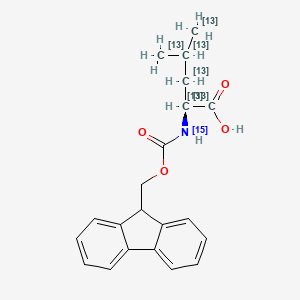
Fmoc-leucine-13C6,15N
Descripción
BenchChem offers high-quality this compound suitable for many research applications. Different packaging options are available to accommodate customers' requirements. Please inquire for more information about this compound including the price, delivery time, and more detailed information at info@benchchem.com.
Structure
3D Structure
Propiedades
Fórmula molecular |
C21H23NO4 |
|---|---|
Peso molecular |
360.36 g/mol |
Nombre IUPAC |
(2S)-2-(9H-fluoren-9-ylmethoxycarbonyl(15N)amino)-4-(113C)methyl(1,2,3,4,5-13C5)pentanoic acid |
InChI |
InChI=1S/C21H23NO4/c1-13(2)11-19(20(23)24)22-21(25)26-12-18-16-9-5-3-7-14(16)15-8-4-6-10-17(15)18/h3-10,13,18-19H,11-12H2,1-2H3,(H,22,25)(H,23,24)/t19-/m0/s1/i1+1,2+1,11+1,13+1,19+1,20+1,22+1 |
Clave InChI |
CBPJQFCAFFNICX-HNIVWWTASA-N |
SMILES isomérico |
[13CH3][13CH]([13CH3])[13CH2][13C@@H]([13C](=O)O)[15NH]C(=O)OCC1C2=CC=CC=C2C3=CC=CC=C13 |
SMILES canónico |
CC(C)CC(C(=O)O)NC(=O)OCC1C2=CC=CC=C2C3=CC=CC=C13 |
Origen del producto |
United States |
Foundational & Exploratory
An In-depth Technical Guide to Fmoc-leucine-13C6,15N for Researchers, Scientists, and Drug Development Professionals
An Introduction to Isotopically Labeled Amino Acids in Modern Research
Fmoc-leucine-13C6,15N is a stable isotope-labeled amino acid that serves as a powerful tool in advanced scientific research, particularly in the fields of proteomics, structural biology, and drug development. This specialized leucine (B10760876) derivative incorporates six Carbon-13 (¹³C) isotopes and one Nitrogen-15 (¹⁵N) isotope, creating a "heavy" version of the amino acid. The strategic incorporation of these stable, non-radioactive isotopes allows for the precise tracking and quantification of leucine-containing peptides and proteins in complex biological systems. The 9-fluorenylmethyloxycarbonyl (Fmoc) protecting group on the alpha-amino group makes it ideally suited for use in solid-phase peptide synthesis (SPPS), the cornerstone of modern peptide and protein synthesis. This guide provides a comprehensive overview of the properties, applications, and experimental protocols associated with this compound.
Core Properties and Specifications
This compound is a white to off-white solid with a defined set of physicochemical properties that are critical for its application in sensitive analytical techniques. The high isotopic and chemical purity of this reagent is paramount for accurate and reproducible experimental outcomes.
| Property | Value | Reference |
| Molecular Formula | C₂₁H₂₃¹³C₆¹⁵NO₄ | --INVALID-LINK-- |
| Molecular Weight | ~360.4 g/mol | --INVALID-LINK-- |
| CAS Number | 1163133-36-5 | --INVALID-LINK-- |
| Isotopic Purity | Typically ≥98% for ¹³C and ¹⁵N | --INVALID-LINK-- |
| Chemical Purity | Typically ≥98% by HPLC | --INVALID-LINK-- |
| Appearance | White to off-white solid | --INVALID-LINK-- |
| Solubility | Soluble in common organic solvents used in SPPS (e.g., DMF, NMP) | --INVALID-LINK-- |
Key Applications in Research and Development
The unique characteristics of this compound make it an indispensable tool in a variety of advanced research applications.
1. Quantitative Proteomics (SILAC): Stable Isotope Labeling by Amino Acids in Cell Culture (SILAC) is a powerful technique for the quantitative analysis of proteomes. In a typical SILAC experiment, two cell populations are grown in culture media that are identical except for the isotopic composition of a specific amino acid. One population is grown in "light" medium containing natural leucine, while the other is grown in "heavy" medium containing this compound. After several cell divisions, the heavy leucine is fully incorporated into the proteome of the second cell population. The two cell populations can then be subjected to different experimental conditions, combined, and the proteins extracted and analyzed by mass spectrometry. The mass difference between the light and heavy peptides allows for the precise quantification of changes in protein abundance.
2. Solid-Phase Peptide Synthesis (SPPS): this compound is a fundamental building block for the synthesis of isotopically labeled peptides. These synthetic peptides are crucial as internal standards for quantitative mass spectrometry, for studying enzyme kinetics, and as probes for receptor-ligand interactions. The Fmoc protecting group allows for the stepwise and controlled assembly of the peptide chain on a solid support.
3. Structural Biology (NMR Spectroscopy): Nuclear Magnetic Resonance (NMR) spectroscopy is a powerful technique for determining the three-dimensional structure and dynamics of proteins and peptides in solution. The incorporation of ¹³C and ¹⁵N isotopes into a peptide enhances the sensitivity and resolution of NMR experiments, facilitating the assignment of resonances and the determination of structural restraints.
4. Metabolic Studies and Flux Analysis: By introducing this compound into biological systems, researchers can trace the metabolic fate of leucine and quantify its incorporation into newly synthesized proteins. This provides valuable insights into metabolic pathways and protein turnover rates in various physiological and pathological states.
5. Pharmaceutical Development: In the development of peptide-based therapeutics, isotopically labeled analogues are used to study pharmacokinetics (absorption, distribution, metabolism, and excretion) and to identify drug metabolites.
Experimental Protocols
Solid-Phase Peptide Synthesis (SPPS) using this compound
This protocol outlines the general steps for incorporating this compound into a peptide sequence using manual Fmoc-based SPPS. Automated synthesizers follow a similar series of steps.
Materials:
-
This compound
-
Appropriate SPPS resin (e.g., Rink Amide resin for C-terminal amides, Wang resin for C-terminal carboxylic acids)
-
Other Fmoc-protected amino acids
-
Coupling reagents (e.g., HCTU, HATU)
-
Base (e.g., N,N-Diisopropylethylamine - DIPEA)
-
Fmoc deprotection solution (e.g., 20% piperidine (B6355638) in DMF)
-
Solvents: N,N-Dimethylformamide (DMF), Dichloromethane (DCM)
-
Washing solvents (e.g., DMF, DCM, isopropanol)
-
Cleavage cocktail (e.g., 95% Trifluoroacetic acid (TFA), 2.5% water, 2.5% triisopropylsilane (B1312306) (TIS))
-
Cold diethyl ether
Procedure:
-
Resin Preparation:
-
Place the desired amount of resin in a reaction vessel.
-
Swell the resin in DMF for at least 30 minutes.
-
-
Fmoc Deprotection:
-
Drain the DMF from the swollen resin.
-
Add the Fmoc deprotection solution (20% piperidine in DMF) to the resin.
-
Agitate the mixture for 5-10 minutes.
-
Drain the solution and repeat the deprotection step for another 5-10 minutes.
-
Wash the resin thoroughly with DMF (3-5 times) and DCM (2-3 times) to remove all traces of piperidine.
-
-
Amino Acid Coupling (Incorporation of this compound):
-
Dissolve this compound (typically 3-5 equivalents relative to the resin loading) and the coupling reagent (e.g., HCTU, slightly less than 1 equivalent to the amino acid) in DMF.
-
Add the base (DIPEA, 2 equivalents relative to the amino acid) to the amino acid solution and pre-activate for 1-2 minutes.
-
Add the activated amino acid solution to the deprotected resin.
-
Agitate the reaction mixture for 1-2 hours. The completion of the coupling can be monitored using a colorimetric test such as the Kaiser test.
-
Drain the coupling solution and wash the resin extensively with DMF and DCM.
-
-
Chain Elongation:
-
Repeat the deprotection and coupling steps for each subsequent amino acid in the peptide sequence.
-
-
Cleavage and Deprotection:
-
After the final amino acid has been coupled and the N-terminal Fmoc group has been removed, wash the resin with DCM and dry it under vacuum.
-
Add the cleavage cocktail to the resin.
-
Gently agitate the mixture for 2-4 hours at room temperature.
-
Filter the resin and collect the filtrate containing the cleaved peptide.
-
Precipitate the peptide by adding the filtrate to cold diethyl ether.
-
Centrifuge the mixture to pellet the peptide, decant the ether, and wash the peptide pellet with cold ether.
-
Dry the peptide pellet under vacuum.
-
-
Purification and Analysis:
-
Purify the crude peptide using reverse-phase high-performance liquid chromatography (RP-HPLC).
-
Confirm the identity and purity of the synthesized peptide by mass spectrometry.
-
SILAC Workflow for Quantitative Proteomics
This protocol provides a general workflow for a SILAC experiment using this compound.
Materials:
-
Cell line of interest
-
SILAC-grade cell culture medium deficient in leucine
-
"Light" L-leucine
-
"Heavy" L-leucine-¹³C₆,¹⁵N
-
Dialyzed fetal bovine serum (dFBS)
-
Cell lysis buffer (e.g., RIPA buffer with protease and phosphatase inhibitors)
-
Protein quantification assay (e.g., BCA assay)
-
Trypsin (mass spectrometry grade)
-
LC-MS/MS system
Procedure:
-
Cell Culture and Labeling:
-
Culture two populations of cells.
-
For the "light" population, supplement the leucine-deficient medium with natural L-leucine.
-
For the "heavy" population, supplement the leucine-deficient medium with L-leucine-¹³C₆,¹⁵N.
-
Culture the cells for at least 6-8 cell divisions to ensure complete incorporation of the labeled amino acid.
-
-
Experimental Treatment:
-
Apply the experimental treatment to one of the cell populations (e.g., drug treatment, growth factor stimulation), while the other serves as a control.
-
-
Cell Harvesting and Lysis:
-
Harvest both cell populations.
-
Combine the "light" and "heavy" cell pellets in a 1:1 ratio based on cell number or protein concentration.
-
Lyse the combined cells using an appropriate lysis buffer.
-
Clarify the lysate by centrifugation to remove cellular debris.
-
-
Protein Digestion:
-
Quantify the protein concentration of the lysate.
-
Denature, reduce, and alkylate the proteins.
-
Digest the proteins into peptides using trypsin overnight at 37°C.
-
-
Peptide Fractionation and LC-MS/MS Analysis:
-
Fractionate the peptide mixture, for example, by strong cation exchange or high pH reverse-phase chromatography, to reduce sample complexity.
-
Analyze the peptide fractions by LC-MS/MS. The mass spectrometer will detect pairs of "light" and "heavy" peptides, which are chemically identical but differ in mass due to the isotopic label.
-
-
Data Analysis:
-
Use specialized software (e.g., MaxQuant) to identify the peptides and quantify the intensity ratios of the "heavy" to "light" peptide pairs.
-
The ratios of the peptide intensities reflect the relative abundance of the corresponding proteins in the two cell populations.
-
Mandatory Visualizations
Signaling Pathway Example: Generic Kinase Cascade
Experimental Workflow: Solid-Phase Peptide Synthesis (SPPS)
Logical Relationship: SILAC Experimental Design
Conclusion
This compound is a versatile and powerful reagent that has become an integral part of modern biochemical and biomedical research. Its application in quantitative proteomics, de novo peptide synthesis, and structural biology provides researchers with the tools to unravel complex biological processes at the molecular level. The detailed protocols and workflows provided in this guide serve as a starting point for the successful implementation of this isotopically labeled amino acid in a variety of experimental settings. As analytical technologies continue to advance, the utility of this compound and other stable isotope-labeled compounds is poised to expand, further driving discovery in science and medicine.
Fmoc-leucine-13C6,15N molecular weight and formula
This guide provides comprehensive technical information on Fmoc-L-leucine-13C6,15N, a critical reagent for researchers, scientists, and professionals involved in drug development and proteomics.
Core Compound Data
Fmoc-L-leucine and its isotopically labeled counterpart, Fmoc-L-leucine-13C6,15N, are fundamental building blocks in solid-phase peptide synthesis. The incorporation of stable isotopes in the latter enables precise quantification in mass spectrometry-based applications. The key quantitative data for these compounds are summarized below.
| Property | Fmoc-L-leucine | Fmoc-L-leucine-13C6,15N |
| Molecular Formula | C21H23NO4[1][2] | (13C)6C15H23(15N)O4[3] |
| Molecular Weight | 353.4 g/mol [1][2] | 360.4 g/mol [3][4] |
| CAS Number | 35661-60-0[1][2][3] | 1163133-36-5[3][4] |
Experimental Protocols
The primary application of Fmoc-L-leucine-13C6,15N is as an internal standard in quantitative proteomics, often in a technique known as Stable Isotope Labeling by Amino Acids in Cell Culture (SILAC). A generalized workflow for a SILAC experiment is as follows:
-
Cell Culture and Labeling: Two populations of cells are cultured. One is grown in a "light" medium containing standard L-leucine, while the other is grown in a "heavy" medium where the standard L-leucine is replaced with Fmoc-L-leucine-13C6,15N. This metabolic incorporation results in all newly synthesized proteins in the "heavy" population having leucine (B10760876) residues labeled with 13C and 15N.
-
Sample Preparation: After a sufficient number of cell doublings to ensure near-complete incorporation of the labeled amino acid, the two cell populations are subjected to different experimental conditions (e.g., drug treatment vs. control). The cells are then harvested, and the proteins are extracted and combined in a 1:1 ratio.
-
Protein Digestion: The combined protein mixture is then digested, typically with trypsin, to generate a complex mixture of peptides.
-
Mass Spectrometry Analysis: The peptide mixture is analyzed by liquid chromatography-mass spectrometry (LC-MS). In the mass spectrometer, peptides containing the "heavy" and "light" leucine will appear as pairs of peaks separated by a specific mass difference.
-
Data Analysis: The relative abundance of the heavy and light peptides is determined by comparing the peak intensities. This ratio directly reflects the relative abundance of the corresponding protein in the two original cell populations, allowing for precise quantification of changes in protein expression in response to the experimental conditions.
Visualized Workflow
The following diagram illustrates the general workflow of a SILAC experiment utilizing isotopically labeled amino acids like Fmoc-L-leucine-13C6,15N.
Caption: A generalized workflow for a Stable Isotope Labeling by Amino Acids in Cell Culture (SILAC) experiment.
References
In-Depth Technical Guide to Fmoc-L-leucine-13C6,15N: Synthesis, Applications, and Experimental Protocols
For Researchers, Scientists, and Drug Development Professionals
This technical guide provides a comprehensive overview of Fmoc-L-leucine-13C6,15N, a stable isotope-labeled amino acid crucial for advanced research in proteomics and drug development. This document details its chemical properties, lists key suppliers, and presents in-depth experimental protocols for its primary application in solid-phase peptide synthesis (SPPS) and subsequent use in quantitative mass spectrometry.
Core Compound Information
Fmoc-L-leucine-13C6,15N is a derivative of the amino acid L-leucine, where six carbon atoms are replaced with the stable isotope carbon-13 (¹³C) and the nitrogen atom is replaced with nitrogen-15 (B135050) (¹⁵N).[1] The N-terminus is protected by a 9-fluorenylmethyloxycarbonyl (Fmoc) group, which is a base-labile protecting group essential for SPPS.[1] This isotopic labeling results in a predictable mass shift, making it an ideal internal standard for quantitative proteomics.[1]
Chemical and Physical Properties
A summary of the key chemical and physical properties of Fmoc-L-leucine-13C6,15N is presented in the table below.
| Property | Value |
| CAS Number | 1163133-36-5[1][2][3] |
| Molecular Formula | (¹³C)₆C₁₅H₂₃(¹⁵N)O₄[1] |
| Molecular Weight | 360.36 g/mol [2] |
| Isotopic Purity | Typically ≥98 atom % for both ¹³C and ¹⁵N[2] |
| Chemical Purity | ≥98% (CP)[2] |
| Appearance | Solid |
| Storage Temperature | Room temperature or refrigerated (+2°C to +8°C), desiccated, and protected from light[2] |
| Mass Shift (M) | +7 Da |
Key Suppliers
Several reputable suppliers provide Fmoc-L-leucine-13C6,15N for research purposes. A selection of these suppliers is listed below.
| Supplier | Website |
| Sigma-Aldrich (Merck) | --INVALID-LINK-- |
| Cambridge Isotope Laboratories, Inc. | --INVALID-LINK--[2] |
| ChemPep Inc. | --INVALID-LINK--[1] |
| Alfa Chemistry | --INVALID-LINK--[3] |
| AnaSpec, Inc. | --INVALID-LINK--[4] |
Applications in Research and Development
The primary application of Fmoc-L-leucine-13C6,15N is in the synthesis of stable isotope-labeled peptides (SIL peptides). These SIL peptides are instrumental as internal standards in quantitative mass spectrometry-based proteomics.
Key applications include:
-
Quantitative Proteomics: SIL peptides are used for the absolute quantification of proteins in complex biological samples through methods like Stable Isotope Labeling by Amino Acids in Cell Culture (SILAC) and protein standard absolute quantification (PSAQ).[1]
-
Biomarker Discovery and Validation: Accurate quantification of proteins using SIL peptides is essential for identifying and validating disease biomarkers.
-
Pharmacokinetic Studies: Labeled peptides help in tracking the absorption, distribution, metabolism, and excretion (ADME) of peptide-based drugs.
-
Structural Biology: The incorporation of ¹³C and ¹⁵N aids in nuclear magnetic resonance (NMR) studies of peptide and protein structures.[1]
-
Metabolic Pathway Tracing: Labeled peptides can be used to trace metabolic pathways within biological systems.[1]
Experimental Protocols
The following sections provide detailed protocols for the synthesis of a SIL peptide using Fmoc-L-leucine-13C6,15N and its subsequent application in a quantitative proteomics workflow.
Solid-Phase Peptide Synthesis (SPPS) of a Labeled Peptide
This protocol outlines the manual synthesis of a peptide incorporating Fmoc-L-leucine-13C6,15N using a standard Fmoc/tBu strategy.
Materials:
-
Fmoc-L-leucine-13C6,15N
-
Other required Fmoc-protected amino acids
-
Rink Amide resin (or other suitable resin)
-
N,N-Dimethylformamide (DMF)
-
Coupling reagents (e.g., HBTU, HOBt, or HATU)
-
N,N-Diisopropylethylamine (DIPEA)
-
Dichloromethane (DCM)
-
Cleavage cocktail (e.g., Trifluoroacetic acid (TFA)/Triisopropylsilane (TIS)/Water)
-
Cold diethyl ether
-
Peptide synthesis vessel
-
Shaker
Procedure:
-
Resin Swelling:
-
Place the desired amount of resin in the synthesis vessel.
-
Add DMF to swell the resin for 30-60 minutes with gentle agitation.
-
Drain the DMF.
-
-
Fmoc Deprotection:
-
Add a 20% solution of piperidine in DMF to the resin.
-
Agitate for 5 minutes and drain.
-
Add a fresh 20% piperidine in DMF solution and agitate for an additional 15 minutes.
-
Drain the solution and wash the resin thoroughly with DMF (5 times).
-
-
Amino Acid Coupling (Incorporation of Fmoc-L-leucine-13C6,15N):
-
In a separate vial, dissolve Fmoc-L-leucine-13C6,15N (typically 3-5 equivalents relative to the resin loading) and a coupling reagent (e.g., HBTU, 3 equivalents) in DMF.
-
Add DIPEA (6 equivalents) to the amino acid solution and allow it to pre-activate for 1-2 minutes.
-
Add the activated amino acid solution to the deprotected resin.
-
Agitate the mixture for 1-2 hours at room temperature.
-
Perform a ninhydrin (B49086) test to confirm the completion of the coupling reaction.
-
-
Chain Elongation:
-
Repeat the Fmoc deprotection (Step 2) and amino acid coupling (Step 3) cycles for each subsequent amino acid in the peptide sequence.
-
-
Final Deprotection:
-
After the final amino acid has been coupled, perform a final Fmoc deprotection (Step 2).
-
-
Cleavage and Deprotection:
-
Wash the resin with DCM and dry thoroughly.
-
Add the cleavage cocktail to the resin.
-
Incubate with agitation for 2-3 hours at room temperature.
-
Filter the resin and collect the filtrate containing the cleaved peptide.
-
-
Peptide Precipitation and Purification:
-
Precipitate the crude peptide by adding the TFA solution to cold diethyl ether.
-
Centrifuge to pellet the peptide and discard the ether.
-
Wash the peptide pellet with cold diethyl ether.
-
Dry the crude peptide under vacuum.
-
Purify the peptide using reverse-phase high-performance liquid chromatography (RP-HPLC).
-
Workflow for Absolute Quantification of a Target Protein
This workflow illustrates the use of the synthesized SIL peptide as an internal standard for the absolute quantification of a target protein in a biological sample using mass spectrometry.
Signaling Pathway Application: A Hypothetical Example
Scenario: Investigating the phosphorylation of a substrate protein by a specific kinase in response to a stimulus. A SIL peptide corresponding to the phosphorylation site of the substrate protein, containing ¹³C₆,¹⁵N-Leucine, would be synthesized. This labeled peptide would serve as an internal standard to quantify the extent of phosphorylation of the endogenous substrate.
In this diagram, the SIL peptide would be used at the "MS Quantification" step to precisely measure the amount of the "Phosphorylated Substrate," thereby providing quantitative insights into the activity of the "Target Kinase" and the overall signaling cascade in response to the "External Stimulus."
References
The Precision of Life: A Technical Guide to Stable Isotope-Labeled Amino Acids in Research and Drug Development
For Researchers, Scientists, and Drug Development Professionals
In the intricate dance of cellular life, proteins and metabolites are the principal dancers. Understanding their choreography is paramount to deciphering disease mechanisms and developing effective therapeutics. Stable isotope-labeled amino acids (SILAAs) have emerged as indispensable tools, offering an unprecedented window into the dynamic world of the proteome and metabolome. This technical guide delves into the core benefits of utilizing SILAAs, providing in-depth methodologies, quantitative data insights, and visual workflows to empower researchers in their quest for scientific discovery.
Chemically identical to their natural counterparts, SILAAs contain heavier, non-radioactive isotopes of elements like carbon (¹³C), nitrogen (¹⁵N), and hydrogen (²H).[][2] This subtle mass difference, detectable by mass spectrometry (MS), allows for the precise tracking and quantification of amino acid metabolism, protein synthesis, and turnover.[][2] The stability and safety of these isotopes make them ideal for in vivo studies in both preclinical models and human subjects.
Core Applications and Quantitative Insights
The versatility of SILAAs extends across numerous applications in biological research and drug development, from fundamental cell biology to clinical diagnostics.
Quantitative Proteomics: Unveiling the Proteome's Dynamics
Stable Isotope Labeling by Amino Acids in Cell Culture (SILAC) is a powerful technique that enables the accurate relative quantification of thousands of proteins simultaneously.[3] In SILAC, cells are cultured in media where a standard essential amino acid is replaced with its heavy isotopic counterpart.[3] This leads to the complete incorporation of the labeled amino acid into the entire proteome. When "heavy" and "light" cell populations are compared, the relative abundance of each protein can be determined with high precision by analyzing the ratio of the isotopic peaks in the mass spectrometer.[3]
Table 1: Quantitative Proteomic Analysis of EGFR Signaling Pathway Using SILAC
This table presents a subset of data from a study investigating the epidermal growth factor receptor (EGFR) signaling pathway in a colorectal cancer cell line. Cells were treated with the EGFR-blocking antibody Cetuximab, and protein phosphorylation changes were quantified using SILAC. The data showcases the ability of SILAC to pinpoint specific changes in signaling cascades.
| Phosphosite | Protein | Treatment Time | Fold Change (Cetuximab/Control) | p-value |
| Y1173 | EGFR | 24h | -2.5 | <0.05 |
| S473 | AKT1 | 24h | -1.8 | <0.05 |
| T202/Y204 | MAPK1/3 (ERK) | 24h | -3.2 | <0.01 |
| S256 | BAD | 24h | -1.5 | <0.05 |
| S9 | GSK3B | 24h | -1.2 | >0.05 |
Data adapted from a study on EGFR signaling in colorectal cancer cells. The fold changes represent the relative abundance of the phosphorylated peptide in treated versus untreated cells.[4][5]
Metabolic Flux Analysis: Mapping the Metabolic Maze
Metabolic flux analysis (MFA) using ¹³C-labeled amino acids provides a dynamic snapshot of cellular metabolism, revealing the rates of metabolic reactions within a network.[6] By tracing the incorporation of ¹³C from labeled amino acids into various metabolites, researchers can quantify the flux through key metabolic pathways, such as glycolysis and the tricarboxylic acid (TCA) cycle.[6] This is particularly valuable in cancer research, where metabolic reprogramming is a hallmark of disease.[6][7]
Table 2: Metabolic Flux Analysis in Cancer Cells Using ¹³C-Labeled Amino Acids
This table summarizes key metabolic flux rates in a cancer cell line cultured with ¹³C-labeled glucose and glutamine. The data highlights the altered metabolic phenotype of cancer cells, characterized by high glycolytic rates and significant glutamine utilization.
| Metabolic Flux | Flux Rate (nmol/10^6 cells/hr) |
| Glucose Uptake | 250 |
| Lactate Secretion | 400 |
| Glutamine Uptake | 80 |
| Flux through Pyruvate Dehydrogenase (PDH) | 50 |
| Flux through Glutaminase (GLS) | 75 |
| Anaplerotic flux from Glutamine to α-Ketoglutarate | 60 |
These are representative values from metabolic flux analysis studies in cancer cell lines and can vary depending on the specific cell type and experimental conditions.[6][8]
Drug Metabolism and Pharmacokinetics (DMPK): Tracing the Fate of Therapeutics
In drug development, understanding the absorption, distribution, metabolism, and excretion (ADME) of a drug candidate is critical. Stable isotope-labeled compounds, including amino acids, are invaluable tools in these studies. By administering a labeled version of a drug, its metabolic fate can be precisely tracked and its metabolites identified and quantified. This aids in understanding the drug's mechanism of action, potential toxicity, and pharmacokinetic profile.
Experimental Protocols
To facilitate the implementation of these powerful techniques, detailed methodologies for key experiments are provided below.
Protocol 1: Stable Isotope Labeling by Amino Acids in Cell Culture (SILAC)
Objective: To achieve complete and efficient labeling of a cell proteome for quantitative proteomic analysis.
Materials:
-
Cell line of interest
-
SILAC-grade cell culture medium deficient in lysine (B10760008) and arginine
-
"Light" L-lysine and L-arginine
-
"Heavy" ¹³C₆-L-lysine and ¹³C₆,¹⁵N₄-L-arginine
-
Dialyzed fetal bovine serum (FBS)
-
Standard cell culture reagents and equipment
-
Mass spectrometer
Methodology:
-
Cell Culture Preparation: Culture two populations of the chosen cell line. One population will be grown in "light" medium, and the other in "heavy" medium.
-
Media Formulation: Prepare the "light" medium by supplementing the lysine- and arginine-deficient medium with "light" L-lysine and L-arginine. Prepare the "heavy" medium by supplementing with "heavy" ¹³C₆-L-lysine and ¹³C₆,¹⁵N₄-L-arginine. Both media should be supplemented with dialyzed FBS to minimize the presence of unlabeled amino acids.
-
Metabolic Labeling: Culture the cells in their respective "light" and "heavy" media for at least five to six cell doublings to ensure complete incorporation (>97%) of the labeled amino acids.
-
Experimental Treatment: Apply the experimental condition (e.g., drug treatment, growth factor stimulation) to one of the cell populations, while the other serves as a control.
-
Cell Lysis and Protein Extraction: Harvest both cell populations and lyse them using a suitable lysis buffer containing protease and phosphatase inhibitors.
-
Protein Quantification and Mixing: Determine the protein concentration of each lysate. Mix equal amounts of protein from the "light" and "heavy" lysates.
-
Protein Digestion: Digest the combined protein mixture into peptides using an appropriate protease, typically trypsin.
-
Mass Spectrometry Analysis: Analyze the resulting peptide mixture using high-resolution mass spectrometry.
-
Data Analysis: Use specialized software to identify peptides and quantify the intensity ratios of the "heavy" to "light" peptide pairs. This ratio reflects the relative abundance of the corresponding protein in the two samples.
Protocol 2: ¹³C Metabolic Flux Analysis (MFA)
Objective: To quantify the rates of metabolic reactions in a cellular system.
Materials:
-
Cell line of interest
-
Defined cell culture medium
-
¹³C-labeled substrate (e.g., [U-¹³C]-glucose, [U-¹³C]-glutamine)
-
Gas chromatography-mass spectrometry (GC-MS) or liquid chromatography-mass spectrometry (LC-MS) system
-
Metabolic quenching solution (e.g., ice-cold methanol)
-
Software for metabolic flux analysis
Methodology:
-
Experimental Design: Define the metabolic network of interest and select the appropriate ¹³C-labeled tracer that will provide the most informative labeling patterns for the pathways under investigation.
-
Tracer Experiment: Culture cells in a defined medium containing the selected ¹³C-labeled tracer until they reach a metabolic and isotopic steady state.
-
Metabolite Extraction: Rapidly quench metabolism by adding ice-cold quenching solution and harvest the cells. Extract intracellular metabolites using a suitable extraction solvent.
-
Sample Analysis: Analyze the metabolite extracts using GC-MS or LC-MS to determine the mass isotopomer distributions of key metabolites. This provides the raw data on the incorporation of ¹³C.
-
Flux Estimation: Utilize a computational model of the cellular metabolic network and specialized software to estimate the intracellular metabolic fluxes by fitting the model to the experimentally measured mass isotopomer distributions.
-
Statistical Analysis: Perform statistical analyses to assess the goodness-of-fit of the estimated fluxes and to calculate confidence intervals for each flux value.
Visualizing Complexity: Workflows and Pathways
To provide a clearer understanding of the described methodologies and their applications, the following diagrams have been generated using the DOT language.
Conclusion
Stable isotope-labeled amino acids are powerful and versatile tools that have revolutionized our ability to study the intricate workings of the cell. From quantitative proteomics to metabolic flux analysis and drug development, SILAAs provide a level of precision and detail that was previously unattainable. By enabling the accurate measurement of protein dynamics and metabolic fluxes, these labeled compounds are instrumental in advancing our understanding of complex biological processes and in the development of novel therapeutic strategies. The methodologies and data presented in this guide serve as a foundation for researchers and scientists to harness the full potential of stable isotope-labeled amino acids in their pursuit of scientific innovation.
References
- 2. chempep.com [chempep.com]
- 3. SILAC: Principles, Workflow & Applications in Proteomics - Creative Proteomics Blog [creative-proteomics.com]
- 4. Systematic Comparison of Label-Free, SILAC, and TMT Techniques to Study Early Adaption toward Inhibition of EGFR Signaling in the Colorectal Cancer Cell Line DiFi - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. pubs.acs.org [pubs.acs.org]
- 6. d-nb.info [d-nb.info]
- 7. researchgate.net [researchgate.net]
- 8. Flux estimation analysis systematically characterizes the metabolic shifts of the central metabolism pathway in human cancer - PMC [pmc.ncbi.nlm.nih.gov]
A Technical Guide to the Core Applications of ¹³C and ¹⁵N Labeled Amino Acids in Proteomics
For Researchers, Scientists, and Drug Development Professionals
Stable isotope-labeled amino acids, particularly those enriched with Carbon-13 (¹³C) and Nitrogen-15 (¹⁵N), have become indispensable tools in modern biological and chemical research.[1][2] These non-radioactive isotopes permit the precise tracking and quantification of amino acids and their metabolic products within complex biological systems.[1] By substituting natural carbon (¹²C) or nitrogen (¹⁴N) atoms with their heavier stable isotopes, researchers can differentiate and trace molecules using analytical techniques like mass spectrometry (MS) and nuclear magnetic resonance (NMR) spectroscopy.[1][] This guide provides an in-depth overview of the fundamental applications of ¹³C and ¹⁵N labeled amino acids, with a focus on quantitative proteomics, metabolic flux analysis, and protein structure determination.
Quantitative Proteomics: Stable Isotope Labeling by Amino Acids in Cell Culture (SILAC)
SILAC is a powerful and widely adopted metabolic labeling technique for accurate protein quantification in proteomics.[1][4][5] It enables the comparison of protein abundance between different cell populations under various experimental conditions.[1][6]
Core Principle
The fundamental principle of SILAC involves culturing two or more cell populations in media that are identical except for the isotopic form of a specific essential amino acid.[1][6] One population is grown in a "light" medium containing the natural amino acid (e.g., ¹²C₆-Arginine), while the other is cultured in a "heavy" medium with a stable isotope-labeled counterpart (e.g., ¹³C₆-Arginine).[1][6] Over several cell divisions, the heavy amino acids are fully incorporated into the proteome of the "heavy" cell population.[7][8]
Following experimental treatment, the cell populations are combined, and the proteins are extracted and digested, typically with trypsin.[8][9] The resulting peptide mixtures are then analyzed by mass spectrometry.[9] Since the "heavy" and "light" peptides are chemically identical, they co-elute during liquid chromatography, but are distinguishable by the mass spectrometer due to their mass difference.[10] The ratio of the signal intensities of the heavy and light peptide pairs directly reflects the relative abundance of the corresponding protein in the two cell populations.[6]
Experimental Workflow: A Generalized SILAC Protocol
The SILAC experiment is broadly divided into two main phases: an adaptation phase and an experimental phase.[11][12][13]
Phase 1: Adaptation
-
Cell Culture Preparation: Two populations of cells are cultured. One is grown in a standard "light" medium, while the other is cultured in a "heavy" medium supplemented with ¹³C or ¹⁵N labeled essential amino acids (commonly Arginine and Lysine).[8][14]
-
Metabolic Labeling: Cells are grown for a sufficient number of cell divisions (at least 5-6) to ensure near-complete incorporation (>97%) of the heavy amino acids into the cellular proteome.[7]
-
Incorporation Check: A small aliquot of the "heavy" labeled cells is harvested, and the proteome is analyzed by mass spectrometry to confirm the efficiency of isotopic label incorporation.[11][12]
Phase 2: Experimentation and Analysis
-
Experimental Treatment: The "light" and "heavy" cell populations are subjected to different experimental conditions (e.g., drug treatment vs. control).[8][12]
-
Sample Pooling: The two cell populations are combined in a 1:1 ratio.[9][14]
-
Protein Extraction and Digestion: Total protein is extracted from the combined cell lysate, and the proteins are digested into peptides using a protease, most commonly trypsin.[8][9]
-
Mass Spectrometry Analysis: The resulting peptide mixture is analyzed by liquid chromatography-tandem mass spectrometry (LC-MS/MS).[8][9]
-
Data Analysis: Specialized software is used to identify peptides and quantify the relative abundance of proteins based on the intensity ratios of the "heavy" and "light" peptide pairs.[9]
A generalized workflow for a SILAC experiment.
Quantitative Data in SILAC
The primary quantitative output of a SILAC experiment is the ratio of heavy to light peptide intensities, which corresponds to the relative abundance of the protein.
| Parameter | Description | Typical Values/Ranges |
| Label Incorporation Efficiency | The percentage of the proteome that has successfully incorporated the heavy amino acid. | > 97% is considered optimal.[7] |
| Peptide Ratio (Heavy/Light) | The ratio of the mass spectrometer signal intensity of the heavy labeled peptide to its light counterpart. | A ratio of 1 indicates no change in protein abundance. Ratios > 1 indicate upregulation, and < 1 indicate downregulation. |
| Protein Ratio | The median or average of the peptide ratios for a given protein. | Provides a quantitative measure of the change in protein expression. |
| Standard Deviation of Ratios | A measure of the variability of peptide ratios for a single protein. | Lower standard deviations indicate higher confidence in the protein quantification. |
Metabolic Flux Analysis (MFA) with ¹³C-Labeled Amino Acids
Metabolic Flux Analysis (MFA) is a powerful technique used to quantify the rates of metabolic reactions within a biological system.[15] ¹³C-labeled amino acids, along with other ¹³C-labeled metabolites like glucose, serve as tracers to map the flow of carbon atoms through metabolic pathways.[][16]
Core Principle
Cells are cultured in a medium containing a ¹³C-labeled substrate. As the cells metabolize this substrate, the ¹³C atoms are incorporated into various downstream metabolites, including amino acids. By analyzing the mass isotopomer distribution (the relative abundance of molecules with different numbers of ¹³C atoms) of these metabolites, typically by mass spectrometry, researchers can deduce the relative activities of different metabolic pathways.[1]
Experimental Workflow for ¹³C-MFA
-
Experimental Design: Define the metabolic network of interest and select the appropriate ¹³C-labeled tracer.
-
Isotopic Labeling: Culture cells in a medium containing the ¹³C-labeled substrate until a metabolic steady state is reached.
-
Sample Collection and Preparation: Rapidly quench metabolism and harvest the cells. Extract the metabolites of interest. For protein-bound amino acids, hydrolyze the cellular protein.
-
Isotopic Labeling Measurement: Analyze the mass isotopomer distributions of the target metabolites using Gas Chromatography-Mass Spectrometry (GC-MS) or LC-MS/MS.
-
Flux Estimation: Use computational models to estimate the intracellular metabolic fluxes that best explain the observed mass isotopomer distributions.
A simplified workflow for ¹³C-Metabolic Flux Analysis.
Quantitative Data in ¹³C-MFA
| Parameter | Description |
| Mass Isotopomer Distribution (MID) | The fractional abundance of each mass isotopomer of a metabolite. |
| Metabolic Flux (v) | The rate of a specific metabolic reaction, typically expressed in units of moles per unit of biomass per unit of time. |
| Flux Ratio | The ratio of two metabolic fluxes, which can provide insights into the relative importance of different pathways. |
Protein Structure and Dynamics with ¹⁵N and ¹³C/¹⁵N Labeling
Stable isotope labeling is a cornerstone of modern NMR spectroscopy for determining the three-dimensional structure and dynamics of proteins.[]
Core Principle
By expressing a protein in a medium where the sole nitrogen source is ¹⁵NH₄Cl and the sole carbon source is ¹³C-glucose, proteins uniformly labeled with ¹⁵N and ¹³C can be produced.[17] This labeling enables the use of multidimensional heteronuclear NMR experiments that correlate the chemical shifts of different nuclei (e.g., ¹H, ¹⁵N, ¹³C), which is essential for assigning the resonances to specific atoms in the protein and for generating the distance and angular restraints needed to calculate a high-resolution structure.
Experimental Workflow for NMR Structural Studies
-
Protein Expression and Labeling: Express the protein of interest in a bacterial or other expression system using a minimal medium containing ¹⁵NH₄Cl and/or ¹³C-glucose as the sole nitrogen and carbon sources, respectively.
-
Protein Purification: Purify the isotopically labeled protein to homogeneity.
-
NMR Sample Preparation: Prepare a concentrated, stable sample of the protein in a suitable buffer for NMR analysis.
-
NMR Data Acquisition: Acquire a suite of multidimensional NMR experiments (e.g., HSQC, HNCA, HN(CO)CA, HNCACB, NOESY).
-
Resonance Assignment and Structure Calculation: Process the NMR data, assign the chemical shifts to specific atoms in the protein sequence, and use this information to calculate the three-dimensional structure of the protein.
A general workflow for protein structure determination using NMR.
