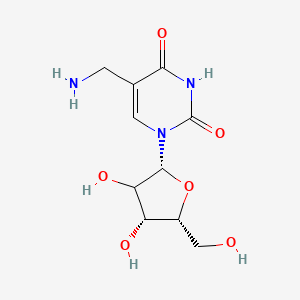
5-(Aminomethyl)uridine
Descripción
BenchChem offers high-quality this compound suitable for many research applications. Different packaging options are available to accommodate customers' requirements. Please inquire for more information about this compound including the price, delivery time, and more detailed information at info@benchchem.com.
Structure
3D Structure
Propiedades
Fórmula molecular |
C10H15N3O6 |
|---|---|
Peso molecular |
273.24 g/mol |
Nombre IUPAC |
5-(aminomethyl)-1-[(2R,4R,5R)-3,4-dihydroxy-5-(hydroxymethyl)oxolan-2-yl]pyrimidine-2,4-dione |
InChI |
InChI=1S/C10H15N3O6/c11-1-4-2-13(10(18)12-8(4)17)9-7(16)6(15)5(3-14)19-9/h2,5-7,9,14-16H,1,3,11H2,(H,12,17,18)/t5-,6+,7?,9-/m1/s1 |
Clave InChI |
ZQVNMALZHZYKQM-WJZMDOFJSA-N |
SMILES isomérico |
C1=C(C(=O)NC(=O)N1[C@H]2C([C@H]([C@H](O2)CO)O)O)CN |
SMILES canónico |
C1=C(C(=O)NC(=O)N1C2C(C(C(O2)CO)O)O)CN |
Origen del producto |
United States |
Foundational & Exploratory
5-(Aminomethyl)uridine chemical structure and properties
An In-Depth Technical Guide to 5-(Aminomethyl)uridine
For Researchers, Scientists, and Drug Development Professionals
This guide provides a comprehensive overview of the chemical structure, properties, biological significance, and relevant experimental methodologies for this compound. The information is intended for professionals in chemical biology, molecular biology, and drug discovery.
Core Chemical Identity and Properties
This compound is a modified pyrimidine (B1678525) nucleoside, structurally analogous to the canonical RNA nucleoside, uridine (B1682114). It features an aminomethyl group (-CH₂NH₂) attached to the C5 position of the uracil (B121893) base. This modification is a key intermediate in the biosynthesis of more complex tRNA modifications.
Chemical Structure
IUPAC Name: 5-(aminomethyl)-1-[(2R,3R,4S,5R)-3,4-dihydroxy-5-(hydroxymethyl)oxolan-2-yl]pyrimidine-2,4-dione[1] SMILES: C1=C(C(=O)NC(=O)N1[C@H]2--INVALID-LINK--CO)O)O)CN[1] InChI Key: ZQVNMALZHZYKQM-JXOAFFINSA-N[1]
Physicochemical and Spectroscopic Data
The following table summarizes the key quantitative properties of this compound. While experimental spectroscopic data is not widely published, computed properties provide valuable insights.
| Property | Value | Reference |
| Molecular Formula | C₁₀H₁₅N₃O₆ | [1][2] |
| Molecular Weight | 273.24 g/mol | [1][2] |
| Exact Mass | 273.09608521 Da | [1] |
| CAS Number | 190448-73-8 | [1][2][3] |
| XLogP3 (Computed) | -2.6 | [1] |
| Hydrogen Bond Donors | 5 | [1] |
| Hydrogen Bond Acceptors | 7 | [1] |
| Rotatable Bond Count | 3 | [1] |
Biological Role and Signaling Pathways
The primary and most well-documented biological role of this compound is as a crucial intermediate in the post-transcriptional modification of transfer RNA (tRNA), particularly at the wobble position (nucleotide 34) of the anticodon loop.
tRNA Modification Pathway
In many prokaryotes, the wobble uridine is hypermodified to 5-methylaminomethyluridine (B1256275) (mnm⁵U) or its 2-thiolated derivative (mnm⁵s²U) to ensure translational fidelity.[4] this compound, often denoted as nm⁵U, is the direct precursor to this final modification.
In Gram-negative bacteria like Escherichia coli, a bifunctional enzyme, MnmC, is involved in the final two steps of the biosynthesis of mnm⁵s²U.[4] The pathway begins with the modification of uridine to 5-carboxymethylaminomethyl-(2-thio)uridine (cmnm⁵(s²)U). The MnmC enzyme then catalyzes the conversion of cmnm⁵(s²)U into 5-aminomethyl-(2-thio)uridine (nm⁵(s²)U), which is subsequently methylated by the same enzyme to form the final product, mnm⁵s²U.[4] In Gram-positive bacteria such as Bacillus subtilis, which lack an MnmC ortholog, this process is carried out by two separate enzymes: YurR converts cmnm⁵(s²)U to nm⁵(s²)U, and the methyltransferase MnmM completes the final methylation step.[5]
References
- 1. Chemical synthesis of the 5-taurinomethyl(-2-thio)uridine modified anticodon arm of the human mitochondrial tRNALeu(UUR) and tRNALys - PMC [pmc.ncbi.nlm.nih.gov]
- 2. medchemexpress.com [medchemexpress.com]
- 3. Modomics - A Database of RNA Modifications [genesilico.pl]
- 4. researchgate.net [researchgate.net]
- 5. GIST Scholar: Characterization of 5-aminomethyl-2-thiouridine tRNA modification biosynthetic pathway in Bacillus subtilis [scholar.gist.ac.kr]
For Researchers, Scientists, and Drug Development Professionals
An In-depth Technical Guide on the Role of 5-(Aminomethyl)uridine in Translation
This technical guide delves into the pivotal, albeit transient, role of this compound (nm5U) in the intricate process of protein synthesis. While not a final functional component of the translational machinery itself, nm5U is a critical intermediate in the biosynthesis of hypermodified nucleosides at the wobble position of transfer RNA (tRNA). These final modifications are essential for ensuring the accuracy and efficiency of codon recognition and maintaining the reading frame during translation.
The Biosynthetic Pathway: this compound as a Key Intermediate
This compound is a modified nucleoside found at position 34 (the wobble position) of the tRNA anticodon. It serves as a precursor to the more complex and functionally significant modification, 5-methylaminomethyluridine (B1256275) (mnm5U), and its 2-thiouridine (B16713) derivative (mnm5s2U). These modifications are widely conserved in prokaryotes and are crucial for the accurate decoding of codons ending in purines (A or G).[1][2][3][4][5][6][7]
The biosynthetic pathway for mnm5(s2)U differs between Gram-negative and Gram-positive bacteria.
In Gram-negative bacteria, such as Escherichia coli:
A bifunctional enzyme, MnmC, is responsible for the final two steps of the synthesis.[2][3][6][7][8]
-
The MnmE-MnmG enzyme complex first converts the wobble uridine (B1682114) to 5-carboxymethylaminomethyluridine (B1212367) (cmnm5U).[1][8][9]
-
The C-terminal domain of MnmC (MnmC1 or MnmC(o)) then catalyzes the FAD-dependent oxidative decarboxylation of cmnm5U to form this compound (nm5U).[1][2][8]
-
Subsequently, the N-terminal domain of MnmC (MnmC2 or MnmC(m)) utilizes S-adenosyl-L-methionine (SAM) as a methyl donor to methylate nm5U, yielding the final product, mnm5U.[1][2][8]
In Gram-positive bacteria, such as Bacillus subtilis, which lack an MnmC ortholog:
Two separate enzymes carry out the final two steps of the pathway.[1][2][4]
-
Similar to Gram-negative bacteria, the pathway begins with the formation of cmnm5U by the MnmE-MnmG complex.[1]
-
An FAD-dependent oxidoreductase, YurR, converts cmnm5U to nm5U.[1]
-
A distinct methyltransferase, MnmM (formerly YtqB), then methylates nm5U to produce mnm5U, using SAM as the methyl source.[1][2][4][7]
The following diagram illustrates these biosynthetic pathways.
Function of the Resulting mnm5(s2)U Modification in Translation
The conversion of this compound to mnm5(s2)U at the wobble position has profound effects on the function of tRNA during translation. These hypermodifications are critical for maintaining translational fidelity and efficiency.
-
Codon Recognition: The primary role of mnm5(s2)U is to restrict the decoding of the third codon position, ensuring specific recognition of codons ending in A and G, while preventing misreading of codons ending in pyrimidines (U or C).[5][10] This is essential for the correct translation of two-codon families.
-
Translational Fidelity and Efficiency: The presence of the mnm5(s2)U modification enhances the stability of the codon-anticodon interaction. This leads to a reduction in translational errors, such as frameshifting, and increases the overall efficiency of protein synthesis.[11] The absence of these modifications can lead to pleiotropic phenotypes, including sensitivity to pH and general translational defects.[11]
-
Codon Preference: Studies have shown that the mnm5U modification can confer a decoding preference for NNG codons over NNA codons.[11]
Quantitative Data on Translational Effects
The impact of these modifications on translation rates has been quantified in E. coli. The data clearly demonstrates the importance of the complete mnm5s2U modification for the efficient translation of specific codons.
| tRNA Modification at U34 | Codon | Translation Rate (codons/s) |
| mnm5s2U (fully modified) | GAG | 7.7 |
| s2U (lacks mnm5 group) | GAG | 1.9 |
| mnm5U (lacks s2 group) | GAG | 6.2 |
| mnm5s2U (fully modified) | GAA | 18 |
| s2U (lacks mnm5 group) | GAA | 47 |
| mnm5U (lacks s2 group) | GAA | 4.5 |
| Data from (18) |
Experimental Protocols and Methodologies
The elucidation of the biosynthetic pathway of mnm5(s2)U and the function of this compound as an intermediate has been made possible through a combination of genetic, biochemical, and structural biology techniques.
Identification of Biosynthetic Genes
A common workflow for identifying the enzymes involved in this modification pathway, particularly in organisms lacking known orthologs, is as follows:
Key Experimental Procedures
-
Comparative Genomics: This approach is used to identify candidate genes responsible for the modification in organisms that lack known enzymes like MnmC. By comparing the genomes of organisms that have the mnm5s2U modification with those that do not, researchers can pinpoint genes that are uniquely present in the former.[2][4]
-
Gene Complementation Assays: To test the function of a candidate gene in vivo, it is expressed in a host organism where the corresponding gene has been deleted (e.g., expressing a B. subtilis candidate gene in an E. coli ΔmnmC strain). The restoration of the mnm5s2U modification is then assessed, typically by mass spectrometry analysis of isolated tRNA.[2][4]
-
In Vitro Methyltransferase and Oxidoreductase Assays: These assays confirm the specific biochemical activity of the purified candidate enzyme. For example, to confirm MnmM activity, the recombinant protein is incubated with a tRNA substrate containing nm5s2U and the methyl donor SAM. The conversion to mnm5s2U is then monitored, often using HPLC or mass spectrometry.[1][2][4]
-
X-ray Crystallography: Determining the crystal structure of the enzymes (like MnmM or YurR), often in complex with the anticodon stem-loop of their tRNA substrate, provides detailed insights into the molecular basis of substrate recognition and catalysis. These structures reveal the key amino acid residues involved in binding the tRNA and performing the chemical transformation.[1][2][4][8]
-
Mass Spectrometry: This is a crucial analytical technique used throughout the research process. It is used to identify and quantify the presence of modified nucleosides like cmnm5U, nm5U, and mnm5U in total tRNA isolates from different bacterial strains, confirming the effects of gene deletions or complementations.[4]
Conclusion
This compound occupies a central, though transient, position in a conserved tRNA modification pathway that is vital for translational accuracy. Its formation and subsequent methylation to 5-methylaminomethyluridine are critical steps that enable tRNAs to correctly and efficiently decode specific codons. Understanding this pathway and the enzymes involved not only deepens our fundamental knowledge of protein synthesis but also presents potential targets for the development of novel antimicrobial agents, as interfering with tRNA modification can be detrimental to bacterial viability. The methodologies outlined here provide a robust framework for the continued exploration of the complex world of RNA modifications and their impact on cellular function.
References
- 1. GIST Scholar: Characterization of 5-aminomethyl-2-thiouridine tRNA modification biosynthetic pathway in Bacillus subtilis [scholar.gist.ac.kr]
- 2. researchgate.net [researchgate.net]
- 3. Identification of a novel 5-aminomethyl-2-thiouridine methyltransferase in tRNA modification - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. Identification of a novel 5-aminomethyl-2-thiouridine methyltransferase in tRNA modification - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Roles of 5-substituents of tRNA wobble uridines in the recognition of purine-ending codons - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. academic.oup.com [academic.oup.com]
- 7. GIST Scholar: Identification of a novel 5-aminomethyl-2-thiouridine methyltransferase in tRNA modification [scholar.gist.ac.kr]
- 8. Structural basis for hypermodification of the wobble uridine in tRNA by bifunctional enzyme MnmC - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Insights into the Mechanism of Installation of 5-Carboxymethylaminomethyl Uridine Hypermodification by tRNA-Modifying Enzymes MnmE and MnmG - PMC [pmc.ncbi.nlm.nih.gov]
- 10. 5-[[(carboxymethyl)amino]methyl]uridine is found in the anticodon of yeast mitochondrial tRNAs recognizing two-codon families ending in a purine - PubMed [pubmed.ncbi.nlm.nih.gov]
- 11. academic.oup.com [academic.oup.com]
An In-depth Technical Guide to the Prokaryotic Biosynthesis of 5-(Aminomethyl)uridine
For Researchers, Scientists, and Drug Development Professionals
Introduction
The post-transcriptional modification of transfer RNA (tRNA) is a critical process in all domains of life, ensuring translational fidelity and efficiency. One such modification, 5-(aminomethyl)uridine (nm5U), and its derivatives, are found at the wobble position (U34) of specific tRNAs in prokaryotes. These modifications are crucial for the accurate decoding of certain codons. The biosynthesis of nm5U is a multi-step enzymatic process involving a core set of highly conserved proteins. This technical guide provides a comprehensive overview of the biosynthesis of this compound in prokaryotes, detailing the enzymatic pathway, quantitative kinetic data of the key enzymes, and methodologies for its study.
The Core Biosynthetic Pathway
The biosynthesis of this compound in prokaryotes is primarily orchestrated by the MnmE and MnmG enzymes, which form a functional heterotetrameric complex (α2β2). This MnmEG complex catalyzes the initial and crucial step of modifying the uridine (B1682114) at position 34 of the tRNA anticodon. The pathway can proceed via two main routes, depending on the substrate utilized for the aminomethyl group.
In many prokaryotes, particularly Gram-negative bacteria such as Escherichia coli, the pathway often proceeds through a 5-carboxymethylaminomethyluridine (B1212367) (cmnm5U) intermediate when glycine (B1666218) is used as a substrate. This intermediate is subsequently converted to nm5U. Alternatively, the MnmEG complex can directly synthesize nm5U using ammonium (B1175870) as the substrate.
The key enzymes involved in this pathway are:
-
MnmE (TrmE): A GTPase that binds tetrahydrofolate (THF) and is involved in the transfer of a methylene (B1212753) group.
-
MnmG (GidA): An FAD-binding protein that interacts with MnmE and the tRNA substrate.
-
MnmC: A bifunctional enzyme found in many Gram-negative bacteria that catalyzes the final two steps in the conversion of cmnm5U to 5-methylaminomethyluridine (B1256275) (mnm5U), with nm5U as an intermediate. The C-terminal domain of MnmC possesses FAD-dependent oxidoreductase activity, responsible for converting cmnm5U to nm5U, while the N-terminal domain has S-adenosyl-L-methionine (SAM)-dependent methyltransferase activity for the subsequent methylation to mnm5U.[1][2]
Quantitative Data
The following tables summarize the available quantitative data for the key enzymatic reactions in the biosynthesis of this compound and its subsequent modification in E. coli.
Table 1: Kinetic Parameters for the MnmEG-Catalyzed Reactions
| Reaction | Substrate | Km (µM) | kcat (s-1) | kcat/Km (s-1µM-1) |
| nm5s2U synthesis | tRNAGlu (ammonium-dependent) | 0.4 ± 0.1 | 0.10 ± 0.01 | 0.25 |
| cmnm5s2U synthesis | tRNAGlu (glycine-dependent) | 0.5 ± 0.1 | 0.08 ± 0.01 | 0.16 |
Table 2: Kinetic Parameters for the MnmC-Catalyzed Reactions
| Reaction | Substrate | Km (nM) | kcat (s-1) |
| cmnm5s2U → nm5s2U (Oxidoreductase activity) | cmnm5s2U-containing tRNAGlu | 600 | 0.34 |
| nm5s2U → mnm5s2U (Methyltransferase activity) | nm5s2U-containing tRNAGlu | 70 | 0.31 |
Signaling Pathways and Experimental Workflows
Biosynthetic Pathway of this compound and its Derivatives
References
The Discovery of 5-(Aminomethyl)uridine in Escherichia coli: A Technical Guide
For Researchers, Scientists, and Drug Development Professionals
Executive Summary
5-(Aminomethyl)uridine (nm5U) is a modified nucleoside found in the wobble position of transfer RNA (tRNA) in Escherichia coli. It serves as a crucial intermediate in the biosynthesis of more complex modified nucleosides, such as 5-methylaminomethyl-2-thiouridine (B1677369) (mnm5s2U), which are vital for accurate and efficient protein synthesis. The discovery and characterization of nm5U and its biosynthetic pathway in E. coli have been pivotal in understanding the intricate mechanisms of tRNA modification and its role in translational fidelity. This technical guide provides an in-depth overview of the discovery of nm5U in E. coli, detailing the enzymatic pathways, experimental protocols used for its identification, and quantitative data related to its synthesis.
Introduction to this compound and its Significance
Post-transcriptional modifications of tRNA are essential for their proper function, including folding, stability, and accurate codon recognition. Modifications at the wobble position (position 34) of the anticodon are particularly critical for decoding messenger RNA (mRNA). In E. coli, the uridine (B1682114) at this position in tRNAs specific for certain amino acids undergoes a series of modifications, leading to the formation of complex nucleosides. This compound (nm5U) is a key intermediate in one such pathway. Its discovery was a significant step in unraveling the complex network of tRNA modification enzymes and their roles in maintaining cellular homeostasis.
The Biosynthetic Pathway of this compound in E. coli
The synthesis of this compound in E. coli is primarily accomplished through a sophisticated enzymatic pathway involving two key components: the MnmE-MnmG enzyme complex and the bifunctional enzyme MnmC.[1] There are two distinct routes for the formation of the aminomethyl group at the C5 position of uridine.
The MnmE-MnmG Complex: The Initial Step
The MnmE-MnmG complex, a heterodimer, catalyzes the initial modification of the wobble uridine.[2][3] This complex can utilize two different substrates to produce two different precursors to the final modified nucleoside:
-
The Ammonium (B1175870) Pathway: In the presence of ammonium as a substrate, the MnmE-MnmG complex can directly synthesize 5-aminomethyluridine (B12866518) (nm5U).[3]
-
The Glycine (B1666218) Pathway: When glycine is used as the substrate, the MnmE-MnmG complex produces 5-carboxymethylaminomethyluridine (B1212367) (cmnm5U).[4]
The Role of the Bifunctional Enzyme MnmC
The MnmC protein possesses two distinct enzymatic domains that are crucial for the subsequent steps of the modification pathway.[1] The discovery and characterization of these activities were instrumental in understanding the complete biosynthesis of mnm5s2U.
-
Oxidoreductase Domain (MnmC(o)): The C-terminal domain of MnmC functions as an FAD-dependent oxidoreductase. This domain catalyzes the conversion of cmnm5U, produced by the MnmE-MnmG complex in the glycine pathway, into nm5U.[4]
-
Methyltransferase Domain (MnmC(m)): The N-terminal domain of MnmC is an S-adenosyl-L-methionine (SAM)-dependent methyltransferase. This domain is responsible for the final step in the synthesis of 5-methylaminomethyluridine (B1256275) (mnm5U) by methylating nm5U.[1]
The identification of these two distinct activities within a single polypeptide was a key finding in elucidating the biosynthetic pathway.[1]
The Discovery of this compound in E. coli Mutants
The definitive identification of this compound as an intermediate in tRNA modification came from the analysis of E. coli mutants deficient in the trmC gene (now known as mnmC). Specifically, the analysis of the trmC2 mutant was pivotal.
In a seminal 1987 study by Hagervall, Edmonds, McCloskey, and Björk, tRNA from a trmC2 mutant strain was isolated and analyzed.[1] Using a combination of chromatographic and mass spectrometric techniques, they identified the presence of 5-aminomethyl-2-thiouridine (B1259639) (nm5s2U), the 2-thiolated form of nm5U.[1] This finding strongly indicated that nm5U is an intermediate that accumulates in the absence of a functional MnmC methyltransferase domain.
In the same study, analysis of a different mutant, trmC1, revealed the accumulation of 5-carboxymethylaminomethyl-2-thiouridine (B1228955) (cmnm5s2U), confirming it as the precursor to nm5s2U in the glycine-dependent pathway.[1] These findings allowed the researchers to propose the sequential order of the biosynthetic pathway.
Quantitative Data on this compound Synthesis
While precise kinetic parameters for all enzymatic steps are not fully elucidated, some quantitative data is available from various studies.
| Enzyme/Complex | Substrate(s) | Product | Kinetic Parameter | Value | Reference |
| MnmC | nm5s2U-tRNA, SAM | mnm5s2U-tRNA | Molecular Activity | 74 min-1 | [1] |
| MnmC | - | - | Cellular Concentration | ~78 molecules/genome equivalent | [1] |
Note: The molecular activity for the MnmC(o) domain (cmnm5U to nm5U) has not been explicitly reported in the reviewed literature. The yield of nm5U from the MnmE-MnmG ammonium pathway is also not quantitatively defined but is an active area of research.
Experimental Protocols
The identification and characterization of this compound in E. coli tRNA relied on a series of meticulous experimental procedures. Below are detailed methodologies for the key experiments.
Isolation of Bulk tRNA from E. coli
This protocol is adapted from standard procedures for tRNA extraction.
-
Cell Culture and Harvest: Grow E. coli cells (e.g., wild-type and mnmC mutant strains) in the desired growth medium to the late logarithmic phase. Harvest the cells by centrifugation.
-
Cell Lysis: Resuspend the cell pellet in a suitable buffer (e.g., Tris-HCl with MgCl2). Lyse the cells using a method such as sonication or French press.
-
Phenol (B47542) Extraction: Extract the cell lysate with an equal volume of buffer-saturated phenol to remove proteins. Centrifuge to separate the aqueous and organic phases.
-
Ethanol Precipitation: Collect the aqueous phase containing the nucleic acids and precipitate the RNA by adding 2-3 volumes of cold ethanol. Incubate at -20°C to facilitate precipitation.
-
tRNA Purification: Collect the RNA pellet by centrifugation. To specifically isolate tRNA, further purification steps such as size-exclusion chromatography or anion-exchange chromatography can be employed.
Enzymatic Digestion of tRNA to Nucleosides
To analyze the nucleoside composition, the purified tRNA must be completely hydrolyzed to its constituent nucleosides.
-
Enzyme Digestion: Dissolve the purified tRNA in a suitable buffer. Add a mixture of nucleases, typically Nuclease P1 followed by bacterial alkaline phosphatase, to digest the tRNA into individual nucleosides.
-
Incubation: Incubate the reaction mixture at 37°C for a sufficient time to ensure complete digestion.
-
Enzyme Inactivation: Inactivate the enzymes, for example, by heat treatment.
Analysis of Nucleosides by High-Performance Liquid Chromatography (HPLC)
HPLC is a powerful technique for separating and quantifying the different nucleosides in a sample.
-
Sample Preparation: Filter the digested tRNA sample to remove any particulate matter.
-
Chromatographic Separation: Inject the sample onto a reverse-phase HPLC column (e.g., a C18 column). Elute the nucleosides using a gradient of a suitable mobile phase, such as ammonium acetate (B1210297) or ammonium formate (B1220265) buffer with an organic modifier like acetonitrile (B52724) or methanol.
-
Detection and Quantification: Monitor the elution of the nucleosides using a UV detector, typically at a wavelength of 254 nm or 314 nm for thiolated nucleosides. The retention time and the peak area are used for identification and quantification, respectively, by comparing them to known standards.
Mass Spectrometry (MS) for Structural Confirmation
Mass spectrometry is essential for the unambiguous identification of modified nucleosides.
-
LC-MS Analysis: Couple the HPLC system to a mass spectrometer (LC-MS). This allows for the determination of the mass-to-charge ratio (m/z) of each eluting nucleoside.
-
Tandem MS (MS/MS): To further confirm the structure, perform tandem mass spectrometry. In this technique, the ion corresponding to the nucleoside of interest is isolated and fragmented, and the resulting fragmentation pattern provides detailed structural information.
In Vitro Reconstitution of the Biosynthetic Pathway
To confirm the function of the enzymes involved, in vitro assays are performed.
-
Protein Purification: Purify the MnmE, MnmG, and MnmC proteins from overexpressing E. coli strains.
-
Reaction Setup: In a reaction buffer, combine the purified enzymes with a tRNA substrate (either total tRNA from a mutant lacking the modification or a specific in vitro transcribed tRNA), and the necessary co-factors (e.g., ammonium or glycine, S-adenosylmethionine, FAD, GTP).
-
Reaction and Analysis: Incubate the reaction mixture and then analyze the tRNA for the presence of the modified nucleoside using the digestion and HPLC/MS methods described above.
Visualizations of Pathways and Workflows
Biosynthetic Pathway of this compound
Caption: Biosynthesis of this compound (nm5U) in E. coli.
Experimental Workflow for the Identification of nm5U
Caption: Workflow for identifying this compound in E. coli tRNA.
Conclusion and Future Perspectives
The discovery of this compound in E. coli was a landmark in the field of tRNA modification. It highlighted the intricate and highly regulated enzymatic pathways that ensure the fidelity of protein synthesis. The identification of the MnmE-MnmG complex and the bifunctional MnmC enzyme has provided a framework for understanding how these modifications are synthesized.
For researchers and drug development professionals, this knowledge offers several avenues for exploration. The enzymes in this pathway could be potential targets for novel antimicrobial agents, as disruption of tRNA modification can be detrimental to bacterial growth. Furthermore, understanding the role of these modifications in translation can inform strategies for optimizing the expression of recombinant proteins in E. coli.
Future research will likely focus on the detailed kinetic characterization of the enzymes involved, the structural basis of their substrate specificity, and the interplay between different tRNA modification pathways. A deeper understanding of these processes will undoubtedly continue to reveal the profound impact of the "epitranscriptome" on cellular function.
References
- 1. Transfer RNA(5-methylaminomethyl-2-thiouridine)-methyltransferase from Escherichia coli K-12 has two enzymatic activities - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. Identification of a novel 5-aminomethyl-2-thiouridine methyltransferase in tRNA modification - PMC [pmc.ncbi.nlm.nih.gov]
- 3. The output of the tRNA modification pathways controlled by the Escherichia coli MnmEG and MnmC enzymes depends on the growth conditions and the tRNA species - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Quantitative analysis of tRNA modifications by HPLC-coupled mass spectrometry [dspace.mit.edu]
The Pivotal Role of 5-(Aminomethyl)uridine at the Wobble Position: An In-depth Technical Guide
For Researchers, Scientists, and Drug Development Professionals
Abstract
Post-transcriptional modifications of transfer RNA (tRNA), particularly at the wobble position (nucleotide 34) of the anticodon, are critical for maintaining translational fidelity and efficiency. This technical guide provides a comprehensive overview of the role of 5-(aminomethyl)uridine (nm5U) and its derivatives at this crucial position. We delve into the biosynthesis of nm5U, its impact on codon recognition and translation kinetics, and its intricate connection to cellular signaling pathways that govern cell growth and stress responses. This document summarizes key quantitative data, provides detailed experimental protocols for studying tRNA modifications, and presents visual representations of the associated molecular pathways to facilitate a deeper understanding of this vital aspect of gene expression.
Introduction
The accurate and efficient translation of the genetic code is fundamental to all life. Transfer RNAs act as the bridge between the messenger RNA (mRNA) template and the nascent polypeptide chain. The fidelity of this process is heavily reliant on the precise recognition of mRNA codons by the tRNA anticodon. The "wobble" hypothesis, proposed by Francis Crick, posits that the base at the first position of the anticodon (position 34) can engage in non-Watson-Crick base pairing with the third base of the codon. This flexibility is finely tuned by a vast array of post-transcriptional modifications. Among these, the modifications at the C5 position of uridine (B1682114) at the wobble position (U34) play a significant role.
This compound (nm5U) is a modification found at the wobble position of certain tRNAs. It is often further modified to 5-methylaminomethyluridine (B1256275) (mnm5U). These modifications are crucial for the accurate decoding of codons with A or G in the third position. Deficiencies in these modifications can lead to translational frameshifting, reduced protein synthesis, and have been implicated in various human diseases, including mitochondrial disorders. This guide will explore the multifaceted role of nm5U at the wobble position, providing a technical resource for researchers in the field.
Biosynthesis of this compound and its Derivatives
The biosynthesis of nm5U and its subsequent methylation to mnm5U is a multi-step enzymatic process. In bacteria, the pathway is well-characterized and involves the MnmE-MnmG complex and the bifunctional enzyme MnmC.
The MnmE-MnmG complex, a GTPase and a FAD-dependent enzyme respectively, catalyzes the formation of 5-carboxymethylaminomethyluridine (B1212367) (cmnm5U) from tRNA, glycine, and ATP. The MnmC enzyme then carries out the final two steps. The C-terminal oxidase domain of MnmC converts cmnm5U to nm5U, and the N-terminal methyltransferase domain subsequently methylates nm5U to mnm5U, using S-adenosyl-L-methionine (SAM) as the methyl donor.[1][2] In some bacteria, two separate enzymes, YurR (MnmC(o)-like) and MnmM (MnmC(m)-like), perform these last two steps.[2]
In eukaryotes, the orthologs of these enzymes are found in the mitochondria, where MTO1 (MnmG) and MTO2 (MnmE) are involved in the formation of the cmnm5 side chain.[3][4] The subsequent steps to form nm5U and mnm5U are less well-characterized in the cytoplasm of eukaryotes.
dot
Role in Codon Recognition and Translation
The presence of nm5U and its derivatives at the wobble position has a profound impact on the efficiency and fidelity of translation. These modifications are critical for the proper decoding of codons ending in purines (A and G).
Translation Efficiency
The absence of wobble modifications like mnm5s2U34 (a 2-thiolated derivative of mnm5U) significantly alters translation rates for specific codons. Studies in Escherichia coli have provided quantitative data on the effect of these modifications on the speed of translation.
| Codon | tRNA Modification Status | Translation Rate (codons/second) | Fold Change |
| GAA | Wild-type (mnm5s2U34) | 18 | - |
| GAA | Lacks 5-methylaminomethyl group (s2U34) | 47 | +2.6 |
| GAA | Lacks 2-thio group (mnm5U34) | 4.5 | -4.0 |
| GAG | Wild-type (mnm5s2U34) | 7.7 | - |
| GAG | Lacks 5-methylaminomethyl group (s2U34) | 1.9 | -4.1 |
| GAG | Lacks 2-thio group (mnm5U34) | 6.2 | -1.2 |
| Data adapted from a study on the influence of mnm5s2U34 modification in tRNAGlu on the translation rate of glutamate (B1630785) codons in E. coli.[5] |
These data indicate that the 5-methylaminomethyl group of mnm5s2U34 enhances the translation of G-ending codons while reducing the rate for A-ending codons, thereby balancing the translation speeds of synonymous codons. The 2-thio modification primarily enhances the recognition of A-ending codons.[5] The lack of these modifications can lead to ribosome pausing at specific codons, which can impact protein folding and overall protein expression levels.[6][7][8]
Translation Fidelity
Wobble modifications are also crucial for maintaining translational fidelity by preventing misreading of near-cognate codons. The absence of these modifications can increase the rate of amino acid misincorporation. While specific quantitative data for nm5U is limited, studies on related modifications suggest that they enhance the stability of the codon-anticodon interaction, allowing for more accurate discrimination against near-cognate tRNAs. Hypomodified tRNAs may have a reduced affinity for their cognate codons, leading to increased competition from non-cognate tRNAs and a higher error rate.[9][10]
Connection to Cellular Signaling Pathways
Defects in tRNA wobble modifications have been shown to impinge on major cellular signaling pathways, primarily the Target of Rapamycin (B549165) (TOR) and the General Amino Acid Control (GAAC) pathways, which are central regulators of cell growth, proliferation, and stress responses.
The TOR Pathway
The TOR pathway is a highly conserved signaling cascade that integrates nutrient availability with cell growth and proliferation. In yeast, loss of wobble uridine modifications, such as those dependent on the Elongator complex, leads to hypersensitivity to the TOR inhibitor rapamycin.[3][11][12] This suggests that proper tRNA modification is required for normal TOR signaling.
The mechanism appears to involve the transcription factor Gln3, which is negatively regulated by the TOR complex 1 (TORC1). Under nutrient-rich conditions, TORC1 promotes the phosphorylation of Gln3, leading to its sequestration in the cytoplasm. When TORC1 is inhibited (e.g., by rapamycin or nutrient limitation), Gln3 is dephosphorylated and translocates to the nucleus to activate the transcription of genes involved in nitrogen catabolite repression (NCR). In cells with defective tRNA wobble modifications, Gln3 is mislocalized to the nucleus even under normal growth conditions.[3][13] This suggests that the translational defects caused by the lack of these modifications are interpreted by the cell as a stress signal that leads to the downregulation of TORC1 activity.
dot
The General Amino Acid Control (GAAC) Pathway
The GAAC pathway is a conserved stress response pathway that is activated by amino acid starvation. A key player in this pathway is the protein kinase GCN2, which is activated by the accumulation of uncharged tRNAs. Activated GCN2 phosphorylates the alpha subunit of eukaryotic initiation factor 2 (eIF2α), which leads to a global reduction in protein synthesis but paradoxically increases the translation of the transcription factor GCN4.[14][15] GCN4 then activates the transcription of genes involved in amino acid biosynthesis.
While the primary activator of GCN2 is uncharged tRNA, there is evidence suggesting a link between tRNA modifications and the GAAC pathway.[16] The inefficient translation caused by the lack of wobble modifications could potentially lead to an increase in uncharged tRNA levels, thereby activating the GCN2-GCN4 cascade.
dot
References
- 1. Translational regulation of yeast GCN4. A window on factors that control initiator-trna binding to the ribosome - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. The Basics: In Vitro Translation | Thermo Fisher Scientific - JP [thermofisher.com]
- 3. biorxiv.org [biorxiv.org]
- 4. A simple real-time assay for in vitro translation - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Translational activation of GCN4 mRNA in a cell-free system is triggered by uncharged tRNAs - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Ribosome Pausing at Inefficient Codons at the End of the Replicase Coding Region Is Important for Hepatitis C Virus Genome Replication - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. Translational control through differential ribosome pausing during amino acid limitation in mammalian cells - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Codon-specific ribosome stalling reshapes translational dynamics during branched-chain amino acid starvation - PMC [pmc.ncbi.nlm.nih.gov]
- 9. [PDF] Wobble tRNA modification and hydrophilic amino acid patterns dictate protein fate | Semantic Scholar [semanticscholar.org]
- 10. journals.asm.org [journals.asm.org]
- 11. academic.oup.com [academic.oup.com]
- 12. [PDF] Multiple mechanisms activate GCN2 eIF2 kinase in response to diverse stress conditions | Semantic Scholar [semanticscholar.org]
- 13. Translational regulation of GCN4 and the general amino acid control of yeast - PubMed [pubmed.ncbi.nlm.nih.gov]
- 14. Wobble modification defect in tRNA disturbs codon–anticodon interaction in a mitochondrial disease | The EMBO Journal [link.springer.com]
- 15. Methods for Kinetic and Thermodynamic Analysis of Aminoacyl-tRNA Synthetases - PMC [pmc.ncbi.nlm.nih.gov]
- 16. Uncharged tRNA activates GCN2 by displacing the protein kinase moiety from a bipartite tRNA-binding domain - PubMed [pubmed.ncbi.nlm.nih.gov]
enzymatic pathway for 5-(Aminomethyl)uridine synthesis
An In-depth Technical Guide on the Enzymatic Synthesis of 5-(Aminomethyl)uridine
Introduction
This compound (nm5U) is a post-transcriptional modification found in the wobble position (U34) of certain transfer RNAs (tRNAs). This modification is crucial for the accuracy and efficiency of protein translation, ensuring correct codon recognition and maintenance of the reading frame. The enzymatic synthesis of nm5U is a multi-step process involving a highly conserved set of enzymes. This guide provides a detailed overview of the core enzymatic pathway, quantitative data, experimental protocols, and visual diagrams for researchers in biochemistry, molecular biology, and drug development.
Core Enzymatic Pathway
The biosynthesis of this compound is initiated by the MnmE-MnmG enzyme complex, which modifies the uridine (B1682114) base at the C5 position. The pathway can proceed through two alternative routes depending on the substrate utilized.
1. MnmE-MnmG Complex Activity
The initial modification is catalyzed by a heterotetrameric α2β2 complex formed by the MnmE and MnmG proteins.[1]
-
MnmE (TrmE): A GTPase that binds tetrahydrofolate (THF) derivatives. GTP hydrolysis is essential for the modification reaction to proceed.[2][3]
-
MnmG (GidA): A flavin adenine (B156593) dinucleotide (FAD) and NADH-binding oxidoreductase that is primarily responsible for binding the tRNA substrate.[1][4]
The MnmEG complex utilizes N5,N10-methylenetetrahydrofolate (CH2THF) as the donor for the one-carbon methylene (B1212753) group that is attached to the C5 of uridine.[5] The reaction can proceed via two distinct pathways:
-
Ammonium-Dependent Pathway: The MnmEG complex can use ammonium (B1175870) (NH4+) as a substrate to directly catalyze the formation of this compound (nm5U) on the tRNA.[2]
-
Glycine-Dependent Pathway: More commonly, the complex utilizes glycine (B1666218) as a substrate, leading to the formation of an intermediate, 5-carboxymethylaminomethyluridine (B1212367) (cmnm5U).[2][5]
2. Conversion of cmnm5U to nm5U by MnmC
In many Gram-negative bacteria, such as Escherichia coli, the cmnm5U intermediate is further processed by the bifunctional enzyme MnmC to yield nm5U.[6][7] MnmC contains two distinct catalytic domains:
-
MnmC(o) Domain: This FAD-dependent oxidase domain catalyzes the oxidative cleavage of the carboxymethyl group from cmnm5U, releasing glycine and forming nm5U.[3][6]
-
MnmC(m) Domain: This S-adenosyl-L-methionine (SAM)-dependent methyltransferase domain subsequently methylates the aminomethyl group of nm5U to produce the final modified nucleoside, 5-methylaminomethyluridine (B1256275) (mnm5U).[3][6]
In Gram-positive bacteria like Bacillus subtilis that lack an mnmC ortholog, these two steps are performed by two separate enzymes, YurR (MnmC(o)-like) and MnmM (MnmC(m)-like), respectively.[6]
Enzymatic Pathway Diagram
Quantitative Data
The following table summarizes the steady-state kinetic parameters for the two enzymatic activities of the E. coli MnmC enzyme, which are central to the final steps of mnm5U biosynthesis.
| Enzyme Activity | Substrate | Km (nM) | kcat (s-1) | Source |
| MnmC (oxidase) | cmnm5s2U-tRNA | 600 | 0.34 | [8][9] |
| MnmC (methyltransferase) | nm5s2U-tRNA | 70 | 0.31 | [8][9] |
The kinetic data indicate that the second reaction (methylation) occurs faster or at a similar rate to the first (oxidative decarboxylation), which suggests a mechanism to prevent the accumulation of the nm5U intermediate.[8][9]
Experimental Protocols
In Vitro Reconstitution of the MnmE-MnmG Reaction
This protocol describes the in vitro synthesis of cmnm5U on a tRNA substrate using purified MnmE and MnmG enzymes.[10][11]
A. Materials and Reagents:
-
Purified MnmE and MnmG proteins
-
In vitro transcribed tRNA (e.g., tRNALys)
-
1 M Tris-HCl, pH 8.0
-
1 M MgCl2
-
3 M KCl
-
Glycerol
-
N5,N10-methylenetetrahydrofolate (CH2THF)
-
Flavin adenine dinucleotide (FAD)
-
Nicotinamide adenine dinucleotide (NADH)
-
Glycine
-
Guanosine-5′-triphosphate (GTP)
-
RNase inhibitor
B. Procedure:
-
Prepare a pre-incubation mixture by combining MnmE and MnmG (final concentrations of 40–50 µM each) in a buffer containing 100 mM Tris-HCl (pH 8.0), 100-150 mM KCl, and 5% glycerol.
-
Incubate the enzyme mixture for 30 minutes.
-
Prepare the final reaction mixture (50 µL total volume) with the following final concentrations:
-
50 mM Tris-HCl
-
5–10 mM MgCl2
-
100–150 mM KCl
-
0.5 mM CH2THF
-
0.5 mM FAD
-
0.5 mM NADH
-
2 mM Glycine
-
2 mM GTP
-
15–20 µg of in vitro transcribed tRNA
-
3-5% Glycerol
-
-
Add the pre-incubated MnmE-MnmG complex to the final reaction mixture.
-
Incubate the reaction overnight (12–14 hours) at 37°C under anoxic conditions to prevent oxidation of cofactors.[5]
-
Stop the reaction and proceed with tRNA purification and analysis.
HPLC-MS Analysis of tRNA Modifications
This protocol provides a general workflow for the identification and quantification of modified nucleosides from a tRNA sample.[12][13]
A. Materials and Reagents:
-
Purified total tRNA or specific tRNA species
-
Nuclease P1
-
Bacterial alkaline phosphatase
-
Ammonium acetate (B1210297) buffer
-
Acetonitrile (HPLC grade)
-
Formic acid (MS grade)
B. Procedure:
-
tRNA Hydrolysis: Digest 1-5 µg of purified tRNA to single nucleosides by incubating with Nuclease P1 followed by bacterial alkaline phosphatase.
-
Chromatographic Separation: Separate the resulting nucleosides using reversed-phase high-performance liquid chromatography (HPLC). A C18 column is typically used with a gradient elution, for example:
-
Mobile Phase A: Water with 0.1% formic acid
-
Mobile Phase B: Acetonitrile with 0.1% formic acid
-
A shallow gradient from 100% A to 95% A over several minutes, followed by a steeper gradient to resolve all compounds.[13]
-
-
Mass Spectrometry Detection: Couple the HPLC output to a tandem quadrupole mass spectrometer (MS/MS) operating in positive ion mode.
-
Quantification: Use dynamic multiple reaction monitoring (DMRM) to identify and quantify individual nucleosides based on their specific precursor-to-product ion transitions and retention times.[12][13]
Experimental Workflow Diagram
References
- 1. The output of the tRNA modification pathways controlled by the Escherichia coli MnmEG and MnmC enzymes depends on the growth conditions and the tRNA species - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Enzymology of tRNA modification in the bacterial MnmEG pathway - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. SAXS analysis of the tRNA-modifying enzyme complex MnmE/MnmG reveals a novel interaction mode and GTP-induced oligomerization - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. academic.oup.com [academic.oup.com]
- 5. Elucidation of the substrate of tRNA-modifying enzymes MnmEG leads to in vitro reconstitution of an evolutionarily conserved uridine hypermodification - PMC [pmc.ncbi.nlm.nih.gov]
- 6. GIST Scholar: Characterization of 5-aminomethyl-2-thiouridine tRNA modification biosynthetic pathway in Bacillus subtilis [scholar.gist.ac.kr]
- 7. Identification of a novel 5-aminomethyl-2-thiouridine methyltransferase in tRNA modification - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Assay of both activities of the bifunctional tRNA-modifying enzyme MnmC reveals a kinetic basis for selective full modification of cmnm5s2U to mnm5s2U - PMC [pmc.ncbi.nlm.nih.gov]
- 9. academic.oup.com [academic.oup.com]
- 10. pubs.acs.org [pubs.acs.org]
- 11. Insights into the Mechanism of Installation of 5-Carboxymethylaminomethyl Uridine Hypermodification by tRNA-Modifying Enzymes MnmE and MnmG - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Quantitative analysis of tRNA modifications by HPLC-coupled mass spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 13. researchgate.net [researchgate.net]
The Pivotal Role of 5-(Aminomethyl)uridine in Codon Recognition: An In-depth Technical Guide
For Researchers, Scientists, and Drug Development Professionals
Abstract
Post-transcriptional modification of transfer RNA (tRNA) is a critical layer of gene expression regulation, ensuring the fidelity and efficiency of protein synthesis. Among the myriad of modified nucleosides, 5-(aminomethyl)uridine (nm5U) and its derivatives, located at the wobble position (U34) of the tRNA anticodon, play a crucial role in the precise decoding of messenger RNA (mRNA) codons. This technical guide provides a comprehensive overview of the biosynthesis of this compound, its impact on codon recognition patterns, and the experimental methodologies used to study these phenomena. We present quantitative data on the kinetics of enzymatic reactions and the effects on translation, detailed experimental protocols for key assays, and visual representations of the underlying molecular pathways and workflows to serve as a valuable resource for researchers in the fields of molecular biology, biochemistry, and drug development.
Introduction
The accurate translation of the genetic code is fundamental to all life. Transfer RNAs act as adaptor molecules, bridging the gap between the nucleotide sequence of mRNA and the amino acid sequence of proteins. The interaction between the mRNA codon and the tRNA anticodon is the linchpin of this process. However, the standard Watson-Crick base pairing rules are often insufficient to explain the observed decoding patterns. The "wobble" hypothesis, proposed by Francis Crick, posits that the base at the first position of the anticodon (position 34) can pair with multiple bases at the third position of the codon. This flexibility is heavily influenced by post-transcriptional modifications of the wobble base.
Derivatives of 5-methyluridine (B1664183) (xm5U), which include 5-(carboxymethylaminomethyl)uridine (cmnm5U), this compound (nm5U), and 5-(methylaminomethyl)uridine (mnm5U), are widely conserved modifications found at the wobble position of many prokaryotic and eukaryotic tRNAs.[1][2] These modifications are crucial for the accurate recognition of codons ending in purines (A or G) and for maintaining the translational reading frame.[3][4] Dysregulation of these modification pathways has been linked to various human diseases, making the enzymes involved potential targets for therapeutic intervention.
This guide will delve into the technical details of the this compound modification pathway, its functional consequences for codon recognition, and the state-of-the-art techniques used to investigate them.
Biosynthesis of this compound and its Derivatives
The biosynthesis of nm5U and its derivatives is a multi-step enzymatic process. In bacteria, the initial step is the formation of 5-carboxymethylaminomethyluridine (B1212367) (cmnm5U), which is subsequently converted to nm5U and then to mnm5U.
The MnmEG Complex: The Initiating Step
The first committed step in the biosynthesis of xm5U modifications is catalyzed by the MnmE and MnmG protein complex.[5][6] MnmE is a GTPase that belongs to the GAD (G protein activated by dimerization) family, while MnmG (also known as GidA) is a FAD-dependent oxidoreductase.[7][8] Together, they form a heterotetrameric α2β2 complex that utilizes glycine (B1666218), methylene-tetrahydrofolate (CH2THF), FAD, NADH, and GTP to install a carboxymethylaminomethyl group onto the C5 position of the wobble uridine (B1682114) (U34) of specific tRNAs.[5][7] The MnmEG complex can also use ammonia (B1221849) instead of glycine as a substrate to directly form 5-aminomethyl (nm5) uridine, depending on the growth conditions.[5][9]
The Bifunctional Enzyme MnmC: Conversion to nm5U and mnm5U
In Gram-negative bacteria like Escherichia coli, the conversion of cmnm5U to the final mnm5U modification is carried out by the bifunctional enzyme MnmC.[6][10][11] MnmC possesses two distinct catalytic domains:
-
MnmC1 (C-terminal domain): An FAD-dependent oxidase that removes the carboxymethyl group from cmnm5U to produce nm5U.[10][11]
-
MnmC2 (N-terminal domain): An S-adenosyl-L-methionine (SAM)-dependent methyltransferase that methylates the amino group of nm5U to yield mnm5U.[10][11]
Alternative Pathways in Other Organisms
Interestingly, many Gram-positive bacteria and plants lack a clear MnmC ortholog, suggesting the existence of alternative enzymatic pathways.[12][13] In Bacillus subtilis, two separate enzymes, YurR (MnmC(o)-like) and MnmM (YtqB, MnmC(m)-like), have been identified to catalyze the two-step conversion of cmnm5s2U to mnm5s2U.[13]
Impact on Codon Recognition and Translation
The modifications at the wobble uridine have a profound impact on the decoding properties of tRNA, influencing both the efficiency and fidelity of translation.
