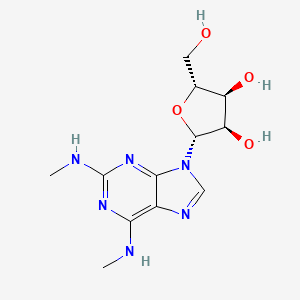
2-Methylamino-N6-methyladenosine
Descripción
BenchChem offers high-quality this compound suitable for many research applications. Different packaging options are available to accommodate customers' requirements. Please inquire for more information about this compound including the price, delivery time, and more detailed information at info@benchchem.com.
Propiedades
Fórmula molecular |
C12H18N6O4 |
|---|---|
Peso molecular |
310.31 g/mol |
Nombre IUPAC |
(2R,3R,4S,5R)-2-[2,6-bis(methylamino)purin-9-yl]-5-(hydroxymethyl)oxolane-3,4-diol |
InChI |
InChI=1S/C12H18N6O4/c1-13-9-6-10(17-12(14-2)16-9)18(4-15-6)11-8(21)7(20)5(3-19)22-11/h4-5,7-8,11,19-21H,3H2,1-2H3,(H2,13,14,16,17)/t5-,7-,8-,11-/m1/s1 |
Clave InChI |
XOYZQQAJKUSOGS-IOSLPCCCSA-N |
SMILES isomérico |
CNC1=C2C(=NC(=N1)NC)N(C=N2)[C@H]3[C@@H]([C@@H]([C@H](O3)CO)O)O |
SMILES canónico |
CNC1=C2C(=NC(=N1)NC)N(C=N2)C3C(C(C(O3)CO)O)O |
Origen del producto |
United States |
Foundational & Exploratory
Unraveling the Epitranscriptomic Code: A Technical Guide to the Biological Significance of Modified Adenosines
For the Attention of Researchers, Scientists, and Drug Development Professionals
This technical guide delves into the profound biological significance of methylated adenosine modifications in RNA, a pivotal area of epitranscriptomics. While the specific modification 2-Methylamino-N6-methyladenosine is not documented in the current scientific literature, this guide will provide a comprehensive overview of two closely related and extensively studied modifications: N6-methyladenosine (m6A) and 2'-O-methyladenosine (Am) . Understanding the roles of these prevalent modifications is crucial for advancing research in cellular regulation, disease pathogenesis, and the development of novel therapeutics.
Introduction to Adenosine Modifications in RNA
Post-transcriptional modifications of RNA molecules add a critical layer of regulatory complexity to gene expression. Among the more than 170 known RNA modifications, methylation of adenosine residues is one of the most common and functionally diverse. These modifications act as a dynamic code, influencing almost every aspect of the RNA life cycle, from processing and nuclear export to translation and decay.[1][2] This guide focuses on two key players in this epitranscriptomic landscape: m6A and Am.
N6-methyladenosine (m6A): The Most Abundant Internal mRNA Modification
N6-methyladenosine (m6A) is the most prevalent internal modification in the messenger RNA (mRNA) of most eukaryotes, from yeast to mammals.[3][4] It is also found in other RNA species, including transfer RNA (tRNA), ribosomal RNA (rRNA), and long non-coding RNAs (lncRNAs).[2][3][5] The m6A modification is dynamically installed, removed, and recognized by a dedicated set of proteins, making it a key regulatory hub in gene expression.
The m6A Regulatory Machinery: "Writers," "Erasers," and "Readers"
The fate of an m6A-modified RNA is determined by a complex interplay of three classes of proteins:
-
Writers (Methyltransferases): This enzymatic complex installs the methyl group onto adenosine residues. The core components are the methyltransferase-like 3 and 14 (METTL3/METTL14) heterodimer, which forms the catalytic core, and Wilms' tumor 1-associated protein (WTAP), which facilitates the complex's localization to RNA.[6][7]
-
Erasers (Demethylases): These enzymes remove the methyl group, allowing for dynamic regulation. The two known m6A demethylases are the fat mass and obesity-associated protein (FTO) and alkB homolog 5 (ALKBH5).[7]
-
Readers (Binding Proteins): These proteins specifically recognize m6A and mediate its downstream effects. The YTH domain-containing family of proteins (YTHDF1, YTHDF2, YTHDF3, YTHDC1, YTHDC2) are the most well-characterized m6A readers.[7][8]
Biological Significance of m6A
The m6A modification plays a crucial role in a wide array of biological processes:
-
RNA Splicing and Processing: m6A can influence pre-mRNA splicing by recruiting splicing factors.[4]
-
mRNA Stability and Degradation: The reader protein YTHDF2 is a major player in this process, binding to m6A-containing mRNAs and targeting them for degradation.[6]
-
Translation Efficiency: The reader protein YTHDF1 can promote the translation of m6A-modified mRNAs.[8]
-
Cellular Differentiation and Development: The dynamic regulation of m6A is essential for processes like hematopoietic stem cell differentiation and embryonic development.[2]
-
Disease Pathogenesis: Dysregulation of m6A has been implicated in various diseases, including cancer, neurodegenerative disorders, and metabolic diseases.[4][6] In many cancers, the expression of m6A writers, erasers, and readers is altered, leading to aberrant gene expression that promotes tumor growth and progression.[4][6]
2'-O-methyladenosine (Am): A Key Player in RNA Stability and Translation
2'-O-methylation is a modification where a methyl group is added to the 2'-hydroxyl group of the ribose sugar of a nucleotide. When this occurs on adenosine, it forms 2'-O-methyladenosine (Am). This modification is found in various RNA species, including tRNA, rRNA, small nuclear RNA (snRNA), and at the 5' cap of mRNA.[5]
Biosynthesis of Am
The enzymatic machinery responsible for Am formation is specific to the type of RNA:
-
tRNA: In humans, the FTSJ1 methyltransferase, in complex with WDR6, is responsible for the 2'-O-methylation of adenosine in the anticodon loop of specific tRNAs.[5]
-
rRNA and snRNA: The fibrillarin (FBL) enzyme, as part of a small nucleolar ribonucleoprotein (snoRNP) complex, catalyzes the site-specific 2'-O-methylation of rRNA and snRNA, guided by snoRNAs.
-
mRNA Cap: The cap-specific methyltransferase CMTR1 is responsible for the 2'-O-methylation of the first transcribed nucleotide of an mRNA, which is often adenosine.
Biological Significance of Am
The Am modification has profound effects on RNA function:
-
Structural Stability: The methyl group at the 2'-hydroxyl position restricts the conformation of the ribose sugar, which enhances the structural stability of the RNA molecule.[5]
-
Protection from Degradation: 2'-O-methylation protects RNA from cleavage by certain cellular nucleases, thereby increasing its half-life.[5]
-
Translation Regulation: In tRNA, Am in the anticodon loop is crucial for accurate codon recognition and efficient translation. In the mRNA cap, the 2'-O-methylation (forming the "cap 1" structure) is important for efficient translation initiation and for distinguishing self from non-self RNA, thereby avoiding an innate immune response.
-
Ribosome Biogenesis: 2'-O-methylation of rRNA is essential for the correct folding, processing, and assembly of ribosomes.
Quantitative Data Summary
The following table summarizes key quantitative aspects of m6A and Am modifications.
| Modification | Abundance in mRNA | Key Enzymes | Cellular Location | Primary Function |
| N6-methyladenosine (m6A) | ~1-2 residues per 1000 nucleotides[4] | Writers: METTL3/14, WTAPErasers: FTO, ALKBH5Readers: YTH family | Nucleus and Cytoplasm | Regulation of splicing, stability, and translation[4] |
| 2'-O-methyladenosine (Am) | Enriched at the 5' cap and internal sites | FTSJ1 (tRNA), Fibrillarin (rRNA/snRNA), CMTR1 (mRNA cap) | Nucleus and Cytoplasm | RNA stability, translation fidelity, ribosome biogenesis[5] |
Experimental Protocols
The study of m6A and Am modifications relies on a variety of sophisticated techniques. Below are outlines of key experimental protocols.
Detection and Quantification of m6A and Am by LC-MS/MS
Liquid chromatography-tandem mass spectrometry (LC-MS/MS) is the gold standard for the accurate quantification of RNA modifications.[9][10][11]
Objective: To quantify the levels of m6A and Am in a total RNA sample.
Methodology Outline:
-
RNA Isolation: High-quality total RNA is extracted from cells or tissues using methods like TRIzol-based extraction or commercial kits. RNA integrity is assessed using a bioanalyzer.
-
RNA Digestion: The purified RNA is digested into single nucleosides using a cocktail of enzymes, typically nuclease P1 followed by bacterial alkaline phosphatase.[9]
-
LC-MS/MS Analysis: The resulting nucleoside mixture is separated by high-performance liquid chromatography (HPLC) and analyzed by a tandem mass spectrometer operating in multiple reaction monitoring (MRM) mode.[9]
-
Quantification: The abundance of each modified nucleoside is determined by comparing its signal to that of a known amount of a stable isotope-labeled internal standard.[9]
Mapping m6A Sites using MeRIP-Seq
Methylated RNA immunoprecipitation followed by sequencing (MeRIP-Seq) is a widely used technique to map the transcriptome-wide locations of m6A.
Objective: To identify the specific locations of m6A within the transcriptome.
Methodology Outline:
-
RNA Fragmentation: Purified mRNA is chemically fragmented into smaller pieces (typically ~100 nucleotides).
-
Immunoprecipitation: The fragmented RNA is incubated with an antibody that specifically recognizes m6A. The antibody-bound RNA fragments are then captured using magnetic beads.
-
Library Preparation and Sequencing: The captured, m6A-containing RNA fragments are reverse-transcribed into cDNA, and a sequencing library is prepared. This library, along with a library from the input RNA (without immunoprecipitation), is then sequenced using a high-throughput sequencing platform.
-
Data Analysis: The sequencing reads are aligned to the reference genome, and peaks are identified where there is a significant enrichment of reads in the immunoprecipitated sample compared to the input. These peaks represent the locations of m6A modifications.
Conclusion and Future Directions
The study of m6A and Am has unveiled a new dimension of gene regulation at the RNA level. These modifications are not merely static decorations but are dynamic and integral components of the cellular machinery that fine-tunes gene expression in response to developmental cues and environmental stimuli. For researchers and professionals in drug development, understanding the enzymes that regulate these modifications presents exciting opportunities for therapeutic intervention. Targeting the m6A "writers," "erasers," or "readers" could offer novel strategies for treating a wide range of diseases, including cancer and viral infections. As our ability to detect and manipulate these modifications continues to improve, the field of epitranscriptomics is poised to revolutionize our understanding of biology and medicine.
References
- 1. Synthesis of 2'-modified N6-methyladenosine phosphoramidites and their incorporation into siRNA - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. Potential roles of N6-methyladenosine (m6A) in immune cells - PMC [pmc.ncbi.nlm.nih.gov]
- 3. N6-Methyladenosine - Wikipedia [en.wikipedia.org]
- 4. Functions of N6-methyladenosine and its role in cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 5. benchchem.com [benchchem.com]
- 6. N6-methyladenosine methyltransferases: functions, regulation, and clinical potential - PMC [pmc.ncbi.nlm.nih.gov]
- 7. In Search of a Function for the N6-Methyladenosine in Epitranscriptome, Autophagy and Neurodegenerative Diseases - PMC [pmc.ncbi.nlm.nih.gov]
- 8. mdpi.com [mdpi.com]
- 9. benchchem.com [benchchem.com]
- 10. Global analysis by LC-MS/MS of N6-methyladenosine and inosine in mRNA reveal complex incidence - PMC [pmc.ncbi.nlm.nih.gov]
- 11. biorxiv.org [biorxiv.org]
The Dawn of a New Layer of Gene Regulation: A Technical Guide to the Discovery and History of N6-methyladenosine (m6A) RNA Modification
For Researchers, Scientists, and Drug Development Professionals
Executive Summary
N6-methyladenosine (m6A) has emerged from relative obscurity to become the most intensely studied internal modification of messenger RNA (mRNA) in eukaryotes. This dynamic and reversible epigenetic mark plays a pivotal role in virtually every aspect of RNA metabolism, from splicing and nuclear export to translation and decay. Its discovery decades ago laid the groundwork for the burgeoning field of epitranscriptomics, and the more recent identification of its regulatory proteins—the "writers," "erasers," and "readers"—has unveiled a complex regulatory network with profound implications for cellular function, development, and disease. This in-depth technical guide provides a comprehensive overview of the seminal discoveries, key experimental methodologies, and the core molecular machinery that underpins our understanding of m6A biology.
The Initial Discovery: A Glimpse into a New Layer of Genetic Regulation
The story of m6A begins in the mid-1970s, a period of foundational discoveries in molecular biology. Researchers employing classic biochemical techniques provided the first evidence of this modified nucleoside within eukaryotic mRNA.
In 1974, independent reports from the laboratories of Robert P. Perry and Fritz Rottman identified the presence of methylated nucleosides within the internal regions of mRNA from mammalian cells.[1] These pioneering studies utilized a combination of radiolabeling and chromatography to establish m6A as a bona fide and widespread component of the transcriptome.[1] By labeling cells with [³H-methyl]-methionine, they could trace the transfer of methyl groups to RNA. Subsequent digestion of the mRNA into individual nucleosides and separation by techniques such as paper chromatography allowed for the identification of N6-methyladenosine.[1] These early investigations estimated that m6A was present at a frequency of approximately one to three modifications per mRNA molecule.[1]
For several decades following its discovery, the functional significance of m6A remained largely enigmatic. The lack of tools to map its precise location and the absence of knowledge about the enzymes that regulate it hampered progress. This period of quiet inquiry, however, set the stage for a renaissance in m6A research.
The m6A Renaissance: Unmasking the Key Players
The 2010s marked a turning point in the field of m6A research, often referred to as the "m6A renaissance." This new era was ushered in by the identification of the key proteins that install, remove, and recognize the m6A mark, finally providing the molecular handles needed to dissect its function.
The "Writers": The Methyltransferase Complex
The breakthrough in understanding how m6A is deposited came with the identification of the methyltransferase complex. This multi-subunit "writer" complex is responsible for catalyzing the addition of a methyl group to the N6 position of adenosine residues within a specific consensus sequence, typically RRACH (where R is a purine, A is the methylated adenosine, and H is a non-guanine base).
The core components of the writer complex include:
-
METTL3 (Methyltransferase-like 3): The primary catalytic subunit of the complex.
-
METTL14 (Methyltransferase-like 14): A crucial scaffold protein that stabilizes METTL3 and facilitates RNA binding.
-
WTAP (Wilms' tumor 1-associating protein): A regulatory component that helps localize the complex to nuclear speckles.
The "Erasers": The Demethylases
A pivotal discovery that cemented the role of m6A as a dynamic regulatory mark was the identification of enzymes that could remove it. These "erasers" demonstrated that m6A modification is a reversible process, allowing for precise temporal and spatial control of gene expression.
The two main m6A demethylases are:
-
FTO (Fat mass and obesity-associated protein): The first m6A demethylase to be discovered, FTO oxidatively removes the methyl group from m6A.
-
ALKBH5 (AlkB homolog 5): Another demethylase that directly removes the methyl group from adenosine.
The "Readers": Effectors of m6A Function
For the m6A mark to exert its biological effects, it must be recognized by specific "reader" proteins. These proteins bind to m6A-containing RNAs and recruit other factors to influence the fate of the transcript. The most well-characterized family of m6A readers are those containing a YT521-B homology (YTH) domain.
Key YTH domain-containing reader proteins include:
-
YTHDF1: Primarily promotes the translation of m6A-modified mRNAs by interacting with translation initiation factors.
-
YTHDF2: The first identified m6A reader, it primarily mediates the degradation of m6A-containing transcripts by recruiting decay machinery.
-
YTHDF3: Appears to work in concert with YTHDF1 and YTHDF2 to modulate both translation and decay.
-
YTHDC1: A nuclear reader that influences the splicing and nuclear export of m6A-modified RNAs.
-
YTHDC2: Involved in regulating mRNA stability and translation.
Quantitative Insights into m6A Modification
The development of high-throughput sequencing and quantitative mass spectrometry has provided a wealth of data on the prevalence and functional impact of m6A.
Table 1: Prevalence of m6A Across Species and RNA Types
| Organism/RNA Type | Method | Key Findings |
| Human mRNA | m6A-seq | Over 12,000 m6A sites identified in more than 7,000 genes.[2] |
| Mouse mRNA | m6A-seq | Highly conserved m6A landscape with human, with enrichment near stop codons and in long exons.[2] |
| Yeast (S. cerevisiae) mRNA | m6A-seq | m6A is predominantly found during meiosis and is enriched in the coding sequence near the stop codon.[3][4] |
| lncRNA | m6A-seq | m6A is present on many lncRNAs, with a distribution that can differ from that on mRNAs.[5] |
| circRNA | m6A-IP-seq | m6A is widespread on circRNAs, with cell-type-specific methylation patterns distinct from linear mRNAs.[6] |
| rRNA | Mass Spectrometry | m6A is present on ribosomal RNA, suggesting a role in ribosome biogenesis and function. |
Table 2: Quantitative Effects of m6A on mRNA Fate
| m6A Regulator Perturbation | Target mRNA/Context | Quantitative Effect |
| METTL3 Knockdown | NRIP1 mRNA | Increased mRNA half-life from 1.4h to 2.5h.[7] |
| METTL3 Knockdown | RNGTT mRNA | Decreased mRNA half-life from 8.89h to 4.78h.[8] |
| YTHDF1 Knockdown | YTHDF1 target transcripts | Reduced translation efficiency (cumulative log2 fold change).[9][10] |
| YTHDF1 Tethering | Reporter mRNA | On-average 42% increased translation.[10] |
| Mettl3 Knockout (mESCs) | Global m6A levels | Over 50-fold reduction in m6A levels.[11] |
Key Signaling Pathways Interacting with the m6A Machinery
The m6A regulatory network does not operate in isolation. It is intricately linked with major cellular signaling pathways, allowing for the dynamic control of gene expression in response to extracellular cues.
TGF-β Signaling Pathway
The Transforming Growth Factor-β (TGF-β) pathway, crucial for development and cellular differentiation, directly interfaces with the m6A machinery. Upon TGF-β stimulation, the downstream effectors SMAD2/3 can interact with the METTL3/METTL14/WTAP writer complex.[12][13] This interaction promotes the deposition of m6A on target transcripts, such as those encoding pluripotency factors, leading to their degradation and facilitating cellular differentiation.[12][13] In the context of cancer, TGF-β can induce m6A modification of the SNAIL mRNA, a key transcription factor in the epithelial-mesenchymal transition (EMT), which is then recognized by YTHDF1 to promote its translation.[13]
References
- 1. benchchem.com [benchchem.com]
- 2. researchgate.net [researchgate.net]
- 3. The yeast RNA methylation complex consists of conserved yet reconfigured components with m6A-dependent and independent roles - PMC [pmc.ncbi.nlm.nih.gov]
- 4. High-resolution mapping reveals a conserved, widespread, dynamic meiotically regulated mRNA methylation program - PMC [pmc.ncbi.nlm.nih.gov]
- 5. N6-Methyladenosine Modification Opens a New Chapter in Circular RNA Biology - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Genome-wide maps of m6A circRNAs identify widespread and cell-type-specific methylation patterns that are distinct from mRNAs - PMC [pmc.ncbi.nlm.nih.gov]
- 7. METTL3-Mediated N6-Methyladenosine Modification Is Involved in the Dysregulation of NRIP1 Expression in Down Syndrome - PMC [pmc.ncbi.nlm.nih.gov]
- 8. METTL3 alters capping enzyme expression and its activity on ribosomal proteins - PMC [pmc.ncbi.nlm.nih.gov]
- 9. researchgate.net [researchgate.net]
- 10. researchgate.net [researchgate.net]
- 11. m6A-ELISA, a simple method for quantifying N6-methyladenosine from mRNA populations - PMC [pmc.ncbi.nlm.nih.gov]
- 12. m6A deposition: a boost from TGFβ - PMC [pmc.ncbi.nlm.nih.gov]
- 13. researchgate.net [researchgate.net]
The Role of N6-methyladenosine (m6A) in Eukaryotic Messenger RNA: An In-depth Technical Guide
An Overview of the Most Abundant Internal mRNA Modification and its Regulatory Functions
N6-methyladenosine (m6A) is the most prevalent and conserved internal modification in eukaryotic messenger RNA (mRNA), playing a pivotal role in post-transcriptional gene regulation.[1][2] This dynamic and reversible epitranscriptomic mark influences nearly every aspect of the mRNA lifecycle, from splicing and nuclear export to translation and decay.[3][4] The dysregulation of m6A has been implicated in a wide range of human diseases, including various cancers, metabolic disorders, and neurodegenerative diseases, making it a focal point for researchers, scientists, and drug development professionals.[5][6] This technical guide provides a comprehensive overview of the core machinery, biological functions, and experimental methodologies related to m6A in eukaryotic mRNA.
The Core Machinery of m6A Modification
The cellular fate of m6A-modified mRNA is orchestrated by a sophisticated interplay of three classes of proteins: "writers," "erasers," and "readers."
Writers: The Methyltransferase Complex
The deposition of the m6A mark is primarily catalyzed by a nuclear methyltransferase complex. The core components of this complex are Methyltransferase-like 3 (METTL3) and Methyltransferase-like 14 (METTL14), which form a stable heterodimer.[7][8] METTL3 serves as the catalytic subunit, while METTL14 acts as a scaffold, recognizing and binding to the target RNA.[7][9] This complex is further associated with other regulatory proteins, including Wilms' tumor 1-associating protein (WTAP), which is crucial for the localization of the METTL3-METTL14 heterodimer to nuclear speckles.[7][10] The writer complex recognizes a consensus sequence, RRACH (where R is a purine, A is the methylated adenosine, and H is a non-guanine base), to install the methyl group onto adenosine residues.[2][11]
Erasers: The Demethylases
The m6A modification is reversible, thanks to the action of demethylases known as "erasers." The two primary m6A erasers are the fat mass and obesity-associated protein (FTO) and AlkB homolog 5 (ALKBH5).[11][12] Both are Fe(II)- and α-ketoglutarate-dependent dioxygenases.[13] FTO was the first identified RNA demethylase and has been shown to play a significant role in energy homeostasis and adipogenesis.[1][12] ALKBH5 has been implicated in processes such as RNA nuclear export and spermatogenesis.[12] These erasers allow for the dynamic regulation of m6A levels in response to various cellular signals and environmental cues.
Readers: The Effector Proteins
The functional consequences of m6A modification are mediated by "reader" proteins that specifically recognize and bind to m6A-containing transcripts. The most well-characterized family of m6A readers is the YT521-B homology (YTH) domain-containing family, which includes YTHDF1, YTHDF2, YTHDF3, YTHDC1, and YTHDC2.[1][14][15] These readers translate the m6A mark into specific downstream effects:
-
YTHDF1: Primarily located in the cytoplasm, YTHDF1 promotes the translation of m6A-modified mRNAs by interacting with translation initiation factors.[10][11]
-
YTHDF2: Also cytoplasmic, YTHDF2 is a key player in mRNA decay. It recognizes m6A-modified transcripts and recruits the CCR4-NOT deadenylase complex to promote their degradation.[14][16]
-
YTHDF3: This reader protein appears to have a synergistic role with YTHDF1 and YTHDF2, promoting both translation and decay of methylated mRNAs.[15]
-
YTHDC1: A nuclear reader, YTHDC1 is involved in regulating the splicing of m6A-modified pre-mRNAs and facilitating their export from the nucleus.[3]
-
YTHDC2: This reader has been shown to enhance translation efficiency while also decreasing the abundance of its target mRNAs.[10]
Other proteins, such as the insulin-like growth factor 2 mRNA-binding proteins (IGF2BPs) and heterogeneous nuclear ribonucleoproteins (HNRNPs), have also been identified as m6A readers, expanding the known repertoire of m6A-mediated regulation.[1][10]
Biological Functions of m6A in mRNA Metabolism
The interplay between writers, erasers, and readers fine-tunes gene expression by modulating various stages of mRNA metabolism.
mRNA Stability and Decay
One of the most significant roles of m6A is the regulation of mRNA stability. The binding of YTHDF2 to m6A-modified transcripts targets them for degradation, thereby controlling their half-life.[17] This process is crucial for the timely removal of transcripts and the maintenance of cellular homeostasis. Conversely, in some contexts, m6A can also stabilize mRNAs, often through the action of IGF2BP proteins.[1]
mRNA Translation
m6A modification can either enhance or repress translation. YTHDF1 promotes the translation of its target mRNAs by facilitating their association with ribosomes.[11] In some instances, m6A in the 5' untranslated region (5' UTR) can promote cap-independent translation by recruiting the translation initiation factor eIF3.[18]
pre-mRNA Splicing
Within the nucleus, m6A plays a role in alternative splicing. The nuclear reader YTHDC1 can influence the inclusion or exclusion of exons by recruiting splicing factors to m6A-modified pre-mRNAs.[3] The demethylases FTO and ALKBH5 have also been shown to regulate alternative splicing events.[3]
mRNA Nuclear Export
The export of mature mRNA from the nucleus to the cytoplasm is another process influenced by m6A. YTHDC1 has been reported to promote the nuclear export of m6A-modified transcripts by facilitating their interaction with the nuclear export machinery.[19] However, there is also evidence suggesting that in some contexts, m6A can lead to nuclear retention of transcripts.[20][21]
Quantitative Data on m6A Regulation
The following tables summarize key quantitative data from various studies, illustrating the impact of m6A on mRNA metabolism.
| Parameter | Condition | Target/Context | Observed Change | Reference(s) |
| Global m6A Levels | FTO Knockdown in HeLa cells | Total mRNA | ~1.5-fold increase in m6A/A ratio | [14] |
| FTO Overexpression in HeLa cells | Total mRNA | ~0.7-fold decrease in m6A/A ratio | [14] | |
| ALKBH5 Knockdown in HeLa cells | Total mRNA | ~9% increase in m6A level | [11] | |
| Colorectal Cancer vs. Healthy Controls | Serum | Significant increase in m6A concentration (5.57 ± 1.67 nM vs. 4.51 ± 1.08 nM) | [22] | |
| Gastric Cancer vs. Healthy Controls | Serum | Significant increase in m6A concentration (6.93 ± 1.38 nM vs. 4.51 ± 1.08 nM) | [22] |
| Parameter | Condition | Target mRNA | Observed Fold Change | Reference(s) |
| mRNA Half-life | METTL3 Knockdown | NRIP1 | ~1.8-fold increase (from 1.4h to 2.5h) | [18] |
| METTL3 Knockdown | RNGTT | ~0.54-fold decrease (from 8.89h to 4.78h) | [6] | |
| YTHDF2 Knockdown | YTHDF2 targets | Average ~30% increase in lifetime | [23] | |
| ALKBH5 Knockdown | CYR61 | ~1.3-fold increase (from 3.8h to 5.0h) | [24] | |
| ALKBH5 Overexpression | CYR61 | ~0.7-fold decrease (from 4.5h to 3.2h) | [24] |
| Parameter | Condition | Target Population | Observed Change | Reference(s) |
| Translation Efficiency | YTHDF1 Knockdown | YTHDF1 target mRNAs | Significant decrease | [3] |
| YTHDF1 Knockdown | m6A-modified mRNA in non-ribosome mRNPs | ~71% increase in m6A/A ratio | [3] | |
| YTHDF1 Knockdown | m6A-modified mRNA in 40-80S fractions | ~44% decrease in m6A/A ratio | [3] | |
| YTHDF1 Knockdown | m6A-modified mRNA in polysome fractions | ~25% decrease in m6A/A ratio | [3] |
Signaling Pathways Modulated by m6A
m6A modification is intricately linked to major cellular signaling pathways, influencing their activity by regulating the expression of key components.
PI3K/AKT Signaling Pathway
The PI3K/AKT pathway is a crucial regulator of cell growth, proliferation, and survival. m6A modification has been shown to modulate this pathway at multiple levels. For instance, the m6A reader YTHDF2 can mediate the degradation of tumor suppressor mRNAs, leading to the activation of AKT phosphorylation. In some cancers, reduced m6A levels are associated with augmented PI3K-Akt signaling.[25]
References
- 1. GitHub - canceromics/MeRIPseqPipe: MeRIPseqPipe:An integrated analysis pipeline for MeRIP-seq data based on Nextflow. [github.com]
- 2. MeRIP-seq: Comprehensive Guide to m6A RNA Modification Analysis - CD Genomics [rna.cd-genomics.com]
- 3. N6-methyladenosine Modulates Messenger RNA Translation Efficiency - PMC [pmc.ncbi.nlm.nih.gov]
- 4. researchgate.net [researchgate.net]
- 5. researchgate.net [researchgate.net]
- 6. researchgate.net [researchgate.net]
- 7. FTO-Dependent m6A Regulates Cardiac Function During Remodeling and Repair - PMC [pmc.ncbi.nlm.nih.gov]
- 8. rna-seqblog.com [rna-seqblog.com]
- 9. Quantitative analysis of m6A RNA modification by LC-MS - PMC [pmc.ncbi.nlm.nih.gov]
- 10. researchgate.net [researchgate.net]
- 11. ALKBH5 Is a Mammalian RNA Demethylase that Impacts RNA Metabolism and Mouse Fertility - PMC [pmc.ncbi.nlm.nih.gov]
- 12. researchgate.net [researchgate.net]
- 13. researchgate.net [researchgate.net]
- 14. researchgate.net [researchgate.net]
- 15. Frontiers | Cis-regulation analysis of RNA m6A methylation and gene expression in colorectal cancer [frontiersin.org]
- 16. researchgate.net [researchgate.net]
- 17. researchgate.net [researchgate.net]
- 18. mdpi.com [mdpi.com]
- 19. YTHDF2 promotes mitotic entry and is regulated by cell cycle mediators - PMC [pmc.ncbi.nlm.nih.gov]
- 20. m6A Topological Transition Coupled to Developmental Regulation of Gene Expression During Mammalian Tissue Development - PMC [pmc.ncbi.nlm.nih.gov]
- 21. Knowledge mapping and current trends of m6A methylation in the field of cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 22. Frontiers | Quantitative Analysis of Methylated Adenosine Modifications Revealed Increased Levels of N6-Methyladenosine (m6A) and N6,2′-O-Dimethyladenosine (m6Am) in Serum From Colorectal Cancer and Gastric Cancer Patients [frontiersin.org]
- 23. m6A-dependent regulation of messenger RNA stability - PMC [pmc.ncbi.nlm.nih.gov]
- 24. The m6A demethylase ALKBH5 controls trophoblast invasion at the maternal-fetal interface by regulating the stability of CYR61 mRNA - PMC [pmc.ncbi.nlm.nih.gov]
- 25. Comprehensive Overview of m6A Detection Methods - CD Genomics [cd-genomics.com]
The Epitranscriptomic Regulator: A Technical Guide to Cellular Pathways Modulated by N6,2'-O-dimethyladenosine (m6Am)
For Researchers, Scientists, and Drug Development Professionals
Introduction
N6,2'-O-dimethyladenosine (m6Am) is a prevalent and dynamic post-transcriptional modification of messenger RNA (mRNA) and other non-coding RNAs. This modification, characterized by a methyl group on the N6 position of adenosine and a methyl group on the 2'-hydroxyl of the ribose, plays a critical role in fine-tuning gene expression. The cellular machinery that installs, removes, and recognizes m6Am—termed "writers," "erasers," and "readers," respectively—governs a multitude of cellular pathways. Dysregulation of m6Am has been implicated in various diseases, most notably cancer, making its regulatory network a promising area for therapeutic intervention. This technical guide provides an in-depth exploration of the core cellular pathways regulated by m6Am, complete with quantitative data, detailed experimental protocols, and visual diagrams to facilitate a comprehensive understanding for researchers and drug development professionals.
The m6Am Regulatory Machinery: Writers, Erasers, and Readers
The dynamic nature of m6Am modification is controlled by a coordinated interplay of enzymes and binding proteins.
-
Writers (Methyltransferases): The primary enzyme responsible for installing the m6Am mark is PCIF1 (Phosphorylated CTD Interacting Factor 1) , also known as CAPAM (Cap-specific Adenosine Methyltransferase). PCIF1 specifically methylates the N6 position of the 2'-O-methylated adenosine at the 5' cap of mRNA. While the METTL3/METTL14 complex is the main writer for N6-methyladenosine (m6A), METTL16 has also been identified as an m6A methyltransferase with specificity for structured RNA regions, such as those in U6 snRNA and the 3' UTR of MAT2A mRNA.[1][2][3] Although its direct role in widespread m6Am installation on mRNA is less clear, its activity can influence the overall methylation landscape.
-
Erasers (Demethylases): The principal eraser of m6Am is the Fat Mass and Obesity-associated protein (FTO) . FTO is an α-ketoglutarate-dependent dioxygenase that efficiently demethylates m6Am to 2'-O-methyladenosine (Am).[4][5] FTO exhibits a significantly higher catalytic efficiency for m6Am compared to m6A, suggesting that m6Am is a primary physiological substrate.[4][6] Another known m6A demethylase, ALKBH5 , has been shown to have minimal to no activity on m6Am, highlighting the specific role of FTO in reversing this modification.[7]
-
Readers (Binding Proteins): The functional consequences of m6Am are mediated by "reader" proteins that recognize and bind to this modification. The YTH domain-containing family of proteins (YTHDF1, YTHDF2, and YTHDF3) are well-characterized readers of m6A. While their binding affinity to m6Am is an area of ongoing research, evidence suggests they can also recognize m6Am-containing transcripts, influencing their fate.[8][9][10] These readers can impact mRNA stability, translation, and localization. For example, YTHDF2 is known to promote the degradation of its target mRNAs.[11][12]
Core Cellular Pathways Regulated by m6Am
The m6Am modification and its regulatory proteins are integral to several fundamental cellular processes, thereby influencing a wide range of biological outcomes.
Regulation of mRNA Stability and Degradation
One of the most well-documented roles of m6Am is in the regulation of mRNA stability. The presence of m6Am at the 5' cap can protect mRNA from decapping and subsequent degradation by exonucleases. The eraser FTO, by removing the m6Am mark, can expose transcripts to degradation pathways. Conversely, the writer PCIF1 can enhance the stability of its target mRNAs. Reader proteins, particularly YTHDF2, can recognize m6Am-modified transcripts and recruit the CCR4-NOT deadenylase complex to promote their decay.[11] This dynamic interplay allows for precise temporal control of gene expression.
Control of mRNA Splicing
m6Am modification, particularly in small nuclear RNAs (snRNAs), has been shown to influence pre-mRNA splicing. FTO-mediated demethylation of m6Am in snRNAs can alter their conformation and interaction with the spliceosome machinery, leading to changes in alternative splicing patterns.[4][13][14] FTO depletion leads to an increase in m6Am levels on snRNAs and is associated with enhanced inclusion of otherwise inefficiently spliced exons.[4][13]
Modulation of mRNA Translation
The 5' cap structure is crucial for the initiation of cap-dependent translation. The presence of m6Am in this region can modulate the recruitment of translation initiation factors and ribosomes, thereby affecting protein synthesis. While some studies suggest that m6Am can enhance translation efficiency, others indicate a repressive role, suggesting that the effect may be context-dependent and influenced by the specific reader proteins involved.[10][15]
Key Signaling Pathways Influenced by m6Am Regulation
The regulatory roles of m6Am extend to critical signaling pathways that are often dysregulated in disease.
The Wnt/β-catenin Signaling Pathway
The Wnt/β-catenin pathway is fundamental for embryonic development, tissue homeostasis, and its aberrant activation is a hallmark of many cancers. Emerging evidence indicates that m6A/m6Am modifications play a significant role in modulating this pathway. For instance, m6A readers can influence the translation of key components of the Wnt signaling cascade. While direct regulation of Wnt pathway components by m6Am is still under investigation, the involvement of FTO in regulating Wnt signaling has been demonstrated, suggesting a potential link.
References
- 1. researchgate.net [researchgate.net]
- 2. Mechanistic insights into m6A modification of U6 snRNA by human METTL16 - PMC [pmc.ncbi.nlm.nih.gov]
- 3. PCIF1 catalyzes m6Am mRNA methylation to regulate gene expression - PMC [pmc.ncbi.nlm.nih.gov]
- 4. FTO controls reversible m6Am RNA methylation during snRNA biogenesis - PMC [pmc.ncbi.nlm.nih.gov]
- 5. biorxiv.org [biorxiv.org]
- 6. m6Am-seq reveals the dynamic m6Am methylation in the human transcriptome - PMC [pmc.ncbi.nlm.nih.gov]
- 7. researchgate.net [researchgate.net]
- 8. m6A-dependent regulation of messenger RNA stability - PMC [pmc.ncbi.nlm.nih.gov]
- 9. researchgate.net [researchgate.net]
- 10. The roles and mechanisms of the m6A reader protein YTHDF1 in tumor biology and human diseases - PMC [pmc.ncbi.nlm.nih.gov]
- 11. YTHDF2 destabilizes m6A-containing RNA through direct recruitment of the CCR4–NOT deadenylase complex - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Understanding YTHDF2-mediated mRNA Degradation By m6A-BERT-Deg - PMC [pmc.ncbi.nlm.nih.gov]
- 13. biorxiv.org [biorxiv.org]
- 14. m.youtube.com [m.youtube.com]
- 15. m6A RNA Methylation Analysis by MS - CD Genomics [rna.cd-genomics.com]
The Role of N6-methyladenosine (m6A) in Cancer Biology and Development: An In-depth Technical Guide
For Researchers, Scientists, and Drug Development Professionals
Executive Summary
N6-methyladenosine (m6A) is the most abundant internal modification of messenger RNA (mRNA) in eukaryotic cells, playing a pivotal role in RNA metabolism, including splicing, nuclear export, stability, and translation. The dynamic and reversible nature of m6A modification, regulated by a complex interplay of "writer," "eraser," and "reader" proteins, has emerged as a critical layer of epigenetic regulation. Aberrant m6A modification has been increasingly implicated in the initiation, progression, and therapeutic resistance of various cancers. This technical guide provides a comprehensive overview of the role of m6A in cancer biology, detailing the molecular machinery, its impact on key signaling pathways, and its potential as a therapeutic target. This document is intended to serve as a resource for researchers, scientists, and drug development professionals in the field of oncology.
The m6A Regulatory Machinery: Writers, Erasers, and Readers
The m6A modification is a dynamically regulated process orchestrated by three classes of proteins:
-
Writers: These are methyltransferases that install the m6A modification onto adenosine residues within a specific consensus sequence (RRACH). The primary writer complex consists of Methyltransferase-like 3 (METTL3) as the catalytic subunit, Methyltransferase-like 14 (METTL14) as a structural and substrate-recognizing component, and Wilms' tumor 1-associated protein (WTAP) which facilitates the localization of the complex to the nuclear speckles.[1]
-
Erasers: These are demethylases that remove the m6A modification, ensuring the reversibility of this epigenetic mark. The two known erasers are the fat mass and obesity-associated protein (FTO) and AlkB homolog 5 (ALKBH5).[2]
-
Readers: These proteins specifically recognize and bind to m6A-modified RNA, mediating the downstream effects of the modification. The YTH domain-containing family of proteins (YTHDF1, YTHDF2, YTHDF3, YTHDC1, and YTHDC2) are the most well-characterized m6A readers. YTHDF1 is known to promote the translation of m6A-modified mRNAs, YTHDF2 primarily mediates their degradation, and YTHDF3 appears to work in concert with both YTHDF1 and YTHDF2.[3]
Dysregulation of m6A Regulators in Cancer
Accumulating evidence demonstrates the widespread dysregulation of m6A writer, eraser, and reader expression in numerous cancer types. This altered expression disrupts the m6A landscape, leading to aberrant gene expression that promotes tumorigenesis.
Quantitative Expression Analysis of Key m6A Regulators in Cancer
The following tables summarize the differential expression of key m6A regulators in various cancers based on data from The Cancer Genome Atlas (TCGA) and other studies.
| METTL3 (Writer) | Cancer Type | Fold Change (Tumor vs. Normal) | Clinical Significance | Reference |
| Lung Adenocarcinoma (LUAD) | Upregulated | Associated with tumor growth and poor prognosis. | [4] | |
| Gastric Cancer (STAD) | Significantly Higher | Correlates with poorer overall survival. | [5] | |
| Liver Hepatocellular Carcinoma (LIHC) | Significantly Higher | Associated with poorer overall survival. | [5] | |
| Bladder Cancer (BLCA) | Significantly Higher | Positively associated with cancer stage and nodal metastasis. | [6] |
| FTO (Eraser) | Cancer Type | Expression Change (Tumor vs. Normal) | Clinical Significance | Reference |
| Breast Cancer (BRCA) | Significantly Higher | Higher positivity in hormone receptor-negative and HER2-amplified cases. | [1] | |
| Lung Squamous Cell Carcinoma (LUSC) | Significantly Lower | High expression is associated with a poor prognosis. | [4] | |
| Most Cancers (Pan-Cancer Analysis) | Downregulated | - | [7] |
| YTHDF1 (Reader) | Cancer Type | Expression Change (Tumor vs. Normal) | Clinical Significance | Reference |
| Colorectal Cancer (CRC) | Upregulated | Associated with tumor depth and size. Overexpression in 61% of cases. | [8] | |
| Gastric Cancer (GC) | Upregulated | Associated with poor prognosis. | [9] | |
| Most Cancers (Pan-Cancer Analysis) | Upregulated | - | [7] |
m6A Modification in Key Cancer-Related Signaling Pathways
The m6A modification machinery exerts its influence on cancer development by modulating the expression of key components of major signaling pathways.
Wnt/β-catenin Signaling Pathway
The Wnt/β-catenin pathway is crucial for embryonic development and its aberrant activation is a hallmark of many cancers. m6A modification has been shown to regulate this pathway at multiple levels. For instance, the m6A reader YTHDF1 can promote the translation of β-catenin, a central player in the Wnt pathway, thereby amplifying Wnt signaling and promoting cancer cell proliferation and stemness.
PI3K/Akt Signaling Pathway
The PI3K/Akt pathway is a central regulator of cell survival, proliferation, and metabolism, and its hyperactivation is common in cancer. m6A modification can influence this pathway by targeting key components. For example, METTL3-mediated m6A modification can enhance the stability of mRNAs encoding positive regulators of the PI3K/Akt pathway, leading to its sustained activation.
p53 Signaling Pathway
The p53 tumor suppressor pathway is a critical barrier against cancer development. m6A modification can directly and indirectly influence p53 signaling. For instance, METTL3 can methylate the mRNA of MDM2, a negative regulator of p53, leading to increased MDM2 expression and subsequent p53 degradation. Conversely, m6A modification can also affect the stability of p53 mRNA itself.[7]
Experimental Protocols for m6A Analysis
Investigating the role of m6A in cancer requires specialized techniques to map and quantify this modification. Methylated RNA Immunoprecipitation followed by sequencing (MeRIP-seq) is a widely used method for transcriptome-wide mapping of m6A.
MeRIP-seq (m6A-seq) Protocol
This protocol outlines the key steps for performing MeRIP-seq to identify m6A sites across the transcriptome.
I. RNA Preparation and Fragmentation
-
Total RNA Extraction: Isolate high-quality total RNA from cells or tissues using a suitable method (e.g., TRIzol reagent). Ensure RNA integrity is high (RIN > 7).
-
mRNA Purification (Optional but Recommended): Purify mRNA from total RNA using oligo(dT) magnetic beads to reduce ribosomal RNA contamination.
-
RNA Fragmentation: Fragment the mRNA into ~100-nucleotide fragments using a fragmentation buffer (e.g., containing Mg2+) and incubation at an elevated temperature (e.g., 94°C) for a specific time. The fragmentation time should be optimized. Immediately stop the reaction on ice.
II. Immunoprecipitation of m6A-containing RNA
-
Antibody-Bead Conjugation: Incubate anti-m6A antibody with Protein A/G magnetic beads to form antibody-bead complexes.
-
Immunoprecipitation: Add the fragmented RNA to the antibody-bead complexes and incubate with rotation at 4°C to allow the antibody to capture m6A-containing RNA fragments.
-
Washing: Wash the beads multiple times with a series of buffers with increasing stringency to remove non-specifically bound RNA fragments.
-
Elution: Elute the m6A-containing RNA fragments from the antibody-bead complexes using an elution buffer (e.g., containing a high concentration of N6-methyladenosine monophosphate).
III. Library Preparation and Sequencing
-
Input Control: Take an aliquot of the fragmented RNA before immunoprecipitation to serve as an input control.
-
Library Construction: Construct sequencing libraries from both the immunoprecipitated (IP) RNA and the input RNA using a standard RNA-seq library preparation kit.
-
Sequencing: Perform high-throughput sequencing of the prepared libraries.
IV. Data Analysis
-
Read Alignment: Align the sequencing reads to a reference genome.
-
Peak Calling: Use a peak-calling algorithm (e.g., MACS2) to identify regions enriched for m6A in the IP sample compared to the input control.
-
Motif Analysis: Analyze the identified m6A peaks for the presence of the consensus m6A motif (RRACH).
-
Differential Methylation Analysis: Compare m6A peak profiles between different conditions (e.g., tumor vs. normal) to identify differentially methylated regions.
m6A-qRT-PCR for Validation
This method is used to validate the m6A modification status of specific gene transcripts identified by MeRIP-seq.
-
Perform MeRIP as described above.
-
Reverse transcribe the eluted m6A-containing RNA and the input RNA into cDNA.
-
Perform quantitative real-time PCR (qRT-PCR) using primers specific to the gene of interest.
-
Calculate the relative enrichment of m6A for the target gene in the IP sample compared to the input control. An increase in the relative enrichment indicates the presence of m6A modification.
m6A in Cancer Therapy and Drug Development
The critical role of m6A modification in cancer biology has opened new avenues for therapeutic intervention. Targeting the m6A regulatory machinery presents a promising strategy for cancer treatment.
-
Inhibitors of m6A Writers: Small molecule inhibitors targeting the catalytic activity of METTL3 are being developed. These inhibitors aim to reduce the overall m6A levels, thereby suppressing the expression of oncogenes.
-
Inhibitors of m6A Erasers: Inhibitors of FTO have shown anti-tumor effects in preclinical models of various cancers, including acute myeloid leukemia (AML) and glioblastoma. By increasing m6A levels on tumor suppressor transcripts, these inhibitors can reactivate their expression.
-
Targeting m6A Readers: Developing molecules that disrupt the interaction between m6A readers and their target mRNAs is another promising approach. This could prevent the translation of oncogenes or promote the degradation of pro-survival factors.
Furthermore, the m6A status of tumors is being explored as a potential biomarker for predicting patient prognosis and response to therapy, including immunotherapy.
Conclusion
The field of epitranscriptomics, with m6A at its forefront, is rapidly expanding our understanding of gene regulation in cancer. The dysregulation of m6A writers, erasers, and readers has profound effects on cancer initiation, progression, and metastasis by altering the expression of a multitude of oncogenes and tumor suppressors. As our knowledge of the intricate mechanisms of m6A-mediated gene regulation grows, so too will the opportunities for developing novel and effective cancer therapies targeting this fundamental biological process. This guide provides a foundational understanding for researchers and clinicians to further explore the exciting potential of m6A in oncology.
References
- 1. p53 Signaling Pathway - Creative Biolabs [creativebiolabs.net]
- 2. mdpi.com [mdpi.com]
- 3. Pan-cancer Analysis Reveals m6A Variation and Cell-specific Regulatory Network in Different Cancer Types - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. An integrated model of FTO and METTL3 expression that predicts prognosis in lung squamous cell carcinoma patients - PMC [pmc.ncbi.nlm.nih.gov]
- 5. PI3K / Akt Signaling | Cell Signaling Technology [cellsignal.com]
- 6. Frontiers | Comprehensive Analysis of Expression Regulation for RNA m6A Regulators With Clinical Significance in Human Cancers [frontiersin.org]
- 7. academic.oup.com [academic.oup.com]
- 8. The m6A Reader YTHDF1 Facilitates the Tumorigenesis and Metastasis of Gastric Cancer via USP14 Translation in an m6A-Dependent Manner - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Comprehensive Analysis of Expression Regulation for RNA m6A Regulators With Clinical Significance in Human Cancers. - National Genomics Data Center (CNCB-NGDC) [ngdc.cncb.ac.cn]
The Pivotal Role of m6A RNA Methylation in Neuronal Development and Disease: A Technical Guide
For Researchers, Scientists, and Drug Development Professionals
Abstract
N6-methyladenosine (m6A) is the most abundant internal modification of messenger RNA (mRNA) in eukaryotes, playing a critical role in the post-transcriptional regulation of gene expression.[1] This dynamic and reversible epitranscriptomic mark, installed by methyltransferases ("writers"), removed by demethylases ("erasers"), and recognized by specific binding proteins ("readers"), is integral to nearly every aspect of mRNA metabolism, including splicing, nuclear export, stability, and translation.[2] The nervous system, in particular, exhibits high levels of m6A modification, underscoring its profound importance in neuronal development, function, and the pathogenesis of a spectrum of neurological disorders.[3] This technical guide provides an in-depth exploration of the molecular mechanisms of m6A, its function in neurogenesis and synaptic plasticity, and its dysregulation in neurological diseases such as Alzheimer's disease, Parkinson's disease, and brain tumors. We present quantitative data on m6A alterations, detailed experimental protocols for its study, and visual representations of key signaling pathways to offer a comprehensive resource for researchers and professionals in the field.
The m6A Machinery: Writers, Erasers, and Readers
The functional consequences of m6A modification are orchestrated by a sophisticated interplay of proteins that install, remove, and recognize this mark.
-
Writers: The m6A methyltransferase complex is primarily composed of the catalytic subunit METTL3 (Methyltransferase-like 3) and its heterodimeric partner METTL14.[4] This complex is further stabilized and guided by associated proteins such as WTAP (Wilms' tumor 1-associating protein).
-
Erasers: The reversibility of m6A methylation is mediated by demethylases. The first identified m6A demethylase was the fat mass and obesity-associated protein (FTO).[5] Another key eraser is ALKBH5 (AlkB homolog 5).[6]
-
Readers: The biological effects of m6A are executed by reader proteins that specifically recognize the m6A mark and influence the fate of the target mRNA. The YTH (YT521-B homology) domain-containing family of proteins, including YTHDF1, YTHDF2, and YTHDF3, are the most well-characterized m6A readers.[7] YTHDF1 is known to promote the translation of m6A-modified mRNAs, while YTHDF2 typically mediates their degradation.[8][9] YTHDC1 is a nuclear reader involved in splicing regulation.
Quantitative Alterations of m6A in Neuronal Development and Disease
The precise regulation of m6A levels is crucial for normal neuronal function. Dysregulation of m6A modification has been quantitatively linked to both developmental processes and pathological conditions.
| Context | Brain Region/Cell Type | Key Finding | Fold Change/Quantitative Data | Reference |
| Neuronal Development | Mouse Embryonic Cortex | Deletion of Mettl14 leads to a significant reduction in m6A levels. | Mettl14 cKO shows a ~70% reduction in m6A/A ratio compared to control. | [1] |
| Mouse Postnatal Cortex | m6A levels in lncRNAs are higher in the postnatal stage compared to the embryonic stage. | A large number of lncRNAs show a >1.5-fold increase in m6A levels. | [2] | |
| Ythdf2-/- Neurospheres | Loss of Ythdf2 leads to an increase in global m6A abundance. | ~10% average increase in m6A abundance compared to wild-type. | [9] | |
| Alzheimer's Disease | APP/PS1 Mouse Cortex | Elevated m6A methylation in the cortex and hippocampus. | Not specified | [10] |
| 5XFAD Mouse Brain | Hypomethylation of transcripts in the 3' UTR. | Not specified | [11] | |
| Human AD Brain | Decreased expression of METTL3 and increased expression of YTHDF1. | METTL3 mRNA decreased by ~20%; YTHDF1 mRNA increased by ~15%. | [12] | |
| Parkinson's Disease | 6-OHDA-induced PC12 cells | Global m6A modification is down-regulated. | Not specified | [13] |
| PD Rat Striatum | Significantly reduced m6A methylation levels. | Not specified | [14] | |
| Human PD Brain | Significant decreases in m6A-RNAs in the frontal cortex, cingulate gyrus, and hippocampus. | Not specified | [15] |
The Role of m6A in Neuronal Development
m6A modification is a critical regulator of the intricate processes of neuronal development, from neurogenesis to the formation of functional neural circuits.
Neurogenesis and Neuronal Differentiation
During cortical development, m6A plays a crucial role in the temporal regulation of neurogenesis. Depletion of the m6A writer Mettl14 in embryonic mouse brains leads to a prolonged cell cycle in radial glia cells and extends cortical neurogenesis into postnatal stages.[1] This is due to the failed m6A-dependent decay of mRNAs that are essential for maintaining the neural stem cell state.[16] The m6A reader YTHDF2 is also critical, as its depletion in mice results in compromised neural development and lethality at late embryonic stages.[6] YTHDF2-mediated degradation of m6A-containing transcripts is necessary for the proper timing of neuronal differentiation.[9]
Axon Guidance and Synaptic Plasticity
m6A modification is also involved in the guidance of developing axons and the establishment of synaptic connections. In developing sympathetic neurons, the neurotrophin Nerve Growth Factor (NGF) promotes the axonal localization of methylated transcripts, suggesting a role for m6A in regulating local protein synthesis required for axon growth. Furthermore, m6A is highly enriched at synapses and is implicated in synaptic plasticity, the cellular basis of learning and memory.[17]
m6A Dysregulation in Neurological Diseases
The critical role of m6A in maintaining neuronal homeostasis means that its dysregulation is increasingly being linked to a variety of neurological disorders.
Alzheimer's Disease (AD)
In the context of AD, studies have reported conflicting findings regarding global m6A levels, with some indicating an increase while others show a decrease.[10][11] However, there is a consensus that the m6A landscape is significantly altered. For instance, in the 5XFAD mouse model of AD, there is a notable hypomethylation of transcripts in their 3' UTRs.[11] The expression of m6A regulatory proteins is also dysregulated in human AD brains, with decreased levels of the writer METTL3 and increased levels of the reader YTHDF1.[12] These changes are thought to contribute to the aberrant gene expression profiles associated with AD pathogenesis.
