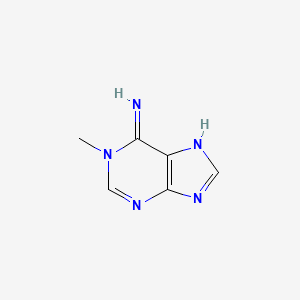
1-Methyladenine
Beschreibung
Structure
3D Structure
Eigenschaften
IUPAC Name |
1-methyl-7H-purin-6-imine |
Source


|
|---|---|---|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
InChI |
InChI=1S/C6H7N5/c1-11-3-10-6-4(5(11)7)8-2-9-6/h2-3,7H,1H3,(H,8,9) |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
InChI Key |
SATCOUWSAZBIJO-UHFFFAOYSA-N |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Canonical SMILES |
CN1C=NC2=C(C1=N)NC=N2 |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Molecular Formula |
C6H7N5 |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
DSSTOX Substance ID |
DTXSID20199405 |
Source
|
| Record name | 1-Methyladenine | |
| Source | EPA DSSTox | |
| URL | https://comptox.epa.gov/dashboard/DTXSID20199405 | |
| Description | DSSTox provides a high quality public chemistry resource for supporting improved predictive toxicology. | |
Molecular Weight |
149.15 g/mol |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
CAS No. |
5142-22-3 |
Source
|
| Record name | 1-Methyladenine | |
| Source | ChemIDplus | |
| URL | https://pubchem.ncbi.nlm.nih.gov/substance/?source=chemidplus&sourceid=0005142223 | |
| Description | ChemIDplus is a free, web search system that provides access to the structure and nomenclature authority files used for the identification of chemical substances cited in National Library of Medicine (NLM) databases, including the TOXNET system. | |
| Record name | Adenine, 1-methyl- | |
| Source | DTP/NCI | |
| URL | https://dtp.cancer.gov/dtpstandard/servlet/dwindex?searchtype=NSC&outputformat=html&searchlist=70896 | |
| Description | The NCI Development Therapeutics Program (DTP) provides services and resources to the academic and private-sector research communities worldwide to facilitate the discovery and development of new cancer therapeutic agents. | |
| Explanation | Unless otherwise indicated, all text within NCI products is free of copyright and may be reused without our permission. Credit the National Cancer Institute as the source. | |
| Record name | 1-Methyladenine | |
| Source | EPA DSSTox | |
| URL | https://comptox.epa.gov/dashboard/DTXSID20199405 | |
| Description | DSSTox provides a high quality public chemistry resource for supporting improved predictive toxicology. | |
| Record name | 1-methyladenine | |
| Source | European Chemicals Agency (ECHA) | |
| URL | https://echa.europa.eu/substance-information/-/substanceinfo/100.023.552 | |
| Description | The European Chemicals Agency (ECHA) is an agency of the European Union which is the driving force among regulatory authorities in implementing the EU's groundbreaking chemicals legislation for the benefit of human health and the environment as well as for innovation and competitiveness. | |
| Explanation | Use of the information, documents and data from the ECHA website is subject to the terms and conditions of this Legal Notice, and subject to other binding limitations provided for under applicable law, the information, documents and data made available on the ECHA website may be reproduced, distributed and/or used, totally or in part, for non-commercial purposes provided that ECHA is acknowledged as the source: "Source: European Chemicals Agency, http://echa.europa.eu/". Such acknowledgement must be included in each copy of the material. ECHA permits and encourages organisations and individuals to create links to the ECHA website under the following cumulative conditions: Links can only be made to webpages that provide a link to the Legal Notice page. | |
| Record name | 1-METHYLADENINE | |
| Source | FDA Global Substance Registration System (GSRS) | |
| URL | https://gsrs.ncats.nih.gov/ginas/app/beta/substances/98K2TG3E3W | |
| Description | The FDA Global Substance Registration System (GSRS) enables the efficient and accurate exchange of information on what substances are in regulated products. Instead of relying on names, which vary across regulatory domains, countries, and regions, the GSRS knowledge base makes it possible for substances to be defined by standardized, scientific descriptions. | |
| Explanation | Unless otherwise noted, the contents of the FDA website (www.fda.gov), both text and graphics, are not copyrighted. They are in the public domain and may be republished, reprinted and otherwise used freely by anyone without the need to obtain permission from FDA. Credit to the U.S. Food and Drug Administration as the source is appreciated but not required. | |
Foundational & Exploratory
The Dual Life of 1-Methyladenine: From Starfish Reproduction to Human Disease
An In-depth Technical Guide for Researchers, Scientists, and Drug Development Professionals
November 20, 2025
Abstract
1-Methyladenine (1-MA) is a fascinating purine derivative with two well-defined and biologically significant roles. In the marine invertebrate world, specifically in starfish, it functions as the primary hormone responsible for inducing oocyte maturation, a critical step in sexual reproduction. In a starkly different context, across a wide range of organisms from bacteria to humans, 1-methyladenine (in its nucleoside form, 1-methyladenosine or m1A) is a key post-transcriptional modification of RNA. This modification plays a crucial role in regulating RNA stability, translation, and function. The dysregulation of m1A modification has been increasingly implicated in various human diseases, most notably cancer, making the enzymes that mediate this modification attractive targets for drug development. This technical guide provides a comprehensive overview of the biological significance of 1-MA, detailing its signaling pathways, the enzymes involved in its metabolism, and its role in both physiological and pathological processes. We present quantitative data, detailed experimental protocols, and visual workflows to serve as a valuable resource for researchers in the fields of cell biology, epigenetics, and pharmacology.
1-Methyladenine as a Maturation-Inducing Hormone in Starfish Oocytes
In many starfish species, oocytes are arrested in the prophase of meiosis I. The release from this meiotic arrest and subsequent maturation to a fertilizable state is triggered by the hormone 1-methyladenine.[1][2] 1-MA is produced by the ovarian follicle cells in response to a gonad-stimulating substance (GSS) released from the radial nerves.[1][2]
Signaling Pathway of 1-Methyladenine in Oocyte Maturation
The action of 1-MA is initiated by its binding to a specific receptor on the oocyte's plasma membrane.[3] While the receptor has not been definitively identified, its activation triggers a cascade of intracellular events culminating in the activation of the Maturation-Promoting Factor (MPF), a key regulator of the cell cycle. The signaling pathway involves a pertussis toxin-sensitive G-protein, where the Gβγ subunit appears to be the primary effector.[4][5] This leads to the activation of downstream kinases, including MAP kinase, and ultimately the activation of MPF (a complex of Cdk1 and Cyclin B).[4]
Quantitative Data
The following tables summarize key quantitative parameters related to the action of 1-MA in starfish oocytes.
Table 1: Dose-Response of 1-Methyladenine in Starfish Oocyte Maturation
| Species | 1-MA Concentration for GVBD | Notes | Reference |
|---|---|---|---|
| Asterina pectinifera | Threshold dose: 0.012 - 0.06 µM | Oocytes from different animals show varying sensitivity. | [6] |
| Pisaster ochraceus | Subthreshold: ~1 - 5 nM | Pre-treatment with subthreshold concentrations accelerates GVBD. | [6] |
| General | 1 µM | Commonly used concentration to induce maturation in vitro. |[5] |
Table 2: 1-Methyladenine Receptor Binding Affinity
| Ligand | Dissociation Constant (Kd) | Binding Capacity | Organism | Reference |
|---|
| [3H]1-Methyladenine | 0.3 µM | 0.02 fmol per cortex | Asterina pectinifera |[7] |
1-Methyladenine (m1A) as an RNA Modification
1-methyladenosine (m1A) is a post-transcriptional modification found in various types of RNA, including transfer RNA (tRNA), ribosomal RNA (rRNA), and messenger RNA (mRNA).[6] This modification involves the addition of a methyl group to the N1 position of adenine. Unlike its hormonal role in starfish, m1A as an RNA modification is a widespread and evolutionarily conserved mechanism for regulating gene expression.
The "Writers" and "Erasers" of m1A
The installation and removal of the m1A modification are carried out by specific enzymes. The methyltransferases that add the methyl group are referred to as "writers," while the demethylases that remove it are known as "erasers."
-
Writers (Methyltransferases): The primary writer complex for m1A in tRNA and mRNA is the TRMT6/TRMT61A complex.[8][9] TRMT6 is the non-catalytic subunit responsible for tRNA binding, while TRMT61A is the catalytic subunit that binds the methyl donor S-adenosyl-L-methionine (SAM).[4]
-
Erasers (Demethylases): The m1A modification is reversible, and the key erasers identified to date are members of the AlkB family of dioxygenases, particularly ALKBH1 and ALKBH3 .[1] These enzymes catalyze the oxidative demethylation of m1A.[1]
Biological Functions and Implications in Cancer
The m1A modification can have profound effects on RNA metabolism:
-
RNA Structure and Stability: The addition of a methyl group at the N1 position of adenine disrupts Watson-Crick base pairing, which can alter the secondary structure of RNA and influence its stability.[6]
-
Translation: m1A modification, particularly in tRNA, is crucial for maintaining translational fidelity and efficiency.[4] In mRNA, its effect on translation can be context-dependent.
-
Cancer: Dysregulation of m1A modification has been linked to various cancers.[6] For instance, the overexpression of the m1A writer TRMT6 has been associated with poor prognosis in colorectal cancer. The eraser ALKBH3 is also implicated in cancer progression, and its inhibition is being explored as a potential therapeutic strategy.[1]
Quantitative Data
Table 3: Enzyme Kinetics of m1A Demethylation by ALKBH3
| Substrate | Km (µM) | kcat (min⁻¹) | Enzyme | Reference |
|---|---|---|---|---|
| m1A-RNA | 1.2 ± 0.2 | 1.5 ± 0.1 | Human ALKBH3 | [1] |
| 1mA-ssDNA | 0.8 ± 0.1 | 2.1 ± 0.1 | Human ALKBH3 | [1] |
| 3mC-ssDNA | 1.0 ± 0.2 | 1.8 ± 0.1 | Human ALKBH3 | [1] |
Note: Specific kinetic data for the TRMT6/TRMT61A complex is an area of active investigation.
Experimental Protocols
This section provides detailed methodologies for key experiments related to the study of 1-methyladenine.
Starfish Oocyte Maturation Assay
This protocol is used to assess the ability of 1-MA or other compounds to induce oocyte maturation, typically measured by Germinal Vesicle Breakdown (GVBD).
Materials:
-
Mature female starfish (e.g., Asterina pectinifera, Marthasterias glacialis)
-
Natural or artificial seawater (NSW or ASW)
-
Calcium-free artificial seawater (CaFASW)
-
1-Methyladenine (1-MA) stock solution (e.g., 1 mM in distilled water)
-
Petri dishes
-
Pasteur pipettes
-
Dissecting microscope
Procedure:
-
Oocyte Collection: Dissect the ovaries from a mature female starfish and gently wash them in NSW.
-
Follicle Cell Removal: To obtain isolated oocytes, gently tease the ovarian lobes with fine forceps in CaFASW to release the oocytes. The lack of calcium helps to dissociate the follicle cells.
-
Washing: Wash the oocytes several times in NSW by gentle decantation to remove debris and follicle cells.
-
Incubation: Transfer a small aliquot of the oocyte suspension to a petri dish containing NSW.
-
Hormone Addition: Add 1-MA to the desired final concentration (e.g., 1 µM).
-
Observation: Observe the oocytes under a dissecting microscope at regular intervals (e.g., every 5-10 minutes).
-
Data Collection: Score the percentage of oocytes that have undergone GVBD, which is characterized by the disappearance of the large, prominent germinal vesicle. A minimum of 100-200 oocytes should be counted for each condition.[4]
Quantification of m1A in RNA by LC-MS/MS
This protocol describes the highly sensitive and quantitative detection of m1A in total RNA or mRNA using liquid chromatography-tandem mass spectrometry.
Materials:
-
Total RNA or purified mRNA sample
-
Nuclease P1
-
Bacterial alkaline phosphatase
-
LC-MS/MS system
-
1-methyladenosine and adenosine standards
Procedure:
-
RNA Digestion:
-
To 1-5 µg of RNA, add Nuclease P1 and incubate at 37°C for 2 hours.
-
Add bacterial alkaline phosphatase and incubate at 37°C for another 2 hours. This will digest the RNA into individual nucleosides.[2]
-
-
Sample Preparation:
-
Centrifuge the digested sample to pellet any undigested material.
-
Transfer the supernatant to a new tube and dilute with an appropriate solvent for LC-MS/MS analysis.
-
-
LC-MS/MS Analysis:
-
Inject the prepared sample into the LC-MS/MS system.
-
Separate the nucleosides using a suitable liquid chromatography method.
-
Detect and quantify adenosine and 1-methyladenosine using tandem mass spectrometry in multiple reaction monitoring (MRM) mode.
-
-
Quantification:
-
Generate a standard curve using known concentrations of adenosine and 1-methyladenosine standards.
-
Calculate the amount of m1A relative to the amount of unmodified adenosine in the sample.[2]
-
m1A-Specific Methylated RNA Immunoprecipitation (MeRIP-Seq)
This protocol allows for the transcriptome-wide identification of m1A-containing RNA transcripts.
Materials:
-
Total RNA
-
m1A-specific antibody
-
Protein A/G magnetic beads
-
RNase inhibitors
-
Buffers for immunoprecipitation, washing, and elution
-
RNA fragmentation reagents
-
Reagents for library preparation for next-generation sequencing
Procedure:
-
RNA Fragmentation: Fragment the total RNA to an average size of 100-200 nucleotides using enzymatic or chemical methods.
-
Immunoprecipitation:
-
Incubate the fragmented RNA with an m1A-specific antibody.
-
Add Protein A/G magnetic beads to capture the antibody-RNA complexes.
-
Wash the beads to remove non-specifically bound RNA.
-
-
Elution and RNA Purification: Elute the m1A-containing RNA fragments from the beads and purify the RNA.
-
Library Preparation and Sequencing: Prepare a cDNA library from the enriched RNA fragments and perform high-throughput sequencing.
-
Data Analysis: Align the sequencing reads to a reference genome/transcriptome and identify peaks of enrichment, which correspond to m1A-modified regions. An input control (fragmented RNA that has not been immunoprecipitated) should be sequenced in parallel to account for biases in fragmentation and sequencing.
Conclusion and Future Directions
1-Methyladenine stands out as a molecule with remarkable functional duality. Its role as a specific signaling hormone in starfish oocyte maturation provides a classic model for studying receptor-mediated signal transduction in development. Concurrently, its identity as a dynamic RNA modification highlights the intricate layer of epitranscriptomic regulation that governs gene expression in a vast array of organisms. The growing body of evidence linking aberrant m1A modification to cancer and other diseases opens up exciting new avenues for therapeutic intervention.
Future research will undoubtedly focus on several key areas. The definitive identification and characterization of the 1-MA receptor in starfish remain a critical goal. For the m1A RNA modification, a deeper understanding of the substrate specificity of the writer and eraser enzymes, as well as the identification of the "reader" proteins that recognize and interpret the m1A mark, will be essential. Furthermore, the development of potent and specific inhibitors for the enzymes involved in m1A metabolism holds great promise for the development of novel therapeutics, particularly in the context of oncology. The continued exploration of the biological significance of 1-methyladenine is poised to yield further insights into fundamental cellular processes and provide new strategies for combating human disease.
References
- 1. researchgate.net [researchgate.net]
- 2. uniprot.org [uniprot.org]
- 3. Reversible RNA Modification N1-methyladenosine (m1A) in mRNA and tRNA - PMC [pmc.ncbi.nlm.nih.gov]
- 4. glenresearch.com [glenresearch.com]
- 5. DNA methyl transferase 1: regulatory mechanisms and implications in health and disease - PMC [pmc.ncbi.nlm.nih.gov]
- 6. TRMT6-mediated tRNA m1A modification acts as a translational checkpoint of histone synthesis and facilitates colorectal cancer progression - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. N1-methyladenosine formation, gene regulation, biological functions, and clinical relevance - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Synthesis of Some 1-Methyladenine Analogs and Their Biological Activities on Starfish Oocyte Maturation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. N1-methyladenosine methylation in tRNA drives liver tumourigenesis by regulating cholesterol metabolism - PMC [pmc.ncbi.nlm.nih.gov]
1-Methyladenine versus N6-methyladenosine: A Technical Guide to Their Core Functions and Regulatory Mechanisms
For Researchers, Scientists, and Drug Development Professionals
Abstract
Post-transcriptional modifications of RNA, particularly methylation of adenosine residues, have emerged as critical regulators of gene expression and cellular function. Among the more than 170 known RNA modifications, 1-methyladenine (m1A) and N6-methyladenosine (m6A) are two of the most prevalent and functionally significant modifications in eukaryotes. While both involve the addition of a methyl group to an adenine base, their distinct chemical structures, locations on RNA molecules, and interactions with specific cellular machinery confer unique and sometimes overlapping roles in RNA metabolism and downstream biological processes. This technical guide provides an in-depth comparison of the core functions of m1A and m6A, detailing their regulatory enzymes, impact on signaling pathways, and the experimental methodologies used for their study. A comprehensive understanding of these epitranscriptomic marks is paramount for researchers in basic science and for professionals in drug development, as their dysregulation is increasingly implicated in a range of pathologies, most notably cancer.
Introduction to m1A and m6A Modifications
N6-methyladenosine (m6A) is the most abundant internal modification in mammalian mRNA, characterized by the methylation of the nitrogen atom at the 6th position of the adenine ring.[1] It is a dynamic and reversible modification, installed by a "writer" complex, removed by "eraser" enzymes, and recognized by "reader" proteins that mediate its downstream effects.[2] The m6A modification is predominantly found within a consensus sequence of G(m6A)C or A(m6A)C and is enriched near stop codons and in 3' untranslated regions (3' UTRs).[2]
1-methyladenine (m1A), in contrast, involves the methylation of the nitrogen atom at the 1st position of the adenine ring. This modification imparts a positive charge to the adenine base, which can disrupt Watson-Crick base pairing.[3] While initially thought to be primarily present in transfer RNA (tRNA) and ribosomal RNA (rRNA), recent advancements in detection technologies have revealed its presence in mRNA as well.[4] In mRNA, m1A is often found in the 5' UTR and is associated with the regulation of translation.[4]
Quantitative Comparison of m1A and m6A
The relative abundance and distribution of m1A and m6A vary across different RNA species and cellular contexts. The following tables summarize key quantitative data regarding these modifications.
Table 1: Abundance of m1A and m6A in Different RNA Types
| RNA Type | m1A Abundance | m6A Abundance | Key References |
| mRNA | ~0.01-0.05% of total adenosine | ~0.1-0.4% of total adenosine | [5] |
| tRNA | Highly abundant, found at specific positions (e.g., 9, 14, 58) | Present, but less studied than in mRNA | [3] |
| rRNA | Present at specific, functionally important sites | Present, with roles in ribosome biogenesis and function | [2][3] |
Table 2: Impact of Regulator Knockdown on Gene Expression
| Regulator Knockdown | Modification Affected | Example Target Gene(s) | Fold Change in Expression | Cellular Context | Key References |
| METTL3 (Writer) | m6A | NRIP1 | Increased mRNA stability and protein expression | HEK293T cells | [6] |
| ALKBH5 (Eraser) | m6A | IGF2BPs target genes | Destabilized | Non-small-cell lung cancer cells | [7] |
| TRMT6/61A (Writer) | m1A | tRF-3b targets | Globally repressed | HEK293T cells | [8] |
| ALKBH3 (Eraser) | m1A | Inflammatory genes | Upregulated | PC3 prostate cancer cells | [9] |
| ALKBH3 (Eraser) | m1A | ErbB2, AKT1S1 | Decreased | Gastrointestinal cancer | [10][11] |
Regulatory Machinery: Writers, Erasers, and Readers
The dynamic nature of m1A and m6A modifications is governed by a dedicated set of proteins that install, remove, and recognize these marks.
m6A Regulatory Proteins
-
Writers: The m6A methyltransferase complex is primarily composed of METTL3 (the catalytic subunit), METTL14 (an RNA-binding platform), and WTAP (a regulatory subunit).
-
Erasers: The demethylation of m6A is carried out by two main enzymes: FTO (fat mass and obesity-associated protein) and ALKBH5.
-
Readers: A diverse group of proteins, known as "readers," bind to m6A and mediate its downstream effects. The most well-characterized family is the YTH domain-containing proteins (YTHDF1, YTHDF2, YTHDF3, YTHDC1, and YTHDC2).
m1A Regulatory Proteins
-
Writers: The installation of m1A is carried out by several enzymes, with TRMT6/TRMT61A being a key complex for both tRNA and a subset of mRNAs.
-
Erasers: The primary m1A demethylases identified to date are ALKBH1 and ALKBH3.
-
Readers: The YTH domain-containing proteins (YTHDF1, YTHDF2, and YTHDF3) have also been shown to recognize and bind to m1A, suggesting a potential for crosstalk between the m1A and m6A pathways.
Signaling Pathways Modulated by m1A and m6A
The epitranscriptomic regulation by m1A and m6A has profound effects on major cellular signaling pathways, thereby influencing a wide range of biological processes, including cell proliferation, survival, and differentiation.
m6A-Regulated Signaling Pathways
The dysregulation of m6A has been extensively linked to the aberrant activity of key oncogenic signaling pathways.
The PI3K/AKT/mTOR pathway is a central regulator of cell growth, proliferation, and survival. Several components of this pathway are subject to m6A modification, influencing their expression and subsequent pathway activation. For instance, m6A modification can regulate the stability and translation of mRNAs encoding key signaling molecules like AKT and mTOR, thereby impacting downstream cellular processes.[10]
Caption: m6A regulation of the PI3K/AKT/mTOR signaling pathway.
The Wnt/β-catenin signaling pathway is crucial for embryonic development and tissue homeostasis. Aberrant activation of this pathway is a hallmark of many cancers. m6A modification has been shown to regulate the expression of key components of the Wnt pathway, such as β-catenin (CTNNB1) and TCF/LEF transcription factors, thereby influencing downstream gene transcription and cellular fate.
Caption: m6A modulation of the Wnt/β-catenin signaling pathway.
The Mitogen-Activated Protein Kinase (MAPK) pathway, particularly the ERK cascade, is a critical signaling route that transduces extracellular signals to the nucleus to regulate gene expression and cell fate. Recent studies have revealed a reciprocal relationship between m6A modification and the MAPK/ERK pathway. ERK can phosphorylate m6A writer proteins, influencing their activity, while m6A modification can, in turn, regulate the expression of components within the MAPK pathway.[11][12]
Caption: Interplay between m6A modification and the MAPK/ERK pathway.
The NF-κB signaling pathway is a master regulator of the inflammatory and immune responses. Dysregulation of this pathway is associated with chronic inflammation and cancer. m6A modification can influence the NF-κB pathway by targeting the mRNAs of key signaling components, such as IKKβ and NF-κB subunits, thereby modulating their expression and the subsequent inflammatory response.[13]
Caption: Regulation of the NF-κB pathway by m6A modification.
m1A-Regulated Signaling Pathways
The role of m1A in modulating signaling pathways is an emerging area of research. Current evidence suggests its involvement in pathways that are also regulated by m6A, hinting at a complex interplay between these two modifications.
Bioinformatic analyses and initial experimental evidence have linked m1A regulatory enzymes to the PI3K/AKT/mTOR and ErbB signaling pathways in the context of gastrointestinal cancer.[10][11] For example, knockdown of the m1A eraser ALKBH3 has been shown to decrease the expression of ErbB2 and AKT1S1, suggesting that m1A modification may play a role in sustaining the activity of these oncogenic pathways.[10][11]
Caption: Emerging role of m1A in regulating the ErbB and mTOR pathways.
Experimental Protocols for m1A and m6A Detection
The study of m1A and m6A modifications relies on a variety of specialized techniques. Below are detailed methodologies for key experiments.
Methylated RNA Immunoprecipitation Sequencing (MeRIP-Seq)
MeRIP-Seq is a widely used technique to map m6A and m1A modifications across the transcriptome.
Caption: General workflow for MeRIP-Seq.
Protocol:
-
RNA Extraction and Fragmentation:
-
Extract total RNA from cells or tissues using a standard method (e.g., TRIzol).
-
Assess RNA integrity using a Bioanalyzer.
-
Fragment the RNA to an average size of 100-200 nucleotides using enzymatic or chemical methods.[8]
-
-
Immunoprecipitation:
-
Washing and Elution:
-
Wash the beads several times to remove non-specifically bound RNA.
-
Elute the methylated RNA fragments from the antibody-bead complexes.
-
-
Library Preparation and Sequencing:
-
Construct sequencing libraries from the eluted RNA and the input control RNA.
-
Perform high-throughput sequencing.
-
-
Data Analysis:
-
Align sequenced reads to the reference genome/transcriptome.
-
Use peak-calling algorithms to identify enriched regions of m6A or m1A in the IP sample relative to the input control.
-
Perform motif analysis to identify consensus sequences for methylation.
-
m1A-Specific Detection Methods
Due to the nature of the m1A modification, specific techniques have been developed for its precise mapping.
-
m1A-MAP (m1A-induced Misincorporation during reverse transcription followed by sequencing): This method exploits the fact that the m1A modification can cause reverse transcriptase to misincorporate nucleotides during cDNA synthesis. By sequencing the cDNA, these misincorporations can be identified, allowing for single-nucleotide resolution mapping of m1A sites.[14]
-
Dimroth Rearrangement-based Sequencing: This method utilizes a chemical reaction (Dimroth rearrangement) to convert m1A to m6A under alkaline conditions.[15] By comparing the sequencing results before and after the rearrangement, m1A sites can be identified.
Quantitative Analysis by Liquid Chromatography-Mass Spectrometry (LC-MS/MS)
LC-MS/MS is the gold standard for quantifying the absolute levels of m1A and m6A in a given RNA sample.
Protocol:
-
RNA Digestion:
-
Purify the RNA of interest (e.g., mRNA).
-
Digest the RNA into single nucleosides using a cocktail of nucleases (e.g., nuclease P1) and phosphatases.
-
-
LC-MS/MS Analysis:
-
Separate the nucleosides using liquid chromatography.
-
Detect and quantify the amounts of adenosine, m1A, and m6A using tandem mass spectrometry.
-
Calculate the ratio of m1A or m6A to total adenosine.
-
Conclusion and Future Perspectives
The study of m1A and m6A RNA modifications has unveiled a new layer of gene regulation that is integral to a vast array of cellular processes. While m6A is more abundant in mRNA and has a well-established role in regulating mRNA fate, the unique chemical properties of m1A and its prevalence in structured RNAs like tRNA and rRNA, as well as its emerging role in mRNA translation, highlight its distinct and critical functions. The overlap in their regulatory machinery, particularly the "reader" proteins, suggests a potential for intricate crosstalk and coordinated regulation of gene expression.
For researchers and drug development professionals, the dysregulation of m1A and m6A pathways in diseases like cancer presents a promising landscape for therapeutic intervention. The development of small molecule inhibitors targeting the "writer" and "eraser" enzymes of these modifications is an active area of research with significant clinical potential. Future studies will undoubtedly continue to unravel the complexities of the epitranscriptome, providing deeper insights into the nuanced roles of m1A and m6A and paving the way for novel diagnostic and therapeutic strategies.
References
- 1. Overview of m6A RNA Methylation - CD Genomics [rna.cd-genomics.com]
- 2. The detection and functions of RNA modification m6A based on m6A writers and erasers - PMC [pmc.ncbi.nlm.nih.gov]
- 3. researchgate.net [researchgate.net]
- 4. m1A RNA Methylation Analysis - CD Genomics [cd-genomics.com]
- 5. Sequencing methods and functional decoding of mRNA modifications - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Frontiers | METTL3-Mediated N6-Methyladenosine Modification Is Involved in the Dysregulation of NRIP1 Expression in Down Syndrome [frontiersin.org]
- 7. m6A demethylase ALKBH5 promotes tumor cell proliferation by destabilizing IGF2BPs target genes and worsens the prognosis of patients with non-small-cell lung cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 8. TRMT6/61A-dependent base methylation of tRNA-derived fragments regulates gene-silencing activity and the unfolded protein response in bladder cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 9. The oxidative demethylase ALKBH3 marks hyperactive gene promoters in human cancer cells - PMC [pmc.ncbi.nlm.nih.gov]
- 10. m1A Regulated Genes Modulate PI3K/AKT/mTOR and ErbB Pathways in Gastrointestinal Cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 11. m1A Regulated Genes Modulate PI3K/AKT/mTOR and ErbB Pathways in Gastrointestinal Cancer - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. researchgate.net [researchgate.net]
- 13. Acute depletion of METTL3 implicates N6-methyladenosine in alternative intron/exon inclusion in the nascent transcriptome - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Base-resolution mapping reveals distinct m1A methylome in nuclear- and mitochondrial-encoded transcripts - PMC [pmc.ncbi.nlm.nih.gov]
- 15. Development of mild chemical catalysis conditions for m1A-to-m6A rearrangement on RNA - PMC [pmc.ncbi.nlm.nih.gov]
The Critical Role of 1-Methyladenine in Transfer RNA: A Technical Guide
For Researchers, Scientists, and Drug Development Professionals
Abstract
1-Methyladenine (m1A), a post-transcriptional modification of transfer RNA (tRNA), is a critical determinant of tRNA structure, stability, and function. This technical guide provides an in-depth analysis of the role of m1A, detailing its chemical nature, precise locations within the tRNA molecule, and its profound impact on the intricate folding and thermodynamic stability of tRNA. We delve into the enzymatic machinery responsible for m1A installation, the Trm and TRMT families of methyltransferases, and elucidate the functional consequences of this modification on tRNA maturation and the fidelity of protein translation. This document summarizes key quantitative data, provides detailed experimental protocols for the study of m1A, and presents visual representations of the associated molecular pathways to serve as a comprehensive resource for researchers in the fields of molecular biology, biochemistry, and drug development.
Introduction to 1-Methyladenine (m1A) in tRNA
1-methyladenine (m1A) is a positively charged, modified nucleobase that plays a pivotal role in ensuring the proper structure and function of transfer RNA (tRNA).[1] This modification, found across all domains of life, involves the addition of a methyl group to the N1 position of adenine.[1][2] The presence of m1A at specific positions within the tRNA molecule is not arbitrary; it is a highly regulated process that is crucial for the structural integrity and biological activity of tRNA.
The m1A modification is introduced post-transcriptionally by specific tRNA methyltransferases.[2] Its presence is vital for preventing the formation of non-canonical base pairs that would otherwise disrupt the iconic L-shaped tertiary structure of tRNA.[2][3] By ensuring the correct three-dimensional fold, m1A contributes significantly to the stability of the tRNA molecule and its ability to participate accurately in protein synthesis.[2][4][5]
Location and Structural Significance of m1A in tRNA
The m1A modification occurs at several conserved positions within the tRNA molecule, most notably at positions 9, 14, 22, 57, and 58.[2][6] The specific location of the m1A modification dictates its precise role in maintaining tRNA structure.
-
m1A9: Located in the D-arm of tRNA, m1A9 is crucial for stabilizing the tertiary structure by preventing the formation of a Watson-Crick base pair between position 9 and position 64 in the T-arm. This allows for the correct interaction between the D-loop and T-loop, which is essential for the L-shaped conformation.[2][3]
-
m1A58: Found in the T-loop, m1A58 is one of the most conserved tRNA modifications and is critical for the overall stability of the tRNA molecule.[1][7] It participates in a network of tertiary interactions that stabilize the elbow region of the tRNA. The positive charge of m1A58 is thought to be involved in the specific recognition of tRNA by proteins.[3]
The methylation at the N1 position of adenine introduces a positive charge and disrupts the Watson-Crick base-pairing face. This steric hindrance prevents A from pairing with U, thereby enforcing the correct folding pathway and stabilizing the final, functional conformation of the tRNA.[2][8]
Quantitative Data on the Impact of m1A
The presence of m1A significantly influences the thermodynamic stability and enzymatic processing of tRNA. The following tables summarize key quantitative findings from the literature.
| tRNA Species | Modification(s) | Change in Melting Temperature (ΔTm) | Reference(s) |
| Thermus thermophilus tRNAs | m1A58, Gm18, m5s2U54 | ~ +10 °C | [2] |
| Human initiator tRNA (tRNAiMet) | Native modifications | 76.2 °C (from normal cells) | [9] |
| Human initiator tRNA (tRNAiMet) | Native modifications | 77.3 °C (from heat-stressed cells) | [9] |
| Human elongator tRNA (tRNAeMet) | Native modifications | 76.6 °C | [9] |
Table 1: Effect of m1A and Other Modifications on tRNA Melting Temperature. This table illustrates the contribution of m1A58, in concert with other modifications, to the thermal stability of tRNA. It also provides the melting temperatures of fully modified human initiator and elongator tRNAs.
| Enzyme | Substrate(s) | KM | kcat | Reference(s) |
| Thermococcus kodakaraensis Trm10 | tRNA-G | 0.18 ± 0.04 µM | (3.9 ± 0.3) x 10-3 min-1 | [10] |
| Thermococcus kodakaraensis Trm10 | tRNA-A | 0.25 ± 0.04 µM | (7.8 ± 0.4) x 10-3 min-1 | [10] |
| Thermococcus kodakaraensis Trm10 | S-adenosylmethionine (SAM) with tRNA-G | 3 µM | - | [10] |
| Thermococcus kodakaraensis Trm10 | S-adenosylmethionine (SAM) with tRNA-A | 6 µM | - | [10] |
Table 2: Kinetic Parameters of Trm10 Methyltransferase. This table presents the Michaelis-Menten constants (KM) and catalytic rates (kcat) for the Trm10 enzyme, which is responsible for m1A9 and m1G9 formation in archaea.