Quantitative Data in NMR Structural Biology
| Parameter | Description |
| Chemical Shift (δ) | The resonance frequency of a nucleus relative to a standard, which is highly sensitive to its local electronic environment. |
| Nuclear Overhauser Effect (NOE) | A measure of the through-space interaction between two protons that are close in space (< 5 Å), providing distance restraints for structure calculation. |
| Scalar Coupling Constant (J) | A measure of the through-bond interaction between two nuclei, which provides information about dihedral angles. |
| Residual Dipolar Coupling (RDC) | Provides information on the orientation of bond vectors relative to the magnetic field in partially aligned molecules. |
Applications in Drug Discovery and Development
The use of ¹³C and ¹⁵N labeled amino acids is integral to various stages of the drug development pipeline.[18][19][20]
-
Target Identification and Validation: SILAC-based proteomics can be used to identify proteins that are differentially expressed or modified upon drug treatment, helping to identify potential drug targets and off-target effects.[19]
-
Biomarker Discovery: Quantitative proteomics can identify proteins whose levels change in response to disease or drug treatment, providing candidate biomarkers for disease diagnosis, prognosis, and monitoring treatment efficacy.[18]
-
Mechanism of Action Studies: By tracking changes in protein expression, post-translational modifications, and metabolic fluxes, researchers can gain insights into the molecular mechanisms by which a drug exerts its effects.[18][20]
A conceptual signaling pathway illustrating drug action.
Conclusion
The applications of ¹³C and ¹⁵N labeled amino acids are foundational to modern biochemical and pharmaceutical research. From quantifying dynamic changes in the proteome with SILAC to elucidating complex metabolic pathways with ¹³C-MFA and determining the high-resolution structures of proteins by NMR, these stable isotope tracers provide an unparalleled level of detail into the workings of biological systems. Their continued use will undoubtedly drive further advances in our understanding of health and disease, and in the development of novel therapeutics.
References
- 1. benchchem.com [benchchem.com]
- 2. chempep.com [chempep.com]
- 4. researchgate.net [researchgate.net]
- 5. Quantitative proteomics using SILAC: Principles, applications, and developments - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. Stable isotope labeling by amino acids in cell culture - Wikipedia [en.wikipedia.org]
- 7. Quantitative Comparison of Proteomes Using SILAC - PMC [pmc.ncbi.nlm.nih.gov]
- 8. chempep.com [chempep.com]
- 9. info.gbiosciences.com [info.gbiosciences.com]
- 10. Stable Isotopic Labeling by Amino Acids in Cell Culture or SILAC | Proteomics [medicine.yale.edu]
- 11. researchgate.net [researchgate.net]
- 12. researchgate.net [researchgate.net]
- 13. SILAC: Principles, Workflow & Applications in Proteomics - Creative Proteomics Blog [creative-proteomics.com]
- 14. SILAC - Based Proteomics Analysis - Creative Proteomics [creative-proteomics.com]
- 15. Amino Acid Metabolic Flux Analysis - Creative Proteomics MFA [creative-proteomics.com]
- 16. Applications of Stable Isotope Labeling in Metabolic Flux Analysis - Creative Proteomics [creative-proteomics.com]
- 17. protein-nmr.org.uk [protein-nmr.org.uk]
- 18. benchchem.com [benchchem.com]
- 19. Proteomics Applications in Health: Biomarker and Drug Discovery and Food Industry - PMC [pmc.ncbi.nlm.nih.gov]
- 20. pharmiweb.com [pharmiweb.com]
Understanding the Isotopic Purity of Fmoc-L-Leucine-¹³C₆,¹⁵N: A Technical Guide
For Researchers, Scientists, and Drug Development Professionals
This in-depth technical guide provides a comprehensive overview of the methods used to determine the isotopic purity of Fmoc-L-leucine-¹³C₆,¹⁵N, a critical reagent in proteomics, drug development, and structural biology. Ensuring the high isotopic enrichment of this stable isotope-labeled amino acid is paramount for the accuracy and reliability of quantitative mass spectrometry-based studies and high-resolution NMR spectroscopy.
Quantitative Data Summary
Fmoc-L-leucine-¹³C₆,¹⁵N is commercially available from several suppliers, with typical specifications for isotopic and chemical purity. The following tables summarize these key quantitative parameters.
Table 1: Typical Isotopic Purity of Commercial Fmoc-L-Leucine-¹³C₆,¹⁵N
| Isotope | Specified Enrichment (atom %) |
| ¹³C | ≥ 98%[1] |
| ¹⁵N | ≥ 98%[1] |
Note: Some suppliers may offer enrichment levels of up to 99%.[2][3]
Table 2: General Specifications for Fmoc-L-Leucine-¹³C₆,¹⁵N
| Parameter | Specification |
| Chemical Purity | ≥ 98%[2] |
| Molecular Weight | 360.36 g/mol [2] |
| Appearance | White to off-white solid |
| Storage Conditions | Refrigerated (+2°C to +8°C), desiccated, and protected from light[2] |
Core Applications
The high isotopic enrichment of Fmoc-L-leucine-¹³C₆,¹⁵N makes it an invaluable tool in several advanced research applications:
-
Quantitative Proteomics: Used in Stable Isotope Labeling by Amino Acids in Cell Culture (SILAC) for the accurate quantification of protein expression levels. The known mass shift between the "heavy" labeled leucine (B10760876) and its "light" counterpart allows for precise relative and absolute quantification of proteins by mass spectrometry.[4]
-
Peptide Synthesis: Serves as a building block in solid-phase peptide synthesis (SPPS) to produce isotopically labeled peptides. These peptides are used as internal standards for the quantification of proteins and peptides in complex biological samples.[4]
-
Structural Biology (NMR): The incorporation of ¹³C and ¹⁵N enhances the sensitivity and resolution of NMR experiments, facilitating the determination of peptide and protein structures and dynamics.[4][5]
-
Metabolic Studies: When incorporated into peptides or proteins, the labeled leucine can be used to trace metabolic pathways and study amino acid metabolism.[4]
Experimental Protocols for Determining Isotopic Purity
The determination of the isotopic enrichment of Fmoc-L-leucine-¹³C₆,¹⁵N is typically performed using high-resolution mass spectrometry and nuclear magnetic resonance (NMR) spectroscopy.
Mass Spectrometry
High-resolution mass spectrometry is a primary method for assessing isotopic purity. It allows for the separation and quantification of the different isotopologues of the molecule.
Methodology:
-
Sample Preparation:
-
Dissolve a small amount (typically 1 mg/mL) of Fmoc-L-leucine-¹³C₆,¹⁵N in a suitable solvent such as acetonitrile (B52724) or a mixture of acetonitrile and water.
-
Prepare a similar solution of unlabeled Fmoc-L-leucine as a reference standard.
-
Further dilute the samples to a final concentration of approximately 1-10 µM for analysis.
-
-
Instrumentation and Parameters:
-
Mass Spectrometer: A high-resolution mass spectrometer, such as an Orbitrap or a Time-of-Flight (TOF) instrument, is required to resolve the isotopic peaks.
-
Ionization Source: Electrospray ionization (ESI) in positive or negative ion mode is commonly used.
-
Mass Analyzer Settings:
-
Resolution: Set to a high resolution (e.g., > 60,000) to ensure baseline separation of the isotopic peaks.
-
Scan Range: Center the scan range around the expected m/z of the analyte. For the protonated molecule [M+H]⁺, this would be around 361.18.
-
Data Acquisition: Acquire data in profile mode to accurately capture the peak shapes of the isotopic cluster.
-
-
-
Data Analysis and Enrichment Calculation:
-
Acquire the mass spectrum of the unlabeled Fmoc-L-leucine to determine its natural isotopic distribution.
-
Acquire the mass spectrum of the Fmoc-L-leucine-¹³C₆,¹⁵N sample.
-
Identify the isotopic cluster corresponding to the molecule. The fully labeled molecule will have a mass shift of +7 Da compared to the unlabeled molecule (6 carbons + 1 nitrogen).
-
Measure the intensities of the monoisotopic peak of the labeled species (M+7) and any peaks corresponding to incompletely labeled species (M, M+1, M+2, etc.).
-
The isotopic enrichment for ¹³C and ¹⁵N can be calculated by comparing the experimentally observed isotopic distribution to the theoretical distribution for a given enrichment level. This can be done using specialized software or by manual calculation, taking into account the natural abundance of isotopes.
-
Nuclear Magnetic Resonance (NMR) Spectroscopy
NMR spectroscopy provides detailed information about the isotopic labeling at specific atomic positions. Both ¹³C and ¹⁵N are NMR-active nuclei.
Methodology:
-
Sample Preparation:
-
Dissolve a sufficient amount of Fmoc-L-leucine-¹³C₆,¹⁵N (typically 5-10 mg) in a suitable deuterated solvent (e.g., DMSO-d₆, CDCl₃).
-
Ensure the sample is fully dissolved to obtain high-resolution spectra.
-
-
¹³C NMR Spectroscopy:
-
Instrument: A high-field NMR spectrometer (e.g., 400 MHz or higher).
-
Experiment: A quantitative ¹³C NMR experiment should be performed. This typically involves a longer relaxation delay (D1) to ensure full relaxation of all carbon nuclei for accurate integration. Inverse-gated proton decoupling is used to suppress the Nuclear Overhauser Effect (NOE) and ensure that the signal intensity is directly proportional to the number of nuclei.
-
Data Analysis:
-
Acquire the ¹³C NMR spectrum. The six leucine carbons should appear as strong signals due to ¹³C enrichment.
-
Look for small signals at the chemical shifts corresponding to the unlabeled ¹²C carbons. These signals arise from the small percentage of molecules that are not fully labeled.
-
The ¹³C enrichment can be calculated by comparing the integral of the ¹³C-labeled carbon signals to the sum of the integrals of the labeled and unlabeled carbon signals for each carbon position.
-
-
-
¹⁵N NMR Spectroscopy:
-
Instrument: A high-field NMR spectrometer equipped with a probe capable of detecting ¹⁵N.
-
Experiment: A direct ¹⁵N NMR spectrum can be acquired. However, due to the low gyromagnetic ratio and long relaxation times of ¹⁵N, this can be time-consuming. More commonly, a proton-detected 2D heteronuclear correlation experiment like a ¹H-¹⁵N HSQC (Heteronuclear Single Quantum Coherence) is used.
-
Data Analysis (¹H-¹⁵N HSQC):
-
In the ¹H-¹⁵N HSQC spectrum, a cross-peak will be observed for the ¹⁵N-labeled amide nitrogen coupled to its attached proton.
-
To quantify the ¹⁵N enrichment, a reference sample with a known concentration of an unlabeled standard can be used, or the intensity of the ¹⁵N-coupled signal can be compared to the intensity of any residual ¹⁴N-H signal (which would be a broad singlet in the ¹H spectrum). A more direct approach is to compare the integral of the proton attached to the ¹⁵N with the integral of a proton on a non-labeled internal standard.
-
-
Visualizations
The following diagrams illustrate the workflows for determining the isotopic purity of Fmoc-L-leucine-¹³C₆,¹⁵N.
Caption: Workflow for determining isotopic purity by mass spectrometry.
Caption: Workflow for determining isotopic purity by NMR spectroscopy.
Conclusion
The verification of isotopic purity is a critical quality control step for Fmoc-L-leucine-¹³C₆,¹⁵N. Both high-resolution mass spectrometry and NMR spectroscopy are powerful analytical techniques capable of providing accurate and detailed information on the isotopic enrichment levels. The choice of method may depend on the available instrumentation and the specific information required. For routine quality control, mass spectrometry offers a rapid and sensitive assessment of the overall isotopic distribution. For more detailed, position-specific information, NMR spectroscopy is the method of choice. By following the detailed protocols outlined in this guide, researchers can confidently assess the quality of their labeled amino acids, ensuring the integrity and accuracy of their experimental results.
References
An In-Depth Technical Guide to Fmoc Deprotection in Solid-Phase Peptide Synthesis
Audience: Researchers, scientists, and drug development professionals.
Introduction to Fmoc Solid-Phase Peptide Synthesis (SPPS)
Solid-Phase Peptide Synthesis (SPPS) is the cornerstone of modern peptide science, enabling the routine construction of peptide chains on an insoluble polymer support.[1] Among the prevalent strategies, the Fmoc (9-fluorenylmethyloxycarbonyl) methodology is widely adopted due to its use of a base-labile Nα-protecting group, which allows for orthogonal, acid-labile side-chain protection and cleavage from the resin.[2][3] This orthogonality preserves the integrity of the growing peptide chain.[4] The iterative cycle of SPPS involves the deprotection of the N-terminal Fmoc group, followed by the coupling of the next Fmoc-protected amino acid.[2] The efficiency and fidelity of the deprotection step are critical, as incomplete Fmoc removal leads to deletion sequences, while harsh conditions can trigger undesirable side reactions, compromising the purity and yield of the final peptide.[5]
The Core Principle: The Fmoc Deprotection Mechanism
The removal of the Fmoc group is a classic example of a base-catalyzed β-elimination reaction (E1cB mechanism).[3][6] The process is initiated by a base, typically a secondary amine like piperidine (B6355638), which abstracts the acidic proton on the C9 position of the fluorenyl ring.[5][7] This abstraction is the rate-determining step.[6] The resulting carbanion is unstable and rapidly undergoes elimination, releasing the free N-terminal amine of the peptide, carbon dioxide, and dibenzofulvene (DBF).[3][7] The highly electrophilic DBF is immediately trapped by the excess amine base to form a stable adduct, which drives the equilibrium of the reaction towards completion.[5][7]
Caption: Base-catalyzed β-elimination mechanism for Fmoc group removal.
Reagents for Fmoc Deprotection
The choice of base and solvent is critical for efficient and clean deprotection. The ideal reagent should rapidly remove the Fmoc group without causing degradation of the peptide or resin linkage.
-
Bases: Secondary amines are preferred as they are effective bases and act as excellent scavengers for the liberated DBF.[5]
-
Piperidine: The most common deprotection reagent, typically used at a concentration of 20% (v/v) in a polar aprotic solvent like N,N-Dimethylformamide (DMF).[2][8]
-
Piperazine (B1678402): A less toxic alternative to piperidine. It can be less efficient at lower concentrations but shows comparable performance to piperidine when used at 10% (w/v) in a DMF/ethanol mixture.[5]
-
4-Methylpiperidine (4MP): An alternative with similar efficiency to piperidine, sometimes favored for reduced toxicity.[1]
-
1,8-Diazabicyclo[5.4.0]undec-7-ene (DBU): A very strong, non-nucleophilic base that provides much faster deprotection than piperidine.[7][9] However, it does not scavenge DBF, necessitating the addition of a nucleophile like piperidine (e.g., 2% DBU / 2% piperidine in DMF) to prevent side reactions.[7][9] DBU can also accelerate aspartimide formation.[7]
-
-
Solvents: Polar aprotic solvents are required to solvate the peptide-resin and facilitate the reaction.
| Reagent Cocktail | Concentration | Solvent | Key Characteristics |
| Piperidine | 20% (v/v) | DMF or NMP | Industry standard; highly effective base and scavenger.[2][4] |
| Piperazine | 5-10% (w/v) | DMF, DMF/Ethanol | Safer alternative, may require longer reaction times or additives.[5][6] |
| 4-Methylpiperidine | 20% (v/v) | DMF | Similar kinetics to piperidine, considered less toxic.[1] |
| DBU / Piperidine | 2% DBU / 2% Piperidine (v/v) | DMF | Very rapid deprotection; useful for sterically hindered residues or aggregated sequences.[9] |
| DBU / Piperazine | 2% DBU / 5% Piperazine | DMF | A rapid and safer alternative to piperidine-based cocktails.[6][11] |
Table 1: Summary of common Fmoc deprotection reagents and their typical usage.
Reaction Kinetics and Optimization
The time required for complete Fmoc deprotection is sequence-dependent and influenced by steric hindrance and on-resin aggregation. Standard protocols often use a two-step deprotection (e.g., 2 minutes followed by 10 minutes) to ensure completion.[12]
Kinetic studies provide insight into the efficiency of different reagents. The half-life (t1/2) of deprotection is a key metric for comparison.
| Deprotection Reagent | Substrate | t1/2 (seconds) | Notes |
| 20% Piperidine in DMF | Fmoc-Val-Resin | ~7 | Represents a standard, unhindered residue.[6] |
| 5% Piperidine in DMF | Fmoc-Val-Resin | ~17 | Slower kinetics at lower concentration.[6] |
| 5% Piperazine in DMF | Fmoc-Val-Resin | ~50 | Significantly slower than piperidine at the same concentration.[6] |
| 2% DBU + 5% Piperazine in DMF | Fmoc-Val-Resin | ~4 | Extremely rapid, rivaling 20% piperidine.[6] |
| Piperazine (PZ) vs. Piperidine (PP) | Fmoc-Arg(Pbf)-Resin | PZ is less efficient at short times (<10 min) | Arginine deprotection is sterically hindered and requires longer times.[5][13] |
| Piperazine (PZ) vs. Piperidine (PP) | Fmoc-Leu-Resin | Efficient deprotection in < 3 min for both | Leucine is unhindered, allowing for rapid deprotection.[5][13] |
Table 2: Comparative kinetics of various Fmoc deprotection reagents. Data highlights the speed of DBU-based systems and the slower nature of piperazine alone.
Common Side Reactions and Mitigation Strategies
While effective, the basic conditions of Fmoc deprotection can catalyze several undesirable side reactions.
-
Aspartimide Formation: This is a major side reaction, particularly in sequences containing Asp-Gly, Asp-Asn, or Asp-Ser motifs.[8][14] The backbone amide nitrogen following the aspartic acid residue attacks the side-chain ester, forming a five-membered succinimide (B58015) ring.[14] This aspartimide intermediate can then be opened by piperidine or water to yield a mixture of desired α-peptide, undesired β-peptide, and their respective piperidide adducts, often accompanied by racemization.[8][15]
-
Diketopiperazine (DKP) Formation: This occurs primarily at the dipeptide stage, where the newly deprotected N-terminal amine of the second residue attacks the C-terminal ester linkage to the resin, cleaving the dipeptide from the support as a cyclic DKP.[3][17] This is most common with Proline or Glycine as one of the first two residues.[17]
-
DBF Adduct Formation with Peptide: If the dibenzofulvene (DBF) by-product is not efficiently scavenged by the base, it can react with the newly liberated N-terminal amine of the peptide, leading to a terminated chain.[3][7]
-
Mitigation: Ensure a sufficient excess of a nucleophilic secondary amine (like piperidine or piperazine) is present in the deprotection solution.[3]
-
Caption: Relationship between desired deprotection and major side reactions.
Monitoring Fmoc Deprotection
Monitoring the completion of the deprotection reaction is crucial for optimizing protocols and troubleshooting difficult syntheses.
-
UV-Vis Spectrophotometry: This is the most common quantitative method. The DBF-piperidine adduct has a strong UV absorbance maximum around 300-304 nm.[18] By collecting the deprotection solution and measuring its absorbance, one can quantify the amount of Fmoc group cleaved. This is often used in automated synthesizers to extend deprotection times until the reaction is complete.[7][18]
-
Kaiser (Ninhydrin) Test: A qualitative colorimetric test to detect the presence of free primary amines on the resin.[12] After deprotection and washing, a few resin beads are heated with ninhydrin (B49086) reagents. A deep blue color (Ruhemann's purple) indicates a positive result (complete deprotection). A yellow or faint color indicates incomplete deprotection. This test does not work for N-alkylated amino acids like proline.
Experimental Protocols
Standard Manual Fmoc Deprotection Protocol
This protocol is for the deprotection of an N-terminal Fmoc group on a peptide-resin.
-
Resin Preparation: If the resin is dry, swell it in DMF for 30-60 minutes in a suitable reaction vessel (e.g., a fritted syringe or specialized glass reactor).[12][19]
-
Initial Wash: Drain the swelling solvent and wash the resin thoroughly with DMF (3 x 1 min).[19]
-
First Deprotection: Add the deprotection reagent (e.g., 20% piperidine in DMF, using ~10 mL per gram of resin) to completely cover the resin.[12][16] Agitate gently (e.g., using a shaker or nitrogen bubbling) for 2-3 minutes.[16] Drain the solution.
-
Second Deprotection: Add a fresh portion of the deprotection reagent and agitate for 10-20 minutes.[2] The duration may be extended for sterically hindered residues.
-
Washing: Drain the deprotection solution. Wash the resin extensively with DMF (5-7 times, 1 min each) to ensure complete removal of the reagent and the DBF-adduct.[12]
-
Confirmation (Optional): Perform a Kaiser test on a small sample of the resin to confirm the presence of free primary amines.[12] The resin is now ready for the next coupling step.
Protocol for UV-Based Quantification of Resin Loading
This protocol determines the substitution level (loading) of the first amino acid attached to the resin.
-
Sample Preparation: Accurately weigh a small amount of dry Fmoc-amino acid-resin (e.g., 2-5 mg) into a vial.
-
Fmoc Cleavage: Add a known volume of 20% piperidine in DMF (e.g., 1.0 mL) to the resin. Vortex or shake for 30 minutes to ensure complete cleavage of the Fmoc group.
-
Dilution: Take a precise aliquot of the supernatant (e.g., 100 µL) and dilute it with a known volume of DMF (e.g., into a 10 mL volumetric flask, filled to the mark) to bring the absorbance into the linear range of the spectrophotometer.[18]
-
Measurement: Measure the absorbance (A) of the diluted solution at ~301 nm against a DMF blank.
-
Calculation: Calculate the resin loading (mmol/g) using the Beer-Lambert law:
-
Loading (mmol/g) = (A × V_dilution) / (ε × w × l)
-
Where:
-
A = Absorbance at 301 nm
-
V_dilution = Total volume of the diluted sample in Liters
-
ε = Molar extinction coefficient of the DBF-piperidine adduct (~7800 L mol⁻¹ cm⁻¹)[18]
-
w = Weight of the dry resin in grams
-
l = Path length of the cuvette in cm (usually 1 cm)
-
-
SPPS Workflow Visualization
The Fmoc deprotection step is a critical part of the iterative cycle of solid-phase peptide synthesis.
Caption: The central role of the deprotection step in the SPPS cycle.
References
- 1. luxembourg-bio.com [luxembourg-bio.com]
- 2. Fmoc Solid Phase Peptide Synthesis: Mechanism and Protocol - Creative Peptides [creative-peptides.com]
- 3. chempep.com [chempep.com]
- 4. genscript.com [genscript.com]
- 5. mdpi.com [mdpi.com]
- 6. pubs.rsc.org [pubs.rsc.org]
- 7. peptide.com [peptide.com]
- 8. Aspartimide Formation and Its Prevention in Fmoc Chemistry Solid Phase Peptide Synthesis - PMC [pmc.ncbi.nlm.nih.gov]
- 9. peptide.com [peptide.com]
- 10. researchgate.net [researchgate.net]
- 11. Piperazine and DBU: a safer alternative for rapid and efficient Fmoc deprotection in solid phase peptide synthesis - RSC Advances (RSC Publishing) [pubs.rsc.org]
- 12. benchchem.com [benchchem.com]
- 13. researchgate.net [researchgate.net]
- 14. benchchem.com [benchchem.com]
- 15. media.iris-biotech.de [media.iris-biotech.de]
- 16. academic.oup.com [academic.oup.com]
- 17. peptide.com [peptide.com]
- 18. rsc.org [rsc.org]
- 19. chem.uci.edu [chem.uci.edu]
An In-depth Technical Guide to the Storage and Stability of Fmoc Protected Amino Acids
For Researchers, Scientists, and Drug Development Professionals
This guide provides a comprehensive overview of the critical parameters governing the storage and stability of 9-fluorenylmethyloxycarbonyl (Fmoc) protected amino acids, essential building blocks in modern solid-phase peptide synthesis (SPPS). Proper handling and storage are paramount to ensure the high purity and reactivity required for the successful synthesis of complex peptides for research, diagnostics, and therapeutic applications.
General Storage Recommendations
Fmoc-protected amino acids are generally stable solids, but their long-term stability is highly dependent on storage conditions. To minimize degradation and preserve purity, the following conditions are recommended.
Key Storage Guidelines:
-
Temperature: For long-term storage, Fmoc-amino acids should be stored at temperatures of 5°C or lower.[1] While they can be kept at room temperature for short periods, such as during shipment or routine lab use, prolonged exposure can lead to degradation.[1][2] For maximum shelf life, storage at -20°C is optimal.[3]
-
Moisture: These compounds are susceptible to moisture, which can facilitate hydrolysis and other degradation pathways. It is crucial to store them in tightly sealed containers in a dry environment, such as a desiccator.[1] Before opening a refrigerated container, it must be allowed to warm to room temperature to prevent condensation of atmospheric moisture onto the product.[1]
-
Light and Air: Exposure to light and air (oxygen) should be minimized. Store containers in the dark or in amber vials.[3] For particularly sensitive amino acids, purging the container with an inert gas like nitrogen or argon before sealing can further enhance stability.[4]
| Parameter | Short-Term Storage (Days to Weeks) | Long-Term Storage (Months to Years) |
| Temperature | Room Temperature or 4°C[1][5] | ≤ 5°C, optimally -20°C[1][3] |
| Atmosphere | Tightly sealed container[1] | Tightly sealed, desiccated, inert gas purge[4] |
| Light | Protect from direct light | Store in the dark (e.g., amber vials)[3] |
Factors Influencing Stability and Key Degradation Pathways
Several factors can compromise the integrity of Fmoc-amino acids during storage. Understanding these factors is key to preventing the formation of impurities that can interfere with peptide synthesis.
-
Temperature & Moisture: Elevated temperatures accelerate all chemical degradation reactions. Moisture can lead to the hydrolysis of the Fmoc group or side-chain protecting groups.
-
Chemical Impurities: Residual reagents from the synthesis of the Fmoc-amino acid, such as acetic acid or ethyl acetate, can cause degradation over time.[6] Acetic acid, for example, can cause N-terminal acetylation (capping) during SPPS, leading to truncated peptide sequences.[6]
-
Inherent Amino Acid Instability: Certain amino acid derivatives are inherently less stable than others.
-
Fmoc-His(Trt)-OH: Prone to racemization, especially during the activation step of peptide coupling.[7]
-
Fmoc-Cys(Trt)-OH, Fmoc-Met-OH, Fmoc-Trp(Boc)-OH: Susceptible to oxidation.[3]
-
Fmoc-Asn(Trt)-OH & Fmoc-Gln(Trt)-OH: While the trityl (Trt) group improves solubility, these can still be liable to side reactions.[8] Unprotected Gln at the N-terminus of a peptide is known to cyclize, shortening shelf life.[3]
-
Common Degradation Pathways
-
Diketopiperazine (DKP) Formation: This is a major concern during the synthesis of dipeptides, particularly those involving Proline or Glycine. The exposed N-terminal amine of the second amino acid can attack the ester linkage to the resin, cleaving a cyclic dipeptide (DKP) from the solid support.[9] While primarily a synthesis issue, the stability of the loaded first amino acid on the resin is critical.
-
Fmoc Group Instability: The presence of any residual base (e.g., free amine impurities) can lead to the premature cleavage of the Fmoc group during storage. This generates the free amino acid, which can lead to double insertions or other side products during synthesis.[6]
-
Side-Chain Protecting Group Lability: Though designed to be stable to the mild base used for Fmoc deprotection, some side-chain protecting groups can be sensitive to other conditions over long-term storage.
Visualization of Key Processes
To better illustrate the concepts discussed, the following diagrams outline the logical relationships and workflows central to handling Fmoc-amino acids.
Caption: Logical diagram of factors influencing Fmoc-amino acid stability.
Caption: Experimental workflow for assessing Fmoc-amino acid stability.
Experimental Protocols for Stability Assessment
Assessing the purity and stability of Fmoc-amino acids is crucial for quality control. Reverse-Phase High-Performance Liquid Chromatography (RP-HPLC) is the primary analytical technique used.[10]
Protocol: RP-HPLC Method for Purity Analysis
This protocol provides a general method for determining the purity of an Fmoc-amino acid derivative. Method optimization may be required for specific amino acids.
1. Materials and Reagents:
-
Fmoc-amino acid sample
-
Acetonitrile (B52724) (ACN), HPLC grade
-
Water, HPLC grade
-
Trifluoroacetic acid (TFA), HPLC grade
-
HPLC system with a UV detector (220 nm or 262 nm)
-
C18 reverse-phase column (e.g., 4.6 x 150 mm, 5 µm particle size)
2. Mobile Phase Preparation:
-
Mobile Phase A: 0.1% TFA in Water (v/v)
-
Mobile Phase B: 0.1% TFA in Acetonitrile (v/v)[11]
-
Procedure: Degas both mobile phases for at least 15 minutes using sonication or vacuum filtration.
-
3. Sample Preparation:
-
Accurately weigh and dissolve the Fmoc-amino acid sample in a suitable solvent (e.g., acetonitrile or a mixture of ACN/water) to a final concentration of approximately 1 mg/mL.[11]
-
Vortex or sonicate briefly to ensure complete dissolution.
-
Filter the sample through a 0.2 µm syringe filter into an HPLC vial.
4. HPLC Conditions:
| Parameter | Value |
| Column | C18 Reverse-Phase (e.g., Sinochrom ODS-BP)[11] |
| Flow Rate | 1.0 mL/min[11] |
| Column Temperature | Room Temperature or 25°C |
| Detection Wavelength | 220 nm or 262 nm[11][12] |
| Injection Volume | 10 µL |
| Gradient Elution | 5% to 95% Mobile Phase B over 20-30 minutes[10] |
5. Data Analysis:
-
Integrate the peaks in the resulting chromatogram.
-
Calculate the purity of the Fmoc-amino acid as the percentage of the main peak area relative to the total area of all peaks.
-
For stability studies, compare the purity at each time point to the initial (T=0) purity. The appearance of new peaks may indicate degradation products, which can be further characterized using mass spectrometry (LC-MS).
Summary of Stability Data
Quantitative stability data for all 20 proteinogenic Fmoc-amino acids under varied conditions is not exhaustively available in public literature, as it is often proprietary information held by manufacturers. However, general stability profiles and known sensitivities are summarized below.
| Fmoc-Amino Acid Derivative | Relative Stability | Key Considerations & Potential Impurities |
| Fmoc-Gly-OH, Fmoc-Ala-OH, Fmoc-Leu-OH | High | Generally very stable. |
| Fmoc-Pro-OH | High | Stable as a monomer; can promote DKP formation in dipeptides.[9] |
| Fmoc-Ser(tBu)-OH, Fmoc-Thr(tBu)-OH | Moderate to High | Side-chain ether is generally stable. |
| Fmoc-Asp(OtBu)-OH, Fmoc-Glu(OtBu)-OH | Moderate to High | Side-chain ester is generally stable. |
| Fmoc-Asn(Trt)-OH, Fmoc-Gln(Trt)-OH | Moderate | Trityl group improves solubility but can be labile.[8] |
| Fmoc-Trp(Boc)-OH | Moderate to Low | Prone to oxidation. Purity specification often slightly lower.[6] |
| Fmoc-Cys(Trt)-OH | Moderate to Low | Thiol side chain is highly susceptible to air oxidation.[13] |
| Fmoc-Met-OH | Moderate to Low | Thioether side chain can oxidize to sulfoxide. |
| Fmoc-His(Trt)-OH | Low | Prone to racemization during storage and activation.[7] |
| Fmoc-Arg(Pbf)-OH | Moderate | Pbf group is bulky and can impact solubility/reactivity. |
Note: The purity of commercially available Fmoc-amino acids has significantly improved, with many suppliers offering >99% purity.[6][14] However, proper storage is essential to maintain this purity over time. Low levels of impurities like free amines or acetic acid can negatively impact stability and synthesis outcomes.[6]
References
- 1. peptide.com [peptide.com]
- 2. reddit.com [reddit.com]
- 3. Proper Storage and Handling Guidelines for Peptides - Yanfen Biotech [en.yanfenbio.com]
- 4. Handling and Storage Guidelines for Peptides and Proteins [sigmaaldrich.com]
- 5. Peptide handling & storage guidelines - How to store a peptide? [sb-peptide.com]
- 6. merckmillipore.com [merckmillipore.com]
- 7. researchgate.net [researchgate.net]
- 8. peptide.com [peptide.com]
- 9. researchgate.net [researchgate.net]
- 10. benchchem.com [benchchem.com]
- 11. CN109115899A - A kind of analysis method of Fmoc amino acid - Google Patents [patents.google.com]
- 12. tandfonline.com [tandfonline.com]
- 13. The investigation of Fmoc-cysteine derivatives in solid phase peptide synthesis - PubMed [pubmed.ncbi.nlm.nih.gov]
- 14. Advances in Fmoc solid‐phase peptide synthesis - PMC [pmc.ncbi.nlm.nih.gov]
A Technical Guide to Fmoc-L-leucine-¹³C₆,¹⁵N: Pricing, Availability, and Applications in Research
For Researchers, Scientists, and Drug Development Professionals
This technical guide provides an in-depth overview of Fmoc-L-leucine-¹³C₆,¹⁵N, a stable isotope-labeled amino acid critical for advanced research in proteomics and drug development. This document details its commercial availability and pricing, outlines comprehensive experimental protocols for its primary applications, and illustrates key biological pathways and experimental workflows.
Commercial Availability and Pricing
Fmoc-L-leucine-¹³C₆,¹⁵N is available from several specialized chemical suppliers. The pricing varies depending on the quantity and the vendor. Below is a summary of publicly available information. Researchers are encouraged to request quotes for bulk quantities.
| Supplier | Catalog Number | Quantity | Price (USD) | Availability |
| Cambridge Isotope Laboratories | CNLM-4345-H-0.1 | 0.1 g | $834.00 | In stock, ready for immediate shipment[1] |
| Sigma-Aldrich | 593532-100MG | 100 mg | $887.00 | Available to ship today[2] |
| 593532-500MG | 500 mg | $2,910.00 | Available to ship today[2] | |
| Anaspec | AS-61408-025 | 0.25 g | $1,285.00 | In production |
| ChemPep | 181224-100MG | 100 mg | Please Inquire | - |
| 181224-500MG | 500 mg | Please Inquire | - |
Core Applications and Technical Properties
Fmoc-L-leucine-¹³C₆,¹⁵N is a non-radioactive, heavy-isotope-labeled form of the essential amino acid leucine (B10760876), protected with a fluorenylmethoxycarbonyl (Fmoc) group. This modification makes it an indispensable tool in two major research areas: Solid-Phase Peptide Synthesis (SPPS) and Stable Isotope Labeling by Amino Acids in Cell Culture (SILAC).
Key Technical Properties:
-
Molecular Formula: (¹³CH₃)₂¹³CH¹³CH₂¹³CH(¹⁵NH-Fmoc)¹³CO₂H[2][3]
-
Isotopic Purity: Typically ≥98% for both ¹³C and ¹⁵N[2]
-
Chemical Purity: Generally ≥98%[1]
The Fmoc protecting group is base-labile, allowing for its removal under mild conditions, which is crucial for the stepwise assembly of peptides in SPPS. The uniform labeling with six ¹³C atoms and one ¹⁵N atom results in a distinct mass shift, enabling accurate quantification in mass spectrometry-based proteomics.
Experimental Protocols
Solid-Phase Peptide Synthesis (SPPS) using Fmoc-L-leucine-¹³C₆,¹⁵N
SPPS allows for the chemical synthesis of peptides by sequentially adding amino acids to a growing peptide chain that is covalently attached to a solid resin support. The use of Fmoc-L-leucine-¹³C₆,¹⁵N enables the production of isotopically labeled peptides, which can serve as internal standards for quantitative mass spectrometry assays.
Materials and Reagents:
-
Fmoc-L-leucine-¹³C₆,¹⁵N
-
Solid support resin (e.g., Wang resin, Rink amide resin)[4]
-
N,N-Dimethylformamide (DMF), peptide synthesis grade
-
Deprotection solution: 20% piperidine (B6355638) in DMF[4]
-
Coupling reagents: e.g., HBTU (2-(1H-benzotriazol-1-yl)-1,1,3,3-tetramethyluronium hexafluorophosphate), DIC (N,N'-diisopropylcarbodiimide)
-
Base: e.g., DIEA (N,N-diisopropylethylamine)
-
Washing solvents: Dichloromethane (DCM), DMF
-
Cleavage cocktail: e.g., 95% Trifluoroacetic acid (TFA), 2.5% water, 2.5% triisopropylsilane (B1312306) (TIS)[4]
-
Cold diethyl ether
Detailed Methodology:
-
Resin Preparation: Swell the chosen resin in DMF in a reaction vessel for at least one hour.[5]
-
First Amino Acid Loading: If starting a new synthesis, couple the first Fmoc-protected amino acid to the resin according to the resin manufacturer's protocol.
-
Fmoc Deprotection:
-
Coupling of Fmoc-L-leucine-¹³C₆,¹⁵N:
-
In a separate vial, dissolve Fmoc-L-leucine-¹³C₆,¹⁵N (typically 3-5 equivalents relative to the resin substitution) and a coupling agent (e.g., HBTU) in DMF.
-
Add a base (e.g., DIEA) to activate the amino acid.
-
Add the activated amino acid solution to the resin.
-
Agitate the reaction vessel for 1-2 hours at room temperature to allow for complete coupling.
-
-
Washing: Wash the resin with DMF to remove excess reagents and byproducts.
-
Repeat Cycle: Repeat the deprotection and coupling steps for each subsequent amino acid in the desired peptide sequence.
-
Final Deprotection: After the final coupling step, perform a final Fmoc deprotection as described in step 3.
-
Cleavage and Deprotection:
-
Wash the peptidyl-resin with DCM and dry it.
-
Add the cleavage cocktail to the resin to cleave the peptide from the resin and remove any side-chain protecting groups. This step should be performed in a fume hood.[6]
-
Incubate for 2-3 hours at room temperature.
-
-
Peptide Precipitation and Purification:
-
Filter the resin and collect the filtrate containing the peptide.
-
Precipitate the peptide by adding the filtrate to cold diethyl ether.[6]
-
Centrifuge to pellet the crude peptide, wash with cold ether, and dry under vacuum.
-
Purify the peptide using reverse-phase high-performance liquid chromatography (RP-HPLC).
-
Stable Isotope Labeling by Amino Acids in Cell Culture (SILAC)
SILAC is a powerful technique for quantitative proteomics that relies on the metabolic incorporation of "heavy" amino acids into proteins. By growing one cell population in a medium containing a heavy isotope-labeled amino acid (e.g., Fmoc-L-leucine-¹³C₆,¹⁵N is used to synthesize the heavy leucine for the media) and a control population in a medium with the corresponding "light" (natural abundance) amino acid, the relative abundance of thousands of proteins can be determined by mass spectrometry.
Materials and Reagents:
-
Cell line of interest (auxotrophic for the amino acid to be labeled, if possible)
-
SILAC-grade cell culture medium deficient in the amino acid to be labeled (e.g., Leucine-free RPMI)
-
Dialyzed fetal bovine serum (dFBS)
-
"Heavy" amino acid: L-leucine-¹³C₆,¹⁵N
-
"Light" amino acid: L-leucine
-
Standard cell culture reagents and equipment
-
Lysis buffer (e.g., RIPA buffer with protease and phosphatase inhibitors)
-
Protein digestion reagents (e.g., DTT, iodoacetamide, trypsin)
-
Mass spectrometer
Detailed Methodology:
-
Media Preparation:
-
Prepare "heavy" and "light" SILAC media by supplementing the amino acid-deficient medium with either the "heavy" or "light" L-leucine to the desired final concentration.
-
Add dFBS and other necessary supplements.
-
-
Cell Adaptation and Label Incorporation:
-
Culture the cells in the "heavy" and "light" media for at least five to six cell divisions to ensure complete incorporation of the labeled amino acid into the proteome.[7]
-
Monitor the incorporation efficiency by mass spectrometry analysis of a small aliquot of cells. Incorporation should be >95%.[7]
-
-
Experimental Treatment:
-
Once fully labeled, treat the cell populations according to the experimental design (e.g., drug treatment vs. vehicle control).
-
-
Cell Harvesting and Lysis:
-
Harvest the "heavy" and "light" cell populations.
-
Combine the cell pellets at a 1:1 ratio based on cell number or protein concentration.
-
Lyse the combined cell pellet using an appropriate lysis buffer.
-
-
Protein Digestion:
-
Quantify the protein concentration of the lysate.
-
Reduce disulfide bonds with DTT and alkylate cysteine residues with iodoacetamide.
