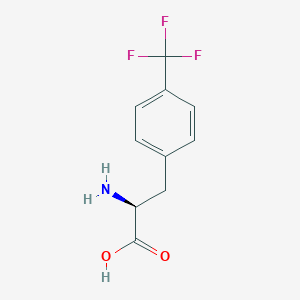
4-(Trifluoromethyl)-L-phenylalanine
Descripción
Structure
3D Structure
Propiedades
IUPAC Name |
(2S)-2-amino-3-[4-(trifluoromethyl)phenyl]propanoic acid |
Source


|
|---|---|---|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
InChI |
InChI=1S/C10H10F3NO2/c11-10(12,13)7-3-1-6(2-4-7)5-8(14)9(15)16/h1-4,8H,5,14H2,(H,15,16)/t8-/m0/s1 |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
InChI Key |
CRFFPDBJLGAGQL-QMMMGPOBSA-N |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Canonical SMILES |
C1=CC(=CC=C1CC(C(=O)O)N)C(F)(F)F |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Isomeric SMILES |
C1=CC(=CC=C1C[C@@H](C(=O)O)N)C(F)(F)F |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Molecular Formula |
C10H10F3NO2 |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
DSSTOX Substance ID |
DTXSID801347041 |
Source
|
| Record name | 4-(Trifluoromethyl)-L-phenylalanine | |
| Source | EPA DSSTox | |
| URL | https://comptox.epa.gov/dashboard/DTXSID801347041 | |
| Description | DSSTox provides a high quality public chemistry resource for supporting improved predictive toxicology. | |
Molecular Weight |
233.19 g/mol |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
CAS No. |
114926-38-4 |
Source
|
| Record name | 4-(Trifluoromethyl)-L-phenylalanine | |
| Source | EPA DSSTox | |
| URL | https://comptox.epa.gov/dashboard/DTXSID801347041 | |
| Description | DSSTox provides a high quality public chemistry resource for supporting improved predictive toxicology. | |
| Record name | 4-(Trifluoromethyl)-L-phenylalanine | |
| Source | European Chemicals Agency (ECHA) | |
| URL | https://echa.europa.eu/information-on-chemicals | |
| Description | The European Chemicals Agency (ECHA) is an agency of the European Union which is the driving force among regulatory authorities in implementing the EU's groundbreaking chemicals legislation for the benefit of human health and the environment as well as for innovation and competitiveness. | |
| Explanation | Use of the information, documents and data from the ECHA website is subject to the terms and conditions of this Legal Notice, and subject to other binding limitations provided for under applicable law, the information, documents and data made available on the ECHA website may be reproduced, distributed and/or used, totally or in part, for non-commercial purposes provided that ECHA is acknowledged as the source: "Source: European Chemicals Agency, http://echa.europa.eu/". Such acknowledgement must be included in each copy of the material. ECHA permits and encourages organisations and individuals to create links to the ECHA website under the following cumulative conditions: Links can only be made to webpages that provide a link to the Legal Notice page. | |
Foundational & Exploratory
4-(Trifluoromethyl)-L-phenylalanine chemical properties
An In-depth Technical Guide to 4-(Trifluoromethyl)-L-phenylalanine
Introduction
This compound is a synthetic amino acid derivative of L-phenylalanine, characterized by the substitution of a hydrogen atom with a trifluoromethyl group at the para position of the phenyl ring. This modification imparts unique chemical and biological properties, making it a compound of significant interest in pharmaceutical research, peptide synthesis, and metabolic studies. The trifluoromethyl group enhances the compound's stability and reactivity, offering a valuable tool for developing novel therapeutics and biochemical probes.[1] This guide provides a comprehensive overview of the chemical properties, experimental protocols, and biological activities of this compound.
Chemical and Physical Properties
This compound is a white to off-white crystalline powder.[2][3] Key chemical and physical properties are summarized in the tables below.
Table 1: General Chemical Properties
| Property | Value | Reference |
| IUPAC Name | (2S)-2-amino-3-[4-(trifluoromethyl)phenyl]propanoic acid | [4] |
| Synonyms | (S)-2-Amino-3-[4-(trifluoromethyl)phenyl]propionic acid, L-4-TRIFLUOROMETHYLPHE, p-trifluoromethylphenylalanine | [4][5][6] |
| CAS Number | 114926-38-4 | [4][5] |
| Molecular Formula | C₁₀H₁₀F₃NO₂ | [4][5] |
| Molecular Weight | 233.19 g/mol | [4][5] |
| Purity | ≥98% | [5] |
Table 2: Physical and Spectroscopic Properties
| Property | Value | Reference |
| Physical Form | White to light-yellow powder or crystals | [3] |
| Solubility | No specific data available in the provided search results. | |
| Melting Point | No specific data available in the provided search results. | [2][7] |
| Storage Temperature | 2°C - 8°C | [8] |
| InChI Key | CRFFPDBJLGAGQL-QMMMGPOBSA-N | [3][4] |
| SMILES | C1=CC(=CC=C1C--INVALID-LINK--N)C(F)(F)F | [4] |
Experimental Protocols
Synthesis of this compound Derivatives
A common method for synthesizing phenylalanine derivatives is through a Negishi cross-coupling reaction. The following protocol is a general representation based on the synthesis of similar phenylalanine analogues.[9][10]
Workflow for the Synthesis of Phenylalanine Derivatives
Caption: General synthesis workflow for phenylalanine derivatives.
Methodology:
-
Esterification: The synthesis can begin with the esterification of a protected serine, such as Cbz-Ser-OH.[9]
-
Appel Iodination: The resulting ester undergoes an Appel iodination to produce the corresponding β-iodoalanine methyl ester.[9]
-
Negishi Cross-Coupling: A key step involves the Negishi cross-coupling of a prefunctionalized aryl bromide (in this case, a bromide with a trifluoromethyl group) with the β-iodoalanine derivative.[9][10]
-
Deprotection: The final step involves the removal of protecting groups to yield the desired this compound derivative.
Peptide Synthesis
This compound can be incorporated into peptide chains using standard solid-phase peptide synthesis (SPPS) or solution-phase methods.[11] The Fmoc (fluorenylmethoxycarbonyl) protecting group is commonly used for the selective protection of the amino group during synthesis.[12]
Biological Activity and Mechanism of Action
Acyltransferase Inhibition
This compound has been identified as an acyltransferase inhibitor.[8] It acts by preventing the formation of fatty acids through the inhibition of the ketoreductase enzyme.[8] This inhibitory action has been shown to induce a cytotoxic effect on cancer cells and inhibit protein synthesis in myeloid leukemia cells.[8] It also exhibits antibacterial activity against organisms such as Salmonella enterica and Mycobacterium tuberculosis.[8]
Inhibitory Action of this compound
Caption: Inhibition of fatty acid synthesis by 4-TFMP.
Neuroprotective Effects of a Derivative
A derivative, 4-Trifluoromethyl-(E)-cinnamoyl]-L-4-F-phenylalanine acid (AE-18), has demonstrated preventive and therapeutic effects in a model of focal cerebral ischemia-reperfusion injury.[13] Its mechanism of action involves the inhibition of excitotoxicity and the improvement of Blood-Brain Barrier (BBB) permeability, as well as enhancing the levels of Vascular Endothelial Growth Factor (VEGF) and Brain-Derived Neurotrophic Factor (BDNF).[13]
Signaling Pathway of a this compound Derivative
Caption: Neuroprotective mechanism of a derivative of this compound.
Safety and Handling
This compound is classified as an irritant.[4] It is known to cause skin irritation (H315), serious eye irritation (H319), and may cause respiratory irritation (H335).[1][4][14]
Table 3: Hazard Information
| Hazard Statement | Description | Reference |
| H315 | Causes skin irritation | [4][14] |
| H319 | Causes serious eye irritation | [4][14] |
| H335 | May cause respiratory irritation | [4][14] |
Handling Precautions:
-
Engineering Controls: Use in a well-ventilated area.[2][14] Emergency eye wash fountains and safety showers should be readily available.[14]
-
Personal Protective Equipment (PPE):
-
Hygiene Measures: Handle in accordance with good industrial hygiene and safety practices. Wash hands thoroughly after handling.[2][14]
First Aid Measures:
-
Inhalation: Remove the person to fresh air. Seek medical attention if breathing difficulties occur.[7][14]
-
Skin Contact: Wash the affected area with plenty of soap and water.[7][14]
-
Eye Contact: Rinse immediately with plenty of water for at least 15 minutes, including under the eyelids.[7][14]
-
Ingestion: Clean mouth with water and drink plenty of water afterward.[7]
References
- 1. 114926-38-4 Cas No. | this compound | Apollo [store.apolloscientific.co.uk]
- 2. peptide.com [peptide.com]
- 3. This compound | 114926-38-4 [sigmaaldrich.com]
- 4. This compound | C10H10F3NO2 | CID 2761501 - PubChem [pubchem.ncbi.nlm.nih.gov]
- 5. scbt.com [scbt.com]
- 6. chemwhat.com [chemwhat.com]
- 7. fishersci.com [fishersci.com]
- 8. This compound | 114926-38-4 | FT43466 [biosynth.com]
- 9. Synthesis and evaluation of phenylalanine-derived trifluoromethyl ketones for peptide-based oxidation catalysis - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Synthesis and evaluation of phenylalanine-derived trifluoromethyl ketones for peptide-based oxidation catalysis - PubMed [pubmed.ncbi.nlm.nih.gov]
- 11. 4-(Trifluoromethyl)- D -phenylalanine = 98.5 HPLC 114872-99-0 [sigmaaldrich.com]
- 12. chemimpex.com [chemimpex.com]
- 13. 4-Trifluoromethyl-(E)-cinnamoyl]-L-4-F-phenylalanine acid exerts its effects on the prevention, post-therapeutic and prolongation of the thrombolytic window in ischemia-reperfusion rats through multiple mechanisms of action - PubMed [pubmed.ncbi.nlm.nih.gov]
- 14. synquestlabs.com [synquestlabs.com]
An In-depth Technical Guide to the Synthesis of 4-(Trifluoromethyl)-L-phenylalanine
For Researchers, Scientists, and Drug Development Professionals
This technical guide provides a comprehensive overview of the primary synthetic methodologies for obtaining 4-(Trifluoromethyl)-L-phenylalanine, a non-canonical amino acid of significant interest in pharmaceutical and medicinal chemistry. The introduction of a trifluoromethyl group at the para-position of the phenyl ring imparts unique electronic properties, enhancing metabolic stability and bioavailability of peptides and small molecule drugs. This document details key synthetic strategies, including asymmetric alkylation via phase-transfer catalysis, asymmetric hydrogenation, Negishi cross-coupling, and enzymatic synthesis, complete with experimental protocols and comparative data.
Core Synthetic Strategies
The enantioselective synthesis of this compound can be achieved through several distinct and effective routes. The choice of method often depends on factors such as desired scale, available starting materials, and required enantiopurity. Below is a summary of the most prominent synthetic approaches.
| Synthesis Method | Key Features | Typical Yield (%) | Enantiomeric Excess (ee%) |
| Asymmetric Alkylation (Phase-Transfer Catalysis) | Utilizes a chiral phase-transfer catalyst to direct the stereoselective alkylation of a glycine (B1666218) enolate equivalent with 4-(trifluoromethyl)benzyl bromide. | 60-85 | >90 |
| Asymmetric Hydrogenation | Employs a chiral transition metal catalyst (e.g., Rhodium or Ruthenium-based) for the enantioselective reduction of a prochiral α,β-unsaturated precursor. | 70-95 | >95 |
| Negishi Cross-Coupling | Involves the palladium-catalyzed coupling of a 4-(trifluoromethyl)phenylzinc reagent with an electrophilic chiral amino acid synthon, such as a β-iodoalanine derivative. | 65-80 | >98 |
| Enzymatic Synthesis | Leverages the high stereoselectivity of enzymes, such as Phenylalanine Ammonia (B1221849) Lyase (PAL), for the amination of 4-(trifluoromethyl)cinnamic acid. | 50-90 (conversion) | >99 |
I. Asymmetric Alkylation via Phase-Transfer Catalysis
This widely used method, often referred to as the O'Donnell asymmetric amino acid synthesis, relies on the alkylation of a Schiff base of a glycine ester under biphasic conditions, facilitated by a chiral phase-transfer catalyst. Cinchona alkaloid-derived catalysts are commonly employed to induce high enantioselectivity.
Experimental Protocol:
Step 1: Synthesis of the Glycine Schiff Base
A mixture of glycine tert-butyl ester hydrochloride (1 equivalent), benzophenone (B1666685) imine (1.1 equivalents), and a non-polar solvent such as dichloromethane (B109758) is stirred at room temperature. A mild base, for instance, triethylamine (B128534) (1.2 equivalents), is added, and the reaction is monitored by TLC until completion. The resulting N-(diphenylmethylene)glycine tert-butyl ester is isolated after a standard aqueous workup and purification by chromatography.
Step 2: Asymmetric Alkylation
To a solution of the N-(diphenylmethylene)glycine tert-butyl ester (1 equivalent) and 4-(trifluoromethyl)benzyl bromide (1.2 equivalents) in a toluene/dichloromethane solvent mixture is added a chiral phase-transfer catalyst, such as O-allyl-N-(9-anthracenylmethyl)cinchonidinium bromide (1-2 mol%). A 50% aqueous solution of potassium hydroxide (B78521) is added, and the biphasic mixture is stirred vigorously at room temperature. The reaction progress is monitored by HPLC.
Step 3: Hydrolysis and Deprotection
Upon completion, the organic layer is separated, and the Schiff base is hydrolyzed by treatment with aqueous citric acid or hydrochloric acid. The resulting protected amino acid is then deprotected (e.g., removal of the tert-butyl ester with trifluoroacetic acid) to yield this compound.
Asymmetric Alkylation Workflow
II. Asymmetric Hydrogenation
This elegant approach involves the enantioselective reduction of a prochiral enamide precursor, typically (Z)-2-acetamido-3-(4-(trifluoromethyl)phenyl)acrylic acid, using a chiral transition metal catalyst. Rhodium and Ruthenium complexes with chiral phosphine (B1218219) ligands are prominent in this field.
Experimental Protocol:
Step 1: Synthesis of the Prochiral Precursor
(Z)-2-acetamido-3-(4-(trifluoromethyl)phenyl)acrylic acid can be synthesized via the Erlenmeyer-Azlactone synthesis. 4-(Trifluoromethyl)benzaldehyde is condensed with N-acetylglycine in the presence of acetic anhydride (B1165640) and sodium acetate. Subsequent hydrolysis of the azlactone intermediate yields the desired acrylic acid derivative.
Step 2: Asymmetric Hydrogenation
The acrylic acid derivative (1 equivalent) is dissolved in a degassed solvent such as methanol (B129727) or dichloromethane. A chiral rhodium catalyst, for example, [Rh(COD)(R,R-Et-DuPhos)]BF4 (0.5-1 mol%), is added under an inert atmosphere. The mixture is then subjected to hydrogen gas (typically 1-10 atm) at room temperature with stirring until the reaction is complete.
Step 3: Deprotection
The resulting N-acetyl-4-(trifluoromethyl)-L-phenylalanine is hydrolyzed using aqueous acid or an acylase enzyme to afford the final product.
Asymmetric Hydrogenation Workflow
III. Negishi Cross-Coupling
The Negishi cross-coupling provides a powerful method for carbon-carbon bond formation. In this context, it is used to couple an organozinc reagent derived from a 4-(trifluoromethyl)phenyl halide with a chiral electrophilic synthon of alanine.
Experimental Protocol:
Step 1: Preparation of the Organozinc Reagent
4-(Trifluoromethyl)phenyl bromide (1 equivalent) is reacted with activated zinc metal in a polar aprotic solvent like tetrahydrofuran (B95107) (THF) to form the corresponding organozinc reagent, 4-(trifluoromethyl)phenylzinc bromide.
Step 2: Negishi Cross-Coupling
To a solution of a protected β-iodo-L-alanine derivative, such as N-Boc-β-iodo-L-alanine methyl ester (1 equivalent), in THF is added a palladium catalyst, for example, Pd(PPh3)4 (2-5 mol%). The freshly prepared organozinc reagent is then added dropwise at room temperature. The reaction is stirred until completion as monitored by LC-MS.
Step 3: Deprotection
The resulting protected this compound is deprotected in a two-step process: saponification of the methyl ester followed by removal of the Boc protecting group with an acid like TFA.
Negishi Cross-Coupling Workflow
IV. Enzymatic Synthesis
Biocatalysis offers a highly selective and environmentally friendly route to chiral amino acids. Phenylalanine ammonia lyase (PAL) is an enzyme that catalyzes the reversible addition of ammonia to the double bond of cinnamic acids.
Experimental Protocol:
Step 1: Substrate Preparation
The starting material, 4-(trifluoromethyl)cinnamic acid, can be prepared via a Knoevenagel or Perkin condensation from 4-(trifluoromethyl)benzaldehyde.
Step 2: Enzymatic Amination
4-(Trifluoromethyl)cinnamic acid is dissolved in an aqueous buffer (e.g., ammonium (B1175870) carbonate or ammonium hydroxide) at a slightly alkaline pH (typically pH 8-10) to provide a high concentration of ammonia. The Phenylalanine Ammonia Lyase (PAL) enzyme, either as a purified protein or as a whole-cell biocatalyst, is added to the solution. The reaction is incubated with gentle agitation at a controlled temperature (e.g., 30-40 °C).
Step 3: Product Isolation
The reaction progress is monitored by HPLC for the formation of the desired amino acid. Once equilibrium is reached or the desired conversion is achieved, the enzyme is removed (e.g., by filtration if immobilized or centrifugation for whole cells). The product is then isolated from the aqueous solution by techniques such as ion-exchange chromatography.
Enzymatic Synthesis Workflow
The Biological Activity of 4-(Trifluoromethyl)-L-phenylalanine: A Technical Guide
For Researchers, Scientists, and Drug Development Professionals
Abstract
4-(Trifluoromethyl)-L-phenylalanine is a synthetic amino acid derivative that has garnered interest in the scientific community for its potential biological activities, primarily as an inhibitor of key enzymes in neurotransmitter biosynthesis. This technical guide provides a comprehensive overview of the known biological effects of this compound, with a focus on its mechanism of action, its impact on signaling pathways, and its potential therapeutic applications. This document summarizes available quantitative data, details relevant experimental protocols, and provides visualizations of key biological pathways and experimental workflows to facilitate a deeper understanding of this compound's properties.
Introduction
This compound is a structural analog of the essential amino acid L-phenylalanine, distinguished by the substitution of a hydrogen atom with a trifluoromethyl group at the para position of the phenyl ring.[1] This modification significantly alters the electronic properties of the aromatic ring, influencing its interactions with biological targets. The primary area of investigation for this compound has been its role as an inhibitor of aromatic amino acid hydroxylases, a family of enzymes crucial for the synthesis of key neurotransmitters.
Physicochemical Properties
A summary of the key physicochemical properties of this compound is presented in Table 1.
Table 1: Physicochemical Properties of this compound [1]
| Property | Value |
| Molecular Formula | C₁₀H₁₀F₃NO₂ |
| Molecular Weight | 233.19 g/mol |
| CAS Number | 114926-38-4 |
| Appearance | White to off-white powder |
| Solubility | Soluble in aqueous solutions |
Biological Activity and Mechanism of Action
The primary biological activity of this compound identified to date is its inhibitory effect on tryptophan hydroxylase (TPH), the rate-limiting enzyme in the biosynthesis of serotonin (B10506) (5-hydroxytryptamine, 5-HT).[2][3]
Inhibition of Tryptophan Hydroxylase (TPH)
TPH catalyzes the conversion of L-tryptophan to 5-hydroxytryptophan (B29612) (5-HTP), the precursor to serotonin.[4] Phenylalanine analogs, including this compound, are known to act as competitive inhibitors of TPH.[5] They compete with the natural substrate, L-tryptophan, for binding to the active site of the enzyme, thereby reducing the rate of serotonin synthesis.[5]
The proposed mechanism of competitive inhibition is illustrated in the following diagram:
Impact on Serotonin Signaling Pathway
By inhibiting TPH, this compound directly impacts the serotonin synthesis pathway, leading to a reduction in the production of serotonin. This has downstream effects on all serotonin-mediated signaling.
Selectivity Profile: TPH vs. PAH
A critical aspect of any enzyme inhibitor is its selectivity. This compound is an analog of L-phenylalanine, the natural substrate for phenylalanine hydroxylase (PAH), the enzyme deficient in phenylketonuria (PKU).[4] Therefore, it is important to consider its potential inhibitory activity against PAH.
While direct comparative studies on the selectivity of this compound for TPH over PAH are not available, studies on similar compounds like p-ethynylphenylalanine have shown high selectivity for TPH with no significant inhibition of PAH.[2][3] This suggests that this compound may also exhibit selectivity for TPH. The structural differences between the active sites of TPH and PAH likely contribute to this selectivity.
Potential Therapeutic Applications
The ability of this compound to inhibit serotonin synthesis suggests potential therapeutic applications in conditions characterized by excessive serotonin production.
Carcinoid Syndrome
Carcinoid syndrome is a paraneoplastic syndrome associated with neuroendocrine tumors that overproduce serotonin, leading to symptoms such as diarrhea and flushing. TPH inhibitors are a therapeutic strategy for managing this condition.[6]
Phenylketonuria (PKU)
In PKU, elevated levels of phenylalanine can competitively inhibit TPH, leading to a deficiency in brain serotonin.[7][8] While this compound is a phenylalanine analog, its primary described role is as a TPH inhibitor. Its potential use in PKU is complex and would require further investigation to understand its effects on both PAH and TPH in the context of this disease.
Experimental Protocols
This section provides detailed methodologies for key experiments relevant to the study of this compound.
Synthesis of this compound
While a specific, detailed protocol for the enantioselective synthesis of this compound is not available in a single source, a plausible route can be constructed based on established methods for the synthesis of fluorinated amino acids.[9][10] One such approach involves the asymmetric alkylation of a chiral glycine (B1666218) enolate equivalent.
Experimental Workflow:
Detailed Protocol (Hypothetical, based on similar syntheses):
-
Protection of Glycine: Start with a suitable chiral glycine equivalent, for example, a Schiff base derived from (S)-(-)-2-hydroxy-pinanone and glycine tert-butyl ester.
-
Deprotonation: Treat the protected glycine with a strong base, such as lithium diisopropylamide (LDA), at low temperature (-78 °C) to generate the chiral enolate.
-
Alkylation: Add 4-(trifluoromethyl)benzyl bromide to the enolate solution and allow the reaction to proceed to form the protected amino acid.
-
Deprotection: Hydrolyze the ester and the chiral auxiliary under acidic conditions to yield the final product, this compound.
-
Purification: Purify the final product by recrystallization or column chromatography.
Tryptophan Hydroxylase Inhibition Assay
This protocol is adapted from established methods for measuring TPH activity.[11]
Materials:
-
Recombinant human TPH1 or TPH2
-
L-tryptophan
-
This compound
-
Tetrahydrobiopterin (BH4) cofactor
-
Catalase
-
Ferrous ammonium (B1175870) sulfate
-
Assay buffer (e.g., 50 mM HEPES, pH 7.4)
-
HPLC system with fluorescence or electrochemical detection
Procedure:
-
Prepare a reaction mixture containing assay buffer, catalase, ferrous ammonium sulfate, and the TPH enzyme.
-
Add varying concentrations of this compound (the inhibitor) to the reaction mixture.
-
Pre-incubate the mixture for a defined period (e.g., 10 minutes) at 37°C.
-
Initiate the reaction by adding L-tryptophan and BH4.
-
Incubate the reaction for a specific time (e.g., 20 minutes) at 37°C.
-
Stop the reaction by adding a quenching solution (e.g., perchloric acid).
-
Centrifuge the samples to pellet precipitated protein.
-
Analyze the supernatant for the production of 5-HTP using HPLC.
-
Calculate the percent inhibition for each concentration of the inhibitor and determine the IC50 value. For Ki determination, perform the assay with varying concentrations of both the inhibitor and the substrate (L-tryptophan) and analyze the data using Michaelis-Menten and Lineweaver-Burk plots.
In Vivo Measurement of Serotonin and Metabolites
This protocol outlines a general procedure for assessing the in vivo effects of this compound on brain serotonin levels.[12][13]
Experimental Workflow:
Procedure:
-
Animal Dosing: Administer this compound to experimental animals (e.g., rats or mice) via a suitable route (e.g., intraperitoneal injection or oral gavage). Include a vehicle-treated control group.
-
Tissue Collection: At various time points after administration, euthanize the animals and rapidly dissect specific brain regions of interest (e.g., striatum, hippocampus, prefrontal cortex).
-
Sample Preparation: Homogenize the brain tissue in a suitable buffer (e.g., perchloric acid) to precipitate proteins and stabilize the analytes.
-
HPLC Analysis: Centrifuge the homogenates and analyze the supernatant for serotonin and its major metabolite, 5-hydroxyindoleacetic acid (5-HIAA), using an HPLC system equipped with a fluorescence or electrochemical detector.
-
Data Analysis: Quantify the concentrations of serotonin and 5-HIAA and compare the levels between the treated and control groups to determine the effect of the compound.
Conclusion
This compound is a promising research tool for studying the serotonergic system. Its likely mechanism of action as a competitive inhibitor of tryptophan hydroxylase makes it a valuable compound for investigating the role of serotonin synthesis in various physiological and pathological processes. While quantitative data on its inhibitory potency and selectivity are still needed, the available information on similar compounds suggests it is a potent and selective inhibitor. The experimental protocols provided in this guide offer a framework for further investigation into the biological activities of this intriguing molecule. Future research should focus on determining its precise kinetic parameters, evaluating its in vivo efficacy and safety, and exploring its full therapeutic potential.
References
- 1. m.youtube.com [m.youtube.com]
- 2. p-ethynylphenylalanine: a potent inhibitor of tryptophan hydroxylase - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. analyticalscience.wiley.com [analyticalscience.wiley.com]
- 4. Phenylalanine hydroxylase - Wikipedia [en.wikipedia.org]
- 5. Inhibition of phenylalanine hydroxylase by p-chlorophenylalanine; dependence on cofactor structure - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. Strategies for the Catalytic Enantioselective Synthesis of α-Trifluoromethyl Amines - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Synthesis and evaluation of phenylalanine-derived trifluoromethyl ketones for peptide-based oxidation catalysis - PMC [pmc.ncbi.nlm.nih.gov]
- 8. pubs.acs.org [pubs.acs.org]
- 9. Measuring serotonin synthesis: from conventional methods to PET tracers and their (pre)clinical implications - PMC [pmc.ncbi.nlm.nih.gov]
- 10. DOT Language | Graphviz [graphviz.org]
- 11. LIQUID CHROMATOGRAPHIC ASSAY FOR CEREBROSPINAL FLUID SEROTONIN - PMC [pmc.ncbi.nlm.nih.gov]
- 12. escholarship.org [escholarship.org]
- 13. Determination of Serotonin and Dopamine Metabolites in Human Brain Microdialysis and Cerebrospinal Fluid Samples by UPLC-MS/MS: Discovery of Intact Glucuronide and Sulfate Conjugates - PMC [pmc.ncbi.nlm.nih.gov]
An In-depth Technical Guide to 4-(Trifluoromethyl)-L-phenylalanine
For Researchers, Scientists, and Drug Development Professionals
Abstract
4-(Trifluoromethyl)-L-phenylalanine (4-CF3-Phe), a non-proteinogenic amino acid, has garnered significant attention within the scientific community for its unique biochemical properties and potential therapeutic applications. This technical guide provides a comprehensive overview of 4-CF3-Phe, encompassing its physicochemical characteristics, synthesis methodologies, and diverse biological activities. The incorporation of a trifluoromethyl group onto the phenyl ring of L-phenylalanine imparts distinct properties, including increased metabolic stability and altered electronic characteristics, making it a valuable tool in drug design and biomedical research. This document details its role as an acyltransferase inhibitor, its application in enhancing the antimicrobial potency of peptides, and its potential as a positron emission tomography (PET) imaging agent. Detailed experimental protocols and quantitative data are presented to facilitate further research and development efforts involving this compound.
Introduction
This compound is a synthetic derivative of the essential amino acid L-phenylalanine. The substitution of a hydrogen atom with a trifluoromethyl group at the para position of the phenyl ring significantly modifies its properties, leading to a range of biological effects. This modification enhances the lipophilicity and metabolic stability of molecules incorporating this amino acid, making it an attractive building block in medicinal chemistry. Its applications span from an inhibitor of fatty acid synthesis to a component of peptides with enhanced biological activity.[1] This guide aims to consolidate the current knowledge on 4-CF3-Phe, providing a technical resource for researchers in academia and the pharmaceutical industry.
Physicochemical Properties
A summary of the key physicochemical properties of this compound is presented in the table below. This data is essential for its handling, formulation, and application in various experimental settings.
| Property | Value | Reference |
| CAS Number | 114926-38-4 | [2][3] |
| Molecular Formula | C₁₀H₁₀F₃NO₂ | [2][4] |
| Molecular Weight | 233.19 g/mol | [2][4] |
| Appearance | White to off-white solid | [5] |
| Purity | ≥98% | [2] |
| Solubility | Slightly soluble in water | [1] |
| Storage | Store at 2°C - 8°C in a well-closed container. | [1] |
Synthesis Methodologies
The synthesis of this compound can be achieved through various organic chemistry routes. One prominent method involves a Negishi cross-coupling reaction, which is a powerful tool for forming carbon-carbon bonds.
General Synthesis Workflow via Negishi Cross-Coupling
A representative synthetic workflow for preparing phenylalanine derivatives, which can be adapted for this compound, is depicted below. This process typically involves the coupling of a pre-functionalized aryl bromide with a suitably protected β-iodoalanine derivative.[5]
Caption: General workflow for the synthesis of this compound.
Experimental Protocol: Negishi Cross-Coupling (Illustrative)
The following is an illustrative protocol based on similar syntheses of phenylalanine derivatives[5]:
-
Preparation of the Aryl Bromide: Start with a commercially available or synthesized 4-(trifluoromethyl)phenyl-containing precursor, such as 2-bromo-4-(trifluoromethyl)benzaldehyde.
-
Preparation of the Coupling Partner: A suitably protected β-iodoalanine derivative is prepared from a readily available starting material like serine.
-
Negishi Cross-Coupling Reaction:
-
In an inert atmosphere (e.g., under argon), dissolve the aryl bromide and the protected β-iodoalanine in a suitable anhydrous solvent (e.g., THF).
-
Add a palladium catalyst (e.g., Pd(PPh₃)₄) and a zinc reagent.
-
The reaction mixture is stirred at room temperature or heated as required, and monitored by TLC or LC-MS for completion.
-
-
Work-up and Purification:
-
Upon completion, the reaction is quenched, and the product is extracted with an organic solvent.
-
The organic layers are combined, dried, and concentrated.
-
The crude product is purified by column chromatography to yield the protected this compound.
-
-
Deprotection: The protecting groups are removed under appropriate conditions (e.g., acid or base hydrolysis) to yield the final product, this compound.
Biological Activity and Applications
This compound exhibits a range of biological activities, making it a compound of interest in drug discovery and chemical biology.
Acyltransferase Inhibition
This compound acts as an acyltransferase inhibitor.[1] By inhibiting this enzyme class, it can interfere with processes such as fatty acid synthesis. This mechanism of action suggests its potential for development as an antimicrobial or anticancer agent.
Antimicrobial Activity
Incorporation of this compound into peptide chains has been shown to enhance their antimicrobial activity.[1] The trifluoromethyl group can increase the peptide's stability and its ability to interact with and disrupt microbial membranes.
Anticancer Potential
Studies have indicated that 4-CF3-Phe can inhibit protein synthesis in myeloid leukemia cells and exhibits cytotoxic effects on various cancer cells.[1] This suggests its potential as a lead compound for the development of novel anticancer therapies.
PET Imaging
Fluorinated amino acids are valuable tracers for positron emission tomography (PET) imaging, particularly in oncology. While specific studies on this compound as a PET agent are emerging, related fluorinated phenylalanine analogs have shown promise for tumor imaging.[6] The presence of the fluorine-containing trifluoromethyl group makes it a candidate for labeling with fluorine-18 (B77423) (¹⁸F) for use in PET scans to visualize metabolic activity in tumors.
Experimental Protocols for Biological Assays
Cell Viability Assay (Illustrative)
To assess the cytotoxic effects of this compound on cancer cells, a standard MTT or similar cell viability assay can be performed.
-
Cell Culture: Plate cancer cells (e.g., myeloid leukemia cell line) in a 96-well plate and incubate overnight.
-
Treatment: Treat the cells with varying concentrations of this compound and incubate for a specified period (e.g., 24, 48, or 72 hours).
-
MTT Addition: Add MTT solution to each well and incubate to allow for the formation of formazan (B1609692) crystals.
-
Solubilization: Add a solubilizing agent (e.g., DMSO) to dissolve the formazan crystals.
-
Data Acquisition: Measure the absorbance at a specific wavelength using a microplate reader.
-
Analysis: Calculate the cell viability as a percentage of the control (untreated cells) and determine the IC₅₀ value.
Safety and Handling
This compound should be handled with appropriate safety precautions in a laboratory setting.
-
Hazard Identification: It is known to cause skin and serious eye irritation, and may cause respiratory irritation.[3][4]
-
Personal Protective Equipment (PPE): Wear protective gloves, clothing, and eye/face protection.[7]
-
Handling: Use in a well-ventilated area and avoid breathing dust.[7]
-
Storage: Store in a cool, dry, and well-ventilated place in a tightly sealed container.[1]
The logical workflow for investigating the biological activity of this compound is outlined below.
Caption: Workflow for the biological investigation of this compound.
Conclusion
This compound is a versatile and valuable compound for researchers in drug development and chemical biology. Its unique properties, conferred by the trifluoromethyl group, have led to its exploration in various therapeutic areas, including oncology and infectious diseases. This technical guide has provided a comprehensive overview of its synthesis, physicochemical properties, biological activities, and handling procedures. The detailed information and protocols presented herein are intended to serve as a valuable resource to stimulate and support further research into the potential of this promising molecule. As research continues, the full therapeutic and diagnostic potential of this compound is yet to be fully realized.
References
- 1. This compound | 114926-38-4 | FT43466 [biosynth.com]
- 2. medchemexpress.com [medchemexpress.com]
- 3. researchgate.net [researchgate.net]
- 4. This compound | C10H10F3NO2 | CID 2761501 - PubChem [pubchem.ncbi.nlm.nih.gov]
- 5. Synthesis and evaluation of phenylalanine-derived trifluoromethyl ketones for peptide-based oxidation catalysis - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Synthesis, uptake mechanism characterization and biological evaluation of (18)F labeled fluoroalkyl phenylalanine analogs as potential PET imaging agents - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. Fluorinated phenylalanines: synthesis and pharmaceutical applications - PMC [pmc.ncbi.nlm.nih.gov]
An In-depth Technical Guide to the Structure of 4-(Trifluoromethyl)-L-phenylalanine
For Researchers, Scientists, and Drug Development Professionals
Abstract
This technical guide provides a comprehensive overview of the structural and physicochemical properties of 4-(Trifluoromethyl)-L-phenylalanine, a non-proteinogenic amino acid of significant interest in medicinal chemistry and drug development. The introduction of the trifluoromethyl group onto the phenyl ring of L-phenylalanine imparts unique electronic and lipophilic characteristics, influencing its biological activity and making it a valuable building block for novel therapeutics. This document details its chemical structure, key physicochemical parameters, and provides a plausible experimental protocol for its asymmetric synthesis. Spectroscopic data for its characterization are also presented. Due to the current unavailability of a public crystal structure, theoretical structural parameters have been included to provide a quantitative understanding of its molecular geometry.
Chemical Structure and Identification
This compound is an analog of the essential amino acid L-phenylalanine, where a trifluoromethyl group is substituted at the para-position of the phenyl ring.
IUPAC Name: (2S)-2-amino-3-[4-(trifluoromethyl)phenyl]propanoic acid[1]
Synonyms: L-4-Trifluoromethylphenylalanine, p-Trifluoromethyl-L-phenylalanine[1]
Molecular Formula: C₁₀H₁₀F₃NO₂[1]
Molecular Weight: 233.19 g/mol [1]
CAS Number: 114926-38-4[1]
Below is a 2D representation of the molecular structure:
Caption: 2D Chemical Structure of this compound.
Physicochemical Properties
The physicochemical properties of this compound are summarized in the table below. These properties are crucial for understanding its behavior in biological systems and for its application in drug design.
| Property | Value | Reference |
| Molecular Weight | 233.19 g/mol | [1] |
| pKa (predicted) | 2.15 ± 0.10 | |
| LogP (predicted) | 1.6598 | |
| Topological Polar Surface Area | 63.3 Ų | [1] |
| Hydrogen Bond Donors | 2 | |
| Hydrogen Bond Acceptors | 2 | |
| Rotatable Bonds | 3 |
Structural Parameters (Theoretical)
In the absence of a publicly available crystal structure for this compound, the following table presents theoretical bond lengths and angles obtained from computational chemistry studies of similar structures. These values provide an estimation of the molecule's geometry.
| Parameter | Bond/Angle | Value (Å or °) |
| Bond Lengths | ||
| Cα - Cβ | ~1.53 | |
| Cβ - Cγ (aromatic) | ~1.51 | |
| Cα - N | ~1.47 | |
| Cα - C' (carboxyl) | ~1.53 | |
| C' = O | ~1.21 | |
| C' - OH | ~1.36 | |
| C (aromatic) - C (aromatic) | ~1.39 | |
| C (aromatic) - C (CF₃) | ~1.50 | |
| C - F | ~1.35 | |
| Bond Angles | ||
| N - Cα - Cβ | ~110° | |
| N - Cα - C' | ~111° | |
| Cβ - Cα - C' | ~110° | |
| Cα - Cβ - Cγ | ~113° | |
| C (aromatic) - C (CF₃) - F | ~111° | |
| F - C (CF₃) - F | ~107° |
Experimental Protocols
Asymmetric Synthesis
A plausible and efficient method for the enantioselective synthesis of this compound is based on the alkylation of a chiral nickel(II) complex of a glycine (B1666218) Schiff base, a method developed by Soloshonok and coworkers for the preparation of various phenylalanine-type amino acids.[2]
Workflow for Asymmetric Synthesis:
Caption: Asymmetric synthesis workflow.
Detailed Methodology:
-
Formation of the Chiral Ni(II)-Glycine Schiff Base Complex:
-
A mixture of the chiral ligand (e.g., (S)-2-[N-(N'-benzylprolyl)amino]benzophenone), glycine, and nickel(II) nitrate (B79036) hexahydrate in methanol (B129727) is refluxed in the presence of a base (e.g., sodium carbonate).[2]
-
The resulting chiral nickel(II) complex of the glycine Schiff base is isolated and purified.
-
-
Asymmetric Alkylation:
-
The chiral Ni(II)-glycine complex is dissolved in a suitable solvent (e.g., acetonitrile).
