BBD
Descripción
Propiedades
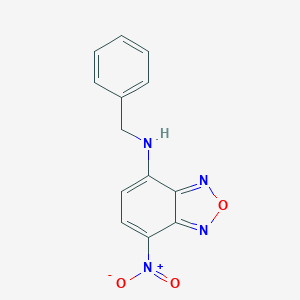
IUPAC Name |
N-benzyl-4-nitro-2,1,3-benzoxadiazol-7-amine |
Source


|
|---|---|---|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
InChI |
InChI=1S/C13H10N4O3/c18-17(19)11-7-6-10(12-13(11)16-20-15-12)14-8-9-4-2-1-3-5-9/h1-7,14H,8H2 |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
InChI Key |
GZFKJMWBKTUNJS-UHFFFAOYSA-N |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Canonical SMILES |
C1=CC=C(C=C1)CNC2=CC=C(C3=NON=C23)[N+](=O)[O-] |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Molecular Formula |
C13H10N4O3 |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
DSSTOX Substance ID |
DTXSID90171475 |
Source
|
| Record name | 7-Nitro-N-(benzyl)benzofurazan-4-amine | |
| Source | EPA DSSTox | |
| URL | https://comptox.epa.gov/dashboard/DTXSID90171475 | |
| Description | DSSTox provides a high quality public chemistry resource for supporting improved predictive toxicology. | |
Molecular Weight |
270.24 g/mol |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
CAS No. |
18378-20-6 |
Source
|
| Record name | 7-Benzylamino-4-nitro-2,1,3-benzoxadiazole | |
| Source | CAS Common Chemistry | |
| URL | https://commonchemistry.cas.org/detail?cas_rn=18378-20-6 | |
| Description | CAS Common Chemistry is an open community resource for accessing chemical information. Nearly 500,000 chemical substances from CAS REGISTRY cover areas of community interest, including common and frequently regulated chemicals, and those relevant to high school and undergraduate chemistry classes. This chemical information, curated by our expert scientists, is provided in alignment with our mission as a division of the American Chemical Society. | |
| Explanation | The data from CAS Common Chemistry is provided under a CC-BY-NC 4.0 license, unless otherwise stated. | |
| Record name | 7-Nitro-N-(benzyl)benzofurazan-4-amine | |
| Source | ChemIDplus | |
| URL | https://pubchem.ncbi.nlm.nih.gov/substance/?source=chemidplus&sourceid=0018378206 | |
| Description | ChemIDplus is a free, web search system that provides access to the structure and nomenclature authority files used for the identification of chemical substances cited in National Library of Medicine (NLM) databases, including the TOXNET system. | |
| Record name | 18378-20-6 | |
| Source | DTP/NCI | |
| URL | https://dtp.cancer.gov/dtpstandard/servlet/dwindex?searchtype=NSC&outputformat=html&searchlist=240867 | |
| Description | The NCI Development Therapeutics Program (DTP) provides services and resources to the academic and private-sector research communities worldwide to facilitate the discovery and development of new cancer therapeutic agents. | |
| Explanation | Unless otherwise indicated, all text within NCI products is free of copyright and may be reused without our permission. Credit the National Cancer Institute as the source. | |
| Record name | 7-Nitro-N-(benzyl)benzofurazan-4-amine | |
| Source | EPA DSSTox | |
| URL | https://comptox.epa.gov/dashboard/DTXSID90171475 | |
| Description | DSSTox provides a high quality public chemistry resource for supporting improved predictive toxicology. | |
| Record name | 7-nitro-N-(benzyl)benzofurazan-4-amine | |
| Source | European Chemicals Agency (ECHA) | |
| URL | https://echa.europa.eu/substance-information/-/substanceinfo/100.038.404 | |
| Description | The European Chemicals Agency (ECHA) is an agency of the European Union which is the driving force among regulatory authorities in implementing the EU's groundbreaking chemicals legislation for the benefit of human health and the environment as well as for innovation and competitiveness. | |
| Explanation | Use of the information, documents and data from the ECHA website is subject to the terms and conditions of this Legal Notice, and subject to other binding limitations provided for under applicable law, the information, documents and data made available on the ECHA website may be reproduced, distributed and/or used, totally or in part, for non-commercial purposes provided that ECHA is acknowledged as the source: "Source: European Chemicals Agency, http://echa.europa.eu/". Such acknowledgement must be included in each copy of the material. ECHA permits and encourages organisations and individuals to create links to the ECHA website under the following cumulative conditions: Links can only be made to webpages that provide a link to the Legal Notice page. | |
| Record name | 7-Nitro-N-(benzyl)benzofurazan-4-amine | |
| Source | FDA Global Substance Registration System (GSRS) | |
| URL | https://gsrs.ncats.nih.gov/ginas/app/beta/substances/MKU6C7CU72 | |
| Description | The FDA Global Substance Registration System (GSRS) enables the efficient and accurate exchange of information on what substances are in regulated products. Instead of relying on names, which vary across regulatory domains, countries, and regions, the GSRS knowledge base makes it possible for substances to be defined by standardized, scientific descriptions. | |
| Explanation | Unless otherwise noted, the contents of the FDA website (www.fda.gov), both text and graphics, are not copyrighted. They are in the public domain and may be republished, reprinted and otherwise used freely by anyone without the need to obtain permission from FDA. Credit to the U.S. Food and Drug Administration as the source is appreciated but not required. | |
Foundational & Exploratory
Box-Behnken Design: A Technical Guide for Experimental Optimization in Scientific Research
For Researchers, Scientists, and Drug Development Professionals
In the landscape of experimental research, particularly within drug development and process optimization, the pursuit of efficiency and precision is paramount. The Box-Behnken Design (BBD) emerges as a powerful statistical tool, offering a strategic approach to understanding and optimizing complex processes. This technical guide provides an in-depth exploration of the core principles of this compound, its practical applications, and detailed methodologies, tailored for scientists and researchers seeking to enhance their experimental designs.
Core Principles of Box-Behnken Design
Developed by George E. P. Box and Donald Behnken in 1960, the Box-Behnken design is a type of response surface methodology (RSM) that provides an efficient alternative to other designs like central composite and full factorial designs.[1] this compound is specifically engineered to fit a quadratic model, making it highly effective for optimization studies where curvature in the response surface is expected.[2]
The fundamental structure of a this compound involves testing each experimental factor at three distinct, equally spaced levels, typically coded as -1 (low), 0 (center), and +1 (high).[3] A key characteristic and significant advantage of the this compound is its deliberate avoidance of experimental runs where all factors are simultaneously at their extreme (high or low) levels.[2][4] This "no corners" approach is particularly beneficial in situations where extreme factor combinations could lead to undesirable, unsafe, or impractical experimental conditions.[4][5]
The design is constructed by combining two-level factorial designs with incomplete block designs.[6] The experimental points are strategically placed at the midpoints of the edges of the design space and at the center.[4] This arrangement allows for the efficient estimation of linear, interaction, and quadratic effects of the factors on the response variable.[1]
The Logical Structure of a Box-Behnken Design
The following diagram illustrates the conceptual structure of a Box-Behnken Design for three factors. Each axis represents a factor, and the points represent the experimental runs. Notice the absence of points at the corners of the cube.
References
- 1. researchgate.net [researchgate.net]
- 2. Applying Box–Behnken Design for Formulation and Optimization of PLGA-Coffee Nanoparticles and Detecting Enhanced Antioxidant and Anticancer Activities - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Box-Behnken Design for Optimization of Formulation Variables for Fast Dissolving Tablet of Urapidil [wisdomlib.org]
- 4. ijper.org [ijper.org]
- 5. Box-Behnken Design for Optimization of Formulation Variables for Fast Dissolving Tablet of Urapidil | Asian Journal of Pharmaceutics (AJP) [asiapharmaceutics.info]
- 6. researchgate.net [researchgate.net]
Principles of Box-Behnken Design: An In-depth Guide for Researchers
For Researchers, Scientists, and Drug Development Professionals
In the landscape of experimental design, particularly within pharmaceutical development and process optimization, the Box-Behnken Design (BBD) emerges as a highly efficient and economical approach. As a cornerstone of Response Surface Methodology (RSM), this compound provides a framework for modeling and analyzing processes where the response of interest is influenced by multiple variables. This guide offers a comprehensive overview of the core principles of this compound, its practical applications, and a detailed protocol for its implementation, tailored for professionals in scientific research and drug development.
Core Principles of Box-Behnken Design
Developed by George E. P. Box and Donald Behnken in 1960, the Box-Behnken design is a type of response surface design that is structured to fit a quadratic model.[1] It is particularly advantageous when the experimental region is known, and the primary goal is to understand the relationships between quantitative experimental variables and a response variable to find the optimal conditions.
At its core, this compound is a three-level incomplete factorial design.[1][2] This means that for each factor or independent variable, three levels are examined: a low level (coded as -1), a central level (coded as 0), and a high level (coded as +1).[1] A key characteristic of this compound is that it does not include experimental runs at the vertices (corners) of the cubic design space, where all factors are at their extreme high or low levels simultaneously.[3][4] Instead, the design points are located at the midpoints of the edges of the experimental space and at the center.[3][5] This feature provides a significant advantage in situations where extreme factor combinations could lead to undesirable outcomes, such as unsafe operating conditions or compromised product quality.[3][4]
BBDs are designed to be rotatable or nearly rotatable, which means the variance of the predicted response is constant at all points equidistant from the center of the design.[6] This property ensures that the quality of the prediction is consistent throughout the design space.
Box-Behnken Design vs. Central Composite Design
A common alternative to this compound is the Central Composite Design (CCD). While both are used for response surface modeling, they differ in their structure and the number of required experimental runs.
| Number of Factors | Box-Behnken Design (Number of Runs) | Central Composite Design (Number of Runs) |
| 3 | 15 (including 3 center points) | 20 (including 6 center points) |
| 4 | 27 (including 3 center points) | 30 (including 6 center points) |
| 5 | 46 (including 6 center points) | 52 (including 10 center points) |
| 6 | 54 (including 6 center points) | 91 (including 10 center points) |
As the table illustrates, for a smaller number of factors (typically 3 or 4), this compound is often more efficient in terms of the number of required experiments.[7][8] However, as the number of factors increases, the efficiency advantage of this compound may diminish.[8]
Advantages and Disadvantages of Box-Behnken Design
Advantages:
-
Efficiency: this compound often requires fewer experimental runs than CCD for the same number of factors, especially for 3 and 4 factors, saving time and resources.[7]
-
Safety: By avoiding extreme combinations of all factors, this compound is particularly useful when such conditions are dangerous, expensive, or could lead to equipment failure.[3][4]
-
Quadratic Model Fitting: The design is specifically structured to efficiently estimate the coefficients of a second-order (quadratic) model.[6]
Disadvantages:
-
Not for Sequential Experimentation: Unlike CCDs, which can be built up from a factorial or fractional factorial design, BBDs are not suitable for sequential experiments.
-
Limited to Second-Order Models: The design is primarily intended for fitting quadratic models and may not be suitable for higher-order polynomial models.[6]
-
Poor Coverage of Corners: The absence of experimental points at the corners of the design space can lead to higher prediction variance in these regions.[1]
Experimental Protocol for Implementing a Box-Behnken Design
The following is a generalized protocol for conducting an experiment using a Box-Behnken design, particularly relevant for drug development and process optimization.
Phase 1: Planning and Design
-
Define the Objective: Clearly state the goal of the experiment, such as optimizing a formulation to maximize drug release or minimizing impurities in a synthesis process.
-
Identify Factors and Ranges:
-
Select the critical independent variables (factors) that are believed to influence the response(s).
-
Determine the low (-1), medium (0), and high (+1) levels for each factor based on preliminary experiments, literature review, or prior knowledge.
-
-
Select the Responses: Identify the dependent variables (responses) that will be measured to assess the outcome of the experiment (e.g., dissolution rate, particle size, yield).
-
Generate the Design Matrix: Use statistical software (e.g., JMP, Minitab, Design-Expert) to generate the Box-Behnken design matrix. This will provide a randomized run order for the experiments. A typical this compound for three factors will consist of 15 runs, including three center points.
Phase 2: Experimentation
-
Prepare Materials and Equipment: Ensure all necessary materials, reagents, and equipment are calibrated and ready for the experiments.
-
Conduct the Experimental Runs: Perform the experiments according to the randomized run order provided by the design matrix. It is crucial to adhere strictly to the specified factor levels for each run.
-
Measure and Record Responses: Accurately measure the defined responses for each experimental run and record the data systematically.
Phase 3: Data Analysis and Optimization
-
Fit the Model: Analyze the experimental data using the same statistical software. Fit a quadratic model to the data for each response. The general form of a second-order polynomial equation is:
Y = β₀ + ΣβᵢXᵢ + ΣβᵢᵢXᵢ² + ΣβᵢⱼXᵢXⱼ
where Y is the predicted response, β₀ is the intercept, βᵢ are the linear coefficients, βᵢᵢ are the quadratic coefficients, and βᵢⱼ are the interaction coefficients.
-
Assess Model Significance and Fit:
-
Use Analysis of Variance (ANOVA) to check the statistical significance of the model.
-
Evaluate the goodness of fit using metrics like the coefficient of determination (R²), adjusted R², and predicted R².
-
-
Interpret the Results:
-
Examine the coefficients of the model to understand the effect of each factor and their interactions on the response.
-
Generate response surface plots (3D) and contour plots (2D) to visualize the relationship between the factors and the response.
-
-
Optimization:
-
Use the model to determine the optimal settings of the factors that will achieve the desired response. This can be done through numerical optimization functions within the statistical software.
-
Define the optimization criteria (e.g., maximize, minimize, target a specific value for each response).
-
-
Validation: Conduct a confirmation experiment at the predicted optimal conditions to verify the model's predictive accuracy.
Applications in Drug Development
Box-Behnken designs are widely applied in various stages of drug development:
-
Formulation Optimization: In the development of extended-release matrix tablets, this compound has been used to optimize the amounts of different polymers to achieve a desired drug release profile.[9]
-
Nanoparticle Formulation: this compound is employed to study the impact of process parameters like homogenization speed and time, and formulation parameters like surfactant concentration on the particle size and encapsulation efficiency of nanoparticles.[3]
-
Analytical Method Development: The design is used to optimize RP-HPLC (Reverse-Phase High-Performance Liquid Chromatography) conditions, such as the pH of the buffer, the percentage of the organic phase, and the flow rate, to achieve optimal separation of drug substances.[1]
-
Process Optimization in Pharmaceutical Manufacturing: this compound can be used to optimize manufacturing processes, such as the iontophoretic delivery of drugs, by studying the effects of variables like current density and pH.
Visualizing Box-Behnken Design Principles
To better understand the structure and workflow of a Box-Behnken design, the following diagrams are provided.
Caption: Logical structure of a 3-factor Box-Behnken Design.
Caption: General experimental workflow for a Box-Behnken Design.
References
- 1. Application of Box-Behnken experimental design and response surface methodology for selecting the optimum RP-HPLC conditions for the simultaneous determination of methocarbamol, indomethacin and betamethasone in their pharmaceutical dosage form - PMC [pmc.ncbi.nlm.nih.gov]
- 2. researchgate.net [researchgate.net]
- 3. Applying Box–Behnken Design for Formulation and Optimization of PLGA-Coffee Nanoparticles and Detecting Enhanced Antioxidant and Anticancer Activities - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Central Composite Design vs. Box-Behnken Design [experimentaldesignhub.com]
- 5. Box–Behnken Designs and Their Applications in Pharmaceutical Product Development [ouci.dntb.gov.ua]
- 6. The Open Educator - 4. Box-Behnken Response Surface Methodology [theopeneducator.com]
- 7. 5.3.3.6.3. Comparisons of response surface designs [itl.nist.gov]
- 8. 11.2.2 - Box-Behnken Designs | STAT 503 [online.stat.psu.edu]
- 9. mdpi.com [mdpi.com]
An In-depth Technical Guide to the Geometry of Box-Behnken Design
For Researchers, Scientists, and Drug Development Professionals
The Box-Behnken design (BBD), conceived by George E. P. Box and Donald Behnken in 1960, is a highly efficient, second-order response surface methodology (RSM) design for modeling and optimizing processes.[1][2] Its unique geometric structure offers distinct advantages, particularly in scenarios where extreme combinations of factor levels are undesirable or infeasible. This guide provides a detailed exploration of the core geometry of the Box-Behnken design, its construction, and its practical implications in experimental design.
Core Principles of Box-Behnken Design
The Box-Behnken design is a three-level incomplete factorial design.[1][2] Each factor, or independent variable, is studied at three equally spaced levels, typically coded as -1 (low), 0 (central), and +1 (high).[1][2] A key characteristic of the this compound is that it does not contain an embedded full or fractional factorial design.[3] Consequently, it avoids experimental runs at the vertices of the cubic experimental region, where all factors are simultaneously at their highest or lowest levels.[4] This feature is particularly advantageous in drug development and other sensitive research areas where extreme conditions could lead to safety concerns, equipment failure, or undesirable side effects.[4]
The design is structured to efficiently estimate the parameters of a second-order (quadratic) model, which is often necessary to capture the curvature in the response surface and identify optimal process conditions.[1][2] BBDs are considered to be rotatable or nearly rotatable, meaning the variance of the predicted response is approximately constant at all points equidistant from the center of the design space.[3][5]
The Geometric Structure: A Sphere Within a Cube
Geometrically, the experimental points of a three-factor Box-Behnken design can be visualized as lying on a sphere within the cubic design space.[3] The design points are located at the midpoints of the edges of this cube and at its center.[3] This arrangement ensures that no experimental runs are performed at the corners of the cube.
This "sphere-like" distribution of points is a direct consequence of the design's construction, which involves a combination of two-level factorial designs and incomplete block designs.[1] For a three-factor design, the this compound is constructed by creating three blocks. In each block, a 2² factorial design is applied to two of the factors, while the third factor is held at its central level (0).[1] This structure is systematically rotated for all factor combinations, and then supplemented with center points.
Logical Structure of a Three-Factor Box-Behnken Design
The following diagram illustrates the logical construction of a three-factor Box-Behnken design. The design is partitioned into three blocks, where each block corresponds to holding one factor at its center level (0) while the other two factors are varied across their high (+1) and low (-1) levels. The center point runs, where all factors are at their central level, are also included.
Caption: Logical construction of a 3-factor Box-Behnken design.
Quantitative Comparison of Box-Behnken Designs
The number of experimental runs required for a Box-Behnken design is a function of the number of factors (k) and the number of center points (C₀). The total number of runs is given by the formula N = 2k(k-1) + C₀. The table below summarizes the design characteristics for different numbers of factors.
| Number of Factors (k) | Factorial Points | Center Points (Typical) | Total Runs (N) |
| 3 | 12 | 3 | 15 |
| 4 | 24 | 3 | 27 |
| 5 | 40 | 6 | 46 |
| 6 | 48 | 6 | 54 |
Table 1: Quantitative summary of Box-Behnken designs for varying numbers of factors.
Experimental Protocols
The successful implementation of a Box-Behnken design relies on a well-defined experimental protocol. A typical workflow is as follows:
-
Factor and Level Selection: Identify the critical process parameters (factors) and define their respective low (-1), medium (0), and high (+1) levels. These levels should be chosen based on prior knowledge, literature review, and preliminary screening experiments.
-
Design Generation: Generate the experimental design matrix using statistical software. This matrix will specify the combination of factor levels for each experimental run, including the randomized run order to minimize the impact of systematic errors.
-
Experimentation: Conduct the experiments according to the randomized run order specified in the design matrix. It is crucial to maintain consistency in experimental procedures and to accurately measure the response variable(s).
-
Data Analysis: After completing all experimental runs, analyze the data using response surface methodology. This involves fitting a second-order polynomial equation to the experimental data and evaluating the statistical significance of the model and its individual terms through analysis of variance (ANOVA).
-
Model Validation and Optimization: Validate the fitted model to ensure its predictive accuracy. Once validated, the model can be used to generate response surface plots and contour plots to visualize the relationship between the factors and the response, and to identify the optimal operating conditions.
Experimental Workflow for a Box-Behnken Design
The following diagram outlines the typical workflow for conducting an experiment using a Box-Behnken design, from the initial planning stages to the final optimization.
Caption: A typical experimental workflow using a Box-Behnken design.
References
The Genesis and Evolution of Box-Behnken Design: A Technical Guide for Modern Research
A cornerstone of response surface methodology (RSM), the Box-Behnken Design (BBD) stands as a testament to statistical ingenuity, offering an efficient and economical approach to optimizing complex processes. Conceived in 1960 by George E. P. Box and Donald Behnken, this experimental design has become an indispensable tool for researchers, scientists, and drug development professionals seeking to understand and refine multi-variable systems. [1][2][3] This in-depth technical guide explores the history, mathematical underpinnings, and practical application of Box-Behnken Design, providing a comprehensive resource for its effective implementation.
A Historical Perspective: The Dawn of an Efficient Design
In the mid-20th century, the field of experimental design was rapidly evolving, driven by the need for more efficient methods to explore the relationships between multiple input variables and a given response. It was within this context that George E. P. Box, a pioneering British statistician, and Donald Behnken, his collaborator, introduced their novel three-level incomplete factorial design.[1][2][3] Their seminal 1960 paper laid the groundwork for a design that would offer a compelling alternative to existing methods like the Central Composite Design (CCD).
The primary motivation behind the development of this compound was to create a design that could fit a second-order (quadratic) model with a reasonable number of experimental runs.[1][2] A key innovation of the Box-Behnken design is its avoidance of extreme corner points, where all factors are at their highest or lowest levels simultaneously.[4][5] This feature is particularly advantageous in situations where such extreme combinations could lead to undesirable or unsafe experimental outcomes, a common concern in industrial and pharmaceutical research.[5][6]
The Mathematical Foundation of Box-Behnken Design
At its core, the Box-Behnken Design is a strategic combination of two-level factorial designs with incomplete block designs.[2][3] This construction allows for the estimation of all the coefficients of a second-order polynomial model:
Y = β₀ + Σβᵢxᵢ + Σβᵢᵢxᵢ² + Σβᵢⱼxᵢxⱼ + ε
where Y is the predicted response, β₀ is the intercept, βᵢ are the linear coefficients, βᵢᵢ are the quadratic coefficients, βᵢⱼ are the interaction coefficients, xᵢ and xⱼ are the coded independent variables, and ε is the random error.
The design consists of a set of points lying at the midpoints of the edges of the experimental space and a central point.[2][7] Each factor is studied at three levels, typically coded as -1, 0, and +1, representing the low, middle, and high values of the factor.[1][3]
Comparing Box-Behnken Design with Central Composite Design
The choice between Box-Behnken Design and Central Composite Design often depends on the specific objectives and constraints of the experiment. The following table provides a quantitative comparison of these two popular response surface designs for a varying number of factors.
| Number of Factors (k) | Design | Total Runs (without center points) | Number of Levels per Factor | Extreme (Corner) Points |
| 3 | Box-Behnken | 12 | 3 | No |
| Central Composite (rotatable) | 14 | 5 | Yes | |
| 4 | Box-Behnken | 24 | 3 | No |
| Central Composite (rotatable) | 24 | 5 | Yes | |
| 5 | Box-Behnken | 40 | 3 | No |
| Central Composite (rotatable) | 42 | 5 | Yes | |
| 6 | Box-Behnken | 54 | 3 | No |
| Central Composite (rotatable) | 74 | 5 | Yes |
Note: The number of center points is typically chosen by the experimenter (e.g., 3-5) and added to the total runs.
As the table illustrates, for a smaller number of factors (k=3), this compound can be more efficient in terms of the number of runs required.[6][8] However, as the number of factors increases, the number of runs for both designs becomes more comparable.[5] A key advantage of this compound is its consistent three-level structure for each factor, whereas CCD requires five levels to achieve rotatability, which may not always be practical.[1][6]
Experimental Protocol: A Step-by-Step Guide to Applying Box-Behnken Design
The successful implementation of a Box-Behnken Design involves a systematic approach, from planning the experiment to analyzing the results. The following protocol outlines the key steps:
Step 1: Define the Experimental Objective and Identify Key Factors and Responses.
-
Clearly state the goal of the optimization study.
-
Identify the independent variables (factors) that are believed to influence the process and the dependent variables (responses) that need to be optimized.
Step 2: Determine the Experimental Range and Levels for Each Factor.
-
Based on prior knowledge and preliminary experiments, define the low (-1), middle (0), and high (+1) levels for each factor.
Step 3: Generate the Box-Behnken Design Matrix.
-
Use statistical software (e.g., JMP, Minitab, Design-Expert) to generate the experimental runs based on the number of factors.[1][9] The software will create a randomized run order to minimize the effect of nuisance variables.
Step 4: Conduct the Experiments.
-
Perform the experimental runs according to the generated design matrix in the specified randomized order.
-
Carefully record the observed response values for each run.
Step 5: Fit the Second-Order Polynomial Model.
-
Use the experimental data to fit a quadratic model that describes the relationship between the factors and the response.
Step 6: Analyze the Model and Assess its Adequacy.
-
Perform an Analysis of Variance (ANOVA) to determine the statistical significance of the model and its individual terms (linear, quadratic, and interaction).[4]
-
Key metrics to evaluate include the p-value (a value < 0.05 typically indicates significance), the coefficient of determination (R²), and the adjusted R².[4] A high R² value suggests that the model explains a large proportion of the variability in the response.
Step 7: Visualize the Response Surface.
-
Generate contour plots and 3D surface plots to visualize the relationship between the factors and the response. These plots are crucial for understanding the interaction effects and identifying the optimal operating conditions.
Step 8: Determine the Optimal Conditions and Validate the Model.
-
Use the model to predict the combination of factor levels that will result in the desired optimal response.
-
Conduct confirmation experiments at the predicted optimal conditions to validate the model's predictive ability.
Mandatory Visualizations
Experimental Workflow for Box-Behnken Design
Caption: A flowchart illustrating the systematic workflow of a Box-Behnken Design experiment.
Logical Relationship in Response Surface Optimization
Caption: A diagram illustrating the logical flow of response surface methodology for process optimization.
Application in Drug Development: A Case Study
Box-Behnken Design has found extensive application in the pharmaceutical industry, particularly in the formulation and optimization of drug delivery systems. A common application is in the development of nanoparticle-based drug delivery systems, where factors such as polymer concentration, sonication time, and surfactant concentration can significantly impact critical quality attributes like particle size, encapsulation efficiency, and drug release profile.
Case Study: Optimization of Polymeric Nanoparticles for Drug Delivery
In a study aimed at optimizing the formulation of irinotecan (B1672180) hydrochloride-loaded polycaprolactone (B3415563) (PCL) nanoparticles, researchers employed a Box-Behnken design.[7]
-
Factors:
-
Amount of PCL (polymer)
-
Amount of Irinotecan Hydrochloride (drug)
-
Concentration of PVA (surfactant)
-
-
Responses:
-
Particle Size
-
Zeta Potential
-
Encapsulation Efficiency
-
The this compound with 15 experimental runs was used to investigate the effects of these three factors at three levels.[7][10] The experimental data was then fitted to a second-order polynomial model. The ANOVA results revealed the significant factors and interactions influencing the responses. For instance, the amount of PCL and the concentration of PVA were found to have a significant impact on the particle size of the nanoparticles.
Through the analysis of response surface plots, the researchers were able to identify the optimal combination of factor levels to achieve the desired nanoparticle characteristics (e.g., smallest particle size and highest encapsulation efficiency).[7] This case study highlights the power of this compound in efficiently navigating the complex formulation landscape to develop robust and effective drug delivery systems.
