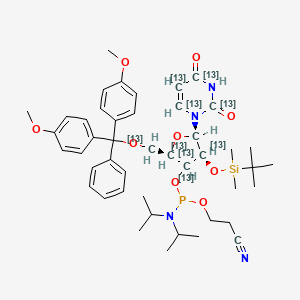
rU Phosphoramidite-13C9
Descripción
BenchChem offers high-quality rU Phosphoramidite-13C9 suitable for many research applications. Different packaging options are available to accommodate customers' requirements. Please inquire for more information about rU Phosphoramidite-13C9 including the price, delivery time, and more detailed information at info@benchchem.com.
Propiedades
Fórmula molecular |
C45H61N4O9PSi |
|---|---|
Peso molecular |
870.0 g/mol |
Nombre IUPAC |
3-[[(2R,4S,5R)-2-[[bis(4-methoxyphenyl)-phenylmethoxy](113C)methyl]-4-[tert-butyl(dimethyl)silyl]oxy-5-(2,4-dioxo(2,4,5,6-13C4)pyrimidin-1-yl)(2,3,4,5-13C4)oxolan-3-yl]oxy-[di(propan-2-yl)amino]phosphanyl]oxypropanenitrile |
InChI |
InChI=1S/C45H61N4O9PSi/c1-31(2)49(32(3)4)59(55-29-15-27-46)57-40-38(56-42(48-28-26-39(50)47-43(48)51)41(40)58-60(10,11)44(5,6)7)30-54-45(33-16-13-12-14-17-33,34-18-22-36(52-8)23-19-34)35-20-24-37(53-9)25-21-35/h12-14,16-26,28,31-32,38,40-42H,15,29-30H2,1-11H3,(H,47,50,51)/t38-,40?,41+,42-,59?/m1/s1/i26+1,28+1,30+1,38+1,39+1,40+1,41+1,42+1,43+1 |
Clave InChI |
SKNLXHRBXYGJOC-YNGWMUEKSA-N |
SMILES isomérico |
CC(C)N(C(C)C)P(OCCC#N)O[13CH]1[13C@H](O[13C@H]([13C@H]1O[Si](C)(C)C(C)(C)C)N2[13CH]=[13CH][13C](=O)N[13C]2=O)[13CH2]OC(C3=CC=CC=C3)(C4=CC=C(C=C4)OC)C5=CC=C(C=C5)OC |
SMILES canónico |
CC(C)N(C(C)C)P(OCCC#N)OC1C(OC(C1O[Si](C)(C)C(C)(C)C)N2C=CC(=O)NC2=O)COC(C3=CC=CC=C3)(C4=CC=C(C=C4)OC)C5=CC=C(C=C5)OC |
Origen del producto |
United States |
Foundational & Exploratory
An In-depth Technical Guide to rU Phosphoramidite-¹³C₉
For Researchers, Scientists, and Drug Development Professionals
This guide provides a comprehensive overview of rU Phosphoramidite-¹³C₉, a stable isotope-labeled ribonucleoside phosphoramidite (B1245037) essential for the synthesis of ¹³C-enriched RNA. Its primary application lies in advanced analytical techniques, particularly Nuclear Magnetic Resonance (NMR) spectroscopy, to elucidate the structure, dynamics, and interactions of RNA molecules at an atomic level. This is of paramount importance in drug discovery and the development of RNA-based therapeutics.
Core Concepts
rU Phosphoramidite-¹³C₉ is a specialized chemical compound used in the automated solid-phase synthesis of RNA. It is a derivative of the natural ribonucleoside, uridine (B1682114), where nine of its carbon atoms have been replaced with the stable isotope, carbon-13 (¹³C). This isotopic labeling serves as a powerful tool for researchers, enabling them to distinguish and trace the uridine residues within a complex RNA molecule using NMR spectroscopy. The phosphoramidite group is a highly reactive phosphorus(III) functional group that allows for the efficient and sequential addition of nucleotide units to a growing RNA chain.[1][2]
The use of ¹³C-labeled phosphoramidites like rU Phosphoramidite-¹³C₉ helps to overcome the significant challenge of spectral overlap in NMR studies of large RNA molecules (greater than 30 nucleotides).[3] By selectively introducing ¹³C labels, researchers can simplify complex NMR spectra, facilitating resonance assignment and the determination of RNA structures and their interactions with proteins or other molecules.[4]
Data Presentation
The key quantitative data for a typical rU Phosphoramidite-¹³C₉, specifically 5'-O-Dimethoxytrityl-2'-O-tert-butyldimethylsilyl-uridine, 3'-[(2-cyanoethyl)-(N,N-diisopropyl)]-phosphoramidite with ¹³C labeling on the uridine moiety, are summarized below. It is important to note that slight variations may exist between different commercial suppliers.
| Property | Value | Reference |
| Chemical Formula | C₃₆¹³C₉H₆₁N₄O₉PSi | [5] |
| Molecular Weight | ~869.98 g/mol | [5] |
| Isotopic Enrichment | ≥ 98% for ¹³C | [6][7] |
| Chemical Purity | ≥ 95% (typically >98% by HPLC and ³¹P-NMR) | [6] |
| Typical Coupling Efficiency | > 98% | [] |
| Appearance | White to off-white powder | |
| Storage Conditions | -20°C to -80°C, desiccated, under inert atmosphere (e.g., Argon) | [6] |
Experimental Protocols
The use of rU Phosphoramidite-¹³C₉ is primarily in the solid-phase synthesis of RNA. Below is a detailed methodology for a standard synthesis cycle.
Solid-Phase RNA Synthesis Cycle
This process is typically performed on an automated DNA/RNA synthesizer. The following steps are repeated for each nucleotide addition to the growing RNA chain, which is attached to a solid support (e.g., controlled pore glass, CPG).
-
Deprotection (Detritylation):
-
The 5'-hydroxyl group of the nucleotide bound to the solid support is protected by a dimethoxytrityl (DMT) group.
-
This DMT group is removed by treating the support with a mild acid, typically a solution of dichloroacetic or trichloroacetic acid in an inert solvent like dichloromethane (B109758) or toluene.
-
This step exposes the 5'-hydroxyl group for the subsequent coupling reaction.
-
-
Coupling:
-
The rU Phosphoramidite-¹³C₉ is activated by an activating agent, such as tetrazole or a derivative like 5-(ethylthio)-1H-tetrazole (ETT) or 5-(benzylthio)-1H-tetrazole (BTT).
-
The activated phosphoramidite is then delivered to the solid support, where it reacts with the free 5'-hydroxyl group of the growing RNA chain.
-
This reaction forms a phosphite (B83602) triester linkage. The coupling time is a critical parameter and is typically in the range of 2-10 minutes. Longer coupling times may be required for modified or sterically hindered phosphoramidites to ensure high efficiency.
-
-
Capping:
-
A small percentage of the 5'-hydroxyl groups may fail to react during the coupling step. These unreacted chains are "capped" to prevent them from participating in subsequent synthesis cycles, which would result in deletion mutations in the final RNA product.
-
Capping is achieved by acetylation using a mixture of acetic anhydride (B1165640) and a catalyst, such as N-methylimidazole (NMI) or 1,2-dimethylaminopyridine (DMAP).
-
-
Oxidation:
-
The newly formed phosphite triester linkage is unstable and is oxidized to a more stable pentavalent phosphate (B84403) triester.
-
This is typically done using a solution of iodine in a mixture of tetrahydrofuran (B95107) (THF), water, and pyridine (B92270) or lutidine.
-
This four-step cycle is repeated until the desired RNA sequence is synthesized.
Post-Synthesis Cleavage and Deprotection
-
Cleavage from Solid Support:
-
Once the synthesis is complete, the RNA is cleaved from the solid support. This is often achieved using concentrated ammonium (B1175870) hydroxide (B78521) or a mixture of ammonium hydroxide and methylamine (B109427) (AMA).
-
-
Removal of Protecting Groups:
-
The same basic solution used for cleavage also removes the protecting groups from the phosphate backbone (cyanoethyl groups) and the nucleobases.
-
The 2'-hydroxyl protecting group (e.g., TBDMS) requires a separate deprotection step, typically using a fluoride (B91410) source such as triethylamine (B128534) trihydrofluoride (TEA·3HF) or tetrabutylammonium (B224687) fluoride (TBAF).
-
-
Purification:
-
The final RNA product is purified using techniques such as high-performance liquid chromatography (HPLC) or polyacrylamide gel electrophoresis (PAGE) to remove truncated sequences and other impurities.
-
Mandatory Visualizations
Solid-Phase RNA Synthesis Workflow
Caption: Workflow of the solid-phase synthesis cycle for incorporating rU Phosphoramidite-¹³C₉.
Investigating Protein-RNA Interactions using ¹³C-Labeled RNA
Caption: Experimental workflow for identifying protein-RNA interaction sites using ¹³C-labeled RNA.
References
- 1. chimia.ch [chimia.ch]
- 2. GSRS [precision.fda.gov]
- 3. rU Phosphoramidite-13C9,15N2 | C45H61N4O9PSi | CID 169493926 - PubChem [pubchem.ncbi.nlm.nih.gov]
- 4. Solid-Phase Chemical Synthesis of Stable Isotope-Labeled RNA to Aid Structure and Dynamics Studies by NMR Spectroscopy - PMC [pmc.ncbi.nlm.nih.gov]
- 5. rU Phosphoramidite-13C9 (DMT-2'O-TBDMS-rU phosphoramidite-13C9) | 稳定同位素 | MCE [medchemexpress.cn]
- 6. 2â²-Deoxycytidine phosphoramidite (¹³Câ, 98%; ¹âµNâ, 98%) CP 95% | Cambridge Isotope Laboratories, Inc. [isotope.com]
- 7. medchemexpress.com [medchemexpress.com]
An In-depth Technical Guide to Stable Isotope Labeling of RNA
For Researchers, Scientists, and Drug Development Professionals
Stable isotope labeling of RNA is a powerful and versatile technique that has become indispensable for the quantitative analysis of RNA metabolism, structure, dynamics, and interactions. By replacing naturally abundant isotopes with their heavier, non-radioactive counterparts (such as ¹³C, ¹⁵N, ²H, and ¹⁸O), researchers can introduce a mass signature into RNA molecules.[1][2][3][4] This label allows for the differentiation and tracking of specific RNA populations within complex biological mixtures, primarily through mass spectrometry (MS) and nuclear magnetic resonance (NMR) spectroscopy.[2][3] This guide provides a comprehensive overview of the core principles, experimental methodologies, data analysis, and applications of stable isotope labeling of RNA, with a focus on its relevance to research and drug development.
Core Concepts of RNA Labeling
The fundamental principle of stable isotope labeling lies in the introduction of a mass difference without significantly altering the chemical properties of the RNA molecule.[4] This allows labeled and unlabeled RNA to behave almost identically in biological systems, making it an ideal tool for tracing RNA fate and function. The choice of isotope and labeling strategy depends on the specific research question and the analytical method to be employed.
Commonly Used Stable Isotopes for RNA Labeling:
| Isotope | Natural Abundance (%) | Common Labeling Approaches | Primary Analytical Techniques |
| ¹³C | ~1.1 | Metabolic Labeling, In Vitro Transcription, Chemical Synthesis | MS, NMR |
| ¹⁵N | ~0.37 | Metabolic Labeling, In Vitro Transcription | MS, NMR |
| ²H (D) | ~0.015 | Metabolic Labeling, In Vitro Transcription | NMR, MS |
| ¹⁸O | ~0.2 | Enzymatic Digestion (post-synthesis), Chemical Synthesis | MS |
Key Labeling Strategies
There are three primary strategies for introducing stable isotopes into RNA molecules: metabolic labeling, in vitro enzymatic synthesis, and chemical synthesis.
Metabolic Labeling
Metabolic labeling involves introducing isotopically labeled precursors into the growth medium of cells or organisms, which then incorporate these labels into their nascent RNA through natural biosynthetic pathways.[5][6] This approach is ideal for studying RNA dynamics in a cellular context.
-
In Vivo Labeling in Bacteria (e.g., E. coli): Bacteria are cultured in minimal media where the sole carbon and/or nitrogen source is a labeled compound, such as ¹³C-glucose or ¹⁵N-ammonium chloride.[7] This results in the uniform labeling of all newly synthesized RNA.
-
In Vivo Labeling in Yeast (e.g., S. cerevisiae): Similar to bacteria, yeast can be grown in defined media containing labeled precursors.[5] A common method involves the use of 4-thiouracil (B160184) (4tU) or 4-thiouridine (B1664626) (4sU) for metabolic labeling of newly transcribed RNA.[5][8]
-
In Vivo Labeling in Mammalian Cells: Mammalian cells can be cultured in specialized media containing labeled amino acids (for studying RNA-protein interactions via techniques like SILAC) or other labeled precursors.[9][10] 4-thiouridine (4sU) is also widely used for metabolic labeling of nascent RNA in mammalian cells.[6][11][12][13]
In Vitro Enzymatic Synthesis
This method utilizes RNA polymerases (such as T7, T3, or SP6) to transcribe RNA from a DNA template in the presence of isotopically labeled nucleotide triphosphates (NTPs).[3] This approach allows for the production of specific, highly pure labeled RNA molecules and offers control over the labeling pattern.
-
Uniform Labeling: All four NTPs (ATP, CTP, GTP, UTP) in the reaction mixture are isotopically labeled, resulting in a uniformly labeled RNA transcript.
-
Selective/Residue-Specific Labeling: Only one or a subset of NTPs is labeled, allowing for the specific labeling of certain types of residues (e.g., only uridines).
-
Segmental Labeling: Different segments of a large RNA molecule are synthesized separately with distinct labeling patterns and then ligated together.[14][15][16] This is particularly useful for NMR studies of large RNAs.
Chemical Synthesis
Solid-phase phosphoramidite (B1245037) chemistry allows for the synthesis of short RNA oligonucleotides with precise, site-specific incorporation of stable isotopes.[3] Labeled phosphoramidites can be chemically synthesized and incorporated at any desired position in the RNA sequence. This method is highly versatile but is generally limited to shorter RNA molecules.
Experimental Protocols
Protocol 1: Metabolic Labeling of RNA in S. cerevisiae with 4-thiouracil (4tU)
This protocol is adapted from methods used for studying mRNA synthesis and decay rates in yeast.[5]
-
Yeast Culture Preparation: Grow S. cerevisiae cells in the appropriate liquid medium to mid-log phase (OD₆₀₀ ≈ 0.5-0.8).
-
Pulse Labeling: Add 4-thiouracil (4tU) to the culture medium to a final concentration of 5 mM. Incubate the culture for a short period (e.g., 6 minutes) to label newly transcribed RNA.
-
Cell Harvesting and Lysis: Rapidly harvest the cells by centrifugation at 4°C. Wash the cell pellet with ice-cold water. Resuspend the pellet in a lysis buffer and lyse the cells, for example, by bead beating.
-
Total RNA Extraction: Extract total RNA from the cell lysate using a standard method such as hot acid phenol-chloroform extraction or a commercial kit.
-
Biotinylation of 4tU-labeled RNA: Resuspend the total RNA in a reaction buffer. Add biotin-HPDP to the RNA solution to biotinylate the 4tU-containing transcripts. Incubate for 1.5 hours at room temperature with rotation.
-
Purification of Labeled RNA: Purify the biotinylated RNA from the unbiotinylated, pre-existing RNA using streptavidin-coated magnetic beads. The labeled RNA will bind to the beads, while the unlabeled RNA remains in the supernatant.
-
Elution of Labeled RNA: Elute the captured RNA from the beads using a reducing agent such as dithiothreitol (B142953) (DTT).
-
Downstream Analysis: The purified, newly synthesized RNA is now ready for downstream applications such as RT-qPCR, microarray analysis, or high-throughput sequencing.
Protocol 2: In Vitro Transcription of a Uniformly ¹³C/¹⁵N-Labeled RNA
This protocol describes the general steps for producing a uniformly labeled RNA molecule for structural studies.
-
DNA Template Preparation: Prepare a linear DNA template containing the sequence of the target RNA downstream of a T7 RNA polymerase promoter. The template can be generated by PCR or by linearization of a plasmid.
-
Transcription Reaction Setup: In an RNase-free microcentrifuge tube, combine the following components at room temperature:
-
Nuclease-free water
-
Transcription buffer (typically contains Tris-HCl, MgCl₂, spermidine)
-
DTT
-
Uniformly ¹³C/¹⁵N-labeled NTPs (ATP, CTP, GTP, UTP)
-
RNase inhibitor
-
DNA template
-
T7 RNA polymerase
-
-
Incubation: Incubate the reaction mixture at 37°C for 2-4 hours.
-
DNase Treatment: Add DNase I to the reaction mixture to digest the DNA template. Incubate for 15-30 minutes at 37°C.
-
RNA Purification: Purify the labeled RNA transcript using denaturing polyacrylamide gel electrophoresis (PAGE), size-exclusion chromatography, or a suitable RNA purification kit.
-
Quantification and Storage: Quantify the purified RNA using UV-Vis spectrophotometry. Store the labeled RNA at -20°C or -80°C.
Protocol 3: Site-Specific Isotope Labeling of a Long RNA
This protocol is based on a method that uses a combination of enzymatic reactions to introduce a label at a specific site.[17][18]
-
Preparation of RNA Fragments: Synthesize two fragments of the target RNA: a 5' fragment and a 3' fragment. The 3' fragment is synthesized with a 5'-terminal guanosine (B1672433).
-
Guanosine Transfer Reaction: Use a trans-acting group I self-splicing intron and an isotopically labeled guanosine 5'-monophosphate (5'-GMP) to replace the 5'-guanosine of the 3' fragment with the labeled GMP.[17][18] This results in a 3' RNA fragment with a site-specific label at its 5' end.[17][18]
-
Ligation: Ligate the 5' non-labeled RNA fragment and the 3' labeled RNA fragment using T4 DNA ligase in the presence of a complementary DNA splint oligonucleotide.[17][18]
-
Purification: Purify the full-length, site-specifically labeled RNA product using denaturing PAGE.
Quantitative Data Presentation
The efficiency and yield of RNA labeling can vary depending on the method and the biological system. The following tables summarize some reported quantitative data.
Table 1: Yields of Labeled RNA and Precursors
| Labeling Method | Organism/System | Labeled Product | Reported Yield | Reference |
| In Vitro Transcription | Cell-free | DIG-labeled RNA | Up to 20 µg from 1 µg DNA template | N/A |
| Metabolic Labeling | E. coli | ¹³C/¹⁵N-labeled NTPs | 180 µmoles per gram of ¹³C-glucose | N/A |
| Metabolic Labeling | E. coli | dsRNA | 624.6 ng/µL (765 bp) and 466.5 ng/µL (401 bp) from 10⁸ cells | N/A |
| Chemo-enzymatic Synthesis | Cell-free | [2,8-¹³C₂]-ATP | 57% | [19] |
| Chemo-enzymatic Synthesis | Cell-free | Uniformly ¹³C/¹⁵N-labeled GTP | 42% | [19] |
| Site-specific Labeling (Enzymatic) | Cell-free | 76-nt labeled RNA | 19% total yield | [17] |
Table 2: Comparison of Isotope Labeling Performance for RNA Analysis
| Feature | ¹⁸O | ¹⁵N | ¹³C | ²H (D) | Reference |
| Primary Application | Quantitative MS | NMR, MS | NMR, MS | NMR, MS | [1] |
| Labeling Method | Enzymatic Digestion, Chemical Synthesis | Metabolic Labeling, In Vitro Transcription | Metabolic Labeling, In Vitro Transcription, Chemical Synthesis | Metabolic Labeling, In Vitro Transcription | [1] |
| Labeling Efficiency | High for in vitro methods | High for metabolic labeling | High for in vitro transcription and metabolic labeling | High for metabolic labeling | [1] |
| Impact on RNA Structure | Minimal to none | Generally minimal | Can cause slight perturbations | Can alter hydrophobic interactions | [1] |
| Cost | Cost-effective for targeted labeling | Can be expensive for uniform labeling | Generally the most expensive for uniform labeling | Relatively less expensive than ¹³C and ¹⁵N | [1] |
Visualization of Workflows and Pathways
Experimental Workflow: Metabolic RNA Labeling and Analysis
The following diagram illustrates a typical workflow for a metabolic RNA labeling experiment, such as SLAMseq, to study RNA stability.
Caption: A generalized workflow for metabolic labeling of RNA to determine RNA stability.
Signaling Pathway: mTORC1 Regulation of mRNA m⁶A Modification
Stable isotope labeling can be used to study how signaling pathways impact RNA modifications. For example, by using labeled precursors, one could trace the changes in m⁶A methylation levels in response to mTORC1 activation.[20] The mTOR signaling pathway is a central regulator of cell growth and metabolism, and it influences mRNA translation and stability.[21][22]
Caption: The mTORC1 signaling pathway's role in regulating mRNA m⁶A modification.
Applications in Research and Drug Development
Stable isotope labeling of RNA has a wide range of applications, from fundamental research to the development of novel therapeutics.
Elucidating RNA Metabolism and Dynamics
By pulse-labeling nascent RNA, researchers can track its synthesis, processing, and decay over time.[6][11][12] This allows for the determination of RNA half-lives on a transcriptome-wide scale, providing insights into gene expression regulation.
Structural and Functional Analysis of RNA
NMR spectroscopy is a powerful tool for determining the three-dimensional structure of RNA in solution. However, for larger RNAs, spectral overlap becomes a major challenge.[2][3] Isotope labeling, particularly with ¹³C, ¹⁵N, and ²H, helps to resolve this issue by allowing for the use of heteronuclear NMR experiments.[2][3] Site-specific and segmental labeling strategies are especially valuable for studying the structure and dynamics of large RNA molecules and their complexes with proteins or small molecules.[2][3][14][15][16]
Quantification of RNA Modifications
Mass spectrometry coupled with stable isotope labeling is the gold standard for the accurate quantification of post-transcriptional RNA modifications.[23][24] By using isotopically labeled internal standards, researchers can precisely measure the abundance of various modifications in different RNA species and under different biological conditions.[7]
Drug Discovery and Development
Stable isotope labeling is increasingly being used in the development of RNA-based therapeutics.
-
Target Identification and Validation: Labeled RNA can be used in binding assays to identify and characterize small molecules or proteins that interact with a specific RNA target.[25][26]
-
Mechanism of Action Studies: Researchers can use stable isotope labeling to investigate how an RNA therapeutic affects the metabolism of endogenous RNAs.[4]
-
Pharmacokinetics and Biodistribution: By labeling an RNA drug with a stable isotope, its stability, degradation kinetics, and distribution in biological systems can be accurately determined.[4][27][28][29] This is a critical component of preclinical studies for RNA therapeutics.[27][28][29]
Conclusion
Stable isotope labeling of RNA is a multifaceted and powerful technique that provides unprecedented insights into the life cycle and function of RNA molecules. From elucidating fundamental biological processes to facilitating the development of next-generation therapeutics, the applications of this methodology are vast and continue to expand. The ability to precisely track and quantify RNA in complex biological systems makes stable isotope labeling an essential tool for researchers, scientists, and drug development professionals in the ever-evolving field of RNA biology.
References
- 1. benchchem.com [benchchem.com]
- 2. pubs.acs.org [pubs.acs.org]
- 3. mdpi.com [mdpi.com]
- 4. benchchem.com [benchchem.com]
- 5. Saccharomyces cerevisiae Metabolic Labeling with 4-thiouracil and the Quantification of Newly Synthesized mRNA As a Proxy for RNA Polymerase II Activity - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Metabolic Labeling of Newly Transcribed RNA for High Resolution Gene Expression Profiling of RNA Synthesis, Processing and Decay in Cell Culture [jove.com]
- 7. Production and Application of Stable Isotope-Labeled Internal Standards for RNA Modification Analysis [mdpi.com]
- 8. researchgate.net [researchgate.net]
- 9. Uniform stable-isotope labeling in mammalian cells: formulation of a cost-effective culture medium - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. Identification of miRNA targets with stable isotope labeling by amino acids in cell culture - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Video: Metabolic Labeling of Newly Transcribed RNA for High Resolution Gene Expression Profiling of RNA Synthesis, Processing and Decay in Cell Culture [jove.com]
- 12. m.youtube.com [m.youtube.com]
- 13. Frontiers | A Protocol for Transcriptome-Wide Inference of RNA Metabolic Rates in Mouse Embryonic Stem Cells [frontiersin.org]
- 14. researchgate.net [researchgate.net]
- 15. Multiple segmental and selective isotope labeling of large RNA for NMR structural studies - PMC [pmc.ncbi.nlm.nih.gov]
- 16. repository.ubn.ru.nl [repository.ubn.ru.nl]
- 17. academic.oup.com [academic.oup.com]
- 18. academic.oup.com [academic.oup.com]
- 19. Isotope-Labeled RNA Building Blocks for NMR Structure and Dynamics Studies - PMC [pmc.ncbi.nlm.nih.gov]
- 20. mTORC1 promotes cell growth via m6A-dependent mRNA degradation - PMC [pmc.ncbi.nlm.nih.gov]
- 21. mTOR Signaling | Cell Signaling Technology [cellsignal.com]
- 22. Regulation of global and specific mRNA translation by the mTOR signaling pathway - PMC [pmc.ncbi.nlm.nih.gov]
- 23. Quantitative Analysis of rRNA Modifications Using Stable Isotope Labeling and Mass Spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 24. Quantitative analysis of rRNA modifications using stable isotope labeling and mass spectrometry - PubMed [pubmed.ncbi.nlm.nih.gov]
- 25. Applications of Stable Isotope-Labeled Molecules | Silantes [silantes.com]
- 26. NMR Characterization of RNA Small Molecule Interactions - PMC [pmc.ncbi.nlm.nih.gov]
- 27. backoffice.biblio.ugent.be [backoffice.biblio.ugent.be]
- 28. researchgate.net [researchgate.net]
- 29. itmedicalteam.pl [itmedicalteam.pl]
Harnessing Precision: A Technical Guide to the Benefits of ¹³C-Labeled Phosphoramidites in Research and Drug Development
Introduction
The site-specific incorporation of stable isotopes into nucleic acids represents a powerful strategy for elucidating their structure, dynamics, and interactions at an atomic level. Among the tools available, ¹³C-labeled phosphoramidites have become indispensable for the chemical synthesis of DNA and RNA oligonucleotides. These specialized reagents enable the precise placement of a carbon-13 (¹³C) isotope at specific nucleobase or ribose positions within a sequence. This level of control is a significant advantage over enzymatic methods, which are generally better suited for uniform labeling.[1] The ability to introduce labels at specific sites simplifies complex analytical spectra and allows researchers to probe local conformational dynamics, which are critical for understanding biological function, drug-target interactions, and the mechanisms of novel oligonucleotide-based therapeutics.[1] This guide provides an in-depth overview of the core benefits, experimental protocols, and applications of this technology for researchers, scientists, and drug development professionals.
Core Benefits and Applications
The strategic use of ¹³C-labeled phosphoramidites offers profound advantages, primarily in the fields of Nuclear Magnetic Resonance (NMR) spectroscopy and Mass Spectrometry (MS), with direct applications in drug development.
Nuclear Magnetic Resonance (NMR) Spectroscopy
NMR spectroscopy is a premier technique for studying the structure and dynamics of biomolecules in solution. The introduction of ¹³C labels significantly enhances its capabilities for nucleic acid analysis.
-
Resolving Spectral Complexity: A primary challenge in NMR studies of nucleic acids, especially those larger than 20-30 nucleotides, is severe resonance overlap in the spectra.[2] Site-specific ¹³C labeling introduces isolated ¹H-¹³C spin pairs, which simplifies crowded spectral regions and facilitates unambiguous resonance assignment.[3][4] This is crucial for accurately determining the three-dimensional structures of complex nucleic acid folds like G-quadruplexes and RNA aptamers.[3]
-
Probing Molecular Structure and Conformation: The chemical shift of a ¹³C nucleus is highly sensitive to its local environment. This property makes ¹³C labels excellent probes for monitoring conformational changes. For instance, the ¹³C chemical shift of a methyl group in N-methylguanine has been shown to be sensitive to DNA duplex formation.[5] Researchers can use ¹³C-labeled nucleotides to study the formation of hairpin loops, the stacking of base pairs, and the intricate folds of ribozymes and viral RNAs.[4][6]
-
Investigating Molecular Dynamics: The function of nucleic acids is intrinsically linked to their dynamic properties.[3] ¹³C labeling is essential for advanced NMR experiments, such as Carr-Purcell-Meiboom-Gill (CPMG) relaxation dispersion and ZZ-exchange spectroscopy, which measure molecular motions on the microsecond to millisecond timescale.[3][4] These experiments, made possible by the simple relaxation behavior of isolated ¹³C-¹H spin pairs, provide critical insights into functional transitions like the folding of riboswitch aptamers upon ligand binding or the interaction of viral DNA with host proteins.[3][4]
Mass Spectrometry (MS)
Mass spectrometry is a powerful analytical technique for identifying and quantifying molecules. ¹³C-labeled oligonucleotides serve as ideal internal standards for quantitative MS-based studies.
-
Accurate Quantification: In drug development, particularly for oligonucleotide therapeutics, accurate quantification in biological matrices is essential for pharmacokinetic and pharmacodynamic (PK/PD) studies. Oligonucleotides synthesized with ¹³C-labeled phosphoramidites can be used as internal standards in liquid chromatography-tandem mass spectrometry (LC-MS/MS) assays. Because these standards are chemically identical to the analyte but mass-shifted, they co-elute and experience similar matrix effects and ionization efficiencies, leading to highly accurate and precise quantification.
-
Stable Isotope Probing (SIP): In the field of systems biology, Stable Isotope Probing (SIP) is used to trace metabolic pathways.[7] While often associated with feeding organisms ¹³C-labeled substrates, the use of synthesized ¹³C-labeled nucleic acids as standards is critical for the analytical component of these studies.[8] A sensitive UHPLC-MS/MS method allows for the quantitation of ¹³C-enrichment in nucleic acids, enabling researchers to measure metabolic flux and understand how cells process nutrients and synthesize essential biomolecules.[7][8]
Advancing Drug Development
The precision afforded by ¹³C-labeled phosphoramidites directly impacts the development of nucleic acid-based therapeutics and diagnostics.
-
Characterizing Drug-Target Interactions: Understanding how a drug binds to its target is fundamental to pharmacology. By incorporating ¹³C labels into a DNA or RNA target, researchers can use NMR to map the drug's binding site and observe any conformational changes that occur upon binding.[9] For example, a study of the glucocorticoid receptor DNA-binding domain used a labeled oligonucleotide to reveal a specific hydrophobic contact between a thymine (B56734) methyl group and a valine residue in the protein.[9]
-
Development of Diagnostic Probes: Labeled phosphoramidites are used to synthesize custom DNA and RNA probes for diagnostic assays, such as polymerase chain reaction (PCR) and fluorescence in situ hybridization (FISH).[10][11] While fluorescent labels are common, isotopic labels can be used in quantitative assays that rely on mass spectrometry for detection.
Quantitative Data Summary
The following tables summarize key quantitative aspects and comparisons relevant to the use of ¹³C-labeled phosphoramidites.
Table 1: Applications of Site-Specific ¹³C Labeling
| ¹³C Label Position | Primary Application(s) | Key Benefit(s) |
| 6-¹³C Pyrimidines | NMR Dynamics (Relaxation Dispersion, ZZ-Exchange), Resonance Assignment | Provides isolated ¹³C-¹H spin pairs, simplifying spectra and enabling the study of μs-ms timescale motions.[3][4] |
| 8-¹³C Purines | NMR Resonance Assignment, Probing G-Quadruplexes | Facilitates assignment in purine-rich regions and helps monitor slow exchange between different folded forms.[3] |
| ¹³C-Methyl Thymine | NMR Studies of Protein-DNA Interactions | Acts as a probe for hydrophobic contacts in the major groove of DNA.[9] |
| ¹³C₅-Ribose | NMR Structure Determination of RNA-Protein Complexes | Resolves ambiguity in resonance assignments and allows for the collection of more structural constraints (NOEs).[12] |
| Uniform ¹³C Labeling | Internal Standards for Mass Spectrometry, Metabolic Flux Analysis | Provides a mass-shifted standard for accurate quantification of nucleic acids and their metabolites.[8][13] |
Table 2: Comparison of Labeling Strategies
| Feature | Site-Specific Labeling (via ¹³C-Phosphoramidites) | Uniform Labeling (via Enzymatic Synthesis) |
| Method | Chemical solid-phase synthesis.[1] | In vitro transcription using labeled NTPs and polymerases (e.g., T7 RNA polymerase).[2] |
| Precision | Any desired position can be labeled.[4] | All residues of a given type (or all residues) are labeled. |
| Primary Use Case | NMR dynamic studies, resolving specific spectral overlaps, probing specific interaction sites.[1][3][4] | NMR of small RNAs, initial resonance assignments, internal standards for MS.[14] |
| Key Advantage | Avoids ¹³C-¹³C scalar couplings, simplifying spectra and enabling quantitative relaxation measurements.[4][15] | Relatively lower cost for labeling an entire molecule; can produce longer RNA strands.[14] |
| Key Limitation | Can be cost-prohibitive for labeling many sites; synthesis length can be a limitation for very long oligos.[2][3] | Broad ¹³C signals due to extensive ¹³C-¹³C couplings complicate spectra and preclude many dynamic NMR experiments.[15] |
Experimental Protocols
Synthesis of ¹³C-Labeled Oligonucleotides via Solid-Phase Phosphoramidite (B1245037) Chemistry
The synthesis of oligonucleotides on a solid support is a cyclical process involving four main steps. A ¹³C-labeled phosphoramidite is introduced during the coupling step at the desired position in the sequence.
-
De-blocking (Detritylation): The 5'-hydroxyl group of the nucleotide bound to the solid support is deprotected by treatment with a mild acid. This exposes the hydroxyl group for the next reaction.
-
Coupling: The ¹³C-labeled phosphoramidite, activated by a reagent like tetrazole, is added. Its 3'-phosphoramidite group reacts with the deprotected 5'-hydroxyl group of the growing chain, forming a phosphite (B83602) triester bond. High coupling yields are routinely achieved.[3]
-
Capping: Any unreacted 5'-hydroxyl groups are acetylated ("capped") to prevent them from participating in subsequent cycles, which prevents the formation of deletion mutants.
-
Oxidation: The unstable phosphite triester linkage is oxidized to a more stable phosphotriester bond using an oxidizing agent, typically an iodine solution.
-
Iteration: The cycle is repeated until the desired sequence is assembled. Finally, the oligonucleotide is cleaved from the solid support, and all remaining protecting groups are removed.
NMR Spectroscopy for Structural and Dynamic Analysis
-
Sample Preparation: The synthesized and purified ¹³C-labeled oligonucleotide is dissolved in an appropriate buffer solution. For exchangeable proton detection, the sample is prepared in 90% H₂O/10% D₂O.
-
Resonance Assignment: A series of multidimensional NMR experiments (e.g., ¹H-¹³C HSQC, HCCH-TOCSY) are performed to assign the chemical shifts of the labeled site and its neighbors. The site-specific label serves as a clear starting point for assignment.[3]
-
Structural Analysis: Nuclear Overhauser Effect (NOE) experiments (e.g., ¹³C-edited NOESY) are used to measure distances between protons, providing the constraints needed to calculate a high-resolution 3D structure.
-
Dynamic Analysis: To study molecular motions, experiments like Carr-Purcell-Meiboom-Gill (CPMG) relaxation dispersion or ZZ-exchange spectroscopy are conducted.[3][4] These experiments measure how the transverse magnetization of the ¹³C nucleus relaxes under different conditions, revealing information about conformational exchange processes on the μs-ms timescale.[3]
Quantitative Analysis by UHPLC-MS/MS
-
Sample Preparation: The biological sample (e.g., plasma, tissue extract) is spiked with a known quantity of the ¹³C-labeled oligonucleotide as an internal standard.
-
Extraction: The nucleic acids (both the analyte and the ¹³C-labeled standard) are extracted from the biological matrix.
-
Enzymatic Digestion: The purified nucleic acids are enzymatically digested into their constituent nucleosides or nucleobases.
-
UHPLC Separation: The resulting mixture of nucleosides/bases is injected into an ultra-high-performance liquid chromatography (UHPLC) system, which separates the components based on their physicochemical properties.
-
MS/MS Detection and Quantification: The eluent from the UHPLC is directed into a tandem mass spectrometer. The instrument is set to monitor specific mass-to-charge (m/z) transitions for both the unlabeled (analyte) and ¹³C-labeled (internal standard) species. The ratio of the peak areas is used to calculate the exact concentration of the analyte in the original sample.[8]
Visualizations
References
- 1. benchchem.com [benchchem.com]
- 2. Synthesis of atom-specific nucleobase and ribose labeled uridine phosphoramidite for NMR analysis of large RNAs: Abstract, Citation (BibTeX) & Reference | Bohrium [bohrium.com]
- 3. Synthesis and incorporation of 13C-labeled DNA building blocks to probe structural dynamics of DNA by NMR - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Stable isotope-labeled RNA phosphoramidites to facilitate dynamics by NMR - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. [PDF] Synthesis of oligodeoxynucleotides containing6-N-([13C]methyl)adenine and2-N-([13C]methyl)guanine | Semantic Scholar [semanticscholar.org]
- 6. Synthesis of a thymidine phosphoramidite labelled with 13C at C6: relaxation studies of the loop region in a 13C labelled DNA hairpin - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. Metabolic Flux Analysis with 13C-Labeling Experiments | www.13cflux.net [13cflux.net]
- 8. Sensitive, Efficient Quantitation of 13C-Enriched Nucleic Acids via Ultrahigh-Performance Liquid Chromatography–Tandem Mass Spectrometry for Applications in Stable Isotope Probing - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Synthesis of isotope labeled oligonucleotides and their use in an NMR study of a protein-DNA complex - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. Beyond the Basics: Specialized Applications of Nucleoside Phosphoramidite Chemistry - WUHU HUAREN SCIENCE AND TECHNOLOGY CO., LTD. [huarenscience.com]
- 11. Exploring Phosphoramidites: Essential Building Blocks in Modern Chemistry and Biotechnology - Amerigo Scientific [amerigoscientific.com]
- 12. Short, synthetic and selectively 13C-labeled RNA sequences for the NMR structure determination of protein–RNA complexes - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Advantages of using biologically generated 13C-labelled multiple internal standards for stable isotope-assisted LC-MS-based lipidomics - Analytical Methods (RSC Publishing) [pubs.rsc.org]
- 14. academic.oup.com [academic.oup.com]
- 15. Selective 13C labeling of nucleotides for large RNA NMR spectroscopy using an E. coli strain disabled in the TCA cycle - PMC [pmc.ncbi.nlm.nih.gov]
The Core Principles of 13C Isotope NMR Spectroscopy: An In-depth Technical Guide
For Researchers, Scientists, and Drug Development Professionals
This guide provides a comprehensive overview of the fundamental principles and practical applications of Carbon-13 Nuclear Magnetic Resonance (¹³C NMR) spectroscopy. As a powerful analytical technique, ¹³C NMR offers direct insight into the carbon framework of molecules, making it an indispensable tool in chemical research, particularly in the fields of structural elucidation, reaction monitoring, and drug discovery. This document details the theoretical underpinnings of ¹³C NMR, presents quantitative data in a structured format, and provides detailed protocols for key experiments.
Fundamental Principles of ¹³C NMR Spectroscopy
Nuclear Magnetic Resonance (NMR) spectroscopy exploits the magnetic properties of atomic nuclei. The ¹³C isotope, possessing a nuclear spin of ½, is NMR active. However, its low natural abundance (approximately 1.1%) and smaller gyromagnetic ratio compared to ¹H make ¹³C NMR inherently less sensitive than proton NMR.[1] Despite this, the wealth of information provided by ¹³C NMR often outweighs the challenges associated with its detection.
A key advantage of ¹³C NMR is the wide range of chemical shifts, typically spanning 0 to 220 ppm.[2][3] This broad spectral window minimizes signal overlap, even in complex molecules, allowing for the resolution of individual carbon atoms.[2][3]
Chemical Shift
The chemical shift (δ) of a ¹³C nucleus is highly sensitive to its local electronic environment. Factors influencing the chemical shift include:
-
Hybridization: sp³-hybridized carbons generally resonate at higher fields (lower ppm values) than sp²-hybridized carbons, which in turn are typically at a higher field than sp-hybridized carbons. Carbonyl carbons are found at the lowest fields (highest ppm values).[2]
-
Electronegativity: The presence of electronegative substituents (e.g., oxygen, nitrogen, halogens) deshields the carbon nucleus, causing a downfield shift to higher ppm values.[2][3]
-
Magnetic Anisotropy: The presence of π-systems, such as in aromatic rings and alkynes, can induce local magnetic fields that either shield or deshield nearby carbon nuclei.
The following diagram illustrates the basic principle of how the electronic environment affects the ¹³C chemical shift.
Spin-Spin Coupling
While ¹³C-¹³C coupling is generally not observed due to the low natural abundance of the ¹³C isotope, heteronuclear coupling between ¹³C and attached protons (¹H) is significant, with coupling constants (¹JCH) typically ranging from 125 to 250 Hz.[1][2] To simplify spectra and improve signal-to-noise, ¹³C NMR spectra are most commonly acquired with broadband proton decoupling, which removes all C-H coupling, resulting in a single sharp peak for each chemically non-equivalent carbon atom.[2][4]
Nuclear Overhauser Effect (NOE)
Broadband proton decoupling leads to a phenomenon known as the Nuclear Overhauser Effect (NOE), which transfers polarization from the abundant ¹H spins to the rare ¹³C spins.[5] This significantly enhances the signal intensity of protonated carbons (CH, CH₂, CH₃). However, the NOE is distance-dependent and less effective for quaternary carbons (carbons with no attached protons).[5] Consequently, the integrals of signals in a standard broadband-decoupled ¹³C NMR spectrum are not proportional to the number of carbon atoms, making the experiment non-quantitative.[2][6]
Quantitative ¹³C NMR
To obtain quantitative data where peak integrals are proportional to the number of carbons, the NOE must be suppressed. This can be achieved through "inverse-gated decoupling," a technique where the proton decoupler is switched on only during the acquisition of the signal and turned off during the relaxation delay. Additionally, a long relaxation delay (typically 5 to 10 times the longest T₁ relaxation time of the carbon atoms in the molecule) is necessary to allow all carbons to fully relax between pulses. The addition of a paramagnetic relaxation agent like chromium(III) acetylacetonate (B107027) (Cr(acac)₃) can shorten the T₁ values and reduce the required relaxation delay.[7]
The following diagram outlines the logical workflow for deciding on a ¹³C NMR experiment based on the desired outcome.
Data Presentation: Quantitative Information
The following tables summarize typical ¹³C chemical shifts and coupling constants, which are crucial for spectral interpretation.
Table 1: Typical ¹³C Chemical Shift Ranges
| Carbon Type | Chemical Shift (ppm) |
| Primary Alkyl (RCH₃) | 10 - 15[8] |
| Secondary Alkyl (R₂CH₂) | 16 - 25[8] |
| Tertiary Alkyl (R₃CH) | 25 - 35[8] |
| Quaternary Alkyl (R₄C) | 30 - 40 |
| C-Halogen (C-Cl, C-Br) | 25 - 50 |
| C-Nitrogen (Aliphatic) | 30 - 65 |
| C-Oxygen (Alcohol, Ether) | 50 - 90 |
| Alkyne (C≡C) | 65 - 90[9] |
| Alkene (C=C) | 100 - 150 |
| Aromatic | 110 - 160 |
| Carboxylic Acid & Ester | 160 - 185 |
| Ketone & Aldehyde | 190 - 220 |
Note: These are approximate ranges and can be influenced by substituents and solvent effects.
Table 2: Typical ¹³C-¹H Coupling Constants
| Coupling Type | Hybridization | Typical Value (Hz) |
| ¹JCH | sp³ | 115 - 140[10][11] |
| ¹JCH | sp² | 150 - 200[11] |
| ¹JCH | sp | 240 - 270[11] |
| ²JCH | (geminal) | -10 to +20 |
| ³JCH | (vicinal) | 1 to 15 |
Experimental Protocols
Detailed methodologies for key ¹³C NMR experiments are provided below. These are general guidelines and may require optimization based on the specific instrument and sample.
Standard 1D ¹³C NMR (Broadband Decoupled)
Objective: To obtain a spectrum showing a single peak for each unique carbon atom.
Methodology:
-
Sample Preparation: Dissolve 10-50 mg of the sample in 0.6-0.7 mL of a deuterated solvent (e.g., CDCl₃, DMSO-d₆) in a standard 5 mm NMR tube.
-
Instrument Setup:
-
Insert the sample, lock on the deuterium (B1214612) signal of the solvent, and shim the magnetic field to achieve homogeneity.
-
Tune and match the ¹³C and ¹H channels of the probe.
-
-
Acquisition Parameters:
-
Pulse Program: A standard single-pulse experiment with proton decoupling (e.g., zgpg30 on Bruker instruments).
-
Pulse Width: Use a 30° or 45° flip angle to allow for a shorter relaxation delay.
-
Spectral Width: Typically 240-250 ppm (e.g., -10 to 230 ppm) to cover the full range of ¹³C chemical shifts.
-
Acquisition Time (AQ): Typically 1-2 seconds. This determines the digital resolution.
-
Relaxation Delay (D1): Typically 1-2 seconds.
-
Number of Scans (NS): Varies from hundreds to thousands, depending on the sample concentration, to achieve an adequate signal-to-noise ratio.
-
-
Processing:
-
Apply a Fourier transform to the Free Induction Decay (FID).
-
Phase the spectrum to obtain pure absorption peaks.
-
Reference the spectrum using the solvent peak or an internal standard (e.g., TMS at 0.0 ppm).
-
DEPT (Distortionless Enhancement by Polarization Transfer)
Objective: To determine the multiplicity of each carbon signal (CH, CH₂, CH₃). Quaternary carbons are not observed.
Methodology:
-
Initial Setup: Perform steps 1 and 2 from the standard 1D ¹³C NMR protocol.
-
DEPT Experiments: Three separate experiments are typically run:
-
Acquisition Parameters:
-
Pulse Program: Use the specific DEPT pulse programs available on the spectrometer.
-
Other parameters like spectral width, acquisition time, and relaxation delay are similar to the standard 1D ¹³C experiment.
-
-
Data Analysis: By comparing the three DEPT spectra with the standard ¹³C spectrum, the multiplicity of each carbon can be assigned.
The following diagram illustrates the information obtained from DEPT experiments.
2D HSQC (Heteronuclear Single Quantum Coherence)
Objective: To identify direct one-bond correlations between protons and carbons.
Methodology:
-
Instrument Setup: Follow the setup for a 1D experiment. It is crucial to have a well-shimmed, non-spinning sample. A 1D ¹H spectrum should be acquired first to determine the proton spectral width.
-
Acquisition Parameters:
-
Pulse Program: A gradient-enhanced HSQC pulse sequence (e.g., hsqcedetgpsisp2.2 on Bruker).
-
Spectral Width (F2 - ¹H dimension): Set to cover all proton signals, typically 10-12 ppm.
-
Spectral Width (F1 - ¹³C dimension): Set to cover the expected range of protonated carbons, often 0-160 ppm.
-
Number of Points (TD): Typically 1024 or 2048 in the direct dimension (F2) and 128 to 256 increments in the indirect dimension (F1).
-
Number of Scans (NS): Typically a multiple of 2 or 4, depending on concentration.
-
¹JCH Coupling Constant: The experiment is optimized for an average one-bond C-H coupling, typically set to 145 Hz.
-
-
Processing:
-
Apply a 2D Fourier transform.
-
Phase the spectrum in both dimensions.
-
The resulting 2D spectrum will show a correlation peak at the intersection of the ¹H and ¹³C chemical shifts for each directly bonded C-H pair.
-
2D HMBC (Heteronuclear Multiple Bond Correlation)
Objective: To identify long-range (typically 2- and 3-bond) correlations between protons and carbons. This is crucial for connecting molecular fragments and assigning quaternary carbons.
Methodology:
-
Instrument Setup: Similar to HSQC, a non-spinning, well-shimmed sample is required. A 1D ¹H spectrum is needed to define the proton spectral width.
-
Acquisition Parameters:
-
Pulse Program: A gradient-enhanced HMBC pulse sequence (e.g., hmbcgplpndqf on Bruker).
-
Spectral Widths (F1 and F2): Similar to HSQC, but the ¹³C dimension (F1) should be extended to include quaternary and carbonyl carbons (e.g., 0-220 ppm).
-
Number of Points (TD): Similar to HSQC.
-
Number of Scans (NS): HMBC is less sensitive than HSQC, so more scans (e.g., 8, 16, or more) are often required.
-
Long-Range Coupling Constant (nJCH): The experiment is optimized for a long-range coupling, typically set to 8-10 Hz.
-
-
Processing:
-
2D Fourier transform is applied. The data is usually processed in magnitude mode, so phasing is not required.
-
The 2D spectrum shows correlation peaks between protons and carbons that are 2, 3, and sometimes 4 bonds apart.
-
Applications in Drug Development
¹³C NMR spectroscopy is a cornerstone technique in the pharmaceutical industry. Its applications include:
-
Structural Verification: Confirming the carbon skeleton of newly synthesized active pharmaceutical ingredients (APIs) and intermediates.
-
Polymorph and Salt Form Characterization: Solid-state ¹³C NMR is particularly powerful for distinguishing between different crystalline forms (polymorphs) of a drug, which can have different physical properties like solubility and stability.[11]
-
Metabolite Identification: Identifying the structure of drug metabolites by comparing their ¹³C NMR spectra to that of the parent drug.
-
Quantitative Analysis: Determining the purity of a drug substance and quantifying components in a mixture.
-
Fragment-Based Drug Discovery: NMR techniques, including ¹³C-observe methods, are used to screen for small molecule fragments that bind to a protein target.[13]
Conclusion
¹³C NMR spectroscopy provides unparalleled detail about the carbon framework of molecules. While it has inherent sensitivity limitations, modern NMR techniques and instrumentation have made it a routine and powerful tool. A thorough understanding of its principles, from chemical shifts and coupling constants to the nuances of quantitative measurements and advanced 2D experiments, is essential for researchers in chemistry and drug development to effectively harness its full potential for molecular structure elucidation and characterization.
References
- 1. nmr.chem.indiana.edu [nmr.chem.indiana.edu]
- 2. Gradient Enhanced HMBC [nmr.chem.ucsb.edu]
- 3. Practical aspects of real‐time pure shift HSQC experiments - PMC [pmc.ncbi.nlm.nih.gov]
- 4. 13.12 DEPT 13C NMR Spectroscopy - Organic Chemistry | OpenStax [openstax.org]
- 5. nmr.chem.columbia.edu [nmr.chem.columbia.edu]
- 6. chem.uiowa.edu [chem.uiowa.edu]
- 7. 13C NMR Chemical Shift [sites.science.oregonstate.edu]
- 8. chem.libretexts.org [chem.libretexts.org]
- 9. users.wfu.edu [users.wfu.edu]
- 10. rubingroup.org [rubingroup.org]
- 11. scribd.com [scribd.com]
- 12. chem.libretexts.org [chem.libretexts.org]
- 13. organicchemistrydata.netlify.app [organicchemistrydata.netlify.app]
The Core Applications of Carbon-13 Labeled Ribonucleosides: An In-depth Technical Guide
For Researchers, Scientists, and Drug Development Professionals
Introduction
Carbon-13 (¹³C), a stable, non-radioactive isotope of carbon, has become an indispensable tool in the life sciences. When incorporated into ribonucleosides, the fundamental building blocks of RNA, ¹³C serves as a powerful probe for elucidating complex biological processes. This technical guide provides an in-depth exploration of the core applications of ¹³C-labeled ribonucleosides, with a focus on metabolic flux analysis, the study of RNA structure and dynamics, and their role in drug development. Detailed experimental protocols, quantitative data summaries, and visual workflows are presented to equip researchers with the knowledge to leverage this technology in their own work.
Metabolic Flux Analysis and RNA Turnover
The dynamic nature of RNA metabolism, including synthesis, modification, and degradation, is crucial for gene expression regulation. ¹³C-labeled ribonucleosides, in conjunction with mass spectrometry, have enabled precise quantification of these dynamics.
The ¹³C-dynamods Method for Quantifying RNA Modification Turnover
A prominent application of ¹³C-labeling is the "¹³C-dynamods" approach, which quantifies the turnover of RNA base modifications.[1][2][3] This method involves introducing a ¹³C-labeled precursor, such as [¹³C-methyl]-methionine, into cell culture.[1][4] The ¹³C-labeled methyl group is then incorporated into newly transcribed and methylated RNA. By tracking the ratio of ¹³C-labeled (heavy) to unlabeled (light) modified ribonucleosides over time using tandem mass spectrometry (LC-MS/MS), the turnover rates of specific RNA modifications can be determined.[1][4][5]
This technique has been instrumental in distinguishing the turnover rates of modifications in different RNA species, such as messenger RNA (mRNA) versus non-coding RNA (ncRNA).[1][2][3] For instance, it has been used to show the distinct kinetics of N6-methyladenosine (m⁶A) and 7-methylguanosine (B147621) (m⁷G) in polyA+-purified RNA.[1][3][6]
Experimental Workflow: ¹³C-dynamods
Caption: Workflow for the ¹³C-dynamods method.
Quantitative Data on RNA Modification Turnover
The ¹³C-dynamods method allows for the determination of turnover frequencies for various modified ribonucleosides. This data can reveal the differential stability of various RNA species and their modifications.
| RNA Modification | RNA Fraction | Turnover Frequency (h⁻¹) (Representative) | Reference |
| N6-methyladenosine (m⁶A) | polyA+ RNA | Fast | [1][3] |
| 7-methylguanosine (m⁷G) | polyA+ RNA | Distinct from m⁶A | [1][3] |
| N6,N6-dimethyladenosine (m⁶₂A) | Small RNAs | Distinct from large rRNAs | [1][3] |
Note: Specific turnover rates can vary depending on cell type and experimental conditions.
Experimental Protocol: ¹³C-dynamods
1. Cell Culture and Labeling:
-
Culture cells in standard medium.
-
For labeling, switch to a methionine-free medium supplemented with [¹³C-methyl]-methionine.[2][7]
-
The concentration and duration of labeling will depend on the specific experiment and cell type. A time-course experiment is often performed.[1]
2. RNA Isolation and Digestion:
-
Harvest cells at different time points after labeling.
-
Isolate total RNA or specific RNA fractions (e.g., polyA+ RNA) using standard protocols.[1][4]
-
Digest the purified RNA to ribonucleosides using a cocktail of nucleases (e.g., nuclease P1) and phosphatases (e.g., bacterial alkaline phosphatase).[1]
3. LC-MS/MS Analysis:
-
Separate the ribonucleosides using liquid chromatography (LC).
-
Detect and quantify the modified and unmodified ribonucleosides using tandem mass spectrometry (MS/MS).[1][2][3]
-
Monitor the mass-to-charge ratio (m/z) for both the unlabeled (m+0) and the ¹³C-labeled (m+1 or m+2 for doubly methylated species) isotopologues of each ribonucleoside of interest.[1][4]
4. Data Analysis:
-
Calculate the isotopologue fraction for each modified ribonucleoside at each time point using the formula: m+1 / (m+1 + m+0).[1][5]
-
The change in this fraction over time reflects the turnover rate of the modification.
