Mnaf
Descripción
Structure
3D Structure
Propiedades
IUPAC Name |
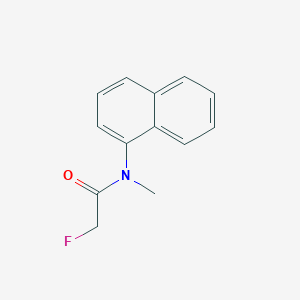
2-fluoro-N-methyl-N-naphthalen-1-ylacetamide |
Source


|
|---|---|---|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
InChI |
InChI=1S/C13H12FNO/c1-15(13(16)9-14)12-8-4-6-10-5-2-3-7-11(10)12/h2-8H,9H2,1H3 |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
InChI Key |
ADRPZEYTIFWCBC-UHFFFAOYSA-N |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Canonical SMILES |
CN(C1=CC=CC2=CC=CC=C21)C(=O)CF |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Molecular Formula |
C13H12FNO |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
DSSTOX Substance ID |
DTXSID1058139 |
Source
|
| Record name | MNAF | |
| Source | EPA DSSTox | |
| URL | https://comptox.epa.gov/dashboard/DTXSID1058139 | |
| Description | DSSTox provides a high quality public chemistry resource for supporting improved predictive toxicology. | |
Molecular Weight |
217.24 g/mol |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
CAS No. |
5903-13-9 |
Source
|
| Record name | MNAF | |
| Source | CAS Common Chemistry | |
| URL | https://commonchemistry.cas.org/detail?cas_rn=5903-13-9 | |
| Description | CAS Common Chemistry is an open community resource for accessing chemical information. Nearly 500,000 chemical substances from CAS REGISTRY cover areas of community interest, including common and frequently regulated chemicals, and those relevant to high school and undergraduate chemistry classes. This chemical information, curated by our expert scientists, is provided in alignment with our mission as a division of the American Chemical Society. | |
| Explanation | The data from CAS Common Chemistry is provided under a CC-BY-NC 4.0 license, unless otherwise stated. | |
| Record name | N-methyl-N-1-naphthyl-2-fluoroacetamide | |
| Source | ChemIDplus | |
| URL | https://pubchem.ncbi.nlm.nih.gov/substance/?source=chemidplus&sourceid=0005903139 | |
| Description | ChemIDplus is a free, web search system that provides access to the structure and nomenclature authority files used for the identification of chemical substances cited in National Library of Medicine (NLM) databases, including the TOXNET system. | |
| Record name | MNAF | |
| Source | EPA DSSTox | |
| URL | https://comptox.epa.gov/dashboard/DTXSID1058139 | |
| Description | DSSTox provides a high quality public chemistry resource for supporting improved predictive toxicology. | |
| Record name | NISSOL | |
| Source | FDA Global Substance Registration System (GSRS) | |
| URL | https://gsrs.ncats.nih.gov/ginas/app/beta/substances/ADL8ZU8B4W | |
| Description | The FDA Global Substance Registration System (GSRS) enables the efficient and accurate exchange of information on what substances are in regulated products. Instead of relying on names, which vary across regulatory domains, countries, and regions, the GSRS knowledge base makes it possible for substances to be defined by standardized, scientific descriptions. | |
| Explanation | Unless otherwise noted, the contents of the FDA website (www.fda.gov), both text and graphics, are not copyrighted. They are in the public domain and may be republished, reprinted and otherwise used freely by anyone without the need to obtain permission from FDA. Credit to the U.S. Food and Drug Administration as the source is appreciated but not required. | |
Foundational & Exploratory
The Unseen Messenger: A Technical History of mRNA's Discovery and its Revolutionary Impact
A deep dive into the seminal experiments and conceptual leaps that unveiled the transient carrier of genetic information, from the initial "unstable intermediate" to the engineered molecules powering modern therapeutics.
This technical guide provides researchers, scientists, and drug development professionals with an in-depth exploration of the history of messenger RNA (mRNA) discovery. We will dissect the pivotal experiments that unraveled the existence and function of this crucial molecule, present the quantitative data that underpinned these discoveries, and detail the methodologies that have become foundational in molecular biology. From the early hypotheses to the groundbreaking work that enabled the current era of mRNA-based therapies, this document serves as a comprehensive reference to the scientific journey that brought the messenger to light.
A Historical Overview: From a "Nuclear Ghost" to the Central Dogma's Emissary
The concept of an intermediary molecule that carries genetic information from DNA in the nucleus to the protein-synthesizing machinery in the cytoplasm was a logical necessity in the burgeoning field of molecular biology in the mid-20th century. Early observations by scientists like Torbjörn Caspersson and Jean Brachet in the 1940s had implicated RNA in protein synthesis due to its abundance in the cytoplasm of actively synthesizing cells. However, the precise nature of this involvement remained elusive.
The prevailing hypothesis for a time was that ribosomal RNA (rRNA), a stable and abundant component of the protein-synthesis machinery (the ribosome), itself served as the template for protein production. This model, however, struggled to explain the rapid changes in protein synthesis observed in response to environmental cues, particularly in bacteria. A stable template like rRNA could not account for the swift induction and cessation of specific enzyme synthesis.
This intellectual impasse set the stage for a paradigm shift, driven by a series of elegant and insightful experiments in the late 1950s and early 1960s.
The "PaJaMo" Experiment and the Dawn of a New Idea
In 1959, a landmark experiment by Arthur Pardee, François Jacob, and Jacques Monod, famously known as the "PaJaMo" experiment, provided the first strong evidence for a short-lived, unstable intermediate in gene expression.[1] They studied the transfer of the lac operon from a male (Hfr) to a female (F-) Escherichia coli bacterium. They observed that the synthesis of β-galactosidase, the enzyme encoded by the lacZ gene, began almost immediately after the gene entered the female cell and ceased just as quickly when the gene was removed. This rapid on-off switching of protein synthesis was incompatible with the idea of a stable rRNA template and strongly suggested the existence of a transient "messenger."[1]
The T2 Phage: A Perfect System to Isolate the Messenger
The definitive proof for the existence of this messenger molecule came from a series of experiments using bacteriophage T2, a virus that infects E. coli.[2] Upon infection, T2 rapidly shuts down the synthesis of host proteins and commandeers the bacterial cell's machinery to produce viral proteins. This provided a unique experimental system to track the flow of genetic information from the viral DNA to the newly synthesized proteins.
In 1956, Elliot Volkin and Lazarus Astrachan had already observed a burst of RNA synthesis immediately after T2 phage infection.[3] This newly synthesized RNA had a base composition that was remarkably similar to that of the T2 phage DNA, and very different from the host E. coli DNA and its stable rRNA.[3][4] This "phage-specific RNA" was also found to be rapidly synthesized and degraded, making it a prime candidate for the elusive messenger.
The Decisive Experiments of 1961
The year 1961 marked a watershed moment in the history of molecular biology with the publication of two back-to-back papers in Nature.[5] These papers, one by Sydney Brenner, François Jacob, and Matthew Meselson, and the other by François Gros and his colleagues, provided unequivocal evidence for the existence of messenger RNA.[5][6][7]
The Brenner, Jacob, and Meselson experiment, in particular, is hailed as a masterpiece of experimental design.[8] They used a clever combination of isotopic labeling and density gradient centrifugation to demonstrate that after T2 infection, newly synthesized, short-lived RNA (the messenger) associates with pre-existing host ribosomes to direct the synthesis of viral proteins.[8] This elegantly disproved the prevailing theory that each gene had its own specific ribosome for protein synthesis.
Concurrently, François Gros and his team, using a pulse-labeling technique with radioactive uracil (B121893), also identified a highly unstable RNA fraction in E. coli that was associated with ribosomes and had a base composition reflecting that of the bacterial DNA.[7]
These seminal experiments firmly established the concept of messenger RNA as the transient carrier of genetic information, a cornerstone of the central dogma of molecular biology. The term "messenger RNA" was coined by François Jacob and Jacques Monod in their comprehensive 1961 paper in the Journal of Molecular Biology that laid out the operon model of gene regulation.[1][9][10][11][12]
Quantitative Data from the Seminal Experiments
The following tables summarize the key quantitative data from the foundational experiments that led to the discovery of mRNA.
| Experiment | Organism/System | Parameter Measured | Value | Significance |
| Volkin & Astrachan (1956) | E. coli infected with T2 phage | Base composition of newly synthesized RNA after infection | Similar to T2 phage DNA (high A+T content) | Indicated that the new RNA was a transcript of the viral DNA, not the host DNA. |
| Brenner, Jacob, Meselson (1961) | E. coli infected with T2 phage | Sedimentation coefficient of ribosomes | 70S | Confirmed the association of the new, unstable RNA with existing host ribosomes. |
| Brenner, Jacob, Meselson (1961) | E. coli infected with T2 phage | Sedimentation coefficient of pulse-labeled RNA | ~14-16S | Showed that the newly synthesized RNA was a distinct molecule from the stable 16S and 23S rRNA. |
| Gros et al. (1961) | E. coli | Half-life of pulse-labeled RNA | ~2 minutes | Demonstrated the high instability of the messenger RNA, consistent with its role in rapid gene regulation. |
Table 1: Key Quantitative Findings in the Discovery of mRNA
| Source of Nucleic Acid | Adenine (%) | Guanine (%) | Cytosine (%) | Thymine/Uracil (%) |
| E. coli DNA | 24.7 | 26.0 | 25.7 | 23.6 |
| T2 Phage DNA | 32.5 | 18.2 | 16.7 | 32.6 |
| E. coli rRNA (stable) | ~25 | ~31 | ~23 | ~21 |
| Phage-induced RNA (pulse-labeled) | ~32 | ~18 | ~17 | ~33 |
Table 2: Comparative Base Composition of Nucleic Acids in T2-infected E. coli (Approximate values based on historical data)
Detailed Methodologies of Key Experiments
This section provides a detailed breakdown of the experimental protocols that were instrumental in the discovery and characterization of mRNA.
The Pulse-Chase Experiment (as performed by Gros et al.)
This technique was crucial for demonstrating the rapid turnover of mRNA.
Objective: To measure the synthesis and degradation rate of the unstable RNA fraction in E. coli.
Materials:
-
E. coli culture in exponential growth phase.
-
Minimal medium (e.g., M9 medium).
-
Radioactive uracil ([¹⁴C]uracil or [³H]uracil) - the "pulse".
-
Non-radioactive ("cold") uracil - the "chase".
-
Trichloroacetic acid (TCA) for precipitation of macromolecules.
-
Scintillation counter for measuring radioactivity.
Protocol:
-
Growth of Bacteria: Grow E. coli in minimal medium to a specific optical density (e.g., OD₆₀₀ of 0.5).
-
The "Pulse": Add a high concentration of radioactive uracil to the culture for a very short period (e.g., 15-30 seconds). During this time, the radioactive uracil is incorporated into newly synthesized RNA.
-
The "Chase": Add a large excess of non-radioactive uracil to the culture. This dilutes the radioactive precursor pool to such an extent that the incorporation of radioactivity into new RNA molecules becomes negligible.
-
Sampling: Take aliquots of the bacterial culture at various time points after the start of the chase (e.g., 0, 1, 2, 5, 10 minutes).
-
Macromolecule Precipitation: Immediately mix each aliquot with cold TCA to precipitate DNA, RNA, and proteins, thus stopping all metabolic processes.
-
Analysis: Filter the TCA precipitates and measure the amount of radioactivity in each sample using a scintillation counter.
-
Data Interpretation: The amount of radioactivity in the RNA fraction will initially be high (at the end of the pulse) and will then decrease over time during the chase as the unstable mRNA molecules are degraded. The rate of this decrease allows for the calculation of the mRNA half-life.
The Brenner, Jacob, and Meselson Experiment
This elegant experiment provided definitive proof for the existence of mRNA and its function.
Objective: To demonstrate that after phage infection, a newly synthesized, unstable RNA molecule (the messenger) associates with pre-existing host ribosomes to direct protein synthesis.
Materials:
-
E. coli strains grown in a "heavy" isotope medium (containing ¹⁵N and ¹³C) to make their ribosomes dense.
-
Bacteriophage T2.
-
"Light" medium (containing the normal ¹⁴N and ¹²C isotopes).
-
Radioactive phosphate (B84403) (³²P) to label newly synthesized RNA.
-
Radioactive sulfur (³⁵S) to label newly synthesized protein.
-
Sucrose (B13894) for creating density gradients.
-
Ultracentrifuge.
-
Cesium chloride (CsCl) for density gradient centrifugation.
Protocol:
-
Preparation of "Heavy" Ribosomes: Grow E. coli for several generations in a medium containing heavy isotopes (¹⁵NH₄Cl and ¹³C-glucose). This ensures that all cellular components, including ribosomes, are dense.
-
Infection and Isotope Shift: Transfer the "heavy" bacteria to a "light" medium (containing ¹⁴N and ¹²C) and immediately infect them with T2 phage.
-
Pulse Labeling: Shortly after infection, add radioactive phosphate (³²P) to the culture for a brief period to label the newly synthesized RNA. In parallel experiments, radioactive sulfur (³⁵S) can be added to label newly synthesized proteins.
-
Cell Lysis and Ribosome Isolation: Lyse the infected bacteria and prepare a crude extract containing the ribosomes.
-
Sucrose Gradient Centrifugation: Layer the cell extract onto a sucrose density gradient and centrifuge at high speed. The ribosomes will sediment based on their size and density.
-
Fractionation and Analysis: Collect fractions from the gradient and measure the absorbance at 260 nm (to locate the ribosomes), the ³²P radioactivity (to locate the newly synthesized RNA), and the ³⁵S radioactivity (to locate the newly synthesized protein).
-
Cesium Chloride Gradient Centrifugation: To definitively separate "heavy" and "light" ribosomes, subject the ribosome-containing fractions to equilibrium density gradient centrifugation in a CsCl gradient.
-
Data Interpretation: The results showed that the pulse-labeled ³²P-RNA (the messenger) was associated with the "heavy" 70S ribosomes, which were synthesized before the infection. This demonstrated that new ribosomes were not synthesized after infection and that the pre-existing host ribosomes were used to translate the viral message.
The Nirenberg and Matthaei In Vitro Protein Synthesis System
This system was instrumental in deciphering the genetic code, a direct consequence of the discovery of mRNA.
Objective: To synthesize proteins in a cell-free system using a synthetic mRNA template.
Materials:
-
E. coli cell extract (containing ribosomes, tRNAs, aminoacyl-tRNA synthetases, and other necessary factors for translation).
-
ATP and GTP as energy sources.
-
A mixture of all 20 amino acids, with one being radioactively labeled (e.g., [¹⁴C]phenylalanine).
-
Synthetic poly-uridylic acid (poly-U) as the artificial mRNA.
-
TCA for protein precipitation.
Protocol:
-
Preparation of Cell-Free Extract: Grow E. coli cells, harvest them, and lyse them to release the cytoplasmic contents. Centrifuge the lysate to remove cell debris, DNA, and endogenous mRNA.
-
In Vitro Translation Reaction: Set up a reaction mixture containing the cell-free extract, ATP, GTP, the mixture of amino acids (with one being radioactive), and the synthetic poly-U mRNA.
-
Incubation: Incubate the reaction mixture at 37°C to allow protein synthesis to occur.
-
Protein Precipitation: Stop the reaction by adding hot TCA to precipitate the newly synthesized proteins.
-
Analysis: Filter the precipitate and measure the radioactivity.
Visualizing the Discovery: Pathways and Workflows
The following diagrams, generated using the DOT language, illustrate the key conceptual and experimental frameworks in the discovery of mRNA.
References
- 1. PrimoVeNde [librarysearch.library.utoronto.ca]
- 2. Enterobacteria phage T2 - Wikipedia [en.wikipedia.org]
- 3. References - RNA, the Epicenter of Genetic Information - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 4. nobel.ornl.gov [nobel.ornl.gov]
- 5. Discovery of messenger RNA in 1961 [pasteur.fr]
- 6. An unstable intermediate carrying information from genes to ribosomes for protein synthesis - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. François Gros: from antibiotics to messenger RNA [comptes-rendus.academie-sciences.fr]
- 8. norkinvirology.wordpress.com [norkinvirology.wordpress.com]
- 9. Genetic regulatory mechanisms in the synthesis of proteins - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. mun.ca [mun.ca]
- 11. Jacob, F. and Monod, J. (1961) Genetic Regulatory Mechanisms in the Synthesis of Proteins. Journal of Molecular Biology, 3, 318-356. - References - Scientific Research Publishing [scirp.org]
- 12. gs.washington.edu [gs.washington.edu]
The Architecture and Orchestration of Eukaryotic Messenger RNA: A Technical Guide for Researchers and Drug Development Professionals
Introduction
Eukaryotic messenger RNA (mRNA) stands as a central molecule in the flow of genetic information, acting as the transient blueprint for protein synthesis. Its intricate structure and the highly regulated processes it undergoes are fundamental to cellular function and homeostasis. For researchers, scientists, and professionals in drug development, a deep understanding of mRNA's lifecycle—from its synthesis and processing to its translation and ultimate decay—is paramount for the innovation of novel therapeutics, including mRNA-based vaccines and therapies. This technical guide provides an in-depth exploration of the core structural and functional aspects of eukaryotic mRNA, complete with quantitative data, detailed experimental protocols, and visual representations of key molecular pathways and workflows.
The Structural Anatomy of Eukaryotic mRNA
A mature eukaryotic mRNA molecule is a meticulously crafted entity, with distinct structural elements that govern its stability, transport, and translational efficiency. These key features include the 5' cap, the 5' untranslated region (UTR), the coding sequence (CDS), the 3' untranslated region (UTR), and the poly(A) tail.
The 5' Cap: A Sentinel for Stability and Translation
At the 5' terminus of every eukaryotic mRNA lies a unique cap structure, which consists of a 7-methylguanosine (B147621) (m7G) nucleotide linked to the first transcribed nucleotide via an unusual 5'-5' triphosphate bridge.[1] This cap is added co-transcriptionally and serves several critical functions: it protects the mRNA from degradation by 5' exonucleases, facilitates its export from the nucleus, and is essential for the recruitment of the ribosomal machinery to initiate translation.[1][2][3]
The cap structure can undergo further modifications. The 2'-hydroxyl group of the first and second nucleotides can be methylated, giving rise to Cap1 and Cap2 structures, respectively.[1][4] While Cap0 (unmethylated) is found in some lower eukaryotes, Cap1 is a hallmark of metazoan mRNA.[3][4] The transition from Cap1 to Cap2 appears to be a slower process that occurs as mRNAs age in the cytoplasm, and this modification can influence how the innate immune system distinguishes self from non-self RNA.[5][6]
Untranslated Regions (UTRs): Hubs of Post-Transcriptional Regulation
Flanking the protein-coding sequence are the 5' and 3' untranslated regions (UTRs), which do not encode for the final protein product but contain a plethora of regulatory elements.
-
5' Untranslated Region (5' UTR): Located between the 5' cap and the start codon, the 5' UTR plays a crucial role in the regulation of translation initiation. It can contain secondary structures, such as stem-loops and upstream open reading frames (uORFs), that can modulate the efficiency of ribosome scanning and start codon recognition.[7][8]
-
3' Untranslated Region (3' UTR): The 3' UTR, situated between the stop codon and the poly(A) tail, is a key platform for post-transcriptional gene regulation. It harbors binding sites for microRNAs (miRNAs) and RNA-binding proteins (RBPs) that influence mRNA stability, localization, and translational activity.[7][9] The length of the 3' UTR can vary through alternative polyadenylation, providing another layer of regulatory complexity.[9][10]
The Coding Sequence (CDS): The Blueprint for Protein Synthesis
The coding sequence, or open reading frame (ORF), carries the genetic code in the form of codons, triplets of nucleotides that specify the sequence of amino acids in the resulting polypeptide chain. The length of the CDS is directly proportional to the size of the protein it encodes.
The Poly(A) Tail: A Dynamic Regulator of mRNA Fate
At the 3' end of most eukaryotic mRNAs is a long stretch of adenosine (B11128) monophosphate residues known as the poly(A) tail. This tail is not encoded in the DNA but is added post-transcriptionally by the enzyme poly(A) polymerase. The poly(A) tail is crucial for mRNA stability, nuclear export, and translation initiation.[11][12][13] The length of the poly(A) tail is dynamic and can be modulated in the cytoplasm, influencing the lifespan and translational status of the mRNA.[13][14][15]
Quantitative Characteristics of Eukaryotic mRNA
The structural features of eukaryotic mRNA exhibit considerable variation in length, which is often linked to their regulatory potential. The following table summarizes typical quantitative data for human mRNA.
| Feature | Average Length (nucleotides) | Range (nucleotides) | Key Functions |
| 5' UTR | ~150 - 218[7][14][16][17] | single digits to several thousands[8] | Regulation of translation initiation, ribosome recruitment |
| Coding Sequence (CDS) | ~1,346[18] | Varies greatly depending on the encoded protein | Template for protein synthesis |
| 3' UTR | ~350 - 1,278[10][17] | Varies widely | mRNA stability, localization, and translational control |
| Poly(A) Tail | ~250 (in mammals)[10][19] | ~70-90 (in yeast)[13][19] to >250 (in mammals)[14] | mRNA stability, nuclear export, translation enhancement |
The Lifecycle of Eukaryotic mRNA: Key Signaling Pathways
The journey of an mRNA molecule from a gene to a protein is a highly regulated process involving several intricate signaling pathways.
mRNA Processing and Splicing
In the nucleus, newly transcribed pre-mRNAs undergo several processing steps to become mature mRNAs. This includes the addition of the 5' cap and the poly(A) tail. A crucial step for most eukaryotic pre-mRNAs is splicing, where non-coding intervening sequences (introns) are removed, and the coding sequences (exons) are joined together. This process is carried out by a large ribonucleoprotein complex called the spliceosome.
mRNA Nuclear Export
Mature mRNAs must be exported from the nucleus to the cytoplasm for translation. This process is mediated by a complex machinery that recognizes and transports export-competent mRNP (messenger ribonucleoprotein) complexes through the nuclear pore complexes (NPCs). The TREX (TRanscription-EXport) complex plays a key role in coupling transcription, splicing, and nuclear export. The export receptor NXF1-NXT1 binds to the mRNP and facilitates its translocation through the NPC.[20][21][22][23][24]
Eukaryotic Translation Initiation
Translation initiation in eukaryotes is a complex process that begins with the formation of the 43S pre-initiation complex (PIC), which includes the small ribosomal subunit (40S), initiator tRNA (Met-tRNAi), and several eukaryotic initiation factors (eIFs). The PIC is recruited to the 5' cap of the mRNA by the eIF4F complex. The PIC then scans the 5' UTR until it recognizes the start codon (AUG), at which point the large ribosomal subunit (60S) joins to form the 80S initiation complex, ready for protein synthesis.[16][17][20][25][26]
mRNA Decay Pathways
The lifespan of an mRNA molecule is tightly controlled, and its degradation is a key aspect of gene regulation. The major pathway for mRNA decay in eukaryotes is the deadenylation-dependent pathway. This process begins with the gradual shortening of the poly(A) tail by deadenylases. Once the tail is sufficiently short, the mRNA can be degraded by two main routes: 5'-to-3' decay, which involves removal of the 5' cap (decapping) followed by exonucleolytic degradation, or 3'-to-5' decay, carried out by the exosome complex.[2][9][25][27][28]
Experimental Protocols for mRNA Analysis
A variety of molecular biology techniques are employed to study the structure, function, and expression of eukaryotic mRNA. Below are detailed methodologies for key experiments.
mRNA Isolation and Purification
Principle: Total RNA is first isolated from cells or tissues. Subsequently, mRNA is purified from the total RNA population by exploiting the affinity of its poly(A) tail for oligo(dT) sequences.
Protocol for Total RNA Isolation from Mammalian Cells: [8][27]
-
Cell Lysis: Lyse cultured mammalian cells directly in the culture dish or after pelleting by adding a monophasic solution of phenol (B47542) and guanidine (B92328) isothiocyanate (e.g., TRIzol reagent). This reagent disrupts cells and denatures proteins while maintaining RNA integrity.
-
Phase Separation: Add chloroform (B151607) to the lysate and centrifuge. This separates the mixture into an upper aqueous phase (containing RNA), an interphase (containing DNA), and a lower organic phase (containing proteins and lipids).
-
RNA Precipitation: Carefully transfer the aqueous phase to a fresh tube and precipitate the RNA by adding isopropanol.
-
RNA Wash: Pellet the RNA by centrifugation, discard the supernatant, and wash the pellet with 75% ethanol (B145695) to remove residual salts and contaminants.
-
RNA Solubilization: Air-dry the RNA pellet briefly and resuspend it in RNase-free water.
Protocol for Oligo(dT)-based mRNA Purification: [26][29][30][31][32][33]
-
Binding: Heat the total RNA sample at 65°C for 5 minutes to disrupt secondary structures, then place it on ice. Add a binding buffer containing a high salt concentration to the RNA and mix it with oligo(dT)-coated magnetic beads or cellulose. The high salt concentration facilitates the hybridization of the mRNA poly(A) tails to the oligo(dT) sequences.
-
Washing: Use a magnet or centrifugation to separate the beads with bound mRNA from the supernatant, which contains non-polyadenylated RNAs (like rRNA and tRNA). Wash the beads several times with a wash buffer to remove any remaining contaminants.
-
Elution: Resuspend the beads in a low-salt elution buffer or RNase-free water and heat at 70-80°C for 2 minutes. This disrupts the hybridization between the poly(A) tails and oligo(dT), releasing the purified mRNA into the solution.
-
Collection: Separate the beads from the eluate containing the purified mRNA.
In Vitro Transcription (IVT) of mRNA
Principle: In vitro transcription is a cell-free method to synthesize large quantities of RNA from a linearized DNA template containing a promoter for a specific RNA polymerase (e.g., T7, SP6).[1][10][11][34][35][36]
Protocol for In Vitro Transcription: [37]
-
Template Preparation: A linearized plasmid DNA or a PCR product containing the gene of interest downstream of a T7 RNA polymerase promoter is used as a template. The template should also include sequences for the 5' and 3' UTRs and a poly(A) tail.
-
Transcription Reaction Setup: In a sterile, RNase-free tube, combine the linearized DNA template, T7 RNA polymerase, ribonucleoside triphosphates (NTPs: ATP, GTP, CTP, UTP), a cap analog (if co-transcriptional capping is desired), and a transcription buffer.
-
Incubation: Incubate the reaction mixture at 37°C for 2-4 hours.
-
DNase Treatment: After incubation, add DNase I to the reaction to digest the DNA template.
-
RNA Purification: Purify the synthesized mRNA using lithium chloride precipitation or a column-based method to remove unincorporated nucleotides, enzymes, and salts.
Northern Blotting
Principle: Northern blotting is a technique used to detect and quantify specific RNA molecules in a complex sample. It involves separating RNA by size via gel electrophoresis, transferring it to a membrane, and then hybridizing it with a labeled probe complementary to the target RNA sequence.[29][38][39][40]
Protocol for Northern Blotting:
-
RNA Electrophoresis: Separate total RNA or purified mRNA samples on a denaturing agarose (B213101) gel containing formaldehyde. This ensures that the RNA molecules are separated based on their size.
-
Transfer: Transfer the separated RNA from the gel to a positively charged nylon or nitrocellulose membrane via capillary action or vacuum blotting.
-
Fixation: Fix the RNA to the membrane by UV cross-linking or baking.
-
Pre-hybridization (Blocking): Incubate the membrane in a pre-hybridization solution to block non-specific binding sites.
-
Hybridization: Incubate the membrane with a labeled single-stranded DNA or RNA probe that is complementary to the target mRNA sequence.
-
Washing: Wash the membrane to remove any unbound or non-specifically bound probe.
-
Detection: Detect the labeled probe using autoradiography (for radioactive probes) or chemiluminescence (for non-radioactive probes) to visualize the band corresponding to the target mRNA.
Reverse Transcription Quantitative PCR (RT-qPCR)
Principle: RT-qPCR is a highly sensitive and specific method for quantifying mRNA levels. It involves two main steps: reverse transcription of mRNA into complementary DNA (cDNA), followed by quantitative PCR (qPCR) to amplify and quantify the amount of a specific cDNA target in real-time.[1]
Protocol for RT-qPCR:
-
RNA Isolation and DNase Treatment: Isolate high-quality total RNA and treat it with DNase I to remove any contaminating genomic DNA.
-
Reverse Transcription (RT): Synthesize first-strand cDNA from the RNA template using a reverse transcriptase enzyme and primers (oligo(dT) primers, random hexamers, or gene-specific primers).
-
Quantitative PCR (qPCR): Set up a qPCR reaction containing the cDNA template, gene-specific forward and reverse primers, a DNA polymerase, and a fluorescent dye (e.g., SYBR Green) or a fluorescently labeled probe (e.g., TaqMan probe).
-
Thermal Cycling and Detection: Perform the qPCR in a real-time PCR thermal cycler, which monitors the fluorescence signal in each cycle. The cycle at which the fluorescence crosses a certain threshold (the quantification cycle, Cq) is inversely proportional to the initial amount of the target cDNA.
-
Data Analysis: Quantify the relative or absolute amount of the target mRNA by comparing the Cq values of the sample to those of a reference gene or a standard curve.
Conclusion and Future Directions
The study of eukaryotic mRNA continues to be a vibrant and rapidly evolving field. From the fundamental principles of its structure and function to its application in cutting-edge therapeutics, mRNA holds immense potential for advancing our understanding of biology and medicine. The methodologies and pathways detailed in this guide provide a solid foundation for researchers and drug development professionals. As our knowledge deepens, particularly in the areas of mRNA modifications (the epitranscriptome) and the intricate regulatory networks that govern mRNA fate, we can anticipate the development of even more sophisticated and targeted mRNA-based technologies to address a wide range of diseases.
References
- 1. What Are the Key Steps in RT-qPCR Workflow? [synapse.patsnap.com]
- 2. Mechanisms of deadenylation-dependent decay - PMC [pmc.ncbi.nlm.nih.gov]
- 3. academic.oup.com [academic.oup.com]
- 4. Frontiers | The expanding role of cap-adjacent modifications in animals [frontiersin.org]
- 5. mRNA ageing shapes the Cap2 methylome in mammalian mRNA - PMC [pmc.ncbi.nlm.nih.gov]
- 6. semanticscholar.org [semanticscholar.org]
- 7. Functional 5′ UTR mRNA structures in eukaryotic translation regulation and how to find them - PMC [pmc.ncbi.nlm.nih.gov]
- 8. azolifesciences.com [azolifesciences.com]
- 9. researchgate.net [researchgate.net]
- 10. researchgate.net [researchgate.net]
- 11. researchgate.net [researchgate.net]
- 12. researchgate.net [researchgate.net]
- 13. researchgate.net [researchgate.net]
- 14. Average lengths of mRNA UTR (UnTranslated Reg - Eukaryotes - BNID 112128 [bionumbers.hms.harvard.edu]
- 15. Average gene length - Various - BNID 111922 [bionumbers.hms.harvard.edu]
- 16. researchgate.net [researchgate.net]
- 17. researchgate.net [researchgate.net]
- 18. mRNA nuclear export at a glance - PMC [pmc.ncbi.nlm.nih.gov]
- 19. researchgate.net [researchgate.net]
- 20. Nuclear export of mRNA | PDF [slideshare.net]
- 21. Reactome | Deadenylation-dependent mRNA decay [reactome.org]
- 22. assets.fishersci.com [assets.fishersci.com]
- 23. Mechanisms of deadenylation-dependent decay - PubMed [pubmed.ncbi.nlm.nih.gov]
- 24. Frontiers | Structure and function of molecular machines involved in deadenylation-dependent 5′-3′ mRNA degradation [frontiersin.org]
- 25. goldbio.com [goldbio.com]
- 26. cdn.elifesciences.org [cdn.elifesciences.org]
- 27. dcvmn.org [dcvmn.org]
- 28. apexbt.com [apexbt.com]
- 29. lifesciences.danaher.com [lifesciences.danaher.com]
- 30. researchgate.net [researchgate.net]
- 31. documents.thermofisher.com [documents.thermofisher.com]
- 32. dokumente.ub.tu-clausthal.de [dokumente.ub.tu-clausthal.de]
- 33. azurebiosystems.com [azurebiosystems.com]
- 34. news-medical.net [news-medical.net]
- 35. m.youtube.com [m.youtube.com]
- 36. mybiosource.com [mybiosource.com]
- 37. Brief guide to RT-qPCR - PMC [pmc.ncbi.nlm.nih.gov]
- 38. Real-Time PCR RNA Quantification Workflow | Thermo Fisher Scientific - SG [thermofisher.com]
- 39. Quantification of mRNA using real-time RT-PCR | Springer Nature Experiments [experiments.springernature.com]
- 40. gene-quantification.de [gene-quantification.de]
An In-depth Technical Guide to Messenger RNA (mRNA), Transfer RNA (tRNA), and Ribosomal RNA (rRNA)
For Researchers, Scientists, and Drug Development Professionals
This technical guide provides a comprehensive overview of the three primary types of ribonucleic acid (RNA) central to molecular biology and drug development: messenger RNA (mRNA), transfer RNA (tRNA), and ribosomal RNA (rRNA). We will delve into their distinct structures, functions, and key quantitative differences, supplemented with detailed experimental protocols and visual representations of core biological processes.
Core Differences in RNA Species
The central dogma of molecular biology outlines the flow of genetic information from DNA to RNA to protein.[1][2] Within this framework, mRNA, tRNA, and rRNA play distinct and indispensable roles in the intricate process of protein synthesis.
Messenger RNA (mRNA) acts as the intermediary molecule that carries genetic information from the DNA in the nucleus to the ribosomes in the cytoplasm.[3] It is a single-stranded molecule whose sequence is complementary to the DNA template from which it is transcribed.[4] The sequence of an mRNA molecule is read in codons, which are sets of three nucleotides that specify a particular amino acid.[5] In eukaryotes, mRNA molecules undergo significant post-transcriptional modifications, including the addition of a 5' cap and a 3' poly-A tail, which are crucial for their stability and recognition by the translational machinery.[6]
Transfer RNA (tRNA) serves as the adaptor molecule that translates the language of nucleotides into the language of amino acids.[3] Each tRNA molecule has a specific anticodon loop that recognizes and binds to a complementary codon on the mRNA.[7] At its 3' end, the tRNA is covalently linked to a specific amino acid that corresponds to the mRNA codon.[7] This unique structure allows tRNA to accurately deliver the correct amino acids to the ribosome for incorporation into the growing polypeptide chain.[3] tRNAs are relatively small and exhibit a characteristic cloverleaf secondary structure and an L-shaped tertiary structure.[6][7]
Ribosomal RNA (rRNA) is the most abundant type of RNA in the cell and is a structural and catalytic component of ribosomes, the cellular machinery responsible for protein synthesis.[5][8] rRNAs associate with ribosomal proteins to form the large and small ribosomal subunits.[9] Within the ribosome, rRNA plays a crucial role in catalyzing the formation of peptide bonds between amino acids, a function that has led to the ribosome being termed a "ribozyme."[10] It also helps in the correct positioning of the mRNA and tRNAs during translation.[10]
Quantitative Data Summary
The following table summarizes key quantitative characteristics of mRNA, tRNA, and rRNA in mammalian cells, providing a comparative overview for researchers.
| Characteristic | Messenger RNA (mRNA) | Transfer RNA (tRNA) | Ribosomal RNA (rRNA) |
| Cellular Abundance (by mass) | ~5% of total RNA[5] | ~15% of total RNA[11] | ~80% of total RNA[5] |
| Size (nucleotides) | Highly variable, typically 300 - 12,000 nt[6] | 75 - 95 nt[5] | Varies by subunit: 18S (~1,900 nt), 5.8S (~160 nt), 28S (~5,000 nt), 5S (~120 nt)[12] |
| Lifespan/Half-life | Highly variable, from minutes to days[10] | Relatively long and stable | Very long and stable |
| Copies per Cell | ~500,000 molecules (highly variable by gene)[11] | Molar level is higher than rRNA due to small size[11] | Constitutes the bulk of cellular RNA[11] |
Mandatory Visualizations
To visually represent the core concepts discussed, the following diagrams have been generated using Graphviz (DOT language).
Caption: The Central Dogma of Molecular Biology.
Caption: The Process of Translation within the Ribosome.
Caption: A Generalized Experimental Workflow for RNA-Seq.
Experimental Protocols
This section provides detailed methodologies for key experiments cited in the study of RNA.
Northern Blotting for mRNA Detection
Northern blotting is a classic technique used to detect and quantify specific mRNA molecules in a sample.[13]
1. RNA Extraction and Quantification:
-
Extract total RNA from cells or tissues using a suitable method (e.g., Trizol reagent).
-
Assess RNA integrity and quantity using a spectrophotometer and gel electrophoresis.
2. Gel Electrophoresis:
-
Prepare a denaturing agarose (B213101) gel (e.g., with formaldehyde) to prevent RNA secondary structures.[14]
-
Load equal amounts of RNA samples into the gel wells.
-
Run the gel to separate RNA molecules based on size.[15]
3. Transfer to Membrane:
-
Transfer the separated RNA from the gel to a positively charged nylon membrane via capillary action or electroblotting.[13]
-
Crosslink the RNA to the membrane using UV light or baking.[15]
4. Probe Hybridization:
-
Prepare a labeled nucleic acid probe (DNA or RNA) that is complementary to the target mRNA sequence.
-
Pre-hybridize the membrane to block non-specific binding sites.
-
Hybridize the membrane with the labeled probe overnight in a hybridization buffer at a specific temperature.[15]
5. Washing and Detection:
-
Wash the membrane under stringent conditions to remove unbound and non-specifically bound probes.[16]
-
Detect the labeled probe using an appropriate method (e.g., autoradiography for radioactive probes, chemiluminescence for non-radioactive probes).
Ribosome Profiling (Ribo-Seq)
Ribosome profiling is a high-throughput sequencing technique that provides a "snapshot" of the ribosomes actively translating mRNAs in a cell at a given moment.[17]
1. Cell Lysis and Ribosome-Protected Fragment (RPF) Generation:
-
Treat cells with a translation inhibitor (e.g., cycloheximide) to arrest ribosomes on the mRNA.
-
Lyse the cells under conditions that maintain the integrity of ribosome-mRNA complexes.
-
Digest the lysate with RNase I to degrade mRNA regions not protected by ribosomes, leaving behind RPFs.[18]
2. Ribosome Isolation:
-
Isolate the monosomes (single ribosomes bound to mRNA) by sucrose (B13894) density gradient centrifugation or size-exclusion chromatography.[17][19]
3. RPF Extraction:
-
Extract the RPFs from the isolated monosomes.
4. Library Preparation for Sequencing:
-
Dephosphorylate the 3' ends of the RPFs.
-
Ligate a pre-adenylated linker to the 3' ends.
-
Reverse transcribe the RPFs into cDNA.
-
Circularize the cDNA.
-
Amplify the library by PCR.[18]
5. Sequencing and Data Analysis:
-
Sequence the prepared library using a next-generation sequencing platform.
-
Align the sequencing reads to a reference genome or transcriptome.
-
Analyze the density and position of the reads to determine which mRNAs are being translated and at what rate.
tRNA Sequencing using mim-tRNAseq
Modification-induced misincorporation tRNA sequencing (mim-tRNAseq) is a method designed to overcome the challenges of sequencing tRNAs, which are heavily modified and have extensive secondary structures.[20][21]
1. tRNA Isolation:
-
Isolate total RNA and enrich for small RNAs, including tRNAs.
2. 3' Deacylation and 3' Adapter Ligation:
-
Deacylate the 3' end of the tRNAs to remove any attached amino acids.
-
Ligate a specific adapter to the 3' end of the tRNAs.
3. Reverse Transcription with a Y-shaped Adapter:
-
Perform reverse transcription using a reverse transcriptase that can read through many of the modified bases in tRNA.
-
A Y-shaped adapter is ligated to the 3' end of the cDNA during reverse transcription.
4. Circularization and Library Amplification:
-
Circularize the resulting cDNA.
-
Amplify the library using PCR.
5. Sequencing and Data Analysis:
-
Sequence the library on a high-throughput sequencer.
-
Use a specialized bioinformatics pipeline to align the reads to a reference tRNA database, taking into account the misincorporations caused by modified bases.[22]
-
This allows for the quantification of tRNA abundance and the identification and quantification of tRNA modifications.[20]
References
- 1. Central dogma of molecular biology - Wikipedia [en.wikipedia.org]
- 2. How is DNA turned into protein? The Central Dogma of Molecular Biology [yourgenome.org]
- 3. mRNA vs. tRNA vs. rRNA: Key Differences and Roles in Cells [synapse.patsnap.com]
- 4. bio.libretexts.org [bio.libretexts.org]
- 5. news-medical.net [news-medical.net]
- 6. byjus.com [byjus.com]
- 7. quora.com [quora.com]
- 8. Types of RNA [ib.bioninja.com.au]
- 9. Translation (biology) - Wikipedia [en.wikipedia.org]
- 10. Messenger RNA half-life measurements in mammalian cells - PubMed [pubmed.ncbi.nlm.nih.gov]
- 11. researchgate.net [researchgate.net]
- 12. RNA size, molecular weight, yield, distribution and conversion | QIAGEN [qiagen.com]
- 13. Northern blot - Wikipedia [en.wikipedia.org]
- 14. Northern Blot [protocols.io]
- 15. bio-protocol.org [bio-protocol.org]
- 16. Modified Northern blot protocol for easy detection of mRNAs in total RNA using radiolabeled probes - PMC [pmc.ncbi.nlm.nih.gov]
- 17. Ribosome Profiling | Ribo-Seq/ART-Seq for ribosome-protected mRNA [illumina.com]
- 18. Ribosome Profiling Protocol - CD Genomics [cd-genomics.com]
- 19. Protocol for Ribosome Profiling in Bacteria [bio-protocol.org]
- 20. Experimental and computational workflow for the analysis of tRNA pools from eukaryotic cells by mim-tRNAseq - PubMed [pubmed.ncbi.nlm.nih.gov]
- 21. mim-tRNA sequencing | omiics.com [omiics.com]
- 22. GitHub - nedialkova-lab/mim-tRNAseq: Modification-induced misincorporation tRNA sequencing [github.com]
The Core Principles of mRNA Transcription and Translation: An In-depth Technical Guide
For Researchers, Scientists, and Drug Development Professionals
This technical guide provides a comprehensive overview of the fundamental principles of messenger RNA (mRNA) transcription and translation, two cornerstone processes in molecular biology that govern the expression of genetic information. This document delves into the intricate molecular mechanisms, key enzymatic players, and regulatory nuances that distinguish these processes in prokaryotic and eukaryotic organisms. Furthermore, it presents quantitative data for comparative analysis and details key experimental protocols utilized in the study of these essential cellular functions.
The Central Dogma: A Foundational Concept
The flow of genetic information in a biological system is articulated by the central dogma of molecular biology. This concept outlines the process by which the instructions encoded in DNA are transcribed into a mobile messenger molecule, mRNA, which is then translated to synthesize functional proteins. This unidirectional flow of information from DNA to RNA to protein is a fundamental principle governing all known life.
mRNA Transcription: Synthesizing the Messenger
Transcription is the process by which a segment of DNA is copied into a complementary RNA molecule, primarily mRNA, by the enzyme RNA polymerase. This process is the first step in gene expression and is tightly regulated.