Conclusion: The Enduring Legacy of Box-Behnken Design
More than six decades after its inception, the Box-Behnken Design continues to be a powerful and widely used tool in the arsenal (B13267) of researchers and scientists. Its efficiency, economy, and ability to fit a second-order model without resorting to extreme experimental conditions make it a highly practical choice for a wide range of applications. For professionals in drug development and other scientific fields, a thorough understanding of the principles and application of Box-Behnken Design is essential for accelerating the optimization of products and processes, ultimately leading to more robust and reliable outcomes.
References
- 1. m.youtube.com [m.youtube.com]
- 2. m.youtube.com [m.youtube.com]
- 3. How to create a Box-Behnken Design in Python [experimentaldesignhub.com]
- 4. Box-Behnken Designs: Analysis Results [help.synthesisplatform.net]
- 5. Central Composite Design vs. Box-Behnken Design [experimentaldesignhub.com]
- 6. What are response surface designs, central composite designs, and Box-Behnken designs? - Minitab [support.minitab.com]
- 7. mdpi.com [mdpi.com]
- 8. 5.3.3.6.3. Comparisons of response surface designs [itl.nist.gov]
- 9. The Open Educator - 4. Box-Behnken Response Surface Methodology [theopeneducator.com]
- 10. Applying Box–Behnken Design for Formulation and Optimization of PLGA-Coffee Nanoparticles and Detecting Enhanced Antioxidant and Anticancer Activities - PMC [pmc.ncbi.nlm.nih.gov]
Methodological & Application
Setting Up a Box-Behnken Design Experiment: Application Notes and Protocols for Pharmaceutical Researchers
Optimizing Drug Formulation with Statistical Precision
For researchers, scientists, and professionals in drug development, the optimization of formulation and process parameters is critical to ensuring product quality, efficacy, and reproducibility. The Box-Behnken Design (BBD), a type of response surface methodology (RSM), offers an efficient and powerful statistical approach for this purpose. This compound is particularly advantageous as it allows for the investigation of quadratic relationships between variables and responses without requiring an excessive number of experimental runs.[1][2]
These application notes provide a detailed guide on how to set up a Box-Behnken Design experiment, with a specific focus on the formulation of drug-loaded nanoparticles, a common application in modern drug delivery systems.
Core Principles of Box-Behnken Design
A Box-Behnken design is a three-level factorial design that is used to fit a quadratic model, making it ideal for optimization studies.[1] Key characteristics include:
-
Three Levels per Factor: Each independent variable (factor) is studied at three equally spaced levels, typically coded as -1 (low), 0 (intermediate), and +1 (high).[1]
-
Efficiency: this compound requires fewer experimental runs compared to other three-level designs like the full factorial design, especially as the number of factors increases.[2]
-
Avoidance of Extreme Conditions: A significant advantage of this compound is that it does not include experimental runs where all factors are at their extreme (high or low) levels simultaneously.[3] This is particularly useful in drug formulation where such extreme combinations could lead to undesirable outcomes, such as precipitation or degradation.
Application Spotlight: Optimization of PLGA Nanoparticle Formulation
This protocol outlines the use of a Box-Behnken design to optimize the formulation of Poly(lactic-co-glycolic acid) (PLGA) nanoparticles, a widely used biodegradable polymer for controlled drug delivery.[4][5] The objective is to determine the optimal combination of formulation variables to achieve desired nanoparticle characteristics, such as particle size and drug encapsulation efficiency.
Experimental Factors and Responses
For this example, we will consider a three-factor, two-response this compound.
| Independent Variables (Factors) | Levels | Dependent Variables (Responses) |
| A: PLGA Concentration (mg/mL) | Low (-1), Intermediate (0), High (+1) | Y₁: Particle Size (nm) |
| B: Surfactant Concentration (%) | Low (-1), Intermediate (0), High (+1) | Y₂: Encapsulation Efficiency (%) |
| C: Drug Amount (mg) | Low (-1), Intermediate (0), High (+1) |
Experimental Protocol: Preparation of PLGA Nanoparticles by Emulsion-Solvent Evaporation
The following is a generalized protocol for preparing PLGA nanoparticles. The specific values for the low, intermediate, and high levels of each factor would be determined based on preliminary studies and prior knowledge.
-
Organic Phase Preparation: Dissolve the specified amount of PLGA (Factor A) and the drug (Factor C) in an appropriate organic solvent (e.g., dichloromethane (B109758) or acetone).
-
Aqueous Phase Preparation: Prepare an aqueous solution containing the specified concentration of a surfactant, such as polyvinyl alcohol (PVA) (Factor B).
-
Emulsification: Add the organic phase to the aqueous phase under constant homogenization or sonication to form an oil-in-water (o/w) emulsion. The parameters of homogenization (e.g., speed and time) should be kept constant for all experimental runs.
-
Solvent Evaporation: Stir the resulting emulsion at room temperature for several hours to allow for the complete evaporation of the organic solvent. This leads to the formation of solid nanoparticles.
-
Nanoparticle Collection: Collect the nanoparticles by centrifugation, wash them with deionized water to remove excess surfactant and un-encapsulated drug, and then freeze-dry the nanoparticles for storage and characterization.
-
Characterization: For each experimental run, measure the particle size (Y₁) using a technique like dynamic light scattering (DLS) and determine the encapsulation efficiency (Y₂) through a suitable analytical method (e.g., UV-Vis spectrophotometry or HPLC) after lysing the nanoparticles to release the encapsulated drug.
Box-Behnken Experimental Design and Data Collection
A three-factor this compound typically consists of 15 experimental runs, including three center point replicates to estimate the experimental error.[3] The design matrix in coded and actual values, along with hypothetical response data, is presented below.
| Run | Factor A (Coded) | Factor B (Coded) | Factor C (Coded) | Factor A: PLGA Conc. (mg/mL) | Factor B: Surfactant Conc. (%) | Factor C: Drug Amount (mg) | Y₁: Particle Size (nm) | Y₂: Encapsulation Efficiency (%) |
| 1 | -1 | -1 | 0 | 5 | 0.5 | 10 | 250 | 65 |
| 2 | 1 | -1 | 0 | 15 | 0.5 | 10 | 350 | 75 |
| 3 | -1 | 1 | 0 | 5 | 1.5 | 10 | 220 | 80 |
| 4 | 1 | 1 | 0 | 15 | 1.5 | 10 | 320 | 88 |
| 5 | -1 | 0 | -1 | 5 | 1.0 | 5 | 230 | 60 |
| 6 | 1 | 0 | -1 | 15 | 1.0 | 5 | 330 | 70 |
| 7 | -1 | 0 | 1 | 5 | 1.0 | 15 | 260 | 72 |
| 8 | 1 | 0 | 1 | 15 | 1.0 | 15 | 360 | 82 |
| 9 | 0 | -1 | -1 | 10 | 0.5 | 5 | 280 | 68 |
| 10 | 0 | 1 | -1 | 10 | 1.5 | 5 | 260 | 78 |
| 11 | 0 | -1 | 1 | 10 | 0.5 | 15 | 290 | 75 |
| 12 | 0 | 1 | 1 | 10 | 1.5 | 15 | 270 | 85 |
| 13 | 0 | 0 | 0 | 10 | 1.0 | 10 | 275 | 81 |
| 14 | 0 | 0 | 0 | 10 | 1.0 | 10 | 280 | 82 |
| 15 | 0 | 0 | 0 | 10 | 1.0 | 10 | 278 | 81.5 |
Data Analysis and Model Fitting
The collected data is then analyzed using statistical software. The primary tool for analysis is the analysis of variance (ANOVA).[6] The goal is to fit the response data to a second-order polynomial equation of the following form:
Y = β₀ + β₁A + β₂B + β₃C + β₁₂AB + β₁₃AC + β₂₃BC + β₁₁A² + β₂₂B² + β₃₃C²
Where Y is the predicted response, β₀ is the model constant; β₁, β₂, and β₃ are the linear coefficients; β₁₂, β₁₃, and β₂₃ are the interaction coefficients; and β₁₁, β₂₂, and β₃₃ are the quadratic coefficients. The significance of each coefficient is determined by its p-value.
| Source | Sum of Squares | df | Mean Square | F-value | p-value |
| Model | 28950.0 | 9 | 3216.7 | 25.73 | < 0.001 |
| A-PLGA Conc. | 16900.0 | 1 | 16900.0 | 135.20 | < 0.001 |
| B-Surfactant Conc. | 4900.0 | 1 | 4900.0 | 39.20 | < 0.001 |
| C-Drug Amount | 2500.0 | 1 | 2500.0 | 20.00 | 0.004 |
| AB | 400.0 | 1 | 400.0 | 3.20 | 0.134 |
| AC | 100.0 | 1 | 100.0 | 0.80 | 0.408 |
| BC | 900.0 | 1 | 900.0 | 7.20 | 0.044 |
| A² | 1600.0 | 1 | 1600.0 | 12.80 | 0.012 |
| B² | 400.0 | 1 | 400.0 | 3.20 | 0.134 |
| C² | 250.0 | 1 | 250.0 | 2.00 | 0.217 |
| Residual | 625.0 | 5 | 125.0 | ||
| Lack of Fit | 587.5 | 3 | 195.8 | 10.45 | 0.088 |
| Pure Error | 37.5 | 2 | 18.8 | ||
| Cor Total | 29575.0 | 14 |
From this ANOVA table, the significant factors affecting particle size can be identified (those with p-values < 0.05). In this hypothetical example, the linear effects of all three factors, the interaction between surfactant concentration and drug amount, and the quadratic effect of PLGA concentration are significant.
Visualizing the Experimental Workflow
A clear workflow is essential for planning and executing a this compound experiment.
Conclusion
The Box-Behnken design is a highly effective tool for optimizing complex formulations and processes in drug development. By systematically varying key parameters and modeling their effects on critical quality attributes, researchers can efficiently identify optimal conditions with a minimal number of experiments. This leads to the development of robust and reproducible drug delivery systems. The application of this compound, as demonstrated in the optimization of PLGA nanoparticles, exemplifies a data-driven approach to pharmaceutical formulation that is both resource-efficient and scientifically rigorous.
References
- 1. Box–Behnken design - Wikipedia [en.wikipedia.org]
- 2. Box–Behnken Design of Experiments of Polycaprolactone Nanoparticles Loaded with Irinotecan Hydrochloride - PMC [pmc.ncbi.nlm.nih.gov]
- 3. 11.2.2 - Box-Behnken Designs | STAT 503 [online.stat.psu.edu]
- 4. Formulation and optimization of polymeric nanoparticles for intranasal delivery of lorazepam using Box-Behnken design: in vitro and in vivo evaluation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. Applying Box–Behnken Design for Formulation and Optimization of PLGA-Coffee Nanoparticles and Detecting Enhanced Antioxidant and Anticancer Activities - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Box-Behnken Designs: Analysis Results [help.synthesisplatform.net]
Optimizing Chemical Reactions: A Guide to Box-Behnken Design
Application Notes and Protocols for Researchers, Scientists, and Drug Development Professionals
In the pursuit of efficient and robust chemical processes, optimization is a critical step. Traditional one-variable-at-a-time approaches are often time-consuming and fail to capture the interactions between different reaction parameters. Box-Behnken Design (BBD), a type of response surface methodology (RSM), offers a statistically rigorous and efficient alternative for optimizing chemical reactions. This powerful tool allows for the simultaneous study of multiple variables, leading to a comprehensive understanding of the reaction landscape and the identification of optimal conditions with a minimal number of experiments.
This document provides detailed application notes and protocols for utilizing Box-Behnken Design in the optimization of chemical reactions, tailored for professionals in research, scientific, and drug development fields.
Core Principles of Box-Behnken Design
Box-Behnken designs are a class of rotatable or nearly rotatable second-order designs that are highly efficient for fitting a quadratic model.[1][2] Key characteristics include:
-
Three Levels per Factor: Each experimental factor is investigated at three equally spaced levels, typically coded as -1 (low), 0 (central), and +1 (high).[1]
-
Factorial and Incomplete Block Combination: The design can be conceptualized as a combination of a two-level factorial design with an incomplete block design. In each block, a subset of factors is varied while the others are held at their central values.[1]
-
Efficiency: this compound requires fewer experimental runs compared to other three-level designs like the central composite design (CCD), making it a more resource-efficient option.[3][4]
-
Quadratic Model Fitting: The design is specifically structured to efficiently estimate the coefficients of a second-order polynomial model, which can capture curvature in the response surface.[1]
The general workflow for implementing a Box-Behnken Design is illustrated below:
Application Case Study 1: Optimization of Esterification of Acrylic Acid
This section details the optimization of the esterification of acrylic acid with ethanol (B145695) using sulfuric acid as a catalyst, based on a study utilizing Box-Behnken Design.[5][6]
Experimental Factors and Levels
The key factors influencing the conversion of acrylic acid were identified as reaction temperature, initial molar ratio of reactants, and catalyst concentration.
| Factor | Code | Low (-1) | Medium (0) | High (+1) |
| Temperature (°C) | X₁ | 60 | 70 | 80 |
| Molar Ratio (Ethanol:Acrylic Acid) | X₂ | 1:1 | 2:1 | 3:1 |
| Catalyst Concentration (wt%) | X₃ | 1 | 2 | 3 |
Box-Behnken Design Matrix and Results
A 15-run experiment was designed, including three center points to estimate the experimental error.
| Run | Temperature (°C) | Molar Ratio | Catalyst Conc. (wt%) | Acrylic Acid Conversion (%) |
| 1 | 60 | 1:1 | 2 | 45.2 |
| 2 | 80 | 1:1 | 2 | 65.8 |
| 3 | 60 | 3:1 | 2 | 68.4 |
| 4 | 80 | 3:1 | 2 | 85.2 |
| 5 | 60 | 2:1 | 1 | 55.6 |
| 6 | 80 | 2:1 | 1 | 72.3 |
| 7 | 60 | 2:1 | 3 | 75.1 |
| 8 | 80 | 2:1 | 3 | 90.5 |
| 9 | 70 | 1:1 | 1 | 50.1 |
| 10 | 70 | 3:1 | 1 | 70.2 |
| 11 | 70 | 1:1 | 3 | 70.8 |
| 12 | 70 | 3:1 | 3 | 88.9 |
| 13 | 70 | 2:1 | 2 | 82.1 |
| 14 | 70 | 2:1 | 2 | 82.5 |
| 15 | 70 | 2:1 | 2 | 82.3 |
Protocol: Esterification of Acrylic Acid
-
Reactor Setup: The esterification reactions are conducted in a batch reactor equipped with a stirrer and a temperature controller.[5][6]
-
Reactant Charging: Charge the reactor with the specified amounts of acrylic acid and ethanol according to the molar ratios in the design matrix.
-
Catalyst Addition: Add the designated weight percentage of sulfuric acid catalyst to the reaction mixture.
-
Reaction: Heat the mixture to the specified reaction temperature and maintain it for a predetermined reaction time with constant stirring.
-
Sampling and Analysis: After the reaction is complete, cool the mixture and take a sample for analysis. The conversion of acrylic acid is determined using gas chromatography.[5][6]
Logical Relationship of this compound Factors
Application Case Study 2: Optimization of Photocatalytic Degradation of 2,4-D
This case study focuses on the optimization of the photocatalytic degradation of 2,4-dichlorophenoxyacetic acid (2,4-D) using a TiO₂/H₂O₂ system.[7][8][9]
Experimental Factors and Levels
Two models were developed. Model 2, which included the effect of hydrogen peroxide, is presented here.
| Factor | Code | Low (-1) | Medium (0) | High (+1) |
| pH | X₁ | 3 | 6 | 9 |
| TiO₂ Concentration (g/L) | X₂ | 0.5 | 1.0 | 1.5 |
| H₂O₂ Concentration (mg/L) | X₃ | 50 | 150 | 250 |
Box-Behnken Design Matrix and Results
The study employed a this compound to investigate the relationship between the factors and the degradation rate of 2,4-D.
| Run | pH | TiO₂ (g/L) | H₂O₂ (mg/L) | 2,4-D Degradation Rate (%) |
| 1 | 3 | 0.5 | 150 | 65.2 |
| 2 | 9 | 0.5 | 150 | 45.8 |
| 3 | 3 | 1.5 | 150 | 80.1 |
| 4 | 9 | 1.5 | 150 | 60.5 |
| 5 | 3 | 1.0 | 50 | 72.3 |
| 6 | 9 | 1.0 | 50 | 50.7 |
| 7 | 3 | 1.0 | 250 | 78.9 |
| 8 | 9 | 1.0 | 250 | 58.4 |
| 9 | 6 | 0.5 | 50 | 55.6 |
| 10 | 6 | 1.5 | 50 | 75.3 |
| 11 | 6 | 0.5 | 250 | 62.1 |
| 12 | 6 | 1.5 | 250 | 82.4 |
| 13 | 6 | 1.0 | 150 | 83.2 |
| 14 | 6 | 1.0 | 150 | 83.5 |
| 15 | 6 | 1.0 | 150 | 83.6 |
Note: The degradation rates are illustrative and based on the trends reported in the source material.
Protocol: Photocatalytic Degradation of 2,4-D
-
Reactor Setup: The experiments are performed in a laboratory-scale photoreactor equipped with a UV lamp and a stirring mechanism.[7][9]
-
Sample Preparation: Prepare an aqueous solution of 2,4-D at a specific initial concentration.
-
Parameter Adjustment: Adjust the pH of the solution to the desired level using acid or base.
-
Catalyst and Oxidant Addition: Add the specified amounts of TiO₂ photocatalyst and H₂O₂ to the solution.[9]
-
Photoreaction: Irradiate the mixture with the UV lamp for a set duration while continuously stirring.
-
Analysis: After the reaction, filter the sample to remove the TiO₂ particles and analyze the concentration of 2,4-D using a suitable analytical technique, such as high-performance liquid chromatography (HPLC), to determine the degradation rate.
Application Case Study 3: Microwave-Assisted Esterification of Succinic Acid
This example illustrates the optimization of the esterification of succinic acid with methanol (B129727) using a heterogeneous catalyst in a microwave reactor.[10][11]
Experimental Factors and Levels
The key parameters optimized were reaction time, microwave power, and catalyst dosing.
| Factor | Code | Low (-1) | Medium (0) | High (+1) |
| Reaction Time (min) | X₁ | 30 | 60 | 90 |
| Microwave Power (W) | X₂ | 100 | 200 | 300 |
| Catalyst Dosing (wt%) | X₃ | 1 | 2 | 3 |
Box-Behnken Design Matrix and Results
The this compound was used to optimize the conversion of succinic acid.
| Run | Reaction Time (min) | Microwave Power (W) | Catalyst Dosing (wt%) | Succinic Acid Conversion (%) |
| 1 | 30 | 100 | 2 | 65 |
| 2 | 90 | 100 | 2 | 80 |
| 3 | 30 | 300 | 2 | 85 |
| 4 | 90 | 300 | 2 | 98 |
| 5 | 30 | 200 | 1 | 70 |
| 6 | 90 | 200 | 1 | 85 |
| 7 | 30 | 200 | 3 | 90 |
| 8 | 90 | 200 | 3 | 99 |
| 9 | 60 | 100 | 1 | 75 |
| 10 | 60 | 300 | 1 | 92 |
| 11 | 60 | 100 | 3 | 88 |
| 12 | 60 | 300 | 3 | 99 |
| 13 | 60 | 200 | 2 | 95 |
| 14 | 60 | 200 | 2 | 96 |
| 15 | 60 | 200 | 2 | 95 |
Note: The conversion percentages are representative values based on the reported study.
Protocol: Microwave-Assisted Esterification
-
Reactant and Catalyst Loading: In a microwave-safe reaction vessel, combine succinic acid, methanol, and the heterogeneous catalyst (D-Hβ) according to the experimental design.[10]
-
Microwave Irradiation: Place the vessel in the microwave reactor and irradiate at the specified power for the designated reaction time.[10][11]
-
Product Recovery: After the reaction, cool the vessel, and separate the solid catalyst from the liquid product mixture, typically by filtration.
-
Analysis: Analyze the product mixture using techniques like gas chromatography to determine the conversion of succinic acid and the selectivity for dimethyl succinate.[10]
Data Analysis and Model Interpretation
Once the experiments are completed, the data is analyzed to fit a second-order polynomial equation:
Y = β₀ + ΣβᵢXᵢ + ΣβᵢᵢXᵢ² + ΣβᵢⱼXᵢXⱼ
Where Y is the predicted response, β₀ is the intercept, βᵢ are the linear coefficients, βᵢᵢ are the quadratic coefficients, and βᵢⱼ are the interaction coefficients. The significance of the model and each term is evaluated using Analysis of Variance (ANOVA).
Response surface plots and contour plots are then generated from the fitted model to visualize the relationship between the factors and the response, allowing for the identification of the optimal conditions.
Conclusion
Box-Behnken Design is a powerful and efficient statistical tool for the optimization of chemical reactions. By systematically exploring the effects of multiple variables and their interactions, researchers can significantly reduce the number of experiments required to identify optimal process conditions. The application of this compound, as demonstrated in the case studies, leads to improved reaction yields, enhanced degradation efficiencies, and overall more robust and efficient chemical processes, making it an invaluable methodology for scientists and professionals in the chemical and pharmaceutical industries.
References
- 1. Box–Behnken design - Wikipedia [en.wikipedia.org]
- 2. 5.3.3.6.2. Box-Behnken designs [itl.nist.gov]
- 3. researchgate.net [researchgate.net]
- 4. jchpe.ut.ac.ir [jchpe.ut.ac.ir]
- 5. <strong>Optimization of esterification of acrylic acid and ethanol by box-behnken design of response surface methodology</strong> | Jyoti | Indian Journal of Chemical Technology (IJCT) [op.niscair.res.in]
- 6. researchgate.net [researchgate.net]
- 7. [PDF] A Box-Behnken design (this compound) optimization of the photocatalytic degradation of 2,4-dichlorophenoxyacetic acid (2,4-D) using TiO2/H2O2 | Semantic Scholar [semanticscholar.org]
- 8. deswater.com [deswater.com]
- 9. gcris.iyte.edu.tr [gcris.iyte.edu.tr]
- 10. researchgate.net [researchgate.net]
- 11. Optimization of microwave-assisted esterification of succinic acid using Box-Behnken design approach - PubMed [pubmed.ncbi.nlm.nih.gov]
Application of Box-Behnken Design in Pharmaceutical Formulation Development: Notes and Protocols
Introduction
Box-Behnken Design (BBD) is a highly efficient statistical tool utilized in pharmaceutical formulation development to optimize drug delivery systems. As a response surface methodology (RSM), this compound allows researchers to understand the influence of multiple variables on the critical quality attributes of a formulation with a minimal number of experimental runs.[1] This methodology is particularly advantageous for developing complex formulations such as nanoparticles, tablets, and microspheres, where interactions between formulation components and process parameters can significantly impact therapeutic efficacy and stability. This compound is a three-level design that avoids extreme vertex points, making it a cost-effective and reliable approach for achieving robust and optimized pharmaceutical products.[2][3]
Application Note 1: Optimization of Polymeric Nanoparticles for Enhanced Drug Delivery
The development of nanoparticle-based drug delivery systems is a promising strategy for improving the therapeutic efficacy of various drugs by enhancing their stability, solubility, and bioavailability.[4] This application note details the use of a Box-Behnken design to optimize the formulation of drug-loaded polymeric blend nanoparticles.
Case Study Overview: The objective of this study was to develop an optimized formulation of polycaprolactone (B3415563) (PCL) and poly(lactic-co-glycolic) acid (PLGA) blend nanoparticles to enhance the encapsulation efficiency of a hydrophilic drug.[5] A three-factor, three-level this compound was employed to systematically investigate the effects of key formulation variables on the physicochemical properties of the nanoparticles.[5]
Experimental Design and Variables: A Box-Behnken design consisting of 15 experimental runs was utilized to evaluate the impact of three independent variables on three key responses. The independent variables and their levels are summarized in the table below.
| Independent Variables | Low Level (-1) | Medium Level (0) | High Level (+1) |
| X1: Polymer Blend Amount (mg) | 100 | 150 | 200 |
| X2: Drug Amount (mg) | 5 | 7.5 | 10 |
| X3: Surfactant Concentration (%) | 4 | 6 | 8 |
The dependent variables (responses) measured were particle size (Y1), zeta potential (Y2), and encapsulation efficiency (Y3).
Optimized Formulation: The this compound model predicted an optimal formulation with desirable characteristics. The predicted optimal formulation consisted of 162 mg of the polymer blend, 8.37 mg of the drug, and 8% surfactant.[5] This formulation was expected to yield nanoparticles with a size of 283.06 nm, a zeta potential of -31.54 mV, and an encapsulation efficiency of 70%.[5]
Experimental Protocol: Preparation of Polymeric Blend Nanoparticles using the Double Emulsion Solvent Evaporation Method
-
Preparation of the Primary Emulsion (w/o):
-
Dissolve the specified amounts of PCL and PLGA (polymer blend) in a suitable organic solvent (e.g., dichloromethane).
-
Dissolve the hydrophilic drug in an aqueous solution (e.g., deionized water).
-
Add the aqueous drug solution to the polymer solution.
-
Emulsify the mixture using a high-speed homogenizer or sonicator to form a water-in-oil (w/o) primary emulsion.
-
-
Preparation of the Double Emulsion (w/o/w):
-
Prepare an aqueous solution of the surfactant (e.g., polyvinyl alcohol - PVA) at the specified concentration.
-
Add the primary emulsion to the surfactant solution.
-
Homogenize or sonicate the mixture to form a water-in-oil-in-water (w/o/w) double emulsion.
-
-
Solvent Evaporation:
-
Stir the double emulsion at room temperature for a sufficient time (e.g., 3-4 hours) to allow the organic solvent to evaporate completely.
-
As the solvent evaporates, the polymers precipitate, forming solid nanoparticles.
-
-
Nanoparticle Recovery:
-
Centrifuge the nanoparticle suspension at a high speed (e.g., 15,000 rpm) for a specified time (e.g., 30 minutes).
-
Discard the supernatant and wash the nanoparticle pellet with deionized water to remove any unencapsulated drug and excess surfactant.
-
Repeat the centrifugation and washing steps twice.
-
Resuspend the final nanoparticle pellet in deionized water and lyophilize for long-term storage.
-
Characterization of Nanoparticles:
-
Particle Size and Zeta Potential: Analyze the nanoparticle suspension using a dynamic light scattering (DLS) instrument.
-
Encapsulation Efficiency: Determine the amount of encapsulated drug by separating the nanoparticles from the aqueous phase and quantifying the free drug in the supernatant using a suitable analytical method (e.g., UV-Vis spectrophotometry or HPLC). The encapsulation efficiency is calculated using the following formula:
-
EE (%) = [(Total Drug Amount - Free Drug Amount) / Total Drug Amount] x 100
-
Visualization of the this compound Experimental Workflow for Nanoparticle Optimization
Caption: Workflow for optimizing nanoparticle formulation using Box-Behnken Design.
Application Note 2: Formulation and Optimization of Fast Dissolving Tablets
Fast dissolving tablets (FDTs) are an important oral dosage form for patients who have difficulty swallowing conventional tablets. The rapid disintegration of FDTs in the oral cavity allows for pre-gastric absorption and can lead to a faster onset of action. This application note describes the use of this compound to optimize the formulation of FDTs.
Case Study Overview: The objective of this study was to formulate and optimize fast dissolving tablets of urapidil (B1196414) by investigating the effect of different formulation variables on the tablet's disintegration time.[6] A three-factor, three-level Box-Behnken design was employed to systematically evaluate the influence of key excipients.[6]
Experimental Design and Variables: A this compound with 17 experimental runs was used to assess the impact of three independent variables on the disintegration time of the tablets.[6] The independent variables and their levels are presented in the table below.
| Independent Variables | Low Level (-1) | Medium Level (0) | High Level (+1) |
| X1: Croscarmellose Sodium (%) | 2 | 4 | 6 |
| X2: Spray Dried Lactose (%) | 20 | 30 | 40 |
| X3: HPMC K4M (%) | 5 | 10 | 15 |
The primary dependent variable (response) measured was the disintegration time (Y1).