RNA Structure and Dynamics Studies by NMR Spectroscopy
Nuclear Magnetic Resonance (NMR) spectroscopy is a powerful technique for determining the three-dimensional structure and dynamics of RNA molecules in solution. The incorporation of ¹³C-labeled ribonucleosides significantly enhances the resolution and information content of NMR experiments.[8][9]
Enhancing NMR Structural Studies
Uniform or selective ¹³C labeling of ribonucleosides allows for the use of ¹³C-edited and ¹³C-¹³C correlation experiments, which are crucial for resolving spectral overlap and assigning resonances in larger RNA molecules.[9][10] This is particularly important for studying protein-RNA complexes.[10] The synthesis of ¹³C-labeled ribonucleoside phosphoramidites has enabled the site-specific incorporation of labeled nucleotides into synthetic RNA oligonucleotides.[10][11][12]
Logical Relationship: Isotopic Labeling for NMR
Caption: Isotopic labeling strategies for RNA NMR studies.
Probing RNA Dynamics
Site-specific ¹³C labeling is also invaluable for studying the conformational dynamics of RNA.[13] By incorporating isolated ¹³C spins, researchers can perform relaxation dispersion and other NMR experiments to probe motions on a wide range of timescales, providing insights into RNA folding, ligand binding, and catalytic mechanisms.
Experimental Protocol: NMR of ¹³C-Labeled RNA
1. Synthesis of ¹³C-Labeled Ribonucleosides and Phosphoramidites:
-
The synthesis often starts from a ¹³C-labeled precursor like D-[¹³C]-glucose or uses chemo-enzymatic methods.[10][14][15]
-
The labeled ribose is then converted into the desired ribonucleoside and subsequently into a phosphoramidite (B1245037) for solid-phase RNA synthesis.[10][11][12]
2. Solid-Phase Synthesis of ¹³C-Labeled RNA:
-
The ¹³C-labeled phosphoramidites are incorporated at specific positions in an RNA oligonucleotide using a standard automated solid-phase synthesizer.[12][13]
3. NMR Sample Preparation:
-
The synthesized RNA is purified, desalted, and dissolved in a suitable NMR buffer.
-
The final sample concentration should be optimized for NMR sensitivity.
4. NMR Data Acquisition:
-
A variety of NMR experiments can be performed, including ¹H-¹³C HSQC, HNC, and other multidimensional experiments.[16][17]
-
The specific set of experiments will depend on the research question, whether it is structure determination, dynamics, or both.
Applications in Drug Development
¹³C-labeled ribonucleosides and their analogs are valuable tools in drug development, primarily for studying drug metabolism and pharmacokinetics (DMPK).[][19]
Tracing Drug Metabolism
By labeling a drug candidate containing a ribonucleoside moiety with ¹³C, its metabolic fate can be traced in vitro or in vivo.[][19] Mass spectrometry can be used to identify and quantify the drug and its metabolites, providing crucial information about metabolic pathways, stability, and potential drug-drug interactions.[]
Signaling Pathway: Drug Metabolism Analysis
Caption: Use of ¹³C-labeling in drug metabolism studies.
Pharmacokinetic Studies
¹³C-labeled compounds are used as tracers in pharmacokinetic studies to determine the absorption, distribution, metabolism, and excretion (ADME) of a drug.[][20] The non-radioactive nature of ¹³C makes it a safer alternative to ¹⁴C for studies in humans.
Target Engagement and Mechanism of Action
In some cases, ¹³C-labeled ribonucleoside analogs can be used to study target engagement and the mechanism of action of a drug. For example, NMR or mass spectrometry can be used to detect the interaction of a ¹³C-labeled drug with its biological target.
Conclusion
Carbon-13 labeled ribonucleosides are a versatile and powerful tool for researchers across various disciplines. From quantifying the intricate dynamics of RNA metabolism to elucidating the high-resolution structures of RNA molecules and facilitating the development of new therapeutics, the applications of these labeled compounds are vast and continue to expand. The methodologies and protocols outlined in this guide provide a solid foundation for scientists to incorporate ¹³C-labeled ribonucleosides into their research, paving the way for new discoveries in the complex world of RNA biology and medicine.
References
- 1. Metabolic turnover and dynamics of modified ribonucleosides by 13C labeling - PMC [pmc.ncbi.nlm.nih.gov]
- 2. researchgate.net [researchgate.net]
- 3. Metabolic turnover and dynamics of modified ribonucleosides by 13C labeling - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. biorxiv.org [biorxiv.org]
- 5. researchgate.net [researchgate.net]
- 6. researchgate.net [researchgate.net]
- 7. pdfs.semanticscholar.org [pdfs.semanticscholar.org]
- 8. pubs.acs.org [pubs.acs.org]
- 9. Stable Isotope Labeled Nucleotides | Leading Provider of Isotope Labeled Solutions [silantes.com]
- 10. Short, synthetic and selectively 13C-labeled RNA sequences for the NMR structure determination of protein–RNA complexes - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Synthesis of isotopically labeled D-[1'-13C]ribonucleoside phosphoramidites - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. Synthesis and incorporation of 13C-labeled DNA building blocks to probe structural dynamics of DNA by NMR - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Solid-Phase Chemical Synthesis of Stable Isotope-Labeled RNA to Aid Structure and Dynamics Studies by NMR Spectroscopy - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Synthesis of [5'-13C]ribonucleosides and 2'-deoxy[5'-13C]ribonucleosides - PubMed [pubmed.ncbi.nlm.nih.gov]
- 15. pubs.acs.org [pubs.acs.org]
- 16. chem.uiowa.edu [chem.uiowa.edu]
- 17. State-of-the-Art Direct 13C and Indirect 1H-[13C] NMR Spectroscopy In Vivo: A Practical Guide - PMC [pmc.ncbi.nlm.nih.gov]
- 19. isotope-science.alfa-chemistry.com [isotope-science.alfa-chemistry.com]
- 20. Carbon-13 Labeled Compounds_TargetMol [targetmol.com]
A Technical Guide to Site-Specific Labeling of Oligonucleotides for Researchers, Scientists, and Drug Development Professionals
Introduction
Site-specifically labeled oligonucleotides are indispensable tools in modern molecular biology, diagnostics, and the development of novel therapeutics. The ability to attach a specific label, such as a fluorophore, biotin, or a drug molecule, to a precise location within a DNA or RNA strand enables a wide range of applications, from the intricate study of biological processes to the targeted delivery of therapeutic agents. This in-depth technical guide provides a comprehensive overview of the core methodologies for site-specific oligonucleotide labeling, offering detailed experimental protocols, quantitative comparisons of different techniques, and visualizations of key workflows and pathways.
Core Methodologies for Site-Specific Oligonucleotide Labeling
The site-specific modification of oligonucleotides can be broadly categorized into two main approaches: post-synthetic labeling of unmodified or uniquely functionalized oligonucleotides, and the incorporation of modified nucleotides during solid-phase synthesis. Each approach offers distinct advantages and is suited to different applications.
Chemical Ligation Strategies
Chemical ligation methods offer a versatile and robust approach for labeling oligonucleotides post-synthesis. These methods typically involve the reaction of a functional group introduced into the oligonucleotide with a reactive label.
Click chemistry, particularly the copper(I)-catalyzed azide-alkyne cycloaddition (CuAAC), has become a popular method for oligonucleotide labeling due to its high efficiency, specificity, and biocompatibility. The reaction forms a stable triazole linkage between an alkyne-modified oligonucleotide and an azide-containing label.[1]
Experimental Protocol: Copper-Catalyzed Azide-Alkyne Cycloaddition (CuAAC) for Oligonucleotide Labeling
This protocol describes the labeling of an alkyne-modified oligonucleotide with an azide-containing fluorescent dye.
Materials:
-
Alkyne-modified oligonucleotide
-
Azide-functionalized fluorescent dye
-
Copper(I)-stabilizing ligand (e.g., TBTA)
-
Sodium ascorbate (B8700270)
-
Copper(II) sulfate (B86663) (CuSO₄)
-
Nuclease-free water
-
DMSO (optional, for dissolving hydrophobic dyes)
-
Purification supplies (e.g., HPLC system or gel electrophoresis equipment)
Procedure:
-
Oligonucleotide Preparation: Dissolve the alkyne-modified oligonucleotide in nuclease-free water to a final concentration of 100 µM.
-
Reaction Mixture Preparation: In a microcentrifuge tube, combine the following in order:
-
Alkyne-modified oligonucleotide (1 equivalent)
-
Azide-functionalized dye (1.5-3 equivalents, dissolved in DMSO if necessary)
-
Copper(I)-stabilizing ligand (e.g., TBTA) (0.1-0.5 equivalents)
-
Freshly prepared 100 mM sodium ascorbate in water (1 equivalent)
-
10 mM CuSO₄ in water (0.1-0.5 equivalents)
-
-
Incubation: Vortex the reaction mixture gently and incubate at room temperature for 1-4 hours, or overnight for higher yields. The reaction can be monitored by HPLC or gel electrophoresis.
-
Purification: Purify the labeled oligonucleotide from unreacted dye and catalyst using reverse-phase HPLC or denaturing polyacrylamide gel electrophoresis (PAGE).
-
Quantification and Storage: Quantify the concentration of the purified labeled oligonucleotide using UV-Vis spectroscopy. Store the labeled oligonucleotide at -20°C, protected from light.
Quantitative Data for Click Chemistry Labeling:
| Parameter | Value | Reference |
| Reaction Yield | Near quantitative | [1][2] |
| Reaction Time | 30 minutes to 4 hours | [1] |
| Scalability | Nanomoles to micromoles | [1] |
| Stability of Linkage | High | [1] |
Diagram: Click Chemistry Workflow
Caption: Workflow for site-specific oligonucleotide labeling using CuAAC click chemistry.
Phosphoramidite chemistry is the gold-standard method for automated solid-phase oligonucleotide synthesis.[3] This methodology can be adapted to incorporate modified nucleotides bearing a reactive functional group (e.g., an amine or thiol) or the desired label directly during the synthesis cycle.
Experimental Protocol: Incorporation of a 5'-Amino-Modifier using Phosphoramidite Chemistry
This protocol outlines the final coupling step to introduce a 5'-amino-modifier phosphoramidite.
Materials:
-
Controlled pore glass (CPG) solid support with the initiated oligonucleotide chain
-
Standard DNA/RNA phosphoramidites and synthesis reagents
-
5'-Amino-Modifier C6 phosphoramidite
-
Activator solution (e.g., ethylthiotetrazole)
-
Oxidizing solution
-
Capping solution
-
Deblocking solution (e.g., trichloroacetic acid in dichloromethane)
-
Cleavage and deprotection solution (e.g., concentrated ammonium (B1175870) hydroxide)
Procedure (Final Coupling Cycle):
-
Deblocking: The final 5'-DMT protecting group of the synthesized oligonucleotide is removed by treatment with the deblocking solution.
-
Coupling: The 5'-Amino-Modifier C6 phosphoramidite is activated with the activator solution and coupled to the free 5'-hydroxyl group of the oligonucleotide.
-
Oxidation: The newly formed phosphite (B83602) triester linkage is oxidized to a stable phosphate (B84403) triester.
-
Capping: Any unreacted 5'-hydroxyl groups are capped to prevent the formation of failure sequences.
-
Cleavage and Deprotection: The oligonucleotide is cleaved from the CPG support and all protecting groups are removed by incubation in concentrated ammonium hydroxide.
-
Purification: The 5'-amino-modified oligonucleotide is purified by HPLC.
-
Post-synthetic Labeling: The purified oligonucleotide can then be labeled with an amine-reactive dye or other molecule.
Quantitative Data for Phosphoramidite-based Labeling:
| Parameter | Value | Reference |
| Coupling Efficiency (per step) | >98% | [3] |
| Overall Yield (for a 20-mer) | Varies with length and modifications | [] |
| Scalability | Milligrams to grams | |
| Purity (post-HPLC) | High |
Diagram: Phosphoramidite Synthesis Cycle
Caption: The four-step cycle of phosphoramidite-based solid-phase oligonucleotide synthesis.
Enzymatic Labeling Strategies
Enzymatic methods provide a mild and highly specific alternative for labeling oligonucleotides, often at their termini. These reactions are catalyzed by enzymes that recognize specific features of the nucleic acid.
T4 Polynucleotide Kinase catalyzes the transfer of the γ-phosphate from ATP to the 5'-hydroxyl terminus of DNA or RNA.[5] By using a γ-modified ATP analog, a functional group or label can be introduced at the 5'-end.
Experimental Protocol: 5'-End Labeling with T4 PNK and γ-S-ATP
This protocol describes the introduction of a phosphorothioate (B77711) group at the 5'-end, which can then be reacted with a maleimide-functionalized label.
Materials:
-
Oligonucleotide with a 5'-hydroxyl group
-
T4 Polynucleotide Kinase
-
10x T4 PNK reaction buffer
-
Adenosine-5'-(γ-thio)-triphosphate (ATPγS)
-
Nuclease-free water
-
Maleimide-functionalized label
-
Purification supplies
Procedure:
-
Kinase Reaction: In a microcentrifuge tube, combine:
-
Oligonucleotide (10-50 pmol)
-
10x T4 PNK reaction buffer (2 µL)
-
ATPγS (to a final concentration of 1 mM)
-
T4 Polynucleotide Kinase (10 units)
-
Nuclease-free water to a final volume of 20 µL
-
-
Incubation: Incubate the reaction at 37°C for 30-60 minutes.
-
Enzyme Inactivation: Heat the reaction at 70°C for 10 minutes to inactivate the T4 PNK.
-
Purification of 5'-thiophosphorylated Oligonucleotide: Purify the modified oligonucleotide using ethanol (B145695) precipitation or a suitable spin column to remove unincorporated ATPγS.
-
Maleimide Labeling: React the purified 5'-thiophosphorylated oligonucleotide with a 10-20 fold molar excess of the maleimide-functionalized label in a suitable buffer (e.g., phosphate buffer, pH 7.0-7.5) for 1-2 hours at room temperature.
-
Final Purification: Purify the final labeled oligonucleotide by HPLC or PAGE.
Quantitative Data for T4 PNK Labeling:
| Parameter | Value | Reference |
| Labeling Efficiency | Dependent on 5'-nucleotide | [6] |
| Reaction Time (Kinase) | 30-60 minutes | [5] |
| Specificity | High for 5'-hydroxyl | [5] |
| Yield (overall) | Moderate | [7] |
Terminal Deoxynucleotidyl Transferase is a template-independent DNA polymerase that adds deoxynucleotides to the 3'-hydroxyl terminus of a DNA molecule.[8] By using labeled or modified dideoxynucleotides (ddNTPs), a single label can be added to the 3'-end.
Experimental Protocol: 3'-End Labeling with TdT and Fluorescently Labeled ddNTP
Materials:
-
DNA oligonucleotide with a 3'-hydroxyl group
-
Terminal Deoxynucleotidyl Transferase (TdT)
-
5x TdT reaction buffer
-
Fluorescently labeled ddNTP (e.g., TAMRA-ddUTP)
-
Nuclease-free water
-
Purification supplies
Procedure:
-
Labeling Reaction: In a microcentrifuge tube, combine:
-
DNA oligonucleotide (10-50 pmol)
-
5x TdT reaction buffer (4 µL)
-
Fluorescently labeled ddNTP (10-50 µM)
-
TdT (20 units)
-
Nuclease-free water to a final volume of 20 µL
-
-
Incubation: Incubate the reaction at 37°C for 30-60 minutes.
-
Enzyme Inactivation: Add EDTA to a final concentration of 10 mM and heat at 70°C for 10 minutes to stop the reaction and inactivate the TdT.
-
Purification: Purify the labeled oligonucleotide from unincorporated ddNTPs using ethanol precipitation or a spin column.
Quantitative Data for TdT Labeling:
| Parameter | Value | Reference |
| Incorporation Rate | At least 30% | [9] |
| Reaction Time | 30-60 minutes | [8] |
| Specificity | High for 3'-hydroxyl | [8] |
| Yield | Good | [10] |
Diagram: Enzymatic End-Labeling Workflow
Caption: General workflows for 5' and 3' enzymatic end-labeling of oligonucleotides.
Unnatural Base Pairs (UBPs)
The expansion of the genetic alphabet through the creation of unnatural base pairs (UBPs) offers a powerful strategy for the site-specific incorporation of functional molecules into DNA and RNA.[11] During enzymatic synthesis (e.g., PCR or in vitro transcription), a polymerase can specifically incorporate a modified nucleotide triphosphate containing the desired label opposite its unnatural counterpart in the template strand.
Conceptual Workflow:
-
Template Design: A DNA template is synthesized containing one of the unnatural bases at the desired labeling site.
-
Enzymatic Incorporation: A polymerase chain reaction (PCR) or in vitro transcription is performed using a mixture of natural nucleotide triphosphates and a triphosphate derivative of the complementary unnatural base, which is conjugated to the desired label.
-
Purification: The full-length, site-specifically labeled oligonucleotide is purified from the reaction mixture.
Quantitative Data for UBP-based Labeling:
| Parameter | Value | Reference |
| Incorporation Efficiency | High with optimized UBPs and polymerases | [12][13] |
| Specificity | High | [11] |
| Versatility | Wide range of labels can be incorporated | [11] |
| Yield | Dependent on PCR/transcription efficiency | [13] |
Diagram: Unnatural Base Pair Labeling Pathway
Caption: Signaling pathway for site-specific labeling via enzymatic incorporation of an unnatural base pair.
Applications in Research and Drug Development
Site-specifically labeled oligonucleotides are crucial for a wide array of applications:
-
Fluorescence Resonance Energy Transfer (FRET): Dual-labeled oligonucleotides with a donor and acceptor fluorophore are used to study nucleic acid structure, hybridization, and interactions with proteins.[14]
-
Single-Molecule Imaging: Highly fluorescently labeled oligonucleotides enable the visualization and tracking of individual nucleic acid molecules in vitro and in living cells.[15][16]
-
In Vivo Imaging: Oligonucleotides labeled with imaging agents (e.g., radioisotopes or near-infrared dyes) can be used to visualize the biodistribution and target engagement of oligonucleotide therapeutics.
-
Drug Delivery: Conjugation of therapeutic oligonucleotides to targeting ligands or delivery vehicles can enhance their cellular uptake and tissue-specific delivery.[][18]
-
Diagnostics: Labeled oligonucleotide probes are fundamental to various diagnostic assays, including PCR, FISH, and microarrays.
Stability of Labeled Oligonucleotides
The stability of labeled oligonucleotides is critical for their successful application. Phosphorothioate modifications, where a non-bridging oxygen in the phosphate backbone is replaced with sulfur, significantly increase nuclease resistance and in vivo stability.[19][20] Fluorescent labels should be protected from light to prevent photobleaching.
Conclusion
The field of site-specific oligonucleotide labeling continues to evolve, offering researchers and drug developers an expanding toolkit of powerful methods. The choice of labeling strategy depends on the specific application, the desired label, and the required scale and purity. By understanding the principles and protocols outlined in this guide, scientists can effectively design and execute experiments that leverage the unique capabilities of precisely modified oligonucleotides to advance our understanding of biology and develop next-generation diagnostics and therapeutics.
References
- 1. lumiprobe.com [lumiprobe.com]
- 2. Pseudo-ligandless Click Chemistry for Oligonucleotide Conjugation - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Oligonucleotide synthesis - Wikipedia [en.wikipedia.org]
- 5. End-Labeling Oligonucleotides with Chemical Tags After Synthesis - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Labeling efficiency of oligonucleotides by T4 polynucleotide kinase depends on 5'-nucleotide - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. epub.ub.uni-muenchen.de [epub.ub.uni-muenchen.de]
- 8. Labeling the 3' Termini of Oligonucleotides Using Terminal Deoxynucleotidyl Transferase - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. scispace.com [scispace.com]
- 10. tandfonline.com [tandfonline.com]
- 11. Unnatural base pair systems toward the expansion of the genetic alphabet in the central dogma - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Highly efficient incorporation of the fluorescent nucleotide analogs tC and tCO by Klenow fragment - PubMed [pubmed.ncbi.nlm.nih.gov]
- 13. Optimized incorporation of an unnatural fluorescent amino acid affords measurement of conformational dynamics governing high-fidelity DNA replication - PubMed [pubmed.ncbi.nlm.nih.gov]
- 14. DNA Probes Using Fluorescence Resonance Energy Transfer (FRET): Designs and Applications - PMC [pmc.ncbi.nlm.nih.gov]
- 15. Strategic labelling approaches for RNA single-molecule spectroscopy - PMC [pmc.ncbi.nlm.nih.gov]
- 16. academic.oup.com [academic.oup.com]
- 18. The delivery of therapeutic oligonucleotides - PMC [pmc.ncbi.nlm.nih.gov]
- 19. In vivo stability and disposition of a self-stabilized oligodeoxynucleotide phosphorothioate in rats - PubMed [pubmed.ncbi.nlm.nih.gov]
- 20. assaygenie.com [assaygenie.com]
A Technical Guide to rU Phosphoramidite-¹³C₉ for Advanced Nucleic Acid Research
For Researchers, Scientists, and Drug Development Professionals
This guide provides an in-depth overview of fully carbon-13 labeled uridine (B1682114) phosphoramidite (B1245037) (rU Phosphoramidite-¹³C₉), a critical reagent for modern nucleic acid research. Its primary application lies in the site-specific incorporation of an NMR-active isotope into RNA oligonucleotides, enabling detailed structural and dynamic studies that are otherwise intractable. By overcoming the challenges of spectral overlap and low sensitivity inherent in studying large RNAs, ¹³C-labeled phosphoramidites have become indispensable tools in drug discovery and molecular biology.
Introduction to Isotope-Labeled Phosphoramidites in Nucleic Acid Research
The study of RNA structure, dynamics, and interactions is fundamental to understanding its diverse biological roles. Nuclear Magnetic Resonance (NMR) spectroscopy is a powerful technique for elucidating these properties at atomic resolution. However, for RNA molecules larger than 30 nucleotides, NMR spectra become exceedingly complex and crowded due to the limited chemical shift dispersion of the four standard nucleotides.
Stable isotope labeling, particularly with ¹³C and ¹⁵N, helps to alleviate these issues. While uniform labeling (where all carbons or nitrogens are isotopes) is useful, it introduces complex scalar and dipolar couplings between adjacent labeled nuclei, complicating the spectra.[1] Selective or site-specific labeling , achieved through the chemical synthesis of RNA using isotope-labeled phosphoramidites, offers a superior solution.[1] By introducing a ¹³C label at a single, specific position within a large RNA molecule, researchers can isolate signals from that site, simplifying spectral analysis and enabling precise measurements of local structure and dynamics.[2]
The rU Phosphoramidite-¹³C₉ is a building block designed for standard automated solid-phase synthesis, allowing for the precise placement of a fully ¹³C-labeled uridine residue within any desired RNA sequence.
Synthesis of ¹³C₉-Labeled Uridine Phosphoramidite
The production of an isotope-labeled phosphoramidite is a multi-step process that combines enzymatic and chemical synthesis to achieve high yields and purity. The general strategy involves synthesizing the ¹³C-labeled ribonucleoside first, followed by chemical modifications to add the necessary protecting groups and the phosphoramidite moiety. A representative chemo-enzymatic pathway is described below.[3][4]
Experimental Protocol: Chemo-Enzymatic Synthesis of [¹³C₉]-Uridine
-
Enzymatic Ribosylation : The process starts with commercially available, fully labeled [U-¹³C₅]-D-Ribose and [U-¹³C₄]-Uracil. A series of enzymatic reactions, using enzymes from the pentose (B10789219) phosphate (B84403) pathway, couples the labeled base to the labeled ribose, ultimately producing [U-¹³C₉]-Uridine 5'-monophosphate (UMP).[5]
-
Dephosphorylation : The resulting UMP is dephosphorylated using an alkaline phosphatase (e.g., rSAP) to yield the desired [U-¹³C₉]-uridine nucleoside.
-
Purification : The crude labeled uridine is purified using boronate affinity chromatography followed by standard column chromatography to ensure high purity before proceeding to chemical modifications.
Experimental Protocol: Conversion to 2'-O-CEM Phosphoramidite
The labeled uridine nucleoside is then chemically converted into a phosphoramidite suitable for RNA synthesis. The 2'-O-cyanoethoxymethyl (CEM) protecting group is highlighted here as it permits the efficient synthesis of large RNAs (>60 nucleotides) with high coupling efficiency.[3][4]
-
5'-O-DMT Protection : The 5'-hydroxyl group of the labeled uridine is protected with a dimethoxytrityl (DMT) group by reacting it with DMT-Cl in pyridine.
-
2'-O-CEM Protection : The 2'-hydroxyl is then protected using 2-cyanoethyl methylthiomethyl ether.
-
Phosphitylation : Finally, the 3'-hydroxyl group is reacted with 2-cyanoethyl N,N-diisopropylchlorophosphoramidite in the presence of a mild base (e.g., diisopropylethylamine) to generate the final 5'-O-DMT-2'-O-CEM-[¹³C₉]-Uridine-3'-O-(β-cyanoethyl-N,N-diisopropyl) phosphoramidite.
-
Purification and Characterization : The final product is purified by silica (B1680970) gel chromatography and characterized by ³¹P NMR, ¹H NMR, ¹³C NMR, and mass spectrometry to confirm its identity and purity (>98%).[6]
Incorporation into RNA via Solid-Phase Synthesis
The ¹³C-labeled phosphoramidite is incorporated into a growing RNA chain using a standard, automated solid-phase synthesis protocol.[7] The synthesis proceeds in the 3' to 5' direction on a solid support, typically controlled pore glass (CPG).
The Synthesis Cycle
The addition of each nucleotide involves a four-step cycle:
-
Detritylation (Deblocking) : The acid-labile DMT group is removed from the 5'-hydroxyl of the nucleotide bound to the solid support, exposing a free hydroxyl group for the next coupling reaction.
-
Coupling : The rU Phosphoramidite-¹³C₉ (or any other phosphoramidite) is activated by a reagent like tetrazole and reacts with the free 5'-hydroxyl group. This forms a phosphite (B83602) triester linkage.
-
Capping : Any unreacted 5'-hydroxyl groups are acetylated to prevent them from participating in subsequent cycles, which would result in deletion sequences (n-1 oligomers).
-
Oxidation : The unstable phosphite triester is oxidized to a stable phosphate triester using an iodine solution.
This cycle is repeated until the desired RNA sequence is synthesized.
Experimental Protocol: Solid-Phase Synthesis
-
Synthesizer Setup : The rU Phosphoramidite-¹³C₉ is dissolved in anhydrous acetonitrile (B52724) to a concentration of 0.1 M and installed on an automated DNA/RNA synthesizer.[8]
-
Synthesis Program : A standard RNA synthesis protocol is used. The coupling time for modified phosphoramidites, especially those with bulky 2'-protecting groups like CEM, is typically set between 2 to 4 minutes to ensure high efficiency.[9]
-
Cleavage and Deprotection : After synthesis, the RNA is cleaved from the solid support and all protecting groups (on the bases, 2'-hydroxyls, and phosphate backbone) are removed using a standard deprotection solution (e.g., a mixture of ammonia (B1221849) and methylamine).
-
Purification : The crude RNA product is purified to isolate the full-length, labeled oligonucleotide from shorter, failed sequences.
| Parameter | Typical Value | Reference |
| Phosphoramidite Conc. | 0.1 M in Acetonitrile | [8] |
| Activator | 0.25 M 5-Ethylthio-1H-tetrazole (ETT) | Biosearch Tech. |
| Coupling Time (CEM) | 2 - 4 minutes | [9] |
| Coupling Efficiency | ~99% | [9] |
| Synthesis Scale | 0.2 to 1.0 µmol | Standard |
Table 1: Typical parameters for solid-phase synthesis using a 2'-O-CEM protected phosphoramidite.
Purification and Analysis
Purification of the synthesized oligonucleotide is crucial for accurate downstream analysis. High-Performance Liquid Chromatography (HPLC) is the standard method.
Experimental Protocol: HPLC Purification
-
Method : Reverse-phase HPLC (RP-HPLC) is often used, which separates oligonucleotides based on hydrophobicity. The DMT group, if left on the 5'-end ("DMT-on" synthesis), makes the full-length product significantly more hydrophobic than failed sequences, aiding separation.
-
Column : A C8 or C18 column is typically used.
-
Mobile Phase : A gradient of acetonitrile in a buffer such as 0.1 M triethylammonium (B8662869) acetate (B1210297) (TEAA) is common.
-
Detection : Elution is monitored by UV absorbance at 260 nm.
-
Desalting : The collected fractions containing the pure RNA are desalted, lyophilized, and stored for NMR analysis.
Application in NMR Spectroscopy
The primary advantage of incorporating rU Phosphoramidite-¹³C₉ is the ability to perform high-resolution NMR experiments focused on a specific site within a large RNA. The isolated ¹³C label acts as a sensitive probe of the local environment.
Key Advantages for NMR
-
Simplified Spectra : Eliminates ¹³C-¹³C scalar couplings that broaden signals and complicate spectra in uniformly labeled samples.[1]
-
Enhanced Resolution : Allows for the unambiguous assignment of resonances from the labeled uridine.
-
Dynamic Studies : Facilitates relaxation dispersion experiments to probe conformational dynamics on the microsecond-to-millisecond timescale.[2]
Experimental Protocol: 2D ¹H-¹³C HSQC NMR
The Heteronuclear Single Quantum Coherence (HSQC) experiment is a cornerstone for studying labeled biomolecules. It provides a 2D map correlating the chemical shifts of ¹³C nuclei with their directly attached protons.
-
Sample Preparation : The purified, ¹³C-labeled RNA is dissolved in an appropriate NMR buffer (e.g., 10 mM sodium phosphate, 50 mM NaCl, in 90% H₂O/10% D₂O) to a final concentration of 0.1 - 1.0 mM.
-
Spectrometer Setup : Data is acquired on a high-field NMR spectrometer (e.g., 600 MHz or higher) equipped with a cryoprobe.
-
Data Acquisition : A standard gradient-enhanced HSQC pulse sequence is used.
| Parameter | Typical Setting | Purpose |
| Temperature | 298 K (25 °C) | Controlled sample environment |
| ¹H Spectral Width | 12 ppm | Covers all proton signals |
| ¹³C Spectral Width | 140-160 ppm | Covers expected carbon signals |
| ¹³C Carrier Freq. | ~70 ppm | Centered on the ribose region |
| Recycle Delay (d1) | 1.0 - 2.0 s | Allows for relaxation between scans |
| Number of Scans (nt) | 2 to 16 | Signal averaging for sensitivity |
| Increments (ni) | 128 - 256 | Resolution in the ¹³C dimension |
Table 2: Representative acquisition parameters for a 2D ¹H-¹³C HSQC experiment on a ¹³C-labeled RNA sample.
By analyzing the chemical shifts, intensities, and line shapes of the cross-peaks in the HSQC spectrum, researchers can gain detailed insights into the structure, flexibility, and interaction interfaces of the RNA molecule at the site of the ¹³C-labeled uridine. This information is invaluable for rational drug design, understanding ribozyme mechanisms, and probing RNA-protein interactions.
References
- 1. researchgate.net [researchgate.net]
- 2. Synthesis and incorporation of 13C-labeled DNA building blocks to probe structural dynamics of DNA by NMR - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Synthesis of an Atom-Specifically 2 H/13 C-Labeled Uridine Ribonucleoside Phosphoramidite - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. scite.ai [scite.ai]
- 5. Chemienzymatic synthesis of uridine nucleotides labeled with [15N] and [13C] - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. researchgate.net [researchgate.net]
- 7. mdpi.com [mdpi.com]
- 8. Protocol for the Solid-phase Synthesis of Oligomers of RNA Containing a 2'-O-thiophenylmethyl Modification and Characterization via Circular Dichroism - PMC [pmc.ncbi.nlm.nih.gov]
- 9. 2D 1H-13C HSQC [nmr.chem.ucsb.edu]
The Indispensable Role of Isotopic Labels in Elucidating RNA Structure and Dynamics
A Technical Guide for Researchers and Drug Development Professionals
The expanding universe of RNA's biological functions—from a simple genetic messenger to a complex regulator, catalyst, and structural scaffold—has intensified the need for high-resolution insights into its three-dimensional structure and dynamic behavior.[1][2][3] However, the inherent properties of RNA, such as its limited four-nucleotide alphabet and conformational heterogeneity, present significant challenges to traditional structural biology techniques like X-ray crystallography and standard Nuclear Magnetic Resonance (NMR) spectroscopy.[1][2][3][4] Isotopic labeling, the strategic substitution of atoms with their heavier, stable isotopes (e.g., ²H, ¹³C, ¹⁵N), has emerged as a revolutionary tool, empowering researchers to overcome these hurdles and unlock a deeper understanding of RNA's functional complexities. This guide provides an in-depth exploration of the core principles, methodologies, and applications of isotopic labeling in modern RNA research.
Core Principles of Isotopic Labeling
Isotopic labeling is a technique where atoms within a molecule are replaced by their stable, non-radioactive isotopes. For RNA studies, the most commonly used isotopes are Deuterium (²H), Carbon-13 (¹³C), and Nitrogen-15 (¹⁵N). The rationale for their use is twofold:
-
For NMR Spectroscopy: While the most abundant isotopes of carbon (¹²C) and nitrogen (¹⁴N) are not NMR-active, ¹³C and ¹⁵N possess a nuclear spin that can be detected by NMR. Incorporating these isotopes into RNA makes it "visible" to a wider range of powerful, multi-dimensional NMR experiments that can resolve individual atomic signals.[4][5][6]
-
For Mass Spectrometry (MS): The mass difference between the light (e.g., ¹²C, ¹⁴N) and heavy (e.g., ¹³C, ¹⁵N) isotopes allows for the differentiation and quantification of molecules from different pools.[7][8][9] This is the foundation for "pulse-chase" experiments that track the synthesis, modification, and degradation of RNA over time.[7][8]
Table 1: Common Stable Isotopes in RNA Research
| Isotope | Natural Abundance (%) | Spin (I) | Key Application(s) in RNA Studies |
| ¹H | 99.98 | 1/2 | Standard NMR; high sensitivity but suffers from spectral overlap in large RNAs.[4] |
| ²H (D) | 0.015 | 1 | Reduces NMR line broadening in large RNAs by minimizing dipolar relaxation pathways; simplifies spectra.[1][10][11] |
| ¹³C | 1.1 | 1/2 | Enables multidimensional heteronuclear NMR for resonance assignment and structure determination; used in MS to track carbon-containing precursors.[4][5][7] |
| ¹⁵N | 0.37 | 1/2 | Enables multidimensional heteronuclear NMR, particularly for studying base pairing and RNA-protein interactions; used in MS for quantification.[4][9][12] |
| ¹⁸O | 0.2 | 0 | Used in MS to label the phosphate (B84403) backbone for studying RNA stability and degradation kinetics.[8] |
Methodologies for Isotopic Labeling of RNA
The preparation of isotopically labeled RNA can be achieved through several distinct strategies, each with its own advantages and limitations. The choice of method depends on the research question, the size of the RNA, and the desired labeling pattern.
Enzymatic Synthesis (In Vitro Transcription)
This is the most prevalent method for producing medium-to-large sized RNAs (20-100+ nucleotides) for NMR studies.[2][13] The process utilizes DNA template-directed transcription by T7 RNA polymerase with isotopically labeled ribonucleoside 5'-triphosphates (rNTPs) as substrates.[1][2][3]
-
Uniform Labeling: To label the entire RNA molecule, rNTPs are prepared from microorganisms (like E. coli) grown in media where the sole carbon and nitrogen sources are ¹³C-glucose and ¹⁵N-ammonium sulfate, respectively.[5][6][14]
-
Nucleotide-Specific Labeling: By providing only one type of labeled rNTP (e.g., ¹³C/¹⁵N-ATP) along with the other three unlabeled rNTPs, only the adenosine (B11128) residues in the RNA will be labeled. This drastically simplifies complex NMR spectra.[1]
-
Segmental Labeling: For very large RNAs, uniform labeling results in intractable spectral complexity. Segmental labeling overcomes this by ligating a smaller, isotopically labeled RNA fragment to a larger, unlabeled fragment (or a fragment with a different labeling scheme).[1][15] This "divide-and-conquer" strategy allows for the high-resolution study of specific domains within a large RNA context.[1][10][15] Ligation is typically performed using T4 DNA ligase or T4 RNA ligase.[1][2]
-
Selective/Atom-Specific Labeling: This advanced strategy involves incorporating rNTPs that are labeled only at specific atomic positions (e.g., [6-¹³C]-uridine).[2][4] This eliminates ¹³C-¹³C scalar couplings, which simplifies NMR experiments and is particularly powerful for studying RNA dynamics.[2][12]
Chemical Solid-Phase Synthesis
This method builds RNA oligonucleotides step-by-step on a solid support using labeled phosphoramidite (B1245037) building blocks.[2][16]
-
Key Advantage: It offers complete control over the placement of isotopic labels, enabling true site-specific labeling at any desired position.[13][16] This is the only method that can completely circumvent spectral overlap.[16]
-
Limitations: Historically, chemical synthesis was limited to short RNA sequences (<20 nt).[17] However, recent advancements have extended this length to ~80 nucleotides.[2] The synthesis of labeled phosphoramidites can be complex and expensive.[16]
Metabolic Labeling (In Vivo)
In this approach, living cells are cultured in a medium containing stable isotope-labeled precursors. These precursors are then incorporated into newly synthesized RNA through the cell's natural metabolic pathways. This method is the cornerstone for studying RNA dynamics using mass spectrometry.[7][13] A prominent example is feeding cells [¹³C-methyl]-methionine to trace the dynamics of RNA methylation.[7]
Table 2: Comparison of RNA Labeling Methodologies
| Method | Principle | Key Advantages | Key Limitations | Primary Application |
| Enzymatic Synthesis | In vitro transcription using T7 RNA polymerase and labeled rNTPs.[1] | Versatile (uniform, specific, segmental labeling); suitable for medium to large RNAs; relatively high yield.[1][2] | Can produce RNAs with heterogeneous 3' ends; requires expensive labeled rNTPs.[1][2] | NMR structure and dynamics of RNAs >20 nt. |
| Chemical Synthesis | Stepwise addition of labeled phosphoramidites on a solid support. | Precise, site-specific labeling at any position; produces highly pure RNA with defined ends.[13][16] | Traditionally limited to shorter RNAs (<80 nt); can be expensive and lower yield for long sequences.[2][17] | NMR studies requiring pinpoint labels; synthesis of modified RNAs. |
| Metabolic Labeling | Cells incorporate labeled precursors from growth media into RNA in vivo.[7] | Probes RNA dynamics in a native cellular context; reveals turnover and modification rates.[7] | Labeling pattern depends on cellular metabolism; complex sample matrix. | Mass spectrometry-based studies of RNA turnover and modification dynamics. |
Applications in RNA Structure and Dynamics
Elucidating RNA Structure with NMR Spectroscopy
NMR spectroscopy is a powerful tool for determining the structure and probing the dynamics of biomolecules in solution.[2][3] However, for RNA, the limited chemical shift dispersion of ¹H signals leads to severe spectral overlap, making analysis of all but the smallest RNAs nearly impossible.[1][4]
Isotopic labeling with ¹³C and ¹⁵N is the key to solving this problem. It enables the use of multidimensional heteronuclear experiments (e.g., ¹H-¹⁵N HSQC, ¹H-¹³C HSQC) that correlate the proton signal with the signal of the attached heavy atom. This spreads the crowded signals into two or three dimensions, allowing for the resolution and assignment of individual resonances, even in larger molecules.[5][18]
For RNAs larger than ~30 kDa, line broadening due to rapid relaxation becomes a significant issue. Perdeuteration (labeling with ²H) is an effective strategy to combat this, as it reduces dipolar relaxation and sharpens NMR signals.[1] Combining selective protonation of certain nucleotide types with a deuterated background and segmental labeling is paving the way for NMR studies of RNAs exceeding 100 kDa.[1][11]
Probing RNA Dynamics with NMR and Mass Spectrometry
RNA is not a static molecule; its function is intimately linked to its conformational dynamics.[3]
-
NMR Dynamics: Isotope labels are essential for advanced NMR experiments that measure molecular motions across a wide range of timescales. Site-specifically incorporating isolated ¹³C-¹H spin pairs allows for the artifact-free measurement of dynamics without interference from neighboring ¹³C atoms, providing crucial insights into functional conformational changes.[2][12]
-
MS Dynamics: Mass spectrometry, when combined with metabolic labeling, provides a quantitative window into the lifecycle of RNA. In a pulse-chase experiment , cells are first "pulsed" with a heavy isotope-labeled precursor, and then transferred to "chase" media with the corresponding light, unlabeled precursor. By measuring the ratio of heavy to light RNA over time with MS, one can directly calculate rates of synthesis, decay, and turnover.[7][8] The "¹³C-dynamods" technique, for example, uses [¹³C-methyl]-methionine to specifically quantify the turnover of methylated ribonucleosides in different RNA classes.[7]
Experimental Protocols
Protocol 1: Uniform ¹³C/¹⁵N Labeling of RNA via In Vitro Transcription
This protocol outlines the general steps for producing a uniformly labeled RNA sample for NMR analysis.
-
Preparation of Labeled NTPs:
-
Grow a suitable E. coli strain (e.g., KRX) in M9 minimal medium supplemented with ¹³C-glucose as the sole carbon source and ¹⁵N-ammonium chloride as the sole nitrogen source.[19]
-
Harvest the cells and perform a total RNA extraction.
-
Hydrolyze the bulk RNA to ribonucleoside 5'-monophosphates (rNMPs).
-
Enzymatically convert the labeled rNMPs to rNTPs using appropriate kinases. Purify the resulting labeled rNTPs.[3]
-
-
In Vitro Transcription:
-
Set up a transcription reaction containing a linear DNA template with a T7 promoter, T7 RNA polymerase, and the purified ¹³C/¹⁵N-labeled rNTPs.
-
Incubate the reaction at 37°C for 2-4 hours.
-
Treat the reaction with DNase to digest the DNA template.
-
-
Purification:
-
Purify the transcribed RNA using denaturing polyacrylamide gel electrophoresis (PAGE).
-
Elute the RNA from the gel slice and desalt it using dialysis or size-exclusion chromatography.
-
Quantify the final RNA product and prepare it in the appropriate NMR buffer.
-
Protocol 2: Segmental Isotopic Labeling of RNA using T4 DNA Ligase
This protocol describes how to ligate a labeled RNA fragment to an unlabeled one.
-
Fragment Preparation:
-
Synthesize two RNA fragments separately via in vitro transcription. For Fragment A (to be labeled), use ¹³C/¹⁵N-labeled rNTPs. For Fragment B, use unlabeled rNTPs.
-
Ensure Fragment A has a 5'-monophosphate and Fragment B has a 3'-hydroxyl group at the ligation junction. Purify both fragments.
-
-
Ligation Reaction:
-
Design a short DNA "splint" oligonucleotide that is complementary to the ends of both Fragment A and Fragment B that are to be joined.
-
In a reaction tube, combine Fragment A, Fragment B, and the DNA splint in equimolar amounts. Heat to ~80°C and allow to cool slowly to anneal the fragments to the splint.
-
Add T4 DNA ligase and the appropriate reaction buffer.
-
Incubate at a suitable temperature (e.g., 16°C or 37°C) for several hours to overnight.
-
-
Purification of Full-Length Product:
-
Purify the full-length, segmentally labeled RNA product from unligated fragments and the DNA splint using denaturing PAGE, as described in Protocol 1.
-
Protocol 3: Metabolic Labeling for Turnover Analysis (Pulse-Chase)
This protocol outlines a pulse-chase experiment to measure RNA turnover via MS.
-
Cell Culture (Pulse):
-
Culture mammalian cells in a medium where a standard metabolite is replaced with its heavy isotope-labeled version (e.g., SILAC medium or medium with [¹³C-methyl]-methionine).
-
Grow the cells for a defined "pulse" period to allow for the incorporation of the heavy label into newly transcribed RNA.
-
-
Chase Period:
-
Remove the heavy-label medium and wash the cells thoroughly.
-
Replace the medium with standard "light" medium containing the unlabeled version of the metabolite. This is the start of the "chase."
-
-
Sample Collection:
-
Harvest cells at various time points throughout the chase period (e.g., 0h, 2h, 4h, 8h, 12h, 24h).
-
-
Analysis:
-
Extract total RNA from each time point.
-
Digest the RNA into individual ribonucleosides.
-
Analyze the samples using liquid chromatography-tandem mass spectrometry (LC-MS/MS).
-
For the target nucleoside, quantify the peak areas for both the heavy (m+n) and light (m+0) isotopologues at each time point.[7]
-
Plot the decay of the heavy-labeled RNA species over time to calculate the RNA half-life.[8]
-
Table 3: Example Quantitative Data from a Pulse-Chase Experiment
| Chase Time (hours) | % Labeled RNA Remaining |
| 0 | 100 |
| 4 | 72 |
| 8 | 50 |
| 12 | 35 |
| 24 | 12 |
| This illustrative data shows the decay of a labeled RNA species. The half-life can be determined as the time at which 50% of the labeled RNA remains (in this case, 8 hours).[8] |
Visualizations of Workflows and Logic
Caption: General workflow for preparing isotopically labeled RNA for structural analysis.
Caption: Logical workflow for segmental isotopic labeling of a large RNA molecule.
Caption: Workflow for studying RNA turnover using a pulse-chase experiment and MS.
Conclusion
Isotopic labeling is no longer a niche technique but a foundational pillar of modern RNA research. By providing methods to simplify complex NMR spectra and to track molecules in living cells, it has made previously intractable problems in RNA structural biology and metabolism accessible.[1][7] For researchers, scientists, and drug development professionals, these techniques are indispensable. They provide the high-resolution data needed to understand the mechanism of action of RNA-targeting drugs, assess the stability and fate of RNA therapeutics, and design novel molecules with improved efficacy and safety profiles.[8] As the field moves towards studying ever larger and more complex RNA systems, the continued innovation in isotopic labeling strategies will be paramount to driving the next wave of discoveries in RNA biology and medicine.
References
- 1. Isotope labeling strategies for NMR studies of RNA - PMC [pmc.ncbi.nlm.nih.gov]
- 2. mdpi.com [mdpi.com]
- 3. Isotope-Labeled RNA Building Blocks for NMR Structure and Dynamics Studies - PMC [pmc.ncbi.nlm.nih.gov]
- 4. pubs.acs.org [pubs.acs.org]
- 5. academic.oup.com [academic.oup.com]
- 6. researchgate.net [researchgate.net]
- 7. Metabolic turnover and dynamics of modified ribonucleosides by 13C labeling - PMC [pmc.ncbi.nlm.nih.gov]
- 8. benchchem.com [benchchem.com]
- 9. Quantitative Analysis of rRNA Modifications Using Stable Isotope Labeling and Mass Spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 10. researchgate.net [researchgate.net]
- 11. researchgate.net [researchgate.net]
- 12. mdpi.com [mdpi.com]
- 13. Synthesizing Stable Isotope-Labeled Nucleic Acids | Silantes [silantes.com]
- 14. researchgate.net [researchgate.net]
- 15. Determining RNA solution structure by segmental isotopic labeling and NMR: application to Caenorhabditis elegans spliced leader RNA 1 - PMC [pmc.ncbi.nlm.nih.gov]
- 16. Solid-Phase Chemical Synthesis of Stable Isotope-Labeled RNA to Aid Structure and Dynamics Studies by NMR Spectroscopy - PMC [pmc.ncbi.nlm.nih.gov]
- 17. academic.oup.com [academic.oup.com]
- 18. Simple, efficient protocol for enzymatic synthesis of uniformly 13C, 15N-labeled DNA for heteronuclear NMR studies - PMC [pmc.ncbi.nlm.nih.gov]
- 19. promega.ca [promega.ca]
Methodological & Application
Application Note and Protocol for the Synthesis of 13C-Labeled RNA Oligonucleotides
For Researchers, Scientists, and Drug Development Professionals
Introduction
Stable isotope labeling of RNA oligonucleotides with Carbon-13 (¹³C) is a powerful technique for investigating RNA structure, dynamics, and interactions with other molecules.[1][2] Site-specific incorporation of ¹³C-labeled nucleotides enables detailed analysis by nuclear magnetic resonance (NMR) spectroscopy and mass spectrometry (MS), providing insights that are often unattainable with unlabeled molecules.[1][2] This application note provides a detailed protocol for the chemical synthesis of ¹³C-labeled RNA oligonucleotides using solid-phase phosphoramidite (B1245037) chemistry.
The ability to introduce ¹³C labels at specific positions within an RNA sequence is a significant advantage of chemical synthesis over enzymatic methods, which typically result in uniform labeling.[1][3] This site-specific labeling simplifies NMR spectra, resolves resonance assignment ambiguities, and allows for the study of specific moieties within a larger RNA molecule.[4][5] This protocol is intended for researchers in biochemistry, structural biology, and drug development who require high-purity, site-specifically ¹³C-labeled RNA for their studies.
Materials and Methods
The synthesis of ¹³C-labeled RNA oligonucleotides is a multi-step process that involves the preparation of ¹³C-labeled phosphoramidite building blocks, automated solid-phase synthesis, and subsequent deprotection and purification of the final product.
Preparation of ¹³C-Labeled RNA Phosphoramidites
The foundation of synthesizing ¹³C-labeled RNA is the availability of the corresponding ¹³C-labeled phosphoramidite monomers. These can be either purchased from commercial suppliers or synthesized in the laboratory.[6] The synthesis of these building blocks typically starts from commercially available ¹³C-labeled precursors, such as ¹³C₆-D-glucose.[3]
A general scheme for the synthesis of a ¹³C-ribose-labeled nucleoside phosphoramidite involves:
-
Synthesis of the ¹³C-labeled ribose sugar.
-
Glycosylation of the nucleobase with the labeled ribose.
-
Protection of the 5'-hydroxyl group with a dimethoxytrityl (DMT) group.
-
Protection of the 2'-hydroxyl group with a suitable protecting group such as tert-butyldimethylsilyl (TBDMS) or tri-iso-propylsilyloxymethyl (TOM).[3][7]
-
Phosphitylation of the 3'-hydroxyl group to introduce the phosphoramidite moiety.
Solid-Phase RNA Synthesis
The automated solid-phase synthesis of RNA oligonucleotides is performed on a DNA/RNA synthesizer. The process follows a cyclical four-step procedure for each nucleotide addition: detritylation, coupling, capping, and oxidation.[6][8]
Experimental Protocol:
-
Synthesizer Setup:
-
Install the appropriate ¹³C-labeled and unlabeled RNA phosphoramidite vials on the synthesizer.
-
Ensure all other necessary reagents (activator, oxidizing agent, capping reagents, and deblocking agent) are fresh and correctly installed.
-
Install the solid support column (e.g., controlled pore glass - CPG) with the first nucleoside pre-attached.
-
-
Synthesis Cycle: The synthesis proceeds in the 3' to 5' direction.[6]
-
Step 1: Detritylation (Deblocking): The 5'-DMT protecting group of the nucleotide attached to the solid support is removed by treatment with a mild acid (e.g., trichloroacetic acid in dichloromethane). This exposes the free 5'-hydroxyl group for the next coupling step.
-
Step 2: Coupling: The ¹³C-labeled phosphoramidite, activated by a tetrazole derivative, is coupled to the free 5'-hydroxyl group of the growing RNA chain. The coupling time may need to be extended for RNA synthesis compared to DNA synthesis to ensure high efficiency.[9]
-
Step 3: Capping: Any unreacted 5'-hydroxyl groups are acetylated to prevent them from participating in subsequent coupling steps. This minimizes the formation of deletion mutants.
-
Step 4: Oxidation: The newly formed phosphite (B83602) triester linkage is oxidized to a more stable phosphate (B84403) triester linkage using an oxidizing agent, typically an iodine solution.
-
-
Final Detritylation: After the final coupling cycle, the terminal 5'-DMT group can be either removed on the synthesizer (DMT-off) or left on for purification purposes (DMT-on).
Deprotection and Cleavage
Following synthesis, the RNA oligonucleotide must be cleaved from the solid support and all protecting groups removed. This is a critical step that requires careful execution to avoid degradation of the RNA.
Experimental Protocol:
-
Cleavage from Solid Support and Base Deprotection:
-
The solid support is treated with a mixture of concentrated ammonium (B1175870) hydroxide (B78521) and methylamine (B109427) (AMA) or a similar reagent.[8] This cleaves the oligonucleotide from the support and removes the protecting groups from the nucleobases.
-
The mixture is typically heated to facilitate the removal of the base protecting groups.[10]
-
-
2'-Hydroxyl Protecting Group Removal:
-
The 2'-hydroxyl protecting groups (e.g., TBDMS) are removed by treatment with a fluoride (B91410) source, such as triethylamine (B128534) trihydrofluoride (TEA·3HF) or tetrabutylammonium (B224687) fluoride (TBAF).[7][10] This step is performed in an organic solvent like dimethyl sulfoxide (B87167) (DMSO) or tetrahydrofuran (B95107) (THF).
-
Purification
High-purity RNA is essential for most applications. The crude deprotected oligonucleotide is purified using high-performance liquid chromatography (HPLC) or polyacrylamide gel electrophoresis (PAGE).
Experimental Protocol (HPLC Purification):
-
Column: A reverse-phase or anion-exchange HPLC column is used.
-
Mobile Phases: Gradients of appropriate buffers are used to elute the full-length product. For example, a common mobile phase for anion-exchange HPLC is a gradient of sodium perchlorate (B79767) or sodium chloride in a buffered solution.
-
Fraction Collection: The peak corresponding to the full-length ¹³C-labeled RNA oligonucleotide is collected.
-
Desalting: The purified RNA is desalted using a size-exclusion column or by ethanol (B145695) precipitation.
Results
The success of the synthesis is evaluated by analyzing the purity and identity of the final product.
Quantitative Data Summary
The efficiency of each coupling step and the overall yield of the synthesis are critical parameters. The following table summarizes typical quantitative data for the synthesis of a ¹³C-labeled RNA oligonucleotide compared to its unlabeled counterpart.
| Parameter | Unlabeled RNA | ¹³C-Labeled RNA |
| Average Stepwise Coupling Efficiency | >99% | >98% |
| Overall Crude Yield (ODU) | Variable | Variable |
| Purity by HPLC (Crude) | 50-70% | 45-65% |
| Final Purified Yield (nmol from 1 µmol synthesis) | 50-150 nmol | 40-120 nmol |
Note: Yields can vary significantly depending on the sequence, length of the oligonucleotide, and the specific synthesis and purification conditions.
Characterization
The identity and purity of the ¹³C-labeled RNA oligonucleotide are confirmed by mass spectrometry and NMR.
-
Mass Spectrometry: Electrospray ionization (ESI) or matrix-assisted laser desorption/ionization (MALDI) mass spectrometry is used to confirm the molecular weight of the synthesized RNA. The observed mass should correspond to the calculated mass of the ¹³C-labeled sequence.[11] The incorporation of each ¹³C atom increases the mass by approximately 1.00335 Da.
-
NMR Spectroscopy: ¹H-¹³C heteronuclear single quantum coherence (HSQC) or other multidimensional NMR experiments are used to verify the site-specific incorporation of the ¹³C labels. The spectra will show correlations only for the protons attached to the ¹³C-labeled carbons.