Experimental Protocols
In Vitro Transcription of tRNA
This protocol describes the generation of unmodified tRNA transcripts for use in subsequent modification and functional assays.
Materials:
-
Linearized plasmid DNA or PCR product containing the tRNA gene downstream of a T7 promoter.
-
T7 RNA polymerase
-
NTPs (ATP, GTP, CTP, UTP)
-
Transcription buffer (40 mM Tris-HCl pH 8.0, 22 mM MgCl₂, 1 mM spermidine, 5 mM DTT)
-
RNase inhibitor
-
DNase I
-
Urea-PAGE supplies
-
Phenol:chloroform:isoamyl alcohol
-
Ethanol and sodium acetate
Procedure:
-
Assemble the transcription reaction on ice:
-
Transcription buffer: 10 µL
-
100 mM DTT: 5 µL
-
40 mM NTP mix: 10 µL
-
Linearized DNA template (1 µg/µL): 1 µL
-
RNase inhibitor (40 U/µL): 1 µL
-
T7 RNA polymerase (50 U/µL): 2 µL
-
Nuclease-free water to 100 µL
-
-
Incubate the reaction at 37°C for 2-4 hours.
-
Add 1 µL of DNase I and incubate for an additional 15 minutes at 37°C to digest the DNA template.
-
Stop the reaction by adding 20 µL of 3 M sodium acetate (pH 5.2) and 200 µL of ethanol. Precipitate at -20°C for at least 1 hour.
-
Centrifuge at 12,000 x g for 30 minutes at 4°C to pellet the RNA.
-
Wash the pellet with 70% ethanol and air dry.
-
Resuspend the RNA in nuclease-free water.
-
Purify the tRNA transcript by denaturing polyacrylamide gel electrophoresis (Urea-PAGE).
-
Excise the tRNA band, crush the gel slice, and elute the RNA overnight in an appropriate buffer (e.g., 0.3 M sodium acetate).
-
Precipitate the purified tRNA with ethanol, wash, and resuspend in nuclease-free water.
tRNA Methyltransferase Assay
This protocol allows for the in vitro analysis of tRNA methyltransferase activity using a radiolabeled methyl donor.
Materials:
-
Purified tRNA methyltransferase (e.g., Trm6/Trm61A complex)
-
Unmodified tRNA substrate
-
S-adenosyl-L-[methyl-¹⁴C]-methionine ([¹⁴C]-SAM)
-
Reaction buffer (e.g., 50 mM Tris-HCl pH 8.0, 10 mM MgCl₂, 5 mM DTT)
-
Trichloroacetic acid (TCA)
-
Filter paper discs
-
Scintillation fluid and counter
Procedure:
-
Set up the reaction mixture in a total volume of 50 µL:
-
Reaction buffer: 5 µL
-
Unmodified tRNA (1 µg/µL): 2 µL
-
[¹⁴C]-SAM (50-60 mCi/mmol): 1 µL
-
Purified enzyme (e.g., 0.1-1 µM): 1 µL
-
Nuclease-free water to 50 µL
-
-
Incubate the reaction at the optimal temperature for the enzyme (e.g., 37°C) for a specified time course (e.g., 0, 5, 10, 20, 30 minutes).
-
Stop the reaction by spotting 25 µL of the reaction mixture onto a filter paper disc.
-
Wash the filter discs three times for 10 minutes each in cold 5% TCA to remove unincorporated [¹⁴C]-SAM.
-
Wash the discs once with 95% ethanol and once with diethyl ether.
-
Dry the filter discs completely.
-
Place each disc in a scintillation vial, add scintillation fluid, and measure the incorporated radioactivity using a scintillation counter.
-
Calculate the amount of methyl groups transferred to the tRNA over time.
Analysis of m1A by HPLC-Coupled Mass Spectrometry (HPLC-MS)
This protocol provides a method for the sensitive detection and quantification of m1A in a tRNA sample.[11][12][13][14][]
Materials:
-
Purified tRNA sample
-
Nuclease P1
-
Bacterial alkaline phosphatase
-
HPLC system with a C18 reverse-phase column
-
Mass spectrometer
Procedure:
-
tRNA Digestion:
-
HPLC Separation:
-
Inject the digested sample onto a C18 reverse-phase HPLC column.
-
Separate the nucleosides using a gradient of a suitable mobile phase (e.g., a gradient of acetonitrile in ammonium acetate buffer).
-
-
Mass Spectrometry Analysis:
-
Couple the HPLC eluent to a mass spectrometer operating in positive ion mode.
-
Monitor for the specific mass-to-charge ratio (m/z) of 1-methyladenosine.
-
Quantify the amount of m1A by comparing its peak area to that of a known standard.
-
X-ray Crystallography of a tRNA-Methyltransferase Complex
This protocol outlines a general workflow for the structural determination of a tRNA-m1A methyltransferase complex.[16]
Materials:
-
Purified tRNA and methyltransferase protein, both at high concentration and purity
-
Crystallization screens
-
Crystallization plates (sitting or hanging drop)
-
Cryoprotectant solutions
-
X-ray diffraction equipment (synchrotron source recommended)
Procedure:
-
Complex Formation:
-
Mix the purified tRNA and protein in a specific molar ratio (e.g., 1:1.2 tRNA:protein) and incubate on ice to allow complex formation.
-
-
Crystallization Screening:
-
Set up crystallization trials using the sitting or hanging drop vapor diffusion method.
-
Screen a wide range of conditions (precipitants, pH, salts, additives) using commercial or custom screens.
-
Incubate the plates at a constant temperature (e.g., 4°C or 20°C) and monitor for crystal growth.
-
-
Crystal Optimization:
-
Once initial crystals are obtained, optimize the crystallization conditions by fine-tuning the concentrations of the components, trying different precipitants, or using additives.
-
-
Cryo-protection and Data Collection:
-
Soak the crystals in a cryoprotectant solution to prevent ice formation during freezing.
-
Flash-cool the crystals in liquid nitrogen.
-
Collect X-ray diffraction data at a synchrotron source.
-
-
Structure Determination:
-
Process the diffraction data to determine the space group and unit cell dimensions.
-
Solve the structure using molecular replacement if a homologous structure is available, or by experimental phasing methods.
-
Build and refine the atomic model of the tRNA-protein complex.
-
Signaling Pathways and Logical Relationships
Enzymatic Installation of m1A58 by the TRMT6/61A Complex
The methylation of adenosine at position 58 in eukaryotic tRNAs is carried out by a heterodimeric enzyme complex composed of TRMT6 and TRMT61A. TRMT61A is the catalytic subunit, while TRMT6 is required for tRNA binding. This process is crucial for tRNA stability and proper translation.
Caption: Enzymatic pathway of m1A58 installation by the TRMT6/61A complex.
Sequential Modification Pathway in the T-arm of Yeast Elongator tRNAs
The maturation of the T-arm of yeast elongator tRNAs follows a specific, ordered sequence of modifications, where the presence of an earlier modification influences the efficiency of subsequent modifications. This hierarchical process ensures the correct folding and function of the tRNA.
Caption: Logical workflow of sequential tRNA T-arm modifications in yeast.
Conclusion
The 1-methyladenine modification is a cornerstone of tRNA structural integrity and functional efficacy. Its strategic placement within the tRNA molecule, orchestrated by a dedicated enzymatic machinery, ensures the correct three-dimensional folding necessary for stable and accurate protein synthesis. The quantitative data and experimental protocols provided in this guide offer a robust framework for researchers to further investigate the nuanced roles of m1A in cellular processes and its potential as a target for therapeutic intervention. The visualized pathways offer a clear perspective on the logical and sequential nature of tRNA maturation, emphasizing the intricate regulatory networks that govern gene expression at the translational level. Further exploration into the dynamics of m1A modification will undoubtedly unveil deeper insights into the complex world of epitranscriptomics and its implications for human health and disease.
References
- 1. Reversible RNA Modification N1-methyladenosine (m1A) in mRNA and tRNA - PMC [pmc.ncbi.nlm.nih.gov]
- 2. m1A Post-Transcriptional Modification in tRNAs - PMC [pmc.ncbi.nlm.nih.gov]
- 3. mdpi.com [mdpi.com]
- 4. Chemical manipulation of m1A mediates its detection in human tRNA - PMC [pmc.ncbi.nlm.nih.gov]
- 5. m1a-post-transcriptional-modification-in-trnas - Ask this paper | Bohrium [bohrium.com]
- 6. m1A RNA Modification in Gene Expression Regulation - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Kinetic characterization of substrate-binding sites of thermostable tRNA methyltransferase (TrmB) | Semantic Scholar [semanticscholar.org]
- 8. pubs.acs.org [pubs.acs.org]
- 9. TRMT6 promotes hepatocellular carcinoma progression through the PI3K/AKT signaling pathway - PMC [pmc.ncbi.nlm.nih.gov]
- 10. researchgate.net [researchgate.net]
- 11. Quantitative analysis of tRNA modifications by HPLC-coupled mass spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Quantitative analysis of tRNA modifications by HPLC-coupled mass spectrometry [dspace.mit.edu]
- 13. HPLC Analysis of tRNA‐Derived Nucleosides - PMC [pmc.ncbi.nlm.nih.gov]
- 14. HPLC Analysis of tRNA‐Derived Nucleosides [en.bio-protocol.org]
- 16. Crystallization and preliminary X-ray diffraction crystallographic study of tRNA m1A58 methyltransferase from Saccharomyces cerevisiae - PMC [pmc.ncbi.nlm.nih.gov]
function of 1-Methyladenine in messenger RNA translation
An In-Depth Technical Guide to the Function of 1-Methyladenine (m1A) in Messenger RNA Translation
For Researchers, Scientists, and Drug Development Professionals
Executive Summary
N1-methyladenosine (m1A) is a dynamic and reversible post-transcriptional modification of messenger RNA (mRNA) that plays a critical and multifaceted role in the regulation of gene expression.[1][2] Unlike the more abundant N6-methyladenosine (m6A), m1A introduces a positive charge that can significantly alter RNA structure and its interactions with proteins.[3][4] This modification is installed by "writer" enzymes, removed by "erasers," and its functional consequences are mediated by "reader" proteins.[1][4] The function of m1A in mRNA translation is context-dependent, primarily determined by its location within the transcript. When present in the 5' untranslated region (5' UTR), m1A generally enhances translation initiation, whereas its presence within the coding sequence (CDS) can be inhibitory.[4][5][6] This guide provides a comprehensive overview of the molecular mechanisms of m1A in translation, summarizes key quantitative data, details relevant experimental protocols, and visualizes the associated cellular pathways.
The Core Regulatory Machinery of m1A on mRNA
The levels and functional outcomes of m1A are controlled by a coordinated interplay of methyltransferases (writers), demethylases (erasers), and RNA-binding proteins (readers).
-
Writers (Methyltransferases): The primary writer complex for m1A on nuclear-encoded mRNAs is the TRMT6/TRMT61A heterodimer, which recognizes specific T-loop-like structures.[7][8] In mitochondria, TRMT10C and TRMT61B are responsible for methylating mitochondrial-encoded mRNAs (mt-mRNAs).[4][7]
-
Erasers (Demethylases): m1A is a reversible mark. The AlkB family of dioxygenases, specifically ALKBH1 and ALKBH3, have been identified as the primary m1A demethylases, removing the methyl group and restoring adenosine.[4][7][9]
-
Readers (Effector Proteins): The functional effects of m1A are mediated by reader proteins that specifically recognize and bind to the modified base. The YTH domain-containing family proteins (YTHDF1, YTHDF2, YTHDF3), initially characterized as m6A readers, have been shown to also bind m1A.[10][11][12] YTHDF2 binding typically recruits the CCR4-NOT deadenylase complex, leading to transcript destabilization and decay.[10][13] Conversely, YTHDF1 and YTHDF3 have been associated with promoting the translation of target mRNAs.[8]
References
- 1. m1A RNA Modification in Gene Expression Regulation - PMC [pmc.ncbi.nlm.nih.gov]
- 2. m1A RNA Modification in Gene Expression Regulation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. The dynamic N1-methyladenosine methylome in eukaryotic messenger RNA - PMC [pmc.ncbi.nlm.nih.gov]
- 4. N1-methyladenosine formation, gene regulation, biological functions, and clinical relevance - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Reversible RNA Modification N1-methyladenosine (m1A) in mRNA and tRNA - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Sequencing Technologies of m1A RNA Modification - CD Genomics [rna.cd-genomics.com]
- 7. academic.oup.com [academic.oup.com]
- 8. biorxiv.org [biorxiv.org]
- 9. academic.oup.com [academic.oup.com]
- 10. YTHDF2 recognition of N1-methyladenosine (m1A)-modified RNA is associated with transcript destabilization - PMC [pmc.ncbi.nlm.nih.gov]
- 11. researchgate.net [researchgate.net]
- 12. YTHDF2 Recognition of N1-Methyladenosine (m1A)-Modified RNA Is Associated with Transcript Destabilization - PubMed [pubmed.ncbi.nlm.nih.gov]
- 13. N6-methyladenosine reader YTHDF family in biological processes: Structures, roles, and mechanisms - PMC [pmc.ncbi.nlm.nih.gov]
1-Methyladenine (m1A): A Comprehensive Technical Guide to a Key Post-Transcriptional Modification
For Researchers, Scientists, and Drug Development Professionals
Introduction
First identified in the 1960s, 1-methyladenine (m1A) is a post-transcriptional modification where a methyl group is added to the N1 position of adenine in an RNA molecule.[1] For many years, m1A was primarily studied in the context of non-coding RNAs like transfer RNA (tRNA) and ribosomal RNA (rRNA), where it is highly abundant and crucial for their structure and function.[2][3] However, recent advancements in high-throughput sequencing and molecular biology have revealed the presence and regulatory roles of m1A in messenger RNA (mRNA) and mitochondrial transcripts, sparking renewed interest in this epitranscriptomic mark.[4][5]
Unlike the more extensively studied N6-methyladenosine (m6A), m1A introduces a positive charge under physiological conditions, which can significantly alter RNA structure by disrupting Watson-Crick base pairing.[6] This modification is dynamically regulated by a set of proteins collectively known as "writers" (methyltransferases), "erasers" (demethylases), and "readers" (m1A-binding proteins), which collectively control its deposition, removal, and functional consequences.[6][7] Emerging evidence indicates that m1A modification plays a critical role in various cellular processes, including the regulation of mRNA translation, stability, and splicing.[1] Aberrant m1A modification has been implicated in the pathogenesis of numerous human diseases, most notably cancer, making the enzymes and binding proteins involved in this pathway promising targets for drug development.[6][8]
This technical guide provides an in-depth overview of m1A as a post-transcriptional modification, covering its regulatory machinery, functional roles, and implications in disease. It also includes detailed experimental protocols for the detection and analysis of m1A, as well as a compilation of quantitative data to serve as a valuable resource for researchers in the field.
The m1A Regulatory Machinery: Writers, Erasers, and Readers
The dynamic regulation of m1A is orchestrated by a coordinated interplay of methyltransferases that deposit the mark, demethylases that remove it, and effector proteins that recognize it and mediate its downstream functions.
Writers: The Methyltransferases
The enzymes responsible for installing the m1A modification are known as "writers." In humans, these are primarily members of the TRMT family of methyltransferases.
-
TRMT6/TRMT61A Complex: This heterodimeric complex is the primary writer of m1A at position 58 (m1A58) of cytoplasmic tRNAs.[9] It recognizes a T-loop-like structure in the tRNA.[10] Interestingly, this complex can also methylate some mRNAs that fortuitously fold into a similar tRNA-like structure.[2]
-
TRMT61B: This enzyme is responsible for the m1A58 modification in mitochondrial tRNAs.[11]
-
TRMT10C: Localized to the mitochondria, TRMT10C catalyzes the formation of m1A at position 9 (m1A9) of mitochondrial tRNAs.[11]
Erasers: The Demethylases
The reversibility of m1A modification is mediated by "erasers," which are demethylases that remove the methyl group from the N1 position of adenine.
-
ALKBH1 and ALKBH3: These members of the AlkB family of dioxygenases have been identified as the primary erasers of m1A.[11] ALKBH3 is particularly noted for its ability to demethylate m1A in mRNA.[12] The activity of these enzymes can be influenced by cellular conditions, such as hypoxia.
Readers: The Effector Proteins
"Reader" proteins specifically recognize and bind to m1A-modified RNA, thereby translating the chemical mark into a functional outcome. The primary readers for m1A identified to date are members of the YTH domain-containing family of proteins.
-
YTHDF1, YTHDF2, and YTHDF3: These cytoplasmic proteins are well-characterized readers of m6A and have also been shown to bind m1A.[11] Their binding can influence the translation and stability of the target RNA. For instance, YTHDF1 is often associated with enhanced translation, while YTHDF2 is linked to mRNA decay.[3][13]
-
YTHDC1: This is a nuclear m1A reader that has been implicated in the regulation of RNA splicing.[14]
References
- 1. EGFR/SRC/ERK-stabilized YTHDF2 promotes cholesterol dysregulation and invasive growth of glioblastoma - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. Base-resolution mapping reveals distinct m1A methylome in nuclear- and mitochondrial-encoded transcripts - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Deciphering the Divergent Gene Expression Landscapes of m6A/m5C/m1A Methylation Regulators in Hepatocellular Carcinoma Through Single-Cell and Bulk RNA Transcriptomic Analysis - PMC [pmc.ncbi.nlm.nih.gov]
- 4. A Novel m1A-Score Model Correlated With the Immune Microenvironment Predicts Prognosis in Hepatocellular Carcinoma - PMC [pmc.ncbi.nlm.nih.gov]
- 5. ARM-seq: AlkB-facilitated RNA methylation sequencing reveals a complex landscape of modified tRNA fragments - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. researchgate.net [researchgate.net]
- 7. ARM-Seq: AlkB-facilitated RNA methylation sequencing reveals a complex landscape of modified tRNA fragments - PMC [pmc.ncbi.nlm.nih.gov]
- 8. The m6A/m5C/m1A Regulated Gene Signature Predicts the Prognosis and Correlates With the Immune Status of Hepatocellular Carcinoma - PMC [pmc.ncbi.nlm.nih.gov]
- 9. qian.human.cornell.edu [qian.human.cornell.edu]
- 10. academic.oup.com [academic.oup.com]
- 11. Frontiers | Harnessing m1A modification: a new frontier in cancer immunotherapy [frontiersin.org]
- 12. researchgate.net [researchgate.net]
- 13. YTHDF1 promotes hepatocellular carcinoma progression via activating PI3K/AKT/mTOR signaling pathway and inducing epithelial-mesenchymal transition - PMC [pmc.ncbi.nlm.nih.gov]
- 14. researchgate.net [researchgate.net]
The Dynamic Duo: A Technical Guide to the Enzymes Governing 1-Methyladenine Modification
For Researchers, Scientists, and Drug Development Professionals
Abstract
1-Methyladenine (m1A) is a reversible post-transcriptional modification of RNA and a rare modification in DNA, playing a crucial role in various biological processes, including translation regulation, RNA stability, and disease pathogenesis. The dynamic installation and removal of this methyl mark are orchestrated by a dedicated set of enzymes: the "writers" that catalyze its formation and the "erasers" that mediate its removal. This technical guide provides an in-depth exploration of the core enzymes responsible for m1A writing and erasing, with a focus on their biochemical functions, regulatory mechanisms, and the experimental methodologies used for their characterization. This document is intended to serve as a comprehensive resource for researchers in academia and industry, providing the foundational knowledge necessary to investigate the therapeutic potential of targeting the m1A epitranscriptomic machinery.
Introduction to 1-Methyladenine (m1A)
N1-methyladenosine (m1A) is a modification where a methyl group is added to the N1 position of adenine. This modification is found in various RNA species, including transfer RNA (tRNA), ribosomal RNA (rRNA), and messenger RNA (mRNA).[1] The addition of a methyl group at the N1 position of adenine introduces a positive charge and disrupts the canonical Watson-Crick base pairing, thereby influencing RNA structure and its interactions with proteins.[2] The dynamic nature of m1A modification, regulated by specific enzymes, suggests its involvement in the fine-tuning of gene expression.
The "Writers" of m1A: Methyltransferases
The deposition of m1A is catalyzed by a family of S-adenosyl-L-methionine (SAM)-dependent methyltransferases. The primary and most well-characterized m1A writer complex is TRMT6/TRMT61A.
The TRMT6/TRMT61A Complex
The TRMT6/TRMT61A complex is the main enzyme responsible for the m1A58 modification in the T-loop of cytoplasmic tRNAs.[3][4] This modification is crucial for the structural integrity and proper function of tRNAs in protein synthesis.
-
TRMT61A: This subunit possesses the catalytic methyltransferase activity.[5]
-
TRMT6: This subunit is catalytically inactive but is essential for recognizing and binding the tRNA substrate.[3]
Dysregulation of the TRMT6/TRMT61A complex has been implicated in various cancers, including bladder cancer and hepatocellular carcinoma, where it can promote cell proliferation and resistance to cellular stress.[3][4]
Other m1A Methyltransferases
Besides the TRMT6/TRMT61A complex, other enzymes have been identified to catalyze m1A formation in different RNA contexts:
-
TRMT61B: Primarily responsible for m1A modification in mitochondrial tRNAs.[2]
-
TRMT10C: Catalyzes m1A modification in mitochondrial rRNA and a specific site in the mitochondrial ND5 mRNA.[2]
-
NML (Nucleomethylin): Involved in m1A modification of 28S rRNA.[2]
The "Erasers" of m1A: Demethylases
The removal of the m1A mark is carried out by dioxygenases belonging to the AlkB family, which catalyze an oxidative demethylation reaction. The key m1A erasers are ALKBH1 and ALKBH3.
ALKBH1
ALKBH1 is the primary demethylase for m1A in tRNAs.[6][7] By removing the methyl group from m1A58, ALKBH1 can regulate tRNA stability and function, thereby influencing translation.[6] Overexpression of ALKBH1 has been linked to metastasis in colorectal cancer.[8]
ALKBH3
ALKBH3 exhibits a broader substrate specificity and can demethylate m1A in both mRNA and tRNA.[7] In mRNA, ALKBH3-mediated demethylation can enhance transcript stability and translation.[9] Like ALKBH1, ALKBH3 is also implicated in cancer progression and is involved in regulating various signaling pathways.[10]
Quantitative Data on m1A Writer and Eraser Activity
Understanding the enzymatic kinetics of m1A writers and erasers is crucial for developing targeted inhibitors. The following table summarizes the available quantitative data.
| Enzyme | Substrate | Km (µM) | kcat (min-1) | kcat/Km (µM-1min-1) | Reference |
| ALKBH3 | m1A-RNA | N/A | N/A | 0.11 | [9] |
| TRMT6/TRMT61A | tRNA | Data not available | Data not available | Data not available | |
| ALKBH1 | tRNA | Data not available | Data not available | Data not available |
N/A: Data not available in the searched literature.
Signaling Pathways Regulated by m1A Modification
The dynamic interplay between m1A writers and erasers influences a multitude of cellular signaling pathways, particularly in the context of cancer.
TRMT6/TRMT61A-Regulated Pathways
The TRMT6/TRMT61A complex has been shown to impact key cancer-related signaling pathways:
-
PI3K/AKT/mTOR Pathway: In gastrointestinal and liver cancers, TRMT6/TRMT61A can promote cell proliferation by activating the PI3K/AKT/mTOR pathway.[11][12]
-
ErbB Signaling Pathway: This pathway is also implicated as being downstream of m1A regulation in gastrointestinal cancers.[12]
ALKBH1/ALKBH3-Regulated Pathways
ALKBH1 and ALKBH3 are involved in a broader range of signaling networks:
-
Wnt Signaling Pathway: Dysregulation of m1A erasers can impact the Wnt pathway, which is critical in development and cancer.
-
Other Pathways: These erasers have also been linked to the AKT, AMPK, NF-κB, Hippo, and Notch signaling pathways, highlighting their multifaceted roles in cellular homeostasis and disease.[6]
Experimental Protocols
In Vitro m1A Methyltransferase Assay (TRMT6/TRMT61A)
This protocol is designed to measure the methyltransferase activity of the purified TRMT6/TRMT61A complex on a tRNA substrate.
Materials:
-
Purified recombinant TRMT6/TRMT61A complex
-
In vitro transcribed or purified tRNA substrate (e.g., tRNAiMet)
-
S-adenosyl-L-[methyl-3H]-methionine ([3H]-SAM)
-
Methylation buffer (50 mM Tris-HCl pH 8.0, 50 mM KCl, 5 mM MgCl2, 1 mM DTT)
-
Scintillation cocktail
-
Filter paper discs (e.g., Whatman 3MM)
-
Trichloroacetic acid (TCA) solutions (10% and 5%)
-
Ethanol (70%)
Procedure:
-
Prepare the reaction mixture in a total volume of 25 µL:
-
5 µL of 5x Methylation buffer
-
1 µg of tRNA substrate
-
0.5 µCi of [3H]-SAM
-
1 µg of purified TRMT6/TRMT61A complex
-
Nuclease-free water to 25 µL
-
-
Incubate the reaction at 37°C for 1 hour.
-
Spot 20 µL of the reaction mixture onto a filter paper disc.
-
Wash the filter discs three times with ice-cold 10% TCA for 15 minutes each.
-
Wash twice with 5% TCA for 5 minutes each.
-
Wash once with 70% ethanol for 5 minutes.
-
Air dry the filter discs completely.
-
Place the dried filter disc in a scintillation vial, add 5 mL of scintillation cocktail, and measure the radioactivity using a scintillation counter.
-
Calculate the amount of incorporated [3H]-methyl groups to determine the enzyme activity.
In Vitro m1A Demethylase Assay (ALKBH1/ALKBH3)
This protocol measures the demethylase activity of ALKBH1 or ALKBH3 on an m1A-containing RNA substrate.
Materials:
-
Purified recombinant ALKBH1 or ALKBH3
-
m1A-containing RNA oligonucleotide (synthetic or in vitro transcribed)
-
Demethylation buffer (50 mM HEPES pH 7.5, 100 µM (NH4)2Fe(SO4)2·6H2O, 1 mM α-ketoglutarate, 2 mM L-ascorbic acid)
-
Nuclease P1
-
Bacterial alkaline phosphatase (BAP)
-
LC-MS/MS system
Procedure:
-
Set up the demethylation reaction in a total volume of 50 µL:
-
5 µL of 10x Demethylation buffer
-
1 µg of m1A-containing RNA substrate
-
500 ng of purified ALKBH1 or ALKBH3
-
Nuclease-free water to 50 µL
-
-
Incubate at 37°C for 2 hours.
-
Terminate the reaction by heat inactivation at 95°C for 5 minutes.
-
Digest the RNA to nucleosides by adding 1 U of Nuclease P1 and incubating at 37°C for 2 hours.
-
Dephosphorylate the nucleosides by adding 1 U of BAP and incubating at 37°C for 1 hour.
-
Analyze the resulting nucleoside mixture by LC-MS/MS to quantify the levels of m1A and adenosine (A).
-
The demethylase activity is determined by the decrease in the m1A/A ratio compared to a no-enzyme control.
m1A Cross-Linking and Immunoprecipitation (m1A-CLIP)
This protocol allows for the transcriptome-wide identification of m1A-modified RNAs that are bound by a specific RNA-binding protein (RBP).
Materials:
-
Cells or tissues of interest
-
UV cross-linker (254 nm)
-
Lysis buffer (e.g., RIPA buffer)
-
Antibody specific to the RBP of interest
-
Protein A/G magnetic beads
-
RNase T1
-
3' and 5' RNA linkers
-
T4 RNA ligase
-
Reverse transcriptase
-
PCR primers
-
High-throughput sequencing platform
Procedure:
-
UV Cross-linking: Irradiate cells or tissues with 254 nm UV light to induce covalent cross-links between proteins and RNA.
-
Cell Lysis and RNA Fragmentation: Lyse the cross-linked cells and partially digest the RNA with RNase T1.
-
Immunoprecipitation: Incubate the cell lysate with an antibody against the RBP of interest, coupled to protein A/G magnetic beads.
-
Washes: Stringently wash the beads to remove non-specifically bound RNAs.
-
Linker Ligation: Ligate RNA linkers to the 3' and 5' ends of the immunoprecipitated RNA fragments.
-
Protein Digestion: Digest the RBP with proteinase K, leaving a small peptide adduct at the cross-link site.
-
Reverse Transcription and PCR: Reverse transcribe the RNA into cDNA and amplify by PCR.
-
Sequencing and Analysis: Sequence the resulting cDNA library and map the reads to the transcriptome. The sites of cross-linking, and thus m1A modification in proximity to the RBP binding site, are identified by characteristic mutations or truncations at the peptide adduct site.
Experimental Workflow for Identifying m1A Regulators
The following diagram illustrates a general workflow for the discovery and characterization of m1A writer and eraser enzymes.
Conclusion and Future Directions
The enzymes that write and erase the m1A modification are emerging as critical regulators of gene expression with profound implications for human health and disease. The TRMT6/TRMT61A complex and the ALKBH1/ALKBH3 demethylases represent key nodes in the epitranscriptomic network. While significant progress has been made in identifying these enzymes and their primary functions, many questions remain. Future research should focus on elucidating the precise molecular mechanisms by which these enzymes are regulated, identifying the full spectrum of their substrates, and understanding how their dysregulation contributes to disease pathogenesis. The development of specific and potent inhibitors for m1A writers and erasers holds great promise for novel therapeutic interventions, particularly in the field of oncology. This technical guide provides a solid foundation for researchers to delve into the exciting and rapidly evolving field of m1A epitranscriptomics.
References
- 1. cg.tuwien.ac.at [cg.tuwien.ac.at]
- 2. Research progress of N1-methyladenosine RNA modification in cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 3. researchgate.net [researchgate.net]
- 4. Depletion of the m1A writer TRMT6/TRMT61A reduces proliferation and resistance against cellular stress in bladder cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 5. genecards.org [genecards.org]
- 6. ALKBH1-Mediated tRNA Demethylation Regulates Translation - PMC [pmc.ncbi.nlm.nih.gov]
- 7. ALKBH1‐mediated m1A demethylation of METTL3 mRNA promotes the metastasis of colorectal cancer by downregulating SMAD7 expression - PMC [pmc.ncbi.nlm.nih.gov]
- 8. researchgate.net [researchgate.net]
- 9. docs.abcam.com [docs.abcam.com]
- 10. researchgate.net [researchgate.net]
- 11. cdn.technologynetworks.com [cdn.technologynetworks.com]
- 12. Crosslinking Immunoprecipitation Protocol Using Dynabeads | Thermo Fisher Scientific - US [thermofisher.com]
the role of TRMT6/TRMT61A in m1A methylation
An In-depth Technical Guide on the Role of TRMT6/TRMT61A in m1A Methylation
Audience: Researchers, scientists, and drug development professionals.
Executive Summary
N1-methyladenosine (m1A) is a dynamic and reversible post-transcriptional RNA modification increasingly recognized for its significant role in regulating RNA function and cellular processes. This modification, particularly at position 58 of cytoplasmic transfer RNAs (tRNAs), is primarily catalyzed by the heterodimeric methyltransferase complex TRMT6/TRMT61A. This guide provides a comprehensive technical overview of the TRMT6/TRMT61A complex, detailing its structure, mechanism, substrates, and profound implications in human health and disease, with a particular focus on oncology. We will explore the signaling pathways it modulates, present key quantitative data, and outline detailed experimental protocols for its study, establishing the TRMT6/TRMT61A complex as a critical regulator of epitranscriptomics and a promising target for therapeutic intervention.
The TRMT6/TRMT61A Methyltransferase Complex
The formation of m1A at position 58 (m1A58) on cytoplasmic tRNAs in eukaryotes is mediated by the TRMT6/TRMT61A complex.[1] This enzyme complex is composed of two distinct subunits that work in concert to recognize and modify their specific tRNA substrates.
-
TRMT61A (TRNA Methyltransferase 61A): This is the catalytic subunit of the complex.[1][2] It is responsible for binding the methyl donor, S-adenosyl-methionine (SAM), and executing the transfer of a methyl group to the N1 position of adenosine.[3][4] While essential for the enzymatic activity, TRMT61A relies on its partner for substrate recognition. TRMT61A has been observed in both the cytoplasm and the nucleus.[5]
-
TRMT6 (TRNA Methyltransferase 6): This subunit is the substrate-binding component.[1][6] It is responsible for recognizing and binding the tRNA molecule, ensuring the correct positioning of the target adenosine (A58) within the catalytic pocket of TRMT61A.[3][4] TRMT6 is strictly localized to the nucleus.[5][7]
The active complex is a heterotetramer, composed of two TRMT6 and two TRMT61A subunits.[2][4] The formation of this complex in the nucleus is crucial for its function. The crystal structure of the human complex bound to tRNA has revealed that the substrate tRNA must undergo a refolding of its T-loop to allow the enzyme access to the A58 methylation target.[3]
Substrate Specificity and Recognition
While the canonical substrate for TRMT6/TRMT61A is tRNA, its activity extends to other RNA species, indicating a broader role in post-transcriptional regulation.