Wobble Pairing and Codon Specificity
The xm5U modifications restrict the wobble pairing capabilities of U34, primarily enabling the recognition of codons ending in A and G, while discriminating against those ending in U and C.[14][15] This restriction is crucial for the correct translation of "split codon boxes" where the four codons starting with the same two bases code for different amino acids. The modification helps to pre-organize the anticodon loop into a conformation that is optimal for binding to purine-ending codons.[16]
Translational Efficiency and Ribosome Pausing
The presence of xm5U modifications generally enhances the rate of translation of their cognate codons.[17] Conversely, the absence of these modifications can lead to ribosome pausing at these codons, as the unmodified tRNA is less efficient at decoding.[17][18] This pausing can have significant downstream consequences, including protein misfolding and the activation of cellular stress responses.[17] Ribosome profiling studies have shown a 1.5- to 2.5-fold increase in ribosome occupancy at AAA, CAA, and GAA codons in organisms lacking the U34 2-thiolation, a modification often found in conjunction with xm5U.[17]
Maintaining Proteome Integrity
By ensuring optimal codon translation rates, tRNA modifications like this compound play a vital role in maintaining proteome integrity.[17] Slower decoding of specific codons due to the lack of these modifications can lead to widespread protein aggregation.[17] This highlights the intricate link between tRNA modification, translational kinetics, and protein homeostasis.
Quantitative Data on Enzymatic Activity and Codon Recognition
The following tables summarize key quantitative data from studies on the enzymes involved in this compound biosynthesis and the impact of these modifications on codon recognition.
Table 1: Kinetic Parameters of MnmC and MnmEG Enzymes
| Enzyme/Domain | Substrate tRNA | Km (µM) | kcat (s-1) | kcat/Km (s-1µM-1) | Reference |
| MnmC (total) | cmnm5s2U-tRNAGlu | 2.1 ± 0.4 | 0.14 ± 0.01 | 0.067 | [9] |
| MnmC(o) | cmnm5s2U-tRNAGlu | 1.8 ± 0.3 | 0.09 ± 0.01 | 0.050 | [9] |
| MnmC(m) | nm5s2U-tRNAGlu | 0.9 ± 0.2 | 0.23 ± 0.02 | 0.256 | [9] |
| MnmEG | U-tRNAGly (Ammonium pathway) | 3.2 ± 0.5 | 0.03 ± 0.002 | 0.009 | [9] |
| MnmEG | U-tRNAGly (Glycine pathway) | 2.8 ± 0.6 | 0.02 ± 0.001 | 0.007 | [9] |
Table 2: Ribosome A-Site Occupancy Changes Upon Loss of U34 Modifications
| Codon | Organism | Fold Change in Occupancy (mutant vs. WT) | tRNA Modification Lost | Reference |
| AAA | S. cerevisiae | 1.2 - 1.36 | mcm5s2U | [17] |
| CAA | S. cerevisiae | 1.2 - 1.36 | mcm5s2U | [17] |
| GAA | S. cerevisiae | ~1.2 | mcm5s2U | [17] |
| AAA | C. elegans | 1.5 - 2.5 | mcm5s2U | [17] |
| CAA | C. elegans | 1.5 - 2.5 | mcm5s2U | [17] |
| GAA | C. elegans | 1.5 - 2.5 | mcm5s2U | [17] |
Table 3: Thermodynamic Parameters of Anticodon Stem-Loop Interactions
| ASL Modification | ΔH° (kcal/mol) | ΔS° (eu) | ΔG°37 (kcal/mol) | Tm (°C) | Reference |
| Unmodified | -45.8 ± 1.2 | -129.0 ± 3.4 | -7.2 | 59.5 ± 0.2 | [19] |
| ψ39 | -52.2 ± 1.1 | -146.1 ± 3.2 | -7.1 | 64.5 ± 0.2 | [19] |
Note: Data for this compound specifically was not available in a comparable format. This table illustrates the stabilizing effect of another common anticodon loop modification, pseudouridine (B1679824) (ψ).
Table 4: Structural Data for MnmM from B. subtilis in complex with Gln-TTG anticodon stem loop and SAM
| Data Collection | |
| PDB ID | 8H0S |
| Resolution (Å) | 2.90 |
| Space group | P 1 |
| Unit cell lengths (Å) | a=43.18, b=60.75, c=94.06 |
| Unit cell angles (°) | α=90.97, β=93.10, γ=101.55 |
| Refinement | |
| R-work | 0.241 |
| R-free | 0.285 |
| RMSD bond lengths (Å) | 0.005 |
| RMSD bond angles (°) | 1.263 |
Data obtained from the Protein Data Bank.[9]
Experimental Protocols
This section provides detailed methodologies for key experiments used to study this compound and its role in codon recognition.
In Vitro Reconstitution of the MnmEG Reaction
This protocol describes the in vitro reconstitution of the enzymatic activity of the MnmE and MnmG complex to produce cmnm5U-modified tRNA.[7][10]
Materials:
-
Purified MnmE and MnmG proteins
-
In vitro transcribed or purified hypomodified tRNA (e.g., from a ΔmnmE strain)
-
1 M Tris-HCl, pH 8.0
-
1 M KCl
-
500 mM MgCl2
-
N5,N10-Methylenetetrahydrofolate (CH2THF)
-
Flavin adenine (B156593) dinucleotide (FAD)
-
Nicotinamide adenine dinucleotide (NADH)
-
Glycine
-
Guanosine-5'-triphosphate (GTP)
-
RNase inhibitor
-
Anoxic glovebox chamber
Procedure:
-
Prepare all buffers and stock solutions under anoxic conditions in a glovebox.
-
Pre-incubate MnmE and MnmG (final concentration ~40-50 µM each) in a solution containing 100 mM Tris-HCl (pH 8.0), 100-150 mM KCl, and 5% glycerol for 30 minutes.
-
Prepare the reaction mixture containing 50 mM Tris-HCl (pH 8.0), 5-10 mM MgCl2, 100-150 mM KCl, 0.5 mM CH2THF, 0.5 mM FAD, 0.5 mM NADH, 2 mM glycine, 2 mM GTP, and 15-20 µg of tRNA per 50 µL reaction.
-
Add RNase inhibitor to the tRNA before adding it to the reaction mixture.
-
Initiate the reaction by adding the pre-incubated MnmEG complex to the reaction mixture.
-
Incubate the reaction overnight (12-14 hours) at 37°C.
-
Stop the reaction and extract the tRNA for analysis by HPLC-mass spectrometry.
Ribosome Profiling to Analyze Codon Occupancy
Ribosome profiling (Ribo-Seq) is a powerful technique to obtain a genome-wide snapshot of translation. This protocol is adapted for studying the effects of tRNA modifications on ribosome pausing.[17][20]
Materials:
-
Yeast or mammalian cells (wild-type and modification-deficient mutant strains)
-
Lysis buffer (e.g., 20 mM Tris-HCl pH 7.4, 150 mM NaCl, 5 mM MgCl2, 1 mM DTT, 100 µg/mL cycloheximide)
-
RNase I
-
Sucrose (B13894) gradient solutions (e.g., 10-50%)
-
RNA extraction kit
-
Library preparation kit for next-generation sequencing
Procedure:
-
Treat cells with cycloheximide to arrest translating ribosomes.
-
Lyse the cells and treat the lysate with RNase I to digest mRNA not protected by ribosomes.
-
Isolate monosomes by sucrose gradient ultracentrifugation.
-
Extract the ribosome-protected mRNA fragments (footprints), typically ~28-30 nucleotides in length.
-
Prepare a cDNA library from the footprints for high-throughput sequencing.
-
Sequence the library and align the reads to a reference transcriptome.
-
Analyze the data to determine ribosome occupancy at each codon. A "pause score" can be calculated by normalizing the ribosome density at a specific codon to the average ribosome density of the corresponding gene.[5][21]
HPLC-Mass Spectrometry for Modified Nucleoside Analysis
This method allows for the sensitive detection and quantification of modified nucleosides, including this compound and its derivatives, from total tRNA.[2][11]
Materials:
-
Purified total tRNA
-
Nuclease P1
-
Bacterial alkaline phosphatase
-
HPLC system coupled to a high-resolution mass spectrometer (e.g., Orbitrap)
-
Reversed-phase C18 column
-
Mobile phase A: 0.1% formic acid in water
-
Mobile phase B: 0.1% formic acid in acetonitrile
Procedure:
-
Digest the purified tRNA to single nucleosides using nuclease P1 and bacterial alkaline phosphatase.
-
Separate the nucleosides by reversed-phase HPLC using a gradient of mobile phase A and B.
-
Detect the eluting nucleosides by mass spectrometry in positive ion mode.
-
Identify this compound and its derivatives based on their accurate mass-to-charge ratio (m/z) and retention time.
-
Quantify the relative abundance of the modified nucleosides by integrating the peak areas from the extracted ion chromatograms.
Conclusion and Future Directions
The post-transcriptional modification of tRNA with this compound and its derivatives is a fundamentally important process that fine-tunes codon recognition and ensures the efficiency and fidelity of protein synthesis. This technical guide has provided a detailed overview of the biosynthesis of these modifications, their functional consequences, and the experimental approaches used to study them. The quantitative data and detailed protocols presented herein serve as a valuable resource for researchers seeking to further unravel the complexities of tRNA modification and its role in gene expression.
Future research in this area will likely focus on several key aspects. Elucidating the precise molecular mechanisms by which these modifications influence ribosome dynamics and protein folding will be a major area of investigation. The development of novel techniques for the site-specific installation of these modifications into synthetic tRNAs will enable more detailed biophysical and structural studies. Furthermore, a deeper understanding of the regulation of the modification pathways and their links to human diseases will open up new avenues for the development of targeted therapeutics. The continued application of high-throughput techniques like ribosome profiling and quantitative mass spectrometry will be instrumental in achieving these goals and further illuminating the intricate world of the epitranscriptome.
References
- 1. biorxiv.org [biorxiv.org]
- 2. researchgate.net [researchgate.net]
- 3. biorxiv.org [biorxiv.org]
- 4. Identification and codon reading properties of 5-cyanomethyl uridine, a new modified nucleoside found in the anticodon wobble position of mutant haloarchaeal isoleucine tRNAs - PMC [pmc.ncbi.nlm.nih.gov]
- 5. PausePred and Rfeet: webtools for inferring ribosome pauses and visualizing footprint density from ribosome profiling data - PMC [pmc.ncbi.nlm.nih.gov]
- 6. researchgate.net [researchgate.net]
- 7. Upregulating tRNAs in Mammalian Cells through Transfection of In Vitro Transcribed tRNAs [protocols.io]
- 8. Chemical synthesis of the 5-taurinomethyl(-2-thio)uridine modified anticodon arm of the human mitochondrial tRNALeu(UUR) and tRNALys - PMC [pmc.ncbi.nlm.nih.gov]
- 9. 8h0s - Crystal structure of MnmM from B. subtilis complexed with Gln-TTG anti-codon stem loop and SAM (2.90 A) - Experimental details - Protein Data Bank Japan [pdbj.org]
- 10. Quantitative analysis of tRNA modifications by HPLC-coupled mass spectrometry [dspace.mit.edu]
- 11. Quantitative analysis of tRNA modifications by HPLC-coupled mass spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Identification of a novel 5-aminomethyl-2-thiouridine methyltransferase in tRNA modification - PMC [pmc.ncbi.nlm.nih.gov]
- 13. researchgate.net [researchgate.net]
- 14. SURVEY AND SUMMARY: Roles of 5-substituents of tRNA wobble uridines in the recognition of purine-ending codons - PMC [pmc.ncbi.nlm.nih.gov]
- 15. scispace.com [scispace.com]
- 16. Anticodon stem-loop tRNA modifications influence codon decoding and frame maintenance during translation - PMC [pmc.ncbi.nlm.nih.gov]
- 17. Optimization of Codon Translation Rates via tRNA Modifications Maintains Proteome Integrity - PMC [pmc.ncbi.nlm.nih.gov]
- 18. scienceopen.com [scienceopen.com]
- 19. Stabilization of the anticodon stem-loop of tRNALys,3 by an A+-C base-pair and by pseudouridine - PubMed [pubmed.ncbi.nlm.nih.gov]
- 20. Tracing Translational Footprint by Ribo-Seq: Principle, Workflow, and Applications to Understand the Mechanism of Human Diseases - PMC [pmc.ncbi.nlm.nih.gov]
- 21. Identification of Ribosome Pause Sites Using a Z-Score Based Peak Detection Algorithm | Semantic Scholar [semanticscholar.org]
The Structural Influence of 5-(Aminomethyl)uridine on the tRNA Anticodon Loop: A Technical Guide
For Researchers, Scientists, and Drug Development Professionals
This technical guide provides an in-depth analysis of the structural impact of the modified nucleoside 5-(aminomethyl)uridine (AmU) on the anticodon loop of transfer RNA (tRNA). The presence of AmU and its derivatives at the wobble position (position 34) of the anticodon is crucial for accurate and efficient protein synthesis. This document summarizes key structural changes, outlines relevant experimental methodologies, and presents a visual representation of the biosynthetic pathway leading to a related modified nucleoside.
Introduction
Post-transcriptional modifications of tRNA are essential for its proper folding, stability, and function in decoding messenger RNA (mRNA) codons. Modifications within the anticodon loop, particularly at the wobble position 34, play a critical role in defining the codon recognition properties of tRNA. This compound and its derivatives, such as 5-methylaminomethyl-2-thiouridine (B1677369) (mnm⁵s²U), are found in various bacterial and eukaryotic tRNAs. These modifications are known to restrict codon recognition to purine-ending codons (A or G) and enhance translational fidelity. The structural basis for this enhanced function lies in the specific conformational changes induced by these modifications within the anticodon loop.
Structural Impact of this compound Derivatives
The primary structural consequence of this compound and its derivatives in the anticodon loop is a significant conformational change that deviates from the canonical A-form helical structure. X-ray crystallography studies of enzymes complexed with anticodon stem-loops (ASLs) containing these modifications have provided critical insights into this structural rearrangement.
A key finding is the "flipped-out" conformation of the modified uridine (B1682114) at position 34 (U34) and the preceding uridine at position 33 (U33). In this conformation, the bases of both U33 and the modified U34 are swiveled out from the helical stack of the anticodon loop. This base flipping is crucial for the recognition of the modified tRNA by enzymes involved in its further modification and by the ribosome during translation. This conformational change is believed to contribute to the stabilization of the codon-anticodon interaction and prevent misreading of codons.
Biosynthetic Pathway of 5-methylaminomethyl-2-thiouridine (mnm⁵s²U)
This compound is an intermediate in the biosynthesis of more complex modifications like 5-methylaminomethyl-2-thiouridine (mnm⁵s²U). Understanding this pathway is crucial for studying the function of these modifications and for developing potential antimicrobial agents that target these enzymatic steps. In Escherichia coli, the biosynthesis of mnm⁵s²U involves a series of enzymatic reactions. The pathway starts with a uridine at position 34 of the tRNA, which is first thiolated at position 2 to form 2-thiouridine (B16713) (s²U). Subsequently, the MnmE and MnmG enzymes catalyze the addition of a carboxymethylaminomethyl group to the C5 position of the uracil (B121893) base, forming cmnm⁵s²U. The bifunctional enzyme MnmC then carries out the final two steps: the MnmC(o) domain removes the carboxymethyl group to yield 5-aminomethyl-2-thiouridine (B1259639) (nm⁵s²U), and the MnmC(m) domain methylates the amino group to produce the final product, mnm⁵s²U[1][2][3].
Experimental Protocols
The study of the structural impact of this compound on the anticodon loop relies on a combination of biochemical and biophysical techniques. Below are generalized protocols for the key experiments. It is important to note that these are foundational methods, and specific parameters may need to be optimized for tRNA containing this compound.
In Vitro Preparation of Modified Anticodon Stem-Loop RNA
The generation of specific RNA sequences, such as the anticodon stem-loop (ASL), containing modified nucleosides is a prerequisite for structural studies. While chemical synthesis can be employed, in vitro transcription is a common method for producing larger quantities of RNA. Incorporating modified nucleosides like this compound often requires specialized techniques.
Protocol: In Vitro Transcription of an Anticodon Stem-Loop
-
Template Preparation: A DNA template encoding the desired ASL sequence is synthesized. The template should include a T7 RNA polymerase promoter sequence upstream of the ASL sequence.
-
Transcription Reaction: The transcription reaction is assembled with the DNA template, T7 RNA polymerase, and a mixture of the four standard ribonucleoside triphosphates (NTPs). To incorporate the modified uridine, a chemically synthesized and protected this compound triphosphate would be required. The availability and incorporation efficiency of such a modified NTP are critical considerations.
-
Purification: The transcribed RNA is purified from the reaction mixture using denaturing polyacrylamide gel electrophoresis (PAGE). The band corresponding to the ASL is excised, and the RNA is eluted from the gel.
-
Desalting and Folding: The purified RNA is desalted using size-exclusion chromatography or dialysis. The RNA is then folded into its correct conformation by heating at 95°C for 5 minutes, followed by slow cooling to room temperature in a buffer containing magnesium chloride.
X-ray Crystallography of the Modified Anticodon Stem-Loop
X-ray crystallography provides high-resolution structural information about macromolecules. To study the structural impact of this compound, the modified ASL can be crystallized, either alone or in complex with a binding partner, such as a protein or another RNA molecule.
Protocol: Crystallization and Structure Determination
-
Sample Preparation: The purified and folded modified ASL is concentrated to a high concentration (typically 5-10 mg/mL).
-
Crystallization Screening: A broad range of crystallization conditions are screened using vapor diffusion methods (hanging drop or sitting drop). This involves mixing the RNA sample with a variety of precipitants, buffers, and salts.
-
Crystal Optimization: Once initial crystals are obtained, the crystallization conditions are optimized to produce larger, well-diffracting crystals.
-
Data Collection: The crystals are cryo-protected and flash-frozen in liquid nitrogen. X-ray diffraction data are collected at a synchrotron source.
-
Structure Determination: The diffraction data are processed, and the structure is solved using molecular replacement, if a suitable model is available, or by experimental phasing methods. The final atomic model is built and refined against the experimental data.
NMR Spectroscopy of the Modified Anticodon Stem-Loop
Nuclear Magnetic Resonance (NMR) spectroscopy is a powerful technique for studying the structure and dynamics of macromolecules in solution. It can provide detailed information about the conformation of the anticodon loop containing this compound.
Protocol: NMR Structural Analysis
-
Sample Preparation: A highly concentrated and pure sample of the modified ASL is prepared in a suitable NMR buffer, often containing deuterium (B1214612) oxide (D₂O).
-
NMR Data Acquisition: A series of one- and two-dimensional NMR experiments are performed, such as ¹H-¹H COSY, TOCSY, and NOESY, as well as ¹H-¹³C and ¹H-¹⁵N HSQC if isotopic labeling is employed.
-
Resonance Assignment: The signals in the NMR spectra are assigned to specific atoms in the RNA molecule.
-
Structural Restraint Generation: The NOESY spectra are used to generate distance restraints between protons that are close in space. Torsion angle restraints can also be derived from other NMR parameters.
-
Structure Calculation: The experimental restraints are used in computational algorithms to calculate a family of three-dimensional structures consistent with the NMR data.
-
Structure Validation: The quality of the calculated structures is assessed using a variety of statistical and structural criteria.
Molecular Dynamics Simulations of the Modified Anticodon Stem-Loop
Molecular dynamics (MD) simulations provide a computational approach to study the dynamic behavior of macromolecules at an atomic level. MD simulations can complement experimental data by providing insights into the conformational flexibility of the anticodon loop.
Protocol: Molecular Dynamics Simulation
-
System Setup: An initial three-dimensional model of the modified ASL is generated, either from experimental data or through homology modeling. The RNA is placed in a simulation box filled with water molecules and counter-ions to neutralize the system.
-
Parameterization: The force field parameters for the non-standard this compound residue need to be developed or obtained from existing libraries.
-
Minimization and Equilibration: The system is energy-minimized to remove any steric clashes. This is followed by a period of equilibration, where the temperature and pressure of the system are gradually brought to the desired values.
-
Production Run: A long-timescale MD simulation is performed to sample the conformational space of the anticodon loop.
-
Trajectory Analysis: The resulting trajectory is analyzed to study various structural and dynamic properties, such as root-mean-square deviation (RMSD), root-mean-square fluctuation (RMSF), hydrogen bonding patterns, and conformational changes.
Conclusion
The presence of this compound and its derivatives in the anticodon loop of tRNA induces a distinct "flipped-out" conformation that is critical for accurate decoding of mRNA. While the qualitative structural impact is well-established, further research is needed to provide detailed quantitative data on the conformational changes. The experimental and computational protocols outlined in this guide provide a framework for researchers to further investigate the structure-function relationships of this important tRNA modification. A deeper understanding of these mechanisms will be invaluable for the fields of molecular biology, drug discovery, and the development of novel therapeutics targeting protein synthesis.
References
5-(Aminomethyl)uridine: A Potential Antitumor Agent Explored
An In-depth Technical Guide for Researchers and Drug Development Professionals
Introduction:
5-(Aminomethyl)uridine, a purine (B94841) nucleoside analog, has emerged as a compound of interest in the field of oncology. Its structural similarity to endogenous nucleosides allows it to interfere with fundamental cellular processes, suggesting its potential as an antitumor agent. This technical guide provides a comprehensive overview of the current understanding of this compound, including its synthesis, proposed mechanisms of action, and available preclinical data. This document is intended for researchers, scientists, and drug development professionals seeking to explore the therapeutic potential of this molecule.
Core Concepts and Mechanism of Action
This compound is thought to exert its antitumor effects through several mechanisms, primarily centered around the disruption of nucleic acid metabolism and the induction of programmed cell death (apoptosis)[1]. As a nucleoside analog, it can be recognized by cellular enzymes involved in DNA and RNA synthesis, leading to the inhibition of these critical processes and ultimately halting cell proliferation[1].
One of the key proposed mechanisms is the inhibition of thymidylate synthase (TS), a crucial enzyme in the de novo synthesis of deoxythymidine monophosphate (dTMP), a necessary precursor for DNA replication[2]. By inhibiting TS, this compound and its derivatives can deplete the cellular pool of dTMP, leading to an imbalance in deoxynucleotide triphosphates (dNTPs) and subsequent DNA damage and cell cycle arrest[2].
Furthermore, the incorporation of this compound or its metabolites into DNA and RNA can lead to the formation of non-functional nucleic acids, triggering cellular stress responses and activating apoptotic pathways[1].
Quantitative Data on Antitumor Activity
While extensive quantitative data for this compound is still emerging, studies on its derivatives provide valuable insights into its potential potency. The following table summarizes the inhibitory constants (Ki) of several N-substituted 5-aminomethyl-2'-deoxyuridine 5'-phosphates against thymidylate synthetase from various sources.
| Compound | Enzyme Source | Ki (µM)[2] |
| 5-(2-dimethylaminoethylaminomethyl)-2'-deoxyuridine 5'-phosphate | Escherichia coli | 6 |
| Calf Thymus | 3.1 | |
| Ehrlich Ascites Tumor | 14 | |
| 5-dimethylaminomethyl-2'-deoxyuridine 5'-phosphate | Escherichia coli | |
| Calf Thymus | ||
| Ehrlich Ascites Tumor | ||
| 5-pyrrolidinylmethyl-2'-deoxyuridine 5'-phosphate | Escherichia coli | |
| Calf Thymus | ||
| Ehrlich Ascites Tumor |
Note: Specific Ki values for the latter two compounds were not explicitly provided in the cited source but were stated to be substrate competitive inhibitors.
Experimental Protocols
This section provides detailed methodologies for key experiments relevant to the evaluation of this compound's antitumor potential.
Synthesis of this compound Derivatives
A general method for the synthesis of N-substituted 5-aminomethyl-2'-deoxyuridines has been described[2]. This protocol can be adapted for the synthesis of this compound.
Procedure:
-
Protection of the Ribofuranosyl Group: Start with a suitable uridine (B1682114) precursor where the hydroxyl groups on the ribose moiety are protected. For example, 1-(3,5-Di-O-p-toluoyl-2-deoxy-beta-D-ribofuranosyl)-5-chloromethyluracil can be used as a starting material[2].
-
Amination: Treat the protected 5-chloromethyluracil derivative with the desired amine to introduce the aminomethyl group at the C5 position of the uracil (B121893) ring[2].
-
Deprotection: Remove the protecting groups from the ribose moiety. This can be achieved by treatment with anhydrous potassium carbonate in methanol (B129727) to yield the free beta-nucleoside[2].
-
Phosphorylation (Optional): To generate the 5'-phosphate derivative, the synthesized nucleoside can be subjected to standard phosphorylation procedures.
Cell Viability Assay (MTT Assay)
This assay is used to assess the cytotoxic effects of this compound on cancer cell lines.
Materials:
-
Cancer cell lines of interest
-
Complete culture medium
-
This compound stock solution (dissolved in a suitable solvent like DMSO)
-
MTT (3-(4,5-dimethylthiazol-2-yl)-2,5-diphenyltetrazolium bromide) solution
-
Solubilization solution (e.g., DMSO or a solution of SDS in HCl)
-
96-well plates
-
Microplate reader
Procedure:
-
Cell Seeding: Seed cancer cells into 96-well plates at a predetermined density and allow them to adhere overnight.
-
Treatment: Treat the cells with serial dilutions of this compound for a specified duration (e.g., 24, 48, or 72 hours). Include a vehicle control (solvent alone).
-
MTT Addition: After the incubation period, add MTT solution to each well and incubate for 2-4 hours at 37°C.
-
Formazan (B1609692) Solubilization: Remove the medium and add the solubilization solution to dissolve the formazan crystals.
-
Absorbance Measurement: Measure the absorbance at a wavelength of 570 nm using a microplate reader.
-
Data Analysis: Calculate the percentage of cell viability relative to the vehicle control and determine the IC50 value (the concentration of the compound that inhibits cell growth by 50%).
Thymidylate Synthase Inhibition Assay
This assay determines the inhibitory activity of this compound or its phosphate (B84403) derivatives on thymidylate synthase.
Materials:
-
Purified thymidylate synthase or cell lysate containing the enzyme
-
[5-³H]dUMP (radiolabeled substrate)
-
5,10-methylenetetrahydrofolate (cofactor)
-
Reaction buffer
-
This compound or its 5'-phosphate derivative
-
Scintillation cocktail and counter
Procedure:
-
Reaction Setup: Prepare a reaction mixture containing the reaction buffer, enzyme, cofactor, and varying concentrations of the inhibitor.
-
Initiation: Start the reaction by adding the radiolabeled substrate, [5-³H]dUMP.
-
Incubation: Incubate the reaction mixture at 37°C for a defined period.
-
Termination: Stop the reaction (e.g., by adding acid).
-
Separation and Measurement: Separate the released tritiated water from the unreacted substrate and measure the radioactivity using a scintillation counter.
-
Data Analysis: Determine the rate of the enzymatic reaction at different inhibitor concentrations and calculate the Ki value.
Western Blot Analysis for Apoptosis Markers
This technique is used to detect changes in the expression of key proteins involved in the apoptotic pathway following treatment with this compound.
Materials:
-
Cancer cells treated with this compound
-
Lysis buffer
-
Protein assay kit
-
SDS-PAGE gels
-
PVDF membrane
-
Blocking buffer
-
Primary antibodies against apoptosis markers (e.g., cleaved Caspase-3, PARP, Bcl-2, Bax)
-
HRP-conjugated secondary antibodies
-
Chemiluminescent substrate
-
Imaging system
Procedure:
-
Cell Lysis: Lyse the treated and control cells to extract total proteins.
-
Protein Quantification: Determine the protein concentration of each lysate.
-
SDS-PAGE: Separate the proteins by size using SDS-polyacrylamide gel electrophoresis.
-
Protein Transfer: Transfer the separated proteins to a PVDF membrane.
-
Blocking: Block the membrane to prevent non-specific antibody binding.
-
Antibody Incubation: Incubate the membrane with primary antibodies specific to the apoptosis markers of interest, followed by incubation with HRP-conjugated secondary antibodies.
-
Detection: Detect the protein bands using a chemiluminescent substrate and an imaging system.
-
Analysis: Analyze the changes in the expression levels of the target proteins between treated and control samples.
Signaling Pathways and Experimental Workflows
The precise signaling pathways modulated by this compound are still under investigation. However, based on its proposed mechanisms of action, several key pathways are likely to be involved.
Proposed Signaling Pathway for Antitumor Activity
The following diagram illustrates a hypothetical signaling cascade initiated by this compound, leading to apoptosis.
Caption: Proposed mechanism of this compound antitumor activity.
Experimental Workflow for In Vitro Evaluation
The following diagram outlines a typical workflow for the in vitro assessment of the antitumor properties of this compound.
References
A Preliminary Investigation of 5-(Aminomethyl)uridine Derivatives: A Technical Guide
For Researchers, Scientists, and Drug Development Professionals
This technical guide provides a comprehensive overview of the synthesis, biological activities, and mechanisms of action of 5-(aminomethyl)uridine derivatives. These compounds, as modified nucleosides, are integral to both fundamental biological processes and the development of novel therapeutic agents. The information presented herein is intended to serve as a foundational resource for professionals engaged in nucleoside chemistry, molecular biology, and drug discovery.
Introduction
Nucleoside analogues are a cornerstone of modern pharmacology, with wide applications in treating viral infections and neoplastic diseases.[1][2] Within this class, derivatives of the pyrimidine (B1678525) nucleoside uridine (B1682114), particularly those substituted at the C5 position of the uracil (B121893) base, have garnered significant attention.[3] this compound and its related structures are notable for their diverse biological functions. They exist naturally as post-transcriptional modifications in transfer RNA (tRNA), where they play a critical role in ensuring the accuracy and efficiency of protein synthesis.[4][5] Furthermore, synthetic derivatives have shown promising activity as anticancer, antiviral, and antimicrobial agents, often by acting as potent enzyme inhibitors.[6][7][8] This guide explores the preliminary data surrounding these versatile molecules.
Synthesis of this compound Derivatives
The synthesis of this compound derivatives typically involves multi-step chemical processes starting from more readily available uridine precursors. A common and effective strategy involves the conversion of a 5-(hydroxymethyl)uridine derivative into a 5-(azidomethyl) intermediate, which is subsequently reduced to the desired 5-(aminomethyl) product.
One synthetic approach begins with the tosylation of 5-(hydroxymethyl)-2'-deoxyuridine, followed by nucleophilic substitution with an azide (B81097) source like lithium azide. The resulting 5-(azidomethyl)-2'-deoxyuridine is then converted to the final amine via catalytic hydrogenation.[8] An alternative, more selective method involves the displacement of a bromo group from a protected 5-(bromomethyl)uridine derivative with lithium azide, followed by deprotection and reduction.[8] Another reported method for the reduction of the azide involves the use of triphenylphosphine (B44618) (Ph₃P) and ammonium (B1175870) hydroxide.[9]
Caption: General synthetic workflow via the azide intermediate route.
Biological Activities and Quantitative Data
This compound derivatives exhibit a broad spectrum of biological activities, positioning them as valuable leads for drug development. Their efficacy spans from enzyme inhibition to direct effects on cell growth and pathogen replication.
Enzyme Inhibition
A primary mechanism through which these derivatives exert their effects is the inhibition of key enzymes in metabolic and signaling pathways. Urea-containing derivatives have been shown to inhibit MraY transferase, an essential enzyme in bacterial cell wall biosynthesis.[6] Others have demonstrated potent and selective inhibition of human NTPDase2, an enzyme implicated in cardiovascular diseases and cancer.[10] The affinity for viral enzymes, such as the Herpes Simplex Virus (HSV-1) encoded pyrimidine deoxyribonucleoside kinase, underscores their antiviral potential.[8]
Table 1: Enzyme Inhibition by this compound and Related Derivatives
| Compound Class | Target Enzyme | Inhibitor Example / Set | Potency (Kᵢ, K_I, IC₅₀) | Reference |
|---|---|---|---|---|
| Urea-containing Uridine Derivatives | MraY Transferase | Library of 10 compounds | IC₅₀: 1.9 µM - 16.7 µM | [6] |
| Uridine-5'-carboxamide Derivatives | Human NTPDase2 | PSB-6426 | Kᵢ = 8.2 µM | [10] |
| Aminoalkylaziridines | Lysyl Oxidase | N-(5-aminopentyl)aziridine | K_I = 0.22 mM | [11][12] |
| Deoxyuridine Analogues | HSV-1 Pyrimidine Deoxyribonucleoside Kinase | 5-(hydroxymethyl)- and 5-(azidomethyl)-2'-deoxyuridine | Good Affinity (qualitative) |[8] |
Anticancer and Antimicrobial Activity
Several this compound derivatives have been evaluated for their antiproliferative effects. 5-(aminomethyl)-2'-deoxyuridine has been shown to inhibit the growth of murine Sarcoma 180 and L1210 leukemia cells in culture.[8] While some acylated uridine derivatives have demonstrated anticancer activity, the potency can be modest.[2][13] The antimicrobial activity is also notable, with various derivatives showing efficacy against both bacterial and fungal pathogens.[1][13]
Table 2: Anticancer and Antimicrobial Activity of Selected Uridine Derivatives
| Compound | Activity Type | Cell Line / Organism | Metric | Value | Reference |
|---|---|---|---|---|---|
| 5-(aminomethyl)-2'-deoxyuridine | Anticancer | Murine Sarcoma 180, L1210 | Growth Inhibition | Active | [8] |
| 2′,3′-di-O-cinnamoyl-5′-O-palmitoyluridine | Anticancer | Ehrlich Ascites Carcinoma (EAC) | IC₅₀ | 1108.22 µg/mL | [2][13] |
| Acylated Uridine Derivative (4) | Antibacterial | Bacillus subtilis | Inhibition Zone | 17 ± 0.20 mm | [13] |
| Acylated Uridine Derivative (4) | Antibacterial | Salmonella typhi | Inhibition Zone | 18 ± 0.75 mm |[13] |
Mechanism of Action: Role in tRNA Modification
In many prokaryotes, the uridine at the wobble position (position 34) of tRNA undergoes a series of post-transcriptional modifications to ensure translational fidelity.[4][14][15] this compound is a key intermediate in the biosynthesis of 5-methylaminomethyluridine (B1256275) (mnm⁵U) and its 2-thiolated analogue (mnm⁵s²U).
This multi-step enzymatic pathway begins with the MnmE-MnmG enzyme complex, which converts the wobble uridine into 5-carboxymethylaminomethyluridine (B1212367) (cmnm⁵U).[16] In Gram-negative bacteria like E. coli, the bifunctional enzyme MnmC then catalyzes the final two steps: an FAD-dependent oxidase domain (MnmC(o)) first transforms cmnm⁵(s²)U into 5-aminomethyl(2-thio)uridine (nm⁵(s²)U), and subsequently, an S-adenosylmethionine (SAM)-dependent methyltransferase domain (MnmC(m)) methylates the amino group to yield the final mnm⁵(s²)U product.[5][14][17] In Gram-positive bacteria such as B. subtilis, which lack an MnmC ortholog, these two steps are carried out by two separate enzymes, YurR and MnmM, respectively.[4]
Caption: Biosynthetic pathway of mnm⁵(s²)U modification in bacteria.
Detailed Experimental Protocols
This section provides methodologies for key experiments cited in the literature, offering a practical guide for researchers.
Protocol 1: Synthesis of 5-Azidomethyl-2′-O-(tert-butyldimethylsilyl)-5′-O-(4,4′-dimethoxytrityl)(-2-thio)uridine[9]
This protocol details the protection of a 5'-DMT nucleoside.
-
Dissolution : Dissolve the 5′-DMT nucleoside (1.0 equivalent) in anhydrous pyridine.
-
Addition of Reagents : Add imidazole (B134444) (3.0 equivalents) and tert-butyldimethylsilyl chloride (1.2 equivalents) to the solution.
-
Reaction : Stir the mixture at room temperature for 24 hours.
-
Quenching : Quench the reaction by adding H₂O.
-
Extraction : Extract the resulting solution with CHCl₃ (3x).
-
Purification : Combine the organic layers, dry over MgSO₄, filter, and concentrate under reduced pressure. The crude product is purified by column chromatography to yield the desired 2'-O-TBDMS and 3'-O-TBDMS isomers.
Protocol 2: Synthesis of 5-Aminomethyl-2′-O-(tert-butyldimethylsilyl)-5′-O-(4,4′-dimethoxytrityl)(-2-thio)uridine[9]
This protocol describes the reduction of the azide to an amine.
-
Dissolution : Dissolve the mixture of 2′- and 3′-TBDMS protected azidomethyluridine isomers (1.0 equivalent) in anhydrous pyridine.
-
Addition of Reducing Agent : Add triphenylphosphine (Ph₃P) (1.8 equivalents).
-
Reaction : Stir the mixture for 24 hours at room temperature.
-
Hydrolysis : Add 25% aqueous NH₄OH and stir for an additional 1 hour at room temperature.
-
Extraction : Extract the solution with CHCl₃ (3x).
-
Purification : Dry the combined organic layers over MgSO₄, remove the solvent under reduced pressure, and co-evaporate the residue with anhydrous toluene. The final product is purified by column chromatography.
Protocol 3: General Workflow for an In Vitro Enzyme Inhibition Assay
This diagram outlines the typical steps for determining the inhibitory constant (Kᵢ or IC₅₀) of a compound against a target enzyme.
Caption: A generalized workflow for enzyme inhibition assays.
Conclusion and Future Perspectives
This compound and its derivatives represent a chemically and biologically rich class of molecules. Their synthesis, while often requiring multiple steps, is well-established, providing access to a wide range of analogues for biological screening. The dual role of these compounds—as essential components of the translational machinery and as potential therapeutic agents—makes them compelling targets for further investigation. Future research should focus on expanding the chemical diversity of these derivatives, elucidating their specific mechanisms of action against various cellular and viral targets, and optimizing their pharmacological properties for preclinical and clinical development. The development of more potent and selective enzyme inhibitors based on this scaffold holds significant promise for addressing unmet needs in oncology and infectious diseases.
References
- 1. Uridine Derivatives: Synthesis, Biological Evaluation, and In Silico Studies as Antimicrobial and Anticancer Agents - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. researchgate.net [researchgate.net]
- 3. New Derivatives of 5-Substituted Uracils: Potential Agents with a Wide Spectrum of Biological Activity - PMC [pmc.ncbi.nlm.nih.gov]
- 4. GIST Scholar: Characterization of 5-aminomethyl-2-thiouridine tRNA modification biosynthetic pathway in Bacillus subtilis [scholar.gist.ac.kr]
- 5. Identification of a novel 5-aminomethyl-2-thiouridine methyltransferase in tRNA modification - PMC [pmc.ncbi.nlm.nih.gov]
- 6. researchgate.net [researchgate.net]
- 7. medchemexpress.com [medchemexpress.com]
- 8. Synthesis and biological activities of 5-(hydroxymethyl, azidomethyl, or aminomethyl)-2'-deoxyuridine and related 5'-substituted analogues - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. Chemical synthesis of the 5-taurinomethyl(-2-thio)uridine modified anticodon arm of the human mitochondrial tRNALeu(UUR) and tRNALys - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Selective nucleoside triphosphate diphosphohydrolase-2 (NTPDase2) inhibitors: nucleotide mimetics derived from uridine-5'-carboxamide - PubMed [pubmed.ncbi.nlm.nih.gov]
- 11. Aminoalkylaziridines as substrates and inhibitors of lysyl oxidase: specific inactivation of the enzyme by N-(5-aminopentyl)aziridine - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. imrpress.com [imrpress.com]
- 13. mdpi.com [mdpi.com]
- 14. researchgate.net [researchgate.net]
- 15. GIST Scholar: Identification of a novel 5-aminomethyl-2-thiouridine methyltransferase in tRNA modification [scholar.gist.ac.kr]
- 16. pubs.acs.org [pubs.acs.org]
- 17. Identification of a novel 5-aminomethyl-2-thiouridine methyltransferase in tRNA modification - PubMed [pubmed.ncbi.nlm.nih.gov]
Methodological & Application
Application Notes and Protocols for the Mass Spectrometry Analysis of 5-(aminomethyl)uridine in tRNA
For Researchers, Scientists, and Drug Development Professionals
Introduction
Post-transcriptional modifications of transfer RNA (tRNA) are critical for maintaining translational fidelity and regulating gene expression. 5-(aminomethyl)uridine (nm5U), a modified nucleoside found in the anticodon wobble position of some tRNAs, and its derivatives, play a crucial role in the accurate decoding of messenger RNA (mRNA). The quantitative analysis of these modifications is essential for understanding their biological function and their potential as therapeutic targets. This document provides detailed application notes and protocols for the mass spectrometry-based analysis of this compound in tRNA.
Liquid chromatography coupled with tandem mass spectrometry (LC-MS/MS) is a powerful and sensitive technique for the identification and quantification of modified nucleosides in RNA.[1] This method involves the enzymatic hydrolysis of tRNA into its constituent nucleosides, followed by chromatographic separation and mass spectrometric detection.[1]
Quantitative Data Presentation
The following tables summarize the relative abundance of this compound (nm5U) and its related modifications in Escherichia coli tRNA under different growth conditions. This data is crucial for understanding the dynamics of tRNA modification pathways. In E. coli, the MnmEG complex can utilize either ammonium (B1175870) to produce nm5U or glycine (B1666218) to produce 5-carboxymethylaminomethyluridine (B1212367) (cmnm5U).[2] The bifunctional enzyme MnmC can then convert cmnm5U to nm5U and subsequently to 5-methylaminomethyluridine (B1256275) (mnm5U).[2]
Table 1: Relative Abundance of U34 Modifications in Total tRNA from E. coli MC1061 in Exponential and Stationary Growth Phases. [2]
| Modification | Exponential Phase (%) | Stationary Phase (%) |
| cmnm5s2U | 94 ± 1 | 4 ± 2 |
| nm5s2U | 6 ± 1 | 96 ± 2 |
Table 2: Relative Abundance of U34 Modifications in Specific tRNA Species from E. coli MC1061 in Exponential Growth Phase. [2]
| tRNA Species | cmnm5s2U (%) | nm5s2U (%) |
| tRNAGln | 99 ± 1 | 1 ± 1 |
| tRNALys | 94 ± 1 | 6 ± 1 |
Experimental Protocols
This section provides a detailed methodology for the analysis of this compound in tRNA, from cell culture to data analysis.
Protocol 1: tRNA Isolation from Bacterial Cells
This protocol is adapted from established methods for bulk tRNA extraction.[3]
Materials:
-
Bacterial cell culture
-
Lysis buffer (e.g., Tris-HCl, EDTA)
-
Phenol:Chloroform:Isoamyl alcohol (25:24:1)
-
Isopropanol
-
Ethanol (B145695) (70%)
-
Nuclease-free water
Procedure:
-
Harvest bacterial cells from culture by centrifugation.
-
Resuspend the cell pellet in lysis buffer and lyse the cells using an appropriate method (e.g., sonication, bead beating).
-
Perform phenol:chloroform extraction to remove proteins and lipids.
-
Precipitate the total RNA from the aqueous phase by adding isopropanol.
-
Wash the RNA pellet with 70% ethanol and air-dry.
-
Resuspend the purified total RNA in nuclease-free water.
-
Quantify the RNA concentration using a spectrophotometer or a fluorometric assay.
Protocol 2: Enzymatic Digestion of tRNA to Nucleosides
This protocol describes the complete hydrolysis of tRNA to its constituent nucleosides.[4][5]
Materials:
-
Purified tRNA
-
Nuclease P1
-
Bacterial Alkaline Phosphatase (BAP)
-
Digestion Buffer (e.g., 20 mM HEPES, 100 mM NaCl, 10 mM MgCl2, pH 7.5)
-
Nuclease-free water
Procedure:
-
In a microcentrifuge tube, combine 1-5 µg of purified tRNA with nuclease-free water to a final volume of 20 µL.
-
Add 2.5 µL of 10X Digestion Buffer.
-
Add 1 µL of Nuclease P1 (e.g., 1 U/µL).
-
Add 1 µL of Bacterial Alkaline Phosphatase (e.g., 1 U/µL).
-
Incubate the reaction mixture at 37°C for 2 hours.
-
Terminate the reaction by heating at 95°C for 5 minutes.
-
Centrifuge the sample to pellet any precipitate and transfer the supernatant for LC-MS/MS analysis.
Protocol 3: LC-MS/MS Analysis of Modified Nucleosides
This protocol outlines the parameters for the chromatographic separation and mass spectrometric detection of nucleosides.[4][5]
Instrumentation:
-
High-Performance Liquid Chromatography (HPLC) system
-
Reversed-phase C18 column (e.g., 2.1 x 150 mm, 1.8 µm)
-
Triple quadrupole mass spectrometer with an electrospray ionization (ESI) source
LC Parameters:
-
Mobile Phase A: 0.1% formic acid in water
-
Mobile Phase B: 0.1% formic acid in acetonitrile
-
Gradient: A linear gradient from 0% to 30% B over 30 minutes.
-
Flow Rate: 0.2 mL/min
-
Column Temperature: 40°C
-
Injection Volume: 5 µL
MS/MS Parameters:
-
Ionization Mode: Positive Electrospray Ionization (ESI+)
-
Multiple Reaction Monitoring (MRM): Monitor the specific precursor-to-product ion transitions for this compound and other target nucleosides.
-
This compound (nm5U): Precursor ion (m/z) 274.1 -> Product ion (m/z) 142.1[6]
-
-
Optimize collision energies and other source parameters for each nucleoside.
Visualizations
Biosynthetic Pathway of this compound and its Derivatives in E. coli
The following diagram illustrates the enzymatic steps involved in the formation of nm5U, cmnm5U, and mnm5U at the wobble position (U34) of tRNA in E. coli.[2][7]
Caption: Biosynthesis of nm5U and its derivatives in E. coli.
Experimental Workflow for tRNA Modification Analysis
This diagram outlines the major steps in the experimental workflow for the quantitative analysis of this compound in tRNA.
Caption: Workflow for LC-MS/MS analysis of tRNA modifications.
Logical Relationship of MnmC Enzyme Function
This diagram illustrates the independent functions of the two domains of the bifunctional MnmC enzyme in E. coli.
Caption: Functional domains of the E. coli MnmC enzyme.
References
- 1. Sequence mapping of transfer RNA chemical modifications by liquid chromatography tandem mass spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 2. The output of the tRNA modification pathways controlled by the Escherichia coli MnmEG and MnmC enzymes depends on the growth conditions and the tRNA species - PMC [pmc.ncbi.nlm.nih.gov]
- 3. researchgate.net [researchgate.net]
- 4. dspace.mit.edu [dspace.mit.edu]
- 5. Quantitative analysis of tRNA modifications by HPLC-coupled mass spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 6. journals.asm.org [journals.asm.org]
- 7. Survey and Validation of tRNA Modifications and Their Corresponding Genes in Bacillus subtilis sp Subtilis Strain 168 - PMC [pmc.ncbi.nlm.nih.gov]
Application Notes and Protocols for the Synthesis of RNA Containing 5-(Aminomethyl)uridine
For Researchers, Scientists, and Drug Development Professionals
Introduction
5-(Aminomethyl)uridine (nm5U) is a naturally occurring modified nucleoside found in transfer RNA (tRNA) that plays a role in the efficiency and fidelity of protein translation.[1][2] The incorporation of this and other modified nucleosides into synthetic RNA is a key strategy in the development of RNA therapeutics and vaccines. Modifications can enhance the stability, reduce the immunogenicity, and improve the translational efficacy of RNA molecules.[3][] These application notes provide detailed protocols for the synthesis of RNA containing this compound using two primary methods: enzymatic incorporation via in vitro transcription (IVT) and chemical synthesis via solid-phase synthesis.
Method 1: Enzymatic Incorporation via In Vitro Transcription (IVT)
This method involves the synthesis of this compound-5'-triphosphate (nm5U-TP), which is then used as a substrate for an RNA polymerase in an in vitro transcription reaction.
Protocol 1.1: Synthesis of this compound-5'-triphosphate (nm5U-TP)
This protocol is adapted from the Ludwig-Eckstein method, a widely used "one-pot, three-step" approach for synthesizing nucleoside triphosphates.[5]
Materials:
-
5-(N-trifluoroacetyl-aminomethyl)uridine (protected precursor)
-
Phosphorus oxychloride (POCl3)
-
Tributylamine
-
Tributylammonium (B8510715) pyrophosphate
-
Pyridine
-
Anhydrous dioxane
-
Triethylammonium (B8662869) bicarbonate (TEAB) buffer
-
DEAE Sepharose or other suitable ion-exchange chromatography resin
Procedure:
-
Monophosphorylation:
-
Dissolve 5-(N-trifluoroacetyl-aminomethyl)uridine in anhydrous pyridine.
-
Cool the solution to 0°C in an ice bath.
-
Slowly add phosphorus oxychloride and stir the reaction at 0°C for 2-4 hours. The progress of the reaction can be monitored by thin-layer chromatography (TLC).
-
-
Activation and Pyrophosphate Addition:
-
In the same reaction vessel, add a solution of tributylammonium pyrophosphate in anhydrous DMF.
-
Add an excess of tributylamine.
-
Stir the reaction mixture at room temperature for 16-24 hours.