Signaling Pathways and Experimental Workflows
Experimental Workflow for Synthesis of ¹³C-Labeled RNA
The following diagram illustrates the complete workflow for the synthesis, purification, and analysis of ¹³C-labeled RNA oligonucleotides.
Caption: Workflow for ¹³C-labeled RNA synthesis.
Conclusion
This application note provides a comprehensive protocol for the synthesis of high-quality, site-specifically ¹³C-labeled RNA oligonucleotides. The use of ¹³C-labeled phosphoramidites in automated solid-phase synthesis, followed by robust deprotection and purification, allows for the production of labeled RNA suitable for advanced structural and functional studies. The ability to precisely introduce ¹³C labels is invaluable for researchers in academia and industry who are working to elucidate the complex roles of RNA in biological systems and to develop novel RNA-based therapeutics.
References
- 1. Oligonucleotide Synthesis Materials | Cambridge Isotope Laboratories, Inc. [isotope.com]
- 2. pubs.acs.org [pubs.acs.org]
- 3. Short, synthetic and selectively 13C-labeled RNA sequences for the NMR structure determination of protein–RNA complexes - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Stable isotope-labeled RNA phosphoramidites to facilitate dynamics by NMR - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
- 6. mdpi.com [mdpi.com]
- 7. atdbio.com [atdbio.com]
- 8. Protocol for the Solid-phase Synthesis of Oligomers of RNA Containing a 2'-O-thiophenylmethyl Modification and Characterization via Circular Dichroism [jove.com]
- 9. Solid-Phase Synthesis of RNA Analogs Containing Phosphorodithioate Linkages - PMC [pmc.ncbi.nlm.nih.gov]
- 10. glenresearch.com [glenresearch.com]
- 11. pubs.acs.org [pubs.acs.org]
Application Notes and Protocols for rU Phosphoramidite-¹³C₉ in Automated DNA/RNA Synthesizers
For Researchers, Scientists, and Drug Development Professionals
Introduction
The site-specific incorporation of stable isotopes, such as Carbon-13 (¹³C), into RNA molecules is a powerful technique for elucidating their three-dimensional structure, dynamics, and interactions with other molecules.[1] This is particularly crucial in the field of drug development, where RNA has emerged as a significant therapeutic target and a therapeutic agent itself.[2][3] The rU Phosphoramidite-¹³C₉, a uridine (B1682114) phosphoramidite (B1245037) with all nine carbon atoms in the ribose and uracil (B121893) base labeled with ¹³C, is a key reagent for these studies. Its use in automated solid-phase synthesis allows for the precise placement of an NMR-active label within a synthetic RNA oligonucleotide.
These application notes provide a comprehensive guide to the use of rU Phosphoramidite-¹³C₉ in automated DNA/RNA synthesizers, covering synthesis protocols, deprotection, purification, and applications in structural biology and drug discovery.
Key Applications
The primary application of RNA oligonucleotides synthesized with rU Phosphoramidite-¹³C₉ is in Nuclear Magnetic Resonance (NMR) spectroscopy.[4][5] The ¹³C labels serve as sensitive probes for:
-
Structure Determination: Facilitating resonance assignment and the determination of high-resolution 3D structures of RNA and RNA-protein complexes.[1]
-
Dynamics Studies: Probing the internal motions and conformational changes of RNA molecules, which are often critical for their biological function.[6]
-
Ligand Binding Studies: Mapping the binding sites and characterizing the interactions of small molecules, potential drug candidates, with RNA targets.[7] This is instrumental in structure-based drug design.
-
In-cell NMR: Studying the structure and behavior of RNA molecules within a cellular environment, providing insights into their function under physiological conditions.
Automated RNA Synthesis Protocol
The following is a generalized protocol for the incorporation of rU Phosphoramidite-¹³C₉ into an RNA oligonucleotide using a standard automated DNA/RNA synthesizer. Parameters may need to be optimized based on the specific synthesizer, the length and sequence of the oligonucleotide, and the other phosphoramidites being used.
Materials:
-
rU Phosphoramidite-¹³C₉ (and other required RNA phosphoramidites)
-
Controlled Pore Glass (CPG) solid support functionalized with the initial nucleoside
-
Activator solution (e.g., 5-Ethylthio-1H-tetrazole (ETT) or 4,5-Dicyanoimidazole (DCI))
-
Capping reagents (Cap A and Cap B)
-
Oxidizer (e.g., Iodine/water/pyridine)
-
Deblocking reagent (e.g., Trichloroacetic acid in dichloromethane)
-
Anhydrous acetonitrile (B52724)
Synthesis Cycle:
The synthesis follows the standard phosphoramidite chemistry cycle for RNA, which consists of four main steps: deblocking, coupling, capping, and oxidation.[8]
Experimental Workflow for Automated RNA Synthesis
Caption: Automated RNA synthesis cycle using phosphoramidite chemistry.
Protocol Steps:
-
Preparation:
-
Dissolve rU Phosphoramidite-¹³C₉ and other phosphoramidites in anhydrous acetonitrile to the manufacturer's recommended concentration (typically 0.1 M to 0.15 M).
-
Install the phosphoramidite vials, reagents, and the CPG column on the synthesizer.
-
Program the desired RNA sequence and synthesis protocol into the synthesizer software.
-
-
Synthesis Cycle:
-
Deblocking: The 5'-dimethoxytrityl (DMT) protecting group is removed from the nucleoside on the solid support by treatment with a mild acid.
-
Coupling: The rU Phosphoramidite-¹³C₉ is activated by the activator and couples to the free 5'-hydroxyl group of the growing RNA chain. A longer coupling time (e.g., 5-15 minutes) may be beneficial for modified phosphoramidites to ensure high coupling efficiency.[9]
-
Capping: Any unreacted 5'-hydroxyl groups are acetylated to prevent the formation of deletion mutants in subsequent cycles.
-
Oxidation: The newly formed phosphite triester linkage is oxidized to a more stable phosphate triester.
-
-
Cleavage and Deprotection:
-
Upon completion of the synthesis, the CPG support is treated with a mixture of aqueous ammonia (B1221849) and methylamine (B109427) (AMA) or other suitable reagents to cleave the RNA from the support and remove the protecting groups from the phosphate backbone and the nucleobases.[9]
-
The 2'-O-protecting groups (e.g., TBDMS or TOM) are removed in a separate step using a fluoride-based reagent.[10][11]
-
Quantitative Data
The coupling efficiency of each phosphoramidite is critical for the overall yield and purity of the final RNA oligonucleotide. While specific data for rU Phosphoramidite-¹³C₉ is not widely published in a comparative format, the use of 2'-O-TOM protected phosphoramidites generally results in high coupling efficiencies, often exceeding 99%.[11][12]
| Parameter | Typical Value (2'-O-TOM protected) | Factors Influencing |
| Coupling Efficiency | > 99% | Activator choice, coupling time, phosphoramidite purity |
| Overall Yield (20-mer) | 30-50% | Synthesis scale, sequence, purification method |
| Purity (post-HPLC) | > 95% | Purification method, synthesis efficiency |
Note: These are typical values and may vary depending on experimental conditions.
Experimental Protocols
Deprotection of Synthetic RNA
Materials:
-
Ammonium hydroxide/methylamine (AMA) solution
-
Triethylamine trihydrofluoride (TEA·3HF)
-
N-methyl-2-pyrrolidone (NMP) or Dimethyl sulfoxide (B87167) (DMSO)
-
Sodium acetate (B1210297)
-
Butanol or Ethanol (B145695)
Protocol:
-
Base and Phosphate Deprotection:
-
Treat the CPG support with AMA solution at 65°C for 15-30 minutes.
-
Cool the solution and transfer the supernatant containing the RNA to a new tube.
-
Evaporate the solution to dryness.
-
-
2'-O-Protecting Group Removal (TBDMS):
-
Resuspend the dried RNA pellet in a solution of TEA·3HF in NMP or DMSO.
-
Incubate at 65°C for 1.5-2.5 hours.
-
-
Quenching and Precipitation:
-
Quench the reaction by adding a solution of sodium acetate.
-
Precipitate the RNA by adding butanol or ethanol and cooling to -20°C.
-
Centrifuge to pellet the RNA, wash with ethanol, and dry the pellet.
-
Purification by HPLC
High-performance liquid chromatography (HPLC) is the preferred method for purifying synthetic RNA to achieve the high purity required for NMR and other applications.[5][13]
Materials:
-
HPLC system with a suitable reverse-phase column (e.g., C18)
-
Mobile Phase A: Triethylammonium acetate (TEAA) buffer
-
Mobile Phase B: Acetonitrile
-
Denaturing agent (optional, e.g., urea) for structured RNAs
Protocol:
-
Sample Preparation: Dissolve the deprotected and precipitated RNA in an appropriate buffer.
-
Chromatography:
-
Equilibrate the column with the starting mobile phase composition.
-
Inject the sample and elute with a gradient of increasing acetonitrile concentration.
-
Monitor the elution profile at 260 nm.
-
-
Fraction Collection: Collect the fractions corresponding to the full-length product.
-
Desalting: Desalt the purified RNA using a suitable method, such as size-exclusion chromatography or ethanol precipitation.
Workflow for RNA Purification and Analysis
Caption: Post-synthesis workflow for purification and quality control.
Application in Drug Development: Studying RNA-Ligand Interactions
A key application of ¹³C-labeled RNA in drug development is the detailed characterization of how a potential drug molecule interacts with its RNA target. NMR titration experiments are a powerful tool for this purpose.[7]
Signaling Pathway: mRNA Translation Initiation
The initiation of mRNA translation is a tightly regulated process and a potential target for therapeutic intervention. The binding of initiation factors and the ribosome to the 5' untranslated region (UTR) of an mRNA can be modulated by small molecules. NMR studies using ¹³C-labeled RNA can elucidate the structural basis of these interactions.
Caption: Targeting mRNA translation initiation with a small molecule.
NMR Titration Experimental Protocol
Objective: To identify the binding site of a small molecule on a ¹³C-labeled RNA.
Materials:
-
Purified ¹³C-labeled RNA
-
Small molecule ligand of interest
-
NMR buffer (e.g., phosphate buffer in D₂O)
Protocol:
-
Sample Preparation: Prepare a series of NMR samples with a constant concentration of the ¹³C-labeled RNA and increasing concentrations of the ligand.
-
NMR Data Acquisition: Acquire a series of 2D ¹H-¹³C HSQC spectra for each sample. This experiment correlates the chemical shifts of protons with their directly attached ¹³C nuclei.
-
Data Analysis:
-
Overlay the spectra from the titration series.
-
Monitor the chemical shift perturbations (CSPs) of the RNA resonances upon addition of the ligand.
-
Residues exhibiting significant CSPs are likely at or near the binding site.
-
By using rU Phosphoramidite-¹³C₉, the uridine residues become specific probes. Changes in their NMR signals upon ligand binding provide precise information about the involvement of these residues in the interaction.
Conclusion
rU Phosphoramidite-¹³C₉ is an invaluable tool for researchers in academia and the pharmaceutical industry. Its incorporation into synthetic RNA via automated solid-phase synthesis enables detailed structural and dynamic studies by NMR spectroscopy. These studies are fundamental to understanding RNA biology and to the rational design of novel RNA-targeted therapeutics. The protocols and data presented here provide a framework for the successful application of this powerful reagent.
References
- 1. HPLC Purification of Chemically Modified RNA Aptamers - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Protocol for the Solid-phase Synthesis of Oligomers of RNA Containing a 2'-O-thiophenylmethyl Modification and Characterization via Circular Dichroism - PMC [pmc.ncbi.nlm.nih.gov]
- 3. academic.oup.com [academic.oup.com]
- 4. CN102439025A - Rna synthesis - phosphoramidites for synthetic rna in the reverse direction, and application in convenient introduction of ligands, chromophores and modifications of synthetic rna at the 3' - end - Google Patents [patents.google.com]
- 5. agilent.com [agilent.com]
- 6. mdpi.com [mdpi.com]
- 7. NMR Characterization of RNA Small Molecule Interactions - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Synthesis of DNA/RNA and Their Analogs via Phosphoramidite and H-Phosphonate Chemistries - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Synthesis, deprotection, analysis and purification of RNA and ribozymes - PMC [pmc.ncbi.nlm.nih.gov]
- 10. researchgate.net [researchgate.net]
- 11. glenresearch.com [glenresearch.com]
- 12. glenresearch.com [glenresearch.com]
- 13. nacalai.com [nacalai.com]
Revolutionizing RNA Research: A Guide to Site-Specific 13C Labeling
Application Note & Protocol
Audience: Researchers, scientists, and drug development professionals.
Introduction: The precise understanding of RNA structure, dynamics, and interactions is paramount in modern molecular biology and drug development. Site-specific incorporation of stable isotopes, such as Carbon-13 (¹³C), into RNA sequences provides a powerful tool for high-resolution structural studies by Nuclear Magnetic Resonance (NMR) spectroscopy. This application note details the primary methodologies for achieving site-specific ¹³C labeling of RNA, presents quantitative data for each technique, and provides detailed experimental protocols to enable researchers to apply these methods in their own laboratories. The ability to introduce ¹³C labels at specific atomic positions within an RNA molecule significantly simplifies complex NMR spectra, facilitating resonance assignment and the characterization of functionally important conformational changes.[1][2][3][4] This is particularly crucial for elucidating the mechanisms of action of RNA-based therapeutics and their interactions with target molecules.[5][6]
Methodologies for Site-Specific ¹³C Labeling of RNA
Three principal strategies are employed for the site-specific incorporation of ¹³C labels into RNA sequences:
-
Solid-Phase Chemical Synthesis: This bottom-up approach involves the chemical synthesis of RNA oligonucleotides on a solid support using ¹³C-labeled phosphoramidite (B1245037) building blocks.[1][3][4] It offers unparalleled control over the placement of isotopic labels at any desired position within the RNA sequence.[1] This method is particularly advantageous for the synthesis of short RNA sequences (typically < 60 nucleotides).[1][7]
-
Enzymatic Synthesis (In Vitro Transcription): This method utilizes enzymes, most commonly T7 RNA polymerase, to synthesize RNA from a DNA template using ¹³C-labeled ribonucleoside triphosphates (NTPs).[8][9] It is well-suited for the production of larger RNA molecules.[8] Site-specificity can be achieved by providing a mix of labeled and unlabeled NTPs, although achieving single-site labeling in a long transcript can be challenging. Chemo-enzymatic approaches that combine chemical synthesis of labeled precursors with enzymatic reactions offer a versatile route to producing specifically labeled NTPs.[10][11][12]
-
Ribozyme-Catalyzed Labeling: This emerging technique employs catalytic RNA molecules (ribozymes) to site-specifically modify an RNA target.[13][14][15] For instance, engineered ribozymes can transfer a ¹³C-labeled group from a cofactor to a specific nucleotide within the target RNA.[13][14][16] This method holds promise for labeling RNA in a highly specific and potentially cellular context.
Quantitative Data Comparison
The choice of labeling strategy often depends on the desired RNA length, the required amount of labeled material, and the specific labeling pattern. The following table summarizes key quantitative parameters for each method.
| Parameter | Solid-Phase Chemical Synthesis | Enzymatic Synthesis (In Vitro Transcription) | Ribozyme-Catalyzed Labeling |
| Typical RNA Length | 2 - 80 nucleotides[1][7] | > 20 nucleotides[1] | Variable, demonstrated on fragments and full-length tRNA[13] |
| Overall Yield | Drops with increasing length, typically in the range of 0.2-0.6 mM in 300 µL for a 1 µmol synthesis[17] | 0.2–2.0 mM in 300 µL for a 20 mL IVT reaction[17] | ~50% isolated yield for a site-specifically labeled fragment[18] |
| Incorporation Efficiency | High, approaching 100% for each coupling step[4] | High, dependent on polymerase fidelity | Variable, can be nearly quantitative under optimal conditions[16] |
| Purity | >95% achievable with purification[7] | High, but can contain 3'-end heterogeneity[3] | High, requires purification to remove ribozyme and cofactors |
| Scalability | Readily scalable by increasing synthesis batches | Scalable to produce milligram quantities[8] | Currently more suited for smaller scale applications |
Experimental Protocols
Protocol 1: Site-Specific ¹³C Labeling of RNA via Solid-Phase Chemical Synthesis
This protocol outlines the general steps for synthesizing an RNA oligonucleotide with a site-specifically incorporated ¹³C-labeled nucleotide using an automated DNA/RNA synthesizer.
Materials:
-
Unlabeled 2'-O-TOM protected ribonucleoside phosphoramidites (A, C, G, U)
-
Site-specifically ¹³C-labeled 2'-O-TOM protected ribonucleoside phosphoramidite (e.g., [1',2',3',4',5'-¹³C₅]-uridine phosphoramidite)[1]
-
Controlled pore glass (CPG) solid support functionalized with the first nucleoside
-
Standard DNA/RNA synthesis reagents (activator, capping reagents, oxidizing agent, deblocking agent)
-
Deprotection solution (e.g., AMA - ammonium (B1175870) hydroxide/methylamine)
-
Desilylation solution (e.g., triethylamine (B128534) trihydrofluoride)
-
HPLC purification system and columns
-
MALDI-TOF mass spectrometer
Procedure:
-
Synthesizer Setup: Program the RNA synthesizer with the desired sequence, specifying the cycle for the incorporation of the ¹³C-labeled phosphoramidite.
-
Automated Synthesis: Initiate the automated synthesis protocol. The synthesizer will perform the following steps for each nucleotide addition:
-
Deblocking: Removal of the 5'-dimethoxytrityl (DMT) protecting group.
-
Coupling: Addition of the next phosphoramidite (either labeled or unlabeled) to the growing RNA chain.
-
Capping: Acetylation of unreacted 5'-hydroxyl groups to prevent the formation of deletion mutants.
-
Oxidation: Conversion of the phosphite (B83602) triester linkage to a more stable phosphate (B84403) triester.
-
-
Cleavage and Deprotection: Following synthesis, cleave the RNA from the solid support and remove the protecting groups using AMA at an elevated temperature.
-
Desilylation: Remove the 2'-O-silyl protecting groups using a suitable fluoride-based reagent.
-
Purification: Purify the crude RNA oligonucleotide using denaturing polyacrylamide gel electrophoresis (PAGE) or high-performance liquid chromatography (HPLC).
-
Analysis: Confirm the identity and purity of the final ¹³C-labeled RNA product by MALDI-TOF mass spectrometry and analytical HPLC.
Protocol 2: Enzymatic Synthesis of a Site-Specifically ¹³C-Labeled RNA Transcript
This protocol describes the in vitro transcription of an RNA molecule with a specific ¹³C-labeled nucleotide using T7 RNA polymerase.
Materials:
-
Linearized plasmid DNA or PCR-generated DNA template with a T7 promoter sequence
-
T7 RNA polymerase
-
Unlabeled ribonucleoside triphosphates (NTPs: ATP, CTP, GTP, UTP)
-
Site-specifically ¹³C-labeled NTP (e.g., [6-¹³C]-UTP)
-
Transcription buffer (containing Tris-HCl, MgCl₂, DTT, spermidine)
-
RNase inhibitor
-
DNase I
-
Denaturing polyacrylamide gel electrophoresis (dPAGE) reagents
-
Elution buffer (e.g., 0.5 M ammonium acetate, 1 mM EDTA)
Procedure:
-
Transcription Reaction Setup: In an RNase-free microcentrifuge tube, combine the transcription buffer, DTT, spermidine, unlabeled NTPs, the ¹³C-labeled NTP, DNA template, RNase inhibitor, and T7 RNA polymerase.
-
Incubation: Incubate the reaction mixture at 37°C for 2-4 hours.
-
DNase Treatment: Add DNase I to the reaction mixture and incubate for an additional 15-30 minutes at 37°C to digest the DNA template.
-
Purification: Purify the transcribed RNA using dPAGE. Visualize the RNA by UV shadowing, excise the corresponding band, and elute the RNA from the gel slice using an appropriate elution buffer.
-
Desalting and Concentration: Desalt and concentrate the purified RNA using spin columns or ethanol (B145695) precipitation.
-
Quantification and Analysis: Determine the concentration of the labeled RNA by UV-Vis spectrophotometry. Verify the integrity and purity of the transcript by dPAGE and mass spectrometry.
Visualizations
Caption: Workflow for solid-phase synthesis of ¹³C-labeled RNA.
Caption: Workflow for enzymatic synthesis of ¹³C-labeled RNA.
Caption: General signaling pathway for ribozyme-catalyzed RNA labeling.
Applications in Drug Development
The ability to produce site-specifically ¹³C-labeled RNA has significant implications for drug development.[5] By using NMR to study the structure and dynamics of these labeled molecules, researchers can:
-
Elucidate Drug Binding Sites: Determine the precise location and mode of interaction between a small molecule drug and its RNA target.
-
Characterize Conformational Changes: Observe how drug binding alters the three-dimensional structure and flexibility of the RNA, providing insights into the mechanism of action.
-
Screen for Novel Binders: Develop high-throughput NMR screening assays to identify new drug candidates that bind to a specific RNA target.
-
Optimize Lead Compounds: Guide the rational design of more potent and selective RNA-targeting drugs by understanding the structure-activity relationship at an atomic level.
Conclusion
Site-specific incorporation of ¹³C labels into RNA is an indispensable tool for modern structural biology and drug discovery. The choice between solid-phase synthesis, enzymatic methods, or ribozyme-catalyzed approaches depends on the specific research question and the properties of the RNA molecule of interest. The detailed protocols and comparative data provided in this application note serve as a valuable resource for researchers seeking to leverage the power of isotope labeling to unravel the complexities of RNA function and to accelerate the development of novel RNA-targeted therapeutics.
References
- 1. Short, synthetic and selectively 13C-labeled RNA sequences for the NMR structure determination of protein–RNA complexes - PMC [pmc.ncbi.nlm.nih.gov]
- 2. pubs.acs.org [pubs.acs.org]
- 3. mdpi.com [mdpi.com]
- 4. Synthesis and incorporation of 13C-labeled DNA building blocks to probe structural dynamics of DNA by NMR - PMC [pmc.ncbi.nlm.nih.gov]
- 5. mdpi.com [mdpi.com]
- 6. RNA-based Therapeutics- Current Progress and Future Prospects - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Chemical synthesis and NMR spectroscopy of long stable isotope labelled RNA - Chemical Communications (RSC Publishing) DOI:10.1039/C7CC06747J [pubs.rsc.org]
- 8. Isotope labeling strategies for NMR studies of RNA - PMC [pmc.ncbi.nlm.nih.gov]
- 9. researchgate.net [researchgate.net]
- 10. Chemo-enzymatic synthesis of selectively 13C/15N-labeled RNA for NMR structural and dynamics studies - PMC [pmc.ncbi.nlm.nih.gov]
- 11. researchgate.net [researchgate.net]
- 12. researchgate.net [researchgate.net]
- 13. Ribozyme‐Catalyzed Site‐Specific Labeling of RNA Using O 6‐alkylguanine SNAP‐Tag Substrates - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Ribozyme-Catalyzed Site-Specific Labeling of RNA Using O6-alkylguanine SNAP-Tag Substrates - PubMed [pubmed.ncbi.nlm.nih.gov]
- 15. Ribozyme - Wikipedia [en.wikipedia.org]
- 16. researchgate.net [researchgate.net]
- 17. Isotope-Labeled RNA Building Blocks for NMR Structure and Dynamics Studies [mdpi.com]
- 18. Site-specific isotope labeling of long RNA for structural and mechanistic studies - PMC [pmc.ncbi.nlm.nih.gov]
Application Notes and Protocols for rU Phosphoramidite-¹³C₉ in NMR Analysis of RNA Structure
For Researchers, Scientists, and Drug Development Professionals
Introduction
The determination of high-resolution three-dimensional structures of RNA is fundamental to understanding its diverse biological roles and for the rational design of RNA-targeting therapeutics. Nuclear Magnetic Resonance (NMR) spectroscopy is a powerful technique for studying the structure and dynamics of biomolecules in solution. However, for RNA molecules, spectral overlap and complexity increase significantly with size, posing a major challenge for traditional NMR methods. The incorporation of stable isotopes, such as Carbon-13 (¹³C), into RNA molecules provides a crucial tool to overcome these limitations.
This document provides detailed application notes and protocols for the use of ribouridine phosphoramidite (B1245037) uniformly labeled with nine ¹³C atoms (rU Phosphoramidite-¹³C₉) in the solid-phase synthesis of RNA for NMR analysis. Site-specific or uniform incorporation of ¹³C-labeled uridine (B1682114) residues significantly enhances spectral resolution and enables the use of advanced NMR experiments to probe RNA structure, dynamics, and interactions with ligands or proteins.
Advantages of ¹³C-Labeling in RNA NMR
The use of rU Phosphoramidite-¹³C₉ offers several key advantages for the structural analysis of RNA by NMR:
-
Resolved Spectral Overlap: The large chemical shift dispersion of ¹³C nuclei helps to resolve overlapping proton signals, which is a common problem in larger RNA molecules.
-
Enhanced Structural Restraints: ¹³C-labeling allows for the measurement of one-bond and multi-bond ¹³C-¹³C and ¹H-¹³C J-coupling constants, which provide valuable dihedral angle information for high-resolution structure determination.
-
Probing Molecular Dynamics: ¹³C relaxation experiments (T₁, T₂, and NOE) on labeled sites provide insights into the internal motions of the RNA molecule on a wide range of timescales, from picoseconds to milliseconds. This is critical for understanding RNA function and its interactions.
-
Facilitating Advanced NMR Experiments: Isotopic labeling is a prerequisite for a variety of powerful heteronuclear NMR experiments, such as HSQC, HMQC, and NOESY-HSQC, which are essential for resonance assignment and structure calculation of larger RNAs.
-
Studying Molecular Interactions: ¹³C-labeled RNA is instrumental in mapping the binding sites of proteins, small molecules, and other nucleic acids. Chemical shift perturbation mapping of the ¹³C signals upon ligand binding provides precise information about the interaction interface.
Data Presentation
The following tables summarize typical quantitative data obtained from NMR analysis of RNA containing ¹³C-labeled uridine residues. These values can vary depending on the local structure, sequence context, and experimental conditions.
Table 1: Representative ¹³C Chemical Shifts for Uridine in a Helical RNA Context
| Atom | Chemical Shift Range (ppm) | Notes |
| C1' | 90.0 - 94.0 | Sensitive to sugar pucker conformation. |
| C2' | 72.0 - 78.0 | Influenced by the 2'-OH protecting group in synthesis. |
| C3' | 70.0 - 76.0 | Reflects backbone conformation. |
| C4' | 82.0 - 86.0 | Involved in the phosphodiester backbone. |
| C5' | 60.0 - 65.0 | Sensitive to backbone torsion angles. |
| C2 | 150.0 - 155.0 | Carbonyl carbon in the uracil (B121893) base. |
| C4 | 163.0 - 168.0 | Carbonyl carbon in the uracil base. |
| C5 | 101.0 - 105.0 | Vinylic carbon in the uracil base. |
| C6 | 140.0 - 145.0 | Vinylic carbon in the uracil base. |
Note: Chemical shifts are referenced to an external standard, typically DSS or TSP.
Table 2: Typical One-Bond ¹H-¹³C J-Coupling Constants in Uridine
| Coupling | Typical Value (Hz) | Structural Information |
| ¹J(H1'-C1') | 160 - 170 | |
| ¹J(H2'-C2') | 145 - 155 | |
| ¹J(H3'-C3') | 145 - 155 | |
| ¹J(H4'-C4') | 145 - 155 | |
| ¹J(H5-C5) | 170 - 180 | |
| ¹J(H6-C6) | 175 - 185 |
Table 3: Representative ¹³C Relaxation Rates for Uridine in a Structured RNA
| Parameter | Typical Value (s⁻¹) | Information Gained |
| R₁ (T₁) | 1.5 - 2.5 | Overall molecular tumbling and fast internal motions. |
| R₂ (T₂) | 10 - 20 | Slower timescale motions (μs-ms) and chemical exchange. |
| Het-NOE | 0.6 - 0.8 | Amplitude of fast internal motions (ps-ns). |
Note: Relaxation rates are dependent on the magnetic field strength and the overall rotational correlation time of the molecule.
Experimental Protocols
Protocol 1: Solid-Phase Synthesis of ¹³C-Labeled RNA
This protocol outlines the general steps for incorporating rU Phosphoramidite-¹³C₉ into an RNA oligonucleotide using an automated solid-phase synthesizer. The use of 2'-O-TOM (tri-isopropylsilyloxymethyl) protecting groups is described here, as it is a common and robust method.
Materials:
-
rU Phosphoramidite-¹³C₉
-
Unlabeled A, G, C, U phosphoramidites (with 2'-O-TOM protection)
-
Controlled Pore Glass (CPG) solid support functionalized with the first nucleoside
-
Activator solution (e.g., DCI or ETT)
-
Oxidizing solution (e.g., I₂ in THF/pyridine/water)
-
Capping reagents (e.g., Acetic Anhydride and N-Methylimidazole)
-
Deblocking solution (e.g., 3% Trichloroacetic acid in Dichloromethane)
-
Anhydrous acetonitrile (B52724)
-
Automated DNA/RNA synthesizer
Procedure:
-
Synthesizer Setup: Dissolve the rU Phosphoramidite-¹³C₉ and unlabeled phosphoramidites in anhydrous acetonitrile to the manufacturer's recommended concentration and install them on the synthesizer.
-
Synthesis Cycle: The automated synthesis proceeds through a series of iterative cycles for each nucleotide addition:
-
Detritylation: Removal of the 5'-dimethoxytrityl (DMT) protecting group from the growing RNA chain on the solid support using the deblocking solution.
-
Coupling: Activation of the incoming phosphoramidite (labeled or unlabeled) with the activator solution and its subsequent coupling to the free 5'-hydroxyl group of the growing chain.
-
Capping: Acetylation of any unreacted 5'-hydroxyl groups to prevent the formation of deletion mutants.
-
Oxidation: Conversion of the phosphite (B83602) triester linkage to a more stable phosphate (B84403) triester using the oxidizing solution.
-
-
Cleavage and Deprotection:
-
After the final synthesis cycle, the CPG support is transferred to a vial.
-
The RNA is cleaved from the support, and the base and phosphate protecting groups are removed by incubation in a mixture of aqueous ammonia (B1221849) and methylamine (B109427) (AMA) at an elevated temperature.
-
-
2'-O-Protecting Group Removal: The 2'-O-TOM groups are removed by treatment with a fluoride (B91410) reagent, such as triethylamine (B128534) trihydrofluoride (TEA·3HF).
-
Purification: The crude RNA is purified by denaturing polyacrylamide gel electrophoresis (PAGE) or high-performance liquid chromatography (HPLC).
-
Desalting and Sample Preparation: The purified RNA is desalted using size-exclusion chromatography or dialysis and then lyophilized. The final RNA sample is dissolved in the appropriate NMR buffer.
Protocol 2: NMR Sample Preparation and Data Acquisition
Materials:
-
Lyophilized, purified ¹³C-labeled RNA
-
NMR buffer (e.g., 10 mM sodium phosphate, 100 mM NaCl, 0.1 mM EDTA, pH 6.5)
-
D₂O for lock signal
-
NMR tubes
Procedure:
-
Sample Dissolution: Dissolve the lyophilized RNA in the NMR buffer to a final concentration of 0.1 - 1.0 mM.
-
Annealing: To ensure proper folding, heat the RNA solution to 95°C for 5 minutes, followed by slow cooling to room temperature.
-
NMR Tube Preparation: Transfer the RNA solution to a clean NMR tube, adding 5-10% D₂O for the lock signal.
-
NMR Spectroscopy:
-
Acquire a one-dimensional ¹H NMR spectrum to assess the overall folding and purity of the RNA.
-
Perform a two-dimensional ¹H-¹³C HSQC experiment to visualize the correlation between directly bonded protons and ¹³C nuclei. This is the primary experiment to leverage the ¹³C labels for resonance assignment.
-
Acquire a suite of multidimensional NMR experiments for structure determination, such as:
-
2D NOESY and 3D ¹³C-edited NOESY-HSQC for obtaining distance restraints.
-
Homonuclear and heteronuclear correlation experiments (e.g., TOCSY, HCCH-TOCSY) for assigning sugar and base resonances.
-
Experiments to measure J-coupling constants for dihedral angle restraints.
-
-
For dynamics studies, perform ¹³C T₁, T₂, and heteronuclear NOE experiments.
-
Visualization of Experimental Workflow and Biological Application
Experimental Workflow
The following diagram illustrates the overall workflow from the synthesis of ¹³C-labeled RNA to its structural analysis by NMR.
Caption: Workflow for RNA structure analysis using ¹³C-labeled phosphoramidites.
Application: Riboswitch-Ligand Interaction
A key application of this technology is in studying the structure of riboswitches, which are regulatory RNA elements that change their conformation upon binding to a specific metabolite, thereby controlling gene expression. The diagram below illustrates the principle of a riboswitch mechanism that can be elucidated using NMR with ¹³C-labeled RNA.
Caption: A riboswitch mechanism elucidated by NMR using ¹³C-labeled RNA.
Conclusion
The use of rU Phosphoramidite-¹³C₉ in the chemical synthesis of RNA is a powerful strategy for high-resolution structural and dynamic studies by NMR spectroscopy. The ability to introduce isotopic labels at specific sites within an RNA molecule provides an unparalleled level of detail, which is essential for understanding the intricate relationship between RNA structure and function. The protocols and data presented here serve as a guide for researchers in academia and industry to apply this technology to their own systems of interest, ultimately advancing the field of RNA biology and RNA-targeted drug discovery.
Illuminating the Druggable Transcriptome: Applications of ¹³C-Labeled RNA in Drug Discovery
For Immediate Release
In the intricate landscape of modern drug discovery, ribonucleic acid (RNA) has emerged as a compelling and increasingly "druggable" target. The ability to precisely probe the structure, dynamics, and interactions of RNA molecules is paramount to developing novel therapeutics. Isotope labeling, particularly with Carbon-13 (¹³C), has become an indispensable tool for researchers, offering unprecedented insights into the RNA world. These application notes provide a comprehensive overview of the utility of ¹³C-labeled RNA in drug discovery, complete with detailed protocols and data interpretation guidelines for researchers, scientists, and drug development professionals.
Key Applications of ¹³C-Labeled RNA in Drug Discovery
The strategic incorporation of ¹³C isotopes into RNA molecules significantly enhances nuclear magnetic resonance (NMR) spectroscopy studies, a cornerstone technique for characterizing RNA-small molecule interactions. The primary applications include:
-
High-Resolution Structural Analysis: ¹³C-labeling helps to overcome the inherent spectral overlap in NMR spectra of RNA, enabling the unambiguous assignment of resonances and the determination of high-resolution three-dimensional structures of RNA-drug complexes.[1] This structural information is critical for structure-based drug design and optimization.
-
Mapping Drug Binding Sites: Chemical Shift Perturbation (CSP) analysis of ¹³C-labeled RNA upon titration with a small molecule ligand allows for the precise identification of the drug's binding site on the RNA target.[2] By monitoring changes in the chemical shifts of specific ¹³C-labeled nucleotides, researchers can map the interaction interface at single-nucleotide resolution.
-
Characterizing RNA Dynamics: Understanding the conformational dynamics of RNA is crucial, as these motions can play a significant role in drug binding and mechanism of action. ¹³C NMR relaxation dispersion experiments on labeled RNA can quantify these dynamics on functionally relevant timescales.[3]
-
Fragment-Based Drug Discovery (FBDD): NMR-based screening of fragment libraries is a powerful approach for identifying starting points for drug development. Using ¹³C-labeled RNA enhances the sensitivity and resolution of these screens, facilitating the identification of low-affinity binders that can be optimized into potent leads.[4][5]
-
In-Cell NMR Studies: The application of ¹³C-labeling extends to studying RNA-drug interactions within the complex environment of a living cell. In-cell NMR provides a more physiologically relevant understanding of how a drug engages its RNA target in its native context.
Quantitative Data Summary
The advantages of using ¹³C-labeled RNA in NMR-based drug discovery are not merely qualitative. The following tables summarize the quantitative improvements observed in key NMR parameters.
Table 1: Comparison of NMR Spectral Properties with and without ¹³C-Labeling
| Parameter | Unlabeled RNA | ¹³C-Labeled RNA | Fold Improvement |
| Average ¹H Linewidth (Hz) | 25-40 | 15-25 | ~1.5 - 2.0 |
| Signal-to-Noise Ratio | Base | ~3-5x Base | 3-5 |
| ¹H Chemical Shift Dispersion (ppm) | ~1.5 | ~1.5 | No significant change |
| ¹³C Chemical Shift Dispersion (ppm) | N/A | ~30 | N/A |
Note: Data is generalized from typical observations in the field. Actual values may vary depending on the specific RNA, labeling strategy, and NMR experimental conditions.
Table 2: Representative Chemical Shift Perturbation (CSP) Data for Drug Binding to a ¹³C-Labeled RNA Target
| Nucleotide Residue | ¹³C Chemical Shift (Apo, ppm) | ¹³C Chemical Shift (Holo, ppm) | Chemical Shift Perturbation (Δδ, ppm) |
| G5-C8 | 137.2 | 137.9 | 0.7 |
| A6-C2 | 153.5 | 154.3 | 0.8 |
| U15-C6 | 141.8 | 141.9 | 0.1 |
| C22-C5 | 97.4 | 98.5 | 1.1 |
| G23-C8 | 136.9 | 138.1 | 1.2 |
This table represents hypothetical data illustrating typical CSP values observed upon ligand binding to a ¹³C-labeled RNA. The magnitude of the perturbation indicates the proximity of the nucleotide to the binding site.
Experimental Protocols
Protocol 1: Synthesis of ¹³C-Labeled RNA by In Vitro Transcription
This protocol describes the synthesis of uniformly ¹³C-labeled RNA using T7 RNA polymerase.
Materials:
-
Linearized DNA template with a T7 promoter
-
¹³C-labeled ribonucleoside triphosphates (¹³C-NTPs) (ATP, GTP, CTP, UTP)
-
T7 RNA Polymerase
-
Transcription Buffer (400 mM Tris-HCl pH 8.0, 60 mM MgCl₂, 100 mM DTT, 20 mM Spermidine)
-
RNase Inhibitor
-
DNase I (RNase-free)
-
Nuclease-free water
Procedure:
-
Assemble the transcription reaction at room temperature in the following order:
-
Nuclease-free water to a final volume of 100 µL
-
20 µL of 5x Transcription Buffer
-
10 µL of each ¹³C-NTP (100 mM stock)
-
1 µg of linearized DNA template
-
2 µL of RNase Inhibitor (40 U/µL)
-
5 µL of T7 RNA Polymerase (50 U/µL)
-
-
Incubate the reaction at 37°C for 2-4 hours.
-
Add 2 µL of DNase I and incubate for an additional 15 minutes at 37°C to digest the DNA template.
-
Purify the RNA transcript using denaturing polyacrylamide gel electrophoresis (PAGE) or a suitable RNA purification kit.
-
Quantify the yield and assess the purity of the ¹³C-labeled RNA by UV-Vis spectroscopy and gel electrophoresis.
Protocol 2: NMR-Based Titration for Characterizing RNA-Ligand Interactions
This protocol outlines a typical NMR titration experiment to measure the binding affinity and map the binding site of a small molecule to a ¹³C-labeled RNA target.
Materials:
-
¹³C-labeled RNA sample (typically 50-100 µM in a suitable NMR buffer)
-
Concentrated stock solution of the small molecule ligand in the same NMR buffer
-
NMR spectrometer equipped with a cryoprobe
-
NMR tubes
Procedure:
-
Prepare the ¹³C-labeled RNA sample in an appropriate NMR buffer (e.g., 25 mM sodium phosphate, 50 mM NaCl, pH 6.5 in 90% H₂O/10% D₂O).
-
Acquire a reference 2D ¹H-¹³C HSQC spectrum of the apo (ligand-free) RNA.
-
Add a small aliquot of the concentrated ligand stock solution to the RNA sample to achieve a specific molar ratio (e.g., 0.25:1 ligand:RNA).
-
Gently mix the sample and allow it to equilibrate.
-
Acquire another 2D ¹H-¹³C HSQC spectrum.
-
Repeat steps 3-5, incrementally increasing the ligand concentration (e.g., 0.5:1, 1:1, 2:1, 5:1 molar ratios).
-
Process and analyze the series of HSQC spectra. Overlay the spectra to visualize the chemical shift perturbations of specific RNA resonances.
-
Calculate the weighted-average chemical shift changes (Δδ) for each assigned resonance at each titration point.
-
Plot the chemical shift perturbations as a function of the ligand concentration and fit the data to a suitable binding isotherm (e.g., a one-site binding model) to determine the dissociation constant (Kd).
Visualizing Workflows and Pathways
Experimental Workflow for NMR-Based Fragment Screening
The following diagram illustrates a typical workflow for identifying and validating small molecule fragments that bind to a ¹³C-labeled RNA target.
Signaling Pathway Example: Targeting a Viral IRES with a Small Molecule
The internal ribosome entry site (IRES) is a structured RNA element found in many viral genomes that is essential for the initiation of protein synthesis. Small molecules that bind to the IRES and disrupt its function are promising antiviral agents. The following diagram illustrates a simplified signaling pathway and the mechanism of action for such a drug, where ¹³C-labeled RNA NMR was instrumental in identifying the binding site and characterizing the interaction.
Conclusion
The use of ¹³C-labeled RNA is a powerful and essential strategy in modern RNA-targeted drug discovery. By providing detailed structural and dynamic information, it enables a rational, structure-based approach to the design and optimization of novel therapeutics. The protocols and workflows outlined in these application notes provide a solid foundation for researchers to leverage the full potential of this technology in their drug discovery programs.
References
- 1. Short, synthetic and selectively 13C-labeled RNA sequences for the NMR structure determination of protein–RNA complexes - PMC [pmc.ncbi.nlm.nih.gov]
- 2. NMR Characterization of RNA Small Molecule Interactions - PMC [pmc.ncbi.nlm.nih.gov]
- 3. mdpi.com [mdpi.com]
- 4. Efficient NMR Screening Approach to Discover Small Molecule Fragments Binding Structured RNA - PMC [pmc.ncbi.nlm.nih.gov]
- 5. mdpi.com [mdpi.com]
Application Notes and Protocols for Quantitative Mass Spectrometry Using ¹³C Labeled Internal Standards
For Researchers, Scientists, and Drug Development Professionals
Introduction
Quantitative mass spectrometry has become an indispensable tool in biological and pharmaceutical research, enabling the precise measurement of molecules in complex mixtures. A key challenge in achieving accurate and reproducible quantification is accounting for variability introduced during sample preparation, chromatographic separation, and mass spectrometric detection. The use of stable isotope-labeled internal standards (SIL-IS) is the gold standard for addressing these challenges. Among the various stable isotopes, Carbon-13 (¹³C) labeled internal standards offer significant advantages, particularly in minimizing chromatographic shifts and matrix effects often observed with deuterium (B1214612) (²H) labeled standards.[1][2][3][4]
These application notes provide detailed protocols for the use of ¹³C labeled internal standards in two major application areas: quantitative proteomics using Stable Isotope Labeling by Amino Acids in Cell Culture (SILAC) and the quantification of small molecule drugs in biological matrices.
Principle of ¹³C Labeled Internal Standards
The fundamental principle behind using a ¹³C labeled internal standard is that it is chemically identical to the analyte of interest but has a different mass due to the incorporation of the heavier ¹³C isotope.[3] This mass difference allows the mass spectrometer to distinguish between the analyte and the internal standard. Because the SIL-IS has nearly identical physicochemical properties to the analyte, it co-elutes during chromatography and experiences the same extraction efficiencies and ionization suppression or enhancement in the mass spectrometer.[1][2][3] By adding a known amount of the ¹³C labeled internal standard to a sample, the ratio of the analyte's signal intensity to the internal standard's signal intensity can be used to accurately calculate the analyte's concentration, effectively normalizing for experimental variations.
Application 1: Quantitative Proteomics using SILAC
Stable Isotope Labeling by Amino Acids in Cell Culture (SILAC) is a powerful metabolic labeling strategy for quantitative proteomics.[5][6] In a typical SILAC experiment, two populations of cells are cultured in media containing either the natural ("light") or ¹³C-labeled ("heavy") essential amino acids, such as arginine and lysine.[5][6] This results in the in vivo incorporation of these amino acids into all newly synthesized proteins.
Experimental Protocol: SILAC for Relative Protein Quantification
1. Cell Culture and Labeling:
-
Culture two populations of cells in parallel.
-
For the "light" population, use SILAC DMEM or RPMI 1640 medium deficient in L-lysine and L-arginine, supplemented with "light" L-lysine and L-arginine.[7]
-
For the "heavy" population, use the same base medium supplemented with ¹³C₆-L-lysine and ¹³C₆-L-arginine.[6]
-
Ensure complete incorporation of the labeled amino acids by culturing the cells for at least five to six cell divisions.
-
Apply the experimental treatment (e.g., drug treatment) to the "heavy" labeled cells while the "light" labeled cells serve as the control.
2. Sample Preparation:
-
Harvest and lyse the "light" and "heavy" cell populations separately.
-
Determine the total protein concentration for each lysate using a BCA assay.[7]
-
Combine equal amounts of protein from the "light" and "heavy" lysates.[7]
-
Reduce disulfide bonds by adding DTT to a final concentration of 10 mM and incubating at 56°C for 45 minutes.[7]
-
Alkylate cysteine residues by adding iodoacetamide (B48618) (IAA) to a final concentration of 25 mM and incubating in the dark at room temperature for 30 minutes.[7]
-
Perform in-solution digestion by diluting the sample and adding trypsin at a 1:50 enzyme-to-protein ratio, followed by overnight incubation at 37°C.[7]
-
Desalt the resulting peptide mixture using a C18 solid-phase extraction (SPE) cartridge.
3. LC-MS/MS Analysis:
-
Resuspend the purified peptides in a solvent suitable for LC-MS/MS analysis (e.g., 0.1% formic acid in water).[7]
-
Inject the peptide mixture onto a reverse-phase C18 analytical column connected to a high-resolution mass spectrometer (e.g., Orbitrap or Q-TOF).[7]
-
Elute the peptides using a gradient of increasing acetonitrile (B52724) concentration in 0.1% formic acid.
-
Acquire data in a data-dependent acquisition (DDA) mode, where the most intense precursor ions are selected for fragmentation (MS/MS).
4. Data Analysis:
-
Process the raw mass spectrometry data using a suitable software package (e.g., MaxQuant, Proteome Discoverer).
-
The software will identify peptides by matching the MS/MS spectra to a protein sequence database.
-
The relative quantification of peptides is achieved by calculating the ratio of the integrated peak areas of the "heavy" and "light" peptide pairs.
-
Protein abundance ratios are then inferred from the corresponding peptide ratios.
Data Presentation: SILAC Quantitative Proteomics Data
| Protein ID | Gene Name | Description | Heavy/Light Ratio | p-value | Regulation |
| P06733 | HSP90AA1 | Heat shock protein HSP 90-alpha | 2.54 | 0.001 | Upregulated |
| P62258 | ACTG1 | Actin, cytoplasmic 1 | 1.02 | 0.950 | Unchanged |
| Q06830 | VIM | Vimentin | 0.45 | 0.005 | Downregulated |
| P14618 | HSPA5 | 78 kDa glucose-regulated protein | 3.12 | <0.001 | Upregulated |
| P60709 | ACTB | Actin, cytoplasmic 2 | 0.98 | 0.890 | Unchanged |
Application 2: Quantification of Small Molecule Drugs in Biological Matrices
The use of ¹³C labeled internal standards is crucial for the accurate quantification of drugs and their metabolites in complex biological matrices such as plasma, urine, and tissue homogenates. The co-elution of the ¹³C labeled internal standard with the unlabeled drug analyte effectively compensates for matrix-induced ion suppression or enhancement, leading to improved accuracy and precision.[1][2]
Experimental Protocol: Small Molecule Drug Quantification
1. Preparation of Calibration Standards and Quality Controls (QCs):
-
Prepare a stock solution of the drug analyte and the ¹³C labeled internal standard in a suitable organic solvent.
-
Create a series of calibration standards by spiking known concentrations of the drug analyte into the blank biological matrix (e.g., drug-free plasma).
-
Prepare QC samples at low, medium, and high concentrations in the same manner.
2. Sample Preparation:
-
To an aliquot of the unknown sample, calibration standard, or QC, add a fixed amount of the ¹³C labeled internal standard solution.
-
Perform sample extraction to remove proteins and other interfering substances. Common methods include:
-
Protein Precipitation: Add a water-miscible organic solvent (e.g., acetonitrile, methanol) to precipitate proteins. Centrifuge and collect the supernatant.
-
Liquid-Liquid Extraction (LLE): Add an immiscible organic solvent to extract the analyte and internal standard.
-
Solid-Phase Extraction (SPE): Pass the sample through a cartridge that retains the analyte and internal standard, which are then eluted with a suitable solvent.
-
-
Evaporate the solvent from the extracted sample and reconstitute in a mobile phase-compatible solvent.
3. LC-MS/MS Analysis:
-
Use a liquid chromatography system coupled to a triple quadrupole mass spectrometer.
-
Develop a chromatographic method that provides good separation of the analyte from potential interferences.
-
Operate the mass spectrometer in Multiple Reaction Monitoring (MRM) mode.
-
Define a specific precursor ion to product ion transition for both the unlabeled drug and the ¹³C labeled internal standard.
-
4. Data Analysis:
-
Integrate the peak areas for the analyte and the internal standard in all samples.
-
Calculate the ratio of the analyte peak area to the internal standard peak area.
-
Construct a calibration curve by plotting the peak area ratio against the known concentration of the calibration standards.
-
Determine the concentration of the drug in the unknown samples and QCs by interpolating their peak area ratios from the calibration curve.
Data Presentation: Quantitative Analysis of a Hypothetical Drug in Human Plasma
Calibration Curve Data
| Standard Concentration (ng/mL) | Analyte Peak Area | IS Peak Area | Peak Area Ratio (Analyte/IS) |
| 1 | 15,234 | 1,510,876 | 0.010 |
| 5 | 76,890 | 1,523,450 | 0.050 |
| 10 | 153,456 | 1,515,678 | 0.101 |
| 50 | 765,432 | 1,520,123 | 0.504 |
| 100 | 1,523,987 | 1,518,765 | 1.003 |
| 500 | 7,612,345 | 1,521,987 | 5.002 |
| 1000 | 15,198,765 | 1,519,000 | 10.006 |
Quality Control Sample Data
| QC Level | Nominal Conc. (ng/mL) | Calculated Conc. (ng/mL) | Accuracy (%) | CV (%) (n=3) |
| Low | 15 | 14.8 | 98.7 | 4.2 |
| Mid | 150 | 153.2 | 102.1 | 2.8 |
| High | 750 | 742.5 | 99.0 | 3.5 |
Signaling Pathway Visualization
The following diagram illustrates a simplified signaling pathway that could be investigated using the quantitative proteomics methods described above. For instance, a researcher might use SILAC to study how a drug targeting a specific receptor kinase affects downstream signaling proteins.
Conclusion
The use of ¹³C labeled internal standards in quantitative mass spectrometry provides a robust and reliable method for obtaining high-quality quantitative data. Whether for large-scale protein expression profiling or for the precise quantification of small molecules, the principles and protocols outlined in these application notes serve as a guide for researchers and scientists in various fields of study. The superior performance of ¹³C labeled standards in mimicking the behavior of their unlabeled counterparts makes them the preferred choice for demanding quantitative applications.
References
- 1. ¹³C labelled internal standards--a solution to minimize ion suppression effects in liquid chromatography-tandem mass spectrometry analyses of drugs in biological samples? - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. researchgate.net [researchgate.net]
- 3. Internal Standards in LC−MS Bioanalysis: Which, When, and How - WuXi AppTec DMPK [dmpkservice.wuxiapptec.com]
- 4. scispace.com [scispace.com]
- 5. grokipedia.com [grokipedia.com]
- 6. SILAC Metabolic Labeling Systems | Thermo Fisher Scientific - HK [thermofisher.com]
- 7. benchchem.com [benchchem.com]
Probing the Structure and Dynamics of RNA with 13C-Edited NMR Spectroscopy: An Application Note and Protocol
For Researchers, Scientists, and Drug Development Professionals
This document provides a detailed guide to the experimental setup for 13C-edited Nuclear Magnetic Resonance (NMR) experiments on RNA. These techniques are pivotal for elucidating the three-dimensional structure and dynamics of RNA molecules at atomic resolution, which is crucial for understanding their biological functions and for the rational design of RNA-targeting therapeutics.
Introduction
Nuclear Magnetic Resonance (NMR) spectroscopy is a powerful technique for studying the structure and dynamics of biomolecules in solution. For RNA, which often suffers from spectral overlap due to the limited chemical shift dispersion of its constituent nucleotides, isotope labeling is a near necessity. Incorporating 13C (and/or 15N) isotopes allows for the use of heteronuclear NMR experiments, which significantly enhance spectral resolution and enable the determination of through-bond and through-space correlations. This application note focuses on the practical aspects of performing 13C-edited NMR experiments on RNA, from sample preparation to data acquisition and processing.
I. Isotope Labeling of RNA for NMR Studies
The foundation of 13C-edited NMR is the successful incorporation of 13C isotopes into the RNA molecule. The most common method is in vitro transcription using T7 RNA polymerase with 13C-labeled ribonucleoside triphosphates (NTPs).[1][2] Both uniform and selective labeling strategies can be employed to simplify spectra and target specific research questions.
A. Uniform 13C Labeling
In this approach, all four NTPs (ATP, GTP, CTP, UTP) are uniformly labeled with 13C. This is the most straightforward method for enabling a wide range of 13C-edited experiments.
B. Selective 13C Labeling
Selective labeling involves the incorporation of 13C at specific atom positions or within specific nucleotide types.[3] This strategy is particularly powerful for reducing spectral crowding in larger RNAs and for targeted structural and dynamics studies.[4] For instance, labeling only the ribose C2' or C1' positions of specific residues can simplify the crowded sugar pucker regions of the spectrum.[3]
Experimental Protocol: In Vitro Transcription for 13C-Labeled RNA
This protocol outlines a general procedure for in vitro transcription of RNA using 13C-labeled NTPs.[2][3]
Materials:
-
Linearized DNA template with a T7 promoter
-
T7 RNA Polymerase
-
13C-labeled NTPs (e.g., from Cambridge Isotope Laboratories)
-
Transcription Buffer (see Table 1)
-
RNase Inhibitor
-
DNase I
-
Purification system (e.g., denaturing polyacrylamide gel electrophoresis - PAGE)
Procedure:
-
Assemble the Transcription Reaction: Combine the components as detailed in Table 1 in a sterile, RNase-free microcentrifuge tube.
-
Incubation: Incubate the reaction at 37°C for 2-4 hours.
-
DNase Treatment: Add DNase I to the reaction mixture and incubate for a further 30 minutes at 37°C to digest the DNA template.
-
Purification: Purify the transcribed RNA using denaturing PAGE. This separates the full-length RNA product from abortive transcripts and unincorporated NTPs.