-
tRNA: The primary and most well-characterized substrate is cytoplasmic tRNA, which is methylated at adenosine 58 in the T-loop. This m1A58 modification is crucial for the structural integrity and stability of tRNA, thereby impacting global protein translation.
-
mRNA: The TRMT6/TRMT61A complex also methylates a specific subset of mRNAs.[8] This methylation occurs within a consensus sequence motif, GUUCRA (where R is A or G), which bears a structural resemblance to the T-loop of tRNAs.[5][8] This targeted modification of mRNA suggests a direct role for TRMT6/TRMT61A in regulating the fate of specific transcripts.
-
tRNA-Derived Fragments (tRFs): Recent studies have shown that TRMT6/TRMT61A is responsible for the m1A modification on 22-nucleotide long 3' tRNA fragments (tRF-3b).[9][10] The methylation occurs at the fourth position (A4) of the tRF, which corresponds to the A58 position of the parent tRNA.[10] This discovery implicates the complex in the regulation of small non-coding RNA functions.
| Substrate Class | Specific Target | Recognition Motif / Position | Functional Consequence |
| tRNA | Cytoplasmic tRNAs | Adenosine at position 58 (A58) | Stabilizes tRNA structure, ensures translational fidelity |
| mRNA | Subset of mRNAs | GUUCRA consensus motif | Translational repression[11] |
| tRFs | 22-nt 3' tRNA fragments (tRF-3b) | Adenosine at position 4 (corresponds to A58) | Negatively affects gene-silencing activity of the tRF[9][10] |
| Table 1: Substrates and functional outcomes of TRMT6/TRMT61A-mediated m1A methylation. |
Role in Cellular Signaling and Disease
Dysregulation of TRMT6/TRMT61A expression and activity is increasingly linked to the pathogenesis of several human cancers. The complex influences tumorigenesis by modulating key signaling pathways.
Hepatocellular Carcinoma (HCC)
In HCC, TRMT6 and TRMT61A are highly expressed in tumor tissues and their elevated levels are negatively correlated with patient survival.[3] The complex drives tumorigenesis through a multi-step signaling cascade:
-
Increased tRNA m1A: Upregulated TRMT6/TRMT61A elevates m1A methylation on a subset of tRNAs.[3]
-
Enhanced PPARδ Translation: This tRNA modification specifically enhances the translation of Peroxisome Proliferator-Activated Receptor Delta (PPARδ) protein.[3]
-
Cholesterol Synthesis: Increased PPARδ triggers cholesterol biogenesis.[3]
-
Hedgehog Signaling Activation: The accumulation of cholesterol activates the Hedgehog signaling pathway, a critical driver of cell growth and proliferation.[3][12]
-
Tumorigenesis: This cascade ultimately promotes the self-renewal of liver cancer stem cells (CSCs) and drives liver tumorigenesis.[3]
Furthermore, TRMT6 has been shown to promote HCC progression through the PI3K/AKT signaling pathway.[13] Overexpression of TRMT6 increases the phosphorylation of PI3K, AKT, and mTOR, while its knockdown has the opposite effect.[13]
Bladder Cancer
TRMT6/TRMT61A is also overexpressed in urothelial carcinoma of the bladder.[10] This overexpression leads to higher m1A modification on tRFs, which correlates with a dysregulation of the tRF "targetome". Functionally, m1A modification within the seed region of these tRFs negatively impacts their gene-silencing activity.[10] Depletion of the TRMT6/TRMT61A complex in bladder cancer cell lines reduces cell proliferation and compromises cell survival under stress, such as that induced by tunicamycin.[14][15] This effect is linked to the Unfolded Protein Response (UPR), as TRMT6/TRMT61A depletion was found to decrease the expression of targets associated with the ATF6 branch of the UPR.[14]
Other Cancers
The oncogenic role of this complex is not limited to HCC and bladder cancer. In glioma, high expression of TRMT6 is associated with poor prognosis and is implicated in regulating key cancer pathways including PI3K-AKT, TGF-beta, mTORC1, and MYC.[16] Inhibition of TRMT6 in glioma cells was shown to suppress proliferation, migration, and invasion.[16]
| Cancer Type | Expression Status | Key Downstream Effects | Associated Pathways |
| Hepatocellular Carcinoma | Upregulated[3] | Enhances PPARδ translation, promotes CSC self-renewal[3] | Hedgehog Signaling, PI3K/AKT/mTOR[3][13] |
| Bladder Cancer | Upregulated[10] | Dysregulates tRF-3 targetome, reduces stress resistance[14] | Unfolded Protein Response (ATF6 branch)[14] |
| Glioma | Upregulated[16] | Promotes proliferation, migration, and invasion[16] | PI3K-AKT, TGF-beta, mTORC1, MYC[16] |
| Table 2: Role and quantitative impact of TRMT6/TRMT61A dysregulation in various cancers. |
Methodologies for Studying TRMT6/TRMT61A and m1A
A robust set of experimental protocols is essential for investigating the function of TRMT6/TRMT61A and mapping its m1A mark across the transcriptome.
Detection and Mapping of m1A Methylation
Several high-throughput and quantitative methods are available to detect m1A.
-
m1A-meRIP-seq (m1A methylated RNA immunoprecipitation sequencing): This antibody-based method is used for transcriptome-wide mapping of m1A.[17]
-
RNA Fragmentation: Total RNA is extracted and chemically or enzymatically fragmented into ~100-200 nucleotide fragments.
-
Immunoprecipitation (IP): The fragments are incubated with an m1A-specific antibody to enrich for m1A-containing RNA. A parallel "input" sample is collected without IP as a control.
-
Library Preparation & Sequencing: RNA from both the IP and input samples is used to construct sequencing libraries, which are then analyzed by high-throughput sequencing.
-
Data Analysis: Reads are mapped to the genome/transcriptome, and peak-calling algorithms are used to identify enriched regions, representing m1A sites.
-
-
TGIRT-seq (Thermostable Group II Intron Reverse Transcriptase Sequencing): This method allows for single-nucleotide resolution mapping of m1A by exploiting the properties of a specific reverse transcriptase.[9]
-
RNA Preparation: Small RNAs (or total RNA) are isolated.
-
Reverse Transcription: Reverse transcription is performed using TGIRT. This enzyme frequently misincorporates a nucleotide when it encounters an m1A-modified base, rather than stalling.[9]
-
Sequencing: The resulting cDNA is sequenced.
-
Mismatch Analysis: Bioinformatic analysis identifies positions with a high rate of mismatches compared to the reference sequence, pinpointing the precise location of m1A modifications.[10]
-
-
Liquid Chromatography-Tandem Mass Spectrometry (LC-MS/MS): This is the gold standard for quantifying the absolute level of m1A modification within a total RNA or purified tRNA sample.[1]
-
RNA Digestion: Purified RNA is completely digested into individual nucleosides using enzymes like nuclease P1 and alkaline phosphatase.
-
Chromatographic Separation: The nucleoside mixture is separated using liquid chromatography.
-
Mass Spectrometry: The eluting nucleosides are ionized and analyzed by a mass spectrometer, which quantifies the amount of adenosine and N1-methyladenosine based on their distinct mass-to-charge ratios.
-
Functional Characterization of TRMT6/TRMT61A
-
siRNA/shRNA-mediated Knockdown: This is a common technique to study the loss-of-function phenotype.
-
Transfection/Transduction: Bladder cancer (e.g., 5637, HT1197) or HCC cell lines are transfected with siRNA pools or transduced with lentiviruses expressing shRNAs targeting TRMT6 and/or TRMT61A.[1][8] A non-targeting scrambled sequence is used as a control.
-
Verification: Knockdown efficiency is confirmed 48-72 hours post-transfection at both the mRNA level (qRT-PCR) and protein level (Western blot).[1][14]
-
Phenotypic Assays: The functional consequences of knockdown are assessed using assays for cell proliferation (e.g., PrestoBlue assay), migration (e.g., wound-healing assay), and response to stress (e.g., tunicamycin treatment followed by survival assay).[1][14][15]
-
-
Site-Directed Mutagenesis and Rescue Experiments: To confirm that the observed phenotype is due to the enzymatic activity of the complex, rescue experiments are performed.
-
Mutant Generation: A mutant version of the complex, such as TRMT6(R377L)/TRMT61A(D181A), is created using site-directed mutagenesis. These mutations abolish tRNA binding and catalytic activity, respectively.[3][4]
-
Rescue Experiment: Cells with endogenous TRMT6/TRMT61A knocked down are co-transfected with either the wild-type (WT) or the catalytically dead mutant constructs.[3]
-
Functional Analysis: The ability of the WT versus the mutant complex to rescue the knockdown phenotype (e.g., restore m1A levels, rescue oncosphere formation) is evaluated. A rescue by WT but not the mutant confirms the phenotype is dependent on the methyltransferase activity.[3]
-
Drug Development and Future Perspectives
The clear involvement of the TRMT6/TRMT61A complex in driving cancer progression makes it an attractive target for therapeutic development. The discovery of small molecule inhibitors against TRMT61A has shown promise. For instance, a virtual screening approach identified compounds that could physically bind to the catalytic domain of TRMT61A and subsequently reduce total m1A levels in bladder cancer cells.[18] These inhibitors were shown to suppress bladder cancer growth both in vitro and in vivo.[18]
Future research should focus on:
-
Developing more potent and selective inhibitors of the TRMT6/TRMT61A complex.
-
Elucidating the full spectrum of mRNA and non-coding RNA substrates for the complex in different cellular contexts.
-
Understanding the upstream regulatory mechanisms that lead to TRMT6/TRMT61A overexpression in cancer.
-
Exploring the therapeutic potential of targeting this complex in combination with existing cancer therapies, particularly those that induce cellular stress.
References
- 1. Frontiers | Depletion of the m1A writer TRMT6/TRMT61A reduces proliferation and resistance against cellular stress in bladder cancer [frontiersin.org]
- 2. uniprot.org [uniprot.org]
- 3. N1-methyladenosine methylation in tRNA drives liver tumourigenesis by regulating cholesterol metabolism - PMC [pmc.ncbi.nlm.nih.gov]
- 4. researchgate.net [researchgate.net]
- 5. researchgate.net [researchgate.net]
- 6. genecards.org [genecards.org]
- 7. TRMT6 protein expression summary - The Human Protein Atlas [proteinatlas.org]
- 8. Base-resolution mapping reveals distinct m1A methylome in nuclear- and mitochondrial-encoded transcripts - PMC [pmc.ncbi.nlm.nih.gov]
- 9. scispace.com [scispace.com]
- 10. TRMT6/61A-dependent base methylation of tRNA-derived fragments regulates gene-silencing activity and the unfolded protein response in bladder cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 11. genecards.org [genecards.org]
- 12. researchgate.net [researchgate.net]
- 13. TRMT6 promotes hepatocellular carcinoma progression through the PI3K/AKT signaling pathway - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Depletion of the m1A writer TRMT6/TRMT61A reduces proliferation and resistance against cellular stress in bladder cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 15. Depletion of the m1A writer TRMT6/TRMT61A reduces proliferation and resistance against cellular stress in bladder cancer - PubMed [pubmed.ncbi.nlm.nih.gov]
- 16. Frontiers | RNA m1A Methyltransferase TRMT6 Predicts Poorer Prognosis and Promotes Malignant Behavior in Glioma [frontiersin.org]
- 17. m1A RNA Methylation Analysis - CD Genomics [cd-genomics.com]
- 18. The N1‐methyladenosine methyltransferase TRMT61A promotes bladder cancer progression and is targetable by small molecule compounds - PMC [pmc.ncbi.nlm.nih.gov]
ALKBH1 and ALKBH3: A Technical Guide to Their Roles as m1A Demethylases in Research and Drug Development
For Researchers, Scientists, and Drug Development Professionals
Abstract
N1-methyladenosine (m1A) is a dynamic and reversible post-transcriptional RNA modification crucial for regulating RNA structure, stability, and function. The demethylation of m1A is catalyzed by members of the AlkB homolog (ALKBH) family of Fe(II)/α-ketoglutarate-dependent dioxygenases, primarily ALKBH1 and ALKBH3. This technical guide provides an in-depth overview of the roles of ALKBH1 and ALKBH3 as m1A demethylases, their substrate specificities, and their involvement in critical cellular processes. We present a compilation of quantitative data, detailed experimental protocols for their study, and visualizations of key signaling pathways and experimental workflows to serve as a comprehensive resource for researchers and professionals in drug development.
Introduction to ALKBH1 and ALKBH3 as m1A Demethylases
ALKBH1 and ALKBH3 are key "eraser" proteins that remove the methyl group from N1-methyladenosine (m1A) in RNA, thereby playing pivotal roles in epitranscriptomics. While both enzymes exhibit m1A demethylase activity, they display distinct substrate preferences and are implicated in different biological pathways.
ALKBH1 is primarily recognized as a tRNA demethylase, targeting m1A at position 58 (m1A58) in the T-loop of various tRNAs.[1][2] This activity is crucial for regulating tRNA stability and function, which in turn impacts translation initiation and elongation.[1] Dysregulation of ALKBH1 has been linked to developmental processes and various diseases, including cancer.[3]
ALKBH3 demonstrates a broader substrate scope, demethylating m1A in both tRNA and mRNA.[4] Additionally, ALKBH3 is known to remove 3-methylcytosine (m3C) from RNA.[4] Its role is prominently highlighted in cancer biology, where it promotes tumor progression by enhancing protein synthesis and generating tRNA-derived small RNAs (tDRs).[4]
Quantitative Data
Substrate Specificity and Cellular m1A Levels
The demethylase activity of ALKBH1 and ALKBH3 directly impacts the cellular abundance of m1A in their respective RNA substrates.
| Enzyme | Primary Substrate(s) | Cellular Impact of Altered Expression | Reference(s) |
| ALKBH1 | tRNA (specifically m1A58) | Knockdown leads to an increase in total tRNA m1A levels. Overexpression leads to a decrease in total tRNA m1A levels. | [1] |
| ALKBH3 | tRNA, mRNA | Knockdown increases m1A and m3C levels in total tRNA. | [4] |
Enzyme Kinetics
Understanding the kinetic parameters of these enzymes is crucial for inhibitor development and for modeling their cellular activity.
| Enzyme | Substrate | Km (μM) | kcat (min-1) | kcat/Km (μM-1min-1) | Reference(s) |
| ALKBH3 | m1A-containing RNA | 9.1 ± 1.2 | 1.0 ± 0.1 | 0.11 | |
| ALKBH3 | 1mA-containing ssDNA | 8.3 ± 1.5 | 1.0 ± 0.1 | 0.12 | |
| ALKBH3 | 3mC-containing ssDNA | 10.0 ± 2.1 | 1.0 ± 0.2 | 0.10 | |
| ALKBH1 | m1A-containing tRNA | Not Available | Not Available | Not Available |
Inhibitors
The development of specific inhibitors for ALKBH1 and ALKBH3 is an active area of research for therapeutic applications.
| Enzyme | Inhibitor | IC50 | Reference(s) |
| ALKBH1 | Compound 13h | 1.39 ± 0.13 μM (enzyme activity assay) | [5][6] |
| ALKBH3 | TD19 | Minimally inhibited at 100 μM | [7] |
| ALKBH3 | Various non-specific inhibitors (e.g., IOX1, N-Oxalylglycine) | Not Available | [8] |
Signaling and Functional Pathways
The demethylase activity of ALKBH1 and ALKBH3 initiates distinct downstream signaling cascades that regulate fundamental cellular processes.
ALKBH1 in Translation Regulation
ALKBH1-mediated demethylation of tRNA impacts protein synthesis. Demethylation of m1A58 on initiator tRNAMet (tRNAiMet) can lead to its degradation, thereby reducing translation initiation. Conversely, the m1A modification on elongator tRNAs can influence their recruitment to the ribosome, affecting translation elongation. This dynamic regulation allows cells to modulate protein synthesis in response to metabolic cues like glucose availability.[1]
ALKBH3 in Cancer Progression
In cancer cells, ALKBH3-mediated demethylation of m1A and m3C in tRNAs increases their susceptibility to cleavage by the ribonuclease angiogenin (ANG).[4] This cleavage generates tRNA-derived small RNAs (tDRs), which have been shown to promote ribosome biogenesis and inhibit apoptosis, thereby contributing to cancer cell proliferation and survival.[4]
Experimental Protocols
In Vitro Demethylation Assay
This assay directly measures the enzymatic activity of purified ALKBH1 or ALKBH3 on a specific m1A-containing RNA substrate.
Workflow:
Protocol:
-
Reaction Mixture: In a final volume of 50 µL, combine:
-
Purified recombinant ALKBH1 or ALKBH3 protein (e.g., 1-5 µM).
-
m1A-containing synthetic RNA oligonucleotide (e.g., 10 µM).
-
Reaction Buffer: 50 mM HEPES (pH 7.5), 50 mM KCl, 1 mM MgCl2.
-
Cofactors: 1 mM α-ketoglutarate, 2 mM L-ascorbic acid, 100 µM (NH4)2Fe(SO4)2·6H2O.
-
-
Incubation: Incubate the reaction mixture at 37°C for a specified time (e.g., 1 hour).
-
Quenching: Stop the reaction by adding 2X stop buffer (e.g., 95% formamide, 20 mM EDTA).
-
Analysis: Analyze the reaction products by liquid chromatography-tandem mass spectrometry (LC-MS/MS) to quantify the ratio of m1A to unmethylated adenosine (A).
Quantification of m1A in Cellular RNA by LC-MS/MS
This protocol allows for the precise measurement of m1A levels in total RNA or specific RNA fractions isolated from cells.
Workflow:
Protocol:
-
RNA Isolation: Isolate total RNA or specific RNA fractions (e.g., tRNA) from cells using a suitable kit or standard phenol-chloroform extraction.
-
RNA Digestion:
-
Digest 1-5 µg of RNA with nuclease P1 (to digest RNA into 5'-mononucleotides) in a suitable buffer at 37°C for 2 hours.
-
Subsequently, add bacterial alkaline phosphatase and incubate at 37°C for another 2 hours to dephosphorylate the nucleotides to nucleosides.
-
-
Sample Preparation: Filter the digested sample to remove enzymes and other contaminants.
-
LC-MS/MS Analysis:
-
Inject the prepared sample onto a reversed-phase C18 column for chromatographic separation of the nucleosides.
-
Perform tandem mass spectrometry in positive ion mode, monitoring the specific mass transitions for adenosine (m/z 268 → 136) and m1A (m/z 282 → 150).
-
-
Quantification: Determine the amount of m1A relative to adenosine by integrating the peak areas from the chromatograms.
Cross-linking and Immunoprecipitation followed by Sequencing (CLIP-Seq)
CLIP-seq is a powerful technique to identify the in vivo RNA targets of ALKBH1 and ALKBH3.
Workflow:
Protocol:
-
UV Cross-linking: Irradiate cultured cells with UV light (254 nm) to covalently cross-link proteins to their interacting RNA molecules.
-
Cell Lysis and RNase Digestion: Lyse the cells and perform a limited digestion with RNase to fragment the RNA.
-
Immunoprecipitation: Incubate the cell lysate with magnetic beads conjugated to an antibody specific for ALKBH1 or ALKBH3 to pull down the protein-RNA complexes.
-
RNA-Protein Complex Isolation and Labeling: Isolate the immunoprecipitated complexes on an SDS-PAGE gel, transfer to a membrane, and label the RNA fragments.
-
Protein Digestion and RNA Isolation: Digest the protein component with Proteinase K and isolate the cross-linked RNA fragments.
-
cDNA Library Preparation and Sequencing: Ligate adapters to the RNA fragments, reverse transcribe to cDNA, PCR amplify, and perform high-throughput sequencing.
-
Data Analysis: Align the sequencing reads to the genome/transcriptome to identify the binding sites of the target protein.
Conclusion and Future Directions
ALKBH1 and ALKBH3 are critical regulators of the m1A epitranscriptomic landscape, with profound implications for gene expression, translation, and disease pathogenesis. The methodologies and data presented in this guide provide a solid foundation for researchers and drug development professionals to further explore the biology of these enzymes and to design novel therapeutic strategies targeting their activity. Future research will likely focus on elucidating the complete repertoire of their substrates, understanding their regulation in different cellular contexts, and developing highly specific and potent inhibitors for clinical applications. The continued investigation of ALKBH1 and ALKBH3 holds great promise for advancing our understanding of RNA-mediated gene regulation and for the development of new treatments for a range of human diseases.
References
- 1. ALKBH1-Mediated tRNA Demethylation Regulates Translation - PMC [pmc.ncbi.nlm.nih.gov]
- 2. researchgate.net [researchgate.net]
- 3. The biological function of demethylase ALKBH1 and its role in human diseases - PMC [pmc.ncbi.nlm.nih.gov]
- 4. The role of demethylase AlkB homologs in cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Discovery of a Potent and Cell-Active Inhibitor of DNA 6mA Demethylase ALKBH1 - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. s3-eu-west-1.amazonaws.com [s3-eu-west-1.amazonaws.com]
- 7. A covalent compound selectively inhibits RNA demethylase ALKBH5 rather than FTO - PMC [pmc.ncbi.nlm.nih.gov]
- 8. scbt.com [scbt.com]
The Expanding Epitranscriptome: A Technical Guide to the Distribution of 1-Methyladenine (m1A) Across RNA Species
For Researchers, Scientists, and Drug Development Professionals
The field of epitranscriptomics is rapidly evolving, revealing a complex layer of gene regulation mediated by chemical modifications to RNA. Among these, 1-methyladenine (m1A), a reversible methylation, has emerged as a critical regulator of RNA structure, function, and metabolism. This technical guide provides an in-depth exploration of the distribution of m1A across various RNA species, details the experimental methodologies for its detection, and illustrates the key signaling pathways it governs. This document is intended to serve as a comprehensive resource for researchers and professionals in drug development seeking to understand and target this important RNA modification.
Quantitative Distribution of 1-Methyladenine (m1A)
The abundance of m1A varies significantly across different types of RNA, reflecting its diverse biological roles. While highly prevalent in non-coding RNAs like transfer RNA (tRNA) and ribosomal RNA (rRNA), its presence in messenger RNA (mRNA) is more dynamic and often associated with specific regulatory functions.[1][2] The following table summarizes the quantitative distribution of m1A across major RNA species based on current literature.
| RNA Species | Location of m1A | Quantitative Data | Key Functions | References |
| mRNA (nuclear-encoded) | Enriched in 5' UTR, near start codon, and at the first nucleotide of the 5' end.[3][4] | m1A/A ratio: ~0.015%–0.054% in mammalian cell lines and up to 0.16% in tissues.[4] Hundreds of m1A sites have been identified in human cell lines.[5][6] | Regulation of translation initiation and efficiency.[7][3][8][9] | [3][4][5][6][8][9] |
| tRNA (cytosolic) | Predominantly at positions 9, 14, and 58.[5][10] | Highly abundant; m1A58 is critical for tRNA stability.[7][5] | Maintaining tRNA structure and stability.[1][7][5][10] | [1][5][10] |
| rRNA (cytosolic) | Found at specific positions, such as 1322 in human 28S rRNA.[7][5][9] | Present at specific, highly conserved sites.[1][9] | Affects ribosome biogenesis.[10] | [1][7][5][9][10] |
| Mitochondrial mRNA (mt-mRNA) | Primarily located in the coding sequence (CDS).[7][5][9] | Over 20 m1A sites have been identified in mitochondrial genes.[7][5] | Inhibition of mitochondrial translation.[7][5][9] | [7][5][9] |
| Mitochondrial tRNA (mt-tRNA) | Found at positions 9 and 58.[7][5][10] | m1A9 is abundant, found in 14 mt-tRNA species; m1A58 is less frequent. | Essential for proper folding and function. | [2][7][5][10] |
| Mitochondrial rRNA (mt-rRNA) | Detected in both 12S and 16S mt-rRNA.[1][9] | Multiple sites have been identified, though some are at low modification levels.[9] | Potential role in mitochondrial ribosome function. | [1][9] |
Experimental Protocols for m1A Detection
The detection and mapping of m1A sites have been enabled by the development of specialized high-throughput sequencing techniques. These methods often exploit the fact that the methyl group on m1A disrupts Watson-Crick base pairing, leading to specific signatures during reverse transcription, such as mismatches or truncations.[7][5][11]
Methylated RNA Immunoprecipitation Sequencing (MeRIP-Seq) for m1A
MeRIP-seq, also referred to as m1A-seq, is a widely used antibody-based method for transcriptome-wide mapping of m1A.[12][13][14] The protocol involves the enrichment of RNA fragments containing m1A using a specific antibody, followed by high-throughput sequencing.
Detailed Methodological Steps:
-
RNA Isolation and Fragmentation: Total RNA is extracted from cells or tissues. The mRNA is then purified, typically using oligo(dT) magnetic beads, and chemically fragmented into smaller pieces (around 100-200 nucleotides).[15]
-
Immunoprecipitation (IP): The fragmented RNA is incubated with an anti-m1A antibody to specifically capture RNA fragments containing the m1A modification.[12][13]
-
Enrichment: Antibody-bound RNA fragments are pulled down using magnetic beads.
-
RNA Elution and Library Preparation: The enriched m1A-containing RNA fragments are eluted and used to construct a cDNA library for sequencing. A parallel "input" library is prepared from a portion of the fragmented RNA before the immunoprecipitation step to serve as a control for non-specific background.[12]
-
Sequencing and Data Analysis: Both the IP and input libraries are sequenced. Bioinformatic analysis involves mapping the reads to a reference genome/transcriptome and identifying enriched regions (peaks) in the IP sample relative to the input, which correspond to m1A sites.[13]
Some variations of the m1A-seq protocol include a demethylation step using enzymes like AlkB to confirm the specificity of the detected sites.[12] Another approach involves Dimroth rearrangement, a chemical treatment that converts m1A to N6-methyladenosine (m6A), which can also be used to validate m1A sites.[4][16]
Mass Spectrometry (LC-MS/MS)
Liquid chromatography-tandem mass spectrometry (LC-MS/MS) is a highly sensitive and quantitative method for detecting and quantifying m1A in total RNA.[12][17] This method involves the enzymatic digestion of RNA into individual nucleosides, followed by their separation and identification based on their mass-to-charge ratio. While LC-MS/MS provides accurate quantification of the overall m1A abundance, it does not provide information about the specific location of the modification within the RNA sequence.[17]
Signaling Pathways and Logical Relationships
The biological effects of m1A are mediated through a coordinated interplay of "writer" enzymes that install the modification, "eraser" enzymes that remove it, and "reader" proteins that recognize m1A and elicit downstream functional consequences.
Caption: The m1A regulatory network, including writers, erasers, readers, and their functional outcomes.
The "writers" are methyltransferases responsible for adding the methyl group to adenine. In the cytoplasm, the TRMT6/TRMT61A complex methylates both tRNAs and some mRNAs.[7][5] In mitochondria, TRMT10C and TRMT61B are key methyltransferases for mitochondrial tRNAs and mRNAs.[7][5][18]
The "erasers" are demethylases that remove the m1A modification, making it a reversible process. ALKBH1 and ALKBH3 have been identified as the primary m1A demethylases for tRNA and mRNA.[7]
The "readers" are proteins that specifically recognize and bind to m1A-modified RNA, thereby mediating its downstream effects. The YTH domain-containing family of proteins (YTHDF1, YTHDF2, YTHDF3, and YTHDC1), initially identified as m6A readers, have also been shown to bind m1A.[19][20][21][22] For instance, YTHDF2 binding to m1A-modified mRNA can lead to transcript destabilization and decay.[21][22][23]
References
- 1. N1-methyladenosine formation, gene regulation, biological functions, and clinical relevance - PMC [pmc.ncbi.nlm.nih.gov]
- 2. m1A RNA Modification in Gene Expression Regulation - PMC [pmc.ncbi.nlm.nih.gov]
- 3. The dynamic N1-methyladenosine methylome in eukaryotic messenger RNA - PMC [pmc.ncbi.nlm.nih.gov]
- 4. academic.oup.com [academic.oup.com]
- 5. academic.oup.com [academic.oup.com]
- 6. Perspectives on topology of the human m1A methylome at single nucleotide resolution - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Reversible RNA Modification N1-methyladenosine (m1A) in mRNA and tRNA - PMC [pmc.ncbi.nlm.nih.gov]
- 8. [PDF] The m1A landscape on cytosolic and mitochondrial mRNA at single-base resolution | Semantic Scholar [semanticscholar.org]
- 9. Base-resolution mapping reveals distinct m1A methylome in nuclear- and mitochondrial-encoded transcripts - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Dysregulated mitochondrial and cytosolic tRNA m1A methylation in Alzheimer’s disease - PMC [pmc.ncbi.nlm.nih.gov]
- 11. rna-seqblog.com [rna-seqblog.com]
- 12. m1A RNA Methylation Analysis - CD Genomics [cd-genomics.com]
- 13. MeRIP-seq for Detecting RNA methylation: An Overview - CD Genomics [cd-genomics.com]
- 14. epigenie.com [epigenie.com]
- 15. researchgate.net [researchgate.net]
- 16. researchgate.net [researchgate.net]
- 17. Comprehensive Overview of m6A Detection Methods - CD Genomics [cd-genomics.com]
- 18. pubs.acs.org [pubs.acs.org]
- 19. pubs.acs.org [pubs.acs.org]
- 20. Identification of YTH Domain-Containing Proteins as the Readers for N1-Methyladenosine in RNA - PubMed [pubmed.ncbi.nlm.nih.gov]
- 21. researchgate.net [researchgate.net]
- 22. YTHDF2 recognition of N1-methyladenosine (m1A)-modified RNA is associated with transcript destabilization - PMC [pmc.ncbi.nlm.nih.gov]
- 23. YTHDF2 Recognition of N1-Methyladenosine (m1A)-Modified RNA Is Associated with Transcript Destabilization - PubMed [pubmed.ncbi.nlm.nih.gov]
The Critical Role of 1-Methyladenine (m1A) Modification in Mitochondrial RNA: A Technical Guide
For Researchers, Scientists, and Drug Development Professionals
Abstract
N1-methyladenosine (m1A) is a post-transcriptional RNA modification that plays a pivotal role in the regulation of mitochondrial gene expression. This dynamic modification, installed by specific methyltransferases, influences the structural stability and function of mitochondrial transfer RNAs (mt-tRNAs), ribosomal RNAs (mt-rRNAs), and messenger RNAs (mt-mRNAs). Dysregulation of m1A modification in mitochondria has been increasingly linked to a spectrum of human diseases, including metabolic disorders, neurodegenerative diseases, and cancer. This technical guide provides a comprehensive overview of m1A modification in mitochondrial RNA, detailing the enzymatic machinery, functional consequences, and its association with disease. Furthermore, we present detailed methodologies for key experiments and structured quantitative data to serve as a valuable resource for researchers and professionals in the field.
Introduction to m1A Modification in Mitochondrial RNA
Mitochondria, the powerhouses of the cell, possess their own genome and translational machinery. The proper functioning of this machinery is heavily reliant on post-transcriptional modifications of mitochondrial-encoded RNAs. Among the more than 160 known RNA modifications, N1-methyladenosine (m1A) is a crucial player in ensuring the fidelity and efficiency of mitochondrial protein synthesis.[1][2] This modification involves the addition of a methyl group to the N1 position of adenine residues.
In mitochondrial RNA, m1A modifications are found in:
-
Mitochondrial transfer RNA (mt-tRNA): Primarily at position 9 (m1A9) and position 58 (m1A58).[2][3][4]
-
Mitochondrial ribosomal RNA (mt-rRNA): Notably at position 947 of the 16S mt-rRNA.[2][5]
-
Mitochondrial messenger RNA (mt-mRNA): A prominent site has been identified in the MT-ND5 transcript.[1][6]
The presence and level of m1A modification are not static; they can vary between tissues and individuals, suggesting a dynamic regulatory role in mitochondrial function.[1]
The Enzymatic Machinery of mt-RNA m1A Modification
The installation of m1A on mitochondrial RNA is carried out by nuclear-encoded methyltransferases that are imported into the mitochondria. The two key enzymes identified to date are TRMT10C and TRMT61B.