-
-
Hydrolysis and Deprotection:
-
Quench the reaction by adding water.
-
Stir for an additional 1 hour at room temperature to hydrolyze the cyclic intermediate.
-
Remove the trifluoroacetyl protecting group by treating with aqueous ammonia (B1221849) at room temperature for 2-4 hours.
-
Evaporate the solvents under reduced pressure.
-
-
Purification:
-
Dissolve the residue in a minimal amount of water.
-
Purify the crude nm5U-TP by ion-exchange chromatography (e.g., DEAE Sepharose column) using a linear gradient of triethylammonium bicarbonate (TEAB) buffer.
-
Collect and pool the fractions containing the triphosphate, and then lyophilize to obtain the final product.
-
Protocol 1.2: In Vitro Transcription with nm5U-TP
This protocol describes a standard in vitro transcription reaction using T7 RNA polymerase. The complete substitution of UTP with nm5U-TP is possible, though optimization may be required.[]
Table 1: In Vitro Transcription Reaction Components
| Component | Final Concentration |
| T7 RNA Polymerase | Variable |
| Transcription Buffer | 1X |
| ATP, CTP, GTP | 2 mM each |
| nm5U-TP | 2 mM |
| Linearized DNA Template | 1 µg |
| RNase Inhibitor | 40 units |
| Nuclease-free Water | To final volume |
Procedure:
-
Assemble the reaction at room temperature in a nuclease-free tube in the order listed in Table 1.
-
Mix gently by pipetting and incubate at 37°C for 2-4 hours.
-
To remove the DNA template, add DNase I and incubate at 37°C for 15 minutes.
-
Purify the RNA using a suitable method, such as lithium chloride precipitation or a column-based purification kit.
Method 2: Chemical Synthesis via Solid-Phase Synthesis
This method involves the synthesis of a this compound phosphoramidite (B1245037) with a protected amino group, which is then incorporated into a growing RNA chain on a solid support. The tert-butyloxycarbonyl (Boc) group is a suitable protecting group for the aminomethyl functionality.[5]
Protocol 2.1: Synthesis of 5'-(N-Boc-aminomethyl)uridine Phosphoramidite
This multi-step synthesis requires standard organic chemistry techniques.
Materials:
-
This compound
-
Di-tert-butyl dicarbonate (B1257347) (Boc)2O
-
Dimethoxytrityl chloride (DMT-Cl)
-
2-Cyanoethyl N,N-diisopropylchlorophosphoramidite
-
Standard solvents and reagents for organic synthesis
Procedure:
-
Boc Protection: React this compound with (Boc)2O in a suitable solvent system (e.g., dioxane/water with a base) to protect the primary amine.
-
5'-OH DMT Protection: Protect the 5'-hydroxyl group of the Boc-protected nucleoside with DMT-Cl in pyridine.
-
Phosphitylation: React the 5'-O-DMT, 5-(N-Boc-aminomethyl)uridine with 2-cyanoethyl N,N-diisopropylchlorophosphoramidite in the presence of a mild base (e.g., diisopropylethylamine) in anhydrous acetonitrile (B52724) to yield the final phosphoramidite.
-
Purify the product by silica (B1680970) gel chromatography.
Protocol 2.2: Solid-Phase RNA Synthesis
This protocol follows the standard four-step phosphoramidite cycle.[6][7]
Table 2: Solid-Phase RNA Synthesis Cycle
| Step | Reagent(s) | Purpose |
| 1. Deblocking | Dichloroacetic acid in dichloromethane | Removes the 5'-DMT protecting group |
| 2. Coupling | Modified/standard phosphoramidite + Activator | Couples the next nucleotide to the growing chain |
| 3. Capping | Acetic anhydride (B1165640) and N-methylimidazole | Blocks unreacted 5'-hydroxyl groups |
| 4. Oxidation | Iodine solution | Oxidizes the phosphite (B83602) triester to phosphate (B84403) |
Procedure:
-
Perform the synthesis on an automated DNA/RNA synthesizer using the custom 5-(N-Boc-aminomethyl)uridine phosphoramidite along with standard RNA phosphoramidites. A longer coupling time (e.g., 5-10 minutes) may be required for the modified phosphoramidite.[8]
-
Cleavage and Deprotection:
-
After synthesis, cleave the RNA from the solid support and remove the base and phosphate protecting groups using a standard deprotection solution (e.g., a mixture of ammonia and methylamine).
-
Remove the 2'-O-silyl protecting groups using a fluoride (B91410) source (e.g., triethylamine (B128534) trihydrofluoride).
-
Remove the Boc protecting group from the aminomethyl functionality by treatment with trifluoroacetic acid (TFA).
-
Purification and Analysis
Protocol 3.1: HPLC Purification of Modified RNA
High-performance liquid chromatography (HPLC) is essential for obtaining high-purity modified RNA, as it can remove contaminants such as double-stranded RNA byproducts.[1]
Materials:
-
Ion-pair reverse-phase HPLC column (e.g., C18)
-
Buffer A: 0.1 M Triethylammonium acetate (B1210297) (TEAA), pH 7.0
-
Buffer B: 0.1 M TEAA, pH 7.0, in 25% acetonitrile
Procedure:
-
Equilibrate the HPLC column with a mixture of Buffer A and Buffer B.
-
Inject the crude RNA sample.
-
Elute the RNA using a linear gradient of Buffer B.
-
Monitor the elution profile by UV absorbance at 260 nm.
-
Collect the fractions corresponding to the full-length modified RNA product.
-
Desalt the purified RNA and lyophilize.
Protocol 3.2: Mass Spectrometry Analysis
Mass spectrometry is used to confirm the successful incorporation of the modified nucleotide.
Procedure:
-
Digest the purified RNA into its constituent nucleosides using a mixture of nucleases (e.g., nuclease P1) and alkaline phosphatase.[9]
-
Analyze the resulting nucleoside mixture by liquid chromatography-tandem mass spectrometry (LC-MS/MS).
-
Identify this compound by its characteristic mass-to-charge ratio (m/z) and retention time compared to a known standard.[10]
Visualizations
References
- 1. researchgate.net [researchgate.net]
- 2. GIST Scholar: Characterization of 5-aminomethyl-2-thiouridine tRNA modification biosynthetic pathway in Bacillus subtilis [scholar.gist.ac.kr]
- 3. promegaconnections.com [promegaconnections.com]
- 5. benchchem.com [benchchem.com]
- 6. Protocol for the Solid-phase Synthesis of Oligomers of RNA Containing a 2'-O-thiophenylmethyl Modification and Characterization via Circular Dichroism - PMC [pmc.ncbi.nlm.nih.gov]
- 7. twistbioscience.com [twistbioscience.com]
- 8. Standard Protocol for Solid-Phase Oligonucleotide Synthesis using Unmodified Phosphoramidites | LGC, Biosearch Technologies [biosearchtech.com]
- 9. Detection and quantitation of RNA base modifications - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Modomics - A Database of RNA Modifications [genesilico.pl]
Application Note: HPLC Analysis of Modified Nucleosides with a Focus on 5-(aminomethyl)uridine
Audience: Researchers, scientists, and drug development professionals.
Introduction
Modified nucleosides, the building blocks of nucleic acids, are critical players in a wide range of biological processes. These post-transcriptional modifications are particularly abundant in transfer RNAs (tRNAs) and are essential for regulating tRNA folding, stability, and the accuracy of protein translation.[1] The field of epitranscriptomics, which studies these RNA modifications, has highlighted their roles in cellular regulation and disease.[1] 5-(aminomethyl)uridine is a modified purine (B94841) nucleoside analog that, like other analogs, can be studied for its potential therapeutic activities.[2]
High-Performance Liquid Chromatography (HPLC) is a cornerstone technique for the separation and quantification of these modified nucleosides.[1] Due to the polar nature of nucleosides, two primary HPLC methods are employed: Reversed-Phase (RP-HPLC) and Hydrophilic Interaction Liquid Chromatography (HILIC).[3][4][5] This application note provides detailed protocols for sample preparation from tRNA and subsequent analysis using both RP-HPLC and HILIC methods, coupled with UV or Mass Spectrometry (MS) detection.
Experimental Protocols
1. Sample Preparation: Enzymatic Hydrolysis of tRNA
To analyze the nucleoside composition, RNA must first be extracted from the biological source and then completely digested into individual nucleosides.
Protocol 1.1: tRNA Digestion to Nucleosides [1][6]
-
Nuclease P1 Digestion:
-
In a microcentrifuge tube, combine up to 20 µg of purified tRNA with nuclease-free water to a final volume of 25 µL.
-
Add 2.5 µL of 10x Nuclease P1 Buffer (100 mM Sodium Acetate, pH 5.3, 10 mM Zinc Chloride).
-
Add 1-2 Units of Nuclease P1.
-
Incubate the reaction at 37°C for 16 hours. This step digests the RNA into nucleoside 5'-monophosphates.
-
-
Dephosphorylation:
-
To the same tube, add 3 µL of 10x Alkaline Phosphatase Buffer (e.g., 500 mM Tris-HCl, pH 8.5, 10 mM EDTA).
-
Add 10 Units of a heat-labile Alkaline Phosphatase.
-
Incubate at 37°C for 2 hours. This removes the 5'-phosphate group, yielding free nucleosides.
-
-
Sample Cleanup:
2. HPLC Analysis Methodologies
Protocol 2.1: Reversed-Phase HPLC with UV Detection (RP-HPLC-UV)
This method is adapted from protocols used for analyzing thiolated and other modified uridines.[8][9][10] It utilizes a C30 column, which provides enhanced retention for polar molecules compared to standard C18 columns.[1]
-
Column: Reversed-phase C30, 5 µm, 4.6 x 150 mm.
-
Mobile Phase A: 10 mM Ammonium Acetate, pH 4.5, in Water/Methanol (97:3 v/v).[8][9]
-
Mobile Phase B: 10 mM Ammonium Acetate, pH 4.5, in Water/Methanol (2:98 v/v).[8][9]
-
Flow Rate: 0.5 mL/min.[7]
-
Injection Volume: 10-20 µL.
-
Detection: UV Diode Array Detector (DAD) scanning a range of wavelengths, with 260 nm being a primary wavelength for nucleosides.[7]
-
Gradient Program:
-
0-30 min: 0% B (Isocratic)
-
30-35 min: 0% to 100% B (Linear Gradient)
-
35-40 min: 100% B (Isocratic)
-
40-45 min: 100% to 0% B (Linear Gradient)
-
45-55 min: 0% B (Re-equilibration)
-
Protocol 2.2: Hydrophilic Interaction Liquid Chromatography with Mass Spectrometry (HILIC-MS/MS)
HILIC is ideal for retaining highly polar nucleosides and is highly compatible with mass spectrometry.[3][11][12] This method provides high sensitivity and specificity for quantification.
-
Column: Amide or Zwitterionic HILIC column, <3 µm, 2.1 x 100 mm.[11][13]
-
Mobile Phase A: 10 mM Ammonium Acetate in Water, pH 9.5.[14][15]
-
Mobile Phase B: Acetonitrile.
-
Flow Rate: 0.3 mL/min.
-
Injection Volume: 2-5 µL.
-
Detection: Triple Quadrupole Mass Spectrometer (MS/MS) with Electrospray Ionization (ESI) in positive ion mode.
-
MS/MS Parameters: Use Multiple Reaction Monitoring (MRM) for quantification. Specific precursor/product ion transitions must be determined for this compound and other target nucleosides by infusing a pure standard.
-
Gradient Program:
-
0-2 min: 95% B (Isocratic)
-
2-10 min: 95% to 50% B (Linear Gradient)
-
10-12 min: 50% B (Isocratic)
-
12-13 min: 50% to 95% B (Linear Gradient)
-
13-20 min: 95% B (Re-equilibration)
-
Data Presentation
Quantitative data and HPLC parameters are summarized below for easy comparison.
Table 1: Summary of HPLC Experimental Conditions
| Parameter | Protocol 2.1: RP-HPLC-UV | Protocol 2.2: HILIC-MS/MS |
|---|---|---|
| Column Type | C30 Reversed-Phase | Amide or Zwitterionic HILIC |
| Mobile Phase A | 10 mM Ammonium Acetate, pH 4.5 in 97:3 Water/Methanol[8][9] | 10 mM Ammonium Acetate, pH 9.5 in Water[14][15] |
| Mobile Phase B | 10 mM Ammonium Acetate, pH 4.5 in 2:98 Water/Methanol[8][9] | Acetonitrile |
| Typical Flow Rate | 0.5 mL/min | 0.3 mL/min |
| Detection | UV Absorbance (260 nm) | ESI-MS/MS (MRM Mode) |
| Primary Use Case | Robust quantification, method development | High sensitivity, complex mixtures, confirmation |
Table 2: Representative Quantitative Performance Data for Nucleoside Analysis The following are typical performance metrics achievable with HILIC-MS/MS methods for nucleoside analysis.[12]
| Analyte Class | Method | Limit of Detection (LOD) Range | Limit of Quantification (LOQ) Range |
|---|
| Nucleosides & Nucleobases | HILIC-UHPLC-TQ-MS/MS | 0.11 - 3.12 ng/mL | 0.29 - 12.48 ng/mL |
Visualizations
Caption: Overall workflow for the analysis of modified nucleosides from biological samples.
Caption: Comparison of separation principles for polar analytes in RP-HPLC vs. HILIC.
References
- 1. HPLC Analysis of tRNA‐Derived Nucleosides - PMC [pmc.ncbi.nlm.nih.gov]
- 2. medchemexpress.com [medchemexpress.com]
- 3. Nucleoside Analysis by Hydrophilic Interaction Liquid Chromatography Coupled with Mass Spectrometry - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. mdpi.com [mdpi.com]
- 5. Nucleobases & Nucleosides by HPLC | Phenomenex [phenomenex.com]
- 6. Chemical synthesis of the 5-taurinomethyl(-2-thio)uridine modified anticodon arm of the human mitochondrial tRNALeu(UUR) and tRNALys - PMC [pmc.ncbi.nlm.nih.gov]
- 7. protocols.io [protocols.io]
- 8. academic.oup.com [academic.oup.com]
- 9. researchgate.net [researchgate.net]
- 10. academic.oup.com [academic.oup.com]
- 11. waters.com [waters.com]
- 12. researchgate.net [researchgate.net]
- 13. Characterization of Nucleosides and Nucleobases in Natural Cordyceps by HILIC–ESI/TOF/MS and HILIC–ESI/MS - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Plant Sample Preparation for Nucleoside/Nucleotide Content Measurement with An HPLC-MS/MS [jove.com]
- 15. researchgate.net [researchgate.net]
Application Notes: Studying 5-(aminomethyl)uridine (nm⁵U) tRNA Modification
For Researchers, Scientists, and Drug Development Professionals
Introduction
Transfer RNA (tRNA) molecules are central to protein synthesis, acting as the adaptor molecules that translate the genetic code into the amino acid sequence of proteins. Their function and stability are heavily reliant on a vast array of over 150 post-transcriptional chemical modifications. These modifications, particularly those in the anticodon loop, are critical for ensuring the accuracy and efficiency of translation.[1]
One such modification is 5-(aminomethyl)uridine (nm⁵U) , found at the wobble position (U34) of certain tRNAs. While it can be a final modification, nm⁵U is more commonly a key intermediate in the biosynthetic pathway of more complex modifications, such as 5-methylaminomethyluridine (B1256275) (mnm⁵U) and 5-methylaminomethyl-2-thiouridine (B1677369) (mnm⁵s²U) in bacteria.[1][2][3][4] These modifications are crucial for the accurate decoding of codons ending in A or G in split codon boxes.[5][6] Studying nm⁵U and its associated pathways provides critical insights into the mechanisms of translational fidelity, bacterial physiology, and potential targets for novel antimicrobial agents.
Biological Significance
The addition of a side chain at the C5 position of wobble uridine (B1682114) is a conserved strategy to maintain the reading frame and stabilize codon-anticodon pairing.[5][7]
-
Translational Fidelity: The modifications downstream of nm⁵U, like mnm⁵U, restrict the conformational flexibility of the anticodon. This ensures that the tRNA correctly recognizes its cognate codons (typically NNA/NNG) and prevents misreading of near-cognate codons, thereby reducing missense errors and translational frameshifting.[5][7]
-
Intermediate in a Critical Pathway: In many bacteria, nm⁵U is an essential intermediate. Its formation and subsequent methylation are catalyzed by a series of enzymes. In E. coli, the MnmE-MnmG complex can generate nm⁵U from ammonium, or it can form 5-carboxymethylaminomethyluridine (B1212367) (cmnm⁵U) from glycine.[1][6][8] The bifunctional enzyme MnmC then converts cmnm⁵U to nm⁵U and subsequently methylates it to mnm⁵U.[1][6][9][10]
-
Bacterial Physiology and Virulence: The absence of enzymes in this pathway leads to the accumulation of unmodified or partially modified tRNAs. This can result in pleiotropic phenotypes, including reduced growth rates, sensitivity to stress conditions, and attenuated virulence in pathogenic bacteria.[11][12]
Applications in Research and Drug Development
-
Antimicrobial Drug Development: The enzymes involved in the nm⁵U/mnm⁵U biosynthetic pathway, such as MnmE, MnmG, and MnmC, are highly conserved in bacteria but may have distinct non-homologous counterparts in different species (e.g., MnmL, MnmM in Gram-positives).[9][13] These enzymes are potential targets for the development of novel antibiotics that disrupt bacterial protein synthesis.
-
Understanding Disease Mechanisms: While the direct role of nm⁵U in human disease is less clear, related modifications in mitochondrial tRNAs are linked to severe human diseases. Studying these pathways can provide insights into the fundamental biology of tRNA modifications and their impact on cellular health.
-
Biomarker Discovery: The tRNA modification profile, or "epitranscriptome," can change in response to environmental stress or disease states. Monitoring the levels of nm⁵U and related modifications could serve as a biomarker for bacterial infection or cellular stress.
Biosynthetic Pathways of nm⁵U and mnm⁵U
The synthesis of this compound (nm⁵U) and its subsequent conversion to 5-methylaminomethyluridine (mnm⁵U) involves different enzymatic pathways in Gram-negative (e.g., E. coli) and Gram-positive (e.g., B. subtilis) bacteria.
References
- 1. Identification of a novel 5-aminomethyl-2-thiouridine methyltransferase in tRNA modification - PMC [pmc.ncbi.nlm.nih.gov]
- 2. researchgate.net [researchgate.net]
- 3. researchgate.net [researchgate.net]
- 4. researchgate.net [researchgate.net]
- 5. The Role of RNA Modifications in Translational Fidelity - PMC [pmc.ncbi.nlm.nih.gov]
- 6. academic.oup.com [academic.oup.com]
- 7. academic.oup.com [academic.oup.com]
- 8. Insights into the Mechanism of Installation of 5-Carboxymethylaminomethyl Uridine Hypermodification by tRNA-Modifying Enzymes MnmE and MnmG - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Alternate routes to mnm5s2U synthesis in Gram-positive bacteria - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Identification of a bifunctional enzyme MnmC involved in the biosynthesis of a hypermodified uridine in the wobble position of tRNA - PMC [pmc.ncbi.nlm.nih.gov]
- 11. The output of the tRNA modification pathways controlled by the Escherichia coli MnmEG and MnmC enzymes depends on the growth conditions and the tRNA species - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Functions of bacterial tRNA modifications: from ubiquity to diversity - PMC [pmc.ncbi.nlm.nih.gov]
- 13. tRNA modifying enzymes MnmE and MnmG are essential for Plasmodium falciparum apicoplast maintenance - PMC [pmc.ncbi.nlm.nih.gov]
Application Notes and Protocols for Incorporating 5-(Aminomethyl)uridine into RNA Probes
For Researchers, Scientists, and Drug Development Professionals
Introduction
The site-specific incorporation of modified nucleotides into RNA probes is a powerful tool for elucidating RNA structure, function, and interactions. 5-(aminomethyl)uridine (nm5U) is a modified pyrimidine (B1678525) that introduces a primary amine group at the C5 position of the uracil (B121893) base. This functional group serves as a versatile chemical handle for the post-transcriptional conjugation of a wide array of molecules, including fluorophores, biotin, crosslinking agents, and affinity tags. This document provides detailed application notes and protocols for the enzymatic incorporation of this compound triphosphate (nm5UTP) into RNA probes using in vitro transcription and subsequent labeling with amine-reactive dyes.
Principle of the Technology
The workflow for generating labeled RNA probes with this compound involves two key steps:
-
Enzymatic Incorporation of nm5UTP: T7 RNA polymerase is utilized for in vitro transcription of a DNA template. During this process, this compound triphosphate (nm5UTP) is used in place of or in combination with uridine (B1682114) triphosphate (UTP). The polymerase incorporates the modified nucleotide into the nascent RNA strand.
-
Post-Transcriptional Labeling: The resulting amine-modified RNA is then purified and subjected to a chemical labeling reaction. The primary amine groups on the incorporated nm5U residues react with N-hydroxysuccinimide (NHS)-ester functionalized molecules, such as fluorescent dyes, to form stable amide bonds.
Applications
RNA probes containing this compound can be utilized in a variety of molecular biology and drug development applications, including:
-
Fluorescence in situ Hybridization (FISH): Labeled RNA probes enable the detection and localization of specific RNA transcripts within fixed cells and tissues.
-
RNA-Protein Interaction Studies: Crosslinking agents can be attached to the amine-modified RNA to identify binding partners.
-
RNA Trafficking and Localization: Fluorescently labeled RNA can be tracked in living cells to study its transport and subcellular distribution.
-
RNA Structure Analysis: The attachment of reporter molecules at specific sites can provide insights into RNA folding and conformational changes.
-
Development of RNA-based Diagnostics and Therapeutics: Modified RNA can be conjugated to various functional molecules for targeted delivery and therapeutic action.
Experimental Protocols
Protocol 1: In Vitro Transcription with this compound Triphosphate (nm5UTP)
This protocol is adapted from standard T7 RNA polymerase transcription protocols, with modifications to accommodate the use of nm5UTP. The efficiency of incorporation of modified nucleotides can be sequence-dependent, and optimization may be required.
Materials:
-
Linearized DNA template with a T7 promoter (0.5-1.0 µg/µL)
-
T7 RNA Polymerase (e.g., NEB #M0251)
-
10X T7 Reaction Buffer
-
Ribonucleotide solution mix (10 mM each of ATP, CTP, GTP)
-
UTP solution (10 mM)
-
This compound triphosphate (nm5UTP) solution (10 mM)
-
RNase Inhibitor (e.g., Promega #N2611)
-
Nuclease-free water
Procedure:
-
Thaw all components on ice. Keep the T7 RNA Polymerase and RNase Inhibitor on ice.
-
Assemble the transcription reaction at room temperature in the following order:
| Component | Volume (for a 20 µL reaction) | Final Concentration |
| Nuclease-free water | to 20 µL | |
| 10X T7 Reaction Buffer | 2 µL | 1X |
| ATP, CTP, GTP mix (10 mM each) | 2 µL | 1 mM each |
| UTP (10 mM) | 1 µL | 0.5 mM |
| nm5UTP (10 mM) | 1 µL | 0.5 mM |
| Linearized DNA template (0.5 µg) | 1 µL | 25 ng/µL |
| RNase Inhibitor | 1 µL | |
| T7 RNA Polymerase | 2 µL |
Note: The ratio of nm5UTP to UTP can be adjusted to control the density of the modification. For complete substitution, omit UTP and use 2 µL of nm5UTP. Optimization of the MgCl2 concentration in the reaction buffer may be necessary when using high concentrations of modified NTPs.
-
Mix the components thoroughly by gentle pipetting.
-
Incubate the reaction at 37°C for 2-4 hours.
-
(Optional) To remove the DNA template, add 1 µL of DNase I (RNase-free) and incubate at 37°C for 15 minutes.
-
Proceed to RNA purification.
Protocol 2: Purification of Amine-Modified RNA
Purification is crucial to remove unincorporated nucleotides, enzymes, and the DNA template. Spin column purification is a reliable method for this purpose.[1]
Materials:
-
RNA cleanup spin column kit (e.g., NEB Monarch RNA Cleanup Kit)
-
Nuclease-free water
Procedure:
-
Follow the manufacturer's protocol for the chosen RNA cleanup kit.
-
Elute the purified RNA in nuclease-free water.
-
Quantify the RNA concentration using a spectrophotometer (e.g., NanoDrop). The A260/A280 ratio should be ~2.0 for pure RNA.
Protocol 3: Post-Transcriptional Labeling with NHS-Ester Dyes
This protocol describes the labeling of amine-modified RNA with a fluorescent dye containing an NHS-ester functional group.
Materials:
-
Purified amine-modified RNA (in nuclease-free water or a suitable buffer)
-
NHS-ester activated fluorescent dye (e.g., Cy3-NHS ester, Alexa Fluor 488 NHS ester)
-
Anhydrous Dimethylformamide (DMF) or Dimethyl sulfoxide (B87167) (DMSO)
-
Sodium bicarbonate buffer (0.1 M, pH 8.5)
-
Ethanol (100% and 70%)
-
3 M Sodium acetate (B1210297) (pH 5.2)
-
Nuclease-free water
Procedure:
-
Resuspend the amine-modified RNA in the sodium bicarbonate buffer to a final concentration of 1-2 mg/mL.
-
Prepare a stock solution of the NHS-ester dye in DMF or DMSO (typically 10-20 mg/mL).
-
Add the NHS-ester dye solution to the RNA solution. A 10-20 fold molar excess of the dye over the incorporated amine groups is recommended.
-
Incubate the reaction for 1-2 hours at room temperature in the dark.
-
To remove the unreacted dye, precipitate the labeled RNA by adding 0.1 volumes of 3 M sodium acetate and 2.5 volumes of ice-cold 100% ethanol.
-
Incubate at -20°C for at least 1 hour.
-
Centrifuge at high speed (e.g., >12,000 x g) for 30 minutes at 4°C to pellet the RNA.
-
Carefully remove the supernatant.
-
Wash the pellet with 70% ethanol.
-
Air-dry the pellet and resuspend in nuclease-free water.
-
The labeled RNA is now ready for use in downstream applications.
Data Presentation
Table 1: Quantitative Data Summary for In Vitro Transcription with Modified UTPs
| Modified UTP | Relative Incorporation Efficiency (%) | Key Observations | Reference |
| 5-aminoallyl-UTP | Good | Efficiently incorporated by T7 RNA polymerase. | [2] |
| 5-amino-UTP (amide linkage) | Moderate | Higher Km compared to unmodified UTP, but similar Vmax. | [3] |
| This compound triphosphate (nm5UTP) | Expected to be Good | Based on the tolerance for similar 5-position modifications, efficient incorporation is anticipated. Optimization of reaction conditions may be beneficial. | Inferred |
Mandatory Visualizations
Caption: Experimental workflow for generating labeled RNA probes.
Caption: Chemical principle of post-transcriptional labeling.
Troubleshooting
| Problem | Possible Cause | Suggested Solution |
| Low yield of transcribed RNA | - Inefficient incorporation of nm5UTP. - Suboptimal reaction conditions. - Degraded reagents. | - Optimize the ratio of nm5UTP to UTP. - Titrate the MgCl2 concentration in the reaction buffer. - Use fresh nucleotide stocks. - Ensure the DNA template is of high quality. |
| Incomplete or truncated transcripts | - High GC content in the template. - Premature termination by the polymerase. | - Decrease the transcription temperature to 30°C.[4] - Ensure the linearized template is fully digested and purified. |
| Low labeling efficiency | - Inactive NHS-ester dye. - Insufficient amine groups on RNA. - Incorrect pH of the labeling buffer. | - Use fresh, anhydrous DMF or DMSO to dissolve the dye. - Increase the ratio of nm5UTP during transcription. - Ensure the pH of the sodium bicarbonate buffer is 8.5. |
| RNA degradation | - RNase contamination. | - Use RNase-free water, tips, and tubes. - Always include an RNase inhibitor in the transcription reaction.[5] |
References
- 1. neb.com [neb.com]
- 2. its.caltech.edu [its.caltech.edu]
- 3. Site-specific RNA modification via initiation of in vitro transcription reactions with m 6 A and isomorphic emissive adenosine analogs - RSC Chemical Biology (RSC Publishing) DOI:10.1039/D4CB00045E [pubs.rsc.org]
- 4. go.zageno.com [go.zageno.com]
- 5. promegaconnections.com [promegaconnections.com]
Application Notes and Protocols for Phosphoramidite Chemistry in 5-(Aminomethyl)uridine Synthesis
For Researchers, Scientists, and Drug Development Professionals
These application notes provide a comprehensive overview and detailed protocols for the synthesis of 5-(aminomethyl)uridine phosphoramidite (B1245037), a key building block for the incorporation of modified nucleosides into synthetic oligonucleotides. The methodologies described herein are compiled from established chemical literature and are intended to guide researchers in the fields of nucleic acid chemistry, drug discovery, and molecular biology.
Introduction
The site-specific incorporation of modified nucleosides, such as this compound, into oligonucleotides is a powerful tool for enhancing their therapeutic properties. Modifications at the 5-position of pyrimidines can improve nuclease resistance, binding affinity to target sequences, and pharmacokinetic profiles of antisense oligonucleotides, siRNAs, and aptamers. The aminomethyl group, in particular, introduces a primary amine that can be further functionalized for the attachment of labels, cross-linking agents, or other moieties to probe biological interactions or enhance therapeutic efficacy. The phosphoramidite approach remains the gold standard for the automated chemical synthesis of oligonucleotides, offering high coupling efficiencies and compatibility with a wide range of modified monomers.[1]
This document outlines the chemical synthesis of the 5'-(dimethoxytrityl)-5-(N-trifluoroacetylaminomethyl)-2'-deoxyuridine-3'-CE-phosphoramidite, a protected form of this compound suitable for solid-phase oligonucleotide synthesis.
Synthetic Strategy Overview
The overall synthetic strategy involves a multi-step process starting from a suitable uridine (B1682114) derivative. The key steps include:
-
Synthesis of 5-(Aminomethyl)-2'-deoxyuridine: Preparation of the core modified nucleoside.
-
Protection of the Aminomethyl Group: Introduction of a trifluoroacetyl (TFA) protecting group to the exocyclic amine to prevent side reactions during subsequent synthesis steps.
-
5'-Hydroxyl Protection: Protection of the 5'-hydroxyl group with a dimethoxytrityl (DMT) group, which is crucial for purification and for the step-wise oligonucleotide synthesis.
-
3'-Phosphitylation: Introduction of the phosphoramidite moiety at the 3'-hydroxyl group, rendering the nucleoside ready for incorporation into an oligonucleotide chain.
Data Presentation
The following tables summarize the key quantitative data for each major step of the synthesis, compiled from literature sources for similar transformations.
Table 1: Synthesis of 5-(N-trifluoroacetylaminomethyl)-2'-deoxyuridine
| Step | Reaction | Reagents | Solvent | Typical Yield | Reference |
| 1 | Synthesis of 5-(Azidomethyl)-2'-deoxyuridine | 5-(Bromomethyl)-3',5'-di-O-acetyl-2'-deoxyuridine, Lithium azide (B81097) | DMF | High | [2] |
| 2 | Reduction to 5-(Aminomethyl)-2'-deoxyuridine | 5-(Azidomethyl)-2'-deoxyuridine, H₂, Pd/C | Ethanol (B145695)/Water | High | [2] |
| 3 | Trifluoroacetylation | 5-(Aminomethyl)-2'-deoxyuridine, Ethyl trifluoroacetate | Methanol | Good to Excellent | [3] |
Table 2: Synthesis of 5'-(Dimethoxytrityl)-5-(N-trifluoroacetylaminomethyl)-2'-deoxyuridine-3'-CE-phosphoramidite
| Step | Reaction | Reagents | Solvent | Typical Yield | Reference |
| 1 | 5'-O-DMT Protection | 5-(N-trifluoroacetylaminomethyl)-2'-deoxyuridine, DMT-Cl, Pyridine (B92270) | Pyridine | 79-92% | |
| 2 | 3'-O-Phosphitylation | 5'-DMT-protected nucleoside, 2-Cyanoethyl N,N-diisopropylchlorophosphoramidite, DIPEA | Dichloromethane (B109758) | 88-98% |
Experimental Protocols
Protocol 1: Synthesis of 5-(N-trifluoroacetylaminomethyl)-2'-deoxyuridine
This protocol describes the synthesis of the N-protected aminomethyluridine derivative, starting from a suitable precursor.
1.1 Synthesis of 5-(Azidomethyl)-2'-deoxyuridine
A selective method involves the displacement of a bromide from 5-(bromomethyl)-3',5'-di-O-acetyl-2'-deoxyuridine with lithium azide, followed by deacetylation.[2]
-
Materials: 5-(Bromomethyl)-3',5'-di-O-acetyl-2'-deoxyuridine, Lithium azide, Dimethylformamide (DMF), Methanolic ammonia (B1221849).
-
Procedure:
-
Dissolve 5-(bromomethyl)-3',5'-di-O-acetyl-2'-deoxyuridine in anhydrous DMF.
-
Add an excess of lithium azide and stir the reaction mixture at room temperature until the starting material is consumed (monitor by TLC).
-
Remove the solvent under reduced pressure.
-
Treat the residue with methanolic ammonia to remove the acetyl protecting groups.
-
Purify the product by silica (B1680970) gel chromatography to obtain 5-(azidomethyl)-2'-deoxyuridine.
-
1.2 Reduction to 5-(Aminomethyl)-2'-deoxyuridine
The azide is reduced to the primary amine by catalytic hydrogenation.[2]
-
Materials: 5-(Azidomethyl)-2'-deoxyuridine, 10% Palladium on charcoal (Pd/C), Ethanol, Water.
-
Procedure:
-
Dissolve 5-(azidomethyl)-2'-deoxyuridine in a mixture of ethanol and water.
-
Add a catalytic amount of 10% Pd/C.
-
Hydrogenate the mixture under a hydrogen atmosphere (e.g., using a balloon or a Parr hydrogenator) at room temperature until the reaction is complete (monitor by TLC).
-
Filter the reaction mixture through Celite to remove the catalyst.
-
Evaporate the solvent to yield 5-(aminomethyl)-2'-deoxyuridine.
-
1.3 Trifluoroacetylation of 5-(Aminomethyl)-2'-deoxyuridine
The exocyclic amine is protected with a trifluoroacetyl group.[3]
-
Materials: 5-(Aminomethyl)-2'-deoxyuridine, Ethyl trifluoroacetate, Triethylamine (B128534), Methanol.
-
Procedure:
-
Suspend 5-(aminomethyl)-2'-deoxyuridine in methanol.
-
Add triethylamine and ethyl trifluoroacetate.
-
Stir the mixture at room temperature overnight.
-
Monitor the reaction by TLC.
-
Upon completion, evaporate the solvent and purify the crude product by silica gel chromatography to afford 5-(N-trifluoroacetylaminomethyl)-2'-deoxyuridine.
-
Protocol 2: Synthesis of 5'-(Dimethoxytrityl)-5-(N-trifluoroacetylaminomethyl)-2'-deoxyuridine
This protocol details the protection of the 5'-hydroxyl group.
-
Materials: 5-(N-trifluoroacetylaminomethyl)-2'-deoxyuridine, 4,4'-Dimethoxytrityl chloride (DMT-Cl), Anhydrous pyridine.
-
Procedure:
-
Co-evaporate the starting nucleoside with anhydrous pyridine to remove residual water.
-
Dissolve the dried nucleoside in anhydrous pyridine.
-
Add DMT-Cl in portions while stirring at room temperature.
-
Monitor the reaction by TLC. The reaction typically proceeds to completion within a few hours.
-
Quench the reaction by adding a small amount of methanol.
-
Evaporate the solvent under reduced pressure.
-
Dissolve the residue in dichloromethane and wash with a saturated aqueous solution of sodium bicarbonate and then with brine.
-
Dry the organic layer over anhydrous sodium sulfate, filter, and concentrate.
-
Purify the product by silica gel chromatography to yield the 5'-O-DMT protected nucleoside.
-
Protocol 3: Synthesis of 5'-(Dimethoxytrityl)-5-(N-trifluoroacetylaminomethyl)-2'-deoxyuridine-3'-CE-phosphoramidite
This protocol describes the final phosphitylation step.
-
Materials: 5'-(Dimethoxytrityl)-5-(N-trifluoroacetylaminomethyl)-2'-deoxyuridine, 2-Cyanoethyl N,N-diisopropylchlorophosphoramidite, N,N-Diisopropylethylamine (DIPEA), Anhydrous dichloromethane.
-
Procedure:
-
Dry the 5'-O-DMT protected nucleoside under high vacuum overnight.
-
Dissolve the dried nucleoside in anhydrous dichloromethane under an inert atmosphere (e.g., argon).
-
Add DIPEA to the solution.
-
Slowly add 2-cyanoethyl N,N-diisopropylchlorophosphoramidite to the stirred solution at room temperature.
-
Stir the reaction for 2-4 hours, monitoring its progress by TLC.
-
Quench the reaction with a small amount of methanol.
-
Dilute the reaction mixture with dichloromethane and wash with a saturated aqueous solution of sodium bicarbonate and brine.
-
Dry the organic layer over anhydrous sodium sulfate, filter, and concentrate under reduced pressure.
-
Purify the crude phosphoramidite by flash chromatography on silica gel (pre-treated with triethylamine) to obtain the final product as a white foam.
-
Mandatory Visualizations
Synthesis Workflow
Caption: Synthetic workflow for this compound phosphoramidite.
Oligonucleotide Synthesis Cycle
Caption: Standard phosphoramidite cycle for oligonucleotide synthesis.
References
- 1. Synthesis and biological activities of 5-trifluoromethyl-5'-azido-2',5'-dideoxyuridine and 5-trifluoromethyl-5'-amino-2',5'-dideoxyuridine - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. researchgate.net [researchgate.net]
- 3. Synthesis and biological activities of 5-(hydroxymethyl, azidomethyl, or aminomethyl)-2'-deoxyuridine and related 5'-substituted analogues - PubMed [pubmed.ncbi.nlm.nih.gov]
Application Notes and Protocols for Enzymatic Incorporation of 5-(Aminomethyl)uridine Triphosphate
For Researchers, Scientists, and Drug Development Professionals
Introduction
5-(Aminomethyl)uridine (5-amU) is a modified nucleoside that, when incorporated into DNA or RNA, introduces a primary amine group into the major groove of the nucleic acid duplex. This functional group serves as a versatile chemical handle for post-synthetic modifications, enabling the attachment of a wide array of functionalities such as fluorophores, biotin, cross-linking agents, or therapeutic molecules. The enzymatic incorporation of this compound triphosphate (5-amU-TP) and its deoxyribonucleoside counterpart, 5-(aminomethyl)-2'-deoxyuridine triphosphate (5-am-dUTP), offers a powerful strategy for the site-specific or global modification of nucleic acids. These modified oligonucleotides are valuable tools in various research and drug development applications, including the development of novel diagnostics, therapeutic aptamers, and modified mRNA therapies.
Applications
The introduction of this compound into nucleic acids opens up a broad spectrum of applications:
-
Drug Development: The primary amine handle allows for the conjugation of drug molecules to DNA or RNA aptamers, enabling targeted drug delivery. In the context of mRNA therapeutics, this modification can be used to attach moieties that enhance stability, delivery, or translational efficiency.
-
Diagnostics: Fluorophore-labeled nucleic acids containing 5-amU can be used as probes in various diagnostic assays, including fluorescence in situ hybridization (FISH) and polymerase chain reaction (PCR).
-
Bioconjugation: The reactive amine group facilitates the covalent attachment of proteins, peptides, or other biomolecules to study nucleic acid-protein interactions or to create novel bioconjugates with tailored functions.
-
SELEX (Systematic Evolution of Ligands by Exponential Enrichment): The incorporation of 5-amU into nucleic acid libraries expands their chemical diversity, potentially leading to the selection of aptamers with enhanced binding affinities and specificities.[1][2][3][4]
-
Structural Biology: The attachment of spectroscopic probes via the aminomethyl linker can aid in the structural elucidation of nucleic acids and their complexes using techniques like Nuclear Magnetic Resonance (NMR) and Förster Resonance Energy Transfer (FRET).
Enzymatic Incorporation of this compound
Incorporation into RNA using T7 RNA Polymerase
T7 RNA polymerase is a DNA-dependent RNA polymerase that is highly specific for its promoter and is widely used for the in vitro synthesis of RNA. It is capable of incorporating various modified nucleotides, including 5-amU-TP, into RNA transcripts.[5][6]
Caption: Workflow for enzymatic synthesis of 5-amU modified RNA.
This protocol is a general guideline and may require optimization depending on the specific template and desired product.
Reaction Components:
| Component | Final Concentration |
| Linearized DNA Template | 0.5 - 1.0 µg |
| 5X Transcription Buffer | 1X |
| 100 mM DTT | 10 mM |
| ATP, CTP, GTP (each) | 5 mM |
| UTP | 2.5 mM |
| 5-amU-TP | 2.5 mM |
| T7 RNA Polymerase | 50 units |
| RNase Inhibitor | 40 units |
| Nuclease-free Water | to 100 µL |
Procedure:
-
Thaw all components on ice.
-
Assemble the reaction mixture in a nuclease-free tube at room temperature in the order listed above.
-
Mix gently by pipetting up and down and centrifuge briefly to collect the contents at the bottom of the tube.
-
Incubate the reaction at 37°C for 2 to 4 hours.
-
To remove the DNA template, add 2 units of DNase I and incubate at 37°C for 15 minutes.
-
Purify the RNA using a spin column-based RNA purification kit or by lithium chloride precipitation.
-
Analyze the integrity and purity of the transcribed RNA using denaturing polyacrylamide or agarose (B213101) gel electrophoresis.
-
Verify the incorporation of 5-amU using HPLC or mass spectrometry.
Quantitative Data:
While specific data for the incorporation efficiency of 5-amU-TP by T7 RNA polymerase is not extensively published, studies on similar 5-substituted uridine (B1682114) triphosphates suggest that they are generally good substrates for T7 RNAP. The yield of modified RNA can be influenced by the ratio of modified to unmodified UTP. A 1:1 ratio is a good starting point for optimization. It has been shown that a mutant T7 RNA polymerase (P266L) can increase the incorporation efficiency and yield of some modified nucleotides.[7][8] Typical in vitro transcription reactions can yield 2 to 5 g/L of mRNA, with optimized processes reaching up to 12 g/L.[9]
| Modification | Polymerase | Relative Yield/Efficiency | Reference |
| 5-thienoguanosine | T7 RNAP (WT) | 40% incorporation, 37 µg yield (100 µL reaction) | [7] |
| 5-thienoguanosine | T7 RNAP (P266L) | 85% incorporation, 50 µg yield (100 µL reaction) | [7] |
Incorporation into DNA using Vent (exo-) DNA Polymerase
Vent (exo-) DNA Polymerase is a thermostable DNA polymerase that lacks 3'→5' proofreading exonuclease activity, which makes it more tolerant to the incorporation of modified nucleotides like 5-am-dUTP.
Caption: Workflow for enzymatic synthesis of 5-amU modified DNA.
This protocol provides a general framework for PCR-based incorporation of 5-am-dUTP. Optimization of primer annealing temperature and MgSO₄ concentration may be necessary.
Reaction Components:
| Component | Final Concentration |
| DNA Template | 1 ng - 1 µg (genomic), 1 pg - 10 ng (plasmid) |
| Forward Primer | 0.5 µM |
| Reverse Primer | 0.5 µM |
| 10X ThermoPol Reaction Buffer | 1X |
| dATP, dCTP, dGTP (each) | 200 µM |
| dTTP | 100 µM |
| 5-am-dUTP | 100 µM |
| 100 mM MgSO₄ | 2-6 mM (optimize) |
| Vent (exo-) DNA Polymerase | 2-4 units/100 µL |
| Nuclease-free Water | to 100 µL |
Thermocycling Conditions:
| Step | Temperature | Time | Cycles |
| Initial Denaturation | 95°C | 2-5 min | 1 |
| Denaturation | 95°C | 30 sec | 25-35 |
| Annealing | Tm - 5°C | 30 sec | |
| Extension | 72°C | 1 min/kb | |
| Final Extension | 72°C | 5-10 min | 1 |
| Hold | 4°C | ∞ |
Procedure:
-
Thaw all reagents on ice.
-
Prepare a master mix containing all components except the DNA template.
-
Aliquot the master mix into individual PCR tubes.
-
Add the DNA template to each tube.
-
Perform PCR using the optimized thermocycling conditions.
-
Analyze the PCR product by agarose gel electrophoresis.
-
Purify the modified DNA using a PCR cleanup kit or gel extraction.
-
Confirm the incorporation of 5-am-dUTP by HPLC or mass spectrometry.
Quantitative Data:
The incorporation efficiency of modified dNTPs by DNA polymerases is dependent on the specific modification and the polymerase used. Vent (exo-) DNA polymerase is known to be relatively permissive towards modifications at the 5-position of pyrimidines. The yield of the PCR product will depend on the amplification efficiency, which may be slightly reduced with the inclusion of modified nucleotides.[10][]
| Polymerase | Modified dNTP | Relative Incorporation Efficiency | Reference |
| Vent DNA Polymerase | dUTP | 15.1% | [12] |
| Q5U DNA Polymerase | dUTP | Similar to dTTP | [13] |
Analysis and Characterization
Verification of Incorporation
High-Performance Liquid Chromatography (HPLC): HPLC is a powerful technique for the analysis and purification of modified oligonucleotides.[12][14][15][16]
-
Protocol Outline:
-
Enzymatically digest the modified nucleic acid to its constituent nucleosides using nucleases and phosphatases.
-
Separate the nucleosides using a reversed-phase C18 column.
-
Detect the nucleosides by UV absorbance.
-
Quantify the amount of this compound relative to the canonical nucleosides.
-
Mass Spectrometry (MS): Mass spectrometry provides a precise measurement of the molecular weight of the modified nucleic acid, confirming the incorporation of the 5-amU modification.[17][18][19]
-
Protocol Outline:
-
Purify the modified oligonucleotide.
-
Analyze the intact mass using ESI-MS or MALDI-TOF MS.
-
Alternatively, digest the nucleic acid and analyze the resulting fragments or nucleosides by LC-MS/MS.
-
Functional Characterization
Thermal Stability (Melting Temperature, Tm): The incorporation of modified nucleosides can affect the thermal stability of nucleic acid duplexes. The melting temperature (Tm) can be determined by monitoring the UV absorbance of the duplex at 260 nm as a function of temperature. While specific data for 5-amU is limited, 5-substituted uridines can have varying effects on duplex stability. For instance, some 5-substituted uridines have been shown to increase the thermal stability of RNA duplexes.[20][21]
Functional Assays: The functional consequences of 5-amU incorporation will depend on the specific application. For example, in the case of aptamers, binding assays (e.g., filter binding, electrophoretic mobility shift assays) should be performed to assess the affinity and specificity of the modified aptamer. For modified mRNA, in vitro translation assays can be used to evaluate the impact of the modification on protein expression.[22][23]
Signaling Pathways and Logical Relationships
The primary utility of incorporating this compound lies in the creation of a reactive site for post-synthetic modification, which can be conceptualized as a branching point for various downstream applications.
Caption: Logic diagram for the application of 5-amU modified nucleic acids.
Conclusion
The enzymatic incorporation of this compound triphosphate provides a robust and versatile platform for the generation of functionally enhanced nucleic acids. The protocols and data presented here offer a comprehensive guide for researchers and drug developers to harness the potential of this modification in a wide range of applications, from fundamental research to the development of next-generation therapeutics and diagnostics. Further optimization of reaction conditions and a more detailed investigation into the structural and functional consequences of this modification will continue to expand its utility in the field of nucleic acid chemistry and biology.