The Stages of Transcription
Transcription is a dynamic process that can be divided into three principal stages: initiation, elongation, and termination.[1]
2.1.1. Initiation: The initiation of transcription begins with the binding of RNA polymerase to a specific DNA sequence known as a promoter, located near the start of a gene.[1] In prokaryotes, a single type of RNA polymerase is responsible for transcribing all genes.[2] The sigma (σ) factor, a subunit of the prokaryotic RNA polymerase, recognizes and binds to the -35 and -10 consensus sequences within the promoter.[3]
In eukaryotes, the process is more complex and involves three different RNA polymerases (I, II, and III), with RNA polymerase II being responsible for transcribing protein-coding genes into mRNA.[4] Eukaryotic transcription initiation requires the assembly of a complex of proteins called general transcription factors (GTFs) at the promoter.[5] These GTFs, such as TFIID which recognizes the TATA box, are essential for recruiting RNA polymerase II to form the pre-initiation complex.[5]
2.1.2. Elongation: Once RNA polymerase is securely bound to the promoter and the DNA double helix is unwound, the elongation phase commences. The polymerase moves along the template DNA strand, synthesizing a complementary pre-mRNA molecule in the 5' to 3' direction.[1] In prokaryotes, the sigma factor dissociates, allowing the core enzyme to proceed with transcription at a rate of approximately 40 nucleotides per second.[2][3][6][7] The characteristic elongation rates in both prokaryotes and eukaryotes are in the range of 10–100 nucleotides per second.[4]
2.1.3. Termination: Transcription concludes when the RNA polymerase encounters a termination signal in the DNA sequence. In prokaryotes, termination can occur through two primary mechanisms: Rho-dependent and Rho-independent termination.[7] Rho-dependent termination involves the Rho protein, which moves along the nascent RNA and causes its dissociation from the polymerase.[7] Rho-independent termination is mediated by a stable hairpin structure that forms in the nascent RNA, followed by a string of uracil (B121893) residues, which destabilizes the RNA-DNA hybrid.[8]
Eukaryotic termination is more complex and is coupled with mRNA processing.[5] For genes transcribed by RNA polymerase II, termination involves the recognition of a polyadenylation signal in the nascent RNA, leading to cleavage of the transcript and the subsequent addition of a poly-A tail.[8]
Eukaryotic mRNA Processing
In eukaryotic cells, the newly synthesized pre-mRNA molecule undergoes several processing steps before it can be exported from the nucleus and translated into a protein.[4][9] These modifications increase the stability of the mRNA and are crucial for its proper translation. The typical lifespan of a eukaryotic mRNA is several hours, whereas a prokaryotic mRNA lasts no more than five seconds.[10][11]
The three main processing events are:
-
5' Capping: A modified guanine (B1146940) nucleotide, called a 7-methylguanosine (B147621) cap, is added to the 5' end of the pre-mRNA.[10][11] This cap protects the mRNA from degradation by exonucleases and is recognized by the ribosome during the initiation of translation.[10][11]
-
3' Polyadenylation: A string of approximately 200 adenine (B156593) nucleotides, known as the poly-A tail, is added to the 3' end of the pre-mRNA by the enzyme poly-A polymerase.[10][11] The poly-A tail also protects the mRNA from degradation and is involved in the initiation of translation.[10][11]
-
Splicing: Eukaryotic genes contain non-coding regions called introns, which are interspersed among the coding regions, or exons.[10] During splicing, the introns are removed from the pre-mRNA by a large RNA-protein complex called the spliceosome, and the exons are joined together to form a continuous coding sequence.[10][11]
mRNA Translation: From Codons to Proteins
Translation is the process by which the genetic information encoded in mRNA is used to synthesize a polypeptide chain, which then folds into a functional protein. This intricate process is carried out by ribosomes, which are complex molecular machines composed of ribosomal RNA (rRNA) and proteins.[7][12]
The Ribosome: The Site of Protein Synthesis
Ribosomes are the cellular machinery responsible for protein synthesis.[7][12] They are composed of two subunits, a large and a small subunit, which come together on an mRNA molecule to initiate translation.[7][13] Ribosomes have three binding sites for transfer RNA (tRNA) molecules: the A (aminoacyl) site, the P (peptidyl) site, and the E (exit) site.[13][14] The A site binds an incoming aminoacyl-tRNA, the P site holds the tRNA carrying the growing polypeptide chain, and the E site is where the uncharged tRNA exits the ribosome.[13][14]
The Stages of Translation
Similar to transcription, translation is a three-stage process: initiation, elongation, and termination.[2][14][15][16][17]
3.2.1. Initiation: Translation initiation begins with the assembly of the ribosomal subunits, the mRNA template, and a special initiator tRNA that carries the amino acid methionine.[14][15] In prokaryotes, the small ribosomal subunit binds to the Shine-Dalgarno sequence on the mRNA, which is located just upstream of the AUG start codon.[18] In eukaryotes, the small ribosomal subunit, along with initiation factors, recognizes and binds to the 5' cap of the mRNA and then scans downstream until it encounters the first AUG start codon.[14]
3.2.2. Elongation: The elongation cycle involves the sequential addition of amino acids to the growing polypeptide chain.[15] An aminoacyl-tRNA with an anticodon complementary to the mRNA codon in the A site binds to the ribosome.[14] A peptide bond is then formed between the amino acid on the A-site tRNA and the growing polypeptide chain attached to the P-site tRNA.[19] The ribosome then translocates one codon down the mRNA, moving the tRNA from the A site to the P site, and the tRNA from the P site to the E site, from where it is released.[2] This cycle repeats for each codon in the mRNA.
3.2.3. Termination: Translation is terminated when the ribosome encounters a stop codon (UAA, UAG, or UGA) in the mRNA.[14][15] Release factors, which are proteins that recognize the stop codons, bind to the A site.[14][19] This binding triggers the hydrolysis of the bond between the polypeptide chain and the tRNA in the P site, releasing the newly synthesized protein.[15] The ribosomal subunits then dissociate from the mRNA.[2]
Quantitative Data Summary
The rates and fidelity of transcription and translation are critical parameters that influence gene expression levels and the integrity of the resulting proteins.
| Parameter | Process | Organism/System | Rate/Fidelity |
| Elongation Rate | Transcription | Prokaryotes (E. coli) | ~40-80 nucleotides/second[2][20] |
| Transcription | Eukaryotes | ~10-100 nucleotides/second[4] | |
| Translation | Prokaryotes (E. coli) | ~12-21 amino acids/second[19] | |
| Translation | Eukaryotes | ~1-8 amino acids/second[21] | |
| Fidelity (Error Rate) | Transcription | Eukaryotes | ~1 in 104 nucleotides[5] |
| Translation | Eukaryotes | ~1 in 103 to 104 amino acids[5] |
Key Experimental Protocols
The study of transcription and translation relies on a variety of powerful experimental techniques. Below are detailed methodologies for three key assays.
In Vitro Transcription using T7 RNA Polymerase
This protocol describes the synthesis of RNA from a DNA template using T7 RNA polymerase.
Methodology:
-
Template Preparation:
-
Transcription Reaction Setup:
-
DNase Treatment and RNA Purification:
-
Add DNase I to the reaction and incubate at 37°C for 15-30 minutes to digest the DNA template.[12]
-
Purify the RNA using phenol/chloroform extraction and ethanol (B145695) precipitation or a column-based RNA purification kit.[12][23]
-
-
Analysis:
-
Analyze the transcript size and integrity by denaturing agarose (B213101) or polyacrylamide gel electrophoresis.
-
Ribosome Profiling
Ribosome profiling (Ribo-Seq) is a technique used to obtain a genome-wide snapshot of translation by sequencing ribosome-protected mRNA fragments.[10]
Methodology:
-
Cell Lysis and Ribosome Stalling:
-
Treat cells with a translation inhibitor, such as cycloheximide, to stall ribosomes on the mRNA.[15]
-
Lyse the cells under conditions that preserve ribosome-mRNA complexes.
-
-
Nuclease Digestion:
-
Treat the cell lysate with a nuclease (e.g., RNase I) to digest all RNA that is not protected by the ribosomes.
-
-
Monosome Isolation:
-
Isolate the monosomes (single ribosomes bound to mRNA fragments) by sucrose (B13894) gradient centrifugation.[15]
-
-
RNA Extraction and Footprint Purification:
-
Extract the RNA from the isolated monosomes.
-
Purify the ribosome-protected footprints (typically 28-30 nucleotides in length) by denaturing polyacrylamide gel electrophoresis (PAGE).[14]
-
-
Library Preparation and Sequencing:
-
Ligate adapters to the 3' and 5' ends of the purified footprints.
-
Perform reverse transcription to convert the RNA footprints into cDNA.
-
Amplify the cDNA by PCR to generate a sequencing library.
-
Sequence the library using a high-throughput sequencing platform.
-
-
Data Analysis:
-
Align the sequencing reads to a reference genome or transcriptome to determine the positions of the ribosomes on the mRNAs.
-
Calculate ribosome density to infer the translation levels of different genes.
-
Dual-Luciferase Reporter Assay
The dual-luciferase reporter assay is a widely used method to study gene expression and regulation. It involves the sequential measurement of the activities of two different luciferases, firefly and Renilla, from a single sample.[9][16]
Methodology:
-
Cell Transfection:
-
Co-transfect cells with two plasmids:
-
An experimental reporter plasmid containing the firefly luciferase gene downstream of a promoter or regulatory element of interest.
-
A control reporter plasmid containing the Renilla luciferase gene under the control of a constitutive promoter.
-
-
-
Cell Lysis:
-
Luciferase Activity Measurement:
-
Data Analysis:
-
Normalize the firefly luciferase activity to the Renilla luciferase activity to account for variations in transfection efficiency and cell number.
-
The normalized reporter activity reflects the activity of the promoter or regulatory element of interest.
-
References
- 1. Translation elongation: measurements and applications - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Prokaryotic Transcription and Translation | Biology for Majors I [courses.lumenlearning.com]
- 3. bio.libretexts.org [bio.libretexts.org]
- 4. Transcription (biology) - Wikipedia [en.wikipedia.org]
- 5. Dynamic basis of fidelity and speed in translation: Coordinated multistep mechanisms of elongation and termination - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Prokaryotic Transcription – Biology [pressbooks-dev.oer.hawaii.edu]
- 7. bio.libretexts.org [bio.libretexts.org]
- 8. researchgate.net [researchgate.net]
- 9. Dual-Luciferase® Reporter Assay System [worldwide.promega.com]
- 10. researchgate.net [researchgate.net]
- 11. Translation Initiation Rate Determines the Impact of Ribosome Stalling on Bacterial Protein Synthesis - PMC [pmc.ncbi.nlm.nih.gov]
- 12. josephgroup.ucsd.edu [josephgroup.ucsd.edu]
- 13. RNAT7 < Lab < TWiki [barricklab.org]
- 14. Ribosome Profiling Protocol - CD Genomics [cd-genomics.com]
- 15. Protocol for Ribosome Profiling in Bacteria [bio-protocol.org]
- 16. Dual-Luciferase® Reporter Assay System Protocol [promega.com]
- 17. quora.com [quora.com]
- 18. Translation in Prokaryotes - PMC [pmc.ncbi.nlm.nih.gov]
- 19. Rate of translation by ribosome at 37°C as a - Bacteria Escherichia coli - BNID 100059 [bionumbers.hms.harvard.edu]
- 20. » What is faster, transcription or translation? [book.bionumbers.org]
- 21. Rate of ribosome progression in eukaryotic ce - Eukaryotes - BNID 107783 [bionumbers.hms.harvard.edu]
- 22. neb.com [neb.com]
- 23. content.protocols.io [content.protocols.io]
- 24. assaygenie.com [assaygenie.com]
- 25. Dual-Luciferase® Reporter (DLR) Assay [protocols.io]
Unraveling the Language of Life: An In-depth Technical Guide to mRNA Codons and the Genetic Code
For Researchers, Scientists, and Drug Development Professionals
This technical guide provides a comprehensive exploration of messenger RNA (mRNA) codons and the intricate system of the genetic code. From the foundational experiments that deciphered this biological language to the nuances of codon usage and the expansion of the canonical amino acid alphabet, this document serves as a detailed resource for professionals in the fields of molecular biology, drug development, and genetic engineering. The content herein is structured to offer both a deep historical context and a thorough understanding of the molecular mechanisms that govern protein synthesis, an essential process for life and a critical target for therapeutic intervention.
The Foundational Principles of the Genetic Code
The genetic code is the set of rules by which information encoded within genetic material (DNA or mRNA sequences) is translated into proteins by living cells. This code is nearly universal among all known organisms, a testament to its ancient origins. The fundamental unit of the genetic code is the codon , a sequence of three consecutive nucleotides in an mRNA molecule that specifies a particular amino acid or signals the termination of translation.[1] With four different nucleotides in mRNA (adenine, guanine, cytosine, and uracil), there are 4^3 or 64 possible codons. Of these, 61 codons specify one of the 20 standard amino acids, while the remaining three function as stop codons , signaling the termination of the polypeptide chain.[2][3] The codon AUG is the most common start codon , initiating protein synthesis and coding for the amino acid methionine.[4]
The flow of genetic information, often referred to as the central dogma of molecular biology, dictates that the genetic instructions in DNA are transcribed into mRNA, which is then translated into protein.
Elucidation of the Genetic Code: Key Experimental Breakthroughs
The cracking of the genetic code in the 1960s was a landmark achievement in molecular biology. This was accomplished through a series of ingenious experiments that laid the groundwork for our current understanding of protein synthesis.
The Nirenberg and Matthaei Experiment: Deciphering the First Codon
In 1961, Marshall Nirenberg and Heinrich Matthaei conducted a groundbreaking experiment that identified the first specific codon.[5] They utilized a cell-free system derived from E. coli that could synthesize proteins when provided with an mRNA template.[6] By adding a synthetic RNA molecule composed solely of uracil (B121893) (poly-U) to this system, they observed the synthesis of a polypeptide chain consisting exclusively of the amino acid phenylalanine.[7][8] This elegantly simple experiment demonstrated that the codon UUU specifies phenylalanine.[6]
Experimental Protocol: The Nirenberg and Matthaei Experiment
-
Preparation of the Cell-Free System (S30 Extract):
-
E. coli cells are cultured and harvested during the mid-logarithmic growth phase.
-
The cells are lysed, typically by grinding with alumina (B75360) or using a French press, to release the cellular contents.[9]
-
The cell lysate is then centrifuged at 30,000 x g to pellet cell debris, resulting in a supernatant known as the S30 extract.[10][11] This extract contains all the necessary components for translation, including ribosomes, tRNAs, aminoacyl-tRNA synthetases, and initiation and elongation factors.
-
DNase is added to the extract to degrade the endogenous bacterial DNA, ensuring that protein synthesis is solely dependent on the exogenously added mRNA.[9]
-
-
In Vitro Translation Reaction:
-
The S30 extract is supplemented with a mixture of all 20 amino acids, an energy source (ATP and GTP), and a system for regenerating ATP (such as creatine (B1669601) phosphate (B84403) and creatine kinase).[9]
-
In the initial experiment, one of the 20 amino acids was radioactively labeled (e.g., ¹⁴C-phenylalanine), while the other 19 were unlabeled.[12] This allowed for the detection of newly synthesized proteins.
-
The synthetic mRNA (e.g., poly-U) is added to the reaction mixture.[6]
-
The reaction is incubated at 37°C to allow for protein synthesis.
-
-
Analysis of the Translation Product:
-
After incubation, the proteins in the mixture are precipitated, typically with trichloroacetic acid (TCA).
-
The precipitate is collected on a filter, and the radioactivity of the filter is measured using a scintillation counter.
-
A significant increase in radioactivity in the tube containing the labeled amino acid and the synthetic mRNA, compared to a control without the synthetic mRNA, indicates that the synthetic mRNA directed the incorporation of that specific amino acid into a polypeptide.[12]
-
Har Gobind Khorana's Use of Repeating Polynucleotides
Building on Nirenberg's work, Har Gobind Khorana developed methods for the chemical synthesis of RNA molecules with defined repeating sequences.[13] This approach was instrumental in deciphering many of the remaining codons. For instance, a synthetic mRNA with a repeating dinucleotide sequence, such as (UC)n, would contain two alternating codons: UCU and CUC. The resulting polypeptide would consist of two alternating amino acids, in this case, serine and leucine.[14] By analyzing the amino acid sequence of the polypeptide produced from various repeating di-, tri-, and tetra-nucleotide RNA templates, Khorana and his team were able to deduce the amino acid assignments for a large number of codons.[14]
Experimental Protocol: Khorana's Repeating Polynucleotide Synthesis and Translation
-
Chemical Synthesis of Repeating Deoxyribopolynucleotides:
-
Short, single-stranded deoxyribonucleotides with defined repeating sequences (e.g., d(TC)n, d(TTC)n) were chemically synthesized using phosphodiester or phosphotriester chemistry. This involved the stepwise addition of protected nucleotides to a growing chain on a solid support.[4][15]
-
These short synthetic DNA strands were then used as templates for DNA polymerase to generate long, double-stranded DNA-like polymers with the same repeating sequence.[5]
-
-
In Vitro Transcription to Produce Repeating RNA:
-
The synthetic, double-stranded DNA with repeating sequences served as a template for RNA polymerase to synthesize long, single-stranded mRNA molecules with the corresponding repeating nucleotide sequence (e.g., (UC)n from d(AG)n:d(TC)n).[14]
-
-
In Vitro Translation and Polypeptide Analysis:
-
The synthetic repeating mRNA was used in a cell-free translation system, similar to that used by Nirenberg and Matthaei.
-
The resulting polypeptide was then purified and its amino acid composition and sequence were determined.
-
By correlating the repeating codon sequence of the mRNA with the repeating amino acid sequence of the polypeptide, the codon assignments could be deduced.
-
The Nirenberg and Leder Triplet Binding Assay
In 1964, Marshall Nirenberg and Philip Leder developed a more direct and efficient method for codon assignment known as the triplet binding assay.[3] They discovered that a single RNA trinucleotide (a three-nucleotide sequence) could bind to a ribosome and promote the binding of the specific tRNA molecule that recognized that codon.[3][16]
Experimental Protocol: The Nirenberg and Leder Filter-Binding Assay
-
Preparation of Components:
-
Ribosomes are isolated from E. coli.
-
tRNA is charged with a specific radioactively labeled amino acid. This is done for all 20 amino acids in separate experiments.
-
All 64 possible RNA trinucleotides are chemically synthesized.[16]
-
-
Binding Reaction:
-
A specific RNA trinucleotide is mixed with ribosomes and the charged, radiolabeled tRNA in a buffer solution.
-
The mixture is incubated to allow for the formation of a trinucleotide-ribosome-tRNA complex.[3]
-
-
Filtration and Detection:
-
The reaction mixture is passed through a nitrocellulose filter.[17]
-
Ribosomes and any associated molecules (the trinucleotide and the charged tRNA) are retained by the filter, while unbound, free tRNA passes through.[3]
-
The radioactivity of the filter is measured. A significantly radioactive filter indicates that the specific radiolabeled aminoacyl-tRNA was bound to the ribosome in the presence of the particular trinucleotide, thus establishing the codon-amino acid relationship.[17]
-
The Standard Genetic Code
Through the combined efforts of these and other researchers, the entire genetic code was deciphered by 1966. The standard genetic code is presented in the table below.
Table 1: The Standard Genetic Code
| 1st base | 2nd base | 3rd base | Amino Acid | Codon |
| U | U | U | Phenylalanine | UUU |
| C | Phenylalanine | UUC | ||
| A | Leucine | UUA | ||
| G | Leucine | UUG | ||
| C | U | Serine | UCU | |
| C | Serine | UCC | ||
| A | Serine | UCA | ||
| G | Serine | UCG | ||
| A | U | Tyrosine | UAU | |
| C | Tyrosine | UAC | ||
| A | STOP | UAA | ||
| G | STOP | UAG | ||
| G | U | Cysteine | UGU | |
| C | Cysteine | UGC | ||
| A | STOP | UGA | ||
| G | Tryptophan | UGG | ||
| C | U | U | Leucine | CUU |
| C | Leucine | CUC | ||
| A | Leucine | CUA | ||
| G | Leucine | CUG | ||
| C | U | Proline | CCU | |
| C | Proline | CCC | ||
| A | Proline | CCA | ||
| G | Proline | CCG | ||
| A | U | Histidine | CAU | |
| C | Histidine | CAC | ||
| A | Glutamine | CAA | ||
| G | Glutamine | CAG | ||
| G | U | Arginine | CGU | |
| C | Arginine | CGC | ||
| A | Arginine | CGA | ||
| G | Arginine | CGG | ||
| A | U | U | Isoleucine | AUU |
| C | Isoleucine | AUC | ||
| A | Isoleucine | AUA | ||
| G | Methionine | AUG | ||
| C | U | Threonine | ACU | |
| C | Threonine | ACC | ||
| A | Threonine | ACA | ||
| G | Threonine | ACG | ||
| A | U | Asparagine | AAU | |
| C | Asparagine | AAC | ||
| A | Lysine | AAA | ||
| G | Lysine | AAG | ||
| G | U | Serine | AGU | |
| C | Serine | AGC | ||
| A | Arginine | AGA | ||
| G | Arginine | AGG | ||
| G | U | U | Valine | GUU |
| C | Valine | GUC | ||
| A | Valine | GUA | ||
| G | Valine | GUG | ||
| C | U | Alanine | GCU | |
| C | Alanine | GCC | ||
| A | Alanine | GCA | ||
| G | Alanine | GCG | ||
| A | U | Aspartic Acid | GAU | |
| C | Aspartic Acid | GAC | ||
| A | Glutamic Acid | GAA | ||
| G | Glutamic Acid | GAG | ||
| G | U | Glycine | GGU | |
| C | Glycine | GGC | ||
| A | Glycine | GGA | ||
| G | Glycine | GGG |
Degeneracy and the Wobble Hypothesis
A key feature of the genetic code is its degeneracy , meaning that most amino acids are specified by more than one codon.[3] This redundancy is not random. In 1966, Francis Crick proposed the wobble hypothesis to explain this phenomenon.[12] The hypothesis states that while the first two bases of the codon form standard Watson-Crick base pairs with the corresponding bases of the tRNA anticodon, the base at the 5' end of the anticodon (which pairs with the 3' base of the codon) has some conformational freedom, or "wobble."[12][18] This allows a single tRNA species to recognize multiple codons that differ only in their third nucleotide.
The main wobble base pairings are:
-
G in the anticodon can pair with U or C in the codon.
-
U in the anticodon can pair with A or G in the codon.
-
Inosine (I), a modified purine (B94841) often found in the anticodon, can pair with U, C, or A in the codon.[12][18]
The thermodynamic stability of these wobble base pairs is comparable to that of standard Watson-Crick pairs.[19] This flexibility in base pairing reduces the number of tRNA species required to translate all 61 sense codons.
References
- 1. josephgroup.ucsd.edu [josephgroup.ucsd.edu]
- 2. academic.oup.com [academic.oup.com]
- 3. Nirenberg and Leder experiment - Wikipedia [en.wikipedia.org]
- 4. crchudequebec.ulaval.ca [crchudequebec.ulaval.ca]
- 5. ias.ac.in [ias.ac.in]
- 6. Nirenberg and Matthaei experiment - Wikipedia [en.wikipedia.org]
- 7. Cell-free protein synthesis, Marshall Nirenberg :: CSHL DNA Learning Center [dnalc.cshl.edu]
- 8. Video: In Vitro Synthesis of Modified mRNA for Induction of Protein Expression in Human Cells [jove.com]
- 9. mun.ca [mun.ca]
- 10. Preparation and testing of E. coli S30 in vitro transcription translation extracts - PubMed [pubmed.ncbi.nlm.nih.gov]
- 11. researchgate.net [researchgate.net]
- 12. Khan Academy [pl.khanacademy.org]
- 13. Experiments for Deciphering the Genetic Code, Contribution of Researchers [pw.live]
- 14. nobelprize.org [nobelprize.org]
- 15. blog.biosearchtech.com [blog.biosearchtech.com]
- 16. The RNA code: Nature’s Rosetta Stone - PMC [pmc.ncbi.nlm.nih.gov]
- 17. Read Lab: Researching Trypanosoma brucei | Protocols | Filter Binding Assay [acsu.buffalo.edu]
- 18. Wobble base pair - Wikipedia [en.wikipedia.org]
- 19. microbenotes.com [microbenotes.com]
The Discovery of Messenger RNA: A Technical Chronicle
Authored for Researchers, Scientists, and Drug Development Professionals
Introduction
The elucidation of the role of messenger RNA (mRNA) as the transient carrier of genetic information from DNA to the protein-synthesizing machinery of the cell was a watershed moment in molecular biology. This discovery, culminating in the early 1960s, laid the foundational framework for our contemporary understanding of gene expression and regulation. More recently, this fundamental knowledge has directly enabled the rapid development of novel therapeutic modalities, most notably mRNA-based vaccines. This in-depth guide provides a technical retrospective of the seminal experiments that unveiled the existence and function of mRNA, detailing the methodologies employed and the quantitative data that underpinned this paradigm shift. The key scientists at the forefront of this discovery were Elliot Volkin, Lazarus Astrachan, Sydney Brenner, François Jacob, Matthew Meselson, Marshall Nirenberg, and Heinrich Matthaei. Their collective work transformed a conceptual gap in the central dogma into a tangible molecular reality.
Foundational Insights: The Unstable RNA of Phage-Infected E. coli
In the mid-1950s, the mechanism by which the genetic blueprint encoded in nuclear DNA directed protein synthesis in the cytoplasm remained a critical unknown. A pivotal early observation came from the work of Elliot Volkin and Lazarus Astrachan, who investigated the metabolic fate of RNA in Escherichia coli upon infection with bacteriophage T2.[1]
The Volkin-Astrachan Experiment (1956)
Volkin and Astrachan's experiments revealed the synthesis of a metabolically distinct and unstable RNA species following phage infection. This RNA was characterized by a high turnover rate and a base composition that mirrored that of the phage DNA, not the host bacterium's DNA. This finding was the first substantive evidence for a transient RNA molecule directly transcribed from a gene.
The core of their methodology was a pulse-chase experiment designed to track the synthesis and degradation of RNA.
-
E. coli Culture and Phage Infection: A culture of E. coli was grown in a standard nutrient broth. The bacterial culture was then infected with T2 bacteriophage.
-
Pulse Labeling: Shortly after infection, a "pulse" of radioactive phosphate (B84403) (³²P) was introduced into the culture medium. This radioactive precursor was incorporated into any newly synthesized nucleic acids.
-
Chase: After a short labeling period, a "chase" of non-radioactive phosphate was added to the medium in a much higher concentration. This diluted the radioactive precursor pool, effectively halting the incorporation of ³²P into newly synthesized molecules.
-
RNA Isolation and Analysis: At various time points during the chase, samples of the bacterial culture were taken. The RNA was extracted and hydrolyzed to its constituent mononucleotides. The radioactivity of each nucleotide was then measured to determine the rate of RNA synthesis and its base composition.
The key quantitative finding from Volkin and Astrachan's work was the direct correlation between the base composition of the newly synthesized, short-lived RNA and the DNA of the infecting T2 phage.
| Nucleotide | Molar Ratios in T2 Phage DNA | Specific Activity Ratios in Newly Synthesized RNA |
| Adenine | 1.00 | 1.00 |
| Guanine | 0.85 | 0.85 |
| Cytosine | 0.70 | 0.72 |
| Thymine/Uracil | 1.00 | 0.97 |
Table 1: Comparison of the base composition of T2 phage DNA and the rapidly labeled RNA synthesized in E. coli post-infection. The data demonstrated that the newly synthesized RNA was a transcript of the phage genome.
The Definitive Demonstration: The Brenner-Jacob-Meselson Experiment
While the work of Volkin and Astrachan provided strong suggestive evidence, the definitive proof of messenger RNA's existence and function came in 1961 from the elegant experiment designed by Sydney Brenner, François Jacob, and Matthew Meselson.[2][3] Their experiment elegantly demonstrated that after phage infection, newly synthesized RNA (the "messenger") associates with pre-existing host cell ribosomes to direct the synthesis of phage proteins.
The Brenner-Jacob-Meselson Experiment (1961)
This experiment ingeniously combined isotope labeling with density gradient centrifugation to distinguish between newly synthesized and pre-existing cellular components.
-
E. coli Growth in "Heavy" Medium: E. coli were cultured for several generations in a medium containing heavy isotopes of carbon (¹³C) and nitrogen (¹⁵N). This resulted in all cellular components, including ribosomes, becoming isotopically labeled and therefore denser than normal.
-
Phage Infection and Transfer to "Light" Medium with Radioactive Label: The "heavy" bacteria were then infected with T2 bacteriophage and simultaneously transferred to a "light" medium containing the normal isotopes of carbon and nitrogen. This medium was supplemented with radioactive phosphate (³²P) to label newly synthesized RNA.
-
Cell Lysis and Ribosome Isolation: After a short period to allow for the synthesis of phage-specific RNA, the bacteria were lysed, and the ribosomes were isolated.
-
Cesium Chloride Density Gradient Centrifugation: The isolated ribosomes were subjected to ultracentrifugation in a cesium chloride (CsCl) density gradient. This technique separates molecules based on their density.
-
Analysis of the Gradient: The centrifuge tube was fractionated, and the amount of radioactivity (indicating newly synthesized RNA) and the optical density at 260 nm (indicating the position of ribosomes) were measured for each fraction.
The results of the Brenner-Jacob-Meselson experiment showed that the newly synthesized, radioactive RNA (labeled with ³²P) was associated with the "heavy" ribosomes (labeled with ¹³C and ¹⁵N) that were present before the phage infection. This demonstrated that new ribosomes were not synthesized after infection and that a messenger RNA molecule was responsible for carrying the genetic information to the existing ribosomes.
| Fraction Number | Ribosome Peak (A₂₆₀) | Radioactivity (counts/min) |
| ... | ... | ... |
| 10 | Low | Low |
| 15 | High (Heavy Ribosomes) | High |
| 20 | Low | Low |
| 25 | Low (Light Ribosomes - control) | Low |
| ... | ... | ... |
Table 2: A simplified representation of the data from the Brenner-Jacob-Meselson experiment. The peak of radioactivity from the newly synthesized RNA co-sedimented with the peak of absorbance for the pre-existing heavy ribosomes, indicating a physical association.
References
Monocistronic vs. Polycistronic mRNA in Prokaryotes: A Technical Guide
For Researchers, Scientists, and Drug Development Professionals
This guide provides an in-depth technical examination of monocistronic and polycistronic messenger RNA (mRNA) in prokaryotic organisms. We will explore the core distinctions in their structure, function, and translational regulation, with a focus on the implications for gene expression, metabolic engineering, and therapeutic development.
Core Concepts: Defining the Transcriptional Landscape in Prokaryotes
Prokaryotic gene expression is characterized by a remarkable efficiency, largely attributable to the organization of genes into operons. This arrangement gives rise to two distinct types of mRNA transcripts:
-
Monocistronic mRNA: This type of mRNA molecule contains the genetic blueprint for a single protein. It has one initiation codon and one termination codon, and its translation results in the synthesis of a single polypeptide chain. While less common in prokaryotes compared to polycistronic transcripts, they are essential for the expression of genes whose products are required under different conditions or in varying amounts from their neighbors.
-
Polycistronic mRNA: A hallmark of prokaryotic gene regulation, polycistronic mRNA is a single transcript that encodes for two or more proteins, often with related functions. This allows for the coordinated synthesis of all the proteins required for a specific metabolic pathway or cellular process from a single transcriptional event.[1][2][3][4][5][6][7] Each protein-coding region within a polycistronic mRNA is referred to as a cistron.
The fundamental difference lies in the number of open reading frames (ORFs) carried by a single mRNA molecule.[4][8] Eukaryotic mRNA is predominantly monocistronic, a feature that allows for more complex, multi-layered gene regulation.[9][10][11] In contrast, the polycistronic nature of prokaryotic mRNA underscores a strategy of genomic economy and rapid, coordinated response to environmental stimuli.[6][12][13]
Structural and Functional Comparison
The structural differences between monocistronic and polycistronic mRNA have profound functional consequences, particularly in the context of protein synthesis and gene regulation.
| Feature | Monocistronic mRNA | Polycistronic mRNA |
| Number of Cistrons | One | Two or more |
| Protein Product | A single polypeptide | Multiple, often functionally related, polypeptides |
| Translation Initiation | A single ribosome binding site (RBS) and start codon | Multiple ribosome binding sites and start codons, one for each cistron |
| Gene Organization | Transcribed from a single gene with its own promoter | Transcribed from an operon containing multiple genes under the control of a single promoter |
| Regulation | Independent regulation of gene expression | Coordinated regulation of all genes within the operon |
| Prevalence | Less common in prokaryotes, but used for specific genes | The predominant form of mRNA in prokaryotes |
Mechanisms of Translation Initiation on Polycistronic mRNA
Translation initiation in prokaryotes is a highly regulated process. On polycistronic transcripts, ribosomes must be able to initiate translation at internal cistrons. Several mechanisms facilitate this:
-
Independent Initiation: Each cistron within a polycistronic mRNA can have its own Shine-Dalgarno (SD) sequence, a ribosomal binding site, located upstream of the start codon. This allows for the independent recruitment of ribosomes and initiation of translation for each protein.
-
Translational Coupling: In some cases, the translation of a downstream cistron is dependent on the translation of the preceding one. This can occur through several mechanisms:
-
Stop-Start Codon Overlap: The stop codon of the upstream cistron may overlap with the start codon of the downstream cistron (e.g., AUGA). In this arrangement, the ribosome terminating translation of the first cistron is in close proximity to the start of the next, facilitating re-initiation.[14]
-
Ribosomal Re-initiation: After terminating translation of an upstream cistron, the 30S ribosomal subunit may remain associated with the mRNA and scan for a nearby downstream start codon to re-initiate translation.
-
The efficiency of translation for each cistron can vary, leading to differential protein expression levels from a single polycistronic transcript. This can be influenced by the strength of the SD sequence, the spacing between cistrons, and the secondary structure of the mRNA.
Experimental Protocols for Characterizing Prokaryotic mRNA
Distinguishing between monocistronic and polycistronic transcripts and quantifying their expression are fundamental tasks in microbial genetics and molecular biology.
Northern Blotting
Objective: To determine the size of an mRNA transcript and to identify if multiple genes are present on a single transcript.
Methodology:
-
RNA Extraction: Isolate total RNA from the prokaryotic organism of interest grown under specific conditions.
-
Denaturing Agarose (B213101) Gel Electrophoresis: Separate the RNA molecules by size on a denaturing agarose gel.
-
Transfer to Membrane: Transfer the separated RNA from the gel to a nylon or nitrocellulose membrane.
-
Probe Hybridization: Hybridize the membrane with a labeled nucleic acid probe specific for a gene of interest.
-
Detection: Detect the signal from the probe. The size of the band will indicate the size of the transcript.
-
Sequential Probing: Strip the first probe and re-hybridize with a probe for a second, adjacent gene. If both probes bind to the same band, it is strong evidence for a polycistronic transcript.
Reverse Transcription-Polymerase Chain Reaction (RT-PCR)
Objective: To determine if two or more genes are co-transcribed on the same mRNA molecule.
Methodology:
-
RNA Extraction and DNase Treatment: Isolate total RNA and treat with DNase to remove any contaminating genomic DNA.
-
Reverse Transcription: Synthesize complementary DNA (cDNA) from the RNA template using reverse transcriptase and a reverse primer that binds to the downstream gene.
-
PCR Amplification: Perform PCR using a forward primer that binds to the upstream gene and the same reverse primer used for cDNA synthesis.
-
Agarose Gel Electrophoresis: Analyze the PCR product on an agarose gel. The presence of a PCR product of the expected size spanning the intergenic region confirms that the two genes are on the same transcript.
Ribosome Profiling
Objective: To determine the translational status of all cistrons within a polycistronic mRNA.
Methodology:
-
Isolate Ribosome-mRNA Complexes: Treat cells with an inhibitor of translation elongation to "freeze" ribosomes on the mRNA. Lyse the cells and isolate the ribosome-mRNA complexes.
-
RNase Digestion: Treat the complexes with RNase to digest any mRNA not protected by the ribosome.
-
Isolate Ribosome-Protected Fragments: Isolate the ribosome-protected mRNA fragments (footprints).
-
Library Preparation and Deep Sequencing: Convert the footprints into a cDNA library and sequence them using next-generation sequencing.
-
Data Analysis: Align the sequencing reads to the genome to identify the precise locations of the ribosomes. The density of reads on each cistron provides a quantitative measure of its translation rate.
Visualizing Prokaryotic Gene Expression
The following diagrams illustrate the key concepts of monocistronic and polycistronic gene expression in prokaryotes.
Caption: Monocistronic mRNA Transcription and Translation.
Caption: Polycistronic mRNA Transcription and Translation.
Implications for Drug Development
The unique features of prokaryotic polycistronic mRNA present several opportunities for the development of novel antibacterial agents:
-
Targeting Translation Initiation: The reliance of prokaryotes on the Shine-Dalgarno sequence for translation initiation is a key difference from eukaryotes. Small molecules that specifically block the interaction between the 16S rRNA and the SD sequence could selectively inhibit bacterial protein synthesis.
-
Disrupting Translational Coupling: For operons that rely on translational coupling for the expression of essential downstream genes, compounds that prematurely terminate translation or disrupt ribosome re-initiation could effectively starve the cell of crucial proteins.
-
Targeting mRNA Stability: The stability of polycistronic mRNA can be influenced by the act of translation itself.[15] Ribosomes can protect the mRNA from degradation by ribonucleases. Drugs that cause ribosome stalling on a specific cistron could potentially expose downstream regions of the mRNA to degradation, leading to a polar effect on gene expression.
A thorough understanding of the mechanisms governing the transcription, translation, and decay of polycistronic mRNA is therefore essential for identifying and validating new antibacterial targets.
Conclusion
The dichotomy between monocistronic and polycistronic mRNA is a fundamental aspect of the divergence in gene expression strategies between prokaryotes and eukaryotes. The prevalence of polycistronic transcripts in prokaryotes reflects a need for rapid and coordinated adaptation to environmental changes. For researchers in the fields of microbiology, synthetic biology, and drug development, a deep appreciation of the intricacies of polycistronic mRNA is paramount for both fundamental discovery and the development of next-generation therapeutics.
References
- 1. majordifferences.com [majordifferences.com]
- 2. letstalkacademy.com [letstalkacademy.com]
- 3. difference.wiki [difference.wiki]
- 4. pediaa.com [pediaa.com]
- 5. researchtweet.com [researchtweet.com]
- 6. fiveable.me [fiveable.me]
- 7. tutorchase.com [tutorchase.com]
- 8. differencebetween.com [differencebetween.com]
- 9. quora.com [quora.com]
- 10. reddit.com [reddit.com]
- 11. forums.studentdoctor.net [forums.studentdoctor.net]
- 12. quora.com [quora.com]
- 13. Study Prep in Pearson+ | College Exam Prep Videos & Practice Problems [pearson.com]
- 14. researchgate.net [researchgate.net]
- 15. Frontiers | Translation Initiation Control of RNase E-Mediated Decay of Polycistronic gal mRNA [frontiersin.org]
Untranslated Regions (UTRs) in mRNA Function: A Technical Guide for Researchers and Drug Development Professionals
Executive Summary
Untranslated regions (UTRs) of messenger RNA (mRNA), flanking the protein-coding sequence, are critical hubs for post-transcriptional gene regulation. Far from being passive spacers, these non-coding sequences harbor a complex array of cis-regulatory elements that dictate the fate of an mRNA molecule, influencing its stability, localization, and translational efficiency. This technical guide provides an in-depth exploration of the functions of 5' and 3' UTRs, detailing the molecular mechanisms through which they control protein expression. We present a synthesis of current quantitative data, detailed experimental protocols for studying UTR function, and visual representations of key pathways and workflows to empower researchers, scientists, and drug development professionals in harnessing the regulatory potential of UTRs for therapeutic and research applications.
Core Functions of Untranslated Regions
The 5' and 3' UTRs of an mRNA molecule are key determinants of its post-transcriptional regulation, controlling processes that range from nuclear export to subcellular localization and ultimately, the rate of protein synthesis and mRNA decay.[1]
The 5' Untranslated Region (5' UTR): A Gateway for Translation
The 5' UTR is the region of an mRNA that is directly upstream of the initiation codon. It plays a pivotal role in the recruitment of the ribosome to the mRNA and in controlling the efficiency of translation initiation.[2] Key regulatory elements within the 5' UTR include:
-
Upstream Open Reading Frames (uORFs): These are short open reading frames that begin with a start codon within the 5' UTR and terminate before the main ORF's start codon. The translation of uORFs generally represses the translation of the downstream main ORF.[2][3][4] This repression can be modulated under cellular stress conditions, allowing for a dynamic regulation of protein synthesis.[5] The presence of uORFs is widespread, occurring in approximately half of all mammalian mRNAs.[2][5]
-
Internal Ribosome Entry Sites (IRESs): IRESs are highly structured RNA elements that allow for cap-independent translation initiation.[6][7][8] This mechanism is particularly important for the expression of certain cellular proteins during stress conditions when cap-dependent translation is inhibited, and is also a common strategy employed by viruses to hijack the host's translational machinery.[6][8]
-
Secondary Structures: The folding of the 5' UTR into complex secondary structures, such as hairpins and G-quadruplexes, can impede the scanning of the pre-initiation complex, thereby inhibiting translation.[9]
-
5' Terminal Oligopyrimidine (TOP) Motifs: These motifs are found in mRNAs encoding ribosomal proteins and other components of the translational machinery. They are crucial for the coordinated regulation of their translation in response to growth signals, often mediated by the mTOR signaling pathway.
The 3' Untranslated Region (3' UTR): A Master Regulator of mRNA Fate
The 3' UTR is the region of an mRNA that follows the stop codon. It is a rich landscape of regulatory elements that control mRNA stability, localization, and translation.[10][11][12][13] Key elements include:
-
AU-rich Elements (AREs): AREs are common motifs found in the 3' UTRs of mRNAs encoding transiently expressed proteins such as cytokines and proto-oncogenes.[10][14][15][16] They are recognized by a variety of RNA-binding proteins (RBPs) that can either promote mRNA degradation or enhance its stability, depending on the specific RBP and cellular context.[16][17][18]
-
microRNA (miRNA) Response Elements (MREs): These are binding sites for microRNAs, which are small non-coding RNAs that play a crucial role in post-transcriptional gene silencing.[10][19] The binding of a miRNA to an MRE in the 3' UTR typically leads to translational repression or mRNA degradation.[17][19][20] The number and type of MREs within a 3' UTR can fine-tune the expression of the target gene.[21]
-
Polyadenylation Signals: The 3' UTR contains the polyadenylation signal (most commonly AAUAAA), which directs the addition of a poly(A) tail to the 3' end of the mRNA.[10] The poly(A) tail is crucial for mRNA stability and for promoting efficient translation through its interaction with poly(A)-binding proteins (PABPs).[10]
Quantitative Insights into UTR-Mediated Regulation
The following tables summarize quantitative data from various studies, illustrating the impact of UTR elements on gene expression.
Table 1: Impact of 5' UTR Elements on Protein Expression
| Regulatory Element | Gene/Reporter System | Organism/Cell Line | Quantitative Effect on Protein Expression | Reference(s) |
| uORF Presence | Luciferase Reporter | Human (HEK 293A) | 30-80% reduction in protein levels | [2][4] |
| uORF-altering Polymorphism | 5 selected human genes | Human | 30-60% decrease in protein levels with uORF-introducing SNP | [3] |
| 5' UTR Length | Transcriptome-wide analysis | Mouse | Strong negative correlation between 5' UTR length and translation efficiency (r = -0.60) | [18] |
| IRES Activity | Bicistronic Luciferase Reporter | Human (Jurkat T-cells) | 15-fold greater activity than negative control | [22] |
| IRES Activity | Bicistronic Reporter | Various cell lines | Activity can vary up to 20-fold between different cell lines for the same IRES | [7][23] |
Table 2: Impact of 3' UTR Elements on mRNA Stability and Protein Expression
| Regulatory Element | Gene/Reporter System | Organism/Cell Line | Quantitative Effect | Reference(s) |
| AU-rich Elements (AREs) | Various endogenous mRNAs | Human | mRNA half-lives correlate with the number of AUUUA motifs; half-lives range from 40.8 to 72.3 min for rapidly degraded transcripts | [13][14] |
| miRNA Binding Sites | Transcriptome-wide analysis | Human/Mouse | Genes with miRNA seeds in both CDS and 3'UTR show mildly but significantly more repression than those with seeds only in the 3'UTR | [20][24] |
| Multiple miRNA Binding Sites | Kif5b mRNA | Mouse (Motor Neurons) | Long 3'UTR variant with multiple miR-129-5p sites shows differential regulation in axons | [21] |
| 3' UTR Length | Transcriptome-wide analysis | Yeast | Average length of a yeast 3' UTR is ~100 bases | [25] |
Experimental Protocols for Studying UTR Function
Investigating the function of UTRs requires a combination of molecular biology, cell biology, and bioinformatics approaches. Below are detailed protocols for two key experimental techniques.
Luciferase Reporter Assay for UTR Analysis
This assay is a widely used method to quantify the regulatory activity of a UTR sequence.[16]
Objective: To measure the effect of a specific 5' or 3' UTR on the expression of a downstream reporter gene (luciferase).
Principle: The UTR of interest is cloned upstream (for 5' UTRs) or downstream (for 3' UTRs) of a luciferase reporter gene in an expression vector. This construct is then transfected into cells, and the resulting luciferase activity is measured as a proxy for translation efficiency and/or mRNA stability. A dual-luciferase system, with a second reporter (e.g., Renilla luciferase) on the same or a separate plasmid, is often used for normalization of transfection efficiency.
Detailed Methodology:
-
Vector Construction:
-
Obtain a luciferase reporter vector (e.g., pGL3, pmirGLO). These vectors typically contain a strong constitutive promoter (e.g., SV40, CMV) driving the expression of firefly luciferase.
-
Amplify the full-length UTR of interest from cDNA using PCR with primers containing appropriate restriction sites.
-
For 5' UTR analysis, clone the PCR product between the promoter and the luciferase start codon.
-
For 3' UTR analysis, clone the PCR product downstream of the luciferase stop codon.[11]
-
Verify the sequence of the final construct by Sanger sequencing.
-
-
Cell Culture and Transfection:
-
Choose an appropriate cell line for your study. For general purposes, HEK293T or HeLa cells are commonly used due to their high transfection efficiency.[10]
-
Plate the cells in a multi-well plate (e.g., 24- or 96-well) to achieve 70-80% confluency on the day of transfection.
-
Co-transfect the cells with the UTR-luciferase reporter construct and a normalization control vector (e.g., a plasmid expressing Renilla luciferase) using a suitable transfection reagent (e.g., Lipofectamine, FuGENE HD).[10]
-
Include appropriate controls, such as an empty reporter vector and a vector with a well-characterized UTR.
-
-
Luciferase Assay:
-
After 24-48 hours of incubation, lyse the cells using a passive lysis buffer.
-
Measure the firefly luciferase activity in the cell lysate using a luminometer after adding the luciferase substrate.
-
Subsequently, measure the Renilla luciferase activity in the same sample by adding the Renilla substrate.
-
Calculate the relative luciferase activity by normalizing the firefly luciferase signal to the Renilla luciferase signal for each sample. This corrects for variations in transfection efficiency and cell number.
-
Ribosome Profiling for UTR Analysis
Ribosome profiling, or Ribo-seq, is a powerful technique that provides a genome-wide snapshot of translation by deep sequencing of ribosome-protected mRNA fragments.[26]
Objective: To determine the precise regions of mRNAs that are being translated, including uORFs within 5' UTRs, and to quantify the translational efficiency of individual transcripts.
Principle: Cells are treated with a translation inhibitor to freeze ribosomes on the mRNA. The lysate is then treated with a nuclease to digest all RNA that is not protected by the ribosomes. The resulting ribosome-protected fragments (RPFs) are isolated, converted to a cDNA library, and subjected to high-throughput sequencing.