Parkinson's Disease (PD)
In PD, a consistent finding is the down-regulation of global m6A levels in both cellular and animal models, as well as in the brains of PD patients.[13][14][15] This reduction in m6A is associated with dopaminergic neuronal death. Overexpression of the demethylase FTO, which reduces m6A levels, can induce apoptosis in dopaminergic neurons.[13]
Brain Tumors
m6A modification plays a dual role in brain tumors like glioblastoma (GBM). The m6A machinery can act as either oncogenes or tumor suppressors depending on the cellular context and the specific mRNA targets. For example, both the m6A writer METTL3 and the eraser ALKBH5 have been shown to be critical for the growth and self-renewal of glioblastoma stem cells (GSCs).[18]
Key Signaling Pathways Modulated by m6A in the Nervous System
m6A exerts its profound effects on neuronal development and disease by modulating key signaling pathways.
Brain-Derived Neurotrophic Factor (BDNF) Signaling
BDNF is a crucial neurotrophin for neuronal survival, growth, and synaptic plasticity. The m6A eraser FTO has been shown to regulate adult neurogenesis by altering the expression of key components of the BDNF pathway that are marked by m6A.[16]
mTOR Signaling Pathway
The mechanistic target of rapamycin (mTOR) pathway is a central regulator of cell growth and proliferation. mTORC1 signaling has been shown to enhance the translation of WTAP, a key component of the m6A writer complex, thereby increasing global m6A levels.[19] This intricate connection highlights how m6A modification is integrated with fundamental cellular signaling networks.
Wnt Signaling Pathway
The Wnt signaling pathway is fundamental for embryonic development and adult tissue homeostasis, including neurogenesis.[20] m6A modification has been shown to regulate the Wnt pathway. For instance, the m6A reader YTHDF1 can control the translation of TCF4, a key transcriptional activator in the Wnt pathway, in an m6A-dependent manner.[21]
Experimental Protocols for m6A Analysis in Neuronal Systems
Studying m6A in the nervous system requires specialized techniques to map its location and quantify its abundance.
Methylated RNA Immunoprecipitation Sequencing (MeRIP-Seq)
MeRIP-seq is the most widely used method for transcriptome-wide mapping of m6A.
Protocol Overview:
-
RNA Extraction and Fragmentation:
-
Isolate total RNA from neuronal cells or brain tissue using a standard protocol (e.g., TRIzol).
-
Fragment the RNA to an average size of 100-200 nucleotides using enzymatic or chemical methods.[2]
-
-
Immunoprecipitation (IP):
-
Incubate the fragmented RNA with an anti-m6A antibody to specifically capture m6A-containing fragments.
-
Use protein A/G magnetic beads to pull down the antibody-RNA complexes.[19]
-
-
RNA Elution and Library Preparation:
-
Elute the m6A-enriched RNA fragments from the beads.
-
Prepare sequencing libraries from both the immunoprecipitated (IP) and input control RNA samples.
-
-
Sequencing and Data Analysis:
-
Perform high-throughput sequencing of the libraries.
-
Align reads to the reference genome and identify m6A peaks by comparing the enrichment in the IP sample over the input control.
-
m6A Individual-Nucleotide Resolution CLIP (miCLIP)
miCLIP provides single-nucleotide resolution mapping of m6A sites.
Protocol Overview:
-
UV Crosslinking and Immunoprecipitation:
-
UV-crosslink an anti-m6A antibody to the RNA in cell lysates. This creates a covalent bond at the m6A site.[1]
-
Perform immunoprecipitation of the antibody-RNA complexes.
-
-
Library Preparation with Truncation/Mutation Signature:
-
During reverse transcription, the crosslinked antibody-peptide remnant causes truncations or specific mutations in the resulting cDNA.[7]
-
Prepare sequencing libraries from the cDNA.
-
-
Sequencing and Data Analysis:
-
Sequence the libraries and identify the precise location of m6A sites by analyzing the positions of truncations and mutations.[21]
-
LC-MS/MS for Global m6A Quantification
Liquid chromatography-tandem mass spectrometry (LC-MS/MS) is the gold standard for quantifying the overall m6A/A ratio in a sample.
Protocol Overview:
-
RNA Digestion:
-
Isolate total RNA and digest it into single nucleosides using a cocktail of nucleases and phosphatases.[3]
-
-
LC-MS/MS Analysis:
-
Separate the nucleosides by liquid chromatography.
-
Quantify the amounts of adenosine (A) and N6-methyladenosine (m6A) using tandem mass spectrometry.[22]
-
-
Data Analysis:
-
Calculate the m6A/A ratio to determine the global m6A level.
-
Future Directions and Therapeutic Implications
The field of epitranscriptomics in the nervous system is rapidly evolving. Future research will likely focus on:
-
Cell-type-specific m6A mapping: Understanding the unique m6A profiles of different neuronal and glial cell types will be crucial for dissecting their specific roles in brain function and disease.
-
Functional validation of m6A sites: Moving beyond mapping to functionally characterizing the impact of individual m6A sites on mRNA fate and neuronal phenotype.
-
Therapeutic targeting of the m6A machinery: The development of small molecule inhibitors and activators of m6A writers and erasers holds promise for novel therapeutic strategies for a range of neurological disorders. For example, modulating FTO activity could be a potential approach for treating certain neurodegenerative diseases.[23]
Conclusion
N6-methyladenosine modification has emerged as a critical layer of gene regulation in the nervous system. Its dynamic nature and profound impact on mRNA metabolism place it at the center of neuronal development, synaptic plasticity, and the pathogenesis of numerous neurological diseases. A deeper understanding of the m6A machinery and its downstream effects, facilitated by advanced experimental techniques, will undoubtedly pave the way for innovative diagnostic and therapeutic approaches for these debilitating conditions. This guide provides a foundational resource for researchers and clinicians to navigate this exciting and rapidly advancing field.
References
- 1. Temporal Control of Mammalian Cortical Neurogenesis by m6A Methylation - PMC [pmc.ncbi.nlm.nih.gov]
- 2. tandfonline.com [tandfonline.com]
- 3. Quantitative analysis of m6A RNA modification by LC-MS - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. The role and regulatory mechanism of m6A methylation in the nervous system - PMC [pmc.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
- 6. Ythdf2-mediated m6A mRNA clearance modulates neural development in mice. | Sigma-Aldrich [sigmaaldrich.com]
- 7. m6A RNA Methylation Analysis by MS - CD Genomics [rna.cd-genomics.com]
- 8. Studying m6A in the brain: a perspective on current methods, challenges, and future directions - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Ythdf2-mediated m6A mRNA clearance modulates neural development in mice - PMC [pmc.ncbi.nlm.nih.gov]
- 10. RBM45 is an m6A-binding protein that affects neuronal differentiation and the splicing of a subset of mRNAs - PubMed [pubmed.ncbi.nlm.nih.gov]
- 11. Frontiers | m6A methylation: Critical roles in aging and neurological diseases [frontiersin.org]
- 12. Reduced m6A modification predicts malignant phenotypes and augmented Wnt/PI3K-Akt signaling in gastric cancer - PubMed [pubmed.ncbi.nlm.nih.gov]
- 13. researchgate.net [researchgate.net]
- 14. Role of m6A modification in dysregulation of Wnt/β-catenin pathway in cancer - PubMed [pubmed.ncbi.nlm.nih.gov]
- 15. The complex roles of m6A modifications in neural stem cell proliferation, differentiation, and self-renewal and implications for memory and neurodegenerative diseases - PMC [pmc.ncbi.nlm.nih.gov]
- 16. m6A Modification in Mammalian Nervous System Development, Functions, Disorders, and Injuries - PMC [pmc.ncbi.nlm.nih.gov]
- 17. epigenie.com [epigenie.com]
- 18. m6A Modifications Play Crucial Roles in Glial Cell Development and Brain Tumorigenesis - PMC [pmc.ncbi.nlm.nih.gov]
- 19. mTORC1 promotes cell growth via m6A-dependent mRNA degradation - PMC [pmc.ncbi.nlm.nih.gov]
- 20. mTORC1-chaperonin CCT signaling regulates m6A RNA methylation to suppress autophagy - PubMed [pubmed.ncbi.nlm.nih.gov]
- 21. qian.human.cornell.edu [qian.human.cornell.edu]
- 22. Quantification of global m6A RNA methylation levels by LC-MS/MS [visikol.com]
- 23. FTO mediates LINE1 m6A demethylation and chromatin regulation in mESCs and mouse development - PMC [pmc.ncbi.nlm.nih.gov]
The evolutionary conservation of N6-methyladenosine modification.
An In-depth Technical Guide to the Evolutionary Conservation of N6-methyladenosine (m6A) Modification
**Executive Summary
N6-methyladenosine (m6A) is the most abundant internal modification on messenger RNA (mRNA) in most eukaryotes, playing a pivotal role in nearly every aspect of RNA metabolism.[1][2] This dynamic and reversible mark is installed by "writer" proteins, removed by "erasers," and interpreted by "reader" proteins, which collectively modulate mRNA splicing, stability, translation, and localization. The machinery and patterns of m6A modification are highly conserved evolutionarily, underscoring their fundamental importance in biological processes from yeast to mammals.[3][4] This technical guide provides a comprehensive overview of the evolutionary conservation of the m6A pathway, presents quantitative data on its conservation across species, details key experimental protocols for its study, and visualizes the core regulatory and experimental workflows. This document is intended for researchers, scientists, and drug development professionals seeking a deeper understanding of the epitranscriptome's role in health and disease.
The m6A Regulatory Machinery: An Ancient System
The biological effects of m6A are orchestrated by a conserved set of proteins that add, remove, and bind to the modification. The core components of this machinery are found across a vast range of eukaryotic species, indicating an early evolutionary origin.[5][6]
-
Writers (Methyltransferases): The primary m6A writer is a nuclear methyltransferase complex. In mammals, this complex consists of the catalytic subunit METTL3, its partner METTL14, and the associated protein WTAP (Wilms' tumor 1-associated protein).[7][8] This core complex is evolutionarily conserved and is believed to have originated from the Last Eukaryotic Common Ancestor (LECA).[6] Homologs are found in most eukaryotes, including plants (MTA, MTB, FIP) and yeast.[9]
-
Erasers (Demethylases): The reversibility of m6A is managed by demethylases known as erasers. The two main erasers identified in mammals are the fat mass and obesity-associated protein (FTO) and AlkB homolog 5 (ALKBH5).[8] These enzymes belong to the ALKB family of dioxygenases and are thought to have emerged in eukaryotes, potentially through horizontal gene transfer from bacteria.[6] While FTO can also demethylate the related m6Am modification, ALKBH5 is considered the primary m6A demethylase.
-
Readers (Binding Proteins): Reader proteins recognize and bind to m6A-modified transcripts to mediate their downstream effects. The most well-characterized family of readers contains the YT521-B homology (YTH) domain.[10][11] This family is broadly divided into the YTHDF and YTHDC clades. While lower eukaryotes like yeast and primitive plants often possess a single YTHDF protein, vertebrates have three paralogs (YTHDF1, YTHDF2, YTHDF3), and higher plants exhibit a significant expansion of this family.[10][12] This expansion suggests a diversification of m6A-mediated functions in more complex organisms.
Conservation of m6A Patterns and Sites
The location of m6A modifications within transcripts is not random and exhibits conserved patterns across species. In eukaryotes, m6A is typically found within a consensus sequence, RRACH (where R is A or G; H is A, C, or U), and is enriched near stop codons and in 3' untranslated regions (3'UTRs).[1][3][13]
Comparative analyses of m6A methylomes have revealed significant conservation of modification sites between related species. For example, a substantial fraction of m6A peaks are shared between humans and mice, and even more so among primates.[13][14] Studies comparing human, chimpanzee, and rhesus macaque methylomes found that approximately 41% of m6A peaks were conserved across all three species, with over 63% shared between the more closely related humans and chimpanzees.[14] This conservation is not merely a consequence of shared ancestry but is indicative of selective pressure.
Conserved m6A sites are often under purifying (negative) selection, suggesting they perform essential, conserved biological functions.[15] Conversely, species-specific or newly gained m6A sites may be under positive selection, potentially contributing to evolutionary adaptation and the emergence of new traits.[3][15] While specific m6A sites show high conservation, some studies suggest that it is the overall methylation status of a gene, rather than the exact nucleotide position, that is the primary target of selection for a significant portion of modified genes.[2]
In contrast to the structured and functional m6A landscape in eukaryotes, the modification in bacterial mRNA is present at much lower levels, appears to be introduced more randomly, and lacks a clear, conserved functional role or enzymatic recognition mechanism.[16][17][18]
Data Presentation: Quantitative Summary
The following tables summarize the quantitative data on the evolutionary conservation of m6A machinery and modification sites.
Table 1: Evolutionary Conservation of Core m6A Regulatory Proteins
| Protein Family | Function | Prokaryotes | Lower Eukaryotes (e.g., Yeast) | Plants | Mammals |
| METTL3/METTL14 | Writer (Methyltransferase) | Absent | Present | Homologs Present (e.g., MTA, MTB) | Present |
| WTAP | Writer (Complex stabilization) | Absent | Present | Homologs Present (e.g., FIP37) | Present |
| ALKBH5/FTO | Eraser (Demethylase) | Homologs exist, but function differs | Absent/Limited | ALKBH family present | Present |
| YTHDF proteins | Reader (mRNA stability/translation) | Absent | One copy | Expanded family (e.g., 11 in Arabidopsis) | Three paralogs (YTHDF1-3) |
| YTHDC proteins | Reader (Splicing/nuclear export) | Absent | Present | Present | Two paralogs (YTHDC1-2) |
Table 2: Cross-Species Conservation of m6A Peaks in Mammals
| Species Comparison | Tissue/Cell Type | Shared m6A Peaks (%) | Reference |
| Human vs. Chimpanzee | Lymphoblastoid Cell Lines | 63.4% | [14] |
| Human vs. Rhesus Macaque | Lymphoblastoid Cell Lines | 50.9% | [14] |
| Human, Chimp, & Rhesus | Lymphoblastoid Cell Lines | 40.7% | [14] |
| Human vs. Mouse | Cerebellum | 62% (modified transcripts) | [13] |
| Human vs. Mouse | 3' UTRs | ~40% (under purifying selection) | [15] |
Mandatory Visualizations
Core m6A Regulatory Pathway
Caption: The core regulatory pathway of m6A modification.
Experimental Workflow for MeRIP-Seq
References
- 1. Exploring m6A RNA Methylation: Writers, Erasers, Readers | EpigenTek [epigentek.com]
- 2. Most m6A RNA Modifications in Protein-Coding Regions Are Evolutionarily Unconserved and Likely Nonfunctional - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Dynamic landscape and evolution of m6A methylation in human - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Physio-pathological effects of m6A modification and its potential contribution to melanoma - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Evolutionary History of RNA Modifications at N6-Adenosine Originating from the R-M System in Eukaryotes and Prokaryotes - PMC [pmc.ncbi.nlm.nih.gov]
- 6. mdpi.com [mdpi.com]
- 7. Rethinking m6A Readers, Writers, and Erasers - PMC [pmc.ncbi.nlm.nih.gov]
- 8. METTL3 and ALKBH5 oppositely regulate m6A modification of TFEB mRNA, which dictates the fate of hypoxia/reoxygenation-treated cardiomyocytes - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Genome-Wide Identification of m6A Writers, Erasers and Readers in Poplar 84K - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Insights into the conservation and diversification of the molecular functions of YTHDF proteins - PMC [pmc.ncbi.nlm.nih.gov]
- 11. The roles and mechanisms of YTH domain-containing proteins in cancer development and progression - PMC [pmc.ncbi.nlm.nih.gov]
- 12. biorxiv.org [biorxiv.org]
- 13. pnas.org [pnas.org]
- 14. pdfs.semanticscholar.org [pdfs.semanticscholar.org]
- 15. academic.oup.com [academic.oup.com]
- 16. m6A modification is incorporated into bacterial mRNA without specific functional benefit - PubMed [pubmed.ncbi.nlm.nih.gov]
- 17. m6A modification is incorporated into bacterial mRNA without specific functional benefit - PMC [pmc.ncbi.nlm.nih.gov]
- 18. researchgate.net [researchgate.net]
The m6A Consensus Sequence: A Deep Dive into Variations, Regulation, and Function
An In-depth Technical Guide for Researchers, Scientists, and Drug Development Professionals
N6-methyladenosine (m6A) is the most abundant internal modification of messenger RNA (mRNA) in most eukaryotes, playing a pivotal role in the regulation of gene expression. This dynamic and reversible epitranscriptomic mark influences mRNA splicing, nuclear export, stability, and translation. The deposition of m6A is not random, but rather targeted to a specific consensus sequence, the recognition of which is crucial for understanding its regulatory functions. This technical guide provides a comprehensive overview of the m6A consensus sequence, its variations, the molecular machinery that governs its deposition and removal, and its interplay with key cellular signaling pathways.
The Canonical m6A Consensus Sequence and Its Variations
The m6A modification is predominantly found within a consensus sequence motif. The most commonly recognized motif is RRACH , where R represents a purine (Adenine or Guanine), A is the methylated adenosine, and H can be Adenine, Cytosine, or Uracil.[1][2] A closely related and frequently observed motif is DRACH , where D can be Adenine, Guanine, or Uracil.[3][4][5] While these motifs are highly enriched at m6A sites, it is important to note that not all instances of these sequences in the transcriptome are methylated.[6]
The prevalence and specific variations of the m6A consensus sequence can differ across species and even between different tissues and developmental stages within the same organism.
Quantitative Distribution of m6A Sites
The transcriptome-wide mapping of m6A has revealed thousands of modification sites across a significant portion of the transcriptome. The following tables summarize key quantitative findings from various studies.
| Organism/Cell Line | Number of m6A Sites Identified | Number of Genes with m6A | Key Findings & Consensus Motif | Reference |
| Human (HEK293T) | 9,536 (putative) | - | CIMS-based miCLIP identified sites primarily in a DRACH context. | [7] |
| Human & Mouse | >18,000 | >7,000 | Highly conserved m6A landscape with a [G/A/U][G>A]m6AC[U>A/C] consensus. | [8] |
| Human (HeLa) | ~18,000 in m6A genes | 6,252 | Mutations in the RRAC motif are suppressed in m6A modified genes. | [7] |
| Mouse (Embryonic Stem Cells) | - | - | METTL3 phosphorylation impacts pluripotency factor expression. | [9] |
| Saccharomyces cerevisiae (sporulating) | - | - | m6A is found in the GpA context, consistent with the broader RRACH motif. | [5] |
| Study Focus | Number of m6A Peaks/Sites | Key Observations | Reference |
| Human and Mouse Transcriptome | >12,000 m6A sites | Typical consensus motif found in over 7,000 human genes. | [10] |
| Human Tissues | Average of 19,100 m6A peaks per tissue | Dynamic m6A methylation across different tissue types. | [11] |
| Mouse Oocytes & Preimplantation Embryos | Average of 11,965 m6A peaks per stage | About 50% of highly expressed genes are marked with m6A. | [11] |
| Mouse Liver Fibrosis Model | 12,166 peaks (control) vs. 15,100 peaks (model) | Significant differences in m6A modification patterns in disease state. | [9] |
The m6A Regulatory Machinery: Writers, Erasers, and Readers
The dynamic nature of m6A modification is governed by a set of proteins that install, remove, and recognize the methyl mark.
-
Writers: The m6A methyltransferase complex, often referred to as the "writer," is responsible for depositing the methyl group onto adenosine. This complex is primarily composed of the catalytic subunit METTL3 and the stabilizing subunit METTL14. Other associated proteins, such as WTAP, VIRMA, RBM15/15B, and ZC3H13, are also crucial for its function and localization.[12]
-
Erasers: The m6A mark can be removed by demethylases, known as "erasers." The two main erasers identified in mammals are FTO (fat mass and obesity-associated protein) and ALKBH5 (alkB homolog 5).[12]
-
Readers: "Reader" proteins specifically recognize and bind to m6A-modified RNA, thereby mediating the downstream effects of the modification. The YTH domain-containing family of proteins (YTHDF1, YTHDF2, YTHDF3, YTHDC1, and YTHDC2) are the most well-characterized m6A readers. Other reader proteins include members of the HNRNP family and IGF2BPs.[13]
Caption: The core regulatory machinery of m6A modification.
Interplay with Cellular Signaling Pathways
The m6A modification landscape is not static but is dynamically regulated by various cellular signaling pathways, allowing cells to rapidly respond to external stimuli. Key signaling pathways that intersect with the m6A machinery include TGF-β, ERK, and mTORC1.
TGF-β Signaling
The Transforming Growth Factor-β (TGF-β) signaling pathway, crucial for cell growth, differentiation, and development, has been shown to directly modulate m6A deposition. The TGF-β effectors, SMAD2 and SMAD3, can interact with the m6A writer complex, influencing the methylation of specific transcripts involved in processes like pluripotency and differentiation.[14][15]
References
- 1. MeRIP-seq Protocol - CD Genomics [rna.cd-genomics.com]
- 2. creative-diagnostics.com [creative-diagnostics.com]
- 3. researchgate.net [researchgate.net]
- 4. Mapping m6A at individual-nucleotide resolution using crosslinking and immunoprecipitation (miCLIP) - PMC [pmc.ncbi.nlm.nih.gov]
- 5. academic.oup.com [academic.oup.com]
- 6. biorxiv.org [biorxiv.org]
- 7. Single-nucleotide resolution mapping of m6A and m6Am throughout the transcriptome - PMC [pmc.ncbi.nlm.nih.gov]
- 8. TGF-β Signaling | Cell Signaling Technology [cellsignal.com]
- 9. Comprehensive Analysis of the Transcriptome-Wide m6A Methylation Modification Difference in Liver Fibrosis Mice by High-Throughput m6A Sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 10. researchgate.net [researchgate.net]
- 11. The RNA m6A landscape of mouse oocytes and preimplantation embryos - PMC [pmc.ncbi.nlm.nih.gov]
- 12. How MeRIP-seq Works: Principles, Workflow, and Applications Explained - CD Genomics [rna.cd-genomics.com]
- 13. creative-diagnostics.com [creative-diagnostics.com]
- 14. researchgate.net [researchgate.net]
- 15. Comprehensive Overview of m6A Detection Methods - CD Genomics [cd-genomics.com]
An In-depth Technical Guide on the Impact of N6-methyladenosine (m6A) on RNA Secondary Structure
A Note on Nomenclature: Initial searches for "2-Methylamino-N6-methyladenosine" did not yield a recognized RNA modification in established databases such as MODOMICS.[1][2][3][4] It is possible that this name is a non-standard descriptor or a variant of a known modification. The components of the name, however, point to N6-methyladenosine (m6A), the most abundant internal modification in eukaryotic mRNA.[5][6] This guide will therefore focus on the well-documented effects of m6A on RNA secondary structure, a topic of significant interest in the fields of molecular biology and drug development. Another related modification, N6,2′-O-dimethyladenosine (m6Am), is found at the 5' cap of mRNA and also plays a role in RNA stability and translation.[7][8][9]
Introduction
N6-methyladenosine (m6A) is a reversible post-transcriptional modification that plays a crucial role in many aspects of RNA metabolism, including splicing, nuclear export, stability, and translation.[10][11][12] The deposition of m6A is managed by a "writer" complex, primarily composed of METTL3 and METTL14, while its removal is carried out by "eraser" enzymes such as FTO and ALKBH5.[13][14][15][16] The biological consequences of m6A are mediated by "reader" proteins that specifically recognize the m6A mark and influence the fate of the modified RNA.[13][14][17]
A growing body of evidence indicates that m6A can directly impact the secondary structure of RNA. This "m6A-switch" mechanism can alter RNA-protein interactions and, consequently, the downstream processing and function of the RNA molecule.[10][18] Understanding the structural and thermodynamic consequences of m6A is therefore critical for elucidating its regulatory roles and for the development of therapeutics targeting RNA-modifying pathways.
Quantitative Impact of m6A on RNA Secondary Structure
The presence of m6A within an RNA duplex has a notable impact on its thermodynamic stability. Generally, m6A is a destabilizing modification when present within a double-stranded region.
Table 1: Thermodynamic Parameters of m6A-Containing RNA Duplexes
| RNA Duplex Context | ΔG°37 (kcal/mol) Unmodified | ΔG°37 (kcal/mol) m6A-modified | ΔΔG°37 (kcal/mol) | Reference |
| Internal U-A pair | - | - | +0.5 to +1.7 | [19][20] |
| Separated internal U-A pair | - | - | +2.06 | [21] |
| Tandem internal U-A pair | - | - | +0.09 | [22] |
Note: A positive ΔΔG°37 indicates destabilization of the duplex by the m6A modification.
In contrast to its destabilizing effect in duplexes, unpaired m6A can have a stabilizing effect due to enhanced stacking interactions compared to unmodified adenosine.[20] This dual nature of m6A's impact—destabilizing helices while stabilizing single-stranded regions—forms the basis of the m6A-switch hypothesis.[10][18] This structural remodeling can expose or conceal binding sites for RNA-binding proteins, thereby modulating their interaction with the RNA.
Experimental Protocols for Studying m6A and RNA Structure
Several experimental techniques are employed to investigate the influence of m6A on RNA secondary structure.
1. m6A Sequencing (m6A-Seq/MeRIP-Seq)
This antibody-based method is the most widely used for transcriptome-wide mapping of m6A.[23]
-
Objective: To identify the locations of m6A modifications across the transcriptome.
-
Methodology:
-
RNA Isolation and Fragmentation: Total RNA or poly(A) RNA is isolated from cells or tissues and fragmented into smaller pieces (typically ~100-200 nucleotides).
-
Immunoprecipitation (IP): The RNA fragments are incubated with an antibody specific to m6A. The antibody-RNA complexes are then captured, usually with magnetic beads.
-
Library Preparation and Sequencing: The enriched m6A-containing RNA fragments are reverse-transcribed into cDNA, and sequencing libraries are prepared for high-throughput sequencing.
-
Data Analysis: Sequencing reads are aligned to a reference genome/transcriptome, and peaks of enrichment are identified, indicating the locations of m6A.
-
2. Nanopore Direct RNA Sequencing
This technology allows for the direct sequencing of native RNA molecules, enabling the detection of modifications without the need for antibodies or chemical labeling.[24][25][26]
-
Objective: To directly detect m6A and other RNA modifications at single-nucleotide resolution.
-
Methodology:
-
Library Preparation: A sequencing adapter is ligated to the 3' end of poly(A)-tailed RNA molecules.
-
Sequencing: The RNA molecules are passed through a nanopore. As each nucleotide traverses the pore, it disrupts an ionic current, generating a characteristic electrical signal. Modified bases produce a signal that is distinct from their unmodified counterparts.
-
Data Analysis: Specialized algorithms are used to analyze the raw signal data and identify the locations of modified bases.
-
3. Structural Probing (e.g., SHAPE-MaP, DMS-seq)
Chemical probing techniques can reveal information about RNA secondary structure in a high-throughput manner.
-
Objective: To determine the secondary structure of RNA molecules and assess the impact of m6A.
-
Methodology:
-
Chemical Modification: RNA is treated with a chemical reagent (e.g., SHAPE reagents, dimethyl sulfate (DMS)) that modifies structurally accessible nucleotides.
-
Reverse Transcription: The modified RNA is reverse-transcribed. The modifications cause the reverse transcriptase to stall or incorporate a mismatch at the modified site.
-
Sequencing and Analysis: The resulting cDNA is sequenced, and the sites of modification are identified. By comparing the modification patterns of m6A-containing and unmodified RNA, changes in secondary structure can be inferred.
-
4. Nuclear Magnetic Resonance (NMR) Spectroscopy
NMR provides high-resolution structural and dynamic information about RNA molecules in solution.[27]
-
Objective: To determine the three-dimensional structure and dynamics of m6A-containing RNA oligonucleotides.
-
Methodology:
-
Sample Preparation: Isotopically labeled (e.g., 13C, 15N) RNA oligonucleotides with and without m6A are synthesized.
-
NMR Data Acquisition: A series of NMR experiments (e.g., NOESY, HSQC) are performed to measure distances between atoms and identify through-bond connectivities.
-
Structure Calculation: The experimental data are used as constraints to calculate a three-dimensional model of the RNA structure.
-
Kinetic Analysis: Techniques like NMR relaxation dispersion can be used to measure the kinetics of RNA hybridization and how m6A affects these rates.[27]
-
5. Liquid Chromatography-Mass Spectrometry (LC-MS)
LC-MS is a highly sensitive and quantitative method for detecting and quantifying modified nucleosides.[28]
-
Objective: To determine the overall abundance of m6A in a given RNA sample.
-
Methodology:
-
RNA Digestion: The RNA sample is enzymatically digested into individual nucleosides.
-
Chromatographic Separation: The nucleosides are separated by liquid chromatography.
-
Mass Spectrometry: The separated nucleosides are ionized and their mass-to-charge ratio is measured by a mass spectrometer, allowing for the identification and quantification of m6A relative to unmodified adenosine.
-
Signaling Pathways and Logical Relationships
The interplay between m6A writers, erasers, and readers constitutes a dynamic regulatory network that can be influenced by various signaling pathways and, in turn, can modulate cellular processes.
Caption: The m6A regulatory pathway, from deposition in the nucleus to functional outcomes in the cytoplasm.
The deposition of m6A by the writer complex is a key regulatory step.[13][14] In the nucleus, m6A can be recognized by reader proteins like YTHDC1, which influences splicing and promotes the export of the modified RNA to the cytoplasm.[12] In the cytoplasm, a different set of reader proteins, including the YTHDF family and IGF2BPs, determine the fate of the m6A-modified transcript, leading to enhanced translation, degradation, or affecting its stability.[10] This entire process can be influenced by cellular signaling pathways, such as the PI3K/Akt/mTOR and TGF-β pathways, which can regulate the expression and activity of the m6A machinery.[29][30]
Caption: The "m6A-switch" mechanism for regulating RNA-protein interactions.
The "m6A-switch" is a prime example of how this modification can directly influence RNA-protein interactions by altering the local RNA structure.[10][18] For instance, the presence of m6A within a hairpin structure can destabilize it, leading to the exposure of a previously hidden binding motif for an RNA-binding protein like HNRNPC.[18]
Caption: A generalized experimental workflow for investigating the impact of m6A on RNA structure.
Investigating the structural consequences of m6A typically involves a multi-pronged approach. After isolating and quality-controlling the RNA, a combination of techniques is often employed. m6A-Seq or nanopore sequencing can identify the locations of the modification, while structural probing methods and NMR can provide insights into the structural changes induced by m6A at those sites. LC-MS can be used to quantify the overall levels of m6A. All of these experimental avenues converge on bioinformatic analysis to integrate the different data types and build a comprehensive picture of m6A's role in shaping the RNA structurome.
References
- 1. Modomics - A Database of RNA Modifications [genesilico.pl]
- 2. Modomics - A Database of RNA Modifications [genesilico.pl]
- 3. MODOMICS: A database of RNA modif... preview & related info | Mendeley [mendeley.com]
- 4. researchgate.net [researchgate.net]
- 5. N6-Methyladenosine - Wikipedia [en.wikipedia.org]
- 6. m6A RNA methylation: from mechanisms to therapeutic potential - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Dynamic regulation of N6,2′-O-dimethyladenosine (m6Am) in obesity - PMC [pmc.ncbi.nlm.nih.gov]
- 8. A comprehensive review of m6A/m6Am RNA methyltransferase structures - PMC [pmc.ncbi.nlm.nih.gov]
- 9. academic.oup.com [academic.oup.com]
- 10. The RNA Modification N6-methyladenosine and Its Implications in Human Disease - PMC [pmc.ncbi.nlm.nih.gov]
- 11. m6A RNA Regulatory Diagram | Cell Signaling Technology [cellsignal.com]
- 12. The N6-Methyladenosine Modification and Its Role in mRNA Metabolism and Gastrointestinal Tract Disease - PMC [pmc.ncbi.nlm.nih.gov]
- 13. m6A writers, erasers, readers and their functions | Abcam [abcam.com]
- 14. Exploring m6A RNA Methylation: Writers, Erasers, Readers | EpigenTek [epigentek.com]
- 15. Rethinking m6A Readers, Writers, and Erasers - PMC [pmc.ncbi.nlm.nih.gov]
- 16. N6-Methyladenosine in RNA and DNA: An Epitranscriptomic and Epigenetic Player Implicated in Determination of Stem Cell Fate - PMC [pmc.ncbi.nlm.nih.gov]
- 17. researchgate.net [researchgate.net]
- 18. N 6-methyladenosine alters RNA structure to regulate binding of a low-complexity protein - PMC [pmc.ncbi.nlm.nih.gov]
- 19. pubs.acs.org [pubs.acs.org]
- 20. researchgate.net [researchgate.net]
- 21. academic.oup.com [academic.oup.com]
- 22. academic.oup.com [academic.oup.com]
- 23. Protocol for antibody-based m6A sequencing of human postmortem brain tissues - PMC [pmc.ncbi.nlm.nih.gov]
- 24. Comprehensive Overview of m6A Detection Methods - CD Genomics [cd-genomics.com]
- 25. youtube.com [youtube.com]
- 26. m.youtube.com [m.youtube.com]
- 27. NMR chemical exchange measurements reveal that N6-methyladenosine slows RNA annealing - PMC [pmc.ncbi.nlm.nih.gov]
- 28. bpb-us-e2.wpmucdn.com [bpb-us-e2.wpmucdn.com]
- 29. m6A in the Signal Transduction Network - PMC [pmc.ncbi.nlm.nih.gov]
- 30. m6A RNA modification modulates PI3K/Akt/mTOR signal pathway in Gastrointestinal Cancer - PMC [pmc.ncbi.nlm.nih.gov]
The Foundational Principles of N6-methyladenosine: A Technical Guide for Researchers and Drug Development Professionals
An In-depth Exploration of the Core M6-adenosine Machinery, Experimental Methodologies, and Quantitative Landscape
N6-methyladenosine (m6A) has emerged as the most abundant internal modification in eukaryotic messenger RNA (mRNA), orchestrating a complex layer of post-transcriptional gene regulation.[1][2] This dynamic and reversible methylation of adenosine residues is a critical regulator at every stage of the mRNA lifecycle, influencing splicing, nuclear export, translation, and decay.[1][2][3][4][5][6][7][8][9][10][11][12][13][14][15][16][17][18][19][20][21][22][23][24][25][26][27][28][29][30][31][32][33][34][35][36][37][[“]][39][40][41][42][43][44][45] Its discovery and the subsequent characterization of the enzymatic machinery that installs ("writers"), removes ("erasers"), and recognizes ("readers") this mark have unveiled a sophisticated network governing a vast array of biological processes. Dysregulation of m6A has been implicated in numerous diseases, including cancer, metabolic disorders, and neurological conditions, making its regulatory pathways attractive targets for therapeutic intervention. This technical guide provides a comprehensive overview of the foundational research, key experimental protocols, and quantitative data underpinning our current understanding of m6A biology.
I. The Core Regulatory Machinery of m6A
The dynamic nature of m6A modification is governed by a trio of protein families: writers, erasers, and readers. These proteins work in concert to establish and interpret the m6A epitranscriptome.
Writers: The M6A Methyltransferase Complex
The deposition of m6A is catalyzed by a nuclear multiprotein complex. The core components are the methyltransferase-like 3 (METTL3) and METTL14 proteins, which form a stable heterodimer.[4][10][11][12][13]
-
METTL3: This is the catalytic subunit of the complex, containing the S-adenosylmethionine (SAM)-binding pocket necessary for methyl group transfer.[4][10][11][12][13]
-
METTL14: While structurally similar to METTL3, METTL14 has a degenerate active site and is catalytically inactive. Its primary role is to provide a structural scaffold, stabilize METTL3, and facilitate RNA substrate recognition.[4][10][11][12][13]
-
WTAP and other regulatory subunits: Wilms' tumor 1-associating protein (WTAP) is a crucial regulatory component that interacts with METTL3 and METTL14, guiding the complex to specific locations within the nucleus. Other associated proteins, such as KIAA1429 (VIRMA), RBM15/15B, and ZC3H13, also contribute to the regulation and substrate specificity of the writer complex.
The writer complex recognizes a consensus sequence motif, RRACH (where R = G or A; H = A, C, or U), for m6A deposition.[14]
Erasers: The M6A Demethylases
The reversibility of m6A modification is a key feature that allows for dynamic regulation of gene expression. This process is mediated by two primary demethylases, both belonging to the Fe(II)/2-oxoglutarate-dependent dioxygenase family.
-
Fat mass and obesity-associated protein (FTO): FTO was the first identified m6A demethylase. It catalyzes the oxidative demethylation of m6A. FTO can also demethylate other adenosine modifications, and its activity is not limited to mRNA.[18][25][28]
-
AlkB homolog 5 (ALKBH5): ALKBH5 is another m6A demethylase that removes the methyl group from adenosine. Unlike FTO, ALKBH5 appears to have a more specific role in mRNA demethylation.[18][21][25][28][33] The demethylation mechanisms of FTO and ALKBH5 are distinct, leading to different rates of formaldehyde release.[28]
Readers: Interpreting the M6A Code
M6A reader proteins are a diverse group of RNA-binding proteins that specifically recognize and bind to m6A-modified transcripts, thereby dictating their downstream fate.
-
YTH Domain-Containing Proteins: The YT521-B homology (YTH) domain-containing family is a major class of m6A readers.
-
YTHDF1: Primarily located in the cytoplasm, YTHDF1 promotes the translation of m6A-containing mRNAs by interacting with translation initiation factors.[9][20][22][32][36]
-
YTHDF2: This reader protein is well-characterized for its role in promoting the degradation of m6A-modified mRNAs by recruiting the CCR4-NOT deadenylase complex.[19][[“]][41][43][45]
-
YTHDF3: The function of YTHDF3 is more complex, as it has been suggested to work in concert with both YTHDF1 to promote translation and YTHDF2 to facilitate decay.
-
-
Insulin-like Growth Factor 2 mRNA-Binding Proteins (IGF2BPs): The IGF2BP family (IGF2BP1, IGF2BP2, and IGF2BP3) represents another class of m6A readers. In contrast to YTHDF2, IGF2BPs enhance the stability and promote the translation of their target mRNAs in an m6A-dependent manner.[6][14][15][16][29]
-
Heterogeneous Nuclear Ribonucleoproteins (HNRNPs): Certain HNRNPs, such as HNRNPA2B1 and HNRNPC, have been identified as nuclear m6A readers. They play a role in regulating pre-mRNA splicing and other nuclear RNA processing events.[1][23][27]
II. Quantitative Landscape of N6-methyladenosine
The abundance and stoichiometry of m6A are critical parameters that influence its regulatory impact. Various techniques have been developed to quantify m6A levels, from global measurements to site-specific analysis.
Table 1: Global m6A Abundance in Mammalian Cells
| Method | Sample Type | m6A/A Ratio (%) | Reference |
| LC-MS/MS | HEK293T mRNA | ~0.3-0.4% | [31] |
| LC-MS/MS | Mouse embryonic stem cell mRNA | ~0.2% | [30] |
| m6A-ELISA | Wild-type mESC mRNA | Relative decrease of >50-fold in Mettl3 KO | [30] |
Table 2: Kinetic Parameters of m6A Demethylases
| Enzyme | Substrate | Km (µM) | kcat (min⁻¹) | Reference |
| FTO | ssRNA with G(m6A)C | 2.5 ± 0.3 | 0.12 ± 0.01 | [21] |
| FTO | ssRNA with A(m6A)C | 3.1 ± 0.4 | 0.10 ± 0.01 | [21] |
| ALKBH5 | ssRNA with G(m6A)C | 1.8 ± 0.2 | 0.25 ± 0.02 | [21] |
| ALKBH5 | ssRNA with A(m6A)C | 2.2 ± 0.3 | 0.21 ± 0.02 | [21] |
III. Key Experimental Protocols for m6A Analysis
A variety of sophisticated techniques have been developed to detect, map, and quantify m6A modifications across the transcriptome.
MeRIP-Seq (m6A-Seq): Transcriptome-Wide m6A Profiling
Methylated RNA Immunoprecipitation followed by Sequencing (MeRIP-Seq) is the most widely used method for transcriptome-wide mapping of m6A.
Protocol Overview:
-
RNA Extraction and Fragmentation:
-
Immunoprecipitation (IP):
-
Incubate the fragmented RNA with an m6A-specific antibody to form RNA-antibody complexes.
-
Capture the complexes using protein A/G magnetic beads.
-
Wash the beads to remove non-specifically bound RNA.
-
-
Elution and Library Preparation:
-
Elute the m6A-containing RNA fragments from the antibody-bead complexes.
-
Prepare sequencing libraries from both the immunoprecipitated (IP) and input (pre-IP) RNA samples.
-
-
Sequencing and Data Analysis:
LC-MS/MS: Absolute Quantification of Global m6A
Liquid Chromatography-Tandem Mass Spectrometry (LC-MS/MS) is the gold standard for accurate and absolute quantification of the global m6A to adenosine (A) ratio in a given RNA sample.[3][7][8][24][31][46]
Protocol Overview:
-
RNA Isolation and Digestion:
-
LC Separation:
-
Separate the resulting nucleosides using reverse-phase liquid chromatography.
-
-
MS/MS Detection and Quantification:
-
Detect and quantify the amounts of adenosine and N6-methyladenosine using a tandem mass spectrometer operating in multiple reaction monitoring (MRM) mode.
-
Generate standard curves using known concentrations of pure adenosine and m6A to ensure accurate quantification.[3][46]
-
The m6A/A ratio is calculated based on the calibrated concentrations of the two nucleosides.[31]
-
SCARLET: Single-Nucleotide Resolution m6A Detection and Stoichiometry
Site-Specific Cleavage and Radioactive-Labeling followed by Ligation-Assisted Extraction and Thin-Layer Chromatography (SCARLET) is a highly sensitive method for determining the precise location and stoichiometry of m6A at a single-nucleotide resolution.[2][40][42][44]
Protocol Overview:
-
Site-Specific Cleavage:
-
A chimeric oligonucleotide is designed to hybridize to the target RNA sequence, creating a substrate for RNase H, which cleaves the RNA at a specific site immediately 5' to the adenosine of interest.
-
-
Radioactive Labeling and Ligation:
-
The 5' end of the cleaved RNA fragment containing the target adenosine is radioactively labeled (e.g., with ³²P).
-
A DNA splint and ligase are used to ligate an adapter to the labeled RNA fragment.
-
-
Digestion and Thin-Layer Chromatography (TLC):
-
The ligated product is digested into individual nucleotides.
-
The radiolabeled adenosine and N6-methyladenosine are separated by two-dimensional thin-layer chromatography.
-
-
Quantification:
IV. Visualizing the m6A Regulatory Network
The intricate relationships between the m6A machinery and its target RNAs can be visualized through signaling pathways and experimental workflows.
Diagrams of Key Processes
Caption: The central dogma of N6-methyladenosine (m6A) regulation.
Caption: Experimental workflow for MeRIP-Seq (m6A-Seq).
Caption: YTHDF2-mediated mRNA decay pathway.
V. Conclusion
The field of epitranscriptomics, with m6A at its forefront, has revolutionized our understanding of gene expression regulation. The foundational discoveries of the writer, eraser, and reader proteins have provided a molecular framework for dissecting the multifaceted roles of this dynamic RNA modification. The development of robust experimental methodologies, from transcriptome-wide mapping to precise quantitative analysis, has empowered researchers to explore the intricate connections between m6A and a wide range of biological processes and human diseases. For professionals in drug development, the components of the m6A pathway present a promising new class of therapeutic targets. As research continues to unravel the complexities of the m6A regulatory network, it is poised to open new avenues for diagnostic and therapeutic innovation.
References
- 1. HNRNPA2B1 is a mediator of m6A-dependent nuclear RNA processing events - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Probing N 6-methyladenosine (m6A) RNA Modification in Total RNA with SCARLET | Springer Nature Experiments [experiments.springernature.com]
- 3. bpb-us-e2.wpmucdn.com [bpb-us-e2.wpmucdn.com]
- 4. The catalytic mechanism of the RNA methyltransferase METTL3 - PMC [pmc.ncbi.nlm.nih.gov]
- 5. MeRIP-seq Protocol - CD Genomics [rna.cd-genomics.com]
- 6. Control of c-myc mRNA stability by IGF2BP1-associated cytoplasmic RNPs - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Liquid Chromatography-Mass Spectrometry for Analysis of RNA Adenosine Methylation | Springer Nature Experiments [experiments.springernature.com]
- 8. researchgate.net [researchgate.net]
- 9. The roles and mechanisms of the m6A reader protein YTHDF1 in tumor biology and human diseases - PMC [pmc.ncbi.nlm.nih.gov]
- 10. biochem-caflisch.uzh.ch [biochem-caflisch.uzh.ch]
- 11. researchgate.net [researchgate.net]
- 12. The catalytic mechanism of the RNA methyltransferase METTL3 - PubMed [pubmed.ncbi.nlm.nih.gov]
- 13. researchgate.net [researchgate.net]
- 14. Stabilization of IGF2BP1 by USP10 promotes breast cancer metastasis via CPT1A in an m6A-dependent manner - PMC [pmc.ncbi.nlm.nih.gov]
- 15. IGF2BP1 overexpression stabilizes PEG10 mRNA in an m6A-dependent manner and promotes endometrial cancer progression [thno.org]
- 16. IGF2BP1 overexpression stabilizes PEG10 mRNA in an m6A-dependent manner and promotes endometrial cancer progression - PMC [pmc.ncbi.nlm.nih.gov]
- 17. lcsciences.com [lcsciences.com]
- 18. Insights into the m6A demethylases FTO and ALKBH5 : structural, biological function, and inhibitor development - PMC [pmc.ncbi.nlm.nih.gov]
- 19. researchgate.net [researchgate.net]
- 20. YTHDF1‐mediated translation amplifies Wnt‐driven intestinal stemness | EMBO Reports [link.springer.com]
- 21. researchgate.net [researchgate.net]
- 22. Frontiers | N6-methyladenosine reader YTHDF family in biological processes: Structures, roles, and mechanisms [frontiersin.org]
- 23. HNRNPA2B1 and HNRNPR stabilize ASCL1 in an m6A-dependent manner to promote neuroblastoma progression - PubMed [pubmed.ncbi.nlm.nih.gov]
- 24. Protocol for preparation and measurement of intracellular and extracellular modified RNA using liquid chromatography-mass spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 25. Targeting the RNA demethylase FTO for cancer therapy - PMC [pmc.ncbi.nlm.nih.gov]
- 26. sysy.com [sysy.com]
- 27. researchgate.net [researchgate.net]
- 28. pnas.org [pnas.org]
- 29. Insulin-like growth factor 2 mRNA-binding protein 1 (IGF2BP1) in hematological diseases - PMC [pmc.ncbi.nlm.nih.gov]
- 30. m6A-ELISA, a simple method for quantifying N6-methyladenosine from mRNA populations - PMC [pmc.ncbi.nlm.nih.gov]
- 31. m6A RNA Degradation Products Are Catabolized by an Evolutionarily Conserved N6-Methyl-AMP Deaminase in Plant and Mammalian Cells - PMC [pmc.ncbi.nlm.nih.gov]
- 32. academic.oup.com [academic.oup.com]
- 33. researchgate.net [researchgate.net]
- 34. A protocol for RNA methylation differential analysis with MeRIP-Seq data and exomePeak R/Bioconductor package - PMC [pmc.ncbi.nlm.nih.gov]
- 35. rna-seqblog.com [rna-seqblog.com]
- 36. researchgate.net [researchgate.net]
- 37. HNRNPA2B1 Is a Mediator of m6A-Dependent Nuclear RNA Processing Events | Semantic Scholar [semanticscholar.org]
- 38. consensus.app [consensus.app]
- 39. Master MeRIP-seq Data Analysis: Step-by-Step Process for RNA Methylation Studies - CD Genomics [rna.cd-genomics.com]
- 40. researchgate.net [researchgate.net]
- 41. researchgate.net [researchgate.net]
- 42. Frontiers | Current progress in strategies to profile transcriptomic m6A modifications [frontiersin.org]
- 43. YTHDF2 mediates the mRNA degradation of the tumor suppressors to induce AKT phosphorylation in N6-methyladenosine-dependent way in prostate cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 44. Probing N6-methyladenosine RNA modification status at single nucleotide resolution in mRNA and long noncoding RNA - PMC [pmc.ncbi.nlm.nih.gov]
- 45. YTHDF2 facilitates UBXN1 mRNA decay by recognizing METTL3-mediated m6A modification to activate NF-κB and promote the malignant progression of glioma - PubMed [pubmed.ncbi.nlm.nih.gov]
- 46. Quantitative analysis of m6A RNA modification by LC-MS - PubMed [pubmed.ncbi.nlm.nih.gov]
Methodological & Application
Detecting RNA Methylation: Application Notes and Protocols for Researchers
A comprehensive guide for the detection and quantification of N6-methyladenosine (m6A), with considerations for other adenosine modifications like 2-Methylamino-N6-methyladenosine (m2,6A).
Introduction
Post-transcriptional modifications of RNA, collectively known as the epitranscriptome, add a significant layer of regulatory complexity to gene expression. Among the more than 170 known RNA modifications, N6-methyladenosine (m6A) is the most abundant internal modification in eukaryotic messenger RNA (mRNA).[1][2][3] This reversible modification is installed by "writer" enzymes (methyltransferases), removed by "erasers" (demethylases), and recognized by "reader" proteins, which mediate its downstream effects on RNA metabolism, including splicing, nuclear export, stability, and translation.[1]
While the user's query specified the detection of this compound (m2,6A), the vast majority of established and validated protocols focus on the detection of m6A. Currently, there is a lack of specific, widely-used protocols for the detection of m2,6A in RNA. However, the principles and techniques developed for m6A analysis, particularly mass spectrometry, provide a foundational framework that can be adapted for the discovery and quantification of other novel RNA modifications.
This document provides detailed application notes and protocols for the robust detection and quantification of m6A in RNA. These methodologies are categorized into sequencing-based, antibody-based, and mass spectrometry-based approaches, each with distinct advantages and applications.
I. Methods for Global m6A Quantification
Several techniques are available to determine the overall levels of m6A in a given RNA population. These methods are crucial for understanding broad changes in m6A levels in response to different stimuli or in various disease states.
A. Liquid Chromatography-Tandem Mass Spectrometry (LC-MS/MS)
LC-MS/MS is considered the gold standard for the accurate quantification of RNA modifications.[4][5] This method involves the enzymatic digestion of RNA into individual nucleosides, which are then separated by liquid chromatography and identified and quantified by mass spectrometry based on their unique mass-to-charge ratios.
Key Features:
-
High Accuracy and Sensitivity: Provides precise and absolute quantification of m6A levels.
-
Versatility: Can be adapted to detect and quantify a wide range of RNA modifications, including potentially m2,6A, provided the appropriate standards are available.
-
No Sequence Information: This method does not provide information about the location of the modification within the RNA sequence.
B. m6A ELISA
The m6A Enzyme-Linked Immunosorbent Assay (ELISA) is a high-throughput method for the relative quantification of m6A in RNA populations.[6] This technique utilizes an m6A-specific antibody to capture and detect m6A in immobilized RNA samples.
Key Features:
-
High-Throughput and Cost-Effective: Suitable for screening a large number of samples.
-
Small Sample Requirement: Requires only a small amount of input RNA.[6]
-
Relative Quantification: Provides relative changes in m6A levels rather than absolute quantification.
C. Dot Blot
A dot blot assay is a simple and rapid method for the semi-quantitative detection of m6A. In this technique, RNA is spotted onto a membrane and detected using an m6A-specific antibody.
Key Features:
-
Simplicity and Speed: A straightforward and quick method for assessing global m6A levels.
-
Semi-Quantitative: Provides a general indication of m6A abundance but lacks the precision of LC-MS/MS or ELISA.
II. Methods for Transcriptome-Wide m6A Mapping
To understand the functional roles of m6A, it is essential to identify its specific locations within the transcriptome. Several high-throughput sequencing-based methods have been developed for this purpose.
A. m6A-Seq/MeRIP-Seq (Methylated RNA Immunoprecipitation Sequencing)
m6A-Seq, also known as MeRIP-Seq, is the most widely used method for transcriptome-wide mapping of m6A.[1][3] This technique involves fragmenting the RNA, followed by immunoprecipitation of the m6A-containing fragments using an m6A-specific antibody. The enriched fragments are then sequenced and mapped to the transcriptome to identify m6A peaks.
Key Features:
-
Transcriptome-Wide Coverage: Enables the identification of m6A sites across the entire transcriptome.
-
Moderate Resolution: Typically identifies m6A-containing regions of about 100-200 nucleotides.[7]
-
Antibody Dependent: The quality of the data is highly dependent on the specificity and efficiency of the m6A antibody used.
B. miCLIP (m6A individual-nucleotide-resolution cross-linking and immunoprecipitation)
miCLIP is a refinement of the antibody-based approach that allows for the identification of m6A sites at single-nucleotide resolution. This method involves UV cross-linking of the m6A antibody to the RNA, followed by immunoprecipitation and stringent washing steps. The cross-linking site, which corresponds to the m6A location, is identified by a characteristic mutation upon reverse transcription.
Key Features:
-
Single-Nucleotide Resolution: Pinpoints the exact location of the m6A modification.
-
Reduced False Positives: The cross-linking step enhances the specificity of m6A identification.
-
Technically Demanding: Requires more specialized procedures compared to standard MeRIP-Seq.
C. Enzyme-Based and Chemical-Based Methods
To overcome the limitations of antibody-based methods, several alternative approaches have been developed.