-
Elution and Desalting: Excise the gel band corresponding to the RNA product, crush it, and elute the RNA overnight in an appropriate buffer. Subsequently, desalt the RNA sample using size-exclusion chromatography or dialysis.
-
Sample Preparation for NMR: Exchange the purified RNA into the desired NMR buffer (see Table 2). The final sample concentration should ideally be between 0.3 and 1 mM.[3]
Table 1: Typical In Vitro Transcription Reaction Components
| Component | Final Concentration |
| Linearized DNA Template | 20-50 nM |
| 13C-labeled rNTPs (each) | 2-5 mM |
| T7 RNA Polymerase | 50-100 µg/mL |
| Transcription Buffer | 1X |
| - 40 mM Tris-HCl, pH 8.0 | |
| - 20-30 mM MgCl₂ | |
| - 10 mM DTT | |
| - 2 mM Spermidine | |
| RNase Inhibitor | 40 units |
Table 2: Common NMR Buffer for RNA
| Component | Final Concentration |
| Sodium Phosphate, pH 6.4 | 10 mM |
| EDTA | 0.1 mM |
| Sodium Azide (NaN₃) | 0.1% |
| DSS (internal reference) | 0.1 mM |
| D₂O | 99.98% |
II. Key 13C-Edited NMR Experiments
Once the 13C-labeled RNA sample is prepared, a suite of heteronuclear NMR experiments can be performed to obtain structural and dynamic information. The two most fundamental experiments are the 2D 1H-13C HSQC and the 3D 13C-edited NOESY-HSQC.
A. 2D 1H-13C Heteronuclear Single Quantum Coherence (HSQC)
The 1H-13C HSQC experiment is the starting point for resonance assignment. It provides a 2D correlation map of each proton to its directly attached carbon atom.[5] This experiment is invaluable for resolving the severe spectral overlap present in 1D proton spectra of RNA.[6]
Experimental Protocol: 2D 1H-13C HSQC
-
Spectrometer Setup: Tune and match the probe for 1H and 13C frequencies on a high-field NMR spectrometer (e.g., 600 MHz or higher).[3]
-
Pulse Sequence: Utilize a standard sensitivity-enhanced HSQC pulse sequence.
-
Acquisition Parameters: Set the spectral widths in both the 1H (direct) and 13C (indirect) dimensions to encompass all expected resonances. Typical acquisition parameters are summarized in Table 3.
-
Data Processing: Process the acquired data using software such as TopSpin, NMRFx Processor, or NMRViewJ.[3] This typically involves Fourier transformation, phase correction, and baseline correction.
B. 3D 13C-Edited NOESY-HSQC
To determine the three-dimensional structure of the RNA, through-space proton-proton correlations are required. The 3D 13C-edited NOESY-HSQC experiment resolves the Nuclear Overhauser Effect (NOE) signals into a third, 13C dimension, which greatly aids in resolving ambiguities in crowded 2D NOESY spectra.[5][7] This experiment is crucial for sequential assignment and identifying long-range contacts that define the RNA's tertiary structure.[8]
Experimental Protocol: 3D 13C-Edited NOESY-HSQC
-
Spectrometer Setup: As with the HSQC, ensure the spectrometer is properly tuned and matched.
-
Pulse Sequence: Employ a standard 13C-edited NOESY-HSQC pulse sequence.
-
Acquisition Parameters: The acquisition parameters will be similar to the 2D HSQC, with the addition of a NOESY mixing time. The optimal mixing time depends on the size of the RNA and the desired NOE contacts, but typically ranges from 100 to 300 ms. Refer to Table 3 for typical parameters. Non-uniform sampling (NUS) can be employed in the indirect dimensions to reduce the experiment time while maintaining high resolution.[9]
-
Data Processing: Processing of 3D data is more involved and requires careful application of Fourier transformation and corrections in all three dimensions.
Table 3: Representative NMR Acquisition Parameters (600 MHz Spectrometer)
| Parameter | 2D 1H-13C HSQC | 3D 13C-edited NOESY-HSQC |
| Spectrometer Frequency | 600 MHz (¹H) | 600 MHz (¹H) |
| Temperature | 25°C | 25°C |
| ¹H (F2) Spectral Width | 14 ppm | 14 ppm |
| ¹³C (F1) Spectral Width | 28 ppm (aliphatic) or 160 ppm (aromatic) | 28 ppm (aliphatic) or 160 ppm (aromatic) |
| ¹H (F1) Spectral Width | N/A | 9 ppm |
| Number of Scans | 16-64 | 8-32 |
| Recycle Delay | 1.0-1.5 s | 1.0-1.5 s |
| NOESY Mixing Time | N/A | 100-300 ms |
III. Experimental and Logical Workflows
The following diagrams illustrate the key workflows in a 13C-edited NMR experiment on RNA.
Caption: Overall experimental workflow for 13C-edited NMR of RNA.
Caption: Magnetization transfer pathway in a 13C-edited NOESY-HSQC experiment.
Conclusion
13C-edited NMR spectroscopy is an indispensable tool for the detailed structural and dynamic characterization of RNA. By leveraging isotope labeling, researchers can overcome the inherent challenges of RNA NMR and gain deep insights into the molecular basis of RNA function. The protocols and workflows outlined in this application note provide a robust framework for conducting these powerful experiments, ultimately facilitating the discovery and development of novel RNA-targeted therapeutics.
References
- 1. Isotope labeling strategies for NMR studies of RNA - PMC [pmc.ncbi.nlm.nih.gov]
- 2. researchgate.net [researchgate.net]
- 3. Combining asymmetric 13C-labeling and isotopic filter/edit NOESY: a novel strategy for rapid and logical RNA resonance assignment - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Selective 13C labeling of nucleotides for large RNA NMR spectroscopy using an E. coli strain disabled in the TCA cycle - PMC [pmc.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
- 6. mdpi.com [mdpi.com]
- 7. NMRGenerator - [1H,13C]-NOESY-HSQC [sites.google.com]
- 8. users.cs.duke.edu [users.cs.duke.edu]
- 9. researchgate.net [researchgate.net]
Application Notes and Protocols for the Deprotection and Purification of 13C Labeled RNA
For Researchers, Scientists, and Drug Development Professionals
Introduction
The use of 13C labeled RNA is indispensable for a range of sophisticated analytical techniques, most notably Nuclear Magnetic Resonance (NMR) spectroscopy, which is pivotal for elucidating the structure, dynamics, and interactions of RNA molecules at an atomic level. The successful synthesis of 13C labeled RNA, whether through chemical solid-phase synthesis or in vitro transcription, is critically followed by robust deprotection and purification steps. These processes are essential to remove protecting groups and impurities that would otherwise interfere with downstream applications, ensuring the final RNA product is of the highest purity and integrity.
This document provides detailed protocols for the deprotection of chemically synthesized 13C labeled RNA and the purification of both chemically synthesized and in vitro transcribed 13C labeled RNA. The methodologies described are based on established laboratory practices and are designed to yield high-quality RNA suitable for demanding applications in research and drug development.
Deprotection of Chemically Synthesized 13C Labeled RNA
Chemical synthesis of RNA oligonucleotides involves the use of protecting groups on the nucleobases (e.g., acetyl, benzoyl) and the 2'-hydroxyl group of the ribose sugar (e.g., tert-butyldimethylsilyl, TBDMS). These groups must be efficiently removed post-synthesis. The following two-step deprotection protocol is widely used.
Protocol 1: Two-Step Deprotection of Chemically Synthesized RNA
Step 1: Removal of Nucleobase and Phosphate (B84403) Protecting Groups
This step utilizes a mixture of aqueous methylamine (B109427) and ammonium (B1175870) hydroxide (B78521) (AMA) to cleave the RNA from the solid support and remove the protecting groups from the nucleobases and the phosphate backbone.[1][2]
-
Reagents and Materials:
-
Ammonium hydroxide/methylamine (AMA) solution (1:1 mixture of 40% aqueous methylamine and 30% aqueous ammonium hydroxide)[1]
-
Controlled-pore glass (CPG) column with synthesized RNA
-
1.5 mL screw-cap tubes
-
Heating block
-
Centrifugal vacuum concentrator (e.g., SpeedVac)
-
-
Procedure:
-
Carefully transfer the CPG beads from the synthesis column to a 1.5 mL screw-cap tube.[3]
-
Add 1 mL of the AMA solution to the tube.[1]
-
Tightly seal the tube and incubate at 65°C for 15-20 minutes.[1][4]
-
Cool the tube on ice for 10 minutes.[1]
-
Centrifuge the tube briefly and carefully transfer the supernatant containing the cleaved RNA to a new tube.
-
Dry the RNA pellet to a white powder using a centrifugal vacuum concentrator with no heat. This may take several hours.[3]
-
Step 2: Removal of 2'-Hydroxyl Protecting Groups (Desilylation)
This step employs a fluoride-containing reagent to remove the 2'-hydroxyl protecting groups, typically TBDMS.[5]
-
Reagents and Materials:
-
Triethylamine (B128534) trihydrofluoride (TEA·3HF) in N-Methylpyrrolidinone (NMP) and triethylamine (TEA)[5] or anhydrous DMSO[4][6]
-
Dried RNA pellet from Step 1
-
Heating block
-
1-Butanol for precipitation[3]
-
3 M Sodium Acetate (B1210297) (NaOAc), pH 5.2[3]
-
-
Procedure:
-
To the dried RNA pellet, add a solution of TEA·3HF. A common formulation is 125 µL of TEA·3HF in 100 µL of anhydrous DMSO.[4]
-
Cool the reaction tube on ice.
-
Precipitate the deprotected RNA by adding 25 µL of 3 M NaOAc (pH 5.2) and 1 mL of 1-butanol.[3]
-
Incubate at -70°C for at least 1 hour.[3]
-
Centrifuge at maximum speed for 30 minutes at 4°C to pellet the RNA.[3]
-
Carefully decant the supernatant.
-
Wash the RNA pellet with 1 mL of 70% ethanol.
-
Briefly dry the pellet in a centrifugal vacuum concentrator with no heat.[3]
-
Resuspend the purified RNA in an appropriate RNase-free buffer (e.g., TE buffer).
-
Purification of 13C Labeled RNA
Following deprotection (for chemically synthesized RNA) or in vitro transcription, the 13C labeled RNA must be purified to remove failed sequences, abortive transcripts, enzymes, and unincorporated nucleotides. The two most common high-resolution purification methods are denaturing polyacrylamide gel electrophoresis (PAGE) and high-performance liquid chromatography (HPLC).
Protocol 2: Purification by Denaturing Polyacrylamide Gel Electrophoresis (PAGE)
Denaturing PAGE separates RNA molecules based on their size with single-nucleotide resolution for shorter sequences.[7] It is a robust method for obtaining highly pure RNA.[7][8]
-
Reagents and Materials:
-
Denaturing polyacrylamide gel (containing 8 M urea)[9]
-
1x TBE buffer (Tris-borate-EDTA)
-
2x Formamide (B127407) loading buffer (containing urea (B33335) and loading dyes)
-
UV lamp (254 nm) for shadowing
-
Sterile scalpel or razor blade
-
Elution buffer (e.g., 0.3 M NaOAc, pH 5.2)[10]
-
Ethanol for precipitation
-
-
Procedure:
-
Prepare and pre-run a denaturing polyacrylamide gel.
-
Resuspend the RNA sample in 2x formamide loading buffer, heat at 95°C for 5 minutes to denature, and then place on ice.
-
Load the sample onto the gel and run at a constant voltage until the desired separation is achieved.[8]
-
Excise the gel slice containing the full-length RNA product using a sterile scalpel.[8][11]
-
Crush the gel slice and soak it in elution buffer overnight at 4°C with gentle agitation.[8][10]
-
Separate the elution buffer containing the RNA from the gel fragments by centrifugation or using a spin column.[10]
-
Precipitate the RNA from the eluate by adding 2-3 volumes of cold ethanol.
-
Wash the RNA pellet with 70% ethanol and resuspend in an appropriate RNase-free buffer.
-
Protocol 3: Purification by High-Performance Liquid Chromatography (HPLC)
HPLC offers a faster and more automated method for RNA purification.[12] Ion-pair reverse-phase HPLC is particularly effective for separating RNA molecules.[12]
-
Reagents and Materials:
-
Procedure:
-
Equilibrate the HPLC column with the starting mobile phase composition.
-
Dissolve the RNA sample in Mobile Phase A.
-
Inject the sample onto the column.
-
Elute the RNA using a linear gradient of Mobile Phase B. A typical gradient might be from 38% to 55% Buffer B over 22 minutes.[13]
-
Monitor the elution profile at 260 nm.[13]
-
Collect the fractions corresponding to the main peak of the full-length RNA product.
-
Combine the collected fractions and lyophilize to remove the volatile TEAA buffer.
-
Resuspend the purified RNA in an appropriate RNase-free buffer.
-
Quantitative Data Summary
The yield and purity of 13C labeled RNA after purification are critical metrics. While specific yields can vary significantly based on the RNA sequence, length, and synthesis/transcription efficiency, the following table provides representative data.
| Purification Method | Typical Recovery | Typical Purity | Reference |
| Denaturing PAGE | ~50% | >95% | [10] |
| HPLC | 45% (ligation yield including HPLC) | >98% | [14] |
Experimental Workflows
The following diagrams illustrate the workflows for the deprotection and purification of 13C labeled RNA.
Caption: Workflow for the deprotection of chemically synthesized 13C labeled RNA.
Caption: Workflow for the purification of 13C labeled RNA using PAGE or HPLC.
References
- 1. chemrxiv.org [chemrxiv.org]
- 2. Non-Chromatographic Purification of Synthetic RNA Using Bio-orthogonal Chemistry - PMC [pmc.ncbi.nlm.nih.gov]
- 3. josephgroup.ucsd.edu [josephgroup.ucsd.edu]
- 4. glenresearch.com [glenresearch.com]
- 5. academic.oup.com [academic.oup.com]
- 6. glenresearch.com [glenresearch.com]
- 7. Isotope labeling strategies for NMR studies of RNA - PMC [pmc.ncbi.nlm.nih.gov]
- 8. youtube.com [youtube.com]
- 9. Purification of radiolabeled RNA products using denaturing gel electrophoresis - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. researchgate.net [researchgate.net]
- 11. researchgate.net [researchgate.net]
- 12. Single-nucleotide resolution of RNAs up to 59 nucleotides by HPLC - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Generating the optimal mRNA for therapy: HPLC purification eliminates immune activation and improves translation of nucleoside-modified, protein-encoding mRNA - PMC [pmc.ncbi.nlm.nih.gov]
- 14. biorxiv.org [biorxiv.org]
Application Notes: Incorporation of ¹³C₉-rU Phosphoramidite into siRNA Constructs
Introduction
The site-specific incorporation of stable isotopes, such as Carbon-13 (¹³C), into small interfering RNA (siRNA) constructs is a powerful technique for modern therapeutic research and development.[1][2] Using ¹³C-labeled phosphoramidites, such as a fully labeled rU Phosphoramidite-¹³C₉, allows for the precise synthesis of siRNA molecules with isotopic labels at specific uridine (B1682114) residues. This labeling strategy is invaluable for a range of applications, from detailed structural analysis to quantitative bioanalytics, without compromising the biological activity of the siRNA.
Key Applications:
-
Pharmacokinetic (PK) and Drug Metabolism (DMPK) Studies: ¹³C-labeled siRNAs serve as ideal internal standards for liquid chromatography-mass spectrometry (LC-MS) based bioanalytical assays. They are chemically identical to the unlabeled drug but mass-shifted, enabling precise quantification in complex biological matrices like plasma and tissue.
-
Structural Biology: While uniform labeling is common for Nuclear Magnetic Resonance (NMR) spectroscopy, site-specific labeling can simplify complex spectra, helping to resolve resonance assignments and probe local conformational dynamics of siRNA duplexes and their interactions with the RNA-induced silencing complex (RISC).[3][4][5]
-
Mechanism of Action Studies: Labeled siRNAs can be traced and distinguished from endogenous nucleic acids, facilitating studies on cellular uptake, RISC loading, and intracellular trafficking.
Experimental Protocols
Protocol 1: Automated Solid-Phase Synthesis of ¹³C₉-Uridine Labeled siRNA
This protocol outlines the standard phosphoramidite (B1245037) chemistry cycle for incorporating a ¹³C₉-rU phosphoramidite into a target siRNA sequence using an automated DNA/RNA synthesizer.
Materials:
-
rU Phosphoramidite-¹³C₉ (dissolved in anhydrous acetonitrile (B52724) to 0.1 M)
-
Standard A, G, C, U RNA phosphoramidites (0.1 M in acetonitrile)
-
Controlled Pore Glass (CPG) solid support functionalized with the first nucleoside of the sequence
-
Activator solution (e.g., 5-Benzylthio-1H-tetrazole, 0.25 M)
-
Deblocking solution (e.g., 3% Trichloroacetic acid in Dichloromethane)
-
Capping solutions (Cap A: Acetic Anhydride/Pyridine/THF; Cap B: N-Methylimidazole/THF)
-
Oxidizer solution (e.g., 0.02 M Iodine in THF/Water/Pyridine)
-
Anhydrous acetonitrile for washing
Procedure:
The synthesis follows a cyclical four-step process for each nucleotide addition.[1][] The synthesizer is programmed to use the rU Phosphoramidite-¹³C₉ solution during the coupling step at the desired position(s) in the sequence.
-
Step 1: Deblocking (Detritylation)
-
The 5'-dimethoxytrityl (DMT) protecting group is removed from the nucleoside bound to the solid support by treating it with the deblocking solution.
-
The column is then washed extensively with anhydrous acetonitrile to remove the acid and the cleaved DMT cation.
-
-
Step 2: Coupling
-
The ¹³C₉-rU phosphoramidite (or any standard phosphoramidite) is co-injected with the activator solution into the synthesis column.
-
The activated phosphoramidite couples to the free 5'-hydroxyl group of the growing oligonucleotide chain. This reaction is highly efficient, with coupling yields typically exceeding 99%.
-
-
Step 3: Capping
-
Any unreacted 5'-hydroxyl groups are acetylated using the capping solutions.
-
This prevents the formation of failure sequences (n-1) in subsequent cycles, simplifying final purification.
-
-
Step 4: Oxidation
-
The newly formed phosphite (B83602) triester linkage is oxidized to a more stable phosphate (B84403) triester linkage using the oxidizer solution.
-
This completes the cycle for one nucleotide addition. The entire cycle is repeated until the full-length siRNA strand is synthesized.
-
Protocol 2: Cleavage, Deprotection, and Purification
After synthesis, the siRNA must be cleaved from the support, have its protecting groups removed, and be purified to ensure it is suitable for biological experiments.
Materials:
-
Ammonium hydroxide/40% aqueous methylamine (B109427) (AMA) solution
-
Triethylamine trihydrofluoride (TEA·3HF)
-
N,N-Dimethylformamide (DMF)
-
Purification Buffers (e.g., for HPLC: Buffer A - 100 mM Triethylammonium Acetate (TEAA), Buffer B - 100 mM TEAA in 50% Acetonitrile)
-
HPLC system with a suitable column (e.g., reverse-phase ion-pairing)
Procedure:
-
Cleavage and Base Deprotection:
-
Transfer the CPG support to a screw-cap vial.
-
Add AMA solution and incubate at 65°C for 15-20 minutes to cleave the oligonucleotide from the support and remove the exocyclic amine protecting groups from the nucleobases.
-
Cool the solution and transfer the supernatant to a new tube. Evaporate to dryness.
-
-
2'-Hydroxyl Deprotection:
-
Resuspend the dried oligonucleotide in a solution of TEA·3HF in DMF.
-
Incubate at 65°C for 2.5 hours to remove the 2'-O-TBDMS or similar silyl (B83357) protecting groups.[7]
-
Quench the reaction and precipitate the crude siRNA.
-
-
Purification:
-
Purify the crude single-stranded siRNA using ion-exchange or reverse-phase HPLC.[7][]
-
Collect fractions corresponding to the full-length product peak.
-
Desalt the purified fractions using a size-exclusion column or ethanol (B145695) precipitation.
-
-
Duplex Annealing:
-
Quantify the sense and antisense strands by UV absorbance at 260 nm.
-
Mix equimolar amounts of the complementary strands in an annealing buffer (e.g., PBS).
-
Heat the solution to 95°C for 5 minutes and allow it to cool slowly to room temperature to form the final siRNA duplex.
-
Protocol 3: Quality Control by Mass Spectrometry
Mass spectrometry is essential to confirm the successful incorporation of the ¹³C₉-rU and to verify the purity of the final siRNA product.
Materials:
-
Purified siRNA duplex
-
LC-MS system (e.g., ESI-QTOF or Orbitrap)
-
LC column for oligonucleotides (e.g., DNAPac RP)
-
Ion-pairing mobile phases (e.g., HFIP/DIPEA or HFIP/TEA)[9]
Procedure:
-
Sample Preparation: Dilute the purified siRNA to a final concentration of approximately 10-20 µM in an appropriate buffer.
-
LC-MS Analysis:
-
Inject the sample onto the LC-MS system.
-
Use a gradient of ion-pairing mobile phases to separate the strands.
-
Acquire mass spectra in negative ion mode. The high-resolution mass spectrometer will produce a charge state distribution for each strand.
-
-
Data Analysis:
-
Deconvolute the raw mass spectrum to determine the zero-charge mass of each strand.
-
Compare the measured mass to the theoretical mass. The incorporation of one ¹³C₉-rU will result in a mass increase of approximately 9.03 Da compared to the unlabeled version (9 carbons x ~1.00335 Da difference between ¹³C and ¹²C).[1]
-
Assess purity by examining the relative abundance of peaks corresponding to failure sequences or other impurities.
-
Data Presentation
Quantitative data is critical for validating the synthesis and application of ¹³C-labeled siRNAs.
Table 1: Theoretical and Observed Mass Data for a ¹³C₉-rU Labeled siRNA Strand
This table illustrates the expected results from a high-resolution mass spectrometry analysis of an example 21-mer siRNA sense strand with a single ¹³C₉-uridine incorporation.
| Strand Sequence (5' to 3') | Isotope Label | Theoretical Mass (Da) | Observed Mass (Da) | Mass Difference (Da) |
| GCAUGCUAGACUAGCUAGCUU | None (Unlabeled) | 6745.21 | 6745.19 | -0.02 |
| GCA**U***GCUAGACUAGCUAGCUU | ¹³C₉-Uridine at U4 | 6754.24 | 6754.22 | -0.02 |
*U denotes the position of the ¹³C₉-uridine residue.
Table 2: Representative Gene Silencing Activity Data
This table shows hypothetical data from an in vitro gene silencing experiment to demonstrate that the isotopic labeling does not interfere with the biological function of the siRNA. The target is Firefly Luciferase in a dual-luciferase reporter assay.
| siRNA Construct | Target Gene | Concentration (nM) | Relative Luciferase Expression (%) | Standard Deviation |
| Unlabeled anti-Luc siRNA | Luciferase | 10 | 18.5 | ± 2.1 |
| ¹³C₉-rU anti-Luc siRNA | Luciferase | 10 | 19.2 | ± 2.5 |
| Scrambled Control siRNA | N/A | 10 | 98.7 | ± 3.4 |
The data shows comparable knockdown efficiency between the unlabeled and the ¹³C-labeled siRNA, indicating the modification is well-tolerated for RNAi activity.[10]
References
- 1. benchchem.com [benchchem.com]
- 2. Oligonucleotide Synthesis Materials | Cambridge Isotope Laboratories, Inc. [isotope.com]
- 3. mdpi.com [mdpi.com]
- 4. Stable isotope-labeled RNA phosphoramidites to facilitate dynamics by NMR - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. Short, synthetic and selectively 13C-labeled RNA sequences for the NMR structure determination of protein–RNA complexes - PMC [pmc.ncbi.nlm.nih.gov]
- 7. ads-tec.co.jp [ads-tec.co.jp]
- 9. documents.thermofisher.com [documents.thermofisher.com]
- 10. pubs.rsc.org [pubs.rsc.org]
Probing the Dynamic Landscape of RNA: A Guide to 13C Relaxation Dispersion NMR
For Researchers, Scientists, and Drug Development Professionals
Application Notes
The intricate functions of RNA molecules are intrinsically linked to their dynamic nature, extending far beyond a single static structure. Understanding these dynamics is paramount for deciphering biological mechanisms and for the rational design of RNA-targeting therapeutics. Nuclear Magnetic Resonance (NMR) spectroscopy, particularly 13C relaxation dispersion, has emerged as a powerful tool to characterize these motions on the microsecond to millisecond timescale. These motions are often associated with transiently formed, low-population "excited states" that can be critical for RNA folding, catalysis, and ligand binding.
This guide provides a comprehensive overview of the methodology for studying RNA dynamics using 13C relaxation dispersion, offering detailed protocols and data presentation strategies to facilitate its application in academic and industrial research. The primary techniques covered are the Carr-Purcell-Meiboom-Gill (CPMG) and R1ρ relaxation dispersion experiments. While CPMG is sensitive to a broad range of exchange rates, its application to uniformly 13C-labeled RNA can be hampered by artifacts from 1JCC scalar couplings.[1] R1ρ experiments, particularly off-resonance approaches, can circumvent some of these challenges and are effective for a wide range of dynamic processes.[2][3]
The workflow for a typical 13C relaxation dispersion study involves several key stages:
-
Isotopic Labeling of RNA: The RNA of interest must be enriched with 13C. This is typically achieved through in vitro transcription using 13C-labeled nucleotide triphosphates (NTPs).[4][5][6] Both uniform and selective labeling strategies can be employed. Selective labeling, for instance at specific ribose or base positions, can help to simplify complex spectra and avoid issues with 13C-13C scalar couplings.[1][7]
-
NMR Data Acquisition: A series of NMR experiments are performed to measure the 13C transverse relaxation rates (R2,eff or R1ρ) under the influence of a variable radiofrequency (RF) field.[2]
-
Data Analysis: The resulting relaxation dispersion profiles (plots of R2,eff or R1ρ versus the applied RF field strength) are then fit to theoretical models to extract quantitative information about the underlying dynamic process.[2] This data includes the exchange rate (kex), the populations of the ground and excited states (pA and pB), and the chemical shift difference between these states (Δω).
The insights gained from these studies can reveal the conformational landscapes of RNA targets, identify cryptic binding pockets present only in transient states, and elucidate the mechanisms of RNA-ligand interactions. This information is invaluable for drug discovery efforts aimed at modulating RNA function.
Key Quantitative Parameters from 13C Relaxation Dispersion
The analysis of 13C relaxation dispersion data yields several key parameters that describe the dynamic process. These are summarized in the table below.
| Parameter | Description | Typical Range of Values for RNA | Significance |
| kex (k_exchange_) | The sum of the forward (k1) and reverse (k-1) rate constants for the exchange between the ground and excited states (kex = k1 + k-1). | ~50 s⁻¹ to 6000 s⁻¹[2] | Describes the timescale of the dynamic process. |
| pB | The fractional population of the minor or "excited" state. | Typically < 10% | Quantifies the relative stability of the transient state. |
| Δω (delta_omega) | The difference in the 13C chemical shift between the ground and excited states. | Varies depending on the nucleus and the structural change. | Provides structural information about the excited state. |
| R2,eff / R1ρ | The effective transverse relaxation rate measured in the experiment. | Varies | The primary experimental observable that is fit to extract other parameters. |
Experimental Protocols
Protocol 1: Preparation of 13C-Labeled RNA by In Vitro Transcription
This protocol outlines the general steps for producing uniformly 13C-labeled RNA suitable for NMR studies.
Materials:
-
Linearized DNA template containing the sequence of interest downstream of a T7 RNA polymerase promoter.
-
13C-labeled ribonucleoside triphosphates (13C-NTPs).
-
T7 RNA polymerase.
-
Transcription buffer (e.g., 40 mM Tris-HCl pH 8.0, 25 mM MgCl2, 10 mM DTT, 2 mM spermidine).
-
RNase inhibitor.
-
DNase I.
-
Buffer exchange columns or dialysis tubing.
-
NMR buffer (e.g., 10 mM sodium phosphate (B84403) pH 6.5, 50 mM NaCl, 0.1 mM EDTA, 10% D2O).
Procedure:
-
Transcription Reaction Setup: In a sterile microcentrifuge tube, combine the transcription buffer, DTT, spermidine, 13C-NTPs, linearized DNA template, and RNase inhibitor.
-
Initiation: Add T7 RNA polymerase to the reaction mixture and incubate at 37°C for 2-4 hours.
-
DNase Treatment: Add DNase I to the reaction mixture to digest the DNA template. Incubate at 37°C for 1 hour.
-
RNA Purification: Purify the transcribed RNA using methods such as denaturing polyacrylamide gel electrophoresis (PAGE), high-performance liquid chromatography (HPLC), or affinity chromatography.
-
Desalting and Buffer Exchange: Desalt the purified RNA and exchange it into the desired NMR buffer using size-exclusion chromatography or dialysis.
-
Concentration and Quality Control: Concentrate the RNA sample to the desired concentration for NMR experiments (typically 0.1 - 1 mM). Assess the purity and integrity of the RNA using gel electrophoresis.
Protocol 2: 13C R1ρ Relaxation Dispersion NMR Experiment
This protocol describes the acquisition of 13C R1ρ relaxation dispersion data.
Prerequisites:
-
A high-field NMR spectrometer equipped with a cryoprobe.
-
A properly tuned and calibrated spectrometer.
-
The 13C-labeled RNA sample in NMR buffer.
Pulse Sequence:
A common pulse sequence for 13C R1ρ experiments is based on a 1D selective Hartmann-Hahn polarization transfer to excite the specific 13C spin of interest.[2]
Experimental Setup:
-
Temperature Calibration: Ensure the sample temperature is stable and accurately calibrated.
-
Pulse Calibration: Calibrate the 1H and 13C pulse widths.
-
Setup R1ρ Experiment:
-
Water Suppression: Use a presaturation method for water suppression.[2]
Data Acquisition:
-
For each combination of ωSL and Ω, record a series of 1D spectra with increasing Trelax values.
-
The relaxation delays should be appropriate for 13C nuclei, typically less than 50 ms.[2]
Protocol 3: Data Analysis of Relaxation Dispersion Curves
Software:
-
NMR data processing software (e.g., NMRPipe).
-
Software for fitting relaxation dispersion data (e.g., CATIA, GLOVE, NESSY).
Procedure:
-
Data Processing: Process the raw NMR data (Fourier transformation, phasing, and baseline correction).
-
Peak Integration: Integrate the peak intensities for each Trelax value in the 1D spectra.
-
Calculate R1ρ: Fit the decay of peak intensity as a function of Trelax to a single exponential decay function to extract the R1ρ value for each spin-lock field strength and offset.[2]
-
Generate Dispersion Profiles: Plot the calculated R1ρ values against the effective spin-lock field strength.
-
Model Fitting: Fit the dispersion profiles to a two-state or three-state model of chemical exchange using specialized software. This fitting procedure will yield the kinetic (kex) and thermodynamic (pB) parameters, as well as the chemical shift difference (Δω).
Visualizations
Caption: Experimental workflow for studying RNA dynamics with 13C relaxation dispersion.
Caption: Two-state model for RNA conformational exchange.
References
- 1. academic.oup.com [academic.oup.com]
- 2. Characterizing RNA Excited States using NMR Relaxation Dispersion - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Characterizing RNA Excited States Using NMR Relaxation Dispersion - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. academic.oup.com [academic.oup.com]
- 5. Biosynthetic preparation of 13C/15N-labeled rNTPs for high-resolution NMR studies of RNAs - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. researchgate.net [researchgate.net]
- 7. digitalcommons.unl.edu [digitalcommons.unl.edu]
A Researcher's Guide to Ordering Custom 13C Labeled RNA Oligonucleotides: Application Notes and Protocols
For Researchers, Scientists, and Drug Development Professionals
The strategic incorporation of stable isotopes, particularly Carbon-13 (¹³C), into RNA oligonucleotides has become an indispensable tool for elucidating the structure, dynamics, and interactions of these vital macromolecules. This guide provides a comprehensive overview of the process for ordering custom ¹³C labeled RNA oligonucleotides, from selecting a synthesis method to performing downstream applications. Detailed protocols for key experimental techniques are also provided to facilitate the seamless integration of ¹³C labeled RNA into your research workflows.
Introduction to ¹³C Labeled RNA Oligonucleotides
Stable isotope labeling of RNA with ¹³C offers a powerful, non-radioactive method to enhance the analytical resolution of techniques like Nuclear Magnetic Resonance (NMR) spectroscopy and Mass Spectrometry (MS).[1][2] By replacing naturally abundant ¹²C with ¹³C at specific or uniform positions within the RNA molecule, researchers can overcome spectral overlap and gain deeper insights into:
-
RNA Structure and Conformation: Determine three-dimensional structures and conformational changes in solution.[1]
-
RNA Dynamics: Study the intricate motions and flexibility of RNA molecules, which are often crucial for their function.
-
RNA-Ligand Interactions: Precisely map the binding sites and characterize the interactions of RNA with proteins, small molecules, and other nucleic acids.
-
Metabolic Labeling and Turnover: Trace the fate of RNA molecules within cells to understand their synthesis and degradation pathways.[3]
Choosing the Right Labeling Strategy and Synthesis Method
The selection of a labeling strategy—uniform or site-specific—depends on the specific research question.
-
Uniform Labeling: All instances of a particular nucleotide (or all nucleotides) are labeled with ¹³C. This is typically achieved through enzymatic synthesis (in vitro transcription) using ¹³C-labeled nucleotide triphosphates (NTPs).[2][4][5] This method is ideal for studying the overall structure and dynamics of an RNA molecule.
-
Site-Specific Labeling: Only specific, user-defined positions within the RNA sequence are labeled with ¹³C. This precise placement is accomplished through chemical synthesis using ¹³C-labeled phosphoramidites.[1][2] This approach is particularly powerful for focusing on a specific region of interest, such as an active site or a binding interface.
The choice between enzymatic and chemical synthesis will impact the cost, yield, and turnaround time of your order.
Workflow for Selecting a Synthesis Method
Caption: Decision workflow for choosing between enzymatic and chemical synthesis for ¹³C labeled RNA.
How to Order Custom ¹³C Labeled RNA Oligonucleotides
Ordering custom ¹³C labeled RNA oligonucleotides typically involves a consultation with the synthesis vendor due to the specialized nature of the request. The general workflow is as follows:
Ordering Workflow
Caption: Step-by-step workflow for ordering a custom ¹³C labeled RNA oligonucleotide.
When requesting a quote, be prepared to provide the following information:
-
RNA Sequence: The exact nucleotide sequence from 5' to 3'.
-
Labeling Pattern:
-
For site-specific labeling , indicate the exact position(s) and the desired ¹³C-labeled nucleobase(s).
-
For uniform labeling , specify which nucleotide(s) should be fully labeled.
-
-
Synthesis Scale: The starting amount of material for the synthesis (e.g., 50 nmol, 200 nmol, 1 µmol). Note that the final yield will be lower than the synthesis scale.
-
Purification Method: Options typically include desalting, High-Performance Liquid Chromatography (HPLC), and Polyacrylamide Gel Electrophoresis (PAGE). For most applications involving labeled RNA, HPLC or PAGE purification is recommended to ensure high purity.
-
Quality Control (QC) Requirements: Standard QC often includes Mass Spectrometry (e.g., MALDI-TOF or ESI-MS) to confirm the molecular weight. Additional QC, such as analytical HPLC or capillary electrophoresis (CE), may be available.
-
Modifications: Specify any other required modifications, such as fluorescent dyes, quenchers, or modified bases.
Quantitative Comparison of Custom Synthesis Options
The cost, turnaround time, and yield of custom ¹³C labeled RNA synthesis can vary significantly based on the complexity of the request. The following tables provide an estimated comparison. Note that most vendors require a custom quote for precise pricing.
Table 1: Estimated Cost of ¹³C Labeled RNA Synthesis
| Feature | Chemical Synthesis (Site-Specific) | Enzymatic Synthesis (Uniform) |
| ¹³C Source | ¹³C-labeled phosphoramidites | ¹³C-labeled NTPs |
| Estimated Cost per ¹³C label | €370 - €460 per labeled base (raw material) | Varies based on NTP cost and synthesis efficiency |
| Base Synthesis Cost | ~$9 - $16 per base (unmodified) | Dependent on vendor and scale |
| Purification (HPLC) | ~$12.5 - $210 per oligo | ~$12.5 - $210 per oligo |
| Overall Cost | High, driven by phosphoramidite (B1245037) cost | Moderate to High, dependent on NTP cost |
Note: Phosphoramidite costs are based on publicly available data and are subject to change. Synthesis and purification costs are general estimates for standard oligonucleotides and will be higher for labeled constructs.
Table 2: Comparison of Turnaround Time, Yield, and Purity
| Parameter | Chemical Synthesis | Enzymatic Synthesis |
| Estimated Turnaround Time | 10-20 business days (longer for complex designs) | 15-25 business days |
| Typical Synthesis Scale | 50 nmol - 15 µmol | Milligram quantities |
| Expected Yield | Lower than unmodified oligos; highly sequence and modification dependent. Post-synthesis modifications can reduce yield by up to 50%.[][7] | Can yield milligram quantities of RNA.[4][5] |
| Purity (with HPLC/PAGE) | >90% | >90% |
| Maximum Length | Routinely up to 80-100 nt; longer is possible but challenging.[8][9] | Can produce very long RNA transcripts.[10] |
Experimental Protocols
Quality Control of Received ¹³C Labeled RNA
Upon receiving your custom ¹³C labeled RNA, it is crucial to perform initial quality control checks.
Protocol: UV Spectrophotometry for Quantification and Purity Assessment
-
Resuspend the Lyophilized Oligonucleotide: Briefly centrifuge the tube to collect the pellet. Resuspend the RNA in an appropriate volume of RNase-free water or buffer to a convenient stock concentration (e.g., 100 µM).
-
Prepare a Dilution: Make a dilution of your stock solution in the same buffer (e.g., 1:100).
-
Measure Absorbance: Use a spectrophotometer to measure the absorbance at 260 nm (A260) and 280 nm (A280).
-
Calculate Concentration: Use the Beer-Lambert law: Concentration (µg/mL) = A260 × dilution factor × extinction coefficient (an average value is ~33 µg/mL for single-stranded RNA). The vendor will typically provide the exact extinction coefficient.
-
Assess Purity: Calculate the A260/A280 ratio. A ratio of ~2.0 is indicative of highly pure RNA.
Application Protocol: NMR Spectroscopy of ¹³C Labeled RNA
NMR spectroscopy is a primary application for ¹³C labeled RNA, enabling detailed structural and dynamic studies.[1]
Protocol: Sample Preparation and Basic 2D ¹H-¹³C HSQC NMR
-
Sample Preparation:
-
Dissolve the ¹³C labeled RNA oligonucleotide in an appropriate NMR buffer (e.g., 10 mM sodium phosphate, 50 mM NaCl, pH 6.5) to a final concentration of 0.1-1.0 mM.
-
Transfer the sample to a clean NMR tube. For experiments observing exchangeable protons, the sample should be in 90% H₂O/10% D₂O. For experiments focusing on non-exchangeable protons, lyophilize the sample and resuspend in 99.9% D₂O.
-
-
NMR Spectrometer Setup:
-
Insert the sample into the NMR spectrometer.
-
Tune and match the probe for ¹H and ¹³C frequencies.
-
Lock the spectrometer on the D₂O signal.
-
Optimize the shim values to obtain a narrow and symmetrical water signal.
-
-
Data Acquisition:
-
Acquire a 1D ¹H spectrum to assess sample quality and concentration.
-
Set up a 2D ¹H-¹³C Heteronuclear Single Quantum Coherence (HSQC) experiment. This experiment correlates the chemical shifts of protons directly bonded to ¹³C atoms.
-
Optimize acquisition parameters, including spectral widths, number of scans, and relaxation delays.
-
-
Data Processing and Analysis:
-
Process the acquired data using appropriate software (e.g., TopSpin, NMRPipe). This involves Fourier transformation, phase correction, and baseline correction.
-
Analyze the 2D HSQC spectrum to identify correlations between ¹H and ¹³C nuclei, aiding in resonance assignment and structural analysis.
-
Application Protocol: Mass Spectrometry of ¹³C Labeled RNA
Mass spectrometry is used to verify the successful incorporation of ¹³C labels and can be used for sequencing and interaction studies.[11][12]
Protocol: LC-MS Analysis of ¹³C Labeled RNA
-
Sample Preparation:
-
Dilute the ¹³C labeled RNA oligonucleotide to a suitable concentration (e.g., 1-10 µM) in an MS-compatible buffer (e.g., 10 mM ammonium (B1175870) acetate).
-
-
LC-MS System Setup:
-
Equilibrate the Liquid Chromatography (LC) system, often a reverse-phase column, with the initial mobile phase.
-
Set up the Mass Spectrometer (e.g., ESI-Q-TOF) with appropriate parameters for oligonucleotide analysis (negative ion mode is common).
-
-
Data Acquisition:
-
Inject the sample onto the LC column.
-
Run a gradient of increasing organic solvent (e.g., acetonitrile) to elute the RNA oligonucleotide.
-
Acquire mass spectra across the elution profile.
-
-
Data Analysis:
-
Deconvolute the raw mass spectrum to determine the molecular weight of the RNA oligonucleotide.
-
Compare the experimentally determined molecular weight with the theoretical mass of the ¹³C labeled RNA to confirm successful labeling. The mass difference will correspond to the number of incorporated ¹³C atoms.
-
Conclusion
Ordering custom ¹³C labeled RNA oligonucleotides is a multi-step process that requires careful planning and communication with the synthesis vendor. By understanding the available synthesis and labeling options, providing detailed specifications, and performing appropriate quality control, researchers can obtain high-quality labeled RNA for advanced structural and functional studies. The protocols provided in this guide offer a starting point for the successful application of ¹³C labeled RNA in your research endeavors, paving the way for new discoveries in RNA biology and drug development.
References
- 1. pubs.acs.org [pubs.acs.org]
- 2. Oligonucleotide Synthesis Materials | Cambridge Isotope Laboratories, Inc. [isotope.com]
- 3. Pricing, Lead Time & Guaranteed Yield - Hokkaido System Science Co.,Ltd. [hssnet.co.jp]
- 4. academic.oup.com [academic.oup.com]
- 5. researchgate.net [researchgate.net]
- 7. Research Oligo Manufacturing – Yield and Quantity | Eurogentec [eurogentec.com]
- 8. Custom RNA synthesis [horizondiscovery.com]
- 9. RNA Synthesis, Custom RNA Synthesis, Specialty RNA Synthesis - Commitment to Quality [biosyn.com]
- 10. Isotope labeling strategies for NMR studies of RNA - PMC [pmc.ncbi.nlm.nih.gov]
- 11. pubs.acs.org [pubs.acs.org]
- 12. academic.oup.com [academic.oup.com]
Application Notes and Protocols for rU Phosphoramidite-¹³C₉ in Biophysical Studies
For Researchers, Scientists, and Drug Development Professionals
Introduction
The strategic incorporation of stable isotopes into biomolecules has revolutionized the field of biophysical chemistry, particularly in the study of nucleic acids. The rU Phosphoramidite-¹³C₉, a uridine (B1682114) phosphoramidite (B1245037) in which all nine carbon atoms are replaced with the ¹³C isotope, is a powerful tool for elucidating the structure, dynamics, and interactions of RNA. This document provides detailed application notes and protocols for the use of rU Phosphoramidite-¹³C₉ in biophysical studies, with a primary focus on Nuclear Magnetic Resonance (NMR) spectroscopy.
The uniform labeling of a single uridine residue within an RNA molecule provides a unique spectroscopic window, simplifying complex NMR spectra and enabling the unambiguous assignment of resonances. This site-specific, heavy-isotope labeling is invaluable for studying large RNA molecules and their complexes with proteins or small molecule ligands, which are often challenging to characterize using traditional methods.
Key Applications
The primary application of rU Phosphoramidite-¹³C₉ is in the site-specific introduction of a uniformly ¹³C-labeled uridine into a synthetic RNA oligonucleotide. This enables a range of biophysical experiments, primarily centered around NMR spectroscopy.
-
Structural Biology: Facilitates the determination of high-resolution structures of RNA and RNA-protein complexes. The ¹³C labels serve as sensitive probes for defining local conformation and intermolecular interfaces.
-
RNA Dynamics: Enables the study of the internal motions of RNA molecules over a wide range of timescales. ¹³C relaxation experiments can provide insights into the flexibility and conformational changes that are crucial for RNA function.
-
Drug Discovery and Development: Aids in the characterization of the binding sites and mechanisms of action of small molecules that target RNA. Observing changes in the NMR signals of the ¹³C-labeled uridine upon ligand binding can provide direct evidence of interaction and structural perturbations.
-
RNA-Protein Interactions: Simplifies the analysis of complex protein-RNA interfaces. By selectively labeling the RNA, the signals from the protein do not interfere, allowing for a clear view of the RNA's role in the interaction.
Data Presentation
The incorporation of a ¹³C₉-labeled uridine into an RNA molecule provides a rich source of quantitative NMR data. The following table summarizes the typical ¹³C chemical shift ranges for uridine in an RNA context. The exact chemical shifts are highly sensitive to the local chemical environment, secondary structure, and any intermolecular interactions.
| Carbon Atom | Typical Chemical Shift Range (ppm) | Notes |
| C1' | 85 - 95 | Sensitive to sugar pucker and glycosidic torsion angle. |
| C2' | 68 - 75 | Chemical shift is indicative of the ribose sugar pucker (C2'-endo vs. C3'-endo). |
| C3' | 69 - 78 | Involved in the phosphodiester backbone; sensitive to backbone conformation. |
| C4' | 80 - 86 | Its chemical shift is correlated with the backbone torsion angles δ and ε. |
| C5' | 60 - 67 | Part of the phosphodiester backbone; sensitive to backbone conformation. |
| C2 | 150 - 155 | Carbonyl carbon in the uracil (B121893) base. |
| C4 | 165 - 170 | Carbonyl carbon in the uracil base. |
| C5 | 100 - 105 | Protonated aromatic carbon; its chemical shift is sensitive to base stacking. |
| C6 | 140 - 145 | Protonated aromatic carbon; its chemical shift is sensitive to base pairing and stacking. |
Note: These are approximate ranges and can vary depending on the specific RNA sequence, structure, and experimental conditions.
Experimental Protocols
Protocol 1: Solid-Phase Synthesis of RNA with Site-Specific ¹³C₉-Uridine Labeling
This protocol outlines the general steps for incorporating rU Phosphoramidite-¹³C₉ into an RNA oligonucleotide using an automated solid-phase synthesizer.
Materials:
-
rU Phosphoramidite-¹³C₉ (e.g., from Cambridge Isotope Laboratories)
-
Unlabeled A, G, C, and U RNA phosphoramidites
-
Controlled Pore Glass (CPG) solid support
-
Standard reagents for phosphoramidite chemistry (activator, capping reagents, oxidizing agent, deprotection solutions)
-
Anhydrous acetonitrile (B52724)
-
Automated DNA/RNA synthesizer
Procedure:
-
Phosphoramidite Preparation: Dissolve the rU Phosphoramidite-¹³C₉ and unlabeled phosphoramidites in anhydrous acetonitrile to the concentration recommended by the synthesizer manufacturer (typically 0.1 M).
-
Synthesizer Setup: Program the RNA sequence into the synthesizer, specifying the position for the incorporation of the ¹³C₉-labeled uridine. Install the reagent bottles and the CPG column corresponding to the 3'-terminal nucleotide of the target sequence.
-
Automated Synthesis Cycle: The synthesis proceeds in a stepwise manner for each nucleotide addition, including the ¹³C₉-uridine. Each cycle consists of four main steps: a. Detritylation: Removal of the 5'-dimethoxytrityl (DMT) protecting group from the growing RNA chain. b. Coupling: Activation of the phosphoramidite and its reaction with the 5'-hydroxyl of the growing chain. c. Capping: Acetylation of any unreacted 5'-hydroxyl groups to prevent the formation of deletion mutants. d. Oxidation: Conversion of the phosphite (B83602) triester linkage to a more stable phosphate (B84403) triester.
-
Cleavage and Deprotection: Following the completion of the synthesis, the RNA is cleaved from the solid support and all protecting groups are removed using a standard deprotection protocol (e.g., with a mixture of ammonia (B1221849) and methylamine).
-
Purification: The crude RNA is purified by denaturing polyacrylamide gel electrophoresis (PAGE) or high-performance liquid chromatography (HPLC).
-
Desalting and Quantification: The purified RNA is desalted (e.g., using a size-exclusion column) and its concentration is determined by UV-Vis spectroscopy.
Protocol 2: NMR Spectroscopy of ¹³C-Labeled RNA
This protocol provides a general workflow for acquiring and analyzing NMR spectra of an RNA molecule containing a ¹³C₉-labeled uridine.
Materials:
-
Purified ¹³C-labeled RNA sample
-
NMR buffer (e.g., 10 mM sodium phosphate, pH 6.5, 100 mM NaCl, 0.1 mM EDTA)
-
D₂O for solvent exchange
-
NMR spectrometer equipped with a cryoprobe
Procedure:
-
Sample Preparation: Dissolve the lyophilized RNA in the NMR buffer to the desired concentration (typically 0.1 - 1.0 mM). For experiments observing exchangeable protons, the final sample should be in 90% H₂O / 10% D₂O. For experiments focusing on non-exchangeable protons, lyophilize the sample and redissolve in 99.96% D₂O.
-
NMR Data Acquisition: a. ¹H-¹³C HSQC (Heteronuclear Single Quantum Coherence): This is the primary experiment to obtain the correlation between the ¹³C nuclei and their directly attached protons. The spectrum will show peaks only for the ¹³C-labeled uridine, significantly simplifying the spectral analysis. b. ¹³C-NOESY-HSQC (Nuclear Overhauser Effect Spectroscopy): This 3D experiment is used to identify spatial proximities between the protons of the labeled uridine and other protons in the RNA or a bound molecule. This is crucial for structure determination. c. ¹³C Relaxation Experiments (T₁, T₂, and het-NOE): These experiments measure the relaxation rates of the ¹³C nuclei, providing information about the dynamics of the labeled uridine residue on different timescales. Uniform ¹³C labeling can introduce complications due to ¹³C-¹³C dipolar couplings, which may need to be accounted for in the data analysis[1].
-
Data Processing and Analysis: a. Process the NMR data using appropriate software (e.g., TopSpin, NMRPipe). b. Assign the resonances of the ¹³C-labeled uridine based on known chemical shift ranges and through-bond and through-space correlations. c. Analyze the NOE data to derive distance restraints for structure calculations. d. Analyze the relaxation data to extract information about the local dynamics of the RNA.
Visualization of Experimental Workflow
The following diagrams illustrate the general workflows for the synthesis of ¹³C-labeled RNA and its application in studying RNA-protein interactions.
Caption: Workflow for solid-phase synthesis of RNA with site-specific ¹³C labeling.
References
Application Notes and Protocols for Solid-Phase Synthesis of RNA with Modified Phosphoramidites
For Researchers, Scientists, and Drug Development Professionals
Introduction
The synthesis of modified RNA oligonucleotides is a cornerstone of modern molecular biology and therapeutic development. Chemical modifications to the RNA backbone and sugar moieties can enhance stability against nucleases, improve binding affinity to target sequences, and modulate immunological responses, making them ideal for applications such as antisense therapy, siRNA-mediated gene silencing, and aptamer-based diagnostics and therapeutics.[1][2][3] This document provides detailed protocols for the solid-phase synthesis of RNA oligonucleotides incorporating three common and impactful modifications: 2'-O-methyl (2'-OMe), 2'-Fluoro (2'-F), and phosphorothioate (B77711) (PS) linkages, using phosphoramidite (B1245037) chemistry.
Overview of Solid-Phase RNA Synthesis
Solid-phase synthesis of RNA oligonucleotides is a cyclical process involving four main chemical reactions for each nucleotide addition: deblocking, coupling, capping, and oxidation (or sulfurization for phosphorothioates).[4] The synthesis is performed on an automated synthesizer using a solid support, typically controlled pore glass (CPG), to which the first nucleoside is attached.[1][5] The oligonucleotide chain is elongated in the 3' to 5' direction.[5]
Key Chemical Modifications
2'-O-Methyl (2'-OMe) Modification
The 2'-O-methyl modification, where a methyl group replaces the hydrogen of the 2'-hydroxyl group of the ribose sugar, is a widely used modification in therapeutic oligonucleotides.[6] This modification increases the nuclease resistance and the thermal stability of RNA duplexes.[3][6] 2'-OMe modified RNAs have been shown to be effective in antisense applications by inhibiting translation of target mRNAs.[1]
2'-Fluoro (2'-F) Modification
The 2'-fluoro modification involves the substitution of the 2'-hydroxyl group with a fluorine atom. This modification confers high binding affinity to complementary RNA strands and significant resistance to nuclease degradation.[7][8] 2'-F modified RNAs are commonly used in the development of aptamers and siRNAs.[7][9]
Phosphorothioate (PS) Linkage
In a phosphorothioate linkage, a non-bridging oxygen atom in the phosphate (B84403) backbone is replaced by a sulfur atom.[10] This modification renders the internucleotide linkage resistant to nuclease digestion, thereby increasing the in vivo stability of the oligonucleotide.[10][11] Phosphorothioate modifications are a common feature in antisense oligonucleotides and siRNAs to enhance their therapeutic potential.[12][13]
Quantitative Data Summary
The choice of modification can significantly impact the efficiency of the synthesis and the properties of the final product. The following tables summarize key quantitative data for the synthesis of modified RNA oligonucleotides.
Table 1: Comparison of Coupling Efficiencies and Synthesis Yields for Modified RNA Phosphoramidites
| Modification | Typical Coupling Efficiency per Step | Theoretical Yield of a 20-mer Oligonucleotide | Reference(s) |
| Unmodified RNA | 98-99% | 60-72% | [14] |
| 2'-O-Methyl (2'-OMe) | 98-99% | 60-72% | [15] |
| 2'-Fluoro (2'-F) | ~97% | ~54% | [16] |
| Phosphorothioate (PS) | >96% | >48% | [17] |
Note: Theoretical yield is calculated as (Coupling Efficiency)^n-1, where n is the number of nucleotides. Actual yields will be lower due to losses during purification and handling.[14][15]
Table 2: Properties of Modified RNA Oligonucleotides
| Modification | Nuclease Resistance | Binding Affinity (Tm) to RNA Target | Common Applications | Reference(s) |
| 2'-O-Methyl (2'-OMe) | Increased | Increased | Antisense, siRNA | [1][3] |
| 2'-Fluoro (2'-F) | Significantly Increased | Increased | Aptamers, siRNA | [7][8] |
| Phosphorothioate (PS) | Significantly Increased | Slightly Decreased | Antisense, siRNA | [10][11] |
Experimental Protocols
The following protocols outline the detailed methodology for the solid-phase synthesis of RNA oligonucleotides with 2'-O-methyl, 2'-fluoro, and phosphorothioate modifications. These protocols are designed for use with an automated DNA/RNA synthesizer.
Protocol 1: Solid-Phase Synthesis of 2'-O-Methyl or 2'-Fluoro Modified RNA
This protocol describes the standard cycle for incorporating 2'-O-methyl or 2'-fluoro modified phosphoramidites.