Detailed Methodology:
-
Cell Lysis and Ribosome Footprinting:
-
Treat cultured cells with a translation elongation inhibitor, such as cycloheximide, to stall ribosomes.[27] For mapping translation initiation sites, a brief treatment with harringtonine (B1672945) can be used to trap initiating ribosomes.[26]
-
Lyse the cells under conditions that preserve ribosome-mRNA complexes.
-
Treat the lysate with a nuclease (e.g., RNase I) to digest unprotected mRNA. The concentration and digestion time need to be carefully optimized for the specific cell type.
-
Stop the digestion and isolate the monosomes (single ribosomes bound to mRNA fragments) by sucrose (B13894) density gradient centrifugation or size-exclusion chromatography.
-
-
RNA Extraction and Library Preparation:
-
Extract the RNA from the isolated monosome fraction. This will yield the ribosome-protected fragments (RPFs), which are typically 28-30 nucleotides in length.
-
Purify the RPFs by polyacrylamide gel electrophoresis (PAGE).
-
Ligate adapters to the 3' end of the RPFs.
-
Perform reverse transcription to generate cDNA.
-
Circularize the cDNA and perform PCR amplification to generate the final sequencing library.
-
-
Sequencing and Data Analysis:
-
Sequence the library using a high-throughput sequencing platform.
-
Align the sequencing reads to the reference genome or transcriptome.
-
Analyze the distribution of reads along the transcripts. High read density in a specific region indicates active translation.
-
The presence of distinct peaks in the 5' UTR can reveal the translation of uORFs.
-
Translational efficiency can be calculated for each gene by normalizing the ribosome profiling read counts to the corresponding mRNA abundance (determined by parallel RNA-seq).
-
Visualizing UTR-Mediated Regulatory Networks and Workflows
Signaling Pathways Influencing UTR-Mediated Translation
The mTOR and TGF-β signaling pathways are prominent examples of cellular cascades that converge on UTRs to regulate protein synthesis.
Caption: mTOR signaling pathway regulating translation of 5' TOP mRNAs.
Caption: TGF-β signaling impacting translation via 3' UTR-binding proteins.
Experimental Workflows
The following diagrams illustrate the workflows for the key experimental protocols described.
Caption: Workflow for a dual-luciferase reporter assay to study UTR function.
Caption: Workflow for ribosome profiling (Ribo-seq).
Implications for Drug Development and Future Perspectives
The intricate regulatory roles of UTRs present a wealth of opportunities for therapeutic intervention. Understanding how UTRs control the expression of disease-relevant genes can lead to the development of novel therapeutic strategies. For instance, small molecules or antisense oligonucleotides could be designed to modulate the interaction between RBPs and specific UTR elements, thereby altering the stability or translation of a target mRNA. Furthermore, the design of synthetic UTRs with optimized regulatory elements is a promising avenue for enhancing the efficacy and safety of mRNA-based therapeutics, such as vaccines and protein replacement therapies.
Future research will continue to unravel the complexity of the "UTR code," employing high-throughput techniques like massively parallel reporter assays (MPRAs) to systematically dissect the function of UTR sequences. The integration of these experimental approaches with advanced computational modeling will provide a deeper understanding of the regulatory logic embedded within UTRs, paving the way for the rational design of UTRs for predictable and precise control of gene expression. This will undoubtedly accelerate the development of next-generation RNA-based medicines and provide invaluable insights into the fundamental principles of gene regulation.
References
- 1. The role of 3′UTR-protein complexes in the regulation of protein multifunctionality and subcellular localization - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Upstream open reading frames cause widespread reduction of protein expression and are polymorphic among humans - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Gene Expression Regulation by Upstream Open Reading Frames and Human Disease - PMC [pmc.ncbi.nlm.nih.gov]
- 4. researchgate.net [researchgate.net]
- 5. Massively parallel reporter assay of 3′UTR sequences identifies in vivo rules for mRNA degradation - PMC [pmc.ncbi.nlm.nih.gov]
- 6. stasevichlab.colostate.edu [stasevichlab.colostate.edu]
- 7. scholarsarchive.library.albany.edu [scholarsarchive.library.albany.edu]
- 8. IRESite—a tool for the examination of viral and cellular internal ribosome entry sites - PMC [pmc.ncbi.nlm.nih.gov]
- 9. researchgate.net [researchgate.net]
- 10. biocat.com [biocat.com]
- 11. Construction of a Full-Length 3'UTR Reporter System for Identification of Cell-Cycle Regulating MicroRNAs - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. researchgate.net [researchgate.net]
- 13. researchgate.net [researchgate.net]
- 14. AU-rich element–mediated mRNA decay via the butyrate response factor 1 controls cellular levels of polyadenylated replication-dependent histone mRNAs - PMC [pmc.ncbi.nlm.nih.gov]
- 15. Decay Rates of Human mRNAs: Correlation With Functional Characteristics and Sequence Attributes - PMC [pmc.ncbi.nlm.nih.gov]
- 16. AU-rich element - Wikipedia [en.wikipedia.org]
- 17. We ARE boosting translation: AU-rich elements for enhanced therapeutic mRNA translation - PMC [pmc.ncbi.nlm.nih.gov]
- 18. biorxiv.org [biorxiv.org]
- 19. Regulation and dysregulation of 3′UTR-mediated translational control - PMC [pmc.ncbi.nlm.nih.gov]
- 20. The Impact of miRNA Target Sites in Coding Sequences and in 3′UTRs | PLOS One [journals.plos.org]
- 21. Multiple Copies of microRNA Binding Sites in Long 3′UTR Variants Regulate Axonal Translation - PMC [pmc.ncbi.nlm.nih.gov]
- 22. Cell type specificity and structural determinants of IRES activity from the 5′ leaders of different HIV-1 transcripts - PMC [pmc.ncbi.nlm.nih.gov]
- 23. researchgate.net [researchgate.net]
- 24. The Impact of miRNA Target Sites in Coding Sequences and in 3′UTRs - PMC [pmc.ncbi.nlm.nih.gov]
- 25. researchmgt.monash.edu [researchmgt.monash.edu]
- 26. The ribosome profiling strategy for monitoring translation in vivo by deep sequencing of ribosome-protected mRNA fragments - PMC [pmc.ncbi.nlm.nih.gov]
- 27. bartellab.wi.mit.edu [bartellab.wi.mit.edu]
Methodological & Application
Application Notes and Protocols for In Vitro Transcription of mRNA for Research
For Researchers, Scientists, and Drug Development Professionals
Introduction
In vitro transcription (IVT) is a robust cell-free method for synthesizing high yields of messenger RNA (mRNA) from a linear DNA template. This technology is pivotal in research, diagnostics, and the development of mRNA-based therapeutics and vaccines. The process involves the enzymatic synthesis of RNA by a phage RNA polymerase, typically T7, SP6, or T3, which recognizes a specific promoter sequence upstream of the gene of interest. The resulting mRNA transcripts can be modified with a 5' cap and a 3' poly(A) tail to ensure stability and efficient translation in eukaryotic cells. This document provides detailed protocols for the synthesis, purification, and quality control of in vitro transcribed mRNA for research applications.
Principle of In Vitro Transcription
The IVT reaction synthesizes RNA molecules by transcribing a linearized DNA template containing a bacteriophage promoter (e.g., T7). The reaction is catalyzed by the corresponding RNA polymerase in the presence of ribonucleoside triphosphates (NTPs).[][2] To produce functional mRNA for use in eukaryotic systems, several modifications are essential:
-
5' Capping: A 7-methylguanosine (B147621) (m7G) cap is added to the 5' end of the mRNA. This structure is crucial for ribosome recruitment, translation initiation, and protecting the mRNA from exonuclease degradation.[3]
-
3' Poly(A) Tailing: A long stretch of adenosine (B11128) residues (poly(A) tail) is added to the 3' end. This tail enhances mRNA stability and promotes efficient translation.[4]
These modifications can be incorporated during (co-transcriptionally) or after (enzymatically) the transcription reaction.
Experimental Workflow
The overall workflow for producing high-quality, functional mRNA via in vitro transcription involves several key stages: preparation of a high-quality DNA template, the in vitro transcription reaction, purification of the synthesized mRNA, and comprehensive quality control assays.
References
Application Notes and Protocols for High-Yield mRNA Synthesis
For Researchers, Scientists, and Drug Development Professionals
Introduction
The production of high-quality, high-yield messenger RNA (mRNA) is a cornerstone of modern biotechnology, fueling advancements in vaccines, protein replacement therapies, and gene editing.[1][2][3] The in vitro transcription (IVT) process allows for the cell-free synthesis of mRNA from a DNA template, offering a rapid and scalable manufacturing platform.[4][][6] Optimizing this process is critical to ensure the resulting mRNA is stable, efficiently translated, and free of immunogenic contaminants.[2][7]
These notes provide a comprehensive overview of the key steps and considerations for maximizing the yield and quality of synthetic mRNA. Detailed protocols for each stage of the workflow, from DNA template preparation to final purification, are included to guide researchers in establishing a robust and efficient mRNA production pipeline.
Section 1: Application Notes - Principles of High-Yield mRNA Synthesis
DNA Template Design and Preparation
The foundation of high-yield IVT is a high-quality, linear DNA template.[] The template must contain several key elements:
-
Bacteriophage Promoter: A strong promoter, typically from the T7 bacteriophage, is required to initiate transcription.[][6]
-
5' Untranslated Region (UTR): This region influences translation efficiency and mRNA stability.
-
Open Reading Frame (ORF): The coding sequence for the protein of interest. Codon optimization and the inclusion of modified nucleotides like N1-methyl-pseudouridine (m1Ψ) can enhance stability and reduce immunogenicity.[]
-
3' Untranslated Region (UTR): This region also plays a role in mRNA stability and translational efficiency.
-
Poly(A) Tail Sequence: A polyadenosine tail is crucial for mRNA stability and translation initiation.[9] It can be encoded directly into the DNA template or added enzymatically after transcription.[10]
The DNA, typically a plasmid, must be linearized by restriction enzyme digestion to ensure run-off transcription and prevent the production of heterogeneous mRNA species.[11][12] Complete linearization and subsequent purification of the DNA template are critical for maximizing IVT reaction efficiency.[][12]
In Vitro Transcription (IVT) Reaction Optimization
The IVT reaction is the core of mRNA synthesis, where T7 RNA polymerase synthesizes mRNA from the DNA template.[6] Several factors significantly impact the yield and quality of the transcript:
-
Enzyme Concentration: Optimizing the concentration of T7 RNA polymerase is crucial. While higher concentrations can increase yield, an excess can lead to the formation of undesirable byproducts like double-stranded RNA (dsRNA).[]
-
NTP Concentration and Ratio: The concentration of the four nucleotide triphosphates (ATP, GTP, CTP, UTP) must be sufficient for high yield. The ratio of magnesium ions (Mg2+) to NTPs is a critical factor, as Mg2+ is an essential cofactor for the polymerase.[13]
-
Reaction Buffer Conditions: The pH and buffer components can significantly influence enzyme activity and mRNA yield.[13] HEPES-based buffers have been shown to result in higher yields compared to Tris-based buffers.[13]
-
Temperature and Incubation Time: IVT reactions are typically performed at 37°C. Optimizing the incubation time (ranging from 30 minutes to 4 hours) can maximize yield without accumulating unwanted byproducts.[10][14]
mRNA Capping for Stability and Translation
The 5' cap is a critical modification that protects mRNA from degradation by exonucleases and is essential for recognition by the ribosome and efficient translation.[9][15] There are two primary methods for capping synthetic mRNA:
-
Co-transcriptional Capping: A cap analog, such as CleanCap® Reagent AG or an Anti-Reverse Cap Analog (ARCA), is added directly to the IVT reaction.[16] The cap analog is incorporated as the first nucleotide of the mRNA transcript.[12][16] This method creates a streamlined "one-pot" synthesis.[7][17] CleanCap® technology is highly efficient, often achieving over 95% capping.[7][16][17]
-
Enzymatic Capping: This post-transcriptional method involves treating the purified mRNA with capping enzymes, such as the Vaccinia Capping Enzyme.[12] While this adds extra steps to the process, it can achieve nearly 100% capping efficiency.[12]
Poly(A) Tailing
The 3' poly(A) tail enhances mRNA stability and promotes efficient translation.[18] As mentioned, this can be encoded in the template DNA or added post-transcriptionally using E. coli Poly(A) Polymerase and ATP.[18][19][20] Enzymatic tailing allows for control over the tail length by adjusting reaction parameters like incubation time and enzyme concentration.[18][19]
Purification of mRNA
Purification is a critical step to remove reaction components such as the DNA template, enzymes, unincorporated NTPs, and immunogenic dsRNA.[4][11][21] Several methods are employed for high-purity mRNA:
-
DNase Treatment: The DNA template is removed by digestion with DNase I.[11]
-
Precipitation: Methods like lithium chloride (LiCl) precipitation can selectively precipitate RNA, but are less scalable and may use hazardous solvents.[11]
-
Chromatography: This is the preferred method for large-scale and high-purity applications.[21][22]
-
Tangential Flow Filtration (TFF): TFF is a rapid and efficient method for buffer exchange, concentration, and removal of smaller impurities like unincorporated NTPs.[21][26][27][28] It is highly scalable and often used in conjunction with chromatography.[4][21]
Section 2: Quantitative Data Summary
The following tables summarize key quantitative data related to high-yield mRNA synthesis methods, providing a basis for comparison.
Table 1: Comparison of mRNA Capping Methods
| Capping Method | Approach | Capping Efficiency | Key Advantages | Key Disadvantages |
| CleanCap® Reagent AG | Co-transcriptional | >95%[16][17] | One-pot reaction, high yield, produces Cap-1 structure.[7][17] | Requires specific "AG" initiation sequence in the DNA template.[29][30] |
| ARCA (Anti-Reverse Cap Analog) | Co-transcriptional | 50-80%[16] | Simpler than enzymatic capping. | Lower efficiency, produces Cap-0 structure requiring further modification.[7][16] |
| Enzymatic Capping | Post-transcriptional | ~100% | High efficiency, independent of initiation sequence. | Requires additional enzymatic and purification steps.[4] |
Table 2: Expected mRNA Yields from Commercial In Vitro Transcription Kits
| Kit Name | Capping Method | Expected Yield (per 20 µL reaction) | Expected Concentration |
| Invitrogen mMessage mMachine™ T7 mRNA Kit with CleanCap® Reagent AG | Co-transcriptional (CleanCap®) | >100 µg | >5 mg/mL[31] |
| HiScribe™ T7 High Yield RNA Synthesis Kit (NEB #E2040) with CleanCap® | Co-transcriptional (CleanCap®) | Up to 180 µg (in a 40 µL reaction) | ~4.5 mg/mL |
| Standard IVT Reaction (Generic) | Varies | 80-100 µg | 4-5 mg/mL |
Note: Yields are highly dependent on the specific DNA template (e.g., length and sequence) and optimization of reaction conditions.[][14]
Section 3: Experimental Protocols
This section provides detailed, step-by-step protocols for a complete high-yield mRNA synthesis workflow.
Protocol 1: High-Yield Co-Transcriptional IVT Reaction
This protocol is optimized for a 40 µL reaction using the CleanCap® Reagent AG for co-transcriptional capping.
Materials:
-
Purified, linearized DNA template (with T7 promoter and AG initiation sequence): 1-2 µg
-
Nuclease-free water
-
10X Reaction Buffer (e.g., from HiScribe™ T7 Kit)
-
ATP, GTP, CTP, UTP solutions (e.g., 100 mM)
-
CleanCap® Reagent AG
-
T7 RNA Polymerase Mix
-
DNase I (RNase-free)
-
Nuclease-free microfuge tubes
Procedure:
-
Thaw all components at room temperature, except for the T7 RNA Polymerase Mix, which should be kept on ice.
-
Gently vortex and spin down all reagents before use.
-
Assemble the reaction at room temperature in the following order:
| Component | Volume | Final Concentration |
| Nuclease-free Water | to 40 µL | - |
| 10X Reaction Buffer | 4 µL | 1X |
| ATP (100 mM) | 2 µL | 5 mM |
| GTP (100 mM) | 0.6 µL | 1.5 mM |
| UTP (100 mM) | 2 µL | 5 mM |
| CTP (100 mM) | 2 µL | 5 mM |
| CleanCap® Reagent AG (100 mM) | 2.4 µL | 6 mM |
| Linearized DNA Template | X µL | 1-2 µg |
| T7 RNA Polymerase Mix | 4 µL | - |
-
Mix gently by flicking the tube and spin down briefly.
-
Incubate the reaction at 37°C for 1 to 2 hours.[14]
-
DNase Treatment: To remove the DNA template, add 2 µL of DNase I (RNase-free) directly to the IVT reaction. Mix gently and incubate at 37°C for 15 minutes.[30]
-
Proceed immediately to mRNA purification (Protocol 3).
Protocol 2: Post-Transcriptional Poly(A) Tailing (Optional)
This protocol is for enzymatically adding a poly(A) tail to mRNA that was transcribed from a template without an encoded poly(A) tail.
Materials:
-
Purified mRNA (from IVT reaction): up to 10 µg
-
Nuclease-free water
-
10X Poly(A) Polymerase Reaction Buffer
-
ATP (10 mM)
-
E. coli Poly(A) Polymerase (e.g., 5 units/µL)
-
RNase Inhibitor (optional)
-
EDTA (0.5 M)
Procedure:
-
In a nuclease-free tube, assemble the following 20 µL reaction:[19]
| Component | Volume | Final Amount/Concentration |
| Purified mRNA | X µL | 1-10 µg |
| 10X Reaction Buffer | 2 µL | 1X |
| ATP (10 mM) | 2 µL | 1 mM |
| E. coli Poly(A) Polymerase | 1 µL | 5 units |
| RNase Inhibitor (optional) | 0.5 µL | 20 units |
| Nuclease-free Water | to 20 µL | - |
-
Mix gently, spin down, and incubate at 37°C for 30 minutes. This should result in a tail length greater than 100 bases.[19] Tail length can be adjusted by modifying incubation time or enzyme amount.[18]
-
Stop the reaction by adding 0.4 µL of 0.5 M EDTA.
-
Proceed to purification.
Protocol 3: mRNA Purification using Oligo(dT) Affinity Chromatography
This protocol provides a general guideline for purifying polyadenylated mRNA. Specific parameters may need optimization based on the chosen resin and column size.
Materials:
-
Oligo(dT) affinity resin (e.g., POROS™ Oligo (dT)25, CIMmultus® Oligo dT)[9][24]
-
Chromatography column
-
Binding Buffer: 10 mM Tris-HCl, 0.5 M NaCl, 1 mM EDTA, pH 7.4[9]
-
Wash Buffer: 10 mM Tris-HCl, 0.1 M NaCl, 1 mM EDTA, pH 7.4 (example, salt concentration may vary)
-
Elution Buffer: 10 mM Tris-HCl, 1 mM EDTA, pH 7.4[9]
-
Sanitization Solution: 0.1 M NaOH[9]
Procedure:
-
Pack the chromatography column with the Oligo(dT) resin according to the manufacturer's instructions.
-
Equilibrate the column with at least 5-10 column volumes (CVs) of Binding Buffer.
-
Adjust the salt concentration of the crude mRNA sample (from Protocol 1 or 2) to match the Binding Buffer by adding concentrated NaCl.
-
Load the sample onto the column.
-
Wash the column with 5-10 CVs of Binding Buffer to remove unbound impurities.
-
Wash the column with 5-10 CVs of Wash Buffer to remove non-specifically bound molecules.
-
Elute the purified mRNA from the column with 3-5 CVs of Elution Buffer.[9] The absence of salt destabilizes the hybridization between the poly(A) tail and the oligo(dT) ligand.[23]
-
Collect the eluate containing the purified mRNA.
-
For subsequent use, sanitize the column with 3-5 CVs of 0.1 M NaOH, followed by re-equilibration with Binding Buffer.[9]
-
The purified mRNA can be further concentrated and buffer-exchanged using Tangential Flow Filtration (TFF).
Section 4: Visualizations
Diagram 1: Overall High-Yield mRNA Synthesis Workflow
Caption: A streamlined workflow for high-yield mRNA production.
Diagram 2: Comparison of Capping Strategies
Caption: Workflow comparison of co-transcriptional vs. enzymatic capping.
Diagram 3: Purification Workflow Logic
Caption: Logical flow of a multi-step mRNA purification process.
References
- 1. Current Analytical Strategies for mRNA-Based Therapeutics - PMC [pmc.ncbi.nlm.nih.gov]
- 2. mRNA Vaccine Platform: mRNA Production and Delivery - PMC [pmc.ncbi.nlm.nih.gov]
- 3. A comprehensive comparison of DNA and RNA vaccines - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. susupport.com [susupport.com]
- 6. cytivalifesciences.com [cytivalifesciences.com]
- 7. trilinkbiotech.com [trilinkbiotech.com]
- 9. documents.thermofisher.com [documents.thermofisher.com]
- 10. jenabioscience.com [jenabioscience.com]
- 11. sigmaaldrich.com [sigmaaldrich.com]
- 12. benchchem.com [benchchem.com]
- 13. documents.thermofisher.com [documents.thermofisher.com]
- 14. neb.com [neb.com]
- 15. Four Major Steps Involved in mRNA Manufacturing - Aldevron Thought Leadership [aldevron.com]
- 16. Co-transcriptional capping [takarabio.com]
- 17. trilinkbiotech.com [trilinkbiotech.com]
- 18. biosearchtech.a.bigcontent.io [biosearchtech.a.bigcontent.io]
- 19. neb.com [neb.com]
- 20. static.igem.org [static.igem.org]
- 21. medwinpublishers.com [medwinpublishers.com]
- 22. Purification Of mRNA By Affinity Chromatography On CIMmultus Oligo dT Column [cellandgene.com]
- 23. sartorius.com.cn [sartorius.com.cn]
- 24. dcvmn.org [dcvmn.org]
- 25. cytivalifesciences.com [cytivalifesciences.com]
- 26. WO2020165158A1 - Mrna purification by tangential flow filtration - Google Patents [patents.google.com]
- 27. cytivalifesciences.com [cytivalifesciences.com]
- 28. sterlitech.com [sterlitech.com]
- 29. neb.com [neb.com]
- 30. neb.com [neb.com]
- 31. In Vitro Transcription Kits for Synthesizing High Yield mRNA | Thermo Fisher Scientific - CL [thermofisher.com]
Application Notes and Protocols for Quantifying mRNA Expression Levels Using RT-qPCR
Audience: Researchers, scientists, and drug development professionals.
Introduction
Reverse transcription-quantitative polymerase chain reaction (RT-qPCR) is a highly sensitive and widely used technique for the detection and quantification of messenger RNA (mRNA) expression levels.[1][2] This method combines the reverse transcription of RNA into complementary DNA (cDNA) with the real-time amplification and quantification of that cDNA.[2][3] Its applications are vast, spanning from gene expression analysis and validation of RNA interference (RNAi) to pathogen detection and disease research.[2] These application notes provide a comprehensive guide to performing RT-qPCR, from experimental design to data analysis, ensuring reliable and reproducible results.
Principle of RT-qPCR
RT-qPCR quantifies mRNA by first converting the RNA template into cDNA using a reverse transcriptase enzyme.[2][4][5] This newly synthesized cDNA then serves as a template for a quantitative PCR (qPCR) reaction.[2][4] The qPCR process amplifies the target cDNA, and the accumulation of the PCR product is monitored in real-time using fluorescent reporters.[2][6][7] The cycle at which the fluorescence signal crosses a predetermined threshold (the quantification cycle or Cq value) is inversely proportional to the initial amount of target mRNA in the sample.[4][7]
There are two main approaches for RT-qPCR:
-
One-Step RT-qPCR: Reverse transcription and qPCR are performed sequentially in a single tube.[2][5] This method is fast, minimizes pipetting errors, and reduces the risk of contamination, making it suitable for high-throughput applications.[2]
-
Two-Step RT-qPCR: Reverse transcription and qPCR are carried out as two separate reactions.[2][5] This approach offers greater flexibility, allowing for the use of different priming strategies and the storage of the resulting cDNA for future analyses of multiple targets.[2]
Experimental Workflow
A typical RT-qPCR experiment involves several key stages, from sample preparation to data interpretation. Careful attention to detail at each step is crucial for obtaining accurate and reproducible results.[3][8]
Caption: Overview of the RT-qPCR experimental workflow.
Detailed Protocols
RNA Isolation and Quality Control
The quality and purity of the starting RNA material are critical for the success of an RT-qPCR experiment.[3][9] Contaminants such as genomic DNA (gDNA), proteins, and PCR inhibitors can significantly impact the results.[10]
Protocol: Total RNA Isolation
-
Sample Collection and Lysis: Homogenize cells or tissues in a lysis buffer containing a chaotropic agent (e.g., guanidinium (B1211019) isothiocyanate) to inactivate RNases.
-
Phase Separation: Add chloroform (B151607) and centrifuge to separate the mixture into an upper aqueous phase (containing RNA), an interphase, and a lower organic phase.
-
RNA Precipitation: Transfer the aqueous phase to a new tube and precipitate the RNA by adding isopropanol.
-
RNA Wash: Wash the RNA pellet with 75% ethanol (B145695) to remove salts and other impurities.
-
RNA Resuspension: Air-dry the pellet and resuspend it in RNase-free water.
Quality Control
Assess RNA quality and quantity using the following methods:
| Parameter | Method | Acceptance Criteria |
| Purity | UV Spectrophotometry (e.g., NanoDrop) | A260/A280 ratio: 1.8 - 2.2A260/A230 ratio: > 2.0 |
| Integrity | Agarose Gel Electrophoresis or Microfluidic Capillary Electrophoresis (e.g., Agilent Bioanalyzer) | Intact ribosomal RNA (rRNA) bands (28S and 18S for eukaryotes) with a 2:1 ratio.[11] |
| Concentration | UV Spectrophotometry or Fluorometric Quantification (e.g., Qubit) | Sufficient for downstream applications. |
Note: It is highly recommended to treat the RNA sample with DNase I to remove any contaminating gDNA.[12]
Reverse Transcription (cDNA Synthesis)
This step converts the isolated RNA into a more stable cDNA template.
Protocol: Two-Step Reverse Transcription
-
Reaction Setup: In a sterile, RNase-free tube, combine the following components:
-
Total RNA (e.g., 1 µg)
-
Primers (Oligo(dT)s, random hexamers, or gene-specific primers)[2]
-
RNase-free water to a final volume of ~10 µL.
-
-
Denaturation and Annealing: Incubate the mixture at 65-70°C for 5 minutes, then place on ice for at least 1 minute. This denatures RNA secondary structures and allows for primer annealing.[4]
-
Master Mix Preparation: Prepare a master mix containing:
-
Reverse Transcriptase Buffer (5X or 10X)
-
dNTPs (10 mM)
-
RNase Inhibitor
-
Reverse Transcriptase Enzyme
-
-
Reverse Transcription Reaction: Add the master mix to the RNA-primer mixture and incubate at the optimal temperature for the reverse transcriptase (typically 42-55°C) for 60 minutes.
-
Enzyme Inactivation: Inactivate the reverse transcriptase by heating at 70-85°C for 5-10 minutes. The resulting cDNA can be stored at -20°C.
qPCR Reaction Setup and Amplification
This stage involves the amplification and real-time detection of the target cDNA.
Primer and Probe Design
Proper primer and probe design is one of the most critical factors for a successful qPCR assay.[13][14]
| Parameter | Recommendation |
| Amplicon Length | 70-200 base pairs[15][16] |
| Primer Length | 18-30 nucleotides[15][16] |
| GC Content | 40-60%[15][16] |
| Melting Temperature (Tm) | 58-62°C, with both primers having a Tm within 5°C of each other.[15][16] |
| Specificity | Primers should be specific to the target sequence and ideally span an exon-exon junction to avoid amplification of gDNA.[10][17] |
Protocol: qPCR Reaction
-
Reaction Mix Preparation: Prepare a master mix for each gene of interest and reference gene, containing:
-
Plate Setup: Dispense the master mix into the wells of a qPCR plate.
-
Template Addition: Add the cDNA template to the appropriate wells. Include no-template controls (NTC) to check for contamination and no-reverse-transcriptase controls (-RT) to check for gDNA contamination.[2][19]
-
Thermal Cycling: Place the plate in a real-time PCR instrument and run the following thermal cycling program:
| Step | Temperature (°C) | Duration | Cycles |
| Initial Denaturation | 95 | 2-10 min | 1 |
| Denaturation | 95 | 10-15 sec | 40 |
| Annealing/Extension | 60 | 30-60 sec |
Note: Thermal cycling conditions may need to be optimized depending on the primers, target, and qPCR master mix used.[20][21]
Data Analysis
The most common method for analyzing relative gene expression is the delta-delta Cq (ΔΔCq) method, also known as the 2-ΔΔCq method.[22][23] This method normalizes the expression of the gene of interest (GOI) to a stably expressed reference (housekeeping) gene and compares the normalized expression in a test sample to a control sample.[22]
Caption: Logical flow of the delta-delta Cq calculation.
Data Presentation
Summarize the quantitative data in a structured table for easy comparison.
Table 1: Raw Cq Values
| Sample | Replicate | Gene of Interest (Cq) | Reference Gene (Cq) |
| Control 1 | 1 | 22.5 | 18.2 |
| 2 | 22.6 | 18.3 | |
| 3 | 22.4 | 18.1 | |
| Treated 1 | 1 | 20.1 | 18.3 |
| 2 | 20.3 | 18.2 | |
| 3 | 20.2 | 18.4 |
Table 2: Calculated Relative Gene Expression
| Sample | Average ΔCq | ΔΔCq | Fold Change (2-ΔΔCq) |
| Control 1 | 4.27 | 0.00 | 1.00 |
| Treated 1 | 1.93 | -2.34 | 5.06 |
Troubleshooting
Common issues in RT-qPCR and their potential solutions.[10][11][24][25][26]
| Issue | Potential Cause(s) | Suggested Solution(s) |
| No amplification or late amplification | Poor RNA quality or quantityInefficient reverse transcriptionSuboptimal primer designPCR inhibitors | Check RNA integrity and purity.Optimize RT reaction conditions.Redesign and validate primers.Dilute the cDNA template to reduce inhibitor concentration.[10] |
| Amplification in No-Template Control (NTC) | Contamination of reagents or workspace | Use dedicated pipettes and work in a clean environment.Use fresh, nuclease-free water and reagents. |
| Poor replicate consistency | Pipetting errorsInconsistent sample quality | Ensure accurate and consistent pipetting.Thoroughly mix all solutions before use.[10] |
| Multiple peaks in melt curve analysis | Non-specific amplification or primer-dimers | Optimize annealing temperature.Redesign primers for higher specificity. |
Conclusion
RT-qPCR is a powerful and sensitive technique for quantifying mRNA expression levels. By following standardized protocols, implementing rigorous quality control measures, and employing appropriate data analysis methods, researchers can obtain reliable and reproducible results that are crucial for advancing research and development in various scientific fields.
References
- 1. Quantification of mRNA using real-time RT-PCR - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. Basic Principles of RT-qPCR | Thermo Fisher Scientific - US [thermofisher.com]
- 3. What Are the Key Steps in RT-qPCR Workflow? [synapse.patsnap.com]
- 4. Brief guide to RT-qPCR - PMC [pmc.ncbi.nlm.nih.gov]
- 5. bio-rad.com [bio-rad.com]
- 6. Quantitative PCR Basics [sigmaaldrich.com]
- 7. neb.com [neb.com]
- 8. gene-quantification.de [gene-quantification.de]
- 9. bio-rad.com [bio-rad.com]
- 10. promegaconnections.com [promegaconnections.com]
- 11. azurebiosystems.com [azurebiosystems.com]
- 12. Eleven Golden Rules of Quantitative RT-PCR - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Design of Primers and Probes for Quantitative Real-Time PCR Methods | Springer Nature Experiments [experiments.springernature.com]
- 14. Design of primers and probes for quantitative real-time PCR methods - PubMed [pubmed.ncbi.nlm.nih.gov]
- 15. tataa.com [tataa.com]
- 16. bio-rad.com [bio-rad.com]
- 17. reddit.com [reddit.com]
- 18. brainly.com [brainly.com]
- 19. idtdna.com [idtdna.com]
- 20. Thermal Cycling Optimization | AAT Bioquest [aatbio.com]
- 21. Reddit - The heart of the internet [reddit.com]
- 22. toptipbio.com [toptipbio.com]
- 23. Analysis of relative gene expression data using real-time quantitative PCR and the 2(-Delta Delta C(T)) Method - PubMed [pubmed.ncbi.nlm.nih.gov]
- 24. dispendix.com [dispendix.com]
- 25. RT-PCR Troubleshooting [sigmaaldrich.com]
- 26. blog.biosearchtech.com [blog.biosearchtech.com]
Purifying Synthetic mRNA: A Guide to Downstream Processing After In Vitro Transcription
Application Notes and Protocols for Researchers, Scientists, and Drug Development Professionals
The production of high-quality messenger RNA (mRNA) through in vitro transcription (IVT) is a cornerstone of modern molecular biology, underpinning revolutionary therapeutic modalities like mRNA vaccines and gene therapies. However, the raw product of an IVT reaction is a heterogeneous mixture containing the desired mRNA transcript alongside unincorporated nucleotides, enzymes, DNA templates, and potential byproducts such as double-stranded RNA (dsRNA).[][2][3][4] Effective purification is therefore a critical step to ensure the safety, efficacy, and stability of the final mRNA product.[4][5][6]
This document provides a detailed overview and protocols for three common methods of mRNA purification following in vitro transcription: Lithium Chloride (LiCl) precipitation, silica-based column chromatography, and oligo(dT) affinity chromatography.
Key Purification Strategies: A Comparative Overview
Choosing the appropriate purification strategy depends on the specific downstream application, required purity, yield, and scalability of the process. For research-scale applications, precipitation or basic column purification may suffice. However, for therapeutic applications, more stringent and scalable methods like affinity chromatography are often preferred.[7][8]
| Purification Method | Principle | Advantages | Disadvantages | Typical Purity (A260/A280) | Typical Recovery |
| Lithium Chloride (LiCl) Precipitation | Selective precipitation of large RNA molecules, leaving smaller nucleic acids (tRNA, 5S rRNA) and unincorporated nucleotides in the supernatant.[][9] | Simple, cost-effective, and efficient for removing unincorporated nucleotides.[10][11] | Less effective at removing DNA and proteins.[9][10] May not efficiently precipitate RNA smaller than 300 nucleotides.[9][12] Residual lithium ions can inhibit downstream applications.[] | 1.8 - 2.1 | Variable, can be lower than other methods. |
| Silica-Based Column Chromatography | RNA binds to a silica (B1680970) membrane in the presence of chaotropic salts, allowing for washing and subsequent elution in a low-salt buffer.[13][14] | Fast, simple, and effective at removing proteins, salts, and unincorporated nucleotides.[12] | Can have limited binding capacity.[8] Potential for carryover of chaotropic salts if not washed properly. | >1.9 | 70-95% |
| Oligo(dT) Affinity Chromatography | Exploits the hybridization between the poly(A) tail of the mRNA and oligo(dT) ligands immobilized on a solid support (e.g., magnetic beads, chromatography resin).[5][7][15] | Highly specific for polyadenylated mRNA, effectively removing DNA, enzymes, and non-polyadenylated RNA fragments.[3][5] Scalable for large-scale manufacturing.[7] | Requires a poly(A) tail on the mRNA. Does not remove other polyadenylated RNA species or dsRNA effectively.[5] | >2.0 | >90%[16][17] |
Experimental Workflows and Protocols
The following sections provide detailed protocols and visual workflows for each purification method.
Lithium Chloride (LiCl) Precipitation
This method is a straightforward approach for concentrating mRNA and removing the bulk of unincorporated nucleotides from an IVT reaction.
References
- 2. IVT Pillar Page [advancingrna.com]
- 3. mRNAワクチン・mRNA治療薬の製造戦略 [sigmaaldrich.com]
- 4. cytivalifesciences.com [cytivalifesciences.com]
- 5. discovery.ucl.ac.uk [discovery.ucl.ac.uk]
- 6. mRNA Purification Methods and Process - Patheon pharma services [patheon.com]
- 7. sartorius.com.cn [sartorius.com.cn]
- 8. lifesciences.danaher.com [lifesciences.danaher.com]
- 9. Star Republic: Guide for Biologists [sciencegateway.org]
- 10. LiCl Precipitation for RNA Purification | Thermo Fisher Scientific - TW [thermofisher.com]
- 11. Lithium chloride purification, a rapid and efficient technique to purify RNA from DSS-treated tissues [protocols.io]
- 12. neb.com [neb.com]
- 13. Spin Columns for DNA and RNA Extraction | Thermo Fisher Scientific - HK [thermofisher.com]
- 14. High-Purity- Column-Based RNA Purification| TIANGEN [en.tiangen.com]
- 15. Simplify your mRNA purification process | Technology Networks [technologynetworks.com]
- 16. Quality by design for mRNA platform purification based on continuous oligo-dT chromatography - PubMed [pubmed.ncbi.nlm.nih.gov]
- 17. documents.thermofisher.com [documents.thermofisher.com]
Application Notes and Protocols for Designing Therapeutic mRNA Constructs
For Researchers, Scientists, and Drug Development Professionals
Introduction
The therapeutic application of messenger RNA (mRNA) has emerged as a powerful and versatile platform for the development of vaccines and protein replacement therapies. The efficacy of these therapeutics is critically dependent on the design of the mRNA construct. Key elements, including the 5' cap, 5' and 3' untranslated regions (UTRs), the protein-coding sequence, and the 3' poly(A) tail, must be carefully optimized to ensure high levels of protein expression, stability, and a favorable safety profile by minimizing innate immune activation.
These application notes provide a comprehensive guide to the rational design of therapeutic mRNA constructs. We offer detailed protocols for the synthesis, purification, and quality control of in vitro transcribed (IVT) mRNA. Furthermore, we present quantitative data to inform the selection of optimal mRNA components and provide visual representations of key biological pathways and experimental workflows to aid in understanding and implementation.
I. Design of Therapeutic mRNA Constructs
The fundamental components of a therapeutic mRNA molecule are engineered to maximize protein production and persistence in the target cells. A typical linear mRNA construct is composed of a 5' cap, a 5' untranslated region (UTR), a codon-optimized open reading frame (ORF), a 3' UTR, and a poly(A) tail.[1] Newer strategies are also exploring self-amplifying and circular RNA formats.[1] The primary objectives in designing an effective mRNA therapeutic are to enhance the magnitude and duration of protein expression while mitigating unwanted innate immune responses.[2]
The 5' Cap: Initiating Translation and Ensuring Stability
The 5' cap is a modified guanosine (B1672433) nucleotide that is crucial for the initiation of translation and protects the mRNA from degradation by 5' exonucleases.[3][] During in vitro transcription (IVT), a cap or a cap analog is incorporated at the 5' end of the mRNA transcript. The choice of cap analog significantly influences the capping efficiency and the translational output of the resulting mRNA.
Data Presentation: Comparison of 5' Cap Analogs
| Cap Analog | Capping Efficiency (%) | Relative Protein Expression | Key Features |
| m7GpppG (mCap) | ~70% | Baseline | Can be incorporated in both correct and reverse orientations, with only the correct orientation being functional.[5] |
| Anti-Reverse Cap Analog (ARCA) | 70-80% | Higher than mCap | Modified to prevent reverse incorporation, leading to a higher proportion of translationally active mRNA.[] |
| CleanCap® Reagent AG (Cap 1) | >95% | Significantly higher than ARCA | A trinucleotide cap analog that ensures correct orientation and incorporates the 2'-O-methylation of the first nucleotide (Cap 1), which helps to evade innate immune recognition.[5][] |
| N7-benzylated dinucleoside tetraphosphates (e.g., b7m2Gp4G) | ~90% | Up to 3-fold higher than m7GpppG | Novel analogs designed to increase affinity for the translation initiation factor eIF4E.[7] |
Untranslated Regions (UTRs): Fine-Tuning Translation and Stability
The 5' and 3' UTRs are non-coding sequences that flank the open reading frame and play critical roles in post-transcriptional regulation, including modulating translation efficiency, mRNA stability, and subcellular localization.[1]
5' UTR: The 5' UTR is instrumental in ribosome recruitment and scanning to initiate translation. An optimal 5' UTR should possess a strong Kozak sequence (e.g., GCC(A/G)CCAUGG) to facilitate efficient recognition of the start codon.[][8] The inclusion of 5' UTRs from highly expressed genes, such as human α-globin and β-globin, has been shown to enhance protein expression.[9]
3' UTR: The 3' UTR influences mRNA stability and can contain binding sites for microRNAs and RNA-binding proteins that regulate translation and degradation.[8] Sequences from highly stable mRNAs, like α-globin, are often used to prolong the half-life of the therapeutic mRNA.[10]
Data Presentation: Effect of UTRs on Protein Expression
| 5' UTR | 3' UTR | Relative Luciferase Expression (in DC2.4 cells at 24h) |
| α-globin | α-globin | Low |
| β-globin | α-globin | High |
| Albumin | α-globin | Moderate |
| CYBA | α-globin | Low |
| Minimal | α-globin | Moderate-Low |
Data adapted from a study comparing different 5' UTRs with a constant α-globin 3' UTR and poly(A) tail.[9] A study by another group found that combinations like 5'Rabb-3'mtRNR-EMCV and 5'TPL-3'Biontech led to high expression of a target protein.[10]
Codon Optimization of the Open Reading Frame (ORF)
The open reading frame (ORF) contains the genetic code for the therapeutic protein. While the amino acid sequence is fixed, the nucleotide sequence can be optimized to enhance translation efficiency and mRNA stability. This is achieved by replacing rare codons with synonymous codons that are more frequently used in the host organism, ensuring a ready supply of corresponding tRNAs for rapid translation.[11] Codon optimization can also be employed to reduce the uridine (B1682114) content of the mRNA, which can help to decrease the activation of innate immune sensors like Toll-like receptors.[10] Several software tools are available to assist in the design of codon-optimized sequences.[2]
The Poly(A) Tail: A Key Determinant of Stability and Translational Efficiency
The poly(A) tail is a stretch of adenosine (B11128) residues at the 3' end of the mRNA that is crucial for mRNA stability and translation.[12] It protects the mRNA from 3' exonuclease degradation and interacts with poly(A)-binding protein (PABP), which in turn interacts with the 5' cap structure to form a closed-loop configuration that promotes efficient ribosome recycling and translation.[13]
The optimal length of the poly(A) tail can be cell-type dependent, but generally, a longer tail is associated with increased stability.[14] However, recent studies suggest that a tail length of around 75 nucleotides may be optimal for cap-dependent translation in human cells.[15][16][17] The inclusion of non-adenosine residues within the poly(A) tail has also been shown to enhance translation efficiency.[18]
Data Presentation: Influence of Poly(A) Tail Length on Translation
| Poly(A) Tail Length (nucleotides) | Relative Translation Rate (in human cell lysates) |
| 0 | Low |
| 25 | Moderate |
| 50 | Moderate |
| 75 | High |
| 100 | Moderate |
| 150 | Moderate |
Data generalized from studies showing a peak in translation efficiency with a 75 nt poly(A) tail for cap-dependent translation.[15][16][17]
II. Experimental Protocols
In Vitro Transcription (IVT) of mRNA
This protocol describes the synthesis of mRNA from a linearized DNA template using a bacteriophage RNA polymerase.
Materials:
-
Linearized plasmid DNA template (containing a T7, SP6, or T3 promoter)
-
Nuclease-free water
-
Transcription buffer (10X)
-
rNTP solution mix (ATP, CTP, GTP, UTP)
-
Cap analog (e.g., CleanCap® Reagent AG)
-
T7 RNA Polymerase
-
RNase Inhibitor
-
DNase I
Procedure:
-
Thaw all reagents on ice.
-
Assemble the transcription reaction at room temperature in the following order:
-
Nuclease-free water to a final volume of 20 µL
-
10X Transcription Buffer (2 µL)
-
rNTPs (as per manufacturer's recommendation)
-
Cap analog (as per manufacturer's recommendation)
-
Linearized DNA template (0.5-1.0 µg)
-
RNase Inhibitor (1 µL)
-
T7 RNA Polymerase (2 µL)
-
-
Mix gently by pipetting and incubate at 37°C for 2 hours.
-
To remove the DNA template, add 1 µL of DNase I to the reaction mixture and incubate at 37°C for 15 minutes.
-
Proceed to mRNA purification.
Purification of mRNA using Oligo(dT) Affinity Chromatography
This method purifies polyadenylated mRNA from the IVT reaction mix.
Materials:
-
IVT reaction mixture
-
Oligo(dT) cellulose (B213188) or magnetic beads
-
Binding Buffer (e.g., 50 mM Na-phosphate, 2 mM EDTA, 250 mM NaCl, pH 7.0)[19]
-
Washing Buffer (e.g., 50 mM Na-phosphate, 2 mM EDTA, pH 7.0)[19]
-
Elution Buffer (e.g., 10 mM Tris, pH 7.0)[19]
-
Nuclease-free tubes and pipette tips
Procedure:
-
Equilibrate the oligo(dT) resin with Binding Buffer.
-
Add the IVT reaction mixture to the equilibrated oligo(dT) resin and incubate at room temperature with gentle mixing to allow the poly(A) tails of the mRNA to bind to the oligo(dT).
-
Wash the resin with Washing Buffer to remove unbound components such as proteins, unincorporated nucleotides, and DNA fragments.
-
Elute the purified mRNA from the resin using Elution Buffer.