-
DART-seq (Deamination of Adenosines, RNA Targeting and Sequencing): An antibody-free method that uses an engineered fusion protein to induce a detectable sequence change adjacent to the m6A site.[2]
-
m6A-SEAL (m6A-selective chemical labeling): This technique employs a chemical probe that specifically labels m6A sites, allowing for their subsequent enrichment and identification through sequencing.[2]
Quantitative Comparison of m6A Detection Methods
| Method | Principle | Resolution | Quantification | Throughput | Key Advantage | Key Limitation |
| LC-MS/MS | Chromatographic separation and mass spectrometry | N/A (Global) | Absolute | Low to Medium | Gold standard for accuracy | No sequence information |
| m6A ELISA | Antibody-based colorimetric detection | N/A (Global) | Relative | High | Fast, scalable, low input RNA | Not absolute quantification |
| Dot Blot | Antibody-based membrane detection | N/A (Global) | Semi-quantitative | High | Simple and rapid | Low precision |
| m6A-Seq/MeRIP-Seq | Antibody enrichment and high-throughput sequencing | ~100-200 nt | Relative | High | Transcriptome-wide mapping | Moderate resolution, antibody bias |
| miCLIP | UV cross-linking, immunoprecipitation, and sequencing | Single-nucleotide | Relative | Medium | High resolution and specificity | Technically complex |
| DART-seq | Enzyme-mediated deamination and sequencing | Single-nucleotide | Relative | High | Antibody-free | Requires engineered proteins |
| m6A-SEAL | Chemical labeling and sequencing | Single-nucleotide | Relative | High | Antibody-free, high specificity | Complex chemical synthesis |
Experimental Protocols
Protocol 1: Global m6A Quantification using LC-MS/MS
This protocol outlines the key steps for the absolute quantification of m6A in total RNA or mRNA.
1. RNA Isolation and Purification:
-
Isolate total RNA from cells or tissues using a standard method (e.g., TRIzol).
-
For mRNA quantification, perform poly(A) selection.
-
Ensure high-quality RNA with an A260/A280 ratio of ~2.0.
2. Enzymatic Digestion of RNA:
-
To 1-2 µg of RNA, add a known amount of a stable isotope-labeled m6A internal standard.
-
Add nuclease P1 and incubate at 42°C for 2 hours to digest the RNA into nucleoside 5'-monophosphates.
-
Add bacterial alkaline phosphatase and incubate at 37°C for 2 hours to dephosphorylate the nucleosides.
3. LC-MS/MS Analysis:
-
Separate the digested nucleosides using a C18 reverse-phase liquid chromatography column.
-
Perform mass spectrometry in positive ion mode using multiple reaction monitoring (MRM) to detect and quantify adenosine and m6A.
-
The amount of m6A is quantified by comparing its peak area to that of the internal standard.
Protocol 2: Transcriptome-Wide m6A Mapping using MeRIP-Seq
This protocol details the procedure for identifying m6A sites across the transcriptome.
1. RNA Preparation and Fragmentation:
-
Isolate total RNA and perform two rounds of poly(A) selection to enrich for mRNA.
-
Chemically fragment the mRNA to an average size of ~100 nucleotides.
2. Immunoprecipitation (IP):
-
Take an aliquot of the fragmented RNA as an input control.
-
Incubate the remaining fragmented RNA with an m6A-specific antibody coupled to magnetic beads.
-
Wash the beads to remove non-specifically bound RNA fragments.
-
Elute the m6A-containing RNA fragments.
3. Library Preparation and Sequencing:
-
Prepare sequencing libraries from both the immunoprecipitated (IP) and input RNA fragments.
-
Perform high-throughput sequencing.
4. Data Analysis:
-
Align the sequencing reads to the reference genome.
-
Use a peak-calling algorithm to identify regions enriched for m6A in the IP sample compared to the input control.
Considerations for Detecting this compound (m2,6A)
As previously mentioned, there are no established, widely-used protocols specifically for the detection of m2,6A in RNA. However, the existing methodologies for m6A can be conceptually adapted.
-
LC-MS/MS: This would be the most promising approach. The detection of m2,6A would require the chemical synthesis of an m2,6A standard and a corresponding stable isotope-labeled internal standard. With these reagents, an LC-MS/MS method could be developed to specifically detect and quantify m2,6A in digested RNA samples. The unique mass-to-charge ratio of m2,6A would allow for its distinction from m6A and other adenosine modifications.
-
Antibody-Based Methods: The development of a highly specific monoclonal or polyclonal antibody against m2,6A would be necessary. This would involve synthesizing an m2,6A immunogen and using it to generate antibodies. Once a specific antibody is validated, it could potentially be used in ELISA, dot blot, or MeRIP-Seq-like protocols to detect and map m2,6A.
Conclusion
The detection and mapping of m6A have significantly advanced our understanding of post-transcriptional gene regulation. A variety of robust methods are available, each with its own strengths and weaknesses, allowing researchers to choose the most appropriate technique based on their specific research question. While methods for the specific detection of this compound are not yet established, the principles of existing techniques, particularly LC-MS/MS, provide a clear path forward for the future investigation of this and other novel RNA modifications.
References
- 1. The detection and functions of RNA modification m6A based on m6A writers and erasers - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Comprehensive Overview of m6A Detection Methods - CD Genomics [cd-genomics.com]
- 3. Frontiers | Current progress in strategies to profile transcriptomic m6A modifications [frontiersin.org]
- 4. biorxiv.org [biorxiv.org]
- 5. researchgate.net [researchgate.net]
- 6. m6A-ELISA, a simple method for quantifying N6-methyladenosine from mRNA populations - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Detection of N6-methyladenosine modification residues (Review) - PMC [pmc.ncbi.nlm.nih.gov]
Protocol for N6-methyladenosine methylated RNA immunoprecipitation sequencing (MeRIP-seq).
Application Notes and Protocols for Researchers, Scientists, and Drug Development Professionals
Introduction
N6-methyladenosine (m6A) is the most abundant internal modification in eukaryotic messenger RNA (mRNA) and plays a critical role in various biological processes, including RNA splicing, stability, translation, and degradation. The dynamic regulation of m6A is carried out by a complex interplay of methyltransferases ('writers'), demethylases ('erasers'), and m6A-binding proteins ('readers'). Dysregulation of m6A modification has been implicated in numerous diseases, including cancer, making it a promising area for therapeutic intervention.
Methylated RNA Immunoprecipitation Sequencing (MeRIP-seq) is a powerful technique that combines immunoprecipitation of m6A-containing RNA fragments with high-throughput sequencing to provide a transcriptome-wide map of m6A modifications.[1][2] This application note provides a detailed protocol for MeRIP-seq, from sample preparation to data analysis, intended for researchers, scientists, and professionals in drug development.
Principle of MeRIP-seq
The MeRIP-seq protocol involves the fragmentation of total RNA, followed by the immunoprecipitation of RNA fragments containing m6A using a specific anti-m6A antibody. The enriched, m6A-containing RNA fragments are then purified and used to construct a sequencing library. A parallel "input" library is prepared from the fragmented RNA before immunoprecipitation to serve as a control for non-specific background and to account for variations in gene expression levels. By comparing the sequencing reads from the immunoprecipitated (IP) sample to the input sample, regions of the transcriptome enriched for m6A can be identified with high confidence.
Quantitative Data Summary
Successful MeRIP-seq experiments depend on optimizing several key quantitative parameters. The following tables summarize the recommended ranges and typical values for critical experimental variables.
Table 1: RNA Input and Fragmentation
| Parameter | Recommended Range | Typical Value | Notes |
| Starting Total RNA | 50 µg - 500 µg | 100 µg | The amount can be optimized based on sample type and m6A abundance. |
| Starting mRNA | 5 µg - 20 µg | 10 µg | Using purified mRNA can improve the signal-to-noise ratio. |
| RNA Integrity Number (RIN) | ≥ 7.0 | > 8.0 | High-quality, intact RNA is crucial for reliable results.[2] |
| RNA Fragmentation Size | 100 - 200 nucleotides | ~150 nucleotides | Chemical or enzymatic fragmentation can be used. |
Table 2: Immunoprecipitation and Sequencing
| Parameter | Recommended Range | Typical Value | Notes |
| Anti-m6A Antibody | 1 - 10 µg per IP | 5 µg | The optimal amount should be determined by titration for each antibody lot and sample type. |
| Protein A/G Magnetic Beads | 20 - 50 µL slurry per IP | 30 µL | Ensure beads are properly blocked to minimize non-specific binding. |
| Sequencing Depth | > 20 million reads per sample | 30-50 million reads | Deeper sequencing increases the sensitivity of m6A peak detection. |
| Read Length | 50 - 150 bp | 100 bp single-end | Paired-end sequencing can provide more information about fragment size and mapping accuracy. |
Table 3: Quality Control Metrics for Data Analysis
| QC Metric | Expected Value/Range | Purpose |
| Raw Reads | ||
| Per base sequence quality | Phred score > 30 | Ensures high-quality sequencing data. |
| Alignment | ||
| Mapping Rate | > 70% | Indicates the percentage of reads that align to the reference genome/transcriptome. |
| Peak Calling | ||
| Number of m6A Peaks | Varies by cell type and condition | Provides an initial assessment of the experiment's success. |
| Peak Distribution | Enrichment in 3' UTRs and near stop codons | Consistent with the known distribution of m6A in mRNA. |
| Motif Enrichment | Presence of the "RRACH" consensus motif | Confirms the specificity of the m6A immunoprecipitation. |
Experimental Protocols
This section provides a detailed step-by-step protocol for performing a MeRIP-seq experiment.
RNA Extraction and Quality Control
-
RNA Extraction: Isolate total RNA from cells or tissues using a TRIzol-based method or a commercial RNA extraction kit, following the manufacturer's instructions.
-
DNase Treatment: Treat the extracted RNA with DNase I to remove any contaminating genomic DNA.
-
RNA Purification: Purify the RNA using a column-based method or ethanol precipitation.
-
Quality Control: Assess the quantity and quality of the purified RNA.
-
Measure the RNA concentration using a spectrophotometer (e.g., NanoDrop).
-
Evaluate RNA integrity by determining the RIN value using an Agilent Bioanalyzer or equivalent instrument. A RIN value of ≥ 7.0 is recommended.[2]
-
RNA Fragmentation
-
Fragmentation Reaction Setup: In an RNase-free tube, combine the desired amount of total RNA with RNA fragmentation buffer.
-
Incubation: Incubate the reaction at a high temperature (e.g., 94°C) for a specific time to achieve the desired fragment size (typically 100-200 nucleotides). The incubation time needs to be optimized for each experiment.
-
Stop Reaction: Immediately stop the fragmentation by adding a stop solution (e.g., EDTA) and placing the tube on ice.
-
Fragment Purification: Purify the fragmented RNA using ethanol precipitation or a spin column.
-
Size Verification: Verify the size distribution of the fragmented RNA using a Bioanalyzer.
Immunoprecipitation (IP)
-
Input Sample: Set aside a fraction (e.g., 10%) of the fragmented RNA to serve as the input control. Store at -80°C.
-
Antibody-Bead Conjugation:
-
Wash Protein A/G magnetic beads with IP buffer.
-
Incubate the beads with the anti-m6A antibody with gentle rotation to allow for antibody binding.
-
-
Immunoprecipitation Reaction:
-
Add the remaining fragmented RNA to the antibody-conjugated beads.
-
Add RNase inhibitors to the reaction mixture.
-
Incubate the mixture overnight at 4°C with gentle rotation to allow the antibody to capture m6A-containing RNA fragments.
-
-
Washing:
-
Pellet the magnetic beads using a magnetic stand and discard the supernatant.
-
Wash the beads multiple times with IP wash buffer to remove non-specifically bound RNA. Perform washes with varying salt concentrations (low and high salt washes) to increase stringency.
-
-
Elution:
-
Elute the m6A-enriched RNA from the beads using an elution buffer containing a competitive agent (e.g., free m6A) or by changing the buffer conditions (e.g., high temperature, change in pH).
-
Collect the supernatant containing the immunoprecipitated RNA.
-
-
RNA Purification: Purify the eluted RNA using ethanol precipitation or a spin column.
Library Preparation and Sequencing
-
Library Construction: Construct sequencing libraries from both the immunoprecipitated (IP) RNA and the input control RNA using a strand-specific RNA library preparation kit. Follow the manufacturer's protocol, typically starting from the reverse transcription step.
-
Quality Control: Assess the quality and quantity of the prepared libraries using a Bioanalyzer and qPCR.
-
Sequencing: Sequence the libraries on a high-throughput sequencing platform (e.g., Illumina).
Data Analysis Workflow
The bioinformatics analysis of MeRIP-seq data is crucial for identifying and interpreting m6A modifications. A typical data analysis workflow is outlined below.
Quality Control of Raw Sequencing Data
-
Use tools like FastQC to assess the quality of the raw sequencing reads. Check for per-base quality scores, GC content, and adapter contamination.[3]
Read Alignment
-
Align the quality-filtered reads from both the IP and input samples to a reference genome or transcriptome using a splice-aware aligner such as STAR or HISAT2.
Peak Calling
-
Identify regions of m6A enrichment (peaks) by comparing the read coverage in the IP sample to the input sample.[3] Tools like MACS2 or exomePeak are commonly used for this purpose.
Peak Annotation and Motif Analysis
-
Annotate the identified m6A peaks to genomic features (e.g., exons, introns, 3' UTRs) to understand their distribution across the transcriptome.
-
Perform motif analysis on the peak sequences to confirm the enrichment of the canonical m6A consensus motif (RRACH).
Differential Methylation Analysis
-
For studies with multiple conditions, identify differentially methylated regions by comparing the m6A peak enrichment between the different experimental groups.
Functional Analysis
-
Perform gene ontology (GO) and pathway enrichment analysis on the genes associated with m6A peaks to understand the biological processes regulated by m6A modification.
Mandatory Visualizations
Experimental Workflow
The following diagram illustrates the key steps in the MeRIP-seq experimental workflow.
Caption: Experimental workflow for MeRIP-seq.
m6A Regulatory Signaling Pathway
The diagram below illustrates the dynamic regulation of m6A modification by 'writer', 'eraser', and 'reader' proteins.
Caption: The m6A RNA methylation pathway.
References
- 1. How MeRIP-seq Works: Principles, Workflow, and Applications Explained - CD Genomics [rna.cd-genomics.com]
- 2. MeRIP-seq for Detecting RNA methylation: An Overview - CD Genomics [cd-genomics.com]
- 3. Master MeRIP-seq Data Analysis: Step-by-Step Process for RNA Methylation Studies - CD Genomics [rna.cd-genomics.com]
Application Notes: Single-Nucleotide Resolution Mapping of N6-methyladenosine (m6A) with miCLIP
N6-methyladenosine (m6A) is the most abundant internal modification in eukaryotic messenger RNA (mRNA) and plays a critical role in regulating nearly all aspects of mRNA metabolism, including splicing, stability, translation, and nuclear export.[1][2][3] Understanding the precise location of m6A is crucial for elucidating its function in various biological processes and its implications in disease.
Traditional methods for m6A mapping, such as methylated RNA immunoprecipitation and sequencing (MeRIP-Seq or m6A-Seq), can identify m6A-enriched regions but are limited to a resolution of 100–200 nucleotides.[1][4][5] This makes it difficult to pinpoint the exact modified adenosine, especially since m6A often appears in clusters and multiple potential modification motifs (DRACH; D=A/G/U, R=A/G, H=A/C/U) can exist within a single MeRIP-Seq peak.[4][6]
m6A Individual-Nucleotide Resolution Crosslinking and Immunoprecipitation (miCLIP) overcomes this limitation by providing single-nucleotide resolution.[7][8] The method adapts the iCLIP (individual-nucleotide resolution UV crosslinking and immunoprecipitation) protocol.[2][9] In miCLIP, an anti-m6A antibody is UV-crosslinked to the RNA, creating a covalent bond.[4][10] During reverse transcription, the peptide remnant that remains attached to the RNA after proteinase K digestion causes specific and predictable events: either termination of the transcript or the introduction of mutations (primarily C→T transitions) in the resulting cDNA.[9][11] These mutational signatures are then identified through high-throughput sequencing and computational analysis to map the precise location of m6A and m6Am (N6,2'-O-dimethyladenosine) residues across the transcriptome.[4][8][9]
The improved miCLIP2 protocol enhances the methodology by enabling the generation of high-complexity libraries from less input material, further expanding its applicability.[2][12]
Quantitative Data: Comparison of m6A Mapping Technologies
The following table summarizes and compares key features of miCLIP with other common m6A mapping techniques.
| Feature | MeRIP-Seq / m6A-Seq | miCLIP / miCLIP2 | meCLIP (m6A-eCLIP) | Third-Generation Sequencing (e.g., Nanopore DRS) |
| Resolution | Low (100-200 nt)[1][4][13] | Single-nucleotide[7][8][14] | Single-nucleotide[15] | Single-nucleotide[16] |
| Principle | m6A antibody enrichment of RNA fragments followed by sequencing.[4] | UV crosslinking of antibody to RNA induces mutations/truncations at m6A sites.[9][10] | Adapts eCLIP protocol; uses separate adapter ligations and omits radioactive labeling.[15][17] | Direct RNA sequencing detects electrical signal disruptions caused by modified bases.[16] |
| Quantitative? | No, provides relative enrichment.[10] | No, identifies sites but not stoichiometry.[18] | No, identifies sites. | Yes, can provide stoichiometric information.[16] |
| Key Advantages | Well-established, relatively straightforward. | High resolution, identifies both m6A and m6Am.[7][8] | Higher efficiency and library complexity, no radioactive labeling.[15][19] | Provides stoichiometry, detects modifications directly without antibodies.[16] |
| Key Disadvantages | Low resolution, cannot pinpoint exact sites.[4][6] | Technically challenging (e.g., radioactive labeling, cDNA circularization), dependent on antibody specificity.[8][14][15] | Dependent on antibody specificity. | Requires specialized equipment and complex data analysis pipelines.[16] |
| Input Material | High amount of starting RNA required.[19] | Original miCLIP requires high input; miCLIP2 is optimized for lower input.[2][3] | Requires less input than miCLIP. | Varies by platform. |
Visualizations: Workflows and Logical Relationships
Caption: The experimental workflow for m6A individual-nucleotide resolution crosslinking and immunoprecipitation (miCLIP).
Caption: The bioinformatic workflow for analyzing miCLIP sequencing data to identify m6A sites.
Experimental Protocols
This section provides a detailed methodology for performing miCLIP, synthesized from established protocols.[4][6]
Part 1: miCLIP Library Generation
-
RNA Preparation and Fragmentation
-
Isolate total RNA from cells or tissues using a standard protocol (e.g., TRIzol).
-
Enrich for poly(A)+ RNA using oligo(dT) magnetic beads.
-
Fragment 5–20 µg of the enriched RNA to an average size of ~35 nucleotides. This can be achieved using RNA fragmentation buffers or enzymatic methods. Purify the fragmented RNA.[6]
-
-
Crosslinking and Immunoprecipitation
-
Incubate the fragmented RNA with an anti-m6A antibody (e.g., from Abcam or Synaptic Systems) in an appropriate buffer.
-
Transfer the mixture to a petri dish on ice and irradiate with 254 nm UV light to crosslink the antibody to the RNA.[9]
-
Add Protein A/G magnetic beads to the mixture to capture the antibody-RNA complexes.
-
Perform stringent washes to remove non-specifically bound RNA.[6]
-
-
3' Adapter Ligation and Radiolabeling
-
While the complexes are on the beads, ligate a 3' RNA adapter using T4 RNA ligase.[4][8]
-
Dephosphorylate the 5' ends of the RNA fragments using alkaline phosphatase.
-
Radiolabel the 5' ends by phosphorylating with T4 polynucleotide kinase (PNK) and [γ-32P]ATP. This step is crucial for visualizing the RNA later.[4][20]
-
-
Purification of RNA-Protein Complexes
-
Elute the complexes from the beads and run them on an SDS-PAGE gel.
-
Transfer the separated complexes to a nitrocellulose membrane. This step ensures that only covalently crosslinked RNA (which is bound to the heavy protein antibody) is retained.[6][9]
-
Expose the membrane to an autoradiography film to visualize the radiolabeled RNA-protein complexes. They will appear as smears extending from the antibody heavy and light chains (~50 kD and ~25 kD).[4]
-
Excise the membrane region corresponding to the RNA-protein complexes.
-
-
RNA Elution and Reverse Transcription
-
Release the RNA from the antibody by digesting the membrane piece with Proteinase K. This leaves a small peptide fragment covalently attached to the RNA at the crosslink site.[8]
-
Purify the eluted RNA.
-
Perform reverse transcription using a primer complementary to the 3' adapter. The residual peptide will cause the reverse transcriptase to either stall (truncation) or misincorporate nucleotides (mutations).[4][9]
-
-
cDNA Library Finalization
-
Purify the resulting cDNA fragments.
-
Circularize the single-stranded cDNA using an RNA ligase.[4][8]
-
Re-linearize the circular cDNA at a site within the RT primer sequence.
-
PCR amplify the cDNA library using primers that add the necessary sequences for high-throughput sequencing.[4]
-
Purify the final PCR product and submit for sequencing.
-
Part 2: Bioinformatic Analysis of miCLIP Data
-
Pre-processing of Sequencing Reads
-
Start with the raw sequencing data in FASTQ format.
-
Trim the 3' adapter sequences from the reads.
-
Demultiplex the samples based on barcodes incorporated in the reverse transcription primers.
-
Remove PCR duplicates. If unique molecular identifiers (UMIs) were used in the RT primer, collapse reads with identical UMIs and mapping coordinates into a single read.[6]
-
-
Alignment to Reference Genome
-
Align the processed reads to the appropriate reference genome using a splice-aware aligner.
-
-
Identification of m6A Sites
-
The core of miCLIP analysis is identifying the signatures of crosslinking. This can be done in two main ways:
-
Crosslink-Induced Mutation Sites (CIMS): Analyze the aligned reads for specific mutations that are enriched compared to a control or background mutation rate. For some antibodies, C→T transitions are a characteristic signature of m6A crosslinking.[9][15]
-
Crosslink-Induced Truncation Sites (CITS): Analyze the 5' ends (start sites) of the aligned reads. A pileup of read starts at a specific nucleotide indicates reverse transcriptase stalling and is a strong indicator of a crosslink site.[9]
-
-
Use specialized bioinformatic tools, such as components of the CTK package, to systematically identify significant mutation and truncation sites.[6]
-
-
Filtering and Annotation
-
Filter the identified significant sites to retain only those located within the canonical m6A consensus motif (DRACH). This step significantly increases confidence in the called m6A sites.[6]
-
Annotate the final list of high-confidence m6A sites with genomic features (e.g., gene name, exon/intron, 5' UTR, CDS, 3' UTR) to facilitate downstream biological interpretation.
-
References
- 1. Mapping m6A at Individual-Nucleotide Resolution Using Crosslinking and Immunoprecipitation (miCLIP) - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. Deep and accurate detection of m6A RNA modifications using miCLIP2 and m6Aboost machine learning - PMC [pmc.ncbi.nlm.nih.gov]
- 3. academic.oup.com [academic.oup.com]
- 4. Mapping m6A at individual-nucleotide resolution using crosslinking and immunoprecipitation (miCLIP) - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Mapping m6A at Individual-Nucleotide Resolution Using Crosslinking and Immunoprecipitation (miCLIP) | Springer Nature Experiments [experiments.springernature.com]
- 6. Transcriptome-wide mapping of m6A and m6Am at single-nucleotide resolution using miCLIP - PMC [pmc.ncbi.nlm.nih.gov]
- 7. miCLIP-m6A [emea.illumina.com]
- 8. miCLIP-m6A - Enseqlopedia [enseqlopedia.com]
- 9. Single-nucleotide resolution mapping of m6A and m6Am throughout the transcriptome - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Three Methods Comparison: GLORI-seq, miCLIP and Mazter-seq - CD Genomics [cd-genomics.com]
- 11. Epitranscriptomic sequencing - Wikipedia [en.wikipedia.org]
- 12. researchgate.net [researchgate.net]
- 13. mdpi.com [mdpi.com]
- 14. miCLIP-m6A [illumina.com]
- 15. Identification of m6A residues at single-nucleotide resolution using eCLIP and an accessible custom analysis pipeline - PMC [pmc.ncbi.nlm.nih.gov]
- 16. researchgate.net [researchgate.net]
- 17. researchgate.net [researchgate.net]
- 18. Quantitative profiling of m6A at single base resolution across the life cycle of rice and Arabidopsis - PMC [pmc.ncbi.nlm.nih.gov]
- 19. Frontiers | Current progress in strategies to profile transcriptomic m6A modifications [frontiersin.org]
- 20. miCLIP-seq - Profacgen [profacgen.com]
Unveiling the Epitranscriptome: Site-Specific Quantification of N6-methyladenosine using SCARLET
Application Notes and Protocols for Researchers, Scientists, and Drug Development Professionals
N6-methyladenosine (m6A) is the most abundant internal modification in eukaryotic messenger RNA (mRNA) and long non-coding RNA (lncRNA), playing a critical role in the regulation of gene expression. The dynamic nature of m6A, controlled by "writer," "reader," and "eraser" proteins, influences RNA splicing, export, stability, and translation. Dysregulation of m6A has been implicated in various diseases, including cancer, making precise quantification of this modification at specific sites crucial for both basic research and therapeutic development.
This document provides detailed application notes and protocols for SCARLET (Site-specific Cleavage and Radioactive-labeling followed by Ligation-assisted Extraction and Thin-layer chromatography) , a robust method for determining the precise location and modification fraction of m6A at single-nucleotide resolution.[1][2][3] SCARLET is considered a "gold standard" for validating m6A sites and quantifying their stoichiometry.[4][5]
Principle of the SCARLET Method
SCARLET combines site-specific RNA cleavage with radioactive labeling and ligation-assisted extraction to isolate the target adenosine nucleotide for analysis by thin-layer chromatography (TLC).[1][6] The key steps involve:
-
Site-Specific Cleavage: A chimeric 2'-O-methyl/2'-H RNA/DNA oligonucleotide complementary to the target region guides RNase H to cleave the RNA immediately 5' to the adenosine of interest.[4][5]
-
Radioactive Labeling: The newly generated 5'-hydroxyl group of the target adenosine is radioactively labeled with [γ-³²P]ATP by T4 polynucleotide kinase (PNK).
-
Splint-Assisted Ligation: A single-stranded DNA (ssDNA) splint oligonucleotide facilitates the ligation of the ³²P-labeled RNA fragment to a longer ssDNA molecule. This ligation is crucial as it protects the labeled nucleotide from subsequent digestion.[6]
-
RNase Digestion: The RNA portion of the ligated product is completely digested by RNases T1 and A.
-
Gel Extraction and Nuclease P1 Digestion: The resulting ³²P-labeled ssDNA-pA or ssDNA-pm6A fragment is purified by denaturing polyacrylamide gel electrophoresis (PAGE). The excised band is then digested with nuclease P1 to release the 5'-monophosphate nucleotides.
-
Thin-Layer Chromatography (TLC): The resulting ³²P-labeled adenosine (pA) and N6-methyladenosine (pm6A) are separated by TLC and quantified to determine the m6A modification fraction.[1][4]
The "m6A Code": Writers, Erasers, and Readers
The biological outcomes of m6A modification are determined by a complex interplay of proteins that install, remove, and recognize the methyl mark. Understanding this "m6A code" is essential for interpreting the functional significance of site-specific m6A quantification data.
Quantitative Data Summary
SCARLET has been successfully applied to determine the m6A modification fraction at various sites in different RNAs and cell lines. The data reveals a wide range of stoichiometry, highlighting the dynamic and site-specific nature of m6A modification.
| RNA Target | Site | Cell Line | m6A Fraction (%) | Reference |
| lncRNA MALAT1 | 2515 | HeLa | 61 | [7] |
| lncRNA MALAT1 | 2577 | HeLa | 80 | [1][7] |
| lncRNA MALAT1 | 2611 | HeLa | 38 | [7] |
| mRNA TPT1 | 687 | HeLa | 15 | [7] |
| mRNA TPT1 | 703 | HeLa | 1 | [7] |
| 18S rRNA | A1832 | HeLa | ~98 | [6] |
| lncRNA TUG1 | Multiple Sites | HeLa | 6-80 | [6] |
| mRNA ACTB | Multiple Sites | HeLa | 6-80 | [6] |
| mRNA BSG | Multiple Sites | HeLa | 6-80 | [6] |
Experimental Protocols
This section provides a detailed, step-by-step protocol for performing SCARLET.
Materials and Reagents
-
RNA: Total RNA or polyA+ selected RNA (1-5 µg)
-
Oligonucleotides:
-
Chimeric 2'-O-methyl/2'-H RNA/DNA oligonucleotide (for RNase H cleavage)
-
ssDNA splint oligonucleotide
-
116-nt ssDNA oligonucleotide
-
-
Enzymes:
-
RNase H
-
T4 Polynucleotide Kinase (PNK)
-
Thermosensitive Alkaline Phosphatase (TAP)
-
T4 DNA Ligase
-
RNase T1
-
RNase A
-
Nuclease P1
-
-
Reagents:
-
[γ-³²P]ATP
-
ATP
-
DMSO
-
Urea
-
Acrylamide/Bis-acrylamide solution
-
TBE buffer
-
Sodium acetate
-
Ethanol
-
TLC cellulose plates
-
TLC running buffer (isopropanol:HCl:water, 70:15:15, v/v/v)[2]
-
SCARLET Workflow Diagram
Detailed Protocol
1. Site-Specific Cleavage and Dephosphorylation [2]
-
In a total volume of 3 µL of 30 mM Tris-HCl (pH 7.5), mix 1 µg of polyA+ RNA with 3 pmol of the corresponding chimeric oligonucleotide.
-
Anneal the oligonucleotide to the RNA by heating at 95°C for 1 minute, followed by incubation at room temperature for 3 minutes. Place on ice.
-
Add 2 µL of a cleavage mixture containing RNase H and TAP.
-
Incubate at 44°C for 1 hour for site-specific cleavage and dephosphorylation.
-
Terminate the reaction by heating at 75°C for 5 minutes, then immediately place on ice.
2. Radioactive Labeling [2]
-
To the reaction mixture from the previous step, add 1 µL of a 6x T4 PNK reaction mixture containing T4 PNK and [γ-³²P]ATP.
-
Incubate at 37°C for 30 minutes to label the 5' end of the cleaved RNA.
3. Splint-Assisted Ligation and RNase Digestion [2]
-
Add 1.5 µL of a splint/ssDNA-116 oligo mixture (4 pmol splint oligos and 5 pmol ssDNA-116 oligos) to the reaction.
-
Anneal the oligos by heating at 75°C for 3 minutes, followed by incubation at room temperature for 3 minutes, and then place on ice.
-
Add 2.5 µL of a 4x ligation mixture containing T4 DNA ligase.
-
Incubate at 37°C for 3.5 hours for splint ligation.
-
Add 1 µL of an RNase T1/A mixture.
-
Incubate at 37°C overnight (approximately 16 hours) for complete RNA digestion.
4. Gel Purification [2]
-
Load the entire sample onto a 10% urea denaturing polyacrylamide gel.
-
Run the gel until the bromophenol blue dye reaches the bottom.
-
Expose the gel to a phosphorimager screen to visualize the radiolabeled bands.
-
Excise the band corresponding to the ligated ssDNA-³²P-(A/m6A)p product.
-
Elute the DNA from the gel slice using a crush and soak buffer.
-
Precipitate the DNA with ethanol.
5. Nuclease P1 Digestion and Thin-Layer Chromatography (TLC) [2]
-
Resuspend the precipitated DNA pellet in 3 µL of a nuclease P1 mixture.
-
Incubate at 37°C for 2 hours for complete digestion into 5'-mononucleotides.
-
Spot the reaction mixture onto a cellulose TLC plate.
-
Develop the chromatogram using a running buffer of isopropanol:HCl:water (70:15:15, v/v/v).
-
Visualize the separated ³²P-labeled pA and pm6A spots using a phosphorimager.
6. Data Analysis
-
Quantify the intensity of the pA and pm6A spots using appropriate software.
-
Calculate the m6A fraction using the following formula: m6A Fraction (%) = [Intensity of pm6A / (Intensity of pA + Intensity of pm6A)] x 100
Conclusion
SCARLET provides a powerful and reliable method for the site-specific quantification of N6-methyladenosine, offering single-nucleotide resolution.[1][2][3] While the procedure is laborious and involves the use of radioisotopes, its accuracy makes it an invaluable tool for researchers and drug development professionals seeking to understand the precise roles of m6A in biological processes and disease.[4][5] The detailed protocols and application notes provided herein should serve as a comprehensive guide for the successful implementation of the SCARLET technique in your research endeavors.
References
- 1. liulab.life.tsinghua.edu.cn [liulab.life.tsinghua.edu.cn]
- 2. Effects of writers, erasers and readers within miRNA-related m6A modification in cancers - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. researchgate.net [researchgate.net]
- 4. Current progress in strategies to profile transcriptomic m6A modifications - PMC [pmc.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
- 6. Probing N6-methyladenosine RNA modification status at single nucleotide resolution in mRNA and long noncoding RNA - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Transcriptome-wide profiling and quantification of N6-methyladenosine by enzyme-assisted adenosine deamination - PMC [pmc.ncbi.nlm.nih.gov]
2-Methylamino-N6-methyladenosine antibody selection and validation for MeRIP.
An initial search for "2-Methylamino-N6-methyladenosine" did not yield information on a recognized standard RNA modification. It is possible that this is a novel or less-common modification, or that the nomenclature is non-standard. The closely related and well-studied N6-methyladenosine (m6A) is a prevalent internal modification in eukaryotic mRNA and plays a crucial role in various biological processes, including RNA stability, splicing, and translation. Given the detailed request for protocols related to MeRIP (methylated RNA immunoprecipitation), this application note will focus on the principles of antibody selection and validation for MeRIP using the well-established m6A modification as a primary example. The methodologies and principles described herein are broadly applicable to other RNA modifications.
Application Note: Antibody Selection and Validation for MeRIP
Introduction to MeRIP
Methylated RNA immunoprecipitation followed by sequencing (MeRIP-seq) is a powerful technique used to map post-transcriptional modifications on a transcriptome-wide scale. The method relies on a specific antibody to enrich for RNA molecules containing the modification of interest. These enriched RNA fragments are then sequenced and mapped to the transcriptome to identify the location of the modifications. The success of a MeRIP-seq experiment is critically dependent on the quality of the antibody used. A highly specific and sensitive antibody is essential for accurate and reproducible results.
Antibody Selection Criteria
Choosing the right antibody is the most critical step for a successful MeRIP-seq experiment. The ideal antibody should exhibit high affinity for the target modification and minimal cross-reactivity with other modifications or unmodified RNA. Key validation experiments should be performed to ensure the antibody's performance.
Quantitative Data Summary for m6A Antibody Performance
The following table summarizes key performance metrics for commercially available anti-m6A antibodies. This data is compiled from various studies and manufacturer's datasheets. Researchers should always perform their own validation experiments.
| Antibody | Host | Application | Specificity (Dot Blot) | Enrichment Efficiency (MeRIP-qPCR) | Vendor |
| Anti-m6A Antibody A | Rabbit | MeRIP, Dot Blot | High | >10-fold enrichment | Vendor 1 |
| Anti-m6A Antibody B | Mouse | MeRIP, Dot Blot | Medium | 5 to 10-fold enrichment | Vendor 2 |
| Anti-m6A Antibody C | Rabbit | MeRIP, Dot Blot | High | >15-fold enrichment | Vendor 3 |
Experimental Protocols
1. Antibody Validation: Dot Blot Assay
This protocol is for validating the specificity of an antibody to the RNA modification of interest.
Materials:
-
Nitrocellulose or PVDF membrane
-
UV crosslinker
-
Blocking buffer (e.g., 5% non-fat milk in TBST)
-
Primary antibody (anti-m6A)
-
HRP-conjugated secondary antibody
-
Chemiluminescent substrate
-
Synthetic RNA oligonucleotides (with and without the modification)
Procedure:
-
Prepare serial dilutions of the synthetic RNA oligonucleotides (e.g., m6A-containing and unmodified adenosine-containing oligos).
-
Spot 1-2 µL of each dilution onto the nitrocellulose membrane.
-
UV-crosslink the RNA to the membrane at 254 nm.
-
Block the membrane with blocking buffer for 1 hour at room temperature.
-
Incubate the membrane with the primary antibody at the recommended dilution overnight at 4°C.
-
Wash the membrane three times with TBST for 10 minutes each.
-
Incubate the membrane with the HRP-conjugated secondary antibody for 1 hour at room temperature.
-
Wash the membrane three times with TBST for 10 minutes each.
-
Apply the chemiluminescent substrate and image the blot.
Expected Results: A strong signal should be observed for the RNA containing the modification, with minimal to no signal for the unmodified RNA.
2. MeRIP-seq Protocol
This is a generalized protocol for MeRIP-seq. Optimization may be required depending on the sample type and antibody used.
Materials:
-
Total RNA
-
RNA fragmentation buffer
-
MeRIP immunoprecipitation buffer
-
Protein A/G magnetic beads
-
Anti-m6A antibody
-
RNase inhibitors
-
RNA purification kit
-
Library preparation kit for sequencing
Procedure:
-
RNA Fragmentation: Fragment the total RNA to an average size of 100-200 nucleotides using RNA fragmentation buffer or enzymatic methods.
-
Immunoprecipitation:
-
Incubate the fragmented RNA with the anti-m6A antibody in MeRIP IP buffer for 2 hours at 4°C.
-
Add pre-washed Protein A/G magnetic beads and incubate for another 2 hours at 4°C with rotation.
-
-
Washing: Wash the beads three to five times with wash buffer to remove non-specifically bound RNA.
-
Elution: Elute the enriched RNA from the beads.
-
RNA Purification: Purify the eluted RNA using an RNA purification kit.
-
Library Preparation and Sequencing: Prepare a sequencing library from the enriched RNA and an input control sample. Sequence the libraries on a high-throughput sequencing platform.
Visualizations
Caption: Workflow of the MeRIP-seq experiment.
Application Notes & Protocols for the Detection of Methylated Adenosine Derivatives
Topic: Chemical Labeling and Detection Strategies for 2-Methylamino-N6-methyladenosine and Related Compounds
Audience: Researchers, scientists, and drug development professionals.
Introduction
Post-transcriptional modifications of RNA add a significant layer of regulatory complexity to gene expression. While N6-methyladenosine (m6A) is the most abundant internal modification in eukaryotic mRNA, a diverse landscape of other modifications exists. This document focuses on chemical and biochemical methodologies for the detection of methylated adenosine derivatives, with a specific consideration for the rare modification, This compound (m2,6A) .
This compound is a known chemical entity, commercially available from suppliers such as Amsbio[1]. However, as of this writing, specific, validated chemical labeling and detection protocols exclusively for m2,6A are not widely documented in scientific literature. Therefore, this guide provides detailed protocols for the robust detection of the closely related and well-characterized N6-methyladenosine (m6A). These methodologies, particularly those based on liquid chromatography-mass spectrometry, serve as a foundational framework that can be adapted and optimized for the detection and quantification of m2,6A. Researchers aiming to study m2,6A will need to undertake specific validation and optimization steps, such as developing specific antibodies or establishing unique mass transition signatures.
Quantitative Data Summary
The accurate quantification of RNA modifications is crucial for understanding their biological roles. Liquid chromatography-tandem mass spectrometry (LC-MS/MS) is the gold standard for absolute quantification. Below is a summary of typical quantitative data obtained for various adenosine modifications in biological samples.
| Modification | Quantification Type | Resolution | Sensitivity | Input RNA Required | Throughput | Key Advantages |
| N6-methyladenosine (m6A) | Absolute (Global m6A/A ratio) | Global | High (fmol to amol) | ng to µg | Moderate | Gold standard for accurate global quantification. |
| N6,2′-O-dimethyladenosine (m6Am) | Absolute (Global m6Am/A ratio) | Global | High (fmol to amol) | ng to µg | Moderate | Can be distinguished from m6A with proper digestion. |
| Site-specific m6A | Stoichiometric (Per-site) | Single-nucleotide | High | ng | High | Provides stoichiometry at specific locations. |
Data compiled from multiple sources indicating the general performance of LC-MS/MS-based methods.[2]
Experimental Protocols
Protocol 1: Global Quantification of Methylated Adenosines by LC-MS/MS
This protocol provides a method for the global quantification of modified nucleosides from total RNA or mRNA and can be adapted to detect this compound, provided a standard is available for instrument calibration.
Materials:
-
Purified RNA (1-5 µg)
-
Nuclease P1
-
Bacterial Alkaline Phosphatase (BAP)
-
Nuclease P1 Buffer (10 mM Ammonium Acetate, pH 5.3)
-
BAP Buffer (50 mM Tris-HCl, pH 8.0)
-
Stable isotope-labeled internal standards (e.g., ¹³C₅-labeled 2'-O-Methyladenosine)
-
LC-MS/MS system with a C18 column
Procedure:
-
RNA Digestion:
-
To 1-2 µg of purified RNA, add the stable isotope-labeled internal standard.
-
Add 2U of Nuclease P1 and incubate at 42°C for 2 hours.
-
Add 1U of Bacterial Alkaline Phosphatase and incubate at 37°C for an additional 2 hours.
-
-
Sample Preparation:
-
Centrifuge the digested sample to pellet any debris.
-
Transfer the supernatant to an LC-MS vial for analysis.
-
-
LC-MS/MS Analysis:
-
Column: C18 reverse-phase column.
-
Mobile Phase A: Water with 0.1% formic acid.
-
Mobile Phase B: Acetonitrile with 0.1% formic acid.
-
Gradient: A linear gradient from 5% to 60% Mobile Phase B over 10 minutes.
-
Flow Rate: 0.3 mL/min.
-
Injection Volume: 5 µL.
-
Ionization Mode: Positive Electrospray Ionization (ESI+).
-
MS/MS Detection: Monitor the specific precursor-to-product ion transitions (Multiple Reaction Monitoring - MRM) for the target nucleosides and their labeled internal standards. For novel modifications like m2,6A, these transitions must be determined empirically using a pure standard.
-
Expected MRM Transitions for Known Modifications:
| Nucleoside | Precursor Ion (m/z) | Product Ion (m/z) |
| Adenosine (A) | 268.1 | 136.1 |
| N6-methyladenosine (m6A) | 282.1 | 150.1 |
| N6,2′-O-dimethyladenosine (m6Am) | 296.1 | 150.1 |
Note: The specific transitions for this compound would need to be determined experimentally.
Protocol 2: Transcriptome-wide Mapping of m6A via MeRIP-seq
This antibody-based enrichment method can be adapted for m2,6A if a specific antibody becomes available.
Materials:
-
Total RNA or purified mRNA
-
m6A-specific antibody (or a future m2,6A-specific antibody)
-
Protein A/G magnetic beads
-
RNA fragmentation buffer
-
Immunoprecipitation (IP) buffer
-
Wash buffers
-
RNA purification kit
-
Next-generation sequencing library preparation kit
Procedure:
-
RNA Fragmentation: Fragment 50-100 µg of RNA to ~100 nucleotide-long fragments by heating in fragmentation buffer.
-
Immunoprecipitation:
-
Incubate the fragmented RNA with an m6A-specific antibody in IP buffer for 2 hours at 4°C.
-
Add Protein A/G magnetic beads and incubate for another 2 hours at 4°C to capture the antibody-RNA complexes.
-
-
Washing: Wash the beads multiple times with wash buffers to remove non-specifically bound RNA.
-
Elution and Purification: Elute the m6A-containing RNA fragments and purify them using an RNA purification kit.
-
Library Preparation and Sequencing: Prepare a sequencing library from the enriched RNA fragments and an input control. Sequence the libraries on a high-throughput sequencing platform.
-
Data Analysis: Align reads to the reference genome and identify enriched peaks, which correspond to the locations of the m6A modification.
Visualizations
Experimental Workflows
Caption: Workflow for LC-MS/MS-based quantification of m2,6A.
Caption: Workflow for antibody-based mapping of m2,6A (MeRIP-seq).
Conceptual Relationships
Caption: The dynamic regulation of N6-methyladenosine (m6A) in RNA.
References
Application Notes and Protocols for Nanopore Direct RNA Sequencing for m6A Detection
References
- 1. m6A modification: recent advances, anticancer targeted drug discovery and beyond - PMC [pmc.ncbi.nlm.nih.gov]
- 2. mdpi.com [mdpi.com]
- 3. manuals.plus [manuals.plus]
- 4. Frontiers | MasterOfPores: A Workflow for the Analysis of Oxford Nanopore Direct RNA Sequencing Datasets [frontiersin.org]
- 5. academic.oup.com [academic.oup.com]
- 6. academic.oup.com [academic.oup.com]
- 7. Direct RNA sequencing enables m6A detection in endogenous transcript isoforms at base-specific resolution - PMC [pmc.ncbi.nlm.nih.gov]
- 8. biorxiv.org [biorxiv.org]
- 9. A comparative evaluation of computational models for RNA modification detection using nanopore sequencing with RNA004 chemistry - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Systematic comparison of tools used for m6A mapping from nanopore direct RNA sequencing - PubMed [pubmed.ncbi.nlm.nih.gov]
- 11. Identification of m6A RNA Modifications by Nanopore Sequencing Protocol - CD Genomics [cd-genomics.com]
- 12. torontomu.primo.exlibrisgroup.com [torontomu.primo.exlibrisgroup.com]
- 13. nanoporetech.com [nanoporetech.com]
- 14. researchgate.net [researchgate.net]
- 15. repositori.upf.edu [repositori.upf.edu]
- 16. Regulation of m6A Methylome in Cancer: Mechanisms, Implications, and Therapeutic Strategies [mdpi.com]
Application Notes and Protocols for In Vitro Transcription of m6A-Modified RNA
For Researchers, Scientists, and Drug Development Professionals
Introduction
N6-methyladenosine (m6A) is the most abundant internal modification in eukaryotic messenger RNA (mRNA) and plays a critical role in regulating RNA metabolism, including splicing, nuclear export, stability, and translation. The ability to generate m6A-modified RNA in vitro is essential for studying the functional consequences of this modification and for developing novel RNA-based therapeutics. These application notes provide detailed protocols for the in vitro synthesis of m6A-modified RNA, methods for its quantification, and procedures for its functional characterization, serving as a comprehensive resource for researchers in the field.
The generation of m6A-modified RNA for experimental purposes primarily relies on in vitro transcription (IVT) reactions where N6-methyladenosine-5'-triphosphate (m6A-TP) is incorporated into the nascent RNA strand by bacteriophage RNA polymerases, such as T7, T3, or SP6. The resulting modified RNA can then be used as a tool to investigate the effects of m6A on RNA-protein interactions, enzymatic activity, and overall gene expression. Unmodified RNA, synthesized in parallel without m6A-TP, serves as a crucial experimental control.
Data Presentation: Quantitative Analysis of m6A-Modified RNA
The following tables summarize key quantitative data related to the synthesis and analysis of m6A-modified RNA.
Table 1: Quantification of m6A Levels in In Vitro Transcribed RNA
| Quantification Method | Sample Type | m6A Percentage of Total Adenosine | Reference |
| m6A-ELISA | IVT RNA with 100% m6A-TP substitution | Detectable, used for standard curve | [1][2][3][4] |
| Colorimetric Assay | Total RNA from prepubertal donor cumulus cells (MII stage) | 0.45% ± 0.01 s.e.m. | [5] |
| Colorimetric Assay | Total RNA from adult donor cumulus cells (MII stage) | 0.29% ± 0.01 s.e.m. | [5] |
| LC-MS/MS | HEK293E cellular mRNA | Variable, used for absolute quantification | [6][7][8] |
Table 2: Relative Enrichment of m6A-Modified RNA in MeRIP-qPCR
| Input Ratio (m6A RNA : Unmodified RNA) | Relative Enrichment over Input | Reference |
| 0.01 fmol : 0.09 fmol | Normalized to 1 | [5] |
| 0.1 fmol : 0 fmol | ~10-fold higher than the 0.01:0.09 mix | [5] |
Experimental Workflows and Signaling Pathways
Diagram 1: Experimental Workflow for Generation and Validation of m6A-Modified RNA
Caption: Workflow for synthesizing and validating m6A-modified RNA.
Diagram 2: The "Writers," "Erasers," and "Readers" of m6A Modification
Caption: Key regulators of m6A RNA modification and its functional outcomes.
Experimental Protocols
Protocol 1: In Vitro Transcription of m6A-Modified RNA
This protocol describes the synthesis of m6A-containing RNA using T7 RNA polymerase. A parallel reaction substituting N6-methyladenosine-5'-triphosphate (m6A-TP) with adenosine-5'-triphosphate (ATP) should be performed as a negative control.
Materials:
-
Linearized DNA template with a T7 promoter
-
T7 RNA Polymerase
-
10X Transcription Buffer
-
Ribonucleotide Solution Mix (GTP, CTP, UTP at 10 mM each)
-
ATP solution (100 mM)
-
N6-methyladenosine-5'-triphosphate (m6A-TP) solution (100 mM)
-
RNase Inhibitor
-
Nuclease-free water
-
RNase-free DNase I
-
RNA purification kit or reagents for LiCl precipitation
Procedure:
-
Reaction Setup: Assemble the following 20 µL reaction at room temperature in an RNase-free microcentrifuge tube.
Component Volume Final Concentration Nuclease-free water to 20 µL - 10X Transcription Buffer 2 µL 1X GTP, CTP, UTP Mix (10 mM each) 2 µL 1 mM each ATP or m6A-TP (100 mM) 2 µL 10 mM Linearized DNA Template X µL 0.5-1.0 µg RNase Inhibitor 1 µL 40 units | T7 RNA Polymerase | 2 µL | - |
-
Incubation: Mix gently by pipetting and centrifuge briefly. Incubate at 37°C for 2-4 hours.
-
DNase Treatment: Add 1 µL of RNase-free DNase I to the reaction and incubate at 37°C for 15-30 minutes to remove the DNA template.[9]
-
RNA Purification: Purify the synthesized RNA using a spin column-based RNA purification kit according to the manufacturer's instructions or by lithium chloride precipitation.[9]
-
Quantification and Quality Control: Determine the RNA concentration by measuring the absorbance at 260 nm. Assess the integrity and size of the RNA transcript by denaturing agarose or polyacrylamide gel electrophoresis.
Protocol 2: Quantification of m6A by ELISA
This protocol provides a method for the relative quantification of m6A in a population of RNA molecules.[1][2][3][4][10]
Materials:
-
Purified m6A-modified and unmodified control RNA
-
96-well microplate
-
Nucleic acid binding solution
-
Anti-m6A primary antibody
-
HRP-conjugated secondary antibody
-
Wash buffer (e.g., PBST)
-
Substrate solution (e.g., TMB)
-
Stop solution (e.g., 1 M H₂SO₄)
-
Plate reader
Procedure:
-
RNA Binding: Add 90 µL of binding solution to each well of a 96-well plate. Add 25-50 ng of each RNA sample to the respective wells. For a standard curve, use serial dilutions of in vitro transcribed RNA with a known m6A content. Incubate the plate at 37°C for 2 hours.[1]
-
Washing: Discard the binding solution and wash each well four times with wash buffer.[1]
-
Primary Antibody Incubation: Add 100 µL of the diluted primary anti-m6A antibody to each well. Incubate for 1 hour at room temperature.[1]
-
Washing: Repeat the washing step as in step 2.
-
Secondary Antibody Incubation: Add 100 µL of the diluted HRP-conjugated secondary antibody to each well. Incubate for 1 hour at room temperature.
-
Washing: Repeat the washing step as in step 2.
-
Detection: Add 100 µL of substrate solution to each well and incubate in the dark until a color change is observed. Stop the reaction by adding 100 µL of stop solution.
-
Measurement: Read the absorbance at 450 nm using a microplate reader. The relative amount of m6A can be determined by comparing the absorbance of the samples to the standard curve.
Protocol 3: Quantification of m6A by LC-MS/MS
This protocol allows for the absolute quantification of m6A levels.[6][7][8][11][12]
Materials:
-
Purified RNA (~1 µg)
-
Nuclease P1
-
Venom phosphodiesterase I or Alkaline Phosphatase
-
LC-MS/MS system
-
m6A and adenosine standards
Procedure:
-
RNA Digestion: To 1 µg of RNA, add nuclease P1 and incubate at 45°C for 2 hours. Subsequently, add alkaline phosphatase or venom phosphodiesterase I and incubate at 37°C for an additional 2 hours to digest the RNA into nucleosides.[11]
-
Sample Preparation: Deproteinate and desalt the digested sample using a spin column.[11]
-
LC-MS/MS Analysis: Inject the prepared sample into the LC-MS/MS system. Separate the nucleosides using a C18 column. Quantify m6A and adenosine using multiple reaction monitoring (MRM) mode.[11]
-
Data Analysis: Create a standard curve using known concentrations of m6A and adenosine standards. Calculate the amount of m6A and adenosine in the sample based on the standard curve. The m6A level is typically expressed as the ratio of m6A to total adenosine.[7]
Protocol 4: Methylated RNA Immunoprecipitation (MeRIP) followed by RT-qPCR
MeRIP-qPCR is used to determine the relative enrichment of m6A at specific sites within an RNA molecule.[5][13][14][15][16]
Materials:
-
Purified m6A-modified and unmodified control RNA
-
RNA fragmentation buffer
-
Anti-m6A antibody
-
Protein A/G magnetic beads
-
IP buffer
-
Elution buffer
-
Reagents for reverse transcription and quantitative PCR (RT-qPCR)
Procedure:
-
RNA Fragmentation: Fragment 1-5 µg of RNA to ~100-200 nucleotide-long fragments by incubating with RNA fragmentation buffer at 94°C for 5 minutes, followed by immediate cooling on ice.[14]
-
Immunoprecipitation:
-
Incubate the anti-m6A antibody with protein A/G magnetic beads in IP buffer for 1 hour at room temperature to form antibody-bead complexes.
-
Add the fragmented RNA to the antibody-bead complexes and incubate for 4 hours at 4°C with gentle rotation. A small fraction of the fragmented RNA should be saved as an input control.[13]
-
-
Washing: Wash the beads three times with IP buffer to remove non-specifically bound RNA.[13]
-
Elution: Elute the m6A-containing RNA fragments from the beads using an elution buffer.