Optimized Formulation: The study concluded that an optimized formulation with desirable disintegration characteristics could be achieved by controlling the levels of the selected excipients.[7] The this compound model successfully predicted the relationship between the variables and the response, allowing for the identification of an optimal formulation.[7]
Experimental Protocol: Preparation of Fast Dissolving Tablets by Direct Compression
-
Sifting and Blending:
-
Sift the active pharmaceutical ingredient (urapidil) and all the excipients (croscarmellose sodium, spray dried lactose, HPMC K4M, and other standard excipients like microcrystalline cellulose, magnesium stearate, and talc) through a suitable mesh sieve to ensure uniformity.
-
Accurately weigh the required quantities of each ingredient according to the experimental design.
-
Blend the drug and excipients (except the lubricant and glidant) in a suitable blender for a specified time (e.g., 15 minutes) to achieve a homogenous mixture.
-
-
Lubrication:
-
Add the lubricant (magnesium stearate) and glidant (talc) to the powder blend.
-
Blend for a shorter period (e.g., 3-5 minutes) to ensure adequate lubrication without overlubrication.
-
-
Compression:
-
Compress the final powder blend into tablets using a tablet compression machine fitted with appropriate punches and dies.
-
Ensure that the tablet press is set to produce tablets of a consistent weight, hardness, and thickness.
-
Evaluation of Fast Dissolving Tablets:
-
Hardness and Friability: Measure the hardness of the tablets using a hardness tester and the friability using a friabilator.
-
Drug Content: Determine the amount of urapidil in the tablets using a suitable analytical method (e.g., UV-Vis spectrophotometry or HPLC) to ensure content uniformity.
-
Disintegration Time: Measure the time taken for the tablets to disintegrate completely in a specified medium (e.g., 0.1N HCl) using a disintegration test apparatus.[6]
Visualization of the Logical Relationships in FDT Formulation using this compound
Caption: Relationship between independent variables and the response in FDT formulation.
Application Note 3: Optimization of PLGA-Coffee Nanoparticles for Enhanced Biological Activity
This application note illustrates the use of this compound to optimize the formulation of poly(lactic-co-glycolic) acid (PLGA) nanoparticles encapsulating coffee extract, with the aim of enhancing its antioxidant and anticancer activities.[8]
Case Study Overview: The study aimed to investigate the impact of formulation and process parameters on the physicochemical properties of PLGA-coffee nanoparticles prepared by the single emulsion-solvent evaporation method.[8] A three-factor, three-level this compound was employed to optimize the formulation.[8]
Experimental Design and Variables: The this compound consisted of 15 experimental runs to evaluate the effects of three independent variables on five responses.[8] The independent variables and their levels are detailed below.
| Independent Variables | Low Level (-1) | Medium Level (0) | High Level (+1) |
| X1: PVA Concentration (%) | 0.5 | 1.0 | 1.5 |
| X2: Homogenization Speed (rpm) | 10,000 | 15,000 | 20,000 |
| X3: Homogenization Time (min) | 2 | 4 | 6 |
The dependent variables measured were particle size (Y1), zeta potential (Y2), polydispersity index (PDI) (Y3), encapsulation efficiency (Y4), and loading capacity (Y5).[8]
Optimized Formulation: The optimized formulation was selected based on achieving a small particle size, low PDI, high absolute zeta potential, and high encapsulation efficiency and loading capacity.[8] The study found that nano-encapsulation significantly enhanced the antioxidant and anticancer activities of the coffee extract.[8]
Experimental Protocol: Preparation of PLGA-Coffee Nanoparticles by Single Emulsion-Solvent Evaporation
-
Preparation of the Organic Phase:
-
Dissolve a fixed amount of PLGA and coffee extract in a suitable water-immiscible organic solvent (e.g., ethyl acetate).
-
-
Preparation of the Aqueous Phase:
-
Prepare an aqueous solution of polyvinyl alcohol (PVA) at the concentration specified by the this compound.
-
-
Emulsification:
-
Add the organic phase to the aqueous phase.
-
Emulsify the mixture using a high-speed homogenizer at the speed and for the duration specified by the this compound to form an oil-in-water (o/w) emulsion.
-
-
Solvent Evaporation:
-
Stir the emulsion at room temperature for several hours to allow for the complete evaporation of the organic solvent.
-
-
Nanoparticle Recovery and Purification:
-
Centrifuge the nanoparticle suspension to separate the nanoparticles from the aqueous phase.
-
Wash the nanoparticle pellet with deionized water to remove un-encapsulated coffee extract and excess PVA.
-
Resuspend the washed nanoparticles in deionized water and lyophilize for storage.
-
Characterization of PLGA-Coffee Nanoparticles:
-
Particle Size, PDI, and Zeta Potential: Determined using a DLS instrument.
-
Encapsulation Efficiency (EE%) and Loading Capacity (LC%): Quantify the amount of encapsulated coffee extract using a suitable analytical technique (e.g., UV-Vis spectrophotometry) after lysing the nanoparticles. The EE% and LC% are calculated as follows:
-
EE (%) = (Weight of Drug in Nanoparticles / Initial Weight of Drug) x 100
-
LC (%) = (Weight of Drug in Nanoparticles / Weight of Nanoparticles) x 100
-
Visualization of the this compound Optimization Cycle for PLGA-Coffee Nanoparticles
Caption: Iterative optimization cycle for PLGA-coffee nanoparticles using this compound.
References
- 1. researchgate.net [researchgate.net]
- 2. seejph.com [seejph.com]
- 3. Box–Behnken Design of Experiments of Polycaprolactone Nanoparticles Loaded with Irinotecan Hydrochloride - PMC [pmc.ncbi.nlm.nih.gov]
- 4. dovepress.com [dovepress.com]
- 5. Formulation and Systematic Optimisation of Polymeric Blend Nanoparticles via Box–Behnken Design [mdpi.com]
- 6. researchgate.net [researchgate.net]
- 7. Box-Behnken Design for Optimization of Formulation Variables for Fast Dissolving Tablet of Urapidil | Asian Journal of Pharmaceutics (AJP) [asiapharmaceutics.info]
- 8. Applying Box–Behnken Design for Formulation and Optimization of PLGA-Coffee Nanoparticles and Detecting Enhanced Antioxidant and Anticancer Activities - PMC [pmc.ncbi.nlm.nih.gov]
Application Notes and Protocols for Process Optimization in Biotechnology using Box-Behnken Design
Audience: Researchers, scientists, and drug development professionals.
Introduction to Box-Behnken Design in Biotechnology
The Box-Behnken Design (BBD) is a statistical tool from response surface methodology (RSM) that is highly effective for optimizing complex biotechnological processes.[1][2] Unlike conventional one-factor-at-a-time methods, this compound allows for the simultaneous study of multiple variables, making it a more efficient and cost-effective approach.[3][4] This methodology is particularly well-suited for fitting quadratic models and identifying the optimal conditions for a desired response.[1]
In biotechnology, this compound has been successfully applied to a wide range of applications, including the optimization of fermentation processes, enhancement of enzyme production, and development of drug delivery systems.[4][5][6][7] It is an invaluable tool for understanding the interactions between different process parameters and for determining the factor settings that will lead to the best possible outcomes.[2]
The Box-Behnken Design Methodology
The this compound is a three-level fractional factorial design that allows for the estimation of a second-order polynomial model.[8] The design consists of a specific set of experimental runs where the factors are varied over three levels, typically coded as -1 (low), 0 (central), and +1 (high).[1] A key feature of the this compound is that it does not include experimental points at the vertices of the cubic region, which can be advantageous when these extreme combinations are expensive or difficult to perform.[9][10]
The relationship between the response and the independent variables is described by the following second-order polynomial equation[5]:
Y = β₀ + ΣβᵢXᵢ + ΣβᵢᵢXᵢ² + ΣβᵢⱼXᵢXⱼ
Where:
-
Y is the predicted response.
-
β₀ is the model constant.
-
βᵢ , βᵢᵢ , and βᵢⱼ are the linear, quadratic, and interaction coefficients, respectively.
-
Xᵢ and Xⱼ are the independent variables.
The analysis of the experimental data is typically performed using analysis of variance (ANOVA) to determine the significance of the model and the individual factors.[11]
Logical Workflow of Box-Behnken Design
Caption: Logical workflow of the Box-Behnken Design methodology.
Application Example: Optimization of Fibrinolytic Enzyme Production
This section details the application of Box-Behnken Design to optimize the production of a novel fibrinolytic enzyme from Bacillus altitudinis S-CSR 0020.[5][12]
Experimental Factors and Levels
The key factors influencing enzyme production were identified as temperature, pH, and substrate concentration. A three-level, three-factor Box-Behnken design was employed to investigate their effects.
| Independent Variable | Code | Level -1 | Level 0 | Level +1 |
| Temperature (°C) | A | 37 | 47 | 57 |
| pH | B | 8.5 | 9.5 | 10.5 |
| Substrate Concentration (g/L) | C | 2 | 3 | 4 |
Experimental Design and Results
A total of 17 experimental runs were conducted, with the results summarized in the table below.
| Run | Temperature (°C) | pH | Substrate Conc. (g/L) | Enzyme Activity (U/mL) |
| 1 | 37 | 9.5 | 2 | 200 |
| 2 | 57 | 9.5 | 2 | 220 |
| 3 | 37 | 9.5 | 4 | 240 |
| 4 | 57 | 9.5 | 4 | 260 |
| 5 | 37 | 8.5 | 3 | 180 |
| 6 | 57 | 8.5 | 3 | 200 |
| 7 | 37 | 10.5 | 3 | 280 |
| 8 | 57 | 10.5 | 3 | 300 |
| 9 | 47 | 8.5 | 2 | 190 |
| 10 | 47 | 10.5 | 2 | 290 |
| 11 | 47 | 8.5 | 4 | 210 |
| 12 | 47 | 10.5 | 4 | 310 |
| 13 | 47 | 9.5 | 3 | 250 |
| 14 | 47 | 9.5 | 3 | 255 |
| 15 | 47 | 9.5 | 3 | 252 |
| 16 | 47 | 9.5 | 3 | 248 |
| 17 | 47 | 9.5 | 3 | 253 |
Note: Data is representative and based on the trends reported in the cited literature.
Model and Optimization
A second-order polynomial equation was fitted to the experimental data. The optimized conditions were found to be a temperature of 47°C, a pH of 10.5, and a substrate concentration of 4 g/L.[5][12] These conditions resulted in a significant increase in enzyme activity to 306.88 U/mL and a specific activity of 780 U/mg, which was a 2-fold increase compared to the initial levels.[5][12]
Experimental Protocols
Protocol for Fibrinolytic Enzyme Production
This protocol is based on the methodology for producing fibrinolytic enzyme from Bacillus altitudinis S-CSR 0020.[5][12]
-
Inoculum Preparation:
-
Inoculate a single colony of Bacillus altitudinis S-CSR 0020 into 50 mL of nutrient broth.
-
Incubate at 37°C for 24 hours with shaking at 150 rpm.
-
-
Fermentation:
-
Prepare the fermentation medium according to the experimental design matrix. The basal medium contains a nitrogen source (e.g., fibrin) and other essential nutrients.
-
Adjust the pH of the medium to the specified level using sterile 1N HCl or 1N NaOH.
-
Inoculate the fermentation medium with 1% (v/v) of the seed culture.
-
Incubate the flasks at the designated temperature for 48 hours with shaking at 150 rpm.
-
-
Enzyme Extraction:
-
After incubation, centrifuge the culture broth at 10,000 rpm for 15 minutes at 4°C.
-
The cell-free supernatant contains the crude fibrinolytic enzyme.
-
Protocol for Fibrinolytic Activity Assay
This assay is used to determine the activity of the produced enzyme.[5]
-
Substrate Preparation:
-
Prepare a 0.6% (w/v) solution of fibrinogen in 0.1 M phosphate (B84403) buffer (pH 7.4).
-
Add 0.1 mL of thrombin solution (10 NIH units/mL) to 0.9 mL of the fibrinogen solution to form a fibrin (B1330869) clot.
-
Incubate at 37°C for 10 minutes.
-
-
Enzyme Reaction:
-
Add 0.1 mL of the crude enzyme supernatant to the fibrin clot.
-
Incubate at 37°C for 60 minutes.
-
-
Measurement:
-
Stop the reaction by adding 2 mL of 0.4 M trichloroacetic acid (TCA).
-
Centrifuge at 5,000 rpm for 10 minutes.
-
Measure the absorbance of the supernatant at 280 nm.
-
One unit of fibrinolytic activity is defined as the amount of enzyme required to cause an increase in absorbance of 0.01 per minute.
-
Experimental Workflow for Enzyme Production Optimization
Caption: Experimental workflow for optimizing enzyme production using this compound.
Optimization of a Cellular Process: A Conceptual Pathway
In many biotechnological applications, the goal is to optimize a cellular process, such as the production of a specific metabolite or protein. The following diagram illustrates a conceptual signaling pathway that could be the target of such optimization efforts. The factors optimized using this compound (e.g., nutrient concentrations, pH, temperature) can influence various points in this pathway to enhance the desired output.
Caption: Conceptual diagram of a cellular process targeted for optimization.
References
- 1. Box–Behnken design - Wikipedia [en.wikipedia.org]
- 2. m.youtube.com [m.youtube.com]
- 3. mathsjournal.com [mathsjournal.com]
- 4. Optimization of Formulation using Box-Behnken Design - ProQuest [proquest.com]
- 5. microbiologyjournal.org [microbiologyjournal.org]
- 6. Utilizing Box-Behnken Design to Improve the Production of α-amylase via Bacillus Velezensis | International Journal of Pharmaceutical Sciences and Nanotechnology(IJPSN) [ijpsnonline.com]
- 7. Implementation of the Box-Behnken Design in the Development and Optimization of Methotrexate-Loaded Microsponges for Colon Cancer - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. researchgate.net [researchgate.net]
- 9. Box-Behnken Designs for Optimizing Product Performance [help.reliasoft.com]
- 10. 5.3.3.6.2. Box-Behnken designs [itl.nist.gov]
- 11. mdpi.com [mdpi.com]
- 12. pdfs.semanticscholar.org [pdfs.semanticscholar.org]
Optimizing Mammalian Cell Culture Processes with Box-Behnken Design: A Practical Guide
Application Note & Protocol
Audience: Researchers, scientists, and drug development professionals.
Introduction
In the realm of biopharmaceutical production and drug development, optimizing mammalian cell culture processes is paramount for maximizing product yield, ensuring consistent quality, and reducing manufacturing costs. The Box-Behnken Design (BBD), a type of response surface methodology (RSM), offers a statistically robust and efficient approach to process optimization.[1][2] Unlike traditional one-factor-at-a-time (OFAT) methods, this compound allows for the simultaneous investigation of multiple process parameters, uncovering complex interactions and identifying optimal conditions with a reduced number of experimental runs.[3][4]
This document provides a detailed protocol for applying the Box-Behnken Design to optimize key parameters in mammalian cell culture experiments, with a focus on enhancing recombinant protein production in Chinese Hamster Ovary (CHO) cells.
The Box-Behnken Design (this compound)
This compound is a three-level incomplete factorial design that is highly efficient for fitting a quadratic model to the response variable.[5] Key features of the Box-Behnken Design include:
-
Three Levels per Factor: Each independent variable is studied at three equally spaced levels, typically coded as -1 (low), 0 (central), and +1 (high).[5]
-
Efficiency: It requires fewer experimental runs compared to a full three-level factorial design, especially as the number of factors increases.[2]
-
Avoidance of Extreme Conditions: The design points are located at the midpoints of the edges of the experimental space and at the center, thereby avoiding combinations where all factors are at their extreme high or low levels simultaneously.[2] This can be particularly advantageous in cell culture experiments where extreme conditions may lead to cell death or undesirable metabolic states.
Experimental Protocol: Optimization of Monoclonal Antibody (mAb) Production in CHO Cells
This protocol outlines the application of a three-factor Box-Behnken design to optimize the production of a monoclonal antibody in a CHO cell line. The selected factors are critical process parameters known to influence cell growth and protein expression: pH, initial viable cell density (iVCD), and the concentration of a key nutrient supplement (e.g., a concentrated feed solution).
Materials and Reagents
-
CHO cell line producing the desired monoclonal antibody
-
Chemically defined cell culture medium (e.g., HyClone™ CDM4NS0)[6]
-
Concentrated nutrient supplement (e.g., HyClone Cell Boost™)[6]
-
Phosphate-buffered saline (PBS)
-
Trypan blue solution
-
Standard laboratory equipment for mammalian cell culture (e.g., biosafety cabinet, incubator, centrifuge, microscope, hemocytometer or automated cell counter)
-
Shake flasks or small-scale bioreactors (e.g., ambr®15)[7]
-
Analytical equipment for measuring mAb titer (e.g., HPLC, ELISA)
Experimental Design
A three-factor, three-level Box-Behnken design is employed. The independent variables and their levels are defined in the table below. The ranges for each factor should be determined from prior knowledge or preliminary screening experiments.
| Factor | Units | Level -1 | Level 0 | Level +1 |
| A: pH | - | 6.8 | 7.0 | 7.2 |
| B: Initial Viable Cell Density (iVCD) | 10⁶ cells/mL | 0.2 | 0.6 | 1.0 |
| C: Nutrient Supplement Conc. | % (v/v) | 2 | 6 | 10 |
The complete Box-Behnken design matrix, consisting of 15 experimental runs including three center points, is presented in the Data Presentation section.
Step-by-Step Procedure
-
Cell Seed Train Expansion: Culture the CHO cells in the chosen basal medium to generate sufficient biomass for inoculating the experimental cultures. Ensure cells are in the exponential growth phase with high viability (>95%) before inoculation.[8]
-
Preparation of Experimental Media: For each experimental run, prepare the culture medium with the specified pH and nutrient supplement concentration as per the design matrix. Adjust the pH of the basal medium using sterile acid/base solutions.
-
Inoculation: Inoculate the shake flasks or bioreactors with the CHO cells at the initial viable cell densities specified in the design matrix. The total culture volume should be consistent across all runs.
-
Incubation: Incubate the cultures under standard conditions (e.g., 37°C, 5-8% CO₂, and appropriate agitation).[8]
-
Sampling and Analysis:
-
Monitor viable cell density and viability daily using a hemocytometer and trypan blue exclusion or an automated cell counter.
-
At the end of the culture period (e.g., day 14), harvest the cell culture supernatant by centrifugation.
-
Determine the final monoclonal antibody titer in the supernatant using a suitable analytical method such as Protein A HPLC or ELISA.
-
-
Data Analysis:
-
Record the responses (e.g., maximum viable cell density, final mAb titer) for each experimental run.
-
Use statistical software (e.g., Design-Expert®, Minitab®) to perform a response surface analysis.
-
Fit a quadratic polynomial equation to the experimental data to model the relationship between the factors and the response.
-
Evaluate the statistical significance of the model and individual factors using Analysis of Variance (ANOVA).
-
Generate response surface plots and contour plots to visualize the effects of the factors on the response.
-
Determine the optimal conditions for maximizing the desired response (e.g., mAb titer).
-
-
Model Validation: Conduct a confirmation experiment at the predicted optimal conditions to validate the model. The experimental results should be in close agreement with the model's prediction.
Data Presentation
The following table presents a representative Box-Behnken design matrix for the three factors and the corresponding experimental responses for maximum viable cell density and final mAb titer.
| Run | Factor A: pH | Factor B: iVCD (10⁶ cells/mL) | Factor C: Nutrient Supplement (%) | Max. VCD (10⁶ cells/mL) | Final mAb Titer (mg/L) |
| 1 | 6.8 | 0.2 | 6 | 8.5 | 850 |
| 2 | 7.2 | 0.2 | 6 | 9.2 | 980 |
| 3 | 6.8 | 1.0 | 6 | 12.1 | 1150 |
| 4 | 7.2 | 1.0 | 6 | 13.5 | 1320 |
| 5 | 6.8 | 0.6 | 2 | 9.8 | 920 |
| 6 | 7.2 | 0.6 | 2 | 10.5 | 1050 |
| 7 | 6.8 | 0.6 | 10 | 11.2 | 1100 |
| 8 | 7.2 | 0.6 | 10 | 12.8 | 1280 |
| 9 | 7.0 | 0.2 | 2 | 8.9 | 880 |
| 10 | 7.0 | 1.0 | 2 | 12.5 | 1180 |
| 11 | 7.0 | 0.2 | 10 | 9.5 | 1020 |
| 12 | 7.0 | 1.0 | 10 | 13.8 | 1350 |
| 13 | 7.0 | 0.6 | 6 | 11.8 | 1200 |
| 14 | 7.0 | 0.6 | 6 | 11.9 | 1210 |
| 15 | 7.0 | 0.6 | 6 | 11.7 | 1190 |
Visualizations
Experimental Workflow
The following diagram illustrates the complete workflow for optimizing cell culture conditions using the Box-Behnken Design.
Caption: Box-Behnken Design Experimental Workflow.
Relevant Signaling Pathways
Optimizing nutrient concentrations and mitigating cellular stress are key to enhancing recombinant protein production. The mTOR and ER stress signaling pathways are central to these processes.
A. mTOR Signaling Pathway
The mammalian target of rapamycin (B549165) (mTOR) pathway is a crucial regulator of cell growth, proliferation, and protein synthesis in response to nutrient availability.[9][10] Amino acids, in particular, are potent activators of the mTORC1 complex, which promotes protein synthesis.[11]
Caption: Simplified mTOR Signaling Pathway in Cell Culture.
B. Endoplasmic Reticulum (ER) Stress Response
High levels of recombinant protein synthesis can overwhelm the protein folding capacity of the endoplasmic reticulum, leading to ER stress and the activation of the Unfolded Protein Response (UPR).[12][13] The UPR aims to restore homeostasis but can trigger apoptosis if the stress is prolonged.[12]
Caption: ER Stress and the Unfolded Protein Response (UPR).
Conclusion
The Box-Behnken Design is a powerful statistical tool for the efficient optimization of mammalian cell culture processes. By systematically evaluating the effects of multiple factors and their interactions, researchers can identify optimal conditions to enhance key performance indicators such as recombinant protein titer. The protocol and examples provided herein offer a practical framework for implementing this compound in your cell culture experiments, leading to more robust and productive bioprocesses.
References
- 1. The Open Educator - 4. Box-Behnken Response Surface Methodology [theopeneducator.com]
- 2. What are response surface designs, central composite designs, and Box-Behnken designs? - Minitab [support.minitab.com]
- 3. cdn.statease.com [cdn.statease.com]
- 4. m.youtube.com [m.youtube.com]
- 5. THE ROLE OF THE mTOR NUTRIENT SIGNALING PATHWAY IN CHONDROCYTE DIFFERENTIATION - PMC [pmc.ncbi.nlm.nih.gov]
- 6. landing1.gehealthcare.com [landing1.gehealthcare.com]
- 7. Optimization of a mAb production process with regard to robustness and product quality using quality by design principles - PMC [pmc.ncbi.nlm.nih.gov]
- 8. The Ultimate Guide to CHO Cell Culture: From Thawing to High-Density Expression_FDCELL [fdcell.com]
- 9. The relationship between mTOR signalling pathway and recombinant antibody productivity in CHO cell lines - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Nutrient Signaling to mTOR and Cell Growth - PMC [pmc.ncbi.nlm.nih.gov]
- 11. academic.oup.com [academic.oup.com]
- 12. The Role of Endoplasmic Reticulum Stress on Reducing Recombinant Protein Production in Mammalian Cells - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Endoplasmic reticulum signaling as a determinant of recombinant protein expression - PubMed [pubmed.ncbi.nlm.nih.gov]
Optimizing Nanoparticle Synthesis: A Practical Guide Using Box-Behnken Design
Application Notes and Protocols for Researchers, Scientists, and Drug Development Professionals
Introduction
In the rapidly advancing field of nanotechnology, the precise and efficient synthesis of nanoparticles with desired physicochemical properties is paramount for their successful application in drug delivery, diagnostics, and therapeutics. Box-Behnken Design (BBD), a type of response surface methodology (RSM), has emerged as a powerful statistical tool for optimizing complex processes, such as nanoparticle synthesis.[1][2] This design is highly efficient and economical as it requires fewer experimental runs compared to other designs like full factorial.[1][2] this compound allows for the investigation of the effects of multiple process variables and their interactions on the critical quality attributes of nanoparticles, such as particle size, encapsulation efficiency, and drug release profile.[1][2] By constructing a polynomial model, this compound helps in identifying the optimal experimental conditions to achieve a desired nanoparticle formulation with minimal experimental effort.[2]
These application notes provide a detailed guide and protocols for utilizing Box-Behnken Design to optimize the synthesis of two distinct and widely used nanoparticle systems: Solid Lipid Nanoparticles (SLNs) for drug delivery and Poly(lactic-co-glycolic) acid (PLGA) nanoparticles for encapsulating natural compounds.
General Workflow for Nanoparticle Optimization using Box-Behnken Design
The optimization of nanoparticle synthesis using Box-Behnken Design follows a systematic workflow. This involves identifying critical process parameters, setting up the experimental design, performing the synthesis and characterization, and finally, analyzing the data to determine the optimal formulation.
Caption: General workflow of Box-Behnken Design for nanoparticle synthesis optimization.
Case Study 1: Optimization of Solid Lipid Nanoparticles (SLNs) for Ophthalmic Drug Delivery
This case study focuses on the optimization of chloramphenicol-loaded SLNs for ophthalmic delivery using a Box-Behnken design.[3][4] The goal is to achieve high entrapment efficiency and drug loading.[3]
Data Presentation
Table 1: Independent Variables and Their Levels for SLN Synthesis
| Independent Variables | Code | Level -1 | Level 0 | Level +1 |
| Solid Lipid (Glyceryl Monostearate) (X₁) | A | 100 mg | 200 mg | 300 mg |
| Surfactant (Poloxamer 188) (X₂) | B | 1.0% | 1.5% | 2.0% |
| Drug/Lipid Ratio (X₃) | C | 1:20 | 1:15 | 1:10 |
Table 2: Box-Behnken Design Matrix with Experimental and Predicted Responses for SLN Synthesis
| Run | X₁ (mg) | X₂ (%) | X₃ (ratio) | Entrapment Efficiency (%) | Drug Loading (%) |
| 1 | 100 | 1.0 | 1:15 | 75.32 | 8.21 |
| 2 | 300 | 1.0 | 1:15 | 78.91 | 9.15 |
| 3 | 100 | 2.0 | 1:15 | 80.11 | 9.54 |
| 4 | 300 | 2.0 | 1:15 | 82.45 | 10.03 |
| 5 | 100 | 1.5 | 1:20 | 70.25 | 6.89 |
| 6 | 300 | 1.5 | 1:20 | 73.68 | 7.54 |
| 7 | 100 | 1.5 | 1:10 | 81.54 | 9.88 |
| 8 | 300 | 1.5 | 1:10 | 83.29 | 10.11 |
| 9 | 200 | 1.0 | 1:20 | 72.14 | 7.12 |
| 10 | 200 | 2.0 | 1:20 | 76.32 | 8.33 |
| 11 | 200 | 1.0 | 1:10 | 79.88 | 9.45 |
| 12 | 200 | 2.0 | 1:10 | 82.17 | 9.96 |
| 13 | 200 | 1.5 | 1:15 | 80.56 | 9.67 |
| 14 | 200 | 1.5 | 1:15 | 80.61 | 9.69 |
| 15 | 200 | 1.5 | 1:15 | 80.58 | 9.68 |
Note: The data in Table 2 is representative and based on the trends reported in the cited literature.[3]
Experimental Protocol: Synthesis of Chloramphenicol-Loaded SLNs
This protocol is based on the melt-emulsion ultrasonication and low-temperature solidification technique.[3]
Materials:
-
Glyceryl monostearate (GMS)
-
Poloxamer 188
-
Deionized water
Equipment:
-
Magnetic stirrer with heating
-
Probe sonicator
-
High-speed centrifuge
-
Water bath
Procedure:
-
Preparation of Lipid Phase: Weigh the specified amount of GMS (according to the this compound matrix) and chloramphenicol and melt them together in a beaker at 75°C under magnetic stirring to form a clear lipid phase.
