-200 nucleotides using enzymatic or chemical methods. Confirm fragment size distribution.
-
Immunoprecipitation:
-
Couple the anti-m1C antibody to magnetic beads.
-
Incubate the fragmented nucleic acids with the antibody-bead complex for 2-4 hours at 4°C.
-
Save a small portion of the fragmented sample as an "Input" control before adding the antibody.[20]
-
-
Washing: Wash the beads multiple times with buffers of increasing stringency to remove non-specifically bound fragments.
-
Elution: Elute the enriched, m1C-containing fragments from the antibody-bead complex.
-
Library Preparation: Prepare sequencing libraries from both the IP and Input samples according to the manufacturer's protocol (e.g., Illumina TruSeq). This includes end-repair, A-tailing, adapter ligation, and PCR amplification.
-
Sequencing & Analysis: Sequence the libraries on a high-throughput platform. For data analysis, align reads to the reference genome/transcriptome and use a peak-calling algorithm (e.g., MACS) to identify m1C-enriched regions by comparing the IP signal to the Input signal.[14]
Protocol 2: Generalized Workflow for Bisulfite Sequencing
-
DNA Isolation & QC: Isolate high-quality genomic DNA. Quantify and check for purity.
-
Fragmentation: Fragment DNA to the desired size for the sequencing platform using sonication or enzymatic methods.
-
Bisulfite Conversion: Treat the fragmented DNA with sodium bisulfite (or use an enzymatic conversion kit). This step converts unmethylated cytosines to uracils.
-
Library Preparation:
-
Perform end-repair and A-tailing on the converted, single-stranded DNA.
-
Ligate methylated sequencing adapters. These adapters contain 5mC instead of C to protect them from conversion in any subsequent clean-up steps.
-
Amplify the library using a high-fidelity polymerase that can read uracil in the template strand.
-
-
Sequencing & Analysis: Sequence the library. During analysis, align reads to both a C-to-T converted and a G-to-A converted reference genome. The methylation level at each cytosine is calculated as the ratio of reads supporting 'C' to the total number of reads covering that site.
Section 5: Visualized Workflows and Logic
Caption: General experimental workflow for m1C detection.
Caption: Troubleshooting logic for low MeRIP-seq yield.
Caption: Logical comparison of bisulfite vs. direct detection.
References
- 1. This compound - Wikipedia [en.wikipedia.org]
- 2. This compound | C5H7N3O | CID 79143 - PubChem [pubchem.ncbi.nlm.nih.gov]
- 3. pubs.acs.org [pubs.acs.org]
- 4. mdpi.com [mdpi.com]
- 5. MeRIP-Seq/m6A-seq [illumina.com]
- 6. researchgate.net [researchgate.net]
- 7. Selective and Sensitive Detection of Methylcytosine by Aerolysin Nanopore under Serum Condition - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. Detection and mapping of 5-methylcytosine and 5-hydroxymethylcytosine with nanopore MspA - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Limited antibody specificity compromises epitranscriptomic analyses - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Lack of Specificity of Commercially Available Antisera: Better Specifications Needed - PMC [pmc.ncbi.nlm.nih.gov]
- 11. antibodiesinc.com [antibodiesinc.com]
- 12. twistbioscience.com [twistbioscience.com]
- 13. DNA Methylation Validation Methods: a Coherent Review with Practical Comparison - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Master MeRIP-seq Data Analysis: Step-by-Step Process for RNA Methylation Studies - CD Genomics [rna.cd-genomics.com]
- 15. How to Troubleshoot Sequencing Preparation Errors (NGS Guide) - CD Genomics [cd-genomics.com]
- 16. bitesizebio.com [bitesizebio.com]
- 17. labinsights.nl [labinsights.nl]
- 18. biorxiv.org [biorxiv.org]
- 19. cd-genomics.com [cd-genomics.com]
- 20. MeRIP Sequencing Q&A - CD Genomics [cd-genomics.com]
Technical Support Center: 1-Methylcytosine (m1C) Mapping
Welcome to the technical support center for 1-Methylcytosine (m1C) mapping. This resource provides researchers, scientists, and drug development professionals with comprehensive troubleshooting guides and frequently asked questions to navigate the complexities of m1C sequencing and overcome common experimental errors.
Troubleshooting Guide
This guide addresses specific issues that may arise during m1C mapping experiments, which primarily rely on analyzing the unique signatures generated during reverse transcription.
Q1: Why am I observing a low RT arrest rate or weak misincorporation signal at known m1C sites?
Possible Causes:
-
Choice of Reverse Transcriptase (RT) Enzyme: The polymerase used is critical. Different reverse transcriptases exhibit varying sensitivities to m1C, resulting in different rates of stalling (arrest) and misincorporation. Some enzymes may read through the m1C modification with higher efficiency, leading to a weaker signal.[1]
-
Low RNA Quality: Degraded or impure RNA can lead to premature termination of reverse transcription, creating background noise that can obscure the specific arrest signal from m1C.
-
Insufficient Sequencing Depth: A weak signal may simply be a result of not having enough reads to confidently call a modification. Low-abundance transcripts require deeper sequencing.
-
Sequence Context: The local sequence environment around the m1C site can influence the RT enzyme's behavior, sometimes dampening the arrest or misincorporation signature.[2][3]
Solutions:
-
Optimize Your Enzyme: Consult literature to choose a reverse transcriptase known to have a strong arrest or misincorporation signature for N1-methylated purines and pyrimidines. Consider testing a panel of different RT enzymes.[1]
-
Ensure High-Quality RNA: Start with high-integrity, pure RNA. Use appropriate RNA extraction methods and perform quality control checks (e.g., using a Bioanalyzer) before proceeding.
-
Increase Sequencing Depth: If you suspect low transcript abundance, increase the number of sequencing reads to improve statistical power.
-
Use Control Sequences: Include synthetic RNA oligonucleotides with known m1C sites in your experiment. This will help validate that the RT enzyme is performing as expected and provides a positive control for your data analysis pipeline.
Q2: My data shows high rates of mismatches and RT stops across the entire transcript, not just at expected m1C sites. What is happening?
Possible Causes:
-
Poor RNA Integrity: Highly degraded RNA will cause the reverse transcriptase to stop frequently, leading to a high background of RT arrest signals that are not specific to m1C.
-
Suboptimal Reaction Conditions: Incorrect concentrations of dNTPs, magnesium, or other buffer components can increase the error rate of the reverse transcriptase, leading to random misincorporations.
-
PCR Artifacts: Errors introduced during the PCR amplification step of library preparation can appear as mismatches in the final sequencing data.
-
Bioinformatic Misalignment: Reads that are incorrectly mapped to the reference genome, especially in repetitive regions, can create artificial mismatch signals.[4]
Solutions:
-
Strict Quality Control: Always begin with high-quality RNA (RIN > 8.0).
-
Optimize RT and PCR Conditions: Titrate key reagents and use a high-fidelity polymerase for the PCR amplification step to minimize errors.
-
Refine Bioinformatic Filters: Use stringent alignment parameters and filter out low-quality reads and PCR duplicates. Implement filtering strategies to remove reads that map to multiple locations.[4]
Q3: The RT signature for a specific m1C site is inconsistent across my biological replicates. Why?
Possible Causes:
-
Variable RNA Quality: Differences in RNA integrity between replicates can lead to variability in RT processivity and error rates.
-
Batch Effects: Processing replicates on different days or with different batches of reagents (especially the RT enzyme) can introduce technical variability.
-
Biological Variation: The stoichiometry of m1C modification can genuinely differ between biological samples or conditions. Not every copy of a specific transcript may be modified.
Solutions:
-
Standardize Protocols: Ensure all replicates are processed identically, from RNA extraction through to library preparation, using the same reagent batches where possible.
-
Assess RNA Quality per Sample: Run quality control on each individual sample before pooling or processing.
-
Increase Replicate Number: Using a higher number of biological replicates can help distinguish consistent biological signals from technical noise.
-
Use Spike-In Controls: Adding a synthetic RNA with a known m1C modification at a fixed stoichiometry to each sample can help normalize the data and identify technical variability.
Frequently Asked Questions (FAQs)
Q1: What is this compound (m1C) and why is it difficult to detect?
This compound (m1C) is a post-transcriptional RNA modification where a methyl group is added to the N1 position of the cytosine base. Unlike 5-methylcytosine (B146107) (5mC), where the methyl group is on the C5 position, the methyl group in m1C is located on the Watson-Crick base-pairing face. This directly interferes with the hydrogen bonds that form the standard C-G base pair, altering the RNA's structural and coding properties.
Q2: How is m1C detected using sequencing?
The detection of m1C relies on exploiting its disruption of Watson-Crick base pairing. During reverse transcription, when the polymerase encounters an m1C nucleotide in the RNA template, two primary events can occur:
-
RT Arrest: The polymerase stalls and terminates cDNA synthesis, creating a truncated product that ends one nucleotide before the m1C site.
-
Misincorporation: The polymerase manages to bypass the m1C but often incorporates a non-complementary base (a mismatch) into the growing cDNA strand.
This combination of RT arrest and misincorporation at a specific site creates a characteristic "RT signature" that can be identified with high-throughput sequencing.[1][3][5]
Q3: Why doesn't standard bisulfite sequencing work for m1C?
Bisulfite sequencing is a chemical method designed to detect 5-methylcytosine (5mC). The chemistry involves the deamination of unmethylated cytosine to uracil. This reaction proceeds via an attack on the C6 position of the cytosine ring. The methyl group at the C5 position in 5mC sterically hinders this reaction, leaving 5mC intact.[6][7] However, the methyl group at the N1 position in m1C does not protect the ring from bisulfite-mediated deamination in the same way. Therefore, bisulfite treatment cannot be used to distinguish m1C from unmodified cytosine.
Q4: What is the general workflow for mapping m1C?
The process involves identifying the locations of RT arrest and misincorporation events in a sequencing dataset and comparing them to a control dataset.
Data & Protocols
Comparison of Reverse Transcriptase Enzymes
The choice of reverse transcriptase is arguably the most critical variable in an m1C mapping experiment. Different enzymes have distinct error and processivity profiles when encountering a modified base. The table below summarizes hypothetical performance characteristics of different RT enzymes based on literature describing signatures for similar N1-methylated bases.[1]
| Reverse Transcriptase | Primary Signature | Arrest Rate (%) | Misincorporation Rate (%) | Processivity | Recommended Use Case |
| Enzyme A (e.g., AMV) | High Arrest | 70 - 85 | 5 - 15 | Low | Best for methods that rely on mapping RT stop sites. |
| Enzyme B (e.g., SuperScript II) | Balanced | 40 - 60 | 30 - 50 | Medium | Good for methods that analyze both arrest and mismatch patterns. |
| Enzyme C (Engineered) | High Misincorporation | 10 - 25 | 75 - 90 | High | Ideal for methods focused on detecting mismatches to identify m1C. |
Key Experimental Methodologies
Below is a generalized protocol for preparing an RNA library for m1C mapping.
Objective: To generate a cDNA library where m1C sites are represented by signatures of reverse transcription arrest and misincorporation.
Materials:
-
Total RNA or poly(A)-selected RNA (High quality, RIN > 8.0)
-
Reverse Transcriptase (choose based on desired signature, see table above)
-
Random hexamers or gene-specific primers
-
dNTP mix
-
Library preparation kit for Illumina sequencing
-
High-fidelity DNA polymerase for PCR amplification
-
Spike-in RNA control containing a known m1C site (recommended)
Protocol:
-
RNA Preparation & Quality Control:
-
Isolate total RNA from your samples. For mRNA-focused studies, perform poly(A) selection.
-
Assess RNA integrity using a method like the Agilent Bioanalyzer. Proceed only with high-quality samples.
-
Quantify the RNA accurately. If using, add the synthetic m1C spike-in control to each sample at a known concentration.
-
-
Reverse Transcription:
-
Set up the reverse transcription reaction in a total volume of 20 µL. Combine 10-100 ng of RNA, primers (e.g., 50 ng random hexamers), and 1 µL of 10 mM dNTP mix. Add nuclease-free water to 13 µL.
-
Heat the mixture to 65°C for 5 minutes, then place immediately on ice for at least 1 minute to denature RNA secondary structures.
-
Add 4 µL of 5X RT buffer, 1 µL of 0.1 M DTT, and 1 µL of RNase inhibitor. Mix gently.
-
Add 1 µL of your chosen Reverse Transcriptase (e.g., 200 units).
-
Incubate the reaction according to the enzyme's specifications (e.g., 25°C for 10 min, then 42°C for 50 min).
-
Terminate the reaction by heating to 70°C for 15 minutes. This first-strand cDNA product now contains the m1C signatures.
-
-
Library Preparation & Sequencing:
-
Proceed immediately with a commercial library preparation kit suitable for your sequencing platform (e.g., Illumina).
-
Follow the manufacturer's protocol for second-strand synthesis, end-repair, A-tailing, and adapter ligation.
-
Perform PCR amplification using a high-fidelity polymerase to enrich your library. Note: Keep the number of PCR cycles to a minimum to avoid introducing bias and errors.
-
Purify the final library and perform quality control to assess library size and concentration.
-
Sequence the library on the appropriate platform to a depth sufficient for your experimental goals.
-
Visualizing the m1C Detection Principle
The ability to map m1C is based on how it disrupts the canonical geometry of a standard C-G base pair during reverse transcription.
References
- 1. Machine learning of reverse transcription signatures of variegated polymerases allows mapping and discrimination of methylated purines in limited transcriptomes - PMC [pmc.ncbi.nlm.nih.gov]
- 2. The reverse transcription signature of N-1-methyladenosine in RNA-Seq is sequence dependent - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. The reverse transcription signature of N-1-methyladenosine in RNA-Seq is sequence dependent - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Pitfalls of mapping high throughput sequencing data to repetitive sequences: Piwi’s genomic targets still not identified - PMC [pmc.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
- 6. researchgate.net [researchgate.net]
- 7. Discovery of bisulfite-mediated cytosine conversion to uracil, the key reaction for DNA methylation analysis — A personal account - PMC [pmc.ncbi.nlm.nih.gov]
how to avoid false positives in MeDIP-seq for 1-Methylcytosine
Welcome to the technical support center for 1-Methylcytosine (B60703) (m1C) MeDIP-seq. This resource is designed for researchers, scientists, and drug development professionals to provide guidance on avoiding false positives and ensuring the accuracy of your m1C MeDIP-seq experiments.
Introduction to m1C MeDIP-seq Challenges
Methylated DNA Immunoprecipitation followed by sequencing (MeDIP-seq) is a powerful technique for genome-wide profiling of DNA modifications. While extensively used for 5-methylcytosine (B146107) (5mC), its application for this compound (m1C) is less established. The primary challenge in m1C MeDIP-seq lies in the limited availability of highly specific and validated antibodies for m1C in a DNA context. Consequently, preventing false positives requires rigorous antibody validation and carefully designed experimental controls. This guide provides a framework for developing and validating your m1C MeDIP-seq workflow to generate reliable and reproducible data.
Frequently Asked Questions (FAQs)
Q1: Is there a standardized and validated protocol for m1C MeDIP-seq?
A1: Currently, there is no widely accepted, standardized protocol for m1C MeDIP-seq. Most researchers adapt existing protocols for 5mC MeDIP-seq. The success of the adaptation is critically dependent on the specificity of the anti-m1C antibody used. Therefore, extensive in-house validation is essential.
Q2: What are the primary sources of false positives in m1C MeDIP-seq?
A2: False positives in m1C MeDIP-seq can arise from several sources:
-
Antibody Cross-Reactivity: The antibody may cross-react with other methylated bases (e.g., 5mC, N6-methyladenine) or unmodified DNA, particularly in specific sequence contexts.
-
Non-Specific Binding: The antibody or the protein A/G beads may bind non-specifically to certain genomic regions, such as those with high GC content or repetitive elements.
-
Suboptimal Experimental Conditions: Inadequate washing, inappropriate antibody concentration, or improper DNA fragmentation can all contribute to background noise and false positives.
-
PCR Amplification Bias: During library preparation, certain DNA fragments may be preferentially amplified, leading to their overrepresentation in the final sequencing data.
Q3: How can I validate the specificity of my anti-m1C antibody?
A3: Antibody validation is the most critical step. A multi-tiered approach is recommended:
-
Dot Blot Analysis: Test the antibody's binding to a dilution series of DNA substrates containing m1C, 5mC, and other relevant modifications, as well as unmodified DNA.
-
MeDIP-qPCR: Perform immunoprecipitation on genomic regions known to be enriched or devoid of m1C. The enrichment of m1C-positive regions and lack of enrichment in m1C-negative regions can be quantified by qPCR.
-
Spike-in Controls: Introduce synthetic DNA fragments with and without m1C into your genomic DNA sample before immunoprecipitation. The specific recovery of the m1C-containing spike-ins can be quantified by qPCR or sequencing.
Q4: What are the essential controls for an m1C MeDIP-seq experiment?
A4: Every m1C MeDIP-seq experiment should include the following controls:
-
Input DNA Control: A sample of the fragmented genomic DNA that has not undergone immunoprecipitation. This is used to correct for biases in DNA fragmentation and sequencing.
-
Non-Specific IgG Control: An immunoprecipitation performed with a non-specific IgG antibody of the same isotype as your anti-m1C antibody. This control helps to identify background signal due to non-specific binding to the beads or other components.
-
Positive and Negative Locus Controls (for MeDIP-qPCR): Genomic regions known to contain and lack m1C, respectively, should be used to validate the enrichment efficiency of each experiment.
Troubleshooting and Best Practices for Avoiding False Positives
Rigorous Antibody Validation
The cornerstone of a successful m1C MeDIP-seq experiment is a highly specific antibody. The following table outlines a hypothetical dot blot result for a well-validated anti-m1C antibody.
| DNA Substrate | 100 ng | 50 ng | 25 ng | 12.5 ng |
| m1C-containing DNA | +++ | +++ | ++ | + |
| 5mC-containing DNA | - | - | - | - |
| Unmodified DNA | - | - | - | - |
| N6-mA-containing DNA | - | - | - | - |
| Signal Intensity: +++ (Strong), ++ (Moderate), + (Weak), - (None) |
Caption: Example of a dot blot analysis to assess the specificity of an anti-1-methylcytosine antibody.
Experimental Workflow and Key Optimization Points
The following diagram illustrates a robust workflow for m1C MeDIP-seq, highlighting critical steps for minimizing false positives.
Caption: Experimental workflow for m1C MeDIP-seq highlighting key control points.
Logical Troubleshooting of False Positives
If you suspect a high rate of false positives in your m1C MeDIP-seq data, follow this troubleshooting logic:
Caption: A logical workflow for troubleshooting false positives in m1C MeDIP-seq.
Detailed Experimental Protocol: Validation of an Anti-m1C Antibody for MeDIP
This protocol outlines the essential steps to validate an antibody for use in m1C MeDIP-seq.
1. Dot Blot Analysis for Specificity
-
Objective: To determine the specificity of the anti-m1C antibody for m1C-containing DNA over other modified and unmodified DNA.
-
Materials:
-
Nitrocellulose or PVDF membrane
-
DNA solutions (100 ng/µL) of:
-
Synthesized oligonucleotide with multiple m1C modifications
-
Synthesized oligonucleotide with multiple 5mC modifications
-
Genomic DNA with no known m1C
-
(Optional) DNA with other modifications of interest
-
-
Anti-m1C antibody
-
Secondary antibody conjugated to HRP
-
Chemiluminescent substrate
-
-
Procedure:
-
Prepare serial dilutions of each DNA sample (e.g., 100 ng, 50 ng, 25 ng, 12.5 ng).
-
Spot 1 µL of each dilution onto the membrane.
-
Allow the membrane to air dry completely.
-
Crosslink the DNA to the membrane using a UV crosslinker.
-
Block the membrane in 5% non-fat milk in TBST for 1 hour at room temperature.
-
Incubate the membrane with the anti-m1C antibody (at the manufacturer's recommended dilution) overnight at 4°C.
-
Wash the membrane three times with TBST for 10 minutes each.
-
Incubate with the HRP-conjugated secondary antibody for 1 hour at room temperature.
-
Wash the membrane three times with TBST for 10 minutes each.
-
Apply the chemiluminescent substrate and image the blot.
-
-
Expected Outcome: A strong signal should only be observed for the m1C-containing DNA in a dose-dependent manner.
2. MeDIP-qPCR for Enrichment Validation
-
Objective: To confirm that the antibody can enrich for known m1C-containing genomic loci.
-
Materials:
-
Genomic DNA from a source known to have m1C-containing and m1C-lacking regions.
-
Validated qPCR primers for a positive control region (m1C-rich) and a negative control region (m1C-poor).
-
Complete MeDIP-seq reagents (as per your adapted protocol).
-
qPCR master mix.
-
-
Procedure:
-
Perform MeDIP using the anti-m1C antibody and a non-specific IgG control.
-
Purify the immunoprecipitated DNA and the input DNA.
-
Perform qPCR on the IP, IgG, and input samples using the primers for the positive and negative control regions.
-
Calculate the percent input enrichment for each region in both the m1C-IP and IgG-IP samples.
-
-
Expected Outcome: The m1C-positive region should show significantly higher enrichment in the anti-m1C IP compared to the IgG control and the m1C-negative region.
By implementing these rigorous validation and troubleshooting steps, researchers can significantly reduce the risk of false positives and generate high-confidence data in their m1C MeDIP-seq experiments.
Optimizing Antibody Concentration for 1-Methylcytosine (m1C) Immunoprecipitation: A Technical Support Center
This technical support center provides researchers, scientists, and drug development professionals with comprehensive troubleshooting guides and frequently asked questions (FAQs) to optimize antibody concentration for 1-Methylcytosine (m1C) immunoprecipitation (IP), a critical step in methylated RNA immunoprecipitation sequencing (MeRIP-seq).
Troubleshooting Guide
This guide addresses common issues encountered during the optimization of antibody concentration for m1C immunoprecipitation.
| Problem | Possible Cause | Recommended Solution |
| Weak or No Signal (Low IP Efficiency) | Insufficient antibody concentration. | Perform an antibody titration experiment to determine the optimal concentration. Start with a range of concentrations and select the one that provides the best enrichment of a known m1C-containing transcript.[1] |
| Poor antibody quality or specificity for m1C. | Ensure the antibody is validated for immunoprecipitation of methylated RNA.[2] If possible, test different anti-m1C antibodies from various suppliers. Polyclonal antibodies may sometimes perform better than monoclonal antibodies in IP experiments. | |
| Suboptimal incubation time. | Optimize the incubation time for the antibody-RNA binding step. This can range from a few hours to overnight at 4°C.[3] | |
| Inefficient capture of the antibody-RNA complex by beads. | Ensure the protein A/G beads are compatible with the antibody isotype.[4] Use a sufficient volume of beads and ensure they are properly washed and blocked before use. | |
| Harsh lysis or washing conditions. | The lysis buffer may be too stringent, disrupting the antibody-RNA interaction. Consider using a less harsh lysis buffer. Similarly, overly stringent wash buffers can elute the target complex. Reduce the number of washes or the stringency of the wash buffer.[1] | |
| High Background | Too much antibody used. | An excess of antibody can lead to non-specific binding. The optimal concentration determined by titration should minimize this.[1] |
| Non-specific binding of RNA to the beads. | Pre-clear the RNA sample by incubating it with beads alone before adding the antibody. This will remove molecules that non-specifically bind to the beads.[1] | |
| Inadequate washing. | Increase the number of washes or the stringency of the wash buffer to remove non-specifically bound RNA.[3] | |
| Contamination with genomic DNA. | Treat the RNA sample with DNase to remove any contaminating genomic DNA, which can be a source of background. | |
| Inconsistent Results | Variability in antibody aliquots. | Avoid repeated freeze-thaw cycles of the antibody stock. Aliquot the antibody upon receipt and store at the recommended temperature. |
| Inconsistent RNA fragmentation. | Ensure consistent and uniform fragmentation of the RNA to the desired size range (typically around 100 nucleotides).[5][6][7] | |
| Variation in experimental conditions. | Maintain consistent incubation times, temperatures, and buffer compositions across experiments. |
Frequently Asked Questions (FAQs)
Q1: Why is antibody titration crucial for m1C MeRIP-seq?
A1: Antibody titration is essential to determine the optimal antibody concentration that provides the highest signal-to-noise ratio. Using too little antibody will result in inefficient pulldown of m1C-containing RNA fragments, while using too much can lead to high background from non-specific binding.[1] Each antibody lot and experimental system may behave differently, necessitating titration for reproducible and reliable results.
Q2: How do I perform an antibody titration for an anti-m1C antibody?