-
A base (e.g., powdered potassium hydroxide) and a phase-transfer catalyst (e.g., tetra-n-butylammonium bromide) are added.
-
The mixture is cooled (e.g., to 0 °C), and 4-(trifluoromethyl)benzyl bromide is added dropwise.
-
The reaction is stirred at low temperature until completion, monitored by TLC.
-
-
Hydrolysis and Isolation:
-
The resulting diastereomerically pure product complex is isolated.
-
The complex is hydrolyzed with aqueous hydrochloric acid to cleave the Schiff base and release the amino acid.[2]
-
The free this compound is separated from the chiral auxiliary by extraction and/or chromatography. The chiral auxiliary can often be recovered and reused.
-
Spectroscopic Characterization
Nuclear Magnetic Resonance (NMR) Spectroscopy:
-
¹H NMR: The proton NMR spectrum is expected to show characteristic signals for the aromatic protons (two doublets in the range of δ 7.0-8.0 ppm), the α-proton (a triplet or doublet of doublets around δ 3.5-4.5 ppm), and the β-protons (two diastereotopic protons appearing as a multiplet around δ 2.8-3.2 ppm).
-
¹³C NMR: The carbon NMR spectrum will display signals for the carboxyl carbon (~175 ppm), the aromatic carbons (in the region of 120-140 ppm, with characteristic splitting for the carbon attached to the CF₃ group), the α-carbon (~55 ppm), and the β-carbon (~37 ppm). The trifluoromethyl carbon will also be observable.
-
¹⁹F NMR: The fluorine NMR spectrum is a key diagnostic tool and will show a singlet for the CF₃ group, typically in the range of -60 to -65 ppm (relative to CFCl₃).[3]
Infrared (IR) Spectroscopy:
The IR spectrum will exhibit characteristic absorption bands corresponding to the functional groups present in the molecule:
-
~3000-3200 cm⁻¹: N-H stretching of the amino group.
-
~2500-3300 cm⁻¹ (broad): O-H stretching of the carboxylic acid.
-
~1700-1725 cm⁻¹: C=O stretching of the carboxylic acid.
-
~1500-1600 cm⁻¹: N-H bending of the amino group and C=C stretching of the aromatic ring.
-
~1100-1350 cm⁻¹: Strong C-F stretching vibrations of the trifluoromethyl group.
Mass Spectrometry (MS):
-
Electrospray Ionization (ESI-MS): In positive ion mode, the protonated molecule [M+H]⁺ at m/z 234.07 is expected to be the base peak. In negative ion mode, the deprotonated molecule [M-H]⁻ at m/z 232.06 can be observed.
-
Fragmentation Pattern: Common fragmentation pathways include the loss of the carboxylic acid group (-45 Da) and cleavage of the side chain.
Signaling Pathways and Logical Relationships
The primary utility of this compound is as a building block in peptide and protein synthesis, where its incorporation can modulate the properties of the resulting macromolecule. The logical relationship for its application in this context is outlined below.
References
An In-depth Technical Guide to 4-(Trifluoromethyl)-L-phenylalanine
For Researchers, Scientists, and Drug Development Professionals
Abstract
4-(Trifluoromethyl)-L-phenylalanine is a synthetic amino acid derivative that has garnered significant interest within the scientific community, particularly in the fields of medicinal chemistry and drug development. The incorporation of a trifluoromethyl group onto the phenyl ring of L-phenylalanine imparts unique physicochemical properties, including increased metabolic stability and altered binding affinities, making it a valuable building block for novel therapeutics. This technical guide provides a comprehensive overview of the key molecular data, a representative synthesis protocol, and a relevant biological signaling pathway associated with this compound.
Core Molecular Data
A summary of the essential quantitative data for this compound is presented in the table below for easy reference and comparison.
| Property | Value | Source(s) |
| Molecular Weight | 233.19 g/mol | [1][2][3] |
| Molecular Formula | C₁₀H₁₀F₃NO₂ | [2] |
| CAS Number | 114926-38-4 | [1][2] |
| Alternate Name | (S)-2-Amino-3-[4-(trifluoromethyl)phenyl]propionic acid | [2] |
| Purity | ≥98% | [2] |
Experimental Protocols
The synthesis of this compound can be achieved through various chemical and enzymatic methods. Below is a representative experimental protocol based on a Negishi cross-coupling reaction, a common method for forming carbon-carbon bonds.
Synthesis via Negishi Cross-Coupling
This protocol outlines a plausible synthetic route and has not been directly copied from a single source but is based on established chemical principles described in the literature.[3]
Materials:
-
(R)-N-Boc-3-iodoalanine methyl ester
-
Zinc dust
-
Tetrakis(triphenylphosphine)palladium(0)
-
Anhydrous Tetrahydrofuran (THF)
-
Hydrochloric acid (HCl)
-
Sodium hydroxide (B78521) (NaOH)
-
Dichloromethane (DCM)
-
Magnesium sulfate (B86663) (MgSO₄)
-
Silica (B1680970) gel for column chromatography
Procedure:
-
Preparation of the Organozinc Reagent: In a flame-dried flask under an inert atmosphere, activate zinc dust by stirring with 1,2-dibromoethane in anhydrous THF. Add (R)-N-Boc-3-iodoalanine methyl ester to the activated zinc suspension and stir at room temperature until the insertion of zinc is complete, forming the organozinc reagent.
-
Negishi Cross-Coupling Reaction: To the freshly prepared organozinc reagent, add 4-bromobenzotrifluoride and a catalytic amount of tetrakis(triphenylphosphine)palladium(0). Stir the reaction mixture at room temperature or with gentle heating until the starting materials are consumed (monitor by TLC or LC-MS).
-
Work-up and Purification: Quench the reaction with a saturated aqueous solution of ammonium (B1175870) chloride. Extract the aqueous layer with dichloromethane. Combine the organic layers, wash with brine, dry over anhydrous magnesium sulfate, and concentrate under reduced pressure. Purify the crude product by silica gel column chromatography to obtain N-Boc-4-(Trifluoromethyl)-L-phenylalanine methyl ester.
-
Deprotection: Hydrolyze the methyl ester using an aqueous solution of sodium hydroxide. Subsequently, remove the Boc protecting group by treatment with hydrochloric acid in an appropriate solvent.
-
Isolation: After deprotection, adjust the pH to the isoelectric point of the amino acid to precipitate the product. Filter the solid, wash with cold water, and dry under vacuum to yield this compound.
Biological Activity and Signaling Pathways
As a structural analog of L-phenylalanine, this compound can influence cellular processes that are regulated by amino acid availability, such as protein synthesis. One of the key signaling pathways involved in sensing amino acid levels is the General Control Nonderepressible 2 (GCN2) pathway. While direct studies on this compound's effect on this specific pathway are not detailed in the provided results, it is a highly relevant mechanism through which phenylalanine analogs can exert their biological effects.[4]
GCN2 Signaling Pathway
The GCN2 pathway is a highly conserved stress-response pathway that is activated by amino acid deprivation. This leads to a global downregulation of protein synthesis while promoting the translation of specific mRNAs that are involved in amino acid biosynthesis and stress adaptation.
Caption: GCN2 signaling pathway activated by amino acid deprivation.
Conclusion
This compound is a crucial molecule in the landscape of modern drug discovery. Its unique properties, stemming from the trifluoromethyl group, offer advantages in designing metabolically stable and effective therapeutic agents. Understanding its fundamental chemical data, synthesis, and potential biological impact through pathways like GCN2 is essential for researchers aiming to harness its full potential in developing next-generation pharmaceuticals.
References
- 1. medchemexpress.com [medchemexpress.com]
- 2. Fluorinated phenylalanines: synthesis and pharmaceutical applications - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Synthesis and evaluation of phenylalanine-derived trifluoromethyl ketones for peptide-based oxidation catalysis - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Phenylalanine modulates casein synthesis in bovine mammary epithelial cells by influencing amino acid transport and protein synthesis pathways - PMC [pmc.ncbi.nlm.nih.gov]
The Fluorine Advantage: A Technical Guide to the Discovery and Application of Fluorinated Amino Acids
For Researchers, Scientists, and Drug Development Professionals
Introduction
The strategic incorporation of fluorine into amino acids has emerged as a transformative tool in chemical biology, medicinal chemistry, and materials science. Although fluorine is almost entirely absent in natural biology, its unique physicochemical properties—high electronegativity, small van der Waals radius, and the ability to form strong C-F bonds—offer unparalleled opportunities to modulate the characteristics of peptides and proteins.[1][2] The introduction of fluorine can enhance thermal and metabolic stability, alter acidity and lipophilicity, and provide a sensitive spectroscopic probe for structural and functional studies.[1][3][4] This technical guide delves into the core aspects of fluorinated amino acids, from their synthesis and physicochemical properties to their application as advanced research tools and therapeutic components.
Methodologies for Synthesis
The synthesis of fluorinated amino acids can be broadly categorized into two main strategies: the use of fluorinated building blocks and the direct fluorination of amino acid precursors. Recent advancements have leveraged transition-metal catalysis and novel fluoroalkylating reagents to achieve high selectivity and efficiency.
Key Synthetic Approaches
-
Asymmetric Phase-Transfer Catalysis: This method is effective for producing enantiomerically pure amino acids. It often involves the alkylation of a glycine-derived Schiff base with a fluorinated benzyl (B1604629) halide in the presence of a chiral phase-transfer catalyst.[5]
-
Chiral Ni(II) Complex-Mediated Alkylation: This strategy utilizes a chiral nickel(II) complex of a glycine (B1666218) Schiff base, which is then alkylated with a fluorinated electrophile. This method has proven versatile for synthesizing a range of fluorinated aromatic and branched-chain amino acids on a gram scale.[6]
-
Electrophilic Fluorination: Reagents such as Selectfluor (F-TEDA-BF4) are widely used for the direct fluorination of C-H bonds, particularly at the α-position of amino acid derivatives, often mediated by a directing group and a metal catalyst like copper.[7]
-
Biocatalytic Methods: Engineered enzymes, such as phenylalanine ammonia (B1221849) lyases (PALs), are being developed for the direct asymmetric amination of fluorinated cinnamic acid analogs, offering a green and highly stereoselective route to these valuable compounds.[8]
Detailed Experimental Protocol: Asymmetric Synthesis of 4-Fluoro-L-phenylalanine Analog
The following protocol is adapted from a method for the synthesis of 4-Fluoro-β-(4-fluorophenyl)-l-phenylalanine, demonstrating a typical asymmetric phase-transfer catalyzed alkylation.[5]
Step 1: Synthesis of 4,4'-Difluorobenzhydryl Bromide (Electrophile)
-
Charge a reactor with 4,4'-difluorobenzhydrol (1.7 kg, 7.72 mol).
-
Add 48% aqueous hydrobromic acid (5.1 L).
-
Stir the resulting slurry for 1 hour at 25 °C.
-
Heat the reaction to 80 °C and stir for 2 hours.
-
Cool the reaction to 25 °C and add water (6.8 L), followed by dichloromethane (B109758) (8.5 L).
-
Stir the biphasic mixture, then separate the layers.
-
Wash the organic layer successively with water (5.1 L) and 5% aqueous sodium bicarbonate (5.1 L). The resulting dichloromethane solution containing the bromide product is used directly in the next step.
Step 2: Phase-Transfer Catalyzed Alkylation and Hydrolysis
-
Combine the dichloromethane solution of the bromide from Step 1 with tert-butyl glycinate-benzophenone Schiff base (commercially available nucleophile).
-
Add a chiral phase-transfer catalyst (e.g., a derivative of Cinchona alkaloid).
-
Add a suitable base (e.g., 50% aqueous potassium hydroxide) and stir vigorously at a controlled temperature (e.g., 0 °C) until the reaction is complete as monitored by HPLC.
-
After the alkylation, quench the reaction and proceed to hydrolysis.
-
Charge a reactor with water (9.0 L) and concentrated hydrochloric acid (9.0 L).
-
Add the crude product from the alkylation step (e.g., 2.0 kg, 4.02 mol).
-
Heat the resulting slurry at reflux for 3-4 hours to hydrolyze the ester and imine protecting groups.
-
Cool the reaction to room temperature and wash with an organic solvent like methyl tert-butyl ether (MTBE) (2 x 20 L) to remove organic impurities.
-
The aqueous layer containing the hydrochloride salt of the final product, 4-Fluoro-β-(4-fluorophenyl)-l-phenylalanine, can then be processed for isolation and purification.
Data Presentation: Physicochemical Properties
Fluorination significantly alters the electronic and steric properties of amino acid side chains, leading to predictable and useful changes in pKa, lipophilicity, and conformational stability.
Table 1: Comparison of Physicochemical Properties
| Amino Acid | pKa (Side Chain) | logP | Comments |
| Tyrosine | 10.1 | -2.25 | Baseline for comparison. |
| 3-Fluoro-L-tyrosine | 8.81 | -1.5 (est.) | The electron-withdrawing fluorine atom lowers the phenol (B47542) pKa, making it more acidic.[9] |
| Phenylalanine | N/A | -1.38 | Baseline for comparison. |
| 4-Fluoro-L-phenylalanine | N/A | -1.19 (est.) | Fluorination generally increases lipophilicity, though the effect can be complex and context-dependent.[10][11] |
| Leucine | N/A | 1.86 | Baseline for comparison. |
| 5,5,5-Trifluoroleucine | N/A | 2.5 (est.) | The CF3 group significantly increases the hydrophobicity of the side chain. |
Note: logP and pKa values can vary based on experimental conditions and measurement techniques. Estimated (est.) values are based on computational models and trends reported in the literature.
Table 2: Impact of Fluorination on Peptide and Protein Thermal Stability
| Protein/Peptide System | Fluorinated Residue | ΔTm (°C) | ΔG° (kcal/mol) | Reference |
| GCN4-p1d Leucine Zipper | 5,5,5-Trifluoroleucine | +13 | +0.5 to +1.2 | [3][12] |
| GCN4-bZip DNA-binding peptide | 5,5,5-Trifluoroleucine | +8 | N/A | [12] |
| α4H 4-Helix Bundle | Hexafluoroleucine | N/A | +9.6 | [13] |
| Cold Shock Protein B (BsCspB) | 5-Fluorotryptophan | -1.2 | -0.38 | [14][15] |
| Cold Shock Protein B (BsCspB) | 3-Fluorophenylalanine | +4.0 | +0.24 | [14][15] |
ΔTm represents the change in the midpoint thermal unfolding temperature compared to the non-fluorinated parent protein. A positive value indicates increased stability. ΔG° is the change in the free energy of folding. The data shows that while highly fluorinated cores often lead to dramatic stabilization, single monofluorinations can have a more modest or even slightly destabilizing effect, highlighting the context-dependent nature of fluorine's influence.[13][14][15]
Visualizations: Workflows and Pathways
Diagram 1: Synthetic Workflow
Caption: Asymmetric synthesis of a fluorinated phenylalanine analog.
Diagram 2: Application in Protease Inhibition
Caption: Fluorinated peptides can inhibit proteolytic pathways.
Diagram 3: Logic for Employing Fluorinated Amino Acids
Caption: Decision guide for using fluorinated amino acids.
Conclusion
The discovery and development of fluorinated amino acids have provided researchers with a powerful and versatile chemical toolbox. The strategic substitution of hydrogen with fluorine allows for the fine-tuning of molecular properties, leading to peptides and proteins with enhanced stability, altered bioactivity, and novel functionalities. From creating hyperstable protein scaffolds to developing sensitive probes for in-cell NMR, the applications are vast and continue to expand.[1][2] As synthetic methodologies become more refined and our understanding of fluorine's subtle effects deepens, these non-canonical building blocks will undoubtedly play an increasingly critical role in advancing drug discovery and protein engineering.
References
- 1. Design, synthesis, and study of fluorinated proteins - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. Fluorinated proteins: from design and synthesis to structure and stability - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. pubs.acs.org [pubs.acs.org]
- 4. pubs.acs.org [pubs.acs.org]
- 5. pubs.acs.org [pubs.acs.org]
- 6. Asymmetric synthesis of fluorinated derivatives of aromatic and γ-branched amino acids via a chiral Ni(II) complex - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Fluorinated phenylalanines: synthesis and pharmaceutical applications - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Direct asymmetric synthesis of β-branched aromatic α-amino acids using engineered phenylalanine ammonia lyases - PMC [pmc.ncbi.nlm.nih.gov]
- 9. researchgate.net [researchgate.net]
- 10. chemrxiv.org [chemrxiv.org]
- 11. researchgate.net [researchgate.net]
- 12. files.core.ac.uk [files.core.ac.uk]
- 13. Structural basis for the enhanced stability of highly fluorinated proteins - PMC [pmc.ncbi.nlm.nih.gov]
- 14. mdpi.com [mdpi.com]
- 15. What does fluorine do to a protein? Thermodynamic, and highly-resolved structural insights into fluorine-labelled variants of the cold shock protein - PMC [pmc.ncbi.nlm.nih.gov]
The Trifluoromethyl Group: A Paradigm Shift in Amino Acid Function and Drug Discovery
An In-depth Technical Guide for Researchers, Scientists, and Drug Development Professionals
The strategic incorporation of the trifluoromethyl (CF₃) group into amino acids has emerged as a powerful tool in medicinal chemistry and chemical biology. This technical guide provides a comprehensive overview of the profound impact of trifluoromethylation on the physicochemical properties, biological activity, and therapeutic potential of amino acids and the peptides and proteins that contain them.
Core Physicochemical Alterations Induced by Trifluoromethylation
The introduction of a trifluoromethyl group dramatically alters the fundamental properties of an amino acid, primarily due to the high electronegativity of fluorine and the unique characteristics of the carbon-fluorine bond.[1][2][3] These changes provide a compelling rationale for the use of trifluoromethylated amino acids in drug design and protein engineering.
Enhanced Lipophilicity
The CF₃ group is significantly more lipophilic than a methyl (CH₃) group, leading to an increase in the overall hydrophobicity of the amino acid.[2][4][5] This enhanced lipophilicity can improve a molecule's ability to cross cellular membranes, a critical factor for the bioavailability of peptide-based drugs.[6]
Increased Metabolic Stability
The carbon-fluorine bond is one of the strongest covalent bonds in organic chemistry.[5][7] This inherent strength makes the trifluoromethyl group exceptionally resistant to metabolic degradation by enzymatic processes, thereby increasing the in vivo half-life of drug candidates.[1][6][8]
Modulation of Acidity (pKa)
The strong electron-withdrawing nature of the trifluoromethyl group significantly influences the acidity of nearby functional groups.[1][7][9] For instance, the pKa of the ammonium (B1175870) group in trifluoromethylated prolines is markedly lower than in proline itself, indicating a substantial increase in acidity.[10] This alteration can impact the ionization state of the amino acid at physiological pH and influence its interactions with biological targets.
Quantitative Data Summary
The following tables summarize the quantitative effects of trifluoromethylation on key physicochemical properties of amino acids.
Table 1: Effect of Trifluoromethylation on the pKa of the Ammonium Group in Proline Analogs
| Compound | pKa of Ammonium Group |
| Proline | 10.68 |
| (2S,4R)-4-Trifluoromethylproline | 8.46 |
| (2S,4S)-4-Trifluoromethylproline | 8.56 |
| (2S)-5-Trifluoromethylproline | 6.07 |
| (2S,4R)-4-Methylproline | 10.73 |
| (2S,4S)-4-Methylproline | 10.54 |
Data sourced from Kubyshkin et al., 2018.[10]
Table 2: Lipophilicity (logP) of N-Acetyl Amino Acid Methyl Esters
| Amino Acid Derivative | logP |
| N-Acetyl-Proline-OMe | -0.67 |
| N-Acetyl-(2S,4R)-4-Trifluoromethylproline-OMe | 0.60 |
| N-Acetyl-Valine-OMe | 0.49 |
Data indicates that 4-trifluoromethylproline exhibits lipophilicity comparable to valine. Sourced from Kubyshkin and Budisa, 2018.[10]
Table 3: Enzyme Inhibition Data for Trifluoromethyl-Containing Compounds
| Inhibitor | Target Enzyme | Inhibition Constant |
| Captopril Analog (CF₃ substituted for CH₃) | Angiotensin-Converting Enzyme (ACE) | IC₅₀ = 0.3 nM[11] |
| Trifluoromethyl Ketone Inhibitor | SARS-CoV 3CL Protease | Kᵢ = 0.3 µM (after 4h incubation)[12] |
| Ac-Ala-Ala-Pro-ambo-Ala-CF₃ | Porcine Pancreatic Elastase | Kᵢ = 0.34 µM[13] |
Experimental Protocols
This section provides detailed methodologies for key experiments relevant to the study of trifluoromethylated amino acids.
Determination of pKa by Potentiometric Titration
Objective: To determine the acid dissociation constants (pKa) of an amino acid.
Materials:
-
0.1 M solution of the amino acid
-
0.1 M Hydrochloric acid (HCl)
-
0.1 M Sodium hydroxide (B78521) (NaOH)
-
Calibrated pH meter and electrode
-
Burette
-
Stir plate and stir bar
-
Beaker
Procedure:
-
Pipette a known volume (e.g., 20 mL) of the 0.1 M amino acid solution into a beaker.
-
Place the beaker on a stir plate and add a stir bar.
-
Immerse the calibrated pH electrode in the solution.
-
Record the initial pH of the amino acid solution.
-
Acid Titration: Add 0.1 M HCl in small, precise increments (e.g., 0.5 mL) from a burette. After each addition, allow the pH to stabilize and record the value. Continue until the pH drops to approximately 1.5.
-
Base Titration: In a separate experiment, titrate a fresh 20 mL aliquot of the amino acid solution with 0.1 M NaOH in a similar incremental manner. Record the pH after each addition until the pH reaches approximately 12.5.
-
Data Analysis: Plot the pH values against the volume of titrant (HCl and NaOH) added. The pKa values correspond to the midpoint of the buffer regions (the flattest parts of the curve).[1][6][14][15]
Measurement of Lipophilicity (logP) by the Shake-Flask Method
Objective: To determine the octanol-water partition coefficient (logP) of an amino acid derivative.
Materials:
-
N-acetylated and methyl-esterified amino acid derivative
-
1-Octanol (pre-saturated with water)
-
Water or buffer (pre-saturated with 1-octanol)
-
Centrifuge tubes
-
Vortex mixer
-
Centrifuge
-
Analytical instrument for quantification (e.g., NMR, HPLC, UV-Vis spectrophotometer)
Procedure:
-
Prepare a stock solution of the amino acid derivative in either the aqueous or octanol (B41247) phase.
-
In a centrifuge tube, add equal volumes of the pre-saturated octanol and aqueous phases.
-
Add a small, known amount of the amino acid derivative stock solution to the tube.
-
Cap the tube tightly and vortex vigorously for a set period (e.g., 10 minutes) to ensure thorough mixing and partitioning.
-
Allow the two phases to separate. Centrifugation may be required to achieve a clean separation.
-
Carefully collect a sample from both the upper (octanol) and lower (aqueous) phases.
-
Quantify the concentration of the amino acid derivative in each phase using an appropriate analytical method.
-
Calculation: The logP is calculated as the base-10 logarithm of the ratio of the concentration in the octanol phase to the concentration in the aqueous phase: logP = log10([solute]octanol / [solute]aqueous).[9][16][17][18][19]
Serine Protease Inhibition Assay
Objective: To determine the inhibitory potency (IC₅₀ or Kᵢ) of a trifluoromethyl ketone-containing peptide against a serine protease.
Materials:
-
Purified serine protease
-
Fluorogenic or chromogenic substrate for the protease
-
Trifluoromethyl ketone inhibitor
-
Assay buffer
-
96-well microplate
-
Microplate reader
Procedure:
-
Prepare a serial dilution of the inhibitor in the assay buffer.
-
In the wells of a 96-well plate, add the enzyme at a fixed concentration and varying concentrations of the inhibitor. Include control wells with no inhibitor (100% activity) and no enzyme (background).
-
Pre-incubate the enzyme and inhibitor for a specific time to allow for binding.
-
Initiate the enzymatic reaction by adding the substrate to all wells.
-
Monitor the change in fluorescence or absorbance over time using a microplate reader.
-
Data Analysis: Calculate the initial reaction rates for each inhibitor concentration. Plot the percentage of enzyme inhibition against the logarithm of the inhibitor concentration. The IC₅₀ is the concentration of inhibitor that reduces the enzyme activity by 50%. The Kᵢ can be calculated from the IC₅₀ using the Cheng-Prusoff equation if the inhibition is competitive.[8][13][20][21]
Visualizations of Key Concepts
Mechanism of Serine Protease Inhibition by a Trifluoromethyl Ketone
The following diagram illustrates the mechanism of action of a trifluoromethyl ketone as a transition-state analog inhibitor of a serine protease.
Caption: Inhibition of a serine protease by a trifluoromethyl ketone.
Workflow for Solid-Phase Peptide Synthesis (SPPS)
This diagram outlines the general workflow for synthesizing a peptide on a solid support, a common method for incorporating trifluoromethylated amino acids.
Caption: General workflow for Solid-Phase Peptide Synthesis (SPPS).
Conclusion
The incorporation of trifluoromethyl groups into amino acids offers a versatile and powerful strategy for modulating their properties and enhancing their therapeutic potential. The unique electronic and steric effects of the CF₃ group lead to improvements in lipophilicity, metabolic stability, and binding affinity, making trifluoromethylated amino acids highly valuable building blocks in drug discovery and protein engineering. The experimental protocols and quantitative data presented in this guide provide a solid foundation for researchers to explore and harness the potential of these fascinating molecules.
References
- 1. pH-titration of amino acids and small peptides, and estimation of isoelectric point (pI) [vlabs.iitkgp.ac.in]
- 2. 4-Trifluoromethoxy proline: synthesis of stereoisomers and lipophilicity study - Organic & Biomolecular Chemistry (RSC Publishing) [pubs.rsc.org]
- 3. benchchem.com [benchchem.com]
- 4. mdpi.com [mdpi.com]
- 5. mdpi.com [mdpi.com]
- 6. Titration Curves of Aminoacids (Procedure) : Biochemistry Virtual Lab I : Biotechnology and Biomedical Engineering : Amrita Vishwa Vidyapeetham Virtual Lab [vlab.amrita.edu]
- 7. researchgate.net [researchgate.net]
- 8. benchchem.com [benchchem.com]
- 9. researchgate.net [researchgate.net]
- 10. researchgate.net [researchgate.net]
- 11. Design, synthesis and enzyme inhibitory activities of new trifluoromethyl-containing inhibitors for angiotensin converting enzyme - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. Design, synthesis, and evaluation of trifluoromethyl ketones as inhibitors of SARS-CoV 3CL protease - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Inhibition of serine proteases by peptidyl fluoromethyl ketones - PubMed [pubmed.ncbi.nlm.nih.gov]
- 14. Protocol for Determining pKa Using Potentiometric Titration - Creative Bioarray | Creative Bioarray [creative-bioarray.com]
- 15. scribd.com [scribd.com]
- 16. Cambridge MedChem Consulting [cambridgemedchemconsulting.com]
- 17. Shake Flask logK - Lokey Lab Protocols [lokeylab.wikidot.com]
- 18. LogP / LogD shake-flask method [protocols.io]
- 19. Experimental lipophilicity scale for coded and noncoded amino acid residues - Organic & Biomolecular Chemistry (RSC Publishing) [pubs.rsc.org]
- 20. researchgate.net [researchgate.net]
- 21. Inhibition of serine proteases by peptidyl fluoromethyl ketones (Journal Article) | OSTI.GOV [osti.gov]
Preliminary Technical Guide on 4-(Trifluoromethyl)-L-phenylalanine
For Researchers, Scientists, and Drug Development Professionals
Abstract
4-(Trifluoromethyl)-L-phenylalanine is a non-canonical amino acid that has garnered significant interest in the fields of biochemistry, pharmacology, and drug development. The incorporation of the trifluoromethyl group onto the phenyl ring of L-phenylalanine imparts unique physicochemical properties, including increased hydrophobicity, metabolic stability, and altered electronic characteristics. These modifications can profoundly influence the conformation, binding affinity, and biological activity of peptides and proteins into which it is incorporated. This document provides a preliminary overview of its properties, synthesis, and potential applications, based on available scientific literature.
Chemical and Physical Properties
This compound is a derivative of the essential amino acid L-phenylalanine.[1][2] Key identifying information and physical properties are summarized in the table below.
| Property | Value | Reference |
| IUPAC Name | (2S)-2-amino-3-[4-(trifluoromethyl)phenyl]propanoic acid | [2] |
| Molecular Formula | C₁₀H₁₀F₃NO₂ | [2][3] |
| Molecular Weight | 233.19 g/mol | [2][3] |
| CAS Number | 114926-38-4 | [2][3] |
| Canonical SMILES | C1=CC(=CC=C1C--INVALID-LINK--N)C(F)(F)F | [2] |
| InChI Key | CRFFPDBJLGAGQL-QMMMGPOBSA-N | [2] |
| Appearance | White to off-white powder | |
| Purity | Typically ≥98% | [3] |
Biological Activity and Applications
The introduction of a trifluoromethyl group can significantly alter the biological properties of peptides and proteins. This modification can enhance protein stability and has been utilized as a probe in NMR studies to investigate protein structure and dynamics.[4][5] While specific quantitative data on the biological activity of this compound itself is limited in publicly available literature, derivatives have shown biological effects. For instance, a cinnamoyl derivative of a related fluorinated phenylalanine has been investigated for its neuroprotective effects in ischemia-reperfusion models.
Experimental Protocols
The primary application of this compound is its incorporation into peptides and proteins. This can be achieved through standard solid-phase peptide synthesis (SPPS) or through genetic incorporation of unnatural amino acids in cellular expression systems.
Solid-Phase Peptide Synthesis (SPPS)
A general protocol for the incorporation of an Fmoc-protected amino acid, which would be applicable to Fmoc-4-(Trifluoromethyl)-L-phenylalanine, is outlined below. It is important to note that the specific coupling times and reagents may need to be optimized for this particular amino acid due to potential differences in reactivity.[7][8][9][10][11]
General Fmoc-SPPS Cycle:
-
Resin Swelling: Swell the appropriate resin (e.g., Rink amide resin for C-terminal amides) in a suitable solvent like N,N-dimethylformamide (DMF) or dichloromethane (B109758) (DCM) for 30-60 minutes.[9][10]
-
Fmoc Deprotection: Remove the Fmoc protecting group from the resin-bound amine by treating with a 20% solution of piperidine (B6355638) in DMF for approximately 20 minutes.[7][9]
-
Washing: Thoroughly wash the resin with DMF to remove excess piperidine and the cleaved Fmoc-adduct.
-
Amino Acid Coupling:
-
Activate the Fmoc-protected this compound (typically 3-5 equivalents relative to the resin loading) with a coupling reagent such as HBTU/HOBt in the presence of a base like N,N-diisopropylethylamine (DIEA) in DMF.[7]
-
Add the activated amino acid solution to the deprotected resin and allow the coupling reaction to proceed for 1-2 hours. The reaction progress can be monitored using a ninhydrin (B49086) test.[10]
-
-
Washing: Wash the resin with DMF and DCM to remove excess reagents and byproducts.
-
Repeat Cycle: Repeat steps 2-5 for each subsequent amino acid in the peptide sequence.
-
Cleavage and Deprotection: After the final amino acid is coupled, cleave the peptide from the resin and remove the side-chain protecting groups using a cleavage cocktail, typically containing trifluoroacetic acid (TFA) and scavengers.
Genetic Incorporation of Unnatural Amino Acids
This compound can be site-specifically incorporated into proteins in vivo using an orthogonal tRNA/aminoacyl-tRNA synthetase pair.[4][12] This technique allows for the production of proteins with a single or multiple unnatural amino acids at defined positions.
Workflow for Unnatural Amino Acid Incorporation:
Caption: Workflow for the genetic incorporation of this compound.
Potential Signaling Pathway Interactions
While direct evidence for this compound modulating specific signaling pathways is not yet prevalent in the literature, the natural amino acid L-phenylalanine is known to influence cellular signaling, particularly the mTOR pathway, which is a central regulator of cell growth and protein synthesis.[13][14][15] L-phenylalanine is transported into the cell via transporters like LAT1, and its intracellular presence can activate mTORC1, leading to the phosphorylation of downstream effectors such as S6K1 and 4EBP1, which in turn promotes protein synthesis.
Given the structural similarity, it is plausible that this compound could also be a substrate for amino acid transporters and potentially influence the mTOR pathway. However, the trifluoromethyl group's electronic and steric properties might alter its transport efficiency and its ability to activate downstream signaling components. Further research is required to elucidate the specific signaling effects of this unnatural amino acid.
Caption: Hypothesized influence on the L-phenylalanine-mediated mTOR signaling pathway.
Conclusion
This compound is a valuable tool for chemical biologists and drug discovery scientists. Its unique properties make it an attractive building block for modifying peptides and proteins to enhance their stability, probe their structure and function, and potentially develop novel therapeutics. While detailed quantitative biological data and specific signaling effects are still areas of active investigation, the established protocols for its incorporation into biomolecules provide a solid foundation for further research. Future studies are warranted to fully characterize its pharmacokinetic profile, biological activity, and impact on cellular signaling pathways.
References
- 1. medchemexpress.com [medchemexpress.com]
- 2. This compound | C10H10F3NO2 | CID 2761501 - PubChem [pubchem.ncbi.nlm.nih.gov]
- 3. scbt.com [scbt.com]
- 4. Site-specific incorporation of a (19)F-amino acid into proteins as an NMR probe for characterizing protein structure and reactivity - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. Fluorine labeling of proteins for NMR studies – Bio-NMR Core [bionmr.cores.ucla.edu]
- 6. Phenylalanine‐Based DNA‐Encoded Chemical Libraries for the Discovery of Potent and Selective Small Organic Ligands Against Markers of Cancer and Immune Cells - PMC [pmc.ncbi.nlm.nih.gov]
- 7. rsc.org [rsc.org]
- 8. researchgate.net [researchgate.net]
- 9. chemistry.du.ac.in [chemistry.du.ac.in]
- 10. digital.csic.es [digital.csic.es]
- 11. Practical Protocols for Solid-Phase Peptide Synthesis 4.0 - PMC [pmc.ncbi.nlm.nih.gov]
- 12. pubs.acs.org [pubs.acs.org]
- 13. mdpi.com [mdpi.com]
- 14. Hyperactivation of mTOR/eIF4E Signaling Pathway Promotes the Production of Tryptophan-To-Phenylalanine Substitutants in EBV-Positive Gastric Cancer - PubMed [pubmed.ncbi.nlm.nih.gov]
- 15. researchgate.net [researchgate.net]
4-(Trifluoromethyl)-L-phenylalanine literature review
An In-depth Technical Guide to 4-(Trifluoromethyl)-L-phenylalanine
Introduction
This compound, often abbreviated as 4-CF3-Phe, is a non-proteinogenic amino acid, a synthetic derivative of the essential amino acid L-phenylalanine.[1] It is distinguished by the substitution of a hydrogen atom with a trifluoromethyl (-CF3) group at the para-position of the phenyl ring. This modification imparts unique physicochemical properties that have made 4-CF3-Phe a valuable building block in medicinal chemistry and drug development.[2][3][4]
The incorporation of the trifluoromethyl group, a well-established bioisostere for chlorine, significantly enhances metabolic stability, lipophilicity, and binding selectivity of molecules.[4] Consequently, 4-CF3-Phe is widely utilized in the synthesis of novel peptides and small-molecule drug candidates to improve their pharmacokinetic and pharmacodynamic profiles.[2][3][4] Its applications range from creating more stable therapeutic peptides to serving as a tool for studying protein structure and function.[2]
Physicochemical Properties
The essential physicochemical and identifying characteristics of this compound are summarized in the table below. This data is critical for its application in synthesis, formulation, and biochemical assays.
| Property | Value | Reference |
| IUPAC Name | (2S)-2-amino-3-[4-(trifluoromethyl)phenyl]propanoic acid | [5][6] |
| Synonyms | (S)-2-Amino-3-[4-(trifluoromethyl)phenyl]propionic acid, L-4-Trifluoromethylphe | [5][7][8] |
| CAS Number | 114926-38-4 | [1][5][8] |
| Molecular Formula | C₁₀H₁₀F₃NO₂ | [5][6][8] |
| Molecular Weight | 233.19 g/mol | [5][8] |
| Appearance | White powder | |
| Purity | ≥98% | [8] |
| InChI Key | CRFFPDBJLGAGQL-QMMMGPOBSA-N | [5] |
Synthesis and Manufacturing
The synthesis of this compound can be achieved through various organic chemistry routes, often focusing on stereoselective methods to obtain the desired L-enantiomer. Key strategies include the asymmetric hydrogenation of α-amidocinnamic acid precursors, alkylation of glycine-derived Schiff bases, and palladium-catalyzed cross-coupling reactions.[9][10][11]
General Synthetic Workflow
A common and robust method for synthesizing phenylalanine analogues involves a Negishi cross-coupling reaction. This approach offers good yields and scalability. The general workflow involves preparing a functionalized aryl halide and a protected amino acid fragment, which are then coupled together.[10][11]
References
- 1. medchemexpress.com [medchemexpress.com]
- 2. Fluorinated phenylalanines: synthesis and pharmaceutical applications - PMC [pmc.ncbi.nlm.nih.gov]
- 3. researchgate.net [researchgate.net]
- 4. mdpi.com [mdpi.com]
- 5. This compound | C10H10F3NO2 | CID 2761501 - PubChem [pubchem.ncbi.nlm.nih.gov]
- 6. 4-Trifluoromethyl-L-phenylalanine, 95% 250 mg | Request for Quote | Thermo Scientific Chemicals [thermofisher.com]
- 7. chemwhat.com [chemwhat.com]
- 8. scbt.com [scbt.com]
- 9. BJOC - Fluorinated phenylalanines: synthesis and pharmaceutical applications [beilstein-journals.org]
- 10. Synthesis and evaluation of phenylalanine-derived trifluoromethyl ketones for peptide-based oxidation catalysis - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Synthesis and evaluation of phenylalanine-derived trifluoromethyl ketones for peptide-based oxidation catalysis - PubMed [pubmed.ncbi.nlm.nih.gov]
Methodological & Application
Application Notes and Protocols for 19F NMR Spectroscopy with 4-(Trifluoromethyl)-L-phenylalanine
For Researchers, Scientists, and Drug Development Professionals
Introduction
Fluorine-19 (¹⁹F) Nuclear Magnetic Resonance (NMR) spectroscopy has emerged as a powerful tool for investigating the structure, dynamics, and interactions of biomolecules. The introduction of fluorine atoms into proteins provides a sensitive spectroscopic probe due to the 100% natural abundance and high gyromagnetic ratio of the ¹⁹F nucleus.[1][2] Furthermore, the near-complete absence of fluorine in biological systems ensures background-free spectra.[1][2] The trifluoromethyl (-CF₃) group is a particularly effective ¹⁹F NMR probe due to the three equivalent fluorine nuclei which enhance signal intensity, and its chemical shift is highly sensitive to the local electrostatic environment, making it an exquisite reporter of conformational changes.[3][4]
4-(Trifluoromethyl)-L-phenylalanine (4-CF₃-Phe), a non-native amino acid, has become a popular choice for these studies. Its site-specific incorporation into proteins allows for the precise placement of a ¹⁹F NMR probe to investigate specific regions of interest, such as active sites or protein-protein interfaces.[3][5][6][7] This document provides detailed application notes and experimental protocols for the use of 4-CF₃-Phe in ¹⁹F NMR studies of proteins.