Materials:
-
2'-O-Methyl or 2'-Fluoro RNA phosphoramidites (A, C, G, U) dissolved in anhydrous acetonitrile (B52724) (0.1 M)
-
Unmodified RNA phosphoramidites (if creating chimeric oligonucleotides)
-
Controlled Pore Glass (CPG) solid support with the desired initial nucleoside
-
Activator solution (e.g., 0.25 M 5-Ethylthio-1H-tetrazole (ETT) in acetonitrile)
-
Oxidizing solution (e.g., 0.02 M Iodine in THF/Pyridine (B92270)/Water)
-
Capping Solution A (Acetic Anhydride/Pyridine/THF) and Capping Solution B (16% N-Methylimidazole/THF)
-
Deblocking solution (3% Trichloroacetic acid (TCA) in dichloromethane)
-
Anhydrous acetonitrile for washing
Procedure:
The synthesis is performed in a cyclical manner, with each cycle consisting of the following four steps:
-
Deblocking (Detritylation):
-
The 5'-dimethoxytrityl (DMT) protecting group is removed from the support-bound nucleoside by treating with the deblocking solution.
-
The column is then thoroughly washed with anhydrous acetonitrile to remove the acid and the cleaved DMT cation.
-
-
Coupling:
-
The 2'-O-methyl or 2'-fluoro phosphoramidite solution and the activator solution are simultaneously delivered to the synthesis column.
-
The activated phosphoramidite reacts with the free 5'-hydroxyl group of the support-bound nucleotide chain.
-
A typical coupling time is 5-10 minutes.[1]
-
After coupling, the column is washed with anhydrous acetonitrile.
-
-
Capping:
-
Any unreacted 5'-hydroxyl groups are acetylated by treatment with the capping solutions.
-
This prevents the elongation of failure sequences (n-1) in subsequent cycles.
-
The column is then washed with anhydrous acetonitrile.
-
-
Oxidation:
-
The newly formed phosphite (B83602) triester linkage is oxidized to a more stable pentavalent phosphate triester using the oxidizing solution.
-
The column is washed with anhydrous acetonitrile.
-
This four-step cycle is repeated for each subsequent nucleotide to be added to the growing RNA chain.
Protocol 2: Incorporation of Phosphorothioate Linkages
To introduce phosphorothioate linkages, the oxidation step in the standard synthesis cycle is replaced with a sulfurization step.
Materials:
-
All materials from Protocol 1, with the exception of the oxidizing solution.
-
Sulfurizing reagent (e.g., 0.05 M 3-((Dimethylamino-methylidene)amino)-3H-1,2,4-dithiazole-3-thione (DDTT) in pyridine or 3-ethoxy-1,2,4-dithiazoline-5-one (EDITH) in acetonitrile).[18]
Procedure:
The synthesis cycle for incorporating a phosphorothioate linkage is as follows:
-
Deblocking (Detritylation): Same as in Protocol 1.
-
Coupling: Same as in Protocol 1.
-
Capping: Same as in Protocol 1.
-
Sulfurization:
-
Instead of the oxidizing solution, the sulfurizing reagent is delivered to the synthesis column.
-
The phosphite triester is converted to a phosphorothioate triester.
-
A typical sulfurization time is 2-5 minutes.[18]
-
The column is then washed with anhydrous acetonitrile.
-
This modified cycle can be used at any desired position within the oligonucleotide to create a phosphorothioate linkage. For fully phosphorothioated RNA, this cycle is used for every nucleotide addition.
Protocol 3: Cleavage and Deprotection of Modified RNA
After the synthesis is complete, the oligonucleotide must be cleaved from the solid support and all protecting groups must be removed.
Materials:
-
Ammonia/methylamine (AMA) solution (1:1 mixture of aqueous ammonium (B1175870) hydroxide (B78521) and aqueous methylamine)
-
Triethylamine trihydrofluoride (TEA·3HF) in N-methyl-2-pyrrolidone (NMP) or Dimethylformamide (DMF) for removal of 2'-silyl protecting groups (if used). Note: This step is not required for 2'-O-methyl or 2'-fluoro modifications.
-
Desalting columns (e.g., NAP-25)
-
HPLC system for purification
Procedure:
-
Cleavage from Support and Base Deprotection:
-
The CPG support is transferred to a sealed vial and incubated with the AMA solution at 65°C for 15-30 minutes.[5] This step cleaves the oligonucleotide from the support and removes the protecting groups from the nucleobases and the phosphate backbone.
-
The supernatant containing the crude oligonucleotide is collected.
-
-
2'-Protecting Group Removal (if applicable):
-
For RNA synthesized with 2'-TBDMS protecting groups, the dried oligonucleotide is resuspended in TEA·3HF/NMP and incubated at 65°C for 1.5-2.5 hours.[5]
-
The reaction is then quenched with an appropriate buffer.
-
-
Purification:
-
The crude deprotected oligonucleotide is purified by high-performance liquid chromatography (HPLC) or polyacrylamide gel electrophoresis (PAGE).[5]
-
The purified oligonucleotide is then desalted using a desalting column.
-
-
Quantification and Analysis:
-
The concentration of the final product is determined by measuring its absorbance at 260 nm.
-
The purity and identity of the modified RNA oligonucleotide are confirmed by mass spectrometry.
-
Visualizations
Experimental Workflow
Caption: Automated solid-phase synthesis cycle for modified RNA.
Modified Phosphoramidite Structures
Caption: Chemical structures of modified RNA phosphoramidites.
Note: The images in the DOT script are placeholders and would need to be replaced with actual chemical structure images for rendering.
Application Example: Targeting Bcl-2 in Cancer Therapy
Antisense oligonucleotides with 2'-O-methyl and phosphorothioate modifications have been developed to target the anti-apoptotic protein Bcl-2, which is overexpressed in many cancers.[7] By binding to the Bcl-2 mRNA, these antisense oligonucleotides can promote its degradation, leading to a decrease in Bcl-2 protein levels and subsequent induction of apoptosis in cancer cells.
References
- 1. Standard Protocol for Solid-Phase Oligonucleotide Synthesis using Unmodified Phosphoramidites | LGC, Biosearch Technologies [biosearchtech.com]
- 2. mdpi.com [mdpi.com]
- 3. pure.au.dk [pure.au.dk]
- 4. Protocol for the Solid-phase Synthesis of Oligomers of RNA Containing a 2'-O-thiophenylmethyl Modification and Characterization via Circular Dichroism - PMC [pmc.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
- 6. Making Sense of Antisense Oligonucleotide Therapeutics Targeting Bcl-2 - PMC [pmc.ncbi.nlm.nih.gov]
- 7. pharmaceuticalintelligence.com [pharmaceuticalintelligence.com]
- 8. Making Sense of Antisense Oligonucleotide Therapeutics Targeting Bcl-2 - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. Phosphorothioate RNA Synthesis Modification [biosyn.com]
- 10. Minimal 2'-O-methyl phosphorothioate linkage modification pattern of synthetic guide RNAs for increased stability and efficient CRISPR-Cas9 gene editing avoiding cellular toxicity - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Antisense-mediated suppression of Bcl-2 highlights its pivotal role in failed apoptosis in B-cell chronic lymphocytic leukaemia - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. scholar.nycu.edu.tw [scholar.nycu.edu.tw]
- 13. New breakthroughs in siRNA therapeutics expand the drug pipeline | CAS [cas.org]
- 14. researchgate.net [researchgate.net]
- 15. glenresearch.com [glenresearch.com]
- 16. [PDF] Solid-Phase Synthesis of Phosphorothioate Oligonucleotides Using Sulfurization Byproducts for in Situ Capping. | Semantic Scholar [semanticscholar.org]
- 17. aacrjournals.org [aacrjournals.org]
- 18. bmrat.biomedpress.org [bmrat.biomedpress.org]
Troubleshooting & Optimization
troubleshooting low coupling efficiency of rU Phosphoramidite-13C9
This technical support center provides troubleshooting guidance and frequently asked questions for researchers, scientists, and drug development professionals experiencing low coupling efficiency with rU Phosphoramidite-13C9 during oligonucleotide synthesis.
Frequently Asked Questions (FAQs)
Q1: What is rU Phosphoramidite-13C9 and what are its primary applications?
A1: rU Phosphoramidite-13C9 is a specialized phosphoramidite (B1245037) used in the solid-phase synthesis of RNA oligonucleotides.[1][2] The "-13C9" designation indicates that the ribose sugar and the uracil (B121893) base of the uridine (B1682114) nucleoside contain nine carbon-13 isotopes. This isotopic labeling makes it a valuable tool for nuclear magnetic resonance (NMR) spectroscopy and mass spectrometry-based studies, allowing for detailed investigation of RNA structure, dynamics, and interactions with other molecules.[3]
Q2: What is "coupling efficiency" and why is it crucial for oligonucleotide synthesis?
A2: Coupling efficiency is the percentage of available 5'-hydroxyl groups on the solid support that successfully react with the incoming phosphoramidite in each synthesis cycle.[4] Achieving a high coupling efficiency (ideally >99%) is critical because any unreacted sites result in truncated sequences.[4] The accumulation of these shorter oligonucleotides reduces the yield of the desired full-length product and complicates downstream purification and applications.[4] Even a small decrease in coupling efficiency can significantly lower the final yield, especially for longer oligonucleotides.[5]
Q3: Does the 13C9 isotopic labeling in rU Phosphoramidite-13C9 negatively impact its coupling efficiency?
A3: There is no direct evidence to suggest that the heavy isotope labeling in rU Phosphoramidite-13C9 inherently causes low coupling efficiency. The chemical reactivity of the phosphoramidite is not significantly altered by the presence of carbon-13 isotopes.[4] Therefore, troubleshooting for low coupling efficiency with this modified phosphoramidite should follow the same principles as for standard, unlabeled phosphoramidites. The primary focus should be on optimizing the synthesis conditions and ensuring the quality of all reagents.[6][]
Q4: How can I monitor the coupling efficiency during the synthesis run?
A4: The most common method for real-time monitoring of coupling efficiency is through trityl cation monitoring.[4] The dimethoxytrityl (DMT) group, which protects the 5'-hydroxyl of the phosphoramidite, is removed at the beginning of each coupling cycle. The released DMT cation is brightly colored and its absorbance can be measured (around 495 nm). A consistent and strong trityl signal indicates high coupling efficiency in the previous cycle. A significant drop in the signal is a direct indication of a coupling problem.[4]
Troubleshooting Guide for Low Coupling Efficiency
Low coupling efficiency is a common issue in oligonucleotide synthesis and can be attributed to several factors. This guide provides a systematic approach to identify and resolve the root cause of the problem.
Diagram: Troubleshooting Workflow
Caption: A step-by-step workflow for diagnosing and resolving low coupling efficiency.
Data Presentation: Common Activators and Their Properties
| Activator | Recommended Concentration | pKa | Characteristics |
| 1H-Tetrazole | 0.45 M | 4.8 | Standard, widely used activator. |
| 5-(Ethylthio)-1H-tetrazole (ETT) | 0.25 M - 0.75 M | 4.3 | More acidic and faster than 1H-Tetrazole. |
| 4,5-Dicyanoimidazole (DCI) | 0.25 M - 1.2 M | 5.2 | Less acidic but highly nucleophilic, leading to rapid coupling. Highly soluble in acetonitrile. |
Data compiled from publicly available information.[4]
Experimental Protocols
Protocol 1: Preparation of Anhydrous Acetonitrile
Objective: To ensure the acetonitrile used for phosphoramidite dissolution and in the synthesizer is free of moisture, a critical factor for high coupling efficiency.[5]
Materials:
-
Acetonitrile (synthesis grade)
-
3Å Molecular sieves (activated)
-
Anhydrous-rated solvent bottle with a septum-sealed cap
-
Inert gas source (Argon or Nitrogen)
Methodology:
-
Activate the 3Å molecular sieves by heating them in a vacuum oven at 250-300°C for at least 3 hours.
-
Allow the sieves to cool to room temperature under a stream of inert gas or in a desiccator.
-
Add the activated molecular sieves to the acetonitrile bottle (approximately 10-20% of the solvent volume).
-
Allow the acetonitrile to stand over the molecular sieves for at least 24 hours before use.
-
When using, ensure the bottle is under a positive pressure of inert gas to prevent atmospheric moisture from entering.
Protocol 2: Analysis of Crude Oligonucleotide by Mass Spectrometry
Objective: To assess the quality of the synthesized oligonucleotide and identify the presence of truncated sequences resulting from low coupling efficiency.
Materials:
-
Crude oligonucleotide sample (deprotected and desalted)
-
Mass spectrometer (ESI-MS or MALDI-TOF MS)
-
Appropriate matrix (for MALDI-TOF) or solvent system (for ESI-MS)
Methodology:
-
Prepare the desalted crude oligonucleotide sample according to the mass spectrometer's requirements.
-
Acquire the mass spectrum of the sample.
-
Analyze the resulting spectrum to identify the mass-to-charge ratio of the major peaks.
-
Confirm that the primary peak corresponds to the expected mass of the full-length oligonucleotide.
-
The presence of significant peaks corresponding to shorter (n-1, n-2, etc.) sequences is indicative of poor coupling efficiency at one or more steps.[4]
Signaling Pathways and Logical Relationships
The following diagram illustrates the chemical steps in one cycle of phosphoramidite-based oligonucleotide synthesis. A failure in the coupling step is the primary cause of low overall yield.
Caption: The four key steps in one cycle of phosphoramidite oligonucleotide synthesis.
References
Technical Support Center: Optimizing Phosphoramidite Stability for RNA Synthesis
This technical support center provides researchers, scientists, and drug development professionals with comprehensive troubleshooting guides and frequently asked questions (FAQs) to address common challenges encountered during RNA synthesis, with a focus on phosphoramidite (B1245037) stability.
Frequently Asked Questions (FAQs)
Q1: What are the primary factors affecting phosphoramidite stability?
A1: Phosphoramidite stability is critical for successful oligonucleotide synthesis.[] The main factors influencing their stability include:
-
Moisture: Phosphoramidites are highly susceptible to hydrolysis. Even trace amounts of water can lead to the formation of inactive H-phosphonate byproducts, which will not couple to the growing oligonucleotide chain.[][2] It is crucial to maintain anhydrous conditions throughout storage and handling.[3][4]
-
Oxidation: The phosphorus (III) center in phosphoramidites is prone to oxidation to phosphorus (V), rendering it inactive for the coupling reaction.[2] This can be minimized by storing and handling phosphoramidites under an inert atmosphere (e.g., argon or nitrogen).[2]
-
Temperature: Elevated temperatures accelerate the degradation of phosphoramidites.[] Therefore, they should be stored at low temperatures, typically -20°C, to maintain their integrity.[2][4]
-
Chemical Purity: The presence of impurities in the phosphoramidite preparation can catalyze decomposition pathways.[] Using high-purity phosphoramidites from reputable suppliers is essential for optimal synthesis results.[2]
-
Activator Choice: The type of activator used can influence the stability of the phosphoramidite in solution. While activators are necessary for the coupling reaction, prolonged exposure can lead to degradation.[][5]
Q2: How should I properly store and handle phosphoramidites to ensure their stability?
A2: Proper storage and handling are paramount to preserving phosphoramidite quality.[3] Here are the best practices:
-
Storage: Solid phosphoramidites should be stored in tightly sealed containers at -20°C under a dry, inert atmosphere like argon or nitrogen.[2][4] For solutions in anhydrous acetonitrile (B52724), short-term storage on the synthesizer is acceptable, but for longer periods, storage at -20°C is recommended.[2]
-
Handling:
-
Always handle phosphoramidites in a well-ventilated area and wear appropriate personal protective equipment (PPE), including gloves and eye protection.[4]
-
To prevent condensation of atmospheric moisture, allow the sealed container of solid phosphoramidite to equilibrate to room temperature before opening.[2]
-
Use anhydrous solvents and reagents for preparing phosphoramidite solutions. DNA synthesis grade acetonitrile with a water content of less than 10 ppm is recommended.[2]
-
Handle solutions under an inert atmosphere using septum-sealed bottles and syringes flushed with inert gas.[2]
-
Some phosphoramidites are viscous oils rather than powders. These should be dissolved directly in the vial by injecting anhydrous acetonitrile through the septum to avoid moisture exposure.[6]
-
Q3: What are the common degradation pathways for phosphoramidites?
A3: The two primary degradation pathways for phosphoramidites are hydrolysis and oxidation.
-
Hydrolysis: This is the most common degradation pathway, where the phosphoramidite reacts with water to form an H-phosphonate and a secondary amine. The resulting H-phosphonate is not active in the coupling reaction, leading to lower synthesis yields.[][2] The rate of hydrolysis can be influenced by the specific nucleoside, with dG being particularly susceptible.[7]
-
Oxidation: The P(III) center of the phosphoramidite can be oxidized to a P(V) species, which is incapable of coupling with the 5'-hydroxyl group of the growing oligonucleotide chain.[2] This is often caused by exposure to air.
-
Acrylonitrile (B1666552) Elimination: A less common but significant degradation pathway involves the elimination of acrylonitrile from the cyanoethyl protecting group. The highly reactive acrylonitrile can then form adducts with the nucleobases, leading to modified oligonucleotides.[2]
Below is a diagram illustrating the main degradation pathways.
Caption: Primary degradation pathways of phosphoramidites.
Q4: How can I assess the quality and purity of my phosphoramidites?
A4: Several analytical techniques are used to determine the purity of phosphoramidites:
-
High-Performance Liquid Chromatography (HPLC): Reversed-phase HPLC (RP-HPLC) is a primary method for assessing purity. Due to the chiral phosphorus center, a pure phosphoramidite will typically show two peaks representing the two diastereomers.[8][9]
-
³¹P Nuclear Magnetic Resonance (³¹P NMR) Spectroscopy: This technique is highly specific for phosphorus-containing compounds and can be used to quantify the amount of the active P(III) species versus inactive P(V) oxidation products.[8][9]
-
Liquid Chromatography-Mass Spectrometry (LC-MS): LC-MS can be used to identify the phosphoramidite and detect any impurities.[10]
| Analytical Method | Parameter Assessed | Typical Specification |
| Reversed-Phase HPLC | Purity | ≥99.0%[9] |
| ³¹P NMR | P(III) Content | ≥99%[9] |
| Karl Fischer Titration | Water Content | ≤0.3 wt.%[9] |
Table 1: Common analytical methods and specifications for phosphoramidite quality control.
Troubleshooting Guides
Problem 1: Low Coupling Efficiency and Low Yield of Full-Length RNA
| Possible Cause | Recommended Solution |
| Phosphoramidite Degradation | - Verify Phosphoramidite Quality: Analyze the purity of the phosphoramidite solution using RP-HPLC and ³¹P NMR.[9] - Use Fresh Reagents: Prepare fresh phosphoramidite solutions, especially if they have been on the synthesizer for an extended period.[2] |
| Moisture Contamination | - Use Anhydrous Reagents: Ensure all solvents and reagents, particularly acetonitrile, are anhydrous (<10 ppm water).[2] - Maintain Inert Atmosphere: Purge synthesizer lines with dry argon or helium.[2] - Use Molecular Sieves: Store molecular sieves in the phosphoramidite and activator solutions to scavenge residual moisture.[2] |
| Incomplete Activation | - Check Activator: Ensure the activator is fresh and has been stored under anhydrous conditions. - Optimize Activator Concentration and Coupling Time: Higher activator concentrations or extended coupling times may improve efficiency, especially for sterically hindered monomers.[][12] |
| Secondary Structure of RNA | - Use Modified Phosphoramidites: Employ phosphoramidites with protecting groups like TOM (tert-butyldimethylsilyloxymethyl) that can reduce steric hindrance.[12] - Optimize Synthesis Conditions: Increase synthesis temperature or use special reagents to disrupt secondary structures.[] |
| Incorrect DNA/RNA Template Concentration | - Verify Template Concentration: Ensure the concentration of the starting template is accurate. Contaminants in the template can also inhibit the reaction.[14] |
Problem 2: Presence of Unexpected Peaks in HPLC or LC-MS Analysis of the Synthesized RNA
| Possible Cause | Recommended Solution |
| Phosphoramidite Impurities | - Source High-Purity Reagents: Use phosphoramidites from reputable suppliers with stringent quality control.[2][15] - Characterize Impurities: Use LC-MS to determine the mass of the impurity and trace its origin.[9] |
| Acrylonitrile Adducts | - Use High-Quality Phosphoramidites: Ensure phosphoramidites are fresh and have been stored correctly to minimize the elimination of acrylonitrile.[2] |
| Inefficient Capping of Failure Sequences | - Check Capping Reagents: Ensure capping reagents (e.g., acetic anhydride (B1165640) and 1-methylimidazole) are fresh and active.[4] - Optimize Capping Step: Ensure the capping step is efficient to block unreacted 5'-hydroxyl groups. |
| Side Reactions During Synthesis | - Review Synthesis Protocol: Investigate potential side reactions related to the specific nucleobases or modifications being used.[] |
Below is a workflow for troubleshooting low-yield RNA synthesis.
Caption: Troubleshooting workflow for low RNA synthesis yield.
Experimental Protocols
Protocol 1: Preparation of Phosphoramidite Solution for Synthesis
Objective: To prepare a solution of a phosphoramidite in anhydrous acetonitrile with minimal exposure to moisture and air.
Materials:
-
Solid phosphoramidite
-
Anhydrous acetonitrile (DNA synthesis grade, <10 ppm water)[2]
-
Molecular sieves (3 Å, activated)[2]
-
Inert gas (argon or nitrogen)
-
Septum-sealed vial
-
Oven-dried syringes and needles
Procedure:
-
Allow the sealed container of solid phosphoramidite to equilibrate to room temperature before opening to prevent condensation.[2]
-
Under a stream of inert gas, quickly weigh the desired amount of phosphoramidite into a tared, dry, septum-sealed vial.
-
Add activated molecular sieves to the vial.
-
Using an oven-dried syringe, draw the required volume of anhydrous acetonitrile from a septum-sealed bottle.
-
Slowly inject the acetonitrile into the vial containing the phosphoramidite.
-
Gently swirl the vial until the phosphoramidite is completely dissolved. For viscous oil phosphoramidites, this may take several minutes.[6]
-
The solution is now ready to be placed on the DNA/RNA synthesizer.
Protocol 2: Quality Assessment of Phosphoramidites by Reversed-Phase HPLC
Objective: To assess the purity of a phosphoramidite sample using RP-HPLC.
Materials and Equipment:
-
HPLC system with a UV detector
-
C18 column (e.g., 250 x 4.6 mm, 5 µm particle size)[8]
-
Mobile Phase A: 0.1 M Triethylammonium acetate (B1210297) (TEAA) in water (pH 7.0)[8]
-
Mobile Phase B: Acetonitrile[8]
-
Phosphoramidite sample
-
Anhydrous acetonitrile for sample preparation
Procedure:
-
Sample Preparation: Prepare a stock solution of the phosphoramidite at 1 mg/mL in anhydrous acetonitrile. Further dilute to a working concentration of 0.1 mg/mL in the same diluent.[10]
-
HPLC Conditions:
-
Injection: Inject the prepared sample onto the HPLC system.
-
Data Analysis:
This technical support guide provides a foundation for understanding and troubleshooting issues related to phosphoramidite stability in RNA synthesis. For more specific issues, always consult the documentation provided by your reagent and instrument suppliers.
References
- 2. benchchem.com [benchchem.com]
- 3. Exploring Phosphoramidites: Essential Building Blocks in Modern Chemistry and Biotechnology - Amerigo Scientific [amerigoscientific.com]
- 4. benchchem.com [benchchem.com]
- 5. Design, synthesis and properties of phosphoramidate 2′,5′-linked branched RNA: Towards the rational design of inhibitors of the RNA Lariat Debranching Enzyme - PMC [pmc.ncbi.nlm.nih.gov]
- 6. glenresearch.com [glenresearch.com]
- 7. The Degradation of dG Phosphoramidites in Solution - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. usp.org [usp.org]
- 9. benchchem.com [benchchem.com]
- 10. lcms.cz [lcms.cz]
- 12. glenresearch.com [glenresearch.com]
- 14. neb.com [neb.com]
- 15. documents.thermofisher.com [documents.thermofisher.com]
Technical Support Center: Purification of 13C-Labeled Synthetic RNA
Welcome to the technical support center for the purification of 13C-labeled synthetic RNA. This resource is designed for researchers, scientists, and drug development professionals to provide troubleshooting guidance and answer frequently asked questions related to the unique challenges encountered during the purification of these specialized molecules.
Troubleshooting Guide
This guide addresses specific issues that may arise during the purification of 13C-labeled synthetic RNA, offering potential causes and solutions in a question-and-answer format.
Q1: Why is the yield of my 13C-labeled RNA consistently low after purification?
Possible Causes:
-
Suboptimal Synthesis: Inefficient coupling during solid-phase synthesis can lead to a higher proportion of failure sequences.
-
Losses During Purification: Significant sample loss can occur during precipitation, extraction from gels, or when using chromatography columns that are not optimized for the scale of your synthesis.
-
Incomplete Elution: The RNA may not be completely eluting from the purification matrix (e.g., PAGE gel slice or chromatography column).
-
RNA Degradation: RNase contamination or harsh chemical treatments can lead to the degradation of the target RNA.[1][2][3]
Solutions:
-
Optimize Synthesis: Ensure high coupling efficiency for each nucleotide addition. The capping step is crucial to terminate failure sequences.[]
-
Minimize Transfer Steps: Reduce the number of tube transfers and precipitation steps to minimize physical loss of the sample.
-
Optimize Elution: For PAGE, ensure the gel slice is thoroughly crushed or soaked to maximize diffusion. For chromatography, use the recommended elution buffers and consider increasing the elution volume or performing a second elution.[5][6]
-
Maintain an RNase-Free Environment: Use RNase-free reagents and consumables. Work in a designated clean area to prevent degradation.[2][7]
Q2: My purified 13C-labeled RNA shows multiple bands on a denaturing PAGE gel. What are these impurities?
Possible Causes:
-
Failure Sequences (n-1, n-2, etc.): These are shorter RNA molecules resulting from incomplete coupling during synthesis.[]
-
Depurination: Loss of purine (B94841) bases (adenine or guanine) can occur, leading to chain cleavage.[]
-
Removal of Protecting Groups: Incomplete removal of protecting groups from the 2'-hydroxyl, such as TBDMS, can result in impurities with higher molecular weight.[]
-
Double-Stranded RNA (dsRNA): Self-complementary sequences can form dsRNA, which may migrate differently on a gel.[8]
Solutions:
-
High-Resolution Purification: Use high-percentage denaturing polyacrylamide gel electrophoresis (PAGE) or high-performance liquid chromatography (HPLC) for better separation of the full-length product from shorter failure sequences.[8][9][10]
-
Optimize Deprotection: Strictly follow the recommended protocols for the removal of all protecting groups.
-
Denaturing Conditions: Ensure complete denaturation of the RNA before loading it onto a gel by using a loading buffer with urea (B33335) and heating the sample.[5]
Q3: Mass spectrometry analysis of my purified 13C-labeled RNA shows unexpected mass shifts. What could be the cause?
Possible Causes:
-
Incomplete Deprotection: Residual protecting groups will add to the mass of the RNA. For example, a remaining TBDMS group adds approximately 114 Da.[]
-
Cation Adduction: The negatively charged phosphate (B84403) backbone of RNA can associate with cations (e.g., Na+, K+), leading to an increase in the observed mass.[11]
-
Oxidation: Phosphorothioate modifications, if present, can be oxidized, leading to a mass change.[12]
-
Hydrolysis: The m7G cap, if present, can undergo hydrolysis, resulting in an +18 Da mass shift due to imidazole (B134444) ring opening.[13]
Solutions:
-
Thorough Desalting: Perform rigorous desalting of the purified RNA sample before MS analysis.
-
Optimized Deprotection: Ensure complete removal of all protecting groups by following optimized protocols.
-
High-Resolution MS: Utilize high-resolution mass spectrometry to accurately identify and characterize any mass discrepancies.
Frequently Asked Questions (FAQs)
Q1: What is the best method to purify 13C-labeled synthetic RNA?
The optimal purification method depends on the length of the RNA, the required purity, and the downstream application. The two most common high-resolution methods are:
-
Denaturing Polyacrylamide Gel Electrophoresis (PAGE): This method provides excellent resolution for separating the full-length RNA from shorter failure sequences, especially for RNAs up to ~30 nucleotides.[9]
-
High-Performance Liquid Chromatography (HPLC): Ion-pair reverse-phase HPLC is a powerful technique for purifying synthetic RNA and can resolve species with different chemical modifications.[8][10] Size-exclusion HPLC is effective at removing degraded or aborted transcripts.[10]
Q2: How can I confirm the purity and identity of my 13C-labeled RNA?
A combination of analytical techniques is recommended:
-
Analytical PAGE or HPLC: To assess the homogeneity of the sample.
-
UV Spectrophotometry: To determine the RNA concentration.
-
Mass Spectrometry (MS): To confirm the molecular weight and verify the incorporation of the 13C labels.[11][14]
Q3: Can the 13C label affect the purification process?
The presence of 13C isotopes increases the mass of the RNA molecule. While this mass difference is small, it is detectable by high-resolution mass spectrometry. For chromatographic and electrophoretic purposes, the effect of 13C labeling on the separation behavior is generally negligible compared to the influence of factors like length, sequence, and secondary structure. However, it is the key identifier in mass-based analytical techniques.
Experimental Protocols
Protocol 1: Denaturing Polyacrylamide Gel Electrophoresis (PAGE) Purification
-
Gel Preparation: Prepare a high-resolution denaturing polyacrylamide gel (e.g., 15-20%) containing 8 M urea in 1x TBE buffer.
-
Sample Preparation: Resuspend the crude synthetic RNA in a loading buffer containing 8 M urea, tracking dyes (e.g., bromophenol blue and xylene cyanol), and heat at 95°C for 3-5 minutes to denature.[5]
-
Electrophoresis: Load the denatured RNA sample onto the gel and run at a constant power until the tracking dyes have migrated to the desired position.
-
Visualization: Visualize the RNA bands using UV shadowing. The product band should be the most intense and slowest migrating band.
-
Excision and Elution: Carefully excise the desired RNA band from the gel. Crush the gel slice and elute the RNA overnight in an appropriate elution buffer (e.g., 0.3 M NaCl).[5][15]
-
Recovery: Separate the eluted RNA from the gel fragments by filtration or centrifugation. Precipitate the RNA using ethanol (B145695) or isopropanol, wash with 70% ethanol, and resuspend in RNase-free water.
Protocol 2: HPLC Purification
-
System Preparation: Use an HPLC system equipped with a suitable column (e.g., anion-exchange or reverse-phase).[16] Equilibrate the column with the initial mobile phase conditions.
-
Mobile Phase: A common mobile phase for anion-exchange HPLC consists of a low salt buffer (Eluent A) and a high salt buffer (Eluent B). For example:
-
Eluent A: 12.5 mM Tris-HCl (pH 7.5)
-
Eluent B: 12.5 mM Tris-HCl (pH 7.5), 1 M NaCl[16]
-
-
Sample Injection: Dissolve the crude RNA in Eluent A and inject it onto the column.
-
Gradient Elution: Elute the RNA using a linear gradient of increasing salt concentration (e.g., 0-50% Eluent B over 45 minutes).[16]
-
Fraction Collection: Collect fractions as the RNA elutes from the column, monitoring the absorbance at 260 nm.
-
Desalting: Pool the fractions containing the pure RNA and desalt using a suitable method, such as a desalting cartridge or ethanol precipitation.[16]
Quantitative Data Summary
Table 1: Comparison of Purification Methods for Synthetic RNA
| Feature | Denaturing PAGE | Anion-Exchange HPLC | Ion-Pair Reverse-Phase HPLC |
| Resolution | High (especially for <30 nt) | High | Very High |
| Throughput | Low to Medium | High | High |
| Scalability | Limited | Good | Good |
| Common Impurities Removed | Failure sequences | Failure sequences, salts | Failure sequences, incompletely deprotected species |
| Post-Purification Steps | Elution, Desalting | Desalting | Desalting |
Visualizations
References
- 1. neb.com [neb.com]
- 2. bitesizebio.com [bitesizebio.com]
- 3. RNA Preparation Troubleshooting [sigmaaldrich.com]
- 5. youtube.com [youtube.com]
- 6. neb.com [neb.com]
- 7. mpbio.com [mpbio.com]
- 8. Generating the optimal mRNA for therapy: HPLC purification eliminates immune activation and improves translation of nucleoside-modified, protein-encoding mRNA - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Isotope labeling strategies for NMR studies of RNA - PMC [pmc.ncbi.nlm.nih.gov]
- 10. nacalai.com [nacalai.com]
- 11. Mass Spectrometry of Modified RNAs: Recent Developments (Minireview) - PMC [pmc.ncbi.nlm.nih.gov]
- 12. assets.fishersci.com [assets.fishersci.com]
- 13. Mind the cap: Detecting degradation impurities in synthetic mRNAs - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Sensitive, Efficient Quantitation of 13C-Enriched Nucleic Acids via Ultrahigh-Performance Liquid Chromatography–Tandem Mass Spectrometry for Applications in Stable Isotope Probing - PMC [pmc.ncbi.nlm.nih.gov]
- 15. researchgate.net [researchgate.net]
- 16. Short, synthetic and selectively 13C-labeled RNA sequences for the NMR structure determination of protein–RNA complexes - PMC [pmc.ncbi.nlm.nih.gov]
Technical Support Center: Minimizing N+1 Impurities in Labeled Oligonucleotide Synthesis
This technical support center provides researchers, scientists, and drug development professionals with comprehensive troubleshooting guides and frequently asked questions (FAQs) to minimize N+1 impurities in labeled oligonucleotide synthesis.
Frequently Asked Questions (FAQs)
Q1: What are N+1 impurities in oligonucleotide synthesis?
A1: N+1 impurities are a type of product-related impurity where an additional nucleotide is added to the full-length oligonucleotide sequence.[1] These are also referred to as "longmers".[2] They can arise from various side reactions during the solid-phase synthesis process and are often challenging to separate from the desired full-length product due to their similar physicochemical properties.[3]
Q2: What are the common causes of N+1 impurities?
A2: The primary causes of N+1 impurities include:
-
Dimer Phosphoramidite (B1245037) Coupling: Acidic activators used during the coupling step can prematurely remove the 5'-dimethoxytrityl (DMT) protecting group from a small fraction of the incoming phosphoramidite. This deprotected phosphoramidite can then react with another activated phosphoramidite in solution to form a dimer, which is subsequently incorporated into the growing oligonucleotide chain. This is particularly prevalent with guanosine (B1672433) (dG) phosphoramidites due to their faster detritylation rate.[4]
-
N3-Cyanoethylation of Thymidine (B127349): During the deprotection step with ammonia (B1221849), acrylonitrile (B1666552), a byproduct of the removal of the cyanoethyl protecting group from the phosphate (B84403) backbone, can react with the N3 position of thymidine residues. This modification results in a +53 Da adduct, which can be mistaken for an N+1 impurity in some analytical methods like reverse-phase HPLC.[4]
Q3: How do N+1 impurities affect my experiments or drug product?
A3: N+1 impurities can have several detrimental effects:
-
Reduced Purity and Yield: The presence of these impurities lowers the overall purity of the synthesized oligonucleotide and reduces the yield of the desired full-length product.
-
Altered Biological Activity: For therapeutic oligonucleotides, N+1 impurities can alter the binding affinity to the target sequence, potentially leading to off-target effects or reduced efficacy.
-
Analytical Challenges: The close similarity in size and properties between the N+1 impurity and the full-length product makes purification difficult, complicating downstream applications and analytical characterization.[3]
Q4: What is the role of phosphoramidite quality in N+1 formation?
A4: The quality of phosphoramidite monomers is critical in preventing the formation of impurities. The repetitive nature of oligonucleotide synthesis means that even small amounts of reactive impurities in the starting materials can accumulate to significant levels in the final product.[3][] Critical reactive impurities in phosphoramidites can be incorporated into the oligonucleotide and are difficult to remove during purification.[3] Therefore, using high-purity phosphoramidites with low levels of reactive impurities is essential for minimizing N+1 and other synthesis-related byproducts.
Troubleshooting Guide
This guide addresses specific issues you might encounter during your oligonucleotide synthesis and analysis, with a focus on N+1 impurities.
Problem 1: A significant peak is observed at the N+1 position in my HPLC chromatogram.
-
Possible Cause A: GG Dimer Addition.
-
Explanation: If your sequence is rich in guanosine residues, the use of a highly acidic activator may be promoting the formation and incorporation of GG dimers.[4]
-
Solution:
-
Switch to a less acidic activator: Consider using activators with a higher pKa, such as 4,5-dicyanoimidazole (B129182) (DCI), which is less likely to cause premature detritylation of the incoming phosphoramidite compared to more acidic activators like 5-ethylthio-1H-tetrazole (ETT) or 1H-tetrazole.[6]
-
Optimize coupling time: While ensuring high coupling efficiency, avoid unnecessarily long coupling times, which can increase the opportunity for side reactions.
-
Ensure high-quality phosphoramidites: Use fresh, high-purity dG phosphoramidites to minimize the presence of already detritylated monomers.
-
-
-
Possible Cause B: N3-Cyanoethylation of Thymidine.
-
Explanation: If your sequence contains thymidine and you are observing a peak that appears to be N+1, it could be the N3-cyanoethyl adduct of your full-length product, which has a mass increase of 53 Da.[4]
-
Solution:
-
Modify the deprotection step:
-
Increase the volume of ammonia used for cleavage and deprotection to better scavenge the acrylonitrile byproduct.
-
Use a mixture of aqueous ammonia and methylamine (B109427) (AMA), as methylamine is a more effective scavenger of acrylonitrile.[4]
-
Incorporate a post-synthesis wash step with a 10% solution of diethylamine (B46881) (DEA) in acetonitrile (B52724) before cleavage and deprotection. This can completely eliminate the N3-cyanoethylation side reaction.[4]
-
-
Confirm with Mass Spectrometry: Use mass spectrometry to determine the exact mass of the impurity. An N+1 peak will have the mass of an additional nucleotide, whereas the N3-cyanoethyl adduct will show a +53 Da mass shift.
-
-
Problem 2: My mass spectrometry results show a mass corresponding to an N+1 impurity, but the HPLC peak is very small or absent.
-
Possible Cause: Co-elution with the main peak.
-
Explanation: The N+1 impurity may have very similar retention characteristics to your full-length product and could be co-eluting, making it difficult to resolve by HPLC.
-
Solution:
-
Optimize HPLC conditions:
-
Adjust the gradient: Use a shallower gradient to improve the separation between the main product and the N+1 impurity.[7]
-
Change the mobile phase: Experiment with different ion-pairing reagents or organic modifiers to alter the selectivity of the separation.
-
Vary the temperature: Increasing the column temperature can sometimes improve resolution.
-
-
Use a different chromatography mode: Consider using an orthogonal method like anion-exchange HPLC (AEX-HPLC), which separates based on charge (number of phosphate groups) and may provide better resolution for N+1 impurities.
-
-
Data Presentation
Table 1: Impact of Activator Choice on N+1 Impurity Formation (Illustrative Data)
| Activator | pKa | Relative N+1 Impurity Level (%) | Key Considerations |
| 1H-Tetrazole | 4.8 | Moderate | Standard activator, but can cause some GG dimer formation.[2] |
| 5-Ethylthio-1H-tetrazole (ETT) | 4.3 | Higher | More acidic, leading to faster coupling but also a higher risk of premature detritylation and N+1 impurities.[4] |
| 4,5-Dicyanoimidazole (DCI) | 5.2 | Lower | Less acidic, reducing the risk of premature detritylation and GG dimer formation, leading to higher fidelity synthesis.[6] |
Note: Actual impurity levels can vary depending on the oligonucleotide sequence, synthesis cycle parameters, and synthesizer platform.
Table 2: Common N+1 and N+1-like Impurities and their Mass Signatures
| Impurity Type | Description | Mass Difference from Full-Length Product |
| True N+1 | Addition of an extra nucleotide | + Mass of the added nucleotide (e.g., dA, dC, dG, dT) |
| N3-Cyanoethylthymidine Adduct | Alkylation of a thymidine residue | + 53 Da |
Experimental Protocols
Protocol 1: HPLC Analysis of N+1 Impurities
This protocol outlines a general method for the analysis of oligonucleotides and their impurities using ion-pair reversed-phase high-performance liquid chromatography (IP-RP-HPLC).
-
Sample Preparation:
-
Dissolve the crude or purified oligonucleotide in nuclease-free water or a suitable buffer to a final concentration of approximately 20 µM.
-
If the sample contains high salt concentrations, perform a desalting step using a size-exclusion spin column or ethanol (B145695) precipitation.
-
-
HPLC System and Column:
-
Use an HPLC system equipped with a UV detector.
-
Employ a C8 or C18 reversed-phase column suitable for oligonucleotide analysis.
-
-
Mobile Phase Preparation:
-
Mobile Phase A: 0.1 M Triethylammonium acetate (B1210297) (TEAA) in nuclease-free water, pH 7.5.
-
Mobile Phase B: 0.1 M TEAA in 50% acetonitrile/50% nuclease-free water, pH 7.5.[7]
-
Filter and degas both mobile phases before use.
-
-
Chromatographic Conditions:
-
Flow Rate: 1.0 mL/min
-
Column Temperature: 50-60 °C
-
Detection Wavelength: 260 nm
-
Injection Volume: 10-20 µL
-
Gradient:
-
0-5 min: 5% B
-
5-25 min: 5-50% B (linear gradient)
-
25-30 min: 50-95% B (wash)
-
30-35 min: 95% B (wash)
-
35-40 min: 5% B (equilibration)
-
-
-
Data Analysis:
-
Integrate the peaks in the chromatogram. The full-length product should be the major peak. N+1 impurities will typically elute slightly later than the main peak.
-
Calculate the percentage of the N+1 impurity relative to the total area of all oligonucleotide-related peaks.
-
Protocol 2: MALDI-TOF Mass Spectrometry for N+1 Impurity Identification
This protocol provides a general procedure for the analysis of oligonucleotides by Matrix-Assisted Laser Desorption/Ionization Time-of-Flight (MALDI-TOF) mass spectrometry.
-
Matrix Preparation:
-
Prepare a saturated solution of 3-hydroxypicolinic acid (3-HPA) in a 50:50 mixture of acetonitrile and water.
-
Add diammonium hydrogen citrate (B86180) to the matrix solution to a final concentration of 10 mg/mL to reduce sodium and potassium adducts.[8]
-
-
Sample Preparation:
-
Dilute the oligonucleotide sample to approximately 1 µM in nuclease-free water.
-
-
Spotting Technique (Dried-Droplet Method):
-
Spot 0.5 µL of the matrix solution onto the MALDI target plate.
-
Allow the matrix to air dry completely at room temperature.
-
Spot 0.5 µL of the oligonucleotide sample directly on top of the dried matrix spot.
-
Allow the sample spot to air dry completely at room temperature.[8]
-
-
Mass Spectrometry Analysis:
-
Use a MALDI-TOF mass spectrometer in negative ion linear mode for oligonucleotide analysis.
-
Calibrate the instrument using an appropriate oligonucleotide standard.
-
Acquire the mass spectrum over a mass range that includes the expected mass of the full-length product and any potential impurities.
-
-
Data Analysis:
-
Determine the mass of the major peak, which should correspond to the full-length oligonucleotide.
-
Look for peaks with masses corresponding to N+1 impurities (mass of full-length product + mass of one nucleotide) and other potential adducts (e.g., +53 Da for N3-cyanoethylthymidine).
-
Visualizations
Caption: Pathways leading to the formation of N+1 and N+1-like impurities.
Caption: Troubleshooting workflow for identifying and minimizing N+1 impurities.
References
- 1. Oligonucleotides Purity and Impurities Analysis | Agilent [agilent.com]
- 2. researchgate.net [researchgate.net]
- 3. documents.thermofisher.com [documents.thermofisher.com]
- 4. glenresearch.com [glenresearch.com]
- 6. nbinno.com [nbinno.com]
- 7. RP-HPLC Purification of Oligonucleotides | Mass Spectrometry Research Facility [massspec.chem.ox.ac.uk]
- 8. MALDI Oligonucleotide Sample Preparation | Mass Spectrometry Research Facility [massspec.chem.ox.ac.uk]
Technical Support Center: Synthesis of Long, Isotopically Labeled RNA
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to assist researchers, scientists, and drug development professionals in improving the yield of long, isotopically labeled RNA sequences for applications such as NMR spectroscopy and structural biology.
Frequently Asked Questions (FAQs)
Q1: What are the most common reasons for low yield during in vitro transcription of long RNA?
A1: Low yields of long RNA transcripts can stem from several factors:
-
Suboptimal Reagent Concentrations: Incorrect concentrations of NTPs, magnesium, or T7 RNA polymerase can significantly hinder transcription efficiency.[1][2][3]
-
Poor DNA Template Quality: Contaminants such as salts or ethanol (B145695) in the DNA template preparation can inhibit RNA polymerase activity.[4][5][] The template must also be fully linearized to prevent read-through.[4]
-
Premature Termination: Secondary structures within the DNA template or the nascent RNA transcript can cause the polymerase to dissociate prematurely.[7] GC-rich templates are particularly prone to this issue.[4]
-
Product Inhibition: Accumulation of pyrophosphate during the reaction can inhibit T7 RNA polymerase.[1][2]
-
RNase Contamination: The presence of RNases will lead to the degradation of the synthesized RNA.[5][8]
Q2: How can I minimize the formation of shorter, abortive transcripts?
A2: Abortive transcripts are short RNA sequences that are a common byproduct of in vitro transcription. To minimize their formation:
-
Optimize Promoter Sequence: The sequence immediately downstream of the T7 promoter can influence the initiation efficiency and the level of abortive synthesis.
-
Use a High-Yield T7 RNA Polymerase: Some commercially available T7 RNA polymerase variants are engineered to reduce the generation of abortive transcripts.[9]
-
Purification: Post-transcription purification methods like denaturing polyacrylamide gel electrophoresis (PAGE) are effective at separating the full-length product from shorter abortive sequences.[10][11][12][13]
Q3: What is the best method to purify long RNA transcripts?
A3: The choice of purification method depends on the desired purity, the length of the RNA, and the downstream application.
-
Denaturing Polyacrylamide Gel Electrophoresis (PAGE): This is a high-resolution method ideal for separating the target RNA from shorter transcripts, abortive sequences, and enzymes.[10][11][12][13][14][15] However, recovery of very long RNAs (>600 nucleotides) from the gel matrix can be inefficient.[15]
-
Size-Exclusion Chromatography (SEC): SEC separates molecules based on size and is a good native purification method that can resolve different RNA conformations and aggregates.[9][16]
-
Affinity Chromatography: This method can be used if the RNA is tagged, allowing for highly specific purification.[17]
-
Silica-Based Spin Columns: These are a quick and convenient method for cleaning up transcription reactions and removing enzymes, DNA templates, and unincorporated nucleotides.[18]
Q4: How can I ensure efficient isotopic labeling of my long RNA?
A4: Efficient isotopic labeling is crucial for NMR studies. Key considerations include:
-
High-Quality Labeled NTPs: Use high-purity, commercially available isotopically labeled (e.g., ¹³C, ¹⁵N) ribonucleoside triphosphates (rNTPs).[19][20][21]
-
Optimized NTP Concentrations: The concentration of the labeled NTPs can be a limiting factor in the transcription reaction.[7] Ensure that the concentration is sufficient to support the synthesis of full-length transcripts.
-
Uniform vs. Segmental Labeling: For very long RNAs, uniform labeling can lead to spectral overlap in NMR. Segmental labeling, where only specific regions of the RNA are labeled, can simplify spectra.[20][22] This can be achieved by ligating labeled and unlabeled RNA fragments.[20][21]
Troubleshooting Guides
Problem 1: Low or No RNA Yield
Possible Causes and Solutions
| Possible Cause | Recommended Solution |
| Poor DNA Template Quality | Re-purify the DNA template using phenol:chloroform extraction followed by ethanol precipitation to remove inhibitors.[5][] Verify template integrity and concentration via gel electrophoresis and spectrophotometry. |
| Inactive T7 RNA Polymerase | Use a fresh aliquot of enzyme and always store it at -20°C in a non-frost-free freezer. Perform a positive control reaction with a known template to verify enzyme activity.[4][8] |
| Suboptimal Reaction Conditions | Optimize the concentration of MgCl₂, as it is critical for polymerase activity. A typical starting concentration is 20-30 mM.[23] Include inorganic pyrophosphatase in the reaction to prevent product inhibition.[1][2] |
| RNase Contamination | Use RNase-free water, reagents, and labware. Wear gloves and work in a clean environment.[5][8] The addition of an RNase inhibitor to the transcription reaction is also recommended.[4] |
Problem 2: Presence of Multiple RNA Bands (Shorter than Expected)
Possible Causes and Solutions
| Possible Cause | Recommended Solution |
| Premature Termination | For GC-rich templates, try lowering the transcription temperature to 30°C to reduce the stability of secondary structures.[4] Increasing the concentration of the limiting NTP can also help drive the reaction to completion.[4][7] |
| Template Degradation | Ensure the DNA template is intact by running an aliquot on an agarose (B213101) gel before setting up the transcription reaction. |
| Cryptic Termination Sites | Some DNA sequences can act as intrinsic termination sites for T7 RNA polymerase. If this is suspected, re-designing the template may be necessary. |
Problem 3: Presence of RNA Bands Longer than Expected
Possible Causes and Solutions
| Possible Cause | Recommended Solution |
| Non-templated 3' Additions | T7 RNA polymerase can add extra non-templated nucleotides to the 3' end of the transcript.[24] This can be minimized by using a DNA template with 2'-O-methyl modifications on the last two nucleotides of the template strand.[13][24] |
| Self-Primed Extension (dsRNA formation) | The synthesized RNA can fold back on itself and act as a primer for the polymerase, resulting in longer double-stranded RNA byproducts.[25] Performing the transcription at a higher temperature with a thermostable T7 RNA polymerase can reduce the formation of these byproducts.[26] |
| Incomplete Template Linearization | If the plasmid DNA template is not completely linearized, the polymerase can transcribe around the entire plasmid, producing long, heterogeneous transcripts.[4] Confirm complete linearization by running the digested plasmid on an agarose gel.[4] |
Experimental Protocols
Protocol 1: High-Yield In Vitro Transcription of Long RNA
This protocol is optimized for the synthesis of milligram quantities of long RNA.
Reagents:
-
Linearized DNA template (0.5-1 µg)
-
10X Transcription Buffer (400 mM Tris-HCl pH 7.9, 60 mM MgCl₂, 100 mM DTT, 20 mM Spermidine)
-
rNTPs (ATP, CTP, GTP, UTP) or isotopically labeled rNTPs (25 mM each)
-
T7 RNA Polymerase (50 U/µL)
-
Inorganic Pyrophosphatase (1 U/µL)
-
RNase Inhibitor (40 U/µL)
-
Nuclease-free water
Procedure:
-
Thaw all components on ice.
-
Assemble the reaction at room temperature in the following order:
-
Nuclease-free water to a final volume of 100 µL
-
10 µL of 10X Transcription Buffer
-
8 µL of each rNTP (final concentration 2 mM each)
-
1 µg of linearized DNA template
-
1 µL of Inorganic Pyrophosphatase
-
1 µL of RNase Inhibitor
-
2 µL of T7 RNA Polymerase
-
-
Mix gently by pipetting and incubate at 37°C for 2-4 hours.
-
After incubation, add 2 µL of DNase I (RNase-free) and incubate at 37°C for 15 minutes to digest the DNA template.
-
Proceed with RNA purification.
Protocol 2: Denaturing PAGE Purification of Long RNA
This protocol is for the purification of the target RNA from a transcription reaction.
Materials:
-
Acrylamide/Bis-acrylamide solution (e.g., 19:1)
-
10X TBE Buffer (Tris-borate-EDTA)
-
Ammonium (B1175870) persulfate (APS)
-
TEMED
-
2X RNA Loading Buffer (e.g., 95% formamide, 18 mM EDTA, 0.025% SDS, xylene cyanol, bromophenol blue)
-
Elution Buffer (e.g., 0.5 M ammonium acetate, 1 mM EDTA)
Procedure:
-
Prepare the Gel:
-
For a 10% denaturing gel, mix appropriate volumes of acrylamide/bis-acrylamide solution, urea, 10X TBE, and water.
-
Dissolve the urea completely, then add APS and TEMED to initiate polymerization.
-
Pour the gel and allow it to polymerize completely.
-
-
Prepare the Sample:
-
Mix the transcription reaction product 1:1 with 2X RNA Loading Buffer.
-
Heat the sample at 95°C for 5 minutes to denature the RNA, then immediately place on ice.[15]
-
-
Electrophoresis:
-
Assemble the gel apparatus and pre-run the gel for about 30 minutes.
-
Load the denatured RNA sample.
-
Run the gel at a constant power until the desired separation is achieved (monitor with tracking dyes).
-
-
Visualize and Excise the Band:
-
Elute the RNA:
-
Crush the gel slice and place it in a microcentrifuge tube.[11]
-
Add elution buffer and incubate overnight at 4°C with gentle shaking.
-
Separate the eluate from the gel fragments by centrifugation.
-
-
Recover the RNA:
-
Precipitate the RNA from the eluate by adding 2.5 volumes of cold 100% ethanol and incubating at -20°C.
-
Pellet the RNA by centrifugation, wash with 70% ethanol, and resuspend in nuclease-free water.
-
Visualizations
Caption: Experimental workflow for producing long, isotopically labeled RNA.
Caption: Troubleshooting guide for low RNA yield in in vitro transcription.
References
- 1. High-yield synthesis of RNA using T7 RNA polymerase and plasmid DNA or oligonucleotide templates - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. researchgate.net [researchgate.net]
- 3. neb.com [neb.com]
- 4. go.zageno.com [go.zageno.com]
- 5. promegaconnections.com [promegaconnections.com]
- 7. Practical Tips for In Vitro Transcription | Thermo Fisher Scientific - US [thermofisher.com]
- 8. bitesizebio.com [bitesizebio.com]
- 9. scispace.com [scispace.com]
- 10. researchgate.net [researchgate.net]
- 11. Reddit - The heart of the internet [reddit.com]
- 12. youtube.com [youtube.com]
- 13. RNA synthesis and purification for structural studies - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Purification of radiolabeled RNA products using denaturing gel electrophoresis - PMC [pmc.ncbi.nlm.nih.gov]
- 15. researchgate.net [researchgate.net]
- 16. Native Purification and Analysis of Long RNAs - PubMed [pubmed.ncbi.nlm.nih.gov]
- 17. A guide to large-scale RNA sample preparation - PMC [pmc.ncbi.nlm.nih.gov]
- 18. neb.com [neb.com]
- 19. Solid-Phase Chemical Synthesis of Stable Isotope-Labeled RNA to Aid Structure and Dynamics Studies by NMR Spectroscopy | MDPI [mdpi.com]
- 20. Isotope labeling strategies for NMR studies of RNA - PMC [pmc.ncbi.nlm.nih.gov]
- 21. Isotope-Labeled RNA Building Blocks for NMR Structure and Dynamics Studies - PMC [pmc.ncbi.nlm.nih.gov]
- 22. researchgate.net [researchgate.net]
- 23. academic.oup.com [academic.oup.com]
- 24. General Strategies for RNA X-ray Crystallography - PMC [pmc.ncbi.nlm.nih.gov]
- 25. academic.oup.com [academic.oup.com]
- 26. neb.com [neb.com]
Technical Support Center: Resolving Resonance Overlap in RNA NMR with 13C Labeling
Welcome to the technical support center for researchers, scientists, and drug development professionals utilizing Nuclear Magnetic Resonance (NMR) spectroscopy for RNA structural analysis. This resource provides troubleshooting guidance and answers to frequently asked questions regarding the use of ¹³C labeling to overcome the challenge of resonance overlap in RNA NMR spectra.