References
- 1. Nucleotides for SELEX/Aptamer Modification - Jena Bioscience [jenabioscience.com]
- 2. Preparation of Chemically Modified DNA Library for SELEX via Incorporation of CLB-dUTP in Primer Extension Reaction - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. pdfs.semanticscholar.org [pdfs.semanticscholar.org]
- 4. mdpi.com [mdpi.com]
- 5. youtube.com [youtube.com]
- 6. tools.thermofisher.com [tools.thermofisher.com]
- 7. A T7 RNA polymerase mutant enhances the yield of 5'-thienoguanosine-initiated RNAs - PMC [pmc.ncbi.nlm.nih.gov]
- 8. A T7 RNA Polymerase Mutant Enhances the Yield of 5'-Thienoguanosine-Initiated RNAs - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. researchgate.net [researchgate.net]
- 10. How much DNA is obtained in the average PCR reaction? [qiagen.com]
- 12. idtdna.com [idtdna.com]
- 13. Using Selective Enzymes to Measure Noncanonical DNA Building Blocks: dUTP, 5-Methyl-dCTP, and 5-Hydroxymethyl-dCTP - PMC [pmc.ncbi.nlm.nih.gov]
- 14. chromtech.com [chromtech.com]
- 15. HPLC Method for Analysis of Oligonucleotides 20 mer on BIST A Column | SIELC Technologies [sielc.com]
- 16. Novel method for DNA methylation analysis using high‐performance liquid chromatography and its clinical application - PMC [pmc.ncbi.nlm.nih.gov]
- 17. idtdna.com [idtdna.com]
- 18. Broadly applicable oligonucleotide mass spectrometry for the analysis of RNA writers and erasers in vitro - PMC [pmc.ncbi.nlm.nih.gov]
- 19. web.colby.edu [web.colby.edu]
- 20. benchchem.com [benchchem.com]
- 21. researchgate.net [researchgate.net]
- 22. Chemical modification of uridine modulates mRNA-mediated proinflammatory and antiviral response in primary human macrophages - PMC [pmc.ncbi.nlm.nih.gov]
- 23. deepblue.lib.umich.edu [deepblue.lib.umich.edu]
Application Notes and Protocols for the Detection of 5-(aminomethyl)uridine using Nanopore Sequencing
For Researchers, Scientists, and Drug Development Professionals
Introduction
The direct detection of RNA modifications is a rapidly advancing field, crucial for understanding the epitranscriptome's role in gene regulation, cellular processes, and the development of RNA-based therapeutics. 5-(aminomethyl)uridine (nm⁵U) is a modified nucleoside found in tRNA that plays a significant role in the efficiency and fidelity of protein translation. Traditional methods for detecting RNA modifications often require complex sample preparation, including reverse transcription and amplification, which can introduce biases and erase the modification information. Oxford Nanopore Technologies' direct RNA sequencing offers a powerful alternative, enabling the direct analysis of native RNA molecules and the identification of modified bases by detecting characteristic changes in the ionic current as the RNA strand passes through a nanopore.[1][2]
These application notes provide a comprehensive overview and a detailed protocol for the detection and quantification of this compound in RNA samples using nanopore direct RNA sequencing. The methodology is based on established principles for identifying other uridine (B1682114) modifications and leverages machine learning approaches to distinguish modified bases from their canonical counterparts based on their unique electrical signatures.[1][3]
Principle of Detection
Nanopore sequencing technology identifies nucleotides by measuring the disruption in ionic current as a single RNA molecule is threaded through a protein nanopore.[2][4] Each k-mer (a short sequence of nucleotides) residing in the pore at a given moment produces a characteristic current signal. The presence of a modified base, such as this compound, alters the size and chemical properties of the nucleotide, resulting in a distinct current signal compared to the canonical uridine.[2][5][6] These signal perturbations, including changes in current intensity (mean, median), signal duration (dwell time), and standard deviation, can be analyzed to identify the location of the modification with single-molecule resolution.[1][2] Machine learning models can be trained on datasets containing known modified and unmodified sequences to accurately identify these signatures in experimental data.[1]
Experimental Workflow
The overall workflow for detecting this compound using nanopore sequencing involves several key stages: RNA sample preparation, direct RNA library preparation, nanopore sequencing, and data analysis for modification detection.
Figure 1: A high-level overview of the experimental and computational workflow for the detection of this compound using nanopore direct RNA sequencing.
Quantitative Data Summary
The performance of nanopore sequencing for RNA modification detection is typically evaluated based on accuracy, sensitivity, and specificity. While specific data for this compound is not yet widely published, performance can be extrapolated from studies on similar uridine modifications like 5-methoxyuridine (B57755) (5moU). The following tables summarize the expected performance metrics based on published data for related modifications.[1]
Table 1: Expected Performance of this compound Detection
| Metric | Expected Value | Reference |
| Accuracy | > 90% | [1] |
| Sensitivity (True Positive Rate) | > 90% | [7] |
| Specificity (True Negative Rate) | > 90% | [7] |
| Area Under ROC Curve (AUROC) | 0.81 - 0.96 | [1][3] |
Table 2: Comparison of Machine Learning Models for Uridine Modification Detection
| Model | Reported AUROC (for 5moU) | Key Features |
| XGBoost | ~0.96 | Gradient boosting framework, high performance.[1] |
| Random Forest (RF) | Not specified, but generally high | Ensemble learning method, robust to overfitting.[1] |
| Support Vector Machine (SVM) | Not specified, but generally high | Effective in high-dimensional spaces.[1] |
Detailed Experimental Protocols
Protocol 1: RNA Sample Preparation and Quality Control
-
RNA Extraction:
-
Isolate total RNA or mRNA from the cells or tissue of interest using a standard RNA extraction kit with a protocol that minimizes RNA degradation.
-
Treat the extracted RNA with DNase I to remove any contaminating genomic DNA.
-
Purify the RNA using a suitable clean-up kit.
-
-
RNA Quality Control:
-
Assess the quantity and purity of the RNA using a spectrophotometer (e.g., NanoDrop). An A260/280 ratio of ~2.0 and an A260/230 ratio of 2.0-2.2 is desirable.
-
Evaluate the integrity of the RNA using a bioanalyzer (e.g., Agilent Bioanalyzer). A high RNA Integrity Number (RIN) of >7 is recommended for optimal results.
-
Protocol 2: Direct RNA Library Preparation (using Oxford Nanopore Direct RNA Sequencing Kit)
This protocol is a generalized version. Always refer to the specific protocol for the Oxford Nanopore Technologies (ONT) Direct RNA Sequencing Kit version you are using.
-
Poly(A) Tailing (for non-polyadenylated RNA):
-
If your RNA of interest is not polyadenylated (e.g., certain non-coding RNAs, bacterial RNA), it will require a poly(A) tailing step using E. coli Poly(A) Polymerase.
-
Incubate the RNA sample with ATP and Poly(A) Polymerase according to the manufacturer's instructions.
-
Purify the polyadenylated RNA.
-
-
Ligation of Sequencing Adapters:
-
Anneal the reverse transcriptase adapter (RTA) to the poly(A) tail of the RNA. This adapter provides a priming site for the motor protein.
-
Ligate the RNA Motor Adapter (RMX) to the 3' end of the RNA using a T4 DNA ligase. This adapter facilitates the entry of the RNA into the nanopore.
-
Purify the adapter-ligated RNA using magnetic beads to remove unligated adapters and enzymes.
-
-
Final Library Preparation:
-
Elute the purified library in the provided elution buffer.
-
Quantify the final library concentration using a Qubit fluorometer.
-
Protocol 3: Nanopore Sequencing
-
Flow Cell Priming:
-
Prime the MinION or GridION flow cell according to the ONT protocol. This involves flushing the flow cell with a priming solution to remove storage buffer and equilibrate the pores.
-
-
Library Loading:
-
Dilute the prepared direct RNA library in the sequencing buffer.
-
Load the diluted library onto the primed flow cell.
-
-
Sequencing Run:
-
Start the sequencing run using the MinKNOW software.
-
Monitor the run in real-time to assess performance metrics such as the number of active pores and read output.
-
Data Analysis Protocol
The analysis of nanopore data to detect RNA modifications is a critical step that involves processing the raw signal data.
Figure 2: A detailed pipeline for the computational analysis of nanopore sequencing data to identify this compound modifications.
Protocol 4: Bioinformatic Analysis
-
Basecalling and Modification Calling:
-
Use a basecalling software that can also detect modifications. Oxford Nanopore's Dorado with appropriate models is the current standard.
-
Run the basecaller on the raw .fast5 or .pod5 files to generate basecalled reads in FASTQ format and modification information typically stored in a BAM file.
-
-
Alignment:
-
Align the basecalled reads to a reference transcriptome or genome using a nanopore-aware aligner like minimap2.
-
-
Signal-level Analysis (for custom model training or validation):
-
For in-depth analysis or to train a custom model for this compound, extract the raw signal data corresponding to each base from the .fast5 or .pod5 files. Tools like tombo or custom scripts can be used for this purpose.
-
Extract features for each k-mer, such as the mean, median, and standard deviation of the ionic current, and the dwell time.
-
-
Statistical and Machine Learning-based Detection:
-
If a pre-trained model for this compound is not available, a new model will need to be trained. This requires sequencing data from in vitro transcribed RNA with 100% incorporation of this compound and a corresponding unmodified control.
-
Use machine learning frameworks like scikit-learn in Python to train a classifier (e.g., XGBoost, Random Forest) on the extracted signal features to distinguish between canonical uridine and this compound.[1]
-
Apply the trained model to the experimental data to predict the modification status at each uridine site.
-
Alternatively, statistical tests can be used to compare the signal distributions between a sample of interest and an unmodified control at each uridine position.
-
-
Quantification and Visualization:
-
Calculate the stoichiometry of the modification at each identified site by determining the fraction of reads that are called as modified.
-
Visualize the modification data along the length of transcripts using tools like the Integrative Genomics Viewer (IGV) with appropriate plugins for viewing modification data from BAM files.
-
Applications in Research and Drug Development
-
Understanding Gene Regulation: Elucidating the role of this compound in modulating tRNA structure and function, and its impact on translation.
-
RNA Therapeutics: Ensuring the correct modification status of in vitro transcribed mRNA therapeutics, as modifications can impact stability, efficacy, and immunogenicity.[1][3]
-
Disease Biomarker Discovery: Investigating the association between changes in this compound levels and disease states.
-
Antibiotic Development: As tRNA modifications are crucial for bacterial viability, understanding their biosynthesis and function can reveal novel antibiotic targets.
Conclusion
Nanopore direct RNA sequencing provides a powerful and direct method for the detection and quantification of this compound. By analyzing the characteristic changes in the ionic current, this technology enables the study of this and other RNA modifications at an unprecedented level of detail. The protocols and data analysis workflows outlined here provide a foundation for researchers to investigate the epitranscriptome and its role in biology and disease. As the technology and computational tools continue to evolve, the accuracy and accessibility of RNA modification detection with nanopore sequencing are expected to further improve.
References
- 1. Detection and Quantification of 5moU RNA Modification from Direct RNA Sequencing Data - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Nanopore Direct RNA Sequencing for Modified Uridine Nucleotides Yields Signals Dependent on the Physical Properties of the Modified Base - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Detection and Quantification of 5moU RNA Modification from Direct RNA Sequencing Data - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. boa.unimib.it [boa.unimib.it]
- 5. Nanopore Direct RNA Sequencing for Modified Uridine Nucleotides Yields Signals Dependent on the Physical Properties of the Modified Base - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. researchgate.net [researchgate.net]
- 7. nanoporetech.com [nanoporetech.com]
Application Notes and Protocols for Metabolic Labeling of RNA with 5-(Aminomethyl)uridine Precursors
For Researchers, Scientists, and Drug Development Professionals
These application notes provide a comprehensive overview and detailed protocols for the metabolic labeling of nascent RNA using 5-(aminomethyl)uridine (AmU) and its precursors. This technique enables the visualization, purification, and downstream analysis of newly transcribed RNA, offering valuable insights into RNA processing, turnover, and localization.
Introduction
Metabolic labeling of RNA is a powerful technique to study the dynamics of the transcriptome. By introducing a modified nucleoside analog, such as this compound, into cellular RNA, researchers can distinguish newly synthesized transcripts from the pre-existing RNA pool. The aminomethyl group on the uridine (B1682114) serves as a bioorthogonal handle, allowing for subsequent chemoselective ligation, commonly known as "click chemistry," to attach probes for visualization or affinity purification.
However, the direct use of this compound for metabolic labeling in wild-type cells is inefficient. This is because this compound is a poor substrate for the endogenous uridine-cytidine kinase 2 (UCK2), a key enzyme in the nucleotide salvage pathway responsible for phosphorylating uridine to its monophosphate form.[1][2] To overcome this limitation, two primary strategies are employed:
-
Metabolic Engineering: Overexpression of a mutant form of UCK2 with an expanded active site can enhance the phosphorylation and subsequent incorporation of this compound into cellular RNA.[2][3]
-
Direct Triphosphate Delivery: The triphosphate form, this compound triphosphate (AmUTP), can be delivered directly into cells via transfection, bypassing the need for enzymatic phosphorylation.[4]
Once incorporated, the aminomethyl group can be targeted for various downstream applications, including fluorescence microscopy, deep sequencing, and proteomics-based approaches to identify RNA-binding proteins.
Data Presentation
Table 1: Comparison of Uridine Analogs for Metabolic RNA Labeling
| Feature | This compound (AmU) / 5-Azidomethyluridine (5-AmU) | 5-Ethynyluridine (EU) | 4-Thiouridine (4sU) | 5-Bromouridine (5BrU) |
| Bioorthogonal Handle | Primary amine / Azide | Terminal alkyne | Thiol | Bromo |
| Detection/Purification | Click Chemistry (e.g., with NHS esters), Biotinylation | Click Chemistry (CuAAC, SPAAC) | Thiol-specific biotinylation, Affinity purification | Immunoprecipitation with anti-BrdU antibody |
| Incorporation Efficiency | Low in wild-type cells; requires mutant UCK2 or AmUTP transfection.[1][4] | Efficiently incorporated via the salvage pathway.[4] | Efficiently incorporated. | Readily incorporated.[3] |
| Cytotoxicity | Generally low, especially with copper-free click chemistry.[5] | Can inhibit cell proliferation at higher concentrations.[5] | Can inhibit rRNA synthesis and processing at higher concentrations.[5] | Minimally toxic.[3] |
| Downstream Applications | Imaging, RNA-seq, proteomics | Imaging, RNA-seq, proteomics.[4] | RNA turnover studies, RNA-seq | RNA turnover studies, immunoprecipitation-based assays |
| Key Advantage | Amenable to copper-free click chemistry, reducing cytotoxicity. | High incorporation efficiency and well-established protocols. | Well-suited for purification and sequencing to study RNA turnover.[5] | Specific antibody-based detection. |
| Key Disadvantage | Poor incorporation in wild-type cells requires metabolic engineering or triphosphate delivery.[4] | Copper-catalyzed click chemistry can be toxic to live cells and degrade RNA.[3] | Can induce mutations during reverse transcription. | Antibody-based detection can have higher background. |
Experimental Protocols
Protocol 1: Metabolic Labeling of Nascent RNA with this compound using Mutant UCK2
This protocol describes the metabolic labeling of RNA in cultured cells overexpressing a mutant UCK2 enzyme.
Materials:
-
Mammalian cells cultured to ~80% confluency
-
Plasmid encoding mutant UCK2
-
Transfection reagent (e.g., Lipofectamine)
-
This compound (AmU) stock solution (100 mM in DMSO)
-
Complete cell culture medium, pre-warmed to 37°C
-
Phosphate-Buffered Saline (PBS), sterile
-
RNA extraction kit (e.g., TRIzol or column-based)
Procedure:
-
Transfection: a. Plate cells to be ~70% confluent on the day of transfection. b. Transfect cells with the mutant UCK2 plasmid using a suitable transfection reagent according to the manufacturer's instructions. c. Incubate for 24-48 hours to allow for protein expression.
-
Metabolic Labeling: a. Prepare labeling medium by diluting the AmU stock solution into pre-warmed complete culture medium to a final concentration of 0.5-1 mM. b. Aspirate the old medium from the cultured cells and gently wash once with sterile PBS. c. Add the labeling medium to the cells. d. Incubate the cells at 37°C in a CO₂ incubator for the desired labeling period (e.g., 1-24 hours). The optimal time will depend on the experimental goals.
-
Cell Harvest and RNA Isolation: a. After incubation, remove the labeling medium and wash the cells twice with cold PBS to halt further incorporation. b. Lyse the cells directly on the plate and proceed with total RNA isolation using a standard protocol.
Protocol 2: Metabolic Labeling of Nascent RNA via this compound Triphosphate (AmUTP) Transfection
This protocol is for the direct delivery of AmUTP into cells, bypassing the need for UCK2-mediated phosphorylation.
Materials:
-
Mammalian cells cultured to ~80% confluency
-
This compound 5'-triphosphate (AmUTP)
-
Transfection reagent suitable for small molecules (e.g., DOTAP)[4]
-
Serum-free cell culture medium
-
Complete cell culture medium
-
Phosphate-Buffered Saline (PBS), sterile
-
RNA extraction kit
Procedure:
-
Preparation of Transfection Complex: a. Dilute AmUTP and the transfection reagent in separate tubes of serum-free medium according to the manufacturer's recommendations. b. Combine the diluted AmUTP and transfection reagent, mix gently, and incubate at room temperature for 15-20 minutes to allow complex formation.
-
Transfection and Labeling: a. Aspirate the culture medium from the cells and wash once with sterile PBS. b. Add the AmUTP-transfection reagent complex to the cells. c. Incubate at 37°C in a CO₂ incubator for 4-6 hours. d. After the incubation, add complete medium and continue to incubate for the desired labeling period.
-
Cell Harvest and RNA Isolation: a. Following the labeling period, remove the medium and wash the cells twice with cold PBS. b. Proceed with total RNA isolation as described in Protocol 1.
Protocol 3: Fluorescent Labeling of AmU-containing RNA via Click Chemistry
This protocol describes the fluorescent labeling of purified AmU-containing RNA.
Materials:
-
AmU-labeled total RNA (from Protocol 1 or 2)
-
NHS-ester-activated fluorescent dye (e.g., NHS-ester-Cy5)
-
Nuclease-free water
-
Reaction buffer (e.g., 0.1 M sodium bicarbonate, pH 8.3)
-
RNA purification kit or ethanol (B145695) precipitation reagents
Procedure:
-
Labeling Reaction: a. In a nuclease-free microcentrifuge tube, dissolve the AmU-labeled RNA in the reaction buffer. b. Add the NHS-ester-activated fluorescent dye to the RNA solution. The final concentration of the dye should be in excess (e.g., 1-5 mM). c. Incubate the reaction at room temperature for 1-2 hours in the dark.
-
Purification of Labeled RNA: a. Purify the fluorescently labeled RNA from the unreacted dye using an RNA purification kit or by ethanol precipitation. b. Resuspend the purified, labeled RNA in nuclease-free water.
-
Quantification and Storage: a. Determine the concentration and labeling efficiency of the RNA using a spectrophotometer (measuring absorbance at 260 nm for RNA and the appropriate wavelength for the fluorophore). b. Store the labeled RNA at -80°C.
Visualizations
Caption: Metabolic pathway for this compound incorporation into nascent RNA.
Caption: General experimental workflow for AmU-based RNA metabolic labeling and analysis.
Caption: Schematic of the click chemistry reaction for labeling AmU-containing RNA.
References
- 1. benchchem.com [benchchem.com]
- 2. Live-cell RNA imaging with metabolically incorporated fluorescent nucleosides - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Interrogating the Transcriptome with Metabolically Incorporated Ribonucleosides - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Bioorthogonal chemistry-based RNA labeling technologies: evolution and current state - PMC [pmc.ncbi.nlm.nih.gov]
- 5. benchchem.com [benchchem.com]
Application Notes and Protocols for the Synthesis of 5-n-Boc-aminomethyluridine Phosphoramidite
Introduction
In the fields of molecular biology, diagnostics, and drug development, the ability to introduce specific modifications into oligonucleotides is of paramount importance.[1] 5-n-Boc-aminomethyluridine is a key modified nucleoside that serves as a versatile building block for the site-specific incorporation of a primary amine into DNA and RNA sequences.[1] This primary amine is initially protected by an acid-labile tert-butyloxycarbonyl (Boc) group, which remains stable throughout standard automated solid-phase oligonucleotide synthesis.[1][2] Following synthesis, the Boc group can be selectively removed to reveal a reactive primary amine. This amine acts as a chemical handle for the post-synthetic conjugation of a wide array of molecules, such as fluorescent dyes, quenchers, biotin, crosslinking agents, and therapeutic payloads.[1][2]
These application notes provide a comprehensive guide for researchers, scientists, and drug development professionals on the synthesis of the 5-n-Boc-aminomethyluridine phosphoramidite (B1245037) building block, its incorporation into oligonucleotides, and subsequent deprotection and functionalization.
Part 1: Synthesis of 5'-DMT-5-(N-Boc-aminomethyl)-2'-deoxyuridine-3'-CE-phosphoramidite
The synthesis of the target phosphoramidite is a multi-step process that begins with a commercially available precursor, 5-iodo-2'-deoxyuridine. The general workflow involves protection of the 5'-hydroxyl group, introduction of the protected aminomethyl linker at the 5-position of the uracil (B121893) base via a Sonogashira coupling reaction, and finally, phosphitylation of the 3'-hydroxyl group.[1]
Synthesis Workflow Diagram
Caption: General synthetic workflow for 5-n-Boc-aminomethyluridine phosphoramidite.
Data Presentation: Reagents and Materials
The following table summarizes the key reagents required for the synthesis protocol.
| Reagent | Purpose | Example Supplier |
| 5-iodo-2'-deoxyuridine | Starting material | Sigma-Aldrich |
| 4,4'-Dimethoxytrityl chloride (DMT-Cl) | Protection of the 5'-hydroxyl group | Glen Research |
| Pyridine (B92270), Anhydrous | Solvent and base for DMT protection | Sigma-Aldrich |
| N-Boc-propargylamine | Source of the protected amino linker | TCI Chemicals |
| Tetrakis(triphenylphosphine)palladium(0) | Catalyst for Sonogashira coupling | Strem Chemicals |
| Copper(I) iodide (CuI) | Co-catalyst for Sonogashira coupling | Alfa Aesar |
| Triethylamine (B128534) (TEA), Anhydrous | Base for Sonogashira coupling | Sigma-Aldrich |
| N,N-Dimethylformamide (DMF), Anhydrous | Solvent for Sonogashira coupling | Acros Organics |
| Palladium on Carbon (Pd/C, 10%) | Catalyst for alkyne reduction | Sigma-Aldrich |
| 2-Cyanoethyl N,N-diisopropylchlorophosphoramidite | Phosphitylating agent | Glen Research |
| N,N-Diisopropylethylamine (DIPEA) | Non-nucleophilic base for phosphitylation | Sigma-Aldrich |
| Dichloromethane (B109758) (DCM), Anhydrous | Solvent for various steps | Acros Organics |
Experimental Protocols
Protocol 1.1: 5'-O-DMT Protection of 5-iodo-2'-deoxyuridine This protocol describes the protection of the 5'-hydroxyl group to prevent its reaction in subsequent steps.[1]
-
Co-evaporate 5-iodo-2'-deoxyuridine (1 equivalent) with anhydrous pyridine twice to remove residual water.
-
Dissolve the dried residue in anhydrous pyridine.
-
Add 4,4'-dimethoxytrityl chloride (DMT-Cl) (1.2 equivalents) in portions over 30 minutes.
-
Stir the reaction at room temperature for 4-6 hours, monitoring progress by Thin Layer Chromatography (TLC).
-
Upon completion, quench the reaction by adding cold methanol (B129727) (0.5 mL per mmol of starting material).
-
Concentrate the mixture under reduced pressure.
-
Redissolve the residue in dichloromethane (DCM).
-
Wash the organic layer sequentially with saturated sodium bicarbonate solution and brine.
-
Dry the organic layer over anhydrous sodium sulfate (B86663) (Na₂SO₄), filter, and concentrate.
-
Purify the product by silica (B1680970) gel column chromatography to yield 5'-O-DMT-5-iodo-2'-deoxyuridine.
Protocol 1.2: Sonogashira Coupling with N-Boc-propargylamine This step introduces the protected aminomethyl linker to the 5-position of the uracil base.[1]
-
Dissolve 5'-O-DMT-5-iodo-2'-deoxyuridine (1 equivalent) in anhydrous N,N-Dimethylformamide (DMF) under an argon atmosphere.
-
Add N-Boc-propargylamine (1.5 equivalents) and anhydrous triethylamine (2.0 equivalents).
-
Degas the solution by bubbling argon through it for 15 minutes.
-
Add copper(I) iodide (CuI) (0.1 equivalents) and tetrakis(triphenylphosphine)palladium(0) (0.05 equivalents).
-
Stir the reaction mixture at room temperature overnight, protected from light. Monitor by TLC.
-
Once the reaction is complete, concentrate the mixture in vacuo.
-
Dissolve the residue in DCM and wash with water and brine.
-
Dry the organic layer over Na₂SO₄, filter, and concentrate.
-
Purify the crude product by silica gel column chromatography.
Protocol 1.3: Alkyne Reduction This protocol reduces the propargyl triple bond to a propyl single bond.
-
Dissolve the product from Protocol 1.2 in methanol or ethyl acetate.
-
Add 10% Palladium on Carbon (Pd/C) catalyst (approx. 10% by weight of the substrate).
-
Stir the suspension under a hydrogen atmosphere (using a balloon or a hydrogenation apparatus) at room temperature for 12-16 hours.
-
Monitor the reaction by TLC or Mass Spectrometry to confirm the disappearance of the starting material.
-
Upon completion, carefully filter the reaction mixture through a pad of Celite to remove the Pd/C catalyst.
-
Rinse the Celite pad with the reaction solvent.
-
Concentrate the filtrate under reduced pressure to yield the reduced product, 5'-DMT-5-(N-Boc-aminopropyl)-2'-deoxyuridine.
Protocol 1.4: Phosphitylation of the 3'-Hydroxyl Group This final step introduces the reactive phosphoramidite moiety required for oligonucleotide synthesis.[1]
-
Dissolve the dried product from Protocol 1.3 (1 equivalent) in anhydrous DCM under an argon atmosphere.
-
Add N,N-diisopropylethylamine (DIPEA) (2.5 equivalents).
-
Cool the solution to 0°C in an ice bath.
-
Add 2-cyanoethyl N,N-diisopropylchlorophosphoramidite (1.5 equivalents) dropwise.
-
Stir the reaction at room temperature for 2-4 hours, monitoring by TLC.
-
Quench the reaction with cold methanol (0.2 mL per mmol of starting material).
-
Dilute with DCM and wash with saturated sodium bicarbonate solution and brine.
-
Dry the organic phase over Na₂SO₄, filter, and concentrate under reduced pressure.
-
Purify the final product by flash column chromatography on silica gel (pre-treated with triethylamine) to yield the target phosphoramidite as a white foam.
Part 2: Incorporation into Oligonucleotides and Deprotection
The synthesized phosphoramidite is ready for use in standard automated solid-phase DNA/RNA synthesizers. The process involves a repeated cycle of four main chemical reactions.[]
Standard Oligonucleotide Synthesis Cycle
Caption: Standard automated solid-phase oligonucleotide synthesis cycle.
Protocol 2.1: Automated Oligonucleotide Synthesis
-
Phosphoramidite Preparation: Dissolve the synthesized 5-n-Boc-aminomethyluridine phosphoramidite in anhydrous acetonitrile (B52724) to a final concentration of 0.1 M.
-
Synthesizer Setup: Install the phosphoramidite solution on a designated port on the DNA synthesizer. Ensure all other standard reagents (A, C, G, T phosphoramidites and ancillary chemicals) are correctly installed.[2]
-
Synthesis Program: Program the desired oligonucleotide sequence into the synthesizer, specifying the position for the modified uridine. A longer coupling time (e.g., 10-15 minutes) may be beneficial for modified phosphoramidites to ensure high coupling efficiency.[2]
-
Initiate Synthesis: Start the automated synthesis protocol.
Protocol 2.2: Oligonucleotide Cleavage and Deprotection
-
Standard Deprotection: After synthesis, transfer the solid support (e.g., CPG) to a vial. Add concentrated ammonium (B1175870) hydroxide (B78521) or a mixture of ammonium hydroxide/methylamine. Incubate at 55°C for 8-12 hours. This step cleaves the oligonucleotide from the support and removes the standard protecting groups from the bases and phosphate (B84403) backbone.
-
Purification: Cool the vial and transfer the supernatant containing the crude oligonucleotide. Dry the solution in a vacuum concentrator. At this point, the 5'-amino group is still protected by the Boc group. Purify the crude oligonucleotide by reverse-phase HPLC or PAGE.[1]
Protocol 2.3: Selective Boc Group Removal
-
Deprotection: Dissolve the purified, Boc-protected oligonucleotide in an appropriate buffer.
-
Treat with trifluoroacetic acid (TFA) (e.g., 80% TFA in water) for 10-30 minutes at room temperature.
-
Quenching and Purification: Quench the reaction by adding a buffer or co-precipitating the oligonucleotide.
-
Purify the final deprotected oligonucleotide using HPLC or a desalting column to remove the cleaved Boc group and TFA. The resulting oligonucleotide now contains a free primary amine, ready for conjugation.
Quantitative Data Summary
The following table presents typical coupling efficiencies observed during automated synthesis.
| Nucleotide Position | Coupling Efficiency (%) |
| Standard A, C, G, T | >99% |
| 5-n-Boc-aminomethyluridine | 97-99% |
| Note: | Coupling efficiencies can vary based on the synthesizer, reagents, and specific sequence. |
Disclaimer: These protocols are intended for guidance and should be adapted and optimized by qualified personnel. All procedures should be performed in a suitable laboratory environment with appropriate safety precautions.
References
Application Notes and Protocols: Utilizing 5-(Aminomethyl)uridine in In Vitro Translation Assays
For Researchers, Scientists, and Drug Development Professionals
Introduction
5-(Aminomethyl)uridine (nm5U) is a naturally occurring modified nucleoside found at the wobble position (position 34) of the anticodon loop in certain transfer RNAs (tRNAs).[1][2][3][4] This modification plays a crucial role in the accurate and efficient decoding of messenger RNA (mRNA) during protein synthesis.[1][2][3][5] In the biosynthesis pathway of modified nucleosides, this compound is an intermediate in the formation of 5-methylaminomethyl-2-thiouridine (B1677369) (mnm5s2U).[1][3][5][6][7]
These application notes provide a comprehensive guide for researchers interested in studying the effects of incorporating this compound into mRNA transcripts for use in in vitro translation assays. Such studies can elucidate the impact of this modification on translational efficiency, fidelity, and overall protein yield. The protocols outlined below are designed for use with commercially available in vitro transcription and translation systems and can be adapted for specific research needs.
Properties of this compound
A summary of the key chemical properties of this compound is provided in the table below.
| Property | Value | Reference |
| Molecular Formula | C10H15N3O6 | [8][9] |
| Molecular Weight | 273.24 g/mol | [8][9] |
| IUPAC Name | 5-(aminomethyl)-1-[(2R,3R,4S,5R)-3,4-dihydroxy-5-(hydroxymethyl)oxolan-2-yl]pyrimidine-2,4-dione | [9] |
| Natural Occurrence | Intermediate in tRNA modification | [1][3][5] |
Experimental Applications
The incorporation of this compound into mRNA can be a valuable tool for a variety of research applications, including:
-
Investigating Translational Efficiency: Determining the rate of protein synthesis from an mRNA template containing nm5U compared to an unmodified template.
-
Assessing Translational Fidelity: Examining the accuracy of codon recognition and amino acid incorporation when nm5U is present in the mRNA.
-
Studying Ribosome-mRNA Interactions: Analyzing how the presence of nm5U in the mRNA affects the binding and movement of the ribosome.
-
Drug Discovery and Development: Screening for small molecules that modulate the translational effects of mRNA modifications.
Experimental Workflow
The general workflow for using this compound in in vitro translation assays involves the synthesis of a modified mRNA transcript followed by its use in a cell-free protein synthesis system.
Caption: Experimental workflow for in vitro translation using modified mRNA.
Protocols
Protocol 1: In Vitro Transcription of mRNA Containing this compound
This protocol describes the synthesis of an mRNA transcript containing this compound using a standard in vitro transcription kit. It is assumed that this compound triphosphate (nm5UTP) is available.
Materials:
-
Linearized plasmid DNA or PCR product with a T7 or SP6 promoter upstream of the gene of interest (e.g., encoding a reporter protein like luciferase).
-
In vitro transcription kit (e.g., T7 or SP6 RNA polymerase-based).
-
ATP, CTP, GTP solutions.
-
UTP and this compound triphosphate (nm5UTP) solutions.
-
RNase-free water.
-
RNA purification kit or phenol:chloroform extraction reagents.
Procedure:
-
Prepare the Transcription Reaction: In an RNase-free microcentrifuge tube, assemble the following components at room temperature in the order listed. The ratio of nm5UTP to UTP can be varied to achieve the desired level of incorporation.
| Component | Volume (µL) | Final Concentration |
| RNase-free Water | to 20 µL | - |
| 5x Transcription Buffer | 4 | 1x |
| 100 mM DTT | 2 | 10 mM |
| ATP (100 mM) | 2 | 10 mM |
| CTP (100 mM) | 2 | 10 mM |
| GTP (100 mM) | 2 | 10 mM |
| UTP (100 mM) | 0.5 | 2.5 mM |
| nm5UTP (10 mM) | 2 | 1 mM |
| Linearized DNA Template | 1 µg | 50 ng/µL |
| T7/SP6 RNA Polymerase | 2 | - |
| Total Volume | 20 |
-
Incubate: Mix the components gently and incubate the reaction at 37°C for 2-4 hours.
-
DNase Treatment (Optional but Recommended): To remove the DNA template, add DNase I to the reaction mixture and incubate at 37°C for 15 minutes.
-
Purify the mRNA: Purify the transcribed mRNA using an RNA purification kit or by phenol:chloroform extraction followed by ethanol (B145695) precipitation.
-
Quantify and Assess Integrity: Determine the concentration of the purified mRNA using a spectrophotometer. Assess the integrity of the transcript by running an aliquot on a denaturing agarose (B213101) gel.
Protocol 2: In Vitro Translation of mRNA Containing this compound
This protocol outlines the use of the modified mRNA in a commercially available in vitro translation system, such as a rabbit reticulocyte lysate system.
Materials:
-
Purified mRNA containing this compound.
-
Unmodified control mRNA.
-
In vitro translation kit (e.g., Rabbit Reticulocyte Lysate).
-
Amino acid mixture (with or without labeled methionine, e.g., 35S-methionine).
-
RNase-free water.
Procedure:
-
Prepare the Translation Reaction: In an RNase-free microcentrifuge tube on ice, assemble the following components.
| Component | Volume (µL) | Final Concentration |
| Rabbit Reticulocyte Lysate | 12.5 | - |
| Amino Acid Mixture (minus Met) | 0.5 | - |
| 35S-Methionine (optional) | 1 | - |
| RNase-free Water | to 25 µL | - |
| Modified or Control mRNA | 1 µg | 40 ng/µL |
| Total Volume | 25 |
-
Incubate: Mix the components gently and incubate the reaction at 30°C for 60-90 minutes.
-
Analyze the Translation Products: The method of analysis will depend on the nature of the protein being synthesized.
-
Reporter Assays: If a reporter protein like luciferase was used, measure the enzymatic activity using a luminometer according to the manufacturer's instructions.
-
SDS-PAGE and Autoradiography: If a radiolabeled amino acid was used, the translation products can be resolved by SDS-PAGE and visualized by autoradiography.
-
Data Presentation
The following tables present hypothetical data to illustrate the potential effects of incorporating this compound into an mRNA transcript encoding luciferase.
Table 1: In Vitro Transcription Yield
| mRNA Template | A260/A280 | Concentration (ng/µL) | Total Yield (µg) |
| Unmodified Control | 2.05 | 1520 | 30.4 |
| 25% nm5U | 2.01 | 1450 | 29.0 |
| 50% nm5U | 1.98 | 1380 | 27.6 |
| 100% nm5U | 1.95 | 1250 | 25.0 |
Table 2: In Vitro Translation Efficiency
| mRNA Template | Luciferase Activity (RLU) | Protein Yield (ng) |
| Unmodified Control | 1,500,000 | 120 |
| 25% nm5U | 1,250,000 | 100 |
| 50% nm5U | 980,000 | 78 |
| 100% nm5U | 650,000 | 52 |
Signaling Pathway and Logical Relationships
The process of translation is a fundamental cellular pathway. The introduction of a modified nucleotide such as this compound can influence multiple stages of this process.
Caption: The stages of translation and the potential impact of nm5U.
Troubleshooting
| Issue | Possible Cause | Solution |
| Low mRNA Yield | - Inefficient incorporation of nm5UTP by RNA polymerase.- Degradation of mRNA. | - Optimize the ratio of nm5UTP to UTP.- Ensure an RNase-free environment. |
| Low Protein Yield | - Modified mRNA inhibits translation initiation or elongation.- Premature termination of translation. | - Titrate the amount of modified mRNA used in the translation reaction.- Analyze truncated protein products by SDS-PAGE. |
| Altered Protein Size | - Frameshifting or read-through of stop codons. | - Sequence the translated protein if possible.- Use different reporter constructs to assess fidelity. |
Conclusion
The use of this compound in in vitro translation assays offers a powerful approach to dissect the role of this specific mRNA modification in protein synthesis. The protocols and information provided herein serve as a starting point for researchers to explore the functional consequences of this and other modified nucleotides. Careful optimization of the experimental conditions will be necessary to obtain robust and reproducible results.
References
- 1. researchgate.net [researchgate.net]
- 2. Identification of a novel 5-aminomethyl-2-thiouridine methyltransferase in tRNA modification - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. Identification of a novel 5-aminomethyl-2-thiouridine methyltransferase in tRNA modification - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Modomics - A Database of RNA Modifications [genesilico.pl]
- 5. GIST Scholar: Characterization of 5-aminomethyl-2-thiouridine tRNA modification biosynthetic pathway in Bacillus subtilis [scholar.gist.ac.kr]
- 6. Structural basis for hypermodification of the wobble uridine in tRNA by bifunctional enzyme MnmC - PMC [pmc.ncbi.nlm.nih.gov]
- 7. researchgate.net [researchgate.net]
- 8. medchemexpress.com [medchemexpress.com]
- 9. 5-Aminomethyluridine | C10H15N3O6 | CID 67113473 - PubChem [pubchem.ncbi.nlm.nih.gov]
Troubleshooting & Optimization
Technical Support Center: Synthesis of 5-(Aminomethyl)uridine RNA Probes
Welcome to the technical support center for the synthesis of 5-(aminomethyl)uridine (AmU) modified RNA probes. This resource provides researchers, scientists, and drug development professionals with detailed troubleshooting guides, frequently asked questions (FAQs), and experimental protocols to navigate the challenges of synthesizing these critical research tools.
Frequently Asked Questions (FAQs)
Q1: What are the primary challenges in synthesizing this compound RNA probes?
A1: The main challenges revolve around the reactive primary amino group on the uridine (B1682114) base. Key difficulties include:
-
Protecting Group Strategy: The aminomethyl group must be protected during solid-phase phosphoramidite (B1245037) chemistry to prevent unwanted side reactions. The choice of protecting group is critical and must be compatible with all synthesis and deprotection steps.[1][2][3]
-
Coupling Efficiency: The modified phosphoramidite may exhibit different coupling kinetics than standard phosphoramidites, potentially leading to lower incorporation efficiency and truncated sequences.[4][5]
-
Deprotection Conditions: The final deprotection steps must quantitatively remove all protecting groups from the base, sugar, and phosphate (B84403) backbone without degrading the RNA probe or the newly exposed aminomethyl group.[6][7][8]
-
Purification: Isolating the full-length, correctly modified RNA probe from failed sequences and other impurities can be challenging due to the probe's modified chemical properties.[9][10][11]
Q2: Which protecting groups are recommended for the aminomethyl function?
A2: A common and effective protecting group for the primary amine is the trifluoroacetyl (-C(O)CF3) group.[1][2][3] This group is stable during the phosphoramidite synthesis cycles but can be readily removed under standard basic deprotection conditions (e.g., aqueous ammonia) used to cleave the oligonucleotide from the solid support and remove other protecting groups.[2][3]
Q3: How does the incorporation of AmU affect the choice of purification method?
A3: The presence of the aminomethyl group can alter the overall charge and hydrophobicity of the RNA probe. While standard methods like desalting are suitable for removing small molecule impurities, more stringent purification is often required to separate the full-length product from failed sequences. High-Performance Liquid Chromatography (HPLC) is the method of choice.[9]
-
Reverse-Phase (RP-HPLC): This method separates molecules based on hydrophobicity. It is effective for purifying modified oligonucleotides.[9][10]
-
Anion-Exchange (AX-HPLC): This method separates molecules based on charge. It provides excellent resolution for oligonucleotides.
For highly sensitive applications, a dual HPLC purification strategy (AX-HPLC followed by RP-HPLC) can yield purities of approximately 90%.[10]
Troubleshooting Guide
This guide addresses specific issues that may arise during the synthesis of AmU-containing RNA probes.
Problem 1: Low Coupling Efficiency of the AmU Phosphoramidite
-
Question: My trityl monitor shows a significant drop in signal after the this compound phosphoramidite coupling step, indicating low efficiency. What could be the cause?
-
Answer:
-
Activator Issues: The efficiency of the coupling reaction is highly dependent on the activator used (e.g., tetrazole or its derivatives).[][13][14] Ensure your activator is fresh, anhydrous, and used at the correct concentration. Some modified phosphoramidites may require a stronger activator or longer coupling times.
-
Phosphoramidite Quality: The AmU phosphoramidite may be degraded due to moisture or improper storage. Use fresh, high-quality phosphoramidite and ensure anhydrous conditions during dissolution and delivery to the synthesizer.
-
Extended Coupling Time: Modified phosphoramidites can have slower reaction kinetics.[4] Try increasing the coupling time for the AmU monomer from a standard 6 minutes to 15-20 minutes to ensure the reaction goes to completion.[4]
-
Problem 2: Incomplete Deprotection of the Aminomethyl Group
-
Question: Mass spectrometry analysis of my final probe shows a mass corresponding to the RNA with the aminomethyl protecting group still attached. How can I ensure complete removal?
-
Answer:
-
Deprotection Conditions: Standard deprotection conditions may be insufficient. While aqueous ammonia (B1221849) is common, ensure the temperature and duration are adequate. For a trifluoroacetyl group, treatment with concentrated aqueous ammonia at room temperature for 8 hours is typically effective.[15]
-
Alternative Deprotection Reagents: Some complex modifications may require different deprotection strategies. However, for a simple trifluoroacetyl group, optimizing the standard ammonia treatment is usually sufficient. Be cautious, as harsh conditions (e.g., very high temperatures or prolonged incubation) can lead to RNA degradation.
-
Problem 3: Final Product is Impure or Shows Degradation
-
Question: My final purified product shows multiple peaks on an analytical HPLC or a smear on a gel, suggesting impurities or degradation. What are the likely causes?
-
Answer:
-
Depurination: Acidic conditions, often used for detritylation (deblocking) during synthesis, can cause depurination (loss of purine (B94841) bases).[6][7][16] While the detritylation step is brief, cumulative damage can occur over many cycles. Ensure your detritylation reagent is fresh and the contact time is minimized. Novel acid-free deprotection methods using only heat and water have been developed to avoid this issue.[6][7][16]
-
Oxidation: If your sequence contains sensitive moieties like thiols, standard iodine-based oxidation can cause side reactions. Using milder oxidizing agents may be necessary.[17]
-
Inefficient Capping: During the synthesis cycle, any unreacted 5'-hydroxyl groups must be "capped" to prevent them from reacting in subsequent cycles, which would create deletion mutants.[18] Ensure your capping reagents are fresh and the reaction time is sufficient.
-
Purification Method: Desalting alone is insufficient to remove failure sequences.[11] Use RP-HPLC or AX-HPLC for a purer final product.[11]
-
Quantitative Data Summary
The success of RNA probe synthesis is often measured by coupling efficiency, which directly impacts the final yield and purity of the full-length product.
| Parameter | High Efficiency Synthesis | Low Efficiency Synthesis | Reference |
| Average Coupling Efficiency | >99% | <70% | [5] |
| Expected Purity (A260/A280) | ~1.85 | ~1.13 | [5] |
| Relative Final Yield | High | Low | [5] |
Note: The values are illustrative and based on comparative data. Actual results will vary based on sequence length, modifications, and synthesis platform.
Experimental Protocols
Protocol 1: Automated Solid-Phase Synthesis of an AmU-Containing RNA Probe
This protocol outlines the key steps in a standard automated phosphoramidite synthesis cycle for incorporating a this compound amidite.
-
Preparation:
-
Dissolve the 5’-(4,4’-dimethoxytrityl)-5-[N-(trifluoroacetyl)aminomethyl]-2’-O-(tert-butyldimethylsilyl)uridine-3’-O-(N,N-diisopropyl-2-cyanoethyl)phosphoramidite and all other standard RNA phosphoramidites in anhydrous acetonitrile (B52724) to the recommended concentration (e.g., 0.1 M).
-
Install the phosphoramidites on an automated DNA/RNA synthesizer.
-
Ensure all other reagents (activator, capping solutions, oxidizing agent, deblocking agent) are fresh and correctly installed.
-
-
Synthesis Cycle: The synthesizer will perform the following steps iteratively for each monomer addition:
-
Step A: Deblocking (Detritylation): The 5'-DMT protecting group of the nucleotide attached to the solid support is removed using a mild acid (e.g., 3% trichloroacetic acid in dichloromethane). This exposes the 5'-hydroxyl group for the next coupling reaction.
-
Step B: Coupling: The prepared AmU phosphoramidite (or a standard phosphoramidite) is activated by an activator (e.g., 0.25 M 5-(3,5-bis(trifluoromethyl)phenyl)-1H-tetrazole) and delivered to the synthesis column.[17] The activated monomer reacts with the free 5'-hydroxyl group. Note: For the AmU monomer, extend the coupling time to 15-20 minutes.[4]
-
Step C: Capping: Any unreacted 5'-hydroxyl groups are acetylated using capping reagents (e.g., acetic anhydride) to prevent the formation of deletion mutations in subsequent cycles.[18]
-
Step D: Oxidation: The newly formed phosphite (B83602) triester linkage is oxidized to a more stable phosphate triester linkage using an oxidizing agent (e.g., 0.02 M iodine in a THF/water/pyridine mixture).[17]
-
-
Cleavage and Deprotection:
-
After the final sequence is assembled, the solid support is treated with concentrated aqueous ammonia at room temperature for 8-12 hours.[15] This single treatment cleaves the RNA from the support, removes the cyanoethyl protecting groups from the phosphate backbone, and removes the protecting groups from the nucleobases, including the trifluoroacetyl group from the this compound.
-
-
2'-OH Deprotection:
-
The silyl (B83357) protecting groups on the 2'-hydroxyls (e.g., TBDMS) are removed by treatment with a fluoride (B91410) source, such as triethylamine (B128534) trihydrofluoride (TEA·3HF) or anhydrous triethylamine/HF in DMSO.
-
-
Purification:
-
The crude RNA probe is purified using an appropriate method, typically RP-HPLC, to isolate the full-length product.[9]
-
Visualizations
Workflow and Troubleshooting Diagrams
The following diagrams illustrate the synthesis workflow and a troubleshooting decision path for common issues.
Caption: General workflow for AmU-RNA probe synthesis.
Caption: Troubleshooting flowchart for low yield synthesis.
References
- 1. researchgate.net [researchgate.net]
- 2. Chemical synthesis of the 5-taurinomethyl(-2-thio)uridine modified anticodon arm of the human mitochondrial tRNALeu(UUR) and tRNALys - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Chemical synthesis of the 5-taurinomethyl(-2-thio)uridine modified anticodon arm of the human mitochondrial tRNA(Leu(UUR)) and tRNA(Lys) - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. mdpi.com [mdpi.com]
- 5. journals.indexcopernicus.com [journals.indexcopernicus.com]
- 6. chemrxiv.org [chemrxiv.org]
- 7. pubs.acs.org [pubs.acs.org]
- 8. Oligonucleotide synthesis under mild deprotection conditions - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Oligonucleotide Purification Methods for Your Research | Thermo Fisher Scientific - RU [thermofisher.com]
- 10. Oligo purification | LGC Biosearch Technologies [oligos.biosearchtech.com]
- 11. Oligonucleotide Purification: Phenomenex [phenomenex.com]
- 13. Mechanistic studies on the phosphoramidite coupling reaction in oligonucleotide synthesis. I. Evidence for nucleophilic catalysis by tetrazole and rate variations with the phosphorus substituents - PubMed [pubmed.ncbi.nlm.nih.gov]
- 14. Mechanistic studies on the phosphoramidite coupling reaction in oligonucleotide synthesis. I. Evidence for nucleophilic catalysis by tetrazole and rate variations with the phosphorus substituents - PMC [pmc.ncbi.nlm.nih.gov]
- 15. researchgate.net [researchgate.net]
- 16. researchgate.net [researchgate.net]
- 17. researchgate.net [researchgate.net]
- 18. twistbioscience.com [twistbioscience.com]
stability of 5-(aminomethyl)uridine under experimental conditions
This technical support center provides researchers, scientists, and drug development professionals with comprehensive guidance on the stability of 5-(aminomethyl)uridine under various experimental conditions.
Frequently Asked Questions (FAQs)
Q1: What are the recommended storage conditions for this compound?
A1: For long-term stability, this compound should be stored as a solid at 4°C, sealed, and protected from moisture. When in solution, it is recommended to store aliquots at -80°C for up to 6 months or at -20°C for up to 1 month.[1] To prevent degradation from repeated freeze-thaw cycles, it is advisable to prepare single-use aliquots.
Q2: Is this compound stable in aqueous solutions at room temperature?
A2: While short-term handling in aqueous solutions at room temperature for the duration of an experiment is generally acceptable, prolonged storage under these conditions is not recommended. The stability can be affected by pH and the presence of nucleases or other reactive species. For aqueous solutions of similar nucleosides, it is often recommended not to store them for more than one day.