Applications of 19F NMR with this compound
Monitoring Protein Conformational Changes
The chemical shift of the ¹⁹F nucleus in 4-CF₃-Phe is exquisitely sensitive to its local environment.[5][8] Changes in protein conformation, such as those induced by ligand binding, protein folding/unfolding, or allosteric regulation, result in alterations in the chemical environment of the incorporated 4-CF₃-Phe, leading to measurable changes in its ¹⁹F NMR chemical shift.[3][5]
-
Protein Folding and Stability: Denaturation studies, often performed using urea (B33335) or temperature gradients, can be monitored by observing the ¹⁹F NMR spectrum of a protein containing 4-CF₃-Phe. In the unfolded state, the 4-CF₃-Phe residues are typically exposed to the solvent, resulting in a single, sharp resonance. As the protein folds, the probes become situated in diverse local environments, leading to a dispersion of chemical shifts.[5][9]
-
Allosteric Regulation: The propagation of conformational changes from an allosteric site to a distant functional site can be tracked by placing 4-CF₃-Phe probes at strategic locations throughout the protein. This allows for the mapping of allosteric communication pathways.
Characterizing Protein-Ligand Interactions
¹⁹F NMR spectroscopy with site-specifically incorporated 4-CF₃-Phe is a powerful technique for characterizing protein-ligand interactions, providing information on binding affinity, kinetics, and the mechanism of binding.[10]
-
Binding Affinity (Kd) Determination: Titrating a protein containing 4-CF₃-Phe with a ligand and monitoring the change in the ¹⁹F chemical shift allows for the determination of the dissociation constant (Kd).[10] The observed chemical shift is a population-weighted average of the free and bound states. The Kd can be calculated by fitting the chemical shift changes to a binding isotherm.[10]
-
Fragment-Based Drug Discovery: The sensitivity and low background of ¹⁹F NMR make it an ideal method for fragment-based screening.[10] Libraries of small, fluorinated fragments can be screened for binding to a target protein, or a protein labeled with 4-CF₃-Phe can be used to screen non-fluorinated fragment libraries.
Probing Protein Dynamics
NMR relaxation parameters, such as the spin-lattice (T₁) and spin-spin (T₂) relaxation times, provide information on the dynamics of the 4-CF₃-Phe side chain. Changes in these parameters upon ligand binding or other perturbations can reveal alterations in protein dynamics at the labeled site.[11] The trifluoromethyl group's rapid rotation simplifies the relaxation analysis in some cases.[11]
Experimental Protocols
Protocol 1: Site-Specific Incorporation of this compound
This protocol describes the genetic incorporation of 4-CF₃-Phe into a protein of interest in E. coli using an orthogonal aminoacyl-tRNA synthetase/tRNA pair that recognizes the amber stop codon (UAG).[1][6]
Materials:
-
Expression plasmid for the protein of interest with a UAG codon at the desired incorporation site.
-
Plasmid encoding the orthogonal aminoacyl-tRNA synthetase/tRNA(CUA) pair for 4-CF₃-Phe (e.g., pDule-tfmF).[6]
-
E. coli expression strain (e.g., BL21(DE3)).
-
This compound (4-CF₃-Phe).
-
Minimal media (e.g., M9).
-
Appropriate antibiotics.
-
IPTG (Isopropyl β-D-1-thiogalactopyranoside).
Procedure:
-
Co-transformation: Transform the E. coli expression strain with both the plasmid for the protein of interest and the plasmid for the orthogonal synthetase/tRNA pair.
-
Starter Culture: Inoculate a single colony into 5 mL of LB medium containing the appropriate antibiotics and grow overnight at 37°C with shaking.
-
Expression Culture: Inoculate 1 L of minimal media containing the appropriate antibiotics with the overnight starter culture.
-
Growth: Grow the culture at 37°C with shaking until the OD₆₀₀ reaches 0.6-0.8.
-
Induction: Add 4-CF₃-Phe to a final concentration of 1 mM. Induce protein expression by adding IPTG to a final concentration of 0.5-1 mM.
-
Expression: Continue to grow the culture at a reduced temperature (e.g., 18-25°C) for 12-16 hours.
-
Harvesting: Harvest the cells by centrifugation.
-
Purification: Purify the 4-CF₃-Phe labeled protein using standard chromatography techniques appropriate for the protein of interest.
Protocol 2: Sample Preparation for 19F NMR
Materials:
-
Purified 4-CF₃-Phe labeled protein.
-
NMR buffer (e.g., 50 mM Phosphate buffer, 150 mM NaCl, pH 7.4).
-
D₂O (Deuterium oxide).
-
Internal reference standard (optional, e.g., trifluoroacetic acid - TFA).
Procedure:
-
Buffer Exchange: Exchange the purified protein into the desired NMR buffer using dialysis or a desalting column.
-
Concentration: Concentrate the protein to the desired concentration for NMR analysis (typically 0.1-1 mM).
-
Add D₂O: Add D₂O to a final concentration of 5-10% (v/v) for the NMR lock.
-
Add Reference: If an internal reference is used, add a small, known concentration. Note that the chemical shift of TFA can be pH-dependent.
-
Transfer to NMR Tube: Transfer the final sample to a clean, high-quality NMR tube.
Protocol 3: 1D 19F NMR Data Acquisition
Instrument Parameters (Example for a 500 MHz Spectrometer):
-
Observe Nucleus: ¹⁹F
-
Decouple Nucleus: ¹H (optional, but recommended to improve resolution)
-
Pulse Program: A standard 1D pulse-acquire sequence with proton decoupling during acquisition.
-
Acquisition Time: 1-2 seconds.
-
Recycle Delay (D1): 1-5 seconds (should be at least 1.5 x T₁ for quantitative measurements).
-
Number of Scans: Dependent on protein concentration and desired signal-to-noise ratio (e.g., 128 to 4096 scans).
-
Temperature: 298 K (or desired experimental temperature).
Procedure:
-
Tune and Match: Tune and match the NMR probe for both ¹⁹F and ¹H frequencies.
-
Lock and Shim: Lock on the D₂O signal and shim the magnetic field to achieve good homogeneity.
-
Acquire Data: Set up the 1D ¹⁹F NMR experiment with the desired parameters and acquire the data.
-
Process Data: Process the acquired Free Induction Decay (FID) with an appropriate window function (e.g., exponential multiplication for sensitivity enhancement) and Fourier transform.
-
Reference Spectrum: Reference the chemical shifts to an external or internal standard.
Data Presentation
Table 1: Representative 19F NMR Relaxation Data for 4-CF₃-Phe
This table presents example T₁ and T₂ relaxation times for 4-CF₃-Phe incorporated at a specific site in a protein, demonstrating the effect of ligand binding on side-chain dynamics.
| Protein State | T₁ (ms) | T₂ (ms) |
| Apo (ligand-free) | 1095.70 ± 68.72 | 89.24 ± 5.84 |
| Ligand-bound | 1496.00 ± 286.71 | 1088.04 ± 217.47 |
Data adapted from a study on the human vinexin SH3 domain with 4-CF₃-Phe at the Phe7 position.[11]
Table 2: Example of 19F Chemical Shift Changes Upon Ligand Binding
This table illustrates typical changes in ¹⁹F chemical shifts of 4-CF₃-Phe upon protein-ligand interaction.
| Protein | Labeled Residue | State | ¹⁹F Chemical Shift (ppm) | Δδ (ppm) |
| Protein X | Phe50-tfmF | Apo | -63.50 | - |
| Protein X | Phe50-tfmF | Ligand-bound | -64.20 | -0.70 |
| Protein Y | Phe120-tfmF | Apo | -62.80 | - |
| Protein Y | Phe120-tfmF | Ligand-bound | -62.50 | +0.30 |
These are hypothetical values for illustrative purposes, based on typical observed shifts.
Visualization of Key Concepts
Conclusion
The site-specific incorporation of this compound provides a powerful and versatile tool for studying protein structure, dynamics, and interactions using ¹⁹F NMR spectroscopy. The high sensitivity of the trifluoromethyl group to its local environment allows for the detection of subtle conformational changes, making it invaluable for academic research and drug development. The protocols and data presented here provide a foundation for researchers to apply this technique to their own systems of interest.
References
- 1. researchgate.net [researchgate.net]
- 2. Fluorine labeling of proteins for NMR studies – Bio-NMR Core [bionmr.cores.ucla.edu]
- 3. pubs.acs.org [pubs.acs.org]
- 4. Fluorine-19 NMR of integral membrane proteins illustrated with studies of GPCRs - PMC [pmc.ncbi.nlm.nih.gov]
- 5. USE OF 19F NMR TO PROBE PROTEIN STRUCTURE AND CONFORMATIONAL CHANGES - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Preparation of site-specifically labeled fluorinated proteins for 19F-NMR structural characterization - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. Site-specific incorporation of a (19)F-amino acid into proteins as an NMR probe for characterizing protein structure and reactivity - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. 19F NMR viewed through two different lenses: ligand-observed and protein-observed 19F NMR applications for fragment-based drug discovery - PMC [pmc.ncbi.nlm.nih.gov]
- 9. researchgate.net [researchgate.net]
- 10. Protein-observed 19F-NMR for fragment screening, affinity quantification and druggability assessment - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Site-specific 19F NMR chemical shift and side chain relaxation analysis of a membrane protein labeled with an unnatural amino acid - PMC [pmc.ncbi.nlm.nih.gov]
Application Notes and Protocols for 4-(Trifluoromethyl)-L-phenylalanine as a Molecular Probe
Audience: Researchers, scientists, and drug development professionals.
Introduction
4-(Trifluoromethyl)-L-phenylalanine (4-TFM-Phe) is a non-canonical amino acid that has emerged as a powerful molecular probe in biomedical research and drug discovery. Its unique trifluoromethyl group serves as a highly sensitive reporter for ¹⁹F Nuclear Magnetic Resonance (NMR) spectroscopy and as a potential label for Positron Emission Tomography (PET) imaging when radiolabeled with ¹⁸F. The ¹⁹F nucleus offers several advantages for biomolecular studies, including 100% natural abundance, high sensitivity, and a large chemical shift range that is exquisitely sensitive to the local chemical environment.[1][2] This sensitivity allows for the detailed investigation of protein structure, dynamics, conformational changes, and interactions with ligands.[3][4]
These application notes provide an overview of the key applications of 4-TFM-Phe, supported by quantitative data, detailed experimental protocols, and visualizations of relevant workflows and pathways.
Key Applications
¹⁹F NMR Spectroscopy for Studying Protein Structure and Interactions
The incorporation of 4-TFM-Phe into a protein of interest provides a powerful tool to monitor structural changes and binding events. The ¹⁹F chemical shift of the trifluoromethyl group is highly sensitive to its local environment, providing a direct readout of conformational changes or ligand binding.[1][2]
Quantitative Data:
The following table summarizes representative ¹⁹F NMR data for a 4-TFM-Phe labeled SH3 domain, demonstrating the changes in relaxation parameters upon ligand binding.[1]
| Parameter | Free SH3 Domain | SH3 Domain + Ligand (P868) |
| T₁ (ms) | 1095.70 ± 68.72 | 1496.00 ± 286.71 |
| T₂ (ms) | 89.24 ± 5.84 | 1088.04 ± 217.47 |
Table 1: ¹⁹F NMR relaxation data for the human vinexin SH3 domain site-specifically labeled with 4-TFM-Phe at the Phe7 position, in the absence and presence of the proline-rich peptide ligand P868.[1] Data was acquired at 298 K on a 400 MHz spectrometer.
Positron Emission Tomography (PET) Imaging
When labeled with the positron-emitting isotope ¹⁸F, 4-TFM-Phe can be used as a tracer for PET imaging, a non-invasive technique to visualize and quantify biological processes in vivo.[5] ¹⁸F-labeled amino acids are valuable for oncology imaging as their uptake is often increased in tumor cells due to upregulated amino acid transporters.[6]
Quantitative Data:
The following table presents key parameters for an ¹⁸F-labeled fluoroalkyl phenylalanine analog used in PET imaging studies.[5]
| Parameter | Value |
| Radiochemical Yield | 11–37% |
| Specific Activity | 21–69 GBq/μmol |
| Tumor-to-Background Ratio (60 min) | 1.45 |
Table 2: Radiosynthesis and in vivo performance of an ¹⁸F-labeled phenylalanine derivative for PET imaging of 9L glioma cells.[5]
Experimental Protocols
Protocol 1: Site-Specific Incorporation of this compound into Proteins for ¹⁹F NMR Studies
This protocol describes the incorporation of 4-TFM-Phe into a protein of interest in E. coli using the amber stop codon suppression method.[7][8]
Materials:
-
pDule-tfmF plasmid (encoding the orthogonal aminoacyl-tRNA synthetase/tRNA(CUA) pair)
-
pBAD expression vector containing the gene of interest with an amber (TAG) codon at the desired incorporation site
-
E. coli competent cells (e.g., DH10B)
-
LB agar (B569324) plates with appropriate antibiotics
-
Autoinduction media (e.g., ZY-5052)
-
This compound (4-TFM-Phe)
-
Appropriate antibiotics
Procedure:
-
Plasmid Transformation: Co-transform the pDule-tfmF plasmid and the pBAD expression vector containing your gene of interest with the amber mutation into competent E. coli cells.
-
Colony Selection: Plate the transformed cells on LB agar plates containing the appropriate antibiotics for both plasmids and incubate overnight at 37°C.
-
Starter Culture: Inoculate a single colony into 5 mL of LB medium with antibiotics and grow overnight at 37°C with shaking.
-
Expression Culture: Inoculate 1 L of autoinduction media with the overnight starter culture. Add 4-TFM-Phe to a final concentration of 1 mM.
-
Protein Expression: Incubate the culture at 37°C with shaking for 24-30 hours.
-
Cell Harvesting: Harvest the cells by centrifugation at 5,000 x g for 15 minutes at 4°C.
-
Protein Purification: Resuspend the cell pellet in a suitable lysis buffer and purify the labeled protein using standard chromatography techniques (e.g., Ni-NTA affinity chromatography if the protein is His-tagged).
-
¹⁹F NMR Analysis: Prepare the purified protein sample in a suitable NMR buffer. Acquire ¹⁹F NMR spectra on a spectrometer equipped with a fluorine probe.
Experimental Workflow:
Protocol 2: Radiosynthesis of ¹⁸F-labeled this compound for PET Imaging
This protocol provides a general procedure for the radiosynthesis of ¹⁸F-labeled phenylalanine analogs. Specific precursors and reaction conditions may need to be optimized for 4-TFM-Phe.[5][9]
Materials:
-
No-carrier-added [¹⁸F]fluoride
-
Suitable precursor for fluorination (e.g., a tosylate or mesylate derivative of a 4-TFM-Phe precursor)
-
Kryptofix 2.2.2 (K₂₂₂)
-
Potassium carbonate (K₂CO₃)
-
Acetonitrile (B52724) (anhydrous)
-
HPLC purification system
-
Solvents for HPLC (e.g., acetonitrile, water, TFA)
Procedure:
-
[¹⁸F]Fluoride Trapping: Trap the aqueous [¹⁸F]fluoride solution on an anion exchange cartridge.
-
Elution and Drying: Elute the [¹⁸F]fluoride from the cartridge into a reaction vessel using a solution of K₂₂₂ and K₂CO₃ in acetonitrile/water. Dry the [¹⁸F]fluoride by azeotropic distillation with anhydrous acetonitrile.
-
Radiolabeling Reaction: Add the precursor dissolved in anhydrous acetonitrile to the dried [¹⁸F]fluoride and heat the reaction mixture (e.g., at 80-120°C) for a specified time (e.g., 10-20 minutes).
-
Purification: Purify the crude reaction mixture using semi-preparative HPLC to isolate the ¹⁸F-labeled product.
-
Formulation: Remove the HPLC solvent and formulate the purified ¹⁸F-labeled tracer in a physiologically compatible solution (e.g., sterile saline with ethanol).
-
Quality Control: Perform quality control tests to determine radiochemical purity, specific activity, and other relevant parameters before in vivo use.
Experimental Workflow:
Signaling Pathway Visualization
Src Homology 3 (SH3) Domain-Mediated Signaling
SH3 domains are protein-protein interaction modules that typically bind to proline-rich sequences in other proteins, playing a crucial role in various cellular signaling pathways.[8] By incorporating 4-TFM-Phe into or near the binding pocket of an SH3 domain, ¹⁹F NMR can be used to study the binding of proline-rich ligands and the subsequent downstream signaling events. The following diagram illustrates a simplified signaling pathway involving an SH3 domain where 4-TFM-Phe could be used as a probe.
Conclusion
This compound is a versatile molecular probe with significant applications in both fundamental and applied biomedical research. Its utility in ¹⁹F NMR spectroscopy allows for detailed, site-specific investigation of protein structure and function, while its potential for ¹⁸F-labeling opens up avenues for non-invasive in vivo imaging with PET. The protocols and data presented here provide a foundation for researchers to employ this powerful tool in their own studies.
References
- 1. Site-specific 19F NMR chemical shift and side chain relaxation analysis of a membrane protein labeled with an unnatural amino acid - PMC [pmc.ncbi.nlm.nih.gov]
- 2. A comparison of chemical shift sensitivity of trifluoromethyl tags: optimizing resolution in 19F NMR studies of proteins - PMC [pmc.ncbi.nlm.nih.gov]
- 3. 1azg - NMR STUDY OF THE SH3 DOMAIN FROM FYN PROTO-ONCOGENE TYROSINE KINASE KINASE COMPLEXED WITH THE SYNTHETIC PEPTIDE P2L CORRESPONDING TO RESIDUES 91-104 OF THE P85 SUBUNIT OF PI3-KINASE, MINIMIZED AVERAGE (PROBMAP) STRUCTURE - Summary - Protein Data Bank Japan [pdbj.org]
- 4. researchgate.net [researchgate.net]
- 5. mdpi.com [mdpi.com]
- 6. 59645 [pdspdb.unc.edu]
- 7. 19F NMR studies of solvent exposure and peptide binding to an SH3 domain - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. SH3 domains: modules of protein–protein interactions - PMC [pmc.ncbi.nlm.nih.gov]
- 9. The SH3 domain of Fyn kinase interacts with and induces liquid–liquid phase separation of the low-complexity domain of hnRNPA2 - PMC [pmc.ncbi.nlm.nih.gov]
Application Notes: Labeling Proteins with 4-(Trifluoromethyl)-L-phenylalanine for Structural and Functional Studies
Introduction
The incorporation of non-canonical amino acids into proteins offers a powerful tool for probing protein structure, dynamics, and function. 4-(Trifluoromethyl)-L-phenylalanine (4-TFM-Phe) is a particularly valuable unnatural amino acid for such studies. The trifluoromethyl group serves as a sensitive reporter for fluorine-19 (¹⁹F) Nuclear Magnetic Resonance (NMR) spectroscopy.[1][2][3][4][5] Due to the high natural abundance of ¹⁹F, its spin-1/2 nucleus, and a large chemical shift range, ¹⁹F NMR provides a high-sensitivity method for investigating protein conformational changes, ligand binding, and protein-protein interactions with minimal background interference from other biological molecules.[1][6][7]
Key Applications
-
¹⁹F NMR Spectroscopy: The primary application of 4-TFM-Phe labeling is for ¹⁹F NMR studies. The chemical shift of the ¹⁹F nucleus is highly sensitive to the local chemical environment, making it an excellent probe for detecting subtle conformational changes in proteins upon ligand binding, inhibitor interaction, or changes in the protein's folding state.[1][2][3][4][5] Simple one-dimensional ¹⁹F NMR experiments can often provide significant insights into protein dynamics.[1]
-
Drug Discovery and Development: By monitoring the changes in the ¹⁹F NMR spectrum of a 4-TFM-Phe labeled protein upon the addition of small molecules, researchers can screen for and characterize the binding of potential drug candidates.[8][9] This technique can provide information on binding affinity and the mechanism of action.
-
Protein Engineering and Stability: The introduction of fluorinated amino acids can enhance the thermal and chemical stability of proteins.[8] 4-TFM-Phe can be used to study the contributions of aromatic interactions to protein stability and function.[10]
-
In-cell NMR: The lack of a natural fluorine background signal in cells makes ¹⁹F NMR an ideal technique for studying proteins in their native cellular environment.[2][5]
Methods of Incorporation
There are two primary methods for incorporating 4-TFM-Phe into proteins:
-
Metabolic Labeling: This method involves growing a host organism, typically an E. coli strain auxotrophic for phenylalanine, in a minimal medium where phenylalanine is replaced with 4-TFM-Phe. To enhance incorporation efficiency, inhibitors of endogenous aromatic amino acid biosynthesis, such as glyphosate, can be used.[1][7] This approach leads to the substitution of most, if not all, phenylalanine residues with 4-TFM-Phe.
-
Site-Specific Incorporation (Amber Suppression): For more precise labeling at a single, defined position, amber suppression technology is employed.[2][4][10] This technique utilizes an engineered aminoacyl-tRNA synthetase and a corresponding suppressor tRNA (tRNA CUA) to recognize the amber stop codon (UAG). When the gene of interest is mutated to contain a UAG codon at the desired location, the engineered synthetase charges the suppressor tRNA with 4-TFM-Phe, which is then incorporated into the protein during translation.[2][4][10]
Experimental Protocols
Protocol 1: Metabolic Labeling of Proteins with 4-TFM-Phe in E. coli
This protocol is adapted from methods for labeling proteins with fluorinated aromatic amino acids.[1]
Materials:
-
E. coli BL21(DE3) cells transformed with the expression plasmid for the protein of interest.
-
Luria-Bertani (LB) medium with appropriate antibiotic.
-
M9 minimal medium.
-
10x M9 salts.
-
4-TFM-Phe.
-
Glucose.
-
NH₄Cl (or ¹⁵NH₄Cl for double labeling).
-
Glyphosate.
-
L-tyrosine and L-tryptophan.
-
Isopropyl β-D-1-thiogalactopyranoside (IPTG).
Procedure:
-
Day 1: Starter Culture:
-
Inoculate a 5 mL LB medium containing the appropriate antibiotic with a single colony of the transformed E. coli.
-
Incubate at 37°C with shaking at 200-250 rpm for 6-8 hours or overnight.
-
-
Day 2: Main Culture and Induction:
-
Prepare 1 L of M9 minimal medium in a 2.8 L baffled flask.
-
Inoculate the M9 medium with the starter culture.
-
Grow the cells at 37°C with shaking until the OD₆₀₀ reaches 0.6-0.8.
-
Reduce the temperature to 18-20°C and shake for 1 hour to cool the culture.
-
Add the following to the culture:
-
1 g/L glyphosate.
-
50 mg/L this compound.
-
50 mg/L L-tyrosine.
-
50 mg/L L-tryptophan.
-
-
Induce protein expression by adding IPTG to a final concentration of 0.5-1 mM.
-
Incubate the culture at 18-20°C with shaking for 18-20 hours.
-
-
Day 3: Cell Harvesting:
-
Harvest the cells by centrifugation at 4,000-6,000 x g for 15-20 minutes at 4°C.
-
Discard the supernatant and store the cell pellet at -80°C until purification.
-
Protocol 2: Site-Specific Incorporation of 4-TFM-Phe using Amber Suppression
This protocol outlines the general workflow for site-specific incorporation.[2][4][10][11]
Materials:
-
E. coli strain (e.g., BL21(DE3)) co-transformed with:
-
The plasmid for the protein of interest containing an amber (TAG) codon at the desired site.
-
A plasmid encoding the engineered aminoacyl-tRNA synthetase and suppressor tRNA specific for 4-TFM-Phe.
-
-
LB medium with appropriate antibiotics for both plasmids.
-
4-TFM-Phe.
-
IPTG and/or L-arabinose for induction, depending on the expression vectors.
Procedure:
-
Transformation: Co-transform the E. coli host strain with the two plasmids and select for colonies on LB agar (B569324) plates containing the appropriate antibiotics.
-
Starter Culture: Grow a starter culture overnight at 37°C in LB medium with antibiotics.
-
Main Culture and Induction:
-
Inoculate a larger volume of LB medium (or minimal medium for specific applications) with the overnight culture.
-
Grow the cells at 37°C to an OD₆₀₀ of 0.6-0.8.
-
Add 4-TFM-Phe to the culture medium (typically 1-2 mM final concentration).
-
Induce the expression of the protein of interest and the synthetase/tRNA pair using the appropriate inducers (e.g., IPTG, L-arabinose).
-
Continue to grow the culture at a reduced temperature (e.g., 20-30°C) for several hours to overnight.
-
-
Cell Harvesting and Purification:
-
Harvest the cells by centrifugation.
-
Purify the labeled protein using standard chromatography techniques (e.g., affinity, ion-exchange, size-exclusion).
-
Confirm the incorporation of 4-TFM-Phe by mass spectrometry.
-
Quantitative Data
The efficiency of 4-TFM-Phe incorporation can vary depending on the method, the specific protein, and the expression conditions.
| Parameter | Method | Typical Value/Range | Reference |
| Incorporation Fidelity | Site-Specific (Amber Suppression) | >95% | [10] |
| Protein Yield (sfGFP) | Site-Specific (HEK cells) | ~34 µg per gram of cell pellet | [10] |
| ¹⁹F NMR Sensitivity | General | 83% of ¹H NMR | [1][7] |
| ¹⁹F Chemical Shift Range | General | >400 ppm | [1] |
Visualizations
Caption: Workflow for metabolic labeling of proteins with 4-TFM-Phe.
Caption: Workflow for site-specific incorporation of 4-TFM-Phe.
References
- 1. Fluorine labeling of proteins for NMR studies – Bio-NMR Core [bionmr.cores.ucla.edu]
- 2. pubs.acs.org [pubs.acs.org]
- 3. researchgate.net [researchgate.net]
- 4. Site-specific incorporation of a (19)F-amino acid into proteins as an NMR probe for characterizing protein structure and reactivity - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
- 6. kops.uni-konstanz.de [kops.uni-konstanz.de]
- 7. researchgate.net [researchgate.net]
- 8. Fluorinated phenylalanines: synthesis and pharmaceutical applications - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Trp/Met/Phe hot spots in protein-protein interactions: potential targets in drug design - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. Tuning phenylalanine fluorination to assess aromatic contributions to protein function and stability in cells - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Genetic Incorporation of the Unnatural Amino Acid p-Acetyl Phenylalanine into Proteins for Site-Directed Spin Labeling - PMC [pmc.ncbi.nlm.nih.gov]
Applications of 4-(Trifluoromethyl)-L-phenylalanine in Drug Design: Application Notes and Protocols
For Researchers, Scientists, and Drug Development Professionals
Introduction
4-(Trifluoromethyl)-L-phenylalanine is a non-canonical amino acid that has garnered significant interest in drug design and discovery. The incorporation of a trifluoromethyl (CF3) group onto the phenyl ring of L-phenylalanine imparts unique physicochemical properties that can enhance the therapeutic potential of peptides and small molecules. The strong electron-withdrawing nature of the CF3 group can influence molecular conformation, lipophilicity, metabolic stability, and binding affinity to biological targets. These attributes make this compound a valuable building block for the development of novel therapeutics, including enzyme inhibitors, peptide and protein analogs, and molecular probes for studying biological systems.
Core Applications in Drug Design
The unique properties of this compound have been exploited in several areas of drug design:
-
Enzyme Inhibition: The trifluoromethyl group can act as a bioisostere for other chemical groups and can form strong interactions with enzyme active sites, leading to potent and selective inhibition.
-
Peptide and Protein Engineering: Incorporation of this modified amino acid into peptides can improve their stability against proteolytic degradation, enhance their binding affinity to receptors, and modulate their pharmacokinetic profiles.
-
Molecular Probes: The 19F nucleus of the trifluoromethyl group serves as a sensitive NMR probe for studying drug-target interactions and protein conformation without the need for isotopic labeling.
Quantitative Data Summary
The following tables summarize the inhibitory activities of various compounds containing a trifluoromethylphenyl moiety, illustrating the potential of this chemical group in designing potent bioactive molecules.
| Compound | Target | IC50 (nM) | Reference Compound | IC50 (nM) |
| Hedgehog Signaling Pathway Inhibitors | ||||
| Compound 13d (a 4-(2-pyrimidinylamino)benzamide with a trifluoromethyl group) | Hedgehog Signaling Pathway | 1.44 | Vismodegib | (not specified) |
| Proteasome Inhibitors | ||||
| Anthracene-bearing trifluoromethyl-containing aziridine (B145994) (Compound 16) | Proteasome (β5 subunit) | 13,600 | (not specified) | (not specified) |
| Diazophenyl-bearing trifluoromethyl-containing aziridine (Compound 18) | Proteasome (β5 subunit) | 14,100 | (not specified) | (not specified) |
Experimental Protocols
Protocol 1: Solid-Phase Peptide Synthesis (SPPS) of a Peptide Containing this compound
This protocol outlines the manual solid-phase synthesis of a model tripeptide (e.g., Ac-Ala-Phe(4-CF3)-Gly-NH2) using Fmoc/tBu chemistry.
Materials:
-
Rink Amide MBHA resin
-
Fmoc-Gly-OH
-
Fmoc-4-(Trifluoromethyl)-L-phenylalanine
-
Fmoc-Ala-OH
-
N,N'-Diisopropylcarbodiimide (DIC)
-
OxymaPure
-
Piperidine (B6355638) solution (20% in DMF)
-
N,N-Dimethylformamide (DMF)
-
Dichloromethane (DCM)
-
Acetic anhydride (B1165640)
-
Trifluoroacetic acid (TFA) cleavage cocktail (e.g., TFA/TIS/H2O 95:2.5:2.5)
-
Diethyl ether
-
Solid-phase synthesis vessel
-
Shaker
Procedure:
-
Resin Swelling: Swell the Rink Amide MBHA resin in DMF for 30 minutes in the synthesis vessel.
-
Fmoc-Glycine Coupling:
-
Drain the DMF.
-
Add a solution of Fmoc-Gly-OH (3 eq), DIC (3 eq), and OxymaPure (3 eq) in DMF to the resin.
-
Shake the mixture for 2 hours at room temperature.
-
Drain the coupling solution and wash the resin with DMF (3x) and DCM (3x).
-
-
Fmoc Deprotection:
-
Add 20% piperidine in DMF to the resin and shake for 5 minutes.
-
Drain the solution.
-
Add fresh 20% piperidine in DMF and shake for another 15 minutes.
-
Drain and wash the resin with DMF (5x) and DCM (3x).
-
-
Fmoc-4-(Trifluoromethyl)-L-phenylalanine Coupling:
-
Repeat step 2 using Fmoc-4-(Trifluoromethyl)-L-phenylalanine.
-
-
Fmoc Deprotection:
-
Repeat step 3.
-
-
Fmoc-Alanine Coupling:
-
Repeat step 2 using Fmoc-Ala-OH.
-
-
Fmoc Deprotection:
-
Repeat step 3.
-
-
N-terminal Acetylation:
-
Add a solution of acetic anhydride (10 eq) and DIPEA (10 eq) in DMF to the resin.
-
Shake for 30 minutes.
-
Drain and wash the resin with DMF (3x) and DCM (3x).
-
-
Cleavage and Deprotection:
-
Wash the resin with DCM and dry under vacuum.
-
Add the TFA cleavage cocktail to the resin and shake for 2-3 hours.
-
Filter the resin and collect the filtrate.
-
Precipitate the crude peptide by adding cold diethyl ether.
-
Centrifuge to pellet the peptide, decant the ether, and wash the pellet with cold ether.
-
Dry the crude peptide under vacuum.
-
-
Purification:
-
Purify the crude peptide by reverse-phase HPLC.
-
Lyophilize the pure fractions to obtain the final peptide.
-
Protocol 2: Enzyme Inhibition Assay
This protocol describes a general procedure for determining the IC50 value of a compound containing this compound against a model enzyme (e.g., a protease).
Materials:
-
Enzyme stock solution
-
Fluorogenic or chromogenic substrate specific for the enzyme
-
Assay buffer (e.g., Tris-HCl, PBS)
-
Inhibitor stock solution (compound dissolved in DMSO)
-
96-well microplate (black or clear, depending on the substrate)
-
Microplate reader
Procedure:
-
Prepare Reagents:
-
Dilute the enzyme stock solution to the desired working concentration in assay buffer.
-
Prepare a series of dilutions of the inhibitor in assay buffer from the DMSO stock. Ensure the final DMSO concentration in the assay is low (e.g., <1%).
-
Dilute the substrate stock solution to the desired working concentration in assay buffer.
-
-
Assay Setup:
-
In a 96-well plate, add 50 µL of the inhibitor dilutions to the appropriate wells.
-
Add 50 µL of assay buffer to the control wells (no inhibitor).
-
Add 50 µL of the enzyme solution to all wells except the blank wells.
-
Add 50 µL of assay buffer to the blank wells.
-
Pre-incubate the plate at the optimal temperature for the enzyme for 10-15 minutes.
-
-
Initiate Reaction:
-
Add 100 µL of the substrate solution to all wells to start the reaction.
-
-
Measurement:
-
Immediately begin monitoring the change in fluorescence or absorbance over time using a microplate reader at the appropriate wavelengths.
-
-
Data Analysis:
-
Calculate the initial reaction rates (V) from the linear portion of the progress curves.
-
Normalize the rates relative to the control (no inhibitor) to get the percent inhibition.
-
Plot the percent inhibition against the logarithm of the inhibitor concentration.
-
Fit the data to a dose-response curve (e.g., sigmoidal curve) to determine the IC50 value.[1]
-
Visualizations
Signaling Pathway Diagram
Figure 1: Simplified PI3K/Akt/mTOR signaling pathway.
Experimental Workflow Diagram
References
Application Notes and Protocols for the Synthesis of Peptides Containing 4-(Trifluoromethyl)-L-phenylalanine
For Researchers, Scientists, and Drug Development Professionals
Introduction
The incorporation of non-canonical amino acids into peptides is a powerful strategy in modern drug discovery and chemical biology. 4-(Trifluoromethyl)-L-phenylalanine (Tfm-Phe) is a particularly valuable building block. The trifluoromethyl group, a bioisostere for the methyl group, can significantly enhance the therapeutic potential of peptides by improving metabolic stability, increasing lipophilicity, and modulating binding affinity to biological targets.[1][2] This document provides detailed protocols for the synthesis, purification, and characterization of peptides containing Tfm-Phe, intended for researchers in academia and the pharmaceutical industry.
Applications in Drug Discovery and Research
The unique properties conferred by the trifluoromethyl group make Tfm-Phe-containing peptides promising candidates for various therapeutic areas. The incorporation of this moiety can lead to peptides with enhanced properties such as:
-
Increased Metabolic Stability: The strong carbon-fluorine bond is resistant to enzymatic degradation, prolonging the in vivo half-life of the peptide.[3]
-
Enhanced Binding Affinity: The electron-withdrawing nature of the trifluoromethyl group can alter the electronic properties of the phenyl ring, potentially leading to stronger interactions with target proteins.[4]
-
Improved Lipophilicity: The trifluoromethyl group increases the lipophilicity of the peptide, which can improve its ability to cross cell membranes.[1]
These attributes have led to the exploration of Tfm-Phe-containing peptides as enzyme inhibitors, therapeutic agents, and tools for studying protein-protein interactions.[3][4]
Synthesis of Peptides Containing this compound
Peptides incorporating Tfm-Phe can be synthesized using either solid-phase peptide synthesis (SPPS) or solution-phase peptide synthesis (SPPS). The choice of method depends on the desired peptide length, scale, and purification strategy.
Solid-Phase Peptide Synthesis (SPPS)
SPPS is the most common method for synthesizing peptides and is well-suited for the incorporation of Tfm-Phe.[5] The Fmoc/tBu (9-fluorenylmethyloxycarbonyl/tert-butyl) strategy is widely used due to its milder deprotection conditions.[6]
Workflow for Solid-Phase Peptide Synthesis of a Tfm-Phe Containing Peptide
References
Site-Specific Incorporation of 4-(Trifluoromethyl)-L-phenylalanine: Application Notes and Protocols
For Researchers, Scientists, and Drug Development Professionals
Introduction
The site-specific incorporation of non-canonical amino acids (ncAAs) into proteins represents a powerful tool in chemical biology, protein engineering, and drug development. This technology allows for the introduction of novel chemical functionalities, such as spectroscopic probes, post-translational modifications, and bioorthogonal handles, at precise locations within a protein of interest. 4-(Trifluoromethyl)-L-phenylalanine (pTFF) is a particularly valuable ncAA. The trifluoromethyl group serves as a sensitive ¹⁹F NMR probe for studying protein structure, dynamics, and interactions without the background signals inherent in other NMR techniques.[1][2][3] Its unique electronic properties can also modulate protein stability and function, making it a valuable tool for developing novel therapeutics.[4][5]
This document provides detailed application notes and protocols for the site-specific incorporation of pTFF into proteins using amber stop codon suppression technology.[1][6] This method relies on an orthogonal aminoacyl-tRNA synthetase/tRNA pair that is engineered to uniquely recognize pTFF and the UAG (amber) stop codon, respectively, thereby enabling its insertion into the growing polypeptide chain.[6][7][8]
Applications
The unique properties of pTFF enable a wide range of applications in research and drug development:
-
¹⁹F Nuclear Magnetic Resonance (NMR) Spectroscopy: The trifluoromethyl group provides a highly sensitive and background-free NMR signal, allowing for the detailed study of protein conformational changes, ligand binding, and protein-protein interactions.[1][2][3]
-
Enzyme Mechanism and Inhibition Studies: The electron-withdrawing nature of the trifluoromethyl group can alter the local electronic environment, providing insights into enzyme catalytic mechanisms and aiding in the design of potent and specific inhibitors.
-
Protein Stability and Folding: The introduction of pTFF can influence protein stability and folding pathways. Studying these effects can enhance the development of more stable and effective protein therapeutics.[4]
-
Drug Discovery and Development: Incorporating pTFF into therapeutic proteins can improve their pharmacological properties, such as increased stability and enhanced binding affinity.[5]
Core Technology: Orthogonal Translation System
The site-specific incorporation of pTFF is achieved through the expansion of the genetic code.[6] This requires a specialized set of tools that work in parallel with the cell's natural translational machinery without cross-reacting with it. This "orthogonal system" consists of:
-
An Orthogonal Aminoacyl-tRNA Synthetase (aaRS): An engineered enzyme that specifically recognizes and attaches pTFF to its partner tRNA.[6][8] Pyrrolysyl-tRNA synthetase (PylRS) from Methanosarcina species is a commonly used scaffold for engineering these synthetases.[6][7][9]
-
An Orthogonal tRNA: A transfer RNA molecule, often a suppressor tRNA with an anticodon (CUA) that recognizes the amber stop codon (UAG), which is specifically recognized by the orthogonal aaRS but not by any of the host cell's endogenous synthetases.[1][8][10]
-
A Gene of Interest with an Amber Codon: The gene encoding the target protein must be mutated to introduce a UAG codon at the desired site of pTFF incorporation.[1]
The following diagram illustrates the workflow for site-specific incorporation of pTFF.