-
Preparation of Aqueous Phase: Dissolve the specified amount of Poloxamer 188 in deionized water and heat to the same temperature as the lipid phase (75°C).
-
Emulsification: Add the hot aqueous phase dropwise to the lipid phase under high-speed stirring (e.g., 1000 rpm) for 10 minutes to form a coarse oil-in-water emulsion.
-
Homogenization: Immediately subject the coarse emulsion to high-intensity probe sonication for a specified time (e.g., 5 minutes) to form a nanoemulsion.
-
Solidification: Quickly disperse the hot nanoemulsion into cold deionized water (2-4°C) under gentle stirring to solidify the lipid nanoparticles.
-
Purification: Centrifuge the SLN dispersion at a high speed (e.g., 15,000 rpm) for 30 minutes to separate the nanoparticles from the supernatant.
-
Washing: Wash the pellet twice with deionized water to remove any unentrapped drug and excess surfactant.
-
Storage: Resuspend the final SLN pellet in a suitable medium for characterization or freeze-dry for long-term storage.
Experimental Workflow Diagram
Caption: Experimental workflow for the synthesis of Solid Lipid Nanoparticles.
Case Study 2: Optimization of PLGA Nanoparticles for Encapsulation of a Natural Compound (Coffee Extract)
This case study demonstrates the use of this compound to optimize the formulation of Poly(lactic-co-glycolic) acid (PLGA) nanoparticles loaded with coffee extract, aiming for minimal particle size and polydispersity index (PDI), and maximal zeta potential and encapsulation efficiency.[5][6]
Data Presentation
Table 3: Independent Variables and Their Levels for PLGA Nanoparticle Synthesis
| Independent Variables | Code | Level -1 | Level 0 | Level +1 |
| PVA Concentration (%) (X₁) | A | 0.5 | 1.0 | 1.5 |
| Homogenization Speed (rpm) (X₂) | B | 10,000 | 15,000 | 20,000 |
| Homogenization Time (min) (X₃) | C | 2 | 4 | 6 |
Table 4: Box-Behnken Design Matrix with Experimental Responses for PLGA Nanoparticle Synthesis
| Run | PVA Conc. (%) | Homogenization Speed (rpm) | Homogenization Time (min) | Particle Size (nm) | PDI | Zeta Potential (mV) | Encapsulation Efficiency (%) |
| 1 | 0.5 | 10,000 | 4 | 450.2 | 0.25 | -15.8 | 75.6 |
| 2 | 1.5 | 10,000 | 4 | 410.5 | 0.21 | -18.2 | 80.1 |
| 3 | 0.5 | 20,000 | 4 | 380.7 | 0.18 | -19.5 | 82.3 |
| 4 | 1.5 | 20,000 | 4 | 350.1 | 0.15 | -21.3 | 85.9 |
| 5 | 0.5 | 15,000 | 2 | 420.8 | 0.23 | -16.5 | 78.4 |
| 6 | 1.5 | 15,000 | 2 | 390.4 | 0.19 | -19.1 | 81.7 |
| 7 | 0.5 | 15,000 | 6 | 360.3 | 0.16 | -20.1 | 84.5 |
| 8 | 1.5 | 15,000 | 6 | 318.6 | 0.07 | -20.5 | 85.9 |
| 9 | 1.0 | 10,000 | 2 | 430.6 | 0.24 | -17.3 | 79.2 |
| 10 | 1.0 | 20,000 | 2 | 370.9 | 0.17 | -20.8 | 83.1 |
| 11 | 1.0 | 10,000 | 6 | 395.2 | 0.20 | -18.8 | 81.0 |
| 12 | 1.0 | 20,000 | 6 | 340.5 | 0.14 | -22.1 | 86.2 |
| 13 | 1.0 | 15,000 | 4 | 375.4 | 0.18 | -19.9 | 82.8 |
| 14 | 1.0 | 15,000 | 4 | 376.1 | 0.18 | -19.8 | 82.9 |
| 15 | 1.0 | 15,000 | 4 | 375.8 | 0.18 | -20.0 | 82.7 |
Note: The data in Table 4 is representative and based on the trends reported in the cited literature.[5][6]
Experimental Protocol: Synthesis of PLGA-Coffee Nanoparticles
This protocol is based on the single emulsion-solvent evaporation method.[5][6]
Materials:
-
Poly(lactic-co-glycolic) acid (PLGA)
-
Coffee extract
-
Dichloromethane (DCM)
-
Polyvinyl alcohol (PVA)
-
Deionized water
Equipment:
-
Homogenizer
-
Ultrasonicator (optional, can be used after homogenization)
-
Magnetic stirrer
-
Centrifuge
Procedure:
-
Preparation of Organic Phase: Dissolve a fixed amount of PLGA and coffee extract in DCM.
-
Preparation of Aqueous Phase: Prepare an aqueous solution of PVA at the concentration specified in the this compound matrix.
-
Emulsification: Add the organic phase dropwise to the aqueous PVA solution while homogenizing at the speed and for the duration specified in the this compound matrix.
-
Solvent Evaporation: Transfer the resulting oil-in-water nano-emulsion to a magnetic stirrer and stir overnight at room temperature to allow for the complete evaporation of the organic solvent (DCM).
-
Nanoparticle Collection: Collect the formed nanoparticles by centrifugation at a high speed (e.g., 20,000 rpm) for 20 minutes.
-
Washing: Discard the supernatant and wash the nanoparticle pellet twice with deionized water to remove excess PVA and unencapsulated coffee extract.
-
Lyophilization: Freeze-dry the final nanoparticle pellet to obtain a powder for long-term storage and characterization.
Conclusion
Box-Behnken Design is a valuable statistical tool for the systematic optimization of nanoparticle synthesis. By employing this compound, researchers can efficiently investigate the influence of various process parameters on the final product characteristics, leading to the development of optimized nanoparticle formulations with desired properties. The protocols and data presented in these application notes serve as a practical guide for implementing this compound in the synthesis of solid lipid nanoparticles and polymeric nanoparticles, which can be adapted for a wide range of other nanosystems. The use of such systematic optimization approaches is crucial for accelerating the translation of nanoparticle-based technologies from the laboratory to clinical and industrial applications.
References
- 1. seejph.com [seejph.com]
- 2. researchgate.net [researchgate.net]
- 3. Development and optimization of solid lipid nanoparticle formulation for ophthalmic delivery of chloramphenicol using a Box-Behnken design - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. [PDF] Development and optimization of solid lipid nanoparticle formulation for ophthalmic delivery of chloramphenicol using a Box-Behnken design | Semantic Scholar [semanticscholar.org]
- 5. Applying Box–Behnken Design for Formulation and Optimization of PLGA-Coffee Nanoparticles and Detecting Enhanced Antioxidant and Anticancer Activities - PMC [pmc.ncbi.nlm.nih.gov]
- 6. mdpi.com [mdpi.com]
Optimizing Processes with Efficiency: A Guide to the 3-Factor Box-Behnken Experimental Design
For researchers, scientists, and drug development professionals seeking to efficiently optimize their processes, the Box-Behnken design (BBD) offers a powerful statistical approach. This response surface methodology (RSM) is particularly valuable when exploring the relationships between multiple variables and a given response, allowing for the development of a quadratic model to identify optimal conditions without the need for a full factorial experiment.
This application note provides a detailed overview of the 3-factor Box-Behnken design, including its experimental matrix, a comprehensive protocol for its application in drug formulation, and a visual representation of the experimental workflow. The key advantage of the Box-Behnken design lies in its ability to investigate the main, interaction, and quadratic effects of factors with fewer experimental runs compared to a central composite design (CCD) for the same number of factors.[1] A notable feature of the this compound is that it does not include combinations where all factors are at their extreme high or low levels simultaneously, which can be advantageous when such conditions are impractical or unsafe to test.[2][3]
Understanding the 3-Factor Box-Behnken Design Matrix
A 3-factor Box-Behnken design is characterized by three independent variables, each set at three equally spaced levels, typically coded as -1 (low), 0 (central), and +1 (high). The design consists of a set of points lying on a sphere within the experimental domain, with replicate center points to estimate the experimental error.[4] A standard 3-factor Box-Behnken design consists of 15 experiments, including three center points.[2]
The experimental runs are strategically placed at the midpoints of the edges of the cubic design space. This arrangement allows for the efficient estimation of the coefficients of a second-order polynomial model.
Table 1: Coded Experimental Design Matrix for a 3-Factor Box-Behnken Design
| Run Order | Factor A | Factor B | Factor C |
| 1 | -1 | -1 | 0 |
| 2 | 1 | -1 | 0 |
| 3 | -1 | 1 | 0 |
| 4 | 1 | 1 | 0 |
| 5 | -1 | 0 | -1 |
| 6 | 1 | 0 | -1 |
| 7 | -1 | 0 | 1 |
| 8 | 1 | 0 | 1 |
| 9 | 0 | -1 | -1 |
| 10 | 0 | 1 | -1 |
| 11 | 0 | -1 | 1 |
| 12 | 0 | 1 | 1 |
| 13 | 0 | 0 | 0 |
| 14 | 0 | 0 | 0 |
| 15 | 0 | 0 | 0 |
Application Protocol: Optimizing a Nanoemulsion Formulation for Drug Delivery
This protocol details the application of a 3-factor Box-Behnken design to optimize the formulation of a nanoemulsion for enhanced drug delivery. The goal is to minimize particle size and maximize encapsulation efficiency.
1. Define Factors and Responses:
-
Independent Variables (Factors):
-
A: Surfactant Concentration (% w/v): The amount of surfactant used can significantly impact droplet size and stability.
-
B: Sonication Time (minutes): The duration of energy input affects the emulsification process and droplet size reduction.
-
C: Oil Phase Concentration (% v/v): The proportion of the oil phase influences the drug loading capacity and emulsion stability.
-
-
Dependent Variables (Responses):
-
Y1: Particle Size (nm): A critical quality attribute for nanoemulsions, affecting stability and bioavailability.
-
Y2: Encapsulation Efficiency (%): The percentage of the drug successfully encapsulated within the nanoemulsion droplets.
-
2. Define Factor Levels:
Based on preliminary studies and literature review, the following levels are chosen for each factor:
Table 2: Factors and Their Levels for Nanoemulsion Formulation Optimization
| Factor | Low (-1) | Central (0) | High (+1) |
| A: Surfactant Concentration (%) | 5 | 10 | 15 |
| B: Sonication Time (min) | 2 | 4 | 6 |
| C: Oil Phase Concentration (%) | 10 | 15 | 20 |
3. Experimental Procedure:
For each of the 15 experimental runs defined in the Box-Behnken design matrix (Table 1), a nanoemulsion formulation is prepared according to the specified levels of the factors.
-
Preparation of the Aqueous Phase: Dissolve the surfactant in the aqueous phase (e.g., purified water) at the concentration specified in the design matrix.
-
Preparation of the Oil Phase: Dissolve the active pharmaceutical ingredient (API) in the oil phase at a fixed concentration.
-
Emulsification: Add the oil phase to the aqueous phase dropwise while stirring.
-
Sonication: Subject the coarse emulsion to high-energy sonication for the duration specified in the design matrix.
-
Characterization:
-
Measure the particle size (Y1) of the resulting nanoemulsion using a dynamic light scattering (DLS) instrument.
-
Determine the encapsulation efficiency (Y2) by separating the free drug from the encapsulated drug using a suitable technique (e.g., ultracentrifugation) and quantifying the drug in each fraction using a validated analytical method (e.g., HPLC).
-
4. Data Analysis:
-
Record the measured responses (particle size and encapsulation efficiency) for each experimental run in the design matrix.
-
Fit the experimental data to a second-order polynomial equation for each response. The general form of the equation is:
Y = β₀ + β₁A + β₂B + β₃C + β₁₂AB + β₁₃AC + β₂₃BC + β₁₁A² + β₂₂B² + β₃₃C²
where Y is the predicted response, β₀ is the model constant; β₁, β₂, and β₃ are the linear coefficients; β₁₂, β₁₃, and β₂₃ are the interaction coefficients; and β₁₁, β₂₂, and β₃₃ are the quadratic coefficients.
-
Use statistical software (e.g., Minitab®, Design-Expert®) to perform analysis of variance (ANOVA) to determine the significance of the model and individual terms.
-
Generate response surface plots and contour plots to visualize the relationship between the factors and responses.
-
Identify the optimal conditions for the factors that minimize particle size and maximize encapsulation efficiency.
Experimental Workflow Diagram
The following diagram illustrates the logical flow of a Box-Behnken design experiment.
Signaling Pathway of Process Optimization
The following diagram conceptualizes the "signaling pathway" of process optimization using the Box-Behnken design, where experimental inputs lead to a refined understanding and an optimized output.
By following this structured approach, researchers can efficiently navigate the experimental landscape, gain a deeper understanding of their processes, and identify optimal conditions with a minimal number of experimental runs, thereby saving time, resources, and accelerating development timelines.
References
Troubleshooting & Optimization
Navigating Box-Behnken Design: A Technical Support Guide
Welcome to the Technical Support Center for Box-Behnken Design (BBD) experiments. This guide is tailored for researchers, scientists, and drug development professionals to troubleshoot common issues encountered during the application of this compound. Here, you will find frequently asked questions and detailed troubleshooting guides to ensure the robustness and validity of your experimental findings.
Frequently Asked Questions (FAQs)
Q1: What is a Box-Behnken Design (this compound) and when should I use it?
A Box-Behnken Design is a type of response surface methodology (RSM) that is used to explore the relationships between several explanatory variables and one or more response variables. It is an efficient design that allows for the estimation of a second-order (quadratic) model.[1][2] You should consider using a this compound when you want to optimize a process and believe that the relationship between the factors and the response is not linear. This compound is particularly advantageous when you need to avoid extreme combinations of factor levels, which might be expensive, unsafe, or impractical to test.[3][4][5][6]
Q2: What are the main advantages of a Box-Behnken Design compared to a Central Composite Design (CCD)?
The primary advantages of a this compound include requiring fewer experimental runs than a full factorial design and avoiding extreme vertex points.[4][6] This makes this compound a cost-effective and safer option in many practical scenarios. Unlike CCDs, BBDs do not have axial points that extend beyond the defined factor ranges, ensuring all experimental runs are within the specified safe operating zone.[4]
Q3: Can I use Box-Behnken Design for screening a large number of factors?
Box-Behnken designs are not ideal for screening a large number of factors. They are most effective for optimization studies when you have already identified the critical factors. For screening purposes, factorial or fractional factorial designs are more appropriate as they can efficiently identify the most influential factors from a larger set.
Q4: My experiment resulted in a significant "lack of fit." What does this mean and how should I proceed?
A significant "lack of fit" indicates that your second-order model does not adequately represent the experimental data.[7][8][9] This suggests that there might be a more complex relationship between the factors and the response, such as higher-order effects. The first step is to investigate the cause by checking for outliers, ensuring that the assumptions of the model (like normality and constant variance of residuals) are met, and considering a transformation of the response variable.[7][8] If these checks do not resolve the issue, you may need to consider a higher-order model.[7][8]
Troubleshooting Guides
Problem 1: Significant Lack of Fit in the Second-Order Model
A significant p-value for the lack of fit test is a common and critical issue in this compound experiments. It suggests that the chosen quadratic model is not a good fit for the observed data.
Troubleshooting Workflow:
Caption: Troubleshooting workflow for a significant lack of fit.
Detailed Steps:
-
Check for Outliers: Examine diagnostic plots such as residuals versus leverage and Cook's distance to identify any influential data points that may be skewing the model.[7] If outliers are present, investigate their cause. They may be due to measurement errors or other experimental anomalies.
-
Verify Model Assumptions: Assess the validity of the regression model's assumptions. Check for the normality of residuals using a Q-Q plot and for homoscedasticity (constant variance) using a residuals versus fitted values plot.[7] Violations of these assumptions can lead to an incorrect model fit.
-
Consider Response Transformation: If the residuals show a non-normal distribution or non-constant variance, a transformation of the response variable (e.g., logarithmic, square root) might be necessary. The Box-Cox plot can help identify an appropriate transformation.
-
Evaluate the Need for a Higher-Order Model: If the above steps do not resolve the lack of fit, it is likely that the true relationship between the factors and the response is more complex than a second-order model can capture.[7]
-
Augment the Design: To fit a third-order model, the original this compound needs to be augmented with additional experimental runs.[10][11] This typically involves adding factorial points and axial points to provide enough data to estimate the additional terms of a cubic model.[10][11]
-
Refit with a Third-Order Model: After augmenting the design, fit a third-order response surface model to the new, larger dataset. This more complex model may provide a better fit and eliminate the lack of fit.
Problem 2: The Optimized Settings are at the Edge of the Design Space
A common issue with this compound is that it does not include experimental runs at the vertices (corners) of the design space. If the optimal response is located at one of these corners, the this compound may not accurately predict it.
Troubleshooting Steps:
-
Examine Contour and Surface Plots: Visualize the response surface to understand the predicted behavior of the response. If the plots show a clear trend towards a corner of the experimental region, it is an indication that the optimum may lie there.
-
Perform Confirmatory Experiments: Conduct a few additional experimental runs at the corner points of interest to validate the model's prediction and to check if a better response can be achieved.
-
Consider an Alternative Design: If your process is well-understood and you suspect the optimum lies at the extremes, a Central Composite Design (CCD) might be a more suitable choice from the outset as it includes these corner points.
Data Presentation
Table 1: Comparison of Box-Behnken Design (this compound) and Central Composite Design (CCD)
| Feature | Box-Behnken Design (this compound) | Central Composite Design (CCD) |
| Number of Factor Levels | 3 levels per factor | Up to 5 levels per factor[4] |
| Experimental Runs | Generally requires fewer runs for the same number of factors.[4] | Typically requires more runs. |
| Factor Combinations | Avoids extreme combinations where all factors are at their high or low levels simultaneously.[3][4][5] | Includes runs at the vertices (corners) of the design space.[3] |
| Sequential Experimentation | Not well-suited for sequential experiments as it does not have an embedded factorial design.[4] | Well-suited for sequential experimentation; can be built up from a factorial or fractional factorial design.[3][5] |
| Design Shape | Spherical design. | Cuboidal with axial points extending beyond the cube. |
| Primary Use Case | Optimization when extreme factor combinations are undesirable or impractical.[3][5] | Optimization and building a robust second-order model, especially when sequential experimentation is desired. |
Experimental Protocols
Case Study: Optimization of Nanoparticle Formulation
This protocol outlines a general approach for optimizing the formulation of nanoparticles using a Box-Behnken design, based on common practices in pharmaceutical development.[12][13]
Objective: To determine the optimal levels of three independent variables (e.g., polymer concentration, surfactant concentration, and sonication time) to achieve a desired particle size and encapsulation efficiency.
1. Factor and Level Selection:
-
Independent Variables (Factors):
-
A: Polymer Concentration (mg/mL)
-
B: Surfactant Concentration (%)
-
C: Sonication Time (minutes)
-
-
Levels: Each factor is studied at three levels: -1 (low), 0 (central), and +1 (high). The actual values for these levels are determined from preliminary single-factor experiments.
2. Experimental Design:
-
A three-factor, three-level Box-Behnken design is generated using statistical software. This design will consist of 15 experimental runs, including 3 center points to estimate the experimental error.
3. Nanoparticle Preparation (Example: Emulsion Solvent Evaporation):
-
Dissolve the polymer and the active pharmaceutical ingredient (API) in an organic solvent.
-
Prepare an aqueous phase containing the surfactant.
-
Emulsify the organic phase in the aqueous phase using homogenization or sonication according to the levels specified in the this compound run order.
-
Evaporate the organic solvent under reduced pressure to form the nanoparticles.
-
Collect and wash the nanoparticles by centrifugation.
4. Response Measurement:
-
Y1: Particle Size (nm): Measured by dynamic light scattering (DLS).
-
Y2: Encapsulation Efficiency (%): Determined by quantifying the amount of unencapsulated API in the supernatant using a suitable analytical method (e.g., HPLC, UV-Vis spectroscopy).
5. Data Analysis:
-
Fit the experimental data to a second-order polynomial equation for each response.
-
Perform Analysis of Variance (ANOVA) to determine the significance of the model and individual terms (linear, quadratic, and interaction).
-
Check the model adequacy using the coefficient of determination (R²), adjusted R², and the lack of fit test.
-
Generate response surface and contour plots to visualize the relationship between the factors and responses.
-
Use the model to predict the optimal conditions for achieving the desired particle size and encapsulation efficiency.
Troubleshooting in this context: If a significant lack of fit is observed, it might indicate that the relationship between, for example, sonication time and particle size is more complex than a quadratic model can describe. In such a case, the troubleshooting workflow described above should be followed. It might be necessary to investigate other factors not included in the initial design or to consider a different nanoparticle preparation method.
Logical Relationship Diagram:
Caption: Logical flow of a Box-Behnken Design experiment.
References
- 1. Box–Behnken design - Wikipedia [en.wikipedia.org]
- 2. The Open Educator - 4. Box-Behnken Response Surface Methodology [theopeneducator.com]
- 3. Central Composite Design vs. Box-Behnken Design [experimentaldesignhub.com]
- 4. What are response surface designs, central composite designs, and Box-Behnken designs? - Minitab [support.minitab.com]
- 5. youtube.com [youtube.com]
- 6. 11.2.2 - Box-Behnken Designs | STAT 503 [online.stat.psu.edu]
- 7. researchgate.net [researchgate.net]
- 8. Stat-Ease [statease.com]
- 9. researchgate.net [researchgate.net]
- 10. tandfonline.com [tandfonline.com]
- 11. researchgate.net [researchgate.net]
- 12. mdpi.com [mdpi.com]
- 13. ijpsonline.com [ijpsonline.com]
Technical Support Center: Box-Behnken Design (BBD)
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to address common issues encountered during the analysis of Box-Behnken Designs (BBD), with a specific focus on handling non-significant model terms.
Frequently Asked Questions (FAQs)
Q1: What does a non-significant model term (p-value > 0.05) indicate in my this compound analysis?
A non-significant model term, identified by a p-value typically greater than 0.05, suggests that there is not enough evidence from your experimental data to conclude that the corresponding factor or interaction has a real effect on the response variable.[1] This could be for several reasons:
-
True Insignificance: The factor or interaction genuinely has no or a negligible effect on the response within the studied range.
-
Experimental Noise: High variability or random error in the experiment may be masking the true effect of the term.
-
Inappropriate Range: The selected levels for the factor may be too close together, resulting in no detectable change in the response.
-
Model Misspecification: The chosen model (e.g., quadratic) may not be the best fit for the actual relationship between the factors and the response.[2]
Q2: Should I always remove non-significant terms from my model?
The decision to remove non-significant terms, a process known as model reduction, is a subject of debate among statisticians.[3]
-
Arguments for Removal: Removing non-significant terms can simplify the model, making it easier to interpret and potentially improving its predictive capability by reducing overfitting.[1][3] Overfitting occurs when the model describes random error or noise instead of the underlying relationship.[1]
-
Arguments Against Removal: There are situations where it is advisable to keep non-significant terms:
-
Hierarchy: If a main effect is non-significant but its interaction or quadratic term is significant, the main effect is typically retained to maintain model hierarchy.
-
Control Variables: If a variable is a known and expected control factor in the field of study, it may be kept to demonstrate that its effect was accounted for.[4]
-
Specific Hypotheses: If the primary goal of the study was to test the significance of that specific term, it should be reported as non-significant.[4]
-
Q3: My overall model is significant, but most of the individual terms are not. What should I do?
This scenario can be perplexing. It indicates that while the model as a whole explains a significant amount of the variation in the response, the individual contributions of many terms are not statistically distinguishable from zero.
Possible Causes and Actions:
-
Multicollinearity: The factors may be correlated, making it difficult to separate their individual effects.[5]
-
Dominant Factor: One factor or interaction might have a very strong effect that overshadows the others.
-
Action: Carefully examine the correlation matrix of the factors. Consider if the experimental design was executed correctly. It might be necessary to refine the factor ranges or even redesign the experiment if multicollinearity is high.[6]
Troubleshooting Guides
Guide 1: Systematic Approach to Non-Significant Terms
This guide provides a step-by-step workflow for addressing non-significant terms in your this compound analysis.
Experimental Protocol: Model Analysis and Diagnostics
-
Initial Model Fit: Fit the full quadratic model to the experimental data.
-
ANOVA Examination: Analyze the Analysis of Variance (ANOVA) table to identify the p-values for each model term (linear, interaction, and quadratic).
-
Diagnostic Plots: Generate and inspect residual plots to check for violations of model assumptions:
-
Normal Plot of Residuals: Points should fall approximately along a straight line.
-
Residuals vs. Predicted Values: Points should be randomly scattered around zero, without any discernible patterns (e.g., a funnel shape, indicating heteroscedasticity).
-
Residuals vs. Run Order: To check for time-dependent trends.
-
-
Lack-of-Fit Test: Evaluate the p-value for the lack-of-fit. A significant lack-of-fit (p < 0.05) indicates that the model does not adequately describe the data, and a higher-order model or data transformation may be needed.[2][7][8]
Guide 2: Interpreting Diagnostic Plots
Understanding the diagnostic plots is crucial for validating your model.
| Plot | Indication of a Problem | Potential Solution |
| Normal Plot of Residuals | Points deviate significantly from the straight line. | Data transformation (e.g., Box-Cox). |
| Residuals vs. Predicted | A clear pattern (e.g., a cone or a curve). | Data transformation; consider a different model. |
| Cook's Distance | Points exceeding the threshold. | Investigate the influential point for errors in data entry or experimental conduct. Consider removing the point if justified.[2] |
Guide 3: The Role of Aliasing
Q: What is aliasing and could it be the reason for my non-significant terms?
A: Aliasing occurs in fractional factorial designs where the effect of one factor or interaction is indistinguishable from that of another.[9] In a standard Box-Behnken design, which is not a fractional factorial design in the typical sense, aliasing of main effects and two-factor interactions is generally not an issue. However, higher-order interactions might be aliased with lower-order terms.[10] If a cubic model is suggested but aliased, it means the design cannot independently estimate all the cubic terms.[10] For a this compound, the primary focus is on fitting a second-order (quadratic) model, and it is specifically designed to do so efficiently.[11][12]
Summary of Quantitative Data Interpretation
When analyzing your this compound results, several key quantitative metrics should be considered.
| Statistic | Good Value | Interpretation |
| P-value (Model) | < 0.05 | The model is statistically significant. |
| P-value (Term) | < 0.05 | The individual model term is statistically significant.[1] |
| P-value (Lack-of-Fit) | > 0.10 | The model adequately fits the data; lack-of-fit is not significant.[7] |
| R-squared (R²) | Close to 1 | Indicates the proportion of variability in the response that is explained by the model. |
| Adjusted R-squared | Close to R² | A modified R² that accounts for the number of terms in the model; useful for comparing models with different numbers of terms.[13] |
| Predicted R-squared | Close to Adjusted R² | Indicates how well the model predicts responses for new observations. A large difference between adjusted and predicted R² can indicate an over-fit model.[1] |
By following these guides and understanding the key concepts, researchers can more effectively troubleshoot non-significant model terms in their Box-Behnken Designs and build more robust and reliable models for their drug development and research processes.