Q3: What are the potential degradation pathways for this compound?
A3: The primary site of instability on the this compound molecule is the aminomethyl group at the C5 position of the uracil (B121893) base. This group is susceptible to oxidation, which can lead to the formation of various oxidation products, including aldonitrone derivatives, hydroxylamines, and imines.[2] Additionally, like other nucleosides, it can be susceptible to enzymatic degradation by nucleosidases or phosphorylases if present in the experimental system. Hydrolysis of the glycosidic bond is also a possibility under strong acidic conditions.
Q4: How does pH affect the stability of this compound?
Troubleshooting Guides
Issue 1: Inconsistent results in enzymatic assays.
-
Possible Cause 1: Degradation of this compound in the assay buffer.
-
Troubleshooting Step: Prepare fresh solutions of this compound for each experiment. If the buffer has a non-neutral pH or contains potentially reactive components, assess the stability of this compound in that buffer over the time course of the experiment using HPLC.
-
-
Possible Cause 2: Interference with enzyme activity.
-
Troubleshooting Step: The primary amine of the aminomethyl group could potentially interact with assay components. Run control experiments without the enzyme to check for non-enzymatic reactions. Test a range of this compound concentrations to identify any inhibitory effects.
-
Issue 2: Low incorporation efficiency in RNA labeling experiments.
-
Possible Cause 1: Poor quality of the this compound stock.
-
Troubleshooting Step: Verify the purity and concentration of your this compound stock solution using UV spectrophotometry and HPLC analysis. Ensure proper storage conditions have been maintained.
-
-
Possible Cause 2: Suboptimal reaction conditions.
-
Troubleshooting Step: Optimize the concentration of this compound triphosphate (if applicable), polymerase, and other reaction components. Ensure the pH and buffer composition are optimal for the polymerase being used.
-
Issue 3: Appearance of unexpected peaks in HPLC analysis.
-
Possible Cause 1: On-column degradation.
-
Troubleshooting Step: Ensure the mobile phase is compatible with this compound. A mobile phase with a neutral pH is generally a good starting point. Check for any active sites on the column that might be causing degradation.
-
-
Possible Cause 2: Degradation during sample preparation or storage.
-
Troubleshooting Step: Minimize the time samples are stored before analysis. If samples need to be stored, keep them at a low temperature (4°C or -20°C) and protect them from light. Analyze a freshly prepared standard to compare with the stored sample. The presence of new peaks in the stored sample indicates degradation.
-
-
Possible Cause 3: Oxidative degradation.
-
Troubleshooting Step: Degas all solvents and use antioxidants in your sample preparation if oxidative degradation is suspected. The aminomethyl group is prone to oxidation.[2]
-
Data Presentation
Table 1: Recommended Storage Conditions for this compound
| Form | Storage Temperature | Duration | Notes |
| Solid | 4°C | Long-term | Sealed, away from moisture. |
| Solvent | -80°C | 6 months | Sealed, away from moisture.[1] |
| Solvent | -20°C | 1 month | Sealed, away from moisture.[1] |
Table 2: Hypothetical Stability of this compound in Aqueous Solution at 37°C (as % of Initial Concentration)
| Time (hours) | pH 5.0 | pH 7.4 | pH 9.0 |
| 0 | 100% | 100% | 100% |
| 24 | 95% | 98% | 92% |
| 48 | 90% | 96% | 85% |
| 72 | 85% | 94% | 78% |
Note: This table presents hypothetical data based on the general stability of nucleosides and is intended for illustrative purposes. Actual stability should be determined experimentally.
Experimental Protocols
Protocol 1: Assessment of this compound Stability by HPLC
This protocol outlines a method to assess the stability of this compound under various conditions (e.g., different pH, temperature).
1. Materials:
- This compound
- HPLC-grade water, acetonitrile, and methanol
- Buffers of desired pH (e.g., phosphate, acetate)
- HPLC system with a UV detector and a C18 reverse-phase column
2. Sample Preparation:
- Prepare a stock solution of this compound in HPLC-grade water or a suitable buffer at a known concentration (e.g., 1 mg/mL).
- For each condition to be tested (e.g., pH 4, 7, 10 at 37°C), dilute the stock solution into the respective buffer.
- Incubate the samples under the specified conditions.
- At designated time points (e.g., 0, 8, 24, 48 hours), withdraw an aliquot and immediately freeze it at -80°C to halt any further degradation until analysis.
3. HPLC Analysis:
- Column: C18 reverse-phase column (e.g., 4.6 x 250 mm, 5 µm).
- Mobile Phase A: 0.1% formic acid in water.
- Mobile Phase B: Acetonitrile.
- Gradient: Start with a low percentage of B (e.g., 5%) and gradually increase to elute any degradation products. A typical gradient might be 5-95% B over 20 minutes.
- Flow Rate: 1.0 mL/min.
- Detection: UV at 267 nm.
- Injection Volume: 10 µL.
4. Data Analysis:
- Quantify the peak area of this compound at each time point.
- Calculate the percentage of this compound remaining relative to the initial time point (t=0).
- Plot the percentage remaining versus time to determine the degradation kinetics.
Visualizations
Caption: Experimental workflow for assessing the stability of this compound.
Caption: Troubleshooting logic for inconsistent enzymatic assay results.
Caption: Potential oxidative degradation pathway of this compound.
References
Technical Support Center: Optimizing Enzymatic Incorporation of 5-(Aminomethyl)uridine
Welcome to the technical support center for the enzymatic incorporation of 5-(aminomethyl)uridine. This resource is designed for researchers, scientists, and drug development professionals to provide troubleshooting guidance and frequently asked questions (FAQs) to facilitate successful experimentation.
Frequently Asked Questions (FAQs)
Q1: What is this compound and why is it used in enzymatic RNA synthesis?
This compound is a modified nucleoside of uridine (B1682114) that contains a primary amine group attached to the C5 position of the uracil (B121893) base. When incorporated into RNA, this modification introduces a reactive handle that can be used for post-transcriptional chemical modifications, such as the attachment of fluorescent dyes, biotin, or other functional moieties. This makes it a valuable tool for studying RNA structure, function, and localization, as well as for the development of RNA-based therapeutics and diagnostics.
Q2: Which RNA polymerase is recommended for incorporating this compound triphosphate (5-amUTP)?
T7 RNA polymerase is a commonly used and effective enzyme for the incorporation of 5-amUTP and other 5-position modified uridine triphosphates during in vitro transcription (IVT).[1] Studies have shown that T7 RNAP can produce good yields of full-length transcripts containing these modifications.[1]
Q3: How does the incorporation efficiency of 5-amUTP compare to that of natural UTP?
The incorporation of 5-amUTP by T7 RNA polymerase can be slightly less efficient than that of the natural UTP. Kinetic studies have shown that 5-position modified UTPs with positively charged groups, such as the amino group in 5-amUTP, can have a significantly higher Michaelis constant (Km) compared to UTP.[1] This indicates a lower binding affinity of the modified nucleotide for the polymerase. However, the maximum reaction rate (Vmax) is often similar to that of UTP, suggesting that once bound, the incorporation itself is not significantly impeded.[1]
Q4: What are the potential downstream applications of RNA containing this compound?
The primary application is post-transcriptional modification. The incorporated aminomethyl group serves as a nucleophilic handle for conjugation with various molecules, including:
-
Fluorophores: For RNA imaging and localization studies.
-
Biotin: For affinity purification and binding assays.
-
Cross-linking agents: To study RNA-protein interactions.
-
Therapeutic payloads: For targeted drug delivery.
Q5: Can the incorporation of this compound affect downstream enzymatic processes like reverse transcription or translation?
Yes, the presence of modified nucleotides can influence subsequent enzymatic reactions. While specific data for this compound is limited, studies on other base modifications have shown that they can impact the fidelity and efficiency of both reverse transcriptases and the translational machinery.[2][3] For instance, some modifications can cause pausing or dissociation of reverse transcriptase, leading to truncated cDNA products. The effect on translation can vary, with some modifications enhancing protein expression while others may be inhibitory.[4] It is therefore crucial to empirically test the performance of your modified RNA in your specific downstream application.
Troubleshooting Guide
This guide addresses common issues encountered during the enzymatic incorporation of this compound triphosphate (5-amUTP).
| Problem | Potential Cause | Recommended Solution |
| Low Yield of Full-Length RNA Transcript | Suboptimal 5-amUTP:UTP Ratio: Complete substitution of UTP with 5-amUTP can significantly reduce yield due to the lower affinity of T7 RNA polymerase for the modified nucleotide.[1] | Titrate the ratio of 5-amUTP to UTP. Start with a partial substitution (e.g., 50% 5-amUTP) and gradually increase the proportion while monitoring the yield and desired level of modification. |
| Inhibitors in the reaction: Contaminants from DNA template preparation (e.g., salts, ethanol) can inhibit RNA polymerase. | Ensure high-quality, purified DNA template. Perform an additional ethanol (B145695) precipitation or use a column-based cleanup kit for the template DNA. | |
| Suboptimal Magnesium Concentration: Magnesium is a critical cofactor for RNA polymerase activity, and its optimal concentration can be affected by the presence of modified NTPs. | Optimize the Mg²⁺ concentration in your transcription reaction. Try a range of concentrations (e.g., 20-40 mM). | |
| Reaction time is too short: The incorporation of modified nucleotides may slow down the overall transcription rate. | Increase the incubation time of the in vitro transcription reaction (e.g., from 2 hours to 4-6 hours). | |
| Presence of Abortive or Truncated Transcripts | Premature Termination: The polymerase may stall or dissociate at sites of multiple consecutive modified nucleotide incorporations or due to secondary structures in the template. | If your template has regions with several consecutive adenines (which would incorporate 5-amU), consider redesigning the template if possible. Lowering the reaction temperature to 30°C may also help to reduce premature termination. |
| Degradation by RNases: Contamination with RNases will lead to degraded RNA products. | Maintain a strict RNase-free environment. Use RNase-free reagents, tips, and tubes. Include an RNase inhibitor in the transcription reaction. | |
| No or Very Low Incorporation of 5-amUTP | Incorrect Nucleotide Concentration: The concentration of 5-amUTP may be too low, or there might be an error in the concentration of other NTPs. | Verify the concentration of your 5-amUTP stock and all other NTPs. Ensure the final concentration of each NTP in the reaction is appropriate (typically in the millimolar range). |
| Inactive Polymerase: The T7 RNA polymerase may have lost its activity due to improper storage or handling. | Use a fresh aliquot of T7 RNA polymerase. As a control, set up a reaction with only unmodified NTPs to confirm enzyme activity. | |
| Difficulty in Purifying Modified RNA | Altered Chemical Properties: The primary amine groups on the RNA can alter its charge and solubility, potentially affecting purification. | Standard RNA purification methods like lithium chloride precipitation or column-based kits are generally effective.[5][6] However, if you encounter issues, consider that the primary amine may be protonated at acidic pH, which could affect its interaction with silica (B1680970) membranes. Ensure that any buffers used are compatible with the modified RNA. |
Data Summary
Table 1: Kinetic Parameters of 5-Position Modified UTP Derivatives with T7 RNA Polymerase
| UTP Derivative | Relative Km (vs. UTP) | Relative Vmax (vs. UTP) |
| UTP | 1.0 | 1.0 |
| 5-amino-UTP | 3.8 | 1.1 |
| 5-phenyl-UTP | 1.1 | 1.0 |
| 5-(4-pyridyl)-UTP | 1.1 | 1.0 |
| 5-(2-pyridyl)-UTP | 1.0 | 0.9 |
| 5-indolyl-UTP | 1.0 | 1.0 |
| 5-isobutyl-UTP | 1.0 | 1.1 |
| 5-imidazole-UTP | 2.5 | 1.0 |
Data adapted from Vaught et al., J. Am. Chem. Soc. 2004, 126, 36, 11231-11237.[1] This table shows that while the binding affinity (inversely related to Km) of 5-amino-UTP is lower than that of UTP, its maximum incorporation rate (Vmax) is comparable.
Experimental Protocols
Protocol 1: Standard In Vitro Transcription (IVT) with this compound Triphosphate
This protocol provides a starting point for the enzymatic synthesis of RNA containing this compound using T7 RNA polymerase. Optimization of the 5-amUTP:UTP ratio and Mg²⁺ concentration may be required for specific templates.
Materials:
-
Linearized DNA template with a T7 promoter (0.5-1.0 µg/µL)
-
T7 RNA Polymerase
-
10x Transcription Buffer (e.g., 400 mM Tris-HCl pH 7.9, 60 mM MgCl₂, 20 mM spermidine, 100 mM DTT)
-
ATP, GTP, CTP solutions (100 mM each)
-
UTP solution (100 mM)
-
This compound triphosphate (5-amUTP) solution (100 mM)
-
RNase Inhibitor
-
Nuclease-free water
Procedure:
-
Thaw Reagents: Thaw all components on ice. Keep the T7 RNA polymerase and RNase inhibitor on ice.
-
Prepare NTP Mix: Prepare a working solution of your desired NTP mix. For a complete substitution of UTP with 5-amUTP, mix equal volumes of ATP, GTP, CTP, and 5-amUTP. For partial substitution, adjust the ratio of UTP to 5-amUTP accordingly (e.g., for 50% substitution, use a 1:1 molar ratio of UTP and 5-amUTP).
-
Assemble the Reaction: In a nuclease-free microcentrifuge tube, assemble the following components at room temperature in the order listed:
| Component | Volume (for 20 µL reaction) | Final Concentration |
| Nuclease-free water | to 20 µL | |
| 10x Transcription Buffer | 2 µL | 1x |
| NTP Mix (with 5-amUTP) | 2 µL | Varies (e.g., 2 mM each) |
| Linearized DNA template | 1 µg | 50 ng/µL |
| RNase Inhibitor | 1 µL | |
| T7 RNA Polymerase | 2 µL |
-
Incubate: Mix gently by flicking the tube and centrifuge briefly to collect the contents at the bottom. Incubate the reaction at 37°C for 2 to 4 hours.
-
DNase Treatment (Optional but Recommended): To remove the DNA template, add 1 µL of RNase-free DNase I and incubate at 37°C for 15 minutes.
-
Purify the RNA: Purify the transcribed RNA using a column-based RNA cleanup kit or by lithium chloride precipitation to remove unincorporated nucleotides, enzymes, and salts.
-
Quantify and Analyze: Determine the concentration of the purified RNA using a spectrophotometer (e.g., NanoDrop). Analyze the integrity of the RNA transcript by denaturing agarose (B213101) or polyacrylamide gel electrophoresis.
Visualizations
References
- 1. researchgate.net [researchgate.net]
- 2. Base modifications affecting RNA polymerase and reverse transcriptase fidelity - PMC [pmc.ncbi.nlm.nih.gov]
- 3. neb.com [neb.com]
- 4. Identification of a novel 5-aminomethyl-2-thiouridine methyltransferase in tRNA modification - PMC [pmc.ncbi.nlm.nih.gov]
- 5. biocompare.com [biocompare.com]
- 6. neb.com [neb.com]
Technical Support Center: 5-(aminomethyl)uridine tRNA Modification Assays
Welcome to the technical support center for troubleshooting tRNA modification assays for 5-(aminomethyl)uridine (nm⁵U) and its derivatives. This guide provides answers to frequently asked questions and solutions to common problems encountered during experimental procedures.
Frequently Asked Questions (FAQs)
Q1: What is this compound and why is its detection important?
A1: this compound (nm⁵U), and its related precursor 5-carboxymethylaminomethyluridine (B1212367) (cmnm⁵U) and final product 5-methylaminomethyluridine (B1256275) (mnm⁵U), are post-transcriptional modifications found at the wobble position (position 34) of the tRNA anticodon.[1][2][3][4] These modifications are crucial for the accurate and efficient decoding of mRNA during protein synthesis.[5][6] Studying these modifications is important as defects in the modification pathways can impact translational fidelity and have been linked to various diseases.[7]
Q2: Which tRNAs typically contain this modification?
A2: In prokaryotes, derivatives of 5-methyluridine (B1664183) are widely conserved at the wobble position of tRNAs that recognize codons with purines (A or G) in the third position.[1][6] For example, in Escherichia coli, mnm⁵U derivatives are found in tRNAs for Lysine, Arginine, and others.[5]
Q3: What are the primary methods for detecting and quantifying this compound modifications?
A3: The main techniques include:
-
Liquid Chromatography-Mass Spectrometry (LC-MS/MS): This is a powerful method for both identifying and quantifying tRNA modifications by analyzing digested tRNA fragments or individual nucleosides.[8][9][10][11]
-
Northern Blotting: This technique can be adapted to detect the presence or absence of specific modifications by observing differential probe hybridization.[12]
-
Next-Generation Sequencing (NGS) Based Methods: Techniques like DM-tRNA-seq exploit the fact that tRNA modifications can cause reverse transcriptase to stall or misincorporate bases, creating a detectable "signature" in the sequencing data.[13][14][15][16]
-
Primer Extension Analysis: This method relies on a modification-sensitive reverse transcriptase that terminates cDNA synthesis at the site of a modification.[17]
Troubleshooting Guides
Category 1: tRNA Isolation and Preparation
| Problem | Potential Cause | Recommended Solution |
| Low tRNA Yield | Inefficient cell lysis or RNA extraction (e.g., incomplete phenol-chloroform separation). | Use a proven extraction method like the hot phenol (B47542) method.[18] Ensure complete phase separation during extraction. Consider using a commercial RNA purification kit optimized for small RNAs. |
| RNA Degradation (Visible as Smears on Gel) | RNase contamination from glassware, solutions, or handling. | Use RNase-free water, reagents, and plasticware. Wear gloves at all times. Add an RNase inhibitor to your reactions. Check the integrity of your total RNA on a denaturing gel before proceeding. |
| DNA or Protein Contamination | Incomplete DNase treatment or insufficient purification. | Perform a rigorous DNase treatment followed by a phenol:chloroform extraction and ethanol (B145695) precipitation.[18] For mass spectrometry, high purity is critical; normalize modification signals to the UV signals of canonical nucleosides to correct for contamination.[10] |
Category 2: Mass Spectrometry (LC-MS/MS)
| Problem | Potential Cause | Recommended Solution |
| Poor or No Signal Intensity | Sample concentration is too low.[19] Inefficient enzymatic digestion. Ion suppression from contaminants. Incorrect instrument settings. | Ensure sufficient starting material (e.g., a minimum of 1-2 µg for a single purified tRNA or ~12 µg for total tRNA analysis).[9] Optimize digestion time and enzyme-to-RNA ratio.[9] Tune and calibrate the mass spectrometer regularly.[19] Experiment with different ionization techniques if available.[19] |
| Inaccurate Mass Measurements | Poor instrument calibration.[19] Presence of salt adducts. | Perform regular mass calibration with appropriate standards.[19] Ensure samples are properly desalted before analysis. |
| Peak Broadening or Splitting | Contaminants in the sample or on the column.[19] Suboptimal chromatographic conditions. | Ensure high sample purity and perform column maintenance. Optimize the mobile phase gradient and flow rate. |
| Incomplete tRNA Digestion | Incorrect enzyme or buffer conditions. Enzyme is inactive. | Use a cocktail of nucleases (like Nuclease P1 followed by phosphodiesterase) for complete digestion to nucleosides.[8] For fragment analysis, ensure RNase T1 is used under optimal conditions to avoid over-digestion.[9] Always check enzyme activity with a control substrate. |
| False Positives (e.g., m³U instead of m³C) | Chemical instability of modifications during sample preparation.[8] | Be aware of potential chemical conversions (e.g., Dimroth rearrangement of m¹A to m⁶A or conversion of m³C to m³U under alkaline conditions).[8] Maintain appropriate pH and temperature during hydrolysis. |
Category 3: Northern Blotting
| Problem | Potential Cause | Recommended Solution |
| No Signal | Incomplete RNA transfer to the membrane.[20] Probe has low specific activity or is degraded. Incorrect hybridization temperature or buffer. | Verify transfer efficiency by staining the gel with ethidium (B1194527) bromide post-transfer.[18] Use freshly prepared, high-specific-activity probes. Optimize hybridization temperature based on probe sequence and modification status, as modifications can affect probe annealing.[12] |
| High Background or Speckling | Probe was not fully diluted in hybridization buffer. Particulates in the hybridization buffer.[20] Membrane was allowed to dry out. | Always dilute the probe into the hybridization solution before adding it to the membrane.[20] Filter hybridization buffers to remove particulates.[20] Ensure the membrane remains moist throughout the procedure. |
| Blotchy or Uneven Signal | Uneven distribution of hybridization solution. Poor quality or mishandled membrane.[20] | Ensure the membrane is fully submerged and agitated during hybridization and washes. Use high-quality nylon membranes and handle them only with forceps at the edges.[20] |
| Non-Specific Bands | Probe is binding to other RNAs (e.g., rRNA). Hybridization or wash stringency is too low. | Design probes to be highly specific to your tRNA of interest. Increase the temperature and/or decrease the salt concentration during the post-hybridization wash steps. |
Category 4: Sequencing-Based Assays (DM-tRNA-seq, etc.)
| Problem | Potential Cause | Recommended Solution |
| Low Read Counts for tRNA | Standard analysis pipelines may discard short, highly modified tRNA reads.[21] | Re-process raw sequencing signals with settings optimized for short reads to increase the recovery of tRNA sequences.[21] |
| Reverse Transcriptase (RT) Fails to Read Through | Some modifications strongly block reverse transcriptase.[22] | Use a highly processive reverse transcriptase enzyme designed to read through modified sites.[22] Be aware that RT drop-off is itself a signature for certain modifications.[16][23] |
| Biased Representation of tRNA Populations | Biases introduced during PCR amplification or library preparation.[22] | Use unique molecular identifiers (UMIs) to remove PCR duplicates.[17] Optimize the number of PCR cycles to avoid over-amplification. |
| Difficulty Distinguishing Modification Signatures | Multiple different modifications can produce similar RT signatures (misincorporation or drop-off). | Combine sequencing data with mass spectrometry analysis to confirm the chemical identity of the modifications.[13][14] Use an enzymatic demethylation step (e.g., with AlkB) and compare treated vs. untreated samples to specifically identify methylation-based modifications.[15] |
Key Experimental Protocols
Protocol 1: Total tRNA Isolation (Hot Phenol Method)
-
Pellet cells from a liquid culture and resuspend in an appropriate buffer.
-
Add an equal volume of acid-phenol:chloroform and vortex vigorously.
-
Incubate at 65°C for 10 minutes with intermittent vortexing.
-
Centrifuge at high speed to separate the aqueous and organic phases.
-
Carefully transfer the upper aqueous phase to a new tube.
-
Repeat the phenol:chloroform extraction until the interphase is clear.
-
Add 0.1 volumes of 3 M sodium acetate (B1210297) (pH 5.2) and 2.5 volumes of ice-cold 100% ethanol.
-
Precipitate the RNA at -20°C or -80°C.
-
Pellet the RNA by centrifugation, wash with 70% ethanol, and resuspend in RNase-free water.
-
Perform DNase treatment to remove any contaminating DNA.[18]
Protocol 2: tRNA Digestion for LC-MS/MS Nucleoside Analysis
-
Take 2-12 µg of purified total tRNA in an RNase-free tube.[9]
-
Denature the tRNA by heating at 100°C for 3 minutes, then immediately chill on ice.[9]
-
Add Nuclease P1 and incubate according to the manufacturer's instructions (e.g., 37°C for 2 hours).
-
Add bacterial alkaline phosphatase and a suitable buffer (e.g., ammonium (B1175870) bicarbonate) and incubate further (e.g., 37°C for 2 hours) to dephosphorylate the nucleotides.
-
Filter the resulting mixture to remove enzymes before injection into the LC-MS system.
-
For absolute quantification, prepare external calibration curves using synthetic standards of the nucleosides of interest.[10]
Protocol 3: Northern Blotting for tRNA
-
Separate 5-10 µg of total RNA per lane on a large 10-15% TBE-Urea polyacrylamide gel.[12][18]
-
Transfer the RNA from the gel to a positively charged nylon membrane using a semi-dry transfer apparatus.[18]
-
Cross-link the RNA to the membrane using UV light.
-
Pre-hybridize the membrane in a suitable hybridization buffer (e.g., UltraHyb) at the calculated temperature for at least 1 hour.[18]
-
Prepare a radiolabeled or biotinylated DNA oligonucleotide probe complementary to the tRNA of interest.
-
Add the probe to the hybridization buffer and incubate overnight with gentle agitation.
-
Perform a series of low- and high-stringency washes to remove unbound probe.
-
Detect the signal using a phosphorimager (for radioactive probes) or a chemiluminescent detection module (for biotinylated probes).[18]
Visualizations
Biosynthetic Pathway of mnm⁵-Uridine Derivatives in E. coli
The biosynthesis of this compound is part of a larger pathway that creates 5-methylaminomethyluridine (mnm⁵U). The process starts with a uridine (B1682114) (U) at the wobble position, which is first converted to 5-carboxymethylaminomethyluridine (cmnm⁵U) by the MnmE and MnmG enzymes.[4] The bifunctional MnmC enzyme then performs the final two steps: its oxidase domain converts cmnm⁵U to 5-aminomethyluridine (B12866518) (nm⁵U), and its methyltransferase domain adds a methyl group to form the final mnm⁵U product.[4][24]
Caption: Biosynthesis of mnm⁵U derivatives in E. coli.
General Experimental Workflow for tRNA Modification Analysis
A typical workflow for analyzing tRNA modifications begins with the isolation of high-quality total RNA from cells. Depending on the required sensitivity, this may be followed by the specific purification of the tRNA species of interest. The prepared RNA is then subjected to an analytical technique such as mass spectrometry or a sequencing-based method to identify and quantify the modifications.
Caption: General workflow for tRNA modification analysis.
Troubleshooting Decision Tree for a 'No Signal' Result
When an experiment yields no signal, a systematic approach is needed to identify the cause. This decision tree helps diagnose common issues in techniques like Northern blotting or LC-MS, starting from the most fundamental components of the experiment.
Caption: Troubleshooting logic for a "No Signal" result.
References
- 1. researchgate.net [researchgate.net]
- 2. Identification of a novel 5-aminomethyl-2-thiouridine methyltransferase in tRNA modification - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Identification of a novel 5-aminomethyl-2-thiouridine methyltransferase in tRNA modification - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. GIST Scholar: Characterization of 5-aminomethyl-2-thiouridine tRNA modification biosynthetic pathway in Bacillus subtilis [scholar.gist.ac.kr]
- 5. Oxidation of 5-methylaminomethyl uridine (mnm5U) by Oxone Leads to Aldonitrone Derivatives - PMC [pmc.ncbi.nlm.nih.gov]
- 6. SURVEY AND SUMMARY: Roles of 5-substituents of tRNA wobble uridines in the recognition of purine-ending codons - PMC [pmc.ncbi.nlm.nih.gov]
- 7. creative-diagnostics.com [creative-diagnostics.com]
- 8. pubs.acs.org [pubs.acs.org]
- 9. Sequence mapping of transfer RNA chemical modifications by liquid chromatography tandem mass spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 10. dspace.mit.edu [dspace.mit.edu]
- 11. pubs.acs.org [pubs.acs.org]
- 12. A versatile tRNA modification-sensitive northern blot method with enhanced performance - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Probing the diversity and regulation of tRNA modifications - PMC [pmc.ncbi.nlm.nih.gov]
- 14. biorxiv.org [biorxiv.org]
- 15. tRNA modification dynamics from individual organisms to metaepitranscriptomics of microbiomes - PMC [pmc.ncbi.nlm.nih.gov]
- 16. Comparative tRNA sequencing and RNA mass spectrometry for surveying tRNA modifications - PMC [pmc.ncbi.nlm.nih.gov]
- 17. academic.oup.com [academic.oup.com]
- 18. Reddit - The heart of the internet [reddit.com]
- 19. gmi-inc.com [gmi-inc.com]
- 20. Top Ten Northern Analysis Tips | Thermo Fisher Scientific - HK [thermofisher.com]
- 21. DSpace [repositori.upf.edu]
- 22. Quantitative analysis of tRNA abundance and modifications by nanopore RNA sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 23. tRNA abundance, modification and fragmentation in nasopharyngeal swabs as biomarkers for COVID-19 severity - PMC [pmc.ncbi.nlm.nih.gov]
- 24. GIST Scholar: Identification of a novel 5-aminomethyl-2-thiouridine methyltransferase in tRNA modification [scholar.gist.ac.kr]
Technical Support Center: 5-(Aminomethyl)uridine Phosphoramidite Synthesis
Welcome to the technical support center for the synthesis of 5-(aminomethyl)uridine phosphoramidite (B1245037). This resource provides troubleshooting guides and frequently asked questions (FAQs) to help researchers, scientists, and drug development professionals overcome common challenges, particularly those related to low reaction yields.
Frequently Asked Questions (FAQs)
Q1: What is the most common cause of low yield in the final phosphoramidite product?
A1: Low yields in this compound phosphoramidite synthesis are often attributed to a combination of factors. The most critical steps prone to yield loss are the protection of the exocyclic aminomethyl group, the dimethoxytritylation of the 5'-hydroxyl group, and the final phosphitylation step. Incomplete reactions, side-product formation, and degradation during purification are common culprits.
Q2: Which protecting group is recommended for the 5-aminomethyl functional group?
A2: The trifluoroacetyl (Tfa) group is a commonly used and effective protecting group for the primary amine of the 5-aminomethyl side chain. It is generally stable during the subsequent synthesis steps and can be removed under mild basic conditions. The use of other protecting groups, such as certain sulfonic acid-protecting groups, has been reported to result in very low yields of the target oligoribonucleotides[1][2].
Q3: Can steric hindrance at the C-5 position affect the reaction efficiency?
A3: Yes, the presence of a bulky substituent at the C-5 position of the uridine (B1682114) can cause significant steric hindrance. This can dramatically decrease the efficiency of subsequent reactions, particularly the 5'-O-dimethoxytritylation step. In some cases, changing the synthesis strategy to introduce the C-5 side chain after protecting the sugar moiety can improve yields[1].
Q4: Are there specific purification methods recommended for the final phosphoramidite product?
A4: Purification of the final phosphoramidite is crucial for successful oligonucleotide synthesis. State-of-the-art purification methods, such as column chromatography on silica (B1680970) gel, are typically employed to obtain the highest possible purity[3]. It is important to handle the phosphoramidite under anhydrous conditions to prevent hydrolysis.
Q5: What are the best practices for handling and storing this compound phosphoramidite?
A5: this compound phosphoramidite is sensitive to moisture and oxidation. It should be stored under an inert atmosphere (e.g., argon or nitrogen) at low temperatures (-20°C is common) in a desiccator. When handling the reagent, it is important to work in a dry environment and allow the container to warm to room temperature before opening to prevent condensation.
Troubleshooting Guides
This section provides a systematic approach to troubleshooting common problems encountered during the synthesis of this compound phosphoramidite.
Problem 1: Low Yield after Protection of the Aminomethyl Group
| Possible Cause | Suggested Solution |
| Incomplete reaction with the protecting group reagent. | Increase the equivalents of the protecting group reagent (e.g., ethyl trifluoroacetate). Monitor the reaction progress using Thin Layer Chromatography (TLC) or Liquid Chromatography-Mass Spectrometry (LC-MS) to ensure complete conversion. |
| Degradation of the starting material or product. | Ensure the reaction is performed under anhydrous and inert conditions. Use freshly distilled solvents. |
| Use of an inappropriate protecting group. | The trifluoroacetyl group is a reliable choice for protecting the aminomethyl function[2]. Avoid protecting groups that require harsh deprotection conditions that could be incompatible with the rest of the molecule. |
Problem 2: Low Yield During 5'-O-Dimethoxytritylation
| Possible Cause | Suggested Solution |
| Steric hindrance from the C-5 substituent. | If the aminomethyl side chain is already installed, a significant decrease in dimethoxytritylation yield may be observed[1]. Consider an alternative synthetic strategy where the 5'-O-DMTr and 2'-O-TBDMS groups are introduced before the installation of the C-5 side chain[1]. |
| Incomplete reaction. | Use a slight excess of 4,4'-dimethoxytrityl chloride (DMTr-Cl) and a suitable base like pyridine (B92270). Ensure the reaction is carried out in an anhydrous solvent. Monitor the reaction by TLC until the starting material is consumed. |
| Presence of water in the reaction mixture. | Use anhydrous solvents and reagents. Dry the starting nucleoside thoroughly before the reaction. |
Problem 3: Low Yield in the Final Phosphitylation Step
| Possible Cause | Suggested Solution |
| Inactive phosphitylating reagent. | Use fresh or properly stored 2-cyanoethyl N,N-diisopropylchlorophosphoramidite. The reagent is highly sensitive to moisture. |
| Presence of moisture. | Conduct the reaction under strictly anhydrous and inert conditions. Use anhydrous solvents and dry glassware. |
| Suboptimal reaction conditions. | Use a non-nucleophilic base such as N,N-diisopropylethylamine (DIPEA). Ensure the reaction temperature is appropriate (typically room temperature). The coupling time for modified phosphoramidites may need to be extended[4]. |
| Impure starting nucleoside. | Ensure the protected nucleoside is of high purity before proceeding to the phosphitylation step. Impurities can interfere with the reaction. |
Data Presentation
Table 1: Comparison of Protecting Groups for the 5-Aminomethyl Function
| Protecting Group | Abbreviation | Common Deprotection Conditions | Reported Issues/Considerations |
| Trifluoroacetyl | Tfa | Aqueous ammonia, NaOH or LiOH in water/ethanol, K2CO3/Na2CO3 in MeOH/H2O[5]. | Generally compatible with standard phosphoramidite chemistry. Widely used for similar modifications[2]. |
| Fluorenylmethyloxycarbonyl | Fmoc | Piperidine solution. | Commonly used in peptide synthesis, may be applicable. |
| tert-Butoxycarbonyl | Boc | Trifluoroacetic acid (TFA)[6][7]. | Acidic deprotection may not be compatible with acid-labile groups like DMTr. |
Experimental Protocols
Protocol 1: Trifluoroacetyl Protection of this compound
This protocol is a generalized procedure based on common practices for protecting primary amines with a trifluoroacetyl group.
-
Preparation: Dissolve this compound in a suitable anhydrous solvent (e.g., pyridine or a mixture of methanol (B129727) and triethylamine).
-
Reaction: Cool the solution in an ice bath. Add ethyl trifluoroacetate (B77799) dropwise with stirring.
-
Monitoring: Allow the reaction to warm to room temperature and stir for several hours. Monitor the reaction progress by TLC or LC-MS.
-
Work-up: Once the reaction is complete, evaporate the solvent under reduced pressure.
-
Purification: Purify the resulting N-trifluoroacetylated product by silica gel column chromatography.
Protocol 2: Standard Phosphitylation of a Protected Nucleoside
This protocol outlines the general steps for the phosphitylation of a 5',2'-protected nucleoside.
-
Preparation: Dry the protected 5-(N-trifluoroacetyl-aminomethyl)-5'-O-DMTr-2'-O-TBDMS-uridine by co-evaporation with anhydrous acetonitrile (B52724) and place it under an inert atmosphere (argon or nitrogen).
-
Dissolution: Dissolve the dried nucleoside in anhydrous dichloromethane (B109758) or acetonitrile.
-
Addition of Reagents: Add N,N-diisopropylethylamine (DIPEA) to the solution, followed by the dropwise addition of 2-cyanoethyl N,N-diisopropylchlorophosphoramidite.
-
Reaction: Stir the reaction mixture at room temperature for 1-2 hours.
-
Monitoring: Monitor the reaction by TLC or ³¹P NMR spectroscopy.
-
Quenching: Quench the reaction by adding a small amount of methanol.
-
Work-up: Dilute the reaction mixture with an appropriate solvent (e.g., ethyl acetate) and wash with a saturated aqueous solution of sodium bicarbonate, followed by brine.
-
Drying and Concentration: Dry the organic layer over anhydrous sodium sulfate, filter, and concentrate under reduced pressure.
-
Purification: Purify the crude product by silica gel column chromatography using a suitable eluent system, often containing a small percentage of triethylamine (B128534) to neutralize the silica gel.
Visualizations
Diagram 1: General Synthesis Workflow
Caption: A generalized workflow for the synthesis of this compound phosphoramidite.
Diagram 2: Troubleshooting Logic for Low Phosphitylation Yield
Caption: A decision tree for troubleshooting low yields in the phosphitylation reaction.
References
- 1. researchgate.net [researchgate.net]
- 2. Chemical synthesis of the 5-taurinomethyl(-2-thio)uridine modified anticodon arm of the human mitochondrial tRNALeu(UUR) and tRNALys - PMC [pmc.ncbi.nlm.nih.gov]
- 3. documents.thermofisher.com [documents.thermofisher.com]
- 4. Synthesis of a Morpholino Nucleic Acid (MNA)-Uridine Phosphoramidite, and Exon Skipping Using MNA/2′-O-Methyl Mixmer Antisense Oligonucleotide | MDPI [mdpi.com]
- 5. Page loading... [guidechem.com]
- 6. organic chemistry - Can a Boc protecting group be removed with trifluoroacetic acid? - Chemistry Stack Exchange [chemistry.stackexchange.com]
- 7. Removal of t-butyl and t-butoxycarbonyl protecting groups with trifluoroacetic acid. Mechanisms, biproduct formation and evaluation of scavengers - PubMed [pubmed.ncbi.nlm.nih.gov]
Technical Support Center: Purification of RNA Containing 5-(aminomethyl)uridine
This technical support center provides researchers, scientists, and drug development professionals with troubleshooting guides and frequently asked questions (FAQs) to address the potential degradation of 5-(aminomethyl)uridine (AmU) during RNA purification.
Troubleshooting Guide
Researchers may encounter challenges in maintaining the integrity of the aminomethyl modification on uridine (B1682114) during standard RNA purification protocols. This guide provides solutions to common problems.
| Problem | Potential Cause | Recommended Solution |
| Low yield of modified RNA | Degradation of AmU: The primary amine of AmU may react with components of lysis or wash buffers, particularly under suboptimal pH conditions. High temperatures can also accelerate degradation. | - Use freshly prepared, pH-adjusted buffers: Ensure all buffers are at a slightly acidic to neutral pH (6.0-7.5). Avoid alkaline conditions. - Work at low temperatures: Perform purification steps on ice or at 4°C where possible to minimize potential side reactions. |
| Loss of RNA during purification: Standard protocols may not be optimized for modified RNA, leading to inefficient binding or elution from columns or beads. | - Increase binding incubation time: Allow for longer incubation of the lysate with the purification matrix (silica or oligo(dT) beads). - Optimize elution: Use pre-warmed (50-60°C), nuclease-free water or a low-salt elution buffer (pH 7.0) and increase the incubation time on the column or beads before centrifugation. | |
| Reduced functionality of purified RNA (e.g., lower translation efficiency, failed downstream enzymatic reactions) | Modification of the primary amine: Residual chaotropic salts (e.g., guanidinium (B1211019) thiocyanate) or other buffer components may adduct to the amine group, altering its chemical properties. | - Perform an additional wash step: Include an extra wash with 80% ethanol (B145695) (for silica (B1680970) columns) to ensure complete removal of salts. - Ensure complete removal of wash buffer: After the final wash, centrifuge the empty column for an additional minute to remove any residual ethanol. |
| Oxidative damage: The aminomethyl group may be susceptible to oxidation, leading to loss of function. | - Work quickly and keep samples covered: Minimize exposure to air and light. - Consider adding a low concentration of a non-interfering antioxidant to the elution buffer if downstream applications permit. | |
| Inconsistent results between purification batches | Variability in reagents or protocol execution: Minor differences in buffer pH, age of reagents, or incubation times can lead to inconsistent modification stability. | - Use a standardized, optimized protocol: Follow the recommended protocols for modified RNA purification consistently. - Aliquot and store reagents properly: Store buffers at their recommended temperatures and avoid repeated freeze-thaw cycles. |
Frequently Asked Questions (FAQs)
Q1: What is the primary cause of this compound degradation during RNA purification?
A1: The primary amine on this compound is a reactive nucleophile. While direct evidence is limited in the context of standard RNA purification buffers, the main concern is its potential reaction with electrophilic components or degradation under non-optimal pH conditions. Lysis buffers containing high concentrations of chaotropic agents like guanidinium thiocyanate, while primarily used for denaturation, could potentially react with primary amines under certain conditions. Additionally, alkaline pH can promote hydrolysis and other degradative reactions of RNA.
Q2: Can I use a standard commercial RNA purification kit to purify RNA containing this compound?
A2: Yes, standard kits can generally be used, but with modifications to the protocol to ensure the stability of the aminomethyl group. Key modifications include ensuring the pH of all buffers is between 6.0 and 7.5, performing washes thoroughly to remove all salts, and working at low temperatures whenever possible.
Q3: How does pH affect the stability of this compound?
A3: RNA is most stable at a slightly acidic to neutral pH.[1] Alkaline conditions (pH > 7.5) can lead to autocatalytic cleavage of the phosphodiester backbone and can also increase the reactivity of the primary amine, potentially leading to unwanted side reactions. Acidic conditions below pH 5 can also lead to RNA degradation, though some studies suggest that slightly acidic pH can protect against phosphodiester bond cleavage.
Q4: Is phenol-chloroform extraction safe for RNA containing this compound?
A4: Phenol-chloroform extraction is generally compatible, provided the pH of the phenol (B47542) is acidic (around 4.5-5.5), which is standard for RNA extraction.[2] This acidic pH helps to retain DNA in the organic phase while the RNA remains in the aqueous phase. It is crucial to perform subsequent ethanol precipitation and washes thoroughly to remove any residual phenol and salts.[3]
Q5: How should I store purified RNA containing this compound?
A5: For long-term storage, precipitate the RNA in ethanol and store at -80°C. For short-term storage, resuspend the RNA in a nuclease-free, buffered solution at pH 7.0 (e.g., TE buffer: 10 mM Tris-HCl, 1 mM EDTA) and store at -80°C. Avoid storing in unbuffered water, as its pH can be slightly acidic and may fluctuate.
Experimental Protocols
Protocol 1: Modified Spin-Column Purification for AmU-RNA
This protocol is adapted from standard silica-based spin-column kits to enhance the stability of this compound.
-
Lysis: Lyse cells or tissue in a guanidinium-based lysis buffer. Ensure the buffer is at room temperature and work quickly.
-
Homogenization: Homogenize the lysate according to the standard protocol.
-
Ethanol Addition: Add 1 volume of 70% ethanol to the lysate and mix well.
-
Binding: Transfer the mixture to a silica spin column and centrifuge for 1 minute at >8,000 x g. Discard the flow-through.
-
First Wash: Add 700 µL of a low-concentration guanidinium wash buffer (if provided) and centrifuge for 1 minute. Discard the flow-through.
-
Second and Third Wash: Perform two washes with 500 µL of 80% ethanol. Centrifuge for 1 minute for each wash and discard the flow-through.
-
Dry Spin: After the final wash, centrifuge the empty column for an additional 2 minutes at maximum speed to completely remove any residual ethanol.[4]
-
Elution: Place the column in a clean collection tube. Add 30-50 µL of pre-warmed (50-60°C) nuclease-free water or TE buffer (pH 7.0) directly to the center of the silica membrane. Incubate for 5 minutes at room temperature.
-
Final Centrifugation: Centrifuge for 2 minutes at >10,000 x g to elute the RNA.
Protocol 2: Modified Oligo(dT) Magnetic Bead Purification for AmU-mRNA
This protocol is for the purification of mRNA containing this compound.
-
Lysis and Homogenization: Lyse cells in the provided lysis/binding buffer and homogenize.
-
Binding: Add the oligo(dT) magnetic beads to the lysate. Incubate according to the manufacturer's protocol, but consider extending the incubation time by 5-10 minutes to ensure efficient binding.
-
Bead Capture: Place the tube on a magnetic stand to capture the beads. Discard the supernatant.
-
Wash Steps: Wash the beads twice with the provided wash buffers. Ensure the beads are fully resuspended during each wash.
-
Final Wash: Perform a final wash with a low-salt wash buffer to remove any remaining contaminants.
-
Elution: Resuspend the beads in 15-30 µL of pre-warmed (50-60°C) nuclease-free water or a low-salt elution buffer (pH 7.0). Incubate for 5 minutes at room temperature.
-
mRNA Collection: Place the tube on the magnetic stand and carefully transfer the supernatant containing the purified mRNA to a new nuclease-free tube.
Visualizations
Caption: Optimized workflow for purifying RNA containing this compound.
References
Technical Support Center: HPLC Separation of 5-(aminomethyl)uridine and its Isomers
This technical support center provides troubleshooting guidance and frequently asked questions (FAQs) to assist researchers, scientists, and drug development professionals in improving the High-Performance Liquid Chromatography (HPLC) separation of 5-(aminomethyl)uridine from its isomers.
FAQs and Troubleshooting Guide
This section addresses common issues encountered during the HPLC separation of this compound and its isomers. The troubleshooting guide follows a logical workflow to help identify and resolve problems systematically.
Frequently Asked Questions (FAQs)
Q1: What are the main challenges in separating this compound from its isomers?
A1: The primary challenges stem from the high polarity and structural similarity of the isomers. This compound and its isomers, such as positional isomers (e.g., N3-aminomethyluridine) and enantiomers, often have very similar physicochemical properties, leading to co-elution or poor resolution in traditional reversed-phase HPLC.[1] The presence of a primary amine group also makes the molecule susceptible to interactions with residual silanols on silica-based columns, which can cause peak tailing.
Q2: Which HPLC modes are most suitable for this separation?
A2: Hydrophilic Interaction Liquid Chromatography (HILIC) and Mixed-Mode Chromatography (MMC) are generally the most effective techniques.[2][3] HILIC is well-suited for retaining and separating highly polar compounds, while MMC combines multiple retention mechanisms (e.g., reversed-phase and ion-exchange), offering unique selectivity for polar and ionizable analytes.[2][3] For separating enantiomers, chiral chromatography with specialized chiral stationary phases (CSPs) is necessary.[4]
Q3: How does mobile phase pH affect the separation?
A3: Mobile phase pH is a critical parameter as it influences the ionization state of the aminomethyl group.[1] Controlling the pH can significantly alter the retention and selectivity of the isomers. For ion-exchange or mixed-mode chromatography, operating at a pH where the primary amine is protonated (pH < pKa of the amine) will enhance retention on a cation-exchange column.
Q4: What are the recommended column chemistries?
A4:
-
For HILIC: Amide, bare silica (B1680970), and zwitterionic stationary phases are commonly used for nucleoside analysis.[5]
-
For Mixed-Mode: Columns with both reversed-phase (e.g., C18) and ion-exchange (e.g., cation-exchange) functionalities are recommended.
-
For Chiral Separations: Polysaccharide-based chiral stationary phases (e.g., cellulose (B213188) or amylose (B160209) derivatives) have shown good results for separating nucleoside analogues.[4]
Troubleshooting Guide
This guide provides a systematic approach to resolving common problems encountered during the HPLC separation of this compound and its isomers.
Problem 1: Poor Resolution or Co-elution of Isomers
Problem 2: Peak Tailing
Problem 3: Inconsistent Retention Times
Data Presentation
The following tables summarize representative quantitative data for the separation of nucleosides and their analogs using different HPLC modes. While specific data for this compound isomers is limited in the public domain, this data for structurally similar compounds provides expected performance benchmarks.
Table 1: Representative HILIC Separation of Uridine Analogs
| Compound | Retention Time (min) | Resolution (Rs) |
| Uridine | 8.5 | - |
| 5-Methyluridine | 9.2 | 2.1 |
| Pseudouridine | 10.1 | 2.8 |
Data adapted from a study on a bare silica HILIC column.[2] Conditions can be optimized for this compound and its isomers.
Table 2: Representative Chiral Separation of Nucleoside Analogs
| Enantiomer | Retention Time (min) | Resolution (Rs) |
| Enantiomer 1 | 12.3 | - |
| Enantiomer 2 | 14.1 | 1.8 |
Data is representative of separations achieved on polysaccharide-based chiral stationary phases for nucleoside analogs.[4]
Experimental Protocols
The following are detailed methodologies for key experiments that can be adapted for the separation of this compound and its isomers.
Protocol 1: HILIC Method for Positional Isomer Separation
This protocol is a starting point for separating polar positional isomers of this compound.
-
Column: Amide-based HILIC column (e.g., 150 mm x 2.1 mm, 1.7 µm).[5]
-
Mobile Phase A: 10 mM Ammonium Formate in Water, pH adjusted to 3.0 with Formic Acid.
-
Mobile Phase B: Acetonitrile.
-
Gradient Program:
-
0-2 min: 95% B
-
2-15 min: Linear gradient from 95% to 80% B
-
15-17 min: Hold at 80% B
-
17.1-20 min: Return to 95% B and equilibrate.
-
-
Flow Rate: 0.3 mL/min.
-
Column Temperature: 30 °C.
-
Detection: UV at 260 nm.
-
Injection Volume: 2 µL.
-
Sample Preparation: Dissolve the sample in a mixture of 95:5 Acetonitrile:Water.