-
Quantify the purified mRNA using a spectrophotometer (A260). The A260/A280 ratio should be approximately 2.0.[20]
Quality Control of mRNA using Capillary Electrophoresis
Capillary electrophoresis (CE) is a high-resolution technique to assess the integrity and purity of the synthesized mRNA.[8][21]
Materials:
-
Purified mRNA sample
-
CE instrument with a suitable gel matrix and fluorescent dye
-
RNA ladder for size estimation
-
Nuclease-free water or appropriate sample loading solution
Procedure:
-
Prepare the mRNA sample by diluting it to the required concentration in nuclease-free water or sample loading solution.
-
Denature the RNA sample by heating at 70°C for 5 minutes, followed by immediate cooling on ice for at least 2 minutes.[14]
-
Load the denatured RNA sample and the RNA ladder onto the CE instrument.
-
Run the electrophoresis according to the instrument's protocol.
-
Analyze the resulting electropherogram to determine the size and purity of the mRNA. The main peak should correspond to the expected size of the full-length transcript, and the percentage of smaller fragments (impurities) should be minimal.
III. Visualization of Key Pathways and Workflows
Experimental Workflow for Therapeutic mRNA Production
Caption: Workflow for the production of therapeutic mRNA.
Innate Immune Sensing of mRNA: TLR7/8 Signaling Pathway
Exogenous single-stranded RNA (ssRNA) can be recognized by Toll-like receptors 7 and 8 (TLR7/8) in the endosome of immune cells, leading to the production of pro-inflammatory cytokines and type I interferons.
Caption: TLR7/8 signaling pathway activated by ssRNA.
Innate Immune Sensing of mRNA: RIG-I Signaling Pathway
Double-stranded RNA (dsRNA), a potential byproduct of in vitro transcription, can be recognized by the cytosolic sensor RIG-I, leading to a potent antiviral response.
Caption: RIG-I signaling pathway activated by dsRNA.
References
- 1. dcvmn.org [dcvmn.org]
- 2. Purification Of mRNA By Affinity Chromatography On CIMmultus Oligo dT Column [advancingrna.com]
- 3. susupport.com [susupport.com]
- 5. Methods of IVT mRNA capping - Behind the Bench [thermofisher.com]
- 7. researchgate.net [researchgate.net]
- 8. Capillary electrophoresis methods for determining the IVT mRNA critical quality attributes of size and purity - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. Optimization of the 5ʹ untranslated region of mRNA vaccines - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Effects of Combinations of Untranslated-Region Sequences on Translation of mRNA - PMC [pmc.ncbi.nlm.nih.gov]
- 11. cytivalifesciences.com [cytivalifesciences.com]
- 12. researchgate.net [researchgate.net]
- 13. The molecular basis of coupling between poly(A)-tail length and translational efficiency | eLife [elifesciences.org]
- 14. sepax-tech.com.cn [sepax-tech.com.cn]
- 15. The impact of mRNA poly(A) tail length on eukaryotic translation stages - PubMed [pubmed.ncbi.nlm.nih.gov]
- 16. academic.oup.com [academic.oup.com]
- 17. researchgate.net [researchgate.net]
- 18. biorxiv.org [biorxiv.org]
- 19. sartorius.com.cn [sartorius.com.cn]
- 20. buchhaus.ch [buchhaus.ch]
- 21. sigmaaldrich.com [sigmaaldrich.com]
Application Notes and Protocols: Cell-Free Protein Synthesis Using mRNA Templates
For Researchers, Scientists, and Drug Development Professionals
Introduction
Cell-free protein synthesis (CFPS) is a powerful in vitro technology that enables the rapid production of proteins without the use of living cells.[1][2] By harnessing the transcriptional and translational machinery of cell lysates, CFPS offers several advantages over traditional cell-based expression systems, including speed, flexibility, and the ability to synthesize complex or toxic proteins.[1][2] This open nature of CFPS allows for direct manipulation of the reaction environment, making it an ideal platform for high-throughput screening, protein engineering, and on-demand biomanufacturing.[2][3]
These application notes provide an overview of the diverse applications of CFPS using mRNA templates in research and drug development, along with detailed protocols for key experimental procedures.
Applications in Research and Drug Development
CFPS has emerged as a transformative technology in various stages of the drug discovery and development pipeline.[4]
1. Therapeutic Protein Production
CFPS enables the rapid synthesis of a wide range of therapeutic proteins, including cytokines, enzymes, and antibodies.[5] The technology is particularly advantageous for producing proteins that are difficult to express in conventional cell-based systems.[2] Companies like Sutro Biopharma utilize their proprietary cell-free platform to produce antibody-drug conjugates (ADCs), bispecific antibodies, and cytokine-based therapies.[5] Another example is the production of the human therapeutic protein filaggrin using a customized E. coli CFPS platform.[5]
2. Antibody and Antibody Fragment Production
The production of monoclonal antibodies and their fragments (e.g., Fabs, scFvs) is a significant application of CFPS.[1][6] This method allows for the rapid and cost-effective generation of antibodies for both research and therapeutic purposes.[1] Eukaryotic cell-free systems, such as those based on Chinese hamster ovary (CHO) cell lysates, are particularly well-suited for synthesizing complex antibodies requiring specific post-translational modifications.[7][8] Researchers have achieved high yields of functional antibodies by optimizing reaction conditions, such as creating a proper redox environment for disulfide bond formation.[6][8]
3. On-Demand Vaccine Manufacturing
CFPS is revolutionizing vaccine development and production by enabling rapid, on-demand synthesis.[9][10] This is particularly critical for responding to emerging infectious diseases and pandemics.[10] The iVAX (in vitro conjugate vaccine expression) platform, for instance, allows for the production of multiple conjugate vaccine doses in just one hour.[9][11] A key advantage is the ability to freeze-dry the cell-free system components, making them shelf-stable for extended periods and easily transportable without the need for a cold chain.[10][12] Rehydration with water at the point of care is all that is needed to initiate vaccine synthesis.[10]
4. High-Throughput Screening and Drug Discovery
The speed and scalability of CFPS make it an ideal tool for high-throughput screening in the early stages of drug discovery.[1] It allows for the rapid generation of target proteins for screening assays to identify and validate potential drug candidates.[1] Furthermore, CFPS aids in the optimization of lead compounds by producing target proteins for binding studies to assess affinity and selectivity.[1]
Quantitative Data Presentation
The following tables summarize reported protein yields from various CFPS systems and reaction formats.
Table 1: Protein Yields in Different Cell-Free Protein Synthesis Systems
| Cell-Free System | Target Protein | Protein Yield | Reference |
| E. coli | Granulocyte-macrophage colony-stimulating factor (GM-CSF) | 700 mg/L | [13] |
| E. coli | Various colicins | Up to maximum production in 3 hours | [14] |
| E. coli (commercial kit) | Generic | ~0.5 mg/mL | [15] |
| HEK293 (human) | Reporter protein | Up to 300 µg/mL | [7] |
| CHO (hamster) | Monoclonal antibodies | Not specified | [8] |
| Wheat Germ | Generic | Not specified | [16] |
Table 2: Comparison of Batch and Continuous-Flow CFPS
| Reaction Format | Description | Advantages | Disadvantages |
| Batch | All reaction components are mixed at the beginning and incubated. | Simple setup, rapid protein synthesis (hours).[13] | Shorter reaction duration, accumulation of inhibitory byproducts.[13] |
| Continuous Exchange/Flow | Fresh substrates are continuously supplied while byproducts are removed. | Extended reaction times, higher protein yields.[13] | More complex setup, requires specialized equipment. |
Experimental Protocols
Protocol 1: mRNA Template Preparation via Two-Step PCR
This protocol describes a cloning-free method to generate linear DNA templates for in vitro transcription.[17]
Materials:
-
Plasmid DNA containing the gene of interest
-
Gene-specific forward and reverse primers for 1st PCR
-
Universal forward and reverse primers for 2nd PCR
-
High-fidelity DNA polymerase
-
dNTPs
-
PCR buffer
-
Nuclease-free water
-
Agarose (B213101) gel, DNA loading dye, and DNA ladder
-
Gel electrophoresis system and documentation system
Procedure:
Step 1: First PCR - Amplification of the Target Gene
-
Design gene-specific forward and reverse primers that anneal to the 5' and 3' ends of your open reading frame (ORF).
-
Set up the first PCR reaction as follows:
-
Plasmid DNA template: 1-10 ng
-
1st PCR Forward Primer: 0.5 µM
-
1st PCR Reverse Primer: 0.5 µM
-
High-fidelity DNA polymerase: Per manufacturer's recommendation
-
dNTPs: 200 µM each
-
PCR Buffer: 1X
-
Nuclease-free water: to a final volume of 50 µL
-
-
Perform PCR using an appropriate annealing temperature and extension time for your target gene.
-
Verify the PCR product by running a small aliquot on an agarose gel. A single band of the expected size should be visible.
Step 2: Second PCR - Addition of Promoter and Terminator Sequences
-
Use the unpurified product from the first PCR as the template for the second PCR.
-
Set up the second PCR reaction as follows:
-
1st PCR product: 1-2 µL
-
2nd PCR Universal Forward Primer (containing T7 promoter): 0.5 µM
-
2nd PCR Universal Reverse Primer (containing T7 terminator): 0.5 µM
-
High-fidelity DNA polymerase: Per manufacturer's recommendation
-
dNTPs: 200 µM each
-
PCR Buffer: 1X
-
Nuclease-free water: to a final volume of 50 µL
-
-
Perform PCR.
-
Analyze the final PCR product on an agarose gel to confirm the correct size.[18]
-
Purify the linear DNA template using a PCR purification kit.
Step 3: In Vitro Transcription
-
Use a commercial in vitro transcription kit (e.g., T7 RNA polymerase-based).
-
Follow the manufacturer's protocol, using the purified linear DNA from Step 2 as the template.
-
Purify the resulting mRNA using an appropriate RNA purification method.
Protocol 2: Preparation of E. coli S30 Cell Extract
This protocol outlines a general procedure for preparing a crude E. coli extract for CFPS.[19]
Materials:
-
E. coli strain (e.g., BL21)
-
2x YPTG media
-
S30 buffer (10 mM Tris-acetate pH 8.2, 14 mM Mg(OAc)₂, 60 mM KOAc, 2 mM DTT)
-
Centrifuge and sterile centrifuge bottles
-
High-pressure homogenizer or sonicator
-
Dialysis tubing
Procedure:
-
Inoculate a starter culture of E. coli and grow overnight.
-
The next day, inoculate a larger volume of 2x YPTG media and grow with vigorous shaking at 37°C until the OD₆₀₀ reaches ~3.0.
-
Harvest the cells by centrifugation at 5,000 x g for 10 minutes at 4°C.
-
Wash the cell pellet three times with ice-cold S30 buffer, centrifuging after each wash.
-
Resuspend the final cell pellet in S30 buffer.
-
Lyse the cells using a high-pressure homogenizer or sonicator on ice.
-
Centrifuge the lysate at 30,000 x g for 30 minutes at 4°C to pellet cell debris.
-
Collect the supernatant (this is the S30 extract).
-
Perform a "run-off" reaction by incubating the extract at 37°C for 80 minutes to degrade endogenous mRNA and ribosomes.
-
Dialyze the extract against S30 buffer overnight at 4°C.
-
Aliquot the final S30 extract and store at -80°C.
Protocol 3: Batch Cell-Free Protein Synthesis Reaction
This protocol provides a basic setup for a batch CFPS reaction using a prepared E. coli extract and an mRNA template.
Materials:
-
Prepared E. coli S30 extract
-
Purified mRNA template
-
Reaction buffer containing:
-
HEPES buffer (pH 7.2)
-
Potassium glutamate
-
Ammonium glutamate
-
Magnesium glutamate
-
Amino acid mixture (all 20)
-
Energy source (e.g., phosphoenolpyruvate (B93156) - PEP)
-
ATP, GTP, CTP, UTP
-
tRNA
-
RNase inhibitor
-
-
Nuclease-free water
Procedure:
-
Thaw all components on ice.
-
In a nuclease-free microcentrifuge tube, combine the following in order:
-
Nuclease-free water
-
Reaction buffer
-
Amino acid mixture
-
Energy source
-
mRNA template (final concentration ~50-100 µg/mL)
-
E. coli S30 extract (typically 20-30% of the final volume)
-
-
Mix gently by pipetting.
-
Incubate the reaction at 37°C for 2-4 hours.[15] Shaking may improve yields.
-
After incubation, the reaction can be analyzed directly by SDS-PAGE and Western blot, or the synthesized protein can be purified.[15]
Visualizations
Caption: General workflow of cell-free protein synthesis.
Caption: Two-step PCR for linear DNA template generation.
Caption: On-demand vaccine production using CFPS.
References
- 1. idtdna.com [idtdna.com]
- 2. isomerase.com [isomerase.com]
- 3. nehakamat.com [nehakamat.com]
- 4. Cell-Free Protein Synthesis: A Promising Option for Future Drug Development - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. pharmasalmanac.com [pharmasalmanac.com]
- 6. mdpi.com [mdpi.com]
- 7. Optimizing Human Cell-Free System for Efficient Protein Production - PMC [pmc.ncbi.nlm.nih.gov]
- 8. tandfonline.com [tandfonline.com]
- 9. On-demand biomanufacturing of protective conjugate vaccines - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Shelf-stable Vaccines Avoid Waste, Expand Access | News | Northwestern Engineering [mccormick.northwestern.edu]
- 11. On-demand, cell-free biomanufacturing of conjugate vaccines at the point-of-care - preLights [prelights.biologists.com]
- 12. Cell-free biotech enables shelf-stable vaccines on demand | Cornell Chronicle [news.cornell.edu]
- 13. Cell-Free Protein Synthesis: Applications Come of Age - PMC [pmc.ncbi.nlm.nih.gov]
- 14. semanticscholar.org [semanticscholar.org]
- 15. youtube.com [youtube.com]
- 16. Cell-Free Protein Synthesis: A Promising Option for Future Drug Development - PMC [pmc.ncbi.nlm.nih.gov]
- 17. Cloning-free template DNA preparation for cell-free protein synthesis via two-step PCR using versatile primer designs with short 3'-UTR - PubMed [pubmed.ncbi.nlm.nih.gov]
- 18. Next Generation Cell Free Protein Expression Kit (Wheat Germ) (CFPS700) PROTOCOL [sigmaaldrich.com]
- 19. A User’s Guide to Cell-Free Protein Synthesis - PMC [pmc.ncbi.nlm.nih.gov]
Application Notes & Protocols: mRNA in Cancer Immunotherapy Research
Introduction
Messenger RNA (mRNA) technology has emerged as a transformative platform in medicine, most notably demonstrated by the rapid development of COVID-19 vaccines.[1][2] This technology's versatility, rapid production capabilities, and safety profile have positioned it at the forefront of cancer immunotherapy research.[3][4] mRNA-based therapeutics offer a novel way to program the patient's own cells to produce proteins that can stimulate a targeted anti-tumor immune response.[2][5] This document provides detailed application notes and experimental protocols for researchers, scientists, and drug development professionals exploring the use of mRNA in oncology.
Application Notes
The core principle of mRNA-based cancer immunotherapy is to deliver a specific mRNA sequence into a patient's cells. These cells then use the mRNA as a template to synthesize proteins—such as tumor-specific antigens or immune-stimulating molecules—that activate the immune system to recognize and eliminate cancer cells.[6][7] This approach avoids the risks of genomic integration associated with DNA-based therapies, as mRNA is a transient molecule that does not enter the cell nucleus.[4][8]
Key applications currently under investigation include:
-
mRNA Cancer Vaccines: These vaccines introduce mRNA encoding tumor-associated antigens (TAAs) or tumor-specific neoantigens.[2][6]
-
Personalized Neoantigen Vaccines: This is a highly individualized approach. A patient's tumor is biopsied and sequenced to identify unique mutations that give rise to neoantigens—proteins not present in normal cells.[1][7] An mRNA vaccine is then manufactured to encode for multiple of these specific neoantigens.[1][9] This "made-to-order" vaccine directs the immune system to attack only the cancer cells, minimizing off-target effects.[5][10] The manufacturing process for a personalized vaccine typically takes 1 to 2 months.[1]
-
"Off-the-Shelf" Antigen Vaccines: These vaccines target TAAs that are commonly overexpressed in certain cancer types (e.g., prostate, melanoma, lung cancer) across many patients.[1][6] This approach allows for a more standardized treatment that is readily available.
-
-
mRNA-Engineered Adoptive Cell Therapy (ACT): This application involves modifying immune cells, such as T cells, outside the body (ex vivo) to enhance their tumor-fighting capabilities.
-
Chimeric Antigen Receptor (CAR) T-Cell Therapy: T cells are extracted from a patient and engineered to express CARs, which are synthetic receptors that recognize specific antigens on tumor cells.[11] Traditionally, this is done using viral vectors, which permanently integrate the CAR gene into the T-cell's DNA, posing risks of long-term side effects.[12] Using mRNA to express the CAR is a safer, transient alternative.[12][13] The CAR expression is temporary, which can reduce toxicity and allow for more controlled, dose-dependent activity.[12] Methods like electroporation are commonly used to deliver the CAR-encoding mRNA into the T cells.[11][14]
-
-
In Situ Immunomodulation with mRNA: This strategy involves the direct, intratumoral injection of mRNA encoding immunomodulatory proteins like cytokines.
-
mRNA-Encoded Cytokines: Cytokines are proteins that play a critical role in regulating immune responses.[15][16] However, systemic administration of recombinant cytokine proteins can cause severe toxicity due to their short half-life and potent, widespread effects.[15][17] Delivering mRNA encoding a cocktail of cytokines (e.g., IL-12, IFN-α, GM-CSF) directly into the tumor microenvironment (TME) allows for localized protein production.[15][18] This approach can transform an immunologically "cold" tumor (lacking immune cells) into a "hot" one by promoting the infiltration and activation of T cells, thereby making the tumor more susceptible to immune attack and other immunotherapies like checkpoint inhibitors.[15]
-
Logical Framework of mRNA Applications in Cancer Immunotherapy
The following diagram illustrates the primary strategies for using mRNA to generate an anti-tumor immune response.
Caption: Overview of mRNA therapeutic strategies and their immunological outcomes.
Data Presentation: Summary of Clinical Trial Data
Numerous clinical trials are underway to evaluate the efficacy of mRNA-based cancer therapies.[19][20] Globally, there are over 60 mRNA cancer vaccines in clinical trials, with several in advanced stages.[19]
| Therapeutic Agent | Cancer Type | Phase | Key Findings | Citations |
| mRNA-4157 (V940) + Pembrolizumab (B1139204) | High-Risk Resected Melanoma | IIb/III | Combined treatment reduced the risk of recurrence or death by 49% and the risk of distant metastasis or death by 65% compared to pembrolizumab alone after 3 years. | [7] |
| Personalized mRNA Vaccine (autogene cevumeran) | Pancreatic Ductal Adenocarcinoma (PDAC) | I | Vaccine-induced T-cell responses were observed in 50% of patients; responders had a significantly longer median recurrence-free survival compared to non-responders. | [7] |
| mRNA-4359 | Advanced Solid Tumors (e.g., Lung, Melanoma) | I | Treatment was well-tolerated. 8 out of 16 evaluable patients demonstrated stable disease (tumor size did not grow and no new tumors appeared). | [21] |
| SAR441000 (mRNA cytokine cocktail) + Cemiplimab | Advanced Solid Tumors | I | Combination therapy was generally well-tolerated and showed anti-tumor activity, with some patients achieving partial responses. | [16] |
Experimental Protocols
Protocol 1: Personalized mRNA Vaccine Workflow
This protocol outlines the major steps from patient sample acquisition to the administration of a personalized cancer vaccine.
Caption: Workflow for personalized mRNA cancer vaccine development.
Methodology:
-
Sample Collection: Obtain a tumor biopsy and a matched normal tissue or blood sample from the patient.
-
Sequencing: Perform whole-exome and transcriptome sequencing on both tumor and normal samples to identify tumor-specific mutations.
-
Neoantigen Prediction: Use bioinformatics algorithms to analyze the mutation data and predict which mutations will result in neoantigens that can bind effectively to the patient's Major Histocompatibility Complex (MHC) molecules and are likely to be immunogenic.[1]
-
mRNA Construct Design & Synthesis:
-
Design a DNA template that includes a T7 promoter, 5' UTR, the coding sequences for selected neoantigens (often linked together), a 3' UTR, and a poly(A) tail.
-
Perform in vitro transcription (IVT) using T7 RNA polymerase, ribonucleoside triphosphates (NTPs), and the DNA template. Modified nucleosides (e.g., pseudouridine) can be incorporated to reduce innate immunogenicity and increase mRNA stability.[8]
-
Purify the resulting mRNA using methods like oligo-dT affinity chromatography or silica-based columns.
-
-
Lipid Nanoparticle (LNP) Formulation:
-
LNPs are typically composed of an ionizable lipid, a phospholipid, cholesterol, and a PEGylated lipid.[22][23]
-
Prepare an aqueous phase containing the purified mRNA in a low pH buffer (e.g., citrate (B86180) buffer, pH 3-4).
-
Prepare an ethanol (B145695) phase with the lipids dissolved at a specific molar ratio.
-
Use a microfluidic mixing device to rapidly mix the aqueous and ethanol phases. The low pH causes the ionizable lipid to become positively charged, facilitating complexation with the negatively charged mRNA backbone, leading to the self-assembly of LNPs.[22]
-
Dialyze the resulting LNP solution against a neutral pH buffer (e.g., PBS) to raise the pH, neutralizing the surface charge and creating a stable particle.
-
-
Quality Control: Perform tests for particle size, zeta potential, mRNA encapsulation efficiency, purity, and sterility before release.
-
Administration: The final vaccine product is typically administered to the patient via intramuscular or intradermal injection.[3]
Protocol 2: mRNA Electroporation of Human T-Cells for CAR Expression
This protocol provides a general method for transiently expressing a CAR in primary human T-cells using mRNA electroporation.[11][24]
Caption: Experimental workflow for generating transient mRNA CAR T-cells.
Methodology:
-
T-Cell Isolation and Expansion:
-
Isolate Peripheral Blood Mononuclear Cells (PBMCs) from a healthy donor or patient's blood using a density gradient medium (e.g., Ficoll-Paque).
-
Activate and expand T-cells by culturing them with anti-CD3/CD28 beads and interleukin-2 (B1167480) (IL-2) for several days.
-
-
Preparation for Electroporation:
-
Electroporation:
-
Place a 4 mm electroporation cuvette on ice.
-
Add the cell suspension to the cuvette.
-
Add the CAR-encoding mRNA to the cell suspension (typically 5-10 µg per 1x10⁶ cells) and mix gently.[25]
-
Incubate on ice for 5 minutes.[25]
-
Deliver an electrical pulse using an electroporator. A square-wave pulse (e.g., 500 V, 5 ms) is often effective, but parameters must be optimized for the specific cell type and instrument.[24]
-
-
Post-Electroporation Culture:
-
Immediately after the pulse, transfer the cells from the cuvette into pre-warmed culture medium containing IL-2 to allow for recovery.
-
-
Analysis of CAR Expression:
-
After 12-24 hours, stain the cells with a fluorophore-conjugated antibody or protein that specifically binds to the extracellular domain of the expressed CAR.
-
Analyze the cells by flow cytometry to determine the percentage of CAR-positive T-cells (transfection efficiency).
-
-
Functional Assays:
-
Co-culture the mRNA-CAR T-cells with target tumor cells (expressing the antigen recognized by the CAR) and control cells (antigen-negative).
-
Measure T-cell activation (e.g., IFN-γ release via ELISA or ELISpot) and target cell lysis (e.g., using a chromium-51 (B80572) release assay or a real-time imaging-based cytotoxicity assay).[26]
-
Protocol 3: Monitoring Antigen-Specific T-Cell Responses
Quantifying the T-cell response is crucial for evaluating the efficacy of any cancer immunotherapy.[27][28]
Signaling Pathway: T-Cell Activation by an mRNA Vaccine
Caption: T-cell activation pathway following mRNA vaccine uptake by an APC.
Common Methodologies:
| Assay | Principle | Primary Measurement | Advantages | Disadvantages | Citations |
| ELISpot (Enzyme-Linked Immunospot) | Captures cytokines (e.g., IFN-γ) secreted by individual T-cells upon antigen stimulation. Each spot represents a single reactive cell. | Frequency of antigen-specific, cytokine-producing cells. | Highly sensitive (can detect <10 reactive cells per million). Quantitative. | Provides limited information on cell phenotype. Requires live cells. | [28][29] |
| Intracellular Cytokine Staining (ICS) by Flow Cytometry | T-cells are stimulated with the antigen in the presence of a protein transport inhibitor, trapping cytokines inside the cell. Cells are then fixed, permeabilized, and stained for surface markers and intracellular cytokines. | Frequency and phenotype (e.g., CD4+, CD8+, memory status) of cytokine-producing cells. Can measure multiple cytokines simultaneously (polyfunctionality). | Provides phenotypic information. Multi-parameter analysis. | Less sensitive than ELISpot. Requires cell fixation, precluding downstream functional analysis. | [29][30] |
| MHC-Multimer (Tetramer/Dextramer) Staining | Fluorophore-labeled MHC molecules, pre-loaded with the specific peptide antigen, are used to directly stain and identify T-cells with a cognate T-cell receptor (TCR). | Frequency and phenotype of T-cells that can bind a specific antigen-MHC complex. | Directly quantifies T-cells by TCR specificity, independent of function. Allows for sorting of live antigen-specific cells. | Requires knowledge of the specific MHC-peptide epitope. May not identify all functional T-cells. | [26][28] |
| Cytotoxicity Assay (e.g., Cr-51 Release) | Effector T-cells are co-cultured with target tumor cells labeled with a radioactive or fluorescent marker. The release of the marker into the supernatant upon cell lysis is measured. | Percentage of specific lysis of target cells. | Directly measures the key effector function of cytotoxic T-cells. | Can be cumbersome, may involve hazardous materials (Cr-51). Indirect measurement of T-cell activity. | [26][28] |
References
- 1. How mRNA Vaccines Might Help Treat Cancer - NCI [cancer.gov]
- 2. mRNA vaccine in cancer therapy: Current advance and future outlook - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Application of mRNA Technology in Cancer Therapeutics - PMC [pmc.ncbi.nlm.nih.gov]
- 4. mRNA-Based Therapeutics in Cancer Treatment - PMC [pmc.ncbi.nlm.nih.gov]
- 5. mRNA Vaccines | American Cancer Society [cancer.org]
- 6. Applications of mRNA Delivery in Cancer Immunotherapy - PMC [pmc.ncbi.nlm.nih.gov]
- 7. rcpath.org [rcpath.org]
- 8. pubs.aip.org [pubs.aip.org]
- 9. Personalised mRNA Cancer Vaccines [cancertrials.co.uk]
- 10. researchgate.net [researchgate.net]
- 11. Engineering mRNA CAR-T Cells for Cancer Immunotherapy - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. Research in mRNA chimeric antigen receptor T cell therapy | Penn Medicine [pennmedicine.org]
- 13. trilinkbiotech.com [trilinkbiotech.com]
- 14. Preclinical efficacy of multi-targeting mRNA-based CAR T cell therapy in resection models of glioblastoma - PubMed [pubmed.ncbi.nlm.nih.gov]
- 15. Frontiers | Local administration of mRNA encoding cytokine cocktail confers potent anti-tumor immunity [frontiersin.org]
- 16. aacrjournals.org [aacrjournals.org]
- 17. news-medical.net [news-medical.net]
- 18. Local delivery of mRNA-encoding cytokines promotes antitumor immunity and tumor eradication across multiple preclinical tumor models [en-cancer.fr]
- 19. trial.medpath.com [trial.medpath.com]
- 20. Current Progress and Future Perspectives of RNA-Based Cancer Vaccines: A 2025 Update - PMC [pmc.ncbi.nlm.nih.gov]
- 21. Experimental mRNA cancer vaccine shows potential for advanced stage cancer patients | King's College London [kcl.ac.uk]
- 22. Lipid Nanoparticle Assisted mRNA Delivery for Potent Cancer Immunotherapy - PMC [pmc.ncbi.nlm.nih.gov]
- 23. Advances in mRNA LNP-Based Cancer Vaccines: Mechanisms, Formulation Aspects, Challenges, and Future Directions [mdpi.com]
- 24. Electroporation of mRNA as Universal Technology Platform to Transfect a Variety of Primary Cells with Antigens and Functional Proteins | Springer Nature Experiments [experiments.springernature.com]
- 25. Protocols for mRNA electroporation [protocols.io]
- 26. criver.com [criver.com]
- 27. Quantifying Antigen-Specific T Cell Responses When Using Antigen-Agnostic Immunotherapies - PMC [pmc.ncbi.nlm.nih.gov]
- 28. journals.asm.org [journals.asm.org]
- 29. Antigen-specificity measurements are the key to understanding T cell responses - PMC [pmc.ncbi.nlm.nih.gov]
- 30. mdpi.com [mdpi.com]
Application Notes and Protocols for mRNA-Mediated CRISPR-Cas9 Gene Editing
For Researchers, Scientists, and Drug Development Professionals
Introduction
The clustered regularly interspaced short palindromic repeats (CRISPR)-Cas9 system has revolutionized the field of gene editing, offering a powerful tool for precise genetic modification. The delivery of the CRISPR-Cas9 components into target cells is a critical step for successful gene editing. The use of messenger RNA (mRNA) to encode the Cas9 nuclease presents a transient and efficient delivery method, mitigating the risks of genomic integration associated with DNA-based systems.[1][2] This document provides detailed application notes and protocols for utilizing mRNA for CRISPR-Cas9 delivery, focusing on lipid nanoparticle (LNP) and electroporation-mediated methods.
Advantages of mRNA-Based CRISPR-Cas9 Delivery
The delivery of Cas9 as an mRNA molecule offers several advantages over plasmid DNA and recombinant Cas9 protein (RNP) delivery methods.[1][3]
-
Transient Expression: mRNA is translated into Cas9 protein in the cytoplasm and is naturally degraded by cellular processes. This transient expression of the nuclease reduces the risk of off-target cleavage that can occur with prolonged Cas9 presence.[4][5]
-
No Risk of Genomic Integration: Unlike plasmid DNA, mRNA does not integrate into the host genome, enhancing the safety profile of the gene-editing process.[1]
-
High Editing Efficiency: mRNA delivery can lead to high levels of Cas9 protein expression, resulting in efficient gene editing.[1][3][6]
-
Flexibility in Delivery: mRNA can be delivered into a wide range of cell types using various methods, including lipid nanoparticles and electroporation.[3]
Key Delivery Strategies
Two of the most effective and widely used methods for delivering Cas9 mRNA and guide RNA (gRNA) into cells are lipid nanoparticles (LNPs) and electroporation.
Lipid Nanoparticle (LNP) Delivery
LNPs are non-viral vectors that can encapsulate and protect mRNA, facilitating its uptake into cells.[7][8][9] They are a promising delivery vehicle for in vivo applications due to their low immunogenicity and scalability.[1][7][10] The composition of the LNP can be tailored to target specific tissues.[1][8]
Electroporation
Electroporation utilizes an electrical pulse to create temporary pores in the cell membrane, allowing for the direct entry of mRNA and gRNA into the cytoplasm.[11][12][13] This method is highly efficient for ex vivo and in vitro applications, particularly for difficult-to-transfect cells like primary cells and stem cells.[11][12]
Experimental Protocols
Protocol 1: In Vitro Transcription of Cas9 mRNA and sgRNA
High-quality mRNA is crucial for efficient translation and subsequent gene editing. This protocol outlines the steps for in vitro transcription (IVT) of Cas9 mRNA and single guide RNA (sgRNA).
Materials:
-
Linearized plasmid DNA template containing the Cas9 or sgRNA sequence downstream of a T7 promoter.[14]
-
In vitro transcription kit (e.g., mMESSAGE mMACHINE™ T7 Transcription Kit).[15]
-
Nuclease-free water.
-
RNA purification kit.
-
Agarose (B213101) gel electrophoresis system.
Procedure:
-
Template Preparation: Linearize the plasmid DNA template using a restriction enzyme that cuts downstream of the insert. Purify the linearized DNA.
-
In Vitro Transcription Reaction: Set up the IVT reaction according to the manufacturer's instructions. A typical reaction includes the linearized DNA template, T7 RNA polymerase, ribonucleotide triphosphates (NTPs), and a cap analog (for mRNA).[14][15]
-
Incubation: Incubate the reaction at 37°C for 2 hours.
-
DNase Treatment: Add DNase to the reaction to remove the DNA template and incubate for 15-30 minutes at 37°C.
-
RNA Purification: Purify the synthesized mRNA or sgRNA using a suitable RNA purification kit to remove unincorporated nucleotides and enzymes.
-
Quality Control: Assess the quality and concentration of the RNA using a spectrophotometer and agarose gel electrophoresis. High-quality RNA should appear as a sharp, single band.[14]
Protocol 2: LNP Formulation for Cas9 mRNA and sgRNA Delivery
This protocol provides a general guideline for the formulation of LNPs encapsulating Cas9 mRNA and sgRNA. The specific lipid composition and ratios may need to be optimized for different applications.[7]
Materials:
-
Ionizable lipid.
-
Helper lipid (e.g., DSPC).
-
Cholesterol.
-
PEG-lipid.[16]
-
Cas9 mRNA and sgRNA in a low pH buffer (e.g., citrate (B86180) buffer, pH 4.0).
-
PBS (pH 7.4).
-
Microfluidic mixing device.
Procedure:
-
Lipid Mixture Preparation: Dissolve the ionizable lipid, helper lipid, cholesterol, and PEG-lipid in ethanol (B145695) at a specific molar ratio.
-
mRNA/sgRNA Solution Preparation: Dilute the Cas9 mRNA and sgRNA in the low pH buffer.
-
LNP Formulation: Use a microfluidic mixing device to rapidly mix the lipid-ethanol solution with the mRNA/sgRNA-aqueous buffer solution at a defined flow rate ratio.
-
Dialysis: Dialyze the resulting LNP suspension against PBS (pH 7.4) to remove ethanol and raise the pH.
-
Characterization: Characterize the LNPs for size, polydispersity index (PDI), and encapsulation efficiency.
Protocol 3: Electroporation of Cas9 mRNA and sgRNA into Primary Cells
This protocol describes the electroporation of Cas9 mRNA and sgRNA into primary cells, such as hepatocytes.[11]
Materials:
-
Isolated primary cells (e.g., primary mouse hepatocytes).[11]
-
Cas9 mRNA and sgRNA.
-
Electroporation buffer specific to the cell type.[13]
-
Electroporation system and cuvettes.
-
Cell culture medium.
Procedure:
-
Cell Preparation: Isolate and prepare a single-cell suspension of the primary cells. Ensure high cell viability (>85%).[11]
-
Electroporation Mix: Resuspend the desired number of cells (e.g., 1.2 x 10^6 cells) in 100 µL of electroporation buffer.[11] Add the Cas9 mRNA (e.g., 4 µg) and sgRNA (e.g., 30 µg) to the cell suspension.[11]
-
Electroporation: Transfer the cell-mRNA-sgRNA mixture to an electroporation cuvette and apply the optimized electrical pulse using the electroporation device.[11][17]
-
Cell Recovery: Immediately after electroporation, gently transfer the cells to a culture plate containing pre-warmed culture medium.[13]
-
Incubation: Incubate the cells at 37°C in a 5% CO2 incubator for 48-72 hours before analysis.[17]
Quantification of Gene Editing Efficiency
Accurate quantification of gene editing events is essential to evaluate the success of the experiment. Several methods can be used to determine the frequency of insertions and deletions (indels) at the target locus.
| Method | Principle | Advantages | Disadvantages |
| Sanger Sequencing with TIDE/ICE Analysis | PCR amplification of the target locus followed by Sanger sequencing. The resulting chromatograms are analyzed by web-based tools (TIDE or ICE) to quantify indel frequencies.[18] | Rapid, cost-effective, and widely accessible.[19] | Less sensitive for detecting low-frequency indels and complex mutations.[19] |
| Next-Generation Sequencing (NGS) | Deep sequencing of PCR amplicons from the target region provides a comprehensive profile of all editing outcomes.[20] | Highly sensitive and quantitative, can identify a wide range of mutations.[19] | More expensive and time-consuming, requires bioinformatics expertise for data analysis.[19] |
| Genomic Cleavage Detection (GCD) Assay | A mismatch-specific endonuclease cleaves heteroduplex DNA formed between wild-type and edited DNA strands. The cleavage products are resolved by gel electrophoresis.[20] | Simple, rapid, and does not require sequencing.[20] | Semi-quantitative and may not detect all types of indels. |
| Reporter Cell Lines | Cells engineered with a reporter gene (e.g., GFP) that is activated or inactivated upon successful gene editing. Editing efficiency is quantified by flow cytometry.[18] | Allows for live-cell analysis and sorting of edited cells. | Requires the generation of a specific reporter cell line for each target. |
Assessment of Off-Target Effects
A major concern in CRISPR-Cas9 gene editing is the potential for off-target mutations at unintended genomic sites.[4] Several strategies can be employed to minimize and detect off-target effects.
Strategies to Minimize Off-Target Effects:
-
Guide RNA Design: Utilize bioinformatics tools to design sgRNAs with high on-target activity and minimal predicted off-target sites.[21]
-
High-Fidelity Cas9 Variants: Employ engineered Cas9 variants (e.g., SpCas9-HF1, eSpCas9) that exhibit reduced off-target cleavage.[4][22]
-
Transient Delivery: The use of mRNA for Cas9 delivery ensures transient expression, which has been shown to reduce off-target effects compared to plasmid DNA delivery.[4][5]
-
RNP Delivery: Delivering the Cas9 protein and sgRNA as a pre-formed ribonucleoprotein (RNP) complex also leads to transient activity and lower off-target rates.[22]
Methods for Off-Target Detection:
-
In Silico Prediction: Computational tools can predict potential off-target sites based on sequence homology to the sgRNA.[4]
-
GUIDE-seq (Genome-wide Unbiased Identification of DSBs Enabled by sequencing): An unbiased method that integrates double-stranded oligodeoxynucleotides (dsODNs) into DNA double-strand breaks (DSBs), allowing for the genome-wide identification of Cas9 cleavage sites.[2]
-
Digenome-seq (Digested Genome Sequencing): An in vitro method that uses Cas9 to digest genomic DNA, followed by whole-genome sequencing to identify cleavage sites.
Visualizations
Caption: Workflow for mRNA-based CRISPR-Cas9 Gene Editing.
Caption: Cellular uptake and mechanism of LNP-delivered mRNA.
Caption: Comparison of CRISPR-Cas9 delivery methods.
References
- 1. Unlocking mRNA-driven CRISPR-Cas9 gene therapy via optimizing mRNA and the delivery vectors - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Protocol for editing fibroblasts with in vitro transcribed Cas9 mRNA and profile off-target editing by optimized GUIDE-seq - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. vernal.bio [vernal.bio]
- 4. Off-target effects in CRISPR/Cas9 gene editing - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Mitigating off-target effects in CRISPR/Cas9-mediated in vivo gene editing - PMC [pmc.ncbi.nlm.nih.gov]
- 6. mRNA-mediated delivery of gene editing tools to human primary muscle stem cells - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Protocol for Delivery of CRISPR/dCas9 Systems for Epigenetic Editing into Solid Tumors Using Lipid Nanoparticles Encapsulating RNA | Springer Nature Experiments [experiments.springernature.com]
- 8. Intracellular Delivery of mRNA for Cell-Selective CRISPR/Cas9 Genome Editing using Lipid Nanoparticles - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. Lipid-Nanoparticle-Based Delivery of CRISPR/Cas9 Genome-Editing Components - PMC [pmc.ncbi.nlm.nih.gov]
- 10. mdpi.com [mdpi.com]
- 11. Electroporation-Mediated Delivery of Cas9 Ribonucleoproteins and mRNA into Freshly Isolated Primary Mouse Hepatocytes [jove.com]
- 12. synthego.com [synthego.com]
- 13. conductscience.com [conductscience.com]
- 14. researchgate.net [researchgate.net]
- 15. In Vitro Transcription Kits for Synthesizing High Yield mRNA | Thermo Fisher Scientific - HK [thermofisher.com]
- 16. researchgate.net [researchgate.net]
- 17. horizondiscovery.com [horizondiscovery.com]
- 18. mdpi.com [mdpi.com]
- 19. academic.oup.com [academic.oup.com]
- 20. Verification of CRISPR Gene Editing Efficiency | Thermo Fisher Scientific - CH [thermofisher.com]
- 21. azolifesciences.com [azolifesciences.com]
- 22. youtube.com [youtube.com]
Troubleshooting & Optimization
Technical Support Center: Troubleshooting Low Protein Expression from In Vitro Transcribed (IVT) mRNA
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to help researchers, scientists, and drug development professionals resolve issues related to low protein expression from in vitro transcribed (IVT) mRNA.
Troubleshooting Guide
Low protein expression from IVT mRNA can be a significant hurdle in research and therapeutic development. This guide provides a systematic approach to identifying and resolving common issues.
Question: My protein expression is low or undetectable. Where do I start troubleshooting?
Answer:
Low protein expression can stem from issues at multiple stages of the workflow, from the quality of the DNA template to the final translation reaction. A stepwise evaluation of your process is the most effective approach. Start by assessing the quality and integrity of your IVT mRNA, then move on to evaluating the key structural features of the mRNA, and finally, scrutinize the translation process itself.
Troubleshooting Workflow Diagram
Caption: A troubleshooting decision tree for low protein expression.
Frequently Asked Questions (FAQs)
mRNA Quality and Integrity
Question: How can I assess the quality and integrity of my IVT mRNA?
Answer: The quality of your IVT mRNA is a critical determinant of its translational efficiency. You should perform the following quality control checks:
-
Denaturing Agarose Gel Electrophoresis: Run your mRNA on a denaturing agarose gel to visualize its integrity. A high-quality mRNA preparation will appear as a sharp, single band at the expected size. Smearing or multiple bands indicate degradation or incomplete transcripts.[][2]
-
Spectrophotometry: Measure the absorbance of your mRNA sample at 260 nm and 280 nm, and at 260 nm and 230 nm. The A260/A280 ratio should be between 1.8 and 2.1, indicating purity from protein contamination. The A260/A230 ratio should be greater than 2.0, indicating freedom from contaminants like phenol (B47542) and guanidine.
Question: What are common sources of RNase contamination and how can I prevent them?
Answer: RNases are ubiquitous enzymes that can rapidly degrade your mRNA.[3][4] To prevent contamination:
-
Use RNase-free reagents and consumables: This includes water, buffers, pipette tips, and tubes.
-
Maintain a dedicated RNase-free workspace: Clean benchtops and equipment with RNase decontamination solutions.
-
Wear gloves at all times and change them frequently.
-
Use an RNase inhibitor in your IVT and subsequent reactions.[3][4]
mRNA Structure and Design
Question: How important is the 5' cap for protein expression?
Answer: The 5' cap is crucial for efficient protein translation in eukaryotes.[5][6][7] It facilitates ribosome binding to the mRNA and protects the mRNA from degradation by 5' exonucleases.[6][8] The type of cap analog used during in vitro transcription can significantly impact translation efficiency. Anti-Reverse Cap Analogs (ARCAs) are often preferred as they are incorporated in the correct orientation, leading to a higher percentage of functional capped mRNA.[9]
Question: What is the optimal length for the poly(A) tail?
Answer: The poly(A) tail, located at the 3' end of the mRNA, enhances mRNA stability and translation efficiency by promoting the recruitment of translation initiation factors.[5][6] While the optimal length can be protein- and system-dependent, a poly(A) tail of 100-250 nucleotides is generally recommended for robust protein expression.[10] Shorter or absent poly(A) tails can lead to rapid mRNA degradation and reduced translation.
Impact of Poly(A) Tail Length on Protein Expression
| Poly(A) Tail Length (nucleotides) | Relative Luciferase Activity (%) |
| 0 | 10 |
| 30 | 40 |
| 60 | 75 |
| 120 | 100 |
| 250 | 95 |
Note: Data is illustrative and based on general findings in the literature. Actual results may vary.
Question: Can the untranslated regions (UTRs) of my mRNA affect protein expression?
Answer: Yes, the 5' and 3' untranslated regions (UTRs) play a significant role in post-transcriptional regulation, including translation initiation and mRNA stability.[10][11] The inclusion of well-characterized UTRs, such as those from the alpha- or beta-globin genes, can significantly enhance protein expression.[10][11] Conversely, suboptimal UTRs can contain inhibitory elements that repress translation.
Question: How does codon usage impact protein expression?
Answer: The genetic code is degenerate, meaning that most amino acids can be encoded by multiple codons. However, the usage of these codons varies between organisms. Using codons that are rare in the expression system can lead to translational pausing and premature termination, resulting in lower protein yields.[10] Codon optimization, which involves replacing rare codons with more frequently used ones without altering the amino acid sequence, can significantly improve protein expression.[10]
Question: Can mRNA secondary structure inhibit translation?
Answer: Strong secondary structures, particularly in the 5' UTR, can impede ribosome scanning and initiation of translation, leading to reduced protein expression.[12][13][14][15] It is advisable to analyze the predicted secondary structure of your mRNA using bioinformatics tools and, if necessary, re-design the sequence to minimize stable hairpin loops near the 5' end.[14]
Signaling Pathway of Translation Initiation
Caption: Key interactions in eukaryotic translation initiation.
In Vitro Transcription and Translation Reactions
Question: My in vitro transcription reaction has a low yield. What could be the cause?
Answer: Low IVT yield can be due to several factors:
-
Degraded or impure DNA template: Ensure your linearized plasmid DNA is of high quality and free from contaminants.[][4]
-
Suboptimal reaction conditions: Factors like temperature, reaction time, and the concentration of nucleotides and magnesium can affect the efficiency of the RNA polymerase.[16][17]
-
Inactive enzyme: The T7 RNA polymerase may be inactive due to improper storage or handling.[3]
Question: How can I purify my IVT mRNA to improve translation efficiency?