References
- 1. Interpret the key results for Analyze Response Surface Design - Minitab [support.minitab.com]
- 2. researchgate.net [researchgate.net]
- 3. sites.miamioh.edu [sites.miamioh.edu]
- 4. When to leave insignificant effects in a model - The Analysis Factor [theanalysisfactor.com]
- 5. stats.stackexchange.com [stats.stackexchange.com]
- 6. researchgate.net [researchgate.net]
- 7. m.youtube.com [m.youtube.com]
- 8. Stat-Ease [statease.com]
- 9. isixsigma.com [isixsigma.com]
- 10. researchgate.net [researchgate.net]
- 11. The Open Educator - 4. Box-Behnken Response Surface Methodology [theopeneducator.com]
- 12. Box–Behnken design - Wikipedia [en.wikipedia.org]
- 13. researchgate.net [researchgate.net]
Optimizing the number of center points in Box-Behnken Design
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to assist researchers, scientists, and drug development professionals in optimizing the number of center points in their Box-Behnken Design (BBD) experiments.
Frequently Asked Questions (FAQs)
Q1: What is the primary purpose of adding center points to a Box-Behnken Design?
A1: Center points, where all factors are set to their median values, serve several critical functions in a Box-Behnken Design:
-
Estimation of Pure Error: Replicated center points provide a robust estimate of the inherent variability of the experiment (pure error), independent of the model being fitted.[1]
-
Detection of Curvature: Center points allow for a statistical test of the overall curvature in the response surface. If the average response at the center points is significantly different from the average response at the factorial and axial points, it indicates the presence of quadratic effects.
-
Improving Prediction Precision: Adding center points can improve the precision of predictions made at or near the center of the design space by reducing the prediction variance in that region.[2]
Q2: How many center points should I use in my Box-Behnken Design?
A2: The optimal number of center points is a balance between the cost of additional experimental runs and the desired level of statistical information. While there is no single rule, general recommendations are based on the number of factors in your design. Statistical software often provides a default number, typically between 3 and 5, which is adequate for most applications. For Small Box-Behnken Designs (Sthis compound), it has been suggested that at most two center points can achieve approximately 90% G-efficiency for response surface exploration.[3]
Q3: Can I run a Box-Behnken Design with zero center points?
A3: While it is possible to run a this compound with no center points, it is generally not recommended. Without center points, you lose the ability to obtain a model-independent estimate of pure error and cannot perform a direct statistical test for the lack of fit of your model.[3] This can hinder the validation of your results and the assessment of the model's adequacy.
Q4: When is it particularly important to add more center points?
A4: Consider increasing the number of center points when:
-
You anticipate significant variability in your experimental process and need a very precise estimate of pure error.
-
The primary goal of your experiment is to optimize the response at the center of your design space.
-
Your budget and resources comfortably allow for additional runs to improve the overall robustness of the design.
Troubleshooting Guides
Issue: Uncertainty in determining the appropriate number of center points.
Solution: Follow this step-by-step guide to determine the number of center points for your experiment.
-
Assess the Number of Factors: The total number of runs in a this compound is influenced by the number of factors and center points. Use the table below as a starting point.
-
Evaluate Experimental Error: If you have prior knowledge of your experimental system's variability, a smaller number of center points (e.g., 2-3) may suffice. If the error is unknown or expected to be large, a higher number (e.g., 4-5) is advisable for a better estimate of pure error.[1][3]
-
Consider the Cost and Time per Run: If experimental runs are expensive or time-consuming, minimize the number of center points while ensuring you have at least two for a minimal estimate of pure error.[3]
-
Check for Rotatability: The number of center points influences the rotatability of the design, which ensures that the variance of the predicted response is constant at any point equidistant from the center.[4][5] While BBDs are inherently near-rotatable, adjusting the number of center points can sometimes improve this property.
Data Presentation
Table 1: Recommended Number of Center Points for Box-Behnken Designs
| Number of Factors (k) | Number of Factorial/Axial Points | Recommended Number of Center Points | Total Number of Runs |
| 3 | 12 | 3 - 5 | 15 - 17 |
| 4 | 24 | 3 - 5 | 27 - 29 |
| 5 | 40 | 4 - 6 | 44 - 46 |
| 6 | 54 | 4 - 6 | 58 - 60 |
| 7 | 56 | 5 - 7 | 61 - 63 |
Note: These recommendations are general guidelines. The final number should be determined based on the specific requirements of the experiment.
Experimental Protocols
Methodology for Determining the Number of Center Points
The selection of the number of center points is a key aspect of the design phase of a Design of Experiments (DoE) approach, such as the Box-Behnken Design, which is widely used in pharmaceutical product development and process optimization.[6][7][8]
-
Define Experimental Goals: Clearly state the objectives of your study. Are you screening for significant factors, optimizing a process, or modeling a response surface? The primary goal will influence the importance of estimating pure error and detecting curvature.
-
Identify Factors and Levels: Determine the independent variables (factors) and their respective low, medium, and high levels (-1, 0, +1) for the experiment.[4]
-
Generate a Base Design: Use statistical software to generate a Box-Behnken Design for the specified number of factors. The software will typically suggest a default number of center points. For a 3-factor design, this often results in 15 total runs, including 3 center points.[2][9]
-
Evaluate Design Properties: Analyze the properties of the generated design. Key metrics to consider are the prediction variance across the design space and the power of the lack-of-fit test. The goal is to have a relatively uniform prediction variance.[2]
-
Adjust and Finalize: If the prediction variance in the center of the design is too high, or if a more precise estimate of pure error is required, increase the number of center points. Conversely, if the experimental cost is a major constraint, you may reduce the number of center points, keeping in mind the trade-offs in statistical power. A minimum of two center points is recommended to still be able to estimate the pure error.[3]
Mandatory Visualization
Caption: Workflow for optimizing the number of center points in a Box-Behnken Design.
References
- 1. product-development-engineers.com [product-development-engineers.com]
- 2. 11.2.2 - Box-Behnken Designs | STAT 503 [online.stat.psu.edu]
- 3. researchgate.net [researchgate.net]
- 4. Box–Behnken design - Wikipedia [en.wikipedia.org]
- 5. fiveable.me [fiveable.me]
- 6. researchgate.net [researchgate.net]
- 7. Optimization of Formulation using Box-Behnken Design - ProQuest [proquest.com]
- 8. Box–Behnken Designs and Their Applications in Pharmaceutical Product Development [ouci.dntb.gov.ua]
- 9. Box-Behnken Designs: Example [help.synthesisplatform.net]
Dealing with outliers in Box-Behnken Design data
This guide provides troubleshooting advice and frequently asked questions for researchers, scientists, and drug development professionals dealing with potential outliers in their Box-Behnken Design (BBD) experimental data.
Frequently Asked Questions (FAQs)
Q1: What is an outlier in the context of a Box-Behnken Design?
An outlier is an observation in your this compound dataset that deviates significantly from other observations.[1] In Response Surface Methodology (RSM), including this compound, an outlier is an inconsistency in the response variable, sometimes referred to as a maverick observation.[2][3] These data points lie far from the rest of the data and can be much larger or smaller than the other values in your experiment.[4]
Q2: Why are outliers a concern in this compound analysis?
Outliers are a significant concern because they can have a disproportionate influence on the statistical analysis. The method of Least Squares (OLS), commonly used to estimate the coefficients of the second-order polynomial model in this compound, is very sensitive to outliers.[5] The presence of outliers can:
-
Lead to a significant lack of fit, suggesting the model is incorrect even when it's appropriate for the system.[8]
Q3: How can I detect potential outliers in my this compound data?
You can use a combination of graphical and statistical methods to identify outliers. It is crucial to investigate these points carefully before making any decisions.[7][10]
-
Graphical Methods: Visualizing the data is often the first step. Methods include generating box plots and scatter plots to identify data points that lie far from the main cluster of data.[4][10] Residual plots from your model analysis are also critical; points with large standardized residuals are potential outliers.
-
Statistical Methods: These provide a more objective way to identify suspect data points.[6] Common statistical tests include the Z-score method and the Interquartile Range (IQR) method.[1][4] For regression-based designs like this compound, Cook's distance is particularly useful as it measures the influence of each data point on the model's predictions.
Troubleshooting Guide: Dealing with Identified Outliers
Problem: I have identified a potential outlier in my this compound results. What should I do?
Once a potential outlier is flagged, a systematic investigation is necessary. You should not automatically delete the data point, as it may contain valuable information about your process.[1][10] Follow the workflow below to determine the appropriate course of action.
Caption: Workflow for handling a suspected outlier in experimental data.
Step 1: Investigate the Cause Before any action is taken, thoroughly investigate the potential cause of the outlier.[10] Common causes include:
-
Data Entry Errors: Simple human errors during data recording or transcription.[10]
-
Measurement or Instrument Errors: A faulty instrument or improper calibration can lead to erroneous readings.[10]
-
Sampling Errors: The sample may not have been representative of the intended conditions.[10]
-
Procedural Deviations: An unintentional change in the experimental procedure for that specific run.
-
Natural Variation: The outlier may be a true, albeit extreme, result representing the natural variability of the process.[1]
Step 2: Decide on a Course of Action Based on the Cause
-
If an Identifiable Error is Found: If you can confirm a data entry, measurement, or procedural error, the course of action is clear.
-
If No Identifiable Error is Found: If the outlier cannot be attributed to a specific error, it should be treated as a legitimate data point.[1] In this case, removing the data is not recommended as it can bias your results and lead to the loss of important information.[10][12] Instead, you should:
-
Retain the data point and analyze the data both with and without the outlier to understand its impact on the model.
-
Use robust analysis methods that are less sensitive to extreme values.
-
Data and Protocols
Table 1: Summary of Common Outlier Detection Methods
| Method | Description | How It Works |
| Box Plot / IQR | A graphical and statistical method that identifies outliers based on their position relative to the quartiles of the data.[4] | An observation is flagged as an outlier if it falls below Q1 - 1.5IQR or above Q3 + 1.5IQR, where Q1 is the first quartile, Q3 is the third quartile, and IQR is the interquartile range (Q3 - Q1).[1] |
| Z-Score | A statistical method that measures how many standard deviations a data point is from the mean. | An observation is typically considered an outlier if its Z-score is greater than 3 or less than -3. This method is most effective when the data is approximately normally distributed.[11] |
| Standardized Residuals | A diagnostic tool in regression analysis that highlights observations for which the model predicts poorly. | In the output of your this compound analysis, examine the standardized residuals. Values that fall outside the range of -3 to +3 are often considered potential outliers. |
| Cook's Distance | A regression diagnostic that measures the effect of deleting a given observation. It considers both the residual and the leverage of the point.[13] | A common rule of thumb is to investigate points with a Cook's distance greater than 4/n, where 'n' is the number of experimental runs. Higher values indicate a highly influential point.[13] |
Table 2: Summary of Strategies for Handling Outliers
| Strategy | Description | When to Use |
| Correction / Removal | Correcting a known error or deleting an invalid data point from the dataset.[1][4] | Use only when you can definitively trace the outlier to a specific, rectifiable error (e.g., data entry mistake, instrument failure).[1][10] |
| Data Transformation | Applying a mathematical function (e.g., logarithmic, square root) to the response variable to reduce the skewness of the data and pull in extreme values.[10][12] | Useful when the data is highly skewed and the variance is not constant. Can help normalize the distribution of residuals. |
| Imputation | Replacing the outlier with an estimated value, such as the mean or median of the dataset.[4][12] | This method should be used with extreme caution, as it can reduce the variance of your dataset and may not accurately represent the true value. Median imputation is generally preferred over mean imputation as it is less affected by other extreme values.[4] |
| Robust Regression | Using an alternative to Ordinary Least Squares (OLS) that is less sensitive to outliers, such as M-estimation.[5][11] This method gives less weight to extreme observations.[5] | Recommended when you have outliers that you cannot justify removing. It provides a model that is more resistant to the influence of these extreme points.[5][12] |
| Retain and Report | Keeping the outlier in the dataset and running the analysis with and without the point. | This is a transparent approach that allows you to assess and report the outlier's impact on the model's coefficients, significance, and overall fit. |
References
- 1. scribbr.com [scribbr.com]
- 2. Outliers and robust response surface designs [vtechworks.lib.vt.edu]
- 3. vtechworks.lib.vt.edu [vtechworks.lib.vt.edu]
- 4. analyticsvidhya.com [analyticsvidhya.com]
- 5. m-hikari.com [m-hikari.com]
- 6. Living with outliers: | BIB - Revista Brasileira de Informação Bibliográfica em Ciências Sociais [bibanpocs.emnuvens.com.br]
- 7. download.garuda.kemdikbud.go.id [download.garuda.kemdikbud.go.id]
- 8. researchgate.net [researchgate.net]
- 9. researchgate.net [researchgate.net]
- 10. How should we handle outliers in our data? | Blogs | Sigma Magic [sigmamagic.com]
- 11. thedocs.worldbank.org [thedocs.worldbank.org]
- 12. nachi-keta.medium.com [nachi-keta.medium.com]
- 13. ssca.org.in [ssca.org.in]
Technical Support Center: Optimizing Box-Behnken Design (BBD) Model Predictability
Welcome to the Technical Support Center for researchers, scientists, and drug development professionals. This resource provides troubleshooting guides and frequently asked questions (FAQs) to help you enhance the predictability of your Box-Behnken Design (BBD) models.
Troubleshooting Guides
This section addresses common issues encountered during this compound experiments and provides actionable solutions to improve model accuracy and predictive power.
Issue 1: Significant "Lack of Fit" in the this compound Model
A significant "Lack of Fit" test (p-value < 0.05) indicates that the model does not adequately describe the relationship between the factors and the response. This is a critical issue that undermines the model's predictive capability.
Troubleshooting Steps:
-
Verify Model Assumptions: Before making any adjustments, ensure that the assumptions of the regression model are met. This includes checking for the normality of residuals, homogeneity of variance (homoscedasticity), and independence of residuals. Violations of these assumptions can lead to an inaccurate assessment of the model's fit.
-
Investigate for Outliers: Outliers, or anomalous data points, can significantly distort the model and contribute to a significant lack of fit.
-
Action: Examine residual plots (e.g., Normal Plot of Residuals, Residuals vs. Predicted) to identify data points with large residuals. Investigate the experimental conditions for these runs to determine if there were any errors in measurement or execution.
-
Resolution: If an outlier is due to a clear experimental error, it may be appropriate to remove it from the dataset and re-run the analysis. However, this should be done with caution and proper justification.
-
-
Consider Higher-Order Models: A standard this compound is designed to fit a second-order (quadratic) model. If the true relationship between the factors and the response is more complex, a second-order model will not be sufficient, leading to a significant lack of fit.
-
Action: Evaluate the significance of higher-order terms (e.g., cubic terms) if your experimental design and software allow for it. You may need to augment your design with additional experimental runs to estimate these higher-order terms accurately.
-
-
Transform the Response Variable: Non-linear relationships can sometimes be linearized by applying a mathematical transformation to the response variable.
-
Action: Use a Box-Cox plot to identify an appropriate power transformation (e.g., logarithm, square root, reciprocal) for your response data. Applying the suggested transformation and re-fitting the model can often resolve the lack of fit.
-
-
Add Center Points: Center points are crucial for estimating pure error and assessing the curvature of the response surface. An insufficient number of center points can lead to an unreliable "Lack of Fit" test.
-
Action: If your initial design has few or no center points, consider augmenting the experiment with additional runs at the center of the design space. This will provide a more robust estimate of the process variability and a more accurate assessment of the model's fit.
-
Quantitative Impact of Troubleshooting "Lack of Fit":
| Troubleshooting Action | Initial Model (with Lack of Fit) | Improved Model |
| Outlier Removal | R² = 0.85, Adj R² = 0.80, Lack of Fit p-value = 0.02 | R² = 0.95, Adj R² = 0.93, Lack of Fit p-value = 0.15 |
| Response Transformation | R² = 0.88, Adj R² = 0.84, Lack of Fit p-value = 0.01 | R² = 0.96, Adj R² = 0.94, Lack of Fit p-value = 0.21 |
| Adding Higher-Order Term | R² = 0.90, Adj R² = 0.87, Lack of Fit p-value = 0.04 | R² = 0.98, Adj R² = 0.97, Lack of Fit p-value = 0.33 |
Issue 2: Poor Model Coefficients (Low R-squared and Adjusted R-squared)
Low R-squared (R²) and adjusted R-squared (Adj R²) values indicate that the model explains a small proportion of the variability in the response, suggesting a poor predictive capability.
Troubleshooting Steps:
-
Review Factor and Level Selection: The choice of factors and their experimental ranges is critical. If the selected factors have a minimal impact on the response, or the chosen ranges are too narrow, the resulting model will be weak.
-
Action: Re-evaluate the scientific literature and preliminary experiments to ensure the most influential factors have been selected. Consider expanding the range of the factor levels to capture a more significant response.
-
-
Investigate Factor Interactions: this compound models are effective at identifying interactions between factors. If significant interaction terms are not included in the model, its predictive power will be diminished.
-
Action: Ensure that all potential two-factor interactions are included in the initial model. Use statistical analysis (e.g., ANOVA) to identify and retain only the significant interaction terms.
-
-
Check for Multicollinearity: Multicollinearity occurs when two or more predictor variables are highly correlated. This can inflate the variance of the regression coefficients and make the model unstable.
-
Action: Calculate the Variance Inflation Factor (VIF) for each model term. A VIF value greater than 10 is often considered an indication of significant multicollinearity. If multicollinearity is present, you may need to remove one of the correlated factors or use a different modeling technique.
-
-
Increase the Number of Experimental Runs: In some cases, a small number of experimental runs may not be sufficient to accurately estimate the model coefficients.
-
Action: Augmenting the design with additional, strategically chosen experimental runs can improve the precision of the coefficient estimates and increase the R-squared values.
-
Quantitative Impact of Improving Model Coefficients:
| Troubleshooting Action | Initial Model | Improved Model |
| Expanding Factor Ranges | R² = 0.65, Adj R² = 0.58 | R² = 0.88, Adj R² = 0.85 |
| Including Interaction Terms | R² = 0.72, Adj R² = 0.66 | R² = 0.91, Adj R² = 0.89 |
Experimental Protocols
This section provides detailed methodologies for key experiments aimed at improving the predictability of this compound models.
Protocol 1: Step-by-Step Box-Behnken Design Experiment for Optimizing a Drug Formulation
This protocol outlines the process for using a this compound to optimize the formulation of a fast-dissolving tablet.[1]
1. Define the Objective and Responses:
- Objective: To determine the optimal formulation for a fast-dissolving tablet with the minimum disintegration time.
- Response: Disintegration Time (in seconds).
2. Select Factors and Levels:
- Based on preliminary studies, the following factors are chosen:
- Factor A: Superdisintegrant concentration (e.g., Croscarmellose Sodium: 1-5%)
- Factor B: Binder concentration (e.g., HPMC K4M: 5-15%)
- Factor C: Diluent concentration (e.g., Spray-dried Lactose: 20-40%)
- The levels for the this compound will be coded as -1 (low), 0 (middle), and +1 (high).
3. Generate the this compound Matrix:
- Use statistical software (e.g., Design-Expert®, Minitab) to generate a 3-factor, 3-level this compound. This will typically result in 15 or 17 experimental runs, including center points.[1]
4. Prepare the Formulations and Perform Experiments:
- Prepare the 17 tablet formulations according to the combinations specified in the this compound matrix.
- Measure the disintegration time for each formulation in triplicate.
5. Analyze the Data and Fit the Model:
- Enter the average disintegration time for each run into the statistical software.
- Fit a quadratic model to the data.
- Use ANOVA to evaluate the significance of the model and individual terms (main effects, interactions, and quadratic effects).
6. Model Validation and Optimization:
- Examine the diagnostic plots (e.g., residuals, lack of fit) to validate the model.
- Use the model to generate response surfaces and contour plots to visualize the relationship between the factors and the response.
- Utilize the optimization feature of the software to identify the factor settings that will result in the minimum disintegration time.
7. Confirmation Experiment:
- Prepare a new batch of tablets using the optimized factor settings.
- Measure the disintegration time and compare it to the value predicted by the model to confirm the model's predictability.
Protocol 2: Optimizing Cell Culture Media Composition using this compound
This protocol details the use of a this compound to optimize the composition of cell culture media for enhanced biomass production.[2][3][4][5][6]
1. Define Objective and Response:
- Objective: To maximize the biomass yield of a specific cell line.
- Response: Biomass concentration (g/L).
2. Select Factors and Levels:
- Identify key media components from literature and preliminary experiments:
- Factor A: Glucose concentration (e.g., 2-6 g/L)
- Factor B: Glutamine concentration (e.g., 0.5-1.5 g/L)
- Factor C: Serum concentration (e.g., 5-15%)
3. Generate the this compound Matrix:
- Create a 3-factor, 3-level this compound using statistical software.
4. Cell Culture Experiments:
- Prepare the different media formulations as defined by the this compound matrix.
- Seed the cells at a constant density in each medium.
- Culture the cells under controlled conditions (temperature, CO2, humidity).
- Harvest the cells at a predetermined time point and measure the biomass concentration.
5. Data Analysis and Modeling:
- Input the biomass concentration data into the software.
- Fit a quadratic model and perform ANOVA.
- Identify the significant factors and interactions affecting biomass yield.
6. Optimization and Verification:
- Use the model to predict the optimal media composition for maximum biomass.
- Conduct a verification experiment using the optimized medium to confirm the model's prediction.
Signaling Pathway and Experimental Workflow Diagrams
Visualizing the relationships between experimental factors and biological pathways is crucial for understanding the system being modeled.
References
Refining factor levels for a more effective Box-Behnken Design
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to help researchers, scientists, and drug development professionals refine factor levels for a more effective Box-Behnken Design (BBD).
Frequently Asked Questions (FAQs)
Q1: What is a Box-Behnken Design and why is it used?
A Box-Behnken Design (this compound) is a type of response surface methodology (RSM) design used for process optimization.[1] It is particularly useful for fitting a quadratic model to the response data.[2] Key features of a this compound include:
-
Three Levels Per Factor: Each factor is studied at three equally spaced levels, typically coded as -1, 0, and +1.[2][3]
-
No Extreme Corner Points: Unlike some other designs, BBDs do not include experimental runs where all factors are at their extreme (high or low) levels simultaneously.[1][4] This is advantageous when such combinations are expensive, dangerous, or technically infeasible.[4][5]
-
Efficiency: BBDs often require fewer experimental runs compared to central composite designs (CCDs) for the same number of factors, making them a cost-effective option.[6]
BBDs are widely used in various fields, including pharmaceutical product development and engineering, to explore the relationships between process variables and responses, and to identify optimal operating conditions.[1][7]
Q2: How do I select the initial low, middle, and high levels for my factors?
Selecting appropriate initial factor levels is critical for the success of your experiment. The initial levels should be chosen based on a combination of prior knowledge, literature review, and preliminary screening experiments.
| Method | Description | Data Source |
| Prior Knowledge & Literature | Utilize existing data from previous experiments, subject matter expertise, and published research to identify a likely operating range for each factor. | Internal reports, scientific papers, patents. |
| One-Factor-at-a-Time (OFAT) | A simple preliminary method where one factor is varied while others are held constant to quickly identify a region of interest. | Initial laboratory experiments. |
| Screening Designs | Use a fractional factorial or Plackett-Burman design to efficiently identify the most significant factors and their approximate effective ranges before conducting a this compound. | Statistically designed screening experiments. |
For example, in a study to optimize the formulation of immediate-release tablets, factors such as the concentration of superdisintegrants like crosslinked carboxymethyl cellulose (B213188) (CMC) and sodium starch glycolate (B3277807) (SSG) would be selected based on their known properties and typical usage levels in similar formulations.[8]
Q3: What are the signs of poorly chosen factor levels?
Poorly chosen factor levels can lead to an ineffective model. Key indicators include:
-
A "flat" response surface: This occurs when none of the factors, their interactions, or their quadratic terms are statistically significant. It suggests that the chosen ranges are too narrow and do not have a strong effect on the response.
-
Optimal conditions at the edge of the design space: If the model predicts that the optimal response is at the extreme high or low level of one or more factors, it indicates that the true optimum may lie outside the current experimental region.
-
Poor model fit statistics: A low R-squared value, a high p-value for the overall model, or a significant lack-of-fit test can all point to issues with the chosen factor ranges.
Troubleshooting Guides
Problem: My response surface is flat, and no factors are significant.
This is a common issue that typically arises when the factor ranges are too narrow. The variation in the factors is not large enough to cause a significant change in the response.
Solution Workflow:
Caption: Troubleshooting workflow for a flat response surface.
Experimental Protocol: Expanding Factor Ranges
-
Analyze Current Ranges: Review the initial low (-1) and high (+1) levels for each factor.
-
Determine New Ranges: Based on scientific understanding of the system, expand the ranges. A common strategy is to widen the range by 50-100%. For example, if the initial range for "Temperature" was 50°C to 70°C, a revised range might be 40°C to 80°C.
-
Define New Levels: Set the new low and high values in your statistical software. The software will automatically calculate the new center point (0 level).[9][10]
-
Generate New Design: Create a new Box-Behnken design with the updated factor levels.
-
Execute Experiments: Perform the experimental runs in a randomized order as specified by the new design.
-
Analyze Results: Analyze the data from the new experiment to fit a new response surface model.
Problem: The model predicts the optimum is outside the tested range.
This indicates that the initial experimental region was not centered around the true optimum.
Solution: Sequential Experimentation
A sequential approach is often the most effective way to move towards the optimal region. The results of the first this compound are used to define the factor levels for a second this compound.
Logical Relationship for Sequential this compound:
Caption: Sequential experimentation workflow for optimization.
Refined Factor Level Selection Table:
This table illustrates how factor levels might be adjusted for a second experiment based on the results of an initial this compound where the optimum for Factor A was predicted to be higher and for Factor B to be lower.
| Factor | Initial this compound Levels | Predicted Optimum from Initial this compound | Refined this compound Levels |
| Factor A: Temperature (°C) | 80 (-1), 90 (0), 100 (+1) | 105°C | 95 (-1), 105 (0), 115 (+1) |
| Factor B: pH | 6.0 (-1), 6.5 (0), 7.0 (+1) | 5.8 | 5.5 (-1), 6.0 (0), 6.5 (+1) |
| Factor C: Concentration (%) | 10 (-1), 15 (0), 20 (+1) | 14.5% | 10 (-1), 15 (0), 20 (+1) |
Experimental Protocols
Protocol: Initial Screening for Factor Ranges using a Factorial Design
-
Identify Potential Factors: Based on literature and expertise, list all factors that could potentially influence the response.
-
Select a Screening Design: Choose a 2-level fractional factorial design to efficiently study a large number of factors.
-
Define Broad Factor Levels: Set two widely spaced levels (low and high) for each factor to maximize the chance of detecting an effect.
-
Execute the Design: Run the experiments in a randomized order.
-
Analyze the Effects: Use statistical software to calculate the main effects and identify the factors that have a statistically significant impact on the response.
-
Select Factors for this compound: The most significant factors are chosen for further optimization using a Box-Behnken Design. The levels from the screening design can help define the initial range for the this compound. Factors with a large effect size will likely require a broad range in the this compound, while those with smaller effects can be explored over a narrower range.