-
Digest the proteins into peptides using a protease such as trypsin.
-
-
Mass Spectrometry Analysis:
-
Analyze the resulting peptide mixture using high-resolution LC-MS/MS.
-
-
Data Analysis:
-
Use specialized software (e.g., MaxQuant, Proteome Discoverer) to identify peptides and quantify the intensity ratios of the "heavy" and "light" peptide pairs.
-
These ratios reflect the relative abundance of the corresponding proteins in the two cell populations.
-
Visualizing Workflows and Pathways
Experimental Workflows
The following diagrams illustrate the general workflows for Fmoc-SPPS and SILAC.
Caption: General workflow for Fmoc-based Solid-Phase Peptide Synthesis (SPPS).
Caption: Experimental workflow for Stable Isotope Labeling by Amino Acids in Cell Culture (SILAC).
Leucine Sensing and the mTORC1 Signaling Pathway
Leucine is a critical signaling molecule that activates the mTORC1 (mechanistic Target of Rapamycin Complex 1) pathway, a central regulator of cell growth, proliferation, and metabolism. The availability of leucine is sensed by cellular proteins, leading to the activation of mTORC1 and subsequent downstream signaling events that promote protein synthesis.
Caption: Simplified diagram of the leucine-sensing mTORC1 signaling pathway.
References
- 1. SILAC Metabolic Labeling Systems | Thermo Fisher Scientific - TW [thermofisher.com]
- 2. Leucine Sensing by the mTORC1 Pathway in the Liver - Andrew Cangelosi [grantome.com]
- 3. researchgate.net [researchgate.net]
- 4. Fmoc Solid Phase Peptide Synthesis: Mechanism and Protocol - Creative Peptides [creative-peptides.com]
- 5. benchchem.com [benchchem.com]
- 6. benchchem.com [benchchem.com]
- 7. tools.thermofisher.com [tools.thermofisher.com]
The Cornerstone of Modern Peptide Synthesis: A Technical Guide to the Fmoc Protecting Group
For Researchers, Scientists, and Drug Development Professionals
The synthesis of peptides, essential molecules in biochemistry, drug development, and materials science, relies on the precise and controlled assembly of amino acids.[1] A key element in achieving this precision is the use of protecting groups, which temporarily block reactive functional groups to prevent unwanted side reactions. Among these, the 9-fluorenylmethyloxycarbonyl (Fmoc) group has become the gold standard for Nα-amino group protection in solid-phase peptide synthesis (SPPS), largely due to its mild cleavage conditions and orthogonality with other protecting groups.[2][3]
This technical guide provides an in-depth exploration of the purpose and application of the Fmoc group in peptide synthesis. It covers the fundamental principles of Fmoc chemistry, detailed experimental protocols for key synthetic steps, quantitative data on reaction parameters, and a discussion of potential challenges and troubleshooting strategies.
The Role and Advantages of the Fmoc Group
The primary function of the Fmoc group is to protect the α-amino group of an amino acid during the peptide bond formation step.[4] This protection prevents the amino group from reacting with the activated carboxyl group of another amino acid, ensuring the controlled, sequential addition of amino acids to the growing peptide chain.[5] The Fmoc group is introduced onto the amino acid via reaction with reagents like Fmoc-chloride (Fmoc-Cl) or Fmoc-N-hydroxysuccinimide (Fmoc-OSu).[6]
The widespread adoption of Fmoc chemistry in SPPS is attributable to several key advantages over the older tert-butyloxycarbonyl (Boc) strategy:
-
Mild Deprotection Conditions: The Fmoc group is base-labile and can be removed under mild basic conditions, typically with a solution of piperidine (B6355638) in N,N-dimethylformamide (DMF).[6][7] This contrasts sharply with the harsh acidic conditions (e.g., trifluoroacetic acid, TFA) required to remove the Boc group, which can degrade sensitive peptide sequences and side chains.[3][4]
-
Orthogonality: The base-lability of the Fmoc group is orthogonal to the acid-labile side-chain protecting groups (e.g., tBu, Trt, Pbf) and the acid-labile linkers used to attach the peptide to the solid support.[2][8] This orthogonality allows for the selective removal of the Nα-Fmoc group at each step of the synthesis without affecting the side-chain protecting groups or the linkage to the resin.[2][7]
-
Compatibility: The milder conditions of Fmoc chemistry are compatible with a wider range of chemistries, including the synthesis of peptides with post-translational modifications like phosphorylation and glycosylation, which are often unstable under the harsh conditions of Boc synthesis.[3][9]
-
Real-Time Monitoring: The cleavage of the Fmoc group produces a dibenzofulvene-piperidine adduct that has a strong UV absorbance around 300 nm.[6][10] This property allows for the real-time spectrophotometric monitoring of the deprotection reaction, providing a quantitative measure of reaction completion and enabling the optimization of synthesis cycles.[6][11]
The Fmoc Solid-Phase Peptide Synthesis (SPPS) Cycle
Fmoc-based SPPS is a cyclical process involving the sequential addition of Fmoc-protected amino acids to a growing peptide chain that is anchored to an insoluble solid support (resin).[12] Each cycle consists of three main steps: deprotection, coupling, and washing.
Fmoc Deprotection Mechanism
The removal of the Fmoc group is a base-catalyzed β-elimination reaction. A base, typically a secondary amine like piperidine, abstracts the acidic proton from the C9 position of the fluorene (B118485) ring. This leads to the elimination of dibenzofulvene and carbon dioxide, releasing the free N-terminal amine of the peptide. The reactive dibenzofulvene is then trapped by excess piperidine to form a stable adduct.[13][14]
Quantitative Data in Fmoc Chemistry
The efficiency of Fmoc deprotection and coupling reactions is critical for the successful synthesis of high-purity peptides. The following tables summarize key quantitative data related to these processes.
Fmoc Deprotection Kinetics
The rate of Fmoc deprotection can be influenced by the deprotection reagent, its concentration, and the specific amino acid residue.
| Deprotection Reagent | Concentration | Amino Acid | Time (min) | Deprotection Efficiency (%) |
| Piperidine (PP) | 20% in DMF | Fmoc-L-Leucine-OH | 3 | ~80 |
| Piperidine (PP) | 20% in DMF | Fmoc-L-Leucine-OH | 7 | >95 |
| Piperidine (PP) | 20% in DMF | Fmoc-L-Arginine(Pbf)-OH | 10 | >95 |
| 4-Methylpiperidine (4MP) | 20% in DMF | Fmoc-L-Leucine-OH | 3 | ~80 |
| 4-Methylpiperidine (4MP) | 20% in DMF | Fmoc-L-Arginine(Pbf)-OH | 10 | >95 |
| Piperazine (PZ) | 10% in DMF/Ethanol (9:1) | Fmoc-L-Leucine-OH | 3 | <80 |
| Piperazine (PZ) | 10% in DMF/Ethanol (9:1) | Fmoc-L-Arginine(Pbf)-OH | 10 | >95 |
Data adapted from studies on deprotection kinetics.[9] Actual times may vary depending on the peptide sequence and synthesis conditions.
Common Coupling Reagents
The choice of coupling reagent is crucial for efficient amide bond formation and minimizing side reactions, particularly racemization.
| Coupling Reagent | Class | Key Advantages |
| HBTU (O-(Benzotriazol-1-yl)-N,N,N',N'-tetramethyluronium hexafluorophosphate) | Aminium/Uronium Salt | Rapid activation, high coupling efficiency, commonly used in automated synthesis.[15] |
| HATU (1-[Bis(dimethylamino)methylene]-1H-1,2,3-triazolo[4,5-b]pyridinium 3-oxid hexafluorophosphate) | Aminium/Uronium Salt | Highly effective for sterically hindered amino acids and difficult couplings. |
| HCTU (O-(6-Chlorobenzotriazol-1-yl)-N,N,N',N'-tetramethyluronium hexafluorophosphate) | Aminium/Uronium Salt | Similar to HBTU, often with slightly faster kinetics. |
| DIC/HOBt (N,N'-Diisopropylcarbodiimide / Hydroxybenzotriazole) | Carbodiimide/Additive | Cost-effective, minimizes racemization, especially for sensitive residues like Cysteine and Histidine. |
| PyBOP (Benzotriazol-1-yl-oxytripyrrolidinophosphonium hexafluorophosphate) | Phosphonium Salt | High reactivity, useful for difficult couplings. |
Detailed Experimental Protocols
The following protocols provide step-by-step instructions for the key stages of manual Fmoc-based SPPS.
Protocol 1: Resin Swelling and Preparation
-
Weigh the appropriate amount of resin (e.g., Wang resin for C-terminal acid, Rink Amide resin for C-terminal amide) into a reaction vessel.
-
Add DMF (approximately 10 mL per gram of resin) to the vessel.
-
Allow the resin to swell for at least 30-60 minutes at room temperature with gentle agitation.[16]
-
Drain the DMF from the reaction vessel.
Protocol 2: Fmoc Deprotection
-
Add a 20% solution of piperidine in DMF to the swollen resin.
-
Agitate the mixture for an initial 5-10 minutes.[17]
-
Drain the deprotection solution.
-
Add a fresh portion of the 20% piperidine in DMF solution and agitate for another 15-20 minutes to ensure complete deprotection.[17]
-
Drain the solution and wash the resin thoroughly with DMF (5-7 times) to remove all traces of piperidine and the dibenzofulvene-piperidine adduct.[16]
Protocol 3: Amino Acid Coupling (using HBTU)
-
In a separate vial, dissolve the Fmoc-protected amino acid (2-4 equivalents relative to the resin loading) and HBTU (2-4 equivalents) in DMF.
-
Add N,N-diisopropylethylamine (DIPEA) (4-8 equivalents) to the amino acid solution to activate the carboxyl group.
-
Allow the activation to proceed for 1-5 minutes.
-
Add the activated amino acid solution to the deprotected peptide-resin.
-
Agitate the reaction mixture for 1-2 hours at room temperature.
-
Monitor the completion of the coupling reaction using the Kaiser test.[18]
-
Once the reaction is complete (negative Kaiser test), drain the coupling solution and wash the resin with DMF (3-5 times).
Protocol 4: Monitoring Coupling with the Kaiser Test
-
Transfer a small sample of the resin beads (10-15 beads) to a small test tube.
-
Add 2-3 drops of each of the following three solutions:
-
Solution A: Potassium cyanide in pyridine.
-
Solution B: Ninhydrin in n-butanol.
-
Solution C: Phenol in n-butanol.[19]
-
-
Heat the test tube at approximately 110°C for 5 minutes.
-
Observe the color of the beads and the solution:
-
Dark blue beads and solution: Positive result, indicating the presence of free primary amines (incomplete coupling).
-
Colorless or faint yellow beads and solution: Negative result, indicating complete coupling.[19]
-
Protocol 5: Cleavage of the Peptide from the Resin and Side-Chain Deprotection
For Wang Resin (C-terminal acid):
-
Wash the final peptide-resin with DCM and dry under vacuum.
-
Prepare a cleavage cocktail, typically TFA/Water/Triisopropylsilane (TIS) in a 95:2.5:2.5 ratio.[7]
-
Add the cleavage cocktail to the resin (approximately 10 mL per gram of resin).
-
Allow the reaction to proceed for 2-3 hours at room temperature with occasional agitation.[7]
-
Filter the resin and collect the filtrate containing the cleaved peptide.
-
Precipitate the crude peptide by adding the filtrate to a 10-fold volume of cold diethyl ether.[20]
-
Centrifuge to pellet the peptide, decant the ether, and wash the pellet with cold ether.
-
Dry the peptide pellet under vacuum.
For Rink Amide Resin (C-terminal amide):
-
Follow the same initial washing and drying steps as for Wang resin.
-
Use a similar TFA-based cleavage cocktail (e.g., TFA/Water/TIS 95:2.5:2.5).
-
The cleavage time is typically 2-3 hours.[21]
-
Follow the same precipitation and washing procedure as for Wang resin.[4]
Potential Side Reactions and Troubleshooting
While Fmoc chemistry is robust, several side reactions can occur, potentially impacting the yield and purity of the final peptide.
-
Aspartimide Formation: Peptides containing aspartic acid are susceptible to the formation of a cyclic aspartimide intermediate under basic conditions, which can lead to racemization and the formation of β-aspartyl peptides.[22] This can be minimized by using shorter deprotection times and adding HOBt to the deprotection solution.
-
Diketopiperazine Formation: At the dipeptide stage, especially with proline as one of the first two residues, intramolecular cyclization can occur, leading to the formation of a diketopiperazine and cleavage of the dipeptide from the resin. Using sterically hindered resins like 2-chlorotrityl chloride resin can suppress this side reaction.
-
Racemization: The loss of stereochemical integrity at the α-carbon can occur during amino acid activation, particularly for sensitive residues like cysteine and histidine. The choice of coupling reagent and the avoidance of excess base can mitigate racemization.
-
Aggregation: Hydrophobic peptide sequences can aggregate on the resin, leading to incomplete coupling and deprotection. Switching to a more polar solvent like N-methylpyrrolidone (NMP), using chaotropic salts, or incorporating backbone-protecting groups can help disrupt aggregation.
References
- 1. peptide.com [peptide.com]
- 2. chempep.com [chempep.com]
- 3. kilobio.com [kilobio.com]
- 4. peptide.com [peptide.com]
- 5. Fmoc Resin Cleavage and Deprotection [sigmaaldrich.com]
- 6. benchchem.com [benchchem.com]
- 7. benchchem.com [benchchem.com]
- 8. tools.thermofisher.com [tools.thermofisher.com]
- 9. Deprotection Reagents in Fmoc Solid Phase Peptide Synthesis: Moving Away from Piperidine? - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Thieme E-Books & E-Journals [thieme-connect.de]
- 11. researchgate.net [researchgate.net]
- 12. benchchem.com [benchchem.com]
- 13. peptide.com [peptide.com]
- 14. merckmillipore.com [merckmillipore.com]
- 15. HBTU activation for automated Fmoc solid-phase peptide synthesis - PubMed [pubmed.ncbi.nlm.nih.gov]
- 16. benchchem.com [benchchem.com]
- 17. americanpeptidesociety.org [americanpeptidesociety.org]
- 18. peptide.com [peptide.com]
- 19. pdfs.semanticscholar.org [pdfs.semanticscholar.org]
- 20. peptide.com [peptide.com]
- 21. Fmoc Solid Phase Peptide Synthesis: Mechanism and Protocol - Creative Peptides [creative-peptides.com]
- 22. Advances in Fmoc solid‐phase peptide synthesis - PMC [pmc.ncbi.nlm.nih.gov]
Methodological & Application
Application Notes and Protocols for Fmoc-Leucine-¹³C₆,¹⁵N in Solid-Phase Peptide Synthesis
For Researchers, Scientists, and Drug Development Professionals
These application notes provide a comprehensive guide for the utilization of Fmoc-Leucine-¹³C₆,¹⁵N in solid-phase peptide synthesis (SPPS). This isotopically labeled amino acid is a powerful tool for a range of applications, including quantitative proteomics, structural biology, and metabolic research.[1][2][][4] The incorporation of stable isotopes allows for the precise tracking and quantification of peptides and proteins using mass spectrometry (MS) and nuclear magnetic resonance (NMR) spectroscopy.[]
Applications of Peptides Incorporating Fmoc-Leucine-¹³C₆,¹⁵N
The synthesis of peptides with site-specific incorporation of stable isotopes like ¹³C and ¹⁵N opens avenues for numerous advanced research applications:
-
Quantitative Proteomics: Labeled peptides serve as ideal internal standards for the absolute quantification of proteins in complex biological samples.[] The known mass shift of the labeled peptide compared to its endogenous counterpart allows for accurate determination of protein expression levels. This is particularly valuable in biomarker discovery and validation.
-
Structural Biology: NMR studies of proteins and peptides benefit from the incorporation of ¹³C and ¹⁵N. These isotopes are NMR-active and provide valuable constraints for determining the three-dimensional structure and dynamics of biomolecules.[5]
-
Metabolic Labeling and Flux Analysis: Introducing peptides containing stable isotopes into biological systems enables the tracing of metabolic pathways and the study of protein turnover.[]
-
Pharmacokinetic Studies: Labeled peptides are crucial for tracking the absorption, distribution, metabolism, and excretion (ADME) of peptide-based drug candidates.[2]
Physicochemical Properties and Handling
Fmoc-L-Leucine-¹³C₆,¹⁵N is chemically identical to its unlabeled counterpart, with the key difference being its increased molecular weight due to the presence of six ¹³C atoms and one ¹⁵N atom.[]
| Property | Value | Reference |
| Molecular Weight | 360.36 g/mol | [2][6] |
| Isotopic Purity | Typically >98% for ¹³C and ¹⁵N | [6] |
| Appearance | White to off-white solid | |
| Solubility | Soluble in common SPPS solvents like DMF and NMP | [2] |
| Storage | Store refrigerated (2-8 °C) and desiccated, protected from light. | [6] |
Experimental Protocols for Solid-Phase Peptide Synthesis
The following protocols are based on standard Fmoc/tBu SPPS chemistry and are optimized for the efficient incorporation of the valuable Fmoc-Leucine-¹³C₆,¹⁵N.
General Workflow of Fmoc-SPPS
The synthesis cycle involves the sequential addition of amino acids to a growing peptide chain attached to a solid support (resin). Each cycle consists of three main steps: Fmoc deprotection, amino acid coupling, and washing.
Figure 1. General workflow for Fmoc solid-phase peptide synthesis.
Detailed Protocol for a Single Coupling Cycle of Fmoc-Leucine-¹³C₆,¹⁵N
This protocol is designed for a manual synthesis on a 0.1 mmol scale. For automated synthesizers, the protocol should be adapted according to the manufacturer's instructions.
Materials:
-
Fmoc-protected amino acid resin (e.g., Wang, Rink Amide)
-
Fmoc-Leucine-¹³C₆,¹⁵N
-
N,N-Dimethylformamide (DMF), peptide synthesis grade
-
Piperidine (B6355638), 20% (v/v) in DMF
-
Coupling reagent (e.g., HBTU, HATU, HCTU, or COMU)
-
Base (e.g., N,N-Diisopropylethylamine (DIPEA) or N-methylmorpholine (NMM))
-
Dichloromethane (DCM)
-
Washing solvents (e.g., DMF, DCM, Isopropanol)
Protocol:
-
Resin Swelling: Swell the resin in DMF for at least 30 minutes in a reaction vessel.[1]
-
Fmoc Deprotection:
-
Washing: Wash the resin thoroughly with DMF (3-5 times) to remove residual piperidine and the dibenzofulvene-piperidine adduct.
-
Coupling of Fmoc-Leucine-¹³C₆,¹⁵N:
-
In a separate vial, dissolve Fmoc-Leucine-¹³C₆,¹⁵N (2-4 equivalents relative to resin loading) and the coupling reagent (e.g., HATU, 1.95 equivalents) in DMF.
-
Add the base (e.g., DIPEA, 3-4 equivalents) to the solution and pre-activate for 1-5 minutes. To minimize the risk of racemization, especially for sensitive amino acids, pre-activation times should be kept short.[9]
-
Add the activated amino acid solution to the deprotected resin.
-
Agitate the reaction mixture for 1-2 hours at room temperature. The completion of the coupling reaction can be monitored using a qualitative ninhydrin (B49086) (Kaiser) test.[1]
-
-
Washing:
-
Drain the coupling solution.
-
Wash the resin thoroughly with DMF (3-5 times) and DCM (3-5 times) to remove excess reagents and byproducts.
-
Cleavage and Final Deprotection
The choice of cleavage cocktail depends on the resin and the amino acid composition of the peptide, particularly the presence of sensitive residues.
Standard Cleavage Cocktail (Reagent K):
| Component | Percentage | Purpose |
| Trifluoroacetic acid (TFA) | 82.5% | Cleaves peptide from resin and removes side-chain protecting groups |
| Water | 5% | Scavenger |
| Phenol | 5% | Scavenger |
| Thioanisole | 5% | Scavenger |
| 1,2-Ethanedithiol (EDT) | 2.5% | Scavenger |
Procedure:
-
Wash the peptide-resin with DCM and dry it under a stream of nitrogen.
-
Add the cleavage cocktail to the resin (typically 10 mL per gram of resin).
-
Gently agitate the mixture at room temperature for 2-4 hours.[10]
-
Filter the resin and collect the filtrate containing the cleaved peptide.
-
Precipitate the peptide by adding the filtrate to cold diethyl ether.
-
Centrifuge the mixture to pellet the peptide.
-
Wash the peptide pellet with cold diethyl ether to remove scavengers and dissolved protecting groups.
-
Dry the crude peptide under vacuum.
Data Presentation: Coupling Reagent Performance
The choice of coupling reagent is critical for achieving high coupling efficiency and minimizing racemization, which is paramount when using expensive isotopically labeled amino acids.
| Coupling Reagent | Activating Agent Class | Typical Equivalents (vs. Amino Acid) | Base (Equivalents) | Key Advantages | Potential Considerations |
| HBTU | Uronium Salt | 1.0 | DIPEA (2.0) | Cost-effective, widely used. | Can lead to guanidinylation of the N-terminus if used in excess.[11] |
| HATU | Uronium Salt | 1.0 | DIPEA (2.0) | High coupling efficiency, especially for hindered amino acids. | More expensive than HBTU. |
| HCTU | Uronium Salt | 1.0 | DIPEA (2.0) | High coupling efficiency, comparable to HATU, more cost-effective.[11] | |
| COMU | Uronium Salt | 1.0 | DIPEA (2.0) | High coupling efficiency, safer handling (non-explosive byproducts).[12][13] | |
| DIC/Oxyma | Carbodiimide/Additive | 1.0 / 1.0 | - | Low risk of racemization. | Slower reaction times compared to uronium salts. |
Note: The optimal coupling conditions should be determined empirically for each specific peptide sequence.
Quality Control: Mass Spectrometry Analysis
After synthesis, the purity and identity of the labeled peptide must be confirmed by mass spectrometry. The observed mass should correspond to the theoretical mass, accounting for the mass shift introduced by the ¹³C and ¹⁵N isotopes.
Example Mass Calculation: For a peptide containing one Leucine-¹³C₆,¹⁵N residue, the expected mass will be 7.014 Da higher than the unlabeled peptide (6 x 1.00335 Da for ¹³C + 1 x 0.99703 Da for ¹⁵N).
The isotopic distribution in the mass spectrum will also be altered, providing a clear signature of successful incorporation. Tandem mass spectrometry (MS/MS) can be used to confirm the position of the labeled leucine (B10760876) residue within the peptide sequence.[14]
Signaling Pathway and Experimental Workflow Diagrams
The synthesized isotopically labeled peptides can be used as internal standards in quantitative proteomics experiments to study signaling pathways.
Figure 2. Workflow for quantitative proteomics using a labeled peptide internal standard.
This workflow illustrates how a peptide synthesized with Fmoc-Leucine-¹³C₆,¹⁵N is used as a "spike-in" standard for the accurate quantification of a target protein in different cell populations.[15]
By following these detailed application notes and protocols, researchers can effectively utilize Fmoc-Leucine-¹³C₆,¹⁵N to synthesize high-quality, isotopically labeled peptides for a wide range of advanced scientific applications.
References
- 1. rsc.org [rsc.org]
- 2. chempep.com [chempep.com]
- 4. chempep.com [chempep.com]
- 5. Segmental and site-specific isotope labelling strategies for structural analysis of posttranslationally modified proteins - PMC [pmc.ncbi.nlm.nih.gov]
- 6. L-Leucine-ð-Fmoc (¹³Câ, 99%; ¹âµN, 99%) - Cambridge Isotope Laboratories, CNLM-4345-H-0.1 [isotope.com]
- 7. Fmoc Amino Acids for SPPS - AltaBioscience [altabioscience.com]
- 8. peptide.com [peptide.com]
- 9. Advances in Fmoc solid‐phase peptide synthesis - PMC [pmc.ncbi.nlm.nih.gov]
- 10. tools.thermofisher.com [tools.thermofisher.com]
- 11. benchchem.com [benchchem.com]
- 12. 2024.sci-hub.st [2024.sci-hub.st]
- 13. bachem.com [bachem.com]
- 14. Rapid mass spectrometric analysis of 15N-Leu incorporation fidelity during preparation of specifically labeled NMR samples - PMC [pmc.ncbi.nlm.nih.gov]
- 15. Use of stable isotope labeling by amino acids in cell culture as a spike-in standard in quantitative proteomics - PubMed [pubmed.ncbi.nlm.nih.gov]
Application Notes and Protocols for Incorporating Labeled Amino Acids into Peptides
For Researchers, Scientists, and Drug Development Professionals
Introduction
The incorporation of labeled amino acids into peptides is a cornerstone technique in modern biological and pharmaceutical research. Labeled peptides, which contain isotopes, fluorescent tags, or other modifications, are indispensable tools for a wide range of applications. These include quantitative proteomics, metabolic labeling, structural analysis via Nuclear Magnetic Resonance (NMR), and tracking peptide-protein interactions.[1][2][3][4] Two primary methodologies dominate the field of labeled peptide synthesis: chemical synthesis via Solid-Phase Peptide Synthesis (SPPS) and biological synthesis using Cell-Free Protein Synthesis (CFPS) systems.[1][5]
SPPS allows for the precise, site-specific incorporation of labeled amino acids into a growing peptide chain, offering unparalleled control over the final product's composition.[4] Conversely, CFPS provides a flexible in vitro environment for the rapid production of peptides and proteins, enabling both uniform and site-specific labeling through techniques like stop codon suppression.[5][6][7] The choice of method depends on factors such as the desired peptide length, the type of label, the required yield, and the specific research application. This document provides detailed protocols for both SPPS and CFPS and summarizes key data to guide researchers in selecting the optimal strategy.
Methods for Incorporating Labeled Amino Acids
Solid-Phase Peptide Synthesis (SPPS)
SPPS is a chemical method that builds a peptide sequence by sequentially adding amino acids to a chain anchored to an insoluble resin support.[4][8] The most common approach, Fmoc/tBu chemistry, involves using the acid-labile tert-butyl (tBu) group for side-chain protection and the base-labile 9-fluorenylmethoxycarbonyl (Fmoc) group for Nα-amino protection.[9] A labeled amino acid, protected in the same manner as its unlabeled counterparts, can be introduced at any specific position in the sequence.[4]
Advantages:
-
High Specificity: Allows for precise, site-specific placement of labels.[4]
-
Versatility: Compatible with a wide range of labels, including stable isotopes (¹³C, ¹⁵N, D), fluorescent dyes, and biotin.[1][10]
-
High Purity: The final product can be purified to high levels (>98%) using High-Performance Liquid Chromatography (HPLC).[11]
Limitations:
-
Peptide Length: Generally inefficient for peptides longer than 50 amino acids due to accumulating side reactions and incomplete couplings.[9]
-
Difficult Sequences: Sequences prone to aggregation can lead to poor synthesis yields.[9][12]
Cell-Free Protein Synthesis (CFPS)
CFPS systems utilize cellular machinery—such as ribosomes, enzymes, and translation factors—in an in vitro environment to synthesize proteins from a DNA template.[5][7] These systems, often derived from E. coli or rabbit reticulocytes, are "open," meaning researchers can directly manipulate the reaction components.[5][7] For labeling, one can either replace all instances of a specific amino acid with its labeled version for uniform labeling or use specialized techniques like amber stop codon suppression with pre-charged tRNAs to achieve site-specific incorporation of non-canonical or labeled amino acids.[6][13][14]
Advantages:
-
Speed: Rapidly produces peptides and proteins, often within hours.[13]
-
Toxic Proteins: Can synthesize proteins that would be toxic to living cells.[7]
-
Flexibility: The open nature of the system allows for easy addition of labeled amino acids and other components.[5][7]
-
Long Peptides: Capable of synthesizing full-length proteins that are inaccessible via SPPS.
Limitations:
-
Yield and Cost: Yields can be lower than in vivo methods, and the reagents can be expensive.[13]
-
Incorporation Efficiency: Achieving high incorporation efficiency for labeled or non-canonical amino acids can be challenging and may require system optimization.[13][]
Quantitative Data Summary
The choice between SPPS and CFPS often involves a trade-off between control, speed, and scale. The tables below summarize key quantitative parameters to aid in this decision.
Table 1: Comparison of SPPS and CFPS for Labeled Peptide Synthesis
| Parameter | Solid-Phase Peptide Synthesis (SPPS) | Cell-Free Protein Synthesis (CFPS) |
| Typical Peptide Length | 2-50 amino acids[9] | Up to full-length proteins (>50 kDa) |
| Labeling Specificity | Site-specific[4] | Uniform or site-specific (with suppression)[6][13] |
| Common Label Types | Stable isotopes, fluorescent tags, biotin[1] | Stable isotopes, fluorescent amino acids[13][14] |
| Typical Yield | Milligrams to grams[11] | Micrograms to milligrams[13] |
| Synthesis Time | Days to weeks (depending on length) | Hours[13] |
| Purity (Post-Purification) | High (>95-98%)[11] | Variable, depends on purification |
| Key Advantage | Precise control over label position[4] | Speed and ability to produce long/toxic proteins[7] |
Table 2: Purity Grades of Synthetic Peptides and Their Applications
| Purity Level (by HPLC) | Description & Impurities | Common Applications |
| Crude / Unpurified | Contains the target peptide along with many impurities (truncated sequences, protecting groups).[11] | High-throughput screening, antibody generation. |
| >80% | Standard purity grade with some truncated sequences removed.[11] | Western blotting, enzyme-substrate studies. |
| >95% | High quality, with most impurities removed.[11] | Quantitative mass spectrometry standards, NMR studies, X-ray crystallography.[11] |
| >98% | Highest purity, for highly sensitive applications.[11] | Clinical trials, structure-activity relationship (SAR) studies. |
Experimental Workflows
The following diagrams illustrate the generalized workflows for incorporating labeled amino acids using SPPS and CFPS.
Caption: Workflow for Solid-Phase Peptide Synthesis (SPPS).
Caption: Workflow for Cell-Free Protein Synthesis (CFPS).
Experimental Protocols
Protocol 1: Site-Specific Labeling via Manual Fmoc-SPPS
This protocol describes the manual synthesis of a peptide on a 100 mg Rink Amide resin scale, incorporating one isotopically labeled amino acid.[16]
Materials and Reagents:
-
Rink Amide resin (100 mg)
-
Fmoc-protected amino acids (standard and labeled)
-
N,N-Dimethylformamide (DMF) or 1-methyl-2-pyrrolidinone (B7775990) (NMP)[16]
-
Deprotection solution: 20% 4-methylpiperidine (B120128) in DMF[16]
-
Activation solution: 0.5 M HATU in DMF[17]
-
Base: 2.0 M N,N-Diisopropylethylamine (DIEA) in NMP[16]
-
Washing solvent: DMF
-
Cleavage cocktail: 95% Trifluoroacetic acid (TFA), 2.5% water, 2.5% triisopropylsilane (B1312306) (TIS)[9]
-
Cold diethyl ether
-
Solid Phase Synthesis vessel or column[16]
Procedure:
-
Resin Swelling: Swell 100 mg of Rink Amide resin in 1 mL of DMF in the synthesis vessel for at least 1 hour (or overnight in a refrigerator).[16]
-
Fmoc Deprotection: Drain the DMF, add 1 mL of deprotection solution, and agitate for 5 minutes. Drain and repeat for another 15 minutes to remove the Fmoc group from the resin-bound amino acid.[8]
-
Washing: Wash the resin thoroughly by adding and draining 1 mL of DMF (5 times) to remove residual piperidine.[8]
-
Amino Acid Activation & Coupling:
-
In a separate vial, dissolve a 4-fold molar excess of the desired Fmoc-amino acid (standard or labeled) and a 3.9-fold molar excess of HATU in DMF.[17]
-
Add an 8-fold molar excess of DIEA to the amino acid/HATU mixture and allow it to pre-activate for 5 minutes.[17]
-
Add the activated amino acid solution to the resin. Agitate for 1-2 hours at room temperature.
-
-
Washing: Drain the coupling solution and wash the resin thoroughly with DMF (5 times).
-
Cycle Repetition: Repeat steps 2-5 for each amino acid in the peptide sequence. Use the labeled Fmoc-amino acid at the desired position in the chain.
-
Final Deprotection: After the final amino acid is coupled, perform a final Fmoc deprotection (Step 2) and wash (Step 3).
-
Cleavage and Global Deprotection:
-
Wash the peptide-resin with dichloromethane (B109758) (DCM) and dry it under vacuum.
-
Add 2 mL of the cleavage cocktail to the dry resin and agitate for 3 hours at room temperature. This cleaves the peptide from the resin and removes side-chain protecting groups.[9]
-
-
Peptide Precipitation & Purification:
-
Filter the resin and collect the TFA solution containing the peptide.
-
Precipitate the crude peptide by adding the TFA solution to a 50 mL tube of cold diethyl ether.
-
Centrifuge to pellet the peptide, decant the ether, and dry the peptide pellet.
-
Purify the peptide using reverse-phase HPLC (RP-HPLC).[11][18][19]
-
Confirm the mass and purity using mass spectrometry.[11]
-
Protocol 2: Uniform Labeling via a Human Cell-Free System
This protocol is adapted from a method for expressing stable isotope-labeled proteins using a human cell-free lysate system.[13] It is suitable for uniform labeling with isotopes like ¹³C₆,¹⁵N₂ L-lysine and ¹³C₆,¹⁵N₄ L-arginine.
Materials and Reagents:
-
Human cell-free in vitro translation (IVT) kit (e.g., Thermo Scientific 1-Step Heavy Protein IVT Kit)[13]
-
DNA template (plasmid or linear) encoding the peptide of interest (preferably with a purification tag like His6).
-
Amino acid mixture lacking the amino acids to be labeled.
-
Stable isotope-labeled amino acids (e.g., ¹³C₆,¹⁵N₂ L-lysine, ¹³C₆,¹⁵N₄ L-arginine).[13]
-
Nuclease-free water.
-
Purification system (e.g., Ni-NTA resin for His-tagged peptides).
Procedure:
-
Reaction Setup: On ice, combine the following in a microcentrifuge tube (example volumes for a 25 µL reaction):
-
HeLa Cell Lysate: 6.25 µL
-
Reaction Mix: 12.5 µL
-
DNA Template: 1-2 µg
-
Labeled Amino Acids: to a final concentration of ≥1 mM (e.g., add stock solutions of heavy lysine (B10760008) and arginine).[13]
-
Nuclease-free water to a final volume of 25 µL.
-
-
Incubation: Mix the components gently and incubate the reaction at 30°C for 4 to 16 hours. Longer incubation times can increase both protein yield and the percentage of isotope incorporation.[13]
-
Purification:
-
After incubation, purify the expressed labeled peptide from the crude reaction mixture. If using a His-tag, use immobilized metal affinity chromatography (IMAC) with a Ni-NTA resin.
-
Wash the resin to remove unbound components from the cell-free lysate.
-
Elute the purified labeled peptide.
-
-
Analysis and Quantification:
-
Analyze the purity and yield of the labeled peptide using SDS-PAGE.
-
Digest the purified peptide into smaller fragments using a protease (e.g., trypsin).
-
Analyze the digested fragments by liquid chromatography-mass spectrometry (LC-MS) to confirm the sequence and determine the efficiency of stable-isotope incorporation.[13] Incorporation efficiency is expected to be >90%.[13]
-
References
- 1. Stable Isotope Labeled Peptides - Creative Peptides [creative-peptides.com]
- 2. cpcscientific.com [cpcscientific.com]
- 3. Synthesis and application of stable isotope labeled peptides [inis.iaea.org]
- 4. Solid Phase Peptide Synthesis with Isotope Labeling | Silantes [silantes.com]
- 5. Cell-Free Approach for Non-canonical Amino Acids Incorporation Into Polypeptides - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Cell-Free Synthesis of Defined Protein Conjugates by Site-directed Cotranslational Labeling - Madame Curie Bioscience Database - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 7. Cell-free protein synthesis - Wikipedia [en.wikipedia.org]
- 8. peptide.com [peptide.com]
- 9. luxembourg-bio.com [luxembourg-bio.com]
- 10. researchgate.net [researchgate.net]
- 11. Peptide Purification and Product Analysis | AltaBioscience [altabioscience.com]
- 12. peptide.com [peptide.com]
- 13. Cell-Free Protein Expression for Generating Stable Isotope-Labeled Proteins | Thermo Fisher Scientific - US [thermofisher.com]
- 14. protocols.io [protocols.io]
- 16. wernerlab.weebly.com [wernerlab.weebly.com]
- 17. pubs.acs.org [pubs.acs.org]
- 18. hplc.eu [hplc.eu]
- 19. agilent.com [agilent.com]
Application Notes: Quantitative Mass Spectrometry using Fmoc-Leucine-¹³C₆,¹⁵N
For Researchers, Scientists, and Drug Development Professionals
Introduction
Stable Isotope Labeling by Amino Acids in Cell Culture (SILAC) is a powerful and widely adopted metabolic labeling strategy for quantitative mass spectrometry-based proteomics.[1][2] This technique relies on the metabolic incorporation of "heavy" stable isotope-labeled amino acids into proteins in living cells.[3] By comparing the mass spectra of heavy-labeled peptides with their "light," unlabeled counterparts, SILAC enables highly accurate relative quantification of protein abundance between different cell populations.[4][5]
Fmoc-L-leucine-¹³C₆,¹⁵N is a specialized, isotopically labeled form of the essential amino acid leucine (B10760876), where all six carbon atoms are replaced with ¹³C and the nitrogen atom is replaced with ¹⁵N.[4][6] This results in a predictable mass shift, making it an ideal reagent for SILAC experiments.[4] Leucine plays a critical role in cellular processes, most notably as a key activator of the mTOR (mechanistic Target of Rapamycin) signaling pathway, a central regulator of cell growth, proliferation, and metabolism.[5] Consequently, using Fmoc-leucine-¹³C₆,¹⁵N in SILAC experiments is a highly effective method for investigating the dynamics of the proteome in response to stimuli that affect the mTOR pathway.[5]
These application notes provide detailed protocols for utilizing Fmoc-leucine-¹³C₆,¹⁵N in quantitative proteomics studies, with a specific focus on investigating the mTOR signaling pathway.
Core Applications
-
Quantitative analysis of protein expression changes: Elucidate proteome-wide responses to various stimuli, such as drug treatment, growth factor stimulation, or stress conditions.
-
Studying signaling pathways: Quantify changes in the abundance of proteins within specific signaling cascades, such as the mTOR pathway, to understand regulatory mechanisms.[7]
-
Protein turnover studies: In "dynamic SILAC" experiments, the rate of incorporation of heavy leucine can be used to measure protein synthesis and degradation rates.
-
Pharmaceutical development: Track the effects of drug candidates on cellular proteomes and identify potential biomarkers of drug efficacy or toxicity.[4]
Principle of the SILAC Method using Fmoc-Leucine-¹³C₆,¹⁵N
The fundamental principle of SILAC involves growing two populations of cells in media that are identical except for the isotopic composition of a specific amino acid, in this case, leucine. One population is cultured in "light" medium containing standard leucine, while the other is cultured in "heavy" medium supplemented with L-leucine-¹³C₆,¹⁵N (derived from Fmoc-L-leucine-¹³C₆,¹⁵N after removal of the Fmoc protecting group during media preparation).
After a sufficient number of cell divisions (typically at least five), the proteome of the "heavy" cell population will have fully incorporated the labeled leucine.[8] The two cell populations can then be subjected to different experimental conditions. Subsequently, the cells are lysed, and the protein extracts are combined in a 1:1 ratio.[9] This early-stage mixing minimizes sample handling-related quantitative errors.[2] The combined protein mixture is then digested, typically with trypsin, and the resulting peptides are analyzed by liquid chromatography-tandem mass spectrometry (LC-MS/MS).