A2: A typical antibody titration involves setting up a series of immunoprecipitation reactions with a fixed amount of fragmented RNA and varying amounts of the anti-m1C antibody. The efficiency of the pulldown is then assessed by RT-qPCR using primers for a known m1C-modified transcript (positive control) and a non-m1C-modified transcript (negative control). The optimal antibody concentration is the one that gives the highest enrichment of the positive control over the negative control and the IgG control.
Q3: What are good positive and negative controls for m1C MeRIP-qPCR?
A3: A good positive control would be a transcript that is known to be highly methylated with m1C in your cell type or a synthetic RNA with a known m1C modification. A negative control would be a transcript known to lack m1C methylation. If known targets are not available, you can screen several housekeeping genes to identify one with low and one with high m1C levels in your system to serve as controls.
Q4: What is the typical concentration range for an anti-m1C antibody in a MeRIP experiment?
A4: The optimal concentration is antibody-dependent and must be determined empirically through titration. However, a common starting range for titration is between 1-10 µg of antibody per immunoprecipitation reaction containing 10-100 µg of fragmented RNA. Refer to the manufacturer's datasheet for initial recommendations.
Q5: How can I validate the specificity of my anti-m1C antibody?
A5: Antibody specificity can be validated through several methods. A dot blot analysis using synthetic RNA oligonucleotides with and without the m1C modification can demonstrate the antibody's preference for m1C. Additionally, performing MeRIP-seq with a knockout or knockdown of an m1C methyltransferase should show a significant reduction in the IP signal.
Experimental Protocols
Detailed Methodology for m1C Antibody Titration
This protocol outlines a typical workflow for determining the optimal concentration of an anti-m1C antibody for MeRIP experiments.
-
Prepare Fragmented RNA:
-
Isolate total RNA from your cells or tissue of interest.
-
Treat with DNase to remove genomic DNA contamination.
-
Fragment the RNA to an average size of ~100 nucleotides using RNA fragmentation buffer or enzymatic methods.
-
Purify the fragmented RNA.
-
-
Set up Immunoprecipitation Reactions:
-
For each titration point, prepare a reaction mix containing a constant amount of fragmented RNA (e.g., 10 µg) in IP buffer.
-
Add varying amounts of the anti-m1C antibody to each reaction tube (e.g., 0.5 µg, 1 µg, 2.5 µg, 5 µg, 10 µg).
-
Include a negative control reaction with a non-specific IgG antibody at the highest concentration used for the anti-m1C antibody.
-
Include an "input" sample that is not subjected to immunoprecipitation.
-
-
Antibody-RNA Binding:
-
Incubate the reactions overnight at 4°C with gentle rotation to allow for the formation of antibody-RNA complexes.
-
-
Capture Immune Complexes:
-
Add pre-washed and blocked protein A/G magnetic beads to each reaction.
-
Incubate for 2-4 hours at 4°C with rotation to capture the antibody-RNA complexes.
-
-
Washing:
-
Wash the beads several times with wash buffer to remove non-specifically bound RNA.
-
-
Elution and RNA Purification:
-
Elute the RNA from the beads using an appropriate elution buffer.
-
Purify the immunoprecipitated RNA.
-
-
Reverse Transcription and qPCR:
-
Reverse transcribe the eluted RNA and the input RNA into cDNA.
-
Perform qPCR using primers for a positive control transcript (known to be m1C methylated) and a negative control transcript (known to be unmethylated).
-
-
Data Analysis:
-
Calculate the percent input for each antibody concentration for both the positive and negative control transcripts.
-
The optimal antibody concentration is the one that yields the highest enrichment of the positive control transcript over the negative control and the IgG control, while keeping the background low.
-
m1C Immunoprecipitation (MeRIP) Protocol
Once the optimal antibody concentration is determined, proceed with the full MeRIP experiment.
-
RNA Preparation and Fragmentation: Prepare and fragment total RNA as described in the antibody titration protocol.
-
Immunoprecipitation:
-
Set up IP reactions with the optimal concentration of anti-m1C antibody and a parallel IgG control reaction.
-
Use a sufficient amount of fragmented RNA (e.g., 50-100 µg) for each reaction.
-
Reserve a portion of the fragmented RNA as the "input" control.
-
Incubate overnight at 4°C with rotation.
-
-
Capture and Washing:
-
Capture the immune complexes with protein A/G beads.
-
Perform a series of washes with low and high salt buffers to remove non-specific interactions.
-
-
RNA Elution and Purification:
-
Elute the m1C-containing RNA fragments from the beads.
-
Purify the IP'd RNA and the input RNA.
-
-
Library Preparation and Sequencing:
-
Prepare sequencing libraries from the immunoprecipitated RNA and the input RNA samples.
-
Perform high-throughput sequencing.
-
-
Data Analysis:
Visualizations
Caption: Workflow for m1C antibody titration.
Caption: Overall workflow for m1C MeRIP-seq.
References
- 1. Immunoprecipitation Troubleshooting Guide | Cell Signaling Technology [cellsignal.com]
- 2. Antibody Immobilization Optimization for Better IP Results - Creative Proteomics [creative-proteomics.com]
- 3. Immunoprecipitation Experimental Design Tips | Cell Signaling Technology [cellsignal.com]
- 4. Immunoprecipitation Troubleshooting | Antibodies.com [antibodies.com]
- 5. researchgate.net [researchgate.net]
- 6. researchgate.net [researchgate.net]
- 7. Detecting m6A methylation regions from Methylated RNA Immunoprecipitation Sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 8. How MeRIP-seq Works: Principles, Workflow, and Applications Explained - CD Genomics [rna.cd-genomics.com]
Technical Support Center: Solvent Effects on the Photophysical Properties of 1-Methylcytosine
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) for researchers investigating the solvent effects on the photophysical properties of 1-Methylcytosine. The information is tailored for researchers, scientists, and drug development professionals.
Frequently Asked Questions (FAQs)
Q1: What are the primary solvent effects observed on the photophysical properties of this compound?
A1: The primary solvent effect on this compound is related to the solvent's ability to form hydrogen bonds. Protic solvents, like water, can form hydrogen bonds with this compound, which significantly influences its excited-state dynamics. This interaction can alter the energy levels of the excited states and affect the rates of radiative (fluorescence) and non-radiative decay processes. In contrast, aprotic solvents, such as acetonitrile, interact differently, leading to distinct photophysical behavior.
Q2: How does the fluorescence of this compound change between protic and aprotic solvents?
A2: A significant effect of the solvent on this compound's fluorescence emission has been demonstrated. The presence of solute-solvent hydrogen bonding in protic solvents like water can alter the structure and reshape the radiative and nonradiative dynamics of its ππ* state compared to aprotic solvents.[1][2]
Q3: Is this compound a good photosensitizer for photodynamic therapy (PDT)?
A3: Based on current research, this compound exhibits a high degree of photostability due to efficient non-radiative deactivation pathways.[1][2] These rapid decay mechanisms back to the ground state are generally not conducive to the efficient population of a long-lived triplet state, which is a key requirement for a good photosensitizer that can generate reactive oxygen species (ROS) like singlet oxygen. While direct studies on its singlet oxygen quantum yield are not extensively reported, its known photophysics suggest it is likely a poor photosensitizer.
Q4: What is the significance of the nπ state in the deactivation of this compound?*
A4: In aqueous solutions, a dark-natured nπ* state with a lifetime of approximately 5.7 ps has been identified as a key intermediate in the ultrafast non-radiative deactivation of this compound.[1][2] This state provides an efficient pathway for the molecule to return to its ground state without emitting light or generating significant amounts of ROS.
Troubleshooting Guides
Issue 1: Low or No Fluorescence Signal Observed
| Possible Cause | Troubleshooting Step |
| Solvent Quenching | In protic solvents like water, efficient non-radiative decay pathways can quench fluorescence. Try using a less polar, aprotic solvent to see if the fluorescence intensity increases. |
| Incorrect Excitation/Emission Wavelengths | Verify the absorption maximum of this compound in your specific solvent and set the excitation wavelength accordingly. Scan a broad emission range to capture the fluorescence spectrum. |
| Sample Concentration Too High (Inner Filter Effect) | High concentrations can lead to reabsorption of emitted fluorescence. Dilute the sample and check for a linear relationship between absorbance and fluorescence intensity. |
| Photodegradation | Although photostable, prolonged exposure to high-intensity light can cause degradation. Use fresh samples and minimize light exposure. |
| Instrument Settings | Ensure the detector gain is optimized and the slit widths are appropriate for your sample's brightness. |
Issue 2: Inconsistent Fluorescence Lifetime Measurements
| Possible Cause | Troubleshooting Step |
| Solvent Impurities | Trace impurities in the solvent can act as quenchers. Use high-purity, spectroscopy-grade solvents. |
| Presence of Oxygen | Dissolved oxygen can quench the excited state. Degas the solvent by bubbling with an inert gas (e.g., nitrogen or argon) before measurements. |
| Inconsistent Solvent Environment | Small changes in solvent polarity or hydrogen bonding capacity (e.g., due to water contamination in aprotic solvents) can affect lifetimes. Ensure consistent solvent preparation. |
| Data Fitting Issues | The decay kinetics may not be mono-exponential. Try fitting the data to a multi-exponential decay model to account for different decay pathways. |
Issue 3: Suspected Low Singlet Oxygen Generation in a Photodynamic Experiment
| Possible Cause | Troubleshooting Step |
| Inefficient Intersystem Crossing (ISC) | The intrinsic photophysics of this compound favor rapid internal conversion over ISC to the triplet state. This is a fundamental property of the molecule. |
| Short Triplet State Lifetime | Even if the triplet state is populated, it may be too short-lived in your solvent to efficiently transfer energy to molecular oxygen. |
| Solvent Effects | Protic solvents can further deactivate the excited states through hydrogen bonding, reducing the likelihood of triplet state formation.[1][2] |
| Choice of Detection Method | Ensure your method for detecting singlet oxygen (e.g., chemical traps like 1,3-diphenylisobenzofuran (B146845) or direct phosphorescence measurement) is sensitive enough for potentially low quantum yields. |
Data Presentation
Table 1: Summary of Solvent-Dependent Photophysical Properties of this compound
| Property | Water (Protic) | Acetonitrile (Aprotic) | Reference |
| Excited State Lifetime (ππ) | ~0.37 ps | ~0.53 ps | [2] |
| nπ State Lifetime | ~5.7 ps | Not prominently observed | [1][2] |
| Primary Deactivation Pathway | Ultrafast non-radiative decay via nπ* state | Non-radiative decay of the ππ* state | [1][2] |
| Fluorescence Emission | Significantly influenced by hydrogen bonding | Dynamics differ from protic solvents | [1][2] |
Experimental Protocols
Protocol 1: Determination of Fluorescence Quantum Yield (Relative Method)
-
Prepare a Reference Standard: Choose a reference compound with a known fluorescence quantum yield that absorbs and emits in a similar spectral region to this compound (e.g., quinine (B1679958) sulfate (B86663) in 0.1 M H₂SO₄).
-
Prepare Sample and Reference Solutions: Prepare a series of dilutions for both the reference and this compound in the solvent of interest. The absorbance of these solutions at the excitation wavelength should be kept below 0.1 to avoid inner filter effects.
-
Measure Absorbance: Record the UV-Vis absorption spectra for all solutions.
-
Measure Fluorescence: Record the fluorescence emission spectra for all solutions using the same excitation wavelength and instrument settings.
-
Integrate Fluorescence Intensity: Calculate the integrated fluorescence intensity (the area under the emission curve) for each spectrum.
-
Plot Data: For both the reference and the sample, plot the integrated fluorescence intensity versus absorbance.
-
Calculate Quantum Yield: The fluorescence quantum yield (Φ_s) of the sample is calculated using the following equation:
Φ_s = Φ_r * (m_s / m_r) * (n_s² / n_r²)
Where:
-
Φ_r is the quantum yield of the reference.
-
m_s and m_r are the slopes of the plots for the sample and reference, respectively.
-
n_s and n_r are the refractive indices of the sample and reference solvents, respectively.
-
Protocol 2: Femtosecond Transient Absorption Spectroscopy
-
Laser Setup: Utilize a femtosecond laser system to generate both a "pump" and a "probe" pulse. The pump pulse excites the sample, and the time-delayed probe pulse measures the change in absorbance.
-
Sample Preparation: Prepare a solution of this compound in the desired solvent in a cuvette with an appropriate path length. The concentration should be adjusted to have a suitable absorbance at the pump wavelength.
-
Data Acquisition: The pump beam excites the sample, and the probe beam, which is a white light continuum, passes through the excited volume. The change in absorbance of the probe light is measured as a function of wavelength and time delay between the pump and probe pulses.
-
Data Analysis: The resulting data is a three-dimensional map of change in absorbance versus wavelength and time. This data can be analyzed to identify the lifetimes of transient species and the kinetics of their decay.
Visualizations
Caption: Workflow for determining the relative fluorescence quantum yield.
Caption: Simplified deactivation pathways for this compound in solution.
References
Technical Support Center: Accurate Quantification of 1-Methylcytosine (m1C) by LC-MS
This technical support center provides troubleshooting guidance and frequently asked questions (FAQs) to assist researchers, scientists, and drug development professionals in improving the accuracy of 1-Methylcytosine (m1C) quantification by Liquid Chromatography-Mass Spectrometry (LC-MS).
Troubleshooting Guides
This section addresses specific issues that may arise during the experimental workflow, from sample preparation to data analysis.
Question: I am observing poor peak shape (tailing, fronting, or broad peaks) for my this compound standard and samples. What are the potential causes and solutions?
Answer: Poor peak shape can significantly impact the accuracy of quantification.[1] Several factors related to the chromatography can lead to this issue.
Potential Causes and Solutions:
| Potential Cause | Recommended Solution |
| Column Overload | Reduce the injection volume or dilute the sample. High concentrations of the analyte can saturate the stationary phase.[1] |
| Column Contamination | Flush the column with a strong solvent or replace the column if flushing does not resolve the issue. Contaminants can interact with the analyte, causing peak distortion.[1] |
| Improper Mobile Phase pH | Ensure the mobile phase pH is appropriate for this compound. The pH should be at least 2 units away from the pKa of the analyte to ensure it is in a single ionic form. |
| Secondary Interactions with Stationary Phase | Add a small amount of a competing agent to the mobile phase (e.g., triethylamine) to block active sites on the column that may be causing secondary interactions. |
| Dead Volume in the LC System | Check all fittings and connections for leaks or improper seating, which can introduce dead volume and cause peak broadening. |
Question: My this compound signal intensity is low and inconsistent between injections. What could be causing this?
Answer: Low and inconsistent signal intensity is a common problem in LC-MS analysis and is often related to ion suppression or issues with the mass spectrometer source.
Potential Causes and Solutions:
| Potential Cause | Recommended Solution |
| Ion Suppression/Matrix Effects | This is a major cause of signal variability where co-eluting compounds from the sample matrix interfere with the ionization of the analyte.[2][3] To mitigate this, improve sample cleanup using techniques like Solid-Phase Extraction (SPE), use a stable isotope-labeled internal standard for this compound, or modify the chromatographic method to separate the analyte from interfering matrix components.[2] |
| Dirty Ion Source | The ion source can become contaminated with prolonged use, leading to reduced ionization efficiency.[1] Clean the ion source components, such as the capillary and lenses, according to the manufacturer's recommendations. |
| Incorrect Ion Source Settings | Optimize ion source parameters like spray voltage, gas flows (nebulizer and drying gas), and temperature for this compound. This can be done by infusing a standard solution and adjusting the parameters to maximize the signal. |
| Sample Degradation | Ensure proper storage of samples and standards to prevent degradation. This compound can be susceptible to degradation under certain conditions. |
Question: I am having trouble with my calibration curve. It's non-linear or has poor reproducibility. How can I fix this?
Answer: A reliable calibration curve is essential for accurate quantification. Non-linearity or poor reproducibility can stem from several sources.
Potential Causes and Solutions:
| Potential Cause | Recommended Solution |
| Detector Saturation | At high concentrations, the detector can become saturated, leading to a non-linear response.[4] Extend the calibration range to lower concentrations or dilute the higher concentration standards. |
| Inappropriate Weighting Factor | In LC-MS, the variance of the response is often not constant across the concentration range (heteroscedasticity). Applying a weighting factor, such as 1/x or 1/x², to the regression can improve the fit of the calibration curve.[5][6] |
| Matrix Effects in Standards | If standards are prepared in a clean solvent while samples are in a complex matrix, matrix effects can cause a discrepancy. Prepare calibration standards in a matrix that closely matches the samples to compensate for these effects.[2] |
| Pipetting or Dilution Errors | Carefully prepare all standards and quality control (QC) samples to minimize human error. Use calibrated pipettes and perform serial dilutions accurately. |
Frequently Asked Questions (FAQs)
Q1: What is the most critical step in the sample preparation for accurate m1C quantification?
A1: The most critical step is the complete enzymatic digestion of RNA or DNA into individual nucleosides without degradation of the target analyte. Incomplete digestion will lead to an underestimation of the m1C amount. It is crucial to use a robust digestion protocol with a sufficient amount of enzymes like nuclease P1 and alkaline phosphatase.
Q2: Why is a stable isotope-labeled internal standard (SIL-IS) for this compound highly recommended?
A2: A SIL-IS is crucial for achieving the highest accuracy and precision in LC-MS quantification.[7] The SIL-IS has nearly identical chemical and physical properties to the unlabeled this compound, meaning it will behave similarly during sample preparation, chromatography, and ionization. This allows it to effectively compensate for variations in extraction recovery, matrix effects, and instrument response, leading to more reliable results.[7]
Q3: How can I minimize matrix effects in my analysis?
A3: Minimizing matrix effects is key to accurate quantification.[2][3] Several strategies can be employed:
-
Effective Sample Cleanup: Use techniques like Solid-Phase Extraction (SPE) to remove interfering compounds from the sample matrix before LC-MS analysis.
-
Chromatographic Separation: Optimize your LC method to separate this compound from co-eluting matrix components.
-
Matrix-Matched Calibration: Prepare your calibration standards in a blank matrix that is as similar as possible to your samples.[2]
-
Use of a Stable Isotope-Labeled Internal Standard: As mentioned above, a SIL-IS is the most effective way to correct for matrix effects that cannot be eliminated through sample preparation or chromatography.
Q4: What are the optimal LC-MS parameters for this compound analysis?
A4: The optimal parameters can vary depending on the instrument. However, a good starting point for method development would be:
-
Column: A C18 reversed-phase column is commonly used for nucleoside separation.
-
Mobile Phase: A gradient of water with a small amount of formic acid (for protonation in positive ion mode) and methanol (B129727) or acetonitrile.
-
Ionization Mode: Electrospray Ionization (ESI) in positive ion mode is typically used for nucleosides.
-
MS/MS Detection: Use Multiple Reaction Monitoring (MRM) for high selectivity and sensitivity. The precursor ion would be the protonated molecular ion of this compound ([M+H]+), and the product ion would be the protonated base fragment.
Experimental Protocols
Detailed Methodology for RNA Digestion to Nucleosides
This protocol is a general guideline and may need optimization for specific sample types.
-
Sample Preparation:
-
Isolate total RNA from your samples using a standard protocol (e.g., TRIzol extraction followed by isopropanol (B130326) precipitation).
-
Quantify the RNA concentration and assess its purity using a spectrophotometer (e.g., NanoDrop).
-
-
Enzymatic Digestion:
-
In a sterile microcentrifuge tube, combine the following:
-
Up to 1 µg of RNA
-
2 µL of 10X Nuclease P1 Buffer
-
1 µL of Nuclease P1 (e.g., 100 U/µL)
-
Nuclease-free water to a final volume of 18 µL.
-
-
Incubate the reaction at 37°C for 2 hours.
-
Add 2 µL of 10X Alkaline Phosphatase Buffer and 1 µL of Calf Intestinal Alkaline Phosphatase (e.g., 20 U/µL).
-
Incubate at 37°C for an additional 1 hour.
-
-
Sample Cleanup (Optional but Recommended):
-
To remove enzymes and other potential interferences, perform a cleanup step using a C18 solid-phase extraction (SPE) cartridge.
-
Condition the SPE cartridge with methanol followed by water.
-
Load the digested sample onto the cartridge.
-
Wash the cartridge with water to remove salts and other polar impurities.
-
Elute the nucleosides with a solution of 50% methanol in water.
-
Dry the eluted sample in a vacuum centrifuge and reconstitute in the initial LC mobile phase for analysis.
-
General LC-MS Method for this compound Quantification
-
LC System: A high-performance liquid chromatography (HPLC) or ultra-high-performance liquid chromatography (UPLC) system.
-
Column: C18 reversed-phase column (e.g., 2.1 x 100 mm, 1.8 µm particle size).
-
Mobile Phase A: 0.1% Formic Acid in Water.
-
Mobile Phase B: 0.1% Formic Acid in Acetonitrile.
-
Gradient:
-
0-2 min: 2% B
-
2-10 min: 2-30% B
-
10-12 min: 30-95% B
-
12-14 min: 95% B
-
14-15 min: 95-2% B
-
15-20 min: 2% B (re-equilibration)
-
-
Flow Rate: 0.3 mL/min.
-
Column Temperature: 40°C.
-
Injection Volume: 5 µL.
-
MS System: A triple quadrupole mass spectrometer.
-
Ionization: ESI, Positive Ion Mode.
-
MRM Transitions:
-
This compound: Precursor m/z -> Product m/z (to be determined by direct infusion of a standard). A common transition is the loss of the ribose sugar.
-
Stable Isotope-Labeled this compound: Precursor m/z -> Product m/z (to be determined by direct infusion of the standard).
-
Data Presentation
Table 1: Comparison of Sample Preparation Methods for Nucleoside Analysis
This table summarizes the recovery and matrix effects of different sample preparation techniques. Data is generalized from typical performance characteristics.
| Sample Preparation Method | Typical Recovery (%) | Matrix Effect (Ion Suppression) | Throughput |
| Protein Precipitation (PPT) | 80-100% | High | High |
| Liquid-Liquid Extraction (LLE) | 70-90% | Moderate | Moderate |
| Solid-Phase Extraction (SPE) | 85-105% | Low | Moderate |
Table 2: Impact of Stable Isotope-Labeled Internal Standard (SIL-IS) on Quantification Accuracy
This table illustrates the typical improvement in precision when using a SIL-IS.
| Analyte | Without SIL-IS (%RSD) | With SIL-IS (%RSD) |
| This compound | 15-25% | < 5% |
Visualizations
Caption: Experimental workflow for m1C quantification by LC-MS.
Caption: Troubleshooting decision tree for common LC-MS issues.
References
- 1. Ultraperformance Liquid Chromatography Tandem Mass Spectrometry Assay of DNA Cytosine Methylation Excretion from Biological Systems - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Detection of ribonucleoside modifications by liquid chromatography coupled with mass spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Positive/negative ion-switching-based LC–MS/MS method for quantification of cytosine derivatives produced by the TET-family 5-methylcytosine dioxygenases - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Comparison of UPLC-MS/MS-based targeted quantitation and conventional quantitative methods for the analysis of MRP1 expression in tumor cell lines - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
- 6. Comparative Analysis of Quantitative Mass Spectrometric Methods for Subcellular Proteomics - PMC [pmc.ncbi.nlm.nih.gov]
- 7. rsc.org [rsc.org]
Technical Support Center: Protocol Refinement for Bisulfite-Free 1-Methylcytosine (m1C) Detection
Welcome to the technical support center for bisulfite-free 1-methylcytosine (B60703) (m1C) detection. This resource provides researchers, scientists, and drug development professionals with troubleshooting guides and frequently asked questions to navigate the nuances of emerging bisulfite-free methodologies.
Troubleshooting Guide
This guide addresses specific issues that may arise during bisulfite-free m1C detection experiments.
| Problem | Possible Cause | Suggested Solution |
| Low Signal-to-Noise Ratio | Incomplete enzymatic conversion of unmethylated cytosines. | Optimize enzyme concentration and incubation time. Ensure DNA is high quality and free of inhibitors. |
| Non-specific antibody binding in enrichment-based methods. | Increase stringency of wash buffers. Titrate antibody to find the optimal concentration. Include a non-specific IgG control.[1][2] | |
| Insufficient amplification of the target region. | Optimize PCR conditions (annealing temperature, cycle number). Design new primers if necessary. | |
| High Background Signal | Incomplete digestion of unmodified DNA in enzyme-based assays. | Ensure optimal activity of the discriminating enzyme. Verify DNA purity. |
| Cross-reactivity of the m1C antibody with other methylated bases. | Use a highly specific, validated monoclonal antibody. Perform dot blot analysis to check for cross-reactivity. | |
| Contamination with previously amplified products. | Use aerosol-resistant pipette tips. Physically separate pre-PCR and post-PCR areas. | |
| Inconsistent Results Between Replicates | Pipetting errors or variability in sample input. | Use calibrated pipettes. Prepare a master mix for reagents. Quantify starting material accurately. |
| Temperature fluctuations during incubation steps. | Use a calibrated incubator or thermal cycler. Ensure even temperature distribution across samples. | |
| Variability in bead handling for immunoprecipitation. | Ensure complete resuspension of beads at each step. Avoid bead loss during washing steps. | |
| Complete Failure to Detect m1C | Absence of m1C in the specific sample or region of interest. | Use a positive control with known m1C sites. |
| Degradation of enzymes or antibodies. | Store reagents at the recommended temperatures. Aliquot reagents to avoid multiple freeze-thaw cycles. | |
| Low starting amount of DNA. | Increase the initial amount of DNA. Consider a whole-genome amplification step if appropriate. |
Frequently Asked Questions (FAQs)
Q1: What are the main advantages of bisulfite-free m1C detection over traditional bisulfite sequencing?