Experimental Protocols
This section provides detailed protocols for the expression of a target protein with site-specifically incorporated pTFF in E. coli.
Protocol 1: Plasmid Preparation and Transformation
-
Gene of Interest Preparation:
-
Subclone the gene of interest into a suitable expression vector (e.g., pBAD) containing an inducible promoter.
-
Introduce an amber stop codon (TAG) at the desired position for pTFF incorporation using site-directed mutagenesis.[11]
-
Verify the sequence of the mutated plasmid by DNA sequencing.
-
-
Co-transformation:
-
Prepare competent E. coli cells (e.g., BL21(DE3)).
-
Co-transform the competent cells with the plasmid containing the gene of interest with the TAG codon and the plasmid encoding the orthogonal aaRS/tRNA pair (e.g., pDULE-tfmF).[1]
-
Plate the transformed cells on LB agar (B569324) plates containing the appropriate antibiotics for both plasmids and incubate overnight at 37°C.
-
Protocol 2: Protein Expression and pTFF Incorporation
-
Starter Culture:
-
Inoculate a single colony from the transformation plate into 5 mL of LB medium containing the appropriate antibiotics.
-
Incubate overnight at 37°C with shaking (250 rpm).[9]
-
-
Expression Culture:
-
Inoculate a larger volume of autoinduction media (or LB media) containing the appropriate antibiotics and 1 mM pTFF with the overnight starter culture (e.g., a 1:100 dilution).[9][11]
-
Incubate the culture at 37°C with shaking (250 rpm) until the OD₆₀₀ reaches 0.6-0.8.
-
If using an inducible promoter (e.g., arabinose for pBAD), add the inducer to the final concentration recommended for the specific vector.
-
Reduce the temperature to 18-25°C and continue to incubate for 16-24 hours to enhance protein solubility and proper folding.[12]
-
-
Cell Harvest:
-
Harvest the cells by centrifugation at 5,000 x g for 15 minutes at 4°C.
-
Discard the supernatant and store the cell pellet at -80°C until purification.
-
Protocol 3: Protein Purification
This protocol assumes the target protein has a C-terminal hexa-histidine (His₆) tag.
-
Cell Lysis:
-
Resuspend the cell pellet in lysis buffer (e.g., 50 mM Tris-HCl pH 8.0, 300 mM NaCl, 10 mM imidazole, 1 mg/mL lysozyme, and protease inhibitors).
-
Incubate on ice for 30 minutes.
-
Sonicate the cell suspension on ice to further disrupt the cells and shear the DNA.
-
Clarify the lysate by centrifugation at 15,000 x g for 30 minutes at 4°C.
-
-
Affinity Chromatography:
-
Equilibrate a Ni-NTA affinity column with wash buffer (50 mM Tris-HCl pH 8.0, 300 mM NaCl, 20 mM imidazole).
-
Load the clarified lysate onto the column.
-
Wash the column with several column volumes of wash buffer to remove unbound proteins.
-
Elute the His-tagged protein with elution buffer (50 mM Tris-HCl pH 8.0, 300 mM NaCl, 250 mM imidazole).
-
Collect the elution fractions.
-
-
Buffer Exchange:
-
Pool the fractions containing the purified protein.
-
Perform buffer exchange into a suitable storage buffer (e.g., PBS) using dialysis or a desalting column.
-
Concentrate the protein if necessary.
-
Protocol 4: Verification of pTFF Incorporation
-
SDS-PAGE and Western Blotting:
-
Analyze the purified protein by SDS-PAGE to assess its purity and molecular weight.
-
Perform a Western blot using an antibody against the protein tag (e.g., anti-His) to confirm the expression of the full-length protein. Successful incorporation of pTFF will result in a band corresponding to the full-length protein. A truncated product may be observed if suppression of the amber codon is incomplete.
-
-
Mass Spectrometry:
-
Use electrospray ionization mass spectrometry (ESI-MS) to confirm the precise mass of the purified protein.[9][13] The observed mass should match the theoretical mass calculated for the protein with pTFF incorporated at the specified site.
-
For larger proteins, "bottom-up" proteomics can be employed. The protein is digested with a protease (e.g., trypsin), and the resulting peptides are analyzed by LC-MS/MS to identify the peptide containing pTFF.[14][15]
-
The following diagram illustrates the mechanism of amber codon suppression for pTFF incorporation.
Quantitative Data Summary
The efficiency of pTFF incorporation can vary depending on the protein, the specific site of incorporation, the expression system, and the culture conditions. The following tables summarize representative quantitative data from published studies.
Table 1: Protein Yields with Site-Specifically Incorporated pTFF
| Protein | Expression System | Incorporation Site | Yield | Reference |
| Superfolder GFP (sfGFP) | E. coli | N150 | ~5-10 mg/L | [9] |
| sfGFP | HEK 293T cells | N150 | 34 µg/g cell pellet | [9][16] |
| Dihydrofolate Reductase (DHFR) | E. coli | Multiple sites | Not specified | [17][18] |
| HDH, NTR, NtrC r | E. coli | Not specified | Not specified | [1] |
Table 2: Incorporation Efficiency of pTFF
| Protein | Method of Determination | Efficiency | Reference |
| sfGFP | ESI-MS | High fidelity | [9] |
| sfGFP | SDS-PAGE/Western Blot | Efficient suppression | [13] |
| Various proteins | ¹⁹F NMR | Sufficient for analysis | [3] |
Optimization and Troubleshooting
Several factors can be optimized to improve the yield and incorporation efficiency of pTFF.
-
Codon Context: The nucleotide sequence surrounding the UAG codon can influence suppression efficiency.
-
Expression Temperature: Lowering the expression temperature (15-25°C) can improve protein folding and solubility, leading to higher yields of functional protein.[12]
-
Inducer Concentration: Optimizing the concentration of the inducer can control the rate of protein expression, which can be beneficial for protein folding.[12]
-
pTFF Concentration: The concentration of pTFF in the growth media should be optimized. While 1 mM is a common starting point, higher concentrations may be necessary for some proteins.
-
Host Strain: Using protease-deficient E. coli strains can reduce the degradation of the target protein.[12]
-
Plasmid Copy Number: The relative copy numbers of the expression plasmid and the orthogonal system plasmid can be adjusted to optimize the balance between target gene expression and the components of the incorporation machinery.
The following diagram illustrates a potential signaling pathway that could be investigated using pTFF incorporation and ¹⁹F NMR.
Conclusion
The site-specific incorporation of this compound provides a robust and versatile platform for detailed studies of protein structure and function, as well as for the development of novel protein therapeutics. The protocols and data presented here offer a comprehensive guide for researchers to successfully implement this powerful technology in their own work. Careful optimization of experimental conditions is key to achieving high yields and efficient incorporation of this valuable non-canonical amino acid.
References
- 1. researchgate.net [researchgate.net]
- 2. Analysis of fluorinated proteins by mass spectrometry - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. pubs.acs.org [pubs.acs.org]
- 4. Fluorinated phenylalanines: synthesis and pharmaceutical applications - PMC [pmc.ncbi.nlm.nih.gov]
- 5. nbinno.com [nbinno.com]
- 6. ir.library.oregonstate.edu [ir.library.oregonstate.edu]
- 7. Optimized orthogonal translation of unnatural amino acids enables spontaneous protein double-labelling and FRET - PMC [pmc.ncbi.nlm.nih.gov]
- 8. mdpi.com [mdpi.com]
- 9. Tuning phenylalanine fluorination to assess aromatic contributions to protein function and stability in cells - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Role of tRNA Orthogonality in an Expanded Genetic Code - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Unraveling Complex Local Protein Environments with 4-Cyano-L-Phenylalanine - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Tips for Optimizing Protein Expression and Purification | Rockland [rockland.com]
- 13. pubs.acs.org [pubs.acs.org]
- 14. Protein Mass Spectrometry Made Simple - PMC [pmc.ncbi.nlm.nih.gov]
- 15. youtube.com [youtube.com]
- 16. biorxiv.org [biorxiv.org]
- 17. Fluorescent biphenyl derivatives of phenylalanine suitable for protein modification - PubMed [pubmed.ncbi.nlm.nih.gov]
- 18. Fluorescent Biphenyl Derivatives of Phenylalanine Suitable for Protein Modification - PMC [pmc.ncbi.nlm.nih.gov]
Application Notes and Protocols: 4-(Trifluoromethyl)-L-phenylalanine in Cancer Research
For Researchers, Scientists, and Drug Development Professionals
Introduction
4-(Trifluoromethyl)-L-phenylalanine is a synthetic amino acid derivative. While direct and extensive research into its specific anticancer properties is limited, its structural features—combining the essential amino acid L-phenylalanine with a trifluoromethyl group—suggest several plausible mechanisms for investigation in oncology. The trifluoromethyl moiety is a common feature in many modern pharmaceuticals, known to enhance metabolic stability and binding affinity.[1][2] This document provides a framework for exploring the potential of this compound as an anticancer agent, based on the activities of structurally related compounds and established cancer biology principles.
These notes offer detailed protocols for researchers to systematically evaluate the efficacy and mechanism of action of this compound in cancer models.
Postulated Mechanisms of Action
Based on the current understanding of cancer cell metabolism and the function of related phenylalanine analogs, several potential mechanisms of action for this compound can be hypothesized.
-
Competitive Inhibition of Amino Acid Transport: Cancer cells exhibit a high demand for amino acids to fuel their rapid proliferation.[3] They often overexpress L-type Amino Acid Transporter 1 (LAT1), which facilitates the uptake of large neutral amino acids, including phenylalanine.[4][5][6] this compound, as an analog of L-phenylalanine, may act as a competitive inhibitor of LAT1, thereby starving cancer cells of essential amino acids required for protein synthesis and growth.[4][5] This could disrupt downstream signaling pathways like mTORC1, which is sensitive to intracellular amino acid levels.[4]
-
Metabolic Disruption and Glycolysis Inhibition: The Warburg effect, a metabolic shift towards aerobic glycolysis, is a hallmark of many cancers.[7][8][9] This process provides the necessary energy and biosynthetic precursors for tumor growth. While direct evidence is lacking for this compound, other molecules with a trifluoromethylphenyl group have been shown to inhibit key metabolic enzymes. For instance, 1-(phenylseleno)-4-(trifluoromethyl) benzene (B151609) was identified as an inhibitor of Lactate Dehydrogenase A (LDHA), a critical enzyme in the glycolytic pathway.[10] It is plausible that this compound could similarly interfere with metabolic enzymes, leading to ATP depletion and cell death.[7]
-
Induction of Apoptosis: Disruption of essential cellular processes, such as protein synthesis and energy metabolism, can trigger programmed cell death, or apoptosis.[11][12] Phenylalanine derivatives and other trifluoromethyl-containing compounds have been shown to induce apoptosis in cancer cells.[13][14] This can occur through the intrinsic pathway, involving mitochondrial dysfunction and the activation of caspases.
Below is a conceptual diagram illustrating the potential interplay of these mechanisms.
Quantitative Data on Related Compounds
| Compound Name | Target Cancer Cell Line | IC50 Value | Notes |
| HXL131 (a novel L-phenylalanine dipeptide) | PC3 (Prostate Cancer) | 5.15 µM (24h) | Inhibits proliferation and induces apoptosis.[15] |
| 3-(3,4-dimethoxyphenyl)-5-(thiophen-2-yl)-4-(trifluoromethyl)isoxazole | MCF-7 (Breast Cancer) | 2.63 µM | A trifluoromethyl-containing isoxazole (B147169) derivative.[16] |
| 3-substituted-2-thioxo-5-(trifluoromethyl)-thiazolo[4,5-d]pyrimidin-7(6H)-one | C32 (Melanoma) | 24.4 µM | Demonstrates the activity of a trifluoromethyl group in a heterocyclic system.[17] |
| (E)-1-(pyridin-4-yl)-3-(quinolin-2-yl)prop-2-en-1-one (PFK15) | DLD1 (Colorectal) | Varies | An inhibitor of PFKFB3, a key regulator of glycolysis.[18] |
Experimental Protocols
The following protocols provide a standard framework for the initial in vitro and in vivo evaluation of this compound.
In Vitro Cytotoxicity Assessment (MTT Assay)
This protocol determines the concentration of this compound that inhibits cell viability by 50% (IC50).
Materials:
-
Cancer cell lines of interest (e.g., MCF-7, PC-3, A549)
-
Complete growth medium (e.g., DMEM, RPMI-1640) with 10% FBS
-
This compound (stock solution in DMSO or PBS)
-
MTT (3-(4,5-dimethylthiazol-2-yl)-2,5-diphenyltetrazolium bromide) solution (5 mg/mL in PBS)
-
Solubilization solution (e.g., DMSO or 0.01 M HCl in 10% SDS)
-
96-well plates
-
Multichannel pipette
-
Plate reader (absorbance at 570 nm)
Procedure:
-
Cell Seeding: Seed cells in a 96-well plate at a density of 5,000-10,000 cells/well in 100 µL of complete medium. Incubate for 24 hours at 37°C, 5% CO2.
-
Compound Treatment: Prepare serial dilutions of this compound in culture medium. Remove the old medium from the cells and add 100 µL of the diluted compound solutions. Include vehicle controls (medium with the same concentration of DMSO as the highest drug concentration).
-
Incubation: Incubate the plates for 48-72 hours.
-
MTT Addition: Add 10 µL of MTT solution to each well and incubate for 3-4 hours at 37°C until purple formazan (B1609692) crystals are visible.[19][20]
-
Solubilization: Add 100 µL of solubilization solution to each well and mix thoroughly to dissolve the formazan crystals.[19]
-
Absorbance Reading: Measure the absorbance at 570 nm using a plate reader.
-
Data Analysis: Calculate the percentage of cell viability relative to the vehicle control and plot a dose-response curve to determine the IC50 value.
Apoptosis Assay (Annexin V/Propidium Iodide Staining)
This assay quantifies the induction of apoptosis following treatment.
Materials:
-
Cancer cells treated with this compound (at IC50 concentration)
-
Annexin V-FITC Apoptosis Detection Kit
-
Flow cytometer
Procedure:
-
Cell Treatment: Treat cells in 6-well plates with this compound for 24-48 hours.
-
Cell Harvesting: Collect both adherent and floating cells. Wash with cold PBS.
-
Staining: Resuspend cells in 1X Binding Buffer. Add Annexin V-FITC and Propidium Iodide (PI) according to the manufacturer's protocol.
-
Incubation: Incubate in the dark for 15 minutes at room temperature.
-
Flow Cytometry: Analyze the cells by flow cytometry within one hour. Differentiate between viable (Annexin V-/PI-), early apoptotic (Annexin V+/PI-), late apoptotic (Annexin V+/PI+), and necrotic (Annexin V-/PI+) cells.
Investigation of Signaling Pathways (Western Blotting)
This protocol assesses changes in protein expression in key signaling pathways.
Materials:
-
Treated and untreated cell lysates
-
Protein assay kit (e.g., BCA)
-
SDS-PAGE gels and running buffer
-
Transfer buffer and PVDF membrane
-
Blocking buffer (e.g., 5% non-fat milk in TBST)
-
Primary antibodies (e.g., anti-LAT1, anti-phospho-mTOR, anti-cleaved caspase-3, anti-β-actin)
-
HRP-conjugated secondary antibodies
-
Chemiluminescent substrate
Procedure:
-
Protein Quantification: Determine the protein concentration of cell lysates.
-
SDS-PAGE: Load equal amounts of protein onto an SDS-PAGE gel and separate by electrophoresis.
-
Protein Transfer: Transfer the separated proteins to a PVDF membrane.
-
Blocking: Block the membrane with blocking buffer for 1 hour at room temperature.
-
Antibody Incubation: Incubate the membrane with primary antibodies overnight at 4°C.
-
Washing and Secondary Antibody: Wash the membrane and incubate with HRP-conjugated secondary antibodies for 1 hour.
-
Detection: Visualize the protein bands using a chemiluminescent substrate and an imaging system.
In Vivo Antitumor Efficacy (Xenograft Model)
This protocol evaluates the effect of this compound on tumor growth in an animal model.
Materials:
-
Immunocompromised mice (e.g., nude or SCID)
-
Cancer cells for implantation
-
This compound formulated for injection (e.g., in saline with a solubilizing agent)
-
Calipers for tumor measurement
Procedure:
-
Tumor Implantation: Subcutaneously inject cancer cells (e.g., 1-5 x 10^6 cells) into the flank of each mouse.
-
Tumor Growth: Allow tumors to grow to a palpable size (e.g., 100-150 mm³).
-
Treatment: Randomize mice into treatment and control groups. Administer this compound (e.g., via intraperitoneal injection) at a predetermined dose and schedule. The control group receives the vehicle.
-
Monitoring: Measure tumor volume and body weight 2-3 times per week.
-
Endpoint: At the end of the study (or when tumors reach a predetermined size), euthanize the mice and excise the tumors for further analysis (e.g., histology, Western blotting).
Visualization of Workflows and Pathways
The following diagrams illustrate key experimental workflows and signaling pathways relevant to the investigation of this compound.
Conclusion and Future Directions
This compound represents an under-investigated molecule with theoretical potential as an anticancer agent. Its structural similarity to L-phenylalanine suggests it may hijack amino acid transport systems that are over-expressed in cancer cells, leading to metabolic disruption. The protocols and conceptual frameworks provided here serve as a comprehensive guide for researchers to initiate a systematic evaluation of its efficacy. Future studies should focus on obtaining definitive quantitative data, elucidating its precise molecular targets, and assessing its therapeutic window in preclinical models.
References
- 1. Fluorinated small molecule derivatives in cancer immunotherapy: emerging frontiers and therapeutic potential - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Fluorinated small molecule derivatives in cancer immunotherapy: emerging frontiers and therapeutic potential - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. mdpi.com [mdpi.com]
- 4. mdpi.com [mdpi.com]
- 5. The role of L-type amino acid transporter 1 in human tumors - PMC [pmc.ncbi.nlm.nih.gov]
- 6. mdpi.com [mdpi.com]
- 7. Inhibition of glycolysis in cancer cells: a novel strategy to overcome drug resistance associated with mitochondrial respiratory defect and hypoxia - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. Glycolysis inhibition for anticancer treatment - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. [PDF] Glycolysis inhibition for anticancer treatment | Semantic Scholar [semanticscholar.org]
- 10. Targeting cancer-specific metabolic pathways for developing novel cancer therapeutics - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Inducing death in tumor cells: roles of the inhibitor of apoptosis proteins - PMC [pmc.ncbi.nlm.nih.gov]
- 12. mdpi.com [mdpi.com]
- 13. In vitro and in vivo antitumor activity of a novel alkylating agent, melphalan-flufenamide, against multiple myeloma cells - PubMed [pubmed.ncbi.nlm.nih.gov]
- 14. RTA404, an Activator of Nrf2, Activates the Checkpoint Kinases and Induces Apoptosis through Intrinsic Apoptotic Pathway in Malignant Glioma [mdpi.com]
- 15. A Novel L-Phenylalanine Dipeptide Inhibits the Growth and Metastasis of Prostate Cancer Cells via Targeting DUSP1 and TNFSF9 - PMC [pmc.ncbi.nlm.nih.gov]
- 16. researchgate.net [researchgate.net]
- 17. Synthesis, Structural Characterization and Anticancer Activity of New 5-Trifluoromethyl-2-thioxo-thiazolo[4,5-d]pyrimidine Derivatives - PMC [pmc.ncbi.nlm.nih.gov]
- 18. Inhibition of Glycolysis Suppresses Cell Proliferation and Tumor Progression In Vivo: Perspectives for Chronotherapy - PubMed [pubmed.ncbi.nlm.nih.gov]
- 19. Cell Viability Assays - Assay Guidance Manual - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 20. texaschildrens.org [texaschildrens.org]
Application Notes and Protocols: Experimental Uses of Fluorinated Phenylalanine Analogs
For Researchers, Scientists, and Drug Development Professionals
Introduction
Fluorinated phenylalanine analogs are powerful tools in chemical biology, protein engineering, and drug discovery. The substitution of hydrogen with fluorine, an element with unique properties such as high electronegativity, small size, and hydrophobicity, allows for subtle yet significant modulation of molecular properties.[1] This has led to their widespread use in stabilizing protein structures, probing protein dynamics and interactions via ¹⁹F Nuclear Magnetic Resonance (NMR) spectroscopy, and enhancing the therapeutic properties of peptides and small molecules.[1][2] These application notes provide an overview of the key experimental uses of fluorinated phenylalanine analogs, along with detailed protocols for their incorporation into proteins and subsequent analysis.
Applications of Fluorinated Phenylalanine Analogs
The introduction of fluorine into the phenylalanine side chain can influence acidity, basicity, hydrophobicity, and conformation, thereby affecting a protein's stability, folding, and interactions.[1]
-
Protein Stabilization: The incorporation of fluorinated phenylalanine analogs, such as (S)-pentafluorophenylalanine, can enhance protein stability, a phenomenon referred to as the 'fluoro-stabilization effect'.[3][4] This increased stability can be advantageous for therapeutic proteins and vaccines by increasing their shelf-life and resistance to degradation.[1][5]
-
¹⁹F NMR Spectroscopy: The fluorine nucleus (¹⁹F) is an excellent probe for NMR studies due to its 100% natural abundance, high gyromagnetic ratio, and large chemical shift dispersion, making it highly sensitive to the local chemical environment.[6] Since fluorine is virtually absent in biological systems, ¹⁹F NMR offers background-free spectra for studying protein conformation, dynamics, ligand binding, and protein-protein interactions.[6][7][8]
-
Drug Design and Development: Fluorination is a common strategy in medicinal chemistry to improve the pharmacokinetic and pharmacodynamic properties of drugs.[2][5] Incorporating fluorinated phenylalanine analogs can enhance metabolic stability, membrane permeability, and binding affinity of drug candidates.[2]
-
Enzyme Mechanism and Inhibition: These analogs can serve as mechanistic probes or inhibitors of enzymes. Their unique electronic properties can alter substrate recognition and catalytic activity, providing insights into enzyme function.[1]
-
PET Imaging: Radiolabeled fluorinated phenylalanine analogs, such as 2-[¹⁸F]-fluoro-ʟ-phenylalanine, are used as tracers in Positron Emission Tomography (PET) for imaging tumors and other metabolic processes.[1]
Quantitative Data Summary
The following tables summarize quantitative data from various studies on the effects of fluorinated phenylalanine analog incorporation.
Table 1: Protein-Ligand Binding Affinities Determined by ¹⁹F NMR
| Protein | Fluorinated Analog | Ligand | Dissociation Constant (Kd) | Reference |
| L-leucine specific receptor (E. coli) | 4-fluoro-L-phenylalanine | 4-fluoro-L-phenylalanine | 0.26 µM | [9] |
| Src homology 3 (SH3) domain | 5-fluorotryptophan* | Proline-rich peptide | 150 µM | [10] |
Note: While not a phenylalanine analog, this data is included to demonstrate the application of ¹⁹F NMR in quantifying binding affinities.
Table 2: Impact of Fluorination on Protein Stability
| Protein | Fluorinated Analog | Change in Folding Free Energy (ΔΔG°fold) | Reference |
| α4H | hexafluoroleucine (hFLeu) | +9.6 kcal/mol | [4] |
| GB1 | pentafluorophenylalanine (Pff) | +0.34 kcal/mol | [3] |
Experimental Protocols
Protocol 1: Site-Specific Incorporation of p-fluoro-Phenylalanine (p-F-Phe) in E. coli using Amber Suppression
This protocol describes the site-specific incorporation of a fluorinated phenylalanine analog into a target protein at a desired position by suppressing an amber stop codon (UAG).[11][12][13][14]
Workflow Diagram:
Caption: Workflow for site-specific incorporation of p-F-Phe.
Materials:
-
E. coli strain (e.g., an analogue-resistant strain)
-
Expression plasmid containing the gene of interest
-
Plasmid carrying the orthogonal aminoacyl-tRNA synthetase/tRNACUA pair for the desired fluorinated analog (e.g., p-F-Phe)
-
p-fluoro-L-phenylalanine
-
Minimal media and appropriate antibiotics
-
Standard molecular biology reagents for site-directed mutagenesis, transformation, and protein purification.
Procedure:
-
Site-Directed Mutagenesis: Introduce an amber stop codon (TAG) at the desired position in the gene of interest within the expression plasmid using a standard site-directed mutagenesis protocol. Verify the mutation by DNA sequencing.
-
Transformation: Co-transform the mutated expression plasmid and the suppressor tRNA/synthetase plasmid into a suitable E. coli expression strain. Plate on selective media containing the appropriate antibiotics.
-
Protein Expression: a. Inoculate a single colony into a small volume of minimal media with antibiotics and grow overnight. b. Use the overnight culture to inoculate a larger volume of minimal media. Grow the cells at 37°C with shaking until the OD₆₀₀ reaches 0.6-0.8. c. Add p-fluoro-L-phenylalanine to the culture to a final concentration of 1 mM. d. Induce protein expression with the appropriate inducer (e.g., IPTG). e. Continue to grow the culture at a reduced temperature (e.g., 18-25°C) for 12-16 hours.
-
Cell Harvesting and Lysis: a. Harvest the cells by centrifugation. b. Resuspend the cell pellet in a suitable lysis buffer and lyse the cells (e.g., by sonication).
-
Protein Purification: Purify the target protein using an appropriate chromatography method (e.g., Ni-NTA affinity chromatography for His-tagged proteins).
-
Analysis: a. Confirm the expression of the full-length protein by SDS-PAGE. b. Verify the incorporation of the fluorinated analog by mass spectrometry. c. Proceed with ¹⁹F NMR analysis.
Protocol 2: Residue-Specific Incorporation of Fluorinated Phenylalanine in E. coli
This protocol allows for the global replacement of all instances of a specific amino acid with its fluorinated analog.[6]
Workflow Diagram:
Caption: Workflow for residue-specific incorporation of fluorinated Phe.
Materials:
-
E. coli BL21(DE3) cells
-
Expression plasmid containing the gene of interest
-
Fluorinated phenylalanine analog (e.g., 4-fluoro-L-phenylalanine)
-
L-phenylalanine, L-tyrosine, L-tryptophan
-
Glyphosate
-
Minimal media (e.g., M9) and appropriate antibiotics
Procedure:
-
Transformation: Transform the expression plasmid into E. coli BL21(DE3) cells.
-
Culture Growth: a. Grow a starter culture overnight in LB medium. b. Inoculate 1 L of minimal media with the starter culture and grow at 37°C until the OD₆₀₀ reaches 0.6.
-
Inhibition and Supplementation: a. Add glyphosate to a final concentration of 1 g/L to inhibit the shikimate pathway, thereby blocking the synthesis of aromatic amino acids.[6] b. Add the desired fluorinated phenylalanine analog (e.g., 50 mg/L of 4-fluoro-L-phenylalanine) along with the other two aromatic amino acids (50 mg/L each of L-tyrosine and L-tryptophan).[6]
-
Induction and Expression: a. Induce protein expression with IPTG (e.g., 0.5 mM). b. Reduce the temperature to 18°C and continue to grow for 18-20 hours.[6]
-
Harvesting and Purification: Harvest the cells and purify the protein as described in Protocol 1.
-
Analysis: Confirm the incorporation of the fluorinated analog using mass spectrometry and proceed with ¹⁹F NMR analysis.
Protocol 3: ¹⁹F NMR for Ligand Binding Analysis
This protocol outlines the general steps for using ¹⁹F NMR to study the binding of a ligand to a protein containing a fluorinated phenylalanine analog.[15][16]
Workflow Diagram:
Caption: Workflow for ligand binding analysis using ¹⁹F NMR.
Materials:
-
Purified protein with incorporated fluorinated phenylalanine analog
-
Ligand of interest
-
NMR buffer (e.g., phosphate (B84403) buffer in D₂O)
-
NMR spectrometer with a fluorine probe
Procedure:
-
Sample Preparation: a. Prepare a stock solution of the ¹⁹F-labeled protein at a known concentration (e.g., 25-100 µM) in a suitable NMR buffer.[16] b. Prepare a concentrated stock solution of the ligand in the same buffer.
-
NMR Data Acquisition: a. Transfer the protein solution to an NMR tube and acquire a 1D ¹⁹F NMR spectrum. This will serve as the reference (unbound state). b. Add a small aliquot of the concentrated ligand stock solution to the NMR tube. c. Mix thoroughly and acquire another 1D ¹⁹F NMR spectrum. d. Repeat step 2c with increasing concentrations of the ligand until no further changes in the ¹⁹F chemical shifts are observed (saturation).
-
Data Analysis: a. Process the NMR spectra (e.g., Fourier transformation, phasing, and baseline correction). b. Measure the chemical shift of the ¹⁹F signal at each ligand concentration. c. Plot the change in chemical shift (Δδ) as a function of the total ligand concentration. d. Fit the resulting binding isotherm to an appropriate binding model (e.g., a one-site binding model) to determine the dissociation constant (Kd).[16]
Signaling Pathway Visualization
The following diagram illustrates a simplified signaling pathway of a G-protein coupled receptor (GPCR), a common target for drug development where fluorinated phenylalanine analogs can be used to study conformational changes upon ligand binding and activation.[17][18][19]
Caption: Simplified GPCR signaling pathway.
Conclusion
Fluorinated phenylalanine analogs offer a versatile and powerful approach to address a wide range of questions in protein science and drug discovery. Their ability to modulate protein properties and serve as sensitive NMR probes provides researchers with unique tools to investigate protein structure, function, and interactions in detail. The protocols and data presented here serve as a guide for the application of these valuable chemical tools in a research setting.
References
- 1. Fluorinated phenylalanines: synthesis and pharmaceutical applications - PMC [pmc.ncbi.nlm.nih.gov]
- 2. pharmacyjournal.org [pharmacyjournal.org]
- 3. Fluorinated Protein and Peptide Materials for Biomedical Applications - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Structural basis for the enhanced stability of highly fluorinated proteins - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Fluorine-a small magic bullet atom in the drug development: perspective to FDA approved and COVID-19 recommended drugs - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Fluorine labeling of proteins for NMR studies – Bio-NMR Core [bionmr.cores.ucla.edu]
- 7. researchgate.net [researchgate.net]
- 8. pubs.acs.org [pubs.acs.org]
- 9. Fluorescence and 19F NMR evidence that phenylalanine, 3-L-fluorophenylalanine and 4-L-fluorophenylalanine bind to the L-leucine specific receptor of Escherichia coli - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. Rapid Quantification of Protein-Ligand Binding via 19F NMR Lineshape Analysis - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Expansion of the genetic code: site-directed p-fluoro-phenylalanine incorporation in Escherichia coli - PMC [pmc.ncbi.nlm.nih.gov]
- 12. researchgate.net [researchgate.net]
- 13. Expansion of the genetic code: site-directed p-fluoro-phenylalanine incorporation in Escherichia coli - PubMed [pubmed.ncbi.nlm.nih.gov]
- 14. Site-Specific Incorporation of Non-canonical Amino Acids by Amber Stop Codon Suppression in Escherichia coli | Springer Nature Experiments [experiments.springernature.com]
- 15. Ligand-Based Competition Binding by Real-Time 19F NMR in Human Cells - PMC [pmc.ncbi.nlm.nih.gov]
- 16. Protein-observed 19F-NMR for fragment screening, affinity quantification and druggability assessment - PMC [pmc.ncbi.nlm.nih.gov]
- 17. Discerning conformational dynamics and binding kinetics of GPCRs by 19F NMR [pubmed.ncbi.nlm.nih.gov]
- 18. Fluorine-19 NMR of integral membrane proteins illustrated with studies of GPCRs - PMC [pmc.ncbi.nlm.nih.gov]
- 19. Advances in the study of GPCRs by 19F NMR - PubMed [pubmed.ncbi.nlm.nih.gov]
Troubleshooting & Optimization
Technical Support Center: 4-(Trifluoromethyl)-L-phenylalanine (pCMF) Protein Expression
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) for researchers, scientists, and drug development professionals working with the site-specific incorporation of the unnatural amino acid 4-(Trifluoromethyl)-L-phenylalanine (pCMF) into proteins.
Frequently Asked Questions (FAQs)
Q1: What is the fundamental principle behind site-specifically incorporating pCMF into a protein?
A1: The site-specific incorporation of pCMF relies on the use of an orthogonal aminoacyl-tRNA synthetase/suppressor tRNA (aaRS/tRNA) pair.[1][2] This engineered pair functions independently of the host cell's native translational machinery. The orthogonal aaRS is specifically evolved to recognize and charge the suppressor tRNA with pCMF. This suppressor tRNA, in turn, recognizes a unique codon, typically an amber stop codon (UAG), that has been introduced at the desired site in the gene of interest. When the ribosome encounters the UAG codon, the pCMF-charged suppressor tRNA delivers the unnatural amino acid, resulting in its incorporation into the growing polypeptide chain.
Q2: Which plasmids are required for expressing a protein with pCMF in E. coli?
A2: Typically, a two-plasmid system is used for expressing proteins with pCMF in E. coli.[2]
-
Expression Plasmid: This plasmid carries the gene of interest with an in-frame amber (UAG) codon at the desired position for pCMF incorporation. It also contains a selectable marker, such as ampicillin (B1664943) resistance.
-
Machinery Plasmid: This plasmid encodes the orthogonal aminoacyl-tRNA synthetase (aaRS) specific for pCMF and its cognate suppressor tRNA (tRNA CUA). A commonly used plasmid for this purpose is pDule-tfmF, which carries a tetracycline (B611298) resistance marker.[2]
Q3: What is the optimal concentration of pCMF to use in the growth medium?
A3: The optimal concentration of pCMF can vary depending on the specific protein being expressed and the expression system. However, a final concentration of 1 mM pCMF in the culture medium is a common starting point.[2] It is recommended to prepare the pCMF stock solution fresh for each experiment.
Q4: Can high concentrations of pCMF be toxic to E. coli?
Q5: What is codon usage bias, and can it affect the expression of my pCMF-containing protein?
A5: Codon usage bias refers to the fact that some codons are used more frequently than others to encode a particular amino acid. This can vary significantly between organisms. If the gene of interest contains codons that are rarely used by E. coli, it can lead to translational stalling and reduced protein expression. While this is a general issue in recombinant protein expression, it can exacerbate low-yield problems when also dealing with the complexities of unnatural amino acid incorporation.
Troubleshooting Guides
Problem 1: Low or No Yield of the Full-Length Protein
| Possible Cause | Suggested Solution |
| Inefficient Amber Suppression | - Optimize pCMF Concentration: Titrate the concentration of pCMF in the growth medium (e.g., 0.5 mM, 1 mM, 2 mM) to find the optimal level for your protein. - Use a More Permissive Synthetase: Consider using a mutated, more "permissive" version of the pCMF synthetase, such as the A65V S158A mutant, which may exhibit improved activity. - Verify Plasmid Integrity: Sequence the expression and machinery plasmids to ensure the amber codon is in the correct location and that the synthetase and tRNA genes are intact. |
| Toxicity of pCMF | - Monitor Cell Growth: After adding pCMF, monitor the optical density (OD600) of your culture to check for growth inhibition. - Reduce pCMF Concentration: If toxicity is suspected, try lowering the concentration of pCMF in the medium. - Delayed Induction: Add pCMF to the culture later in the growth phase, just before inducing protein expression. |
| Suboptimal Expression Conditions | - Lower Induction Temperature: Inducing protein expression at a lower temperature (e.g., 18-25°C) for a longer period (e.g., 16-24 hours) can improve protein folding and solubility.[4] - Optimize Inducer Concentration: Titrate the concentration of the inducer (e.g., IPTG, arabinose) to find the optimal level for your protein. Lower inducer concentrations can sometimes lead to higher yields of soluble protein. - Test Different E. coli Strains: Some strains are better suited for expressing challenging proteins. Consider trying strains like BL21(DE3)pLysS or Rosetta(DE3). |
| Codon Usage Bias | - Codon Optimization: If your gene of interest contains a high percentage of rare codons for E. coli, consider synthesizing a codon-optimized version of the gene. |
Problem 2: Protein is Expressed but is Insoluble (Inclusion Bodies)
| Possible Cause | Suggested Solution |
| Protein Misfolding | - Lower Expression Temperature: This is one of the most effective methods for improving protein solubility. Try expressing your protein at temperatures as low as 15-18°C.[4] - Reduce Inducer Concentration: A lower rate of protein synthesis can give the polypeptide chain more time to fold correctly. - Co-expression with Chaperones: Co-express molecular chaperones (e.g., GroEL/GroES, DnaK/DnaJ) to assist in proper protein folding. |
| Disulfide Bond Formation | - Use Specialized Strains: For proteins with disulfide bonds, use E. coli strains that have a more oxidizing cytoplasm, such as SHuffle or Origami. |
| Lysis Buffer Composition | - Optimize Lysis Buffer: Include additives in your lysis buffer that can help solubilize proteins, such as non-detergent sulfobetaines (NDSBs), low concentrations of mild detergents (e.g., Triton X-100, Tween-20), or glycerol. |
Problem 3: Mass Spectrometry Analysis Shows No or Low Incorporation of pCMF
| Possible Cause | Suggested Solution |
| Inefficient Charging of tRNA | - Check Synthetase Activity: If possible, perform an in vitro aminoacylation assay to confirm that your orthogonal synthetase is active and capable of charging the suppressor tRNA with pCMF. - Increase Synthetase Expression: If using an inducible promoter for the synthetase, ensure it is being expressed adequately. |
| Competition with Release Factor 1 (RF1) | - Use RF1 Knockout/Knockdown Strains: In E. coli, Release Factor 1 (RF1) is responsible for terminating translation at UAG codons. Using an E. coli strain where the gene for RF1 (prfA) has been deleted or its expression is reduced can significantly improve the efficiency of unnatural amino acid incorporation. |
| Sample Preparation for Mass Spectrometry | - Proper Digestion: Ensure complete digestion of your protein with a protease (e.g., trypsin) to generate peptides of an appropriate size for mass spectrometry analysis. - Enrichment of pCMF-containing Peptides: If incorporation efficiency is very low, you may need to enrich for the pCMF-containing peptide before mass spectrometry analysis. |
Quantitative Data
Obtaining direct, side-by-side quantitative comparisons of protein yield with and without pCMF incorporation from the literature is challenging, as yields are highly protein-dependent. However, the following table provides a representative example of what one might expect. Actual yields will vary.
| Protein | Expression Condition | Typical Yield (mg/L of culture) |
| Model Protein (e.g., GFP) | Wild-type (no pCMF) | 10 - 50 |
| Model Protein (e.g., GFP) | With pCMF incorporation | 5 - 25 |
Note: The yield of the pCMF-containing protein is often lower than the wild-type protein due to the added complexity of the amber suppression system.