Frequently Asked Questions (FAQs)
Q1: Why is resonance overlap a significant problem in RNA NMR?
A1: Resonance overlap is a major obstacle in RNA NMR because RNA molecules are composed of only four different nucleotides (adenosine, guanosine, cytidine, and uridine).[1][2] This limited diversity of building blocks leads to a narrow chemical shift dispersion for many protons and carbons, particularly in the ribose moieties.[1][3] As the size of the RNA molecule increases, the number of signals grows, leading to severe spectral crowding and making it difficult to resolve and assign individual resonances.[1][3][4] This issue is further exacerbated by increased line broadening in larger RNAs.[1]
Q2: How does ¹³C labeling help in resolving resonance overlap?
A2: Incorporating ¹³C isotopes into RNA molecules allows for the use of heteronuclear NMR experiments that correlate proton signals with the chemical shifts of their directly attached ¹³C nuclei.[3][5] Since ¹³C chemical shifts are more dispersed than proton shifts, this spreads the signals out into additional dimensions, significantly reducing overlap.[6] This enables the use of powerful techniques like 3D and 4D NMR spectroscopy, which are essential for assigning resonances in larger RNAs.[3][4]
Q3: What are the common ¹³C labeling strategies for RNA NMR?
A3: Several ¹³C labeling strategies are employed, each with its own advantages for specific applications:
-
Uniform ¹³C Labeling: In this approach, all carbon atoms in the RNA molecule are replaced with ¹³C. This is the most straightforward method for enabling a wide range of heteronuclear correlation experiments.[1] However, for larger RNAs, it can reintroduce spectral crowding in the carbon dimension and lead to signal broadening due to ¹³C-¹³C scalar couplings.[1][7][8]
-
Selective ¹³C Labeling: This strategy involves labeling specific carbon positions or specific nucleotide types.[1][3][4] For instance, one might label only the ribose C1' position or only the cytosine residues. This simplifies spectra by reducing the number of ¹³C-attached protons, making it easier to focus on specific regions of interest.[9]
-
Segmental ¹³C Labeling: For very large RNAs, a specific segment or domain of the molecule can be ¹³C-labeled while the rest remains unlabeled.[4][6][10] This is achieved by enzymatic ligation of labeled and unlabeled RNA fragments.[4] This method dramatically simplifies the spectrum, allowing for detailed analysis of a particular region within a large RNA.[10]
Troubleshooting Guides
Problem 1: Severe spectral crowding in the ribose region of a uniformly ¹³C-labeled RNA.
Cause: The ribose protons (H2', H3', H4', H5', H5'') of all four nucleotide types resonate in a very narrow chemical shift range (approximately 4-5 ppm).[3] In a uniformly labeled sample, this leads to significant overlap in both the proton and carbon dimensions.
Solution:
-
Implement Selective Labeling: Utilize specific ¹³C-labeled precursors during in vitro transcription to label only certain carbon positions in the ribose. For example, using [1'-¹³C]-NTPs will only show signals from the C1'-H1' pairs, significantly reducing crowding.[7]
-
Employ Isotope-Filtered/Edited NOESY: These experiments can selectively observe NOEs involving protons attached to ¹³C, effectively filtering out signals from unlabeled regions or vice versa.[9]
-
Consider Deuteration: Partial deuteration of the ribose, particularly at the H3', H4', and H5'/5'' positions, can simplify spectra and reduce dipolar relaxation, leading to sharper lines.[3][11]
Problem 2: Broad linewidths and poor sensitivity in spectra of a large (>50 nt) ¹³C-labeled RNA.
Cause: Larger molecules tumble more slowly in solution, leading to efficient transverse relaxation (T2 relaxation), which results in broader lines and reduced signal intensity.[1][4] ¹H-¹³C dipolar coupling further contributes to this relaxation.[4]
Solution:
-
Use TROSY-based Experiments: Transverse Relaxation-Optimized Spectroscopy (TROSY) is a powerful technique that significantly reduces transverse relaxation rates for large molecules, resulting in narrower linewidths and improved sensitivity.[1][12]
-
Optimize Sample Conditions: Lowering the sample temperature can sometimes sharpen lines, but be mindful of potential structural changes. Adjusting buffer conditions and salt concentration can also impact RNA flexibility and tumbling.
-
Employ Segmental Labeling: By only labeling the region of interest, the number of coupled spins is reduced, which can help mitigate relaxation-induced broadening for the observed signals.[4][10]
Problem 3: Ambiguous sequential assignments using standard NOESY experiments.
Cause: Even with ¹³C labeling, overlap in the proton dimension can make it difficult to unambiguously connect sequential nucleotide residues through NOEs.
Solution:
-
Utilize 3D and 4D Experiments: Higher-dimensional experiments, such as 3D HCCH-TOCSY and 4D ¹³C,¹³C-edited NOESY, provide additional frequency dimensions that can resolve ambiguities present in 2D NOESY spectra.[3][13]
-
Asymmetric Labeling Strategies: A novel approach combines strategic ¹³C labeling with filter/edit type NOESY experiments. For example, labeling C1' in G/C residues and C2' in A/U residues can simplify the "fingerprint" region of the NOESY spectrum.[9]
-
Through-bond Correlation Experiments: Experiments like HCCH-COSY can confirm intranucleotide correlations, helping to validate assignments made from NOESY data.[3][9]
Problem 4: Artifacts in ¹³C-edited NOESY spectra.
Cause: Imperfect pulse sequences and hardware limitations can lead to artifact signals in filtered or edited experiments, potentially leading to incorrect assignments.
Solution:
-
Optimize Pulse Sequences: Ensure that pulse calibrations are accurate, especially for ¹³C pulses. The use of shaped pulses, such as hyperbolic secant pulses, can provide more uniform inversion over the entire ¹³C spectral range, reducing offset effects and artifacts.[14]
-
Implement Phase Cycling: Proper phase cycling is crucial for suppressing unwanted signals and artifacts.
-
Use Double-Filtered NOESY: A ¹³C double-filtered NOESY experiment can be used to specifically detect intermolecular NOEs (e.g., in an RNA-protein complex) with strongly reduced intramolecular artifacts.[14]
Experimental Protocols
Protocol 1: Preparation of Uniformly ¹³C/¹⁵N-Labeled RNA by In Vitro Transcription
This protocol outlines the general steps for producing uniformly isotopically labeled RNA for NMR studies.
-
Prepare Labeled NTPs: Obtain or synthesize ribonucleoside triphosphates (NTPs) that are uniformly labeled with ¹³C and ¹⁵N. These can be produced by growing E. coli on ¹³C-glucose and ¹⁵N-ammonium salts as the sole carbon and nitrogen sources, followed by extraction and conversion of ribonucleoside monophosphates to triphosphates.[5]
-
In Vitro Transcription Reaction: Set up a standard in vitro transcription reaction using a DNA template encoding the RNA of interest, T7 RNA polymerase, and the labeled NTPs.
-
Purification: Purify the transcribed RNA using denaturing polyacrylamide gel electrophoresis (PAGE).
-
Elution and Desalting: Electro-elute the RNA from the gel, followed by ethanol (B145695) precipitation and desalting.
-
Sample Preparation for NMR: Dissolve the purified, labeled RNA in the desired NMR buffer at a concentration typically in the range of 0.1 to 1 mM.
Protocol 2: Segmental Isotope Labeling of RNA
This protocol provides a general workflow for creating a segmentally labeled RNA molecule.
-
Prepare Labeled and Unlabeled RNA Fragments: Synthesize the desired RNA fragments separately. One fragment will be isotopically labeled (e.g., ¹³C/¹⁵N) using the method described in Protocol 1, while the other fragment(s) will be synthesized using unlabeled NTPs.
-
Ligation: Ligate the labeled and unlabeled fragments together using an enzyme such as T4 RNA ligase or T4 DNA ligase with a DNA splint.[3][4]
-
Purification of the Ligated Product: Purify the full-length, segmentally labeled RNA product from the unligated fragments and enzymes, typically using PAGE.
-
NMR Sample Preparation: Prepare the final sample for NMR analysis as described in Protocol 1.
Quantitative Data Summary
The following table summarizes typical labeling efficiencies and concentrations used in ¹³C-labeling experiments for RNA NMR.
| Parameter | Typical Value | Reference |
| ¹³C Enrichment Level | >95% | [7] |
| Final RNA Concentration for NMR | 0.1 - 1.0 mM | [10][11] |
| Sample Volume for NMR | ~150 - 500 µL | [10] |
Visualizations
Caption: Experimental workflow for RNA structure determination using ¹³C labeling and NMR.
Caption: Decision tree for troubleshooting resonance overlap in RNA NMR experiments.
References
- 1. pubs.acs.org [pubs.acs.org]
- 2. Isotope-Labeled RNA Building Blocks for NMR Structure and Dynamics Studies - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Applications of NMR to structure determination of RNAs large and small - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Isotope labeling strategies for NMR studies of RNA - PMC [pmc.ncbi.nlm.nih.gov]
- 5. academic.oup.com [academic.oup.com]
- 6. researchgate.net [researchgate.net]
- 7. Selective 13C labeling of nucleotides for large RNA NMR spectroscopy using an E. coli strain disabled in the TCA cycle - PMC [pmc.ncbi.nlm.nih.gov]
- 8. RNA Dynamics by NMR Spectroscopy - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Combining asymmetric 13C-labeling and isotopic filter/edit NOESY: a novel strategy for rapid and logical RNA resonance assignment - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Determining RNA solution structure by segmental isotopic labeling and NMR: application to Caenorhabditis elegans spliced leader RNA 1 - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Preparation of partially 2H/13C-labelled RNA for NMR studies. Stereo-specific deuteration of the H5′′ in nucleotides - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Segmental and site-specific isotope labelling strategies for structural analysis of posttranslationally modified proteins - RSC Chemical Biology (RSC Publishing) DOI:10.1039/D1CB00045D [pubs.rsc.org]
- 13. researchgate.net [researchgate.net]
- 14. repository.ubn.ru.nl [repository.ubn.ru.nl]
Technical Support Center: Optimizing Activator Solutions for Modified Phosphoramidites
This technical support center provides researchers, scientists, and drug development professionals with troubleshooting guides and frequently asked questions (FAQs) to address specific issues encountered during the optimization of activator solutions for modified phosphoramidites in oligonucleotide synthesis.
Frequently Asked Questions (FAQs)
Q1: What is the role of an activator in phosphoramidite (B1245037) chemistry?
In solid-phase oligonucleotide synthesis, the activator plays a crucial role in the coupling step. Its primary function is to activate the phosphoramidite monomer for subsequent reaction with the free 5'-hydroxyl group of the growing oligonucleotide chain.[1][][3] The mechanism involves the protonation of the diisopropylamino group of the phosphoramidite by the activator, followed by nucleophilic substitution to form a highly reactive intermediate.[1][4] This activated species then readily reacts with the 5'-hydroxyl group to form a phosphite (B83602) triester linkage.[]
Q2: How do different activators influence the coupling reaction?
Activators significantly impact the rate and efficiency of the coupling reaction based on their acidity (pKa) and nucleophilicity.[1][4] More acidic activators can lead to faster coupling rates but also increase the risk of undesired side reactions, such as premature removal of the 5'-dimethoxytrityl (DMT) protecting group, which can lead to the formation of n+1 oligonucleotides.[4][5] The choice of activator is particularly critical when working with sterically hindered or modified phosphoramidites, where standard activators may result in lower coupling efficiencies.[1][6]
Q3: What are the most common activators used for modified phosphoramidites?
Several activators are commonly used, each with distinct properties. The choice often depends on the specific modification on the phosphoramidite and the scale of the synthesis. Common activators include:
-
1H-Tetrazole: A traditional and widely used activator. However, it has limited solubility in acetonitrile (B52724) and may not be optimal for sterically hindered phosphoramidites.[4][6]
-
5-(Ethylthio)-1H-tetrazole (ETT): More acidic than 1H-Tetrazole, leading to faster coupling reactions.[7] It is a good choice for many modified phosphoramidites.[5][6]
-
5-(Benzylthio)-1H-tetrazole (BTT): Similar to ETT, it is more acidic than 1H-Tetrazole and provides efficient coupling for sterically demanding monomers like 2'-O-TBDMS RNA phosphoramidites.[6]
-
4,5-Dicyanoimidazole (B129182) (DCI): A non-tetrazole-based activator that is highly soluble in acetonitrile and acts as a nucleophilic catalyst.[1][8] DCI is effective for a broad range of phosphoramidites and can significantly increase the rate of coupling.[1][8][9]
Q4: When should I consider using a different activator?
You should consider optimizing your activator solution or trying a different activator under the following circumstances:
-
Low coupling efficiency: If you observe a significant drop in the trityl signal or see a high proportion of truncated sequences in your analysis.[7]
-
Working with modified phosphoramidites: Sterically hindered modifications, such as 2'-O-modifications in RNA synthesis, often require more potent activators than standard DNA phosphoramidites.[1][6]
-
Sequence-dependent issues: Certain sequences, like those with high GC content or repetitive stretches, can present challenges for coupling and may benefit from a different activator or optimized conditions.[]
-
Scale-up of synthesis: For larger-scale synthesis, less acidic activators like DCI might be preferred to minimize side reactions like depurination.[6]
Troubleshooting Guide
This guide addresses common problems encountered during the optimization of activator solutions for modified phosphoramidites.
Problem: Low Coupling Efficiency
Low coupling efficiency is a frequent issue, leading to a higher proportion of truncated oligonucleotide sequences and reduced yield of the desired full-length product.[7]
| Possible Cause | Recommended Solution |
| Inappropriate Activator or Concentration | The chosen activator may not be sufficiently reactive for the specific modified phosphoramidite.[7] Increase the activator concentration or switch to a more potent activator like ETT, BTT, or DCI.[1][] |
| Degraded Activator Solution | Activator solutions can degrade over time, especially if exposed to moisture. Prepare fresh activator solution and ensure all reagents and solvents are anhydrous.[11] |
| Suboptimal Coupling Time | Modified phosphoramidites, particularly those with bulky protecting groups, may require longer coupling times to react completely.[][] Extend the coupling time in your synthesis protocol.[] |
| Poor Quality Phosphoramidite | The phosphoramidite itself may be of low quality or have degraded.[7] Use high-purity phosphoramidites and store them under appropriate anhydrous conditions.[] |
| Instrument or Fluidics Issues | Problems with the DNA synthesizer, such as leaks or blockages, can prevent the correct delivery of reagents.[7] Perform regular maintenance on your synthesizer to ensure proper operation. |
Problem: Formation of n+1 Species (Double Addition)
The presence of oligonucleotides that are one nucleotide longer than the target sequence (n+1) can complicate purification.
| Possible Cause | Recommended Solution |
| Premature Detritylation by Acidic Activator | Highly acidic activators can cause a small amount of the 5'-DMT group to be removed from the phosphoramidite monomer in solution.[4] This leads to the coupling of a dimer. |
| * Switch to a less acidic activator, such as DCI (pKa 5.2).[6][7] | |
| * Reduce the concentration of the acidic activator. | |
| * Minimize the time the phosphoramidite and activator are in contact before being delivered to the synthesis column. |
Activator Comparison for Modified Phosphoramidites
The following table summarizes the properties and recommended concentrations of common activators.
| Activator | pKa | Recommended Concentration | Key Characteristics & Applications |
| 1H-Tetrazole | 4.8[7] | 0.45 M[7] | Standard, widely used activator. May show reduced efficiency with sterically hindered phosphoramidites.[1][6] Limited solubility in acetonitrile.[4][6] |
| 5-(Ethylthio)-1H-tetrazole (ETT) | 4.3[7] | 0.25 M - 0.75 M[7] | More acidic and provides faster coupling than 1H-Tetrazole.[7] Good for many modified phosphoramidites.[5][6] |
| 5-(Benzylthio)-1H-tetrazole (BTT) | 4.1[6] | 0.3 M[6] | Highly efficient for sterically hindered phosphoramidites, such as 2'-OTBDMS RNA monomers, significantly reducing coupling times.[6] |
| 4,5-Dicyanoimidazole (DCI) | 5.2[1][7] | 0.25 M - 1.2 M[7] | Less acidic but highly nucleophilic, leading to rapid coupling.[1][7][8] Highly soluble in acetonitrile.[1][4] A good universal activator.[1] |
Experimental Protocols
Protocol 1: Quantitative Assessment of Coupling Efficiency via Trityl Cation Monitoring
Objective: To quantitatively assess the stepwise coupling efficiency during oligonucleotide synthesis.[7]
Methodology:
-
Synthesizer Setup: Ensure the DNA synthesizer is equipped with a trityl cation monitor and the detector is set to measure absorbance at approximately 495 nm.[7]
-
Synthesis Initiation: Begin the automated oligonucleotide synthesis protocol.
-
Deblocking Step: During each deblocking step, the acidic reagent (e.g., trichloroacetic acid) will cleave the DMT group from the 5'-end of the newly added nucleotide.[7]
-
Data Collection: The released orange-colored DMT cation is carried by the solvent through the detector. The instrument's software records the absorbance peak for each cycle.[7]
-
Efficiency Calculation: The stepwise coupling efficiency is calculated by comparing the absorbance of the trityl cation released at each step to the previous one. A consistent or slightly decreasing peak area indicates high coupling efficiency. A significant drop in peak area indicates a coupling failure.
Protocol 2: Analysis of Crude Oligonucleotide Purity by HPLC
Objective: To qualitatively assess the success of the synthesis and identify the presence of truncated sequences.
Methodology:
-
Sample Preparation: After synthesis, cleave the oligonucleotide from the solid support and deprotect it.
-
HPLC Analysis: Analyze the crude, desalted oligonucleotide sample using reverse-phase or anion-exchange HPLC.
-
Data Interpretation: The full-length product (FLP) will typically be the major, late-eluting peak. Shorter, truncated sequences (failure sequences) will elute earlier. The relative peak areas can be used to estimate the purity of the crude product. A large number of early-eluting peaks indicates significant issues with coupling efficiency.[7]
Diagrams
Caption: The four main steps in one cycle of solid-phase oligonucleotide synthesis.
Caption: A step-by-step workflow for diagnosing and resolving low coupling efficiency.
References
- 1. academic.oup.com [academic.oup.com]
- 3. tcichemicals.com [tcichemicals.com]
- 4. glenresearch.com [glenresearch.com]
- 5. researchgate.net [researchgate.net]
- 6. chemie-brunschwig.ch [chemie-brunschwig.ch]
- 7. benchchem.com [benchchem.com]
- 8. Efficient activation of nucleoside phosphoramidites with 4,5-dicyanoimidazole during oligonucleotide synthesis - PMC [pmc.ncbi.nlm.nih.gov]
- 9. researchgate.net [researchgate.net]
- 11. blog.biosearchtech.com [blog.biosearchtech.com]
Technical Support Center: Synthetic RNA Cleavage and Deprotection
This technical support center provides troubleshooting guidance and frequently asked questions (FAQs) for researchers, scientists, and drug development professionals encountering common issues during the cleavage and deprotection of synthetic RNA.
Frequently Asked Questions (FAQs)
Q1: What are the most common issues observed during the cleavage and deprotection of synthetic RNA?
The most frequently encountered problems include incomplete removal of protecting groups (particularly the 2'-O-silyl groups), degradation of the RNA molecule, low recovery yield, and the formation of side products due to base modification.[1][2]
Q2: Why is my RNA degraded after deprotection, and how can I prevent it?
RNA is highly susceptible to degradation by ribonucleases (RNases), which are ubiquitous in the laboratory environment. Degradation can occur if RNase-free reagents and techniques are not strictly used throughout the process.[3] To prevent degradation, it is crucial to:
-
Work in a dedicated RNase-free area.
-
Use certified RNase-free water, buffers, and pipette tips.
-
Wear gloves at all times and change them frequently.
-
Use sterile, disposable plasticware.
-
Store RNA at -80°C.[4]
Q3: What causes incomplete deprotection of the 2'-O-silyl group?
Incomplete removal of the 2'-O-tert-butyldimethylsilyl (TBDMS) or other silyl (B83357) protecting groups is a common issue. This can be caused by:
-
Water content in reagents: Reagents for desilylation, such as tetrabutylammonium (B224687) fluoride (B91410) (TBAF), are sensitive to water, which can reduce their effectiveness.[1]
-
Insufficient reaction time or temperature: The deprotection reaction may not go to completion if the incubation time is too short or the temperature is not optimal.
-
Secondary structure of the RNA: Complex secondary structures can hinder the access of the deprotection reagent to the silyl groups.
Q4: Can the deprotection conditions cause modifications to the RNA bases?
Yes, certain deprotection conditions can lead to unwanted side reactions. For example, using ammonium (B1175870) hydroxide (B78521) with benzoyl-protected cytidine (B196190) can result in transamination. To avoid this, it is recommended to use acetyl-protected cytidine when deprotecting with reagents containing methylamine, such as AMA (a mixture of ammonium hydroxide and aqueous methylamine).[2][5]
Troubleshooting Guides
Problem 1: Low Yield of Purified RNA
Possible Causes and Solutions
| Possible Cause | Recommended Solution |
| Incomplete Cleavage from Solid Support | Ensure the cleavage reagent (e.g., AMA, methylamine) is fresh and used in the correct volume. Increase incubation time or temperature as recommended in the protocol. |
| RNA Degradation | Strictly adhere to RNase-free techniques. Use fresh, high-quality reagents. Analyze a small aliquot of the crude product by gel electrophoresis to check for degradation before purification.[4] |
| Loss During Purification | Optimize the purification method. For cartridge-based purification, ensure the cartridge is not overloaded. For precipitation, ensure complete precipitation by using appropriate temperatures and centrifugation times. |
| Inaccurate Quantification | Verify the accuracy of your quantification method. Use a spectrophotometer or a fluorometric assay designed for RNA. |
Problem 2: Incomplete Deprotection
Symptoms:
-
Presence of additional peaks or shoulders in HPLC analysis.
-
Shift in molecular weight observed in mass spectrometry.
-
Reduced biological activity of the RNA.
Possible Causes and Solutions
| Possible Cause | Recommended Solution |
| Inefficient 2'-O-Silyl Group Removal | Use anhydrous desilylation reagents. Ensure the RNA is fully dissolved in the deprotection cocktail. For TBAF, be aware of its sensitivity to water. Consider using alternative reagents like triethylamine (B128534) trihydrofluoride (TEA·3HF), which can be more reliable.[1][6] |
| Incomplete Base Protecting Group Removal | Ensure the correct deprotection solution and conditions are used for the specific base protecting groups on your RNA. For example, AMA is effective for rapid deprotection of standard protecting groups when acetyl-protected cytidine is used.[2][5] |
| RNA Secondary Structure | Before the final deprotection step, heat the RNA briefly in an appropriate solvent (e.g., DMSO) to disrupt secondary structures.[7] |
Problem 3: RNA Degradation
Symptoms:
-
Smearing on a denaturing polyacrylamide or agarose (B213101) gel.[8]
-
Loss of the 2:1 ratio of 28S to 18S ribosomal RNA bands (for total RNA preps).[8]
-
Low yield of full-length product.
Possible Causes and Solutions
| Possible Cause | Recommended Solution |
| RNase Contamination | Decontaminate work surfaces, pipettes, and gel electrophoresis equipment with RNase-inactivating solutions. Use dedicated, RNase-free reagents and consumables.[4] |
| Harsh Deprotection Conditions | While effective for deprotection, prolonged exposure to harsh basic conditions at high temperatures can lead to some degradation. Optimize deprotection time to be sufficient for complete removal of protecting groups without excessive degradation.[1] |
| Improper Storage | Store purified RNA at -80°C in an RNase-free buffer or water. Avoid repeated freeze-thaw cycles. |
Data Presentation: Comparison of Deprotection Reagents
The choice of deprotection reagent can significantly impact the yield and purity of the final RNA product. Below is a summary of findings from comparative studies.
Table 1: Comparison of Base Deprotection Reagents
| Deprotection Reagent | Conditions | Outcome | Reference |
| Methylamine (MA) | 65°C, 10 min | Gave greater full-length product compared to NH4OH/EtOH. | [1] |
| AMA (NH4OH/Methylamine) | 65°C, 10 min | Rapid and efficient deprotection, especially with Ac-dC. | [2][5] |
| NH4OH/Ethanol (3:1) | 65°C, 4 hours | Standard but slower method; can be destructive. | [1] |
Table 2: Comparison of 2'-O-Silyl Deprotection Reagents
| Desilylation Reagent | Conditions | Yield | Notes | Reference |
| TEA·3HF | 65°C, 2.5 hours | 2.4 µg RNA / mg CPG | More reliable and gives significantly higher yields. Volatile, simplifying purification. | [9] |
| TBAF | Room Temp, 18 hours | 0.03 µg RNA / mg CPG | Performance is sensitive to water content. Non-volatile, requiring extensive desalting which can lead to lower yields. | [1][9] |
Experimental Protocols
Protocol 1: Cleavage and Base Deprotection using AMA
This protocol is suitable for routine deprotection of RNA synthesized with standard protecting groups, including acetyl-protected cytidine.
-
Transfer the solid support from the synthesis column to a sterile screw-cap vial.
-
Add 1 mL of AMA solution (1:1 mixture of concentrated ammonium hydroxide and 40% aqueous methylamine).
-
Seal the vial tightly and heat at 65°C for 10-15 minutes.[5][10]
-
Cool the vial to room temperature.
-
Transfer the supernatant containing the cleaved and deprotected RNA to a new sterile tube.
-
Wash the solid support with 0.5 mL of RNase-free water and combine the supernatant with the initial solution.
-
Dry the combined solution in a vacuum concentrator.
Protocol 2: 2'-O-TBDMS Deprotection using TEA·3HF
This protocol is for the removal of the 2'-O-TBDMS protecting group.
-
Completely dissolve the dried RNA pellet from the previous step in 100 µL of anhydrous DMSO. Gentle heating at 65°C for a few minutes may be necessary.[7]
-
Add 125 µL of triethylamine trihydrofluoride (TEA·3HF).
-
Mix well and incubate at 65°C for 2.5 hours.[7]
-
Cool the reaction mixture on ice.
-
Quench the reaction by adding an appropriate quenching buffer (e.g., 1.75 mL of Glen-Pak RNA Quenching Buffer if proceeding to cartridge purification) or by proceeding to precipitation.[7]
References
- 1. academic.oup.com [academic.oup.com]
- 2. glenresearch.com [glenresearch.com]
- 3. mpbio.com [mpbio.com]
- 4. neb.com [neb.com]
- 5. glenresearch.com [glenresearch.com]
- 6. Removal of t-butyldimethylsilyl protection in RNA-synthesis. Triethylamine trihydrofluoride (TEA, 3HF) is a more reliable alternative to tetrabutylammonium fluoride (TBAF) - PMC [pmc.ncbi.nlm.nih.gov]
- 7. glenresearch.com [glenresearch.com]
- 8. glenresearch.com [glenresearch.com]
- 9. par.nsf.gov [par.nsf.gov]
- 10. glenresearch.com [glenresearch.com]
Technical Support Center: High-Resolution NMR Spectroscopy of Large RNAs
Welcome to the technical support center for researchers, scientists, and drug development professionals engaged in the NMR structural analysis of large RNA molecules. This resource provides troubleshooting guidance and answers to frequently asked questions to help you overcome common challenges and improve the resolution of your NMR spectra.
Frequently Asked Questions (FAQs)
Q1: Why are the NMR spectra of my large RNA sample showing broad lines and severe signal overlap?
A1: This is a common challenge when working with large RNA molecules (>50 nucleotides).[1][2] The primary reasons for broad lines and signal overlap are:
-
Slow Tumbling: Large RNAs tumble slowly in solution, which leads to efficient transverse (T2) relaxation and, consequently, broad NMR signals.[1]
-
Spectral Crowding: RNA is composed of only four different nucleotides, leading to a limited chemical shift dispersion, especially for ribose protons which resonate in a narrow spectral region.[1][3] This "signal degeneracy" results in severe resonance overlap as the size of the RNA increases.[1][4]
-
Scalar and Dipolar Couplings: Large one-bond 1H-13C dipolar couplings and 1H-1H scalar couplings contribute significantly to line broadening.[1][4]
Q2: What is the most common initial strategy to simplify a crowded NMR spectrum of a large RNA?
A2: Isotopic labeling is the foundational strategy.[4][5] Uniformly labeling your RNA with 13C and 15N allows for the use of heteronuclear correlation experiments (like 1H-15N or 1H-13C HSQC), which spread out the proton signals based on the chemical shifts of the directly attached heavy atoms, thereby reducing spectral overlap.[1] However, for larger RNAs, this alone may not be sufficient and can introduce line broadening due to 13C-13C scalar couplings.[1]
Q3: How can I further reduce line broadening in my isotopically labeled large RNA sample?
A3: Deuteration is a powerful technique to combat line broadening.[1][6][7] By replacing non-exchangeable protons with deuterium (B1214612) (2H), you can:
-
Reduce Dipolar Relaxation: The smaller magnetic moment of deuterium significantly reduces 1H-1H and 1H-13C dipolar relaxation pathways, leading to narrower line widths.[1][4]
-
Simplify Spectra: Replacing protons with deuterium effectively removes their signals from 1H NMR spectra, simplifying crowded regions.[1]
Q4: What is segmental labeling and when should I consider using it?
A4: Segmental labeling is a "divide and conquer" strategy where a large RNA is assembled from smaller, selectively labeled fragments.[8][9][10] This allows you to isotopically label only a specific domain or region of the RNA, while the rest remains unlabeled (or is labeled differently).[8] This dramatically simplifies the resulting NMR spectrum, making it possible to study specific regions within a large RNA complex without interference from the rest of the molecule.[8][11] Consider using this method for RNAs larger than ~70 nucleotides or for studying specific domains in RNA-protein complexes.[2][11]
Q5: What is TROSY and how does it help in studying large RNAs?
A5: Transverse Relaxation-Optimized Spectroscopy (TROSY) is an NMR experiment designed to mitigate the effects of rapid transverse relaxation in large molecules.[12][13] It works by selecting the narrowest component of a multiplet, which arises from the constructive interference between dipole-dipole (DD) and chemical shift anisotropy (CSA) relaxation mechanisms.[12][13] This results in significantly sharper lines and increased sensitivity for large biomolecules, extending the size limit of RNAs that can be studied by solution NMR.[12][14][15] The TROSY effect is most beneficial at high magnetic fields.[13]
Troubleshooting Guides
Issue 1: My 1H-15N HSQC spectrum of a 15N-labeled RNA is still too crowded to assign.
| Potential Cause | Troubleshooting Step | Expected Outcome |
| Overlapping Resonances | Implement nucleotide-specific labeling. Prepare four separate samples, each with only one type of nucleotide (A, U, G, or C) being 15N-labeled. | Each spectrum will only contain signals from one type of nucleotide, drastically reducing overlap and facilitating assignments. |
| Signal Broadening | Combine 15N-labeling with ribose deuteration. This reduces dipolar relaxation from nearby ribose protons. | Sharper imino proton signals, improving spectral resolution. |
| Conformational Heterogeneity | Optimize sample conditions (temperature, pH, buffer, ions). Perform temperature titration to check for conformational changes. | A more homogeneous sample will yield a cleaner spectrum with fewer, sharper peaks. |
Issue 2: Even with uniform 13C/15N labeling and deuteration, my spectra have poor resolution.
| Potential Cause | Troubleshooting Step | Expected Outcome |
| 13C-13C scalar couplings | Use selective 13C labeling schemes. For example, label only the C8/C6 positions of purines/pyrimidines.[1] | Eliminates strong 13C-13C J-couplings, leading to narrower lines and increased signal-to-noise.[1] |
| Extreme Line Broadening due to Size | Employ TROSY-based experiments (e.g., 1H-15N HSQC-TROSY). | Significant reduction in linewidth for large RNAs, enabling the study of molecules up to ~100 kDa or more.[2][15][16] |
| Residual Protons in Deuterated Sample | Use highly deuterated starting materials for NTP synthesis or purchase high-purity deuterated NTPs. Optimize D2O percentage in the final sample buffer. | Minimizes residual proton signals and their contribution to relaxation, resulting in sharper lines. |
Issue 3: My segmental labeling ligation reaction has a low yield.
| Potential Cause | Troubleshooting Step | Expected Outcome |
| Incorrect RNA fragment termini | Ensure the donor fragment has a 5'-monophosphate and the acceptor fragment has a 3'-hydroxyl group for T4 RNA ligase.[4] Use ribozymes or DNAzymes to generate homogeneous 3' and 5' ends.[2][17] | Correct termini are essential for efficient ligation. Homogeneous ends prevent side reactions and improve yield. |
| Suboptimal Ligation Conditions | Optimize the concentration of T4 RNA ligase, ATP, and the DNA splint (if using a template-directed ligation). Adjust temperature and incubation time. | Increased efficiency of the ligation reaction, leading to a higher yield of the final product. |
| RNA degradation | Add RNase inhibitors to the reaction. Work in an RNase-free environment. Purify RNA fragments carefully before ligation. | Prevents degradation of RNA fragments, ensuring they are available for the ligation reaction. |
Quantitative Data Summary
Table 1: Impact of Deuteration on NMR Linewidths
| Labeling Scheme | Typical Linewidth Reduction | Reference |
| Perdeuteration | Can lead to significantly narrower 1H NMR signals. | [4] |
| Specific Deuteration (e.g., at ribose) | T1 and T2 relaxation rates can be approximately twice as long as unlabeled RNA.[6] | [6] |
| Ribose Perdeuteration | Purine H8 transverse relaxation rates reduced ~20-fold.[18] | [18] |
Key Experimental Protocols
Protocol 1: In Vitro Transcription for Isotopic Labeling
This protocol describes the preparation of isotopically labeled RNA using T7 RNA polymerase.
Materials:
-
Linearized plasmid DNA or synthetic DNA oligonucleotide template with a T7 promoter.
-
T7 RNA polymerase.
-
Unlabeled and desired isotopically labeled (13C, 15N, 2H) ribonucleoside triphosphates (rNTPs).
-
Transcription buffer (e.g., 40 mM Tris-HCl pH 8.0, 25 mM MgCl2, 1 mM spermidine, 10 mM DTT).
-
RNase inhibitor.
-
Inorganic pyrophosphatase.
-
DNase I (RNase-free).
Methodology:
-
Assemble the transcription reaction on ice by combining the transcription buffer, DTT, spermidine, rNTPs (labeled and unlabeled), DNA template, RNase inhibitor, and inorganic pyrophosphatase.
-
Initiate the reaction by adding T7 RNA polymerase.
-
Incubate the reaction at 37°C for 2-4 hours.
-
Terminate the reaction by adding DNase I to digest the DNA template. Incubate for 30 minutes at 37°C.
-
Purify the RNA transcript using denaturing polyacrylamide gel electrophoresis (PAGE) or anion-exchange chromatography.[2][19][20]
-
Desalt and buffer-exchange the purified RNA into the desired NMR buffer.
Protocol 2: Segmental Labeling using T4 RNA Ligase
This protocol outlines a general procedure for ligating two RNA fragments, where one is isotopically labeled.
Materials:
-
Purified, isotopically labeled RNA fragment (donor) with a 5'-monophosphate.
-
Purified, unlabeled RNA fragment (acceptor) with a 3'-hydroxyl.
-
DNA splint oligonucleotide (complementary to the ligation junction).
-
T4 RNA Ligase 1.
-
Ligation buffer (containing ATP and MgCl2).
-
RNase inhibitor.
Methodology:
-
Anneal the RNA fragments to the DNA splint by mixing the three components, heating to 95°C for 2 minutes, and then slow-cooling to room temperature.
-
Add the ligation buffer, RNase inhibitor, and T4 RNA ligase to the annealed mixture.
-
Incubate the reaction at 16°C overnight.
-
Purify the full-length ligated RNA product from unreacted fragments and the DNA splint using denaturing PAGE.
-
Elute, desalt, and refold the final RNA product into the NMR buffer.
Visualizations
References
- 1. Advances that facilitate the study of large RNA structure and dynamics by nuclear magnetic resonance spectroscopy - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Applications of NMR to structure determination of RNAs large and small - PMC [pmc.ncbi.nlm.nih.gov]
- 3. pubs.acs.org [pubs.acs.org]
- 4. Isotope labeling strategies for NMR studies of RNA - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Isotope labeling and segmental labeling of larger RNAs for NMR structural studies - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. pubs.acs.org [pubs.acs.org]
- 7. Synthesis of specifically deuterated nucleotides for NMR studies on RNA - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. academic.oup.com [academic.oup.com]
- 9. mdpi.com [mdpi.com]
- 10. researchgate.net [researchgate.net]
- 11. researchgate.net [researchgate.net]
- 12. ethz.ch [ethz.ch]
- 13. Transverse relaxation-optimized spectroscopy - Wikipedia [en.wikipedia.org]
- 14. Enhanced TROSY Effect in [2-19 F, 2-13 C] Adenosine and ATP Analogs Facilitates NMR Spectroscopy of Very Large Biological RNAs in Solution - PubMed [pubmed.ncbi.nlm.nih.gov]
- 15. researchgate.net [researchgate.net]
- 16. A guide to large-scale RNA sample preparation - PMC [pmc.ncbi.nlm.nih.gov]
- 17. academic.oup.com [academic.oup.com]
- 18. pubs.acs.org [pubs.acs.org]
- 19. NMR Characterization of RNA Small Molecule Interactions - PMC [pmc.ncbi.nlm.nih.gov]
- 20. RNA Structure Determination by NMR | Springer Nature Experiments [experiments.springernature.com]
avoiding phosphoramidite degradation during storage and handling
Technical Support Center: Phosphoramidite (B1245037) Stability
This technical support center provides guidance on the proper storage and handling of phosphoramidites to minimize degradation and ensure optimal performance in oligonucleotide synthesis.
Frequently Asked Questions (FAQs)
Q1: What are the primary causes of phosphoramidite degradation?
A1: The primary causes of phosphoramidite degradation are exposure to moisture and oxidation.[1][2] Phosphoramidites are highly susceptible to hydrolysis, which occurs when they come into contact with water, even in trace amounts.[1][2][3] They are also prone to oxidation when exposed to air.[1] Additionally, exposure to acidic conditions can cause rapid degradation.
Q2: How should I store my phosphoramidites to ensure long-term stability?
A2: For long-term stability, phosphoramidites should be stored as a dry powder at or below -20°C under an inert atmosphere, such as argon or nitrogen.[1] This minimizes exposure to moisture and oxygen, which are the main drivers of degradation.
Q3: My phosphoramidite has been at room temperature for a short period. Is it still usable?
A3: While prolonged exposure to ambient temperatures is not recommended, short periods may be acceptable, especially if the vial is unopened and properly sealed. However, the stability of phosphoramidites in solution at room temperature decreases over time, with guanosine (B1672433) (dG) phosphoramidites being particularly prone to degradation.[1] It is advisable to perform a quality control check, such as ³¹P NMR or RP-HPLC, to assess the purity of the phosphoramidite before use.
Q4: I've dissolved my phosphoramidites in acetonitrile (B52724). How long can I store the solution?
A4: The stability of phosphoramidites in solution is significantly lower than in their powdered form. The rate of degradation in solution depends on the specific nucleoside, the concentration, and the water content of the solvent.[1][4][5] Generally, dG phosphoramidites are the least stable in solution.[1][4][5][6] It is best practice to use freshly prepared solutions. If storage is necessary, it should be for a short duration at -20°C over molecular sieves to minimize water content.[5]
Q5: What are the visible signs of phosphoramidite degradation?
A5: Visible signs of degradation can include a change in the appearance of the powder from a crisp, dry solid to a gummy or discolored substance. However, significant degradation can occur without any visible changes. Therefore, analytical methods are necessary for a definitive assessment of purity.
Troubleshooting Guide
| Issue | Potential Cause | Recommended Action |
| Low coupling efficiency in oligonucleotide synthesis | Phosphoramidite degradation | 1. Verify the age and storage conditions of the phosphoramidite. 2. Perform a quality control check using ³¹P NMR or RP-HPLC to assess purity. 3. If degradation is confirmed, use a fresh vial of phosphoramidite. 4. Ensure the acetonitrile used for dissolution is anhydrous (<30 ppm water). |
| Unexpected peaks in chromatogram after synthesis | Impurities in the phosphoramidite | 1. Analyze the phosphoramidite starting material by RP-HPLC to identify any impurities. 2. Review the handling procedures to ensure no contaminants were introduced during dissolution. |
| dG phosphoramidite shows rapid degradation in solution | Inherent instability of dG | 1. dG phosphoramidites are known to be the least stable, especially in solution.[1][4][5][6] 2. Prepare fresh solutions of dG phosphoramidite immediately before use. 3. Consider using smaller aliquots to avoid repeated warming and cooling of the stock solution. |
| Phosphoramidite powder appears clumpy or discolored | Moisture contamination | 1. Discard the vial as it has likely been compromised by moisture. 2. Review storage and handling procedures to prevent future occurrences. Ensure vials are tightly sealed and stored in a desiccated environment. |
Quantitative Data on Phosphoramidite Degradation
The stability of phosphoramidites in solution varies depending on the nucleobase. The following table summarizes the degradation of standard phosphoramidites in an acetonitrile solution stored under an inert atmosphere for five weeks.
| Phosphoramidite | Purity Reduction after 5 Weeks in Acetonitrile |
| T, dC | 2% |
| dA | 6% |
| dG | 39% |
| (Data sourced from a study analyzing the impurity profiles of phosphoramidite solutions by HPLC-MS)[4][5] |
Experimental Protocols for Quality Control
1. Purity Analysis by Reversed-Phase High-Performance Liquid Chromatography (RP-HPLC)
This method is used to separate and quantify the phosphoramidite and its impurities.
-
Column: C18 column (e.g., 250 x 4.6 mm, 5 µm particle size)[7]
-
Mobile Phase A: 0.1M Triethylammonium acetate (B1210297) (TEAA) in water (pH 7.0)[7]
-
Mobile Phase B: Acetonitrile[7]
-
Gradient: A suitable gradient to elute the phosphoramidite and its impurities.
-
Flow Rate: 1 mL/min[7]
-
Temperature: Ambient[7]
-
Sample Preparation: Dissolve the phosphoramidite in acetonitrile to a concentration of approximately 1.0 mg/mL.[7]
-
Injection Volume: 10 µL
-
Detection: UV at 260 nm
2. Purity Analysis by ³¹P Nuclear Magnetic Resonance (³¹P NMR) Spectroscopy
This technique provides information about the phosphorus-containing species in the sample, allowing for the detection of phosphoramidite and its degradation products.
-
Spectrometer: 80 MHz or higher[8]
-
Acquisition Parameters:
-
Sample Preparation: Prepare a sample of approximately 0.3 g/mL in an appropriate deuterated solvent (e.g., CDCl₃) with 1% triethylamine (B128534) (v/v).[7]
-
Reference: 5% H₃PO₄ in D₂O can be used as an external reference.[7]
-
Analysis: The phosphoramidite typically appears as two diastereomeric peaks between 140 and 155 ppm.[8] Degradation products, such as H-phosphonates, will appear at different chemical shifts.
3. Identification by Mass Spectrometry (MS)
This method confirms the molecular weight of the phosphoramidite.
-
Method: Flow injection analysis without a column.[7]
-
Mobile Phase: 100% Acetonitrile[7]
-
Flow Rate: 0.5 mL/min[7]
-
Ionization Mode: Electrospray Ionization (ESI) positive polarity[7]
-
Mass Analyzer: Orbitrap or similar high-resolution mass spectrometer[7]
-
Scan Range: 150–2000 m/z[7]
-
Sample Preparation: Prepare a solution of approximately 0.1 mg/mL in acetonitrile.[7]
Visualizations
Caption: Primary degradation pathways for phosphoramidites.
Caption: Quality control workflow for phosphoramidites.
Caption: Troubleshooting logic for low coupling efficiency.
References
- 1. researchgate.net [researchgate.net]
- 2. researchgate.net [researchgate.net]
- 3. The Degradation of dG Phosphoramidites in Solution - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. Solution stability and degradation pathway of deoxyribonucleoside phosphoramidites in acetonitrile - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. tandfonline.com [tandfonline.com]
- 6. 2024.sci-hub.ru [2024.sci-hub.ru]
- 7. usp.org [usp.org]
- 8. Phosphoramidite compound identification and impurity control by Benchtop NMR - Magritek [magritek.com]
Technical Support Center: Scaling Up 13C-Labeled Oligonucleotide Synthesis
This technical support center provides troubleshooting guidance and frequently asked questions (FAQs) to assist researchers, scientists, and drug development professionals in addressing the challenges associated with scaling up the synthesis of 13C-labeled oligonucleotides.
Troubleshooting Guide
This guide is designed in a question-and-answer format to directly address specific issues that may be encountered during the synthesis, purification, and analysis of 13C-labeled oligonucleotides at a larger scale.
Synthesis
Question: We are observing a significant decrease in coupling efficiency as we scale up our synthesis of a 13C-labeled oligonucleotide. What are the potential causes and solutions?
Answer: A drop in coupling efficiency is a common challenge when scaling up any oligonucleotide synthesis, and the high cost of 13C-labeled phosphoramidites makes this issue particularly critical.[1][2] The primary culprit is often the presence of moisture.[3]
Potential Causes:
-
Water Contamination: Water reacts with the activated phosphoramidite (B1245037), preventing it from coupling to the growing oligonucleotide chain.[3] At larger scales, it is more challenging to maintain completely anhydrous conditions.
-
Reagent Quality and Stability: The 13C-labeled phosphoramidites themselves may have lower stability or contain impurities.[4][5] Their thermal stability can vary, and degradation can lead to byproducts that interfere with the synthesis.[4][5]
-
Fluid dynamics: In larger synthesis columns, inefficient mixing or channeling can lead to incomplete reagent delivery to the solid support.
Troubleshooting Steps & Solutions:
-
Ensure Anhydrous Conditions:
-
Use fresh, high-purity, anhydrous acetonitrile (B52724) (ACN) with a water content below 15 ppm.[3]
-
Dry all reagents, including the activator solution and the argon or helium used on the synthesizer, with in-line drying filters.[3]
-
Store 13C-labeled phosphoramidites under a dry, inert atmosphere and consider drying them over molecular sieves before use.[6]
-
-
Optimize Reagent Concentrations and Ratios:
-
Evaluate Phosphoramidite Stability:
-
If you suspect the stability of the 13C-labeled phosphoramidite is an issue, you can perform a small-scale test synthesis or an NMR analysis to check for degradation products.[6]
-
-
Consider a Double Coupling Step:
-
For particularly valuable or difficult couplings, a second addition of the 13C-labeled phosphoramidite and activator can be performed to drive the reaction to completion.
-
Question: After scaling up, we are seeing an increase in n-1 and other shortmer impurities in our crude product. How can we address this?
Answer: An increase in shortmer sequences is a direct consequence of incomplete coupling at each cycle.[8] Any 5'-OH groups that fail to react will not be extended in subsequent cycles, leading to truncated oligonucleotides.[7]
Potential Causes:
-
Low Coupling Efficiency: This is the most direct cause, as discussed in the previous question.
-
Inefficient Capping: The capping step is designed to block any unreacted 5'-OH groups to prevent them from reacting in later cycles.[7][9] If the capping is inefficient, these unreacted chains can continue to grow, leading to oligonucleotides with internal deletions.
Troubleshooting Steps & Solutions:
-
Address Coupling Efficiency: First and foremost, implement the steps outlined above to maximize coupling efficiency. Even a small increase from 98.5% to 99.5% can significantly improve the yield of the full-length product.[10]
-
Optimize the Capping Step:
-
Ensure that the capping reagents (e.g., acetic anhydride (B1165640) and N-methylimidazole) are fresh and anhydrous.
-
Consider a "cap/ox/cap" cycle, where a second capping step is performed after oxidation. This can help to remove any residual water from the support before the next coupling step.[7]
-
-
Solid Support Considerations:
-
Ensure that the solid support is not overloaded, as this can lead to steric hindrance and reduced accessibility of the growing chains.
-
Purification
Question: We are struggling to achieve the desired purity of our scaled-up 13C-labeled oligonucleotide using reverse-phase HPLC. The peaks are broad, and separation from failure sequences is poor.
Answer: Purifying large quantities of oligonucleotides presents its own set of challenges.[1][11] While reverse-phase HPLC is a powerful technique, its resolution can decrease with increasing oligonucleotide length.[8][12]
Potential Causes:
-
Column Overloading: Exceeding the capacity of the HPLC column is a common issue in large-scale purification, leading to broad peaks and poor separation.
-
Suboptimal Ion-Pairing Reagent: The choice and concentration of the ion-pairing reagent are critical for good separation.
-
Secondary Structure Formation: The oligonucleotide may be forming secondary structures (e.g., hairpins or duplexes) that can lead to peak broadening.
-
Presence of Co-eluting Impurities: Truncated sequences or those with modifications can sometimes co-elute with the full-length product.[13]
Troubleshooting Steps & Solutions:
-
Optimize HPLC Method:
-
Reduce Column Loading: Perform a loading study to determine the optimal amount of crude oligonucleotide for your column.
-
Adjust Gradient: A shallower gradient can improve the separation between the full-length product and closely eluting impurities.
-
Vary Ion-Pairing Reagent: Experiment with different ion-pairing reagents (e.g., triethylammonium (B8662869) acetate (B1210297) - TEAA, hexylammonium acetate - HAA) and concentrations to improve resolution.[14]
-
Increase Temperature: Running the purification at an elevated temperature (e.g., 50-60°C) can help to disrupt secondary structures.
-
-
Consider an Alternative Purification Method:
-
Ion-Exchange Chromatography (IEX): IEX is an excellent method for purifying oligonucleotides, especially at a large scale, due to its high loading capacity and resolving power based on charge.[14][15]
-
Polyacrylamide Gel Electrophoresis (PAGE): For very high purity requirements, PAGE can be used, although it is generally less amenable to very large quantities.[8][14]
-
Analysis
Question: The 13C NMR spectrum of our purified, scaled-up oligonucleotide shows broad signals and unexpected complexity. Is this normal?
Answer: The NMR spectra of large biomolecules like oligonucleotides can be complex, and this is often exacerbated by the presence of 13C labels.
Potential Causes:
-
Slow Tumbling: Large molecules tumble slowly in solution, which leads to broader NMR signals.
-
Conformational Heterogeneity: The oligonucleotide may exist in multiple conformations in solution, each giving rise to a different set of NMR signals.
-
13C-13C Coupling: If you have incorporated multiple adjacent 13C labels, you may observe complex signal splitting due to 13C-13C J-coupling.
-
Residual Impurities: Even after purification, there may be residual impurities that contribute to the complexity of the spectrum.
Troubleshooting Steps & Solutions:
-
Optimize NMR Acquisition Parameters:
-
Increase Temperature: Acquiring the spectrum at a higher temperature can increase molecular tumbling and sharpen the signals.
-
Use a Higher Field Magnet: A higher field spectrometer will provide better signal dispersion.[16]
-
Employ 2D NMR Techniques: 2D experiments like 1H-13C HSQC can help to resolve overlapping signals and simplify the spectrum.
-
Consider Isotope-Edited Experiments: If you have specifically designed your labeling pattern, you can use isotope-edited NMR experiments to selectively observe signals from the labeled sites.
-
-
Sample Preparation:
-
Ensure the sample is free of paramagnetic impurities, which can cause significant line broadening.
-
Optimize the buffer conditions (pH, salt concentration) to favor a single, stable conformation.
-
Question: Our mass spectrometry results show a broader isotopic distribution than expected for our 13C-labeled oligonucleotide. Why is this, and how can we confirm the mass?
Answer: The incorporation of 13C atoms will shift the isotopic distribution of your molecule.
Potential Causes:
-
Incomplete Isotopic Incorporation: If the 13C-labeled phosphoramidites have an isotopic purity of less than 100%, you will have a mixed population of molecules with different numbers of 13C atoms, leading to a broader isotopic distribution.
-
Co-eluting Species: The presence of impurities with similar masses can also broaden the observed isotopic pattern.
-
Mass Spectrometer Resolution: The resolution of the mass spectrometer may not be sufficient to resolve the individual isotopic peaks.
Troubleshooting Steps & Solutions:
-
Deconvolution of Mass Spectra: Use the deconvolution software provided with the mass spectrometer to determine the parent mass of the oligonucleotide from the multiple charge states observed in ESI-MS.[17]
-
High-Resolution Mass Spectrometry: Use a high-resolution mass spectrometer (e.g., Orbitrap or FT-ICR) to accurately determine the monoisotopic mass and resolve the isotopic distribution.
-
Tandem Mass Spectrometry (MS/MS): Fragmentation analysis can be used to confirm the sequence of the oligonucleotide and the location of the 13C labels.
Frequently Asked Questions (FAQs)
1. What are the primary economic challenges when scaling up 13C-labeled oligonucleotide synthesis?
The primary economic challenges are the high cost of the 13C-labeled phosphoramidites and the large quantities of high-purity solvents and reagents required for large-scale synthesis and purification.[1][2][11] Any inefficiencies in the process, such as low coupling yields or difficult purifications, are magnified at scale and can lead to significant financial losses.[1]
2. How does the choice of solid support impact the scale-up process?
The choice of solid support is critical. It must have a suitable loading capacity for the desired scale of synthesis and be robust enough to withstand the mechanical and chemical stresses of the process. The pore size and particle size of the support can also affect reagent diffusion and reaction kinetics, which become more important at a larger scale.
3. Are there any safety concerns specific to scaling up 13C-labeled oligonucleotide synthesis?
While 13C is a stable, non-radioactive isotope, the general safety precautions for handling the chemical reagents used in oligonucleotide synthesis must be strictly followed. Some phosphoramidites can have poor thermal stability and may pose risks if not handled correctly.[4][5] Additionally, the large volumes of flammable solvents used in scaled-up synthesis and purification require appropriate storage and handling facilities.
4. What level of purity is typically required for 13C-labeled oligonucleotides used in different applications?
The required purity depends on the intended application. For structural studies by NMR, very high purity (>95%) is essential to obtain high-quality spectra. For use in cellular assays or as therapeutic agents, purity requirements are also very high to avoid off-target effects and ensure safety.[18] For less sensitive applications, a lower purity may be acceptable.
5. How can we ensure batch-to-batch consistency when scaling up production?
Ensuring batch-to-batch consistency requires strict process control and robust quality control measures.[11] This includes:
-
Using well-characterized and high-quality raw materials.
-
Implementing standardized and automated synthesis and purification protocols.[11]
-
Performing thorough in-process monitoring and final product analysis, including HPLC, mass spectrometry, and NMR.
