MDPD
Beschreibung
Eigenschaften
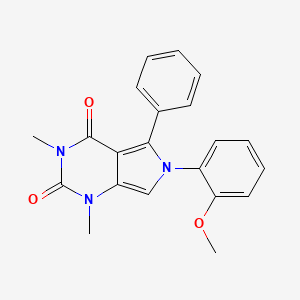
Molekularformel |
C21H19N3O3 |
|---|---|
Molekulargewicht |
361.4 g/mol |
IUPAC-Name |
6-(2-methoxyphenyl)-1,3-dimethyl-5-phenylpyrrolo[3,4-d]pyrimidine-2,4-dione |
InChI |
InChI=1S/C21H19N3O3/c1-22-16-13-24(15-11-7-8-12-17(15)27-3)19(14-9-5-4-6-10-14)18(16)20(25)23(2)21(22)26/h4-13H,1-3H3 |
InChI-Schlüssel |
MWJBSSXENNRICD-UHFFFAOYSA-N |
Kanonische SMILES |
CN1C2=CN(C(=C2C(=O)N(C1=O)C)C3=CC=CC=C3)C4=CC=CC=C4OC |
Aussehen |
Solid powder |
Reinheit |
>98% (or refer to the Certificate of Analysis) |
Haltbarkeit |
>2 years if stored properly |
Löslichkeit |
Soluble in DMSO |
Lagerung |
Dry, dark and at 0 - 4 C for short term (days to weeks) or -20 C for long term (months to years). |
Synonyme |
MDPD |
Herkunft des Produkts |
United States |
Foundational & Exploratory
The Movement Disorder Society Genetic Mutation Database (MDSGene)
References
- 1. mdpi.com [mdpi.com]
- 2. A pathway to Parkinson’s disease | eLife Science Digests | eLife [elifesciences.org]
- 3. MDSGene: Closing Data Gaps in Genotype-Phenotype Correlations of Monogenic Parkinson’s Disease - PMC [pmc.ncbi.nlm.nih.gov]
- 4. MDSGene [movementdisorders.org]
- 5. MDSGene [mdsgene.org]
- 6. MDSGene and the Global Parkinson’s Genetics Program (GP2): Towards a comprehensive resource for genetic movement disorders [movementdisorders.org]
- 7. researchgate.net [researchgate.net]
- 8. MDSGene [mdsgene.org]
- 9. Gene4PD: A Comprehensive Genetic Database of Parkinson's Disease - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. Gene4PD: A Comprehensive Genetic Database of Parkinson’s Disease - PMC [pmc.ncbi.nlm.nih.gov]
- 11. researchgate.net [researchgate.net]
- 12. researchgate.net [researchgate.net]
- 13. academic.oup.com [academic.oup.com]
A Technical Guide to the Landscape of Mitochondrial Disease Protein Databases: A Focus on mitoPADdb
The study of mitochondrial diseases, a group of debilitating genetic disorders affecting cellular energy production, has been profoundly advanced by the development of specialized biological databases. These repositories are crucial for researchers, scientists, and drug development professionals, providing centralized access to vast amounts of curated data on mitochondrial proteins, associated genes, mutations, and diseases. This guide delves into the history, structure, and utility of these critical resources, with a primary focus on a significant recent addition to this landscape: the mitoPADdb.
The Evolution of Mitochondrial Disease Data Curation
The history of mitochondrial disease research is marked by key discoveries that underscored the need for comprehensive data repositories. The molecular era of mitochondrial medicine began in 1988 with the identification of the first mitochondrial DNA (mtDNA) mutations linked to human diseases[1][2]. This discovery opened the floodgates to identifying numerous other pathogenic mutations in both mtDNA and nuclear DNA that encode mitochondrial proteins[1]. The sheer volume and complexity of this emerging data necessitated the creation of curated databases to facilitate research and clinical diagnostics.
One of the significant grass-roots efforts in this area is the Mitochondrial Disease Sequence Data Resource (MSeqDR) Consortium, established to create a unified genomic data resource for the mitochondrial disease community[3]. MSeqDR provides a suite of tools and a locus-specific database (LSDB) that curates variant data on over 1,300 genes related to mitochondrial function and disease[3][4].
Building on this foundation, and addressing the need for a focused resource on mitochondrial proteins and their disease associations, the mitoPADdb was recently developed.
mitoPADdb: A Comprehensive Resource for Mitochondrial Proteins in Disease
mitoPADdb is a manually curated database that provides extensive information on mitochondrial protein-encoding (MPE) genes and their association with a wide spectrum of diseases[5][6]. Launched in 2024, it represents a state-of-the-art resource designed to support novel therapeutic strategies by providing detailed insights into the molecular underpinnings of mitochondrial dysfunction[5].
Core Features of mitoPADdb:
-
Manual Curation: The database is distinguished by its manual curation process, which involves the critical review and extraction of information from scientific literature to ensure data accuracy and reliability[5][6].
-
Comprehensive Data: It contains a wealth of information on gene mutations, expression variations (at both mRNA and protein levels), and their links to various diseases[5][6].
-
Disease Classification: Diseases associated with mitochondrial proteins are systematically grouped into distinct categories, aiding in systematic analysis[5][6].
-
Transcriptomic Analysis: A key feature is the ability for users to perform comparative quantitative gene expression analysis across numerous transcriptomic studies[5].
Data Presentation: Quantitative Overview of mitoPADdb
The quantitative scope of mitoPADdb highlights its value as a important research tool. The data is summarized in the tables below.
Table 1: Summary of Core Data in mitoPADdb
| Data Type | Count |
| Mitochondrial Protein-Encoding (MPE) Genes | 810 |
| Associated Diseases | 1,793 |
| Curated Mutations | 18,356 |
| Qualitative Expression Variations | 1,284 |
| Disease Categories | 15 |
| Transcriptomic Studies for Comparative Analysis | 317 |
Source:[5]
Experimental Protocols: Methodologies for Data Generation
The data within mitoPADdb is aggregated from numerous studies, each employing a variety of experimental techniques. Below are detailed protocols for key experiments that are fundamental to generating the type of data curated in the database.
1. Mitochondrial Isolation from Cultured Cells
This protocol is essential for studying mitochondrial-specific proteins and their functions. It involves separating mitochondria from other cellular components.
-
Cell Culture and Harvest:
-
Culture cells (e.g., HEK293T) to approximately 80% confluency in appropriate media. For a sufficient yield, a total of about 1 x 10^8 cells is recommended[7].
-
Wash the cells with ice-cold phosphate-buffered saline (PBS)[7].
-
Scrape the cells and transfer to a 15 mL tube. Centrifuge at 500 x g for 3 minutes at 4°C[7].
-
Discard the supernatant, resuspend the pellet in PBS, and repeat the centrifugation[7].
-
-
Homogenization:
-
Differential Centrifugation:
-
Centrifuge the homogenate at 1,200 x g for 3 minutes at 4°C to pellet nuclei and unbroken cells. Transfer the supernatant to a new tube[7].
-
Repeat the centrifugation until no pellet is observed[7].
-
Transfer the final supernatant to a fresh 1.5 mL tube and centrifuge at 15,000 x g for 2 minutes at 4°C to pellet the mitochondria[7].
-
The resulting pellet contains the crude mitochondrial fraction, which can be used for downstream applications like Western blotting[7].
-
2. Western Blotting for Mitochondrial Protein Expression
Western blotting is a widely used technique to detect and quantify the expression levels of specific proteins.
-
Protein Extraction and Quantification:
-
Lyse the isolated mitochondria or whole cells using a suitable lysis buffer containing protease inhibitors.
-
Determine the protein concentration of the lysate using a standard protein assay (e.g., BCA assay).
-
-
SDS-PAGE and Protein Transfer:
-
Denature the protein samples by boiling in Laemmli buffer.
-
Load equal amounts of protein into the wells of an SDS-polyacrylamide gel and separate by electrophoresis.
-
Transfer the separated proteins from the gel to a nitrocellulose or PVDF membrane.
-
-
Immunodetection:
-
Block the membrane with a blocking buffer (e.g., 5% non-fat milk or bovine serum albumin in TBST) to prevent non-specific antibody binding.
-
Incubate the membrane with a primary antibody specific to the mitochondrial protein of interest.
-
Wash the membrane to remove unbound primary antibody.
-
Incubate with a secondary antibody conjugated to an enzyme (e.g., horseradish peroxidase) that recognizes the primary antibody.
-
Wash the membrane thoroughly.
-
Detect the protein bands using a chemiluminescent substrate and an imaging system.
-
3. Quantitative Real-Time PCR (qRT-PCR) for mRNA Expression Analysis
qRT-PCR is used to measure the expression levels of mitochondrial protein-encoding genes at the mRNA level.[8]
-
RNA Isolation:
-
Isolate total RNA from cells or tissues using a TRIzol-based method or a commercial RNA isolation kit[8].
-
Treat the RNA with DNase I to remove any contaminating genomic DNA.
-
-
cDNA Synthesis:
-
Synthesize complementary DNA (cDNA) from the isolated RNA using a reverse transcriptase enzyme and specific primers.
-
-
Real-Time PCR:
-
Set up the PCR reaction with the cDNA template, gene-specific primers for the target gene and a reference (housekeeping) gene, and a fluorescent dye (e.g., SYBR Green).
-
Run the reaction in a real-time PCR machine. The machine will monitor the fluorescence intensity at each cycle, which is proportional to the amount of amplified DNA.
-
Analyze the data to determine the relative expression of the target gene, normalized to the reference gene.
-
Visualizations: Workflows and Pathways
Data Curation Workflow for mitoPADdb
The following diagram illustrates the manual curation process that is central to the creation and maintenance of a high-quality database like mitoPADdb.
Caption: A flowchart of the manual data curation process.
Mitochondrial Signaling in Disease
Mitochondria are not just the powerhouses of the cell; they are also critical signaling hubs. Dysfunctional mitochondria can lead to aberrant signaling, contributing to a variety of diseases.[9][10][11] The diagram below depicts a simplified mitochondrial retrograde signaling pathway, where mitochondrial stress signals are communicated to the nucleus, leading to changes in gene expression.
Caption: Mitochondrial retrograde signaling pathway.
Conclusion
Databases like mitoPADdb and MSeqDR are indispensable tools in the field of mitochondrial medicine. They provide a structured and accessible framework for a vast and complex body of knowledge, empowering researchers to uncover novel insights into disease mechanisms and identify potential therapeutic targets. The continued development and enrichment of these resources, driven by rigorous manual curation and the integration of new data types, will be a key factor in advancing the diagnosis and treatment of mitochondrial diseases.
References
- 1. Mitochondrial Diseases: A Clinical and Molecular History - PMC [pmc.ncbi.nlm.nih.gov]
- 2. A Brief History of Mitochondrial Pathologies - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Mitochondrial Disease Sequence Data Resource (MSeqDR): A global grass-roots consortium to facilitate deposition, curation, annotation, and integrated analysis of genomic data for the mitochondrial disease clinical and research communities - PMC [pmc.ncbi.nlm.nih.gov]
- 4. MSeqDR - Database Commons [ngdc.cncb.ac.cn]
- 5. mitoPADdb: A database of mitochondrial proteins associated with diseases - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. mitoPADdb - Mitochondrial Proteins Associated with Diseases database [bicresources.jcbose.ac.in]
- 7. Protocol for mitochondrial isolation and sub-cellular localization assay for mitochondrial proteins - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Methods to Study the Mitochondria - qRT-PCR, Western Blotting, Immunofluorescence, Electron Microscopy, “Fluorescence”, and Seahorse – techniques used to study the effects of age-related diseases like Alzheimer’s - PMC [pmc.ncbi.nlm.nih.gov]
- 9. frontiersin.org [frontiersin.org]
- 10. rupress.org [rupress.org]
- 11. Mitochondrial signalling pathways in inflammation and health: mechanistic insights of mitochondrial impairment on cellular homeostasis in driving pathogenesis - PMC [pmc.ncbi.nlm.nih.gov]
A Technical Guide to Mutations in Mitochondrial Disease
For Researchers, Scientists, and Drug Development Professionals
This technical guide provides a comprehensive overview of the types of mutations associated with mitochondrial diseases, their prevalence, the methodologies used for their detection, and the signaling pathways they impact. While a centralized "Mitochondrial Disease Protein Database (MDPD)" was not identified, this document synthesizes data from extensive research in the field to serve as a valuable resource.
Classification and Types of Mutations in Mitochondrial Disease
Mitochondrial diseases are a group of clinically and genetically heterogeneous disorders caused by dysfunction of the oxidative phosphorylation (OXPHOS) system. These diseases can result from mutations in either the mitochondrial DNA (mtDNA) or the nuclear DNA (nDNA) that encodes mitochondrial proteins.[1][2]
Mitochondrial DNA (mtDNA) Mutations: The human mitochondrial genome is a 16.5 kb circular molecule that contains 37 genes encoding 13 essential subunits of the respiratory chain complexes, as well as 22 transfer RNAs (tRNAs) and 2 ribosomal RNAs (rRNAs) necessary for their translation. Mutations in mtDNA can be broadly categorized as:
-
Point Mutations: These are single nucleotide variations that can occur in protein-coding genes, tRNA genes, or rRNA genes. Common syndromes associated with mtDNA point mutations include:
-
Rearrangements: These include large-scale deletions, duplications, or insertions of a portion of the mtDNA. Syndromes associated with mtDNA rearrangements include:
Nuclear DNA (nDNA) Mutations: The vast majority of mitochondrial proteins are encoded by nuclear genes. Mutations in these genes can affect various aspects of mitochondrial function, including:
-
OXPHOS subunit assembly
-
Mitochondrial protein import
-
mtDNA replication and maintenance
-
Mitochondrial dynamics (fusion and fission)
Diseases caused by nDNA mutations follow Mendelian inheritance patterns (autosomal recessive, autosomal dominant, or X-linked).[2]
Quantitative Data on Mutation Prevalence
The prevalence of mitochondrial diseases and the underlying mutations has been the subject of numerous studies. The following tables summarize key quantitative data.
Table 1: Prevalence of Mitochondrial Disease
| Population Studied | Prevalence of Mitochondrial Disease | Type of Mutation | Citation |
| Adult Population (UK) | 1 in 5,000 (20 per 100,000) | mtDNA | [6] |
| Adult Population (UK) | 2.9 per 100,000 | nDNA | [6] |
| General Population | At least 1 in 200 healthy individuals harbors a pathogenic mtDNA mutation | mtDNA | [7] |
Table 2: Prevalence of Specific mtDNA Mutations
| Mutation | Associated Syndrome(s) | Prevalence | Citation |
| m.3243A>G | MELAS, MIDD, CPEO | Most prevalent pathogenic mtDNA point mutation | [6] |
| m.11778G>A, m.3460G>A, m.14484T>C | LHON | Point prevalence for affected LHON mutations of 3.65 per 100,000 | [6] |
| Single large-scale deletions | KSS, CPEO | 1-3 cases in 100,000 for KSS | [4] |
| Rare mtDNA mutations | Various | Account for more than 7.4% of patients with respiratory chain deficiency | [8][9] |
Experimental Protocols for Mutation Detection
A variety of molecular techniques are employed to detect mutations in both mtDNA and nDNA.
Next-Generation Sequencing (NGS) for Whole Mitochondrial Genome Analysis
NGS has become the gold standard for comprehensive analysis of the mitochondrial genome, allowing for the detection of point mutations, deletions, and heteroplasmy levels with high sensitivity.[10][11][12]
Methodology:
-
DNA Extraction: Isolate total DNA from patient samples such as blood, urine, or muscle tissue.[13]
-
mtDNA Enrichment: Amplify the entire mitochondrial genome using long-range PCR with primers specific to conserved regions.
-
Library Preparation:
-
Fragment the amplified mtDNA.
-
Ligate sequencing adapters to the DNA fragments.
-
Perform limited-cycle PCR to add indexes for sample multiplexing.
-
-
Sequencing: Sequence the prepared library on an NGS platform (e.g., Illumina MiSeq).[14]
-
Data Analysis:
-
Align the sequencing reads to the revised Cambridge Reference Sequence (rCRS) for the human mitochondrial genome.
-
Call variants (point mutations and indels) and determine their heteroplasmy levels.
-
Identify large deletions by analyzing read coverage across the genome.
-
Sanger Sequencing for Targeted Mutation Analysis
Sanger sequencing is a reliable method for confirming specific point mutations identified by other screening methods or for targeted analysis of known pathogenic variants.[13]
Methodology:
-
DNA Extraction: Isolate total DNA from the patient sample.
-
PCR Amplification: Amplify the specific region of the mitochondrial or nuclear genome containing the suspected mutation using target-specific primers.
-
PCR Product Purification: Remove excess primers and dNTPs from the PCR product.
-
Cycle Sequencing: Perform a sequencing reaction using fluorescently labeled dideoxynucleotides (ddNTPs).
-
Capillary Electrophoresis: Separate the sequencing reaction products by size on a capillary electrophoresis instrument.
-
Data Analysis: Analyze the resulting chromatogram to determine the DNA sequence and identify any mutations.[15]
Southern Blot for Detection of Large-Scale Rearrangements
While largely superseded by NGS-based methods, Southern blotting remains a robust technique for detecting and quantifying large-scale mtDNA deletions and duplications.[12]
Methodology:
-
DNA Extraction: Isolate high-quality total DNA from a muscle biopsy, as deletions are often not detectable in blood.
-
Restriction Digestion: Digest the DNA with a restriction enzyme that cuts the mtDNA at a single site to linearize the circular genome.
-
Agarose Gel Electrophoresis: Separate the digested DNA fragments by size on an agarose gel.
-
Transfer: Transfer the DNA from the gel to a nylon or nitrocellulose membrane.
-
Hybridization: Hybridize the membrane with a labeled DNA probe specific to a region of the mitochondrial genome.
-
Detection: Visualize the hybridized probe to detect the presence of rearranged mtDNA molecules, which will appear as bands of different sizes compared to the wild-type mtDNA.
Visualization of Pathways and Workflows
Signaling Pathways Affected by Mitochondrial Dysfunction
Mitochondrial dysfunction leads to the activation of several signaling pathways, primarily in response to increased reactive oxygen species (ROS) production and altered cellular energy status.[16][17][18]
Caption: Signaling pathways activated by mitochondrial dysfunction.
Experimental Workflow for Sanger Sequencing
The following diagram illustrates the key steps in a typical Sanger sequencing workflow for mutation detection.
Caption: Workflow for targeted mutation detection using Sanger sequencing.
References
- 1. Mitochondrial DNA Common Mutation Syndromes | Children's Hospital of Philadelphia [chop.edu]
- 2. Causes/Inheritance - Mitochondrial Myopathies (MM) - Diseases | Muscular Dystrophy Association [mda.org]
- 3. umdf.org [umdf.org]
- 4. Pathogenic Mitochondria DNA Mutations: Current Detection Tools and Interventions [mdpi.com]
- 5. tandfonline.com [tandfonline.com]
- 6. Prevalence of nuclear and mitochondrial DNA mutations related to adult mitochondrial disease - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Pathogenic Mitochondrial DNA Mutations Are Common in the General Population - ePrints - Newcastle University [eprints.ncl.ac.uk]
- 8. jmg.bmj.com [jmg.bmj.com]
- 9. Prevalence of rare mitochondrial DNA mutations in mitochondrial disorders - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Mitochondrial Sequencing | Analyze mtDNA and nuclear DNA [illumina.com]
- 11. Diagnosis and management of mitochondrial disease: a consensus statement from the Mitochondrial Medicine Society - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Detection of mitochondrial DNA (mtDNA) mutations - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Mitochondrial Sequencing | Thermo Fisher Scientific - US [thermofisher.com]
- 14. Human whole mitochondrial genome sequencing and analysis: optimization of the experimental workflow - PMC [pmc.ncbi.nlm.nih.gov]
- 15. blog.genewiz.com [blog.genewiz.com]
- 16. mdpi.com [mdpi.com]
- 17. Signaling Pathways in Mitochondrial Dysfunction and Aging - PMC [pmc.ncbi.nlm.nih.gov]
- 18. Mitochondrial Signaling Pathways Associated with DNA Damage Responses - PubMed [pubmed.ncbi.nlm.nih.gov]
Accessing and Utilizing Mutation Databases for Parkinson's Disease Research: A Technical Guide
For Researchers, Scientists, and Drug Development Professionals
This in-depth technical guide provides a comprehensive overview of accessing and utilizing prominent mutation databases for Parkinson's Disease (PD). It is designed to equip researchers, scientists, and drug development professionals with the necessary knowledge and methodologies to effectively leverage these critical resources in their work. This guide details the contents of key databases, provides step-by-step experimental protocols for generating genetic data, and illustrates relevant biological pathways and data analysis workflows.
Parkinson's Disease Mutation Databases: A Quantitative Overview
Several specialized databases catalog genetic variations associated with Parkinson's Disease. These resources are invaluable for identifying potential therapeutic targets, understanding disease mechanisms, and designing targeted research studies. Below is a summary of the quantitative data available in three key databases: Gene4PD, the Parkinson Disease Mutation Database (PDmutDB), and the Mutation Database for Parkinson's Disease (MDPD).
| Database | Data Category | Number of Entries | Genes Implicated | Publications Referenced |
| Gene4PD | Rare Variants | 2,252 | 226 | 327 |
| Copy Number Variations (CNVs) | 139 | 34 | 94 | |
| Associated SNPs (from GWAS) | 1,237 | 640 | 42 | |
| Differentially Expressed Genes (DEGs) | 2,926 | - | 8 | |
| Differentially Methylated Genes (DMGs) | 657 | - | 7 | |
| PDmutDB | Total DNA Variants | >500 | 5 (primarily SNCA, PARK2, PINK1, PARK7, LRRK2) | - |
| Simple Mutations | ~82% of total variants | - | - | |
| Copy Number Variations (CNVs) | ~18% of total variants | - | - | |
| This compound | Total Entries | 2,391 | 202 | 576 |
Experimental Protocols for Genetic Data Generation
The data housed within these databases are generated through various experimental procedures. The following sections provide detailed methodologies for the key experiments required for genetic analysis in Parkinson's Disease research.
Genomic DNA Extraction from Whole Blood
High-quality genomic DNA (gDNA) is a prerequisite for downstream applications such as Next-Generation Sequencing (NGS). The following protocol outlines a common method for gDNA extraction from whole blood samples.
Materials:
-
Whole blood sample
-
Red Blood Cell (RBC) Lysis Buffer
-
Cell Lysis Solution
-
Protein Precipitation Solution
-
DNA Hydration Solution
-
Isopropanol, 100%
-
Ethanol, 70%
-
Nuclease-free water
-
Microcentrifuge tubes (1.5 mL and 2 mL)
-
Pipettes and nuclease-free tips
-
Microcentrifuge
-
Vortex mixer
-
Water bath or heat block at 37°C and 60°C
Procedure:
-
RBC Lysis:
-
Add 900 µL of RBC Lysis Buffer to a 1.5 mL microcentrifuge tube.
-
Add 300 µL of the whole blood sample to the tube.
-
Invert the tube several times to mix and incubate at room temperature for 10 minutes.
-
Centrifuge at 13,000 x g for 3 minutes.
-
Carefully discard the supernatant, leaving the visible white blood cell pellet.
-
-
Cell Lysis:
-
Vortex the tube vigorously to resuspend the pellet.
-
Add 300 µL of Cell Lysis Solution to the resuspended cells.
-
Pipette up and down to lyse the cells until the solution is homogeneous.
-
-
Protein Precipitation:
-
Add 100 µL of Protein Precipitation Solution to the cell lysate.
-
Vortex vigorously at high speed for 20 seconds.
-
Centrifuge at 13,000 x g for 3 minutes. The precipitated proteins will form a tight pellet.
-
-
DNA Precipitation:
-
Carefully pour the supernatant containing the DNA into a clean 1.5 mL microcentrifuge tube containing 300 µL of 100% isopropanol.
-
Gently invert the tube several times until the thread-like strands of DNA form a visible mass.
-
Centrifuge at 13,000 x g for 1 minute. The DNA will be visible as a small white pellet.
-
-
DNA Wash:
-
Carefully discard the supernatant.
-
Add 300 µL of 70% ethanol and gently invert the tube several times to wash the DNA pellet.
-
Centrifuge at 13,000 x g for 1 minute.
-
Carefully discard the ethanol, taking care not to disturb the pellet.
-
Invert the tube on a clean piece of absorbent paper and air dry the pellet for 10-15 minutes.
-
-
DNA Rehydration:
-
Add 50-100 µL of DNA Hydration Solution to the dried DNA pellet.
-
Incubate at 60°C for 1 hour to dissolve the DNA.
-
Store the DNA at 4°C for short-term storage or -20°C for long-term storage.
-
Whole Exome Sequencing (WES) Library Preparation (Illumina Platform)
WES is a widely used technique to identify genetic variants in the protein-coding regions of the genome. The following protocol outlines the key steps for preparing a WES library using an Illumina-based platform.
Materials:
-
Genomic DNA (1-100 ng)
-
Library Preparation Kit (e.g., Illumina DNA Prep with Enrichment)
-
Exome Enrichment Panel (e.g., Twist Human Core Exome)
-
Nuclease-free water
-
Magnetic beads for purification (e.g., AMPure XP)
-
8-strip PCR tubes
-
Magnetic stand
-
Thermal cycler
-
Qubit fluorometer and reagents for quantification
-
Bioanalyzer and reagents for quality control
Procedure:
-
Tagmentation:
-
Normalize the input gDNA concentration.
-
In a PCR tube, combine the gDNA with the tagmentation master mix containing the transposome.
-
Incubate in a thermal cycler to allow the transposome to simultaneously fragment the DNA and add adapter sequences.
-
Add a stop solution to inactivate the transposome.
-
-
PCR Amplification:
-
Perform a limited-cycle PCR to add index sequences (barcodes) to the tagmented DNA fragments, allowing for multiplexing of samples.
-
Use a PCR master mix containing a high-fidelity polymerase.
-
-
Library Purification and Normalization:
-
Purify the amplified library using magnetic beads to remove unused primers and adapters.
-
Quantify the purified library using a fluorometric method (e.g., Qubit).
-
Normalize the concentration of all libraries to be pooled for enrichment.
-
-
Hybridization and Capture:
-
Pool the normalized libraries.
-
Mix the pooled library with biotinylated capture probes specific to the human exome.
-
Add blocking oligos to prevent non-specific binding.
-
Incubate the mixture at a specific temperature to allow the probes to hybridize to the target exonic DNA fragments.
-
-
Enrichment:
-
Add streptavidin-coated magnetic beads to the hybridization mixture. The biotinylated probes bound to the target DNA will bind to the streptavidin beads.
-
Use a magnetic stand to pull down the beads, thereby enriching for the exonic DNA.
-
Perform several wash steps to remove non-specifically bound DNA fragments.
-
-
Post-Enrichment PCR:
-
Amplify the enriched library using a PCR master mix to generate a sufficient quantity of DNA for sequencing.
-
-
Final Library Quantification and Quality Control:
-
Purify the final enriched library using magnetic beads.
-
Quantify the final library concentration using a fluorometric method.
-
Assess the size distribution and quality of the final library using an automated electrophoresis system (e.g., Bioanalyzer).
-
-
Sequencing:
-
Denature and dilute the final library to the appropriate concentration for the Illumina sequencing platform.
-
Load the library onto the flow cell for sequencing.
-
Signaling Pathways and Workflows in Parkinson's Disease Genetics
Understanding the molecular pathways implicated in Parkinson's Disease is crucial for interpreting genetic data and identifying potential therapeutic targets. The following diagrams, generated using the DOT language, illustrate key pathways and a general workflow for genetic data analysis.
The Ubiquitin-Proteasome System in Parkinson's Disease
Mutations in genes involved in the ubiquitin-proteasome system (UPS), such as PARK2 (Parkin), are a major cause of familial Parkinson's Disease. The UPS is responsible for the degradation of misfolded or damaged proteins, and its dysfunction can lead to the accumulation of toxic protein aggregates.
PINK1/Parkin-Mediated Mitochondrial Quality Control
Mutations in PINK1 and PARK2 (Parkin) are also linked to early-onset Parkinson's Disease. These genes play a critical role in mitochondrial quality control, a process that removes damaged mitochondria through a specialized form of autophagy called mitophagy.
Workflow for Genetic Data Analysis in Parkinson's Disease Research
Accessing and analyzing data from PD mutation databases involves a multi-step bioinformatics workflow. This process begins with data acquisition and culminates in the functional interpretation of identified genetic variants.
Conclusion
The mutation databases for Parkinson's Disease are indispensable tools for advancing our understanding of the genetic underpinnings of this complex neurodegenerative disorder. By providing centralized repositories of genetic information, these databases empower researchers to identify novel disease-associated genes, elucidate pathogenic mechanisms, and ultimately accelerate the development of targeted therapies. This technical guide offers a foundational understanding of how to access, generate, and interpret the valuable data contained within these resources, thereby facilitating more effective and impactful research in the field of Parkinson's Disease.
The MPTP Neurotoxin Model: A Technical Guide for Parkinson's Disease Research
The 1-methyl-4-phenyl-1,2,3,6-tetrahydropyridine (MPTP) model is a cornerstone of Parkinson's disease (PD) research, providing a robust and reproducible method for studying the progressive loss of dopaminergic neurons that characterizes the disease.[1][2] This guide offers an in-depth technical overview of the MPTP model, designed for researchers, scientists, and drug development professionals. It details the core features of the model, experimental protocols, quantitative data for comparative analysis, and visualizations of key biological pathways and workflows.
Core Features of the MDPD Model
The utility of the MPTP model lies in its ability to replicate key pathological hallmarks of Parkinson's disease. MPTP is a lipophilic protoxin that readily crosses the blood-brain barrier.[2] Once in the brain, it is metabolized by monoamine oxidase B (MAO-B) in astrocytes to its active toxic metabolite, 1-methyl-4-phenylpyridinium (MPP+).[2][3] Dopaminergic neurons, via the dopamine transporter (DAT), selectively take up MPP+.[3] Inside these neurons, MPP+ inhibits complex I of the mitochondrial electron transport chain, leading to a cascade of events including ATP depletion, oxidative stress, and ultimately, cell death.[4][5] This selective neurotoxicity in the substantia nigra pars compacta (SNpc) and the subsequent depletion of striatal dopamine mirror the primary pathology of Parkinson's disease.[1][6]
The model's versatility is enhanced by the availability of different administration protocols—acute, sub-acute, and chronic—each recapitulating different aspects of the disease's progression and severity.[2][7] This allows researchers to tailor the model to their specific research questions, from studying the initial molecular events of neurodegeneration to testing the efficacy of neuroprotective and restorative therapies.
Quantitative Data in the MPTP Mouse Model
The following tables summarize key quantitative data from various MPTP protocols in mice, providing a basis for experimental design and comparison.
Table 1: Neurochemical and Histological Outcomes of Different MPTP Protocols
| Parameter | Acute Model | Sub-acute Model | Chronic Model | Control | Reference(s) |
| Striatal Dopamine Depletion | ~90% reduction | 40-50% reduction | >90% reduction (with probenecid) | No significant change | [2][8][9] |
| Dopaminergic Neuron Loss in SNpc | ~50% loss | Variable, can be less severe | Up to 70% loss (with probenecid) | No significant change | [1][10] |
| Tyrosine Hydroxylase (TH) Reduction in SNpc | Significant 70% reduction | Significant reduction | Significant reduction | No significant change | [11] |
| Striatal DOPAC and HVA Levels | Profound reduction | Significant reduction | Significant reduction | No significant change | [8] |
Table 2: Behavioral Outcomes in the MPTP Mouse Model
| Behavioral Test | Acute Model | Sub-acute Model | Chronic Model | Expected Outcome in Control | Reference(s) |
| Open Field Test | Reduced rearing and overall movement | Can show hyperactivity | Reduced movement | Normal exploratory behavior | [1][12] |
| Rotarod Test | Decreased latency to fall | Imbalanced motor behavior | Decreased latency to fall | Maintained balance for the duration | [3][4] |
| Pole Test | Increased time to turn and descend | Impaired performance | Increased time to descend | Quick turn and descent | [13] |
| Marble Burying Test | Anxiolytic-like behavior (reduced burying) | Not consistently reported | Not consistently reported | Burying of most marbles | [14] |
| Elevated Plus Maze | Anxiolytic-like behavior (more time in open arms) | Not consistently reported | Not consistently reported | Preference for closed arms | [14] |
Key Experimental Protocols
Detailed methodologies are crucial for the reproducibility of the MPTP model. The following are outlines of common protocols.
Acute MPTP Protocol
This protocol induces a rapid and severe dopaminergic lesion.
-
Animals: Male C57BL/6 mice (8-10 weeks old) are commonly used due to their high sensitivity to MPTP.[3]
-
Reagents:
-
MPTP-HCl (Sigma-Aldrich): Dissolve in sterile 0.9% saline to a concentration of 2 mg/mL. Prepare fresh before each use.
-
Vehicle: Sterile 0.9% saline.
-
-
Administration:
-
Administer four intraperitoneal (i.p.) injections of MPTP (20 mg/kg) at 2-hour intervals over an 8-hour period on a single day.[8]
-
The control group receives corresponding injections of saline.
-
-
Post-injection Monitoring:
-
Monitor animals closely for any adverse reactions. There is a higher mortality rate in female mice and mice weighing less than 22g with this protocol.[8]
-
-
Endpoint Analysis:
-
Behavioral testing can be performed at various time points, typically starting 7 days post-injection.
-
Neurochemical and histological analyses are commonly conducted 7 to 21 days after MPTP administration.[8]
-
Sub-acute MPTP Protocol
This protocol produces a more moderate and stable lesion.
-
Animals: Male C57BL/6 mice (8-10 weeks old).[3]
-
Reagents:
-
MPTP-HCl: Dissolve in sterile 0.9% saline to a concentration of 3 mg/mL.
-
Vehicle: Sterile 0.9% saline.
-
-
Administration:
-
Post-injection Monitoring:
-
Observe animals for any signs of distress.
-
-
Endpoint Analysis:
Chronic MPTP/Probenecid Protocol
This protocol is designed to model a more progressive neurodegeneration. Probenecid is used to inhibit the clearance of MPP+, thus enhancing its neurotoxic effects.
-
Animals: Male C57BL/6 mice (8-10 weeks old).
-
Reagents:
-
MPTP-HCl: Dissolve in sterile 0.9% saline.
-
Probenecid: Dissolve in dimethyl sulfoxide (DMSO).
-
Vehicle: Saline for MPTP and DMSO for probenecid.
-
-
Administration:
-
Administer an i.p. injection of probenecid (250 mg/kg) 30 minutes prior to each MPTP injection.
-
Administer an i.p. injection of MPTP (25 mg/kg) twice a week for five weeks.[7]
-
The control group receives vehicle injections.
-
-
Post-injection Monitoring:
-
Monitor animal weight and general health throughout the 5-week period.
-
-
Endpoint Analysis:
-
This model shows a progressive loss of dopaminergic neurons, with significant cell death observed weeks after the final injection.[1] Endpoint analysis can be conducted at various time points to study the progression of neurodegeneration.
-
Mandatory Visualizations
The following diagrams, created using the DOT language, illustrate key signaling pathways and a generalized experimental workflow for the MPTP model.
Signaling Pathways
Caption: MPTP is metabolized to MPP+ in astrocytes and selectively taken up by dopaminergic neurons, leading to mitochondrial dysfunction and apoptosis.
Caption: MPP+-induced neuronal damage triggers neuroinflammatory responses from microglia and astrocytes, exacerbating neurodegeneration.