Experimental Protocols
Protocol: Expression of a pCMF-Containing Protein in E. coli
This protocol is a general guideline and may require optimization for your specific protein of interest.
1. Transformation:
-
Co-transform your expression plasmid (containing the gene of interest with a UAG codon) and the pDule-tfmF machinery plasmid into a suitable E. coli expression strain (e.g., BL21(DE3)).
-
Plate the transformed cells on LB agar (B569324) plates containing the appropriate antibiotics for both plasmids (e.g., ampicillin and tetracycline).
-
Incubate the plates overnight at 37°C.
2. Starter Culture:
-
Inoculate a single colony from the transformation plate into 5-10 mL of LB medium containing both antibiotics.
-
Grow the starter culture overnight at 37°C with shaking.
3. Expression Culture:
-
The next day, inoculate 1 L of fresh LB medium (in a 2L baffled flask for good aeration) with the overnight starter culture. The starting OD600 should be around 0.05-0.1.
-
Add both antibiotics to the culture.
-
Grow the culture at 37°C with shaking until the OD600 reaches 0.6-0.8.
4. Induction:
-
Prepare a fresh 100 mM stock solution of pCMF in sterile water. You may need to add a small amount of NaOH to dissolve it completely.
-
Add the pCMF solution to the culture to a final concentration of 1 mM.
-
Induce protein expression by adding the appropriate inducer (e.g., IPTG to a final concentration of 0.1-1 mM).
-
Reduce the incubator temperature to 18-25°C and continue to grow the culture for 16-24 hours with shaking.
5. Cell Harvest and Lysis:
-
Harvest the cells by centrifugation at 4,000 x g for 20 minutes at 4°C.
-
Discard the supernatant and resuspend the cell pellet in a suitable lysis buffer (e.g., 50 mM Tris-HCl pH 8.0, 300 mM NaCl, 10 mM imidazole, 1 mM PMSF, and lysozyme).
-
Lyse the cells by sonication or using a French press.
-
Clarify the lysate by centrifugation at 15,000 x g for 30 minutes at 4°C to separate the soluble and insoluble fractions.
6. Protein Purification:
-
Purify the soluble protein from the supernatant using an appropriate chromatography method (e.g., Ni-NTA affinity chromatography for His-tagged proteins).
-
Analyze the purified protein by SDS-PAGE and confirm the incorporation of pCMF by mass spectrometry.
Visualizations
Caption: Experimental workflow for pCMF incorporation.
Caption: Troubleshooting logic for low protein yield.
References
Technical Support Center: Optimizing 4-(Trifluoromethyl)-L-phenylalanine Incorporation
This technical support center provides troubleshooting guidance and answers to frequently asked questions for researchers, scientists, and drug development professionals working with 4-(Trifluoromethyl)-L-phenylalanine (TFMPA). Our goal is to help you enhance the incorporation efficiency of this non-canonical amino acid into your proteins of interest.
Frequently Asked Questions (FAQs)
Q1: What is the general principle behind incorporating TFMPA into a protein?
A1: The site-specific incorporation of TFMPA into a protein is achieved through the use of an orthogonal translation system. This system consists of an engineered aminoacyl-tRNA synthetase (aaRS) and its cognate transfer RNA (tRNA). The engineered aaRS specifically recognizes TFMPA and attaches it to the orthogonal tRNA. This charged tRNA then recognizes a specific codon (often a stop codon like UAG, the amber codon) that has been introduced at the desired site in the gene encoding the protein of interest, leading to the incorporation of TFMPA during translation.[1][2]
Q2: Which expression systems are suitable for TFMPA incorporation?
A2: TFMPA can be incorporated in a variety of expression systems, including prokaryotic (e.g., E. coli) and eukaryotic cells (e.g., mammalian cell lines), as well as in cell-free protein synthesis (CFPS) systems.[2][3] CFPS systems are particularly advantageous as they allow for direct manipulation of the reaction environment, bypassing concerns about cell viability and membrane transport of the unnatural amino acid.[4][5][6]
Q3: Is TFMPA toxic to expression host cells?
A3: High concentrations of some non-canonical amino acids can be toxic to host cells.[7] For instance, supplementing cultures with 5 mM of some ortho-substituted phenylalanine derivatives led to cell death.[7] It is recommended to perform dose-response experiments to determine the optimal concentration of TFMPA that supports efficient incorporation without significantly impacting cell growth.[3] Cell-free systems circumvent this issue entirely as cell viability is not a factor.[4][6]
Q4: How can I be sure that TFMPA has been successfully incorporated into my protein?
A4: Successful incorporation of TFMPA can be verified using mass spectrometry (MS). By comparing the molecular weight of the expressed protein with its theoretical mass (both with and without TFMPA), you can confirm the incorporation and its efficiency.[3][7]
Troubleshooting Guides
This section addresses common issues encountered during TFMPA incorporation experiments.
Problem 1: Low or No Protein Expression
Possible Cause 1: Inefficient aaRS/tRNA Pair
-
Solution: The efficiency of the orthogonal aaRS/tRNA pair is crucial. Ensure you are using a synthetase that has been specifically evolved or selected for TFMPA. Polyspecific synthetases that recognize other phenylalanine analogs may also be effective.[8] Optimizing the recognition between the orthogonal tRNA and the synthetase can significantly increase incorporation efficiencies.[9]
Possible Cause 2: Suboptimal TFMPA Concentration
-
Solution: The concentration of TFMPA in the growth media or cell-free reaction is a critical parameter. Too low a concentration will limit incorporation, while excessively high concentrations can be toxic to cells.[7] It is recommended to perform a titration experiment to determine the optimal concentration, typically in the range of 1-2 mM for many fluorinated phenylalanine analogs in mammalian cells.[3]
Possible Cause 3: Inefficient Amber Codon Suppression
-
Solution: The amber stop codon (UAG) is often used to encode the non-canonical amino acid. However, in many organisms, this codon is recognized by release factor 1 (RF1), which terminates translation. To improve incorporation efficiency, consider using an E. coli strain where the gene for RF1 has been deleted.[4] Cell-free systems can also be prepared from such strains.
Problem 2: Truncated Protein Product
Possible Cause 1: Competition with Release Factors
-
Solution: As mentioned above, the presence of release factors that recognize the stop codon used for TFMPA incorporation can lead to premature termination of translation. Using an RF1 knockout strain is a highly effective solution in E. coli.[4]
Possible Cause 2: Insufficient Charged Orthogonal tRNA
-
Solution: The concentration of the charged orthogonal tRNA must be sufficient to outcompete the release factors. In cell-free systems, the concentrations of the orthogonal tRNA and aaRS can be easily adjusted to optimize protein yield.[8] Increasing the plasmid ratio of the orthogonal tRNA/aaRS to the protein of interest can also enhance incorporation in cell-based systems.[10]
Problem 3: Misincorporation of Canonical Amino Acids
Possible Cause 1: Near-Cognate Suppression
-
Solution: Endogenous tRNAs can sometimes recognize and suppress the amber codon, leading to the incorporation of canonical amino acids. This is known as near-cognate suppression. In cell-free systems, it is possible to remove these competing tRNA isoacceptors from the total tRNA pool to increase the fidelity of non-canonical amino acid incorporation.[11]
Possible Cause 2: Promiscuous Engineered aaRS
-
Solution: The engineered aaRS may not be perfectly specific for TFMPA and could recognize and activate other canonical amino acids, most commonly phenylalanine. Further engineering of the synthetase's substrate-binding pocket may be necessary to improve specificity.[12]
Data Presentation
Table 1: Comparison of Unnatural Amino Acid Incorporation Efficiencies in a Cell-Free System
| Unnatural Amino Acid | Protein Yield (mg/mL) | Suppression Efficiency (%) | Reference |
| p-azido-L-phenylalanine (pAzF) | 0.9 - 1.7 | 50 - 88 | [13] |
| p-propargyloxy-L-phenylalanine (pPaF) | 0.9 - 1.7 | 50 - 88 | [13] |
Note: This data is for pAzF and pPaF in a cell-free system and serves as a reference for expected efficiencies with similar phenylalanine analogs.
Experimental Protocols
Protocol 1: General Workflow for TFMPA Incorporation in E. coli
-
Transformation: Co-transform an appropriate E. coli strain (e.g., an RF1 knockout strain) with two plasmids: one encoding the protein of interest with an in-frame amber (UAG) codon at the desired position, and the other encoding the orthogonal TFMPA-specific aaRS and its cognate tRNA.
-
Culture Growth: Grow the transformed cells in a suitable medium to a desired optical density (e.g., OD600 of 0.6-0.8).
-
Induction: Induce the expression of the protein of interest and the orthogonal system components. Simultaneously, supplement the culture medium with the optimal concentration of TFMPA (typically 1-2 mM).
-
Harvesting: After a suitable incubation period, harvest the cells by centrifugation.
-
Protein Purification: Lyse the cells and purify the protein of interest using standard chromatography techniques.
-
Analysis: Confirm the incorporation of TFMPA using mass spectrometry.
Mandatory Visualizations
Caption: Enzymatic pathway for the incorporation of TFMPA.
Caption: Troubleshooting workflow for low protein yield.
References
- 1. Advances in Biosynthesis of Non-Canonical Amino Acids (ncAAs) and the Methods of ncAAs Incorporation into Proteins [mdpi.com]
- 2. Incorporation of non-canonical amino acids - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Tuning phenylalanine fluorination to assess aromatic contributions to protein function and stability in cells - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Emerging Methods for Efficient and Extensive Incorporation of Non-canonical Amino Acids Using Cell-Free Systems - PMC [pmc.ncbi.nlm.nih.gov]
- 5. [PDF] Emerging Methods for Efficient and Extensive Incorporation of Non-canonical Amino Acids Using Cell-Free Systems | Semantic Scholar [semanticscholar.org]
- 6. Cell-free protein synthesis - Wikipedia [en.wikipedia.org]
- 7. pubs.acs.org [pubs.acs.org]
- 8. s3-ap-southeast-2.amazonaws.com [s3-ap-southeast-2.amazonaws.com]
- 9. Improving orthogonal tRNA-synthetase recognition for efficient unnatural amino acid incorporation and application in mammalian cells - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. Evaluation and optimisation of unnatural amino acid incorporation and bioorthogonal bioconjugation for site-specific fluorescent labelling of proteins expressed in mammalian cells - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Increasing the fidelity of noncanonical amino acid incorporation in cell-free protein synthesis - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. Engineering aminoacyl-tRNA synthetases for use in synthetic biology - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Cell-free co-production of an orthogonal transfer RNA activates efficient site-specific non-natural amino acid incorporation - PMC [pmc.ncbi.nlm.nih.gov]
Technical Support Center: Synthesis of 4-(Trifluoromethyl)-L-phenylalanine
This technical support center provides troubleshooting guidance and frequently asked questions (FAQs) for researchers, scientists, and drug development professionals engaged in the synthesis of 4-(Trifluoromethyl)-L-phenylalanine.
Troubleshooting Guide
Issue: Low or No Product Yield
-
Q1: My Negishi cross-coupling reaction is giving a low yield or stalling. What are the potential causes and solutions?
A1: Low yields or stalling in Negishi couplings for this synthesis can be attributed to several factors:
-
Catalyst Deactivation: The presence of certain functional groups in your starting materials or intermediates can coordinate to the palladium catalyst and deactivate it.
-
Solution: Increase the catalyst loading. If the reaction mixture turns black, it may indicate palladium black precipitation, a sign of catalyst decomposition. Consider screening different ligands that are more robust to the reaction conditions.
-
-
Incomplete Reaction: The strong electron-withdrawing nature of the trifluoromethyl group can deactivate the aromatic ring, making the reaction more challenging.[]
-
Solution: Extend the reaction time or increase the reaction temperature. The use of a more active catalyst or a different ligand, such as SPhos, has been shown to improve yields in similar reactions.
-
-
Poor Quality of Organozinc Reagent: The organozinc reagent is sensitive to air and moisture.
-
Solution: Ensure strictly anhydrous and inert conditions during the preparation and use of the organozinc reagent. Prepare the reagent fresh for the best results.
-
-
-
Q2: My enzymatic synthesis is resulting in low conversion. What should I troubleshoot?
A2: Low conversion in enzymatic synthesis can be due to several factors related to the enzyme's activity and the reaction equilibrium.
-
Unfavorable Equilibrium: The amination of the corresponding cinnamic acid derivative to form the phenylalanine analogue can have an unfavorable equilibrium.
-
Solution: Use a high concentration of the ammonia (B1221849) source to push the equilibrium towards the product. Immobilizing the enzyme can also enhance its stability and reusability, potentially leading to higher overall yields.
-
-
Enzyme Inhibition or Deactivation: High concentrations of substrate or product can inhibit the enzyme. The enzyme may also be denatured by suboptimal pH or temperature.
-
Solution: Optimize the substrate concentration. Ensure the reaction is carried out at the optimal pH and temperature for the specific enzyme being used.
-
-
Cofactor Limitation: If the enzymatic reaction requires a cofactor, its regeneration might be the rate-limiting step.
-
Solution: Implement an efficient cofactor regeneration system in your reaction setup.
-
-
Issue: Product Purification Challenges
-
Q3: I'm having difficulty purifying the final product. What strategies can I employ?
A3: Purification of this compound can be challenging due to its physical properties and potential impurities.
-
Similar Polarity of Product and Impurities: Byproducts or unreacted starting materials may have similar polarity to the desired product, making chromatographic separation difficult.
-
Solution: Explore different solvent systems for column chromatography. If using silica (B1680970) gel, consider switching to a different stationary phase, such as alumina (B75360), which has a different selectivity. Recrystallization is also a powerful purification technique for crystalline solids.
-
-
Product Instability: The product may be unstable under certain purification conditions.
-
Solution: If using silica gel, which is acidic, consider using a less acidic stationary phase like neutral alumina to avoid potential degradation of acid-sensitive protecting groups.
-
-
Issue: Side Reactions and Impurity Formation
-
Q4: I am observing significant byproduct formation. What are the likely side reactions and how can I minimize them?
A4: The synthesis of this compound can be prone to several side reactions.
-
Homocoupling of the Organozinc Reagent: The organozinc reagent can couple with itself, reducing the amount available to react with the aryl halide.
-
Solution: Control the stoichiometry of the reactants carefully. Slow addition of the organozinc reagent to the reaction mixture can sometimes minimize this side reaction.
-
-
Racemization: Harsh reaction conditions, particularly with strong bases or high temperatures, can lead to racemization at the chiral center.
-
Solution: Use milder reaction conditions where possible. For methods involving chiral auxiliaries, ensure the auxiliary is robust and effectively controls the stereochemistry.
-
-
Oxidation: The starting materials or product may be susceptible to oxidation.
-
Solution: Maintain an inert atmosphere (e.g., nitrogen or argon) throughout the reaction and workup. Degas solvents before use to remove dissolved oxygen.[]
-
-
Frequently Asked Questions (FAQs)
-
Q5: What are the most common synthetic routes to prepare this compound?
A5: The most common and effective methods include:
-
Palladium-catalyzed Cross-Coupling Reactions: The Negishi cross-coupling of a protected β-iodoalanine derivative with a 4-trifluoromethylphenylzinc reagent is a key method.[2][3]
-
Enzymatic Synthesis: Phenylalanine ammonia lyases (PALs) can catalyze the amination of 4-(trifluoromethyl)cinnamic acid to produce the desired amino acid. This method offers high enantioselectivity.
-
Asymmetric Synthesis using Chiral Auxiliaries: Attaching a chiral auxiliary to a glycine (B1666218) or alanine (B10760859) synthon allows for diastereoselective alkylation with a 4-(trifluoromethyl)benzyl halide. Subsequent removal of the auxiliary yields the enantiomerically pure amino acid.
-
-
Q6: How critical are anhydrous and inert conditions for the synthesis?
A6: For many of the synthetic steps, particularly those involving organometallic reagents like organozinc compounds in Negishi couplings, strictly anhydrous and inert conditions are crucial.[] Moisture and oxygen can quench the reagents and deactivate the catalyst, leading to significantly lower yields.
-
Q7: Are there any specific safety precautions I should take when working with trifluoromethylated compounds?
A7: While this compound itself has a defined safety profile, many of the reagents used in its synthesis can be hazardous. Always consult the Safety Data Sheet (SDS) for each chemical. Trifluoromethylating agents and some palladium catalysts can be toxic and should be handled with appropriate personal protective equipment (PPE) in a well-ventilated fume hood.
Data Presentation
Table 1: Comparison of Synthetic Methods for this compound and Related Derivatives
| Synthetic Method | Key Reagents | Typical Yield | Enantiomeric Excess (e.e.) | Key Advantages | Key Challenges |
| Negishi Cross-Coupling | Protected β-iodoalanine, 4-(trifluoromethyl)phenylzinc halide, Pd catalyst (e.g., Pd2(dba)3/SPhos) | 54-65%[2][3] | >99% (from chiral starting material) | Good functional group tolerance; direct C-C bond formation. | Requires strictly anhydrous/inert conditions; catalyst deactivation can be an issue. |
| Enzymatic Synthesis (PAL) | 4-(Trifluoromethyl)cinnamic acid, Phenylalanine Ammonia Lyase (PAL), NH3 source | Variable (can reach >80% conversion) | >99% | High enantioselectivity; "green" reaction conditions. | Unfavorable reaction equilibrium; potential for enzyme inhibition. |
| Asymmetric Alkylation (Chiral Auxiliary) | Glycine or alanine Schiff base with a chiral auxiliary, 4-(trifluoromethyl)benzyl bromide, base | 70-90% | >98% | High diastereoselectivity; reliable stereochemical control. | Requires additional steps for attachment and removal of the auxiliary. |
Experimental Protocols
1. Negishi Cross-Coupling for the Synthesis of Protected this compound
This protocol is a representative procedure based on literature methods.[2][3]
-
Step 1: Preparation of the Organozinc Reagent.
-
To a flame-dried flask under an argon atmosphere, add zinc dust.
-
Activate the zinc dust by stirring with 1,2-dibromoethane (B42909) in anhydrous THF, followed by removal of the supernatant.
-
To the activated zinc, add a solution of 4-bromo(trifluoromethyl)benzene in anhydrous THF dropwise.
-
Stir the mixture at room temperature until the aryl bromide is consumed (monitor by TLC or GC-MS). The resulting solution is the organozinc reagent.
-
-
Step 2: Cross-Coupling Reaction.
-
To a separate flame-dried flask under argon, add the palladium catalyst (e.g., Pd2(dba)3) and the ligand (e.g., SPhos).
-
Add a solution of the protected β-iodo-L-alanine derivative in anhydrous THF.
-
To this mixture, add the freshly prepared organozinc reagent from Step 1 via cannula.
-
Heat the reaction mixture to the desired temperature (e.g., 50-60 °C) and stir until the starting material is consumed (monitor by TLC or HPLC).
-
Cool the reaction to room temperature and quench with a saturated aqueous solution of ammonium (B1175870) chloride.
-
Extract the aqueous layer with an organic solvent (e.g., ethyl acetate).
-
Combine the organic layers, dry over anhydrous sodium sulfate, filter, and concentrate under reduced pressure.
-
Purify the crude product by column chromatography on silica gel to obtain the protected this compound.
-
2. Enzymatic Synthesis of this compound
This protocol is a generalized procedure based on the use of Phenylalanine Ammonia Lyase (PAL).
-
Prepare a buffered aqueous solution at the optimal pH for the chosen PAL (typically pH 8.5-10).
-
Add the substrate, 4-(trifluoromethyl)cinnamic acid, to the buffer. A co-solvent like DMSO may be needed to aid solubility.
-
Add a high concentration of an ammonia source (e.g., ammonium carbonate or ammonium hydroxide).
-
Add the Phenylalanine Ammonia Lyase (either as a purified enzyme or as whole cells expressing the enzyme).
-
Incubate the reaction mixture at the optimal temperature for the enzyme (e.g., 30-40 °C) with gentle agitation.
-
Monitor the reaction progress by HPLC, observing the disappearance of the starting material and the appearance of the product.
-
Once the reaction has reached the desired conversion, stop the reaction by denaturing the enzyme (e.g., by adding acid or a water-miscible organic solvent).
-
Isolate the product by standard methods such as ion-exchange chromatography or crystallization.
Mandatory Visualization
Caption: Workflow for the synthesis of this compound via Negishi coupling.
Caption: Troubleshooting logic for addressing low product yield in synthesis.
References
Technical Support Center: Enhancing Yield of 4-(Trifluoromethyl)-L-phenylalanine Labeled Proteins
This technical support center provides researchers, scientists, and drug development professionals with comprehensive troubleshooting guides and frequently asked questions (FAQs) to address challenges encountered during the expression of proteins labeled with the non-canonical amino acid 4-(Trifluoromethyl)-L-phenylalanine (tfmF).
Troubleshooting Guides
This section offers systematic approaches to diagnose and resolve common issues leading to low yields of tfmF-labeled proteins.
Guide 1: Step-by-Step Troubleshooting of Low Protein Yield
Low or no expression of the target protein is a frequent challenge. This guide provides a structured workflow to identify the root cause.
Guide 2: Decision Pathway for Optimizing Amber Suppression Efficiency
Inefficient amber (UAG) stop codon suppression is a primary cause of truncated protein products and low yields of the full-length labeled protein.
Data Presentation
Table 1: Impact of Expression Conditions on Labeled Protein Yield
This table summarizes the expected impact of various experimental parameters on the final yield of soluble, tfmF-labeled protein.
| Parameter | Condition 1 | Yield (mg/L) | Condition 2 | Yield (mg/L) | Rationale |
| Induction Temperature | 37°C | Low | 18-25°C | High | Lower temperatures slow down protein synthesis, which can promote proper folding and reduce the formation of insoluble inclusion bodies.[1] |
| IPTG Concentration | 1.0 mM | Variable | 0.1-0.4 mM | Often Higher | High inducer concentrations can lead to rapid, overwhelming protein expression, resulting in misfolding and aggregation.[1][2] |
| tfmF Concentration | 0.5 mM | Low | 1-2 mM | High | Sufficient concentration of the non-canonical amino acid is crucial for efficient incorporation. However, very high concentrations can be toxic to the cells.[3][4] |
| Host Strain | Standard BL21(DE3) | Moderate | C321.ΔA (RF1 knockout) | High | Deletion of Release Factor 1 (RF1) eliminates competition for the UAG codon, significantly improving suppression efficiency.[5][6] |
Table 2: Comparison of Expression Vectors and Orthogonal Pairs
The choice of plasmids for expressing the target protein and the orthogonal machinery is critical.
| Expression System Component | Option A | Option B | Key Consideration |
| Target Protein Vector | High-copy number (e.g., pUC-based) | Low to medium-copy number (e.g., pET, pBAD) | High-copy vectors can lead to metabolic burden and protein aggregation. Medium-copy vectors often provide a better balance for soluble expression.[7] |
| aaRS/tRNA Vector | pDule | pEVOL | pDule and pEVOL are commonly used systems for expressing the MjTyrRS/tRNA pair for tfmF incorporation. The choice may depend on the specific construct and experimental setup.[3] |
| aaRS/tRNA Expression | Separate plasmids | Single plasmid | A single plasmid system can ensure a more consistent ratio of the aaRS and tRNA, which can be beneficial for incorporation efficiency. |
Experimental Protocols
Detailed Protocol for High-Yield Expression of tfmF-Labeled Protein in E. coli
This protocol provides a step-by-step guide for expressing a target protein with site-specifically incorporated this compound using the pDule-tfmF system in E. coli BL21(DE3).
Materials:
-
E. coli BL21(DE3) competent cells
-
Expression plasmid containing the gene of interest with an in-frame amber (TAG) codon at the desired labeling site.
-
pDule-tfmF plasmid (or equivalent) expressing the engineered tyrosyl-tRNA synthetase (MjTyrRS) and its cognate suppressor tRNA.
-
This compound (tfmF)
-
Luria-Bertani (LB) agar (B569324) plates and broth
-
Appropriate antibiotics (e.g., ampicillin (B1664943) for the expression plasmid, tetracycline (B611298) for pDule)
-
Isopropyl β-D-1-thiogalactopyranoside (IPTG)
Procedure:
-
Co-transformation:
-
Thaw a tube of E. coli BL21(DE3) competent cells on ice.
-
Add 100-200 ng of the expression plasmid and 100-200 ng of the pDule-tfmF plasmid to the cells.
-
Incubate on ice for 30 minutes.
-
Heat-shock the cells at 42°C for 45 seconds and immediately return to ice for 2 minutes.
-
Add 900 µL of SOC medium and incubate at 37°C for 1 hour with shaking.
-
Plate 100-200 µL of the transformation mixture onto LB agar plates containing the appropriate antibiotics.
-
Incubate overnight at 37°C.
-
-
Starter Culture:
-
Inoculate a single colony from the transformation plate into 10 mL of LB broth with the required antibiotics.
-
Grow overnight at 37°C with shaking at 220-250 rpm.
-
-
Expression Culture:
-
Inoculate 1 L of LB broth containing the antibiotics with the 10 mL overnight starter culture.
-
Grow at 37°C with shaking until the optical density at 600 nm (OD₆₀₀) reaches 0.6-0.8.[2]
-
-
Induction:
-
Add this compound to a final concentration of 1 mM. Ensure it is fully dissolved.
-
Induce protein expression by adding IPTG to a final concentration of 0.4 mM.[2]
-
Reduce the temperature to 20°C and continue to incubate overnight (16-18 hours) with shaking.
-
-
Cell Harvest and Analysis:
-
Harvest the cells by centrifugation at 5,000 x g for 15 minutes at 4°C.
-
Discard the supernatant and store the cell pellet at -80°C or proceed with protein purification.
-
To check for expression, a small aliquot of the culture can be lysed and analyzed by SDS-PAGE and Western blot.
-
Frequently Asked Questions (FAQs)
Q1: I don't see any protein expression on my gel. What should I check first?
A1: First, confirm the integrity of your expression vector by sequencing to ensure the gene of interest is in the correct reading frame and the amber codon is present. Also, perform a control transformation with a known working plasmid to check the competency of your E. coli cells and the effectiveness of your antibiotics. Finally, verify your induction protocol, ensuring the cell density was optimal (OD₆₀₀ of 0.6-0.8) before adding a fresh stock of IPTG.
Q2: My protein is expressed, but it's all in the insoluble fraction. How can I improve its solubility?
A2: Protein insolubility is often due to misfolding and aggregation. To improve solubility, try lowering the induction temperature to 18-25°C and reducing the IPTG concentration to 0.1-0.4 mM.[1] You can also consider using a solubility-enhancing fusion tag (e.g., MBP, GST) or co-expressing molecular chaperones.
Q3: I see a band for my full-length protein, but also a strong band at a lower molecular weight. What does this indicate?
A3: This typically indicates inefficient suppression of the amber codon, leading to a significant amount of truncated protein. To address this, you can try to optimize the ratio of the aminoacyl-tRNA synthetase and suppressor tRNA, for example, by using a single plasmid system or promoters of different strengths. Using an E. coli strain with a knockout of Release Factor 1 (RF1), such as C321.ΔA, is also a highly effective strategy to reduce truncation.[5][6]
Q4: Can the this compound be toxic to the cells?
A4: Yes, high concentrations of non-canonical amino acids can be toxic to E. coli, leading to inhibited growth and reduced protein yield. While a concentration of 1-2 mM is generally recommended for efficient incorporation, it is advisable to perform a titration to find the optimal concentration for your specific protein and experimental setup. If you observe a significant decrease in cell growth after adding tfmF, try reducing its concentration.[1]
Q5: How critical is the nucleotide sequence surrounding the amber codon?
A5: The local sequence context, particularly the nucleotide immediately following the UAG codon, can influence the efficiency of suppression versus termination.[8] Purine bases (A or G) at the +4 position (immediately following the UAG codon) have been shown to enhance suppression efficiency in prokaryotes. If you are still experiencing low yields after optimizing other parameters, consider modifying the codon context through site-directed mutagenesis.
References
- 1. The global gene expression response of Escherichia coli to L-phenylalanine - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. neb.com [neb.com]
- 3. biorxiv.org [biorxiv.org]
- 4. 【Poster_MBSJ 2024】 Exploration of optimal conditions for the incorporation of noncanonical amino acids by amber suppression using the PURE system | Posters | Resources | PUREfrex® | GeneFrontier Corporation [purefrex.genefrontier.com]
- 5. Frontiers | Comparative Analyses of the Transcriptome and Proteome of Escherichia coli C321.△A and Further Improving Its Noncanonical Amino Acids Containing Protein Expression Ability by Integration of T7 RNA Polymerase [frontiersin.org]
- 6. Translation System Engineering in Escherichia coli Enhances Non-Canonical Amino Acid Incorporation into Proteins - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Impact of the Expression System on Recombinant Protein Production in Escherichia coli BL21 - PMC [pmc.ncbi.nlm.nih.gov]
- 8. purefrex.genefrontier.com [purefrex.genefrontier.com]
Technical Support Center: 19F NMR of Fluorinated Proteins
Welcome to the technical support center for 19F NMR of fluorinated proteins. This resource is designed for researchers, scientists, and drug development professionals to provide troubleshooting guidance and frequently asked questions (FAQs) related to common issues encountered during 19F NMR experiments.
Frequently Asked Questions (FAQs)
Q1: Why is the signal-to-noise ratio (S/N) in my 19F NMR spectrum poor?
A1: A poor signal-to-noise ratio in 19F NMR spectra of fluorinated proteins can arise from several factors:
-
Low Protein Concentration: The signal intensity is directly proportional to the concentration of the fluorinated protein.[1]
-
Suboptimal Labeling Efficiency: Incomplete incorporation of the fluorinated amino acid will result in a weaker signal.
-
Precipitation or Aggregation: Protein instability leading to precipitation or aggregation reduces the amount of soluble, NMR-visible protein.[1]
-
Broad Linewidths: Significant line broadening, often due to slow molecular tumbling or intermediate exchange, can reduce the peak height and thus the apparent S/N.[2][3]
-
Instrumental Factors: Improper probe tuning and matching, incorrect pulse calibration, or a suboptimal number of scans can all lead to poor S/N.
Q2: What causes the peaks in my 19F NMR spectrum to be so broad?
A2: Broad peaks, or poor resolution, are a common challenge in the NMR of macromolecules. In 19F NMR of fluorinated proteins, several factors contribute to line broadening:
-
Slow Molecular Tumbling: Larger proteins tumble more slowly in solution, leading to more efficient transverse relaxation (shorter T2) and broader lines.[4]
-
Chemical Shift Anisotropy (CSA): The chemical shift of the 19F nucleus is highly sensitive to its orientation with respect to the magnetic field. For larger molecules, incomplete averaging of this anisotropy due to slower tumbling is a major cause of line broadening, and this effect increases with the square of the magnetic field strength.[1]
-
Conformational Exchange: If the fluorinated residue is in a region of the protein that is undergoing conformational exchange on an intermediate timescale (microseconds to milliseconds), this can lead to significant line broadening.[5]
-
Protein Aggregation: Aggregation increases the effective size of the molecule, leading to very broad signals.[1]
-
Paramagnetic Broadening: Proximity to a paramagnetic center (e.g., a metal ion or a spin label) can cause significant line broadening.[5]
Q3: My protein seems to be unstable under NMR conditions. What can I do?
A3: Protein stability is crucial for successful NMR experiments.[6] If you suspect your fluorinated protein is unstable, consider the following:
-
Buffer Optimization: Systematically screen different buffer conditions, including pH, salt concentration, and the addition of stabilizing osmolytes (e.g., glycerol, sucrose) or reducing agents (e.g., DTT, TCEP) if you have cysteine residues.
-
Temperature Optimization: Lowering the temperature can sometimes improve stability, but be aware that it will also increase the viscosity and potentially broaden the lines.
-
Protease Inhibitors: Add protease inhibitors to your sample to prevent degradation, especially if the sample will be in the spectrometer for a long time.
-
Check for Aggregation: Use techniques like dynamic light scattering (DLS) to check for aggregation before and after your NMR experiment.
-
Assess the Impact of Fluorine Labeling: While often considered minimally perturbing, fluorine incorporation can sometimes destabilize a protein.[2][3] It may be necessary to test different fluorinated amino acids or labeling sites.
Q4: How can I be sure that the fluorine label has been incorporated correctly?
A4: Verifying the successful and specific incorporation of the fluorine label is a critical first step.
-
Mass Spectrometry: Electrospray ionization mass spectrometry (ESI-MS) is the most direct way to confirm the incorporation of the fluorinated amino acid.[1] The expected mass increase can be calculated, and the observed mass will confirm the extent of labeling.
-
SDS-PAGE Analysis: While not directly confirming fluorine incorporation, running an SDS-PAGE gel can confirm the expression of the protein at the expected molecular weight.[1]
-
NMR Spectroscopy: The presence of signals in the 19F NMR spectrum is a direct confirmation of fluorine incorporation. However, mass spectrometry is required to quantify the efficiency of incorporation.[1]
Q5: I am observing unexpected or multiple 19F NMR signals. What could be the cause?
A5: The observation of unexpected or multiple 19F NMR signals can be due to several reasons:
-
Proteolytic Degradation: Degradation of the protein can lead to smaller, more mobile fluorinated fragments that give rise to sharp, unexpected signals.[1]
-
Conformational Heterogeneity: The protein may exist in multiple, slowly exchanging conformations, each giving rise to a distinct 19F signal.[5]
-
Incomplete or Non-Specific Labeling: In some cases, biosynthetic labeling methods can result in low-level misincorporation of the fluorinated amino acid at unintended sites.
-
Impurities: Small molecule impurities containing fluorine can give rise to sharp signals in the spectrum.[1]
Troubleshooting Guides
Issue 1: Low Signal-to-Noise (S/N) Ratio
Troubleshooting Workflow
Caption: Troubleshooting workflow for low signal-to-noise in 19F NMR.
Issue 2: Poor Spectral Resolution (Broad Peaks)
Troubleshooting Workflow
Caption: Troubleshooting workflow for poor spectral resolution in 19F NMR.
Data Presentation: Quantitative Parameters
| Parameter | Typical Value/Range | Significance |
| Protein Concentration | 25 - 100 µM[1] | Directly affects signal-to-noise. |
| 19F Chemical Shift Range | >400 ppm[7] | High sensitivity to local environment.[2][7] |
| Typical Linewidths | 10s of Hz to >100 Hz | Reflects protein size, dynamics, and conformational homogeneity. |
| T1 Relaxation Times | 0.2 - 2 s | Provides information on molecular motion. |
| T2 Relaxation Times | 10s of ms (B15284909) to <100 ms | Inversely related to linewidth; sensitive to slow motions. |
| Labeling Efficiency | >80% desired[7] | Maximizes signal and simplifies spectral interpretation. |
Experimental Protocols
Protocol 1: Biosynthetic Incorporation of Fluorinated Aromatic Amino Acids
This protocol describes a general method for labeling a protein with a fluorinated aromatic amino acid (e.g., 3-fluoro-tyrosine) in E. coli.[7]
Materials:
-
E. coli BL21(DE3) cells harboring the expression plasmid for the protein of interest.
-
Minimal media (e.g., M9) with appropriate antibiotics.
-
Glucose (or other carbon source).
-
Fluorinated amino acid (e.g., 3-fluoro-tyrosine).
-
Unlabeled tyrosine, phenylalanine, and tryptophan.
-
IPTG (isopropyl β-D-1-thiogalactopyranoside).
Procedure:
-
Growth of Starter Culture: Inoculate a small volume of LB medium with a single colony of the expression strain and grow overnight at 37°C.
-
Inoculation of Minimal Media: Inoculate a larger volume of minimal media with the overnight culture to an OD600 of ~0.1. Grow at 37°C with shaking until the OD600 reaches 0.6-0.8.
-
Inhibition of Aromatic Amino Acid Synthesis: Add glyphosate to the culture to a final concentration of 1 mM to inhibit the endogenous synthesis of aromatic amino acids.[7]
-
Addition of Amino Acids: Immediately after adding glyphosate, add the fluorinated amino acid (e.g., 3-fluoro-tyrosine to ~0.5 mM) and the other two unlabeled aromatic amino acids (phenylalanine and tryptophan to ~0.5 mM each).[7]
-
Induction of Protein Expression: Add IPTG to a final concentration of 0.5-1 mM to induce protein expression.
-
Expression: Continue to grow the culture at a reduced temperature (e.g., 18-25°C) for 12-16 hours.
-
Harvesting and Purification: Harvest the cells by centrifugation. The cell pellet can be stored at -80°C. Purify the labeled protein using the established protocol for the unlabeled protein.[7]
-
Verification: Confirm the incorporation and efficiency of labeling by mass spectrometry.
Protocol 2: 1D 19F NMR Data Acquisition
This protocol provides a basic workflow for acquiring a one-dimensional 19F NMR spectrum of a fluorinated protein.
Sample Preparation:
-
Prepare the fluorinated protein sample in a suitable NMR buffer (e.g., 50 mM phosphate, 150 mM NaCl, pH 7.0) containing 5-10% D2O for the field-frequency lock.
-
Typical protein concentrations are in the range of 25-100 µM.[1]
-
Add a chemical shift reference compound if desired (e.g., trifluoroacetic acid, TFA).[4][8]
NMR Spectrometer Setup:
-
Insert the sample into the spectrometer.
-
Lock the spectrometer on the D2O signal.
-
Tune and match the 19F channel of the probe.
-
Set the temperature (e.g., 298 K).
Acquisition Parameters:
-
Pulse Sequence: Use a simple one-pulse sequence.
-
Spectral Width: Set a wide spectral width to encompass the expected chemical shift range of the 19F label (e.g., 50-100 ppm).
-
Carrier Frequency: Set the transmitter frequency to the center of the expected spectral region.
-
Acquisition Time: Typically 0.1-0.5 seconds.
-
Relaxation Delay: Set to 1-2 seconds (approximately 1.5 x the longest T1).
-
Number of Scans: This will depend on the sample concentration and desired S/N. Start with a few hundred scans and increase as needed.
Processing:
-
Apply an exponential window function to improve S/N (at the cost of some resolution).
-
Fourier transform the FID.
-
Phase the spectrum.
-
Reference the chemical shifts.
Logical Relationship: Impact of Molecular Tumbling on Linewidth
Caption: The relationship between protein properties and NMR linewidth.