-
TRMT10C (tRNA methyltransferase 10C): Also known as MRPP1, TRMT10C is a key component of the mitochondrial RNase P complex.[7][8] It is responsible for the m1A9 and m1G9 modifications in mt-tRNAs.[3][9] TRMT10C works in a subcomplex with SDR5C1 (also known as HSD17B10 or MRPP2) to catalyze this methylation.[7][9][10] This modification is crucial for the proper folding and structural stability of mt-tRNAs.[3][7] TRMT10C has also been identified as the methyltransferase responsible for the m1A modification in the MT-ND5 mRNA.[6][11]
-
TRMT61B (tRNA methyltransferase 61B): This enzyme is responsible for the m1A58 modification in a subset of mt-tRNAs, including tRNA-Leu(UUR), tRNA-Lys, and tRNA-Ser(UCN).[12] Additionally, TRMT61B mediates the m1A modification at position 947 of the 16S mt-rRNA.[5][13] Unlike its cytosolic counterpart which functions as a heterodimer, TRMT61B is thought to function as a homo-oligomer.[12]
The interplay of these enzymes ensures the precise methylation of specific adenine residues across the mitochondrial transcriptome, highlighting a sophisticated regulatory network.
Functional Significance of m1A in Mitochondrial RNA
The m1A modification exerts its influence on mitochondrial gene expression through several mechanisms:
-
Structural Stabilization of mt-tRNA: The m1A9 modification is critical for the correct folding and stabilization of the tertiary structure of mt-tRNAs.[3][14] This is essential for their recognition by aminoacyl-tRNA synthetases and for their proper function in translation. The m1A58 modification in the T-loop of mt-tRNAs also contributes to their structural integrity and stability.[2][4]
-
Regulation of Mitochondrial Translation: m1A modifications in both mt-tRNA and mt-rRNA are generally associated with promoting efficient protein synthesis.[2] The modification in 16S mt-rRNA is believed to stabilize the mature mitoribosome.[1] Conversely, m1A modification within the coding sequence of mt-mRNAs, such as in MT-ND5, can act as a translational repressor.[6][11][15] This is likely due to the disruption of Watson-Crick base pairing, which can lead to ribosomal stalling.[1][16]
-
Mitochondrial RNA Processing: TRMT10C is a subunit of the mitochondrial RNase P, an enzyme essential for the 5' processing of precursor mt-tRNAs from polycistronic transcripts.[7][8] This dual functionality suggests a tight coupling between mt-tRNA maturation and modification.
Association with Human Diseases
Given the central role of m1A in mitochondrial function, it is not surprising that its dysregulation is implicated in various human pathologies.
-
Mitochondrial Disorders: Mutations in the TRMT10C gene have been linked to combined oxidative phosphorylation deficiency, leading to severe mitochondrial dysfunction.[8] Knockdown of TRMT10C in cell models results in reduced mitochondrial respiration.[4]
-
Neurodegenerative Diseases: Altered levels of m1A in both mitochondrial and cytosolic tRNAs have been observed in the context of Alzheimer's disease, suggesting a potential contribution of epitranscriptomic dysregulation to the disease's mitochondrial dysfunction.[14]
-
Cancer: The expression of TRMT61B has been found to be upregulated in highly aneuploid cancer cells, and its depletion can compromise mitochondrial function and reduce tumorigenicity.[17] This suggests that targeting mitochondrial RNA methylation could be a potential therapeutic strategy in certain cancers. Furthermore, genetic variants associated with m1A/G modification levels have been linked to an increased risk for diseases such as breast cancer and psoriasis.[1][18]
Quantitative Data on m1A Modification in Mitochondrial RNA
The following tables summarize key quantitative findings from the literature regarding the levels and effects of m1A modification in mitochondrial RNA.
Table 1: Variation in Inferred m1A Methylation Levels at Specific Mitochondrial RNA Sites
| Mitochondrial RNA Site | Dataset | Tissue/Cell Type | Inferred Methylation Range | Reference |
| mt-RNR2 (position 2617) | CARTaGENE | Whole Blood | 0.48 - 0.72 | [1] |
| mt-RNR2 (position 2617) | Geuvadis | Lymphoblastoid Cell Line | 0.11 - 0.76 | [1] |
Table 2: Impact of TRMT61B Modulation on Mitochondrial Protein Levels
| Protein | Condition | Fold Change vs. Control | Method | Reference |
| MT-CO2 | TRMT61B Knockdown | Reduced | Western Blot | [16] |
| MT-ATP6 | TRMT61B Knockdown | No significant change | Western Blot | [16] |
Experimental Protocols
Detailed methodologies are crucial for the accurate study of m1A modifications. Below are outlines of key experimental protocols.
Detection of m1A Modification by Primer Extension
This method is used to detect specific m1A sites and assess their relative abundance. The presence of m1A can cause reverse transcriptase to pause or terminate, leading to a truncated product.
Protocol Outline:
-
RNA Isolation: Isolate total RNA or mitochondrial RNA from cells or tissues of interest.
-
Primer Design: Design a DNA primer that anneals downstream of the putative m1A site. The primer should be radiolabeled (e.g., with 32P) or fluorescently labeled for detection.
-
Primer Annealing: Anneal the labeled primer to the RNA template.
-
Reverse Transcription: Perform a reverse transcription reaction using a reverse transcriptase enzyme.
-
Gel Electrophoresis: Separate the cDNA products on a denaturing polyacrylamide gel.
-
Detection: Visualize the bands corresponding to the full-length and truncated products. A band at the position corresponding to the nucleotide preceding the m1A site indicates the presence of the modification.
-
Quantification: The relative abundance of the truncated product compared to the full-length product can be used to estimate the stoichiometry of the m1A modification.
High-Throughput Sequencing of m1A (m1A-seq)
This technique allows for the transcriptome-wide mapping of m1A sites at single-nucleotide resolution. It relies on the property of m1A to induce misincorporations and truncations during reverse transcription.
Protocol Outline:
-
RNA Fragmentation: Fragment the poly(A)-selected or ribo-depleted RNA to a desired size range.
-
Immunoprecipitation (IP): Use an m1A-specific antibody to enrich for RNA fragments containing the m1A modification.
-
Library Preparation: Prepare sequencing libraries from both the immunoprecipitated RNA and the input RNA (as a control). This involves adapter ligation, reverse transcription, and PCR amplification.
-
Sequencing: Perform high-throughput sequencing of the prepared libraries.
-
Data Analysis: Align the sequencing reads to the reference genome/transcriptome. Identify m1A sites by looking for characteristic patterns of reverse transcription errors (misincorporations) and truncations that are enriched in the IP sample compared to the input.
A variation of this method, red-m1A-seq , involves the chemical reduction of m1A with sodium borohydride (NaBH4) to enhance the mutation and read-through rates during reverse transcription, thereby improving sensitivity and accuracy.[19]
Functional Analysis using siRNA-mediated Knockdown
This approach is used to investigate the functional role of the m1A methyltransferases.
Protocol Outline:
-
siRNA Design and Synthesis: Design and synthesize small interfering RNAs (siRNAs) targeting the mRNA of the methyltransferase of interest (e.g., TRMT10C or TRMT61B). A non-targeting siRNA should be used as a negative control.
-
Cell Culture and Transfection: Culture the desired cell line and transfect the cells with the siRNAs using a suitable transfection reagent.
-
Validation of Knockdown: After a suitable incubation period (e.g., 48-72 hours), harvest the cells and validate the knockdown efficiency at the mRNA level (using RT-qPCR) and/or the protein level (using Western blotting).
-
Functional Assays: Perform functional assays to assess the consequences of the methyltransferase knockdown. These can include:
-
Analysis of m1A levels at specific sites using primer extension or mass spectrometry.
-
Measurement of mitochondrial respiration and oxygen consumption rates.
-
Assessment of mitochondrial protein synthesis via metabolic labeling.
-
Analysis of cell viability and proliferation.
-
Visualizing Key Pathways and Workflows
Diagrams generated using Graphviz provide a clear visual representation of the complex processes involved in m1A modification.
Caption: Overview of m1A modification pathways in mitochondria.
Caption: Experimental workflow for m1A-seq.
Conclusion and Future Directions
The study of m1A modification in mitochondrial RNA is a rapidly evolving field. It is now clear that this epitranscriptomic mark is a critical regulator of mitochondrial gene expression and is deeply intertwined with cellular health and disease. Future research will likely focus on several key areas:
-
Identification of m1A "erasers" and "readers" in mitochondria: While the "writers" are known, the proteins that recognize and remove m1A, or mediate its downstream effects, within the mitochondria remain to be fully characterized.
-
Understanding the dynamics of m1A modification: Investigating how m1A levels are regulated in response to different physiological and pathological stimuli will provide deeper insights into its role in cellular adaptation and disease progression.
-
Therapeutic targeting of m1A pathways: The development of small molecule inhibitors or activators of m1A methyltransferases could offer novel therapeutic avenues for a range of diseases, from mitochondrial disorders to cancer.
This technical guide provides a solid foundation for understanding the core aspects of m1A modification in mitochondrial RNA. The provided data, protocols, and visual aids are intended to empower researchers, scientists, and drug development professionals to further explore this exciting and impactful area of biology.
References
- 1. Analysis of mitochondrial m1A/G RNA modification reveals links to nuclear genetic variants and associated disease processes - PMC [pmc.ncbi.nlm.nih.gov]
- 2. N1-methyladenosine formation, gene regulation, biological functions, and clinical relevance - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Advances in the Structural and Functional Understanding of m1A RNA Modification - PMC [pmc.ncbi.nlm.nih.gov]
- 4. m1A Post-Transcriptional Modification in tRNAs - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Mitochondrial 16S rRNA Is Methylated by tRNA Methyltransferase TRMT61B in All Vertebrates - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. weizmann.elsevierpure.com [weizmann.elsevierpure.com]
- 7. wikicrow.ai [wikicrow.ai]
- 8. genecards.org [genecards.org]
- 9. academic.oup.com [academic.oup.com]
- 10. uniprot.org [uniprot.org]
- 11. The m1A landscape on cytosolic and mitochondrial mRNA at single-base resolution - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. researchgate.net [researchgate.net]
- 13. researchgate.net [researchgate.net]
- 14. Dysregulated mitochondrial and cytosolic tRNA m1A methylation in Alzheimer’s disease - PMC [pmc.ncbi.nlm.nih.gov]
- 15. academic.oup.com [academic.oup.com]
- 16. Base-resolution mapping reveals distinct m1A methylome in nuclear- and mitochondrial-encoded transcripts - PMC [pmc.ncbi.nlm.nih.gov]
- 17. biorxiv.org [biorxiv.org]
- 18. Analysis of mitochondrial m1A/G RNA modification reveals links to nuclear genetic variants and associated disease processes - PubMed [pubmed.ncbi.nlm.nih.gov]
- 19. Chemical manipulation of m1A mediates its detection in human tRNA - PMC [pmc.ncbi.nlm.nih.gov]
The Pivotal Role of 1-Methyladenine (m1A) in the Epitranscriptomic Regulation of Gene Expression
An In-depth Technical Guide for Researchers and Drug Development Professionals
Introduction
The landscape of gene expression is not solely dictated by the sequence of nucleotides. A complex layer of regulation occurs at the post-transcriptional level through chemical modifications of RNA, collectively known as the epitranscriptome.[1] Among the more than 170 identified RNA modifications, N1-methyladenosine (m1A) has emerged as a critical, dynamic, and reversible mark influencing multiple facets of RNA metabolism.[2][3] Initially identified decades ago in abundant non-coding RNAs like transfer RNA (tRNA) and ribosomal RNA (rRNA), recent advancements in high-throughput sequencing have unveiled its presence and functional significance in messenger RNA (mRNA) and long non-coding RNAs (lncRNAs).[1][2][4]
The m1A modification involves the addition of a methyl group to the N1 position of adenine.[2] This seemingly simple alteration has profound structural and functional consequences. By blocking the Watson-Crick base-pairing face of adenine, m1A disrupts canonical A-U pairing and can lead to the formation of non-canonical Hoogsteen base pairs, thereby altering RNA secondary structure and its interactions with proteins.[2][5] This guide provides a comprehensive overview of the molecular machinery governing m1A, its multifaceted roles in gene expression, and the experimental methodologies employed to investigate its functions, with a focus on its implications for cellular physiology and disease.
The m1A Regulatory Machinery: Writers, Erasers, and Readers
Similar to DNA epigenetics, the m1A epitranscriptomic mark is dynamically regulated by a trio of protein classes: "writers" that install the mark, "erasers" that remove it, and "readers" that recognize it and mediate downstream biological effects.[3][4][6]
-
Writers (Methyltransferases): These enzymes are responsible for catalyzing the transfer of a methyl group to the N1 position of adenosine. The primary writer complex for m1A in both tRNA and mRNA in the cytoplasm is the TRMT6/TRMT61A heterodimer.[7][8] In mitochondria, TRMT10C is responsible for installing m1A on mitochondrial transcripts, while TRMT61B modifies mitochondrial tRNAs.[9][10]
-
Erasers (Demethylases): The reversibility of m1A modification is managed by demethylases. The human AlkB homolog family of proteins, specifically ALKBH1 and ALKBH3, function as m1A erasers.[11] These Fe(II)- and α-ketoglutarate-dependent dioxygenases oxidatively remove the methyl group, restoring adenosine and thereby reversing the modification's effects.[12][13] ALKBH3 has been shown to demethylate m1A in both mRNA and tRNA.[14][15]
-
Readers (Binding Proteins): Reader proteins specifically recognize the m1A modification and translate it into a functional outcome. The YTH domain-containing family of proteins (YTHDF1, YTHDF2, YTHDF3, and YTHDC1), initially characterized as readers for N6-methyladenosine (m6A), have also been shown to bind m1A.[11][16] YTHDF proteins primarily function in the cytoplasm, influencing mRNA stability and translation, while YTHDC1 is a nuclear protein implicated in RNA processing and export.[16][17]
Physiological Functions of m1A in Gene Expression
m1A modification exerts its influence at multiple checkpoints of gene expression, from transcript stability and translation to cellular stress responses.
Regulation of mRNA Stability
A key function of m1A is the modulation of mRNA decay. The reader protein YTHDF2 has been identified as a primary mediator of this process.[16] Upon binding to m1A-modified transcripts, YTHDF2 can recruit decay machinery, leading to transcript destabilization and degradation.[16] This mechanism is analogous to its well-documented role in m6A-mediated mRNA decay.[16] Depletion of YTHDF2 results in an increased abundance of m1A-containing transcripts, while depletion of the eraser ALKBH3, which increases m1A levels, leads to the destabilization of known m1A-modified RNAs.[16][18] Conversely, some studies suggest that YTHDF3 binding to m1A-modified mRNA can enhance stability.[5] This suggests a context-dependent regulation of mRNA stability orchestrated by different reader proteins.
Control of mRNA Translation
The role of m1A in translation is complex and highly dependent on its location within the transcript.
-
Translation Promotion: Transcriptome-wide mapping has revealed that m1A is significantly enriched in the 5' untranslated region (5' UTR), particularly around the translation start codon and upstream of the first splice site.[19][20][21] This specific positioning is conserved between humans and mice and is positively correlated with protein production.[1][20] It is proposed that m1A modification in these structured 5' UTR regions helps to resolve RNA secondary structures, thereby facilitating ribosome scanning and translation initiation.[19]
-
Translation Inhibition: In contrast, when m1A is present within the coding sequence (CDS), it can inhibit translation.[4][22] This is particularly evident in mitochondrial transcripts, where m1A sites are predominantly found in the CDS.[6] The presence of m1A can interfere with the codon-anticodon pairing during ribosomal transit, leading to translational repression.[5][10]
Furthermore, m1A plays a critical structural role in tRNA.[2][23] Modifications like m1A at position 58 (m1A58) are crucial for maintaining the correct three-dimensional L-shape of tRNA, which is essential for its stability and function in delivering amino acids to the ribosome.[4][22][23] Demethylation of tRNA by ALKBH1 or ALKBH3 can impact translation efficiency.[6][13]
Role in Cellular Stress Response
Emerging evidence highlights a protective role for m1A during cellular stress. In response to stressors like heat shock, cells halt most translation and sequester mRNAs into stress granules (SGs) to protect them from degradation.[8] The m1A-generating complex TRMT6/61A accumulates in SGs, and m1A is enriched in the RNA fraction of these granules.[8] It is suggested that m1A-modified mRNAs dissociate from polysomes more efficiently upon stress, facilitating their rapid sequestration into SGs.[7] This mechanism allows for the protection of transcripts and enables a more efficient recovery of protein synthesis once the stress is relieved.[8]
Quantitative Data on m1A Function
The following tables summarize key quantitative findings from studies investigating the impact of m1A and its regulatory proteins on gene expression.
Table 1: Effect of m1A Regulators on Transcript Abundance and Stability
| Regulator | Experimental System | Observation | Quantitative Effect | Reference |
| YTHDF2 | Human Cells | Depletion of YTHDF2 | Increased abundance of 7 out of 8 tested m1A-modified transcripts | [5] |
| ALKBH3 | Human Cells | Depletion of ALKBH3 (m1A eraser) | Decreased stability of known m1A-containing RNAs | [16][18] |
| YTHDF3 | Human Cells | Overexpression of YTHDF3 | Decreased abundance and decay rate of IGF1R mRNA | [5] |
| YTHDC1 | HeLa Cells | Knockdown of YTHDC1 | >2-fold extension of the apparent half-life of nuclear m6A methylation (implying a role in export) | [24][25] |
Table 2: Binding Affinities of Reader Proteins for m1A-Modified RNA
| Protein | RNA Substrate | Method | Dissociation Constant (Kd) | Note | Reference |
| YTHDF1 | m1A-modified oligo | Biophysical assay | Comparable affinity to m6A-recognition | Binding occurs in diverse sequence contexts | [16] |
| YTHDF2 | m1A-modified oligo | Biophysical assay | Comparable affinity to m6A-recognition | Binding occurs in diverse sequence contexts | [16] |
| YTHDC1 | m1A-modified oligo | Chemical proteomics | No m1A-specific RNA binding observed | Contrasts with YTHDF proteins | [16] |
Experimental Protocols for m1A Analysis
Studying the m1A epitranscriptome requires specialized techniques to map its location and elucidate its function.
Protocol 1: m1A-Seq for Transcriptome-Wide Mapping
m1A-Seq, also known as m1A-meRIP-Seq, is an antibody-based enrichment method coupled with high-throughput sequencing to identify m1A sites across the transcriptome.[19]
Methodology:
-
RNA Isolation and Fragmentation: Total RNA or poly(A)-selected mRNA is isolated from cells or tissues. The RNA is then chemically or enzymatically fragmented into smaller pieces (typically ~100 nucleotides).[10][19]
-
Immunoprecipitation (IP): The fragmented RNA is incubated with an antibody specific to m1A. The antibody-RNA complexes are then captured, usually with magnetic beads.[19]
-
RNA Elution and Library Preparation: The m1A-containing RNA fragments are eluted from the antibody-bead complexes. A portion of the initial fragmented RNA is kept as an input control (without IP) to account for non-specific background and transcript abundance.[19] Both the IP and input samples are then used to construct cDNA libraries for sequencing.
-
Sequencing and Data Analysis: The libraries are sequenced using a high-throughput platform. The resulting sequence reads are aligned to a reference genome/transcriptome. Peaks are called by identifying regions where the IP sample shows a significant enrichment of reads compared to the input control.[19]
Protocol 2: Single-Nucleotide Resolution m1A Mapping
A key challenge with standard m1A-Seq is its limited resolution. Methods have been developed to achieve single-base resolution by exploiting the fact that m1A can stall or induce misincorporations during reverse transcription (RT).[10][26]
Methodology:
-
m1A Enrichment: The protocol begins similarly to m1A-Seq with RNA fragmentation and immunoprecipitation.[10]
-
Reverse Transcription: This is the critical step. The enriched RNA is reverse transcribed using specific reverse transcriptase enzymes.
-
Control Reaction (Dimroth Rearrangement): To confirm that the RT signatures are specific to m1A, a parallel control reaction is often performed. The enriched RNA is treated under alkaline conditions, which induces a Dimroth rearrangement, converting m1A into m6A.[1][10] Since m6A does not typically cause RT stalling or misincorporation, its presence eliminates the specific m1A signature, thus validating the identified site.[10]
-
Sequencing and Analysis: Libraries are prepared and sequenced. The analysis pipeline is designed to identify specific signatures: an abrupt stop in read coverage (truncation) or a high frequency of single nucleotide polymorphisms (misincorporations) at specific adenosine positions, which are absent in the Dimroth-treated control.[10]
Implications for Disease and Drug Development
The dynamic nature of m1A modification and its profound impact on gene expression position it as a key player in various physiological and pathological processes, particularly in cancer.[3][11][27] Aberrant expression of m1A writers, erasers, and readers has been linked to tumorigenesis, proliferation, and metastasis in various cancers, including bladder cancer, hepatocellular carcinoma, and prostate cancer.[11][13][28][29]
For instance, the demethylase ALKBH3 is highly expressed in several cancers, and its activity has been shown to promote cancer cell proliferation by enhancing protein synthesis through tRNA demethylation.[13] This makes ALKBH3 a potential therapeutic target.[13] Similarly, the expression levels of m1A regulatory proteins may serve as prognostic biomarkers.[3][30] The development of small molecule inhibitors targeting the catalytic activity of m1A writers and erasers represents a promising avenue for novel therapeutic strategies in oncology and other diseases driven by epitranscriptomic dysregulation.
1-Methyladenine is a vital epitranscriptomic modification that adds a significant layer of regulatory complexity to gene expression. Governed by a dynamic interplay of writer, eraser, and reader proteins, m1A influences the fate of RNA transcripts by modulating their structure, stability, and translational efficiency. Its roles are context-dependent, promoting translation when positioned near the start codon while destabilizing transcripts or inhibiting translation when located elsewhere. Furthermore, its function in the cellular stress response underscores its importance in maintaining cellular homeostasis. As our understanding of the m1A landscape and its molecular machinery deepens, so too does its potential for exploitation in diagnostics and therapeutics, heralding a new frontier for RNA-targeted drug development.
References
- 1. The dynamic N1-methyladenosine methylome in eukaryotic messenger RNA - PMC [pmc.ncbi.nlm.nih.gov]
- 2. m1A RNA Modification in Gene Expression Regulation - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Clinician’s Guide to Epitranscriptomics: An Example of N1-Methyladenosine (m1A) RNA Modification and Cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Reversible RNA Modification N1-methyladenosine (m1A) in mRNA and tRNA - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. encyclopedia.pub [encyclopedia.pub]
- 6. N1-methyladenosine formation, gene regulation, biological functions, and clinical relevance - PMC [pmc.ncbi.nlm.nih.gov]
- 7. researchgate.net [researchgate.net]
- 8. The protective role of m1A during stress-induced granulation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. mdpi.com [mdpi.com]
- 10. weizmann.elsevierpure.com [weizmann.elsevierpure.com]
- 11. The landscape of m1A modification and its posttranscriptional regulatory functions in primary neurons | eLife [elifesciences.org]
- 12. researchgate.net [researchgate.net]
- 13. AlkB homolog 3-mediated tRNA demethylation promotes protein synthesis in cancer cells - PMC [pmc.ncbi.nlm.nih.gov]
- 14. researchgate.net [researchgate.net]
- 15. researchgate.net [researchgate.net]
- 16. YTHDF2 recognition of N1-methyladenosine (m1A)-modified RNA is associated with transcript destabilization - PMC [pmc.ncbi.nlm.nih.gov]
- 17. researchgate.net [researchgate.net]
- 18. collaborate.princeton.edu [collaborate.princeton.edu]
- 19. m1A RNA Methylation Analysis - CD Genomics [cd-genomics.com]
- 20. The dynamic N(1)-methyladenosine methylome in eukaryotic messenger RNA - PubMed [pubmed.ncbi.nlm.nih.gov]
- 21. Frontiers | Regulation of Gene Expression Associated With the N6-Methyladenosine (m6A) Enzyme System and Its Significance in Cancer [frontiersin.org]
- 22. researchgate.net [researchgate.net]
- 23. pubs.acs.org [pubs.acs.org]
- 24. YTHDC1 mediates nuclear export of N6-methyladenosine methylated mRNAs - PMC [pmc.ncbi.nlm.nih.gov]
- 25. YTHDC1 mediates nuclear export of N6-methyladenosine methylated mRNAs | eLife [elifesciences.org]
- 26. rna-seqblog.com [rna-seqblog.com]
- 27. researchgate.net [researchgate.net]
- 28. researchgate.net [researchgate.net]
- 29. N1-methyladenosine modification in cancer biology: Current status and future perspectives - PMC [pmc.ncbi.nlm.nih.gov]
- 30. Clinician's Guide to Epitranscriptomics: An Example of N1-Methyladenosine (m1A) RNA Modification and Cancer - PubMed [pubmed.ncbi.nlm.nih.gov]
Whitepaper: The Structural Impact of 1-Methyladenosine on RNA Secondary Structure
Audience: Researchers, scientists, and drug development professionals.
Executive Summary
N1-methyladenosine (m1A) is a post-transcriptional RNA modification where a methyl group is added to the N1 position of adenine. This seemingly subtle alteration carries profound implications for RNA biology. By fundamentally altering the hydrogen bonding capacity of the adenine base, m1A acts as a potent modulator of RNA secondary and tertiary structure. Unlike the canonical Watson-Crick base pairing that underpins duplex RNA, the N1-methylated adenine sterically blocks this interaction, leading to significant structural destabilization, local melting, and the formation of non-canonical pairs. This modification is not static; it is dynamically installed and removed by a dedicated suite of "writer" and "eraser" enzymes and interpreted by "reader" proteins, forming a critical layer of epitranscriptomic regulation. This technical guide provides an in-depth exploration of the biochemical principles of m1A, its quantitative impact on RNA thermodynamics, the enzymatic machinery governing its prevalence, and the experimental protocols used to elucidate its structural consequences.
The Biochemical Nature of 1-Methyladenosine (m1A)
The addition of a methyl group to the N1 position of adenine, a nitrogen atom integral to the Watson-Crick interface, fundamentally alters its pairing potential.[1][2] This methylation prevents the formation of the standard A-U base pair by physically obstructing the hydrogen bond donor site.[1] Furthermore, under physiological conditions, the m1A modification imparts a positive electrostatic charge to the adenine base, which can influence electrochemical interactions critical for RNA structure and protein binding.[2][3]
The primary structural consequences of m1A incorporation are:
-
Disruption of Watson-Crick Pairing: The methyl group at the N1 position sterically clashes with the pairing face of uracil (or thymine), effectively blocking the canonical A-U base pair.[1][4] This is the most significant and direct structural impact of the modification.
-
Duplex Destabilization: As a result of the pairing disruption, m1A is a potent destabilizer of A-form RNA duplexes.[5][6] This destabilization is significantly more pronounced in RNA than the equivalent modification (m1dA) is in B-form DNA.[5][7]
-
Promotion of Non-Canonical Structures: In specific contexts, particularly within tRNA, the N1-methylated adenosine can participate in non-canonical base pairing through its Hoogsteen face.[8][9] These interactions are crucial for establishing and maintaining the complex three-dimensional L-shape of tRNAs.[2][8]
-
Induction of Local Unpairing: The presence of m1A can induce a localized "melting" or conformational shift in the RNA duplex, creating single-stranded regions or favoring alternative structures like hairpin loops where the m1A residue resides in the unpaired loop region.[1][5][6]
Quantitative Impact on RNA Duplex Stability
The structural disruption caused by m1A has been quantified through thermodynamic studies. UV melting experiments consistently show that introducing a single m1A modification significantly lowers the melting temperature (Tm) and increases the Gibbs free energy (ΔG°) of an RNA duplex, indicating a less stable structure. The destabilization is primarily enthalpic.[5] In A-RNA, m1A can lead to a conformation resembling a base-opened state.[5][7]
| RNA Duplex Context | Modification | Thermodynamic Destabilization (ΔΔG°) | Reference |
| A-RNA Duplexes | m1rA and m1rG | 4.3 – 6.5 kcal mol⁻¹ | [5] |
| B-DNA Duplexes | m1dA | 1.8 – 3.4 kcal mol⁻¹ | [5] |
| A-RNA vs. B-DNA | m1A/m1G | RNA is destabilized by an additional ≈1.1–4.7 kcal mol⁻¹ compared to DNA | [5][7] |
| Comparison to m6A | m6A in A-RNA | 0.5 – 1.7 kcal mol⁻¹ | [5][10] |
Table 1: Summary of quantitative data on the thermodynamic destabilization induced by N1-methyladenosine in nucleic acid duplexes.
The Enzymatic Machinery of m1A Regulation
The level and location of m1A are tightly controlled by a set of dedicated enzymes, often referred to as "writers," "erasers," and "readers." This dynamic regulation allows m1A to function as a responsive epitranscriptomic mark.
-
Writers (Methyltransferases): These enzymes catalyze the transfer of a methyl group from S-adenosyl-l-methionine (SAM) to the N1 position of adenine.[11]
-
TRMT6/TRMT61A Complex: Responsible for m1A58 in cytosolic and mitochondrial tRNAs and also modifies some mRNAs that contain a tRNA T-loop-like structure.[1][2][11]
-
TRMT10C: Installs m1A9 in mitochondrial tRNAs and can also modify mitochondrial mRNA.[8][11]
-
TRMT61B: Catalyzes m1A58 in mitochondrial tRNAs and has been implicated in modifying mitochondrial rRNA.[2][8]
-
NML (RRP8): A nucleolar protein that methylates 28S rRNA.[2][11]
-
-
Erasers (Demethylases): These enzymes remove the methyl group, reverting m1A back to adenosine.
-
Readers (Binding Proteins): These proteins specifically recognize the m1A modification and mediate its downstream functional consequences, such as altering mRNA stability or translation.
Experimental Protocols for Structural Analysis
Several specialized techniques have been developed to map m1A sites and probe their structural consequences. These methods often leverage the unique chemical properties of m1A, such as its ability to stall reverse transcriptase or its susceptibility to specific chemical treatments.
m1A Immunoprecipitation and Sequencing (m1A-seq / MeRIP-seq)
This antibody-based enrichment method is a common first-pass approach for transcriptome-wide mapping of m1A.
-
RNA Fragmentation: Total cellular RNA is isolated and fragmented into smaller pieces (typically ~100-200 nucleotides).
-
Immunoprecipitation (IP): The fragmented RNA is incubated with an antibody specific to m1A. It is critical to use highly specific antibodies to avoid cross-reactivity with other modifications like m6A or the m7G cap.[8][13]
-
Enrichment: Antibody-bound RNA fragments are captured, typically using magnetic beads.
-
Library Preparation & Sequencing: The enriched, m1A-containing RNA fragments are reverse transcribed into cDNA, prepared into a sequencing library, and analyzed via high-throughput sequencing.
-
Data Analysis: Sequencing reads are mapped back to the transcriptome to identify enriched regions, revealing the locations of m1A modifications.
m1A-ID-seq (m1A sequencing with antibody-enrichment and specific enzymatic reaction)
This method adds an enzymatic demethylation step to improve specificity and validate antibody-based enrichment.[12]
-
RNA Isolation and Fragmentation: As with m1A-seq.
-
Sample Splitting: The fragmented RNA is divided into two portions.
-
Immunoprecipitation: Both portions are subjected to m1A immunoprecipitation.
-
Demethylation Treatment: One portion of the enriched RNA is treated with a demethylase (e.g., E. coli AlkB) to remove m1A marks, while the other portion is left untreated as a control.[12]
-
Sequencing and Analysis: Both samples are sequenced. True m1A sites will show high enrichment in the control sample but significantly reduced enrichment in the demethylase-treated sample.[12]
Chemical Probing and Reverse Transcription-Based Methods
These methods exploit the fact that m1A disrupts the Watson-Crick face of adenine, making it behave like an unpaired base to certain chemical probes and causing polymerase stalling.
-
Dimethyl Sulfate (DMS) Probing: DMS methylates the N1 position of accessible (unpaired) adenines and the N3 of accessible cytosines. Since m1A is already methylated at this position, its primary signature in these experiments is a strong stop to reverse transcription one nucleotide 3' to the modification site.[14] When coupled with high-throughput sequencing (DMS-MaPseq), this provides nucleotide-resolution information on RNA structure, where m1A sites appear as strong and consistent termination signals.