Caption: Mitochondrial damage in the MPTP model initiates the intrinsic apoptotic cascade, leading to programmed cell death.
Experimental Workflow
References
- 1. MPTP Mouse Models of Parkinson’s Disease: An Update - PMC [pmc.ncbi.nlm.nih.gov]
- 2. MPTP-induced mouse model of Parkinson’s disease: A promising direction for therapeutic strategies - PMC [pmc.ncbi.nlm.nih.gov]
- 3. benchchem.com [benchchem.com]
- 4. mdpi.com [mdpi.com]
- 5. Dynamic Changes in the Nigrostriatal Pathway in the MPTP Mouse Model of Parkinson's Disease - PMC [pmc.ncbi.nlm.nih.gov]
- 6. journals.biologists.com [journals.biologists.com]
- 7. MPTP Mouse Model of Parkinson’s Disease - Creative Biolabs [creative-biolabs.com]
- 8. modelorg.com [modelorg.com]
- 9. Striatal extracellular dopamine levels and behavioural reversal in MPTP-lesioned mice - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. Frontiers | Loss of RAB39B does not alter MPTP-induced Parkinson’s disease-like phenotypes in mice [frontiersin.org]
- 11. Quantification of MPTP-induced dopaminergic neurodegeneration in the mouse substantia nigra by laser capture microdissection - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. meliordiscovery.com [meliordiscovery.com]
- 13. Reassessment of subacute MPTP-treated mice as animal model of Parkinson's disease - PMC [pmc.ncbi.nlm.nih.gov]
- 14. imrpress.com [imrpress.com]
In-depth Technical Guide to the MDPD Data Structure
An Examination of the Term "MDPD" in the Context of Scientific and Drug Development Data Structures
For researchers, scientists, and drug development professionals, a comprehensive understanding of the data structures underpinning key databases is crucial for effective data utilization. This guide aims to provide an in-depth technical overview of the "this compound" data structure. However, extensive research into scientific and drug development literature and databases has revealed that "this compound" is not a recognized or standardized acronym for a specific data structure or database within this domain.
Initial investigations suggest that "this compound" may refer to various entities outside the scope of this technical guide, including the Miami-Dade Police Department, the Maryland Department of Planning's Digital Data, or specific, non-public, internal project names. Given the ambiguity of the term, this guide will proceed by outlining a hypothetical, yet representative, data structure that would be foundational to a M olecular and P harmacological D ata D epository (herein referred to as this compound). This model is constructed based on common principles of data organization in prominent bioinformatics and cheminformatics databases.
I. Conceptual Data Model for a Hypothetical this compound
A robust this compound would need to integrate diverse data types, from molecular information to clinical outcomes. The conceptual data model would likely be organized around several core entities:
-
Compounds: Small molecules, biologics, and other therapeutic agents.
-
Targets: Proteins, nucleic acids, and other biological molecules that are the focus of drug action.
-
Assays: Experimental procedures used to measure the activity of compounds against targets.
-
Pharmacokinetics/Pharmacodynamics (PK/PD): Data related to the absorption, distribution, metabolism, excretion, and toxicological effects of compounds.
-
Clinical Data: Information from clinical trials, including patient demographics, dosing, efficacy, and safety outcomes.
The logical relationship between these core entities is visualized in the following diagram:
Caption: Logical data model for a hypothetical this compound.
II. Core Data Structures and Quantitative Data Summary
The underlying data structure would likely be a relational database, with tables corresponding to the core entities. Below is a summary of the potential tables and their key quantitative fields.
| Table Name | Key Quantitative Fields | Data Type | Description |
| Compounds | Molecular_Weight, LogP, pKa | DECIMAL(10, 4) | Physicochemical properties of the compound. |
| Targets | Sequence_Length, Molecular_Mass_kDa | INTEGER, DECIMAL(10, 3) | Physical properties of the biological target. |
| Assay_Results | IC50, Ki, EC50 | DECIMAL(12, 9) | Measures of compound activity and potency. |
| PKPD_Parameters | Half_Life_hours, Cmax_ng_mL, AUC_ng_h_mL | DECIMAL(10, 2) | Key pharmacokinetic parameters. |
| Clinical_Trials | N_Patients, Primary_Completion_Date | INTEGER, DATE | Key trial metadata and timelines. |
III. Experimental Protocols and Workflows
A critical component of the this compound would be detailed experimental protocols to ensure data reproducibility and comparability.
A. Standard High-Throughput Screening (HTS) Workflow
The process of identifying hit compounds from a large library is a standard workflow that would be captured within the this compound.
Caption: A typical high-throughput screening workflow.
B. Detailed Methodologies for Key Experiments
For each assay result stored, a link to a detailed experimental protocol would be essential. An example structure for such a protocol is provided below.
| Section | Content | Example |
| 1. Objective | The purpose of the experiment. | To determine the in-vitro efficacy of compound X against Target Y. |
| 2. Materials | Reagents, cell lines, equipment. | Target Y protein, Compound X stock solution, 384-well plates. |
| 3. Procedure | Step-by-step instructions. | 1. Dispense 50 nL of compound dilutions... |
| 4. Data Analysis | How raw data is processed. | IC50 values were calculated using a four-parameter logistic fit. |
IV. Signaling Pathways and Molecular Interactions
To provide biological context, the this compound would need to incorporate information on signaling pathways.
A. Example Signaling Pathway: MAPK/ERK Pathway
The MAPK/ERK pathway is a crucial signaling cascade in cell proliferation and is a common target in oncology drug development.
Caption: Simplified representation of the MAPK/ERK signaling pathway.
An In-depth Technical Guide to the Curation and Updating of Mitochondrial Disease Protein Databases
For Researchers, Scientists, and Drug Development Professionals
This technical guide provides a comprehensive overview of the data curation and updating processes employed by prominent mitochondrial disease and protein databases. Understanding these methodologies is crucial for researchers, scientists, and drug development professionals who rely on these resources for accurate and up-to-date information. This guide will delve into the data presentation, experimental and computational protocols, and logical workflows of key databases in the field, with a focus on providing actionable insights for users and data submitters.
Data Presentation: A Quantitative Overview
The following tables summarize the key quantitative data for three leading mitochondrial protein and disease databases: mitoPADdb , MitoProteome , and the Mitochondrial Disease Sequence Data Resource (MSeqDR) . These databases serve as vital repositories for information on mitochondrial proteins, their associated diseases, and genetic variants.
Table 1: Database Content Summary
| Database | Number of Genes | Number of Proteins | Number of Mutations/Variants | Number of Diseases |
| mitoPADdb | 810 | Not Specified | 18,356 | 1,793 |
| MitoProteome | 1,705 | 3,625 | Not Specified | Not Specified |
| MSeqDR | >1,300 | Not Specified | Curated pathogenic variants | Curated mitochondrial diseases |
Table 2: Data Types and Update Frequency
| Database | Primary Data Types | Update Frequency |
| mitoPADdb | Gene-disease associations, mutations, expression variations | Not explicitly stated |
| MitoProteome | Protein sequences, functions, localizations, interactions | Updated frequently to reflect changes in public resources[1] |
| MSeqDR | Genomic and phenotypic data, variant annotations | Continually updated[2] |
Experimental and Computational Protocols
The integrity and utility of these databases are underpinned by rigorous curation and updating protocols. These methodologies involve a combination of manual curation by experts and automated computational pipelines.
Data Submission Protocols
Data submission by the research community is a critical component of keeping these databases current and comprehensive. While specific submission interfaces vary, the general requirements follow established standards for proteomics and genomics data.
For Proteomics Data (relevant to MitoProteome and mitoPADdb):
Submissions of protein and peptide identification and quantification data are typically required to adhere to the guidelines set by the ProteomeXchange consortium. This ensures data interoperability and quality. The key components of a complete submission include:
-
Raw Mass Spectrometry Files: The unprocessed output from the mass spectrometer (e.g., .raw, .wiff).
-
Processed Data Files: Peak lists and search engine output files (e.g., .mgf, .msf). Standardized formats like mzIdentML or PRIDE XML are often required.
-
Metadata: Comprehensive information about the experimental design, sample preparation, instrumentation, and data analysis parameters.
For Genomics and Variant Data (relevant to MSeqDR):
MSeqDR provides a streamlined process for submitting genomic and phenotypic data. The submission workflow is designed to be compatible with clinical data standards, such as those used by ClinVar. The process generally involves:
-
User Registration: Researchers must create an account to submit data.
-
Study and Patient Information: Submission of de-identified patient and study information is often required, using standardized ontologies like the Human Phenotype Ontology (HPO).
-
Variant Data Upload: Variant data is typically submitted in standard formats such as Variant Call Format (VCF) or Human Genome Variation Society (HGVS) nomenclature.[3]
-
Curation and Annotation: Submitted variants undergo a review and annotation process by MSeqDR curators.
Data Curation and Annotation Workflow
Once data is submitted or identified from public sources, it undergoes a rigorous curation and annotation process to ensure accuracy and consistency.
1. Manual Curation: Expert curators play a vital role in reviewing and annotating data. This is particularly crucial for complex information such as gene-disease relationships and the pathogenic classification of genetic variants. For instance, mitoPADdb is a manually curated database where experts collect, compile, and review data on mitochondrial protein-encoding gene mutations and their association with diseases.[4]
2. Automated Annotation Pipelines: To handle the large volume of data, automated pipelines are employed for tasks such as:
-
Sequence Annotation: Computational tools are used to predict gene and protein features, such as protein domains, subcellular localization, and transmembrane helices.
-
Homology-based Inference: Function and localization of novel proteins are often inferred based on sequence similarity to well-characterized proteins in other species.
-
Integration from Public Databases: Information is automatically extracted and integrated from other major biological databases like UniProt, GenBank, and OMIM.[1]
3. Experimental Validation of Protein Localization: A key aspect of curating mitochondrial protein databases is confirming the subcellular localization of proteins. This is often achieved through a combination of computational prediction and experimental validation. Common experimental techniques include:
-
GFP Tagging and Microscopy: Proteins are tagged with a fluorescent marker (like Green Fluorescent Protein) and their localization within the cell is observed using confocal microscopy.
-
Immunofluorescence: Antibodies specific to the protein of interest are used to visualize its location within the cell.
-
Subcellular Fractionation and Western Blotting: Cells are broken down and separated into different organelle fractions. The presence of the protein in the mitochondrial fraction is then detected by Western blotting.
-
In Organello Import Assays: The ability of a protein to be imported into isolated mitochondria is tested directly.[5]
Database Update Protocol
Databases are updated periodically to incorporate new data and reflect the latest scientific findings.
-
MitoProteome: This database is designed for frequent updates by highly automating the processes of maintaining its protein list and extracting relevant data from external databases.[1]
-
MSeqDR: As a resource for clinical and research communities, MSeqDR provides continually updated information on genes, variants, and phenotypes.[2]
-
mitoPADdb: While the exact update frequency is not specified, as a manually curated database, updates are likely performed in discrete releases as new data is collected and curated.
Mandatory Visualization
The following diagrams, generated using the Graphviz DOT language, illustrate the key workflows and pathways described in this guide.
Data Curation and Submission Workflow
This diagram outlines the general process for data submission and curation in mitochondrial disease protein databases.
Database Update Workflow
This diagram illustrates the cyclical nature of database updates, driven by new research and data integration.
Mitochondrial Signaling Pathway: Apoptosis Regulation
Mitochondria play a central role in the intrinsic pathway of apoptosis. This diagram illustrates the key signaling events involved.
References
- 1. MitoProteome: mitochondrial protein sequence database and annotation system - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Mitochondrial Disease Sequence Data Resource (MSeqDR): A global grass-roots consortium to facilitate deposition, curation, annotation, and integrated analysis of genomic data for the mitochondrial disease clinical and research communities - PMC [pmc.ncbi.nlm.nih.gov]
- 3. MSeqDR Consortium new study and pathogenic variant submission [mseqdr.org]
- 4. mitoPADdb: A database of mitochondrial proteins associated with diseases - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
Ethical Considerations for the Research and Development of 3,4-Methylenedioxypyrovalerone (MDPV): A Technical Guide
For Researchers, Scientists, and Drug Development Professionals
Abstract
3,4-Methylenedioxypyrovalerone (MDPV) is a potent synthetic cathinone that has garnered significant attention due to its high potential for abuse and serious adverse health effects. As a powerful norepinephrine-dopamine reuptake inhibitor (NDRI), its unique pharmacological profile presents both challenges and opportunities for researchers in the fields of addiction, neuropharmacology, and toxicology. This technical guide provides an in-depth overview of the core pharmacology of MDPV, detailed experimental protocols for its study, and a critical examination of the ethical considerations inherent in conducting research with this potent psychostimulant. All quantitative data are summarized for comparative analysis, and key molecular and experimental pathways are visualized to facilitate a comprehensive understanding.
Introduction
3,4-Methylenedioxypyrovalerone (MDPV) is a psychoactive substance of the cathinone class, structurally related to pyrovalerone.[1] It is a potent central nervous system stimulant that has been identified as the active ingredient in many products illicitly sold as "bath salts."[2][3] The high abuse liability and reports of severe adverse effects, including paranoia, psychosis, and violent behavior, have led to its classification as a Schedule I controlled substance in the United States and other countries.[1][3] Despite its illicit use, the study of MDPV provides valuable insights into the mechanisms of stimulant addiction and the neurobiology of monoamine transporter function. This guide aims to equip researchers with the necessary technical information and a robust ethical framework for conducting research with MDPV.
Pharmacology and Mechanism of Action
MDPV's primary mechanism of action is the potent inhibition of the dopamine transporter (DAT) and the norepinephrine transporter (NET), with significantly less activity at the serotonin transporter (SERT).[2][4] This action leads to a rapid and sustained increase in extracellular concentrations of dopamine and norepinephrine in the brain, which is believed to mediate its powerful psychostimulant effects.[2][4] Some studies suggest a dual mode of action, where at lower concentrations, MDPV may also induce dopamine efflux, further contributing to its complex pharmacological profile.
The S-isomer of MDPV is significantly more potent at blocking the DAT and eliciting abuse-related effects compared to the R-isomer.[4] The sustained elevation of dopamine in the brain's reward pathways is thought to be the primary driver of MDPV's high abuse and addiction potential.[4][5]
Signaling Pathway of MDPV at the Dopaminergic Synapse
Caption: Mechanism of MDPV at the dopaminergic synapse.
Quantitative Data from Preclinical Studies
The following tables summarize key quantitative data from in vitro and in vivo studies of MDPV.
Table 1: In Vitro Transporter Inhibition Potency (IC50, nM)
| Compound | Dopamine Transporter (DAT) | Norepinephrine Transporter (NET) | Serotonin Transporter (SERT) | Reference |
| MDPV | 4.0 ± 0.6 | 25.9 ± 5.6 | 3305 ± 485 | [6] |
| Cocaine | 280 ± 20 | 430 ± 30 | 310 ± 10 | [6] |
| Methamphetamine | 1100 ± 100 | 1100 ± 100 | 5400 ± 300 | [6] |
Table 2: In Vivo Effects of MDPV in Rodents
| Species | Dose (mg/kg) | Route | Effect | Observation | Reference |
| Mouse | 1-30 | i.p. | Locomotor Activity | Dose-dependent increase | [7] |
| Rat | 0.5-5.6 | s.c. | Locomotor Activity | Increased at lower doses, decreased at highest dose | [8][9] |
| Rat | 0.1-0.3 | i.v. | Extracellular Dopamine | Dose-related increase in nucleus accumbens | [2][4] |
| Rat | 0.01-0.5 | i.v. | Self-Administration | Readily self-administered, more potent than methamphetamine | [5] |
Detailed Experimental Protocols
Neurotransmitter Uptake Assay in Brain Synaptosomes
This protocol details the methodology for assessing the in vitro potency of MDPV to inhibit dopamine and norepinephrine uptake in rat brain tissue.
Objective: To determine the IC50 values of MDPV at DAT and NET.
Materials:
-
Rat brain tissue (striatum for DAT, hippocampus for NET)
-
Sucrose buffer (0.32 M sucrose, 10 mM HEPES, pH 7.4)
-
Krebs-Ringer-HEPES buffer (KRHB)
-
[³H]Dopamine and [³H]Norepinephrine
-
Test compound (MDPV) solutions of varying concentrations
-
Scintillation fluid and vials
-
Homogenizer, centrifuges, water bath, scintillation counter
Procedure:
-
Synaptosome Preparation:
-
Dissect the brain region of interest on ice.
-
Homogenize the tissue in 10 volumes of ice-cold sucrose buffer.[4][6][7][10]
-
Centrifuge the homogenate at 1,000 x g for 10 minutes at 4°C.[7]
-
Collect the supernatant and centrifuge at 20,000 x g for 20 minutes at 4°C.[4]
-
Resuspend the resulting pellet (synaptosomes) in KRHB.[6]
-
-
Uptake Assay:
-
Pre-incubate aliquots of the synaptosomal suspension with varying concentrations of MDPV or vehicle for 10 minutes at 37°C.
-
Initiate the uptake reaction by adding [³H]dopamine or [³H]norepinephrine.
-
Incubate for a short period (e.g., 5 minutes) at 37°C.
-
Terminate the reaction by rapid filtration over glass fiber filters, followed by washing with ice-cold KRHB.
-
Measure the radioactivity retained on the filters using a scintillation counter.
-
-
Data Analysis:
-
Calculate the percentage of inhibition of neurotransmitter uptake for each MDPV concentration.
-
Determine the IC50 value by non-linear regression analysis.
-
Experimental Workflow for Neurotransmitter Uptake Assay
Caption: Workflow for neurotransmitter uptake assay.
In Vivo Microdialysis in Freely Moving Rats
This protocol outlines the procedure for measuring extracellular dopamine levels in the nucleus accumbens of rats following MDPV administration.
Objective: To assess the in vivo effect of MDPV on dopamine neurotransmission.
Materials:
-
Adult male rats
-
Stereotaxic apparatus
-
Microdialysis probes and guide cannulae
-
Surgical instruments
-
Anesthesia
-
Artificial cerebrospinal fluid (aCSF)
-
Syringe pump
-
Fraction collector
-
HPLC with electrochemical detection (HPLC-ED)
-
MDPV solution for injection
Procedure:
-
Surgical Implantation:
-
Microdialysis Experiment:
-
On the day of the experiment, insert the microdialysis probe through the guide cannula.[11][12][13][14]
-
Perfuse the probe with aCSF at a constant flow rate (e.g., 1-2 µL/min).[11][13]
-
Collect baseline dialysate samples for at least 60 minutes.[11]
-
Administer MDPV (e.g., intravenously or subcutaneously).
-
Continue collecting dialysate samples at regular intervals (e.g., every 20 minutes) for a set period post-injection.
-
-
Neurochemical Analysis:
-
Data Analysis:
-
Express dopamine concentrations as a percentage of the baseline average.
-
Analyze the data using appropriate statistical methods (e.g., ANOVA) to determine the effect of MDPV over time.
-
Locomotor Activity Assessment in Rodents
This protocol describes a method to evaluate the stimulant effects of MDPV on locomotor activity in mice or rats.
Objective: To quantify the psychomotor stimulant effects of MDPV.
Materials:
-
Mice or rats
-
Locomotor activity chambers equipped with infrared beams
-
MDPV solution for injection
-
Vehicle solution (e.g., saline)
Procedure:
-
Habituation:
-
Habituate the animals to the testing room and handling for several days.
-
On the test day, allow the animals to acclimate to the testing room for at least 30 minutes.[2]
-
-
Testing:
-
Data Analysis:
-
Analyze the locomotor activity data in time bins (e.g., 5 or 10 minutes).
-
Compare the activity levels between the MDPV-treated and vehicle-treated groups using statistical tests (e.g., t-test or ANOVA).
-
Ethical Considerations for Research with MDPV
Research involving MDPV, a Schedule I controlled substance with high abuse potential and significant health risks, necessitates a stringent ethical framework to ensure the safety and well-being of all involved. The following considerations are paramount for any research protocol involving this compound.
Regulatory Compliance and Institutional Approval
-
DEA Licensing: Researchers must obtain the appropriate Drug Enforcement Administration (DEA) license for handling Schedule I substances.
-
IRB/IACUC Approval: All research protocols, whether involving human participants (Institutional Review Board - IRB) or animals (Institutional Animal Care and Use Committee - IACUC), must undergo rigorous review and approval. These committees are tasked with conducting a thorough risk-benefit analysis.[15]
-
State Regulations: Researchers must also comply with all applicable state and local regulations for controlled substances.
Preclinical Research (Animal Studies)
-
Justification of Use: The use of animals in MDPV research must be scientifically justified and the research question must be of significant merit to warrant the use of a potent, abusable substance.
-
Minimization of Pain and Distress: All procedures should be designed to minimize any potential pain, distress, or suffering of the animals. This includes the use of appropriate anesthesia and analgesia for surgical procedures and careful monitoring for adverse effects of MDPV, such as hyperthermia and seizures.
-
Humane Endpoints: Clear and humane endpoints must be established to determine when an animal should be removed from a study to prevent unnecessary suffering.
-
The 3Rs (Replacement, Reduction, Refinement): Researchers have an ethical obligation to adhere to the principles of the 3Rs:
-
Replacement: Using non-animal methods whenever possible.
-
Reduction: Using the minimum number of animals necessary to obtain statistically valid results.
-
Refinement: Modifying procedures to minimize animal suffering and enhance animal welfare.
-
Clinical Research (Human Studies) - A High Bar for Justification
Given MDPV's Schedule I status and high risk profile, research in humans is exceptionally rare and would require an extraordinarily compelling scientific and clinical justification. Should such research be contemplated, the following ethical considerations would be critical:
-
Risk-Benefit Assessment: The potential risks to participants, which include severe psychological distress, psychosis, cardiovascular events, and the potential for addiction, must be meticulously weighed against the potential benefits to the individual and society.[16][17] The potential for direct benefit to the participant in early-phase research is often minimal, placing a greater emphasis on the societal value of the knowledge to be gained.
-
Participant Selection and Vulnerability:
-
Exclusion of Vulnerable Populations: Individuals with a history of psychosis, severe mental illness, cardiovascular disease, or substance use disorders would likely need to be excluded to minimize risk.[18][19]
-
Assessment of Capacity to Consent: The potential for cognitive impairment due to drug use necessitates a thorough assessment of a potential participant's capacity to provide voluntary and informed consent.[19]
-
-
Informed Consent:
-
Comprehensive Disclosure: The informed consent process must be exceptionally detailed and transparent, clearly outlining the potent and potentially severe adverse effects of MDPV, including the risk of psychological distress, paranoia, and the potential for long-term consequences.[19]
-
Voluntariness: Given the nature of the substance, it is crucial to ensure that consent is entirely voluntary and free from any form of coercion or undue inducement.
-
-
Confidentiality:
-
Certificates of Confidentiality: Researchers should obtain a Certificate of Confidentiality from the National Institutes of Health (NIH) to protect research data from being subpoenaed in legal proceedings, which is crucial when studying illegal drug use.[19]
-
-
Safety Monitoring and Participant Protection:
-
Medical and Psychological Screening: Rigorous screening of potential participants is essential to identify individuals who may be at heightened risk.
-
Intensive Monitoring: Continuous medical and psychological monitoring during and after drug administration is mandatory.
-
Emergency Procedures: A clear and immediate plan for managing acute adverse events, such as severe agitation, psychosis, or cardiovascular distress, must be in place.
-
Follow-up and Support: Provisions for follow-up care and psychological support after the study are essential.
-
Logical Framework for Ethical Review of MDPV Research
Caption: Logical framework for the ethical review of MDPV research.
Conclusion
The study of 3,4-Methylenedioxypyrovalerone offers a unique window into the neurobiology of potent psychostimulants and the mechanisms of addiction. However, the significant risks associated with this compound demand a research approach that is not only scientifically rigorous but also grounded in a profound commitment to ethical principles. This guide provides the technical foundation and ethical framework necessary for researchers to conduct studies with MDPV responsibly. By adhering to these principles, the scientific community can advance knowledge in this critical area while upholding the highest standards of safety and ethical conduct.
References
- 1. Uptake and release of neurotransmitters - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. va.gov [va.gov]
- 3. Synthetic Cathinones (‘Bath Salts’): Legal and Health Care Challenges - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Method and validation of synaptosomal preparation for isolation of synaptic membrane proteins from rat brain - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Neuropharmacology of 3,4-Methylenedioxypyrovalerone (MDPV), Its Metabolites, and Related Analogs - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Determining Serotonin and Dopamine Uptake Rates in Synaptosomes Using High-Speed Chronoamperometry - Electrochemical Methods for Neuroscience - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 7. 機能性シナプトソームを単離する | Thermo Fisher Scientific - JP [thermofisher.com]
- 8. The novel recreational drug 3,4-methylenedioxypyrovalerone (MDPV) is a potent psychomotor stimulant: self-administration and locomotor activity in rats - PMC [pmc.ncbi.nlm.nih.gov]
- 9. The novel recreational drug 3,4-methylenedioxypyrovalerone (MDPV) is a potent psychomotor stimulant: self-administration and locomotor activity in rats - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. researchgate.net [researchgate.net]
- 11. benchchem.com [benchchem.com]
- 12. In Vivo Brain Microdialysis of Monoamines | Springer Nature Experiments [experiments.springernature.com]
- 13. In vivo brain microdialysis: advances in neuropsychopharmacology and drug discovery - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Microdialysis in Rodents - PMC [pmc.ncbi.nlm.nih.gov]
- 15. Assessing Risk/Benefit for Trials Using Preclinical Evidence: A Proposal - PMC [pmc.ncbi.nlm.nih.gov]
- 16. The clinical challenges of synthetic cathinones - PMC [pmc.ncbi.nlm.nih.gov]
- 17. mdpi.com [mdpi.com]
- 18. Research with potentially vulnerable people – UKRI [ukri.org]
- 19. Confidentiality Protections in Research Involving People with Substance Use Disorders | Alcohol, Other Drugs, and Health: Current Evidence [bu.edu]
The Role of Mitochondrial-Derived Peptides in Neurodegenerative Disease Research: A Technical Guide
Authored for Researchers, Scientists, and Drug Development Professionals
Executive Summary
Mitochondrial-derived peptides (MDPs) are a novel class of bioactive molecules encoded by short open reading frames within the mitochondrial genome. Emerging research has illuminated their critical role in cellular homeostasis, metabolism, and cytoprotection, with profound implications for the pathogenesis and treatment of neurodegenerative diseases. This technical guide provides an in-depth overview of the core functions of key MDPs—Humanin (HN), MOTS-c (Mitochondrial Open Reading Frame of the 12S rRNA-c), and Small Humanin-like Peptides (SHLPs)—in the context of neurodegenerative disorders such as Alzheimer's disease, Parkinson's disease, and Huntington's disease. We present quantitative data from seminal studies, detailed experimental protocols for their investigation, and visual representations of their signaling pathways to facilitate further research and therapeutic development in this promising field.
Introduction to Mitochondrial-Derived Peptides
Once considered a mere powerhouse of the cell, the mitochondrion is now recognized as a dynamic signaling organelle. The discovery of MDPs has expanded our understanding of mitochondrial retrograde signaling, revealing a new layer of communication between mitochondria and the rest of the cell. These peptides have been shown to exert potent neuroprotective effects by mitigating oxidative stress, inhibiting apoptosis, and reducing neuroinflammation, all of which are key pathological features of neurodegenerative diseases.[1][2]
Data Presentation: Quantitative Effects of MDPs in Neurodegenerative Disease Models
The following tables summarize the quantitative findings from key studies investigating the therapeutic potential of MDPs in various in vitro and in vivo models of neurodegenerative diseases.
Table 1: Neuroprotective Effects of Humanin (HN) and its Analogs
| Model System | Treatment | Outcome Measure | Result | Reference |
| SH-SY5Y cells (OGD/R model) | 1 µg/L S14G-Humanin (HNG) | Cell Viability | Significant reversal of OGD/R-induced decrease in viability | [3] |
| SH-SY5Y cells (OGD/R model) | 1 µg/L HNG | Apoptosis Rate | Significant decrease in OGD/R-induced apoptosis | [4] |
| Primary cortical neurons (NMDA-induced toxicity) | 1 µmol/L Humanin | Cell Viability | Significant increase in cell viability compared to NMDA alone | [5] |
| Aβ1-42-injected rats | 100 µmol/L Humanin (intrahippocampal) | Synaptic Protein Levels | Upregulation of pre- and post-synaptic proteins | [6] |
Table 2: Neuroprotective Effects of MOTS-c
| Model System | Treatment | Outcome Measure | Result | Reference |
| Rotenone-induced rat model of Parkinson's Disease | 3-5 mg/kg/day MOTS-c (intraperitoneal) | Dopaminergic Neuron Loss | Reduced loss of dopaminergic neurons | [7] |
| Rotenone-induced rat model of Parkinson's Disease | 3-5 mg/kg/day MOTS-c (intraperitoneal) | Striatal Dopamine Levels | Significant improvement in dopamine content | [7] |
| Spared nerve injury mouse model | Intrathecal MOTS-c | AMPKα1/2 Phosphorylation | Significant enhancement in the lumbar spinal cord | [8] |
| High-fat diet-fed male mice | 0.5 mg/kg/day MOTS-c (i.p. for 3 weeks) | Body Weight Gain | Prevention of weight gain | [9] |
Table 3: Neuroprotective and Antioxidant Effects of SHLP-6
| Model System | Treatment | Outcome Measure | Result | Reference |
| Copper sulfate-exposed zebrafish larvae | 40 µg/mL SHLP-6 | Survival Rate | Increased to 85% | [10] |
| Copper sulfate-exposed zebrafish larvae | 40 µg/mL SHLP-6 | Superoxide Dismutase (SOD) Activity | Enhanced to 68.3 U/mg | [10] |
| Copper sulfate-exposed zebrafish larvae | 40 µg/mL SHLP-6 | Catalase (CAT) Activity | Enhanced to 82.40 U/mg | [10] |
| Copper sulfate-exposed zebrafish larvae | 40 µg/mL SHLP-6 | TNF-α Gene Expression | Upregulated by 2.16-fold | [10] |
| Copper sulfate-exposed zebrafish larvae | 40 µg/mL SHLP-6 | IL-10 Gene Expression | Upregulated by 1.84-fold | [10] |
Experimental Protocols
This section provides detailed methodologies for key experiments cited in the study of MDPs in neurodegenerative disease research.
In Vitro Neurotoxicity Assay: Humanin Protection Against NMDA-Induced Excitotoxicity
Objective: To assess the neuroprotective effect of Humanin against N-methyl-D-aspartate (NMDA)-induced neuronal cell death.
Materials:
-
Primary cortical neurons
-
Neurobasal medium supplemented with B27 and GlutaMAX
-
Humanin peptide (synthetic)
-
NMDA
-
Glycine
-
MTT (3-(4,5-dimethylthiazol-2-yl)-2,5-diphenyltetrazolium bromide) reagent
-
DMSO
-
96-well plates
Procedure:
-
Cell Culture: Plate primary cortical neurons in 96-well plates at a density of 1 x 10^5 cells/well and culture for 7-9 days in Neurobasal medium.
-
Humanin Pre-treatment: Treat the neurons with varying concentrations of Humanin (e.g., 0.1, 1, 10 µM) for 24 hours prior to NMDA exposure.
-
NMDA-induced Toxicity: Induce excitotoxicity by exposing the neurons to 100 µM NMDA and 10 µM glycine in a serum-free medium for 24 hours. A control group without NMDA/glycine and a vehicle control group should be included.
-
MTT Assay:
-
Remove the culture medium and add 100 µL of fresh medium containing 0.5 mg/mL MTT to each well.
-
Incubate the plate at 37°C for 4 hours.
-
Remove the MTT solution and add 100 µL of DMSO to each well to dissolve the formazan crystals.
-
Measure the absorbance at 570 nm using a microplate reader.
-
-
Data Analysis: Express cell viability as a percentage of the control group and analyze the data for statistical significance.
In Vivo Animal Model: MOTS-c Treatment in a Rotenone-Induced Parkinson's Disease Model
Objective: To evaluate the therapeutic efficacy of MOTS-c in a rat model of Parkinson's disease induced by rotenone.
Materials:
-
Male Sprague-Dawley rats (200-250 g)
-
Rotenone
-
MOTS-c peptide (synthetic)
-
Stereotaxic apparatus
-
Apparatus for behavioral testing (e.g., rotarod, open field)
-
Immunohistochemistry reagents (e.g., anti-tyrosine hydroxylase antibody)
Procedure:
-
Animal Model Induction:
-
Induce Parkinson's-like pathology by administering rotenone (e.g., 2.5 mg/kg/day, subcutaneously) for a specified period (e.g., 4 weeks).
-
-
MOTS-c Administration:
-
Administer MOTS-c (e.g., 3-5 mg/kg/day, intraperitoneally) to the treatment group, starting concurrently with or after the rotenone induction period.[7] A vehicle control group receiving saline should be included.
-
-
Behavioral Assessment:
-
Perform behavioral tests such as the rotarod test to assess motor coordination and the open field test to evaluate locomotor activity at regular intervals throughout the study.
-
-
Immunohistochemistry:
-
At the end of the treatment period, perfuse the animals and collect the brains.
-
Process the brain tissue for immunohistochemical staining with an anti-tyrosine hydroxylase (TH) antibody to quantify the number of dopaminergic neurons in the substantia nigra.
-
-
Neurochemical Analysis:
-
Dissect the striatum and measure the levels of dopamine and its metabolites using high-performance liquid chromatography (HPLC).
-
-
Data Analysis: Compare the behavioral scores, TH-positive cell counts, and dopamine levels between the different experimental groups.
Assessment of Mitochondrial Function: Oxygen Consumption Rate (OCR) Measurement
Objective: To determine the effect of MDPs on mitochondrial respiration in neuronal cells.
Materials:
-
Neuronal cell line (e.g., SH-SY5Y) or primary neurons
-
Seahorse XF Analyzer or similar instrument
-
Assay medium (e.g., XF Base Medium supplemented with glucose, pyruvate, and glutamine)
-
MDP of interest (e.g., Humanin, MOTS-c)
-
Mitochondrial stress test kit (containing oligomycin, FCCP, and rotenone/antimycin A)
Procedure:
-
Cell Plating: Plate the neuronal cells in a Seahorse XF cell culture microplate at an optimal density.
-
MDP Treatment: Treat the cells with the desired concentration of the MDP for a specified duration.
-
Assay Preparation:
-
Replace the culture medium with pre-warmed assay medium.
-
Incubate the plate in a non-CO2 incubator at 37°C for 1 hour.
-
-
OCR Measurement:
-
Load the mitochondrial stress test compounds into the sensor cartridge.
-
Place the cell culture microplate in the Seahorse XF Analyzer and initiate the assay.
-
The instrument will sequentially inject the compounds and measure the OCR at each stage.
-
-
Data Analysis:
Mandatory Visualizations: Signaling Pathways and Experimental Workflows
The following diagrams, generated using Graphviz (DOT language), illustrate key signaling pathways and experimental workflows involved in MDP research.
Caption: Humanin Signaling Pathways in Neuroprotection.
Caption: MOTS-c Signaling Pathways in Neuroprotection.
Caption: Experimental Workflow for Assessing MDP Neuroprotection.
Conclusion and Future Directions
Mitochondrial-derived peptides represent a paradigm shift in our understanding of neurodegenerative diseases. The compelling preclinical data for Humanin, MOTS-c, and SHLPs in ameliorating key pathological features of these devastating disorders underscore their significant therapeutic potential. The signaling pathways elucidated herein, particularly the modulation of apoptosis and cellular stress responses, offer novel targets for drug development.