Protocol 2: Chiral HPLC Method for Enantiomer Separation
This protocol provides a foundation for resolving enantiomers of this compound.
-
Column: Polysaccharide-based chiral stationary phase (e.g., Chiralpak IA or ID, 250 mm x 4.6 mm, 5 µm).
-
Mobile Phase: A mixture of n-Hexane and Ethanol (e.g., 80:20 v/v). The ratio may need to be optimized.
-
Flow Rate: 1.0 mL/min.
-
Column Temperature: 25 °C.
-
Detection: UV at 260 nm.
-
Injection Volume: 10 µL.
-
Sample Preparation: Dissolve the sample in the mobile phase.
Protocol 3: Mixed-Mode HPLC Method for Isomer Separation
This protocol is a starting point for utilizing both reversed-phase and ion-exchange mechanisms.
-
Column: Mixed-mode column with C18 and cation-exchange functionality (e.g., 150 mm x 4.6 mm, 5 µm).
-
Mobile Phase A: 20 mM Ammonium Acetate in Water, pH adjusted to 4.5.
-
Mobile Phase B: Acetonitrile.
-
Gradient Program:
-
0-5 min: 5% B
-
5-20 min: Linear gradient from 5% to 50% B
-
20-25 min: Hold at 50% B
-
25.1-30 min: Return to 5% B and equilibrate.
-
-
Flow Rate: 1.0 mL/min.
-
Column Temperature: 35 °C.
-
Detection: UV at 260 nm.
-
Injection Volume: 5 µL.
-
Sample Preparation: Dissolve the sample in Mobile Phase A.
References
- 1. mdpi.com [mdpi.com]
- 2. chromatographyonline.com [chromatographyonline.com]
- 3. Mixed-mode chromatography in pharmaceutical and biopharmaceutical applications - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. Diastereomeric resolution of nucleoside analogues, new potential antiviral agents, using high-performance liquid chromatography on polysaccharide-type chiral stationary phases - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. Characterization of Nucleosides and Nucleobases in Natural Cordyceps by HILIC–ESI/TOF/MS and HILIC–ESI/MS - PMC [pmc.ncbi.nlm.nih.gov]
minimizing misincorporation in sequencing of 5-(aminomethyl)uridine
This technical support center provides troubleshooting guidance and frequently asked questions (FAQs) for researchers working with 5-(aminomethyl)uridine (AmU) in sequencing applications. The information provided is designed to help minimize misincorporation events and improve data quality.
Frequently Asked Questions (FAQs)
Q1: What is this compound and why is it challenging for sequencing?
A1: this compound is a modified nucleoside. The presence of the aminomethyl group at the C5 position of the uracil (B121893) base can interfere with the enzymatic processes central to standard sequencing workflows. Reverse transcriptase (RT) and DNA polymerase enzymes may stall or misread this modified base, leading to truncated sequencing reads or the incorporation of an incorrect nucleotide in the complementary DNA (cDNA) strand. This can result in sequencing artifacts that complicate data analysis.
Q2: What are the potential sequencing artifacts associated with this compound?
A2: While specific data for this compound is still emerging, based on studies of similarly modified nucleotides, researchers should be aware of two primary potential artifacts:
-
Read Truncation: The reverse transcriptase may dissociate from the RNA template at or near the this compound site, leading to incomplete cDNA synthesis and a drop in sequencing coverage at that position.
-
Base Misincorporation: The RT enzyme may misinterpret this compound and incorporate a nucleotide other than adenosine (B11128) into the cDNA strand. The exact misincorporation pattern can be enzyme-dependent. For some modified uridines, a U-to-C substitution is a common artifact.
Q3: Which sequencing platforms are suitable for analyzing RNA containing this compound?
A3: Both next-generation sequencing (NGS) platforms that rely on reverse transcription and PCR, as well as third-generation platforms, can be used, each with its own considerations.
-
NGS (e.g., Illumina): These platforms require cDNA synthesis and amplification, making them susceptible to the artifacts mentioned above. Careful enzyme selection and library preparation are crucial.
-
Third-Generation Sequencing (e.g., Pacific Biosciences SMRT, Oxford Nanopore Technologies):
-
PacBio SMRT Sequencing: This platform can be used for sequencing cDNA derived from RNA containing modified bases and may provide insights into polymerase kinetics that can help identify modified sites.
-
Oxford Nanopore Direct RNA Sequencing: This technology sequences the native RNA molecule directly, avoiding biases from reverse transcription and PCR. The presence of this compound can be detected by characteristic changes in the ionic current signal as the RNA strand passes through the nanopore. This method offers a promising approach for the direct detection of this modification.[1]
-
Q4: How does the choice of reverse transcriptase affect sequencing fidelity for this compound?
A4: The choice of reverse transcriptase is critical. Different RTs exhibit varying efficiencies and fidelities when encountering modified nucleotides. Some reverse transcriptases are engineered to have higher processivity and to read through modified bases more effectively. It is advisable to screen several RTs to identify one that minimizes stalling and misincorporation with your specific RNA template.
Troubleshooting Guide
Issue 1: Low Sequencing Coverage or Read Drop-off at Expected Modification Sites
Possible Cause: The reverse transcriptase is stalling at the this compound site.
Solutions:
-
Enzyme Selection: Test a panel of reverse transcriptases. Enzymes known for high processivity and the ability to read through modified bases are good candidates.
-
Reaction Conditions: Optimize the reverse transcription reaction conditions. This may include adjusting the reaction temperature (within the enzyme's optimal range), incubation time, and the concentration of dNTPs and magnesium.
-
Template Quality: Ensure the RNA template is of high quality and free of contaminants that could inhibit the reverse transcriptase.
Issue 2: High Rate of Specific Base Substitutions (e.g., U-to-C) at Uracil Positions
Possible Cause: The reverse transcriptase is misincorporating a nucleotide opposite the this compound.
Solutions:
-
Enzyme Fidelity: Switch to a reverse transcriptase with higher fidelity. While all enzymes will have some error rate, some are less prone to misincorporation at modified sites.
-
Direct RNA Sequencing: If available, utilize Oxford Nanopore Direct RNA Sequencing to bypass the reverse transcription step and directly detect the modification.[1]
-
Data Analysis: If using an NGS approach, be aware of the potential for characteristic misincorporation patterns. Bioinformatic pipelines can be designed to identify and potentially filter or analyze these systematic errors.
Quantitative Data on Misincorporation
Direct quantitative data on misincorporation rates for this compound is limited in the current literature. However, data from studies on other modified uridines can provide a useful reference for the types of effects that may be observed. The following table summarizes the combined error rates of T7 RNA polymerase and various reverse transcriptases for several modified ribonucleotides, as determined by PacBio SMRT sequencing.
| Modified Base | Reverse Transcriptase | Total Error Rate (errors/base x 10⁻⁶) |
| Unmodified RNA | M-MuLV | 75 ± 11 |
| 5-methyluridine (m⁵U) | M-MuLV | 54 ± 2 |
| 5-hydroxymethyluridine (hm⁵U) | M-MuLV | 188 ± 24 |
| Unmodified RNA | AMV | 75 ± 11 |
| 5-methyluridine (m⁵U) | AMV | 73 ± 5 |
| 5-hydroxymethyluridine (hm⁵U) | AMV | 192 ± 8 |
Data adapted from a study on the fidelity of RNA synthesis and reverse transcription of modified ribonucleotides.[2] This table illustrates that modifications at the C5 position of uridine (B1682114) can either have a minimal effect on fidelity (m⁵U) or increase the error rate (hm⁵U) depending on the nature of the modification and the reverse transcriptase used.[2]
Experimental Protocols
Protocol: Best Practices for cDNA Synthesis from RNA Containing this compound for NGS
This protocol provides a general framework. Optimization of specific components, particularly the choice of reverse transcriptase, is highly recommended.
-
RNA Preparation:
-
Start with high-quality, intact total RNA or poly(A)-selected RNA.
-
Perform DNase treatment to remove any contaminating DNA.
-
Quantify the RNA and assess its integrity using a Bioanalyzer or similar instrument.
-
-
Primer Annealing:
-
In a sterile, RNase-free PCR tube, combine:
-
RNA template (10 ng - 1 µg)
-
Random hexamers or oligo(dT) primers
-
dNTP mix (10 mM each)
-
Nuclease-free water to a final volume of 13 µL.
-
-
Heat the mixture to 65°C for 5 minutes, then immediately place on ice for at least 1 minute to anneal the primers.
-
-
Reverse Transcription:
-
Prepare a master mix for the reverse transcription reaction. For a 20 µL reaction, combine:
-
5X RT Buffer: 4 µL
-
0.1 M DTT: 1 µL
-
RNase Inhibitor: 1 µL
-
Reverse Transcriptase (select a high-processivity, high-fidelity enzyme): 1 µL
-
-
Add 7 µL of the master mix to the 13 µL primer-annealed RNA.
-
Incubate at the recommended temperature for the chosen reverse transcriptase (e.g., 50-55°C) for 60 minutes.
-
Heat-inactivate the enzyme at the temperature and time recommended by the manufacturer (e.g., 70°C for 15 minutes).
-
-
Second-Strand Synthesis and Library Preparation:
-
Proceed with a standard second-strand synthesis protocol.
-
Follow the manufacturer's instructions for the chosen NGS library preparation kit for adapter ligation, and PCR amplification. Use a high-fidelity DNA polymerase for amplification to avoid introducing further errors.
-
-
Quality Control and Sequencing:
-
Perform quality control on the final library to assess size distribution and concentration.
-
Sequence on the desired platform.
-
Visualizations
Caption: Workflow for preparing this compound-containing RNA for NGS.
Caption: Troubleshooting common issues in sequencing this compound.
References
troubleshooting enzymatic ligation of RNA containing modified nucleosides
This technical support center provides troubleshooting guidance and frequently asked questions (FAQs) for researchers, scientists, and drug development professionals working with the enzymatic ligation of RNA containing modified nucleosides.
Frequently Asked Questions (FAQs)
Q1: My ligation reaction with a 2'-O-methylated RNA substrate is showing very low efficiency. What are the common causes and how can I improve it?
A1: Low ligation efficiency with 2'-O-methylated RNA is a common issue. The methyl group at the 2' position of the ribose sugar can cause steric hindrance, which inhibits the activity of RNA ligases like T4 RNA Ligase 1.[1][2] This modification is known to reduce the efficiency of enzymatic reactions at the RNA 3'-terminus.[1][2]
Troubleshooting Steps:
-
Enzyme Choice: Consider using T4 RNA Ligase 2, truncated (T4 Rnl2tr). This enzyme has shown significantly improved ligation efficiency for 2'-O-methylated RNA substrates compared to T4 RNA Ligase 1.[3] An ancestral RNA ligase, AncT4_2, has also been shown to have high activity toward modified RNA fragments, including those with 2'-O-methyl substitutions.[4]
-
Reaction Additives: The addition of Polyethylene Glycol (PEG) 8000 to a final concentration of 25% (w/v) can dramatically increase the ligation efficiency of both unmodified and 2'-O-methylated RNAs, often approaching 100%.[3]
-
Enzyme Concentration: For 2'-O-methyl-modified RNAs, increasing the concentration of T4 Rnl2tr (e.g., to 200 units) can maximize the extent of ligation.[3]
-
Incubation Time and Temperature: While reactions can proceed at room temperature (22°C) or 16°C, extending the incubation time (e.g., overnight) can be beneficial, especially when PEG concentrations are lower.[3]
-
RNA Secondary Structure: Secondary structures in the RNA can shield the ends, preventing ligation. Adding DMSO to 10% (v/v) can help to disrupt these structures and increase ligation efficiency.[5]
Q2: I am trying to ligate an RNA molecule containing pseudouridine (B1679824) (Ψ). Are there specific considerations for this modification?
A2: Yes, pseudouridine (Ψ), being an isomer of uridine, can influence RNA structure and enzymatic reactions.[6][7] While T4 DNA ligase can be used for ligation on an RNA template containing pseudouridine, the efficiency can be sensitive to the modification.[8] Ligation-based methods have been developed to specifically detect and quantify pseudouridine, highlighting that its presence affects ligation dynamics.[6][7][8]
Troubleshooting Steps:
-
Ligation-Based Detection Methods: If your goal is to detect or quantify pseudouridine, specific ligation-based methods like BIHIND-qPCR or BIHIND-seq can be employed.[6][7] These methods are designed to be sensitive to the presence of Ψ.
-
Enzyme and Substrate Optimization: The efficiency of ligation can be influenced by the specific ligase and the sequence context surrounding the pseudouridine. A systematic approach to test different ligases (e.g., T4 DNA ligase, T4 RNA ligase) and reaction conditions may be necessary.[8][9]
-
Structural Considerations: Pseudouridine can alter the local RNA structure due to an additional hydrogen bond donor.[6] This can either favor or hinder the accessibility of the ligation site. Consider performing a structural prediction of your RNA to assess the potential impact.
Q3: My ligation reaction is failing, and I suspect issues with my reaction components or protocol. What are some general troubleshooting steps I can take?
A3: Ligation failures can often be traced back to problems with the reaction setup or the integrity of the components.
General Troubleshooting Workflow:
Caption: A logical workflow for troubleshooting common enzymatic ligation issues.
Detailed Checks:
-
ATP and Mg²⁺: Ensure that the ATP in your buffer has not degraded, especially if the buffer is old. Both ATP and Mg²⁺ are critical for ligase activity.[10]
-
Contaminants: High salt concentrations or the presence of EDTA can inhibit ligation. Purify your RNA fragments if you suspect contamination.[10]
-
Phosphatase Inactivation: If you performed a dephosphorylation step, ensure the phosphatase (like CIP, BAP, or SAP) has been completely inactivated, as any residual activity will prevent ligation.[10]
-
Ligase Inactivity: Test the activity of your ligase on a control substrate to ensure it is still active.[10]
-
RNA Secondary Structure: As mentioned, complex secondary structures can block the ends of the RNA. Consider a denaturation step (e.g., 95°C for 5 minutes followed by rapid chilling on ice) or the addition of DMSO.[11]
Quantitative Data Summary
The efficiency of enzymatic ligation is highly dependent on the type of modification, the ligase used, and the reaction conditions. The tables below summarize key quantitative findings from various studies.
Table 1: Ligation Efficiency of 2'-O-methylated RNA with Different Ligases and Conditions
| RNA Substrate | Ligase | Key Reaction Condition | Ligation Efficiency (%) | Reference |
| Unmodified RNA | T4 Rnl2tr | 25% PEG 8000 | 94.2 ± 2.67 | [3] |
| 2'-O-methylated RNA | T4 Rnl2tr | 25% PEG 8000 | 96.3 ± 0.17 | [3] |
| Unmodified RNA | T4 Rnl1 | Standard Buffer | 86.7 ± 9.44 | [3] |
| 2'-O-methylated RNA | T4 Rnl1 | Standard Buffer | 29.5 ± 2.67 | [3] |
| 2'-O-methylated RNA (3'-A) | T4 Rnl1 | Standard Buffer | 63.0 ± 3.9 | [3] |
| 2'-O-methylated RNA (3'-C) | T4 Rnl1 | Standard Buffer | 78.8 ± 3.2 | [3] |
| 2'-O-methylated RNA (3'-G) | T4 Rnl1 | Standard Buffer | 72.0 ± 2.6 | [3] |
| 2'-O-methylated RNA (3'-U) | T4 Rnl1 | Standard Buffer | 36.0 ± 1.3 | [3] |
Table 2: Effect of PEG 8000 on Ligation Efficiency
| RNA Substrate | Ligase | PEG 8000 Conc. (% w/v) | Ligation Efficiency (%) | Reference |
| Unmodified & 2'-O-methylated | T4 Rnl2tr | 25 | ~100 | [3] |
| Unmodified & 2'-O-methylated | T4 Rnl2tr | <25 | Decreased efficiency | [3] |
| cDNA to RNA | T4 Rnl1 | 0 | 0.35 ± 0.18 | [3] |
| cDNA to RNA | T4 Rnl1 | 25 | 61.03 ± 5.8 | [3] |
Experimental Protocols
Protocol 1: High-Efficiency Ligation of 2'-O-methylated RNA
This protocol is optimized for the ligation of RNA substrates with 3'-terminal 2'-O-methylation.
Materials:
-
T4 RNA Ligase 2, truncated (T4 Rnl2tr)
-
PEG 8000 (25% w/v solution)
-
Adenylated DNA adapter
-
RNA substrate with 3'-OH
-
10X T4 RNA Ligase Reaction Buffer
-
Nuclease-free water
Procedure:
-
Set up the ligation reaction on ice as follows:
-
1 µL 10X T4 RNA Ligase Reaction Buffer
-
1 µL RNA substrate (e.g., 10 µM)
-
1 µL Adenylated DNA adapter (e.g., 20 µM)
-
4 µL 25% PEG 8000
-
1 µL T4 Rnl2tr (e.g., 200 units)
-
Nuclease-free water to a final volume of 10 µL
-
-
Mix gently by pipetting and centrifuge briefly to collect the contents.
-
Incubate the reaction at 22°C for 2 hours or at 16°C overnight.
-
Stop the reaction by adding an equal volume of 2X RNA loading dye and heating at 70°C for 5 minutes.
-
Analyze the ligation product by denaturing polyacrylamide gel electrophoresis (PAGE).
Experimental Workflow for High-Efficiency Ligation:
Caption: Step-by-step workflow for the enzymatic ligation of modified RNA.
Protocol 2: Splinted Ligation of Two RNA Fragments
This method uses a DNA splint to bring two RNA fragments into proximity for ligation by T4 DNA Ligase or T4 RNA Ligase 2. This is useful for creating longer, site-specifically modified RNA molecules.[12][13][14]
Materials:
-
RNA fragment 1 (acceptor, with 3'-OH)
-
RNA fragment 2 (donor, with 5'-phosphate)
-
DNA splint oligonucleotide (complementary to the ends of both RNA fragments)
-
T4 DNA Ligase or T4 RNA Ligase 2
-
10X Ligase Reaction Buffer
-
Nuclease-free water
Procedure:
-
In a nuclease-free tube, combine:
-
1 µL RNA fragment 1 (e.g., 10 µM)
-
1 µL RNA fragment 2 (e.g., 10 µM)
-
1 µL DNA splint (e.g., 12 µM)
-
Nuclease-free water to 5 µL
-
-
Heat the mixture to 90°C for 2 minutes, then cool slowly to room temperature to allow for annealing.
-
Add the following components:
-
1 µL 10X Ligase Reaction Buffer
-
1 µL T4 DNA Ligase or T4 RNA Ligase 2
-
Nuclease-free water to a final volume of 10 µL
-
-
Incubate at the optimal temperature for the chosen ligase (e.g., 16°C overnight for T4 DNA Ligase or 37°C for 1 hour for T4 RNA Ligase 2).
-
Analyze the products by denaturing PAGE.
Signaling Pathway for Splinted Ligation:
Caption: The assembly and ligation process in a splint-mediated reaction.
References
- 1. Detection and Analysis of RNA Ribose 2′-O-Methylations: Challenges and Solutions - PMC [pmc.ncbi.nlm.nih.gov]
- 2. researchgate.net [researchgate.net]
- 3. Optimization of enzymatic reaction conditions for generating representative pools of cDNA from small RNA - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Enzymatic Conjugation of Modified RNA Fragments by Ancestral RNA Ligase AncT4_2 - PMC [pmc.ncbi.nlm.nih.gov]
- 5. neb.com [neb.com]
- 6. Pseudouridine Detection and Quantification using Bisulfite Incorporation Hindered Ligation - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Pseudouridine Detection and Quantification Using Bisulfite Incorporation Hindered Ligation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. Identification of recognition residues for ligation-based detection and quantitation of pseudouridine and N6-methyladenosine - PMC [pmc.ncbi.nlm.nih.gov]
- 9. A systematic, ligation-based approach to study RNA modifications - PMC [pmc.ncbi.nlm.nih.gov]
- 10. neb.com [neb.com]
- 11. researchgate.net [researchgate.net]
- 12. researchgate.net [researchgate.net]
- 13. biorxiv.org [biorxiv.org]
- 14. Optimizing splinted ligation of highly structured small RNAs - PMC [pmc.ncbi.nlm.nih.gov]
Technical Support Center: Analysis of 5-(aminomethyl)uridine by Mass Spectrometry
This technical support center provides troubleshooting guidance and frequently asked questions (FAQs) for researchers, scientists, and drug development professionals working with the mass spectrometry analysis of 5-(aminomethyl)uridine.
Troubleshooting Guides
Issue 1: Difficulty in detecting a clear peak for this compound.
-
Question: I am not observing a distinct peak for this compound in my LC-MS/MS analysis. What are the possible causes and solutions?
-
Answer: Several factors could contribute to a weak or absent signal for this compound. Uridine (B1682114) and its derivatives can be challenging to protonate in the positive ion mode, which may result in low sensitivity.[1] Consider the following troubleshooting steps:
-
Optimize Ionization Source:
-
Switch to negative ion mode to see if sensitivity improves.
-
Adjust ion source parameters such as capillary voltage, gas flow, and temperature to optimize ionization efficiency.
-
-
Mobile Phase Modification:
-
Ensure the mobile phase contains a suitable modifier to promote protonation, such as 0.1% formic acid.
-
Consider derivatization of the aminomethyl group to enhance its ionization efficiency.
-
-
Check for Matrix Effects: Co-eluting compounds from the sample matrix can suppress the ionization of this compound.[2][3][4] To assess this, perform a post-extraction spike of a known concentration of this compound into a blank matrix extract and compare the signal to the same concentration in a clean solvent. If matrix effects are significant, improve sample preparation by including a solid-phase extraction (SPE) step or by using a more effective protein precipitation method.
-
Issue 2: Suspected misidentification of this compound due to an isobaric interference.
-
Question: I am observing a peak at the expected m/z of this compound, but I suspect it might be an isobaric compound. How can I confirm the identity of my analyte?
-
Answer: Misidentification due to isobaric or isomeric compounds is a common challenge in the analysis of modified nucleosides.[1] To confirm the identity of this compound, you should employ a combination of chromatographic and mass spectrometric techniques:
-
Chromatographic Separation: Optimize your liquid chromatography method to separate this compound from potential isomers.
-
Column Chemistry: Test different column stationary phases. A Hydrophilic Interaction Liquid Chromatography (HILIC) column can provide different selectivity compared to a standard C18 column for polar compounds like nucleosides.[1]
-
Gradient Optimization: A shallower gradient can improve the resolution between closely eluting compounds.
-
-
High-Resolution Mass Spectrometry (HRMS): If available, use an HRMS instrument to obtain an accurate mass measurement of the precursor ion. This can help to distinguish this compound from compounds with the same nominal mass but different elemental compositions.
-
Tandem Mass Spectrometry (MS/MS): Compare the fragmentation pattern of your analyte with a known standard of this compound. The fragmentation pattern serves as a molecular fingerprint.
-
Frequently Asked Questions (FAQs)
Q1: What are the common types of misidentification in the mass spectrometry analysis of modified nucleosides like this compound?
A1: There are three primary types of misidentification to be aware of during the LC-MS analysis of modified nucleosides[1]:
-
Type I: Structural Isomers: These are molecules with the same chemical formula but different atomic arrangements. For example, 5-(aminomethyl)pseudouridine would be an isomer of this compound. These compounds have the same exact mass and can only be distinguished by chromatographic separation or unique fragmentation patterns.[1]
-
Type II: Mass Analogs: These are different molecules with very close molecular weights that may not be resolved by a low-resolution mass spectrometer.
-
Type III: Isotopic Crosstalk: The signal from an isotopic peak of a highly abundant co-eluting compound can be mistaken for the monoisotopic peak of the analyte of interest. This is particularly relevant for uridine derivatives, which can experience crosstalk from cytidine (B196190) derivatives.[1]
Q2: What is the predicted fragmentation pattern of this compound in positive ion mode?
Key fragmentation pathways are expected to be:
-
Neutral loss of the ribose moiety: This is a common fragmentation for nucleosides, resulting in a protonated nucleobase. The neutral loss of the ribose sugar (C5H8O4) has a mass of 132.0423 Da.
-
Fragmentation of the aminomethyl side chain: Alpha-cleavage next to the amine is a common fragmentation pathway for amines. This could involve the loss of NH3 or cleavage of the C-C bond between the uracil (B121893) ring and the aminomethyl group.
-
A known product ion for this compound is observed at m/z 142. [2]
Q3: How can I minimize matrix effects in my analysis?
A3: Matrix effects, which are the suppression or enhancement of ionization of an analyte by co-eluting matrix components, are a significant challenge in quantitative LC-MS.[2][3][4] To minimize their impact:
-
Improve Sample Preparation: Use more rigorous sample cleanup methods like solid-phase extraction (SPE) to remove interfering matrix components.
-
Optimize Chromatography: Improve the chromatographic separation to resolve the analyte from matrix components.
-
Use a Stable Isotope-Labeled Internal Standard (SIL-IS): A SIL-IS of this compound is the ideal way to compensate for matrix effects, as it will be affected in the same way as the analyte.
-
Method of Standard Addition: If a SIL-IS is not available, the method of standard addition can be used to quantify the analyte in the presence of matrix effects.
Quantitative Data
Table 1: Mass Spectrometric Data for this compound and a Related Compound
| Compound | Formula | Monoisotopic Mass (Da) | [M+H]+ (m/z) | Key Product Ion (m/z) |
| This compound | C10H15N3O6 | 273.0961[2] | 274.1039[2] | 142[2] |
| 5-aminomethyl-2-thiouridine (B1259639) | C10H15N3O5S | 289.0732[1] | 290.0810[1] | 158[1] |
Table 2: Hypothetical Example of Data for Distinguishing this compound from a Potential Isomer
This table is a template to illustrate the type of data that should be generated to differentiate between isomers. The values for 5-(aminomethyl)pseudouridine are hypothetical.
| Compound | Retention Time (min) | Precursor Ion (m/z) | Key Fragment Ions (m/z) |
| This compound | 5.2 | 274.1039 | 142.1, ... |
| 5-(aminomethyl)pseudouridine | 4.8 | 274.1039 | ..., ..., ... |
Experimental Protocols
General Protocol for the LC-MS/MS Analysis of Modified Uridines
This protocol provides a starting point for the analysis of this compound. Optimization of the chromatographic and mass spectrometric parameters is essential for achieving the desired sensitivity and selectivity.
1. Sample Preparation (from RNA)
-
Enzymatically digest 1-5 µg of total RNA to nucleosides using nuclease P1 followed by bacterial alkaline phosphatase.
-
Remove proteins using a 10 kDa molecular weight cutoff filter.
-
Dry the sample under vacuum and reconstitute in the initial mobile phase.
2. Liquid Chromatography
-
Column: A reversed-phase C18 column (e.g., 2.1 x 100 mm, 1.8 µm) is a common starting point. For increased retention of polar compounds, a HILIC column can be used.
-
Mobile Phase A: 0.1% Formic Acid in Water
-
Mobile Phase B: 0.1% Formic Acid in Acetonitrile
-
Gradient: A shallow gradient is recommended to ensure good separation of isomers. For example:
-
0-5 min: 2% B
-
5-25 min: 2-30% B
-
25-26 min: 30-95% B
-
26-30 min: 95% B
-
30-31 min: 95-2% B
-
31-35 min: 2% B
-
-
Flow Rate: 0.2-0.4 mL/min
-
Column Temperature: 40 °C
-
Injection Volume: 5-10 µL
3. Mass Spectrometry
-
Ionization Mode: Positive Electrospray Ionization (ESI+)
-
MS Method: Multiple Reaction Monitoring (MRM) for quantification or full scan with data-dependent MS/MS for identification.
-
MRM Transitions (Hypothetical):
-
Quantifier: 274.1 -> 142.1
-
Qualifier: 274.1 -> [Predicted Fragment 2]
-
-
Collision Energy: Optimize for each transition using a standard of this compound.
-
Source Parameters:
-
Capillary Voltage: 3.5-4.5 kV
-
Gas Temperature: 300-350 °C
-
Gas Flow: 8-12 L/min
-
Nebulizer Pressure: 30-45 psi
-
Visualizations
Caption: Potential sources of misidentification in mass spectrometry.
Caption: Troubleshooting workflow for peak detection issues.
Caption: Biosynthetic pathway of modified uridines in tRNA.
References
Technical Support Center: Optimizing Deprotection of Boc-Protected 5-(Aminomethyl)uridine
This technical support center provides researchers, scientists, and drug development professionals with comprehensive troubleshooting guides and frequently asked questions (FAQs) to address common challenges encountered during the deprotection of Boc-protected 5-(aminomethyl)uridine.
Frequently Asked Questions (FAQs)
Q1: What is the fundamental mechanism of Boc deprotection?
A1: The tert-butyloxycarbonyl (Boc) group is an acid-labile protecting group. The deprotection mechanism involves protonation of the carbamate (B1207046) by a strong acid, followed by the cleavage of the C-O bond. This generates a stable t-butyl cation and a carbamic acid intermediate, which then decomposes into the free amine and carbon dioxide.[1][2]
Q2: What are the standard reaction conditions for this deprotection?
A2: Standard conditions typically involve treating the Boc-protected this compound with a strong acid in an organic solvent. The most common methods are:
-
Trifluoroacetic Acid (TFA): A solution of 20-50% TFA in dichloromethane (B109758) (DCM) is widely used, with reaction times ranging from 30 minutes to a few hours at room temperature.[1][2][3]
-
Hydrogen Chloride (HCl): A 4M solution of HCl in an organic solvent like 1,4-dioxane (B91453) or methanol (B129727) is another effective option.[1][3]
Q3: What are the most common side reactions to be aware of?
A3: The primary side reactions of concern during the Boc deprotection of this compound are:
-
Incomplete Deprotection: A significant amount of the starting material remains unreacted.[1]
-
t-Butylation: The electrophilic t-butyl cation generated can alkylate nucleophilic sites, particularly the electron-rich uracil (B121893) ring.[1]
-
Trifluoroacetylation: When using TFA, the newly deprotected amine can be acylated by a trifluoroacetyl group, forming an undesired amide byproduct.[1]
-
Degradation: Harsh acidic conditions can potentially lead to the cleavage of the acid-sensitive N-glycosidic bond in the uridine (B1682114) structure.[1][4]
Q4: Why is the use of "scavengers" often recommended?
A4: Scavengers are added to the reaction mixture to "trap" the highly reactive t-butyl cation that is formed during the deprotection. This prevents the t-butyl cation from reacting with nucleophilic sites on the uridine molecule (t-butylation), thus minimizing side product formation. Common scavengers include anisole (B1667542), cresol, or thiophenol.[1][2]
Q5: Are there milder, alternative methods for Boc deprotection if my compound is particularly acid-sensitive?
A5: Yes, if the this compound derivative is sensitive to strong acids, thermal deprotection can be considered. This involves heating the compound in a suitable solvent, which can cleave the Boc group without the need for strong, corrosive acids.[2] Additionally, Lewis acids like trimethylsilyl (B98337) iodide (TMSI) or zinc bromide can be used under non-protic conditions.[5]
Troubleshooting Guide
| Problem | Possible Cause(s) | Suggested Solution(s) |
| Incomplete Reaction (Significant starting material remains) | 1. Insufficient acid concentration or equivalents. 2. Reaction time is too short. 3. Low reaction temperature. 4. Water present in the reaction mixture. | 1. Increase the concentration of TFA (e.g., from 25% to 50%) or use a higher molar equivalent of HCl.[1][6] 2. Extend the reaction time and monitor closely using TLC or LC-MS.[7] 3. Allow the reaction to proceed at room temperature if it was started at 0°C. 4. Ensure all solvents and reagents are anhydrous. |
| Formation of Side Products (Observed by TLC/LC-MS) | 1. t-Butylation: The t-butyl cation is reacting with the uridine ring. 2. Trifluoroacetylation: The deprotected amine is reacting with TFA. 3. Degradation: The glycosidic bond is being cleaved due to harsh acidic conditions. | 1. Add a scavenger such as anisole or thioanisole (B89551) to the reaction mixture to trap the t-butyl cation.[1][2] 2. Use HCl in dioxane instead of TFA. If TFA must be used, perform the reaction at a lower temperature (0°C) and for a shorter duration. 3. Use a lower concentration of acid or switch to a milder deprotection method, such as thermal deprotection.[2] |
| Difficult Product Isolation (Oily residue, poor crystallization) | 1. The product is the TFA salt, which can be oily. 2. Residual acid or scavengers are present. | 1. Consider using 4M HCl in dioxane, as HCl salts are often more crystalline and easier to handle as free-flowing solids.[3] 2. After removing the acid in vacuo, perform a basic workup by dissolving the residue in an organic solvent and washing with a saturated sodium bicarbonate solution to neutralize any remaining acid.[7] Co-evaporation with a solvent like toluene (B28343) can also help remove residual TFA.[8] |
| Product is Unstable During Workup | 1. The free amine of this compound may be unstable under certain pH conditions. | 1. Minimize the time the product is in a strongly basic or acidic aqueous solution during workup. After neutralization, promptly extract the product into an organic solvent. |
Experimental Protocols
Protocol 1: Deprotection using Trifluoroacetic Acid (TFA) in Dichloromethane (DCM)
This is a standard and robust method for Boc deprotection.[2]
Materials:
-
Boc-protected this compound
-
Anhydrous Dichloromethane (DCM)
-
Trifluoroacetic Acid (TFA)
-
Saturated sodium bicarbonate (NaHCO₃) solution (for workup)
-
Anhydrous sodium sulfate (B86663) (Na₂SO₄) or magnesium sulfate (MgSO₄)
-
Standard laboratory glassware and magnetic stirrer
Procedure:
-
Dissolve the Boc-protected this compound in anhydrous DCM (approx. 0.1 M concentration) in a round-bottom flask.
-
Cool the solution to 0°C in an ice bath.
-
Prepare a deprotection solution of 25-50% TFA in DCM (v/v).
-
Add the TFA solution (typically 10 equivalents) dropwise to the stirring substrate solution at 0°C.
-
After addition, remove the ice bath and allow the reaction to warm to room temperature.
-
Stir for 1-4 hours, monitoring the reaction progress by Thin Layer Chromatography (TLC) or Liquid Chromatography-Mass Spectrometry (LC-MS) until the starting material is consumed.[7]
-
Once complete, remove the solvent and excess TFA under reduced pressure.
-
For isolation of the free amine, re-dissolve the residue in a suitable solvent and carefully neutralize with a saturated aqueous solution of NaHCO₃.
-
Extract the product with an organic solvent, dry the organic layer with Na₂SO₄ or MgSO₄, filter, and concentrate in vacuo.
Protocol 2: Monitoring the Deprotection Reaction by TLC
Procedure:
-
Spot the reaction mixture on a silica (B1680970) gel TLC plate alongside the starting material.
-
Elute with a suitable solvent system (e.g., a mixture of DCM and methanol).
-
The deprotected product (free amine) is more polar and will have a lower Rf value than the Boc-protected starting material.
-
Visualize the spots using a ninhydrin (B49086) stain (which detects primary amines) or under UV light.[7]
Visual Guides
References
- 1. benchchem.com [benchchem.com]
- 2. benchchem.com [benchchem.com]
- 3. reddit.com [reddit.com]
- 4. On the mechanism of the acid-catalyzed hydrolysis of uridine to uracil. Evidence for 6-hydroxy-5,6-dihydrouridine intermediates [pubmed.ncbi.nlm.nih.gov]
- 5. Amine Protection / Deprotection [fishersci.co.uk]
- 6. Comparison of 55% TFA/CH2Cl2 and 100% TFA for Boc group removal during solid-phase peptide synthesis - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. benchchem.com [benchchem.com]
- 8. reddit.com [reddit.com]
Technical Support Center: Quantifying 5-(aminomethyl)uridine and its Isomers by HPLC-MS
Welcome to the technical support center for the HPLC-MS analysis of 5-(aminomethyl)uridine (AmU) and its isomers. This resource provides troubleshooting guidance and frequently asked questions (FAQs) to assist researchers, scientists, and drug development professionals in overcoming the challenges associated with the quantification of these modified nucleosides.
Frequently Asked Questions (FAQs)
Q1: What are the primary isomers of this compound (AmU) that pose a challenge in HPLC-MS analysis?
A1: The primary isomer of concern is 5-(methylaminomethyl)uridine (mnm5U). This compound is also referred to as nm5U in the literature.[1][2][3] These two molecules are structurally very similar, differing only by a methyl group on the terminal amine, which can make their chromatographic separation difficult. Both are naturally occurring modifications found in transfer RNA (tRNA).[1][2][3]
Q2: Why is it difficult to separate this compound (AmU/nm5U) and 5-(methylaminomethyl)uridine (mnm5U) using standard reversed-phase HPLC?
A2: Standard reversed-phase HPLC separates molecules primarily based on their hydrophobicity. AmU and mnm5U are both highly polar molecules with very similar structures and, consequently, similar hydrophobicities. This lack of significant difference in their interaction with the stationary phase often leads to co-elution, where both compounds elute from the column at or near the same time, making accurate quantification challenging.
Q3: What chromatographic strategies can be employed to improve the separation of AmU and its isomers?
A3: To improve the separation of these polar isomers, consider the following strategies:
-
Hydrophilic Interaction Liquid Chromatography (HILIC): HILIC is a powerful technique for separating highly polar compounds.[4][5][6][7] It utilizes a polar stationary phase and a mobile phase with a high concentration of a less polar organic solvent, creating a water-enriched layer on the stationary phase. This allows for the separation of polar analytes based on their partitioning between the mobile phase and the aqueous layer.
-
Column Selection: The choice of HPLC column is critical. For HILIC, columns with amide, bare silica, or cyclofructan-based stationary phases can provide different selectivities for polar compounds.[4][5][7] For reversed-phase, a column with a different stationary phase chemistry (e.g., phenyl-hexyl instead of C18) might offer alternative selectivity.
-
Mobile Phase Optimization:
-
pH: Adjusting the pH of the mobile phase can alter the ionization state of the aminomethyl group, which can in turn affect the retention and selectivity.
-
Buffer Concentration: In HILIC, the salt concentration in the mobile phase can influence the thickness of the aqueous layer on the stationary phase and affect retention.[5]
-
Organic Modifier: Switching between acetonitrile (B52724) and methanol (B129727) as the organic modifier can change the selectivity of the separation.
-
Q4: If chromatographic separation is incomplete, how can mass spectrometry be used to differentiate and quantify AmU and mnm5U?
A4: Even with co-elution, mass spectrometry can provide specificity for quantification if the isomers have distinct fragmentation patterns.
-
Tandem Mass Spectrometry (MS/MS): By selecting the protonated molecular ion of each isomer and subjecting it to collision-induced dissociation (CID), you can generate unique product ions for each compound. These unique product ions can then be used for quantification in a multiple reaction monitoring (MRM) experiment.
-
High-Resolution Mass Spectrometry (HRMS): HRMS can help confirm the elemental composition of precursor and product ions, adding confidence to the identification of each isomer. Higher-energy collisional dissociation (HCD) can generate unique fragmentation "fingerprints" to identify specific isomers even when they are not chromatographically separated.[8][9]
-
Ion Mobility Spectrometry (IMS): IMS separates ions based on their size, shape, and charge in the gas phase.[8] This technique can separate isomers that co-elute from the LC column and have the same mass-to-charge ratio.[8]
Q5: Can derivatization be used to improve the separation and detection of AmU and its isomers?
A5: Yes, derivatization can be a valuable tool. By reacting the primary amine of AmU with a suitable reagent, you can alter its chemical properties to improve chromatographic separation and/or enhance mass spectrometric detection. For example, derivatization can increase the hydrophobicity of the molecule, making it more amenable to reversed-phase chromatography. It can also introduce a readily ionizable group, improving sensitivity in the mass spectrometer.
Troubleshooting Guide
| Problem | Potential Cause | Troubleshooting Steps |
| Co-elution of AmU and mnm5U peaks | Insufficient chromatographic resolution due to similar polarity and structure. | 1. Switch to a HILIC column: This is often the most effective solution for separating polar isomers.[4][5][6][7] 2. Optimize the mobile phase: a. Adjust the pH to alter the ionization of the aminomethyl group. b. Vary the buffer concentration in HILIC mode.[5] c. Try a different organic modifier (e.g., methanol instead of acetonitrile). 3. Change the stationary phase chemistry: If using reversed-phase, try a column with a different selectivity (e.g., phenyl-hexyl, pentafluorophenyl). 4. Decrease the temperature: Lowering the column temperature can sometimes improve the resolution of closely eluting peaks. |
| Poor peak shape (tailing or fronting) | Secondary interactions with the stationary phase, especially with residual silanols. | 1. Adjust mobile phase pH: Ensure the pH is appropriate to minimize interactions with silanols. 2. Add a competing base: For reversed-phase, adding a small amount of a competing amine (e.g., triethylamine) to the mobile phase can reduce peak tailing. 3. Use a column with end-capping: Select a column that is well end-capped to minimize exposed silanol (B1196071) groups. |
| Low sensitivity in MS detection | Poor ionization efficiency of the analytes. | 1. Optimize ESI source parameters: Adjust spray voltage, gas flows, and temperature. 2. Modify the mobile phase: Add a small amount of a volatile acid (e.g., formic acid) or base (e.g., ammonium (B1175870) hydroxide) to promote protonation or deprotonation. 3. Consider derivatization: Introduce a group that is more readily ionized. |
| Inability to distinguish isomers by MS/MS | Similar fragmentation patterns. | 1. Optimize collision energy: Systematically vary the collision energy to find a value that produces unique fragment ions for each isomer. 2. Utilize different fragmentation techniques: If available, explore techniques like HCD, which can provide different fragmentation information.[8][9] 3. Employ ion mobility spectrometry: If available, this can separate the isomers in the gas phase prior to MS analysis.[8] |
Experimental Protocols
Sample Preparation: Enzymatic Hydrolysis of tRNA
-
Isolate total tRNA: Use a suitable RNA isolation kit or a phenol-chloroform extraction method to obtain total tRNA from your biological sample.
-
Enzymatic Digestion:
-
To 1-5 µg of total tRNA, add nuclease P1 (to digest RNA to 5'-mononucleotides) in a suitable buffer (e.g., 10 mM ammonium acetate, pH 5.3).
-
Incubate at 37°C for 2-4 hours.
-
Add bacterial alkaline phosphatase (to dephosphorylate the mononucleotides to nucleosides) and a suitable buffer (e.g., 50 mM Tris-HCl, pH 8.0).
-
Incubate at 37°C for an additional 2 hours.
-
-
Sample Cleanup:
-
Filter the reaction mixture through a 0.22 µm filter to remove enzymes and other particulates.
-
The sample is now ready for HPLC-MS analysis.
-
HPLC-MS Method Development: HILIC Approach
-
HPLC System: A UHPLC or HPLC system coupled to a triple quadrupole or high-resolution mass spectrometer.
-
Column: HILIC column (e.g., Amide, Bare Silica, or Cyclofructan-based stationary phase), 2.1 x 100 mm, 1.7 µm particle size.
-
Mobile Phase A: 10 mM Ammonium Acetate in Water (adjust pH as needed, e.g., with acetic acid or ammonium hydroxide).
-
Mobile Phase B: Acetonitrile.
-
Gradient:
-
Start with a high percentage of Mobile Phase B (e.g., 95%).
-
Gradually decrease the percentage of Mobile Phase B over 10-15 minutes to elute the polar analytes.
-
Include a column wash and re-equilibration step at the end of the gradient.
-
-
Flow Rate: 0.2 - 0.4 mL/min.
-
Column Temperature: 30-40°C.
-
Injection Volume: 1-5 µL.
-
Mass Spectrometer:
-
Ionization Mode: Positive Electrospray Ionization (ESI+).
-
Scan Mode: Full scan to determine the m/z of protonated AmU and mnm5U, followed by product ion scans to determine their fragmentation patterns.
-
MRM Mode (for quantification):
-
AmU (nm5U): Precursor ion (M+H)+ -> Product ion(s)
-
mnm5U: Precursor ion (M+H)+ -> Product ion(s)
-
Note: The specific m/z values for precursor and product ions need to be determined experimentally.
-
-
Visualizations
Caption: Experimental workflow for the quantification of this compound and its isomers.
Caption: Logical workflow for troubleshooting the co-elution of this compound isomers.
References
- 1. Identification of a novel 5-aminomethyl-2-thiouridine methyltransferase in tRNA modification - PMC [pmc.ncbi.nlm.nih.gov]
- 2. researchgate.net [researchgate.net]
- 3. Identification of a novel 5-aminomethyl-2-thiouridine methyltransferase in tRNA modification - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. chromatographyonline.com [chromatographyonline.com]
- 5. mdpi.com [mdpi.com]
- 6. Separation of nucleobases, nucleosides, nucleotides and oligonucleotides by hydrophilic interaction liquid chromatography (HILIC): A state-of-the-art review - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. researchgate.net [researchgate.net]
- 8. benchchem.com [benchchem.com]
- 9. Differentiating positional isomers of nucleoside modifications by higher-energy collisional dissociation mass spectrometry (HCD MS) - PMC [pmc.ncbi.nlm.nih.gov]
Validation & Comparative
Confirming the Position of 5-(aminomethyl)uridine in tRNA Sequencing: A Comparative Guide
For researchers, scientists, and drug development professionals, accurately identifying and locating post-transcriptional modifications in transfer RNA (tRNA) is crucial for understanding gene regulation, cellular stress responses, and disease pathogenesis. One such modification, 5-(aminomethyl)uridine (am5U or nm5U), often found at the wobble position (position 34) of the anticodon loop, plays a significant role in decoding fidelity.[1][2][3][4] This guide provides a comparative analysis of modern high-throughput sequencing technologies for confirming the position of am5U in tRNA, supported by experimental data and detailed protocols.
The inherent characteristics of tRNA, namely its stable secondary structure and extensive modifications, present significant challenges for traditional RNA sequencing methods.[5][6] Modifications can stall or inhibit the reverse transcriptase (RT) enzyme, leading to incomplete reads and biased representation of the tRNA pool.[7] Several specialized techniques have been developed to overcome these hurdles, each with distinct advantages and limitations for detecting modified nucleosides like am5U.
This guide will focus on a comparison of three leading methodologies:
-
Modification-induced Misincorporation tRNA Sequencing (mim-tRNAseq): A method that leverages the infidelity of reverse transcriptase at modified sites to create a unique mutational signature.
-
AlkB-facilitated RNA Methylation Sequencing (ARM-Seq): This technique employs an enzyme to remove specific methyl groups that block reverse transcription, thereby enabling full-length sequencing.
-
Nanopore direct tRNA sequencing (Nano-tRNAseq): A third-generation sequencing approach that reads native RNA molecules directly, avoiding the biases of reverse transcription and amplification.[8][9][10][11]
Comparative Analysis of Sequencing Methods
The choice of sequencing method depends on the specific research question, available resources, and the desired level of detail regarding the modification. While direct comparative data for this compound is limited, we can infer the performance of each method based on their mechanisms and performance with other complex modifications at the wobble position.
| Method | Principle for Detecting am5U | Advantages | Limitations | Quantitative Performance for Complex Wobble Modifications |
| mim-tRNAseq | The bulky aminomethyl group at the C5 position of uridine (B1682114) is expected to cause steric hindrance for the reverse transcriptase, leading to a specific pattern of nucleotide misincorporation at that position.[7][12] | High-throughput and cost-effective. Provides quantitative information on tRNA abundance and modification stoichiometry from a single experiment.[7] | Indirect detection method. The specific misincorporation signature for am5U is not yet characterized. Requires a robust computational pipeline to analyze mutational patterns.[12] | Can accurately quantify tRNA abundance and modification status for modifications that induce misincorporation.[7] |
| ARM-Seq | Not directly applicable for am5U. The AlkB enzyme specifically removes N1-methyladenosine, N3-methylcytidine, and N1-methylguanosine.[13][14][15] | Effective for overcoming RT stalls caused by specific methylations, allowing for full-length tRNA sequencing.[13][14] | The demethylase has a limited substrate range and does not act on am5U. | High efficiency in detecting target methylations, leading to a significant increase in full-length reads for tRNAs containing m1A, m3C, or m1G.[13] |
| Nano-tRNAseq | As the native tRNA molecule passes through a nanopore, the am5U modification would cause a characteristic disruption in the ionic current. This electrical signal can be used to directly identify the modification and its position.[8][10][16] | Direct detection of modifications without the need for reverse transcription or PCR amplification, avoiding associated biases.[8][9] Can sequence full-length tRNAs and detect multiple modifications on a single molecule.[8] | Lower throughput and higher error rates in basecalling compared to second-generation sequencing. Requires specialized bioinformatics tools to analyze the raw signal data.[8][10] | Has been shown to detect and differentiate 43 distinct RNA modifications.[17] Can quantify site-specific modification changes across tRNA isoacceptors.[8] |
Experimental Protocols
Detailed methodologies are crucial for the successful implementation of these advanced sequencing techniques. Below are summaries of the key steps for mim-tRNAseq and Nano-tRNAseq, the most promising methods for the detection of am5U.
mim-tRNAseq Protocol
This protocol is adapted from established methods for modification-induced misincorporation tRNA sequencing.[7]
-
RNA Isolation: Extract total RNA from cells or tissues using a method that preserves small RNAs, such as TRIzol extraction followed by a specialized kit for small RNA enrichment.