A1: Traditional bisulfite sequencing causes significant DNA degradation and can lead to biased results. Bisulfite-free methods, such as enzymatic conversion and antibody-based enrichment, offer several advantages:
-
Preservation of DNA Integrity: These methods use milder reaction conditions, which minimizes DNA fragmentation and loss.[3][4] This is particularly crucial when working with low-input samples like cell-free DNA (cfDNA).[5]
-
Higher Sensitivity and Efficiency: By avoiding DNA damage, bisulfite-free techniques can result in higher library complexity, better mapping rates, and more even genome coverage.[6]
-
Direct Detection: Some methods allow for the direct detection of m1C without affecting unmodified cytosines, which can simplify data analysis.[7][8]
Q2: How do enzyme-based bisulfite-free methods for methylation detection work?
A2: Enzyme-based methods, such as Enzymatic Methyl-seq (EM-seq), typically involve a two-step enzymatic process. First, an enzyme like TET2 is used to oxidize methylated cytosines. This modification protects them from the subsequent deamination step. In the second step, an enzyme such as APOBEC3A deaminates only the unmodified cytosines, converting them to uracils.[6][9] During subsequent PCR, these uracils are read as thymines, allowing for the differentiation between methylated and unmethylated cytosines at single-base resolution.
Q3: What are the key considerations when choosing an anti-m1C antibody for enrichment-based methods?
A3: The specificity and affinity of the primary antibody are critical for successful m1C enrichment. Key considerations include:
-
Specificity: The antibody should be highly specific for m1C with minimal cross-reactivity to other cytosine modifications (e.g., 5mC, 5hmC) or unmodified cytosine. This should be validated by the manufacturer or in-house using techniques like dot blots or ELISAs with modified and unmodified DNA oligonucleotides.
-
Clonality: Monoclonal antibodies are often preferred as they recognize a single epitope, leading to higher batch-to-batch consistency.[10]
-
Application Validation: Ensure the antibody has been validated for the intended application (e.g., immunoprecipitation).
Q4: Can bisulfite-free methods distinguish between m1C and other cytosine modifications like 5mC?
A4: The ability to distinguish between different cytosine modifications depends on the specific bisulfite-free method employed.
-
Enrichment-based methods rely on the specificity of the antibody used. A highly specific anti-m1C antibody will only pull down DNA fragments containing m1C.
-
Enzyme-based methods may distinguish between different modifications based on the specific enzymes used. For example, some enzymatic workflows can be adapted to specifically detect 5hmC in addition to 5mC.[3][11] The development of specific enzymatic reactions for m1C is an active area of research.
Q5: What are some critical controls to include in a bisulfite-free m1C detection experiment?
A5: Including proper controls is essential for data interpretation and troubleshooting.
-
Positive Control: A DNA sample with known m1C sites to validate that the experimental workflow is functioning correctly.
-
Negative Control: An unmethylated DNA sample to assess the level of background signal or non-specific conversion/enrichment.
-
No Antibody/IgG Control (for enrichment): A control where the specific anti-m1C antibody is omitted or replaced with a non-specific IgG of the same isotype to determine the level of non-specific binding to the beads or sample.
-
Spike-in Controls: Synthetic DNA oligonucleotides with and without m1C can be added to the sample to monitor the efficiency of the reaction or enrichment process.
Experimental Protocols & Workflows
Protocol 1: Generalized Enzymatic Conversion for m1C Detection
This protocol provides a general workflow for m1C detection using enzymatic conversion. Specific enzyme concentrations and incubation times should be optimized based on the manufacturer's instructions and sample type.
-
DNA Preparation:
-
Start with high-quality, purified genomic DNA.
-
Quantify the DNA accurately using a fluorometric method.
-
Fragment the DNA to the desired size for downstream applications (e.g., sequencing) using sonication or enzymatic digestion.
-
-
End Repair and A-tailing (for sequencing library preparation):
-
Perform end repair and A-tailing on the fragmented DNA to prepare it for adapter ligation.
-
-
Adapter Ligation:
-
Ligate sequencing adapters to the prepared DNA fragments.
-
-
Protection of m1C:
-
Incubate the adapter-ligated DNA with a specific enzyme or chemical agent that modifies m1C, rendering it resistant to subsequent deamination. This step is specific to the chemistry being used to differentiate m1C.
-
-
Enzymatic Deamination of Unmodified Cytosines:
-
Treat the DNA with a deaminase enzyme (e.g., APOBEC3A) to convert unmodified cytosines to uracils. 5mC and protected m1C will remain as cytosines.
-
-
PCR Amplification:
-
Amplify the converted DNA using primers that anneal to the ligated adapters. During PCR, uracils will be replaced by thymines.
-
-
Sequencing and Data Analysis:
-
Sequence the amplified library.
-
Align the sequencing reads to a reference genome.
-
Analyze the C-to-T conversion rates to identify the locations of m1C.
-
Workflow for Enzymatic m1C Detection
Caption: Workflow of a typical enzyme-based bisulfite-free m1C detection method.
Protocol 2: m1C Immunoprecipitation (m1C-IP)
This protocol outlines a general procedure for enriching m1C-containing DNA fragments using a specific antibody.
-
DNA Preparation and Fragmentation:
-
Isolate high-quality genomic DNA.
-
Fragment the DNA to an average size of 200-500 bp by sonication.
-
-
Antibody-Bead Conjugation:
-
Wash magnetic beads (e.g., Protein A/G) with an appropriate buffer.
-
Incubate the beads with the anti-m1C antibody to allow for conjugation.
-
-
Immunoprecipitation:
-
Denature the fragmented DNA by heating.
-
Incubate the denatured DNA with the antibody-conjugated beads overnight at 4°C with gentle rotation.
-
-
Washing:
-
Wash the beads multiple times with high-stringency buffers to remove non-specifically bound DNA.
-
-
Elution:
-
Elute the bound DNA from the beads using an elution buffer.
-
-
DNA Purification:
-
Purify the eluted DNA to remove proteins and other contaminants.
-
-
Downstream Analysis:
-
The enriched DNA can be analyzed by qPCR to quantify m1C at specific loci or by high-throughput sequencing (m1C-IP-seq) for genome-wide mapping.
-
Workflow for m1C Immunoprecipitation
Caption: Workflow for antibody-based enrichment of m1C-containing DNA fragments.
References
- 1. apps.dtic.mil [apps.dtic.mil]
- 2. Improving monoclonal antibody selection and engineering using measurements of colloidal protein interactions - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Single-cell bisulfite-free 5mC and 5hmC sequencing with high sensitivity and scalability - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Novel enzyme-based reduced representation method for DNA methylation profiling with low inputs - PMC [pmc.ncbi.nlm.nih.gov]
- 5. An all-in-one strategy for bisulfite-free DNA methylation detection by temperature-programmed enzymatic reactions - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. Enzymatic methyl sequencing detects DNA methylation at single-base resolution from picograms of DNA - PMC [pmc.ncbi.nlm.nih.gov]
- 7. researchgate.net [researchgate.net]
- 8. biorxiv.org [biorxiv.org]
- 9. Treat Your Sample Gently - Enzymatic Methyl-Sequencing vs. Bisulfite Methyl-Sequencing [cegat.com]
- 10. Primary Antibody Selection for IHC: Monoclonal vs. Polyclonal : Novus Biologicals [novusbio.com]
- 11. researchgate.net [researchgate.net]
minimizing DNA degradation during 1-Methylcytosine analysis
Welcome to the technical support center for 1-methylcytosine (B60703) (1mC) analysis. This resource is designed for researchers, scientists, and drug development professionals to provide guidance on minimizing DNA degradation during 1mC analysis and to offer solutions to common experimental challenges.
Frequently Asked Questions (FAQs)
Q1: What are the primary methods for analyzing this compound (1mC) and how do they impact DNA integrity?
A1: The main methods for 1mC analysis are designed to be gentler on DNA compared to traditional bisulfite sequencing used for 5-methylcytosine. The most common techniques include:
-
1mC-specific antibody-based immunoprecipitation followed by sequencing (1mC-IP-seq or MeDIP-seq): This method uses an antibody to enrich for DNA fragments containing 1mC. It avoids harsh chemical treatments, thus preserving DNA integrity to a large extent. DNA degradation is primarily a risk during the initial DNA shearing and subsequent purification steps.
-
Liquid Chromatography-Mass Spectrometry (LC-MS): This technique provides a highly sensitive and quantitative analysis of 1mC. DNA is enzymatically digested into individual nucleosides, which are then analyzed. This method avoids harsh chemicals, but care must be taken during the enzymatic digestion to prevent DNA degradation.
-
Nanopore Sequencing: This emerging technology allows for the direct detection of modified bases, including 1mC, as a single DNA molecule passes through a nanopore. This method is non-destructive and provides long reads, making it ideal for preserving DNA integrity.
Q2: My DNA samples are precious and available in limited quantities. Which 1mC analysis method is best for minimizing sample loss and degradation?
A2: For limited and precious samples, methods that avoid harsh chemical treatments are highly recommended. Both 1mC-IP-seq and LC-MS can be adapted for low-input samples. Nanopore sequencing is also an excellent option as it analyzes single DNA molecules, though it may require specific library preparation protocols for low-input samples. Enzymatic approaches are generally preferred over chemical ones to maintain the integrity of the DNA.
Q3: Can I use bisulfite sequencing to detect 1mC?
A3: Standard bisulfite sequencing is not suitable for specifically identifying 1mC. The harsh chemical conditions of bisulfite treatment lead to significant DNA degradation and do not differentiate 1mC from other cytosine modifications like 5-methylcytosine.
Troubleshooting Guide
This guide addresses specific issues that can arise during 1mC analysis, with a focus on preventing DNA degradation.
| Problem | Potential Cause | Recommended Solution |
| Low DNA yield after 1mC-IP | Inefficient Immunoprecipitation: Antibody not binding effectively to 1mC. | - Ensure the antibody is validated for 1mC specificity. - Optimize antibody concentration and incubation time. - Verify that the blocking steps are effective to reduce non-specific binding. |
| Over-fragmentation of DNA: DNA fragments are too small, leading to loss during purification steps. | - Optimize sonication or enzymatic digestion conditions to achieve the desired fragment size range (typically 200-500 bp). - Use a method for size selection that minimizes the loss of smaller fragments. | |
| Loss of DNA during purification: Inefficient DNA binding to or elution from purification columns/beads. | - Ensure complete elution by using the recommended buffer and incubation times. - For column-based methods, make sure the column is not overloaded. | |
| High background in 1mC-IP-seq | Non-specific antibody binding: Antibody is binding to unmodified DNA or other cellular components. | - Increase the stringency of the wash buffers. - Optimize the blocking step before adding the antibody. - Titrate the antibody to find the optimal concentration that maximizes signal-to-noise. |
| Incomplete chromatin shearing: Large DNA fragments may be non-specifically trapped. | - Ensure chromatin is sheared to the appropriate size range. | |
| Evidence of DNA degradation in final library (e.g., smears on gel) | Harsh lysis conditions: Mechanical or chemical lysis is too aggressive. | - Optimize lysis buffer composition and incubation times. - Use enzymatic lysis where possible. |
| Nuclease contamination: Endogenous or exogenous nucleases are degrading the DNA. | - Work in a nuclease-free environment. - Add nuclease inhibitors to buffers where appropriate. - Minimize freeze-thaw cycles of samples and reagents. | |
| Suboptimal enzymatic digestion (for LC-MS): Incomplete or over-digestion of DNA. | - Use high-quality, nuclease-free enzymes. - Optimize enzyme concentration and digestion time. - Ensure the buffer conditions are optimal for the enzyme cocktail. |
Experimental Protocols & Data
Quantitative Comparison of DNA Integrity in Different Methylation Analysis Methods
While specific quantitative data for 1mC analysis is still emerging, the following table provides a general comparison of DNA degradation levels associated with different types of methylation analysis techniques.
| Method | Principle | Typical DNA Input | Relative DNA Degradation Level | Key Considerations for DNA Integrity |
| 1mC-IP-seq | Antibody enrichment of 1mC-containing DNA | 1-10 µg | Low | DNA shearing (sonication or enzymatic) is the primary source of fragmentation. Careful optimization is needed. |
| LC-MS | Enzymatic digestion to nucleosides | 1 µg | Very Low | Relies on complete enzymatic digestion. Nuclease contamination can be a concern. |
| Nanopore Sequencing | Direct sequencing of single DNA molecules | Variable (can be low) | Negligible | Preserves native DNA structure. DNA fragmentation during extraction and library prep should be minimized for long reads. |
| Bisulfite Sequencing (for comparison) | Chemical conversion of unmethylated cytosines | 100 ng - 1 µg | High | Harsh chemical and temperature conditions cause significant DNA fragmentation and loss.[1] |
Detailed Methodologies
Protocol: this compound DNA Immunoprecipitation (1mC-IP-seq)
-
DNA Extraction and Fragmentation:
-
Isolate genomic DNA using a standard kit, ensuring minimal degradation.
-
Fragment DNA to an average size of 200-500 bp using sonication or enzymatic digestion.
-
Critical Step: Optimize fragmentation to avoid over-shearing, which can lead to low yield. Assess fragment size on an agarose (B213101) gel or with a bioanalyzer.
-
-
Immunoprecipitation:
-
Denature the fragmented DNA by heating.
-
Incubate the single-stranded DNA with a 1mC-specific antibody overnight at 4°C.
-
Add protein A/G magnetic beads to capture the antibody-DNA complexes.
-
Wash the beads multiple times with buffers of increasing stringency to remove non-specifically bound DNA.
-
-
Elution and DNA Purification:
-
Elute the immunoprecipitated DNA from the antibody-bead complex.
-
Reverse cross-links if applicable.
-
Purify the enriched DNA using a spin column or magnetic beads.
-
-
Library Preparation and Sequencing:
-
Prepare a sequencing library from the immunoprecipitated DNA and an input control.
-
Perform high-throughput sequencing.
-
Visualizations
References
how to handle low abundance of 1-Methylcytosine in samples
This guide provides troubleshooting advice and answers to frequently asked questions for researchers dealing with the low abundance of 1-methylcytosine (B60703) (m1C), a critical RNA modification.
Frequently Asked Questions (FAQs)
Q1: What is this compound (m1C) and where is it found?
A1: this compound (m1C) is a post-transcriptional modification of RNA molecules. Unlike its well-known DNA counterpart, 5-methylcytosine (B146107) (5mC), m1C involves the methylation at the N1 position of the cytosine ring. This modification is found in various types of RNA, including transfer RNA (tRNA), ribosomal RNA (rRNA), and has also been identified in messenger RNA (mRNA) and long non-coding RNA (lncRNA).
Q2: What makes detecting low-abundance m1C in samples so challenging?
A2: The detection of m1C is challenging due to several factors:
-
Low Stoichiometry: m1C modifications may only be present on a small fraction of a specific RNA species within a cell, making it difficult to detect against the background of unmodified RNA.
-
Technical Limitations: Many current detection methods suffer from high error rates, low specificity, or poor repeatability.[1]
-
Distinguishing from Other Modifications: It is crucial to use methods that can specifically identify m1C without cross-reacting with other cytosine modifications like 5-methylcytosine (m5C), which is also present in RNA.[2]
-
Sample Input Requirements: Sensitive detection often requires a significant amount of starting material (total RNA), which may not be available for rare samples.
Q3: What are the primary strategies for handling the low abundance of m1C?
A3: The main strategies involve either enriching the sample for m1C-containing RNA fragments or using highly sensitive detection technologies.
-
Affinity-Based Enrichment: This approach uses antibodies that specifically bind to m1C to immunoprecipitate (IP) RNA fragments containing the modification.[3][4][5] These enriched fragments can then be analyzed by next-generation sequencing (m1C-MeRIP-seq).
-
Highly Sensitive Direct Detection: Methods like liquid chromatography-tandem mass spectrometry (LC-MS/MS) can provide accurate quantification of m1C levels from very small amounts of total RNA.[6][7] Emerging technologies like nanopore sequencing allow for the direct detection of RNA modifications without the need for amplification or chemical conversion, identifying modifications based on distinct electrical signals.[8][9][10]
Q4: How do I choose the right detection method for my research?
A4: The choice of method depends on your specific research question.
-
For genome-wide mapping of m1C sites, an enrichment-based method like m1C-MeRIP-seq is suitable.
-
For absolute quantification of total m1C levels in a sample (without location information), LC-MS/MS is the gold standard.
-
For single-base resolution mapping and detection without antibodies or chemical treatments, nanopore direct RNA sequencing is a powerful, albeit newer, option.
The decision tree diagram below provides a guide for selecting the appropriate method.
Method Selection and Experimental Workflow
The following diagrams illustrate a general workflow for m1C analysis and a decision guide for selecting the most appropriate methodology.
Caption: General workflow for analyzing low-abundance this compound (m1C).
References
- 1. academic.oup.com [academic.oup.com]
- 2. biocompare.com [biocompare.com]
- 3. epigenie.com [epigenie.com]
- 4. A Mini-review of the Computational Methods Used in Identifying RNA 5-Methylcytosine Sites - PMC [pmc.ncbi.nlm.nih.gov]
- 5. An Overview of Current Detection Methods for RNA Methylation - PMC [pmc.ncbi.nlm.nih.gov]
- 6. LC-MS-MS quantitative analysis reveals the association between FTO and DNA methylation | PLOS One [journals.plos.org]
- 7. LC-MS-MS quantitative analysis reveals the association between FTO and DNA methylation - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Selective and Sensitive Detection of Methylcytosine by Aerolysin Nanopore under Serum Condition - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. Research Portal [laro.lanl.gov]
- 10. scispace.com [scispace.com]
Technical Support Center: Optimizing DNA Fragmentation for 1-Methylcytosine (1mC) MeDIP
This technical support center provides researchers, scientists, and drug development professionals with comprehensive troubleshooting guides and FAQs to optimize the DNA fragmentation step for 1-Methylcytosine (1mC) Methylated DNA Immunoprecipitation (MeDIP) experiments.
Frequently Asked Questions (FAQs)
Q1: What is the optimal DNA fragment size for 1mC MeDIP-seq?
A1: The ideal DNA fragment size for MeDIP-seq is generally between 200 and 600 base pairs (bp).[1][2] This range is a balance between two competing factors:
-
Antibody Binding Efficiency: The antibody used for immunoprecipitation requires more than a single methylated cytosine for efficient binding. Fragments that are too short reduce the probability of containing multiple 1mC residues, which can lead to poor enrichment.[1]
-
Resolution of Methylation Mapping: Larger DNA fragments can decrease the resolution of methylation mapping, making it difficult to pinpoint the precise location of the methylated regions.[1]
Some protocols may use a broader range of 200-800 bp or even 300-1000 bp.[3] For applications requiring higher resolution, fragments closer to the 200 bp end of the spectrum are preferable.
Q2: What are the common methods for DNA fragmentation in MeDIP protocols?
A2: The two most common methods for DNA fragmentation are sonication and enzymatic digestion.
-
Sonication: This is a widely used method that shears DNA into random fragments using ultrasonic waves.[3] It is known for its speed and avoidance of enzymatic biases.[3]
-
Enzymatic Digestion: This method uses nucleases, such as Micrococcal Nuclease (MNase) or restriction enzymes like MseI, to digest DNA.[2][4] Enzymatic digestion can provide a more uniform fragment size distribution.[4]
Q3: How can I assess the quality and size of my fragmented DNA?
A3: After fragmentation, it is crucial to check the size distribution of the DNA fragments. This is typically done by running an aliquot of the fragmented DNA on an agarose (B213101) gel alongside a DNA ladder. For higher resolution analysis, a Bioanalyzer or a similar capillary electrophoresis-based system can be used.
Q4: Can I use the same fragmentation protocol for different cell or tissue types?
A4: While the general principles remain the same, the optimal fragmentation conditions, especially for sonication, can vary depending on the cell or tissue type, cell density, and cross-linking time.[5] It is highly recommended to optimize the fragmentation protocol for each new experimental condition.
Troubleshooting Guide
| Problem | Potential Cause | Recommended Solution |
| Low or no PCR product from enriched DNA | Poor DNA quality (degraded or contains inhibitors). | Ensure the starting genomic DNA is of high quality with a 260/280 ratio >1.6.[6] Purify DNA to remove any potential enzymatic inhibitors. |
| Inefficient DNA fragmentation (fragments are too large or too small). | Verify the DNA fragment size on an agarose gel or Bioanalyzer. The optimal range is typically 100-600 bp.[6] Re-optimize sonication or enzymatic digestion conditions. | |
| Insufficient amount of starting DNA. | The recommended input DNA amount can range from 50 ng to 500 ng per reaction.[6] For optimal results, use 100-200 ng per well.[6] | |
| High background (enrichment of unmethylated control regions) | Non-specific binding of the antibody. | Ensure the use of a highly specific anti-1-Methylcytosine antibody. Perform blocking steps as recommended in the protocol. |
| Incomplete washing steps. | Follow the recommended number and duration of wash steps to remove non-specifically bound DNA. | |
| Inconsistent fragmentation results between samples | Variations in sample processing. | Ensure uniform cell density, lysis, and sonication conditions for all samples. When using a sonicator, ensure proper placement of tubes and adequate cooling.[7] |
| Sample viscosity. | High sample viscosity can impede efficient sonication. Ensure complete cell lysis and consider diluting the sample if necessary. |
Quantitative Data Summary
Table 1: Recommended Input DNA Amounts for MeDIP
| Parameter | Recommended Range | Optimal Amount | Reference |
| Input DNA per reaction | 50 ng - 500 ng | 100 ng - 200 ng | [6] |
| Input DNA for low-input protocols | As low as 25 ng | 50 ng - 100 ng | [4] |
Table 2: Example Sonication Parameters (Instrument Dependent)
| Instrument | Power Setting | Pulse Cycle | Total Time | Reference |
| Fisher 700 W Sonic Dismembrator | 20% amplitude | 1s on / 1s off | 2 series of 110s | |
| Diagenode Bioruptor XL | Low (L) power | 5s on / 5s off | 10 - 20 min | [7] |
| Cole-Parmer Ultrasonic Homogenizer 4710 Series | 5 Volts | 20% pulse | 2 min | [8] |
Note: These are example parameters and must be optimized for your specific instrument, sample type, and desired fragment size.
Experimental Protocols
Protocol 1: DNA Fragmentation by Sonication
-
DNA Preparation: Dilute 0.5-8 µg of purified genomic DNA in a final volume of 80 µl with deionized water in a 1.5 ml microfuge tube.
-
Sonication Setup: Use a sonicator with a cooling chamber or water bath to maintain a low temperature during sonication.
-
Sonication: Sonicate the DNA sample using optimized parameters for your instrument. For example, with a Fisher 700 W sonic dismembrator, use 20% amplitude with pulses of 1 second on and 1 second off for a total of two series of 110 seconds, replenishing the ice in the cooling chamber between series.
-
Fragment Analysis: After sonication, take a 4 µl aliquot of the sonicated DNA and run it on a 1.5% agarose gel with a DNA ladder to verify that the fragment sizes are in the desired range of 200-800 bp.
Protocol 2: Enzymatic Digestion of DNA (using MNase)
-
Chromatin Preparation: Isolate chromatin from cells or tissues.
-
MNase Digestion: Resuspend the chromatin pellet in MNase digestion buffer. Add the optimized amount of Micrococcal Nuclease (MNase) and incubate at 37°C for a predetermined time to achieve the desired fragmentation. The reaction is stopped by adding EDTA.
-
DNA Purification: Purify the DNA from the digested chromatin using a standard phenol-chloroform extraction or a DNA purification kit.
-
Fragment Analysis: Analyze the fragment size distribution on a 1.5% agarose gel or a Bioanalyzer.