-
Nuclear Magnetic Resonance (NMR) Spectroscopy and X-ray Crystallography: For high-resolution structural information, these biophysical techniques are the gold standard. They can be used to solve the three-dimensional structure of RNA oligonucleotides containing m1A, directly visualizing the local conformation, including non-canonical pairs or base flipping, and providing empirical evidence for the structural disruptions predicted by other methods.[5][8][15]
Conclusion and Future Directions
The N1-methyladenosine modification is a powerful endogenous tool for manipulating RNA structure. By disrupting the fundamental Watson-Crick base pair, m1A introduces a significant point of instability, forcing local conformational changes that are critical for the proper folding of non-coding RNAs like tRNA and for the dynamic regulation of mRNA translation and stability.[1][3] The continued development of precise, antibody-free detection methods and the application of high-resolution structural biology will further illuminate how this single methyl group leverages the principles of physical chemistry to enact widespread biological control. For professionals in drug development, the enzymes that write and erase m1A represent a promising class of therapeutic targets for diseases, including cancers, where epitranscriptomic regulation is misaligned.[3][12]
References
- 1. m1A RNA Modification in Gene Expression Regulation - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Reversible RNA Modification N1-methyladenosine (m1A) in mRNA and tRNA - PMC [pmc.ncbi.nlm.nih.gov]
- 3. mdpi.com [mdpi.com]
- 4. pnas.org [pnas.org]
- 5. m1A and m1G Potently Disrupt A-RNA Structure Due to the Intrinsic Instability of Hoogsteen Base Pairs - PMC [pmc.ncbi.nlm.nih.gov]
- 6. m(1)A and m(1)G disrupt A-RNA structure through the intrinsic instability of Hoogsteen base pairs - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. researchgate.net [researchgate.net]
- 8. Advances in the Structural and Functional Understanding of m1A RNA Modification - PMC [pmc.ncbi.nlm.nih.gov]
- 9. pubs.acs.org [pubs.acs.org]
- 10. pubs.acs.org [pubs.acs.org]
- 11. N1-methyladenosine formation, gene regulation, biological functions, and clinical relevance - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Research progress of N1-methyladenosine RNA modification in cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 13. royalsocietypublishing.org [royalsocietypublishing.org]
- 14. academic.oup.com [academic.oup.com]
- 15. Effect of 1-methyladenine on thermodynamic stabilities of double-helical DNA structures - PubMed [pubmed.ncbi.nlm.nih.gov]
An In-depth Technical Guide to the Cellular Pathways Regulated by 1-Methyladenine
For Researchers, Scientists, and Drug Development Professionals
This technical guide provides a comprehensive overview of the cellular pathways modulated by 1-methyladenine (1-MA). Primarily known for its role as the natural hormone that induces oocyte maturation in starfish, 1-MA's influence extends to fundamental cellular processes. This document details the signaling cascades initiated by extracellular 1-MA in oocytes and delves into the intracellular regulatory functions of its isomeric form, N1-methyladenosine (m¹A), a critical RNA modification. The guide is structured to provide researchers and drug development professionals with detailed experimental methodologies, quantitative data for comparative analysis, and clear visual representations of the key pathways.
The Dichotomy of 1-Methyladenine: A Signaling Molecule and an RNA Modifier
1-Methyladenine exists in two distinct functional contexts within cellular biology. In the marine invertebrate model, particularly starfish, 1-MA acts as an external signaling molecule, a hormone that binds to a cell surface receptor to initiate a signaling cascade culminating in the reinitiation of meiosis in oocytes.[1] This process is a classic example of G-protein coupled receptor (GPCR) signaling.
Conversely, as N1-methyladenosine (m¹A), it is a post-transcriptional modification of RNA molecules, including messenger RNA (mRNA), transfer RNA (tRNA), and ribosomal RNA (rRNA).[2][3] This modification is part of the growing field of epitranscriptomics and plays a crucial role in regulating gene expression by affecting RNA stability, translation, and interaction with RNA-binding proteins.[4][5] The enzymatic machinery of "writers" (methyltransferases), "erasers" (demethylases), and "readers" (m¹A-binding proteins) governs the dynamic nature of this modification.[3]
The 1-Methyladenine Signaling Pathway in Starfish Oocyte Maturation
The induction of oocyte maturation by 1-MA in starfish is a well-studied model for the G2/M phase transition of the cell cycle. The pathway is initiated by the binding of 1-MA to a yet-to-be-fully-identified G-protein coupled receptor on the oocyte surface.[6][7] This binding event triggers a cascade of intracellular events leading to the activation of the master mitotic regulator, Maturation-Promoting Factor (MPF), a complex of Cyclin B and Cdk1.
G-Protein Activation and Downstream Effectors
Upon 1-MA binding, the associated heterotrimeric G-protein is activated, leading to the dissociation of the Gβγ subunit from the Gα subunit.[7] The liberated Gβγ subunit acts as the primary effector, initiating two parallel pathways that converge on the activation of MPF.[6]
One critical downstream target of Gβγ is Phosphoinositide 3-kinase (PI3K).[6] The activation of PI3K leads to the production of phosphatidylinositol (3,4,5)-trisphosphate (PIP3), a key second messenger.[6] This, in turn, activates the serine/threonine kinase Akt (also known as Protein Kinase B) and Serum/Glucocorticoid-regulated Kinase (SGK).[6][7] Both Akt and SGK are implicated in the subsequent phosphorylation and regulation of downstream targets that control the activity of MPF.[6][8]
Regulation of MPF (Cdk1/Cyclin B) Activity
The activation of MPF is a tightly regulated process involving a balance between inhibitory and activating phosphorylations on the Cdk1 subunit. The kinases Wee1 and Myt1 phosphorylate Cdk1 on Threonine-14 and Tyrosine-15, keeping the complex inactive.[9] The phosphatase Cdc25 removes these inhibitory phosphates, leading to Cdk1 activation.[9]
The 1-MA signaling pathway ultimately tips this balance in favor of activation. Akt/SGK can phosphorylate and inactivate Myt1, while also phosphorylating and activating Cdc25.[6] This dual action leads to a rapid dephosphorylation and activation of the pre-existing pool of Cdk1/Cyclin B (pre-MPF), driving the oocyte into M-phase.[9] This initial activation is then amplified through a positive feedback loop where active MPF further activates Cdc25 and inhibits Wee1/Myt1.[9]
Visualization of the 1-MA Signaling Pathway
Caption: 1-Methyladenine signaling cascade in starfish oocytes.
The Role of N1-methyladenosine (m¹A) in RNA Regulation
Distinct from its role as an extracellular signal, the isomeric form N1-methyladenosine (m¹A) is a widespread internal modification within various RNA species. This epitranscriptomic mark is dynamically installed, removed, and interpreted by a suite of specialized proteins to fine-tune gene expression at the post-transcriptional level.
The m¹A Regulatory Machinery
The m¹A modification is controlled by three classes of proteins:
-
"Writers" (Methyltransferases): These enzymes catalyze the addition of a methyl group to the N1 position of adenine. Key writers include the TRMT6/TRMT61A complex and TRMT10C.[3]
-
"Erasers" (Demethylases): These enzymes remove the methyl group, making the modification reversible. ALKBH1 and ALKBH3 are well-characterized m¹A demethylases.[3]
-
"Readers" (Binding Proteins): These proteins recognize and bind to m¹A-modified RNA, mediating downstream effects. The YTH domain-containing family of proteins (e.g., YTHDF1, YTHDF2, YTHDF3, and YTHDC1) are prominent m¹A readers.[3]
Functional Consequences of m¹A Modification
The presence of m¹A can have profound effects on the fate of an RNA molecule:
-
RNA Structure: The methyl group at the N1 position disrupts Watson-Crick base pairing, which can alter the local secondary and tertiary structure of RNA.[2]
-
RNA Stability: Depending on the context and the reader proteins involved, m¹A can either promote RNA degradation or enhance its stability.[5]
-
Translation: m¹A modifications, particularly in the 5' untranslated region (UTR) of mRNAs, can influence the efficiency of protein translation.[4]
-
Cellular Signaling: Dysregulation of m¹A has been implicated in various diseases, including cancer. The m¹A machinery can influence major signaling pathways such as the PI3K/AKT/mTOR pathway.[10]
Visualization of the m¹A Regulatory Cycle
Caption: The dynamic cycle of m¹A RNA modification.
Quantitative Data Summary
The following tables summarize key quantitative data related to the effects of 1-methyladenine on starfish oocyte maturation.
Table 1: Dose-Response of 1-Methyladenine on Germinal Vesicle Breakdown (GVBD)
| 1-MA Concentration (µM) | % GVBD (typical) | Time to 50% GVBD (min) |
| < 0.05 | 0% | - |
| 0.05 - 0.125 | 0 - 50% (variable) | > 30 |
| 0.25 - 0.5 | 100% | ~20-25 |
| ≥ 1.0 | 100% | ~15-20 |
Data compiled from typical results reported in the literature. Actual values may vary depending on the starfish species and experimental conditions.[11]
Table 2: Key Kinetic Parameters of 1-MA Induced Oocyte Maturation
| Parameter | Typical Value | Description |
| Hormone-Dependent Period (HDP) | ~6-15 min | The minimum time 1-MA must be present to irreversibly trigger maturation.[12] |
| Time to GVBD | ~15-30 min | The time from 1-MA application to the visible breakdown of the germinal vesicle.[11] |
| MPF Activation | Peaks at GVBD | The activity of Cdk1/Cyclin B rises sharply and peaks around the time of GVBD.[13] |
Experimental Protocols
This section provides detailed methodologies for key experiments used to study the effects of 1-methyladenine.
Starfish Oocyte Maturation Assay
Objective: To assess the ability of 1-methyladenine or other compounds to induce oocyte maturation, measured by Germinal Vesicle Breakdown (GVBD).
Materials:
-
Mature female starfish
-
Artificial seawater (ASW)
-
1-Methyladenine (1-MA) stock solution (1 mM in distilled water)
-
Petri dishes
-
Dissecting tools
-
Inverted microscope
Procedure:
-
Isolate ovaries from a mature female starfish.
-
Gently wash the ovaries in ASW to remove excess debris.
-
Tease the ovarian wall with fine forceps to release the immature oocytes.
-
Wash the oocytes several times with ASW by decantation to obtain a clean suspension of single, immature oocytes with intact germinal vesicles.
-
Transfer a small aliquot of the oocyte suspension to a Petri dish containing fresh ASW.
-
Add 1-MA to the desired final concentration (typically 1 µM for maximal response).
-
Incubate the oocytes at a constant temperature (e.g., 20°C).
-
At regular time intervals (e.g., every 5 minutes), observe the oocytes under an inverted microscope.
-
Score the percentage of oocytes that have undergone GVBD. GVBD is characterized by the disappearance of the distinct nuclear envelope.[12]
-
For dose-response experiments, set up parallel incubations with a range of 1-MA concentrations.
Measurement of MPF (Cdk1/Cyclin B) Activity
Objective: To quantify the kinase activity of MPF in oocyte lysates.
Materials:
-
Oocyte samples (at different time points after 1-MA stimulation)
-
Lysis buffer (e.g., containing β-glycerophosphate, EGTA, MgCl₂, DTT, and protease/phosphatase inhibitors)
-
Histone H1 (as a substrate)
-
[γ-³²P]ATP
-
Kinase reaction buffer
-
SDS-PAGE equipment
-
Phosphorimager or autoradiography film
Procedure:
-
Collect oocytes at desired time points and lyse them in ice-cold lysis buffer.
-
Clarify the lysates by centrifugation to remove yolk and cellular debris.
-
Determine the protein concentration of the supernatant.
-
Set up the kinase reaction by mixing a small amount of oocyte lysate with kinase reaction buffer, Histone H1, and [γ-³²P]ATP.
-
Incubate the reaction at 30°C for a defined period (e.g., 10-20 minutes).
-
Stop the reaction by adding SDS-PAGE sample buffer and boiling.
-
Separate the proteins by SDS-PAGE.
-
Dry the gel and expose it to a phosphorimager screen or autoradiography film to visualize the phosphorylated Histone H1.
-
Quantify the band intensity to determine the relative MPF activity.[14]
Experimental Workflow for Identifying Pathway Components
The following diagram illustrates a typical workflow for identifying and validating components of the 1-MA signaling pathway.
Caption: Workflow for validating a candidate protein in the 1-MA pathway.
Conclusion
1-Methyladenine plays a multifaceted role in cellular regulation. As an extracellular hormone in starfish, it triggers a well-defined signaling cascade involving G-proteins, PI3K, and Akt/SGK to activate the master mitotic regulator MPF, providing an excellent model system for studying cell cycle control. As an intracellular RNA modification, m¹A is a key player in the epitranscriptomic landscape, with its dynamic regulation by writers, erasers, and readers influencing gene expression at the post-transcriptional level. Understanding these distinct but equally important roles of 1-methyladenine is crucial for advancing our knowledge in developmental biology, cell cycle regulation, and RNA biology, and may offer novel targets for therapeutic intervention in diseases where these pathways are dysregulated. This guide provides a foundational resource for researchers aiming to explore the intricate world of 1-methyladenine-regulated cellular pathways.
References
- 1. researchgate.net [researchgate.net]
- 2. Harnessing m1A modification: a new frontier in cancer immunotherapy - PMC [pmc.ncbi.nlm.nih.gov]
- 3. N1-methyladenosine formation, gene regulation, biological functions, and clinical relevance - PMC [pmc.ncbi.nlm.nih.gov]
- 4. The landscape of m1A modification and its posttranscriptional regulatory functions in primary neurons | eLife [elifesciences.org]
- 5. researchgate.net [researchgate.net]
- 6. Oocyte Maturation in Starfish - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Oocyte Maturation in Starfish - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. A Role of PI3K/Akt Signaling in Oocyte Maturation and Early Embryo Development - PMC [pmc.ncbi.nlm.nih.gov]
- 9. MPF-based meiotic cell cycle control: Half a century of lessons from starfish oocytes - PMC [pmc.ncbi.nlm.nih.gov]
- 10. N1-methyladenosine modification in cancer biology: Current status and future perspectives - PMC [pmc.ncbi.nlm.nih.gov]
- 11. health.uconn.edu [health.uconn.edu]
- 12. vliz.be [vliz.be]
- 13. Progressive activation of CyclinB1-Cdk1 coordinates entry to mitosis - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Protein kinase assays for measuring MPF and MAPK activities in mouse and rat oocytes and early embryos - PubMed [pubmed.ncbi.nlm.nih.gov]
The Evolutionary Conservation and Functional Significance of 1-Methyladenine (m1A) RNA Modification: A Technical Guide
For Researchers, Scientists, and Drug Development Professionals
Abstract
N1-methyladenosine (m1A) is a dynamic and reversible post-transcriptional RNA modification that plays a crucial, evolutionarily conserved role in regulating gene expression across all domains of life. This technical guide provides an in-depth exploration of the m1A modification, detailing its prevalence, the enzymatic machinery responsible for its deposition and removal, and its functional implications in various biological processes. We present a comprehensive overview of the current methodologies for m1A detection and analysis, including detailed experimental protocols. Furthermore, this guide summarizes key quantitative data and visualizes the intricate signaling pathways and molecular interactions influenced by this critical RNA modification, offering valuable insights for researchers and professionals in drug development.
Introduction: The Expanding World of the Epitranscriptome
The "epitranscriptome" encompasses a diverse array of over 170 chemical modifications to RNA molecules that occur post-transcriptionally.[1] These modifications are not merely static decorations but are dynamically regulated by a complex interplay of enzymes, often referred to as "writers," "erasers," and "readers."[2] Among these, N1-methyladenosine (m1A) has emerged as a significant regulator of RNA metabolism, influencing RNA structure, stability, and translation.[1]
The m1A modification involves the addition of a methyl group to the N1 position of adenine. This addition disrupts the canonical Watson-Crick base pairing and imparts a positive charge under physiological conditions, thereby significantly altering the local RNA structure and its interactions with proteins.[1][3] Initially identified in non-coding RNAs like transfer RNA (tRNA) and ribosomal RNA (rRNA), recent advancements in high-throughput sequencing have revealed its presence and regulatory roles in messenger RNA (mRNA) as well.[1][4] This guide delves into the evolutionary conservation of m1A, its functional significance, and the technical approaches to study this pivotal RNA modification.
Evolutionary Conservation of m1A Modification
The m1A modification is a widespread and evolutionarily conserved feature of RNA, found in bacteria, archaea, and eukaryotes, including in mitochondrial transcripts.[1][4] Its presence across such a broad range of organisms underscores its fundamental biological importance.
Distribution of m1A in Different RNA Types
The location and abundance of m1A vary depending on the RNA type and the organism.
-
tRNA: m1A is highly abundant in tRNA, where it is found at several conserved positions, most notably at position 58 (m1A58) in the TΨC loop.[4] The m1A58 modification is critical for maintaining the structural integrity and stability of tRNA.[4] Other positions, such as 9, 14, 22, and 57, are also subject to m1A modification in the tRNAs of various species.[5]
-
rRNA: m1A is also a conserved modification in rRNA. For instance, m1A is found at position 1322 of the 28S rRNA in humans, which is located in the peptidyl transferase center of the ribosome, suggesting a role in translation.[4]
-
mRNA: In mammalian mRNA, m1A is a less abundant modification compared to N6-methyladenosine (m6A).[4] It is often enriched in the 5' untranslated region (5' UTR) near the translation start site and has been associated with enhanced translation.[6] In contrast, m1A modifications within the coding sequence (CDS), particularly in mitochondrial mRNAs, have been shown to inhibit translation.[6]
The m1A Regulatory Machinery: Writers, Erasers, and Readers
The dynamic nature of m1A modification is controlled by a dedicated set of proteins that are also evolutionarily conserved.
-
Writers (Methyltransferases): These enzymes catalyze the addition of the methyl group to adenine. The primary writer complex for m1A58 in eukaryotic cytosolic tRNA and some mRNAs is a heterodimer of TRMT6 and TRMT61A.[1] In mitochondria, TRMT61B and TRMT10C are responsible for m1A methylation.[4]
-
Erasers (Demethylases): These enzymes remove the methyl group from m1A. The AlkB family of dioxygenases, including ALKBH1 and ALKBH3 in mammals, have been identified as m1A erasers.[1]
-
Readers: These proteins recognize and bind to m1A-modified RNA, mediating its downstream effects. The YTH domain-containing family of proteins (YTHDF1, YTHDF2, YTHDF3, and YTHDC1) have been shown to bind m1A, influencing the stability and translation of the modified transcripts.[1]
Below is a logical diagram illustrating the interplay between m1A writers, erasers, and readers.
Quantitative Analysis of m1A Modification
The abundance of m1A varies significantly across different organisms, cell types, and RNA species. Quantitative analysis is crucial for understanding its regulatory roles.
| Organism/Cell Line | RNA Type | m1A Abundance (m1A/A ratio) | Reference(s) |
| Mammalian Cells | |||
| Human (HEK293T, HeLa, HepG2) | mRNA | ~0.015% - 0.054% | [4] |
| Mouse Embryonic Fibroblasts | mRNA | ~0.015% - 0.054% | [4] |
| Mammalian Tissues | |||
| Mouse Brain, Kidney | mRNA | Up to 0.16% | [4] |
| Other Eukaryotes | |||
| Saccharomyces cerevisiae | tRNA | High (present in many tRNAs) | [4] |
| Prokaryotes | |||
| Escherichia coli | tRNA | Present in specific tRNAs | [4] |
Note: Quantitative data for m1A, especially kinetic parameters for its modifying enzymes, are still being actively researched. The provided values represent the current understanding based on available literature.
Functional Roles of m1A Modification
The m1A modification exerts its influence on a wide range of cellular processes, primarily by affecting RNA structure and interactions.
Regulation of Translation
m1A plays a dual role in the regulation of protein synthesis.
-
Translation Enhancement: m1A modifications in the 5' UTR of mRNAs have been shown to promote translation.[3][6] The presence of m1A near the start codon can enhance ribosome loading and translation initiation.[6]
-
Translation Inhibition: Conversely, m1A within the coding sequence (CDS) of both nuclear and mitochondrial mRNAs can inhibit translation by stalling the ribosome.[6]
Maintenance of RNA Structure and Stability
The m1A modification is crucial for the proper folding and stability of non-coding RNAs. In tRNA, m1A58 is essential for maintaining the canonical L-shaped tertiary structure, which is critical for its function in translation.[1]
Involvement in Signaling Pathways
Recent studies have implicated m1A modification in the regulation of key cellular signaling pathways.
-
PI3K/AKT/mTOR Pathway: This pathway is a central regulator of cell growth, proliferation, and survival.[7] Dysregulation of m1A writers and erasers has been shown to affect the activity of this pathway in gastrointestinal cancers.[8][9][10][11][12]
-
ErbB Pathway: The ErbB family of receptor tyrosine kinases is involved in cell proliferation and differentiation.[8] m1A modification has been linked to the regulation of this pathway, also in the context of gastrointestinal cancers.[8][9][11][13]
Below is a diagram illustrating the potential influence of m1A modification on the PI3K/AKT/mTOR signaling pathway.
Experimental Protocols for m1A Detection
Several high-throughput sequencing-based methods have been developed to map m1A modifications across the transcriptome at single-nucleotide resolution.
m1A-Seq (m1A Immunoprecipitation Sequencing)
This method relies on the specific enrichment of m1A-containing RNA fragments using an m1A-specific antibody.
Protocol Overview:
-
RNA Fragmentation: Isolate total RNA or poly(A)+ RNA and fragment it into small pieces (typically ~100 nucleotides).
-
Immunoprecipitation (IP): Incubate the fragmented RNA with an m1A-specific antibody conjugated to magnetic beads.
-
Washing: Wash the beads to remove non-specifically bound RNA fragments.
-
Elution: Elute the m1A-containing RNA fragments from the antibody.
-
Library Preparation: Prepare a cDNA library from the enriched RNA fragments for next-generation sequencing.
-
Sequencing and Data Analysis: Sequence the library and analyze the data to identify enriched regions, which correspond to m1A sites.
Techniques for Single-Nucleotide Resolution
To pinpoint the exact location of m1A, m1A-seq is often combined with techniques that exploit the chemical properties of m1A.
-
Dimroth Rearrangement: Under alkaline conditions and heat, m1A can be chemically converted to N6-methyladenosine (m6A).[14] Since reverse transcriptase can read through m6A without stalling or misincorporation, comparing the sequencing results of treated and untreated samples can help identify m1A sites.[14]
Protocol for Dimroth Rearrangement:
-
Incubate the m1A-enriched RNA fragments in a sodium carbonate/bicarbonate buffer (pH ~10.4) at an elevated temperature (e.g., 60°C) for a defined period (e.g., 1 hour).[14]
-
Neutralize the reaction and purify the RNA before proceeding to library preparation.
-
-
AlkB Demethylation: The E. coli AlkB enzyme and its human homologs (ALKBH1, ALKBH3) can demethylate m1A back to adenosine.[15][16][17] Comparing sequencing libraries from AlkB-treated and untreated samples allows for the identification of m1A sites.[15][16][17]
Protocol for AlkB Demethylation:
-
Incubate the RNA with purified AlkB enzyme in a reaction buffer containing necessary cofactors (e.g., Fe(II), α-ketoglutarate, and ascorbate) at 37°C.[15]
-
Stop the reaction and purify the RNA for library preparation.
-
m1A-MAP (m1A-induced Misincorporation-assisted Profiling)
This method leverages the fact that reverse transcriptase often misincorporates nucleotides or terminates when it encounters an m1A modification.[18][19] By sequencing the cDNA, these misincorporation "signatures" can be used to identify m1A sites at single-base resolution.[18][19] This technique is often combined with m1A immunoprecipitation and AlkB demethylation for enhanced sensitivity and specificity.[18][19]
Below is a workflow diagram for a typical m1A-seq experiment incorporating single-nucleotide resolution techniques.
Implications for Drug Development
The critical roles of m1A modification in cellular processes, particularly in diseases like cancer, make the enzymes involved in its regulation attractive targets for therapeutic intervention.[8] The dysregulation of m1A writers and erasers has been linked to altered signaling pathways that promote cancer cell proliferation and survival.[8][9][10][11][12] Therefore, the development of small molecule inhibitors or activators of these enzymes holds promise for novel cancer therapies. A thorough understanding of the evolutionary conservation and functional diversity of the m1A machinery is essential for designing specific and effective drugs with minimal off-target effects.
Conclusion
The 1-methyladenine modification is a fundamentally important and evolutionarily conserved feature of the epitranscriptome. Its dynamic regulation by a dedicated set of writers, erasers, and readers allows for fine-tuning of gene expression at the post-transcriptional level. The continued development of sophisticated detection methodologies will further illuminate the intricate roles of m1A in health and disease, paving the way for new diagnostic and therapeutic strategies. This technical guide provides a solid foundation for researchers and drug development professionals to explore the multifaceted world of m1A RNA modification.
References
- 1. m1A RNA Modification in Gene Expression Regulation - PMC [pmc.ncbi.nlm.nih.gov]
- 2. academic.oup.com [academic.oup.com]
- 3. m1A Post-Transcriptional Modification in tRNAs - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Reversible RNA Modification N1-methyladenosine (m1A) in mRNA and tRNA - PMC [pmc.ncbi.nlm.nih.gov]
- 5. pubs.acs.org [pubs.acs.org]
- 6. m1A RNA Methylation Analysis - CD Genomics [cd-genomics.com]
- 7. PI3K/AKT/mTOR pathway - Wikipedia [en.wikipedia.org]
- 8. m1A Regulated Genes Modulate PI3K/AKT/mTOR and ErbB Pathways in Gastrointestinal Cancer - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. m1A Regulated Genes Modulate PI3K/AKT/mTOR and ErbB Pathways in Gastrointestinal Cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 10. m1A Regulated Genes Modulate PI3K/AKT/mTOR and ErbB Pathways in Gastrointestinal Cancer | Semantic Scholar [semanticscholar.org]
- 11. researchgate.net [researchgate.net]
- 12. m6A RNA modification modulates PI3K/Akt/mTOR signal pathway in Gastrointestinal Cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Modomics - A Database of RNA Modifications [genesilico.pl]
- 14. Development of mild chemical catalysis conditions for m1A-to-m6A rearrangement on RNA - PMC [pmc.ncbi.nlm.nih.gov]
- 15. ARM-Seq: AlkB-facilitated RNA methylation sequencing reveals a complex landscape of modified tRNA fragments - PMC [pmc.ncbi.nlm.nih.gov]
- 16. High-throughput small RNA sequencing enhanced by AlkB-facilitated RNA de-Methylation (ARM-seq) - PMC [pmc.ncbi.nlm.nih.gov]
- 17. escholarship.org [escholarship.org]
- 18. Base-resolution mapping reveals distinct m1A methylome in nuclear- and mitochondrial-encoded transcripts - PMC [pmc.ncbi.nlm.nih.gov]
- 19. qian.human.cornell.edu [qian.human.cornell.edu]
Methodological & Application
Application Notes and Protocols for the Detection of 1-Methyladenine (m1A) in RNA
For Researchers, Scientists, and Drug Development Professionals
Introduction
N1-methyladenosine (m1A) is a prevalent and reversible post-transcriptional RNA modification found in various RNA species, including messenger RNA (mRNA), transfer RNA (tRNA), and ribosomal RNA (rRNA).[1][2] This modification plays a crucial role in regulating RNA stability, structure, and translation, thereby impacting a wide range of biological processes and being implicated in human diseases such as cancer.[3] The dynamic nature of m1A, installed by "writer" enzymes and removed by "erasers," makes it a key component of the epitranscriptome.[4] Accurate and sensitive detection of m1A is therefore essential for understanding its biological functions and for the development of novel therapeutic strategies.
This document provides detailed application notes and protocols for various methods used to detect and quantify m1A in RNA, tailored for researchers, scientists, and professionals in drug development.
I. Overview of m1A Detection Methods
The detection of m1A in RNA can be broadly categorized into three main approaches:
-
Antibody-based Methods: These methods utilize antibodies specific to m1A to enrich for m1A-containing RNA fragments, which are then identified by high-throughput sequencing.
-
Sequencing-based Methods Exploiting Chemical Properties: These techniques leverage the unique chemical properties of m1A, such as its ability to induce reverse transcription (RT) arrest or misincorporation, to identify its location at single-nucleotide resolution.
-
Direct Quantification and Site-Specific Validation Methods: These include mass spectrometry for global quantification and specialized techniques for validating specific m1A sites.
The choice of method depends on the specific research question, including the desired resolution, sensitivity, and whether a global or site-specific analysis is required.
II. Quantitative Comparison of m1A Detection Methods
The following table summarizes the key quantitative parameters of the most common m1A detection methods to facilitate easy comparison.
| Method | Principle | Resolution | Sensitivity | Input RNA Required | Throughput | Key Advantages | Key Limitations |
| m1A-seq/MeRIP-seq | Antibody-based enrichment of m1A-containing RNA fragments followed by sequencing.[5][6] | ~100-200 nucleotides | Moderate to High | 1-10 µg of poly(A)+ RNA or 50-100 µg of total RNA | High | Transcriptome-wide profiling, well-established protocols. | Low resolution, potential antibody cross-reactivity. |
| m1A-MAP | Antibody enrichment followed by TGIRT-based reverse transcription, which induces misincorporation at m1A sites.[7][8] | Single nucleotide | High | 1-5 µg of poly(A)+ RNA | High | Single-base resolution, high sensitivity. | Relies on antibody enrichment, potential for RT bias. |
| red-m1A-seq | Chemical reduction of m1A to improve mutation and readthrough rates during reverse transcription.[9] | Single nucleotide | High | As low as 100 ng of total RNA | High | High sensitivity and accuracy, antibody-independent options. | Involves chemical treatment which may affect RNA integrity. |
| Direct RNA Sequencing (Nanopore) | Direct sequencing of native RNA molecules, detecting m1A based on characteristic changes in electrical current. | Single nucleotide | Moderate | 100-500 ng of poly(A)+ RNA | High | Direct detection without amplification bias, provides stoichiometric information.[10] | Higher error rates compared to other sequencing platforms, bioinformatics analysis is still developing. |
| LC-MS/MS | Liquid chromatography-tandem mass spectrometry to quantify the m1A/A ratio in total RNA.[11] | Not applicable (global) | High | 1-5 µg of total RNA | Low | Gold standard for quantification, highly accurate. | Does not provide sequence context, low throughput. |
| SCARLET | Site-specific cleavage, radioactive labeling, and thin-layer chromatography to validate and quantify m1A at a specific site. | Single nucleotide | High | 1 µg of total RNA | Low | Quantitative at single-base resolution, antibody-independent.[12] | Low throughput, involves radioactive materials. |
III. Experimental Protocols
This section provides detailed methodologies for key experiments cited in the detection of m1A.
Protocol 1: m1A-seq (Methylated RNA Immunoprecipitation Sequencing)
This protocol describes the general workflow for enriching m1A-containing RNA fragments for subsequent high-throughput sequencing.[5][6]
Materials:
-
Total RNA or poly(A)+ selected RNA
-
m1A-specific antibody
-
Protein A/G magnetic beads
-
RNA fragmentation buffer
-
Immunoprecipitation (IP) buffer
-
Wash buffers
-
RNase inhibitors
-
Elution buffer
-
RNA purification kit
-
Library preparation kit for sequencing
Procedure:
-
RNA Preparation and Fragmentation:
-
Start with high-quality total RNA or poly(A)+ selected RNA.
-
Fragment the RNA to an average size of 100-200 nucleotides using RNA fragmentation buffer or enzymatic methods.
-
Purify the fragmented RNA.
-
-
Immunoprecipitation (IP):
-
Couple the m1A-specific antibody to Protein A/G magnetic beads.
-
Incubate the fragmented RNA with the antibody-bead complex in IP buffer supplemented with RNase inhibitors. This is typically done overnight at 4°C with gentle rotation.
-
A small fraction of the fragmented RNA should be saved as an "input" control.
-
-
Washing:
-
Wash the beads several times with low- and high-salt wash buffers to remove non-specifically bound RNA fragments.
-
-
Elution and RNA Purification:
-
Elute the m1A-enriched RNA from the beads using an appropriate elution buffer.
-
Purify the eluted RNA using an RNA purification kit.
-
-
Library Preparation and Sequencing:
-
Prepare sequencing libraries from the immunoprecipitated RNA and the input control RNA using a strand-specific RNA-seq library preparation kit.
-
Perform high-throughput sequencing.
-
-
Data Analysis:
-
Align the sequencing reads to the reference genome.
-
Identify m1A peaks by comparing the read distribution in the IP sample to the input control.
-
Protocol 2: m1A-MAP (m1A-Misincorporation Assisted Profiling)
This protocol provides a method for single-nucleotide resolution mapping of m1A sites.[7][8]
Materials:
-
m1A-immunoprecipitated RNA (from Protocol 1)
-
Thermostable Group II Intron Reverse Transcriptase (TGIRT)
-
Reverse transcription primers
-
dNTPs
-
cDNA purification kit
-
PCR amplification reagents
-
Sequencing library preparation kit
Procedure:
-
Reverse Transcription with TGIRT:
-
Perform reverse transcription on the m1A-enriched RNA and input control RNA using TGIRT. This enzyme has a higher tendency to read through m1A sites while introducing misincorporations into the cDNA.
-
Use gene-specific or random primers for reverse transcription.
-
-
cDNA Purification and Library Preparation:
-
Purify the resulting cDNA.
-
Perform second-strand synthesis and prepare sequencing libraries.
-
-
Sequencing and Data Analysis:
-
Perform high-throughput sequencing.
-
Align reads to the reference genome.
-
Identify m1A sites by detecting positions with a significantly higher misincorporation rate in the IP sample compared to the input and/or a demethylase-treated control.
-
Protocol 3: Liquid Chromatography-Tandem Mass Spectrometry (LC-MS/MS) for Global m1A Quantification
This protocol outlines the steps for quantifying the overall m1A levels in a total RNA sample.[11]
Materials:
-
Total RNA
-
Nuclease P1
-
Bacterial alkaline phosphatase
-
LC-MS/MS system
-
m1A and adenosine standards
Procedure:
-
RNA Digestion:
-
Digest the total RNA to single nucleosides using nuclease P1 followed by bacterial alkaline phosphatase.
-
-
LC-MS/MS Analysis:
-
Separate the nucleosides by liquid chromatography.