-
RNA Purification: Purify the eluted RNA and the input control RNA.
-
RT-qPCR: Perform RT-qPCR on the immunoprecipitated RNA and the input control RNA using primers specific to the gene of interest. The relative enrichment of m6A at the target site can be calculated as the percentage of input recovery.[15]
References
- 1. m6A-ELISA, a simple method for quantifying N6-methyladenosine from mRNA populations - PMC [pmc.ncbi.nlm.nih.gov]
- 2. An Improved m6A-ELISA for Quantifying N6 -methyladenosine in Poly(A)-purified mRNAs - PMC [pmc.ncbi.nlm.nih.gov]
- 3. bio-protocol.org [bio-protocol.org]
- 4. researchgate.net [researchgate.net]
- 5. researchgate.net [researchgate.net]
- 6. bpb-us-e2.wpmucdn.com [bpb-us-e2.wpmucdn.com]
- 7. Quantitative analysis of m6A RNA modification by LC-MS - PMC [pmc.ncbi.nlm.nih.gov]
- 8. researchgate.net [researchgate.net]
- 9. benchchem.com [benchchem.com]
- 10. m6A-ELISA, a simple method for quantifying N6-methyladenosine from mRNA populations | Crick [crick.ac.uk]
- 11. Quantification of global m6A RNA methylation levels by LC-MS/MS [visikol.com]
- 12. Liquid Chromatography-Mass Spectrometry for Analysis of RNA Adenosine Methylation | Springer Nature Experiments [experiments.springernature.com]
- 13. An experimental workflow for identifying RNA m6A alterations in cellular senescence by methylated RNA immunoprecipitation sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 14. sysy.com [sysy.com]
- 15. sigmaaldrich.com [sigmaaldrich.com]
- 16. Detection of N6-methyladenosine in SARS-CoV-2 RNA by methylated RNA immunoprecipitation sequencing - PMC [pmc.ncbi.nlm.nih.gov]
Application Notes and Protocols for CRISPR-Cas9 Based Methods in m6A Functional Studies
Introduction to N6-methyladenosine (m6A)
N6-methyladenosine (m6A) is the most prevalent internal modification found in eukaryotic messenger RNA (mRNA) and plays a crucial role in various aspects of RNA metabolism, including splicing, nuclear export, stability, and translation.[1] This dynamic and reversible modification is installed by a "writer" complex, primarily composed of METTL3 and METTL14, and can be removed by "eraser" enzymes such as FTO and ALKBH5.[2][3][4][5] The functional consequences of m6A are mediated by "reader" proteins, which contain YTH domains (YTHDF1, YTHDF2, YTHDC1, etc.) and recognize the m6A mark to influence the fate of the modified mRNA.[1][6] The advent of CRISPR-Cas technology has enabled precise manipulation of m6A marks, providing powerful tools to investigate the site-specific functions of this epitranscriptomic modification.[1][7][8]
CRISPR-Cas Systems for Targeted m6A Editing
The core principle of using CRISPR for m6A studies involves fusing a catalytically inactive Cas protein (dCas9 or dCas13) to an m6A writer, eraser, or reader protein.[1][7][8][9] This fusion protein is then guided to a specific RNA molecule by a single guide RNA (sgRNA), enabling targeted manipulation of m6A at desired locations.[2][10] While dCas9 can be programmed to target RNA with the help of a PAM-presenting oligonucleotide (PAMer), the RNA-targeting dCas13 proteins (like dCas13b) are often preferred as they natively bind to RNA without the need for a PAM sequence.[3][10][11][12]
Application Notes
Targeted m6A Deposition ("Writing")
By fusing the catalytic domain of the m6A methyltransferase METTL3 (often in a single-chain construct with METTL14) to a dCas protein, researchers can site-specifically install m6A marks on target RNAs.[1][2][9][10] This "m6A writer" system allows for the investigation of the direct consequences of methylation at a particular site.
-
Functional Studies: This approach can be used to determine the effect of m6A on mRNA stability, translation efficiency, and splicing. For instance, targeted m6A methylation of a transcript has been shown to alter its mRNA levels.[1] Placing an m6A mark in the 5' UTR can promote cap-independent translation, while adding it to the 3' UTR can lead to mRNA degradation.[2][9]
-
Therapeutic Potential: Inducing m6A modifications on specific transcripts could be explored for therapeutic purposes, such as modulating the expression of disease-related genes.
Targeted m6A Removal ("Erasing")
Conversely, fusing dCas proteins to m6A demethylases ("erasers") like ALKBH5 or FTO enables the removal of m6A marks from specific transcripts.[1][2][9] This "m6A eraser" system is invaluable for studying the function of endogenous m6A modifications.
-
Functional Dissection: By demethylating a specific site, researchers can assess the importance of that particular m6A mark for the RNA's function. For example, the targeted demethylation of MYC mRNA has been shown to downregulate its expression.[1] Similarly, demethylating CYB5A mRNA increases its stability.[11]
-
Disease Research: Targeted demethylation of transcripts coding for oncoproteins like EGFR and MYC has been shown to suppress cancer cell proliferation, highlighting the therapeutic potential of this approach.[13]
Targeted Recruitment of m6A "Readers"
To understand the downstream effects of m6A recognition, dCas proteins can be fused to m6A reader proteins, such as those from the YTH domain family (e.g., YTHDF1, YTHDF2).[1][3]
-
Elucidating Mechanisms: This method allows for the targeted recruitment of specific readers to an RNA of interest, thereby mimicking the effect of m6A methylation and triggering its downstream consequences. For example, targeting YTHDF2 to a transcript can lead to its degradation, while targeting YTHDF1 can enhance its translation.[1][9] This helps to directly link a specific reader protein to a functional outcome for a given mRNA.
Quantitative Data Summary
The following tables summarize quantitative data from studies utilizing CRISPR-based m6A editing tools.
Table 1: Effects of Targeted m6A Demethylation by dCas13b-ALKBH5
| Target Gene | gRNA Target Region | Demethylation Efficiency | Effect on mRNA Level | Cell Line |
| CYB5A | Downstream of m6A site | ~80% reduction in m6A | Significant upregulation | HEK293T |
| CTNNB1 | 5' UTR | ~60% reduction in m6A | Significant upregulation | HeLa |
| EGFR | - | Significant m6A reduction | Downregulation | HeLa |
| MYC | - | Significant m6A reduction | Downregulation | HeLa |
| Data compiled from studies on dCas13b-ALKBH5 fusion proteins.[11][12][14][15] |
Table 2: Effects of Targeted m6A Editing by dCas9 Fusions
| Editor | Target Gene | Target Region | Effect on m6A | Functional Outcome | Cell Line |
| M3M14-dCas9 (Writer) | Actb | 3' UTR | Increased m6A | mRNA degradation | HEK293T |
| ALKBH5-dCas9 (Eraser) | Malat1 | A2577 | Decreased m6A | Destabilized RNA structure | HEK293T |
| FTO-dCas9 (Eraser) | Malat1 | A2577 | Decreased m6A | Destabilized RNA structure | HEK293T |
| Data compiled from studies on dCas9-based m6A editors.[2][10][16] |
Visualizations
Caption: The m6A Regulatory Machinery.
Caption: General workflow for CRISPR-dCas mediated m6A editing.
Caption: Targeted m6A "Writing" and its functional consequences.
Caption: Targeted m6A "Erasing" and its functional consequences.
Experimental Protocols
Protocol 1: Targeted m6A Demethylation using dCas13b-ALKBH5
This protocol describes the targeted removal of an m6A mark from a specific RNA transcript using a dCas13b-ALKBH5 fusion protein.[11][14]
1. Materials:
-
Expression vector for dCas13b-ALKBH5 fusion protein (e.g., pC0046-dPspCas13b-GS-ALKBH5).
-
Expression vector for sgRNA targeting the RNA of interest.
-
Mammalian cell line (e.g., HEK293T, HeLa).
-
Cell culture medium and reagents.
-
Transfection reagent (e.g., Lipofectamine 3000).
-
Control plasmids: non-targeting sgRNA and catalytically inactive dCas13b-ALKBH5 mutant.
2. Procedure:
-
Cell Seeding: Seed cells in 6-well plates to reach 70-80% confluency on the day of transfection.
-
Plasmid Transfection: Co-transfect the cells with the dCas13b-ALKBH5 expression vector (1.5 µg) and the specific sgRNA expression vector (1.0 µg) using Lipofectamine 3000 according to the manufacturer's protocol.[11][14]
-
Controls: In parallel wells, transfect cells with control plasmids, including a non-targeting sgRNA with the dCas13b-ALKBH5 vector, and the target-specific sgRNA with a catalytically dead dCas13b-ALKBH5 vector.
-
Incubation: Incubate the cells for 48-72 hours post-transfection to allow for the expression of the CRISPR components and targeted demethylation.
-
Cell Harvesting and RNA Extraction: Harvest the cells and extract total RNA using a commercial RNA extraction kit (e.g., TRIzol reagent).
-
Analysis: Proceed to MeRIP-qPCR (Protocol 2) or SELECT (Protocol 3) to quantify the change in m6A levels at the target site. Analyze changes in mRNA abundance using RT-qPCR.
Protocol 2: Quantification of m6A Levels by MeRIP-qPCR
This protocol is for the quantification of m6A levels at a specific RNA site following a targeted editing experiment.[17][18][19]
1. Materials:
-
Total RNA from experimental and control cells (at least 300 µg per sample is recommended if starting from total RNA, or 5 µg if starting with purified mRNA).[17]
-
Magna MeRIP™ m6A Kit (or equivalent components: anti-m6A antibody, Protein A/G magnetic beads, IP buffer).
-
RNA fragmentation buffer.
-
Reagents for reverse transcription and qPCR.
-
Primers flanking the target m6A site and a negative control region on the same transcript.
2. Procedure:
-
RNA Fragmentation: Fragment 5-300 µg of total RNA into ~100 nucleotide-long fragments by incubating in RNA fragmentation buffer.
-
Immunoprecipitation (IP): a. Set aside 10% of the fragmented RNA as an "input" control. b. Incubate the remaining fragmented RNA with an anti-m6A antibody overnight at 4°C with rotation. A negative control IP with normal mouse IgG should be run in parallel.[17] c. Add Protein A/G magnetic beads to the RNA-antibody mixture and incubate for 2 hours at 4°C to capture the antibody-RNA complexes. d. Wash the beads multiple times with IP buffer to remove non-specific binding. e. Elute the m6A-containing RNA fragments from the beads.
-
RNA Purification: Purify the RNA from both the IP (MeRIP) and input samples.
-
Reverse Transcription: Perform reverse transcription on the eluted RNA and input RNA to generate cDNA.
-
qPCR Analysis: a. Perform qPCR using primers specific to the target region and a negative control region. b. Calculate the m6A enrichment for the target site by first normalizing the MeRIP Ct value to the input Ct value (ΔCt = Ct[MeRIP] - Ct[Input]). c. The fold enrichment is often calculated relative to the negative control IgG sample or a negative control region on the transcript.[17][18] A decrease in fold enrichment in the experimental sample compared to the control indicates successful demethylation.
Protocol 3: Site-Specific m6A Quantification using SELECT
SELECT (single-base elongation- and ligation-based qPCR amplification) is an antibody-free method to quantify m6A levels at a specific site.[12][16][20]
1. Materials:
-
Total RNA from experimental and control cells.
-
DNA splint oligonucleotides specific to the target site.
-
Reverse transcriptase (RT) that is sensitive to m6A.
-
DNA ligase.
-
qPCR reagents and primers.
2. Principle: The SELECT method relies on the principle that m6A modification can block or impede the reverse transcription process at a specific site. A specially designed DNA splint brings a primer and a probe close to the target adenosine. If the adenosine is methylated (m6A), reverse transcription is stalled, preventing subsequent ligation and amplification. If the site is unmethylated, the reaction proceeds, leading to a qPCR signal.
3. Procedure:
-
Hybridization: Anneal two DNA splint oligonucleotides to the target RNA, immediately flanking the adenosine of interest.
-
Reverse Transcription & Ligation: Perform a reverse transcription reaction. The RT will extend from a primer until it reaches the target adenosine. If the base is unmodified, the extension product reaches the adjacent probe, and they are joined by a DNA ligase. If the base is m6A, the extension is blocked, and ligation does not occur.
-
qPCR: The ligated product is then amplified and quantified by qPCR.
-
Data Analysis: The m6A level is determined by comparing the qPCR signal from the experimental sample to that of a control sample or an in vitro-transcribed unmethylated standard.[12] A higher qPCR signal corresponds to a lower m6A level. The results are typically normalized to the total abundance of the target transcript, measured by conventional RT-qPCR.[16]
References
- 1. benchchem.com [benchchem.com]
- 2. qian.human.cornell.edu [qian.human.cornell.edu]
- 3. whatisepigenetics.com [whatisepigenetics.com]
- 4. biochem-caflisch.uzh.ch [biochem-caflisch.uzh.ch]
- 5. jme.bioscientifica.com [jme.bioscientifica.com]
- 6. Rethinking m6A Readers, Writers, and Erasers - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Targeted RNA m6A Editing Using Engineered CRISPR-Cas9 Conjugates | Springer Nature Experiments [experiments.springernature.com]
- 8. Targeted RNA m6A Editing Using Engineered CRISPR-Cas9 Conjugates - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. epigenie.com [epigenie.com]
- 10. qian.human.cornell.edu [qian.human.cornell.edu]
- 11. Targeted mRNA demethylation using an engineered dCas13b-ALKBH5 fusion protein - PMC [pmc.ncbi.nlm.nih.gov]
- 12. biorxiv.org [biorxiv.org]
- 13. researchgate.net [researchgate.net]
- 14. rcastoragev2.blob.core.windows.net [rcastoragev2.blob.core.windows.net]
- 15. biorxiv.org [biorxiv.org]
- 16. Programmable RNA N6-methyladenosine editing by CRISPR-Cas9 conjugates - PMC [pmc.ncbi.nlm.nih.gov]
- 17. sigmaaldrich.com [sigmaaldrich.com]
- 18. sigmaaldrich.com [sigmaaldrich.com]
- 19. merckmillipore.com [merckmillipore.com]
- 20. Frontiers | Current progress in strategies to profile transcriptomic m6A modifications [frontiersin.org]
Troubleshooting & Optimization
How to reduce background noise in N6-methyladenosine immunoprecipitation.
This technical support center provides troubleshooting guidance and answers to frequently asked questions to help researchers, scientists, and drug development professionals reduce background noise in N6-methyladenosine (m6A) immunoprecipitation (MeRIP or m6A-IP) experiments.
Frequently Asked Questions (FAQs)
Q1: What are the most common sources of high background noise in a MeRIP-seq experiment?
High background noise in MeRIP-seq can originate from several sources, including non-specific binding of RNA to the antibody or beads, insufficient washing, poor antibody quality, and issues with the input RNA quality.[1][2] Non-specific binding can be caused by electrostatic or hydrophobic interactions between the RNA and the immunoprecipitation components.[3]
Q2: How critical is the starting amount of RNA for a successful MeRIP-seq experiment with low background?
The starting amount of total RNA is a critical parameter. While traditional protocols often require large amounts (up to 300 µg), optimized methods allow for successful m6A profiling with as little as 500 ng to 2 µg of total RNA.[4][5] Using an excessive amount of input RNA may lead to increased non-specific binding.[6] Conversely, too little starting material can result in low signal-to-noise ratios.[1]
Q3: How do I choose the right anti-m6A antibody and determine the optimal concentration?
The choice of anti-m6A antibody is a crucial determinant of MeRIP-seq quality.[7] Different antibodies have varying performance, and it is essential to use a highly specific and validated antibody.[8] The optimal antibody concentration should be determined through titration to ensure efficient pulldown of m6A-containing RNA without increasing non-specific binding.[4] Studies have shown that for some antibodies, a lower concentration can yield a higher number of identified m6A peaks compared to higher concentrations.[7]
Q4: What is the importance of the input control in MeRIP-seq?
The input control, which is an aliquot of the fragmented RNA saved before immunoprecipitation, is essential for accurate m6A peak calling.[4] It represents the baseline abundance of RNA transcripts and is used to distinguish true m6A enrichment from background noise and transcriptional abundance.[9]
Troubleshooting Guide: High Background Noise
Problem: High background signal is observed in my MeRIP-seq data, leading to a low signal-to-noise ratio.
Below are potential causes and recommended solutions to troubleshoot and reduce high background noise in your m6A immunoprecipitation experiments.
| Potential Cause | Recommended Solution |
| Non-Specific Binding to Beads | Pre-clear the RNA lysate: Incubate the fragmented RNA with protein A/G beads before adding the anti-m6A antibody to remove molecules that non-specifically bind to the beads. Block the beads: Incubate the beads with a blocking agent like BSA to reduce non-specific binding sites.[2] |
| Suboptimal Antibody Concentration | Titrate the antibody: Perform pilot experiments with a range of antibody concentrations to find the optimal amount that maximizes the signal from m6A-containing transcripts while minimizing background.[4][8] |
| Inefficient Washing Steps | Optimize washing buffers: Use a series of washes with varying salt concentrations (low-salt and high-salt buffers) to effectively remove non-specifically bound RNA. An extensive high/low salt washing protocol has been shown to outperform competitive elution methods in improving the signal-to-noise ratio.[10] Increase the number and duration of washes: Perform at least 3-5 washes, and consider increasing the incubation time for each wash to enhance the removal of background molecules.[6][11] |
| Poor Quality of Starting RNA | Assess RNA integrity: Ensure that the starting total RNA is of high quality with a high RNA Integrity Number (RIN), as degraded RNA can contribute to background.[12] |
| Contaminated Reagents | Use fresh buffers: Prepare fresh IP and wash buffers before each experiment to avoid contamination that can lead to increased background.[1][9] |
Quantitative Data Summary
The following tables provide a summary of key quantitative parameters that should be optimized for a successful MeRIP-seq experiment with low background.
Table 1: Recommended Ranges for Key MeRIP-seq Parameters
| Parameter | Recommended Range/Value | Notes |
| Starting Total RNA | 500 ng - 300 µg | Optimized protocols can work with as little as 500 ng.[4][5] |
| RNA Fragmentation Size | ~100-200 nucleotides | Critical for the resolution of m6A peak detection.[4] |
| Anti-m6A Antibody | Varies by manufacturer | Titration is recommended to determine the optimal concentration.[4] |
| Sequencing Depth | >20 million reads per sample | Deeper sequencing can improve the sensitivity of peak detection.[4] |
Table 2: Comparison of Anti-m6A Antibody Concentrations for MeRIP-seq
| Antibody | Starting Total RNA | Recommended Antibody Amount | Reference |
| Millipore (ABE572, MABE1006) | 15 µg | 5 µg | [8][13] |
| Cell Signaling Technology (CST, #56593) | 0.1 µg - 1 µg | 1.25 µg - 2.5 µg | [8][10] |
Experimental Protocols
Optimized Washing Protocol for Reduced Background
This protocol is based on an extensive high/low salt washing procedure that has been shown to improve the signal-to-noise ratio in MeRIP-seq experiments.[10][14]
-
After incubating the fragmented RNA with the antibody-bead complex, wash the beads twice with IP buffer.
-
Wash the beads twice with a low-salt IP buffer (e.g., 10 mM Tris-HCl pH 7.5, 50 mM NaCl, and 0.1% IGEPAL CA-630).[10]
-
Wash the beads twice with a high-salt IP buffer (e.g., 10 mM Tris-HCl pH 7.5, 500 mM NaCl, and 0.1% IGEPAL CA-630).[10]
-
Perform each wash for 10 minutes at 4°C with gentle rotation.[10]
-
After the final wash, proceed with RNA elution.
Visualizations
References
- 1. An experimental workflow for identifying RNA m6A alterations in cellular senescence by methylated RNA immunoprecipitation sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 2. How to obtain a low background in immunoprecipitation assays | Proteintech Group [ptglab.com]
- 3. Nonspecific Binding: Main Factors of Occurrence and Strategies - WuXi AppTec DMPK [dmpkservice.wuxiapptec.com]
- 4. benchchem.com [benchchem.com]
- 5. Refined RIP-seq protocol for epitranscriptome analysis with low input materials - PMC [pmc.ncbi.nlm.nih.gov]
- 6. researchgate.net [researchgate.net]
- 7. Comparative analysis of improved m6A sequencing based on antibody optimization for low-input samples - PMC [pmc.ncbi.nlm.nih.gov]
- 8. rna-seqblog.com [rna-seqblog.com]
- 9. bosterbio.com [bosterbio.com]
- 10. A low-cost, low-input method establishment for m6A MeRIP-seq - PMC [pmc.ncbi.nlm.nih.gov]
- 11. MeRIP-seq Protocol - CD Genomics [rna.cd-genomics.com]
- 12. MeRIP-seq for Detecting RNA methylation: An Overview - CD Genomics [cd-genomics.com]
- 13. researchgate.net [researchgate.net]
- 14. researchgate.net [researchgate.net]
Optimizing antibody concentration for successful m6A MeRIP-seq.
This guide provides troubleshooting advice and frequently asked questions to help researchers, scientists, and drug development professionals optimize antibody concentration for successful N6-methyladenosine (m6A) Methylated RNA Immunoprecipitation Sequencing (MeRIP-seq) experiments.
Frequently Asked Questions (FAQs)
1. What is the recommended starting concentration of m6A antibody for MeRIP-seq?
The optimal antibody concentration is a critical factor for successful MeRIP-seq and can vary depending on the antibody manufacturer, the amount of input RNA, and the specific tissue or cell type.[1] It is always recommended to perform a titration experiment to determine the best concentration for your specific experimental conditions.[2] However, published studies provide a good starting point.
2. How do I validate a new m6A antibody for MeRIP-seq?
Antibody validation is crucial for reliable MeRIP-seq results.[3] A new antibody can be validated through a dot blot analysis using synthetic RNA oligonucleotides. This involves testing the antibody's binding specificity to m6A compared to other modifications like N1-methyladenosine (m1A) and unmodified adenosine.[3] Additionally, performing MeRIP-qPCR on known methylated and unmethylated transcripts can functionally validate the antibody's performance in an immunoprecipitation setting.[3]
3. What are appropriate positive and negative controls for antibody titration in MeRIP-seq?
For positive controls, use qPCR primers for transcripts known to be highly methylated with m6A in your cell or tissue type. For negative controls, use primers for transcripts known to have very low or no m6A modification. A negative control immunoprecipitation using a non-specific IgG antibody of the same isotype should also be included to assess background binding.[4][5]
4. How does antibody concentration affect MeRIP-seq efficiency and specificity?
The concentration of the anti-m6A antibody directly impacts both the efficiency and specificity of the immunoprecipitation. Using too little antibody can result in low enrichment of m6A-containing RNA fragments, while using too much can lead to high background signal from non-specific binding.[3] The goal of optimization is to find the concentration that provides the highest signal-to-noise ratio.
5. What are the signs of using too much or too little antibody in a MeRIP-seq experiment?
-
Too little antibody: Low yield of immunoprecipitated RNA, low enrichment of positive control transcripts, and a low number of identified m6A peaks.
-
Too much antibody: High background signal in negative control regions, low signal-to-noise ratio, and poor reproducibility between replicates.
Troubleshooting Guide
Issue: Low enrichment of m6A-containing RNA
Question: My m6A MeRIP-seq experiment shows very low enrichment of known m6A-positive transcripts. Could this be due to suboptimal antibody concentration?
Answer: Yes, suboptimal antibody concentration is a common cause of low enrichment. Both insufficient and excessive antibody amounts can lead to this issue. It is crucial to perform an antibody titration to identify the optimal concentration for your specific experimental conditions. Following a detailed antibody titration protocol is highly recommended.
Issue: High background signal
Question: I'm observing high background in my MeRIP-seq, with significant binding to negative control regions. How can I reduce this?
Answer: High background is often a result of using too much antibody, leading to non-specific binding. To address this, you should optimize the antibody concentration by performing a titration experiment. Additionally, ensuring stringent washing steps after the immunoprecipitation can help reduce non-specific binding of RNA to the beads.[3] Pre-clearing your RNA sample by incubating it with beads alone before adding the antibody can also help minimize background.[3]
Issue: Poor reproducibility between replicates
Question: My MeRIP-seq biological replicates are not correlating well. Could inconsistent antibody concentration be the cause?
Answer: Inconsistent antibody concentration between replicates can certainly contribute to poor reproducibility.[6] It is critical to use a precisely optimized and consistent amount of antibody for each replicate. Variations in antibody amount can lead to differences in enrichment efficiency and background levels, resulting in low correlation between samples. Always use the same validated batch of antibody for all experiments in a study to minimize variability.[7]
Data Presentation
Table 1: Recommended Starting Concentrations of Anti-m6A Antibodies for MeRIP-seq
| Antibody Vendor | Catalog Number | Starting RNA Amount | Recommended Antibody Amount | Reference |
| Millipore | ABE572 | 15 µg total RNA | 5 µg | [8][1] |
| Millipore | MABE1006 | 15 µg total RNA | 5 µg | [8][1] |
| Cell Signaling Technology (CST) | #56593 | Low-input total RNA | 1.25 µg | [8][1][9] |
| Diagenode | C15200082 | 40 µg total RNA | 2 µg (titration of 1-10 µg recommended) | [4] |
Table 2: Example Positive and Negative Controls for MeRIP-qPCR Validation
| Control Type | Gene Target (Human) | Rationale |
| Positive Control | EEF1A1, TPT1 | Generally have high and consistent m6A methylation. |
| Negative Control | GAPDH, ACTB | Generally have low m6A methylation. |
| Negative IP Control | Normal Mouse/Rabbit IgG | Accounts for non-specific binding to the beads and antibody.[5] |
Experimental Protocols
Detailed Methodology for Antibody Titration in m6A MeRIP-seq
This protocol outlines the steps to determine the optimal antibody concentration for your MeRIP-seq experiment.
-
RNA Preparation and Fragmentation:
-
Antibody-Bead Conjugation:
-
Prepare a series of antibody concentrations to be tested (e.g., 1 µg, 2.5 µg, 5 µg, and 10 µg).
-
For each concentration, couple the anti-m6A antibody to Protein A/G magnetic beads.[3]
-
Include a negative control with non-specific IgG at the highest concentration used for the anti-m6A antibody.
-
-
Immunoprecipitation (IP):
-
Divide the fragmented RNA into equal aliquots for each antibody concentration and the IgG control.
-
Incubate the fragmented RNA with the antibody-coupled beads in IP buffer for 2 hours to overnight at 4°C with rotation.[3]
-
Reserve a small fraction of the fragmented RNA as an "input" control before adding the beads.[11]
-
-
Washing and Elution:
-
RNA Purification and Quantification:
-
Purify the eluted RNA from the IP samples and the input sample.
-
Quantify the RNA yield for each titration point.
-
-
Reverse Transcription and qPCR Analysis:
-
Data Analysis and Optimal Concentration Selection:
-
Plot the enrichment of the positive control transcript against the antibody concentration.
-
Plot the enrichment of the negative control transcript against the antibody concentration.
-
The optimal antibody concentration is the one that gives the highest enrichment for the positive control with the lowest enrichment for the negative control (i.e., the highest signal-to-noise ratio).
-
Visualizations
References
- 1. Comparative analysis of improved m6A sequencing based on antibody optimization for low-input samples - PMC [pmc.ncbi.nlm.nih.gov]
- 2. benchchem.com [benchchem.com]
- 3. benchchem.com [benchchem.com]
- 4. N6-methyladenosine (m6A) antibody - RIP Grade (C15200082) | Diagenode [diagenode.com]
- 5. blog.cellsignal.com [blog.cellsignal.com]
- 6. Limits in the detection of m6A changes using MeRIP/m6A-seq - PMC [pmc.ncbi.nlm.nih.gov]
- 7. bosterbio.com [bosterbio.com]
- 8. rna-seqblog.com [rna-seqblog.com]
- 9. A low-cost, low-input method establishment for m6A MeRIP-seq - PMC [pmc.ncbi.nlm.nih.gov]
- 10. MeRIP-seq Protocol - CD Genomics [rna.cd-genomics.com]
- 11. sigmaaldrich.com [sigmaaldrich.com]
- 12. researchgate.net [researchgate.net]
Technical Support Center: Navigating m6A Sequencing with Low RNA Input
Welcome to the technical support center for researchers, scientists, and drug development professionals. This resource provides troubleshooting guidance and answers to frequently asked questions (FAQs) to help you overcome the challenges associated with low RNA input for N6-methyladenosine (m6A) sequencing.
Frequently Asked Questions (FAQs)
Q1: What are the primary challenges when performing m6A sequencing with low amounts of starting RNA?
A1: The main challenges with low-input m6A sequencing are multi-faceted. They include insufficient yield of m6A-enriched RNA, high background noise, and variability in results. The specificity and efficiency of the anti-m6A antibody, the quality and quantity of the initial RNA sample, the effectiveness of RNA fragmentation, and the thoroughness of washing steps during immunoprecipitation are all critical factors that can significantly impact the experiment's success. Reproducibility can be a concern, with some studies showing that m6A peak overlap between experiments can be as low as 30-60%, even within the same cell type.
Q2: What is the minimum amount of total RNA required for a successful MeRIP-Seq experiment?
A2: Traditionally, Methylated RNA Immunoprecipitation Sequencing (MeRIP-Seq) protocols required substantial amounts of total RNA, often around 300 µg.[1] However, with recent advancements and protocol optimizations, it is now feasible to perform MeRIP-Seq with as little as 500 ng of total RNA.[2] Some highly optimized methods claim success with even lower inputs, in the nanogram range, depending on the specific kit and antibody used. For instance, some methods can be adapted for as little as 1-2 µg of total RNA, and in some cases, down to 50 ng.[1]
Q3: How can I assess the quality and integrity of my low-input RNA sample?
A3: For low-input samples, it is crucial to accurately assess RNA quality. Use a Bioanalyzer or similar capillary electrophoresis-based system to determine the RNA Integrity Number (RIN). A higher RIN value generally indicates better quality RNA. Additionally, quantify your RNA using a fluorometric method (e.g., Qubit) for higher accuracy compared to spectrophotometry, especially for low concentrations.
Q4: Which m6A sequencing method is best suited for very low RNA input, including single cells?
A4: For extremely low RNA inputs, such as those from single cells, traditional MeRIP-Seq is often not feasible. Newer, specialized techniques have been developed to address this challenge. scDART-seq (single-cell Deamination Adjacent to RNA Modification Targets sequencing) is a method specifically designed for transcriptome-wide m6A profiling in single cells.[3] It utilizes a fusion protein to induce C-to-U edits near m6A sites, which can then be identified through sequencing.[3] This antibody-free approach avoids the pitfalls of immunoprecipitation with scarce material.
Troubleshooting Guide
| Issue | Potential Cause | Recommended Solution |
| Low yield of immunoprecipitated (IP) RNA | 1. Insufficient starting material: The amount of RNA is below the optimal range for the protocol. 2. Inefficient immunoprecipitation: The antibody may not be binding effectively to the m6A-containing RNA fragments. 3. Suboptimal RNA fragmentation: RNA fragments may be too long or too short for efficient immunoprecipitation. | 1. Increase RNA input: If possible, start with a higher amount of total RNA. 2. Optimize antibody concentration: Perform a titration experiment to determine the optimal antibody concentration for your sample type. Ensure the antibody is validated for immunoprecipitation. 3. Standardize fragmentation: Carefully follow the protocol for RNA fragmentation to achieve the desired size range (typically around 100-200 nucleotides). |
| High background/low signal-to-noise ratio | 1. Non-specific binding of antibody: The antibody may be binding to unmodified RNA or other cellular components. 2. Insufficient washing: Washing steps may not be stringent enough to remove non-specifically bound molecules. 3. Contamination with genomic DNA: gDNA contamination can lead to non-specific signals. | 1. Use a high-quality, validated antibody: Select an antibody with proven specificity for m6A. 2. Increase washing stringency: Increase the number of washes or use buffers with higher salt concentrations to reduce non-specific binding.[1] 3. Perform DNase treatment: Ensure your RNA sample is treated with DNase to remove any contaminating genomic DNA. |
| Inconsistent results between replicates | 1. Variability in starting material: Differences in RNA quality or quantity between replicates. 2. Inconsistent experimental technique: Variations in pipetting, incubation times, or washing steps. 3. Batch-to-batch variation of antibody: Different lots of the same antibody can have varying performance. | 1. Normalize starting material: Carefully quantify and assess the quality of RNA for each replicate to ensure consistency. 2. Standardize the protocol: Maintain consistent technique across all replicates. 3. Validate new antibody lots: If using a new batch of antibody, perform a validation experiment to ensure its performance is consistent with previous lots. |
| Low library complexity/high duplication rate | 1. Insufficient amount of starting material for library preparation: The amount of IP RNA is too low, leading to amplification bias. 2. Too many PCR cycles: Excessive PCR amplification can lead to the overrepresentation of certain fragments. | 1. Start with sufficient RNA: If possible, increase the initial amount of RNA to yield more IP RNA for library construction. 2. Optimize PCR cycles: Perform a qPCR to determine the optimal number of PCR cycles for library amplification to avoid over-amplification. |
Data Presentation: Quantitative Comparison of Low-Input m6A Sequencing Methods
The following tables summarize key quantitative data from studies utilizing low-input RNA for m6A sequencing, providing a comparative overview of different methods and conditions.
Table 1: Comparison of MeRIP-Seq Performance with Varying RNA Input and Antibodies
| Starting Total RNA | Antibody | Antibody Amount | Number of m6A Peaks Identified | Reference |
| 15 µg | Millipore (ABE572) | 5 µg | ~30,957 | [4] |
| 1 µg | CST (#56593) | 2.5 µg | ~23,188 | [4] |
| 0.5 µg | CST (#56593) | 1.25 µg | ~14,842 | [4] |
| 0.1 µg | CST (#56593) | 1.25 µg | Significantly decreased | [4][5] |
| 15 µg | Millipore (MABE1006) | 5 µg | Higher than 2.5 µg | [6] |
| 15 µg | CST (#56593) | 1.25 µg | Higher than 2.5 µg and 5 µg | [6] |
Table 2: Overview of Low-Input m6A Sequencing Technologies
| Method | Principle | Minimum RNA Input | Resolution | Key Advantage |
| MeRIP-Seq (Optimized) | Antibody-based enrichment of m6A-containing RNA fragments followed by sequencing. | ~500 ng total RNA | ~100-200 nt | Well-established with optimized protocols for lower inputs. |
| SELECT-m6A Sequencing | Enzymatic enrichment of m6A-modified RNA fragments.[7] | Not specified, but designed for limited samples. | Single-base | Antibody-free, reducing bias and providing high resolution.[7] |
| scDART-seq | Fusion protein-mediated C-to-U editing adjacent to m6A sites.[3] | Single-cell level | Single-nucleotide | Enables transcriptome-wide m6A profiling in individual cells.[3] |
Experimental Protocols
Detailed Methodology: Low-Input MeRIP-Seq
This protocol is adapted from optimized methods for low-input MeRIP-Seq.[2]
-
RNA Preparation and Fragmentation:
-
Start with 500 ng to 2 µg of high-quality total RNA (RIN > 7).
-
Fragment the RNA to an average size of 100-200 nucleotides using RNA fragmentation buffer or enzymatic methods.
-
Purify the fragmented RNA using a spin column or ethanol precipitation.
-
-
Immunoprecipitation:
-
Couple an m6A-specific antibody (e.g., from Millipore or Cell Signaling Technology) to protein A/G magnetic beads. The optimal antibody amount should be determined empirically, but typically ranges from 1.25 to 5 µg.[4][6]
-
Incubate the fragmented RNA with the antibody-bead complex in IP buffer for 2-4 hours at 4°C with gentle rotation.
-
Wash the beads extensively with low-salt and high-salt wash buffers to remove non-specifically bound RNA.
-
-
Elution and Library Preparation:
-
Elute the m6A-containing RNA fragments from the beads.
-
Purify the eluted RNA.
-
Use a low-input RNA library preparation kit (e.g., SMARTer Stranded Total RNA-Seq Kit v2 - Pico Input Mammalian) to construct the sequencing library from the immunoprecipitated RNA and a corresponding input control sample.[4]
-
-
Sequencing and Data Analysis:
-
Sequence the libraries on a high-throughput sequencing platform.
-
Perform data analysis by aligning reads to the reference genome, followed by peak calling using software like MACS2 to identify m6A-enriched regions.
-
Detailed Methodology: SELECT-m6A Sequencing
This methodology is based on the principles of the SELECT-m6A sequencing technique.[7]
-
RNA Preparation:
-
Extract high-quality total RNA from the sample. This method is designed to be effective with limited RNA quantities.
-
-
m6A Enrichment:
-
Utilize an enzymatic approach to specifically enrich for RNA fragments containing m6A modifications. This antibody-free method relies on enzymes that can distinguish between methylated and unmethylated adenosine.
-
-
Library Preparation and Sequencing:
-
After enrichment, amplify the m6A-containing RNA fragments.
-
Prepare a sequencing library using a high-resolution sequencing technology. The SELECT method aims for single-base resolution.[7]
-
-
Data Analysis:
-
Process the sequencing data using bioinformatics tools to map the precise locations of m6A modifications across the transcriptome.
-
Detailed Methodology: scDART-seq
This protocol outlines the key steps involved in a scDART-seq experiment.[3][8]
-
Cell Preparation and Transfection:
-
Culture and transfect the cells of interest with a plasmid expressing the APOBEC1-YTH fusion protein.
-
-
Induction and Single-Cell Isolation:
-
Induce the expression of the fusion protein.
-
Prepare a single-cell suspension from the cultured cells.
-
Isolate single cells using a droplet-based or plate-based platform (e.g., 10x Genomics or SMART-seq2).
-
-
Reverse Transcription and cDNA Amplification:
-
Perform reverse transcription and cDNA amplification for each single cell according to the chosen single-cell RNA-seq protocol.
-
-
Library Preparation and Sequencing:
-
Construct sequencing libraries from the amplified cDNA.
-
Sequence the libraries on a high-throughput sequencing platform.
-
-
Data Analysis:
-
Align the sequencing reads to the reference genome.
-
Use specialized bioinformatics tools to identify C-to-U editing events, which indicate the locations of m6A modifications at single-nucleotide resolution within each cell.
-
Mandatory Visualization
m6A Regulation of the PI3K/AKT/MAPK Signaling Pathways
The following diagram illustrates the regulatory role of m6A modification on the PI3K/AKT and MAPK signaling pathways. m6A writers (e.g., METTL3/14), erasers (e.g., FTO, ALKBH5), and readers (e.g., YTHDF proteins) can modulate the expression of key components in these pathways, thereby influencing cellular processes such as proliferation, survival, and differentiation.[7][9][10]
Caption: m6A-mediated regulation of PI3K/AKT and MAPK signaling pathways.
References
- 1. semanticscholar.org [semanticscholar.org]
- 2. Comparison of m6A Sequencing Methods - CD Genomics [cd-genomics.com]
- 3. scDART-seq reveals distinct m6A signatures and mRNA methylation heterogeneity in single cells - PMC [pmc.ncbi.nlm.nih.gov]
- 4. portlandpress.com [portlandpress.com]
- 5. A low-cost, low-input method establishment for m6A MeRIP-seq - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. Comparative analysis of improved m6A sequencing based on antibody optimization for low-input samples - PMC [pmc.ncbi.nlm.nih.gov]
- 7. SELECT-m6A Sequencing Service - CD Genomics [cd-genomics.com]
- 8. scDART-seq: Mapping m6A at the single-cell level - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. Role of m6A modification in regulating the PI3K/AKT signaling pathway in cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 10. m6A RNA modification modulates PI3K/Akt/mTOR signal pathway in Gastrointestinal Cancer - PMC [pmc.ncbi.nlm.nih.gov]
Dealing with antibody specificity issues in 2-Methylamino-N6-methyladenosine detection.
This technical support center provides troubleshooting guidance and frequently asked questions (FAQs) for researchers, scientists, and drug development professionals working with 2-Methylamino-N6-methyladenosine (m6A) detection. The following information addresses common issues related to antibody specificity and provides detailed experimental protocols.
Frequently Asked Questions (FAQs)
Q1: What are the most common causes of high background in an m6A dot blot?
A1: High background in m6A dot blots can stem from several factors. A primary reason is the antibody concentration being too high, leading to non-specific binding. Additionally, inadequate blocking of the membrane or insufficient washing steps can leave excess antibody that contributes to background signal. The quality of the RNA sample itself is also crucial; contaminants or degraded RNA can interact non-specifically with the antibody or membrane.[1][2]
Q2: My MeRIP-seq experiment has a low signal-to-noise ratio. What are the likely causes?
A2: A low signal-to-noise ratio in MeRIP-seq can be due to inefficient immunoprecipitation (IP) or high non-specific binding. The choice of antibody is critical, as different commercial antibodies exhibit varying affinities and specificities.[1] Low input RNA amounts can also lead to poor enrichment of m6A-containing fragments.[3][4] Furthermore, issues with RNA fragmentation, where fragments are either too large or too small, can impact the efficiency of the IP step.
Q3: How can I validate the specificity of my anti-m6A antibody?
A3: Validating the specificity of an anti-m6A antibody is crucial for reliable results. One robust method is to use knockout (KO) models for m6A writer enzymes like METTL3. In cells lacking the writer enzyme, the m6A signal should be significantly reduced or absent compared to wild-type cells.[5][6][7] Another approach is to perform competition assays. By incubating the antibody with free m6A nucleotides before adding it to the sample, the specific signal should be diminished as the antibody's binding sites become occupied. Additionally, using in vitro transcribed RNA with and without m6A can serve as positive and negative controls to assess antibody specificity.[8]
Q4: What is the ideal RNA fragment size for a MeRIP-seq experiment?
A4: For MeRIP-seq, the recommended RNA fragment size is typically around 100-200 nucleotides.[9] This size range provides a good balance for efficient immunoprecipitation and sufficient resolution for identifying m6A peaks. Fragmentation can be achieved chemically or enzymatically, and it is important to verify the fragment size distribution using a Bioanalyzer before proceeding with the IP.[9]
Q5: Are there alternatives to antibody-based methods for m6A detection?
A5: Yes, several antibody-independent methods for m6A detection exist. These can be useful for validating antibody-based findings and overcoming specificity issues. Mass spectrometry-based approaches provide quantitative information on m6A abundance but do not pinpoint the exact location within the RNA sequence.[10] Other methods, such as those based on m6A-sensitive enzymes or chemical labeling, can offer single-nucleotide resolution.[11]
Troubleshooting Guides
Dot Blot Troubleshooting
| Issue | Potential Cause | Recommended Solution |
| High Background | Antibody concentration too high. | Titrate the antibody to find the optimal concentration that maximizes signal-to-noise ratio.[2] |
| Inadequate blocking. | Increase blocking time to at least 1 hour and ensure the blocking agent (e.g., non-fat milk or BSA) is fresh.[12] | |
| Insufficient washing. | Increase the number and duration of wash steps after primary and secondary antibody incubations.[12] | |
| No or Weak Signal | Low m6A levels in the sample. | Use a positive control with known high m6A levels. Consider enriching for mRNA, as m6A is more abundant in mRNA than in total RNA.[13] |
| Inefficient antibody binding. | Ensure the antibody is validated for the application and stored correctly. Use a recommended antibody dilution.[14] | |
| RNA not properly crosslinked to the membrane. | Ensure proper UV crosslinking of the RNA to the membrane after spotting.[14] | |
| Inconsistent Spots | Uneven spotting of RNA. | Carefully pipette the RNA samples onto the membrane, ensuring each spot is of a consistent volume and shape. Allow the spots to dry completely before proceeding. |
| Membrane drying out during incubation. | Ensure the membrane is fully submerged in buffer during all incubation and washing steps. |
MeRIP-Seq Troubleshooting
| Issue | Potential Cause | Recommended Solution |
| Low Yield of Immunoprecipitated RNA | Insufficient input RNA. | Start with a sufficient amount of high-quality total RNA (e.g., 500 ng or more).[4] |
| Inefficient antibody-bead coupling. | Ensure proper mixing and incubation of the antibody with the protein A/G beads. | |
| Inefficient elution. | Optimize the elution conditions, ensuring the elution buffer is effective at disrupting the antibody-RNA interaction. | |
| High Background/Non-specific Binding | Antibody cross-reactivity. | Validate the antibody using knockout models or competition assays.[5][6][7] Use a high-quality, validated antibody. |
| Insufficient washing after IP. | Increase the number and stringency of washes to remove non-specifically bound RNA.[2] | |
| Contamination with genomic DNA. | Perform a thorough DNase treatment of the RNA sample before fragmentation.[15] | |
| Poor Library Quality | Degraded RNA. | Assess RNA integrity using a Bioanalyzer before starting the experiment. Use only high-quality, intact RNA.[15] |
| Inefficient library preparation steps. | Follow the library preparation kit's protocol carefully and use appropriate quality control checks. | |
| Inconsistent Results Between Replicates | Variability in experimental technique. | Ensure consistent handling of all samples throughout the protocol, from RNA extraction to library preparation. |
| Batch effects from reagents. | Use reagents from the same lot for all samples in an experiment whenever possible. |
Quantitative Comparison of Commercial Anti-m6A Antibodies
| Antibody | Supplier | Reported Specificity | Signal-to-Noise Ratio (Qualitative) | Validated Applications | Reference |
| Anti-m6A (Clone 13) | Millipore | High | Good | MeRIP-seq | [16] |
| Anti-m6A | Synaptic Systems | High | Good | MeRIP-seq, Dot Blot | [16] |
| Anti-m6A | New England Biolabs (NEB) | Moderate | Moderate | MeRIP-seq | [16] |
| Anti-m6A (RM362) | Invitrogen | Reacts with m6A in RNA and DNA. No cross-reactivity with unmodified adenosine. | Not specified | Not specified | |
| Anti-m6A (D9D9W) | Cell Signaling Technology | High specificity for m6A. No cross-reactivity with unmodified adenosine, N6-dimethyladenosine, N1-methyladenosine, or 2'-O-methyladenosine. | Not specified | ELISA, Dot Blot |
Note: The performance of antibodies can vary between lots and experimental conditions. It is crucial to validate each new antibody and lot in your specific application.
Experimental Protocols
Detailed Dot Blot Protocol for m6A Detection
-
RNA Preparation:
-
Isolate total RNA from cells or tissues using a standard protocol (e.g., TRIzol).
-
To enrich for m6A, purify mRNA from the total RNA using oligo(dT) magnetic beads.
-
Quantify the RNA concentration using a spectrophotometer.[12]
-
-
RNA Denaturation and Spotting:
-
Prepare serial dilutions of your RNA samples (e.g., 100 ng, 50 ng, 25 ng) in RNase-free water.
-
Denature the RNA samples by heating at 95°C for 3 minutes, then immediately place on ice.[12]
-
Carefully spot 1-2 µL of each denatured RNA sample onto a nitrocellulose or nylon membrane.[17]
-
Allow the membrane to air dry completely.
-
-
Crosslinking and Blocking:
-
Antibody Incubation:
-
Incubate the membrane with a validated anti-m6A primary antibody at the optimized dilution in blocking buffer overnight at 4°C with gentle shaking.[14]
-
Wash the membrane three to four times for 5-10 minutes each with washing buffer (e.g., PBST/TBST).[12][17]
-
Incubate the membrane with a horseradish peroxidase (HRP)-conjugated secondary antibody at the appropriate dilution in blocking buffer for 1 hour at room temperature.[14]
-
-
Detection:
Key Steps in a MeRIP-Seq Workflow
-
RNA Preparation and Fragmentation:
-
Immunoprecipitation (IP):
-
Incubate the fragmented RNA with a validated anti-m6A antibody. A portion of the fragmented RNA should be set aside as the input control.[11]
-
Capture the antibody-RNA complexes using protein A/G magnetic beads.[11]
-
Wash the beads extensively to remove non-specifically bound RNA.
-
Elute the m6A-containing RNA fragments from the beads.
-
-
Library Preparation and Sequencing:
-
Construct sequencing libraries from both the immunoprecipitated RNA and the input control RNA.
-
Perform high-throughput sequencing.
-
-
Data Analysis:
-
Perform quality control on the raw sequencing reads.
-
Align the reads from both the IP and input samples to a reference genome.[18]
-
Identify m6A peaks by comparing the read enrichment in the IP sample to the input control using peak calling software like MACS2.[18]
-
Annotate the identified m6A peaks to genomic features (e.g., exons, introns, UTRs).
-
Perform differential methylation analysis between different conditions if applicable.[19]
-
Visualizations
References
- 1. The detection and functions of RNA modification m6A based on m6A writers and erasers - PMC [pmc.ncbi.nlm.nih.gov]
- 2. agrisera.com [agrisera.com]
- 3. An experimental workflow for identifying RNA m6A alterations in cellular senescence by methylated RNA immunoprecipitation sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Refined RIP-seq protocol for epitranscriptome analysis with low input materials - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Redirecting [linkinghub.elsevier.com]
- 6. Use of mouse knockout models to validate the specificity of monoclonal antibodies - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. researchgate.net [researchgate.net]
- 8. m6A-ELISA, a simple method for quantifying N6-methyladenosine from mRNA populations - PMC [pmc.ncbi.nlm.nih.gov]
- 9. benchchem.com [benchchem.com]
- 10. Comprehensive Overview of m6A Detection Methods - CD Genomics [cd-genomics.com]
- 11. MeRIP-seq and Its Principle, Protocol, Bioinformatics, Applications in Diseases - CD Genomics [cd-genomics.com]
- 12. Dot Blot Analysis of N6-methyladenosine RNA Modification Levels - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Dot Blot Analysis for Measuring Global N6-Methyladenosine Modification of RNA | Springer Nature Experiments [experiments.springernature.com]
- 14. Dot Blot Analysis of N6-methyladenosine RNA Modification Levels [bio-protocol.org]
- 15. sigmaaldrich.com [sigmaaldrich.com]
- 16. researchgate.net [researchgate.net]
- 17. Detecting RNA Methylation by Dot Blotting | Proteintech Group [ptglab.com]
- 18. Master MeRIP-seq Data Analysis: Step-by-Step Process for RNA Methylation Studies - CD Genomics [rna.cd-genomics.com]
- 19. GitHub - canceromics/MeRIPseqPipe: MeRIPseqPipe:An integrated analysis pipeline for MeRIP-seq data based on Nextflow. [github.com]
Technical Support Center: Efficient m6A Sequencing Library Preparation
Welcome to the technical support center for N6-methyladenosine (m6A) sequencing library preparation. This resource provides researchers, scientists, and drug development professionals with comprehensive troubleshooting guides, frequently asked questions (FAQs), and detailed protocols to enhance the efficiency and success of your m6A-seq experiments.
Troubleshooting Guide
This guide addresses specific issues that may arise during m6A library preparation, offering potential causes and solutions in a direct question-and-answer format.
Issue 1: Low Final Library Yield
-
Q: Why is my final library concentration too low for sequencing?
-
A: Low library yield is a common issue that can stem from several factors throughout the MeRIP-seq protocol. Key causes include poor quality or insufficient input RNA, inefficient immunoprecipitation (IP), and loss of material during cleanup steps.[1][2]
-
Input RNA Quality: High-quality RNA is crucial for success.[3] Ensure your total RNA has a RIN value ≥ 7.0 and optimal purity ratios (A260/280 >1.8, A260/230 >1.0).[4] Contaminants can inhibit downstream enzymatic reactions.[2][5]
-
Input RNA Quantity: While protocols are being developed for low-input samples, starting with a sufficient amount of total RNA (e.g., ≥ 50 µg) or mRNA is recommended to ensure enough m6A-containing fragments are available for enrichment.[4][6]
-
RNA Fragmentation: Over-fragmentation can lead to the loss of small fragments during cleanup steps. Conversely, under-fragmentation results in poor IP efficiency. Aim for fragments predominantly in the ~100-200 nucleotide range.[7][8]
-
Immunoprecipitation (IP) Efficiency: The quality and amount of the anti-m6A antibody are critical.[3][9] Use a validated, high-affinity antibody and optimize the antibody-to-RNA ratio.[10][11] Inefficient antibody-bead coupling can also reduce pull-down efficiency.
-
Bead Cleanup Steps: Material can be lost during bead-based purification steps. Ensure beads are not aspirated, and elution conditions are optimal. Using freshly prepared 70-80% ethanol is critical, as lower concentrations can prematurely elute the library from the beads.[12]
-
Issue 2: High Percentage of PCR Duplicates
-
Q: My sequencing data shows a high rate of PCR duplicates. What causes this and how can I reduce it?
-
A: High PCR duplication rates often indicate low library complexity, meaning the initial pool of unique fragments was limited. This forces the PCR step to amplify the same molecules repeatedly.
-
Low Input Material: The most common cause is starting with too little RNA, which results in a less complex cDNA library before amplification.[13][14]
-
Over-amplification: Using too many PCR cycles can exhaust the unique templates and lead to preferential amplification of existing molecules.[15] It's recommended to determine the optimal cycle number by qPCR before the final amplification.
-
Inefficient Enrichment: If the m6A IP is inefficient, the starting material for PCR will be sparse, leading to higher duplication.
-
Solution - Use of UMIs: To mitigate this, especially for low-input samples or deep sequencing projects, incorporate Unique Molecular Identifiers (UMIs) into the library preparation workflow.[13][14] UMIs are random barcodes that tag each unique molecule before amplification, allowing bioinformatics tools to distinguish true biological duplicates from PCR artifacts.[14][16]
-
Issue 3: Presence of Adapter Dimers
-
Q: I see a prominent peak around 120-130 bp in my final library electropherogram. What is it and how do I remove it?
-
A: This peak typically represents adapter-dimers, which form when sequencing adapters ligate to each other instead of the cDNA fragments.[17] They consume sequencing reads and reduce data quality.
-
Causes: Adapter-dimer formation is often caused by using an excessive concentration of adapters relative to the amount of input cDNA. This is more common in libraries with low starting yields.[2]
-
Solutions:
-
Optimize Adapter Concentration: Titrate the adapter concentration to match the amount of input material.