References
- 1. Protein-observed 19F-NMR for fragment screening, affinity quantification and druggability assessment - PMC [pmc.ncbi.nlm.nih.gov]
- 2. pubs.acs.org [pubs.acs.org]
- 3. USE OF 19F NMR TO PROBE PROTEIN STRUCTURE AND CONFORMATIONAL CHANGES - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Site-specific 19F NMR chemical shift and side chain relaxation analysis of a membrane protein labeled with an unnatural amino acid - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Use of 19F NMR to probe protein structure and conformational changes - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. Insights into Protein Stability in Cell Lysate by 19 F NMR Spectroscopy - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. Fluorine labeling of proteins for NMR studies – Bio-NMR Core [bionmr.cores.ucla.edu]
- 8. pubs.acs.org [pubs.acs.org]
Technical Support Center: 4-(Trifluoromethyl)-L-phenylalanine
Welcome to the technical support center for 4-(Trifluoromethyl)-L-phenylalanine. This resource is designed to assist researchers, scientists, and drug development professionals in overcoming common solubility challenges encountered during their experiments. Here you will find troubleshooting guides, frequently asked questions (FAQs), and detailed experimental protocols to ensure the successful use of this compound in your research.
Troubleshooting Guide
This guide addresses specific issues you may encounter when trying to dissolve this compound.
Q1: Why is my this compound not dissolving in water at room temperature?
A1: this compound has low solubility in water.[1] The presence of the hydrophobic trifluoromethylphenyl group contributes to its poor aqueous solubility at neutral pH. Like other amino acids, its solubility is influenced by the zwitterionic nature of the molecule, which can lead to strong intermolecular interactions in its crystalline form, further reducing solubility.
Q2: I've heated the aqueous solution, but the compound still won't dissolve completely. What should I do?
A2: While heating can increase solubility, it may not be sufficient on its own. For aqueous solutions, a combination of heating and ultrasonication is recommended. A known protocol involves heating the solution to 70°C with ultrasonic agitation to achieve a solubility of up to 2 mg/mL.[2][3] If this is still insufficient for your required concentration, consider adjusting the pH or using a co-solvent.
Q3: My compound precipitated out of the aqueous solution after cooling. How can I prevent this?
A3: Precipitation upon cooling is common for compounds with temperature-dependent solubility. To maintain a stable solution, you can:
-
Prepare fresh solutions: Make your solutions immediately before use.
-
Store at elevated temperatures: If your experiment allows, maintain the solution at a slightly elevated temperature.
-
Adjust the pH: Moving the pH away from the isoelectric point can significantly increase and stabilize solubility.
-
Use a co-solvent: Adding a small percentage of an organic solvent like DMSO or ethanol (B145695) to your aqueous buffer can help maintain solubility.
Q4: Can I use an organic solvent to dissolve this compound?
A4: Yes, using an organic solvent is a common and effective strategy. The trifluoromethyl group increases the lipophilicity of the molecule, suggesting good solubility in many organic solvents.[4] It is soluble in ethanol.[1] For preparing stock solutions, DMSO or DMF are excellent choices. You can then dilute the stock solution into your aqueous experimental medium. Be mindful of the final concentration of the organic solvent in your assay, as it may affect biological systems.
Solubility Data
The following table summarizes the available solubility data for this compound.
| Solvent/System | Quantitative Solubility | Qualitative Assessment | Notes |
| Water | 2 mg/mL | Low | Requires heating to 70°C and ultrasonication.[2][3] |
| Ethanol | Data not available | Soluble | [1] |
| DMSO | Data not available | Expected to be soluble | Based on the hydrophobic nature and general behavior of similar compounds. |
| DMF | Data not available | Expected to be soluble | A common solvent for hydrophobic compounds. |
| Methanol | Data not available | Expected to be soluble | Similar to ethanol. |
| PBS (pH 7.4) | Data not available | Low | Similar to water; pH adjustment may be necessary. |
Experimental Protocols
Protocol 1: Preparation of a Concentrated Stock Solution in an Organic Solvent
This protocol is suitable for preparing a high-concentration stock solution for long-term storage and subsequent dilution into various experimental media.
Materials:
-
This compound powder
-
Dimethyl sulfoxide (B87167) (DMSO) or Dimethylformamide (DMF)
-
Sterile microcentrifuge tubes or vials
-
Vortex mixer
-
Calibrated pipettes
Procedure:
-
Weigh the desired amount of this compound powder in a sterile vial.
-
Add the appropriate volume of DMSO or DMF to achieve the target concentration.
-
Vortex the mixture thoroughly until the solid is completely dissolved. Gentle warming (to 30-40°C) can be applied if necessary.
-
Aliquot the stock solution into smaller, single-use volumes to avoid repeated freeze-thaw cycles.
-
Store the stock solutions at -20°C or -80°C for long-term stability.
Protocol 2: Preparation of an Aqueous Solution for Cell-Based Assays
This protocol describes how to prepare a solution of this compound in an aqueous buffer, such as PBS, for direct use in cell culture experiments.
Materials:
-
This compound powder
-
Phosphate-Buffered Saline (PBS), pH 7.4
-
1 M HCl and 1 M NaOH for pH adjustment
-
Heating plate and/or ultrasonic water bath
-
Sterile syringe filters (0.22 µm)
-
Sterile conical tubes
Procedure:
-
Add the desired amount of this compound powder to a sterile conical tube.
-
Add a portion of the PBS to the tube.
-
Gently heat the suspension to approximately 70°C while sonicating in a water bath until the solid dissolves.[2][3]
-
Allow the solution to cool to room temperature. If precipitation occurs, proceed with pH adjustment.
-
If the compound does not fully dissolve or precipitates upon cooling, adjust the pH of the solution. Add 1 M HCl dropwise to lower the pH or 1 M NaOH dropwise to raise the pH until the compound dissolves. Amino acids are typically more soluble at pH values away from their isoelectric point.
-
Once the compound is fully dissolved, adjust the final volume with PBS.
-
Sterilize the solution by passing it through a 0.22 µm syringe filter into a new sterile tube.
-
This solution should be prepared fresh for each experiment.
Frequently Asked Questions (FAQs)
Q1: What is the recommended storage condition for solid this compound?
A1: The solid powder should be stored in a tightly sealed container in a refrigerator or at -20°C for long-term stability.
Q2: How should I store solutions of this compound?
A2: Stock solutions prepared in anhydrous organic solvents like DMSO or DMF are stable for several months when stored at -20°C or -80°C. Aqueous solutions are less stable and should ideally be prepared fresh before each use. If storage is necessary, filter-sterilize and store at 4°C for short periods (up to a few days), though stability should be validated for your specific experimental conditions.
Q3: Is this compound stable in solution?
A3: While specific stability data is limited, solutions in anhydrous organic solvents are generally stable when stored properly. Aqueous solutions, especially at non-neutral pH or when exposed to light and elevated temperatures, may be more prone to degradation over time. It is recommended to prepare aqueous solutions fresh.
Q4: Can the trifluoromethyl group affect my biological assay?
A4: The trifluoromethyl group is known to increase the lipophilicity and metabolic stability of molecules.[4][5] This can influence how the molecule interacts with cells and biological targets. It is important to consider these properties when designing experiments and to include appropriate controls.
Q5: How does the purity of this compound affect its solubility?
A5: Impurities can sometimes affect the dissolution process. It is always recommended to use high-purity material from a reputable supplier to ensure reproducible results.
Visual Troubleshooting and Workflow Diagrams
The following diagrams illustrate the decision-making process for dissolving this compound and troubleshooting common solubility issues.
Caption: A step-by-step workflow for selecting a solvent and dissolving this compound.
References
Technical Support Center: Refining Purification Protocols for Fluorinated Proteins
This technical support center provides researchers, scientists, and drug development professionals with comprehensive troubleshooting guides and frequently asked questions (FAQs) to address specific challenges encountered during the purification of fluorinated proteins.
Troubleshooting Guide
This guide addresses common problems in a question-and-answer format to help you navigate experimental hurdles.
Question: My fluorinated protein expression is very low. What can I do?
Answer: Low expression of fluorinated proteins is a common issue. Here are several factors to consider:
-
Toxicity of Fluorinated Amino Acids: Highly fluorinated amino acids can sometimes be toxic to the expression host. Consider optimizing the concentration of the fluorinated analog in the growth media. For bacterial expression, using auxotrophic strains that cannot synthesize the corresponding natural amino acid can improve incorporation efficiency.[1]
-
Codon Optimization: While not always a guaranteed solution, optimizing the codons of your gene for the specific expression host (e.g., E. coli or mammalian cells) may help mitigate some expression issues.[2]
-
Expression System: Bacterial expression systems are commonly used, but for complex eukaryotic proteins, mammalian suspension cultures (like HEK293 cells) might yield better results, although they are more complex to manage.[2][3][4]
-
Promoter and Induction Conditions: Ensure that the promoter controlling your gene expression is suitable and that induction conditions (e.g., IPTG concentration, induction temperature, and duration) are optimized. Lowering the induction temperature (e.g., to 16-20°C) can sometimes reduce protein aggregation and improve the yield of soluble protein.[5]
Question: My fluorinated protein is aggregating during purification. How can I prevent this?
Answer: Protein aggregation is a significant challenge, often exacerbated by the hydrophobic nature of fluorinated residues.[6] Consider the following strategies:
-
Buffer Composition:
-
pH: Operate at a pH where your protein is most stable and soluble. This is typically a pH unit away from the protein's isoelectric point (pI).[7][8]
-
Additives: Include additives in your lysis and purification buffers to enhance solubility. Options include:
-
Reducing Agents: DTT or TCEP (5-10 mM) can prevent the formation of incorrect disulfide bonds that may lead to aggregation.[8]
-
Detergents: Low concentrations of non-ionic detergents (e.g., 0.1% Tween-20, Triton X-100, or CHAPS) can help solubilize proteins, especially those with exposed hydrophobic regions.[5][7]
-
Stabilizers: Glycerol (5-20%) can act as a cryoprotectant and stabilizing agent.[7][9]
-
-
-
Protein Concentration: Keep the protein concentration as low as practically possible during all purification steps to reduce the likelihood of aggregation.[7]
-
Temperature Control: Perform purification steps at 4°C to minimize aggregation and proteolysis. For long-term storage, flash-freeze aliquots and store them at -80°C.[7]
Question: The fluorinated protein does not bind to the affinity column (e.g., Ni-NTA). What is the cause?
Answer: Failure to bind to an affinity column can be frustrating. Here are some potential causes and solutions:[10]
-
Inaccessible Affinity Tag: The fluorinated residues might be causing the protein to fold in a way that buries the affinity tag (e.g., His-tag). You can try:
-
Denaturing Purification: Perform the purification under denaturing conditions (e.g., with 6 M guanidine-HCl or 8 M urea) to expose the tag, followed by on-column refolding.[9]
-
Longer Linker: If re-cloning is an option, insert a flexible linker (e.g., a glycine-serine linker) between your protein and the tag.[11]
-
-
Incorrect Buffer Conditions:
-
pH: Ensure the binding buffer pH is optimal for the tag's interaction with the resin. For His-tags, a pH between 7.5 and 8.0 is typical.[12]
-
Competing Agents: For His-tag purification, ensure there are no high concentrations of competing agents like imidazole (B134444) in your lysate. Also, be aware that some buffer components or chelating agents (like EDTA) can strip the metal ions from the column.
-
-
Tag Integrity: Verify the DNA sequence of your construct to ensure the tag is in-frame and that no mutations have occurred.[10] You can also confirm the presence of the tag on the expressed protein using a Western blot with a tag-specific antibody.[10]
Question: How can I optimize the separation of my fluorinated protein using chromatography?
Answer: The unique properties of fluorinated proteins can be leveraged for effective chromatographic separation.[13]
-
Reverse-Phase Chromatography (RPC): This is a powerful technique for fluorinated molecules. Optimal separation can often be achieved through a "hetero-pairing" of the column and eluent.[13][14]
-
Temperature: Increasing the column temperature (e.g., to 45°C) can improve separation and achieve baseline resolution in some cases.[13][14]
-
Hydrophobic Interaction Chromatography (HIC): This method separates proteins based on hydrophobicity and can be effective for fluorinated proteins. Proteins bind at high salt concentrations and are eluted by decreasing the salt gradient.[15]
Frequently Asked Questions (FAQs)
Q1: What are the main advantages of incorporating fluorine into proteins?
A1: Incorporating fluorine can impart unique and beneficial properties to proteins. Fluorination is a recognized strategy to enhance the thermal and chemical stability of proteins, often with minimal disruption to the protein's native structure and function.[1][16][17][18] The extreme inertness and stability associated with fluorocarbons can also make proteins more resistant to proteolytic degradation.[16][17] Furthermore, the fluorine atom serves as a sensitive reporter for ¹⁹F-NMR studies, allowing for detailed investigation of protein structure, dynamics, and interactions without background interference from other atoms in the biological system.[19][20]
Q2: Which expression system is best for producing fluorinated proteins?
A2: The choice depends on the protein and the desired yield.
-
E. coli : This is a cost-effective and common choice, especially when using auxotrophic strains to ensure high incorporation rates of the fluorinated amino acid.[1][20]
-
Mammalian Cells: For complex eukaryotic proteins that require specific post-translational modifications, mammalian suspension cells like HEK293 are preferred.[2][4] These systems can produce properly folded proteins, and protocols for large-scale production are available.[2]
-
Cell-Free Systems: These systems allow for precise control over the components of the reaction, which can be advantageous for incorporating non-canonical amino acids, though scaling up can be a challenge.[2]
Q3: Does fluorination affect protein structure and function?
A3: Generally, the incorporation of fluorinated amino acids is designed to be minimally perturbative. Fluorinated side chains can replace hydrophobic amino acids while closely preserving their shape, leading to enhanced stability without significant structural changes.[16][17] However, the impact must be assessed on a case-by-case basis. While many studies report retained biological activity, altered electrostatic properties due to fluorination could potentially affect ligand binding or protein-protein interactions.[1][21] It is crucial to perform functional assays on the purified fluorinated protein to confirm its activity compared to the wild-type version.[21]
Q4: What is the "fluorous effect" and can it be used for purification?
A4: The "fluorous effect" refers to the tendency of highly fluorinated molecules to self-associate and separate from hydrocarbon-based molecules, similar to how oil and water separate.[16][17] This property has been effectively used in organic synthesis for a purification strategy known as fluorous separation, where fluorocarbon-tagged molecules are extracted into a fluorinated solvent.[16][17][18] While it was initially proposed that this could be used for specific protein-protein interactions or purification, evidence for strong, favorable fluorine-fluorine interactions within protein cores is mixed.[1][16] However, the distinct properties of fluorinated proteins can be exploited in chromatography, as seen with fluorinated columns or eluents.[13]
Quantitative Data Summary
The following tables summarize key quantitative data related to the expression and purification of fluorinated proteins as reported in the literature.
Table 1: Reported Yields and Incorporation Efficiency of Fluorinated Proteins
| Protein Target | Expression System | Fluorinated Amino Acid | Yield | Incorporation Efficiency | Reference |
| KIX Domain | E. coli DL39(DE3) | 3-Fluoro-L-tyrosine (3FY) | Up to 70 mg/L | Not specified | [20] |
| KIX Domain | E. coli DL39(DE3) | 4-Fluoro-L-phenylalanine (4FF) | Up to 65 mg/L | Not specified | [20] |
| KIX Domain | E. coli BL21(DE3) | 5-Fluoro-L-tryptophan (5FW) | Up to 62 mg/L | Not specified | [20] |
| Bromodomain Brd4 | E. coli | 5-Fluoro-L-tryptophan (5FW) | 120 mg/L | >94% | [21] |
| Various Proteins | Human Cells | Various (3FY, 4FF, 5FW, 6FW) | Not specified | ~30% to ~60% | [19] |
Table 2: Impact of Fluorination on Protein Stability and Binding Affinity
| Protein System | Fluorinated Residue | Effect on Stability | Change in Binding Affinity (Kd) | Reference |
| Globular α-β protein NTL9 | trifluoro-valine (tFVal) | Increased stability by 1.4 kcal/mol per residue | Not specified | [1] |
| Bromodomain Brd4 | 5-Fluoro-L-tryptophan (5FW) | Not specified | No significant change for some ligands; 4.7-fold difference for another | [21] |
| EGFR-targeting protein | Fluorinated peptides | Not specified | Affinity varied; optimal fluorine content (15 atoms) retained high affinity (Kd ~189 nM) | [22] |
Experimental Protocols
Protocol 1: Expression and His-tag Purification of a Fluorinated Protein in E. coli
This protocol is a general guideline and should be optimized for your specific protein.
1. Expression: a. Transform an appropriate E. coli expression strain (e.g., BL21(DE3) or a suitable auxotroph) with your expression plasmid. b. Inoculate a starter culture in a standard medium (e.g., LB) with the appropriate antibiotic and grow overnight at 37°C. c. Inoculate the main culture in a minimal medium (e.g., M9) supplemented with all necessary amino acids except the one to be replaced. Add the fluorinated amino acid analog. d. Grow the culture at 37°C with shaking until it reaches an OD₆₀₀ of 0.6-0.8. e. Induce protein expression with IPTG (optimize concentration, e.g., 0.1-1 mM) and reduce the temperature to 16-25°C. Continue to grow for another 4-16 hours. f. Harvest the cells by centrifugation (e.g., 6,000 x g for 15 minutes at 4°C).
2. Lysis: a. Resuspend the cell pellet in ice-cold Lysis Buffer (e.g., 50 mM Tris-HCl pH 8.0, 300 mM NaCl, 10 mM Imidazole, 1 mM DTT, 1 mM PMSF).[5][22] b. Lyse the cells using sonication on ice or by passing them through a high-pressure homogenizer. c. Clarify the lysate by centrifugation (e.g., 20,000 x g for 30 minutes at 4°C) to pellet cell debris.
3. Affinity Chromatography (IMAC): [9][19] a. Equilibrate a Ni-NTA column with 5-10 column volumes (CV) of Lysis Buffer. b. Load the clarified lysate onto the column at a slow flow rate. c. Wash the column with 10-20 CV of Wash Buffer (e.g., 50 mM Tris-HCl pH 8.0, 300 mM NaCl, 20-40 mM Imidazole) to remove non-specifically bound proteins. d. Elute the target protein with 5-10 CV of Elution Buffer (e.g., 50 mM Tris-HCl pH 8.0, 300 mM NaCl, 250-500 mM Imidazole). e. Collect fractions and analyze them by SDS-PAGE to identify those containing the purified protein.
4. Buffer Exchange/Desalting (Optional): a. Pool the pure fractions. b. If necessary, perform buffer exchange into a final storage buffer (e.g., using a desalting column or dialysis) that is free of imidazole and suitable for downstream applications.
Visualizations
Experimental and Logical Workflows
The following diagrams illustrate key processes and logical relationships in the purification of fluorinated proteins.
References
- 1. Fluorine: A new element in protein design - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Expression and Purification of Fluorinated Proteins from Mammalian Suspension Culture - PMC [pmc.ncbi.nlm.nih.gov]
- 3. researchgate.net [researchgate.net]
- 4. Expression and purification of fluorinated proteins from mammalian suspension culture - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. A novel approach for the purification of aggregation prone proteins - PMC [pmc.ncbi.nlm.nih.gov]
- 6. utsouthwestern.edu [utsouthwestern.edu]
- 7. info.gbiosciences.com [info.gbiosciences.com]
- 8. bitesizebio.com [bitesizebio.com]
- 9. med.upenn.edu [med.upenn.edu]
- 10. goldbio.com [goldbio.com]
- 11. bitesizebio.com [bitesizebio.com]
- 12. goldbio.com [goldbio.com]
- 13. Optimize the Separation of Fluorinated Amphiles Using High-Performance Liquid Chromatography - PMC [pmc.ncbi.nlm.nih.gov]
- 14. researchgate.net [researchgate.net]
- 15. youtube.com [youtube.com]
- 16. pubs.acs.org [pubs.acs.org]
- 17. Fluorinated proteins: from design and synthesis to structure and stability - PubMed [pubmed.ncbi.nlm.nih.gov]
- 18. Structural basis for the enhanced stability of highly fluorinated proteins - PMC [pmc.ncbi.nlm.nih.gov]
- 19. Direct Expression of Fluorinated Proteins in Human Cells for 19F In-Cell NMR Spectroscopy - PMC [pmc.ncbi.nlm.nih.gov]
- 20. Protein-observed 19F-NMR for fragment screening, affinity quantification and druggability assessment - PMC [pmc.ncbi.nlm.nih.gov]
- 21. Protein-Observed Fluorine NMR Is a Complementary Ligand Discovery Method to 1H CPMG Ligand-Observed NMR - PMC [pmc.ncbi.nlm.nih.gov]
- 22. Multivalent Fluorinated Nanorings for On-Cell 19F NMR - PMC [pmc.ncbi.nlm.nih.gov]
Technical Support Center: Minimizing Toxicity of Unnatural Amino Acids in Cells
This technical support center provides researchers, scientists, and drug development professionals with troubleshooting guides and frequently asked questions (FAQs) to address common issues encountered when working with unnatural amino acids (UAAs).
Frequently Asked Questions (FAQs)
Q1: What are the primary causes of unnatural amino acid (UAA) toxicity in cells?
A1: The toxicity of unnatural amino acids in cellular experiments can stem from several factors:
-
Metabolic Stress: The introduction of a UAA can disrupt normal metabolic pathways. Cells may attempt to process the UAA, leading to the production of toxic byproducts or the depletion of essential metabolites. This can also lead to the generation of reactive oxygen species (ROS), causing oxidative stress.
-
Protein Misfolding and Aggregation: The incorporation of a UAA can interfere with the proper folding of the target protein. Misfolded proteins can accumulate in the endoplasmic reticulum (ER), triggering the Unfolded Protein Response (UPR), a cellular stress response. If the stress is prolonged, the UPR can initiate apoptosis (programmed cell death).[1][2][3]
-
Misincorporation into Endogenous Proteins: If the orthogonal translation system (OTS) is not perfectly specific, the UAA can be mistakenly incorporated into native proteins. This can lead to widespread protein dysfunction and cellular toxicity.[4][5][6]
-
Inhibition of Essential Enzymes: The UAA or its metabolites may act as inhibitors of essential cellular enzymes, disrupting critical biological processes.
-
Inherent Cytotoxicity: Some UAAs, due to their chemical structure, may be inherently toxic to cells, independent of their incorporation into proteins.
Q2: How can I optimize the concentration of the UAA to maximize protein yield while minimizing toxicity?
A2: Optimizing the UAA concentration is a critical step. A concentration that is too low will result in poor incorporation efficiency and low protein yield, while a concentration that is too high can lead to cytotoxicity. The optimal concentration is cell-line and UAA-specific. A good starting point is to perform a dose-response experiment.
Troubleshooting Guides
Problem 1: Low or No Expression of the UAA-Containing Protein
Possible Causes and Solutions:
| Possible Cause | Recommended Action |
| Suboptimal UAA Concentration | Perform a titration of the UAA concentration (e.g., 0.1 mM to 2 mM) to find the optimal balance between expression and toxicity.[7] |
| Inefficient Orthogonal Translation System (OTS) | - Ensure the aminoacyl-tRNA synthetase (aaRS) and tRNA are from a compatible orthogonal system. - Increase the copy number of the suppressor tRNA plasmid.[8] - Use a cell line with improved UAA incorporation machinery, if available. |
| Poor UAA Solubility or Stability in Media | - Prepare fresh UAA solutions. - Test different solvents for the UAA stock solution (e.g., DMSO, NaOH) and ensure the final solvent concentration in the media is non-toxic. - Consider using peptide versions of the UAA to improve solubility.[9] |
| Codon Usage Bias | The efficiency of UAA incorporation can be influenced by the nucleotides surrounding the amber stop codon (UAG).[10] If possible, use synonymous codons for the flanking amino acids to optimize the context. |
| Toxicity Leading to Cell Death Before Protein Expression | - Lower the UAA concentration. - Reduce the induction time or use a weaker promoter for the target protein. - Monitor cell viability during the experiment. |
Problem 2: High Cell Death or Poor Cell Viability
Possible Causes and Solutions:
| Possible Cause | Recommended Action |
| UAA Concentration is Too High | Reduce the UAA concentration. Perform a toxicity assay (e.g., MTT assay) to determine the IC50 of the UAA for your cell line. |
| Metabolic Stress and Oxidative Stress | - Supplement the culture media with antioxidants like N-acetylcysteine (NAC). - Perform a ROS assay to quantify oxidative stress. - Analyze cellular metabolites to identify any metabolic imbalances. |
| Activation of the Unfolded Protein Response (UPR) and Apoptosis | - Lower the expression level of the UAA-containing protein to reduce the load on the ER. - Analyze for markers of UPR activation (e.g., phosphorylated PERK, IRE1α, and cleaved ATF6) and apoptosis (e.g., cleaved caspase-3). |
| Misincorporation into Native Proteins | - Ensure the use of a highly specific orthogonal aaRS. - Perform mass spectrometry analysis of total cell lysate to check for off-target UAA incorporation. |
Quantitative Data Summary
Table 1: Recommended UAA Concentrations and Observed Protein Yields in Different Expression Systems.
| Expression System | Unnatural Amino Acid (UAA) | Typical Concentration Range | Typical Protein Yield | Reference |
| E. coli | p-acetyl-L-phenylalanine | 1 mM | ~40 mg/L | [11] |
| E. coli | p-azido-L-phenylalanine | 1 mM | Varies (e.g., 1.8 mg from 2 mL culture) | [12] |
| HEK293 Cells | p-azido-L-phenylalanine (AzF) | 50 - 400 µM | Dependent on expression system | [1] |
| HEK293 Cells | trans-cyclooctene-L-lysine (TCO*A) | > 50 µM | Dependent on expression system | [1] |
| CHO Cells | N6-((2-azidoethoxy)carbonyl)-l-lysine | Not specified | 3 g/L (in perfusion) | [13] |
Note: Protein yields are highly dependent on the specific protein, expression vector, and culture conditions.
Key Experimental Protocols
Cell Viability Assessment: MTT Assay
This protocol is used to assess cell metabolic activity as an indicator of cell viability.
Materials:
-
MTT (3-(4,5-dimethylthiazol-2-yl)-2,5-diphenyltetrazolium bromide) solution (5 mg/mL in PBS)
-
Solubilization solution (e.g., DMSO or 0.01 M HCl in 10% SDS)
-
96-well plates
-
Plate reader (570 nm absorbance)
Procedure:
-
Seed cells in a 96-well plate at a desired density and allow them to adhere overnight.
-
Treat the cells with varying concentrations of the UAA for the desired experimental time. Include untreated cells as a control.
-
Add 10 µL of MTT solution to each well.
-
Incubate the plate for 2-4 hours at 37°C until a purple precipitate is visible.
-
Add 100 µL of solubilization solution to each well and mix thoroughly to dissolve the formazan (B1609692) crystals.
-
Read the absorbance at 570 nm using a plate reader.
-
Calculate cell viability as a percentage of the untreated control.[14][15][16][17][18]
Assessment of Oxidative Stress: ROS Detection Assay
This protocol measures the levels of reactive oxygen species (ROS) in cells.
Materials:
-
DCFDA (2',7'–dichlorofluorescin diacetate) or other suitable ROS-sensitive fluorescent probe
-
Cell culture medium without phenol (B47542) red
-
Fluorescence microscope or plate reader (Ex/Em ~495/529 nm)
Procedure:
-
Culture cells in a suitable format (e.g., 96-well plate or chamber slide).
-
Treat cells with the UAA for the desired time. Include a positive control (e.g., H₂O₂) and an untreated control.
-
Wash the cells with serum-free medium or PBS.
-
Load the cells with the ROS detection reagent (e.g., DCFDA) according to the manufacturer's instructions, typically for 30-60 minutes at 37°C.
-
Wash the cells to remove excess probe.
-
Measure the fluorescence intensity using a fluorescence microscope or plate reader.[11]
Detection of UPR Activation: Western Blotting
This protocol is for detecting key markers of the Unfolded Protein Response.
Materials:
-
Cell lysis buffer (e.g., RIPA buffer) with protease and phosphatase inhibitors
-
Primary antibodies against p-PERK, p-IRE1α, and cleaved ATF6
-
HRP-conjugated secondary antibodies
-
Chemiluminescent substrate
-
Western blotting equipment
Procedure:
-
Treat cells with the UAA for various time points.
-
Lyse the cells and quantify the protein concentration.
-
Separate the protein lysates by SDS-PAGE and transfer to a PVDF or nitrocellulose membrane.
-
Block the membrane and incubate with primary antibodies overnight at 4°C.
-
Wash the membrane and incubate with HRP-conjugated secondary antibodies.
-
Detect the signal using a chemiluminescent substrate and an imaging system.[2][13][19]
Apoptosis Detection: Caspase-3 Activity Assay
This assay measures the activity of caspase-3, a key executioner caspase in apoptosis.
Materials:
-
Caspase-3 substrate (e.g., Ac-DEVD-pNA for colorimetric or Ac-DEVD-AMC for fluorometric)
-
Cell lysis buffer
-
Plate reader (405 nm for colorimetric, Ex/Em 380/460 nm for fluorometric)
Procedure:
-
Treat cells with the UAA to induce apoptosis.
-
Lyse the cells according to the assay kit protocol.
-
Add the caspase-3 substrate to the cell lysates.
-
Incubate at 37°C for 1-2 hours.
-
Measure the absorbance or fluorescence using a plate reader. The signal is proportional to the caspase-3 activity.[14][15][16][17][20]
Visualizations
Caption: Troubleshooting workflow for UAA-induced toxicity.
Caption: UPR signaling pathway activated by misfolded UAA-proteins.
References
- 1. Evaluation and optimisation of unnatural amino acid incorporation and bioorthogonal bioconjugation for site-specific fluorescent labelling of proteins expressed in mammalian cells - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Methods for studying ER stress and UPR markers in human cells - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. Rational incorporation of any unnatural amino acid into proteins by machine learning on existing experimental proofs - PMC [pmc.ncbi.nlm.nih.gov]
- 4. academic.oup.com [academic.oup.com]
- 5. reef2reef.com [reef2reef.com]
- 6. Quantification of Urinary Albumin by Using Protein Cleavage and LC-MS/MS - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Genetic Code Expansion in Mammalian Cells: a Plasmid System Comparison - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Toward efficient multiple-site incorporation of unnatural amino acids using cell-free translation system - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Optimizing the stability and solubility of cell culture media ingredients - Evonik Industries [healthcare.evonik.com]
- 10. Identification of permissive amber suppression sites for efficient non-canonical amino acid incorporation in mammalian cells - PMC [pmc.ncbi.nlm.nih.gov]
- 11. mdpi.com [mdpi.com]
- 12. Condensed E. coli Cultures for Highly Efficient Production of Proteins Containing Unnatural Amino Acids - PMC [pmc.ncbi.nlm.nih.gov]
- 13. researchgate.net [researchgate.net]
- 14. Caspase Activity Assay - Creative Bioarray | Creative Bioarray [creative-bioarray.com]
- 15. caspase3 assay [assay-protocol.com]
- 16. Caspase-3 Activity Assay Kit | Cell Signaling Technology [cellsignal.com]
- 17. mpbio.com [mpbio.com]
- 18. Measuring ER stress and the unfolded protein response using mammalian tissue culture system - PMC [pmc.ncbi.nlm.nih.gov]
- 19. Methods for Studying ER Stress and UPR Markers in Human Cells | Springer Nature Experiments [experiments.springernature.com]
- 20. merckmillipore.com [merckmillipore.com]
Technical Support Center: 4-(Trifluoromethyl)-L-phenylalanine (TFMPhe) Incorporation
This technical support center provides troubleshooting guidance and answers to frequently asked questions for researchers, scientists, and drug development professionals working with 4-(Trifluoromethyl)-L-phenylalanine (TFMPhe).
Troubleshooting Guide
This guide addresses common issues encountered during the site-specific incorporation of TFMPhe into proteins.
Problem 1: Low or No Yield of the Target Protein Containing TFMPhe
| Potential Cause | Suggested Solution |
| Inefficient Aminoacyl-tRNA Synthetase (aaRS) | The engineered aaRS may not efficiently charge TFMPhe onto the suppressor tRNA. Solution: Use a previously evolved TyrRS enzyme selective for TFMPhe.[1] Alternatively, consider using a polyspecific RS enzyme that has shown efficacy for TFMPhe incorporation.[2] |
| Poor Suppressor tRNA Performance | The suppressor tRNA may be a limiting factor in protein synthesis. Solution: Utilize an engineered tRNATyr suppressor with mutations such as G34C/G37A in the anticodon loop, which can improve aminoacylation kinetics and overall protein yield.[1] |
| Suboptimal Reagent Concentrations | Incorrect concentrations of the aaRS, tRNA, or TFMPhe can hinder incorporation. Solution: Optimize the concentrations of these components. Cell-free protein synthesis (CFPS) systems offer a significant advantage here, as they allow for the precise adjustment of each element.[2] |
| Competition with Release Factor 1 (RF1) | In E. coli, RF1 can compete with the suppressor tRNA at the amber stop codon (UAG), leading to premature termination of translation. Solution: Employ a genomically recoded E. coli strain, such as C321.ΔA, where all UAG codons are replaced, and RF1 is deleted.[3] This eliminates competition and significantly boosts incorporation efficiency. |
| Toxicity of TFMPhe to Host Cells | High concentrations of TFMPhe or the expressed protein can be toxic to living cells, leading to poor growth and low protein yields. Solution: Switch to a Cell-Free Protein Synthesis (CFPS) system. CFPS systems are not constrained by cell viability and can tolerate components that might be toxic to live cells.[3][4] |
Problem 2: Misincorporation of Canonical Amino Acids
| Potential Cause | Suggested Solution |
| Lack of Orthogonality | The engineered aaRS may still recognize and charge a natural amino acid, or an endogenous synthetase may charge the suppressor tRNA. Solution: Ensure the use of a truly orthogonal aaRS/tRNA pair. The Methanocaldococcus jannaschii TyrRS:tRNATyr pair is a well-established orthogonal system for use in E. coli.[1] |
| Promiscuous Phenylalanyl-tRNA Synthetase (PheRS) | The host's native PheRS may be able to recognize and incorporate TFMPhe at phenylalanine codons, leading to off-target incorporation. Solution: While less common for TFMPhe, if this is suspected, engineering a more stringent endogenous PheRS may be necessary.[5] |
Frequently Asked Questions (FAQs)
Q1: What is the primary method for incorporating TFMPhe into a protein at a specific site?
A1: The most common and effective method is nonsense suppression, specifically amber (UAG) codon suppression. This technique utilizes an "orthogonal translation system" (OTS) composed of an engineered aminoacyl-tRNA synthetase (aaRS) and a corresponding suppressor tRNA (o-tRNA).[6] The aaRS is specifically evolved to recognize TFMPhe and charge it onto the o-tRNA. This o-tRNA is engineered to recognize the amber stop codon in the mRNA sequence of the target protein, leading to the insertion of TFMPhe at that specific site.[7]
Q2: Why are Cell-Free Protein Synthesis (CFPS) systems often recommended for TFMPhe incorporation?
A2: CFPS systems offer several key advantages for incorporating non-canonical amino acids like TFMPhe:
-
Higher Yields: CFPS can produce significantly higher protein yields compared to in vivo expression, which is crucial when using expensive non-canonical amino acids.[2]
-
Direct Control: The open nature of CFPS allows for direct manipulation and optimization of the concentrations of all components, including the aaRS, suppressor tRNA, and TFMPhe.[2][3]
-
Overcoming Toxicity: CFPS systems bypass issues of cell viability, making it possible to produce proteins that may be toxic to the host cell or use reagents that are not cell-permeable.[3][4]
-
Efficiency: Without the cell membrane barrier, the transport of TFMPhe into the translation machinery is not a limiting factor.[3]
Q3: Can the suppressor tRNA itself be optimized?
A3: Yes. The efficiency of the suppressor tRNA is a critical factor. Systematic testing and engineering of the tRNA can lead to significant improvements in incorporation efficiency. For the commonly used M. jannaschii tRNATyr, introducing two substitutions in the anticodon loop (G34C/G37A) has been shown to enhance aminoacylation kinetics and improve the yield of proteins containing various non-canonical amino acids, including TFMPhe.[1]
Q4: What is an orthogonal aaRS/tRNA pair and why is it important?
A4: An orthogonal pair is an aaRS and tRNA that function independently of the host cell's own synthetases and tRNAs.[1] This orthogonality is crucial for high-fidelity incorporation. It ensures that:
-
The engineered aaRS does not charge any of the cell's endogenous tRNAs with TFMPhe.
-
The host cell's endogenous synthetases do not charge the engineered suppressor tRNA with any of the 20 canonical amino acids.[1]
This prevents the misincorporation of amino acids and ensures that TFMPhe is inserted only at the desired codon.
Q5: How can I confirm that TFMPhe has been successfully incorporated into my protein?
A5: The most definitive method for confirming successful and site-specific incorporation is mass spectrometry. By analyzing the intact protein, you can verify that its molecular weight corresponds to the expected mass with the TFMPhe substitution.[8] Further analysis through peptide mapping and tandem mass spectrometry (LC-MS/MS) after proteolytic digestion can pinpoint the exact location of the incorporated TFMPhe.[6]
Quantitative Data Summary
Table 1: Comparison of Protein Yields in Cell-Free Protein Synthesis (CFPS)
| Protein | Non-Canonical Amino Acid | Incorporation Method | Yield (mg/mL) | Suppression Efficiency | Reference |
| sfGFP | p-azido-L-phenylalanine (pAzF) | Co-production of o-tRNA in CFPS | 0.9 - 1.7 | 50 - 88% | [9] |
| sfGFP | p-propargyloxy-L-phenylalanine (pPaF) | Co-production of o-tRNA in CFPS | 0.9 - 1.7 | 50 - 88% | [9] |
| Human MEK1 Kinase | Phosphoserine | CFPS with C321.ΔA E. coli extract | Up to milligram quantities | High | [3] |
Note: While specific yield data for TFMPhe was not detailed in the provided search results, the data for structurally similar phenylalanine analogs demonstrate the high efficiency achievable with optimized CFPS methods.
Experimental Protocols
Protocol 1: TFMPhe Incorporation using an E. coli Cell-Free Protein Synthesis (CFPS) System
This protocol is adapted from established methods for non-canonical amino acid incorporation in a robust CFPS platform.[6]
1. Preparation of E. coli S30 Extract: a. Grow E. coli cells (e.g., BL21(DE3)) to mid-log phase in 2xYT-P medium. b. Harvest cells by centrifugation and wash the pellets extensively with S30 buffer A. c. Resuspend the cell pellets in S30 buffer A and lyse the cells using a high-pressure homogenizer. d. Centrifuge the lysate to remove cell debris. e. Incubate the supernatant (the extract) at 37°C for 80 minutes to degrade endogenous nucleic acids. f. Perform dialysis of the extract against S30 buffer B overnight. g. Centrifuge the dialyzed extract, collect the supernatant, flash-freeze in liquid nitrogen, and store at -80°C.
2. Preparation of Orthogonal Translation System (OTS) Components: a. Overexpress and purify the engineered aminoacyl-tRNA synthetase specific for TFMPhe (TFMPheRS) using a standard His-tag affinity chromatography protocol.[6] b. Prepare the suppressor tRNA (o-tRNA) via in vitro transcription from a linearized plasmid or a PCR product containing a T7 promoter.[9][10]
3. CFPS Reaction Assembly: a. On ice, combine the following components in a microcentrifuge tube:
- S30 E. coli extract
- Premixed solution containing buffers, NTPs, amino acids (excluding tyrosine/phenylalanine if competing), and an energy regeneration source (e.g., phosphoenolpyruvate).[6]
- Plasmid DNA encoding the target protein with an in-frame amber (TAG) codon at the desired incorporation site.