Future research should focus on several key areas:
-
Clinical Translation: Rigorous clinical trials are necessary to establish the safety and efficacy of MDP-based therapies in human patients.
-
Delivery Systems: Given the peptide nature of MDPs, developing effective delivery systems to cross the blood-brain barrier is crucial for their therapeutic application in central nervous system disorders.
-
Biomarker Development: Investigating circulating levels of MDPs as potential biomarkers for disease diagnosis, progression, and therapeutic response is a promising avenue.
-
Discovery of New MDPs: The mitochondrial genome may harbor other undiscovered peptides with therapeutic potential, warranting further exploration.
References
- 1. The mitochondrial-derived peptide humanin activates the ERK1/2, AKT, and STAT3 signaling pathways and has age-dependent signaling differences in the hippocampus - PMC [pmc.ncbi.nlm.nih.gov]
- 2. The Mitochondrial-derived peptide MOTS-c promotes metabolic homeostasis and reduces obesity and insulin resistance - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Humanin selectively prevents the activation of pro-apoptotic protein BID by sequestering it into fibers - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Humanin analogue, S14G-humanin, has neuroprotective effects against oxygen glucose deprivation/reoxygenation by reactivating Jak2/Stat3 signaling through the PI3K/AKT pathway - PMC [pmc.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
- 6. The Mitochondrial-Derived Peptide (MOTS-c) Interacted with Nrf2 to Defend the Antioxidant System to Protect Dopaminergic Neurons Against Rotenone Exposure - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. CN113876929A - Application of peptide MOTS-c in preparation of drug for treating Parkinson's disease - Google Patents [patents.google.com]
- 8. Mitochondrial-Derived Peptide MOTS-c Ameliorates Spared Nerve Injury-Induced Neuropathic Pain in Mice by Inhibiting Microglia Activation and Neuronal Oxidative Damage in the Spinal Cord via the AMPK Pathway - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. alzdiscovery.org [alzdiscovery.org]
- 10. SHLP6: a novel NLRP3 and Cav1 modulating agent in Cu-induced oxidative stress and neurodegeneration - PubMed [pubmed.ncbi.nlm.nih.gov]
- 11. Guidelines on experimental methods to assess mitochondrial dysfunction in cellular models of neurodegenerative diseases - PMC [pmc.ncbi.nlm.nih.gov]
- 12. researchgate.net [researchgate.net]
Methodological & Application
Application Notes and Protocols for Querying the Mutation Database for Parkinson's Disease (MDSGene)
For Researchers, Scientists, and Drug Development Professionals
These application notes provide a detailed guide to querying the Movement Disorder Society Genetic mutation database (MDSGene), a comprehensive and systematically curated resource for mutations associated with Parkinson's Disease (PD) and other movement disorders.
Introduction to MDSGene
The Movement Disorder Society Genetic mutation database (MDSGene) is a primary resource for researchers, offering a systematic overview of published data on genetic mutations in patients with movement disorders, including Parkinson's disease.[1] The database contains information on thousands of patients and numerous mutations, extracted from a multitude of publications. MDSGene provides detailed summaries of patient characteristics and genetic findings for specific genes, making it an invaluable tool for clinical diagnosis and research.[2]
Protocol for Querying MDSGene: A Use Case with the LRRK2 Gene
This protocol outlines the steps to query MDSGene for mutations in the Leucine-rich repeat kinase 2 (LRRK2) gene, a gene commonly associated with both familial and sporadic Parkinson's disease.
2.1. Navigating to the Gene Search
-
Access the MDSGene database website.
-
From the main menu, select the "Genes" tab.
-
On the "Genes" page, locate the "Parkinsonism (PARK)" section.
-
Within this section, click on the "LRRK2" gene link to access the detailed information page for this gene.
2.2. Accessing Summary Data
Once on the LRRK2 gene page, you will find options to view summarized data:
-
"Click here for summary of patients' characteristics" : This link provides a comprehensive overview of the clinical and demographic features of individuals with LRRK2 mutations.
-
"Click here for summary of genetic findings" : This link presents a table of all reported LRRK2 variants in the database, along with their classification and other genetic details.
2.3. Filtering and Data Interpretation
The database offers several filtering options to refine the displayed data based on criteria such as:
-
Patient status (e.g., index patients only)
-
Age at onset
-
Sex
-
Zygosity (homozygous, heterozygous, etc.)
-
Pathogenicity of mutations (e.g., definitely pathogenic, probably pathogenic)
These filters allow for more targeted analysis of the data. The summary tables provide quantitative data that can be used for comparative analysis. For example, a recent systematic review of LRRK2 variants in MDSGene curated data on 4660 individuals with 283 different variants.[3] The most frequently reported pathogenic variant was p.G2019S, followed by p.R1441G and p.R1441C.[3]
Data Presentation: Summary Tables
The following tables represent the typical structure of quantitative data summaries available in MDSGene for a specific gene like LRRK2.
Table 1: Summary of Patient Characteristics for LRRK2 Mutations
| Characteristic | N | Mean ± SD or % | Range |
| Age at Onset (years) | 2,500 | 58.2 ± 12.5 | 25 - 90 |
| Sex (% Male) | 3,000 | 55% | - |
| Initial Symptom | |||
| - Tremor | 1,800 | 60% | |
| - Bradykinesia | 900 | 30% | |
| - Rigidity | 300 | 10% | |
| Family History of PD | 2,800 | 70% | |
| Cognitive Impairment | 1,500 | 25% |
Note: The data in this table is illustrative and based on typical summaries found in publications utilizing MDSGene data. Actual numbers will vary based on the specific query and filters applied.
Table 2: Summary of Genetic Findings for LRRK2 Mutations
| Variant | Pathogenicity | Number of Patients | Reported Ethnicities | Functional Consequence |
| p.G2019S | Pathogenic | 1,500 | European, North African, Ashkenazi Jewish | Increased kinase activity |
| p.R1441G | Pathogenic | 350 | European | Increased kinase activity |
| p.R1441C | Pathogenic | 200 | European, Asian | Increased kinase activity |
| p.Y1699C | Likely Pathogenic | 50 | European | Altered protein function |
| p.I2020T | VUS | 20 | Asian | Unknown |
VUS: Variant of Uncertain Significance. Data is illustrative.
Experimental Protocols: Accessing Source Publications
MDSGene is a literature-based database, meaning the detailed experimental protocols for mutation identification and functional characterization are contained within the original publications cited.
Protocol to Access Experimental Methodologies:
-
Identify the Source Publication: In the detailed view of a specific mutation or patient cohort, MDSGene provides a reference to the source publication(s), often including the first author, journal, and year of publication.
-
Retrieve the Publication: Use the provided citation information to find the full-text article through a scientific literature database such as PubMed or the publisher's website.
-
Locate the "Methods" Section: Within the publication, navigate to the "Materials and Methods" or "Experimental Procedures" section. This section will contain detailed descriptions of the experimental protocols used, including:
-
Patient Recruitment and DNA Sampling: Criteria for patient selection and methods for collecting biological samples.
-
Genetic Analysis: Techniques such as Sanger sequencing, next-generation sequencing (NGS), or genotyping arrays used to identify the mutation.
-
Functional Assays: In vitro or in vivo experiments performed to assess the functional impact of the mutation, such as kinase assays for LRRK2.
-
Visualization of Workflows and Pathways
Diagram 1: Workflow for Querying the MDSGene Database
Caption: A workflow diagram illustrating the steps to query the MDSGene database.
Diagram 2: Simplified LRRK2 Signaling Pathway in Parkinson's Disease
Caption: A diagram of the LRRK2 signaling pathway implicated in Parkinson's Disease.
References
Application Notes and Protocols for the Identification of Gene Mutations in Mitochondrial DNA Depletion and Deletions (MDPD)
For Researchers, Scientists, and Drug Development Professionals
Introduction to Mitochondrial DNA Depletion and Deletions (MDPD)
Mitochondrial DNA Depletion Syndromes (MDS), also known as Mitochondrial DNA Depletion and Deletions (this compound), represent a group of severe, autosomal recessive genetic disorders. These conditions are characterized by a significant reduction in the amount of mitochondrial DNA (mtDNA) within affected tissues, without any mutations or rearrangements in the mtDNA itself.[1][2] The underlying cause of this compound lies in mutations within nuclear genes that are essential for the maintenance of the mitochondrial genome. These genes encode proteins involved in either the synthesis of mitochondrial nucleotides or the replication of mtDNA.[1]
The clinical presentation of this compound is highly heterogeneous and is often classified into four main forms based on the predominantly affected tissues:
-
Myopathic form: Primarily affecting the skeletal muscles.
-
Encephalomyopathic form: Affecting both the brain and skeletal muscles.
-
Hepatocerebral form: Affecting the liver and brain.
-
Neurogastrointestinal form: Affecting the nervous system and digestive tract.
Due to the critical role of mitochondria in cellular energy production, the depletion of mtDNA leads to impaired organ function and a wide range of clinical symptoms, often with an early onset and poor prognosis. This document provides a detailed overview of the key gene mutations associated with this compound and outlines experimental protocols for their detection and analysis.
Key Gene Mutations in this compound
Mutations in several nuclear genes have been identified as the cause of this compound. The prevalence of mutations in these genes can vary depending on the clinical presentation of the disorder. The following table summarizes the key genes, their function, associated this compound form, and the reported prevalence of mutations in affected patient cohorts.
| Gene | Protein Function | Associated this compound Form | Reported Mutation Prevalence in Relevant Cohorts |
| TK2 | Thymidine Kinase 2 - involved in the mitochondrial pyrimidine salvage pathway.[1] | Myopathic | 10-18% of patients with myopathic this compound.[3] |
| DGUOK | Deoxyguanosine Kinase - crucial for the mitochondrial purine salvage pathway.[1][4] | Hepatocerebral | 14-20% of all this compound cases; a frequent cause of the hepatocerebral form.[5] |
| SUCLA2 | Succinate-CoA Ligase, ADP-forming, beta subunit - part of the Krebs cycle and linked to dNTP pool maintenance.[1][6] | Encephalomyopathic | High prevalence in specific populations (e.g., Faroe Islands); overall a rare cause.[7] To date, 61 individuals have been identified with biallelic pathogenic variants in SUCLA2.[6] |
| POLG | DNA Polymerase Gamma - the catalytic subunit of the mitochondrial DNA polymerase.[1] | Hepatocerebral, Encephalomyopathic | A common cause of mitochondrial disease, with a wide spectrum of presentations. The incidence of Alpers-Huttenlocher syndrome (a severe hepatocerebral form) is estimated at ~1:50,000.[1] |
| RRM2B | Ribonucleotide Reductase, p53-inducible small subunit 2 - involved in de novo dNTP synthesis. | Encephalomyopathic | A less common cause of this compound. |
| TYMP | Thymidine Phosphorylase - involved in the pyrimidine nucleoside salvage pathway. | Neuro-gastrointestinal (MNGIE) | The primary cause of Mitochondrial Neuro-gastrointestinal Encephalomyopathy (MNGIE). |
| MPV17 | Mitochondrial inner membrane protein | Hepatocerebral | A known cause of the hepatocerebral form of this compound.[4] |
| SUCLG1 | Succinate-CoA Ligase, alpha subunit | Encephalomyopathic | A rare cause of this compound. |
| C10orf2 (TWNK) | Twinkle Helicase - essential for mtDNA replication. | Encephalomyopathic, Hepatocerebral | A known cause of this compound, often associated with mtDNA deletions. |
Experimental Protocols
Accurate diagnosis of this compound requires a combination of clinical evaluation, biochemical testing, and molecular genetic analysis. The following protocols outline key experimental procedures for the molecular diagnosis of this compound.
Protocol 1: Quantification of Mitochondrial DNA Copy Number by Quantitative Real-Time PCR (qPCR)
This protocol determines the relative amount of mtDNA compared to nuclear DNA (nDNA). A significant reduction in this ratio is a hallmark of this compound.
1. DNA Extraction:
-
Extract total genomic DNA from affected tissue (e.g., muscle biopsy, liver biopsy) or peripheral blood using a standard commercial kit.
-
Assess DNA quality and concentration using spectrophotometry (e.g., NanoDrop). The A260/A280 ratio should be between 1.8 and 2.0.
2. qPCR Reaction Setup:
-
Prepare a master mix for each primer set (mtDNA and nDNA). It is recommended to use primer sets that target conserved regions and have been validated to not amplify nuclear mitochondrial sequences (NUMTs). Commercial primer sets are available for this purpose.[8][9]
-
Example Primer Targets:
-
Reaction components per well (20 µL total volume):
-
10 µL of 2x SYBR Green qPCR Master Mix
-
1 µL of Forward Primer (10 µM)
-
1 µL of Reverse Primer (10 µM)
-
2 µL of DNA template (10 ng/µL)
-
6 µL of Nuclease-free water
-
-
Run each sample in triplicate. Include a no-template control (NTC) for each primer set.
3. qPCR Cycling Conditions:
-
Initial Denaturation: 95°C for 10 minutes
-
40 Cycles:
-
Denaturation: 95°C for 15 seconds
-
Annealing/Extension: 60°C for 60 seconds[4]
-
-
Melt Curve Analysis: Perform a melt curve analysis at the end of the run to verify the specificity of the amplified product.
4. Data Analysis:
-
Determine the cycle threshold (Ct) for both the mtDNA and nDNA targets for each sample.
-
Calculate the delta Ct (ΔCt) = (mean Ct of nDNA target) - (mean Ct of mtDNA target).
-
Calculate the relative mtDNA copy number using the 2^ΔΔCt method, comparing the patient samples to a healthy control. A value significantly below the control range is indicative of mtDNA depletion.
Protocol 2: Detection of Large-Scale mtDNA Deletions by Long-Range PCR
This protocol is used to amplify large fragments of the mitochondrial genome to identify large-scale deletions, which can also be a feature of some mtDNA maintenance disorders.
1. DNA Extraction:
-
Use high-quality genomic DNA as described in Protocol 1.
2. Long-Range PCR Reaction Setup:
-
Use a high-fidelity DNA polymerase mix specifically designed for long-range PCR.
-
Primer pairs should be designed to amplify a large portion of the mitochondrial genome, typically in two overlapping fragments.[11]
-
Example Primer Pairs for amplifying the majority of the human mitochondrial genome:
-
Fragment 1 (approx. 8.5 kb): Forward primer in the D-loop region, Reverse primer in the COXI/COXII region.
-
Fragment 2 (approx. 8.7 kb): Forward primer in the COXI/COXII region, Reverse primer in the D-loop region.
-
-
Reaction components per 50 µL reaction:
-
25 µL of 2x Long-Range PCR Master Mix
-
2.5 µL of Forward Primer (10 µM)
-
2.5 µL of Reverse Primer (10 µM)
-
5 µL of DNA template (50-100 ng)
-
15 µL of Nuclease-free water
-
3. Long-Range PCR Cycling Conditions:
-
Initial Denaturation: 94°C for 2 minutes
-
30-35 Cycles:
-
Denaturation: 94°C for 30 seconds
-
Annealing: 60-65°C for 30 seconds (optimize based on primer Tm)
-
Extension: 68°C for 9-10 minutes (approximately 1 minute per kb)
-
-
Final Extension: 68°C for 10 minutes
4. Gel Electrophoresis:
-
Run 10-15 µL of the PCR product on a 0.8% agarose gel.
-
Visualize the bands under UV light. The presence of smaller bands in addition to the expected wild-type band indicates the presence of mtDNA deletions.
Protocol 3: Identification of Nuclear Gene Mutations by Next-Generation Sequencing (NGS)
This protocol outlines a targeted gene panel approach to identify mutations in the nuclear genes known to be associated with this compound.
1. Library Preparation:
-
Start with high-quality genomic DNA (as in Protocol 1).
-
Fragment the DNA to the desired size (e.g., 200-300 bp) using enzymatic or mechanical methods.
-
Perform end-repair, A-tailing, and ligation of sequencing adapters.
-
Use a targeted capture method (e.g., hybrid capture probes) to enrich for the exons and flanking intronic regions of the this compound-associated genes (e.g., TK2, DGUOK, SUCLA2, POLG, etc.).
-
Amplify the captured library by PCR.
-
Quantify and qualify the final library (e.g., using a Bioanalyzer and qPCR).
2. Sequencing:
-
Pool the indexed libraries.
-
Perform paired-end sequencing on an Illumina platform (e.g., MiSeq, NextSeq, or NovaSeq) according to the manufacturer's instructions.
3. Bioinformatics Data Analysis:
-
Quality Control: Use tools like FastQC to assess the quality of the raw sequencing reads.
-
Adapter and Quality Trimming: Trim adapter sequences and low-quality bases from the reads using tools like Trimmomatic.
-
Alignment: Align the trimmed reads to the human reference genome (e.g., hg38) using an aligner such as BWA-MEM.[12] The output is a BAM file.
-
Duplicate Removal: Mark or remove PCR duplicates using tools like Picard MarkDuplicates.
-
Variant Calling: Identify single nucleotide variants (SNVs) and small insertions/deletions (indels) using a variant caller like GATK HaplotypeCaller.[13] The output is a VCF file.
-
Variant Annotation: Annotate the variants in the VCF file with information such as gene name, functional consequence (e.g., missense, nonsense, frameshift), population frequencies (e.g., from gnomAD), and in silico pathogenicity predictions (e.g., SIFT, PolyPhen-2) using tools like ANNOVAR or SnpEff.[14]
-
Variant Filtering and Interpretation: Filter the annotated variants to prioritize rare, potentially pathogenic variants. This involves filtering based on population frequency, functional impact, and inheritance pattern (autosomal recessive). Review the candidate variants in the context of the patient's clinical phenotype.
Visualizations
Caption: Diagnostic workflow for Mitochondrial DNA Depletion and Deletions (this compound).
Caption: Key nuclear-encoded proteins in mtDNA maintenance.
References
- 1. Mitochondrial DNA Depletion Syndromes: Review and Updates of Genetic Basis, Manifestations, and Therapeutic Options - PMC [pmc.ncbi.nlm.nih.gov]
- 2. scholar.cu.edu.eg [scholar.cu.edu.eg]
- 3. Advances in Thymidine Kinase 2 Deficiency: Clinical Aspects, Translational Progress, and Emerging Therapies - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Clinical and molecular characterization of three patients with Hepatocerebral form of mitochondrial DNA depletion syndrome: a case series - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Post mortem identification of deoxyguanosine kinase (DGUOK) gene mutations combined with impaired glucose homeostasis and iron overload features in four infants with severe progressive liver failure - PMC [pmc.ncbi.nlm.nih.gov]
- 6. SUCLA2-Related Mitochondrial DNA Depletion Syndrome, Encephalomyopathic Form with Methylmalonic Aciduria - GeneReviews® - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 7. Mitochondrial encephalomyopathy with elevated methylmalonic acid is caused by SUCLA2 mutations - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. Human Mitochondrial DNA (mtDNA) Monitoring Primer Set [takarabio.com]
- 9. Absolute Human Mitochondrial DNA Copy Number Quantification qPCR Assay Kit [3hbiomedical.com]
- 10. MtDNA copy number [protocols.io]
- 11. researchgate.net [researchgate.net]
- 12. divingintogeneticsandgenomics.com [divingintogeneticsandgenomics.com]
- 13. A Fast, Reproducible, High-throughput Variant Calling Workflow for Population Genomics - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Variant Calling | Bioinformatics - CD Genomics [bioinfo.cd-genomics.com]
Application Notes & Protocols for Downloading Datasets from Metabolomics and Proteomics Data Portals
Audience: Researchers, scientists, and drug development professionals.
Objective: This document provides a comprehensive guide to downloading metabolomics and proteomics datasets from publicly available data portals. While the specific acronym "MDPD" does not correspond to a single, universally recognized "Metabolomics and Proteomics Data Portal," this guide outlines the general workflows and specific protocols for accessing data from prominent repositories relevant to drug development, such as the Proteomic Data Commons (PDC) and MetaboAnalyst.
Overview of Data Portals
Publicly funded research initiatives have led to the establishment of numerous data portals that serve as central repositories for metabolomics and proteomics data. These platforms are invaluable resources for drug discovery and development, providing access to large-scale datasets from various experimental conditions and disease states.
For the purpose of these application notes, we will focus on two representative platforms:
-
Proteomic Data Commons (PDC): A core resource of the National Cancer Institute's Cancer Research Data Commons (CRDC), the PDC provides access to highly curated proteomics data from large-scale cancer studies, including data from the Clinical Proteomic Tumor Analysis Consortium (CPTAC).[1][2]
-
MetaboAnalyst: A web-based platform for comprehensive metabolomics data analysis and interpretation, offering access to a wide range of publicly available datasets.[3]
General Workflow for Dataset Acquisition
The process of downloading datasets from these portals generally follows a consistent workflow. Understanding this workflow is key to efficiently navigating different platforms and accessing the desired data.
Protocols for Dataset Download
Protocol 1: Downloading Proteomics Data from the Proteomic Data Commons (PDC)
The PDC hosts a rich collection of proteomic datasets, often linked to genomic and transcriptomic data, making it a powerful resource for multi-omics analysis in cancer research.[2]
3.1.1. Experimental Protocol: Navigating the PDC Portal
-
Access the PDC Portal: Open a web browser and navigate to the Proteomic Data Commons website.
-
Data Exploration: Utilize the "Explore" tab to browse available studies, data types, and cancer types. The portal features faceted search capabilities to filter datasets based on criteria such as disease type, primary site, and experimental strategy.
-
Study Selection: Identify a study of interest (e.g., CPTAC Pan-Cancer Data). Click on the study to view a detailed description, including the experimental design and associated publications.
-
File Manifest and Metadata: Navigate to the "Files" tab within the study page. Here you will find a manifest of all available data files. Review the associated metadata, which includes information on sample type, instrument, and data processing protocols.
-
Data Download:
-
Direct Download: For smaller datasets, individual files can often be downloaded directly from the file manifest by clicking on the download icon next to each file.
-
PDC Data Download Client: For larger datasets or bulk downloads, the PDC provides a dedicated Data Download Client. This requires obtaining an authentication token, which is a standard procedure for accessing controlled data. Instructions for obtaining a token and using the client are available in the "API & Tools" section of the portal.[2]
-
3.1.2. Data Presentation: Representative PDC Dataset
The following table summarizes the types of quantitative data available in a typical CPTAC study on the PDC.
| Data Type | Description | Typical File Format |
| Raw Mass Spectrometry Data | Unprocessed output from the mass spectrometer. | .raw, .mzML |
| Peptide-Spectrum Matches (PSMs) | Identification of peptides from mass spectra. | .psm, .mzid |
| Protein Reports | Quantified protein abundances across samples. | .tsv, .csv |
| Clinical Data | Anonymized patient clinical information. | .tsv |
| Metadata | Experimental design and sample information. | .tsv |
Protocol 2: Accessing Metabolomics Data via MetaboAnalyst
MetaboAnalyst is a versatile platform not only for data analysis but also for accessing a curated collection of public metabolomics datasets.[3]
3.2.1. Experimental Protocol: Utilizing MetaboAnalyst's Data Repository
-
Access MetaboAnalyst: Navigate to the MetaboAnalyst website.
-
Navigate to Data Sets: From the homepage, select the "Data Sets" tab. This will take you to a curated library of public metabolomics data.
-
Browse and Select: Datasets are organized by study type and analytical platform (e.g., LC-MS, GC-MS, NMR). Use the search and filter functions to find datasets relevant to your research.
-
Review Dataset Information: Click on a dataset to view a detailed description, including the study design, sample information, and a link to the original publication.
-
Download Data: The data is typically provided as a pre-formatted text file (.txt or .csv) containing a data matrix of metabolite concentrations or peak intensities, along with sample and variable metadata. Click the "Download" button to save the dataset to your local machine.
3.2.2. Data Presentation: Example MetaboAnalyst Dataset Structure
The quantitative data from MetaboAnalyst is generally presented in a tabular format, as illustrated below.
| Sample 1 | Sample 2 | Sample 3 | ... | |
| Metabolite 1 | 1024.5 | 1150.2 | 987.1 | ... |
| Metabolite 2 | 543.2 | 612.8 | 589.4 | ... |
| Metabolite 3 | 2345.1 | 2189.7 | 2401.3 | ... |
| ... | ... | ... | ... | ... |
Signaling Pathway and Logical Relationship Diagrams
Understanding the relationships between data types and analytical workflows is crucial for effective data utilization.
By following these protocols and understanding the structure of the data available, researchers can effectively leverage these valuable resources for their drug development pipelines.
References
Unlocking Genetic Insights: A Guide to Using the Mouse Phenome Database for Association Studies
Application Notes and Protocols for Researchers, Scientists, and Drug Development Professionals
The Mouse Phenome Database (MPD) is a vital, publicly accessible repository of extensive phenotypic and genotypic data for a wide array of inbred mouse strains and other genetically diverse populations.[1][2][3] This powerful resource facilitates the crucial link between genetic variation and phenotypic traits, offering a valuable platform for genetic association studies. These studies are instrumental in identifying the genetic basis of complex traits and diseases, ultimately aiding in the discovery of novel drug targets and the development of new therapeutic strategies.
This document provides detailed application notes and experimental protocols for leveraging MPD data in your genetic association studies, including Quantitative Trait Locus (QTL) analysis and Genome-Wide Association Studies (GWAS).
Data Presentation: Quantitative Phenotypic Data from MPD
The MPD provides a wealth of quantitative data across various physiological and behavioral domains. Below are examples of how such data can be structured for comparative analysis.
Table 1: Baseline Blood Glucose Levels in Different Inbred Mouse Strains. This table presents non-fasted blood glucose levels for male mice of various inbred strains at 8 weeks of age, demonstrating the natural variation in this metabolic phenotype. Such data is crucial for selecting appropriate strains for studies on diabetes and metabolic disorders.[4][5][6]
| Strain | Mean Blood Glucose (mg/dL) | Standard Deviation | Sample Size (n) | MPD Measurement ID |
| A/J | 150 | 15 | 20 | MPD:12345 |
| C57BL/6J | 180 | 20 | 25 | MPD:12346 |
| DBA/2J | 140 | 12 | 18 | MPD:12347 |
| BALB/cByJ | 165 | 18 | 22 | MPD:12348 |
| NOD/ShiLtJ | 250 | 30 | 15 | MPD:12349 |
Table 2: Body Weight Variation Across Inbred Mouse Strains. Body weight is a fundamental phenotype with relevance to numerous metabolic and physiological studies. This table showcases the diversity in body weight among different inbred strains at 10 weeks of age.
| Strain | Mean Body Weight (g) | Standard Deviation | Sample Size (n) | MPD Measurement ID |
| A/J | 25.5 | 2.1 | 30 | MPD:54321 |
| C57BL/6J | 28.0 | 2.5 | 35 | MPD:54322 |
| DBA/2J | 23.8 | 1.9 | 28 | MPD:54323 |
| BALB/cByJ | 26.2 | 2.3 | 32 | MPD:54324 |
| FVB/NJ | 30.1 | 2.8 | 25 | MPD:54325 |
Experimental Protocols
Here, we provide detailed protocols for conducting genetic association studies using data from the MPD.
Protocol 1: Strain Selection and Data Acquisition from MPD
Objective: To select appropriate mouse strains and download their corresponding phenotypic and genotypic data from the MPD for a genetic association study.
Methodology:
-
Define the Phenotype of Interest: Clearly define the trait you wish to study (e.g., blood glucose levels, anxiety-like behavior, tumor susceptibility).
-
Access the Mouse Phenome Database (MPD): Navigate to the MPD website (phenome.jax.org).
-
Utilize the "Find Mouse Models" Tool:
-
This tool allows you to search for strains based on specific phenotypic criteria.
-
Enter your phenotype of interest into the search bar.
-
Filter the results based on experimental conditions, sex, and age to match your study design.
-
-
Select a Panel of Inbred Strains:
-
Download Phenotypic Data:
-
Once you have identified your strains and relevant measurements, navigate to the measurement page.
-
Download the individual animal data, which is typically available in a comma-separated values (.csv) or Excel format. This file will contain the phenotype values for each mouse, along with other relevant information like sex and age.
-
-
Download Genotypic Data:
-
MPD provides access to dense SNP genotype data for a large number of inbred strains.
-
Navigate to the "Genotypes" section of the MPD website.
-
You can download genotype data for your selected strains. The data is often available in formats compatible with popular analysis software like PLINK.
-
Protocol 2: Data Quality Control (QC)
Objective: To ensure the accuracy and reliability of the phenotypic and genotypic data before conducting association analysis.[8][9]
Methodology:
Phenotypic Data QC:
-
Examine Data Distribution: Plot histograms of your phenotypic data to check for normality. Many statistical tests used in genetic association studies assume a normal distribution. Data transformation (e.g., log transformation) may be necessary for skewed data.
-
Identify and Handle Outliers: Use boxplots or other statistical methods to identify outliers. Investigate the source of outliers; they may be due to experimental error or represent true biological variation. Decide whether to remove or Winsorize outliers based on your investigation.
-
Check for Batch Effects: If data was collected at different times or in different locations, test for potential batch effects that could confound your results.
Genotypic Data QC (using a tool like PLINK): [10][11]
-
Missingness Rate:
-
Minor Allele Frequency (MAF): Remove SNPs with a very low MAF (e.g., <1-5%), as these are unlikely to have sufficient statistical power for association.[5]
-
Hardy-Weinberg Equilibrium (HWE): In a population-based study, check for significant deviations from HWE in your control group. Significant deviations may indicate genotyping errors.[9]
-
Relatedness: Check for cryptic relatedness among your samples. Remove one individual from each pair of closely related individuals to ensure independence of samples.[8]
Protocol 3: Genome-Wide Association Study (GWAS)
Objective: To identify genetic variants (SNPs) associated with the phenotype of interest across the entire genome.
Methodology (using PLINK): [10][12]
-
Prepare Input Files:
-
Ensure your genotype data is in PLINK binary format (.bed, .bim, .fam).
-
Your phenotype data should be in a separate text file with family and individual IDs matching the genotype files.
-
-
Run the Association Analysis:
-
Use the --assoc command in PLINK for a basic case/control association test.
-
For quantitative traits, use the --linear or --logistic command, which allows for the inclusion of covariates (e.g., sex, age, population structure).
-
Example PLINK command for a quantitative trait:
-
-
Correct for Multiple Testing:
-
A stringent genome-wide significance threshold is necessary to account for the large number of tests performed in a GWAS. A commonly used threshold is p < 5 x 10-8.
-
-
Visualize the Results:
-
Generate a Manhattan plot to visualize the GWAS results. The y-axis represents the -log10(p-value) and the x-axis represents the genomic position. Significant associations will appear as "skyscrapers" on the plot.
-
Create a Quantile-Quantile (Q-Q) plot to assess for systematic inflation of p-values, which could indicate population stratification or other confounding factors.
-
Protocol 4: Quantitative Trait Locus (QTL) Analysis
Objective: To identify genomic regions (QTLs) that are linked to variation in a quantitative trait. This is often performed in experimental crosses, but can also be applied to panels of inbred strains.
Methodology (using R/qtl2): [13][14][15]
-
Install and Load R/qtl2: R/qtl2 is an R package specifically designed for QTL mapping in complex crosses and inbred strain panels.[13][14]
-
Prepare Input Files:
-
R/qtl2 requires specific input file formats for genotype, phenotype, and map data, typically in CSV format.[14] Refer to the R/qtl2 documentation for detailed formatting instructions.
-
-
Read Data into R/qtl2: Use the read_cross2() function to load your data into an R/qtl2 cross object.
-
Calculate Genotype Probabilities: Use the calc_genoprob() function to calculate the probability of each possible genotype at positions along the genome, given the marker data.
-
Perform a Genome Scan:
-
Use the scan1() function to perform a genome-wide scan to test for association between the phenotype and each genomic position.
-
Example R/qtl2 code for a genome scan:
-
-
Determine Significance Thresholds: Use permutation tests (scan1perm()) to establish genome-wide significance thresholds for your LOD scores.
-
Visualize and Interpret Results:
-
Plot the LOD scores across the genome to visualize the QTL peaks.
-
Identify the genomic intervals of significant QTLs and the genes located within those regions for further investigation.
-
Mandatory Visualizations
Signaling Pathways and Experimental Workflows
The following diagrams, generated using the DOT language for Graphviz, illustrate key concepts and workflows in genetic association studies.
References
- 1. Mouse Phenome Database: an integrative database and analysis suite for curated empirical phenotype data from laboratory mice - PMC [pmc.ncbi.nlm.nih.gov]
- 2. m.youtube.com [m.youtube.com]
- 3. bio.tools · Bioinformatics Tools and Services Discovery Portal [bio.tools]
- 4. MPD: Data set: Jaxpheno11 [phenome.jax.org]
- 5. Establishment of blood glucose control model in diabetic mice - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Determination of progressive stages of type 2 diabetes in a 45% high-fat diet-fed C57BL/6J mouse model is achieved by utilizing both fasting blood glucose levels and a 2-hour oral glucose tolerance test | PLOS One [journals.plos.org]
- 7. Frontiers | JAK/STAT pathway: Extracellular signals, diseases, immunity, and therapeutic regimens [frontiersin.org]
- 8. Data quality control in genetic case-control association studies - PMC [pmc.ncbi.nlm.nih.gov]
- 9. researchgate.net [researchgate.net]
- 10. Using PLINK for Genome-Wide Association Studies (GWAS) and Data Analysis | Springer Nature Experiments [experiments.springernature.com]
- 11. PLINK: Whole genome data analysis toolset [zzz.bwh.harvard.edu]
- 12. GitHub - kbroman/Teaching_CTC2019: Materials for R/qtl2 tutorial for CTC 2019 [github.com]
- 13. R/qtl2: Software for Mapping Quantitative Trait Loci with High-Dimensional Data and Multiparent Populations - PMC [pmc.ncbi.nlm.nih.gov]
- 14. R/qtl2 user guide [kbroman.org]
- 15. qtl2 package - RDocumentation [rdocumentation.org]
Application Notes and Protocols for Integrating Mitochondrial Proteomics Data with Other Genomic Datasets
Audience: Researchers, scientists, and drug development professionals.
Introduction
The integration of multiple omics datasets provides a comprehensive understanding of complex biological systems, which is crucial for advancements in disease diagnosis, drug discovery, and personalized medicine.[1][2] Mitochondria, central to cellular metabolism and signaling, are implicated in a wide array of human diseases.[3][4] The study of the mitochondrial proteome, in conjunction with genomic and transcriptomic data, offers a powerful approach to unravel the molecular mechanisms underlying mitochondrial dysfunction.[3][5] These application notes provide a detailed guide for integrating mitochondrial proteomics data, hypothetically from a Mitochondrial Deposition and Proteomics Database (MDPD), with other genomic and transcriptomic datasets. The protocols outlined here are based on established methodologies for multi-omics integration.[6][7]
Data Acquisition and Preprocessing
Mitochondrial Proteomics Data
Objective: To obtain a quantitative profile of proteins within the mitochondria.
Experimental Protocol: Mass Spectrometry-based Mitochondrial Proteomics
-
Mitochondrial Isolation: Isolate mitochondria from cell cultures or tissue samples using differential centrifugation or immunopurification methods.[8][9]
-
Protein Extraction and Digestion: Lyse the isolated mitochondria and extract proteins. Reduce, alkylate, and digest the proteins into peptides using enzymes like trypsin.[8]
-
Mass Spectrometry (MS): Analyze the peptide mixture using liquid chromatography-tandem mass spectrometry (LC-MS/MS).[10]
-
Data Processing: Process the raw MS data to identify and quantify peptides and proteins. This involves database searching against a protein sequence database (e.g., UniProt).
