1-Methylcytosine
Descripción
Structure
3D Structure
Propiedades
IUPAC Name |
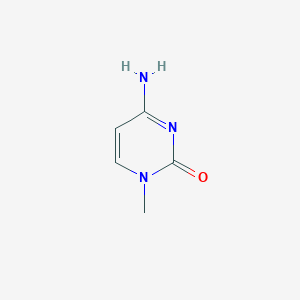
4-amino-1-methylpyrimidin-2-one |
Source


|
|---|---|---|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
InChI |
InChI=1S/C5H7N3O/c1-8-3-2-4(6)7-5(8)9/h2-3H,1H3,(H2,6,7,9) |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
InChI Key |
HWPZZUQOWRWFDB-UHFFFAOYSA-N |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Canonical SMILES |
CN1C=CC(=NC1=O)N |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Molecular Formula |
C5H7N3O |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
DSSTOX Substance ID |
DTXSID60149949 |
Source
|
| Record name | 1-Methylcytosine | |
| Source | EPA DSSTox | |
| URL | https://comptox.epa.gov/dashboard/DTXSID60149949 | |
| Description | DSSTox provides a high quality public chemistry resource for supporting improved predictive toxicology. | |
Molecular Weight |
125.13 g/mol |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
CAS No. |
1122-47-0 |
Source
|
| Record name | 1-Methylcytosine | |
| Source | CAS Common Chemistry | |
| URL | https://commonchemistry.cas.org/detail?cas_rn=1122-47-0 | |
| Description | CAS Common Chemistry is an open community resource for accessing chemical information. Nearly 500,000 chemical substances from CAS REGISTRY cover areas of community interest, including common and frequently regulated chemicals, and those relevant to high school and undergraduate chemistry classes. This chemical information, curated by our expert scientists, is provided in alignment with our mission as a division of the American Chemical Society. | |
| Explanation | The data from CAS Common Chemistry is provided under a CC-BY-NC 4.0 license, unless otherwise stated. | |
| Record name | 1-Methylcytosine | |
| Source | ChemIDplus | |
| URL | https://pubchem.ncbi.nlm.nih.gov/substance/?source=chemidplus&sourceid=0001122470 | |
| Description | ChemIDplus is a free, web search system that provides access to the structure and nomenclature authority files used for the identification of chemical substances cited in National Library of Medicine (NLM) databases, including the TOXNET system. | |
| Record name | 1-Methylcytosine | |
| Source | DrugBank | |
| URL | https://www.drugbank.ca/drugs/DB04314 | |
| Description | The DrugBank database is a unique bioinformatics and cheminformatics resource that combines detailed drug (i.e. chemical, pharmacological and pharmaceutical) data with comprehensive drug target (i.e. sequence, structure, and pathway) information. | |
| Explanation | Creative Common's Attribution-NonCommercial 4.0 International License (http://creativecommons.org/licenses/by-nc/4.0/legalcode) | |
| Record name | 1122-47-0 | |
| Source | DTP/NCI | |
| URL | https://dtp.cancer.gov/dtpstandard/servlet/dwindex?searchtype=NSC&outputformat=html&searchlist=47693 | |
| Description | The NCI Development Therapeutics Program (DTP) provides services and resources to the academic and private-sector research communities worldwide to facilitate the discovery and development of new cancer therapeutic agents. | |
| Explanation | Unless otherwise indicated, all text within NCI products is free of copyright and may be reused without our permission. Credit the National Cancer Institute as the source. | |
| Record name | 1-Methylcytosine | |
| Source | EPA DSSTox | |
| URL | https://comptox.epa.gov/dashboard/DTXSID60149949 | |
| Description | DSSTox provides a high quality public chemistry resource for supporting improved predictive toxicology. | |
| Record name | 4-amino-1-methyl-1,2-dihydropyrimidin-2-one | |
| Source | European Chemicals Agency (ECHA) | |
| URL | https://echa.europa.eu/information-on-chemicals | |
| Description | The European Chemicals Agency (ECHA) is an agency of the European Union which is the driving force among regulatory authorities in implementing the EU's groundbreaking chemicals legislation for the benefit of human health and the environment as well as for innovation and competitiveness. | |
| Explanation | Use of the information, documents and data from the ECHA website is subject to the terms and conditions of this Legal Notice, and subject to other binding limitations provided for under applicable law, the information, documents and data made available on the ECHA website may be reproduced, distributed and/or used, totally or in part, for non-commercial purposes provided that ECHA is acknowledged as the source: "Source: European Chemicals Agency, http://echa.europa.eu/". Such acknowledgement must be included in each copy of the material. ECHA permits and encourages organisations and individuals to create links to the ECHA website under the following cumulative conditions: Links can only be made to webpages that provide a link to the Legal Notice page. | |
| Record name | 1-METHYLCYTOSINE | |
| Source | FDA Global Substance Registration System (GSRS) | |
| URL | https://gsrs.ncats.nih.gov/ginas/app/beta/substances/1J54NE82RV | |
| Description | The FDA Global Substance Registration System (GSRS) enables the efficient and accurate exchange of information on what substances are in regulated products. Instead of relying on names, which vary across regulatory domains, countries, and regions, the GSRS knowledge base makes it possible for substances to be defined by standardized, scientific descriptions. | |
| Explanation | Unless otherwise noted, the contents of the FDA website (www.fda.gov), both text and graphics, are not copyrighted. They are in the public domain and may be republished, reprinted and otherwise used freely by anyone without the need to obtain permission from FDA. Credit to the U.S. Food and Drug Administration as the source is appreciated but not required. | |
Foundational & Exploratory
The Enigmatic Epitranscriptomic Mark: A Technical Guide to the Biological Significance of 1-Methylcytosine
For the attention of: Researchers, Scientists, and Drug Development Professionals
Executive Summary
1-Methylcytosine (m1C) is a post-transcriptional RNA modification that remains one of the most enigmatic marks in the epitranscriptome. Unlike its well-studied isomer, 5-methylcytosine (m5C), and the prevalent N6-methyladenosine (m6A), the biological significance, enzymatic machinery, and precise locations of m1C in native RNA are largely uncharacterized. This technical guide provides a comprehensive overview of the current, albeit limited, state of knowledge regarding m1C. It is designed to equip researchers with the foundational understanding necessary to explore this nascent field, highlighting significant knowledge gaps and potential avenues for future investigation. Due to the scarcity of quantitative data and established pathways involving m1C, this document will focus on the foundational biochemistry, inferred functions based on related modifications, and the analytical methodologies that can be adapted for its study.
Introduction to this compound
This compound is a modified nucleobase where a methyl group is attached to the nitrogen atom at the first position of the cytosine ring. This modification is distinct from the more common 5-methylcytosine, where the methyl group is on the fifth carbon. This seemingly subtle difference in the location of the methyl group has profound implications for the base's chemical properties and its potential biological functions.
The Enzymatic Machinery: The Search for "Writers" and "Erasers"
A critical gap in our understanding of m1C biology is the identity of the enzymes responsible for its deposition ("writers") and potential removal ("erasers").
Putative Methyltransferases ("Writers")
While dedicated m1C methyltransferases have yet to be definitively identified, the TRM10 family of enzymes has been a focus of investigation due to their role in N1-methylation of purines.
-
Yeast Trm10p: This enzyme is known to catalyze the formation of N1-methylguanine (m1G) at position 9 of tRNAs.[1][2]
-
Human TRMT10A and TRMT10B: These are human orthologs of the yeast Trm10. Functional studies have shown that TRMT10A is an m1G9-specific methyltransferase for a subset of nuclear-encoded tRNAs, while TRMT10B is the first identified m1A9-specific tRNA methyltransferase in eukaryotes.[1] The human mitochondrial enzyme, TRMT10C , is a dual-specificity methyltransferase responsible for both m1A9 and m1G9 in mitochondrial tRNAs.
Despite the activity of the TRM10 family on N1 of purines, there is currently no direct evidence to suggest they are responsible for the N1-methylation of cytosine. The substrate specificity of these enzymes appears to be directed towards adenine and guanine. The search for the bona fide m1C writer enzyme(s) is a key area for future research.
Demethylases ("Erasers")
The reversible nature of many RNA modifications is crucial for their regulatory roles. However, no demethylase for this compound in RNA has been identified to date. The ALKB family of enzymes are known to act as demethylases for various methylated bases, but their activity on m1C has not been demonstrated.
Biological Roles and Significance of this compound
Direct experimental evidence for the biological function of m1C is scarce. However, insights can be gleaned from the well-documented roles of other N1-methylated nucleosides, particularly N1-methyladenosine (m1A), in tRNA.
Role in tRNA Structure and Stability
N1-methylation at the Watson-Crick face of a base disrupts canonical base pairing. This property is thought to be critical for maintaining the correct tertiary structure of tRNA.
-
Structural Integrity: In nematode mitochondrial tRNAs that lack a T-arm, the presence of m1A at position 9 is indispensable for their proper folding and function.[3][4] The methyl group at the N1 position prevents non-canonical base pairing that would otherwise lead to a misfolded and inactive tRNA molecule. It is plausible that m1C could play a similar role in stabilizing the structure of certain tRNAs or other structured RNAs.
Impact on Translation
By influencing tRNA structure and stability, N1-methylation can have a significant impact on the process of translation.
-
tRNA Quality Control: The absence of m1G9 methylation in yeast, due to the deletion of the TRM10 gene, leads to the degradation of specific tRNAs, such as tRNATrp, suggesting a role for N1-methylation in tRNA quality control pathways.
-
Translation Fidelity: Modifications in the anticodon loop of tRNA are known to be critical for accurate codon recognition. While m1C has not been found in the anticodon loop, its presence elsewhere in the tRNA body could allosterically affect the anticodon presentation and influence decoding fidelity.
Potential Roles in Other RNA Species
The existence and function of m1C in other RNA types, such as mRNA, rRNA, and long non-coding RNAs, are completely unexplored. Given the emerging roles of other rare modifications in these RNA species, this represents a significant frontier in epitranscriptomics.
Association with Human Disease
The link between this compound and human disease is currently unestablished. However, mutations in the human TRMT10A gene, which encodes the m1G9 tRNA methyltransferase, are associated with a syndrome characterized by young-onset diabetes and microcephaly. This highlights the critical importance of N1-methylation of purines in tRNA for normal human development and cellular function. Future research may uncover similar associations for m1C, particularly in the context of neurodevelopmental disorders or cancer.
Methodologies for the Study of this compound
The lack of specific and sensitive high-throughput methods for detecting m1C has been a major impediment to its study. Below are the current and potential methodologies that can be employed.
Liquid Chromatography-Mass Spectrometry (LC-MS/MS)
Currently, the gold standard for the detection and quantification of a wide range of RNA modifications, including m1C, is LC-MS/MS.
-
Principle: RNA is enzymatically digested into single nucleosides, which are then separated by liquid chromatography and identified and quantified by tandem mass spectrometry.
-
Advantages: High sensitivity and accuracy, and the ability to quantify the absolute abundance of the modification.
-
Limitations: This method provides a global quantification of the modification and does not provide information about its specific location within an RNA molecule.
-
RNA Isolation: Isolate total RNA from the sample of interest using a standard protocol (e.g., TRIzol extraction followed by column purification). Ensure high purity and integrity of the RNA.
-
RNA Digestion: Digest 1-5 µg of total RNA to single nucleosides using a mixture of nuclease P1 and phosphodiesterase I, followed by dephosphorylation with alkaline phosphatase.
-
LC Separation: Separate the resulting nucleosides using a reversed-phase high-performance liquid chromatography (HPLC) system.
-
MS/MS Detection: Couple the HPLC to a triple quadrupole mass spectrometer operating in multiple reaction monitoring (MRM) mode. Use a stable isotope-labeled internal standard for 1-methylcytidine for absolute quantification. The specific mass transitions for 1-methylcytidine would need to be optimized.
-
Data Analysis: Quantify the amount of 1-methylcytidine relative to the canonical nucleosides (A, C, G, U).
Sequencing-Based Methods (Potential and In Development)
There are currently no established, widely used sequencing-based methods specifically for this compound. However, existing technologies could potentially be adapted.
-
Methylated RNA Immunoprecipitation followed by Sequencing (MeRIP-Seq): This technique relies on a specific antibody that recognizes the modification of interest.
-
Workflow: RNA is fragmented and then immunoprecipitated using an m1C-specific antibody. The enriched RNA fragments are then sequenced.
-
Challenge: The development of a highly specific and high-affinity antibody for this compound is a prerequisite for this method.
-
-
Enzymatic or Chemical-Based Sequencing: Methods that rely on chemical or enzymatic treatment to differentiate modified from unmodified bases could be developed. For example, a hypothetical enzyme that specifically recognizes and cleaves at m1C sites could be used to map its location.
Quantitative Data Summary
Due to the nascent stage of this compound research, there is a significant lack of quantitative data regarding its abundance and stoichiometry in different organisms, tissues, or RNA species. The development of robust and sensitive detection methods will be crucial for populating such datasets in the future.
Signaling Pathways and Logical Relationships
Currently, there are no known signaling or metabolic pathways that are regulated by or involve this compound. The enzymatic pathways for its synthesis and removal are also unknown.
Conclusion and Future Directions
This compound represents a significant knowledge gap in the field of epitranscriptomics. While its existence is known, its biological importance remains to be elucidated. The future of m1C research will depend on the successful execution of several key objectives:
-
Identification of Enzymatic Machinery: The discovery of the specific "writer" and "eraser" enzymes for m1C is paramount. This will enable the use of genetic tools (e.g., knockout and overexpression models) to study the functional consequences of this modification.
-
Development of Detection Methods: The creation of a robust, high-throughput sequencing method for m1C, analogous to m6A-seq or m5C-bisulfite sequencing, will be transformative for the field, allowing for transcriptome-wide mapping of m1C sites.
-
Functional Characterization: Once the enzymatic machinery and detection methods are in place, detailed functional studies can be undertaken to understand the role of m1C in tRNA biology, translation, and its potential involvement in other RNA species and cellular processes.
-
Disease Association: Investigating the levels of m1C and the expression of its modifying enzymes in various diseases, particularly neurodevelopmental disorders and cancer, may reveal novel diagnostic markers or therapeutic targets.
References
- 1. Functional characterization of the human tRNA methyltransferases TRMT10A and TRMT10B - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Quantitative analysis of tRNA modifications by HPLC-coupled mass spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 3. pnas.org [pnas.org]
- 4. High-resolution quantitative profiling of tRNA abundance and modification status in eukaryotes by mim-tRNAseq - PMC [pmc.ncbi.nlm.nih.gov]
Role of 1-Methylcytosine in RNA and DNA stability.
An in-depth analysis of the scientific literature reveals that 1-methylcytosine (m1C) is a rare and significantly understudied modification in both RNA and DNA, especially when compared to its well-known isomer, 5-methylcytosine (m5C). While the query requests a detailed technical guide on the role of m1C in nucleic acid stability, the available research is insufficient to provide extensive quantitative data, established experimental protocols, or validated biological pathways specifically for m1C.
This guide will summarize the limited existing knowledge on m1C and, to provide context and fulfill the structural requirements of the request, will present the equivalent detailed information for the extensively researched 5-methylcytosine (m5C). This comparative approach highlights the significant knowledge gap in the field regarding m1C and provides the user with the requested technical formats using a relevant, albeit different, modification.
Overview of this compound (m1C)
This compound is a derivative of the pyrimidine base cytosine, with a methyl group attached to the nitrogen atom at position 1 (N1) of the ring structure.[1] This position is critically involved in the canonical Watson-Crick base pairing with guanine. The presence of a methyl group at the N1 position fundamentally disrupts this standard hydrogen bonding pattern, suggesting that m1C would be a destabilizing lesion if it were to occur within a standard DNA or RNA duplex.
Role of m1C in DNA
Current research on m1C in DNA is sparse. It is not considered a standard epigenetic mark. Instead, methylation at ring nitrogens of purines and pyrimidines (e.g., N1-methyladenine and N3-methylcytosine) is typically characterized as DNA damage induced by alkylating agents.[2] Organisms have evolved specific repair mechanisms, such as oxidative demethylation by AlkB family enzymes or base excision repair, to remove such lesions and maintain genome integrity.[2][3] While not extensively documented, it is presumed that m1C in DNA would be similarly recognized as damage and targeted for repair.
In the field of synthetic biology, the m1C nucleoside has been used as a component of an expanded genetic alphabet known as "hachimoji DNA".[1] In this artificial system, m1C is designed to pair with isoguanine, demonstrating its capacity for forming alternative, non-canonical base pairs.
Role of m1C in RNA
There is a significant lack of evidence for the natural occurrence or functional role of m1C in RNA. Unlike m5C, which is a known modification in various RNA species, m1C has not been identified as a component of the natural "epitranscriptome." Theoretical and biophysical studies have used m1C as a model compound to investigate the intrinsic photophysical properties of cytosine nucleosides, but these studies do not address its role in RNA stability or function within a biological context.
The Well-Studied Isomer: 5-Methylcytosine (m5C) as a Functional Analog
In contrast to m1C, 5-methylcytosine (m5C) is an abundant and functionally significant modification in both DNA and RNA. The methyl group at the C5 position resides in the major groove of the DNA helix and does not interfere with Watson-Crick pairing, allowing it to serve as a stable epigenetic and epitranscriptomic mark.
Role of m5C in DNA Stability
The addition of a methyl group at the C5 position of cytosine generally increases the thermal stability of the DNA duplex. This stabilization is attributed to favorable enthalpic contributions from enhanced base stacking and hydrophobic interactions of the methyl group with neighboring bases.
Table 1: Quantitative Data on the Effect of 5-Methylcytosine (m5C) on DNA Duplex Stability
| Nucleic Acid Type | Modification Context | Observed Effect | Measurement Technique | Reference |
|---|---|---|---|---|
| DNA Duplex | Substitution of C with m5C in a hairpin stem | Increase in Melting Temperature (Tm) from 74°C to 82°C | UV Melting Analysis | |
| DNA Duplex | Poly(G-C) vs. Poly(G-m5C) | Increase in Tm from 86.5°C to 92.2°C | UV Melting Analysis | |
| DNA Duplex | Multiple m5C substitutions in CpG context | Tm upshifted by approx. 0.5 - 1.0 °C per m5C | FRET Melting Analysis |
| DNA Triplex | m5C in the third (Hoogsteen) strand | Increase in Tm of ~10°C; expanded pH range for stability | UV Melting Analysis | |
Role of m5C in RNA Stability and Function
In RNA, m5C is a widespread modification found in transfer RNA (tRNA), ribosomal RNA (rRNA), and messenger RNA (mRNA). In tRNA, m5C is known to enhance structural stability and integrity. For example, methylation by the enzyme NSUN2 protects tRNAs from endonucleolytic cleavage under stress conditions, thereby increasing their half-life and supporting protein synthesis. In mRNA, m5C has been shown to modulate mRNA stability, export from the nucleus, and translation efficiency.
Table 2: Functional Roles of 5-Methylcytosine (m5C) in RNA
| RNA Type | Location of m5C | Enzyme ("Writer") | Function | Reference |
|---|---|---|---|---|
| tRNA | Variable Loop, Anticodon Loop | NSUN2, TRDMT1 (DNMT2) | Enhances structural stability, protects against cleavage, regulates translation | |
| mRNA | 5' and 3' UTRs, near start codon | NSUN2, NSUN6 | Modulates mRNA stability (increase or decrease), influences nuclear export, enhances translation |
| rRNA | Conserved positions | NSUN family members | Facilitates correct ribosome assembly and function | |
Enzymatic Regulation and Signaling of m5C
The levels of m5C are dynamically regulated by "writer" enzymes (methyltransferases) that install the mark, "eraser" enzymes (demethylases) that remove it, and "reader" proteins that recognize the mark and mediate its downstream effects.
-
Writers (Methyltransferases): In mammals, the DNMT (DNA Methyltransferase) family of enzymes establishes and maintains m5C in DNA. In RNA, members of the NOL1/NOP2/SUN domain (NSUN) family and TRDMT1 (also known as DNMT2) are the primary m5C methyltransferases.
-
Erasers (Demethylases): In DNA, the Ten-Eleven Translocation (TET) family of dioxygenases can oxidize m5C to 5-hydroxymethylcytosine (5hmC) and further derivatives, initiating a pathway of active demethylation. TET enzymes have also been shown to oxidize m5C in RNA, suggesting a potential erasure mechanism.
-
Readers: Proteins with methyl-CpG-binding domains (MBDs) recognize m5C in DNA to regulate chromatin structure and transcription. In RNA, the YBX1 and ALYREF proteins have been identified as m5C readers that mediate mRNA stability and nuclear export, respectively.
Below is a diagram illustrating the lifecycle and functional regulation of m5C in nucleic acids.
Caption: Lifecycle of 5-methylcytosine (m5C) regulation and function.
Experimental Protocols for m5C Detection
While no specific protocols exist for m1C, several methods are widely used to detect and map m5C at single-nucleotide resolution. The inability of these methods to detect m1C underscores the distinct chemistry of the two isomers.
Bisulfite Sequencing (BS-Seq)
This is the gold standard for m5C detection in both DNA and RNA. The protocol involves treating nucleic acids with sodium bisulfite, which deaminates cytosine to uracil, while m5C remains unreactive. Subsequent reverse transcription (for RNA) and PCR amplification convert uracil to thymine. By comparing the treated sequence to an untreated reference, cytosines that remain as 'C' are identified as methylated.
-
Applicability to m1C: This method cannot detect m1C. The N1 methylation of m1C does not protect the C4 amino group from deamination, and the critical C5 position is unmethylated, meaning m1C would likely be read as a 'T' after treatment, making it indistinguishable from unmodified cytosine.
Workflow for RNA Bisulfite Sequencing (BS-Seq)
Caption: Generalized workflow for detecting m5C in RNA via bisulfite sequencing.
Methylated RNA Immunoprecipitation (MeRIP-Seq)
This antibody-based method involves using an antibody specific to m5C to enrich for RNA fragments containing the modification. The enriched RNA fragments are then sequenced and mapped to the transcriptome to identify regions with high m5C density.
-
Principle:
-
RNA Fragmentation: Isolate total RNA and fragment it into smaller pieces (e.g., 100-200 nucleotides).
-
Immunoprecipitation (IP): Incubate fragmented RNA with an anti-m5C antibody conjugated to magnetic beads.
-
Washing and Elution: Wash the beads to remove non-specifically bound RNA, then elute the m5C-containing fragments.
-
Library Preparation and Sequencing: Prepare a sequencing library from the eluted RNA fragments and an input control, followed by high-throughput sequencing.
-
Data Analysis: Identify peaks where the IP sample is significantly enriched over the input control, indicating the location of m5C clusters.
-
-
Applicability to m1C: This method would require a highly specific antibody that can distinguish m1C from both unmodified cytosine and other methylated forms like m5C. The development and validation of such an antibody would be a prerequisite for adapting this technique.
Implications for Drug Development
Given the central role of m5C in epigenetics and its dysregulation in diseases like cancer, the enzymes involved in its metabolism (DNMTs, TETs, NSUNs) have become attractive targets for therapeutic intervention. For example, DNMT inhibitors are used in the treatment of certain cancers. The lack of knowledge about m1C means its potential as a therapeutic target is entirely unexplored. If m1C were found to be generated by a specific enzyme and play a role in a disease process, that enzyme could represent a novel drug target.
Conclusion
The role of this compound (m1C) in RNA and DNA stability remains a significant unknown in the field of nucleic acid biology. Unlike its thoroughly investigated isomer, 5-methylcytosine (m5C), m1C is not recognized as a natural epigenetic or epitranscriptomic mark. Its chemical nature suggests it would be a disruptive lesion within a standard nucleic acid duplex, and it is likely handled by cellular DNA repair pathways. The lack of quantitative data, specific detection protocols, and identified regulatory enzymes for m1C prevents the creation of a detailed technical guide on its function. Future research is required to determine if m1C has any undiscovered biological roles. For now, the extensive knowledge of m5C provides a valuable framework for understanding how a single methyl group, depending on its position, can have profoundly different impacts on nucleic acid structure, stability, and function.
References
1-Methylcytosine: On the Frontier of Epigenetic Discovery
An In-depth Technical Guide for Researchers, Scientists, and Drug Development Professionals
Executive Summary
The landscape of epigenetics is in a constant state of evolution, with research continually unveiling new layers of gene regulation. While 5-methylcytosine (5mC) has long been established as a cornerstone of epigenetic control, its lesser-known isomer, 1-methylcytosine (m1C), is emerging as a potential novel epigenetic marker. This technical guide provides a comprehensive overview of m1C, contrasting it with the well-characterized 5mC and outlining the experimental frameworks necessary to elucidate its function. We delve into the methodologies for its detection and quantification, explore the potential enzymatic machinery responsible for its placement and removal, and discuss its prospective roles in gene regulation and disease. This document serves as a foundational resource for researchers poised to investigate the next frontier of cytosine methylation.
Introduction: A Tale of Two Cytosines
Cytosine methylation is a fundamental epigenetic modification that plays a critical role in gene expression, cellular differentiation, and the development of diseases such as cancer.[1][2] The most prevalent and extensively studied form of this modification is 5-methylcytosine (5mC), where a methyl group is added to the 5th carbon of the cytosine ring.[3] This modification is a key component of the epigenetic machinery that includes "writer" enzymes (DNA methyltransferases or DNMTs), "eraser" enzymes (Ten-Eleven Translocation or TET enzymes), and "reader" proteins that recognize the methylated base and enact downstream effects.[4][5]
However, the cytosine ring can be methylated at other positions. This compound (m1C) is an isomer of 5mC where the methyl group is attached to the N1 position of the cytosine base. While 5mC's role in both DNA and RNA is increasingly understood, the biological significance of m1C as an epigenetic marker is a nascent field of inquiry. This guide will provide a technical framework for exploring m1C as a novel player in the epigenetic landscape.
Quantitative Analysis of this compound
A critical first step in establishing a new epigenetic marker is to quantify its abundance in different biological contexts. While global hypomethylation of 5mC is a known hallmark of cancer, the levels of m1C in normal and diseased tissues are largely unknown.
Table 1: Comparative Abundance of Cytosine Modifications in Mammalian Tissues
| Modification | Abundance in Normal Tissues | Abundance in Cancer Tissues | Method of Quantification |
| 5-methylcytosine (5mC) | 7.6% of cytosines in Mus musculus | Generally decreased (global hypomethylation) | Mass Spectrometry, Bisulfite Sequencing |
| 5-hydroxymethylcytosine (5hmC) | Varies by tissue, highest in brain | Generally decreased | Mass Spectrometry, TAB-seq |
| This compound (m1C) | Currently Undetermined | Currently Undetermined | Mass Spectrometry (putative) |
Experimental Protocol: Quantification of Global m1C by Mass Spectrometry
Liquid chromatography-tandem mass spectrometry (LC-MS/MS) is the gold standard for the accurate quantification of modified nucleosides.
Methodology:
-
Genomic DNA/RNA Isolation: Extract high-quality nucleic acids from cells or tissues of interest.
-
Enzymatic Hydrolysis: Digest the DNA/RNA to individual nucleosides using a cocktail of enzymes such as DNase I, nuclease P1, and alkaline phosphatase.
-
LC-MS/MS Analysis: Separate the nucleosides by liquid chromatography and detect and quantify them using a tandem mass spectrometer operating in multiple reaction monitoring (MRM) mode.
-
Quantification: Determine the amount of m1C relative to unmodified cytosine by comparing the signal intensities to a standard curve generated with known amounts of pure m1C and cytosine nucleosides.
Genome-wide Mapping of this compound
Identifying the precise genomic or transcriptomic locations of m1C is crucial to understanding its function. Methodologies developed for 5mC can be adapted, but require the development of m1C-specific reagents.
Antibody-Based Detection: The Hypothetical m1C-IP-seq
Methylated DNA immunoprecipitation followed by sequencing (MeDIP-seq) has been a powerful tool for mapping 5mC. A similar approach for m1C would require a highly specific monoclonal antibody.
Hypothetical Experimental Workflow: m1C-IP-seq
Caption: Hypothetical workflow for this compound immunoprecipitation sequencing (m1C-IP-seq).
Detailed Protocol: m1C-IP-seq (Putative)
-
DNA/RNA Fragmentation: Shear nucleic acid to a desired size range (e.g., 200-500 bp).
-
Immunoprecipitation: Incubate the fragmented nucleic acids with a validated monoclonal antibody specific for this compound.
-
Immune Complex Capture: Use secondary antibody-conjugated magnetic beads to capture the antibody-DNA/RNA complexes.
-
Washing: Perform stringent washes to remove non-specifically bound fragments.
-
Elution and Purification: Elute the m1C-containing fragments and purify the nucleic acid.
-
Library Preparation and Sequencing: Prepare a sequencing library from the enriched fragments and perform high-throughput sequencing.
-
Data Analysis: Align reads to the reference genome/transcriptome and use peak-calling algorithms to identify regions enriched for m1C.
Note: The critical and currently missing component for this protocol is a validated, high-affinity, and specific antibody against this compound.
The Enzymatic Machinery of this compound
The establishment and removal of epigenetic marks are tightly controlled by "writer" and "eraser" enzymes. While the enzymes for 5mC are well-characterized, those for m1C are yet to be identified.
"Writers": The Search for a this compound Methyltransferase
In mammals, DNMTs are responsible for creating 5mC marks. It is plausible that a yet-unidentified methyltransferase is responsible for depositing m1C. The discovery of such an enzyme would be a significant breakthrough in the field.
"Erasers": Potential Mechanisms for m1C Demethylation
The removal of 5mC can occur passively through DNA replication or actively via the TET enzyme-mediated oxidation pathway. It is possible that a similar enzymatic pathway exists for the demethylation of m1C, potentially involving a specific DNA glycosylase.
Logical Relationship: The m1C Epigenetic Cycle
Caption: The putative enzymatic cycle of this compound deposition and removal.
Biological Functions and Signaling Pathways
The ultimate goal of studying m1C is to understand its biological function. Drawing parallels from 5mC, m1C could be involved in transcriptional regulation, mRNA stability, and translation.
Potential Role in Transcriptional Regulation
If present in DNA, m1C in promoter regions or gene bodies could influence gene expression by either blocking the binding of transcription factors or recruiting specific "reader" proteins that recognize this modification.
Potential Role in RNA Metabolism
In RNA, 5mC has been shown to affect mRNA stability and translation. It is conceivable that m1C in mRNA could also be recognized by specific reader proteins that modulate the fate of the transcript. The YTH domain family of proteins are well-known readers of N6-methyladenosine (m6A) in RNA, and it is possible that a distinct family of reader proteins exists for m1C.
Signaling Pathway: Hypothetical m1C-Mediated Gene Regulation
Caption: A hypothetical signaling pathway illustrating the potential roles of m1C in the nucleus and cytoplasm.
This compound in Disease
Aberrant DNA methylation is a hallmark of many diseases, including cancer and neurological disorders. If m1C is indeed a new epigenetic marker, its dysregulation could also be implicated in pathology. Future research should focus on comparing m1C levels and genomic distribution in healthy versus diseased tissues to explore its potential as a biomarker or therapeutic target.
Conclusion and Future Directions
This compound stands at the precipice of epigenetic research. While the current body of knowledge is sparse, the experimental frameworks established for its well-studied counterpart, 5-methylcytosine, provide a clear roadmap for future investigation. The development of specific tools for m1C detection, the identification of its "writer" and "eraser" enzymes, and the characterization of its "reader" proteins will be pivotal in unlocking its biological significance. The exploration of m1C promises to add a new dimension to our understanding of gene regulation and may open up novel avenues for diagnostics and therapeutics in a range of human diseases. This technical guide serves as a call to action for the scientific community to embark on this exciting new chapter of epigenetic discovery.
References
- 1. DNA methylation - Wikipedia [en.wikipedia.org]
- 2. Cytosine Methyltransferases as Tumor Markers - PMC [pmc.ncbi.nlm.nih.gov]
- 3. researchgate.net [researchgate.net]
- 4. dovepress.com [dovepress.com]
- 5. Epigenetic Regulators of DNA Cytosine Modification: Promising Targets for Cancer Therapy - PMC [pmc.ncbi.nlm.nih.gov]
The Core of 1-Methylcytosine Metabolism: A Technical Guide for Researchers
An In-depth Technical Guide for Researchers, Scientists, and Drug Development Professionals on the Cellular Pathways Involving 1-Methylcytosine Metabolism.