- Purified TFMPheRS.
- In vitro transcribed suppressor tRNA.
- This compound (TFMPhe) solution (e.g., 100 mM stock).[6] b. Incubate the reaction mixture at the optimal temperature (e.g., 37°C) for several hours.
4. Analysis of Protein Expression and Incorporation: a. Analyze a small aliquot of the reaction by SDS-PAGE to visualize protein expression. b. Purify the target protein using an appropriate method (e.g., His-tag affinity chromatography). c. Confirm the incorporation of TFMPhe using electrospray ionization mass spectrometry (ESI-MS) on the intact, purified protein.[8]
Visualizations
Caption: Experimental workflow for site-specific incorporation of TFMPhe.
Caption: Troubleshooting logic for overcoming low TFMPhe incorporation rates.
References
- 1. Improved Incorporation of Noncanonical Amino Acids by an Engineered tRNATyr Suppressor - PMC [pmc.ncbi.nlm.nih.gov]
- 2. s3-ap-southeast-2.amazonaws.com [s3-ap-southeast-2.amazonaws.com]
- 3. Emerging Methods for Efficient and Extensive Incorporation of Non-canonical Amino Acids Using Cell-Free Systems - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Cell-free protein synthesis - Wikipedia [en.wikipedia.org]
- 5. pubs.acs.org [pubs.acs.org]
- 6. Efficient Incorporation of Unnatural Amino Acids into Proteins with a Robust Cell-Free System - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Incorporating Unnatural Amino Acids into Recombinant Proteins in Living Cells [labome.com]
- 8. Tuning phenylalanine fluorination to assess aromatic contributions to protein function and stability in cells - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Cell-free co-production of an orthogonal transfer RNA activates efficient site-specific non-natural amino acid incorporation - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Incorporation of non-canonical amino acids - PMC [pmc.ncbi.nlm.nih.gov]
Validation & Comparative
Validating the Incorporation of 4-(Trifluoromethyl)-L-phenylalanine by Mass Spectrometry: A Comparative Guide
In the expanding field of protein engineering and drug discovery, the site-specific incorporation of non-canonical amino acids (ncAAs) offers a powerful tool to introduce novel functionalities into proteins. 4-(Trifluoromethyl)-L-phenylalanine (TFMPA) is a valuable ncAA due to the unique properties of the trifluoromethyl group, which can serve as a sensitive ¹⁹F NMR probe and modulate protein stability and interactions. Rigorous validation of its incorporation is crucial for the accurate interpretation of experimental results. This guide provides a comparative overview of mass spectrometry-based methods for validating the incorporation of TFMPA, alongside a comparison with other commonly used phenylalanine analogs, supported by experimental data and detailed protocols.
Comparison of Non-Canonical Phenylalanine Analogs
The choice of a non-canonical amino acid for protein engineering depends on the desired functionality and the efficiency of its incorporation. Here, we compare TFMPA with two other widely used phenylalanine analogs: 4-Azido-L-phenylalanine (AzF) and 4-Fluoro-L-phenylalanine (4-F-Phe).
| Feature | This compound (TFMPA) | 4-Azido-L-phenylalanine (AzF) | 4-Fluoro-L-phenylalanine (4-F-Phe) |
| Primary Application | ¹⁹F NMR spectroscopy, protein stability studies, altering protein-protein interactions. | Bioorthogonal "click" chemistry for labeling with probes (e.g., fluorophores, biotin).[1][2] | ¹⁹F NMR spectroscopy, minimal structural perturbation. |
| Incorporation Efficiency | High fidelity, with yields depending on the expression system and the specific aminoacyl-tRNA synthetase used.[3] | Generally high, enabling efficient protein labeling.[4] | Can be incorporated with high efficiency, sometimes competing with endogenous phenylalanine. |
| Detection by Mass Spectrometry | Readily detectable by a characteristic mass shift. | Detectable by mass shift; the azido (B1232118) group can be specifically targeted for enrichment. | Detectable by a smaller mass shift compared to TFMPA. |
| Potential for Misincorporation | Low when using an evolved, orthogonal aminoacyl-tRNA synthetase/tRNA pair.[5][3] | Low with appropriate orthogonal systems. | Can be misincorporated at phenylalanine sites by the endogenous phenylalanyl-tRNA synthetase in some systems. |
| Chemical Stability | The trifluoromethyl group is chemically inert and stable under physiological conditions. | The azido group is stable but reactive under specific "click" chemistry conditions.[1] | The fluoro group is stable. |
Quantitative Analysis of Incorporation Efficiency by Mass Spectrometry
Mass spectrometry is the gold standard for confirming the site-specific incorporation of ncAAs and quantifying the efficiency. Electrospray ionization (ESI) and matrix-assisted laser desorption/ionization (MALDI) are the most common ionization techniques used. High-resolution mass spectrometers, such as time-of-flight (TOF) and Orbitrap analyzers, are essential for accurately measuring the mass difference between the wild-type and the modified protein or peptide.
Table 1: Quantitative Incorporation Fidelity of Fluorinated Phenylalanine Analogs in sfGFP
| Non-Canonical Amino Acid | Synthetase | Incorporation Fidelity (%) | Misincorporation (Natural Amino Acid) (%) |
| 2,6-difluoro-Phe | PheX-D6 | 95.0 | 5.0 |
| 2,3,6-trifluoro-Phe | PheX-D6 | 100.0 | 0.0 |
| 2,3,5,6-tetrafluoro-Phe | PheX-D6 | 98.7 | 1.3 |
| pentafluoro-Phe | PheX-D6 | 98.2 | 1.8 |
| 2-fluoro-Phe | PheX-B5 | 95.6 | 4.4 |
| 2,6-difluoro-Phe | PheX-B5 | 81.8 | 18.2 |
| 2,3,6-trifluoro-Phe | PheX-B5 | 88.1 | 11.9 |
| 2,3,5,6-tetrafluoro-Phe | PheX-B5 | 97.9 | 2.1 |
| pentafluoro-Phe | PheX-B5 | 97.5 | 2.5 |
Data adapted from a study on site-specific encoding of fluorinated Phe residues within superfolder GFP (sfGFP) in E. coli, analyzed by ESI mass spectrometry.
Experimental Protocols
Site-Specific Incorporation of TFMPA into a Target Protein
This protocol outlines the general steps for incorporating TFMPA at a specific site in a target protein using an engineered aminoacyl-tRNA synthetase (aaRS) and a suppressor tRNA in E. coli.
Workflow for TFMPA Incorporation
Caption: Workflow for the incorporation of TFMPA into a target protein.
-
Vector Preparation:
-
Clone the gene of interest into an expression vector. Introduce an amber stop codon (TAG) at the desired site for TFMPA incorporation using site-directed mutagenesis.
-
Use a separate, compatible plasmid carrying the gene for the engineered TFMPA-specific aminoacyl-tRNA synthetase (TFMPA-RS) and the corresponding suppressor tRNA (e.g., tRNA CUA).
-
-
Transformation:
-
Co-transform a suitable E. coli expression strain (e.g., BL21(DE3)) with both the target protein plasmid and the TFMPA-RS/tRNA plasmid.
-
-
Cell Culture and Protein Expression:
-
Grow the transformed cells in a suitable medium (e.g., LB or minimal medium) with appropriate antibiotics at 37°C to an OD₆₀₀ of 0.6-0.8.
-
Supplement the medium with 1 mM this compound.
-
Induce protein expression with an appropriate inducer (e.g., 1 mM IPTG) and continue to grow the culture at a reduced temperature (e.g., 20-30°C) for several hours or overnight.
-
-
Cell Harvesting and Protein Purification:
-
Harvest the cells by centrifugation.
-
Lyse the cells using sonication or a French press in a suitable lysis buffer.
-
Purify the target protein using an appropriate chromatography method (e.g., Ni-NTA affinity chromatography for His-tagged proteins).[6]
-
Mass Spectrometry Analysis of the Intact Protein
This method provides a quick confirmation of TFMPA incorporation by analyzing the total mass of the purified protein.
-
Sample Preparation:
-
Desalt the purified protein solution using a suitable method (e.g., dialysis or a desalting column) into a buffer compatible with mass spectrometry (e.g., 0.1% formic acid in water/acetonitrile).[7]
-
-
LC-MS Analysis:
-
Inject the desalted protein sample into a liquid chromatography-mass spectrometry (LC-MS) system.
-
Use a reversed-phase column (e.g., C4 or C8) suitable for protein separation.
-
Acquire mass spectra in the positive ion mode using an ESI source.
-
-
Data Analysis:
-
Deconvolute the resulting mass spectrum to determine the zero-charge mass of the protein.
-
Compare the observed mass with the theoretical mass of the protein with and without TFMPA incorporation. The incorporation of TFMPA results in a specific mass shift.
-
In-Solution Digestion and Peptide Analysis by LC-MS/MS
This "bottom-up" proteomics approach provides definitive evidence of site-specific incorporation by identifying the peptide containing TFMPA.
Workflow for Mass Spectrometry Validation
Caption: Workflow for validation of TFMPA incorporation by mass spectrometry.
-
Denaturation, Reduction, and Alkylation:
-
Denature the purified protein in a solution containing a chaotropic agent (e.g., 8 M urea (B33335) or 6 M guanidine (B92328) hydrochloride).[8]
-
Reduce disulfide bonds by adding a reducing agent (e.g., 10 mM dithiothreitol, DTT) and incubating at 37-56°C for 1 hour.
-
Alkylate the free sulfhydryl groups by adding an alkylating agent (e.g., 55 mM iodoacetamide) and incubating in the dark at room temperature for 45-60 minutes.
-
-
Proteolytic Digestion:
-
Dilute the protein solution to reduce the concentration of the denaturant (e.g., to < 1 M urea).
-
Add a protease, such as trypsin, at an appropriate enzyme-to-substrate ratio (e.g., 1:50 to 1:100 w/w).
-
Incubate at 37°C for 12-16 hours.
-
-
Peptide Desalting:
-
Acidify the digest with trifluoroacetic acid (TFA) to a final concentration of 0.1-1%.
-
Desalt the peptides using a C18 solid-phase extraction (SPE) cartridge or tip.
-
-
LC-MS/MS Analysis:
-
Inject the desalted peptides into an LC-MS/MS system.
-
Separate the peptides using a reversed-phase C18 column with a gradient of acetonitrile (B52724) in 0.1% formic acid.
-
Acquire tandem mass spectra (MS/MS) of the eluting peptides using a data-dependent acquisition mode.
-
-
Data Analysis:
-
Search the acquired MS/MS data against a protein sequence database that includes the sequence of the target protein with the TFMPA substitution.
-
Use a proteomics software suite (e.g., MaxQuant, Proteome Discoverer, or Mascot) to identify the peptides.
-
Manually inspect the MS/MS spectrum of the TFMPA-containing peptide to confirm the sequence and the presence of the mass modification corresponding to TFMPA.
-
Conclusion
Validating the incorporation of this compound is a critical step in ensuring the reliability of studies that utilize this powerful non-canonical amino acid. Mass spectrometry, through both intact protein analysis and bottom-up proteomics approaches, provides definitive evidence of successful and site-specific incorporation. By following the detailed protocols and considering the comparative data presented in this guide, researchers can confidently employ TFMPA and other ncAAs to advance their work in protein engineering and drug development.
References
- 1. Synthesis and explosion hazards of 4-Azido-L-phenylalanine - PMC [pmc.ncbi.nlm.nih.gov]
- 2. vectorlabs.com [vectorlabs.com]
- 3. High-yield cell-free protein synthesis for site-specific incorporation of unnatural amino acids at two sites - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. Synthesis and protein incorporation of azido-modified unnatural amino acids - RSC Advances (RSC Publishing) [pubs.rsc.org]
- 5. s3-ap-southeast-2.amazonaws.com [s3-ap-southeast-2.amazonaws.com]
- 6. Sample Preparation | Stanford University Mass Spectrometry [mass-spec.stanford.edu]
- 7. massspec.unm.edu [massspec.unm.edu]
- 8. 質量分析用のサンプル調製 | Thermo Fisher Scientific - JP [thermofisher.com]
A Comparative Guide to Unnatural Amino Acids: 4-(Trifluoromethyl)-L-phenylalanine vs. Alternatives
For Researchers, Scientists, and Drug Development Professionals
The incorporation of unnatural amino acids (UAAs) into proteins has become a powerful tool in protein engineering and drug discovery, enabling the introduction of novel chemical functionalities to tailor protein properties.[1][2] This guide provides a comparative analysis of 4-(Trifluoromethyl)-L-phenylalanine against two other widely used phenylalanine analogs: 4-Bromo-L-phenylalanine and 4-Azido-L-phenylalanine. We will delve into their respective impacts on protein incorporation, stability, and cytotoxicity, supported by experimental data and detailed protocols.
Overview of Compared Unnatural Amino Acids
This compound (TFMP) is a fluorinated analog of phenylalanine. The trifluoromethyl group is a strong electron-withdrawing group, which can influence protein folding and stability through altered electrostatic interactions.[3]
4-Bromo-L-phenylalanine (BrP) introduces a halogen atom onto the phenyl ring. The bromine atom can participate in halogen bonding and provides a site for further chemical modification through cross-coupling reactions.
4-Azido-L-phenylalanine (AzP) contains an azide (B81097) group, a versatile functional handle for bioorthogonal chemistry, such as "click" chemistry and Staudinger ligation.[4][5][6][7] This allows for the site-specific labeling and conjugation of proteins.[4][5][6][7]
Quantitative Performance Comparison
The following tables summarize key performance metrics for the three UAAs. It is important to note that direct comparative studies under identical conditions are limited, and the data presented here are compiled from various sources.
| Unnatural Amino Acid | Incorporation Efficiency (%) | Protein Yield (mg/L) | Reference |
| This compound | Not explicitly quantified, but successful incorporation leading to functional protein has been demonstrated. | ~5-15 (in some systems) | [8] |
| 4-Bromo-L-phenylalanine | Not explicitly quantified in direct comparison. | Not consistently reported. | |
| 4-Azido-L-phenylalanine | Can be variable, but optimization can significantly increase yields. | 5-6 (in some MetA mutants) | [2] |
Table 1: Incorporation Efficiency and Protein Yield. The efficiency of UAA incorporation can be influenced by the specific orthogonal tRNA/aminoacyl-tRNA synthetase pair used, the expression host, and culture conditions.
| Unnatural Amino Acid | Model Protein | Change in Melting Temperature (ΔTm) | Reference |
| This compound | E. coli Transketolase (TK) | +7.5 °C | [3] |
| 4-Bromo-L-phenylalanine | Not explicitly quantified in direct comparison. | Not consistently reported. | |
| 4-Azido-L-phenylalanine | MetA | No significant change reported in the primary study, but local structural deviations were observed in simulations. | [2][6] |
| p-Benzoylphenylalanine (for comparison) | MetA | +21 °C | [2] |
Table 2: Impact on Protein Stability. The change in melting temperature (ΔTm) is a common metric for assessing protein stability. Positive values indicate stabilization, while negative values suggest destabilization.
| Unnatural Amino Acid | Cell Line | IC50 (µM) | Reference |
| Halogenated MMAF analogues (general trend) | Various cancer cell lines | Similar to the parent molecule, suggesting halogenation is well-tolerated. | [1] |
| 3,5-dibromo-L-tyrosine (related halogenated amino acid) | Rat cultured neurons | IC50 for depressing mEPSC frequency: 127.5 ± 13.3 | [9] |
| Azidoalanine (related azido (B1232118) amino acid) | Chinese hamster cells and human fibroblasts | Weakly genotoxic, causing a ~twofold increase in sister chromatid exchanges. | [10] |
Table 3: Cytotoxicity Data. Direct comparative cytotoxicity data for these specific UAAs is sparse. The presented data is for related compounds and should be interpreted with caution. Further studies are needed for a direct comparison.
Experimental Protocols
Detailed methodologies for key experiments are provided below to facilitate the replication and validation of these findings.
Protocol 1: Site-Specific Incorporation of Unnatural Amino Acids in E. coli using Amber Suppression
This protocol is adapted for the incorporation of TFMP, BrP, or AzP using the pEVOL plasmid system, which expresses an orthogonal aminoacyl-tRNA synthetase/tRNA pair.
Materials:
-
E. coli BL21(DE3) cells
-
Expression plasmid for the protein of interest with an amber (TAG) codon at the desired incorporation site.
-
pEVOL plasmid encoding the appropriate orthogonal aminoacyl-tRNA synthetase/tRNA pair for the specific UAA.
-
This compound, 4-Bromo-L-phenylalanine, or 4-Azido-L-phenylalanine.
-
Luria-Bertani (LB) agar (B569324) and broth.
-
Appropriate antibiotics (e.g., ampicillin (B1664943) and chloramphenicol).
-
Isopropyl β-D-1-thiogalactopyranoside (IPTG).
-
L-arabinose.
Procedure:
-
Co-transform E. coli BL21(DE3) cells with the expression plasmid and the corresponding pEVOL plasmid.
-
Plate the transformed cells on LB agar plates containing the appropriate antibiotics and incubate overnight at 37°C.
-
Inoculate a single colony into 5 mL of LB broth with antibiotics and grow overnight at 37°C with shaking.
-
The next day, inoculate the starter culture into 1 L of LB broth with antibiotics.
-
Add the desired UAA to a final concentration of 1 mM.
-
Grow the culture at 37°C with shaking until the OD600 reaches 0.6-0.8.
-
Induce protein expression by adding IPTG to a final concentration of 1 mM and L-arabinose to a final concentration of 0.2% (w/v).
-
Continue to grow the culture overnight at a reduced temperature (e.g., 18-25°C) to enhance protein folding and solubility.
-
Harvest the cells by centrifugation and purify the protein of interest using standard chromatography techniques.
-
Verify UAA incorporation using mass spectrometry.
References
- 1. Halogenation at the Phenylalanine Residue of Monomethyl Auristatin F Leads to a Favorable cis/trans Equilibrium and Retained Cytotoxicity - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Enhancing Protein Stability with Genetically Encoded Noncanonical Amino Acids - PMC [pmc.ncbi.nlm.nih.gov]
- 3. research.manchester.ac.uk [research.manchester.ac.uk]
- 4. Synthesis and Protein Incorporation of Azido-Modified Unnatural Amino Acids - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Synthesis and explosion hazards of 4-Azido-L-phenylalanine - PMC [pmc.ncbi.nlm.nih.gov]
- 6. scbt.com [scbt.com]
- 7. 4-Azido-L-phenylalanine [baseclick.eu]
- 8. Development of a single culture E. coli expression system for the enzymatic synthesis of fluorinated tyrosine and its incorporation into proteins - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Neuroprotective action of halogenated derivatives of L-phenylalanine - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. Genotoxicity of azidoalanine in mammalian cells - PubMed [pubmed.ncbi.nlm.nih.gov]
A Comparative Guide to 4-(Trifluoromethyl)-L-phenylalanine and 4-Fluorophenylalanine in Protein Studies
In the realm of protein engineering and drug discovery, the ability to probe protein structure, dynamics, and interactions with precision is paramount. Unnatural amino acids (UAAs) equipped with unique biophysical probes have become indispensable tools for these investigations. Among these, fluorine-containing phenylalanine analogs stand out due to the favorable nuclear magnetic resonance (NMR) properties of the ¹⁹F nucleus. This guide provides a detailed comparison of two commonly used analogs, 4-(Trifluoromethyl)-L-phenylalanine (tfm-Phe) and 4-Fluorophenylalanine (F-Phe), for researchers, scientists, and drug development professionals.
Overview of Fluorinated Phenylalanine Analogs
4-Fluorophenylalanine (F-Phe) and this compound (tfm-Phe) are synthetic analogs of the natural amino acid L-phenylalanine. They are primarily used to introduce a ¹⁹F NMR probe into a protein of interest. The ¹⁹F nucleus boasts high NMR sensitivity (83% relative to ¹H) and its near-complete absence in biological systems ensures background-free signal detection.[1] This allows for the precise monitoring of local environmental changes around the labeled site in response to ligand binding, conformational shifts, or protein-protein interactions.[2][3]
While both analogs serve as ¹⁹F NMR probes, the substitution of a single fluorine atom (F-Phe) versus a trifluoromethyl group (tfm-Phe) imparts distinct physicochemical properties that influence their suitability for different experimental goals.
Quantitative Data Comparison
The fundamental differences in the chemical and physical properties of F-Phe and tfm-Phe dictate their behavior and utility in protein studies.
| Property | 4-Fluorophenylalanine (F-Phe) | This compound (tfm-Phe) | Reference |
| Molecular Formula | C₉H₁₀FNO₂ | C₁₀H₁₀F₃NO₂ | [4][5] |
| Molecular Weight | 183.18 g/mol | 233.19 g/mol | [6][7] |
| Structure | Phenyl ring with a single fluorine atom at the para position. | Phenyl ring with a trifluoromethyl group at the para position. | |
| van der Waals Radius | F: ~1.35 Å (similar to H: ~1.2 Å) | CF₃ group is significantly larger. | [1] |
| Electronic Effect | Moderately electron-withdrawing. | Strongly electron-withdrawing. | |
| Hydrophobicity (LogP) | -1.9 | -0.6 | [6][7] |
| Key Applications | Minimally perturbative probe for protein structure, dynamics, and ligand binding via ¹⁹F NMR.[2][8] | High-sensitivity ¹⁹F NMR probe; studying hydrophobic interactions and protein stability.[9][10] | |
| Structural Perturbation | Generally considered a minimal structural perturbation, often replacing Phe with little effect on protein stability or function.[1][11] | The bulkier CF₃ group can be more perturbing but can also be used to enhance protein stability through specific interactions.[10] |
Detailed Comparison of Performance and Applications
Structural and Electronic Impact on Proteins
The choice between F-Phe and tfm-Phe often hinges on the degree of structural perturbation that can be tolerated.
-
4-Fluorophenylalanine (F-Phe): The fluorine atom is a close isostere of a hydrogen atom, with a similar van der Waals radius.[1] This minimal size difference means that F-Phe can often substitute for phenylalanine without significantly altering the protein's structure, stability, or function.[11] Its moderate electron-withdrawing nature can subtly influence local electrostatic interactions, making it a sensitive reporter of changes in its environment.
-
This compound (tfm-Phe): The trifluoromethyl group is substantially bulkier and more hydrophobic than a single fluorine atom. This can lead to more significant structural perturbations. However, this property can also be exploited. The strong electron-withdrawing nature of the CF₃ group can alter the aromatic properties of the phenyl ring, influencing cation-π or π-π stacking interactions.[10] In some cases, the incorporation of tfm-Phe has been shown to enhance protein stability.[10]
Applications in ¹⁹F NMR Spectroscopy
Both analogs are powerful tools for protein-observed ¹⁹F NMR studies, but they offer different advantages.
-
F-Phe: Provides a single, sharp ¹⁹F NMR signal that is exquisitely sensitive to its local chemical environment.[2] This makes it ideal for:
-
tfm-Phe: The three magnetically equivalent fluorine atoms of the CF₃ group give rise to a single, intense NMR signal. This enhanced signal intensity can be a significant advantage when working with low-concentration or large protein samples.[9] It is particularly useful for:
-
Studies requiring higher sensitivity.
-
Probing interactions within hydrophobic pockets.
-
Investigating the role of aromatic interactions in protein stability and function.[10]
-
Experimental Protocols
Protocol 1: Site-Specific Incorporation of UAAs in E. coli
The most precise method for incorporating F-Phe or tfm-Phe is through the genetic code expansion via amber (UAG) stop codon suppression. This requires an orthogonal aminoacyl-tRNA synthetase (aaRS)/tRNA pair that is specific for the desired UAA.[9][12][13]
1. System Components:
- Expression Plasmid: A plasmid encoding the gene of interest with a UAG (amber) stop codon engineered at the desired incorporation site.
- Orthogonal System Plasmid: A second plasmid (e.g., pEVOL) encoding the engineered aaRS and its cognate tRNA.[13] Specific synthetases have been evolved for both F-Phe and tfm-Phe.[9][14]
- Bacterial Strain: An E. coli expression strain, such as BL21(DE3).
- Media: Luria-Bertani (LB) or minimal media, supplemented with the appropriate antibiotics and the unnatural amino acid.
2. Methodology:
- Transformation: Co-transform both the expression plasmid and the orthogonal system plasmid into competent E. coli cells. Plate on selective agar (B569324) plates containing the appropriate antibiotics.
- Starter Culture: Inoculate a single colony into 5-10 mL of LB media with antibiotics and grow overnight at 37°C.
- Expression Culture: Inoculate a larger volume (e.g., 1 L) of expression media (auto-induction or minimal media) with the starter culture. Supplement the media with 1-2 mM of the desired UAA (F-Phe or tfm-Phe).
- Induction: For inducible systems, grow the culture at 37°C to an OD₆₀₀ of 0.6-0.8. Then, add the inducer (e.g., IPTG for the T7 promoter and L-arabinose for the pEVOL plasmid) and reduce the temperature to 18-25°C for overnight expression.[13]
- Harvesting and Purification: Harvest the cells by centrifugation. Lyse the cells and purify the target protein using standard chromatography techniques (e.g., Ni-NTA affinity chromatography for His-tagged proteins).
- Verification: Confirm the successful incorporation of the UAA using mass spectrometry (ESI-MS).[14]
Protocol 2: Protein-Observed ¹⁹F NMR Spectroscopy
This protocol outlines the general steps for acquiring ¹⁹F NMR spectra of a labeled protein.
1. Sample Preparation:
- Dialyze the purified, UAA-labeled protein into an appropriate NMR buffer (e.g., 20 mM Phosphate, 50 mM NaCl, pH 7.0). The buffer should be free of any fluorine-containing compounds.
- Concentrate the protein sample to a suitable concentration (typically 50-500 µM).
- Add 5-10% D₂O for the spectrometer lock.
- Add a known concentration of a fluorine-containing compound (e.g., trifluoroacetic acid) as an internal chemical shift reference.
2. Data Acquisition:
- Use a high-field NMR spectrometer equipped with a cryoprobe for optimal sensitivity.
- Acquire a simple one-dimensional (1D) ¹⁹F NMR spectrum. Key parameters include the spectral width, number of scans, and relaxation delay.
- For ligand titration experiments, acquire a baseline 1D ¹⁹F spectrum of the protein alone. Then, acquire a series of spectra after the addition of increasing concentrations of the ligand.
3. Data Analysis:
- Process the spectra using appropriate software (e.g., TopSpin, NMRPipe).
- Monitor changes in the ¹⁹F chemical shift, line width, and intensity upon addition of a ligand or induction of a conformational change.
- For binding studies, plot the change in chemical shift (Δδ) against the ligand concentration and fit the data to a suitable binding isotherm (e.g., one-site binding model) to calculate the dissociation constant (Kd).[2]
Mandatory Visualizations
Caption: Workflow for site-specific incorporation of unnatural amino acids in E. coli.
Caption: Logical workflow for protein analysis using ¹⁹F NMR spectroscopy.
Conclusion and Recommendations
Both this compound and 4-Fluorophenylalanine are exceptionally valuable tools for interrogating protein science. The choice between them should be guided by the specific research question and the tolerance of the system to structural perturbation.
-
Choose 4-Fluorophenylalanine (F-Phe) when the primary goal is to introduce a minimally invasive probe to monitor subtle changes in the local environment, such as ligand binding or minor conformational shifts, without significantly altering the protein's native properties.
-
Choose this compound (tfm-Phe) when a stronger NMR signal is required, for example, in studies with low protein concentrations or very large proteins. It is also a good choice for probing hydrophobic interactions, though researchers must carefully validate that the bulkier group does not disrupt the protein's structure or function in a way that confounds data interpretation.
By understanding the distinct characteristics of these two powerful analogs, researchers can select the optimal tool to unlock detailed molecular insights into complex biological systems.
References
- 1. pubs.acs.org [pubs.acs.org]
- 2. pubs.acs.org [pubs.acs.org]
- 3. Fluorinated phenylalanines: synthesis and pharmaceutical applications - PMC [pmc.ncbi.nlm.nih.gov]
- 4. caymanchem.com [caymanchem.com]
- 5. 4-Trifluoromethyl-L-Phenylalanin, 95 %, Thermo Scientific Chemicals 1 g | Buy Online [thermofisher.com]
- 6. 4-fluoro-L-phenylalanine | C9H10FNO2 | CID 716312 - PubChem [pubchem.ncbi.nlm.nih.gov]
- 7. This compound | C10H10F3NO2 | CID 2761501 - PubChem [pubchem.ncbi.nlm.nih.gov]
- 8. USE OF 19F NMR TO PROBE PROTEIN STRUCTURE AND CONFORMATIONAL CHANGES - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Preparation of site-specifically labeled fluorinated proteins for 19F-NMR structural characterization - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. researchgate.net [researchgate.net]
- 11. pubs.acs.org [pubs.acs.org]
- 12. In vivo incorporation of unnatural amino acids to probe structure, dynamics and ligand binding in a large protein by Nuclear Magnetic Resonance spectroscopy - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Genetic Incorporation of the Unnatural Amino Acid p-Acetyl Phenylalanine into Proteins for Site-Directed Spin Labeling - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Tuning phenylalanine fluorination to assess aromatic contributions to protein function and stability in cells - PMC [pmc.ncbi.nlm.nih.gov]
A Comparative Guide to Functional Assays for Proteins with 4-(Trifluoromethyl)-L-phenylalanine
For Researchers, Scientists, and Drug Development Professionals
The incorporation of non-canonical amino acids, such as 4-(Trifluoromethyl)-L-phenylalanine (TFMPhe), into proteins offers a powerful tool to probe and modulate protein function, stability, and interactions. The trifluoromethyl group provides a unique biophysical probe without significantly altering the steric profile of the phenylalanine side chain. This guide provides a comparative overview of key functional assays used to characterize proteins containing TFMPhe, supported by representative experimental data and detailed protocols.
Assessment of Catalytic Activity: Enzyme Kinetics
The introduction of TFMPhe into or near the active site of an enzyme can influence its catalytic efficiency by altering electronic properties and interactions with substrates or transition states. A common model system for studying such effects is Escherichia coli Dihydrofolate Reductase (DHFR), an enzyme crucial for nucleotide synthesis.
Comparison of Kinetic Parameters
The table below presents representative kinetic data comparing wild-type DHFR with a variant containing TFMPhe at a key active site residue. The data illustrates a common outcome where the electron-withdrawing nature of the trifluoromethyl group can impact catalysis.
| Enzyme | Km (μM) | kcat (s⁻¹) | kcat/Km (M⁻¹s⁻¹) |
| Wild-Type DHFR | 8.5 | 12 | 1.4 x 10⁶ |
| DHFR (Phe -> TFMPhe) | 15.2 | 7.5 | 4.9 x 10⁵ |
Note: The data presented are representative values to illustrate the potential effects of TFMPhe incorporation on enzyme kinetics. Actual values will be protein and site-specific.
Experimental Protocol: DHFR Activity Assay
This protocol outlines the measurement of DHFR activity by monitoring the decrease in absorbance at 340 nm, which corresponds to the oxidation of the cofactor NADPH.[1][2][3][4]
Materials:
-
Purified wild-type and TFMPhe-containing DHFR
-
Dihydrofolate (DHF) solution
-
NADPH solution
-
Assay Buffer: 50 mM MES, 25 mM Tris, 25 mM ethanolamine, 100 mM NaCl, pH 7.0
-
UV-Visible Spectrophotometer
Procedure:
-
Set the spectrophotometer to read absorbance at 340 nm in kinetic mode at 25°C.
-
In a quartz cuvette, prepare a reaction mixture containing Assay Buffer and a fixed concentration of NADPH (e.g., 100 µM).
-
Add the DHFR enzyme (wild-type or mutant) to the cuvette to a final concentration of 15-30 nM and mix gently.
-
Initiate the reaction by adding varying concentrations of the substrate, DHF (e.g., 5-50 µM).
-
Immediately start recording the decrease in absorbance at 340 nm for 1-3 minutes.
-
Calculate the initial reaction rates from the linear portion of the absorbance vs. time plot using the molar extinction coefficient of NADPH.
-
Determine Km and kcat by fitting the initial rate data to the Michaelis-Menten equation.
References
A Guide to Structural Analysis of Proteins Containing 4-(Trifluoromethyl)-L-phenylalanine and its Alternatives
For Researchers, Scientists, and Drug Development Professionals
The site-specific incorporation of non-natural amino acids (nnAAs) into proteins has emerged as a powerful tool for elucidating protein structure, function, and dynamics. Among these, 4-(Trifluoromethyl)-L-phenylalanine (tfm-Phe) has gained prominence as a sensitive reporter for ¹⁹F Nuclear Magnetic Resonance (NMR) spectroscopy and a useful probe in X-ray crystallography. This guide provides a comprehensive comparison of tfm-Phe with other commonly used phenylalanine analogs, offering quantitative data on their impact on protein expression, stability, and structural determination. Detailed experimental protocols for key techniques are also provided to facilitate the practical application of these methods in the laboratory.
Comparison of this compound and Alternative Probes
The choice of a non-natural amino acid for protein structural analysis depends on the specific experimental goals and the protein system under investigation. While tfm-Phe offers a strong ¹⁹F NMR signal due to its three fluorine atoms, other analogs provide unique advantages. The following tables summarize the performance of tfm-Phe in comparison to 4-Fluoro-L-phenylalanine (4F-Phe), 4-Cyano-L-phenylalanine (pCNPhe), and p-Azido-L-phenylalanine (pAzF).
Performance Metrics in Protein Expression and Stability
| Non-Natural Amino Acid | Protein Expression Yield (Relative to Wild Type) | Change in Thermal Stability (ΔTm) | Key Considerations |
| This compound (tfm-Phe) | Generally high, often comparable to wild type[1] | Can be stabilizing or destabilizing depending on the local environment. In some cases, a significant increase in Tm has been observed. | The bulky trifluoromethyl group can sometimes cause minor structural perturbations. |
| 4-Fluoro-L-phenylalanine (4F-Phe) | High, often with minimal impact on expression levels. | Generally minimal effect on protein stability. | The single fluorine atom provides a less sensitive ¹⁹F NMR probe compared to tfm-Phe. |
| 4-Cyano-L-phenylalanine (pCNPhe) | Can be lower than wild type, context-dependent. | Generally well-tolerated with minor effects on stability. | The nitrile group is a useful vibrational probe for infrared spectroscopy. |
| p-Azido-L-phenylalanine (pAzF) | Yields can be variable and are often lower than wild type. | Can be destabilizing, requiring careful selection of the incorporation site[2]. | The azido (B1232118) group allows for bioorthogonal "click" chemistry for labeling with probes. |
Application in Structural Biology Techniques
| Non-Natural Amino Acid | ¹⁹F NMR Chemical Shift Dispersion | X-ray Crystallography Resolution | Advantages in Structural Analysis |
| This compound (tfm-Phe) | High, sensitive to the local electrostatic environment. | High-resolution structures have been obtained. | Strong ¹⁹F NMR signal from three fluorine atoms enhances sensitivity. Useful for studying protein conformation and ligand binding[1]. |
| 4-Fluoro-L-phenylalanine (4F-Phe) | Moderate, sensitive to local environment changes. | High-resolution structures are achievable. | Minimal structural perturbation, making it a good mimic of phenylalanine. |
| 4-Cyano-L-phenylalanine (pCNPhe) | Not applicable for ¹⁹F NMR. | High-resolution structures have been reported[3][4]. | The nitrile group serves as a unique vibrational probe for IR spectroscopy to study local environments. |
| p-Azido-L-phenylalanine (pAzF) | Not applicable for ¹⁹F NMR. | High-resolution structures have been obtained. | Enables site-specific labeling with various probes, including fluorophores and cross-linkers, for diverse structural studies. |
Experimental Protocols
Detailed methodologies are crucial for the successful incorporation of nnAAs and subsequent structural analysis. The following sections provide step-by-step protocols for key experiments.
Site-Specific Incorporation of Non-Natural Amino Acids in E. coli
This protocol describes the amber stop codon suppression method for incorporating nnAAs into a target protein expressed in E. coli.
Workflow for Site-Specific nnAA Incorporation
Caption: Workflow for nnAA incorporation.
Materials:
-
E. coli expression strain (e.g., BL21(DE3))
-
Expression plasmid for the protein of interest with a TAG amber stop codon at the desired incorporation site.
-
pEvolv (or similar) plasmid encoding the orthogonal aminoacyl-tRNA synthetase (aaRS) and tRNA pair specific for the desired nnAA.
-
Luria-Bertani (LB) medium and agar (B569324) plates.
-
Appropriate antibiotics for plasmid selection.
-
The desired non-natural amino acid (e.g., this compound).
-
Inducing agents (e.g., Isopropyl β-D-1-thiogalactopyranoside (IPTG), L-arabinose).
Procedure:
-
Co-transformation: Transform the E. coli expression strain with both the target protein plasmid and the pEvolv plasmid using a standard heat shock or electroporation protocol.
-
Plating and Colony Selection: Plate the transformed cells on LB agar plates containing the appropriate antibiotics and incubate overnight at 37°C. Select a single colony to inoculate a starter culture.
-
Starter Culture: Inoculate 5-10 mL of LB medium containing the selective antibiotics with the chosen colony and grow overnight at 37°C with shaking.
-
Expression Culture: The next day, inoculate a larger volume of LB medium (e.g., 1 L) containing the antibiotics with the starter culture.
-
Growth and Induction: Grow the culture at 37°C with shaking until the optical density at 600 nm (OD₆₀₀) reaches 0.6-0.8.
-
Induction and nnAA Addition: Add the desired non-natural amino acid to a final concentration of 1-2 mM. Induce protein expression by adding the appropriate inducers (e.g., IPTG and L-arabinose) to their final concentrations.
-
Expression: Continue to grow the culture at a reduced temperature (e.g., 18-25°C) for 12-16 hours to enhance proper protein folding.
-
Cell Harvesting: Harvest the cells by centrifugation at 4°C. The cell pellet can be stored at -80°C or used immediately for protein purification.
-
Protein Purification: Resuspend the cell pellet in a suitable lysis buffer and purify the target protein using standard chromatography techniques (e.g., affinity chromatography based on a His-tag).
¹⁹F NMR Spectroscopy of Proteins Containing Fluorinated Amino Acids
This protocol outlines the general steps for acquiring and processing ¹⁹F NMR data for a protein labeled with a fluorinated amino acid.
Workflow for ¹⁹F NMR Spectroscopy
Caption: ¹⁹F NMR experimental workflow.
Materials:
-
Purified protein containing the fluorinated amino acid.
-
NMR buffer (e.g., phosphate (B84403) or Tris buffer) containing 5-10% D₂O for lock.
-
NMR spectrometer equipped with a fluorine probe.