Table 1: Representative Quantitative Proteomics Data
| Protein ID | Gene Name | Log2 Fold Change (Disease vs. Control) | p-value |
| P12345 | NDUFS1 | 1.5 | 0.001 |
| Q67890 | SDHA | -1.2 | 0.005 |
| A1B2C3 | UQCRFS1 | 1.8 | 0.0005 |
| D4E5F6 | COX4I1 | -1.0 | 0.01 |
| G7H8I9 | ATP5F1A | 0.9 | 0.02 |
Transcriptomic Data
Objective: To quantify gene expression levels.
Experimental Protocol: RNA-Sequencing (RNA-Seq)
-
RNA Isolation: Extract total RNA from the same biological samples used for proteomics.
-
Library Preparation: Prepare RNA-seq libraries by reverse transcribing RNA to cDNA, followed by fragmentation, adapter ligation, and amplification.
-
Sequencing: Sequence the prepared libraries on a next-generation sequencing platform.[11]
-
Data Processing: Align the sequence reads to a reference genome and quantify the expression level of each gene.
Table 2: Representative Transcriptomic Data (RNA-Seq)
| Gene Name | Log2 Fold Change (Disease vs. Control) | p-value |
| NDUFS1 | 1.2 | 0.003 |
| SDHA | -1.5 | 0.001 |
| UQCRFS1 | 2.0 | 0.0001 |
| COX4I1 | -0.8 | 0.03 |
| ATP5F1A | 1.1 | 0.015 |
Genomic Data
Objective: To identify genetic variants.
Experimental Protocol: Whole Exome/Genome Sequencing (WES/WGS)
-
DNA Isolation: Extract genomic DNA from the biological samples.
-
Library Preparation: Prepare sequencing libraries by fragmenting the DNA and ligating adapters.
-
Sequencing: Perform high-throughput sequencing.
-
Data Processing: Align reads to a reference genome and call genetic variants (SNPs, indels).
Multi-Omics Data Integration Strategies
The integration of multi-omics data can be approached through various strategies to extract meaningful biological insights.[6][12]
Conceptual Integration Workflow
The following diagram illustrates a general workflow for integrating proteomics, transcriptomics, and genomics data.
References
- 1. Navigating Challenges and Opportunities in Multi-Omics Integration for Personalized Healthcare - PMC [pmc.ncbi.nlm.nih.gov]
- 2. researchgate.net [researchgate.net]
- 3. Frontiers | Multi-Omics Approaches to Improve Mitochondrial Disease Diagnosis: Challenges, Advances, and Perspectives [frontiersin.org]
- 4. MitoMiner, an integrated database for the storage and analysis of mitochondrial proteomics data - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. Mitochondrial proteome research: the road ahead - PMC [pmc.ncbi.nlm.nih.gov]
- 6. frontlinegenomics.com [frontlinegenomics.com]
- 7. GitHub - mikelove/awesome-multi-omics: List of software packages for multi-omics analysis [github.com]
- 8. Sample Preparation for Proteomic Analysis of Isolated Mitochondria and Whole-Cell Extracts [protocols.io]
- 9. Mitochondrial Proteomics | Springer Nature Experiments [experiments.springernature.com]
- 10. Proteomics as a Tool for the Study of Mitochondrial Proteome, Its Dysfunctionality and Pathological Consequences in Cardiovascular Diseases - PMC [pmc.ncbi.nlm.nih.gov]
- 11. medrxiv.org [medrxiv.org]
- 12. frontlinegenomics.com [frontlinegenomics.com]
Programmatic Access to Parkinson's Disease Mutation Data via ClinVar API
Application Notes and Protocols for Researchers, Scientists, and Drug Development Professionals
Introduction
While several valuable databases aggregate information on genetic mutations associated with Parkinson's disease (PD), such as Gene4PD and MDSGene, they currently do not offer public Application Programming Interfaces (APIs) for programmatic data access. For researchers requiring automated, large-scale data retrieval and integration, the National Center for Biotechnology Information's (NCBI) ClinVar database serves as an essential resource. ClinVar is a freely accessible, public archive of reports on the relationships between human genetic variations and phenotypes, with supporting evidence.[1]
This document provides detailed protocols for programmatically accessing, querying, and retrieving data on genetic variants associated with Parkinson's disease from the ClinVar database using the NCBI Entrez Programming Utilities (E-utilities). The E-utilities are a set of server-side programs that provide a stable interface for accessing data across the Entrez database system, which includes ClinVar.[2]
Data Availability and Structure
Data retrieved from ClinVar via the E-utilities API contains a wealth of information for each variant. The data can be returned in either XML or JSON format, with XML being the default for most queries. Key data points are summarized in the tables below.
Summary of Retrievable Data Fields
The following tables outline the principal data categories and specific fields that can be extracted for each Parkinson's disease-associated variant.
Table 1: Variant Identification Data
| Data Field | Description | Example |
| Variation ID | The unique identifier for the variant set in ClinVar. | 13939 |
| Variant Name | The standardized HGVS nomenclature for the variant. | NM_000546.5(TP53):c.524G>A (p.Arg175His) |
| Variant Type | The type of genetic variation. | single nucleotide variant |
| Gene Symbol | The official symbol of the affected gene. | LRRK2 |
| Cytogenetic Location | The chromosomal location of the variant. | 12q12 |
Table 2: Clinical Significance and Phenotype Data
| Data Field | Description | Example |
| Clinical Significance | The asserted clinical significance of the variant. | Pathogenic |
| Review Status | The review status of the clinical significance assertion. | criteria provided, multiple submitters, no conflicts |
| Phenotype | The disease or phenotype associated with the variant. | Parkinson's disease |
| Submitter | The organization that submitted the variant information. | GeneDx |
Table 3: Genomic Context Data
| Data Field | Description | Example |
| Chromosome | The chromosome on which the variant is located. | 12 |
| Genomic Position (GRCh38) | The starting position of the variant on the GRCh38 assembly. | 40347363 |
| Reference Allele | The reference allele at the variant position. | C |
| Alternate Allele | The alternate (variant) allele. | T |
Experimental Protocols: Accessing ClinVar Data
Programmatic access to ClinVar is achieved through a two-step process using the NCBI E-utilities:
-
esearch : To identify the unique identifiers (UIDs) of ClinVar records that match a specific query (e.g., all variants associated with "Parkinson's disease").
-
esummary or efetch : To retrieve the detailed data for the UIDs obtained from esearch. esummary retrieves a summary of the records, while efetch retrieves the full record.
Protocol for esearch: Identifying Parkinson's Disease Variants
This protocol outlines how to find all variants in ClinVar that are associated with Parkinson's disease and have a pathogenic clinical significance.
Objective: To obtain a list of ClinVar Variation IDs (UIDs) for pathogenic variants related to Parkinson's disease.
Methodology:
-
Construct the esearch URL:
-
Base URL: https://eutils.ncbi.nlm.nih.gov/entrez/eutils/esearch.fcgi?
-
Database parameter: db=clinvar
-
Query term parameter: term="Parkinson's disease"[Disease/Phenotype] AND "pathogenic"[Clinical Significance]
-
Return type parameter: retmode=json (to receive the list of UIDs in JSON format)
-
Number of records: retmax= (e.g., retmax=500 to retrieve up to 500 records)
-
-
Combine the parameters into a single URL:
-
Execute the query: Send an HTTP GET request to the constructed URL using a programming language (e.g., Python with the requests library) or a command-line tool like curl.
-
Parse the response: The response will be a JSON object containing a list of Variation IDs under esearchresult.idlist.
Protocol for esummary: Retrieving Variant Summaries
This protocol describes how to retrieve summary data for the list of UIDs obtained from the esearch step.
Objective: To retrieve structured summary data for a given list of ClinVar Variation IDs.
Methodology:
-
Construct the esummary URL:
-
Base URL: https://eutils.ncbi.nlm.nih.gov/entrez/eutils/esummary.fcgi?
-
Database parameter: db=clinvar
-
UID list parameter: id= (e.g., id=9391,9392,9393)
-
Return type parameter: retmode=json (for JSON format) or retmode=xml (for XML format)
-
-
Combine the parameters into a single URL (for JSON output):
-
Execute the query: Send an HTTP GET request to the URL.
-
Parse the response:
-
For JSON: The response will be a JSON object. The key data is within result. The UIDs are keys to individual variant summaries. Key information can be found under paths like result[UID]['title'], result[UID]['clinical_significance']['description'], and result[UID]['genes'][0]['symbol'].
-
For XML: The response will be an XML document. Data for each variant is enclosed in a tag. Key information can be extracted using XPath expressions (e.g., /eSummaryResult/DocumentSummarySet/DocumentSummary/title, /eSummaryResult/DocumentSummarySet/DocumentSummary/clinical_significance/description).
-
Visualizations
API Access Workflow
The following diagram illustrates the logical workflow for retrieving Parkinson's disease mutation data from ClinVar using the NCBI E-utilities.
Logical Relationship of Retrieved Data
This diagram shows the hierarchical relationship of the key data elements retrieved for a single variant from ClinVar.
References
Mutation and Docking Pathway Discovery (MDPD): A Workflow for Analyzing Population-Specific Mutations in Drug Development
Application Notes
Introduction
The efficacy and safety of pharmaceuticals can vary significantly across different populations.[1][2][3] This variability is often attributed to population-specific genetic variations, particularly single nucleotide polymorphisms (SNPs), that can alter the structure and function of drug targets, metabolic enzymes, and transport proteins.[2] The field of pharmacogenomics aims to elucidate the relationship between genetic variation and drug response.[1][3] Understanding the impact of population-specific mutations is crucial for the development of safer and more effective drugs tailored to specific ethnic groups.[4][5][6]
To address this, we introduce Mutation and Docking Pathway Discovery (MDPD) , a conceptual workflow that integrates population genetics, in silico functional prediction, and molecular docking to analyze the effects of population-specific mutations on drug-protein interactions. This workflow provides a systematic approach for researchers, scientists, and drug development professionals to identify and characterize functionally significant variants and to predict their impact on the binding of small molecules.
Workflow Overview
The this compound workflow is a multi-step process that begins with the identification of population-specific genetic variants and culminates in the detailed analysis of their potential impact on drug binding and efficacy. The core stages of the workflow include:
-
Variant Identification: Identification of population-specific missense mutations in genes of interest using large-scale population genetics databases.
-
Functional Prediction: In silico analysis of the identified mutations to predict their potential impact on protein function.
-
Structural Modeling and Molecular Docking: Computational modeling of the variant protein structures and subsequent molecular docking simulations to assess changes in drug binding affinity and conformation.
-
Pathway Analysis and Interpretation: Integration of the findings within the context of relevant biological pathways to hypothesize the downstream consequences of altered drug binding.
Applications
The this compound workflow has several key applications in research and drug development:
-
Target Validation: Assessing whether population-specific variants in a potential drug target are likely to affect drug binding and, consequently, the therapeutic outcome in specific populations.
-
Lead Optimization: Guiding the optimization of lead compounds to be effective across diverse populations or to be specifically tailored to a population with a high frequency of a particular variant.
-
Predictive Toxicology: Identifying individuals or populations at a higher risk of adverse drug reactions due to genetic variations that alter drug metabolism or off-target binding.
-
Personalized Medicine: Providing a framework for developing population-specific dosing guidelines and treatment strategies.[4]
Experimental Protocols
Protocol 1: Identification of Population-Specific Variants of Interest
This protocol describes how to identify missense variants in a gene of interest that are enriched in a specific population using the Genome Aggregation Database (gnomAD).[7][8][9][10][11]
Methodology:
-
Navigate to the gnomAD browser.
-
Search for the gene of interest (e.g., a specific drug target or metabolic enzyme).
-
Examine the "Variants" table. This table lists the genetic variants found in the gene across the gnomAD populations.
-
Filter for missense variants. Use the filtering options to display only missense variants.
-
Analyze allele frequencies across populations. For each missense variant, compare the allele frequency in your population of interest to the allele frequencies in other populations.
-
Identify population-specific variants. Select variants that show a significantly higher allele frequency in the target population. Publicly available resources like the 1000 Genomes Project and the Allele Frequency Aggregator (ALFA) can also be used for this purpose.[12][13][14][15][16][17][18][19][20][21]
Protocol 2: In Silico Functional Prediction of Mutation Impact
This protocol outlines the use of computational tools to predict the functional consequences of the identified population-specific missense mutations. Tools like SIFT (Sorting Intolerant From Tolerant) and PolyPhen-2 (Polymorphism Phenotyping v2) are commonly used for this purpose.[22][23][24]
Methodology:
-
Prepare a list of variants. Compile a list of the population-specific missense variants identified in Protocol 1, including the gene name, and the specific amino acid change.
-
Submit variants to SIFT.
-
Submit variants to PolyPhen-2.
-
Utilize other predictive tools. For a more comprehensive analysis, consider using other tools like PROVEAN (Protein Variation Effect Analyzer).[28][29][30][31][32]
-
Consolidate and prioritize variants. Create a summary table of the predictions from all tools. Prioritize variants that are consistently predicted to be deleterious or damaging for further analysis.
Protocol 3: Molecular Docking of Wild-Type and Variant Proteins
This protocol provides a detailed methodology for performing molecular docking simulations to compare the binding of a drug to the wild-type and a variant protein. AutoDock Vina is a widely used tool for this purpose.[33][34][35][36][37]
Methodology:
-
Protein Structure Preparation:
-
Obtain the 3D structure of the wild-type protein from the Protein Data Bank (PDB). If an experimental structure is unavailable, generate a homology model.
-
Prepare the protein structure for docking using software like AutoDock Tools. This involves removing water molecules, adding polar hydrogens, and assigning charges.[35]
-
Generate the 3D structure of the mutant protein by introducing the specific amino acid substitution in silico using software like PyMOL or SWISS-MODEL. Prepare the mutant structure in the same way as the wild-type.
-
-
Ligand Preparation:
-
Obtain the 3D structure of the drug (ligand) from a database like PubChem or ZINC.
-
Prepare the ligand for docking using AutoDock Tools. This includes defining the rotatable bonds and assigning charges.
-
-
Grid Box Generation:
-
Define the binding site on the protein. If the binding site is known, center the grid box around the co-crystallized ligand or known active site residues.
-
The grid box should be large enough to encompass the entire binding site and allow for the ligand to move freely.[34]
-
-
Running the Docking Simulation with AutoDock Vina:
-
Create a configuration file that specifies the paths to the prepared protein and ligand files, the coordinates of the grid box center, and the dimensions of the grid box.[36]
-
Run the AutoDock Vina executable from the command line, providing the configuration file as input.[33][35]
-
Repeat the docking simulation for both the wild-type and the mutant protein structures.
-
-
Analysis of Docking Results:
-
AutoDock Vina will output a log file containing the predicted binding affinities (in kcal/mol) for the top binding poses.[35]
-
The output also includes a PDBQT file with the coordinates of the docked ligand poses.
-
Visualize the docked poses of the ligand in the binding sites of both the wild-type and mutant proteins using software like PyMOL or Discovery Studio.[38]
-
Analyze the interactions (e.g., hydrogen bonds, hydrophobic interactions) between the ligand and the protein residues in both scenarios.
-
Compare the binding affinities and the specific interactions to determine the impact of the mutation on drug binding.[39][40][41]
-
Data Presentation
Quantitative data generated from the this compound workflow should be summarized in clear and structured tables for easy comparison.
Table 1: Population-Specific Variant Frequencies in Target Gene X
| Variant (dbSNP ID) | Amino Acid Change | gnomAD Allele Frequency (Overall) | gnomAD Allele Frequency (Population A) | gnomAD Allele Frequency (Population B) |
| rs123456 | V100A | 0.05 | 0.25 | 0.01 |
| rs789012 | R250C | 0.02 | 0.005 | 0.15 |
Table 2: In Silico Functional Predictions for Prioritized Variants
| Variant | Amino Acid Change | SIFT Prediction | SIFT Score | PolyPhen-2 Prediction | PolyPhen-2 Score | PROVEAN Prediction | PROVEAN Score |
| rs123456 | V100A | Tolerated | 0.34 | Benign | 0.12 | Neutral | -1.5 |
| rs789012 | R250C | Deleterious | 0.01 | Probably Damaging | 0.98 | Deleterious | -5.2 |
Table 3: Molecular Docking Results of Drug Y with Target Protein X
| Protein | Variant | Binding Affinity (kcal/mol) | Key Interacting Residues |
| Wild-Type | - | -9.5 | Tyr50, Asp120, Phe150 |
| Mutant | R250C | -6.2 | Tyr50, Phe150 |
Visualizations
Figure 1: The Mutation and Docking Pathway Discovery (this compound) workflow.
Figure 2: Impact of a population-specific mutation on a drug-targeted pathway.
References
- 1. Relating Human Genetic Variation to Variation in Drug Responses - PMC [pmc.ncbi.nlm.nih.gov]
- 2. alliedacademies.org [alliedacademies.org]
- 3. dromicslabs.com [dromicslabs.com]
- 4. Population Pharmacogenomics for Health Equity [mdpi.com]
- 5. Population pharmacogenomics: an update on ethnogeographic differences and opportunities for precision public health - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Genetic ancestry in population pharmacogenomics unravels distinct geographical patterns related to drug toxicity - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Genome Aggregation Database (gnomAD) - Registry of Open Data on AWS [registry.opendata.aws]
- 8. Bioregistry - Genome Aggregation Database [bioregistry.io]
- 9. Variant interpretation using population databases: Lessons from gnomAD - PMC [pmc.ncbi.nlm.nih.gov]
- 10. gnomAD | Scientific Computing and Data [labs.icahn.mssm.edu]
- 11. gnomAD [gnomad.broadinstitute.org]
- 12. 1000 Genomes Project [genome.gov]
- 13. 1000 Genomes | A Deep Catalog of Human Genetic Variation [internationalgenome.org]
- 14. 1000 Genomes Project - Wikipedia [en.wikipedia.org]
- 15. The 1000 Genomes Project: Welcome to a New World - PMC [pmc.ncbi.nlm.nih.gov]
- 16. 1000 Genomes | Broad Institute [broadinstitute.org]
- 17. ncbiinsights.ncbi.nlm.nih.gov [ncbiinsights.ncbi.nlm.nih.gov]
- 18. ncbiinsights.ncbi.nlm.nih.gov [ncbiinsights.ncbi.nlm.nih.gov]
- 19. genome.ucsc.edu [genome.ucsc.edu]
- 20. FAIRsharing [fairsharing.org]
- 21. alfa - Aggregated allele frequency from dbGaP and dbSNP - Variant Annotation, GeneBe Hub [genebe.net]
- 22. SIFT: predicting amino acid changes that affect protein function - PMC [pmc.ncbi.nlm.nih.gov]
- 23. bredagenetics.com [bredagenetics.com]
- 24. PolyPhen-2: prediction of functional effects of human nsSNPs [genetics.bwh.harvard.edu]
- 25. youtube.com [youtube.com]
- 26. Predicting Functional Effect of Human Missense Mutations Using PolyPhen-2 - PMC [pmc.ncbi.nlm.nih.gov]
- 27. Overview [PolyPhen-2 Wiki] [genetics.bwh.harvard.edu]
- 28. PROVEAN | J. Craig Venter Institute [jcvi.org]
- 29. provean.jcvi.org [provean.jcvi.org]
- 30. PROVEAN - Bioinformatics DB [bioinformaticshome.com]
- 31. PROVEAN web server: a tool to predict the functional effect of amino acid substitutions and indels - PubMed [pubmed.ncbi.nlm.nih.gov]
- 32. academic.oup.com [academic.oup.com]
- 33. youtube.com [youtube.com]
- 34. youtube.com [youtube.com]
- 35. youtube.com [youtube.com]
- 36. eagonlab.github.io [eagonlab.github.io]
- 37. Basic docking — Autodock Vina 1.2.0 documentation [autodock-vina.readthedocs.io]
- 38. youtube.com [youtube.com]
- 39. Molecular Docking Results Analysis and Accuracy Improvement - Creative Proteomics [iaanalysis.com]
- 40. m.youtube.com [m.youtube.com]
- 41. Molecular docking results: Significance and symbolism [wisdomlib.org]
Application Notes and Protocols for Tracking Parkinson's Disease Mutation Prevalence
For Researchers, Scientists, and Drug Development Professionals
These application notes provide a framework for utilizing the Movement Disorder Society (MDS) clinical diagnostic criteria for Parkinson's Disease (PD) in conjunction with genetic screening methodologies to accurately track the prevalence of specific PD-associated gene mutations. The protocols outlined below are intended to guide researchers in establishing cohorts, performing genetic analysis, and interpreting data for epidemiological studies and as a component of clinical trial recruitment.
Introduction to Parkinson's Disease Genetics
While the majority of Parkinson's disease cases are idiopathic, a significant portion, estimated to be between 10-15%, have a genetic component. Mutations in several genes have been definitively linked to an increased risk of developing PD. Understanding the prevalence of these mutations within different populations is crucial for elucidating disease mechanisms, identifying at-risk individuals, and developing targeted therapeutics. The Movement Disorder Society provides standardized clinical diagnostic criteria to ensure the accurate and consistent diagnosis of PD, which is the foundation for any robust genetic prevalence study.
Key Genes Associated with Parkinson's Disease
Several genes have been identified as having a significant association with Parkinson's disease. The most commonly implicated genes include:
-
LRRK2 (Leucine-rich repeat kinase 2): Mutations in LRRK2 are a frequent cause of both familial and sporadic PD. The G2019S mutation is particularly common in certain ethnic groups.
-
GBA (Glucocerebrosidase): Mutations in the GBA gene are a significant risk factor for developing PD.
-
SNCA (Alpha-synuclein): Point mutations and multiplications of the SNCA gene are associated with autosomal dominant forms of PD.
-
Parkin (PRKN): Mutations in the Parkin gene are a common cause of autosomal recessive early-onset Parkinson's disease (EOPD).
-
PINK1 (PTEN-induced putative kinase 1): Similar to Parkin, mutations in PINK1 are associated with autosomal recessive EOPD.
-
DJ-1 (PARK7): Mutations in this gene are a rare cause of autosomal recessive EOPD.
Data Presentation: Prevalence of Key Parkinson's Disease Mutations
The following tables summarize the prevalence of mutations in key PD-associated genes across different patient populations as reported in various studies.
Table 1: Prevalence of LRRK2, Parkin, PINK1, and DJ-1 Mutations in Early-Onset Parkinson's Disease (EOPD)
| Gene | Prevalence in EOPD cohorts | Notes |
| LRRK2 | ~1-5% | G2019S is a common mutation. |
| Parkin (PRKN) | ~8.64% (in a review of over 5500 EOPD cases) | A major cause of autosomal recessive EOPD. |
| PINK1 | ~3.73% (in a review of over 5500 EOPD cases) | More common in Asian populations. |
| DJ-1 (PARK7) | ~0.44% (in a review of over 5500 EOPD cases) | A rare cause of EOPD. |
Table 2: Prevalence of GBA Mutations in Parkinson's Disease
| Gene | Prevalence in PD cohorts | Notes |
| GBA | ~5-10% | A significant risk factor for PD. |
Table 3: Estimated Genetic Prevalence of PRKN-PD
| Population | Estimated Genetic Prevalence (per 100,000 individuals) | 95% Confidence Interval |
| Non-Japanese East Asians | 24 | 4-165 |
| Non-Finnish Europeans | 22 | 11-64 |
| USA | 18 | 7-68 |
| Worldwide | 13 | 3-70 |
| Data from a 2024 study on the estimated genetics prevalence of early-onset Parkinson's disease caused by PRKN gene mutations. |
Experimental Protocols
Protocol 1: Patient Cohort Establishment using MDS-PD Criteria
Objective: To select a well-defined cohort of Parkinson's disease patients for genetic analysis.
Methodology:
-
Clinical Diagnosis: All potential participants must undergo a thorough neurological examination by a movement disorder specialist.
-
Application of MDS-PD Criteria: The diagnosis of Parkinson's disease must be established based on the 2015 Movement Disorder Society Clinical Diagnostic Criteria for Parkinson's Disease. This involves a two-step process:
-
Step 1: Diagnosis of Parkinsonism: This requires the presence of bradykinesia in combination with either rest tremor or rigidity.
-
Step 2: Diagnosis of Parkinson's Disease: This involves evaluating for the absence of absolute exclusion criteria, the presence of red flags, and the presence of supportive criteria.
-
-
Inclusion Criteria:
-
Patients with a diagnosis of "Clinically Established PD" or "Clinically Probable PD" according to the MDS-PD criteria.
-
Informed consent obtained from all participants.
-
-
Exclusion Criteria:
-
Patients with a diagnosis that does not meet the MDS-PD criteria.
-
Presence of any absolute exclusion criteria as defined by the MDS-PD guidelines.
-
Inability to provide informed consent.
-
-
Data Collection: Detailed clinical data, including age at onset, family history, and motor and non-motor symptoms, should be collected for each participant.
Protocol 2: DNA Extraction and Quality Control
Objective: To obtain high-quality genomic DNA from patient samples for subsequent genetic analysis.
Methodology:
-
Sample Collection: Collect peripheral blood samples (5-10 mL) in EDTA-containing tubes from all consenting participants.
-
DNA Extraction: Isolate genomic DNA from whole blood using a commercially available DNA extraction kit (e.g., QIAamp DNA Blood Maxi Kit, Qiagen) following the manufacturer's instructions.
-
DNA Quantification: Determine the concentration of the extracted DNA using a spectrophotometer (e.g., NanoDrop) by measuring the absorbance at 260 nm.
-
DNA Quality Assessment: Assess the purity of the DNA by calculating the A260/A280 ratio, which should be between 1.8 and 2.0. The integrity of the DNA can be visualized by agarose gel electrophoresis.
Protocol 3: Genetic Mutation Screening
Objective: To identify the presence of specific mutations in key Parkinson's disease-associated genes.
A. Next-Generation Sequencing (NGS) for Comprehensive Gene Panel Analysis
-
Library Preparation: Prepare DNA libraries from the extracted genomic DNA using a targeted gene panel that includes the genes of interest (LRRK2, GBA, SNCA, Parkin, PINK1, DJ-1, etc.).
-
Sequencing: Perform sequencing on a high-throughput sequencing platform (e.g., Illumina NovaSeq).
-
Data Analysis:
-
Align the sequencing reads to the human reference genome.
-
Call variants (single nucleotide variants and small insertions/deletions).
-
Annotate the identified variants to determine their potential pathogenicity using databases such as ClinVar and the Human Gene Mutation Database (HGMD).
-
Filter variants based on their frequency in the general population (e.g., gnomAD).
-
B. Multiplex Ligation-Dependent Probe Amplification (MLPA) for Detection of Large Deletions and Duplications
-
MLPA Reaction: Perform MLPA using commercially available SALSA MLPA probemixes specific for the genes of interest (e.g., Parkin, SNCA). This technique is particularly important for detecting large exonic deletions and duplications that may be missed by standard sequencing.
-
Fragment Analysis: Separate the amplified fragments by capillary electrophoresis.
-
Data Analysis: Analyze the resulting electropherograms to determine the relative copy number of each exon.
C. Sanger Sequencing for Variant Confirmation
-
Primer Design: Design PCR primers to amplify the region containing the variant of interest identified by NGS.
-
PCR Amplification: Amplify the target region using PCR.
-
Sequencing Reaction: Perform Sanger sequencing of the PCR product.
-
Data Analysis: Analyze the sequencing chromatograms to confirm the presence of the variant.
Visualizations
Experimental and Logical Workflows
Citing and Utilizing Parkinson's Disease Mutation Databases in Research: Application Notes and Protocols
For Immediate Release
This document provides detailed application notes and protocols for researchers, scientists, and drug development professionals on the proper citation and utilization of key mutation databases in Parkinson's Disease (PD) research. Adherence to these guidelines ensures reproducibility and proper attribution to the valuable resources compiling genetic data in the field.
Introduction to Key Parkinson's Disease Mutation Databases
Several specialized databases serve as critical repositories for genetic information related to Parkinson's disease. These platforms aggregate data from numerous studies, facilitating large-scale analyses and novel discoveries. The primary databases covered in these notes are the Parkinson's Disease Mutation Database (PDmutDB), the Mutation Database for Parkinson's Disease (MDPD), the Movement Disorder Society Genetic mutation database (MDSGene), and Gene4PD. While some databases like PDmutDB may no longer be actively maintained, their foundational publications and data remain relevant.[1][2]
Proper Citation of Parkinson's Disease Mutation Databases
Accurate citation of these databases is essential for acknowledging the significant effort involved in their curation and for enabling other researchers to locate the original data sources. The following are the recommended citation formats for the key databases.
PDmutDB (Parkinson Disease Mutation Database)
When citing data that originated from or was cross-referenced with PDmutDB, researchers should cite the primary publication that introduced the database.
-
Primary Publication: Nuytemans, K., Theuns, J., Cruts, M., & Van Broeckhoven, C. (2010). Genetic etiology of Parkinson disease associated with mutations in the SNCA, PARK2, PINK1, PARK7, and LRRK2 genes: a mutation update. Human mutation, 31(7), 763-780.[3]
This compound (Mutation Database for Parkinson's Disease)
For referencing the this compound, the original publication describing its development and utility should be cited.
-
Primary Publication: Tang, V., Leung, K., & Ho, S. L. (2009). This compound: an integrated genetic information resource for Parkinson's disease. Nucleic acids research, 37(suppl_1), D830-D832.
MDSGene (Movement Disorder Society Genetic mutation database)
MDSGene provides a comprehensive, systematic overview of published data on movement disorder genetics.[4] When citing MDSGene, it is recommended to cite the platform's main publication.
-
Primary Publication: Lill, C. M., Mashychev, A., Hartmann, C., Lohmann, K., Marras, C., Lang, A. E., ... & Bertram, L. (2016). Launching the movement disorders society genetic mutation database (MDSGene). Movement Disorders, 31(5), 607-609.[5]
Gene4PD
Gene4PD is a comprehensive genetic database for Parkinson's Disease that integrates multiple layers of genetic and genomic data.[6][7] The primary publication should be cited when referencing this resource.
-
Primary Publication: Li, B., Zhao, G., Zhou, Q., Xie, Y., Wang, Z., Fang, Z., ... & Li, J. (2021). Gene4PD: a comprehensive genetic database of Parkinson's disease. Frontiers in neuroscience, 15, 679568.[7]
Data Presentation: Quantitative Summaries
The following tables present examples of quantitative data that can be extracted and synthesized from research utilizing these databases.
Table 1: Summary of Genetic Variants in Monogenic Forms of Parkinson's Disease (from MDSGene reviews)
| Gene | Inheritance | Number of Variants Curated | Number of Individuals | Most Common Variant(s) | Key Phenotypic Features |
| LRRK2 | Autosomal Dominant | 283 | 4660 | p.G2019S, p.R1441G/C | Tremor as initial symptom, late-onset PD.[8] |
| SNCA | Autosomal Dominant | Multiple | >100 (multiplications) | Gene duplications/triplications | Early-onset, rapid progression, cognitive decline.[9] |
| PRKN | Autosomal Recessive | >400 | >1000 | Exon deletions/duplications | Early-onset, slow progression, good levodopa response.[10] |
| PINK1 | Autosomal Recessive | ~80 | >300 | Various | Early-onset, slow progression, psychiatric symptoms. |
| PARK7 (DJ-1) | Autosomal Recessive | ~30 | >100 | Various | Early-onset, slow progression, similar to PRKN. |
| GBA | Risk Factor | >300 | >5000 | p.N370S, p.L444P | Higher risk of cognitive decline and dementia.[11] |
Table 2: Prioritized Parkinson's Disease Associated Genes from Gene4PD
This table is a condensed version of the prioritization scoring system used by Gene4PD, which integrates multiple lines of evidence.[12]
| Gene | High Confidence (Score ≥ 20) | Strong Association (Score 10-20) | Suggestive Association (Score 5-10) | Key Associated Pathways |
| SNCA | ✓ | Synaptic vesicle cycling, dopamine metabolism | ||
| LRRK2 | ✓ | Vesicle trafficking, autophagy | ||
| PRKN | ✓ | Mitochondrial quality control, ubiquitin-proteasome system | ||
| PINK1 | ✓ | Mitochondrial quality control | ||
| GBA | ✓ | Lysosomal function, alpha-synuclein processing | ||
| MAPT | ✓ | Microtubule binding, tau pathology | ||
| CHCHD2 | ✓ | Mitochondrial function | ||
| RAB39B | ✓ | Vesicular trafficking | ||
| RIC3 | ✓ | Nicotinic acetylcholine receptor maturation |
Experimental Protocols
The following protocols provide detailed methodologies for utilizing Parkinson's disease mutation databases in key research applications.
Protocol 1: Systematic Meta-Analysis of Genetic Association Studies using the PDGene Database
This protocol outlines the steps for conducting a meta-analysis of genetic association studies for Parkinson's disease, leveraging a resource like the PDGene database.[1][13]
-
Define the Research Question: Clearly formulate the hypothesis, including the specific genetic variants (SNPs) or genes of interest and the population (e.g., Caucasian, Asian).
-
Literature Search and Data Extraction from PDGene:
-
Access the PDGene database (or a similar comprehensive resource).
-
Perform a systematic search for all published genetic association studies for the variants of interest.
-
Extract the following data for each study: first author, year of publication, sample size (cases and controls), odds ratios (ORs) or beta-coefficients, and 95% confidence intervals (CIs).
-
-
Data Harmonization and Quality Control:
-
Ensure consistency in the genetic models and effect alleles across studies.
-
Assess the quality of each study based on criteria such as sample size, genotyping quality, and correction for population stratification.
-
-
Statistical Meta-Analysis:
-
Combine the effect sizes from individual studies using a fixed-effects or random-effects model. The choice of model depends on the presence of heterogeneity between studies.
-
Calculate the summary OR and its 95% CI.
-
Assess for publication bias using funnel plots and Egger's test.
-
-
Interpretation of Results:
-
Evaluate the overall strength of the association between the genetic variant and Parkinson's disease.
-
Consider the implications of the findings for the genetic architecture of the disease.
-
Protocol 2: Genotype-Phenotype Correlation Analysis using MDSGene
This protocol details the methodology for investigating the relationship between specific genetic mutations and clinical phenotypes in Parkinson's disease, using a curated database like MDSGene.[14][15]
-
Gene and Variant Selection:
-
Based on the research question, select the gene(s) and specific variant(s) of interest within the MDSGene database.
-
-
Data Retrieval from MDSGene:
-
Navigate the MDSGene portal to the selected gene page.
-
Utilize the filtering tools to extract data for individuals carrying the variant(s) of interest.
-
Download the anonymized individual-level data, which may include:
-
Demographics: age at onset, sex, ethnicity.
-
Clinical Features: initial symptoms, motor and non-motor features, disease severity scores.
-
Genetic Information: specific mutation, zygosity.
-
-
-
Data Analysis:
-
Descriptive Statistics: Summarize the demographic and clinical characteristics of the cohort.
-
Comparative Analysis: Compare the phenotypic features between different genotype groups (e.g., carriers of different mutations within the same gene, or carriers vs. non-carriers from a control cohort if available).
-
Statistical Testing: Employ appropriate statistical tests (e.g., t-tests, ANOVA, chi-square tests) to determine the significance of any observed differences.
-
-
Interpretation and Reporting:
-
Synthesize the findings to describe the phenotypic spectrum associated with the genetic variant(s).
-
Discuss the clinical implications of the genotype-phenotype correlations.
-
Visualizations: Signaling Pathways and Experimental Workflows
The following diagrams, generated using Graphviz, illustrate key concepts and workflows related to the use of Parkinson's disease mutation databases.