Visualizations
Experimental Workflow for 1mC MeDIP-seq
Caption: Workflow of this compound MeDIP-seq.
References
- 1. Methylated DNA immunoprecipitation(MeDIP) - Dna methylation | Diagenode [diagenode.com]
- 2. An optimized two-step chromatin immunoprecipitation protocol to quantify the associations of two separate proteins and their common target DNA - PMC [pmc.ncbi.nlm.nih.gov]
- 3. MeDIP | ABIN2866109 [antibodies-online.com]
- 4. Methylated DNA immunoprecipitation(MeDIP) - Dna methylation | Diagenode [diagenode.com]
- 5. An Optimized Chromatin Immunoprecipitation Protocol for Quantification of Protein-DNA Interactions - PMC [pmc.ncbi.nlm.nih.gov]
- 6. fnkprddata.blob.core.windows.net [fnkprddata.blob.core.windows.net]
- 7. Genome-Wide Mapping of DNA Methylation 5mC by Methylated DNA Immunoprecipitation (MeDIP)-Sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Comprehensive whole DNA methylome analysis by integrating MeDIP-seq and MRE-seq - PMC [pmc.ncbi.nlm.nih.gov]
best practices for designing primers for 1mC bisulfite sequencing
This technical support center provides researchers, scientists, and drug development professionals with best practices, troubleshooting guidance, and frequently asked questions for designing robust primers for bisulfite sequencing experiments.
Frequently Asked Questions (FAQs)
Q1: What is the primary purpose of bisulfite sequencing?
Bisulfite sequencing is a method used to determine the methylation patterns of DNA.[1][2][3] Treatment of DNA with sodium bisulfite converts unmethylated cytosine residues to uracil, while methylated cytosines (5-methylcytosine or 5mC) remain unchanged.[2][3] Subsequent PCR amplification and sequencing allow for the identification of methylation sites at single-nucleotide resolution.[1]
Q2: Can bisulfite sequencing detect 1-methyladenine (B1486985) (1mA) or other modified bases?
Standard bisulfite sequencing is specific for the detection of 5-methylcytosine (B146107) (5mC).[3] It does not detect other modified bases like 1-methyladenine (1mA), 5-hydroxymethylcytosine (B124674) (5hmC), or N6-methyladenosine (m6A).[4] While bisulfite treatment can lead to the degradation of DNA containing certain modifications, it is not a reliable method for their direct detection. Specific enzymatic or chemical treatment protocols combined with sequencing are required to identify these other DNA modifications.
Q3: Why are primers for bisulfite-converted DNA longer than standard PCR primers?
Bisulfite treatment significantly reduces the complexity of the DNA sequence by converting most cytosines to thymines (after PCR), resulting in AT-rich DNA.[5][6] Longer primers (typically 26-35 base pairs) are necessary to ensure specific binding to these low-complexity templates and to achieve a suitable annealing temperature for successful PCR amplification.[5][7][8]
Q4: What are the key considerations for designing primers for bisulfite sequencing?
Successful primer design is critical for accurate methylation analysis.[5][9] Key considerations include primer length, annealing temperature (Tm), GC content, and the avoidance of CpG sites within the primer sequence to prevent methylation-biased amplification.[5][7][8]
Q5: Which software tools are available for designing bisulfite sequencing primers?
Several software tools can simplify and automate the design of primers for bisulfite-converted DNA. Popular choices include:
These tools help in designing primers with optimal characteristics and can perform in silico specificity checks against the bisulfite-converted genome.[12]
Primer Design Best Practices
Adhering to established best practices for primer design is crucial for the success of bisulfite sequencing experiments. The following table summarizes the key quantitative parameters for optimal primer design.
| Parameter | Recommendation | Rationale |
| Primer Length | 26–35 base pairs | Increases specificity and melting temperature (Tm) for AT-rich bisulfite-converted DNA.[6][7][8] |
| Amplicon Size | 150–500 base pairs | Bisulfite treatment can cause DNA degradation, so shorter amplicons are more efficiently amplified.[5][7][8] |
| Annealing Temperature (Tm) | > 60°C | Ensures specific primer binding and reduces non-specific amplification.[7][8] |
| GC Content | As high as possible without compromising specificity | Helps to increase the primer Tm. Including G's is particularly effective.[6][7] |
| CpG sites in Primer Sequence | Avoid if possible | To prevent amplification bias towards either methylated or unmethylated alleles.[5][7][8] |
| Non-CpG 'C's in Primer | Include a sufficient number | To ensure primers are specific for bisulfite-converted DNA.[15] |
| Primer Concentration | 0.5 µM (final concentration) | Optimal concentration for most PCR reactions with bisulfite-treated DNA.[7][8] |
Experimental Workflow for Primer Design
The following diagram illustrates the general workflow for designing primers for bisulfite sequencing.
Caption: Workflow for designing and validating bisulfite sequencing primers.
Detailed Protocol: Primer Design and Validation
This protocol outlines the steps for designing and validating primers for the amplification of a specific target region from bisulfite-converted DNA.
Materials:
-
Computer with internet access
-
DNA sequence of the target region
-
Primer design software (e.g., MethPrimer, BiSearch)
-
In silico PCR and sequence analysis tools (e.g., NCBI BLAST)
Methodology:
-
Obtain Target Sequence: Retrieve the genomic DNA sequence of interest from a database such as NCBI GenBank or Ensembl. Ensure you have sufficient flanking sequence (approx. 500-1000 bp) around the region of interest to allow for flexibility in primer placement.[10]
-
In Silico Bisulfite Conversion: Use a tool within your chosen primer design software or a standalone web tool to perform an in silico bisulfite conversion of your target sequence. This will generate the forward and reverse strand sequences where all unmethylated cytosines are converted to thymines.
-
Primer Design using Software:
-
Input the original (unconverted) DNA sequence into the primer design software.[10]
-
Specify the target region for methylation analysis.
-
Set the primer design parameters according to the recommendations in the "Primer Design Best Practices" table above.
-
Ensure the software is configured to design primers for bisulfite-converted DNA. The software will automatically account for the sequence changes on both strands.
-
-
Primer Selection Criteria:
-
The software will typically suggest several primer pairs. Select pairs that flank the region of interest and produce an amplicon within the desired size range (150-500 bp).
-
Critically, ensure that the selected primers do not contain any CpG dinucleotides.[7][15] If unavoidable, the CpG should be located at the 5' end of the primer, and a degenerate base (Y for C/T) should be used at the cytosine position.[5][7][8]
-
Primers should be designed to be specific to one of the bisulfite-converted strands (either the forward or reverse strand of the original DNA).[7][15]
-
-
In Silico Specificity Analysis:
-
Experimental Validation:
-
Once suitable primers are designed and synthesized, their performance must be validated experimentally.
-
Perform a gradient PCR using bisulfite-converted DNA as a template to determine the optimal annealing temperature.[5][9] The optimal temperature will yield a single, strong band of the expected size with minimal non-specific products.
-
Use a hot-start DNA polymerase to minimize non-specific amplification, which is common with AT-rich templates.[5][6]
-
Troubleshooting Guide
Problem: No PCR Product or Weak Amplification
| Possible Cause | Recommended Solution |
| Inefficient Bisulfite Conversion or DNA Degradation | Verify the success of bisulfite conversion using control DNA. Ensure that the amplicon size is not too large (<500 bp is recommended).[7][8] |
| Suboptimal Annealing Temperature | Perform a gradient PCR to determine the optimal annealing temperature for your specific primer set and template.[5][9] |
| Poor Primer Design | Re-design primers following the best practices. Ensure primers are long enough (26-35 bp) and have a sufficiently high Tm (>60°C).[7][8] |
| Incorrect Primer Concentration | Titrate the primer concentration. A final concentration of 0.5 µM is often a good starting point.[7][8] |
Problem: Non-Specific PCR Products (Multiple Bands)
| Possible Cause | Recommended Solution |
| Low Annealing Temperature | Increase the annealing temperature in increments of 1-2°C. A gradient PCR is highly recommended for optimization.[16] |
| Primers Amplify Non-Target Regions | Perform an in silico specificity check (BLAST) against the bisulfite-converted genome. Re-design primers if significant off-target binding sites are predicted. |
| Primer-Dimers | Use a hot-start Taq polymerase to minimize primer-dimer formation during PCR setup.[5][6] |
Problem: Amplification Bias (Preferential amplification of methylated or unmethylated alleles)
| Possible Cause | Recommended Solution |
| CpG Sites within Primer Sequence | Design primers that are devoid of CpG sites.[7][15] This is the most common cause of methylation bias. |
| Suboptimal Annealing Temperature | An incorrect annealing temperature can sometimes favor the amplification of one allele over the other. Optimize the annealing temperature using a gradient PCR. |
Logical Relationship of Bisulfite Sequencing Principles
The following diagram illustrates the core principle of how bisulfite sequencing distinguishes between methylated and unmethylated cytosines.
Caption: Principle of bisulfite-mediated C-to-U conversion.
References
- 1. Bisulfite sequencing in DNA methylation analysis | Abcam [abcam.com]
- 2. Bisulfite sequencing - Wikipedia [en.wikipedia.org]
- 3. Bisulfite Sequencing: Introduction, Features, Workflow, and Applications - CD Genomics [cd-genomics.com]
- 4. biorxiv.org [biorxiv.org]
- 5. bioscience.co.uk [bioscience.co.uk]
- 6. epigenie.com [epigenie.com]
- 7. neb.com [neb.com]
- 8. neb.com [neb.com]
- 9. zymoresearch.com [zymoresearch.com]
- 10. Primer Design for Pyrosequencing [protocols.io]
- 11. BiSearch: Primer Design and Search Tool [bisearch.pbrg.hu]
- 12. BiSearch: primer-design and search tool for PCR on bisulfite-treated genomes - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Applied Biosystems Unveils Primer Design Software and Bisulfite Conversion Kit | Technology Networks [technologynetworks.com]
- 14. zymoresearch.com [zymoresearch.com]
- 15. Primer Design Rules for Bisulfite Conversion Based PCR - 每日生物评论 [bio-review.com]
- 16. researchgate.net [researchgate.net]
Validation & Comparative
Navigating the Nuances of Cytosine Methylation: A Guide to Differentiating 5-Methylcytosine in Sequencing Data
An in-depth comparison of sequencing methodologies for the precise identification of 5-methylcytosine (B146107), a key epigenetic marker. This guide addresses the common challenge of distinguishing 5-methylcytosine from other cytosine modifications, with a special note on the status of 1-methylcytosine (B60703) detection.
For researchers, scientists, and drug development professionals, the accurate detection of DNA modifications is paramount to unraveling the complexities of gene regulation and disease. Among the most studied epigenetic marks is the methylation of cytosine, predominantly in the form of 5-methylcytosine (5mC). The presence of 5mC at gene promoters is typically associated with transcriptional repression, playing a crucial role in cellular differentiation, genomic imprinting, and the silencing of transposable elements.
However, the landscape of cytosine modifications is more complex than the simple presence or absence of a methyl group at the 5th carbon position. The discovery of other modified bases, such as 5-hydroxymethylcytosine (B124674) (5hmC), 5-formylcytosine (B1664653) (5fC), and 5-carboxylcytosine (5caC), has highlighted the need for sequencing methods that can precisely distinguish between these functionally distinct epigenetic marks.
A key challenge in the field has been the development of techniques that can differentiate 5mC from its oxidized derivatives, particularly 5hmC, which is an intermediate in the DNA demethylation pathway and may also act as a stable epigenetic mark in its own right. Standard bisulfite sequencing, the historical gold standard for DNA methylation analysis, is unable to distinguish between 5mC and 5hmC, leading to a composite signal that can obscure the true epigenetic state of a genomic locus.
This guide provides a comprehensive comparison of modern sequencing techniques designed to specifically identify and quantify 5-methylcytosine, with a focus on methods that can differentiate it from 5-hydroxymethylcytosine. We will delve into the experimental protocols, performance metrics, and underlying principles of these advanced methodologies.
The Status of this compound (1mC) in DNA Sequencing
While the user's query specifically mentioned the differentiation of this compound (1mC) from 5-methylcytosine (5mC), it is important to clarify the current standing of 1mC in the context of DNA sequencing. This compound is a known isomer of 5-methylcytosine. However, unlike 5mC, which is a widespread and functionally significant epigenetic mark in the DNA of both eukaryotes and prokaryotes, 1mC is not considered a common or biologically relevant modification in DNA. Its presence and functional role in DNA are not well-established, and consequently, there has been minimal focus on developing high-throughput sequencing methods to detect it or differentiate it from 5mC.
Therefore, this guide will focus on the critical and well-established challenge of differentiating 5-methylcytosine from its biologically significant derivative, 5-hydroxymethylcytosine, as this represents the current frontier in the precise analysis of the DNA methylome.
Comparison of Key Sequencing Methods for 5mC and 5hmC Differentiation
Several innovative techniques have emerged to overcome the limitations of traditional bisulfite sequencing. These methods employ either chemical or enzymatic approaches to differentially modify 5mC and 5hmC, allowing for their distinct identification at single-base resolution. The table below summarizes the key characteristics of the most prominent methods.
| Method | Principle | DNA Input | Read Length | Throughput | Advantages | Disadvantages |
| Oxidative Bisulfite Sequencing (oxBS-Seq) | Chemical oxidation of 5hmC to 5fC, which is then susceptible to bisulfite conversion to uracil. 5mC remains as cytosine. | 100 ng - 1 µg | Short-read compatible | High | Direct quantification of 5mC. | Requires two parallel experiments (BS-Seq and oxBS-Seq) and subtraction analysis. Can cause DNA degradation. |
| TET-assisted Bisulfite Sequencing (TAB-Seq) | Enzymatic glucosylation of 5hmC to protect it from TET enzyme oxidation. TET then oxidizes 5mC to 5caC, which is susceptible to bisulfite conversion. | 100 ng - 2 µg | Short-read compatible | High | Direct detection of 5hmC. | Multi-step enzymatic and chemical process. Can be technically challenging. |
| Enzymatic Methyl-seq (EM-seq) | Enzymatic protection of 5mC and 5hmC from deamination by APOBEC. Unmodified cytosines are converted to uracil. | 10 ng - 200 ng | Short-read compatible | High | Less DNA damage than bisulfite-based methods. Higher mapping efficiency. | Does not inherently distinguish 5mC from 5hmC. Requires combination with other methods for differentiation. |
Experimental Protocols and Workflows
Oxidative Bisulfite Sequencing (oxBS-Seq)
The oxBS-Seq method provides a means to directly quantify 5mC levels by comparing the results of two parallel sequencing experiments: standard bisulfite sequencing (BS-Seq) and oxidative bisulfite sequencing.
Experimental Protocol:
-
DNA Fragmentation: Genomic DNA is fragmented to the desired size for library preparation.
-
Library Preparation: Sequencing adapters are ligated to the fragmented DNA.
-
Sample Splitting: The adapter-ligated library is split into two aliquots.
-
Oxidation (oxBS aliquot): One aliquot is treated with an oxidizing agent (e.g., potassium perruthenate) to convert 5hmC to 5-formylcytosine (5fC).
-
Bisulfite Conversion: Both the oxidized and non-oxidized aliquots are treated with sodium bisulfite. This converts unmethylated cytosines and 5fC to uracil, while 5mC remains as cytosine. In the BS-Seq aliquot, both 5mC and 5hmC are resistant to conversion.
-
PCR Amplification: The converted DNA is amplified by PCR.
-
Sequencing: Both libraries are sequenced.
-
Data Analysis: The sequencing reads are aligned to a reference genome. The 5mC level at a specific cytosine position is determined by the percentage of reads that retain a cytosine in the oxBS-Seq data. The 5hmC level is inferred by subtracting the 5mC level (from oxBS-Seq) from the combined 5mC + 5hmC level (from BS-Seq).
TET-assisted Bisulfite Sequencing (TAB-Seq)
TAB-Seq offers a direct method for mapping 5hmC by protecting it from the enzymatic oxidation that converts 5mC.
Experimental Protocol:
-
DNA Fragmentation and Library Preparation: Similar to oxBS-Seq.
-
Glucosylation: 5hmC residues are protected by glucosylation using β-glucosyltransferase (β-GT).
-
TET Oxidation: The DNA is treated with a TET enzyme, which oxidizes 5mC to 5-carboxylcytosine (5caC). The protected 5hmC is not affected.
-
Bisulfite Conversion: The DNA is treated with sodium bisulfite. Unmethylated cytosines and 5caC are converted to uracil, while the protected 5hmC remains as cytosine.
-
PCR Amplification and Sequencing: The library is amplified and sequenced.
-
Data Analysis: Cytosines that are read as 'C' in the final sequencing data correspond to the original locations of 5hmC.
Enzymatic Methyl-seq (EM-seq)
EM-seq provides a gentler alternative to bisulfite conversion, resulting in higher quality sequencing libraries. While the standard EM-seq protocol detects both 5mC and 5hmC, it can be combined with other steps to differentiate them.
Experimental Protocol (Standard EM-seq):
-
DNA Fragmentation and Library Preparation: Similar to other methods.
-
TET2 Oxidation and Glucosylation: The DNA is treated with TET2 enzyme to oxidize 5mC to its derivatives and a glucosyltransferase to protect 5hmC.
-
APOBEC Deamination: The APOBEC enzyme is used to deaminate unprotected cytosines to uracils. The protected 5mC and 5hmC are not deaminated.
-
PCR Amplification and Sequencing: The library is amplified and sequenced.
-
Data Analysis: Cytosines that remain as 'C' represent the locations of either 5mC or 5hmC.
To differentiate 5mC and 5hmC using an enzymatic approach, a workflow similar to oxBS-Seq can be employed, where one aliquot undergoes a process to specifically deaminate 5hmC while protecting 5mC, and another aliquot undergoes the standard EM-seq protocol.
Conclusion
The ability to accurately differentiate 5-methylcytosine from other cytosine modifications, particularly 5-hydroxymethylcytosine, is crucial for a comprehensive understanding of the epigenetic regulation of the genome. While the direct differentiation of this compound from 5-methylcytosine in sequencing data is not a current focus of the field due to the low abundance and unclear biological role of 1mC in DNA, a suite of powerful techniques is available to distinguish the well-established and functionally significant 5mC and 5hmC.
Methods such as oxBS-Seq and TAB-Seq, along with enzymatic approaches like EM-seq, provide researchers with the tools to generate high-resolution maps of these critical epigenetic marks. The choice of method will depend on the specific research question, available instrumentation, and the amount and quality of the starting DNA material. As sequencing technologies continue to evolve, we can anticipate the development of even more direct and efficient methods for a complete and accurate characterization of the DNA methylome, further advancing our insights into health and disease.
A Comparative Analysis of 1-Methylcytosine and 5-Hydroxymethylcytosine: Unraveling the Roles of Two Cytosine Analogs
For researchers, scientists, and drug development professionals, understanding the nuanced differences between modified cytosine bases is critical for advancing epigenetic research and therapeutic development. This guide provides a comprehensive comparative analysis of 1-methylcytosine (B60703) (m1C) and 5-hydroxymethylcytosine (B124674) (5hmC), focusing on their physicochemical properties, biological functions, genomic distribution, and the experimental methods used for their detection. While 5hmC is a well-established epigenetic mark, the role of m1C in mammalian DNA remains largely enigmatic, a key distinction that will be explored herein.
Executive Summary
This guide illuminates the stark contrasts between the well-characterized epigenetic modification 5-hydroxymethylcytosine (5hmC) and the lesser-known this compound (m1C) within the context of mammalian genomics. 5hmC is a pivotal intermediate in DNA demethylation and a stable epigenetic mark influencing gene expression. In contrast, the natural occurrence and biological significance of m1C in mammalian DNA are not well-established, with its study being more prominent in the fields of RNA modification and synthetic biology. This comparative analysis serves to highlight the established importance of 5hmC in epigenetic regulation and to underscore the current knowledge gaps surrounding m1C in DNA.
Physicochemical Properties
The structural differences between this compound and 5-hydroxymethylcytosine, specifically the position of the methyl or hydroxymethyl group on the cytosine ring, fundamentally influence their chemical properties and how they are recognized by cellular machinery.
| Property | This compound (m1C) | 5-Hydroxymethylcytosine (5hmC) |
| Chemical Formula | C₅H₇N₃O | C₅H₇N₃O₂ |
| Molar Mass | 125.13 g/mol | 141.13 g/mol |
| Modification Site | Methyl group at the N1 position of the cytosine ring. | Hydroxymethyl group at the C5 position of the cytosine ring. |
| Hydrogen Bonding | The methyl group at the N1 position can alter the hydrogen bonding capacity compared to cytosine. | The hydroxyl group provides an additional site for hydrogen bonding, potentially altering interactions with proteins and nucleic acids. |
Biological Function and Significance
The biological roles of 5hmC are multifaceted and central to epigenetic regulation, whereas the functions of m1C in mammalian DNA are currently not well understood.
This compound (m1C):
-
In Mammalian DNA: The natural presence and biological role of m1C in mammalian genomic DNA are not clearly established in the current scientific literature.
-
In RNA: m1C is a known modification in various RNA species, where it plays a role in RNA stability and translation.
-
In Synthetic Biology: m1C has been utilized in synthetic genetic systems, such as "hachimoji DNA," an eight-letter genetic alphabet, where it pairs with isoguanine.[1]
5-Hydroxymethylcytosine (5hmC):
-
Intermediate in DNA Demethylation: 5hmC is a key intermediate in the active DNA demethylation pathway. It is generated from the oxidation of 5-methylcytosine (B146107) (5mC) by the Ten-Eleven Translocation (TET) family of dioxygenases.[2] 5hmC can be further oxidized to 5-formylcytosine (B1664653) (5fC) and 5-carboxylcytosine (5caC), which are then excised by DNA glycosylases as part of the base excision repair pathway, ultimately leading to the restoration of an unmodified cytosine.[2]
-
Stable Epigenetic Mark: Beyond its role as a transient intermediate, 5hmC is also recognized as a stable epigenetic mark in its own right.[3] It is particularly abundant in neurons and embryonic stem cells.[4]
-
Gene Regulation: The presence of 5hmC is generally associated with active gene expression.[5] It is often found in the bodies of active genes and at enhancers. The conversion of 5mC to 5hmC can disrupt the binding of methyl-CpG-binding proteins, which are typically associated with transcriptional repression.[4]
Genomic Distribution
The genomic localization of 5hmC is well-documented and linked to its regulatory functions. The genomic distribution of m1C in mammalian DNA, if any, remains to be determined.
| Feature | This compound (m1C) | 5-Hydroxymethylcytosine (5hmC) |
| Presence in Mammalian DNA | Not well-documented as a natural modification. | Present as a natural epigenetic modification. |
| Abundance | Unknown in native mammalian DNA. | Varies by cell type, but is particularly enriched in the brain and embryonic stem cells. |
| Genomic Localization | Unknown in native mammalian DNA. | Enriched in gene bodies of actively transcribed genes, enhancers, and promoters.[4] |
Signaling and Metabolic Pathways
The enzymatic machinery and pathways governing the lifecycle of 5hmC are well-defined. In contrast, the enzymes responsible for the potential deposition ("writers") and removal ("erasers") of m1C in mammalian DNA have not been identified.
Caption: The TET-mediated oxidation pathway for active DNA demethylation.
Experimental Protocols for Detection
Detection of 5-Hydroxymethylcytosine (5hmC)
A key challenge in studying 5hmC is distinguishing it from 5mC. Several methods have been developed to achieve this at single-base resolution.
1. Oxidative Bisulfite Sequencing (oxBS-Seq):
-
Principle: This method involves a chemical oxidation step that converts 5hmC to 5fC. Subsequent bisulfite treatment converts 5fC and unmodified cytosine to uracil, while 5mC remains unchanged. By comparing the results of oxBS-Seq with standard bisulfite sequencing (which detects both 5mC and 5hmC as cytosine), the locations of 5hmC can be inferred.[6]
-
Protocol Outline:
-
Genomic DNA is fragmented.
-
One aliquot of DNA is subjected to oxidation with potassium perruthenate (KRuO₄), which converts 5hmC to 5fC.
-
Both the oxidized and unoxidized aliquots are then treated with sodium bisulfite.
-
Libraries are prepared and sequenced.
-
Sequencing reads are aligned to a reference genome, and the methylation status of each cytosine is determined by comparing the two datasets.
-
2. TET-Assisted Bisulfite Sequencing (TAB-Seq):
-
Principle: This method utilizes the enzymatic activity of TET proteins to specifically identify 5hmC. First, 5hmC is protected by glucosylation. Then, TET enzymes are used to oxidize 5mC to 5caC. Subsequent bisulfite treatment converts unmodified cytosine and 5caC to uracil, leaving only the protected 5hmC to be read as cytosine.