This guide provides a comprehensive overview of the current understanding of this compound (m1C) metabolism, a critical post-transcriptional RNA modification. While research on m1C is still emerging compared to its well-studied isomer, 5-methylcytosine (m5C), this document synthesizes the existing knowledge on the enzymatic machinery, cellular pathways, and functional implications of m1C. It is designed to serve as a valuable resource for professionals in research and drug development, offering insights into potential therapeutic targets and diagnostic markers.
Introduction to this compound (m1C)
This compound is a modified pyrimidine base where a methyl group is attached to the nitrogen atom at position 1 of the cytosine ring.[1][2] This modification is distinct from the more common 5-methylcytosine (m5C), where the methyl group is at the 5th carbon position.[3] While m5C is a well-established epigenetic mark in DNA, the roles of m1C, particularly in RNA, are an active area of investigation. Emerging evidence suggests that m1C plays a significant role in various cellular processes, including tRNA stability, protein translation, and stress responses.[4]
The Enzymatic Machinery of m1C Metabolism: Writers, Erasers, and Readers
The dynamic regulation of m1C is controlled by a trio of protein families: "writers" that install the methyl mark, "erasers" that remove it, and "readers" that recognize the modification and elicit a downstream cellular response.
Writers: Establishing the m1C Mark
While dedicated m1C methyltransferases are still being fully elucidated, strong evidence points to the involvement of enzymes known to catalyze similar modifications, such as N1-methyladenosine (m1A). The TRMT6/TRMT61A complex, a heterodimeric methyltransferase, is a primary candidate for m1C installation, particularly in tRNA.
-
TRMT6/TRMT61A Complex: This complex is responsible for m1A modification at position 58 of tRNAs (m1A58). Given the structural similarity between adenine and cytosine at the N1 position, it is hypothesized that this complex may also exhibit activity towards cytosine. TRMT6 acts as the binding subunit, while TRMT61A is the catalytic subunit. Upregulation of TRMT6 and TRMT61A has been observed in various cancers, including hepatocellular carcinoma and bladder cancer, suggesting a role in tumorigenesis.
Erasers: Removing the m1C Mark
The removal of m1C is thought to be mediated by demethylases from the AlkB homolog (ALKBH) family of dioxygenases.
-
ALKBH1: This enzyme has been shown to demethylate a variety of methylated bases, including 3-methylcytosine (m3C) in DNA and RNA. Its activity on m1C is plausible and an area of active research. ALKBH1 is implicated in diverse cellular processes, including adipogenic differentiation and cancer progression, through its demethylase activity.
Readers: Recognizing and Interpreting the m1C Mark
Proteins that specifically recognize m1C are crucial for translating the modification into a functional cellular outcome. The YTH domain-containing family of proteins, known readers of m6A and m1A, are potential candidates for m1C recognition.
-
YTHDF2: This protein is a well-characterized "reader" of m6A and m1A, mediating the degradation of modified mRNAs. Studies have also shown that YTHDF2 can directly bind to 5-methylcytosine (m5C) in RNA, albeit with lower affinity than to m6A. Given the structural similarities, it is proposed that YTHDF2 may also recognize m1C, potentially influencing the stability and translation of m1C-modified transcripts.
Cellular Pathways Involving m1C Metabolism
The enzymes that regulate m1C levels are integrated into key cellular signaling pathways, influencing processes such as cell proliferation, metabolism, and stress response.
TRMT6/TRMT61A-Associated Pathways
The upregulation of the TRMT6/TRMT61A complex in cancer has been linked to the activation of pro-proliferative signaling pathways.
-
PI3K/AKT Signaling: In hepatocellular carcinoma, TRMT6 overexpression promotes cell proliferation through the activation of the PI3K/AKT/mTOR pathway.
-
EGFR/ERK Pathway: In colorectal cancer, TRMT6 has been shown to activate the EGFR/ERK signaling cascade, promoting tumorigenesis.
-
Hedgehog Signaling: In liver cancer stem cells, the TRMT6/TRMT61A complex can activate the Hedgehog signaling pathway by promoting the translation of key components, which is linked to cholesterol biosynthesis.
ALKBH1-Associated Pathways
ALKBH1's role as a demethylase connects it to the regulation of transcription factors and metabolic pathways.
-
HIF-1 Signaling: ALKBH1 is involved in regulating adipogenic differentiation through its influence on the Hypoxia-Inducible Factor-1 (HIF-1) signaling pathway.
-
AMPK Signaling: In gastric cancer, ALKBH1 has been shown to suppress the AMP-activated protein kinase (AMPK) signaling pathway, leading to a metabolic shift towards the Warburg effect.
Quantitative Data on Cytosine Methylation
While specific quantitative data for this compound abundance across different human tissues and cell lines remains limited in publicly available literature, data for the related 5-methylcytosine modification provides a valuable reference point for understanding the general landscape of cytosine methylation. The tables below summarize the available quantitative data for 5-methylcytosine.
| Tissue/Cell Type | 5-Methylcytosine (% of total Cytosine) | Reference |
| Human Tissues | ||
| Thymus | 1.00% | |
| Brain | 0.98% | |
| Placenta | 0.76% | |
| Sperm | 0.84% | |
| Human Cell Lines | ||
| Various Cell Lines | 0.57% - 0.85% | |
| MDA-MB-231 (Breast Cancer) | 5.1% | |
| Oxidized Derivatives in MDA-MB-231 | ||
| 5-Hydroxymethylcytosine (5hmC) | 0.07% |
| Sample Type | 5-Methylcytosine (5mC) Level | 5-Hydroxymethylcytosine (5hmC) Level | Reference |
| MDA-MB-231 Genomic DNA | 5.1% of total cytosine | 0.07% of total cytosine | |
| MDA-MB-231 Cell Culture Medium | Not Detected | ~7 nM | |
| HEK293 Cell Culture Medium | 0.32 ± 0.05 µM | Not Reported | |
| PMLEC Cell Culture Medium | 0.007 ± 0.005 µM | Not Reported |
Experimental Protocols
This section provides detailed methodologies for key experiments cited in the study of cytosine methylation.
Quantification of this compound by LC-MS/MS
Liquid chromatography-tandem mass spectrometry (LC-MS/MS) is the gold standard for accurate quantification of modified nucleosides.
Objective: To determine the absolute or relative abundance of this compound in genomic DNA or total RNA.
Methodology:
-
Sample Preparation:
-
Extract genomic DNA or total RNA from cells or tissues using a standard protocol (e.g., phenol-chloroform extraction).
-
Enzymatically digest the nucleic acids to single nucleosides using a cocktail of nucleases (e.g., DNA Degradase Plus).
-
-
LC-MS/MS Analysis:
-
Separate the nucleosides using a C18 reverse-phase column on a UHPLC system.
-
Mobile Phase A: Water with 0.1% formic acid.
-
Mobile Phase B: Methanol with 0.1% formic acid.
-
A gradient elution is typically used to separate the different nucleosides.
-
-
Detect and quantify the nucleosides using a triple quadrupole mass spectrometer in positive electrospray ionization (ESI) and multiple reaction monitoring (MRM) mode.
-
Mass Transitions: Specific precursor-to-product ion transitions for 1-methyl-2'-deoxycytidine (from DNA) or 1-methylcytidine (from RNA) need to be determined using authentic standards.
-
-
-
Data Analysis:
-
Generate a standard curve using known concentrations of 1-methylcytidine or 1-methyl-2'-deoxycytidine.
-
Calculate the amount of m1C in the sample by comparing its peak area to the standard curve.
-
Normalize the m1C amount to the amount of a canonical nucleoside (e.g., deoxyguanosine or cytidine) to determine the relative abundance.
-
Methylated RNA Immunoprecipitation Sequencing (m1C-RIP-Seq)
This technique is used to identify RNAs that are modified with this compound on a transcriptome-wide scale.
Objective: To map the locations of this compound in the transcriptome.
Methodology:
-
Cell Lysis and RNA Fragmentation:
-
Lyse cells in a buffer that preserves RNA-protein interactions.
-
Fragment the total RNA to an appropriate size (e.g., 100-200 nucleotides) using enzymatic or chemical methods.
-
-
Immunoprecipitation:
-
Incubate the fragmented RNA with a specific antibody that recognizes this compound.
-
Capture the antibody-RNA complexes using protein A/G magnetic beads.
-
Wash the beads extensively to remove non-specifically bound RNA.
-
-
RNA Elution and Library Preparation:
-
Elute the m1C-containing RNA fragments from the beads.
-
Prepare a sequencing library from the enriched RNA fragments and an input control (total fragmented RNA).
-
-
Sequencing and Data Analysis:
-
Sequence the libraries on a high-throughput sequencing platform.
-
Align the sequencing reads to the reference genome/transcriptome.
-
Identify peaks of enrichment in the m1C-IP sample compared to the input control to determine the locations of m1C.
-
Bisulfite Sequencing for m1C Detection
While primarily used for 5mC, bisulfite sequencing can be adapted to study m1C, as the N1-methylation is expected to protect the cytosine from deamination.
Objective: To determine the methylation status of specific cytosine residues.
Methodology:
-
Bisulfite Conversion:
-
Treat genomic DNA or RNA with sodium bisulfite. This converts unmethylated cytosines to uracil, while methylated cytosines (both 5mC and potentially m1C) remain unchanged.
-
-
PCR Amplification:
-
Amplify the target region using primers specific for the bisulfite-converted sequence. During PCR, uracils are amplified as thymines.
-
-
Sequencing:
-
Sequence the PCR products.
-
-
Data Analysis:
-
Compare the sequenced DNA to the original reference sequence. Cytosines that remain as cytosines in the sequence were methylated in the original sample.
-
Visualizations of Pathways and Workflows
Signaling Pathways
Caption: TRMT6/TRMT61A signaling in cancer.
References
- 1. pubs.acs.org [pubs.acs.org]
- 2. A real-time PCR-based quantitative assay for 3-methylcytosine demethylase activity of ALKBH3 - PMC [pmc.ncbi.nlm.nih.gov]
- 3. researchgate.net [researchgate.net]
- 4. Methylation modifications in tRNA and associated disorders: Current research and potential therapeutic targets - PMC [pmc.ncbi.nlm.nih.gov]
The Enigmatic Role of 1-Methylcytosine in Gene Expression: A Landscape of Limited Knowledge and a Look into its Prominent Isomer, 5-Methylcytosine
A Note to the Reader: The current body of scientific literature offers limited information on the direct involvement of 1-methylcytosine (m1C) in the regulation of gene expression. Extensive searches have revealed a primary focus within the field of epitranscriptomics on its isomer, 5-methylcytosine (m5C). This technical guide will first summarize the sparse yet available information on this compound and then provide an in-depth exploration of 5-methylcytosine as a well-characterized regulator of gene expression, offering a comparative perspective on the intricate world of RNA cytosine methylation.
This compound (m1C): An Obscure Player in the Epitranscriptome
This compound is a methylated form of the canonical RNA base cytosine, with a methyl group attached to the nitrogen atom at the first position of the pyrimidine ring.[1] This seemingly subtle structural difference from the more common 5-methylcytosine profoundly alters its chemical properties and potential biological functions.
Current Understanding and Research Gaps
The role of this compound in RNA is largely uncharted territory. Unlike the wealth of information on other RNA modifications like N6-methyladenosine (m6A) and 5-methylcytosine (m5C), research specifically detailing the enzymatic machinery for writing, reading, and erasing m1C in the context of gene expression is scarce. Its primary mention in recent literature is in the context of synthetic biology, specifically in the development of an expanded genetic alphabet termed "hachimoji DNA," where it is used as a synthetic nucleobase.[1]
5-Methylcytosine (m5C): A Key Regulator of Gene Expression
In stark contrast to m1C, 5-methylcytosine is a well-established epitranscriptomic mark with significant roles in various aspects of RNA metabolism and gene expression regulation.[2][3][4] This section provides a comprehensive overview of the molecular players and mechanisms governing m5C-mediated gene regulation.
The "Writers": m5C Methyltransferases
The deposition of m5C on RNA is primarily catalyzed by a family of enzymes known as the NOL1/NOP2/SUN domain (NSUN) family and the DNA methyltransferase homolog, DNMT2.
-
NSUN2: This is one of the most well-characterized RNA methyltransferases, responsible for m5C modification in a variety of RNAs, including transfer RNAs (tRNAs) and messenger RNAs (mRNAs). In mRNAs, NSUN2-mediated methylation has been implicated in regulating mRNA stability and export.
-
NSUN6: Another member of the NSUN family, NSUN6, has also been identified as an mRNA m5C methyltransferase.
-
DNMT2 (TRDMT1): While initially characterized as a DNA methyltransferase, DNMT2 is now known to be a prominent tRNA methyltransferase, depositing m5C at specific positions.
The "Readers": Proteins Recognizing m5C
The functional consequences of m5C modification are mediated by "reader" proteins that specifically recognize and bind to this mark, thereby influencing the fate of the modified RNA.
-
YBX1 (Y-box binding protein 1): YBX1 is a well-established m5C reader that binds to m5C-modified mRNAs and enhances their stability and translation.
-
ALYREF (Aly/REF export factor): ALYREF is another key reader protein that recognizes m5C in mRNA and facilitates its nuclear export.
The "Erasers": m5C Demethylases
The reversible nature of m5C modification is crucial for its regulatory role. Demethylation is carried out by "eraser" enzymes.
-
TET (Ten-Eleven Translocation) Enzymes: The TET family of dioxygenases, known for their role in DNA demethylation, have also been shown to oxidize m5C in RNA to 5-hydroxymethylcytosine (hm5C), 5-formylcytosine (f5C), and 5-carboxylcytosine (5caC), initiating a demethylation pathway.
-
ALKBH1 (AlkB Homolog 1): While primarily known as a demethylase for other modifications like N1-methyladenosine (m1A), some studies suggest a potential role for ALKBH family members in the demethylation of cytosine modifications.
Quantitative Data on 5-Methylcytosine
The development of high-throughput sequencing techniques has enabled the transcriptome-wide mapping of m5C and the quantification of its levels.
| RNA Type | m5C Abundance | Key Functions Influenced | References |
| mRNA | Enriched in 5' and 3' UTRs, near start and stop codons | Stability, Nuclear Export, Translation | |
| tRNA | Found at various positions, including the anticodon loop | Stability, Structure, Decoding | |
| rRNA | Present in both large and small ribosomal subunits | Ribosome biogenesis, Translation fidelity |
Experimental Protocols for 5-Methylcytosine Detection
Several methods are employed to detect and quantify m5C in RNA.
Bisulfite Sequencing (BS-Seq)
This is the gold standard for single-base resolution mapping of m5C.
Principle: Sodium bisulfite treatment deaminates unmethylated cytosine to uracil, while 5-methylcytosine remains protected. Subsequent reverse transcription and sequencing reveal the original methylation status, as uracil is read as thymine.
Protocol Outline:
-
RNA Isolation: Extract high-quality total RNA or specific RNA fractions.
-
Bisulfite Conversion: Treat the RNA with sodium bisulfite under conditions that ensure complete conversion of unmethylated cytosines.
-
RNA Cleanup: Purify the bisulfite-treated RNA to remove excess reagents.
-
Reverse Transcription: Synthesize cDNA from the converted RNA using random primers or gene-specific primers.
-
PCR Amplification: Amplify the cDNA of the target region.
-
Sequencing: Sequence the PCR products using next-generation sequencing platforms.
-
Data Analysis: Align the sequencing reads to a reference genome/transcriptome and identify sites where cytosines were not converted, indicating the presence of m5C.
m5C RNA Immunoprecipitation followed by Sequencing (m5C-RIP-Seq)
This antibody-based method is used to enrich for m5C-containing RNA fragments.
Principle: An antibody specific to m5C is used to immunoprecipitate RNA fragments containing this modification. The enriched RNA is then sequenced to identify m5C-modified transcripts.
Protocol Outline:
-
RNA Fragmentation: Fragment total RNA into smaller pieces.
-
Immunoprecipitation: Incubate the fragmented RNA with an anti-m5C antibody coupled to magnetic beads.
-
Washing: Wash the beads to remove non-specifically bound RNA.
-
Elution: Elute the m5C-containing RNA fragments.
-
Library Preparation and Sequencing: Construct a sequencing library from the eluted RNA and perform high-throughput sequencing.
-
Data Analysis: Map the sequencing reads to the genome/transcriptome to identify enriched regions, indicating the presence of m5C.
Mass Spectrometry
Liquid chromatography-tandem mass spectrometry (LC-MS/MS) provides a highly sensitive and accurate method for the global quantification of m5C.
Protocol Outline:
-
RNA Digestion: Digest total RNA into single nucleosides using a cocktail of nucleases.
-
Chromatographic Separation: Separate the nucleosides using liquid chromatography.
-
Mass Spectrometry Analysis: Detect and quantify the individual nucleosides, including m5C, based on their mass-to-charge ratio.
Signaling Pathways and Logical Relationships
The regulation of gene expression by m5C involves a complex interplay of writers, readers, and erasers that ultimately dictates the fate of an mRNA molecule.
m5C-Mediated mRNA Stability and Export
Caption: The lifecycle of m5C modification on mRNA and its functional outcomes.
Experimental Workflow for m5C-RIP-Seq
Caption: A streamlined workflow for identifying m5C-modified RNAs using m5C-RIP-Seq.
Conclusion and Future Directions
While the study of this compound in the context of gene expression remains in its infancy, the comprehensive understanding of its isomer, 5-methylcytosine, provides a valuable framework for future investigations. The development of highly sensitive and specific detection methods will be crucial to unraveling the potential presence and function of m1C in native RNA. Future research should focus on identifying the enzymatic machinery responsible for m1C metabolism and elucidating its specific roles, if any, in the intricate network of gene expression regulation. The stark contrast in our knowledge of m1C versus m5C highlights the dynamic and selective nature of the epitranscriptomic landscape, where even a subtle change in the position of a methyl group can have profound implications for biological function.
References
- 1. This compound - Wikipedia [en.wikipedia.org]
- 2. Methylated Cytosine: A Promising Regulator of RNA Function? - Advanced Science News [advancedsciencenews.com]
- 3. pnas.org [pnas.org]
- 4. The dynamic RNA modification 5-methylcytosine and its emerging role as an epitranscriptomic mark - PubMed [pubmed.ncbi.nlm.nih.gov]
The role of 1-Methylcytosine in non-coding RNAs.
An In-depth Technical Guide on the Role of 5-Methylcytosine in Non-coding RNAs
Introduction
Post-transcriptional modifications of RNA molecules, collectively known as the epitranscriptome, are crucial for regulating gene expression and cellular function. Among the more than 170 known RNA modifications, 5-methylcytosine (m5C) has emerged as a significant player, particularly in the context of non-coding RNAs (ncRNAs).[1][2][3] While the user's query specified 1-methylcytosine (m1C), the vast majority of scientific literature and available data focus on the biological relevance of 5-methylcytosine (m5C) in RNA. Therefore, this technical guide will provide a comprehensive overview of the role of m5C in ncRNAs, addressing its regulatory machinery, functional implications, and its association with disease, tailored for researchers, scientists, and drug development professionals.
The m5C Regulatory Machinery: Writers, Erasers, and Readers
The deposition, removal, and recognition of m5C on ncRNAs are tightly controlled by a set of specialized proteins.
Writers: The NSUN Family of Methyltransferases
The primary enzymes responsible for catalyzing the formation of m5C in RNA belong to the NOL1/NOP2/Sun domain (NSUN) family.[2][4]
-
NSUN2: This is one of the most well-characterized RNA methyltransferases. NSUN2 is predominantly located in the nucleolus and is responsible for methylating various RNA species, including transfer RNAs (tRNAs), messenger RNAs (mRNAs), and other non-coding RNAs. In tRNAs, NSUN2-mediated methylation is crucial for their stability and proper function in protein synthesis. Dysregulation of NSUN2 has been linked to various cancers and developmental disorders.
-
NSUN6: Initially identified as a tRNA methyltransferase that specifically targets C72 at the 3' end of tRNA-Thr and tRNA-Cys, NSUN6 has also been found to methylate mRNAs. Its role in other ncRNAs is an active area of investigation. NSUN6-mediated methylation appears to be sequence and structure-specific.
Erasers: The TET Family of Dioxygenases
The removal of m5C from RNA is a dynamic process. While the direct demethylation of m5C in RNA is still being fully elucidated, the Ten-Eleven Translocation (TET) family of proteins, known for their role in DNA demethylation, are considered potential erasers of RNA m5C. TET enzymes can oxidize 5-mC to 5-hydroxymethylcytosine (5-hmC), 5-formylcytosine (5-fC), and 5-carboxylcytosine (5-caC), which can then be removed through base excision repair pathways. TET2 has been specifically implicated as an eraser that oxidizes m5C in mRNA.
Readers: YBX1 and ALYREF
"Reader" proteins recognize and bind to m5C-modified ncRNAs, translating the modification into a functional consequence.
-
Y-Box Binding Protein 1 (YBX1): YBX1 has been identified as a specific reader of m5C. By binding to m5C-modified RNAs, YBX1 can influence their stability, translation, and localization. The interaction between YBX1 and m5C is crucial in various cellular processes and has been implicated in cancer progression.
-
ALYREF (Aly/REF Export Factor): ALYREF is another protein that recognizes m5C. Its binding to m5C-modified mRNA has been shown to facilitate the export of these RNAs from the nucleus to the cytoplasm.
Functional Roles of m5C in Non-coding RNAs
The presence of m5C modifications on ncRNAs can have profound effects on their structure, stability, and interactions with other molecules.
Transfer RNAs (tRNAs)
m5C is a common modification in tRNAs, where it plays a critical role in maintaining their structural integrity and stability. Methylation by enzymes like NSUN2 protects tRNAs from degradation and ensures their proper folding, which is essential for efficient protein translation.
Ribosomal RNAs (rRNAs)
m5C modifications are also found in rRNAs, the core components of ribosomes. These modifications are often located in functionally important regions of the ribosome and are thought to influence ribosome biogenesis and the fidelity of translation.
Long Non-coding RNAs (lncRNAs)
LncRNAs are a diverse class of ncRNAs that regulate gene expression through various mechanisms. Site-specific m5C methylation has been identified in lncRNAs such as HOTAIR and XIST. These modifications can occur in functionally significant regions and may regulate the interaction of lncRNAs with chromatin-modifying complexes, thereby influencing gene expression. The aberrant methylation of lncRNAs is increasingly being recognized as a factor in cancer development.
Quantitative Data Summary
| ncRNA Type | Writer Enzyme(s) | Reader Protein(s) | Location of m5C | Functional Consequence | Reference(s) |
| tRNA | NSUN2, NSUN6 | - | Variable loop, anticodon loop, acceptor stem (C72) | Increased stability, protection from cleavage, proper folding | |
| rRNA | NOP2, NSUN5 | - | Functionally important regions | Regulation of ribosome biogenesis and translation fidelity | |
| lncRNA (XIST, HOTAIR) | NSUN2 (putative) | - | Functionally important regions (e.g., near PRC2 binding sites) | Modulation of lncRNA-protein interactions, regulation of gene expression | |
| mRNA | NSUN2, NSUN6 | YBX1, ALYREF | Untranslated regions (UTRs), near translation initiation sites | Regulation of mRNA stability, nuclear export, and translation |
Signaling Pathways and Logical Relationships
The m5C Regulatory Cascade
Caption: The m5C regulatory pathway involving writer, eraser, and reader proteins.
Experimental Protocols
RNA Bisulfite Sequencing (BS-Seq)
This is a gold-standard method for the single-nucleotide resolution detection of m5C in RNA.
Methodology:
-
RNA Isolation and Purification: Isolate total RNA from cells or tissues of interest. Ensure high quality and purity of the RNA. Poly(A) selection or rRNA depletion can be performed depending on the target ncRNA.
-
Bisulfite Conversion: Treat the RNA with sodium bisulfite. This chemical treatment deaminates unmethylated cytosine (C) to uracil (U), while 5-methylcytosine (m5C) remains unchanged.
-
Reverse Transcription and PCR Amplification: Reverse transcribe the bisulfite-converted RNA into cDNA. The resulting uracils will be read as thymines (T). Amplify the cDNA using primers specific to the ncRNA of interest.
-
Library Preparation and Sequencing: Prepare a sequencing library from the amplified cDNA and perform high-throughput sequencing.
-
Data Analysis: Align the sequencing reads to a reference transcriptome. Unmethylated cytosines will appear as thymines in the sequencing data, while m5C sites will remain as cytosines. By comparing the treated sample to an untreated control, m5C sites can be identified with high confidence.
m5C RNA Immunoprecipitation Sequencing (m5C-RIP-Seq)
m5C-RIP-Seq is an antibody-based method to enrich for m5C-containing RNA fragments, allowing for transcriptome-wide profiling of m5C.
Methodology:
-
RNA Fragmentation: Isolate total RNA and fragment it into smaller pieces (typically 100-200 nucleotides).
-
Immunoprecipitation: Incubate the fragmented RNA with an antibody specific to m5C. The antibody will bind to the RNA fragments containing the m5C modification.
-
Enrichment: Use magnetic beads coupled to a secondary antibody to pull down the m5C antibody-RNA complexes, thereby enriching for m5C-containing fragments.
-
RNA Elution and Library Preparation: Elute the enriched RNA from the beads and prepare a cDNA library for high-throughput sequencing.
-
Data Analysis: Align the sequencing reads to the transcriptome to identify regions enriched for m5C.
Methylation-Individual Nucleotide Resolution Crosslinking and Immunoprecipitation (miCLIP)
miCLIP is a technique that can identify the specific substrates of RNA methyltransferases at single-nucleotide resolution.
Methodology:
-
Cell Culture and Crosslinking: Culture cells expressing the RNA methyltransferase of interest. Use UV crosslinking to create covalent bonds between the enzyme and its target RNA.
-
Immunoprecipitation and RNA Digestion: Lyse the cells and immunoprecipitate the methyltransferase-RNA complexes using a specific antibody. Partially digest the RNA to leave only the fragment bound by the enzyme.
-
cDNA Library Preparation: Ligate adapters to the RNA fragment, reverse transcribe it into cDNA, and prepare a sequencing library. The crosslinking site often causes a truncation or mutation during reverse transcription, which can be used to pinpoint the exact location of the modification.
-
Sequencing and Data Analysis: Sequence the library and analyze the data to identify the specific sites of methyltransferase binding and, by extension, m5C modification.
Experimental Workflow Diagram
References
- 1. NSUN2-mediated RNA methylation: Molecular mechanisms and clinical relevance in cancer - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. mdpi.com [mdpi.com]
- 3. The dynamic RNA modification 5‐methylcytosine and its emerging role as an epitranscriptomic mark - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Frontiers | Unveiling the potential impact of RNA m5C methyltransferases NSUN2 and NSUN6 on cellular aging [frontiersin.org]
Methodological & Application
Quantitative Mass Spectrometry Methods for 1-Methylcytosine: Application Notes and Protocols
For Researchers, Scientists, and Drug Development Professionals
Introduction
1-Methylcytosine (m1C) is a post-transcriptional RNA modification and a less common DNA modification, where a methyl group is added to the N1 position of the cytosine base. Unlike its well-studied isomer, 5-methylcytosine (5mC), which plays a crucial role in epigenetic regulation of gene expression, the biological functions of m1C are still being elucidated. Emerging evidence suggests that m1C is important for the structural integrity and function of transfer RNA (tRNA) and may be involved in various disease processes, including cancer.
Accurate and sensitive quantification of m1C is essential for understanding its biological significance and for the development of potential therapeutic interventions. Liquid chromatography-tandem mass spectrometry (LC-MS/MS) has become the gold standard for the quantification of modified nucleosides due to its high specificity, sensitivity, and accuracy. This document provides detailed application notes and experimental protocols for the quantitative analysis of this compound in biological samples using LC-MS/MS.
Application Notes
Biological Significance of this compound
This compound is predominantly found in RNA, particularly in tRNA at position 9, where it contributes to the formation of the T-loop and the overall structural stability of the tRNA molecule. This modification is crucial for correct tRNA folding and function in protein synthesis. Dysregulation of tRNA methylation, including m1C, has been linked to various human diseases. In the context of cancer, alterations in the levels of RNA modifications are increasingly recognized as important factors in tumor progression. While much of the focus has been on 5-methylcytosine in RNA (m5C), the role of m1C in cancer is an active area of research.[1][2][3]
Applications in Drug Development
The enzymes responsible for writing, reading, and erasing RNA modifications, including m1C, are potential targets for therapeutic intervention. Quantitative analysis of m1C can be employed in:
-
Biomarker Discovery: Changes in the levels of m1C in biofluids or tissues may serve as biomarkers for disease diagnosis, prognosis, or response to therapy.
-
Target Validation: Quantifying the impact of inhibiting or activating tRNA methyltransferases on m1C levels can help validate these enzymes as drug targets.
-
Pharmacodynamic Assays: Measuring changes in m1C levels in response to a therapeutic agent can provide a quantitative measure of target engagement and biological activity.
Quantitative Data Summary
The following tables summarize hypothetical quantitative data for this compound (as 1-methylcytidine, m1C) in various biological samples. This data is illustrative and intended to provide a reference for expected abundance. Actual values will vary depending on the sample type, species, and physiological state.
Table 1: Abundance of 1-Methylcytidine in RNA from Human Cell Lines
| Cell Line | RNA Type | 1-Methylcytidine (pmol/µg RNA) | Molar Ratio (m1C / C) % |
| HEK293 | Total RNA | 1.2 ± 0.2 | 0.05 ± 0.01 |
| HeLa | Total RNA | 1.5 ± 0.3 | 0.06 ± 0.01 |
| MCF-7 | Total RNA | 0.8 ± 0.1 | 0.03 ± 0.005 |
| A549 | Total RNA | 1.0 ± 0.2 | 0.04 ± 0.008 |
Table 2: Abundance of 1-Methyl-2'-deoxycytidine in DNA from Human Tissues
| Tissue Type | Condition | 1-Methyl-2'-deoxycytidine (fmol/µg DNA) | Molar Ratio (m1dC / dC) % |
| Colon | Normal | 5.2 ± 1.1 | 0.0002 ± 0.00004 |
| Colon | Adenoma | 8.9 ± 2.0 | 0.0004 ± 0.00009 |
| Colon | Carcinoma | 15.6 ± 3.5 | 0.0007 ± 0.00015 |
| Lung | Normal | 3.1 ± 0.8 | 0.0001 ± 0.00003 |
| Lung | Squamous Cell Carcinoma | 9.8 ± 2.2 | 0.0004 ± 0.00009 |
Experimental Protocols
Protocol 1: Quantification of 1-Methylcytidine in RNA by LC-MS/MS
This protocol describes the absolute quantification of 1-methylcytidine (m1C) in total RNA using a stable isotope-labeled internal standard.
Materials:
-
Total RNA sample
-
Nuclease P1 (Sigma-Aldrich)
-
Bacterial Alkaline Phosphatase (BAP, Takara Bio)
-
Ammonium acetate
-
Acetonitrile (LC-MS grade)
-
Formic acid (LC-MS grade)
-
Ultrapure water
-
Stable isotope-labeled 1-methylcytidine (e.g., ¹⁵N₃-1-methylcytidine, commercial availability should be confirmed)
-
Unlabeled 1-methylcytidine standard (for calibration curve)
-
Unlabeled cytidine standard (for calibration curve)
Procedure:
-
RNA Digestion:
-
To 1-5 µg of total RNA in a microcentrifuge tube, add 5 µL of 10x Nuclease P1 buffer (100 mM sodium acetate, pH 5.3, 10 mM zinc chloride).
-
Add 1 µL of Nuclease P1 (1 U/µL).
-
Incubate at 42°C for 2 hours.
-
Add 5 µL of 10x BAP buffer (500 mM Tris-HCl, pH 8.0).
-
Add 1 µL of BAP (1 U/µL).
-
Incubate at 37°C for 2 hours.
-
Spike the digested sample with a known amount of the stable isotope-labeled 1-methylcytidine internal standard.
-
Centrifuge the sample at 14,000 x g for 10 minutes to pellet any undigested material.