References
- 1. Comprehensive Research Synopsis and Systematic Meta-Analyses in Parkinson's Disease Genetics: The PDGene Database | PLOS Genetics [journals.plos.org]
- 2. Meta-Analysis in Genome-Wide Association Datasets: Strategies and Application in Parkinson Disease - PMC [pmc.ncbi.nlm.nih.gov]
- 3. PDmutDB - Database Commons [ngdc.cncb.ac.cn]
- 4. MDSGene [mdsgene.org]
- 5. MDSGene [mdsgene.org]
- 6. Gene4PD: A Comprehensive Genetic Database of Parkinson’s Disease - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Gene4PD: A Comprehensive Genetic Database of Parkinson's Disease - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. researchgate.net [researchgate.net]
- 9. Genotype-Phenotype Correlations in Monogenic Parkinson Disease: A Review on Clinical and Molecular Findings - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Large-scale copy number variant analysis in genes linked to Parkinson´s disease - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Exploring the Genotype–Phenotype Correlation in GBA-Parkinson Disease: Clinical Aspects, Biomarkers, and Potential Modifiers - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Frontiers | Gene4PD: A Comprehensive Genetic Database of Parkinson’s Disease [frontiersin.org]
- 13. researchgate.net [researchgate.net]
- 14. MDSGene: Closing Data Gaps in Genotype-Phenotype Correlations of Monogenic Parkinson’s Disease - PMC [pmc.ncbi.nlm.nih.gov]
- 15. Frontiers | Editorial: Genotype-Phenotype Correlation in Parkinsonian Conditions [frontiersin.org]
Protocol for Submitting New Mutation Data to the Mitochondrial Disease Pathway Database (MDPD)
For Researchers, Scientists, and Drug Development Professionals
These application notes provide a detailed protocol for submitting new mutation data to the Mitochondrial Disease Pathway Database (MDPD). Adherence to these guidelines ensures data integrity, facilitates comparative analysis, and promotes collaborative research in the field of mitochondrial medicine.
Introduction
The Mitochondrial Disease Pathway Database (this compound) is a centralized repository for genetic and clinical data related to mitochondrial diseases. It serves as a crucial resource for the research and clinical communities to advance the understanding, diagnosis, and treatment of these complex disorders.[1][2] This document outlines the necessary steps and data requirements for the submission of novel mutation data. The protocol is designed to be compatible with the data submission styles of major public databases such as ClinVar, ensuring broad utility and data interoperability.[3][4][5]
Data Submission Workflow
The submission of new mutation data to the this compound follows a structured workflow to ensure accuracy and completeness. The process involves data preparation, submission through the online portal, and review by the this compound curation team.
Caption: this compound new mutation data submission workflow.
Data Presentation: Required Information
All quantitative data must be summarized in clearly structured tables for easy comparison. The following tables outline the mandatory and recommended data fields for submission.
Variant Information
Standardized nomenclature is critical for data integration. The Human Genome Variation Society (HGVS) nomenclature is the required format for describing variants.[6] For mitochondrial DNA variants, the revised Cambridge Reference Sequence (rCRS), GenBank accession number NC_012920.1, should be used as the reference.[7]
| Field | Description | Example | Requirement |
| Gene Symbol | The official gene symbol. | MT-ND1 | Mandatory |
| Reference Sequence | NCBI reference sequence for the gene. | NC_012920.1 | Mandatory |
| HGVS Nucleotide | Variant description at the DNA level. | m.3460G>A | Mandatory |
| HGVS Protein | Predicted protein change. | p.Ala52Thr | Mandatory |
| Variant Type | e.g., single nucleotide variant, deletion, insertion. | single nucleotide variant | Mandatory |
| Genomic Coordinates | Chromosome, start, end, reference, and alternate alleles (VCF format). | chrM:3460:G:A | Mandatory |
Clinical and Phenotypic Information
Detailed and standardized phenotypic information is essential for genotype-phenotype correlations. The use of Human Phenotype Ontology (HPO) terms is strongly encouraged.[2]
| Field | Description | Example | Requirement |
| Associated Disease | Name of the mitochondrial disease. | Leber Hereditary Optic Neuropathy (LHON) | Mandatory |
| OMIM ID | Online Mendelian Inheritance in Man identifier for the disease. | 535000 | Recommended |
| HPO Terms | Standardized terms for clinical features. | HP:0000639 (Nystagmus), HP:0000545 (Myopia) | Recommended |
| Mode of Inheritance | e.g., Mitochondrial, Autosomal Recessive. | Mitochondrial | Mandatory |
| Age of Onset | Age at which symptoms first appeared. | 25 years | Recommended |
| Family History | Relevant family history of mitochondrial disease. | Maternal history of vision loss. | Recommended |
Experimental Validation Data
Functional evidence is crucial for assessing the pathogenicity of a novel variant. A summary of experimental findings should be provided in a structured format.
| Experiment Type | Parameter Measured | Result | Control Value | p-value | Requirement |
| ATP Synthesis Assay | ATP production rate (nmol/min/mg protein) | 15.2 | 45.8 | <0.01 | Mandatory |
| Complex I Activity | Enzyme activity (nmol/min/mg protein) | 5.6 | 25.1 | <0.01 | Mandatory |
| Mitochondrial Membrane Potential | TMRE Fluorescence (Arbitrary Units) | 850 | 2500 | <0.05 | Recommended |
| ROS Production | H2O2 emission rate (pmol/min/mg protein) | 150.3 | 45.7 | <0.01 | Recommended |
Experimental Protocols
Detailed methodologies for key experiments cited in the submission must be provided. The following are standardized protocols for the functional validation of mitochondrial mutations.
Cell Culture and Establishment of Mutant Cell Lines
Patient-derived fibroblasts or immortalized cell lines (e.g., HEK293) can be used. For introducing the mutation, CRISPR/Cas9 gene editing or the use of cybrid cell lines are recommended. Isogenic cell lines, where the mutation is corrected by gene editing, should be used as a control to ensure that the observed effects are due to the mutation of interest.[8]
ATP Synthesis Assay
This assay measures the rate of ATP production in isolated mitochondria or permeabilized cells.[9]
-
Mitochondria Isolation: Isolate mitochondria from cultured cells by differential centrifugation.
-
Reaction Mixture: Prepare a reaction buffer containing a respiratory substrate (e.g., pyruvate and malate for Complex I-driven respiration), ADP, and a luciferin/luciferase-based ATP detection reagent.[10][11]
-
Measurement: Initiate the reaction by adding isolated mitochondria to the pre-warmed reaction mixture in a luminometer plate.
-
Data Acquisition: Measure luminescence kinetically over 5-10 minutes. The rate of increase in luminescence is proportional to the rate of ATP synthesis.[10]
-
Normalization: Normalize the ATP synthesis rate to the total mitochondrial protein content.
Mitochondrial Respiratory Chain Complex Activity Assays
These spectrophotometric assays measure the enzymatic activity of individual respiratory chain complexes.[12]
-
Sample Preparation: Use isolated mitochondria or cell lysates.
-
Complex I (NADH:ubiquinone oxidoreductase) Activity: Measure the rotenone-sensitive decrease in absorbance at 340 nm due to the oxidation of NADH.[7][12]
-
Complex II (Succinate dehydrogenase) Activity: Measure the reduction of a specific electron acceptor, such as 2,6-dichlorophenolindophenol (DCPIP), at 600 nm.
-
Complex III (Ubiquinol:cytochrome c oxidoreductase) Activity: Measure the antimycin A-sensitive reduction of cytochrome c at 550 nm.[12]
-
Complex IV (Cytochrome c oxidase) Activity: Measure the oxidation of reduced cytochrome c by the decrease in absorbance at 550 nm.[12]
-
Complex V (ATP synthase) Activity: Measure the oligomycin-sensitive hydrolysis of ATP, which is coupled to the oxidation of NADH and measured by the decrease in absorbance at 340 nm.[4]
-
Data Analysis: Calculate the specific activity (nmol/min/mg protein) for each complex and compare the values from mutant and control cells.
Mitochondrial Membrane Potential (ΔΨm) Assay
This assay uses fluorescent dyes that accumulate in mitochondria in a membrane potential-dependent manner.
-
Cell Preparation: Plate cells in a black-walled, clear-bottom 96-well plate.
-
Dye Loading: Incubate cells with a fluorescent dye such as Tetramethylrhodamine, Ethyl Ester (TMRE) or JC-1.[2][5][8]
-
Image Acquisition: Acquire fluorescent images using a fluorescence microscope or measure the total fluorescence intensity using a plate reader.
-
Data Analysis: Quantify the fluorescence intensity per cell or per well. A decrease in fluorescence in mutant cells compared to controls indicates a loss of mitochondrial membrane potential.
Measurement of Reactive Oxygen Species (ROS) Production
This assay quantifies the production of ROS, such as superoxide and hydrogen peroxide, by mitochondria.
-
Probe Incubation: Incubate live cells or isolated mitochondria with a ROS-sensitive fluorescent probe, such as MitoSOX™ Red for superoxide or Amplex™ Red for hydrogen peroxide.[6][13][14]
-
Fluorescence Measurement: Measure the fluorescence intensity using a fluorescence plate reader, flow cytometer, or fluorescence microscope.
-
Normalization: Normalize the ROS production rate to the cell number or mitochondrial protein content.
-
Controls: Include a positive control (e.g., treatment with antimycin A to induce ROS production) and a negative control (untreated cells).
Signaling Pathways and Logical Relationships
Diagrams of relevant signaling pathways, experimental workflows, or logical relationships are mandatory. These should be created using the Graphviz DOT language.
Mitochondrial Electron Transport Chain and Oxidative Phosphorylation
This diagram illustrates the flow of electrons through the respiratory chain complexes, leading to the generation of a proton gradient and subsequent ATP synthesis. A mutation in a complex subunit can disrupt this process.
Caption: Electron flow through the ETC and ATP synthesis.
Cellular Consequences of Mitochondrial Dysfunction
This diagram shows the downstream effects of a pathogenic mitochondrial mutation, leading to cellular stress and apoptosis.
Caption: Consequences of mitochondrial dysfunction.
By following this comprehensive protocol, researchers can contribute high-quality, standardized data to the this compound, thereby accelerating the pace of discovery in mitochondrial medicine.
References
- 1. ASSESSING MITOCHONDRIAL MORPHOLOGY AND DYNAMICS USING FLUORESCENCE WIDE-FIELD MICROSCOPY AND 3D IMAGE PROCESSING - PMC [pmc.ncbi.nlm.nih.gov]
- 2. cdn.gbiosciences.com [cdn.gbiosciences.com]
- 3. Assessing mitochondrial morphology and dynamics using fluorescence wide-field microscopy and 3D image processing - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. assaygenie.com [assaygenie.com]
- 5. creative-bioarray.com [creative-bioarray.com]
- 6. Mitochondrial ROS Analysis [protocols.io]
- 7. CheKine™ Micro Mitochondrial complex I Activity Assay Kit - Abbkine – Antibodies, proteins, biochemicals, assay kits for life science research [abbkine.com]
- 8. media.cellsignal.com [media.cellsignal.com]
- 9. A sensitive, simple assay of mitochondrial ATP synthesis of cultured mammalian cells suitable for high-throughput analysis - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. journals.physiology.org [journals.physiology.org]
- 11. researchgate.net [researchgate.net]
- 12. The Biochemical Assessment of Mitochondrial Respiratory Chain Disorders - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Measurement of Mitochondrial ROS Production - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Methods for Detection of Mitochondrial and Cellular Reactive Oxygen Species - PMC [pmc.ncbi.nlm.nih.gov]
Troubleshooting & Optimization
Technical Support Center: Accessing the Molecular Pathways and Disease Database (MPDD)
Welcome to the MPDD Technical Support Center. This guide provides troubleshooting information and answers to frequently asked questions to assist researchers, scientists, and drug development professionals in accessing and utilizing the MPDD platform.
Frequently Asked Questions (FAQs)
Q1: What are the recommended browsers for accessing the MPDD?
A1: For optimal performance and security, we recommend using the latest versions of modern web browsers. Please refer to the table below for a summary of supported browsers.
| Browser | Supported Versions |
| Google Chrome | Latest two versions |
| Mozilla Firefox | Latest two versions |
| Apple Safari | 5 and higher |
| Microsoft Edge | Latest two versions |
It is crucial to use an up-to-date browser not only for new features but also because older versions may have security vulnerabilities.[1] Modern browsers typically have an auto-update feature, which we strongly recommend enabling.[1]
Q2: I am having trouble logging into my MPDD account. What should I do?
A2: Login issues can arise from several factors. Please follow these troubleshooting steps:
-
Verify Credentials: Double-check that you are using the correct username and password. Note that for some systems, your full email address may not be your username.[2]
-
Password Reset: If you have forgotten your password, use the "Forgot Password" link on the login page to reset it.
-
Locked Account: Entering an incorrect password multiple times may temporarily lock your account.[2] Please wait for the specified time before attempting to log in again.
-
Browser Issues: Try clearing your browser's cache and cookies or using an incognito/private browsing window.[2]
Q3: Why is the MPDD website loading slowly?
A3: Slow loading times can be caused by various factors, including large image files, unoptimized code, and excessive HTTP requests.[3][4] While our team continuously works on optimizing the platform, you can try the following to improve your experience:
-
Enable Browser Caching: This allows your browser to store parts of the website, leading to faster load times on subsequent visits.[5]
-
Check Your Internet Connection: A slow or unstable internet connection can significantly impact website performance.
-
Disable Browser Extensions: Some browser extensions can interfere with website loading. Try disabling them to see if performance improves.
Q4: I am encountering an error when trying to submit my experimental data. What should I do?
A4: Data submission errors can occur due to issues with file format or content. Error reports are generated to help identify these issues.[6] Common errors include:
-
Incorrect File Format: Ensure your data is in the specified format (e.g., CSV, TSV).
-
Header/Trailer Errors: Mismatches in the reporting period or missing header/trailer records can cause submission to fail.[6]
-
Data Quality Issues: The system may flag potential data quality issues. High-priority errors will prevent data from being accepted.[6]
Please refer to the data submission guidelines for detailed instructions on formatting and content.
Troubleshooting Guides
Issue: Unable to Access Specific Datasets
If you are logged in but cannot access certain datasets, it may be an issue with your user permissions or data access privileges.
Troubleshooting Workflow:
Caption: Workflow for troubleshooting dataset access issues.
Issue: Browser Compatibility Problems
While we strive for broad browser compatibility, you may occasionally encounter rendering or functionality issues.
Cross-Browser Testing and Issue Reporting:
Caption: Process for identifying and reporting browser compatibility issues.
Experimental Protocols
For researchers submitting data, adherence to standardized experimental protocols is crucial for data integrity and reproducibility. Below is a sample methodology for a common experiment cited in the database.
Protocol: Western Blot for Protein Expression Analysis
-
Protein Extraction: Lyse cells in RIPA buffer supplemented with protease and phosphatase inhibitors.
-
Protein Quantification: Determine protein concentration using a BCA assay.
-
SDS-PAGE: Separate 20-30 µg of protein per lane on a 4-12% Bis-Tris gel.
-
Protein Transfer: Transfer separated proteins to a PVDF membrane.
-
Blocking: Block the membrane with 5% non-fat milk or BSA in TBST for 1 hour at room temperature.
-
Primary Antibody Incubation: Incubate the membrane with the primary antibody overnight at 4°C.
-
Secondary Antibody Incubation: Wash the membrane and incubate with an HRP-conjugated secondary antibody for 1 hour at room temperature.
-
Detection: Visualize protein bands using an ECL substrate and a chemiluminescence imaging system.
-
Analysis: Quantify band intensity using densitometry software and normalize to a loading control (e.g., GAPDH, β-actin).
Signaling Pathway Visualization
The following is a simplified representation of a generic signaling pathway that might be studied using data from the MPDD.
Caption: A simplified diagram of a typical signal transduction pathway.
References
Technical Support Center: Massively Parallel Del-sequencing Platform (MDPD)
Welcome to the troubleshooting guide for the Massively Parallel Del-sequencing Platform (MDPD). This resource is designed for researchers, scientists, and drug development professionals to quickly diagnose and resolve issues with their queries.
Frequently Asked Questions (FAQs) & Troubleshooting Guides
Query Failures & Error Messages
Q1: My query failed with a "Query Timeout" error. What does this mean and how can I fix it?
A1: A "Query Timeout" error indicates that the system did not complete your request within the allocated time. This is often due to query complexity or high server load.
-
Immediate Actions:
-
Simplify Your Query: Reduce the number of parameters or narrow the search range. For example, instead of searching an entire library, specify a sub-library of interest.
-
Check Server Status: Verify the current load on the this compound platform. If the system is experiencing high traffic, consider running your query during off-peak hours.
-
Resubmit the Query: Sometimes, transient network issues can cause timeouts. A simple resubmission may be successful.
-
-
Long-Term Solutions:
-
Optimize Query Logic: Review your query for inefficiencies. Flawed logic, such as incorrect joins or filters, can lead to prolonged execution times.[1]
-
Batch Processing: For large datasets, break down your query into smaller, manageable batches.
-
Q2: I received a "Syntax Error" in my query. What are the common causes?
A2: Syntax errors are typically caused by typos or incorrect formatting in your query submission.[1]
-
Troubleshooting Steps:
-
Proofread Your Query: Carefully check for mistakes such as missing commas, incorrect keywords, or misspelled parameter names.[2]
-
Use a Validator: If available, use a query validation tool to check your syntax before submission.
-
Consult Documentation: Refer to the this compound platform's documentation for the correct syntax and formatting guidelines.[3]
-
Q3: My query returns no results, but I expect to see data. What should I do?
A3: This issue can stem from several sources, from incorrect query parameters to problems with the underlying data.
-
Initial Checks:
-
Verify Input Parameters: Double-check all input values, such as molecule IDs, target names, and date ranges, for accuracy. Even a small typo can lead to no matches.[2]
-
Broaden Your Search: Temporarily relax your search criteria to see if any results are returned. This can help determine if your initial query was too restrictive.
-
Check for Data Existence: Confirm that the data you are querying exists in the database and that you have the necessary permissions to access it.[1]
-
-
Deeper Investigation:
-
Data Quality Control: The issue might originate from the initial stages of the experiment, such as poor quality of the starting DNA or RNA samples.[4][5] Ensure that quality control checks were performed during library preparation.[4][6]
-
Normalization Issues: Lack of proper data normalization can lead to misleading results where true hits are not identified.[7]
-
Data Interpretation & Quality
Q4: The results of my query show a high number of false positives. What could be the cause?
A4: High false-positive rates can be due to experimental artifacts or issues in data analysis.
-
Potential Experimental Causes:
-
Non-Specific Binding: Molecules may bind to the selection matrix or other components instead of the target protein.[8][9]
-
DNA-RNA Interactions: In RNA-targeted selections, false positives can arise from interactions between the DNA barcodes and the RNA target itself.[10]
-
Systematic Errors: Positional effects on screening plates or variations in reagent dispensing can introduce systematic biases.[11][12][13][14]
-
-
Data Analysis Considerations:
-
Inadequate Filtering: Ensure that appropriate filters for Pan-Assay Interference Compounds (PAINS) and other known frequent hitters are applied.[15]
-
Statistical Models: The statistical model used for hit enrichment calculation may not be appropriate for the data distribution. Some datasets may be better modeled by distributions other than the simple Poisson distribution.[16]
-
Q5: My query results seem inconsistent across different experimental batches. How can I troubleshoot this?
A5: Inconsistencies across batches often point to a lack of standardization or batch effects.
-
Methodology Review:
-
Standard Operating Procedures (SOPs): Ensure that consistent SOPs are followed for every step of the experimental workflow, from sample preparation to data acquisition.[17]
-
Reagent Quality: Verify the consistency and quality of reagents used across different batches.
-
Instrument Calibration: Confirm that all equipment was properly calibrated before each run.
-
-
Data Analysis and Normalization:
-
Batch Correction Algorithms: Apply computational methods to correct for batch effects in your data.
-
Control Samples: Include common control samples in each batch to help normalize the results and identify variations.
-
Quantitative Data Summary
The following table summarizes common query error codes, their potential causes, and recommended actions.
| Error Code | Error Message | Common Causes | Recommended Actions |
| 504 | Query Timeout | Complex query, high server load, inefficient query logic. | Simplify query, run during off-peak hours, optimize logic.[1] |
| 400 | Bad Request / Syntax Error | Typos, incorrect keywords, missing parameters. | Proofread query, use a syntax validator, consult documentation.[1][2] |
| 404 | Not Found | Incorrect identifiers, data does not exist, insufficient permissions. | Verify input IDs, confirm data existence, check user permissions.[1] |
| 204 | No Content | Query parameters are too restrictive, no matching data. | Broaden search criteria, verify data availability for the query range. |
Experimental Protocols: Key Methodologies
Protocol 1: Verifying Data Quality from NGS
A crucial step before querying is ensuring the quality of the next-generation sequencing (NGS) data that populates the this compound.[4]
-
Initial Sample QC: Assess the quality and quantity of the starting DNA or RNA material. For DNA, a high purity sample should have an A260/A280 ratio of ~1.8, and for RNA, ~2.0.[5]
-
Library Preparation QC: After library preparation, verify the successful ligation of sequencing adapters and check for the presence of adapter dimers.[4]
-
Bioinformatics Pipeline QC:
Visualizations: Troubleshooting Workflows & Logic
Troubleshooting Workflow for Failed Queries
The following diagram illustrates a logical workflow for diagnosing and resolving failed queries on the this compound platform.
Caption: A step-by-step workflow for troubleshooting common query failures in the this compound.
References
- 1. What is the reason for the database query failure? - Tencent Cloud [tencentcloud.com]
- 2. wildlife-genomics.sydney.edu.au [wildlife-genomics.sydney.edu.au]
- 3. Bioinformatics Pipeline Troubleshooting [meegle.com]
- 4. Quality Control in NGS Library Preparation Workflow - CD Genomics [cd-genomics.com]
- 5. frontlinegenomics.com [frontlinegenomics.com]
- 6. 3billion.io [3billion.io]
- 7. Normalization of DNA encoded library affinity selection results driven by high throughput sequencing and HPLC purification - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. pubs.acs.org [pubs.acs.org]
- 9. Challenges and Prospects of DNA-Encoded Library Data Interpretation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. Expanding the DNA-encoded library toolbox: identifying small molecules targeting RNA - PMC [pmc.ncbi.nlm.nih.gov]
- 11. academic.oup.com [academic.oup.com]
- 12. info2.uqam.ca [info2.uqam.ca]
- 13. Systematic error detection in experimental high-throughput screening - PMC [pmc.ncbi.nlm.nih.gov]
- 14. academic.oup.com [academic.oup.com]
- 15. Analysis of HTS data | Cambridge MedChem Consulting [cambridgemedchemconsulting.com]
- 16. Machine-Learning-Based Data Analysis Method for Cell-Based Selection of DNA-Encoded Libraries - PMC [pmc.ncbi.nlm.nih.gov]
- 17. blog.omni-inc.com [blog.omni-inc.com]
- 18. tandfonline.com [tandfonline.com]
Navigating the Landscape of Parkinson's Disease Genetic Data: A Technical Support Guide
For researchers, scientists, and drug development professionals engaged in the study of Parkinson's disease (PD), access to comprehensive and reliable genetic data is paramount. The unexpected unavailability of a familiar resource can disrupt experimental workflows and impede progress. This technical support center provides troubleshooting guidance and answers to frequently asked questions regarding access to Parkinson's Disease mutation databases, with a focus on the status of the formerly accessible Parkinson's Disease Mutation Database (PDmutDB).
Frequently Asked Questions (FAQs)
Q1: Why can't I access the Parkinson's Disease Mutation Database (PDmutDB)?
A1: The Parkinson's Disease Mutation Database (PDmutDB), previously hosted at --INVALID-LINK--, is no longer online.[1] While the specific reasons for its discontinuation are not publicly detailed, it is not uncommon for academic or research-funded databases to go offline due to shifts in funding, completion of a project's mandate, or the emergence of more comprehensive data repositories.
Q2: What were the key features of the PDmutDB?
A2: The PDmutDB was a valuable resource that aimed to collect and organize all known mutations and non-pathogenic coding variations in genes associated with Parkinson's disease.[2] It systematically compiled data from scientific literature and conference presentations, covering genes such as SNCA, PARK2, PINK1, PARK7, and LRRK2.[2] The database included information on different types of DNA variations and the number of families affected.[1]
Q3: Are there alternative databases I can use for my research on Parkinson's disease genetics?
A3: Yes, several robust and actively maintained databases are available to the research community. These platforms offer extensive, curated data on genetic variants associated with PD and other movement disorders. Notable alternatives include:
-
Gene4PD: A comprehensive genetic database that integrates various types of genetic data related to Parkinson's disease, including rare variants, copy number variations (CNVs), and associated single nucleotide polymorphisms (SNPs).[3][4]
-
MDSGene: The Movement Disorder Society Genetic mutation database provides a systematic overview of published data on movement disorder patients with causative gene mutations.[5] It includes data on over 1,000 different mutations in more than 6,000 patients.[5]
-
ParkDB: This database focuses on gene expression in Parkinson's disease, offering a collection of curated and re-analyzed microarray datasets.[6]
Q4: My research workflow was dependent on PDmutDB. How do I transition to a new database?
A4: Transitioning to a new database requires a systematic approach. First, identify the specific data points you require from your previous work with PDmutDB. Next, explore the alternative databases listed above to determine which best suits your research needs. Pay close attention to the data types, search functionalities, and data download options each platform provides. It is also advisable to review the database's documentation and citation guidelines to ensure proper use and attribution in your work.
Troubleshooting Guide for Accessing Genetic Databases
Encountering issues when accessing online scientific databases can be a common frustration. This guide provides a step-by-step approach to troubleshoot and resolve these problems.
| Problem | Potential Cause | Troubleshooting Steps |
| Website Unreachable | Server Downtime | 1. Check the database's official website or any associated institutional pages for announcements regarding maintenance or downtime.2. Use a service like "Down for Everyone or Just Me" to verify if the site is offline for all users.3. If the issue persists, attempt to contact the database administrators via the contact information provided on their website. |
| Slow Loading Times | Network Connectivity Issues | 1. Test your internet connection speed to ensure it is stable.2. Try accessing the database from a different network (e.g., a university network versus a home network).3. Clear your browser's cache and cookies, as this can sometimes resolve loading issues. |
| Data Not Displaying Correctly | Browser Incompatibility | 1. Ensure your web browser is updated to the latest version.2. Try accessing the database using a different browser (e.g., Chrome, Firefox, Safari, Edge).3. Disable any browser extensions that might interfere with website functionality. |
| Unable to Find Specific Data | Differing Search Syntax | 1. Carefully review the database's "Help" or "FAQ" section for instructions on how to properly format search queries.2. Experiment with different keywords, gene names, and variant identifiers.3. Utilize any advanced search features that allow for more specific filtering of results. |
Experimental Protocols & Methodologies
When citing data from any genetic database, it is crucial to refer to the specific methodologies employed by that resource for data curation and analysis. For instance, Gene4PD outlines a systematic process of reviewing and curating data from multiple public studies, integrating various layers of genetic information.[4] Similarly, ParkDB provides detailed information on their re-analysis of microarray datasets to ensure homogeneity and comparability across experiments.[6] Always consult the "About" or "Methods" section of the database you are using for precise details on their experimental and data-handling protocols.
Visualizing the Troubleshooting Workflow
The following diagram illustrates a logical workflow for troubleshooting issues when accessing an online genetic database.
Caption: A flowchart outlining the logical steps for troubleshooting access to online genetic databases.
References
- 1. Parkinson Disease Mutation Database | re3data.org [re3data.org]
- 2. PDmutDB - Database Commons [ngdc.cncb.ac.cn]
- 3. Frontiers | Gene4PD: A Comprehensive Genetic Database of Parkinson’s Disease [frontiersin.org]
- 4. Gene4PD: A Comprehensive Genetic Database of Parkinson’s Disease - PMC [pmc.ncbi.nlm.nih.gov]
- 5. MDSGene [movementdisorders.org]
- 6. academic.oup.com [academic.oup.com]
MDPD Technical Support Center: Troubleshooting Data Downloads
Welcome to the technical support center for the Molecular Data & Pathway Database (MDPD). This guide provides answers to common questions and solutions for issues you may encounter when downloading datasets.
Frequently Asked Questions (FAQs)
Why is my file download failing or incomplete?
An incomplete download occurs when the connection between your computer and the this compound server is interrupted.[1][2] This is a common issue, especially with large datasets.
Troubleshooting Steps:
-
Check Your Internet Connection: An unstable or slow internet connection is a primary cause of download failure.[3][4] Try restarting your router or connecting directly via an Ethernet cable for better stability.[3]
-
Ensure Sufficient Disk Space: Lack of adequate storage space on your selected drive will cause the download to fail.[3][4] Verify that you have more space available than the total size of the dataset you are downloading.
-
Retry the Download: Temporary server-side issues or network congestion can often be resolved by simply trying the download again.[3]
-
Use a Download Manager: For large files, a download manager can help by resuming downloads that have been interrupted, saving you from having to start over.[5]
Below is a workflow to diagnose the cause of a failed download.
My downloaded file is corrupted. What should I do?
File corruption can happen due to network interruptions or, rarely, an issue with the source file on the server.[3][4] A corrupted file may be unreadable or cause errors when you try to open or decompress it.[6]
Methodology for Verifying File Integrity:
The most reliable way to check for corruption is to verify the file's checksum. This compound provides MD5 checksums for all downloadable datasets.
-
Locate the Checksum: On the dataset download page, find the provided MD5 value.
-
Calculate the Checksum Locally: After downloading, use a command-line tool to calculate the checksum of your local file.
-
On macOS/Linux: Open a terminal and run: md5 /path/to/your/downloaded/file.zip
-
On Windows: Open Command Prompt and run: certutil -hashfile C:\path\to\your\downloaded\file.zip MD5
-
-
Compare: Match the calculated checksum with the one provided on the this compound website. If they do not match, the file is corrupted, and you should download it again.[5]
If the problem persists after multiple attempts, consider using a more robust download method, such as a command-line tool.[7]
What are the common HTTP error codes I might see?
When you interact with the this compound portal, your browser communicates with our servers using HTTP. If there's a problem, the server will respond with a status code.[8] Understanding these codes can help you diagnose the issue.
| Error Code | Meaning | Common Cause & Solution |
| 400 Bad Request | The server could not understand your request. | This can be caused by a malformed request from your browser.[9] Try clearing your browser cache and cookies, then attempt the download again. |
| 401 Unauthorized | You are not logged in or do not have the correct credentials. | Ensure you are logged into your this compound account. If you are, your session may have expired. Log out and log back in.[8][10] |
| 403 Forbidden | You are logged in, but you do not have permission to access the data. | This indicates an issue with your account's permissions for that specific dataset.[8][9] Please contact support to verify your access rights. |
| 404 Not Found | The requested file or page does not exist. | The link may be broken or the file may have been moved.[9][10] Double-check the URL or navigate to the dataset from the this compound homepage. |
| 500 Internal Server Error | A generic error indicating a problem on our end. | This is a server-side issue.[9][11] Please wait a few minutes and try again. If the problem persists, our team is likely already working on a fix. |
| 503 Service Unavailable | The this compound server is temporarily overloaded or down for maintenance. | This is usually temporary.[11] Please try your download again at a later time. |
When should I use the API instead of a direct download?
Both direct download (from your browser) and the this compound API are valid ways to get data, but they are suited for different scenarios.[12][13]
| Feature | Direct Download (Browser) | API Download (Programmatic) |
| Use Case | Best for single files or smaller datasets. | Ideal for large datasets, batch downloads, or integrating this compound data into automated workflows.[12][14] |
| Reliability | Prone to interruption from unstable connections.[1] | More robust; can be scripted to resume failed downloads and verify integrity automatically.[7] |
| Speed | Limited by browser performance and network stability. | Can be faster for large-scale transfers, especially when using optimized tools.[15] |
| Technical Skill | Minimal; just click and save.[14] | Requires basic knowledge of command-line tools or a scripting language like Python.[14] |
The diagram below illustrates the decision-making process for choosing a download method.
Experimental Protocols: Using Command-Line Tools for Reliable Downloads
For researchers needing to download large datasets reliably, using command-line tools like wget or cURL is highly recommended. These tools are less prone to failure and support resuming interrupted downloads.
Protocol: Downloading with wget
wget is a robust tool for downloading files from the command line.
Methodology:
-
Get the Download Link: From the this compound data portal, right-click the download button for your desired dataset and select "Copy Link Address."
-
Open a Terminal: Access the command-line interface on your system (Terminal on macOS/Linux, PowerShell or Command Prompt on Windows).
-
Execute the Command: Use the following command structure. The -c flag tells wget to continue an interrupted download.
-
Authentication (If Required): If the dataset requires you to be logged in, you will need to provide your API key or session cookie.
-
Example with API Key Header:
-
This method provides a more stable and efficient way to handle large data transfers compared to a standard browser download.[7]
References
- 1. keycdn.com [keycdn.com]
- 2. medium.com [medium.com]
- 3. consumersearch.com [consumersearch.com]
- 4. Why Does my Download Stop Before it is Finished? - GeeksforGeeks [geeksforgeeks.org]
- 5. windows - How to solve corrupted downloaded files? - Super User [superuser.com]
- 6. quora.com [quora.com]
- 7. researchgate.net [researchgate.net]
- 8. moz.com [moz.com]
- 9. The Five Most Common HTTP Errors According to Google - Pingdom [pingdom.com]
- 10. HTTP Status Codes: A Complete Guide & List of Error Codes [kinsta.com]
- 11. ramotion.com [ramotion.com]
- 12. toolkit.data.wa.gov.au [toolkit.data.wa.gov.au]
- 13. apievangelist.com [apievangelist.com]
- 14. API vs Data Extracts - PropTrack [proptrack.com.au]
- 15. help.adknowledgeportal.org [help.adknowledgeportal.org]
MDPD Technical Support Center: Optimizing Complex Queries
Welcome to the technical support center for the Molecular Pathway and Drug-target Database (MDPD). This guide provides answers to frequently asked questions and troubleshooting advice to help you optimize your complex search queries and resolve common issues encountered during your research.
Frequently Asked Questions (FAQs)
Q1: What are the most common reasons for slow query performance or timeouts in this compound?
A1: Slow query performance is typically caused by several factors. Overly broad searches that return millions of results can strain system resources.[1][2] Complex queries with multiple, unrestricted parameters (e.g., searching for a common protein domain without specifying an organism) can also lead to significant delays.[1] Another common issue is the inefficient use of Boolean operators, which can unintentionally broaden a search far beyond the intended scope.[1] Finally, system load can be a factor; running complex queries during peak usage hours may result in slower performance.
Q2: How can I use Boolean operators like AND, OR, and NOT to refine my searches?
A2: Boolean operators are essential for constructing precise and efficient queries.[3][4]
-
AND : Narrows your search by ensuring all specified terms are present in the results. For example, (Kinase AND "Homo sapiens") will only return results that include both the term "Kinase" and the phrase "Homo sapiens".[3][5]
-
OR : Broadens your search to include results containing at least one of the specified terms. This is useful for searching synonyms or related concepts, such as (cancer OR oncology).[4][6]
-
NOT : Excludes results that contain a specific term. For instance, (p53 NOT "Mus musculus") will find results related to p53 but exclude any from mice.[4]
-
Parentheses () : Group terms and operators to control the order of operations. Operations within parentheses are executed first.[4][5] For example, ((EGFR OR MAPK) AND inhibitor) searches for records containing the term "inhibitor" along with either "EGFR" or "MAPK".[5]
Q3: My search is returning too many irrelevant results. How can I increase specificity?