-
Detect and quantify the amounts of m1A and adenosine using tandem mass spectrometry in multiple reaction monitoring (MRM) mode.
-
-
Quantification:
-
Generate standard curves for m1A and adenosine.
-
Calculate the m1A/A ratio in the sample by comparing the peak areas to the standard curves.
-
IV. Visualizations: Workflows and Signaling Pathways
Workflow Diagrams
The following diagrams illustrate the experimental workflows for key m1A detection methods.
Caption: Workflow for m1A-seq/MeRIP-seq.
Caption: Workflow for m1A-MAP.
Signaling Pathway
This diagram illustrates the key enzymes involved in the regulation of m1A modification and its downstream effects.
Caption: The m1A Regulatory Pathway.
V. Conclusion
The detection and quantification of 1-Methyladenine in RNA is a rapidly evolving field with a growing number of available techniques. The choice of method should be carefully considered based on the specific research goals, available resources, and the desired level of resolution and quantification. The protocols and comparative data presented in these application notes are intended to guide researchers in selecting and implementing the most appropriate methods for their studies, ultimately contributing to a deeper understanding of the role of m1A in biology and disease.
References
- 1. YTHDF2 Recognition of N1-Methyladenosine (m1A)-Modified RNA Is Associated with Transcript Destabilization - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. TRMT6/61A-dependent base methylation of tRNA-derived fragments regulates gene-silencing activity and the unfolded protein response in bladder cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Depletion of the m1A writer TRMT6/TRMT61A reduces proliferation and resistance against cellular stress in bladder cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 4. The landscape of m1A modification and its posttranscriptional regulatory functions in primary neurons | eLife [elifesciences.org]
- 5. An experimental workflow for identifying RNA m6A alterations in cellular senescence by methylated RNA immunoprecipitation sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 6. m1A Sequencing - CD Genomics [rna.cd-genomics.com]
- 7. Base-resolution mapping reveals distinct m1A methylome in nuclear- and mitochondrial-encoded transcripts - PMC [pmc.ncbi.nlm.nih.gov]
- 8. qian.human.cornell.edu [qian.human.cornell.edu]
- 9. Chemical manipulation of m1A mediates its detection in human tRNA - PMC [pmc.ncbi.nlm.nih.gov]
- 10. A comparative evaluation of computational models for RNA modification detection using nanopore sequencing with RNA004 chemistry - PMC [pmc.ncbi.nlm.nih.gov]
- 11. researchgate.net [researchgate.net]
- 12. Identification of YTH Domain-Containing Proteins as the Readers for N1-Methyladenosine in RNA. [escholarship.org]
Application Notes and Protocols for Single-Base Resolution Mapping of 1-Methyladenine (m1A) Sites
For Researchers, Scientists, and Drug Development Professionals
Introduction
1-Methyladenine (m1A) is a post-transcriptional RNA modification that plays a crucial role in regulating various biological processes, including mRNA stability, translation, and protein synthesis.[1] Unlike the more extensively studied N6-methyladenosine (m6A), m1A introduces a positive charge under physiological conditions, which can significantly alter RNA structure and its interactions with proteins. The advent of high-throughput sequencing techniques has enabled the transcriptome-wide mapping of m1A sites at single-base resolution, providing valuable insights into its regulatory functions and its implications in diseases such as cancer.[2][3]
These application notes provide an overview of the key methodologies for single-base resolution m1A mapping, detailed experimental protocols, and a summary of quantitative data from various human cell lines. Furthermore, we explore the applications of m1A mapping in the context of drug discovery and development.
Key Methodologies for Single-Base Resolution m1A Mapping
The precise mapping of m1A sites at the single-nucleotide level primarily relies on the signature events induced by the m1A modification during reverse transcription (RT). The methyl group at the N1 position of adenine disrupts Watson-Crick base pairing, causing the reverse transcriptase to either stall, leading to truncation of the cDNA, or misincorporate a different nucleotide.[4][5] The two most prominent methods that leverage these principles are m1A-seq and m1A-MAP (m1A-misincorporation-assisted profiling) .
Both techniques typically involve the following core steps:
-
RNA Fragmentation: Total RNA or poly(A)-selected RNA is fragmented into smaller pieces (typically around 100 nucleotides).
-
Immunoprecipitation (IP): An antibody specific to m1A is used to enrich for RNA fragments containing the modification.
-
Reverse Transcription: The enriched RNA fragments are reverse transcribed into cDNA. This step is crucial for generating the m1A-specific signatures.
-
Library Preparation and High-Throughput Sequencing: The cDNA is then used to prepare a sequencing library, which is subsequently sequenced on a high-throughput platform.
-
Bioinformatic Analysis: The sequencing data is analyzed to identify sites of misincorporation or truncation, thereby pinpointing the locations of m1A modifications at single-base resolution.
To enhance the accuracy and specificity of m1A detection, control experiments are essential. These often include:
-
Input Control: A portion of the fragmented RNA is sequenced without immunoprecipitation to account for background signals.
-
Demethylase Treatment: Treatment with an m1A demethylase, such as AlkB, removes the methyl group from m1A, converting it back to adenine. A decrease in the misincorporation or truncation signal after demethylase treatment provides strong evidence for the presence of m1A.[4]
-
Dimroth Rearrangement: This chemical treatment converts m1A to the more stable m6A, which does not typically cause reverse transcriptase stalling or misincorporation.[5]
Quantitative Data of m1A Sites in Human Cell Lines
The following table summarizes the number of identified m1A sites in commonly used human cell lines, as reported in key publications. It is important to note that the number of identified sites can vary depending on the specific technique, sequencing depth, and bioinformatic pipeline used.
| Cell Line | Number of m1A Sites (mRNA) | Key Publication(s) |
| HEK293T | ~473-740 | Li et al., 2017[3][4] |
| HeLa | Variable, data often combined with other cell lines | General literature on RNA modification |
| HepG2 | Variable, data often combined with other cell lines | General literature on RNA modification |
Note: The precise number of m1A sites can differ between studies due to variations in experimental and computational methods.
Experimental Protocols
Protocol 1: m1A-MAP (m1A-Misincorporation-Assisted Profiling)
This protocol is adapted from Li et al., 2017, Molecular Cell.[4][6]
1. RNA Preparation and Fragmentation:
-
Isolate total RNA from the cell line of interest using a standard RNA extraction method (e.g., TRIzol).
-
Enrich for poly(A)+ RNA using oligo(dT) magnetic beads.
-
Fragment the poly(A)+ RNA to an average size of 100 nucleotides using a suitable RNA fragmentation buffer.
2. m1A Immunoprecipitation:
-
Incubate the fragmented RNA with an anti-m1A antibody (e.g., from Synaptic Systems) in IP buffer overnight at 4°C.
-
Add protein A/G magnetic beads and incubate for an additional 2 hours at 4°C to capture the antibody-RNA complexes.
-
Wash the beads extensively to remove non-specifically bound RNA.
-
Elute the m1A-containing RNA fragments from the beads.
3. Demethylase Treatment (Control):
-
For the control sample, treat the eluted RNA with a recombinant AlkB protein to demethylate m1A.
4. Library Preparation and Sequencing:
-
Perform 3' dephosphorylation and 5' phosphorylation of the RNA fragments.
-
Ligate a 3' adapter to the RNA fragments.
-
Perform reverse transcription using a reverse transcriptase that is prone to misincorporation at m1A sites (e.g., TGIRT).
-
Ligate a 5' adapter to the cDNA.
-
Amplify the library by PCR.
-
Perform high-throughput sequencing of the prepared libraries.
5. Data Analysis:
-
Align the sequencing reads to the reference genome.
-
Identify single nucleotide variants (SNVs) relative to the reference genome.
-
Calculate the misincorporation rate at each adenine position.
-
Compare the misincorporation rates between the IP and demethylase-treated control samples to identify bona fide m1A sites.
Protocol 2: m1A-seq
This protocol is based on the methodology described by Safra et al., 2017, Nature.[5][7]
1. RNA Preparation and Fragmentation:
-
Follow the same procedure as in the m1A-MAP protocol for RNA isolation, poly(A)+ selection, and fragmentation.
2. m1A Immunoprecipitation:
-
Follow the same immunoprecipitation procedure as in the m1A-MAP protocol.
3. Dimroth Rearrangement (Control):
-
For the control sample, perform Dimroth rearrangement on the eluted RNA to convert m1A to m6A.
4. Reverse Transcription:
-
Perform reverse transcription using two different reverse transcriptases in separate reactions:
-
A highly processive reverse transcriptase (e.g., TGIRT) that tends to cause misincorporation at m1A sites.
-
A less processive reverse transcriptase (e.g., SuperScript III) that is more prone to truncation at m1A sites.
-
5. Library Preparation and Sequencing:
-
Follow a standard library preparation protocol for the generated cDNA, including adapter ligation and PCR amplification.
-
Sequence the libraries using a high-throughput sequencing platform.
6. Data Analysis:
-
Align the sequencing reads to the reference genome.
-
Analyze the data for both misincorporation and truncation events at adenine residues.
-
Compare the signals between the IP and Dimroth-treated control samples to identify genuine m1A sites.
Visualizations
Caption: Experimental workflow for single-base resolution m1A mapping.
Applications in Drug Development
The ability to map m1A sites at single-base resolution has significant implications for drug discovery and development.
Target Identification and Validation
The enzymes responsible for adding and removing m1A modifications, known as "writers" (e.g., TRMT6/TRMT61A) and "erasers" (e.g., ALKBH1/3), respectively, represent potential therapeutic targets.[2] Dysregulation of these enzymes has been linked to various diseases, including cancer. m1A mapping can be used to:
-
Identify the substrates of specific writers and erasers: By comparing the m1A landscape in cells with and without the knockout or inhibition of a particular enzyme, researchers can identify its direct targets.
-
Validate the on-target effects of small molecule inhibitors: m1A mapping can confirm that a drug candidate effectively modulates the activity of its intended writer or eraser enzyme by observing changes in the m1A methylation status of its target RNAs.
References
- 1. embopress.org [embopress.org]
- 2. Clinician’s Guide to Epitranscriptomics: An Example of N1-Methyladenosine (m1A) RNA Modification and Cancer [mdpi.com]
- 3. Base-Resolution Mapping Reveals Distinct m1A Methylome in Nuclear- and Mitochondrial-Encoded Transcripts - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. Base-resolution mapping reveals distinct m1A methylome in nuclear- and mitochondrial-encoded transcripts - PMC [pmc.ncbi.nlm.nih.gov]
- 5. weizmann.elsevierpure.com [weizmann.elsevierpure.com]
- 6. qian.human.cornell.edu [qian.human.cornell.edu]
- 7. The m1A landscape on cytosolic and mitochondrial mRNA at single-base resolution - PubMed [pubmed.ncbi.nlm.nih.gov]
Application Notes and Protocols for Ligation-Assisted Differentiation for N1-methyladenosine (m1A) Quantification
For Researchers, Scientists, and Drug Development Professionals
Introduction
N1-methyladenosine (m1A) is a post-transcriptional RNA modification that plays a crucial role in regulating RNA structure and function.[1][2] Found in various RNA species, including messenger RNA (mRNA), transfer RNA (tRNA), and ribosomal RNA (rRNA), m1A influences processes such as translation, RNA stability, and protein-RNA interactions. The dynamic nature of m1A modification suggests its involvement in diverse biological processes and its potential as a biomarker in diseases like cancer. Consequently, robust and quantitative methods for detecting m1A at single-nucleotide resolution are in high demand.
Ligation-assisted differentiation is a highly sensitive and specific method for the quantification of m1A. This technique leverages the principle that the methyl group on the N1 position of adenosine disrupts Watson-Crick base pairing with uridine. This disruption significantly reduces the efficiency of specific DNA ligases in joining two adjacent DNA probes hybridized to the RNA template. By quantifying the amount of ligated product using quantitative real-time PCR (qPCR), the abundance of m1A at a specific site can be accurately determined.
This document provides detailed application notes and protocols for the quantification of m1A in both mRNA and tRNA using ligation-assisted differentiation.
Principle of the Method
The core principle of ligation-assisted m1A quantification lies in the differential ligation efficiency of a DNA ligase on an RNA template containing either an unmodified adenosine (A) or a N1-methyladenosine (m1A).
-
Probe Hybridization: Two specific DNA probes are designed to hybridize to the target RNA sequence immediately flanking the adenosine site of interest. The 5' probe has a 5'-phosphate group, and the 3' probe has a 3'-hydroxyl group at the ligation junction.
-
Ligation Reaction: A DNA ligase is added to the reaction. If the target site contains an unmodified adenosine, it forms a standard Watson-Crick base pair with the thymidine in the complementary DNA probe, allowing for efficient ligation of the two DNA probes.
-
Ligation Inhibition by m1A: If the target site contains m1A, the methyl group hinders the formation of a stable base pair with thymidine. This structural disruption significantly reduces the efficiency of the ligase, resulting in a much lower amount of ligated product.
-
Quantification by qPCR: The amount of ligated DNA product is then quantified using qPCR with primers specific to the ligated sequence. The difference in the amount of ligation product between a sample and a control (or a sample with a known m1A level) is used to calculate the stoichiometry of m1A at the specific site.
Certain ligases, such as T3 DNA ligase and SplintR ligase, have been shown to exhibit high discrimination between A and m1A, making them ideal for this application.
I. Quantification of m1A in mRNA using T3 DNA Ligase
This protocol is adapted from the method described for the quantification of m1A in specific mRNAs, such as the BRD2 mRNA.
Experimental Workflow
References
Application Notes and Protocols for m1A-Sequencing (m1A-seq)
For Researchers, Scientists, and Drug Development Professionals
N1-methyladenosine (m1A) is a prevalent and reversible post-transcriptional RNA modification that plays a crucial role in regulating gene expression and various biological processes.[1] The study of m1A, part of the expanding field of epitranscriptomics, has been greatly advanced by the development of high-throughput sequencing methods to map its presence across the transcriptome. These techniques are essential for understanding the functional roles of m1A in health and disease, including cancer, and for the development of novel therapeutic strategies.[2]
This document provides detailed application notes and protocols for several key m1A-sequencing (m1A-seq) methodologies.
Introduction to m1A and its Significance
N1-methyladenosine is a modification where a methyl group is added to the N1 position of adenosine. This modification can alter the structure of RNA, affecting processes such as translation, RNA stability, and protein-RNA interactions.[1][3] m1A is found in various RNA species, including messenger RNA (mRNA), transfer RNA (tRNA), and ribosomal RNA (rRNA).[3][4] In mRNA, m1A is often enriched near the 5' untranslated region (5' UTR) and the start codon, where it can enhance translation initiation.[3][5][6] The enzymes responsible for adding (writers) and removing (erasers) the m1A modification are key to its dynamic regulation.
Overview of m1A-Sequencing Technologies
Several high-throughput sequencing methods have been developed to identify m1A sites at the transcriptome-wide level. These methods primarily rely on two key principles:
-
Immunoprecipitation (IP): Utilizing an antibody specific to m1A to enrich for RNA fragments containing the modification.[3][4]
-
Reverse Transcription (RT) Signatures: Exploiting the fact that the m1A modification can cause the reverse transcriptase enzyme to stall or misincorporate nucleotides during cDNA synthesis.[7][8]
This document will detail the protocols for prominent m1A-seq techniques, including m1A-meRIP-seq (methylated RNA immunoprecipitation sequencing), m1A-ID-seq (m1A individual-nucleotide-resolution cross-linking and immunoprecipitation), and m1A-MAP (misincorporation-assisted profiling of m1A).
Quantitative Data Summary
The following table summarizes the number of m1A sites identified in human cells using different m1A-seq methods, providing a comparative overview of their detection capabilities.
| Method | Cell Line(s) | Number of m1A Sites Identified in mRNA | Key Findings | Reference |
| m1A-meRIP-seq | HeLa, HepG2, HEK293 | 4,151 coding and 63 non-coding transcripts | m1A is enriched at translation initiation sites and upstream of the first splice site. | [5] |
| m1A-ID-seq | Human transcriptome | 901 novel m1A modification sites | m1A peaks are predominantly enriched near the 5' UTR and start codon. | [9] |
| m1A-MAP | HEK293T | Distinct classes of m1A methylome | Identification of m1A in 5'-UTR, GUUCRA motifs, and mitochondrial transcripts. | [10] |
Experimental Protocols
I. m1A-meRIP-seq Protocol
This method combines methylated RNA immunoprecipitation with high-throughput sequencing to identify m1A-containing RNA fragments.
1. RNA Preparation and Fragmentation:
-
Isolate total RNA from cells or tissues of interest using a standard RNA extraction method (e.g., TRIzol). Ensure high quality of RNA with an OD260/280 ratio ≥ 1.8 and RIN ≥ 7.[4]
-
Purify poly(A)+ RNA (mRNA) from the total RNA using oligo(dT) magnetic beads.
-
Fragment the purified mRNA to an average size of ~100 nucleotides using RNA fragmentation buffer or sonication.
2. m1A Immunoprecipitation (IP):
-
Incubate the fragmented RNA with an anti-m1A antibody in IP buffer overnight at 4°C with gentle rotation.
-
Add protein A/G magnetic beads to the RNA-antibody mixture and incubate for 2 hours at 4°C to capture the antibody-RNA complexes.
-
Wash the beads multiple times with wash buffers of increasing stringency to remove non-specifically bound RNA.
-
Elute the m1A-containing RNA fragments from the beads.
3. Library Preparation and Sequencing:
-
Construct a sequencing library from the eluted m1A-enriched RNA fragments and from an input control sample (fragmented RNA that did not undergo IP).
-
Perform reverse transcription, second-strand synthesis, adapter ligation, and PCR amplification.
-
Sequence the libraries on a high-throughput sequencing platform (e.g., Illumina).
4. Data Analysis:
-
Align the sequencing reads to the reference genome.
-
Identify enriched regions (peaks) in the IP sample compared to the input control using peak-calling algorithms (e.g., MACS2).
-
Annotate the identified peaks to determine the location of m1A sites within the transcriptome.
Caption: Workflow of the m1A-meRIP-seq protocol.
II. m1A-ID-seq Protocol
This protocol achieves single-nucleotide resolution by combining antibody enrichment with enzymatic demethylation.
1. RNA Fragmentation and Immunoprecipitation:
-
Follow the same steps for RNA preparation, purification, and fragmentation as in the m1A-meRIP-seq protocol.
-
Perform immunoprecipitation using an anti-m1A antibody to enrich for m1A-containing fragments.
2. Demethylation and Reverse Transcription:
-
Divide the immunoprecipitated RNA into two equal portions.
-
Treat one portion with a demethylase enzyme, such as E. coli AlkB, to remove the methyl group from m1A, converting it back to adenosine.[9] The other portion remains untreated.
-
Perform reverse transcription on both the demethylated and untreated samples. The m1A in the untreated sample will cause truncations in the resulting cDNA.
3. Library Preparation and Sequencing:
-
Prepare sequencing libraries from both the demethylated (full-length cDNA) and untreated (truncated cDNA) samples.
-
Sequence the libraries.
4. Data Analysis:
-
Align the reads from both libraries to the reference genome.
-
Identify m1A sites by comparing the read stop positions (truncations) in the untreated sample to the full-length reads in the demethylated sample.
Caption: Workflow of the m1A-ID-seq protocol.
III. m1A-MAP Protocol
This method achieves base resolution by detecting misincorporations during reverse transcription.
1. RNA Preparation and Enrichment:
-
Prepare and fragment RNA as described previously.
-
Enrich for m1A-containing fragments using an anti-m1A antibody.
2. Demethylase Treatment (Optional but Recommended):
-
Similar to m1A-ID-seq, the enriched RNA can be split and one half treated with a demethylase to serve as a control for identifying true m1A-induced misincorporations.[11]
3. Reverse Transcription with a Processive Reverse Transcriptase:
-
Perform reverse transcription using a highly processive enzyme like Thermostable Group II Intron Reverse Transcriptase (TGIRT).[10][12] TGIRT has a higher tendency to read through the m1A modification, often incorporating a mismatched nucleotide in the cDNA.[10][13]
4. Library Preparation and Sequencing:
-
Prepare sequencing libraries from the cDNA.
-
Sequence the libraries to a high depth.
5. Data Analysis:
-
Align the sequencing reads to the reference genome.
-
Identify positions with a high frequency of single nucleotide polymorphisms (SNPs) or mismatches in the m1A-enriched sample compared to the input and/or demethylated control. These mismatch signatures indicate the precise location of m1A.[10]
Caption: Workflow of the m1A-MAP protocol.
Signaling and Functional Pathway
The m1A modification is part of a dynamic regulatory network involving "writer," "eraser," and "reader" proteins. This pathway ultimately impacts gene expression at the level of translation.
Caption: The m1A regulatory pathway.
Applications in Research and Drug Development
The ability to map m1A across the transcriptome has significant implications for various research areas and for drug development:
-
Understanding Disease Mechanisms: Aberrant m1A modification patterns have been linked to various diseases, including cancer.[2] m1A-seq can be used to identify disease-specific m1A signatures, providing insights into pathogenesis.
-
Target Identification and Validation: The enzymes that regulate m1A modification (writers and erasers) represent potential therapeutic targets.[2] m1A-seq can be used to assess the on-target and off-target effects of drugs designed to inhibit these enzymes.
-
Biomarker Discovery: m1A profiles in patient samples could serve as novel biomarkers for diagnosis, prognosis, and prediction of treatment response.
-
RNA Therapeutics: Understanding how m1A modification affects the stability and translational efficiency of RNA can inform the design of more effective mRNA-based vaccines and therapeutics.
References
- 1. m1A RNA Modification in Gene Expression Regulation - PMC [pmc.ncbi.nlm.nih.gov]
- 2. mdpi.com [mdpi.com]
- 3. m1A RNA Methylation Analysis - CD Genomics [cd-genomics.com]
- 4. m1A Sequencing - CD Genomics [rna.cd-genomics.com]
- 5. epigenie.com [epigenie.com]
- 6. N1-methyladenosine formation, gene regulation, biological functions, and clinical relevance - PMC [pmc.ncbi.nlm.nih.gov]
- 7. rna-seqblog.com [rna-seqblog.com]
- 8. academic.oup.com [academic.oup.com]
- 9. Research progress of N1-methyladenosine RNA modification in cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Base-resolution mapping reveals distinct m1A methylome in nuclear- and mitochondrial-encoded transcripts - PMC [pmc.ncbi.nlm.nih.gov]
- 11. qian.human.cornell.edu [qian.human.cornell.edu]
- 12. academic.oup.com [academic.oup.com]
- 13. weizmann.elsevierpure.com [weizmann.elsevierpure.com]
Application Notes and Protocols for the Chemical Synthesis of 1-Methyladenine Phosphoramidite
For Researchers, Scientists, and Drug Development Professionals
Introduction
1-Methyladenosine (m1A) is a post-transcriptional modification found in various RNA molecules, playing a crucial role in stabilizing RNA structures and modulating RNA-protein interactions.[1][2] The site-specific incorporation of m1A into synthetic oligonucleotides is a powerful tool for investigating the biological functions of this modified nucleoside in contexts such as tRNA folding, gene expression, and the development of RNA-based therapeutics.[1][3][4] However, the chemical synthesis of 1-Methyladenine phosphoramidite presents unique challenges due to the nucleobase's inherent basicity (pKa ≈ 8.25), which makes it susceptible to Dimroth rearrangement to the more stable N6-methyladenosine isomer under standard basic deprotection conditions.[1][4]
These application notes provide a comprehensive overview and detailed protocols for the chemical synthesis of 1-Methyladenine phosphoramidite and its subsequent incorporation into oligonucleotides. The methodologies described herein are designed to overcome the challenges associated with the lability of the 1-methyladenine moiety, ensuring high-yield and high-purity synthesis of m1A-containing oligonucleotides.
Key Applications
-
Probing RNA Structure and Function: Site-specific incorporation of m1A allows for detailed studies of its impact on RNA secondary and tertiary structure, as well as its role in RNA-protein recognition and catalytic activity.[1]
-
Investigating RNAi and Aptamer Technology: Modified oligonucleotides containing m1A can be used to enhance the stability, specificity, and therapeutic efficacy of siRNAs and aptamers.
-
Development of RNA-based Diagnostics and Therapeutics: The synthesis of m1A-modified oligonucleotides is essential for the development of novel diagnostic probes and therapeutic agents that target specific RNA molecules.
-
Substrate for DNA/RNA Repair Enzyme Studies: Oligonucleotides containing m1A serve as valuable substrates for studying the activity and mechanism of DNA and RNA repair enzymes like the AlkB family of demethylases.[5][6]
Quantitative Data Summary
The following table summarizes key quantitative data associated with the synthesis and incorporation of 1-Methyladenine phosphoramidite.
| Parameter | Value | Notes | Reference |
| Coupling Efficiency | >99% | Achieved with 0.45M 1H-Tetrazole in acetonitrile as the activator for the deoxy version (m1dA). For the ribo version, 0.25M 5-Benzylthio-1H-tetrazole in acetonitrile is recommended for optimal coupling. | [3] |
| Coupling Time | 10 - 15 minutes | A longer coupling time is generally recommended for modified phosphoramidites to ensure high efficiency. | [1][7] |
| Phosphoramidite Conc. | 0.12 M | A slightly higher concentration compared to standard phosphoramidites may be beneficial. | [1] |
| Deprotection Conditions | 2M NH3 in Methanol (anhydrous) | 24-60 hours at room temperature is recommended to avoid Dimroth rearrangement. The duration depends on the other protecting groups used in the synthesis. | [1][3][7] |
| Byproduct Formation | N6-methyladenine | Can occur during standard ammonium hydroxide deprotection at elevated temperatures. Rigorous purification by HPLC is necessary to separate the desired m1A-containing oligonucleotide from this isomer. | [5][6] |
Experimental Protocols
Protocol 1: Synthesis of N6-Chloroacetyl-5'-O-DMT-1-methyladenosine
This protocol describes the protection of the exocyclic amine of 1-methyladenosine, a critical step before phosphitylation. The chloroacetyl group is used as it can be removed under conditions that minimize the risk of Dimroth rearrangement.[1]
Materials:
-
1-Methyladenosine
-
Dry Pyridine
-
Trimethylsilyl chloride (TMSCl)
-
Chloroacetic anhydride
-
Dichloromethane (DCM)
-
10% Sodium bicarbonate solution
-
Silica gel for column chromatography
Procedure:
-
Co-evaporate 1-methyladenosine with dry pyridine.
-
Dissolve the dried 1-methyladenosine in dry pyridine.
-
Cool the solution to 0°C in an ice bath.
-
Add trimethylsilyl chloride (TMSCl) dropwise and stir the solution at 0°C for 45 minutes to protect the hydroxyl groups.
-
In a separate flask, dissolve chloroacetic anhydride in a mixture of dry pyridine and dichloroethane.
-
Cool the chloroacetic anhydride solution to -20°C.
-
Slowly add the silylated 1-methyladenosine solution to the chloroacetic anhydride solution.
-
Allow the reaction to proceed at 0°C for 30 minutes.
-
Quench the reaction by adding cold 10% aqueous sodium bicarbonate.
-
Stir the mixture for 30 minutes at 0°C and then for 1.5 hours at room temperature to remove the silyl protecting groups.
-
Extract the product with dichloromethane.
-
Dry the organic layer over anhydrous sodium sulfate, filter, and evaporate the solvent under reduced pressure.
-
Purify the crude product by silica gel column chromatography to yield N6-chloroacetyl-1-methyladenosine.
-
Protect the 5'-hydroxyl group with dimethoxytrityl chloride (DMT-Cl) in pyridine to obtain N6-chloroacetyl-5'-O-DMT-1-methyladenosine.
Protocol 2: Phosphitylation of Protected 1-Methyladenosine
This protocol details the conversion of the protected nucleoside into the corresponding phosphoramidite, making it ready for automated oligonucleotide synthesis.
Materials:
-
N6-chloroacetyl-5'-O-DMT-1-methyladenosine (or other suitably protected 1-methyladenosine)
-
Anhydrous Dichloromethane (DCM)
-
N,N-Diisopropylethylamine (DIPEA)
-
2-Cyanoethyl N,N-diisopropylchlorophosphoramidite
-
Anhydrous Acetonitrile
-
Ethyl acetate
-
Saturated sodium bicarbonate solution
-
Brine
Procedure:
-
Dissolve the protected 1-methyladenosine in anhydrous dichloromethane under an inert atmosphere (e.g., argon).
-
Add N,N-diisopropylethylamine (DIPEA) to the solution.
-
Cool the mixture to 0°C.
-
Slowly add 2-Cyanoethyl N,N-diisopropylchlorophosphoramidite.
-
Stir the reaction at room temperature for 2-4 hours, monitoring by TLC.
-
Once the reaction is complete, dilute the mixture with ethyl acetate.
-
Wash the organic layer sequentially with saturated sodium bicarbonate solution and brine.
-
Dry the organic layer over anhydrous sodium sulfate, filter, and concentrate under reduced pressure.
-
Purify the resulting phosphoramidite by precipitation from a suitable solvent system (e.g., dichloromethane/hexane) or by flash chromatography on silica gel pre-treated with triethylamine.
Protocol 3: Automated Solid-Phase Oligonucleotide Synthesis
This protocol outlines the incorporation of the 1-Methyladenine phosphoramidite into a growing oligonucleotide chain using a standard automated DNA/RNA synthesizer.
Materials:
-
1-Methyladenine phosphoramidite solution (0.12 M in anhydrous acetonitrile)
-
Standard DNA/RNA phosphoramidites (e.g., Pac-A, iPr-Pac-G, Ac-C, U) for mild deprotection
-
Activator solution (e.g., 0.25 M 5-Benzylthio-1H-tetrazole in acetonitrile)
-
Capping, oxidation, and deblocking reagents for the synthesizer
-
Controlled Pore Glass (CPG) solid support
Procedure:
-
Program the DNA/RNA synthesizer with the desired oligonucleotide sequence.
-
Install the 1-Methyladenine phosphoramidite vial on the synthesizer.
-
Use a prolonged coupling time of 10-15 minutes for the 1-Methyladenine phosphoramidite to ensure high coupling efficiency.
-
For the other standard phosphoramidites, use standard coupling times.
-
It is recommended to use phosphoramidites and capping reagents compatible with mild deprotection conditions (e.g., UltraMILD reagents) to preserve the integrity of the 1-methyladenine base.[3][7]
-
After the synthesis is complete, keep the final DMT group on if purification by reverse-phase HPLC is intended.
Protocol 4: Cleavage and Deprotection of the Oligonucleotide
This is a critical step that requires non-standard, anhydrous conditions to prevent the Dimroth rearrangement of 1-methyladenine to N6-methyladenine.
Materials:
-
CPG-bound oligonucleotide
-
Anhydrous 2 M Ammonia in Methanol
-
Tetrabutylammonium fluoride (TBAF) solution (for RNA)
-
Ammonium acetate solution
Procedure:
-
Transfer the CPG support with the synthesized oligonucleotide to a sealed vial.
-
Add an anhydrous solution of 2 M ammonia in methanol.
-
Incubate at room temperature for 24-60 hours.[1][7] The longer incubation time is necessary for the removal of more robust protecting groups like isobutyryl on guanine.
-
After incubation, decant the methanolic ammonia solution containing the cleaved and deprotected oligonucleotide.
-
Evaporate the solvent to dryness.
-
For RNA: Resuspend the residue in a 1 M TBAF solution to remove the 2'-O-TBDMS protecting groups. Incubate at room temperature for 18 hours.
-
Quench the TBAF reaction by adding an equal volume of 1.5 M ammonium acetate solution.
-
Desalt the oligonucleotide using a size-exclusion column (e.g., NAP-25).
-
Lyophilize the purified oligonucleotide.
Protocol 5: Purification and Analysis
High-performance liquid chromatography (HPLC) is essential for purifying the final oligonucleotide and ensuring the removal of any byproducts, including the N6-methyladenine isomer.[5]
Materials:
-
Crude deprotected oligonucleotide
-
HPLC system with UV detector
-
Reverse-phase and/or anion-exchange HPLC columns
-
Appropriate mobile phases (e.g., acetonitrile and triethylammonium acetate buffer for reverse-phase; ammonium acetate or perchlorate gradients for anion-exchange)
-
Mass spectrometer for identity confirmation
Procedure:
-
Dissolve the lyophilized oligonucleotide in an appropriate aqueous buffer.
-
Purify the oligonucleotide by reverse-phase HPLC (if DMT-on) or anion-exchange HPLC.
-
Collect the fractions corresponding to the full-length product.
-
If DMT-on purification was used, treat the collected fraction with a mild acid (e.g., 80% acetic acid) to remove the DMT group, followed by another purification or desalting step.
-
Analyze the purity of the final product by analytical HPLC.
-
Confirm the identity and integrity of the m1A-containing oligonucleotide by mass spectrometry. The mass should correspond to the expected molecular weight.
Diagrams
Chemical Synthesis Workflow
Caption: Workflow for the synthesis and incorporation of 1-Methyladenine phosphoramidite.
Logical Relationship of Deprotection and Byproduct Formation
Caption: Impact of deprotection conditions on product and byproduct formation.