Quantitative Data Summary
Table 1: Typical Coupling Efficiencies and Impact on Full-Length Product Yield
| Coupling Efficiency per Step | Expected % Full-Length Product (20-mer) | Expected % Full-Length Product (50-mer) |
| 98.0% | 68% | 13% |
| 99.0% | 82% | 61% |
| 99.5% | 90% | 78% |
Data adapted from literature sources to illustrate the critical impact of coupling efficiency on the overall yield of the desired full-length oligonucleotide.[3][10]
Table 2: Comparison of Large-Scale Oligonucleotide Purification Methods
| Method | Principle | Typical Purity | Advantages for Scale-Up | Disadvantages for Scale-Up |
| Reverse-Phase HPLC (RP-HPLC) | Separation based on hydrophobicity | >85% | Rapid, good for modified oligos | Resolution decreases with length, potential for column overloading |
| Ion-Exchange Chromatography (IEX) | Separation based on charge | >95% | High loading capacity, excellent resolution | Can be more time-consuming to develop |
| Polyacrylamide Gel Electrophoresis (PAGE) | Separation based on size and charge | >98% | Very high resolution | Not easily scalable to large quantities |
This table summarizes information from multiple sources to provide a comparative overview of common purification techniques.[8][12][14][15]
Experimental Protocols
Protocol 1: General Procedure for Solid-Phase Synthesis of a 13C-Labeled Oligonucleotide
This protocol outlines the key steps in a single coupling cycle using an automated DNA/RNA synthesizer.
-
Deblocking (Detritylation): The 5'-dimethoxytrityl (DMT) protecting group is removed from the support-bound oligonucleotide by treating with a solution of a mild acid (e.g., trichloroacetic acid in dichloromethane).[9]
-
Coupling: The 13C-labeled phosphoramidite and an activator (e.g., 5-ethylthio-1H-tetrazole) are dissolved in anhydrous acetonitrile and delivered to the synthesis column. The reaction couples the new base to the 5'-OH of the growing chain.[19]
-
Capping: Any unreacted 5'-OH groups are acetylated by treating with a mixture of acetic anhydride and N-methylimidazole. This prevents the formation of deletion mutants.[7][9]
-
Oxidation: The newly formed phosphite (B83602) triester linkage is oxidized to a more stable phosphate (B84403) triester using a solution of iodine in a mixture of tetrahydrofuran, water, and pyridine.[7][9]
-
Washing: The column is thoroughly washed with acetonitrile between each step to remove excess reagents and byproducts.
This cycle is repeated until the desired sequence is assembled.
Protocol 2: Cleavage, Deprotection, and Initial Purification
-
Cleavage from Support: After the final synthesis cycle, the oligonucleotide is cleaved from the solid support using a concentrated solution of ammonium (B1175870) hydroxide (B78521) or a mixture of ammonium hydroxide and methylamine.[20]
-
Deprotection: The same basic solution is used to remove the protecting groups from the nucleobases and the phosphate backbone. The mixture is heated to ensure complete deprotection.
-
Crude Product Isolation: The solid support is filtered off, and the resulting solution containing the crude oligonucleotide is evaporated to dryness.
-
Desalting: The crude product is redissolved in water and desalted using a size-exclusion chromatography column or cartridge to remove small molecule impurities.[8]
Visualizations
Caption: Workflow for 13C-labeled oligonucleotide synthesis and purification.
Caption: Troubleshooting decision tree for low product yield.
References
- 1. susupport.com [susupport.com]
- 2. oxfordglobal.com [oxfordglobal.com]
- 3. glenresearch.com [glenresearch.com]
- 4. blog.entegris.com [blog.entegris.com]
- 5. A Thermal Stability Study Of Phosphoramidites Employed In Oligonucleotide Synthesis [bioprocessonline.com]
- 6. trilinkbiotech.com [trilinkbiotech.com]
- 7. blog.biosearchtech.com [blog.biosearchtech.com]
- 8. Oligonucleotide Purification [sigmaaldrich.com]
- 9. idtdna.com [idtdna.com]
- 10. Considerations and Strategies for Oligonucleotide Manufacturing Scale-Up - Oligonucleotide CMC Strategies - Gated [turtlmedia.informa.com]
- 11. The Analytical Scientist | Oligonucleotides: Synthesis and Manufacturing Hurdles [theanalyticalscientist.com]
- 12. Oligonucleotide Purification Methods for Your Research | Thermo Fisher Scientific - US [thermofisher.com]
- 13. What affects the yield of your oligonucleotides synthesis [biosyn.com]
- 14. Recent Methods for Purification and Structure Determination of Oligonucleotides - PMC [pmc.ncbi.nlm.nih.gov]
- 15. lcms.cz [lcms.cz]
- 16. news-medical.net [news-medical.net]
- 17. web.colby.edu [web.colby.edu]
- 18. exactmer.com [exactmer.com]
- 19. benchchem.com [benchchem.com]
- 20. Synthesis and incorporation of 13C-labeled DNA building blocks to probe structural dynamics of DNA by NMR - PMC [pmc.ncbi.nlm.nih.gov]
Technical Support Center: Troubleshooting PCR with Isotopically Labeled Primers
This guide provides researchers, scientists, and drug development professionals with a comprehensive resource for troubleshooting Polymerase Chain Reaction (PCR) experiments that utilize isotopically labeled primers, particularly those labeled with ³²P. The information is presented in a question-and-answer format to directly address common issues.
Frequently Asked Questions (FAQs)
Q1: What are the most common applications of PCR with isotopically labeled primers?
PCR with isotopically labeled primers is a highly sensitive technique used for various applications, including:
-
Detection of low-abundance nucleic acids: The high specific activity of isotopes like ³²P allows for the detection of very small amounts of target DNA or RNA.
-
DNA footprinting and protein-DNA interaction studies: To precisely map the binding sites of proteins on a DNA molecule.
-
Microsatellite and STR analysis: For genotyping and genetic mapping.
-
Quantitative analysis of PCR products: By measuring the radioactivity incorporated into the amplified fragments.
Q2: What are the key steps in performing a PCR with isotopically labeled primers?
The overall workflow involves three main stages:
-
Primer Labeling: Typically, one of the PCR primers is end-labeled with a radioactive isotope, most commonly ³²P, using an enzyme like T4 Polynucleotide Kinase.
-
PCR Amplification: The PCR is performed using the labeled primer, along with an unlabeled counterpart, and standard PCR reagents.
-
Analysis: The radiolabeled PCR products are typically separated by gel electrophoresis and visualized by autoradiography.
Q3: What are the critical parameters to consider for primer design in this type of PCR?
In addition to the standard primer design considerations (e.g., length, GC content, melting temperature), it is important to:
-
Ensure the primer has a free 5'-hydroxyl group for efficient labeling by T4 Polynucleotide Kinase.
-
Design primers that are specific to the target sequence to minimize non-specific amplification, which can be a significant source of background signal.[1][2]
-
Avoid sequences that can form stable secondary structures or primer-dimers, as these can also be labeled and contribute to background.[3]
Troubleshooting Guides
Problem 1: Faint or No Bands on Autoradiogram
This is a common issue that can arise from problems in either the primer labeling step or the PCR amplification itself.
Question: I don't see any bands on my autoradiogram after exposing the gel. What could be the problem?
Answer: The absence of a signal can be due to several factors. A systematic approach to troubleshooting is recommended.
Possible Causes and Solutions
| Possible Cause | Recommended Solution |
| Inefficient Primer Labeling | - Verify the activity of the T4 Polynucleotide Kinase. Use a positive control to check enzyme function.- Ensure the quality of the [γ-³²P]ATP, as its short half-life can lead to reduced activity.- Confirm that the primer has a free 5'-hydroxyl group. If necessary, dephosphorylate the primer before the labeling reaction.- Optimize the labeling reaction conditions, including the concentrations of primer, ATP, and enzyme.[4][5] |
| PCR Failure | - Check all PCR components (template DNA, dNTPs, polymerase, buffer) for integrity and proper concentration.[6]- Optimize the annealing temperature. An incorrect annealing temperature can lead to no amplification.[3][7][8][9][10]- Verify the integrity of the template DNA. Degraded template can result in failed amplification.[1]- Increase the number of PCR cycles if the target is of low abundance.[1][11] |
| Issues with Autoradiography | - Ensure the gel was properly dried before exposure to the film.- Check the expiration date of the X-ray film.- Increase the exposure time. |
Problem 2: High Background on Autoradiogram
A high background can obscure the specific PCR product and make data interpretation difficult.
Question: My autoradiogram shows a high background signal, making it difficult to see the specific bands. What can I do to reduce the background?
Answer: High background is often caused by unincorporated radiolabeled nucleotides or non-specific PCR products.
Possible Causes and Solutions
| Possible Cause | Recommended Solution |
| Unincorporated [γ-³²P]ATP | - Purify the labeled primer after the kinase reaction to remove unincorporated [γ-³²P]ATP. This can be done using spin columns or other purification methods. |
| Non-specific PCR Products | - Increase the annealing temperature in increments of 2°C to improve primer binding specificity.- Reduce the concentration of the labeled primer in the PCR reaction.- Decrease the amount of template DNA used in the reaction.[11][12]- Reduce the number of PCR cycles.[11] |
| Primer-Dimers | - Optimize primer design to avoid complementarity between the primers.[3]- Reduce the primer concentration in the PCR.[13] |
| Contamination | - Use fresh reagents and a clean workspace to avoid contamination with extraneous DNA that could be amplified.[12] |
Problem 3: Smeared Bands on Autoradiogram
Smeared bands can indicate a variety of issues with the PCR or gel electrophoresis.
Question: The bands on my autoradiogram appear as smears rather than sharp, distinct bands. What is the cause of this?
Answer: Smearing can result from several factors, including issues with the template DNA, PCR conditions, or the gel itself.
Possible Causes and Solutions
| Possible Cause | Recommended Solution |
| Degraded Template DNA | - Use high-quality, intact template DNA. Check the integrity of the template on an agarose (B213101) gel before use.[2] |
| Too Much Template DNA | - Reduce the amount of template DNA in the PCR reaction.[6] |
| Excessive PCR Cycles | - Reduce the number of PCR cycles to avoid the accumulation of non-specific products.[11] |
| Suboptimal PCR Conditions | - Optimize the concentration of MgCl₂, dNTPs, and polymerase.[13]- Adjust the extension time; excessively long extension times can sometimes lead to smearing.[6] |
| Gel Electrophoresis Issues | - Ensure the gel is properly prepared and run under appropriate voltage conditions.[12] |
Experimental Protocols
Protocol 1: 5' End-Labeling of PCR Primers with [γ-³²P]ATP
This protocol describes the labeling of a PCR primer at the 5' end using T4 Polynucleotide Kinase.
Materials:
-
Forward PCR primer (10 µM)
-
T4 Polynucleotide Kinase (10 U/µL)
-
10X T4 PNK Reaction Buffer
-
[γ-³²P]ATP (3000 Ci/mmol, 10 mCi/ml)
-
Nuclease-free water
-
Spin column for purification
Procedure:
-
Set up the following reaction mixture on ice in a sterile microcentrifuge tube:
-
1 µL 10X T4 PNK Reaction Buffer
-
1 µL Forward Primer (10 pmol)
-
5 µL [γ-³²P]ATP
-
1 µL T4 Polynucleotide Kinase (10 units)
-
2 µL Nuclease-free water
-
Total Volume: 10 µL
-
-
Mix gently and incubate at 37°C for 30 minutes.
-
Heat inactivate the enzyme at 65°C for 20 minutes.
-
Purify the labeled primer from unincorporated [γ-³²P]ATP using a suitable spin column according to the manufacturer's instructions.
-
Measure the radioactivity of the purified labeled primer using a scintillation counter to determine the specific activity.
Protocol 2: PCR with a ³²P-Labeled Primer
This protocol outlines the setup of a PCR using one radiolabeled primer.
Materials:
-
³²P-labeled forward primer (from Protocol 1)
-
Unlabeled reverse primer (10 µM)
-
Template DNA
-
dNTP mix (10 mM)
-
Taq DNA Polymerase (5 U/µL)
-
10X PCR Buffer
-
Nuclease-free water
Procedure:
-
Set up the PCR reaction on ice. A typical 25 µL reaction is as follows:
-
2.5 µL 10X PCR Buffer
-
0.5 µL dNTP mix (200 µM final concentration)
-
0.5 µL ³²P-labeled forward primer (final concentration 0.2 µM)
-
0.5 µL Unlabeled reverse primer (final concentration 0.2 µM)
-
1 µL Template DNA (<100 ng)
-
0.25 µL Taq DNA Polymerase (1.25 units)
-
19.75 µL Nuclease-free water
-
Total Volume: 25 µL
-
-
Transfer the reaction to a thermocycler and perform PCR with optimized cycling conditions. A general protocol is:
-
Initial Denaturation: 95°C for 30 seconds
-
25-30 Cycles:
-
Denaturation: 95°C for 15-30 seconds
-
Annealing: 50-65°C for 15-60 seconds
-
Extension: 68°C for 1 minute/kb
-
-
Final Extension: 68°C for 5 minutes
-
-
Analyze the PCR products by polyacrylamide gel electrophoresis followed by autoradiography.
Quantitative Data Summary
The following tables provide recommended concentration ranges for key components in the labeling and PCR steps.
Table 1: Recommended Concentrations for Primer Labeling Reaction
| Component | Recommended Concentration/Amount |
| Primer | 1-50 pmol |
| [γ-³²P]ATP | 30-100 µCi |
| T4 Polynucleotide Kinase | 10-20 units |
| 10X T4 PNK Buffer | 1X |
Table 2: Recommended Concentrations for PCR with Labeled Primers
| Component | Final Concentration |
| Labeled Primer | 0.1 - 0.5 µM |
| Unlabeled Primer | 0.1 - 0.5 µM |
| dNTPs | 200 µM of each |
| MgCl₂ | 1.5 - 2.5 mM |
| Taq DNA Polymerase | 1 - 2.5 units per 50 µL reaction |
| Template DNA | 1 ng - 1 µg (genomic DNA) |
Visualizations
Caption: Workflow for PCR with isotopically labeled primers.
Caption: Troubleshooting logic for common PCR issues with labeled primers.
References
- 1. bio-rad.com [bio-rad.com]
- 2. PCR Troubleshooting Guide | Thermo Fisher Scientific - US [thermofisher.com]
- 3. Optimization of Annealing Temperature and other PCR Parameters [genaxxon.com]
- 4. watchmakergenomics.com [watchmakergenomics.com]
- 5. neb.com [neb.com]
- 6. Troubleshouting for PCR - troubleshooting pcr no bands [greenbiogene.com]
- 7. Optimization of the annealing temperature for DNA amplification in vitro - PMC [pmc.ncbi.nlm.nih.gov]
- 8. biology.stackexchange.com [biology.stackexchange.com]
- 9. How to Simplify PCR Optimization Steps for Primer Annealing | Thermo Fisher Scientific - HK [thermofisher.com]
- 10. Optimization of Annealing Temperature To Reduce Bias Caused by a Primer Mismatch in Multitemplate PCR - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Troubleshooting your PCR [takarabio.com]
- 12. pcrbio.com [pcrbio.com]
- 13. PCR Troubleshooting [caister.com]
Validation & Comparative
A Head-to-Head Comparison: The Advantages of Chemical Synthesis for Site-Specific Protein Labeling
For researchers, scientists, and drug development professionals, the precise modification of proteins is a cornerstone of innovation. Site-specific labeling, the targeted attachment of a probe or molecule to a specific amino acid residue, offers unparalleled control in studying protein function, tracking cellular processes, and developing novel therapeutics like antibody-drug conjugates (ADCs). While genetic and enzymatic methods provide valuable tools for protein labeling, chemical synthesis approaches have emerged with distinct advantages in versatility, precision, and the sheer breadth of modifications possible. This guide provides an objective comparison of chemical synthesis with alternative methods, supported by experimental data and detailed protocols.
Chemically modified proteins are pivotal in various fields of pharmaceutical research and development, from basic drug discovery to the creation of enhanced biopharmaceuticals such as ADCs.[1][2][3] The ability to introduce non-natural modifications with surgical precision is a key strength of chemical protein synthesis.[4] This contrasts with traditional methods that often result in heterogeneous products, complicating characterization and potentially impacting protein function.[5]
Comparative Analysis of Site-Specific Labeling Methods
The choice of a labeling strategy depends on the specific experimental needs, including the desired precision, the nature of the label, and the biological context. Here, we compare the key features of chemical, enzymatic, and genetic labeling methods.
| Feature | Chemical Synthesis | Enzymatic Labeling | Genetic Tagging (e.g., GFP) |
| Specificity | High to Absolute | High | High (at the protein level) |
| Versatility of Labels | Virtually unlimited (fluorophores, biotin, drugs, crosslinkers, probes) | Limited to enzyme's substrate scope | Limited to fluorescent proteins |
| Label Size | Small molecules to large polymers | Varies with label and enzyme | Large (~27 kDa), potential for functional interference |
| Reaction Conditions | Can be performed in vitro and in living systems under mild, bioorthogonal conditions | Mild, physiological conditions | In vivo expression |
| Homogeneity | High | High | High |
| Workflow Complexity | Can require multi-step synthesis of probes and protein engineering | Requires expression of both target protein and enzyme | Requires genetic fusion of the tag to the protein of interest |
| Temporal Control | High (labeling can be initiated at a specific time) | Moderate to High | Low (constitutive or inducible expression) |
In-Depth Look at Chemical Labeling Techniques
Chemical synthesis for site-specific labeling primarily relies on two powerful strategies: the incorporation of unnatural amino acids (UAAs) with bioorthogonal functional groups and the use of self-labeling protein tags like SNAP-tag and HaloTag.
Unnatural Amino Acid (UAA) Incorporation and Bioorthogonal Chemistry
This "gold standard" method provides the highest degree of precision by genetically encoding a UAA with a unique chemical handle (e.g., an azide (B81097) or alkyne) at a specific site in the protein. This handle then serves as a target for a bioorthogonal "click" reaction with a probe carrying the complementary functional group.[6][7]
Advantages:
-
Minimal Perturbation: The small size of the UAA minimizes interference with the protein's natural structure and function.[8]
-
Absolute Site-Specificity: The label is attached at a single, defined amino acid residue.[8]
-
Broad Applicability: A wide variety of probes can be attached using highly efficient and specific click chemistry reactions.[9]
Experimental Workflow: UAA Incorporation and Click Chemistry Labeling
Experimental Protocol: UAA Incorporation and Copper(I)-Catalyzed Azide-Alkyne Cycloaddition (CuAAC)
-
Plasmid Construction: Introduce an amber stop codon (TAG) at the desired labeling site in the gene of interest via site-directed mutagenesis.[10]
-
Cell Culture and Transfection: Co-transfect mammalian cells with the plasmid containing the gene of interest and a plasmid encoding the orthogonal aminoacyl-tRNA synthetase/tRNA pair specific for the chosen UAA.
-
UAA Supplementation: Culture the cells in a medium supplemented with the UAA (e.g., p-azido-L-phenylalanine).
-
Protein Expression and Harvest: Allow for protein expression for 24-48 hours before harvesting the cells.
-
Click Reaction (in vitro):
-
Lyse the cells and purify the protein of interest containing the UAA.
-
Prepare a reaction mixture containing the purified protein, an alkyne-modified fluorescent dye, a copper(I) source (e.g., CuSO4 and a reducing agent like sodium ascorbate), and a copper-chelating ligand (e.g., TBTA) in a suitable buffer (e.g., PBS).
-
Incubate the reaction at room temperature for 1-2 hours.
-
-
Purification and Analysis: Remove excess reagents by dialysis or size-exclusion chromatography. Analyze the labeled protein by SDS-PAGE and in-gel fluorescence scanning.
Self-Labeling Protein Tags: SNAP-tag® and HaloTag®
These methods involve fusing the protein of interest to a small, engineered enzyme (the "tag") that specifically and covalently reacts with a synthetic substrate.[11] This substrate carries the desired label.
Advantages:
-
High Specificity and Efficiency: The enzymatic reaction is highly specific and efficient, leading to high labeling yields.
-
Versatility: A wide range of substrates with different labels are commercially available or can be synthesized.[12]
-
Live-Cell Imaging: Cell-permeable substrates allow for the labeling of intracellular proteins in living cells.[13]
Experimental Workflow: SNAP-tag® Labeling
Experimental Protocol: In Vitro Labeling of Purified SNAP-tag® Fusion Protein
-
Protein Preparation: Thaw the purified SNAP-tag® fusion protein and keep it on ice.
-
Reaction Setup: In a microcentrifuge tube, combine the following in order:
-
Deionized water
-
10X PBS buffer
-
10 mM DTT
-
SNAP-tag® fusion protein (to a final concentration of ~5 µM)
-
SNAP-tag® substrate (e.g., a fluorescent benzylguanine derivative, to a final concentration of ~10 µM)[14]
-
-
Incubation: Incubate the reaction mixture for 30 minutes at 37°C in the dark.[14]
-
Analysis: Analyze the labeling efficiency by running the sample on an SDS-PAGE gel and detecting the fluorescence using a gel scanner.[14]
Experimental Protocol: Labeling of HaloTag® Fusion Proteins in Live Cells
-
Cell Culture: Seed cells expressing the HaloTag® fusion protein in a suitable imaging dish.
-
Preparation of Staining Solution: Dilute the HaloTag® ligand (e.g., a fluorescent chloroalkane derivative) in pre-warmed complete cell culture medium to the desired final concentration (typically in the nanomolar to low micromolar range).
-
Labeling: Replace the cell culture medium with the staining solution and incubate the cells for 15-60 minutes at 37°C and 5% CO2.[15]
-
Washing: Remove the staining solution and wash the cells three times with pre-warmed complete medium to remove unbound ligand.[15]
-
Imaging: After a final incubation in fresh medium to allow for diffusion of any remaining unbound probe, the cells are ready for fluorescence microscopy.[15]
Concluding Remarks
Chemical synthesis offers a powerful and versatile platform for the site-specific labeling of proteins, providing researchers with unparalleled control over the type and placement of modifications. The ability to introduce a vast array of functional probes with minimal perturbation to the target protein makes these methods indispensable for a wide range of applications in basic research and drug development. While genetic and enzymatic methods have their merits, the precision and flexibility of chemical synthesis approaches, particularly those combining UAA incorporation with bioorthogonal chemistry, are driving the next wave of innovation in protein science. The continued development of new bioorthogonal reactions and self-labeling tags will further expand the capabilities of chemical protein labeling, enabling more sophisticated studies of complex biological systems.
References
- 1. neb.com [neb.com]
- 2. SNAP labeling protocol [abberior.rocks]
- 3. Site-specific incorporation of non-natural amino acids into proteins in mammalian cells with an expanded genetic code | Semantic Scholar [semanticscholar.org]
- 4. [PDF] Bioorthogonal click chemistry-based labelling of proteins in living neuronal cell lines and primary neurons | Semantic Scholar [semanticscholar.org]
- 5. Recent progress in enzymatic protein labelling techniques and their applications - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Bioorthogonal click chemistry-based labelling of proteins in living neuronal cell lines and primary neurons [protocols.io]
- 7. Using unnatural amino acids to selectively label proteins for cellular imaging: a cell biologist viewpoint - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Site-Specific Labeling of Proteins Using Unnatural Amino Acids - PMC [pmc.ncbi.nlm.nih.gov]
- 9. interchim.fr [interchim.fr]
- 10. researchgate.net [researchgate.net]
- 11. Site-Specific Protein Labeling with SNAP-Tags - PMC [pmc.ncbi.nlm.nih.gov]
- 12. HaloTag® Technology: A Powerful Tool for Protein Labeling and Analysis [worldwide.promega.com]
- 13. Snap-tag Labeling — Galloway Lab Protocols documentation [gallowaylabmit.github.io]
- 14. neb.com [neb.com]
- 15. forum.microlist.org [forum.microlist.org]
A Comparative Guide to Isotopic Labeling for RNA Structural Studies: 13C vs. 15N/2H
For researchers, scientists, and drug development professionals navigating the complexities of RNA structure, Nuclear Magnetic Resonance (NMR) spectroscopy is a powerful tool. However, the inherent challenges of spectral overlap and signal broadening, particularly with larger RNA molecules, necessitate the use of isotopic labeling. This guide provides an objective comparison of 13C, 15N, and 2H labeling strategies, supported by experimental data and detailed protocols, to aid in the selection of the most appropriate method for your research needs.
The determination of high-resolution RNA structures is crucial for understanding their diverse biological functions and for the rational design of RNA-targeting therapeutics. While NMR spectroscopy offers the unique ability to study the structure and dynamics of RNA in solution, its application to molecules larger than 50 nucleotides is often hampered by severe spectral complexity.[1] Isotopic enrichment with 13C, 15N, and 2H (deuterium) has become an indispensable strategy to overcome these limitations. Each labeling approach offers distinct advantages and is suited for different aspects of RNA structural analysis.
At a Glance: Comparing Labeling Strategies
The choice between 13C, 15N, and 2H labeling, or a combination thereof, depends on the size of the RNA, the specific structural questions being addressed, and the desired level of spectral simplification.
| Feature | 13C Labeling | 15N Labeling | 2H (Deuterium) Labeling |
| Primary Application | Resonance assignment, structure determination | Probing hydrogen bonding and base pairing, resonance assignment | Simplifying spectra, studying large RNAs, improving relaxation properties |
| Key Advantage | Provides through-bond correlations for sequential assignment | Directly probes nitrogen atoms involved in base pairing | Dramatically reduces proton density, leading to narrower linewidths and reduced spectral overlap[1][2][3][4] |
| Effect on Spectra | Increases spectral dispersion into a third (13C) dimension | Increases spectral dispersion into a third (15N) dimension | Simplifies 1H-1H NOESY spectra by removing proton signals[1] |
| Molecular Weight Limit | Effective for RNAs up to ~50 nucleotides when uniformly labeled[4]; can be extended with selective labeling | Useful for RNAs of various sizes, often in conjunction with 13C labeling | Essential for RNAs >50-70 nucleotides[1] |
| Impact on Relaxation | Can increase relaxation rates due to 13C-1H dipolar interactions, leading to broader lines[2] | Minimal impact on proton relaxation | Significantly reduces dipolar relaxation, leading to longer T2 relaxation times and narrower lines[3][4] |
| Cost of Labeled Precursors | High for uniformly 13C-labeled NTPs | Generally less expensive than 13C-labeled NTPs | Perdeuterated NTPs are commercially available but can be costly[2] |
Delving Deeper: The Role of Each Isotope
13C Labeling: The Backbone of Resonance Assignment
Uniform or selective incorporation of the stable 13C isotope is a cornerstone of RNA NMR. By spreading out the proton signals into a carbon dimension, 3D and 4D heteronuclear NMR experiments become possible, which are essential for resolving ambiguity and achieving sequential resonance assignments.[5][6]
However, for larger RNAs, uniform 13C labeling can introduce significant line broadening due to one-bond 13C-1H dipolar interactions and 1JCC scalar couplings.[7][8] To mitigate this, selective 13C labeling of specific positions (e.g., ribose or base carbons) or specific nucleotide types can be employed.[7][8]
15N Labeling: A Window into Base Pairing and Interactions
Nitrogen-15 labeling is particularly powerful for investigating the hydrogen bonding network that defines RNA secondary and tertiary structure. The imino and amino groups of guanine (B1146940) and uracil, as well as the amino groups of adenine (B156593) and cytosine, are directly involved in Watson-Crick and non-canonical base pairing.[9] 1H-15N HSQC spectra provide a "fingerprint" of the RNA, where each peak corresponds to a specific nitrogen-bound proton, making it an excellent tool for monitoring structural changes upon ligand binding or environmental perturbations.[9][10] Because 14N has a quadrupole moment that leads to broad NMR signals, the spin-1/2 15N isotope is preferred for high-resolution studies.[11]
2H (Deuterium) Labeling: Taming Complexity for Large RNAs
For RNAs exceeding 50-70 nucleotides, extensive signal overlap and rapid transverse relaxation make structure determination by conventional NMR methods nearly impossible.[1] Deuteration, the substitution of hydrogen with deuterium, is a powerful strategy to overcome these hurdles. By replacing non-exchangeable protons (at carbon atoms) with deuterium, the proton density is dramatically reduced, leading to significant spectral simplification and a marked reduction in line broadening.[1][2][3][4]
Specifically, deuteration of the ribose H3', H4', H5'/H5'' positions and the pyrimidine (B1678525) H5 position significantly simplifies the crowded ribose region of the spectrum.[1] This allows for the unambiguous assignment of remaining proton resonances and the measurement of crucial long-range NOEs.[1] Importantly, full deuteration is not a viable option for RNA as it would eliminate too many protons needed for structural restraints.[1] Therefore, selective deuteration in combination with protonation at specific sites is the preferred approach.[1][2]
Experimental Workflows and Methodologies
The preparation of isotopically labeled RNA for NMR studies typically involves in vitro transcription using T7 RNA polymerase and labeled nucleotide triphosphates (NTPs). The general workflow is depicted below.
Detailed Experimental Protocols
1. Preparation of Labeled NTPs
While commercially available, labeled NTPs can be prohibitively expensive.[12] An alternative is the enzymatic synthesis of NTPs from cheaper labeled precursors like glucose.
-
Protocol for Enzymatic Synthesis of Labeled NTPs:
-
Grow E. coli on a minimal medium containing the desired isotopic source (e.g., 13C-glucose, 15NH4Cl, or in D2O for deuteration).[5][13]
-
Harvest the cells and extract total RNA or ribosomal RNA.
-
Hydrolyze the RNA to nucleoside monophosphates (NMPs).
-
Enzymatically convert the NMPs to NTPs using appropriate kinases.[14]
-
Purify the labeled NTPs using chromatography.
-
2. In Vitro Transcription of Labeled RNA
-
Protocol for In Vitro Transcription:
-
Assemble the transcription reaction on ice:
-
Transcription buffer (40 mM Tris-HCl pH 8.0, MgCl2, spermidine, DTT)
-
Linearized DNA template
-
Labeled NTPs (e.g., uniformly 13C/15N-labeled, or a mix of deuterated and protonated NTPs)
-
T7 RNA polymerase
-
-
Incubate the reaction at 37°C for 2-4 hours.[10]
-
Treat the reaction with DNase I to digest the DNA template.[10]
-
3. Purification of Labeled RNA
-
Protocol for RNA Purification:
-
Purify the transcribed RNA by denaturing polyacrylamide gel electrophoresis (PAGE).[10]
-
Visualize the RNA band by UV shadowing.
-
Excise the gel band and elute the RNA overnight in an appropriate buffer.
-
Desalt and concentrate the RNA using spin columns or dialysis.[10][13]
-
Quantify the RNA concentration using UV-Vis spectroscopy.
-
4. NMR Sample Preparation
-
Protocol for NMR Sample Preparation:
-
Dissolve the purified, labeled RNA in the desired NMR buffer (e.g., phosphate (B84403) buffer with NaCl and MgCl2).[13]
-
Anneal the RNA by heating to 95°C for 5 minutes followed by slow cooling to room temperature.
-
Transfer the sample to an NMR tube. For experiments observing exchangeable protons, the final buffer should contain 90% H2O/10% D2O. For non-exchangeable protons, the sample is lyophilized and redissolved in 99.9% D2O.
-
Logical Relationships in Labeling Strategies
The choice of labeling strategy is dictated by the specific research question and the size of the RNA molecule.
Conclusion
The strategic use of 13C, 15N, and 2H isotopic labeling has revolutionized the study of RNA structure and dynamics by NMR. While 13C and 15N labeling are fundamental for resonance assignment and probing specific interactions in smaller RNAs, deuteration is the key to extending the size limit of RNA molecules amenable to high-resolution NMR analysis. By carefully selecting the appropriate labeling scheme, researchers can overcome the inherent challenges of RNA NMR and gain unprecedented insights into the intricate world of RNA biology. This guide provides a framework for making informed decisions to advance the structural understanding of these vital macromolecules.
References
- 1. Applications of NMR to structure determination of RNAs large and small - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Isotope labeling strategies for NMR studies of RNA - PMC [pmc.ncbi.nlm.nih.gov]
- 3. pubs.acs.org [pubs.acs.org]
- 4. Preparation of partially 2H/13C-labelled RNA for NMR studies. Stereo-specific deuteration of the H5′′ in nucleotides - PMC [pmc.ncbi.nlm.nih.gov]
- 5. academic.oup.com [academic.oup.com]
- 6. academic.oup.com [academic.oup.com]
- 7. Selective 13C labeling of nucleotides for large RNA NMR spectroscopy using an E. coli strain disabled in the TCA cycle - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Asymmetry of 13C labeled 3-pyruvate affords improved site specific labeling of RNA for NMR spectroscopy - PMC [pmc.ncbi.nlm.nih.gov]
- 9. The Role of Nitrogen-15 in NMR Spectroscopy for Molecular Structure Analysis - China Isotope Development [asiaisotopeintl.com]
- 10. benchchem.com [benchchem.com]
- 11. biophysics - Why is nitrogen isotopic labelling required for protein NMR? - Biology Stack Exchange [biology.stackexchange.com]
- 12. Isotope-Labeled RNA Building Blocks for NMR Structure and Dynamics Studies [mdpi.com]
- 13. academic.oup.com [academic.oup.com]
- 14. researchgate.net [researchgate.net]
Validating 13C Incorporation: A Comparative Guide to Mass Spectrometry Techniques
For researchers, scientists, and drug development professionals, accurately tracking the metabolic fate of 13C-labeled substrates is paramount for understanding cellular physiology, identifying drug targets, and optimizing bioprocesses. Mass spectrometry stands as the gold standard for quantifying 13C incorporation, offering a suite of powerful techniques to elucidate metabolic fluxes. This guide provides an objective comparison of the leading mass spectrometry-based methods for validating 13C incorporation, supported by experimental data and detailed protocols.
The core of 13C metabolic flux analysis (13C-MFA) lies in the precise measurement of isotopic enrichment in metabolites after cells are fed a 13C-labeled substrate.[1][2][3] This enrichment data is then used to calculate the rates of metabolic reactions, providing a detailed map of cellular metabolism.[3][4] The choice of mass spectrometry technique is critical and depends on the specific research question, the class of metabolites being analyzed, and the required sensitivity and precision.
Comparative Analysis of Mass Spectrometry Platforms
The three most common mass spectrometry platforms for 13C incorporation studies are Gas Chromatography-Mass Spectrometry (GC-MS), Liquid Chromatography-Mass Spectrometry (LC-MS), and Isotope Ratio Mass Spectrometry (IRMS). Each presents distinct advantages and limitations.
| Feature | Gas Chromatography-Mass Spectrometry (GC-MS) | Liquid Chromatography-Mass Spectrometry (LC-MS) | Isotope Ratio Mass Spectrometry (IRMS) |
| Analytes | Volatile and thermally stable compounds (derivatization often required for non-volatile metabolites like amino acids and organic acids) | Wide range of non-volatile and thermally labile compounds (e.g., nucleotides, lipids, polar metabolites) | Primarily measures the isotopic ratio of bulk samples or specific compounds after conversion to simple gases (e.g., CO2) |
| Precision | High precision for isotopologue distribution analysis.[1] | Good precision, but can be affected by matrix effects and ion suppression.[5] | Extremely high precision for bulk isotope ratio measurements.[6][7] |
| Sensitivity | High sensitivity, especially with chemical ionization techniques.[8][9] | High sensitivity, particularly with modern high-resolution instruments.[10] | Very high sensitivity, capable of detecting minute variations in isotope ratios.[6][8] |
| Sample Preparation | Often requires derivatization to increase volatility, which can introduce variability.[11] | Simpler sample preparation, often involving only extraction and filtration.[10] | Can range from simple combustion for bulk analysis to complex purification for compound-specific analysis.[6] |
| Throughput | Moderate to high throughput. | High throughput, especially with ultra-high-performance liquid chromatography (UHPLC). | Lower throughput for compound-specific analysis due to purification steps. |
| Cost | Relatively lower instrument cost. | Higher instrument cost, especially for high-resolution systems. | High instrument cost. |
Experimental Workflows and Protocols
The general workflow for a 13C labeling experiment followed by mass spectrometry analysis involves several key steps.
Key Experimental Protocols
1. Cell Culture and Labeling:
-
Cells are cultured in a defined medium to ensure accurate metabolic modeling.[1]
-
At a specific growth phase (e.g., mid-log phase), the medium is replaced with one containing the 13C-labeled substrate (e.g., [U-13C]-glucose, [1,2-13C]-glucose).[3]
-
The labeling duration is critical and must be sufficient to achieve isotopic steady-state for the metabolites of interest.[1]
2. Metabolite Extraction:
-
Rapid quenching of metabolic activity is crucial to prevent changes in metabolite levels. This is often achieved by using cold solvents like methanol (B129727) or by flash-freezing in liquid nitrogen.
-
Metabolites are then extracted using a suitable solvent system, such as a mixture of methanol, chloroform, and water, to separate polar and nonpolar metabolites.
3. Sample Preparation for GC-MS Analysis (Derivatization):
-
For GC-MS analysis, non-volatile metabolites like amino acids and organic acids must be derivatized to increase their volatility. A common method is silylation using reagents like N-tert-butyldimethylsilyl-N-methyltrifluoroacetamide (MTBSTFA).[11]
4. Mass Spectrometry Analysis:
-
GC-MS: The derivatized sample is injected into the gas chromatograph, where compounds are separated based on their boiling points and interactions with the column. The separated compounds then enter the mass spectrometer for ionization and detection of mass isotopologue distributions.[1]
-
LC-MS: The extracted metabolites are separated by liquid chromatography based on their polarity and other chemical properties. The eluent is then introduced into the mass spectrometer for ionization (e.g., electrospray ionization) and analysis.[5][10]
-
IRMS: For compound-specific isotope analysis, the compound of interest is first purified (e.g., by HPLC) and then combusted to CO2, which is then introduced into the IRMS to measure the 13C/12C ratio with high precision.[6]
Data Presentation and Interpretation
The output from the mass spectrometer is a mass spectrum showing the distribution of mass isotopologues for each metabolite. This data is then corrected for the natural abundance of 13C to determine the fractional enrichment.[12]
Signaling Pathways and Metabolic Networks
The ultimate goal of 13C incorporation studies is often to map the flow of carbon through metabolic pathways. For example, in cancer metabolism research, tracing 13C-labeled glucose can reveal the activity of glycolysis, the pentose (B10789219) phosphate (B84403) pathway, and the TCA cycle.[2]
Conclusion
The validation of 13C incorporation using mass spectrometry is a powerful approach for quantitative metabolic analysis. The choice between GC-MS, LC-MS, and IRMS depends on the specific analytical needs of the study. GC-MS offers high precision for volatile compounds, while LC-MS provides versatility for a wide range of metabolites.[7][10] IRMS delivers the highest precision for isotope ratio measurements.[6] By carefully selecting the appropriate technique and following robust experimental and data analysis protocols, researchers can gain deep insights into the intricate workings of cellular metabolism, accelerating discoveries in basic science and drug development.
References
- 1. High-resolution 13C metabolic flux analysis | Springer Nature Experiments [experiments.springernature.com]
- 2. d-nb.info [d-nb.info]
- 3. Overview of 13c Metabolic Flux Analysis - Creative Proteomics [creative-proteomics.com]
- 4. Publishing 13C metabolic flux analysis studies: A review and future perspectives - PMC [pmc.ncbi.nlm.nih.gov]
- 5. cdnsciencepub.com [cdnsciencepub.com]
- 6. Mass spectrometric methods for determination of [13C]Leucine enrichment in human muscle protein - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. openpub.fmach.it [openpub.fmach.it]
- 8. researchgate.net [researchgate.net]
- 9. A Simple Method for Measuring Carbon-13 Fatty Acid Enrichment in the Major Lipid Classes of Microalgae Using GC-MS - PMC [pmc.ncbi.nlm.nih.gov]
- 10. researchgate.net [researchgate.net]
- 11. mdpi.com [mdpi.com]
- 12. A roadmap for interpreting 13C metabolite labeling patterns from cells - PMC [pmc.ncbi.nlm.nih.gov]
A Researcher's Guide to 2'-O-Protecting Groups for RNA Synthesis: A Comparative Analysis of TBDMS, TOM, and ACE
The chemical synthesis of ribonucleic acid (RNA) is a cornerstone of modern molecular biology, enabling advancements in therapeutics (e.g., siRNA, mRNA vaccines), diagnostics, and fundamental research. A critical challenge in RNA synthesis is the protection of the 2'-hydroxyl (2'-OH) group of the ribose sugar. This group must be shielded throughout the automated solid-phase synthesis cycle to prevent undesired side reactions, such as chain cleavage and phosphodiester bond migration, and then be cleanly removed to yield the final, functional RNA oligonucleotide.[1][2]
The choice of the 2'-O-protecting group profoundly impacts the efficiency, yield, and purity of the final product. This guide provides a comparative analysis of three widely used protecting groups: tert-butyldimethylsilyl (TBDMS), tri-iso-propylsilyloxymethyl (TOM), and bis(2-acetoxyethoxy)methyl orthoester (ACE), offering researchers the data needed to select the optimal strategy for their specific application.
Comparative Performance Data
The selection of a 2'-O-protecting group is a trade-off between coupling efficiency, steric hindrance, and the conditions required for its final removal. The following table summarizes the key quantitative and qualitative performance metrics for TBDMS, TOM, and ACE chemistries.
| Feature | TBDMS (tert-butyldimethylsilyl) | TOM (Tri-iso-propylsilyloxymethyl) | ACE (bis(2-acetoxyethoxy)methyl) |
| Protecting Group Type | Silyl Ether | Silyl Acetal | Orthoester |
| Stepwise Coupling Efficiency | >98%[3] | >99%[4] | >99%[5][6] |
| Coupling Time | Longer (e.g., up to 6 min) due to steric bulk.[2][7] | Shorter, comparable to 2'-OMe monomers due to reduced steric hindrance.[8][9] | Very fast, comparable to DNA synthesis (<60 seconds).[10] |
| Key Advantage | Established, widely used, and cost-effective.[11] | High coupling efficiency, prevents 2'-3' migration, ideal for long RNA synthesis.[8][9][12] | Mildest deprotection; RNA can be purified with protecting groups on, enhancing stability against RNases.[2][10][13] |
| Main Drawback | Steric hindrance lowers coupling efficiency; risk of 2'-3' phosphodiester migration during basic deprotection.[2][8][9] | Higher cost compared to TBDMS monomers. | Requires a different 5'-O-protecting group (silyl ether instead of DMT) and specialized synthesis cycle reagents.[10][13] |
| Deprotection Reagents | 1. Base/Phosphate (B84403): Aqueous Ammonia/Ethanol (B145695) or AMA.[1][11] 2. 2'-OH: Fluoride (B91410) source (TBAF in THF, or TEA·3HF).[1][14] | 1. Base/Phosphate: AMA or Ethanolic Methylamine (B109427) (EMAM).[8][9] 2. 2'-OH: Fluoride source (TEA·3HF).[9] | 1. Phosphate/Cleavage/Base: S2Na2, then 40% Methylamine.[10] 2. 2'-OH: Mild acid buffer (e.g., pH 3.8, AcOH/TEMED).[2][10][15] |
| Deprotection Conditions | 1. Base: 55°C, 1-17 hours (depending on base protecting groups).[1] 2. 2'-OH: Room temp to 65°C, 2.5-24 hours.[1][11] | 1. Base: 65°C for 10 min (AMA) or 35°C for 6 hours (EMAM).[9] 2. 2'-OH: 65°C for 2.5 hours.[9] | 1. Base: 55°C for 10 min.[10] 2. 2'-OH: 60°C for 30 min.[5] |
Workflow and Mechanism of Action
Solid-phase RNA synthesis follows a four-step cycle for each nucleotide addition. The 2'-O-protecting group's primary role is to remain stable during these cycles and influence the efficiency of the coupling step.
Detailed Experimental Protocols
The following are generalized protocols for the final cleavage and deprotection steps for each chemistry. Exact times and temperatures may vary based on the specific nucleobase protecting groups used and the length of the oligonucleotide.
Protocol 1: TBDMS Deprotection
This is a two-step process involving base/phosphate deprotection followed by 2'-O-TBDMS group removal.
Materials:
-
Ammonium Hydroxide/Ethanol (3:1 v/v) OR Ammonium Hydroxide/Methylamine (AMA, 1:1 v/v).
-
1M Tetrabutylammonium fluoride (TBAF) in THF OR Triethylamine trihydrofluoride (TEA·3HF).
-
Anhydrous DMSO.
Procedure:
-
Base and Phosphate Deprotection:
-
Transfer the solid support-bound oligonucleotide to a screw-cap vial.
-
Add 1 mL of AMA solution and incubate at 65°C for 10-20 minutes.[11] Alternatively, use Ammonium Hydroxide/Ethanol (3:1) and incubate at 55°C for 1-17 hours.[1]
-
Cool the vial, transfer the supernatant to a new tube, and lyophilize to dryness.
-
-
2'-O-TBDMS Deprotection (Desilylation):
-
Re-dissolve the dried oligonucleotide pellet in 100-115 µL of anhydrous DMSO.
-
Add 125 µL of TEA·3HF, mix well, and incubate at 65°C for 2.5 hours.[11][16]
-
Alternatively, for TBAF deprotection, re-dissolve the pellet in 1M TBAF in THF and incubate at room temperature for 12-24 hours.[1]
-
Quench the reaction and desalt the resulting RNA oligonucleotide using ethanol precipitation, dialysis, or a suitable desalting cartridge.
-
Protocol 2: TOM Deprotection
The deprotection of TOM-protected RNA is generally faster for the base-removal step.
Materials:
-
Ammonium Hydroxide/Methylamine (AMA, 1:1 v/v).
-
Triethylamine trihydrofluoride (TEA·3HF).
-
Anhydrous DMSO.
Procedure:
-
Cleavage and Base Deprotection:
-
Place the solid support in a vial with 1.5 mL of AMA solution.
-
Seal the vial and heat at 65°C for 10 minutes.[9]
-
Cool the vial, transfer the solution containing the cleaved oligonucleotide to a sterile tube, and dry completely.
-
-
2'-O-TOM Deprotection:
-
Follow the same procedure as for TBDMS deprotection: re-dissolve the pellet in 100-115 µL of anhydrous DMSO, add 125 µL of TEA·3HF, mix, and heat at 65°C for 2.5 hours.[9]
-
Quench and desalt the final RNA product.
-
Protocol 3: ACE Deprotection
ACE chemistry utilizes a unique, orthogonal deprotection scheme that avoids harsh fluoride treatment.
Materials:
-
1M Disodium-2-carbamoyl-2-cyanoethylene-1,1-dithiolate trihydrate (S2Na2) in DMF.
-
40% Methylamine in water.
-
Acidic deprotection buffer (e.g., 0.1 M Acetate buffer, pH 3.8).
Procedure:
-
Phosphate Deprotection:
-
On the solid support, treat the oligonucleotide with 1 M S2Na2 in DMF for 30 minutes to remove the methyl phosphate protecting groups.[10]
-
-
Cleavage and Base Deprotection:
-
Wash the support, then treat with 40% aqueous methylamine at 55°C for 10 minutes. This step cleaves the RNA from the support, removes exocyclic amine protecting groups, and modifies the 2'-ACE group for the final acid-labile step.[10]
-
Collect the solution and lyophilize. At this stage, the RNA is stable and can be purified by HPLC or PAGE with the modified 2'-O-protecting group still attached.[2][10]
-
-
2'-O-ACE Deprotection:
-
Re-dissolve the (optionally purified) RNA in the acidic buffer (pH 3.8).
-
Incubate at 60°C for 30 minutes to completely remove the 2'-orthoester group.[5]
-
Desalt to obtain the final RNA product.
-
Conclusion and Recommendations
The optimal 2'-O-protecting group depends heavily on the synthetic goal.
-
TBDMS: Remains a viable, cost-effective option for the routine synthesis of shorter RNA sequences (<40 nt) where maximizing yield is not the primary concern.[5]
-
TOM: Represents a significant improvement for synthesizing long and complex RNA oligonucleotides .[8][9] Its reduced steric hindrance leads to higher stepwise coupling efficiencies, which is critical as the cumulative yield drops exponentially with sequence length.[12] The prevention of 2'-5' linkages is another key advantage for ensuring the biological activity of the final product.[8][9]
-
ACE: Is the method of choice when mild deprotection conditions are paramount or when the RNA sequence is particularly sensitive to degradation. The ability to purify the RNA while it is still protected offers a unique advantage, minimizing exposure to ubiquitous RNases and improving the final purity of challenging sequences.[2][13]
References
- 1. glenresearch.com [glenresearch.com]
- 2. atdbio.com [atdbio.com]
- 3. pubs.acs.org [pubs.acs.org]
- 4. glenresearch.com [glenresearch.com]
- 5. cdn.technologynetworks.com [cdn.technologynetworks.com]
- 6. horizondiscovery.com [horizondiscovery.com]
- 7. Chemical synthesis of a very long oligoribonucleotide with 2-cyanoethoxymethyl (CEM) as the 2′-O-protecting group: structural identification and biological activity of a synthetic 110mer precursor-microRNA candidate - PMC [pmc.ncbi.nlm.nih.gov]
- 8. massbio.org [massbio.org]
- 9. glenresearch.com [glenresearch.com]
- 10. horizondiscovery.com [horizondiscovery.com]
- 11. glenresearch.com [glenresearch.com]
- 12. benchchem.com [benchchem.com]
- 13. glenresearch.com [glenresearch.com]
- 14. kulturkaufhaus.de [kulturkaufhaus.de]
- 15. Synthesis of Nucleobase-Modified RNA Oligonucleotides by Post-Synthetic Approach - PMC [pmc.ncbi.nlm.nih.gov]
- 16. glenresearch.com [glenresearch.com]
A Comparative Guide to Short RNA Synthesis: Chemical Synthesis vs. In Vitro Transcription
For researchers, scientists, and drug development professionals, the choice between chemical synthesis and in vitro transcription for producing short RNAs like siRNAs is a critical decision that impacts experimental outcomes, timelines, and costs. This guide provides an objective comparison of these two methods, supported by experimental data and detailed protocols, to aid in selecting the most appropriate strategy for your research needs.
The production of short interfering RNAs (siRNAs) and other small RNA molecules is fundamental to a wide range of applications, from basic research in gene function to the development of novel RNA-based therapeutics. The two primary methods for generating these short RNAs are solid-phase chemical synthesis and in vitro transcription (IVT). Each approach offers distinct advantages and disadvantages in terms of yield, purity, cost, scalability, and the ability to incorporate chemical modifications.
At a Glance: Key Differences
| Feature | Chemical Synthesis | In Vitro Transcription (IVT) |
| Typical Yield | Milligrams to grams | Micrograms to milligrams |
| Purity | High (>90-97% with HPLC purification)[1] | Variable, may contain abortive sequences and other byproducts[2][3] |
| Cost | Higher, especially for small-scale and screening | Lower, particularly for screening multiple sequences[2][4][5][6] |
| Scalability | Highly scalable for large-scale production | Scalable, but can be more complex to optimize for very large scales |
| Length of RNA | Typically up to ~50-100 nucleotides | Can produce longer RNAs, but less precise for very short sequences |
| Chemical Modifications | Wide variety of modifications possible at specific positions[7] | Limited to modified NTPs, not all positions can be modified |
| Turnaround Time | Days to weeks, depending on complexity and scale | Can be completed in less than 24 hours for a single sequence[8] |
| Sequence Constraints | None | T7 RNA polymerase has a preference for a 5'-G residue for optimal transcription[2] |
In-Depth Comparison
Chemical Synthesis: Precision and Power in Modification
Solid-phase chemical synthesis is the gold standard for producing highly pure, chemically modified short RNAs.[] This method involves the stepwise addition of nucleotide phosphoramidites to a growing RNA chain attached to a solid support.[1][][10] The key advantage of this approach lies in its precision, allowing for the incorporation of a vast array of chemical modifications at any desired position within the RNA sequence.[7]
These modifications are critical for therapeutic applications, as they can enhance stability against nuclease degradation, improve pharmacokinetic properties, reduce immunogenicity, and minimize off-target effects.[7] Common modifications include:
-
2'-O-Methyl (2'-OMe): This modification at the 2' position of the ribose sugar increases nuclease resistance and reduces the potential for off-target effects.[11][12][13]
-
Phosphorothioate (B77711) (PS) linkages: Replacing a non-bridging oxygen with a sulfur atom in the phosphate (B84403) backbone significantly enhances resistance to exonucleases.[14][15]
-
Locked Nucleic Acids (LNAs): These modifications lock the ribose sugar in a specific conformation, increasing thermal stability and binding affinity.[7]
The ability to introduce such a diverse chemical landscape makes chemical synthesis the preferred method for developing siRNA drug candidates. However, this precision comes at a higher cost, particularly for initial screening of multiple siRNA sequences.[4][6]
In Vitro Transcription: Speed and Cost-Effectiveness for Screening
In vitro transcription (IVT) offers a rapid and cost-effective alternative for producing short RNAs, making it particularly well-suited for high-throughput screening of siRNA candidates.[8][16] This enzymatic method utilizes a DNA template containing a bacteriophage promoter (typically T7) to direct RNA polymerase to synthesize the desired RNA sequence.[16]
The primary advantages of IVT are its speed and lower cost compared to chemical synthesis.[4][6] Researchers can quickly generate multiple siRNA sequences to identify the most potent ones before committing to the more expensive chemical synthesis for further development. However, IVT has some limitations. The purity of IVT-produced RNA can be a concern, as the reaction can generate abortive transcripts and other byproducts that may require additional purification steps.[2][3] Furthermore, T7 RNA polymerase exhibits a strong preference for initiating transcription with a guanosine (B1672433) (G) residue, which can constrain the design of the 5' end of the siRNA.[2] While some modifications can be incorporated using modified nucleotide triphosphates (NTPs), the options are far more limited compared to chemical synthesis.[2]
Experimental Protocols
Detailed Protocol for Solid-Phase Chemical Synthesis of siRNA
This protocol outlines the general steps for automated solid-phase synthesis of a single RNA strand. The complementary strand is synthesized separately, and then the two strands are annealed to form the final siRNA duplex.
Materials:
-
DNA/RNA synthesizer
-
Controlled pore glass (CPG) solid support pre-loaded with the first nucleoside
-
RNA phosphoramidites (A, C, G, U) with appropriate protecting groups
-
Activator solution (e.g., 5-ethylthio-1H-tetrazole)
-
Oxidizing solution (e.g., iodine solution)
-
Capping reagents (e.g., acetic anhydride (B1165640) and N-methylimidazole)
-
Deblocking solution (e.g., trichloroacetic acid in dichloromethane)
-
Cleavage and deprotection solution (e.g., ammonia/methylamine mixture)
-
Triethylamine trihydrofluoride (TEA·3HF) for 2'-hydroxyl deprotection
-
HPLC system for purification
-
Synthesis Cycle (repeated for each nucleotide addition): a. Deblocking (Detritylation): The 5'-dimethoxytrityl (DMT) protecting group is removed from the support-bound nucleoside using an acidic solution. b. Coupling: The next phosphoramidite (B1245037) is activated and coupled to the free 5'-hydroxyl group of the growing RNA chain. c. Capping: Any unreacted 5'-hydroxyl groups are acetylated to prevent the formation of deletion mutants. d. Oxidation: The phosphite (B83602) triester linkage is oxidized to a more stable phosphate triester.