-
Protocol Outline:
-
Genomic DNA is fragmented.
-
5hmC residues are glucosylated using β-glucosyltransferase (β-GT).
-
TET enzymes are used to oxidize 5mC to 5caC.
-
The DNA is treated with sodium bisulfite.
-
Libraries are prepared and sequenced.
-
Cytosines that remain as cytosine in the final sequence represent the original locations of 5hmC.
-
3. Enzymatic Methyl-seq (EM-seq):
-
Principle: This is a newer, enzyme-based method that avoids the use of bisulfite, which can cause DNA degradation. It involves a series of enzymatic reactions to differentiate between cytosine modifications.
-
Protocol Outline:
-
TET2 enzyme is used to oxidize 5mC and 5hmC.
-
APOBEC deaminase then converts unmodified cytosines to uracils.
-
The resulting DNA is amplified and sequenced. This allows for the direct detection of 5mC and 5hmC.
-
4. Mass Spectrometry:
-
Principle: Liquid chromatography-tandem mass spectrometry (LC-MS/MS) can be used for the global quantification of 5hmC. DNA is hydrolyzed into individual nucleosides, which are then separated by chromatography and detected by mass spectrometry.
-
Protocol Outline:
-
Genomic DNA is enzymatically or chemically hydrolyzed to single nucleosides.
-
The nucleosides are separated using liquid chromatography.
-
The abundance of 5-hydroxymethyldeoxycytidine is quantified by a mass spectrometer.
-
Caption: Overview of experimental workflows for cytosine modification detection.
Conclusion
The comparative analysis of this compound and 5-hydroxymethylcytosine reveals a significant disparity in our current understanding of these two cytosine modifications in the context of mammalian DNA. 5-Hydroxymethylcytosine is a well-established epigenetic player with defined roles in gene regulation and DNA demethylation, supported by a robust toolkit of experimental methods for its study. In contrast, this compound's presence and function in mammalian genomic DNA remain largely speculative, representing a potential frontier in epigenetic research. For scientists and professionals in drug development, the clear importance of 5hmC in health and disease provides a solid foundation for further investigation and therapeutic targeting. The enigmatic nature of m1C in DNA, however, presents an open field for discovery, with the potential to unveil novel regulatory mechanisms. Future research will be critical in determining whether m1C is a bona fide, albeit rare, epigenetic mark in mammalian DNA or if its primary biological relevance is confined to other nucleic acid species.
References
- 1. Functional coupling between writers, erasers and readers of histone and DNA methylation - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Histone Modification Enzymes: Exploring the Writers and Erasers | EpigenTek [epigentek.com]
- 3. DNA of Drosophila melanogaster contains 5‐methylcytosine | The EMBO Journal [link.springer.com]
- 4. academic.oup.com [academic.oup.com]
- 5. Methods for Detection and Mapping of Methylated and Hydroxymethylated Cytosine in DNA - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Overview of DNA Methylation Sequencing Methods - CD Genomics [cd-genomics.com]
Validating 1-Methylcytosine MeDIP-seq Results: A Guide to qPCR Confirmation and Alternative Methods
A critical step in epigenomic research is the validation of high-throughput sequencing data. For scientists investigating 1-methylcytosine (B60703) (m1C), a less-studied DNA modification compared to 5-methylcytosine (B146107) (5mC), robust validation of Methylated DNA Immunoprecipitation Sequencing (MeDIP-seq) results is paramount. Quantitative Polymerase Chain Reaction (qPCR) serves as a widely accepted and cost-effective method for this purpose. This guide provides a comprehensive overview of validating m1C MeDIP-seq results with qPCR, including detailed experimental protocols, data interpretation, and a comparison with alternative validation techniques.
The Role of qPCR in MeDIP-seq Validation
MeDIP-seq utilizes an antibody to enrich for DNA fragments containing the methylation mark of interest, in this case, m1C. While powerful for genome-wide profiling, this technique is susceptible to biases related to antibody specificity and the density of the methylation mark. qPCR validation provides a targeted approach to confirm the enrichment of m1C in specific genomic regions identified by MeDIP-seq.
The core principle involves designing qPCR primers for specific loci identified as enriched (positive targets) or not enriched (negative controls) in the MeDIP-seq data. The relative enrichment of these regions in the immunoprecipitated (IP) DNA fraction is then compared to the input DNA (pre-IP). A successful validation will show significant enrichment of positive targets in the IP sample compared to the input, while negative controls should show little to no enrichment.
Experimental Workflow and Logical Relationships
The process of validating m1C MeDIP-seq results with qPCR follows a logical workflow, from the initial MeDIP-seq experiment to the final data analysis.
Caption: Workflow for m1C MeDIP-seq and qPCR validation.
Detailed Experimental Protocols
This compound MeDIP
A specific and high-affinity antibody against this compound is crucial for a successful MeDIP experiment. The general protocol for MeDIP is as follows, but it is essential to optimize conditions for the specific m1C antibody used.
-
Genomic DNA Isolation and Fragmentation: Isolate high-quality genomic DNA from the cells or tissues of interest. Fragment the DNA to an average size of 200-800 bp using sonication or enzymatic digestion.
-
Denaturation: Denature the fragmented DNA by heating to 95°C for 10 minutes, followed by immediate cooling on ice. This is important as many anti-methylcytosine antibodies have a higher affinity for single-stranded DNA.
-
Immunoprecipitation:
-
Incubate the denatured DNA with a specific anti-1-methylcytosine antibody overnight at 4°C with gentle rotation.
-
Add Protein A/G magnetic beads to the DNA-antibody mixture and incubate for at least 2 hours at 4°C to capture the antibody-DNA complexes.
-
Wash the beads multiple times with IP buffer to remove non-specifically bound DNA.
-
Elute the immunoprecipitated DNA from the beads.
-
A small fraction of the fragmented DNA should be saved as "input" control before the immunoprecipitation step.
-
-
DNA Purification: Purify the eluted DNA and the input DNA.
qPCR Validation
-
Primer Design:
-
Positive Controls: Design primers for genomic regions showing strong enrichment in the m1C MeDIP-seq data.
-
Negative Controls: Design primers for regions that are known to be unmethylated for m1C or showed no enrichment in the MeDIP-seq data. Housekeeping gene promoters that are typically unmethylated can be potential candidates, but their m1C status should be confirmed if possible.
-
-
Quantitative PCR:
-
Perform qPCR using a SYBR Green or probe-based assay.
-
Set up reactions for both the IP and input DNA samples for each primer pair.
-
Include a no-template control for each primer pair to check for contamination.
-
Run the qPCR reaction in triplicate for each sample and primer pair.
-
-
Data Analysis:
-
Calculate the average cycle threshold (Ct) value for each triplicate.
-
Determine the percentage of input using the following formula: % Input = 2^((Ct(Input) - log2(Input Dilution Factor)) - Ct(IP)) * 100 The Input Dilution Factor accounts for the fact that the input is a small fraction of the total DNA used for the IP.
-
Alternatively, calculate the fold enrichment over a negative control region: Fold Enrichment = 2^((Ct(IP, Negative Control) - Ct(Input, Negative Control)) - (Ct(IP, Target) - Ct(Input, Target)))
-
Data Presentation: Interpreting qPCR Validation Results
The results of the qPCR validation should be summarized in a clear and concise table. A successful validation is indicated by a significantly higher percentage of input or fold enrichment for the positive control regions compared to the negative control regions.
| Target Region | MeDIP-seq Peak Signal | Average Ct (Input) | Average Ct (IP) | % Input | Fold Enrichment (vs. Negative Control) | Validation Status |
| Positive Control 1 | High | 25.2 | 22.8 | 5.2% | 26.0 | Validated |
| Positive Control 2 | High | 26.1 | 23.5 | 6.1% | 30.5 | Validated |
| Negative Control 1 | Low/None | 27.5 | 27.3 | 0.2% | 1.0 | Validated |
| Negative Control 2 | Low/None | 28.1 | 28.0 | 0.15% | 0.75 | Validated |
Note: The data presented in this table is hypothetical and for illustrative purposes only.
Comparison with Alternative Validation Methods
While qPCR is a robust and widely used method, other techniques can also be employed to validate m1C MeDIP-seq results. The choice of method often depends on the specific research question, available resources, and the desired resolution.
| Method | Principle | Advantages | Disadvantages |
| qPCR | Targeted amplification of specific DNA sequences. | Cost-effective, high-throughput, and quantitative. | Provides information only for the targeted regions. |
| Bisulfite Sequencing | Chemical conversion of unmethylated cytosines to uracil, while methylated cytosines remain unchanged. This method is the gold standard for 5mC but its direct applicability to m1C is not well-established and may require specific optimization. | Single-base resolution, provides quantitative methylation levels. | Can be expensive and labor-intensive for validating multiple regions. The chemical treatment can degrade DNA. Specific protocols for m1C are not widely available. |
| Methylation-Sensitive Restriction Enzyme qPCR (MSRE-qPCR) | Digestion of genomic DNA with restriction enzymes that are sensitive to methylation at their recognition sites, followed by qPCR. | Relatively simple and does not require bisulfite conversion. | Limited to the analysis of specific restriction sites. Enzymes with proven specificity for m1C are not commonly available. |
| Dot Blot Analysis | Immobilized DNA is probed with an m1C-specific antibody. | Provides a semi-quantitative assessment of global m1C levels. | Not locus-specific, low resolution. |
Logical Relationship of Validation Methods
The choice of a validation method is guided by the desired level of detail and the specific information required to confirm the MeDIP-seq findings.
Caption: Comparison of m1C MeDIP-seq validation methods.
A Comparative Guide to DNA Methylation Analysis: Bisulfite Sequencing vs. Enzymatic Methods
An Objective Comparison for Researchers, Scientists, and Drug Development Professionals
The study of DNA methylation, a key epigenetic modification, is crucial for understanding gene regulation, development, and disease. For years, bisulfite sequencing has been the benchmark for mapping DNA methylation at single-base resolution. However, newer enzymatic methods have emerged as a gentler alternative, promising higher quality data and greater sensitivity. This guide provides an objective comparison of these two powerful techniques.
A Note on 1-methylcytosine (B60703) (1mC): While this guide addresses the user's query on 1mC, it is important to note that the vast majority of comparative literature and commercially available kits for both bisulfite and enzymatic conversion are optimized for and validated on 5-methylcytosine (B146107) (5mC) and 5-hydroxymethylcytosine (B124674) (5hmC). These are the most common and extensively studied cytosine modifications in mammals. Direct, quantitative comparisons for 1mC detection using these methods are not widely available. Therefore, this comparison focuses on the well-established performance of these techniques for 5mC and 5hmC analysis.
Methodology at a Glance: Two Approaches to Unmasking Methylation
The core principle of both methods is to distinguish between methylated and unmethylated cytosines. This is achieved by converting unmethylated cytosines into a different base (uracil), which is then read as thymine (B56734) during sequencing, while methylated cytosines are preserved. The fundamental difference lies in the mechanism of this conversion.
Bisulfite Sequencing (BS-Seq): A Chemical Approach
Bisulfite sequencing relies on a harsh chemical reaction.[1] Genomic DNA is treated with sodium bisulfite, which chemically deaminates unmethylated cytosine (C) to uracil (B121893) (U).[2] Methylated cytosines (5mC) and hydroxymethylated cytosines (5hmC) are largely resistant to this conversion.[3] During the subsequent PCR amplification, the uracils are read as thymines (T). By comparing the treated sequence to a reference genome, researchers can identify the original methylation status of each cytosine.[4]
Enzymatic Methyl-seq (EM-seq): A Biological Approach
Enzymatic methods offer a gentler, multi-step biological process to achieve the same outcome.[5] A popular enzymatic method, EM-seq, involves two key enzymatic reactions:
-
Protection: The TET2 enzyme first oxidizes 5mC and 5hmC. This modification protects them from subsequent deamination.[3][6]
-
Conversion: The APOBEC enzyme then specifically deaminates only the unprotected, unmodified cytosines, converting them to uracils.[6][7]
Like bisulfite sequencing, the resulting DNA library has uracils in place of unmethylated cytosines, which are read as thymines during sequencing.[3]
Visualizing the Workflows
The following diagrams illustrate the distinct processes of Bisulfite Sequencing and Enzymatic Methyl-seq.
Data Presentation: Performance Metrics
The choice between bisulfite and enzymatic methods often involves a trade-off between established protocols and the superior data quality afforded by gentler sample treatment. The following table summarizes key performance metrics compiled from various studies.
| Performance Metric | Bisulfite Sequencing (BS-Seq) | Enzymatic Methyl-seq (EM-seq) | Advantage of EM-seq |
| DNA Damage | High due to harsh chemical treatment, leading to significant DNA fragmentation and loss.[5][8] | Minimal, as enzymatic reactions are milder and better preserve DNA integrity.[3] | Higher quality DNA for sequencing, more reliable data, especially from precious or degraded samples.[5] |
| Library Yield | Lower, especially with low-input or fragmented DNA samples.[9] | Significantly higher library yields from the same input amount of DNA.[9][10] | More efficient use of limited sample material. |
| Library Complexity | Lower, with a higher percentage of PCR duplicate reads due to DNA loss and fragmentation.[5] | Higher, with fewer PCR duplicates, leading to more unique methylation events captured.[5] | More comprehensive and accurate representation of the methylome. |
| GC Bias | Exhibits lower relative coverage over GC-rich regions due to DNA fragmentation during the harsh bisulfite treatment.[11] | More even GC coverage and dinucleotide distribution.[7] | Better performance in analyzing CpG islands and other GC-rich regulatory regions. |
| CpG Detection | Detects fewer CpG sites compared to EM-seq at the same sequencing depth. | Can detect approximately 15% more methylation sites than bisulfite methods.[12] | Provides a more comprehensive view of the methylome.[12] |
| Input DNA | Traditionally requires higher input amounts (micrograms), though protocols for lower inputs exist. | Effective with as little as 100 picograms of DNA.[5][7] | Ideal for applications with limited starting material, such as cfDNA and FFPE samples.[7] |
| 5mC vs. 5hmC | Cannot distinguish between 5mC and 5hmC; both are protected from conversion.[13] | Standard protocol also does not distinguish between 5mC and 5hmC.[6] | N/A (Specialized protocols like oxBS-seq or TAB-seq are needed for either baseline method to differentiate).[13] |
Experimental Protocols: A General Overview
Below are generalized methodologies for the key conversion steps in both techniques. Note that specific reagent quantities, incubation times, and temperatures will vary based on the commercial kit and sample type used.
Key Experiment: Bisulfite Conversion of Genomic DNA
Objective: To convert unmethylated cytosines to uracils in a sample of genomic DNA.
Methodology:
-
DNA Denaturation: Genomic DNA is denatured, typically by chemical treatment (e.g., NaOH) and/or heat, to ensure it is single-stranded. This is critical as bisulfite only reacts with single-stranded DNA.
-
Bisulfite Reaction: The denatured DNA is incubated with a sodium bisulfite solution at a controlled temperature (e.g., 55°C) for a period ranging from minutes to several hours.[9][11] This step facilitates the deamination of unmethylated cytosine to uracil.
-
DNA Cleanup: The DNA is purified to remove bisulfite and other chemicals. This is commonly done using a spin column with specialized binding and wash buffers.
-
Desulfonation: The DNA is treated with a desulfonation buffer (often containing NaOH) at room temperature to remove sulfonate groups from the uracil bases.
-
Final Cleanup and Elution: The converted DNA is washed again and eluted from the column, ready for PCR amplification and library preparation.
Key Experiment: Enzymatic Conversion of Genomic DNA (EM-seq Protocol)
Objective: To enzymatically convert unmethylated cytosines to uracils.
Methodology:
-
Library Preparation (Pre-conversion): Unlike some bisulfite workflows, EM-seq often begins after initial library preparation steps like fragmentation, end-repair, and adapter ligation.
-
Oxidation of 5mC and 5hmC: The DNA library is incubated with TET2 enzyme and an Oxidation Enhancer. This reaction oxidizes 5mC and 5hmC, effectively "protecting" them from the subsequent deamination step.[3]
-
Deamination of Unmodified Cytosines: The APOBEC enzyme is added to the reaction. This enzyme specifically targets and deaminates the unmodified cytosine bases, converting them to uracil.[7]
-
Final Cleanup: The enzymatically converted DNA library is purified using magnetic beads to remove enzymes and reaction components. The resulting library is then ready for PCR amplification.
Conclusion and Recommendations
Both bisulfite sequencing and enzymatic methods are powerful tools for single-base resolution DNA methylation analysis.
Bisulfite sequencing is a long-established method with a vast body of literature and well-understood protocols.[4] However, its primary drawback is the harsh chemical treatment that leads to DNA degradation, lower library yields, and biased genome coverage.[7]
Enzymatic Methyl-seq represents a significant technological advancement. Its gentle enzymatic reactions preserve DNA integrity, resulting in higher quality sequencing libraries, more uniform coverage (especially in GC-rich regions), and superior performance with low-input and challenging samples like cfDNA and FFPE DNA.[5][7] While the upfront cost of enzymatic kits may be higher, the improved data quality can lead to more efficient sequencing and more reliable results, potentially reducing the need for deeper sequencing to overcome biases.
For researchers, scientists, and drug development professionals, the choice depends on the application:
-
For projects with limited or precious sample material, or those requiring the highest data quality and most uniform coverage of the methylome, enzymatic methods are the superior choice .
-
For projects with ample starting DNA where established workflows are prioritized, bisulfite sequencing remains a viable, albeit more damaging, option .
References
- 1. researchgate.net [researchgate.net]
- 2. youtube.com [youtube.com]
- 3. The new NEBNext Enzymatic Methyl-seq (EM-seq) - New England Biolabs GmbH [neb-online.de]
- 4. DNA methylation detection: Bisulfite genomic sequencing analysis - PMC [pmc.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
- 6. Enzymatic methyl-seq - Wikipedia [en.wikipedia.org]
- 7. Enzymatic methyl sequencing detects DNA methylation at single-base resolution from picograms of DNA - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. biorxiv.org [biorxiv.org]
- 9. Ultra-mild bisulfite outperforms existing methods for 5-methylcytosine detection with low input DNA - PMC [pmc.ncbi.nlm.nih.gov]
- 10. researchgate.net [researchgate.net]
- 11. Ultrafast bisulfite sequencing detection of 5-methylcytosine in DNA and RNA - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Overview of EM-seq: A New Detection Approach for DNA Methylation - CD Genomics [cd-genomics.com]
- 13. A Novel method for the simultaneous identification of methylcytosine and hydroxymethylcytosine at a single base resolution - PMC [pmc.ncbi.nlm.nih.gov]
1-Methylcytosine vs. 5-Methylcytosine: A Comparative Guide to Functional Differences
For Researchers, Scientists, and Drug Development Professionals
This guide provides a comprehensive comparison of the functional differences between two methylated cytosine isomers: 1-methylcytosine (B60703) (m1C) and 5-methylcytosine (B146107) (m5C). While both are post-transcriptional or post-replicative modifications, their biological roles, enzymatic machinery, and functional impacts differ significantly. This document summarizes the current understanding, presents available quantitative data, details relevant experimental protocols, and provides visual diagrams of key pathways.
Introduction to this compound and 5-Methylcytosine
This compound (m1C) is a modified nucleobase where a methyl group is attached to the nitrogen atom at the first position of the cytosine ring.[1] It is predominantly found in RNA molecules, particularly in transfer RNA (tRNA), where it plays a crucial role in maintaining structural integrity and function. Its presence in DNA is not well-established in physiological contexts and is more commonly associated with DNA damage or synthetic genetic systems.
5-Methylcytosine (m5C) is a well-characterized epigenetic mark in DNA, where a methyl group is added to the fifth carbon of the cytosine ring.[2] In mammals, m5C is a key regulator of gene expression, playing a critical role in processes such as genomic imprinting, X-chromosome inactivation, and the silencing of transposable elements.[3] Beyond its role in DNA, m5C is also a prevalent modification in various types of RNA, including messenger RNA (mRNA), ribosomal RNA (rRNA), and tRNA, where it influences RNA stability, export, and translation.[4][5]
Comparative Analysis of Functional Differences
The distinct locations of the methyl group in m1C and m5C lead to different chemical properties and, consequently, divergent biological functions.
| Feature | This compound (m1C) | 5-Methylcytosine (m5C) |
| Primary Location | RNA (predominantly tRNA) | DNA (CpG islands) and various RNAs (mRNA, rRNA, tRNA) |
| Primary Function | Structural stabilization of RNA, particularly tRNA.[1] | In DNA: Transcriptional silencing, epigenetic regulation.[3] In RNA: Regulation of RNA stability, nuclear export, and translation efficiency.[4][5][6] |
| Enzymatic Writers | tRNA methyltransferases (e.g., TRMT6/TRMT61A complex for the analogous m1A) | In DNA: DNA methyltransferases (DNMTs). In RNA: NOL1/NOP2/SUN domain (NSUN) family proteins (e.g., NSUN2, NSUN6).[4][7] |
| Enzymatic Erasers | Putative: ALKBH family of demethylases (e.g., ALKBH1, ALKBH3).[8] | In DNA and RNA: Ten-eleven translocation (TET) family of dioxygenases.[9] |
| Impact on Base Pairing | Disrupts Watson-Crick base pairing by blocking the hydrogen bond donor at the N1 position.[10] | Does not directly alter Watson-Crick base pairing with guanine. |
| Role in Disease | Dysregulation linked to certain cancers through effects on tRNA and protein synthesis. | In DNA: Aberrant methylation patterns are a hallmark of many cancers and developmental disorders.[11] In RNA: Implicated in cancer progression through effects on mRNA stability and translation of oncogenes.[12][13] |
Quantitative Data Summary
Direct comparative quantitative data for m1C and m5C are scarce. The following tables summarize available data on the individual effects of these modifications.
Table 1: Quantitative Effects of this compound on tRNA Function
| tRNA Species | Effect of m1C (or analogous m1A) | Quantitative Change | Reference |
| Initiator methionyl-tRNA | Essential for proper folding and stability. | Absence of m1A58 leads to heterogeneous tRNA conformations. | [14] |
| Various tRNAs | Demethylation by ALKBH1 attenuates translation initiation. | ALKBH1-demethylated tRNA significantly enhances protein translation efficiency in vitro. | [10][15] |
Table 2: Quantitative Effects of 5-Methylcytosine on mRNA Function
| mRNA Target | Effect of m5C | Quantitative Change | Reference |
| HDGF | Increased mRNA stability. | YBX1, an m5C reader, recruits ELAVL1 to stabilize HDGF mRNA. | [5] |
| IRF3 | Decreased mRNA stability. | NSUN2-mediated m5C modification accelerates IRF3 mRNA degradation. | [16] |
| p27 | Reduced translation. | NSUN2-mediated methylation in the 5' UTR reduces p27 protein levels. | [16] |
| CDK1 | Enhanced translation. | NSUN2-mediated methylation in the 3' UTR enhances CDK1 protein levels. | [16] |
| Various mRNAs | Altered nuclear export. | Knockdown of NSUN2 or the m5C reader ALYREF significantly decreases the cytoplasmic to nuclear ratio of target mRNAs.[7] | [7] |
Experimental Protocols
Detection of 5-Methylcytosine in RNA by Bisulfite Sequencing (RNA-BS-Seq)
This method allows for the single-nucleotide resolution mapping of m5C in RNA.[4][17][18]
Principle: Sodium bisulfite treatment deaminates unmethylated cytosine to uracil, while 5-methylcytosine remains unchanged. Subsequent reverse transcription and sequencing reveal the original methylation status, with uracils being read as thymines.[19]
Detailed Protocol:
-
RNA Isolation: Isolate total RNA from the sample of interest using a standard method like TRIzol extraction. Assess RNA integrity using a Bioanalyzer or gel electrophoresis.
-
Poly(A) RNA Enrichment (for mRNA analysis): Enrich for polyadenylated RNA using oligo(dT) magnetic beads.
-
Bisulfite Conversion:
-
Fragment the RNA to a suitable size (e.g., 100-200 nucleotides).
-
Use a commercial RNA bisulfite conversion kit (e.g., Zymo EZ RNA Methylation Kit) or a "homebrew" solution. The reaction typically involves incubation of the RNA with sodium bisulfite and hydroquinone (B1673460) at elevated temperatures.
-
Reaction Mix Example:
-
RNA sample (up to 5 µg)
-
Sodium bisulfite solution
-
DNA protection buffer (as per kit instructions)
-
-
Thermal Cycling: Perform the bisulfite reaction using a thermal cycler with a program of denaturation and incubation steps (e.g., 5 cycles of 70°C for 5 min and 60°C for 60 min).[5]
-
-
Desalting and Desulfonation:
-
Purify the bisulfite-treated RNA using spin columns to remove excess bisulfite.