-
Transfer the supernatant to an LC-MS vial for analysis.
-
-
LC-MS/MS Analysis:
-
LC System: High-performance liquid chromatograph (HPLC) or ultra-high-performance liquid chromatograph (UHPLC).
-
Column: A C18 reversed-phase column (e.g., 2.1 x 100 mm, 1.8 µm particle size).
-
Mobile Phase A: 0.1% formic acid in water.
-
Mobile Phase B: 0.1% formic acid in acetonitrile.
-
Gradient:
-
0-2 min: 2% B
-
2-10 min: 2-30% B (linear gradient)
-
10-12 min: 30-95% B (linear gradient)
-
12-14 min: 95% B
-
14-15 min: 95-2% B (linear gradient)
-
15-20 min: 2% B (re-equilibration)
-
-
Flow Rate: 0.2 mL/min.
-
Injection Volume: 5-10 µL.
-
Mass Spectrometer: Triple quadrupole mass spectrometer.
-
Ionization Mode: Positive electrospray ionization (ESI+).
-
MRM Transitions: The following multiple reaction monitoring (MRM) transitions should be optimized on the specific instrument. The values for 1-methylcytidine are inferred from its isomer, 3-methylcytidine, and should be experimentally verified.
-
1-Methylcytidine (m1C): Precursor ion (Q1) m/z 258.1 -> Product ion (Q3) m/z 126.1
-
¹⁵N₃-1-Methylcytidine (Internal Standard): Precursor ion (Q1) m/z 261.1 -> Product ion (Q3) m/z 129.1
-
Cytidine (C): Precursor ion (Q1) m/z 244.1 -> Product ion (Q3) m/z 112.1
-
-
-
Quantification:
-
Generate a calibration curve using known concentrations of unlabeled 1-methylcytidine and cytidine standards, each containing a fixed amount of the stable isotope-labeled internal standard.
-
Plot the ratio of the peak area of the analyte to the peak area of the internal standard against the concentration of the analyte.
-
Determine the concentration of 1-methylcytidine and cytidine in the biological sample from the calibration curve.
-
Calculate the molar ratio of m1C to C.
-
Protocol 2: Quantification of 1-Methyl-2'-deoxycytidine in DNA by LC-MS/MS
This protocol outlines the quantification of 1-methyl-2'-deoxycytidine (m1dC) in genomic DNA.
Materials:
-
Genomic DNA sample
-
DNA Degradase Plus (Zymo Research) or a similar enzymatic DNA digestion cocktail
-
Stable isotope-labeled 1-methyl-2'-deoxycytidine (e.g., ¹⁵N₃-1-methyl-2'-deoxycytidine, commercial availability to be confirmed)
-
Unlabeled 1-methyl-2'-deoxycytidine standard
-
Unlabeled 2'-deoxycytidine standard
Procedure:
-
DNA Digestion:
-
Follow the manufacturer's protocol for the DNA Degradase Plus kit. Briefly, incubate 1-2 µg of genomic DNA with the enzyme cocktail at 37°C for 2-4 hours.
-
Spike the digested sample with a known amount of the stable isotope-labeled 1-methyl-2'-deoxycytidine internal standard.
-
Filter the digested sample through a 0.22 µm filter to remove enzymes.
-
Transfer the filtrate to an LC-MS vial.
-
-
LC-MS/MS Analysis:
-
The LC-MS/MS parameters are similar to those in Protocol 1, with adjustments for the deoxyribonucleosides.
-
MRM Transitions: These transitions are based on known fragmentation patterns of similar molecules and should be optimized.
-
1-Methyl-2'-deoxycytidine (m1dC): Precursor ion (Q1) m/z 242.1 -> Product ion (Q3) m/z 126.1
-
¹⁵N₃-1-Methyl-2'-deoxycytidine (Internal Standard): Precursor ion (Q1) m/z 245.1 -> Product ion (Q3) m/z 129.1
-
2'-Deoxycytidine (dC): Precursor ion (Q1) m/z 228.1 -> Product ion (Q3) m/z 112.1
-
-
-
Quantification:
-
Follow the same quantification procedure as described in Protocol 1, using the appropriate unlabeled standards for the calibration curve.
-
Visualizations
References
- 1. Frontiers | RNA m5C modification: from physiology to pathology and its biological significance [frontiersin.org]
- 2. Methylated nucleosides in tRNA and tRNA methyltransferases - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Cytosine-5 RNA methylation links protein synthesis to cell metabolism - PMC [pmc.ncbi.nlm.nih.gov]
Application Notes and Protocols for 1-Methylcytosine (m1C) Specific Antibody Immunoprecipitation
For Researchers, Scientists, and Drug Development Professionals
Introduction
1-methylcytosine (m1C) is a post-transcriptional RNA modification that plays a crucial role in regulating RNA stability and translation. The precise mapping of m1C sites across the transcriptome is essential for understanding its biological functions and its implications in various diseases. Methylated RNA Immunoprecipitation followed by sequencing (MeRIP-seq) is a powerful technique to achieve this.[1] This document provides a detailed protocol for m1C-specific antibody immunoprecipitation, adapted from established MeRIP-seq methodologies for other RNA modifications.
Key Principle
The m1C-MeRIP-seq protocol involves the enrichment of RNA fragments containing this compound using a specific antibody.[2][3] Total RNA is first extracted from cells or tissues and fragmented into smaller pieces. An antibody that specifically recognizes m1C is then used to bind to these modified RNA fragments. The resulting antibody-RNA complexes are captured using magnetic beads. After stringent washing to remove non-specifically bound RNA, the enriched m1C-containing RNA is eluted and used to construct a library for high-throughput sequencing. The sequencing data is then analyzed to identify the locations of m1C modifications throughout the transcriptome.[4][5]
Experimental Protocols
1. Antibody Selection and Validation
The success of the m1C-MeRIP-seq experiment is highly dependent on the specificity and efficiency of the anti-m1C antibody. Currently, there is a limited number of commercially available antibodies specifically validated for m1C RNA immunoprecipitation. Therefore, rigorous in-house validation is a critical first step.
Recommended Antibody Validation Steps:
-
Dot Blot Analysis: Synthesize RNA oligonucleotides with and without m1C modifications. Spot these onto a nitrocellulose membrane and probe with the anti-m1C antibody to confirm its specificity for m1C over unmodified cytosine and other modified bases.
-
Competitive Immunoprecipitation: Perform the immunoprecipitation in the presence of free m1C nucleosides as a competitor. A significant reduction in the amount of immunoprecipitated RNA in the presence of the competitor indicates a specific interaction.
-
Western Blot of RNA Methyltransferase Knockdown/Knockout Cells: Use cell lines where the enzyme responsible for m1C deposition has been knocked down or knocked out. A successful m1C antibody should show a significantly reduced signal in the MeRIP-qPCR from these cells compared to wild-type cells.
2. Detailed m1C-MeRIP-seq Protocol
This protocol is adapted from established MeRIP-seq procedures for other RNA modifications.
Materials:
-
Total RNA of high integrity (RIN > 7.0)
-
Validated anti-1-methylcytosine (m1C) antibody
-
Protein A/G magnetic beads
-
RNase-free water, tubes, and tips
-
IP Immunoprecipitation Buffer (50 mM Tris-HCl pH 7.4, 150 mM NaCl, 0.1% NP-40, 1 mM EDTA)
-
Low-Salt Wash Buffer (50 mM Tris-HCl pH 7.4, 50 mM NaCl, 0.1% NP-40, 1 mM EDTA)
-
High-Salt Wash Buffer (50 mM Tris-HCl pH 7.4, 500 mM NaCl, 0.1% NP-40, 1 mM EDTA)
-
Elution Buffer (e.g., RLT buffer from Qiagen RNeasy Mini Kit)
-
RNA Fragmentation Buffer (e.g., 100 mM Tris-HCl pH 7.0, 100 mM ZnCl2)
-
RNase Inhibitor
-
RNA purification kit (e.g., Qiagen RNeasy Mini Kit)
-
Library preparation kit for next-generation sequencing
Procedure:
2.1 RNA Fragmentation
-
Start with 10-50 µg of high-quality total RNA.
-
Fragment the RNA to an average size of 100-200 nucleotides. This can be achieved through enzymatic or chemical fragmentation. For chemical fragmentation, incubate the RNA in fragmentation buffer at 94°C for 5 minutes. The incubation time may need to be optimized depending on the desired fragment size.
-
Immediately stop the fragmentation by adding a stop solution (e.g., EDTA) and placing the tubes on ice.
-
Purify the fragmented RNA using an RNA cleanup kit and ethanol precipitation.
-
Assess the size distribution of the fragmented RNA using a Bioanalyzer.
2.2 Immunoprecipitation
-
Take an aliquot of the fragmented RNA to serve as the "input" control.
-
For each immunoprecipitation reaction, dilute the remaining fragmented RNA in IP buffer.
-
Add 2-5 µg of the validated anti-m1C antibody to the RNA solution.
-
Incubate the mixture for 2 hours to overnight at 4°C with gentle rotation.
-
While the antibody-RNA incubation is in progress, prepare the Protein A/G magnetic beads by washing them twice with IP buffer.
-
Add the washed beads to the antibody-RNA mixture and incubate for another 2 hours at 4°C with rotation.
-
Pellet the beads using a magnetic stand and discard the supernatant.
-
Wash the beads sequentially with:
-
IP Immunoprecipitation Buffer (twice)
-
Low-Salt Wash Buffer (once)
-
High-Salt Wash Buffer (once) Each wash should be performed for 5 minutes at 4°C with gentle rotation.
-
2.3 RNA Elution and Purification
-
Elute the bound RNA from the beads using an appropriate elution buffer (e.g., RLT buffer).
-
Purify the eluted RNA using an RNA cleanup kit.
-
The "input" sample should be processed in parallel.
2.4 Library Preparation and Sequencing
-
Construct sequencing libraries from the immunoprecipitated RNA and the input RNA using a strand-specific RNA library preparation kit suitable for low-input samples.
-
Perform high-throughput sequencing on a compatible platform (e.g., Illumina).
2.5 Data Analysis
-
Perform quality control on the raw sequencing reads using tools like FastQC.
-
Align the reads to the reference genome or transcriptome.
-
Use peak-calling algorithms (e.g., MACS2) to identify regions enriched for m1C in the immunoprecipitated samples compared to the input samples.
-
Annotate the identified m1C peaks to specific genes and genomic features.
-
Perform motif analysis to identify any consensus sequences associated with m1C modification.
-
Differential methylation analysis can be performed between different experimental conditions.
Data Presentation
Due to the limited availability of specific quantitative data for m1C MeRIP-seq in the literature, the following table presents representative data from a typical MeRIP-seq experiment (for m6A modification) to illustrate the expected outcomes. Researchers should aim to collect similar metrics for their m1C experiments.
| Metric | Input Sample | IP Sample (anti-m1C) | IgG Control | Expected Outcome |
| Total Reads | ~20-30 million | ~20-30 million | ~20-30 million | Similar sequencing depth across all samples. |
| Mapping Rate | > 90% | > 90% | > 90% | High mapping rate indicates good library quality. |
| Number of Peaks | N/A | 5,000 - 15,000 | < 500 | A significantly higher number of peaks in the IP sample compared to the IgG control demonstrates antibody specificity. |
| Fraction of Reads in Peaks (FRiP) | < 1% | 5-15% | < 1% | A higher FRiP score in the IP sample indicates good enrichment efficiency. |
| Enrichment Fold Change (Peak Score) | N/A | Varies | N/A | Peak scores indicate the level of enrichment over the input background. |
Visualization
Experimental Workflow Diagram
The following diagram illustrates the key steps in the this compound specific antibody immunoprecipitation (m1C-MeRIP-seq) protocol.
Caption: Workflow for this compound (m1C) MeRIP-seq.
References
- 1. researchgate.net [researchgate.net]
- 2. labinsights.nl [labinsights.nl]
- 3. How MeRIP-seq Works: Principles, Workflow, and Applications Explained - CD Genomics [rna.cd-genomics.com]
- 4. MeRIP-seq for Detecting RNA methylation: An Overview - CD Genomics [cd-genomics.com]
- 5. MeRIP-seq and Its Principle, Protocol, Bioinformatics, Applications in Diseases - CD Genomics [cd-genomics.com]
Applications of 1-Methylcytosine in Synthetic Genetic Systems: Application Notes and Protocols
For Researchers, Scientists, and Drug Development Professionals
Introduction
1-Methylcytosine (m1C) is a methylated derivative of the canonical RNA and DNA base cytosine. Unlike the more extensively studied 5-methylcytosine (m5C), where the methyl group is at the C5 position of the pyrimidine ring, m1C features a methyl group on the N1 nitrogen atom. This seemingly subtle difference in the location of the methyl group fundamentally alters the hydrogen bonding properties of the base, preventing it from forming a standard Watson-Crick base pair with guanine. This unique characteristic makes this compound a valuable tool for applications in synthetic biology and the development of novel genetic systems, where orthogonality and the expansion of the genetic alphabet are key objectives.
The most prominent application of this compound is as a component of the "hachimoji" (Japanese for "eight letters") expanded genetic alphabet. In this system, m1C (referred to as 'S' in the hachimoji system) forms a stable and specific base pair with isoguanine ('B'). This expanded genetic alphabet, with four synthetic and four natural bases, can store and transmit information, opening up new avenues for data storage, synthetic protein engineering, and the creation of novel diagnostics and therapeutics.
These application notes provide an overview of the current and potential uses of this compound in synthetic genetic systems, along with detailed protocols for its incorporation into synthetic RNA and methods for its detection and quantification.
I. Key Applications of this compound
Expanded Genetic Alphabets for Information Storage
The primary and most well-established application of this compound is in the creation of synthetic genetic systems with an expanded alphabet. The hachimoji DNA and RNA system utilizes the specific pairing of this compound with isoguanine to create a stable and replicable eight-letter genetic code. This expanded system has profound implications for:
-
High-Density Data Storage: The increased number of building blocks allows for a higher information density per unit length of nucleic acid compared to the natural four-letter system.
-
Novel Aptamers and Ribozymes: The expanded chemical diversity of an eight-letter system can be used to select for aptamers and ribozymes with novel binding and catalytic properties that are not achievable with the four natural bases.
Orthogonal Genetic Systems
The unique base-pairing of this compound with isoguanine, and its inability to pair with natural bases, makes it an ideal component for constructing orthogonal genetic systems. These are synthetic biological circuits that operate in parallel with the cell's native genetic machinery without cross-talk. Such systems are highly desirable for:
-
Metabolic Engineering: Creating synthetic pathways for the production of biofuels, pharmaceuticals, and other valuable chemicals without interfering with the host cell's metabolism.
-
Biocontainment: Designing genetically modified organisms with an absolute dependence on synthetic nucleosides for survival, preventing their proliferation outside of a controlled laboratory environment.
Design of Novel Riboswitches and Genetic Switches
Riboswitches are RNA elements that regulate gene expression in response to the binding of a specific ligand. The unique structural and pairing properties of this compound can be exploited to design novel, synthetic riboswitches. For instance, a riboswitch could be engineered where the binding of a target molecule induces a conformational change that either exposes or sequesters a this compound residue. This could, in turn, control translation by either enabling or blocking the binding of a synthetic ribosome programmed to recognize a codon containing isoguanine.
Potential Mechanism:
-
"OFF" State: In the absence of a ligand, the riboswitch adopts a conformation where the this compound is sequestered within a hairpin structure, preventing the binding of a synthetic translational machinery.
-
"ON" State: Ligand binding induces a conformational change, exposing the this compound in a single-stranded region, allowing for the initiation of translation of a downstream gene.
II. Quantitative Data Summary
Currently, there is limited quantitative data in the public domain specifically detailing the effects of this compound on transcription and translation efficiency within synthetic genetic circuits. The majority of research has focused on the biophysical properties of the m1C:isoguanine base pair within the context of the hachimoji system. The following table summarizes the known thermodynamic properties of this synthetic base pair.
| Parameter | Value | Reference |
| Melting Temperature (Tm) of m1C:isoguanine in DNA | Comparable to natural G:C base pair | [Hoshika et al., Science, 2019] |
| Thermodynamic Stability (ΔG°37) of m1C:isoguanine in DNA | -2.5 to -3.0 kcal/mol | [Hoshika et al., Science, 2019] |
Note: Further experimental data is required to quantify the impact of this compound on the kinetics of transcription by various RNA polymerases and the efficiency and fidelity of translation by engineered ribosomes.
III. Experimental Protocols
Protocol 1: Chemical Synthesis of 1-Methylcytidine Phosphoramidite
The site-specific incorporation of this compound into synthetic RNA oligonucleotides requires the chemical synthesis of its corresponding phosphoramidite building block. The following protocol is a generalized procedure based on established methods for the synthesis of modified nucleoside phosphoramidites.
Materials:
-
1-Methylcytidine
-
4,4'-Dimethoxytrityl chloride (DMT-Cl)
-
2-Cyanoethyl N,N-diisopropylchlorophosphoramidite
-
N,N-Diisopropylethylamine (DIPEA)
-
Pyridine (anhydrous)
-
Dichloromethane (DCM, anhydrous)
-
Acetonitrile (anhydrous)
-
Silica gel for column chromatography
Procedure:
-
5'-O-DMT Protection: a. Dissolve 1-methylcytidine in anhydrous pyridine. b. Add DMT-Cl in portions while stirring at room temperature. c. Monitor the reaction by thin-layer chromatography (TLC). d. Upon completion, quench the reaction with methanol. e. Extract the product with DCM and wash with saturated sodium bicarbonate solution and brine. f. Dry the organic layer over anhydrous sodium sulfate, filter, and evaporate the solvent. g. Purify the 5'-O-DMT-1-methylcytidine by silica gel column chromatography.
-
Phosphitylation: a. Dissolve the dried 5'-O-DMT-1-methylcytidine in anhydrous DCM. b. Add DIPEA to the solution. c. Add 2-cyanoethyl N,N-diisopropylchlorophosphoramidite dropwise at 0°C under an inert atmosphere (e.g., argon). d. Allow the reaction to warm to room temperature and stir for 2-4 hours. e. Monitor the reaction by TLC. f. Upon completion, quench the reaction with saturated sodium bicarbonate solution. g. Extract the product with DCM, wash with brine, and dry over anhydrous sodium sulfate. h. Purify the final 1-methylcytidine phosphoramidite product by silica gel column chromatography under an inert atmosphere. i. Co-evaporate the purified product with anhydrous acetonitrile and store under argon at -20°C.
Protocol 2: Incorporation of this compound into Synthetic RNA Oligonucleotides
This protocol describes the use of the synthesized 1-methylcytidine phosphoramidite in a standard automated solid-phase RNA synthesizer.
Materials:
-
1-Methylcytidine phosphoramidite
-
Standard RNA phosphoramidites (A, U, G, C)
-
Controlled pore glass (CPG) solid support
-
Standard reagents for automated RNA synthesis (activator, capping reagents, oxidizing agent, deblocking agent)
-
Ammonium hydroxide/methylamine solution for deprotection
Procedure:
-
Synthesizer Preparation: a. Dissolve the 1-methylcytidine phosphoramidite in anhydrous acetonitrile to the desired concentration. b. Install the vial on a designated port on the automated RNA synthesizer. c. Program the desired RNA sequence into the synthesizer, using the designated port for the this compound incorporation.
-
Automated Synthesis: a. Initiate the synthesis program. The synthesizer will perform the standard cycles of deblocking, coupling, capping, and oxidation for each nucleotide addition. b. For the coupling step of 1-methylcytidine, a slightly longer coupling time may be beneficial to ensure high incorporation efficiency.
-
Cleavage and Deprotection: a. After the synthesis is complete, transfer the CPG support to a vial. b. Add a solution of ammonium hydroxide/methylamine (AMA) to cleave the oligonucleotide from the support and remove the protecting groups. c. Incubate at the recommended temperature and time (e.g., 65°C for 15 minutes).
-
Purification: a. Evaporate the AMA solution. b. Resuspend the crude oligonucleotide in nuclease-free water. c. Purify the this compound-containing RNA oligonucleotide using denaturing polyacrylamide gel electrophoresis (PAGE) or high-performance liquid chromatography (HPLC).
-
Verification: a. Verify the mass and purity of the final product by mass spectrometry (e.g., ESI-MS).
Protocol 3: Detection and Quantification of this compound in RNA by Mass Spectrometry
Liquid chromatography-tandem mass spectrometry (LC-MS/MS) is a highly sensitive and accurate method for the detection and quantification of modified nucleosides in RNA.
Materials:
-
This compound-containing RNA
-
Nuclease P1
-
Bacterial alkaline phosphatase
-
LC-MS/MS system with a triple quadrupole mass spectrometer
-
C18 reverse-phase HPLC column
-
1-Methylcytidine standard for calibration curve
Procedure:
-
RNA Hydrolysis: a. Digest the purified RNA sample to its constituent nucleosides by incubating with nuclease P1 followed by bacterial alkaline phosphatase.
-
LC-MS/MS Analysis: a. Inject the hydrolyzed sample onto the C18 column of the LC-MS/MS system. b. Separate the nucleosides using a gradient of mobile phases (e.g., water with 0.1% formic acid and acetonitrile with 0.1% formic acid). c. Detect the nucleosides by monitoring the specific parent-to-daughter ion transitions for each nucleoside in multiple reaction monitoring (MRM) mode. The transition for 1-methylcytidine will be specific and distinct from that of cytosine and other methylated cytosine isomers.
-
Quantification: a. Prepare a standard curve using known concentrations of the 1-methylcytidine standard. b. Quantify the amount of this compound in the sample by comparing its peak area to the standard curve. c. Normalize the amount of this compound to the amount of a canonical nucleoside (e.g., adenosine) to determine its relative abundance.
IV. Visualizations
Caption: Workflow for the synthesis, incorporation, and analysis of this compound in RNA.
Caption: Base pairing in the Hachimoji expanded genetic alphabet.
Caption: Proposed logic for a this compound-based synthetic riboswitch.
Unveiling the Interactome of 1-Methylcytosine: A Guide to Advanced Techniques
For Immediate Release
[City, State] – [Date] – In the burgeoning field of epitranscriptomics, the reversible methylation of RNA bases has emerged as a critical regulator of gene expression and cellular function. Among these modifications, 1-methylcytosine (m1C) is gaining prominence for its role in diverse biological processes, from tRNA stability to the regulation of mRNA translation. To empower researchers, scientists, and drug development professionals in this dynamic area, we present a comprehensive guide to the cutting-edge techniques for studying the intricate interactions between this compound and its binding proteins.
These detailed application notes and protocols provide a robust framework for identifying and characterizing m1C-binding proteins, quantifying their binding affinities, and elucidating the functional consequences of these interactions.
I. Identifying this compound-Binding Proteins
The initial step in understanding the functional role of m1C is the identification of proteins that specifically recognize and bind to this modification. This can be achieved through a combination of in vivo and in vitro approaches.
RNA Immunoprecipitation followed by Sequencing (RIP-seq)
RNA Immunoprecipitation (RIP) is a powerful antibody-based technique used to map RNA-protein interactions in vivo.[1] By employing an antibody specific to m1C, researchers can enrich for m1C-containing RNA-protein complexes from cellular lysates. Subsequent high-throughput sequencing of the co-precipitated RNAs (RIP-seq) reveals the transcriptome-wide landscape of m1C and provides a list of potential m1C-binding proteins that can be identified by mass spectrometry.
Workflow for m1C-RIP-seq:
Figure 1. Workflow of m1C RNA Immunoprecipitation Sequencing (m1C-RIP-seq).
Cross-Linking and Immunoprecipitation (CLIP)
For a more precise identification of direct protein-RNA interaction sites, Cross-Linking and Immunoprecipitation (CLIP) is the method of choice. This technique utilizes UV irradiation to create covalent cross-links between proteins and RNA molecules that are in close proximity.[2] Following immunoprecipitation with an m1C-specific antibody, the cross-linked RNA fragments are sequenced, providing single-nucleotide resolution of the binding sites.
RNA Pull-down Assay Coupled with Mass Spectrometry
An in vitro approach to identify m1C-binding proteins involves the use of a biotinylated RNA probe containing m1C.[3][4] This "bait" RNA is incubated with a cellular lysate, allowing proteins to bind. The RNA-protein complexes are then captured using streptavidin-coated beads. After stringent washing, the bound proteins are eluted and identified by mass spectrometry.[5]
Experimental Workflow for m1C RNA Pull-down:
Figure 2. Workflow for m1C RNA pull-down assay followed by mass spectrometry.
II. Quantifying this compound-Protein Interactions
Once potential m1C-binding proteins are identified, it is crucial to quantify the affinity and kinetics of these interactions. Several biophysical techniques are available for this purpose.
| Technique | Principle | Parameters Measured | Throughput |
| Electrophoretic Mobility Shift Assay (EMSA) | Separation of protein-RNA complexes from free RNA on a non-denaturing gel based on size and charge. | Binding affinity (Kd) | Low to Medium |
| Microscale Thermophoresis (MST) | Measures the directed movement of molecules in a microscopic temperature gradient, which changes upon binding. | Binding affinity (Kd) | High |
| Biolayer Interferometry (BLI) | An optical biosensing technique that measures changes in the interference pattern of light reflected from a biosensor surface upon molecular binding. | Binding affinity (Kd), association rate (ka), dissociation rate (kd) | High |
| Surface Plasmon Resonance (SPR) | An optical technique that detects changes in the refractive index at the surface of a sensor chip as molecules bind and dissociate. | Binding affinity (Kd), association rate (ka), dissociation rate (kd) | Medium to High |
| Filter-Binding Assay | A simple method where protein-RNA complexes are retained on a nitrocellulose filter while free RNA passes through. | Binding affinity (Kd) | High |
III. Detailed Experimental Protocols
This section provides detailed protocols for some of the key techniques mentioned above.
Protocol 1: Electrophoretic Mobility Shift Assay (EMSA) for m1C-Protein Interaction
Objective: To qualitatively and quantitatively assess the binding of a protein to an m1C-containing RNA probe.
Materials:
-
Purified recombinant protein of interest.
-
Synthetic RNA oligonucleotide containing m1C (and a corresponding unmodified control), end-labeled with a radioactive or fluorescent tag.
-
Binding buffer (e.g., 10 mM Tris-HCl pH 7.5, 50 mM KCl, 1 mM DTT, 5% glycerol).
-
Native polyacrylamide gel (e.g., 6%).
-
TBE buffer (Tris-borate-EDTA).
-
Loading dye (non-denaturing).
-
Imaging system (e.g., phosphorimager or fluorescence scanner).
Procedure:
-
Binding Reaction: In a microcentrifuge tube, combine the labeled RNA probe (at a fixed, low concentration, e.g., 1 nM) with increasing concentrations of the purified protein in the binding buffer.
-
Incubation: Incubate the reactions at room temperature for 20-30 minutes to allow binding to reach equilibrium.
-
Gel Electrophoresis: Add non-denaturing loading dye to each reaction and load the samples onto a pre-run native polyacrylamide gel. Run the gel in TBE buffer at a constant voltage in a cold room or with a cooling system.
-
Imaging and Analysis: After electrophoresis, visualize the bands using the appropriate imaging system. The free probe will migrate faster, while the protein-bound probe will be "shifted" to a higher molecular weight position. The fraction of bound probe can be quantified to determine the dissociation constant (Kd).
Protocol 2: RNA Pull-down Assay
Objective: To identify proteins that bind to an m1C-containing RNA in vitro.
Materials:
-
Biotinylated m1C-containing RNA probe and an unmodified control probe.
-
Cell lysate.
-
Streptavidin-coated magnetic beads.
-
Binding buffer (e.g., 20 mM Tris-HCl pH 7.5, 150 mM NaCl, 1 mM EDTA, 0.1% Triton X-100, supplemented with protease and RNase inhibitors).
-
Wash buffer (similar to binding buffer, may have higher salt concentration).
-
Elution buffer (e.g., SDS-PAGE sample buffer).
-
SDS-PAGE and Western blotting reagents or access to a mass spectrometry facility.
Procedure:
-
Probe Preparation: Synthesize or obtain biotinylated RNA probes with and without m1C.
-
Lysate Preparation: Prepare a whole-cell or nuclear lysate from the cells of interest.
-
Binding: Incubate the biotinylated RNA probe with the cell lysate in binding buffer for 1-2 hours at 4°C with gentle rotation.
-
Capture: Add pre-washed streptavidin magnetic beads to the binding reaction and incubate for another hour at 4°C.
-
Washing: Pellet the beads using a magnetic stand and wash them several times with wash buffer to remove non-specific binders.
-
Elution: Elute the bound proteins from the beads by resuspending them in elution buffer and heating at 95°C for 5-10 minutes.
-
Analysis: Analyze the eluted proteins by SDS-PAGE followed by Western blotting with an antibody against a candidate protein, or by mass spectrometry for a global identification of interacting proteins.
IV. Signaling Pathways and Functional Implications
The identification of m1C reader proteins is the first step towards understanding their downstream effects. These reader proteins can influence various cellular processes by modulating RNA stability, translation, and localization. For instance, some YTH domain-containing proteins, initially identified as m6A readers, have also been shown to recognize other methylated bases, including m5C, which is structurally similar to m1C. The binding of these readers can recruit other effector proteins, thereby initiating signaling cascades that impact gene expression.
Logical Relationship of m1C-mediated Gene Regulation:
Figure 3. A simplified model of m1C-mediated gene regulation.
Further research is needed to delineate the specific signaling pathways initiated by m1C recognition. The techniques outlined in this guide will be instrumental in identifying the key players and unraveling the complex regulatory networks governed by this important RNA modification.
References
- 1. researchgate.net [researchgate.net]
- 2. evannostrandlab.com [evannostrandlab.com]
- 3. RNA Pull Down: Principles, Probe Design, and Data Analysis - Creative Proteomics [iaanalysis.com]
- 4. researchgate.net [researchgate.net]
- 5. Pull-down of Biotinylated RNA and Associated Proteins - PMC [pmc.ncbi.nlm.nih.gov]
Unveiling 1-Methylcytosine: A Guide to Single-Molecule Analysis
For Researchers, Scientists, and Drug Development Professionals
Application Note
The precise identification and quantification of epigenetic and epitranscriptomic modifications are paramount to understanding cellular function, disease progression, and the development of novel therapeutics. Among the over 170 known RNA modifications, 1-methylcytosine (m1C) is a post-transcriptional modification that plays a crucial role in regulating the structural stability of tRNA and rRNA. Emerging evidence also points to its presence in mRNA, suggesting a broader role in gene expression. Traditional methods for detecting RNA modifications often rely on destructive chemical treatments and amplification steps, which can lead to the loss of information and introduce biases. Single-molecule sequencing technologies, namely Single Molecule, Real-Time (SMRT) sequencing from Pacific Biosciences (PacBio) and Nanopore sequencing from Oxford Nanopore Technologies (ONT), offer a revolutionary approach to directly detect base modifications on native DNA and RNA molecules, preserving the integrity of the sample and providing a wealth of information at the single-molecule level.
This document provides a comprehensive overview and detailed protocols for the single-molecule analysis of this compound. We will delve into the principles of m1C detection using SMRT and Nanopore sequencing, present available quantitative data, and provide step-by-step experimental and computational workflows.
Principles of Single-Molecule Detection of this compound
Both SMRT and Nanopore sequencing platforms detect base modifications by observing subtle changes in the sequencing process as a native nucleic acid strand is analyzed. These changes serve as a "signature" for the presence of a modified base.
SMRT Sequencing (PacBio): In SMRT sequencing, a DNA polymerase is fixed at the bottom of a zero-mode waveguide (ZMW) and synthesizes a complementary strand from a circularized DNA or cDNA template. The incorporation of fluorescently labeled nucleotides is observed in real-time. The presence of a modified base, such as m1C in an RNA-derived cDNA template, can alter the kinetics of the DNA polymerase. This is primarily observed as a change in the interpulse duration (IPD) , the time between successive nucleotide incorporations. By comparing the IPD at a specific position to a control or a computational model of unmodified bases, the presence of a modification can be inferred. While the kinetic signature for 5-methylcytosine (5mC) is subtle, other modifications can produce more pronounced signals.[1][2] The specific kinetic signature of m1C has not been as extensively characterized as that of other modifications, necessitating the generation of specific training data for accurate identification.