References
- 1. Chemical incorporation of 1-methyladenosine into oligonucleotides - PMC [pmc.ncbi.nlm.nih.gov]
- 2. N1-methyladenosine formation, gene regulation, biological functions, and clinical relevance - PMC [pmc.ncbi.nlm.nih.gov]
- 3. glenresearch.com [glenresearch.com]
- 4. glenresearch.com [glenresearch.com]
- 5. Characterization of Byproducts from Chemical Syntheses of Oligonucleotides Containing 1-Methyladenine and 3-Methylcytosine - PMC [pmc.ncbi.nlm.nih.gov]
- 6. pubs.acs.org [pubs.acs.org]
- 7. glenresearch.com [glenresearch.com]
Application Notes and Protocols for Incorporating 1-Methyladenine into Synthetic Oligonucleotides
For Researchers, Scientists, and Drug Development Professionals
Introduction
1-Methyladenine (m1A) is a post-transcriptional modification found in various RNA molecules, including transfer RNA (tRNA), ribosomal RNA (rRNA), and messenger RNA (mRNA).[1][2][3][4][5] This modification plays a crucial role in regulating RNA structure and function, thereby influencing biological processes such as translation and cellular responses to stress.[2][5][6][7][8] The ability to incorporate m1A into synthetic oligonucleotides is paramount for a deeper understanding of its biological significance and for the development of novel RNA-based therapeutics and diagnostic tools.[4][5][9]
This document provides detailed application notes and protocols for the chemical incorporation of 1-methyladenine into synthetic oligonucleotides. It covers the synthesis of the necessary phosphoramidite building block, solid-phase oligonucleotide synthesis, and the critical deprotection steps required to prevent undesired side reactions.
Challenges in Incorporating 1-Methyladenine
The primary challenge in the chemical synthesis of m1A-containing oligonucleotides is the susceptibility of the 1-methyladenine base to Dimroth rearrangement.[10][11] Under standard alkaline deprotection conditions (e.g., aqueous ammonia), m1A can rearrange to the more stable N6-methyladenosine (m6A), a different modification with distinct biological implications.[10][12] The half-life for this rearrangement in 25% aqueous ammonia at room temperature is approximately 36 hours.[10][13] Additionally, the polar nature of m1A can present challenges in handling and during synthesis.[14][15]
To overcome these challenges, a strategy involving a base-labile protecting group for the m1A base and anhydrous deprotection conditions is employed.[10][12]
Chemical Synthesis of 1-Methyladenine Phosphoramidite
The successful incorporation of m1A into synthetic oligonucleotides begins with the preparation of a suitably protected phosphoramidite monomer. A common and effective strategy involves the use of a chloroacetyl protecting group for the exocyclic amine of 1-methyladenosine.[10]
Synthesis Pathway Overview
Caption: Synthesis of 1-Methyladenine Phosphoramidite.
Quantitative Data for Monomer Synthesis
The following table summarizes typical yields for the key steps in the synthesis of the 1-methyladenosine phosphoramidite monomer.
| Step | Product | Typical Yield (%) | Reference |
| Tritylation | 5'-O-monomethoxytrityl-1-methyladenosine | 68 | [10][13] |
| Chloroacetylation & O-deacylation | N6-chloroacetyl-5′-O-monomethoxytrityl-1-methyladenosine | 80 | [13] |
Solid-Phase Oligonucleotide Synthesis
The incorporation of the m1A phosphoramidite into an oligonucleotide sequence is performed using a standard automated DNA/RNA synthesizer.
Experimental Workflow
Caption: Workflow for m1A Oligonucleotide Synthesis.
Quantitative Data for Solid-Phase Synthesis
| Parameter | Condition | Result | Reference |
| Coupling Activator | 0.25M 5-Benzylthio-1H-tetrazole in acetonitrile | 96% coupling efficiency | [11][16] |
| 0.45M 1H-Tetrazole in acetonitrile (for m1dA) | >99% coupling efficiency | [11] | |
| Coupling Time | 15 minutes | Recommended for optimal coupling | [11][16][17] |
| Deprotection (Bases) | 2M Ammonia in anhydrous methanol, room temp. | 24-60 hours | [11][17] |
| Deprotection (2'-OH for RNA) | 1M TBAF in THF, room temp. | 18 hours | [10] |
| m1A Stability | 2M Ammonia in methanol, room temp. | Stable for at least 3 days | [10][13] |
| 25% aqueous ammonia, room temp. | 36-hour half-life (Dimroth rearrangement) | [10][13] |
Experimental Protocols
Protocol 1: Solid-Phase Synthesis of an m1A-Containing Oligonucleotide
-
Synthesizer Setup : Use a standard automated DNA/RNA synthesizer (e.g., ABI 392).
-
Reagents :
-
Synthesis Cycle :
-
Post-Synthesis : Keep the final oligonucleotide on the solid support with the 5'-DMT group on for purification purposes.
Protocol 2: Cleavage and Deprotection of m1A-Containing Oligonucleotides
Caution : This procedure must be performed under anhydrous conditions to prevent Dimroth rearrangement.
-
Reagent Preparation : Prepare a 2M solution of ammonia in anhydrous methanol.
-
Cleavage and Base Deprotection :
-
Transfer the solid support with the synthesized oligonucleotide to a sealed vial.
-
Add the 2M ammonia in methanol solution.
-
Incubate at room temperature for 60 hours.[10][16] For oligonucleotides synthesized with UltraMild phosphoramidites, 24 hours may be sufficient.[11][17]
-
After incubation, filter the solution to remove the solid support.
-
Evaporate the solvent to dryness.
-
-
2'-Hydroxyl Deprotection (for RNA) :
-
To the dried residue, add a 1M solution of tetrabutylammonium fluoride (TBAF) in THF.
-
Incubate at room temperature for 18 hours.[10]
-
Quench the reaction by adding an appropriate buffer (e.g., 1.5 M NH4OAc).
-
-
Desalting : Desalt the oligonucleotide using a suitable method, such as a NAP-25 column.
Protocol 3: Purification and Analysis
-
Purification :
-
Purify the crude oligonucleotide by reverse-phase high-performance liquid chromatography (RP-HPLC) with the 5'-DMT group on ("trityl-on").[18] This method effectively separates the full-length product from shorter failure sequences.
-
After collecting the full-length product, remove the DMT group using a mild acidic treatment (e.g., 80% acetic acid).
-
Further purify the detritylated oligonucleotide using RP-HPLC or anion-exchange HPLC. Anion-exchange HPLC can be particularly useful for separating m1A-containing oligonucleotides due to the positive charge of the m1A base.[12]
-
-
Analysis :
-
Confirm the identity and purity of the final product using mass spectrometry (e.g., ESI-MS or MALDI-TOF).[10][19][20] This is crucial to verify the correct mass and to ensure that no Dimroth rearrangement to m6A has occurred.
-
Purity can also be assessed by analytical HPLC and/or denaturing polyacrylamide gel electrophoresis (PAGE).[21]
-
Biological Significance and Signaling
1-Methyladenine is not merely a structural component of RNA; it is an active participant in cellular signaling and regulation.
Role in Translation
m1A modifications, particularly in tRNA, are crucial for maintaining the structural integrity of the molecule, which is essential for efficient and accurate translation.[2][5] The presence of m1A in the 5' untranslated region (UTR) of mRNA has been shown to enhance translation initiation.[7][8]
DNA/RNA Demethylation Pathway
m1A is a substrate for the AlkB family of dioxygenases, which are involved in the direct reversal of alkylation damage to DNA and RNA.[6][14][22] This demethylation process is a key component of cellular nucleic acid repair and epitranscriptomic regulation.
Caption: AlkB-mediated demethylation of 1-Methyladenine.
Reader Proteins and Downstream Effects
The biological effects of m1A are mediated by "reader" proteins that specifically recognize this modification. The YTH domain-containing family of proteins (YTHDF1, YTHDF2, YTHDF3, and YTHDC1) have been identified as readers of m1A.[1][15][23][24][25] This recognition can influence mRNA stability and translation, thereby regulating gene expression.
Applications in Research and Drug Development
The ability to synthesize oligonucleotides containing m1A opens up numerous avenues for research and therapeutic development:
-
Studying RNA Structure and Function : Probing the effects of m1A on RNA folding, stability, and interactions with proteins.
-
Investigating DNA Repair Mechanisms : Creating substrates for studying the activity of AlkB and other DNA repair enzymes.[12][19]
-
Antisense and RNAi Therapeutics : Developing modified oligonucleotides with enhanced stability and specific biological activities.[4][9]
-
Diagnostic Tools : Designing probes for the detection of specific RNA modifications.
By following the protocols and considering the data presented in these application notes, researchers can successfully incorporate 1-methyladenine into synthetic oligonucleotides, paving the way for new discoveries in RNA biology and therapeutic innovation.
References
- 1. N6-methyladenosine reader YTHDF family in biological processes: Structures, roles, and mechanisms - PMC [pmc.ncbi.nlm.nih.gov]
- 2. N1-methyladenosine formation, gene regulation, biological functions, and clinical relevance - PMC [pmc.ncbi.nlm.nih.gov]
- 3. The Molecular Basis of Human ALKBH3 Mediated RNA N1 -methyladenosine (m1 A) Demethylation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. Reversible RNA Modification N1-methyladenosine (m1A) in mRNA and tRNA - PMC [pmc.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
- 6. AlkB mystery solved: oxidative demethylation of N1-methyladenine and N3-methylcytosine adducts by a direct reversal mechanism - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. N1-methyladenosine modification in cancer biology: Current status and future perspectives - PMC [pmc.ncbi.nlm.nih.gov]
- 8. The dynamic N1-methyladenosine methylome in eukaryotic messenger RNA - PMC [pmc.ncbi.nlm.nih.gov]
- 9. researchgate.net [researchgate.net]
- 10. Chemical incorporation of 1-methyladenosine into oligonucleotides - PMC [pmc.ncbi.nlm.nih.gov]
- 11. glenresearch.com [glenresearch.com]
- 12. pubs.acs.org [pubs.acs.org]
- 13. tandfonline.com [tandfonline.com]
- 14. researchgate.net [researchgate.net]
- 15. Frontiers | YTH Domain Proteins: A Family of m6A Readers in Cancer Progression [frontiersin.org]
- 16. glenresearch.com [glenresearch.com]
- 17. glenresearch.com [glenresearch.com]
- 18. atdbio.com [atdbio.com]
- 19. Characterization of Byproducts from Chemical Syntheses of Oligonucleotides Containing 1-Methyladenine and 3-Methylcytosine - PMC [pmc.ncbi.nlm.nih.gov]
- 20. sg.idtdna.com [sg.idtdna.com]
- 21. Oligonucleotide Purification Methods for Your Research | Thermo Fisher Scientific - US [thermofisher.com]
- 22. Repair of 3-methylthymine and 1-methylguanine lesions by bacterial and human AlkB proteins - PMC [pmc.ncbi.nlm.nih.gov]
- 23. Identification of YTH Domain-Containing Proteins as the Readers for N1-Methyladenosine in RNA - PubMed [pubmed.ncbi.nlm.nih.gov]
- 24. Frontiers | Main N6-Methyladenosine Readers: YTH Family Proteins in Cancers [frontiersin.org]
- 25. The roles and mechanisms of the m6A reader protein YTHDF1 in tumor biology and human diseases - PMC [pmc.ncbi.nlm.nih.gov]
Application Notes and Protocols: 1-Methyladenine in Epigenetic Modulator Research
For Researchers, Scientists, and Drug Development Professionals
Introduction
1-Methyladenine (1-meA), and its corresponding ribonucleoside N1-methyladenosine (m1A), are significant players in the field of epigenetics, particularly as a post-transcriptional modification of RNA. This modification is a dynamic and reversible process crucial for regulating RNA stability, translation, and other cellular processes. The enzymes that add (writers), remove (erasers), and recognize (readers) this methyl mark are key targets for therapeutic development in various diseases, including cancer.
These application notes provide a comprehensive overview of the role of 1-methyladenine (in the form of m1A-modified substrates) in studying epigenetic modulators, with a focus on the demethylase ALKBH3. Detailed protocols for relevant assays are provided to facilitate research in this area.
Data Presentation
The study of 1-methyladenine in epigenetics often involves the analysis of enzyme kinetics and the quantification of cellular responses. The following tables summarize key quantitative data related to the eraser enzyme ALKBH3 and the impact of m1A modification.
Table 1: Kinetic Parameters of ALKBH3 Demethylase Activity
| Substrate | kcat (min⁻¹) | Km (µM) | kcat/Km (µM⁻¹min⁻¹) | Reference |
| m1A-containing RNA | 0.88 ± 0.05 | 8.0 ± 1.2 | 0.11 | [1] |
| 1mA-containing ssDNA | 0.96 ± 0.06 | 8.0 ± 1.1 | 0.12 | [1] |
| 3mC-containing ssDNA | 0.80 ± 0.04 | 8.1 ± 1.0 | 0.10 | [1] |
Table 2: Cellular Effects of m1A Modification and its Regulators
| Cellular Process | Observation | Cell Line(s) | Quantitative Change | Reference |
| Protein Translation | Genes with m1A around the start codon show higher protein levels. | HepG2, HEK293, HeLa | ~1.7-fold average increase | [2] |
| Cell Proliferation | Knockdown of ALKBH3 impairs cellular proliferation. | Human cancer cells | Data not specified | [3] |
| tRNA Stability | Lack of m1A58 in tRNAiMet leads to its decay. | S. cerevisiae, S. pombe | Data not specified | [4][5] |
| Gene Expression | Hypomethylation of ethylene-related genes in tomato ripening. | Tomato | Correlation observed | [6] |
Signaling Pathways
The regulation of m1A modification has been shown to impact significant signaling pathways implicated in cancer and development.
References
- 1. The Molecular Basis of Human ALKBH3 Mediated RNA N1-methyladenosine (m1A) Demethylation - PMC [pmc.ncbi.nlm.nih.gov]
- 2. The dynamic N1-methyladenosine methylome in eukaryotic messenger RNA - PMC [pmc.ncbi.nlm.nih.gov]
- 3. AlkB homolog 3-mediated tRNA demethylation promotes protein synthesis in cancer cells - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Initiator tRNA lacking 1-methyladenosine is targeted by the rapid tRNA decay pathway in evolutionarily distant yeast species - PMC [pmc.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
- 6. The dynamic N1-methyladenosine RNA methylation provides insights into the tomato fruit ripening - PubMed [pubmed.ncbi.nlm.nih.gov]
Application Notes and Protocols for Studying 1-Methyladenine in Starfish Oocyte Maturation
For Researchers, Scientists, and Drug Development Professionals
These application notes provide a comprehensive overview and detailed protocols for studying the induction of oocyte maturation in starfish by 1-Methyladenine (1-MeAde). This model system is pivotal for research in cell cycle control, signal transduction, and developmental biology, offering a naturally synchronized and abundant source of gametes.
Introduction
Starfish oocytes are arrested at the G2/M phase boundary of meiosis I and resume meiosis upon stimulation by the hormone 1-Methyladenine, produced by the surrounding follicle cells.[1][2] This process, known as oocyte maturation, is characterized by germinal vesicle breakdown (GVBD), chromosome condensation, and the formation of a fertilizable egg.[1][2] The signaling cascade initiated by 1-MeAde is a valuable model for understanding G-protein coupled receptor (GPCR) signaling and the activation of Maturation-Promoting Factor (MPF), a universal regulator of the G2/M transition in eukaryotic cells.[3][4]
Signaling Pathway of 1-Methyladenine in Starfish Oocyte Maturation
1-Methyladenine acts on the oocyte surface, binding to a yet-unidentified receptor that is coupled to a pertussis toxin-sensitive G-protein of the Gi family.[3][5][6][7] Upon hormone binding, the G-protein dissociates, releasing the Gβγ subunit complex.[3][8][9] The free Gβγ then activates a cascade of downstream effectors:
-
Phosphoinositide 3-kinase (PI3K) is activated by Gβγ.[3][8][9]
-
PI3K activation leads to the subsequent activation of TORC2 and PDK1 .[8][9]
-
These kinases then phosphorylate and activate Serum and Glucocorticoid-regulated Kinase (SGK) .[8][9]
-
Activated SGK has two critical functions:
-
The phosphorylation of Cdc25 (an activating phosphatase) and Myt1 (an inhibitory kinase) leads to the dephosphorylation and activation of the Cyclin B-Cdk1 complex , also known as Maturation-Promoting Factor (MPF).[8][9]
-
The activation of MPF is the direct trigger for Germinal Vesicle Breakdown (GVBD) and the resumption of meiosis.[8][9][10]
This signaling pathway highlights a non-canonical G-protein signaling route that is independent of traditional second messengers like cAMP or Ca2+.
Quantitative Data
The following tables summarize key quantitative parameters associated with 1-MeAde-induced oocyte maturation in starfish.
| Parameter | Value | Species | Reference |
| 1-MeAde Threshold Concentration | 2.5 x 10⁻⁸ M to 2.5 x 10⁻⁷ M | Marthasterias glacialis, Asterias rubens | [11] |
| 1-MeAde Effective Concentration for GVBD | 1 µM - 10 µM | Asterina pectinifera, Astropecten aranciacus | [7][12][13] |
| Timing of GVBD | 15 - 25 minutes | Patiria miniata | [12] |
| Intracellular pH (pHi) - Immature Oocyte | ~6.7 | Various | [8][9] |
| Intracellular pH (pHi) - Mature Oocyte | ~6.9 | Various | [8][9] |
| Dissociation Constant (Kd) of 1-MeAde Receptor | 0.3 µM | Asterina pectinifera | [14] |
Experimental Protocols
Protocol 1: Isolation of Starfish Oocytes
This protocol describes the preparation of a homogenous suspension of immature starfish oocytes.
Materials:
-
Ripe female starfish
-
Artificial seawater (ASW) or natural seawater (NSW)
-
0.1 M KCl
-
Cheesecloth
-
Beakers
-
Pasteur pipettes
Procedure:
-
Induce spawning by injecting 0.2 ml of 0.1 M KCl into the coelomic cavity of a ripe female starfish.
-
After several minutes, the starfish will begin to shed oocytes. Collect the shed oocytes in a beaker of ASW or NSW.
-
Alternatively, dissect the ovaries from the starfish and gently tear them open in a beaker of seawater to release the oocytes.
-
Wash the oocytes several times by decantation with fresh seawater to remove debris and follicle cells.
-
Filter the oocyte suspension through several layers of cheesecloth to obtain a clean, homogenous population of immature oocytes, identifiable by their large germinal vesicle.
-
Store the oocytes at a cool temperature (e.g., 16-18°C) until use.
Protocol 2: Induction of Oocyte Maturation with 1-Methyladenine
This protocol details the induction of synchronous oocyte maturation using 1-MeAde.
Materials:
-
Homogenous suspension of immature starfish oocytes
-
1 mM stock solution of 1-Methyladenine in distilled water
-
Petri dishes or multi-well plates
-
Microscope
Procedure:
-
Prepare a working solution of 1-MeAde by diluting the stock solution in seawater to the desired final concentration (typically 1-10 µM).
-
Place a sample of the immature oocyte suspension into a petri dish or well of a multi-well plate.
-
Add the 1-MeAde working solution to the oocytes and gently swirl to mix.
-
Incubate the oocytes at a constant temperature (e.g., 18-20°C).
-
Monitor the oocytes periodically under a microscope for signs of maturation, primarily the breakdown of the germinal vesicle (GVBD). The oocyte will become uniformly opaque upon GVBD.
-
Record the percentage of oocytes that have undergone GVBD at various time points.
Protocol 3: Preparation of Oocyte Lysates for Biochemical Analysis
This protocol is for preparing cell lysates to study protein phosphorylation and enzyme activities during maturation.
Materials:
-
Maturing oocyte suspension at various time points post-1-MeAde addition
-
Lysis buffer (e.g., containing Tris-HCl, NaCl, EDTA, protease and phosphatase inhibitors)
-
Microcentrifuge tubes
-
Microcentrifuge
Procedure:
-
At desired time points after 1-MeAde addition, collect a sample of the oocyte suspension.
-
Pellet the oocytes by gentle centrifugation (e.g., 500 x g for 1 minute).
-
Remove the supernatant and add ice-cold lysis buffer to the oocyte pellet.
-
Homogenize the oocytes by pipetting up and down or by passing through a fine-gauge needle.
-
Incubate the lysate on ice for 15-30 minutes to ensure complete lysis.
-
Clarify the lysate by centrifugation at high speed (e.g., 14,000 x g for 15 minutes at 4°C).
-
Collect the supernatant, which contains the soluble proteins, for downstream applications such as Western blotting, kinase assays, or immunoprecipitation.
Applications in Drug Development
The starfish oocyte maturation system serves as a valuable tool for:
-
Screening and characterization of GPCR modulators: The specificity of the 1-MeAde receptor allows for the screening of novel agonists and antagonists.[15]
-
Identification of novel cell cycle inhibitors: Compounds that block GVBD can be identified and their mechanism of action downstream of 1-MeAde can be elucidated.
-
Studying the mechanism of action of kinase inhibitors: The well-defined signaling cascade provides a platform to test the efficacy and specificity of inhibitors targeting PI3K, SGK, Cdk1, and other kinases.
By utilizing these detailed notes and protocols, researchers can effectively employ the starfish oocyte model to advance our understanding of fundamental cellular processes and to discover novel therapeutic agents.
References
- 1. researchgate.net [researchgate.net]
- 2. 1-Methyladenine: a starfish oocyte maturation-inducing substance | Zygote | Cambridge Core [cambridge.org]
- 3. Components of the signaling pathway linking the 1-methyladenine receptor to MPF activation and maturation in starfish oocytes - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. MPF-based meiotic cell cycle control: Half a century of lessons from starfish oocytes - PMC [pmc.ncbi.nlm.nih.gov]
- 5. A receptor linked to a Gi-family G-protein functions in initiating oocyte maturation in starfish but not frogs - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. The primary structure of the alpha subunit of a starfish guanosine-nucleotide-binding regulatory protein involved in 1-methyladenine-induced oocyte maturation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. Pertussis toxin inhibits 1-methyladenine-induced maturation in starfish oocytes - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. Oocyte Maturation in Starfish - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. Oocyte Maturation in Starfish - PMC [pmc.ncbi.nlm.nih.gov]
- 10. The role of the germinal vesicle in producing maturation-promoting factor (MPF) as revealed by the removal and transplantation of nuclear material in starfish oocytes - PubMed [pubmed.ncbi.nlm.nih.gov]
- 11. vliz.be [vliz.be]
- 12. health.uconn.edu [health.uconn.edu]
- 13. mdpi.com [mdpi.com]
- 14. Characterization of 1-methyladenine binding in starfish oocyte cortices - PMC [pmc.ncbi.nlm.nih.gov]
- 15. Interaction of N1-substituted adenines with 1-methyladenine receptors of starfish oocytes in induction of maturation - PubMed [pubmed.ncbi.nlm.nih.gov]
Analysis of 1-Methyladenosine in Urine as a Disease Biomarker: Application Notes and Protocols
For Researchers, Scientists, and Drug Development Professionals
Introduction
1-Methyladenosine (1-mA) is a modified nucleoside that is formed during the repair of DNA and RNA damaged by alkylating agents. It is also a natural modification in certain RNA molecules.[1][2][3] Under normal physiological conditions, there is a basal level of 1-mA excretion in urine. However, elevated levels of urinary 1-mA have been associated with increased cellular turnover and DNA/RNA damage, making it a promising non-invasive biomarker for various pathological conditions, including cancer and potentially inflammatory diseases. This document provides a comprehensive overview of the analysis of 1-methyladenosine in urine as a disease biomarker, including detailed experimental protocols and a summary of reported quantitative data.
1-Methyladenosine as a Biomarker in Disease
Elevated levels of 1-methyladenosine in urine have been observed in patients with various types of cancer, suggesting its potential as a general tumor marker.[4][5] The increased turnover of RNA in rapidly proliferating cancer cells, as well as DNA damage induced by endogenous or exogenous alkylating agents, can lead to a higher rate of 1-mA formation and subsequent excretion.[1]
Recent studies have begun to explore the role of RNA modifications, including N1-methyladenosine, in the pathogenesis of inflammatory and autoimmune diseases. While much of the focus has been on the related N6-methyladenosine (m6A), the broader field of epitranscriptomics suggests that alterations in RNA modification patterns are linked to immune responses and inflammatory processes.[6][7] Further research is needed to specifically elucidate the role of urinary 1-methyladenosine in these conditions.
Quantitative Data Summary
The following table summarizes the reported concentrations of 1-methyladenosine in urine from healthy individuals and patients with cancer. It is important to note that values can vary depending on the analytical method used and the normalization strategy (e.g., per volume or per creatinine level).
| Condition | Analyte | Matrix | Concentration | Method | Reference |
| Healthy Individuals | 1-Methyladenosine | Serum | 28.3 ± 7.9 ng/mL | ELISA | [4] |
| Cancer Patients (Mixed) | 1-Methyladenosine | Serum | Elevated in 16% of cases (>44.1 ng/mL cutoff) | ELISA | [4] |
| Cancer Patients (Mixed) | 1-Methyladenosine | Urine | Elevated in 44% of cases (>3.23 nmol/µmol creatinine cutoff) | ELISA | [4] |
Note: The provided data for cancer patients is based on a mixed cohort and a cutoff value rather than a mean and standard deviation.
Signaling and Excretion Pathway of 1-Methyladenosine
The presence of 1-methyladenosine in urine is a direct result of cellular processes involving nucleic acid damage and repair. Alkylating agents, both endogenous (e.g., S-adenosylmethionine) and exogenous (e.g., environmental toxins, chemotherapeutic drugs), can methylate adenine bases in DNA and RNA at the N1 position, forming 1-methyladenine.[2][8] This lesion can disrupt base pairing and block replication and transcription.[9]
Cells have evolved specific repair mechanisms to counteract this type of damage. The primary pathways for the repair of 1-methyladenine in DNA are:
-
Direct Repair by AlkB Homologs: Enzymes such as ALKBH1 and ALKBH3 can directly remove the methyl group from 1-methyladenine through oxidative demethylation, restoring the original adenine base.[8]
-
Base Excision Repair (BER): This multi-step pathway is initiated by a DNA glycosylase, such as alkyladenine DNA glycosylase (AAG), which recognizes and excises the damaged 1-methyladenine base.[3][8] This creates an apurinic/apyrimidinic (AP) site, which is then further processed by other enzymes to restore the correct DNA sequence.[9][10]
The excised 1-methyladenine base is not further metabolized and is subsequently released into the bloodstream and excreted in the urine as 1-methyladenosine.
Experimental Protocols
The accurate quantification of 1-methyladenosine in urine typically requires a sensitive and specific analytical method such as liquid chromatography-tandem mass spectrometry (LC-MS/MS). The following sections outline a general workflow and a detailed protocol for this analysis.
Experimental Workflow
The overall workflow for the analysis of urinary 1-methyladenosine involves several key steps, from sample collection to data analysis.
Detailed Protocol for LC-MS/MS Quantification of 1-Methyladenosine in Urine
This protocol provides a step-by-step guide for the quantification of 1-methyladenosine in human urine using solid-phase extraction and LC-MS/MS.
1. Materials and Reagents
-
1-Methyladenosine analytical standard
-
Isotopically labeled internal standard (e.g., 1-Methyladenosine-d3)
-
LC-MS grade water, acetonitrile, methanol, and formic acid
-
Ammonium acetate
-
Solid-phase extraction (SPE) cartridges (e.g., mixed-mode cation exchange or reversed-phase)
-
Human urine samples
2. Sample Collection and Storage
-
Collect mid-stream urine samples in sterile containers.
-
Immediately after collection, centrifuge the samples at 2,000 x g for 10 minutes at 4°C to pellet cellular debris.
-
Transfer the supernatant to clean tubes and store at -80°C until analysis.
3. Sample Preparation (Solid-Phase Extraction)
This is a general protocol and may require optimization depending on the specific SPE cartridge used.
-
Conditioning: Condition the SPE cartridge by passing 1-2 column volumes of methanol followed by 1-2 column volumes of LC-MS grade water.
-
Equilibration: Equilibrate the cartridge with 1-2 column volumes of an appropriate buffer (e.g., ammonium acetate buffer at a specific pH).
-
Sample Loading: Thaw urine samples on ice. Dilute an aliquot of the urine sample (e.g., 1 mL) with the equilibration buffer and spike with the internal standard. Load the sample onto the SPE cartridge at a slow, steady flow rate.
-
Washing: Wash the cartridge with a weak solvent (e.g., the equilibration buffer or a low percentage of organic solvent) to remove interfering matrix components.
-
Elution: Elute the retained 1-methyladenosine with a stronger solvent (e.g., a higher percentage of organic solvent, potentially with an acid or base modifier). Collect the eluate.
-
Dry-down and Reconstitution: Evaporate the eluate to dryness under a gentle stream of nitrogen. Reconstitute the residue in a small volume of the initial LC mobile phase for injection.
4. LC-MS/MS Analysis
-
Liquid Chromatography (LC):
-
Column: A HILIC (Hydrophilic Interaction Liquid Chromatography) column is often suitable for separating polar compounds like nucleosides. A C18 column can also be used with an appropriate mobile phase.
-
Mobile Phase A: Water with 0.1% formic acid and 10 mM ammonium acetate.
-
Mobile Phase B: Acetonitrile with 0.1% formic acid.
-
Gradient: A typical gradient might start with a high percentage of mobile phase B, with a gradual increase in mobile phase A to elute the polar analytes. An example gradient is as follows:
Time (min) %A %B 0.0 5 95 1.0 5 95 7.0 50 50 8.0 50 50 8.1 5 95 | 12.0 | 5 | 95 |
-
Flow Rate: 0.3 - 0.5 mL/min.
-
Injection Volume: 5 - 10 µL.
-
-
Tandem Mass Spectrometry (MS/MS):
-
Ionization Mode: Positive Electrospray Ionization (ESI+).
-
Analysis Mode: Multiple Reaction Monitoring (MRM).
-
MRM Transitions: The specific precursor and product ions for 1-methyladenosine need to be optimized on the specific mass spectrometer used. A common transition is:
-
1-Methyladenosine: Precursor ion (Q1) m/z 282.1 -> Product ion (Q3) m/z 150.1.[11]
-
The product ion corresponds to the protonated 1-methyladenine base after fragmentation of the glycosidic bond.
-
-
Optimize other MS parameters such as collision energy and declustering potential for maximum signal intensity.
-
5. Data Analysis and Quantification
-
Generate a calibration curve using known concentrations of the 1-methyladenosine analytical standard spiked into a surrogate matrix (e.g., artificial urine or water).
-
Calculate the peak area ratio of the analyte to the internal standard for both the standards and the unknown samples.
-
Determine the concentration of 1-methyladenosine in the urine samples by interpolating their peak area ratios on the calibration curve.
-
Normalize the results to urinary creatinine concentration to account for variations in urine dilution.
Conclusion
The analysis of urinary 1-methyladenosine holds significant promise as a non-invasive biomarker for monitoring diseases associated with increased DNA/RNA damage and cellular turnover, particularly cancer. The LC-MS/MS method described provides a robust and sensitive approach for the accurate quantification of this modified nucleoside. Further research is warranted to establish its clinical utility for a broader range of diseases, including specific cancer types and inflammatory conditions, and to standardize reference ranges in different populations.
References
- 1. Systematic Review: Urine Biomarker Discovery for Inflammatory Bowel Disease Diagnosis - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. urotoday.com [urotoday.com]
- 3. Frontiers | The Regulators Associated With N6-Methyladenosine in Lung Adenocarcinoma and Lung Squamous Cell Carcinoma Reveal New Clinical and Prognostic Markers [frontiersin.org]
- 4. Comparison of serum and urinary levels of modified nucleoside, 1-methyladenosine, in cancer patients using a monoclonal antibody-based inhibition ELISA - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. N1-methyladenosine modification in cancer biology: Current status and future perspectives - PMC [pmc.ncbi.nlm.nih.gov]
- 6. researchgate.net [researchgate.net]
- 7. N6 -Methyladenosine and Rheumatoid Arthritis: A Comprehensive Review - PMC [pmc.ncbi.nlm.nih.gov]
- 8. A DNA repair-independent role for alkyladenine DNA glycosylase in alkylation-induced unfolded protein response - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Structural basis for enzymatic excision of N1-methyladenine and N3-methylcytosine from DNA - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Regulation of DNA Alkylation Damage Repair: Lessons and Therapeutic Opportunities - PMC [pmc.ncbi.nlm.nih.gov]
- 11. LC-MS/MS Determination of Modified Nucleosides in The Urine of Parkinson’s Disease and Parkinsonian Syndromes Patients - PMC [pmc.ncbi.nlm.nih.gov]
Application Notes and Protocols for High-Throughput Screening of m1A Methyltransferase Inhibitors
For Researchers, Scientists, and Drug Development Professionals
Introduction
N1-methyladenosine (m1A) is a dynamic, post-transcriptional RNA modification that plays a critical role in regulating RNA structure, stability, and translation. The enzymes responsible for installing this modification, m1A methyltransferases (writers), such as the TRMT6/TRMT61A complex, are emerging as promising therapeutic targets in various diseases, including cancer. The development of robust high-throughput screening (HTS) assays is crucial for the discovery of small molecule inhibitors of these enzymes.