-
Ligand/small molecule for titration experiments (optional).
Procedure:
-
Sample Preparation: Prepare the purified protein sample in a suitable NMR buffer at a concentration typically in the range of 50-500 µM. Add D₂O for the spectrometer lock signal.
-
Spectrometer Setup: Tune and match the fluorine probe on the NMR spectrometer.
-
Data Acquisition:
-
Acquire a one-dimensional (1D) ¹⁹F NMR spectrum. Key parameters to set include the spectral width (typically broad for ¹⁹F), the number of scans (depending on protein concentration and desired signal-to-noise), and the recycle delay.
-
For studying interactions, acquire a series of 1D ¹⁹F NMR spectra while titrating in a ligand or binding partner.
-
-
Data Processing:
-
Process the acquired free induction decay (FID) using appropriate software (e.g., TopSpin, NMRPipe).
-
Apply Fourier transformation, phase correction, and baseline correction to obtain the final spectrum.
-
-
Data Analysis:
-
Analyze the chemical shifts, line widths, and intensities of the ¹⁹F signals.
-
Changes in these parameters upon ligand titration can provide information on binding affinity, kinetics, and conformational changes.
-
Protein Crystallization and X-ray Diffraction
This protocol provides a general guideline for the crystallization of proteins containing nnAAs for X-ray crystallographic analysis.
Workflow for Protein Crystallization and X-ray Diffraction
Caption: Protein crystallization workflow.
Materials:
-
Highly pure and concentrated protein containing the nnAA.
-
Crystallization screening kits (various buffers, precipitants, and salts).
-
Crystallization plates (e.g., 96-well sitting or hanging drop plates).
-
Cryoprotectant solutions.
-
Cryo-loops for crystal harvesting.
-
Access to an X-ray diffraction facility (synchrotron).
Procedure:
-
Protein Preparation: Ensure the protein sample is highly pure (>95%) and concentrated (typically 5-20 mg/mL) in a low-salt buffer.
-
Crystallization Screening:
-
Set up crystallization trials using commercially available sparse matrix screens.
-
Use the hanging-drop or sitting-drop vapor diffusion method, mixing a small volume of the protein solution with an equal volume of the reservoir solution.
-
-
Crystal Growth and Optimization:
-
Incubate the crystallization plates at a constant temperature (e.g., 4°C or 20°C) and monitor for crystal growth over several days to weeks.
-
Once initial crystal hits are identified, optimize the crystallization conditions by fine-tuning the concentrations of the precipitant, buffer pH, and additives.
-
-
Crystal Harvesting and Cryo-protection:
-
Carefully harvest the crystals from the drop using a cryo-loop.
-
Briefly soak the crystal in a cryoprotectant solution (typically the reservoir solution supplemented with a cryoprotectant like glycerol (B35011) or ethylene (B1197577) glycol) to prevent ice formation during freezing.
-
Flash-cool the crystal in liquid nitrogen.
-
-
X-ray Diffraction Data Collection:
-
Mount the frozen crystal on the goniometer at a synchrotron beamline.
-
Collect a complete diffraction dataset by rotating the crystal in the X-ray beam.
-
-
Structure Determination:
-
Process the diffraction data to obtain the reflection intensities.
-
Solve the phase problem using methods like molecular replacement.
-
Build and refine the atomic model of the protein into the electron density map to obtain the final three-dimensional structure.
-
References
Unveiling the Enhanced Stability of Fluorinated Proteins: A Comparative Guide
For researchers, scientists, and drug development professionals, the quest for more stable and robust proteins is a continuous endeavor. The introduction of fluorine into protein structures has emerged as a promising strategy to enhance their stability. This guide provides an objective comparison of the stability of fluorinated versus non-fluorinated proteins, supported by experimental data and detailed methodologies.
The incorporation of fluorinated amino acids into proteins has been shown to significantly increase their resistance to thermal and chemical denaturation, as well as proteolytic degradation.[1][2][3] This enhanced stability is primarily attributed to the increased hydrophobic surface area of the fluorinated residues, which strengthens the hydrophobic core of the protein.[2][3] Unlike what might be intuitively expected, this stabilization does not arise from special "fluorous" interactions between fluorine atoms.[2]
Quantitative Stability Analysis
To provide a clear comparison, the following tables summarize key stability parameters for fluorinated and non-fluorinated proteins from various studies.
| Protein/Peptide | Modification | Melting Temperature (Tm) (°C) | Change in Tm (°C) | Reference |
| Protein G B1 domain | Pff vs. Phe | Higher for Pff | Not specified | [4] |
| Protein G B1 domain | Hfl > Qfl > Leu | Increased with fluorination | Not specified | [4] |
| Protein G B1 domain | Atb > Abu | Increased with fluorination | Not specified | [4] |
Table 1: Thermal Stability Data. Comparison of melting temperatures (Tm) for fluorinated and non-fluorinated proteins. Pff: pentafluorophenylalanine; Phe: phenylalanine; Hfl: hexafluoroleucine; Qfl: tetrafluoroleucine; Leu: leucine; Atb: (S)-2-amino-4,4,4-trifluorobutyric acid; Abu: (S)-2-aminobutyric acid.
| Protein | Modification | Free Energy of Unfolding (ΔG°fold) (kcal/mol) | Change in ΔG°fold (kcal/mol) | Reference |
| α4H | Non-fluorinated | -18.0 ± 0.2 | - | [2] |
| α4F3a | 50% core fluorination (hFLeu) | -27.6 ± 0.1 | -9.6 | [2] |
| Streptococcal protein G | Leu → Hfl mutation | - | -0.43 ± 0.14 | [5] |
| Streptococcal protein G | Phe → Pff mutation | - | -0.45 ± 0.20 | [5] |
Table 2: Thermodynamic Stability Data. Comparison of the free energy of unfolding (ΔG°fold) for fluorinated and non-fluorinated proteins. A more negative ΔG°fold indicates greater stability. hFLeu: hexafluoroleucine.
| Peptide Series | Modification | Protease Resistance | Observation | Reference |
| Buforin and Magainin analogues | Fluorinated derivatives | Moderately better | Retained or enhanced bacteriostatic activity | [6] |
| Model peptides | α-Tfm amino acid substitution at P1 position | Absolute stability | Compared to unsubstituted peptide against α-chymotrypsin | [7] |
| Model peptides | α-Tfm amino acid substitution at P2 and P'2 positions | Considerable stability | Compared to unsubstituted peptide against α-chymotrypsin | [7] |
Table 3: Proteolytic Stability Data. Comparison of the resistance of fluorinated and non-fluorinated peptides to proteolytic degradation.
Experimental Protocols
Detailed methodologies are crucial for reproducing and building upon these findings. Below are outlines of the key experimental protocols used to assess protein stability.
Thermal Denaturation by Circular Dichroism (CD) Spectroscopy
This method monitors the change in the secondary structure of a protein as a function of temperature.
-
Sample Preparation: The protein of interest is prepared in a suitable buffer (e.g., phosphate (B84403) buffer) to a final concentration of 2-50 µM.
-
CD Measurement: The CD spectrum is recorded, typically at a wavelength corresponding to a feature of the protein's secondary structure (e.g., 222 nm for α-helical proteins).
-
Thermal Unfolding: The temperature is gradually increased (e.g., 2°C/min) over a defined range (e.g., 10-90°C).
-
Data Analysis: The change in ellipticity is plotted against temperature. The midpoint of the transition curve represents the melting temperature (Tm), a key indicator of thermal stability.
Chemical Denaturation by Fluorescence Spectroscopy
This technique measures the change in the local environment of tryptophan residues as the protein unfolds in the presence of a chemical denaturant.
-
Sample Preparation: A series of protein samples are prepared with increasing concentrations of a denaturant (e.g., guanidinium (B1211019) chloride or urea).
-
Fluorescence Measurement: The intrinsic tryptophan fluorescence of each sample is measured by exciting at ~295 nm and recording the emission spectrum (typically 320-400 nm).
-
Data Analysis: The wavelength of maximum emission or the fluorescence intensity at a specific wavelength is plotted against the denaturant concentration. The data is then fitted to a two-state unfolding model to determine the free energy of unfolding (ΔG°) in the absence of denaturant.
In Vitro Proteolysis Assay
This assay assesses the resistance of a protein to degradation by proteases.
-
Reaction Setup: The protein (fluorinated or non-fluorinated) is incubated with a specific protease (e.g., trypsin, chymotrypsin) at a defined temperature and pH.
-
Time-Course Sampling: Aliquots are taken from the reaction mixture at different time points.
-
Reaction Quenching: The proteolytic reaction in the aliquots is stopped, for example, by adding a protease inhibitor or by heat inactivation.
-
Analysis: The amount of intact protein remaining at each time point is quantified using techniques like SDS-PAGE or HPLC. The rate of degradation provides a measure of proteolytic stability.
Visualizing the Impact of Stability: The Ubiquitin-Proteasome Pathway
The enhanced stability of fluorinated proteins can have significant implications for their cellular fate. One of the key pathways governing protein degradation is the ubiquitin-proteasome system. A more stable protein is less likely to be recognized by the cellular machinery that targets proteins for degradation.
Caption: Ubiquitin-Proteasome Pathway and Protein Stability.
This diagram illustrates how a stabilized (fluorinated) protein is less likely to be recognized by the E3 ubiquitin ligase, thereby avoiding polyubiquitination and subsequent degradation by the proteasome. This leads to a longer intracellular half-life and potentially prolonged therapeutic effect.
Conclusion
The strategic incorporation of fluorine into proteins offers a powerful tool for enhancing their stability without significantly altering their native structure or biological activity. The provided data and experimental protocols serve as a valuable resource for researchers aiming to leverage fluorination to develop more robust and effective protein-based therapeutics and research tools. As our understanding of the nuanced effects of fluorination continues to grow, so too will the potential applications of these hyper-stable biomolecules.
References
- 1. Protein kinases that regulate chromosome stability and their downstream targets - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. Structural basis for the enhanced stability of highly fluorinated proteins - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Fluorinated proteins: from design and synthesis to structure and stability [pubmed.ncbi.nlm.nih.gov]
- 4. [PDF] Effect of highly fluorinated amino acids on protein stability at a solvent-exposed position on an internal strand of protein G B1 domain. | Semantic Scholar [semanticscholar.org]
- 5. tandfonline.com [tandfonline.com]
- 6. Antimicrobial activity and protease stability of peptides containing fluorinated amino acids - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. Impact of fluorination on proteolytic stability of peptides: a case study with α-chymotrypsin and pepsin - PubMed [pubmed.ncbi.nlm.nih.gov]
A Comparative Guide to Validating the Biological Effects of 4-(Trifluoromethyl)-L-phenylalanine Incorporation
For Researchers, Scientists, and Drug Development Professionals
The site-specific incorporation of non-canonical amino acids (ncAAs) into proteins represents a powerful tool for probing and engineering protein structure and function. Among these, 4-(Trifluoromethyl)-L-phenylalanine (TFMP) has emerged as a valuable analogue for investigating the role of aromatic residues in protein folding, stability, and molecular interactions. This guide provides a comparative analysis of the biological effects of TFMP incorporation, supported by experimental data and detailed methodologies for its validation.
Biophysical Effects of TFMP Incorporation: A Comparative Analysis
The introduction of the trifluoromethyl group, a strong electron-withdrawing moiety, into the phenyl ring of phenylalanine can significantly alter the electronic and steric properties of the amino acid side chain. These alterations can, in turn, influence protein stability and function.
Impact on Protein Stability
The incorporation of TFMP can have varied effects on protein stability, largely dependent on the local environment of the substitution site. The trifluoromethyl group is more hydrophobic than a methyl group, which can lead to enhanced protein stability if the residue is buried in the hydrophobic core. However, the steric bulk and altered electrostatic potential of the TFMP side chain can also be destabilizing if it disrupts favorable interactions within the protein structure.
A common method to assess these changes is through thermal shift assays, which measure the melting temperature (Tm) of a protein. An increase in Tm upon TFMP incorporation generally signifies enhanced stability.
| Non-Canonical Amino Acid | Protein System | Change in Melting Temperature (ΔTm) | Reference |
| This compound (TFMP) | E. coli transketolase | +7.5 °C | [1] |
| 4-Fluoro-L-phenylalanine | E. coli transketolase | Abolished aggregation at 50 °C | [1] |
| p-Benzoyl-L-phenylalanine | E. coli metA | +21 °C | [2] |
| p-Isothiocyanate-L-phenylalanine | E. coli metA | +24 °C | [3][4] |
Table 1: Comparison of the effects of various non-canonical amino acids on protein thermal stability.
Probing Protein Environment with ¹⁹F NMR
The trifluoromethyl group of TFMP serves as a sensitive reporter for its local environment, making it an excellent probe for ¹⁹F Nuclear Magnetic Resonance (NMR) spectroscopy. The chemical shift of the ¹⁹F signal is highly sensitive to changes in the surrounding electrostatic environment, providing valuable insights into protein conformation, ligand binding, and dynamics.[5][6][7] The large chemical shift dispersion of ¹⁹F allows for the resolution of distinct conformational states of a protein.[1][5]
| Parameter | This compound (TFMP) | Other Fluorinated Probes (e.g., 4-Fluoro-L-phenylalanine) |
| ¹⁹F NMR Signal | Single sharp resonance from the -CF₃ group. | Single resonance from the C-F bond. |
| Chemical Shift Sensitivity | Highly sensitive to local electrostatic environment. | Sensitive to local environment, but often with a smaller chemical shift range compared to -CF₃. |
| Applications | Monitoring conformational changes, ligand binding, protein-protein interactions, in-vivo studies.[6][7] | Probing protein structure and dynamics. |
Table 2: Comparison of TFMP with other fluorinated amino acids as ¹⁹F NMR probes.
Experimental Validation Workflows
Accurate validation of TFMP incorporation and its biological effects is crucial. The following sections detail the experimental protocols for key validation techniques.
Experimental Workflow for TFMP Incorporation and Validation
Detailed Experimental Protocols
Site-Specific Incorporation of TFMP in E. coli
Methodology: This protocol utilizes an engineered orthogonal aminoacyl-tRNA synthetase/tRNA pair to incorporate TFMP in response to an amber (TAG) stop codon introduced at the desired site in the gene of interest.
-
Plasmid Preparation:
-
Prepare the expression plasmid containing the gene of interest with a TAG codon at the desired incorporation site and a purification tag (e.g., His-tag).
-
Prepare a separate plasmid encoding the orthogonal tRNA synthetase and tRNA specific for TFMP.
-
-
Transformation:
-
Co-transform competent E. coli cells (e.g., DH10B) with both the expression plasmid and the orthogonal system plasmid.
-
Plate on selective media (e.g., LB agar (B569324) with appropriate antibiotics).
-
-
Protein Expression:
-
Inoculate a starter culture in a non-inducing medium and grow overnight.
-
Inoculate a larger volume of expression medium containing 1 mM TFMP and the necessary antibiotics with the starter culture.
-
Induce protein expression (e.g., with IPTG) at an appropriate cell density (e.g., OD₆₀₀ of 0.6-0.8).
-
Continue to grow the culture at a reduced temperature (e.g., 18-25°C) for 16-24 hours.
-
-
Cell Harvesting and Lysis:
-
Harvest the cells by centrifugation.
-
Resuspend the cell pellet in lysis buffer and lyse the cells (e.g., by sonication or high-pressure homogenization).
-
Clarify the lysate by centrifugation to remove cell debris.
-
-
Protein Purification:
-
Purify the protein from the clarified lysate using an appropriate chromatography method based on the purification tag (e.g., Ni-NTA affinity chromatography for His-tagged proteins).
-
Validation of TFMP Incorporation by Mass Spectrometry
Methodology: Electrospray ionization mass spectrometry (ESI-MS) is used to determine the precise molecular weight of the purified protein, confirming the successful incorporation of TFMP.
-
Sample Preparation:
-
Desalt and concentrate the purified protein sample.
-
The final protein concentration should be in the range of 10-50 µM in a volatile buffer (e.g., ammonium (B1175870) acetate).
-
-
Mass Spectrometry Analysis:
-
Infuse the sample into the ESI-MS instrument.
-
Acquire the mass spectrum over an appropriate m/z range.
-
-
Data Analysis:
-
Deconvolute the resulting multi-charged ion series to obtain the zero-charge mass of the protein.
-
Compare the experimentally determined mass with the theoretical mass calculated for the protein with TFMP incorporated. A successful incorporation will result in a mass shift corresponding to the difference between the mass of TFMP and the mass of the amino acid it replaced.
-
Assessment of Protein Stability by Thermal Shift Assay (TSA)
Methodology: TSA, also known as differential scanning fluorimetry (DSF), measures the thermal stability of a protein by monitoring its unfolding as a function of temperature in the presence of a fluorescent dye that binds to exposed hydrophobic regions.
-
Reagent Preparation:
-
Prepare a stock solution of the purified protein (with and without TFMP) at a concentration of approximately 0.1-0.2 mg/mL.
-
Prepare a working solution of a fluorescent dye (e.g., SYPRO Orange) in the assay buffer.
-
-
Assay Setup:
-
In a 96-well PCR plate, mix the protein solution with the dye solution in each well.
-
Include a no-protein control (buffer and dye only).
-
-
Data Acquisition:
-
Place the plate in a real-time PCR instrument.
-
Program the instrument to increase the temperature incrementally (e.g., from 25°C to 95°C) and measure the fluorescence at each step.
-
-
Data Analysis:
-
Plot the fluorescence intensity as a function of temperature.
-
The melting temperature (Tm) is the temperature at which 50% of the protein is unfolded, typically corresponding to the inflection point of the melting curve.
-
Calculate the first derivative of the melting curve; the peak of the derivative plot represents the Tm.
-
Compare the Tm of the TFMP-containing protein with the wild-type protein to determine the change in thermal stability.
-
Probing the Local Environment with ¹⁹F NMR Spectroscopy
Methodology: ¹⁹F NMR is a powerful technique to study the local environment of the incorporated TFMP.
-
Sample Preparation:
-
Prepare a highly concentrated and pure sample of the TFMP-labeled protein (typically 0.1-1 mM) in a suitable NMR buffer containing 5-10% D₂O.
-
-
NMR Data Acquisition:
-
Acquire one-dimensional ¹⁹F NMR spectra on a high-field NMR spectrometer equipped with a fluorine probe.
-
Use an appropriate reference standard for chemical shift calibration (e.g., trifluoroacetic acid).
-
-
Data Analysis:
-
Analyze the chemical shift, line width, and intensity of the ¹⁹F resonance.
-
Changes in the chemical shift upon addition of a ligand or under different conditions can provide information about binding events and conformational changes near the TFMP residue.
-
Impact on Cellular Signaling and Protein-Protein Interactions
While the biophysical consequences of TFMP incorporation are well-documented, its effects on complex cellular processes such as signaling pathways and protein-protein interactions are an active area of research. Aromatic residues are often critical components of protein-protein interaction interfaces.[8] The altered electronics and sterics of the TFMP side chain can modulate these interactions, either by enhancing or disrupting binding affinities.
Further investigation is required to fully elucidate the downstream consequences of TFMP incorporation on specific signaling cascades. The tools and methodologies described in this guide provide a robust framework for conducting such studies, paving the way for a deeper understanding of the intricate roles of aromatic residues in cellular function.
References
- 1. researchgate.net [researchgate.net]
- 2. Enhancing Protein Stability with Genetically Encoded Noncanonical Amino Acids - PMC [pmc.ncbi.nlm.nih.gov]
- 3. A Single Reactive Noncanonical Amino Acid is Able to Dramatically Stabilize Protein Structure - PMC [pmc.ncbi.nlm.nih.gov]
- 4. A Single Reactive Noncanonical Amino Acid Is Able to Dramatically Stabilize Protein Structure - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. A comparison of chemical shift sensitivity of trifluoromethyl tags: optimizing resolution in 19F NMR studies of proteins - PMC [pmc.ncbi.nlm.nih.gov]
- 6. pubs.acs.org [pubs.acs.org]
- 7. Site-specific incorporation of a (19)F-amino acid into proteins as an NMR probe for characterizing protein structure and reactivity - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. Tuning phenylalanine fluorination to assess aromatic contributions to protein function and stability in cells - PMC [pmc.ncbi.nlm.nih.gov]
comparison of different methods for unnatural amino acid incorporation
The site-specific incorporation of unnatural amino acids (UAAs) into proteins has emerged as a powerful tool in chemical biology, enabling the introduction of novel functionalities to probe and engineer biological systems. This guide provides a comparative overview of the most prevalent methods for UAA incorporation, tailored for researchers, scientists, and drug development professionals. We will delve into the mechanisms, performance metrics, and experimental considerations for each technique, supported by detailed protocols and visual workflows.
Overview of Methods
The site-specific incorporation of UAAs primarily relies on the hijacking and reprogramming of the cellular translational machinery. This is typically achieved by introducing an orthogonal aminoacyl-tRNA synthetase (aaRS) and its cognate tRNA pair, which functions independently of the host's endogenous synthetases and tRNAs.[1][2][3][4] This orthogonal pair is engineered to recognize a specific codon—often a repurposed stop codon or a novel codon—and deliver the UAA to the ribosome for incorporation into a growing polypeptide chain. The most established methods for achieving this are amber suppression, sense codon reassignment, and frameshift suppression.[5][6]
Performance Comparison
The choice of UAA incorporation method often depends on the desired application, the host organism, and the trade-offs between efficiency, fidelity, and the number of UAAs to be incorporated. The following tables provide a summary of the key performance metrics for each method based on available experimental data. It is important to note that direct comparisons can be challenging due to variations in experimental conditions, including the specific UAA, the protein of interest, the host organism, and the orthogonal pair used.
| Method | Typical Protein Yield | Fidelity (Misincorporation Rate) | Key Advantages | Key Limitations |
| Amber Suppression | Several milligrams to tens of milligrams per liter of E. coli culture.[7] Up to 1 µg per 2 x 10^7 mammalian cells. | >99%[7] | High efficiency and fidelity; widely established with many available orthogonal pairs.[8] | Competition with release factor 1 (RF1) can lead to truncated protein products.[9] Limited to a single UAA per protein in most cases. |
| Sense Codon Reassignment | Can be quantitative for specific codons.[10] | High, but dependent on the competition with the endogenous tRNA. | Enables incorporation of UAAs at sense codons, potentially allowing for multiple different UAAs in a single protein.[6] | Competition with the endogenous aminoacyl-tRNA for the reassigned codon can reduce efficiency and fidelity.[6] Requires depletion of the endogenous tRNA corresponding to the reassigned codon. |
| Frameshift Suppression | Generally lower than amber suppression.[11] | High, as the quadruplet codon is not recognized by endogenous tRNAs. | Allows for the incorporation of multiple, distinct UAAs into the same protein by using different quadruplet codons.[11] | Lower suppression efficiency compared to nonsense suppression.[11] The efficiency of decoding four-nucleotide codons can be a limiting factor.[12] |
| Cell-Free Systems | Can achieve high yields (mg/mL) depending on the system (e.g., E. coli S30 extract vs. PURE system).[13][14] | Can be very high, especially in PURE systems where components are defined. | Open nature allows for easy manipulation of components, overcoming cell viability and membrane permeability issues.[5][13] Enables incorporation of a wide variety of UAAs. | Can be more expensive than in vivo methods, particularly PURE systems.[13] |
Experimental Protocols
This section provides detailed methodologies for the key UAA incorporation techniques.
Amber Stop Codon Suppression in E. coli
This protocol describes the site-specific incorporation of a UAA in response to an amber stop codon (UAG) in E. coli.[15]
Materials:
-
E. coli expression strain (e.g., BL21(DE3)).
-
Expression plasmid for the target protein containing an in-frame amber codon at the desired position.
-
Plasmid encoding the orthogonal aminoacyl-tRNA synthetase (aaRS) and suppressor tRNA (tRNACUA).
-
Unnatural amino acid (UAA).
-
Standard cell culture media (e.g., LB or TB).
-
Inducing agent (e.g., IPTG).
-
Antibiotics for plasmid selection.
Procedure:
-
Transformation: Co-transform the E. coli expression strain with the plasmid encoding the target protein and the plasmid encoding the orthogonal aaRS/tRNA pair.
-
Culture Growth: Inoculate a single colony into 5 mL of LB medium containing the appropriate antibiotics and grow overnight at 37°C with shaking.
-
Expression Culture: The next day, inoculate 1 L of TB medium with the overnight culture. Grow at 37°C with shaking until the OD600 reaches 0.6-0.8.
-
UAA Addition: Add the UAA to the culture to a final concentration of 1-10 mM.
-
Induction: Induce protein expression by adding IPTG to a final concentration of 0.1-1 mM.
-
Expression: Reduce the temperature to 18-25°C and continue to shake the culture for 12-16 hours.
-
Cell Harvest and Lysis: Harvest the cells by centrifugation. Resuspend the cell pellet in lysis buffer and lyse the cells using sonication or a French press.
-
Protein Purification: Purify the UAA-containing protein from the cell lysate using appropriate chromatography techniques (e.g., affinity chromatography, ion-exchange chromatography).
-
Verification: Confirm the incorporation of the UAA using mass spectrometry.
Orthogonal aaRS-tRNA Pair Selection and Evolution
This protocol outlines the directed evolution process to generate a new orthogonal aaRS that specifically recognizes a desired UAA.
Materials:
-
E. coli strain for selection (e.g., a strain with an auxotrophy that can be complemented by a reporter gene).
-
A library of mutant aaRS genes.
-
A plasmid encoding the orthogonal tRNA.
-
A reporter plasmid containing a selectable marker (e.g., chloramphenicol (B1208) acetyltransferase, CAT) with an in-frame amber codon.
-
A counter-selection plasmid containing a toxic gene (e.g., barnase) with an in-frame amber codon.
-
The desired UAA.
-
Minimal and rich media with and without the UAA and with appropriate antibiotics and selection agents (e.g., chloramphenicol).
Procedure:
-
Positive Selection:
-
Co-transform the selection E. coli strain with the aaRS library, the orthogonal tRNA plasmid, and the positive reporter plasmid.
-
Plate the transformed cells on minimal medium containing the UAA and the selection agent (e.g., chloramphenicol).
-
Only cells expressing an active aaRS that can charge the tRNA with the UAA will survive, as this will lead to the expression of the resistance gene.
-
-
Negative Selection (Counter-Selection):
-
Isolate the plasmids from the surviving colonies of the positive selection.
-
Transform a new batch of selection E. coli with the isolated plasmids and the counter-selection plasmid.
-
Plate the transformed cells on rich medium without the UAA but with the inducer for the toxic gene.
-
Cells expressing an aaRS that can charge the tRNA with a natural amino acid will express the toxic barnase gene and will not survive.
-
-
Iteration: Repeat the positive and negative selection steps for several rounds to enrich for aaRS variants that are highly specific for the UAA.
-
Characterization: Sequence the enriched aaRS variants and characterize their activity and specificity in vitro and in vivo.
Visualizing the Workflows
To better understand the underlying processes, the following diagrams illustrate the key workflows in UAA incorporation.
References
- 1. mdpi.com [mdpi.com]
- 2. Reprogramming natural proteins using unnatural amino acids - RSC Advances (RSC Publishing) DOI:10.1039/D1RA07028B [pubs.rsc.org]
- 3. Rapid discovery and evolution of orthogonal aminoacyl-tRNA synthetase–tRNA pairs [research.google]
- 4. Rapid discovery and evolution of orthogonal aminoacyl-tRNA synthetase–tRNA pairs - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Efficient Incorporation of Unnatural Amino Acids into Proteins with a Robust Cell-Free System - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Cell-Free Approach for Non-canonical Amino Acids Incorporation Into Polypeptides - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Expanding the Genetic Code for Biological Studies - PMC [pmc.ncbi.nlm.nih.gov]
- 8. mdpi.com [mdpi.com]
- 9. Frontiers | Unnatural amino acid incorporation in E. coli: current and future applications in the design of therapeutic proteins [frontiersin.org]
- 10. Item - Combining Sense and Nonsense Codon Reassignment for Site-Selective Protein Modification with Unnatural Amino Acids - figshare - Figshare [figshare.com]
- 11. In vivo incorporation of multiple unnatural amino acids through nonsense and frameshift suppression - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Using genetically incorporated unnatural amino acids to control protein functions in mammalian cells - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Frontiers | Advances and Challenges in Cell-Free Incorporation of Unnatural Amino Acids Into Proteins [frontiersin.org]
- 14. researchgate.net [researchgate.net]
- 15. Site-Specific Incorporation of Non-canonical Amino Acids by Amber Stop Codon Suppression in Escherichia coli | Springer Nature Experiments [experiments.springernature.com]
Safety Operating Guide
Proper Disposal of 4-(Trifluoromethyl)-L-phenylalanine: A Guide for Laboratory Professionals
Ensuring the safe and compliant disposal of chemical reagents is a critical component of laboratory safety and environmental responsibility. This guide provides detailed procedures for the proper disposal of 4-(Trifluoromethyl)-L-phenylalanine, a halogenated amino acid derivative commonly used in pharmaceutical research and development. Adherence to these protocols is essential to minimize risks to personnel and the environment.
Immediate Safety and Handling Precautions
Before handling this compound, it is imperative to consult the Safety Data Sheet (SDS). This compound is categorized as a halogenated organic solid. While some safety data sheets for similar compounds indicate no known OSHA hazards, others suggest it may cause skin irritation, serious eye irritation, and respiratory irritation[1]. Therefore, appropriate personal protective equipment (PPE), including safety goggles, gloves, and a lab coat, should be worn at all times. All handling of the solid should be performed in a well-ventilated area, preferably within a chemical fume hood, to avoid the inhalation of dust particles[2].
Core Disposal Principle: Hazardous Waste Management
This compound must be treated as hazardous chemical waste. Under no circumstances should it be disposed of down the drain or mixed with general laboratory or municipal trash[2][3]. Improper disposal can lead to environmental contamination and regulatory non-compliance. The primary method for the ultimate disposal of halogenated organic compounds is high-temperature incineration conducted by a licensed hazardous waste management facility[3].
Waste Segregation and Collection
Proper segregation of chemical waste is crucial to prevent dangerous reactions and to facilitate correct disposal. This compound waste must be segregated as a halogenated organic solid [4].
Waste Segregation Guidelines
| Waste Type | Segregation Requirement | Incompatible Materials |
|---|---|---|
| This compound (Solid) | Collect in a dedicated, labeled container for halogenated organic solids. | Do not mix with non-halogenated waste, acids, bases, or oxidizing agents[4][5]. |
| Contaminated Labware (e.g., gloves, weigh boats, wipes) | Dispose of as halogenated hazardous waste in a designated, sealed container or bag[4]. | Do not mix with non-hazardous trash. |
| Solutions containing this compound | Collect in a dedicated, labeled container for halogenated organic liquid waste. | Do not mix with non-halogenated solvents. Keep separate from acidic or alkaline waste streams[5][6]. |
Containers for waste collection must be made of a compatible material, such as glass or polyethylene, and must have a tightly sealing cap[4][5][7]. All waste containers must be clearly labeled with "Hazardous Waste," the full chemical name "this compound," and the approximate concentration if in solution[5][7].
Spill Management Protocol
In the event of a spill, the following steps should be taken:
-
Evacuate and Secure: Alert personnel in the immediate area and restrict access[4].
-
Ventilate: Ensure the area is well-ventilated.
-
Utilize PPE: Wear appropriate PPE, including respiratory protection if significant dust is generated[2].
-
Contain and Clean: For a small spill, carefully sweep up the solid material and place it into a suitable, labeled container for disposal[2]. Avoid actions that create dust. For a large spill, use an inert absorbent material like sand or vermiculite (B1170534) to contain the powder before collection[3][4].
-
Decontaminate: Clean the spill area with soap and water or another suitable solvent. All cleaning materials, including contaminated wipes and PPE, must be collected and disposed of as halogenated hazardous waste[4].
Disposal Workflow Diagram
The following diagram outlines the step-by-step process for the proper disposal of this compound waste.
Caption: Workflow for the safe disposal of this compound.
By adhering to these procedures, researchers and laboratory professionals can ensure the safe handling and compliant disposal of this compound, fostering a secure and environmentally conscious research environment. Always consult with your institution's Environmental Health and Safety (EHS) department for specific local regulations and guidance[4].
References
- 1. This compound | C10H10F3NO2 | CID 2761501 - PubChem [pubchem.ncbi.nlm.nih.gov]
- 2. peptide.com [peptide.com]
- 3. benchchem.com [benchchem.com]
- 4. benchchem.com [benchchem.com]
- 5. rtong.people.ust.hk [rtong.people.ust.hk]
- 6. campusoperations.temple.edu [campusoperations.temple.edu]
- 7. braun.matse.illinois.edu [braun.matse.illinois.edu]
Personal protective equipment for handling 4-(Trifluoromethyl)-L-phenylalanine
This guide provides critical safety and logistical information for handling 4-(Trifluoromethyl)-L-phenylalanine, tailored for researchers, scientists, and drug development professionals. Adherence to these procedures is vital for ensuring laboratory safety, environmental protection, and regulatory compliance.
Hazard Identification and Personal Protective Equipment (PPE)
This compound may cause skin, eye, and respiratory irritation[1]. It is essential to use appropriate personal protective equipment to minimize exposure.
Table 1: Recommended Personal Protective Equipment (PPE)
| Protection Type | Recommended Equipment | Specifications & Rationale |
| Eye and Face Protection | Chemical safety goggles or eyeglasses | Must comply with OSHA's eye and face protection regulations in 29 CFR 1910.133 or European Standard EN166 to protect from splashes.[2] |
| Hand Protection | Chemical-resistant gloves | Wear appropriate protective gloves to prevent skin exposure.[2] Nitrile gloves are a suitable option for short-term protection.[3] |
| Body Protection | Laboratory coat | Wear a lab coat to prevent skin contact.[2][4] |
| Respiratory Protection | NIOSH-approved respirator | Use a respirator when handling the substance in a way that generates dust or aerosols, especially in poorly ventilated areas.[5] A particle filter is a recommended type.[2] |
Handling and Storage Procedures
Proper handling and storage are crucial to maintain the stability of the compound and ensure the safety of laboratory personnel.
Operational Plan:
-
Engineering Controls : Always handle this compound in a well-ventilated area, preferably within a chemical fume hood to minimize inhalation of dust and aerosols.[4][5]
-
Grounding : Use non-sparking tools and prevent fire caused by electrostatic discharge.[4]
-
Personal Hygiene : Wash hands thoroughly after handling the chemical and before eating, drinking, or smoking.[5]
-
Storage : Keep containers tightly closed in a dry, cool, and well-ventilated place.[2][5]
-
Incompatible Materials : Avoid contact with strong oxidizing agents and strong acids.[5]
First Aid Measures
In case of accidental exposure, immediate first aid is critical.
Table 2: First Aid Protocols
| Exposure Route | First Aid Instructions |
| Inhalation | Move the person to fresh air. If symptoms occur, get medical attention immediately.[2] |
| Skin Contact | Wash off immediately with plenty of water for at least 15 minutes. Get medical attention.[2] |
| Eye Contact | Rinse immediately with plenty of water, also under the eyelids, for at least 15 minutes. Get medical attention.[2] |
| Ingestion | Clean mouth with water and drink plenty of water afterward. Get medical attention if symptoms occur.[2] |
Accidental Release and Disposal Plan
In the event of a spill, prompt and appropriate action is necessary to contain and clean up the material safely.
Spill Containment and Cleanup:
-
Ventilate the area.
-
Wear appropriate PPE as outlined in Table 1.
-
Contain the spill : Use an inert absorbent material like sand or earth to absorb the spilled substance.
-
Collect the material : Use spark-proof tools to collect the absorbed material and place it into a suitable, closed container for disposal.[4][6]
-
Clean the area : Thoroughly clean the spill area.
Disposal Plan:
-
Waste Collection : Collect waste this compound in a properly labeled, sealed container.[6] Do not mix with other waste streams.[6]
-
Storage Pending Disposal : Store the waste container in a designated hazardous waste storage area that is cool, dry, and well-ventilated.[6]
-
Professional Disposal : Dispose of the chemical waste through a licensed professional waste disposal service.[6][7] The recommended method for halogenated organic compounds is incineration in a chemical incinerator equipped with an afterburner and scrubber.[6]
-
Contaminated Materials : Dispose of any contaminated items, such as PPE and cleaning materials, as hazardous waste in the same manner as the chemical itself.[6]
Operational Workflow
Caption: Workflow for handling this compound.
References
- 1. This compound | C10H10F3NO2 | CID 2761501 - PubChem [pubchem.ncbi.nlm.nih.gov]
- 2. fishersci.com [fishersci.com]
- 3. benchchem.com [benchchem.com]
- 4. This compound - Safety Data Sheet [chemicalbook.com]
- 5. peptide.com [peptide.com]
- 6. benchchem.com [benchchem.com]
- 7. store.apolloscientific.co.uk [store.apolloscientific.co.uk]
Retrosynthesis Analysis
AI-Powered Synthesis Planning: Our tool employs the Template_relevance Pistachio, Template_relevance Bkms_metabolic, Template_relevance Pistachio_ringbreaker, Template_relevance Reaxys, Template_relevance Reaxys_biocatalysis model, leveraging a vast database of chemical reactions to predict feasible synthetic routes.
One-Step Synthesis Focus: Specifically designed for one-step synthesis, it provides concise and direct routes for your target compounds, streamlining the synthesis process.
Accurate Predictions: Utilizing the extensive PISTACHIO, BKMS_METABOLIC, PISTACHIO_RINGBREAKER, REAXYS, REAXYS_BIOCATALYSIS database, our tool offers high-accuracy predictions, reflecting the latest in chemical research and data.
Strategy Settings
| Precursor scoring | Relevance Heuristic |
|---|---|
| Min. plausibility | 0.01 |
| Model | Template_relevance |
| Template Set | Pistachio/Bkms_metabolic/Pistachio_ringbreaker/Reaxys/Reaxys_biocatalysis |
| Top-N result to add to graph | 6 |
Feasible Synthetic Routes




Featured Recommendations
| Most viewed |
|
|
|---|---|---|
| Most popular with customers |
|
Descargo de responsabilidad e información sobre productos de investigación in vitro
Tenga en cuenta que todos los artículos e información de productos presentados en BenchChem están destinados únicamente con fines informativos. Los productos disponibles para la compra en BenchChem están diseñados específicamente para estudios in vitro, que se realizan fuera de organismos vivos. Los estudios in vitro, derivados del término latino "in vidrio", involucran experimentos realizados en entornos de laboratorio controlados utilizando células o tejidos. Es importante tener en cuenta que estos productos no se clasifican como medicamentos y no han recibido la aprobación de la FDA para la prevención, tratamiento o cura de ninguna condición médica, dolencia o enfermedad. Debemos enfatizar que cualquier forma de introducción corporal de estos productos en humanos o animales está estrictamente prohibida por ley. Es esencial adherirse a estas pautas para garantizar el cumplimiento de los estándares legales y éticos en la investigación y experimentación.