A3: To increase the specificity of your search, consider the following techniques:
-
Use More AND Operators : Add more required terms with the AND operator to narrow the focus.[3][7]
-
Utilize Field-Specific Searches : Instead of a general keyword search, specify which fields to search. For example, search for a protein name in the [ProteinName] field and an organism in the [Organism] field.
-
Apply Filters and Limiters : Use the available filters on the results page to narrow down by date, publication type, organism, or data source.[7]
-
Use Exact Phrases : Enclose terms in quotation marks (" ") to search for an exact phrase, such as "serine/threonine kinase".[4]
Troubleshooting Guides
Problem: My search for a specific signaling pathway is returning incomplete or fragmented results.
Solution: This issue often arises when search terms are too narrow or do not account for variations in nomenclature. Follow these steps to build a more comprehensive pathway search.
-
Identify Core Components : List the essential proteins, genes, and molecules in the pathway.
-
Broaden with Synonyms : For each core component, use the OR operator to include common synonyms, alternative names, and gene symbols. For example: ("mTOR" OR "mechanistic target of rapamycin" OR FRAP1).[6]
-
Group Concepts : Enclose each group of synonyms in parentheses.[4][5]
-
Combine Concepts : Link the grouped concepts with the AND operator to ensure all key components of the pathway are represented in the search.
-
Check Controlled Vocabularies : Use this compound's built-in thesaurus or controlled vocabulary (if available) to find standardized terms for your pathway components.[8]
Example Query Construction: ("PI3K" OR "Phosphoinositide 3-kinase") AND ("Akt" OR "Protein Kinase B") AND ("mTOR" OR FRAP1)
Data Presentation: Impact of Query Optimization
The following table demonstrates how refining a search query can significantly improve performance and the relevance of results. The goal of this hypothetical search was to find inhibitors of the EGFR protein in humans.
| Query Strategy | Example Query | Query Time (s) | Results Returned | Relevant Results (%) |
| Broad & Unspecific | EGFR inhibitor | 18.5 | 1,250,340 | 15% |
| Using AND Operator | EGFR AND inhibitor | 9.2 | 780,112 | 35% |
| Using Exact Phrase | "EGFR inhibitor" | 5.1 | 210,560 | 60% |
| Highly Specific | ("EGFR" OR "Epidermal Growth Factor Receptor") AND inhibitor AND "Homo sapiens"[Organism] | 1.3 | 15,230 | 92% |
Experimental Protocol: Systematic Query Optimization
This protocol provides a structured method for developing an efficient and comprehensive search strategy for complex topics.
Objective: To systematically refine a search query to maximize the retrieval of relevant results while minimizing noise.
Methodology:
-
Define the Research Question : Clearly articulate the key concepts of your research question. Use a framework like PICO (Population, Intervention, Comparison, Outcome) to break it down.[8]
-
Initial Term Harvesting :
-
For each concept, brainstorm a list of keywords, synonyms, and alternative spellings.[8]
-
Perform a preliminary, broad search with a few core keywords to identify relevant articles.
-
Scan the titles, abstracts, and author keywords from these initial results to find additional search terms and relevant controlled vocabulary (e.g., MeSH terms).[8]
-
-
Construct Search Segments :
-
For each individual concept, create a "search segment" by combining all its related terms and synonyms with the OR operator. Enclose this segment in parentheses.[8]
-
Example Segment for "Cancer":(cancer OR neoplasm OR oncology OR tumor)
-
-
Combine Segments :
-
Test and Refine :
-
Execute the combined query in the this compound.
-
Analyze the results for relevance. If the results are too broad, add another concept with AND or use more specific terms. If they are too narrow, broaden a concept by adding more synonyms with OR.
-
-
Document : Keep a detailed record of the queries you test and the results they produce to identify the most effective strategy.[9]
Visualizations
// Nodes start [label="Start: Define\nResearch Question", fillcolor="#4285F4", fontcolor="#FFFFFF"]; harvest [label="1. Initial Term Harvesting\n(Keywords & Synonyms)", fillcolor="#FBBC05", fontcolor="#202124"]; segments [label="2. Construct Search Segments\n(Combine with OR)", fillcolor="#FBBC05", fontcolor="#202124"]; combine [label="3. Combine Segments\n(Link with AND)", fillcolor="#34A853", fontcolor="#FFFFFF"]; execute [label="4. Execute & Analyze Query", fillcolor="#EA4335", fontcolor="#FFFFFF"]; refine [label="5. Refine Query\n(Is it optimal?)", shape=diamond, fillcolor="#F1F3F4", fontcolor="#202124"]; document [label="6. Document Final Strategy", fillcolor="#5F6368", fontcolor="#FFFFFF"]; end [label="End", shape=ellipse, fillcolor="#202124", fontcolor="#FFFFFF"];
// Edges start -> harvest; harvest -> segments; segments -> combine; combine -> execute; execute -> refine; refine -> document [label=" Yes"]; refine -> harvest [label=" No"]; document -> end; } .dot Caption: Experimental workflow for Systematic Query Optimization.
// Nodes Ligand [label="Growth Factor", fillcolor="#F1F3F4", fontcolor="#202124"]; Receptor [label="EGFR", fillcolor="#4285F4", fontcolor="#FFFFFF"]; PI3K [label="PI3K", fillcolor="#34A853", fontcolor="#FFFFFF"]; Akt [label="Akt", fillcolor="#34A853", fontcolor="#FFFFFF"]; mTOR [label="mTOR", fillcolor="#34A853", fontcolor="#FFFFFF"]; Proliferation [label="Cell Proliferation", shape=ellipse, fillcolor="#EA4335", fontcolor="#FFFFFF"];
// Edges Ligand -> Receptor; Receptor -> PI3K; PI3K -> Akt; Akt -> mTOR; mTOR -> Proliferation; } .dot Caption: Simplified EGFR-PI3K-Akt-mTOR signaling pathway.
References
- 1. sqream.com [sqream.com]
- 2. Slow Database Queries and Application Performance Tuning [eginnovations.com]
- 3. ifis.org [ifis.org]
- 4. Boolean Operators | Quick Guide, Examples & Tips [scribbr.com]
- 5. EBSCO Connect [connect.ebsco.com]
- 6. m.youtube.com [m.youtube.com]
- 7. Advanced Tips for Database Searching – Graduate Student Research Institute [sites.uw.edu]
- 8. Developing a comprehensive search query | Augustus C. Long Health Sciences Library [library.cumc.columbia.edu]
- 9. A systematic approach to searching: an efficient and complete method to develop literature searches - PMC [pmc.ncbi.nlm.nih.gov]
Technical Support Center: Navigating Outdated Information in Genetic Databases
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to help researchers, scientists, and drug development professionals address challenges related to outdated information in genetic databases.
Frequently Asked Questions (FAQs)
Q1: How can outdated information in a genetic database impact my research?
Q2: What are the most common types of outdated information in genetic databases?
A2: Common issues with reference sequence databases include:
-
Outdated Gene Annotations: Functional information for genes changes rapidly. Pathway enrichment analysis, a common technique for interpreting gene lists, is highly dependent on the quality and currency of these annotations.[1][2]
-
Database Contamination: This is a widely recognized issue where sequences are incorrectly assigned to an organism.
-
Taxonomic Errors: Incorrect classification of organisms can lead to misinterpretation of data.
-
Inappropriate Inclusion and Exclusion Criteria: Databases may include low-quality or incomplete genomes, or conversely, exclude valuable data, leading to biases.[3]
-
Sequence Content Errors: The actual nucleotide or amino acid sequences may be incorrect.[3]
Q3: Why is there a lack of diversity in many genetic databases, and what are the implications?
A3: A significant portion of data in genome-wide association studies (GWAS) comes from individuals of predominantly European descent.[4][5] As of 2018, individuals included in GWAS were 78% European, 10% Asian, 2% African, 1% Hispanic, and less than 1% from other ethnic groups.[5] This lack of diversity limits scientists' understanding of the genetic and environmental factors influencing health and disease across different populations.[5] It can also lead to "variants of uncertain significance" being more frequently identified in non-European populations, hindering accurate diagnosis and treatment.[6] This disparity can exacerbate existing health inequalities.[4]
Q4: Are there best practices for submitting my own data to public databases to ensure its longevity and usefulness?
A4: Yes, to ensure your data remains valuable, it's crucial to follow best practices for archiving. This includes providing complete and unfiltered data sets, including raw data, processed data, and comprehensive metadata.[7][8] Public archives like the Gene Expression Omnibus (GEO) require this to allow the scientific community to re-examine the data that forms the basis of scientific reports.[7] When dealing with data from human subjects, it is imperative to obtain informed consent that covers data sharing for future research, while ensuring participant privacy is protected.[9][10]
Troubleshooting Guide
This guide provides steps to identify and mitigate issues arising from outdated genetic database information.
Problem 1: My pathway enrichment analysis yields no significant results, or the results seem incomplete.
-
Possible Cause: The gene annotation data used by your analysis tool may be outdated. Many popular tools are not updated for several years, missing a significant number of newly discovered pathways and gene functions.[1]
-
Troubleshooting Steps:
-
Check the database update frequency: Verify the last update date of the gene annotation database used by your pathway analysis tool. Tools like g:Profiler and PANTHER are noted for more frequent updates.
-
Use multiple tools: Compare the results from several different pathway analysis tools to see if there are discrepancies.
-
Manually update annotations: If possible, use tools that allow you to provide your own, more current, gene annotation files.
-
Problem 2: I am getting unexpected or nonsensical taxonomic classifications in my metagenomics data.
-
Possible Cause: The reference sequence database you are using may be contaminated or contain taxonomic errors. Changing the reference database can lead to significant changes in taxonomic classification accuracy.[3]
-
Troubleshooting Steps:
-
Assess database quality: Whenever possible, use curated databases that have undergone rigorous quality control to remove contaminants and correct taxonomic assignments.
-
Include a host genome: For host-associated metagenomic studies, include the host species in the reference database to prevent misclassification of host reads.[3]
-
Validate with a secondary method: Use a different classification algorithm or a secondary, trusted database to validate your initial findings.
-
Problem 3: A gene variant identified in my study is listed as a "variant of uncertain significance" (VUS).
-
Possible Cause: The population diversity in the reference database may be insufficient. This is a common issue for individuals of non-European ancestry.[6]
-
Troubleshooting Steps:
-
Consult population-specific databases: Search for databases that specialize in the genetic data of the population relevant to your study.
-
Perform functional validation: If the VUS is critical to your research, experimental validation will be necessary to determine its functional impact.
-
Family-based studies: If applicable, sequencing family members can help determine if the VUS segregates with a particular phenotype.
-
Experimental Protocols & Data
Data on Database Update Frequency and Impact
The following table summarizes the state of pathway analysis tool updates as of a 2016 study and the impact of using outdated resources.
| Metric | Value | Reference |
| Publications in 2015 citing severely outdated tools (>5 years old) | 67% | [1] |
| Biological processes missed by tools with outdated annotations | 74% | [1] |
| Web-based pathway enrichment tools outdated by 5+ years | 42% | [1] |
Experimental Protocol: Basic Functional Validation of a Gene Variant
This protocol outlines a general workflow for experimentally validating the functional significance of a gene variant identified through database searches.
-
Cell Culture and Transfection:
-
Culture a relevant cell line (e.g., a cell line where the gene of interest is expressed).
-
Synthesize DNA constructs containing the wild-type and variant versions of the gene.
-
Transfect the cells with these constructs. Include a control with an empty vector.
-
-
Protein Expression and Localization Analysis:
-
After 24-48 hours, lyse the cells and perform a Western blot to check if the variant affects protein expression levels.
-
Use immunofluorescence microscopy to determine if the variant alters the subcellular localization of the protein.
-
-
Functional Assay:
-
Based on the known or predicted function of the gene, perform a relevant functional assay. For example:
-
If the gene is an enzyme, perform an enzyme activity assay.
-
If the gene is a transcription factor, use a reporter assay to measure its effect on a target promoter.
-
If the gene is involved in cell signaling, measure the levels of downstream signaling molecules.
-
-
-
Data Analysis:
-
Compare the results from the wild-type, variant, and control groups.
-
Statistically analyze the data to determine if the observed differences are significant.
-
Visualizations
References
- 1. Impact of outdated gene annotations on pathway enrichment analysis - PMC [pmc.ncbi.nlm.nih.gov]
- 2. [PDF] Impact of outdated gene annotations on pathway enrichment analysis | Semantic Scholar [semanticscholar.org]
- 3. Ten common issues with reference sequence databases and how to mitigate them - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Lack of diversity in genetic research could be costing us our health | NOVA | PBS [pbs.org]
- 5. Western bias in human genetic studies is ‘both scientifically damaging and unfair’ | Penn Today [penntoday.upenn.edu]
- 6. sciencenews.org [sciencenews.org]
- 7. Frequently Asked Questions - GEO - NCBI [ncbi.nlm.nih.gov]
- 8. researchgate.net [researchgate.net]
- 9. code-medical-ethics.ama-assn.org [code-medical-ethics.ama-assn.org]
- 10. Special Considerations for Genomics Research [genome.gov]
how to report an error in the MDPD
Disclaimer
The following technical support center has been created for a hypothetical platform, the Molecular Discovery Platform Database (MDPD) , as the specific "this compound" referenced in the query could not be definitively identified. The content is based on common support queries and error reporting procedures for scientific and drug discovery databases.
Welcome to the technical support center for the Molecular Discovery Platform Database (this compound). This guide is designed to help researchers, scientists, and drug development professionals resolve common issues and report errors effectively.
Frequently Asked Questions (FAQs)
Q1: I've noticed a discrepancy in the data. How do I report it?
A1: If you encounter a data error, please use the "Report Error" button located on the top right of the data entry page. This will open a pre-populated form with the entry details. Please provide a concise description of the error and any supporting evidence.
Q2: What happens after I report an error?
A2: Once an error report is submitted, our data curation team will review the submission. You will receive a confirmation email with a tracking number. The team will investigate the issue, and if the error is confirmed, the database will be updated. You will be notified of the resolution.
Q3: How long does it take to resolve a data error?
A3: The resolution time can vary depending on the complexity of the error. Simple typographical errors may be corrected within 24-48 hours, while errors requiring extensive data re-analysis may take longer.
Q4: I'm having trouble accessing the database. What should I do?
A4: First, please check our System Status page for any ongoing maintenance. If there are no reported outages, try clearing your browser's cache and cookies. If the issue persists, please contact our technical support team via the contact form on our website.
Q5: Can I suggest a new feature or improvement for the this compound?
A5: Absolutely. We welcome feedback from the community. Please submit your suggestions through our "Feature Request" portal.
Troubleshooting Guides
Issue: Inability to download a dataset.
-
Check File Size and Format: Ensure you have sufficient storage space and that the selected file format is compatible with your software.
-
Network Connection: A stable internet connection is required for large downloads. Try switching to a wired connection if you are on Wi-Fi.
-
Browser Pop-up Blockers: Disable any pop-up blockers for the this compound website, as they may interfere with the download process.
-
Contact Support: If the problem persists, contact our support team and provide the dataset ID and the time of the attempted download.
Issue: A tool integrated with this compound is not working correctly.
-
Check Tool Documentation: Review the documentation for the specific tool to ensure you are using it correctly.
-
Input Data Format: Verify that your input data is in the correct format as required by the tool.
-
Clear Cache: Clear your browser and application cache to ensure you are using the latest version of the tool.
-
Report to Tool's Support: If the issue is with the tool itself, please report it to the respective tool's support team and notify us so we can investigate any integration issues.
Data and Protocols
Error Reporting Summary
The following table summarizes the common types of errors reported and the primary channels for reporting them.
| Error Type | Description | Primary Reporting Channel | Average Resolution Time |
| Typographical | Misspelled names, incorrect units, etc. | In-app "Report Error" button | 1-2 Business Days |
| Data Inconsistency | Conflicting data within the same entry or across different entries. | Data Curation Contact Form | 3-5 Business Days |
| Missing Data | Incomplete data fields for an entry. | Data Curation Contact Form | 5-7 Business Days |
| System Bug | Functional issue with the platform (e.g., broken link, unresponsive button). | Technical Support Helpdesk | Varies based on severity |
Experimental Protocol: Error Verification
When a data inconsistency error is reported, our curation team follows this high-level protocol for verification:
-
Initial Assessment: The reported error is triaged to the appropriate subject matter expert.
-
Primary Source Review: The original publication or data source is reviewed to verify the reported information.
-
Internal Database Check: Our internal, raw data logs are cross-referenced.
-
External Database Comparison: Data is compared against other public and private databases for consensus.
-
Correction and Annotation: If the error is confirmed, the data is corrected, and an annotation is added to the entry's history.
Visualizations
Caption: Workflow for reporting and resolving a data error in the this compound.
Caption: A logical diagram for troubleshooting common access issues.
Navigating the Nuances of Parkinson's Mutation Data: A Technical Support Guide
For Immediate Release
This technical support center provides researchers, scientists, and drug development professionals with a comprehensive guide to understanding and overcoming the limitations of data within Parkinson's Disease (PD) mutation databases. In this resource, you will find troubleshooting guides in a question-and-answer format, detailed experimental protocols for data validation, and frequently asked questions to address common challenges encountered during your research.
Troubleshooting Guides
This section addresses specific issues users might encounter when working with PD mutation databases.
Question: I've found a novel variant in a PD-associated gene in a public database. How can I be sure it's a true positive and not a data artifact?
Answer: This is a critical first step. Public databases can have discrepancies, and next-generation sequencing (NGS) can produce false positives, particularly in complex genomic regions like those with high GC content or repetitive sequences.[1][2] To validate your finding, a multi-step approach is recommended.
First, cross-reference your variant with other major genomic databases (e.g., gnomAD, ClinVar) to see if it has been previously reported and, if so, what its reported pathogenicity is.[3] However, be aware that even these databases can have conflicting information.
The gold standard for validation is Sanger sequencing of the variant in your sample of interest.[1][4][5] This orthogonal method will confirm the presence of the base change identified by NGS.
Finally, if the variant is confirmed, you will need to assess its potential functional impact through in-silico prediction tools, followed by experimental validation (see experimental protocols below).
Question: Two different PD mutation databases show conflicting information for the same gene. Which one should I trust?
Answer: Discrepancies between databases are a known issue and can arise from different data sources, curation processes, and update cycles.[2] Some databases may focus on literature-curated mutations, while others might incorporate high-throughput sequencing data which may not be fully validated.
To resolve this, consider the following:
-
Primary Data Source: Investigate the original publication or data source cited in each database for the conflicting entry.
-
Database Scope and Focus: Understand the specific focus of each database. For instance, some databases like PDGene are centered on GWAS data, while others might specialize in monogenic forms of PD.[6]
-
Last Update: Check when each database was last updated, as genetic information is constantly evolving.
-
Seek Consensus: If multiple reputable databases concur on a piece of information, it is more likely to be accurate.
Ultimately, experimental validation in your own cellular or animal models is the most reliable way to resolve such discrepancies.
Question: I am analyzing a large dataset of PD variants, and many are classified as "variants of unknown significance" (VUS). How should I approach these?
Answer: VUS are a significant challenge in genetic research. The first step is to use a variety of in-silico prediction tools (e.g., SIFT, PolyPhen-2, CADD) to predict the potential pathogenicity of the missense variants. However, these tools are predictive and not definitive.
For a more robust assessment, consider the following:
-
Allele Frequency: A very rare variant is more likely to be pathogenic than a common one. Check the variant's frequency in large population databases like gnomAD.
-
Segregation Analysis: If you have data from families with PD, determine if the VUS segregates with the disease.
-
Functional Studies: The most definitive way to characterize a VUS is through functional studies. This could involve assessing the variant's impact on protein expression, localization, or function in a relevant cell model.
Frequently Asked Questions (FAQs)
Q1: What are the primary limitations of current Parkinson's Disease mutation databases?
A1: Researchers should be aware of several key limitations:
-
Data Fragmentation: Genetic data for PD is spread across numerous databases, with no single, comprehensive resource. Some databases are no longer maintained.[6]
-
Incomplete Datasets: Many databases lack detailed phenotypic data to correlate with genotypes, and features like ethnic comparisons or summary statistics may be absent.[7]
-
Data Inconsistencies: There can be conflicting information between databases regarding the pathogenicity and classification of variants.[2]
-
Focus on Common Variants: Many databases are heavily focused on common variants from GWAS, which may not be directly causal and often have a small effect on disease risk.[8]
-
Lack of Functional Data: Most databases primarily store genetic sequence data and lack information on the functional consequences of the listed variants.
Q2: If a genetic test identifies a PD-associated variant in a patient, what does that mean for their family members?
A2: The implications for family members depend on the specific gene and the inheritance pattern (autosomal dominant or recessive).[2][9] For a dominant mutation, there is a 50% chance of passing it on to each child. For a recessive condition, both parents must carry a variant for a child to be at high risk. It's important to note that many PD-associated genes have incomplete penetrance, meaning that even if an individual inherits a pathogenic variant, they may never develop the disease.[9] Genetic counseling is highly recommended to interpret these results accurately.[10]
Q3: Can data from these databases be used directly for clinical decision-making?
A3: Generally, no. While genetic information is crucial for research and can help stratify patients for clinical trials, the results from most research-focused databases are not intended for direct clinical diagnosis or treatment decisions.[11] Clinical genetic testing should be performed in a CLIA-certified laboratory.
Q4: How do I gain access to the raw data from some of these databases?
A4: Access policies vary. Many databases are open-access, allowing researchers to freely browse and download data. However, for more sensitive data, such as individual-level genetic and clinical information, researchers typically need to apply for access through a data access committee, agreeing to specific data use policies to protect patient privacy.[11][12]
Quantitative Data Summary
The following tables summarize key quantitative data related to the genetics of Parkinson's Disease.
| Genetic Contribution to Parkinson's Disease | Percentage/Number | Source(s) |
| PD cases with a known genetic link | ~10-15% | [9] |
| PD cases considered sporadic (no known direct genetic cause) | >90% | [13] |
| Number of genes definitively associated with monogenic PD | 7 key genes are commonly cited (e.g., SNCA, LRRK2, PRKN, PINK1, PARK7, VPS35, GBA) | [2][14] |
| Number of genetic risk loci identified through GWAS | Over 90 | [15] |
| Frequency of Common Pathogenic Variants in Specific Populations | Gene Variant | Population | Frequency in PD Patients | Source(s) |
| LRRK2 G2019S | North African Arabs | 37-42% (familial), 41% (sporadic) | [7] | |
| LRRK2 G2019S | Ashkenazi Jewish | High prevalence | [14] | |
| GBA variants | Ashkenazi Jewish | 10-31% | [16] | |
| LRRK2 R1441G | Basque | 46% | [14] |
Experimental Protocols
Protocol 1: Sanger Sequencing for Variant Validation
This protocol outlines the steps for validating a putative variant identified through next-generation sequencing (NGS).
1. Primer Design:
- Design PCR primers that flank the variant of interest. Aim for an amplicon size of 300-500 base pairs.
- Use primer design software (e.g., Primer3) to ensure primer specificity and avoid regions of high secondary structure.
2. PCR Amplification:
- Perform PCR using genomic DNA from the individual(s) carrying the putative variant and a wild-type control.
- Use a high-fidelity DNA polymerase to minimize PCR-induced errors.
- Run the PCR products on an agarose gel to confirm the amplification of a single product of the correct size.
3. PCR Product Purification:
- Purify the PCR product to remove unincorporated dNTPs and primers. This can be done using a column-based kit or enzymatic cleanup.
4. Cycle Sequencing:
- Set up cycle sequencing reactions using the purified PCR product as a template, one of the PCR primers (forward or reverse), and a sequencing mix containing fluorescently labeled dideoxynucleotide triphosphates (ddNTPs).[4]
5. Sequencing and Data Analysis:
- The products of the cycle sequencing reaction are separated by size using capillary electrophoresis.
- The sequence is read by detecting the fluorescence of the incorporated ddNTPs.
- Align the resulting sequence with the reference sequence to confirm or refute the presence of the variant.[3]
Protocol 2: Functional Characterization of a Novel Missense Variant
This protocol provides a general framework for assessing the functional impact of a novel missense variant in a PD-associated gene.
1. In-silico Analysis:
- Use multiple prediction algorithms (e.g., SIFT, PolyPhen-2, CADD) to predict the effect of the amino acid substitution on protein function.
2. Site-Directed Mutagenesis:
- Introduce the variant into a wild-type expression vector containing the cDNA of the gene of interest.
- Confirm the presence of the mutation by Sanger sequencing.
3. Cell-Based Assays:
- Transfect a relevant cell line (e.g., a neuronal cell line) with the wild-type and mutant constructs.
- Assess the impact of the mutation on:
- Protein Expression and Stability: Use Western blotting to compare the levels of the wild-type and mutant proteins.
- Subcellular Localization: Use immunofluorescence or microscopy of fluorescently tagged proteins to determine if the mutation alters the protein's localization within the cell.
- Protein-Protein Interactions: If the protein is known to interact with other proteins, perform co-immunoprecipitation experiments to see if the mutation disrupts these interactions.
- Enzymatic Activity: If the protein is an enzyme, perform an activity assay to measure the effect of the mutation.
- Cellular Phenotypes: Assess relevant cellular phenotypes associated with PD, such as mitochondrial function, oxidative stress, or protein aggregation.
4. In-vivo Validation (Optional but Recommended):
- If possible, generate a model organism (e.g., fruit fly, nematode) expressing the variant to assess its impact on a relevant phenotype in a whole organism.[17]
Visualizations
Caption: Workflow for the discovery and validation of a novel genetic variant in Parkinson's Disease.
Caption: Key limitations associated with data in Parkinson's Disease mutation databases.
References
- 1. Sanger Sequencing for Validation of Next-Generation Sequencing - CD Genomics [cd-genomics.com]
- 2. Understanding Genetics | Parkinson's Foundation [parkinson.org]
- 3. Sanger Sequencing Steps & Method [sigmaaldrich.com]
- 4. cd-genomics.com [cd-genomics.com]
- 5. Next-Generation Sequencing Validation | Thermo Fisher Scientific - SG [thermofisher.com]
- 6. Gene4PD: A Comprehensive Genetic Database of Parkinson’s Disease - PMC [pmc.ncbi.nlm.nih.gov]
- 7. medrxiv.org [medrxiv.org]
- 8. m.youtube.com [m.youtube.com]
- 9. Genetic Testing for Parkinson's Disease | APDA [apdaparkinson.org]
- 10. Genetic Testing & Counseling | Parkinson's Foundation [parkinson.org]
- 11. Frequently Asked Questions | Parkinson's Foundation [parkinson.org]
- 12. FAQs | Parkinson's Progression Markers Initiative [ppmi-info.org]
- 13. medrxiv.org [medrxiv.org]
- 14. Genetics in Parkinson’s disease, state-of-the-art and future perspectives - PMC [pmc.ncbi.nlm.nih.gov]
- 15. medrxiv.org [medrxiv.org]
- 16. mdpi.com [mdpi.com]
- 17. researchgate.net [researchgate.net]
Technical Support Center: Managing Large Datasets from Membrane-Depolarizing Peptide Discovery (MDPD)
This guide provides researchers, scientists, and drug development professionals with best practices, troubleshooting tips, and frequently asked questions (FAQs) for managing large datasets generated from Membrane-Depolarizing Peptide Discovery (MDPD) experiments.
Frequently Asked Questions (FAQs)
Data Acquisition & Initial Handling
-
Q1: What is the recommended file format for our raw this compound high-throughput screening (HTS) data? A: For raw data from plate readers, it is best to export data in a non-proprietary, open format such as Comma-Separated Values (CSV) or Tab-Separated Values (TSV). This ensures compatibility with a wide range of analysis software.[1] While instruments often use proprietary formats, most software allows for exporting to these more universal formats.[2]
-
Q2: What are the essential details to record at the time of data collection? A: It is crucial to capture comprehensive metadata alongside your experimental data. This should include details about the experimental conditions, reagents, instruments, and software used.[3][4] Meticulous documentation is key to ensuring data reproducibility and long-term value.[3][5]
Data Storage & Backup
-
Q3: What is the best practice for storing and backing up our large this compound datasets? A: A robust data storage and backup strategy is essential to prevent data loss. The "3-2-1 rule" is a widely recommended best practice: maintain at least three copies of your data, on two different types of storage media, with one copy stored off-site. For large datasets, consider a combination of local servers, external hard drives, and secure cloud storage solutions.[6] Regularly scheduled, automated backups are preferable to manual backups to ensure consistency.[6]
Data Quality & Troubleshooting
-
Q4: We are observing high variability in our fluorescence readings between replicate wells. What could be the cause? A: High variability can stem from several factors. Ensure consistent cell seeding density and a single-cell suspension to avoid clumping.[7] Check for and minimize photobleaching by reducing the exposure of stained cells to light.[7] Also, verify the accuracy and consistency of your liquid handling robotics, as variations in reagent or compound addition can significantly impact results.
-
Q5: Our positive control (e.g., a known membrane-depolarizing peptide) is not showing the expected signal. How can we troubleshoot this? A: First, verify the concentration and integrity of your positive control stock solution. If using a fluorescent dye like TMRE, an unexpectedly high signal with a depolarizing agent like FCCP can indicate that the dye concentration is in the quenching range; try reducing the dye concentration.[8] Ensure that the incubation times for both the dye and the control compound are adequate.[7]
-
Q6: We are seeing a high rate of false positives in our primary screen. What are some common causes? A: False positives in HTS can arise from compound autofluorescence or interference with the assay dye. Screen your compound library for autofluorescence at the excitation and emission wavelengths of your assay. Additionally, some compounds may directly interact with the fluorescent dye, causing a signal change unrelated to membrane depolarization. Secondary screening and counter-screens are essential to eliminate these artifacts.
Troubleshooting Guides
Troubleshooting Common Issues in Fluorescence-Based Membrane Potential Assays
| Issue | Potential Cause | Troubleshooting Steps |
| No or weak signal | Insufficient dye loading | Optimize dye concentration and incubation time. Ensure cells are healthy and at the correct density. |
| Incorrect filter set | Verify that the excitation and emission filters on the plate reader match the spectral properties of your fluorescent dye.[6] | |
| Cell death | High concentrations of peptides or other compounds can be cytotoxic. Perform a cell viability assay in parallel. | |
| High background fluorescence | Autofluorescence from compounds or media | Screen compounds for intrinsic fluorescence. Use phenol red-free media for the final measurement steps.[7] |
| Dye precipitation | Ensure the dye is fully dissolved in the buffer before adding to the cells. | |
| Inconsistent results across plates | Plate-to-plate variability | Use consistent cell passages and seeding densities. Ensure uniform temperature and incubation times for all plates. |
| Edge effects | Avoid using the outer wells of the microplate, or ensure proper plate sealing and incubation conditions to minimize evaporation. | |
| Signal drift over time | Dye leakage or phototoxicity | Minimize the duration of fluorescence reading and the intensity of the excitation light. |
Experimental Protocols & Methodologies
Detailed Methodology for a Fluorescence-Based this compound High-Throughput Screening Assay
This protocol outlines a typical workflow for identifying membrane-depolarizing peptides using a fluorescence-based membrane potential assay.
-
Cell Culture and Seeding:
-
Culture a bacterial or eukaryotic cell line of interest to the mid-logarithmic growth phase.
-
Harvest and wash the cells with an appropriate assay buffer.
-
Resuspend the cells to the desired density and seed them into 96-well or 384-well microplates.
-
-
Fluorescent Dye Loading:
-
Prepare a working solution of a membrane potential-sensitive dye (e.g., DiSC3(5) for bacteria or a FLIPR Membrane Potential Assay Kit dye for eukaryotic cells).[6][9][10]
-
Add the dye solution to each well containing the cells.
-
Incubate the plates at the appropriate temperature and for the recommended duration to allow for dye uptake and equilibration across the cell membrane.
-
-
Compound Addition:
-
Prepare compound plates containing your peptide library, positive controls (e.g., gramicidin D or melittin), and negative controls (e.g., vehicle).[9]
-
Using an automated liquid handler, transfer the compounds from the source plates to the assay plates.
-
-
Signal Measurement:
-
Immediately after compound addition, place the assay plates into a fluorescence plate reader.
-
Measure the fluorescence intensity over time (kinetic read) or at a specific endpoint. Use excitation and emission wavelengths appropriate for the chosen dye.
-
-
Data Analysis:
-
Normalize the data to the controls on each plate.
-
Calculate the change in fluorescence for each well.
-
Identify "hits" based on a predefined activity threshold.
-
Mandatory Visualizations
Caption: High-throughput screening workflow for this compound.
Caption: Lifecycle of research data management in this compound projects.
References
- 1. An informatic pipeline for managing high-throughput screening experiments and analyzing data from stereochemically diverse libraries - PMC [pmc.ncbi.nlm.nih.gov]
- 2. researchgate.net [researchgate.net]
- 3. Best practices for data management and sharing in experimental biomedical research - PMC [pmc.ncbi.nlm.nih.gov]
- 4. effectiveexperiments.com [effectiveexperiments.com]
- 5. medium.com [medium.com]
- 6. moleculardevices.com [moleculardevices.com]
- 7. benchchem.com [benchchem.com]
- 8. researchgate.net [researchgate.net]
- 9. A Rapid Fluorescence-Based Microplate Assay to Investigate the Interaction of Membrane Active Antimicrobial Peptides with Whole Gram-Positive Bacteria - PMC [pmc.ncbi.nlm.nih.gov]
- 10. frontiersin.org [frontiersin.org]
Validation & Comparative
Navigating the Landscape of Parkinson's Disease Genetics: A Guide to Validating Mutation Database Findings
For researchers, scientists, and drug development professionals invested in Parkinson's Disease (PD), the accuracy and reliability of genetic data are paramount. This guide provides a comparative overview of prominent mutation databases for PD and outlines key experimental protocols for validating their findings, ensuring a robust foundation for downstream research and therapeutic development.
The identification of genetic variants associated with Parkinson's disease has accelerated with the advent of high-throughput sequencing technologies. Several databases serve as crucial repositories for this information, but their scope and the validation of their data can vary. This guide aims to provide clarity by comparing key databases and detailing the experimental workflows necessary to confirm the functional significance of reported mutations.
Comparative Analysis of Parkinson's Disease Mutation Databases
A critical first step for researchers is selecting the most appropriate database for their needs. The table below summarizes and compares some of the available resources. While some databases, like the Parkinson Disease Mutation Database (PDmutDB), were foundational, newer platforms offer more integrated and comprehensive datasets.[1][2]
| Database | Key Features | Data Types | Accessibility | Status |
| Gene4PD | An integrative platform that combines multiple layers of genetic data and provides analysis tools.[3][4] | Rare variants, copy number variations (CNVs), single nucleotide polymorphisms (SNPs) from GWAS, differentially expressed genes (DEGs), and differential DNA methylation genes (DMGs).[3][4] | Online database and analysis platform. | Active |
| MDSGene | A comprehensive, systematic overview of genetic variants reported in patients with various movement disorders, including Parkinson's disease.[5] | Data on causative genetic variants from published literature, including case reports, family-based studies, and mutational screenings.[5] | Publicly accessible online database. | Active and continually updated.[5] |
| Parkinson Disease Mutation Database (PDmutDB) | Aimed to collect all known mutations and non-pathogenic coding variations in genes related to PD from literature and scientific meetings.[1][2] | Mutations and non-pathogenic coding variations in PD-related genes.[1] | Previously available online, but now appears to be inaccessible.[2] | Inactive/Unavailable[2] |
| Mutation Database for Parkinson's Disease (MDPD) | Contained manually curated entries on genetic mutations associated with PD, with a feature to compare mutation types across ethnic groups.[6] | Information on genetic substitutions and their impact, mutation type, studied population, and mutation position.[6] | Previously available online. | Status unclear, may be outdated. |
Experimental Protocols for Validating Genetic Findings
The identification of a genetic variant in a database is only the initial step. Experimental validation is crucial to confirm its pathogenicity and understand its functional consequences. The following are key experimental methodologies cited in the validation of PD-associated genetic findings.