-
tRNA Deacylation and Repair: Deacylate charged tRNAs by incubating the RNA sample in a basic buffer (e.g., 100 mM Tris-HCl, pH 9.0) at 37°C for 45 minutes. This is followed by enzymatic treatment to repair the 3' ends of the tRNAs.
-
Adapter Ligation: Ligate a pre-adenylated 3' DNA adapter to the tRNA molecules using a truncated and mutated T4 RNA ligase 2. This is followed by the ligation of a 5' RNA adapter.
-
Reverse Transcription: Perform reverse transcription using a thermostable group II intron reverse transcriptase (TGIRT), which has a higher processivity and a distinct misincorporation profile at modified bases. Use a primer that is complementary to the 3' adapter.
-
PCR Amplification: Amplify the resulting cDNA library using primers that are complementary to the adapter sequences. The number of PCR cycles should be optimized to avoid over-amplification.
-
Sequencing and Data Analysis: Sequence the library on an Illumina platform. The resulting sequencing reads are then processed through a specialized bioinformatic pipeline that aligns the reads to a reference tRNA library and identifies modification-induced mismatches.[12]
Nano-tRNAseq Protocol
This protocol is based on the Nano-tRNAseq method for direct sequencing of native tRNA molecules.[8][11]
-
RNA Isolation: Isolate total RNA, ensuring the preservation of tRNA modifications. Polyadenylate the 3' ends of the tRNAs using E. coli Poly(A) Polymerase.
-
Adapter Ligation: Ligate a 5' RNA adapter that is complementary to the 3' CCA tail of mature tRNAs. This is followed by the ligation of a 3' adapter required for nanopore sequencing.
-
Library Preparation: Prepare the sequencing library using the Oxford Nanopore Technologies Direct RNA Sequencing Kit, following the manufacturer's instructions. This involves ligating the motor protein to the RNA molecules.
-
Nanopore Sequencing: Load the prepared library onto a MinION or other nanopore sequencing device. The raw electrical signal data is collected as the individual tRNA molecules pass through the nanopores.
-
Data Analysis: Reprocess the raw nanopore current intensity signals to increase the yield of tRNA reads.[8][10] Use specialized software to align the reads to a reference tRNA database and analyze the signal for deviations that correspond to modified bases. Machine learning models can be trained to recognize the specific electrical signatures of different modifications.[18]
Visualizing the Workflow and Logic
To better illustrate the experimental and logical frameworks, the following diagrams were generated using the Graphviz DOT language.
Caption: Workflow for mim-tRNAseq.
Caption: Logic for selecting a tRNA sequencing method for am5U detection.
References
- 1. researchgate.net [researchgate.net]
- 2. Identification of a novel 5-aminomethyl-2-thiouridine methyltransferase in tRNA modification - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. Identification of a novel 5-aminomethyl-2-thiouridine methyltransferase in tRNA modification - PMC [pmc.ncbi.nlm.nih.gov]
- 4. GIST Scholar: Characterization of 5-aminomethyl-2-thiouridine tRNA modification biosynthetic pathway in Bacillus subtilis [scholar.gist.ac.kr]
- 5. Efficient and quantitative high-throughput tRNA sequencing - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. researchgate.net [researchgate.net]
- 7. High-resolution quantitative profiling of tRNA abundance and modification status in eukaryotes by mim-tRNAseq - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Quantitative analysis of tRNA abundance and modifications by nanopore RNA sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 9. repositori.upf.edu [repositori.upf.edu]
- 10. rna-seqblog.com [rna-seqblog.com]
- 11. Quantitative analysis of tRNA abundance and modifications by nanopore RNA sequencing - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. rna-seqblog.com [rna-seqblog.com]
- 13. ARM-Seq: AlkB-facilitated RNA methylation sequencing reveals a complex landscape of modified tRNA fragments - PMC [pmc.ncbi.nlm.nih.gov]
- 14. ARM-seq: AlkB-facilitated RNA methylation sequencing reveals a complex landscape of modified tRNA fragments | Scilit [scilit.com]
- 15. researchgate.net [researchgate.net]
- 16. Nanopore Direct RNA-Seq Unraveling tRNA Abundance and Modifications - CD Genomics [cd-genomics.com]
- 17. Comparative analysis of 43 distinct RNA modifications by nanopore tRNA sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 18. youtube.com [youtube.com]
A Comparative Guide to 5-(aminomethyl)uridine and Other Wobble Uridine Modifications in Translational Decoding
For Researchers, Scientists, and Drug Development Professionals
The fidelity and efficiency of protein synthesis are critically dependent on the precise recognition of mRNA codons by their cognate tRNAs. This process is fine-tuned by a vast array of post-transcriptional modifications, particularly at the wobble position (U34) of the tRNA anticodon. These modifications play a crucial role in modulating the decoding properties of tRNA, ensuring accurate reading of synonymous codons and maintaining the translational reading frame. Among these, 5-(aminomethyl)uridine (nm5U) and its derivatives are key players in prokaryotic and organellar translation. This guide provides an objective comparison of this compound with other prominent wobble uridine (B1682114) modifications, supported by experimental data, to aid researchers in understanding their distinct roles in translation.
Overview of Wobble Uridine Modifications
Wobble uridine modifications are chemical alterations to the uridine base at the first position of the anticodon. These modifications are essential for expanding or restricting the decoding capacity of a single tRNA to recognize multiple codons, a phenomenon first proposed by Francis Crick in his wobble hypothesis. The type of modification dictates the specific codon recognition patterns. This guide focuses on the comparison of this compound (nm5U) with its biosynthetic precursors and related derivatives, such as 5-carboxymethylaminomethyluridine (B1212367) (cmnm5U) and 5-methylaminomethyluridine (B1256275) (mnm5U), as well as eukaryotic counterparts like 5-methoxycarbonylmethyluridine (B127866) (mcm5U) and 5-carbamoylmethyluridine (B1230082) (ncm5U). Additionally, the influence of 2-thiolation (the addition of a sulfur atom at the C2 position), which often co-occurs with these C5 modifications (e.g., mnm5s2U, mcm5s2U), will be considered.
Biosynthesis of this compound and Related Modifications
The biosynthetic pathways for these modifications are complex and involve multiple enzymatic steps, which differ between prokaryotes and eukaryotes.
In Prokaryotes:
The synthesis of mnm5U and its derivatives in bacteria like Escherichia coli begins with the MnmE-MnmG complex, which modifies U34 to either 5-aminomethyluridine (B12866518) (nm5U) or 5-carboxymethylaminomethyluridine (cmnm5U), using ammonium (B1175870) or glycine (B1666218) as substrates, respectively.[1][2] In Gram-negative bacteria, the bifunctional enzyme MnmC then catalyzes the conversion of cmnm5U to nm5U, which is subsequently methylated to form mnm5U.[2] In some Gram-positive bacteria that lack MnmC, other enzymes like MnmL and MnmM perform these final steps.[3][4]
In Eukaryotes:
In eukaryotes, the formation of mcm5U and ncm5U modifications is initiated by the Elongator complex (composed of Elp1-Elp6 subunits).[5] The subsequent methylation step to form mcm5U is carried out by the Trm9/Trm112 complex. The 2-thiolation is a separate pathway involving proteins like Ncs2/Ncs6 (Tuc1/Tuc2 in yeast).
Quantitative Comparison of Decoding Performance
The primary role of wobble uridine modifications is to modulate codon recognition. The following tables summarize experimental data comparing the effects of different modifications on translation.
In Vitro Decoding Efficiency in E. coli
This table presents data from an in vitro translation assay using E. coli tRNAGly with different modifications at the wobble position. The efficiency of decoding synonymous glycine codons (GGA and GGG) was measured.
| Modification at U34 of tRNAGly | Relative Peptide Yield (GGA Codon) | Relative Peptide Yield (GGG Codon) |
| Unmodified (U) | 1.00 | 1.00 |
| 5-methyluridine (m5U) | ~0.80 | ~1.00 |
| 5-aminomethyluridine (nm5U) | ~0.60 | ~1.00 |
| 5-methylaminomethyluridine (mnm5U) | ~0.50 | ~1.50 |
| Data is estimated from graphical representations in the source publication.[6] |
Interpretation: The presence of mnm5U enhances the decoding of the GGG codon, while nm5U and m5U have little to no effect compared to the unmodified tRNA.[6] Conversely, all three modifications show a reduced efficiency in decoding the GGA codon.[6] This suggests that the complete mnm5 modification is necessary for efficient U•G wobble pairing with G-ending codons in this context.
In Vivo Translation Rates in E. coli
The following data show the impact of different modifications on the rate of translation of GAA and GAG codons in E. coli.
| Modification at U34 | Translation Rate of GAA (codons/sec) | Translation Rate of GAG (codons/sec) |
| 5-methylaminomethyl-2-thiouridine (mnm5s2U) | 18 | 7.7 |
| 2-thiouridine (s2U) | 47 | 1.9 |
| 5-methylaminomethyluridine (mnm5U) | 4.5 | 6.2 |
| Source:[7] |
Interpretation: The 2-thio (s2) modification dramatically increases the reading speed of the A-ending GAA codon but is inefficient for the G-ending GAG codon.[7] The mnm5 modification, on the other hand, restricts the reading of the GAA codon while enhancing the reading of the GAG codon.[7] The combined mnm5s2U modification appears to balance the decoding of both codons.[7]
Ribosome Binding Affinity
The affinity of tRNA for the ribosome is a critical factor in decoding. While direct quantitative data for nm5U is limited, studies on related modifications provide valuable insights.
| tRNA Anticodon Stem Loop (ASL) | Ribosome Binding Affinity (Kd) |
| Unmodified human tRNALys3UUU ASL | No detectable binding |
| s2U34-modified human tRNALys3UUU ASL | 176 ± 62 nM |
| Native E. coli tRNALysmnm5s2UUU | 70 ± 7 nM |
| Source:[8] |
Interpretation: The 2-thiolation (s2U) is sufficient to restore ribosome binding to an otherwise inactive unmodified tRNA anticodon stem loop.[8] The presence of the mnm5 group in the native tRNA further enhances this binding affinity.[8] This highlights the critical role of the s2 modification in establishing the correct anticodon conformation for ribosome interaction.
Functional Roles of this compound and Other Wobble Uridine Modifications
Based on the available data, the functional roles of these modifications can be summarized as follows:
-
This compound (nm5U): Acts as a key intermediate in the biosynthesis of mnm5U.[9] On its own, it does not appear to significantly enhance U•G wobble pairing but may play a role in the overall structural integrity of the anticodon loop.[6]
-
5-methylaminomethyluridine (mnm5U) and 5-carboxymethylaminomethyluridine (cmnm5U): The mnm5 modification is crucial for efficient decoding of G-ending codons by promoting U•G wobble pairing.[7] It also contributes to maintaining the correct reading frame during translation.[2] cmnm5U is the precursor to nm5U in the glycine-dependent pathway.[9][10]
-
5-methoxycarbonylmethyluridine (mcm5U) and 5-carbamoylmethyluridine (ncm5U): These eukaryotic modifications are important for the efficient reading of both A- and G-ending codons.[11] Their absence can lead to translational slowdown and pleiotropic phenotypes.[5]
-
2-thiouridine (s2U) derivatives (e.g., mnm5s2U, mcm5s2U): The 2-thio modification significantly enhances the affinity of tRNA for the ribosome and is particularly important for the efficient decoding of A-ending codons.[7][8] It restricts the flexibility of the uridine, promoting a conformation that favors Watson-Crick-like pairing.
The interplay between the C5 and C2 modifications is crucial for fine-tuning the decoding properties of the tRNA, allowing for efficient and accurate translation of a specific set of codons.
Experimental Protocols
Analysis of tRNA Modifications by HPLC-Coupled Mass Spectrometry
This method allows for the identification and quantification of modified nucleosides in tRNA.
-
tRNA Isolation and Purification:
-
Grow bacterial or yeast cells to the desired density and harvest by centrifugation.
-
Extract total RNA using a hot phenol-chloroform method.
-
Purify total tRNA from the total RNA extract using anion-exchange chromatography (e.g., DEAE-cellulose column) or size-exclusion HPLC.
-
-
Enzymatic Hydrolysis of tRNA:
-
Digest the purified tRNA (typically 1-5 µg) to individual nucleosides using a mixture of nuclease P1 (to cleave phosphodiester bonds) and bacterial alkaline phosphatase (to remove the 5'-phosphate).
-
Incubate the reaction mixture at 37°C for 2-4 hours.
-
-
HPLC-MS/MS Analysis:
-
Separate the resulting nucleosides by reversed-phase HPLC using a C18 column with a gradient of acetonitrile (B52724) in an aqueous buffer (e.g., ammonium acetate).
-
Analyze the eluting nucleosides using a triple quadrupole mass spectrometer operating in positive ion mode with dynamic multiple reaction monitoring (MRM).
-
Identify and quantify each modified nucleoside based on its specific retention time and mass transition (parent ion to fragment ion).
-
Detailed protocols can be found in Su et al., 2014 and Lin et al., 2023.
In Vitro Translation Assay
This assay measures the efficiency of a specific tRNA in translating a given codon.
-
Preparation of Components:
-
Prepare or obtain an in vitro translation system (e.g., E. coli S30 extract).
-
Synthesize or purify the specific tRNA with the desired modification at the wobble position.
-
Synthesize short mRNAs containing the codon of interest, typically with a start codon and a radioactive amino acid codon (e.g., [35S]-methionine) for detection.
-
-
Translation Reaction:
-
Combine the in vitro translation system, the specific tRNA, the mRNA template, and a mixture of amino acids (including the radiolabeled one) in a reaction buffer.
-
Incubate the reaction at 37°C for a defined period (e.g., 30-60 minutes).
-
-
Analysis of Translation Products:
-
Separate the translated peptides by SDS-PAGE.
-
Visualize and quantify the radiolabeled peptides using a phosphorimager.
-
Normalize the peptide yield to a control reaction to determine the relative translation efficiency.
-
Further details on in vitro translation systems are available from various commercial suppliers and in the literature.[12]
Logical Relationships in Wobble Uridine Function
The following diagram illustrates the hierarchical and synergistic relationships between different wobble uridine modifications in determining the final decoding properties of a tRNA.
Conclusion
This compound is a central intermediate in the biosynthesis of more complex wobble uridine modifications in prokaryotes. While it does not appear to be the primary effector of enhanced U•G wobble pairing, its presence is a prerequisite for the formation of mnm5U, which plays a significant role in decoding G-ending codons. The decoding landscape is further shaped by the presence or absence of the 2-thio modification, which is critical for efficient reading of A-ending codons and ribosome binding. The interplay between these modifications highlights a sophisticated system for fine-tuning translation that is essential for cellular function. Understanding these intricate details is paramount for researchers in molecular biology and for professionals in drug development targeting bacterial protein synthesis.
References
- 1. Modification of the wobble uridine in bacterial and mitochondrial tRNAs reading NNA/NNG triplets of 2-codon boxes - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. Identification of a novel 5-aminomethyl-2-thiouridine methyltransferase in tRNA modification - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Alternate routes to mnm5s2U synthesis in Gram-positive bacteria - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. journals.asm.org [journals.asm.org]
- 5. tandfonline.com [tandfonline.com]
- 6. Contribution of tRNA sequence and modifications to the decoding preferences of E. coli and M. mycoides tRNAGlyUCC for synonymous glycine codons - PMC [pmc.ncbi.nlm.nih.gov]
- 7. SURVEY AND SUMMARY: Roles of 5-substituents of tRNA wobble uridines in the recognition of purine-ending codons - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Single atom modification (O-->S) of tRNA confers ribosome binding - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. The output of the tRNA modification pathways controlled by the Escherichia coli MnmEG and MnmC enzymes depends on the growth conditions and the tRNA species - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Insights into the Mechanism of Installation of 5-Carboxymethylaminomethyl Uridine Hypermodification by tRNA-Modifying Enzymes MnmE and MnmG - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Modification of the wobble uridine in bacterial and mitochondrial tRNAs reading NNA/NNG triplets of 2-codon boxes - PMC [pmc.ncbi.nlm.nih.gov]
- 12. The Basics: In Vitro Translation | Thermo Fisher Scientific - DE [thermofisher.com]
A Comparative Guide to Functional Assays for tRNA With and Without 5-(Aminomethyl)uridine
This guide provides a comprehensive comparison of functional assays for transfer RNA (tRNA) molecules, focusing on the impact of the post-transcriptional modification 5-(aminomethyl)uridine (nm5U). The presence or absence of this modification, particularly at the wobble position (U34) of the anticodon, can significantly influence tRNA function, affecting decoding accuracy and overall translational efficiency. This document is intended for researchers, scientists, and drug development professionals working in the fields of molecular biology, biochemistry, and drug discovery.
Introduction to this compound and its Significance
Post-transcriptional modifications of tRNA are crucial for their proper folding, stability, and function in protein synthesis.[1] this compound (nm5U) is a modification found at the wobble position (uridine 34) of the anticodon in certain tRNAs. This modification and its derivatives, such as 5-methylaminomethyluridine (B1256275) (mnm5U), play a critical role in ensuring accurate and efficient translation.[1]
The absence of these modifications, often due to mutations in the enzymes responsible for their biosynthesis, can lead to translational frameshifting and reduced translational efficiency.[1] In Escherichia coli, the bifunctional enzyme MnmC is responsible for the final two steps in the biosynthesis of mnm5U, which involves the formation of nm5U as an intermediate.[2][3][4][5] Therefore, studying tRNA from mnmC mutant strains provides a valuable model for understanding the functional consequences of lacking this critical modification.
This guide will delve into the key functional assays used to characterize and compare tRNAs with and without this compound: aminoacylation assays, ribosome binding assays, and in vitro translation assays. We will provide detailed experimental protocols, present available quantitative data for comparison, and illustrate the underlying pathways and workflows with diagrams.
Biosynthesis of this compound and its Derivatives
The biosynthesis of 5-methylaminomethyl-2-thiouridine (B1677369) (mnm⁵s²U) from 5-carboxymethylaminomethyl-2-thiouridine (B1228955) (cmnm⁵s²U) in E. coli is catalyzed by the bifunctional enzyme MnmC. This process involves two key steps: an FAD-dependent demodification to 5-aminomethyl-2-thiouridine (B1259639) (nm⁵s²U), followed by an S-adenosylmethionine (SAM)-dependent methylation to the final mnm⁵s²U product.
Quantitative Comparison of Functional Assays
While direct side-by-side quantitative comparisons of tRNA performance with and without this compound in various functional assays are limited in the literature, we can compile available data to infer the impact of this modification. The following tables summarize key findings.
Aminoacylation Kinetics
Aminoacylation is the crucial first step in tRNA function, where a specific amino acid is attached to the tRNA by its cognate aminoacyl-tRNA synthetase (aaRS). The efficiency of this process can be quantified by determining the Michaelis-Menten kinetic parameters, Km and kcat. A lower Km indicates a higher affinity of the aaRS for the tRNA, and a higher kcat indicates a faster catalytic rate.
Table 1: Steady-State Kinetics of the MnmC Enzyme [4]
| Reaction Step | Substrate | Km (nM) | kcat (s-1) | kcat/Km (nM-1s-1) |
| 1. Demodification | cmnm⁵s²U-tRNAGlu | 600 | 0.34 | 0.00057 |
| 2. Methylation | nm⁵s²U-tRNAGlu | 70 | 0.31 | 0.0044 |
This data represents the kinetics of the modification enzyme itself, not the aminoacylation of the resulting tRNA. The significantly lower Km for the second step suggests that the enzyme is kinetically tuned to avoid the accumulation of the intermediate nm⁵(s²)U-containing tRNA.[4]
Ribosome Binding Affinity
In Vitro Translation Efficiency
The ultimate measure of tRNA function is its ability to support protein synthesis. In vitro translation systems allow for the quantification of protein yield in a controlled environment. The absence of wobble uridine (B1682114) modifications like mnm⁵U has been shown to reduce translational efficiency and increase frameshifting.[1]
Experimental Protocols
This section provides detailed methodologies for the key functional assays discussed in this guide.
Aminoacylation Assay
This protocol is adapted from established methods for measuring tRNA aminoacylation kinetics.[6][7][8][9][10]
Objective: To determine the kinetic parameters (Km and kcat) of an aminoacyl-tRNA synthetase for a specific tRNA.
Materials:
-
Purified tRNA (with and without this compound modification)
-
Purified cognate aminoacyl-tRNA synthetase (aaRS)
-
Radiolabeled amino acid (e.g., [³H]- or [¹⁴C]-labeled)
-
ATP
-
Reaction buffer (e.g., 30 mM HEPES-KOH pH 7.5, 30 mM KCl, 15 mM MgCl₂)
-
Trichloroacetic acid (TCA)
-
Glass fiber filters
-
Scintillation fluid and counter
Procedure:
-
Prepare a reaction mixture containing the reaction buffer, ATP, and the radiolabeled amino acid.
-
Initiate the reaction by adding the aaRS and varying concentrations of the tRNA substrate.
-
Incubate the reactions at a constant temperature (e.g., 37°C).
-
At specific time points, quench aliquots of the reaction mixture by spotting them onto glass fiber filters and immersing the filters in cold 5% TCA.
-
Wash the filters extensively with cold 5% TCA to remove unincorporated radiolabeled amino acid, followed by a final wash with ethanol.
-
Dry the filters and measure the incorporated radioactivity using a scintillation counter.
-
Calculate the initial rates of aminoacylation for each tRNA concentration.
-
Plot the initial rates against the tRNA concentration and fit the data to the Michaelis-Menten equation to determine Km and kcat.
References
- 1. Identification of a novel 5-aminomethyl-2-thiouridine methyltransferase in tRNA modification - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Identification of a bifunctional enzyme MnmC involved in the biosynthesis of a hypermodified uridine in the wobble position of tRNA - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Identification of a bifunctional enzyme MnmC involved in the biosynthesis of a hypermodified uridine in the wobble position of tRNA - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. Assay of both activities of the bifunctional tRNA-modifying enzyme MnmC reveals a kinetic basis for selective full modification of cmnm5s2U to mnm5s2U - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Crystal structure of the bifunctional tRNA modification enzyme MnmC from Escherichia coli - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. researchgate.net [researchgate.net]
- 7. Kinetics of tRNA folding monitored by aminoacylation - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Aminoacyl-tRNA synthetases - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Distinct kinetic mechanisms of the two classes of Aminoacyl-tRNA synthetases - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. Kinetic discrimination of tRNA identity by the conserved motif 2 loop of a class II aminoacyl-tRNA synthetase - PMC [pmc.ncbi.nlm.nih.gov]
Decoding the Genetic Code: A Comparative Analysis of 5-(aminomethyl)uridine and its Role in Codon Recognition
In the intricate machinery of protein synthesis, the precise recognition of messenger RNA (mRNA) codons by transfer RNA (tRNA) is paramount for maintaining cellular function and fidelity. This process is heavily influenced by post-transcriptional modifications of tRNA nucleosides, particularly at the wobble position of the anticodon. Among these, 5-(aminomethyl)uridine (AmU) and its derivatives play a crucial role in ensuring accurate and efficient translation. This guide provides a comparative analysis of the role of AmU and related modified nucleosides in codon recognition, supported by experimental data and detailed methodologies for researchers, scientists, and drug development professionals.
The Significance of Wobble Position Modifications
The "wobble" hypothesis, first proposed by Francis Crick, posits that the base at the first position of the anticodon (position 34) can pair with multiple bases at the third position of the mRNA codon.[1] This flexibility is modulated by a vast array of chemical modifications to the wobble uridine (B1682114), which can either expand or restrict codon recognition. Modifications at the C5 position of uridine, such as those that form this compound derivatives, are critical in fine-tuning this process, particularly for codons ending in purines (adenine and guanine).[1]
Comparative Analysis of Codon Recognition by Uridine Derivatives
While direct quantitative data for this compound (AmU) is limited in the literature, extensive research on its immediate derivatives, such as 5-methylaminomethyluridine (B1256275) (mnm⁵U) and 5-methylaminomethyl-2-thiouridine (B1677369) (mnm⁵s²U), provides valuable insights into its function. These derivatives are found in tRNAs that recognize specific codons, and their presence significantly impacts translational efficiency and accuracy.
Table 1: Translational Rates for Codons Recognized by tRNAs with Uridine Derivatives [1]
| tRNA Modification | Codon | Translation Rate (codons/s) |
| mnm⁵s²U | GAG | 7.7 |
| s²U | GAG | 1.9 |
| mnm⁵U | GAG | 6.2 |
| mnm⁵s²U | GAA | 18 |
| s²U | GAA | 47 |
| mnm⁵U | GAA | 4.5 |
Table 2: Effect of mnm⁵-Modification Absence on Misreading Frequencies [2]
| tRNA | Codon Mispair | Fold Change in Misreading |
| tRNALys | UAG | ~11-fold decrease |
| tRNALys | AGG | ~11-fold decrease |
| tRNALys | UAA | ~4-fold decrease |
| tRNALys | AGA | ~4-fold decrease |
| tRNALys | AAU | ~4-fold decrease |
| tRNAGlu | GGG | Significant decrease |
| tRNAGlu | Other error-prone mutants | Significant increase |
The data indicate that the mnm⁵ modification, a derivative of AmU, has a context-dependent role in translational accuracy. In tRNALys, its absence leads to a decrease in misreading, suggesting it may be important for the overall stability of the codon-anticodon interaction, even at near-cognate codons.[2] Conversely, for tRNAGlu, the absence of the mnm⁵ group increases misreading at several codons, highlighting its role in maintaining fidelity.[2] The 2-thiolation (s²) in combination with the mnm⁵ modification also significantly influences translation rates, demonstrating the synergistic effects of multiple modifications.[1]
Structural Basis for Codon Recognition
The modifications at the wobble position influence the conformational dynamics of the anticodon loop. Proton NMR analyses have revealed that derivatives of 5-methyl-2-thiouridine (B1588163) (like mnm⁵s²U) favor a C3'-endo conformation of the ribose ring.[3] This conformation is thought to be crucial for the specific recognition of adenosine (B11128) in the third codon position.[3] The 5-substituent, derived from AmU, contributes to this conformational preference.
Experimental Methodologies
A variety of in vitro and in vivo techniques are employed to validate the role of modified nucleosides in codon recognition.
In Vitro Translation Assays
These assays are fundamental for directly measuring the efficiency and fidelity of translation with tRNAs containing specific modifications.
Protocol for a Reconstituted Cell-Free Protein Synthesis System: [4]
-
Preparation of Components:
-
Purify ribosomes, individual tRNAs (both modified and unmodified), aminoacyl-tRNA synthetases (aaRSs), and translation factors (initiation, elongation, and release factors).
-
Synthesize mRNA templates with specific codons of interest. For quantitative analysis, radioactively labeled amino acids (e.g., [¹⁴C]- or [³⁵S]-labeled) are used.
-
-
Aminoacylation of tRNA:
-
Incubate the purified tRNA with its cognate aaRS, the corresponding radioactively labeled amino acid, and ATP in a suitable reaction buffer (e.g., 100 mM HEPES-KOH pH 7.6, 15 mM MgCl₂, 40 mM KCl, 1 mM DTT, 4 mM ATP).[4]
-
-
Translation Reaction:
-
Combine the purified ribosomes, aminoacylated tRNA, mRNA template, and translation factors in a translation buffer.
-
Incubate the reaction mixture at 37°C to allow for protein synthesis.
-
-
Analysis:
-
Precipitate the synthesized proteins (e.g., using trichloroacetic acid).
-
Quantify the incorporation of the radiolabeled amino acid using scintillation counting to determine the efficiency of translation for specific codons.
-
To measure misreading, use an mRNA template with a near-cognate codon and quantify the incorporation of the incorrect amino acid.
-
Ribosome Filter Binding Assay
This technique is used to measure the binding affinity of a tRNA to the ribosome in the presence of a specific mRNA codon.
Protocol for Ribosome Filter Binding Assay: [5][6]
-
Labeling of tRNA:
-
Dephosphorylate the 3' end of the tRNA using alkaline phosphatase.
-
Label the tRNA with [γ-³²P]ATP using T4 polynucleotide kinase.
-
Purify the labeled tRNA by gel electrophoresis.
-
-
Binding Reaction:
-
Incubate purified ribosomes with the specific mRNA codon (as a short oligonucleotide) and the ³²P-labeled aminoacylated tRNA in a binding buffer (e.g., 80 mM K-cacodylate, 10 mM MgCl₂, 150 mM NH₄Cl).[5]
-
Allow the components to incubate to reach binding equilibrium.
-
-
Filtration:
-
Pass the reaction mixture through a nitrocellulose filter under vacuum. The ribosome-mRNA-tRNA complexes will be retained on the filter, while unbound tRNA will pass through.
-
-
Quantification:
-
Wash the filter to remove non-specific binding.
-
Quantify the radioactivity retained on the filter using a scintillation counter or phosphorimager.
-
By varying the concentration of the tRNA while keeping the ribosome and mRNA concentrations constant, a binding curve can be generated to determine the dissociation constant (Kd).
-
Visualizing the Molecular Mechanisms
Graphviz diagrams are provided to illustrate the key processes involved in codon recognition and the experimental workflows.
Caption: Mechanism of codon recognition involving a modified uridine at the wobble position.
Caption: Experimental workflow for in vitro translation assays.
Caption: Experimental workflow for ribosome filter binding assays.
References
- 1. SURVEY AND SUMMARY: Roles of 5-substituents of tRNA wobble uridines in the recognition of purine-ending codons - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Effects of tRNA modification on translational accuracy depend on intrinsic codon–anticodon strength - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Molecular mechanism of codon recognition by tRNA species with modified uridine in the first position of the anticodon - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Reconstituted cell-free protein synthesis using in vitro transcribed tRNAs - PMC [pmc.ncbi.nlm.nih.gov]
- 5. josephgroup.ucsd.edu [josephgroup.ucsd.edu]
- 6. Read Lab: Researching Trypanosoma brucei | Protocols | Filter Binding Assay [acsu.buffalo.edu]
A Comparative Guide to mnm5U and cmnm5U in Translation for Researchers
An in-depth analysis of the roles, biosynthesis, and translational impact of 5-methylaminomethyluridine (B1256275) (mnm5U) and its precursor, 5-carboxymethylaminomethyluridine (B1212367) (cmnm5U), two critical tRNA modifications.
Introduction
In the intricate process of protein synthesis, the accurate and efficient translation of the genetic code is paramount. Post-transcriptional modifications of transfer RNA (tRNA), particularly at the wobble position (U34) of the anticodon, are essential for maintaining translational fidelity and efficiency.[1][2] Among the myriad of known modifications, 5-methylaminomethyluridine (mnm5U) and its precursor, 5-carboxymethylaminomethyluridine (cmnm5U), are crucial for the proper decoding of codons ending in purine (B94841) nucleotides (A or G) within split codon boxes.[3] This guide provides a detailed comparative analysis of mnm5U versus cmnm5U, delving into their biosynthesis, their respective impacts on translation, and the experimental methodologies employed for their investigation.
Biosynthesis: A Two-Step Refinement
The journey to these vital tRNA modifications begins with the synthesis of cmnm5U. The enzymatic complex MnmE/MnmG (also known as GidA) catalyzes the transfer of a carboxymethylaminomethyl group from glycine (B1666218) to the U34 position of specific tRNAs, thereby forming cmnm5U.[2][4]
In many bacteria, such as Escherichia coli, this is not the final step. The bifunctional enzyme MnmC orchestrates a further two-step conversion to mnm5U. The C-terminal domain of MnmC (MnmC1) first converts cmnm5U to a 5-aminomethyluridine (B12866518) (nm5U) intermediate. Following this, the N-terminal domain (MnmC2) utilizes S-adenosyl-L-methionine (SAM) as a methyl donor to methylate nm5U, yielding the final mnm5U modification.[1][4] Consequently, organisms that lack the gene for MnmC will have tRNAs containing cmnm5U as the terminal modification at this position.[4]
Figure 1: Biosynthetic pathway for the formation of cmnm5U and mnm5U at the wobble position of tRNA.
Comparative Translational Performance: An Evolutionary Fine-Tuning
Both mnm5U and cmnm5U are critical for the accurate decoding of NNA/G codons. However, the conversion to mnm5U is considered a fine-tuning step that further enhances translational performance. Studies on mnmE mutants, which lack both modifications, have demonstrated a marked reduction in the ribosomal recruitment of the corresponding tRNA, particularly for codons ending in G.[3] This suggests that the presence of either modification is crucial, but the prevalence of the MnmC-mediated pathway in many organisms points to an evolutionary advantage for mnm5U.
| Feature | cmnm5U | mnm5U | Source |
| Codon Recognition | Facilitates the recognition of NNA/G codons. | Optimizes the recognition of NNA/G codons, with a more pronounced effect on G-ending codons. | [3] |
| Translational Fidelity | Essential for maintaining the correct reading frame. | Provides a higher level of reading frame maintenance, thereby reducing frameshift errors. | [3] |
| Translational Efficiency | Supports the efficient translation of cognate codons. | Significantly enhances translational efficiency by strengthening the codon-anticodon interaction. | [3] |
| Prevalence | The final modification in organisms lacking the mnmC gene (e.g., Bacillus subtilis). | The final modification in organisms that possess the mnmC gene (e.g., Escherichia coli). | [4] |
Experimental Protocols for Analysis
Mass Spectrometry-Based Quantification of tRNA Modifications
Objective: To accurately identify and quantify the levels of mnm5U and cmnm5U in a total tRNA pool.
Methodology:
-
tRNA Isolation: Total RNA is extracted from the target cells, followed by the purification of the tRNA fraction using methods such as polyacrylamide gel electrophoresis (PAGE) or high-performance liquid chromatography (HPLC).
-
Nucleoside Digestion: The purified tRNA is enzymatically hydrolyzed to its individual nucleosides using a combination of nucleases, most commonly nuclease P1, followed by dephosphorylation with alkaline phosphatase.
-
LC-MS/MS Analysis: The resulting nucleoside mixture is subjected to liquid chromatography-tandem mass spectrometry (LC-MS/MS). The nucleosides are separated by reverse-phase HPLC and then identified and quantified by the mass spectrometer based on their unique mass-to-charge ratios and fragmentation patterns.[4][5][6][7]
-
Data Analysis: The abundance of mnm5U and cmnm5U is determined by comparing the integrated peak areas from the chromatogram against a standard curve generated with known amounts of the modified nucleosides or by normalization to a universally present, unmodified nucleoside.
Figure 2: A generalized workflow for the analysis of tRNA modifications using mass spectrometry.
Ribosome Profiling for In Vivo Translational Analysis
Objective: To determine the in vivo effects of mnm5U and cmnm5U on the rate of translation elongation.
Methodology:
-
Sample Preparation: Wild-type and mutant cells (e.g., an mnmC deletion strain that accumulates cmnm5U) are cultured and harvested.
-
Ribosome Footprinting: Cell lysates are treated with a ribonuclease to degrade any mRNA that is not protected by ribosomes. The resulting ribosome-protected mRNA fragments (RPFs) are isolated.
-
Library Preparation and Sequencing: The RPFs are purified, and a cDNA library is constructed for high-throughput sequencing.[8][9][10]
-
Data Analysis: The sequencing reads are aligned to a reference transcriptome. The density of reads at each codon is calculated to create a ribosome occupancy profile. An increased ribosome density at specific codons in the mnmC mutant compared to the wild-type indicates a slower translocation rate, thus revealing the codons that are more efficiently translated by tRNAs containing mnm5U versus cmnm5U.
Conclusion
The tRNA modifications mnm5U and cmnm5U are indispensable for the accurate and efficient translation of a specific subset of codons. The conversion of cmnm5U to mnm5U represents an evolutionary refinement that further optimizes the decoding process. The robust experimental techniques of mass spectrometry and ribosome profiling provide powerful avenues to investigate the functional significance of these and other tRNA modifications. This guide offers a foundational understanding for researchers and professionals in drug development, enabling a deeper appreciation for the nuanced roles of tRNA modifications in health and disease.
References
- 1. The output of the tRNA modification pathways controlled by the Escherichia coli MnmEG and MnmC enzymes depends on the growth conditions and the tRNA species - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Further insights into the tRNA modification process controlled by proteins MnmE and GidA of Escherichia coli - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Improvement of reading frame maintenance is a common function for several tRNA modifications - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Alternate routes to mnm5s2U synthesis in Gram-positive bacteria - PMC [pmc.ncbi.nlm.nih.gov]
- 5. pubs.acs.org [pubs.acs.org]
- 6. Insights into the Mechanism of Installation of 5-Carboxymethylaminomethyl Uridine Hypermodification by tRNA-Modifying Enzymes MnmE and MnmG - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Elucidation of the substrate of tRNA-modifying enzymes MnmEG leads to in vitro reconstitution of an evolutionarily conserved uridine hypermodification - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Ribosome Profiling Reveals a Cell-Type-Specific Translational Landscape in Brain Tumors - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Ribosome Profiling and Mass Spectrometry Reveal Widespread Mitochondrial Translation Defects in a Striatal Cell Model of Huntington Disease - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. Ribosome Profiling and Mass Spectrometry Reveal Widespread Mitochondrial Translation Defects in a Striatal Cell Model of Huntington Disease - PMC [pmc.ncbi.nlm.nih.gov]
A Comparative Guide to the Functional Differences Between 5-(aminomethyl)uridine and 5-taurinomethyluridine
For Researchers, Scientists, and Drug Development Professionals
This guide provides a detailed comparison of the functional differences between two critical modified ribonucleosides found in transfer RNA (tRNA): 5-(aminomethyl)uridine (nm5U) and 5-taurinomethyluridine (τm5U). These modifications, located at the wobble position (the first nucleotide of the anticodon), play a crucial role in the efficiency and fidelity of protein synthesis. Understanding their distinct functions is vital for research in molecular biology, genetics, and the development of novel therapeutics targeting translation.
Introduction to Wobble Uridine (B1682114) Modifications
In the process of translation, the ribosome moves along a messenger RNA (mRNA) molecule, reading its codons to synthesize a corresponding protein. Transfer RNAs act as adaptors, recognizing specific mRNA codons and delivering the correct amino acid. The interaction between the mRNA codon and the tRNA anticodon is fundamental to the accuracy of this process. The third position of the codon often exhibits "wobble," allowing a single tRNA to recognize multiple codons. This flexibility is frequently modulated by chemical modifications of the nucleoside at position 34 of the tRNA anticodon. This compound and 5-taurinomethyluridine are two such modifications that, despite their structural similarities, have distinct biological roles and are found in different domains of life.
This compound (nm5U) is primarily found in prokaryotic tRNAs. It serves as a key intermediate in the biosynthesis of more complex modifications like 5-methylaminomethyluridine (B1256275) (mnm5U).[1][2][3] These modifications are essential for the accurate decoding of codons with A or G in the third position.[1][2]
5-taurinomethyluridine (τm5U) is a characteristic modification in mitochondrial tRNAs of eukaryotes, including humans.[4][5][6] Its presence is critical for the proper translation of mitochondrial-encoded proteins. Deficiencies in τm5U are directly linked to severe human mitochondrial diseases, such as MELAS (Mitochondrial Encephalomyopathy, Lactic Acidosis, and Stroke-like episodes) and MERRF (Myoclonic Epilepsy with Ragged-Red Fibers).[4][5][7][8]
Biosynthesis Pathways
The biosynthetic pathways for nm5U and τm5U highlight their distinct origins and the different enzymes involved.
Biosynthesis of this compound (nm5U) in Bacteria:
The formation of nm5U is a step in the multi-enzyme synthesis of 5-methylaminomethyl(-2-thio)uridine (mnm5(s2)U).[1][2][3]
-
The MnmE-MnmG enzyme complex first modifies the wobble uridine to 5-carboxymethylaminomethyluridine (B1212367) (cmnm5U).[1][2]
-
In Gram-negative bacteria like Escherichia coli, the bifunctional enzyme MnmC then catalyzes the conversion of cmnm5U to nm5U.[2][3] In other bacteria, such as Bacillus subtilis, this step is carried out by the enzyme YurR.[1]
-
Finally, nm5U is methylated by the methyltransferase domain of MnmC (in E. coli) or the MnmM enzyme (in B. subtilis) to produce mnm5U.[1][2][3]
Biosynthesis of 5-taurinomethyluridine (τm5U) in Mitochondria:
The synthesis of τm5U involves the direct incorporation of taurine (B1682933) and is catalyzed by a dedicated set of enzymes in the mitochondria.[4][9]
-
The process is initiated by the MTO1 and GTPBP3 enzyme complex.[9][10]
-
This complex utilizes 5,10-methylene-tetrahydrofolate as a carbon donor and directly conjugates taurine to the C5 position of the wobble uridine.[9][10][11]
Functional Differences in Codon Recognition
The primary function of both nm5U and τm5U is to enhance the decoding of codons ending in purines (A or G). However, the specific context and efficiency of this function differ.
Derivatives of nm5U, like mnm5U, are crucial for stabilizing the U•G wobble base pair, thereby promoting the efficient reading of NNG codons while preventing the misreading of NNU/C codons.[2][12] The C5 modification restricts the conformation of the anticodon loop, ensuring proper alignment with the codon in the ribosomal A-site.
Similarly, τm5U is essential for the accurate decoding of UUA and UUG codons by mitochondrial tRNALeu(UUR) and AAA and AAG codons by tRNALys.[4][8] The lack of this modification leads to a severe decoding defect, particularly for the NNG codons, resulting in impaired mitochondrial protein synthesis.[4] The taurine moiety at the C5 position is critical for stabilizing the U•G wobble pair.[4][13]
Quantitative Data Summary
While direct comparative quantitative data between nm5U and τm5U from a single study is limited, the functional impact of xm5U-type modifications has been assessed through various experiments. The following table summarizes key findings related to the function of these modifications.
| Feature | This compound (as part of mnm5U) | 5-taurinomethyluridine (τm5U) | Reference |
| Primary Location | Prokaryotic tRNA | Eukaryotic mitochondrial tRNA | [1],[4] |
| Codon Recognition | NNA/NNG | NNA/NNG | [2],[8] |
| Effect on U•G Wobble | Stabilizes U•G pairing | Critically stabilizes U•G pairing | [12],[7] |
| Disease Association | None directly reported for nm5U deficiency | Deficiency linked to MELAS and MERRF | [4],[7] |
| Translational Fidelity | Enhances accuracy by preventing misreading of NNU/C codons | Essential for fidelity; deficiency leads to translational defects | [1],[4] |
Experimental Protocols
The study of tRNA modifications and their functional consequences relies on a combination of biochemical and biophysical techniques.
Experimental Workflow for tRNA Modification Analysis:
A. tRNA Isolation and Mass Spectrometry Analysis
This protocol outlines the general steps for identifying and quantifying nm5U or τm5U in tRNA.
-
tRNA Purification:
-
Total RNA is extracted from the cells of interest (e.g., bacteria or human cell lines).
-
tRNA is enriched from the total RNA pool, often using anion-exchange chromatography or size-exclusion chromatography.
-
Specific tRNA isoacceptors can be further purified using methods like affinity chromatography with biotinylated DNA probes.
-
-
Enzymatic Hydrolysis:
-
Purified tRNA is completely digested into its constituent nucleosides using a cocktail of enzymes, typically including nuclease P1 and phosphodiesterase I, followed by alkaline phosphatase.
-
-
LC-MS/MS Analysis:
-
The resulting nucleoside mixture is separated by reverse-phase high-performance liquid chromatography (HPLC).
-
The eluate is introduced into a tandem mass spectrometer (MS/MS) for detection and quantification.
-
Modified nucleosides are identified based on their specific mass-to-charge ratio and fragmentation patterns. Quantification is achieved by comparing the peak areas of the modified nucleosides to those of unmodified nucleosides or internal standards.
-
B. Ribosome Binding Assay
This assay measures the ability of a specific tRNA to bind to a ribosome programmed with a particular mRNA codon.
-
Preparation of Components:
-
Purified ribosomes (70S for prokaryotes, 80S for eukaryotes).
-
Synthesized mRNA constructs containing the codons of interest.
-
Aminoacylated tRNA (charged with a radiolabeled amino acid) containing the modification of interest.
-
-
Binding Reaction:
-
Ribosomes, mRNA, and the charged tRNA are incubated together in a suitable buffer.
-
The mixture is allowed to reach equilibrium.
-
-
Quantification:
-
The reaction mixture is passed through a nitrocellulose filter, which retains ribosome-bound tRNA but allows free tRNA to pass through.
-
The amount of radioactivity on the filter is measured using a scintillation counter, providing a quantitative measure of tRNA binding to the ribosome-mRNA complex.
-
C. In Vitro Translation Assay
This assay assesses the overall efficiency and fidelity of translation using a reconstituted system.
-
System Reconstitution:
-
A reaction mixture is prepared containing purified ribosomes, translation factors (initiation, elongation, and release factors), amino acids (one or more of which is radiolabeled), ATP, GTP, and a pool of tRNAs (with or without the specific modification).
-
A specific mRNA template is added to initiate the reaction.
-
-
Translation and Analysis:
-
The reaction is incubated at an optimal temperature to allow for protein synthesis.
-
The synthesized polypeptide is precipitated (e.g., using trichloroacetic acid) and the amount of incorporated radiolabeled amino acid is quantified to determine the rate and extent of translation.
-
The fidelity can be assessed by using mRNA templates with ambiguous codons and analyzing the misincorporation of amino acids.
-
Conclusion
This compound and 5-taurinomethyluridine are both critical modifications at the wobble position of tRNA that enhance the decoding of purine-ending codons. However, they operate in distinct biological contexts, with nm5U being a key intermediate in the biosynthesis of mnm5U in prokaryotes and τm5U being a vital, final modification in eukaryotic mitochondria. The direct link between τm5U deficiency and severe human diseases underscores its critical role in mitochondrial gene expression and cellular health. Further comparative studies using the experimental approaches outlined above will be invaluable in elucidating the subtle yet significant differences in their mechanisms of action and their impact on the intricate process of protein synthesis.
References
- 1. Eukaryotic Wobble Uridine Modifications Promote a Functionally Redundant Decoding System - PMC [pmc.ncbi.nlm.nih.gov]
- 2. pdxscholar.library.pdx.edu [pdxscholar.library.pdx.edu]
- 3. discovery.researcher.life [discovery.researcher.life]
- 4. "Kinetic Analysis Reveals t6A-protein Specificity for t6A and hn6A tRNA" by Cassandra Mae Harker [pdxscholar.library.pdx.edu]
- 5. tRNA Modifications: Impact on Structure and Thermal Adaptation - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Kinetic Analysis of tRNA Methyltransferases - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. Modified uridines with C5-methylene substituents at the first position of the tRNA anticodon stabilize U.G wobble pairing during decoding - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. Influence of wobble uridine modifications on eukaryotic translation [umu.diva-portal.org]
- 9. Beyond the Anticodon: tRNA Core Modifications and Their Impact on Structure, Translation and Stress Adaptation - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Transcriptome-wide analysis of roles for tRNA modifications in translational regulation - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Comparative patterns of modified nucleotides in individual tRNA species from a mesophilic and two thermophilic archaea - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Anticodon stem-loop tRNA modifications influence codon decoding and frame maintenance during translation - PMC [pmc.ncbi.nlm.nih.gov]
- 13. tRNA wobble modifications and protein homeostasis - PMC [pmc.ncbi.nlm.nih.gov]
Validating 5-(aminomethyl)uridine Function: A Comparative Guide to Using Knockout Strains
For Researchers, Scientists, and Drug Development Professionals
This guide provides a comprehensive comparison of methodologies for validating the function of 5-(aminomethyl)uridine (nm5U), a modified nucleoside found in transfer RNA (tRNA), with a focus on the use of knockout strains. We present supporting experimental data, detailed protocols for key experiments, and visual workflows to facilitate a deeper understanding of how genetic manipulation can elucidate the role of this specific tRNA modification in cellular processes.
Introduction to this compound and the Power of Knockout Strains
This compound is a post-transcriptional modification found at the wobble position (position 34) of the anticodon loop in certain tRNAs. This modification is crucial for accurate and efficient protein synthesis. The biosynthesis of nm5U is a multi-step enzymatic process, and its absence can lead to significant phenotypic changes, including altered growth rates, increased sensitivity to stress, and reduced translational fidelity.
Knockout strains, in which one or more genes responsible for the biosynthesis of nm5U are inactivated, represent a powerful tool for studying its function. By comparing the phenotype of a knockout strain to its wild-type counterpart, researchers can directly attribute observed differences to the absence of the modification, thereby validating its cellular role. This approach offers a more definitive functional analysis compared to in vitro assays, which may not fully recapitulate the complex intracellular environment.