In the mass spectrometer, a given peptide containing leucine will appear as a pair of peaks separated by a specific mass difference corresponding to the number of leucine residues and the mass of the isotopic labels (a mass shift of 7 Da per leucine residue for ¹³C₆,¹⁵N). The relative intensity of these peaks directly reflects the relative abundance of the protein in the two cell populations.
Experimental Protocols
SILAC Media Preparation
Materials:
-
SILAC-grade cell culture medium deficient in L-leucine (e.g., DMEM or RPMI-1640)
-
Dialyzed Fetal Bovine Serum (dFBS)
-
Penicillin-Streptomycin solution
-
L-Glutamine
-
"Light" L-leucine (natural abundance)
-
"Heavy" L-leucine-¹³C₆,¹⁵N (prepared from Fmoc-L-leucine-¹³C₆,¹⁵N)
-
Sterile filters (0.22 µm)[9]
Protocol:
-
Prepare two separate batches of complete cell culture medium.
-
"Light" Medium: Supplement the leucine-deficient medium with dFBS, penicillin-streptomycin, L-glutamine, and "light" L-leucine to the normal physiological concentration.
-
"Heavy" Medium: Supplement the leucine-deficient medium with dFBS, penicillin-streptomycin, L-glutamine, and "heavy" L-leucine-¹³C₆,¹⁵N to the same final concentration as the "light" medium.
-
Sterile-filter both media preparations using a 0.22 µm filter and store at 4°C, protected from light.[10]
Cell Culture and Metabolic Labeling
Protocol:
-
Culture the cells of interest in standard "light" medium to establish the cell line.
-
For the "heavy" population, passage the cells into the "heavy" SILAC medium.
-
Culture the cells for at least five to six cell doublings to ensure near-complete incorporation of the heavy leucine.[8][11] The required duration will depend on the cell line's doubling time.
-
Monitor the incorporation efficiency by harvesting a small aliquot of cells from the "heavy" population, extracting proteins, digesting them, and analyzing by LC-MS/MS. The incorporation efficiency should be >95%.[11]
-
Once complete labeling is confirmed, the cells are ready for the experimental treatment.
Experimental Treatment and Sample Harvesting
Protocol:
-
Treat the "light" and "heavy" cell populations according to the experimental design (e.g., control vs. drug-treated).
-
After the treatment period, wash the cells twice with ice-cold phosphate-buffered saline (PBS).[3]
-
Harvest the cells from both populations.
-
Combine the "light" and "heavy" cell pellets in a 1:1 ratio based on cell count.
Protein Extraction, Digestion, and Sample Preparation for Mass Spectrometry
Materials:
-
Lysis buffer (e.g., RIPA buffer) with protease and phosphatase inhibitors
-
Dithiothreitol (DTT)
-
Iodoacetamide (IAA)
-
Trypsin, MS-grade
-
Formic acid
-
Acetonitrile
-
C18 desalting columns
Protocol:
-
Lyse the combined cell pellet in lysis buffer on ice.[9]
-
Clarify the lysate by centrifugation to remove cell debris.[9]
-
Determine the protein concentration of the lysate (e.g., using a BCA assay).
-
Reduction and Alkylation:
-
Add DTT to a final concentration of 10 mM and incubate at 56°C for 30 minutes.
-
Cool the sample to room temperature and add IAA to a final concentration of 55 mM. Incubate in the dark for 30 minutes.
-
-
In-solution Digestion:
-
Dilute the protein sample with ammonium (B1175870) bicarbonate buffer to reduce the concentration of denaturants.
-
Add MS-grade trypsin at a 1:50 (trypsin:protein) ratio and incubate overnight at 37°C.
-
-
Peptide Desalting:
-
Acidify the peptide solution with formic acid.
-
Desalt the peptides using a C18 column according to the manufacturer's instructions.
-
Elute the peptides and dry them under vacuum.
-
-
Reconstitute the dried peptides in a suitable solvent for LC-MS/MS analysis (e.g., 0.1% formic acid).
LC-MS/MS Analysis and Data Processing
Protocol:
-
Analyze the peptide sample on a high-resolution mass spectrometer (e.g., an Orbitrap-based instrument) coupled to a nano-liquid chromatography system.
-
Set up the data acquisition method to perform data-dependent acquisition (DDA) or data-independent acquisition (DIA).
-
Process the raw mass spectrometry data using a software package that supports SILAC quantification, such as MaxQuant.[12]
-
Configure the software to search for the specific mass modifications corresponding to leucine-¹³C₆,¹⁵N.
-
The software will identify peptides, determine the heavy-to-light ratios for each peptide pair, and aggregate these ratios to provide a quantitative measure of protein abundance.
Data Presentation
Quantitative proteomics data should be presented in a clear, structured format to facilitate interpretation and comparison. The following tables provide examples of how to present results from a SILAC experiment investigating the mTOR pathway.
Table 1: Quantified Proteins in the mTOR Signaling Pathway
| Protein Name | Gene Symbol | Heavy/Light Ratio | p-value | Regulation |
| Serine/threonine-protein kinase mTOR | MTOR | 1.05 | 0.89 | Unchanged |
| Regulatory-associated protein of mTOR | RPTOR | 2.54 | 0.01 | Upregulated |
| Ribosomal protein S6 kinase beta-1 | RPS6KB1 | 2.89 | 0.005 | Upregulated |
| Eukaryotic translation initiation factor 4E-binding protein 1 | EIF4EBP1 | 0.45 | 0.02 | Downregulated |
| Tuberous sclerosis 1 | TSC1 | 1.12 | 0.75 | Unchanged |
| Tuberous sclerosis 2 | TSC2 | 0.98 | 0.91 | Unchanged |
Table 2: Top 10 Upregulated Proteins Upon mTOR Activation
| Protein Name | Gene Symbol | Heavy/Light Ratio | Function |
| Protein A | GENEA | 5.67 | Cell Cycle Progression |
| Protein B | GENEB | 4.98 | Lipid Synthesis |
| Protein C | GENEC | 4.52 | Ribosome Biogenesis |
| Protein D | GENED | 4.11 | Nucleotide Synthesis |
| Protein E | GENEE | 3.87 | Autophagy Inhibition |
| Protein F | GENEF | 3.56 | Protein Synthesis |
| Protein G | GENEG | 3.21 | Glycolysis |
| Protein H | GENEH | 3.01 | Angiogenesis |
| Protein I | GENEI | 2.95 | Cell Proliferation |
| Protein J | GENEJ | 2.91 | Transcription |
Table 3: Top 10 Downregulated Proteins Upon mTOR Activation
| Protein Name | Gene Symbol | Heavy/Light Ratio | Function |
| Protein K | GENEK | 0.18 | Apoptosis |
| Protein L | GENEL | 0.25 | Autophagy Induction |
| Protein M | GENEM | 0.31 | Cell Adhesion |
| Protein N | GENEN | 0.39 | DNA Repair |
| Protein O | GENEO | 0.42 | Stress Response |
| Protein P | GENEP | 0.48 | Protein Degradation |
| Protein Q | GENEQ | 0.51 | Cell Cycle Arrest |
| Protein R | GENER | 0.55 | Ion Transport |
| Protein S | GENES | 0.59 | Cytoskeletal Organization |
| Protein T | GENET | 0.62 | Signal Transduction |
Visualizations
mTOR Signaling Pathway
The following diagram illustrates a simplified representation of the mTOR signaling pathway, highlighting the central role of leucine as an activator.
Caption: Simplified mTOR signaling pathway activated by Leucine.
SILAC Experimental Workflow
This diagram outlines the key steps in a typical SILAC experiment using Fmoc-leucine-¹³C₆,¹⁵N.
Caption: Experimental workflow for quantitative proteomics with Fmoc-leucine-¹³C₆,¹⁵N.
Conclusion
The use of Fmoc-leucine-¹³C₆,¹⁵N in a SILAC-based quantitative proteomics workflow provides a robust and accurate method for investigating the cellular proteome. Its application is particularly powerful for dissecting nutrient-sensing pathways like mTOR signaling. By following the detailed protocols and data presentation guidelines outlined in these notes, researchers can gain valuable insights into the complex molecular events that govern cellular function in both health and disease.
References
- 1. researchgate.net [researchgate.net]
- 2. Using SILAC to Develop Quantitative Data-Independent Acquisition (DIA) Proteomic Methods | Springer Nature Experiments [experiments.springernature.com]
- 3. youtube.com [youtube.com]
- 4. SILAC: Principles, Workflow & Applications in Proteomics - Creative Proteomics Blog [creative-proteomics.com]
- 5. benchchem.com [benchchem.com]
- 6. L-Leucine-ð-Fmoc (¹³Câ, 99%; ¹âµN, 99%) - Cambridge Isotope Laboratories, CNLM-4345-H-0.1 [isotope.com]
- 7. Analysis of the mTOR Interactome using SILAC technology revealed NICE-4 as a novel regulator of mTORC1 activity - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. info.gbiosciences.com [info.gbiosciences.com]
- 9. ckisotopes.com [ckisotopes.com]
- 10. tools.thermofisher.com [tools.thermofisher.com]
- 11. info.gbiosciences.com [info.gbiosciences.com]
- 12. researchgate.net [researchgate.net]
Application Notes and Protocols: Fmoc-leucine-13C6,15N as an Internal Standard for LC-MS Analysis
For Researchers, Scientists, and Drug Development Professionals
This document provides detailed application notes and protocols for the use of Fmoc-leucine-13C6,15N as an internal standard in Liquid Chromatography-Mass Spectrometry (LC-MS) analysis. The primary application of this stable isotope-labeled compound is in quantitative proteomics, where it serves as a crucial component for the synthesis of isotopically labeled peptides. These peptides are then used as internal standards for the accurate quantification of target peptides in complex biological matrices.
Principle and Application
Stable isotope-labeled (SIL) compounds are the gold standard for internal standards in quantitative mass spectrometry.[1] They are chemically identical to the analyte of interest, ensuring they co-elute during chromatography and exhibit the same ionization behavior in the mass spectrometer.[1] However, their difference in mass, due to the incorporation of heavy isotopes like ¹³C and ¹⁵N, allows them to be distinguished from the endogenous, unlabeled analyte by the mass spectrometer.[1] This enables precise and accurate quantification by correcting for variability during sample preparation, injection, and ionization.[1]
This compound is an N-terminally protected amino acid containing six ¹³C atoms and one ¹⁵N atom. The 9-fluorenylmethyloxycarbonyl (Fmoc) group is a protecting group used in Solid-Phase Peptide Synthesis (SPPS). Therefore, the primary application of this compound is not for the direct analysis of free amino acids, but rather as a building block to create a stable isotope-labeled peptide. This "heavy" peptide is then spiked into a sample to serve as an internal standard for the quantification of its corresponding "light" (unlabeled) native peptide. This is a common practice in targeted proteomics for biomarker validation and pharmacokinetic studies of peptide drugs.
The overall workflow involves:
-
Synthesis: A peptide identical in sequence to the target analyte is synthesized, incorporating this compound at a specific position.
-
Quantification of Standard: The concentration of the synthesized heavy peptide is accurately determined.
-
Sample Preparation: A known amount of the heavy peptide internal standard is spiked into the biological sample (e.g., plasma, tissue lysate) containing the target peptide.
-
LC-MS/MS Analysis: The sample is analyzed by LC-MS/MS, monitoring for the specific mass transitions of both the light (analyte) and heavy (internal standard) peptides.
-
Data Analysis: The ratio of the peak areas of the analyte to the internal standard is used to calculate the exact concentration of the analyte in the original sample.
References
Synthesis of Labeled Peptides for NMR Spectroscopy Studies: Application Notes and Protocols
For Researchers, Scientists, and Drug Development Professionals
Introduction
Nuclear Magnetic Resonance (NMR) spectroscopy is a powerful analytical technique for elucidating the three-dimensional structure, dynamics, and interactions of biomolecules at an atomic level.[1] For peptides, which are pivotal in numerous biological processes and represent a growing class of therapeutics, NMR studies provide invaluable insights into their conformation and binding modes.[1] To enhance the sensitivity and simplify the spectral complexity of NMR experiments, especially for larger peptides, isotopic labeling is an indispensable tool.[2][3]
This document provides detailed application notes and protocols for the two primary methods of synthesizing isotopically labeled peptides: Solid-Phase Peptide Synthesis (SPPS) and recombinant protein expression. The choice of method depends on factors such as the desired peptide length, the specific labeling scheme, required yield, and cost-effectiveness.
Labeling Strategies for NMR Spectroscopy
The most commonly used stable isotopes for labeling peptides for NMR studies are ¹³C, ¹⁵N, and ²H (deuterium). These isotopes possess nuclear spin properties that make them NMR-active, and their incorporation allows for a variety of advanced NMR experiments.
There are two main labeling strategies:
-
Uniform Labeling: All instances of a particular element are replaced with its heavy isotope (e.g., all carbons are ¹³C, all nitrogens are ¹⁵N). This is typically achieved through recombinant expression in minimal media containing ¹³C-glucose and ¹⁵NH₄Cl as the sole carbon and nitrogen sources, respectively.[4]
-
Selective or Site-Specific Labeling: Only specific amino acid types or specific atoms within an amino acid are labeled. This is often accomplished using SPPS with isotopically labeled Fmoc-amino acid building blocks or through recombinant expression in auxotrophic bacterial strains supplemented with labeled amino acids.[5]
Methods for Synthesizing Labeled Peptides
Solid-Phase Peptide Synthesis (SPPS)
SPPS is the method of choice for synthesizing short to medium-length peptides (typically up to 50 amino acids) with high purity and the flexibility to incorporate unnatural or modified amino acids, including those with site-specific isotopic labels.[6] The most common approach is Fmoc (9-fluorenylmethyloxycarbonyl) chemistry.[6]
| Parameter | Typical Value/Range | Notes |
| Coupling Efficiency | >99% | Crucial for the synthesis of long peptides. Even a small decrease in efficiency per step significantly lowers the overall yield.[] |
| Crude Purity | 50-95% | Highly dependent on the peptide sequence, length, and synthesis conditions. "Difficult sequences" can lead to lower purity.[8][9] |
| Final Purity (after HPLC) | >95% to >98% | Required for most NMR and biological applications.[9][10] |
| Overall Yield | 10-50% | Dependent on the number of coupling cycles and the efficiency of each step. |
This protocol outlines the manual synthesis of a ¹³C and/or ¹⁵N-labeled peptide using Fmoc chemistry.
Materials:
-
Fmoc-protected amino acids (standard and isotopically labeled)
-
Rink Amide resin (for C-terminal amide) or Wang resin (for C-terminal carboxylic acid)
-
N,N-Dimethylformamide (DMF)
-
Dichloromethane (DCM)
-
Coupling reagents: HBTU (O-(Benzotriazol-1-yl)-N,N,N',N'-tetramethyluronium hexafluorophosphate) and HOBt (Hydroxybenzotriazole)
-
Activator base: DIPEA (N,N-Diisopropylethylamine)
-
Cleavage cocktail: Trifluoroacetic acid (TFA), triisopropylsilane (B1312306) (TIS), and water
-
Cold diethyl ether
-
Peptide synthesis vessel
-
Shaker
Procedure:
-
Resin Swelling:
-
Place the resin in the synthesis vessel.
-
Add DMF and allow the resin to swell for 30-60 minutes with gentle agitation.[]
-
Drain the DMF.
-
-
Fmoc Deprotection:
-
Add a 20% solution of piperidine in DMF to the resin.
-
Agitate for 5-10 minutes.
-
Drain the solution and repeat the piperidine treatment for another 10-15 minutes to ensure complete removal of the Fmoc group.[]
-
Wash the resin thoroughly with DMF (3-5 times) to remove residual piperidine.
-
-
Amino Acid Coupling:
-
In a separate vial, dissolve the Fmoc-protected amino acid (either unlabeled or the desired isotopically labeled variant) and coupling reagents (e.g., HBTU/HOBt) in DMF.
-
Add DIPEA to the amino acid solution and pre-activate for 1-2 minutes.[]
-
Add the activated amino acid solution to the deprotected resin.
-
Agitate for 1-2 hours at room temperature.
-
To confirm completion, perform a ninhydrin (B49086) test. A negative result (beads remain colorless) indicates successful coupling.
-
Wash the resin with DMF (3-5 times).
-
-
Chain Elongation:
-
Repeat steps 2 and 3 for each amino acid in the peptide sequence.
-
-
Cleavage and Deprotection:
-
After the final amino acid is coupled and deprotected, wash the resin with DCM and dry it.
-
Prepare a cleavage cocktail (e.g., 95% TFA, 2.5% TIS, 2.5% water).
-
Add the cleavage cocktail to the resin.
-
Incubate with agitation for 2-3 hours at room temperature.[]
-
Filter the solution to separate the peptide-containing cleavage mixture from the resin beads.
-
-
Peptide Precipitation and Purification:
-
Precipitate the crude peptide by adding the TFA solution to a 10-fold excess of cold diethyl ether.[]
-
Centrifuge to pellet the peptide, discard the ether, and repeat the wash 2-3 times.
-
Dry the crude peptide pellet under vacuum.
-
Purify the peptide using reverse-phase high-performance liquid chromatography (RP-HPLC).
-
Confirm the identity and purity of the final product by mass spectrometry.
-
Recombinant Peptide Expression
For longer peptides and proteins, or when uniform labeling is desired, recombinant expression in a bacterial host like Escherichia coli is the more cost-effective and practical approach.[11] This method involves expressing the target peptide, often as a fusion protein to enhance stability and aid in purification.
| Parameter | Typical Value/Range | Notes |
| Expression Yield | 10-100 mg/L of culture | Highly dependent on the specific peptide, expression vector, host strain, and culture conditions.[12] |
| Final Purity (after purification) | >95% | Achievable with multi-step purification protocols (e.g., affinity and size-exclusion chromatography). |
| Isotopic Incorporation Efficiency | >98% | For ¹⁵N and ¹³C in E. coli grown in minimal media with labeled precursors.[4] |
| Cost-Effectiveness | High for large-scale production | The cost of labeled minimal media is significantly lower than that of multiple labeled Fmoc-amino acids for long peptides.[12] |
This protocol describes the expression and purification of a uniformly ¹⁵N and ¹³C-labeled peptide expressed as a His-tagged fusion protein in E. coli.
Materials:
-
E. coli expression strain (e.g., BL21(DE3)) transformed with the expression vector for the target peptide.
-
M9 minimal media components.
-
¹⁵NH₄Cl and ¹³C-glucose.
-
Trace elements solution.
-
MgSO₄ and CaCl₂ solutions.
-
Appropriate antibiotic.
-
Isopropyl β-D-1-thiogalactopyranoside (IPTG).
-
Lysis buffer (e.g., 50 mM Tris-HCl, 300 mM NaCl, 10 mM imidazole, pH 8.0).
-
Lysozyme, DNase I.
-
Ni-NTA affinity chromatography column.
-
Wash buffer (lysis buffer with 20 mM imidazole).
-
Elution buffer (lysis buffer with 250 mM imidazole).
-
Size-exclusion chromatography (SEC) column.
-
Cleavage agent (e.g., TEV protease) if the tag needs to be removed.
Procedure:
-
Preparation of Minimal Media:
-
Prepare 1 L of M9 minimal media containing ¹⁵NH₄Cl as the sole nitrogen source and ¹³C-glucose as the sole carbon source.
-
Supplement with trace elements, MgSO₄, CaCl₂, and the appropriate antibiotic.
-
-
Cell Culture and Growth:
-
Inoculate a 5 mL starter culture in M9 minimal media and grow overnight at 37°C.
-
Use the starter culture to inoculate 1 L of the labeling media.
-
Grow the culture at 37°C with vigorous shaking until the OD₆₀₀ reaches 0.6-0.8.
-
-
Induction of Expression:
-
Induce protein expression by adding IPTG to a final concentration of 0.5-1 mM.
-
Continue to grow the culture for 4-6 hours at 30°C or overnight at 18-25°C.
-
-
Cell Harvesting and Lysis:
-
Harvest the cells by centrifugation.
-
Resuspend the cell pellet in lysis buffer.
-
Lyse the cells by sonication or high-pressure homogenization.
-
Clarify the lysate by centrifugation to remove cell debris.
-
-
Affinity Purification:
-
Load the clarified lysate onto a pre-equilibrated Ni-NTA column.
-
Wash the column with wash buffer to remove unbound proteins.
-
Elute the His-tagged fusion protein with elution buffer.
-
-
Tag Cleavage (Optional):
-
If necessary, cleave the affinity tag from the peptide using a specific protease (e.g., TEV protease).
-
Re-purify the sample using the Ni-NTA column to remove the cleaved tag and the protease.
-
-
Size-Exclusion Chromatography (SEC):
-
Further purify the labeled peptide using a SEC column to remove aggregates and other impurities.
-
-
Quality Control:
-
Assess the purity of the final peptide by SDS-PAGE.
-
Confirm the identity and isotopic incorporation by mass spectrometry.
-
Visualizations
Experimental Workflow for Fmoc-SPPS of Labeled Peptides
Caption: Workflow for Solid-Phase Peptide Synthesis (SPPS) using Fmoc chemistry.
Experimental Workflow for Recombinant Expression of Labeled Peptides
Caption: Workflow for recombinant expression and purification of labeled peptides.
Logical Relationship: Principle of AQUA Proteomics
Caption: Principle of Absolute Quantification (AQUA) using labeled peptides.
Conclusion
The synthesis of isotopically labeled peptides is a critical enabling technology for advanced NMR studies in structural biology and drug discovery. Solid-phase peptide synthesis offers unparalleled flexibility for creating short to medium-length peptides with site-specific labels and modifications. For longer peptides and when uniform labeling is required, recombinant expression in E. coli provides a cost-effective and high-yield alternative. The detailed protocols and comparative data presented in this application note serve as a comprehensive guide for researchers to select and implement the most appropriate method for their specific research needs.
References
- 1. bachem.com [bachem.com]
- 2. dbt.univr.it [dbt.univr.it]
- 3. pubs.acs.org [pubs.acs.org]
- 4. pubs.acs.org [pubs.acs.org]
- 5. eprints.whiterose.ac.uk [eprints.whiterose.ac.uk]
- 6. chempep.com [chempep.com]
- 8. luxembourg-bio.com [luxembourg-bio.com]
- 9. gyrosproteintechnologies.com [gyrosproteintechnologies.com]
- 10. researchgate.net [researchgate.net]
- 11. High-yield expression of isotopically labeled peptides for use in NMR studies - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. Recombinant versus synthetic peptide synthesis: the perks and drawbacks [manufacturingchemist.com]
Application Notes and Protocols for Calculating Isotopic Enrichment with Fmoc-leucine-13C6,15N
For Researchers, Scientists, and Drug Development Professionals
These application notes provide a detailed guide for utilizing Fmoc-L-leucine-(¹³C₆,¹⁵N) in stable isotope labeling experiments to calculate isotopic enrichment. The protocols outlined are broadly applicable to studies in protein turnover, metabolic flux analysis, and quantitative proteomics, offering valuable insights for basic research and drug development.
Introduction to Isotopic Enrichment with Fmoc-leucine-13C6,15N
Stable Isotope Labeling by Amino Acids in Cell Culture (SILAC) is a powerful technique for quantitative mass spectrometry.[1] By incorporating stable isotopes into proteins, researchers can accurately compare protein abundance between different cell populations. Fmoc-L-leucine-(¹³C₆,¹⁵N) is a protected amino acid containing six carbon-13 and one nitrogen-15 (B135050) isotopes, making it an ideal tool for these studies. When introduced into cell culture media, it is incorporated into newly synthesized proteins. The resulting mass shift allows for the differentiation and quantification of "heavy" (labeled) versus "light" (unlabeled) proteins by mass spectrometry.
The primary applications of this compound include:
-
Protein Turnover Analysis: Measuring the rates of protein synthesis and degradation.
-
Metabolic Flux Analysis: Tracing the flow of leucine (B10760876) through metabolic pathways.[2]
-
Quantitative Proteomics: Comparing protein expression levels between different experimental conditions.
Experimental Design and Workflow
A typical experiment involving this compound follows a pulsed SILAC (pSILAC) approach.[1] This involves replacing the standard "light" leucine in the cell culture medium with the "heavy" this compound for a defined period.
Diagram: Pulsed SILAC Experimental Workflow
Caption: A generalized workflow for a pulsed SILAC experiment using this compound.
Detailed Experimental Protocols
Cell Culture and Metabolic Labeling
Objective: To incorporate this compound into the cellular proteome.
Materials:
-
Cells of interest (e.g., HeLa, HEK293)
-
Standard cell culture medium (leucine-containing)
-
Leucine-free cell culture medium
-
Fmoc-L-leucine-(¹³C₆,¹⁵N)
-
Dialyzed fetal bovine serum (dFBS)
Protocol:
-
Cell Seeding: Plate cells at a desired density and allow them to adhere and grow in standard "light" medium supplemented with 10% dFBS.
-
Medium Preparation: Prepare the "heavy" SILAC medium by supplementing leucine-free medium with Fmoc-L-leucine-(¹³C₆,¹⁵N) at the same concentration as leucine in the standard medium. Also, add 10% dFBS.
-
Labeling Initiation: Once cells reach the desired confluency (typically 60-80%), aspirate the "light" medium, wash the cells once with sterile PBS, and replace it with the "heavy" medium. This marks time point zero (T₀).
-
Time Course: Harvest cells at various time points (e.g., 0, 4, 8, 12, 24, 48 hours) to monitor the incorporation of the heavy leucine.
Sample Preparation for Mass Spectrometry
Objective: To extract and digest proteins for LC-MS/MS analysis.
Protocol:
-
Cell Lysis: Harvest cells by scraping or trypsinization. Wash the cell pellet with ice-cold PBS and lyse the cells using a suitable lysis buffer (e.g., RIPA buffer with protease inhibitors).
-
Protein Quantification: Determine the protein concentration of each lysate using a standard protein assay (e.g., BCA assay).
-
Protein Digestion:
-
Take a fixed amount of protein (e.g., 50 µg) from each time point.
-
Reduce disulfide bonds with dithiothreitol (B142953) (DTT) at 56°C for 30 minutes.
-
Alkylate cysteine residues with iodoacetamide (B48618) (IAA) in the dark at room temperature for 20 minutes.
-
Digest the proteins into peptides overnight at 37°C using a suitable protease (e.g., trypsin).
-
-
Peptide Cleanup: Desalt the peptide samples using C18 solid-phase extraction (SPE) cartridges to remove salts and detergents that can interfere with mass spectrometry analysis.
-
Sample Storage: Store the purified peptides at -80°C until LC-MS/MS analysis.
LC-MS/MS Analysis
Objective: To separate and detect the "light" and "heavy" leucine-containing peptides.
Instrumentation: A high-resolution Orbitrap mass spectrometer coupled to a nano-liquid chromatography system is recommended.
Typical LC-MS/MS Parameters:
| Parameter | Setting |
| Column | C18 reversed-phase, 75 µm ID x 15 cm |
| Mobile Phase A | 0.1% formic acid in water |
| Mobile Phase B | 0.1% formic acid in acetonitrile |
| Gradient | 5-40% B over 60-120 minutes |
| Flow Rate | 300 nL/min |
| MS1 Resolution | 60,000 - 120,000 |
| MS2 Resolution | 15,000 - 30,000 |
| Activation Type | Higher-energy C-trap dissociation (HCD) |
| Data Acquisition | Data-dependent acquisition (DDA) |
Calculation of Isotopic Enrichment
Isotopic enrichment is determined by analyzing the mass spectra of peptides containing leucine. The presence of this compound results in a mass shift compared to the unlabeled peptide.
Data Analysis Workflow
Diagram: Isotopic Enrichment Calculation Workflow
Caption: A flowchart illustrating the data analysis pipeline for calculating isotopic enrichment.
Mathematical Formula
The isotopic enrichment for a given peptide at a specific time point can be calculated using the following formula:
Isotopic Enrichment (%) = [ AH / (AL + AH) ] * 100
Where:
-
AH is the peak area of the "heavy" peptide (containing this compound).
-
AL is the peak area of the "light" peptide (containing natural abundance leucine).
For proteins with multiple leucine-containing peptides, the average enrichment across all identified peptides for that protein is typically calculated.
Protein Turnover Calculation
The rate of protein synthesis (k_syn) can be determined by fitting the isotopic enrichment data over time to a first-order kinetics model:
Enrichment(t) = 1 - e-ksyn * t
Where:
-
Enrichment(t) is the isotopic enrichment at time t.
-
ksyn is the synthesis rate constant.
-
t is the time.
The protein half-life (t₁/₂) can then be calculated as:
t₁/₂ = ln(2) / kdeg
Assuming a steady state where the rate of synthesis equals the rate of degradation (k_syn = k_deg).
Quantitative Data Presentation
The following tables provide examples of quantitative data that can be obtained from experiments using stable isotope labeling.
Table 1: Protein Turnover Rates in HeLa Cells
This table presents a subset of protein turnover data from a study on HeLa cells using a pulsed SILAC approach.[3]
| Protein | Gene Name | Half-life (hours) |
| Histone H4 | HIST1H4A | 145.2 |
| Actin, cytoplasmic 1 | ACTB | 78.5 |
| Tubulin alpha-1A chain | TUBA1A | 45.1 |
| Pyruvate kinase PKM | PKM | 33.6 |
| 60S ribosomal protein L4 | RPL4 | 25.3 |
| Heat shock protein HSP 90-alpha | HSP90AA1 | 18.9 |
| Ornithine decarboxylase | ODC1 | 1.2 |
Note: This data is illustrative and derived from published literature. Actual results may vary depending on experimental conditions.
Table 2: Typical Metabolic Flux Ratios in Cancer Cells
This table shows representative flux ratios in cancer cells determined using ¹³C-labeling experiments, which can be similarly investigated using ¹³C₆,¹⁵N-leucine to trace specific pathways.[2]
| Metabolic Pathway | Flux Ratio | Typical Range in Cancer Cells |
| Glycolysis vs. Pentose Phosphate Pathway | Lactate production / Glucose uptake | 0.6 - 1.5 |
| Anaplerosis vs. Cataplerosis | Pyruvate carboxylase / PEP carboxykinase | Highly variable |
| Glutaminolysis | Glutamine uptake / Glucose uptake | 0.1 - 0.5 |
Signaling Pathway Visualization
Isotopic labeling with this compound can be used to study how signaling pathways affect protein synthesis and degradation.
Diagram: Simplified mTOR Signaling and Protein Synthesis
Caption: The mTOR pathway integrates signals from growth factors and nutrients to regulate protein synthesis.
Applications in Drug Development
The ability to precisely quantify changes in protein dynamics makes this compound a valuable tool in drug development for:
-
Target Engagement and Validation: Assessing whether a drug interacts with its intended protein target and modulates its turnover.
-
Mechanism of Action Studies: Elucidating how a drug affects specific metabolic or signaling pathways.
-
Biomarker Discovery: Identifying proteins whose synthesis or degradation rates are altered in response to drug treatment, which can serve as pharmacodynamic biomarkers.
-
Toxicity Studies: Evaluating off-target effects of a drug by monitoring changes in the turnover of a broad range of proteins.
By providing a quantitative readout of cellular processes, isotopic labeling with this compound offers a powerful platform to accelerate and inform various stages of the drug discovery and development pipeline.
References
Application Notes and Protocols for Fmoc-Leucine-¹³C₆,¹⁵N Coupling Reactions
For Researchers, Scientists, and Drug Development Professionals
These application notes provide detailed protocols and technical guidance for the efficient coupling of Fmoc-L-Leucine-¹³C₆,¹⁵N in solid-phase peptide synthesis (SPPS). The use of isotopically labeled amino acids is critical for applications in quantitative proteomics, structural biology, and as tracers in pharmaceutical development.[1][2][3] This document outlines optimal reaction conditions, common coupling reagents, and protocols to ensure high coupling efficiency and minimize side reactions.
Introduction to Fmoc-Leucine-¹³C₆,¹⁵N in Peptide Synthesis
Fmoc-L-Leucine-¹³C₆,¹⁵N is an isotopically labeled amino acid derivative where the leucine (B10760876) backbone is enriched with six ¹³C atoms and one ¹⁵N atom.[1] This stable isotope labeling provides a distinct mass shift, making it an invaluable tool for mass spectrometry-based quantitative proteomics, such as SILAC (Stable Isotope Labeling by Amino Acids in Cell Culture).[1] It also finds significant application in nuclear magnetic resonance (NMR) spectroscopy for structural studies of peptides and proteins.[1]
The coupling of Fmoc-L-Leucine-¹³C₆,¹⁵N follows the general principles of Fmoc-based solid-phase peptide synthesis.[4] The isotopic labeling does not significantly alter the chemical reactivity of the amino acid; therefore, standard coupling protocols for Fmoc-Leucine can be applied.
Comparative Data of Common Coupling Reagents
The choice of coupling reagent is critical for achieving high yields and minimizing racemization, especially with sterically hindered amino acids.[5] Uronium/aminium salts like HATU, HBTU, and HCTU are highly effective for such couplings.[5] The following table summarizes common coupling reagents and their typical performance in Fmoc-amino acid couplings.
| Coupling Reagent | Activating Agent | Base | Typical Equivalents (AA:Reagent:Base) | Typical Coupling Time | Coupling Efficiency | Potential for Racemization |
| HATU | 1-Hydroxy-7-azabenzotriazole | DIPEA or 2,4,6-Collidine | 1 : 0.95 : 2 | 30 - 60 min | > 95% | Low |
| HBTU | 1-Hydroxybenzotriazole | DIPEA or NMM | 1 : 0.95 : 2 | 30 - 60 min | > 90% | Low |
| HCTU | 6-Chloro-1-hydroxybenzotriazole | DIPEA or NMM | 1 : 0.95 : 2 | 20 - 45 min | > 95% | Low |
| DIC/HOBt | 1-Hydroxybenzotriazole | - | 1 : 1 : - | 1 - 4 hours | > 85% | Moderate |
| PyBOP | 1-Hydroxybenzotriazole | DIPEA or NMM | 1 : 1 : 2 | 1 - 2 hours | > 90% | Low |
| COMU | OxymaPure | DIPEA or 2,4,6-Collidine | 1 : 1 : 2 | 20 - 45 min | > 95% | Low |
AA: Amino Acid; DIPEA: N,N-Diisopropylethylamine; NMM: N-Methylmorpholine. Data compiled from multiple sources.[5][6][7]
Experimental Protocols
This section provides detailed protocols for a standard coupling cycle of Fmoc-L-Leucine-¹³C₆,¹⁵N in manual or automated solid-phase peptide synthesis.
Resin Preparation and Swelling
-
Place the desired amount of resin (e.g., Wang, Rink Amide, or 2-Chlorotrityl chloride resin) in a reaction vessel.
-
Add N,N-Dimethylformamide (DMF) to the resin and allow it to swell for at least 30-60 minutes at room temperature.[8]
-
After swelling, drain the DMF.
Fmoc Deprotection
-
Add a 20% solution of piperidine (B6355638) in DMF to the swollen resin.[4]
-
Agitate the mixture for an initial 3 minutes, then drain the solution.[9]
-
Add a fresh 20% piperidine in DMF solution and continue agitation for another 10-15 minutes to ensure complete Fmoc removal.[9]
-
Drain the piperidine solution and wash the resin thoroughly with DMF (5-7 times) to remove all traces of piperidine.[5]
Caption: Fmoc deprotection workflow.
Amino Acid Activation and Coupling
The following protocols outline the activation and coupling steps using two common and highly efficient coupling reagents, HATU and HCTU.
Protocol 1: Coupling using HATU
-
Activation Solution Preparation: In a separate vial, dissolve Fmoc-L-Leucine-¹³C₆,¹⁵N (3-5 equivalents relative to resin substitution) and HATU (3-5 equivalents) in DMF.[5]
-
Add N,N-Diisopropylethylamine (DIPEA) (6-10 equivalents) to the amino acid solution.
-
Allow the mixture to pre-activate for 1-5 minutes at room temperature.[5]
-
Coupling Reaction: Add the pre-activated amino acid solution to the deprotected resin.
-
Agitate the reaction mixture for 30-60 minutes at room temperature. The reaction progress can be monitored using a qualitative ninhydrin (B49086) (Kaiser) test.
-
Washing: Once the coupling is complete (indicated by a negative Kaiser test), drain the coupling solution and wash the resin thoroughly with DMF (5-7 times).[5]
Caption: HATU-mediated coupling workflow.
Protocol 2: Coupling using HCTU
-
Activation Solution Preparation: In a separate vial, dissolve Fmoc-L-Leucine-¹³C₆,¹⁵N (3-5 equivalents) and HCTU (3-5 equivalents) in DMF.
-
Add DIPEA (6-10 equivalents) to the solution. Pre-activation time is generally shorter for HCTU.
-
Coupling Reaction: Immediately add the activated solution to the deprotected resin.
-
Agitate the reaction mixture for 20-45 minutes at room temperature. Monitor the reaction with a Kaiser test.
-
Washing: After a negative Kaiser test, drain the reaction solution and wash the resin extensively with DMF (5-7 times).
Final Cleavage and Deprotection
-
After the final coupling and deprotection cycle, wash the resin with Dichloromethane (DCM) and dry it under vacuum.
-
Prepare a cleavage cocktail appropriate for the resin and side-chain protecting groups used. A standard cocktail is Trifluoroacetic acid (TFA)/Triisopropylsilane (TIS)/Water (95:2.5:2.5, v/v/v).[6]
-
Add the cleavage cocktail to the resin and allow the reaction to proceed for 2-3 hours at room temperature.[10]
-
Filter the resin and collect the filtrate containing the cleaved peptide.
-
Precipitate the peptide by adding cold diethyl ether.
-
Centrifuge the mixture to pellet the peptide, wash with cold ether, and dry under vacuum.[6]
-
The crude peptide can then be purified by reverse-phase high-performance liquid chromatography (RP-HPLC).[6]
Caption: General solid-phase peptide synthesis cycle.
Potential Side Reactions and Mitigation
-
Racemization: The risk of racemization is minimized by using uronium/aminium-based coupling reagents like HATU, HCTU, and COMU, which allow for rapid reaction times.[7] Pre-activation times should be kept to a minimum.
-
Aggregation: Hydrophobic sequences are prone to aggregation, which can hinder both coupling and deprotection steps.[11] If aggregation is suspected, switching to a more polar solvent like N-Methylpyrrolidone (NMP), increasing the coupling temperature, or using microwave-assisted synthesis can be beneficial.[11]
-
Incomplete Coupling: For sterically hindered couplings, a double coupling (repeating the coupling step before the next deprotection) may be necessary to drive the reaction to completion.
By following these guidelines and protocols, researchers can successfully incorporate Fmoc-L-Leucine-¹³C₆,¹⁵N into synthetic peptides for a wide range of applications in research and drug development.
References
- 1. chempep.com [chempep.com]
- 2. Solid Phase Peptide Synthesis with Isotope Labeling | Silantes [silantes.com]
- 3. Isotopic labeling - Wikipedia [en.wikipedia.org]
- 4. Fmoc Solid Phase Peptide Synthesis: Mechanism and Protocol - Creative Peptides [creative-peptides.com]
- 5. benchchem.com [benchchem.com]
- 6. benchchem.com [benchchem.com]
- 7. pubs.acs.org [pubs.acs.org]
- 8. chem.uci.edu [chem.uci.edu]
- 9. rsc.org [rsc.org]
- 10. luxembourg-bio.com [luxembourg-bio.com]
- 11. peptide.com [peptide.com]
Application Note and Protocol: Solvent Selection for Dissolving Fmoc-Leucine-¹³C₆,¹⁵N
For Researchers, Scientists, and Drug Development Professionals
This document provides detailed guidance on the selection of appropriate solvents for the dissolution of Fmoc-Leucine-¹³C₆,¹⁵N, a critical isotopically labeled building block used in solid-phase peptide synthesis (SPPS), quantitative proteomics, and structural biology. Proper dissolution is paramount for ensuring accurate quantification, efficient reaction kinetics, and high-purity synthesis of labeled peptides.