References
- 1. product-development-engineers.com [product-development-engineers.com]
- 2. Box–Behnken design - Wikipedia [en.wikipedia.org]
- 3. m.youtube.com [m.youtube.com]
- 4. jmp.com [jmp.com]
- 5. 11.2.2 - Box-Behnken Designs | STAT 503 [online.stat.psu.edu]
- 6. What are response surface designs, central composite designs, and Box-Behnken designs? - Minitab [support.minitab.com]
- 7. Box–Behnken Designs and Their Applications in Pharmaceutical Product Development [ouci.dntb.gov.ua]
- 8. bibliotekanauki.pl [bibliotekanauki.pl]
- 9. Creating Box-Behnken Designs [help.synthesisplatform.net]
- 10. Specify the factors for Create Response Surface Design (Box-Behnken) - Minitab [support.minitab.com]
Technical Support Center: Box-Behnken Design Curvature Issues
Welcome to the technical support center for Response Surface Methodology (RSM). This guide provides troubleshooting assistance for researchers, scientists, and drug development professionals encountering curvature issues when using Box-Behnken Designs (BBD).
Frequently Asked Questions (FAQs)
Q1: What does "significant curvature" mean in my Box-Behnken model?
A: Significant curvature indicates that the relationship between your experimental factors and the measured response is not linear. A straight line or a flat plane cannot adequately describe how the response changes as you vary the factors. Instead, the response surface has a noticeable curve or peak. Box-Behnken designs are specifically chosen to detect and model this type of second-order (quadratic) relationship.[1][2][3][4] If curvature is statistically significant, it suggests that your quadratic model is likely appropriate and can help you find optimal process conditions.[5]
Q2: How do I statistically detect curvature and assess my model's fit?
A: You can diagnose curvature and model adequacy by examining the Analysis of Variance (ANOVA) table generated by your statistical software. Look for these key indicators:
-
Model p-value: A low p-value (typically < 0.05) for the overall model indicates that your factors significantly affect the response.
-
Quadratic Terms: Low p-values for the squared terms (e.g., A², B²) in your model confirm that curvature is a significant component of the response.[2]
-
Lack-of-Fit Test: This is a crucial test for model adequacy.[6][7] It compares the variability of your data around the fitted model to the "pure" variability from your replicated runs (usually the center points).[7][8]
-
A non-significant Lack-of-Fit p-value (> 0.05) is desirable. It means the model fits the data well, and any deviation is likely due to random noise.[8]
-
A significant Lack-of-Fit p-value (< 0.05) is a red flag. It indicates that the quadratic model is not fully capturing the complex relationship in your data, even if the overall model is significant.[6][7]
-
Q3: My ANOVA table shows a significant model and significant curvature, but also a significant "Lack of Fit." What should I do?
A: This is a common but challenging situation. It means your model is capturing a major part of the data's structure (the curvature), but there are still systematic variations that it can't explain.[6] Here is a step-by-step troubleshooting workflow:
-
Consider a Response Transformation: The relationship might be better modeled on a different scale. Use a Box-Cox plot to see if a transformation of your response variable (e.g., log, square root) could stabilize the variance and improve the model fit.[7]
-
Evaluate Higher-Order Models: The significant Lack of Fit may suggest that a more complex, third-order relationship exists.[6][9][10][11] Standard BBDs are not designed to estimate these higher-order terms efficiently.[9][11] Your next step might be to augment the design.
Q4: What are the next steps if my quadratic model is inadequate due to complex curvature?
A: If you've ruled out outliers and transformations, and the Lack of Fit is still significant, the underlying response surface is likely more complex than a quadratic model can handle. The recommended action is to augment your existing Box-Behnken design with additional experimental runs. This allows you to fit a higher-order (e.g., third-order) polynomial model without discarding your initial data.[9][10][11] Augmenting the design with factorial and axial points can provide the necessary data to estimate these more complex effects.[10][11]
Data Presentation: Interpreting ANOVA Results
The table below illustrates hypothetical ANOVA results for two scenarios to help you identify key metrics for diagnosing model fit and curvature.
| Source of Variation | Scenario A: Good Fit | Scenario B: Poor Fit (Significant Lack of Fit) | ||
| F-Value | p-Value | F-Value | p-Value | |
| Model | 55.60 | < 0.0001 | 45.10 | < 0.0001 |
| Linear Terms (A, B, C) | 65.30 | < 0.0001 | 58.20 | < 0.0001 |
| Quadratic Terms (A², B², C²) | 70.80 | < 0.0001 | 62.50 | < 0.0001 |
| Interaction Terms (AB, AC, BC) | 30.50 | 0.0015 | 15.30 | 0.0150 |
| Lack of Fit | 2.15 | 0.1580 | 12.50 | 0.0021 |
| Pure Error | - | - | - | - |
| R-squared (R²) | 0.9810 | 0.9750 | ||
| Adjusted R-squared | 0.9650 | 0.9530 |
Interpretation:
-
In Scenario A , the model, curvature terms, and interactions are significant. Crucially, the Lack of Fit is not significant (p > 0.05), indicating the quadratic model is an excellent fit for the data.
-
In Scenario B , while the model and curvature terms are significant, the Lack of Fit is also highly significant (p < 0.05). This suggests the quadratic model is missing key information and further investigation is required.[6][7]
Troubleshooting Workflow Diagram
The following diagram outlines the logical steps for diagnosing and addressing curvature issues in a Box-Behnken design.
Caption: Troubleshooting workflow for Box-Behnken Design curvature analysis.
Experimental Protocol: Augmenting a this compound
If a quadratic model is insufficient, you can augment your this compound to fit a third-order model. This protocol describes how to add factorial and axial points to an existing 3-factor this compound.
Objective: To gather sufficient data points to estimate the terms in a third-order polynomial model (e.g., A³, ABC, A²B).
Background: A standard this compound for 3 factors has 12 non-center points and several center points. To fit a third-order model, additional points are required. This is achieved by adding a 2³ full factorial design (8 corner points) and a 3-factor axial design (6 star points).[10][11]
Materials:
-
Original Box-Behnken design data.
-
Statistical software package (e.g., Minitab, JMP, Design-Expert).
-
Experimental system and materials.
Methodology:
-
Define Factor Levels: Your original this compound has three levels: -1 (low), 0 (center), and +1 (high). The new points will introduce two additional levels, -α and +α for axial points, and potentially new levels -a and +a for factorial points.[10][11] A common choice is α = 1.682 for rotatability in a 3-factor design, and a=1.
-
Add 2³ Factorial Points: These are the "corner" points of the design space that are absent in a this compound.[4][12] The experimental runs to be added are (in coded units):
-
(-1, -1, -1)
-
(+1, -1, -1)
-
(-1, +1, -1)
-
(+1, +1, -1)
-
(-1, -1, +1)
-
(+1, -1, +1)
-
(-1, +1, +1)
-
(+1, +1, +1)
-
-
Add Axial (Star) Points: These points extend beyond the original factorial space to provide more information about the model's behavior at the extremes.[1] The runs to be added are (in coded units, where α is the axial distance):
-
(-α, 0, 0)
-
(+α, 0, 0)
-
(0, -α, 0)
-
(0, +α, 0)
-
(0, 0, -α)
-
(0, 0, +α)
-
-
Perform New Experiments: Conduct the 14 new experimental runs (8 factorial + 6 axial) in a randomized order to prevent systematic bias.
-
Combine and Analyze Data: Combine the data from your original this compound with the data from the new runs. Use your statistical software to fit a third-order (cubic) response surface model to the complete dataset.
-
Evaluate the New Model: Assess the significance of the third-order terms in the new ANOVA table. Check if the Lack of Fit has become non-significant, indicating that the augmented model better explains the experimental behavior.
References
- 1. What are response surface designs, central composite designs, and Box-Behnken designs? - Minitab [support.minitab.com]
- 2. 6sigma.us [6sigma.us]
- 3. The Open Educator - 4. Box-Behnken Response Surface Methodology [theopeneducator.com]
- 4. product-development-engineers.com [product-development-engineers.com]
- 5. Response Surface Methods for Optimization [help.reliasoft.com]
- 6. researchgate.net [researchgate.net]
- 7. Stat-Ease [statease.com]
- 8. The Open Educator - 5. Lack-of-fit Test [theopeneducator.com]
- 9. tandfonline.com [tandfonline.com]
- 10. tandfonline.com [tandfonline.com]
- 11. researchgate.net [researchgate.net]
- 12. researchgate.net [researchgate.net]
Technical Support Center: Applying Box-Behnken Design in Biological Systems
This technical support center provides troubleshooting guidance and frequently asked questions (FAQs) for researchers, scientists, and drug development professionals applying Box-Behnken Design (BBD) to biological experiments.
Frequently Asked Questions (FAQs)
Q1: What is a Box-Behnken Design (this compound) and when should I use it for my biological experiments?
A1: Box-Behnken Design is a type of response surface methodology (RSM) that helps in optimizing processes by identifying the relationships between several independent variables and one or more response variables.[1][2] It is particularly useful for fitting a quadratic model.[1] In biological systems, this compound is advantageous when extreme combinations of factors (the "corners" of the experimental design) could lead to undesirable outcomes, such as cell death or complete inhibition of a biological process.[3] this compound avoids these extreme points by positioning experimental runs at the midpoint of each edge and the center of the design space.[3][4] It is an efficient design, often requiring fewer experimental runs compared to other designs like Central Composite Design (CCD), especially for three or four variables.[3]
Q2: What are the main limitations of using this compound in a biological context?
A2: While beneficial, this compound has some limitations in biological research. A key limitation is that it is not well-suited for sequential experiments, as it does not have an embedded factorial design.[4] This means you cannot build upon a smaller initial experiment to expand the design. Additionally, a this compound does not exist for only two factors.[3] The inherent variability or "noise" in biological systems can also pose a challenge to obtaining a robust model with a good fit.[5][6]
Q3: How many experimental runs are required for a this compound?
A3: The number of experimental runs in a this compound depends on the number of factors being investigated and the number of center points. The formula for the number of runs is N = 2k(k-1) + C₀, where 'k' is the number of factors and 'C₀' is the number of center points. Center points are crucial for estimating experimental error and checking for curvature. A minimum of 3-5 center points is generally recommended for a reliable estimation of pure error.
Q4: Can I screen for important factors using a this compound?
A4: this compound is primarily an optimization design, not a screening design. It is most effective when you have already identified the critical factors and want to find their optimal levels. For screening a large number of potential factors, other designs like Plackett-Burman or fractional factorial designs are more appropriate. Once the significant factors are identified, a this compound can be employed to optimize their interactions and determine the optimal conditions.[7]
Troubleshooting Guide
Problem 1: My this compound model has a low R-squared value, indicating a poor fit to my biological data.
-
Possible Cause: High biological variability or "noise" is common in biological systems and can obscure the true relationship between factors and responses.[5][6][8] This inherent stochasticity in processes like gene expression and cell signaling can lead to a poor model fit.[6][8]
-
Troubleshooting Steps:
-
Increase the number of center points: This provides a better estimate of the pure experimental error, which can help in assessing the significance of the lack-of-fit.
-
Re-evaluate the factor ranges: The chosen ranges for your factors might not be where the most significant changes in the response occur. Consider preliminary single-factor experiments to identify more appropriate ranges.
-
Check for outliers: Biological experiments are prone to outliers.[9][10] Use statistical tools to identify and potentially remove outliers. However, any removal of data points should be justified and documented.[10]
-
Consider data transformation: Transforming the response variable (e.g., using a logarithmic or square root transformation) can sometimes help to stabilize the variance and improve the model fit.
-
Add more experimental runs: Increasing the total number of runs can improve the power of the experiment to detect significant effects.[11]
-
Problem 2: The predicted optimum from my this compound is not reproducible in validation experiments.
-
Possible Cause: The model may be overfitted, or there might be uncontrolled sources of variation in your experimental system. The inherent variability in biological systems can also contribute to this issue.[8]
-
Troubleshooting Steps:
-
Verify the model's lack-of-fit: A significant lack-of-fit indicates that the chosen model (e.g., quadratic) does not adequately describe the true relationship.[11] In such cases, a higher-order model might be necessary, or the experimental region may need to be redefined.
-
Conduct multiple validation runs: Perform several experiments at the predicted optimal conditions to confirm the result. A single validation run may not be sufficient due to biological variability.
-
Examine the response surface: Look at the shape of the response surface around the predicted optimum. A flat surface indicates that the response is not very sensitive to changes in the factors in that region, which can lead to variability in the validation experiments.
-
Review your experimental protocol for consistency: Ensure that all experimental conditions (e.g., cell passage number, reagent lots, incubation times) are kept as consistent as possible between the initial this compound runs and the validation experiments.
-
Problem 3: I am observing significant cell death or inhibition at some of the experimental points.
-
Possible Cause: Even though this compound avoids the extreme corners of the design space, some combinations of factor levels might still be detrimental to the biological system.
-
Troubleshooting Steps:
-
Narrow the factor ranges: If you have an idea of which factor or combination of factors is causing the issue, reduce the range for those factors.
-
Utilize prior knowledge: Incorporate existing knowledge about the biological system to set more realistic and less extreme factor levels.
-
Consider a different design: If toxicity or inhibition is a major concern even within the this compound framework, a more conservative experimental design might be necessary.
-
Data Presentation: Comparison of this compound Applications in Biological Systems
The following tables summarize quantitative data from studies that have successfully applied Box-Behnken Design for optimization in various biological applications.
Table 1: Optimization of Monoclonal Antibody (mAb) Production in CHO Cells
| Factor | Low Level | High Level | Optimal Level | Response (mAb Titer) |
| Temperature (°C) | 35 | 39 | 36.8 | \multirow{3}{*}{Increased from 1.2 g/L to 2.5 g/L} |
| pH | 6.8 | 7.2 | 7.05 | |
| Dissolved Oxygen (%) | 30 | 70 | 55 |
Table 2: Optimization of Enzyme Activity
| Factor | Low Level | High Level | Optimal Level | Response (Enzyme Activity) |
| Temperature (°C) | 40 | 60 | 47 | \multirow{3}{*}{2-fold increase in specific activity} |
| pH | 6 | 8 | 7.5 | |
| Substrate Conc. (g/L) | 2 | 6 | 4 |
Table 3: Optimization of Microbial Fermentation for Secondary Metabolite Production
| Factor | Low Level | High Level | Optimal Level | Response (Metabolite Yield) |
| Glucose Conc. (g/L) | 20 | 40 | 32.5 | \multirow{3}{*}{1.7-fold increase in yield} |
| Incubation Time (h) | 48 | 96 | 72 | |
| Inoculum Size (%) | 2 | 6 | 4.5 |
Experimental Protocols
Protocol 1: Step-by-Step Methodology for Media Optimization in CHO Cell Culture using this compound
-
Factor and Level Selection:
-
Identify 3-4 critical media components to optimize (e.g., glucose concentration, a key amino acid concentration, and a growth factor concentration).
-
Define a low, medium, and high level for each factor based on preliminary experiments or literature review.
-
-
Experimental Design Generation:
-
Use statistical software (e.g., JMP, Design-Expert, Minitab) to generate a Box-Behnken design with the selected factors and levels. Include at least 3-5 center points.
-
-
Cell Culture and Experiment Execution:
-
Thaw a vial of CHO cells and expand them in a standard culture medium. Ensure a consistent cell passage number for all experimental runs.
-
Prepare the different media formulations according to the this compound matrix.
-
Inoculate the cells at a consistent seeding density into shake flasks or a multi-well plate containing the different media formulations.
-
Incubate the cultures under standard conditions (e.g., 37°C, 5% CO₂, shaking at 120 rpm).
-
Monitor cell growth and viability daily using a cell counter.
-
-
Response Measurement:
-
At the end of the culture period (e.g., day 7 or 10), harvest the cell culture supernatant.
-
Measure the response of interest, which could be product titer (e.g., monoclonal antibody concentration measured by ELISA or HPLC), viable cell density, or another relevant metric.
-
-
Data Analysis:
-
Enter the response data into the statistical software.
-
Fit a quadratic model to the data and perform an Analysis of Variance (ANOVA) to determine the statistical significance of the model and individual factors.
-
Analyze the response surface plots and contour plots to visualize the relationship between the factors and the response.
-
Identify the optimal levels of the factors that maximize (or minimize) the response.
-
-
Model Validation:
-
Perform additional experiments at the predicted optimal conditions to validate the model's prediction.
-
Protocol 2: Detailed Methodology for Enzyme Immobilization Optimization using this compound
-
Factor and Level Selection:
-
Choose 3-4 key parameters for immobilization (e.g., enzyme concentration, support material concentration, cross-linker concentration, pH).
-
Set three levels (low, medium, high) for each factor.
-
-
Experimental Design Generation:
-
Generate a this compound matrix using statistical software, including center points.
-
-
Enzyme Immobilization Procedure:
-
For each experimental run in the this compound matrix, prepare the immobilization mixture according to the specified factor levels.
-
For example, in a typical protocol, this would involve:
-
Preparing a buffer solution at the specified pH.
-
Adding the support material and allowing it to swell or activate.
-
Adding the enzyme solution at the specified concentration.
-
Adding the cross-linking agent at the specified concentration.
-
-
Allow the immobilization reaction to proceed for a defined period under controlled temperature and agitation.
-
After immobilization, wash the immobilized enzyme thoroughly to remove any unbound enzyme.
-
-
Response Measurement:
-
Measure the activity of the immobilized enzyme using a standard enzyme assay.
-
Also, measure the protein concentration in the washing solution to determine the amount of unbound enzyme, which can be used to calculate the immobilization efficiency.
-
The primary response is typically the activity of the immobilized enzyme.
-
-
Data Analysis:
-
Analyze the data using statistical software to fit a quadratic model and perform ANOVA.
-
Generate response surface plots to understand the effects of the factors on enzyme activity.
-
Determine the optimal conditions for immobilization.
-
-
Model Validation:
-
Prepare the immobilized enzyme using the predicted optimal conditions and measure its activity to confirm the model's accuracy.
-
Mandatory Visualizations
References
- 1. Box–Behnken design - Wikipedia [en.wikipedia.org]
- 2. biorxiv.org [biorxiv.org]
- 3. 11.2.2 - Box-Behnken Designs | STAT 503 [online.stat.psu.edu]
- 4. The Open Educator - 4. Box-Behnken Response Surface Methodology [theopeneducator.com]
- 5. The Relationship Between Biological Noise and Its Application: Understanding System Failures and Suggesting a Method to Enhance Functionality Based on the Constrained Disorder Principle | MDPI [mdpi.com]
- 6. researchgate.net [researchgate.net]
- 7. A statistical approach to improve compound screening in cell culture media - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Challenges in measuring and understanding biological noise - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Outliers and robust response surface designs [vtechworks.lib.vt.edu]
- 10. Outlier detection [molmine.com]
- 11. researchgate.net [researchgate.net]
Technical Support Center: Improving Process Robustness with Box-Behnken Design (BBD)
This guide provides troubleshooting advice and frequently asked questions for researchers, scientists, and drug development professionals using Box-Behnken Design (BBD) to enhance process robustness.
Frequently Asked Questions (FAQs)
Q1: What is a Box-Behnken Design (this compound) and why is it used for process robustness?
A Box-Behnken Design (this compound) is a type of response surface methodology (RSM) that helps in understanding and optimizing processes.[1][2] It is particularly useful for fitting a quadratic model to the response data. For robustness studies, this compound is advantageous because it allows for the evaluation of the effects of multiple factors on a process outcome with fewer experimental runs than a full factorial design.[3][4] Its structure intentionally avoids extreme experimental conditions where all factors are at their highest or lowest levels simultaneously, which is crucial for maintaining process stability and safety.
Key features of this compound include:
-
Each factor is studied at three levels: low (-1), medium (0), and high (+1).[5][6]
-
It is a spherical, rotatable, or nearly rotatable design, meaning the prediction variance is consistent at points equidistant from the center of the design space.[7][8]
-
It does not include corner points, which can be beneficial when extreme combinations of factor levels are impractical or unsafe.[3][9][10]
Q2: What is the difference between a Box-Behnken Design (this compound) and a Central Composite Design (CCD)?
This compound and Central Composite Design (CCD) are both popular response surface designs, but they have different structures and applications. A key difference is that CCDs include points at the "corners" of the design space as well as "star" or "axial" points that can extend beyond the original factor ranges.[9] In contrast, BBDs place experimental runs at the midpoints of the edges of the design space and do not have axial points.[9]
| Feature | Box-Behnken Design (this compound) | Central Composite Design (CCD) |
| Experimental Points | Located at the midpoints of the edges of the design space and the center.[9] | Includes factorial (corner) points, axial (star) points, and center points.[7] |
| Factor Levels | Always three levels per factor.[3] | Can have up to five levels per factor.[3] |
| Extreme Combinations | Avoids combinations where all factors are at their extreme settings.[3][9] | Includes runs with all factors at their extreme settings. |
| Experimental Runs | Generally requires fewer runs for three factors.[11] | Can require more runs, especially with a high number of factors. |
| Sequential Experimentation | Not well-suited for sequential experiments as it doesn't have an embedded factorial design.[3] | Can be built upon a previous factorial experiment.[3] |
Q3: How do I choose the factors and their levels for a this compound experiment?
Choosing the right factors and their corresponding levels is critical for a successful this compound experiment.
-
Factor Selection: Start by identifying the critical process parameters (CPPs) that are likely to have a significant impact on your critical quality attributes (CQAs). This can be based on prior knowledge, risk assessment, or screening experiments like Plackett-Burman designs.
-
Level Selection: For each factor, you need to define three levels: low (-1), medium (0), and high (+1).
-
The low and high levels should be chosen to be far enough apart to observe a significant effect but still within a range that is operationally feasible and safe. These levels should represent the extremes of your expected operating range.
-
The medium level (center point) should be the midpoint between the low and high levels and ideally represent the current or expected optimal operating condition.
-
Q4: My this compound model shows a significant lack of fit. What should I do?
A significant "lack of fit" indicates that your chosen model (typically a quadratic model for this compound) does not adequately describe the relationship between the factors and the response. Here are some troubleshooting steps:
-
Check for Outliers: Examine your data for any experimental runs that have unusual results. An outlier can significantly skew the model.
-
Consider Higher-Order Models: While this compound is designed for a second-order (quadratic) model, the true relationship might be more complex.[5] You may need to consider augmenting the design to fit a third-order model, although this is less common.[12]
-
Transform the Response: Applying a transformation (e.g., logarithmic, square root) to your response variable can sometimes help to linearize the relationship and improve the model fit.
-
Re-evaluate Factor Ranges: The chosen ranges for your factors might be too wide, leading to complex, non-quadratic behavior. Consider running a new experiment with narrower factor ranges.
Troubleshooting Guide
| Issue | Possible Cause(s) | Recommended Action(s) |
| Poor Model Prediction (Low R-squared) | - Insignificant factors included in the model.- High experimental error.- Incorrect model chosen. | - Use statistical software to identify and remove insignificant terms from the model.- Increase the number of center points to get a better estimate of the experimental error.- Ensure the quadratic model is appropriate for the response surface. |
| Difficulty in Finding an Optimum | - The optimal conditions are outside the experimental region.- The response surface is flat (no significant curvature). | - Expand the factor ranges in a subsequent experiment.- If the goal is optimization and no curvature is found, a first-order model from a factorial design might be sufficient. |
| Missing Data Points | - Experimental failure or loss of a sample. | - If only a few data points are missing, some statistical software can still analyze the incomplete dataset. For a more robust approach, methods like minimaxloss design can be constructed to be resilient to missing observations.[12][13] |
| Inconsistent Results at Center Points | - High process variability.- Uncontrolled sources of variation. | - Investigate the experimental setup for sources of noise.- Ensure consistent execution of the experimental protocol.- A large variance in center points can indicate that the process is not stable. |
Experimental Protocol: Using this compound for Process Robustness
This protocol outlines the steps to design, execute, and analyze a this compound experiment to establish a robust process.
Objective: To identify a "design space" where the process is insensitive to small variations in the input parameters.
Step 1: Define Factors and Responses
-
Identify 3 to 7 critical process parameters (factors) that could affect your process.
-
Define the critical quality attributes (responses) you want to measure.
-
Establish the low (-1), center (0), and high (+1) levels for each factor.
Step 2: Generate the Experimental Design
-
Use statistical software (e.g., JMP, Minitab, Design-Expert) to create the this compound matrix. The number of runs will depend on the number of factors.
Table of Box-Behnken Design Runs for 3 and 4 Factors
| Number of Factors | Number of Runs |
| 3 | 15 (including 3 center points) |
| 4 | 27 (including 3 center points) |
Step 3: Execute the Experiments
-
Randomize the order of the experimental runs to minimize the impact of time-dependent variables.
-
Carefully follow the experimental protocol for each run as defined by the design matrix.
-
Record the responses for each run.
Step 4: Analyze the Results
-
Fit a quadratic model to the experimental data for each response.
-
Use Analysis of Variance (ANOVA) to determine the statistical significance of the model and its terms (linear, interaction, and quadratic).
-
Examine the model's goodness of fit using metrics like R-squared, adjusted R-squared, and the lack-of-fit test.
Step 5: Interpret the Response Surface
-
Generate response surface plots (3D surfaces and 2D contour plots) to visualize the relationship between the factors and the response.
-
Identify the region in the contour plot where the response is consistently within the desired specifications. This is your robust operating region or "design space."
Step 6: Confirm the Robustness
-
Select a few points within the identified robust region and perform confirmation runs.
-
The results of these runs should match the model's predictions and meet your quality criteria.
Visualizations
Caption: Experimental workflow for improving process robustness using Box-Behnken Design.
Caption: Logical diagram for troubleshooting common issues in this compound data analysis.
References
- 1. youtube.com [youtube.com]
- 2. dergipark.org.tr [dergipark.org.tr]
- 3. What are response surface designs, central composite designs, and Box-Behnken designs? - Minitab [support.minitab.com]
- 4. The Open Educator - 4. Box-Behnken Response Surface Methodology [theopeneducator.com]
- 5. Box–Behnken design - Wikipedia [en.wikipedia.org]
- 6. engineerfix.com [engineerfix.com]
- 7. fiveable.me [fiveable.me]
- 8. jmp.com [jmp.com]
- 9. Central Composite Design vs. Box-Behnken Design [experimentaldesignhub.com]
- 10. 11.2.2 - Box-Behnken Designs | STAT 503 [online.stat.psu.edu]
- 11. 5.3.3.6.3. Comparisons of response surface designs [itl.nist.gov]
- 12. jirss.irstat.ir [jirss.irstat.ir]
- 13. researchgate.net [researchgate.net]
Validation & Comparative
A Researcher's Guide to Experimental Validation of Box-Behnken Design Models
For researchers and drug development professionals, optimizing complex processes is paramount. Response Surface Methodology (RSM) is a critical statistical tool for this, and the Box-Behnken Design (BBD) is a particularly efficient RSM design.[1][2] this compound is adept at fitting a quadratic model, making it suitable for identifying optimal process parameters without requiring an excessive number of experimental runs.[3][4] This guide provides a comprehensive comparison of this compound with other designs and outlines a detailed protocol for its experimental validation.
Comparative Analysis of Experimental Designs
Box-Behnken Designs are a type of response surface design that efficiently estimates first- and second-order coefficients of a quadratic model.[3][5] Unlike Central Composite Designs (CCDs), BBDs do not include runs where all factors are at their extreme settings, which can be advantageous when such conditions are dangerous, expensive, or infeasible.[6][7] This makes this compound particularly useful in fields like chemical engineering and pharmaceutical development where process safety is a primary concern.[8][9]
| Feature | Box-Behnken Design (this compound) | Central Composite Design (CCD) | Full Factorial Design |
| Primary Use | Optimization, fitting second-order (quadratic) models.[7] | Optimization, fitting second-order models.[10] | Screening, estimating main effects and interactions. |
| Number of Levels | 3 levels per factor (-1, 0, +1).[8] | 3 to 5 levels, including "star" points that can be outside the original range.[5] | Typically 2 or 3 levels per factor. |
| Experimental Runs | Fewer runs than CCD for 3 or 4 factors.[11] | Generally more runs than this compound for the same number of factors.[5] | Requires the largest number of runs (levels^factors). |
| Design Points | Excludes corner points; all points are within the safe operating zone.[6][12] | Includes corner points and axial (star) points which may be outside the factor range.[9] | Includes all combinations of factor levels, including all corners. |
| Sequentiality | Not suited for sequential experiments as it's not based on an embedded factorial design.[5][7] | Well-suited for sequential experimentation; can be built upon a factorial design.[11] | Can be run in blocks and augmented for sequential experiments. |
| Rotatability | Rotatable or nearly rotatable, ensuring consistent prediction variance at points equidistant from the center.[10][12] | Can be made fully rotatable.[13] | Not inherently rotatable. |
Experimental Validation Workflow
The validation of a this compound model is a crucial step to ensure its predictive accuracy and robustness before implementation.[1] The process involves a systematic approach from initial design to final confirmation.