Comparative Analysis of Knockout Strains
The generation of knockout strains targeting the biosynthetic pathway of nm5U allows for a systematic investigation of its function. Key genes in this pathway that are often targeted for knockout include mnmE, mnmG, and mnmC in Gram-negative bacteria, and their functional analogs in other organisms. The table below summarizes quantitative data from studies utilizing knockout strains to investigate the function of nm5U and related modifications.
| Gene Knockout | Organism | Phenotypic Impact | Quantitative Data | Alternative Approaches & Limitations |
| mnmE | Escherichia coli | Impaired growth at low pH, altered stress response.[1] | - Growth: No growth in LB broth at pH 4.5.[1]- Translational Fidelity: Increased frameshifting. | In vitro enzymatic assays: Can confirm enzyme function but not the cellular consequence of its absence. Chemical inhibition: May have off-target effects. |
| mnmG | Escherichia coli | Similar to mnmE knockout, often studied in conjunction. | - tRNA Modification: Complete loss of (c)mnm5U modification. | RNA interference (RNAi): Can provide transient knockdown but may not achieve complete loss of function. |
| mnmC | Escherichia coli | Accumulation of nm5U precursor, reduced translational efficiency. | - Modification Level: Absence of mnm5U with accumulation of nm5U. | Overexpression of modifying enzymes: Can reveal aspects of the pathway but may not reflect physiological function. |
| trmA (trm2 in yeast) | E. coli, S. cerevisiae | Altered tRNA modification patterns, desensitization to translocation inhibitors.[2] | - Growth: Reduced fitness in competition assays.[3] | Mass Spectrometry of purified tRNA: Identifies modifications but doesn't directly link them to a cellular phenotype without a genetic model. |
Experimental Protocols
Detailed methodologies are crucial for reproducing and building upon existing research. Below are protocols for key experiments used to characterize the phenotype of knockout strains deficient in this compound.
Protocol 1: Generation of a CRISPR-Cas9 Knockout Strain in E. coli
This protocol outlines the steps for creating a gene knockout of a key enzyme in the nm5U biosynthetic pathway, such as mnmE, in E. coli using the CRISPR-Cas9 system.
1. gRNA Design and Plasmid Construction:
- Design a single guide RNA (sgRNA) targeting a 20-nucleotide sequence within the coding region of the target gene. Ensure the target sequence is followed by a Protospacer Adjacent Motif (PAM) sequence (e.g., NGG for Streptococcus pyogenes Cas9).
- Synthesize and clone the sgRNA sequence into a Cas9-expressing plasmid.
- Co-transform the Cas-sgRNA plasmid and a repair template (a short single-stranded DNA oligonucleotide with the desired deletion and flanking homology arms) into electrocompetent E. coli.
2. Selection and Screening:
- Plate the transformed cells on selective media.
- Screen individual colonies for the desired deletion using colony PCR with primers flanking the target region. A successful knockout will result in a smaller PCR product compared to the wild-type.
3. Verification:
- Confirm the deletion by Sanger sequencing of the PCR product from positive colonies.
- Verify the loss of protein expression via Western blot analysis using an antibody against the target protein.
Protocol 2: Analysis of tRNA Modification Status by Mass Spectrometry
This protocol describes the quantitative analysis of tRNA modifications to confirm the absence of nm5U in a knockout strain.
1. tRNA Isolation:
- Grow wild-type and knockout strains to mid-log phase.
- Isolate total RNA using a suitable method (e.g., hot phenol (B47542) extraction).
- Purify tRNA from the total RNA using anion-exchange chromatography or size-exclusion chromatography.
2. tRNA Digestion:
- Digest the purified tRNA to single nucleosides using a cocktail of nucleases (e.g., nuclease P1, snake venom phosphodiesterase, and alkaline phosphatase).
3. LC-MS/MS Analysis:
- Separate the digested nucleosides using liquid chromatography (LC).
- Analyze the separated nucleosides using tandem mass spectrometry (MS/MS) to identify and quantify the presence or absence of nm5U and its precursors by comparing the chromatograms of the knockout and wild-type samples.[2][4][5]
Protocol 3: Translational Fidelity Assay (LacZ Frameshift Assay)
This protocol measures the rate of ribosomal frameshifting, a common consequence of wobble base modification deficiencies.
1. Reporter Plasmid Transformation:
- Transform wild-type and knockout strains with a reporter plasmid containing a lacZ gene with a programmed +1 or -1 frameshift site.
2. β-Galactosidase Assay:
- Grow the transformed strains under inducing conditions.
- Prepare cell lysates and measure the β-galactosidase activity using a colorimetric substrate (e.g., ONPG).
- Normalize the β-galactosidase activity to the total protein concentration. An increase in β-galactosidase activity in the knockout strain compared to the wild-type indicates a higher rate of frameshifting.[6]
Visualizing the Pathways and Workflows
Diagrams generated using Graphviz provide a clear visual representation of the complex biological and experimental processes involved in validating this compound function.
Biosynthesis of this compound in E. coli.
Workflow for generating and validating a knockout strain.
Logical flow from gene knockout to phenotypic outcome.
Conclusion
The use of knockout strains provides a robust and indispensable framework for validating the in vivo function of this compound. By ablating the biosynthetic pathway and observing the resultant cellular consequences, researchers can definitively link this tRNA modification to critical processes such as translational fidelity, stress response, and overall cellular fitness. The combination of genetic engineering with advanced analytical techniques like mass spectrometry and ribosome profiling offers a powerful synergistic approach to unraveling the complex roles of tRNA modifications in biology and disease. This guide serves as a foundational resource for designing and interpreting experiments aimed at elucidating the function of this compound and other modified nucleosides.
References
- 1. Identification of Genes Required for Growth of Escherichia coli MG1655 at Moderately Low pH - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Quantitative analysis of tRNA modifications by HPLC-coupled mass spectrometry [dspace.mit.edu]
- 3. Dynamic changes in tRNA modifications and abundance during T cell activation - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Beyond the Anticodon: tRNA Core Modifications and Their Impact on Structure, Translation and Stress Adaptation - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Quantitative analysis of tRNA abundance and modifications by nanopore RNA sequencing [immaginabiotech.com]
- 6. The Role of RNA Modifications in Translational Fidelity - PMC [pmc.ncbi.nlm.nih.gov]
Unveiling the Genetic Blueprint for 5-(aminomethyl)uridine Synthesis: A Comparative Genomics Guide
For Researchers, Scientists, and Drug Development Professionals
This guide provides a comprehensive comparison of methodologies used to identify the genes responsible for the synthesis of 5-(aminomethyl)uridine (nm5U) and its derivatives, crucial modifications in transfer RNA (tRNA) that ensure translational fidelity. By leveraging the power of comparative genomics, researchers have successfully pinpointed key enzymes in this pathway, opening new avenues for understanding microbial physiology and developing novel antimicrobial agents. This document details the experimental workflows, presents comparative data on enzyme orthologs, and provides actionable protocols for researchers in the field.
The Power of Comparison: Identifying Key Enzymes in nm5U Synthesis
The biosynthesis of this compound and its methylated derivative, 5-methylaminomethyluridine (B1256275) (mnm5U), involves a multi-step enzymatic pathway. In Gram-negative bacteria like Escherichia coli, the bifunctional enzyme MnmC catalyzes the final two steps. However, many Gram-positive bacteria and other organisms possessing these tRNA modifications lack a clear MnmC homolog. This evolutionary puzzle has been solved through comparative genomics, a powerful approach that identifies functionally related genes by analyzing their phylogenetic distribution and genomic context.[1][2]
This strategy led to the successful identification of two key enzymes in Bacillus subtilis that functionally replace the activities of the single MnmC protein:
-
YurR (MnmC(o)-like enzyme): An FAD-dependent oxidoreductase responsible for the conversion of carboxymethylaminomethyluridine (cmnm5U) to 5-aminomethyluridine (B12866518) (nm5U).[3]
-
MnmM (YtqB) (MnmC(m)-like enzyme): An S-adenosyl-L-methionine (SAM)-dependent methyltransferase that catalyzes the final methylation step, converting nm5U to mnm5U.[4][5][6]
The identification of these "missing" genes highlights the utility of in silico analysis combined with experimental validation for elucidating complex biochemical pathways.
Comparative Analysis of Key Biosynthetic Enzymes
The discovery of YurR and MnmM in B. subtilis provides an excellent case study for comparing alternative enzymatic solutions for the same biochemical transformation. Below is a summary of the key enzymes involved in the final steps of mnm5U synthesis in representative Gram-negative and Gram-positive bacteria.
| Enzyme | Organism | Function | Domain Architecture | Cofactor(s) |
| MnmC | Escherichia coli | Bifunctional: Oxidoreductase and Methyltransferase | Fused FAD-dependent oxidase and SAM-dependent methyltransferase domains | FAD, SAM |
| YurR | Bacillus subtilis | Oxidoreductase | Single-domain FAD-dependent oxidoreductase | FAD |
| MnmM | Bacillus subtilis | Methyltransferase | Single-domain SAM-dependent methyltransferase | SAM |
Experimental Data: A Comparative Look at Enzyme Performance
While comprehensive kinetic data for YurR and a direct comparison with the oxidase domain of MnmC are still emerging in the literature, studies on MnmM and other methyltransferases provide insights into their catalytic efficiency. The following table summarizes available kinetic parameters for MnmM and a representative methyltransferase to illustrate the typical data generated in such studies.
| Enzyme | Substrate | Km (µM) | kcat (min-1) | kcat/Km (M-1s-1) | Reference |
| TkTrm10 (tRNA methyltransferase) | tRNA-G | 0.18 ± 0.04 | (3.9 ± 0.3) x 10-3 | 361 | [7] |
| TkTrm10 (tRNA methyltransferase) | tRNA-A | 0.25 ± 0.04 | (7.8 ± 0.4) x 10-3 | 520 | [7] |
| NTMT1 (protein N-terminal methyltransferase) | RCC1-12 peptide | 0.89 | 0.59 | 1.1 x 104 | [8] |
Note: The kinetic parameters for MnmM from B. subtilis are not yet available in the public domain. The data for TkTrm10 and NTMT1 are provided as examples of typical methyltransferase kinetics.
Visualizing the Logic: Workflows and Pathways
Comparative Genomics Workflow for Gene Identification
The following diagram illustrates the general workflow used to identify novel tRNA modification genes, such as yurR and mnmM.
Caption: A generalized workflow for identifying tRNA modification genes using comparative genomics.
Biosynthetic Pathway of mnm5U in Different Bacteria
The following diagrams illustrate the distinct enzymatic strategies for the final steps of 5-methylaminomethyluridine synthesis in Gram-negative and Gram-positive bacteria.
References
- 1. Identification of genes encoding tRNA modification enzymes by comparative genomics - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. Identification of Genes Encoding tRNA Modification Enzymes by Comparative Genomics - PMC [pmc.ncbi.nlm.nih.gov]
- 3. GIST Scholar: Characterization of 5-aminomethyl-2-thiouridine tRNA modification biosynthetic pathway in Bacillus subtilis [scholar.gist.ac.kr]
- 4. Identification of a novel 5-aminomethyl-2-thiouridine methyltransferase in tRNA modification - PMC [pmc.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
- 6. Identification of a novel 5-aminomethyl-2-thiouridine methyltransferase in tRNA modification - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. researchgate.net [researchgate.net]
- 8. Kinetic Mechanism of Protein N-terminal Methyltransferase 1 - PMC [pmc.ncbi.nlm.nih.gov]
A Comparative Guide to Validating Mass Spectrometry Data for 5-(Aminomethyl)uridine with Synthetic Standards
For Researchers, Scientists, and Drug Development Professionals
The accurate quantification of post-transcriptional modifications in RNA, such as 5-(aminomethyl)uridine (nm⁵U), is crucial for understanding its role in various biological processes and for the development of novel therapeutics. Mass spectrometry (MS)-based methods, particularly liquid chromatography-tandem mass spectrometry (LC-MS/MS), have become the gold standard for the sensitive and specific detection of such modifications. The validation of these methods using synthetic standards is paramount to ensure data accuracy and reliability. This guide provides a comparative overview of the validation of mass spectrometry data for this compound, detailing the synthesis of a chemical standard and outlining the expected performance of LC-MS/MS analysis.
Experimental Workflow for Validation
The overall process for validating mass spectrometry data for this compound using a synthetic standard involves several key stages, from the chemical synthesis of the standard to the final data analysis.
Experimental Protocols
Detailed methodologies for the synthesis of the this compound standard and its analysis by LC-MS/MS are provided below.
Synthesis of this compound Standard
The synthesis of this compound can be achieved through a multi-step process, starting from commercially available uridine (B1682114). A key intermediate is 5-azidomethyluridine, which is then reduced to the desired product.
Step 1: Synthesis of 5-Azidomethyluridine
A detailed protocol for the synthesis of 5-azidomethyluridine from a protected uridine derivative has been described in the literature. This process typically involves:
-
Protection of the ribose hydroxyl groups: Uridine is first protected, for example, with an isopropylidene group, to prevent side reactions.
-
Introduction of a leaving group at the 5-position: The 5-position of the uracil (B121893) base is functionalized, often by bromination, to introduce a good leaving group.
-
Nucleophilic substitution with azide (B81097): The leaving group is then displaced by an azide ion (e.g., from sodium azide) to form 5-azidomethyluridine.
-
Deprotection of the ribose hydroxyls: The protecting groups on the ribose are removed to yield 5-azidomethyluridine.
Step 2: Reduction of 5-Azidomethyluridine to this compound
The final step is the reduction of the azido (B1232118) group to an amino group. A common and effective method for this transformation is the Staudinger reaction.
-
Reaction Setup: Dissolve the 5-azidomethyluridine intermediate in an anhydrous solvent such as pyridine.
-
Addition of Reducing Agent: Add triphenylphosphine (B44618) (Ph₃P) to the solution. The reaction is typically stirred at room temperature for 24 hours.
-
Hydrolysis: After the reaction is complete, aqueous ammonia (B1221849) is added to hydrolyze the intermediate phosphazene.
-
Extraction and Purification: The product is extracted from the aqueous solution using an organic solvent like chloroform. The combined organic layers are dried and the solvent is removed. The crude product is then purified by column chromatography to yield pure this compound.
Characterization: The final product should be thoroughly characterized by Nuclear Magnetic Resonance (NMR) spectroscopy and mass spectrometry to confirm its identity and purity before use as a standard.
LC-MS/MS Analysis of this compound
The quantitative analysis of this compound in biological samples, such as tRNA digests, is typically performed using a validated LC-MS/MS method.
-
Sample Preparation:
-
Isolate total RNA from the biological sample of interest.
-
Enzymatically digest the RNA to its constituent nucleosides using a cocktail of enzymes such as nuclease P1 and alkaline phosphatase.
-
-
Liquid Chromatography:
-
Column: A reversed-phase C18 column is commonly used for the separation of modified nucleosides.
-
Mobile Phase A: An aqueous solution containing a volatile buffer, such as ammonium (B1175870) acetate (B1210297) or formic acid (e.g., 10 mM ammonium acetate, pH 5.3).
-
Mobile Phase B: An organic solvent, typically acetonitrile (B52724) or methanol.
-
Gradient: A gradient elution is employed to separate the nucleosides, starting with a low percentage of mobile phase B and gradually increasing to elute the more hydrophobic compounds.
-
-
Mass Spectrometry:
-
Ionization: Electrospray ionization (ESI) in positive ion mode is generally used for the analysis of nucleosides.
-
Detection: A triple quadrupole mass spectrometer is operated in Multiple Reaction Monitoring (MRM) mode for high selectivity and sensitivity.
-
MRM Transitions: Specific precursor-to-product ion transitions for this compound need to be determined by infusing the synthetic standard into the mass spectrometer. For example, the precursor ion would be the protonated molecule [M+H]⁺, and the product ion would typically be the corresponding nucleobase fragment.
-
Quantitative Data Comparison
| Performance Metric | Typical Value Range | Reference |
| Limit of Detection (LOD) | 0.05 nmol/L to 1.25 µmol/L | [1] |
| Limit of Quantification (LOQ) | 0.10 nmol/L to 2.50 µmol/L | [1] |
| Linearity (R²) | > 0.99 | [2] |
| Accuracy (% Recovery) | 85% - 115% | [3] |
| Precision (% RSD) | < 15% | [3][4] |
Disclaimer: The values presented in this table are for other modified nucleosides and are intended to provide a general guideline for the expected performance of a validated LC-MS/MS method for this compound. Actual performance may vary depending on the specific instrumentation, method parameters, and sample matrix.
Alternative Validation Strategies
In the absence of a synthetic standard, or as a complementary approach, other methods can be used to validate the identification of this compound. One such approach is chemical derivatization, which alters the mass of the target nucleoside, allowing for its specific detection. While not a direct quantitative validation, it provides strong evidence for the presence of the modification. For example, methods developed for the validation of pseudouridine, an isomer of uridine, can be conceptually adapted. These include:
-
Cyanoethylation: Reaction with acrylonitrile (B1666552) can selectively modify certain nucleosides, leading to a predictable mass shift that can be detected by MS.
-
CMCT Derivatization: The use of N-cyclohexyl-N'-(2-morpholinoethyl)carbodiimide metho-p-toluenesulfonate (CMCT) can also induce a mass shift in specific nucleosides.
These methods, however, do not provide the same level of quantitative accuracy as a stable isotope-labeled internal standard or a well-characterized synthetic standard for generating a calibration curve.
Biological Pathway of this compound
This compound is a modification found in the anticodon of certain tRNAs, where it plays a role in the fidelity of translation. In Escherichia coli, its biosynthesis is a multi-step enzymatic process.
Conclusion
The validation of mass spectrometry data using a well-characterized synthetic standard is essential for the accurate quantification of this compound. This guide provides a framework for the synthesis of this standard and the development and validation of an LC-MS/MS method. While specific quantitative performance data for this compound is not yet widely published, the provided information on typical method performance for similar compounds offers a valuable reference for researchers. The use of synthetic standards, in conjunction with robust analytical methodologies, will continue to be a cornerstone of reliable research in the dynamic field of epitranscriptomics and its application in drug development.
References
- 1. A suggested standard for validation of LC-MS/MS based analytical series in diagnostic laboratories - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Simultaneous Quantification of Nucleosides and Nucleotides from Biological Samples - PMC [pmc.ncbi.nlm.nih.gov]
- 3. researchgate.net [researchgate.net]
- 4. Evaluating the reproducibility of quantifying modified nucleosides from ribonucleic acids by LC–UV–MS - PMC [pmc.ncbi.nlm.nih.gov]
Cross-Validation of tRNA Sequencing and Mass Spectrometry for 5-(aminomethyl)uridine Detection
A Comparative Guide for Researchers
The accurate detection and quantification of post-transcriptional modifications in transfer RNA (tRNA) are crucial for understanding their roles in cellular processes and disease. Among the more than 100 known tRNA modifications, 5-(aminomethyl)uridine (nm5U) and its derivatives are key players in ensuring translational fidelity. This guide provides a comprehensive comparison of two primary methodologies for the analysis of nm5U: tRNA sequencing (tRNA-seq) and mass spectrometry (MS).
This document offers an objective comparison of the performance of these techniques, supported by experimental principles and data for related modifications. It is intended for researchers, scientists, and drug development professionals seeking to select the most appropriate method for their experimental needs.
At a Glance: tRNA Sequencing vs. Mass Spectrometry for nm5U Analysis
| Feature | tRNA Sequencing | Mass Spectrometry (LC-MS/MS) |
| Principle | Indirect detection via reverse transcription (RT) signatures (mismatches, stops) or direct detection with nanopore sequencing. | Direct detection and quantification based on mass-to-charge ratio of nucleosides. |
| Sample Input | Micrograms of total RNA or purified tRNA. | Micrograms of purified tRNA. |
| Sensitivity | High, but dependent on the RT enzyme's response to the modification. Nanopore sequencing shows promise for single-molecule sensitivity.[1][2] | High, with limits of quantification in the low femtomole range.[3] |
| Specificity | Can provide sequence context and location of the modification. However, different modifications can produce similar RT signatures. | High, provides unambiguous identification of the chemical structure of the modification. |
| Quantification | Semi-quantitative (e.g., Modification Index) for RT-based methods. Nanopore sequencing offers potential for direct quantification.[1][4] | Highly quantitative, providing absolute or relative amounts of the modified nucleoside.[5][6][7] |
| Throughput | High-throughput, capable of analyzing the entire tRNA population in a single experiment. | Lower throughput, typically analyzing one sample at a time. |
| Data Output | Sequencing reads, modification profiles across all tRNAs, relative abundance of tRNA isoacceptors. | Mass spectra, precise quantification of specific modified nucleosides. |
| Strengths | High throughput, provides sequence context, good for discovery of modification sites. | Gold standard for chemical identification, highly accurate quantification. |
| Limitations | Indirect detection can be ambiguous, quantification can be biased by RT efficiency.[8] | Does not provide sequence context (which tRNA isoacceptor is modified), lower throughput.[3] |
Signaling Pathway: Biosynthesis of mnm5(s2)U
The modification this compound is an intermediate in the biosynthesis of more complex modifications, such as 5-methylaminomethyl-2-thiouridine (B1677369) (mnm5s2U), which is found at the wobble position of certain tRNAs and is crucial for accurate decoding of messenger RNA. The pathway involves a series of enzymatic steps.
Experimental Workflow: A Cross-Validation Approach
A robust strategy for characterizing tRNA modifications involves a combination of tRNA sequencing and mass spectrometry. tRNA-seq can be used for a high-throughput survey to identify potential modification sites, which are then validated and precisely quantified using mass spectrometry.
Experimental Protocols
tRNA Sequencing for this compound
This protocol is adapted from methodologies for detecting modified nucleosides that leave a signature upon reverse transcription.[4][8]
1. RNA Isolation and Purification:
-
Isolate total RNA from cells or tissues using a standard Trizol-based method.
-
Purify tRNA from the total RNA pool using a high-performance liquid chromatography (HPLC) system or a commercial kit.
2. Library Preparation:
-
Optional Demethylase Treatment: For some modifications, treatment with demethylating enzymes (e.g., AlkB) can help in identifying specific methylation marks by comparing treated and untreated samples.
-
3' Adapter Ligation: Ligate a specific adapter to the 3' end of the tRNAs. This is often designed to be complementary to the CCA motif found at the 3' end of mature tRNAs.
-
Reverse Transcription: Perform reverse transcription using a primer complementary to the 3' adapter. The choice of reverse transcriptase is critical, as different enzymes have varying efficiencies of reading through or stalling at modified bases.
-
5' Adapter Ligation and PCR Amplification: Ligate a 5' adapter and amplify the resulting cDNA library using PCR.
3. Sequencing and Data Analysis:
-
Sequence the prepared libraries on a high-throughput sequencing platform (e.g., Illumina).
-
Map the sequencing reads to a reference library of tRNA genes.
-
Analyze the mapped reads for signatures of modification at the suspected location of nm5U. This includes identifying increased rates of nucleotide misincorporation or premature termination of reverse transcription (RT stops) at the position of the modified uridine.
-
Calculate a "Modification Index" (MI) which combines the frequencies of mutations and RT stops to provide a semi-quantitative measure of the modification level.[4]
Mass Spectrometry for this compound
This protocol outlines the quantitative analysis of nm5U using liquid chromatography-tandem mass spectrometry (LC-MS/MS), a highly accurate method for quantifying modified nucleosides.[5][6][7]
1. tRNA Isolation and Purification:
-
Isolate total RNA and purify the tRNA fraction as described for tRNA sequencing. High purity is essential for accurate quantification.
2. Enzymatic Hydrolysis:
-
Digest the purified tRNA into individual nucleosides using a cocktail of enzymes, such as nuclease P1 and alkaline phosphatase. This ensures the complete breakdown of the tRNA into its constituent nucleosides.
3. Liquid Chromatography Separation:
-
Separate the resulting nucleoside mixture using a reversed-phase HPLC column. A gradient of solvents (e.g., water with formic acid and acetonitrile (B52724) with formic acid) is typically used to achieve optimal separation of the different nucleosides.
4. Mass Spectrometry Analysis:
-
The eluent from the HPLC is introduced into a tandem mass spectrometer (e.g., a triple quadrupole instrument).
-
The mass spectrometer is operated in dynamic multiple reaction monitoring (DMRM) mode. This involves selecting the precursor ion corresponding to nm5U and then fragmenting it to produce specific product ions. The transition from the precursor to the product ion is highly specific for the target nucleoside.
-
Identify nm5U based on its retention time from the HPLC and its specific mass transition.
5. Quantification:
-
Quantify the amount of nm5U by comparing the area under the peak for its specific mass transition to a standard curve generated using a known amount of a synthetic nm5U standard.
-
The results can be expressed as the absolute amount of nm5U or as a ratio relative to one of the canonical nucleosides (e.g., uridine or adenosine).
Conclusion
Both tRNA sequencing and mass spectrometry are powerful techniques for the study of tRNA modifications like this compound. tRNA sequencing, particularly high-throughput methods, offers a comprehensive view of the modification landscape across all tRNAs, making it an excellent tool for discovery and for assessing the relative abundance of modified tRNAs. However, for unambiguous chemical identification and precise quantification, mass spectrometry remains the gold standard.
For researchers aiming to fully characterize the role of nm5U, a cross-validation approach is recommended. The high-throughput nature of tRNA sequencing can be leveraged to identify tRNA species and conditions where nm5U levels may be altered, followed by targeted and accurate quantification using mass spectrometry to validate these findings. This integrated approach provides both a global view and precise measurements, leading to a more complete understanding of the function of this important tRNA modification.
References
- 1. Quantitative analysis of tRNA abundance and modifications by nanopore RNA sequencing [immaginabiotech.com]
- 2. m.youtube.com [m.youtube.com]
- 3. Quantitative analysis of tRNA abundance and modifications by nanopore RNA sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 4. pdfs.semanticscholar.org [pdfs.semanticscholar.org]
- 5. Quantitative analysis of tRNA modifications by HPLC-coupled mass spectrometry [dspace.mit.edu]
- 6. Quantitative analysis of tRNA modifications by HPLC-coupled mass spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Quantitative analysis of ribonucleoside modifications in tRNA by HPLC-coupled mass spectrometry - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. Combining tRNA sequencing methods to characterize plant tRNA expression and post-transcriptional modification - PMC [pmc.ncbi.nlm.nih.gov]
Decoding with Precision: A Comparative Analysis of 5-(aminomethyl)uridine and Pseudouridine in Translation Fidelity
For Immediate Publication
Shanghai, China – December 11, 2025 – In the intricate process of protein synthesis, the fidelity of translation is paramount. Modified nucleosides within RNA molecules play a critical role in ensuring the accurate decoding of the genetic code. This guide provides a detailed comparison of two such modifications, 5-(aminomethyl)uridine and pseudouridine (B1679824), and their respective impacts on translational fidelity. This objective analysis, supported by experimental data, is intended for researchers, scientists, and professionals in the field of drug development.
The accuracy of protein synthesis is a fundamental cellular process, with errors potentially leading to dysfunctional proteins and cellular stress. Modified nucleosides, such as this compound and its derivatives found in the transfer RNA (tRNA) anticodon loop, and the more widespread pseudouridine found in both tRNA and messenger RNA (mRNA), are key regulators of this process. Understanding their distinct effects is crucial for fields ranging from basic molecular biology to the development of RNA-based therapeutics.
Comparative Effects on Translation Fidelity: A Data-Driven Overview
The influence of this compound and pseudouridine on translation fidelity is context-dependent, with their position in the RNA molecule (tRNA or mRNA) and the surrounding sequence playing a significant role. The following table summarizes quantitative data from various studies, highlighting the distinct and sometimes contrasting effects of these two modifications.
| Modification | Location | Organism/System | Observed Effect on Fidelity | Quantitative Data | Reference |
| This compound derivatives (e.g., mnm⁵s²U) | tRNA (wobble position) | E. coli | Increases fidelity by stabilizing codon-anticodon pairing, reducing frameshifting and error rates. | The absence of the mnm⁵ modification in tRNAGlu reduced the translation rate of the GAG codon from 7.7 to 1.9 codons/s, while increasing the rate for the GAA codon from 18 to 47 codons/s, indicating altered codon preference and potential for mistranslation. | [1][2] |
| Pseudouridine (Ψ) | mRNA (coding region) | Reconstituted E. coli translation system & human cells | Decreases fidelity by promoting amino acid substitution and nonsense suppression. | The presence of Ψ in a UUU codon increased the rate of near-cognate Val-tRNAVal reacting on that codon. Fully Ψ-modified reporters in HEK cells showed ~1% amino acid substitution. | [3][4] |
| Pseudouridine (Ψ) | mRNA | Human cells | Indirectly enhances translation efficiency by reducing PKR activation, which is a general inhibitor of translation. This effect is not directly on fidelity but on overall protein output. | Pseudouridine-containing mRNAs activate the translational repressor PKR to a lesser degree than uridine-containing mRNAs. | [5] |
| Pseudouridine (Ψ) | tRNA (anticodon stem-loop) | Bacteria (P. putida, P. aeruginosa, E. coli) | Maintains fidelity by stabilizing the anticodon loop structure, helping to maintain the correct reading frame. | Lack of pseudouridine at position 38/39 in tRNALeu has been observed to increase frameshifting. In P. putida, the absence of TruA (a pseudouridine synthase) led to a ~1.5-fold increase in +1 frameshifting. | [6] |
Experimental Methodologies
The assessment of translation fidelity relies on a variety of sophisticated experimental protocols. Below are detailed methodologies for key experiments cited in the comparison.
In Vitro Translation Fidelity Assay
This method directly assesses the impact of modified nucleosides on the speed and accuracy of the ribosome using a highly purified and reconstituted E. coli translation system.[7][8]
Protocol:
-
Preparation of Components:
-
Purify ribosomes, initiation factors (IF1, IF2, IF3), elongation factors (EF-Tu, EF-G, EF-Ts), and release factors from E. coli.
-
Prepare aminoacyl-tRNAs by charging purified tRNA molecules with their cognate amino acids using aminoacyl-tRNA synthetases.
-
Synthesize mRNA templates containing the codon of interest, with or without the desired modification (e.g., this compound or pseudouridine).
-
-
Translation Reaction:
-
Assemble the translation reaction mixture containing purified ribosomes, factors, aminoacyl-tRNAs, mRNA template, and an energy regeneration system (GTP and ATP).
-
Initiate translation and monitor the formation of dipeptides or longer peptides over time.
-
-
Analysis:
-
Quantify the rate of cognate amino acid incorporation versus near-cognate or incorrect amino acid incorporation using techniques like liquid chromatography-mass spectrometry (LC-MS) to determine misincorporation rates.[9]
-
Measure the rates of peptide bond formation and ribosome translocation to assess the speed of translation.
-
Dual-Luciferase Reporter Assay for Stop Codon Readthrough and Frameshifting
This cell-based assay is used to quantify the frequency of translational errors such as stop codon readthrough and ribosomal frameshifting.[6][10]
Protocol:
-
Reporter Construct Design:
-
Create a plasmid vector containing a primary reporter gene (e.g., Renilla luciferase) followed by a sequence that can induce frameshifting or a stop codon.
-
Downstream of this element, place a second reporter gene (e.g., Firefly luciferase) in a different reading frame (for frameshifting assays) or after the stop codon (for readthrough assays).
-
The expression of the second reporter is dependent on a translational error event.
-
-
Cell Transfection and Culture:
-
Transfect the reporter construct into the desired cell line.
-
Culture the cells under standard conditions to allow for expression of the reporter proteins.
-
-
Luciferase Assay:
-
Lyse the cells and measure the activity of both Renilla and Firefly luciferases using a luminometer.
-
-
Data Analysis:
-
The ratio of Firefly to Renilla luciferase activity is calculated to determine the frequency of the frameshifting or readthrough event. A higher ratio indicates lower translational fidelity.
-
Ribosome Profiling (Ribo-Seq)
Ribosome profiling is a high-throughput sequencing technique used to obtain a snapshot of all the ribosome positions on mRNA in a cell at a specific moment. It can reveal sites of ribosomal pausing, which can be influenced by modified nucleosides.[11][12][13]
Protocol:
-
Translation Arrest and Cell Lysis:
-
Treat cells with a translation inhibitor (e.g., cycloheximide) to freeze ribosomes on the mRNA.
-
Lyse the cells under conditions that preserve ribosome-mRNA complexes.
-
-
Nuclease Digestion:
-
Treat the cell lysate with RNase I to digest all mRNA that is not protected by ribosomes. This results in ribosome-protected fragments (RPFs) of mRNA.
-
-
Ribosome Isolation and RPF Purification:
-
Isolate the monosomes (single ribosomes) by sucrose (B13894) gradient centrifugation.
-
Extract the RPFs from the isolated ribosomes.
-
-
Library Preparation and Sequencing:
-
Ligate adapters to the 3' and 5' ends of the RPFs.
-
Perform reverse transcription to convert the RPFs into cDNA.
-
Amplify the cDNA library by PCR and sequence it using next-generation sequencing.
-
-
Data Analysis:
-
Align the sequencing reads to a reference genome or transcriptome to map the positions of the ribosomes.
-
Analyze the density of ribosomes at specific codons or regions to identify potential sites of translational pausing or altered decoding.
-
Visualizing the Mechanisms and Workflows
To better illustrate the concepts and processes discussed, the following diagrams have been generated using the DOT language.
References
- 1. SURVEY AND SUMMARY: Roles of 5-substituents of tRNA wobble uridines in the recognition of purine-ending codons - PMC [pmc.ncbi.nlm.nih.gov]
- 2. academic.oup.com [academic.oup.com]
- 3. pnas.org [pnas.org]
- 4. Why U Matters: Detection and functions of pseudouridine modifications in mRNAs - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Incorporation of pseudouridine into mRNA enhances translation by diminishing PKR activation - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Variance in translational fidelity of different bacterial species is affected by pseudouridines in the tRNA anticodon stem-loop - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Investigating the consequences of mRNA modifications on protein synthesis using in vitro translation assays - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Investigating the consequences of mRNA modifications on protein synthesis using in vitro translation assays - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. sutrobio.com [sutrobio.com]
- 10. Translation fidelity coevolves with longevity - PMC [pmc.ncbi.nlm.nih.gov]
- 11. biorxiv.org [biorxiv.org]
- 12. biorxiv.org [biorxiv.org]
- 13. Ribosome Profiling Protocol - CD Genomics [cd-genomics.com]
Unraveling Functional Redundancy in Wobble Uridine Modifications: A Comparative Guide
For Researchers, Scientists, and Drug Development Professionals
The accurate and efficient translation of the genetic code is paramount to cellular function. At the heart of this process lies the transfer RNA (tRNA), which acts as the crucial adaptor molecule, matching messenger RNA (mRNA) codons with their corresponding amino acids. The fidelity of this process is heavily reliant on a vast array of post-transcriptional modifications, particularly at the wobble position (U34) of the tRNA anticodon. These modifications fine-tune codon recognition and translation efficiency. This guide provides a comparative analysis of the functional redundancy of key wobble uridine (B1682114) modifications, supported by experimental data, detailed protocols, and pathway visualizations to aid researchers in this complex field.
The Concept of Functional Redundancy
In eukaryotes, the uridine at the wobble position is nearly always modified. Common modifications include 5-methoxycarbonylmethyluridine (B127866) (mcm⁵U), 5-carbamoylmethyluridine (B1230082) (ncm⁵U), and 5-methoxycarbonylmethyl-2-thiouridine (B1256268) (mcm⁵s²U).[1][2][3] These modifications play a crucial role in preventing translational frameshifting and ensuring efficient decoding of specific codons.[2][4] The concept of "functional redundancy" in this context suggests that while these modifications are critical, the absence of one can, to some extent, be compensated for, either by the presence of another modification or by cellular mechanisms such as the overexpression of the hypomodified tRNA.[1][5]
Studies in Saccharomyces cerevisiae have been instrumental in elucidating this phenomenon. For instance, mutants lacking the Elongator complex, which is essential for the formation of the mcm⁵ and ncm⁵ side chains, exhibit a range of pleiotropic phenotypes.[2][6] However, these defects can often be suppressed by overexpressing the tRNAs that would normally carry these modifications, indicating that the primary issue is a reduction in translational efficiency rather than a complete loss of function.[4][5]
Comparative Analysis of Wobble Uridine Modification Effects
The absence of specific wobble uridine modifications leads to quantifiable changes in translation, impacting codon decoding rates and overall protein expression. The following tables summarize key quantitative data from studies in yeast models.
Table 1: Impact of Modification Loss on Codon-Specific Translation
Ribosome profiling experiments measure the density of ribosomes at each codon, providing a snapshot of translation elongation speed. A higher ribosome occupancy indicates slower decoding.
| Codon | Corresponding tRNA & Modification | Mutant Strain | Relative Ribosome Occupancy (Fold Change vs. Wild-Type) | Reference |
| AAA (Lys) | tRNA-Lys(UUU) - mcm⁵s²U | elp3Δ (lacks mcm⁵) | ~1.5 - 2.0 | [5] |
| CAA (Gln) | tRNA-Gln(UUG) - mcm⁵s²U | elp3Δ (lacks mcm⁵) | ~1.5 - 2.0 | [5] |
| GAA (Glu) | tRNA-Glu(UUC) - mcm⁵s²U | elp3Δ (lacks mcm⁵) | No significant change | [5] |
| AGA (Arg) | tRNA-Arg(UCU) - mcm⁵U | elp3Δ (lacks mcm⁵) | Increased pausing | [7] |
Data is synthesized from ribosome profiling studies in S. cerevisiae.
Table 2: Phenotypic Suppression by tRNA Overexpression
The viability of certain modification-deficient mutants can be rescued by increasing the gene dosage of the affected tRNAs, highlighting a compensatory mechanism.
| Mutant Strain | Deficient Modification(s) | Phenotype | Suppressor | Outcome | Reference |
| elp3Δ tuc1Δ | mcm⁵ and s² (complete loss of mcm⁵s²U) | Lethal | Overexpression of tRNA-Lys(UUU) | Viability restored | [8] |
| elp3Δ | mcm⁵ and ncm⁵ | Slow growth, zymocin resistance | Overexpression of tRNA-Lys(UUU) and tRNA-Gln(UUG) | Growth defects rescued | [6] |
| elp3Δ urm1Δ | mcm⁵ and s² | Severe growth defect | Overexpression of tRNA-Lys(UUU) | Partial rescue of growth | [9] |
Signaling Pathways and Experimental Workflows
Wobble Uridine Modification Pathway
The biosynthesis of mcm⁵ and ncm⁵ side chains is a multi-step process initiated by the Elongator complex. This pathway is crucial for the proper functioning of a subset of tRNAs.
References
- 1. researchgate.net [researchgate.net]
- 2. Sequence mapping of transfer RNA chemical modifications by liquid chromatography tandem mass spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Measurement of average decoding rates of the 61 sense codons in vivo - PMC [pmc.ncbi.nlm.nih.gov]
- 4. academic.oup.com [academic.oup.com]
- 5. Wobble uridine modifications–a reason to live, a reason to die?! - PMC [pmc.ncbi.nlm.nih.gov]
- 6. diva-portal.org [diva-portal.org]
- 7. Northern Blot of tRNA in Yeast [bio-protocol.org]
- 8. A robust method for measuring aminoacylation through tRNA-Seq - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Measurement of average decoding rates of the 61 sense codons in vivo | eLife [elifesciences.org]
Safety Operating Guide
Essential Guide to the Proper Disposal of 5-(Aminomethyl)uridine
For researchers, scientists, and professionals in drug development, the proper management and disposal of chemical reagents are paramount to ensuring laboratory safety and environmental compliance. This guide provides detailed, step-by-step procedures for the safe disposal of 5-(Aminomethyl)uridine, a nucleoside analog used in various research applications. Adherence to these protocols is critical for minimizing risks and maintaining a safe research environment.
Safety and Handling Profile
Quantitative Data Summary
Due to the limited availability of a specific SDS, detailed quantitative data for this compound is scarce. The following table summarizes available information for the related compound, Uridine, to provide a general toxicological context.
| Parameter | Value | Compound | Source |
| Intraperitoneal LD50 (mouse) | 4,335 mg/kg | Uridine | Cayman Chemical |
| Intraperitoneal TDLo (rat) | 5 g/kg | Uridine | Cayman Chemical |
Note: This data is for Uridine and should be used as a general reference only. This compound may have different toxicological properties.
Step-by-Step Disposal Protocol
The primary directive for the disposal of this compound is to utilize a licensed and approved hazardous waste disposal facility. The following procedures outline the necessary steps for managing this chemical waste within a laboratory setting.
Waste Identification and Segregation:
-
Characterize the Waste: Identify all components of the waste stream containing this compound. Determine if it is in solid form, dissolved in a solvent, or mixed with other reagents.
-
Segregate the Waste: Do not mix this compound waste with other waste streams unless explicitly permitted by your institution's environmental health and safety (EHS) office. It should be collected in a dedicated, clearly labeled hazardous waste container.
Waste Accumulation and Storage:
-
Container Selection: Use a chemically resistant, leak-proof container with a secure screw-top cap. The container must be compatible with all components of the waste.
-
Labeling: Clearly label the waste container with "Hazardous Waste," the full chemical name "this compound," and any other components in the mixture. Include the approximate concentrations and accumulation start date.
-
Storage: Store the sealed waste container in a designated, well-ventilated, and secure area, away from heat, ignition sources, and incompatible materials. Storage should be temporary and for the purpose of accumulating a sufficient quantity for disposal.
Arranging for Professional Disposal:
-
Contact EHS: Notify your institution's Environmental Health and Safety (EHS) office or equivalent department to arrange for the pickup and disposal of the hazardous waste.
-
Engage a Licensed Disposal Service: Your EHS office will work with a licensed hazardous waste disposal company. Provide them with a comprehensive description of the waste, including its chemical composition and any known hazards. A Safety Data Sheet (SDS), if available, should be provided.
-
Recommended Disposal Methods: For nitrogen-containing organic compounds such as this compound, the following methods are generally recommended by professional disposal services:
-
Incineration: Chemical incineration in a facility equipped with afterburners and scrubbers is a common and effective method. This process must be carefully managed to control the emission of nitrogen oxides (NOx).
-
Hazardous Waste Landfill: If incineration is not an option, disposal in a permitted hazardous waste landfill may be used.
-
Disposal Workflow Diagram
The following diagram illustrates the logical flow for the proper disposal of this compound.
Safeguarding Your Research: A Comprehensive Guide to Handling 5-(Aminomethyl)uridine
FOR IMMEDIATE USE BY RESEARCHERS, SCIENTISTS, AND DRUG DEVELOPMENT PROFESSIONALS
This guide provides essential safety and logistical information for the handling and disposal of 5-(Aminomethyl)uridine, a purine (B94841) nucleoside analog. Adherence to these procedures is critical to ensure personal safety and maintain the integrity of your research.
Pre-Handling and Risk Assessment
Before working with this compound, a thorough risk assessment is mandatory.[1][2] This compound is a nucleoside analog with potential antitumor activity, and like many compounds of this class, its toxicological properties may not be fully characterized.[3] Therefore, it should be handled with care, assuming it is hazardous.
Key Considerations:
-
Review Safety Data Sheets (SDS): Although a specific SDS for this compound was not located, reviewing the SDS for similar compounds like Uridine can provide valuable insights.[4][5] Uridine is known to cause skin and eye irritation and may cause respiratory irritation.[5]
-
Understand the Hazards: Be aware of the potential for skin, eye, and respiratory tract irritation.[5][6]
-
Plan Your Experiment: Meticulously plan each step of your experiment to minimize exposure and the generation of waste.[2]
-
Emergency Preparedness: Know the location of all safety equipment, including eyewash stations, safety showers, fire extinguishers, and first aid kits.[7][8]
Personal Protective Equipment (PPE)
The use of appropriate PPE is the most critical barrier between the researcher and potential chemical exposure.[1][9] The following table outlines the minimum required PPE for handling this compound.
| Body Part | Required PPE | Specifications and Best Practices |
| Eyes/Face | Safety Goggles and Face Shield | Safety goggles must be worn at all times.[7] A face shield should be worn over goggles when there is a risk of splashes, such as when preparing solutions or transferring large volumes.[10] |
| Hands | Chemical-Resistant Gloves | Disposable nitrile gloves are the minimum requirement.[10][11] Consider double-gloving for added protection.[9][11] Gloves must be changed immediately if contaminated.[11] |
| Body | Laboratory Coat | A flame-resistant lab coat that fits properly and is fully buttoned is required.[9] |
| Feet | Closed-Toe Shoes | Shoes must fully cover the feet; sandals or other open-toed footwear are strictly prohibited.[8][9] |
Operational Plan: Step-by-Step Handling Procedures
3.1. Preparation and Weighing:
-
Designated Area: Conduct all handling of solid this compound in a designated area, such as a chemical fume hood or a glove box, to minimize inhalation exposure.[2][6]
-
Surface Protection: Before weighing, cover the work surface with disposable bench paper.[6]
-
Weighing: Use a tared, sealed container for weighing to prevent dispersal of the powder.
-
Solution Preparation: When dissolving the compound, add the solvent slowly to the solid to avoid splashing.
3.2. Experimental Use:
-
Containment: All procedures involving this compound should be performed within a certified chemical fume hood.
-
Aerosol Minimization: Avoid any activity that could generate aerosols, such as vigorous shaking or sonication of open containers.[6]
-
Transfers: Use appropriate tools, such as spatulas or powder funnels, for transferring solid material. For liquid transfers, use calibrated pipettes with disposable tips.
3.3. Storage:
-
Short-term Storage (-20°C): For use within one month, store the stock solution at -20°C in a sealed, clearly labeled container.[3]
-
Long-term Storage (-80°C): For storage up to six months, maintain the stock solution at -80°C.[3]
-
General Storage: Store away from moisture in a cool, dry, and well-ventilated area.[3]
Disposal Plan
Proper disposal of chemical waste is crucial to protect personnel and the environment.[1][7]
| Waste Type | Disposal Procedure |
| Solid Waste | Collect all solid waste, including contaminated gloves, bench paper, and pipette tips, in a designated, clearly labeled hazardous waste container. |
| Liquid Waste | Dispose of all solutions containing this compound in a properly labeled, sealed, and chemical-resistant hazardous waste container. Do not pour down the drain.[7] |
| Sharps Waste | Needles, syringes, and other contaminated sharps must be disposed of in a designated sharps container. |
All waste containers must be clearly labeled with the contents and associated hazards.[1][2] Follow your institution's specific guidelines for hazardous waste disposal.
Emergency Procedures
In the event of an exposure or spill, immediate and appropriate action is critical.
| Incident | Immediate Action |
| Skin Contact | Immediately flush the affected area with copious amounts of water for at least 15 minutes and remove contaminated clothing.[4][6] |
| Eye Contact | Immediately flush eyes with a gentle stream of water for at least 15 minutes, holding the eyelids open.[4][6] |
| Inhalation | Move the affected person to fresh air.[4] |
| Ingestion | Do NOT induce vomiting. Rinse the mouth with water.[4] |
| Spill | Evacuate the immediate area. For small spills, absorb the material with an inert absorbent and place it in a sealed container for disposal. For large spills, evacuate the lab and contact your institution's emergency response team. |
In all cases of exposure, seek immediate medical attention after initial decontamination. Report all incidents to your supervisor.
Caption: A logical workflow for the safe handling of this compound.
References
- 1. solubilityofthings.com [solubilityofthings.com]
- 2. greenwgroup.com [greenwgroup.com]
- 3. medchemexpress.com [medchemexpress.com]
- 4. sigmaaldrich.com [sigmaaldrich.com]
- 5. cdn.caymanchem.com [cdn.caymanchem.com]
- 6. Article - Laboratory Safety Manual - ... [policies.unc.edu]
- 7. csub.edu [csub.edu]
- 8. hmc.edu [hmc.edu]
- 9. Personal Protective Equipment (PPE) in the Laboratory: A Comprehensive Guide | Lab Manager [labmanager.com]
- 10. Personal Protective Equipment Requirements for Laboratories – Environmental Health and Safety [ehs.ncsu.edu]
- 11. Chapter 10: Personal Protective Equipment for Biohazards | Environmental Health & Safety | West Virginia University [ehs.wvu.edu]
Featured Recommendations
| Most viewed |


|
|
|---|---|---|
| Most popular with customers |
|
Descargo de responsabilidad e información sobre productos de investigación in vitro
Tenga en cuenta que todos los artículos e información de productos presentados en BenchChem están destinados únicamente con fines informativos. Los productos disponibles para la compra en BenchChem están diseñados específicamente para estudios in vitro, que se realizan fuera de organismos vivos. Los estudios in vitro, derivados del término latino "in vidrio", involucran experimentos realizados en entornos de laboratorio controlados utilizando células o tejidos. Es importante tener en cuenta que estos productos no se clasifican como medicamentos y no han recibido la aprobación de la FDA para la prevención, tratamiento o cura de ninguna condición médica, dolencia o enfermedad. Debemos enfatizar que cualquier forma de introducción corporal de estos productos en humanos o animales está estrictamente prohibida por ley. Es esencial adherirse a estas pautas para garantizar el cumplimiento de los estándares legales y éticos en la investigación y experimentación.