Physicochemical Properties Overview
Fmoc-L-Leucine-¹³C₆,¹⁵N is a derivative of the amino acid leucine, featuring a fluorenylmethoxycarbonyl (Fmoc) protecting group on the α-amino group and isotopic labeling with six Carbon-13 atoms and one Nitrogen-15 atom.[1] The presence of the large, nonpolar Fmoc group significantly influences its solubility, rendering it generally soluble in organic solvents and sparingly soluble in aqueous solutions.[2][3][4] The isotopic labeling does not significantly alter the solubility characteristics compared to its unlabeled counterpart. This compound typically appears as a white to off-white crystalline solid.[3][5]
Solvent Selection Guide
The choice of solvent for dissolving Fmoc-Leucine-¹³C₆,¹⁵N is dictated by the intended application, such as solid-phase peptide synthesis (SPPS), preparation of stock solutions for cell culture (e.g., SILAC), or analytical purposes like HPLC and mass spectrometry.
Recommended Solvents for Solid-Phase Peptide Synthesis (SPPS)
In SPPS, the solvent must effectively solvate the resin and the growing peptide chain to ensure efficient coupling and deprotection steps.[6] The most commonly used solvents for dissolving Fmoc-amino acids, including Fmoc-Leucine-¹³C₆,¹⁵N, are polar aprotic solvents.
-
N,N-Dimethylformamide (DMF): Widely regarded as the solvent of choice for SPPS due to its excellent dissolving power for Fmoc-amino acids and good resin-swelling properties.[3][4][6]
-
N-Methyl-2-pyrrolidone (NMP): An alternative to DMF, often considered a superior solvent due to its higher polarity, which can enhance coupling efficiency, particularly in difficult sequences.[6] However, both DMF and NMP are classified as hazardous chemicals.[7][8][9]
-
Dimethyl Sulfoxide (DMSO): A strong polar aprotic solvent capable of dissolving Fmoc-Leucine.[2][4][5] It is sometimes used as a co-solvent to disrupt peptide aggregation.[6]
Solvents for Stock Solution Preparation
For applications requiring the preparation of concentrated stock solutions, several organic solvents are suitable.
-
Ethanol, Methanol, and Acetonitrile: These are effective solvents for dissolving Fmoc-Leucine.[2][3][5][10] Stock solutions in these solvents can be further diluted into aqueous buffers for specific assays, although precipitation may occur.
-
Dimethyl Sulfoxide (DMSO): Due to its high dissolving capacity and miscibility with water, DMSO is an excellent choice for preparing highly concentrated stock solutions.[2][4][5]
"Greener" Solvent Alternatives
Growing environmental and safety concerns have led to the exploration of more sustainable solvents for peptide synthesis.[7][8][9]
-
2-Methyltetrahydrofuran (2-MeTHF) and Cyclopentyl Methyl Ether (CPME): These have been investigated as potential replacements for DMF and NMP in SPPS.[7]
-
N-butylpyrrolidinone (NBP): Shows promise as a non-toxic and biodegradable alternative that performs on par with DMF in peptide synthesis.[9]
Quantitative Solubility Data
The following table summarizes the approximate solubility of Fmoc-L-Leucine in various solvents. The values for the isotopically labeled compound are expected to be comparable.
| Solvent | Chemical Formula | Solvent Type | Approximate Solubility (mg/mL) | Reference |
| N,N-Dimethylformamide (DMF) | C₃H₇NO | Polar Aprotic | ~30 | [2][5] |
| Dimethyl Sulfoxide (DMSO) | C₂H₆OS | Polar Aprotic | ~30 | [2][5] |
| Ethanol | C₂H₅OH | Polar Protic | ~30 | [2][5] |
| Methanol | CH₃OH | Polar Protic | Readily Soluble | [3] |
| 1:1 Ethanol:PBS (pH 7.2) | - | Aqueous/Organic Mixture | ~0.5 | [2][5] |
| Water | H₂O | Polar Protic | Sparingly Soluble | [3][4] |
Experimental Protocols
Protocol for Preparing a Stock Solution in an Organic Solvent
This protocol describes the preparation of a 10 mg/mL stock solution of Fmoc-Leucine-¹³C₆,¹⁵N in DMF.
Materials:
-
Fmoc-Leucine-¹³C₆,¹⁵N
-
N,N-Dimethylformamide (DMF), anhydrous
-
Vortex mixer
-
Sonicator (optional)
-
Calibrated analytical balance
-
Appropriate glassware (e.g., volumetric flask)
Procedure:
-
Weighing: Accurately weigh the desired amount of Fmoc-Leucine-¹³C₆,¹⁵N in a clean, dry container.
-
Solvent Addition: Transfer the weighed solid to a volumetric flask. Add a portion of DMF to the flask, approximately half of the final desired volume.
-
Dissolution: Gently swirl the flask to wet the solid. Use a vortex mixer to agitate the solution until the solid is completely dissolved. If dissolution is slow, brief sonication in a water bath can be applied.
-
Final Volume Adjustment: Once the solid is fully dissolved, add DMF to the final volume mark on the volumetric flask.
-
Mixing: Invert the flask several times to ensure a homogenous solution.
-
Storage: Store the stock solution at an appropriate temperature, typically -20°C, and protect it from light and moisture. It is recommended to purge the headspace with an inert gas like argon or nitrogen before sealing.[2][5]
Protocol for Use in Solid-Phase Peptide Synthesis (SPPS)
This protocol outlines the general steps for incorporating Fmoc-Leucine-¹³C₆,¹⁵N into a peptide sequence using a manual or automated peptide synthesizer.
Materials:
-
Fmoc-Leucine-¹³C₆,¹⁵N
-
Peptide synthesis grade DMF or NMP
-
Resin with a free amino group
-
Coupling reagents (e.g., HCTU, HATU)
-
Base (e.g., N,N-Diisopropylethylamine - DIPEA)
-
Deprotection solution (e.g., 20% piperidine (B6355638) in DMF)
Procedure:
-
Resin Swelling: Swell the resin in the reaction vessel with DMF for at least 30-60 minutes.[11]
-
Fmoc Deprotection: Remove the Fmoc group from the resin-bound amino acid by treating it with a 20% piperidine solution in DMF.[11][12]
-
Washing: Thoroughly wash the resin with DMF to remove residual piperidine and the Fmoc-piperidine adduct.[11]
-
Amino Acid Activation: In a separate vessel, dissolve Fmoc-Leucine-¹³C₆,¹⁵N and a coupling reagent (e.g., HCTU) in DMF. Add a base like DIPEA to activate the carboxylic acid group.
-
Coupling: Add the activated Fmoc-Leucine-¹³C₆,¹⁵N solution to the resin. Allow the coupling reaction to proceed for the recommended time (typically 1-2 hours).
-
Washing: Wash the resin with DMF to remove any unreacted reagents.
-
Repeat the deprotection, washing, activation, and coupling steps for the subsequent amino acids in the peptide sequence.
Visualizations
The following diagrams illustrate key workflows related to the use of Fmoc-Leucine-¹³C₆,¹⁵N.
Caption: Workflow for selecting a suitable solvent for Fmoc-Leucine-¹³C₆,¹⁵N.
Caption: General workflow for incorporating Fmoc-Leucine-¹³C₆,¹⁵N in SPPS.
References
- 1. chempep.com [chempep.com]
- 2. fnkprddata.blob.core.windows.net [fnkprddata.blob.core.windows.net]
- 3. Fmoc-L-Leucine (Fmoc-Leu-OH) BP EP USP CAS 35661-60-0 Manufacturers and Suppliers - Price - Fengchen [fengchengroup.com]
- 4. CAS 35661-60-0: Fmoc-leucine | CymitQuimica [cymitquimica.com]
- 5. cdn.caymanchem.com [cdn.caymanchem.com]
- 6. peptide.com [peptide.com]
- 7. biotage.com [biotage.com]
- 8. tandfonline.com [tandfonline.com]
- 9. Exciting Update on Green Solvents for Peptide Synthesis - RG Discovery [rgdiscovery.com]
- 10. Peptide Synthesis Solvents | Biosolve Shop [shop.biosolve-chemicals.eu]
- 11. benchchem.com [benchchem.com]
- 12. chem.uci.edu [chem.uci.edu]
Application of Fmoc-Leucine-¹³C₆,¹⁵N in Metabolic and Proteomic Analysis: Principles, Protocols, and Data Interpretation
For Researchers, Scientists, and Drug Development Professionals
Abstract
Fmoc-L-leucine-¹³C₆,¹⁵N is a stable isotope-labeled amino acid that serves as a critical tool in advanced biochemical and biomedical research. While its direct application in classical metabolic flux analysis (MFA) by introduction to live cells is not a standard practice due to the presence of the fluorenylmethyloxycarbonyl (Fmoc) protecting group, its primary and highly valuable application lies in the synthesis of isotopically labeled peptides. These peptides are instrumental as internal standards for highly accurate and precise quantification of proteins and for studying protein turnover dynamics, which are key aspects of cellular metabolism. This document provides a comprehensive overview of the principles, applications, and detailed protocols related to the use of Fmoc-L-leucine-¹³C₆,¹⁵N in proteomic and metabolic studies.
Introduction to Metabolic Flux Analysis and the Role of Stable Isotopes
Metabolic flux analysis (MFA) is a powerful technique used to quantify the rates (fluxes) of metabolic reactions within a biological system.[1][2][3] By introducing substrates labeled with stable isotopes, such as ¹³C and ¹⁵N, researchers can trace the flow of atoms through metabolic pathways.[1][4] This allows for the elucidation of cellular metabolic phenotypes in various physiological and pathological states, making it invaluable for drug development and disease research.[5][6]
Fmoc-L-leucine-¹³C₆,¹⁵N is a derivative of the essential amino acid leucine (B10760876), where all six carbon atoms are replaced with ¹³C and the nitrogen atom is replaced with ¹⁵N.[7][8][9] The Fmoc group is a protecting group for the amine functional group, essential for controlled, stepwise peptide synthesis.[7]
Primary Application: Synthesis of Isotopically Labeled Peptides for Quantitative Proteomics
The principal application of Fmoc-L-leucine-¹³C₆,¹⁵N is in solid-phase peptide synthesis (SPPS) to create "heavy" peptides.[5][7][10] These synthetic peptides, with their known mass shift due to the incorporated stable isotopes, are ideal internal standards for mass spectrometry-based quantitative proteomics.[5][7]
Key Uses of Synthesized Labeled Peptides:
-
Absolute Quantification of Proteins: By spiking a known concentration of the heavy labeled peptide into a biological sample, the absolute quantity of the corresponding endogenous ("light") peptide, and by extension the protein, can be accurately determined.
-
Protein Turnover Studies: These labeled peptides can be used as standards in dynamic labeling experiments, such as Stable Isotope Labeling by Amino Acids in Cell Culture (SILAC), to precisely measure the rates of protein synthesis and degradation.[7]
-
Pharmacokinetic Studies of Peptide Drugs: The isotopic label allows for the clear differentiation and tracking of peptide-based pharmaceuticals and their metabolites in biological systems.[7]
Why Direct Use of Fmoc-Leucine-¹³C₆,¹⁵N in Cell Culture for MFA is Not Feasible
The direct introduction of Fmoc-L-leucine-¹³C₆,¹⁵N into cell culture media for metabolic labeling is not a standard or documented practice for several reasons:
-
The Fmoc Protecting Group: The Fmoc group is not readily cleaved by cellular enzymes. It is chemically removed under basic conditions (e.g., using piperidine) that are not compatible with living cells.[1] Therefore, the labeled leucine would not be available for incorporation into newly synthesized proteins or for participation in other metabolic pathways.
-
Potential for Off-Target Effects: Some studies have shown that Fmoc-L-leucine can act as a partial agonist of peroxisome proliferator-activated receptor γ (PPARγ), a nuclear receptor involved in adipogenesis and glucose metabolism. This pharmacological activity would confound any metabolic flux analysis results.
Experimental Protocols
Protocol 1: Solid-Phase Peptide Synthesis (SPPS) of a Labeled Peptide using Fmoc-Leucine-¹³C₆,¹⁵N
This protocol outlines the general steps for synthesizing a peptide containing a ¹³C₆,¹⁵N-labeled leucine residue.
Materials:
-
Fmoc-L-leucine-¹³C₆,¹⁵N
-
Other required Fmoc-protected amino acids
-
Solid support resin (e.g., Wang resin, Rink amide resin)
-
Coupling reagents (e.g., HBTU, HATU)
-
Base (e.g., DIEA)
-
Deprotection solution: 20% piperidine (B6355638) in DMF
-
Solvents: DMF, DCM
-
Cleavage cocktail (e.g., TFA/TIS/H₂O)
-
Ether for precipitation
Procedure:
-
Resin Preparation: Swell the resin in DMF.
-
First Amino Acid Coupling: Couple the first Fmoc-protected amino acid to the resin using a coupling reagent and a base.
-
Fmoc Deprotection: Remove the Fmoc group from the first amino acid by treating with 20% piperidine in DMF.
-
Subsequent Amino Acid Couplings: Sequentially couple the remaining Fmoc-protected amino acids, including Fmoc-L-leucine-¹³C₆,¹⁵N at the desired position in the peptide sequence. Each coupling step is followed by an Fmoc deprotection step.
-
Final Deprotection: Remove the Fmoc group from the N-terminal amino acid.
-
Cleavage and Side-Chain Deprotection: Cleave the synthesized peptide from the resin and remove the side-chain protecting groups using a cleavage cocktail.
-
Precipitation and Purification: Precipitate the crude peptide in cold ether, and then purify it using reverse-phase high-performance liquid chromatography (RP-HPLC).
-
Characterization: Confirm the identity and purity of the labeled peptide using mass spectrometry and HPLC.
Protocol 2: Protein Quantification using a Labeled Peptide Standard
This protocol describes the use of the synthesized labeled peptide for absolute quantification of a target protein in a complex biological sample.
Materials:
-
Purified and quantified ¹³C₆,¹⁵N-labeled peptide standard
-
Biological sample (e.g., cell lysate, plasma)
-
Trypsin or other proteolytic enzyme
-
LC-MS/MS system
Procedure:
-
Sample Preparation: Lyse cells or prepare the biological sample to extract proteins.
-
Protein Digestion: Digest the proteins into peptides using trypsin.
-
Spiking of Labeled Standard: Add a known amount of the purified ¹³C₆,¹⁵N-labeled peptide standard to the digested sample.
-
LC-MS/MS Analysis: Analyze the sample using liquid chromatography-tandem mass spectrometry (LC-MS/MS). The mass spectrometer will be programmed to detect and quantify both the "light" (endogenous) and "heavy" (labeled standard) peptides.
-
Data Analysis: Determine the ratio of the peak areas of the light and heavy peptides. Using this ratio and the known concentration of the spiked-in heavy peptide, calculate the absolute concentration of the endogenous peptide, and thus the protein.
Data Presentation
The quantitative data obtained from an experiment using a labeled peptide standard can be summarized in a table for clear comparison.
Table 1: Example Data for Absolute Quantification of Protein X in Control and Treated Cells
| Sample Group | Endogenous Peptide Peak Area (Light) | Labeled Peptide Standard Peak Area (Heavy) | Peak Area Ratio (Light/Heavy) | Amount of Protein X (fmol/µg total protein) |
| Control 1 | 1.25 x 10⁷ | 2.50 x 10⁷ | 0.50 | 50.0 |
| Control 2 | 1.30 x 10⁷ | 2.52 x 10⁷ | 0.52 | 52.0 |
| Control 3 | 1.22 x 10⁷ | 2.48 x 10⁷ | 0.49 | 49.0 |
| Control Avg. | 1.26 x 10⁷ | 2.50 x 10⁷ | 0.50 | 50.3 |
| Treated 1 | 2.45 x 10⁷ | 2.49 x 10⁷ | 0.98 | 98.0 |
| Treated 2 | 2.55 x 10⁷ | 2.51 x 10⁷ | 1.02 | 102.0 |
| Treated 3 | 2.48 x 10⁷ | 2.50 x 10⁷ | 0.99 | 99.0 |
| Treated Avg. | 2.49 x 10⁷ | 2.50 x 10⁷ | 1.00 | 99.7 |
Assuming 100 fmol of labeled peptide was spiked into 10 µg of total protein digest.
Signaling Pathways and Logical Relationships
The quantification of protein levels is crucial for understanding signaling pathways. For example, leucine itself is a nutrient signal that activates the mTORC1 pathway, a central regulator of cell growth and proliferation.
By using Fmoc-L-leucine-¹³C₆,¹⁵N to synthesize labeled standards for key proteins in this pathway (e.g., mTOR, S6K1), researchers can precisely quantify how their abundance changes in response to various stimuli or drug treatments, providing deeper insights into the regulation of cellular metabolism.
Conclusion
Fmoc-L-leucine-¹³C₆,¹⁵N is a vital reagent for modern quantitative proteomics and the study of protein metabolism. While not suitable for direct use in live-cell metabolic flux analysis, its role in the synthesis of stable isotope-labeled peptide standards is indispensable. These standards enable the highly accurate quantification of proteins and the analysis of their turnover rates, providing crucial data for researchers in basic science and drug development to understand the complex machinery of the cell.
References
- 1. fiveable.me [fiveable.me]
- 2. researchgate.net [researchgate.net]
- 3. researchgate.net [researchgate.net]
- 4. Methods for Removing the Fmoc Group | Springer Nature Experiments [experiments.springernature.com]
- 5. chempep.com [chempep.com]
- 6. sigmaaldrich.com [sigmaaldrich.com]
- 7. (S)-N-Fmoc-L-norleucine-13C6,15N | 1346617-52-4 | Benchchem [benchchem.com]
- 8. Fluorenylmethyloxycarbonyl protecting group - Wikipedia [en.wikipedia.org]
- 9. Isotope Labeling in Mammalian Cells - PMC [pmc.ncbi.nlm.nih.gov]
- 10. L-Leucine-ð-Fmoc (¹³Câ, 99%; ¹âµN, 99%) - Cambridge Isotope Laboratories, CNLM-4345-H-0.1 [isotope.com]
Experimental Design for Stable Isotope Labeling: Application Notes and Protocols
For Researchers, Scientists, and Drug Development Professionals
Introduction
Stable isotope labeling is a powerful technique for tracing the metabolic fate of molecules in biological systems. By replacing atoms with their heavier, non-radioactive isotopes (e.g., ¹³C for ¹²C, ¹⁵N for ¹⁴N), researchers can accurately track and quantify dynamic changes in proteins and metabolites. This approach is instrumental in drug development for elucidating mechanisms of action, identifying biomarkers, and understanding metabolic reprogramming in disease.[1][2][3] This document provides detailed application notes and protocols for two widely used stable isotope labeling techniques: Stable Isotope Labeling by Amino Acids in Cell Culture (SILAC) for quantitative proteomics and ¹³C-Metabolic Flux Analysis (¹³C-MFA) for probing cellular metabolism.
Core Principles of Stable Isotope Labeling
The fundamental concept behind stable isotope labeling is the introduction of a "heavy" labeled compound into a biological system.[1][3] This compound is metabolized and incorporated into macromolecules and metabolic intermediates. Mass spectrometry (MS) or nuclear magnetic resonance (NMR) spectroscopy is then used to distinguish between the labeled ("heavy") and unlabeled ("light") molecules based on their mass difference.[3][4] This allows for the precise quantification of metabolic turnover and flux.
Application Note 1: Quantitative Proteomics using SILAC
Stable Isotope Labeling by Amino Acids in Cell Culture (SILAC) is a metabolic labeling strategy used to quantify relative protein abundance between different cell populations.[5][6] Cells are grown in media where specific essential amino acids (typically lysine (B10760008) and arginine) are replaced with their heavy stable isotope counterparts.[5][6] After a number of cell divisions, these heavy amino acids are fully incorporated into the proteome.[2][7]
Key Applications in Drug Development:
-
Target Engagement and Mechanism of Action Studies: Quantify changes in protein expression or post-translational modifications upon drug treatment to understand how a compound interacts with its target and downstream pathways.[2]
-
Biomarker Discovery: Identify proteins that are differentially expressed in response to a drug or disease state, which can serve as potential biomarkers for efficacy or toxicity.
-
Off-Target Effect Analysis: Profile global proteome changes to identify unintended protein interactions and potential off-target effects of a drug candidate.
Experimental Workflow and Protocol
The SILAC workflow is divided into two main phases: an adaptation phase for complete labeling and an experimental phase for differential treatment and analysis.[2][7]
Figure 1: SILAC Experimental Workflow.
Protocol: SILAC Labeling of Mammalian Cells
-
Media Preparation:
-
Prepare "light" and "heavy" SILAC media using DMEM or RPMI-1640 lacking L-lysine and L-arginine.
-
Supplement the "light" medium with normal L-lysine (¹²C₆H₁₂N₂O₂) and L-arginine (¹²C₆H₁₄N₄O₂).
-
Supplement the "heavy" medium with stable isotope-labeled L-lysine (e.g., ¹³C₆-Lys) and L-arginine (e.g., ¹³C₆¹⁵N₄-Arg).
-
Add 10% dialyzed fetal bovine serum to both media to minimize the concentration of unlabeled amino acids.[7]
-
-
Cell Culture and Labeling:
-
Experimental Treatment:
-
Once labeling is complete, treat the "heavy" labeled cells with the drug of interest and the "light" labeled cells with a vehicle control.
-
-
Sample Collection and Preparation:
-
Harvest and count the cells from both populations.
-
Combine an equal number of cells from the "light" and "heavy" populations.[7]
-
Lyse the combined cell pellet and extract the proteins.
-
-
Protein Digestion and Mass Spectrometry:
-
Data Analysis:
-
Use specialized software to identify peptides and quantify the intensity ratios of "heavy" to "light" peptide pairs. This ratio reflects the relative abundance of the protein in the drug-treated versus control cells.
-
Data Presentation
Quantitative proteomics data from SILAC experiments are typically presented in a table format, highlighting the proteins with significant changes in abundance.
| Protein Accession | Gene Symbol | Protein Name | H/L Ratio | p-value | Regulation |
| P04637 | TP53 | Cellular tumor antigen p53 | 2.54 | 0.001 | Upregulated |
| P62258 | HSP90AB1 | Heat shock protein HSP 90-beta | 0.45 | 0.005 | Downregulated |
| Q06830 | RPS6KA1 | Ribosomal protein S6 kinase alpha-1 | 1.89 | 0.012 | Upregulated |
| P60709 | ACTB | Actin, cytoplasmic 1 | 1.02 | 0.950 | Unchanged |
Table 1: Example of Quantitative Proteomics Data from a SILAC Experiment. The table shows the relative abundance (H/L Ratio) of proteins in drug-treated ("Heavy") versus control ("Light") cells. A ratio greater than 1 indicates upregulation, while a ratio less than 1 indicates downregulation. The p-value indicates the statistical significance of the change.
Application Note 2: ¹³C-Metabolic Flux Analysis (¹³C-MFA)
¹³C-Metabolic Flux Analysis is a technique used to quantify the rates (fluxes) of intracellular metabolic reactions.[3] Cells are cultured in a medium containing a ¹³C-labeled substrate, such as [U-¹³C₆]-glucose. As the cells metabolize the labeled substrate, the ¹³C atoms are incorporated into various downstream metabolites. The resulting mass isotopomer distributions (MIDs) of these metabolites are measured by mass spectrometry.[3]
Key Applications in Drug Development:
-
Metabolic Reprogramming: Characterize how cancer cells or other diseased cells alter their metabolic pathways to support growth and proliferation.
-
Target Validation: Determine the impact of inhibiting a specific enzyme on the flux through a metabolic pathway.
-
Mechanism of Action: Elucidate how a drug alters cellular metabolism to exert its therapeutic effect.[3]
Experimental Workflow and Protocol
A typical ¹³C-MFA experiment involves culturing cells with a ¹³C-labeled tracer, extracting metabolites, analyzing their labeling patterns, and using computational modeling to estimate fluxes.[9]
Figure 2: ¹³C-Metabolic Flux Analysis Workflow.
Protocol: ¹³C-Labeling and Metabolite Extraction
-
Cell Culture and Labeling:
-
Culture cells in a defined medium.
-
Replace the primary carbon source with its ¹³C-labeled counterpart (e.g., [U-¹³C₆]-glucose).
-
Incubate the cells until they reach isotopic steady state. The time to reach steady state depends on the cell type and the metabolic pathway being studied.[10]
-
-
Metabolism Quenching and Metabolite Extraction:
-
Rapidly quench metabolic activity by washing the cells with ice-cold saline and then adding a cold extraction solvent, typically 80% methanol.[11]
-
Scrape the cells and transfer the cell lysate to a microcentrifuge tube.
-
Centrifuge to pellet cell debris and collect the supernatant containing the metabolites.
-
-
Sample Analysis:
-
Analyze the metabolite extract using gas chromatography-mass spectrometry (GC-MS) or liquid chromatography-mass spectrometry (LC-MS) to determine the mass isotopomer distributions of key metabolites.[3]
-
-
Data Analysis and Flux Calculation:
Data Presentation
The results of a ¹³C-MFA study are typically presented as a flux map, often summarized in a table comparing fluxes between different conditions.
| Reaction | Control Flux (mmol/gDW/h) | Drug-Treated Flux (mmol/gDW/h) | Fold Change | p-value |
| Glycolysis (Glucose -> Pyruvate) | 10.5 ± 0.8 | 5.2 ± 0.5 | 0.50 | 0.002 |
| Pentose Phosphate Pathway | 2.1 ± 0.3 | 4.3 ± 0.4 | 2.05 | 0.001 |
| TCA Cycle (Citrate Synthase) | 6.8 ± 0.6 | 3.1 ± 0.4 | 0.46 | 0.003 |
| Anaplerosis (Pyruvate Carboxylase) | 1.5 ± 0.2 | 3.2 ± 0.3 | 2.13 | 0.001 |
Table 2: Example of Metabolic Flux Data from a ¹³C-MFA Experiment. The table shows a comparison of metabolic fluxes through key pathways in control versus drug-treated cells. Fluxes are reported as millimoles per gram of dry cell weight per hour.
Visualization of a Signaling Pathway
Stable isotope labeling proteomics is frequently used to investigate how drugs affect signaling pathways. The diagram below illustrates a simplified mTOR signaling pathway, a key regulator of cell growth and metabolism, which is a common target in drug development.
Figure 3: Simplified mTOR Signaling Pathway.
Conclusion
Stable isotope labeling experiments, including SILAC for proteomics and ¹³C-MFA for metabolomics, are indispensable tools in modern drug discovery and development. They provide quantitative insights into the dynamic cellular processes that are perturbed by disease and therapeutic interventions. The detailed protocols and data presentation guidelines provided in this document offer a framework for designing and executing robust and informative stable isotope labeling studies.
References
- 1. SILAC Metabolic Labeling Systems | Thermo Fisher Scientific - AR [thermofisher.com]
- 2. SILAC: Principles, Workflow & Applications in Proteomics - Creative Proteomics Blog [creative-proteomics.com]
- 3. benchchem.com [benchchem.com]
- 4. m.youtube.com [m.youtube.com]
- 5. Frontiers | 13C metabolic flux analysis: Classification and characterization from the perspective of mathematical modeling and application in physiological research of neural cell [frontiersin.org]
- 6. SILAC - Based Proteomics Analysis - Creative Proteomics [creative-proteomics.com]
- 7. info.gbiosciences.com [info.gbiosciences.com]
- 8. Use of Stable Isotope Labeling by Amino Acids in Cell Culture (SILAC) for Phosphotyrosine Protein Identification and Quantitation - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Overview of 13c Metabolic Flux Analysis - Creative Proteomics [creative-proteomics.com]
- 10. d-nb.info [d-nb.info]
- 11. Metabolite extraction for mass spectrometry [bio-protocol.org]
- 12. High-resolution 13C metabolic flux analysis | Springer Nature Experiments [experiments.springernature.com]
- 13. Publishing 13C metabolic flux analysis studies: A review and future perspectives - PMC [pmc.ncbi.nlm.nih.gov]
Troubleshooting & Optimization
Technical Support Center: Solid-Phase Peptide Synthesis (SPPS)
Welcome to the technical support center for Solid-Phase Peptide Synthesis (SPPS). This resource is designed for researchers, scientists, and professionals in drug development. Below, you will find troubleshooting guides and frequently asked questions (FAQs) to address common issues encountered during SPPS, with a focus on overcoming poor coupling efficiency.
Frequently Asked Questions (FAQs)
Q1: What are the primary indicators of poor coupling efficiency in SPPS?
Poor coupling efficiency is primarily indicated by the presence of deletion sequences in the crude peptide product. This can be detected through several analytical methods:
-
Kaiser Test: A positive Kaiser test (a blue or purple color) after a coupling step indicates the presence of unreacted primary amines on the resin, signifying an incomplete reaction.[1][2][3]
-
HPLC Analysis: A complex chromatogram of the crude product with multiple peaks, particularly those with earlier retention times than the target peptide, suggests the presence of shorter, deletion sequences.
-
Mass Spectrometry (MS): Mass analysis of the crude product will show peaks corresponding to the molecular weights of the target peptide minus one or more amino acid residues.
Q2: What is a "difficult sequence" and how does it contribute to poor coupling?
A "difficult sequence" refers to a peptide chain that is prone to forming stable secondary structures, such as β-sheets, on the solid support. This phenomenon, known as on-resin aggregation, is a major cause of poor coupling efficiency.[3] Aggregation can physically block reactive sites, hindering the access of reagents to the growing peptide chain and leading to incomplete deprotection and coupling reactions.[3] Sequences rich in hydrophobic or β-branched amino acids (e.g., Val, Ile, Leu, Phe) are often categorized as difficult.[3]
Q3: Can the choice of solvent impact coupling efficiency?
Yes, the solvent plays a critical role in solvating the peptide-resin complex, which is essential for efficient reactions. N-methylpyrrolidone (NMP) is often considered a superior solvent to N,N-dimethylformamide (DMF) as it is more polar and can improve coupling yields by better solvating the resin and peptide chains.[4] However, DMF is also widely used. It is crucial to use high-purity, fresh solvents, as impurities in DMF, such as dimethylamine, can cause premature Fmoc deprotection.
Q4: How do I choose the right coupling reagent?
The choice of coupling reagent is critical and often depends on the specific peptide sequence. For routine syntheses, standard reagents may be sufficient. However, for difficult sequences, more potent reagents are necessary. Onium salt-based reagents like HATU, HBTU, and COMU are generally more efficient than carbodiimides.[5][6] COMU is often highlighted for its high efficiency, lower tendency for racemization, and better safety profile compared to HBTU.[5][6]
Troubleshooting Guides
Issue 1: Positive Kaiser Test After Coupling
A positive Kaiser test indicates incomplete coupling. This troubleshooting guide will help you address this issue systematically.
-
Resin beads turn blue or purple after performing the Kaiser test post-coupling.
-
Mass spectrometry of the final product reveals deletion sequences.
Caption: A workflow for troubleshooting a positive Kaiser test.
Issue 2: Identification of Deletion Sequences by Mass Spectrometry
The presence of peptides with lower than expected molecular weights in the mass spectrum is a clear sign of failed coupling at one or more steps.
-
MS analysis shows peaks corresponding to [M-amino acid]+.
-
HPLC chromatogram shows multiple peaks, often eluting before the main product.
| Observed Mass Difference from Target Peptide (Da) | Probable Cause | Recommended Actions |
| -57.05 | Glycine (B1666218) deletion | For subsequent syntheses, consider double coupling for glycine residues, especially in sterically hindered positions. |
| -71.08 | Alanine deletion | If part of a difficult sequence, use a stronger coupling reagent like HATU or COMU. |
| -99.13 | Valine deletion | Valine is a β-branched amino acid. Increase coupling time, use a more potent coupling reagent, or increase the reaction temperature. |
| -113.16 | Leucine/Isoleucine deletion | These are also β-branched and hydrophobic. Consider using pseudoproline dipeptides if the sequence allows, or switch to a solvent with better solvating properties like NMP. |
| -147.17 | Phenylalanine deletion | Phenylalanine is bulky and hydrophobic. Ensure adequate resin swelling and consider using structure-breaking additives. |
| -156.18 | Arginine deletion | Arginine coupling can be difficult due to its bulky side chain. Double coupling is often recommended. Ensure the protecting group (e.g., Pbf) is appropriate. |
Experimental Protocols
Kaiser (Ninhydrin) Test Protocol
This qualitative test is used to detect free primary amines on the resin.
-
Solution A: 1 g of ninhydrin (B49086) in 20 mL of n-butanol.
-
Solution B: 40 g of phenol (B47542) in 20 mL of n-butanol.
-
Solution C: 1.0 mL of a 0.001 M aqueous KCN solution diluted with 49 mL of pyridine.
-
Collect a small sample of resin beads (approximately 10-15 beads) in a small test tube.
-
Add 2-3 drops of each of Solution A, Solution B, and Solution C to the test tube.
-
Heat the test tube at 100-110°C for 5 minutes.[1]
-
Observe the color of the beads and the solution.
-
Intense Blue/Purple: Indicates a high concentration of free amines (incomplete coupling).
-
Faint Blue/Purple: Suggests a nearly complete reaction. Consider extending the coupling time or performing a second coupling.
-
Yellow/Colorless: Indicates the absence of free primary amines (complete coupling).
HPLC Analysis of Crude Peptide Purity
This protocol outlines a general method for analyzing the purity of a crude synthetic peptide by reverse-phase HPLC (RP-HPLC).
-
HPLC System: Equipped with a UV detector.
-
Column: A C18 reverse-phase column is suitable for a wide range of peptides.[7][8][9]
-
Mobile Phase A: 0.1% Trifluoroacetic Acid (TFA) in HPLC-grade water.[7][8][9]
-
Mobile Phase B: 0.1% Trifluoroacetic Acid (TFA) in HPLC-grade acetonitrile (B52724) (ACN).[7][8][9]
-
Sample Solvent: Mobile Phase A or a mixture of water and acetonitrile.
-
Sample Preparation: Dissolve the crude peptide in the sample solvent to a concentration of approximately 1 mg/mL. Filter the sample through a 0.22 µm or 0.45 µm syringe filter.
-
Method Setup:
-
Injection and Data Acquisition: Inject 10-20 µL of the prepared sample and run the HPLC method.
-
Data Analysis: Integrate the peaks in the chromatogram. The purity is typically calculated as the area of the main peak divided by the total area of all peaks, expressed as a percentage.
Comparative Data
Coupling Reagent Efficiency
The efficiency of coupling reagents can vary significantly, especially for challenging sequences. The following table provides a qualitative comparison of common coupling reagents.
| Coupling Reagent | Relative Efficiency | Propensity for Racemization | Notes |
| DIC/HOBt | Good | Low with HOBt | A classic and cost-effective choice for standard couplings. |
| HBTU | Very Good | Moderate | A widely used and effective reagent. |
| HATU | Excellent | Low | Highly effective for sterically hindered amino acids and difficult sequences.[11][12] |
| COMU | Excellent | Very Low | Shows high efficiency, good solubility, and a favorable safety profile.[5][6] |
Signaling Pathways and Workflows
Caption: The iterative cycle of SPPS and the integrated troubleshooting loop.
References
- 1. chempep.com [chempep.com]
- 2. americanpeptidesociety.org [americanpeptidesociety.org]
- 3. benchchem.com [benchchem.com]
- 4. researchgate.net [researchgate.net]
- 5. pubs.acs.org [pubs.acs.org]
- 6. benchchem.com [benchchem.com]
- 7. hplc.eu [hplc.eu]
- 8. benchchem.com [benchchem.com]
- 9. lcms.cz [lcms.cz]
- 10. mdpi.com [mdpi.com]
- 11. Development of the Schedule for Multiple Parallel “Difficult” Peptide Synthesis on Pins - PMC [pmc.ncbi.nlm.nih.gov]
- 12. americanlaboratory.com [americanlaboratory.com]
Technical Support Center: Troubleshooting Common Side Reactions in Fmoc Peptide Synthesis
Welcome to the technical support center for Fmoc solid-phase peptide synthesis (SPPS). This resource is designed for researchers, scientists, and drug development professionals to quickly diagnose and resolve common side reactions encountered during their experiments.
Frequently Asked Questions (FAQs)
Q1: What are the most common side reactions in Fmoc SPPS?
The most frequently encountered side reactions in Fmoc-based solid-phase peptide synthesis include:
-
Aspartimide Formation: Cyclization of aspartic acid residues, leading to peptide backbone rearrangement and the formation of difficult-to-remove impurities.[1][2]
-
Diketopiperazine (DKP) Formation: Cyclization of the N-terminal dipeptide, resulting in its cleavage from the resin and termination of the peptide chain.[3][4][5][6]
-
Incomplete Deprotection: Failure to completely remove the Fmoc group from the N-terminal amino acid, leading to deletion sequences.[7][8][9]
-
Aggregation: Self-association of peptide chains on the solid support, which can hinder both coupling and deprotection steps.[10][11][12][13]
-
Racemization: Loss of stereochemical integrity of an amino acid, leading to the formation of diastereomeric peptides with potentially altered biological activity.[12][14][15][16]
-
Oxidation of Sensitive Residues: Modification of susceptible amino acids such as methionine, tryptophan, and cysteine during synthesis or cleavage.
Troubleshooting Guides
Aspartimide Formation
Q: My peptide, which contains an Asp-Gly sequence, shows multiple peaks with the same mass in the HPLC analysis. What could be the issue?
This is a classic sign of aspartimide formation, a significant side reaction especially prevalent in sequences where aspartic acid is followed by a small amino acid like glycine (B1666218) (Asp-Gly).[1][17] The piperidine (B6355638) used for Fmoc deprotection can catalyze the formation of a cyclic aspartimide intermediate. This intermediate can then be attacked by piperidine or trace water, leading to the formation of α- and β-aspartyl peptides, as well as their D-isomers, which are often difficult to separate chromatographically.[1]
References
- 1. media.iris-biotech.de [media.iris-biotech.de]
- 2. researchgate.net [researchgate.net]
- 3. pubs.acs.org [pubs.acs.org]
- 4. researchgate.net [researchgate.net]
- 5. Optimized Fmoc-Removal Strategy to Suppress the Traceless and Conventional Diketopiperazine Formation in Solid-Phase Peptide Synthesis - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. chempep.com [chempep.com]
- 7. Incomplete Fmoc deprotection in solid-phase synthesis of peptides - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. benchchem.com [benchchem.com]
- 9. benchchem.com [benchchem.com]
- 10. Aggregation of resin-bound peptides during solid-phase peptide synthesis. Prediction of difficult sequences - PubMed [pubmed.ncbi.nlm.nih.gov]
- 11. experts.arizona.edu [experts.arizona.edu]
- 12. peptide.com [peptide.com]
- 13. benchchem.com [benchchem.com]
- 14. Evaluation of acid-labile S-protecting groups to prevent Cys racemization in Fmoc solid-phase peptide synthesis - PMC [pmc.ncbi.nlm.nih.gov]
- 15. Evaluation of acid-labile S-protecting groups to prevent Cys racemization in Fmoc solid-phase peptide synthesis - PubMed [pubmed.ncbi.nlm.nih.gov]
- 16. benchchem.com [benchchem.com]
- 17. benchchem.com [benchchem.com]
Technical Support Center: Optimizing Fmoc Deprotection for Labeled Amino Acids
This guide provides researchers, scientists, and drug development professionals with comprehensive troubleshooting strategies, frequently asked questions (FAQs), and detailed protocols for optimizing the Nα-Fmoc deprotection step, with a special focus on challenges presented by labeled amino acids during Solid-Phase Peptide Synthesis (SPPS).
Frequently Asked Questions (FAQs)
Q1: What is the fundamental mechanism of Fmoc deprotection?
A1: The removal of the 9-fluorenylmethoxycarbonyl (Fmoc) group is a base-catalyzed β-elimination reaction.[1] A base, typically a secondary amine like piperidine (B6355638), abstracts the acidic proton from the C9 carbon of the fluorenyl ring.[1][2][3] This initiates the cleavage, releasing the free N-terminal amine of the peptide, carbon dioxide, and a highly reactive dibenzofulvene (DBF) intermediate.[1][2][3] The secondary amine used as the base also serves to trap, or "scavenge," the DBF to form a stable adduct, driving the reaction to completion.[1][2][3]
Q2: Why is piperidine the most common reagent for Fmoc removal?