Nanopore Sequencing (Oxford Nanopore Technologies): Nanopore sequencing involves the passage of a single strand of DNA or RNA through a protein nanopore embedded in a membrane. As the molecule translocates through the pore, it disrupts an ionic current flowing through it. Each k-mer (a short sequence of bases) creates a characteristic disruption in the current, which is measured and used to determine the base sequence. A modified base within a k-mer will produce a distinct current signal compared to its unmodified counterpart.[3][4] For m1C, the methyl group at the N1 position of the cytosine ring will alter the size and electrochemical properties of the base as it passes through the nanopore, leading to a detectable shift in the ionic current. Machine learning models are trained on data from synthetic RNAs with known m1C modifications to accurately identify these specific current signals in experimental data.[5]
Quantitative Data Presentation
While extensive quantitative data for the single-molecule detection of this compound is still emerging, the performance of these platforms for other cytosine modifications provides a benchmark for expected performance. The accuracy of detecting any modification is highly dependent on the quality of the training data and the specific bioinformatic models used.
| Technology | Modification | Metric | Reported Value | Caveats and Considerations |
| SMRT Sequencing | 5-methylcytosine (5mC) | Sensitivity | ~90% | Data for 5mC in DNA; performance for m1C in RNA may differ. Requires high sequencing coverage. |
| Specificity | ~94% | |||
| Nanopore Sequencing | 5-methylcytosine (5mC) | Accuracy | ~87% (read level) | Data for 5mC in DNA. Performance is highly dependent on the base-calling and modification detection models. |
| RNA modifications (general) | Accuracy | Varies by modification and context | Current models are primarily trained for more abundant modifications like m6A. |
Note: The table summarizes available data for related modifications. Specific performance metrics for m1C will need to be established through dedicated experiments.
Experimental Protocols
The following protocols provide a framework for the single-molecule analysis of this compound. The key to successful modification detection is the generation of high-quality sequencing data from both the sample of interest and appropriate controls.
Protocol 1: Preparation of m1C-Containing RNA Standards for Model Training
Accurate identification of m1C requires machine learning models trained on sequences with known m1C locations. This is achieved by generating synthetic RNA standards.
Objective: To synthesize RNA molecules with this compound at defined positions for use as training and validation data for SMRT and Nanopore sequencing analysis pipelines.
Materials:
-
Linearized DNA template containing a T7 promoter and the desired sequence.
-
T7 RNA Polymerase.
-
NTPs (ATP, GTP, UTP).
-
1-methylcytidine-5'-triphosphate (m1CTP).
-
Cytidine-5'-triphosphate (CTP).
-
RNase Inhibitor.
-
DNase I.
-
Purification kit for RNA.
Procedure:
-
In Vitro Transcription:
-
Set up two in vitro transcription reactions.
-
Reaction 1 (m1C-containing): Include ATP, GTP, UTP, and m1CTP. Omit CTP to ensure incorporation of m1C at all cytosine positions.
-
Reaction 2 (Unmodified control): Include all four standard NTPs (ATP, GTP, CTP, UTP).
-
Add the linearized DNA template, T7 RNA Polymerase, and RNase Inhibitor to each reaction.
-
Incubate at 37°C for 2-4 hours.
-
-
DNase Treatment:
-
Add DNase I to each reaction to digest the DNA template.
-
Incubate at 37°C for 15-30 minutes.
-
-
RNA Purification:
-
Purify the transcribed RNA using a suitable RNA purification kit, following the manufacturer's instructions.
-
-
Quality Control:
-
Assess the integrity and concentration of the purified RNA using a Bioanalyzer or similar instrument.
-
Confirm the incorporation of m1C in the experimental sample using techniques like mass spectrometry.
-
Protocol 2: Library Preparation and Sequencing for m1C Analysis
A. SMRT Sequencing (PacBio) - cDNA Sequencing Workflow
Objective: To prepare a cDNA library from RNA samples for m1C analysis on the PacBio Sequel or Revio systems.
Materials:
-
Purified RNA (from your sample of interest and m1C standards).
-
SMRTbell Express Template Prep Kit 2.0.
-
Reverse transcriptase.
-
Primers for reverse transcription (oligo(dT) or gene-specific).
Procedure:
-
Reverse Transcription:
-
Convert the RNA to first-strand cDNA using a reverse transcriptase and appropriate primers. This step is crucial as the modification itself is not directly sequenced, but its presence on the RNA template can influence the fidelity and processivity of the reverse transcriptase, which may be reflected in the resulting cDNA.
-
-
Second-Strand Synthesis:
-
Synthesize the second strand of the cDNA.
-
-
SMRTbell Library Construction:
-
Follow the PacBio protocol for SMRTbell library construction. This involves DNA damage repair, end-repair/A-tailing, and ligation of SMRTbell adapters to the double-stranded cDNA.
-
-
Sequencing:
-
Sequence the prepared library on a PacBio sequencing instrument. Ensure sufficient sequencing depth to confidently call modifications.
-
B. Nanopore Direct RNA Sequencing (Oxford Nanopore Technologies)
Objective: To prepare a direct RNA library for m1C analysis on an Oxford Nanopore sequencing device. This method has the advantage of directly sequencing the native RNA molecule.
Materials:
-
Purified RNA (from your sample of interest and m1C standards).
-
Direct RNA Sequencing Kit (e.g., SQK-RNA004).
-
Poly(A) Tailing Kit (if your RNA is not already polyadenylated).
Procedure:
-
Poly(A) Tailing (Optional):
-
If your RNA of interest is not polyadenylated (e.g., some non-coding RNAs), add a poly(A) tail using a Poly(A) Polymerase.
-
-
Adapter Ligation:
-
Ligate the ONT sequencing adapter to the 3' end of the RNA molecules. This adapter contains a motor protein that guides the RNA through the nanopore.
-
-
Library Preparation:
-
Follow the Oxford Nanopore Direct RNA Sequencing protocol for library preparation.
-
-
Sequencing:
-
Load the prepared library onto a Nanopore flow cell and commence sequencing.
-
Protocol 3: Bioinformatic Analysis for m1C Detection
Objective: To process the raw sequencing data to identify and quantify this compound modifications.
A. SMRT Sequencing Data Analysis
Software:
-
PacBio SMRT Link software suite.
-
Custom scripts or third-party tools for kinetic data analysis.
Workflow:
-
Data Pre-processing:
-
Generate Circular Consensus Sequence (CCS) reads (HiFi reads) from the raw sequencing data.
-
-
Alignment:
-
Align the CCS reads to a reference genome or transcriptome.
-
-
Kinetic Data Extraction:
-
Extract the interpulse duration (IPD) values for each base position from the raw data.
-
-
Modification Detection:
-
Use the ipdSummary tool in SMRT Link or other specialized software to compare the IPD values of the sample to a control (either the unmodified in vitro transcribed standard or a computational model).
-
Train a machine learning model using the m1C-containing and unmodified RNA standards to recognize the specific kinetic signature of m1C.
-
Apply the trained model to the experimental data to identify putative m1C sites.
-
B. Nanopore Direct RNA Sequencing Data Analysis
Software:
-
Oxford Nanopore's basecaller (e.g., Dorado).
-
Software for modification detection (e.g., Tombo, MINES, m6Anet, or custom models).
-
Tools for signal alignment and visualization (e.g., SquiggleKit).
Workflow:
-
Basecalling and Signal-Level Data:
-
Perform basecalling on the raw FAST5 files using a basecaller like Dorado. It is crucial to retain the signal-level data (squiggles).
-
-
Alignment:
-
Align the basecalled reads to a reference transcriptome.
-
-
Signal-to-Sequence Alignment (Resquiggling):
-
Use tools like tombo resquiggle to align the raw current signal to the reference sequence. This step is essential for accurate modification detection.
-
-
Modification Detection:
-
Model Training: Train a machine learning model (e.g., a recurrent neural network) using the signal data from the m1C-containing and unmodified RNA standards. The model will learn to differentiate the current signals associated with m1C from those of unmodified cytosine.
-
Prediction: Apply the trained model to the resquiggled data from the experimental sample to predict the probability of m1C at each cytosine position.
-
Comparative Analysis: Alternatively, use tools that compare the signal distributions between the sample of interest and a control sample (unmodified standard) to identify sites with significant signal differences.
-
Visualizations
Experimental and Computational Workflows
Caption: Workflow for single-molecule analysis of this compound.
Nanopore m1C Detection Principle
Caption: Principle of this compound detection with nanopore sequencing.
References
- 1. pacb.com [pacb.com]
- 2. Genome-wide detection of cytosine methylation by single molecule real-time sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 3. boa.unimib.it [boa.unimib.it]
- 4. Detecting DNA cytosine methylation using nanopore sequencing | Springer Nature Experiments [experiments.springernature.com]
- 5. nanoporetech.com [nanoporetech.com]
Application Notes and Protocols for In Vitro Transcription Assays Studying 1-Methylcytosine Effects
For Researchers, Scientists, and Drug Development Professionals
Introduction
1-Methylcytosine (m1C) is a post-transcriptional RNA modification that has been identified in various RNA species, including tRNA, rRNA, and mRNA. The presence of m1C in RNA has been implicated in the regulation of RNA stability, translation, and the immune response. In vitro transcription (IVT) serves as a powerful tool to generate RNA containing m1C, enabling detailed studies of its functional and structural impact. These application notes provide a comprehensive overview and detailed protocols for utilizing IVT assays to investigate the effects of this compound on transcription.
Application Notes
Impact of this compound on In Vitro Transcription Efficiency
The incorporation of modified nucleotides, such as this compound triphosphate (m1CTP), during in vitro transcription can influence the overall yield of the resulting RNA. T7 RNA polymerase, a commonly used enzyme for IVT, exhibits varying efficiency with modified NTPs. While T7 RNA polymerase is known to be highly processive, the presence of a methyl group on the N1 position of cytosine may introduce steric hindrance, potentially affecting the rate of nucleotide incorporation and the overall transcript yield.
Quantitative analysis of RNA yield is crucial to assess the impact of m1C incorporation. Spectrophotometric methods (A260) or fluorescent dye-based assays can be employed for accurate quantification. It is recommended to perform parallel IVT reactions with and without m1CTP to directly compare the transcription efficiency.
Investigating Transcriptional Pausing Induced by this compound
RNA polymerase does not move along the DNA template at a constant speed; it can pause at specific sequences. The incorporation of modified nucleotides can create or enhance these pause sites. Transcriptional pausing can be a regulatory mechanism affecting co-transcriptional folding of the RNA and recruitment of other factors. High-resolution gel electrophoresis of the IVT products can reveal the presence of shorter RNA fragments, indicative of polymerase pausing. Further analysis using techniques like native elongating transcript sequencing (NET-seq) can map these pause sites at nucleotide resolution, although this is a more advanced application.
Assessing the Fidelity of Transcription with this compound
The accuracy of nucleotide incorporation by RNA polymerase is known as transcriptional fidelity. Errors in transcription can lead to the production of non-functional or even toxic proteins. It is important to determine if the presence of m1CTP in the IVT reaction affects the fidelity of T7 RNA polymerase. This can be assessed by sequencing the resulting RNA transcripts and comparing them to the DNA template. Any discrepancies would indicate a potential decrease in fidelity.
Data Presentation
Quantitative data from in vitro transcription assays should be summarized in clearly structured tables to facilitate comparison between different experimental conditions.
| Experimental Condition | Template DNA (ng) | Incubation Time (hr) | RNA Yield (µg) | Relative Yield (%) |
| Standard NTPs | 500 | 2 | 100 | 100 |
| 100% m1CTP substitution | 500 | 2 | 85 | 85 |
| 50% m1CTP substitution | 500 | 2 | 95 | 95 |
Table 1: Effect of m1CTP Substitution on In Vitro Transcription Yield. This table illustrates a hypothetical comparison of RNA yields from IVT reactions with standard cytosine triphosphate (CTP) versus partial and full substitution with this compound triphosphate (m1CTP).
| Transcript Position | Pausing Score (Standard NTPs) | Pausing Score (100% m1CTP) | Fold Change |
| 150 | 1.2 | 3.6 | 3.0 |
| 275 | 0.8 | 2.4 | 3.0 |
| 410 | 1.5 | 1.6 | 1.1 |
Table 2: Analysis of Transcriptional Pausing Sites. This table presents a hypothetical analysis of transcriptional pausing, indicating an increase in pausing at specific sites within the transcript when m1C is incorporated.
| Nucleotide Position | Expected Nucleotide | Observed Nucleotide (Standard NTPs) | Observed Nucleotide (100% m1CTP) | Error Frequency |
| 212 | C | C | C | 0 |
| 345 | G | G | A | 1 in X transcripts |
| 567 | A | A | A | 0 |
Table 3: Assessment of Transcriptional Fidelity. This table provides a template for recording and comparing the fidelity of transcription by noting any misincorporations observed in sequencing data from RNA produced with and without m1C.
Experimental Protocols
Protocol 1: In Vitro Transcription with this compound Triphosphate
This protocol describes the synthesis of RNA containing this compound using T7 RNA polymerase.
Materials:
-
Linearized DNA template with a T7 promoter (500 ng/µL)
-
Nuclease-free water
-
10X Transcription Buffer (400 mM Tris-HCl pH 8.0, 200 mM MgCl₂, 10 mM spermidine, 100 mM DTT)
-
ATP, GTP, UTP solution (100 mM each)
-
CTP solution (100 mM)
-
This compound triphosphate (m1CTP) solution (100 mM)
-
RNase Inhibitor (40 U/µL)
-
T7 RNA Polymerase (50 U/µL)
-
DNase I (RNase-free, 1 U/µL)
Procedure:
-
Thaw all reagents on ice. Keep enzymes on ice.
-
Assemble the transcription reaction at room temperature in the following order:
| Component | Volume for 20 µL Reaction | Final Concentration |
| Nuclease-free water | to 20 µL | - |
| 10X Transcription Buffer | 2 µL | 1X |
| ATP, GTP, UTP (100 mM each) | 0.8 µL | 4 mM each |
| CTP or m1CTP (100 mM) | 0.8 µL | 4 mM |
| Linearized DNA template | 1 µL | 25 ng/µL |
| RNase Inhibitor | 1 µL | 2 U/µL |
| T7 RNA Polymerase | 1 µL | 2.5 U/µL |
-
Mix gently by pipetting and centrifuge briefly to collect the reaction at the bottom of the tube.
-
Incubate at 37°C for 2 hours.
-
To remove the DNA template, add 1 µL of DNase I to the reaction and incubate at 37°C for 15 minutes.
-
Purify the RNA using a suitable RNA purification kit or by phenol:chloroform extraction followed by ethanol precipitation.
-
Quantify the RNA yield using a spectrophotometer or a fluorometric assay.
-
Analyze the RNA integrity and for the presence of pause products by denaturing agarose or polyacrylamide gel electrophoresis.
Protocol 2: Quantification of this compound Incorporation by LC-MS/MS
This protocol outlines the digestion of m1C-containing RNA to nucleosides and subsequent analysis by liquid chromatography-tandem mass spectrometry (LC-MS/MS) to quantify the level of modification.
Materials:
-
Purified m1C-containing RNA (from Protocol 1)
-
Nuclease P1 (1 U/µL)
-
Bacterial Alkaline Phosphatase (1 U/µL)
-
10X Nuclease P1 Buffer
-
10X Bacterial Alkaline Phosphatase Buffer
-
Nuclease-free water
-
LC-MS grade water
-
LC-MS grade acetonitrile
-
Formic acid
-
1-Methylcytidine standard
Procedure:
-
In a nuclease-free tube, combine 1-5 µg of purified RNA with nuclease-free water to a final volume of 20 µL.
-
Add 2.5 µL of 10X Nuclease P1 Buffer and 1 µL of Nuclease P1.
-
Incubate at 37°C for 2 hours.
-
Add 3 µL of 10X Bacterial Alkaline Phosphatase Buffer and 1 µL of Bacterial Alkaline Phosphatase.
-
Incubate at 37°C for 1 hour.
-
Filter the digested sample through a 0.22 µm filter to remove enzymes.
-
Analyze the sample by LC-MS/MS.
-
Separate the nucleosides using a C18 reverse-phase column with a gradient of water and acetonitrile containing 0.1% formic acid.
-
Detect and quantify the canonical nucleosides (A, C, G, U) and 1-methylcytidine using a mass spectrometer operating in multiple reaction monitoring (MRM) mode.
-
-
Generate a standard curve using the 1-methylcytidine standard to accurately quantify the amount of m1C in the sample.
-
Calculate the percentage of m1C relative to the total cytosine content.
Visualizations
Caption: Experimental workflow for studying m1C effects.
Caption: Potential effects of m1C on transcription.
Caption: Conceptual m1C modification and recognition pathway.
Analysis of 1-Methylcytosine in Cellular Stress Responses: Application Notes and Protocols
For Researchers, Scientists, and Drug Development Professionals
Introduction
1-Methylcytosine (m1C) is a post-transcriptional RNA modification that plays a crucial role in various cellular processes, including RNA stability, translation, and the response to cellular stress. Unlike its more extensively studied isomer, 5-methylcytosine (m5C), m1C involves the methylation of the N1 position of the cytosine ring. This modification is dynamically regulated by methyltransferases and demethylases, and its dysregulation has been implicated in several diseases. These application notes provide a comprehensive overview of the role of m1C in cellular stress responses, along with detailed protocols for its detection and analysis.
Under various stress conditions, such as oxidative stress and heat shock, the cellular epitranscriptome undergoes significant changes. The levels of m1C on different RNA species, particularly transfer RNA (tRNA) and ribosomal RNA (rRNA), are modulated to fine-tune gene expression and promote cell survival. The key enzymes responsible for this regulation are the NSUN family of methyltransferases and the ALKBH family of demethylases. Understanding the dynamics of m1C modification provides valuable insights into the molecular mechanisms of stress adaptation and may reveal novel therapeutic targets for diseases associated with cellular stress.
Key Players in m1C Regulation and Function in Cellular Stress
| Molecule | Type | Function in Cellular Stress |
| NSUN2 | Methyltransferase | Catalyzes the formation of m5C and is also implicated in m1C deposition on tRNA and other RNAs. Under stress, NSUN2 can relocalize and its activity may be modulated, affecting tRNA stability and the translation of stress-responsive proteins.[1][2][3] |
| ALKBH1 | Demethylase | An iron and α-ketoglutarate-dependent dioxygenase that can demethylate N1-methyladenosine (m1A) and is also suggested to have activity towards other methylated bases. Its role in m1C demethylation is an area of active investigation. ALKBH1 is involved in regulating tRNA cleavage under stress conditions.[4][5] |
| tRNA | Transfer RNA | A primary target of m1C modification. m1C modification, particularly at the T-stem loop, contributes to the structural integrity of tRNA. Lack of proper methylation can lead to increased tRNA cleavage by stress-responsive ribonucleases like angiogenin, resulting in tRNA-derived small fragments (tRFs) that can modulate translation. |
| Stress Granules | RNP Granules | Cytoplasmic foci where translationally stalled mRNAs and RNA-binding proteins accumulate during stress. m1C-modified RNAs and their associated proteins may be recruited to stress granules, influencing their formation and function. |
Quantitative Analysis of m1C in Response to Cellular Stress
The following table summarizes findings on the modulation of RNA modifications and related enzymes in response to cellular stress. While direct quantitative data for m1C is still emerging, data for related modifications and the enzymes involved provide a strong indication of the dynamic nature of the epitranscriptome under stress.
| Stress Condition | RNA Type | Change in Modification/Enzyme Level | Cell Type | Reference |
| Heat Shock | mRNA | Increase in N1-methyladenosine (m1A) | Human cells | |
| Oxidative Stress (H2O2) | mRNA | Enhanced translation of SHC mRNA via NSUN2-mediated methylation | HUVECs | |
| Oxidative Stress (Arsenite) | tRNA | Increased cleavage of unmethylated tRNAs | Human cells | |
| UV Radiation | - | Increased expression of NSUN2 | Human and mouse primary keratinocytes | |
| Glucose Deprivation | tRNA | ALKBH1-mediated demethylation of m1A affects translation | Human cells |
Signaling Pathways and Regulatory Mechanisms
Cellular stress triggers a cascade of signaling events that lead to the modulation of m1C levels on RNA. The following diagram illustrates a proposed pathway for the regulation of tRNA stability by m1C modification under stress conditions.
Caption: Regulation of tRNA stability by m1C under cellular stress.
Experimental Protocols
Protocol 1: RNA Immunoprecipitation (RIP) for m1C-modified RNA
This protocol describes the immunoprecipitation of m1C-modified RNA using an anti-m1C antibody, followed by quantification of specific RNA targets by RT-qPCR.
Materials:
-
Anti-m1C antibody
-
Protein A/G magnetic beads
-
RIP buffer (e.g., 150 mM KCl, 25 mM Tris pH 7.4, 5 mM EDTA, 0.5 mM DTT, 0.5% NP40, 100 U/mL RNase inhibitor, protease inhibitors)
-
Wash buffer (e.g., 50 mM Tris-HCl pH 7.4, 150 mM NaCl, 1 mM MgCl2, 0.05% NP-40)
-
RNA extraction kit
-
RT-qPCR reagents
Procedure:
-
Cell Lysis: Harvest approximately 1x10^7 cells and lyse them in 1 mL of ice-cold RIP buffer.
-
Lysate Clarification: Centrifuge the lysate at 14,000 rpm for 15 minutes at 4°C to pellet cell debris.
-
Immunoprecipitation:
-
Pre-clear the supernatant by incubating with 20 µL of protein A/G magnetic beads for 1 hour at 4°C with rotation.
-
Collect the supernatant and add 5-10 µg of anti-m1C antibody. Incubate overnight at 4°C with gentle rotation. A parallel immunoprecipitation with a non-specific IgG should be performed as a negative control.
-
Add 40 µL of protein A/G magnetic beads and incubate for 2 hours at 4°C with rotation to capture the antibody-RNA complexes.
-
-
Washing:
-
Pellet the beads using a magnetic stand and discard the supernatant.
-
Wash the beads three times with 1 mL of ice-cold wash buffer.
-
-
RNA Elution and Purification:
-
Elute the RNA from the beads by resuspending them in 100 µL of a suitable elution buffer (e.g., proteinase K digestion buffer followed by heat inactivation).
-
Purify the RNA from the eluate using a standard RNA extraction kit.
-
-
Analysis:
-
Perform reverse transcription of the purified RNA to generate cDNA.
-
Analyze the abundance of specific RNA targets by RT-qPCR.
-
Caption: Experimental workflow for m1C RNA Immunoprecipitation (RIP).
Protocol 2: RNA Bisulfite Sequencing for m1C Analysis
This protocol allows for the single-nucleotide resolution mapping of m1C sites in RNA. Bisulfite treatment converts unmethylated cytosines to uracil, while m1C residues are resistant to this conversion.
Materials:
-
RNA bisulfite conversion kit
-
RNA purification kit
-
Reverse transcriptase and primers for specific RNA targets
-
PCR amplification reagents
-
DNA sequencing service or instrument
Procedure:
-
RNA Isolation: Isolate total RNA from cells of interest and ensure its integrity.
-
Bisulfite Conversion:
-
Treat 1-2 µg of total RNA with a bisulfite conversion reagent according to the manufacturer's instructions. This step involves denaturation of the RNA followed by incubation with the bisulfite solution.
-
Purify the bisulfite-converted RNA.
-
-
Reverse Transcription:
-
Perform reverse transcription on the converted RNA using gene-specific primers to generate cDNA.
-
-
PCR Amplification:
-
Amplify the cDNA region of interest using PCR. The primers should be designed to be specific for the converted sequence (i.e., containing uracils instead of unmethylated cytosines).
-
-
Sequencing:
-
Sequence the PCR products using Sanger or next-generation sequencing.
-
-
Data Analysis:
-
Align the sequencing reads to a reference sequence.
-
Identify the positions where cytosines are retained in the sequenced reads. These positions correspond to m1C sites in the original RNA molecule.
-
Caption: Workflow for RNA bisulfite sequencing to detect m1C.
Conclusion and Future Directions
The study of this compound in cellular stress responses is a rapidly evolving field. The dynamic regulation of m1C on tRNA and other RNA species represents a critical layer of gene expression control that allows cells to adapt to adverse conditions. The protocols outlined in these application notes provide robust methods for the investigation of m1C, enabling researchers to explore its role in various physiological and pathological contexts.
Future research will likely focus on elucidating the precise mechanisms of NSUN2 and ALKBH1 regulation in response to different stressors, identifying the full spectrum of m1C-modified RNAs, and understanding the functional consequences of these modifications on a global scale. For drug development professionals, targeting the enzymes that regulate m1C homeostasis may offer novel therapeutic strategies for diseases characterized by chronic cellular stress, such as neurodegenerative disorders and cancer.
References
- 1. RNA methyltransferase NSUN2 promotes stress-induced HUVEC senescence - PMC [pmc.ncbi.nlm.nih.gov]
- 2. The RNA Methyltransferase NSUN2 and Its Potential Roles in Cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Aberrant methylation of tRNAs links cellular stress to neuro-developmental disorders - PMC [pmc.ncbi.nlm.nih.gov]
- 4. The stress specific impact of ALKBH1 on tRNA cleavage and tiRNA generation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
Troubleshooting & Optimization
Technical Support Center: 1-Methylcytosine (m1C) Antibody Solutions
Welcome to the technical support center for 1-methylcytosine (m1C) antibody troubleshooting. This resource is designed for researchers, scientists, and drug development professionals to address common challenges related to m1C antibody specificity and cross-reactivity. Here you will find frequently asked questions (FAQs), detailed troubleshooting guides, and experimental protocols to ensure the accuracy and reliability of your m1C-related experiments.
Frequently Asked Questions (FAQs)
Q1: What are the common cross-reactivity concerns with this compound (m1C) antibodies?
A1: The primary concern with m1C antibodies is their potential cross-reactivity with other methylated or modified nucleosides present in RNA and DNA. Due to structural similarities, antibodies raised against m1C may also recognize other modifications, leading to false-positive signals. The most common potential cross-reactants include:
-
5-methylcytosine (5mC): A common epigenetic mark in DNA and also found in RNA.
-
5-hydroxymethylcytosine (5hmC): An oxidation product of 5mC.
-
N6-methyladenosine (m6A): The most abundant internal modification in eukaryotic mRNA.
-
Unmodified cytosine (C): High abundance of unmodified cytosine can sometimes lead to low-level non-specific binding.
It is crucial to validate the specificity of your m1C antibody against these and other relevant modified nucleosides in the context of your specific application.
Q2: My MeRIP-seq (Methylated RNA Immunoprecipitation followed by sequencing) experiment with an anti-m1C antibody shows unexpected peaks. Could this be due to cross-reactivity?
A2: Yes, unexpected peaks in a MeRIP-seq experiment are a strong indicator of potential antibody cross-reactivity.[1] If the antibody is not highly specific for m1C, it may enrich for RNA fragments containing other modifications, leading to the identification of false-positive m1C sites.[2] It is essential to perform rigorous antibody validation before interpreting MeRIP-seq data. We recommend performing dot blot or competitive ELISA assays to confirm the specificity of your antibody.
Q3: How can I validate the specificity of my this compound (m1C) antibody?
A3: Antibody validation is critical to ensure reliable experimental outcomes.[3][4] We recommend a multi-pronged approach to validate your m1C antibody:
-
Dot Blot Analysis: This is a straightforward method to assess the binding of the antibody to various modified and unmodified nucleosides spotted on a membrane.[5]
-
Competitive ELISA: This quantitative method can determine the antibody's binding affinity and specificity by competing for binding with free modified nucleosides.
-
MeRIP-qPCR with Controls: Use synthetic RNAs with and without m1C modifications as positive and negative controls in a small-scale MeRIP experiment, followed by qPCR analysis.
Detailed protocols for these validation experiments are provided below.
Troubleshooting Guides
This section addresses common issues encountered during experiments using this compound (m1C) antibodies.
Issue 1: High Background or Non-Specific Signal in Dot Blot
-
Possible Cause:
-
Antibody concentration is too high.
-
Inadequate blocking of the membrane.
-
Non-specific binding of the secondary antibody.
-
Cross-reactivity with other modifications.
-
-
Troubleshooting & Optimization:
-
Titrate the primary antibody: Perform a dilution series to find the optimal concentration that gives a strong signal for m1C with minimal background.
-
Optimize blocking: Increase the blocking time or try a different blocking agent (e.g., 5% non-fat dry milk in TBST, or specialized commercial blocking buffers).
-
Run a secondary antibody control: Incubate a membrane with only the secondary antibody to ensure it is not the source of the background signal.
-
Perform a competitive dot blot: Pre-incubate the antibody with free m1C nucleoside before probing the membrane. A significant reduction in signal will confirm specificity.
-
Issue 2: Inconsistent or Low Enrichment in MeRIP-seq
-
Possible Cause:
-
Poor antibody performance or low affinity for m1C.
-
Inefficient immunoprecipitation.
-
RNA degradation.
-
Low abundance of m1C in the sample.
-
-
Troubleshooting & Optimization:
-
Validate the antibody: Before proceeding with MeRIP-seq, confirm the antibody's ability to enrich for m1C-containing RNA using MeRIP-qPCR with positive and negative control RNAs.
-
Optimize IP conditions: Adjust the antibody and bead volumes, and incubation times. Ensure proper washing steps to remove non-specific binders.
-
Check RNA integrity: Run an aliquot of your input RNA on a gel or Bioanalyzer to ensure it is not degraded. The RIN (RNA Integrity Number) should be high.
-
Increase input material: If the abundance of m1C is low, increasing the amount of starting RNA can improve enrichment.
-
dot { graph [rankdir="LR", splines=ortho, nodesep=0.4]; node [shape=box, style="rounded,filled", fontname="Arial", fontsize=10, margin="0.2,0.1"]; edge [fontname="Arial", fontsize=9];
// Nodes Start [label="Start:\nUnexpected MeRIP-seq Peaks", fillcolor="#FBBC05", fontcolor="#202124"]; CheckSpecificity [label="Is antibody specificity\nvalidated for m1C?", shape=diamond, fillcolor="#F1F3F4", fontcolor="#202124"]; PerformValidation [label="Perform Antibody Validation:\n- Dot Blot\n- Competitive ELISA", fillcolor="#4285F4", fontcolor="#FFFFFF"]; CrossReactivity [label="Cross-reactivity\nConfirmed?", shape=diamond, fillcolor="#F1F3F4", fontcolor="#202124"]; NewAntibody [label="Source a new,\nvalidated antibody", fillcolor="#EA4335", fontcolor="#FFFFFF"]; OptimizeMeRIP [label="Re-run MeRIP-seq with\nvalidated antibody and\nappropriate controls", fillcolor="#34A853", fontcolor="#FFFFFF"]; TroubleshootMeRIP [label="Troubleshoot MeRIP Protocol:\n- Check RNA integrity\n- Optimize IP conditions\n- Increase input RNA", fillcolor="#4285F4", fontcolor="#FFFFFF"]; AnalyzeData [label="Analyze data with\nconfidence", fillcolor="#34A853", fontcolor="#FFFFFF"];
// Edges Start -> CheckSpecificity; CheckSpecificity -> PerformValidation [label="No"]; CheckSpecificity -> TroubleshootMeRIP [label="Yes"]; PerformValidation -> CrossReactivity; CrossReactivity -> NewAntibody [label="Yes"]; CrossReactivity -> OptimizeMeRIP [label="No"]; NewAntibody -> PerformValidation; TroubleshootMeRIP -> AnalyzeData; OptimizeMeRIP -> AnalyzeData; } Caption: Troubleshooting workflow for unexpected MeRIP-seq results.
Data Presentation
A critical step in troubleshooting cross-reactivity is to quantitatively assess the binding of the this compound (m1C) antibody to its target and to potential off-targets. Due to the limited availability of public data on the cross-reactivity of commercial m1C antibodies, we strongly recommend that researchers generate these data for their specific antibody lot. The following tables provide a template for presenting such validation data.