-
Improve Cleanup: Perform an additional bead-based cleanup step, carefully adjusting the bead-to-sample ratio (e.g., 0.9X) to selectively remove smaller fragments like adapter-dimers.[1][17]
-
Quality Control: Run a sample of the library on a fragment analyzer (e.g., Bioanalyzer) immediately after ligation to check for dimers before proceeding to amplification.[1]
-
-
Issue 4: Low m6A Enrichment Efficiency
-
Q: How can I confirm successful m6A enrichment, and what should I do if it's low?
-
A: Low enrichment means that the immunoprecipitated sample (IP) is not significantly different from the input control, indicating a failure to specifically pull down m6A-containing RNA fragments.
-
Validation with qPCR: Before sequencing, validate the enrichment of known m6A-positive and m6A-negative gene transcripts via qRT-PCR. A successful IP will show a high recovery of positive controls and low recovery of negative controls.
-
Antibody Quality: The primary cause of low enrichment is often a poor-quality or non-specific anti-m6A antibody.[3] Always use an antibody validated for MeRIP applications.[10][18]
-
Washing Steps: Insufficient or overly stringent washing during the IP protocol can lead to high background or loss of specifically bound RNA, respectively. Follow the protocol's washing recommendations carefully.[3]
-
Blocking: Ensure proper blocking of the protein A/G beads to prevent non-specific binding of RNA.[18]
-
Frequently Asked Questions (FAQs)
-
Q1: How much starting RNA do I need for an m6A-seq experiment?
-
A1: Standard protocols often recommend starting with a significant amount of total RNA (e.g., 50-300 µg) or purified mRNA (e.g., 5 µg) to ensure sufficient m6A-modified fragments for robust enrichment.[4][8] However, low-input methods are emerging, with some protocols working with as little as 0.1-1 µg of total RNA, though this may require protocol optimization and a highly efficient antibody.[6][9][11]
-
Q2: How do I choose the right anti-m6A antibody?
-
A2: Antibody selection is a critical determinant of MeRIP-seq quality.[3][9] Use a monoclonal antibody that has been specifically validated for immunoprecipitation of m6A-RNA. Check publications and manufacturer data for evidence of high specificity and efficiency.[10][19] It is advisable to test different antibody concentrations to optimize the IP for your specific tissue or cell type.[9]
-
Q3: What are the key quality control checkpoints in the m6A-seq workflow?
-
A3: Key QC steps include:
-
Initial RNA Quality: Assess RNA integrity (RIN value) and purity (spectrophotometer ratios).[1][4]
-
RNA Fragmentation: Check fragment size distribution on a Bioanalyzer or similar instrument to ensure fragments are ~100-200 nt.[18]
-
Enrichment Validation: Perform qRT-PCR on positive and negative control transcripts after IP.
-
Final Library QC: Analyze the final library size distribution and concentration using a fragment analyzer and a fluorometric method (e.g., Qubit).[1][5]
-
-
Q4: Should I perform rRNA depletion?
-
A4: Yes. Since m6A modifications are most commonly studied on mRNA and lncRNAs, ribosomal RNA (rRNA), which constitutes the majority of total RNA, should be removed. This is typically achieved by starting with poly(A)-selected mRNA or by performing rRNA depletion on the total RNA sample before fragmentation.[20]
Quantitative Data Summary
The following tables provide a summary of typical quantitative parameters for m6A-seq library preparation.
Table 1: Input RNA Recommendations and Quality Control
| Parameter | Recommended Value | Notes |
| Starting Material | ||
| Total RNA (Standard) | 50 - 300 µg | Ensures high library complexity.[8] |
| Total RNA (Low-Input) | 0.1 - 15 µg | Requires protocol optimization and a highly efficient antibody.[6] |
| mRNA | ≥ 2 µg | Bypasses the need for rRNA depletion.[3] |
| RNA Quality | ||
| RIN (RNA Integrity Number) | ≥ 7.0 | Critical for ensuring RNA is not degraded.[4] |
| A260/280 Ratio | > 1.8 | Indicates purity from protein contamination.[4] |
| A260/230 Ratio | > 1.0 | Indicates purity from phenol, salts, and other contaminants.[4] |
Table 2: Library Preparation and Sequencing Metrics
| Parameter | Recommended Value | Notes |
| RNA Fragment Size | ~100 - 200 nt | Optimal for both IP efficiency and mapping resolution.[7][8] |
| Anti-m6A Antibody | 1 - 10 µg per IP | Optimal amount should be determined by the end-user.[10] |
| PCR Cycles | 10 - 15 cycles | Should be optimized to avoid over-amplification.[15] |
| Sequencing Depth | > 40 million reads | Recommended for comprehensive transcriptome coverage.[4] |
| Read Type | 150 bp Paired-End | Provides better mapping accuracy and transcript identification.[4] |
Visualized Workflows and Logic
Diagram 1: General MeRIP-Seq Workflow
Caption: Overview of the methylated RNA immunoprecipitation sequencing (MeRIP-seq) workflow.
Diagram 2: Troubleshooting Low Library Yield
Caption: A decision tree for troubleshooting the causes of low library yield.
Detailed Experimental Protocols
Protocol 1: m6A RNA Immunoprecipitation (MeRIP)
This protocol is a generalized representation and should be adapted based on specific kit instructions and optimization experiments.
-
RNA Fragmentation:
-
Take 50-100 µg of rRNA-depleted or poly(A)-selected RNA in an RNase-free tube.
-
Add RNA fragmentation buffer.
-
Incubate at an elevated temperature (e.g., 70-94°C) for a time determined during optimization (e.g., 5-10 minutes) to obtain fragments of ~100-200 nt.[6][18]
-
Immediately add a stop solution (e.g., 0.5 M EDTA) and place the reaction on ice.[18]
-
Purify the fragmented RNA using a suitable RNA cleanup kit or ethanol precipitation.
-
-
Immunoprecipitation:
-
Save 5-10% of the fragmented RNA as the "Input" control and store it at -80°C.
-
Prepare Protein A/G magnetic beads by washing them three times with IP buffer.[3]
-
Incubate the beads with 5-10 µg of a validated anti-m6A antibody in IP buffer for 1-2 hours at 4°C with rotation.[18] This allows the antibody to bind to the beads.
-
After incubation, wash the antibody-bead complex three times with IP buffer to remove any unbound antibody.[3]
-
Add the remaining fragmented RNA to the antibody-bead complex.
-
Incubate for 2-4 hours or overnight at 4°C with gentle rotation to allow the antibody to capture m6A-containing fragments.[3]
-
-
Washing and Elution:
-
After the IP incubation, place the tube on a magnetic stand and discard the supernatant.
-
Wash the beads sequentially with a series of buffers to remove non-specifically bound RNA. This typically includes a low-salt buffer, a high-salt buffer, and a final wash with the standard IP buffer.[3] Perform each wash for 3-5 minutes at 4°C with rotation.
-
Elute the m6A-containing RNA from the antibody-bead complex using an appropriate elution buffer, often containing Proteinase K, by incubating at 37-55°C.
-
-
RNA Purification:
-
Purify the eluted RNA (the "IP" sample) and the stored "Input" sample using an RNA cleanup kit or phenol-chloroform extraction followed by ethanol precipitation.
-
The purified RNA is now ready for downstream library construction.
-
Protocol 2: Library Construction from IP and Input RNA
-
First-Strand cDNA Synthesis:
-
Prime the purified IP and Input RNA with random hexamers.
-
Perform reverse transcription using a high-fidelity reverse transcriptase to generate first-strand cDNA.[2]
-
-
Second-Strand cDNA Synthesis:
-
Synthesize the second strand of cDNA using DNA Polymerase I and RNase H. The result is double-stranded cDNA (dsDNA).
-
-
End-Repair, A-tailing, and Adapter Ligation:
-
Perform end-repair on the dsDNA fragments to create blunt ends.
-
Add a single 'A' nucleotide to the 3' ends of the fragments (A-tailing).
-
Ligate sequencing adapters (which have a 'T' overhang) to the A-tailed fragments. Use a diluted adapter concentration to minimize dimer formation.[17]
-
-
PCR Amplification:
-
Purify the adapter-ligated DNA using magnetic beads to remove unligated adapters.
-
Amplify the library using PCR primers that bind to the adapter sequences. Use a minimal number of cycles (e.g., 10-15) to avoid introducing bias and high duplication rates.[15]
-
-
Final Cleanup and Quantification:
-
Purify the final PCR product using magnetic beads to remove primer-dimers and other artifacts.
-
Assess the final library quality on a fragment analyzer to check the size distribution and confirm the absence of significant adapter-dimers.
-
Quantify the library concentration using a fluorometric method (e.g., Qubit) or qPCR for the most accurate measurement of sequenceable molecules. The library is now ready for sequencing.
-
References
- 1. How to Troubleshoot Sequencing Preparation Errors (NGS Guide) - CD Genomics [cd-genomics.com]
- 2. stackwave.com [stackwave.com]
- 3. An experimental workflow for identifying RNA m6A alterations in cellular senescence by methylated RNA immunoprecipitation sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 4. lcsciences.com [lcsciences.com]
- 5. illumina.com [illumina.com]
- 6. A low-cost, low-input method establishment for m6A MeRIP-seq - PMC [pmc.ncbi.nlm.nih.gov]
- 7. How CUT&RUN Helps Improve Methylated RNA Immunoprecipitation | EpigenTek [epigentek.com]
- 8. Magna MeRIP™ m6A Kit- Transcriptome-wide Profiling of N6-Methyladenosine | 17-10499 [merckmillipore.com]
- 9. researchgate.net [researchgate.net]
- 10. N6-methyladenosine (m6A) antibody - RIP Grade (C15200082) | Diagenode [diagenode.com]
- 11. A low-cost, low-input method establishment for m6A MeRIP-seq - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. biocompare.com [biocompare.com]
- 13. dnatech.ucdavis.edu [dnatech.ucdavis.edu]
- 14. Elimination of PCR duplicates in RNA-seq and small RNA-seq using unique molecular identifiers - PMC [pmc.ncbi.nlm.nih.gov]
- 15. The trouble with PCR duplicates | The Molecular Ecologist [molecularecologist.com]
- 16. researchgate.net [researchgate.net]
- 17. neb.com [neb.com]
- 18. sysy.com [sysy.com]
- 19. Development and validation of monoclonal antibodies against N6-methyladenosine for the detection of RNA modifications - PMC [pmc.ncbi.nlm.nih.gov]
- 20. trumpet: transcriptome-guided quality assessment of m6A-seq data - PMC [pmc.ncbi.nlm.nih.gov]
Navigating Batch Effects in Large-Scale MeRIP-seq Studies: A Technical Guide
This technical support center provides researchers, scientists, and drug development professionals with comprehensive guidance on identifying, mitigating, and correcting for batch effects in large-scale Methylated RNA Immunoprecipitation Sequencing (MeRIP-seq) studies. Adherence to the protocols and best practices outlined here will enhance the reliability and reproducibility of your epitranscriptomic data.
Frequently Asked Questions (FAQs)
Q1: What are batch effects in the context of MeRIP-seq?
Q2: What are the most common sources of batch effects in MeRIP-seq experiments?
A2: Common sources of batch effects in MeRIP-seq include:
-
Variations in Immunoprecipitation (IP) Efficiency: Differences in antibody lots, bead performance, or incubation times can lead to variable enrichment of methylated RNA fragments across batches.[2]
-
Reagent and Kit Lot Differences: Using different lots of enzymes, buffers, or library preparation kits can introduce systematic bias.[4]
-
Personnel Differences: Variations in technique between different lab members processing the samples.[4]
-
Sequencing Run Variations: Samples sequenced on different days or on different sequencers can exhibit batch effects.[4]
-
RNA Quality and Integrity: Differences in RNA integrity (RIN scores) between batches can affect fragmentation and library preparation.
Q3: How can I detect batch effects in my MeRIP-seq data?
A3: Batch effects can be diagnosed through several exploratory data analysis techniques:
-
Principal Component Analysis (PCA): This is a primary method to visualize the major sources of variation in your data. If samples cluster by batch rather than biological condition on the PCA plot, it is a strong indication of a batch effect.[5]
-
t-SNE and UMAP Plots: Similar to PCA, these dimensionality reduction techniques can reveal if samples group by batch.[5]
-
Hierarchical Clustering: Dendrograms from hierarchical clustering can show if samples from the same batch cluster together, irrespective of their biological group.[6]
Q4: Is it possible to prevent batch effects during the experimental phase?
A4: While complete prevention is challenging, careful experimental design can significantly minimize batch effects.[7] Key strategies include:
-
Randomization: Randomize your samples across different batches to ensure that each batch has a balanced representation of your biological conditions of interest.[8]
-
Standardized Protocols: Use the same detailed protocol, reagent lots, and equipment for all samples.[8]
-
Consistent Personnel: Have the same person perform critical steps of the experiment, such as the immunoprecipitation, for all samples if possible.[4]
-
Use of Spike-in Controls: The addition of synthetic RNA with known methylation status can help normalize for technical variability, particularly in IP efficiency.[9]
Troubleshooting Guides
Issue 1: Strong clustering by batch observed in PCA plots.
Cause: This is a classic sign of significant batch effects, where technical variability is outweighing the biological signal in your data.[5]
Solution:
-
Verify Experimental Records: Double-check your lab notes to confirm which samples belong to which batch and if there were any documented deviations in the protocol.
-
Assess Data Quality: Use tools like FastQC for general sequencing quality and trumpet for MeRIP-seq specific metrics to ensure data quality is consistent across batches.[6]
-
Apply Computational Batch Correction: Utilize computational methods to adjust for batch effects. Common approaches include:
-
Including Batch as a Covariate: In differential methylation analysis tools like RADAR or DESeq2, you can include the batch information as a covariate in the statistical model.[10][11]
-
Using Specialized Batch Correction Tools: Tools like ComBat or the removeBatchEffect function from the limma R package can be used to adjust the data prior to downstream analysis.[1][12]
-
Issue 2: Inconsistent immunoprecipitation (IP) efficiency across batches.
Cause: Variability in the IP step is a major source of batch effects in MeRIP-seq. This can be due to differences in antibody-bead conjugation, washing stringency, or elution efficiency.
Solution:
-
Implement Spike-in Controls: The most effective way to address variable IP efficiency is by using spike-in controls. These are synthetic RNA molecules with known methylation patterns that are added to each sample before the IP step. The recovery of these spike-ins can then be used to normalize the data.[9]
-
Optimize IP Protocol: Before starting a large-scale experiment, optimize your IP protocol to ensure it is robust and reproducible. This includes titrating the antibody concentration and optimizing washing conditions.
-
Monitor with QC Metrics: Utilize quality control metrics that assess the strength of the immunoprecipitation signal, such as the Exome Signal Extraction Scaling (ESES) provided by the trumpet R package.[6]
Experimental Protocols
Protocol 1: MeRIP-seq Experimental Design to Minimize Batch Effects
-
Sample Grouping and Randomization:
-
Clearly define your biological groups of interest.
-
If samples must be processed in multiple batches, ensure that each batch contains a balanced representation of all biological groups.[7] For example, if you have two conditions (treatment and control) and are processing them in two batches, each batch should contain both treatment and control samples.
-
Maintain a detailed record of which samples were processed in which batch.[7]
-
-
Reagent and Protocol Standardization:
-
Prepare a single, large batch of all necessary reagents and buffers to be used for the entire experiment.
-
If using kits, try to use kits from the same manufacturing lot.
-
Follow a single, detailed, and standardized protocol for all samples.
-
-
Spike-in Control Addition (Recommended):
-
Obtain a commercially available RNA spike-in control with a known methylation status (e.g., from E. coli).
-
Prior to RNA fragmentation, add a consistent amount of the spike-in RNA to each total cellular RNA sample. A common practice is to add a small, fixed amount (e.g., 23 ng of E. coli K-12 RNA per 5 µg of total cellular RNA).[9]
-
Protocol 2: Computational Batch Correction using limma::removeBatchEffect
This protocol assumes you have a matrix of normalized methylation enrichment values (e.g., log2 fold change of IP over input) and a metadata file indicating the batch for each sample.
-
Load Data into R:
-
Load your enrichment matrix and metadata into your R environment.
-
-
Create a Design Matrix:
-
Create a design matrix that includes your biological conditions of interest.
-
-
Apply removeBatchEffect:
-
Use the removeBatchEffect function from the limma package, specifying your enrichment matrix, the batch variable, and your design matrix.
-
-
Visualize Corrected Data:
-
Generate a new PCA plot using the corrected_enrichment_matrix to confirm that the samples no longer cluster by batch.
-
Data Presentation
Table 1: Impact of Batch Effects on Differential Methylation Analysis
| Feature | Uncorrected Data | Data Corrected with limma::removeBatchEffect |
| Principal Component 1 Variance Explained | 45% (Correlated with Batch) | 30% (Correlated with Biological Condition) |
| Number of Differentially Methylated Regions (DMRs) | 2,500 | 1,200 |
| Overlap of DMRs with Known Biology | Low | High |
| False Discovery Rate (FDR) Control | Poor | Good |
Table 2: Comparison of Batch Correction Methods for MeRIP-seq
| Method | Principle | Pros | Cons | Recommended Use Case |
| limma::removeBatchEffect | Linear model-based adjustment of the data matrix.[12] | Simple to implement, effective for known batches. | Can over-correct if the design is not well-balanced. | For datasets with clear, known batch information and a balanced design. |
| ComBat | Empirical Bayes framework to adjust for batch effects. | Robust for small sample sizes and can handle complex batch structures. | May not be optimal for count-based data without transformation. | Suitable for a wide range of batch effect scenarios, especially with smaller sample sizes. |
| Including Batch as a Covariate | Incorporates the batch variable directly into the statistical model of differential analysis tools (e.g., RADAR, DESeq2).[10] | Statistically rigorous, accounts for batch effects during significance testing. | The batch effect is modeled but not removed from the raw data for visualization. | The recommended approach for differential methylation analysis when batch information is available. |
Visualizations
References
- 1. pluto.bio [pluto.bio]
- 2. youtube.com [youtube.com]
- 3. d-nb.info [d-nb.info]
- 4. 10xgenomics.com [10xgenomics.com]
- 5. pythiabio.com [pythiabio.com]
- 6. trumpet: transcriptome-guided quality assessment of m6A-seq data - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Experimental design considerations | Transcriptomics CB321qc [hbctraining.github.io]
- 8. researchgate.net [researchgate.net]
- 9. RADAR: differential analysis of MeRIP-seq data with a random effect model - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Analyzing MeRIP-seq data with RADAR [scottzijiezhang.github.io]
- 11. Removing batch effect with limma::removeBatchEffect() actually exacerbates the effect [support.bioconductor.org]
- 12. ComBat-met: adjusting batch effects in DNA methylation data - PMC [pmc.ncbi.nlm.nih.gov]
Navigating the Nuances of Normalization in Differential m6A Methylation Analysis: A Technical Guide
Technical Support Center
Welcome to the technical support center for differential N6-methyladenosine (m6A) methylation analysis. This guide is designed to assist researchers, scientists, and drug development professionals in navigating the critical step of data normalization. Here, you will find answers to frequently asked questions, troubleshooting strategies for common issues, and detailed experimental protocols to ensure the accuracy and reproducibility of your findings.
Frequently Asked Questions (FAQs)
Q1: Why is normalization essential for differential m6A methylation analysis?
Q2: What are the most common normalization strategies for MeRIP-seq data?
A2: Several strategies are employed to normalize MeRIP-seq data. The choice of method depends on the experimental design and the specific sources of variation that need to be addressed. The main approaches are:
-
Normalization to Input Control: This is the most fundamental normalization step. The IP signal is normalized to the corresponding input control sample, which represents the total RNA abundance before immunoprecipitation. This helps to distinguish true m6A enrichment from high gene expression.[1][2][4]
-
Library Size Normalization: Standard RNA-seq normalization methods are often applied to both the IP and input samples to account for differences in sequencing depth. Common methods include Counts Per Million (CPM), Transcripts Per Kilobase Million (TPM), and the median-of-ratios method used in DESeq2.[5][6]
-
Spike-in Normalization: This method involves adding a known amount of exogenous RNA (with or without m6A modifications) to each sample before the IP step. The spike-in control serves as an internal standard to normalize for technical variability, particularly differences in IP efficiency between samples.[7][8]
-
Batch Effect Correction: When experiments are conducted in multiple batches, systematic variations can be introduced. Computational methods like ComBat can be used to identify and correct for these batch effects.[2][9][10]
Q3: How do I choose the right normalization strategy for my experiment?
A3: The selection of a normalization strategy is critical and should be guided by your experimental design.
-
For basic differential methylation analysis, normalization to input control is a mandatory first step.
-
If you observe significant differences in sequencing depth between your libraries, library size normalization is recommended.
-
When you suspect variability in immunoprecipitation efficiency between your samples (e.g., due to different experimental conditions or batches), using spike-in controls is the most robust approach.
-
If your samples were processed in different batches, it is advisable to check for and correct batch effects .
The following flowchart illustrates a decision-making process for selecting a normalization strategy:
Troubleshooting Guide
Problem 1: After normalization to input, some known methylated genes do not show enrichment.
-
Possible Cause 1: Low Immunoprecipitation (IP) Efficiency. The antibody may not have efficiently pulled down the methylated RNA fragments. This can be due to issues with the antibody itself, the incubation time, or the washing steps.
-
Solution: Ensure you are using a validated, high-quality anti-m6A antibody. Optimize your IP protocol, including antibody concentration and incubation times. Consider using spike-in controls in future experiments to monitor and normalize for IP efficiency.[11]
-
-
Possible Cause 2: Over-fragmentation of RNA. If the RNA is fragmented into very small pieces, the antibody may not be able to bind effectively, or the resulting fragments may be too short for accurate mapping.
-
Solution: Optimize your RNA fragmentation protocol to ensure a consistent and appropriate size range (typically 100-200 nucleotides).
-
-
Possible Cause 3: Inappropriate background subtraction. The input signal for that specific gene might be disproportionately high, masking the IP enrichment.
-
Solution: Carefully inspect the raw read counts for both IP and input samples for the genes . Some differential methylation analysis tools, like RADAR, are designed to better handle the relationship between input and IP signals.[5]
-
Problem 2: High variability between biological replicates after normalization.
-
Possible Cause 1: Uncorrected Batch Effects. If your replicates were processed on different days or by different technicians, there may be systematic batch effects that are not accounted for by standard normalization methods.
-
Possible Cause 2: Biological Variability. True biological differences between your samples can sometimes be large.
-
Solution: Ensure your experimental design has sufficient statistical power by including an adequate number of biological replicates.
-
-
Possible Cause 3: Inconsistent IP Efficiency. The efficiency of the immunoprecipitation can vary between samples, even within the same batch.
-
Solution: The most effective way to address this is by using spike-in controls for normalization.[7]
-
Problem 3: Differential methylation results are heavily biased towards highly expressed genes.
-
Possible Cause: Confounding of methylation and gene expression. Changes in gene expression can influence the number of reads in both the input and IP samples, which can be misinterpreted as changes in methylation.
-
Solution: Ensure that your differential methylation analysis method properly accounts for gene expression levels. Some methods, like RADAR, use gene-level read counts from the input library as a robust measure of gene expression to adjust the IP signal.[5][12] It is also crucial to perform differential expression analysis in parallel to help interpret the differential methylation results.
-
Data Presentation: Comparison of Normalization Strategies
| Normalization Strategy | Principle | Advantages | Disadvantages | When to Use |
| Input Normalization | Calculates the ratio of IP signal to input signal for each genomic region. | Conceptually simple and accounts for differences in gene expression.[1][2] | Can be sensitive to noise in low-expression genes and does not account for IP efficiency differences. | Always. This is the fundamental normalization step for MeRIP-seq. |
| Library Size Normalization (e.g., DESeq2 median-of-ratios) | Scales read counts to account for differences in sequencing depth between libraries.[5] | Robust to outliers and widely used in RNA-seq analysis.[6] | Assumes that the majority of genes are not differentially methylated, which may not always be true. | When there are significant differences in library sizes between samples. |
| Spike-in Normalization | Adds a constant amount of exogenous RNA to each sample to act as an internal control for technical variability.[7] | Directly accounts for variations in IP efficiency and other technical aspects of the workflow.[8] | Requires careful planning and execution to ensure accurate spiking. Can increase the cost of the experiment. | When high accuracy is required and IP efficiency is expected to vary between samples or conditions. |
| Batch Effect Correction (e.g., ComBat) | Identifies and removes systematic technical variation associated with processing samples in different batches.[9][10] | Can significantly reduce variability between replicates and increase the power to detect true biological differences. | Can potentially remove true biological variation if the experimental design is confounded with batch. | When samples are processed in multiple batches. |
Experimental Protocols
Protocol 1: Normalization using Input Control
This protocol outlines the bioinformatic steps for normalizing MeRIP-seq IP data against the corresponding input control data.
-
Alignment: Align the raw sequencing reads from both IP and input samples to the reference genome using a splice-aware aligner like STAR.
-
Peak Calling: Use a peak calling tool such as MACS2 or exomePeak to identify regions of m6A enrichment in the IP samples relative to the input samples. This process inherently uses the input as a local background control.[2]
-
Quantification: Count the number of reads within the identified peaks for both the IP and input samples for each replicate.
-
Differential Methylation Analysis: Use a specialized tool for differential m6A analysis, such as RADAR or TRESS. These tools will typically take the raw read counts for both IP and input as input and incorporate the input normalization within their statistical models.[5][13]
Protocol 2: Spike-in Normalization for MeRIP-seq
This protocol provides a general framework for incorporating spike-in controls into a MeRIP-seq experiment.
-
Spike-in Selection: Choose a set of in vitro transcribed RNAs that are not present in your experimental organism. These can be obtained commercially (e.g., ERCC RNA Spike-In Mix). It is beneficial to have both unmethylated and m6A-methylated spike-in transcripts.
-
Spiking: Before RNA fragmentation, add a precise and equal amount of the spike-in RNA mix to each of your total RNA samples. The amount to add should be determined empirically to ensure that the spike-in reads constitute a small but readily detectable fraction of the total reads.
-
MeRIP-seq Procedure: Proceed with your standard MeRIP-seq protocol, including RNA fragmentation, immunoprecipitation, and library preparation.
-
Data Analysis: a. Align the sequencing reads to a combined reference genome that includes both the experimental organism's genome and the sequences of the spike-in transcripts. b. Calculate a normalization factor for each sample based on the number of reads that map to the spike-in transcripts. c. Apply this normalization factor to the read counts of the endogenous transcripts to correct for technical variability.
Mandatory Visualization
The following diagram illustrates the general workflow of a MeRIP-seq experiment and where the key normalization steps are applied.
This technical support guide provides a foundational understanding of normalization strategies in differential m6A methylation analysis. For more in-depth information and specific command-line implementations, users are encouraged to consult the documentation of the individual software packages mentioned.
References
- 1. Master MeRIP-seq Data Analysis: Step-by-Step Process for RNA Methylation Studies - CD Genomics [rna.cd-genomics.com]
- 2. researchgate.net [researchgate.net]
- 3. rna-seqblog.com [rna-seqblog.com]
- 4. How MeRIP-seq Works: Principles, Workflow, and Applications Explained - CD Genomics [rna.cd-genomics.com]
- 5. Analyzing MeRIP-seq data with RADAR [scottzijiezhang.github.io]
- 6. pluto.bio [pluto.bio]
- 7. Refined RIP-seq protocol for epitranscriptome analysis with low input materials - PMC [pmc.ncbi.nlm.nih.gov]
- 8. researchgate.net [researchgate.net]
- 9. Differential methilation analysis batch effect removal [support.bioconductor.org]
- 10. biorxiv.org [biorxiv.org]
- 11. Statistical modeling of immunoprecipitation efficiency of MeRIP-seq data enabled accurate detection and quantification of epitranscriptome - PMC [pmc.ncbi.nlm.nih.gov]
- 12. RADAR: differential analysis of MeRIP-seq data with a random effect model - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Differential RNA methylation analysis for MeRIP-seq data under general experimental design - PMC [pmc.ncbi.nlm.nih.gov]
Avoiding RNA degradation during the m6A detection protocol.
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to help researchers, scientists, and drug development professionals avoid RNA degradation during N6-methyladenosine (m6A) detection experiments.
Frequently Asked Questions (FAQs)
Q1: What are the primary causes of RNA degradation during m6A detection protocols?
A1: RNA is highly susceptible to degradation due to its single-stranded nature. The primary culprits are RNases, enzymes that are ubiquitous in the environment and on laboratory surfaces.[1][2] Other significant factors include:
-
Chemical Hydrolysis: Exposure to high temperatures or non-optimal pH can lead to the breakdown of the RNA phosphodiester backbone.[1][3]
-
Improper Sample Handling: Inadequate storage, repeated freeze-thaw cycles, and prolonged exposure of samples to the environment can introduce RNases and compromise RNA integrity.[1]
-
Contaminated Reagents and Equipment: Using non-certified RNase-free water, buffers, pipette tips, and tubes is a common source of RNase contamination.[1][4]
Q2: How can I create and maintain an RNase-free work environment?
A2: Establishing a dedicated, RNase-free workspace is critical for successful RNA work.[1] Key practices include:
-
Designated Area: Use a specific bench or area solely for RNA experiments to minimize cross-contamination.[1]
-
Surface Decontamination: Regularly clean benchtops, pipettes, and other equipment with RNase-deactivating solutions.[1][2]
-
Use of Certified Consumables: Whenever possible, use sterile, disposable plasticware certified as RNase-free.[3]
-
Personal Protective Equipment (PPE): Always wear gloves and change them frequently, especially after touching any surface that may not be RNase-free.[2][5]
Q3: What are RNase inhibitors, and when should I use them?
A3: RNase inhibitors are proteins that bind to and inactivate RNases, thereby protecting your RNA samples from degradation. They are a crucial component of many buffers used in RNA isolation and subsequent enzymatic reactions. For instance, products like RNasin® Ribonuclease Inhibitor are commonly added to reaction mixtures.[6] It is advisable to include RNase inhibitors in lysis buffers during RNA extraction from tissues rich in endogenous RNases and in enzymatic reactions like reverse transcription and immunoprecipitation.[5][7]
Q4: What is a good RNA Integrity Number (RIN), and why is it important for m6A detection?
A4: The RNA Integrity Number (RIN) is a numerical score from 1 to 10 that assesses the integrity of an RNA sample. A higher RIN value indicates less degradation. For m6A sequencing protocols like MeRIP-seq, a RIN value of 7.0 or higher is generally recommended to ensure that the RNA is of sufficient quality for reliable results.[8] Degraded RNA (low RIN) can lead to a loss of methylation site information, 3' bias in sequencing data, and reduced alignment efficiency.[8][9]
Q5: How does RNA degradation specifically affect MeRIP-seq results?
A5: RNA degradation can significantly impact the accuracy and reliability of MeRIP-seq in several ways:
-
Loss of m6A Sites: If the RNA is fragmented due to degradation before the intentional fragmentation step, true m6A sites may be lost, leading to false-negative results.[8]
-
Biased Enrichment: Degraded RNA can lead to non-specific binding during the immunoprecipitation step, resulting in a higher background signal.
-
Reduced Library Complexity: Degraded RNA will result in lower quality sequencing libraries, which can impact the ability to detect less abundant methylated transcripts.[10]
Troubleshooting Guide
| Issue | Potential Cause | Recommended Solution |
| Low RNA yield after extraction | Incomplete cell or tissue lysis. | Ensure complete homogenization of the sample. For tissues, consider bead-beating or the use of liquid nitrogen to facilitate disruption.[5] |
| RNA degradation during extraction. | Work quickly and keep samples on ice. Use an appropriate lysis buffer containing RNase inhibitors.[5] | |
| Smearing on a gel or low RIN value | RNase contamination. | Review your RNase-free work practices.[1] Use fresh, certified RNase-free reagents and consumables.[4] |
| Improper sample storage. | Aliquot RNA samples to minimize freeze-thaw cycles and store them at -80°C for long-term storage.[5] | |
| High background in control (IgG) samples | Non-specific binding of RNA to beads. | Pre-clear the fragmented RNA by incubating it with protein A/G beads alone before the immunoprecipitation with the m6A antibody.[10] |
| Antibody concentration is too high. | Optimize the antibody concentration to reduce non-specific binding.[10] | |
| Inconsistent results between replicates | Variability in RNA quality or quantity. | Ensure consistent RNA quality (RIN > 7) and use the same starting amount of RNA for all replicates.[8][10] |
| Inefficient immunoprecipitation. | Validate the lot-to-lot consistency of your anti-m6A antibody.[10] Ensure proper coupling of the antibody to the beads. |
Quantitative Data Summary
Table 1: Recommended Starting Material and Expected Yields for Poly(A) RNA Isolation
| Organism | Starting Total RNA (minimum) | Expected Poly(A) RNA Yield | Number of Technical Replicates |
| Yeast | 50-80 µg | ~300 ng (from 80 µg) | 6 |
| Mammalian Cells | 10 µg | ~60 ng | 6 |
| Data adapted from an improved m6A-ELISA protocol, which highlights the importance of high-quality poly(A) RNA.[11] |
Table 2: RNA Quality Control Metrics and Recommendations
| Metric | Good Quality | Acceptable Quality | Poor Quality (potential issues) |
| RIN (RNA Integrity Number) | ≥ 8 | 7-8 | < 7 (loss of 5' end information, 3' bias)[8][9] |
| A260/A280 Ratio | ~2.0 | 1.8-2.1 | < 1.8 (protein contamination) or > 2.1 (residual phenol) |
| A260/A230 Ratio | > 2.0 | 1.8-2.2 | < 1.8 (carbohydrate, salt, or solvent contamination) |
Experimental Protocols
Protocol 1: RNA Quality Control Assessment
-
Quantification: Use a spectrophotometer (e.g., NanoDrop) to measure the absorbance at 260 nm to determine the RNA concentration. Assess purity by checking the A260/A280 and A260/A230 ratios.
-
Integrity Analysis:
-
Load approximately 100-200 ng of total RNA onto an Agilent Bioanalyzer or a similar automated electrophoresis system.
-
Run the appropriate RNA assay (e.g., RNA 6000 Nano).
-
The system will generate an electropherogram and a RIN value. A sharp 18S and 28S ribosomal RNA peak (for eukaryotes) and a high RIN value are indicative of intact RNA.
-
Protocol 2: Key Steps in MeRIP-seq to Minimize RNA Degradation
This protocol highlights critical steps within a typical MeRIP-seq workflow where RNA degradation can occur and provides preventative measures.
-
RNA Fragmentation:
-
Action: Fragment the poly(A)+ RNA to an average size of ~100 nucleotides. This is typically done using a fragmentation buffer and incubation at an elevated temperature (e.g., 94°C for 5 minutes).[7]
-
Anti-degradation Tip: Immediately stop the fragmentation reaction by placing the tubes on ice and adding a stop buffer (e.g., EDTA) to chelate the metal ions that catalyze the reaction.
-
-
Immunoprecipitation (IP):
-
Washing:
-
Action: Wash the beads several times with a high-stringency wash buffer to remove non-specifically bound RNA.
-
Anti-degradation Tip: Keep the tubes on a magnetic stand and on ice during the washing steps to minimize RNA exposure to ambient temperatures.
-
-
Elution and Purification:
-
Action: Elute the enriched RNA from the beads and purify it.
-
Anti-degradation Tip: Use nuclease-free water for elution.[12] Proceed immediately to library preparation or store the eluted RNA at -80°C.
-
Visualizations
References
- 1. Best practices for RNA storage and sample handling | QIAGEN [qiagen.com]
- 2. biotium.com [biotium.com]
- 3. lifescience.roche.com [lifescience.roche.com]
- 4. bpb-us-e2.wpmucdn.com [bpb-us-e2.wpmucdn.com]
- 5. Enhance your transcriptome analysis: tips for optimal RNA — BioEcho Life Sciences [bioecho.com]
- 6. An experimental workflow for identifying RNA m6A alterations in cellular senescence by methylated RNA immunoprecipitation sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 7. m6A RNA Immunoprecipitation sequencing (MeRIP-seq) and data analysis [bio-protocol.org]
- 8. MeRIP-seq for Detecting RNA methylation: An Overview - CD Genomics [cd-genomics.com]
- 9. knowledge.illumina.com [knowledge.illumina.com]
- 10. benchchem.com [benchchem.com]
- 11. bio-protocol.org [bio-protocol.org]
- 12. New England Biolabs, Inc. EpiMark N6-Methyladenosine Enrichment Kit – 20 | Fisher Scientific [fishersci.com]
Technical Support Center: m6A-seq Peak Calling and Parameter Optimization
This technical support center provides troubleshooting guidance and frequently asked questions (FAQs) for researchers, scientists, and drug development professionals working with m6A-seq data. Our goal is to address common challenges encountered during peak calling and parameter optimization to ensure robust and reliable identification of m6A sites.
Troubleshooting Guide
This section addresses specific issues that may arise during the analysis of m6A-seq data.
Question: My peak calling software is producing an excessive number of peaks. What are the likely causes and how can I resolve this?
Answer:
An unexpectedly high number of peaks can often be attributed to several factors, ranging from experimental variability to bioinformatics pipeline parameters. Here’s a breakdown of potential causes and solutions:
-
High Background/Low Signal-to-Noise: The quality of the immunoprecipitation (IP) is crucial. Inefficient enrichment of m6A-containing fragments or high non-specific binding of the antibody can lead to a noisy dataset where it is difficult to distinguish true peaks from the background.
-
Solution: Before sequencing, assess the enrichment efficiency of your MeRIP experiment using qPCR on known m6A-positive and negative control transcripts. After sequencing, visually inspect the alignment files in a genome browser to assess the signal-to-noise ratio. If the background is high, you may need to optimize your IP protocol.[1]
-
-
Inappropriate Peak Calling Parameters: The parameters used in the peak calling software significantly impact the number of identified peaks.
-
Solution: The most direct way to reduce the number of called peaks is to use a more stringent statistical cutoff. Decrease the p-value or, more appropriately, the False Discovery Rate (FDR) or q-value threshold. For example, in MACS2, you can lower the -q value from the default of 0.05 to 0.01 or even lower.[1] Additionally, increasing the fold-enrichment threshold can help filter out less prominent peaks.
-
-
PCR Duplicates and Multi-mapping Reads: A high number of PCR duplicates can create artificial peaks. Reads that map to multiple locations in the transcriptome can also lead to spurious peak calls.
-
Solution: It is a standard practice to remove PCR duplicates before peak calling. Tools like Picard MarkDuplicates can be used for this purpose. For multi-mapping reads, a common approach is to only consider uniquely mapped reads for peak calling. This can be achieved by filtering the BAM file based on the mapping quality (MAPQ) score. A MAPQ score of >= 30 is often a good starting point.[2]
-
-
Repetitive Elements: Repetitive regions of the transcriptome can sometimes be falsely identified as enriched peaks.
-
Solution: Filter your peak list against a database of known repetitive elements for your organism of interest.
-
Question: I am not getting any or very few significant peaks from my analysis. What could be the problem?
Answer:
A low number of peaks can be equally concerning and may indicate issues with the experiment or the analysis.
-
Inefficient Immunoprecipitation: The most likely experimental cause is a failed or inefficient MeRIP.
-
Solution: As with the issue of too many peaks, it is critical to validate the IP efficiency with qPCR on control transcripts before proceeding with sequencing. Ensure the antibody used is specific and of high quality.
-
-
Low Sequencing Depth: Insufficient sequencing depth can limit the statistical power to detect true m6A peaks, especially for transcripts with low abundance.
-
Solution: While there is no single magic number for required sequencing depth, deeper sequencing generally allows for the detection of more peaks. For human and mouse, a minimum of 10-20 million mapped reads for both IP and input samples is often recommended, though this can vary depending on the complexity of the transcriptome and the desired sensitivity.
-
-
Overly Stringent Peak Calling Parameters: While stringent parameters can reduce false positives, they can also lead to the loss of true peaks.
-
Solution: Try relaxing the p-value or FDR cutoff in your peak calling software. You can also lower the fold-enrichment threshold. It can be helpful to start with more relaxed parameters to see if any peaks are detected and then gradually increase the stringency.
-
-
Incorrect Normalization: Differences in library size between the IP and input samples need to be accounted for through proper normalization.
-
Solution: Most peak calling software designed for enrichment-based sequencing data, including those used for m6A-seq, have built-in normalization methods. Ensure that you are using a tool appropriate for this type of data. Some pipelines also advocate for normalization strategies like the median-of-ratio method prior to peak calling.[3]
-
-
Problem with Control Sample: If the input control has unusually high signal in regions where peaks are expected, it can mask the enrichment in the IP sample.
-
Solution: Inspect the read distribution of your input sample in a genome browser to ensure it reflects the expected transcriptome-wide expression profile.
-
Question: The peaks I've identified are very broad. How can I get more precise peak locations?
Answer:
Broad peaks can make it difficult to pinpoint the exact location of the m6A modification.
-
RNA Fragmentation: The size of the RNA fragments generated before immunoprecipitation directly influences the resolution of the peaks. Larger fragments will lead to broader peaks.
-
Solution: Optimize the RNA fragmentation step in your experimental protocol to consistently generate fragments in the desired size range, typically around 100-200 nucleotides.[4]
-
-
Peak Calling Algorithm: Some peak callers are designed to identify broad regions of enrichment, while others are better at pinpointing summits.
-
Solution: For identifying the most likely single nucleotide location of methylation, look for software that reports peak summits. MACS2, for example, provides a _summits.bed file that lists the single-base position with the highest read pileup within each peak.[5]
-
-
Motif Analysis: True m6A sites are often associated with a specific consensus sequence motif (e.g., DRACH).
-
Solution: Perform a motif analysis on your called peaks. The presence of the expected m6A motif near the center of your peaks can give you more confidence in their location. Tools like HOMER can be used for this purpose.[6]
-
FAQs on Peak Calling Software and Parameter Optimization
This section provides answers to frequently asked questions about specific software and general parameter tuning.
Question: Which peak calling software should I use for my m6A-seq data?
Answer:
There are several software packages available for m6A-seq peak calling, each with its own strengths and weaknesses. The choice of software can depend on the specifics of your experimental design and your comfort level with different analysis tools.
| Software | Key Features | Considerations |
| MACS2 | Originally designed for ChIP-seq, but widely adapted for m6A-seq. It is computationally efficient and provides detailed output including peak summits.[7][8] | May not be specifically optimized for the nuances of RNA-based data, such as transcriptome-level normalization. |
| exomePeak | An R/Bioconductor package specifically designed for analyzing affinity-based epitranscriptome sequencing data like m6A-seq. It supports biological replicates and can perform differential methylation analysis.[9] | May be less computationally efficient than MACS2 for very large datasets. |
| MeTPeak | A graphical model-based method that aims to model biological variances in MeRIP-seq data more explicitly. It uses a Hidden Markov Model to account for dependencies between adjacent genomic regions.[10] | The statistical model is more complex, which may require a deeper understanding for advanced troubleshooting. |
It is often recommended to try more than one peak caller and compare the results. Peaks that are consistently identified by multiple algorithms are generally considered to be of higher confidence.
Question: How do I choose the right parameters for my peak calling software?
Answer:
Parameter optimization is a critical step in m6A-seq data analysis. The optimal parameters can vary depending on the dataset. Here is a guide to some of the most important parameters and how to approach their optimization:
| Parameter | Description | Guidance on Optimization |
| Fragment Size/Extension Size | This parameter informs the peak caller about the average size of the RNA fragments that were sequenced. | It is crucial to set this parameter to a value that accurately reflects the library preparation. An incorrect fragment size can lead to inaccurate peak calling. You can estimate the fragment size from a Bioanalyzer trace or by analyzing the distance between paired-end reads. |
| p-value/FDR (q-value) Cutoff | These statistical thresholds determine the significance of a called peak. The p-value represents the probability of observing the enrichment by chance, while the FDR is the expected proportion of false positives among the called peaks. | The choice of cutoff is a trade-off between sensitivity and specificity. A more stringent cutoff (e.g., FDR < 0.01) will result in fewer, but likely higher-confidence, peaks. A more lenient cutoff (e.g., FDR < 0.05) will yield more peaks but may include more false positives. It is generally recommended to use the FDR (q-value) for multiple testing correction.[11] |
| Fold Enrichment | This is the ratio of the signal in the IP sample to the signal in the input/control sample. | A higher fold enrichment threshold will select for more prominent peaks. A typical starting point is a fold enrichment of 2 or higher. |
| Read Length | The length of the sequencing reads. | This is usually automatically detected by the software from the input files, but it's good practice to ensure it is correct. |
| Genome Size | The effective size of the genome or transcriptome being analyzed. | For MACS2, this is an important parameter (-g). Using a pre-defined value for your organism (e.g., hs for human, mm for mouse) is recommended. |
Question: What is the general workflow for m6A-seq data analysis?
Answer:
A typical m6A-seq data analysis workflow involves several key steps, from raw sequencing reads to a list of annotated m6A peaks.
References
- 1. How To Analyze ChIP-seq Data For Absolute Beginners Part 4: From FASTQ To Peaks With MACS2 - NGS Learning Hub [ngs101.com]
- 2. academic.oup.com [academic.oup.com]
- 3. academic.oup.com [academic.oup.com]
- 4. benchchem.com [benchchem.com]
- 5. Peak calling with MACS2 | Introduction to ChIP-Seq using high-performance computing [hbctraining.github.io]
- 6. m6A peak calling and motif analysis [bio-protocol.org]
- 7. tandfonline.com [tandfonline.com]
- 8. Comprehensive Overview of m6A Detection Methods - CD Genomics [cd-genomics.com]
- 9. Bioconductor - exomePeak [bioconductor.org]
- 10. A novel algorithm for calling mRNA m6A peaks by modeling biological variances in MeRIP-seq data - PMC [pmc.ncbi.nlm.nih.gov]
- 11. researchgate.net [researchgate.net]
Navigating the MeRIP-seq Maze: A Technical Guide to Reliable RNA Methylation Profiling
Technical Support Center
Welcome to the technical support center for Methylated RNA Immunoprecipitation Sequencing (MeRIP-seq). This guide is designed for researchers, scientists, and drug development professionals to provide clear, actionable advice on ensuring a robust and reliable MeRIP-seq workflow. Here you will find troubleshooting guides and frequently asked questions (FAQs) to address specific issues you may encounter during your experiments.
Frequently Asked Questions (FAQs) & Troubleshooting Guides
Section 1: Initial Sample Quality Control
Q1: What are the critical quality control (QC) parameters for the starting RNA material?
A1: The quality of your input RNA is paramount for a successful MeRIP-seq experiment. Poor RNA quality can lead to a loss of methylation site information or false-negative results.[1] Key QC checkpoints include:
-
Integrity: Assessed using an Agilent Bioanalyzer or similar instrument. An RNA Integrity Number (RIN) of ≥ 7.0 is generally required.[1]
-
Purity: Spectrophotometric ratios (A260/A280 and A260/230) should be within the optimal range (typically ~2.0) to ensure the absence of protein and other contaminants that can interfere with enzymatic reactions and antibody binding.[1]
-
Quantity: A sufficient amount of total RNA is crucial for successful immunoprecipitation. While protocols are being developed for low-input samples, a starting amount of 15-300 µg of total RNA is often recommended, though some protocols work with as little as 2 µg.[2][3]
| Parameter | Recommended Value | Assessment Method |
| RNA Integrity Number (RIN) | ≥ 7.0 | Agilent Bioanalyzer |
| A260/A280 Ratio | ~2.0 | Spectrophotometer (e.g., NanoDrop) |
| A260/A230 Ratio | ~2.0 | Spectrophotometer (e.g., NanoDrop) |
| Total RNA Quantity | 2-300 µg (protocol dependent) | Qubit or other fluorometric method |
Q2: My RNA samples have a low RIN value. Can I still proceed with the experiment?
A2: Proceeding with a low RIN value (<7.0) is not recommended as it indicates RNA degradation.[1] Degraded RNA can lead to the loss of methylated fragments, resulting in an underrepresentation of true m6A peaks and potentially biased results. It is best to re-extract RNA from your samples to ensure high quality.
Section 2: Antibody Validation and Immunoprecipitation
Q3: How do I choose and validate an anti-m6A antibody?
A3: The specificity and efficiency of the anti-m6A antibody are critical for the success of a MeRIP-seq experiment.[4][5] Suboptimal antibody performance can lead to nonspecific enrichment and inaccurate identification of methylation sites.[1][4]
Key Validation Steps:
-
Vendor Specification Review: Check the manufacturer's data for evidence of specificity, such as dot blots with methylated and unmethylated RNA oligos, and validation in applications like MeRIP.
-
In-house Validation (Recommended):
-
Dot Blot: Perform a dot blot with synthetic m6A-containing and non-m6A-containing RNA oligonucleotides to confirm specificity.
-
MeRIP-RT-qPCR: Validate the antibody by performing MeRIP on a known methylated transcript (positive control) and a known unmethylated transcript (negative control), followed by RT-qPCR. A significant enrichment of the positive control should be observed.[6]
-
Comparison of Different m6A Antibodies: Studies have shown that different commercially available anti-m6A antibodies can yield varying results in terms of the number of peaks identified and signal-to-noise ratio.[7] It is advisable to consult literature for comparisons or perform an in-house comparison of a few antibodies if possible.
Q4: I am observing high background or non-specific binding in my immunoprecipitation (IP). What can I do to reduce it?
A4: High background can obscure true methylation signals. Here are some troubleshooting steps:
-
Optimize Washing Steps: Increasing the number and stringency of washes after the antibody-RNA incubation can help reduce non-specific binding. This can include using buffers with varying salt concentrations (low-salt and high-salt washes).[2]
-
Blocking: Pre-blocking the magnetic beads with a blocking agent like BSA or yeast tRNA can help prevent non-specific binding of RNA to the beads.
-
Antibody Concentration: Titrate the amount of antibody used for the IP. Using too much antibody can increase non-specific interactions.
-
Incubation Time: Optimizing the incubation time for the antibody and RNA can also help.[8]
Section 3: RNA Fragmentation and Library Preparation
Q5: What is the optimal fragment size for MeRIP-seq, and how do I achieve it?
A5: The goal of fragmentation is to generate RNA fragments of a suitable size for sequencing and to enable the localization of m6A peaks. A fragment size of approximately 100-200 nucleotides is commonly targeted.[1][2][9]
Fragmentation Methods:
-
Chemical Fragmentation: This is the most common method and typically involves using a fragmentation buffer at an elevated temperature (e.g., 70°C).[1][2] The duration of the incubation is critical and should be optimized to achieve the desired fragment size.
-
Enzymatic Fragmentation: Using enzymes like RNase III.
QC of Fragmentation: After fragmentation, it is essential to check the size distribution of the RNA fragments using an Agilent Bioanalyzer. This will confirm that the fragmentation was successful and that the fragments are within the desired size range.
Q6: What are the key QC checkpoints during library preparation?
A6: After the immunoprecipitation and RNA purification, the enriched RNA fragments are converted into a cDNA library for sequencing.
-
Library Concentration and Size Distribution: After library amplification, the concentration should be quantified using a fluorometric method (e.g., Qubit), and the size distribution should be checked on a Bioanalyzer. The library should show a peak corresponding to the expected size of the cDNA library (fragment size + adapter sequences).
-
PCR Cycles: The number of PCR cycles for library amplification should be optimized to avoid over-amplification, which can introduce bias.[2]
| QC Checkpoint | Expected Outcome | Assessment Method |
| Fragmented RNA Size | ~100-200 nt | Agilent Bioanalyzer |
| Final Library Size | ~250-350 bp (depends on fragment size) | Agilent Bioanalyzer |
| Library Concentration | Sufficient for sequencing platform | Qubit or qPCR |
Section 4: Sequencing and Bioinformatic Analysis
Q7: What are the important QC metrics for MeRIP-seq sequencing data?
A7: After sequencing, the raw data must be assessed for quality before proceeding with downstream analysis.
-
Base Quality Scores: Tools like FastQC can be used to check the quality of the sequencing reads.[1][10] The Phred quality score for the majority of bases should be high (typically >30).
-
Adapter Content: Check for and trim any remaining adapter sequences from the reads using tools like Trimmomatic or Cutadapt.[10][11]
-
rRNA Contamination: The percentage of reads mapping to ribosomal RNA (rRNA) should be low, as high levels can reduce the effective sequencing depth for your target RNA.[10]
Q8: How do I assess the efficiency of my immunoprecipitation from the sequencing data?
A8: The enrichment of methylated fragments in the IP sample compared to the input control is a key indicator of a successful experiment.
-
Peak Calling: Use a peak calling algorithm, such as MACS2, to identify regions of enrichment (peaks) in the IP sample relative to the input.[11] A successful experiment will yield a significant number of high-confidence peaks.
-
Enrichment Metrics: Some analysis tools, like the trumpet R package, can provide metrics to assess the strength of the immunoprecipitation signal.[12]
-
Motif Analysis: Known m6A motifs, such as "RRACH" (where R is G or A; H is A, C, or U), should be enriched in the identified peaks.[8]
| Bioinformatic QC Metric | Expected Outcome | Common Tools |
| Per Base Sequence Quality | Phred Score > 30 | FastQC |
| Adapter Content | Low to none after trimming | FastQC, Trimmomatic, Cutadapt |
| rRNA Contamination | Low percentage of reads | Alignment against rRNA sequences |
| Number of Peaks | Varies, but should be significant | MACS2, MeTPeak |
| Motif Enrichment | Enrichment of known m6A motifs | HOMER, MEME |
Experimental Workflow and Protocols
MeRIP-seq Experimental Workflow
The following diagram illustrates the key steps in a typical MeRIP-seq workflow.
Caption: A schematic of the MeRIP-seq experimental workflow.
Detailed Protocol: m6A RNA Immunoprecipitation (MeRIP)
This protocol is a generalized example. Specific details may need to be optimized for your particular antibody and sample type.
-
RNA Fragmentation:
-
Antibody-Bead Conjugation:
-
Wash Protein A/G magnetic beads with IP buffer.