Answer: Purification of IVT mRNA is essential to remove reaction components that can inhibit translation, such as unincorporated nucleotides, enzymes, and the DNA template.[18][19] Common purification methods include:
-
LiCl precipitation: Effective for removing most proteins and unincorporated nucleotides.
-
Silica-based columns: Provide a rapid and efficient way to purify high-quality mRNA.
-
HPLC (High-Performance Liquid Chromatography): Offers the highest purity and is often used for therapeutic applications.[11][19]
Question: What are dsRNA contaminants and why are they a problem?
Answer: Double-stranded RNA (dsRNA) is a common byproduct of in vitro transcription that can be a potent activator of the innate immune system, leading to the shutdown of translation and potential cytotoxicity.[17][20] It is crucial to minimize the generation of dsRNA during IVT and/or remove it during purification, especially for in vivo applications.[17]
Experimental Protocols
Protocol 1: Assessment of mRNA Integrity by Denaturing Agarose Gel Electrophoresis
-
Prepare a 1.2% denaturing agarose gel:
-
Dissolve 1.2 g of agarose in 88 ml of RNase-free water.
-
Add 10 ml of 10X MOPS buffer.
-
Microwave to dissolve the agarose, then cool to ~60°C.
-
Add 2 ml of 37% formaldehyde (B43269) and pour the gel in a fume hood.
-
-
Prepare the mRNA sample:
-
In an RNase-free tube, mix:
-
2 µl of 10X MOPS buffer
-
3.5 µl of formaldehyde
-
10 µl of formamide
-
1-3 µg of your IVT mRNA
-
Add RNase-free water to a final volume of 20 µl.
-
-
Incubate at 65°C for 15 minutes, then place on ice.
-
Add 2 µl of formaldehyde gel loading dye.
-
-
Run the gel:
-
Load the samples and an RNA ladder.
-
Run the gel in 1X MOPS buffer at 5-7 V/cm until the dye has migrated sufficiently.
-
-
Visualize the RNA:
-
Stain the gel with an appropriate nucleic acid stain (e.g., ethidium (B1194527) bromide or SYBR Green) and visualize under UV light.
-
Protocol 2: In Vitro Translation using Rabbit Reticulocyte Lysate
-
Thaw reagents on ice: Rabbit reticulocyte lysate, reaction buffer, amino acid mixture, and control mRNA.
-
Set up the reaction: In a sterile, RNase-free microfuge tube, combine the following on ice (for a 25 µl reaction):
-
12.5 µl Rabbit Reticulocyte Lysate
-
2.5 µl 10X Reaction Buffer
-
1.25 µl Amino Acid Mixture (minus methionine or leucine (B10760876) for radiolabeling)
-
0.5 µl RNase Inhibitor
-
1 µg of your IVT mRNA
-
(Optional) 1 µl of radiolabeled amino acid (e.g., [³⁵S]-methionine)
-
RNase-free water to 25 µl.
-
-
Incubate the reaction: Incubate at 30°C for 60-90 minutes.
-
Analyze the protein product: Analyze the translation products by SDS-PAGE and autoradiography (if radiolabeled) or Western blotting.
References
- 2. agilent.com [agilent.com]
- 3. bitesizebio.com [bitesizebio.com]
- 4. promegaconnections.com [promegaconnections.com]
- 5. The End in Sight: Poly(A), Translation and mRNA Stability in Eukaryotes - Madame Curie Bioscience Database - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 6. tutorchase.com [tutorchase.com]
- 7. What is the significance of the 5’ cap and poly-A tail in eukaryotic mRNA processing ? | Sathee Forum [forum.prutor.ai]
- 8. youtube.com [youtube.com]
- 9. neb.com [neb.com]
- 10. trilinkbiotech.com [trilinkbiotech.com]
- 11. Recent Advances and Innovations in the Preparation and Purification of In Vitro-Transcribed-mRNA-Based Molecules - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Deciphering the rules by which dynamics of mRNA secondary structure affect translation efficiency in Saccharomyces cerevisiae - PMC [pmc.ncbi.nlm.nih.gov]
- 13. researchgate.net [researchgate.net]
- 14. Role of mRNA Secondary Structure in Translational Repression of the Maize Transcriptional Activator Lc - PMC [pmc.ncbi.nlm.nih.gov]
- 15. pnas.org [pnas.org]
- 16. mRNA Synthesis Scale-Up Tips | Thermo Fisher Scientific - US [thermofisher.com]
- 17. promegaconnections.com [promegaconnections.com]
- 18. purilogics.com [purilogics.com]
- 19. IVT mRNA Purification Services - mRNA-based Drug R&D Service [mrnabased-drug.com]
- 20. Advancements of in vitro transcribed mRNA (IVT mRNA) to enable translation into the clinics - PMC [pmc.ncbi.nlm.nih.gov]
Technical Support Center: Enhancing the Stability of Synthetic mRNA
Welcome to the technical support center for synthetic mRNA stability. This resource is designed for researchers, scientists, and drug development professionals to provide guidance on improving the stability and translational efficiency of in vitro transcribed (IVT) mRNA. Here you will find answers to frequently asked questions, detailed troubleshooting guides for common experimental issues, comprehensive experimental protocols, and quantitative data to inform your experimental design.
Frequently Asked Questions (FAQs)
Q1: What are the primary factors that influence the stability of synthetic mRNA?
A1: The stability of synthetic mRNA is a critical factor for its efficacy in therapeutic applications and is influenced by several key elements of its structure. These include the 5' cap structure, the length and composition of the 3' poly(A) tail, the sequences of the 5' and 3' untranslated regions (UTRs), and the presence of modified nucleotides within the coding sequence.[1] Each of these components can be optimized to protect the mRNA from degradation by cellular nucleases and to enhance its translational efficiency.
Q2: How does the 5' cap contribute to mRNA stability?
A2: The 5' cap, a modified guanosine (B1672433) nucleotide added to the 5' end of the mRNA, is crucial for its stability and function.[2][3] It protects the mRNA from degradation by 5' exonucleases and facilitates the recruitment of the ribosomal machinery for translation initiation.[2] Different cap analogs, such as anti-reverse cap analogs (ARCAs), can be incorporated during in vitro transcription to ensure proper orientation and improve translational efficiency.[4]
Q3: What is the optimal length for a poly(A) tail to maximize mRNA stability and protein expression?
A3: The poly(A) tail, a string of adenosine (B11128) residues at the 3' end of the mRNA, protects it from 3' exonuclease degradation and plays a role in translation termination and ribosome recycling.[4][5] While it was traditionally thought that longer poly(A) tails confer greater stability, recent studies suggest a more complex relationship. A minimum length of around 30 nucleotides is generally required for stability.[4] However, some studies indicate that highly translated and stable mRNAs can have shorter poly(A) tails of about 30 adenosines.[6] For in vitro applications, a tail length of approximately 75 nucleotides has been shown to be optimal for cap-dependent translation in human cell lysates.[5][7]
Q4: How do untranslated regions (UTRs) affect mRNA stability?
A4: The 5' and 3' untranslated regions (UTRs) contain regulatory elements that significantly impact mRNA stability and translation. The 5' UTR can contain secondary structures that influence ribosome scanning and initiation. The 3' UTR often harbors binding sites for microRNAs and RNA-binding proteins that can either promote degradation or enhance stability.[8][9] For example, AU-rich elements (AREs) in the 3' UTR are known to be destabilizing motifs.[8] The inclusion of UTRs from highly stable genes, such as alpha- and beta-globin, is a common strategy to improve the stability of synthetic mRNA.
Q5: What is the purpose of using modified nucleotides in synthetic mRNA?
A5: Incorporating modified nucleotides, such as pseudouridine (B1679824) (Ψ) and N1-methylpseudouridine (m1Ψ), into the mRNA sequence can significantly enhance its stability and reduce its immunogenicity.[10] These modifications can make the mRNA more resistant to degradation by cellular nucleases and can dampen the innate immune response that is often triggered by foreign RNA.[1][10] This leads to a longer half-life of the mRNA in the cell and sustained protein production.
Troubleshooting Guides
Problem 1: My synthetic mRNA is degrading rapidly, leading to low protein yield.
Possible Cause & Solution:
-
Suboptimal 5' Capping: Inefficient or incorrect capping can expose the 5' end of the mRNA to exonucleases.
-
Troubleshooting Steps:
-
Verify the integrity and concentration of your cap analog.
-
Consider using an anti-reverse cap analog (ARCA) to ensure proper orientation.
-
Alternatively, perform enzymatic capping after transcription, which can be more efficient than co-transcriptional capping.
-
Analyze capping efficiency using methods like RNase H digestion followed by gel electrophoresis or LC-MS.
-
-
-
Inadequate Poly(A) Tail: A short or absent poly(A) tail can lead to rapid degradation from the 3' end.
-
Troubleshooting Steps:
-
Ensure your DNA template encodes for a poly(A) tail of sufficient length (e.g., 75-150 nucleotides).
-
Alternatively, use enzymatic polyadenylation with Poly(A) Polymerase after in vitro transcription to add a poly(A) tail.[10][11]
-
Analyze the length of the poly(A) tail using methods like gel electrophoresis or specialized sequencing techniques.
-
-
-
Destabilizing UTR Sequences: The UTRs in your construct may contain elements that promote mRNA decay.
-
Troubleshooting Steps:
-
Analyze your 5' and 3' UTR sequences for known destabilizing motifs, such as AU-rich elements (AREs).
-
Replace the native UTRs with sequences from highly stable mRNAs, such as those from the alpha- or beta-globin genes.
-
-
-
RNase Contamination: RNases are ubiquitous and can rapidly degrade your mRNA.
-
Troubleshooting Steps:
-
Use RNase-free water, reagents, and labware throughout your entire workflow.
-
Wear gloves and work in a clean environment.
-
Consider adding an RNase inhibitor to your reactions.
-
-
Problem 2: Protein expression from my synthetic mRNA is lower than expected, even with good mRNA integrity.
Possible Cause & Solution:
-
Inefficient Translation Initiation: The 5' cap or 5' UTR may not be optimal for ribosome recruitment.
-
Troubleshooting Steps:
-
Experiment with different cap analogs, as some can enhance translation more effectively than others.[12][13][14]
-
Optimize the 5' UTR sequence. Ensure it lacks strong secondary structures that could impede ribosome scanning.
-
Incorporate a Kozak consensus sequence around the start codon to promote efficient translation initiation.
-
-
-
Codon Usage is Not Optimized: The codon usage in your coding sequence may not be ideal for the expression system you are using.
-
Troubleshooting Steps:
-
Use codon optimization software to design your coding sequence with codons that are frequently used in the target organism or cell type. This can improve the rate of translation elongation.
-
-
-
Innate Immune Response: The synthetic mRNA may be triggering an innate immune response, leading to translational shutdown.
-
Troubleshooting Steps:
-
Incorporate modified nucleotides like pseudouridine (Ψ) or N1-methylpseudouridine (m1Ψ) during in vitro transcription to reduce the immunogenicity of the mRNA.[10]
-
Ensure your mRNA is highly purified to remove any double-stranded RNA (dsRNA) byproducts, which are potent inducers of the immune response. HPLC purification is an effective method for this.[8]
-
-
Quantitative Data Summary
Table 1: Comparison of Different 5' Cap Analogs on mRNA Stability and Translation Efficiency
| Cap Analog | Relative Translation Efficiency (compared to m7GpppG) | Key Features |
| m7GpppG (Standard Cap) | 1.0 | Standard cap analog. |
| m2,7,3'-O GpppG (ARCA) | ~1.5 - 2.0 | Anti-reverse cap analog, ensures correct orientation. |
| b7m2Gp4G | 2.55 | N7-benzylated dinucleoside tetraphosphate (B8577671) with high affinity for eIF4E.[14] |
| m7Gp3m7G | 2.6 | Dinucleoside cap analog with two 7-methylguanosine (B147621) units.[14] |
| b7m3'-OGp4G | 2.8 | N7-benzylated dinucleoside tetraphosphate with 3'-O-methylation.[14] |
| m7Gp4m7G | 3.1 | Dinucleoside cap analog with a tetraphosphate bridge.[14] |
| Medronate-FlashCap | N/A (photoactivatable) | Resistant to the decapping enzyme DcpS, enhancing stability.[15] |
Table 2: Impact of Poly(A) Tail Length on mRNA Stability and Protein Expression
| Poly(A) Tail Length | Effect on Stability | Effect on Translation | Notes |
| < 16 nt | Unstable | Not translated efficiently.[4] | Insufficient to protect from 3' exonucleases. |
| ~30 nt | Minimum length for stability | Sufficient for efficient translation.[4][6] | Can be found on stable, highly-translated mRNAs. |
| ~75 nt | Stable | Optimal for cap-dependent translation in human cell lysates.[5] | May facilitate the formation of a "closed-loop" structure for efficient translation. |
| > 150 nt | Stable | Efficiently translated, but may not be significantly better than shorter tails.[4] | Commonly used in synthetic mRNA constructs. |
Table 3: Effect of Untranslated Regions (UTRs) on mRNA Half-Life
| UTR Source | Effect on mRNA Half-Life | Notes |
| Alpha-globin 3' UTR | Stabilizing | Contains elements that recruit stabilizing proteins. |
| Beta-globin 3' UTR | Stabilizing | Widely used to enhance the stability of synthetic mRNAs. |
| Chemokine 3' UTRs | Variable | Can be stabilizing or destabilizing depending on the specific chemokine and the presence of regulatory elements like AREs.[8] |
| ML-designed 3' UTRs | Can be highly stabilizing | Machine learning models can be used to design synthetic 3' UTRs that significantly increase mRNA half-life, leading to higher protein output.[16][17] |
Experimental Protocols
Protocol 1: In Vitro Transcription of Synthetic mRNA with Modified Nucleosides
This protocol describes the synthesis of mRNA from a linear DNA template using T7 RNA polymerase and the co-transcriptional incorporation of modified nucleotides and a cap analog.
Materials:
-
Linearized plasmid DNA or PCR product with a T7 promoter (1 µg)
-
Nuclease-free water
-
10x Transcription Buffer
-
NTP/modified NTP mix (e.g., ATP, GTP, CTP, and a 1:1 mixture of UTP and N1-methylpseudouridine-TP)
-
Cap analog (e.g., ARCA)
-
T7 RNA Polymerase
-
RNase Inhibitor
-
DNase I
-
RNA purification kit
Procedure:
-
Thaw all reagents on ice.
-
In a nuclease-free microcentrifuge tube, assemble the following reaction at room temperature in the specified order:
-
Nuclease-free water to a final volume of 20 µL
-
2 µL of 10x Transcription Buffer
-
1 µL of each NTP/modified NTP
-
1 µg of linearized DNA template
-
4 µL of Cap analog/GTP mix
-
1 µL of RNase Inhibitor
-
2 µL of T7 RNA Polymerase
-
-
Mix gently by flicking the tube and centrifuge briefly to collect the reaction at the bottom.
-
Incubate the reaction at 37°C for 2 hours.
-
To remove the DNA template, add 1 µL of DNase I to the reaction mixture and incubate at 37°C for 15 minutes.
-
Purify the mRNA using an RNA purification kit according to the manufacturer's instructions.
-
Elute the mRNA in nuclease-free water and determine the concentration and purity using a spectrophotometer. The A260/A280 ratio should be ~2.0.
-
Assess the integrity of the mRNA by denaturing agarose (B213101) gel electrophoresis.
Protocol 2: Enzymatic Poly(A) Tailing of In Vitro Transcribed mRNA
This protocol describes the addition of a poly(A) tail to the 3' end of an in vitro transcribed RNA using E. coli Poly(A) Polymerase.[10][11][18][19][20]
Materials:
-
Purified IVT RNA (up to 10 µg)
-
Nuclease-free water
-
10x Poly(A) Polymerase Reaction Buffer
-
ATP (10 mM)
-
E. coli Poly(A) Polymerase
-
EDTA (0.5 M)
-
RNA purification kit
Procedure:
-
In a nuclease-free microcentrifuge tube, combine the following on ice:
-
Purified IVT RNA (up to 10 µg)
-
Nuclease-free water to a final volume of 40 µL
-
5 µL of 10x Poly(A) Polymerase Reaction Buffer
-
5 µL of 10 mM ATP
-
-
Add 1 µL of E. coli Poly(A) Polymerase, mix gently, and centrifuge briefly.
-
Incubate the reaction at 37°C for 30 minutes. The incubation time can be adjusted to control the length of the poly(A) tail.
-
Stop the reaction by adding 2 µL of 0.5 M EDTA.
-
Purify the polyadenylated mRNA using an RNA purification kit.
-
Elute the mRNA in nuclease-free water and assess its integrity and the addition of the poly(A) tail by denaturing agarose gel electrophoresis.
Protocol 3: Assessment of mRNA Half-Life in Cell Culture using Actinomycin (B1170597) D
This protocol describes a method to determine the half-life of a specific mRNA in cultured cells by inhibiting transcription with Actinomycin D and measuring the decay of the mRNA over time.[21]
Materials:
-
Cultured mammalian cells
-
Actinomycin D stock solution (e.g., 5 mg/mL in DMSO)
-
Cell culture medium
-
Phosphate-buffered saline (PBS)
-
RNA extraction kit
-
Reverse transcription reagents
-
qPCR master mix and primers for the target mRNA and a stable housekeeping gene
Procedure:
-
Seed cells in multiple plates or wells to allow for harvesting at different time points. Grow the cells to the desired confluency.
-
Treat the cells with Actinomycin D at a final concentration of 5 µg/mL to inhibit transcription.
-
Harvest the cells at various time points after the addition of Actinomycin D (e.g., 0, 2, 4, 8, 12, and 24 hours). The 0-hour time point represents the initial mRNA level before decay.
-
At each time point, wash the cells with PBS and extract total RNA using an RNA extraction kit.
-
Synthesize cDNA from an equal amount of total RNA from each time point using reverse transcriptase.
-
Perform quantitative PCR (qPCR) using primers specific for your target mRNA and a stable housekeeping gene (e.g., GAPDH or ACTB) to normalize the data.
-
Calculate the relative amount of the target mRNA at each time point, normalized to the housekeeping gene and relative to the 0-hour time point.
-
Plot the percentage of remaining mRNA versus time on a semi-logarithmic graph.
-
Determine the mRNA half-life (t1/2) from the time it takes for the mRNA level to decrease by 50%.
Visualizations
Caption: Workflow for the synthesis of stabilized mRNA.
Caption: Key structural elements of a stabilized synthetic mRNA.
Caption: Major pathways of mRNA degradation in eukaryotic cells.
References
- 1. Cap Analogs – Enhance mRNA stability and translation efficiency - Jena Bioscience [jenabioscience.com]
- 2. Roles of mRNA poly(A) tails in regulation of eukaryotic gene expression - PMC [pmc.ncbi.nlm.nih.gov]
- 3. The impact of mRNA poly(A) tail length on eukaryotic translation stages - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Widespread Effects of Chemokine 3’-UTRs on mRNA Degradation and Protein Production in Human Cells - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Multiplexed Assays of Human Disease-relevant Mutations Reveal UTR Dinucleotide Composition as a Major Determinant of RNA Stability [elifesciences.org]
- 6. neb.com [neb.com]
- 7. biosearchtech.a.bigcontent.io [biosearchtech.a.bigcontent.io]
- 8. researchgate.net [researchgate.net]
- 9. researchgate.net [researchgate.net]
- 10. Novel cap analogs for in vitro synthesis of mRNAs with high translational efficiency - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Stabilized 5′ Cap Analogue for Optochemical Activation of mRNA Translation - PMC [pmc.ncbi.nlm.nih.gov]
- 12. researchgate.net [researchgate.net]
- 13. biorxiv.org [biorxiv.org]
- 14. neb.com [neb.com]
- 15. Poly(A) Tailing Kit | Thermo Fisher Scientific - HK [thermofisher.com]
- 16. apexbt.com [apexbt.com]
- 17. mRNA Stability Assay Using transcription inhibition by Actinomycin D in Mouse Pluripotent Stem Cells - PMC [pmc.ncbi.nlm.nih.gov]
- 18. mRNA Stability Assay Using transcription inhibition by Actinomycin D in Mouse Pluripotent Stem Cells. | Sigma-Aldrich [sigmaaldrich.com]
- 19. research.monash.edu [research.monash.edu]
- 20. Inhibiting transcription in cultured metazoan cells with actinomycin D to monitor mRNA turnover - PMC [pmc.ncbi.nlm.nih.gov]
- 21. Evaluating the Stability of mRNAs and Noncoding RNAs | Springer Nature Experiments [experiments.springernature.com]
common challenges in mRNA lipid nanoparticle delivery
Welcome to the technical support center for mRNA lipid nanoparticle (LNP) delivery. This resource is designed for researchers, scientists, and drug development professionals to troubleshoot common challenges encountered during the formulation, characterization, and application of mRNA-LNPs.
Frequently Asked Questions (FAQs)
Formulation & Stability
-
Q1: My mRNA-LNP formulation is showing signs of aggregation and increased particle size over time. What are the potential causes and solutions?
-
A1: Aggregation and particle size increase are common stability issues.[1] Potential causes include suboptimal lipid composition, improper storage conditions, and issues with the buffer system. To troubleshoot, consider the following:
-
Lipid Composition: The ratio of ionizable lipids, helper lipids, cholesterol, and PEG-lipids is crucial for stability.[1][2] Ensure precise molar ratios are used during formulation.
-
Storage Temperature: mRNA-LNP formulations are sensitive to temperature.[1][3] Ultra-low temperature storage (typically -70°C to -80°C) is often required to prevent mRNA degradation and maintain LNP integrity.[1]
-
Buffer System: The pH and composition of the buffer are critical.[1] A slightly acidic to neutral pH range (5.5 - 7.5) helps protect the mRNA from hydrolysis.[1] Buffers such as citrate, phosphate (B84403), or acetate (B1210297) can enhance stability.[1]
-
Cryoprotectants: For frozen storage, the addition of cryoprotectants like sucrose (B13894) or trehalose (B1683222) can prevent particle aggregation during freeze-thaw cycles.[4][5]
-
-
-
Q2: I am observing low mRNA encapsulation efficiency. How can I improve it?
-
A2: Low encapsulation efficiency can stem from several factors in the formulation process. To improve it, consider these points:
-
Mixing Process: The method and speed of mixing the lipid-ethanol phase with the aqueous mRNA phase are critical.[2] Rapid mixing techniques, such as using a microfluidic device, can ensure uniform particle formation and high encapsulation.[2][6]
-
pH of Aqueous Buffer: The pH of the aqueous buffer containing the mRNA should be acidic (typically around pH 4).[7] This ensures the ionizable lipid is positively charged, facilitating electrostatic interaction with the negatively charged mRNA backbone.
-
Lipid-to-mRNA Ratio: Optimizing the ratio of total lipids to mRNA is essential for efficient encapsulation.[6]
-
-
-
Q3: What factors contribute to mRNA degradation within the LNPs, and how can I minimize it?
-
A3: The primary cause of mRNA degradation within LNPs is hydrolysis.[3] The presence of water in the LNP core can lead to the breakdown of the mRNA molecule.[3] To minimize degradation:
-
mRNA Optimization: Modifying the mRNA structure itself, such as optimizing the nucleotide composition, can improve its intrinsic stability.[3]
-
LNP Core Environment: While challenging to control directly, a better understanding of the environment within the LNP core can inform adjustments to the LNP structure to better protect the mRNA.[3]
-
Lyophilization: Drying techniques, such as lyophilization (freeze-drying), can remove water and significantly improve the long-term stability of mRNA-LNP formulations.[3][]
-
-
In Vitro & In Vivo Delivery
-
Q4: My in vitro transfection efficiency is low. What are the key parameters to optimize?
-
A4: Low transfection efficiency can be a complex issue with multiple contributing factors.[9] Key areas for optimization include:
-
LNP Composition: The type and ratio of lipids, particularly the ionizable lipid, are critical for endosomal escape.[9][10][11]
-
Particle Size and Zeta Potential: Uniform particle size and a slightly positive or neutral zeta potential at physiological pH are important for cellular uptake.[12][9]
-
Cell Health and Density: Ensure the cell line used for transfection is healthy and seeded at an appropriate density.[7]
-
mRNA Loading: Interestingly, the LNP fraction with the highest mRNA loading may not always have the highest transfection competence.[9] It's important to characterize different LNP subpopulations.
-
-
-
Q5: I am observing significant off-target effects and accumulation in the liver. How can I improve tissue-specific targeting?
-
A5: LNPs have a natural tendency to accumulate in the liver.[2][11] To achieve extrahepatic targeting, several strategies can be employed:
-
Ligand-Modified LNPs: The surface of LNPs can be modified with ligands such as antibodies or peptides that bind to receptors on the target cells.[11]
-
Charge-Tunable LNPs: Adjusting the lipid composition to alter the surface charge can influence biodistribution to tissues like the muscle, lungs, or brain.[11]
-
Selective Organ Targeting (SORT) Molecules: The incorporation of specific molecules into the LNP formulation has shown promise in directing LNPs to tissues other than the liver.[13]
-
-
-
Q6: My LNP formulation is causing an inflammatory response. How can I reduce its immunogenicity?
-
A6: Both the lipid components and the mRNA can trigger an immune response.[2][10] To reduce immunogenicity:
-
Optimize Lipid Composition: The choice of ionizable lipid can influence the activation of immune sensors like Toll-like receptors (TLRs).[10] Using novel, more biocompatible ionizable lipids can reduce inflammatory responses.[11]
-
mRNA Modifications: Modifying the mRNA with non-canonical nucleosides can help to reduce its recognition by the innate immune system.
-
PEGylated Lipids: The inclusion of PEG-lipids helps to create a "stealth" coating that can shield the LNP from the immune system and prolong circulation time.[14]
-
-
Scale-Up & Manufacturing
-
Q7: We are struggling with batch-to-batch consistency during scale-up. What are the critical process parameters to control?
-
A7: Maintaining consistency when moving from lab-scale to large-scale production is a significant challenge.[15] Key parameters to monitor and control include:
-
Mixing Technology: The transition from small-scale mixing methods (e.g., vortexing) to larger-scale systems (e.g., T-junction mixing, microfluidics) must be carefully validated to ensure consistent particle formation.[16]
-
Flow Rates and Ratios: Precise control over the flow rates of the lipid and mRNA solutions is crucial for reproducible particle size and encapsulation efficiency.
-
Temperature Control: The temperature of the mixing and purification steps can impact LNP characteristics.[17]
-
-
-
Q8: What are the primary challenges in adapting lab-scale LNP production technology for industrial manufacturing?
-
A8: Scaling up LNP production involves more than just using larger volumes. Key challenges include:
-
Technology Transfer: Techniques that work well in a lab setting, like microfluidics, may not be easily scalable.[15] The manufacturing process may need to be adapted to different equipment.[16]
-
Sterility and Contamination Control: Large-scale production requires stringent sterile conditions to prevent contamination and degradation of the sensitive mRNA payload.[15]
-
Analytical Characterization at Scale: Implementing robust quality control methods to monitor LNP attributes throughout the large-scale manufacturing process is essential.[6]
-
-
Troubleshooting Guides
Guide 1: Low Transfection Efficiency
This guide provides a step-by-step approach to troubleshooting low transfection efficiency in your experiments.
Caption: Troubleshooting workflow for low mRNA-LNP transfection efficiency.
Detailed Steps:
-
Verify LNP Physicochemical Properties:
-
Particle Size and Polydispersity Index (PDI): Measure using Dynamic Light Scattering (DLS). Ideal size is typically 50-150 nm with a PDI < 0.2.
-
Zeta Potential: Determine the surface charge. Near-neutral or slightly positive values are often optimal for in vivo delivery.[9]
-
Encapsulation Efficiency: Quantify the amount of encapsulated mRNA using a RiboGreen assay or similar method.
-
-
Evaluate Cellular Parameters:
-
Cell Viability: Perform a cell viability assay (e.g., MTT, trypan blue exclusion) to ensure the LNPs are not overly toxic to the cells.
-
Cell Line and Passage Number: Some cell lines are more difficult to transfect. Ensure you are using a suitable cell line at a low passage number.
-
Seeding Density: Optimize the number of cells seeded per well.
-
-
Optimize LNP Formulation:
-
Lipid Ratios: Systematically vary the molar ratios of the four lipid components (ionizable, helper, cholesterol, PEG-lipid).
-
Ionizable Lipid Choice: The pKa of the ionizable lipid is critical for endosomal escape. Consider screening different ionizable lipids.
-
N/P Ratio: Optimize the nitrogen-to-phosphate ratio (the molar ratio of amine groups in the ionizable lipid to phosphate groups in the mRNA).
-
-
Assess mRNA Integrity:
-
Pre-encapsulation: Run the mRNA on a gel (e.g., agarose, capillary electrophoresis) to confirm its integrity before formulation.
-
Post-extraction: Extract the mRNA from the LNPs and check its integrity to ensure the formulation process is not causing degradation.
-
Guide 2: LNP Formulation Instability
This guide outlines a logical flow for diagnosing and addressing LNP instability issues like aggregation and size changes.
Caption: Troubleshooting guide for mRNA-LNP formulation instability.
Detailed Steps:
-
Review Storage Conditions:
-
Analyze Buffer System:
-
Evaluate Lipid Composition:
-
PEG-lipid Content: The amount of PEG-lipid can influence stability. Too little may not prevent aggregation, while too much can hinder cellular uptake.
-
Lipid Quality: Ensure the lipids used are of high purity and have not degraded.
-
-
Assess Freeze-Thaw Stability:
Quantitative Data Summary
Table 1: Common Analytical Techniques for mRNA-LNP Characterization
| Parameter | Analytical Technique(s) | Purpose |
| Particle Size & Polydispersity | Dynamic Light Scattering (DLS) | Measures the average size and size distribution of the LNPs.[6][18] |
| mRNA Encapsulation Efficiency | RiboGreen Assay, UV-Vis Spectroscopy | Quantifies the percentage of mRNA successfully encapsulated within the LNPs.[18] |
| Lipid Composition & Purity | HPLC-CAD, LC/MS | Separates and quantifies the individual lipid components and assesses their purity.[18][19] |
| mRNA Integrity | Capillary Gel Electrophoresis (CGE), Agarose Gel Electrophoresis | Assesses the integrity and purity of the mRNA before and after encapsulation. |
| Zeta Potential | Laser Doppler Electrophoresis | Measures the surface charge of the LNPs, which influences stability and cellular interactions.[20] |
| Particle Morphology | Cryogenic Transmission Electron Microscopy (Cryo-TEM) | Visualizes the structure and morphology of the LNPs. |
| Subpopulation Analysis | Density Gradient Ultracentrifugation, Size Exclusion Chromatography (SEC) | Separates different LNP subpopulations based on density or size for further characterization.[20][21] |
Experimental Protocols
Protocol 1: Determination of mRNA Encapsulation Efficiency using RiboGreen Assay
Objective: To quantify the percentage of mRNA encapsulated within the LNPs.
Materials:
-
mRNA-LNP sample
-
Quant-iT RiboGreen RNA Assay Kit
-
TE buffer (10 mM Tris-HCl, 1 mM EDTA, pH 7.5)
-
Triton X-100 (10% solution)
-
96-well microplate (black, flat-bottom)
-
Plate reader with fluorescence detection (excitation ~480 nm, emission ~520 nm)
Procedure:
-
Prepare RiboGreen Working Solution: Dilute the concentrated RiboGreen reagent in TE buffer according to the manufacturer's instructions. Protect from light.
-
Prepare mRNA Standard Curve:
-
Prepare a series of known concentrations of your specific mRNA in TE buffer.
-
In a 96-well plate, add a fixed volume of each mRNA standard to wells in triplicate.
-
Add the RiboGreen working solution to each well.
-
Incubate for 5 minutes at room temperature, protected from light.
-
Measure the fluorescence.
-
-
Measure Free mRNA in LNP Sample:
-
In the 96-well plate, add your mRNA-LNP sample to wells in triplicate.
-
Add the RiboGreen working solution.
-
Incubate and measure fluorescence as with the standards. This reading corresponds to the amount of unencapsulated (free) mRNA.
-
-
Measure Total mRNA in LNP Sample:
-
In a separate set of wells, add your mRNA-LNP sample.
-
Add a lytic agent (e.g., 10% Triton X-100 to a final concentration of 1%) to disrupt the LNPs and release the encapsulated mRNA.
-
Incubate for 10 minutes at 37°C.
-
Add the RiboGreen working solution.
-
Incubate and measure fluorescence. This reading corresponds to the total amount of mRNA.
-
-
Calculation:
-
Use the standard curve to determine the concentration of free mRNA and total mRNA in your samples.
-
Encapsulation Efficiency (%) = [ (Total mRNA - Free mRNA) / Total mRNA ] * 100
-
Protocol 2: LNP Formulation using Microfluidic Mixing
Objective: To formulate mRNA-LNPs with controlled size and high encapsulation efficiency using a microfluidic device.
Materials:
-
Microfluidic mixing device (e.g., NanoAssemblr) and associated cartridges.
-
Syringe pumps.
-
Lipid solution: Ionizable lipid, DSPC, cholesterol, and PEG-lipid dissolved in ethanol (B145695) at the desired molar ratio.[7]
-
mRNA solution: mRNA dissolved in an acidic aqueous buffer (e.g., 25 mM sodium acetate, pH 4).[7]
-
Dialysis buffer (e.g., PBS, pH 7.4).[7]
Procedure:
-
Prepare Solutions:
-
Prepare the lipid-ethanol mixture and the mRNA-aqueous buffer solution. Ensure both are clear and fully dissolved. Filter if necessary.
-
-
Setup Microfluidic System:
-
Prime the microfluidic system and cartridge with the respective solvents (ethanol and aqueous buffer) as per the manufacturer's instructions.
-
Load the lipid solution into one syringe and the mRNA solution into another.
-
-
Mixing and LNP Formation:
-
Set the desired total flow rate and flow rate ratio (typically 3:1 aqueous to ethanol).[7]
-
Start the syringe pumps to initiate the mixing process within the microfluidic cartridge. The rapid mixing of the two streams induces the self-assembly of the LNPs.
-
-
Collection and Purification:
-
Collect the resulting LNP suspension from the outlet of the cartridge.
-
Purify the LNPs to remove the ethanol and unencapsulated mRNA. This is typically done by dialysis against the desired final buffer (e.g., PBS) overnight.[7]
-
-
Characterization:
-
After purification, characterize the LNPs for particle size, PDI, and encapsulation efficiency as described in other protocols.
-
Sterile filter the final formulation and store at -80°C.[21]
-
References
- 1. What Ensures Stability in mRNA Lipid Nanoparticle Systems [eureka.patsnap.com]
- 2. How mRNA Lipid Nanoparticles Optimize Drug Delivery [eureka.patsnap.com]
- 3. pharmaexcipients.com [pharmaexcipients.com]
- 4. Research Advances on the Stability of mRNA Vaccines - PMC [pmc.ncbi.nlm.nih.gov]
- 5. biopharminternational.com [biopharminternational.com]
- 6. susupport.com [susupport.com]
- 7. pubs.acs.org [pubs.acs.org]
- 9. precigenome.com [precigenome.com]
- 10. Recent Advances in Lipid Nanoparticles and Their Safety Concerns for mRNA Delivery - PMC [pmc.ncbi.nlm.nih.gov]
- 11. gencefebio.com [gencefebio.com]
- 12. tandfonline.com [tandfonline.com]
- 13. Five Challenges Of Applying Lipid Nanoparticles As Delivery Tools For Therapeutic Agents [progen.com]
- 14. sigmaaldrich.com [sigmaaldrich.com]
- 15. helixbiotech.com [helixbiotech.com]
- 16. pharmasource.global [pharmasource.global]
- 17. Scaling up RNA-LNPs: Strategies for successful and consistent clinical manufacturing - Pharmaceutical Technology [pharmaceutical-technology.com]
- 18. blog.curapath.com [blog.curapath.com]
- 19. Analytical Solutions for mRNA-LNP characterization | Agilent [agilent.com]
- 20. pubs.acs.org [pubs.acs.org]
- 21. Analytical Characterization of Heterogeneities in mRNA-Lipid Nanoparticles Using Sucrose Density Gradient Ultracentrifugation - PMC [pmc.ncbi.nlm.nih.gov]
Technical Support Center: Optimizing Codon Usage for Enhanced mRNA Translation
This technical support center provides troubleshooting guidance and frequently asked questions (FAQs) to assist researchers, scientists, and drug development professionals in optimizing codon usage for enhanced mRNA translation.
Frequently Asked Questions (FAQs)
Q1: What is codon usage bias and why is it important for mRNA translation?
A1: Codon usage bias refers to the phenomenon where different organisms and even different tissues within the same organism prefer to use certain synonymous codons (codons that code for the same amino acid) over others.[1][2][3][4] This preference is often correlated with the abundance of corresponding transfer RNA (tRNA) molecules in the cell.[5][6][7] When expressing a gene in a host organism (heterologous expression), matching the codon usage of the gene to that of the host can significantly enhance the efficiency of mRNA translation and, consequently, protein expression levels.[8][9] Mismatched codon usage can lead to ribosomal stalling, premature termination of translation, and reduced protein yield.[6]
Q2: What is "codon optimization" and how is it performed?
A2: Codon optimization is the process of modifying the nucleotide sequence of a gene to improve its expression in a specific host organism, without altering the amino acid sequence of the encoded protein.[8][10] This is achieved by replacing rare or non-preferred codons with synonymous codons that are more frequently used in the target host.[8] The process typically involves:
-
Codon Usage Table Analysis: Analyzing the codon frequency of the target organism to identify preferred codons.[8]
-
Software Tools: Utilizing bioinformatics tools and algorithms to automatically replace codons in a given sequence.[10][11]
-
Gene Synthesis: Synthesizing the optimized DNA sequence for subsequent cloning and expression.[8]
Q3: Besides codon preference, what other factors should be considered during codon optimization?
A3: While replacing rare codons is a primary goal, a comprehensive codon optimization strategy should also consider:
-
GC Content: The overall GC content of the optimized sequence can affect mRNA stability and secondary structure. It's often adjusted to be within a range suitable for the host organism.[12][13]
-
mRNA Secondary Structure: Strong secondary structures, especially near the translation initiation site (the first ~48 base pairs), can hinder ribosome binding and initiation.[2][7][12][13] Optimization algorithms often aim to minimize these structures.
-
Avoidance of Problematic Sequences: This includes cryptic splice sites, polyadenylation signals, and sequences that could lead to transcriptional silencing or mRNA instability.[12][13]
-
Codon Ramp: Some studies suggest that a "ramp" of less optimal codons at the beginning of the coding sequence can slow down the initial phase of translation, which may promote proper protein folding.[5]
Troubleshooting Guide
Issue 1: Low or no protein expression after codon optimization.
| Possible Cause | Troubleshooting Step |
| Suboptimal Codon Usage Table: The codon usage table used for optimization may not be appropriate for the specific cell line or strain being used. | Solution: Use a more specific codon usage table if available (e.g., for a specific human tissue).[4] Consider empirical testing of a few different optimization strategies. |
| mRNA Secondary Structure: Strong secondary structures at the 5' end of the mRNA may be inhibiting translation initiation. | Solution: Re-analyze the optimized sequence using RNA folding prediction software. If a strong hairpin is predicted near the start codon, consider manually editing the first 10-15 codons to disrupt the structure, while still using relatively frequent codons.[2][7] |
| Inefficient Transcription: The issue might be at the transcriptional level rather than translational. | Solution: Verify mRNA levels using RT-qPCR. If mRNA levels are low, check the promoter, enhancer elements, and the overall integrity of the expression vector. |
| Protein Instability or Degradation: The expressed protein may be unstable or rapidly degraded in the host cell. | Solution: Perform a pulse-chase experiment to assess protein stability. Consider adding a stabilizing tag to the protein. |
| Toxicity of the Expressed Protein: High levels of the expressed protein may be toxic to the host cells. | Solution: Use an inducible expression system to control the timing and level of protein expression. Titrate the inducer concentration to find a non-toxic expression level. |
Issue 2: The expressed protein is misfolded or forms inclusion bodies.
| Possible Cause | Troubleshooting Step |
| Translation Rate is Too High: Aggressive codon optimization can lead to a very high rate of translation, which may not allow sufficient time for the nascent polypeptide chain to fold correctly.[2][9][11] | Solution: Consider a "less optimized" or "ramped" approach where the 5' end of the coding sequence contains a mixture of optimal and suboptimal codons to slow down the initial translation rate.[5] |
| Lack of Appropriate Chaperones: The host cell may lack the specific chaperones required for the proper folding of the heterologous protein. | Solution: Co-express molecular chaperones that are known to assist in the folding of the protein of interest. |
| Suboptimal Growth/Expression Conditions: Temperature, pH, and other culture conditions can significantly impact protein folding. | Solution: Optimize expression conditions. For example, lowering the expression temperature (e.g., from 37°C to 30°C or 25°C) can sometimes improve protein solubility. |
Experimental Protocols
Protocol 1: Codon Usage Analysis using Online Tools
This protocol describes how to use a web-based tool to analyze the codon usage of a gene of interest and compare it to the codon usage of a host organism.
Materials:
-
Computer with internet access
-
DNA or protein sequence of the gene of interest
-
Name of the target expression host (e.g., Homo sapiens, Escherichia coli K12)
Methodology:
-
Select a Codon Usage Analysis Tool: Several online tools are available, such as the GenScript Rare Codon Analysis Tool or the Codon Usage Calculator from BiologicsCorp.[14][15][16][17]
-
Input Your Sequence: Copy and paste the coding sequence (CDS) of your gene into the input box of the tool.
-
Select the Host Organism: Choose the appropriate expression host from the provided list.
-
Run the Analysis: Initiate the analysis. The tool will calculate various parameters, including:
-
Codon Adaptation Index (CAI): A measure of how well the codon usage of your gene matches the codon usage of highly expressed genes in the host. A CAI value closer to 1.0 indicates better adaptation.[7][8]
-
Frequency of Optimal Codons (FOP): The proportion of codons that are considered optimal in the host organism.
-
Codon Frequency Table: A detailed breakdown of the usage of each codon in your sequence compared to the host's usage.
-
-
Interpret the Results: A low CAI or a high number of rare codons indicates that codon optimization may be beneficial.
Protocol 2: In Vitro Transcription and Translation (IVT) of Optimized mRNA
This protocol provides a general workflow for the in vitro synthesis of mRNA from an optimized DNA template and its subsequent translation to assess protein expression.
Materials:
-
Linearized plasmid DNA or PCR product containing the optimized gene downstream of a T7 promoter.
-
In vitro transcription kit (containing T7 RNA polymerase, NTPs, buffer, and RNase inhibitor).[18]
-
DNase I
-
RNA purification kit
-
In vitro translation kit (e.g., rabbit reticulocyte lysate system)
-
Detection reagents (e.g., anti-protein antibody for Western blot, or reagents for functional assay)
Methodology:
-
In Vitro Transcription: a. Set up the in vitro transcription reaction according to the manufacturer's protocol, using your linearized DNA template.[][20] b. Incubate the reaction at the recommended temperature (usually 37°C) for the specified time. c. Treat the reaction with DNase I to remove the DNA template.[18]
-
mRNA Purification: a. Purify the synthesized mRNA using an appropriate RNA purification kit to remove unincorporated NTPs, enzymes, and salts. b. Quantify the purified mRNA and assess its integrity using gel electrophoresis.
-
In Vitro Translation: a. Set up the in vitro translation reaction according to the manufacturer's protocol, adding your purified mRNA as the template. b. Incubate the reaction at the recommended temperature.
-
Protein Expression Analysis: a. Analyze a portion of the translation reaction by SDS-PAGE and Western blotting using an antibody specific to your protein of interest to confirm its synthesis and size. b. Alternatively, if the protein has a measurable activity (e.g., enzymatic activity), perform a functional assay on the translation reaction.
Visualizations
Caption: Workflow for codon optimization and expression analysis.
Caption: Troubleshooting logic for low protein expression.
References
- 1. What Is Codon Usage Bias and Why It Matters in Gene Expression [synapse.patsnap.com]
- 2. Codon usage bias - Wikipedia [en.wikipedia.org]
- 3. blog.addgene.org [blog.addgene.org]
- 4. Frontiers | Codon-optimization in gene therapy: promises, prospects and challenges [frontiersin.org]
- 5. Codon Bias as a Means to Fine-Tune Gene Expression - PMC [pmc.ncbi.nlm.nih.gov]
- 6. www2.eecs.berkeley.edu [www2.eecs.berkeley.edu]
- 7. Codon Optimization Protocol - Creative Biogene [creative-biogene.com]
- 8. idtdna.com [idtdna.com]
- 9. camenabio.com [camenabio.com]
- 10. Codon Optimization & Its Impact on mRNA Translation Efficiency - Creative Biolabs [ribosome.creative-biolabs.com]
- 11. Codon Optimization for Different Expression Systems: Key Points and Case Studies - CD Biosynsis [biosynsis.com]
- 12. twistbioscience.com [twistbioscience.com]
- 13. twistbioscience.com [twistbioscience.com]
- 14. genscript.com [genscript.com]
- 15. Codon Usage Calculator - Free Online Analysis Tool - BiologicsCorp [biologicscorp.com]
- 16. Codon Usage Calculator - Bioinformatics Tools [jamiemcgowan.ie]
- 17. punnettsquare.org [punnettsquare.org]
- 18. cytivalifesciences.com [cytivalifesciences.com]
- 20. landmarkbio.com [landmarkbio.com]
Technical Support Center: Reducing Immunogenicity of In Vitro Transcribed mRNA
Welcome to the technical support center for researchers, scientists, and drug development professionals working with in vitro transcribed (IVT) mRNA. This resource provides troubleshooting guides and frequently asked questions (FAQs) to help you minimize the immunogenicity of your IVT mRNA, ensuring higher translation efficiency and reduced cellular toxicity.