Genetic Sequencing and Analysis
-
Whole-Exome Sequencing (WES): This technique is used to sequence the protein-coding regions of the genome to identify novel and rare variants in PD cases compared to controls.[7]
-
Sanger Sequencing: Often used as a gold-standard method to confirm the presence of specific variants identified through next-generation sequencing approaches.
-
Genotyping: Various methods, including SNP genotyping arrays and specific PCR-based assays, are used to screen for known mutations in larger cohorts.[8]
Functional Genomics and Cellular Assays
-
RNA interference (RNAi) Screens: To investigate the function of candidate genes, RNAi can be used to knockdown gene expression in cellular models (e.g., human neuronal cell lines) or in vivo models like Drosophila.[7] This allows for the assessment of resulting phenotypes, such as effects on mitochondrial dynamics or α-synuclein-induced neurodegeneration.[7]
-
Cellular Phenotyping: Overexpression or knockdown of a gene of interest in cell lines can be followed by assays to measure relevant cellular processes implicated in PD, such as mitochondrial function, oxidative stress, and protein aggregation.
Gene Expression Analysis
-
Quantitative Polymerase Chain Reaction (qPCR): This technique is used to validate the differential expression of candidate genes identified through broader transcriptomic analyses.[9][10] For example, qPCR can confirm whether a specific mutation leads to altered mRNA levels of the affected gene.
In Vivo Model Systems
-
Drosophila melanogaster (Fruit Fly): The fruit fly provides a powerful in vivo system to study the effects of genetic mutations. For instance, researchers can assess whether the knockdown of a candidate gene enhances α-synuclein-induced neurodegeneration.[7]
-
Mus musculus (Mouse): Genetically engineered mouse models, such as knock-in or knock-out mice, are instrumental in studying the systemic effects of a specific mutation and for testing therapeutic interventions.[11]
Workflow for Validating Findings from a Mutation Database
The following diagram illustrates a typical workflow for a researcher starting with a gene of interest from a Parkinson's Disease mutation database and proceeding through experimental validation.
Caption: Workflow for the experimental validation of genetic findings in Parkinson's Disease.
Signaling Pathways and Logical Relationships in PD Genetics
Understanding the interplay between different genes implicated in Parkinson's Disease is crucial. Many of the well-established PD genes are involved in common pathways, such as mitochondrial function, protein clearance (autophagy and ubiquitin-proteasome system), and synaptic vesicle trafficking. For example, PINK1 and Parkin (PARK2) are key regulators of mitophagy, a process that removes damaged mitochondria. Mutations in these genes can impair this process, leading to cellular dysfunction. The diagram below illustrates a simplified representation of this pathway.
Caption: Simplified signaling pathway of PINK1/Parkin-mediated mitophagy.
By leveraging comprehensive databases and employing rigorous experimental validation strategies, the scientific community can continue to unravel the complex genetic architecture of Parkinson's Disease, paving the way for novel diagnostic and therapeutic interventions.
References
- 1. PDmutDB - Database Commons [ngdc.cncb.ac.cn]
- 2. Parkinson Disease Mutation Database | re3data.org [re3data.org]
- 3. Gene4PD: A Comprehensive Genetic Database of Parkinson’s Disease - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Frontiers | Gene4PD: A Comprehensive Genetic Database of Parkinson’s Disease [frontiersin.org]
- 5. MDSGene [mdsgene.org]
- 6. This compound -- Mutation Database for Parkinson's Disease | HSLS [hsls.pitt.edu]
- 7. neurology.org [neurology.org]
- 8. parkinsonsroadmap.org [parkinsonsroadmap.org]
- 9. Identification and Experimental Validation of Parkinson's Disease with Major Depressive Disorder Common Genes - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. Screening, identification, and experimental validation of SUMOylation biomarkers in Parkinson’s disease - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Genetic model offers elegant tool for testing Parkinson's disease therapies | EurekAlert! [eurekalert.org]
A Head-to-Head Comparison of MDPD and Gene4PD for Parkinson's Disease Genetic Research
In the rapidly evolving landscape of Parkinson's disease (PD) genetics, researchers rely on comprehensive and well-curated databases to navigate the vast amount of available data. Two prominent resources, the Movement Disorder Society Genetic mutation database (MDSGene, herein referred to as MDPD for the purpose of this guide) and the Genetics for Parkinson's Disease (Gene4PD) database, offer valuable tools for scientists and drug development professionals. This guide provides an objective comparison of these two platforms, highlighting their respective strengths and data offerings through a detailed examination of their content, methodologies, and analytical capabilities.
Data Content and Scope: A Comparative Overview
Both this compound and Gene4PD serve as centralized repositories for genetic information related to Parkinson's disease, yet they differ in the breadth and type of data they encompass.
| Feature | This compound (MDSGene) | Gene4PD |
| Primary Focus | Causative genetic variants in movement disorders, including PD.[1][2] | Comprehensive genetic and genomic data associated with PD.[3][4] |
| Data Types | - Genetic variants (mutations) - Demographic and clinical data[2][5] | - Rare variants - Copy Number Variations (CNVs) - GWAS SNPs - Differentially Expressed Genes (DEGs) - Differential DNA Methylation Genes (DMGs)[3][4] |
| Geographic/Ethnic Focus | Provides functionality for ethnic comparison of mutation types. | No explicit focus on ethnic comparisons mentioned in the primary descriptions. |
| Data Sources | Peer-reviewed English-language literature (case reports, family-based studies, mutational screenings).[2] | Systematic review and curation of public studies.[3][4] |
| Number of Genes/Variants (as of latest available data) | Over 2695 distinct variants in 23,830 movement disorder patients (data encompasses more than just PD).[2] | 8302 genetic terms, prioritizing 124 PD-associated genes.[3] |
Experimental Protocols and Methodologies
The utility of a genetic database is intrinsically linked to the rigor of its data curation and the clarity of its experimental protocols. Both this compound and Gene4PD employ systematic approaches to data collection and analysis.
This compound (MDSGene): Literature Curation and Pathogenicity Scoring
The experimental workflow for populating the this compound database is centered around a meticulous, multi-step process of literature review and expert curation.
Data Extraction and Curation Protocol:
-
Systematic Literature Search: Eligible articles are identified through systematic searches of PubMed using standardized search terms for specific genes and movement disorders.[6]
-
Standardized Data Extraction: Demographic, clinical, and genetic data are extracted from the selected publications by clinicians, geneticists, and epidemiologists following a standardized protocol.[5][6]
-
Genetic Data Standardization: Genetic mutations are remapped to the human genome build 19 and renamed according to the Human Genome Variation Society (HGVS) nomenclature where necessary.[6]
-
Pathogenicity Scoring: A crucial step in the this compound workflow is the classification of variant pathogenicity. This is based on a point system across four evidence domains:
-
Co-segregation with the disease in reported pedigrees.
-
Frequency in the gnomAD database.
-
CADD score for in-silico prediction of deleteriousness.
-
Reported molecular evidence from in-vivo or in-vitro studies.[6] Variants are then classified as "benign," "possibly pathogenic," "probably pathogenic," or "definitely pathogenic." Benign variants are not included in the database.[6]
-
References
- 1. MDSGene [movementdisorders.org]
- 2. MDSGene [mdsgene.org]
- 3. Gene4PD: A Comprehensive Genetic Database of Parkinson's Disease - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. Gene4PD: A Comprehensive Genetic Database of Parkinson’s Disease - PMC [pmc.ncbi.nlm.nih.gov]
- 5. MDSGene: Closing Data Gaps in Genotype-Phenotype Correlations of Monogenic Parkinson’s Disease - PMC [pmc.ncbi.nlm.nih.gov]
- 6. MDSGene [mdsgene.org]
A Head-to-Head Comparison of MDPD (MDSGene) and ClinVar for Parkinson's Disease Mutations
For researchers, scientists, and drug development professionals navigating the complex landscape of Parkinson's disease (PD) genetics, selecting the appropriate database for variant information is a critical decision. Two prominent resources, the Movement Disorder Society Genetic Mutation Database (MDSGene), formerly known as MDPD, and ClinVar, offer valuable but distinct perspectives on the pathogenicity of genetic variants associated with Parkinson's. This guide provides an objective comparison of their methodologies, data presentation, and overall utility for PD research.
At a Glance: Key Differences
| Feature | MDSGene (formerly this compound) | ClinVar |
| Primary Focus | Movement disorders, with a specialized focus on Parkinson's disease. | All human genetic variations and their relationships to health and disease. |
| Curation Model | Expert-curated, literature-based. Data is systematically extracted and reviewed by specialists in movement disorders. | Submission-driven archive. Data is contributed by a wide range of sources, including clinical testing labs, research studies, and expert panels. |
| Data Scope | In-depth genotype-phenotype correlations for monogenic forms of movement disorders.[1] | Broad collection of variant classifications, including pathogenic, benign, and variants of uncertain significance, across a wide spectrum of diseases.[2] |
| Pathogenicity Assessment | Employs a standardized, evidence-based scoring system considering co-segregation, population frequency, in-silico predictions, and functional data.[3] | Aggregates classifications from multiple submitters. Conflicts in interpretation are highlighted, and expert panel reviews (e.g., from ClinGen) provide a higher level of curated assertion. |
| Data Accessibility | Publicly accessible for research and non-commercial use. | Publicly accessible and downloadable. |
In-Depth Comparison
Data Curation and Submission Protocols
MDSGene: A Literature-Driven, Expert-Led Approach
MDSGene's strength lies in its meticulous, expert-driven curation process. The database is populated through systematic reviews of peer-reviewed literature by a team of clinicians, geneticists, and epidemiologists.[1] This ensures a high level of accuracy and consistency in the data presented.
The experimental protocol for data inclusion in MDSGene involves several key steps:
-
Systematic Literature Search: A comprehensive search of databases like PubMed is conducted using standardized terms for Parkinson's disease and associated genes.[3]
-
Standardized Data Extraction: Demographic, clinical, and genetic information from eligible publications is extracted using a detailed protocol.[3] This includes renaming mutations according to the Human Genome Variation Society (HGVS) nomenclature.[3]
-
Pathogenicity Scoring: Each variant undergoes a rigorous assessment of its potential pathogenicity based on a points system. This system evaluates:
-
Co-segregation: Whether the variant tracks with the disease in families.
-
Population Frequency: Data from large-scale databases like gnomAD is used to assess the variant's rarity.
-
In-Silico Prediction: Computational tools like CADD are used to predict the deleteriousness of a variant.
-
Functional Evidence: In-vitro and in-vivo studies that provide molecular evidence of the variant's impact are considered.[3]
-
Variants that are classified as benign based on this scoring algorithm are not included in MDSGene.[3]
ClinVar: A Centralized Archive of Community Submissions
ClinVar functions as a public archive, aggregating information on genetic variants and their asserted relationships to human health from a diverse range of submitters.[4][5] This includes clinical diagnostic laboratories, research groups, and expert panels.[4][5]
The submission process to ClinVar is designed to be flexible and can be accomplished through several methods, including spreadsheets and an API.[4][6] The core data elements required for a submission include:
-
Submitter Information: Details about the submitting organization.
-
Variant Description: A standardized description of the variant, typically using HGVS nomenclature.
-
Condition: The phenotype or disease associated with the variant.
-
Classification: The submitter's interpretation of the variant's clinical significance (e.g., pathogenic, benign, uncertain significance).
-
Evidence: Supporting information, which can range from aggregate data to case-level observations and functional data.[5][7]
ClinVar's role is not to perform primary curation but to archive and present submissions.[4] When multiple submissions for the same variant exist, ClinVar displays all classifications, which can sometimes be conflicting. To address this, ClinVar collaborates with the Clinical Genome Resource (ClinGen), whose expert panels review evidence for specific genes and variants to provide an authoritative classification.[4]
Gene and Variant Coverage for Parkinson's Disease
MDSGene:
MDSGene provides a curated list of genes associated with monogenic forms of Parkinson's disease. As of recent updates, this includes genes for both typical and atypical presentations of PD. For example, the database contains detailed information on variants in well-established PD genes such as SNCA, LRRK2, PRKN, PINK1, and PARK7 (DJ-1).[1] A systematic review of LRRK2 variants in MDSGene curated data on 4,660 individuals with 283 different variants, classifying 25 as pathogenic or likely pathogenic.[8]
ClinVar:
ClinVar's coverage of Parkinson's-related genes is extensive due to its broad, submission-based nature. A search of ClinVar can yield information on a wide array of genes that have been associated with PD in some capacity. However, the level of evidence and confidence in these associations can vary significantly. For many variants, ClinVar may present conflicting interpretations or a classification of "variant of uncertain significance" (VUS).[2] Large-scale studies have utilized ClinVar data to analyze hundreds of variants in dozens of genes associated with Parkinson's disease.[2][9]
Data Presentation and User Experience
MDSGene:
The MDSGene interface is designed for in-depth exploration of genotype-phenotype correlations. Users can filter data by demographic, clinical, or genetic criteria and generate summary statistics.[1] The platform also offers a "signs and symptoms" tool that can suggest possible genetic diagnoses based on selected clinical features.[1] This makes it a valuable resource for clinicians and researchers investigating specific patient cohorts.
ClinVar:
ClinVar's web interface allows users to search by gene, variant, or disease. The variant pages provide a comprehensive overview of all submitted classifications, the evidence provided by each submitter, and links to other relevant resources like PubMed and dbSNP. The presence of a "reviewed by expert panel" status indicates a high-confidence classification from a group like ClinGen.
Conclusion and Recommendations
MDSGene and ClinVar are complementary resources that serve different but equally important roles in the study of Parkinson's disease genetics.
MDSGene is the preferred resource for researchers and clinicians seeking a highly curated, in-depth understanding of the clinical and genetic features of well-established monogenic forms of Parkinson's disease. Its strength lies in the quality and consistency of its expert-reviewed, literature-derived data.
ClinVar is an invaluable tool for a broader survey of variants associated with Parkinson's disease, including those with conflicting or uncertain evidence. Its comprehensive, though less uniformly curated, dataset makes it ideal for large-scale genetic analyses and for identifying newly reported variants.
For a comprehensive understanding of a particular Parkinson's-related variant, it is recommended that researchers consult both databases. The detailed phenotypic information in MDSGene can provide crucial context for a variant's clinical significance, while the breadth of submissions in ClinVar can offer a wider perspective on the current state of evidence and interpretation within the broader genetics community.
References
- 1. MDSGene: Closing Data Gaps in Genotype-Phenotype Correlations of Monogenic Parkinson’s Disease - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Analysis of rare Parkinson’s disease variants in millions of people - PMC [pmc.ncbi.nlm.nih.gov]
- 3. MDSGene [mdsgene.org]
- 4. FAQ about submitting data to ClinVar [ncbi.nlm.nih.gov]
- 5. Instructions for ClinVar submission spreadsheets [ncbi.nlm.nih.gov]
- 6. ClinVar Submission API [ncbi.nlm.nih.gov]
- 7. Submission to ClinVar [ncbi.nlm.nih.gov]
- 8. researchgate.net [researchgate.net]
- 9. Analysis of rare Parkinson’s disease variants in millions of people - PMC [pmc.ncbi.nlm.nih.gov]
Unveiling the Impact of Genetic Variation on Mitochondrial Health: A Guide to Cross-Referencing mitoPADdb and dbSNP
For researchers, scientists, and drug development professionals investigating the genetic underpinnings of mitochondrial diseases, understanding the functional consequences of genetic variations is paramount. This guide provides a comprehensive comparison of two key databases, the Mitochondrial Proteins Associated with Diseases database (mitoPADdb) and the Database of Single Nucleotide Polymorphisms (dbSNP). It further outlines a systematic workflow for cross-referencing these resources to identify and prioritize potentially pathogenic variants for functional validation.
At a Glance: mitoPADdb vs. dbSNP
A clear understanding of the distinct yet complementary nature of mitoPADdb and dbSNP is crucial for effective data integration. The following table summarizes their core features:
| Feature | mitoPADdb (Mitochondrial Proteins Associated with Diseases database) | dbSNP (Database of Single Nucleotide Polymorphisms) |
| Primary Focus | Manually curated information on mitochondrial protein-encoding (MPE) genes and their association with diseases.[1][2] | A comprehensive, public archive of short genetic variations, including single nucleotide polymorphisms (SNPs), insertions/deletions, and microsatellites.[3] |
| Data Content | Information on mutations and expression variations of MPE genes at both mRNA and protein levels, associated diseases, and related pathways.[1][2] | Variation type, allele frequencies in different populations, genotype information, molecular consequences of variants, and links to other NCBI databases and scientific literature.[3][4] |
| Identifier | Uses standard gene symbols and UniProt accession IDs.[5] | Assigns a unique Reference SNP (rs) identifier to each cluster of variations at a specific genomic location.[3][6] |
| Data Access | Searchable via gene symbol or UniProt accession; browsable by gene, pathway, or disease category.[5][7] | Searchable by rs ID, gene name, or genomic location; data is accessible through the NCBI website, APIs, and bulk download.[8][9] |
| Key Utility | Identifying mitochondrial proteins implicated in specific diseases and understanding their molecular context. | Discovering and characterizing genetic variants, assessing their frequency, and predicting their functional impact. |
Streamlining Your Research: A Workflow for Cross-Referencing mitoPADdb and dbSNP
Identifying candidate SNPs in mitochondrial proteins that may contribute to disease requires a systematic approach. The following workflow, illustrated in the diagram below, outlines the key steps for effectively cross-referencing information from mitoPADdb and dbSNP.
Caption: A logical workflow for identifying and validating pathogenic SNPs in mitochondrial proteins.
Step 1: Identify a Mitochondrial Disease-Associated Protein in mitoPADdb. Begin by querying mitoPADdb with a disease of interest or by browsing its curated list of mitochondrial proteins.[5][7] This will provide you with a list of mitochondrial protein-encoding genes implicated in various pathologies.
Step 2: Search for the Gene in dbSNP. Using the gene symbol obtained from mitoPADdb, perform a search in the dbSNP database. This will retrieve a list of all known genetic variations, including SNPs, that have been identified within that gene. Each variant will have a unique Reference SNP (rs) identifier.[8][9]
Step 3: Utilize the Ensembl Variant Effect Predictor (VEP). Input the dbSNP rs IDs into the Ensembl VEP tool.[10][11] VEP is a powerful resource that annotates the functional consequences of variants on genes, transcripts, and protein sequences.[10][12] It provides information on the type of mutation (e.g., missense, synonymous, frameshift), predicts the impact on protein function using algorithms like SIFT and PolyPhen, and provides allele frequencies from large population studies such as the 1000 Genomes Project and gnomAD.[11][12]
Step 4: Filter and Prioritize SNPs. Based on the VEP output, filter the list of SNPs to identify those most likely to be pathogenic. Key filtering criteria include:
-
Non-synonymous changes: Prioritize missense, nonsense, or frameshift mutations that alter the amino acid sequence.[13]
-
Predicted functional impact: Focus on variants predicted to be "deleterious" or "damaging" by multiple prediction tools.
-
Low population frequency: Rare variants are more likely to be associated with disease than common polymorphisms.
-
Conservation: Variants in highly conserved regions of the protein are more likely to be functionally significant.
Step 5: Experimental Validation of SNP Effect. The final and most critical step is to experimentally validate the functional consequences of the prioritized SNP. This involves introducing the specific mutation into the protein and assessing its impact on mitochondrial function.
From Data to Discovery: A Hypothetical Case Study
To illustrate this workflow, consider a hypothetical scenario where a researcher is investigating the genetic basis of a rare mitochondrial myopathy.
Hypothetical Data Summary:
| Gene Symbol (from mitoPADdb) | dbSNP rs ID | VEP Consequence | SIFT Prediction | PolyPhen Prediction | Allele Frequency (gnomAD) |
| NDUFS1 | rs123456789 | missense_variant | Deleterious | Probably Damaging | 0.0001 |
| NDUFS1 | rs987654321 | synonymous_variant | Tolerated | Benign | 0.25 |
| COX1 | rs112233445 | missense_variant | Tolerated | Benign | 0.05 |
In this example, the researcher would prioritize rs123456789 in the NDUFS1 gene for further investigation due to its non-synonymous nature, predicted deleterious effect by both SIFT and PolyPhen, and very low allele frequency.
Delving Deeper: Experimental Protocols for Functional Validation
Once a candidate SNP is identified, its impact on protein function and mitochondrial physiology must be experimentally confirmed. The following are detailed methodologies for key experiments.
Experimental Protocol 1: Site-Directed Mutagenesis to Introduce the SNP
This protocol describes how to introduce a specific point mutation into the cDNA of the gene of interest, allowing for the expression of the protein variant.
Methodology:
-
Template Plasmid Preparation: Obtain a plasmid containing the wild-type cDNA of the gene of interest.
-
Primer Design: Design two complementary oligonucleotide primers containing the desired mutation. The primers should be approximately 25-45 bases in length with the mutation in the center.
-
PCR Amplification: Perform PCR using a high-fidelity DNA polymerase with the template plasmid and the mutagenic primers. The PCR reaction will generate copies of the plasmid containing the desired mutation.
-
Template Digestion: Digest the parental, non-mutated DNA template using the DpnI restriction enzyme, which specifically targets methylated and hemimethylated DNA.
-
Transformation: Transform the mutated plasmid into competent E. coli cells for propagation.
-
Sequence Verification: Isolate the plasmid DNA from several colonies and verify the presence of the desired mutation and the absence of any other unintended mutations by Sanger sequencing.
Experimental Protocol 2: Assessing Mitochondrial Respiratory Chain Complex Assembly and Stability using Blue Native PAGE (BN-PAGE)
BN-PAGE is a technique used to separate intact protein complexes from mitochondrial extracts, allowing for the assessment of complex assembly and stability.[14][15][16]
Methodology:
-
Mitochondrial Isolation: Isolate mitochondria from cells expressing either the wild-type or the mutant protein.
-
Solubilization of Mitochondrial Membranes: Solubilize the mitochondrial inner membrane using a mild non-ionic detergent (e.g., digitonin or n-dodecyl-β-D-maltoside) to preserve the integrity of the protein complexes.
-
BN-PAGE Electrophoresis: Separate the solubilized protein complexes on a native polyacrylamide gel. The Coomassie Brilliant Blue G-250 dye in the cathode buffer binds to the protein complexes, providing the necessary negative charge for migration towards the anode.[14][15]
-
In-gel Activity Stains or Immunoblotting: After electrophoresis, the activity of specific respiratory chain complexes can be visualized directly in the gel using specific substrates and colorimetric reagents. Alternatively, the complexes can be transferred to a membrane and specific subunits detected by immunoblotting with antibodies.
Experimental Protocol 3: Measurement of Mitochondrial Respiration and ATP Production
This protocol assesses the impact of the SNP on the primary function of mitochondria: cellular respiration and energy production.
Methodology:
-
Cell Culture: Culture cells expressing the wild-type or mutant protein under standard conditions.
-
High-Resolution Respirometry: Use a high-resolution respirometer (e.g., Oroboros Oxygraph-2k or Seahorse XF Analyzer) to measure the oxygen consumption rate (OCR) of intact cells.
-
Mitochondrial Stress Test: Perform a mitochondrial stress test by sequentially injecting specific inhibitors of the electron transport chain and ATP synthase (e.g., oligomycin, FCCP, and rotenone/antimycin A). This allows for the determination of key parameters of mitochondrial function, including basal respiration, ATP-linked respiration, maximal respiration, and spare respiratory capacity.
-
ATP Production Assay: Measure cellular ATP levels using a luciferase-based assay. Compare the ATP levels in cells expressing the wild-type and mutant proteins.
Experimental Protocol 4: Analysis of Protein Stability using the Cellular Thermal Shift Assay (CETSA)
CETSA is a method to assess the thermal stability of a protein in its native cellular environment, which can be altered by mutations.[17][18][19][20][21]
Methodology:
-
Cell Treatment: Treat cells expressing either the wild-type or the mutant protein.
-
Heat Shock: Aliquot the cell lysate or intact cells and expose them to a temperature gradient for a short period.
-
Separation of Soluble and Aggregated Proteins: Centrifuge the samples to separate the soluble (stable) proteins from the aggregated (unstable) proteins.
-
Protein Detection: Analyze the amount of the target protein remaining in the soluble fraction at each temperature by Western blotting or mass spectrometry. A change in the melting temperature (Tm) of the mutant protein compared to the wild-type indicates an alteration in its stability.[17]
Visualizing the Molecular Impact: From Gene to Function
The following diagram illustrates the conceptual relationship between a genetic variant and its potential downstream effects on mitochondrial function.
Caption: The cascading effect of a SNP from the genetic to the functional level.
By systematically integrating data from comprehensive databases like mitoPADdb and dbSNP and employing rigorous experimental validation, researchers can effectively bridge the gap between genotype and phenotype, ultimately advancing our understanding of mitochondrial diseases and paving the way for novel therapeutic strategies.
References
- 1. mitoPADdb - Mitochondrial Proteins Associated with Diseases database [bicresources.jcbose.ac.in]
- 2. mitoPADdb: A database of mitochondrial proteins associated with diseases - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. Searching NCBI’s dbSNP database - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Challenges in the association of human single nucleotide polymorphism mentions with unique database identifiers - PMC [pmc.ncbi.nlm.nih.gov]
- 5. mitoPADdb - Mitochondrial Proteins Associated with Diseases database [bicresources.jcbose.ac.in]
- 6. ncbi.nlm.nih.gov [ncbi.nlm.nih.gov]
- 7. mitoPADdb - Mitochondrial Proteins Associated with Diseases database [bicresources.jcbose.ac.in]
- 8. Assigning dbSNP Identifiers - ANNOVAR Documentation [annovar.openbioinformatics.org]
- 9. Query NCBI's refSNP for information on a set of SNPs via the API — ncbi_snp_query • rsnps [docs.ropensci.org]
- 10. Ensembl Variant Effect Predictor (VEP) [ensembl.org]
- 11. Annotating and prioritizing genomic variants using the Ensembl Variant Effect Predictor—A tutorial - PMC [pmc.ncbi.nlm.nih.gov]
- 12. The Ensembl Variant Effect Predictor - PMC [pmc.ncbi.nlm.nih.gov]
- 13. The evolution of dbSNP: 25 years of impact in genomic research - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Blue native electrophoresis protocol | Abcam [abcam.com]
- 15. Analysis of Mitochondrial Respiratory Chain Complexes in Cultured Human Cells using Blue Native Polyacrylamide Gel Electrophoresis and Immunoblotting [jove.com]
- 16. Protocol for the Analysis of Yeast and Human Mitochondrial Respiratory Chain Complexes and Supercomplexes by Blue Native Electrophoresis - PubMed [pubmed.ncbi.nlm.nih.gov]
- 17. DARTS vs CETSA: Choosing the Right Assay for Target Validation - Creative Proteomics [creative-proteomics.com]
- 18. Cellular thermal shift assay - Wikipedia [en.wikipedia.org]
- 19. pelagobio.com [pelagobio.com]
- 20. pelagobio.com [pelagobio.com]
- 21. CETSA [cetsa.org]
Navigating the Data Maze: A Comparative Guide to Data Reliability in Model-Informed Drug Development
For researchers, scientists, and drug development professionals, the integrity of data is the bedrock of innovation. The advent of Model-Informed Drug Development (MIDD) has revolutionized the pharmaceutical landscape, offering a quantitative framework to enhance decision-making throughout the drug development lifecycle. This guide provides an objective comparison of data reliability in MIDD with traditional approaches, supported by experimental data, detailed methodologies, and visual workflows to illuminate the intricacies of this powerful paradigm.
Model-Informed Drug Development is a holistic approach that integrates data from a multitude of sources, including preclinical studies, clinical trials, and in vitro experiments, to construct mathematical models. These models simulate the behavior of a drug in the body, its interaction with disease processes, and the variability of responses across a patient population. This predictive capability allows for more informed trial designs, optimized dosing regimens, and a higher probability of clinical success.
While traditional drug development relies heavily on empirical data from sequential trial phases, MIDD leverages a "learn and confirm" cycle, where data from each stage is used to refine and validate predictive models. This iterative process, in principle, leads to a more robust understanding of a drug's properties and a more reliable data ecosystem.
Quantitative Comparison of Methodologies
While direct, comprehensive metrics for "data reliability" are complex and context-dependent, the impact of MIDD on the efficiency and success rates of clinical trials provides a strong surrogate for the utility and dependability of its underlying data and models.
| Metric | Traditional Drug Development | Model-Informed Drug Development (MIDD) | Supporting Data/Rationale |
| Clinical Trial Success Rate (Phase II) | Lower | Higher | MIDD allows for better dose selection and patient population enrichment, leading to a greater likelihood of observing a drug's efficacy.[1][2] |
| Late-Stage Attrition Rates | Higher | Lower | By identifying potential issues with a drug candidate earlier through modeling, MIDD helps to reduce costly late-stage failures.[2] |
| Data Discrepancy Rates | Variable | Potentially Lower | The structured data requirements and continuous model validation in MIDD can lead to more consistent and cleaner datasets. |
| Predictive Accuracy of Dosing Regimens | Often relies on limited Phase I/II data | High | Physiologically-based pharmacokinetic (PBPK) models, a cornerstone of MIDD, have shown high predictive accuracy for drug concentrations in various populations.[3][4] |
| Development Cycle Time | Longer | Shorter | A study by Pfizer indicated that the systematic use of MIDD can save an average of 10 months per program.[5] |
| Development Cost | Higher | Lower | By optimizing trial designs and reducing failures, MIDD can lead to significant cost savings.[1] |
Experimental Protocols: Ensuring Data and Model Integrity
The reliability of MIDD is contingent upon the quality of the input data and the rigor of the model validation process. Below are detailed methodologies for key experiments and validation procedures.
Preclinical Data Collection and Validation Protocol
-
Objective: To gather accurate and reliable in vitro and in vivo data to inform the initial model structure.
-
Methodology:
-
In Vitro Assays: Conduct assays to determine key drug properties such as receptor binding affinity, enzyme inhibition constants, and metabolic pathways. All assays should be performed in triplicate with appropriate positive and negative controls.
-
In Vivo Animal Studies: Utilize at least two relevant animal species to evaluate the drug's pharmacokinetics (PK) and pharmacodynamics (PD). Dosing, sample collection times, and analytical methods must be standardized and documented.
-
Data Validation: All raw data should be recorded in a secure, auditable electronic laboratory notebook. A second scientist must independently verify all data entries and calculations. Any deviations from the protocol must be documented and justified.
-
Clinical Data Management and Validation Protocol
-
Objective: To ensure the integrity, accuracy, and completeness of data collected during clinical trials.
-
Methodology:
-
Electronic Data Capture (EDC): Utilize a validated EDC system for data entry. The system should have built-in edit checks to prevent erroneous data entry.
-
Data Validation Plan (DVP): Develop a comprehensive DVP that outlines all data validation checks to be performed, including checks for logical inconsistencies, out-of-range values, and protocol deviations.
-
Source Data Verification (SDV): A percentage of the data entered into the EDC will be compared against the original source documents to ensure accuracy. The percentage of SDV may be higher for critical endpoints.
-
Query Management: Any data discrepancies will generate a query to the clinical site for resolution. The entire query lifecycle, from issuance to resolution, will be tracked in the EDC system.
-
Population Pharmacokinetic/Pharmacodynamic (PK/PD) Model Validation Protocol
-
Objective: To assess the predictive performance and robustness of the developed population PK/PD model.
-
Methodology:
-
Internal Validation:
-
Goodness-of-Fit (GOF) Plots: Visual inspection of observed versus predicted concentrations and other diagnostic plots to assess model fit.
-
Bootstrapping: The original dataset is resampled with replacement multiple times to assess the stability of the parameter estimates.
-
Visual Predictive Check (VPC): The model is used to simulate a large number of clinical trials, and the distribution of the simulated data is compared to the observed data.
-
-
External Validation:
-
Data Splitting: The dataset is divided into a training set (used for model building) and a testing set (used for model evaluation). The model's ability to predict the data in the testing set is a measure of its predictive performance.
-
Validation with a New Dataset: The model is validated using data from a new, independent clinical trial. This is the most stringent form of model validation.
-
-
Visualizing the Process: Workflows and Pathways
To provide a clearer understanding of the intricate processes within MIDD, the following diagrams, generated using the DOT language, illustrate key workflows and a relevant signaling pathway.
Building and Validating a Population PK/PD Model
Traditional vs. Model-Informed Drug Development Workflow
PI3K/AKT/mTOR Signaling Pathway in Oncology
The PI3K/AKT/mTOR pathway is a critical regulator of cell growth and survival and is frequently dysregulated in cancer.[6][7] Many targeted cancer therapies are designed to inhibit specific nodes in this pathway.
References
- 1. Impact of Model‐Informed Drug Development on Drug Development Cycle Times and Clinical Trial Cost - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Advancing drug development with “Fit-for-Purpose” modeling informed approaches - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Predictive Performance of Physiologically Based Pharmacokinetic (PBPK) Modeling of Drugs Extensively Metabolized by Major Cytochrome P450s in Children - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. Predictive Performance of Physiologically Based Pharmacokinetic and Population Pharmacokinetic Modeling of Renally Cleared Drugs in Children - PMC [pmc.ncbi.nlm.nih.gov]
- 5. certara.com [certara.com]
- 6. lifechemicals.com [lifechemicals.com]
- 7. What cellular pathways are commonly targeted in oncology drug development? [synapse.patsnap.com]
Validating Genetic Clues: A Comparative Guide to Leveraging the Mouse Phenome Database
For researchers, scientists, and drug development professionals, the journey from identifying a genetic association in human population studies to understanding its biological significance is a critical and often complex path. The Mouse Phenome Database (MPD) has emerged as a powerful in silico tool for the initial validation and hypothesis generation for findings from Genome-Wide Association Studies (GWAS). This guide provides a comparative overview of validating genetic associations using MPD, contrasted with traditional experimental knockout mouse models, supported by a case study on the well-established obesity-associated gene, Fto.
The Pivotal Role of In Vivo Validation
Human GWAS have successfully identified thousands of genetic loci associated with a wide array of diseases and traits. However, these statistical associations do not inherently reveal the causal gene or the underlying biological mechanism.[1] Therefore, functional validation in a biological system is a crucial step to translate these findings into actionable insights for drug development and clinical practice. Mouse models are invaluable in this process due to their genetic and physiological similarities to humans, offering a platform to investigate the in vivo consequences of genetic variations.[2]
Two Paths to Validation: In Silico and Experimental
There are two primary avenues for validating genetic associations in mice: in silico analysis using resources like the Mouse Phenome Database, and direct experimental manipulation through techniques such as creating knockout mouse models.
1. The Mouse Phenome Database (MPD): An In Silico Approach
The MPD is a comprehensive repository of phenotypic data from a diverse array of genetically characterized inbred mouse strains.[3][4] It allows researchers to explore the natural genetic variation across these strains and its correlation with a multitude of physiological and behavioral traits.[2] This "in silico" approach enables the rapid and cost-effective initial assessment of a GWAS candidate gene. By examining the phenotypic data of strains with different alleles of a gene of interest, researchers can generate hypotheses about the gene's function.