-
Incubate the beads with the anti-m6A antibody at 4°C with rotation to allow for antibody conjugation.[1]
-
-
Immunoprecipitation:
-
Take an aliquot of the fragmented RNA to serve as the "input" control.
-
Add the remaining fragmented RNA to the antibody-bead mixture.
-
Incubate at 4°C with rotation to allow the antibody to bind to m6A-containing RNA fragments.
-
-
Washing and Elution:
-
Wash the beads several times with IP buffer, followed by low-salt and high-salt wash buffers to remove non-specifically bound RNA.[2]
-
Elute the bound RNA from the beads.
-
-
RNA Purification:
-
Purify the eluted RNA (IP sample) and the input control sample using a suitable RNA cleanup kit.
-
Logical Relationships in MeRIP-seq Data Analysis
The following diagram illustrates the logical flow of data analysis, from raw sequencing reads to biological insights.
Caption: Logical flow of MeRIP-seq bioinformatic analysis.
References
- 1. MeRIP-seq for Detecting RNA methylation: An Overview - CD Genomics [cd-genomics.com]
- 2. A low-cost, low-input method establishment for m6A MeRIP-seq - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Refined RIP-seq protocol for epitranscriptome analysis with low input materials - PMC [pmc.ncbi.nlm.nih.gov]
- 4. MeRIP-Seq/m6A-seq [illumina.com]
- 5. Validation strategies for antibodies targeting modified ribonucleotides - PMC [pmc.ncbi.nlm.nih.gov]
- 6. researchgate.net [researchgate.net]
- 7. researchgate.net [researchgate.net]
- 8. MeRIP-seq: Comprehensive Guide to m6A RNA Modification Analysis - CD Genomics [rna.cd-genomics.com]
- 9. Improving MeRIP with CUT&RUN Technology | EpigenTek [epigentek.com]
- 10. Master MeRIP-seq Data Analysis: Step-by-Step Process for RNA Methylation Studies - CD Genomics [rna.cd-genomics.com]
- 11. MeRIP-seq and Its Principle, Protocol, Bioinformatics, Applications in Diseases - CD Genomics [cd-genomics.com]
- 12. trumpet: transcriptome-guided quality assessment of m6A-seq data - PMC [pmc.ncbi.nlm.nih.gov]
Interpreting ambiguous peaks in N6-methyladenosine sequencing data.
Welcome to the technical support center for N6-methyladenosine (m6A) sequencing data analysis. This resource is designed for researchers, scientists, and drug development professionals to navigate the complexities of interpreting m6A sequencing data, with a focus on resolving ambiguous peaks.
Frequently Asked Questions (FAQs)
Here are some common questions about ambiguous peaks in m6A sequencing data.
Q1: What are the common causes of ambiguous or false-positive peaks in m6A-seq (MeRIP-seq) data?
A1: Ambiguous or false-positive peaks in m6A sequencing can arise from several experimental and technical factors. These include non-specific binding of the anti-m6A antibody, contamination with DNA, errors during PCR amplification, and alignment errors, especially in regions of low sequence complexity.[1][2] The inherent noise in immunoprecipitation-based sequencing techniques can also contribute to a high proportion of false-positive peak calls.[1]
Q2: How reproducible are m6A-seq experiments, and what level of peak overlap should I expect between replicates?
A2: The reproducibility of m6A-seq can be variable. Studies have shown that the overlap of m6A peaks between different experiments, even in the same cell type, can range from approximately 30% to 60%.[3][4] This variability highlights the importance of stringent experimental protocols, multiple biological replicates, and robust bioinformatics analysis to identify high-confidence peaks.
Q3: What is the typical resolution of standard m6A-seq (MeRIP-seq), and can it identify the exact location of the methylated adenosine?
A3: Standard antibody-based m6A-seq methods, such as MeRIP-seq, typically have a resolution of 100-200 nucleotides, corresponding to the size of the fragmented RNA.[5][6] This means they identify an enriched region (a "peak") but cannot pinpoint the exact single methylated adenosine within that region.[6] Higher-resolution techniques like miCLIP or single-molecule sequencing are required for base-level identification.[7][8]
Q4: How important is the input control sample in m6A-seq analysis?
A4: The input control is critical for accurate m6A peak calling. It represents the baseline transcriptome abundance, against which the immunoprecipitated (IP) sample is compared.[1][5] Proper normalization to the input control allows for the differentiation of true m6A enrichment from high gene expression, thus minimizing false positives.[9]
Troubleshooting Guide: Interpreting Ambiguous Peaks
This guide provides solutions to specific issues you may encounter during the analysis of your m6A sequencing data.
Issue 1: My peak calling software has identified an unexpectedly high number of m6A peaks.
-
Question: I have thousands more peaks than reported in similar studies. How can I determine if these are real?
-
Answer:
-
Assess Data Quality: Begin by running a quality control check on your raw sequencing data using tools like FastQC.[2][10] Look for issues such as PCR artifacts (over-represented sequences), adapter contamination, or a high proportion of ribosomal RNA (rRNA), which can lead to inaccurate peak calling.[2][10]
-
Review Peak Calling Parameters: The stringency of the peak calling algorithm significantly impacts the number of identified peaks.[10] Ensure that you are using appropriate parameters, such as a stringent p-value or FDR (False Discovery Rate) threshold (e.g., < 0.05), to filter out low-confidence peaks.[10]
-
Check for Motif Enrichment: Authentic m6A sites are often located within a specific consensus motif, most commonly "RRACH" (where R is G or A; H is A, C, or U).[11][12] Use a motif analysis tool (e.g., HOMER) to check if this motif is enriched in your called peaks. A lack of enrichment may indicate a high number of false positives.
-
Visualize Peaks: Manually inspect some of the high and low-scoring peaks in a genome browser (like IGV). True peaks should show a clear enrichment in the IP sample compared to the input control.[11] Peaks that mirror the input signal are likely due to high gene expression rather than methylation.
-
Issue 2: A peak of interest is present in one replicate but absent or very weak in others.
-
Question: How should I handle peaks that are not consistently detected across all my biological replicates?
-
Answer:
-
Increase Replicate Number: Poor reproducibility is a known challenge in MeRIP-seq.[3] Using at least three biological replicates is recommended to increase statistical power and identify consistent methylation events.
-
Use a Reproducibility Filter: During bioinformatic analysis, only consider peaks that are present in at least two of your biological replicates. This is a common and effective strategy to filter out stochastic noise and improve the reliability of your peak set.[1]
-
Perform Quantitative Validation: For key genes of interest, it is essential to validate the m6A modification using an independent method. Gene-specific m6A qPCR is a common approach for this purpose.[13][14]
-
Issue 3: A called peak does not contain the canonical "RRACH" m6A motif.
-
Question: I've identified a strongly enriched peak, but it lacks the expected m6A consensus motif. Could this still be a valid m6A site?
-
Answer:
-
Consider Non-Canonical Motifs: While "RRACH" is the most common motif, m6A can occur in other sequence contexts, although this is less frequent.
-
Rule out Other Modifications: The anti-m6A antibody can sometimes cross-react with other RNA modifications, such as N6,2'-O-dimethyladenosine (m6Am), which is found at the 5' cap of some mRNAs. Check the location of your peak; if it is near the transcription start site, it might represent m6Am.
-
Validate Experimentally: The most definitive way to confirm a novel or non-canonical m6A site is through experimental validation. Methods that provide single-nucleotide resolution, such as SELECT-qPCR or miCLIP, can confirm the presence and location of the modification.[7][15]
-
Data Presentation
Table 1: Variability in m6A Peak Calling Across Different Bioinformatic Pipelines
The table below illustrates how the choice of peak calling software and parameters can lead to significant variation in the number of identified m6A peaks from the same dataset.
| Peak Calling Pipeline | Number of Peaks Identified | Percentage of Unique Peaks* | Reference |
| Pipeline A (e.g., MACS2) | ~40,000 | 53.4% | [16] |
| Pipeline B (e.g., exomePeak) | ~25,000 | 30.5% (average) | [16] |
| Pipeline C (e.g., MeTPeak) | ~18,000 | N/A | [17] |
| Pipeline D (e.g., CVm6A) | ~13,770 | 15.2% | [16] |
*Percentage of peaks that do not overlap with peaks identified by other pipelines.
Experimental Protocols & Workflows
Diagram 1: General Experimental Workflow for MeRIP-seq
Caption: Overview of the Methylated RNA Immunoprecipitation Sequencing (MeRIP-seq) workflow.
Diagram 2: Troubleshooting Workflow for Ambiguous Peaks
Caption: A logical workflow for the validation and interpretation of ambiguous m6A peaks.
Protocol 1: Gene-Specific m6A Validation by qPCR (MeRIP-qPCR)
This protocol describes a method to validate the m6A status of a specific gene transcript identified from sequencing data.[13][18]
Objective: To determine the relative enrichment of m6A on a target RNA transcript compared to an unmodified control transcript.
Methodology:
-
RNA Preparation:
-
Extract total RNA from the cell or tissue sample of interest.
-
Purify mRNA to reduce rRNA contamination.
-
Fragment the mRNA to an average size of ~100 nucleotides using RNA fragmentation buffer.[19] A portion of this fragmented RNA should be saved as the "Input" control.
-
-
Immunoprecipitation (IP):
-
Incubate the fragmented mRNA with an anti-m6A antibody.[19]
-
Add Protein A/G magnetic beads to pull down the antibody-RNA complexes.
-
Wash the beads extensively to remove non-specifically bound RNA.
-
Elute the m6A-containing RNA fragments from the beads.
-
-
RNA Purification:
-
Purify the RNA from both the eluted IP fraction and the saved Input fraction.
-
-
Reverse Transcription and qPCR:
-
Perform reverse transcription on the RNA from both the IP and Input samples to generate cDNA.
-
Perform quantitative PCR (qPCR) using primers specific to the gene of interest. It is also recommended to use primers for a negative control gene (known to be unmethylated) and a positive control gene (known to be methylated).
-
Calculate the relative enrichment of the target transcript in the IP sample compared to the input sample. This is often expressed as a percentage of input. An increase in this value compared to a negative control or an experimental condition where the m6A writer enzyme is knocked down indicates m6A modification.[15]
-
References
- 1. m6aViewer: software for the detection, analysis, and visualization of N6-methyladenosine peaks from m6A-seq/ME-RIP sequencing data - PMC [pmc.ncbi.nlm.nih.gov]
- 2. trumpet: transcriptome-guided quality assessment of m6A-seq data - PMC [pmc.ncbi.nlm.nih.gov]
- 3. researchgate.net [researchgate.net]
- 4. researchgate.net [researchgate.net]
- 5. academic.oup.com [academic.oup.com]
- 6. academic.oup.com [academic.oup.com]
- 7. Comprehensive Overview of m6A Detection Methods - CD Genomics [cd-genomics.com]
- 8. Frontiers | How Do You Identify m6 A Methylation in Transcriptomes at High Resolution? A Comparison of Recent Datasets [frontiersin.org]
- 9. MoAIMS: efficient software for detection of enriched regions of MeRIP-Seq - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Master MeRIP-seq Data Analysis: Step-by-Step Process for RNA Methylation Studies - CD Genomics [rna.cd-genomics.com]
- 11. Comprehensive Analysis of the Transcriptome-Wide m6A Methylation Modification Difference in Liver Fibrosis Mice by High-Throughput m6A Sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 12. MeRIP-seq: Comprehensive Guide to m6A RNA Modification Analysis - CD Genomics [rna.cd-genomics.com]
- 13. researchgate.net [researchgate.net]
- 14. researchgate.net [researchgate.net]
- 15. Deep and accurate detection of m6A RNA modifications using miCLIP2 and m6Aboost machine learning - PMC [pmc.ncbi.nlm.nih.gov]
- 16. Variable calling of m6A and associated features in databases: a guide for end-users - PMC [pmc.ncbi.nlm.nih.gov]
- 17. Detecting m6A methylation regions from Methylated RNA Immunoprecipitation Sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 18. An experimental workflow for identifying RNA m6A alterations in cellular senescence by methylated RNA immunoprecipitation sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 19. 2.8. m6A MeRIP-Seq (Methylated RNA Immunoprecipitation and Sequencing) [bio-protocol.org]
Technical Support Center: Optimizing MeRIP-seq Fragmentation
This technical support center provides troubleshooting guidance and frequently asked questions to assist researchers, scientists, and drug development professionals in optimizing RNA fragmentation conditions for Methylated RNA Immunoprecipitation Sequencing (MeRIP-seq) experiments.
Troubleshooting Guide
This guide addresses specific issues that may arise during the RNA fragmentation step of a MeRIP-seq protocol.
| Issue | Potential Cause | Recommended Solution |
| RNA is under-fragmented (fragments are too large) | Insufficient incubation time or incorrect temperature. | Increase the incubation time or ensure the thermal cycler is calibrated to the correct temperature. A time-course experiment is recommended to determine the optimal fragmentation time.[1] |
| Inactive fragmentation buffer. | Prepare fresh fragmentation buffer. Ensure proper storage of buffer components, especially if they are sensitive to degradation. | |
| RNA is over-fragmented (fragments are too small) | Excessive incubation time or temperature. | Reduce the incubation time or temperature. Even a small increase in time can lead to significant over-fragmentation.[1] |
| High concentration of divalent cations (e.g., ZnCl² or MgCl²). | Ensure the fragmentation buffer is prepared with the correct concentration of all components. | |
| Inconsistent fragmentation results between samples | Variation in starting RNA amount or quality. | Standardize the amount and quality of the starting total RNA for all samples. Ensure RNA integrity is high (RIN > 7.0).[2] |
| Pipetting errors when preparing the fragmentation reaction. | Ensure accurate pipetting of RNA and fragmentation buffer. Prepare a master mix for multiple reactions to minimize variability. | |
| Low yield of fragmented RNA after purification | Inefficient ethanol precipitation. | Ensure the correct volumes of sodium acetate and ethanol are used. Incubate at -80°C to maximize precipitation.[3] Use of a carrier like glycogen can also improve recovery.[3] |
| Pellet loss during washing steps. | Be careful not to disturb the pellet when aspirating the supernatant after centrifugation.[3] |
Frequently Asked Questions (FAQs)
What is the optimal fragment size for MeRIP-seq?
The generally accepted optimal RNA fragment size for MeRIP-seq is between 100 and 200 nucleotides.[4][5] This size range provides a good balance between the resolution of m6A peak detection and the efficiency of immunoprecipitation.[4]
What are the common methods for RNA fragmentation in MeRIP-seq?
The two primary methods for RNA fragmentation in MeRIP-seq are:
-
Chemical Fragmentation: This method typically uses a fragmentation buffer containing divalent metal cations (like ZnCl₂ or MgCl₂) and heat to induce hydrolysis of the phosphodiester bonds.[4][6]
-
Enzymatic Fragmentation: This approach utilizes RNases, such as RNase III, to cleave the RNA into smaller fragments. The extent of fragmentation is controlled by the enzyme concentration and incubation time.[7]
How can I verify the size of my fragmented RNA?
The size distribution of fragmented RNA should be verified using a microfluidics-based electrophoresis system, such as an Agilent Bioanalyzer.[4] This provides a more accurate assessment of the fragment size distribution compared to traditional agarose gel electrophoresis.
Why is it important to stop the fragmentation reaction promptly?
It is crucial to stop the fragmentation reaction immediately at the end of the incubation period to prevent over-fragmentation. This is typically achieved by adding a chelating agent like EDTA, which sequesters the divalent cations and inactivates the fragmentation process, followed by placing the sample on ice.[3][4]
Should I use total RNA or mRNA for fragmentation?
MeRIP-seq can be performed using either total RNA or purified mRNA.[1] If starting with total RNA, a higher initial amount is generally required (e.g., 300 µg) compared to starting with mRNA (e.g., 5 µg).[1] The choice may depend on the abundance of the target RNA and the specific research question.
Experimental Protocols
Chemical RNA Fragmentation Protocol
This protocol is a common method for fragmenting RNA for MeRIP-seq using a metal-ion-based fragmentation buffer.
-
Preparation: In a thin-walled PCR tube, combine your RNA sample with the fragmentation buffer. A typical reaction setup is:
-
Incubation: Vortex the tube briefly and spin down. Place the tube in a preheated thermal cycler and incubate at a specific temperature for a defined period. The exact time and temperature need to be optimized. Common starting points are 70°C for 4-5 minutes or 94°C for a shorter duration.[1][6]
-
Stopping the Reaction: Immediately after incubation, add 2 µL of 0.5 M EDTA to the tube to stop the reaction. Vortex and spin down, then place the tube on ice.[3]
-
Purification: Purify the fragmented RNA using ethanol precipitation. Add one-tenth volume of 3 M sodium acetate, glycogen to a final concentration of 100 µg/ml, and 2.5 volumes of 100% ethanol.[3] Incubate at -80°C overnight.[3]
-
Pelleting and Washing: Centrifuge at high speed (e.g., 15,000 x g) for 25 minutes at 4°C to pellet the RNA.[3] Carefully discard the supernatant and wash the pellet with 75% ethanol.[3]
-
Resuspension: Air-dry the pellet and resuspend it in RNase-free water.[3]
-
Quality Control: Assess the size distribution of the fragmented RNA using a Bioanalyzer. The target size should be around 100-200 nucleotides.[4]
Quantitative Data Summary
Table 1: Exemplary Chemical Fragmentation Conditions
| Parameter | Condition 1 | Condition 2 | Condition 3 |
| Starting RNA | 3-5 µg total RNA | 10 µg total RNA | 18 µg total RNA |
| Fragmentation Buffer | 10x (100 mM Tris-HCl, 100 mM ZnCl₂)[6] | RNA Fragmentation Reagents | 10x Fragmentation Buffer |
| Incubation Temperature | 70°C[6] | 70°C[2] | 94°C[3] |
| Incubation Time | 4-5 minutes[6] | 10 minutes[2] | 5 minutes[3] |
| Stopping Reagent | 0.5 M EDTA | Not specified | 0.5 M EDTA[3] |
| Target Fragment Size | ~100 nt[6] | ~100 nt[2] | ~100 nt[3] |
Visualizations
Caption: Overview of the MeRIP-seq experimental workflow.
Caption: Decision-making workflow for optimizing RNA fragmentation.
References
- 1. sigmaaldrich.com [sigmaaldrich.com]
- 2. MeRIP-seq for Detecting RNA methylation: An Overview - CD Genomics [cd-genomics.com]
- 3. sysy.com [sysy.com]
- 4. benchchem.com [benchchem.com]
- 5. MeRIP Sequencing Q&A - CD Genomics [cd-genomics.com]
- 6. researchgate.net [researchgate.net]
- 7. MeRIP-seq Protocol - CD Genomics [rna.cd-genomics.com]
Technical Support Center: Troubleshooting Reproducibility in 2-Methylamino-N6-methyladenosine (m2,6A) Experiments
Welcome to the technical support center for 2-Methylamino-N6-methyladenosine (m2,6A) research. This resource provides troubleshooting guides and frequently asked questions (FAQs) to help researchers, scientists, and drug development professionals address common challenges that can lead to poor reproducibility in m2,6A experiments.
Frequently Asked Questions (FAQs)
Q1: What are the most common sources of variability in m2,6A detection and quantification?
Poor reproducibility in m2,6A experiments often stems from a few key areas:
-
Antibody Specificity and Cross-Reactivity: The specificity of antibodies used for immunoprecipitation is critical. Antibodies raised against N6-methyladenosine (m6A) may cross-react with m2,6A, and vice-versa, leading to inaccurate enrichment. It is crucial to validate antibody specificity thoroughly.
-
Sample Quality and Preparation: The integrity of the RNA sample is paramount. Degradation of RNA can lead to inconsistent results. Furthermore, incomplete enzymatic digestion of RNA into single nucleosides is a common issue in mass spectrometry-based methods.[1][2]
-
Low Abundance of m2,6A: m2,6A is often a low-abundance modification, which can make its detection and quantification challenging, amplifying the impact of any experimental inconsistencies.
-
Data Analysis Pipeline: In sequencing-based methods like MeRIP-seq, the computational pipeline used for peak calling and differential methylation analysis can introduce variability.[3][4] Consistent use of analysis parameters and appropriate statistical models is essential.
Q2: How can I validate the specificity of my anti-m2,6A antibody?
Antibody validation is a critical step to ensure reliable results. Here are several approaches:
-
Dot Blot Analysis: This is a straightforward method to check for cross-reactivity. Spot synthetic RNA oligonucleotides containing m2,6A, m6A, and unmodified adenosine onto a membrane and probe with your antibody.[5]
-
ELISA: An enzyme-linked immunosorbent assay (ELISA) can provide a more quantitative assessment of antibody binding affinity and specificity.
-
Competitive Binding Assays: Perform immunoprecipitation in the presence of free m2,6A or m6A nucleosides as competitors. A specific antibody will show reduced binding to the target RNA in the presence of its corresponding free nucleoside.
-
Use of Knockout or Knockdown Models: If the enzyme responsible for m2,6A deposition is known, using cell lines or organisms with this enzyme knocked out or knocked down can serve as a negative control to validate antibody specificity.
Q3: What are the best practices for sample preparation for LC-MS/MS analysis of m2,6A?
Liquid chromatography-tandem mass spectrometry (LC-MS/MS) is a gold-standard for quantifying modified nucleosides. To ensure reproducibility:
-
High-Quality RNA Extraction: Start with high-purity, intact RNA. Use appropriate RNA extraction kits and assess RNA integrity using methods like capillary electrophoresis.
-
Complete Enzymatic Digestion: Ensure complete digestion of RNA into single nucleosides. This typically involves a two-step enzymatic digestion using a nuclease (like nuclease P1) followed by a phosphatase (like calf intestinal phosphatase).[1][4][6][7] Incomplete digestion will lead to underestimation of m2,6A levels.
-
Stable Isotope-Labeled Internal Standards: The use of a stable isotope-labeled m2,6A internal standard is highly recommended for accurate quantification. This standard is added at the beginning of the sample preparation process and corrects for variability in sample processing and instrument response.
-
Proper Cleanup: After digestion, samples should be cleaned up to remove enzymes and other interfering substances. This can be done using solid-phase extraction (SPE) or filtration.
Troubleshooting Guides
Issue 1: High Variability Between Replicates in MeRIP-seq Experiments
Possible Causes & Solutions
| Cause | Recommended Troubleshooting Steps |
| Inconsistent RNA Fragmentation | Ensure consistent RNA fragmentation by using a reliable method (e.g., enzymatic or chemical fragmentation) and verifying fragment size distribution for each sample using a Bioanalyzer or similar instrument. The target fragment size is typically around 100-200 nucleotides.[8][9] |
| Variable Immunoprecipitation (IP) Efficiency | Optimize the antibody-to-bead ratio and the amount of input RNA. Ensure thorough and consistent washing of the beads to remove non-specifically bound RNA. Use a consistent incubation time and temperature for all samples.[10][11] |
| Pipetting Errors | Use calibrated pipettes and proper pipetting techniques to minimize volume variations, especially when handling small volumes.[12][13] |
| Inconsistent Library Preparation | Use a high-quality library preparation kit and follow the manufacturer's protocol strictly. Quantify the final libraries accurately before sequencing. |
| Batch Effects | If processing a large number of samples, process them in smaller, manageable batches or randomize the sample order to minimize batch-to-batch variation. |
Issue 2: Low or No Signal in LC-MS/MS Quantification of m2,6A
Possible Causes & Solutions
| Cause | Recommended Troubleshooting Steps |
| Incomplete RNA Digestion | Optimize the enzymatic digestion protocol. Increase the enzyme concentration or incubation time. Ensure the buffer conditions (pH, co-factors) are optimal for the enzymes used.[1][2] |
| Loss of Sample During Preparation | Be cautious during sample transfer and cleanup steps. Use low-binding tubes and pipette tips. Optimize the solid-phase extraction (SPE) protocol to ensure efficient recovery of nucleosides. |
| Suboptimal LC-MS/MS Parameters | Optimize the mass spectrometer parameters for m2,6A detection, including the precursor and product ion masses, collision energy, and ion source settings.[14] Develop a sensitive multiple reaction monitoring (MRM) method. |
| Low Abundance of m2,6A in the Sample | Increase the starting amount of RNA. If possible, enrich for the RNA species expected to contain m2,6A. |
| Degradation of m2,6A | Ensure samples are stored properly at -80°C and avoid repeated freeze-thaw cycles. Prepare fresh standards for calibration. |
Issue 3: Discrepancies Between Different Detection Methods (e.g., MeRIP-seq vs. LC-MS/MS)
Possible Causes & Solutions
| Cause | Recommended Troubleshooting Steps |
| Antibody Bias in MeRIP-seq | As mentioned, antibody cross-reactivity with other modifications (like m6A) can lead to an overestimation of m2,6A levels in MeRIP-seq. Validate antibody specificity rigorously.[15][16] |
| Quantification Differences | MeRIP-seq provides relative enrichment, while LC-MS/MS provides absolute or relative quantification of the modification. The results are not directly comparable in terms of absolute numbers but should show similar trends. |
| RNA Secondary Structure | The accessibility of the m2,6A modification within the RNA secondary structure can affect both antibody binding in MeRIP and enzymatic digestion for LC-MS/MS, potentially leading to discrepancies.[17][18][19][20] Consider denaturing RNA before processing. |
| Data Normalization | Ensure that the data from both methods are appropriately normalized. For MeRIP-seq, this involves normalizing to input controls. For LC-MS/MS, normalization to the corresponding unmodified nucleoside (adenosine) is common. |
Experimental Protocols & Workflows
General Workflow for m2,6A MeRIP-seq
References
- 1. pubs.acs.org [pubs.acs.org]
- 2. Complete enzymatic digestion of double-stranded RNA to nucleosides enables accurate quantification of dsRNA - Analytical Methods (RSC Publishing) [pubs.rsc.org]
- 3. Analysis approaches for the identification and prediction of N6-methyladenosine sites - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Quantitative analysis of m6A RNA modification by LC-MS - PMC [pmc.ncbi.nlm.nih.gov]
- 5. agrisera.com [agrisera.com]
- 6. bpb-us-e2.wpmucdn.com [bpb-us-e2.wpmucdn.com]
- 7. escholarship.org [escholarship.org]
- 8. researchgate.net [researchgate.net]
- 9. sysy.com [sysy.com]
- 10. How MeRIP-seq Works: Principles, Workflow, and Applications Explained - CD Genomics [rna.cd-genomics.com]
- 11. sigmaaldrich.com [sigmaaldrich.com]
- 12. ethosbiosciences.com [ethosbiosciences.com]
- 13. ELISA Troubleshooting Guide | Thermo Fisher Scientific - AT [thermofisher.com]
- 14. Frontiers | Quantitative Analysis of Methylated Adenosine Modifications Revealed Increased Levels of N6-Methyladenosine (m6A) and N6,2′-O-Dimethyladenosine (m6Am) in Serum From Colorectal Cancer and Gastric Cancer Patients [frontiersin.org]
- 15. N6-Methyladenosine (m6A) (D9D9W) Rabbit Monoclonal Antibody | Cell Signaling Technology [cellsignal.com]
- 16. The detection and functions of RNA modification m6A based on m6A writers and erasers - PMC [pmc.ncbi.nlm.nih.gov]
- 17. academic.oup.com [academic.oup.com]
- 18. The Effect of RNA Secondary Structure on the Self-Assembly of Viral Capsids - PMC [pmc.ncbi.nlm.nih.gov]
- 19. The impact of RNA secondary structure on read start locations on the Illumina sequencing platform - PMC [pmc.ncbi.nlm.nih.gov]
- 20. Frontiers | Limits of experimental evidence in RNA secondary structure prediction [frontiersin.org]
How to minimize PCR duplicates in m6A sequencing libraries.
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to help researchers, scientists, and drug development professionals minimize PCR duplicates in m6A sequencing libraries, ensuring high-quality and reliable data.
Troubleshooting Guide: High PCR Duplicate Rates
High PCR duplicate rates in m6A sequencing libraries can compromise the accuracy of m6A peak calling and quantification. This guide provides a systematic approach to diagnosing and resolving this common issue.
Problem: My m6A sequencing library has a high percentage of PCR duplicates.
Possible Cause 1: Low Library Complexity
Library complexity, the number of unique molecules in your starting library, is the most critical factor influencing PCR duplicate rates.[1][2][3] Low complexity means fewer unique fragments are available for amplification, leading to a higher proportion of reads arising from the same original molecule.
Solutions:
-
Increase RNA Input: The amount of starting material is directly related to library complexity.[2][4] Whenever possible, increase the amount of total RNA or poly(A)+ RNA used for immunoprecipitation. For low-input samples, using UMIs is highly recommended.[5]
-
Optimize Immunoprecipitation (IP): An inefficient IP will result in a low yield of m6A-containing RNA fragments, reducing the complexity of the library. Ensure your antibody is validated and used at the optimal concentration. Optimize IP conditions such as incubation time and washing steps.
-
Assess RNA Quality: Starting with high-quality, intact RNA is crucial. Degraded RNA can lead to inefficient reverse transcription and reduced library complexity.
Possible Cause 2: Excessive PCR Amplification
While the number of PCR cycles is a secondary factor compared to library complexity, over-amplification can still contribute to higher duplicate rates, especially with low-input samples.[2][6]
Solutions:
-
Minimize PCR Cycles: Perform a qPCR titration to determine the optimal number of PCR cycles needed to generate sufficient library for sequencing without entering the plateau phase of amplification.
-
Use a High-Fidelity Polymerase: A high-fidelity DNA polymerase can help ensure uniform amplification across all fragments, reducing amplification bias.
Possible Cause 3: Suboptimal Library Preparation
Issues during the library preparation steps following immunoprecipitation can also lead to reduced complexity and increased duplicates.
Solutions:
-
Incorporate Unique Molecular Identifiers (UMIs): UMIs are short, random sequences ligated to RNA fragments before PCR amplification.[7] They allow for the precise identification of PCR duplicates, as reads originating from the same initial molecule will have the same UMI and mapping coordinates.[2][5] This is the most effective method for mitigating PCR duplicates, especially for low-input samples.[8]
-
Ensure Efficient Adapter Ligation: Inefficient ligation of sequencing adapters will result in fewer molecules being available for amplification. Use high-quality adapters and optimize the ligation reaction conditions.
Frequently Asked Questions (FAQs)
Q1: What are PCR duplicates and why are they a problem in m6A sequencing?
PCR duplicates are multiple sequencing reads that originate from a single RNA fragment in the initial library.[2] They are generated during the PCR amplification step of library preparation. In m6A sequencing (MeRIP-seq), a high rate of PCR duplicates can lead to an overestimation of signal in m6A peaks, potentially causing false positives and inaccurate quantification of m6A levels.
Q2: What is a typical acceptable PCR duplicate rate for m6A sequencing?
The acceptable duplicate rate can vary depending on the sample type, input amount, and the specific goals of the experiment. However, for MeRIP-seq, which often deals with lower input material after immunoprecipitation, higher duplicate rates (e.g., >20-30%) are not uncommon but should be investigated.[9] The use of UMIs can help distinguish true biological signal from PCR artifacts, making higher initial duplicate rates more manageable after bioinformatic removal.
Q3: How do Unique Molecular Identifiers (UMIs) help in minimizing PCR duplicates?
UMIs are short, random nucleotide sequences that are added to each RNA fragment before PCR amplification.[7] This gives each molecule a unique tag. After sequencing, reads with the same genomic alignment and the same UMI are identified as PCR duplicates and can be computationally removed.[10] This allows for more accurate quantification of the original number of m6A-containing fragments.
Q4: Does the number of PCR cycles directly cause high duplicate rates?
Not directly. The primary drivers of high PCR duplicate rates are low library complexity (insufficient starting material) and high sequencing depth.[2][11] While excessive PCR cycles can exacerbate the issue, especially with low-complexity libraries, simply reducing the number of cycles without addressing the underlying complexity may not solve the problem and could lead to insufficient library yield.
Q5: Can I just remove duplicates bioinformatically without using UMIs?
Standard bioinformatic tools can remove duplicate reads based on their mapping coordinates (start and end positions). However, this approach can be problematic in RNA-seq and m6A-seq because different RNA fragments can naturally have the same start and end points, especially for highly expressed and short transcripts.[2][11] Removing these "natural" duplicates can introduce bias and lead to an underestimation of gene expression and m6A abundance.[5] Therefore, using UMIs is the recommended and more accurate method for duplicate removal.[2]
Quantitative Data Summary
The following tables summarize the impact of RNA input amount and the use of UMIs on PCR duplicate rates, based on data from RNA sequencing experiments.
Table 1: Effect of RNA Input Amount on PCR Duplicate Rate
| RNA Input Amount | Approximate PCR Duplicate Rate (without UMIs) |
| > 250 ng | < 7% |
| 125 ng | 8 - 18% |
| < 15 ng | 34 - 96% |
Data adapted from studies on general RNA-seq, which shows a strong negative correlation between input amount and the proportion of PCR duplicates.[6][8]
Table 2: Comparison of Duplicate Removal Methods
| Method for Duplicate Removal | Effect on Data Reproducibility | Notes |
| None | Baseline | High potential for bias from PCR duplicates. |
| Based on Mapping Coordinates | Improved | Can introduce bias by removing "natural" duplicates.[2] |
| Based on Mapping Coordinates + UMIs | Most Improved | Accurately identifies and removes PCR duplicates.[2] |
Experimental Protocols
Protocol 1: m6A-Seq Library Preparation with UMI Adapters
This protocol outlines the key steps for performing MeRIP-seq with the incorporation of UMI adapters to enable accurate PCR duplicate removal.
-
RNA Preparation and Fragmentation:
-
Isolate total RNA from cells or tissues, ensuring high quality (RIN > 7).
-
Fragment the RNA to an average size of ~100-200 nucleotides using chemical or enzymatic methods.
-
-
Immunoprecipitation (IP):
-
Incubate the fragmented RNA with an m6A-specific antibody to form RNA-antibody complexes.
-
Capture the complexes using protein A/G magnetic beads.
-
Wash the beads to remove non-specifically bound RNA.
-
Elute the m6A-containing RNA fragments.
-
-
Library Preparation with UMI Adapters:
-
End Repair and A-tailing: Perform end-repair and A-tailing on the eluted RNA fragments to prepare them for adapter ligation.
-
UMI Adapter Ligation: Ligate adapters containing a Unique Molecular Identifier (UMI) to both ends of the RNA fragments. It is crucial that this step occurs before PCR amplification.
-
Reverse Transcription: Synthesize the first strand of cDNA using reverse transcriptase.
-
Second Strand Synthesis: Synthesize the second strand of cDNA.
-
PCR Amplification: Amplify the cDNA library using a minimal number of cycles determined by qPCR. Use primers that are complementary to the adapter sequences.
-
Library Purification and Size Selection: Purify the amplified library and perform size selection to remove adapter dimers and select the desired fragment size range.
-
-
Library Quality Control and Sequencing:
-
Assess the library quality and concentration using a Bioanalyzer and qPCR.
-
Sequence the library on a high-throughput sequencing platform.
-
Visualizations
Caption: MeRIP-Seq workflow incorporating UMIs for accurate PCR duplicate removal.
Caption: Decision logic for identifying PCR duplicates using UMIs.
References
- 1. MeRIP-seq and Its Principle, Protocol, Bioinformatics, Applications in Diseases - CD Genomics [cd-genomics.com]
- 2. Elimination of PCR duplicates in RNA-seq and small RNA-seq using unique molecular identifiers - PMC [pmc.ncbi.nlm.nih.gov]
- 3. biorxiv.org [biorxiv.org]
- 4. echemi.com [echemi.com]
- 5. greshamlab.bio.nyu.edu [greshamlab.bio.nyu.edu]
- 6. m.youtube.com [m.youtube.com]
- 7. Unique Molecular Identifiers (UMIs) | For sequencing accuracy [illumina.com]
- 8. The impact of PCR duplication on RNAseq data generated using NovaSeq 6000, NovaSeq X, AVITI, and G4 sequencers - PMC [pmc.ncbi.nlm.nih.gov]
- 9. youtube.com [youtube.com]
- 10. Frontiers | UMIc: A Preprocessing Method for UMI Deduplication and Reads Correction [frontiersin.org]
- 11. researchgate.net [researchgate.net]
Validation & Comparative
Validating N6-methyladenosine Sequencing Results: A Comparative Guide to qPCR-Based Methods
For researchers, scientists, and drug development professionals, accurate identification and quantification of N6-methyladenosine (m6A) modifications are crucial for understanding gene regulation and its role in disease. While transcriptome-wide sequencing methods provide a global view of m6A distribution, validation of these findings is a critical step to confirm the presence and potential dynamic changes of this epigenetic mark at specific gene loci. This guide provides a comprehensive comparison of qPCR-based methods for validating m6A sequencing results, complete with experimental data, detailed protocols, and workflow visualizations.
N6-methyladenosine (m6A) is the most abundant internal modification in eukaryotic mRNA and plays a pivotal role in various biological processes, including RNA stability, splicing, and translation. High-throughput sequencing techniques, such as methylated RNA immunoprecipitation sequencing (MeRIP-seq or m6A-seq), have revolutionized the field by enabling transcriptome-wide mapping of m6A. However, the inherent nature of these enrichment-based methods necessitates orthogonal validation of the identified m6A peaks. Quantitative PCR (qPCR) offers a sensitive, specific, and widely accessible platform for this purpose.
Comparison of qPCR-Based Validation Methods
Several qPCR-based methodologies have been developed to validate m6A sequencing data, each with its own principles and advantages. The most common method is MeRIP-qPCR, which mirrors the initial steps of MeRIP-seq on a smaller scale. Other innovative techniques, such as SELECT (single-base elongation and ligation-based qPCR amplification method) and m6A-RT-qPCR, offer alternative approaches to quantify m6A levels at specific sites.
| Method | Principle | Advantages | Disadvantages | Typical Output |
| MeRIP-qPCR | Immunoprecipitation of m6A-containing RNA fragments followed by RT-qPCR of target transcripts.[1][2][3] | Directly validates the enrichment seen in MeRIP-seq. Relatively straightforward and widely used. | Relies on antibody specificity. Does not provide single-nucleotide resolution. | Fold enrichment of m6A-modified RNA over input or IgG control. |
| SELECT | m6A modification hinders the single-base elongation by DNA polymerase and ligation by DNA ligase, which is then quantified by qPCR.[4] | Antibody-independent. Provides single-base resolution. Can determine the fraction of m6A at a specific site.[4] | Requires careful primer design and optimization. May be more technically demanding than MeRIP-qPCR. | Relative m6A methylation level or percentage. |
| m6A-RT-qPCR | The reverse transcriptase BstI has diminished capacity to read through an m6A-modified residue, leading to a quantifiable difference in cDNA synthesis compared to a standard reverse transcriptase.[5][6][7] | Antibody-independent. Provides information about m6A presence at a specific site. | Indirect measurement based on enzyme kinetics. Requires careful control and optimization of the reverse transcription step. | Relative m6A quantification, often expressed as a ratio of signals from two different reverse transcriptases.[6] |
Quantitative Data Summary
The following table summarizes representative quantitative data from studies that have used qPCR to validate m6A sequencing results. This data illustrates the concordance that can be achieved between high-throughput sequencing and targeted qPCR validation.
| Study Focus | Sequencing Method | Validation Method | Target Gene(s) | Sequencing Result (Fold Change/Peak Intensity) | qPCR Validation Result (Fold Enrichment/Relative Methylation) | Correlation/Concordance |
| Cellular Senescence | MeRIP-seq | MeRIP-qPCR | CDKN2A (p16) | Increased m6A peak intensity in senescent cells | 2.5-fold enrichment in senescent cells compared to control | Consistent with sequencing data |
| Hypertrophic Scar | m6A-seq | m6A-specific qPCR | COL11A1, COL8A1, CYP1A1, AR | Consistent changes in m6A levels observed in sequencing | Changes in m6A levels were consistent with sequencing results | High reliability of transcriptome-wide m6A-seq data indicated[8] |
| HIV Infection | MeRIP-seq | MeRIP-RT-qPCR | PSIP1 | Altered m6A peaks | Magnitude of changes correlated with MeRIP-seq (Pearson's R = 0.57)[9] | Moderate positive correlation |
| Celiac Disease | Not specified | m6A-RT-qPCR | SOCS1, SOCS3 | Not applicable | Altered relative levels of m6A in specific motifs observed in patients[6] | Demonstrates utility in clinical samples |
Experimental Protocols
MeRIP-qPCR Protocol
This protocol describes the validation of m6A peaks identified by MeRIP-seq using methylated RNA immunoprecipitation followed by quantitative PCR.[1][2][10]
1. RNA Preparation and Fragmentation:
-
Isolate total RNA from cells or tissues of interest using a standard method.
-
Purify mRNA from total RNA to reduce ribosomal RNA background.
-
Fragment the mRNA to an average size of ~100 nucleotides using RNA fragmentation buffer or enzymatic methods.[8]
2. Immunoprecipitation (IP):
-
For each sample, prepare two tubes: one for the m6A IP and one for the negative control (e.g., IgG antibody).
-
Incubate a portion of the fragmented RNA (input) with an anti-m6A antibody or an IgG control antibody in IP buffer.
-
Add protein A/G magnetic beads to each tube to capture the antibody-RNA complexes.
-
Wash the beads several times with IP buffer to remove non-specifically bound RNA.
3. RNA Elution and Purification:
-
Elute the RNA from the magnetic beads using an elution buffer.
-
Purify the eluted RNA and the input RNA using a suitable RNA purification kit.
4. Reverse Transcription (RT) and qPCR:
-
Perform reverse transcription on the eluted RNA from the IP and IgG samples, as well as the input RNA, to generate cDNA.
-
Set up qPCR reactions using SYBR Green or a probe-based assay with primers specific to the m6A peak region of the target gene.
-
Analyze the qPCR data to determine the cycle threshold (Ct) values.
5. Data Analysis:
-
Calculate the fold enrichment of m6A in the IP sample relative to the input or IgG control using the delta-delta Ct method. A significant enrichment in the m6A IP compared to the control indicates a validated m6A peak.
SELECT Protocol (Single-Base Elongation and Ligation-Based qPCR)
This antibody-independent method provides single-nucleotide resolution validation.[4]
1. Primer Design:
-
Design two DNA primers that anneal to the RNA template immediately adjacent to the target adenosine, with a one-nucleotide gap.
2. Elongation and Ligation:
-
Anneal the primers to the total RNA.
-
Perform a single-base extension reaction using a DNA polymerase and a specific dNTP that is complementary to the nucleotide in the gap. The presence of m6A will hinder this extension.
-
Ligate the extended primer to the adjacent primer using a DNA ligase. The efficiency of ligation is also reduced by the presence of m6A.
3. qPCR Quantification:
-
Use the ligated product as a template for qPCR with primers flanking the target site.
-
The amount of qPCR product is inversely proportional to the m6A level at the target site.
4. Data Analysis:
-
Compare the qPCR signal from the sample to that of an in vitro transcribed unmethylated control to determine the relative methylation level.
Visualizing the Validation Workflow
Comparison with Other Alternatives
While qPCR-based methods are the most common for validating m6A sequencing, other techniques can also be employed:
-
Mass Spectrometry (LC-MS/MS): This is the gold standard for quantifying the overall m6A/A ratio in a sample. However, it does not provide information on the location of the m6A modification within specific transcripts.
-
Sanger Sequencing of RT-PCR Products: This can sometimes reveal m6A-induced mutations or truncations after certain chemical treatments but is generally not a quantitative method.
-
Nanopore Direct RNA Sequencing: This emerging technology can directly detect RNA modifications, including m6A, at single-nucleotide resolution without the need for immunoprecipitation. While powerful, the analysis pipelines are still under development.
Conclusion
Validating N6-methyladenosine sequencing results is an indispensable step in m6A research. qPCR-based methods, particularly MeRIP-qPCR, provide a robust, sensitive, and accessible means to confirm the findings from transcriptome-wide studies. The choice of validation method will depend on the specific research question, the desired resolution, and the available resources. By carefully selecting and executing a validation strategy, researchers can increase the confidence in their m6A sequencing data and pave the way for a deeper understanding of the epitranscriptomic landscape.
References
- 1. RNA m6A immunoprecipitation RT-qPCR [bio-protocol.org]
- 2. m6A-RIP-qPCR [bio-protocol.org]
- 3. sigmaaldrich.com [sigmaaldrich.com]
- 4. Current progress in strategies to profile transcriptomic m6A modifications - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Relative Quantification of Residue-Specific m6A RNA Methylation Using m6A-RT-QPCR | Springer Nature Experiments [experiments.springernature.com]
- 6. researchgate.net [researchgate.net]
- 7. researchgate.net [researchgate.net]
- 8. An experimental workflow for identifying RNA m6A alterations in cellular senescence by methylated RNA immunoprecipitation sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Limits in the detection of m6A changes using MeRIP/m6A-seq - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Comprehensive analysis of transcriptome‐wide M6A methylation for hepatic ischaemia reperfusion injury in mice - PMC [pmc.ncbi.nlm.nih.gov]
Independent Validation of m6A Sites: A Comparative Guide to Site-Specific Cleavage and Ligation-Based Assays
For researchers, scientists, and drug development professionals navigating the complexities of epitranscriptomics, the accurate validation of N6-methyladenosine (m6A) sites is paramount. This guide provides an objective comparison of leading site-specific cleavage and ligation-based assays for independent m6A validation, supported by experimental data and detailed protocols. We delve into the methodologies of MAZTER-seq, m6A-REF-seq, SELECT, and LEAD-m6A-seq, alongside a comparative look at alternative validation techniques.
N6-methyladenosine (m6A) is the most abundant internal modification on eukaryotic messenger RNA, playing a crucial role in regulating RNA metabolism, including splicing, stability, and translation. While high-throughput sequencing methods provide a global view of the m6A landscape, independent validation of specific m6A sites is essential to confirm these findings and to functionally characterize individual methylation events. This guide focuses on antibody-independent methods that offer high specificity and, in some cases, quantitative information about m6A stoichiometry.
Comparative Analysis of m6A Validation Methods
The choice of an m6A validation method depends on various factors, including the desired resolution, sensitivity, required RNA input, and the specific biological question being addressed. The following tables provide a quantitative and qualitative comparison of key site-specific cleavage and ligation-based assays against other common validation techniques.
Quantitative Performance Metrics
| Method | Principle | Resolution | Typical RNA Input | Sensitivity | Specificity | Quantitative? |
| MAZTER-seq | m6A-sensitive RNase (MazF) cleavage | Single nucleotide[1][2] | 25-50 ng (MazF-qPCR)[3] | Moderate | High (sequence-dependent) | Yes (stoichiometric)[1] |
| m6A-REF-seq | m6A-sensitive RNase (MazF) cleavage | Single nucleotide | Not specified | Moderate | High (sequence-dependent) | Yes (semi-quantitative) |
| SELECT | m6A-inhibited ligation and extension | Single nucleotide[4] | As low as 20 ng poly(A) RNA[5] | High | High | Yes (relative quantification) |
| LEAD-m6A-seq | Locus-specific extension and sequencing | Single nucleotide[6][7] | Low (not specified)[6] | High | High | Yes (semi-quantitative)[6][7] |
| MeRIP-qPCR | Antibody-based enrichment | ~100-200 nucleotides | 2 µg total RNA (optimized)[8] | Variable | Moderate (antibody-dependent) | No (enrichment-based) |
| dRNA-seq | Direct RNA sequencing (Nanopore) | Single nucleotide | ~5 µg total RNA[9] | High | Moderate-High | Yes (stoichiometric) |
Qualitative Methodological Comparison
| Method | Advantages | Disadvantages |
| MAZTER-seq | Antibody-independent, quantitative, single-nucleotide resolution.[1] | Limited to 'ACA' sequence context, covering ~16-25% of m6A sites.[10] |
| m6A-REF-seq | Antibody-independent, single-nucleotide resolution. | Limited to 'ACA' sequence context. |
| SELECT | Antibody-independent, high sensitivity, low RNA input.[4] | Locus-specific (not for transcriptome-wide discovery). |
| LEAD-m6A-seq | High-throughput validation of multiple sites, covers all consensus motifs.[6] | Semi-quantitative, requires custom probe design. |
| MeRIP-qPCR | Widely used, relatively straightforward. | Low resolution, antibody-dependent (potential for bias), not quantitative.[11] |
| dRNA-seq | Direct detection without amplification bias, provides long-read information. | Higher error rates, complex data analysis. |
Experimental Workflows and Protocols
Detailed methodologies are crucial for the successful implementation of these validation assays. Below are the experimental workflows and summarized protocols for the key techniques discussed.
MAZTER-seq (m6A-sensitive RNase Cleavage and Sequencing)
MAZTER-seq utilizes the endonuclease MazF, which cleaves RNA at unmethylated 'ACA' motifs but is blocked by methylation at the adenosine (m6A-CA).[2][3] The ratio of cleaved to uncleaved products, determined by high-throughput sequencing, provides a quantitative measure of m6A stoichiometry at specific sites.
Protocol Summary:
-
RNA Preparation: Isolate total RNA and perform poly(A) selection to enrich for mRNA.
-
MazF Digestion: Treat the poly(A) RNA with MazF endonuclease. This will cleave the RNA at unmethylated 'ACA' sites.
-
Library Preparation: Perform end-repair on the digested RNA fragments, ligate sequencing adapters, and then carry out reverse transcription followed by PCR amplification to generate a cDNA library.
-
Sequencing: Sequence the prepared library using a high-throughput sequencing platform.
-
Data Analysis: Map the sequencing reads to the reference transcriptome. Analyze the start and end positions of the reads to identify MazF cleavage sites. The ratio of reads that span a given 'ACA' site (indicating methylation) to the reads that start or end at that site (indicating no methylation) is used to calculate the m6A stoichiometry.
SELECT (Single-Base Elongation and Ligation-based qPCR)
The SELECT method relies on the principle that m6A modification can hinder the single-base elongation by a DNA polymerase and the subsequent ligation of two DNA probes annealed to the target RNA.[4] The difference in ligation efficiency between a control and an m6A-containing sample is quantified by qPCR.
Protocol Summary:
-
RNA Preparation: Start with purified RNA (e.g., 20 ng of poly(A) RNA).[5]
-
Probe Annealing: Design and anneal two specific DNA probes, an upstream probe and a downstream probe, to the target RNA sequence flanking the putative m6A site. The probes are designed to leave a single-nucleotide gap at the site of interest.
-
Enzymatic Reactions:
-
Elongation: Perform a single-base elongation reaction using a polymerase such as Bst 2.0 DNA polymerase. The presence of m6A will impede this extension.
-
Ligation: Ligate the extended upstream probe to the downstream probe using a ligase like SplintR ligase. Ligation efficiency is dependent on the successful elongation in the previous step.
-
-
Quantification: Use qPCR with primers specific to the ligated product to quantify the amount of ligation.
-
Data Analysis: Compare the qPCR cycle threshold (Ct) values between the sample of interest and a negative control (e.g., RNA from a methyltransferase knockout or knockdown, or in vitro transcribed unmethylated RNA) to determine the relative abundance of m6A.
Alternative Validation Methods
Beyond site-specific cleavage and ligation-based assays, several other methods can be employed for m6A site validation.
-
Antibody-Based Methods (MeRIP-qPCR): Methylated RNA Immunoprecipitation followed by quantitative PCR (MeRIP-qPCR) is a common method that relies on an m6A-specific antibody to enrich for methylated RNA fragments. While widely used, it suffers from lower resolution (~100-200 nucleotides) and potential antibody-related biases.[11] The starting amount of total RNA required can be substantial, although optimized protocols have reduced this to as low as 2 µg.[8]
-
Direct RNA Sequencing (dRNA-seq): Nanopore-based direct RNA sequencing allows for the direct detection of m6A modifications on native RNA molecules without the need for reverse transcription or amplification.[9] This method provides single-nucleotide resolution and information on the stoichiometry of methylation. However, the analysis of dRNA-seq data to accurately call m6A sites is computationally intensive and still an active area of development.
Logical Relationships in m6A Validation
The overall process of identifying and validating m6A sites involves a logical progression from transcriptome-wide discovery to site-specific confirmation and functional characterization.
References
- 1. Deciphering the "m6A Code" via Antibody-Independent Quantitative Profiling - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. Counting the Cuts: MAZTER-Seq Quantifies m6A Levels Using a Methylation-Sensitive Ribonuclease - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. Three Methods Comparison: GLORI-seq, miCLIP and Mazter-seq - CD Genomics [cd-genomics.com]
- 4. researchgate.net [researchgate.net]
- 5. researchgate.net [researchgate.net]
- 6. LEAD-m6A-seq for Locus-specific Detection of N6-methyladenosine and Quantification of Differential Methylation - PMC [pmc.ncbi.nlm.nih.gov]
- 7. LEAD-m6 A-seq for Locus-Specific Detection of N6 -Methyladenosine and Quantification of Differential Methylation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. pdfs.semanticscholar.org [pdfs.semanticscholar.org]
- 9. m6A level and isoform characterization sequencing (m6A-LAIC-seq) reveals the census and complexity of the m6A epitranscriptome - PMC [pmc.ncbi.nlm.nih.gov]
- 10. m6A RNA modifications are measured at single-base resolution across the mammalian transcriptome - PMC [pmc.ncbi.nlm.nih.gov]
- 11. en.genemind.com [en.genemind.com]
A Researcher's Guide to N6-methyladenosine (m6A) Detection: A Comparative Analysis
For researchers, scientists, and drug development professionals navigating the complex landscape of epitranscriptomics, the accurate detection of N6-methyladenosine (m6A) is paramount. This guide provides an objective comparison of the leading m6A detection methods, summarizing their performance, detailing experimental protocols, and offering insights into their respective strengths and limitations.
N6-methyladenosine, the most abundant internal modification in eukaryotic messenger RNA (mRNA), plays a critical role in various biological processes, including mRNA stability, splicing, and translation. The development of robust and precise m6A detection methodologies is crucial for advancing our understanding of its role in health and disease. This guide compares four major categories of m6A detection techniques: antibody-based, antibody-based with crosslinking, enzyme-based, and direct sequencing methods.