A2: Piperidine is a cyclic secondary amine that is highly effective at both initiating the deprotection mechanism and scavenging the resulting dibenzofulvene (DBF) byproduct.[2][4] Standard protocols often utilize a 20-30% solution of piperidine in a polar solvent like N,N-dimethylformamide (DMF), which provides rapid and efficient Fmoc removal for most peptide sequences.[1][3][5]
Q3: How can I monitor the progress of the deprotection reaction?
A3: There are both quantitative and qualitative methods.
-
Quantitative UV-Vis Spectrophotometry: This is a common method used in automated synthesizers.[6] The dibenzofulvene-piperidine adduct has a distinct UV absorbance around 300-312 nm.[1][6][7] By monitoring the absorbance of the solution flowing from the reactor, one can track the release of the Fmoc group in real-time and ensure the reaction goes to completion.[6][7]
-
Qualitative Colorimetric Tests: The Ninhydrin (Kaiser) test is widely used to detect the presence of free primary amines after deprotection.[7][8] A positive result (blue or brown beads) indicates a successful deprotection, while a negative result (yellow/colorless) suggests the Fmoc group is still attached.[6][8] Other tests like the TNBS test can also be used.[6]
Q4: Are there alternatives to piperidine for Fmoc deprotection?
A4: Yes, several alternatives are used to address issues like side reactions or for regulatory reasons, as piperidine is a controlled substance.[4] Common alternatives include piperazine (B1678402), 4-methylpiperidine (B120128) (4MP), and 1,8-Diazabicyclo[5.4.0]undec-7-ene (DBU).[4][9] Piperazine has been shown to cause fewer side reactions, such as aspartimide formation, compared to piperidine.[4][9] More recent "green" alternatives like 3-(diethylamino)propylamine (B94944) (DEAPA) and 1,5-diazabicyclo[4.3.0]non-5-ene (DBN) are also being explored.[10][11]
Troubleshooting Guide
Issue 1: Incomplete Fmoc Deprotection
Q: My analysis (e.g., Kaiser test, HPLC of a cleaved sample) indicates that the Fmoc group was not completely removed. What are the common causes and solutions?
A: Incomplete deprotection is a frequent issue that can lead to deletion sequences in the final peptide product.[4] The primary causes and troubleshooting steps are outlined below.
Common Causes:
-
Peptide Aggregation: As the peptide chain elongates, it can fold into secondary structures like β-sheets, which physically block reagent access to the N-terminus.[6][7][12] This is common in sequences with repeating hydrophobic residues.[6]
-
Steric Hindrance: Bulky amino acids (e.g., Val, Ile, Aib) or amino acids with large side-chain protecting groups near the N-terminus can impede the approach of the piperidine base.[4][7] Large fluorescent labels can introduce significant steric bulk, creating similar challenges.
-
Poor Resin Solvation: Inadequate swelling of the resin or poor solvation of the peptide chain can hinder the diffusion of the deprotection reagent.[7]
-
Insufficient Reagent or Time: Standard deprotection times may not be sufficient for "difficult sequences".[7] The concentration or freshness of the piperidine solution may also be a factor.
Troubleshooting Workflow: The following flowchart provides a logical approach to diagnosing and solving incomplete deprotection.
Issue 2: Side Reaction Formation
Q: I'm observing unexpected peaks in my HPLC analysis after synthesis. What are common side reactions during Fmoc deprotection?
A: Base-mediated deprotection can sometimes lead to unwanted side reactions, particularly with sensitive sequences.
-
Aspartimide Formation: This is a significant side reaction where the side chain of an aspartic acid residue cyclizes to form a stable five-membered ring.[9][11] This is particularly problematic when the next residue in the sequence is small, like glycine.[11] This reaction can be catalyzed by the bases used for deprotection.[9]
-
Solution: Using a milder base like piperazine can significantly reduce the rate of aspartimide formation.[4][9] Adding 0.1M 1-hydroxybenzotriazole (B26582) (HOBt) to the deprotection solution has also been shown to have a beneficial effect.[9]
-
-
Racemization: Base-mediated racemization can occur, especially at the C-terminal cysteine residue.[9]
-
DBF Adduct Formation with Peptide: If the dibenzofulvene (DBF) byproduct is not efficiently scavenged by the base, it can react with the newly liberated N-terminal amine of the peptide, leading to an irreversible modification.
-
Solution: Ensure a sufficient excess of a secondary amine (like piperidine or piperazine) is used to act as an effective scavenger.[2]
-
Issue 3: Challenges with Labeled Amino Acids
Q: Does the presence of a fluorescent label on an amino acid affect Fmoc deprotection?
A: Yes, it can. While the fundamental chemistry remains the same, the physical properties of the label can introduce challenges.
-
Steric Hindrance: Many fluorescent dyes are large, bulky aromatic structures.[13] When attached to an amino acid side chain (e.g., on Lysine), the label can sterically hinder the approach of the deprotection base to the N-terminal Fmoc group, similar to the effect of bulky protecting groups.[4][7] This can lead to slow or incomplete deprotection.
-
Solution: Treat the labeled residue as a "difficult" amino acid. Extend the deprotection time, perform a double deprotection, or consider using a stronger base system like DBU/piperidine if standard conditions fail.[7]
-
-
Aggregation: The hydrophobic and aromatic nature of many dyes can promote inter-chain or intra-chain aggregation, especially as the peptide elongates. This can reduce reagent accessibility.
-
Solution: Employ strategies to disrupt aggregation. This can include using specialized solvents or adding chaotropic agents.
-
Quantitative Data Summary
The selection of a deprotection reagent and its concentration is critical for balancing efficiency with the minimization of side reactions.
Table 1: Comparison of Common Fmoc Deprotection Reagents
| Reagent | Typical Concentration | Solvent | Key Characteristics & Considerations |
| Piperidine (PP) | 20-30% (v/v)[5] | DMF / NMP | The most common and highly effective reagent; can cause side reactions like aspartimide formation.[4][9] |
| Piperazine (PZ) | 10% (w/v)[4] | DMF/Ethanol | A good alternative to piperidine, showing reduced side reactions.[4][9] Solubility can be a limiting factor.[4] |
| 4-Methylpiperidine (4MP) | 20% (v/v)[4] | DMF | Performance is comparable to piperidine; considered a viable replacement.[4] |
| DBU | 2% (v/v) (often with Piperidine)[7] | DMF | A very strong, non-nucleophilic base used for difficult sequences; may promote other side reactions if used improperly.[7][9] |
| DBN | 2% (v/v)[11] | Green Solvents | A promising "green" alternative showing high efficiency at low concentrations and minimizing racemization.[11] |
Experimental Protocols
Protocol 1: Standard Fmoc Deprotection
This protocol is suitable for most standard peptide sequences.
-
Resin Swelling: Swell the peptide-resin in DMF for at least 30 minutes.
-
Initial Deprotection: Drain the DMF and add a solution of 20% piperidine in DMF to the resin (approx. 10 mL per gram of resin).[14][15] Agitate for 3-5 minutes.[1][14][15]
-
Drain: Drain the deprotection solution.
-
Second Deprotection: Add a fresh portion of 20% piperidine in DMF and agitate for an additional 10-15 minutes.[1]
-
Final Wash: Drain the solution and wash the resin thoroughly with DMF (5-7 times) to remove all residual piperidine and the dibenzofulvene-piperidine adduct.[1]
-
Confirmation (Optional): Perform a Kaiser test to confirm the presence of a free primary amine.[7]
Protocol 2: Deprotection for Difficult or Labeled Residues (DBU Method)
This protocol should be used judiciously for sequences prone to aggregation or steric hindrance.
-
Resin Swelling: Swell the peptide-resin in DMF for at least 30 minutes.
-
Prepare Reagent: Prepare a deprotection cocktail of 2% DBU and 20% piperidine in DMF.[7]
-
Deprotection: Add the deprotection cocktail to the resin and agitate for 5-15 minutes, carefully monitoring the reaction progress.[7]
-
Drain and Wash: Drain the solution and wash the resin extensively with DMF (at least 5 times) to remove all traces of DBU and piperidine.[7]
Protocol 3: Monitoring Deprotection by UV-Vis Spectroscopy
This method quantifies the release of the Fmoc group.
-
Collect Filtrate: After the Fmoc deprotection step, collect the combined piperidine solutions in a volumetric flask of a known volume (e.g., 10 mL).[1]
-
Dilute: Dilute the solution to the mark with DMF.[1]
-
Measure Absorbance: Using a UV spectrophotometer, measure the absorbance of the solution at ~301 nm, using DMF as the blank.[1][6]
-
Calculate Loading: Use the Beer-Lambert law (A = εbc) to calculate the concentration of the DBF-piperidine adduct and thereby determine the extent of Fmoc removal. The molar extinction coefficient (ε) for the adduct is approximately 7800 M⁻¹cm⁻¹.
Visualized Workflows and Mechanisms
Diagrams help clarify the complex processes involved in peptide synthesis.
References
- 1. benchchem.com [benchchem.com]
- 2. researchgate.net [researchgate.net]
- 3. Methods for Removing the Fmoc Group | Springer Nature Experiments [experiments.springernature.com]
- 4. Deprotection Reagents in Fmoc Solid Phase Peptide Synthesis: Moving Away from Piperidine? - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Deprotection - Wordpress [reagents.acsgcipr.org]
- 6. benchchem.com [benchchem.com]
- 7. benchchem.com [benchchem.com]
- 8. luxembourg-bio.com [luxembourg-bio.com]
- 9. ovid.com [ovid.com]
- 10. Replacing piperidine in solid phase peptide synthesis: effective Fmoc removal by alternative bases - Green Chemistry (RSC Publishing) [pubs.rsc.org]
- 11. tandfonline.com [tandfonline.com]
- 12. Incomplete Fmoc deprotection in solid-phase synthesis of peptides - PubMed [pubmed.ncbi.nlm.nih.gov]
- 13. Fluorescent labeling and modification of proteins - PMC [pmc.ncbi.nlm.nih.gov]
- 14. peptide.com [peptide.com]
- 15. benchchem.com [benchchem.com]
Technical Support Center: Minimizing Isotopic Scrambling in Labeling Experiments
Welcome to the technical support center for researchers, scientists, and drug development professionals. This resource provides in-depth troubleshooting guides and frequently asked questions (FAQs) to help you minimize isotopic scrambling in your labeling experiments, ensuring the integrity and accuracy of your data.
Frequently Asked questions (FAQs)
Q1: What is isotopic scrambling and why is it a significant issue in labeling experiments?
Isotopic scrambling refers to the randomization of isotope labeling patterns in molecules, deviating from what is expected based on known metabolic pathways.[1] This occurs through various biochemical reactions, leading to an equilibrium distribution of isotopes within a set of atoms in a chemical species.[1] Scrambling is a critical issue, particularly in techniques like 13C Metabolic Flux Analysis (13C-MFA), because these methods rely on the precise tracking of labeled atoms to calculate metabolic fluxes.[2] If scrambling occurs, the measured mass isotopomer distributions will not accurately reflect the activity of the primary metabolic pathways of interest, leading to erroneous flux calculations.[2]
Q2: What are the primary causes of isotopic scrambling?
Isotopic scrambling can arise from several biochemical and procedural sources:
-
Reversible Reactions: High rates of reversible enzymatic reactions can lead to the redistribution of labeled carbons within a molecule and connected metabolite pools.[2]
-
Metabolic Branch Points and Convergences: Pathways where metabolites can be produced from multiple sources or can enter various downstream pathways can contribute to scrambling.[2]
-
Futile Cycles: The simultaneous operation of two opposing metabolic pathways can lead to the continual cycling of metabolites and scrambling of isotopic labels.[2]
-
Background CO2 Fixation: The incorporation of unlabeled CO2 from the atmosphere or bicarbonate in the medium into metabolic intermediates can dilute the 13C enrichment and alter labeling patterns.[2]
-
Slow or Incomplete Quenching: If metabolic activity is not stopped instantaneously during sample collection, enzymatic reactions can continue, leading to altered labeling patterns.[2]
-
Metabolite Degradation during Extraction: The instability of metabolites during the extraction process can also contribute to misleading labeling data.[2]
Q3: How can I determine if my experiment has reached an isotopic steady state?
Reaching an isotopic steady state, where the enrichment of the isotope in metabolites becomes stable over time, is crucial for many metabolic flux analysis studies. To determine if your experiment has reached this state, you should perform a time-course experiment. This involves collecting samples at multiple time points after introducing the labeled substrate and measuring the mass isotopomer distribution of key metabolites. Isotopic steady state is achieved when the labeling patterns of these metabolites no longer change significantly over time.[2]
Troubleshooting Guides
This section addresses specific issues you may encounter during your labeling experiments.
Problem 1: Unexpectedly Low Isotope Incorporation in Downstream Metabolites
Symptoms: Mass spectrometry data shows low enrichment of the isotopic label in metabolites that are downstream of the labeled substrate.
| Possible Cause | Troubleshooting Steps |
| Slow Substrate Uptake or Metabolism | - Verify Substrate Uptake: Measure the concentration of the labeled substrate in the medium over time to confirm it is being consumed. - Check Cell Viability and Health: Ensure that the cells are healthy and metabolically active. Poor cell health can lead to reduced metabolic activity. - Optimize Substrate Concentration: The concentration of the labeled substrate may be too low. Consider increasing the concentration, but be mindful of potential toxic effects.[2] |
| Dilution by Unlabeled Sources | - Analyze Media Components: Check for the presence of unlabeled sources of the same metabolite in the culture medium. - Consider Endogenous Pools: Be aware of large endogenous unlabeled pools of the metabolite within the cells. |
| Incorrect Sampling Time | - Perform a Time-Course Experiment: Collect samples at various time points to track the incorporation of the label over time. This will help identify the optimal labeling duration.[2] |
Problem 2: Mass Isotopomer Distributions Suggest Scrambling in the TCA Cycle
Symptoms: The observed mass isotopomer distributions (MIDs) for Tricarboxylic Acid (TCA) cycle intermediates are inconsistent with expected labeling patterns from the provided tracer.
| Possible Cause | Troubleshooting Steps |
| High Pyruvate Dehydrogenase (PDH) vs. Pyruvate Carboxylase (PC) Activity | - Model Fitting: Utilize 13C-MFA software to estimate the relative fluxes through PDH and PC. Significant flux through both pathways can lead to complex labeling patterns.[2] |
| Reversible Reactions within the TCA Cycle | - Analyze Labeling in Multiple Intermediates: Examining the labeling patterns of several TCA cycle intermediates can provide a more comprehensive picture of metabolic activity.[2] |
| Futile Cycles | - Literature Review: Consult literature for the specific cell type or organism to understand the potential for futile cycles. |
Problem 3: Inconsistent Results Between Biological Replicates
Symptoms: Significant variability in labeling patterns is observed across biological replicates.
| Possible Cause | Troubleshooting Steps |
| Inconsistent Quenching | - Standardize Quenching Time: Ensure the time from sample collection to quenching is minimized and kept consistent across all samples.[2] |
| Incomplete Metabolite Extraction | - Test Different Extraction Solvents: Common extraction solvents include methanol (B129727), ethanol, and chloroform/methanol mixtures. The optimal solvent will depend on the metabolites of interest.[2] |
| Analytical Variability in Mass Spectrometry | - Regular Instrument Calibration: Ensure the mass spectrometer is regularly tuned and calibrated to maintain mass accuracy and sensitivity. - Check for Leaks: Gas leaks can affect instrument performance and lead to loss of sensitivity. - Monitor System Suitability: Run standard samples periodically to ensure the analytical system is performing consistently.[2] |
Problem 4: Arginine-to-Proline Conversion in SILAC Experiments
Symptoms: In Stable Isotope Labeling by Amino Acids in Cell Culture (SILAC) experiments using labeled arginine, unexpected labeling of proline-containing peptides is observed.
Cause: Some cell lines can metabolically convert arginine to proline, leading to the incorporation of the "heavy" isotope into proline.[3][4] This complicates data analysis and can lead to inaccurate protein quantification.
| Mitigation Strategy | Description |
| Supplement with Unlabeled Proline | Adding a high concentration of unlabeled proline to the SILAC medium can suppress the metabolic conversion of labeled arginine.[5] |
| Use Arginine-to-Proline Conversion-Deficient Cell Lines | Genetically modifying cell lines to knock out enzymes responsible for arginine catabolism, such as arginase, can prevent the conversion.[6] |
| Computational Correction | Software tools can be used to computationally correct for the contribution of converted proline to the peptide isotopic distribution.[7] |
Quantitative Data Summary
Table 1: Comparison of Quenching Methods for Metabolomics
The choice of quenching method is critical to rapidly halt metabolic activity and prevent isotopic scrambling. Below is a comparison of different quenching methods and their effectiveness.
| Quenching Method | Temperature | Key Findings | Reference |
| Cold Methanol (60% v/v) | -40°C | Conventional and effective for yeast metabolomics.[8] | [8] |
| Methanol-Acetonitrile-Water | -20°C | Can lead to lower concentrations of phosphorylated sugars and nucleotides compared to cold methanol.[1][8] | [1][8] |
| Liquid Nitrogen | -196°C | Found to be most optimal for HeLa cells when followed by 50% acetonitrile (B52724) extraction, minimizing metabolite loss.[9] | [9] |
| Cold Aqueous Methanol (40% v/v) | -25°C | Optimal for Penicillium chrysogenum, resulting in an average metabolite recovery of 95.7%.[10] | [10] |
| Rapid Filtration followed by 100% Cold Methanol | -80°C | Exhibits the highest quenching efficiency for suspension cultures of Synechocystis sp.[11] | [11] |
Experimental Protocols
Protocol 1: Rapid Quenching and Metabolite Extraction for Adherent Mammalian Cells
This protocol is designed to rapidly halt metabolism and efficiently extract metabolites from adherent cell cultures for 13C-labeling experiments.[12][13]
Materials:
-
Culture dishes with adherent cells
-
Labeled media (pre-warmed to 37°C)
-
Glucose-free media
-
Quenching solution: 80:20 methanol:water, chilled to -70°C to -80°C[12]
-
Cell scrapers
-
Microcentrifuge tubes
-
Centrifuge capable of 4°C and >6,000 x g
Procedure:
-
One hour before labeling, replace the media with fresh media supplemented with dialyzed fetal calf serum to remove unlabeled small molecules.[12]
-
At the time of labeling, remove the media and perform a quick wash (less than 30 seconds) with glucose-free media.[12]
-
Add the pre-warmed labeled media to the cells and incubate for the desired time.
-
At the end of the incubation, immediately and completely remove the labeled media.
-
Add a sufficient volume of the chilled quenching solution to cover the cell monolayer (e.g., 700 µl for a standard dish).[12]
-
Immediately place the culture dishes at -75°C for 10 minutes to ensure complete metabolic quenching.[12][13]
-
Incubate the dishes on ice for 10-15 minutes to allow for freeze-thaw lysis of the cells.[12][13]
-
On a bed of dry ice, scrape the cells off the culture dish.
-
Transfer the cell lysate to a pre-chilled microcentrifuge tube.
-
Vortex for 10 minutes, with cycles of 30 seconds of vortexing followed by 1 minute of incubation on ice.[12][13]
-
Centrifuge the lysate at 6,000 x g for 5 minutes at 4°C.[12][13]
-
Collect the supernatant containing the extracted metabolites.
-
Store the extracts at -80°C until analysis. For LC-MS analysis, it is best to analyze within 24 hours of extraction.[12]
Protocol 2: Assessing SILAC Labeling Efficiency
This protocol outlines the steps to determine the incorporation efficiency of heavy amino acids in a SILAC experiment. A labeling efficiency of over 97% is recommended for accurate quantification.[14][15]
Materials:
-
Cells cultured in "light" and "heavy" SILAC media
-
Phosphate-Buffered Saline (PBS)
-
Lysis buffer
-
Trypsin
-
LC-MS/MS system
Procedure:
-
Culture a small population of cells in the "heavy" SILAC medium for at least five cell doublings.[14][15]
-
Harvest a fraction of the "heavy" labeled cells (e.g., one million cells).
-
Wash the cell pellet twice with cold PBS, centrifuging at 500 x g for 5-10 minutes between washes.[16]
-
Lyse the cells using a compatible lysis buffer.
-
Perform an in-solution or in-gel digestion of the proteins using trypsin.[14]
-
Analyze the resulting peptide mixture by LC-MS/MS.
-
Analyze the mass spectrometry data to determine the percentage of heavy amino acid incorporation. This is done by comparing the peak areas of the light and heavy forms of identified peptides.[16]
-
If the incorporation efficiency is below 97%, continue culturing the cells for additional doublings and repeat the assessment.[14][15]
Visualizations
Caption: Troubleshooting workflow for low isotope incorporation.
Caption: Primary causes of isotopic scrambling.
Caption: General workflow for a SILAC experiment.
References
- 1. biorxiv.org [biorxiv.org]
- 2. benchchem.com [benchchem.com]
- 3. Quantitative analysis of SILAC data sets using spectral counting - PMC [pmc.ncbi.nlm.nih.gov]
- 4. researchgate.net [researchgate.net]
- 5. Preventing arginine-to-proline conversion in a cell-line-independent manner during cell cultivation under stable isotope labeling by amino acids in cell culture (SILAC) conditions [agris.fao.org]
- 6. A genetic engineering solution to the "arginine conversion problem" in stable isotope labeling by amino acids in cell culture (SILAC) - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. A Computational Approach to Correct Arginine-to-Proline Conversion in Quantitative Proteomics - PMC [pmc.ncbi.nlm.nih.gov]
- 8. research.tudelft.nl [research.tudelft.nl]
- 9. A systematic evaluation of quenching and extraction procedures for quantitative metabolome profiling of HeLa carcinoma cell under 2D and 3D cell culture conditions - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. Optimization of cold methanol quenching for quantitative metabolomics of Penicillium chrysogenum - PMC [pmc.ncbi.nlm.nih.gov]
- 11. 13C-Isotope-Assisted Assessment of Metabolic Quenching During Sample Collection from Suspension Cell Cultures - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. bio-protocol.org [bio-protocol.org]
- 13. en.bio-protocol.org [en.bio-protocol.org]
- 14. info.gbiosciences.com [info.gbiosciences.com]
- 15. Quantitative Comparison of Proteomes Using SILAC - PMC [pmc.ncbi.nlm.nih.gov]
- 16. m.youtube.com [m.youtube.com]
Technical Support Center: Purification of Isotopically Labeled Peptides by HPLC
This technical support center is designed for researchers, scientists, and drug development professionals to provide troubleshooting guidance and frequently asked questions (FAQs) for the purification of isotopically labeled peptides using High-Performance Liquid Chromatography (HPLC).
Frequently Asked Questions (FAQs)
Q1: Why is it challenging to separate isotopically labeled peptides from their unlabeled counterparts by HPLC?
A1: Isotopically labeled peptides are chemically and physically almost identical to their unlabeled (natural abundance) counterparts.[1] Standard reversed-phase HPLC separates molecules based on properties like hydrophobicity, which are minimally affected by the substitution of atoms with their heavier isotopes (e.g., ¹²C with ¹³C, ¹⁴N with ¹⁵N).[2][3] Consequently, labeled and unlabeled peptides typically have very similar, if not identical, retention times, leading to co-elution.[2][4]
Q2: Can different types of isotopes affect the HPLC separation?
A2: Yes. While heavy-atom isotopes like ¹³C and ¹⁵N generally do not cause a significant shift in retention time, deuterium (B1214612) (²H) labeling can.[2] Replacing hydrogen with deuterium can slightly alter the peptide's hydrophobicity, often resulting in a small decrease in retention time in reversed-phase chromatography.[5] This is known as the "inverse isotope effect."[5] While this can be a challenge for quantitative assays that rely on co-elution, it can sometimes be exploited to achieve separation during purification.
Q3: How can I confirm the purity of my isotopically labeled peptide?
A3: Purity assessment for isotopically labeled peptides has two components: chemical purity and isotopic purity.
-
Chemical Purity: This refers to the absence of non-peptide impurities (e.g., residual solvents, reagents from synthesis).[6] It is typically assessed by analytical HPLC with UV detection (at 210-220 nm), which will show the presence of other peptide-related impurities like truncated or deletion sequences.[6][7]
-
Isotopic Purity (or Enrichment): This refers to the percentage of the peptide that is fully labeled with the desired isotopes. It is crucial to confirm the absence of unlabeled or partially labeled species. This can only be determined using mass spectrometry (MS) coupled with HPLC (HPLC-MS).[1][6] By analyzing the mass-to-charge ratio (m/z) of the eluting peptide, you can quantify the distribution of different isotopic forms.[8]
Q4: What is a typical acceptable level of isotopic enrichment?
A4: For most applications, especially those using the labeled peptide as an internal standard for quantitative mass spectrometry, an isotopic purity of >99% is recommended to ensure the highest sensitivity and accuracy.[2][6]
Troubleshooting Guides
This section provides solutions to common problems encountered during the HPLC purification of isotopically labeled peptides.
Problem 1: Co-elution of Labeled and Unlabeled Peptides
Symptoms:
-
Analytical HPLC-MS shows two or more species with very similar retention times but different masses corresponding to the labeled and unlabeled peptide.
-
Inability to achieve baseline separation, making it difficult to isolate the pure labeled peptide.
Possible Causes & Solutions:
| Possible Cause | Solution |
| Inherent Similarity of Peptides | The labeled and unlabeled peptides have nearly identical physicochemical properties. |
| Optimize Gradient: Use a very shallow gradient around the elution point of the peptide. A slow increase in the organic mobile phase (e.g., 0.1-0.5% per minute) can sometimes resolve closely eluting species.[9] | |
| Change Mobile Phase Additives: While trifluoroacetic acid (TFA) is common, experimenting with other ion-pairing agents or different pH levels might slightly alter the selectivity and improve separation.[9][10] | |
| Exploit Deuterium Isotope Effect: If your peptide is deuterium-labeled, the slight retention time shift might be sufficient for separation with a highly optimized method. If not, and co-elution is a problem for your application, consider synthesizing the peptide with ¹³C or ¹⁵N labels instead.[2] | |
| Column Overload | Injecting too much sample can cause peak broadening and loss of resolution, masking any small separation that might be achievable. |
| Reduce Sample Load: Perform a loading study to determine the maximum amount of peptide that can be injected without compromising resolution. |
Problem 2: Poor Peak Shape (Tailing or Broadening)
Symptoms:
-
Asymmetrical peaks with a "tail" or excessively wide peaks, which can hide impurities and lead to poor fractionation.
Possible Causes & Solutions:
| Possible Cause | Solution |
| Secondary Interactions | The peptide may be interacting with active silanol (B1196071) groups on the silica-based column packing. |
| Increase TFA Concentration: Ensure a sufficient concentration of an ion-pairing agent like TFA (typically 0.1%) in your mobile phases to mask silanol interactions.[11] | |
| Use a Different Column: Consider using a column with a different stationary phase (e.g., C4 instead of C18 for larger peptides) or one specifically designed for peptide separations with end-capping to minimize silanol activity.[9][12] | |
| Peptide Aggregation | Hydrophobic peptides can aggregate on the column, leading to broad peaks. |
| Increase Column Temperature: Raising the column temperature (e.g., to 40-60°C) can often disrupt aggregation and improve peak shape.[12] | |
| Add Organic Solvent to Sample: Dissolve the peptide in a small amount of a strong organic solvent (like acetonitrile (B52724) or isopropanol) before diluting it with the initial mobile phase. |
Problem 3: Low Recovery of the Labeled Peptide
Symptoms:
-
The amount of purified peptide obtained after lyophilization is significantly lower than expected based on the amount of crude material injected.
Possible Causes & Solutions:
| Possible Cause | Solution |
| Peptide Adsorption | The peptide may be irreversibly binding to the column or other components of the HPLC system. |
| Column Passivation: Before injecting your sample, you can try passivating the column by injecting a sacrificial protein or peptide to block active sites. | |
| Check for Hydrophobicity: Highly hydrophobic peptides may require a stronger organic solvent (e.g., isopropanol) in the mobile phase for efficient elution. | |
| Poor Solubility | The peptide may be precipitating in the mobile phase during the run. |
| Check Solubility: Ensure your peptide is fully soluble in the initial mobile phase conditions. If not, adjust the starting percentage of the organic solvent. | |
| Increase Temperature: As with poor peak shape, increasing the column temperature can improve solubility.[12] |
Experimental Protocols
Protocol 1: General Method Development for Preparative HPLC of a Labeled Peptide
Objective: To develop a robust preparative HPLC method to purify a synthetic isotopically labeled peptide.
Methodology:
-
Analytical Method Development:
-
Column: Start with a C18 analytical column (e.g., 4.6 x 250 mm, 5 µm).[11]
-
Mobile Phase A: 0.1% TFA in HPLC-grade water.
-
Mobile Phase B: 0.1% TFA in acetonitrile.
-
Scouting Gradient: Run a broad linear gradient from 5% to 95% B over 30-45 minutes to determine the approximate elution time of the peptide.
-
Gradient Optimization: Based on the scouting run, design a shallower gradient around the elution point. For example, if the peptide elutes at 40% B, a new gradient could be 30% to 50% B over 20-30 minutes.[9]
-
Purity Check: Analyze the crude peptide with the optimized analytical method using HPLC-MS to identify the retention times of the target labeled peptide and any impurities (including unlabeled peptide).
-
-
Scale-up to Preparative HPLC:
-
Column: Use a preparative column with the same stationary phase as the analytical column.
-
Flow Rate Adjustment: Adjust the flow rate according to the preparative column's diameter. A common formula is: Flow Rate (prep) = Flow Rate (analyt) * (Diameter (prep)² / Diameter (analyt)²).
-
Gradient Adjustment: The optimized analytical gradient can be directly transferred to the preparative system.
-
Sample Loading: Dissolve the crude peptide in a minimal amount of a suitable solvent (e.g., DMSO, then dilute with Mobile Phase A) and inject it onto the column. Do not exceed the loading capacity determined in your loading study.
-
-
Fraction Collection and Analysis:
-
Lyophilization:
-
Freeze the pooled fractions and lyophilize them to obtain the purified peptide as a powder.[11]
-
Visualizations
A troubleshooting workflow for common HPLC purification issues.
References
- 1. pubs.acs.org [pubs.acs.org]
- 2. Recommendations for the generation, quantification, storage and handling of peptides used for mass spectrometry-based assays - PMC [pmc.ncbi.nlm.nih.gov]
- 3. researchgate.net [researchgate.net]
- 4. Convenient preparation of deuterium-labeled analogs of peptides containing N-substituted glycines for a stable isotope dilution LC-MS quantitative analysis - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. benchchem.com [benchchem.com]
- 6. cdr.lib.unc.edu [cdr.lib.unc.edu]
- 7. bachem.com [bachem.com]
- 8. almacgroup.com [almacgroup.com]
- 9. HPLC Tech Tip: Approach to Peptide Analysis | Phenomenex [phenomenex.com]
- 10. agilent.com [agilent.com]
- 11. peptide.com [peptide.com]
- 12. Tips for optimization of peptide separation by reversed-phase | YMC CO., LTD. [ymc.co.jp]
- 13. protocols.io [protocols.io]
Technical Support Center: Enhancing Yield and Purity of Synthetic Labeled Peptides
This technical support center is a dedicated resource for researchers, scientists, and drug development professionals to navigate the complexities of synthetic labeled peptide production. Here, you will find comprehensive troubleshooting guides and frequently asked questions (FAQs) designed to address specific challenges encountered during synthesis, purification, and characterization, ultimately helping you improve the yield and purity of your peptides.
Frequently Asked Questions (FAQs)
Q1: What are the primary contributors to low yield in synthetic labeled peptide synthesis?
Low yields in labeled peptide synthesis can arise from a combination of factors throughout the solid-phase peptide synthesis (SPPS) process. The most common issues include incomplete coupling of amino acids or the label itself, and unsuccessful removal of the Fmoc protecting group.[1] Peptide aggregation on the resin, where peptide chains clump together, can also hinder reactions and reduce yield.[2] Additionally, side reactions during synthesis, suboptimal quality of reagents, and challenges during the final cleavage from the resin and subsequent purification can all significantly impact the final product amount.[1]
Q2: How can I identify the cause of low purity in my synthetic peptide?
Low purity is often indicated by multiple peaks in a High-Performance Liquid Chromatography (HPLC) chromatogram.[1] Analyzing the crude peptide product using mass spectrometry (MS) is the most effective method to pinpoint the nature of impurities.[2] Common impurities include:
-
Deletion Sequences: Peptides missing one or more amino acids.
-
Truncated Sequences: Peptides that have prematurely stopped growing.[3]
-
Incompletely Deprotected Sequences: Peptides still carrying protecting groups on their side chains.[3]
-
Products of Side Reactions: Unwanted chemical modifications that occur during synthesis.[3]
Q3: What defines a "difficult sequence" in peptide synthesis, and how does it impact yield and purity?
"Difficult sequences" are peptide chains prone to forming stable secondary structures, like β-sheets, on the resin, which leads to aggregation.[2] This aggregation obstructs the access of reagents to the growing peptide chain, causing incomplete deprotection and coupling reactions. Consequently, this results in lower yields and reduced purity of the desired peptide.[2] Sequences rich in hydrophobic amino acids (e.g., Val, Ile, Leu, Phe) are often categorized as difficult.[2]
Q4: How does the choice of coupling reagent influence the yield and purity of my peptide?
The selection of a coupling reagent is a critical factor that directly affects the yield and purity of the synthesized peptide. Modern coupling reagents, primarily onium-type salts like HATU and COMU, are highly reactive and can suppress racemization, a common side reaction that affects purity.[4] For routine syntheses, reagents like HBTU and PyBOP are effective and economical. However, for more challenging or "difficult" sequences, more potent reagents are often necessary to achieve high yields.[4][5]
Q5: What are the best practices for storing and handling synthetic labeled peptides to maintain their integrity?
For optimal long-term stability, lyophilized peptides should be stored at -20°C or colder, away from bright light.[3] Before use, it is crucial to allow the peptide to equilibrate to room temperature before opening the container to prevent moisture absorption, which can degrade the peptide.[3] When preparing peptide solutions, it's recommended to make aliquots to avoid repeated freeze-thaw cycles.[3]
Troubleshooting Guides
Issue 1: Low Yield of the Target Peptide
Symptoms:
-
The final amount of purified peptide is significantly lower than theoretically expected.
-
Mass spectrometry analysis of the crude product shows a complex mixture with the desired peptide as a minor component.
Possible Causes and Solutions:
| Cause | Recommended Solution |
| Incomplete Fmoc-Deprotection | Extend the deprotection time or use a stronger deprotection reagent. Ensure the deprotection solution is fresh, as reagents like piperidine (B6355638) can degrade over time.[2] |
| Poor Coupling Efficiency | For difficult couplings, perform a "double coupling" where the amino acid is coupled twice.[1] Consider switching to a more powerful coupling reagent like HATU or COMU.[4] For sterically hindered amino acids, extending the coupling time can also be beneficial. |
| Peptide Aggregation on Resin | Incorporate pseudoproline dipeptides or other structure-disrupting elements into the peptide sequence. Using a higher synthesis temperature can also help to disrupt aggregation.[3] |
| Inefficient Cleavage from Resin | Optimize the cleavage cocktail based on the peptide sequence and resin type. For peptides containing sensitive residues like tryptophan or methionine, ensure appropriate scavengers are included in the cocktail.[6] If the initial cleavage is incomplete, the resin can be subjected to a second cleavage step. |
Issue 2: Low Purity of the Crude Peptide
Symptoms:
-
Analytical HPLC of the crude product shows multiple peaks of significant intensity besides the main product peak.
-
Mass spectrometry reveals the presence of deletion sequences, truncated peptides, or other modifications.[7]
Possible Causes and Solutions:
| Cause | Recommended Solution |
| Deletion Sequences | This is typically due to incomplete coupling. Implement strategies to improve coupling efficiency as described in the "Low Yield" section.[8] |
| Truncated Sequences | Truncation can be caused by incomplete Fmoc-deprotection. Optimize the deprotection step.[8] Capping unreacted amino groups after each coupling step with a reagent like acetic anhydride (B1165640) can prevent the formation of truncated sequences.[3] |
| Side Reactions (e.g., Racemization, Oxidation) | Minimize racemization by using appropriate coupling reagents and additives.[4] For peptides containing methionine or tryptophan, which are prone to oxidation, degas all solvents and work under an inert atmosphere if possible.[3] |
| Incomplete Removal of Side-Chain Protecting Groups | Ensure the cleavage cocktail and reaction time are sufficient for complete deprotection of all amino acid side chains.[3] Analysis of the crude product by mass spectrometry can help identify any remaining protecting groups.[7] |
Quantitative Data Summary
Table 1: Comparative Yield of a Model Peptide with Different Coupling Reagents
| Coupling Reagent | Additive | Base | Solvent | Reaction Time (min) | Yield (%) |
| HATU | HOAt | DIPEA | DMF | 30 | ~99 |
| HBTU | HOBt | DIPEA | DMF | 30 | ~95-98 |
| TBTU | HOBt | DIPEA | DMF | 30 | ~95-98 |
| PyBOP | HOBt | DIPEA | DMF | 30 | ~95 |
| COMU | - | DIPEA | DMF | 15-30 | >99 |
Data synthesized from multiple studies to provide a comparative overview. Yields can vary based on the specific peptide sequence and reaction conditions.[4]
Table 2: Effect of N-Methylation on the Aggregation of α-Synuclein (71-82) Peptide Fragments
| Peptide Fragment | Modification | Aggregation Propensity (ThT Fluorescence) |
| GVTAVAQKTV | None | High |
| GVT(N-Me)AVAQKTV | Single N-methylation | Significantly Reduced |
| TAVAQKTVDQ | None | Moderate |
| T(N-Me)AVAQKTVDQ | Single N-methylation | Significantly Reduced |
Adapted from a study on α-synuclein aggregation, demonstrating that N-methylation can significantly reduce the aggregation potential of peptide fragments.[9]
Experimental Protocols
Protocol 1: Solid-Phase Peptide Synthesis (SPPS) - General Fmoc-Based Protocol
-
Resin Swelling: Swell the appropriate resin in dimethylformamide (DMF) for at least 30 minutes in a reaction vessel.
-
Fmoc-Deprotection: Remove the Fmoc protecting group from the resin by treating it with 20% piperidine in DMF for 5-10 minutes. Repeat this step once.
-
Washing: Wash the resin thoroughly with DMF to remove the piperidine and the cleaved Fmoc group.
-
Amino Acid Coupling:
-
Pre-activate the Fmoc-protected amino acid (3-5 equivalents) with a suitable coupling reagent (e.g., HBTU/HOBt or HATU) and a base (e.g., DIPEA) in DMF.
-
Add the activated amino acid solution to the resin.
-
Allow the coupling reaction to proceed for 30-60 minutes.
-
-
Washing: Wash the resin with DMF to remove excess reagents and byproducts.
-
Monitoring the Coupling: Perform a Kaiser test on a small sample of the resin to check for the presence of free primary amines. A negative result (yellow beads) indicates a complete coupling.[2]
-
Repeat: Repeat steps 2-6 for each amino acid in the peptide sequence.
-
Final Deprotection: After the final coupling step, perform a final Fmoc deprotection (step 2).
-
Final Wash: Wash the peptide-resin extensively with DMF, followed by dichloromethane (B109758) (DCM), and then dry the resin under vacuum.
Protocol 2: On-Resin Labeling with a Fluorescent Dye
-
Peptide Synthesis: Synthesize the peptide sequence on the resin following Protocol 1, but keep the N-terminal Fmoc group on after the last amino acid coupling.
-
Selective Deprotection (if applicable): If labeling a side chain, selectively remove the orthogonal protecting group (e.g., Mmt, Dde) using appropriate reagents.