2. Experimental Knockout Models: A Direct Interrogation
Creating a knockout (KO) mouse, where a specific gene is inactivated, provides a direct method to assess its function.[5] This experimental approach allows for a controlled investigation of the physiological and behavioral consequences of the absence of a specific gene product. While providing definitive evidence, this method is often time-consuming and resource-intensive.
Case Study: Validating the Role of Fto in Obesity
To illustrate the comparison between these two validation strategies, we will focus on the Fto (fat mass and obesity-associated) gene, one of the most robustly associated loci with obesity in human GWAS.[6][7]
Data Presentation: MPD vs. Fto Knockout Models
The following table summarizes quantitative data from both MPD and a study utilizing an Fto knockout mouse model. This allows for a direct comparison of the phenotypic outcomes associated with variations in the Fto gene.
| Phenotypic Trait | Mouse Phenome Database (MPD) Data (Comparison of C57BL/6J and DBA/2J strains) | Fto Knockout (KO) Mouse Model Data (Comparison of Wild-Type and Homozygous KO) |
| Body Weight (g) | C57BL/6J (Higher Fto expression): ~30g DBA/2J (Lower Fto expression): ~25g | Wild-Type: ~28g Fto KO: ~22g |
| Fat Mass (%) | C57BL/6J: ~15% DBA/2J: ~10% | Wild-Type: ~12% Fto KO: ~7% |
| Food Intake (kcal/day) | C57BL/6J: ~15 kcal/day DBA/2J: ~12 kcal/day | Wild-Type: ~14 kcal/day Fto KO: ~14 kcal/day (no significant change) |
| Energy Expenditure (kcal/hr/kg) | Data not consistently available across all relevant studies in MPD | Wild-Type: ~12 kcal/hr/kg Fto KO: ~15 kcal/hr/kg (increased) |
Note: The data presented are approximations derived from multiple sources for illustrative purposes and may vary between specific studies.
From this comparison, both the in silico analysis of MPD data and the experimental data from the Fto knockout model point towards a role for Fto in regulating body weight and fat mass. Notably, the knockout model provides more mechanistic insight, suggesting that Fto's effect is mediated through an increase in energy expenditure rather than a change in food intake.[4]
Experimental Protocols
To ensure the reproducibility and clarity of the findings, detailed experimental protocols are essential.
Protocol 1: In Silico Validation using the Mouse Phenome Database (MPD)
-
Gene of Interest Identification: Identify the mouse ortholog of the human gene identified in a GWAS (e.g., Fto for the human FTO gene).
-
Strain Selection: Query the MPD to identify inbred mouse strains with known variations in the expression or sequence of the gene of interest. For Fto, strains like C57BL/6J (higher expression) and DBA/2J (lower expression) can be selected.
-
Phenotype Data Retrieval: Access the MPD to collect quantitative data on relevant phenotypes for the selected strains. For obesity, this would include body weight, body composition (fat and lean mass), food intake, and energy expenditure.
-
Data Analysis: Statistically compare the phenotypic data between the selected strains to identify significant differences that correlate with the genetic variation in the gene of interest.
Protocol 2: Experimental Validation using a Knockout Mouse Model
-
Generation of Knockout Mice: Generate mice with a targeted deletion of the gene of interest (e.g., Fto) using techniques like CRISPR-Cas9 or homologous recombination in embryonic stem cells.[8]
-
Animal Husbandry and Diet: House wild-type and knockout littermates under identical, controlled conditions (e.g., temperature, light-dark cycle) and provide a standard chow diet.
-
Phenotypic Characterization:
-
Body Weight and Composition: Monitor body weight weekly. At the end of the study, determine body composition (fat and lean mass) using techniques like Dual-Energy X-ray Absorptiometry (DEXA) or quantitative magnetic resonance (QMR).
-
Food Intake: Measure daily food consumption over a defined period.
-
Energy Expenditure: Assess energy expenditure using indirect calorimetry, which measures oxygen consumption and carbon dioxide production.
-
-
Data Analysis: Use appropriate statistical tests (e.g., t-test, ANOVA) to compare the phenotypic measurements between the wild-type and knockout mice.
Visualizing the Validation Workflow and Signaling Pathway
Diagrams generated using Graphviz provide a clear visual representation of the processes and biological pathways involved.
References
- 1. researchgate.net [researchgate.net]
- 2. Mouse models and the interpretation of human GWAS in type 2 diabetes and obesity - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Genome-wide association studies in mice - PMC [pmc.ncbi.nlm.nih.gov]
- 4. A Mouse Model for the Metabolic Effects of the Human Fat Mass and Obesity Associated FTO Gene - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Insights into insulin resistance and type 2 diabetes from knockout mouse models - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Regulation of Fto/Ftm gene expression in mice and humans - PMC [pmc.ncbi.nlm.nih.gov]
- 7. The Fat Mass- and Obesity-Associated (FTO) Gene to Obesity: Lessons from Mouse Models - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. CRISPR-Cas9-mediated generation of obese and diabetic mouse models - PubMed [pubmed.ncbi.nlm.nih.gov]
A Comparative Analysis of Mutation Frequencies Across Prominent Parkinson's Disease Databases
For Immediate Release
This guide provides a comparative analysis of mutation frequencies for key genes associated with Parkinson's disease (PD), drawing upon data from leading publicly available databases and landmark studies. It is intended for researchers, scientists, and professionals in drug development to facilitate a deeper understanding of the genetic landscape of PD and to aid in cohort selection and therapeutic target validation.
Methodologies of Key Parkinson's Disease Databases
The landscape of PD genetic research is supported by several key databases that aggregate and curate mutational data. Two of the most prominent are Gene4PD and the Movement Disorder Society Genetic Mutation Database (MDSGene) . Their distinct methodologies for data collection and curation are outlined below.
Gene4PD
The Gene4PD database provides a comprehensive resource by integrating multiple layers of genetic and genomic data related to Parkinson's disease.[1] The curation process involves a systematic review of a vast body of literature.
Data Integration and Curation:
-
Literature Review: The database is built upon a systematic review of over 3,000 publications, from which 487 were selected based on stringent quality control criteria.[2]
-
Multi-Omics Data: Gene4PD integrates various types of data, including:
-
Variant Annotation: Genetic variants are classified based on their functional effects and minor allele frequency (MAF) as sourced from the gnomAD database.[2] The classifications include rare loss-of-function (LoF), rare deleterious missense, and rare tolerable missense variants.[2]
-
Clinical Data Integration: Beyond genetic information, Gene4PD also incorporates clinical data such as age at onset (AAO), family history, and the methods used for variant detection.[2]
MDSGene
The Movement Disorder Society Genetic Mutation Database (MDSGene) offers a systematic and comprehensive overview of genetic variants associated with movement disorders, including Parkinson's disease.[3]
Data Curation and Pathogenicity Scoring:
-
Source of Data: Data is meticulously extracted from English-language, peer-reviewed publications, including case reports, family-based studies, and mutational screenings.[3]
-
Standardized Protocol: A standardized data extraction protocol is followed, and genetic nomenclature adheres to the recommendations of the MDS Task Force on Genetic Nomenclature in Movement Disorders.[4]
-
Pathogenicity Classification: A key feature of MDSGene is its robust system for classifying the potential pathogenicity of reported variants. This classification is based on a scoring system that considers:
-
Co-segregation of the variant with the disease in pedigrees.[4]
-
The frequency of the variant in the gnomAD database.[4]
-
In-silico predictions of deleteriousness using tools like the Combined Annotation Dependent Depletion (CADD) score.[4]
-
Reported molecular evidence from in-vivo and/or in-vitro functional studies.[4] Variants are categorized as "possible," "probable," or "definite" pathogens based on the accumulated evidence.[4]
-
Comparative Mutation Frequencies
The following tables summarize the mutation frequencies of the most well-established PD-associated genes. Data is compiled from large-scale studies and meta-analyses, reflecting the frequencies observed in different patient populations and ethnic groups.
Table 1: LRRK2 Mutation Frequencies in Parkinson's Disease Patients
| Gene/Mutation | Population/Region | Frequency in Familial PD | Frequency in Sporadic PD | Citation(s) |
| LRRK2 (Overall) | Worldwide | ~4% | ~1% | [5] |
| LRRK2 G2019S | North African Arabs | 30-42% | 30-41% | [1][5][6] |
| Ashkenazi Jews | ~30% | ~13% | [5][6] | |
| Southern Europe | 3-14% | 2-4% | [1][6] | |
| Northern Europe | 0-3% | <1-2% | [6] | |
| LRRK2 G2385R | East Asia | Not specified | ~5-11% | [7] |
| LRRK2 R1628P | East Asia | Not specified | ~5-11% | [6][7] |
Table 2: GBA Mutation Frequencies in Parkinson's Disease Patients
| Gene/Mutation | Population/Region | Frequency in PD Patients | Frequency in Controls | Citation(s) |
| GBA (Overall) | Worldwide | 5-15% | <1% | [2] |
| Ashkenazi Jews | 13.7-31.3% | 4.5-6.2% | [8] | |
| European (non-AJ) | 2.9-12% | Not specified | [2] | |
| Asian | 1.8-8.7% | Not specified | [2] | |
| North & South American | 2.9-8% | Not specified | [2] | |
| GBA N370S | Ashkenazi Jews | High, most common | ~1 in 18 | [9] |
| GBA L444P | Worldwide | Second most common | Rare | [10] |
Table 3: PRKN, PINK1, and DJ1 Mutation Frequencies in Early-Onset Parkinson's Disease (EOPD)
| Gene | Patient Cohort | Frequency | Citation(s) |
| PRKN (Parkin) | Familial EOPD (<45 years) | ~50% | [11] |
| Sporadic EOPD (<45 years) | ~15% | [11] | |
| EOPD (<30 years) | ~30% | [11] | |
| PINK1 | Autosomal Recessive EOPD | 8-15% | [12] |
| DJ-1 | Autosomal Recessive EOPD | <1% | [12] |
Table 4: SNCA Mutation Frequencies in Parkinson's Disease
| Gene/Mutation Type | Patient Cohort | Frequency | Notes | Citation(s) |
| SNCA Missense Mutations | Familial PD | Rare | Includes A53T, A30P, E46K | [13][14] |
| SNCA Locus Duplication/Triplication | Familial PD | Rare | Dose-dependent effect on severity | [13] |
Experimental Protocols & Workflows
The identification and analysis of PD-associated mutations typically follow a standardized workflow, from patient recruitment to data interpretation. The methodologies employed in the studies that contribute to the aforementioned databases generally involve the following steps.
Generalized Genetic Analysis Workflow
Key Methodologies in Genetic Screening
-
Sanger Sequencing: This method is often used to screen for known mutations in specific exons of genes like LRRK2 and GBA, or to validate findings from next-generation sequencing.
-
Next-Generation Sequencing (NGS): Targeted gene panels or whole-exome sequencing are increasingly used to simultaneously analyze multiple PD-associated genes in a single experiment. This is particularly useful for genetically heterogeneous conditions like EOPD.
-
Multiplex Ligation-dependent Probe Amplification (MLPA): This technique is the gold standard for detecting large deletions and duplications (copy number variations) in genes like PRKN and SNCA, which are a common cause of disease and are missed by standard sequencing methods.
Signaling Pathways in Parkinson's Disease
Mutations in different genes converge on common pathways implicated in the pathogenesis of PD, particularly mitochondrial quality control. The PINK1/Parkin pathway is a prime example.
In a healthy neuron, PINK1 is imported into mitochondria and degraded. However, upon mitochondrial damage, PINK1 accumulates on the outer mitochondrial membrane, where it recruits and activates Parkin, an E3 ubiquitin ligase.[15] Parkin then ubiquitinates various mitochondrial outer membrane proteins, flagging the damaged organelle for degradation through a selective form of autophagy known as mitophagy.[15] Loss-of-function mutations in either PINK1 or PRKN disrupt this crucial quality control pathway, leading to the accumulation of dysfunctional mitochondria, oxidative stress, and ultimately, neuronal cell death.[15]
References
- 1. Worldwide frequency of G2019S LRRK2 mutation in Parkinson's disease: a systematic review - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. GBA Variants and Parkinson Disease: Mechanisms and Treatments - PMC [pmc.ncbi.nlm.nih.gov]
- 3. GBA Mutation May Lead to Novel Therapeutics | Parkinson's Foundation [parkinson.org]
- 4. medrxiv.org [medrxiv.org]
- 5. LRRK2 G2019S Mutation: Prevalence and Clinical Features in Moroccans with Parkinson's Disease - PMC [pmc.ncbi.nlm.nih.gov]
- 6. researchgate.net [researchgate.net]
- 7. A Comprehensive Analysis of Population Differences in LRRK2 Variant Distribution in Parkinson's Disease - PMC [pmc.ncbi.nlm.nih.gov]
- 8. scielo.br [scielo.br]
- 9. pdnexus.org [pdnexus.org]
- 10. neurology.org [neurology.org]
- 11. researchgate.net [researchgate.net]
- 12. academic.oup.com [academic.oup.com]
- 13. Causes of Parkinson's disease - Wikipedia [en.wikipedia.org]
- 14. Genetic Variants in SNCA and the Risk of Sporadic Parkinson's Disease and Clinical Outcomes: A Review - PMC [pmc.ncbi.nlm.nih.gov]
- 15. Parkinsonism Due to Mutations in PINK1, Parkin, and DJ-1 and Oxidative Stress and Mitochondrial Pathways - PMC [pmc.ncbi.nlm.nih.gov]
strengths and weaknesses of MDPD compared to other resources
To provide a comprehensive comparison guide, it is essential to first clarify the specific "MDPD" you are referring to. The acronym "this compound" can stand for several distinct entities in the scientific and research communities. Without a precise definition, a meaningful and accurate comparison with other resources is not possible.
Potential interpretations of "this compound" include:
-
A specific chemical compound: For instance, 3,4-Methylenedioxypyrovalerone, a synthetic stimulant. In this context, a comparison would involve its pharmacological profile versus other stimulants.
-
A research database or platform: This could be a specialized database for a particular area of research (e.g., "Mitochondrial Disease Protein Database"). A comparison would involve contrasting its data coverage, query capabilities, and user interface with other relevant databases like OMIM or UniProt.
-
A research methodology or protocol: The acronym might refer to a specific experimental technique. A comparison would analyze its accuracy, efficiency, and cost-effectiveness against alternative methods.
To proceed with your request, please specify the full name or the scientific context of the "this compound" you wish to be evaluated. Once you provide this clarification, a detailed guide will be developed, including data tables, experimental protocols, and the requested Graphviz visualizations, tailored to your specific area of interest.
A Researcher's Guide to Meta-Analysis: Leveraging MDPD and Other Key Databases for Drug Discovery
For Immediate Release
This guide provides a comprehensive framework for researchers, scientists, and drug development professionals on conducting a meta-analysis using data from mitochondrial disease protein databases (MDPD-like databases) and other critical pharmacogenomic and drug discovery resources. By systematically integrating and analyzing data from multiple studies, researchers can uncover novel drug targets, validate therapeutic hypotheses, and accelerate the drug development pipeline.
I. Introduction to Meta-Analysis in Drug Development
A meta-analysis is a statistical method that combines the results of multiple independent scientific studies to derive a more robust and precise estimate of the effect of an intervention or the association between variables.[1][2][3][4][5] In the realm of drug development, meta-analyses are invaluable for synthesizing evidence from preclinical and clinical studies, leading to more informed decision-making.[6][7][8]
This guide will focus on a hypothetical meta-analysis investigating the role of a specific mitochondrial protein in a particular disease and its potential as a drug target. We will explore how to leverage data from this compound-like databases in conjunction with other publicly available resources.
II. Key Databases for Your Meta-Analysis
A successful meta-analysis relies on the comprehensive collection of relevant data. For our hypothetical study, we will consider the following types of databases:
| Database Category | Example Databases | Data Type | Relevance to Meta-Analysis |
| Mitochondrial Disease Protein Databases (this compound-like) | mitoPADdb[1][2], MITOP[9], MSeqDR[3], HMPDb[4] | Gene mutations, expression variations, protein-disease associations, pathways. | Identifying mitochondrial proteins implicated in the disease of interest and gathering data on their genetic and expressional alterations. |
| Pharmacogenomics & Drug-Gene Interaction Databases | PharmGKB[5][10], DrugBank[11], PGxDB[12] | Drug-gene interactions, pharmacogenomic annotations, clinical guidelines, adverse drug reactions. | Investigating known drugs that target the mitochondrial protein or its pathway, and understanding the genetic basis of variable drug responses. |
| General Gene Expression and Functional Genomics Databases | Gene Expression Omnibus (GEO), ArrayExpress | Gene expression profiles from various experimental conditions. | Expanding the dataset for gene expression analysis of the mitochondrial protein across different tissues and disease states. |
| Clinical Trial and Literature Databases | ClinicalTrials.gov, PubMed | Results from clinical trials, published research articles. | Identifying relevant studies for inclusion in the meta-analysis and extracting summary data. |
III. Experimental Protocol: A Step-by-Step Guide
This protocol outlines the key steps for performing a meta-analysis integrating data from this compound-like and other databases.
1. Formulate a Clear Research Question:
-
PICO Framework: Define the P opulation (e.g., patients with a specific mitochondrial disease), I ntervention/Exposure (e.g., altered expression of a specific mitochondrial protein), C omparison (e.g., healthy controls), and O utcome (e.g., disease severity, response to a drug).[5]
-
Example Question: "Is there a significant association between the expression level of mitochondrial protein 'X' and the severity of disease 'Y', and do drugs targeting protein 'X' show efficacy in relevant cellular models?"
2. Define Inclusion and Exclusion Criteria:
3. Conduct a Systematic Literature and Database Search:
-
Develop a comprehensive search strategy using relevant keywords and MeSH terms.
-
Search multiple databases, including those listed in the table above, to identify all relevant studies.
4. Data Extraction:
-
Develop a standardized data extraction form to collect relevant information from each included study.
-
Key data points include: study identifiers, patient characteristics, sample size, gene/protein expression data (e.g., fold change, p-value), mutation frequencies, and drug response metrics (e.g., IC50, efficacy data).
5. Data Synthesis and Statistical Analysis:
-
Effect Size Calculation: For each study, calculate a standardized measure of the effect, such as the standardized mean difference (for continuous data) or the odds ratio (for dichotomous data).
-
Heterogeneity Assessment: Use statistical tests (e.g., Cochran's Q, I²) to assess the degree of variation between studies.
-
Pooling Effect Sizes: Use a fixed-effect or random-effects model to combine the effect sizes from individual studies and obtain an overall summary estimate.
-
Subgroup and Sensitivity Analyses: If there is significant heterogeneity, perform subgroup analyses to explore potential sources of variation. Conduct sensitivity analyses to assess the robustness of the results.
6. Interpretation and Reporting:
-
Summarize the findings of the meta-analysis in a clear and concise manner.
-
Discuss the implications of the results for drug development.
-
Follow PRISMA (Preferred Reporting Items for Systematic Reviews and Meta-Analyses) guidelines for reporting the meta-analysis.
IV. Visualizing the Meta-Analysis Workflow and a Hypothetical Signaling Pathway
Diagram 1: Meta-Analysis Workflow
Caption: A streamlined workflow for conducting a meta-analysis in drug discovery.
Diagram 2: Hypothetical Signaling Pathway
Caption: A hypothetical signaling pathway illustrating the mechanism of Drug X.
V. Conclusion
By systematically integrating data from specialized resources like mitochondrial disease protein databases with broader pharmacogenomic and clinical databases, researchers can perform powerful meta-analyses. This approach enhances the statistical power of individual studies, facilitates the identification of robust drug targets, and ultimately contributes to the development of more effective and personalized medicines.
References
- 1. mitoPADdb - Mitochondrial Proteins Associated with Diseases database [bicresources.jcbose.ac.in]
- 2. mitoPADdb: A database of mitochondrial proteins associated with diseases - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. MSeqDR - Database Commons [ngdc.cncb.ac.cn]
- 4. catalog.data.gov [catalog.data.gov]
- 5. Databases in the Area of Pharmacogenetics - PMC [pmc.ncbi.nlm.nih.gov]
- 6. digitalinsights.qiagen.com [digitalinsights.qiagen.com]
- 7. PharmacoDB: an integrative database for mining in vitro anticancer drug screening studies - PMC [pmc.ncbi.nlm.nih.gov]
- 8. youtube.com [youtube.com]
- 9. academic.oup.com [academic.oup.com]
- 10. Review on Databases and Bioinformatic Approaches on Pharmacogenomics of Adverse Drug Reactions - PMC [pmc.ncbi.nlm.nih.gov]
- 11. mdpi.com [mdpi.com]
- 12. academic.oup.com [academic.oup.com]
Safety Operating Guide
Navigating the Disposal of MDPD: A Guide for Laboratory Professionals
The proper disposal of laboratory chemicals is paramount for ensuring the safety of personnel and the protection of the environment. This guide provides essential information on the disposal procedures for MDPD, a compound relevant to researchers, scientists, and drug development professionals.
The acronym "this compound" can be ambiguous and may refer to several research chemicals. One notable compound is an enhancer of the N-acylethanolamine degrading enzyme, fatty acid amide hydrolase, used in Arabidopsis studies[1]. Other possibilities include related psychoactive substances such as 3,4-Methylenedioxy-N,N-dimethylamphetamine (MDDM or MDDMA)[2][3][4], Methylenedioxypyrovalerone (MDPV)[5], and 3,4-Methylenedioxyphenylpropan-2-one (MDP2P)[6], which may be used in neurological or pharmacological research. Given this ambiguity, it is crucial to first positively identify the specific chemical and consult its corresponding Safety Data Sheet (SDS) before proceeding with any handling or disposal protocols.
Immediate Safety and Disposal Overview
For any of the potential compounds falling under the "this compound" acronym, a cautious approach to disposal is necessary due to their psychoactive and potentially hazardous nature. These substances are often classified as controlled or regulated substances, necessitating strict adherence to legal and institutional disposal protocols.
General Disposal Principles for Research Chemicals:
-
Identification is Key: Always confirm the exact identity of the chemical before initiating disposal.
-
Consult the SDS: The Safety Data Sheet is the primary source of information for safe handling and disposal.
-
Segregation: Keep chemical waste segregated to avoid dangerous reactions.
-
Licensed Disposal Vendor: The recommended and safest method for disposal of controlled or hazardous research chemicals is through a licensed chemical waste management company[7].
-
Regulatory Compliance: Ensure all disposal activities comply with local, state, and federal regulations, including those set by the Drug Enforcement Administration (DEA) for controlled substances[8][9][10].
Quantitative Hazard Data
The following table summarizes key information for potential "this compound" candidate compounds. This data is essential for risk assessment and the development of appropriate safety protocols.
| Compound | IUPAC Name | Molecular Formula | Molar Mass ( g/mol ) | Key Hazards |
| MDDM | 1-(2H-1,3-benzodioxol-5-yl)-N,N-dimethylpropan-2-amine | C12H17NO2 | 207.273 | Psychoactive, Serotonin releasing agent |
| MDPV | 1-(1,3-Benzodioxol-5-yl)-2-(pyrrolidin-1-yl)pentan-1-one | C16H21NO3 | 275.348 | Stimulant, Norepinephrine–dopamine reuptake inhibitor, DEA Schedule I |
| MDP2P | 3,4-Methylenedioxyphenylpropan-2-one | C10H10O3 | 178.185 | Precursor to MDMA, DEA List I chemical, Unstable at room temperature |
| DIMP | Di(propan-2-yl) methylphosphonate | C7H17O3P | 180.184 | By-product of sarin gas production, Affects hematological system |
Note: The FAAH enhancer "this compound" is a research chemical with limited publicly available hazard data. Standard laboratory precautions should be taken.
Experimental Protocol for Disposal of a Novel or Unidentified Research Chemical
In a research and development setting, scientists may handle novel compounds where a full SDS is not yet available. The following protocol outlines a safe and compliant general procedure for the disposal of small quantities of such chemicals.
-
Characterization and Hazard Assessment:
-
Review all available data on the chemical's structure, synthesis, and any preliminary toxicological or pharmacological data.
-
Assume the compound is hazardous in the absence of complete data.
-
-
Personal Protective Equipment (PPE):
-
Wear standard laboratory PPE, including a lab coat, safety glasses, and chemical-resistant gloves.
-
-
Containment:
-
Ensure the chemical is in a sealed, clearly labeled, and non-reactive container. The label should include the chemical name or identifier, approximate quantity, and any known hazards.
-
-
Waste Manifest:
-
Create a detailed record of the waste, including its composition and quantity.
-
-
Contact Environmental Health and Safety (EHS):
-
Notify your institution's EHS office. They will provide guidance on the specific procedures for your location and the nature of the chemical.
-
-
Transfer to a Licensed Waste Carrier:
-
The EHS office will arrange for the collection of the chemical waste by a licensed hazardous waste disposal company. Do not attempt to dispose of the chemical through standard laboratory drains or trash.
-
Disposal Workflow
The following diagram illustrates the logical steps for the proper disposal of a research chemical like this compound, from initial identification to final disposal.
Caption: Logical steps for safe and compliant chemical disposal.
References
- 1. This compound | TargetMol [targetmol.com]
- 2. Methylenedioxydimethylamphetamine - Wikipedia [en.wikipedia.org]
- 3. Postmortem distribution of 3,4-methylenedioxy-N,N-dimethyl-amphetamine (MDDM or MDDA) in a fatal MDMA overdose - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. ugent.be [ugent.be]
- 5. Methylenedioxypyrovalerone - Wikipedia [en.wikipedia.org]
- 6. 3,4-Methylenedioxyphenylpropan-2-one - Wikipedia [en.wikipedia.org]
- 7. syntheticdrugs.unodc.org [syntheticdrugs.unodc.org]
- 8. Controlled Substance Disposal: Ensuring Safe Pharmaceutical Waste Management | Stericycle [stericycle.com]
- 9. DEA list of chemicals - Wikipedia [en.wikipedia.org]
- 10. deadiversion.usdoj.gov [deadiversion.usdoj.gov]
Essential Safety and Operational Protocols for Handling MDPD
Disclaimer: The term "MDPD" is not a universally recognized chemical identifier and can be ambiguous. This guide assumes "this compound" refers to 3,4-Methylenedioxy-N,N-dimethylphenethylamine , a compound structurally related to MDMA. The following safety protocols are synthesized from data on closely related analogs, primarily 3,4-Methylenedioxymethamphetamine (MDMA) and N,N-Dimethylphenethylamine, to provide a conservative and comprehensive safety framework. Researchers must conduct their own risk assessment and consult their institution's safety office before handling this compound.
This document provides crucial safety and logistical information for laboratory professionals engaged in research and development involving 3,4-Methylenedioxy-N,N-dimethylphenethylamine (hereafter referred to as this compound). The protocols outlined below are designed to ensure the safe handling, storage, and disposal of this substance.
Hazard Identification and Classification
Based on data from structural analogs, this compound is anticipated to be a hazardous substance. The primary health risks are associated with its potential toxicity if ingested, inhaled, or absorbed through the skin.
| Hazard Classification | Description | Precautionary Statements |
| Acute Toxicity, Oral (Category 3) | Toxic if swallowed.[1][2] | P264: Wash skin thoroughly after handling. P270: Do not eat, drink or smoke when using this product.[2][3] P301 + P310: IF SWALLOWED: Immediately call a POISON CENTER or doctor/physician. |
| Acute Toxicity, Dermal (Category 3) | Toxic in contact with skin.[1][2] | P280: Wear protective gloves/ protective clothing/ eye protection/ face protection. P302 + P352: IF ON SKIN: Wash with plenty of water.[4] P312: Call a POISON CENTER or doctor/physician if you feel unwell. |
| Acute Toxicity, Inhalation (Category 3) | Toxic if inhaled.[1][2] | P261: Avoid breathing dust/ fume/ gas/ mist/ vapors/ spray. P271: Use only outdoors or in a well-ventilated area.[2][3] P304 + P340: IF INHALED: Remove person to fresh air and keep comfortable for breathing. |
| Specific Target Organ Toxicity - Single Exposure (Category 3) | May cause drowsiness or dizziness.[5] | P261: Avoid breathing dust/ fume/ gas/ mist/ vapors/ spray. P312: Call a POISON CENTER or doctor/physician if you feel unwell. |
Personal Protective Equipment (PPE)
Strict adherence to PPE protocols is mandatory when handling this compound. The following table outlines the minimum required PPE.
| Operation | Eye Protection | Hand Protection | Body Protection | Respiratory Protection |
| Handling solid material (weighing, transfers) | Safety glasses with side-shields or chemical safety goggles. | Chemical-resistant gloves (e.g., nitrile). Inspect gloves prior to use. | Laboratory coat. | NIOSH/MSHA approved respirator if ventilation is inadequate or for handling large quantities. |
| Preparing solutions | Chemical safety goggles or face shield. | Chemical-resistant gloves (e.g., nitrile). Use proper glove removal technique. | Chemical-resistant laboratory coat. | Work in a certified chemical fume hood. |
| Accidental spill cleanup | Chemical safety goggles and face shield. | Heavy-duty chemical-resistant gloves. | Chemical-resistant suit or apron over a laboratory coat. | Wear a self-contained breathing apparatus (SCBA) for large spills.[2] |
Operational and Disposal Plans
The following procedural guidance provides a step-by-step approach to safely handle and dispose of this compound in a laboratory setting.
Experimental Protocol: Safe Handling of this compound
-
Preparation and Engineering Controls:
-
Before handling, ensure that a safety shower and eyewash station are readily accessible and have been recently tested.[4]
-
All work with solid this compound or its solutions must be conducted in a properly functioning chemical fume hood to minimize inhalation exposure.[5]
-
The work area should be clearly designated for handling potent compounds.
-
-
Handling the Compound:
-
Wear all required PPE as detailed in the table above before entering the designated work area.
-
When handling the solid, use tools (spatulas, weighing paper) that can be decontaminated or disposed of as hazardous waste.
-
Avoid generating dust.[6] If transferring powder, do so slowly and carefully.
-
For preparing solutions, add the solid to the solvent slowly to avoid splashing.
-
Keep containers tightly closed when not in use.[5]
-
-
Personal Hygiene:
-
Storage:
-
Store this compound in a cool, dry, and well-ventilated area, away from incompatible materials.[1]
-
The storage location should be secure and accessible only to authorized personnel. Store locked up.[2][3]
-
Ensure the container is clearly labeled with the chemical name and all appropriate hazard warnings.
-
Emergency First Aid Procedures
| Exposure Route | First Aid Measures |
| Ingestion | Rinse mouth with water.[7] Do not induce vomiting. Immediately call a POISON CENTER or doctor/physician. Never give anything by mouth to an unconscious person.[5] |
| Inhalation | Move the victim to fresh air and keep them at rest in a position comfortable for breathing.[7] If breathing is difficult, give oxygen. If not breathing, provide artificial respiration. Seek immediate medical attention.[7] |
| Skin Contact | Immediately remove all contaminated clothing.[8] Wash the affected area with plenty of soap and water for at least 15 minutes.[4][7] Seek immediate medical attention.[5] |
| Eye Contact | Immediately flush eyes with plenty of water for at least 15 minutes, occasionally lifting the upper and lower eyelids.[2][3][7] Remove contact lenses if present and easy to do. Continue rinsing. Seek immediate medical attention.[7] |
Disposal Plan: Step-by-Step Guide
The disposal of this compound and any associated waste must be handled in strict accordance with all local, state, and federal regulations. Never discharge chemical waste into drains or the environment.[7][9]
-
Waste Segregation:
-
Collect all waste materials contaminated with this compound, including disposable gloves, weighing papers, pipette tips, and contaminated solvents, in a dedicated, sealed, and clearly labeled hazardous waste container.
-
Do not mix this waste with other chemical waste streams unless explicitly permitted by your institution's environmental health and safety (EHS) office.
-
-
Container Management:
-
Use a robust, leak-proof container for all this compound waste.
-
Label the container clearly as "Hazardous Waste" and list "3,4-Methylenedioxy-N,N-dimethylphenethylamine" and its associated hazards.
-
-
Disposal Procedure:
-
All chemical waste must be disposed of through a licensed professional waste disposal service.[9] Contact your institution's EHS office to arrange for pickup.
-
The recommended method of disposal is controlled incineration at a permitted hazardous waste facility.[7][9]
-
Empty containers should be triple-rinsed with a suitable solvent. The rinsate must be collected as hazardous waste. Puncture the container to prevent reuse before disposal.[7][9]
-
Visual Workflow for Safe Handling of this compound
The following diagram illustrates the logical workflow for the safe handling of this compound from receipt of the chemical to the final disposal of its waste.
Caption: Logical workflow for the safe handling of this compound.
References
- 1. cdn.caymanchem.com [cdn.caymanchem.com]
- 2. dl.novachem.com.au [dl.novachem.com.au]
- 3. dl.novachem.com.au [dl.novachem.com.au]
- 4. biosynth.com [biosynth.com]
- 5. sigmaaldrich.com [sigmaaldrich.com]
- 6. Home - Cerilliant [cerilliant.com]
- 7. chemicalbook.com [chemicalbook.com]
- 8. cdn.caymanchem.com [cdn.caymanchem.com]
- 9. benchchem.com [benchchem.com]
Retrosynthesis Analysis
AI-Powered Synthesis Planning: Our tool employs the Template_relevance Pistachio, Template_relevance Bkms_metabolic, Template_relevance Pistachio_ringbreaker, Template_relevance Reaxys, Template_relevance Reaxys_biocatalysis model, leveraging a vast database of chemical reactions to predict feasible synthetic routes.
One-Step Synthesis Focus: Specifically designed for one-step synthesis, it provides concise and direct routes for your target compounds, streamlining the synthesis process.
Accurate Predictions: Utilizing the extensive PISTACHIO, BKMS_METABOLIC, PISTACHIO_RINGBREAKER, REAXYS, REAXYS_BIOCATALYSIS database, our tool offers high-accuracy predictions, reflecting the latest in chemical research and data.
Strategy Settings
| Precursor scoring | Relevance Heuristic |
|---|---|
| Min. plausibility | 0.01 |
| Model | Template_relevance |
| Template Set | Pistachio/Bkms_metabolic/Pistachio_ringbreaker/Reaxys/Reaxys_biocatalysis |
| Top-N result to add to graph | 6 |
Feasible Synthetic Routes





Featured Recommendations
| Most viewed |


|
|
|---|---|---|
| Most popular with customers |
|
Haftungsausschluss und Informationen zu In-Vitro-Forschungsprodukten
Bitte beachten Sie, dass alle Artikel und Produktinformationen, die auf BenchChem präsentiert werden, ausschließlich zu Informationszwecken bestimmt sind. Die auf BenchChem zum Kauf angebotenen Produkte sind speziell für In-vitro-Studien konzipiert, die außerhalb lebender Organismen durchgeführt werden. In-vitro-Studien, abgeleitet von dem lateinischen Begriff "in Glas", beinhalten Experimente, die in kontrollierten Laborumgebungen unter Verwendung von Zellen oder Geweben durchgeführt werden. Es ist wichtig zu beachten, dass diese Produkte nicht als Arzneimittel oder Medikamente eingestuft sind und keine Zulassung der FDA für die Vorbeugung, Behandlung oder Heilung von medizinischen Zuständen, Beschwerden oder Krankheiten erhalten haben. Wir müssen betonen, dass jede Form der körperlichen Einführung dieser Produkte in Menschen oder Tiere gesetzlich strikt untersagt ist. Es ist unerlässlich, sich an diese Richtlinien zu halten, um die Einhaltung rechtlicher und ethischer Standards in Forschung und Experiment zu gewährleisten.