-
Perform desulfonation by incubating the RNA in an alkaline solution (e.g., Tris buffer, pH 9.0) at 37°C.[5]
-
-
cDNA Synthesis:
-
Reverse transcribe the bisulfite-converted RNA into cDNA using random hexamers or gene-specific primers and a reverse transcriptase that can read through uracil.
-
-
Library Preparation and Sequencing:
-
Prepare a sequencing library from the cDNA using a standard library preparation kit for next-generation sequencing (NGS).
-
Perform high-throughput sequencing.
-
-
Data Analysis:
-
Align the sequencing reads to a reference transcriptome.
-
Identify sites where cytosines were not converted to thymines; these represent potential m5C sites.
-
Use specialized bioinformatics tools to filter for high-confidence m5C sites and quantify methylation levels.
-
Simultaneous Quantification of this compound and 5-Methylcytosine by Mass Spectrometry
Liquid chromatography-tandem mass spectrometry (LC-MS/MS) is the gold standard for the accurate quantification of various nucleoside modifications and can distinguish between isomers like m1C and m5C.[8][20][21]
Principle: RNA is enzymatically hydrolyzed into individual nucleosides. These nucleosides are then separated by liquid chromatography based on their physicochemical properties and detected by a mass spectrometer, which identifies them based on their unique mass-to-charge ratios and fragmentation patterns.
General Protocol:
-
RNA Isolation and Digestion:
-
Isolate total RNA or the RNA species of interest.
-
Digest the RNA to single nucleosides using a cocktail of enzymes, such as nuclease P1, snake venom phosphodiesterase, and alkaline phosphatase.
-
-
Liquid Chromatography Separation:
-
Inject the nucleoside mixture onto a high-performance liquid chromatography (HPLC) or ultra-high-performance liquid chromatography (UHPLC) system.
-
Use a suitable column (e.g., C18 reverse-phase) and a gradient of mobile phases (e.g., water with formic acid and acetonitrile (B52724) with formic acid) to separate the different nucleosides. m1C and m5C will have different retention times.
-
-
Mass Spectrometry Detection:
-
The eluent from the LC is introduced into a tandem mass spectrometer (e.g., a triple quadrupole instrument).
-
The mass spectrometer is operated in multiple reaction monitoring (MRM) mode. This involves selecting the specific precursor ion (the protonated nucleoside) and monitoring for a specific product ion after fragmentation.
-
MRM Transitions:
-
Cytidine (C): m/z 244.1 → 112.1
-
1-Methylcytidine (m1C): m/z 258.1 → 126.1
-
5-Methylcytidine (m5C): m/z 258.1 → 126.1 (Note: While the transition is the same as m1C, they are separated by chromatography).
-
-
-
Quantification:
-
Generate standard curves using known concentrations of pure m1C and m5C nucleosides.
-
Quantify the amount of m1C and m5C in the sample by comparing their peak areas to the standard curves.
-
Signaling Pathways and Experimental Workflows
Signaling Pathway for 5-Methylcytosine in DNA
The methylation of DNA at CpG sites is a dynamic process involving "writer" and "eraser" enzymes that establish and remove this epigenetic mark, respectively.
Caption: DNA methylation pathway showing the roles of DNMTs and TETs.
Signaling Pathway for 5-Methylcytosine in mRNA
The methylation of mRNA by NSUN enzymes and its recognition by reader proteins like ALYREF can influence mRNA fate.
Caption: Role of m5C in mRNA processing and export.
Experimental Workflow for Comparative Analysis
This workflow outlines a potential experimental design to directly compare the functional effects of m1C and m5C.
Caption: Workflow for comparing the functional impact of m1C and m5C.
Conclusion
This compound and 5-methylcytosine, despite their structural similarity, exhibit distinct biological roles dictated by the position of their methyl group. m5C is a versatile regulatory mark found in both DNA and RNA, with well-established roles in epigenetic gene silencing and post-transcriptional regulation. In contrast, m1C is primarily a structural component of RNA, particularly tRNA, and its role in gene regulation is less direct. The ongoing development of sensitive detection methods, such as advanced mass spectrometry and specialized sequencing techniques, will be crucial for further elucidating the nuanced functional differences between these two important modifications and their implications in health and disease. This understanding is vital for researchers in basic science and for professionals in drug development targeting epigenetic and epitranscriptomic pathways.
References
- 1. Multiple links between 5-methylcytosine content of mRNA and translation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. documents.thermofisher.com [documents.thermofisher.com]
- 3. Structures of tRNAs with an expanded anticodon loop in the decoding center of the 30S ribosomal subunit - PMC [pmc.ncbi.nlm.nih.gov]
- 4. A Guide to RNA Bisulfite Sequencing (m5C Sequencing) - CD Genomics [rna.cd-genomics.com]
- 5. Bisulfite RNA sequencing [bio-protocol.org]
- 6. Advances in mRNA 5-methylcytosine modifications: Detection, effectors, biological functions, and clinical relevance - PMC [pmc.ncbi.nlm.nih.gov]
- 7. 5-methylcytosine promotes mRNA export — NSUN2 as the methyltransferase and ALYREF as an m5C reader - PMC [pmc.ncbi.nlm.nih.gov]
- 8. The biological function of demethylase ALKBH1 and its role in human diseases - PMC [pmc.ncbi.nlm.nih.gov]
- 9. TET-mediated 5-methylcytosine oxidation in tRNA promotes translation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. AlkB homolog 3-mediated tRNA demethylation promotes protein synthesis in cancer cells - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Discovering DNA Methylation, the History and Future of the Writing on DNA - PMC [pmc.ncbi.nlm.nih.gov]
- 12. NSUN2-mediated mRNA m5C Modification Regulates the Progression of Hepatocellular Carcinoma - PMC [pmc.ncbi.nlm.nih.gov]
- 13. mdpi.com [mdpi.com]
- 14. Protocol for profiling RNA m5C methylation at base resolution using m5C-TAC-seq - PMC [pmc.ncbi.nlm.nih.gov]
- 15. ALKBH1-Mediated tRNA Demethylation Regulates Translation - PMC [pmc.ncbi.nlm.nih.gov]
- 16. NSUN2-mediated m5C methylation of IRF3 mRNA negatively regulates type I interferon responses during various viral infections - PMC [pmc.ncbi.nlm.nih.gov]
- 17. Bisulfite Sequencing of RNA for Transcriptome-Wide Detection of 5-Methylcytosine - PubMed [pubmed.ncbi.nlm.nih.gov]
- 18. researchgate.net [researchgate.net]
- 19. RNA cytosine methylation analysis by bisulfite sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 20. Methods for Detection and Mapping of Methylated and Hydroxymethylated Cytosine in DNA - PMC [pmc.ncbi.nlm.nih.gov]
- 21. Quantitation of 5-methylcytosine by one-dimensional high-performance thin-layer chromatography - PubMed [pubmed.ncbi.nlm.nih.gov]
A Researcher's Guide to Investigating the Cross-Reactivity of 5-Methylcytosine Antibodies with 1-Methylcytosine
For researchers, scientists, and drug development professionals, understanding the specificity of antibodies is paramount to generating reliable experimental data. This guide provides a framework for assessing the potential cross-reactivity of commercially available antibodies against 5-methylcytosine (B146107) (5-mC) with its structural isomer, 1-methylcytosine (B60703) (1-mC). While manufacturers often provide data on specificity against non-methylated cytosine and 5-hydroxymethylcytosine, information regarding 1-mC is typically absent. This guide offers a direct comparison of the two molecules, detailed experimental protocols to test for cross-reactivity, and a logical framework for interpreting the results.
Structural Comparison: 5-Methylcytosine vs. This compound
The primary determinant of antibody specificity is the structure of the antigen. 5-methylcytosine and this compound are positional isomers, meaning they share the same chemical formula but differ in the location of the methyl group on the cytosine ring. This seemingly small difference can have a significant impact on the epitope recognized by an antibody.
In 5-methylcytosine, the methyl group is attached to the 5th carbon of the pyrimidine (B1678525) ring.[1][2][3] This is the well-known epigenetic mark in eukaryotes. In contrast, this compound has a methyl group attached to the nitrogen atom at the 1st position of the ring.[4] This structural variance alters the shape and charge distribution of the molecule, which are critical features for antibody recognition.
| Feature | 5-Methylcytosine (5-mC) | This compound (1-mC) |
| Chemical Formula | C5H7N3O | C5H7N3O |
| Molar Mass | 125.13 g/mol | 125.13 g/mol |
| Position of Methyl Group | Carbon 5 of the pyrimidine ring | Nitrogen 1 of the pyrimidine ring |
| IUPAC Name | 4-amino-5-methylpyrimidin-2(1H)-one | 4-amino-1-methylpyrimidin-2(1H)-one |
| Biological Significance | Common epigenetic mark in eukaryotes | Less common, found in some RNAs |
Experimental Protocols for Assessing Cross-Reactivity
To empirically determine the cross-reactivity of a 5-mC antibody with 1-mC, standard immunological assays such as Dot Blot and Enzyme-Linked Immunosorbent Assay (ELISA) can be employed.
Dot Blot Assay
A dot blot is a simple and rapid method to screen for antibody binding to a specific antigen.[5][6][7]
Objective: To qualitatively assess the binding of a 5-mC antibody to 5-mC and 1-mC.
Materials:
-
Nitrocellulose or PVDF membrane
-
5-mC antibody (primary antibody)
-
HRP-conjugated secondary antibody
-
DNA or nucleosides: 5-methylcytosine, this compound, and cytosine (unmethylated control)
-
Blocking buffer (e.g., 5% non-fat dry milk or 3% BSA in TBST)
-
Wash buffer (e.g., TBST)
-
Chemiluminescent substrate
-
Imaging system
Protocol:
-
Antigen Spotting: Spot serial dilutions of 5-mC, 1-mC, and cytosine-containing DNA or nucleosides directly onto the nitrocellulose membrane. Allow the spots to dry completely.
-
Blocking: Incubate the membrane in blocking buffer for 1 hour at room temperature to prevent non-specific antibody binding.
-
Primary Antibody Incubation: Incubate the membrane with the 5-mC primary antibody (diluted in blocking buffer) for 1-2 hours at room temperature or overnight at 4°C.
-
Washing: Wash the membrane three times with wash buffer for 10 minutes each to remove unbound primary antibody.
-
Secondary Antibody Incubation: Incubate the membrane with the HRP-conjugated secondary antibody (diluted in blocking buffer) for 1 hour at room temperature.
-
Washing: Repeat the washing step as in step 4.
-
Detection: Apply the chemiluminescent substrate to the membrane and capture the signal using an imaging system.
Interpretation of Results: A strong signal in the spots corresponding to 5-mC and a weak or absent signal in the spots for 1-mC and cytosine would indicate high specificity of the antibody for 5-mC. A significant signal for 1-mC would suggest cross-reactivity.
Competitive ELISA
A competitive ELISA is a quantitative method to determine the specificity and cross-reactivity of an antibody.[8][9]
Objective: To quantify the binding affinity of the 5-mC antibody for 5-mC and its potential cross-reactivity with 1-mC.
Materials:
-
96-well microtiter plate
-
5-mC conjugated to a carrier protein (e.g., BSA) for coating
-
5-mC antibody (primary antibody)
-
HRP-conjugated secondary antibody
-
Free nucleosides: 5-methylcytosine, this compound, and cytosine (competitors)
-
Coating buffer, blocking buffer, wash buffer
-
TMB substrate and stop solution
-
Microplate reader
Protocol:
-
Coating: Coat the wells of the microtiter plate with the 5-mC-BSA conjugate overnight at 4°C.
-
Washing and Blocking: Wash the plate with wash buffer and then block the wells with blocking buffer for 1-2 hours at room temperature.
-
Competition: In separate tubes, pre-incubate the 5-mC antibody with serial dilutions of the free nucleosides (5-mC, 1-mC, and cytosine) for 1-2 hours.
-
Incubation: Add the antibody-competitor mixtures to the coated wells and incubate for 1-2 hours at room temperature.
-
Washing: Wash the wells to remove unbound antibodies and competitors.
-
Secondary Antibody Incubation: Add the HRP-conjugated secondary antibody to each well and incubate for 1 hour.
-
Washing: Wash the wells thoroughly.
-
Detection: Add the TMB substrate and incubate until a color change is observed. Stop the reaction with the stop solution.
-
Measurement: Read the absorbance at 450 nm using a microplate reader.
Interpretation of Results: The signal intensity will be inversely proportional to the amount of free competitor that binds to the primary antibody. By comparing the concentration of 1-mC required to inhibit the signal by 50% (IC50) to the IC50 of 5-mC, the degree of cross-reactivity can be quantified. A significantly higher IC50 for 1-mC compared to 5-mC indicates low cross-reactivity.
Visualizing the Experimental Workflows
To further clarify the experimental processes, the following diagrams illustrate the workflows for the Dot Blot and Competitive ELISA assays.
Caption: Dot Blot experimental workflow for assessing antibody specificity.
Caption: Competitive ELISA workflow for quantifying antibody cross-reactivity.
Conclusion
Due to the significant structural differences between 5-methylcytosine and this compound, it is plausible that highly specific monoclonal antibodies raised against 5-mC will exhibit minimal to no cross-reactivity with 1-mC. However, without direct experimental evidence, this remains an assumption. The provided experimental protocols offer a robust framework for researchers to independently validate the specificity of their 5-mC antibodies. By performing these assays, researchers can ensure the accuracy and reliability of their findings in the fields of epigenetics, diagnostics, and drug development.
References
- 1. researchgate.net [researchgate.net]
- 2. 5-Methylcytosine - Wikipedia [en.wikipedia.org]
- 3. 5-Methylcytosine | C5H7N3O | CID 65040 - PubChem [pubchem.ncbi.nlm.nih.gov]
- 4. This compound - Wikipedia [en.wikipedia.org]
- 5. creative-diagnostics.com [creative-diagnostics.com]
- 6. Dot Blot: A Quick and Easy Method for Separation-Free Protein Detection [jacksonimmuno.com]
- 7. Dot Blot Protocol & Troubleshooting Guide | Validated Antibody Collection - Creative Biolabs [creativebiolabs.net]
- 8. elisakits.co.uk [elisakits.co.uk]
- 9. creative-diagnostics.com [creative-diagnostics.com]
Unveiling the Methylome: Third-Generation Sequencing Revolutionizes 1-Methylcytosine Mapping
The direct, real-time detection of 1-methylcytosine (B60703) (m1C), an important epigenetic modification, is being transformed by third-generation sequencing (TGS) technologies. Offering significant advantages over traditional methods, Pacific Biosciences (PacBio) Single-Molecule, Real-Time (SMRT) sequencing and Oxford Nanopore Technologies (ONT) sequencing provide researchers, scientists, and drug development professionals with powerful tools to explore the intricacies of the methylome.
Third-generation sequencing platforms are enabling the direct detection of DNA and RNA base modifications, including m1C, without the need for chemical conversion methods like bisulfite sequencing.[1][2] This fundamental difference overcomes the major limitations of traditional approaches, which can cause DNA degradation and introduce biases.[3] The ability to sequence native DNA and RNA molecules preserves the original epigenetic information, offering a more accurate and comprehensive view of methylation patterns.[4][5]
A New Era of Direct Detection: PacBio SMRT and Oxford Nanopore
PacBio's SMRT sequencing technology identifies base modifications by monitoring the kinetics of DNA polymerase during sequencing. As the polymerase incorporates nucleotides, the presence of a modified base, such as m1C, causes a characteristic change in the timing of the fluorescence pulse.[1][2] This "kinetic signature" allows for the direct identification and quantification of modified bases in real-time.[1]
Oxford Nanopore sequencing, on the other hand, detects base modifications by measuring changes in the ionic current as a single strand of DNA or RNA passes through a protein nanopore.[6][7] Each base, including modified ones like m1C, creates a unique disruption in the current, allowing for its direct identification.[6][7]
Performance Advantages Over Traditional Methods
While direct quantitative comparisons for m1C are still emerging, the performance of TGS for the more extensively studied 5-methylcytosine (B146107) (5mC) modification provides a strong indication of its capabilities. These platforms offer high accuracy in identifying modified bases. For instance, computational models for PacBio data have demonstrated high performance in detecting 5mC, and Nanopore-based methylation detection shows a strong correlation with traditional bisulfite sequencing data.[6][8]
The primary advantages of third-generation sequencing for m1C mapping lie in its ability to:
-
Directly detect m1C: Eliminating the need for bisulfite or enzymatic conversion, which can damage DNA and lead to biased results.[3]
-
Sequence long reads: Enabling the analysis of methylation patterns over long genomic distances and in repetitive regions that are challenging for short-read technologies.
-
Preserve native DNA/RNA: Sequencing the original molecules ensures a more accurate representation of the methylome.[4][5]
-
Simultaneously sequence and detect modifications: Genetic and epigenetic information is obtained in a single experiment.[2]
Comparative Overview of Sequencing Technologies
The following table summarizes the key performance metrics of third-generation sequencing platforms in comparison to traditional bisulfite sequencing for cytosine modification mapping. It is important to note that while specific performance for m1C is still being extensively characterized, the data for 5mC provides a strong proxy.
| Feature | PacBio SMRT Sequencing | Oxford Nanopore Sequencing | Bisulfite Sequencing (Second-Generation) |
| Detection Principle | Polymerase kinetics | Ionic current change | Chemical conversion of unmethylated cytosines |
| Direct Detection | Yes | Yes | No (Infers methylation) |
| Read Length | Long (avg. 10-20 kb, up to >100 kb) | Ultra-long (up to Mb) | Short (50-300 bp) |
| DNA/RNA Input | Native DNA/RNA | Native DNA/RNA | Chemically treated DNA |
| Accuracy (Base Calling) | High (>99.9% with HiFi reads) | Improving (90-99% raw read, consensus accuracy higher) | Very High (>99.9%) |
| Modification Detection Accuracy | High (reported >90% sensitivity and specificity for 5mC) | High (strong correlation with bisulfite sequencing for 5mC) | High (but prone to conversion-related artifacts) |
| PCR Bias | No (PCR-free library preparation) | No (PCR-free library preparation available) | Yes (amplification required after bisulfite treatment) |
| Data Output | Moderate to High | High to Very High | Very High |
| Throughput | Moderate to High | High to Very High | Very High |
Experimental Workflows
The experimental workflow for m1C mapping using third-generation sequencing is significantly streamlined compared to traditional methods due to the absence of a conversion step.
Detailed Experimental Protocols
The following provides a general outline of the key experimental steps for m1C mapping using PacBio and Oxford Nanopore sequencing. Specific kit instructions and instrument manuals should be consulted for detailed protocols.
PacBio SMRT Sequencing for m1C Mapping
-
DNA/RNA Isolation: Extract high-quality, high-molecular-weight DNA or RNA from the sample of interest. Purity is critical for optimal sequencing performance.
-
Library Preparation (SMRTbell™ Template Preparation):
-
DNA Fragmentation: Shear DNA to the desired size range (e.g., >10 kb for long-read applications).
-
DNA Damage Repair and End-Repair: Enzymatically repair any DNA damage and create blunt ends.
-
A-tailing: Add a single 'A' nucleotide to the 3' ends of the DNA fragments.
-
SMRTbell Adapter Ligation: Ligate hairpin adapters to both ends of the DNA fragments to create circular SMRTbell templates.
-
Purification: Clean up the library to remove small fragments and excess reagents.
-
-
Sequencing Primer Annealing and Polymerase Binding: Anneal a sequencing primer to the SMRTbell templates and bind the DNA polymerase.
-
SMRT Sequencing: Load the prepared SMRTbell library onto the PacBio instrument (e.g., Sequel IIe or Revio) and perform sequencing.
-
Data Analysis:
-
Primary Analysis: The instrument software generates raw data (movies of fluorescent pulses).
-
Secondary Analysis: Generate Circular Consensus Sequencing (CCS) reads (HiFi reads) for high accuracy.
-
m1C Detection: Use PacBio's SMRT Link software or third-party tools (e.g., ccsmeth) to analyze the polymerase kinetics (interpulse duration) to identify m1C modifications.[8]
-
Oxford Nanopore Sequencing for m1C Mapping
-
DNA/RNA Isolation: Extract high-quality DNA or RNA. For long reads, ensure minimal fragmentation.
-
Library Preparation (e.g., Ligation Sequencing Kit):
-
DNA Repair and End-Prep: Repair DNA ends and perform A-tailing in a single enzymatic step.
-
Adapter Ligation: Ligate sequencing adapters, which include a motor protein, to the prepared DNA ends.
-
Purification: Clean up the library using magnetic beads.
-
-
Flow Cell Priming and Library Loading: Prime the Nanopore flow cell and load the prepared library.
-
Nanopore Sequencing: Initiate the sequencing run on an Oxford Nanopore device (e.g., MinION, GridION, or PromethION).
-
Data Analysis:
-
Basecalling: Convert the raw electrical signal data (squiggles) into DNA/RNA sequences using basecalling software (e.g., Guppy or Dorado).
-
Alignment: Align the basecalled reads to a reference genome.
-
m1C Detection: Use specialized software (e.g., Tombo, DeepSignal) to analyze the raw signal data at each base position to detect deviations indicative of m1C.
-
Conclusion
Third-generation sequencing technologies from PacBio and Oxford Nanopore are poised to become the new standard for epigenetic research, including the mapping of this compound. By providing a direct and unbiased view of the methylome, these platforms empower researchers to uncover the complex roles of m1C in gene regulation, development, and disease with unprecedented detail and accuracy. The streamlined workflows and the richness of the data generated will undoubtedly accelerate discoveries in this exciting field.
References
- 1. pacb.com [pacb.com]
- 2. Overview of PacBio SMRT sequencing: principles, workflow, and applications - CD Genomics [cd-genomics.com]
- 3. mdpi.com [mdpi.com]
- 4. nanoporetech.com [nanoporetech.com]
- 5. nanoporetech.com [nanoporetech.com]
- 6. Detecting DNA cytosine methylation using nanopore sequencing - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. biorxiv.org [biorxiv.org]
- 8. biorxiv.org [biorxiv.org]
comparison of different bioinformatics tools for 1mC data analysis
A Comprehensive Guide to Bioinformatics Tools for N1-methyladenosine (1mC) Data Analysis
For researchers, scientists, and drug development professionals venturing into the burgeoning field of epitranscriptomics, the analysis of N1-methyladenosine (1mC) modifications in RNA presents both exciting opportunities and significant computational challenges. The selection of appropriate bioinformatics tools is paramount for the accurate identification and quantification of 1mC sites from high-throughput sequencing data. This guide provides an objective comparison of currently available bioinformatics tools for 1mC data analysis, supported by a summary of their performance metrics and detailed experimental protocols for generating 1mC sequencing data.
Unveiling 1mC: An Overview of Sequencing Technologies
The landscape of 1mC detection has been shaped by the development of specialized sequencing technologies. Understanding these methods is crucial for selecting the appropriate analysis pipeline. Two primary approaches are prevalent:
-
Antibody-Based Methods (1mC-RIP-Seq): This technique, also known as RNA immunoprecipitation sequencing (RIP-seq), utilizes an antibody specific to 1mC to enrich for RNA fragments containing this modification.[1][2] These enriched fragments are then sequenced, and the resulting data is analyzed to identify "peaks" that correspond to regions with a high likelihood of 1mC modification.
-
Direct RNA Sequencing: Technologies like Oxford Nanopore sequencing enable the direct sequencing of native RNA molecules without the need for reverse transcription or amplification.[3][4][5][6][7] The presence of a 1mC modification can cause a detectable shift in the electrical current as the RNA strand passes through the nanopore, allowing for its direct identification at single-nucleotide resolution.
A Comparative Look at 1mC Data Analysis Tools
The analysis of 1mC sequencing data primarily involves the identification of methylation sites, often referred to as "peak calling" in the context of antibody-based methods, or direct modification detection from the raw sequencing signal. A variety of computational tools, largely leveraging machine learning and deep learning, have been developed for this purpose.
While a comprehensive, independent benchmarking study across all available tools remains a developing area of research, existing publications proposing new methods often provide valuable comparisons against established tools. These comparisons typically evaluate performance based on metrics such as sensitivity, specificity, accuracy, and the Area Under the Receiver Operating Characteristic (ROC) curve (AUC).
Here, we summarize the landscape of available tools, categorized by their underlying algorithmic approach.
Machine Learning-Based Tools
These tools employ classical machine learning algorithms, such as Support Vector Machines (SVM) and Random Forests, to distinguish between methylated and non-methylated sites based on sequence features.