Table 1: Dot Blot Specificity of Anti-1-Methylcytosine Antibody
| Antigen Spotted | 100 ng | 50 ng | 25 ng | 12.5 ng |
| This compound (m1C) | +++ | +++ | ++ | + |
| 5-methylcytosine (5mC) | - | - | - | - |
| 5-hydroxymethylcytosine (5hmC) | - | - | - | - |
| N6-methyladenosine (m6A) | - | - | - | - |
| Cytosine (C) | - | - | - | - |
| Signal Intensity: +++ (Strong), ++ (Moderate), + (Weak), - (None) |
Table 2: Competitive ELISA for Anti-1-Methylcytosine Antibody Specificity
| Competitor Nucleoside | IC50 (µM) |
| This compound (m1C) | [Insert experimental value] |
| 5-methylcytosine (5mC) | [Insert experimental value] |
| 5-hydroxymethylcytosine (5hmC) | [Insert experimental value] |
| N6-methyladenosine (m6A) | [Insert experimental value] |
| Cytosine (C) | [Insert experimental value] |
| IC50 is the concentration of the competitor nucleoside required to inhibit 50% of the antibody binding to the coated m1C antigen. A lower IC50 indicates higher binding affinity. |
Experimental Protocols
Protocol 1: Dot Blot for Antibody Specificity
This protocol is adapted from standard dot blot procedures.
Materials:
-
Nitrocellulose or PVDF membrane
-
Modified and unmodified nucleosides or synthetic RNA oligonucleotides (m1C, 5mC, 5hmC, C, etc.)
-
Phosphate Buffered Saline (PBS)
-
Blocking buffer (e.g., 5% non-fat dry milk or 3% BSA in TBST)
-
Primary anti-m1C antibody
-
HRP-conjugated secondary antibody
-
Chemiluminescent substrate
-
Imaging system
Procedure:
-
Sample Preparation: Prepare serial dilutions of your modified and unmodified nucleosides or oligonucleotides in PBS.
-
Spotting: Carefully spot 1-2 µL of each dilution onto the nitrocellulose membrane. Allow the spots to dry completely.
-
Crosslinking (optional but recommended for oligonucleotides): UV crosslink the nucleic acids to the membrane.
-
Blocking: Block the membrane in blocking buffer for 1 hour at room temperature with gentle agitation.
-
Primary Antibody Incubation: Incubate the membrane with the anti-m1C antibody (at its optimal dilution) in blocking buffer for 1-2 hours at room temperature or overnight at 4°C.
-
Washing: Wash the membrane three times for 5-10 minutes each with TBST.
-
Secondary Antibody Incubation: Incubate the membrane with the HRP-conjugated secondary antibody (diluted in blocking buffer) for 1 hour at room temperature.
-
Washing: Repeat the washing step as in step 6.
-
Detection: Incubate the membrane with the chemiluminescent substrate according to the manufacturer's instructions and capture the signal using an imaging system.
dot { graph [rankdir="TB", splines=ortho, nodesep=0.3]; node [shape=box, style="rounded,filled", fontname="Arial", fontsize=10, margin="0.2,0.1"]; edge [fontname="Arial", fontsize=9];
// Nodes Prep [label="Prepare Nucleoside Dilutions", fillcolor="#F1F3F4", fontcolor="#202124"]; Spot [label="Spot onto Membrane", fillcolor="#4285F4", fontcolor="#FFFFFF"]; Block [label="Block Membrane", fillcolor="#FBBC05", fontcolor="#202124"]; PrimaryAb [label="Incubate with Primary Ab (anti-m1C)", fillcolor="#EA4335", fontcolor="#FFFFFF"]; Wash1 [label="Wash", fillcolor="#F1F3F4", fontcolor="#202124"]; SecondaryAb [label="Incubate with Secondary Ab (HRP)", fillcolor="#34A853", fontcolor="#FFFFFF"]; Wash2 [label="Wash", fillcolor="#F1F3F4", fontcolor="#202124"]; Detect [label="Detect with Chemiluminescent Substrate", fillcolor="#4285F4", fontcolor="#FFFFFF"]; Analyze [label="Analyze Signal Intensity", fillcolor="#FBBC05", fontcolor="#202124"];
// Edges Prep -> Spot -> Block -> PrimaryAb -> Wash1 -> SecondaryAb -> Wash2 -> Detect -> Analyze; } Caption: Experimental workflow for Dot Blot analysis.
Protocol 2: Competitive ELISA for Antibody Specificity
This protocol is a general guideline for performing a competitive ELISA.
Materials:
-
High-binding 96-well ELISA plates
-
m1C-conjugated BSA (for coating)
-
Free modified and unmodified nucleosides (m1C, 5mC, 5hmC, C, etc.) as competitors
-
Coating buffer (e.g., carbonate-bicarbonate buffer, pH 9.6)
-
Blocking buffer (e.g., 1% BSA in PBS)
-
Wash buffer (e.g., PBST)
-
Primary anti-m1C antibody
-
HRP-conjugated secondary antibody
-
TMB substrate
-
Stop solution (e.g., 2M H2SO4)
-
Plate reader
Procedure:
-
Coating: Coat the wells of the ELISA plate with m1C-conjugated BSA in coating buffer overnight at 4°C.
-
Washing: Wash the plate three times with wash buffer.
-
Blocking: Block the plate with blocking buffer for 1-2 hours at room temperature.
-
Competition: In separate tubes, pre-incubate the anti-m1C antibody with serial dilutions of the competitor nucleosides for 30 minutes.
-
Incubation: Add the antibody-competitor mixtures to the coated and blocked wells. Incubate for 1-2 hours at room temperature.
-
Washing: Wash the plate three times with wash buffer.
-
Secondary Antibody Incubation: Add the HRP-conjugated secondary antibody to each well and incubate for 1 hour at room temperature.
-
Washing: Wash the plate five times with wash buffer.
-
Detection: Add TMB substrate to each well and incubate in the dark until a blue color develops.
-
Stopping the Reaction: Add the stop solution to each well. The color will change to yellow.
-
Reading: Read the absorbance at 450 nm using a plate reader. The signal intensity will be inversely proportional to the amount of competitor nucleoside that bound to the primary antibody.
dot { graph [rankdir="TB", splines=ortho, nodesep=0.3]; node [shape=box, style="rounded,filled", fontname="Arial", fontsize=10, margin="0.2,0.1"]; edge [fontname="Arial", fontsize=9];
// Nodes Coat [label="Coat Plate with m1C-BSA", fillcolor="#4285F4", fontcolor="#FFFFFF"]; Block [label="Block Plate", fillcolor="#FBBC05", fontcolor="#202124"]; PrepareMix [label="Prepare Ab + Competitor Mixes", fillcolor="#F1F3F4", fontcolor="#202124"]; IncubatePlate [label="Add Mixes to Plate & Incubate", fillcolor="#EA4335", fontcolor="#FFFFFF"]; Wash1 [label="Wash", fillcolor="#F1F3F4", fontcolor="#202124"]; SecondaryAb [label="Add Secondary Ab (HRP)", fillcolor="#34A853", fontcolor="#FFFFFF"]; Wash2 [label="Wash", fillcolor="#F1F3F4", fontcolor="#202124"]; Detect [label="Add TMB Substrate", fillcolor="#4285F4", fontcolor="#FFFFFF"]; Stop [label="Add Stop Solution", fillcolor="#FBBC05", fontcolor="#202124"]; Read [label="Read Absorbance at 450 nm", fillcolor="#34A853", fontcolor="#FFFFFF"];
// Edges Coat -> Block -> PrepareMix -> IncubatePlate -> Wash1 -> SecondaryAb -> Wash2 -> Detect -> Stop -> Read; } Caption: Experimental workflow for Competitive ELISA.
References
- 1. Sensitivity and specificity of immunoprecipitation of DNA containing 5-Methylcytosine - PMC [pmc.ncbi.nlm.nih.gov]
- 2. MeRIP-seq for Detecting RNA methylation: An Overview - CD Genomics [cd-genomics.com]
- 3. Commercial antibodies and their validation - PMC [pmc.ncbi.nlm.nih.gov]
- 4. f1000research-files.f1000.com [f1000research-files.f1000.com]
- 5. academic.oup.com [academic.oup.com]
Technical Support Center: Strategies to Differentiate 1-Methylcytosine from other Cytosine Modifications
Welcome to the technical support center for the differentiation of 1-methylcytosine (1mC) from other cytosine modifications. This resource is designed for researchers, scientists, and drug development professionals to provide troubleshooting guidance and frequently asked questions (FAQs) for common experimental challenges.
Introduction to this compound
This compound (1mC) is a methylated form of the DNA and RNA base cytosine. Unlike the more extensively studied 5-methylcytosine (5mC), the methyl group in 1mC is attached to the nitrogen atom at position 1 (N1) of the cytosine ring. This distinct methylation position alters the hydrogen bonding properties of the base and necessitates specific detection methodologies for its differentiation from other cytosine modifications such as 5-methylcytosine (5mC), 5-hydroxymethylcytosine (5hmC), 5-formylcytosine (5fC), and 5-carboxylcytosine (5caC).
This guide focuses on two primary strategies for the detection and quantification of 1mC: Methylated DNA Immunoprecipitation followed by Sequencing (MeDIP-seq) and Liquid Chromatography-Mass Spectrometry (LC-MS).
Troubleshooting Guides
Methylated DNA Immunoprecipitation Sequencing (MeDIP-seq) for 1mC
MeDIP-seq is a powerful technique for genome-wide profiling of DNA modifications. It relies on the use of a specific antibody to enrich for DNA fragments containing the modification of interest, which are then identified by high-throughput sequencing. The success of this method is critically dependent on the specificity and quality of the antibody used.
Experimental Workflow:
Troubleshooting Common Issues in 1mC MeDIP-seq:
| Issue | Possible Cause | Recommended Solution |
| Low yield of immunoprecipitated DNA | 1. Inefficient immunoprecipitation.[1] 2. Suboptimal antibody concentration. 3. Insufficient amount of starting material.[2] 4. Loss of DNA during purification steps.[3][4] | 1. Increase incubation time with the antibody (e.g., overnight at 4°C).[4] 2. Titrate the antibody to determine the optimal concentration for your sample. 3. Start with a higher amount of genomic DNA if possible. Low-input protocols are available but may require optimization. 4. Use low DNA binding tubes and reagents. Be careful during washing and elution steps to avoid sample loss. |
| High background/Low signal-to-noise ratio | 1. Non-specific binding of the antibody. 2. Incomplete washing of the beads. 3. Cross-reactivity of the antibody with other cytosine modifications. | 1. Increase the stringency of the wash buffers. Include additional wash steps. 2. Ensure thorough resuspension of beads during washes. 3. Validate antibody specificity using dot blot or ELISA with DNA standards for 1mC, 5mC, and other modifications. |
| Poor correlation with validation methods (e.g., qPCR) | 1. Inefficient enrichment of known 1mC-containing regions. 2. PCR bias during library amplification. | 1. Optimize the immunoprecipitation conditions (antibody concentration, incubation time, washing stringency). 2. Use a high-fidelity polymerase with minimal bias and optimize the number of PCR cycles. |
| Difficulty finding a specific 1mC antibody | Limited commercial availability of validated antibodies specifically for Nthis compound in DNA. | 1. Thoroughly search literature for custom antibody generation protocols or collaborations. 2. Consider alternative methods like LC-MS/MS that do not rely on antibodies. |
Liquid Chromatography-Mass Spectrometry (LC-MS) for 1mC Quantification
LC-MS is a highly sensitive and quantitative method for the analysis of nucleosides. It involves the enzymatic digestion of DNA into individual nucleosides, followed by their separation by liquid chromatography and detection by mass spectrometry. This method can accurately quantify the absolute amount of 1mC and other modified nucleosides in a given sample.
Experimental Workflow:
Troubleshooting Common Issues in 1mC LC-MS Analysis:
| Issue | Possible Cause | Recommended Solution |
| Poor peak shape (fronting, tailing, or splitting) | 1. Column contamination or degradation. 2. Inappropriate mobile phase composition or pH. 3. Sample overload. | 1. Flush the column with a strong solvent or replace the column if necessary. Use a guard column to protect the analytical column. 2. Optimize the mobile phase composition, including additives and pH, to improve peak shape. 3. Reduce the amount of sample injected onto the column. |
| Low signal intensity or poor sensitivity | 1. Inefficient ionization in the mass spectrometer. 2. Contamination of the ion source. 3. Suboptimal MS parameters. | 1. Optimize ion source parameters (e.g., temperature, gas flows). Consider using a different ionization mode if applicable. 2. Clean the ion source regularly according to the manufacturer's instructions. 3. Optimize MS parameters such as collision energy and fragmentor voltage for 1mC. |
| Inaccurate quantification | 1. Matrix effects (ion suppression or enhancement). 2. Incomplete DNA digestion. 3. Instability of nucleosides during sample preparation. | 1. Use stable isotope-labeled internal standards for 1mC to correct for matrix effects. 2. Optimize the enzymatic digestion protocol to ensure complete hydrolysis of DNA to nucleosides. 3. Minimize sample processing time and keep samples on ice to prevent degradation. |
| Carryover between samples | Contamination from a previous high-concentration sample. | 1. Implement a rigorous wash protocol for the injection needle and sample loop between runs. 2. Inject blank samples between experimental samples to monitor for carryover. |
Quantitative Data Summary
The choice of method for differentiating and quantifying 1mC depends on the specific research question, available resources, and desired level of resolution. The following table provides a general comparison of MeDIP-seq and LC-MS.
| Parameter | MeDIP-seq | LC-MS/MS |
| Resolution | Lower (~150 bp) | Not applicable (global quantification) |
| Sensitivity | Dependent on antibody affinity and sequencing depth. Can detect low-abundance modifications. | High, can detect femtomole levels of nucleosides. |
| Specificity | Highly dependent on the specificity of the 1mC antibody. | High, based on chromatographic retention time and mass-to-charge ratio. |
| Quantification | Semi-quantitative (relative enrichment). | Absolute quantification. |
| Throughput | High (genome-wide). | Lower (sample-by-sample). |
| Cost | Higher, includes sequencing costs. | Lower per sample for targeted analysis. |
| DNA Input | Micrograms to nanograms of DNA. | Nanograms to micrograms of DNA. |
Experimental Protocols
Detailed MeDIP-seq Protocol (General - Adaptable for 1mC)
This protocol is a general guideline for MeDIP-seq and should be optimized for a specific 1mC antibody if one becomes available.
1. DNA Preparation:
-
Isolate high-quality genomic DNA from cells or tissues.
-
Fragment the DNA to an average size of 200-800 bp by sonication or enzymatic digestion.
-
Verify the fragment size by agarose gel electrophoresis.
2. Immunoprecipitation:
-
Denature the fragmented DNA by heating at 95°C for 10 minutes, followed by rapid cooling on ice.
-
Add the 1mC-specific antibody to the denatured DNA and incubate overnight at 4°C with rotation.
-
Add Protein A/G magnetic beads to the DNA-antibody mixture and incubate for 2 hours at 4°C with rotation to capture the complexes.
-
Wash the beads multiple times with IP buffer to remove non-specifically bound DNA.
-
Elute the methylated DNA from the beads using an elution buffer.
3. DNA Purification and Library Preparation:
-
Purify the eluted DNA using phenol-chloroform extraction followed by ethanol precipitation or a suitable column-based kit.
-
Prepare a sequencing library from the immunoprecipitated DNA and an input control sample using a standard library preparation kit for next-generation sequencing.
4. Sequencing and Data Analysis:
-
Sequence the libraries on a high-throughput sequencing platform.
-
Analyze the sequencing data by aligning reads to a reference genome and using peak-calling algorithms to identify enriched regions of 1mC.
Detailed LC-MS/MS Protocol for 1mC Quantification
1. DNA Digestion:
-
Quantify the amount of genomic DNA accurately.
-
Digest 1-10 µg of DNA to single nucleosides using a cocktail of enzymes such as DNA degradase plus or a combination of nuclease P1, and alkaline phosphatase.
-
Spike the sample with a known amount of a stable isotope-labeled 1-methyl-2'-deoxycytidine internal standard if available.
2. LC Separation:
-
Use a reverse-phase C18 column suitable for nucleoside analysis.
-
Develop a gradient elution method using a mobile phase typically consisting of water with a small amount of acid (e.g., 0.1% formic acid) and an organic solvent like acetonitrile or methanol.
3. MS Detection:
-
Operate the mass spectrometer in positive electrospray ionization (ESI) mode.
-
Use Multiple Reaction Monitoring (MRM) to specifically detect the transition of the precursor ion (protonated 1-methyl-2'-deoxycytidine) to a specific product ion. The exact m/z values will need to be determined for 1mC.
4. Quantification:
-
Generate a standard curve using known concentrations of a 1-methyl-2'-deoxycytidine standard.
-
Integrate the peak areas for the 1mC analyte and the internal standard in the experimental samples.
-
Calculate the concentration of 1mC in the original DNA sample based on the standard curve.
Frequently Asked Questions (FAQs)
Q1: Can I use a 5-mC antibody for 1mC MeDIP-seq?
A1: It is highly unlikely that a 5-mC antibody will efficiently recognize 1mC due to the different positions of the methyl group, which significantly alters the shape and hydrogen bonding potential of the base. It is crucial to use an antibody specifically validated for 1mC for reliable results.
Q2: How does bisulfite sequencing react with 1mC?
A2: Standard bisulfite sequencing protocols are designed to deaminate unmethylated cytosine to uracil, while 5-methylcytosine is protected. The behavior of N1-methylated cytosine under bisulfite treatment is not as well-characterized as 5mC and may lead to ambiguous results. Therefore, bisulfite sequencing is not a recommended method for specifically identifying 1mC.
Q3: What are the alternatives to antibody-based methods for 1mC detection?
A3: Besides LC-MS/MS, other potential methods include those based on specific chemical modifications or enzymatic reactions that are selective for the N1 position of cytosine. Research in this area is ongoing, and new methods may become available.
Q4: How can I validate the presence of 1mC identified by MeDIP-seq?
A4: Locus-specific validation can be performed by designing primers for the enriched regions and using techniques like quantitative PCR (qPCR) on the immunoprecipitated DNA. However, this only confirms enrichment and not the specific modification. For definitive validation, sequencing of the enriched fragments or analysis by an orthogonal method like LC-MS/MS on the genomic DNA would be necessary.
Q5: What are the key considerations for sample preparation in LC-MS analysis of 1mC?
A5: Complete enzymatic digestion of the DNA to nucleosides is critical for accurate quantification. Additionally, preventing the degradation of nucleosides during sample preparation by keeping samples cold and minimizing processing time is important. The use of an appropriate internal standard is also highly recommended to control for variability in sample processing and matrix effects.
References
Technical Support Center: Best Practices for 1-Methylcytosine (m1C) Data Analysis
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) for researchers, scientists, and drug development professionals working with 1-Methylcytosine (m1C) data. The information is presented in a question-and-answer format to directly address specific issues that may be encountered during experimental design and data analysis.
Disclaimer: Research and established methodologies for this compound (1mC) are still emerging, especially when compared to the more extensively studied 5-methylcytosine (5mC). Consequently, many of the best practices outlined below are adapted from the well-established field of 5mC analysis. Researchers should carefully consider the unique chemical properties of 1mC when applying these methods.
Frequently Asked Questions (FAQs)
Section 1: Introduction to this compound (1mC)
Q1: What is this compound (1mC) and how does it differ from 5-Methylcytosine (5mC)?
This compound (1mC) is a methylated form of the DNA base cytosine, where a methyl group is attached to the nitrogen atom at position 1 of the pyrimidine ring.[1] This distinguishes it from the more common and well-studied 5-methylcytosine (5mC), where the methyl group is on the 5th carbon atom of the ring.[1] This difference in the location of the methyl group affects the molecule's hydrogen bonding capabilities.[1] While 5mC is a crucial epigenetic mark in mammals involved in gene regulation, 1mC is less common in natural biological systems and is a known component of the artificially expanded genetic information system (AEGIS), also known as hachimoji DNA.[1][2]
Section 2: Experimental Design and Data Generation
Q2: How should I design an experiment to study 1mC?
A robust experimental design is critical for meaningful statistical analysis. Key considerations include:
-
Clear Hypothesis: Define a clear research question. Are you looking for global changes in 1mC levels, or site-specific differential methylation?
-
Replicates: Include a sufficient number of biological replicates to ensure statistical power. The exact number will depend on the expected effect size and variability of your samples.
-
Controls: Use appropriate positive and negative controls. For example, a synthetic DNA spike-in with known 1mC modifications can help assess the efficiency of the detection method.
-
Randomization: Randomize sample processing to minimize batch effects.
Q3: What are the current methods for detecting and quantifying 1mC?
Specific, high-throughput methods for 1mC are not as established as those for 5mC. However, several techniques can potentially be used or adapted.
| Method | Principle | Resolution | Pros | Cons |
| Nanopore Sequencing | A DNA strand passes through a protein nanopore, causing characteristic disruptions in an ionic current. Different base modifications produce distinct signals. | Single-base | Direct detection without PCR amplification; can potentially distinguish various modifications. | Higher error rates compared to other sequencing methods; requires specialized bioinformatic tools for modification calling. |
| Liquid Chromatography-Mass Spectrometry (LC-MS) | DNA is hydrolyzed into individual nucleosides, which are then separated by chromatography and identified by their mass-to-charge ratio. | Global % of 1mC | Highly accurate and quantitative for global levels. | Does not provide sequence-specific information; requires larger amounts of input DNA. |
| Enzymatic Methyl-Seq (EM-seq) - Adapted | A series of enzymatic reactions protect methylated cytosines from deamination, while unmodified cytosines are converted to uracils. | Single-base | Less DNA damage compared to bisulfite sequencing. | The enzymes used are specific for 5mC and 5hmC, and their activity on 1mC would need to be validated. |
| Bisulfite Sequencing - Adapted | Treatment with sodium bisulfite converts unmethylated cytosines to uracil, while methylated cytosines are protected. | Single-base | Gold standard for 5mC analysis. | The chemical behavior of 1mC under bisulfite treatment is not well-characterized and may differ from 5mC; the harsh chemicals can degrade DNA. |
Section 3: Data Analysis Workflow and Quality Control
Q4: What is a general workflow for analyzing 1mC sequencing data?
A typical bioinformatics workflow for 1mC data analysis, adapted from 5mC pipelines, would involve several key stages, from raw sequencing reads to biological interpretation.
Q5: What are the essential quality control (QC) steps for 1mC data?
-
Raw Read Quality: Assess the quality of your sequencing reads using tools like FastQC. Look for per-base quality scores, GC content, and adapter contamination.
-
Alignment Rate: After aligning reads to a reference genome, a low mapping rate might indicate sample contamination or issues with the sequencing library.
-
Modification Calling Confidence: For methods like nanopore sequencing, it's important to filter modification calls based on a confidence score or probability to reduce false positives.
-
Coverage: Ensure you have sufficient sequencing depth across the sites or regions of interest to make reliable methylation calls.
Section 4: Statistical Analysis
Q6: How do I choose the right statistical test for differential 1mC analysis?
The choice of statistical test depends on your experimental design, the number of replicates, and the nature of your data. The decision tree below can guide you in selecting an appropriate method.
Q7: What are Differentially Methylated Sites (DMSs) and Regions (DMRs)?
-
Differentially Methylated Site (DMS): A single 1mC site that shows a statistically significant difference in methylation level between experimental conditions.
-
Differentially Methylated Region (DMR): A genomic region containing multiple 1mC sites that, as a group, show a significant difference in methylation between conditions. Analyzing DMRs can be more powerful than single-site analysis as it reduces the burden of multiple testing and can identify coordinated changes in methylation.
Q8: What bioinformatics tools can I use for 1mC data analysis?
While there are no tools specifically designed for 1mC, many popular 5mC analysis packages can be adapted. This typically requires formatting your 1mC data (counts of methylated and unmethylated reads per site) into a format that these tools can accept.
| Tool | Language/Platform | Primary Function | Notes |
| DMRichR | R | Differential methylation analysis and visualization. | Accepts count matrices (Bismark-style). |
| methylKit | R (Bioconductor) | Differential methylation analysis for single CpGs and regions. | Requires specific input formats but is flexible. |
| DSS (Dispersion Shrinkage for Sequencing data) | R (Bioconductor) | Performs differential methylation analysis using a beta-binomial model. Can work with few replicates. | Robust for count-based sequencing data. |
| edgeR | R (Bioconductor) | Originally for RNA-seq, but can be adapted for differential methylation analysis. | Uses negative binomial models. |
| limma | R (Bioconductor) | Can perform differential methylation analysis on M-values (logit-transformed methylation proportions). | Powerful for complex experimental designs. |
Troubleshooting Guide
Q: My alignment rate is very low. What could be the problem?
-
A: This could be due to several factors:
-
Sample Contamination: Your sample may be contaminated with DNA from another species.
-
Poor Read Quality: Low-quality reads may fail to align. Check your initial QC reports.
-
Inappropriate Reference Genome: Ensure you are aligning to the correct reference genome for your organism.
-
Challenges with Non-Canonical Bases: If you are using an analysis pipeline that is not designed to handle 1mC, it may struggle with alignment. This is a key area where 1mC-specific tools are needed.
-
Q: I don't have biological replicates. Can I still perform differential methylation analysis?
-
A: Without biological replicates, you cannot perform statistical tests to determine if the observed differences are significant. You can calculate the absolute difference in methylation levels between your samples, but you cannot confidently conclude that these differences are not due to random chance or technical variability.
Q: My results show a large number of differentially methylated sites. How can I be sure they are real?
-
A: It's important to use a stringent statistical cutoff, including an adjustment for multiple testing (e.g., False Discovery Rate, FDR). Additionally, consider the magnitude of the methylation difference. Small but statistically significant changes may not be biologically relevant. Prioritize sites or regions with larger changes in methylation for further validation.
Q: How can I validate my findings from high-throughput sequencing?
-
A: Findings should ideally be validated using an independent method. For 1mC, this is challenging due to the lack of established targeted assays. Potential approaches could include developing a custom targeted sequencing panel or, if the changes are significant enough, potentially a specialized PCR-based assay, though this would require significant methods development.
References
Technical Support Center: Normalization Methods for Quantitative 1-Methylcytosine Studies
Welcome to the technical support center for quantitative 1-methylcytosine (m1C) studies. This resource provides researchers, scientists, and drug development professionals with detailed troubleshooting guides and frequently asked questions to navigate the complexities of normalizing m1C data.
Troubleshooting Guide
This guide addresses specific issues that may arise during the quantitative analysis of this compound, particularly when using LC-MS/MS.
| Problem | Potential Cause(s) | Recommended Solution(s) |
| High Variability Between Technical Replicates | 1. Inconsistent sample preparation (e.g., RNA extraction, digestion).2. Pipetting errors.3. Fluctuations in LC-MS/MS instrument performance.[1][2] | 1. Standardize Protocols: Ensure all sample preparation steps are performed consistently. Use a master mix for enzymatic digestions.2. Use Calibrated Pipettes: Regularly calibrate pipettes to ensure accuracy.3. Incorporate an Internal Standard: Add a stable isotope-labeled (SIL) internal standard for m1C at the beginning of the sample preparation process to account for variability in sample processing and instrument response.[3] |
| Poor Signal Intensity for m1C | 1. Low abundance of m1C in the sample.2. Suboptimal ionization efficiency in the mass spectrometer.3. Sample degradation.4. Ion suppression due to matrix effects.[1][4] | 1. Increase Sample Input: Start with a larger amount of total RNA if possible.2. Optimize MS Settings: Tune the mass spectrometer specifically for the m/z transition of 1-methylcytidine. Experiment with different ionization sources (e.g., ESI, APCI) if available.3. Ensure RNase-Free Environment: Use RNase inhibitors and RNase-free labware to prevent RNA degradation.4. Improve Sample Cleanup: Use solid-phase extraction (SPE) or other cleanup methods to remove interfering matrix components before LC-MS/MS analysis. |
| Inconsistent Endogenous Control (Housekeeping RNA) Expression | 1. The chosen endogenous control is not stably expressed under your experimental conditions (e.g., drug treatment, disease state).2. The endogenous control has a very different abundance level compared to the target m1C-containing RNA. | 1. Validate Your Endogenous Control: Before starting your main experiment, test the expression stability of several candidate endogenous controls (e.g., specific snoRNAs, snRNAs, or rRNAs) across all your experimental conditions. Use algorithms like geNorm or NormFinder to identify the most stable ones.2. Use Multiple Endogenous Controls: Normalize your data to the geometric mean of two or more validated stable endogenous controls for more robust results. |
| Spike-in Control Shows High Variability or Degradation | 1. The synthetic spike-in RNA is degraded by RNases in the sample.2. Inconsistent addition of the spike-in to each sample. | 1. Use Modified Spike-ins: Consider using spike-in RNAs with modifications that increase their stability.2. Optimize Spike-in Addition: Add the spike-in as early as possible in the workflow (e.g., during RNA lysis) to account for variability in the entire process. Ensure precise and consistent pipetting of the spike-in. |
| Quantification Results Are Not Reproducible | 1. Chemical instability of m1C during sample preparation (e.g., due to pH changes).2. Inaccurate calibration curve. | 1. Maintain Stable pH: Be aware that some modified nucleosides, like 1-methyladenosine (m1A), can undergo chemical rearrangement (Dimroth rearrangement) at alkaline pH. While this is less common for m1C, it is crucial to maintain a consistent and appropriate pH throughout sample preparation.2. Prepare Fresh Standards: Prepare calibration standards fresh and ensure they are handled in the same manner as the samples. Use a stable isotope-labeled internal standard to correct for any degradation or loss during preparation. |
Frequently Asked Questions (FAQs)
Q1: What is the difference between absolute and relative quantification for m1C studies?
Answer:
-
Absolute Quantification aims to determine the exact number of m1C molecules per cell or per unit of RNA. This is typically achieved by creating a calibration curve with known concentrations of a 1-methylcytidine standard. This method is useful when the absolute amount of the modification is of interest.
-
Relative Quantification measures the change in m1C levels between different samples (e.g., treated vs. untreated). The results are expressed as a fold change relative to a reference sample. This approach requires normalization to a stable internal reference to account for variations in sample input and processing.
Q2: Which normalization method is best for my quantitative m1C experiment?
Answer: The best normalization method depends on your experimental design and the specific research question. Here is a comparison of common methods:
| Normalization Method | Principle | Advantages | Disadvantages | Best For... |
| Spike-in Control | A known amount of a synthetic RNA or nucleoside analog (ideally, a stable isotope-labeled version of 1-methylcytidine) is added to each sample. | - Accounts for variability throughout the entire workflow (extraction, digestion, and analysis).- Enables absolute or relative quantification.- Independent of endogenous gene expression changes. | - Requires a high-quality, stable spike-in control.- Can be costly.- Potential for inconsistent addition if not done carefully. | - Absolute quantification.- Experiments where global changes in RNA levels are expected.- Analysis of samples from diverse sources where finding a universal endogenous control is difficult. |
| Endogenous Control (Housekeeping RNA) | The level of m1C is normalized to the level of a stably expressed RNA molecule (e.g., a specific snoRNA, snRNA, or rRNA). | - Cost-effective.- Accounts for variations in RNA input and reverse transcription efficiency (for qPCR-based methods). | - Requires extensive validation to ensure the control is not affected by experimental conditions.- Not all housekeeping genes are stable across all cell types and treatments.- Not suitable for absolute quantification. | - Relative quantification in well-characterized systems where stable endogenous controls have been validated.- Studies with a large number of samples where cost is a consideration. |
| Total Ion Current (TIC) Normalization | The signal intensity of m1C is divided by the total ion current of the entire LC-MS run for that sample. | - Simple to apply computationally.- Does not require additional reagents. | - Assumes that the total amount of ionizable material is the same across all samples, which is often not true.- Can be heavily influenced by a few highly abundant ions, leading to inaccurate normalization. | - Generally not recommended for quantitative studies of specific modifications due to its unreliability. It may be used for preliminary data exploration. |
| Normalization to Canonical Nucleosides | The amount of m1C is expressed as a ratio to one or more of the four canonical nucleosides (A, C, G, U) measured in the same sample. | - Accounts for variations in the total amount of RNA analyzed.- Can be performed using the same LC-MS/MS data. | - Assumes that the overall composition of canonical nucleosides does not change with the experimental conditions.- May not account for differential RNA degradation. | - Relative quantification where the goal is to determine the proportion of cytosine that is methylated.- Studies where it is difficult to find a stable endogenous RNA. |
Q3: How do I choose and validate an endogenous control for m1C studies?