Caption: Workflow for the experimental validation of a Box-Behnken Design model.
Detailed Experimental Protocol
This protocol outlines the steps to generate and validate a this compound model for optimizing a hypothetical drug formulation process.
1. Define Experimental Scope:
-
Objective: To maximize drug dissolution rate.
-
Response Variable (Y): Percentage of drug dissolved in 30 minutes.
-
Independent Factors (Variables):
-
X1: Concentration of Polymer A (mg)
-
X2: Compression Force (kN)
-
X3: Lubricant Amount (mg)
-
2. Generate the Box-Behnken Design Matrix:
-
Using statistical software (e.g., JMP, Minitab), generate a this compound for the three factors.[13] This typically results in a 15-run or 17-run experiment, including center points.
-
Establish three levels for each factor: low (-1), medium (0), and high (+1).
3. Conduct Experiments:
-
Randomize the run order to minimize the impact of nuisance variables.
-
Execute each of the 15 experimental runs according to the conditions specified in the design matrix.
-
Perform multiple replicates (e.g., 3) for the center point runs to get a reliable estimate of the experimental error.
-
Carefully measure and record the response (drug dissolution %) for each run.
4. Model Fitting and Statistical Analysis:
-
Fit the experimental data to a second-order polynomial equation using multiple regression analysis.
-
Perform an Analysis of Variance (ANOVA) to assess the statistical significance of the model and individual terms (linear, interaction, and quadratic).[14][15] A p-value less than 0.05 is typically considered significant.[16]
-
Evaluate the model's goodness-of-fit using metrics like the coefficient of determination (R²), adjusted R², and predicted R².[16]
-
Analyze the residuals to ensure they are normally distributed and have constant variance.
5. Confirmation and Validation:
-
Use the generated model to predict the optimal operating conditions that maximize the drug dissolution rate.
-
Perform a set of confirmation experiments (typically 3-5 runs) at these predicted optimal conditions.[17][18]
-
Measure the experimental response and compare it to the model's predicted response.
Data Presentation for Model Validation
The core of the validation lies in comparing the predicted outcomes from the model with actual experimental results.
Table 2: Predicted vs. Experimental Validation Data
| Run | Polymer A (mg) | Compression Force (kN) | Lubricant (mg) | Predicted Dissolution (%) | Experimental Dissolution (%) | Residual |
| Optimum 1 | 55 | 11.5 | 2.5 | 94.5 | 93.8 | -0.7 |
| Optimum 2 | 55 | 11.5 | 2.5 | 94.5 | 95.1 | +0.6 |
| Optimum 3 | 55 | 11.5 | 2.5 | 94.5 | 94.2 | -0.3 |
| Check Point 1 | 50 | 10.0 | 3.0 | 89.2 | 88.5 | -0.7 |
| Check Point 2 | 60 | 13.0 | 2.0 | 91.7 | 92.5 | +0.8 |
A validated model will show close agreement between the predicted and experimental values, with small residuals. This confirmation step is essential to verify that the model is a reliable representation of the process and can be used for optimization and prediction.[17][19]
References
- 1. 6sigma.us [6sigma.us]
- 2. thescipub.com [thescipub.com]
- 3. Box–Behnken design - Wikipedia [en.wikipedia.org]
- 4. Box-Behnken Design Calculator - numiqo [numiqo.com]
- 5. What are response surface designs, central composite designs, and Box-Behnken designs? - Minitab [support.minitab.com]
- 6. Central Composite Design vs. Box-Behnken Design [experimentaldesignhub.com]
- 7. jmp.com [jmp.com]
- 8. engineerfix.com [engineerfix.com]
- 9. 11.2.2 - Box-Behnken Designs | STAT 503 [online.stat.psu.edu]
- 10. fiveable.me [fiveable.me]
- 11. researchgate.net [researchgate.net]
- 12. product-development-engineers.com [product-development-engineers.com]
- 13. The Open Educator - 4. Box-Behnken Response Surface Methodology [theopeneducator.com]
- 14. researchgate.net [researchgate.net]
- 15. Box-Behnken Designs: Analysis Results [help.synthesisplatform.net]
- 16. Application of Box-Behnken experimental design and response surface methodology for selecting the optimum RP-HPLC conditions for the simultaneous determination of methocarbamol, indomethacin and betamethasone in their pharmaceutical dosage form - PMC [pmc.ncbi.nlm.nih.gov]
- 17. tandfonline.com [tandfonline.com]
- 18. osti.gov [osti.gov]
- 19. researchgate.net [researchgate.net]
Navigating Experimental Optimization: A Comparative Guide to Box-Behnken and Central Composite Designs
In the landscape of experimental design and process optimization, particularly within scientific research and drug development, selecting the appropriate methodology is paramount to achieving robust and efficient outcomes. Among the most powerful tools in Response Surface Methodology (RSM) are the Box-Behnken Design (BBD) and the Central Composite Design (CCD). This guide provides an objective comparison of these two designs, supported by experimental data, to aid researchers, scientists, and drug development professionals in making informed decisions for their optimization studies.
Core Design Philosophies: A Tale of Two Geometries
At their core, this compound and CCD differ fundamentally in their geometric structure and the selection of experimental points within the design space.
Central Composite Design (CCD) is built upon a factorial or fractional factorial design, augmented with center points and "star" or "axial" points.[1][2] These axial points extend beyond the established high and low levels of the factors, allowing for the estimation of curvature in the response surface.[1][2] This design inherently requires five levels for each factor being investigated.[2]
Box-Behnken Design (this compound) , in contrast, utilizes a three-level design where the experimental points are located at the midpoints of the edges of the design space and at the center.[3] A key characteristic of this compound is that it does not include experimental runs at the extreme corners of the design space, where all factors are simultaneously at their highest or lowest levels.[4] This makes this compound a particularly advantageous choice when such extreme combinations could lead to unsafe operating conditions or undesirable outcomes.[4]
At a Glance: Key Differences Summarized
| Feature | Box-Behnken Design (this compound) | Central Composite Design (CCD) |
| Number of Factor Levels | 3 | 5 |
| Experimental Points | Midpoints of edges, center point | Factorial points (corners), axial (star) points, center point |
| Inclusion of Extreme Points | No | Yes |
| Suitability for Sequential Experiments | Less suited | Well-suited (can augment a factorial design) |
| Number of Runs (for k factors) | Generally more economical for k < 5 | Can be more extensive, especially as k increases |
| Rotatability | Nearly rotatable | Can be made rotatable |
Efficiency in a Numbers Game: Comparing Experimental Runs
The number of required experimental runs is a critical consideration in terms of time, cost, and resource allocation. While the exact number can vary based on the number of center points, a general comparison reveals a key advantage of this compound for a smaller number of factors.
| Number of Factors (k) | Typical Number of Runs for this compound | Typical Number of Runs for CCD |
| 3 | 15 | 20 |
| 4 | 27 | 30 |
| 5 | 46 | 52 |
| 6 | 54 | 91 |
| 7 | 62 | 143 |
Note: The number of runs for CCD can vary depending on the choice of the factorial portion (full or fractional) and the number of center points.
As the number of factors increases beyond four, the economic advantage of this compound in terms of fewer experimental runs becomes more pronounced.[5]
Performance in Practice: Experimental Showdowns
Direct comparative studies across various applications provide valuable insights into the practical performance of this compound and CCD.
Case Study 1: Optimization of Nanoparticle Formulation
In a study focused on optimizing a fullerene nanoemulsion for transdermal delivery, both this compound and CCD were employed to investigate the effects of homogenization rate, sonication amplitude, and sonication time on particle size, ζ-potential, and viscosity.[6]
| Design | Predicted Optimal Particle Size (nm) | Predicted Optimal ζ-potential (mV) | Predicted Optimal Viscosity (pascal seconds) | R² for Particle Size | R² for ζ-potential | R² for Viscosity |
| This compound | 148.5 | -55.2 | 39.9 | 0.9625 | 0.9736 | 0.9281 |
| CCD | 152.5 | -52.6 | 44.6 | 0.9765 | 0.9734 | 0.9569 |
The results indicated that the CCD model provided a slightly better fit for predicting particle size and viscosity, as evidenced by the higher R² values.[6] The study concluded that for this particular application, the CCD was a better design.[6]
Case Study 2: Biosynthesis of Silver Nanoparticles
A comparative study on the optimization of silver particle biosynthesis using Curcuma longa extract evaluated both this compound and CCD. The investigation focused on the concentration of the extract, temperature, time, and silver nitrate (B79036) concentration.[7]
| Design | Predicted Absorbance | Actual Absorbance | Residual Standard Error (%) | R² |
| This compound | 1.100 | ~1.1 | 0.30 | 0.9889 |
| CCD | 1.078 | ~1.1 | 2.52 | 0.9448 |
In this case, the this compound model demonstrated higher accuracy and reliability, with its predicted absorbance value being closer to the actual experimental value and a significantly lower residual standard error.[7] The study concluded that the this compound model was more accurate for this optimization process.[7]
Experimental Protocols: A Step-by-Step Overview
To provide a practical understanding of how these designs are implemented, the following are generalized experimental protocols for the optimization of a hypothetical nanoparticle formulation.
Box-Behnken Design: Experimental Workflow for Nanoparticle Optimization
Caption: Workflow for nanoparticle optimization using a Box-Behnken Design.
Detailed Methodology (this compound Example):
-
Factor and Level Selection: Based on preliminary studies, identify the critical process parameters (e.g., polymer concentration, drug amount, and surfactant concentration) and define three levels for each: low (-1), medium (0), and high (+1).
-
Design Matrix Generation: Use statistical software to generate the this compound matrix, which will specify the combination of factor levels for each experimental run. For three factors, this typically results in 15 runs, including three center point replications.[8]
-
Nanoparticle Preparation: Prepare the nanoparticle formulations according to the randomized experimental run order. A common method is the emulsion solvent evaporation technique.[9]
-
Dissolve the polymer and drug in a suitable organic solvent.
-
Disperse this organic phase in an aqueous phase containing a surfactant to form an emulsion.
-
Evaporate the organic solvent to allow for nanoparticle formation.
-
-
Response Measurement: Characterize the resulting nanoparticles for the desired responses, such as particle size (using dynamic light scattering) and encapsulation efficiency (using spectrophotometry or chromatography).
-
Data Analysis: Fit the experimental data to a second-order polynomial equation. Analyze the response surfaces and contour plots to understand the effects of the factors and their interactions on the responses.
-
Optimization and Validation: Use the model to predict the optimal conditions to achieve the desired nanoparticle characteristics. Prepare and characterize a new batch of nanoparticles at these optimal settings to validate the model's predictive capability.
Central Composite Design: Experimental Workflow for Tablet Disintegration Optimization
Caption: Workflow for optimizing tablet disintegration using a Central Composite Design.
Detailed Methodology (CCD Example):
-
Initial Factorial Design: Begin with a two-level full or fractional factorial design to screen for the most significant factors affecting tablet disintegration (e.g., concentration of a superdisintegrant and a binder).
-
Augmentation to CCD: If the initial screening indicates significant curvature in the response, augment the factorial design to a CCD by adding axial and center points. The axial points will be set at levels beyond the initial low and high settings.
-
Tablet Preparation: Prepare the tablet formulations according to the complete CCD matrix using a method such as direct compression.[10] This involves blending the active pharmaceutical ingredient (API) with the excipients (superdisintegrant, binder, filler, lubricant) and compressing the blend into tablets.
-
Response Evaluation: Evaluate the prepared tablets for the key responses, such as disintegration time (using a disintegration tester) and tablet hardness (using a hardness tester).[10]
-
Model Fitting and Analysis: Fit the experimental data to a quadratic model. Use analysis of variance (ANOVA) to determine the significance of the model and individual terms.
-
Design Space and Optimization: Generate response surface plots to visualize the relationship between the factors and the responses. Define a design space where the desired quality attributes are met and identify the optimal formulation.
-
Confirmation: Prepare and test the optimized tablet formulation to confirm the model's predictions.
Making the Right Choice: this compound vs. CCD
The decision to use a Box-Behnken Design or a Central Composite Design should be based on the specific objectives of the study, the nature of the factors being investigated, and any practical constraints.
Choose Box-Behnken Design when:
-
The experimental system is well-understood, and a quadratic model is anticipated.[1]
-
Extreme combinations of factors are undesirable, unsafe, or impossible to test.[4]
-
Efficiency in the number of experimental runs for three to five factors is a primary concern.[5]
Choose Central Composite Design when:
-
Sequential experimentation is advantageous; you can start with a factorial design and add points later if needed.[1]
-
A rotatable design is important for uniform prediction precision.[4]
-
Exploring the extremes of the factor ranges is necessary to fully understand the design space.
-
The process is not well-understood, and the flexibility to build upon initial screening experiments is valuable.[11]
References
- 1. Central Composite Design (CCD) [2021.help.altair.com]
- 2. 5.3.3.6.1. Central Composite Designs (CCD) [itl.nist.gov]
- 3. Central Composite Design vs. Box-Behnken Design [experimentaldesignhub.com]
- 4. What are response surface designs, central composite designs, and Box-Behnken designs? - Minitab [support.minitab.com]
- 5. 5.3.3.6.3. Comparisons of response surface designs [itl.nist.gov]
- 6. dovepress.com [dovepress.com]
- 7. eprints.usm.my [eprints.usm.my]
- 8. pdfs.semanticscholar.org [pdfs.semanticscholar.org]
- 9. Formulation and Optimization of Polymeric Nanoparticles for Intranasal Delivery of Lorazepam Using Box-Behnken Design: In Vitro and In Vivo Evaluation - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Optimization of fast disintegration tablets using pullulan as diluent by central composite experimental design - PMC [pmc.ncbi.nlm.nih.gov]
- 11. researchgate.net [researchgate.net]
Navigating Experimental Optimization: A Comparative Guide to Box-Behnken Design and Full Factorial Design
In the landscape of experimental optimization, particularly within scientific research and drug development, the choice of an appropriate experimental design is paramount to achieving robust and efficient results. Among the various methodologies, Box-Behnken Design (BBD) and Full Factorial Design (FFD) stand out as powerful tools. This guide provides an objective comparison of their performance, supported by experimental data, to aid researchers in selecting the optimal design for their specific needs.
At a Glance: Key Differences
| Feature | Box-Behnken Design (this compound) | Full Factorial Design (FFD) |
| Primary Use | Optimization, fitting quadratic models | Screening, identifying main effects and interactions |
| Number of Factor Levels | 3 (low, medium, high) | Typically 2 (low, high), but can be more |
| Experimental Runs | More economical, fewer runs than FFD for 3+ factors | Exhaustive, number of runs increases exponentially with factors |
| Detection of Effects | Main effects, interaction effects, and quadratic effects | Main effects and all interaction effects |
| Experimental Region | Spherical, avoids extreme factor combinations | Cubical, includes all corner points (extreme combinations) |
| Sequential Experimentation | Not well-suited | Can be built sequentially |
Deeper Dive: A Quantitative Comparison
A study comparing different experimental designs for the optimization of a chromatographic method provides valuable insights into the practical differences between this compound and FFD. The objective was to optimize the separation of fluconazole (B54011) and its impurities by varying three factors: the percentage of acetonitrile (B52724) in the mobile phase, the concentration of the aqueous phase buffer, and the pH of the aqueous phase.
Table 1: Comparison of Experimental Runs
| Design | Number of Factors | Number of Levels | Total Experimental Runs |
| Box-Behnken Design | 3 | 3 | 15 (including 3 center points) |
| Full Factorial Design | 3 | 3 | 27 |
| Full Factorial Design | 3 | 2 | 8 |
As the data indicates, for three factors, a three-level full factorial design requires significantly more experimental runs than a Box-Behnken design. Even a two-level full factorial design, while more economical than a three-level FFD, provides less information about potential non-linear relationships.
Experimental Protocols
To understand the basis of the comparative data, the following generalized experimental protocol for the chromatographic method development is provided:
Objective: To determine the optimal chromatographic conditions for the separation of a drug substance from its impurities.
Factors (Independent Variables):
-
X1: Percentage of organic solvent (e.g., Acetonitrile) in the mobile phase.
-
X2: Concentration of the buffer in the aqueous phase (e.g., Ammonium Formate).
-
X3: pH of the aqueous phase.
Responses (Dependent Variables):
-
Y1: Resolution between critical peak pairs.
-
Y2: Retention time of the main peak.
-
Y3: Tailing factor of the main peak.
Box-Behnken Design Protocol:
-
Define the low (-1), medium (0), and high (+1) levels for each of the three factors.
-
Construct the experimental design matrix consisting of 15 runs as specified by the this compound. This includes combinations of factors at their low and high levels, with one factor held at the center level, and replicate runs at the center point of all factors.
-
Perform the 15 chromatographic experiments in a randomized order to minimize the effect of systematic errors.
-
Record the responses (resolution, retention time, tailing factor) for each experimental run.
-
Analyze the data using response surface methodology to fit a quadratic model and identify the optimal conditions.
Full Factorial Design (3-Level) Protocol:
-
Define the low (-1), medium (0), and high (+1) levels for each of the three factors.
-
Construct the experimental design matrix consisting of all 27 possible combinations of the factor levels (33).
-
Perform the 27 chromatographic experiments in a randomized order.
-
Record the responses for each experimental run.
-
Analyze the data to determine the main effects, two-factor interactions, and three-factor interactions, as well as quadratic effects.
Visualizing the Designs
The fundamental difference in the structure of these designs can be visualized to better understand their application.
Caption: High-level workflow comparison of Full Factorial and Box-Behnken Designs.
The logical relationship between the number of factors and the required experimental runs further highlights their differences.
Caption: Relationship between the number of factors and experimental runs for each design.
Core Strengths and Weaknesses
Full Factorial Design (FFD)
Strengths:
-
Comprehensive Analysis: FFD allows for the estimation of all main effects and all possible interaction effects between the factors.[1][2] This provides a complete picture of the system being studied.
-
Ideal for Screening: It is an excellent choice for screening experiments where the goal is to identify the most influential factors and their interactions from a larger set of variables.[1]
Weaknesses:
-
Resource Intensive: The number of required experimental runs grows exponentially with the number of factors, making it impractical and costly for a large number of factors.[1][3]
-
Includes Extreme Conditions: FFD tests all combinations of factor levels, including the "corner points" where all factors are at their extreme high or low levels simultaneously.[4] This may not be feasible or safe in all experimental settings.
Box-Behnken Design (this compound)
Strengths:
-
Efficiency: this compound requires significantly fewer experimental runs compared to a three-level FFD, especially as the number of factors increases.[4][5] This saves time, resources, and materials.
-
Avoids Extreme Conditions: A key advantage of this compound is that it does not include experimental runs at the extreme vertices of the experimental space.[4][5] This is particularly beneficial when extreme combinations of factors could lead to undesirable or unsafe outcomes.
-
Effective for Optimization: this compound is a response surface methodology design that is highly effective for optimizing processes and fitting a quadratic model to describe the response surface.[6][7]
Weaknesses:
-
Not for Screening All Interactions: While it can estimate main and two-factor interaction effects, it does not estimate all possible higher-order interactions like a full factorial design.
-
Not Ideal for Sequential Experimentation: Unlike FFDs, BBDs do not have an embedded factorial design, making them less suitable for sequential experimentation where experiments are built upon previous ones.[5]
Conclusion: Making the Right Choice
The decision between a Box-Behnken Design and a Full Factorial Design hinges on the primary objective of the experiment and the number of factors being investigated.
-
Choose Full Factorial Design when:
-
The primary goal is to screen a moderate number of factors to identify the most significant ones and understand all possible interactions.
-
The number of factors is relatively small (typically 2-4), and the resources for a larger number of experiments are available.
-
Investigating the behavior of the system at extreme factor combinations is important and safe.
-
-
Choose Box-Behnken Design when:
-
The primary goal is to optimize a process with a known set of 3 to 7 important factors.
-
It is necessary to model curvature in the response surface.
-
Budgetary and time constraints are a concern, and a more economical design is required.
-
Extreme combinations of factor levels must be avoided due to safety or other practical constraints.
-
For researchers and professionals in drug development, where optimization of formulations and processes is critical, the Box-Behnken design often presents a more efficient and practical approach once the key factors have been identified.[6][8] Conversely, in the early stages of development, a full factorial design can be invaluable for thoroughly screening potential variables and their complex interplay.[2][9] Ultimately, a clear understanding of the experimental goals and constraints will guide the selection of the most appropriate and powerful design.
References
- 1. Full Factorial Design | Air Academy Associates [airacad.com]
- 2. 6sigma.us [6sigma.us]
- 3. rjpdft.com [rjpdft.com]
- 4. product-development-engineers.com [product-development-engineers.com]
- 5. What are response surface designs, central composite designs, and Box-Behnken designs? - Minitab [support.minitab.com]
- 6. Box–Behnken Designs and Their Applications in Pharmaceutical Product Development | springerprofessional.de [springerprofessional.de]
- 7. Box–Behnken design - Wikipedia [en.wikipedia.org]
- 8. researchgate.net [researchgate.net]
- 9. Factorial Design: Biostatistics and Research Methodology - Pharmacy Infoline [pharmacyinfoline.com]
A Researcher's Guide to Statistical Validation of Box-Behnken Designs
For researchers, scientists, and drug development professionals, the optimization of processes and formulations is a critical endeavor. The Box-Behnken Design (BBD) offers an efficient and robust statistical approach for this purpose. However, the successful implementation of a this compound hinges on its rigorous statistical validation. This guide provides a comprehensive comparison of the statistical validation of a Box-Behnken Design against alternative designs, supported by experimental data and detailed protocols.
Unveiling the Box-Behnken Design
A Box-Behnken Design is a type of response surface methodology (RSM) that is used to explore the relationship between several explanatory variables and one or more response variables. Unlike other designs, BBDs do not include runs at the extreme corners of the experimental region.[1] This makes them particularly advantageous when the corner points represent extreme or unsafe experimental conditions.
The Cornerstone of Validation: Statistical Analysis
The validation of a Box-Behnken Design is a multi-faceted process that relies on several key statistical tools to ensure the reliability and predictive power of the resulting model. The primary methods include Analysis of Variance (ANOVA), assessing the goodness of fit with the coefficient of determination (R²), and scrutinizing the model's adequacy through a lack-of-fit test and residual analysis.
Experimental Protocol for Statistical Validation of a Box-Behnken Design:
-
Model Fitting: A second-order polynomial model is typically fitted to the experimental data obtained from the this compound. This quadratic model can capture the curvature in the response surface.[2]
-
Analysis of Variance (ANOVA): ANOVA is performed to assess the overall significance of the model and the significance of individual model terms (linear, quadratic, and interaction).[3][4] Key outputs from the ANOVA table include:
-
F-value: A high F-value indicates that the model is significant.
-
p-value: A p-value less than 0.05 is generally considered to indicate that the model or a model term is statistically significant.[5]
-
-
Goodness of Fit (R²): The coefficient of determination (R²) and the adjusted R² are examined. An R² value close to 1 suggests that the model explains a large proportion of the variability in the response.
-
Lack-of-Fit Test: This test determines if the model adequately describes the functional relationship between the factors and the response. A non-significant lack-of-fit (p-value > 0.05) is desirable, indicating that the model is a good fit.
-
Residual Analysis: The residuals (the differences between the observed and predicted values) are analyzed to check the assumptions of the model. This is typically done by examining residual plots:
-
Normal Probability Plot of Residuals: The points should fall approximately along a straight line, indicating that the residuals are normally distributed.[6]
-
Residuals vs. Predicted Values: The points should be randomly scattered around the zero line, indicating constant variance.[6]
-
Residuals vs. Run Order: This plot helps to identify any time-dependent trends in the residuals.
-
Comparative Analysis: Box-Behnken Design vs. Central Composite Design
A popular alternative to the Box-Behnken Design is the Central Composite Design (CCD). While both are used for response surface modeling, they have distinct characteristics that influence their suitability for different applications.
| Feature | Box-Behnken Design (this compound) | Central Composite Design (CCD) |
| Experimental Points | Three levels per factor (-1, 0, +1). Does not include corner points.[1] | Five levels per factor for rotatable designs. Includes corner points and "star" points outside the main experimental region.[1] |
| Number of Runs | Generally requires fewer experimental runs than a CCD for the same number of factors.[7] | Can require a larger number of runs, especially as the number of factors increases.[1] |
| Suitability | Ideal for avoiding extreme factor combinations, which may be expensive or unsafe.[1] | Useful for sequential experimentation and when a full understanding of the entire experimental region, including the corners, is necessary.[1] |
| Design Flexibility | Less flexible for sequential experimentation as it doesn't have an embedded factorial design.[8] | More flexible for sequential experimentation as it can be built upon a factorial design.[1] |
Illustrative Case Study: Optimization of a Chemical Reaction
To illustrate the statistical validation process, consider a hypothetical case study on optimizing the yield of a chemical reaction with three factors: Temperature (°C), Pressure (psi), and Reaction Time (hours).
| Source | DF | Sum of Squares | Mean Square | F-value | p-value |
| Model | 9 | 289.45 | 32.16 | 29.83 | < 0.0001 |
| Linear | 3 | 154.21 | 51.40 | 47.67 | < 0.0001 |
| Quadratic | 3 | 112.88 | 37.63 | 34.89 | < 0.0001 |
| Interaction | 3 | 22.36 | 7.45 | 6.91 | 0.0125 |
| Residual | 5 | 5.39 | 1.08 | ||
| Lack of Fit | 3 | 4.12 | 1.37 | 2.14 | 0.2987 |
| Pure Error | 2 | 1.27 | 0.64 | ||
| R² | 0.9823 | Adj R² | 0.9504 |
In this example, the this compound model is highly significant (p < 0.0001) with a high R² value. The lack-of-fit is not significant (p > 0.05), indicating a good model fit.
| Source | DF | Sum of Squares | Mean Square | F-value | p-value |
| Model | 9 | 315.78 | 35.09 | 32.15 | < 0.0001 |
| Linear | 3 | 168.92 | 56.31 | 51.59 | < 0.0001 |
| Quadratic | 3 | 121.45 | 40.48 | 37.09 | < 0.0001 |
| Interaction | 3 | 25.41 | 8.47 | 7.76 | 0.0058 |
| Residual | 10 | 10.92 | 1.09 | ||
| Lack of Fit | 5 | 8.67 | 1.73 | 3.09 | 0.1245 |
| Pure Error | 5 | 2.25 | 0.45 | ||
| R² | 0.9665 | Adj R² | 0.9364 |
The hypothetical CCD also shows a significant model. A direct comparison of the F-values and R² might suggest slight differences in model fit, which would need to be considered in the context of the experimental goals and constraints.
Visualizing the Validation Workflow
The logical flow of statistically validating a Box-Behnken Design can be visualized as follows:
Conclusion
The statistical validation of a Box-Behnken Design is a critical step in ensuring the development of a robust and predictive model for process or formulation optimization. Through a systematic approach involving ANOVA, goodness-of-fit tests, and residual analysis, researchers can have confidence in their experimental findings. When choosing between a this compound and an alternative like a CCD, a careful consideration of the experimental goals, safety constraints, and the need for sequential experimentation is paramount. Both designs, when properly validated, are powerful tools in the arsenal (B13267) of the modern researcher.