Frequently Asked Questions (FAQs)
Q1: What is causing the immunogenicity of my IVT mRNA?
A1: The innate immune system can recognize IVT mRNA as foreign, primarily due to two main factors:
-
Double-stranded RNA (dsRNA) contaminants: dsRNA is a common byproduct of the IVT process and a potent activator of innate immune sensors.[1][2][3][4] The T7 RNA polymerase used in IVT can generate dsRNA through mechanisms like template-independent transcription.[2]
-
Unmodified single-stranded RNA (ssRNA): The ssRNA molecule itself can be recognized by pattern recognition receptors (PRRs) such as Toll-like receptors (TLRs), RIG-I, and MDA5.[5][6] The presence of a 5'-triphosphate group on uncapped mRNA is a key trigger for RIG-I.[4][5]
Q2: What are the consequences of high immunogenicity in my experiments?
A2: High immunogenicity of IVT mRNA can lead to several undesirable outcomes:
-
Reduced Protein Expression: Activation of immune sensors like protein kinase R (PKR) can lead to a shutdown of translation, significantly lowering the yield of your target protein.[1][2]
-
Cellular Toxicity and Death: The production of pro-inflammatory cytokines (e.g., TNF-α, interferons) can induce inflammation and lead to apoptosis or other forms of cell death.[2][7]
-
Compromised Therapeutic Efficacy: In a therapeutic context, high immunogenicity can lead to adverse side effects and reduce the overall effectiveness of the mRNA-based drug.[4]
Q3: How can I reduce the immunogenicity of my IVT mRNA?
A3: There are three main strategies to reduce the immunogenicity of your IVT mRNA:
-
Incorporate Modified Nucleotides: Replacing standard uridine (B1682114) with modified versions like pseudouridine (B1679824) (ψ) or N1-methylpseudouridine (m1ψ) can significantly reduce innate immune recognition.[4][8][9]
-
Purify the IVT mRNA: Removing dsRNA contaminants is crucial. High-performance liquid chromatography (HPLC) is a highly effective method for this purpose.[3][7]
-
Optimize the IVT Reaction and mRNA Design: This includes using a proper 5' cap structure, optimizing the poly(A) tail length, and refining the transcription conditions.[4][10][11]
Troubleshooting Guides
Problem 1: High levels of pro-inflammatory cytokines (e.g., TNF-α, IFN-β) after transfecting cells with IVT mRNA.
Possible Cause: Your IVT mRNA is likely contaminated with dsRNA or lacks proper modifications, leading to the activation of innate immune pathways.
Solutions:
-
Purify your IVT mRNA to remove dsRNA:
-
Incorporate modified nucleotides into your IVT reaction:
-
Ensure proper 5' capping of your mRNA:
Problem 2: Low or no protein expression from my IVT mRNA.
Possible Cause: The innate immune response triggered by your mRNA may be causing translational shutdown. Alternatively, the mRNA itself may be unstable or inefficiently translated.
Solutions:
-
Reduce Immunogenicity: Follow the steps outlined in Problem 1 to minimize the innate immune response, which can directly inhibit translation.
-
Optimize the Poly(A) Tail:
-
Verify mRNA Integrity:
-
Action: Run your purified mRNA on a denaturing agarose (B213101) gel to check for degradation. Ensure you are using RNase-free reagents and techniques throughout your workflow.[]
-
Quantitative Data on Immunogenicity Reduction
The following tables summarize the impact of different strategies on reducing the immunogenicity of IVT mRNA.
Table 1: Effect of Nucleotide Modifications on Cytokine Induction
| Nucleotide Modification | Relative TNF-α Secretion | Relative IFN-α Secretion | Reference |
| Unmodified Uridine | 100% | 100% | [8] |
| Pseudouridine (ψ) | Significantly Reduced | Significantly Reduced | [8] |
| N1-methylpseudouridine (m1ψ) | Significantly Reduced | Significantly Reduced | [8] |
| 5-methoxyuridine (mo5U) | Significantly Reduced | Not Detected | [17][18] |
Table 2: Impact of Purification Methods on dsRNA Removal and Translation
| Purification Method | dsRNA Removal Efficiency | Fold Increase in Protein Expression | Reference |
| None | - | 1x | [12] |
| Cellulose Chromatography | >90% | Enhanced Translation | [12][19] |
| HPLC | High | Up to 1,000-fold in some cells | [3][7] |
Experimental Protocols
Protocol 1: HPLC Purification of IVT mRNA to Remove dsRNA
This protocol provides a general guideline for purifying IVT mRNA using reverse-phase HPLC.
-
Initial Purification: Before HPLC, perform an initial purification of the IVT reaction mix using LiCl precipitation to remove enzymes, DNA template, and unincorporated nucleotides.[7]
-
HPLC System and Column: Use an HPLC system with a suitable reverse-phase column.
-
Mobile Phases:
-
Buffer A: Aqueous buffer (e.g., 0.1 M TEAA)
-
Buffer B: Acetonitrile (B52724)
-
-
Gradient Elution:
-
Equilibrate the column with a low percentage of Buffer B.
-
Load the mRNA sample onto the column.
-
Apply a linear gradient of increasing Buffer B concentration to elute the mRNA. dsRNA, being more hydrophobic, will elute at a higher acetonitrile concentration than ssRNA.
-
-
Fraction Collection and Analysis:
-
Collect fractions across the elution peak.
-
Analyze the fractions containing the ssRNA peak for purity and integrity using gel electrophoresis.
-
-
Desalting and Concentration: Pool the pure fractions and desalt and concentrate the mRNA using ethanol (B145695) precipitation or a suitable spin column.
Protocol 2: Quantification of dsRNA using a Dot Blot Assay
This protocol allows for the semi-quantitative detection of dsRNA in your IVT mRNA samples.
-
Sample Preparation: Serially dilute your IVT mRNA sample and a known dsRNA standard.
-
Membrane Transfer: Spot the dilutions onto a nylon membrane and allow them to dry completely.
-
UV Crosslinking: Crosslink the RNA to the membrane using a UV crosslinker.
-
Blocking: Block the membrane with a suitable blocking buffer (e.g., 5% non-fat milk in TBST) for 1 hour at room temperature.
-
Primary Antibody Incubation: Incubate the membrane with a dsRNA-specific antibody (e.g., J2 antibody) overnight at 4°C.
-
Washing: Wash the membrane three times with TBST for 10 minutes each.
-
Secondary Antibody Incubation: Incubate the membrane with a horseradish peroxidase (HRP)-conjugated secondary antibody for 1 hour at room temperature.
-
Detection: Add a chemiluminescent substrate and visualize the signal using an imaging system. Compare the signal intensity of your samples to the dsRNA standard curve to estimate the amount of dsRNA.
Visualizations
Signaling Pathways of Innate Immune Recognition of IVT mRNA
Caption: Innate immune sensing of IVT mRNA byproducts.
Workflow for Reducing IVT mRNA Immunogenicity
Caption: Optimized workflow to minimize IVT mRNA immunogenicity.
References
- 1. researchgate.net [researchgate.net]
- 2. Preventing Double-Stranded RNA Contamination in mRNA Manufac | Technology Networks [technologynetworks.com]
- 3. researchgate.net [researchgate.net]
- 4. Immunogenicity of In Vitro Transcribed mRNA: Mechanisms, Effects, and Strategies - Creative Biolabs [mrna.creative-biolabs.com]
- 5. Reducing double-stranded RNA formation in in vitro transcription using a novel RNA polymerase [go.trilinkbiotech.com]
- 6. researchgate.net [researchgate.net]
- 7. HPLC Purification of IVT mRNA - mRNA-based Drug R&D Service [mrnabased-drug.com]
- 8. Exploring the Impact of mRNA Modifications on Translation Efficiency and Immune Tolerance to Self-Antigens - PMC [pmc.ncbi.nlm.nih.gov]
- 9. promegaconnections.com [promegaconnections.com]
- 10. Chemo‐Enzymatic Modification of the 5′ Cap Maintains Translation and Increases Immunogenic Properties of mRNA - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Modifications of mRNA vaccine structural elements for improving mRNA stability and translation efficiency - PMC [pmc.ncbi.nlm.nih.gov]
- 12. A Facile Method for the Removal of dsRNA Contaminant from In Vitro-Transcribed mRNA - PMC [pmc.ncbi.nlm.nih.gov]
- 13. academic.oup.com [academic.oup.com]
- 14. researchgate.net [researchgate.net]
- 15. Enhancing mRNA Therapeutics in Two Shakes of a Poly(A) Tail | VectorBuilder [en.vectorbuilder.com]
- 17. researchgate.net [researchgate.net]
- 18. researchgate.net [researchgate.net]
- 19. Recent Advances and Innovations in the Preparation and Purification of In Vitro-Transcribed-mRNA-Based Molecules - PMC [pmc.ncbi.nlm.nih.gov]
mRNA Transfection Troubleshooting and Technical Support Center
Welcome to the mRNA Transfection Technical Support Center. This guide is designed to assist researchers, scientists, and drug development professionals in troubleshooting their mRNA transfection experiments. Below you will find a series of frequently asked questions (FAQs) and detailed troubleshooting guides in a question-and-answer format to help you resolve common issues and optimize your experimental outcomes.
Frequently Asked Questions (FAQs)
Q1: What is the difference between transient and stable transfection?
Transient transfection involves the introduction of nucleic acids into cells that are not integrated into the host cell's genome. This results in temporary expression of the target protein, typically lasting from 24 to 96 hours. In contrast, stable transfection involves the integration of the nucleic acid into the host genome, leading to long-term, stable expression of the gene of interest. Messenger RNA (mRNA) can only be transiently transfected as it is a temporary molecule and does not integrate into the genome.[1]
Q2: How quickly can I expect to see protein expression after mRNA transfection?
One of the key advantages of mRNA transfection is the rapid onset of protein expression. Since mRNA does not need to enter the nucleus for transcription, translation can begin in the cytoplasm almost immediately after delivery.[2][3] Expression of the encoded protein can often be detected in as little as 90 minutes to 4 hours post-transfection, with protein levels peaking between 24 to 48 hours.[1]
Q3: Do I need to change the cell culture medium after transfection?
It is generally not necessary to change the medium within the first 24 hours after transfection, as this minimizes handling of the cells.[2] However, if you observe high levels of cytotoxicity, replacing the transfection medium with fresh, complete growth medium 4-6 hours post-transfection can help reduce cell death.[4]
Q4: Can I use serum and antibiotics in the medium during transfection?
For optimal complex formation between the mRNA and the transfection reagent, it is recommended to use a serum-free and antibiotic-free medium.[2] However, once the complexes are formed and added to the cells, transfection can often proceed in a serum-containing medium. Some modern transfection reagents are compatible with serum, but it is always best to consult the manufacturer's protocol.
Troubleshooting Guides
This section provides detailed solutions to common problems encountered during mRNA transfection experiments.
Low Transfection Efficiency
Q5: My transfection efficiency is very low. What are the possible causes and how can I improve it?
Low transfection efficiency can be caused by a variety of factors, from the health of your cells to the quality of your mRNA. Below is a summary of potential causes and solutions.
Potential Causes and Troubleshooting Strategies for Low Transfection Efficiency
| Potential Cause | Troubleshooting Strategy |
| Poor Cell Health | Use healthy, actively dividing cells. Ensure cell viability is high and that cells are free from contamination, such as mycoplasma.[1][5] |
| Suboptimal Cell Confluency | The optimal cell confluency for transfection is typically between 70-90%.[4][5] If confluency is too low, cells may not be healthy enough for efficient uptake. If it is too high, contact inhibition can reduce transfection efficiency.[4] |
| Incorrect mRNA to Transfection Reagent Ratio | The ratio of mRNA to transfection reagent is critical. Titrate the amount of transfection reagent while keeping the mRNA amount constant to determine the optimal ratio for your specific cell type.[1] |
| Low-Quality or Degraded mRNA | Use high-purity mRNA with a 260/280 absorbance ratio between 1.8 and 2.1.[2][6] Verify mRNA integrity by running a sample on a gel. Ensure your mRNA has a 5' cap and a poly-A tail for stability and efficient translation.[2][7] |
| Suboptimal Incubation Time | The incubation time of the transfection complexes with the cells can be optimized. A typical range is 4-6 hours, but this can be extended if cytotoxicity is not an issue.[4] |
| Cell Line is Difficult to Transfect | Some cell lines, particularly primary cells, are inherently more difficult to transfect.[5] For these, you may need to use a transfection reagent specifically designed for hard-to-transfect cells or consider alternative methods like electroporation.[1][4] |
Experimental Workflow for Optimizing mRNA Transfection
Caption: A generalized workflow for a typical mRNA transfection experiment.
High Cytotoxicity
Q6: My cells are dying after transfection. How can I reduce cytotoxicity?
Cell death following transfection is a common issue and can obscure the results of your experiment. The primary causes are often related to the transfection reagent itself or the cellular response to foreign mRNA.
Potential Causes and Troubleshooting Strategies for High Cytotoxicity
| Potential Cause | Troubleshooting Strategy |
| Transfection Reagent Toxicity | Reduce the amount of transfection reagent used.[1] Choose a reagent known for low toxicity or one that is specifically validated for your cell type.[1] Shorten the incubation time of the transfection complexes with the cells to 4-6 hours.[4] |
| Toxicity from Nucleic Acids | An excessive amount of mRNA can be toxic to cells. Reduce the concentration of mRNA used in the transfection.[1] |
| Innate Immune Response | Exogenous mRNA can trigger an innate immune response, leading to cell death. Use purified mRNA to remove dsRNA contaminants.[8] Incorporating modified nucleosides (e.g., pseudouridine) into the mRNA can help to reduce its immunogenicity.[4] |
| Poor Cell Health Pre-transfection | Ensure cells are healthy and not stressed before starting the experiment. Do not use cells that are at a very high or very low passage number.[6] |
| Harsh Transfection Conditions | If using serum-free medium for transfection, ensure the incubation period is not excessively long, as this can stress the cells. Return cells to complete growth medium promptly after the initial incubation.[1] |
Innate Immune Signaling Pathways Activated by Exogenous mRNA
Caption: Signaling pathways of the innate immune response to exogenous mRNA.[5][9][10]
No or Low Protein Expression
Q7: I have good transfection efficiency, but I'm not seeing any protein expression. What could be the problem?
A lack of protein expression despite successful transfection often points to issues with the mRNA molecule itself or downstream cellular processes.
Troubleshooting Guide for No or Low Protein Expression
| Potential Cause | Troubleshooting Strategy |
| mRNA Lacks Essential Structural Elements | Ensure your mRNA has a 5' cap and a poly-A tail. These are crucial for mRNA stability and efficient translation by the ribosome.[2][7] |
| Poor mRNA Quality | The purity of the mRNA is critical. Ensure the 260/280 ratio is between 1.8 and 2.1.[2][6] Run an aliquot on a gel to check for a single, sharp band corresponding to the correct size.[2] |
| Incorrect mRNA Sequence | Verify the sequence of your DNA template to ensure the open reading frame is correct and in-frame. Point mutations or frameshifts can lead to a non-functional or truncated protein.[11] |
| Protein is Being Degraded | The expressed protein may be unstable and rapidly degraded by the cell. You can perform a time-course experiment to check for protein expression at earlier time points. |
| Issues with Protein Detection | The method used for detecting the protein (e.g., Western blot, flow cytometry) may not be sensitive enough or the antibody may not be working correctly. Include a positive control in your detection assay. |
| "Leaky" Expression and Cell Growth Inhibition | In some systems, there can be a low level of protein expression even without an inducer, which can be toxic and prevent cells from growing to a sufficient density for detectable overexpression.[11] |
Logical Troubleshooting Flow for mRNA Transfection Issues
Caption: A decision-making flowchart for troubleshooting common mRNA transfection problems.
Experimental Protocols
Protocol: Standard mRNA Transfection in a 12-well Plate
This protocol provides a general guideline for mRNA transfection. It is crucial to optimize these conditions for your specific cell type and experimental setup.
Materials:
-
Healthy, actively dividing cells
-
Complete growth medium
-
Serum-free medium (e.g., Opti-MEM)
-
High-quality, purified mRNA (with 5' cap and poly-A tail)
-
Transfection reagent (e.g., Lipofectamine MessengerMAX)
-
12-well tissue culture plates
-
RNase-free tubes and pipette tips
Procedure:
-
Cell Seeding: The day before transfection, seed cells in a 12-well plate at a density that will result in 70-90% confluency on the day of transfection. For example, plate 1.5 x 10^5 cells per well and incubate overnight.[12]
-
Preparation of mRNA-Transfection Reagent Complexes:
-
In an RNase-free tube, dilute 1.5 µg of mRNA into 100 µL of serum-free medium.[12]
-
In a separate RNase-free tube, dilute 2 µL of transfection reagent into 100 µL of serum-free medium and incubate for 5 minutes at room temperature.[12]
-
Combine the diluted mRNA and the diluted transfection reagent. Mix gently by pipetting and incubate for 20 minutes at room temperature to allow for complex formation.[12]
-
-
Transfection:
-
Gently aspirate the growth medium from the cells.
-
Wash the cells once with 500 µL of DPBS per well.[12]
-
Add the 200 µL of mRNA-transfection reagent complexes dropwise to each well.
-
Incubate the cells at 37°C in a CO2 incubator for 4-6 hours.
-
-
Post-Transfection:
-
After the incubation period, you may choose to remove the transfection medium and replace it with 1 mL of fresh, complete growth medium. This step is recommended if you observe high cytotoxicity.
-
Return the plate to the incubator.
-
-
Analysis:
-
Analyze protein expression at your desired time point (typically 24-48 hours post-transfection) using an appropriate method such as Western blot, flow cytometry, or immunofluorescence microscopy.
-
References
- 1. Activation of IFN-β expression by a viral mRNA through RNase L and MDA5 - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Cytosolic Innate Immune Sensing and Signaling upon Infection - PMC [pmc.ncbi.nlm.nih.gov]
- 3. mRNA expression of toll-like receptors 3, 7, 8, and 9 in the nasopharyngeal epithelial cells of coronavirus disease 2019 patients - PMC [pmc.ncbi.nlm.nih.gov]
- 4. mRNA is an endogenous ligand for Toll-like receptor 3 - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
- 6. Toll-Like Receptor Signaling Pathways - PMC [pmc.ncbi.nlm.nih.gov]
- 7. researchgate.net [researchgate.net]
- 8. Innate immune mechanisms of mRNA vaccines - PMC [pmc.ncbi.nlm.nih.gov]
- 9. researchgate.net [researchgate.net]
- 10. researchgate.net [researchgate.net]
- 11. merckmillipore.com [merckmillipore.com]
- 12. researchgate.net [researchgate.net]
Technical Support Center: Optimizing mRNA Capping Efficiency
This technical support center provides troubleshooting guidance and frequently asked questions (FAQs) to help researchers, scientists, and drug development professionals improve mRNA capping efficiency during in vitro transcription (IVT).
Frequently Asked Questions (FAQs) & Troubleshooting
Q1: My co-transcriptional capping efficiency is low. What are the common causes and how can I improve it?
A1: Low capping efficiency in co-transcriptional capping reactions is a common issue. Several factors can contribute to this problem. Here’s a breakdown of potential causes and troubleshooting strategies:
-
Suboptimal Cap Analog to GTP Ratio: The cap analog competes with GTP for incorporation at the 5' end of the mRNA transcript.[1] A low ratio of cap analog to GTP will favor initiation with GTP, resulting in a higher proportion of uncapped transcripts.
-
Solution: Increase the molar ratio of cap analog to GTP. A common starting point is a 4:1 ratio (e.g., 4 mM cap analog to 1 mM GTP). This higher ratio biases the reaction towards initiation with the cap analog.[2] However, be aware that excessively high ratios can sometimes decrease overall mRNA yield.[3]
-
-
Choice of Cap Analog: The type of cap analog used significantly impacts capping efficiency.
-
mCap (standard cap analog): This analog can be incorporated in both the correct (forward) and incorrect (reverse) orientations, with the reverse orientation being non-functional for translation. This inherent property limits the effective capping efficiency.[1]
-
ARCA (Anti-Reverse Cap Analog): ARCA is modified to prevent reverse incorporation, leading to higher functional capping efficiency compared to mCap.[1] However, its efficiency can still be variable, often in the range of 50-80%.[4][]
-
Trinucleotide Cap Analogs (e.g., CleanCap®): These are the latest generation of cap analogs and offer the highest co-transcriptional capping efficiencies, often exceeding 95%.[4][6] They are incorporated as a single unit, which is a more efficient process.[3]
-
-
RNA Polymerase Selection: While most standard T7, SP6, or T3 RNA polymerases are compatible with co-transcriptional capping, some newer, engineered polymerases are specifically designed for improved cap incorporation.[1][7]
-
Solution: Consider using an RNA polymerase engineered for high capping efficiency, such as Codex® HiCap RNA Polymerase, which has been shown to achieve high capping rates even with reduced amounts of cap analog.[7]
-
-
Transcription Initiation Sequence: Some cap analogs have specific requirements for the transcription start site.
-
Solution: Ensure your DNA template's initiation sequence is compatible with your chosen cap analog. For example, CleanCap® Reagent AG requires an AG initiation sequence.[3]
-
Q2: I'm observing a significant amount of uncapped mRNA even with post-transcriptional enzymatic capping. What could be the problem?
A2: While enzymatic capping is generally very efficient (often approaching 100%), several factors can lead to incomplete capping.[8]
-
Incomplete 5' Triphosphate End: The capping enzyme requires a 5'-triphosphate on the mRNA transcript to initiate the capping reaction. If the in vitro transcription reaction produces transcripts with 5'-diphosphate or monophosphate ends, these will not be capped.
-
Solution: Ensure your IVT reaction is optimized for producing full-length transcripts with intact 5'-triphosphate ends. This includes using high-quality NTPs and an optimized buffer system.
-
-
Enzyme Quality and Activity: The activity of the capping enzyme (e.g., Vaccinia Capping Enzyme or Faustovirus Capping Enzyme) is critical.
-
Inhibitors in the RNA Preparation: Contaminants from the IVT reaction, such as high concentrations of pyrophosphate or certain salts, can inhibit the capping enzyme.
-
Solution: Purify the uncapped mRNA transcript after the IVT reaction and before the enzymatic capping step to remove inhibitors.[8]
-
-
Secondary Structure at the 5' End: Complex secondary structures at the 5' end of the mRNA can hinder the accessibility of the capping enzyme.[8]
-
Solution: Performing the capping reaction at a higher temperature can help to resolve secondary structures. FCE is particularly useful here due to its broader temperature tolerance.[10]
-
Q3: Should I choose co-transcriptional or post-transcriptional (enzymatic) capping for my application?
A3: The choice between co-transcriptional and post-transcriptional capping depends on your specific experimental needs, scale, and desired quality of the final mRNA product.[9]
| Feature | Co-transcriptional Capping | Post-transcriptional (Enzymatic) Capping |
| Workflow | Single-step reaction (IVT and capping combined)[4] | Two-step process (IVT followed by a separate capping reaction)[3] |
| Time & Labor | Faster and less labor-intensive[11] | More time-consuming due to additional reaction and purification steps[11] |
| Capping Efficiency | Variable (50-80% with ARCA, >95% with CleanCap®)[4][6] | Generally very high (approaching 100%)[8] |
| mRNA Yield | Can be lower due to competition between cap analog and GTP[3] | Can be higher as the IVT reaction is not compromised by cap analogs[9] |
| Scalability | Well-suited for generating a variety of transcripts quickly[9] | Recommended for large-scale manufacturing[9] |
| Cost | Can be more cost-effective, especially with newer polymerases[7][11] | Can be more expensive due to the cost of enzymes, especially at scale[12] |
Quantitative Data Summary
The following table summarizes the reported capping efficiencies for different capping methods.
| Capping Method | Cap Analog/Enzyme | Reported Capping Efficiency | Cap Structure |
| Co-transcriptional | ARCA (Anti-Reverse Cap Analog) | ~70%[6] (can range from 50-80%[4][]) | Cap-0 |
| Co-transcriptional | CleanCap® Reagent AG | >95%[3][6] | Cap-1 |
| Post-transcriptional | Vaccinia Capping Enzyme (VCE) | Nearly 100% (when optimized)[8] | Cap-0 (requires additional enzyme for Cap-1) |
| Post-transcriptional | Faustovirus Capping Enzyme (FCE) | High efficiency, often higher than VCE[1][9] | Cap-0 (requires additional enzyme for Cap-1) |
Experimental Protocols
Protocol 1: High-Efficiency Co-transcriptional Capping using CleanCap® Reagent AG
This protocol is a general guideline and should be optimized for your specific template and application.
-
IVT Reaction Setup:
-
Assemble the following components at room temperature in the order listed:
-
Nuclease-free water
-
10x Reaction Buffer
-
Linearized DNA template (0.5-1 µg)
-
ATP, CTP, UTP (final concentration of each will vary based on kit)
-
GTP (final concentration will be lower to accommodate the cap analog)
-
CleanCap® Reagent AG (at a specified concentration, often in a 4:1 ratio to GTP)
-
T7 RNA Polymerase Mix
-
-
Gently mix the components and centrifuge briefly.
-
-
Incubation:
-
Incubate the reaction at 37°C for 1-2 hours.
-
-
DNase Treatment:
-
Add DNase I to the reaction mixture to digest the DNA template.
-
Incubate at 37°C for 15 minutes.
-
-
Purification:
-
Purify the capped mRNA using a suitable method, such as lithium chloride precipitation or a column-based purification kit.
-
Protocol 2: Post-Transcriptional Enzymatic Capping using Vaccinia Capping Enzyme (VCE)
-
In Vitro Transcription:
-
Perform a standard IVT reaction to generate uncapped mRNA.
-
Purify the mRNA to remove NTPs, DNA template, and polymerase.
-
-
Enzymatic Capping Reaction Setup:
-
In a nuclease-free tube, combine:
-
Purified uncapped mRNA (up to 100 µg)
-
10x Capping Buffer
-
GTP
-
S-adenosylmethionine (SAM)
-
Vaccinia Capping Enzyme
-
Nuclease-free water to the final volume.
-
-
Mix gently and centrifuge briefly.
-
-
Incubation:
-
Incubate the reaction at 37°C for 1 hour.[8]
-
-
Purification:
-
Purify the capped mRNA using an appropriate method to remove the enzyme and reaction components.
-
Protocol 3: Analysis of Capping Efficiency by LC-MS
-
mRNA Digestion:
-
Digest the purified mRNA sample with a nuclease (e.g., RNase T1 or RNase H with a specific DNA probe) to generate short fragments from the 5' end.[13]
-
-
LC-MS Analysis:
-
Analyze the digested fragments using liquid chromatography-mass spectrometry (LC-MS).[13]
-
The mass spectrometer will detect the mass of the 5'-terminal fragments, allowing for the identification and quantification of capped versus uncapped species.
-
Visualizations
Caption: Workflow for co-transcriptional mRNA capping.
Caption: Workflow for post-transcriptional (enzymatic) mRNA capping.
Caption: Decision tree for selecting an mRNA capping strategy.
References
- 1. lifesciences.danaher.com [lifesciences.danaher.com]
- 2. Getting IVT Right: Improving Capping Efficiency [aldevron.com]
- 3. Methods of IVT mRNA capping - Behind the Bench [thermofisher.com]
- 4. Co-transcriptional capping [takarabio.com]
- 6. trilinkbiotech.com [trilinkbiotech.com]
- 7. Getting IVT Right Improving Capping Efficiency [cellandgene.com]
- 8. areterna.com [areterna.com]
- 9. neb.com [neb.com]
- 10. neb.com [neb.com]
- 11. maravai.com [maravai.com]
- 12. youtube.com [youtube.com]
- 13. agilent.com [agilent.com]
Technical Support Center: Scaling Up mRNA Production
This technical support center provides troubleshooting guidance and answers to frequently asked questions for researchers, scientists, and drug development professionals engaged in scaling up mRNA production.
Troubleshooting Guides
In Vitro Transcription (IVT)
Question: Why is my large-scale IVT reaction yielding less mRNA than expected?
Answer: Low mRNA yield in large-scale IVT reactions can stem from several factors. Here’s a step-by-step guide to troubleshoot this issue:
-
Assess DNA Template Quality and Quantity:
-
Problem: Degraded, impure, or incorrectly quantified DNA template is a common cause of low yield. Contaminants from plasmid purification can inhibit RNA polymerase.[][2]
-
Solution:
-
Confirm template integrity by running an aliquot on an agarose (B213101) gel. A crisp band at the expected size indicates good quality. Smearing may indicate degradation.[]
-
Ensure the template is fully linearized, as incomplete linearization can lead to truncated transcripts.[2]
-
Purify the DNA template using a reliable kit to remove any inhibitors.[2]
-
Accurately quantify the template concentration before starting the IVT reaction.
-
-
-
Optimize IVT Reaction Components:
-
Problem: Suboptimal concentrations of key reagents can limit the reaction.
-
Solution:
-
Magnesium Ions (Mg²⁺): The ratio of magnesium to NTPs is critical. An imbalance can negatively impact enzyme activity.[3] Consider titrating the Mg²⁺ concentration to find the optimal level for your specific template and scale.
-
NTPs: Ensure the concentration of each nucleotide triphosphate is not limiting. In some cases, increasing the concentration of a limiting nucleotide can improve the yield of full-length transcripts.[4]
-
RNA Polymerase: While essential, excessive enzyme concentration does not proportionally increase yield and can lead to the formation of double-stranded RNA (dsRNA) byproducts.[] Titrate the polymerase concentration to find the most efficient amount for your reaction scale.
-
-
-
Control Reaction Conditions:
-
Problem: Time, temperature, and mixing can significantly affect IVT efficiency at scale.
-
Solution:
-
Incubation Time: Extend the reaction time, as larger volumes may require more time to reach maximum yield. Monitor the reaction at different time points to determine the optimal duration.[5]
-
Temperature: While 37°C is standard, some templates benefit from lower (e.g., 16°C) or higher temperatures to improve transcript quality and yield.[4][5] Ensure uniform temperature throughout the reaction vessel to avoid generating truncated products.[5]
-
Mixing: For large-volume reactions, ensure proper mixing to maintain homogeneity of reagents without introducing excessive shear forces that could damage the DNA template or nascent mRNA.
-
-
-
Prevent RNase Contamination:
-
Problem: RNases can degrade your mRNA product, leading to low yields of full-length transcripts.
-
Solution:
-
Maintain a sterile, RNase-free work environment.
-
Use RNase-free reagents and consumables.
-
Incorporate an RNase inhibitor into your IVT reaction.[2]
-
-
Question: How can I reduce the formation of double-stranded RNA (dsRNA) impurities in my IVT reaction?
Answer: dsRNA is a common byproduct of IVT that can trigger an immune response, making its removal critical for therapeutic applications.[6][7] Here are strategies to minimize its formation:
-
Optimize IVT Conditions: High concentrations of RNA polymerase and extended reaction times can contribute to dsRNA formation.[] Fine-tuning these parameters can help reduce byproduct generation.
-
Use High-Purity Reagents: Ensure your NTPs and DNA template are of high quality, as impurities can sometimes contribute to side reactions.
-
Consider Specialized RNA Polymerases: Some commercially available RNA polymerases are engineered to reduce dsRNA formation while maintaining high mRNA yields.[8][9]
-
Post-IVT Purification: Implement robust purification steps to remove any dsRNA that does form. Chromatography methods are particularly effective.[10][11] Some protocols also utilize RNase III digestion, which specifically degrades dsRNA, though this requires careful optimization to avoid impacting your single-stranded mRNA product.[11]
mRNA Purification
Question: My chromatography-based purification is resulting in low mRNA recovery. What could be the issue?
Answer: Low recovery during large-scale chromatography purification can be frustrating. Consider these potential causes and solutions:
-
Suboptimal Chromatography Matrix:
-
Problem: The large size of mRNA molecules can make them susceptible to shear stress and poor interaction with traditional resin pores.[12]
-
Solution:
-
-
Inefficient Binding or Elution:
-
Problem: The conditions for binding mRNA to the column or eluting it may not be optimized for your specific mRNA and scale.
-
Solution:
-
Affinity Chromatography (Oligo-dT): Ensure your mRNA has a poly(A) tail for efficient binding. The length and integrity of the poly(A) tail can impact binding efficiency.
-
Anion Exchange Chromatography: The salt gradient used for elution is crucial. A gradient that is too steep may cause co-elution with impurities, while a gradient that is too shallow may result in broad peaks and low recovery. Optimize the salt concentration and gradient slope.
-
Buffer Composition: Ensure the pH and composition of your binding and elution buffers are optimal for the interaction between your mRNA and the chromatography matrix.
-
-
-
mRNA Degradation:
-
Problem: mRNA is susceptible to degradation by RNases, which can be introduced during the purification process.
-
Solution:
-
Maintain an RNase-free environment throughout the purification process.
-
Use RNase-free buffers and equipment.
-
Work quickly and at cold temperatures where possible to minimize enzymatic activity.
-
-
Lipid Nanoparticle (LNP) Formulation
Question: I'm observing inconsistent mRNA encapsulation efficiency and high polydispersity in my scaled-up LNP formulation. What should I check?
Answer: Achieving consistent LNP properties at scale requires precise control over the formulation process. Here’s a troubleshooting guide:
-
Mixing Process:
-
Problem: The method and speed of mixing the lipid-ethanol phase with the mRNA-aqueous phase are critical for consistent nanoparticle formation. Manual or vortex mixing can be inconsistent at larger scales.[13]
-
Solution:
-
Utilize a microfluidic mixing device. These systems provide rapid, controlled, and reproducible mixing, leading to more uniform particle size and higher encapsulation efficiency.[13]
-
Ensure the flow rates of both phases are precisely controlled and optimized for your formulation.
-
-
-
Lipid and mRNA Quality:
-
Problem: The quality and ratio of your lipids and the integrity of your mRNA can impact LNP formation.
-
Solution:
-
Use high-purity lipids from a reliable supplier.
-
Verify the integrity and concentration of your mRNA before formulation. Degraded mRNA may not encapsulate as efficiently.
-
Optimize the N:P ratio (the molar ratio of nitrogen in the ionizable lipid to phosphate (B84403) in the mRNA). This ratio significantly affects encapsulation and the final properties of the LNPs.[14][15]
-
-
-
Buffer Conditions:
-
Problem: The pH of the aqueous buffer is critical for the ionization of the cationic lipid and its interaction with the negatively charged mRNA.
-
Solution:
-
Ensure the pH of your aqueous buffer is acidic (typically around pH 4.0) to facilitate the electrostatic interaction required for encapsulation.
-
After formulation, the buffer should be exchanged to a neutral pH (e.g., PBS) to stabilize the LNPs.
-
-
Frequently Asked Questions (FAQs)
IVT
-
Q1: What is the optimal incubation time for a large-scale IVT reaction?
-
A1: There is no single optimal time; it is dependent on the specific template and reaction conditions. For larger scale reactions, longer incubation times (e.g., 4-6 hours or more) may be necessary to maximize yield. It is recommended to perform a time-course experiment to determine the point at which mRNA production plateaus.[5][16]
-
-
Q2: Can I reuse my DNA template for multiple IVT reactions?
-
A2: While technically possible, it is generally not recommended for therapeutic mRNA production due to the risk of degradation and cross-contamination. For consistent, high-quality mRNA, it is best to use a fresh aliquot of purified, linearized DNA template for each reaction.
-
Purification
-
Q3: What are the most common impurities to remove during mRNA purification?
-
Q4: Is one chromatography method sufficient for purifying therapeutic-grade mRNA?
-
A4: Often, a single chromatography step is not enough to achieve the high purity required for therapeutic applications. A multi-step purification process, for example combining affinity chromatography with ion-exchange chromatography, can be more effective at removing a wider range of impurities.[19]
-
LNP Formulation
-
Q5: What is a typical encapsulation efficiency to aim for?
-
A5: A high encapsulation efficiency, often greater than 90%, is desirable to maximize the delivery of the mRNA payload and ensure a consistent product.
-
-
Q6: How can I assess the stability of my mRNA-LNP formulation?
-
A6: Stability can be assessed by monitoring key quality attributes such as particle size, polydispersity index (PDI), zeta potential, and encapsulation efficiency over time at different storage conditions (e.g., 4°C, -20°C, -80°C).[14]
-
Data and Protocols
Quantitative Data Summary
Table 1: Impact of IVT Reaction Parameters on mRNA Yield and Integrity
| Parameter | Condition | Effect on Yield | Effect on Integrity | Reference |
| Mg²⁺ Concentration | Increasing from 6 mM to 75 mM | Non-linear; initial increase followed by a decrease | Non-linear; initial increase followed by a decrease | [20] |
| IVT Reaction Time | Increasing from 2h to 6h | Generally increases up to a plateau | Can decrease with very long incubation times | [5][20] |
| T7 RNA Polymerase | Increasing Concentration | Increases up to a point, then plateaus | Can decrease due to increased dsRNA formation | [][3] |
| NTP Concentration | Increasing Total NTPs | Increases yield up to an optimal ratio with Mg²⁺ | Can be negatively impacted if ratio to Mg²⁺ is suboptimal | [3] |
Table 2: Comparison of mRNA Purification Methods
| Purification Method | Principle | Advantages | Disadvantages | Scalability | Reference |
| LiCl Precipitation | Selective precipitation of RNA | Simple, inexpensive | Co-precipitates dsRNA and other impurities | Limited | [17] |
| Oligo(dT) Affinity | Binds to poly(A) tail of mRNA | High selectivity for polyadenylated mRNA | Does not remove polyadenylated fragments; potential for non-specific binding | Good | [17][19] |
| Anion Exchange | Binds to negatively charged phosphate backbone | High resolution, separates based on charge | Can be sensitive to buffer conditions | Excellent | [19] |
| Size Exclusion | Separates based on molecular size | Effective at removing small impurities (NTPs, salts) | Lower resolution for species of similar size | Good | [19] |
Experimental Protocols
Protocol 1: Analysis of mRNA Capping Efficiency by LC-MS
This protocol outlines a general workflow for determining the 5' capping efficiency of an mRNA sample using liquid chromatography-mass spectrometry (LC-MS).
-
mRNA Digestion:
-
To a solution containing a known amount of purified mRNA (e.g., 5-10 µg), add a specific RNase (e.g., RNase H with a complementary DNA probe, or RNase T1) to cleave the 5' end of the mRNA, releasing a short oligonucleotide containing the cap structure.[21][22][23]
-
The DNA probe for RNase H-mediated cleavage is designed to be complementary to a region near the 5' end of the mRNA.[24][25]
-
Incubate the reaction according to the enzyme manufacturer's recommendations (e.g., 30-60 minutes at 37°C or 50°C for thermostable RNase H).[21][23]
-
(Optional) Treat the sample with a phosphatase to remove residual phosphate groups from the ends of the oligonucleotides.[23]
-
-
Sample Cleanup (if necessary):
-
LC-MS Analysis:
-
Inject the purified oligonucleotide sample onto an ion-pair reversed-phase (IP-RP) HPLC column.[26]
-
Use a mobile phase system typically consisting of an ion-pairing agent (e.g., TEAA or HFIP/DBA) and an organic solvent gradient (e.g., acetonitrile (B52724) or methanol) to separate the capped and uncapped oligonucleotide fragments.[21][26]
-
The eluent from the HPLC is directed into a high-resolution mass spectrometer (e.g., Q-TOF or Orbitrap).
-
The mass spectrometer will detect the precise mass of the eluting fragments.
-
-
Data Analysis:
-
Identify the peaks corresponding to the capped and uncapped 5' fragments based on their expected masses.
-
Calculate the capping efficiency by comparing the peak areas of the capped species to the total peak area of all 5' end species (capped + uncapped).[24]
-
The formula is: Capping Efficiency (%) = [Peak Area (Capped) / (Peak Area (Capped) + Peak Area (Uncapped))] * 100.
-
Protocol 2: Assessment of mRNA Poly(A) Tail Length
This protocol describes a common method for analyzing the length and distribution of the poly(A) tail on an mRNA sample.
-
cDNA Synthesis:
-
Start with a known amount of purified mRNA.
-
Anneal an oligo(dT) primer that has a unique adapter sequence on its 5' end to the poly(A) tail of the mRNA.
-
Perform a reverse transcription reaction using a reverse transcriptase enzyme to synthesize the first strand of cDNA.
-
-
PCR Amplification:
-
Use the resulting cDNA as a template for a PCR reaction.
-
One primer will be specific to the unique adapter sequence on the oligo(dT) primer.
-
The other primer will be a forward primer specific to a sequence in the 3' untranslated region (3' UTR) of your mRNA, upstream of the poly(A) tail.
-
-
Gel Electrophoresis:
-
Run the PCR products on a high-resolution agarose or polyacrylamide gel.[27]
-
The resulting products will appear as a smear or a series of bands. The size of the products directly corresponds to the length of the poly(A) tail.
-
A sample with a homogenous, short poly(A) tail will produce a tight band, while a sample with a long and heterogeneous poly(A) tail will produce a smear.[27]
-
-
Analysis:
-
Use a DNA ladder to estimate the size range of the PCR products and thus the poly(A) tail lengths.
-
Densitometry analysis of the gel image can provide a distribution profile of the poly(A) tail lengths.
-
Visualizations
Caption: High-level workflow for mRNA production from plasmid DNA to final product.
Caption: Troubleshooting logic for addressing low yield in in vitro transcription.
Caption: Key steps in the formulation of mRNA lipid nanoparticles (LNPs).
References
- 2. promegaconnections.com [promegaconnections.com]
- 3. biorxiv.org [biorxiv.org]
- 4. Practical Tips for In Vitro Transcription | Thermo Fisher Scientific - HK [thermofisher.com]
- 5. mRNA Synthesis Scale-Up Tips | Thermo Fisher Scientific - JP [thermofisher.com]
- 6. mRNA quality control: Easy detection of dsRNA impurities - News Blog - Jena Bioscience [jenabioscience.com]
- 7. etherna.be [etherna.be]
- 8. Preventing Double-Stranded RNA Contamination in mRNA Manufac | Technology Networks [technologynetworks.com]
- 9. linearxdna.com [linearxdna.com]
- 10. researchgate.net [researchgate.net]
- 11. m.youtube.com [m.youtube.com]
- 12. Part 1: Chromatography Purification for mRNA [sartorius.com]
- 13. youtube.com [youtube.com]
- 14. mRNA lipid nanoparticle formulation, characterization and evaluation - PMC [pmc.ncbi.nlm.nih.gov]
- 15. Payload distribution and capacity of mRNA lipid nanoparticles - PMC [pmc.ncbi.nlm.nih.gov]
- 16. bitesizebio.com [bitesizebio.com]
- 17. cytivalifesciences.com [cytivalifesciences.com]
- 18. mRNA Product Purification Process Strategies [cellandgene.com]
- 19. lifesciences.danaher.com [lifesciences.danaher.com]
- 20. Optimization of In Vitro Transcription by Design of Experiment to Achieve High Self-Amplifying RNA Integrity - PMC [pmc.ncbi.nlm.nih.gov]
- 21. lcms.cz [lcms.cz]
- 22. agilent.com [agilent.com]
- 23. pubs.acs.org [pubs.acs.org]
- 24. researchgate.net [researchgate.net]
- 25. neb.com [neb.com]
- 26. RNA analysis by ion-pair reversed-phase high performance liquid chromatography - PMC [pmc.ncbi.nlm.nih.gov]
- 27. Assays for determining poly(A) tail length and the polarity of mRNA decay in mammalian cells - PMC [pmc.ncbi.nlm.nih.gov]
Validation & Comparative
Comparative Analysis of In Vivo mRNA-LNP Delivery Efficiency
An essential aspect of developing mRNA-based therapeutics lies in the effective and targeted delivery of mRNA molecules to the desired cells in vivo. Lipid nanoparticles (LNPs) have emerged as the leading platform for mRNA delivery, underscored by the success of the COVID-19 mRNA vaccines.[1][2] This guide provides a comparative analysis of different mRNA-LNP formulations, focusing on their in vivo delivery efficiency, supported by experimental data and detailed protocols.
The in vivo performance of mRNA-LNPs is critically influenced by their composition, particularly the ionizable lipids, helper lipids, cholesterol, and polyethylene (B3416737) glycol (PEG)-lipids that constitute the nanoparticles.[1][3] Different formulations exhibit varied biodistribution and protein expression profiles.
Influence of Lipid Composition on Biodistribution and Expression
Studies have compared various LNP formulations to assess their potency, expression kinetics, and biodistribution. For instance, following intramuscular injection in mice, LNPs formulated with SM-102 or ALC-0315 lipids have been shown to be highly potent.[4] The choice of helper lipid also plays a significant role; LNPs prepared with DOPE (dioleylphosphatidylethanolamine) and β-sitosterol have demonstrated more efficient mRNA transfection in murine dendritic cells compared to those with DSPC (distearoylphosphatidylcholine), especially at lower mRNA doses.[5]
Biodistribution studies reveal that after intramuscular injection, LNPs can distribute systemically, with a significant presence in the liver.[6] However, the distribution of LNPs does not always linearly correlate with transgene expression, suggesting that the efficiency of mRNA release and translation varies between tissues.[6] For example, even with lower LNP accumulation in the liver compared to the injection site muscle, comparable levels of protein expression can be achieved in both tissues.[6] Intravenous administration generally leads to systemic distribution, with the liver being a primary site of accumulation.[7][8]
Below are tables summarizing the in vivo performance of different LNP formulations based on published data.