Answer:
-
Candidate Selection: Do not assume that common housekeeping genes for mRNA (like GAPDH or ACTB) are suitable. For RNA modification studies, stable non-coding RNAs such as small nucleolar RNAs (snoRNAs), small nuclear RNAs (snRNAs), or ribosomal RNAs (rRNAs) are often better candidates.
-
Expression Stability Analysis: Extract RNA from a representative set of your samples, including all experimental conditions and controls.
-
Quantify Candidates: Measure the expression levels of your candidate endogenous controls using a reliable method (e.g., qRT-PCR or LC-MS/MS).
-
Use Stability Analysis Software: Input the raw expression data (e.g., Ct values for qRT-PCR) into software like geNorm, NormFinder, or BestKeeper. These tools will rank the candidates based on their expression stability.
-
Select the Best Control(s): Choose the gene or, preferably, the combination of two or more genes that are ranked as most stable. Normalizing to the geometric mean of multiple stable controls increases the reliability of your results.
Q4: My LC-MS/MS shows a lot of background noise. How can I improve my m1C signal?
Answer: High background noise in LC-MS/MS can obscure the signal of low-abundance modifications like m1C. Here are some troubleshooting steps:
-
Check Your Solvents: Ensure you are using high-purity, LC-MS grade solvents and that they are freshly prepared. Contaminants in solvents are a common source of background noise.
-
Clean the Ion Source: The ion source of the mass spectrometer can become contaminated over time. Follow the manufacturer's protocol for cleaning the source.
-
Improve Sample Cleanup: As mentioned in the troubleshooting guide, matrix effects from complex biological samples can cause ion suppression and increase background. Incorporate a robust sample cleanup step, such as solid-phase extraction (SPE), before analysis.
-
Optimize Chromatography: A well-optimized liquid chromatography method can separate your analyte of interest (1-methylcytidine) from other interfering compounds, reducing background noise at the time of elution. Experiment with different column chemistries and gradient profiles.
Experimental Protocols
Protocol 1: Normalization using a Stable Isotope-Labeled (SIL) Spike-in for Absolute Quantification of m1C by LC-MS/MS
This protocol is adapted from methods for quantifying other RNA modifications.
-
Preparation of Standards and Spike-in:
-
Prepare a calibration curve using a commercially available 1-methylcytidine standard of known concentrations.
-
Obtain or synthesize a stable isotope-labeled internal standard (SIL-IS), such as [¹³C₅,¹⁵N₂]-1-methylcytidine. Prepare a stock solution of the SIL-IS at a known concentration.
-
-
Sample Preparation:
-
Extract total RNA from your samples using a robust method like TRIzol, ensuring an RNase-free environment.
-
To each RNA sample, add a fixed amount of the SIL-IS. The amount should be chosen to be within the linear range of detection of your instrument.
-
Digest the RNA-SIL-IS mixture to nucleosides using a combination of nucleases (e.g., nuclease P1) and phosphatases (e.g., bacterial alkaline phosphatase). This is typically done by incubating at 37°C for 2-4 hours.
-
-
LC-MS/MS Analysis:
-
Inject the digested nucleoside mixture onto an appropriate LC column (e.g., a C18 column).
-
Separate the nucleosides using a gradient of solvents, such as ammonium acetate buffer and acetonitrile.
-
Analyze the eluent using a triple quadrupole mass spectrometer in Multiple Reaction Monitoring (MRM) mode. Set up transitions for both endogenous (native) 1-methylcytidine and the SIL-IS.
-
-
Data Analysis:
-
Integrate the peak areas for both the native m1C and the SIL-IS m1C.
-
Calculate the ratio of the peak area of the native m1C to the peak area of the SIL-IS.
-
Use the calibration curve generated from the un-labeled standard to determine the absolute amount of m1C in your original sample, corrected for any sample loss by the recovery of the SIL-IS.
-
Visualizations
Workflow for Normalization Strategy Selection
Caption: A decision-making workflow for selecting a normalization strategy in quantitative m1C studies.
Conceptual Pathway: m1C Regulation of Protein Synthesis and Cellular Metabolism
While a classical linear signaling pathway for m1C is not well-defined, its role in modulating RNA function can impact major cellular processes. This diagram illustrates the conceptual relationship between the m1C writer enzyme NSUN2, tRNA methylation, protein synthesis, and downstream metabolic pathways, based on studies of the closely related 5-methylcytosine.
Caption: Conceptual model of m1C/m5C's role in linking stress responses to translation and metabolism.
References
Addressing the instability of 1-Methylcytosine during sample preparation.
Welcome to the technical support center for researchers, scientists, and drug development professionals working with 1-methylcytosine (m1C). This resource provides troubleshooting guides and frequently asked questions (FAQs) to address the inherent instability of m1C during sample preparation and analysis.
Frequently Asked Questions (FAQs)
Q1: What is this compound (m1C) and why is its stability a concern?
A1: this compound (m1C) is a modified nucleobase where a methyl group is attached to the nitrogen atom at position 1 of the cytosine ring. Unlike its isomer 5-methylcytosine (5mC), which is a well-studied epigenetic mark, m1C is more chemically labile. Its instability, particularly the susceptibility to deamination, can lead to inaccurate quantification and misinterpretation of its presence and potential biological role during routine laboratory procedures.
Q2: What are the main factors that contribute to the degradation of this compound during sample preparation?
A2: The primary factors leading to m1C degradation are:
-
pH: m1C is susceptible to hydrolysis, and the rate of this degradation is influenced by pH. Both acidic and alkaline conditions can accelerate the deamination of m1C.
-
Temperature: Elevated temperatures, often used in protocols like DNA denaturation and bisulfite conversion, significantly increase the rate of hydrolytic deamination of m1C.
-
Chemical Treatments: Harsh chemical reagents, most notably sodium bisulfite used in traditional methylation analysis, can induce deamination of m1C. Formaldehyde, a common tissue fixative, can also lead to nucleic acid modifications and degradation.[1][2][3]
Q3: How does the instability of this compound compare to that of 5-methylcytosine?
A3: While both are methylated forms of cytosine, this compound is generally considered less stable than 5-methylcytosine. The N1-methylation in m1C makes the exocyclic amino group more susceptible to hydrolytic attack compared to the C5-methylation in 5mC. However, both are more prone to spontaneous deamination than unmodified cytosine.
Q4: Are there alternative methods to bisulfite sequencing for analyzing this compound that can minimize its degradation?
A4: Yes, enzymatic-based methods offer a gentler alternative to the harsh chemical treatment of bisulfite sequencing. Methods like Enzymatic Methyl-seq (EM-seq) use a series of enzymes to differentiate between modified and unmodified cytosines, thereby avoiding the use of sodium bisulfite and reducing DNA/RNA degradation.[4][5] These methods can improve the preservation of labile modifications like m1C.
Troubleshooting Guides
This section provides solutions to common problems encountered during the analysis of this compound.
Issue 1: Loss of m1C signal after DNA/RNA extraction.
My m1C signal is significantly lower than expected after nucleic acid isolation.
-
Possible Cause 1: Suboptimal Lysis Conditions.
-
Solution: Optimize your lysis protocol to be as gentle as possible while still being effective. Avoid prolonged high-temperature incubations and harsh chemical detergents if possible. Consider enzymatic lysis methods appropriate for your sample type.
-
-
Possible Cause 2: Nuclease Contamination.
-
Solution: Ensure a nuclease-free workflow. Use nuclease-free reagents and consumables. Work quickly and on ice to minimize the activity of endogenous nucleases. The addition of RNase inhibitors (for RNA) or chelating agents like EDTA (to inhibit DNases) is crucial.
-
-
Possible Cause 3: Improper Sample Storage.
-
Solution: Store purified nucleic acids at -80°C for long-term preservation. Avoid repeated freeze-thaw cycles, which can lead to sample degradation. For tissue samples, flash-freezing in liquid nitrogen and storage at -80°C is recommended.
-
Issue 2: Inaccurate quantification of m1C using bisulfite sequencing.
I suspect that my bisulfite sequencing results are not accurately reflecting the true m1C levels.
-
Possible Cause 1: Deamination of m1C during bisulfite treatment.
-
Solution: The harsh conditions of bisulfite conversion (low pH and high temperature) can cause deamination of m1C to thymine, leading to an underestimation of m1C levels.
-
Mitigation Strategy 1: Modified Bisulfite Protocols. Consider using commercially available kits with modified, less harsh bisulfite conversion protocols that may involve lower temperatures or shorter incubation times.
-
Mitigation Strategy 2: Alternative Methods. Switch to an enzymatic-based method like EM-seq, which avoids bisulfite treatment altogether and is less likely to degrade m1C.
-
-
-
Possible Cause 2: Incomplete Conversion of Unmethylated Cytosines.
-
Solution: Incomplete conversion of unmodified cytosine to uracil can lead to false-positive methylation signals. Ensure complete denaturation of the DNA before bisulfite treatment and follow the recommended incubation times and temperatures for your chosen protocol. Including a known unmethylated control DNA in your experiment can help assess the conversion efficiency.
-
Issue 3: Sample degradation during long-term storage.
I am working with archived samples and am concerned about the integrity of m1C.
-
Possible Cause: Degradation over time.
-
Solution: The stability of m1C in long-term storage depends heavily on the storage conditions.
-
Recommended Storage: For purified nucleic acids, storage at -80°C in a buffered solution (e.g., TE buffer) is crucial. For tissues, flash-freezing and storage at -80°C is the gold standard.
-
Assessing Integrity: Before starting extensive experiments on archived samples, it is advisable to assess the overall integrity of the nucleic acids using methods like gel electrophoresis or a Bioanalyzer. While this does not directly measure m1C stability, significant degradation of the DNA/RNA backbone is a strong indicator that labile bases like m1C may also be compromised.
-
-
Quantitative Data on Cytosine Deamination
The following table summarizes the deamination rates of cytosine and this compound under different conditions, highlighting the instability of m1C.
| Compound | pH | Temperature (°C) | Rate Constant (s⁻¹) | Reference |
| This compound | 2.45 | 25 | 2.8 x 10⁻¹⁰ | |
| Cytosine | 7.0 | 25 | 1.6 x 10⁻¹⁰ | |
| This compound | Various | 130 | Varies with pH |
Experimental Protocols
Protocol 1: General Recommendations for Preserving m1C during Nucleic Acid Extraction
This protocol provides general guidelines to minimize m1C degradation during standard DNA/RNA isolation procedures.
-
Sample Collection and Storage:
-
Whenever possible, process fresh samples immediately.
-
If storage is necessary, flash-freeze tissues in liquid nitrogen and store at -80°C.
-
For biofluids, follow established protocols for stabilization and store at -80°C.
-
-
Lysis and Homogenization:
-
Perform all steps on ice to minimize enzymatic activity.
-
Use lysis buffers containing chelating agents (e.g., EDTA) to inhibit DNases. For RNA extraction, include potent RNase inhibitors.
-
Minimize mechanical shearing forces that can cause DNA damage.
-
-
Purification:
-
Use column-based purification kits that offer rapid and efficient purification.
-
Ensure all wash steps are performed correctly to remove inhibitors and contaminants.
-
-
Elution and Storage:
-
Elute DNA/RNA in a buffered solution (e.g., TE buffer, pH 7.0-8.0) rather than water to maintain pH stability.
-
Store the purified nucleic acids in small aliquots at -80°C to avoid multiple freeze-thaw cycles.
-
Protocol 2: Conceptual Workflow for Enzymatic Methylation Analysis of m1C
This outlines a conceptual workflow for analyzing m1C using an enzymatic approach, which is less harsh than bisulfite sequencing.
-
DNA/RNA Preparation: Isolate high-quality genomic DNA or RNA following the recommendations in Protocol 1.
-
Enzymatic Conversion:
-
Utilize a commercial enzymatic methyl-seq kit (e.g., NEBNext® Enzymatic Methyl-seq Kit).
-
The general principle involves:
-
Protection of 5mC and 5hmC: TET2 enzyme oxidizes 5mC and 5hmC.
-
Deamination of unmodified cytosine: A cytidine deaminase (e.g., APOBEC) then converts unmodified cytosines to uracils. This compound is not a natural substrate for these enzymes in the same way as 5mC, and its fate in these reactions would need to be empirically determined for the specific kit. However, the avoidance of harsh chemical treatment is the primary advantage.
-
-
-
Library Preparation and Sequencing:
-
Prepare a sequencing library from the enzymatically treated DNA.
-
Perform next-generation sequencing.
-
-
Data Analysis:
-
Align reads to a reference genome.
-
Analyze the methylation status at each cytosine position. Cytosines that are read as cytosines were protected from deamination (e.g., were originally 5mC or 5hmC), while those read as thymines were originally unmodified cytosines. The signal for m1C would need to be carefully calibrated with appropriate controls.
-
Visualizations
Caption: Workflow for m1C analysis comparing bisulfite and enzymatic methods.
Caption: A troubleshooting guide for low this compound signal.
References
- 1. researchgate.net [researchgate.net]
- 2. academic.oup.com [academic.oup.com]
- 3. Frontiers | Global and Site-Specific Changes in 5-Methylcytosine and 5-Hydroxymethylcytosine after Extended Post-mortem Interval [frontiersin.org]
- 4. Control of carry-over contamination for PCR-based DNA methylation quantification using bisulfite treated DNA - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Effects of ionization on stability of this compound — DFT and PCM studies - PMC [pmc.ncbi.nlm.nih.gov]
Technical Support Center: Optimizing PCR for 1-Methylcytosine-Containing Templates
Welcome to our dedicated technical support center for researchers, scientists, and drug development professionals working with 1-Methylcytosine (1mC)-containing DNA templates. This resource provides in-depth troubleshooting guides and frequently asked questions (FAQs) to help you overcome common challenges and successfully amplify your templates of interest.
Troubleshooting Guide
This guide addresses specific issues you may encounter during the PCR amplification of 1mC-containing DNA.
Problem 1: No PCR Product or Very Low Yield
Possible Causes and Solutions:
-
Suboptimal Annealing Temperature: The presence of 1mC can alter the melting temperature (Tm) of the DNA template. An incorrect annealing temperature can lead to inefficient primer binding or no binding at all.
-
Inappropriate DNA Polymerase: Not all DNA polymerases can efficiently read through modified bases like 1mC. The polymerase may stall or have reduced processivity.
-
Solution: Select a DNA polymerase known for its robustness and ability to amplify challenging or modified templates. High-processivity enzymes or those engineered for difficult templates may be beneficial.[4] Consider polymerases used for direct PCR applications, as they are often more tolerant to inhibitors and template variations.[5]
-
-
Incorrect Magnesium Concentration: Magnesium is a critical cofactor for DNA polymerase activity, and its optimal concentration can be template-specific.
-
Solution: Titrate the MgCl₂ concentration in your PCR reaction. Typical ranges are 1.5-2.5 mM, but optimization may be required.
-
-
Poor Template Quality or Low Quantity: Degraded DNA or the presence of PCR inhibitors can prevent amplification.
-
Solution: Assess the integrity of your template DNA on an agarose gel. Ensure high purity with a 260/280 nm absorbance ratio of ~1.8. If inhibitors are suspected, try diluting the template.
-
-
Insufficient Number of Cycles: A low starting amount of template may require more amplification cycles.
-
Solution: Increase the number of PCR cycles in increments of 3-5, up to a maximum of 40.
-
Problem 2: Non-Specific PCR Products (Multiple Bands)
Possible Causes and Solutions:
-
Annealing Temperature is Too Low: This allows primers to bind to non-target sequences.
-
Solution: Increase the annealing temperature in increments of 1-2°C. A gradient PCR is also useful here.
-
-
High Primer Concentration: Excess primers can lead to the formation of primer-dimers and other non-specific products.
-
Solution: Reduce the primer concentration. A typical starting concentration is 0.1-0.5 µM.
-
-
High Magnesium Concentration: Too much Mg²⁺ can reduce the stringency of primer annealing.
-
Solution: Decrease the MgCl₂ concentration in your reaction.
-
-
Poor Primer Design: Primers may have homology to other regions in the genome or form secondary structures.
-
Solution: Redesign primers to be highly specific to your target sequence. Use primer design software to check for potential off-target binding sites and self-dimerization.
-
Problem 3: Smeared PCR Products
Possible Causes and Solutions:
-
Too Much Template DNA: An excessive amount of template can lead to the generation of a smear.
-
Solution: Reduce the amount of template DNA in the reaction.
-
-
Suboptimal PCR Conditions: A combination of factors, including low annealing temperature and high MgCl₂ concentration, can contribute to smearing.
-
Solution: Optimize your PCR conditions, including annealing temperature, MgCl₂ concentration, and the number of cycles.
-
-
Degraded Template DNA: Using degraded DNA can result in a smear.
-
Solution: Verify the integrity of your template DNA before use.
-
Frequently Asked Questions (FAQs)
Q1: How does this compound in a DNA template affect PCR amplification?
A1: this compound (1mC) is a modified base that can impact PCR in several ways. It can alter the thermal stability of the DNA duplex, potentially affecting the optimal denaturation and annealing temperatures. Furthermore, some DNA polymerases may exhibit reduced processivity or fidelity when encountering 1mC, leading to lower yields or an increased error rate. Optimization of PCR conditions is often necessary to ensure efficient and accurate amplification.
Q2: Which type of DNA polymerase is best for amplifying 1mC-containing templates?
A2: While specific data for 1mC is limited, a general recommendation for modified templates is to use a robust and high-processivity DNA polymerase. Hot-start polymerases are recommended to minimize non-specific amplification and primer-dimer formation. For particularly challenging templates, enzymes designed for "direct PCR" may be more tolerant of template modifications and inhibitors. It is advisable to screen a few different polymerases to find the one that performs best for your specific template and primer set.
Q3: How should I design primers for a 1mC-containing template?
A3: Primer design for 1mC templates follows standard principles. Aim for a primer length of 18-25 nucleotides with a GC content of 40-60%. The melting temperatures (Tm) of the forward and reverse primers should be within 5°C of each other. Use primer design software to avoid regions with secondary structures and potential off-target binding sites. It is crucial to perform a BLAST search to ensure primer specificity.
Q4: What are the recommended starting concentrations for key PCR components when working with 1mC templates?
A4: The following table provides recommended starting concentrations, which should be optimized for your specific experiment.
| Component | Recommended Starting Concentration | Optimization Range |
| dNTPs | 200 µM of each | 50 - 400 µM |
| MgCl₂ | 1.5 mM | 1.0 - 2.5 mM |
| Primers | 0.2 µM of each | 0.1 - 1.0 µM |
| DNA Polymerase | As per manufacturer's recommendation | - |
| Template DNA | 1-100 ng | Varies with template complexity |
Q5: Can I use quantitative PCR (qPCR) to amplify 1mC-containing DNA?
A5: Yes, qPCR can be used for the amplification and quantification of 1mC-containing templates. However, it is important to validate the efficiency of your qPCR assay, as the presence of 1mC could potentially affect polymerase efficiency and, consequently, the accuracy of quantification. Running a standard curve with a known amount of your 1mC-containing template is crucial for accurate quantification.
Experimental Protocols
Protocol 1: Detailed Methodology for Optimizing Annealing Temperature using Gradient PCR
-
Primer and Template Preparation: Resuspend primers in nuclease-free water or TE buffer to a stock concentration of 100 µM. Dilute to a working concentration of 10 µM. Quantify the concentration of your 1mC-containing template DNA.
-
Reaction Setup: Prepare a master mix containing all PCR components except the template DNA. Aliquot the master mix into separate PCR tubes. Add the template DNA to each tube.
-
Gradient Cycler Programming: Set up a thermal cycler with a temperature gradient for the annealing step. A typical gradient might span 10-15°C, centered around the estimated Tm of your primers (e.g., 50°C to 65°C).
-
Thermal Cycling Conditions:
-
Initial Denaturation: 95°C for 2-5 minutes.
-
Denaturation: 95°C for 30 seconds.
-
Annealing: Gradient (e.g., 50-65°C) for 30 seconds.
-
Extension: 72°C for 30-60 seconds per kb of amplicon length.
-
Repeat for 30-35 cycles.
-
Final Extension: 72°C for 5-10 minutes.
-
-
Analysis: Analyze the PCR products on an agarose gel. The lane corresponding to the temperature that yields a single, sharp band of the correct size is the optimal annealing temperature.
Visualizations
Caption: Troubleshooting workflow for PCR with 1mC templates.
Caption: Logical relationships in optimizing PCR for 1mC DNA.
References
Technical Support Center: 1-Methylcytosine Immunoprecipitation (m1C IP)
This technical support center provides troubleshooting guidance and answers to frequently asked questions for researchers encountering poor yield or other issues during 1-Methylcytosine (m1C) immunoprecipitation experiments.
Frequently Asked Questions (FAQs) & Troubleshooting Guides
Issue 1: Very low or no yield of immunoprecipitated RNA.
Q: I performed an m1C IP, but my final yield of enriched RNA is extremely low or undetectable. What are the potential causes and how can I troubleshoot this?
A: Low or no yield is a common issue in immunoprecipitation experiments and can stem from several factors throughout the protocol. Here is a breakdown of potential causes and solutions:
Potential Cause 1: Poor Antibody Quality or Inappropriate Antibody Concentration
-
Troubleshooting:
-
Antibody Validation: Ensure the primary antibody used is validated for immunoprecipitation (IP) or RNA immunoprecipitation (RIP).[1][2][3] Not all antibodies that work in other applications (like Western blotting) are suitable for IP, as they may not recognize the native conformation of the target.[4]
-
Antibody Titration: The optimal antibody concentration is crucial. Too little antibody will result in inefficient pulldown, while too much can lead to increased non-specific binding and background. Perform a titration experiment to determine the ideal antibody concentration for your specific sample type and amount.
-
Proper Antibody Storage and Handling: Ensure the antibody has been stored according to the manufacturer's instructions and has not undergone multiple freeze-thaw cycles, which can lead to degradation.
-
Potential Cause 2: Insufficient Amount or Poor Quality of Starting Material
-
Troubleshooting:
-
Increase Starting Material: If the concentration of m1C in your sample is low, you may need to increase the initial amount of total RNA or cells used.
-
RNA Integrity: Assess the quality of your starting RNA using a method like capillary electrophoresis (e.g., Agilent Bioanalyzer). Degraded RNA will lead to poor IP results.
-
Avoid Freeze-Thaw Cycles: Whenever possible, use fresh cell lysates. Repeated freezing and thawing can lead to protein and RNA degradation.
-
Potential Cause 3: Inefficient RNA Fragmentation
-
Troubleshooting:
-
Optimize Fragmentation: The size of the RNA fragments is critical for successful IP. Over-fragmentation can destroy antibody epitopes, while under-fragmentation can lead to inefficient pulldown and lower resolution. Optimize your fragmentation method (e.g., enzymatic or chemical) and incubation time to achieve the desired fragment size range (typically 100-500 nucleotides).
-
Potential Cause 4: Suboptimal Lysis and IP Buffer Conditions
-
Troubleshooting:
-
Lysis Buffer Composition: The lysis buffer must effectively solubilize the cells or tissue while preserving the integrity of the RNA and the m1C modification. Ensure your lysis buffer is compatible with the downstream IP steps and contains RNase inhibitors.
-
Buffer pH and Salt Concentration: Extreme pH or salt concentrations can interfere with antibody-antigen binding. Typically, a physiological pH and salt concentration are recommended, but these may need to be optimized.
-
Potential Cause 5: Inadequate Bead Preparation and Binding
-
Troubleshooting:
-
Bead Type: Ensure you are using the correct type of beads (e.g., Protein A, Protein G, or Protein A/G) that have a high affinity for the isotype of your primary antibody.
-
Bead Washing and Blocking: Thoroughly wash the beads before use to remove any storage buffers or preservatives. To reduce non-specific binding, pre-block the beads with a blocking agent like BSA or salmon sperm DNA.
-
Incubation Times: Optimize the incubation times for antibody-bead binding and for the antibody-bead complex with the sample lysate. These can range from a few hours to overnight.
-
Potential Cause 6: Inefficient Elution
-
Troubleshooting:
-
Elution Buffer Choice: The elution buffer must be strong enough to disrupt the antibody-antigen interaction without degrading the RNA. Common elution methods include using a low pH buffer (e.g., glycine-HCl) or a buffer containing SDS.
-
Neutralization: If using a low pH elution buffer, it is critical to neutralize the eluate immediately with a high pH buffer to prevent RNA degradation.
-
Incubation Time and Temperature: Optimize the elution incubation time and temperature to ensure complete release of the RNA from the beads.
-
Issue 2: High background of non-specific RNA in the final eluate.
Q: My m1C IP resulted in a good yield, but subsequent analysis shows a high level of non-specific RNA. How can I reduce this background?
A: High background is often caused by non-specific binding of RNA or other molecules to the beads or the antibody.
Potential Cause 1: Non-Specific Binding to Beads
-
Troubleshooting:
-
Pre-clearing the Lysate: Before adding your specific antibody, incubate the cell lysate with beads alone. This step will capture proteins and nucleic acids that non-specifically bind to the beads, which can then be discarded.
-
Bead Blocking: As mentioned previously, blocking the beads with BSA or another suitable blocking agent before adding the antibody can significantly reduce non-specific binding.
-
Potential Cause 2: Inadequate Washing Steps
-
Troubleshooting:
-
Increase Wash Stringency: Increase the salt concentration or the amount of detergent (e.g., Tween-20 or NP-40) in your wash buffers to disrupt weaker, non-specific interactions.
-
Increase Number of Washes: Perform additional wash steps to more thoroughly remove unbound molecules. Be careful not to be overly stringent, as this could also elute your target RNA.
-
Potential Cause 3: Too Much Antibody or Lysate
-
Troubleshooting:
-
Optimize Concentrations: Using an excessive amount of antibody or cell lysate can lead to increased non-specific binding. Titrate both to find the optimal balance between specific signal and background.
-
Quantitative Data Summary
The following table provides a general overview of expected yields and parameters that can be optimized. Actual results will vary depending on the cell type, the abundance of m1C, and the specific protocol used.
| Parameter | Typical Range | High Yield | Low Yield | Troubleshooting Focus |
| Starting Total RNA | 10 - 100 µg | ≥ 50 µg | < 10 µg | Increase starting material. |
| Antibody Concentration | 1 - 10 µg | Optimized Titration | Suboptimal | Titrate antibody concentration. |
| RNA Fragment Size | 100 - 500 nt | 150 - 300 nt | < 100 nt or > 500 nt | Optimize fragmentation time/method. |
| Final Yield (% of Input) | 0.1 - 1% | > 0.5% | < 0.1% | Review all protocol steps. |
Experimental Protocols
Detailed Methodology for this compound Immunoprecipitation (m1C IP)
This protocol is a generalized procedure and may require optimization for your specific experimental conditions.
1. RNA Preparation and Fragmentation
-
Isolate total RNA from your cells or tissue of interest using a standard method (e.g., TRIzol).
-
Assess RNA integrity and quantity.
-
Fragment the RNA to an average size of 100-500 nucleotides. This can be done using an RNA fragmentation buffer and incubating at 94°C for 1-5 minutes, followed by immediate chilling on ice. The exact time will need to be optimized.
2. Bead Preparation
-
Resuspend magnetic Protein A/G beads by vortexing.
-
Transfer the desired amount of beads to a new tube.
-
Wash the beads twice with IP buffer (e.g., a Tris-based buffer with NaCl and a non-ionic detergent). Use a magnetic stand to separate the beads from the supernatant.
-
Resuspend the beads in IP buffer containing a blocking agent (e.g., 1% BSA) and incubate for 1 hour at 4°C with rotation.
3. Immunoprecipitation
-
To the fragmented RNA, add IP buffer and the optimized amount of anti-m1C antibody.
-
Incubate for 2 hours to overnight at 4°C with gentle rotation to allow for antibody-RNA binding.
-
Add the pre-blocked beads to the RNA-antibody mixture.
-
Incubate for another 1-4 hours at 4°C with gentle rotation.
4. Washing
-
Pellet the beads using a magnetic stand and discard the supernatant.
-
Wash the beads three to five times with ice-cold wash buffer. The stringency of the wash buffer can be adjusted by varying the salt and detergent concentrations. For each wash, resuspend the beads completely and incubate for 5 minutes at 4°C with rotation.
5. Elution
-
After the final wash, remove all supernatant.
-
Resuspend the beads in elution buffer (e.g., 100 mM Glycine-HCl, pH 2.5).
-
Incubate for 5-10 minutes at room temperature with agitation.
-
Separate the beads with a magnetic stand and transfer the supernatant containing the eluted RNA to a new tube.
-
Immediately neutralize the eluate with a Tris-based buffer to a physiological pH.
6. RNA Purification
-
Purify the eluted RNA using a standard RNA clean-up kit or phenol-chloroform extraction followed by ethanol precipitation.
-
Elute the final RNA in nuclease-free water. The RNA is now ready for downstream applications such as RT-qPCR or sequencing.
Visualizations
Caption: Workflow for this compound Immunoprecipitation (m1C IP).
Caption: Troubleshooting logic for addressing poor m1C IP yield.
References
Validation & Comparative
Validating 1-Methylcytosine Sequencing Findings: A Comparative Guide
For researchers, scientists, and drug development professionals, validating the results of 1-methylcytosine (m1C) sequencing is a critical step to ensure the accuracy and reliability of their findings. This guide provides an objective comparison of common validation methods, complete with experimental data and detailed protocols, to aid in the selection of the most appropriate technique for your research needs.
This compound (m1C) is a post-transcriptional RNA modification implicated in various biological processes, including the regulation of gene expression.[1][2][3] As high-throughput sequencing technologies for m1C detection become more prevalent, the need for robust and orthogonal validation methods is paramount to confirm the presence and quantify the abundance of this modification. This guide explores three primary methods for validating m1C sequencing findings: Liquid Chromatography-Mass Spectrometry (LC-MS), m1C Immunoprecipitation followed by qPCR (m1C-IP-qPCR), and Dot Blot Analysis.
Comparison of m1C Validation Methods
The choice of a validation method depends on several factors, including the desired level of quantification, sample availability, and the specific research question. The following table summarizes the key features of the three most common orthogonal validation techniques for m1C sequencing.
| Feature | Liquid Chromatography-Mass Spectrometry (LC-MS) | m1C Immunoprecipitation (m1C-IP-qPCR) | Dot Blot Analysis |
| Principle | Separation and identification of individual nucleosides based on their mass-to-charge ratio. | Enrichment of m1C-containing RNA fragments using an m1C-specific antibody, followed by quantitative PCR of target RNAs. | Immobilization of total RNA on a membrane and detection of m1C using a specific antibody. |
| Quantification | Absolute and highly accurate. | Relative quantification of enrichment. | Semi-quantitative.[4][5] |
| Sensitivity | High, capable of detecting low-abundance modifications. | Moderate to high, dependent on antibody affinity and specificity. | Low to moderate. |
| Specificity | Very high, provides unambiguous identification. | Dependent on the specificity of the m1C antibody. | Dependent on the specificity of the m1C antibody. |
| Sample Input | Typically requires microgram quantities of RNA. | Can be performed with nanogram to microgram amounts of RNA. | Requires microgram quantities of RNA. |
| Throughput | Lower, sample processing can be time-consuming. | Higher, can be adapted for multi-well formats. | High, suitable for screening multiple samples. |
| Information Provided | Absolute quantity of m1C in the total RNA pool. | Relative enrichment of m1C at specific RNA targets. | Global m1C levels in the total RNA. |
| Use Case | Gold standard for absolute quantification of m1C. | Validation of m1C presence at specific sites identified by sequencing. | Rapid and cost-effective screening for global changes in m1C levels. |
Experimental Protocols
Detailed methodologies for each validation technique are provided below. These protocols serve as a starting point and may require optimization based on specific experimental conditions and sample types.
Liquid Chromatography-Mass Spectrometry (LC-MS) for Absolute m1C Quantification
LC-MS is the gold standard for the absolute quantification of RNA modifications. It involves the enzymatic digestion of RNA into individual nucleosides, followed by their separation and detection based on their unique mass-to-charge ratios.
Methodology:
-
RNA Digestion:
-
Start with 1-5 µg of total RNA.