-
Dye Coupling:
-
Dissolve the fluorescent dye-acid (3-5 equivalents) and a coupling reagent (e.g., HATU) in DMF.
-
Add a base (e.g., DIPEA) to the mixture.
-
Add the activated dye solution to the peptide-resin.
-
Allow the reaction to proceed for 2-4 hours, or until completion as monitored by a colorimetric test.
-
-
Washing: Wash the resin thoroughly with DMF and DCM to remove any unreacted dye and coupling reagents.[1]
Protocol 3: Peptide Cleavage from the Resin and Deprotection
-
Resin Preparation: Place the dry, labeled peptide-resin in a reaction vessel.
-
Cleavage Cocktail Addition: Add a freshly prepared cleavage cocktail to the resin. A common cocktail is 95% Trifluoroacetic Acid (TFA), 2.5% Triisopropylsilane (TIS), and 2.5% water. The specific composition may need to be optimized based on the peptide sequence.[1]
-
Cleavage Reaction: Gently agitate the mixture at room temperature for 2-3 hours.
-
Peptide Precipitation: Filter the resin and collect the filtrate. Precipitate the peptide from the filtrate by adding cold diethyl ether.
-
Peptide Collection: Centrifuge the mixture to pellet the peptide. Decant the ether and wash the peptide pellet with cold ether two more times.
-
Drying: Dry the crude peptide pellet under vacuum.
Protocol 4: HPLC Purification of Labeled Peptides
-
Sample Preparation: Dissolve the crude peptide in a suitable solvent, typically a mixture of water and acetonitrile (B52724) (ACN) with 0.1% TFA.
-
Column and Mobile Phases: Use a reversed-phase C18 column. The mobile phases are typically:
-
Mobile Phase A: 0.1% TFA in water.
-
Mobile Phase B: 0.1% TFA in ACN.
-
-
Gradient Elution: Purify the peptide using a linear gradient of increasing Mobile Phase B. A typical gradient might be from 5% to 65% B over 30-60 minutes. The gradient should be optimized for the specific peptide.
-
Fraction Collection: Collect fractions corresponding to the major peaks detected by UV absorbance (typically at 214 nm and 280 nm).
-
Analysis of Fractions: Analyze the collected fractions by analytical HPLC and mass spectrometry to identify the fractions containing the pure labeled peptide.
-
Lyophilization: Pool the pure fractions and freeze-dry (lyophilize) to obtain the final purified peptide as a fluffy white powder.
Protocol 5: Mass Spectrometry (MS) Characterization
-
Sample Preparation: Dissolve a small amount of the crude or purified peptide in a suitable solvent for MS analysis (e.g., 50% ACN in water with 0.1% formic acid).
-
Mass Analysis: Infuse the sample into the mass spectrometer (e.g., ESI-MS or MALDI-TOF) to determine the molecular weight of the peptide.
-
Data Interpretation: Compare the observed molecular weight with the theoretical calculated mass of the labeled peptide. This confirms the identity of the product and can reveal the presence of impurities such as deletion sequences, truncated products, or incompletely deprotected species.[7]
Visualizations
Caption: Troubleshooting workflow for low yield and purity in peptide synthesis.
Caption: Labeled peptide activation of a G-Protein Coupled Receptor signaling pathway.
References
- 1. benchchem.com [benchchem.com]
- 2. benchchem.com [benchchem.com]
- 3. gyrosproteintechnologies.com [gyrosproteintechnologies.com]
- 4. benchchem.com [benchchem.com]
- 5. Greening the synthesis of peptide therapeutics: an industrial perspective - RSC Advances (RSC Publishing) DOI:10.1039/D0RA07204D [pubs.rsc.org]
- 6. tools.thermofisher.com [tools.thermofisher.com]
- 7. agilent.com [agilent.com]
- 8. benchchem.com [benchchem.com]
- 9. benchchem.com [benchchem.com]
Navigating Peptide Synthesis: A Guide to Minimizing Deletion Sequences
Technical Support Center
For researchers, scientists, and drug development professionals engaged in Solid Phase Peptide Synthesis (SPPS), the emergence of deletion sequences is a common yet frustrating hurdle that can compromise the purity and yield of the final peptide product. Deletion sequences arise from incomplete coupling of an amino acid to the growing peptide chain, resulting in a final product that is missing one or more residues. This guide provides detailed troubleshooting strategies and answers to frequently asked questions to help you minimize and eliminate these unwanted byproducts.
Troubleshooting Guide: Addressing Deletion Sequences
This section offers a systematic approach to diagnosing and resolving issues related to deletion sequences during your SPPS experiments.
Issue: Mass spectrometry (MS) analysis of the crude product reveals the presence of peptides with masses corresponding to the target peptide minus one or more amino acid residues.
This is a direct indication of deletion sequences. The following steps will help you identify and rectify the root cause.
Step 1: On-Resin Monitoring of Coupling Completion
Before delving into extensive optimization, it is crucial to confirm whether the coupling reactions are proceeding to completion.
-
Action: Perform a qualitative colorimetric test, such as the Kaiser test or the TNBS (2,4,6-trinitrobenzenesulfonic acid) test, on a small sample of resin beads after the coupling step.[1]
-
Interpretation:
-
Positive Result (e.g., blue/purple beads with the Kaiser test): Indicates the presence of free primary amines on the resin, confirming that the coupling was incomplete.[1][2][3]
-
Negative Result (e.g., yellow/colorless beads): Suggests that most of the free amines have been coupled. However, be aware that N-terminal proline will give a brownish-red color with the Kaiser test, and this test is not reliable for secondary amines.[4]
-
Step 2: Optimizing the Coupling Protocol
If incomplete coupling is confirmed, the following strategies can be employed to enhance coupling efficiency.
-
Double Coupling: This is a straightforward and often effective method to drive the reaction to completion. After the initial coupling reaction, the resin is washed, and the coupling procedure is repeated with a fresh solution of the amino acid and coupling reagents.[5][6] This is particularly useful for sterically hindered amino acids like arginine or when coupling to a proline residue.[5]
-
Increase Reagent Concentration: Increasing the concentration of the amino acid and coupling reagent solutions (e.g., to 0.5 M) can increase the probability of molecular interactions and improve reaction kinetics.[5]
-
Extend Reaction Time: For difficult couplings, extending the reaction time from the standard 1-2 hours to 4-24 hours can help achieve completion.[1][3]
Step 3: Evaluating and Changing Reagents
The choice of reagents plays a critical role in the efficiency of the coupling reaction.
-
Coupling Reagents: If you are using a carbodiimide-based reagent like DCC or DIC, consider switching to a more potent onium salt-based reagent.[1] Uronium/aminium salts like HBTU, HATU, HCTU, and COMU are known for their high coupling efficiency, especially for hindered amino acids.[1][7][8][9] HATU and COMU are often recommended for particularly challenging couplings.[1]
-
Additives: The addition of HOBt or OxymaPure® to carbodiimide-mediated couplings can reduce side reactions and improve efficiency.[8][9]
-
Solvents: Ensure the use of high-purity, anhydrous DMF or NMP. For sequences prone to aggregation, consider using solvent mixtures like DMF/DMSO or adding chaotropic salts such as LiCl.[1][10]
Step 4: Addressing "Difficult Sequences"
Certain peptide sequences are inherently prone to aggregation on the solid support, which hinders reagent access and leads to incomplete coupling.[2][11]
-
Sequence Analysis: Identify regions with a high content of hydrophobic or β-branched amino acids (e.g., Val, Ile, Leu, Phe).[2]
-
Resin Selection: Use resins with good swelling properties, such as PEG-based resins (e.g., NovaPEG, NovaSyn® TG), especially for long or hydrophobic peptides.[10]
-
Elevated Temperature: Increasing the reaction temperature to 30-50°C can help disrupt secondary structures and improve reaction rates. However, this should be done with caution as it may increase the risk of racemization.[1][12]
-
Disrupting Secondary Structures: Incorporating pseudoproline dipeptides or backbone-protecting groups like Dmb or Hmb can disrupt the hydrogen bonding that leads to aggregation.[10]
Frequently Asked Questions (FAQs)
Q1: What are the primary causes of deletion sequences in SPPS?
A1: Deletion sequences are primarily caused by incomplete coupling reactions.[13] This can be due to several factors, including:
-
Steric Hindrance: Bulky amino acids or protecting groups can physically block the reaction site.[3][5]
-
Peptide Aggregation: The growing peptide chain can fold into secondary structures on the resin, preventing reagents from reaching the N-terminus.[2][10][14]
-
Suboptimal Reaction Conditions: Insufficient reaction time, low reagent concentration, or the use of a weak coupling reagent can lead to incomplete reactions.[1][6]
-
Poor Resin Swelling: If the resin does not swell properly, the reactive sites within the beads may be inaccessible.[2]
Q2: When should I use a "double coupling" strategy?
A2: A double coupling strategy is recommended in the following situations:
-
When incorporating sterically hindered amino acids like Arginine, Tyrosine, or Tryptophan.[5]
-
When coupling an amino acid to a Proline residue.[5]
-
When synthesizing a peptide with a sequence of identical amino acids in a row.[5]
-
When a colorimetric test (e.g., Kaiser test) indicates an incomplete coupling after the first attempt.[6]
Q3: Can the deprotection step also contribute to the formation of deletion sequences?
A3: Yes, indirectly. If the Fmoc deprotection step is incomplete, the N-terminus of the growing peptide chain will remain blocked, preventing the next amino acid from coupling. This results in a truncated sequence, which is a type of deletion.[2][4] It is crucial to ensure complete deprotection, which can be monitored using UV absorbance of the piperidine-dibenzofulvene adduct in automated synthesizers or confirmed with a positive Kaiser test before the subsequent coupling step.[4]
Q4: How do I choose the right coupling reagent?
A4: The choice of coupling reagent depends on the difficulty of the sequence.
-
For routine couplings: Carbodiimides like DIC in the presence of an additive like OxymaPure® are often sufficient.
-
For difficult couplings and sterically hindered amino acids: Onium salt-based reagents are preferred. HATU and HCTU are highly effective and widely used.[7][8] COMU is another powerful option, particularly for challenging sequences.[1] Phosphonium salts like PyBOP are also very efficient but may be more expensive.[7]
Q5: What is peptide aggregation and how can I prevent it?
A5: Peptide aggregation occurs when growing peptide chains on the resin interact with each other through hydrogen bonds, forming insoluble secondary structures like β-sheets.[10][14] This can block reactive sites and lead to incomplete reactions. To prevent aggregation:
-
Use high-swelling PEG-based resins.[10]
-
Synthesize at elevated temperatures.[12]
-
Use solvents known to disrupt secondary structures, such as NMP or mixtures containing DMSO.[10][11]
-
Incorporate structure-disrupting elements like pseudoproline dipeptides at regular intervals in the sequence.[10]
Comparison of Strategies to Reduce Deletion Sequences
| Strategy | Principle | Advantages | Disadvantages |
| Double Coupling | Repeats the coupling step to drive the reaction to completion. | Simple to implement, highly effective for specific difficult couplings.[5][6] | Increases synthesis time and reagent consumption. |
| Use of Potent Coupling Reagents (e.g., HATU, HCTU) | Employs highly reactive reagents to accelerate the coupling reaction and overcome steric hindrance.[7][8] | Significantly improves coupling efficiency, especially for difficult sequences.[9] | Higher cost compared to carbodiimides. |
| Elevated Temperature | Increases reaction kinetics and helps disrupt secondary structures that cause aggregation.[1][12] | Can significantly improve yields for difficult sequences. | May increase the risk of side reactions, such as racemization.[1] |
| Chaotropic Solvents/Salts (e.g., DMSO, LiCl) | Disrupts hydrogen bonding networks that lead to peptide aggregation.[1][10] | Effective at solubilizing aggregating sequences. | May require optimization of solvent compatibility with the resin and reagents. |
| Pseudoproline Dipeptides | Temporarily introduces a "kink" in the peptide backbone, disrupting the formation of secondary structures.[10] | Highly effective at preventing aggregation in long or hydrophobic sequences. | Only applicable at Serine or Threonine residues; requires specialized dipeptide building blocks.[10] |
Experimental Protocol: Double Coupling for a Hindered Amino Acid
This protocol outlines the manual steps for performing a double coupling of Fmoc-Arg(Pbf)-OH, a commonly encountered challenging residue.
Materials:
-
Peptide-resin with a free N-terminal amine
-
Fmoc-Arg(Pbf)-OH
-
Coupling reagent (e.g., HBTU)
-
Activator base (e.g., DIPEA)
-
Anhydrous DMF
-
DCM
-
Deprotection solution (e.g., 20% piperidine (B6355638) in DMF)
-
Washing solvents (DMF, DCM)
-
Reaction vessel for SPPS
Procedure:
-
Resin Preparation:
-
Swell the peptide-resin in DMF for at least 30 minutes.
-
Perform the Fmoc deprotection of the N-terminal amino acid using 20% piperidine in DMF.
-
Wash the resin thoroughly with DMF (5-7 times) and then with DCM (3 times) to remove all traces of piperidine.
-
Perform a Kaiser test on a few beads to confirm the presence of free primary amines.
-
-
First Coupling:
-
In a separate vessel, dissolve 3-5 equivalents of Fmoc-Arg(Pbf)-OH and a slightly lower equivalency of HBTU (e.g., 2.9-4.9 eq.) in DMF.
-
Add 6-10 equivalents of DIPEA to the activation mixture.
-
Immediately add the activation mixture to the resin.
-
Agitate the reaction vessel for 1-2 hours at room temperature.
-
Drain the reaction solution and wash the resin thoroughly with DMF (5-7 times).
-
-
Intermediate Check (Optional but Recommended):
-
Take a small sample of the resin and perform a Kaiser test. If the test is negative (yellow beads), the coupling may be complete. If it is positive (blue beads), proceed with the second coupling.
-
-
Second Coupling:
-
Prepare a fresh activation mixture of Fmoc-Arg(Pbf)-OH, HBTU, and DIPEA as described in step 2.
-
Add the fresh activation mixture to the washed resin.
-
Agitate the reaction vessel for another 1-2 hours at room temperature.
-
Drain the reaction solution and wash the resin thoroughly with DMF (5-7 times) followed by DCM (3 times).
-
-
Final Check:
-
Perform a final Kaiser test on a small sample of the resin to confirm the completion of the coupling (beads should be yellow).
-
Troubleshooting Workflow for Deletion Sequences
The following diagram illustrates a logical workflow for identifying and resolving the root causes of deletion sequences in your SPPS experiments.
Caption: A troubleshooting workflow for diagnosing and resolving deletion sequences in SPPS.
References
- 1. benchchem.com [benchchem.com]
- 2. benchchem.com [benchchem.com]
- 3. benchchem.com [benchchem.com]
- 4. benchchem.com [benchchem.com]
- 5. biotage.com [biotage.com]
- 6. kilobio.com [kilobio.com]
- 7. jpt.com [jpt.com]
- 8. How to Optimize Peptide Synthesis? - Creative Peptides [creative-peptides.com]
- 9. bachem.com [bachem.com]
- 10. Overcoming Aggregation in Solid-phase Peptide Synthesis [sigmaaldrich.com]
- 11. biotage.com [biotage.com]
- 12. gyrosproteintechnologies.com [gyrosproteintechnologies.com]
- 13. 6 peptide impurities that appear during the synthesis & storage of peptides: | MolecularCloud [molecularcloud.org]
- 14. researchgate.net [researchgate.net]
Validation & Comparative
The Gold Standard: Validating Mass Spectrometry Data with Labeled Internal Standards
A comparative guide for researchers, scientists, and drug development professionals.
In the realm of quantitative mass spectrometry, achieving accurate and reproducible results is paramount. The inherent variability in sample preparation, chromatographic separation, and mass spectrometric detection can introduce significant errors, compromising data integrity. The use of internal standards is a cornerstone of robust analytical method validation, with stable isotope-labeled (SIL) internal standards widely regarded as the gold standard. This guide provides a comprehensive comparison of different internal standards, supported by experimental data and detailed protocols, to aid researchers in selecting the optimal validation strategy for their analytical needs.
The Critical Role of Internal Standards
An internal standard (IS) is a compound of known concentration added to all samples, calibrators, and quality controls at the earliest stage of the analytical workflow.[1] The fundamental principle is that the IS, being chemically and physically similar to the analyte of interest, will experience and thus correct for variations throughout the analytical process.[1][2] This includes analyte loss during extraction, inconsistencies in injection volume, instrument drift, and ionization suppression or enhancement, often referred to as matrix effects.[1][2] Quantification is then based on the ratio of the analyte's signal to that of the internal standard, rather than the absolute signal of the analyte, which can fluctuate.[1][3]
Comparison of Internal Standards: Performance and Characteristics
The choice of internal standard is a critical decision in method development. The ideal IS mimics the analyte's behavior throughout the entire analytical process. The two main categories of internal standards used in mass spectrometry are stable isotope-labeled (SIL) internal standards and structural analogs.
| Feature | Stable Isotope-Labeled (SIL) Internal Standard | Structural Analog Internal Standard |
| Chemical & Physical Properties | Nearly identical to the analyte.[4] | Similar, but not identical, to the analyte.[5] |
| Chromatographic Behavior | Co-elutes with the analyte.[6] | May have a different retention time.[5][7] |
| Ionization Efficiency | Identical to the analyte, providing the best correction for matrix effects.[8] | May respond differently to matrix effects, potentially introducing errors.[1] |
| Accuracy & Precision | Generally provides higher accuracy and precision.[5] | Can provide good results, but may be less precise than SIL standards.[5] |
| Cost & Availability | Often more expensive and may not be commercially available for all analytes.[5][7] | Generally less expensive and more readily available.[5] |
| Potential Issues | Deuterium-labeled standards may exhibit isotopic effects, leading to slight retention time shifts.[5][6][7] High isotopic purity is required.[9] | May not fully compensate for all sources of variability, especially matrix effects.[1] |
Quantitative Performance Data
The following table summarizes a comparison of an assay's performance using a structural analog versus a stable isotope-labeled internal standard for the quantification of the depsipeptide kahalalide F.
| Internal Standard Type | Mean Bias (%) | Standard Deviation (%) | Statistical Significance (p-value) |
| Structural Analog | 96.8 | 8.6 | p=0.02 (compared to SIL IS) |
| Stable Isotope-Labeled (SIL) | 100.3 | 7.6 | N/A |
These experimental data demonstrate the theoretical superiority of SIL internal standards, showing a statistically significant improvement in the precision of the method with the implementation of the SIL internal standard.[5]
Experimental Protocols
Quantification of a Small Molecule Drug (e.g., Gefitinib) in Human Plasma
This protocol outlines a typical workflow for the quantification of a small molecule drug in a biological matrix using a labeled internal standard.
a. Preparation of Standards:
-
Prepare stock solutions of the analyte (e.g., Gefitinib) and the stable isotope-labeled internal standard (e.g., Gefitinib-d6) in a suitable organic solvent like methanol.[1]
-
Prepare calibration standards by spiking known concentrations of the analyte stock solution into blank human plasma. A typical range would be 5-1000 ng/mL.[1]
-
Prepare Quality Control (QC) samples at low, medium, and high concentrations in the same manner.[1]
b. Sample Preparation (Protein Precipitation):
-
To 100 µL of each plasma sample (calibrator, QC, or unknown), add a fixed volume (e.g., 25 µL) of the internal standard working solution (e.g., 500 ng/mL).[1]
-
Vortex briefly to ensure thorough mixing.
-
Add 300 µL of acetonitrile (B52724) to precipitate plasma proteins.[1]
-
Vortex vigorously for 1 minute.
-
Centrifuge the samples at 12,000 x g for 10 minutes at 4°C to pellet the precipitated proteins.[1]
-
Transfer the clear supernatant to a clean vial or a 96-well plate for LC-MS/MS analysis.[1]
c. LC-MS/MS Analysis:
-
Inject the prepared samples onto a liquid chromatography-tandem mass spectrometry (LC-MS/MS) system.
-
Utilize a triple quadrupole mass spectrometer operating in electrospray ionization (ESI) positive mode.[1]
-
Monitor specific precursor-to-product ion transitions (Multiple Reaction Monitoring - MRM) for both the analyte and the internal standard.[1][10]
d. Data Analysis:
-
Calculate the peak area ratio of the analyte to the internal standard for each sample.[10]
-
Construct a calibration curve by plotting the peak area ratio against the nominal concentration of the calibration standards. A linear regression with 1/x or 1/x² weighting is commonly used.[10]
-
Determine the concentration of the analyte in the unknown samples by interpolating their peak area ratios from the calibration curve.[1]
Relative Protein Quantification using Stable Isotope Labeling by Amino Acids in Cell Culture (SILAC)
This protocol describes a metabolic labeling strategy for quantitative proteomics.
a. Cell Culture and Labeling:
-
Culture two populations of cells in parallel.
-
One population (the "heavy" sample) is grown in a medium containing a stable isotope-labeled amino acid (e.g., ¹³C₆-Arginine). The other population (the "light" sample) is grown in a medium with the natural, unlabeled version of the amino acid.[1]
b. Experimental Treatment:
-
Apply the experimental treatment (e.g., drug administration) to the "heavy" labeled cells. The "light" labeled cells serve as the control.[1]
c. Sample Preparation:
-
Harvest and lyse both cell populations separately.
-
Measure the protein concentration for each lysate (e.g., using a BCA assay).[1]
-
Combine the "light" and "heavy" lysates in a 1:1 protein ratio.[1]
-
Separate the combined protein mixture using SDS-PAGE.
-
Excise the gel bands and perform an in-gel digestion with an enzyme like trypsin.[1]
-
Extract the resulting peptides from the gel.[1]
d. LC-MS/MS Analysis:
-
Analyze the extracted peptides on a high-resolution mass spectrometer, such as an Orbitrap.[1]
-
The instrument acquires MS1 scans to detect the "light" and "heavy" peptide pairs, followed by MS2 scans for peptide identification.[1]
e. Data Analysis:
-
Process the raw data using specialized software (e.g., MaxQuant).[1]
-
The software identifies the peptide pairs and calculates the Heavy/Light (H/L) ratio from their respective MS1 peak intensities.[1]
-
Protein ratios are then calculated based on the median of all unique peptide ratios identified for that specific protein. The H/L ratio indicates the fold change in protein abundance between the treated and control samples.[1]
Visualizing the Workflow
The following diagram illustrates the general workflow for validating mass spectrometry data using a labeled internal standard.
Caption: Mass spectrometry workflow with internal standard.
Conclusion
The use of internal standards is indispensable for achieving high-quality, reliable data in quantitative mass spectrometry.[1] Stable isotope-labeled internal standards represent the pinnacle of this practice, offering the most accurate correction for a wide range of analytical variabilities, most notably matrix effects.[1] While structural analogs can be a viable alternative when SIL standards are unavailable or cost-prohibitive, their limitations must be carefully considered and validated.[5][7] The detailed protocols and comparative data presented in this guide are intended to equip researchers with the necessary knowledge to implement robust validation strategies in their mass spectrometry workflows, ultimately leading to more accurate and reproducible scientific outcomes.
References
- 1. benchchem.com [benchchem.com]
- 2. The Role of Internal Standards In Mass Spectrometry | SCION Instruments [scioninstruments.com]
- 3. nebiolab.com [nebiolab.com]
- 4. Designing Stable Isotope Labeled Internal Standards - Acanthus Research [acanthusresearch.com]
- 5. scispace.com [scispace.com]
- 6. m.youtube.com [m.youtube.com]
- 7. Stable isotopically labeled internal standards in quantitative bioanalysis using liquid chromatography/mass spectrometry: necessity or not? - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. documents.thermofisher.com [documents.thermofisher.com]
- 9. fda.gov [fda.gov]
- 10. benchchem.com [benchchem.com]
A Head-to-Head Comparison: Labeled vs. Unlabeled Quantitative Proteomics
For researchers, scientists, and drug development professionals navigating the complex landscape of quantitative proteomics, the choice between labeled and unlabeled methodologies is a critical decision that profoundly impacts experimental outcomes. This guide provides an objective comparison of these two approaches, supported by experimental data, detailed protocols, and clear visual workflows to inform your selection process.
The ultimate goal of quantitative proteomics is to accurately determine the relative or absolute abundance of proteins in a sample. Labeled methods, such as Tandem Mass Tags (TMT) and Stable Isotope Labeling by Amino acids in Cell culture (SILAC), introduce isotopic tags to peptides, enabling multiplexed analysis and direct comparison of samples within a single mass spectrometry run. In contrast, unlabeled methods quantify proteins based on the signal intensity or spectral counts of their constituent peptides, offering a simpler workflow but with its own set of advantages and challenges.
Quantitative Data Comparison
The choice between labeled and unlabeled proteomics often involves a trade-off between proteome coverage, accuracy, reproducibility, cost, and multiplexing capability. The following tables summarize key quantitative performance metrics based on comparative studies.
Table 1: Performance Metrics of Labeled vs. Unlabeled Proteomics
| Feature | Labeled Proteomics (e.g., TMT, SILAC) | Unlabeled Proteomics (e.g., LFQ) |
| Proteome Coverage | Lower, as sample complexity increases with labeling.[1][2] | Higher, with up to three times more protein identifications in some studies.[1][2] |
| Quantification Accuracy | Higher, especially for low-abundance proteins.[1][2] | Moderate, with a wider dynamic range for detecting significant changes.[1] |
| Reproducibility/Precision | Higher, as samples are combined early, minimizing run-to-run variability.[3] | Lower, susceptible to variations in sample preparation and instrument performance.[4] |
| Throughput (Multiplexing) | High, with the ability to analyze up to 16 samples in a single run.[1] | Limited to sequential analysis of individual samples. |
| Cost | Higher, due to the cost of isotopic labeling reagents.[3][4] | Lower, as no expensive labeling reagents are required.[3][4] |
| Sample Preparation | More complex, involving additional labeling and quenching steps.[1] | Simpler and less time-consuming.[1][4] |
| Data Analysis Complexity | High, requiring specialized software for reporter ion analysis.[1] | High, requiring advanced algorithms for alignment and normalization.[4] |
Table 2: Experimental Data from Comparative Studies
| Study Aspect | Labeled Proteomics (Super-SILAC) | Unlabeled Proteomics (LFQ) | Reference |
| Proteins Identified (Cancer Cell Lines) | ~3500 | ~5000 | [Tebbe et al.] |
| Precision (Replicate Measurements) | Slightly higher | Slightly lower | [Tebbe et al.] |
| Proteins Identified (Hepatoma Cell Lines) | ~1000 (TMT) | ~3000 | [1][2] |
| Differential Protein Expression Detected (Adenovirus Infection) | 30% (TMT) | 50% | [1] |
Experimental Protocols
Detailed and consistent experimental protocols are paramount for reproducible quantitative proteomics. Below are representative methodologies for a popular labeled (TMT) and a common label-free (LFQ) workflow.
Labeled Proteomics: Tandem Mass Tag (TMT) Protocol
This protocol outlines the key steps for TMT-based quantitative proteomics.
-
Protein Extraction and Digestion:
-
Lyse cells or tissues in a suitable buffer containing protease and phosphatase inhibitors.
-
Determine protein concentration using a standard assay (e.g., BCA).
-
Reduce protein disulfide bonds with dithiothreitol (B142953) (DTT) and alkylate with iodoacetamide (B48618) (IAA).
-
Digest proteins into peptides using an enzyme such as trypsin.
-
-
TMT Labeling:
-
Reconstitute the TMT reagents in an organic solvent (e.g., anhydrous acetonitrile).
-
Add the appropriate TMT reagent to each peptide sample.
-
Incubate to allow the labeling reaction to proceed.
-
Quench the reaction with hydroxylamine.
-
-
Sample Pooling and Fractionation:
-
Combine the TMT-labeled samples in equal amounts.
-
Fractionate the pooled peptide mixture using techniques like high-pH reversed-phase chromatography to reduce sample complexity.
-
-
LC-MS/MS Analysis:
-
Analyze the fractionated peptides using a high-resolution mass spectrometer.
-
The mass spectrometer isolates a precursor ion (a labeled peptide from all samples), fragments it, and measures the intensity of the reporter ions, which corresponds to the relative abundance of the peptide in each sample.
-
-
Data Analysis:
-
Use specialized software to identify peptides and quantify the reporter ion intensities.
-
Normalize the data and perform statistical analysis to determine differentially expressed proteins.
-
Unlabeled Proteomics: Label-Free Quantification (LFQ) Protocol
This protocol provides a general workflow for intensity-based label-free quantification.
-
Protein Extraction and Digestion:
-
Follow the same procedure as in the labeled proteomics protocol for protein extraction, reduction, alkylation, and digestion for each individual sample.
-
-
LC-MS/MS Analysis:
-
Analyze each peptide sample separately using a high-resolution mass spectrometer.
-
The mass spectrometer acquires precursor ion scans (MS1) and fragments the most intense ions to generate tandem mass spectra (MS2) for peptide identification.
-
-
Data Analysis:
-
Utilize specialized software for the following steps:
-
Peak Detection and Feature Alignment: Identify peptide precursor ions and align them across all LC-MS/MS runs based on their mass-to-charge ratio and retention time.
-
Peptide Identification: Search the MS2 spectra against a protein sequence database to identify the peptides.
-
Protein Quantification: Calculate the area under the curve for the aligned peptide precursor ions to determine their intensity. Sum the intensities of the peptides corresponding to each protein to determine the protein's relative abundance.
-
Normalization and Statistical Analysis: Normalize the protein abundance data to account for variations in sample loading and perform statistical tests to identify significantly changing proteins.
-
-
Visualizing the Workflows
To further clarify the distinct processes of labeled and unlabeled proteomics, the following diagrams illustrate the experimental workflows.
Caption: Workflow for TMT-based labeled quantitative proteomics.
References
- 1. Label-free vs Label-based Proteomics - Creative Proteomics [creative-proteomics.com]
- 2. A Review on Quantitative Multiplexed Proteomics - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Label-Free vs. Label-Based Quantitative Proteomics | Silantes [silantes.com]
- 4. Advantages and Disadvantages of Label-Free Quantitative Proteomics | MtoZ Biolabs [mtoz-biolabs.com]
A Head-to-Head Battle in Quantitative Proteomics: Fmoc-Leucine-¹³C₆,¹⁵N Synthetic Peptides versus SILAC
For researchers, scientists, and drug development professionals navigating the complex landscape of quantitative proteomics, the choice of quantification strategy is paramount. This guide provides a comprehensive performance evaluation of two prominent methods: the use of stable isotope-labeled synthetic peptides, featuring Fmoc-leucine-¹³C₆,¹⁵N, and Stable Isotope Labeling by Amino Acids in Cell Culture (SILAC). We present a detailed comparison of their performance, supported by experimental data, to empower informed decisions in your research.
At the heart of precise protein quantification lies the ability to accurately differentiate and measure protein abundance between samples. Both the use of synthetic peptides incorporating heavy amino acids like Fmoc-leucine-¹³C₆,¹⁵N and the SILAC metabolic labeling approach achieve this through the introduction of mass shifts detectable by mass spectrometry. However, their fundamental principles and experimental workflows differ significantly, leading to distinct advantages and limitations in their application.
Performance Evaluation: A Quantitative Comparison
The primary distinction between these two methods lies in the stage at which the "heavy" and "light" samples are combined. In SILAC, metabolic labeling ensures that proteins are labeled in vivo, allowing for the combination of cell populations at the very beginning of the sample preparation process.[1][2] This early mixing minimizes variability introduced during sample handling, digestion, and fractionation. Conversely, synthetic peptides labeled with compounds like Fmoc-leucine-¹³C₆,¹⁵N are typically "spiked" into samples after protein extraction and digestion.[3] This difference in workflow has a direct impact on the precision and reproducibility of the quantification.
A study comparing metabolic labeling (SILAC) with a chemical labeling method—which shares the characteristic of later sample mixing with the synthetic peptide approach—provides valuable insights into the expected performance differences. The data from this study highlights the superior reproducibility of SILAC.
| Performance Metric | SILAC | Synthetic Peptide (Spike-in) / Chemical Labeling | Key Takeaway |
| Precision (Variability within one experiment) | Standard Deviation of log₂ Ratio: 0.175 | Standard Deviation of log₂ Ratio: ~0.255 - 0.324 | SILAC demonstrates higher precision with lower variability in quantification within a single experiment due to the early mixing of samples.[3] |
| Repeatability (Variability across different days) | Standard Deviation of log₂ Ratio: 0.0591 | Standard Deviation of log₂ Ratio: ~4 times higher than SILAC | The repeatability of the SILAC workflow is significantly better, making it more robust for longitudinal studies or experiments conducted over a period of time.[3] |
| Coefficient of Variation (CV) | Typically lower | Can be 1.3 to 1.4-fold higher | Assays using spike-in standards can show a higher coefficient of variation compared to stable isotope-labeled internal standards that more closely mimic the endogenous protein's behavior.[4] |
| Applicability | Limited to actively dividing cells in culture.[5] | Applicable to virtually any sample type, including tissues and clinical samples. | Synthetic peptides offer greater flexibility for a wider range of biological samples. |
| Quantification Type | Primarily relative quantification. | Enables absolute quantification (e.g., AQUA).[6][7] | Synthetic peptides are the method of choice for determining the absolute amount of a protein. |
Experimental Protocols: A Step-by-Step Guide
The choice between these methods will largely depend on the experimental goals and the nature of the samples. Below are detailed methodologies for both approaches.
Method 1: Absolute Quantification using Fmoc-Leucine-¹³C₆,¹⁵N Synthetic Peptides (AQUA Workflow)
This method is ideal for the absolute quantification of specific target proteins and is applicable to a wide array of sample types. The Fmoc-leucine-¹³C₆,¹⁵N is used during solid-phase synthesis to generate a heavy version of a proteotypic peptide from the target protein.
Experimental Protocol:
-
Protein Digestion:
-
Lyse cells or tissues to extract the total protein content.
-
Determine the protein concentration using a suitable method (e.g., BCA assay).
-
Reduce disulfide bonds with DTT and alkylate cysteine residues with iodoacetamide.
-
Digest the proteins into peptides using an enzyme such as trypsin.
-
-
Internal Standard Spiking:
-
Synthesize a heavy peptide standard using Fmoc-leucine-¹³C₆,¹⁵N and other necessary labeled amino acids. The sequence of this peptide should be identical to a unique tryptic peptide from the protein of interest.
-
Accurately quantify the concentration of the synthetic heavy peptide.
-
Spike a known amount of the heavy peptide into the digested protein sample.
-
-
LC-MS/MS Analysis:
-
Separate the peptides using liquid chromatography (LC).
-
Analyze the eluted peptides using a mass spectrometer (MS) operating in a targeted mode, such as Selected Reaction Monitoring (SRM) or Parallel Reaction Monitoring (PRM).
-
The mass spectrometer will detect both the endogenous "light" peptide and the spiked-in "heavy" peptide standard.
-
-
Data Analysis:
-
Quantify the peak areas for both the light and heavy peptides.
-
Calculate the absolute quantity of the endogenous peptide (and thus the protein) by comparing the ratio of the light to heavy peptide signals with the known concentration of the spiked-in standard.[6]
-
Method 2: Relative Quantification using SILAC
SILAC is a powerful technique for accurate relative quantification of protein abundance between different cell populations. It is particularly well-suited for studying the effects of various treatments or conditions on the proteome of cultured cells.
Experimental Protocol:
-
Cell Culture and Labeling:
-
Culture two populations of cells in parallel.
-
One population is grown in "light" medium containing normal amino acids (e.g., L-arginine and L-lysine).
-
The other population is grown in "heavy" medium where the normal amino acids are replaced with their stable isotope-labeled counterparts (e.g., ¹³C₆-L-arginine and ¹³C₆,¹⁵N₂-L-lysine).
-
Cells should be cultured for at least five passages to ensure complete incorporation of the heavy amino acids.[1]
-
-
Experimental Treatment and Cell Harvesting:
-
Apply the experimental treatment to one cell population while the other serves as a control.
-
Harvest both the "light" and "heavy" cell populations.
-
-
Sample Mixing and Protein Digestion:
-
Combine the "light" and "heavy" cell pellets at a 1:1 ratio based on cell number or protein concentration.
-
Lyse the combined cells and extract the proteins.
-
Digest the protein mixture into peptides using trypsin.
-
-
LC-MS/MS Analysis:
-
Separate the resulting peptide mixture using LC.
-
Analyze the peptides by MS. The mass spectrometer will detect pairs of "light" and "heavy" peptides, which are chemically identical but differ in mass.
-
-
Data Analysis:
-
Identify the peptide pairs and determine the ratio of their signal intensities.
-
This ratio directly reflects the relative abundance of the corresponding protein in the two cell populations.[8]
-
Visualizing the Workflows and a Key Signaling Pathway
To further clarify the methodologies and their application, the following diagrams illustrate the experimental workflows and a relevant biological pathway often studied using these quantitative proteomics techniques.
Figure 1: Simplified mTOR signaling pathway, a key regulator of cell growth and protein synthesis, often investigated using quantitative proteomics.
Figure 2: Experimental workflow for absolute protein quantification using a heavy synthetic peptide standard, such as one containing Fmoc-leucine-¹³C₆,¹⁵N.
Figure 3: Experimental workflow for relative protein quantification using the SILAC metabolic labeling approach.
Conclusion: Making the Right Choice for Your Research
The performance evaluation of Fmoc-leucine-¹³C₆,¹⁵N in the context of synthetic peptides versus SILAC reveals a trade-off between precision, applicability, and the type of quantitative data desired.
Choose Fmoc-leucine-¹³C₆,¹⁵N-based synthetic peptides when:
-
Your research requires the absolute quantification of one or more target proteins.
-
You are working with samples that are not amenable to metabolic labeling, such as clinical tissues, biofluids, or non-dividing cells .
-
Flexibility in experimental design and sample type is a priority.
Opt for the SILAC method when:
-
High precision and reproducibility are critical for detecting subtle changes in protein expression.
-
Your research involves relative quantification between different experimental conditions in cultured cells.
-
You are performing discovery-based proteomics to identify global changes across the proteome.
By understanding the distinct performance characteristics and experimental requirements of each method, researchers can confidently select the most appropriate strategy to achieve robust and reliable quantitative proteomics data, ultimately accelerating scientific discovery and therapeutic development.
References
- 1. Quantitative Comparison of Proteomes Using SILAC - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Quantitative analysis of SILAC data sets using spectral counting - PMC [pmc.ncbi.nlm.nih.gov]
- 3. pubs.acs.org [pubs.acs.org]
- 4. Evaluation of Protein Quantification using Standard Peptides Containing Single Conservative Amino Acid Replacements - PMC [pmc.ncbi.nlm.nih.gov]
- 5. SILAC-Based Quantitative PTM Analysis - Creative Proteomics [creative-proteomics.com]
- 6. Absolute quantification of protein and post-translational modification abundance with stable isotope–labeled synthetic peptides - PMC [pmc.ncbi.nlm.nih.gov]
- 7. researchgate.net [researchgate.net]
- 8. researchgate.net [researchgate.net]
A Comparative Guide to Protein Quantification: Unveiling the Linearity of Labeled Peptide Standard Curves
For researchers, scientists, and professionals in drug development, accurate and reproducible protein quantification is paramount. Mass spectrometry-based targeted proteomics has emerged as a powerful tool for this purpose, with the use of stable isotope-labeled (SIL) peptide standard curves being a gold-standard method for absolute quantification.[1] This guide provides a detailed comparison of this method with label-free alternatives, supported by experimental data and protocols, to aid in the selection of the most appropriate quantification strategy.