Deep Learning-Based Tools
Harnessing the power of neural networks, deep learning models can learn complex patterns from sequencing data to identify 1mC sites with high accuracy. These models often utilize convolutional neural networks (CNNs) and recurrent neural networks (RNNs).
Ensemble Learning-Based Tools
Ensemble methods combine the predictions of multiple individual models to improve overall performance and robustness.
Table 1: Comparison of Bioinformatics Tools for 1mC Data Analysis
| Tool Category | Tool Name(s) | Underlying Algorithm | Key Features | Performance Metrics (Illustrative) | Reference |
| Machine Learning | - | Support Vector Machine (SVM), Random Forest | Utilizes sequence-based features for classification. | Sensitivity, Specificity, Accuracy, AUC | - |
| Deep Learning | DeepPromise | Convolutional Neural Networks (CNNs) | Can learn complex patterns directly from sequence data. | High accuracy in predicting modification sites. | [3][4] |
| Ensemble Learning | - | Combination of multiple classifiers | Aims to improve prediction accuracy and robustness. | Generally shows improved performance over single models. | - |
Note: Specific performance metrics are often reported in the primary publications of each tool and can vary depending on the dataset used for evaluation. A comprehensive, standardized benchmarking across all tools is needed for a definitive comparison.
Experimental Protocols: A Foundation for Robust Analysis
The quality of the insights derived from bioinformatics analysis is intrinsically linked to the quality of the experimental data. Below are detailed methodologies for the key 1mC sequencing experiments.
1mC-RIP-Seq (RNA Immunoprecipitation Sequencing) Protocol
This protocol outlines the general steps for enriching 1mC-containing RNA fragments for subsequent sequencing.[1][2]
Diagram 1: 1mC-RIP-Seq Experimental Workflow
Caption: Workflow for 1mC-RIP-Seq.
Methodology:
-
Cell Lysis and RNA Fragmentation: Cells are lysed to release RNA, which is then fragmented into smaller, manageable sizes.
-
Immunoprecipitation: The fragmented RNA is incubated with an antibody specific to 1mC.
-
Complex Capture: Protein A/G magnetic beads are used to capture the antibody-RNA complexes.
-
Washing: The beads are washed to remove non-specifically bound RNA.
-
Elution: The enriched 1mC-containing RNA is eluted from the beads.
-
RNA Purification: The eluted RNA is purified.
-
Library Preparation and Sequencing: A sequencing library is prepared from the purified RNA, followed by high-throughput sequencing.
Direct RNA Sequencing Protocol (Oxford Nanopore)
This protocol describes the general steps for sequencing native RNA molecules to detect 1mC modifications.[3][4][5][6][7]
Diagram 2: Direct RNA Sequencing Workflow
Caption: Workflow for Direct RNA Sequencing.
Methodology:
-
RNA Isolation: High-quality total RNA is isolated from the sample.
-
Poly(A) Tailing (Optional): For RNA species that are not naturally polyadenylated, a poly(A) tail is added enzymatically.[3]
-
Adapter Ligation: Sequencing adapters are ligated to the RNA molecules.
-
Nanopore Sequencing: The prepared RNA library is loaded onto a nanopore flow cell for sequencing.
-
Data Analysis: The raw electrical signal data is basecalled, and specialized algorithms are used to detect base modifications like 1mC from the signal deviations.
Logical Relationships in 1mC Data Analysis
The choice of bioinformatics tools is intrinsically linked to the experimental method used to generate the data.
Diagram 3: Logical Flow of 1mC Data Analysis
Caption: Decision flow for 1mC data analysis.
Conclusion and Future Directions
The analysis of 1mC RNA modifications is a rapidly evolving field. While a number of powerful bioinformatics tools are available, there is a clear need for standardized benchmarking datasets and workflows to allow for more direct and objective comparisons of their performance. As direct RNA sequencing technologies continue to improve in accuracy and throughput, we can anticipate the development of even more sophisticated algorithms for the precise and quantitative analysis of 1mC and other RNA modifications. For researchers entering this field, a thorough understanding of both the experimental methodologies and the computational tools is essential for generating high-quality, reliable results that will drive new discoveries in RNA biology and its role in health and disease.
References
- 1. How to Prepare a Library for RIP-Seq: A Comprehensive Guide - CD Genomics [cd-genomics.com]
- 2. docs.abcam.com [docs.abcam.com]
- 3. Direct Sequencing of RNA and RNA Modification Identification Using Nanopore - PMC [pmc.ncbi.nlm.nih.gov]
- 4. nanoporetech.com [nanoporetech.com]
- 5. nanoporetech.com [nanoporetech.com]
- 6. researchgate.net [researchgate.net]
- 7. Nanopore Direct RNA Sequencing | Long-Read Sequencing - CD Genomics [cd-genomics.com]
A Comparative Guide to Cytosine Modifications: 1-Methylcytosine, 5-Formylcytosine, and 5-Carboxylcytosine
For Researchers, Scientists, and Drug Development Professionals
In the intricate landscape of epigenetics, modifications to DNA and RNA bases play a pivotal role in regulating gene expression and cellular function. Beyond the canonical bases, a growing family of modified cytosines has emerged as key players in these regulatory networks. This guide provides a comprehensive comparison of three such modifications: 1-Methylcytosine (1mC), 5-Formylcytosine (B1664653) (5fC), and 5-Carboxylcytosine (5caC), offering insights into their distinct chemical properties, biological roles, and the experimental methodologies used to study them.
At a Glance: Key Differences
| Feature | This compound (1mC) | 5-Formylcytosine (5fC) | 5-Carboxylcytosine (5caC) |
| Position of Modification | Nitrogen-1 (N1) of the cytosine ring | Carbon-5 (C5) of the cytosine ring | Carbon-5 (C5) of the cytosine ring |
| Modification Group | Methyl group (-CH₃) | Formyl group (-CHO) | Carboxyl group (-COOH) |
| Primary Role in DNA | Primarily found in RNA; role in mammalian DNA is not well-established. Part of synthetic genetic systems (hachimoji DNA). | Intermediate in active DNA demethylation; potential stable epigenetic mark. | Intermediate in active DNA demethylation; potential stable epigenetic mark. |
| Biosynthesis | In RNA, catalyzed by RNA methyltransferases (e.g., NSUN family). In DNA, natural biosynthesis in mammals is not well-characterized. | Oxidation of 5-methylcytosine (B146107) (5mC) and 5-hydroxymethylcytosine (B124674) (5hmC) by Ten-Eleven Translocation (TET) enzymes. | Oxidation of 5-formylcytosine (5fC) by Ten-Eleven Translocation (TET) enzymes. |
| Impact on DNA Stability | Can slightly decrease or have a context-dependent effect on DNA duplex stability. | Destabilizes the DNA double helix. | Destabilizes the DNA double helix. |
| Interaction with Proteins | Altered hydrogen bonding potential compared to cytosine. | Can form covalent DNA-protein crosslinks with proteins like histones. | Recognized and excised by Thymine-DNA Glycosylase (TDG). |
| Effect on Transcription | In RNA, influences tRNA structure and function. In DNA, impact is less clear. | Can impede transcription by RNA polymerase II.[1] | Can impede transcription by RNA polymerase II.[1] |
Delving Deeper: A Detailed Comparison
Chemical Structures
The fundamental difference between these three modified cytosines lies in the position and nature of the chemical group attached to the cytosine ring.
-
This compound (1mC): A methyl group is attached to the nitrogen atom at the 1-position of the pyrimidine (B1678525) ring.[2] This modification alters the Watson-Crick base-pairing face of the molecule.
-
5-Formylcytosine (5fC): A formyl group is attached to the carbon atom at the 5-position.[3]
-
5-Carboxylcytosine (5caC): A carboxyl group is attached to the carbon atom at the 5-position.
Biosynthesis and Biological Functions
The biosynthetic pathways and biological roles of these modifications are distinct, reflecting their diverse functions in cellular processes.
5-Formylcytosine and 5-Carboxylcytosine are key intermediates in the active DNA demethylation pathway in mammals. This process is crucial for epigenetic reprogramming and the dynamic regulation of gene expression. The pathway is initiated by the Ten-Eleven Translocation (TET) family of dioxygenases, which iteratively oxidize the well-known epigenetic mark, 5-methylcytosine (5mC).
This cascade is a critical mechanism for erasing DNA methylation marks, thereby enabling changes in gene expression patterns during development and in response to environmental stimuli. Both 5fC and 5caC can be recognized and excised by Thymine-DNA Glycosylase (TDG) as part of the base excision repair (BER) pathway, which ultimately replaces the modified base with an unmodified cytosine.
Beyond their role as transient intermediates, emerging evidence suggests that 5fC and 5caC may also function as stable epigenetic marks in their own right. They have been shown to influence DNA structure and can modulate the binding of proteins to DNA, thereby affecting transcription. For instance, 5fC has been observed to form covalent crosslinks with histone proteins, which can impact chromatin architecture and gene regulation.[3][4]
In contrast to 5fC and 5caC, the natural occurrence and function of 1mC in mammalian DNA are not as well understood. While it is a known component of "hachimoji DNA," a synthetic genetic system with an expanded eight-letter genetic alphabet where it pairs with isoguanine, its role in endogenous mammalian DNA remains an area of active investigation.[2]
However, 1mC is a well-established modification in various types of RNA molecules, including transfer RNA (tRNA) and ribosomal RNA (rRNA). In RNA, 1mC is introduced post-transcriptionally by a family of enzymes known as RNA methyltransferases, such as those from the NOL1/NOP2/SUN domain (NSUN) family.[5] This modification can influence the structure, stability, and function of RNA molecules. For example, in tRNA, 1mC can affect decoding accuracy and the overall efficiency of protein translation.[6]
Experimental Data Summary
The following tables summarize key experimental data comparing the properties and effects of 1mC, 5fC, and 5caC.
Table 1: Biochemical and Biophysical Properties
| Property | This compound (1mC) | 5-Formylcytosine (5fC) | 5-Carboxylcytosine (5caC) |
| Effect on DNA Melting Temperature (Tm) | Context-dependent, can slightly decrease Tm | Decreases Tm | Decreases Tm |
| Impact on DNA-Protein Interactions | Alters hydrogen bonding potential | Forms reversible covalent crosslinks with histone lysines[3][4] | Substrate for TDG recognition and excision |
| Relative Abundance in Mammalian Tissues (as % of total cytosine) | Not well-quantified in DNA; present in RNA | ~0.0002% - 0.002%[7] | Lower than 5fC[7] |
Table 2: Functional Consequences
| Functional Aspect | This compound (1mC) | 5-Formylcytosine (5fC) | 5-Carboxylcytosine (5caC) |
| Effect on Transcription | In RNA, modulates tRNA function.[6] | Reduces the rate and substrate specificity of RNA Polymerase II.[1] | Reduces the rate and substrate specificity of RNA Polymerase II.[1] |
| Role in DNA Repair | Not directly implicated in major DNA repair pathways. | Excision by TDG as part of Base Excision Repair. | Excision by TDG as part of Base Excision Repair. |
| Genomic Localization | In RNA, found in tRNA and rRNA. In DNA, localization is unclear. | Enriched at poised enhancers.[8] | Enriched at regulatory elements. |
Experimental Protocols
Accurate detection and quantification of these low-abundance modifications are crucial for understanding their biological roles. A variety of sophisticated techniques have been developed for this purpose.
Protocol 1: Quantification of 5fC and 5caC by Liquid Chromatography-Tandem Mass Spectrometry (LC-MS/MS)
This method provides highly sensitive and accurate quantification of modified nucleosides.
Methodology:
-
Genomic DNA Isolation: Isolate high-quality genomic DNA from cells or tissues of interest.
-
DNA Digestion: Enzymatically digest the DNA to individual nucleosides using a cocktail of DNase I, nuclease P1, and alkaline phosphatase.
-
LC-MS/MS Analysis: Separate the nucleosides using ultra-performance liquid chromatography (UPLC) and detect and quantify them using a tandem mass spectrometer operating in multiple reaction monitoring (MRM) mode. Stable isotope-labeled internal standards for each modified nucleoside are used for accurate quantification.
Protocol 2: Bisulfite-Free, Base-Resolution Sequencing of 5-Formylcytosine (fC-CET)
This method allows for the genome-wide mapping of 5fC at single-base resolution without the harsh chemical treatment of traditional bisulfite sequencing.[4]
Methodology:
-
Selective Chemical Labeling: Treat genomic DNA with a chemical reagent that selectively reacts with the formyl group of 5fC.
-
Adduct Formation: The chemical reaction forms a stable adduct on the 5fC base.
-
PCR Amplification: During PCR amplification, the polymerase misreads the 5fC adduct as a thymine (B56734) (T).
-
Sequencing and Analysis: Sequence the amplified DNA and compare it to a reference genome. The C-to-T transitions indicate the original positions of 5fC.
Protocol 3: Detection of DNA-Protein Crosslinks by Mass Spectrometry
This protocol is used to identify proteins that are covalently linked to DNA, such as histones crosslinked to 5fC.[9][10][11]
Methodology:
-
In Vivo Crosslinking: Treat cells with a crosslinking agent (if studying induced crosslinks) or isolate nuclei to preserve endogenous crosslinks.
-
Isolation of DNA-Protein Complexes: Lyse the cells and isolate the DNA-protein complexes, often through cesium chloride density gradient centrifugation or specialized isolation kits.
-
Protease Digestion: Digest the protein component of the crosslinked complexes with a protease, such as trypsin, leaving the crosslinked peptide attached to the DNA.
-
DNA Digestion: Digest the DNA to release the peptide-nucleoside adducts.
-
LC-MS/MS Analysis: Analyze the resulting peptide-adducts by LC-MS/MS to identify the protein and the specific amino acid that was crosslinked to the DNA.
Conclusion
This compound, 5-Formylcytosine, and 5-Carboxylcytosine represent a fascinating layer of epigenetic and epitranscriptomic regulation. While 5fC and 5caC are integral to the dynamic process of DNA demethylation and may also act as stable epigenetic marks, the primary role of 1mC in mammals appears to be in the realm of RNA modification. The continued development of sensitive and specific detection methods will be crucial in further unraveling the complex biological functions of these modified cytosines and their implications in health and disease, offering potential avenues for novel therapeutic interventions.
References
- 1. 5-Formyl- and 5-carboxyl-cytosine reduce the rate and substrate specificity of RNA polymerase II transcription - PMC [pmc.ncbi.nlm.nih.gov]
- 2. This compound - Wikipedia [en.wikipedia.org]
- 3. Bisulfite-free and Base-resolution Analysis of 5-formylcytosine at Whole-genome Scale - PMC [pmc.ncbi.nlm.nih.gov]
- 4. researchgate.net [researchgate.net]
- 5. mdpi.com [mdpi.com]
- 6. Methylated Cytosine: A Promising Regulator of RNA Function? - Advanced Science News [advancedsciencenews.com]
- 7. Tissue-Specific Differences in DNA Modifications (5-Hydroxymethylcytosine, 5-Formylcytosine, 5-Carboxylcytosine and 5-Hydroxymethyluracil) and Their Interrelationships - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. researchgate.net [researchgate.net]
- 9. Mass Spectrometry Based Tools to Characterize DNA-Protein Cross-Linking by Bis-electrophiles - PMC [pmc.ncbi.nlm.nih.gov]
- 10. researchgate.net [researchgate.net]
- 11. Isolation and detection of DNA–protein crosslinks in mammalian cells - PMC [pmc.ncbi.nlm.nih.gov]
A Comparative Analysis of 1-Methylcytosine (1mC) Levels Across Diverse Mammalian Tissues
The epitranscriptome, encompassing all post-transcriptional modifications to RNA, plays a pivotal role in regulating gene expression. Among the more than 170 known RNA modifications, 1-methylcytosine (B60703) (1mC) is a crucial mark influencing RNA stability and translation. Understanding the tissue-specific distribution of 1mC is essential for elucidating its biological functions and its potential role in disease. This guide provides a quantitative comparison of 1mC levels across various mouse tissues, details the experimental methodology for its quantification, and illustrates the regulatory framework of RNA methylation.
Quantitative Comparison of 1mC Levels
The relative abundance of 1mC in total RNA varies significantly across different tissues, suggesting tissue-specific regulation and function of this modification. The following table summarizes the relative expression levels of 1mC across six mouse tissues, as determined by mass spectrometry. The data reveals that tissues such as the liver and kidney exhibit higher relative levels of 1mC compared to the brain, heart, lung, and muscle.
| Tissue | Relative 1mC Level |
| Brain | Low |
| Heart | Low |
| Kidney | High |
| Liver | High |
| Lung | Low |
| Muscle | Low |
Data is derived from heatmap analysis of relative RNA modification levels in mouse tissues and represents a qualitative summary of high versus low abundance.
Experimental Protocols
The gold-standard method for the accurate quantification of RNA modifications like 1mC is Liquid Chromatography-Mass Spectrometry (LC-MS/MS). This technique allows for the sensitive and specific detection of modified nucleosides within a complex biological sample.
Protocol: Quantification of 1mC in Total RNA by LC-MS/MS
-
RNA Isolation: Total RNA is extracted from fresh or frozen tissue samples using a standard method such as TRIzol reagent or a commercial RNA purification kit. It is crucial to prevent RNA degradation by maintaining an RNase-free environment.
-
RNA Purity and Concentration Measurement: The purity and concentration of the isolated RNA are determined using a spectrophotometer. The A260/A280 ratio should be approximately 2.0 for pure RNA.
-
Enzymatic Hydrolysis of RNA:
-
A defined amount of total RNA (e.g., 1-5 µg) is digested into individual nucleosides.
-
This is typically achieved by a two-step enzymatic reaction. First, the RNA is incubated with nuclease P1 at 37°C for 2-4 hours to digest the RNA into 5'-mononucleotides.
-
Following this, bacterial alkaline phosphatase is added and the mixture is incubated for another 2-4 hours at 37°C to dephosphorylate the mononucleotides into nucleosides.
-
-
Sample Preparation for LC-MS/MS:
-
The enzymatic reaction is stopped, and the enzymes are removed, often by filtration through a molecular weight cutoff filter (e.g., 10 kDa).
-
For absolute quantification, a known amount of a stable isotope-labeled internal standard for 1mC is added to the sample.
-
The sample is then dried under vacuum and reconstituted in a solvent compatible with the LC-MS/MS system (e.g., 5% acetonitrile (B52724) in water).
-
-
LC-MS/MS Analysis:
-
The prepared sample is injected into a liquid chromatography system coupled to a tandem mass spectrometer.
-
The nucleosides are separated by reverse-phase chromatography.
-
The mass spectrometer is operated in multiple reaction monitoring (MRM) mode to specifically detect and quantify the transition of the parent ion (protonated 1-methylcytidine) to a specific daughter ion (protonated this compound base).
-
-
Data Analysis:
-
The amount of 1mC in the sample is quantified by comparing the peak area of the endogenous 1mC to that of the stable isotope-labeled internal standard.
-
The 1mC level can be expressed as an absolute amount (e.g., fmol/µg of total RNA) or as a ratio relative to the amount of unmodified cytosine (C).
-
Visualization of RNA Methylation Regulation
The levels of RNA modifications like 1mC are dynamically regulated by a trio of protein classes: "writers," "erasers," and "readers." This regulatory mechanism is fundamental to the functional impact of the epitranscriptome.
This diagram illustrates the general principle of RNA methylation regulation. "Writer" enzymes add the methyl group, "erasers" remove it, and "readers" bind to the modified RNA to elicit downstream functional consequences. While the specific enzymes for 1mC are still under active investigation, this model, well-established for other modifications like 5-methylcytosine (B146107) (m5C), provides a conceptual framework for understanding how 1mC levels are controlled and exert their biological effects.
A Researcher's Guide to Validating Novel 1-Methylcytosine Sites in the Genome
For researchers, scientists, and drug development professionals, the accurate validation of epigenetic modifications is paramount. This guide provides an objective comparison of current methodologies for validating novel 1-methylcytosine (B60703) (m1C) sites within the genome, complete with supporting data and detailed experimental protocols.
This compound (m1C) is a modified DNA base, distinct from the more extensively studied 5-methylcytosine (B146107) (5mC). While 5mC is located at the C5 position of the cytosine ring, which does not interfere with Watson-Crick base pairing, m1C involves methylation of the N1 position, which directly participates in the hydrogen bonding with guanine. This fundamental structural difference suggests that m1C may have unique biological roles and necessitates specific methodologies for its accurate detection and validation. This guide will delve into the current landscape of techniques that can be employed to validate these novel epigenetic marks.
Comparison of this compound Validation Methods
The validation of novel m1C sites requires a multi-faceted approach, often combining a high-throughput screening method with a highly specific and quantitative validation technique. Below is a comparison of methods that can be adapted or are specifically designed for the validation of m1C in genomic DNA.
| Method | Principle | Resolution | Throughput | Quantitative? | Key Advantages | Key Disadvantages |
| Liquid Chromatography-Tandem Mass Spectrometry (LC-MS/MS) | Enzymatic digestion of DNA to nucleosides, followed by separation and quantification based on mass-to-charge ratio. | Global % | Low | Yes (Absolute) | Gold standard for quantification of modified bases. Highly accurate and sensitive. Can detect a wide range of modifications simultaneously. | Does not provide sequence context. Requires specialized equipment. |
| Methylated DNA Immunoprecipitation Sequencing (MeDIP-Seq) - Hypothetical for m1C | Immunoprecipitation of DNA fragments containing the modification of interest using a specific antibody, followed by high-throughput sequencing. | ~150 bp | High | Semi-quantitative | Genome-wide screening. Well-established protocol for 5mC. | Dependent on the availability and specificity of a high-quality m1C antibody. Potential for off-target antibody binding. Lower resolution. |
| Enzymatic Digestion with m1C-sensitive Enzymes - Hypothetical | Use of restriction enzymes or DNA glycosylases that are either blocked by or specifically recognize m1C within their recognition sequence. | Site-specific | Low to Medium | Semi-quantitative | Can be cost-effective for targeted validation. | Dependent on the discovery and characterization of m1C-specific enzymes. Limited to specific recognition sites. |
| Non-Bisulfite Sequencing Methods (e.g., Enzymatic Methyl-seq) - Potential for m1C | Enzymatic conversion of unmodified cytosines to other bases, leaving modified cytosines intact for detection by sequencing. | Single-base | High | Yes (Relative) | Avoids DNA degradation associated with bisulfite treatment. Potentially adaptable for various modifications. | Behavior with m1C is not yet well-characterized. May not distinguish between different cytosine modifications. |
Experimental Protocols and Workflows
Liquid Chromatography-Tandem Mass Spectrometry (LC-MS/MS) for Global m1C Quantification
LC-MS/MS is the most reliable method for the absolute quantification of m1C in a DNA sample. It provides a global percentage of m1C relative to total cytosine or guanine.
Protocol Outline:
-
Genomic DNA Extraction: Isolate high-quality genomic DNA from the sample of interest.
-
DNA Digestion: Enzymatically digest the DNA to individual nucleosides using a cocktail of DNase I, snake venom phosphodiesterase, and alkaline phosphatase.[1][2]
-
LC Separation: Separate the resulting nucleosides using ultra-high-performance liquid chromatography (UHPLC) with a C18 column.
-
MS/MS Detection: Detect and quantify the nucleosides using a triple quadrupole mass spectrometer in multiple reaction monitoring (MRM) mode. Specific mass transitions for 1-methyl-2'-deoxycytidine would need to be established and optimized.[3][4][5]
-
Quantification: Calculate the amount of m1C relative to the amount of a canonical nucleoside (e.g., deoxyguanosine) using a standard curve generated with known amounts of pure nucleosides.
Workflow Diagram:
Hypothetical MeDIP-Seq Workflow for Genome-Wide m1C Screening
While the availability of a validated antibody specific to m1C in the context of double-stranded DNA is a critical prerequisite, a MeDIP-seq approach would be a powerful tool for genome-wide screening of potential m1C sites.
Protocol Outline:
-
Genomic DNA Extraction and Fragmentation: Isolate genomic DNA and shear it to a desired fragment size (e.g., 200-800 bp) by sonication.
-
Immunoprecipitation: Incubate the fragmented DNA with a highly specific anti-1-methylcytosine antibody to enrich for DNA fragments containing m1C.[6][7][8]
-
Library Preparation: Prepare a sequencing library from the immunoprecipitated DNA and a corresponding input control library from the fragmented DNA that did not undergo immunoprecipitation.
-
High-Throughput Sequencing: Sequence both libraries on a next-generation sequencing platform.
-
Data Analysis: Align reads to a reference genome and identify enriched regions (peaks) in the MeDIP sample compared to the input control. These peaks represent putative m1C sites.