-
Digest the RNA to nucleosides using a mixture of nuclease P1 and bacterial alkaline phosphatase.
-
-
LC Separation:
-
Separate the resulting nucleosides using a C18 reverse-phase HPLC column.
-
-
MS Detection:
-
Analyze the eluted nucleosides using a triple quadrupole mass spectrometer in multiple reaction monitoring (MRM) mode.
-
Quantify the amount of m1C by comparing its signal to a standard curve generated from known concentrations of an m1C standard.
-
m1C Immunoprecipitation followed by qPCR (m1C-IP-qPCR)
This method validates the presence of m1C at specific RNA loci identified by sequencing. It relies on the enrichment of m1C-containing RNA fragments using an antibody specific to m1C, followed by quantitative PCR (qPCR) to measure the abundance of target RNAs in the immunoprecipitated fraction.
Methodology:
-
RNA Fragmentation:
-
Fragment 10-50 µg of total RNA to an average size of 100-200 nucleotides.
-
-
Immunoprecipitation:
-
Incubate the fragmented RNA with an anti-m1C antibody.
-
Capture the antibody-RNA complexes using protein A/G magnetic beads.
-
Wash the beads to remove non-specifically bound RNA.
-
-
RNA Elution and Purification:
-
Elute the enriched RNA from the beads.
-
Purify the RNA using a standard RNA purification kit.
-
-
Reverse Transcription and qPCR:
-
Reverse transcribe the enriched RNA and input RNA (a small fraction of the starting material) into cDNA.
-
Perform qPCR using primers specific to the target RNA regions identified from the sequencing data.
-
Calculate the enrichment of the target RNA in the IP fraction relative to the input.
-
Dot Blot Analysis for Global m1C Levels
Dot blot is a simple and rapid method for the semi-quantitative assessment of global m1C levels in a sample. It involves immobilizing total RNA onto a membrane and detecting the m1C modification using a specific antibody.
Methodology:
-
RNA Denaturation and Spotting:
-
Denature 1-2 µg of total RNA by heating.
-
Spot the denatured RNA directly onto a nitrocellulose or nylon membrane.
-
-
Membrane Blocking and Antibody Incubation:
-
Block the membrane to prevent non-specific antibody binding.
-
Incubate the membrane with an anti-m1C primary antibody.
-
Wash the membrane and incubate with a horseradish peroxidase (HRP)-conjugated secondary antibody.
-
-
Detection:
-
Add a chemiluminescent substrate and detect the signal using an imaging system.
-
The intensity of the dot is proportional to the amount of m1C in the sample.
-
Visualizing Validation Workflows
The following diagrams illustrate the experimental workflows for the described validation methods.
Logical Relationship of Validation Methods
The following diagram illustrates the relationship between the primary sequencing experiment and the orthogonal validation methods, highlighting the different levels of information each technique provides.
References
- 1. Frontiers | Roles of RNA Modifications in Diverse Cellular Functions [frontiersin.org]
- 2. RNA m5C modification: from physiology to pathology and its biological significance - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Frontiers | RNA modifications and their role in gene expression [frontiersin.org]
- 4. Detecting RNA Methylation by Dot Blotting | Proteintech Group [ptglab.com]
- 5. How to Read Dot Blot Results - TotalLab [totallab.com]
A Comparative Functional Analysis of 1-Methylcytosine and 5-Methylcytosine: Unraveling the Nuances of Cytosine Methylation
For Researchers, Scientists, and Drug Development Professionals: A comprehensive guide to the distinct biological roles, enzymatic regulation, and analytical methodologies for 1-Methylcytosine (m1C) and 5-Methylcytosine (m5C).
In the intricate landscape of epigenetic and epitranscriptomic regulation, the methylation of cytosine stands out as a critical modification influencing a vast array of biological processes. While 5-methylcytosine (m5C) has long been the poster child of DNA methylation and a key player in gene silencing, the functional significance of its isomer, this compound (m1C), is steadily gaining recognition, particularly in the realm of RNA biology. This guide provides a detailed comparative analysis of m1C and m5C, offering insights into their distinct functions, the enzymatic machinery that governs their deposition and removal, and the experimental approaches to their study.
At a Glance: Key Distinctions Between m1C and m5C
| Feature | This compound (m1C) | 5-Methylcytosine (m5C) |
| Primary Location | Predominantly found in RNA (tRNA, rRNA, mRNA).[1] | Abundant in DNA (CpG islands) and also present in various RNAs (tRNA, rRNA, mRNA).[2][3][4][5] |
| Primary Function | Modulates RNA structure and function, including tRNA stability and translation. | In DNA, primarily involved in transcriptional repression and gene silencing. In RNA, influences mRNA stability, export, and translation. |
| Methyl Group Position | Nitrogen atom at position 1 (N1) of the cytosine ring. | Carbon atom at position 5 (C5) of the cytosine ring. |
| "Writer" Enzymes | Primarily RNA methyltransferases (e.g., TRMTs in some contexts). | DNA methyltransferases (DNMTs) for DNA; NSUN family proteins for RNA. |
| "Eraser" Enzymes | Less well-characterized; potential role for ALKBH family dioxygenases. | TET family of dioxygenases (for DNA and RNA); DNA glycosylases in DNA repair pathways. |
| "Reader" Proteins | Emerging research suggests specific RNA-binding proteins. | Methyl-CpG-binding domain (MBD) proteins for DNA; YBX1 and ALYREF for RNA. |
Functional Roles: Beyond a Simple Methyl Group
The distinct positioning of the methyl group in m1C and m5C leads to profound differences in their functional consequences.
This compound (m1C): A Guardian of RNA Integrity and Function
Primarily identified in transfer RNA (tRNA) and ribosomal RNA (rRNA), m1C plays a crucial role in maintaining the structural integrity and proper functioning of these non-coding RNAs. In tRNA, m1C at position 9 (m1G9) is implicated in the correct folding of mitochondrial tRNAs. Emerging evidence also points to the presence and potential regulatory roles of m1C in messenger RNA (mRNA), where it may influence translation.
5-Methylcytosine (m5C): The Master Regulator of Gene Expression
In DNA, m5C is a cornerstone of epigenetics, predominantly occurring at CpG dinucleotides. Its presence in gene promoter regions is strongly associated with transcriptional silencing, playing pivotal roles in genomic imprinting, X-chromosome inactivation, and the suppression of transposable elements.
In the epitranscriptome, m5C is found in various RNA species and is involved in regulating mRNA stability, nuclear export, and translation. For instance, m5C modification in mRNA can be recognized by "reader" proteins like YBX1, which can then recruit other factors to influence the fate of the transcript.
The Enzymatic Machinery: Writers, Erasers, and Readers
The dynamic regulation of m1C and m5C is orchestrated by a dedicated cast of enzymes and binding proteins.
The Writers: Depositing the Methyl Mark
For m1C, the primary "writers" are RNA methyltransferases. For example, members of the Trm family of enzymes have been implicated in m1A and m1G methylation in tRNA, and similar enzymes are likely responsible for m1C deposition.
For m5C, the "writers" are well-characterized. In DNA, the DNA methyltransferases (DNMTs), including DNMT1 for maintenance and DNMT3A/B for de novo methylation, are responsible for establishing and preserving m5C patterns. In RNA, members of the NOL1/NOP2/Sun domain (NSUN) family of proteins, such as NSUN2 and NSUN6, are the primary m5C methyltransferases.
The Erasers: Removing the Methyl Mark
The removal of these methyl marks, or "erasure," is an active area of research.
For m1C, the erasure mechanisms are not as clearly defined as for m5C. However, some members of the AlkB family of dioxygenases (ALKBH) have been shown to demethylate N1-methyladenine and N3-methylcytosine in DNA and RNA, suggesting a potential role in m1C removal.
For m5C, the erasure process in DNA is a multi-step pathway initiated by the Ten-Eleven Translocation (TET) family of enzymes. TET enzymes oxidize m5C to 5-hydroxymethylcytosine (5hmC), 5-formylcytosine (5fC), and 5-carboxylcytosine (5caC). These oxidized forms can then be recognized and excised by Thymine-DNA Glycosylase (TDG) as part of the Base Excision Repair (BER) pathway, ultimately restoring an unmodified cytosine. TET enzymes have also been shown to oxidize m5C in RNA.
Experimental Protocols: Detecting and Quantifying m1C and m5C
A variety of techniques are available to study m1C and m5C, each with its own advantages and limitations.
Quantitative Data Summary
| Technique | Analyte | Principle | Resolution | Throughput | Key Considerations |
| Liquid Chromatography-Mass Spectrometry (LC-MS) | m1C & m5C | Separation and quantification of nucleosides based on mass-to-charge ratio. | Global quantification | Low | Highly accurate and quantitative for global levels. |
| Bisulfite Sequencing (BS-Seq) | m5C in DNA/RNA | Chemical conversion of unmethylated cytosine to uracil, leaving m5C unchanged. | Single-base | High | Gold standard for m5C mapping; harsh chemical treatment can degrade RNA. |
| Methylated DNA Immunoprecipitation (MeDIP-Seq) | m5C in DNA | Immunoprecipitation of methylated DNA fragments using an anti-m5C antibody. | ~150 bp | High | Enrichment-based, may be biased towards hypermethylated regions. |
| RNA Immunoprecipitation (RIP) | m1C & m5C in RNA | Immunoprecipitation of RNA-binding proteins to identify associated modified RNAs. | Gene-level | Moderate | Depends on the availability of specific antibodies to reader proteins. |
Detailed Methodologies
1. Quantitative Mass Spectrometry for Global m1C and m5C Quantification
This method provides a highly accurate measurement of the total amount of m1C and m5C in a given DNA or RNA sample.
-
Protocol:
-
Nucleic Acid Isolation and Digestion: Isolate total DNA or RNA from the sample of interest. Digest the nucleic acids into individual nucleosides using a cocktail of nucleases (e.g., nuclease P1, snake venom phosphodiesterase, and alkaline phosphatase).
-
Chromatographic Separation: Separate the resulting nucleosides using liquid chromatography (LC), typically with a reversed-phase column.
-
Mass Spectrometry Analysis: Introduce the separated nucleosides into a mass spectrometer. The instrument will ionize the nucleosides and separate them based on their mass-to-charge ratio.
-
Quantification: Quantify the abundance of m1C and m5C by comparing their signal intensities to those of standard curves generated from known amounts of purified m1C and m5C nucleosides.
-
2. Bisulfite Sequencing for Single-Base Resolution Mapping of m5C in RNA (RNA-BS-Seq)
This technique allows for the precise identification of m5C sites throughout the transcriptome.
-
Protocol:
-
RNA Isolation and Fragmentation: Isolate total RNA and fragment it to a suitable size for sequencing (typically 100-200 nucleotides).
-
Bisulfite Conversion: Treat the fragmented RNA with sodium bisulfite. This chemical treatment deaminates unmethylated cytosines to uracils, while 5-methylcytosines remain unchanged.
-
Reverse Transcription and Library Preparation: Reverse transcribe the bisulfite-converted RNA into cDNA. During this step, the uracils are read as thymines. Prepare a sequencing library from the cDNA.
-
High-Throughput Sequencing: Sequence the prepared library on a next-generation sequencing platform.
-
Data Analysis: Align the sequencing reads to a reference transcriptome. Sites that were originally m5C will appear as cytosines in the sequencing reads, while unmethylated cytosines will appear as thymines.
-
3. Methylated DNA Immunoprecipitation Sequencing (MeDIP-Seq) for Genome-Wide m5C Profiling
MeDIP-Seq is a powerful tool for identifying regions of the genome that are enriched for m5C.
-
Protocol:
-
Genomic DNA Isolation and Fragmentation: Isolate genomic DNA and shear it into fragments of 200-800 base pairs using sonication or enzymatic digestion.
-
Immunoprecipitation: Incubate the fragmented DNA with a specific antibody that recognizes 5-methylcytosine. This will pull down the DNA fragments containing m5C.
-
Library Preparation and Sequencing: Isolate the immunoprecipitated DNA and prepare a sequencing library. Sequence the library using a high-throughput sequencing platform.
-
Data Analysis: Align the sequencing reads to a reference genome to identify regions with a high density of reads, which correspond to m5C-enriched regions.
-
Signaling Pathways and Experimental Workflows
Concluding Remarks
The study of cytosine methylation is a rapidly evolving field. While 5-methylcytosine has been extensively studied for its profound impact on gene regulation in the context of DNA, the functional roles of both m5C and m1C in RNA are becoming increasingly apparent. This comparative guide highlights the significant differences in their biological contexts, regulatory mechanisms, and functional outputs. For researchers and drug development professionals, understanding these distinctions is paramount for designing targeted therapeutic strategies that can precisely modulate the activity of specific methylation pathways. As new technologies for detecting and manipulating these modifications continue to emerge, we can anticipate a deeper understanding of the intricate language of the methylome and epitranscriptome, paving the way for novel diagnostic and therapeutic interventions.
References
- 1. Chemical and Conformational Diversity of Modified Nucleosides Affects tRNA Structure and Function - PMC [pmc.ncbi.nlm.nih.gov]
- 2. The je ne sais quoi of 5-methylcytosine in messenger RNA - PMC [pmc.ncbi.nlm.nih.gov]
- 3. academic.oup.com [academic.oup.com]
- 4. RNA 5-methylcytosine modification and its emerging role as an epitranscriptomic mark - PMC [pmc.ncbi.nlm.nih.gov]
- 5. 5-methylcytosine in RNA: detection, enzymatic formation and biological functions - PMC [pmc.ncbi.nlm.nih.gov]
A Researcher's Guide to Orthogonal Validation of 1-Methylcytosine (m1C) Sites
An Objective Comparison of High-Throughput Sequencing and Locus-Specific Validation Methods for the Epitranscriptome
For researchers, scientists, and drug development professionals navigating the complexities of RNA epigenetics, the accurate identification of 1-methylcytosine (m1C) sites is paramount. This guide provides a comprehensive comparison of orthogonal methods used to validate putative m1C sites identified through high-throughput sequencing. We present a critical evaluation of sequencing-based and locus-specific techniques, supported by experimental data and detailed protocols to ensure robust and reliable characterization of this important RNA modification.
High-Throughput Mapping of m1C: An Overview
The initial discovery of m1C sites across the transcriptome is often achieved through specialized next-generation sequencing (NGS) techniques. These methods provide a genome-wide view of potential m1C locations, which then require rigorous validation by independent, or orthogonal, methods.
One prominent high-throughput method is m1C-MaP-seq (this compound-MaP-seq), which leverages the principle that the presence of m1C can induce misincorporations during reverse transcription. By sequencing the resulting cDNA library, sites of frequent mismatches can be identified as potential m1C locations. Another antibody-based approach, m1C-MeRIP-seq (methylated RNA immunoprecipitation sequencing), utilizes an antibody specific to m1C to enrich for RNA fragments containing this modification, which are then sequenced to identify enriched regions.
While powerful for discovery, these high-throughput methods are not without their limitations, including potential for false positives and variability in efficiency. Therefore, orthogonal validation is a critical step to confirm the presence and location of m1C.
Orthogonal Validation Methods: A Comparative Analysis
To ensure the accuracy of m1C mapping, at least one independent method should be used to validate the findings from high-throughput sequencing. The choice of orthogonal method depends on factors such as the required resolution, throughput, and the specific biological question being addressed. Here, we compare three commonly employed orthogonal validation techniques: Locus-Specific RT-qPCR , Primer Extension , and Liquid Chromatography-Mass Spectrometry (LC-MS) .
| Method | Principle | Resolution | Throughput | Quantitative? | Key Advantages | Key Limitations |
| Locus-Specific RT-qPCR | Differential amplification of RNA based on the presence of m1C, which can affect reverse transcription efficiency or primer binding. | Locus-specific | Moderate | Semi-quantitative | Relatively simple and cost-effective. | Indirect detection; results can be influenced by RNA secondary structure. |
| Primer Extension | Reverse transcriptase stalls or terminates at the m1C site, leading to a truncated cDNA product that can be detected and quantified. | Single-nucleotide | Low to moderate | Yes | Provides single-nucleotide resolution; directly detects the modification site. | Can be labor-intensive; requires radiolabeling or fluorescent labeling. |
| LC-MS | Direct detection and quantification of m1C nucleosides from digested RNA samples based on their mass-to-charge ratio. | Not site-specific | Low | Yes (absolute) | Gold standard for quantification; highly specific. | Does not provide sequence context; requires specialized equipment and expertise. |
Experimental Workflows
To aid in the practical application of these validation methods, we provide visual workflows generated using the DOT language.
Detailed Experimental Protocols
Locus-Specific RT-qPCR
-
RNA Preparation: Isolate total RNA from the sample of interest using a standard protocol (e.g., TRIzol extraction). Treat the RNA with DNase I to remove any contaminating genomic DNA.
-
Reverse Transcription: Perform reverse transcription on the RNA sample. To assess the impact of m1C, it is recommended to use two different reverse transcriptases, one of which is known to be more sensitive to m1C and may stall or misincorporate at the modification site.
-
qPCR: Design primers flanking the putative m1C site. Perform quantitative PCR using a real-time PCR system.
-
Data Analysis: Compare the quantification cycle (Cq) values obtained from the different reverse transcription reactions. A significant difference in Cq values can indicate the presence of a modification that impedes reverse transcription.
Primer Extension
-
Primer Labeling: Synthesize a DNA oligonucleotide primer complementary to the RNA sequence downstream of the putative m1C site. Label the 5' end of the primer with a radioactive isotope (e.g., ³²P) or a fluorescent dye.
-
Hybridization: Anneal the labeled primer to the total RNA sample.
-
Primer Extension: Perform a reverse transcription reaction. The reverse transcriptase will extend the primer until it reaches the 5' end of the RNA or encounters a modification that causes it to stall.
-
Analysis: Separate the reaction products on a denaturing polyacrylamide gel. Visualize the products by autoradiography or fluorescence imaging. The presence of a truncated product corresponding to the size expected for a stall at the putative m1C site confirms its presence.
Liquid Chromatography-Mass Spectrometry (LC-MS)
-
RNA Digestion: Isolate total RNA and digest it completely into individual nucleosides using a cocktail of nucleases (e.g., nuclease P1, snake venom phosphodiesterase, and alkaline phosphatase).
-
LC Separation: Separate the resulting nucleosides using high-performance liquid chromatography (HPLC).
-
MS/MS Analysis: Analyze the separated nucleosides by tandem mass spectrometry (MS/MS). The m1C nucleoside will have a characteristic mass-to-charge ratio that allows for its unambiguous identification and quantification.
-
Quantification: Determine the absolute or relative amount of m1C in the sample by comparing its signal intensity to that of a known standard.
Conclusion
The validation of this compound sites is a critical step in epitranscriptomic research. While high-throughput sequencing methods provide an essential starting point for identifying potential m1C sites, orthogonal validation is necessary to ensure the accuracy and reliability of these findings. This guide provides a framework for selecting and implementing appropriate orthogonal validation methods, empowering researchers to confidently characterize the m1C landscape and its role in biological processes and disease. By combining high-throughput discovery with rigorous locus-specific validation, the field can move towards a more complete and accurate understanding of the epitranscriptome.
Unveiling the Epitranscriptomic Code: A Comparative Guide to 1-Methylcytosine (m1C) and N6-Methyladenosine (m6A)
An in-depth analysis of the functional distinctions, regulatory mechanisms, and experimental considerations for two key RNA modifications.
In the intricate landscape of post-transcriptional gene regulation, chemical modifications to RNA molecules, collectively known as the epitranscriptome, have emerged as critical regulators of cellular processes. Among the more than 170 identified RNA modifications, N6-methyladenosine (m6A) has been extensively studied and is the most abundant internal modification in eukaryotic messenger RNA (mRNA).[1][2] In contrast, 1-methylcytosine (m1C), while also a significant modification, has been less thoroughly characterized, particularly in mRNA. This guide provides a comprehensive comparison of the functional differences between m1C and m6A, offering insights for researchers, scientists, and drug development professionals.
Core Functional Differences and Molecular Machinery
The functional consequences of m1C and m6A are dictated by a dedicated cast of proteins known as "writers," "erasers," and "readers." These proteins are responsible for the installation, removal, and recognition of the methyl marks, respectively, thereby translating the chemical modification into a biological outcome.
N6-methyladenosine (m6A): A Well-Orchestrated Regulator of mRNA Fate
The m6A modification is a dynamic and reversible process governed by a well-defined set of proteins.
-
Writers: The m6A methyltransferase complex, often referred to as the "writer" complex, is a multicomponent machinery. The core components include the catalytic subunit METTL3 and the stabilizing partner METTL14.[3] This complex is further associated with other proteins like WTAP, VIRMA, KIAA1429, RBM15/15B, and ZC3H13, which are crucial for its localization and activity.[2]
-
Erasers: The demethylation of m6A is carried out by two key "erasers": fat mass and obesity-associated protein (FTO) and alkB homolog 5 (ALKBH5).[3] These enzymes facilitate the removal of the methyl group, allowing for the dynamic regulation of m6A levels in response to various cellular signals.
-
Readers: A diverse group of "reader" proteins recognize and bind to m6A-modified RNA, mediating its downstream effects. The most prominent family of m6A readers are the YTH domain-containing proteins (YTHDF1, YTHDF2, YTHDF3, YTHDC1, and YTHDC2). These proteins can influence mRNA stability, translation, and splicing. Other reader proteins include members of the HNRNP and IGF2BP families.
The interplay of these writers, erasers, and readers fine-tunes gene expression by affecting nearly every aspect of the mRNA lifecycle, from processing and nuclear export to translation and decay.
This compound (m1C): An Emerging Player with Distinct Roles
In contrast to the well-elucidated machinery for m6A, the proteins that specifically write, erase, and read m1C on mRNA are less comprehensively understood. Much of the current knowledge about m1C modification comes from studies on transfer RNA (tRNA) and ribosomal RNA (rRNA), where it plays a crucial role in maintaining structural integrity and facilitating proper translation.
-
Writers: In the context of tRNA, several methyltransferases responsible for m1C formation have been identified. However, the specific enzymes that deposit m1C on mRNA are still being actively investigated.
-
Erasers: Similar to writers, the enzymes responsible for the removal of m1C from mRNA have not been definitively characterized. The TET (ten-eleven translocation) family of enzymes, known for their role in DNA demethylation by oxidizing 5-methylcytosine, have been suggested to potentially play a role in RNA demethylation, but their specific activity on m1C in mRNA requires further investigation.
-
Readers: The proteins that specifically recognize and bind to m1C-modified mRNA to mediate its functional consequences are also an area of ongoing research.
The functional impact of m1C on mRNA is thought to involve the regulation of mRNA stability and translation, although the precise mechanisms are not as well-defined as those for m6A.
Comparative Overview of Regulatory Proteins
| Feature | N6-methyladenosine (m6A) | This compound (m1C) |
| Writer Complex | METTL3/METTL14, WTAP, VIRMA, KIAA1429, RBM15/15B, ZC3H13 | Largely uncharacterized for mRNA; known in tRNA. |
| Eraser Enzymes | FTO, ALKBH5 | Not definitively identified for mRNA; potential role for TET enzymes suggested. |
| Reader Proteins | YTHDF1-3, YTHDC1-2, HNRNP family, IGF2BP family | Largely uncharacterized for mRNA. |
Signaling Pathways and Biological Processes
Both m1C and m6A are implicated in a variety of biological processes and are intertwined with cellular signaling pathways.
m6A's Central Role in Cellular Signaling
The m6A modification is a key regulator in numerous signaling pathways, influencing processes such as cell proliferation, differentiation, and apoptosis. Dysregulation of m6A has been linked to various diseases, including cancer.
-
PI3K/Akt Pathway: The m6A machinery can modulate the PI3K/Akt signaling pathway. For instance, METTL14-mediated degradation of SOX4 mRNA can inhibit the malignant progression of colorectal cancer by suppressing PI3K/Akt signaling.
-
Wnt/β-catenin Pathway: m6A modification can influence the Wnt/β-catenin signaling pathway. For example, FTO-mediated demethylation of HOXB13 mRNA can lead to increased HOXB13 protein expression and activation of the Wnt pathway.
-
mTOR Pathway: The mTOR signaling pathway, a central regulator of cell growth and metabolism, is also influenced by m6A.
The following diagram illustrates the central role of the m6A regulatory machinery in influencing these key signaling pathways.
m1C's Emerging Roles in Cellular Function
While the direct links between m1C in mRNA and specific signaling pathways are still under investigation, its well-established role in tRNA suggests its importance in maintaining translational fidelity and efficiency. Dysregulation of tRNA modifications, including m1C, can impact protein synthesis and cellular homeostasis, which could have downstream effects on various signaling cascades. Further research is needed to elucidate the specific signaling networks directly modulated by m1C in mRNA.
Experimental Methodologies
The detection and quantification of m1C and m6A rely on distinct experimental approaches.
Detecting N6-methyladenosine (m6A)
A widely used technique for mapping m6A across the transcriptome is Methylated RNA Immunoprecipitation followed by sequencing (MeRIP-seq) . This method involves the following key steps:
-
RNA Fragmentation: Total RNA is fragmented into smaller pieces.
-
Immunoprecipitation: An antibody specific to m6A is used to enrich for RNA fragments containing the modification.
-
Library Preparation and Sequencing: The enriched RNA fragments are then used to construct a sequencing library, which is subsequently sequenced using high-throughput sequencing technologies.
The following diagram outlines the general workflow for MeRIP-seq.
Detecting this compound (m1C)
The detection of m1C often utilizes a technique based on bisulfite sequencing , which is also a cornerstone for DNA methylation analysis. The principle behind this method is the differential reactivity of cytosine and its methylated forms to sodium bisulfite.
-
Bisulfite Treatment: RNA is treated with sodium bisulfite, which deaminates unmethylated cytosine to uracil, while this compound remains unchanged.
-
Reverse Transcription and PCR: The treated RNA is then reverse-transcribed into cDNA and amplified by PCR. During this process, the uracils are read as thymines.
-
Sequencing and Analysis: The amplified DNA is sequenced, and by comparing the sequence to the original untreated sequence, the positions of m1C can be identified as cytosines that were not converted to thymines.
The following diagram illustrates the principle of bisulfite sequencing for m1C detection.
Quantitative Data Summary
Direct quantitative comparison of the absolute abundance of m1C and m6A in mRNA across different cell types and conditions is an active area of research. Generally, m6A is considered to be significantly more abundant than m1C in mRNA.
| Modification | Typical Abundance in mRNA |
| N6-methyladenosine (m6A) | ~0.1 - 0.4% of total adenosines |
| This compound (m1C) | Less abundant than m6A, precise quantification in mRNA is ongoing. |
Note: The abundance can vary depending on the cell type, developmental stage, and environmental conditions.
Detailed Experimental Protocols
MeRIP-seq Protocol for m6A Detection
-
RNA Preparation: Isolate total RNA from cells or tissues and subsequently purify poly(A) RNA. Ensure high quality and integrity of the RNA.
-
RNA Fragmentation: Fragment the poly(A) RNA to an average size of ~100 nucleotides using chemical or enzymatic methods.
-
Immunoprecipitation:
-
Incubate the fragmented RNA with an anti-m6A antibody to form RNA-antibody complexes.
-
Capture the complexes using protein A/G magnetic beads.
-
Perform stringent washing steps to remove non-specifically bound RNA.
-
-
Elution: Elute the m6A-containing RNA fragments from the beads.
-
Library Construction and Sequencing:
-
Construct a sequencing library from the eluted RNA fragments and an input control (fragmented RNA that did not undergo immunoprecipitation).
-
Perform high-throughput sequencing.
-
-
Data Analysis: Align the sequencing reads to the reference genome and identify enriched regions (peaks) in the MeRIP sample compared to the input control. These peaks represent regions with m6A modifications.
RNA Bisulfite Sequencing Protocol for m1C Detection
-
RNA Preparation: Isolate total RNA and ensure it is free of DNA contamination.
-
Bisulfite Conversion:
-
Denature the RNA to ensure all cytosines are accessible.
-
Treat the RNA with sodium bisulfite under controlled temperature and time conditions to convert unmethylated cytosines to uracils.
-
Purify the bisulfite-treated RNA.
-
-
Reverse Transcription: Reverse transcribe the bisulfite-converted RNA into cDNA using random primers or gene-specific primers.
-
PCR Amplification: Amplify the cDNA region of interest using primers designed to be specific for the converted sequence (i.e., containing thymines instead of cytosines, except at potential m1C sites).
-
Sequencing: Sequence the PCR products.
-
Data Analysis: Align the sequences to the reference sequence and identify positions where a cytosine is retained, indicating the presence of a this compound.
Conclusion
N6-methyladenosine (m6A) and this compound (m1C) are two important epitranscriptomic marks with distinct functional roles and regulatory mechanisms. While m6A is a well-characterized and abundant modification with a clear impact on mRNA fate and cellular signaling, m1C in mRNA is an emerging area of research with many of its molecular players and functional consequences yet to be fully elucidated. The continued development of sensitive and specific detection methods will be crucial for unraveling the complexities of the m1C epitranscriptome and its interplay with m6A in regulating gene expression in health and disease. This comparative guide provides a foundational understanding for researchers and professionals seeking to explore the dynamic world of RNA modifications.
References
A Comparative Guide to RNA Modifications in Gene Regulation: 1-Methylcytosine in the Spotlight
For researchers, scientists, and drug development professionals, understanding the nuanced landscape of post-transcriptional RNA modifications is paramount for deciphering the complex mechanisms of gene regulation. This guide provides a comprehensive comparison of 1-methylcytosine (m1C) alongside other key RNA modifications—N6-methyladenosine (m6A), 5-methylcytosine (m5C), and pseudouridine (Ψ)—highlighting their roles in controlling gene expression.
This document delves into the experimental data supporting the distinct and overlapping functions of these modifications, details the methodologies for their study, and visualizes the key signaling pathways they influence.
At a Glance: Comparative Overview of RNA Modifications
While all four modifications play crucial roles in post-transcriptional gene regulation, they exhibit distinct characteristics in their distribution, enzymatic machinery, and functional consequences.
| Feature | This compound (m1C) | N6-Methyladenosine (m6A) | 5-Methylcytosine (m5C) | Pseudouridine (Ψ) |
| Location on RNA | Primarily tRNA, also found in mRNA and rRNA | Most abundant internal modification in mRNA, enriched near stop codons and in 3' UTRs.[1] | Found in various RNAs including tRNA, rRNA, and mRNA.[2] | The most abundant RNA modification, found in tRNA, rRNA, snRNA, and mRNA. |
| "Writer" Enzymes | TRM10C, TRMT6/TRMT61A | METTL3/METTL14/WTAP complex | NSUN protein family, DNMT2 | Pseudouridine synthases (PUS) |
| "Eraser" Enzymes | ALKBH1, ALKBH3 | FTO, ALKBH5 | TET family proteins (indirect) | Believed to be largely irreversible |
| "Reader" Proteins | YTHDF3 | YTHDF1/2/3, YTHDC1/2, IGF2BP1/2/3 | YBX1, ALYREF | Some evidence for PUM2 |
| Primary Impact on mRNA | Thought to enhance translation efficiency. | Affects mRNA stability, splicing, and translation.[1] | Influences mRNA stability and nuclear export. | Stabilizes RNA structure, can alter codon recognition and translation. |
Deep Dive: Functional Comparison and Quantitative Insights
The impact of these RNA modifications on gene expression is multifaceted, influencing everything from the stability of an mRNA transcript to the efficiency with which it is translated into a protein.
mRNA Stability
The half-life of an mRNA molecule is a critical determinant of its protein-coding potential. RNA modifications can act as signals for degradation or protection.
-
m6A: The presence of m6A is often associated with decreased mRNA stability. The YTHDF2 reader protein can recognize m6A-modified transcripts and recruit them to decay pathways. For instance, knockout of the m6A writer METTL3 has been shown to result in longer half-lives of m6A-containing mRNAs.[3] In mouse embryonic stem cells, m6A is a major driver of mRNA stability, explaining roughly 30% of the variation in mRNA half-lives.[4] Overexpression of m6A methyltransferases has been observed to increase the half-life of certain mRNAs, such as AGO2, from approximately 4.9 hours to as long as 9.5 hours.