Quantitative Performance Comparison
The selection of an appropriate m6A detection method depends on the specific research question, available resources, and desired resolution. The following tables provide a summary of key quantitative and qualitative performance metrics for popular m6A detection methods.
Table 1: Performance Metrics of m6A Detection Methods
| Method Category | Specific Method | Resolution | Sensitivity | Specificity | Quantitative Nature |
| Antibody-Based | MeRIP-seq / m6A-seq | ~100-200 nt | Moderate | Moderate to High | Semi-quantitative |
| Antibody-Based with Crosslinking | miCLIP-seq | Single nucleotide | High | High | Semi-quantitative |
| Enzyme-Based | DART-seq | Single nucleotide | High | High | Semi-quantitative |
| Direct Sequencing | Nanopore Direct RNA-seq | Single nucleotide | High | High | Quantitative (stoichiometry) |
Note: Direct head-to-head quantitative comparisons of sensitivity and specificity across all methods from a single study are limited. The performance metrics are synthesized from multiple sources and may vary depending on the experimental context and data analysis pipeline.
Table 2: Practical Comparison of m6A Detection Methods
| Method | Key Advantages | Key Disadvantages | Input RNA Requirement |
| MeRIP-seq / m6A-seq | Well-established, relatively simple protocol. | Lower resolution, potential for antibody-related bias and non-specific binding, reproducibility can be a concern (peak overlap between studies can be 30-60%)[1][2]. | High (micrograms of total RNA) |
| miCLIP-seq | Single-nucleotide resolution, reduced non-specific binding due to crosslinking. | Labor-intensive protocol, potential for UV-crosslinking biases. | High (micrograms of poly(A) RNA) |
| DART-seq | Antibody-free, single-nucleotide resolution, requires low input RNA. | Requires expression of a fusion protein, potential for off-target effects of the deaminase. | Low (nanograms of total RNA)[3][4] |
| Nanopore Direct RNA-seq | Direct detection without antibodies or enzymes, provides long reads for isoform-specific analysis, can determine stoichiometry. | Data analysis can be complex, reliant on evolving computational models for modification calling. Accuracy of some models reported to be 94-98%[5]. | Low to moderate (nanograms of poly(A) RNA) |
Experimental Workflows and Signaling Pathways
To aid in the selection and implementation of these techniques, this section provides diagrams of the experimental workflows for MeRIP-seq, miCLIP-seq, DART-seq, and Nanopore Direct RNA Sequencing.
Detailed Experimental Protocols
This section provides an overview of the key steps for each of the discussed m6A detection methods. For detailed, step-by-step instructions, it is recommended to consult the original publications and manufacturer's protocols.
MeRIP-seq (Methylated RNA Immunoprecipitation Sequencing)
-
RNA Extraction and Fragmentation: Isolate total RNA from the sample of interest and ensure high quality. Fragment the RNA to an average size of 100-200 nucleotides using enzymatic or chemical methods[3][6].
-
Immunoprecipitation: Incubate the fragmented RNA with an anti-m6A antibody. Capture the antibody-RNA complexes using Protein A/G magnetic beads[3][7].
-
Washing and Elution: Perform stringent washing steps to remove non-specifically bound RNA. Elute the m6A-containing RNA fragments from the beads[3].
-
Library Preparation and Sequencing: Prepare sequencing libraries from the immunoprecipitated RNA (IP) and a corresponding input control sample (fragmented RNA before IP). Perform high-throughput sequencing[6][7].
-
Data Analysis: Align sequencing reads to a reference genome/transcriptome. Use peak-calling algorithms to identify regions enriched for m6A in the IP sample compared to the input control[6][8].
miCLIP-seq (m6A individual-nucleotide-resolution cross-linking and immunoprecipitation)
-
RNA Fragmentation and UV Crosslinking: Isolate and fragment poly(A) RNA. Incubate the fragmented RNA with an anti-m6A antibody and expose to UV light to induce covalent crosslinks between the antibody and the RNA at the m6A site[9].
-
Immunoprecipitation and Adapter Ligation: Immunoprecipitate the crosslinked RNA-antibody complexes. Ligate a 3' adapter to the RNA fragments[9].
-
Radiolabeling and Purification: Radiolabel the 5' ends of the RNA fragments. Purify the RNA-protein complexes using SDS-PAGE and transfer to a membrane[9].
-
Protein Digestion and Reverse Transcription: Digest the antibody with Proteinase K, leaving a peptide remnant at the crosslink site. Perform reverse transcription, during which the peptide remnant causes mutations or truncations in the resulting cDNA at the m6A site[9].
-
Library Preparation and Sequencing: Purify the cDNA, circularize, and then relinearize it. Amplify the library via PCR and perform high-throughput sequencing.
-
Data Analysis: Align reads and analyze the positions of mutations and truncations to identify m6A sites at single-nucleotide resolution[9].
DART-seq (Deamination Adjacent to RNA Modification Targets)
-
Expression of Fusion Protein: Introduce and express a fusion protein consisting of the m6A-binding YTH domain and the cytidine deaminase APOBEC1 in the cells of interest[3][4].
-
Targeted Deamination: The YTH domain of the fusion protein binds to m6A sites, guiding the APOBEC1 enzyme to deaminate nearby cytosine (C) residues to uracil (U)[3][4].
-
RNA Extraction and Library Preparation: Isolate total RNA from the cells. Prepare standard RNA sequencing libraries[3][4].
-
Sequencing and Data Analysis: Perform high-throughput sequencing. Align the reads to a reference genome/transcriptome and identify C-to-T mutations, which indicate the proximity of an m6A site[3][4].
Nanopore Direct RNA Sequencing
-
RNA Isolation and Library Preparation: Isolate poly(A) RNA from the sample. Ligate sequencing adapters directly to the RNA molecules[10][11].
-
Sequencing: Load the prepared RNA library onto a Nanopore flow cell. As individual RNA molecules pass through the nanopores, changes in the ionic current are measured in real-time[11][12].
-
Data Acquisition and Basecalling: The raw electrical signal data is collected and translated into RNA sequences using basecalling software[11][12].
-
m6A Detection: Specialized computational models analyze the raw signal data and/or basecalling errors to identify the presence and stoichiometry of m6A at single-nucleotide resolution. These models are trained to recognize the distinct electrical signatures produced by modified bases compared to their canonical counterparts[1][5].
Conclusion
The field of m6A detection is rapidly evolving, with each method offering a unique set of advantages and limitations. Antibody-based methods like MeRIP-seq are well-established but offer lower resolution. miCLIP-seq improves upon this by providing single-nucleotide resolution through crosslinking. Newer, antibody-independent methods like DART-seq and Nanopore direct RNA sequencing offer high sensitivity, single-nucleotide resolution, and, in the case of Nanopore, the ability to directly quantify modification stoichiometry on native RNA molecules. The choice of method should be carefully considered based on the specific biological question, the amount of starting material, and the desired level of resolution and quantitative information. As these technologies continue to improve, they will undoubtedly provide deeper insights into the dynamic and critical role of m6A in gene regulation and human health.
References
- 1. m.youtube.com [m.youtube.com]
- 2. MePMe-seq: antibody-free simultaneous m6A and m5C mapping in mRNA by metabolic propargyl labeling and sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 3. DART-seq: an antibody-free method for global m6A detection - PMC [pmc.ncbi.nlm.nih.gov]
- 4. researchgate.net [researchgate.net]
- 5. nanoporetech.com [nanoporetech.com]
- 6. benchchem.com [benchchem.com]
- 7. MeRIP-seq Protocol - CD Genomics [rna.cd-genomics.com]
- 8. Evaluation of N6-methyldeoxyadenosine antibody-based genomic profiling in eukaryotes - PMC [pmc.ncbi.nlm.nih.gov]
- 9. DART-seq [protocols.io]
- 10. rna-seqblog.com [rna-seqblog.com]
- 11. sysy.com [sysy.com]
- 12. researchgate.net [researchgate.net]
A Head-to-Head Comparison: Cross-Validating MeRIP-seq with Mass Spectrometry for Accurate RNA Methylation Analysis
A comprehensive guide for researchers, scientists, and drug development professionals on the synergistic use of MeRIP-seq and mass spectrometry to confidently identify and quantify N6-methyladenosine (m6A) modifications in RNA. This guide provides a detailed comparison of the two techniques, supporting experimental data, and complete protocols for both methodologies.
The study of epitranscriptomics, particularly the reversible methylation of adenosine at the N6 position (m6A), has unveiled a critical layer of gene regulation implicated in numerous biological processes and diseases. Methylated RNA Immunoprecipitation Sequencing (MeRIP-seq) has become a cornerstone for transcriptome-wide mapping of m6A. However, the inherent limitations of antibody-based enrichment necessitate orthogonal validation to ensure data accuracy and reliability. Mass spectrometry (MS) has emerged as the gold standard for the absolute quantification of modified nucleosides, providing a robust method for cross-validating MeRIP-seq findings. This guide delves into a comparative analysis of these two powerful techniques, offering insights into their respective strengths, weaknesses, and their combined utility in advancing RNA methylation research.
Quantitative Data Presentation: A Comparative Overview
The cross-validation of MeRIP-seq data with mass spectrometry is crucial for confirming the presence and quantifying the abundance of m6A. While MeRIP-seq provides transcriptome-wide localization of m6A peaks, it is a semi-quantitative method susceptible to antibody specificity issues.[1][2] In contrast, liquid chromatography-tandem mass spectrometry (LC-MS/MS) offers precise and absolute quantification of m6A levels but lacks the ability to pinpoint the exact location of the modification within the RNA sequence.[3]
A key aspect of cross-validation involves comparing the global m6A levels determined by LC-MS/MS with the overall enrichment observed in MeRIP-seq. For instance, in studies involving the knockout of the m6A methyltransferase Mettl3, LC-MS/MS has been used to confirm the virtual absence of m6A, thereby validating the specificity of m6A peaks identified by MeRIP-seq in wild-type samples.[4]
Furthermore, the overlap between m6A sites identified by MeRIP-seq and other single-nucleotide resolution mapping techniques, which are often validated by mass spectrometry, provides another layer of confidence. Studies have shown varying degrees of overlap, with some reporting that a significant percentage of MeRIP-seq peaks can be confirmed by more direct detection methods. For example, one study found that 66.9% to 68.4% of their identified m6A sites overlapped with existing MeRIP-seq m6A peaks.[5]
| Feature | MeRIP-seq | Mass Spectrometry (LC-MS/MS) |
| Principle | Immunoprecipitation of m6A-containing RNA fragments using an anti-m6A antibody, followed by high-throughput sequencing.[6][7] | Separation and detection of individual nucleosides based on their mass-to-charge ratio after enzymatic digestion of RNA.[8] |
| Resolution | Low resolution (100-200 nucleotides).[5][9] | Not applicable for localization; provides global quantification.[3] |
| Quantification | Relative or semi-quantitative.[10] | Absolute and relative quantification.[8] |
| Starting Material | Can be performed with low-input total RNA (as low as 2 µg).[9] | Typically requires >50 µg of total RNA for robust quantification.[11][12][13] |
| Data Output | Genome-wide map of m6A-enriched regions (peaks).[6] | Precise ratio of m6A to adenosine (A).[14] |
| Key Advantage | Transcriptome-wide localization of m6A modifications.[3] | Gold standard for accurate and absolute quantification of m6A.[8] |
| Key Limitation | Potential for non-specific antibody binding and inability to provide precise stoichiometry.[2] | Inability to identify the specific location of m6A modifications within the RNA sequence.[3] |
Experimental Workflows
To facilitate a deeper understanding of the cross-validation process, the following diagrams illustrate the experimental workflows for MeRIP-seq and LC-MS/MS.
Detailed Experimental Protocols
MeRIP-seq Protocol
This protocol provides a general framework for performing MeRIP-seq. Optimization of antibody concentration and fragmentation conditions may be necessary for different sample types.[9]
-
RNA Isolation and Fragmentation:
-
Isolate total RNA from cells or tissues using a standard RNA extraction method, ensuring high quality and integrity.
-
Fragment the total RNA to an average size of 100-200 nucleotides using enzymatic or chemical fragmentation methods.[10]
-
Take an aliquot of the fragmented RNA to serve as the "input" control.
-
-
Immunoprecipitation:
-
Incubate the fragmented RNA with an anti-m6A antibody to form RNA-antibody complexes.
-
Add protein A/G magnetic beads to capture the RNA-antibody complexes.
-
Perform a series of washes with high and low salt buffers to remove non-specifically bound RNA.
-
-
Elution and Library Preparation:
-
Elute the m6A-containing RNA fragments from the beads.
-
Purify the eluted RNA.
-
Construct sequencing libraries from both the immunoprecipitated (IP) and input RNA samples.
-
-
Sequencing and Data Analysis:
-
Perform high-throughput sequencing of the prepared libraries.
-
Align the sequencing reads to a reference genome or transcriptome.
-
Use peak-calling algorithms to identify regions of m6A enrichment in the IP sample relative to the input control.[10]
-
Perform differential methylation analysis between different experimental conditions.
-
LC-MS/MS Protocol for m6A Quantification
This protocol outlines the steps for the absolute quantification of m6A in RNA.[11][12][13]
-
RNA Isolation and mRNA Enrichment:
-
Enzymatic Digestion to Nucleosides:
-
Digest the enriched mRNA into individual nucleosides using a combination of nuclease P1 and alkaline phosphatase.[8]
-
-
LC-MS/MS Analysis:
-
Separate the digested nucleosides using liquid chromatography.
-
Detect and quantify the amounts of adenosine (A) and N6-methyladenosine (m6A) using tandem mass spectrometry in multiple reaction monitoring (MRM) mode.[8]
-
-
Data Analysis:
-
Generate standard curves using known concentrations of pure adenosine and m6A to ensure accurate quantification.
-
Calculate the absolute amount of m6A and adenosine in the sample.
-
Determine the m6A/A ratio to represent the overall level of m6A modification.
-
Conclusion
The cross-validation of MeRIP-seq with mass spectrometry represents a powerful strategy for obtaining a comprehensive and accurate understanding of the m6A epitranscriptome. While MeRIP-seq provides the invaluable context of m6A's location across the transcriptome, mass spectrometry offers the definitive, quantitative measure of its abundance. By integrating these two methodologies, researchers can confidently identify m6A-regulated pathways and their roles in health and disease, paving the way for novel therapeutic interventions. This guide provides the foundational knowledge and protocols for researchers to effectively implement this cross-validation approach in their own studies.
References
- 1. m6ACali: machine learning-powered calibration for accurate m6A detection in MeRIP-Seq - PMC [pmc.ncbi.nlm.nih.gov]
- 2. researchgate.net [researchgate.net]
- 3. MeRIP-seq for Detecting RNA methylation: An Overview - CD Genomics [cd-genomics.com]
- 4. Systematic comparison of tools used for m6A mapping from nanopore direct RNA sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 5. m6A-SAC-seq for quantitative whole transcriptome m6A profiling - PMC [pmc.ncbi.nlm.nih.gov]
- 6. MeRIP-seq: Comprehensive Guide to m6A RNA Modification Analysis - CD Genomics [rna.cd-genomics.com]
- 7. MeRIP-Seq/m6A-seq [illumina.com]
- 8. m6A RNA Methylation Analysis by MS - CD Genomics [rna.cd-genomics.com]
- 9. Comparative analysis of improved m6A sequencing based on antibody optimization for low-input samples - PMC [pmc.ncbi.nlm.nih.gov]
- 10. A protocol for RNA methylation differential analysis with MeRIP-Seq data and exomePeak R/Bioconductor package - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Quantitative analysis of m6A RNA modification by LC-MS - PMC [pmc.ncbi.nlm.nih.gov]
- 12. bpb-us-e2.wpmucdn.com [bpb-us-e2.wpmucdn.com]
- 13. researchgate.net [researchgate.net]
- 14. researchgate.net [researchgate.net]
Unveiling the Functional Significance of m6A: A Comparative Guide to Validation Assays
For researchers, scientists, and drug development professionals navigating the complex world of epitranscriptomics, the functional validation of N6-methyladenosine (m6A) sites is a critical step in elucidating gene regulation and its role in disease. The luciferase reporter assay has long been a staple for this purpose. However, the advent of newer technologies prompts a crucial question: is it the most effective tool for every research question? This guide provides an objective comparison of the widely used luciferase reporter assay with cutting-edge alternatives, supported by experimental data and detailed protocols to empower informed decisions in your m6A research.
N6-methyladenosine (m6A) is the most abundant internal modification on eukaryotic mRNA, influencing virtually every aspect of RNA metabolism, from splicing and stability to translation and nuclear export.[1][2][3] Identifying the functional consequences of m6A at specific sites is paramount to understanding its biological roles. This guide delves into the methodologies employed to validate the function of these crucial regulatory marks.
The Workhorse: Luciferase Reporter Assays
The luciferase reporter assay is a widely adopted, indirect method for assessing the functional impact of m6A sites, typically within the 3' untranslated region (UTR) of a target mRNA.[1][2] The principle is straightforward: the 3' UTR containing the putative m6A site is cloned downstream of a luciferase reporter gene. The activity of the luciferase enzyme, which produces a measurable luminescent signal, serves as a proxy for protein expression.
To validate the function of an m6A site, two constructs are typically compared: a wild-type (WT) construct containing the intact m6A consensus motif (RRACH) and a mutant (MUT) construct where the adenosine within the motif is substituted, preventing methylation.[1][2] A significant difference in luciferase activity between the WT and MUT constructs suggests that the m6A modification influences the post-transcriptional regulation of the gene, affecting either mRNA stability or translation efficiency.
Experimental Workflow: Luciferase Reporter Assay
Head-to-Head Comparison: Luciferase Assay vs. Modern Alternatives
While the luciferase reporter assay is a valuable tool, it is not without its limitations. The use of exogenous plasmids can lead to overexpression artifacts, and the assay indirectly measures the effect on a reporter protein rather than the endogenous transcript. Newer methods have emerged to address these shortcomings, offering more direct and in vivo validation of m6A function.
| Feature | Luciferase Reporter Assay | CRISPR-dCas13 Mediated m6A Editing | SELECT-qPCR |
| Principle | Indirectly measures the effect of m6A on reporter gene expression from a plasmid. | Directly adds or removes m6A marks on endogenous RNA transcripts. | Directly detects and quantifies m6A at specific sites on endogenous RNA. |
| Readout | Luminescence (protein level). | Phenotypic change, protein level, or RNA stability of the endogenous gene. | qPCR amplification (RNA level). |
| Context | Exogenous plasmid, potential for overexpression artifacts. | Endogenous transcript in its native cellular environment. | Endogenous transcript. |
| Resolution | Site-specific (through mutagenesis). | Site-specific (gRNA-directed). | Single-nucleotide resolution. |
| Quantitative | Semi-quantitative (relative change). | Qualitative to semi-quantitative. | Quantitative (relative m6A abundance). |
| Throughput | High-throughput compatible. | Lower throughput. | Moderate throughput. |
| Key Advantage | Well-established, relatively simple, and high-throughput. | In vivo validation in a native context, avoiding overexpression. | Antibody-independent, high specificity, and quantitative. |
| Key Limitation | Indirect readout, potential for artifacts from plasmid overexpression. | Technically more complex, potential for off-target effects. | Requires specific primer design for each site, not a discovery tool. |
In Focus: CRISPR-dCas13 Mediated m6A Editing
A groundbreaking alternative to reporter assays is the use of CRISPR-Cas systems to directly manipulate m6A marks on endogenous RNA. By fusing a catalytically inactive Cas13 (dCas13) protein to an m6A writer (e.g., METTL3/14) or eraser (e.g., ALKBH5), researchers can achieve targeted methylation or demethylation of specific adenosine residues guided by a guide RNA (gRNA).[4][5] This powerful technique allows for the study of m6A function in its native context, avoiding the potential pitfalls of plasmid-based systems.[6]
Experimental Workflow: CRISPR-dCas13 m6A Editing
A Quantitative Alternative: SELECT-qPCR
For researchers seeking a quantitative and antibody-independent method to validate m6A sites, the single-base elongation and ligation-based qPCR amplification method (SELECT) offers a robust solution.[7] This technique exploits the ability of m6A to impede the single-base elongation by a DNA polymerase and the subsequent ligation of two DNA probes hybridized to the target RNA. The efficiency of the ligation, which is inversely proportional to the m6A level, is then quantified by qPCR. This method provides single-nucleotide resolution and can be used to determine the relative abundance of m6A at a specific site.[7]
Experimental Workflow: SELECT-qPCR
Supporting Experimental Data
A study investigating the role of m6A in the coding sequence (CDS) of the MALAT1 non-coding RNA provides a valuable comparison between the luciferase reporter assay and the SELECT method.[8] The researchers inserted a structural motif from MALAT1 containing a well-characterized m6A site into a fusion reporter construct.
Table 1: Comparison of Luciferase Assay and SELECT for MALAT1 m6A Site Validation [8]
| Method | Wild-Type (WT) | A->G Mutant | METTL3/14 Knockdown (on WT) |
| Relative Luciferase Activity | 1.0 | ~1.0 | ~0.82-0.85 |
| SELECT-qPCR (m6A signal) | Positive | Negative | Reduced |
Data are illustrative and based on the findings reported in the study. The luciferase assay showed a decrease in reporter activity upon knockdown of the m6A writers, suggesting m6A enhances translation in this context. The A->G mutation, which ablates methylation, did not show a similar decrease. The SELECT-qPCR results confirmed the presence of m6A at the target site in the WT construct and its reduction upon writer knockdown.
Detailed Experimental Protocols
Luciferase Reporter Assay for m6A Validation
Materials:
-
pGL3-based luciferase reporter vector
-
3' UTR of the gene of interest
-
Site-directed mutagenesis kit
-
Mammalian cell line (e.g., HEK293T)
-
Transfection reagent
-
Dual-luciferase reporter assay system
-
Luminometer
Procedure:
-
Plasmid Construction:
-
Amplify the 3' UTR of the gene of interest containing the putative m6A site(s).
-
Clone the amplified 3' UTR fragment into the pGL3 vector downstream of the firefly luciferase gene to create the wild-type (WT) construct.
-
Use a site-directed mutagenesis kit to introduce a point mutation (e.g., A to T) at the adenosine residue of the m6A consensus motif (RRACH) in the WT construct to create the mutant (MUT) construct.
-
Verify the sequences of both WT and MUT constructs by Sanger sequencing.
-
-
Cell Culture and Transfection:
-
Seed HEK293T cells in a 24-well plate at a density that will result in 70-80% confluency at the time of transfection.
-
Co-transfect the cells with the WT or MUT luciferase reporter plasmid along with a Renilla luciferase plasmid (for normalization of transfection efficiency) using a suitable transfection reagent according to the manufacturer's instructions.
-
-
Luciferase Assay:
-
After 24-48 hours of incubation, lyse the cells.
-
Measure the firefly and Renilla luciferase activities sequentially using a dual-luciferase reporter assay system and a luminometer.
-
-
Data Analysis:
-
Normalize the firefly luciferase activity to the Renilla luciferase activity for each sample to account for variations in transfection efficiency.
-
Compare the normalized luciferase activity of the WT construct to that of the MUT construct. A statistically significant difference indicates a functional role for the m6A site.
-
CRISPR-dCas13 Mediated m6A Editing Protocol
Materials:
-
Expression vectors for dCas13 fused to an m6A writer (e.g., METTL3) or eraser (e.g., ALKBH5)
-
Expression vector for the guide RNA (gRNA)
-
Mammalian cell line of interest
-
Transfection or viral transduction reagents
-
Reagents for downstream analysis (e.g., qPCR, Western blotting)
Procedure:
-
gRNA Design and Cloning:
-
Design a gRNA that is complementary to the target RNA sequence flanking the m6A site of interest.
-
Clone the gRNA sequence into a suitable expression vector.
-
-
Cell Transfection/Transduction:
-
Co-transfect or co-transduce the cells with the dCas13-editor and gRNA expression vectors. Include appropriate controls, such as a non-targeting gRNA.
-
-
Functional Analysis:
-
After a suitable incubation period (e.g., 48-72 hours), harvest the cells.
-
Analyze the functional consequences of the targeted m6A editing. This can include:
-
RT-qPCR to measure changes in the target mRNA stability.
-
Western blotting to assess changes in the protein expression of the target gene.
-
Phenotypic assays to evaluate changes in cellular processes.
-
-
-
Validation of Editing (Optional but Recommended):
-
Isolate RNA and perform m6A-specific immunoprecipitation followed by qPCR (MeRIP-qPCR) or use the SELECT-qPCR method to confirm the change in m6A status at the target site.
-
SELECT-qPCR Protocol for m6A Validation
Materials:
-
Total or poly(A) selected RNA
-
Two DNA probes flanking the target adenosine
-
DNA polymerase with limited single-base elongation activity on m6A-containing templates
-
DNA ligase
-
qPCR primers specific to the ligated product
-
qPCR master mix and instrument
Procedure:
-
Probe Design:
-
Design two DNA probes that hybridize to the target RNA immediately adjacent to the adenosine to be interrogated.
-
-
Hybridization, Elongation, and Ligation:
-
Hybridize the two DNA probes to the RNA sample.
-
Perform a single-base elongation reaction using a specific DNA polymerase. The presence of m6A will impede this elongation.
-
Perform a ligation reaction. Efficient ligation will only occur if the single-base elongation was successful (i.e., in the absence of m6A).
-
-
qPCR Quantification:
-
Use the reaction product as a template for qPCR with primers that specifically amplify the ligated product.
-
The amount of qPCR product is inversely proportional to the level of m6A at the target site.
-
-
Data Analysis:
-
Compare the qPCR signal from the target site to a control unmethylated site or to a sample where the m6A writer has been knocked down to determine the relative m6A abundance.
-
Conclusion: Choosing the Right Tool for the Job
The functional validation of m6A sites is a multifaceted process, and the optimal method depends on the specific research question, available resources, and desired level of detail.
-
Luciferase reporter assays remain a valuable, high-throughput tool for initial screening and for studying the overall regulatory effect of a sequence containing m6A sites.
-
CRISPR-dCas13 mediated m6A editing offers the significant advantage of studying the function of m6A in its native context on the endogenous transcript, providing more physiologically relevant insights.
-
SELECT-qPCR provides a highly specific, quantitative, and antibody-independent method for validating and measuring the relative abundance of m6A at single-nucleotide resolution.
For a comprehensive understanding of m6A function, a multi-pronged approach is often the most powerful. For instance, a researcher might use a luciferase reporter assay for an initial screen of multiple putative m6A sites, followed by CRISPR-dCas13 mediated editing to validate the most promising candidates in vivo, and SELECT-qPCR to quantify the changes in m6A levels. By carefully considering the strengths and limitations of each method, researchers can design robust experiments to unravel the intricate roles of m6A in health and disease.
References
- 1. Examining the Roles of m6A Sites in mRNA Using the Luciferase Gene Fused With Mutated RRACH Motifs - PMC [pmc.ncbi.nlm.nih.gov]
- 2. researchgate.net [researchgate.net]
- 3. Examining the Roles of m6A Sites in mRNA Using the Luciferase Gene Fused With Mutated RRACH Motifs - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. Programmable RNA N6-methyladenosine editing by CRISPR-Cas9 conjugates - PMC [pmc.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
- 6. epigenie.com [epigenie.com]
- 7. researchgate.net [researchgate.net]
- 8. m6A in mRNA coding regions promotes translation via the RNA helicase-containing YTHDC2 - PMC [pmc.ncbi.nlm.nih.gov]
Validating m6A-Dependent Effects: A Comparative Guide to Knockdown of m6A Writers and Erasers
For researchers, scientists, and drug development professionals, understanding the functional consequences of N6-methyladenosine (m6A) modifications on RNA is crucial. A primary method for elucidating these effects is the targeted knockdown of the enzymes responsible for adding (writers) and removing (erasers) this epigenetic mark. This guide provides a comparative overview of commonly used knockdown strategies for key m6A writers (METTL3 and METTL14) and erasers (FTO and ALKBH5), supported by experimental data and detailed protocols to aid in experimental design and interpretation.
The dynamic and reversible nature of m6A modification is orchestrated by a complex interplay of writer, eraser, and reader proteins. The core writer complex consists of the catalytic subunit METTL3 and the stabilizing partner METTL14. The primary erasers are the demethylases FTO and ALKBH5. Knockdown of these key enzymes allows for the investigation of m6A's role in a multitude of cellular processes, from gene expression regulation to signaling pathway modulation.
Comparison of Knockdown Strategies for m6A Writers: METTL3 vs. METTL14
METTL3 and METTL14 form a heterodimer that is essential for the majority of m6A deposition. While both are critical for methyltransferase activity, their individual knockdown can lead to distinct downstream effects, suggesting some non-redundant functions.
Quantitative Data Summary:
| Target | Knockdown Method | Cell Line | Knockdown Efficiency | Impact on Global m6A Levels | Key Downstream Effects | Reference |
| METTL3 | siRNA | K562 | >80% | Significant Decrease | 578 up-regulated, 480 down-regulated genes. Upregulation of CDKN1A and CCND1.[1] | [1] |
| METTL14 | siRNA | K562 | >80% | Significant Decrease | 235 up-regulated, 210 down-regulated genes. Less pronounced effect on CDKN1A and CCND1 compared to METTL3 knockdown.[1] | [1] |
| METTL3 | CRISPR-Cas9 | U2OS | Not specified (knockout) | Decreased | 1,803 alternatively spliced genes, enriched in cell cycle-related functions.[2] | [2] |
| METTL14 | Knockout | mESCs | Not specified (knockout) | Comparable decrease to METTL3 KO | Induced more nuclear RNA downregulation (3,863 genes) compared to METTL3 KO (751 genes).[3] | [3] |
Comparison of Knockdown Strategies for m6A Erasers: FTO vs. ALKBH5
FTO and ALKBH5 are the two known m6A demethylases, both belonging to the AlkB family of dioxygenases. While both remove methyl groups from adenosine, they exhibit different substrate specificities and can have non-overlapping biological roles.
Quantitative Data Summary:
| Target | Knockdown Method | Cell Line | Knockdown Efficiency | Impact on Global m6A Levels | Key Downstream Effects | Reference |
| FTO | shRNA | U87 | >70% | Significant Increase | Greater increase in m6A content compared to ALKBH5 knockdown. Reduced cell viability.[4] | [4] |
| ALKBH5 | shRNA | U87 | >70% | Moderate Increase | Less pronounced effect on m6A levels and no significant effect on cell viability.[4] | [4] |
| FTO | siRNA | HeLa | >70% | Increased | Overexpression of ALKBH5 in FTO knockdown cells partially rescued the increase in m6A levels.[5] | [5] |
| ALKBH5 | Knockdown | Not specified | Not specified | ~9% increase in total mRNA m6A | Overexpression led to a ~29% decrease in m6A levels.[6] | [6] |
Signaling Pathways and Experimental Workflows
The regulation of m6A modification is intricately linked to various signaling pathways. Knockdown of m6A writers or erasers can, therefore, have profound effects on these cellular communication networks.
Caption: The m6A RNA modification is dynamically regulated by writer and eraser enzymes.
Caption: A typical workflow for validating m6A-dependent effects using knockdown approaches.
Caption: METTL3/14 knockdown can influence the p53 signaling pathway, affecting cell cycle regulation.[1]
Experimental Protocols
siRNA-mediated Knockdown of m6A Writers/Erasers
Objective: To transiently reduce the expression of a target m6A writer or eraser using small interfering RNA.
Materials:
-
Target-specific siRNA and non-targeting control siRNA.
-
Lipofectamine RNAiMAX transfection reagent.
-
Opti-MEM I Reduced Serum Medium.
-
Appropriate cell line and culture medium.
-
6-well plates.
Protocol:
-
Cell Seeding: The day before transfection, seed cells in a 6-well plate at a density that will result in 30-50% confluency at the time of transfection.
-
siRNA-Lipofectamine Complex Formation:
-
For each well, dilute 50 pmol of siRNA into 250 µL of Opti-MEM I Medium and mix gently.
-
In a separate tube, dilute 5 µL of Lipofectamine RNAiMAX into 250 µL of Opti-MEM I Medium and mix gently.
-
Combine the diluted siRNA and diluted Lipofectamine RNAiMAX (total volume = 500 µL). Mix gently and incubate for 5 minutes at room temperature.
-
-
Transfection: Add the 500 µL of siRNA-lipid complex to each well containing cells and medium. Gently rock the plate to ensure even distribution.
-
Incubation: Incubate the cells at 37°C in a CO2 incubator for 24-72 hours.
-
Validation: Harvest cells at the desired time point to validate knockdown efficiency by qPCR and Western blot.
shRNA-mediated Knockdown of m6A Writers/Erasers
Objective: To achieve stable, long-term knockdown of a target m6A writer or eraser using short hairpin RNA delivered via lentiviral vectors.
Materials:
-
Lentiviral vector encoding shRNA targeting the gene of interest and a non-targeting control shRNA.
-
Lentiviral packaging plasmids (e.g., psPAX2, pMD2.G).
-
HEK293T cells for virus production.
-
Transfection reagent (e.g., Lipofectamine 2000).
-
Target cell line.
-
Polybrene.
Protocol:
-
Lentivirus Production:
-
Co-transfect HEK293T cells with the shRNA expression vector and packaging plasmids using a suitable transfection reagent.
-
Collect the virus-containing supernatant at 48 and 72 hours post-transfection.
-
Filter the supernatant through a 0.45 µm filter and concentrate the virus if necessary.
-
-
Transduction of Target Cells:
-
Seed the target cells in a 6-well plate.
-
On the day of transduction, replace the medium with fresh medium containing the lentiviral supernatant and Polybrene (final concentration 4-8 µg/mL).
-
Incubate for 24 hours.
-
-
Selection: 48 hours post-transduction, replace the medium with fresh medium containing the appropriate selection antibiotic (e.g., puromycin) to select for stably transduced cells.
-
Validation: Expand the selected cells and validate knockdown efficiency by qPCR and Western blot.
CRISPR-Cas9 Mediated Knockout of m6A Writers/Erasers
Objective: To generate a stable knockout cell line for an m6A writer or eraser by introducing frameshift mutations using the CRISPR-Cas9 system.
Materials:
-
Expression vector for Cas9 nuclease and a single guide RNA (sgRNA) targeting the gene of interest.
-
Transfection reagent.
-
Target cell line.
-
Fluorescence-activated cell sorting (FACS) or limiting dilution supplies for single-cell cloning.
Protocol:
-
sgRNA Design: Design and clone two or more sgRNAs targeting an early exon of the gene of interest into a Cas9 expression vector.
-
Transfection: Transfect the target cells with the Cas9/sgRNA expression plasmid.
-
Single-Cell Cloning: 48-72 hours post-transfection, isolate single cells by FACS (if the vector contains a fluorescent marker) or by limiting dilution into 96-well plates.
-
Expansion and Screening: Expand the single-cell clones and screen for knockout by Western blot to identify clones with complete loss of protein expression.
-
Genotype Confirmation: Confirm the presence of insertions or deletions (indels) at the target locus in the knockout clones by Sanger sequencing of the PCR-amplified genomic region.
Quantification of Global m6A Levels by LC-MS/MS
Objective: To accurately measure the global m6A to adenosine (A) ratio in mRNA.[7][8][9][10][11]
Materials:
-
mRNA isolated from cells (at least 1 µg).
-
Nuclease P1.
-
Venom phosphodiesterase I.
-
Alkaline phosphatase.
-
LC-MS/MS system.
-
m6A and adenosine standards.
Protocol:
-
mRNA Digestion:
-
Incubate 1 µg of mRNA with 2 U of nuclease P1 in 10 µL of 0.1 M ammonium acetate (pH 5.3) at 45°C for 2 hours.[10]
-
Add 11 µL of 1 M sodium bicarbonate and 0.002 U of venom phosphodiesterase I, and incubate at 37°C for 2 hours.[10]
-
Alternatively, after nuclease P1 digestion, add alkaline phosphatase and incubate to dephosphorylate the nucleoside 5'-monophosphates.[11]
-
-
Sample Preparation: Deproteinate and desalt the digested sample.[10]
-
LC-MS/MS Analysis:
-
Data Analysis: Calculate the m6A/A ratio based on the standard curves generated from the m6A and adenosine standards.[7]
Concluding Remarks
The choice of knockdown strategy for studying m6A writers and erasers depends on the specific research question, the cell type, and the desired duration of the effect. siRNA offers a rapid and transient knockdown, suitable for initial screening and short-term studies. shRNA provides a more stable and long-term solution, ideal for generating stable cell lines. CRISPR-Cas9-mediated knockout results in a complete and permanent loss of gene function, which is the gold standard for studying the essentiality of a gene.
References
- 1. researchgate.net [researchgate.net]
- 2. METTL3 regulates alternative splicing of cell cycle-related genes via crosstalk between mRNA m6A modifications and splicing factors - PMC [pmc.ncbi.nlm.nih.gov]
- 3. academic.oup.com [academic.oup.com]
- 4. researchgate.net [researchgate.net]
- 5. Meclofenamic acid selectively inhibits FTO demethylation of m6A over ALKBH5 - PMC [pmc.ncbi.nlm.nih.gov]
- 6. books.rsc.org [books.rsc.org]
- 7. Quantitative analysis of m6A RNA modification by LC-MS - PMC [pmc.ncbi.nlm.nih.gov]
- 8. bpb-us-e2.wpmucdn.com [bpb-us-e2.wpmucdn.com]
- 9. Quantitative analysis of m6A RNA modification by LC-MS [escholarship.org]
- 10. Quantification of global m6A RNA methylation levels by LC-MS/MS [visikol.com]
- 11. Current progress in strategies to profile transcriptomic m6A modifications - PMC [pmc.ncbi.nlm.nih.gov]
Decoding the Epitranscriptome: A Comparative Guide to m6A and m1A mRNA Modifications
For researchers, scientists, and drug development professionals, understanding the nuances of post-transcriptional modifications is paramount. Among the more than 170 known RNA modifications, N6-methyladenosine (m6A) and N1-methyladenosine (m1A) have emerged as critical regulators of messenger RNA (mRNA) function. While both are simple methylations of adenosine, their distinct locations, regulatory machinery, and functional consequences paint a picture of two unique epitranscriptomic languages influencing gene expression.
This guide provides an objective comparison of the functions of m6A and m1A in mRNA, supported by experimental data and detailed methodologies. We delve into their respective roles in mRNA stability, translation, and splicing, offering a comprehensive resource for navigating this dynamic field of RNA biology.
At a Glance: Key Differences Between m6A and m1A
| Feature | N6-methyladenosine (m6A) | N1-methyladenosine (m1A) |
| Abundance | Most abundant internal modification in eukaryotic mRNA.[1][2] | Less abundant than m6A in mRNA.[3][4] |
| Location on mRNA | Enriched in 3' UTRs, near stop codons, and within long internal exons.[5] | Enriched around the start codon and upstream of the first splice site.[4][6] |
| Consensus Sequence | RRACH (R=G or A; H=A, C or U).[7] | GUUCRA motif, structurally similar to the tRNA TΨC loop.[3] |
| Charge at Physiological pH | Neutral | Positive charge, which can alter RNA structure.[3][8] |
| Primary Function | Diverse roles in mRNA splicing, nuclear export, stability, and translation.[1][2] | Primarily promotes translation efficiency and affects RNA stability.[6][9] |
The Regulatory Machinery: Writers, Erasers, and Readers
The functional impact of both m6A and m1A is orchestrated by a dedicated set of proteins that install ("writers"), remove ("erasers"), and recognize ("readers") these methyl marks.[3][5]
| Protein Class | N6-methyladenosine (m6A) | N1-methyladenosine (m1A) |
| Writers (Methyltransferases) | Complex: METTL3 (catalytic), METTL14 (scaffold), WTAP, VIRMA, RBM15/15B, ZC3H13.[5][7][10] | Complex: TRMT6/TRMT61A.[3][8] In mitochondria: TRMT10C, TRMT61B.[3] |
| Erasers (Demethylases) | FTO, ALKBH5.[5][10] | ALKBH1, ALKBH3, FTO.[3][11] |
| Readers (Binding Proteins) | YTH Domain Family: YTHDF1, YTHDF2, YTHDF3, YTHDC1, YTHDC2.[7][12][13] Other: HNRNPA2B1, HNRNPC, HNRNPG, IGF2BP1/2/3, eIF3.[7][13][14] | YTH Domain Family: YTHDF1, YTHDF2, YTHDF3, YTHDC1.[11][15][16] Other: HRSP12.[17] |
Functional Consequences: A Head-to-Head Comparison
mRNA Stability
m6A: The role of m6A in mRNA stability is context-dependent and largely mediated by the YTHDF reader proteins. YTHDF2 is the most well-characterized reader that promotes mRNA decay by recruiting deadenylase complexes or relocating transcripts to processing bodies (P-bodies) for degradation.[1][18] Conversely, IGF2BP proteins have been shown to stabilize m6A-modified mRNAs.
m1A: The positive charge of m1A can significantly alter local RNA structure, which is thought to contribute to its role in stabilizing RNA molecules.[3][9] However, there is also evidence for a more complex role. The m1A reader HRSP12 can promote the degradation of mRNAs that also contain an m6A mark, suggesting a cooperative mechanism between the two modifications in regulating mRNA decay.[17][19]
mRNA Translation
m6A: m6A modification can either enhance or repress translation. YTHDF1 is reported to promote the translation of m6A-containing mRNAs by interacting with translation initiation factors.[18] The m6A writer METTL3 can also directly enhance translation, independent of its methyltransferase activity, by recruiting eIF3.[18] In some contexts, m6A in the 5' UTR can promote cap-independent translation.[20]
m1A: A primary function of m1A is the promotion of translation.[4][6] Its enrichment near the translation start site is consistent with this role.[4] The presence of m1A is positively correlated with protein production, and it is thought to facilitate ribosome binding.[6][9]
mRNA Splicing
m6A: m6A deposition occurs co-transcriptionally and can influence pre-mRNA splicing.[2] The nuclear reader YTHDC1 can recruit splicing factors, such as SRSF3, to promote exon inclusion, or antagonize others, like SRSF10, to facilitate exon skipping.[2] The m6A machinery can also interact with spliceosome components.
m1A: The location of m1A marks upstream of the first splice site suggests a potential role in splicing.[4] However, the direct mechanisms and functional consequences of m1A in regulating mRNA splicing are less well-characterized compared to m6A and remain an active area of investigation.
Visualizing the Pathways
To better understand the molecular workflows, the following diagrams illustrate the key regulatory pathways for m6A and m1A, as well as a typical experimental workflow for their detection.
References
- 1. m6A RNA methylation: from mechanisms to therapeutic potential - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Dynamic regulation and functions of mRNA m6A modification - PMC [pmc.ncbi.nlm.nih.gov]
- 3. N1-methyladenosine formation, gene regulation, biological functions, and clinical relevance - PMC [pmc.ncbi.nlm.nih.gov]
- 4. epigenie.com [epigenie.com]
- 5. The Proteins of mRNA Modification: Writers, Readers, and Erasers - PMC [pmc.ncbi.nlm.nih.gov]
- 6. pubs.acs.org [pubs.acs.org]
- 7. Exploring m6A RNA Methylation: Writers, Erasers, Readers | EpigenTek [epigentek.com]
- 8. benchchem.com [benchchem.com]
- 9. researchgate.net [researchgate.net]
- 10. m6A writers, erasers, readers and their functions | Abcam [abcam.com]
- 11. researchgate.net [researchgate.net]
- 12. Frontiers | m6A Reader: Epitranscriptome Target Prediction and Functional Characterization of N6-Methyladenosine (m6A) Readers [frontiersin.org]
- 13. Reading m6A in the transcriptome: m6A-binding proteins - PMC [pmc.ncbi.nlm.nih.gov]
- 14. m6A reader proteins: the executive factors in modulating viral replication and host immune response - PMC [pmc.ncbi.nlm.nih.gov]
- 15. Harnessing m1A modification: a new frontier in cancer immunotherapy - PMC [pmc.ncbi.nlm.nih.gov]
- 16. m1A regulator‑mediated methylation modifications and gene signatures and their prognostic value in multiple myeloma - PMC [pmc.ncbi.nlm.nih.gov]
- 17. m1A and m6A modifications function cooperatively to facilitate rapid mRNA degradation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 18. researchgate.net [researchgate.net]
- 19. researchgate.net [researchgate.net]
- 20. Frontiers | The Biological Function, Mechanism, and Clinical Significance of m6A RNA Modifications in Head and Neck Carcinoma: A Systematic Review [frontiersin.org]
Navigating the Epitranscriptome: A Guide to Differential m6A Peak Calling Tools
For researchers, scientists, and drug development professionals venturing into the dynamic landscape of RNA epigenetics, identifying changes in N6-methyladenosine (m6A) modification is crucial. This guide provides an objective comparison of leading bioinformatics tools for differential m6A peak calling from MeRIP-Seq data, supported by experimental data to inform your choice of analytical software.
The reversible methylation of adenosine at the N6 position (m6A) is the most abundant internal modification on eukaryotic mRNA, influencing every stage of the RNA life cycle, from splicing and nuclear export to stability and translation. Consequently, aberrant m6A patterns have been implicated in a wide range of human diseases, including cancer. The development of Methylated RNA Immunoprecipitation followed by sequencing (MeRIP-Seq) has enabled transcriptome-wide profiling of m6A. A key analytical challenge, however, is the accurate identification of differentially methylated regions (DMRs) between different conditions. A variety of bioinformatics tools have been developed to address this, each employing distinct statistical models.
This guide benchmarks several popular tools for differential m6A analysis, providing a head-to-head comparison of their performance based on a comprehensive evaluation using both synthetic and real-world datasets.
A Comparative Overview of Differential m6A Analysis Tools
The selection of a bioinformatics tool for differential m6A peak calling can significantly impact the biological insights derived from MeRIP-Seq data. The tools compared in this guide are among the most cited in the field and utilize diverse statistical approaches to identify DMRs. A summary of their key features is presented below.
| Tool | Statistical Model | Key Features |
| TRESS | Hierarchical Negative Binomial Model | Accounts for technical and biological variations; flexible for general experimental designs. |
| exomePeak2 | Generalized Linear Model (Poisson or Negative Binomial) | Considers over-dispersion of read counts and GC content bias.[1] |
| RADAR | Negative Binomial Model | Accommodates variability of pre-immunoprecipitation RNA levels. |
| MeTDiff | Beta-Binomial Model with Likelihood Ratio Test | Models the ratio of methylated reads to total reads.[2] |
| exomePeak | Fisher's Exact Test | One of the earliest tools; pools replicates, which can ignore inter-replicate variability.[2] |
| FET-HMM | Fisher's Exact Test with Hidden Markov Model | Integrates spatial dependency of methylation status along the genome.[2] |
Performance Benchmark: A Quantitative Comparison
The performance of these tools was systematically evaluated using simulated and real MeRIP-Seq data. The key performance metrics included True Discovery Rate (TDR), sensitivity (the proportion of true positives correctly identified), and False Discovery Rate (FDR).
Performance on Simulated Data
A comprehensive simulation study was conducted to assess the tools' performance under controlled conditions. The results, summarized in the table below, highlight the trade-offs between sensitivity and control of false discoveries.
| Tool | Average Sensitivity | Average FDR | Overall Performance Ranking |
| TRESS | High | Low | 1 (tie) |
| exomePeak2 | High | Low | 1 (tie) |
| exomePeak | High | High | 3 |
| FET-HMM | Moderate | Moderate | 4 |
| RADAR | Low (improves with sample size) | Low | 5 |
| MeTDiff | Low | Low | 6 |
Data synthesized from a comparative study by Cui et al., 2023.[1][2]
TRESS and exomePeak2 consistently demonstrated the best overall performance, achieving high sensitivity while maintaining a low False Discovery Rate.[1] In contrast, while the original exomePeak showed high sensitivity, it came at the cost of a higher FDR.[3] MeTDiff and RADAR were generally more conservative, with lower sensitivity, particularly in experiments with small sample sizes.[1]
Performance on Real-World Datasets
The tools were also applied to publicly available MeRIP-Seq datasets to assess their performance in a real-world context. The number of DMRs identified and their overlap across different tools were examined.
| Tool | Number of DMRs Identified (WT vs. METTL3-knockdown) |
| exomePeak2 | 5,272 |
| RADAR | 2,924 |
| TRESS | 1,413 |
| exomePeak | 1,397 |
| MeTDiff | 161 |
Data from a study evaluating differential analysis methods, with a consistent FDR cutoff of 0.05.[1]
exomePeak2 identified the highest number of DMRs, while MeTDiff was the most conservative.[1] The overlap of identified DMRs between the top-performing tools, TRESS and exomePeak2, was substantial, indicating a degree of consensus in their predictions.
Experimental Protocols and Workflows
A typical bioinformatics workflow for differential m6A peak calling from MeRIP-Seq data involves several key steps, from raw data processing to the identification and annotation of DMRs.
Standard MeRIP-Seq Experimental Workflow
Bioinformatic Analysis Pipeline for Differential m6A Peak Calling
References
A Researcher's Guide to Comparing m6A Profiles Across Diverse Cellular Landscapes
For Immediate Publication
Shanghai, China – December 17, 2025 – In the rapidly advancing field of epitranscriptomics, the ability to compare N6-methyladenosine (m6A) profiles across different cell types and conditions is paramount for unraveling the complexities of gene regulation in health and disease. This guide provides a comprehensive comparison of current methodologies, offering researchers, scientists, and drug development professionals the essential information to select the most appropriate techniques for their experimental goals. We present a detailed overview of key experimental protocols, data analysis pipelines, and a head-to-head comparison of the most prevalent m6A profiling technologies.
N6-methyladenosine (m6A) is the most abundant internal modification in eukaryotic messenger RNA (mRNA) and plays a crucial role in various biological processes, including mRNA stability, splicing, and translation.[1][2] Dysregulation of m6A modification has been implicated in a wide range of diseases, including cancer and neurodegenerative disorders.[3][4][5] Therefore, the precise mapping and comparative analysis of m6A profiles are critical for understanding its regulatory functions.
Comparing the Tools of the Trade: A Head-to-Head Look at m6A Profiling Techniques
The selection of an appropriate m6A profiling method is critical and depends on the specific research question, available starting material, and desired resolution. Here, we compare the most widely used techniques: MeRIP-seq (m6A-seq), miCLIP-seq, and Nanopore direct RNA sequencing.
| Feature | MeRIP-seq (m6A-seq) | miCLIP-seq | Nanopore Direct RNA Sequencing |
| Principle | Immunoprecipitation of m6A-containing RNA fragments using an m6A-specific antibody, followed by high-throughput sequencing.[3][6] | UV cross-linking of the m6A antibody to RNA, followed by immunoprecipitation and sequencing, which introduces characteristic mutations or truncations at the m6A site.[7][8] | Direct sequencing of native RNA molecules, where the m6A modification causes a detectable change in the electrical current signal.[3][9] |
| Resolution | Low (100-200 nucleotides), identifies enriched regions (peaks) rather than precise sites.[10][11] | Single-nucleotide resolution.[7][12] | Single-nucleotide resolution.[3] |
| Input RNA Amount | High (typically 300 μg of total RNA, though optimized protocols can use as low as 500 ng).[6][13] | Low input is possible.[12][14] | Low, can be performed on single molecules. |
| Quantitative? | Semi-quantitative, provides relative enrichment. | Can provide information on methylation stoichiometry. | Quantitative, can determine the fraction of modified transcripts at a specific site. |
| Antibody Dependent? | Yes.[11] | Yes.[11] | No.[3] |
| Key Advantages | Well-established, robust, and widely used.[15] | High resolution, allows for precise mapping of m6A sites.[7][12] | Direct detection without amplification bias, provides long reads, and can detect other modifications simultaneously.[3] |
| Key Disadvantages | Low resolution, potential for antibody-related bias, and requires a large amount of starting material.[10][16] | More complex experimental workflow.[1] | Higher error rate in base calling compared to second-generation sequencing, and data analysis is computationally intensive.[9] |
Delving into the Details: Experimental Protocols
Accurate and reproducible results begin with a robust experimental protocol. Below are the detailed methodologies for two of the most common m6A profiling techniques.
MeRIP-seq (Methylated RNA Immunoprecipitation Sequencing) Protocol
MeRIP-seq is a widely adopted method for transcriptome-wide mapping of m6A.[15] The protocol involves the enrichment of m6A-containing RNA fragments through immunoprecipitation with an anti-m6A antibody.[17]
1. RNA Preparation and Fragmentation:
-
Extract total RNA from the cells or tissues of interest, ensuring high quality and integrity.[18]
-
Fragment the total RNA to an average size of 100-200 nucleotides using enzymatic or chemical methods.[6]
2. Immunoprecipitation:
-
Incubate the fragmented RNA with an m6A-specific antibody to form RNA-antibody complexes.[18]
-
Capture the complexes using protein A/G magnetic beads.[17]
-
Perform stringent washes to remove non-specifically bound RNA.
3. Library Construction and Sequencing:
-
Elute the m6A-enriched RNA fragments from the beads.
-
Construct sequencing libraries from both the immunoprecipitated (IP) and input control RNA. The input control is a sample of the fragmented RNA that did not undergo immunoprecipitation.[6]
-
Perform high-throughput sequencing.
miCLIP-seq (m6A individual-Nucleotide-Resolution Cross-Linking and Immunoprecipitation) Protocol
miCLIP-seq offers single-nucleotide resolution mapping of m6A sites by inducing mutations or truncations at the modification site during reverse transcription.[7][8]
1. UV Cross-linking and Immunoprecipitation:
-
Incubate fragmented RNA with an anti-m6A antibody.
-
Expose the mixture to UV light to covalently cross-link the antibody to the RNA at the m6A site.[8]
-
Perform immunoprecipitation using protein A/G beads to capture the cross-linked complexes.
2. RNA Processing and Library Preparation:
-
Ligate a 3' adapter to the RNA fragments.