-
Cleavage and Deprotection: a. After the final synthesis cycle, the RNA oligomer is cleaved from the CPG support using a basic solution (e.g., ammonia/methylamine). This step also removes the protecting groups from the phosphate backbone and the nucleobases. b. The 2'-hydroxyl protecting groups (e.g., TBDMS) are removed using a fluoride-containing reagent like TEA·3HF.
-
Purification: The crude RNA product is purified by high-performance liquid chromatography (HPLC) to remove truncated sequences and other impurities.
-
Annealing: The purified sense and antisense strands are mixed in equimolar amounts in an annealing buffer, heated, and then slowly cooled to form the final siRNA duplex.
Detailed Protocol for In Vitro Transcription of siRNA
This protocol describes the generation of a single siRNA strand using a DNA template and T7 RNA polymerase. The complementary strand is synthesized in a separate reaction.
Materials:
-
Linearized DNA template containing a T7 promoter upstream of the siRNA sequence
-
T7 RNA Polymerase
-
Ribonucleotide triphosphates (ATP, CTP, GTP, UTP)
-
Transcription buffer
-
RNase inhibitor
-
DNase I (RNase-free)
-
Purification kit (e.g., spin column-based)
-
Annealing buffer
-
Transcription Reaction Setup: a. In a nuclease-free tube, combine the transcription buffer, rNTPs, RNase inhibitor, and the linearized DNA template. b. Add T7 RNA polymerase to initiate the reaction. c. Incubate the reaction at 37°C for 2-4 hours.
-
DNase Treatment: a. Add RNase-free DNase I to the reaction mixture to digest the DNA template. b. Incubate at 37°C for 15-30 minutes.
-
Purification: a. Purify the transcribed RNA using a suitable method, such as a spin column-based kit, to remove unincorporated nucleotides, enzymes, and salts.
-
Quantification: Determine the concentration of the purified RNA using a spectrophotometer.
-
Annealing: a. Combine equimolar amounts of the purified sense and antisense RNA strands in an annealing buffer. b. Heat the mixture to 95°C for 2-5 minutes. c. Allow the mixture to cool slowly to room temperature to facilitate duplex formation.
-
Verification: Analyze the formation of the siRNA duplex by non-denaturing polyacrylamide gel electrophoresis (PAGE).
Visualizing the Workflows
Caption: Workflow for Chemical Synthesis of siRNA.
Caption: Workflow for In Vitro Transcription of siRNA.
Decision-Making Framework
The choice between chemical synthesis and in vitro transcription ultimately depends on the specific requirements of the study.
Caption: Decision guide for choosing a synthesis method.
Conclusion
References
- 1. wenzhanglab.com [wenzhanglab.com]
- 2. A Simple and Cost-Effective Approach for In Vitro Production of Sliced siRNAs as Potent Triggers for RNAi - PMC [pmc.ncbi.nlm.nih.gov]
- 3. mdpi.com [mdpi.com]
- 4. A simple and cost-effective method for producing small interfering RNAs with high efficacy - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Cost-effective method of siRNA preparation and its application to inhibit hepatitis B virus replication in HepG2 cells - PMC [pmc.ncbi.nlm.nih.gov]
- 6. researchgate.net [researchgate.net]
- 7. Modification Options For siRNA - ELLA Biotech [ellabiotech.com]
- 8. researchgate.net [researchgate.net]
- 10. mdpi.com [mdpi.com]
- 11. Small interfering RNAs containing full 2′-O-methylribonucleotide-modified sense strands display Argonaute2/eIF2C2-dependent activity - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Fluorescence Cross-Correlation Spectroscopy Reveals Mechanistic Insights into the Effect of 2′-O-Methyl Modified siRNAs in Living Cells - PMC [pmc.ncbi.nlm.nih.gov]
- 13. researchgate.net [researchgate.net]
- 14. Single-Stranded Phosphorothioated Regions Enhance Cellular Uptake of Cholesterol-Conjugated siRNA but Not Silencing Efficacy - PMC [pmc.ncbi.nlm.nih.gov]
- 15. Chirality matters: stereo-defined phosphorothioate linkages at the termini of small interfering RNAs improve pharmacology in vivo - PMC [pmc.ncbi.nlm.nih.gov]
- 16. researchgate.net [researchgate.net]
- 17. Solid-Phase Chemical Synthesis of Stable Isotope-Labeled RNA to Aid Structure and Dynamics Studies by NMR Spectroscopy - PMC [pmc.ncbi.nlm.nih.gov]
A Comparative Guide to Assessing the Purity of 13C Labeled Oligonucleotides by HPLC and Alternative Methods
For researchers, scientists, and drug development professionals working with 13C labeled oligonucleotides, ensuring the purity of these critical reagents is paramount for the accuracy and reproducibility of their studies. High-performance liquid chromatography (HPLC) stands as a cornerstone technique for this purpose, offering robust and reliable purity assessment. This guide provides a comprehensive comparison of HPLC methods with alternative techniques, supported by experimental data and detailed protocols, to aid in the selection of the most appropriate analytical strategy.
Introduction to Purity Assessment of 13C Labeled Oligonucleotides
The introduction of a 13C stable isotope label into an oligonucleotide can be a powerful tool for various applications, including nuclear magnetic resonance (NMR) and mass spectrometry (MS) based structural and functional studies. However, the synthesis of these labeled molecules can present unique challenges, potentially leading to a variety of impurities. These impurities may include failure sequences (shortmers, n-1), sequences with incomplete deprotection, or other modifications. Therefore, rigorous purity analysis is essential.
While 13C labeling is not expected to dramatically alter the fundamental chromatographic behavior of oligonucleotides, subtle changes in retention time compared to their unlabeled counterparts may occur. The primary analytical techniques for assessing oligonucleotide purity are Ion-Pair Reversed-Phase HPLC (IP-RP-HPLC) and Ion-Exchange HPLC (IEX-HPLC). Additionally, Mass Spectrometry (MS), Hydrophilic Interaction Liquid Chromatography (HILIC), and Size-Exclusion Chromatography (SEC) offer complementary and sometimes orthogonal approaches to purity and integrity assessment.
Comparison of Analytical Techniques for Purity Assessment
The choice of analytical technique depends on the specific requirements of the analysis, such as the need for mass confirmation, the types of impurities to be resolved, and compatibility with downstream applications.
| Technique | Principle of Separation | Primary Application for Purity Assessment | Advantages | Limitations |
| IP-RP-HPLC | Partitioning based on hydrophobicity, enhanced by an ion-pairing agent that neutralizes the negative charge of the phosphate (B84403) backbone. | High-resolution separation of full-length product from failure sequences (n-1, n+1) and other synthesis-related impurities.[1][2] | Excellent resolution for a wide range of oligonucleotide lengths.[3] MS-compatible mobile phases (e.g., TEA/HFIP) are available.[4] | Ion-pairing reagents can be difficult to remove and may interfere with some downstream applications.[5] |
| IEX-HPLC | Separation based on the net negative charge of the oligonucleotide's phosphate backbone. | Separation of oligonucleotides based on length (number of phosphate groups).[3][6] Effective for resolving sequences with significant secondary structure.[3] | High resolving power for length-based impurities.[6] Does not require ion-pairing reagents. | Generally not compatible with direct MS analysis due to high salt concentrations in the mobile phase.[5] |
| Mass Spectrometry (MS) | Measurement of the mass-to-charge ratio of ionized molecules. | Confirmation of the molecular weight of the target 13C labeled oligonucleotide and identification of impurities based on their mass.[7][8][9] | Provides unambiguous mass confirmation. Highly sensitive.[10] Can be coupled with LC for LC-MS analysis.[6] | May not resolve isomers. Quantification can be challenging without appropriate standards. |
| HILIC | Partitioning of polar analytes between a polar stationary phase and a less polar mobile phase. | An alternative MS-compatible method for separating polar oligonucleotides and their impurities.[11][12] | Good compatibility with MS.[5][11] Offers orthogonal selectivity to RP-HPLC. | May have lower resolution for length-based impurities compared to IP-RP-HPLC and IEX-HPLC.[12] |
| SEC | Separation based on the hydrodynamic volume of the molecule. | Analysis of high molecular weight impurities, such as aggregates and multimers.[5][13] | Performed under non-denaturing conditions.[14] Useful for assessing the oligomeric state. | Limited resolution for separating species of similar size, such as n-1 impurities from the full-length product.[14] |
Experimental Protocols
Detailed methodologies are crucial for obtaining reliable and reproducible results. Below are representative protocols for the key HPLC-based techniques.
Ion-Pair Reversed-Phase HPLC (IP-RP-HPLC) Protocol
This method is highly effective for the separation of detritylated synthetic oligonucleotides and is compatible with MS when appropriate volatile ion-pairing agents are used.[1]
Instrumentation:
-
HPLC or UHPLC system with a UV detector and preferably a mass spectrometer.
-
Thermostatted column compartment.
Materials:
-
Column: A C18 reversed-phase column suitable for oligonucleotide analysis (e.g., Waters ACQUITY Premier OST, Agilent AdvanceBio Oligonucleotide). Pore size of 130 Å is generally suitable for single-stranded oligonucleotides.[4]
-
Mobile Phase A: 15 mM Triethylamine (TEA) and 400 mM Hexafluoroisopropanol (HFIP) in water.
-
Mobile Phase B: 15 mM TEA and 400 mM HFIP in 50:50 Methanol:Water.
-
Sample Preparation: Dissolve the 13C labeled oligonucleotide in Mobile Phase A or water to a concentration of approximately 10-20 µM.
Chromatographic Conditions:
-
Flow Rate: 0.2 - 0.4 mL/min for a 2.1 mm ID column.
-
Column Temperature: 60 °C (elevated temperature helps to denature secondary structures).[4]
-
UV Detection: 260 nm.
-
Gradient:
-
0-2 min: 10% B
-
2-17 min: 10-30% B (adjust the gradient slope for optimal resolution)
-
17-18 min: 30-95% B
-
18-20 min: 95% B (column wash)
-
20-22 min: 95-10% B
-
22-25 min: 10% B (equilibration)
-
-
Injection Volume: 5-10 µL.
Ion-Exchange HPLC (IEX-HPLC) Protocol
IEX-HPLC is a powerful technique for separating oligonucleotides based on their length due to the charge of the phosphate backbone.[3]
Instrumentation:
-
HPLC or UHPLC system with a UV detector. A bio-inert system is recommended to avoid interactions with metal surfaces.
-
Thermostatted column compartment.
Materials:
-
Column: A strong anion-exchange column designed for oligonucleotide analysis (e.g., Thermo Scientific DNAPac PA200).
-
Mobile Phase A: 20 mM Tris-HCl, pH 8.0.
-
Mobile Phase B: 20 mM Tris-HCl, 1 M NaCl, pH 8.0.
-
Sample Preparation: Dissolve the 13C labeled oligonucleotide in Mobile Phase A or water to a concentration of approximately 10-20 µM.
Chromatographic Conditions:
-
Flow Rate: 1.0 mL/min for a 4.0 mm ID column.
-
Column Temperature: 30-60 °C.
-
UV Detection: 260 nm.
-
Gradient:
-
0-1 min: 0% B
-
1-21 min: 0-100% B
-
21-25 min: 100% B
-
25-26 min: 100-0% B
-
26-30 min: 0% B (equilibration)
-
-
Injection Volume: 10-20 µL.
Visualization of Workflows and Comparisons
Diagrams created using Graphviz (DOT language) provide a clear visual representation of the experimental workflows and logical relationships.
References
- 1. elementlabsolutions.com [elementlabsolutions.com]
- 2. Recent Methods for Purification and Structure Determination of Oligonucleotides - PMC [pmc.ncbi.nlm.nih.gov]
- 3. biorxiv.org [biorxiv.org]
- 4. lcms.cz [lcms.cz]
- 5. Sensitive, Efficient Quantitation of 13C-Enriched Nucleic Acids via Ultrahigh-Performance Liquid Chromatography–Tandem Mass Spectrometry for Applications in Stable Isotope Probing - PMC [pmc.ncbi.nlm.nih.gov]
- 6. documents.thermofisher.com [documents.thermofisher.com]
- 7. web.colby.edu [web.colby.edu]
- 8. idtdna.com [idtdna.com]
- 9. bachem.com [bachem.com]
- 10. Using Mass Spectrometry for Oligonucleotide and Peptides [thermofisher.com]
- 11. Oligonucleotide Analysis by Hydrophilic Interaction Liquid Chromatography-Mass Spectrometry in the Absence of Ion-Pair Reagents - PMC [pmc.ncbi.nlm.nih.gov]
- 12. A liquid chromatography - mass spectrometry method to measure ¹³C-isotope enrichment for DNA stable-isotope probing - PubMed [pubmed.ncbi.nlm.nih.gov]
- 13. researchgate.net [researchgate.net]
- 14. Ion-pair reversed-phase high-performance liquid chromatography analysis of oligonucleotides: retention prediction - PubMed [pubmed.ncbi.nlm.nih.gov]
A Researcher's Guide to Oligonucleotide Labeling: A Cost-Benefit Analysis of 13C-Labeled Phosphoramidites Versus Common Alternatives
For researchers, scientists, and drug development professionals, the precise labeling of oligonucleotides is a critical step in a myriad of applications, from elucidating complex biological mechanisms to developing novel therapeutics. The choice of label can significantly impact experimental outcomes, influencing sensitivity, structural integrity of the nucleic acid, and overall project cost. This guide provides an objective comparison of 13C-labeled phosphoramidites with two widely used alternatives: fluorescent dyes and biotin (B1667282).
This analysis delves into the quantitative performance, cost-effectiveness, and methodological nuances of each labeling strategy, supported by experimental data and detailed protocols. Our aim is to equip you with the necessary information to make an informed decision for your specific research needs.
At a Glance: Comparing Labeling Strategies
The selection of an appropriate label for oligonucleotide synthesis hinges on a balance between the desired application, required sensitivity, and budgetary constraints. Below is a summary of the key characteristics of 13C isotopic labeling, fluorescent dye labeling, and biotin labeling.
| Feature | 13C-Labeled Phosphoramidites | Fluorescent Dye Phosphoramidites | Biotin Phosphoramidites |
| Primary Application | NMR Spectroscopy, Mass Spectrometry | Fluorescence Microscopy, qPCR, Flow Cytometry | Affinity Purification, Immunoassays, Biosensors |
| Detection Method | Nuclear Magnetic Resonance, Mass Spectrometry | Fluorescence Detection | Colorimetric/Chemiluminescent/Fluorometric |
| Signal Sensitivity | Moderate, dependent on isotopic enrichment and magnetic field strength | High, single-molecule detection possible | High, signal amplification is common |
| Impact on Structure | Minimal, structurally non-perturbative | Can cause steric hindrance and affect hybridization[1][2] | Can cause steric hindrance; the streptavidin interaction is bulky[3] |
| Multiplexing Capability | Limited by spectral overlap in NMR | High, multiple spectrally distinct dyes available | Limited, though some strategies exist |
| Relative Cost | High | Moderate to High | Low to Moderate |
In-Depth Analysis: Performance and Cost
A deeper dive into the quantitative aspects of each labeling method reveals distinct advantages and disadvantages that can guide your selection process.
Quantitative Performance Comparison
| Performance Metric | 13C-Labeled Phosphoramidites | Fluorescent Dye Phosphoramidites | Biotin Phosphoramidites |
| Signal-to-Noise Ratio | Moderate; can be enhanced with higher isotopic enrichment and advanced NMR techniques.[][5][6][7] | High; can be optimized by choice of dye-quencher pairs and probe design.[8][9][10][11] | High; signal amplification strategies (e.g., enzyme-linked assays) are common. |
| Coupling Efficiency | Generally high (>98%), comparable to standard phosphoramidites. | High (>98%), though some bulky dyes may show slightly lower efficiency. | High (>98%), comparable to standard phosphoramidites. |
| Effect on Hybridization | Negligible impact on melting temperature (Tm) and hybridization kinetics.[12] | Can stabilize or destabilize duplexes depending on the dye and its position; may cause steric hindrance.[1][2] | The biotin tag itself has minimal effect, but the subsequent binding of streptavidin can sterically hinder hybridization and enzymatic processes.[3][13] |
| Photostability | Not applicable (stable isotope). | Varies significantly between dyes; photobleaching can be a limitation. | Not applicable. |
| Versatility | Primarily for structural biology (NMR) and metabolic tracing (MS). | Broadly applicable in molecular biology, diagnostics, and imaging.[14] | Primarily for capture, purification, and detection assays.[] |
Cost Comparison
The cost of oligonucleotide labeling is a multi-faceted issue, encompassing the initial price of the phosphoramidite (B1245037), the complexity of the synthesis, and the required instrumentation for detection.
| Cost Component | 13C-Labeled Phosphoramidites | Fluorescent Dye Phosphoramidites | Biotin Phosphoramidites |
| Phosphoramidite Price | High (e.g., ~$3000 - $4500 for 25 mg of a single 13C,15N-labeled deoxynucleoside phosphoramidite). | Moderate to High (e.g., ~$150 - $700 for a vial sufficient for multiple syntheses, depending on the dye). | Low to Moderate (e.g., ~$100 - $300 for a vial sufficient for multiple syntheses). |
| Synthesis Cost | Higher due to the cost of the labeled amidites. | Higher than unlabeled, with cost varying by dye. | Slightly higher than unlabeled. |
| Instrumentation Cost | Very High (NMR spectrometer, Mass spectrometer). | Moderate to High (Fluorometer, qPCR machine, fluorescence microscope). | Low to Moderate (Plate reader, blotting equipment). |
| Overall Project Cost | High, typically reserved for detailed structural and mechanistic studies. | Moderate, widely accessible for a range of applications. | Low, a cost-effective choice for many routine applications. |
Note: Prices are estimates based on publicly available information and can vary significantly between suppliers and based on the scale of synthesis and purity requirements.
Experimental Protocols and Methodologies
The choice of labeling method also dictates the experimental workflow. Below are outlines of the key steps involved in synthesizing oligonucleotides with each type of label.
Synthesis of 13C-Labeled Oligonucleotides
The incorporation of 13C-labeled nucleosides into an oligonucleotide follows the standard phosphoramidite solid-phase synthesis cycle. The key difference lies in the use of a 13C-labeled phosphoramidite at the desired position(s).
Experimental Workflow for 13C-Labeled Oligonucleotide Synthesis
Caption: Workflow for solid-phase synthesis of a 13C-labeled oligonucleotide.
A detailed protocol for the synthesis of 13C-labeled DNA building blocks and their incorporation into DNA can be found in publications by Kreutz et al.[16]. Enzymatic methods for producing uniformly 13C,15N-labeled DNA have also been developed and provide an alternative to chemical synthesis.[17][18]
Synthesis of Fluorescently Labeled Oligonucleotides
Fluorescent dyes can be incorporated at the 5' or 3' end, or internally within an oligonucleotide. 5'-labeling is commonly achieved by using a dye-conjugated phosphoramidite in the final coupling step of solid-phase synthesis.
Experimental Workflow for 5'-Fluorescent Labeling
Caption: General workflow for 5'-fluorescent labeling of an oligonucleotide.
Detailed protocols for fluorescent labeling can be found from various commercial suppliers and in the literature.[19][20][21] Post-synthesis labeling methods, where a reactive dye is conjugated to an amino-modified oligonucleotide, are also available.[14]
Synthesis of Biotin-Labeled Oligonucleotides
Similar to fluorescent dyes, biotin can be incorporated at either terminus or internally. Biotin phosphoramidites are readily available for use in standard solid-phase synthesis.
Experimental Workflow for Internal Biotin Labeling
Caption: Workflow for internal biotin labeling using a modified phosphoramidite.
Protocols for biotinylating nucleic acids are well-established and can be found from various suppliers and in publications.[22][23][24] Enzymatic methods for incorporating biotinylated nucleotides are also widely used.[]
Logical Relationships in Labeling Strategy Selection
The decision-making process for choosing a labeling strategy involves considering the primary research question, the required level of detail, and the available resources.
Decision Tree for Oligonucleotide Labeling
Caption: Decision-making flowchart for selecting an oligonucleotide labeling method.
Conclusion
The choice between 13C-labeled phosphoramidites, fluorescent dyes, and biotin is a critical decision in the design of experiments involving oligonucleotides.
-
13C-labeled phosphoramidites are unparalleled for applications requiring detailed structural and dynamic information at the atomic level, such as NMR and mass spectrometry-based studies. While the initial cost is high, the non-perturbative nature of isotopic labeling provides invaluable insights into the native state of nucleic acids and their interactions.
-
Fluorescent dye phosphoramidites offer a versatile and highly sensitive solution for a broad range of applications, including cellular imaging, real-time PCR, and flow cytometry. The wide array of available dyes allows for multiplexed experiments, although potential steric hindrance and photobleaching should be considered.
-
Biotin phosphoramidites provide a robust and cost-effective method for applications centered around affinity capture, purification, and detection. The strength of the biotin-streptavidin interaction is a significant advantage, but the large size of the streptavidin protein can be a limiting factor in some contexts.
By carefully considering the specific requirements of your research, the quantitative performance data, and the cost-benefit analysis presented in this guide, you can confidently select the optimal labeling strategy to achieve your scientific goals.
References
- 1. researchgate.net [researchgate.net]
- 2. researchgate.net [researchgate.net]
- 3. researchgate.net [researchgate.net]
- 5. fiveable.me [fiveable.me]
- 6. chem.libretexts.org [chem.libretexts.org]
- 7. University of Ottawa NMR Facility Blog: Effect of 1H Tuning on the Signal-to-Noise Ratio in 13C NMR Spectra [u-of-o-nmr-facility.blogspot.com]
- 8. Fluorescence signal-to-noise optimisation for real-time PCR using universal reporter oligonucleotides - Analytical Methods (RSC Publishing) [pubs.rsc.org]
- 9. Single-Labeled Oligonucleotides Showing Fluorescence Changes upon Hybridization with Target Nucleic Acids - PMC [pmc.ncbi.nlm.nih.gov]
- 10. researchgate.net [researchgate.net]
- 11. Fluorescence signal-to-noise optimisation for real-time PCR using universal reporter oligonucleotides - Analytical Methods (RSC Publishing) DOI:10.1039/C8AY00812D [pubs.rsc.org]
- 12. Modeling the Infrared Spectroscopy of Oligonucleotides with 13C Isotope Labels - PubMed [pubmed.ncbi.nlm.nih.gov]
- 13. A streptavidin variant with slower biotin dissociation and increased mechanostability - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Fluorescent Labeled Oligos,Oligo Fluorescent Labeling By Name [biosyn.com]
- 16. Synthesis and incorporation of 13C-labeled DNA building blocks to probe structural dynamics of DNA by NMR - PMC [pmc.ncbi.nlm.nih.gov]
- 17. academic.oup.com [academic.oup.com]
- 18. academic.oup.com [academic.oup.com]
- 19. Fluorescent dye phosphoramidite labelling of oligonucleotides - PubMed [pubmed.ncbi.nlm.nih.gov]
- 20. Dye-Labeled Phosphoramidites | Thermo Fisher Scientific - TW [thermofisher.com]
- 21. atdbio.com [atdbio.com]
- 22. Labeling DNA for Single-Molecule Experiments: Methods of Labeling Internal Specific Sequences on Double-Stranded DNA - PMC [pmc.ncbi.nlm.nih.gov]
- 23. Biotinylation Guidelines—Creating Biotinylated DNA | Thermo Fisher Scientific - US [thermofisher.com]
- 24. idtdna.com [idtdna.com]
A Researcher's Guide to Isotopic Labeling Strategies for RNA NMR Spectroscopy
An objective comparison of performance and methodologies for researchers, scientists, and drug development professionals.
Nuclear Magnetic Resonance (NMR) spectroscopy is a powerful technique for elucidating the structure and dynamics of RNA molecules at atomic resolution. However, the inherent spectral complexity and signal overlap in larger RNAs present significant challenges. Isotopic labeling, the incorporation of stable isotopes such as ¹³C, ¹⁵N, and ²H, is an indispensable tool to overcome these limitations. This guide provides a comprehensive comparison of different isotopic labeling strategies for RNA NMR, supported by quantitative data and detailed experimental protocols, to aid researchers in selecting the optimal approach for their specific research questions.
Comparison of Isotopic Labeling Strategies
The choice of an isotopic labeling strategy is a critical decision that depends on the size of the RNA, the specific scientific question being addressed, and available resources. The following tables provide a quantitative comparison of the most common labeling approaches.
| Labeling Strategy | Primary Application | Typical RNA Size | Advantages | Disadvantages | Relative Cost |
| Uniform Labeling | Initial assignments, small RNAs | < 30 nt | Straightforward to implement, provides information on all residues. | Severe signal overlap and line broadening in larger RNAs.[1] | Low to Moderate |
| Selective Labeling (Nucleotide-specific) | Assignment of larger RNAs, studying specific regions | 30-70 nt | Reduces spectral complexity by labeling only one or two nucleotide types.[2][3][4] | Multiple labeled samples are required for complete assignment. | Moderate |
| Selective Labeling (Atom-specific) | Probing specific interactions, dynamics studies | Any size | Simplifies spectra and allows for specific distance or dynamics measurements.[1][5] | Can be chemically challenging and expensive to synthesize labeled precursors. | High |
| Segmental Labeling | Studying domains within large RNAs | > 70 nt | Drastically simplifies spectra by labeling only a specific segment of a large RNA.[3][6][7] | Technically challenging, requiring enzymatic or chemical ligation. | High |
| Deuteration | Reducing line broadening in large RNAs | > 50 nt | Significantly improves spectral resolution and sensitivity by reducing dipolar couplings.[8] | Can lead to loss of NOE information if fully deuterated. | Moderate to High |
Performance Metrics of Different Labeling Approaches
| Labeling Method | Typical Yield (mg/L of in vitro transcription) | Impact on NMR Spectra | Key Considerations |
| Uniform ¹³C, ¹⁵N Labeling | 1-5 mg | Increased spectral dispersion but significant signal overlap in larger molecules. | Cost-effective for initial studies on small RNAs. |
| Selective A, U, G, or C Labeling | 1-5 mg | Significant reduction in spectral crowding, facilitating resonance assignment.[7] | Requires synthesis of four separate samples for complete assignment. |
| Ribose-specific Deuteration (e.g., at H5', H5'') | 0.5-2 mg | Reduces linewidths of remaining protons, enhancing spectral quality.[8] | Synthesis of specifically deuterated NTPs is complex. |
| Segmental Labeling via Enzymatic Ligation | 0.1-1 mg (final ligated product) | Allows for the study of specific regions in very large RNAs with minimal spectral overlap.[7][9] | Ligation efficiency can be a major bottleneck. |
Experimental Workflows and Methodologies
The successful implementation of an isotopic labeling strategy relies on robust experimental protocols. The following diagrams illustrate the general workflows for preparing isotopically labeled RNA for NMR studies.
Caption: General workflow for preparing an isotopically labeled RNA sample for NMR spectroscopy.
Caption: Decision tree for choosing an appropriate RNA isotopic labeling strategy based on RNA size.
Caption: Conceptual diagram of segmental isotopic labeling of RNA.
Detailed Experimental Protocols
In Vitro Transcription for Uniform Labeling
This protocol describes a typical in vitro transcription reaction for generating uniformly ¹³C- and ¹⁵N-labeled RNA.
Materials:
-
Linearized DNA template with a T7 promoter
-
T7 RNA polymerase
-
¹³C, ¹⁵N-labeled rNTPs (A, U, G, C)
-
Transcription buffer (40 mM Tris-HCl pH 8.0, 25 mM MgCl₂, 10 mM DTT, 2 mM spermidine)
-
RNase inhibitor
Procedure:
-
Set up the transcription reaction on ice by combining the transcription buffer, linearized DNA template (final concentration ~50 nM), ¹³C, ¹⁵N-rNTPs (final concentration ~5 mM each), and RNase inhibitor.
-
Initiate the reaction by adding T7 RNA polymerase (final concentration ~0.1 mg/mL).
-
Incubate the reaction at 37°C for 2-4 hours.
-
Stop the reaction by adding EDTA to a final concentration of 50 mM.
-
Purify the RNA transcript using denaturing polyacrylamide gel electrophoresis (PAGE) or high-performance liquid chromatography (HPLC).
-
Elute the RNA from the gel or collect the appropriate HPLC fraction.
-
Desalt and concentrate the RNA sample.
-
Assess the purity and concentration of the RNA by UV-Vis spectroscopy and denaturing PAGE.
Segmental Labeling using T4 RNA Ligase
This protocol outlines a general procedure for the enzymatic ligation of an isotopically labeled RNA fragment to two unlabeled fragments.
Materials:
-
Purified labeled and unlabeled RNA fragments (with 5'-hydroxyl and 3'-phosphate, and 5'-phosphate and 3'-hydroxyl termini for ligation)
-
T4 RNA ligase
-
Ligation buffer (50 mM Tris-HCl pH 7.5, 10 mM MgCl₂, 10 mM DTT, 1 mM ATP)
-
DNA splint (a DNA oligonucleotide complementary to the ligation junction)
-
RNase inhibitor
Procedure:
-
Anneal the RNA fragments to the DNA splint by mixing them in a 1:1:1 molar ratio in the ligation buffer without ATP and ligase. Heat to 95°C for 2 minutes and then cool slowly to room temperature.
-
Add ATP, DTT, and RNase inhibitor to the annealed mixture.
-
Initiate the ligation by adding T4 RNA ligase.
-
Incubate the reaction at 16°C overnight.
-
Purify the full-length ligated RNA product by denaturing PAGE or HPLC.
-
Verify the integrity and successful ligation of the product.
Concluding Remarks
The strategic use of isotopic labeling is paramount for the successful application of NMR spectroscopy to challenging RNA systems. Uniform labeling provides a foundational approach for smaller RNAs, while selective and segmental labeling strategies are powerful tools for dissecting the structure and dynamics of larger, more complex molecules.[2][3][4] The choice of the optimal labeling strategy requires careful consideration of the scientific question, the size and nature of the RNA, and the available resources. The quantitative data and protocols provided in this guide serve as a valuable resource for researchers to make informed decisions and advance our understanding of the critical roles of RNA in biology and disease.
References
- 1. pubs.acs.org [pubs.acs.org]
- 2. Isotope labeling strategies for NMR studies of RNA - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. Isotope labeling strategies for NMR studies of RNA - PMC [pmc.ncbi.nlm.nih.gov]
- 4. researchgate.net [researchgate.net]
- 5. mdpi.com [mdpi.com]
- 6. Isotope labeling and segmental labeling of larger RNAs for NMR structural studies - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. academic.oup.com [academic.oup.com]
- 8. dspace.mit.edu [dspace.mit.edu]
- 9. Determining RNA solution structure by segmental isotopic labeling and NMR: application to Caenorhabditis elegans spliced leader RNA 1 - PMC [pmc.ncbi.nlm.nih.gov]
Confirming the Sequence Integrity of Synthetic 13C Labeled RNA: A Comparative Guide
For researchers, scientists, and drug development professionals, ensuring the precise sequence of synthetic RNA is a critical quality control step. This is particularly true for isotopically labeled molecules, such as those containing 13C, which are often used in sophisticated structural and mechanistic studies. This guide provides an objective comparison of the leading methods for verifying the sequence integrity of synthetic RNA, supported by experimental data and detailed protocols.
The primary methodologies for confirming RNA sequence integrity are Reverse Transcription Sanger Sequencing (RT-Sanger), Next-Generation Sequencing (NGS) or RNA-Seq, and Mass Spectrometry (MS). Each technique offers a unique combination of accuracy, throughput, cost, and resolution, making the selection of the most appropriate method dependent on the specific experimental needs.
Comparative Analysis of RNA Sequence Verification Methods
The choice of a sequence verification method should be guided by factors such as the length of the RNA, the required level of accuracy, the number of samples to be analyzed, and the available budget. The following table summarizes the key quantitative performance metrics for each of the primary techniques.
| Feature | RT-Sanger Sequencing | Next-Generation Sequencing (RNA-Seq) | Mass Spectrometry (MS) |
| Accuracy | 99.99%[1][2][3] | >99% (platform dependent) | High, capable of detecting subtle mass changes |
| Read Length | Up to 1000 base pairs[1][3][4] | Short reads (e.g., up to 300 bp for Illumina) to long reads (platform dependent)[1] | Not directly applicable; analyzes oligonucleotide fragments |
| Sequence Coverage | Targeted to specific regions | Whole transcriptome or targeted | >80-90% achievable with optimized protocols[5][6][7] |
| Throughput | Low (single fragment at a time)[1] | High (millions of fragments simultaneously)[1] | High-throughput with automation[6] |
| Sensitivity | Lower; variants detected at ~15-20% of the sequence population[1] | High; detection limit can be as low as 1%[1] | High, capable of detecting low-level impurities[5] |
| Cost per Sample | Higher for large numbers of genes | Lower for high-throughput applications[8][9] | Varies with instrumentation and workflow |
| Turnaround Time | Relatively fast for single samples | Longer due to library preparation and data analysis | Rapid, with workflows as short as 90 minutes[5] |
Experimental Workflows
The following diagrams illustrate the typical experimental workflows for each of the discussed RNA sequence verification methods.
Detailed Experimental Protocols
Reverse Transcription Sanger Sequencing (RT-Sanger)
RT-Sanger sequencing is a highly accurate method ideal for verifying the sequence of a specific RNA or for validating findings from other methods.[3][10] The process begins with the conversion of the RNA into complementary DNA (cDNA).
1. Reverse Transcription:
-
A sequence-specific primer is annealed to the synthetic RNA template.
-
A reverse transcriptase enzyme, such as MarathonRT which is noted for its high processivity with structured RNA, is used to synthesize a single strand of cDNA.[10]
-
The reaction mixture typically includes the RNA template, primer, reverse transcriptase, and dNTPs.
2. PCR Amplification:
-
The newly synthesized cDNA is then amplified using standard Polymerase Chain Reaction (PCR) with a pair of primers flanking the region of interest.
3. Cycle Sequencing:
-
The amplified cDNA serves as a template for a subsequent cycle sequencing reaction.
-
This reaction includes a DNA polymerase, dNTPs, and fluorescently labeled dideoxynucleotide triphosphates (ddNTPs).
-
The incorporation of a ddNTP terminates the extension of the DNA strand.[3]
4. Capillary Electrophoresis:
-
The resulting DNA fragments of varying lengths are separated by size using capillary electrophoresis.
-
A laser excites the fluorescent labels on the ddNTPs, and a detector reads the color of the fluorescence to determine the terminal nucleotide of each fragment.
5. Data Analysis:
-
The sequence is then computationally assembled based on the ordered fragments.
Next-Generation Sequencing (RNA-Seq)
RNA-Seq offers a high-throughput approach to sequence entire transcriptomes, making it suitable for analyzing multiple synthetic RNA constructs simultaneously or for a comprehensive, unbiased view of the RNA sequence.
1. RNA Isolation and QC:
-
Begin with the purified synthetic 13C labeled RNA.
-
Assess the quality and quantity of the RNA.
2. Library Preparation: [11][12]
-
Fragmentation: The RNA is fragmented into smaller, manageable pieces.
-
cDNA Synthesis: The RNA fragments are reverse transcribed into cDNA.
-
End Repair and Adapter Ligation: The ends of the cDNA fragments are repaired, and sequencing adapters are ligated to both ends. These adapters contain sequences necessary for binding to the sequencer's flow cell and for primer annealing.
-
Amplification: The adapter-ligated cDNA is amplified via PCR to create a sufficient quantity of library for sequencing.
3. Sequencing:
-
The prepared library is loaded onto a next-generation sequencer (e.g., Illumina platform).
-
The sequencer performs massively parallel sequencing, generating millions of short reads corresponding to the sequences of the cDNA fragments.
4. Data Analysis:
-
Quality Control: The raw sequencing reads are assessed for quality.
-
Mapping: The reads are aligned to a reference sequence (the expected sequence of the synthetic RNA).
-
Variant Calling: Any discrepancies between the sequencing reads and the reference sequence are identified, indicating potential errors in the synthesis.
Mass Spectrometry (MS)
Mass spectrometry provides a direct and highly sensitive method for RNA sequence analysis, capable of identifying modifications and confirming the mass of the RNA and its fragments.[13] A common approach involves enzymatic digestion followed by liquid chromatography-mass spectrometry (LC-MS).
1. Enzymatic Digestion: [6]
-
The synthetic RNA is digested into smaller oligonucleotides using an RNase enzyme, such as RNase T1, which cleaves at specific nucleotides (e.g., after guanosine (B1672433) residues).[6]
-
Partial digestion can be employed to generate a ladder of overlapping fragments, which aids in sequence reconstruction.[5]
2. Liquid Chromatography (LC) Separation:
-
The resulting oligonucleotide fragments are separated based on their physicochemical properties (e.g., size, hydrophobicity) using high-performance liquid chromatography (HPLC).
3. Mass Spectrometry (MS and MS/MS) Analysis:
-
The separated fragments are introduced into a mass spectrometer.
-
The mass-to-charge ratio of each fragment is precisely measured (MS1 scan).
-
Selected fragments are then further fragmented, and the masses of the resulting sub-fragments are measured (MS/MS or tandem MS).[13]
4. Data Analysis:
-
The masses of the initial fragments and their fragmentation patterns are used to determine the sequence of each oligonucleotide.
-
The overlapping sequences of the fragments are then assembled to reconstruct the full sequence of the original RNA. Specialized software can automate this process.[5]
Conclusion
The confirmation of sequence integrity for synthetic 13C labeled RNA is paramount for the validity of subsequent research. RT-Sanger sequencing remains the gold standard for high-accuracy, targeted verification. RNA-Seq provides a powerful, high-throughput tool for comprehensive analysis of one or many RNA species. Mass spectrometry offers a rapid and sensitive alternative, particularly adept at identifying modifications and providing high sequence coverage. The selection of the optimal method will depend on a careful consideration of the specific research goals, sample characteristics, and available resources.
References
- 1. integra-biosciences.com [integra-biosciences.com]
- 2. Sanger sequencing - Wikipedia [en.wikipedia.org]
- 3. cd-genomics.com [cd-genomics.com]
- 4. news-medical.net [news-medical.net]
- 5. pubs.acs.org [pubs.acs.org]
- 6. m.youtube.com [m.youtube.com]
- 7. Mass spectrometry-based mRNA sequence mapping via complementary RNase digests and bespoke visualisation tools - PMC [pmc.ncbi.nlm.nih.gov]
- 8. alitheagenomics.com [alitheagenomics.com]
- 9. rna-seqblog.com [rna-seqblog.com]
- 10. RT-based Sanger sequencing of RNAs containing complex RNA repetitive elements - PubMed [pubmed.ncbi.nlm.nih.gov]
- 11. Deciphering RNA-seq Library Preparation: From Principles to Protocol - CD Genomics [cd-genomics.com]
- 12. Protocol for RNA-seq library preparation starting from a rare muscle stem cell population or a limited number of mouse embryonic stem cells - PMC [pmc.ncbi.nlm.nih.gov]
- 13. MASS SPECTROMETRY OF RNA: LINKING THE GENOME TO THE PROTEOME - PMC [pmc.ncbi.nlm.nih.gov]
A Comparative Guide to the Phosphoramidite Method for Incorporating Non-Natural Bases
For researchers, scientists, and drug development professionals venturing into the realm of modified oligonucleotides, the choice of synthesis methodology is a critical decision that impacts yield, purity, and the successful incorporation of non-natural bases. The phosphoramidite (B1245037) method, a cornerstone of chemical DNA and RNA synthesis for decades, remains a powerful and versatile tool for this purpose. This guide provides an objective comparison of the phosphoramidite method with enzymatic approaches for incorporating non-natural bases, supported by experimental data and detailed protocols.
Key Advantages of the Phosphoramidite Method
The phosphoramidite method offers several distinct advantages for the synthesis of oligonucleotides containing non-natural bases:
-
Versatility: A vast library of phosphoramidite monomers with modified bases, sugars, and backbones is commercially available, offering unparalleled flexibility in oligonucleotide design.[1] This chemical approach is not limited by the substrate specificity of enzymes, allowing for the incorporation of a wider variety of non-natural moieties.
-
High Coupling Efficiency: For standard nucleobases, the phosphoramidite coupling reaction is remarkably efficient, with stepwise yields often exceeding 99%.[2] This high efficiency is crucial for the synthesis of longer oligonucleotides with high fidelity. While the efficiency can be slightly lower for some bulky non-natural bases, optimization of coupling times and activators can often lead to successful incorporation.
-
Established and Automated: The phosphoramidite method is a well-established and highly automated process.[2] Automated DNA synthesizers are widely available, enabling the routine synthesis of modified oligonucleotides with high throughput and reproducibility.
-
Direct Synthesis: The desired sequence is synthesized directly, one base at a time. This provides precise control over the placement of non-natural bases within the oligonucleotide sequence.
Performance Comparison: Phosphoramidite vs. Enzymatic Methods
The primary alternative to chemical synthesis is the use of enzymatic methods, typically involving a DNA polymerase and a modified nucleoside triphosphate. The choice between these two approaches often depends on the specific non-natural base, the desired length of the oligonucleotide, and the scale of the synthesis.
While direct, comprehensive comparative data across a wide range of non-natural bases is limited in the literature, the following table summarizes key performance indicators based on available experimental data.
| Parameter | Phosphoramidite Method | Enzymatic Method (Primer Extension/PCR) | Notes |
| Coupling/Incorporation Efficiency | >99% for standard bases; can be lower for bulky non-natural bases (e.g., 60% for a tyrosine-phosphoramidite)[3] | Generally high for accepted substrates (e.g., ~1% mutation rate for Ds-Pa pair after 10 PCR cycles) | Efficiency is highly dependent on the specific non-natural base and optimization of reaction conditions. |
| Fidelity | High, primarily limited by the efficiency of the capping step to terminate failed sequences. | High for polymerases with proofreading activity, but fidelity can be lower for non-natural substrates. | Mismatches can occur with both methods, but the sources of error are different. |
| Yield | Generally high and predictable for short to medium-length oligonucleotides. Overall yield decreases with increasing length. | Can be high due to amplification (PCR), but initial incorporation efficiency can be a limiting factor. | Phosphoramidite synthesis offers better overall yields for highly modified sequences where enzymatic amplification is not feasible.[4] |
| Versatility (Range of Non-Natural Bases) | Very broad; a wide variety of modified phosphoramidites are commercially available or can be chemically synthesized. | Limited by the substrate specificity of the polymerase. Often requires engineering of the polymerase for efficient incorporation of a specific non-natural base. | The phosphoramidite method is generally more versatile for incorporating a diverse range of chemical modifications. |
| Scalability | Well-established for both small and large-scale synthesis. | PCR-based methods are excellent for amplification but may not be suitable for large-scale production of the initial modified template. | Phosphoramidite chemistry is currently the more established method for large-scale synthesis of modified oligonucleotides. |
| Reaction Conditions | Anhydrous organic solvents, harsh chemicals for deprotection. | Aqueous buffers, mild temperatures. | Enzymatic methods are more environmentally friendly.[1] |
Experimental Protocols
To provide a practical comparison, here are detailed protocols for the incorporation of the non-natural hydrophobic base dNaM using both the phosphoramidite method and an enzymatic primer extension assay.
Chemical Incorporation of dNaM via Phosphoramidite Chemistry
This protocol outlines the steps for incorporating a dNaM phosphoramidite into a DNA oligonucleotide using an automated DNA synthesizer.[5]
Materials:
-
dNaM-CE Phosphoramidite
-
Standard DNA phosphoramidites (dA, dC, dG, T)
-
Activator solution (e.g., 0.25 M 5-Ethylthio-1H-tetrazole (ETT) in acetonitrile)
-
Capping solution (Cap A and Cap B)
-
Oxidizing solution (e.g., 0.02 M iodine in THF/Pyridine/Water)
-
Deblocking solution (e.g., 3% Trichloroacetic acid (TCA) in dichloromethane)
-
Anhydrous acetonitrile
-
Controlled Pore Glass (CPG) solid support functionalized with the initial nucleoside
-
Cleavage and deprotection solution (e.g., concentrated ammonium (B1175870) hydroxide)
Procedure (Standard Automated Synthesis Cycle):
-
Deblocking: The 5'-dimethoxytrityl (DMT) protecting group is removed from the support-bound nucleoside by treatment with the deblocking solution.
-
Coupling: The phosphoramidite of the next base in the sequence is activated by the activator and coupled to the free 5'-hydroxyl group of the growing oligonucleotide chain.
-
Capping: Any unreacted 5'-hydroxyl groups are acetylated by the capping solution to prevent the formation of deletion mutants in subsequent cycles.
-
Oxidation: The newly formed phosphite (B83602) triester linkage is oxidized to a more stable phosphate (B84403) triester linkage using the oxidizing solution.
-
Repeat: The cycle of deblocking, coupling, capping, and oxidation is repeated until the desired oligonucleotide sequence is synthesized.
-
Cleavage and Deprotection: The synthesized oligonucleotide is cleaved from the solid support, and all protecting groups are removed by treatment with the cleavage and deprotection solution.
Enzymatic Incorporation of dNaM via Primer Extension
This protocol describes a typical primer extension assay to incorporate a single dNaM nucleotide opposite its complementary partner (e.g., dTPT3) in a template strand using a DNA polymerase.[5]
Materials:
-
Template DNA containing the complementary unnatural base (e.g., dTPT3)
-
Primer DNA
-
DNA Polymerase (e.g., Klenow Fragment (3'→5' exo-))
-
10X Reaction Buffer
-
dATP, dCTP, dGTP, TTP (100 µM each)
-
dNaMTP (100 µM)
-
Nuclease-free water
-
Gel loading buffer (e.g., 95% formamide, 20 mM EDTA)
Procedure:
-
Annealing: Anneal the primer to the template DNA by mixing them in a 1:1.2 molar ratio in 1X reaction buffer. Heat the mixture to 95°C for 5 minutes and then slowly cool to room temperature.
-
Reaction Setup: Prepare the reaction mixture on ice by adding the annealed primer/template, dNTPs (including dNaMTP), and nuclease-free water.
-
Initiation and Incubation: Initiate the reaction by adding the DNA polymerase. Incubate the reaction at 37°C for 15-30 minutes.
-
Termination: Stop the reaction by adding an equal volume of gel loading buffer.
-
Analysis: Denature the samples by heating at 95°C for 5 minutes and analyze the products by denaturing polyacrylamide gel electrophoresis (PAGE) to confirm the incorporation of the dNaM base.
Visualizing the Workflows
The following diagrams illustrate the cyclical nature of the phosphoramidite method and a typical workflow for enzymatic incorporation of a non-natural base.
Conclusion
The phosphoramidite method remains the gold standard for the synthesis of oligonucleotides containing a wide array of non-natural bases due to its versatility, high efficiency, and the maturity of the technology. While enzymatic methods offer advantages in terms of milder reaction conditions and the potential for amplification, they are currently limited by the substrate scope of available polymerases. The choice of method will ultimately depend on the specific non-natural modification, the desired scale of synthesis, and the research or therapeutic application. For applications requiring novel and diverse chemical modifications, the phosphoramidite method continues to be an indispensable tool for advancing the fields of synthetic biology, diagnostics, and drug development.
References
Safety Operating Guide
Proper Disposal of rU Phosphoramidite-¹³C₉: A Comprehensive Guide for Laboratory Personnel
This guide provides essential safety and logistical information for the proper disposal of rU Phosphoramidite-¹³C₉, a crucial reagent in oligonucleotide synthesis. Adherence to these step-by-step procedures is vital for ensuring a safe laboratory environment and maintaining regulatory compliance. This document aims to be the preferred resource for researchers, scientists, and drug development professionals by offering clear, actionable guidance on chemical handling and disposal.
Immediate Safety and Handling Precautions
rU Phosphoramidite-¹³C₉ is a hazardous substance that demands careful handling to mitigate potential risks.[1][2] Always work in a well-ventilated area, preferably within a chemical fume hood.[1] The use of appropriate personal protective equipment (PPE) is mandatory.
Hazard Identification and Personal Protective Equipment
| Hazard Classification | Description | Recommended Personal Protective Equipment (PPE) |
| Acute Oral Toxicity | Harmful if swallowed.[2] | Safety goggles, chemical-resistant gloves, lab coat.[1] |
| Skin Corrosion/Irritation | Causes skin irritation.[2] | Chemical-resistant gloves, lab coat.[1] |
| Serious Eye Damage/Irritation | Causes serious eye irritation.[2] | Safety goggles or face shield.[3] |
| Respiratory Irritation | May cause respiratory irritation.[2] | Use within a chemical fume hood.[1] |
In the event of a spill, absorb the material with an inert substance such as vermiculite (B1170534) or dry sand.[1] Collect the absorbed material in a sealed container for disposal and decontaminate the affected surface with alcohol.[1] Prevent the chemical from entering drains or waterways.[1]
Disposal Plan: A Step-by-Step Approach
The primary method for the safe disposal of rU Phosphoramidite-¹³C₉ waste involves a controlled deactivation process through hydrolysis, followed by disposal as hazardous waste in accordance with local, state, and federal regulations.[1] The reactive phosphoramidite (B1245037) group is moisture-sensitive and can be intentionally hydrolyzed to a less reactive species.[1]
This protocol is designed for the deactivation of small quantities of expired or unused solid rU Phosphoramidite-¹³C₉ waste or residues in empty containers.
Materials:
-
rU Phosphoramidite-¹³C₉ waste
-
Anhydrous acetonitrile (B52724) (ACN)
-
5% w/v aqueous solution of sodium bicarbonate (NaHCO₃)
-
Appropriately sealed and labeled hazardous waste container
-
Stir plate and stir bar (optional, for larger quantities)
-
Personal Protective Equipment (PPE) as specified above
Procedure:
-
Preparation: Conduct all operations within a certified chemical fume hood. Ensure all necessary PPE is worn correctly.[1]
-
Dissolution: For solid waste, carefully dissolve the rU Phosphoramidite-¹³C₉ in a minimal amount of anhydrous acetonitrile. For empty containers, rinse the container with a small volume of anhydrous acetonitrile to dissolve any remaining residue.[1]
-
Quenching/Hydrolysis: Slowly and with stirring, add the acetonitrile solution of the phosphoramidite to the 5% aqueous sodium bicarbonate solution.[1] A weak base is used to facilitate hydrolysis and neutralize any acidic byproducts.[1]
-
Reaction Time: Allow the mixture to stir at room temperature for a minimum of 24 hours to ensure complete hydrolysis of the phosphoramidite.[1]
-
Waste Collection: Transfer the resulting aqueous mixture to a properly labeled hazardous waste container designated for aqueous chemical waste.[1]
-
Final Disposal: The sealed hazardous waste container should be disposed of through your institution's environmental health and safety (EHS) office or a licensed chemical waste disposal contractor.[1]
Disposal Workflow
The following diagram illustrates the logical workflow for the proper disposal of rU Phosphoramidite-¹³C₉.
Caption: Disposal workflow for rU Phosphoramidite-¹³C₉.
References
Essential Safety and Handling Guide for rU Phosphoramidite-¹³C₉
This guide provides crucial safety and logistical information for laboratory personnel, including researchers, scientists, and drug development professionals, who handle rU Phosphoramidite-¹³C₉. Adherence to these procedures is vital for ensuring personal safety and maintaining the integrity of the product.
Personal Protective Equipment (PPE)
When working with rU Phosphoramidite-¹³C₉, the use of appropriate personal protective equipment is mandatory to prevent exposure.[1] The recommended PPE is detailed below.
| PPE Category | Item | Specifications |
| Eye/Face Protection | Safety Goggles/Glasses | Must be tested and approved under government standards such as NIOSH (US) or EN 166 (EU).[2] |
| Face Shield | Recommended when there is a risk of splashing.[2] | |
| Skin Protection | Chemical-Impermeable Gloves | Handle with nitrile gloves. Always inspect gloves before use and dispose of them properly if contaminated.[2] |
| Laboratory Coat | A standard laboratory coat must be worn.[2] | |
| Respiratory Protection | NIOSH-approved Respirator | A respirator (e.g., N95 or P1 type dust mask) is necessary if ventilation is inadequate or if dust is generated.[2] |
| Self-contained Breathing Apparatus (SCBA) | Required in the event of a fire or a major spill.[2] |
Hazard Identification and First Aid
rU Phosphoramidite is classified as harmful if swallowed, causes skin and serious eye irritation, and may cause respiratory irritation.[3]
Precautionary Statements:
-
Avoid breathing dust, fume, gas, mist, vapors, or spray.[3]
-
Wash hands and any exposed skin thoroughly after handling.[1][4]
-
Use only outdoors or in a well-ventilated area.[3]
Emergency First Aid Procedures:
-
If Swallowed: Call a poison center or doctor if you feel unwell and rinse your mouth.[4]
-
In Case of Skin Contact: Wash off immediately with soap and plenty of water. If skin irritation occurs, seek medical advice.
-
In Case of Eye Contact: Rinse cautiously with water for several minutes. Remove contact lenses if present and easy to do. Continue rinsing. If eye irritation persists, get medical attention.[4]
-
If Inhaled: Move the person to fresh air. If breathing is difficult, give artificial respiration. Consult a physician if symptoms persist.[5]
Handling and Storage
Proper handling and storage are essential to ensure the safety of laboratory personnel and maintain the integrity of the reagent.[1]
Handling:
-
Handle in a well-ventilated area.[1]
-
Avoid contact with skin and eyes.[1]
-
Prevent the formation of dust and aerosols.[1]
-
Keep the container tightly sealed to avoid moisture and air exposure.[2]
Storage:
-
The recommended storage temperature is -20°C under nitrogen.[2][6]
-
Store in a dry, well-ventilated area away from heat and oxidizing agents.[1][2]
-
When stored at -20°C, it should be used within one month. For longer-term storage up to 6 months, -80°C is recommended.[6]
Disposal Plan
Proper disposal of rU Phosphoramidite-¹³C₉ and any contaminated materials is critical to prevent environmental contamination and ensure regulatory compliance.
-
Waste Segregation: All waste contaminated with the compound should be collected in a designated, properly labeled, and sealed container.[2]
-
Disposal Method: Do not dispose of the chemical into drains or the environment.[2] Arrange for a licensed disposal company to handle surplus and non-recyclable solutions.[2] Disposal should be in accordance with all applicable regional, national, and local laws and regulations.[4]
Experimental Workflow
The following diagram illustrates the standard workflow for handling rU Phosphoramidite-¹³C₉ in a laboratory setting.
References
Featured Recommendations
| Most viewed |


|
|
|---|---|---|
| Most popular with customers |
|
Descargo de responsabilidad e información sobre productos de investigación in vitro
Tenga en cuenta que todos los artículos e información de productos presentados en BenchChem están destinados únicamente con fines informativos. Los productos disponibles para la compra en BenchChem están diseñados específicamente para estudios in vitro, que se realizan fuera de organismos vivos. Los estudios in vitro, derivados del término latino "in vidrio", involucran experimentos realizados en entornos de laboratorio controlados utilizando células o tejidos. Es importante tener en cuenta que estos productos no se clasifican como medicamentos y no han recibido la aprobación de la FDA para la prevención, tratamiento o cura de ninguna condición médica, dolencia o enfermedad. Debemos enfatizar que cualquier forma de introducción corporal de estos productos en humanos o animales está estrictamente prohibida por ley. Es esencial adherirse a estas pautas para garantizar el cumplimiento de los estándares legales y éticos en la investigación y experimentación.