Quantitative Data Summary
Table 1: Comparison of Luciferase Expression for Different LNP Formulations (Intramuscular Injection)
| LNP Formulation | Key Lipid Component(s) | Animal Model | mRNA Dose | Peak Expression Organ(s) | Relative Expression Level (vs. Control) | Reference |
| LNP-1 | SM-102 | BALB/c Mice | 10 µg | Liver, Muscle | High | [4][6] |
| LNP-2 | ALC-0315 | BALB/c Mice | 10 µg | Liver, Muscle | High | [4] |
| DDA-cLNP | DDA, DOPE | BALB/c Mice | 1.5 µg SAM | Injection Site | Strong humoral and cellular response | [4] |
| DOTAP-cLNP | DOTAP, DOPE | BALB/c Mice | 1.5 µg SAM | Systemic | Strong humoral and cellular response | [4] |
Table 2: Comparison of Luciferase Expression for Different LNP Formulations (Intravenous Injection)
| LNP Formulation | Key Lipid Component(s) | Animal Model | mRNA Dose | Peak Expression Organ(s) | Key Finding | Reference |
| LNP-A | C12-200 | C57BL/6 Mice | 0.1 mg/kg | Liver | Strong bioluminescence in the upper abdomen | [1][3] |
| LNP-B | D-Lin-MC3, DOPE | C57BL/6 Mice | 1-5 µg | Spleen, Liver | DOPE-containing LNPs more effective than DSPC-LNPs | [5] |
| LNP-C | cKK-E12 | BALB/c Mice | Not specified | Liver, Spleen | Larger particle size (~150 nm) | [9] |
| HDLNPs | DLin-KC2-DMA | Albino B6 Mice | 0.3 mg/kg | Liver, Spleen | Highest mRNA loading, but least potent | [10][11] |
Experimental Protocols
Detailed methodologies are crucial for the reproducible evaluation of mRNA-LNP delivery efficiency.
mRNA-LNP Formulation via Microfluidic Mixing
This protocol describes the formulation of LNPs encapsulating mRNA using a microfluidic mixing device.[1][2]
-
Preparation of Lipid and mRNA Solutions :
-
Prepare stock solutions of the ionizable lipid, phospholipid (e.g., DSPC or DOPE), cholesterol, and lipid-PEG in 100% ethanol (B145695).[12]
-
Combine the lipid components in a conical tube at the desired molar ratio (e.g., 35/16/46.5/2.5 of ionizable lipid:helper lipid:cholesterol:lipid-PEG).[1] Dilute the lipid mixture with ethanol to a final volume that is 25% of the total final LNP solution volume.[1]
-
Thaw the mRNA (e.g., encoding Firefly Luciferase) on ice. Dilute the mRNA in a 10 mM citric acid buffer (pH 4.0) to a final volume that is three times the volume of the organic lipid phase.[1]
-
-
Microfluidic Mixing :
-
Load the lipid-ethanol solution into one syringe and the mRNA-buffer solution into another.
-
Set up the microfluidic mixing instrument with a total flow rate of 10 ml/min and a flow rate ratio of 3:1 (aqueous:organic).[9]
-
Initiate the mixing process to allow for the self-assembly of mRNA-LNPs.
-
-
Purification and Characterization :
-
Dialyze the formulated LNPs against phosphate-buffered saline (PBS, pH 7.4) overnight to remove ethanol and non-encapsulated mRNA.[9]
-
Concentrate the LNP solution using centrifugal filters.[9]
-
Characterize the LNPs for size, polydispersity index (PDI), and mRNA encapsulation efficiency using dynamic light scattering and a RiboGreen assay, respectively.[13]
-
In Vivo Evaluation of mRNA-LNP Efficiency
This protocol outlines the steps for assessing mRNA-LNP delivery efficiency in a murine model.[1][7]
-
Animal Model : C57BL/6 or BALB/c mice (6-8 weeks old) are commonly used.[7]
-
Administration :
-
Bioluminescence Imaging (for Luciferase mRNA) :
-
At selected time points post-injection (e.g., 3, 6, 24 hours), administer D-luciferin substrate via intraperitoneal injection (150 mg/kg body weight).[1]
-
Anesthetize the mice and perform whole-body imaging using an In Vivo Imaging System (IVIS).[1][2] A consistent time interval (e.g., 10 minutes) between luciferin (B1168401) injection and imaging is critical for stable signals.[1]
-
Quantify the bioluminescent signal (total flux) in specific regions of interest (e.g., liver, spleen, injection site).[12]
-
-
Ex Vivo Analysis :
Mechanism of LNP-mediated mRNA Delivery
The delivery of mRNA to the cytoplasm of a target cell by an LNP is a multi-step process.
-
Systemic Circulation and Tissue Accumulation : After administration (e.g., IV), LNPs circulate in the bloodstream. Their biodistribution is influenced by factors like size and PEGylation.[8] Many LNP formulations tend to accumulate in the liver.[8]
-
Cellular Uptake : LNPs are primarily taken up by cells through endocytosis.
-
Endosomal Escape : This is a critical step where the ionizable lipids within the LNP, which are protonated in the acidic environment of the endosome, disrupt the endosomal membrane. This allows the encapsulated mRNA to be released into the cytoplasm.
-
Translation : Once in the cytoplasm, the mRNA is translated by the cell's ribosomal machinery to produce the encoded protein (e.g., luciferase, a vaccine antigen, or a therapeutic protein).
References
- 1. mitchell-lab.seas.upenn.edu [mitchell-lab.seas.upenn.edu]
- 2. Testing the In Vitro and In Vivo Efficiency of mRNA-Lipid Nanoparticles Formulated by Microfluidic Mixing - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. researchgate.net [researchgate.net]
- 4. researchgate.net [researchgate.net]
- 5. In Cellulo and In Vivo Comparison of Cholesterol, Beta-Sitosterol and Dioleylphosphatidylethanolamine for Lipid Nanoparticle Formulation of mRNA - ProQuest [proquest.com]
- 6. Biodistribution and Non-linear Gene Expression of mRNA LNPs Affected by Delivery Route and Particle Size - PMC [pmc.ncbi.nlm.nih.gov]
- 7. mRNA lipid nanoparticle formulation, characterization and evaluation - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Biodistribution of RNA-LNP, a review - Inside Therapeutics [insidetx.com]
- 9. cdn2.caymanchem.com [cdn2.caymanchem.com]
- 10. pubs.acs.org [pubs.acs.org]
- 11. Transfection Potency of Lipid Nanoparticles Containing mRNA Depends on Relative Loading Levels - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Video: Testing the In Vitro and In Vivo Efficiency of mRNA-Lipid Nanoparticles Formulated by Microfluidic Mixing [jove.com]
- 13. Ionizable lipid nanoparticles encapsulating barcoded mRNA for accelerated in vivo delivery screening - PMC [pmc.ncbi.nlm.nih.gov]
A Head-to-Head Comparison: Unveiling the Advantages of mRNA Vaccines Over Traditional Subunit Vaccines
For Immediate Publication
Shanghai, China – December 15, 2025 – The advent of messenger RNA (mRNA) vaccines has marked a paradigm shift in vaccinology, offering a potent and rapidly adaptable platform for combating infectious diseases. This guide provides a comprehensive comparison of the distinct advantages of mRNA vaccines over traditional subunit vaccines, supported by experimental data and detailed methodologies for researchers, scientists, and drug development professionals.
Executive Summary
mRNA vaccines have demonstrated superiority over traditional subunit vaccines in several key areas. Notably, they elicit a more robust and broader immune response, encompassing both potent neutralizing antibodies and strong T-cell mediated immunity. This is largely attributed to their intrinsic adjuvant properties and the in vivo production of antigens, which allows for presentation via both MHC class I and class II pathways. Furthermore, the cell-free, scalable manufacturing process of mRNA vaccines offers unparalleled speed in development and production, a critical advantage in pandemic scenarios. While subunit vaccines have a well-established safety profile, mRNA vaccines have also proven to be safe and effective, with their rapid degradation in the body minimizing the risk of long-term side effects.
Data Presentation: Performance and Immunogenicity
The following tables summarize key quantitative data from preclinical and clinical studies comparing the performance of mRNA and subunit vaccines, primarily in the context of SARS-CoV-2.
Table 1: Comparative Immunogenicity of mRNA vs. Subunit Vaccines in Mice
| Parameter | mRNA Vaccine (LNP-formulated) | Subunit Vaccine (Adjuvanted Protein) | Reference |
| RBD-specific IgG Titer (Day 35) | Significantly Higher | High | |
| Neutralizing Antibody Titer (Day 35) | Significantly Higher | High | |
| IgG Subtype Bias | Th1-biased (Higher IgG2a) | Th2-biased (Dominant IgG1) | |
| IFN-γ Secreting T-cells (ELISpot) | Significantly Higher | Lower | |
| Memory T-cell Response | More specific memory T-cells | Fewer specific memory T-cells |
Table 2: Efficacy and Safety in Human Clinical Trials (COVID-19)
| Parameter | mRNA Vaccines (e.g., BNT162b2, mRNA-1273) | Subunit Vaccines (e.g., NVX-CoV2373) | Reference |
| Efficacy against Symptomatic Disease | >90% | ~90% | [1] |
| Induction of Cellular Immunity | Robust T-cell responses | Weaker cellular responses | [2] |
| Manufacturing Speed | Rapid (weeks to months) | Slower (months to years) | [3][4][5] |
| Adjuvant Requirement | Self-adjuvanted | Requires adjuvants | [6][7] |
| Safety Profile | Generally well-tolerated; transient local and systemic reactions | Well-established safety; may require adjuvants that can cause local reactions | [8][9] |
Signaling Pathways and Mechanism of Action
The differential immune responses elicited by mRNA and subunit vaccines stem from their distinct mechanisms of action.
mRNA Vaccine Signaling Pathway
mRNA vaccines, typically encapsulated in lipid nanoparticles (LNPs), are taken up by antigen-presenting cells (APCs) such as dendritic cells. The mRNA is then translated into the target antigen in vivo. This intracellular production allows for the antigen to be processed and presented on both MHC class I and class II molecules, leading to the activation of both CD8+ cytotoxic T-lymphocytes and CD4+ helper T-cells. Furthermore, the mRNA itself can act as a pathogen-associated molecular pattern (PAMP), stimulating innate immune receptors like Toll-like receptors (TLRs), which contributes to its self-adjuvanting properties.[10]
Caption: Signaling pathway of an mRNA vaccine leading to adaptive immunity.
Subunit Vaccine Signaling Pathway
Subunit vaccines deliver purified antigens directly, often with an adjuvant to stimulate the immune response.[7] These exogenous antigens are taken up by APCs and are primarily processed through the endosomal pathway for presentation on MHC class II molecules. This preferentially activates CD4+ helper T-cells, which in turn help B-cells produce antibodies. The activation of CD8+ T-cells is generally less efficient with subunit vaccines compared to mRNA vaccines.[6]
Caption: Signaling pathway of a subunit vaccine leading to adaptive immunity.
Experimental Protocols
This section provides detailed methodologies for key experiments used to compare the immunogenicity of mRNA and subunit vaccines.
Experimental Workflow: Comparative Immunogenicity in Mice
The following workflow outlines a typical head-to-head comparison of an mRNA and a subunit vaccine in a mouse model.
Caption: Workflow for comparing mRNA and subunit vaccine immunogenicity.
Protocol 1: ELISA for SARS-CoV-2 RBD-Specific IgG
This protocol is for the quantitative detection of IgG antibodies against the SARS-CoV-2 receptor-binding domain (RBD).
Materials:
-
96-well high-binding microtiter plates
-
Recombinant SARS-CoV-2 RBD protein
-
Coating Buffer (e.g., PBS, pH 7.4)
-
Wash Buffer (e.g., PBS with 0.05% Tween-20)
-
Blocking Buffer (e.g., PBS with 1% BSA)
-
Dilution Buffer (e.g., PBS with 0.1% BSA and 0.05% Tween-20)
-
Mouse serum samples
-
HRP-conjugated anti-mouse IgG detection antibody
-
TMB substrate solution
-
Stop Solution (e.g., 2N H₂SO₄)
-
Microplate reader
Procedure:
-
Coating: Coat the wells of a 96-well plate with 100 µL of recombinant RBD protein (e.g., 2 µg/mL in Coating Buffer) and incubate overnight at 4°C.
-
Washing: Wash the plate three times with 200 µL of Wash Buffer per well.
-
Blocking: Block non-specific binding by adding 200 µL of Blocking Buffer to each well and incubate for 1-2 hours at room temperature.
-
Sample Incubation: Wash the plate three times. Add 100 µL of serially diluted mouse serum (starting at 1:100 in Dilution Buffer) to the wells. Incubate for 2 hours at room temperature.
-
Detection Antibody: Wash the plate five times. Add 100 µL of HRP-conjugated anti-mouse IgG detection antibody (diluted in Dilution Buffer) to each well. Incubate for 1 hour at room temperature.
-
Substrate Development: Wash the plate five times. Add 100 µL of TMB substrate solution to each well and incubate in the dark for 15-30 minutes.
-
Stopping the Reaction: Add 50 µL of Stop Solution to each well.
-
Reading: Measure the optical density (OD) at 450 nm using a microplate reader. The antibody titer is determined as the reciprocal of the highest dilution that gives an OD value above a predetermined cutoff.
Protocol 2: ELISpot for IFN-γ Secretion
This assay quantifies the number of antigen-specific IFN-γ-secreting T-cells.
Materials:
-
96-well PVDF membrane ELISpot plates
-
Anti-mouse IFN-γ capture antibody
-
Biotinylated anti-mouse IFN-γ detection antibody
-
Streptavidin-Alkaline Phosphatase (ALP) conjugate
-
BCIP/NBT substrate solution
-
RPMI-1640 medium with 10% FBS
-
Recombinant antigen or peptide pool
-
Splenocytes from immunized mice
Procedure:
-
Plate Coating: Pre-wet the ELISpot plate with 35% ethanol (B145695) for 1 minute, then wash with sterile PBS. Coat the wells with anti-mouse IFN-γ capture antibody overnight at 4°C.
-
Blocking: Wash the plate and block with RPMI-1640 medium containing 10% FBS for at least 2 hours at 37°C.
-
Cell Plating and Stimulation: Prepare a single-cell suspension of splenocytes. Add 2.5 x 10⁵ to 5 x 10⁵ cells per well. Stimulate the cells with the specific antigen or peptide pool. Include negative (no antigen) and positive (e.g., Concanavalin A) controls. Incubate for 18-24 hours at 37°C in a 5% CO₂ incubator.
-
Detection: Lyse the cells and wash the plate. Add biotinylated anti-mouse IFN-γ detection antibody and incubate for 2 hours at room temperature.
-
Enzyme Conjugation: Wash the plate and add Streptavidin-ALP conjugate. Incubate for 1 hour at room temperature.
-
Spot Development: Wash the plate and add BCIP/NBT substrate solution. Monitor for the development of spots. Stop the reaction by washing with distilled water.
-
Analysis: Air-dry the plate and count the spots using an ELISpot reader. Results are expressed as spot-forming units (SFU) per million cells.
Protocol 3: Plaque Reduction Neutralization Test (PRNT)
This assay measures the titer of functional neutralizing antibodies that can block viral entry into cells.
Materials:
-
Vero E6 cells (or other susceptible cell line)
-
Live virus (e.g., SARS-CoV-2)
-
Cell culture medium (e.g., DMEM with 2% FBS)
-
Heat-inactivated mouse serum samples
-
Agarose or methylcellulose (B11928114) overlay
-
Crystal violet staining solution
Procedure:
-
Cell Seeding: Seed Vero E6 cells in 24-well plates to form a confluent monolayer.
-
Serum Dilution and Virus Neutralization: Serially dilute the heat-inactivated mouse serum. Mix the diluted serum with a known amount of virus (e.g., 100 plaque-forming units) and incubate for 1 hour at 37°C to allow antibodies to neutralize the virus.
-
Infection: Add the serum-virus mixture to the Vero E6 cell monolayers and incubate for 1 hour at 37°C.
-
Overlay: Remove the inoculum and add a semi-solid overlay (e.g., medium with 1% methylcellulose) to restrict virus spread to adjacent cells.
-
Incubation: Incubate the plates for 3-5 days at 37°C in a 5% CO₂ incubator until plaques are visible.
-
Staining and Counting: Fix the cells (e.g., with 4% paraformaldehyde) and stain with crystal violet to visualize the plaques. Count the number of plaques in each well.
-
Titer Calculation: The PRNT₅₀ titer is the reciprocal of the highest serum dilution that results in a 50% reduction in the number of plaques compared to the virus-only control.
Conclusion
The evidence strongly supports the advantages of mRNA vaccines over traditional subunit vaccines in several critical aspects. Their ability to induce a balanced and robust humoral and cellular immune response, coupled with their unprecedented manufacturing speed, positions them as a transformative technology in the fight against infectious diseases. While subunit vaccines remain a valuable tool in the vaccinologist's arsenal, the versatility and efficacy of the mRNA platform are likely to drive the future of vaccine development. Further research should continue to explore the long-term durability of the immune responses induced by both platforms and optimize their respective formulations for enhanced performance against a broader range of pathogens.
References
- 1. m.youtube.com [m.youtube.com]
- 2. revvity.com [revvity.com]
- 3. creative-diagnostics.com [creative-diagnostics.com]
- 4. fortislife.com [fortislife.com]
- 5. hiv-forschung.de [hiv-forschung.de]
- 6. Comparison of Immune Responses Elicited by SARS-CoV-2 mRNA and Recombinant Protein Vaccine Candidates - PMC [pmc.ncbi.nlm.nih.gov]
- 7. medium.com [medium.com]
- 8. ELISPOT protocol | Abcam [abcam.com]
- 9. ibl-international.com [ibl-international.com]
- 10. researchgate.net [researchgate.net]
A Comparative Guide to mRNA Therapeutics and Protein Replacement Therapy
For Researchers, Scientists, and Drug Development Professionals
The landscape of therapeutic intervention for diseases caused by deficient or dysfunctional proteins is rapidly evolving. For decades, protein replacement therapy has been the standard of care for many such conditions. However, the recent success of mRNA vaccines has propelled mRNA-based therapeutics to the forefront as a versatile and powerful alternative. This guide provides an objective comparison of these two modalities, supported by experimental data and detailed methodologies, to aid researchers and drug development professionals in making informed decisions for their therapeutic strategies.
Mechanism of Action: A Tale of Two Delivery Systems
The fundamental difference between mRNA therapeutics and protein replacement therapy lies in what is delivered to the patient and where the therapeutic protein is produced.
mRNA Therapeutics: In Vivo Protein Production
mRNA therapy provides the genetic instructions (messenger RNA) that encode a specific protein.[1] This mRNA is encapsulated in a delivery vehicle, typically lipid nanoparticles (LNPs), which protects it from degradation and facilitates its entry into target cells.[2] Once inside the cell, the host cell's own translational machinery, the ribosomes, reads the mRNA sequence and synthesizes the therapeutic protein.[1][3] This process mimics the natural protein production pathway within the cell.
Caption: Mechanism of action for mRNA therapeutics.
Protein Replacement Therapy: Ex Vivo Protein Production and Delivery
In contrast, protein replacement therapy involves the direct administration of a purified, functional protein that has been manufactured externally (ex vivo).[2] This is a long-established approach for treating diseases caused by a missing or defective protein.[1] The recombinant proteins are typically produced in large-scale cell cultures, purified to a high degree, and then administered to the patient, usually intravenously.[4]
Caption: Mechanism of action for protein replacement therapy.
Performance Comparison: A Tabular Overview
The choice between mRNA therapeutics and protein replacement therapy often depends on a variety of factors, including the specific disease, the nature of the protein, and the desired therapeutic outcome. The following tables provide a quantitative comparison of the two modalities.
Table 1: Efficacy and Pharmacokinetics
| Parameter | mRNA Therapeutics | Protein Replacement Therapy |
| Protein Expression | Intracellular and secreted proteins | Primarily extracellular proteins |
| Duration of Effect | Potentially longer-lasting due to sustained protein production[1] | Dependent on the protein's half-life, often requiring frequent administration[1] |
| Dosing Frequency | Less frequent dosing may be possible | Can range from daily to bi-weekly infusions |
| Onset of Action | Dependent on cellular uptake and translation | Immediate upon administration[1] |
Table 2: Safety and Immunogenicity
| Parameter | mRNA Therapeutics | Protein Replacement Therapy |
| Immunogenicity | Can trigger innate immune responses, though modifications can reduce this.[5][6] Lower risk of anti-drug antibodies (ADAs) to the therapeutic protein itself.[7] | Risk of developing neutralizing antibodies (ADAs) against the recombinant protein, which can reduce efficacy.[1] |
| Genomic Integration | No risk of genomic integration as mRNA does not enter the cell nucleus.[8] | No risk of genomic integration. |
| Side Effects | Primarily related to the delivery vehicle (e.g., LNP-related infusion reactions).[9] | Infusion-related reactions and potential for immune responses to the protein. |
Table 3: Manufacturing and Logistics
| Parameter | mRNA Therapeutics | Protein Replacement Therapy |
| Manufacturing Process | Cell-free in vitro transcription, a relatively rapid and scalable chemical process.[2] | Complex and lengthy process involving cell culture, protein expression, and multi-step purification.[2][4] |
| Production Time | Shorter development and manufacturing timelines.[9] | Longer timelines due to the complexity of biological production. |
| Cost | Potentially lower manufacturing costs.[9][10] | High manufacturing costs due to the need for large-scale bioreactors and extensive purification.[3][4][11] |
| Storage and Stability | Often requires ultra-cold storage, though research is ongoing to improve stability.[9] | Generally more stable, with established cold-chain logistics. |
Experimental Protocols
To facilitate the evaluation and comparison of these therapies, this section provides an overview of key experimental protocols.
mRNA Synthesis: In Vitro Transcription (IVT)
This protocol outlines the basic steps for synthesizing mRNA in a cell-free system.[7][12][13][14]
-
Template Preparation: A linearized plasmid DNA or a PCR product containing the gene of interest downstream of a T7 promoter is used as the template.[7][14]
-
Transcription Reaction: The DNA template is incubated with T7 RNA polymerase, ribonucleoside triphosphates (NTPs), and an RNase inhibitor in a transcription buffer.[13][14] To reduce immunogenicity, modified nucleotides (e.g., pseudouridine) can be incorporated.
-
Capping: A 5' cap structure is added to the mRNA either co-transcriptionally using a cap analog or post-transcriptionally using capping enzymes.[13] This is crucial for mRNA stability and translation initiation.
-
Tailing: A poly(A) tail is added to the 3' end of the mRNA using poly(A) polymerase to enhance stability and translational efficiency.[12]
-
Purification: The synthesized mRNA is purified to remove enzymes, unincorporated nucleotides, and the DNA template.
Lipid Nanoparticle (LNP) Formulation for mRNA Delivery
This protocol describes a common method for encapsulating mRNA into LNPs.[4][9][10][15]
-
Lipid Mixture Preparation: A mixture of lipids, including an ionizable cationic lipid, a PEG-lipid, cholesterol, and a helper lipid, is dissolved in ethanol.[15]
-
Aqueous Phase Preparation: The purified mRNA is dissolved in an acidic aqueous buffer.
-
Mixing: The ethanolic lipid solution and the aqueous mRNA solution are rapidly mixed, often using a microfluidic device. The change in polarity causes the lipids to self-assemble around the mRNA, forming LNPs.
-
Purification and Buffer Exchange: The LNP formulation is purified and the buffer is exchanged to a neutral pH buffer (e.g., PBS) through dialysis or tangential flow filtration.
Recombinant Protein Production and Purification
This protocol provides a general workflow for producing therapeutic proteins.[3][16][17]
-
Gene Cloning and Expression Vector Construction: The gene encoding the protein of interest is cloned into an expression vector suitable for the chosen host system (e.g., mammalian cells, bacteria).
-
Cell Culture and Protein Expression: The expression vector is introduced into the host cells, which are then cultured in large-scale bioreactors under conditions that induce protein expression.
-
Cell Lysis and Clarification: The cells are harvested and lysed to release the protein. The lysate is then clarified by centrifugation or filtration to remove cell debris.
-
Chromatography: The target protein is purified from the clarified lysate using a series of chromatography steps. A common strategy involves:
-
Capture: Affinity chromatography is often used as the initial capture step.[16]
-
Intermediate Purification: Techniques like ion-exchange chromatography further remove impurities.[16]
-
Polishing: Size-exclusion chromatography is used as a final polishing step to remove any remaining contaminants and aggregates.[16]
-
-
Formulation: The purified protein is formulated in a stable buffer for administration.
Quantification of Protein Expression: ELISA
Enzyme-Linked Immunosorbent Assay (ELISA) is a plate-based assay for detecting and quantifying proteins.[18][19][20]
-
Coating: A microplate is coated with a capture antibody specific to the target protein.
-
Blocking: The remaining protein-binding sites on the plate are blocked to prevent non-specific binding.
-
Sample Incubation: The samples (e.g., cell lysates, patient serum) are added to the wells, and the target protein is captured by the antibody.
-
Detection Antibody: A second, detection antibody (also specific to the target protein) is added. This antibody is typically conjugated to an enzyme.
-
Substrate Addition: A substrate for the enzyme is added, which results in a measurable color change. The intensity of the color is proportional to the amount of protein in the sample.
Analysis of Protein Expression: Western Blot
Western blotting is used to detect specific proteins in a sample.[21][22]
-
Sample Preparation: Proteins are extracted from cells or tissues by lysis.
-
Gel Electrophoresis: The protein lysate is separated by size using SDS-polyacrylamide gel electrophoresis (SDS-PAGE).
-
Protein Transfer: The separated proteins are transferred from the gel to a membrane (e.g., PVDF or nitrocellulose).
-
Blocking: The membrane is blocked to prevent non-specific antibody binding.
-
Antibody Incubation: The membrane is incubated with a primary antibody specific to the target protein, followed by a secondary antibody conjugated to an enzyme.
-
Detection: A substrate is added that reacts with the enzyme to produce a chemiluminescent or colorimetric signal, which is then detected.
Enzyme Activity Assay
For therapeutic proteins that are enzymes, their functional activity must be assessed.[23][24][25][26]
-
Assay Setup: The purified enzyme is added to a reaction mixture containing its specific substrate under optimal conditions (e.g., pH, temperature).
-
Reaction Monitoring: The enzymatic reaction is monitored over time by measuring the appearance of a product or the disappearance of the substrate. This can often be done spectrophotometrically.[23]
-
Activity Calculation: The rate of the reaction is used to calculate the enzyme's specific activity.
Visualizing the Experimental Workflow
The following diagram illustrates a typical experimental workflow for comparing the efficacy of an mRNA therapeutic to a protein replacement therapy in vitro.
Caption: Comparative experimental workflow.
Clinical Applications
Both mRNA therapeutics and protein replacement therapies have a broad range of clinical applications, with some overlap and some distinct areas of focus.
mRNA Therapeutics:
-
Vaccines: The most prominent application to date is in vaccines for infectious diseases (e.g., COVID-19).[27]
-
Cancer Immunotherapy: mRNA can be used to encode tumor antigens to stimulate an anti-tumor immune response.
-
Protein Replacement: This is an emerging area for mRNA therapeutics, with clinical trials underway for diseases like cystic fibrosis and various metabolic disorders.[28]
-
Gene Editing: mRNA can be used to deliver the components of gene-editing systems like CRISPR-Cas9.
Protein Replacement Therapy:
-
Enzyme Replacement Therapies (ERTs): A mainstay for lysosomal storage disorders such as Gaucher disease and Fabry disease.
-
Hormone Deficiencies: Used to treat conditions like diabetes (insulin) and growth hormone deficiency.
-
Hematological Disorders: Replacement of clotting factors for hemophilia.
-
Antibody Therapies: Monoclonal antibodies are a major class of protein therapeutics used in oncology and immunology.
Conclusion
mRNA therapeutics and protein replacement therapy are both powerful tools in the fight against a wide range of diseases. Protein replacement therapy is a well-established modality with a proven track record, particularly for extracellular proteins.[1] In contrast, mRNA therapeutics represent a newer, highly versatile platform with the potential for rapid development and the ability to produce intracellular proteins in vivo.[1][5]
The choice between these two approaches will depend on the specific therapeutic context. For acute conditions requiring immediate protein function, traditional protein replacement may be preferred.[5] For chronic diseases, particularly those involving intracellular protein deficiencies, mRNA therapy holds immense promise for providing a longer-lasting and potentially more cost-effective treatment.[5] As mRNA technology continues to mature, particularly in the areas of delivery and stability, its role in protein replacement and other therapeutic areas is set to expand significantly.
References
- 1. Highly sensitive ELISA-based assay for quantifying protein levels in neuronal cultures - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. mRNA in the Context of Protein Replacement Therapy - PMC [pmc.ncbi.nlm.nih.gov]
- 3. americanpharmaceuticalreview.com [americanpharmaceuticalreview.com]
- 4. mRNA lipid nanoparticle formulation, characterization and evaluation - PMC [pmc.ncbi.nlm.nih.gov]
- 5. gencefebio.com [gencefebio.com]
- 6. mRNA therapeutics: New vaccination and beyond - PMC [pmc.ncbi.nlm.nih.gov]
- 7. T7 In Vitro mRNA Synthesis with Separate Capping and PolyA (V1 08.11.25) [protocols.io]
- 8. Purification Workflow For The Production of Highly Pure Recombinant Proteins [drugdiscoveryonline.com]
- 9. biomol.com [biomol.com]
- 10. researchgate.net [researchgate.net]
- 11. In Vitro Synthesis of Modified mRNA for Induction of Protein Expression in Human Cells - PMC [pmc.ncbi.nlm.nih.gov]
- 12. youtube.com [youtube.com]
- 13. cytivalifesciences.com [cytivalifesciences.com]
- 14. In vitro RNA Synthesis - New England Biolabs GmbH [neb-online.de]
- 15. Lipid Nanoparticles - Echelon Biosciences [echelon-inc.com]
- 16. sinobiological.com [sinobiological.com]
- 17. avantorsciences.com [avantorsciences.com]
- 18. ELISA Protocol [protocols.io]
- 19. ELISA Assay Technique | Thermo Fisher Scientific - SG [thermofisher.com]
- 20. Protein assay ELISA [qiagen.com]
- 21. benchchem.com [benchchem.com]
- 22. addgene.org [addgene.org]
- 23. rsc.org [rsc.org]
- 24. Assay Procedure for Protease [sigmaaldrich.com]
- 25. static1.squarespace.com [static1.squarespace.com]
- 26. Complex I Enzyme Activity Assay Kit. Colorimetric. (ab109721) | Abcam [abcam.com]
- 27. researchgate.net [researchgate.net]
- 28. fiercebiotech.com [fiercebiotech.com]
comparing different methods for mRNA purity analysis
For Researchers, Scientists, and Drug Development Professionals
The burgeoning field of mRNA-based therapeutics and vaccines necessitates robust and reliable analytical methods to ensure the purity, integrity, and safety of the final product. The presence of impurities, such as truncated mRNA fragments, double-stranded RNA (dsRNA), or residual components from the manufacturing process, can significantly impact the efficacy and immunogenicity of the therapeutic. This guide provides an objective comparison of common and advanced methods for mRNA purity analysis, supported by experimental data and detailed protocols to aid researchers in selecting the most appropriate techniques for their specific needs.
Key Methods for mRNA Purity and Integrity Assessment
Several analytical techniques are employed to characterize mRNA purity, each with its own set of advantages and limitations. The primary methods discussed in this guide are:
-
Capillary Gel Electrophoresis (CGE)
-
Ion-Pair Reversed-Phase High-Performance Liquid Chromatography (IP-RP-HPLC)
-
Size Exclusion Chromatography (SEC)
-
UV Spectroscopy
-
Next-Generation Sequencing (NGS)
The selection of a suitable method or combination of methods depends on the specific quality attribute being assessed, the desired resolution, and the throughput requirements of the analysis.
Quantitative Comparison of mRNA Analysis Methods
The following table summarizes the key quantitative performance parameters of the different mRNA purity analysis methods.
| Method | Principle | Primary Application | Resolution | Limit of Quantitation (LOQ) | Analysis Time | Throughput |
| Capillary Gel Electrophoresis (CGE) | Size-based separation in a gel matrix under an electric field. | Integrity, purity, and size heterogeneity of mRNA.[1][2][3][4] | High resolution, capable of separating species with small size differences.[1][2][4] | Below 1% for impurities.[5][5] | 40-60 minutes per sample for traditional CGE; <2.5 hours for a 96-well plate with microchip CGE.[6][7] | Low to medium for traditional CGE; High for microchip CGE.[6][7] |
| IP-RP-HPLC | Separation based on hydrophobicity using an ion-pairing agent. | Purity analysis, separation of full-length mRNA from truncated forms and dsRNA.[8][9][10] | High, can resolve mRNA species with and without poly(A) tails and other modifications.[6][11] | LOD: 0.014 g/L; LOQ: 0.043 g/L for dsRNA.[12] | 15-30 minutes per sample.[8][12] | Medium to high. |
| Size Exclusion Chromatography (SEC) | Separation based on molecular size. | Detection of aggregates and high molecular weight impurities.[13] | Lower than CGE and IP-RP-HPLC for resolving species of similar size.[14] | Dependent on the specific impurity and detection method. | ~30 minutes per sample. | Medium. |
| UV Spectroscopy | Measurement of light absorbance at specific wavelengths. | Quantification of mRNA concentration and assessment of general purity (protein and organic solvent contamination).[15] | Not a separation technique; provides bulk purity assessment. | ~4 µg/ml RNA (for A260 of 0.1).[2] | < 5 minutes per sample. | High. |
| Next-Generation Sequencing (NGS) | Massively parallel sequencing of RNA fragments. | Comprehensive sequence verification, identification of variants, and quantification of impurities with sequence differences.[][17] | Single-base resolution. | Dependent on sequencing depth. | Days for library preparation, sequencing, and data analysis. | High (for number of reads), but long overall turnaround time. |
Experimental Protocols
Detailed methodologies for the key experiments are provided below.
Capillary Gel Electrophoresis (CGE)
Objective: To assess the integrity and purity of mRNA by separating full-length transcripts from fragments and impurities based on size.
Methodology:
-
Sample Preparation:
-
Dilute the mRNA sample to a concentration of approximately 25 µg/mL.[5] A minimum of 5 µL of the sample is typically required.[5]
-
To denature the mRNA and eliminate secondary structures, mix the sample with a high concentration of formamide (B127407) (>80% v/v) and heat at 70°C for 10 minutes, followed by cooling on ice for at least 5 minutes.[7] The addition of 4 M urea (B33335) before heating can also improve peak shape.[18]
-
-
Instrumentation and Setup:
-
Electrophoresis:
-
Data Analysis:
-
Detect the migrating RNA species as they pass the detector. The signal is recorded as an electropherogram.
-
Determine the size of the mRNA and its fragments by comparing their migration times to an RNA reference ladder of known sizes.[1][5]
-
Quantify the purity by calculating the percentage of the area of the main peak (full-length mRNA) relative to the total area of all peaks.
-
Ion-Pair Reversed-Phase High-Performance Liquid Chromatography (IP-RP-HPLC)
Objective: To determine the purity of mRNA by separating the full-length product from impurities such as truncated transcripts and dsRNA.
Methodology:
-
Sample Preparation:
-
Dilute the mRNA sample in an appropriate buffer.
-
-
Instrumentation and Setup:
-
Use an HPLC system with a UV detector set at 260 nm.
-
Equilibrate a reversed-phase column (e.g., C18) with the initial mobile phase conditions.
-
-
Chromatography:
-
Mobile Phase: Use a gradient of an aqueous buffer (Mobile Phase A) and an organic solvent (Mobile Phase B), both containing an ion-pairing agent like triethylammonium (B8662869) acetate (B1210297) (TEAA). A typical gradient could be from 35% to 55% Mobile Phase B over 15 minutes.[8]
-
Temperature: Perform the separation at an elevated temperature (e.g., 75°C) to denature the mRNA.[19]
-
Injection and Elution: Inject the sample onto the column. The ion-pairing agent interacts with the negatively charged phosphate (B84403) backbone of the mRNA, and the separation occurs based on the hydrophobicity of the different mRNA species.
-
-
Data Analysis:
-
Monitor the elution profile at 260 nm.
-
Identify the main peak corresponding to the full-length mRNA. Impurities like shorter fragments typically elute earlier, while some dsRNA forms may elute later.
-
Calculate the purity based on the relative peak areas.
-
Size Exclusion Chromatography (SEC)
Objective: To detect and quantify high molecular weight impurities such as mRNA aggregates.
Methodology:
-
Sample Preparation:
-
Prepare the mRNA sample in a mobile phase-compatible buffer.
-
-
Instrumentation and Setup:
-
Use an HPLC or UHPLC system with a UV detector (260 nm).
-
Equilibrate a size exclusion column with the appropriate pore size for the expected mRNA size range.
-
-
Chromatography:
-
Mobile Phase: Use an isocratic mobile phase, typically a buffered saline solution.
-
Injection and Elution: Inject the sample onto the column. Molecules are separated based on their size in solution. Larger molecules (aggregates) will elute first, as they are excluded from the pores of the stationary phase, while smaller molecules will have a longer retention time.
-
-
Data Analysis:
-
Analyze the resulting chromatogram to identify peaks corresponding to aggregates, the monomeric mRNA, and any smaller fragments.
-
Quantify the percentage of aggregates by comparing the peak area of the aggregate peak to the total peak area.
-
UV Spectroscopy
Objective: To determine the concentration of mRNA and to assess its purity with respect to protein and organic contaminants.
Methodology:
-
Sample Preparation:
-
Dilute the mRNA sample in a suitable buffer (e.g., TE buffer).
-
-
Measurement:
-
Use a UV-Vis spectrophotometer to measure the absorbance of the diluted sample at 260 nm, 280 nm, and 230 nm.
-
-
Data Analysis:
-
Concentration: Calculate the mRNA concentration using the Beer-Lambert law, where an absorbance of 1.0 at 260 nm (A260) is equivalent to approximately 40 µg/mL of single-stranded RNA.[2]
-
Purity Ratios:
-
A260/A280 Ratio: Assess protein contamination. A ratio of ~2.0 is generally considered pure for RNA.[15] A lower ratio indicates the presence of protein.
-
A260/A230 Ratio: Assess contamination by organic compounds (e.g., phenol, guanidine). A pure RNA sample should have an A260/A230 ratio of 2.0-2.2.[20]
-
-
Next-Generation Sequencing (NGS)
Objective: To obtain a comprehensive sequence analysis of the mRNA sample to verify the sequence and identify and quantify any sequence variants or impurities.
Methodology:
-
Library Preparation:
-
RNA QC: Assess the quality of the input RNA using methods like UV spectroscopy and capillary electrophoresis to ensure it meets the requirements for library preparation.[17][20][21]
-
mRNA Fragmentation: Fragment the mRNA to a suitable size for sequencing.
-
cDNA Synthesis: Convert the fragmented mRNA into complementary DNA (cDNA).
-
Adapter Ligation: Ligate sequencing adapters to the ends of the cDNA fragments.
-
Library Amplification: Amplify the library using PCR to generate enough material for sequencing.[21]
-
-
Sequencing:
-
Sequence the prepared library on an NGS platform.
-
-
Data Analysis:
-
Read Alignment: Align the sequencing reads to the expected reference sequence of the mRNA.
-
Variant Calling: Identify any single nucleotide variants (SNVs), insertions, or deletions.
-
Impurity Identification: Identify and quantify reads that do not align to the target sequence, which may represent impurities.
-
Visualization of Experimental Workflows
The following diagrams illustrate the workflows for the key mRNA purity analysis methods.
References
- 1. researchgate.net [researchgate.net]
- 2. Quantitating RNA | Thermo Fisher Scientific - SG [thermofisher.com]
- 3. waters.com [waters.com]
- 4. Determining RNA Integrity And Purity By Capillary Gel Electrophoresis [bioprocessonline.com]
- 5. sigmaaldrich.com [sigmaaldrich.com]
- 6. pubs.acs.org [pubs.acs.org]
- 7. Development of a microchip capillary electrophoresis method for determination of the purity and integrity of mRNA in lipid nanoparticle vaccines - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Characterisation and analysis of mRNA critical quality attributes using liquid chromatography based methods - PMC [pmc.ncbi.nlm.nih.gov]
- 9. researchgate.net [researchgate.net]
- 10. researchgate.net [researchgate.net]
- 11. Comprehensive Impurity Profiling of mRNA: Evaluating Current Technologies and Advanced Analytical Techniques - PMC [pmc.ncbi.nlm.nih.gov]
- 12. A (RP)UHPLC/UV analytical method to quantify dsRNA during the mRNA vaccine manufacturing process - Analytical Methods (RSC Publishing) DOI:10.1039/D4AY00560K [pubs.rsc.org]
- 13. lifesciences.danaher.com [lifesciences.danaher.com]
- 14. nacalai.com [nacalai.com]
- 15. rna-seqblog.com [rna-seqblog.com]
- 17. NGS Workflow Steps | Illumina sequencing workflow [illumina.com]
- 18. diva-portal.org [diva-portal.org]
- 19. RNA analysis by ion-pair reversed-phase high performance liquid chromatography - PMC [pmc.ncbi.nlm.nih.gov]
- 20. Evaluating Quality of Input RNA For NGS Library Preparation - [nordicbiosite.com]
- 21. Quality Control in NGS Library Preparation Workflow - CD Genomics [cd-genomics.com]
A Comparative Guide to mRNA Delivery Systems: Efficacy, Protocols, and Data
The rapid development and success of mRNA-based vaccines have spotlighted the critical role of delivery systems in therapeutic efficacy. The inherent instability of mRNA and its difficulty in crossing cell membranes necessitate sophisticated carrier systems to protect the nucleic acid cargo and ensure its delivery to the cytoplasm for protein translation.[1][2] This guide provides an objective comparison of the leading mRNA delivery technologies—Lipid Nanoparticles (LNPs), Polymer-Based Carriers, and Viral-Like Particles (VLPs)—supported by experimental data and detailed protocols for researchers, scientists, and drug development professionals.
Lipid Nanoparticles (LNPs): The Clinical Vanguard
LNPs are the most clinically advanced mRNA delivery platform, famously utilized in the FDA-approved COVID-19 vaccines by Moderna and Pfizer-BioNTech.[3][4] These particles are typically composed of four main components: an ionizable lipid to encapsulate the negatively charged mRNA and facilitate endosomal escape, a phospholipid for structural integrity, cholesterol to enhance stability, and a PEGylated lipid to increase circulation time.[2][5][6]
Performance & Efficacy: LNPs demonstrate high encapsulation efficiency and potent in vivo transfection, particularly in the liver, which is a major target for many gene therapies but a limitation for other applications.[3][7][8] Recent advancements have focused on developing novel ionizable lipids (e.g., SM-102, ALC-0315, C12-200) and optimizing their chemical structures, such as stereochemistry, to boost delivery efficiency and enable targeting of extrahepatic tissues like the spleen and immune cells.[2][4][9] For instance, one study reported that LNPs formulated with the C12-200 ionizable lipid achieved an average hydrodynamic diameter of 76.16 nm and an encapsulation efficiency of 92.3%.[5] Another study highlighted newly developed DMKD-PS LNPs that showed remarkable stability and superior protein expression in immune cells compared to other commercial nanoparticles.[10]
Challenges: Despite their success, challenges remain, including the tendency for liver accumulation, the need for cold-chain storage to maintain stability, and the potential for inflammatory responses.[2][3][10]
Quantitative Data: LNP Formulations
| Formulation | Key Lipid Component | Size (nm) | Polydispersity Index (PDI) | Encapsulation Efficiency (%) | Primary Target Organ (In Vivo) | Reference |
| C12-200 LNP | C12-200 | 76.16 | 0.098 | 92.3 | Liver, Spleen | [5] |
| SM-102 LNP | SM-102 | ~200 | >0.2 (without mRNA) | High | Liver | [10] |
| ALC-0315 LNP | ALC-0315 | ~200 | >0.2 (without mRNA) | High | Liver | [10] |
| DMKD-PS LNP | DMKD-PS | <150 | <0.2 | High | Immune Cells | [10] |
| Hybrid F-L319/L319 LNP | Fluorinated L319 | Not Specified | Not Specified | Enhanced | Spleen | [11] |
Polymer-Based Carriers: The Versatile Platform
Polymer-based nanoparticles, or polyplexes, are formed through the electrostatic interaction between cationic polymers and mRNA.[12] This class of carriers is highly versatile due to the vast chemical space of polymers, allowing for fine-tuning of properties like biodegradability, charge, and the addition of targeting ligands.[6][13]
Performance & Efficacy: Commonly used polymers include Poly(β-amino esters) (PBAEs), Polyethyleneimine (PEI), and poly(amine-co-ester) (PACE).[6][14] While historically showing lower transfection efficiency than LNPs, recent developments have produced highly effective formulations. For example, researchers at Yale developed biodegradable PACE polymer nanoparticles that achieved high transfection rates in lung epithelial and antigen-presenting cells, proving effective as a mucosal vaccine against SARS-CoV-2 in mice.[14] The key advantage of polymers is their potential for targeted delivery to tissues beyond the liver, addressing a major limitation of traditional LNPs.[13]
Challenges: Potential cytotoxicity and lower transfection efficiency compared to the best LNP formulations have been historical hurdles for polymer-based systems.[12] However, the development of biodegradable polymers with complex architectures is helping to overcome these issues.[6]
Quantitative Data: Polymer-Based Formulations
| Polymer Type | Architecture | Application | Key Finding | Reference |
| Poly(amine-co-ester) (PACE) | Blended (E14 + PACE-PEG) | Mucosal Lung Vaccine | Induced robust immune response and protected mice from lethal viral challenge. | [14] |
| Poly(β-amino esters) (PBAE) | Hyperbranched | Lung Cell Delivery | Effective for delivering luciferase mRNA via inhalation. | [6] |
| Polyethyleneimine (PEI) | Linear and Branched | General mRNA Vector | One of the earliest polymers used, forms stable complexes with mRNA. | [6][12] |
Viral-Like Particles (VLPs): The Bio-Inspired Carrier
VLPs are multi-protein structures that mimic the conformation of native viruses but lack viral genetic material, making them non-infectious.[15][16] They can be engineered to package and deliver mRNA, leveraging the natural efficiency of viral entry into cells while avoiding the risks associated with viral vectors.