-
Purify the antibody-RNA complexes on a nitrocellulose membrane and digest the antibody with proteinase K, leaving a small peptide adduct at the cross-link site.[8]
-
Perform reverse transcription. The reverse transcriptase will either terminate or introduce a mutation (C-to-T transition) at the cross-linked site.[12]
-
Circularize the resulting cDNA, re-linearize it, and perform PCR amplification to generate the sequencing library.[8]
3. Sequencing and Data Analysis:
-
Sequence the prepared libraries.
-
Bioinformatic analysis focuses on identifying the characteristic mutations or truncations to pinpoint the exact m6A location.[12]
Visualizing the Workflow: From Sample to Sequence
To better illustrate the experimental processes, the following diagrams outline the workflows for MeRIP-seq and miCLIP-seq.
Figure 1: Experimental workflow for MeRIP-seq.
Figure 2: Experimental workflow for miCLIP-seq.
From Raw Reads to Biological Insight: The Data Analysis Pipeline
Regardless of the chosen profiling method, a robust bioinformatics pipeline is essential for extracting meaningful biological information. The general workflow involves several key steps from raw sequencing reads to the identification of differentially methylated regions.
Figure 3: Bioinformatic pipeline for m6A-seq data analysis.
Key Steps in Differential m6A Methylation Analysis
-
Quality Control and Alignment : Raw sequencing reads are first assessed for quality and trimmed to remove adapters and low-quality bases.[6] The cleaned reads are then aligned to a reference genome or transcriptome.[6]
-
Peak Calling : For MeRIP-seq data, "peak calling" software like MACS2 is used to identify regions with a significant enrichment of reads in the IP sample compared to the input control.[6][19] These enriched regions represent putative m6A sites.
-
Differential Methylation Analysis : To compare m6A profiles between different conditions, statistical packages such as DESeq2 or exomePeak are employed.[19][20] These tools identify statistically significant differences in peak enrichment, revealing differentially methylated regions (DMRs).[4][21]
-
Annotation and Functional Analysis : The identified differential m6A peaks are annotated to specific genes and genomic features.[6] Subsequent Gene Ontology (GO) and pathway analyses can then elucidate the biological processes and signaling pathways that may be regulated by changes in m6A methylation.[6][22]
Conclusion
The study of m6A methylation is a dynamic and expanding field. The ability to accurately profile and compare m6A patterns across different biological contexts is crucial for advancing our understanding of its role in gene regulation and disease. This guide provides a foundational framework for researchers to navigate the available technologies and analysis methods. By carefully considering the strengths and limitations of each approach, scientists can design robust experiments that will continue to shed light on the intricate world of the epitranscriptome.
References
- 1. Comprehensive Overview of m6A Detection Methods - CD Genomics [cd-genomics.com]
- 2. m6A Profiling - CD Genomics [rna.cd-genomics.com]
- 3. Comparison of m6A Sequencing Methods - CD Genomics [cd-genomics.com]
- 4. academic.oup.com [academic.oup.com]
- 5. Single-cell m6A profiling in the mouse brain uncovers cell type-specific RNA methylomes and age-dependent differential methylation - PMC [pmc.ncbi.nlm.nih.gov]
- 6. benchchem.com [benchchem.com]
- 7. miCLIP-seq - Profacgen [profacgen.com]
- 8. Transcriptome-wide mapping of m6A and m6Am at single-nucleotide resolution using miCLIP - PMC [pmc.ncbi.nlm.nih.gov]
- 9. academic.oup.com [academic.oup.com]
- 10. m6A-SAC-seq for quantitative whole transcriptome m6A profiling - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Frontiers | How Do You Identify m6 A Methylation in Transcriptomes at High Resolution? A Comparison of Recent Datasets [frontiersin.org]
- 12. miCLIP-seq Services - CD Genomics [cd-genomics.com]
- 13. Refined RIP-seq protocol for epitranscriptome analysis with low input materials - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Results for "miclip" | Springer Nature Experiments [experiments.springernature.com]
- 15. Frontiers | Current progress in strategies to profile transcriptomic m6A modifications [frontiersin.org]
- 16. Current progress in strategies to profile transcriptomic m6A modifications - PMC [pmc.ncbi.nlm.nih.gov]
- 17. MeRIP-seq and Its Principle, Protocol, Bioinformatics, Applications in Diseases - CD Genomics [cd-genomics.com]
- 18. MeRIP-seq Protocol - CD Genomics [rna.cd-genomics.com]
- 19. A bioinformatics analysis of the contribution of m6A methylation to the occurrence of diabetes mellitus - PMC [pmc.ncbi.nlm.nih.gov]
- 20. A protocol for RNA methylation differential analysis with MeRIP-Seq data and exomePeak R/Bioconductor package - PMC [pmc.ncbi.nlm.nih.gov]
- 21. tandfonline.com [tandfonline.com]
- 22. Comprehensive Analysis of Key m6A Modification Related Genes and Immune Infiltrates in Human Aortic Dissection - PMC [pmc.ncbi.nlm.nih.gov]
A Comparative Guide to the In Vivo Validation of m6A Function Using Animal Models
For Researchers, Scientists, and Drug Development Professionals
N6-methyladenosine (m6A) is the most abundant internal modification on eukaryotic mRNA, playing a pivotal role in RNA metabolism, including splicing, export, stability, and translation. The dynamic and reversible nature of m6A, governed by "writer," "eraser," and "reader" proteins, has implicated it in a vast array of biological processes and diseases. Validating the physiological function of these m6A regulators in vivo is crucial for understanding their mechanisms and for the development of novel therapeutic strategies. Animal models, particularly genetically engineered mice, have been instrumental in dissecting the complex roles of the m6A machinery.
This guide provides an objective comparison of the performance of various animal models used to validate m6A function in vivo, supported by experimental data. We will delve into the phenotypes of key m6A regulator knockout models, present detailed experimental protocols, and visualize the intricate relationships within the m6A pathway.
Comparison of In Vivo Models for m6A Regulators
The in vivo consequences of ablating key m6A regulatory proteins highlight their fundamental roles in development and homeostasis. Global knockout of core components of the m6A machinery often leads to embryonic or early postnatal lethality, necessitating the use of conditional knockout strategies to investigate their functions in specific tissues and at different developmental stages.
m6A Writers: The Catalysts of Methylation
The primary m6A writer complex consists of the catalytic subunit METTL3 and its partner METTL14.
METTL3 (Methyltransferase-like 3)
Global knockout of Mettl3 in mice results in embryonic lethality around embryonic day 3.5 (E3.5) to E8.5, with blastocysts failing to progress to the epiblast egg cylinder stage.[1][2][3] This early lethality underscores the essential role of m6A modification in fundamental developmental processes. To circumvent this, conditional knockout (cKO) models have been developed. For instance, podocyte-specific knockout of Mettl3 in a diabetic mouse model has been shown to alleviate kidney damage.[4] Myeloid-specific deletion of Mettl3 can attenuate tumor growth in mice, suggesting a role in tumor immune escape.[5]
| Model | Genotype | Key Phenotype | Quantitative Data | Reference |
| Global Knockout | Mettl3-/- | Embryonic lethality | No viable pups obtained | [1][3] |
| Cardiovascular cKO | Tagln-Cre; Mettl3flox/flox | Postnatal lethality | >70% mortality within 12 hours of birth | [6] |
| Myeloid-specific cKO | Lyz2-Cre; Mettl3flox/flox | Attenuated tumor growth in a colon cancer model | Significant reduction in tumor volume compared to controls | [5] |
m6A Erasers: The Demethylases
The primary m6A erasers in mammals are FTO (Fat mass and obesity-associated protein) and ALKBH5 (AlkB homolog 5).
FTO (Fat mass and obesity-associated protein)
The phenotype of Fto knockout mice can vary depending on the specific genetic manipulation and the developmental stage of deletion. Germline deletion of Fto often leads to postnatal growth retardation and reduced body weight.[7][8] However, some studies report a relatively normal body composition, while others describe a lean phenotype with increased energy expenditure.[7][9][10] Adult-onset global loss of Fto can lead to an increase in fat mass and a decrease in lean mass.[8]
| Model | Genotype | Key Phenotype | Quantitative Data | Reference |
| Global Knockout | Fto-/- | Postnatal growth retardation, altered metabolism | ~13% lighter body weight at 20 weeks; increased O2 consumption in the light phase | [8] |
| Point Mutation | FtoI367F | Reduced fat mass, increased energy expenditure | 16-18% reduction in total fat mass at 24 weeks | [10] |
| Adult-onset Knockout | UBC-Cre-ERT2; Ftoflox/flox | Increased fat mass, decreased lean mass | Significant increase in fat mass as a proportion of body weight at 9 weeks of age | [8] |
| Neural-specific cKO | Nestin-Cre; Ftoflox/flox | Similar growth retardation to global KO | Significantly lower body weight and length compared to controls | [7] |
m6A Readers: The Effectors of Function
The YTH domain-containing family of proteins (YTHDF1, YTHDF2, YTHDF3, YTHDC1, YTHDC2) are the primary readers that recognize m6A marks and mediate downstream effects.
YTHDF2 (YTH N6-methyladenosine RNA binding protein 2)
Global knockout of Ythdf2 in mice also results in embryonic lethality, with most embryos dying between E14.5 and E18.5.[11][12] Surviving Ythdf2-/- mice are often recovered in sub-Mendelian ratios.[13] A key phenotype observed in Ythdf2 knockout models is female-specific infertility, with oocytes that are unable to support early zygotic development.[13][14][15] Male Ythdf2-/- mice are fertile, although some studies report mild degenerative changes in the seminiferous tubules.[13][16]
| Model | Genotype | Key Phenotype | Quantitative Data | Reference |
| Global Knockout | Ythdf2-/- | Embryonic lethality, female infertility | ~80% of pups die shortly after birth; homozygous females are sterile | [13][17] |
| Conditional Knockout (germline) | Zp3-Cre; Ythdf2flox/flox | Female infertility | Oocytes can be fertilized but fail to develop beyond the 8-cell stage | [14] |
Experimental Protocols
Detailed and reproducible protocols are essential for the in vivo validation of m6A function. Below are outlines for key experimental procedures.
Generation of Conditional Knockout Mice using CRISPR/Cas9 and Cre-LoxP
This method allows for the tissue-specific and/or temporally controlled deletion of a target gene.
Principle: The Cre-LoxP system utilizes the Cre recombinase to recognize and excise a DNA sequence flanked by two LoxP sites ("floxed"). By generating a mouse with a floxed target gene and crossing it with a mouse expressing Cre under a specific promoter, the gene can be knocked out in a desired manner. CRISPR/Cas9 technology has streamlined the generation of these floxed mice.[18][19][20][21]
Protocol Outline:
-
Design and Synthesis:
-
Design two single guide RNAs (sgRNAs) that target the introns flanking the critical exon(s) of the gene of interest.
-
Design two single-stranded oligodeoxynucleotide (ssODN) donor templates. Each ssODN should contain a LoxP site flanked by homology arms corresponding to the genomic sequences adjacent to the sgRNA cut sites.
-
-
Zygote Microinjection:
-
Prepare a microinjection mix containing Cas9 mRNA, the two sgRNAs, and the two ssODN donors.
-
Microinject the mix into the pronuclei of fertilized mouse zygotes.
-
-
Embryo Transfer and Founder Screening:
-
Transfer the microinjected zygotes into pseudopregnant female mice.
-
Genotype the resulting pups by PCR to identify founder mice that have correctly integrated both LoxP sites in cis (on the same allele). This often requires a sequential breeding strategy where mice with one LoxP site are first generated and then used as embryo donors for the insertion of the second LoxP site.[21]
-
-
Breeding and Conditional Knockout Generation:
-
Breed the floxed founder mice to establish a colony.
-
Cross the floxed mice with a suitable Cre-driver mouse line (e.g., a line expressing Cre under a tissue-specific promoter like Nestin-Cre for neuronal tissues or a tamoxifen-inducible Cre like UBC-Cre-ERT2 for adult-onset knockout).
-
Genotype the offspring to identify mice with the desired conditional knockout genotype.
-
m6A-Seq (MeRIP-Seq) Protocol for Mouse Tissue
This technique maps the location of m6A modifications across the transcriptome.
Principle: m6A-containing RNA fragments are immunoprecipitated using an anti-m6A antibody, followed by high-throughput sequencing. The resulting data reveals enriched regions of m6A modification.[22][23][24]
Protocol Outline:
-
RNA Isolation and Fragmentation:
-
Isolate total RNA from the mouse tissue of interest using a method like TRIzol extraction.
-
Purify poly(A) RNA from the total RNA.
-
Chemically fragment the poly(A) RNA into ~100-nucleotide fragments.
-
-
Immunoprecipitation:
-
Incubate the fragmented RNA with an anti-m6A antibody that has been pre-bound to protein A/G magnetic beads. An input sample (a fraction of the fragmented RNA) should be saved for later comparison.
-
Wash the beads to remove non-specifically bound RNA.
-
Elute the m6A-containing RNA fragments from the antibody-bead complex.
-
-
Library Preparation and Sequencing:
-
Prepare sequencing libraries from both the immunoprecipitated (IP) and input RNA samples. This involves reverse transcription, second-strand synthesis, adapter ligation, and PCR amplification.
-
Perform high-throughput sequencing on the prepared libraries.
-
-
Data Analysis:
-
Align the sequencing reads to the mouse reference genome.
-
Use peak-calling algorithms to identify regions of m6A enrichment in the IP sample relative to the input sample.
-
Metabolic Analysis of Knockout Mice
Comprehensive metabolic phenotyping is crucial for studying m6A regulators like FTO.
Principle: A combination of techniques is used to assess energy balance, glucose homeostasis, and body composition.[25][26]
Protocol Outline:
-
Body Composition Analysis:
-
Use Dual-Energy X-ray Absorptiometry (DEXA) or quantitative Nuclear Magnetic Resonance (qNMR) to measure lean mass, fat mass, and total body water.
-
-
Energy Expenditure Measurement:
-
House mice individually in metabolic cages (e.g., Comprehensive Lab Animal Monitoring System - CLAMS) to continuously monitor oxygen consumption (VO2), carbon dioxide production (VCO2), food and water intake, and locomotor activity over several days.
-
Calculate the respiratory exchange ratio (RER = VCO2/VO2) to determine the primary fuel source (carbohydrates vs. fats).
-
Analyze energy expenditure data using Analysis of Covariance (ANCOVA) with body mass as a covariate to account for differences in body size.
-
-
Glucose Homeostasis Assessment:
-
Glucose Tolerance Test (GTT): After an overnight fast, administer an intraperitoneal (IP) or oral gavage of glucose and measure blood glucose levels at various time points (e.g., 0, 15, 30, 60, 90, 120 minutes) to assess glucose clearance.
-
Insulin Tolerance Test (ITT): After a short fast, administer an IP injection of insulin and measure blood glucose levels to assess insulin sensitivity.
-
Euglycemic-Hyperinsulinemic Clamp: This is the gold standard for assessing insulin sensitivity, involving a constant infusion of insulin and a variable infusion of glucose to maintain euglycemia.
-
Visualizing m6A Biology
Diagrams generated using Graphviz (DOT language) can effectively illustrate complex biological pathways and experimental workflows.
m6A Regulatory Pathway
Caption: The m6A RNA modification pathway.
Experimental Workflow for Conditional Knockout Mouse Analysis
Caption: Workflow for generating and analyzing conditional knockout mice.
References
- 1. Mettl3 MGI Mouse Gene Detail - MGI:1927165 - methyltransferase 3, N6-adenosine-methyltransferase complex catalytic subunit [informatics.jax.org]
- 2. METTL3 Regulates Liver Homeostasis, Hepatocyte Ploidy, and Circadian Rhythm–Controlled Gene Expression in Mice - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Enzymes flying under the radar: Cryptic METTL3 can persist in knockout cells | PLOS Biology [journals.plos.org]
- 4. cyagen.com [cyagen.com]
- 5. cyagen.com [cyagen.com]
- 6. researchgate.net [researchgate.net]
- 7. The Fat Mass and Obesity Associated Gene FTO Functions in the Brain to Regulate Postnatal Growth in Mice - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Adult Onset Global Loss of the Fto Gene Alters Body Composition and Metabolism in the Mouse - PMC [pmc.ncbi.nlm.nih.gov]
- 9. A Mouse Model for the Metabolic Effects of the Human Fat Mass and Obesity Associated FTO Gene | PLOS Genetics [journals.plos.org]
- 10. A Mouse Model for the Metabolic Effects of the Human Fat Mass and Obesity Associated FTO Gene - PMC [pmc.ncbi.nlm.nih.gov]
- 11. researchgate.net [researchgate.net]
- 12. researchgate.net [researchgate.net]
- 13. The RNA m6A Reader YTHDF2 Is Essential for the Post-transcriptional Regulation of the Maternal Transcriptome and Oocyte Competence - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Context-dependent functional compensation between Ythdf m6A readers | bioRxiv [biorxiv.org]
- 15. Frontiers | N6-methyladenosine reader YTHDF family in biological processes: Structures, roles, and mechanisms [frontiersin.org]
- 16. Context-dependent functional compensation between Ythdf m6A reader proteins - PMC [pmc.ncbi.nlm.nih.gov]
- 17. researchgate.net [researchgate.net]
- 18. Generation of Conditional Knockout Mice by Sequential Insertion of Two loxP Sites In Cis Using CRISPR/Cas9 and Single-Stranded DNA Oligonucleotides | Springer Nature Experiments [experiments.springernature.com]
- 19. Rapid generation of conditional knockout mice using the CRISPR-Cas9 system and electroporation for neuroscience research - PMC [pmc.ncbi.nlm.nih.gov]
- 20. Conditional Knockout Mouse - Creative Biogene CRISPR/Cas9 Platform [creative-biogene.com]
- 21. Generation of Conditional Knockout Mice by Sequential Insertion of Two loxP Sites In Cis Using CRISPR/Cas9 and Single-Stranded DNA Oligonucleotides - PMC [pmc.ncbi.nlm.nih.gov]
- 22. Genome-Wide Location Analyses of N6-Methyladenosine Modifications (m6A-seq) - PMC [pmc.ncbi.nlm.nih.gov]
- 23. researchgate.net [researchgate.net]
- 24. pdfs.semanticscholar.org [pdfs.semanticscholar.org]
- 25. Methods and Models for Metabolic Assessment in Mice - PMC [pmc.ncbi.nlm.nih.gov]
- 26. A guide to analysis of mouse energy metabolism - PMC [pmc.ncbi.nlm.nih.gov]
Navigating the MeRIP-seq Data Maze: A Comparative Guide to Analysis Software
For researchers, scientists, and drug development professionals venturing into the dynamic world of epitranscriptomics, the analysis of Methylated RNA Immunoprecipitation Sequencing (MeRIP-seq) data presents both an opportunity and a challenge. Identifying differential RNA methylation patterns across multiple datasets is crucial for unraveling the regulatory roles of modifications like N6-methyladenosine (m6A). This guide provides an objective comparison of leading software and tools designed for this purpose, supported by experimental data and detailed protocols to empower informed decisions in your research.
The landscape of MeRIP-seq analysis is populated by a variety of tools, each with its own statistical underpinnings and operational nuances. These tools are pivotal in progressing from raw sequencing reads to biologically meaningful insights. This guide will delve into a selection of prominent software, evaluating their performance in key areas of MeRIP-seq data analysis.
The MeRIP-seq Analysis Workflow: A Common Path to Discovery
Before comparing specific tools, it's essential to understand the typical bioinformatics pipeline for MeRIP-seq data analysis. This workflow transforms raw sequencing data into a list of differentially methylated regions.
Head-to-Head: A Comparative Look at Key Software
The selection of a computational tool for differential methylation analysis can significantly impact the outcome of a MeRIP-seq study. Here, we compare some of the most widely used software packages.
Standalone Tools for Differential Methylation Analysis
These tools are specialized packages primarily focused on identifying differentially methylated regions from processed MeRIP-seq data.
| Feature | exomePeak[1][2][3] | MACS2[4][5] | TRESS[6][7][8][9] | RADAR[10][11][12][13][14] |
| Primary Function | Differential RNA methylation analysis | Peak calling for ChIP-seq and MeRIP-seq | Differential RNA methylation analysis | Differential RNA methylation analysis |
| Statistical Model | Binomial distribution based on read counts in exons | Poisson distribution to model read counts | Hierarchical negative binomial model | Random effect model |
| Input Format | BAM files and a gene annotation file (GTF) | Aligned reads in BAM or BED format | Paired IP and input BAM files | Paired IP and input BAM files |
| Key Strengths | Specifically designed for MeRIP-seq, good for exon-centric analysis. | Widely used, robust, and well-documented. | Accounts for various sources of variation, flexible for complex experimental designs.[8] | Accommodates variability in both pre-IP expression and post-IP counts.[13] |
| Considerations | May have lower sensitivity compared to some other methods.[15] | Originally designed for ChIP-seq, may not be optimal for all MeRIP-seq characteristics.[16] | Can be computationally intensive for large datasets. | Requires careful consideration of bin size. |
Integrated Analysis Pipelines
For researchers seeking a more streamlined approach, integrated pipelines offer an all-in-one solution, from raw data processing to differential analysis and visualization.
| Feature | MeRIPseqPipe[17][18][19][20][21] |
| Primary Function | Integrated pipeline for complete MeRIP-seq data analysis |
| Core Components | Nextflow-based workflow integrating tools for QC, alignment, peak calling, and differential analysis. |
| Supported Tools | Includes various options for each analysis step (e.g., STAR, HISAT2 for alignment; MACS2, MeTPeak for peak calling).[17] |
| Key Strengths | Highly reproducible and scalable, user-friendly for those with limited programming skills.[19] |
| Considerations | Requires familiarity with Nextflow and Docker for customization. |
Performance Benchmarking: A Quantitative Look
A comprehensive evaluation of eight differential methylation analysis methods on synthetic and real datasets revealed key performance differences.[15]
| Method | Sensitivity | Precision | FDR Control | Type I Error | Runtime |
| TRESS | Low | High | Good | Good | Fast |
| exomePeak2 | Low | High | Good | Good | Moderate |
| DRME | High | Low | Poor | Inflated | Moderate |
| exomePeak | High | Low | Poor | Inflated | Moderate |
| RADAR | Moderate | Moderate | Moderate | Moderate | Slow |
| MeTDiff | Moderate | Moderate | Moderate | Moderate | Moderate |
| QNB | Low | Moderate | Good | Good | Fast |
| MACS2 | Low | Low | Poor | Inflated | Fast |
Note: Performance can vary depending on the dataset characteristics, such as sample size and the proportion of differentially methylated regions.[15]
Experimental Protocols: The Foundation of Reliable Comparisons
The validity of any comparative analysis rests on the quality of the underlying experimental data. The benchmarking study cited above utilized both synthetic and real MeRIP-seq datasets to evaluate the performance of different software.
Synthetic Data Generation: The simulation framework adopted a Gamma-Poisson model to generate read counts, allowing for controlled variation in sample sizes and proportions of differentially methylated regions (DMRs).[15] This in-silico approach provides a ground truth against which the accuracy of each tool can be measured.
Real Data Analysis: The study also used publicly available MeRIP-seq datasets, such as those from studies involving METTL3 knockdown, to assess the performance of the tools in a real-world biological context.[15] Raw FASTQ files were mapped to the human reference genome using STAR, and the resulting BAM files were used as input for the differential methylation analysis tools.[15]
Logical Relationships of MeRIP-seq Analysis Tools
The various tools in the MeRIP-seq analysis ecosystem are interconnected, with the output of one often serving as the input for another. This diagram illustrates the typical relationships between different software components.
Conclusion: Selecting the Right Tool for the Job
The choice of software for comparing multiple MeRIP-seq datasets depends on several factors, including the specific research question, the experimental design, and the user's computational expertise. For researchers prioritizing high precision and reliable control of false discoveries, TRESS and exomePeak2 emerge as strong contenders, albeit with potentially lower sensitivity.[15] When high sensitivity is paramount and a higher false discovery rate is acceptable, DRME and the original exomePeak may be more suitable.[15]
For those who prefer a comprehensive, automated workflow, MeRIPseqPipe offers an excellent solution by integrating multiple well-established tools into a single, reproducible pipeline.[19][20] Ultimately, a thorough understanding of the strengths and weaknesses of each tool, as outlined in this guide, will enable researchers to select the most appropriate software to unlock the secrets hidden within their MeRIP-seq data.
References
- 1. rna-seqblog.com [rna-seqblog.com]
- 2. A protocol for RNA methylation differential analysis with MeRIP-Seq data and exomePeak R/Bioconductor package - PMC [pmc.ncbi.nlm.nih.gov]
- 3. A protocol for RNA methylation differential analysis with MeRIP-Seq data and exomePeak R/Bioconductor package - Xi'an Jiaotong-Liverpool University [scholar.xjtlu.edu.cn]
- 4. Master MeRIP-seq Data Analysis: Step-by-Step Process for RNA Methylation Studies - CD Genomics [rna.cd-genomics.com]
- 5. benchchem.com [benchchem.com]
- 6. Analyzing mRNA Epigenetic Sequencing Data with TRESS - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. Analyzing mRNA Epigenetic Sequencing Data with TRESS | Springer Nature Experiments [experiments.springernature.com]
- 8. academic.oup.com [academic.oup.com]
- 9. GitHub - ZhenxingGuo0015/TRESS: Toobox for RNA Methylation Sequencing Analysis [github.com]
- 10. researchgate.net [researchgate.net]
- 11. Analyzing MeRIP-seq data with RADAR [scottzijiezhang.github.io]
- 12. RADAR/README.md at master · scottzijiezhang/RADAR · GitHub [github.com]
- 13. RADAR: differential analysis of MeRIP-seq data with a random effect model - PubMed [pubmed.ncbi.nlm.nih.gov]
- 14. researchgate.net [researchgate.net]
- 15. Evaluation of epitranscriptome-wide N6-methyladenosine differential analysis methods - PMC [pmc.ncbi.nlm.nih.gov]
- 16. tandfonline.com [tandfonline.com]
- 17. GitHub - canceromics/MeRIPseqPipe: MeRIPseqPipe:An integrated analysis pipeline for MeRIP-seq data based on Nextflow. [github.com]
- 18. GitHub - lazyky/meripseqpipe: MeRIP-seq analysis pipeline arranged multiple alignment tools, peakCalling tools, Merge Peaks' methods and methylation analysis methods. [github.com]
- 19. academic.oup.com [academic.oup.com]
- 20. academic.oup.com [academic.oup.com]
- 21. researchgate.net [researchgate.net]
Assessing the Functional Impact of N6-methyladenosine (m6A) with Ribosome Profiling: A Comparative Guide
N6-methyladenosine (m6A) is the most abundant internal modification on messenger RNA (mRNA) in eukaryotes, playing a pivotal role in nearly every aspect of the mRNA life cycle, including splicing, nuclear export, stability, and translation.[1] Understanding the functional consequences of m6A on protein synthesis is crucial for researchers in basic science and drug development. Ribosome profiling, a powerful technique that provides a snapshot of all ribosome positions on transcripts, has emerged as a key tool for dissecting the role of m6A in regulating translation at a global scale.[2]
This guide provides a comprehensive overview of how to assess the functional impact of m6A using ribosome profiling, compares it with alternative methods, and presents supporting experimental data and protocols for researchers, scientists, and drug development professionals.
Ribosome Profiling: A High-Resolution Look at m6A in Translation
Ribosome profiling, or Ribo-seq, enables the precise mapping of ribosome-protected mRNA fragments (RPFs), revealing the exact locations of ribosomes on a transcript.[3] By quantifying the density of ribosomes on each mRNA, researchers can infer the rate of protein synthesis for thousands of genes simultaneously.[2] When combined with m6A mapping data, Ribo-seq can directly measure how m6A modification affects translation efficiency (TE), which is typically calculated as the ratio of ribosome footprint abundance to total mRNA abundance for a given gene.
The Functional Dichotomy of m6A in Translation
Ribosome profiling studies have revealed that the functional impact of m6A on translation is highly context-dependent, varying based on its location within the mRNA transcript.[4]
-
5' Untranslated Region (UTR): In the 5'UTR, m6A can promote cap-independent translation, particularly under stress conditions like heat shock, by directly recruiting the translation initiation factor eIF3.[4] It can also slow down ribosome scanning to facilitate translation initiation at non-canonical sites.[4]
-
Coding Sequence (CDS): Within the coding region, m6A can have dual effects. It can impede tRNA accommodation, thereby slowing down translation elongation.[5][6] Conversely, it has also been shown to relieve ribosome stalling at specific codons.[4] Recent studies suggest m6A is a potent inducer of ribosome stalling, which can lead to ribosome collisions and ultimately trigger mRNA degradation.[7]
-
3' Untranslated Region (UTR): m6A in the 3'UTR, particularly near the stop codon, generally promotes translation. This is often mediated by the m6A reader protein YTHDF1, which binds to m6A-modified mRNA and recruits translation initiation machinery, possibly through mRNA looping.[4]
Below is a diagram illustrating the various functional impacts of m6A on the translation process.
Experimental Approach: Ribosome Profiling Workflow
The general workflow for a ribosome profiling experiment to assess m6A's impact involves several key steps, from cell treatment to data analysis. This typically involves comparing cells with normal m6A levels to cells where an m6A writer (e.g., METTL3) or reader (e.g., YTHDF1) has been depleted.
Detailed Experimental Protocol: Ribosome Profiling
This protocol provides a generalized overview. Specific reagents and incubation times may require optimization.
-
Cell Culture and Treatment: Culture cells of interest (e.g., HeLa cells). For comparative analysis, use siRNA to knock down a key m6A-pathway protein (e.g., METTL3, YTHDF1) in one batch, with a control siRNA for the other.
-
Translation Arrest and Cell Harvest:
-
Treat cells with a translation elongation inhibitor, such as cycloheximide (100 µg/mL), for 2-5 minutes to freeze ribosomes on the mRNA.
-
Immediately place plates on ice, wash with ice-cold PBS containing cycloheximide, and harvest cells.
-
-
Cell Lysis: Lyse cells in a polysome lysis buffer containing detergents (e.g., Triton X-100) and cycloheximide.
-
Nuclease Digestion:
-
Clarify the lysate by centrifugation.
-
Treat the supernatant with RNase I to digest mRNA that is not protected by ribosomes. The amount of RNase I must be carefully titrated to ensure complete digestion of unprotected RNA without degrading ribosomes.
-
-
Ribosome Monosome Isolation:
-
Stop the digestion with a ribonuclease inhibitor.
-
Load the digest onto a sucrose density gradient (e.g., 10-50%) and centrifuge to separate monosomes (single ribosomes) from polysomes, ribosomal subunits, and free RNA.
-
Fractionate the gradient and collect the monosome peak.
-
-
RNA Extraction: Extract the RNA fragments (the RPFs) from the monosome fraction using a method like Trizol extraction or a dedicated RNA cleanup kit. RPFs are typically ~28-30 nucleotides in length.
-
Library Preparation and Sequencing:
-
Isolate the RPFs by size selection on a denaturing polyacrylamide gel.
-
Ligate sequencing adapters to the 3' end of the RPFs.
-
Perform reverse transcription to generate cDNA.
-
Circularize the cDNA and perform PCR amplification to generate the final sequencing library.
-
Sequence the library on a high-throughput platform.
-
-
Parallel RNA-Seq: Prepare a standard RNA-seq library from total cellular mRNA isolated from the same cell batches. This is essential for normalizing the ribosome footprint data and calculating translation efficiency.[8]
Quantitative Data and Alternative Methods
Ribosome profiling provides rich quantitative data on translation. Knockdown of m6A machinery, followed by Ribo-seq, has demonstrated clear effects on the translation of m6A-modified transcripts.
Quantitative Impact of m6A Pathway on Translation
| Target Protein | Experimental System | Key Finding | Effect on Translation Efficiency (TE) | Reference |
| YTHDF1 | HeLa Cells | YTHDF1 knockdown reduces the translation of its target mRNAs. | TE of YTHDF1 targets decreased. | [4] |
| METTL3 | HeLa Cells | Depletion of the m6A writer METTL3 mirrors the effect of YTHDF1 depletion. | TE of YTHDF1/METTL3 co-targets decreased. | [4] |
| m6A in CDS | E. coli in vitro system | m6A modification within a codon slows down tRNA accommodation. | 1.5-fold to 2-fold decrease in the rate of tRNA binding and GTP hydrolysis. | [5] |
Comparison of Methods to Assess Translation
While ribosome profiling offers unparalleled resolution, other methods can also provide insights into the translational status of mRNAs.
| Feature | Ribosome Profiling (Ribo-seq) | Polysome Profiling |
| Principle | High-throughput sequencing of ribosome-protected mRNA fragments. | Separation of mRNAs based on the number of associated ribosomes via sucrose gradient centrifugation. |
| Resolution | Single nucleotide precision, reveals ribosome pausing sites. | Low resolution; categorizes mRNAs into non-translating, lightly translating, or heavily translating (polysome) fractions. |
| Data Output | Quantitative ribosome density across the entire transcriptome. | Relative abundance of specific mRNAs in different fractions, typically measured by RT-qPCR or microarray.[9] |
| Throughput | High (genome-wide). | Low to medium; often focused on a few genes of interest. |
| Complexity | High; requires specialized protocols and complex bioinformatic analysis. | Moderate; technically demanding but conceptually simpler than Ribo-seq. |
| Application for m6A | Directly measures changes in TE for m6A-modified transcripts upon perturbation of m6A machinery. | Can show if an m6A-modified transcript shifts between polysome and non-polysome fractions. |
Complementary Methods: Mapping m6A Sites
To correlate translation changes with m6A, one must first identify which transcripts are methylated. Several high-throughput methods exist for transcriptome-wide m6A mapping. The choice of method depends on the desired resolution and whether quantitative information is needed.
| Method | Principle | Resolution | Stoichiometry | Key Advantage | Key Limitation |
| MeRIP-Seq / m6A-Seq | Immunoprecipitation of fragmented RNA with an m6A-specific antibody, followed by sequencing.[10][11] | Low (~100-200 nt). | No. | Robust, widely used, and cost-effective.[10] | Low resolution; antibody bias. |
| miCLIP | UV cross-linking of the m6A antibody to RNA, causing specific mutations or truncations during reverse transcription.[12] | Single nucleotide. | No. | High resolution mapping of modification sites. | Technically complex procedure. |
| m6A-SAC-Seq | Antibody-free enzymatic and chemical labeling of m6A, inducing mutations at m6A sites during reverse transcription.[13] | Single nucleotide. | Yes. | Provides quantitative, base-resolution mapping.[13] | Requires recombinant enzyme and chemical synthesis. |
| Nanopore DRS | Direct RNA sequencing on the Nanopore platform, detecting m6A based on distinct electrical signals.[14][15] | Single nucleotide. | Yes (in principle). | Detects modifications on native, full-length RNA; no amplification bias.[1] | Higher error rate; complex data analysis. |
The workflow below compares antibody-dependent and antibody-independent approaches for m6A mapping.
References
- 1. Frontiers | Studying m6A in the brain: a perspective on current methods, challenges, and future directions [frontiersin.org]
- 2. Ribosome Profiling: Global Views of Translation - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Inferring efficiency of translation initiation and elongation from ribosome profiling - PMC [pmc.ncbi.nlm.nih.gov]
- 4. m6A-Mediated Translation Regulation - PMC [pmc.ncbi.nlm.nih.gov]
- 5. N6-methyladenosine in mRNA disrupts tRNA selection and translation elongation dynamics - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Modulation of translational decoding by m6A modification of mRNA [ideas.repec.org]
- 7. researchwithnj.com [researchwithnj.com]
- 8. Quantitative Comparisons of Translation Activity by Ribosome Profiling with Internal Standards - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. researchgate.net [researchgate.net]
- 10. Current progress in strategies to profile transcriptomic m6A modifications - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Frontiers | Current progress in strategies to profile transcriptomic m6A modifications [frontiersin.org]
- 12. m6A Profiling - CD Genomics [rna.cd-genomics.com]
- 13. m6A-SAC-seq for quantitative whole transcriptome m6A profiling - PMC [pmc.ncbi.nlm.nih.gov]
- 14. researchgate.net [researchgate.net]
- 15. Systematic comparison of tools used for m6A mapping from nanopore direct RNA sequencing - PMC [pmc.ncbi.nlm.nih.gov]
Navigating the Epitranscriptome: A Guide to Correlating m6A Changes with Gene Expression
For researchers, scientists, and drug development professionals, understanding the intricate dance between N6-methyladenosine (m6A) RNA modifications and gene expression is paramount. This guide provides a comprehensive comparison of methodologies to correlate m6A changes with gene expression alterations derived from RNA-sequencing (RNA-seq) data, supported by experimental protocols and data analysis workflows.
The dynamic nature of m6A modifications plays a crucial role in post-transcriptional gene regulation, influencing mRNA stability, splicing, and translation.[1] Dysregulation of m6A has been implicated in various diseases, including cancer, making the accurate analysis of its interplay with gene expression a critical area of research. This guide will navigate the experimental and computational landscapes, offering a clear comparison of tools and protocols to empower your research.
Comparing the Tools of the Trade: Bioinformatic Analysis of m6A-Seq Data
The journey from raw sequencing data to meaningful biological insights hinges on a robust bioinformatic pipeline. A typical workflow involves quality control, read alignment, peak calling to identify m6A-enriched regions, and differential methylation analysis. Several tools are available for these tasks, each with its own set of algorithms and performance characteristics. Below is a comparative summary of some of the most widely used tools for m6A peak calling and differential methylation analysis.
| Tool | Primary Function | Algorithm/Approach | Key Features | Reported Performance/Considerations |
| exomePeak/exomePeak2 | Peak Calling & Differential Methylation | Based on a binomial distribution model, with exomePeak2 offering improved statistical modeling (Poisson GLM).[2][3][4][5] | Supports multiple biological replicates, removes PCR artifacts, and can perform differential analysis between conditions.[4][6] | exomePeak has been noted to have a higher false discovery rate and type I error in some comparisons.[7] exomePeak2 shows improved performance in terms of precision and runtime.[7] |
| MeTDiff | Differential Methylation Analysis | Employs a beta-binomial model to account for read count variations.[8][9][10] | Explicitly models read variation, offering a powerful likelihood ratio test for differential methylation.[8][11] | Reported to have higher sensitivity and specificity compared to exomePeak in some studies.[8][11] However, other benchmarks suggest its performance can be unstable.[7] |
| MoAIMS | Peak Calling & Signal Inference | Utilizes a mixture negative-binomial model.[7][12][13] | Fast processing speed, compatible with various RNA-seq protocols, and can infer the proportion of modified RNA.[12][13] | Demonstrates competitive performance in detecting m6A enriched regions and offers an intuitive evaluation of treatment effects.[12][13] |
| MACS2 | Peak Calling | Originally designed for ChIP-seq data, it models the shift size of tags to find enriched regions. | Widely used and well-established for peak calling in various sequencing data types. | While commonly used for m6A-seq, its genomic-based model may not be optimal for transcriptomic data, potentially leading to inaccuracies in peak identification within exons and introns.[14] Some studies suggest it can identify more peaks than tools specifically designed for m6A-seq.[15][16] |
| HOMER | Motif Discovery & Peak Calling | Uses a differential motif discovery algorithm based on the hypergeometric distribution.[6][17] | Excellent for identifying enriched sequence motifs within called peaks, which can help validate the presence of the m6A consensus motif (RRACH).[6][18] | Primarily a motif finder, its peak calling functionality is also used in m6A-seq analysis pipelines.[14][18] |
The Experimental Foundation: A Detailed MeRIP-Seq Protocol
Methylated RNA Immunoprecipitation followed by sequencing (MeRIP-seq or m6A-seq) is the most common technique for transcriptome-wide m6A profiling.[1][19] The following protocol outlines the key steps involved.
I. RNA Preparation and Quality Control
-
Total RNA Extraction: Isolate total RNA from cells or tissues using a method that ensures high purity and integrity, such as TRIzol reagent or column-based kits.
-
RNA Quality Control: Assess the quality of the extracted RNA using a Bioanalyzer or similar instrument. High-quality RNA should have an RNA Integrity Number (RIN) of 7.0 or higher.
II. mRNA Enrichment and Fragmentation
-
mRNA Enrichment (Optional but Recommended): Enrich for messenger RNA (mRNA) from the total RNA pool using oligo(dT) magnetic beads to capture polyadenylated transcripts.
-
RNA Fragmentation: Fragment the enriched mRNA to an average size of 100-200 nucleotides. This can be achieved through enzymatic digestion (e.g., with RNase III) or chemical fragmentation.[20]
III. Immunoprecipitation (IP)
-
Antibody Incubation: Incubate the fragmented RNA with a highly specific anti-m6A antibody to allow for the formation of RNA-antibody complexes.[20]
-
Immunomagnetic Capture: Add protein A/G magnetic beads to the mixture to capture the RNA-antibody complexes.
-
Washing: Perform a series of washes to remove non-specifically bound RNA fragments.
IV. Library Preparation and Sequencing
-
Elution: Elute the m6A-containing RNA fragments from the magnetic beads.
-
Input Control: It is crucial to prepare a parallel "input" library from a small fraction of the fragmented RNA before the immunoprecipitation step. This serves as a control for non-specific background and allows for the normalization of m6A enrichment.
-
Library Construction: Construct sequencing libraries from both the immunoprecipitated (IP) and input RNA samples. This typically involves reverse transcription, second-strand synthesis, adapter ligation, and PCR amplification.
-
Sequencing: Perform high-throughput sequencing of the prepared libraries on a platform such as Illumina.
The Analytical Blueprint: From Raw Reads to Biological Correlation
The subsequent bioinformatic analysis integrates the data from both the MeRIP-seq and a standard RNA-seq experiment to correlate m6A changes with gene expression alterations.
The Logic of Correlation: A Deeper Dive into Integrative Analysis
The core of the analysis lies in statistically correlating the changes in m6A methylation with the changes in gene expression. This allows for the classification of genes into different regulatory categories.
A common approach to this integrative analysis is to perform a quadrant analysis based on the log2 fold changes of m6A methylation and gene expression. This categorizes genes into four groups: hyper-methylated and up-regulated, hyper-methylated and down-regulated, hypo-methylated and up-regulated, and hypo-methylated and down-regulated. Statistical tests, such as Pearson correlation, are then applied to determine the significance of these relationships.[2][21][22] Genes falling into these categories can then be subjected to functional enrichment analysis (e.g., Gene Ontology and KEGG pathways) to uncover the biological processes being regulated by m6A.
By carefully selecting the appropriate experimental and bioinformatic methodologies, researchers can effectively unravel the complex interplay between m6A methylation and gene expression, paving the way for new discoveries in disease mechanisms and therapeutic development.
References
- 1. researchgate.net [researchgate.net]
- 2. researchgate.net [researchgate.net]
- 3. A protocol for RNA methylation differential analysis with MeRIP-Seq data and exomePeak R/Bioconductor package - PMC [pmc.ncbi.nlm.nih.gov]
- 4. rna-seqblog.com [rna-seqblog.com]
- 5. A protocol for RNA methylation differential analysis with MeRIP-Seq data and exomePeak R/Bioconductor package - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. Homer Software and Data Download [homer.ucsd.edu]
- 7. Evaluation of epitranscriptome-wide N6-methyladenosine differential analysis methods - PMC [pmc.ncbi.nlm.nih.gov]
- 8. RNA-seq workflow: gene-level exploratory analysis and differential expression [csama2025.bioconductor.eu]
- 9. rna-seqblog.com [rna-seqblog.com]
- 10. bio-rad.com [bio-rad.com]
- 11. MeTDiff: A Novel Differential RNA Methylation Analysis for MeRIP-Seq Data - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. Bioinformatics Workflow of RNA-Seq - CD Genomics [cd-genomics.com]
- 13. researchgate.net [researchgate.net]
- 14. biorxiv.org [biorxiv.org]
- 15. Genetic drivers of m6A methylation in human brain, lung, heart and muscle - PMC [pmc.ncbi.nlm.nih.gov]
- 16. researchgate.net [researchgate.net]
- 17. Homer Software and Data Download [homer.ucsd.edu]
- 18. Master MeRIP-seq Data Analysis: Step-by-Step Process for RNA Methylation Studies - CD Genomics [rna.cd-genomics.com]
- 19. Current progress in strategies to profile transcriptomic m6A modifications - PMC [pmc.ncbi.nlm.nih.gov]
- 20. MeRIP-seq Protocol - CD Genomics [rna.cd-genomics.com]
- 21. Profiling Analysis of N6-Methyladenosine mRNA Methylation Reveals Differential m6A Patterns during the Embryonic Skeletal Muscle Development of Ducks - PMC [pmc.ncbi.nlm.nih.gov]
- 22. researchgate.net [researchgate.net]
Safety Operating Guide
Standard Operating Procedure for the Disposal of 2-Methylamino-N6-methyladenosine
Disclaimer: This document provides general guidance for the proper disposal of 2-Methylamino-N6-methyladenosine in a laboratory setting. A specific Safety Data Sheet (SDS) for this compound was not located; therefore, these procedures are based on established best practices for the disposal of hazardous chemical waste. All laboratory personnel must adhere to their institution's specific waste management policies, as well as local, state, and federal regulations.
Purpose
This procedure outlines the necessary steps for the safe handling and disposal of this compound to ensure the safety of laboratory personnel and to maintain environmental compliance. As a modified nucleoside analogue, this compound should be treated as hazardous chemical waste unless specific toxicological data becomes available to suggest otherwise.
Personal Protective Equipment (PPE)
Before handling this compound for disposal, all personnel must wear the following minimum PPE:
-
Gloves: Nitrile or other chemically resistant gloves.
-
Eye Protection: Safety glasses with side shields or chemical splash goggles.
-
Lab Coat: A standard laboratory coat must be worn and fully buttoned.
Waste Segregation and Collection
Proper segregation of chemical waste is critical to prevent dangerous reactions.[1][2][3]
-
Waste Stream: this compound waste must be collected in a dedicated hazardous waste container. Do not mix this waste with other chemical waste streams unless compatibility has been confirmed.[2][4]
-
Solid Waste:
-
Place contaminated solid materials, such as unused compound, contaminated personal protective equipment (e.g., gloves), and weighing papers, into a designated solid hazardous waste container.
-
This container should be a durable, leak-proof container with a secure lid.
-
-
Liquid Waste:
-
Collect solutions containing this compound in a separate, clearly labeled liquid hazardous waste container.
-
The container must be made of a material compatible with the solvents used (e.g., a glass bottle for most organic solvents).[3]
-
Do not fill liquid waste containers beyond 90% capacity to allow for vapor expansion and prevent spills.[3]
-
-
Sharps Waste:
-
Needles, syringes, or other contaminated sharps must be disposed of in a designated sharps container. If the sharps are contaminated with this compound, they should be managed as hazardous sharps waste.
-
Waste Container Labeling
Accurate and clear labeling of waste containers is a regulatory requirement and essential for safety.[5]
-
All hazardous waste containers must be labeled with a "Hazardous Waste" tag as soon as the first drop of waste is added.
-
The label must include:
-
The full chemical name: "this compound". Avoid using abbreviations or chemical formulas.
-
The major constituents and their approximate percentages if it is a mixed waste stream.
-
The date on which waste was first added to the container (accumulation start date).[5]
-
The associated hazards (e.g., "Toxic," "Irritant"). Since the specific hazards are not fully characterized, it is prudent to assume it may be toxic and an irritant.
-
Storage of Hazardous Waste
Waste must be stored safely in the laboratory prior to collection.
-
Store hazardous waste containers in a designated satellite accumulation area within the laboratory.[2]
-
Ensure that the storage area is away from general traffic and that containers are not at risk of being knocked over.
-
Use secondary containment, such as a chemical-resistant tray or bin, for all liquid hazardous waste containers to contain any potential leaks or spills.[1][2][4]
-
Keep waste containers securely closed at all times, except when adding waste.[4]
Disposal Procedure
Disposal of hazardous waste must be handled by trained professionals.
-
Do not dispose of this compound down the drain or in the regular trash.[4][6] This is a violation of environmental regulations and can pose a significant hazard.
-
Do not attempt to neutralize or chemically treat the waste unless you have a validated and approved protocol for doing so.
-
Arrange for the collection of the hazardous waste through your institution's Environmental Health and Safety (EHS) department or a licensed hazardous waste disposal contractor.[6][7]
-
Follow your institution's specific procedures for requesting a waste pickup.
Spill Management
In the event of a spill, prompt and appropriate action is necessary.
-
If a spill occurs, alert others in the area and evacuate if necessary.
-
For small spills that you are trained to handle, use a chemical spill kit to absorb the material.
-
All materials used to clean up the spill, including absorbent pads and contaminated PPE, must be disposed of as hazardous waste in the same manner as the original compound.[6]
-
For large or unmanageable spills, contact your institution's EHS or emergency response team immediately.[6]
As requested, this response provides procedural, step-by-step guidance for the proper disposal of this compound. However, the capabilities to generate visualizations such as tables and Graphviz diagrams are not available.
References
- 1. danielshealth.com [danielshealth.com]
- 2. Management of Waste - Prudent Practices in the Laboratory - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 3. acewaste.com.au [acewaste.com.au]
- 4. Hazardous Waste Disposal Guide - Research Areas | Policies [policies.dartmouth.edu]
- 5. gzlabfurniture.com [gzlabfurniture.com]
- 6. vumc.org [vumc.org]
- 7. mtu.edu [mtu.edu]
Personal protective equipment for handling 2-Methylamino-N6-methyladenosine
Disclaimer: No specific Safety Data Sheet (SDS) is currently available for 2-Methylamino-N6-methyladenosine. The following guidance is based on the safety information for the closely related compound, N6-methyladenosine, and general best practices for handling nucleoside analogs in a laboratory setting. It is imperative to conduct a thorough risk assessment for your specific experimental conditions and to handle this compound with caution as its toxicological properties have not been fully characterized.
This guide provides researchers, scientists, and drug development professionals with essential safety and logistical information for handling this compound. Adherence to these procedures is critical for ensuring personnel safety and minimizing environmental impact.
Personal Protective Equipment (PPE)
The minimum required PPE when handling this compound, particularly in solid form, includes a lab coat, protective eyewear, and appropriate gloves.[1] Based on the potential for this compound to be a skin and eye irritant, as is common with related molecules, a comprehensive PPE protocol is essential.
Table 1: Personal Protective Equipment (PPE) Recommendations
| Equipment | Specification | Purpose |
| Eye and Face Protection | Safety glasses with side shields or chemical splash goggles. A face shield may be required for procedures with a high risk of splashing. | To protect eyes from dust particles and chemical splashes. |
| Hand Protection | Chemical-resistant gloves (e.g., nitrile). | To prevent skin contact with the compound. |
| Body Protection | A standard laboratory coat. | To protect skin and clothing from contamination. |
| Respiratory Protection | Not generally required under normal use with adequate ventilation.[2] If handling large quantities or if dust generation is likely, a NIOSH-approved respirator may be necessary. | To prevent inhalation of airborne particles. |
Always inspect PPE for integrity before use and remove it carefully to avoid cross-contamination.[2]
Operational Plan: Safe Handling Procedures
Safe handling of this compound requires adherence to standard laboratory safety practices to minimize exposure.
Pre-Handling:
-
Read and understand this safety guide thoroughly.
-
Ensure that a safety shower and eyewash station are readily accessible.
-
Prepare a designated handling area, preferably within a chemical fume hood, to ensure adequate ventilation.[3]
Handling:
-
Wear all required PPE as specified in Table 1.
-
Handle the compound in a well-ventilated area, such as a chemical fume hood, to avoid the inhalation of any dust or aerosols.[3]
-
Avoid direct contact with the skin, eyes, and clothing.[2]
-
When weighing or transferring the solid compound, take care to minimize the generation of dust.[2]
-
After handling, wash hands thoroughly with soap and water.[4]
-
Do not eat, drink, or smoke in the laboratory.[4]
First Aid Measures:
-
In case of eye contact: Immediately flush eyes with plenty of water for at least 15 minutes, occasionally lifting the upper and lower eyelids. Seek medical attention.[3]
-
In case of skin contact: Immediately wash the affected area with soap and water. Remove contaminated clothing. If irritation persists, seek medical attention.[3]
-
If inhaled: Move the person to fresh air. If breathing is difficult, give oxygen. Seek medical attention if symptoms occur.[3]
-
If swallowed: Do NOT induce vomiting. Rinse mouth with water and seek immediate medical attention.[4]
Disposal Plan
Proper disposal of this compound and any contaminated materials is crucial to prevent environmental contamination and ensure regulatory compliance.
-
Chemical Waste: Dispose of unused this compound as chemical waste in accordance with local, state, and federal regulations. Do not dispose of it down the drain.[5]
-
Contaminated Materials: All disposable labware (e.g., pipette tips, tubes) and PPE (e.g., gloves) that have come into contact with the compound should be collected in a designated, sealed waste container for hazardous materials.
-
Spills: In the event of a spill, avoid generating dust.[2] Carefully sweep up the solid material and place it in a sealed container for disposal.[2] Clean the spill area with an appropriate solvent and decontaminate it.
Experimental Workflow Diagram
The following diagram outlines the key steps for the safe handling of this compound in a laboratory setting.
Caption: Workflow for Safe Handling of this compound.
References
Featured Recommendations
| Most viewed |


|
|
|---|---|---|
| Most popular with customers |
|
Descargo de responsabilidad e información sobre productos de investigación in vitro
Tenga en cuenta que todos los artículos e información de productos presentados en BenchChem están destinados únicamente con fines informativos. Los productos disponibles para la compra en BenchChem están diseñados específicamente para estudios in vitro, que se realizan fuera de organismos vivos. Los estudios in vitro, derivados del término latino "in vidrio", involucran experimentos realizados en entornos de laboratorio controlados utilizando células o tejidos. Es importante tener en cuenta que estos productos no se clasifican como medicamentos y no han recibido la aprobación de la FDA para la prevención, tratamiento o cura de ninguna condición médica, dolencia o enfermedad. Debemos enfatizar que cualquier forma de introducción corporal de estos productos en humanos o animales está estrictamente prohibida por ley. Es esencial adherirse a estas pautas para garantizar el cumplimiento de los estándares legales y éticos en la investigación y experimentación.