References
- 1. Central Composite Design vs. Box-Behnken Design [experimentaldesignhub.com]
- 2. The Open Educator - 4. Box-Behnken Response Surface Methodology [theopeneducator.com]
- 3. The Open Educator - 3. Analyze and Explain Response Surface Methodology [theopeneducator.com]
- 4. youtube.com [youtube.com]
- 5. Analysis of variance table for Analyze Response Surface Design - Minitab [support.minitab.com]
- 6. Box-Behnken Designs: Plots [help.synthesisplatform.net]
- 7. 11.2.2 - Box-Behnken Designs | STAT 503 [online.stat.psu.edu]
- 8. youtube.com [youtube.com]
Confirming Optimal Conditions Predicted by Box-Behnken Design: A Comparative Guide
For researchers, scientists, and drug development professionals leveraging the statistical power of Box-Behnken Design (BBD), the prediction of optimal process conditions is a pivotal milestone. However, the journey from theoretical optimum to validated process reality requires a robust confirmation phase. This guide provides a comprehensive comparison of methodologies to experimentally validate the optimal conditions predicted by your this compound model, ensuring the reliability and reproducibility of your findings.
Experimental Validation: A Step-by-Step Protocol
The cornerstone of confirming this compound predictions is the execution of well-designed validation experiments. The primary objective is to compare the experimental response at the predicted optimal factor settings with the response value forecasted by the this compound model.
Experimental Protocol for Confirmation Runs
-
Identify Optimal Conditions: From your this compound analysis, pinpoint the precise values for each factor that are predicted to yield the optimal response.
-
Prepare for Experimentation: Set up your experimental apparatus and prepare all necessary reagents and materials as you would for any of the initial this compound runs.
-
Conduct Confirmation Experiments: Run a minimum of three to five replicate experiments at the exact optimal conditions predicted by the model.[1] Running triplicates is a common and statistically sound practice.
-
Record Observations: Meticulously measure and record the response variable for each replicate experiment.
-
Calculate Experimental Mean and Standard Deviation: Determine the average response from your replicate runs and calculate the standard deviation to understand the variability in your experimental results.
Data Presentation: Predicted vs. Experimental Outcomes
Clear and concise data presentation is crucial for a direct comparison between the predicted and experimental results. Structured tables allow for an at-a-glance assessment of the model's predictive accuracy.
Table 1: Predicted Optimal Conditions and Response
| Factor | Predicted Optimal Value |
| Factor A (e.g., Temperature, °C) | Value A |
| Factor B (e.g., pH) | Value B |
| Factor C (e.g., Concentration, M) | Value C |
| Predicted Response | Predicted Value |
Table 2: Experimental Confirmation Results
| Replicate | Experimental Response |
| 1 | Result 1 |
| 2 | Result 2 |
| 3 | Result 3 |
| Experimental Mean | Average of Results |
| Standard Deviation | Calculated SD |
Table 3: Comparative Analysis
| Metric | Value |
| Predicted Response | Predicted Value |
| Experimental Mean Response | Average of Results |
| Difference (%) | Calculate Percentage Difference |
Statistical Analysis: Validating the Prediction
A visual comparison of the predicted and experimental mean is insightful, but statistical testing provides a more rigorous validation of your this compound model's predictive power. Two primary statistical approaches are recommended: the one-sample t-test and the confidence interval method.
Method 1: One-Sample t-Test
The one-sample t-test is an effective tool to determine if the mean of your experimental results is statistically different from the predicted optimal response.
Experimental Protocol:
-
State the Hypotheses:
-
Null Hypothesis (H₀): There is no significant difference between the experimental mean and the predicted response.
-
Alternative Hypothesis (H₁): There is a significant difference between the experimental mean and the predicted response.
-
-
Calculate the t-statistic: Use the formula for the one-sample t-test.
-
Determine the p-value: Based on the calculated t-statistic and the degrees of freedom (number of replicates - 1), find the corresponding p-value.
-
-
If the p-value is greater than your chosen significance level (commonly α = 0.05), you fail to reject the null hypothesis. This indicates that your this compound model's prediction is statistically validated by your experimental results.
-
If the p-value is less than 0.05, you reject the null hypothesis, suggesting a statistically significant difference between the predicted and experimental outcomes. This may warrant a re-evaluation of your model or experimental setup.
-
Method 2: Confidence Interval
Calculating a confidence interval for your experimental mean provides a range within which the true mean of the response is likely to fall.
Experimental Protocol:
-
Calculate the Confidence Interval: Based on your experimental mean, standard deviation, and the number of replicates, calculate the 95% confidence interval.
-
Compare with the Predicted Value:
-
If the predicted response value from your this compound model falls within the calculated 95% confidence interval of the experimental mean, it provides strong evidence that the model is a reliable predictor of the optimal conditions.
-
If the predicted value falls outside the confidence interval, it suggests that the model may not be accurately predicting the response at the optimal settings.
-
Workflow for Confirming this compound-Predicted Optimal Conditions
References
A Comparative Guide to Assessing the Reliability of Box-Behnken Design Results
An Objective Look at Ensuring Model Validity in Response Surface Methodology
For researchers and drug development professionals, establishing the reliability of experimental models is paramount. The Box-Behnken Design (BBD) is a highly efficient tool within Response Surface Methodology (RSM) for process optimization.[1][2] It is specifically engineered to fit a quadratic model, which is often the primary goal in optimization studies.[3][4] This guide provides a comparative framework for assessing the reliability of this compound results, offering detailed experimental protocols and contrasting this compound with its common alternative, the Central Composite Design (CCD).
Comparing Box-Behnken Design (this compound) and Central Composite Design (CCD)
This compound and CCD are two leading designs in RSM for building second-order (quadratic) models.[3] However, they differ significantly in their structure and experimental efficiency. This compound is known for requiring fewer experimental runs compared to CCD for the same number of factors, which can lead to considerable savings in time and resources.[5][6]
A key advantage of this compound is its avoidance of extreme experimental conditions.[7][8] The design places points on the midpoints of the edges of the design space, ensuring that no run combines all factors at their highest or lowest levels simultaneously.[6][8] This is particularly beneficial in pharmaceutical and chemical research where extreme combinations of factors like temperature and pressure could be unsafe or lead to impractical results.[8] In contrast, CCD includes axial points that lie outside the main "cube" of factorial points, which may be impossible to conduct within safe operating limits.[5][6]
However, CCD possesses a distinct advantage in its flexibility for sequential experimentation.[8] Because CCD is built upon a factorial or fractional factorial design, an experiment can be started with a simpler first-order model and later augmented with axial and center points to explore curvature if needed.[6][8] this compound does not have this embedded factorial design.[5]
| Feature | Box-Behnken Design (this compound) | Central Composite Design (CCD) | Rationale & Impact on Reliability |
| Number of Levels per Factor | 3 (-1, 0, +1) | Up to 5 (-α, -1, 0, +1, +α) | This compound's three-level structure is sufficient for a quadratic model.[3][4] CCD's five levels can test up to a fourth-order model, offering more insight into complex, unknown processes.[3] |
| Experimental Runs (3 Factors) | 15 (including 3 center points) | 20 (including 6 center points) | This compound is more economical, reducing experimental load and potential for error.[6] |
| Experimental Runs (4 Factors) | 27 (including 3 center points) | 30 (including 6 center points) | The efficiency of this compound continues as the number of factors increases.[7] |
| Design Point Location | Sits within the defined factor range; no extreme corner points.[5][8] | Includes corner points and axial points that can be outside the factor range.[5][6] | This compound provides a safer operating zone, potentially increasing the practicality and reliability of experimental runs.[5][8] |
| Sequential Experimentation | Not well-suited as it lacks an embedded factorial design.[5] | Excellent; can be built sequentially from a factorial design.[6][8] | CCD allows for a staged approach, which can be more reliable when exploring new processes where curvature is uncertain.[8] |
| Rotatability | Nearly rotatable or rotatable for specific designs.[3] | Can be made fully rotatable.[3][5] | Rotatable designs provide constant prediction variance at points equidistant from the center, which is a desirable property for uniform model reliability across the design space.[5] |
Experimental Protocol: A Step-by-Step Guide to Validating this compound Model Reliability
Assessing the reliability of a model generated from a Box-Behnken Design involves a rigorous, multi-step statistical validation process. The goal is to ensure the model accurately represents the experimental data and has strong predictive power.
Caption: Workflow for Assessing this compound Model Reliability.
1. Experimental Design and Execution:
-
Define Factors and Levels: Clearly identify the independent variables (factors) and their respective low, medium, and high levels (-1, 0, +1).
-
Generate this compound Matrix: Use statistical software to create the Box-Behnken design matrix, which dictates the specific combinations of factor levels for each experimental run.
-
Perform Experiments: Conduct the experiments in a randomized order as specified by the design matrix to prevent systematic bias.
2. Model Fitting and Statistical Significance:
-
Fit Data to a Quadratic Model: Use the experimental results to fit a second-order polynomial equation.
-
Perform Analysis of Variance (ANOVA): ANOVA is crucial for determining the statistical significance of the model and its individual terms (linear, interaction, and quadratic).[9][10]
-
Evaluate Model Significance: A p-value for the model less than 0.05 indicates that the model is statistically significant and can effectively predict the response.[10]
3. Reliability and Diagnostic Assessment:
-
Assess Goodness-of-Fit:
-
R-squared (R²): This value indicates the proportion of variation in the response that is explained by the model. A higher value (closer to 1.0) is generally better.[9]
-
Adjusted R²: This is a modified R² that accounts for the number of terms in the model. It is a more reliable indicator of model quality than R².[9]
-
Predicted R²: This value measures how well the model predicts responses for new observations. A close agreement between Adjusted R² and Predicted R² is essential for a reliable model.[11]
-
-
Check the Lack-of-Fit Test: This test compares the variability of the model to the variability of the pure error from replicated runs.[12] A non-significant Lack-of-Fit (p-value > 0.10) is desirable, as it indicates that the model fits the data well.[12][13] A significant Lack-of-Fit suggests the model may be inadequate.[12][14]
-
Analyze Diagnostic Plots: Visual inspection of residual plots is critical for verifying model assumptions.[15][16]
-
Predicted vs. Actual Plot: Points should cluster tightly around a 45-degree line, indicating a strong correlation between the model's predictions and the actual experimental results.[11]
-
Residuals vs. Fitted Values Plot: This plot should show a random scatter of points around the zero line.[17] Any discernible pattern (like a curve or a funnel shape) suggests a violation of model assumptions, such as non-linearity or non-constant variance.[18][19]
-
Normal Q-Q Plot: The residuals should fall approximately along a straight line, which confirms the assumption that the residuals are normally distributed.[17][20]
-
Visualizing Design Differences
The fundamental difference in the experimental points chosen by this compound and CCD can be visualized to understand their respective strengths. This compound focuses on combinations at the center and midpoints of the edges, whereas CCD explores the corners and extends beyond the primary design space with axial points.
Caption: Comparison of this compound and CCD Design Points.
By following this comprehensive guide, researchers can confidently assess the reliability of their Box-Behnken Design results, ensuring that the derived models are robust, predictive, and suitable for process optimization in critical applications like drug development.
References
- 1. Response Surface Methodology - Overview & Applications | Neural Concept [neuralconcept.com]
- 2. Box-Behnken Design Calculator - numiqo [numiqo.com]
- 3. The Open Educator - 4. Box-Behnken Response Surface Methodology [theopeneducator.com]
- 4. Box–Behnken design - Wikipedia [en.wikipedia.org]
- 5. What are response surface designs, central composite designs, and Box-Behnken designs? - Minitab [support.minitab.com]
- 6. researchgate.net [researchgate.net]
- 7. 11.2.2 - Box-Behnken Designs | STAT 503 [online.stat.psu.edu]
- 8. youtube.com [youtube.com]
- 9. Box-Behnken Designs: Analysis Results [help.synthesisplatform.net]
- 10. researchgate.net [researchgate.net]
- 11. researchgate.net [researchgate.net]
- 12. Stat-Ease [statease.com]
- 13. The Open Educator - 5. Lack-of-fit Test [theopeneducator.com]
- 14. statisticshowto.com [statisticshowto.com]
- 15. 6sigma.us [6sigma.us]
- 16. medium.com [medium.com]
- 17. Diagnostic Plots for Model Evaluation - GeeksforGeeks [geeksforgeeks.org]
- 18. Interpreting Residual Plots to Improve Your Regression [qualtrics.com]
- 19. Part 7 Diagnostics and Transformations | MGMTFT 402 - Data and Decisions [bookdown.org]
- 20. scribd.com [scribd.com]
Navigating Formulation Variables: A Guide to Sensitivity Analysis of Box-Behnken Design Models in Drug Development
For researchers, scientists, and drug development professionals seeking to optimize their formulations, understanding the influence of each variable is paramount. A Box-Behnken Design (BBD) is a powerful statistical tool for this optimization. However, the true strength of this model is unlocked through a thorough sensitivity analysis, which quantifies how small changes in input factors affect the desired outcomes. This guide provides a comparative overview of sensitivity analysis techniques for a this compound model, supported by experimental data from a case study on nanoparticle formulation.
A Box-Behnken Design is a type of response surface methodology that efficiently identifies the optimal settings for multiple experimental variables with fewer experimental runs compared to a full factorial design.[1][2] This makes it a cost-effective and time-efficient choice in pharmaceutical development.[3] A key advantage of the this compound is that it avoids extreme combinations of all factors simultaneously, which can be crucial when dealing with potentially unstable or unsafe formulations.
Unveiling Factor Influence: A Comparative Look at Sensitivity Analysis Methods
Once a predictive model is established through a this compound, a sensitivity analysis is crucial to understand the robustness of the formulation and identify the most critical process parameters. This analysis can range from straightforward graphical interpretations to more complex quantitative methods.
Local Sensitivity Analysis: The One-at-a-Time (OAT) Approach
The most direct method for assessing sensitivity in a this compound model is the One-at-a-Time (OAT) approach, often visualized through perturbation plots. In this method, the effect of a single factor on a specific response is examined while all other factors are held constant at a central reference point. A steep slope or curvature in the plot for a particular factor indicates that the response is highly sensitive to changes in that factor. Conversely, a relatively flat line suggests that the response is insensitive to that variable.
Global Sensitivity Analysis: A Holistic View
While OAT is intuitive, it doesn't capture the interactions between factors. Global Sensitivity Analysis (GSA) methods provide a more comprehensive understanding by evaluating the influence of factors across their entire range and considering their interactions. A prominent GSA method is the calculation of Sobol' indices, which partition the variance of the model output into contributions from individual factors and their interactions. While the direct calculation of Sobol' indices is computationally intensive, the coefficients of the quadratic model generated by the this compound can provide a strong indication of the main, interaction, and quadratic effects of the factors on the response.
Case Study: Formulation of Irinotecan-Loaded Nanoparticles
To illustrate the application of sensitivity analysis, we will use data from a study by B.S.M. and C.M. (2023) on the optimization of irinotecan (B1672180) hydrochloride-loaded polycaprolactone (B3415563) (PCL) nanoparticles using a this compound.[1]
Experimental Design
The study utilized a three-factor, three-level this compound to investigate the effects of:
-
X1: Amount of Polymer (PCL) (mg)
-
X2: Amount of Drug (Irinotecan) (mg)
-
X3: Surfactant Concentration (PVA) (%)
on three key responses:
-
Y1: Particle Size (nm)
-
Y2: Zeta Potential (mV)
-
Y3: Encapsulation Efficiency (%)
A total of 15 experimental runs, including three center points, were conducted.
Experimental Protocol: Nanoparticle Formulation
The nanoparticles were prepared using a double emulsion solvent evaporation technique. Briefly, the drug was dissolved in an aqueous phase and emulsified in an organic phase containing the polymer. This primary emulsion was then added to a second aqueous phase containing the surfactant and homogenized to form the final nanoparticles. The organic solvent was subsequently removed by evaporation.
Data Presentation and Analysis
The experimental data and the coefficients of the quadratic models for each response are summarized below.
Box-Behnken Design Matrix and Experimental Results
| Run | X1: Polymer (mg) | X2: Drug (mg) | X3: Surfactant (%) | Y1: Size (nm) | Y2: Zeta Potential (mV) | Y3: Encapsulation Efficiency (%) |
| 1 | 54 | 3 | 4 | 280.1 | -12.3 | 55.2 |
| 2 | 162 | 3 | 4 | 388.1 | -10.1 | 60.1 |
| 3 | 54 | 9 | 4 | 203.6 | -15.2 | 75.3 |
| 4 | 162 | 9 | 4 | 310.5 | -13.8 | 82.4 |
| 5 | 54 | 6 | 2 | 250.7 | -7.6 | 65.8 |
| 6 | 162 | 6 | 2 | 350.2 | -9.2 | 70.2 |
| 7 | 54 | 6 | 6 | 220.4 | -18.5 | 68.1 |
| 8 | 162 | 6 | 6 | 330.9 | -19.6 | 72.5 |
| 9 | 108 | 3 | 2 | 320.6 | -8.5 | 58.9 |
| 10 | 108 | 9 | 2 | 260.3 | -11.5 | 78.6 |
| 11 | 108 | 3 | 6 | 290.8 | -17.8 | 62.3 |
| 12 | 108 | 9 | 6 | 240.1 | -16.9 | 80.1 |
| 13 | 108 | 6 | 4 | 300.5 | -14.1 | 69.5 |
| 14 | 108 | 6 | 4 | 301.2 | -14.3 | 69.8 |
| 15 | 108 | 6 | 4 | 300.8 | -14.2 | 69.6 |
Data adapted from B.S.M. and C.M. (2023).[1]
Regression Coefficients of the Quadratic Model
| Coefficient | Y1: Size (nm) | Y2: Zeta Potential (mV) | Y3: Encapsulation Efficiency (%) |
| Intercept | 300.83 | -14.20 | 69.63 |
| Linear | |||
| X1 (Polymer) | 51.58 | 1.56 | 4.95 |
| X2 (Drug) | -35.25 | -1.19 | 11.08 |
| X3 (Surfactant) | -27.55 | -4.89 | 1.78 |
| Quadratic | |||
| X1X1 | 18.26 | 1.15 | -1.59 |
| X2X2 | -20.49 | 0.80 | -1.92 |
| X3X3 | 2.51 | -1.05 | -0.64 |
| Interaction | |||
| X1X2 | -1.25 | 0.23 | 0.53 |
| X1X3 | -10.35 | -0.15 | 0.25 |
| X2X3 | 5.15 | -0.38 | 0.18 |
Data adapted from B.S.M. and C.M. (2023).[1]
Sensitivity Analysis of the Nanoparticle Formulation
Local Sensitivity Analysis (OAT) from Model Coefficients
The linear coefficients of the regression model provide a direct measure of the sensitivity of the response to each factor at the center of the design space.
-
Particle Size (Y1): The largest linear coefficient belongs to the Amount of Polymer (X1: 51.58), indicating that particle size is most sensitive to changes in polymer concentration. The negative coefficient for the Amount of Drug (X2: -35.25) suggests that increasing the drug amount leads to a decrease in particle size.
-
Zeta Potential (Y2): The Surfactant Concentration (X3: -4.89) has the most significant linear effect on zeta potential, with a higher concentration leading to a more negative charge.
-
Encapsulation Efficiency (Y3): The Amount of Drug (X2: 11.08) is the most influential factor for encapsulation efficiency, with a higher drug amount leading to a significant increase in efficiency.
Comparison with an Alternative Design: Full Factorial
A full factorial design would have required 3^3 = 27 runs, significantly more than the 15 runs of the this compound. While providing more data points, the increased experimental effort might not be justified, especially in early-stage development. The this compound provides sufficient data to fit a quadratic model and perform a meaningful sensitivity analysis with greater efficiency.
Visualizing the Workflow and Comparisons
Workflow for this compound and Sensitivity Analysis.
Comparison of this compound and Full Factorial Design.
Conclusion
The sensitivity analysis of a Box-Behnken Design model is a critical step in pharmaceutical formulation development. By systematically evaluating the influence of each factor, researchers can identify critical process parameters, understand the robustness of their formulation, and confidently define a design space for consistent product quality. While simple graphical methods provide a quick assessment of sensitivity, a deeper analysis of the model coefficients offers a more quantitative understanding. The efficiency and effectiveness of the this compound make it an invaluable tool for accelerating the drug development process.
References
Safety Operating Guide
Proper Disposal Procedures for Laboratory Chemicals: A General Guide
Disclaimer: The following guide provides a general framework for the proper disposal of laboratory chemicals. The acronym "BBD" is ambiguous and can refer to multiple substances. It is imperative to correctly identify any chemical and consult its specific Safety Data Sheet (SDS) before handling or disposal. This document uses "BDD™ (Bacdown® Detergent Disinfectant)" as an illustrative example.
I. Immediate Safety and Logistical Information
The first and most critical step in the proper disposal of any laboratory chemical is to identify the substance and understand its associated hazards. This information is available in the manufacturer-provided Safety Data Sheet (SDS), formerly known as the Material Safety Data Sheet (MSDS).
Key Steps Before Disposal:
-
Positive Identification: Confirm the exact name and nature of the chemical to be disposed of. Do not proceed if the substance cannot be identified.
-
Locate the Safety Data Sheet (SDS): The SDS is a comprehensive document providing critical information about the chemical's properties, hazards, and safe handling procedures.[1] It will include a dedicated section on disposal considerations.
-
Personal Protective Equipment (PPE): Based on the SDS, don the appropriate PPE. For many laboratory chemicals, this will include safety glasses, gloves, and a lab coat. For BDD™, the SDS recommends wearing protective gloves, clothing, and eye/face protection.[2][3]
-
Review Institutional Protocols: Be familiar with your institution's specific waste disposal guidelines and emergency procedures. These protocols are designed to ensure compliance with local, state, and federal regulations.
II. General Disposal Plan for Laboratory Chemicals
The following is a step-by-step guide for the disposal of a typical laboratory chemical. This procedure should be adapted based on the specific information found in the chemical's SDS.
Step 1: Segregation of Waste
Proper segregation is crucial to prevent dangerous chemical reactions and to ensure waste is handled correctly.
-
Chemical Compatibility: Never mix different chemical wastes unless explicitly instructed to do so by a verified protocol. Incompatible chemicals can generate heat, toxic gases, or explosions. BDD™ should not be mixed with oxidizers or reducing agents.[2]
-
Waste Streams: Segregate waste into designated containers for different waste streams, such as:
-
Halogenated solvents
-
Non-halogenated solvents
-
Acidic waste
-
Basic waste
-
Solid waste
-
Sharps
-
Step 2: Container Selection and Labeling
-
Container Type: Use containers that are chemically compatible with the waste they will hold. For liquid waste, ensure the container is leak-proof and has a secure cap.[4][5] For sharps, use a designated puncture-resistant sharps container.[4][5]
-
Labeling: All waste containers must be clearly labeled with the following information:
-
The words "Hazardous Waste"
-
The full name of the chemical(s)
-
The specific hazards (e.g., flammable, corrosive, toxic)
-
The date accumulation started
-
Step 3: Waste Accumulation and Storage
-
Storage Location: Store waste containers in a designated, well-ventilated satellite accumulation area.
-
Secondary Containment: Use secondary containment trays to capture any potential leaks or spills.
-
Container Closure: Keep waste containers closed at all times, except when adding waste.
Step 4: Final Disposal
-
Institutional Procedures: Follow your institution's specific procedures for having chemical waste removed. This typically involves contacting the Environmental Health and Safety (EHS) department.
-
Transportation: If transporting waste within the facility, use a secondary container to prevent spills.[6]
III. Specific Disposal Protocol: BDD™ (Bacdown® Detergent Disinfectant)
The following information is derived from the Safety Data Sheet for BDD™, a laboratory disinfectant.[3][7]
Chemical Properties and Hazards:
| Property | Value |
| Appearance | Yellow Liquid |
| pH | 10.7 - 12.7 |
| Boiling Point | >212 °F |
| Solubility | Complete |
| Hazard Classification | Causes severe skin burns and eye damage.[2] |
Disposal Methodology:
-
Small Spills:
-
Wear appropriate PPE (gloves, eye protection).
-
Absorb the spill with an inert material (e.g., vermiculite, dry sand, or earth).
-
Place the absorbent material into a designated container for chemical waste.
-
Clean the spill area with water.
-
-
Large Spills:
-
Evacuate the area and prevent entry.
-
Contact your institution's EHS or emergency response team.
-
If safe to do so, stop the leak and dike the spill to prevent it from entering drains or sewers.[2]
-
-
Unused Product and Contaminated Materials:
Experimental Protocols Cited:
This document does not cite specific experimental protocols but rather refers to standardized safety and disposal procedures as outlined in Safety Data Sheets and general laboratory safety guidelines.
IV. Visualization of Disposal Workflow
The following diagram illustrates the decision-making process for the proper disposal of a laboratory chemical.
Caption: Logical workflow for the proper disposal of laboratory chemicals.
References
- 1. Documents [bdbiosciences.com]
- 2. bdbiosciences.com [bdbiosciences.com]
- 3. msdsdigital.com [msdsdigital.com]
- 4. Regulated Waste | Free Healthcare Bloodborne Pathogens Online Training Video | Online Bloodborne Pathogens Training in OSHA Bloodborne Pathogens [probloodborne.com]
- 5. Incident Waste Decision Support Tool (I-WASTE DST) | US EPA [iwaste.epa.gov]
- 6. research.hawaii.edu [research.hawaii.edu]
- 7. polysciences.com [polysciences.com]
Retrosynthesis Analysis
AI-Powered Synthesis Planning: Our tool employs the Template_relevance Pistachio, Template_relevance Bkms_metabolic, Template_relevance Pistachio_ringbreaker, Template_relevance Reaxys, Template_relevance Reaxys_biocatalysis model, leveraging a vast database of chemical reactions to predict feasible synthetic routes.
One-Step Synthesis Focus: Specifically designed for one-step synthesis, it provides concise and direct routes for your target compounds, streamlining the synthesis process.
Accurate Predictions: Utilizing the extensive PISTACHIO, BKMS_METABOLIC, PISTACHIO_RINGBREAKER, REAXYS, REAXYS_BIOCATALYSIS database, our tool offers high-accuracy predictions, reflecting the latest in chemical research and data.
Strategy Settings
| Precursor scoring | Relevance Heuristic |
|---|---|
| Min. plausibility | 0.01 |
| Model | Template_relevance |
| Template Set | Pistachio/Bkms_metabolic/Pistachio_ringbreaker/Reaxys/Reaxys_biocatalysis |
| Top-N result to add to graph | 6 |
Feasible Synthetic Routes




Featured Recommendations
| Most viewed |
|
|
|---|---|---|
| Most popular with customers |
|
Descargo de responsabilidad e información sobre productos de investigación in vitro
Tenga en cuenta que todos los artículos e información de productos presentados en BenchChem están destinados únicamente con fines informativos. Los productos disponibles para la compra en BenchChem están diseñados específicamente para estudios in vitro, que se realizan fuera de organismos vivos. Los estudios in vitro, derivados del término latino "in vidrio", involucran experimentos realizados en entornos de laboratorio controlados utilizando células o tejidos. Es importante tener en cuenta que estos productos no se clasifican como medicamentos y no han recibido la aprobación de la FDA para la prevención, tratamiento o cura de ninguna condición médica, dolencia o enfermedad. Debemos enfatizar que cualquier forma de introducción corporal de estos productos en humanos o animales está estrictamente prohibida por ley. Es esencial adherirse a estas pautas para garantizar el cumplimiento de los estándares legales y éticos en la investigación y experimentación.