-
m5C: The role of m5C in mRNA stability is more context-dependent. For example, NSUN2-mediated m5C modification of the lncRNA NR_033928 enhances its stability, which in turn increases the stability of GLS mRNA in gastric cancer.
-
m1C & Ψ: Quantitative data directly comparing the effects of m1C and pseudouridine on the half-life of specific mRNAs is currently limited. However, the structural stabilization provided by pseudouridine suggests it may generally contribute to increased mRNA stability.
Table 1: Quantitative Effects of RNA Modifications on mRNA Half-life
| RNA Modification | Target mRNA (Example) | Cell Type | Change in Half-life | Reference |
| m6A | AGO2 | Human Dermal Fibroblasts | Increase from 4.9h to 9.5h (with METTL3/14 overexpression) | |
| m6A | Various transcripts | Mouse Embryonic Stem Cells | Knockout of METTL3 leads to longer half-lives |
Note: This table will be expanded as more quantitative data becomes available, particularly for m1C and Ψ.
Translation Efficiency
The rate at which an mRNA is translated into a protein can be significantly modulated by the presence of modified nucleotides.
-
m6A: m6A can either promote or inhibit translation depending on the context and the reader proteins involved. The YTHDF1 reader is known to promote the translation of m6A-modified mRNAs.
-
m5C: The effect of m5C on translation is position-dependent. m5C modifications within the coding sequence (CDS) are generally associated with reduced translation efficiency, while those in the 3' untranslated region (3' UTR) can enhance translation.
-
m1C: While less studied, m1C is thought to generally enhance translation efficiency.
-
Ψ: Pseudouridine's ability to alter RNA structure can impact ribosome binding and translocation, thereby influencing translation. m6A-containing mRNAs generally exhibit higher translation efficiency than those without the modification.
Table 2: Quantitative Effects of RNA Modifications on Translation Efficiency
| RNA Modification | Target mRNA (Example) | Cell Type/System | Fold Change in Protein Expression | Reference |
| m6A | General transcripts | Arabidopsis | m6A-containing mRNAs have higher translation efficiency |
Note: This table will be populated with more specific quantitative data as it becomes available.
Signaling Pathways Under RNA Modification Control
RNA modifications are not isolated events; they are integral components of cellular signaling networks, influencing pathways that govern cell growth, proliferation, and stress responses.
The PI3K-Akt Signaling Pathway
The PI3K-Akt pathway is a central regulator of cell survival and proliferation.
-
m6A: The m6A machinery can regulate the PI3K-Akt pathway by targeting the mRNAs of key components. For example, the m6A reader IGF2BP2 can stabilize the mRNA of key upstream activators of this pathway.
-
m5C: m5C modifications have also been implicated in the regulation of the PI3K-Akt pathway, often in the context of cancer.
Below is a diagram illustrating the core components of the PI3K-Akt signaling pathway.
The MAPK/ERK Signaling Pathway
The MAPK/ERK pathway is another critical signaling cascade involved in cell proliferation, differentiation, and survival.
-
m6A: m6A modification has been shown to regulate the expression of key components of the MAPK/ERK pathway, thereby influencing its activity.
-
m5C: Dysregulation of m5C has been linked to aberrant MAPK/ERK signaling in various diseases.
The following diagram outlines the key steps in the MAPK/ERK signaling pathway.
References
- 1. Global Co-regulatory Cross Talk Between m6A and m5C RNA Methylation Systems Coordinate Cellular Responses and Brain Disease Pathways - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Research progress on the PI3K/AKT signaling pathway in gynecological cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 3. DOT | Graphviz [graphviz.org]
- 4. ERK1/2/5 Signaling Interactive Pathway: Novus Biologicals [novusbio.com]
Unveiling the Role of Methylated Cytosine in Biological Processes: A Comparative Guide
A Comparative Analysis of 1-Methylcytosine and 5-Methylcytosine
In the landscape of epigenetic and epitranscriptomic regulation, cytosine methylation stands as a critical modification influencing a myriad of biological processes. While 5-methylcytosine (m5C) is a well-documented modification with established roles in RNA and DNA, its isomer, this compound (m1C), remains comparatively enigmatic in natural biological systems. This guide provides a comprehensive comparison, focusing on the validated roles of m5C due to the extensive available research, while also contextualizing the current understanding of m1C.
This compound (m1C): An Overview
This compound is a methylated form of the DNA and RNA base cytosine, where a methyl group is attached to the nitrogen atom at the first position of the cytosine ring.[1] Unlike the more common 5-methylcytosine, there is limited evidence for a widespread, validated role of this compound in natural biological processes. Its most notable described function is in a synthetic genetic system known as "hachimoji DNA," where it pairs with isoguanine.[1][2] While it is identified as a metabolite, its endogenous functions, including the existence of dedicated "writer" and "reader" proteins, are not well-established in the scientific literature.[3]
5-Methylcytosine (m5C): A Key Regulator in RNA Function
In stark contrast, 5-methylcytosine (m5C), with a methyl group at the fifth carbon of the cytosine ring, is a prevalent and functionally significant modification in various RNA species, including messenger RNA (mRNA), transfer RNA (tRNA), and ribosomal RNA (rRNA).[4] The regulation of m5C is a dynamic process orchestrated by a suite of proteins that install, recognize, and potentially remove this mark.
Key Players in the m5C Regulatory Pathway:
-
Writers (Methyltransferases): These enzymes are responsible for adding the methyl group to cytosine residues. Key writers include NSUN2 and NSUN6, which are members of the NOL1/NOP2/SUN domain (NSUN) family.
-
Readers (Binding Proteins): These proteins specifically recognize and bind to m5C-modified RNA, mediating downstream effects. A prominent example is the Y-box binding protein 1 (YBX1).
The interplay between these proteins fine-tunes gene expression at the post-transcriptional level, impacting RNA stability, translation, and nuclear export.
Comparative Performance Data: The Impact of m5C on mRNA Stability and Translation
The following tables summarize quantitative data from key studies, illustrating the impact of m5C modification on gene expression. These studies typically involve the knockdown or knockout of m5C writer enzymes and subsequent analysis of target mRNA and protein levels.
Table 1: Effect of NSUN2 Depletion on Target mRNA and Protein Levels
| Target Gene | Cell Line | Change in m5C Level | Change in mRNA Stability | Change in Protein Expression | Reference Study |
| HDGF | Urothelial Carcinoma | ↓ | Decreased | ↓ | Chen et al., 2019 |
| FABP5 | Osteosarcoma | ↓ | Decreased | ↓ | Yang et al., 2023 |
| IRF3 | Viral Infection Model | ↓ | Increased | ↑ | Wang et al., 2023a |
Table 2: Role of the m5C Reader YBX1 in Regulating mRNA Fate
| Target Gene | Cellular Context | YBX1 Binding | Effect on mRNA | Downstream Biological Process | Reference Study |
| HDGF | Bladder Cancer | m5C-dependent | Increased Stability | Promotes Oncogenesis | Chen et al., 2019 |
| Various mRNAs | Embryonic Stem Cells | m5C-dependent | Enhanced Stability & Translation | Maternal-to-Zygotic Transition | Yang et al., 2019b |
Experimental Protocols for the Validation of m5C Function
The validation of m5C's role in biological processes relies on a combination of techniques to map m5C sites, identify m5C-binding proteins, and assess the functional consequences of this modification.
m5C-Specific RNA Immunoprecipitation followed by Sequencing (m5C-RIP-Seq)
This technique is used to identify RNAs that are modified with m5C.
Protocol:
-
RNA Fragmentation: Total RNA is extracted from cells and fragmented into smaller pieces (typically ~100 nucleotides).
-
Immunoprecipitation: The fragmented RNA is incubated with an antibody that specifically recognizes m5C.
-
Washing: The antibody-RNA complexes are captured on beads, and unbound RNA is washed away.
-
RNA Elution and Purification: The m5C-containing RNA fragments are eluted from the antibody-bead complexes and purified.
-
Library Preparation and Sequencing: The purified RNA is converted into a cDNA library and sequenced using high-throughput sequencing.
-
Data Analysis: Sequencing reads are mapped to the transcriptome to identify regions enriched for m5C.
Bisulfite Sequencing of RNA (BS-Seq)
This method allows for the single-nucleotide resolution mapping of m5C sites.
Protocol:
-
RNA Isolation: High-quality total RNA is isolated from the sample of interest.
-
Bisulfite Conversion: The RNA is treated with sodium bisulfite, which deaminates unmethylated cytosine to uracil, while 5-methylcytosine remains unchanged.
-
Reverse Transcription and PCR: The bisulfite-converted RNA is reverse transcribed into cDNA, and the region of interest is amplified by PCR.
-
Sequencing: The PCR products are sequenced.
-
Data Analysis: By comparing the sequence of the treated RNA to the original sequence, cytosines that were not converted to uracil (and are read as cytosine in the sequence) are identified as methylated.
Aza-IP: Covalent Linkage and Immunoprecipitation of m5C Methyltransferases
This technique identifies the specific RNA targets of m5C writer enzymes.
Protocol:
-
5-Azacytidine Treatment: Cells are treated with 5-azacytidine, a cytidine analog that gets incorporated into newly synthesized RNA.
-
Covalent Crosslinking: When an m5C methyltransferase attempts to methylate the 5-azacytidine, a stable covalent bond is formed between the enzyme and the RNA.
-
Cell Lysis and Immunoprecipitation: Cells are lysed, and an antibody specific to the methyltransferase of interest (e.g., NSUN2) is used to immunoprecipitate the enzyme-RNA complexes.
-
RNA Isolation and Identification: The crosslinks are reversed, and the associated RNA is purified and identified through sequencing.
Visualizing the m5C Regulatory Pathway
The following diagrams, generated using the DOT language, illustrate key aspects of the 5-methylcytosine regulatory pathway and experimental workflows.
Caption: The m5C signaling pathway involves writer enzymes, reader proteins, and downstream effects.
Caption: Workflow for identifying m5C-modified RNAs using m5C-RIP-Seq.
Caption: Logical flow from m5C modification to altered protein expression.
Conclusion and Future Directions
The study of 5-methylcytosine has unveiled a sophisticated layer of post-transcriptional gene regulation with profound implications for cellular function and disease. The established roles of m5C writers like NSUN2 and readers such as YBX1 in modulating mRNA stability and translation provide a solid framework for further investigation and potential therapeutic targeting.
In contrast, the biological significance of this compound in natural systems remains largely uncharted territory. Future research is needed to determine if m1C has endogenous roles, to identify the machinery that may regulate it, and to explore its potential impact on biological processes. A deeper understanding of both m1C and m5C will undoubtedly provide a more complete picture of how cytosine methylation contributes to the complexity of gene regulation.
References
Distinguishing the Functional Roles of 1-Methylcytosine in the Nucleus and Cytoplasm: A Comparative Guide
For Researchers, Scientists, and Drug Development Professionals
This guide provides a comprehensive comparison of the functional roles of 1-methylcytosine (m1C) in the nuclear and cytoplasmic compartments of eukaryotic cells. It delves into the distinct enzymatic machinery, molecular pathways, and functional consequences of this critical RNA modification, supported by experimental data and detailed methodologies.
Overview of this compound (m1C)
This compound (m1C) is a post-transcriptional RNA modification where a methyl group is added to the N1 position of the cytosine base. While less studied than its isomer 5-methylcytosine (m5C), emerging evidence highlights its crucial roles in regulating RNA stability, translation, and other fundamental cellular processes. The subcellular localization of m1C and its associated regulatory proteins are key determinants of its diverse functions.
Comparative Analysis of m1C in the Nucleus and Cytoplasm
The functional dichotomy of m1C between the nucleus and cytoplasm is governed by the localization of its "writer" and "eraser" enzymes, the nature of its RNA substrates, and its interaction with "reader" proteins that decipher the modification into a functional output.
Data Presentation: Quantitative Comparison
| Feature | Nucleus | Cytoplasm |
| Primary RNA Substrates | Pre-mRNA, snRNA (potential) | tRNA, mRNA, tRNA-derived fragments (tRFs) |
| Key "Writer" Enzymes | TRMT6 (part of TRMT6/TRMT61A complex) | TRMT6/TRMT61A complex |
| Key "Eraser" Enzymes | ALKBH3, FTO | ALKBH1, ALKBH3, FTO |
| Known "Reader" Proteins | Largely unknown | YTHDF domain-containing proteins (potential) |
| Primary Functional Roles | Potential role in pre-mRNA processing | Regulation of tRNA stability, mRNA translation, gene silencing by tRFs |
Functional Roles of m1C in the Nucleus
The functions of m1C in the nucleus are still being elucidated. The primary m1C writer for tRNA, the TRMT6/TRMT61A complex, has a subunit (TRMT6) that is strictly localized to the nucleus. This suggests a potential role for nuclear m1C modification, possibly on RNA species other than mature tRNA, or in the early stages of tRNA biogenesis.
-
Potential Role in pre-mRNA Processing : The presence of m1C writers and erasers in the nucleus suggests a possible role in modulating pre-mRNA splicing and other processing events[1][2]. However, direct evidence for m1C-dependent regulation of these processes is currently limited.
Signaling Pathway and Experimental Workflow
The following diagram illustrates the hypothetical nuclear metabolism of m1C.
Functional Roles of m1C in the Cytoplasm
The cytoplasmic functions of m1C are better characterized, primarily revolving around the regulation of translation.
-
tRNA Stability and Function : The most well-established role of cytoplasmic m1C is the modification of tRNA at position 58 (m1A58) by the TRMT6/TRMT61A complex[3]. This modification is crucial for the structural integrity and stability of tRNA[4]. Demethylation of m1A58 by the eraser ALKBH1 can lead to tRNA cleavage and subsequent inhibition of protein synthesis.
-
Regulation of mRNA Translation : m1C modification within mRNA, particularly in the 5' untranslated region (5' UTR), has been shown to influence translation efficiency. The eraser ALKBH3 can demethylate m1C in mRNA, thereby modulating protein production.
-
Gene Silencing by tRNA-Derived Fragments (tRFs) : Recent studies have shown that m1C modification on tRFs, which are small non-coding RNAs derived from tRNAs, can regulate their gene-silencing activity.
Signaling Pathway and Experimental Workflow
The diagram below illustrates the established role of m1C in cytoplasmic tRNA metabolism and its impact on translation.
Experimental Protocols
Protocol 1: Subcellular RNA Fractionation and Sequencing (subRNA-seq)
This protocol allows for the isolation and sequencing of RNA from nuclear and cytoplasmic fractions to determine the subcellular localization of m1C-modified transcripts.
Materials:
-
Cell culture reagents
-
Phosphate-buffered saline (PBS)
-
Cytoplasmic Lysis Buffer (e.g., 10 mM Tris-HCl pH 7.4, 150 mM NaCl, 0.15% NP-40, RNase inhibitors)
-
Sucrose Buffer (e.g., 0.25 M sucrose, 10 mM MgCl2)
-
Nuclei Wash Buffer (e.g., 0.5% BSA in PBS, RNase inhibitors)
-
RNA extraction kit (e.g., TRIzol or column-based kits)
-
DNase I
-
Next-generation sequencing library preparation kit
Procedure:
-
Cell Harvest: Harvest approximately 10^7 cells by centrifugation. Wash the cell pellet with ice-cold PBS.
-
Cytoplasmic Lysis: Resuspend the cell pellet in 200 µL of ice-cold Cytoplasmic Lysis Buffer. Incubate on ice for 5 minutes.
-
Separation of Nuclei: Layer the lysate over 500 µL of Sucrose Buffer in a microcentrifuge tube. Centrifuge at 16,000 x g for 10 minutes at 4°C.
-
Cytoplasmic RNA Isolation: Carefully collect the supernatant, which contains the cytoplasmic fraction. Proceed with RNA extraction using a standard protocol.
-
Nuclear RNA Isolation: Wash the nuclear pellet with 800 µL of Nuclei Wash Buffer and centrifuge at 1,150 x g for 1 minute at 4°C. Discard the supernatant. Resuspend the nuclei in an appropriate buffer for RNA extraction.
-
RNA Purification and DNase Treatment: Purify RNA from both fractions. Perform an on-column or in-solution DNase I digestion to remove any contaminating genomic DNA.
-
Library Preparation and Sequencing: Prepare sequencing libraries from the nuclear and cytoplasmic RNA. Perform high-throughput sequencing.
-
Data Analysis: Align reads to the reference genome. Analysis of m1C can be performed using specialized bioinformatic tools that detect the reverse transcription stops or mutations characteristic of m1C.
Protocol 2: m1C RNA Immunoprecipitation followed by Sequencing (m1C-RIP-seq)
This protocol enables the identification of m1C-containing RNA transcripts by immunoprecipitating them with an m1C-specific antibody.
Materials:
-
m1C-specific antibody
-
Protein A/G magnetic beads
-
RIP Buffer (e.g., 150 mM KCl, 25 mM Tris-HCl pH 7.4, 5 mM EDTA, 0.5 mM DTT, 0.5% NP-40, RNase inhibitors, protease inhibitors)
-
High-salt wash buffer (e.g., RIP buffer with 500 mM KCl)
-
Low-salt wash buffer (e.g., RIP buffer with 50 mM KCl)
-
RNA extraction reagents
-
Sequencing library preparation kit
Procedure:
-
Cell Lysis: Lyse cells in RIP Buffer.
-
Immunoprecipitation: Incubate the cell lysate with an m1C-specific antibody overnight at 4°C. Add protein A/G magnetic beads and incubate for another 2-4 hours.
-
Washing: Wash the beads sequentially with RIP buffer, low-salt wash buffer, and high-salt wash buffer to remove non-specific binding.
-
RNA Elution and Purification: Elute the RNA from the beads using an appropriate elution buffer and purify it using a standard RNA extraction method.
-
Library Preparation and Sequencing: Construct a sequencing library from the immunoprecipitated RNA and perform high-throughput sequencing.
-
Data Analysis: Analyze the sequencing data to identify enriched peaks, which represent m1C-modified regions of the transcriptome.
Conclusion
The functional roles of this compound are intricately linked to its subcellular location. In the cytoplasm, m1C is a key regulator of tRNA stability and translation, with a well-defined enzymatic machinery. The nuclear functions of m1C are less understood but represent an exciting area of future research, with potential implications for pre-mRNA processing and gene expression regulation. The experimental protocols provided in this guide offer a framework for researchers to further investigate the distinct roles of m1C in the nucleus and cytoplasm, ultimately contributing to a more complete understanding of the epitranscriptome and its impact on cellular function and disease.
References
- 1. How to Prepare a Library for RIP-Seq: A Comprehensive Guide - CD Genomics [cd-genomics.com]
- 2. Global analysis by LC-MS/MS of N6-methyladenosine and inosine in mRNA reveal complex incidence - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Subcellular distribution, localization, and function of noncoding RNAs - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. fmboisvert.recherche.usherbrooke.ca [fmboisvert.recherche.usherbrooke.ca]
1-Methylcytosine as a Drug Target: A Comparative Guide to an Uncharted Epigenetic Landscape
An objective comparison of the validation status of 1-methylcytosine (m1C) against the established epigenetic drug target, 5-methylcytosine (5mC), for researchers, scientists, and drug development professionals.
The field of epigenetics has ushered in a new era of therapeutic innovation, with interventions targeting the enzymes that modify DNA and histones gaining significant traction in oncology and beyond. Among these, the methylation of cytosine is a key regulatory mechanism. While 5-methylcytosine (5mC) is an extensively studied epigenetic mark and a validated drug target, this compound (m1C) remains an enigmatic modification with a largely unexplored therapeutic potential. This guide provides a comparative analysis of the validation of m1C as a drug target, juxtaposed with the well-established landscape of 5mC-targeting therapies.
The Established Precedent: 5-Methylcytosine as a Drug Target
5-methylcytosine is the most common covalent modification of DNA in humans and plays a critical role in regulating gene expression.[1][2] The addition of a methyl group to the 5th carbon of cytosine, primarily within CpG dinucleotides, is a fundamental epigenetic mechanism for gene silencing.[1] Alterations in 5mC patterns are a hallmark of many diseases, particularly cancer, where hypermethylation of tumor suppressor gene promoters leads to their silencing and contributes to tumorigenesis.[3][4]
The enzymatic machinery responsible for writing, reading, and erasing the 5mC mark is well-characterized, providing concrete targets for therapeutic intervention. DNA methyltransferases (DNMTs) are the "writers" that establish and maintain 5mC patterns, while the Ten-Eleven Translocation (TET) family of enzymes act as "erasers" by oxidizing 5mC to 5-hydroxymethylcytosine (5hmC) and other intermediates, initiating a demethylation pathway.
The validation of 5mC as a drug target is underscored by the clinical success of DNMT inhibitors. These drugs, such as azacitidine and decitabine, are nucleoside analogs that become incorporated into DNA and trap DNMTs, leading to their degradation and a reduction in DNA methylation. This can lead to the re-expression of silenced tumor suppressor genes.
This compound: An Unexplored Frontier
In stark contrast to 5mC, this compound (m1C) is a structural isomer where the methyl group is attached to the nitrogen atom at position 1 of the cytosine ring. While chemically defined, its biological role in mammalian cells is virtually unknown. Current knowledge of m1C is largely confined to its use in synthetic biological systems, such as "hachimoji DNA," an eight-letter genetic alphabet where it pairs with isoguanine.
Crucially, there is a lack of evidence for the natural, regulated occurrence of m1C in mammalian DNA or RNA. The specific enzymes that would act as "writers" or "erasers" for m1C have not been identified. Consequently, a direct link between m1C and any disease state in humans has not been established. This absence of fundamental biological understanding means that this compound is not currently a validated drug target.
Comparative Validation Status: this compound vs. 5-Methylcytosine
The following table summarizes the stark differences in the validation status of m1C and 5mC as drug targets.
| Feature | This compound (m1C) | 5-Methylcytosine (5mC) |
| Natural Occurrence in Mammals | Not definitively observed in a regulated manner. | Abundant and well-characterized epigenetic mark on DNA. |
| "Writer" Enzymes | Unknown in mammals. | DNA Methyltransferases (DNMT1, DNMT3A, DNMT3B). |
| "Eraser" Enzymes | Unknown in mammals. | Ten-Eleven Translocation (TET1, TET2, TET3) enzymes initiate oxidation. |
| Role in Disease | No established link to human disease. | Aberrant methylation is a known driver in cancer and other diseases. |
| Available Inhibitors | None developed for therapeutic use. | DNMT inhibitors (e.g., Azacitidine, Decitabine) are FDA-approved. |
| Clinical Validation | None. | Clinically validated target in hematological malignancies. |
Signaling Pathways and Experimental Workflows
The diagrams below illustrate the well-defined 5-methylcytosine pathway and a hypothetical workflow for the initial validation of this compound as a potential drug target.
Experimental Protocols for Validation
To elevate this compound from a chemical curiosity to a validated drug target, a series of foundational experiments are required. The methodologies would need to be adapted from those successfully used to elucidate the 5mC pathway.
Detection and Quantification of this compound
-
Methodology: Liquid Chromatography with tandem Mass Spectrometry (LC-MS/MS). This is the gold standard for detecting and quantifying modified nucleosides.
-
Protocol Outline:
-
Genomic DNA or total RNA is extracted from mammalian cells or tissues.
-
The nucleic acids are enzymatically hydrolyzed to individual nucleosides.
-
The resulting nucleoside mixture is separated by high-performance liquid chromatography (HPLC).
-
The eluate is introduced into a tandem mass spectrometer.
-
The mass spectrometer is set to detect the specific mass-to-charge ratio of 1-methyl-2'-deoxycytidine (from DNA) or 1-methylcytidine (from RNA) and its fragmentation pattern, allowing for precise identification and quantification against a standard curve.
-
Identification of m1C-Modifying Enzymes
-
Methodology: In vitro enzymatic assays coupled with proteomics.
-
Protocol Outline:
-
A synthetic DNA or RNA oligonucleotide substrate containing unmodified cytosine is prepared.
-
The substrate is incubated with nuclear or cytoplasmic protein extracts from mammalian cells in the presence of the methyl donor S-adenosylmethionine (SAM).
-
The formation of m1C on the substrate is monitored by LC-MS/MS.
-
If methyltransferase activity is detected, the protein extract is subjected to biochemical fractionation (e.g., column chromatography) to purify the active enzyme(s).
-
The purified protein bands are identified using mass spectrometry-based proteomics.
-
For demethylases, a similar approach would be used with an m1C-containing substrate, looking for its conversion back to cytosine.
-
Cellular Assays for Target Validation
-
Methodology: CRISPR-Cas9-mediated knockout or siRNA-mediated knockdown of candidate enzymes.
-
Protocol Outline:
-
Once a candidate "writer" or "eraser" enzyme is identified, its gene is targeted for knockout using CRISPR-Cas9 or knockdown using siRNA in a relevant cell line.
-
The global levels of m1C in these modified cells are measured by LC-MS/MS to confirm the enzyme's activity on m1C.
-
Phenotypic assays are performed to determine the effect of m1C dysregulation on cell proliferation, apoptosis, and other cancer-related phenotypes.
-
Conclusion
The validation of 5-methylcytosine as a drug target provides a clear roadmap for what is required to bring a novel epigenetic modification into the therapeutic arena. At present, this compound is at the very beginning of this journey. While it represents an intriguing possibility for a novel epigenetic signaling pathway, fundamental questions about its existence, regulation, and function in mammals remain unanswered. For researchers and drug developers, this compound is a high-risk, high-reward area of investigation. The successful identification of its regulatory machinery and a link to disease could unlock an entirely new class of epigenetic drug targets. Until then, it remains a compelling but unvalidated concept in the shadow of its well-established 5-methyl counterpart.
References
Safety Operating Guide
Personal protective equipment for handling 1-Methylcytosine
For Researchers, Scientists, and Drug Development Professionals
This guide provides immediate and essential safety protocols, operational procedures, and disposal plans for handling 1-Methylcytosine in a laboratory setting. Adherence to these guidelines is critical for ensuring personnel safety and regulatory compliance.
Hazard Assessment and Personal Protective Equipment (PPE)
This compound is classified with the following hazards:
-
H302: Harmful if swallowed
-
H315: Causes skin irritation
-
H319: Causes serious eye irritation
-
H335: May cause respiratory irritation
Due to these potential hazards, the use of appropriate Personal Protective Equipment (PPE) is mandatory to minimize exposure.
| Protection Type | Specific Recommendations | Rationale |
| Eye and Face Protection | Chemical safety goggles. A face shield should be worn in situations with a high risk of splashing. | To protect against eye irritation from dust particles or splashes.[1] |
| Hand Protection | Chemical-resistant nitrile gloves. Regularly inspect gloves for any signs of degradation or puncture. | To prevent skin contact and irritation.[1] For incidental contact, nitrile gloves are appropriate; however, they should be changed immediately upon contamination. |
| Body Protection | A lab coat worn over long pants and closed-toe shoes. | To protect skin from accidental spills and splashes. |
| Respiratory Protection | Work in a well-ventilated area, preferably within a certified chemical fume hood, especially when handling the powder form. | To minimize the inhalation of potentially harmful dust particles that can cause respiratory irritation.[1] |
Operational Plan: Step-by-Step Handling Procedure
A systematic approach to handling this compound is crucial for minimizing risks. The following workflow outlines the key steps from receiving the compound to its final disposal.
Figure 1: Safe Handling Workflow for this compound
Experimental Protocol for Safe Handling:
-
Preparation:
-
Before handling, ensure all required PPE is readily available and in good condition.
-
Prepare the designated work area, preferably within a chemical fume hood, by laying down absorbent bench paper.
-
Assemble all necessary equipment (e.g., spatula, weigh boat, vials, solvents).
-
-
Weighing and Handling:
-
To minimize dust generation, avoid pouring the powdered this compound. Use a spatula to carefully transfer the desired amount.
-
If preparing a solution, add the solvent to the pre-weighed solid slowly to prevent splashing.
-
Keep containers of this compound closed when not in use.
-
-
Post-Experiment:
-
Decontaminate all non-disposable equipment that has come into contact with this compound using an appropriate solvent.
-
Carefully clean the work surface.
-
Emergency Procedures: Spill Management
In the event of a spill, prompt and appropriate action is required to contain the hazard.
| Spill Scenario | Containment and Cleanup Procedure |
| Small Powder Spill | 1. Alert personnel in the immediate area. 2. Wearing appropriate PPE, gently cover the spill with a damp paper towel to avoid raising dust. 3. Carefully scoop the material into a designated hazardous waste container. 4. Clean the spill area with a suitable solvent (e.g., 70% ethanol) followed by soap and water. 5. Collect all cleanup materials as hazardous waste. |
| Small Liquid Spill | 1. Alert personnel in the immediate area. 2. Wearing appropriate PPE, cover the spill with an inert absorbent material (e.g., vermiculite or sand). 3. Once absorbed, scoop the material into a designated hazardous waste container. 4. Clean the spill area with a suitable solvent followed by soap and water. 5. Collect all cleanup materials as hazardous waste. |
| Large Spill | 1. Evacuate the immediate area. 2. Alert your institution's Environmental Health and Safety (EHS) department and follow their emergency procedures. 3. Do not attempt to clean up a large spill without proper training and equipment. |
Disposal Plan
Proper disposal of this compound and contaminated materials is essential to prevent environmental contamination and ensure regulatory compliance.
Disposal Protocol:
-
Waste Segregation: All waste containing this compound, including unused product, reaction byproducts, and contaminated materials (e.g., gloves, absorbent pads, weigh boats), must be collected in a designated, properly labeled hazardous waste container.
-
Container Management: Use chemically resistant containers that are compatible with the waste. Keep waste containers securely closed, except when adding waste.
-
Labeling: Clearly label the waste container with "Hazardous Waste" and the full chemical name: "this compound."
-
Disposal: Arrange for the disposal of the hazardous waste through your institution's EHS office. Do not dispose of this compound down the drain or in the regular trash. Based on guidelines for similar non-hazardous nucleobases, trace amounts on disposables may be permissible for regular lab trash if not grossly contaminated; however, it is best practice to treat all chemically contaminated waste as hazardous.[2][3]
By adhering to these safety and logistical guidelines, researchers can minimize the risks associated with handling this compound and maintain a safe laboratory environment.
References
Retrosynthesis Analysis
AI-Powered Synthesis Planning: Our tool employs the Template_relevance Pistachio, Template_relevance Bkms_metabolic, Template_relevance Pistachio_ringbreaker, Template_relevance Reaxys, Template_relevance Reaxys_biocatalysis model, leveraging a vast database of chemical reactions to predict feasible synthetic routes.
One-Step Synthesis Focus: Specifically designed for one-step synthesis, it provides concise and direct routes for your target compounds, streamlining the synthesis process.
Accurate Predictions: Utilizing the extensive PISTACHIO, BKMS_METABOLIC, PISTACHIO_RINGBREAKER, REAXYS, REAXYS_BIOCATALYSIS database, our tool offers high-accuracy predictions, reflecting the latest in chemical research and data.
Strategy Settings
| Precursor scoring | Relevance Heuristic |
|---|---|
| Min. plausibility | 0.01 |
| Model | Template_relevance |
| Template Set | Pistachio/Bkms_metabolic/Pistachio_ringbreaker/Reaxys/Reaxys_biocatalysis |
| Top-N result to add to graph | 6 |
Feasible Synthetic Routes




Featured Recommendations
| Most viewed |
|
|
|---|---|---|
| Most popular with customers |
|
Descargo de responsabilidad e información sobre productos de investigación in vitro
Tenga en cuenta que todos los artículos e información de productos presentados en BenchChem están destinados únicamente con fines informativos. Los productos disponibles para la compra en BenchChem están diseñados específicamente para estudios in vitro, que se realizan fuera de organismos vivos. Los estudios in vitro, derivados del término latino "in vidrio", involucran experimentos realizados en entornos de laboratorio controlados utilizando células o tejidos. Es importante tener en cuenta que estos productos no se clasifican como medicamentos y no han recibido la aprobación de la FDA para la prevención, tratamiento o cura de ninguna condición médica, dolencia o enfermedad. Debemos enfatizar que cualquier forma de introducción corporal de estos productos en humanos o animales está estrictamente prohibida por ley. Es esencial adherirse a estas pautas para garantizar el cumplimiento de los estándares legales y éticos en la investigación y experimentación.