Performance & Efficacy: VLPs offer the potential for highly specific cell targeting by modifying their surface proteins.[16] They have shown promise in vaccination strategies, including heterologous prime-boost regimens where an mRNA vaccine is followed by a VLP boost, which can enhance antibody responses.[15] Studies have demonstrated that VLPs can effectively protect mRNA from degradation by ribonucleases and show negligible toxicity.[17]
Challenges: The primary challenges for VLPs are the complexity of manufacturing and purification compared to synthetic systems like LNPs and polymers. Their cargo capacity may also be more limited. While effective at packaging mRNA, their transfection efficiency can be lower than that of optimized LNP systems.[17]
Quantitative Data: VLP Formulations
| VLP Base | Cargo | Key Finding | Advantage | Reference |
| Artificial Coat Proteins | EGFP & Luciferase mRNA | Protected mRNA from RNases and serum; low transfection efficiency compared to lipoplexes. | Negligible toxicity, minimal hemolytic activity. | [17] |
| SARS-CoV-2 VLPs | Not specified (used as vaccine) | Efficiently boosts antibodies primed with an mRNA vaccine. | Can improve efficacy and economics of vaccine protocols. | [15] |
| Engineered VLPs | Up to 4 genes (mRNA) | Can be aerosolized for pulmonary delivery and surface-modified for targeting. | Tunable payload and targeting capabilities. | [16] |
Mandatory Visualizations
Experimental Workflow for mRNA Delivery System Evaluation
References
- 1. researchgate.net [researchgate.net]
- 2. mdpi.com [mdpi.com]
- 3. Biodegradable Polymer-Lipid Nanoparticles for Effective In Vivo mRNA Delivery for MRS Spring Meeting 2024 - IBM Research [research.ibm.com]
- 4. pnas.org [pnas.org]
- 5. mitchell-lab.seas.upenn.edu [mitchell-lab.seas.upenn.edu]
- 6. mRNA Delivery: Challenges and Advances through Polymeric Soft Nanoparticles - PMC [pmc.ncbi.nlm.nih.gov]
- 7. researchgate.net [researchgate.net]
- 8. RNA Therapeutics: Smarter Design, Safer Delivery | Technology Networks [technologynetworks.com]
- 9. Advancements in Lipid Nanoparticle Engineering for Targeted mRNA Delivery and Enhanced Immunogenicity (2020-2024) [insights.pluto.im]
- 10. mdpi.com [mdpi.com]
- 11. scispace.com [scispace.com]
- 12. mdpi.com [mdpi.com]
- 13. Polymer-Based mRNA Delivery Strategies for Advanced Therapies - PubMed [pubmed.ncbi.nlm.nih.gov]
- 14. trial.medpath.com [trial.medpath.com]
- 15. Frontiers | Virus-Like Particles Are Efficient Tools for Boosting mRNA-Induced Antibodies [frontiersin.org]
- 16. Technology - Virus-Like Particles for mRNA Delivery [suny.technologypublisher.com]
- 17. research.wur.nl [research.wur.nl]
A Researcher's Guide to Validating Protein Expression Following mRNA Transfection
For researchers and drug development professionals, the successful transfection of messenger RNA (mRNA) is just the first step. The ultimate goal is the expression of the target protein. Validating and quantifying this protein expression is a critical checkpoint in any experimental workflow. This guide provides a comprehensive comparison of four widely used techniques for this purpose: Western blotting, Enzyme-Linked Immunosorbent Assay (ELISA), Flow Cytometry, and Immunofluorescence Microscopy.
This guide will delve into the principles of each method, present a quantitative comparison of their performance, and provide detailed experimental protocols. Additionally, it includes visualizations of the underlying biological and experimental processes to aid in understanding and implementation.
Method Comparison: A Quantitative Overview
Choosing the right validation method depends on various factors, including the specific experimental question, the required sensitivity, the desired throughput, and budget constraints. The following table summarizes the key performance characteristics of each technique.
| Feature | Western Blot | ELISA | Flow Cytometry | Immunofluorescence Microscopy |
| Principle | Size-based protein separation followed by antibody detection. | Capture and detection of a protein in a plate-based assay using antibodies. | Single-cell analysis of protein expression using fluorescently labeled antibodies. | Visualization of protein localization within a cell using fluorescently labeled antibodies. |
| Primary Output | Protein size and relative quantity. | Absolute or relative protein quantity. | Percentage of positive cells and protein expression level per cell. | Protein localization and relative expression level. |
| Sensitivity | Nanogram (ng/mL) range.[1] | Picogram (pg/mL) to nanogram (ng/mL) range.[1] | High, at the single-cell level.[2] | High, for visualizing low abundance proteins. |
| Dynamic Range | Narrow (typically 1-2 orders of magnitude).[3] | Wide (typically 3-4 orders of magnitude).[4] | Wide (can span several decades of fluorescence intensity).[5] | Can be quantitative with proper controls and analysis, with a good linear range.[6] |
| Throughput | Low to moderate.[7] | High (96- or 384-well plates).[8] | High (thousands of cells per second).[9] | Low to moderate. |
| Cost per Sample | Moderate. Reagent costs can vary. | Low to moderate, especially for large numbers of samples.[10] | High initial instrument cost, moderate per-sample reagent cost.[11] | Moderate to high, depending on antibodies and imaging equipment. |
| Quantitative | Semi-quantitative.[1] | Highly quantitative.[1] | Highly quantitative at the single-cell level.[12] | Semi-quantitative to quantitative with advanced analysis.[6] |
| Multiplexing | Possible with different fluorescent antibodies. | Limited, though some multiplex ELISA formats exist. | High, allows for the analysis of multiple proteins simultaneously.[10] | High, allows for co-localization studies of multiple proteins. |
Signaling Pathways and Experimental Workflows
To understand the context of these validation methods, it's essential to visualize the biological process of mRNA translation and the experimental steps involved in each technique.
The Journey from mRNA to Protein: Eukaryotic Translation Initiation
The process of converting the genetic information encoded in mRNA into a protein is known as translation. The initiation phase is a critical regulatory step. The following diagram illustrates the key events in eukaryotic translation initiation.
Caption: Eukaryotic translation initiation pathway.
Experimental Workflow Diagrams
The following diagrams outline the key steps for each of the four protein validation techniques.
Western Blot Workflow
Caption: Western Blot experimental workflow.
ELISA Workflow (Sandwich)
Caption: Sandwich ELISA experimental workflow.
Flow Cytometry Workflow (Intracellular Staining)
References
- 1. researchgate.net [researchgate.net]
- 2. enovatia.com [enovatia.com]
- 3. What Is Dynamic Range - ExpertCytometry [expertcytometry.com]
- 4. Proof of the Quantitative Potential of Immunofluorescence by Mass Spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 5. biocompare.com [biocompare.com]
- 6. Shedding Light on Intracellular Proteins using Flow Cytometry - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. ELISA vs. Flow Cytometry: Which is Right for Your Immunology Study? - XL BIOTEC [xlbiotec.com]
- 8. akadeum.com [akadeum.com]
- 9. Quantification of intracellular proteins and monitoring therapy using flow cytometry - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. Quantitative single-cell analysis of immunofluorescence protein multiplex images illustrates biomarker spatial heterogeneity within breast cancer subtypes - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Rates | Proteomics Platform [proteomics.bsd.uchicago.edu]
- 12. Detecting intracellular translocation of native proteins quantitatively at the single cell level - Chemical Science (RSC Publishing) DOI:10.1039/C4SC00578C [pubs.rsc.org]
A Comparative Guide to mRNA Capping Technologies for Researchers and Drug Development Professionals
The 5' cap is a critical modification for the stability, translation efficiency, and in vivo performance of messenger RNA (mRNA). For researchers and developers in the burgeoning field of mRNA therapeutics and vaccines, selecting the optimal capping strategy is a crucial step in ensuring the efficacy and safety of their products. This guide provides a comparative analysis of the most prevalent mRNA capping technologies, supported by experimental data and detailed protocols to inform your selection process.
Introduction to mRNA Capping
In eukaryotic cells, the 5' end of an mRNA molecule is modified with a 7-methylguanosine (B147621) (m7G) cap. This cap structure is essential for protecting the mRNA from degradation by exonucleases, facilitating its transport from the nucleus to the cytoplasm, and promoting its efficient translation into protein. For in vitro transcribed (IVT) mRNA used in research and therapeutic applications, this capping step must be performed synthetically. The two primary methods for in vitro mRNA capping are post-transcriptional enzymatic capping and co-transcriptional capping using cap analogs.
Comparative Analysis of mRNA Capping Technologies
The choice of capping technology significantly impacts key attributes of the final mRNA product, including capping efficiency, mRNA yield, protein expression levels, and immunogenicity. The following sections provide a detailed comparison of the leading methods.
Data Presentation: Performance Metrics of Capping Technologies
The table below summarizes the key performance indicators for the most common mRNA capping technologies: enzymatic capping, Anti-Reverse Cap Analog (ARCA), and CleanCap®.
| Feature | Enzymatic Capping | Co-transcriptional (ARCA) | Co-transcriptional (CleanCap®) |
| Capping Efficiency | >95%[1][2] | 50-80%[3] | >95%[3][4] |
| Cap Structure | Cap-0 or Cap-1 (with additional enzyme)[5] | Primarily Cap-0[3][5] | Cap-1[4] |
| mRNA Yield | High (separate from IVT) | Lower (due to GTP competition)[6] | High (no GTP reduction needed)[6] |
| Process Complexity | Multi-step, requires purification[5] | Single-step "one-pot" reaction | Single-step "one-pot" reaction[5] |
| Protein Expression | High | Moderate | High to Very High[7][8] |
| Immunogenicity | Lower (with Cap-1)[5] | Potentially higher (Cap-0)[5] | Lower (natural Cap-1 structure)[5] |
| Cost-Effectiveness | Higher cost at scale[9] | More cost-effective for smaller scale | Most cost-effective at scale[9] |
In-depth Look at Capping Technologies
Enzymatic Capping
This traditional method involves a two-step process. First, uncapped mRNA is synthesized through in vitro transcription. Subsequently, the purified mRNA is treated with capping enzymes, typically from the Vaccinia virus, to add the 5' cap structure.[5]
-
Advantages: High capping efficiency, approaching 100%, and the ability to generate a natural Cap-1 structure with the addition of a 2'-O-methyltransferase.[1][2] This method offers precise control over the capping reaction.
-
Disadvantages: The multi-step process is more time-consuming and complex, involving additional purification steps that can lead to a loss of mRNA yield.[5] The cost of enzymes can also be a significant factor, especially at a large scale.[9]
Co-transcriptional Capping with ARCA
Co-transcriptional capping simplifies the workflow by incorporating a cap analog directly into the in vitro transcription reaction. The Anti-Reverse Cap Analog (ARCA) was a significant advancement as it is designed to be incorporated only in the correct orientation, leading to a higher percentage of translatable mRNA compared to first-generation cap analogs.[6]
-
Advantages: A streamlined "one-pot" reaction that is less labor-intensive than enzymatic capping.
-
Disadvantages: Capping efficiency is typically lower, ranging from 50-80%, due to the competition between the cap analog and GTP for incorporation by the RNA polymerase.[3] This competition also necessitates a lower GTP concentration, which can reduce the overall mRNA yield.[6] Furthermore, ARCA primarily generates a Cap-0 structure, which can be more immunogenic in vivo than the Cap-1 structure found in higher eukaryotes.[3][5]
Co-transcriptional Capping with CleanCap®
CleanCap® technology represents a newer generation of co-transcriptional capping that utilizes a trinucleotide cap analog. This approach is designed to overcome the limitations of both enzymatic capping and ARCA.
-
Advantages: CleanCap® boasts a high capping efficiency of over 95% and generates a natural Cap-1 structure in a single "one-pot" reaction.[3][4] It does not require a reduction in GTP concentration, leading to higher mRNA yields compared to ARCA.[6] The streamlined process and high efficiency make it a cost-effective solution for large-scale mRNA production.[9]
-
Disadvantages: The technology may have intellectual property constraints and associated licensing costs.[3]
Experimental Workflows and Signaling Pathways
To provide a clearer understanding of the processes involved, the following diagrams illustrate the workflows for the different capping technologies and a generalized signaling pathway for mRNA translation.
Caption: Comparative workflows for enzymatic and co-transcriptional mRNA capping.
Caption: Simplified signaling pathway of eukaryotic mRNA translation initiation.
Detailed Experimental Protocols
For researchers looking to implement or evaluate these capping technologies, the following are detailed protocols for key experiments.
Protocol 1: Enzymatic mRNA Capping using Vaccinia Capping Enzyme
This protocol is adapted for capping up to 10 µg of RNA in a 20 µl reaction.
Materials:
-
Purified uncapped RNA (up to 10 µg)
-
Nuclease-free water
-
10X Capping Buffer (e.g., NEB #M2080S)
-
10 mM GTP
-
32 mM S-adenosylmethionine (SAM)
-
Vaccinia Capping Enzyme (e.g., NEB #M2080S)
-
RNase Inhibitor (optional)
Procedure:
-
In a nuclease-free microfuge tube, combine the purified RNA and nuclease-free water to a final volume of 15.0 µl.
-
To denature secondary structures, heat the RNA solution at 65°C for 5 minutes, then immediately place it on ice for 5 minutes.
-
Prepare the capping reaction mixture at room temperature by adding the following components in the specified order:
-
Denatured RNA (from step 2): 15.0 µl
-
10X Capping Buffer: 2.0 µl
-
10 mM GTP: 1.0 µl
-
SAM (dilute 32 mM stock to 2 mM just before use): 1.0 µl
-
Vaccinia Capping Enzyme: 1.0 µl
-
Total Volume: 20 µl
-
-
(Optional) Add 0.5 µl of RNase Inhibitor to the reaction.
-
Mix gently by pipetting and spin down briefly.
-
Incubate the reaction at 37°C for 30-60 minutes.
-
Proceed with purification of the capped RNA using an appropriate RNA cleanup kit.
Protocol 2: Co-transcriptional mRNA Capping with CleanCap® Reagent AG
This protocol is for a 40 µl in vitro transcription reaction.
Materials:
-
Linearized DNA template with a T7 promoter followed by an AG initiation sequence (1 µg)
-
Nuclease-free water
-
10X Reaction Buffer (e.g., from HiScribe™ T7 High Yield RNA Synthesis Kit)
-
ATP, CTP, UTP (100 mM each)
-
GTP (100 mM)
-
CleanCap® Reagent AG
-
T7 RNA Polymerase Mix
-
DNase I (RNase-free)
Procedure:
-
Thaw all components at room temperature, keeping the T7 RNA Polymerase Mix on ice.
-
Assemble the reaction at room temperature in the following order:
-
Nuclease-free Water: to a final volume of 40 µl
-
10X Reaction Buffer: 4.0 µl
-
100 mM ATP: 2.0 µl
-
100 mM CTP: 2.0 µl
-
100 mM UTP: 2.0 µl
-
100 mM GTP: 2.0 µl
-
CleanCap® Reagent AG: 8.0 µl
-
Linearized DNA Template (1 µg): X µl
-
T7 RNA Polymerase Mix: 4.0 µl
-
-
Mix thoroughly by pipetting and spin down briefly.
-
Incubate at 37°C for 2 hours.
-
To remove the DNA template, add 2 µl of DNase I and incubate at 37°C for 15 minutes.
-
Purify the capped mRNA using an RNA cleanup kit.
Protocol 3: Co-transcriptional mRNA Capping with ARCA
This protocol is for a standard 20 µl in vitro transcription reaction.
Materials:
-
Linearized DNA template with a T7 promoter followed by a G (1 µg)
-
Nuclease-free water
-
10X Reaction Buffer
-
ATP, CTP, UTP (100 mM each)
-
GTP (100 mM)
-
ARCA (e.g., NEB #S1411)
-
T7 RNA Polymerase Mix
-
DNase I (RNase-free)
Procedure:
-
Thaw all components at room temperature, keeping the T7 RNA Polymerase Mix on ice.
-
Prepare a 4:1 ratio of ARCA to GTP. For a standard reaction, this might be 4 mM ARCA and 1 mM GTP.
-
Assemble the reaction at room temperature:
-
Nuclease-free Water: to a final volume of 20 µl
-
10X Reaction Buffer: 2.0 µl
-
100 mM ATP: 2.0 µl
-
100 mM CTP: 2.0 µl
-
100 mM UTP: 2.0 µl
-
ARCA/GTP mix: X µl
-
Linearized DNA Template (1 µg): X µl
-
T7 RNA Polymerase Mix: 2.0 µl
-
-
Mix thoroughly and spin down.
-
Incubate at 37°C for 2 hours.
-
Perform DNase I treatment as described in Protocol 2.
-
Purify the capped mRNA.
Protocol 4: Determination of Capping Efficiency by LC-MS
This is a generalized workflow for assessing capping efficiency.
Materials:
-
Purified capped mRNA
-
Biotinylated DNA probe complementary to the 5' end of the mRNA
-
RNase H
-
Streptavidin-coated magnetic beads
-
Buffers for hybridization, washing, and elution
-
LC-MS system
Procedure:
-
Hybridize the biotinylated DNA probe to the 5' end of the mRNA sample.
-
Incubate the mRNA:DNA hybrid with RNase H to cleave the 5' end of the mRNA.
-
Capture the biotinylated probe and the attached 5' mRNA fragment using streptavidin-coated magnetic beads.
-
Wash the beads to remove uncapped mRNA and other reaction components.
-
Elute the 5' capped fragment from the beads.
-
Analyze the eluted fragment by LC-MS to identify and quantify the capped and uncapped species based on their unique mass-to-charge ratios.
-
Calculate capping efficiency as the ratio of the signal from the capped species to the total signal from all 5' end species.
Protocol 5: In Vitro Protein Expression Assay
This protocol uses a commercially available human in vitro translation kit.
Materials:
-
Capped mRNA encoding a reporter protein (e.g., Luciferase or GFP)
-
In vitro translation kit (e.g., Thermo Scientific 1-Step Human Coupled IVT Kit)
-
Nuclease-free water
Procedure:
-
Thaw the components of the in vitro translation kit on ice.
-
In a nuclease-free tube, assemble the reaction according to the manufacturer's instructions, typically including the cell lysate, reaction mix, and accessory proteins.
-
Add a standardized amount of capped mRNA to the reaction mixture.
-
Incubate the reaction at 30°C for up to 5 hours.
-
Quantify the expressed protein using an appropriate method (e.g., luciferase assay for Luciferase, fluorescence measurement for GFP).
-
Compare the protein expression levels from mRNAs produced with different capping technologies.
Protocol 6: In Vivo Luciferase Expression Assay in Mice
This is a general protocol for assessing in vivo protein expression.
Materials:
-
Capped mRNA encoding Firefly Luciferase, formulated in lipid nanoparticles (LNPs)
-
Mice (e.g., C57BL/6)
-
D-Luciferin substrate
-
In vivo imaging system (IVIS)
Procedure:
-
Administer the LNP-formulated mRNA to mice via intravenous or intramuscular injection at a specified dose.
-
At various time points post-injection (e.g., 6, 24, 48 hours), inject the mice intraperitoneally with D-Luciferin substrate.
-
Anesthetize the mice and place them in an in vivo imaging system.
-
Acquire bioluminescence images to detect the light emitted from the luciferase activity.
-
Quantify the bioluminescence signal (e.g., in photons/second) in the region of interest (e.g., liver for systemic delivery) to determine the level and duration of protein expression.
-
Compare the expression profiles of mRNAs with different cap structures.[7]
Conclusion
The selection of an appropriate mRNA capping technology is a critical decision in the development of mRNA-based therapeutics and vaccines. Enzymatic capping provides high efficiency and control but with increased complexity and cost. Co-transcriptional capping with ARCA offers a simplified workflow but with compromises in efficiency and the type of cap structure. The newer CleanCap® technology combines the benefits of high efficiency, a natural Cap-1 structure, and a streamlined "one-pot" reaction, making it a compelling choice for many applications, particularly at a larger scale. Researchers and drug developers should carefully consider the trade-offs between these methods in the context of their specific needs for yield, purity, biological activity, and manufacturing scalability. The experimental protocols provided in this guide offer a starting point for the evaluation and implementation of these powerful technologies.
References
- 1. neb-online.de [neb-online.de]
- 2. youtube.com [youtube.com]
- 3. Co-transcriptional capping [takarabio.com]
- 4. neb.com [neb.com]
- 5. 5 Things to Know About mRNA Capping for Next-Generation Vaccines and Therapies | Scientist.com [app.scientist.com]
- 6. neb-online.de [neb-online.de]
- 7. trilinkbiotech.com [trilinkbiotech.com]
- 8. glenresearch.com [glenresearch.com]
- 9. maravai.com [maravai.com]
A Researcher's Guide to Benchmarking Codon Optimization Algorithms for Enhanced mRNA Expression
For researchers, scientists, and drug development professionals at the forefront of mRNA technology, selecting the optimal codon optimization algorithm is a critical step in maximizing protein expression and therapeutic efficacy. This guide provides an objective comparison of available algorithms, supported by experimental data, to facilitate informed decision-making in your research and development workflows.
The landscape of mRNA therapeutics is rapidly evolving, with codon optimization emerging as a cornerstone for enhancing the stability and translational efficiency of mRNA molecules.[1][2][3] Codon optimization involves the strategic selection of synonymous codons—different codons that encode the same amino acid—to improve protein production.[1][3][4] This process can significantly impact mRNA stability, translation rates, and ultimately, the yield of the desired protein.[1][5][6]
This guide delves into the key performance metrics for evaluating codon optimization algorithms and presents a comparative analysis based on published experimental data. We also provide detailed experimental protocols to aid in the replication and validation of these findings.
Key Performance Metrics for Codon Optimization
A multi-faceted approach is essential for a comprehensive evaluation of codon optimization algorithms.[7][8][9] Beyond simply maximizing the Codon Adaptation Index (CAI), which measures the preference for codons that are frequently used in highly expressed genes, a robust algorithm should also consider:
-
GC Content: The percentage of guanine (B1146940) and cytosine bases in a sequence influences mRNA stability and translational efficiency.[7][8][9][10]
-
mRNA Secondary Structure: The folding of the mRNA molecule, predicted by the minimum free energy (MFE or ΔG), plays a crucial role in its stability and accessibility to the translational machinery.[7][8][9][10][11]
-
Codon-Pair Bias (CPB): The frequency of adjacent codon pairs can also influence translation efficiency.[7][8][9]
-
mRNA Stability and Half-Life: A key determinant of the overall protein expression level is the longevity of the mRNA molecule within the cell.[12]
-
Protein Expression Levels: The ultimate measure of an algorithm's success is the quantifiable increase in the target protein.
-
Immunogenicity: For therapeutic applications, particularly vaccines, the ability of the optimized mRNA to elicit a robust immune response is paramount.[1][12][13]
Comparative Analysis of Codon Optimization Algorithms
Numerous codon optimization tools are available, ranging from free online software to sophisticated commercial packages. These tools often employ different underlying algorithms and optimization parameters.[7][8][9] A comparative analysis of widely used tools such as JCat, OPTIMIZER, ATGme, and GeneOptimizer has revealed significant variability in the resulting sequences and their performance.[7][8][9][10]
More recent advancements have led to the development of algorithms that co-optimize for multiple parameters, such as mRNA stability and codon usage.[2][11][12][13][14] One such algorithm, LinearDesign , has demonstrated significant improvements in mRNA half-life, protein expression, and in vivo immunogenicity compared to traditional codon optimization benchmarks.[12][13]
The following tables summarize key experimental findings from studies benchmarking various codon optimization strategies.
Table 1: Impact of Codon Optimization on mRNA Stability
| Optimization Strategy | Reporter Gene | Change in mRNA Half-life | Reference |
| Optimal to Non-optimal Codons | RPS20 | 10-fold reduction | [5] |
| Non-optimal to Optimal Codons | LSM8 | >7-fold increase | [5] |
| LinearDesign Optimization | SARS-CoV-2 Spike & VZV gE | Substantially improved | [12] |
Table 2: Effect of Codon Optimization on Protein Expression
| Optimization Algorithm/Strategy | Reporter Gene/Protein | Fold Increase in Protein Expression | Host System | Reference |
| Codon Optimization | Bacterial Luciferase (luxA/luxB) | Significantly increased | Mammalian (HEK293) | [4] |
| Codon Optimization | Human 37-kDa iLRP | Up to 300 mg/L yield | E. coli | [15] |
| RiboCode (Deep Learning Model) | Gaussia Luciferase (Gluc) | Up to 72-fold | In vitro | [16][17] |
| LinearDesign | SARS-CoV-2 Spike & VZV gE | Substantially improved | In vitro & In vivo | [12][13] |
Table 3: Enhancement of Immunogenicity through Codon Optimization
| Optimization Algorithm | Vaccine Target | Fold Increase in Antibody Titer (in vivo) | Reference |
| LinearDesign | COVID-19 mRNA Vaccine | Up to 128-fold | [12][13] |
| RiboCode | Influenza Hemagglutinin mRNA | ~10-fold (neutralizing antibodies) | [6][16][17] |
Experimental Protocols
To ensure the reproducibility and validation of codon optimization strategies, detailed experimental protocols are essential. Below are generalized methodologies for key experiments cited in this guide.
In Vitro Transcription of mRNA
-
Plasmid Linearization: The DNA plasmid containing the gene of interest downstream of a T7 promoter is linearized using a restriction enzyme that cuts downstream of the 3' untranslated region (UTR).
-
In Vitro Transcription Reaction: The linearized plasmid is used as a template for in vitro transcription using T7 RNA polymerase. The reaction mixture typically includes the DNA template, T7 RNA polymerase, RNase inhibitor, and a mixture of the four nucleotide triphosphates (ATP, GTP, CTP, and UTP). For modified mRNA, modified nucleotides like m1Ψ-5'-triphosphate can be substituted for UTP.
-
DNase Treatment: Following transcription, the DNA template is removed by treatment with DNase I.
-
mRNA Purification: The synthesized mRNA is purified using a method such as lithium chloride precipitation or silica-based spin columns.
-
Quality Control: The integrity and concentration of the purified mRNA are assessed using gel electrophoresis and spectrophotometry.
Cell Culture and Transfection
-
Cell Line Maintenance: A suitable mammalian cell line, such as HEK293T or HeLa cells, is maintained in the appropriate growth medium supplemented with fetal bovine serum and antibiotics.
-
Seeding: Cells are seeded into multi-well plates to achieve a target confluency (e.g., 70-90%) at the time of transfection.
-
Transfection: The purified mRNA is transfected into the cells using a lipid-based transfection reagent or electroporation. The mRNA and transfection reagent are typically diluted in serum-free medium before being added to the cells.
-
Incubation: The cells are incubated for a specified period (e.g., 24-48 hours) to allow for mRNA translation and protein expression.
Quantification of Protein Expression
-
Cell Lysis: Transfected cells are washed with phosphate-buffered saline (PBS) and then lysed using a radioimmunoprecipitation assay (RIPA) buffer containing protease inhibitors.
-
Protein Quantification: The total protein concentration in the cell lysates is determined using a protein assay, such as the bicinchoninic acid (BCA) assay.
-
SDS-PAGE and Transfer: Equal amounts of protein from each sample are separated by sodium dodecyl sulfate-polyacrylamide gel electrophoresis (SDS-PAGE) and then transferred to a polyvinylidene difluoride (PVDF) membrane.
-
Immunoblotting: The membrane is blocked to prevent non-specific antibody binding and then incubated with a primary antibody specific to the protein of interest. After washing, the membrane is incubated with a secondary antibody conjugated to an enzyme (e.g., horseradish peroxidase).
-
Detection: The protein bands are visualized by adding a chemiluminescent substrate and capturing the signal using an imaging system. The band intensities are quantified using densitometry software.
-
Co-transfection: Cells are co-transfected with the experimental mRNA encoding a reporter protein (e.g., Firefly luciferase) and a control mRNA encoding a second reporter (e.g., Renilla luciferase).
-
Cell Lysis: At a set time point post-transfection, cells are lysed using a passive lysis buffer.
-
Luminometry: The luciferase activity in the cell lysates is measured using a luminometer. The Firefly luciferase activity is normalized to the Renilla luciferase activity to control for transfection efficiency and cell number.
Experimental Workflow for Benchmarking Codon Optimization Algorithms
The following diagram illustrates a typical workflow for the comprehensive evaluation of codon optimization algorithms.
References
- 1. Codon-optimization in gene therapy: promises, prospects and challenges - PMC [pmc.ncbi.nlm.nih.gov]
- 2. mRNA Folding Algorithms for Structure and Codon Optimization [arxiv.org]
- 3. Frontiers | Codon-optimization in gene therapy: promises, prospects and challenges [frontiersin.org]
- 4. Codon Optimization for Different Expression Systems: Key Points and Case Studies - CD Biosynsis [biosynsis.com]
- 5. Codon optimality is a major determinant of mRNA stability - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Deep generative optimization of mRNA codon sequences for enhanced mRNA translation and therapeutic efficacy - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Comparative Analysis of Codon Optimization Tools: Advancing toward a Multi-Criteria Framework for Synthetic Gene Design - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Comparative Analysis of Codon Optimization Tools: Advancing toward a Multi-Criteria Framework for Synthetic Gene Design [jmb.or.kr]
- 9. Comparative Analysis of Codon Optimization Tools: Advancing toward a Multi-Criteria Framework for Synthetic Gene Design - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. jmb.or.kr [jmb.or.kr]
- 11. academic.oup.com [academic.oup.com]
- 12. researchgate.net [researchgate.net]
- 13. Algorithm for optimized mRNA design improves stability and immunogenicity - PMC [pmc.ncbi.nlm.nih.gov]
- 14. researchgate.net [researchgate.net]
- 15. Codon optimization significantly enhanced the expression of human 37-kDa iLRP in Escherichia coli - PMC [pmc.ncbi.nlm.nih.gov]
- 16. biorxiv.org [biorxiv.org]
- 17. researchgate.net [researchgate.net]
A Comparative Guide: siRNA versus mRNA for Transient Gene Expression Studies
For researchers, scientists, and drug development professionals navigating the landscape of transient gene expression, the choice between small interfering RNA (siRNA) and messenger RNA (mRNA) is pivotal. Each technology offers a distinct approach to modulating gene function, with unique advantages and considerations. This guide provides an objective comparison of their performance, supported by experimental data, detailed methodologies, and visual pathway analysis to inform your experimental design.
At a Glance: Key Differences Between siRNA and mRNA
| Feature | siRNA (Small Interfering RNA) | mRNA (Messenger RNA) |
| Primary Function | Gene Silencing (Post-transcriptional) | Protein Expression |
| Mechanism of Action | RNA interference (RNAi) pathway, leading to cleavage and degradation of a specific target mRNA. | Serves as a template for protein synthesis by ribosomes in the cytoplasm. |
| Cellular Machinery | Dicer, RNA-induced silencing complex (RISC) | Ribosomes, translation initiation and elongation factors |
| Typical Application | Gene knockdown, pathway analysis, target validation. | Protein production, functional rescue, vaccine development, gene replacement. |
| Duration of Effect | Typically 3-7 days, can persist longer in non-dividing cells.[1] | Generally transient, with protein expression lasting from hours to a few days.[2] |
| Potential Off-Target Effects | Can silence unintended mRNAs with partial sequence homology.[3][4][5] | Can trigger innate immune responses; impurities from in vitro transcription can cause toxicity.[6][7][8] |
Performance Comparison: Efficiency, Kinetics, and Duration
The choice between siRNA and mRNA often hinges on the desired biological outcome and the temporal dynamics required for the experiment.
Onset and Duration of Action
-
mRNA: In contrast, protein expression from transfected mRNA can be detected as early as 2-6 hours post-transfection.[2] This is because mRNA is directly translated in the cytoplasm, bypassing the need for nuclear entry and transcription.[1] Protein expression levels typically peak within 5-24 hours and then decline as the mRNA is degraded.[10][11][12] The transient nature of mRNA expression makes it suitable for applications requiring short-term protein production.[2]
Quantitative Performance Metrics
The following table summarizes typical quantitative data for siRNA-mediated knockdown and mRNA-mediated expression, compiled from various studies. Note that efficiencies can vary significantly depending on the cell type, delivery method, and specific sequences used.
| Parameter | siRNA | mRNA |
| Typical Efficacy | ≥70% reduction in target mRNA levels.[13] | High transfection efficiency (>90% of cells expressing the protein). |
| Time to Peak Effect | 24-72 hours for maximal mRNA/protein knockdown.[9] | 5-24 hours for peak protein expression.[10][11] |
| Duration of Effect (in dividing cells) | 3-7 days.[1] | Hours to a few days.[2] |
| Typical Concentration for Transfection | 1-100 nM. | Varies depending on the delivery system and cell type. |
| Primary Readout | Reduction in mRNA (via qRT-PCR) and protein (via Western blot) levels.[13] | Protein expression level (via Western blot, ELISA, or reporter assays). |
Experimental Protocols
Detailed and optimized protocols are crucial for successful and reproducible experiments. Below are representative protocols for the transfection of siRNA and mRNA into a common cell line, HeLa.
siRNA Transfection Protocol for Gene Knockdown in HeLa Cells
This protocol is adapted for a 24-well plate format using a lipid-based transfection reagent.
Materials:
-
HeLa cells
-
siRNA targeting the gene of interest (20 µM stock)
-
Non-targeting control siRNA (20 µM stock)
-
Opti-MEM® I Reduced Serum Medium
-
Lipofectamine™ RNAiMAX Transfection Reagent
-
Complete growth medium (e.g., DMEM with 10% FBS)
-
24-well tissue culture plates
Procedure:
-
Cell Seeding: The day before transfection, seed HeLa cells in a 24-well plate at a density that will result in 30-50% confluency at the time of transfection (e.g., 30,000 cells per well in 500 µl of complete growth medium without antibiotics).
-
Preparation of siRNA-Lipid Complexes (per well): a. In a sterile microcentrifuge tube, dilute 6 pmol of siRNA in 50 µl of Opti-MEM®. Mix gently. b. In a separate sterile microcentrifuge tube, mix Lipofectamine™ RNAiMAX gently, then dilute 0.8 µl in 50 µl of Opti-MEM®. Mix gently. c. Combine the diluted siRNA with the diluted Lipofectamine™ RNAiMAX. Mix gently and incubate for 10-20 minutes at room temperature to allow for complex formation.
-
Transfection: a. Add the 100 µl of siRNA-lipid complex dropwise to the cells in the 24-well plate. b. Gently rock the plate back and forth to ensure even distribution.
-
Incubation: Incubate the cells at 37°C in a CO2 incubator for 24-72 hours.
-
Analysis: After the incubation period, harvest the cells to analyze mRNA levels by qRT-PCR or protein levels by Western blot.
In Vitro Transcribed (IVT) mRNA Transfection Protocol for Protein Expression
This protocol is a general guideline for the transfection of IVT mRNA into mammalian cells in a 12-well plate format.
Materials:
-
HEK293 cells (or other suitable cell line)
-
In vitro transcribed, capped, and polyadenylated mRNA (e.g., encoding a fluorescent protein for optimization)
-
Opti-MEM® I Reduced Serum Medium
-
Cationic lipid-based mRNA transfection reagent
-
Complete cell culture medium
-
12-well tissue culture plates
-
Nuclease-free water and consumables
Procedure:
-
Cell Seeding: The day before transfection, seed cells in a 12-well plate to achieve 70-90% confluency on the day of transfection.
-
Preparation of mRNA-Lipid Complexes (per well): a. In a sterile, nuclease-free tube, dilute 2.5 µg of mRNA in 250 µl of Opti-MEM®. b. In a separate sterile, nuclease-free tube, add 2 µl of the cationic lipid transfection reagent to 250 µl of Opti-MEM®. c. Combine the diluted mRNA and the diluted transfection reagent. Mix gently by pipetting. d. Incubate the mixture for 10-15 minutes at room temperature to form the lipoplexes.
-
Transfection: a. Aspirate the old medium from the cells and wash once with DPBS. b. Add the 500 µl of the mRNA-lipid complex to the well.
-
Incubation and Analysis: a. Incubate the cells for 4 hours at 37°C and 5% CO2. b. After 4 hours, aspirate the transfection mixture and add 1 ml of fresh, complete cell culture medium. c. Protein expression can be analyzed at various time points (e.g., 6, 24, 48 hours) by fluorescence microscopy (for fluorescent proteins), Western blot, or other appropriate assays.[14]
Signaling Pathways and Off-Target Effects
Both siRNA and mRNA can trigger intracellular signaling pathways, primarily those related to the innate immune system's recognition of foreign nucleic acids.
siRNA-Mediated Gene Silencing and Immune Response
siRNA functions through the endogenous RNAi pathway. Exogenous double-stranded siRNA is recognized by the Dicer enzyme and loaded into the RISC complex. The guide strand of the siRNA then directs RISC to the target mRNA, leading to its cleavage and subsequent degradation.
However, as a double-stranded RNA (dsRNA), siRNA can be recognized by pattern recognition receptors (PRRs) like Toll-like receptor 3 (TLR3) in endosomes and RIG-I and MDA5 in the cytoplasm.[13][15] This can trigger a downstream signaling cascade leading to the production of type I interferons and inflammatory cytokines.
mRNA Translation and Immune Recognition
Transfected mRNA is directly utilized by the cell's translational machinery in the cytoplasm to produce the encoded protein. The 5' cap and 3' poly(A) tail of synthetic mRNA are crucial for efficient translation and stability.
As a single-stranded RNA (ssRNA), exogenous mRNA can be recognized by endosomal TLR7 and TLR8, and cytoplasmic sensors like PKR.[10] This recognition can lead to an inflammatory response and, in the case of PKR activation, a general shutdown of protein synthesis. The presence of dsRNA contaminants in in vitro transcribed mRNA preparations is a significant contributor to this immune stimulation.[6]
Experimental Workflow Comparison
The overall experimental workflows for siRNA and mRNA studies share some similarities, such as the need for transfection, but differ in their downstream analysis.
Conclusion
The decision to use siRNA or mRNA for transient gene expression studies should be guided by the specific research question. For studies requiring the down-regulation of a gene to understand its function, siRNA is the tool of choice. Conversely, when the goal is to express a protein to study its function, for functional rescue, or in therapeutic contexts, mRNA is the preferred molecule. Both technologies are powerful and offer transient modulation of gene expression, a key feature for many experimental designs. A thorough understanding of their mechanisms, performance characteristics, and potential for off-target effects will enable researchers to design more precise and impactful studies.
References
- 1. mRNA as a Versatile Tool for Exogenous Protein Expression: Abstract, Citation (BibTeX) & Reference | Bohrium [bohrium.com]
- 2. promegaconnections.com [promegaconnections.com]
- 3. Comparative assessment of siRNA and shRNA off target effects: what is slowing clinical development: Abstract, Citation (BibTeX) & Reference | Bohrium [bohrium.com]
- 4. Comparison of siRNA-induced off-target RNA and protein effects - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Off Target Effects in small interfering RNA or siRNA [biosyn.com]
- 6. Frontiers | Understanding the impact of in vitro transcription byproducts and contaminants [frontiersin.org]
- 7. cellculturedish.com [cellculturedish.com]
- 8. cellculturedish.com [cellculturedish.com]
- 9. siRNA-Induced mRNA Knockdown and Phenotype | Thermo Fisher Scientific - HK [thermofisher.com]
- 10. Transfection Efficiency and Transgene Expression Kinetics of mRNA Delivered in Naked and Nanoparticle Format - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Protein Expression Correlates Linearly with mRNA Dose over Up to Five Orders of Magnitude In Vitro and In Vivo - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Kinetics of mRNA delivery and protein translation in dendritic cells using lipid-coated PLGA nanoparticles - PMC [pmc.ncbi.nlm.nih.gov]
- 13. researchgate.net [researchgate.net]
- 14. researchgate.net [researchgate.net]
- 15. researchgate.net [researchgate.net]
Safety Operating Guide
Navigating the Disposal of Unidentified Laboratory Chemicals: A Procedural Guide
I. Immediate Safety and Identification Protocol
When encountering a substance like "Mnaf" with no immediate, recognizable disposal instructions, the primary goal is to ensure safety and gather necessary information.
-
Consult the Safety Data Sheet (SDS): The SDS is the most critical document for any chemical, providing comprehensive information on its properties, hazards, and safe handling, including disposal considerations.[1] If you are working with "this compound," a corresponding SDS must be available. This document will be the primary source for determining the appropriate disposal route.
-
Contact Your Environmental Health and Safety (EHS) Office: Your institution's EHS department is the definitive resource for guidance on waste disposal.[2] They are equipped to interpret the SDS and provide specific instructions that comply with federal, state, and local regulations.[2][3]
-
Proper Labeling and Segregation:
-
Isolate the "this compound" waste from other chemical waste streams to prevent accidental mixing of incompatible substances.[2][4]
-
Ensure the waste container is clearly labeled with "Hazardous Waste" and the full chemical name ("this compound" and any other known identifiers).[5]
-
The container must be in good condition, compatible with the chemical, and kept closed except when adding waste.[5]
-
II. Prohibited Disposal Methods
Under no circumstances should an unknown chemical or hazardous substance be disposed of through conventional means. The following methods are strictly prohibited:
-
Sink Disposal: Flushing chemicals down the drain is forbidden.[2]
-
Regular Trash: Disposal in the regular solid waste is not permitted.[2]
-
Mixing with Other Waste: Do not combine "this compound" with other chemical waste unless explicitly instructed to do so by your EHS office.[2]
III. Step-by-Step Disposal Workflow
The following workflow outlines the procedural steps for the proper disposal of an unidentified or internally designated chemical.
Caption: Workflow for the proper disposal of an unidentified laboratory chemical.
IV. Quantitative Data and Experimental Protocols
As "this compound" does not correspond to a known chemical in public databases, there is no quantitative data or specific experimental protocols for its degradation or neutralization available. Any laboratory-scale experiments to treat or neutralize "this compound" should only be conducted after a thorough risk assessment and with the explicit approval of the institution's EHS and safety committees.[2] For many hazardous or controlled substances, chemical destruction is performed by specialized hazardous waste management companies.[2]
V. Summary of Best Practices
To ensure safety and compliance when handling and disposing of substances like "this compound," adhere to the following principles:
| Best Practice | Rationale |
| Always consult the SDS | Provides essential information on hazards, handling, and disposal.[1] |
| Involve EHS early | Ensures compliance with all regulations and access to expert guidance.[2] |
| Segregate and label waste | Prevents dangerous chemical reactions and ensures proper handling.[2][5] |
| Use designated waste containers | Ensures chemical compatibility and prevents leaks or spills.[5] |
| Maintain an inventory | Tracks chemical usage and waste generation, aiding in waste minimization.[3] |
By following these procedures, laboratory professionals can handle the disposal of any chemical, including those with internal identifiers like "this compound," in a manner that is safe, compliant, and environmentally responsible.
References
- 1. Lab Safety | Museum of the North [uaf.edu]
- 2. benchchem.com [benchchem.com]
- 3. Hazardous Waste Disposal Procedures | The University of Chicago Environmental Health and Safety [safety.uchicago.edu]
- 4. Mine Safety Agency Issues Serious Accident Alert On Safe Handling Of Chemicals | Jackson Lewis P.C. - JDSupra [jdsupra.com]
- 5. campussafety.lehigh.edu [campussafety.lehigh.edu]
Retrosynthesis Analysis
AI-Powered Synthesis Planning: Our tool employs the Template_relevance Pistachio, Template_relevance Bkms_metabolic, Template_relevance Pistachio_ringbreaker, Template_relevance Reaxys, Template_relevance Reaxys_biocatalysis model, leveraging a vast database of chemical reactions to predict feasible synthetic routes.
One-Step Synthesis Focus: Specifically designed for one-step synthesis, it provides concise and direct routes for your target compounds, streamlining the synthesis process.
Accurate Predictions: Utilizing the extensive PISTACHIO, BKMS_METABOLIC, PISTACHIO_RINGBREAKER, REAXYS, REAXYS_BIOCATALYSIS database, our tool offers high-accuracy predictions, reflecting the latest in chemical research and data.
Strategy Settings
| Precursor scoring | Relevance Heuristic |
|---|---|
| Min. plausibility | 0.01 |
| Model | Template_relevance |
| Template Set | Pistachio/Bkms_metabolic/Pistachio_ringbreaker/Reaxys/Reaxys_biocatalysis |
| Top-N result to add to graph | 6 |
Feasible Synthetic Routes




Featured Recommendations
| Most viewed |
|
|
|---|---|---|
| Most popular with customers |
|
Descargo de responsabilidad e información sobre productos de investigación in vitro
Tenga en cuenta que todos los artículos e información de productos presentados en BenchChem están destinados únicamente con fines informativos. Los productos disponibles para la compra en BenchChem están diseñados específicamente para estudios in vitro, que se realizan fuera de organismos vivos. Los estudios in vitro, derivados del término latino "in vidrio", involucran experimentos realizados en entornos de laboratorio controlados utilizando células o tejidos. Es importante tener en cuenta que estos productos no se clasifican como medicamentos y no han recibido la aprobación de la FDA para la prevención, tratamiento o cura de ninguna condición médica, dolencia o enfermedad. Debemos enfatizar que cualquier forma de introducción corporal de estos productos en humanos o animales está estrictamente prohibida por ley. Es esencial adherirse a estas pautas para garantizar el cumplimiento de los estándares legales y éticos en la investigación y experimentación.