The core principle of the labeled peptide approach, often referred to as the Absolute Quantification (AQUA) method, involves spiking a known concentration of a synthetic, heavy-isotope-labeled version of a target peptide into a biological sample.[2][3] This SIL peptide serves as an internal standard, exhibiting nearly identical chemical and physical properties to its endogenous, "light" counterpart.[4] By analyzing the sample using techniques like Selected Reaction Monitoring (SRM) or Parallel Reaction Monitoring (PRM), a ratio of the signal from the light (endogenous) peptide to the heavy (internal standard) peptide is measured.[5] A calibration curve is generated by plotting these ratios against a series of known concentrations of the SIL peptide, allowing for the precise determination of the absolute amount of the target peptide in the sample.[6][7]
Linearity of Quantification: Labeled Peptides vs. Label-Free Methods
A key performance metric for any quantitative assay is its linearity—the ability to produce results that are directly proportional to the concentration of the analyte over a given range. The use of a labeled peptide standard curve consistently demonstrates excellent linearity over a wide dynamic range.
Table 1: Linearity of Quantification using a Labeled Peptide Standard Curve
| Concentration of Labeled Peptide (fmol) | Peak Area Ratio (Endogenous/Internal Standard) |
| 10 | 0.12 |
| 50 | 0.58 |
| 100 | 1.15 |
| 250 | 2.90 |
| 500 | 5.75 |
| 1000 | 11.60 |
| Linearity (R²) | 0.998 |
This table summarizes typical data demonstrating the high degree of linearity (R² > 0.99) achievable with the labeled peptide standard curve method over several orders of magnitude.[8]
In contrast, label-free quantification methods, which infer protein abundance from the signal intensity of unlabeled peptides or the number of spectral counts, can also exhibit a linear response.[9] However, they are often more susceptible to variations in sample preparation and mass spectrometer performance, which can impact the linearity and reproducibility of the results.[10]
Table 2: Comparison of Key Performance Characteristics
| Characteristic | Labeled Peptide Standard Curve | Label-Free Quantification |
| Quantification | Absolute | Relative (can be semi-absolute) |
| Linearity | Excellent (typically R² > 0.99) over a wide dynamic range.[8] | Good, but can be more variable.[9] |
| Precision & Accuracy | High, due to the use of an internal standard for normalization.[1] | Lower, as it's more sensitive to experimental variations. |
| Throughput | Lower, requires synthesis of labeled peptides for each target. | Higher, no need for specific labeled standards. |
| Cost | Higher, due to the cost of synthesizing labeled peptides.[3] | Lower, no cost for labeling reagents.[11] |
| Complexity | More complex upfront method development. | Simpler sample preparation, but more complex data analysis. |
Experimental Workflow and Protocols
The successful implementation of a labeled peptide quantification strategy requires a well-defined experimental workflow.
Caption: Workflow for absolute protein quantification using a labeled peptide standard.
Detailed Experimental Protocol
1. Peptide Selection and Synthesis:
-
Select 2-3 proteotypic peptides for each target protein to ensure accurate quantification.[2]
-
Synthesize these peptides with stable isotope-labeled amino acids (e.g., ¹³C, ¹⁵N).[2]
-
The purity of the synthesized peptides should be high (>95%).
2. Preparation of Standard Curve:
-
Prepare a stock solution of the stable isotope-labeled (SIL) peptide of known concentration.
-
Perform serial dilutions of the SIL peptide stock to create a series of calibration standards with at least five concentration points.[7]
-
A blank (no heavy peptide) and a double blank (matrix only) should be included.[7]
3. Sample Preparation:
-
Extract total protein from the biological sample.
-
Perform proteolytic digestion of the protein extract (e.g., using trypsin).
-
Add a fixed, known amount of the SIL peptide internal standard to each digested sample.
4. LC-MS/MS Analysis:
-
Analyze the prepared samples and calibration standards by liquid chromatography-tandem mass spectrometry (LC-MS/MS).
-
Use a targeted acquisition method such as Selected Reaction Monitoring (SRM) or Parallel Reaction Monitoring (PRM) to monitor specific precursor-fragment ion transitions for both the light (endogenous) and heavy (labeled) peptides.
5. Data Analysis:
-
Integrate the peak areas for the selected transitions of both the light and heavy peptides.
-
Calculate the peak area ratio (light/heavy) for each standard and sample.
-
Construct a calibration curve by plotting the peak area ratios of the standards against their known concentrations.
-
Perform a linear regression analysis on the calibration curve to determine the equation of the line and the coefficient of determination (R²).
-
Use the equation of the line to calculate the concentration of the endogenous peptide in the biological samples based on their measured peak area ratios.[7]
Conclusion
The use of a labeled peptide standard curve for protein quantification offers exceptional linearity, precision, and accuracy, making it a robust method for absolute quantification. While label-free methods provide a cost-effective and higher-throughput alternative for relative quantification, they may not offer the same level of quantitative rigor. The choice between these methods will ultimately depend on the specific research question, the desired level of accuracy, and the available resources. For applications requiring precise and absolute concentration values, such as biomarker validation and pharmacokinetic studies, the linearity and reliability of the labeled peptide standard curve method remain the benchmark.
References
- 1. m.youtube.com [m.youtube.com]
- 2. Absolute quantification of protein and post-translational modification abundance with stable isotope–labeled synthetic peptides - PMC [pmc.ncbi.nlm.nih.gov]
- 3. mdpi.com [mdpi.com]
- 4. Stable Isotope Labeled peptides - SB-PEPTIDE - Peptide catalog [sb-peptide.com]
- 5. researchgate.net [researchgate.net]
- 6. skyline.ms [skyline.ms]
- 7. Standard Concentration Curve and Absolute Concentration Determination | Proteomics [medicine.yale.edu]
- 8. researchgate.net [researchgate.net]
- 9. pubs.acs.org [pubs.acs.org]
- 10. pubs.acs.org [pubs.acs.org]
- 11. Label-Free Quantification: Advantages, Applications & Tools - Creative Proteomics [creative-proteomics.com]
A Head-to-Head Battle for Peptide Purity: HPLC-FLD vs. UHPLC-MS/MS
For researchers, scientists, and drug development professionals navigating the complexities of peptide analysis, the choice of analytical technique is paramount. This guide provides an objective comparison of two powerful methods: High-Performance Liquid Chromatography with Fluorescence Detection (HPLC-FLD) and Ultra-High-Performance Liquid Chromatography with Tandem Mass Spectrometry (UHPLC-MS/MS). We delve into their principles, performance, and protocols, supported by experimental data to inform your selection process.
At the forefront of peptide quantification, both HPLC-FLD and UHPLC-MS/MS offer distinct advantages and cater to different analytical needs. HPLC-FLD is a robust and cost-effective technique that provides excellent sensitivity for peptides that are naturally fluorescent or have been chemically tagged with a fluorescent label. In contrast, UHPLC-MS/MS stands out for its exceptional sensitivity, unparalleled selectivity, and the ability to provide structural information, making it a gold standard for complex peptide mixtures and trace-level analysis.
At a Glance: Performance Metrics
The selection of an analytical method often hinges on key performance indicators. The table below summarizes the quantitative data for HPLC-FLD and UHPLC-MS/MS in the context of peptide analysis. It is important to note that a direct head-to-head comparison study for the same peptide was not available in the public domain; therefore, the data presented is a compilation from different studies and should be interpreted as representative performance for each technique.
| Performance Metric | HPLC-FLD | UHPLC-MS/MS |
| Limit of Detection (LOD) | 2.8 ng/mL (for Obestatin)[1] | 0.1 ng/mL (for Almonertinib) |
| Limit of Quantification (LOQ) | 9.4 ng/mL (for Obestatin)[1] | 0.1 ng/mL (for Almonertinib) |
| Linearity (Concentration Range) | 20 to 1000 ng/mL[1] | 0.1 to 1000 ng/mL |
| Precision (%RSD) | < 10%[1] | < 15% |
| Accuracy | 92% to 107%[1] | Within ±15% of nominal concentration |
| Analysis Time | ~30 minutes | < 10 minutes |
| Selectivity | Moderate to High (dependent on derivatization and matrix) | Very High (based on mass-to-charge ratio) |
| Cost | Lower | Higher |
Unpacking the Methodologies: Experimental Protocols
Detailed and reproducible experimental protocols are the bedrock of reliable analytical data. Below are representative methodologies for both HPLC-FLD and UHPLC-MS/MS for peptide analysis.
HPLC-FLD Protocol for Peptide Analysis (with Derivatization)
For peptides lacking a natural fluorophore, pre-column derivatization is a common strategy to enable sensitive fluorescence detection. This protocol outlines a general procedure using 9-fluorenylmethyl chloroformate (FMOC-Cl), a widely used derivatizing agent for primary and secondary amines.
1. Sample Preparation and Derivatization:
-
Peptide Standard/Sample Preparation: Dissolve the peptide in a suitable buffer (e.g., 0.1 M borate (B1201080) buffer, pH 9.5).
-
Derivatization Reaction:
-
To 100 µL of the peptide solution, add 100 µL of a 15 mM solution of FMOC-Cl in acetone.
-
Vortex the mixture for 30-60 seconds and allow it to react at room temperature for 10-20 minutes.
-
Quench the reaction by adding 100 µL of a 0.1 M glycine (B1666218) solution to react with the excess FMOC-Cl.
-
Filter the final solution through a 0.22 µm syringe filter before injection.
-
2. HPLC-FLD Conditions:
-
HPLC System: A standard HPLC system equipped with a fluorescence detector.
-
Column: A reversed-phase C18 column (e.g., 4.6 x 150 mm, 5 µm particle size).
-
Mobile Phase A: 0.1% Trifluoroacetic acid (TFA) in water.
-
Mobile Phase B: 0.1% TFA in acetonitrile.
-
Gradient Elution: A linear gradient from 10% to 70% Mobile Phase B over 20 minutes.
-
Flow Rate: 1.0 mL/min.
-
Column Temperature: 30 °C.
-
Fluorescence Detector Settings:
-
Excitation Wavelength (λex): 265 nm.
-
Emission Wavelength (λem): 315 nm.
-
UHPLC-MS/MS Protocol for Peptide Analysis
This protocol is a representative method for the rapid and sensitive quantification of peptides in a biological matrix, such as plasma.
1. Sample Preparation (Solid-Phase Extraction - SPE):
-
Plasma Sample Pre-treatment: Acidify 100 µL of plasma with 100 µL of 4% phosphoric acid in water.
-
SPE Cartridge Conditioning: Condition a mixed-mode cation exchange SPE cartridge with 1 mL of methanol (B129727) followed by 1 mL of water.
-
Sample Loading: Load the pre-treated plasma sample onto the SPE cartridge.
-
Washing: Wash the cartridge with 1 mL of 0.1 M acetate (B1210297) buffer followed by 1 mL of methanol.
-
Elution: Elute the peptides with 1 mL of 5% ammonium (B1175870) hydroxide (B78521) in methanol.
-
Evaporation and Reconstitution: Evaporate the eluate to dryness under a stream of nitrogen and reconstitute the residue in 100 µL of the initial mobile phase.
2. UHPLC-MS/MS Conditions:
-
UHPLC System: A UHPLC system coupled to a triple quadrupole mass spectrometer.
-
Column: A reversed-phase C18 column suitable for high pressure (e.g., 2.1 x 50 mm, 1.7 µm particle size).
-
Mobile Phase A: 0.1% Formic acid in water.
-
Mobile Phase B: 0.1% Formic acid in acetonitrile.
-
Gradient Elution: A rapid gradient from 5% to 50% Mobile Phase B over 5 minutes.
-
Flow Rate: 0.4 mL/min.
-
Column Temperature: 40 °C.
-
Mass Spectrometer Settings:
-
Ionization Mode: Electrospray Ionization (ESI) in positive mode.
-
Scan Type: Multiple Reaction Monitoring (MRM).
-
MRM Transitions: Specific precursor-to-product ion transitions for the target peptide and an internal standard.
-
Collision Energy: Optimized for each peptide.
-
Source Parameters: Optimized for desolvation temperature, gas flow, and ion spray voltage.
-
Visualizing the Workflow and Comparison
To better understand the analytical processes and their key differences, the following diagrams illustrate the experimental workflows and a logical comparison of the two techniques.
References
A Researcher's Guide to Fmoc-L-leucine-¹³C₆,¹⁵N Isotopic Standards
For researchers in proteomics, metabolomics, and drug development, the quality of isotopically labeled amino acids is paramount for generating reliable and reproducible data. Fmoc-L-leucine-¹³C₆,¹⁵N is a critical reagent used as a building block in the synthesis of labeled peptides, which serve as internal standards for mass spectrometry-based quantification.[1][2] This guide provides a comparative overview of commercially available Fmoc-L-leucine-¹³C₆,¹⁵N standards, focusing on key quality attributes derived from supplier certificates of analysis and product data sheets.
Comparative Analysis of Supplier Specifications
The quality of an Fmoc-amino acid is defined by several critical parameters that can significantly impact the outcome of a peptide synthesis. High chemical and enantiomeric purity ensures the integrity of the final peptide, while high isotopic enrichment is crucial for accurate quantification.[3][4][5] Impurities such as free amino acids or residual acetate (B1210297) can lead to failed sequences and difficult purification.[3][6][7]
Below is a summary of specifications for Fmoc-L-leucine-¹³C₆,¹⁵N from various suppliers. Data is compiled from publicly available certificates of analysis and product pages. Researchers should always consult the lot-specific certificate of analysis provided with their purchase for the most accurate information.
| Parameter | MedChemExpress [8] | Sigma-Aldrich [9] | Cambridge Isotope Laboratories [1] |
| Product Name | Fmoc-leucine-13C6,15N | Fmoc-Leu-OH-13C6,15N | L-Leucine-N-Fmoc (¹³C₆, 99%; ¹⁵N, 99%) |
| Appearance | White to off-white (Solid) | Solid | Not specified |
| Chemical Purity (HPLC) | 99.90% | ≥99% (CP) | ≥98% |
| Isotopic Purity/Enrichment | 99.4% atom ¹³C, 99.8% atom ¹⁵N | 98 atom % ¹³C, 98 atom % ¹⁵N | 99% for ¹³C₆, 99% for ¹⁵N |
| Optical Activity | Not specified | [α]20/D -25°, c = 0.5 in DMF | Not specified |
| Storage Temperature | Powder: -20°C (3 years) | Room temperature | Refrigerated (+2°C to +8°C) |
| Molecular Weight | 360.36 | 360.36 | 360.36 |
| CAS Number | 1163133-36-5 | 1163133-36-5 | 1163133-36-5 |
The Impact of Purity on Experimental Outcomes
The use of high-purity Fmoc-amino acids directly translates to higher yields and purer final peptide products.[4][7] Contaminants can introduce significant issues:
-
Enantiomeric Impurities (D-isomers): Lead to the synthesis of incorrect peptide stereoisomers, which can have different biological activities and be difficult to separate from the target peptide.[3]
-
Acetate and Acetic Acid: Can act as capping agents, terminating peptide chain elongation prematurely and resulting in a higher prevalence of truncated sequences.[3][6]
-
Free Amino Acids: Unprotected amino acids can lead to the undesirable insertion of multiple amino acids during a single coupling step.[3][5]
The logical flow from high-quality starting material to reliable results is illustrated below.
Experimental Protocol: Use in Peptide Synthesis
Fmoc-L-leucine-¹³C₆,¹⁵N is primarily used in Solid-Phase Peptide Synthesis (SPPS). Below is a generalized workflow for incorporating this labeled amino acid into a peptide sequence.
Materials:
-
Fmoc-L-leucine-¹³C₆,¹⁵N standard
-
Solid support resin (e.g., Rink Amide, Wang)
-
Fmoc-protected amino acids
-
Deprotection solution: 20% piperidine (B6355638) in DMF
-
Coupling reagents: HBTU/HOBt or DIC/Oxyma
-
Base: DIPEA
-
Washing solvents: DMF, DCM, Methanol
-
Cleavage cocktail (e.g., 95% TFA, 2.5% TIS, 2.5% H₂O)
-
Precipitation solvent: Cold diethyl ether
Methodology:
-
Resin Swelling: Swell the resin in DMF for 30-60 minutes.
-
Fmoc Deprotection: Remove the Fmoc protecting group from the resin-bound amino acid by treating it with 20% piperidine in DMF.
-
Washing: Thoroughly wash the resin with DMF to remove residual piperidine.
-
Coupling: Dissolve Fmoc-L-leucine-¹³C₆,¹⁵N, coupling reagents, and a base (like DIPEA) in DMF. Add this solution to the deprotected resin and allow it to react for 1-2 hours.
-
Washing: Wash the resin with DMF to remove excess reagents.
-
Repeat Cycle: Repeat steps 2-5 for each subsequent amino acid in the peptide sequence.
-
Final Deprotection: Once the sequence is complete, perform a final Fmoc deprotection.
-
Cleavage and Deprotection: Treat the resin with a cleavage cocktail to cleave the peptide from the resin and remove side-chain protecting groups.
-
Precipitation: Precipitate the crude peptide in cold diethyl ether, centrifuge to form a pellet, and decant the ether.
-
Purification: Purify the labeled peptide using reverse-phase HPLC.
-
Analysis: Confirm the mass of the final labeled peptide using mass spectrometry.
The following diagram illustrates this experimental workflow.
References
- 1. L-Leucine-ð-Fmoc (¹³Câ, 99%; ¹âµN, 99%) - Cambridge Isotope Laboratories, CNLM-4345-H-0.1 [isotope.com]
- 2. chempep.com [chempep.com]
- 3. Novabiochem® Fmoc-Amino Acids [sigmaaldrich.com]
- 4. merckmillipore.com [merckmillipore.com]
- 5. media.iris-biotech.de [media.iris-biotech.de]
- 6. 相关内容暂不可用 [sigmaaldrich.com]
- 7. merck-lifescience.com.tw [merck-lifescience.com.tw]
- 8. file.medchemexpress.com [file.medchemexpress.com]
- 9. Fmoc-Leu-OH-13C6,15N 13C 98atom , 15N 98atom , 99 CP 1163133-36-5 [sigmaaldrich.com]
A Researcher's Guide to Inter-Laboratory Comparison of Quantitative Proteomics Results
For researchers, scientists, and drug development professionals, achieving reproducible and reliable quantitative proteomics data across different laboratories is a critical challenge. This guide provides an objective comparison of common quantitative proteomics workflows, supported by experimental data from various inter-laboratory studies. It aims to offer insights into the performance of these methods, helping you make informed decisions for your research.
The complexity of proteomics experiments, from sample preparation to data analysis, introduces numerous potential sources of variability.[1][2] Inter-laboratory studies are therefore essential for assessing the reproducibility and robustness of different quantitative approaches, ultimately fostering standardization and innovation in the field.[3]
Comparing Quantitative Proteomics Workflows
Three popular mass spectrometry-based approaches for protein quantification are label-free quantification (LFQ), isobaric labeling with tandem mass tags (TMT), and data-independent acquisition (DIA). Each method presents distinct advantages and limitations in terms of proteome coverage, quantitative accuracy, precision, and reproducibility.
A comparative study assessing LFQ, dimethyl labelling (DML), and TMT found that while label-based methods generally yield a lower false-positive rate, TMT and LFQ performed similarly in terms of proteome coverage.[4] Another study comparing DIA and TMT workflows noted that TMT identified 15-20% more proteins with slightly better quantitative precision, whereas DIA demonstrated better quantitative accuracy.[5]
| Parameter | Label-Free Quantification (LFQ) | Tandem Mass Tag (TMT) | Data-Independent Acquisition (DIA) | Source |
| Proteome Coverage | Good, but can be limited by data-dependent acquisition. | High, identified 15-20% more proteins than DIA in one study. | High, over 5000 proteins identified. | [4][5] |
| Quantitative Precision | Can be lower compared to label-based methods. | High, slightly better than DIA. | Good, with low coefficients of variation. | [4][5][6] |
| Quantitative Accuracy | Generally good, but can be affected by missing values. | Good, but DIA showed better accuracy in one comparison. | High, demonstrated better quantitative accuracy than TMT. | [4][5][6] |
| Missing Values | Higher incidence (e.g., 12% in one LFQ-DDA study). | Low within a single multiplex experiment. | Very low (e.g., 0.078% in one LFQ-DIA study). | [7][8] |
| Inter-Laboratory Reproducibility | Can be challenging due to variations in LC-MS runs. | Generally good, as samples are multiplexed and analyzed together. | Readily transferable between facilities. | [1][5][8] |
| Best For | Large-scale screening, studies where labeling is not feasible. | High-throughput, multiplexed comparison of multiple samples. | Deep proteome coverage with high accuracy and low missing values. | [4][5][7] |
Experimental Workflow Overviews
The general workflow for quantitative proteomics involves several key stages, each of which can influence the final results. Careful experimental design, including randomization and the use of quality controls, is crucial for obtaining reliable data.[9][10]
Below are simplified diagrams illustrating the typical workflows for LFQ, TMT, and DIA.
References
- 1. Repeatability and Reproducibility in Proteomic Identifications by Liquid Chromatography—Tandem Mass Spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 2. A framework for quality control in quantitative proteomics - PMC [pmc.ncbi.nlm.nih.gov]
- 3. abrf.memberclicks.net [abrf.memberclicks.net]
- 4. researchgate.net [researchgate.net]
- 5. pubs.acs.org [pubs.acs.org]
- 6. Benchmarking of Quantitative Proteomics Workflows for Limited Proteolysis Mass Spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 7. pubs.acs.org [pubs.acs.org]
- 8. m.youtube.com [m.youtube.com]
- 9. Designing Successful Proteomics Experiments - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. academic.oup.com [academic.oup.com]
Navigating the Matrix: A Comparative Guide to Assessing Matrix Effects in LC-MS with Stable Isotope Standards
For researchers, scientists, and drug development professionals striving for the highest accuracy and reliability in liquid chromatography-mass spectrometry (LC-MS) bioanalysis, the challenge of matrix effects is a constant consideration. This guide provides an objective comparison of methodologies to assess and mitigate matrix effects, with a focus on the gold-standard approach using stable isotope-labeled internal standards (SIL-IS). We present supporting experimental data, detailed protocols, and visual workflows to empower you in making informed decisions for your analytical method development and validation.
Matrix effects, the suppression or enhancement of analyte ionization due to co-eluting components from the sample matrix, can significantly compromise the accuracy, precision, and sensitivity of LC-MS assays.[1][2] The primary goal in addressing this challenge is to ensure that the analytical method provides consistent and reliable quantification of the target analyte, irrespective of the inherent variability between different biological samples.
The Gold Standard: Stable Isotope-Labeled Internal Standards
The use of a stable isotope-labeled internal standard (SIL-IS) is widely regarded as the most effective strategy to compensate for matrix effects.[3][4] A SIL-IS is a form of the analyte of interest in which one or more atoms have been replaced with a heavier isotope (e.g., ¹³C, ¹⁵N, ²H). Because SIL-IS are chemically and physically almost identical to the analyte, they co-elute chromatographically and experience the same ionization suppression or enhancement.[4] By calculating the ratio of the analyte peak area to the SIL-IS peak area, variability introduced by the matrix effect can be effectively normalized.
However, the use of SIL-IS is not without its limitations. The "deuterium isotope effect" can sometimes lead to a slight chromatographic separation between the deuterated standard and the native analyte, potentially exposing them to different matrix effects. Furthermore, the synthesis of custom SIL-IS can be costly and time-consuming.
Alternative Approaches: Standard Addition and Analog Internal Standards
When a SIL-IS is not feasible, other methods can be employed to assess and correct for matrix effects. These include the method of standard addition and the use of a structural analog as an internal standard.
-
Standard Addition: This method involves adding known amounts of the analyte standard to aliquots of the sample itself.[3][5] By creating a calibration curve within the sample matrix, the native concentration of the analyte can be determined by extrapolation. This approach can be highly accurate as it inherently accounts for the specific matrix effects of each sample. However, it is more labor-intensive than the internal standard approach.[5]
-
Analog Internal Standard: A structural analog is a compound that is chemically similar to the analyte but not identical. While more readily available and less expensive than a SIL-IS, its ability to compensate for matrix effects is dependent on how closely it mimics the chromatographic and ionization behavior of the analyte. If the analog does not co-elute perfectly with the analyte, it may not experience the same degree of matrix effect, leading to less accurate correction.[3]
Performance Comparison: A Data-Driven Assessment
To provide a clear comparison of these methods, the following table summarizes quantitative data from a study that evaluated the accuracy and precision of determining the concentration of an analyte in the presence of significant matrix effects, using a SIL-IS, standard addition, and a co-eluting analog internal standard. The external standard method (no internal standard) is included as a negative control to demonstrate the impact of uncorrected matrix effects.
| Method | Accuracy (% Error) | Precision (% RSD) |
| External Standard (Negative Control) | 39.0% | 0.612 |
| Stable Isotope-Labeled Internal Standard (SIL-IS) | Reference | 0.561 |
| Standard Addition | 7.36% - 8.64% | Not Reported |
| Co-eluting Analog Internal Standard | Not specified, but less accurate than SIL-IS | 0.852 |
Data adapted from "Strategies for the Detection and Elimination of Matrix Effects in Quantitative LC–MS Analysis". The SIL-IS method was used as the reference for accuracy comparison.[3]
As the data illustrates, the use of a SIL-IS provides the benchmark for accuracy in compensating for matrix effects. The standard addition method also demonstrates high accuracy. The co-eluting analog internal standard, while an improvement over no internal standard, shows lower precision in this particular study.[3]
Experimental Protocols
Detailed methodologies are crucial for the successful implementation of these techniques. Below are protocols for the key experiments used to assess matrix effects.
Protocol 1: Quantitative Assessment of Matrix Effect using the Post-Extraction Addition Method
This method is considered the "golden standard" for quantitatively determining the extent of matrix effects (ion suppression or enhancement).[6]
Objective: To quantify the absolute matrix effect by comparing the analyte response in a neat solution to the response in an extracted blank matrix.
Procedure:
-
Prepare three sets of samples at two concentration levels (low and high QC):
-
Set A (Neat Solution): Spike the analyte and SIL-IS (if used) into the final mobile phase or reconstitution solvent.
-
Set B (Post-Extraction Spike): Process at least six different lots of blank biological matrix through the entire sample preparation procedure. After the final extraction step, spike the analyte and SIL-IS into the extracted matrix.
-
Set C (Pre-Extraction Spike): Spike the analyte and SIL-IS into the blank biological matrix before the sample preparation procedure. (This set is used to determine recovery but is often performed alongside the matrix effect assessment).
-
-
Analyze all samples by LC-MS.
-
Calculate the Matrix Factor (MF):
-
MF = (Peak area of analyte in Set B) / (Peak area of analyte in Set A)
-
An MF < 1 indicates ion suppression.
-
An MF > 1 indicates ion enhancement.
-
An MF = 1 indicates no matrix effect.
-
-
Calculate the IS-Normalized Matrix Factor:
-
IS-Normalized MF = (MF of analyte) / (MF of SIL-IS)
-
A value close to 1.0 indicates that the SIL-IS effectively tracks and compensates for the matrix effect.[2]
-
Protocol 2: Qualitative Assessment of Matrix Effects using the Post-Column Infusion Method
This method provides a visual representation of where matrix effects occur throughout the chromatographic run.[6]
Objective: To qualitatively identify regions of ion suppression or enhancement in the chromatogram.
Procedure:
-
Set up the LC-MS system with a 'T' connector placed between the analytical column and the mass spectrometer inlet.
-
Infuse a standard solution of the analyte at a constant flow rate into the mobile phase eluting from the column using a syringe pump. This will generate a stable, elevated baseline signal for the analyte.
-
Inject an extracted blank matrix sample.
-
Monitor the analyte's signal throughout the chromatographic run.
-
A dip in the baseline indicates a region of ion suppression .
-
A rise in the baseline indicates a region of ion enhancement .
-
-
By comparing the retention time of the analyte in a standard injection with the regions of suppression/enhancement, you can determine if co-eluting matrix components are likely to affect its quantification.
Protocol 3: Correction of Matrix Effects using the Standard Addition Method
This method is particularly useful when a blank matrix is unavailable or when dealing with endogenous compounds.[3]
Objective: To determine the concentration of an analyte in a sample by creating a calibration curve within the sample itself.
Procedure:
-
Divide the unknown sample into at least four equal aliquots.
-
Leave one aliquot un-spiked.
-
Spike the remaining aliquots with increasing, known concentrations of the analyte standard. A typical spiking series might be 0.5x, 1x, and 1.5x the expected native concentration.
-
Process all aliquots through the entire sample preparation and analysis procedure.
-
Plot the peak area of the analyte versus the concentration of the added standard.
-
Perform a linear regression on the data points.
-
Determine the absolute value of the x-intercept. This value represents the concentration of the analyte in the original, un-spiked sample.
Visualizing the Workflows
To further clarify the experimental processes, the following diagrams illustrate the workflows for assessing and compensating for matrix effects.
Conclusion
The assessment and mitigation of matrix effects are critical for generating high-quality, reliable data in LC-MS bioanalysis. While stable isotope-labeled internal standards remain the preferred method for their superior ability to compensate for these effects, the standard addition method offers a highly accurate alternative, particularly when a SIL-IS is unavailable. The choice of method will depend on the specific requirements of the assay, including the availability of a blank matrix, cost considerations, and the desired throughput. By understanding the principles and performance of each technique, and by implementing robust experimental protocols, researchers can confidently navigate the complexities of the matrix and ensure the integrity of their analytical results.
References
- 1. Research Portal [researchportal.scu.edu.au]
- 2. Assessment of matrix effect in quantitative LC-MS bioanalysis - PMC [pmc.ncbi.nlm.nih.gov]
- 3. chromatographyonline.com [chromatographyonline.com]
- 4. Compensate for or Minimize Matrix Effects? Strategies for Overcoming Matrix Effects in Liquid Chromatography-Mass Spectrometry Technique: A Tutorial Review - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Comparison of calibration strategies for accurate quantitation by isotope dilution mass spectrometry: a case study of ochratoxin A in flour - PMC [pmc.ncbi.nlm.nih.gov]
- 6. researchgate.net [researchgate.net]
Safety Operating Guide
Essential Guide to the Proper Disposal of Fmoc-Leucine-¹³C₆,¹⁵N
This document provides comprehensive guidance on the safe and proper disposal of Fmoc-leucine-¹³C₆,¹⁵N, a stable isotope-labeled amino acid derivative commonly used in proteomics and peptide synthesis. Adherence to these procedures is critical for ensuring laboratory safety and regulatory compliance.
Fmoc-leucine-¹³C₆,¹⁵N is labeled with stable, non-radioactive isotopes of carbon and nitrogen.[1][2] Consequently, its disposal does not necessitate special precautions for radioactivity.[1][] The disposal protocol should align with that for the unlabeled equivalent, Fmoc-L-leucine, and follow institutional and local regulations for non-hazardous or hazardous chemical waste, depending on its classification and any potential contamination with other hazardous substances.
Hazard Identification and Safety Precautions
Safety Data Sheets (SDS) for the unlabeled compound, Fmoc-L-leucine, present some differing hazard classifications. While one source indicates it is not considered hazardous under the OSHA Hazard Communication Standard[4], another classifies it as harmful if swallowed, in contact with skin, or inhaled, and as a cause of skin and serious eye irritation[5]. Given this, it is prudent to handle Fmoc-leucine-¹³C₆,¹⁵N with care, employing standard laboratory personal protective equipment (PPE).
Recommended Personal Protective Equipment (PPE):
-
Eye Protection: Safety glasses or goggles[6].
-
Hand Protection: Compatible chemical-resistant gloves[6].
-
Respiratory Protection: Use a NIOSH/MSHA or European Standard EN 149 approved respirator if dust is generated and exposure limits are exceeded[4].
-
Body Protection: Lab coat.
Quantitative Data Summary
The following table summarizes key quantitative data for Fmoc-leucine-¹³C₆,¹⁵N.
| Property | Value | Reference |
| Molecular Formula | (¹³CH₃)₂¹³CH¹³CH₂¹³CH(¹⁵NH-Fmoc)¹³CO₂H | |
| Molecular Weight | 360.36 g/mol | [7] |
| CAS Number | 1163133-36-5 | [7] |
| Appearance | Solid | [6] |
| Melting Point | 152-156 °C | [6] |
| Storage Temperature | Refrigerated (+2°C to +8°C), desiccated, and protected from light | [7] |
Step-by-Step Disposal Protocol
This protocol outlines the procedure for the disposal of pure, unadulterated Fmoc-leucine-¹³C₆,¹⁵N, as well as materials contaminated with it.
1. Waste Characterization:
- Determine if the Fmoc-leucine-¹³C₆,¹⁵N waste is contaminated with any other hazardous chemicals.
- If mixed with other substances, the disposal protocol for the most hazardous component of the mixture must be followed.
2. Waste Segregation:
- Do not mix Fmoc-leucine-¹³C₆,¹⁵N waste with incompatible materials.
- Avoid mixing with strong oxidizing agents or amines[4].
- Keep aqueous wastes separate from organic solvents[8].
3. Packaging and Labeling:
- Solid Waste:
- Collect pure Fmoc-leucine-¹³C₆,¹⁵N solid waste and contaminated materials (e.g., gloves, weighing paper) in a designated, robust, and sealable container.
- Label the container clearly with "Fmoc-leucine-¹³C₆,¹⁵N Waste" and include the full chemical name. Do not use abbreviations[9].
- Liquid Waste (if in solution):
- Collect in a compatible, leak-proof container.
- Ensure the container is properly sealed when not in use[9].
- Label the container with the full chemical name and concentration of all components.
- All waste containers must have a completed hazardous waste tag as required by your institution's Environmental Health and Safety (EHS) department[8][9].
4. Storage:
- Store waste containers in a designated, well-ventilated area, away from heat and sources of ignition[4].
- Ensure containers are stored in secondary containment to prevent spills[9].
5. Final Disposal:
- Arrange for waste pickup through your institution's EHS department or a certified hazardous waste disposal company.
- Never dispose of Fmoc-leucine-¹³C₆,¹⁵N down the drain or in the regular trash[9].
Experimental Workflow and Disposal Decision-Making
The following diagram illustrates the logical workflow for the proper disposal of Fmoc-leucine-¹³C₆,¹⁵N.
Caption: Disposal workflow for Fmoc-leucine-¹³C₆,¹⁵N.
References
- 1. moravek.com [moravek.com]
- 2. chempep.com [chempep.com]
- 4. fishersci.com [fishersci.com]
- 5. cdn.caymanchem.com [cdn.caymanchem.com]
- 6. Fmoc-Leu-OH-15N 15N 98atom , 98 CP 200937-57-1 [sigmaaldrich.com]
- 7. L-Leucine-ð-Fmoc (¹³Câ, 99%; ¹âµN, 99%) - Cambridge Isotope Laboratories, CNLM-4345-H-0.1 [isotope.com]
- 8. mwcog.org [mwcog.org]
- 9. Hazardous Waste Disposal Guide - Research Areas | Policies [policies.dartmouth.edu]
Personal protective equipment for handling Fmoc-leucine-13C6,15N
Essential Safety and Handling Guide for Fmoc-leucine-13C6,15N
For researchers, scientists, and drug development professionals, ensuring the safe and effective handling of specialized chemical reagents like this compound is paramount to both personal safety and research integrity. This guide provides immediate, essential safety protocols and logistical information for the operational use and disposal of this compound.
This compound is a stable isotope-labeled amino acid derivative crucial for various applications in proteomics and drug development. While stable isotopes do not pose a radiological hazard, the chemical properties of the molecule and associated reagents necessitate careful handling.[1][2] Safety Data Sheets (SDS) for Fmoc-leucine and its isotopically labeled analogues indicate potential hazards including skin irritation, serious eye irritation, and possible respiratory irritation.[3][4] Therefore, adherence to stringent safety protocols is mandatory.
Personal Protective Equipment (PPE)
A comprehensive approach to personal protection is critical to minimize exposure and prevent contamination. The following table summarizes the required PPE for handling this compound.
| PPE Category | Item | Specifications and Use |
| Eye and Face Protection | Safety Goggles | Chemical splash goggles are required to protect against liquid splashes and chemical vapors.[5] |
| Face Shield | Recommended when there is a significant risk of splashing, particularly when handling bulk quantities or during vigorous mixing operations. | |
| Body Protection | Laboratory Coat | A standard, properly fitting lab coat is the minimum requirement to protect clothing and skin from potential splashes.[5] Fire-resistant coats are advised when working with flammable solvents.[6] |
| Hand Protection | Chemical-Resistant Gloves | Nitrile gloves are commonly used for handling chemicals of this nature.[6] For prolonged contact or when handling concentrated solutions, consider double-gloving. |
| Respiratory Protection | Respirator | A NIOSH-approved respirator is necessary when handling the compound as a powder to avoid inhalation of fine particles, or when working in poorly ventilated areas.[6] The type should be based on a risk assessment. |
Operational and Disposal Plan
Proper operational procedures and waste disposal are crucial for maintaining a safe laboratory environment.
Receiving and Storage:
-
Upon receipt, inspect the container for any damage.
-
Store in a cool, dry, and well-ventilated area, away from incompatible materials such as strong oxidizing agents.[7]
-
The recommended storage temperature is typically refrigerated (+2°C to +8°C) and desiccated, with protection from light.[8]
Handling and Use:
-
Preparation: Always work in a certified chemical fume hood, especially when handling the solid compound or volatile solvents.[9]
-
Weighing: To prevent inhalation of dust, handle the solid form with care. Use appropriate engineering controls like a ventilated balance enclosure.
-
Dissolving: When preparing solutions, slowly add the solid to the solvent to avoid splashing.
-
Reaction: If used in solid-phase peptide synthesis (SPPS), be aware of the hazards associated with all other reagents, such as piperidine (B6355638) and trifluoroacetic acid (TFA), which are commonly used for Fmoc deprotection and cleavage.[10][11]
Disposal Plan:
-
Unused Product: Unused or expired this compound should be disposed of as chemical waste in accordance with local, state, and federal regulations. Do not dispose of it down the drain.
-
Contaminated Materials: All materials that have come into contact with the compound, including pipette tips, gloves, and empty vials, must be collected in a designated and clearly labeled hazardous waste container.[6]
-
Waste Solvents: Solvents used in reactions or for cleaning should be collected in appropriate, labeled hazardous waste containers.
Visualizing Safety and Operational Workflows
To further clarify the procedural steps for ensuring safety, the following diagrams illustrate the decision-making process for PPE selection and the overall operational and disposal workflow.
Caption: PPE selection workflow for handling this compound.
Caption: Step-by-step operational and disposal plan.
References
- 1. Safe use of radioisotopes - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. documents.manchester.ac.uk [documents.manchester.ac.uk]
- 3. file.medchemexpress.com [file.medchemexpress.com]
- 4. cdn.caymanchem.com [cdn.caymanchem.com]
- 5. m.youtube.com [m.youtube.com]
- 6. benchchem.com [benchchem.com]
- 7. fishersci.com [fishersci.com]
- 8. L-Leucine-ð-Fmoc (¹³Câ, 99%; ¹âµN, 99%) - Cambridge Isotope Laboratories, CNLM-4345-H-0.1 [isotope.com]
- 9. americanpeptidesociety.org [americanpeptidesociety.org]
- 10. genscript.com [genscript.com]
- 11. bachem.com [bachem.com]
Featured Recommendations
| Most viewed |


|
|
|---|---|---|
| Most popular with customers |
|
Descargo de responsabilidad e información sobre productos de investigación in vitro
Tenga en cuenta que todos los artículos e información de productos presentados en BenchChem están destinados únicamente con fines informativos. Los productos disponibles para la compra en BenchChem están diseñados específicamente para estudios in vitro, que se realizan fuera de organismos vivos. Los estudios in vitro, derivados del término latino "in vidrio", involucran experimentos realizados en entornos de laboratorio controlados utilizando células o tejidos. Es importante tener en cuenta que estos productos no se clasifican como medicamentos y no han recibido la aprobación de la FDA para la prevención, tratamiento o cura de ninguna condición médica, dolencia o enfermedad. Debemos enfatizar que cualquier forma de introducción corporal de estos productos en humanos o animales está estrictamente prohibida por ley. Es esencial adherirse a estas pautas para garantizar el cumplimiento de los estándares legales y éticos en la investigación y experimentación.