Workflow Diagram:
Challenges and Future Directions
The validation of novel this compound sites in the genome is an emerging field with several challenges. The primary hurdle is the lack of commercially available, validated reagents such as m1C-specific antibodies and enzymes. Furthermore, the chemical properties of m1C, particularly its disruption of the Watson-Crick base pairing face, suggest that it may be a rare modification in double-stranded DNA, potentially arising from DNA damage or having very specific, transient functions.
Future research will likely focus on:
-
Antibody and Enzyme Discovery: Development and rigorous validation of antibodies and enzymes that specifically recognize m1C in a DNA context.
-
Advancements in Sequencing: Adaptation of third-generation, long-read sequencing technologies that can directly detect modified bases without the need for chemical or enzymatic conversion.
-
Chemical Labeling Techniques: The development of chemical methods to specifically label m1C, allowing for its selective enrichment and detection.
References
- 1. Comprehensive Insights into DNA Methylation Analysis - CD Genomics [cd-genomics.com]
- 2. Discrimination of methylcytosine from hydroxymethylcytosine in DNA molecules - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Quantification of Global DNA Methylation Status by LC-MS/MS [visikol.com]
- 4. LC-MS-MS quantitative analysis reveals the association between FTO and DNA methylation | PLOS One [journals.plos.org]
- 5. LC-MS-MS quantitative analysis reveals the association between FTO and DNA methylation - PMC [pmc.ncbi.nlm.nih.gov]
- 6. mdpi.com [mdpi.com]
- 7. Methylated DNA immunoprecipitation and high-throughput sequencing (MeDIP-seq) using low amounts of genomic DNA - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. Overview of Methylated DNA Immunoprecipitation Sequencing (MeDIP-seq) - CD Genomics [cd-genomics.com]
Comparative Functional Assays for Cytosine and its Methylated Form
This guide provides a detailed comparison of the functional differences between cytosine and its biologically prevalent methylated form, 5-methylcytosine (B146107) (5mC). While the user query specified 1-methylcytosine (B60703), it is important to note that in the context of DNA and RNA in eukaryotes, 5-methylcytosine is the predominant and functionally significant modification. This compound is an isomer with the methyl group on a different atom of the cytosine ring and is less commonly studied in this context, sometimes used as a model compound in specific biophysical studies. This guide will therefore focus on the comparative functional assays of cytosine and 5-methylcytosine, which is of primary interest to researchers in epigenetics and drug development.
The methylation of cytosine to 5-methylcytosine is a critical epigenetic modification that plays a fundamental role in regulating gene expression, genomic stability, and cellular differentiation.[1][2] This guide will delve into the quantitative differences in their interactions with key proteins, their impact on DNA stability, and the experimental methodologies used to distinguish and quantify them.
Data Presentation: Quantitative Comparison of Cytosine and 5-Methylcytosine
The addition of a methyl group to cytosine significantly alters its biochemical properties, leading to differential recognition by various proteins and affecting the local DNA structure. The following table summarizes key quantitative data from functional assays comparing unmethylated and methylated DNA.
| Parameter | Unmethylated Cytosine (C) | 5-Methylcytosine (5mC) | Fold Difference | Significance | References |
| UHRF1 SRA Domain Binding Affinity (Kd) | ~12.1 ± 1.7 nM (for fully methylated) | ~1.7 - 1.8 nM (for hemi-methylated) | ~7-fold higher affinity for hemi-methylated DNA | UHRF1 preferentially binds to hemi-methylated DNA, a key step in the maintenance of DNA methylation patterns after replication.[3] | [3] |
| DNMT1 Activity (unmethylated vs. hemi-methylated substrate) | Low (de novo methylation) | High (maintenance methylation) | 15 to 80-fold preference for hemi-methylated DNA | DNMT1 efficiently copies existing methylation patterns onto the newly synthesized DNA strand during replication.[4][5] | [4][5] |
| DNA Duplex Stability (Melting Temperature) | Lower | Higher | Not specified | 5-methylcytosine stabilizes the DNA double helix.[6][7] | [6][7] |
| DNA Helicase Unwinding Speed | Faster | Slower | Not specified | Increased DNA stability due to methylation can impede the activity of helicases involved in replication and transcription.[7] | [7] |
| DNA Polymerase Replication Speed | Faster | Slower | Not specified | Methylation can slow down the rate of DNA replication.[7] | [7] |
Experimental Protocols: Key Assays for Comparative Analysis
Several techniques are employed to differentiate between cytosine and 5-methylcytosine. Below are detailed protocols for two widely used methods: Methylated DNA Immunoprecipitation Sequencing (MeDIP-Seq) and Bisulfite Sequencing.
1. Methylated DNA Immunoprecipitation Sequencing (MeDIP-Seq)
MeDIP-Seq is an antibody-based method used to enrich for methylated DNA fragments from a genomic sample.[8][9][10][11][12]
-
DNA Fragmentation:
-
Immunoprecipitation:
-
Denature the fragmented DNA at 95°C for 10 minutes and immediately place on ice.[8][10]
-
Add a specific antibody against 5-methylcytosine to the denatured DNA.[8][9]
-
Incubate overnight at 4°C with gentle rotation to allow for the formation of DNA-antibody complexes.[8]
-
Add magnetic beads conjugated with a secondary antibody (e.g., anti-mouse IgG) and incubate for 2 hours at 4°C.[10]
-
Use a magnetic rack to capture the bead-antibody-DNA complexes and discard the supernatant.[10]
-
Wash the beads multiple times with IP buffer to remove non-specifically bound DNA.[10]
-
-
DNA Elution and Library Preparation:
-
Elute the methylated DNA from the beads using an elution buffer.
-
Purify the eluted DNA.
-
Prepare a sequencing library from the enriched methylated DNA fragments for high-throughput sequencing.
-
2. Bisulfite Sequencing
Bisulfite sequencing is considered the gold standard for single-base resolution DNA methylation analysis.[13][14] It relies on the chemical conversion of unmethylated cytosines to uracil, while methylated cytosines remain unchanged.[14]
-
Bisulfite Conversion:
-
Start with 200-500 ng of genomic DNA.
-
Denature the DNA using NaOH.
-
Treat the denatured DNA with a freshly prepared sodium bisulfite solution.
-
Incubate at 55°C for 16 hours, with cycles of 95°C for 5 minutes every 3 hours to maintain denaturation.[15]
-
Desalt the DNA using a purification column.
-
Desulfonate the DNA by adding NaOH and incubating at 37°C for 15 minutes.
-
Precipitate the DNA with ethanol.
-
Resuspend the purified, converted DNA in buffer.
-
-
Library Preparation and Sequencing:
-
Perform PCR to amplify the target regions from the bisulfite-converted DNA. The PCR primers are designed to be specific for the converted sequence.
-
During PCR, the uracils are replaced with thymines.
-
Prepare a sequencing library from the PCR products.
-
Sequence the library using a high-throughput sequencing platform.
-
-
Data Analysis:
-
Align the sequencing reads to a reference genome.
-
Compare the aligned reads to the original reference sequence.
-
Cytosines that remain as cytosines in the reads were methylated, while those that are read as thymines were unmethylated.
-
Mandatory Visualization
DNA Methylation Maintenance Pathway
References
- 1. 5-Methylcytosine - Wikipedia [en.wikipedia.org]
- 2. epigenie.com [epigenie.com]
- 3. research.mcdb.ucla.edu [research.mcdb.ucla.edu]
- 4. Accuracy of DNA methylation pattern preservation by the Dnmt1 methyltransferase - PMC [pmc.ncbi.nlm.nih.gov]
- 5. academic.oup.com [academic.oup.com]
- 6. 5-Methyl-cytosine stabilizes DNA but hinders DNA hybridization revealed by magnetic tweezers and simulations - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Cytosine base modifications regulate DNA duplex stability and metabolism - PMC [pmc.ncbi.nlm.nih.gov]
- 8. MeDIP Application Protocol | EpigenTek [epigentek.com]
- 9. researchportal.helsinki.fi [researchportal.helsinki.fi]
- 10. Video: Methylated DNA Immunoprecipitation [jove.com]
- 11. Methylated DNA immunoprecipitation (MeDIP) - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. Protocol for Methylated DNA Immunoprecipitation (MeDIP) Analysis | Springer Nature Experiments [experiments.springernature.com]
- 13. DNA Methylation: Bisulfite Sequencing Workflow — Epigenomics Workshop 2025 1 documentation [nbis-workshop-epigenomics.readthedocs.io]
- 14. Principles and Workflow of Whole Genome Bisulfite Sequencing - CD Genomics [cd-genomics.com]
- 15. Bisulfite Protocol | Stupar Lab [stuparlab.cfans.umn.edu]
performance comparison of different commercial MeDIP kits for 1mC
For researchers, scientists, and drug development professionals embarking on epigenome-wide association studies, the choice of a Methylated DNA Immunoprecipitation (MeDIP) kit is a critical first step. This guide provides an objective comparison of the performance of several commercially available MeDIP kits for the enrichment of 5-methylcytosine (B146107) (5mC) containing DNA, supported by experimental data.
A key study by Brebi-Mieville et al. published in Epigenetics (2012) provides a head-to-head comparison of three popular commercial kits: the MagMeDIP Kit™ from Diagenode, the Methylated-DNA IP Kit from Zymo Research, and the Methylamp™ Methylated DNA Capture Kit from Epigentek.[1] The evaluation focused on enrichment efficiency and reaction yield using both fresh tissue and cell line samples with varying DNA inputs.[1]
Quantitative Performance Data
The following tables summarize the key performance metrics of the evaluated MeDIP kits.
Kit Feature Comparison
| Feature | Diagenode MagMeDIP Kit | Zymo Research Methylated-DNA IP Kit | Epigentek Methylamp™ MeDIP Kit | Proteintech MeDIP Kit | Abcam MeDIP Kit (ab117133) |
| Principle | Magnetic bead-based | Magnetic bead-based | Microplate-based | Magnetic bead-based | Microplate-based |
| Input DNA | 10 ng - 1 µg[2] | 50 - 500 ng | 0.5 - 1 µg | Not specified | 0.5 - 1 µg[3] |
| Antibody | Anti-5-methylcytosine | Anti-5-Methylcytosine Monoclonal Antibody | Anti-5-methylcytosine | Monoclonal 5-methylcytosine antibody | Anti-5-Methylcytosine |
| Processing Time | Not specified | A few hours | ~3 hours | Not specified | < 3 hours[3] |
| Downstream Apps | qPCR, NGS[2] | PCR, bisulfite treatment, WGA, sequencing, microarray | PCR, microarray, NGS | qPCR, NGS | PCR, Southern blot, microarray |
Performance Metrics from Comparative Study (Brebi-Mieville et al., 2012)
The study assessed the enrichment efficiency and reaction yield for each kit using 0.5 µg and 1 µg of DNA from a fresh tissue sample and a cell line. A successful enrichment was defined as a conversion of the methylated to unmethylated DNA ratio from 1:4 to 10:1 or higher, and a reaction yield of 80% or higher.[1]
Enrichment Efficiency:
| Kit | Outcome |
| Diagenode MagMeDIP Kit | Successfully enriched methylated DNA, achieving a 1:4 to 10:1 conversion ratio.[1][4] |
| Zymo Research Methylated-DNA IP Kit | Data on conversion ratio not explicitly stated in the comparative study's abstract. |
| Epigentek Methylamp™ MeDIP Kit | Data on conversion ratio not explicitly stated in the comparative study's abstract. |
Reaction Yield:
| Kit | 0.5 µg DNA (Tissue) | 1 µg DNA (Tissue) | 0.5 µg DNA (Cell Line) | 1 µg DNA (Cell Line) | Positive Control |
| Diagenode MagMeDIP Kit | Highest Yield[1][4] | Highest Yield[1][4] | Highest Yield[1][4] | Highest Yield[1][4] | Highest Yield[1][4] |
| Zymo Research Methylated-DNA IP Kit | Lower than Diagenode[1] | Lower than Diagenode[1] | Lower than Diagenode[1] | Lower than Diagenode[1] | Lower than Diagenode[1] |
| Epigentek Methylamp™ MeDIP Kit | Lower than Diagenode[1] | Lower than Diagenode[1] | Lower than Diagenode[1] | Lower than Diagenode[1] | Lower than Diagenode[1] |
The study also noted that the hybridization efficiency to genome-wide methylation arrays was better for DNA enriched with the Diagenode MagMeDIP kit compared to the Epigentek Methylamp™ kit.[1]
Experimental Protocols
The following are summaries of the experimental protocols as described in the comparative study by Brebi-Mieville et al. (2012) and the manufacturer's instructions.
General Workflow
The general workflow for MeDIP involves the following key steps:
-
DNA Fragmentation: Genomic DNA is sheared to a desired size range, typically 200-1000 bp, using sonication or enzymatic digestion.
-
Denaturation: The fragmented DNA is denatured to produce single-stranded DNA, which is necessary for antibody binding.
-
Immunoprecipitation: The denatured DNA is incubated with a monoclonal antibody specific to 5-methylcytosine.
-
Capture: The antibody-DNA complexes are captured using either magnetic beads or a pre-coated microplate.
-
Washing: The captured complexes are washed to remove non-specific binding and unmethylated DNA.
-
Elution: The enriched methylated DNA is eluted from the antibody.
-
Purification: The eluted DNA is purified and ready for downstream applications.
Specific Protocols from the Comparative Study
Diagenode MagMeDIP Kit™: The protocol involves the use of magnetic beads for the capture of the antibody-DNA complex. The specific details of the buffers and incubation times are proprietary to the kit.
Zymo Research Methylated-DNA IP Kit: This kit also utilizes a magnetic bead-based capture method. The manufacturer's protocol was followed in the study.
Epigentek Methylamp™ Methylated DNA Capture Kit: This kit employs a microplate-based system where the wells are coated with the anti-5-methylcytosine antibody.[1] The fragmented and denatured DNA is added to the wells for immunoprecipitation.[1]
Visualizing the MeDIP Workflow
The following diagram illustrates the general experimental workflow for Methylated DNA Immunoprecipitation (MeDIP).
Caption: A diagram illustrating the general workflow of a MeDIP experiment.
Logical Relationships in Kit Selection
The choice of a MeDIP kit often depends on a balance of performance, throughput, and the specific requirements of the downstream application.
Caption: A diagram showing the logical considerations for selecting a MeDIP kit.
Conclusion
Based on the comparative data from Brebi-Mieville et al. (2012), the Diagenode MagMeDIP Kit demonstrated the highest reaction yield and successful enrichment efficiency among the three kits tested.[1][4] This makes it a strong candidate for applications requiring high recovery of methylated DNA, such as genome-wide array hybridization and next-generation sequencing. The microplate-based format of the Epigentek Methylamp™ kit may offer advantages for higher throughput applications. The Zymo Research kit provides a solid, magnetic bead-based option for various downstream analyses.
It is important to note that antibody specificity is a crucial factor in MeDIP performance. Most commercially available kits utilize antibodies that are highly specific for 5mC and do not cross-react with 5-hydroxymethylcytosine (B124674) (5hmC), ensuring targeted enrichment of the desired epigenetic mark. Researchers should always validate the performance of their chosen kit in their own experimental context.
References
- 1. Clinical and public health research using methylated DNA Immunoprecipitation (MeDIP): A comparison of commercially available kits to examine differential DNA methylation across the genome - PMC [pmc.ncbi.nlm.nih.gov]
- 2. MagMeDIP Kit for efficient immunoprecipitation of methylated DNA | Diagenode [diagenode.com]
- 3. content.abcam.com [content.abcam.com]
- 4. Clinical and public health research using methylated DNA immunoprecipitation (MeDIP) A comparison of commercially available kits to examine differential DNA methylation across the genome [diagenode.com]
Safety Operating Guide
Essential Guide to the Proper Disposal of 1-Methylcytosine
For researchers, scientists, and professionals in drug development, the proper handling and disposal of chemical reagents are paramount to ensuring laboratory safety and environmental compliance. This document provides a comprehensive, step-by-step guide for the safe disposal of 1-Methylcytosine, a methylated form of the DNA base cytosine. Adherence to these procedures is critical for minimizing risks and maintaining a safe research environment.
Immediate Safety and Handling Precautions
Before initiating any disposal procedures, it is crucial to be aware of the hazards associated with this compound. Based on the Globally Harmonized System of Classification and Labelling of Chemicals (GHS), this compound is classified as a hazardous substance.
Hazard Identification and Safety Measures:
| Hazard Classification | GHS Hazard Statement | Immediate Safety Precautions |
| Acute Toxicity (Oral) | H302: Harmful if swallowed | Do not eat, drink, or smoke when using this product. If swallowed, seek immediate medical attention. |
| Skin Irritation | H315: Causes skin irritation | Wear protective gloves and lab coat. In case of skin contact, wash immediately with plenty of water. |
| Eye Irritation | H319: Causes serious eye irritation | Wear safety glasses or goggles. If in eyes, rinse cautiously with water for several minutes. |
| Respiratory Irritation | H335: May cause respiratory irritation | Work in a well-ventilated area or use a chemical fume hood. Avoid breathing dust. |
Source: PubChem CID 79143[1]
Logistical and Operational Disposal Plan
The disposal of this compound must be handled as a regulated chemical waste. Under no circumstances should it be disposed of in the regular trash or down the sanitary sewer.
Step-by-Step Disposal Protocol:
-
Waste Identification and Segregation:
-
Clearly identify the waste as "this compound, Hazardous Chemical Waste."
-
Do not mix this compound waste with other chemical waste streams unless explicitly permitted by your institution's Environmental Health and Safety (EHS) department. Incompatible wastes can react dangerously.
-
-
Containerization:
-
Use a designated, leak-proof, and chemically compatible container for collecting this compound waste. The container should be in good condition with a secure screw-top cap.
-
The original product container, if empty and in good condition, can be used for waste collection.
-
-
Labeling:
-
Properly label the waste container with the following information:
-
The words "Hazardous Waste"
-
The full chemical name: "this compound"
-
The associated hazards (e.g., "Harmful if swallowed," "Causes skin and eye irritation," "May cause respiratory irritation")
-
The accumulation start date (the date the first drop of waste was added to the container)
-
The name of the principal investigator or lab supervisor
-
-
-
Storage:
-
Store the sealed waste container in a designated satellite accumulation area (SAA) within the laboratory.
-
The SAA should be at or near the point of generation and under the control of laboratory personnel.
-
Ensure secondary containment is used to prevent spills.
-
-
Disposal Request:
-
Once the container is full or has been in accumulation for the maximum time allowed by your institution (typically 6-12 months), contact your institution's EHS department to request a waste pickup.
-
Follow your institution's specific procedures for scheduling a hazardous waste collection.
-
Experimental Protocol Considerations
When designing experiments involving this compound, it is prudent to incorporate waste minimization strategies from the outset. This includes:
-
Source Reduction: Purchase and use the smallest quantity of this compound necessary for your experiments.
-
Avoidance of Contamination: Do not mix non-hazardous materials with this compound waste, as this will increase the volume of hazardous waste that requires disposal.
Visualizing the Disposal Workflow
The following diagram illustrates the logical workflow for the proper disposal of this compound.
References
Safeguarding Your Research: A Comprehensive Guide to Handling 1-Methylcytosine
Essential safety protocols and logistical plans are critical for the secure and effective handling of chemical compounds in research and development. This guide provides immediate, actionable information for laboratory personnel working with 1-Methylcytosine, a methylated form of the DNA base cytosine. Adherence to these procedures is paramount to ensure personal safety and maintain the integrity of your experimental work.
Hazard and Exposure Information
This compound is classified as a substance that is harmful if swallowed and can cause skin, eye, and respiratory irritation.[1] It is essential for all personnel to be familiar with the potential hazards before commencing any work. The following table summarizes the key hazard information.
| Hazard Classification | Description | GHS Pictogram |
| Acute Toxicity, Oral (Category 4) | Harmful if swallowed.[1] | |
| Skin Irritation (Category 2) | Causes skin irritation.[1] | |
| Eye Irritation (Category 2A) | Causes serious eye irritation.[1] | |
| Specific target organ toxicity — Single exposure (Category 3), Respiratory tract irritation | May cause respiratory irritation.[1] |
Personal Protective Equipment (PPE)
To mitigate the risks associated with handling this compound, the following personal protective equipment is mandatory.
| PPE Category | Item | Standard |
| Eye and Face Protection | Chemical splash goggles or safety glasses | Must meet ANSI Z.87.1 1989 standard.[2] |
| Hand Protection | Disposable nitrile gloves | Inspect before each use and change immediately upon contact with the chemical.[2] |
| Body Protection | Laboratory coat | A Nomex® laboratory coat with cotton clothing underneath is recommended. Coats should be fully buttoned.[2] |
| Foot Protection | Closed-toe shoes | Shoes must cover the entire foot.[2] |
| Respiratory Protection | Not generally required for small quantities handled with adequate engineering controls. | Use in a well-ventilated area or a chemical fume hood. If dust or aerosols are generated, a NIOSH-approved respirator may be necessary.[3] |
Operational Plan: Step-by-Step Handling Procedure
A systematic approach to handling this compound is crucial for safety and experimental success.
1. Preparation:
-
Ensure the work area, typically a chemical fume hood, is clean and uncluttered.
-
Verify that all necessary PPE is available and in good condition.
-
Have a chemical spill kit readily accessible.
-
Prepare all necessary equipment and reagents before handling the compound.
2. Handling:
-
Wear all required PPE before opening the container of this compound.
-
Handle the solid compound carefully to avoid generating dust.
-
If creating a solution, add the solid to the solvent slowly.
-
Keep the container tightly closed when not in use.[3]
3. Post-Handling:
-
Decontaminate the work area thoroughly.
-
Wash hands and any exposed skin with soap and water immediately after handling.
Disposal Plan
Proper disposal of this compound and any contaminated materials is essential to prevent environmental contamination and ensure laboratory safety.
-
Solid Waste: Collect unused this compound and any contaminated disposable materials (e.g., gloves, weighing paper) in a designated, labeled hazardous waste container.
-
Liquid Waste: Dispose of solutions containing this compound in a designated, labeled hazardous liquid waste container.
-
Container Disposal: Empty containers should be triple-rinsed with a suitable solvent, and the rinsate collected as hazardous liquid waste. The rinsed container can then be disposed of according to institutional guidelines.
-
Regulatory Compliance: All waste disposal must be carried out in accordance with local, state, and federal regulations.
Experimental Workflow for Safe Handling
The following diagram illustrates the key steps for the safe handling of this compound from receipt to disposal.
Caption: A flowchart outlining the essential steps for the safe handling and disposal of this compound in a laboratory setting.
References
Retrosynthesis Analysis
AI-Powered Synthesis Planning: Our tool employs the Template_relevance Pistachio, Template_relevance Bkms_metabolic, Template_relevance Pistachio_ringbreaker, Template_relevance Reaxys, Template_relevance Reaxys_biocatalysis model, leveraging a vast database of chemical reactions to predict feasible synthetic routes.
One-Step Synthesis Focus: Specifically designed for one-step synthesis, it provides concise and direct routes for your target compounds, streamlining the synthesis process.
Accurate Predictions: Utilizing the extensive PISTACHIO, BKMS_METABOLIC, PISTACHIO_RINGBREAKER, REAXYS, REAXYS_BIOCATALYSIS database, our tool offers high-accuracy predictions, reflecting the latest in chemical research and data.
Strategy Settings
| Precursor scoring | Relevance Heuristic |
|---|---|
| Min. plausibility | 0.01 |
| Model | Template_relevance |
| Template Set | Pistachio/Bkms_metabolic/Pistachio_ringbreaker/Reaxys/Reaxys_biocatalysis |
| Top-N result to add to graph | 6 |
Feasible Synthetic Routes




Featured Recommendations
| Most viewed |
|
|
|---|---|---|
| Most popular with customers |
|
Avertissement et informations sur les produits de recherche in vitro
Veuillez noter que tous les articles et informations sur les produits présentés sur BenchChem sont destinés uniquement à des fins informatives. Les produits disponibles à l'achat sur BenchChem sont spécifiquement conçus pour des études in vitro, qui sont réalisées en dehors des organismes vivants. Les études in vitro, dérivées du terme latin "in verre", impliquent des expériences réalisées dans des environnements de laboratoire contrôlés à l'aide de cellules ou de tissus. Il est important de noter que ces produits ne sont pas classés comme médicaments et n'ont pas reçu l'approbation de la FDA pour la prévention, le traitement ou la guérison de toute condition médicale, affection ou maladie. Nous devons souligner que toute forme d'introduction corporelle de ces produits chez les humains ou les animaux est strictement interdite par la loi. Il est essentiel de respecter ces directives pour assurer la conformité aux normes légales et éthiques en matière de recherche et d'expérimentation.