These application notes provide detailed protocols for biochemical and cell-based HTS assays designed to identify and characterize inhibitors of m1A methyltransferases. The methodologies are adapted from established, robust HTS formats for other methyltransferases and tailored for the specific requirements of m1A writers, including the use of relevant RNA substrates.
Biochemical High-Throughput Screening Assays
Biochemical assays are essential for primary screening campaigns to identify direct inhibitors of m1A methyltransferase activity. Two primary methodologies are presented here: a fluorescence-based assay and a luminescence-based assay. Both are homogeneous "add-and-read" formats suitable for high-throughput screening in 1536-well plates.
Key Reagents and General Considerations
-
Enzyme: Recombinant human TRMT6/TRMT61A complex.
-
Substrate: A synthetic RNA oligonucleotide containing a single adenosine target for methylation. A tRNA-derived fragment (tRF) known to be a substrate for TRMT6/61A is recommended.
-
Methyl Donor: S-adenosyl-L-methionine (SAM).
-
Assay Plates: 1536-well, low-volume, solid-bottom plates (e.g., white for luminescence, black for fluorescence).
-
Detection Reagents: Specific to the chosen assay format (detailed below).
-
Control Inhibitor: A known methyltransferase inhibitor, such as Sinefungin or a more specific inhibitor if available. Thiram has been identified as an inhibitor of the TRMT6/TRMT61A complex.
-
Buffer: A general assay buffer can be optimized, but a starting point is 50 mM Tris-HCl (pH 8.0), 5 mM MgCl₂, 1 mM DTT, and 0.01% Tween-20.
Experimental Workflow: Biochemical HTS
The following diagram illustrates the general workflow for a biochemical HTS campaign to identify m1A methyltransferase inhibitors.
Protocol 1: Luminescence-Based MTase-Glo™ Assay
This assay quantifies the amount of S-adenosyl-L-homocysteine (SAH) produced, which is directly proportional to the methyltransferase activity.
Materials:
-
MTase-Glo™ Reagent and MTase-Glo™ Detection Solution (Promega)
-
Recombinant TRMT6/TRMT61A
-
tRNA-derived fragment (tRF) substrate
-
S-adenosyl-L-methionine (SAM)
-
Control inhibitor (e.g., Sinefungin)
-
Assay Buffer: 50 mM Tris-HCl (pH 8.0), 5 mM MgCl₂, 1 mM DTT, 0.01% Tween-20
-
1536-well white, solid-bottom plates
Procedure (1536-well format):
-
Compound Dispensing: Dispense 20 nL of compounds in DMSO and controls into the assay plate using an acoustic dispenser.
-
Enzyme/Substrate Addition: Prepare a 2X enzyme/substrate solution in Assay Buffer containing TRMT6/61A and the tRF substrate. Add 2 µL of this solution to each well.
-
Reaction Initiation: Prepare a 2X SAM solution in Assay Buffer. Add 2 µL of the SAM solution to each well to start the reaction. The final reaction volume is 4 µL.
-
Incubation: Incubate the plate at room temperature for 60 minutes.
-
SAH Detection:
-
Add 2 µL of MTase-Glo™ Reagent to each well.
-
Incubate at room temperature for 30 minutes.
-
Add 4 µL of MTase-Glo™ Detection Solution to each well.
-
Incubate at room temperature for 30 minutes.
-
-
Data Acquisition: Measure the luminescence signal using a plate reader.
Data Analysis:
-
Normalize the data using negative controls (DMSO) and positive controls (inhibitor).
-
Calculate the percent inhibition for each compound.
-
Hits are typically defined as compounds exhibiting inhibition above a certain threshold (e.g., >50% or 3 standard deviations from the mean of the negative controls).
Protocol 2: Fluorescence-Based SAHH-Coupled Assay
This assay couples the production of SAH to the generation of a fluorescent signal via S-adenosyl-L-homocysteine hydrolase (SAHH) and a thiol-reactive fluorescent probe.
Materials:
-
S-adenosyl-L-homocysteine hydrolase (SAHH)
-
Thiol-reactive fluorescent probe (e.g., ThioGlo®)
-
Recombinant TRMT6/61A
-
tRNA-derived fragment (tRF) substrate
-
S-adenosyl-L-methionine (SAM)
-
Control inhibitor
-
Assay Buffer: 50 mM Tris-HCl (pH 8.0), 5 mM MgCl₂, 1 mM DTT, 0.01% Tween-20
-
1536-well black, solid-bottom plates
Procedure (1536-well format):
-
Compound Dispensing: Dispense 20 nL of compounds and controls into the assay plate.
-
Enzyme/Substrate/SAHH Addition: Prepare a solution in Assay Buffer containing TRMT6/61A, the tRF substrate, and SAHH. Add 2 µL of this solution to each well.
-
Reaction Initiation: Prepare a solution of SAM in Assay Buffer. Add 2 µL of the SAM solution to each well.
-
Incubation: Incubate at room temperature for 60 minutes.
-
Signal Development: Add 1 µL of the fluorescent probe solution to each well.
-
Incubation: Incubate at room temperature for 15-30 minutes, protected from light.
-
Data Acquisition: Measure the fluorescence intensity (e.g., Ex/Em appropriate for the chosen probe) using a plate reader.
Quantitative Data from HTS Campaigns
The following tables summarize representative quantitative data from HTS campaigns for methyltransferase inhibitors. Note that extensive HTS data for m1A methyltransferase inhibitors is not yet widely available in the public domain; therefore, data from other methyltransferase screens are included for illustrative purposes.
Table 1: HTS Assay Performance Metrics
| Assay Type | Target | Substrate Type | Z' Factor | Hit Rate (%) | Reference |
| MTase-Glo™ | NSD2 | Nucleosome | 0.92 | 3.3 | [1] |
| SAHH-Coupled Fluorescence | NTMT1 | Peptide | 0.65 ± 0.01 | N/A | [2] |
| MTase-Glo™ | NTMT1 | Peptide | 0.70 ± 0.01 | N/A | [2] |
Table 2: IC₅₀ Values of Identified Methyltransferase Inhibitors
| Compound | Target | Assay Type | IC₅₀ (µM) | Reference |
| Thiram | TRMT6/TRMT61A | Not specified | Potent inhibitor | [3] |
| Ac-RCC1-10 | NTMT1 | SAHH-Coupled Fluorescence | 7.61 ± 1.84 | [2] |
| Ac-RCC1-10 | NTMT1 | MTase-Glo™ | 11.1 ± 0.8 | [2] |
| Chaetocin | NSD2 | MTase-Glo™ | Confirmed hit | [1] |
Cell-Based High-Throughput Screening Assays
Cell-based assays are critical for validating hits from primary biochemical screens in a more physiologically relevant context. These assays can provide information on cell permeability, target engagement, and effects on downstream signaling pathways.
Experimental Workflow: Cell-Based HTS
Protocol 3: Luciferase Reporter Assay for Downstream Signaling
This assay measures the effect of inhibitors on a downstream signaling pathway regulated by m1A methylation, such as the Unfolded Protein Response (UPR).
Principle: A reporter construct containing a luciferase gene under the control of a promoter with response elements for a specific transcription factor (e.g., ATF6 for the UPR) is introduced into cells. Inhibition of TRMT6/61A can modulate the UPR, leading to a change in luciferase expression.
Materials:
-
HEK293T or other suitable cell line
-
Luciferase reporter plasmid with an ER stress response element (ERSE)
-
Transfection reagent
-
Dual-Luciferase® Reporter Assay System (Promega)
-
Cell culture medium and supplements
-
White, clear-bottom 96- or 384-well plates
Procedure:
-
Transfection: Co-transfect cells with the ERSE-luciferase reporter plasmid and a control plasmid (e.g., Renilla luciferase) for normalization.
-
Cell Plating: Plate the transfected cells into 96- or 384-well plates and allow them to adhere.
-
Compound Treatment: Treat the cells with a dilution series of the test compounds for 24-48 hours. Include a positive control for UPR induction (e.g., tunicamycin) and a vehicle control (DMSO).
-
Cell Lysis: Lyse the cells according to the Dual-Luciferase® Reporter Assay System protocol.
-
Luciferase Assay: Measure both Firefly and Renilla luciferase activity in a plate luminometer.
-
Data Analysis: Normalize the Firefly luciferase activity to the Renilla luciferase activity. Determine the effect of the compounds on the UPR pathway.
Protocol 4: In-Cell Target Engagement Assay (InCELL Hunter™)
This assay measures the direct binding of a compound to the target protein within the cell, based on compound-induced stabilization of the target protein.
Principle: The target m1A methyltransferase (e.g., TRMT61A) is fused to a small enzyme fragment (the enzyme donor, ED). In the presence of a binding compound, the target protein is stabilized. After cell lysis, a larger, inactive enzyme fragment (the enzyme acceptor, EA) is added, which complements the ED to form an active enzyme, generating a chemiluminescent signal that is proportional to the amount of stabilized target protein.
Materials:
-
InCELL Hunter™ cell line expressing the ED-tagged m1A methyltransferase.
-
InCELL Hunter™ detection reagents (Eurofins DiscoverX).
-
Cell culture medium and supplements.
-
Assay plates (e.g., 384-well).
Procedure:
-
Cell Plating: Plate the InCELL Hunter™ cells in the assay plates.
-
Compound Addition: Add the test compounds to the cells and incubate for a specified period (e.g., 6-16 hours) to allow for target engagement and protein turnover.
-
Detection: Add the InCELL Hunter™ detection reagents, which include the EA and the chemiluminescent substrate.
-
Incubation: Incubate at room temperature to allow for enzyme complementation and signal development.
-
Data Acquisition: Measure the chemiluminescence using a plate reader.
-
Data Analysis: An increase in signal indicates that the compound has entered the cell and engaged with the target protein, leading to its stabilization.
Signaling Pathways and Logical Relationships
The activity of m1A methyltransferases, particularly the TRMT6/TRMT61A complex, has been linked to several key cellular signaling pathways. Inhibition of this complex is expected to modulate these pathways.
References
MadID: High-Resolution Mapping of Protein-DNA Interactions for Research and Drug Discovery
Application Notes and Protocols
Introduction
Methyl Adenine Identification (MadID) is a powerful technique for the high-resolution, genome-wide mapping of protein-DNA interactions. This method offers significant advantages over traditional approaches like Chromatin Immunoprecipitation sequencing (ChIP-seq) and DNA adenine methyltransferase identification (DamID). MadID utilizes a protein of interest fused to a non-specific adenine methyltransferase, M.EcoGII, to "mark" DNA in close proximity to the protein's binding sites with N6-methyladenine (m6A). This modification can then be detected by various downstream applications, including next-generation sequencing, to precisely identify the genomic loci of these interactions.
The key advantage of MadID lies in the sequence-independent nature of M.EcoGII, which allows for methylation of any adenine residue.[1][2] This overcomes the primary limitation of DamID, which relies on the Dam methyltransferase that only recognizes and methylates GATC motifs, leading to biased and lower-resolution maps.[1][2] MadID provides deeper and more uniform coverage of the genome, enabling the study of protein interactions in previously inaccessible regions like telomeres and centromeres.[1][2] These characteristics make MadID a valuable tool for researchers in basic science and drug development, facilitating the discovery of novel drug targets and the elucidation of disease mechanisms related to aberrant protein-DNA interactions.
Key Advantages of MadID
-
High Resolution: The non-specific nature of M.EcoGII allows for methylation of all adenine residues, providing a much higher resolution of protein binding sites compared to the GATC-dependent DamID.[1][2]
-
Unbiased Genome-wide Coverage: MadID is not limited by the distribution of specific sequence motifs, enabling the mapping of interactions in regions inaccessible to DamID, such as GATC-poor regions, telomeres, and centromeres.[1][2][3]
-
Versatility: The m6A mark can be detected by various methods, including m6A-specific immunoprecipitation followed by sequencing (MadID-seq), qPCR, or immunostaining, offering flexibility in experimental design.[1][3]
-
In Vivo Application: MadID is performed in living cells, providing a more accurate representation of protein-DNA interactions in their native chromatin context.
Quantitative Comparison of MadID and DamID
| Feature | MadID | DamID | Reference |
| Enzyme | M.EcoGII | Dam Methyltransferase | [1][3] |
| Recognition Site | Any Adenine | GATC | [1][3] |
| Genomic Coverage (Human) | ~29% of the genome is accessible | ~0.9% of the genome is accessible | [3] |
| Resolution | High (base-pair level potential) | Lower (dependent on GATC density) | [1][3] |
| Bias | Low sequence bias | Biased towards GATC-containing regions | [3] |
| Applicability in GATC-poor regions | Yes | No | [1][3] |
Experimental Workflow
The MadID experimental workflow can be broken down into several key stages, from the initial cloning of the fusion protein to the final data analysis.
Caption: A schematic overview of the MadID experimental workflow.
Detailed Experimental Protocols
Generation of M.EcoGII Fusion Constructs
This protocol describes the cloning of a gene of interest in frame with the M.EcoGII methyltransferase in a suitable expression vector. Inducible expression systems, such as tetracycline-inducible or Shield-destabilization domain systems, are recommended to control the expression of the potentially toxic methyltransferase.
Materials:
-
Expression vector containing M.EcoGII (e.g., pRetroX-PTuner DD-linker-M.EcoGII)[4]
-
Gene of interest (GOI) cDNA
-
Restriction enzymes and T4 DNA ligase
-
Competent E. coli
-
Standard molecular cloning reagents and equipment
Protocol:
-
Vector and Insert Preparation:
-
Amplify the coding sequence of your GOI using PCR with primers that add appropriate restriction sites for cloning into the MadID vector.
-
Digest both the MadID vector and the PCR product with the chosen restriction enzymes.
-
Purify the digested vector and insert using a gel extraction kit.
-
-
Ligation:
-
Set up a ligation reaction with the digested vector and insert at a suitable molar ratio (e.g., 1:3).
-
Incubate as recommended by the ligase manufacturer.
-
-
Transformation:
-
Transform the ligation mixture into competent E. coli cells.
-
Plate the transformed cells on selective agar plates and incubate overnight at 37°C.
-
-
Verification:
-
Pick several colonies and grow overnight cultures.
-
Isolate plasmid DNA using a miniprep kit.
-
Verify the correct insertion of the GOI by restriction digest and Sanger sequencing.
-
Generation of Stable Cell Lines
This protocol outlines the generation of a stable mammalian cell line expressing the M.EcoGII fusion protein. Lentiviral transduction is a common and efficient method for this purpose.
Materials:
-
HEK293T cells for lentivirus production
-
Lentiviral packaging plasmids (e.g., psPAX2, pMD2.G)
-
Target mammalian cell line
-
Transfection reagent
-
Polybrene
-
Puromycin or other selection antibiotic
Protocol:
-
Lentivirus Production:
-
Co-transfect HEK293T cells with the MadID expression vector and the lentiviral packaging plasmids.
-
Harvest the virus-containing supernatant 48-72 hours post-transfection.
-
Filter the supernatant through a 0.45 µm filter.
-
-
Transduction:
-
Plate the target cells and allow them to adhere.
-
Add the viral supernatant to the cells in the presence of polybrene.
-
Incubate for 24-48 hours.
-
-
Selection:
-
Replace the virus-containing medium with fresh medium containing the appropriate selection antibiotic (e.g., puromycin).
-
Maintain the cells under selection until a stable, resistant population is established.
-
-
Validation:
-
Confirm the expression of the M.EcoGII fusion protein upon induction by Western blotting using an antibody against a tag on the fusion protein (e.g., V5).
-
MadID-seq: Library Preparation and Sequencing
This protocol describes the steps for preparing a genomic DNA library for next-generation sequencing from cells expressing the M.EcoGII fusion protein.
Materials:
-
Genomic DNA extraction kit
-
m6A-specific antibody
-
Protein A/G magnetic beads
-
DNA fragmentation equipment (e.g., sonicator)
-
NGS library preparation kit (e.g., Illumina DNA Prep)
-
Standard molecular biology reagents and equipment
Protocol:
-
Induction and Genomic DNA Extraction:
-
Induce the expression of the M.EcoGII fusion protein in the stable cell line for an optimized duration (e.g., 24 hours).
-
Harvest the cells and extract genomic DNA using a commercial kit.
-
-
DNA Fragmentation:
-
Fragment the genomic DNA to a desired size range (e.g., 200-500 bp) by sonication.
-
-
m6A Immunoprecipitation (m6A-IP):
-
Incubate the fragmented DNA with an m6A-specific antibody overnight at 4°C.
-
Add Protein A/G magnetic beads to pull down the antibody-DNA complexes.
-
Wash the beads extensively to remove non-specifically bound DNA.
-
Elute the m6A-containing DNA fragments.
-
-
Library Preparation:
-
Perform end-repair, A-tailing, and adapter ligation on the immunoprecipitated DNA using a commercial NGS library preparation kit.
-
Amplify the library by PCR.
-
-
Sequencing:
-
Quantify and assess the quality of the library.
-
Sequence the library on a compatible next-generation sequencing platform.
-
Data Analysis Workflow
The analysis of MadID-seq data involves several bioinformatic steps to identify and annotate the genomic regions enriched for m6A.
Caption: A flowchart of the MadID-seq data analysis pipeline.
Applications in Drug Development
MadID is a valuable tool for various stages of the drug development process, from target identification and validation to understanding mechanisms of drug action and resistance.
Target Identification and Validation
-
Mapping Drug-Target Interactions: MadID can be used to map the genome-wide binding sites of a drug target. This information can help to identify the genes and pathways regulated by the target, providing insights into its function and its potential as a therapeutic target.
-
Identifying Off-Target Effects: By mapping the binding sites of a drug-target fusion protein in the presence and absence of a drug, researchers can identify potential off-target binding sites of the drug, which is crucial for assessing drug safety.
Elucidating Disease Mechanisms
-
Studying Aberrant Protein-DNA Interactions: Many diseases, including cancer, are characterized by altered gene expression programs driven by aberrant protein-DNA interactions. MadID can be used to map these altered interactions in disease models, providing insights into the molecular mechanisms of the disease.
-
Investigating Chromatin Dynamics in Disease: MadID can be employed to study how disease states or drug treatments alter the organization of chromatin and the accessibility of genomic regions to regulatory proteins.
Biomarker Discovery
-
Identifying Disease-Specific Protein-DNA Interaction Signatures: MadID profiles from healthy and diseased tissues can be compared to identify disease-specific patterns of protein-DNA interactions. These signatures could potentially be used as biomarkers for diagnosis, prognosis, or patient stratification.
Conclusion
MadID represents a significant advancement in the field of genomics, providing an unbiased and high-resolution method for mapping protein-DNA interactions. Its versatility and broad applicability make it an invaluable tool for researchers seeking to understand the intricate regulatory networks that govern cellular processes in both health and disease. For professionals in drug development, MadID offers a powerful approach to identify and validate novel drug targets, elucidate mechanisms of drug action, and discover new biomarkers, ultimately contributing to the development of more effective and safer therapies.
References
- 1. Methyl Adenine Identification (MadID): High-Resolution Detection of Protein-DNA Interactions - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. researchgate.net [researchgate.net]
- 3. MadID, a Versatile Approach to Map Protein-DNA Interactions, Highlights Telomere-Nuclear Envelope Contact Sites in Human Cells - PMC [pmc.ncbi.nlm.nih.gov]
- 4. addgene.org [addgene.org]
Troubleshooting & Optimization
Technical Support Center: Detection of Low-Abundance 1-Methyladenine (m1A)
This technical support center provides troubleshooting guidance and frequently asked questions (FAQs) for researchers, scientists, and drug development professionals working on the detection of 1-Methyladenine (m1A), a rare but significant RNA modification.
Frequently Asked Questions (FAQs)
Q1: Why is the detection of 1-Methyladenine (m1A) so challenging?
The detection of m1A is primarily challenging due to its very low abundance in many RNA species, particularly mRNA.[1][2] The m1A/A ratio in mRNA from various human cell lines is estimated to be around 0.02%, which is approximately 5-10% of the much more abundant N6-methyladenosine (m6A) modification.[3] This low stoichiometry makes it difficult to distinguish true signals from background noise. Furthermore, the lack of highly specific and sensitive detection methods has been a significant hurdle.[4][5]
Q2: What are the common methods for detecting m1A, and what are their limitations?
Several methods are used for m1A detection, each with its own set of advantages and disadvantages. The choice of method depends on the desired coverage, resolution, cost, and required expertise.[6]
| Method | Principle | Advantages | Common Challenges/Limitations |
| m1A Immunoprecipitation followed by Sequencing (m1A-seq) | Uses an antibody to enrich for RNA fragments containing m1A, which are then sequenced. | Transcriptome-wide mapping. | Antibody cross-reactivity with the 5' m7G cap structure is a major issue, leading to false positives, particularly in 5' UTRs.[1][7][8] Specificity of different antibodies can vary greatly. |
| Liquid Chromatography-Mass Spectrometry (LC-MS/MS) | Quantifies modified nucleosides in total RNA or purified RNA species after enzymatic digestion. | Highly quantitative and can detect a wide range of modifications. Does not rely on antibodies. | Provides global quantification but no sequence context. Requires specialized equipment and expertise.[5] |
| Ligation-Assisted Differentiation | Exploits the fact that the methyl group in m1A disrupts Watson-Crick base pairing, leading to lower ligation efficiency. This difference is then quantified by qPCR.[9] | Site-specific and quantitative.[9] | Not a transcriptome-wide method; requires prior knowledge of potential modification sites.[6] |
| Bioinformatic Approaches (e.g., analysis of misincorporations in RNA-seq) | Identifies potential m1A sites by looking for specific error signatures (misincorporations) in deep sequencing data.[7][8] | Antibody-free. Can analyze existing deep sequencing datasets. | Requires very deep sequencing data. Low stoichiometry sites may be indistinguishable from sequencing errors.[1] |
Q3: I am seeing a strong enrichment of m1A peaks in the 5' UTR of my transcripts using m1A-seq. Is this a real biological finding?
While some studies have reported m1A enrichment in 5' UTRs, this is now widely considered to be an artifact caused by the cross-reactivity of certain m1A antibodies with the N7-methylguanosine (m7G) cap at the 5' end of eukaryotic mRNAs.[1][2][7][8] It is crucial to validate these findings with an independent, antibody-free method or use a different m1A antibody that has been shown to lack cap-binding cross-reactivity.[7][8]
Troubleshooting Guides
Issue 1: Low or No Signal in m1A-seq Experiments
Symptoms:
-
Low read counts in the immunoprecipitated (IP) fraction compared to the input.
-
No clear enrichment peaks are observed after data analysis.
Possible Causes and Solutions:
| Cause | Troubleshooting Step |
| Low abundance of m1A in the sample | m1A is known to be a rare modification in mRNA.[1] Consider using a positive control RNA known to contain m1A (e.g., mitochondrial MT-ND5 transcript) to validate the IP procedure.[1][7] Increase the amount of starting RNA material if possible. |
| Inefficient Immunoprecipitation | Ensure the antibody is validated for IP and used at the recommended concentration. Optimize incubation times and washing stringency. Check the integrity of your RNA before starting the experiment. |
| Poor RNA Quality | Use high-quality, intact RNA. RNA degradation can lead to the loss of modified fragments and overall poor results. Assess RNA integrity using a Bioanalyzer or similar method. |
| Suboptimal Library Preparation | Low input amounts for library preparation can lead to library failure or low complexity. Use a library preparation kit specifically designed for low RNA input. |
Issue 2: High Background or Non-Specific Peaks in m1A-seq
Symptoms:
-
High number of reads in the negative control (e.g., IgG IP).
-
Enrichment peaks are broad and not well-defined.
-
High enrichment at the 5' end of transcripts, suggesting cap cross-reactivity.[7][8]
Possible Causes and Solutions:
| Cause | Troubleshooting Step |
| Antibody Cross-Reactivity | This is a major issue, especially with the 5' cap.[1][7][8] Solution: 1. Use an alternative m1A antibody that has been demonstrated to have no cap-binding activity.[7] 2. Validate candidate sites with an orthogonal, antibody-independent method like ligation-assisted quantification or mass spectrometry.[6][9] |
| Non-Specific Antibody Binding | Increase the stringency of the wash buffers (e.g., higher salt concentration). Perform a pre-clearing step with protein A/G beads before adding the specific antibody to reduce non-specific binding. |
| Contaminants in the Sample | Ensure the RNA sample is free of contaminants like salts, phenol, or ethanol, which can interfere with enzymatic reactions and antibody binding.[10] |
Issue 3: Difficulty Validating m1A Sites Identified by High-Throughput Sequencing
Symptoms:
-
A candidate m1A site from m1A-seq cannot be confirmed using a site-specific method.
Possible Causes and Solutions:
| Cause | Troubleshooting Step |
| False Positive from Primary Screen | As discussed, antibody-based methods are prone to false positives.[1][7][8] The original finding may be an artifact. It is critical to use a secondary, independent method for validation. |
| Low Stoichiometry of Modification | The modification at a specific site may be present in only a very small fraction of the RNA molecules. The validation method may not be sensitive enough to detect this low level of modification. Consider using a more sensitive quantitative method. |
| Methodological Differences | Different methods rely on different principles. For example, a ligation-based assay's efficiency can be affected by local RNA secondary structure, which might not impact an antibody-based method in the same way.[9] |
Experimental Protocols
Protocol 1: Ligation-Assisted Differentiation for Site-Specific m1A Quantification
This protocol provides a conceptual overview of a method for quantifying m1A at a specific site, as described by Xiong et al.[9]
-
RNA Preparation: Isolate total RNA or mRNA from the cells or tissues of interest.
-
Primer/Splint Design: Design a DNA splint and a ligation probe that are complementary to the RNA sequence flanking the suspected m1A site. The ligation junction should be directly opposite the adenine base .
-
Hybridization: Anneal the splint and ligation probe to the target RNA.
-
Ligation Reaction: Perform a ligation reaction using a ligase that is sensitive to the m1A modification. T3 DNA ligase has been shown to have good discrimination between m1A and unmodified adenosine.[9] The presence of m1A will inhibit the ligation efficiency compared to an unmodified adenine.
-
Quantitative PCR (qPCR): Use the ligated product as a template for qPCR. The amount of qPCR product is proportional to the ligation efficiency.
-
Quantification: Compare the qPCR signal from the target sample to a standard curve generated from in vitro transcribed RNAs with known m1A stoichiometry (0% and 100% m1A) at the site of interest. This allows for the calculation of the m1A percentage in the experimental sample.
Visualizations
Caption: High-level workflow for m1A-seq experiments.
Caption: m1A antibody cross-reactivity with the 5' m7G cap.
References
- 1. Antibody cross-reactivity accounts for widespread appearance of m1A in 5’UTRs - PMC [pmc.ncbi.nlm.nih.gov]
- 2. researchgate.net [researchgate.net]
- 3. N1-methyladenosine formation, gene regulation, biological functions, and clinical relevance - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Mammalian DNA N6-methyladenosine: Challenges and new insights - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Identification and quantification of DNA N6-methyladenine modification in mammals: A challenge to modern analytical technologies - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. mdpi.com [mdpi.com]
- 7. Antibody cross-reactivity accounts for widespread appearance of m1A in 5’UTRs [ideas.repec.org]
- 8. Antibody cross-reactivity accounts for widespread appearance of m1A in 5'UTRs - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. Quantification and Single-Base Resolution Analysis of N 1-Methyladenosine in mRNA by Ligation-Assisted Differentiation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. Troubleshooting your sequencing results - The University of Nottingham [nottingham.ac.uk]
Optimizing m1A-Seq Library Preparation: A Technical Support Resource
This technical support center provides researchers, scientists, and drug development professionals with a comprehensive guide to optimizing N1-methyladenosine (m1A)-seq library preparation protocols. It includes troubleshooting guides, frequently asked questions (FAQs), detailed experimental methodologies, and quantitative data to facilitate robust and reproducible m1A mapping experiments.
Troubleshooting Guide & FAQs
This section addresses common issues encountered during m1A-seq library preparation in a question-and-answer format.
Frequently Asked Questions (FAQs)
Q1: What is m1A-seq and what are its main applications?
A1: N1-methyladenosine (m1A) sequencing, or m1A-seq, is a high-throughput sequencing technique designed to map the location of m1A modifications across the transcriptome.[1][2] This method typically involves immunoprecipitation of m1A-containing RNA fragments using a specific antibody, followed by next-generation sequencing.[1][2] Its applications include understanding the role of m1A in regulating mRNA translation, tRNA structure and function, and its involvement in various biological processes and diseases.[1][3]
Q2: What are the critical steps in an m1A-seq (MeRIP-seq) protocol?
A2: The key steps of a methylated RNA immunoprecipitation sequencing (MeRIP-seq) protocol for m1A are:
-
RNA Extraction and Quality Control: Isolation of high-quality total RNA from cells or tissues.
-
RNA Fragmentation: Breaking the RNA into smaller fragments (typically around 100-200 nucleotides).
-
Immunoprecipitation (IP): Enrichment of m1A-containing RNA fragments using an m1A-specific antibody.
-
Library Construction: Converting the enriched RNA fragments into a cDNA library suitable for sequencing.
-
Sequencing: High-throughput sequencing of the prepared library.
-
Data Analysis: Aligning reads to a reference genome/transcriptome and identifying m1A peaks.[4][5]
Q3: How much starting RNA material is required for m1A-seq?
A3: The required amount of starting total RNA can vary, but generally, a higher input leads to better results. While some optimized protocols can work with as little as 500 ng of total RNA, standard protocols often recommend at least 10-15 µg to ensure sufficient material for both the immunoprecipitated (IP) and input control libraries.[4][6][7] For low-input samples, specialized kits and protocols may be necessary.[6][8]
Q4: How can I validate the specificity of my m1A antibody?
A4: Validating the specificity of the m1A antibody is crucial for reliable results. Common methods include:
-
Dot Blot Assay: This involves spotting synthetic oligonucleotides with and without the m1A modification onto a membrane and probing with the antibody to check for specific binding.[9][10][11]
-
ELISA (Enzyme-Linked Immunosorbent Assay): A competitive ELISA can be used where the antibody is incubated with free m1A nucleosides before being added to m1A-coated plates. A reduction in signal indicates specific binding.[9]
-
Mass Spectrometry: Analyzing the immunoprecipitated material to confirm the enrichment of m1A-containing fragments.[3]
Q5: What are the differences between m1A-seq, m1A-MAP, and m1A-ID-seq?
A5: These are all methods for detecting m1A, but they employ different strategies:
-
m1A-seq (MeRIP-seq): Relies on antibody-based enrichment of m1A-containing RNA fragments.[1]
-
m1A-MAP (m1A-Mutation-based Profiling): Combines m1A immunoprecipitation with the use of a reverse transcriptase that induces mutations at m1A sites, allowing for single-nucleotide resolution mapping.[1]
-
m1A-ID-seq (m1A-Individual-nucleotide-resolution Demethylase-based sequencing): Uses an antibody for enrichment followed by treatment with a demethylase (like AlkB) to remove the m1A modification. Comparing treated and untreated samples allows for precise identification of m1A sites.[1]
Troubleshooting Common Problems
Issue 1: Low Library Yield
Q: My final library concentration is too low for sequencing. What are the possible causes and solutions?
A: Low library yield is a common issue in m1A-seq. The following table outlines potential causes and corresponding troubleshooting strategies.
| Potential Cause | Recommended Solution(s) |
| Poor RNA Quality | Ensure the starting total RNA has high integrity (RIN > 7.0) and purity (A260/280 ~2.0, A260/230 > 1.8).[4] Use fresh preparations or properly stored samples. |
| Insufficient Starting Material | Increase the amount of input total RNA. For precious or low-input samples, consider a low-input library preparation kit.[6][7][12] |
| Inefficient RNA Fragmentation | Optimize fragmentation time and temperature to achieve the desired fragment size range (e.g., 100-200 nt). Over- or under-fragmentation can lead to loss of material during size selection. |
| Inefficient Immunoprecipitation | Validate the m1A antibody for specificity and efficiency. Ensure optimal antibody concentration and incubation time. Use high-quality protein A/G beads. |
| Loss of Material During Cleanup Steps | Be cautious during bead-based purification steps. Avoid over-drying the beads, which can make resuspension difficult. Ensure complete elution of the library from the beads.[13] |
| Adapter-Dimer Formation | Excessive adapter-dimers can compete with the library fragments during PCR amplification, leading to a lower yield of the desired library. Optimize the adapter-to-insert ratio and perform an additional bead-based cleanup if necessary.[13][14] |
| Suboptimal PCR Amplification | Optimize the number of PCR cycles. Too few cycles will result in low yield, while too many can introduce bias and increase duplicate rates. |
Issue 2: High Background / Low Enrichment Efficiency
Q: My m1A-seq data shows high background signal and poor enrichment for known m1A-containing transcripts. How can I improve this?
A: High background can obscure true m1A signals. Consider the following factors:
| Potential Cause | Recommended Solution(s) |
| Non-specific Antibody Binding | Ensure the m1A antibody is highly specific. Perform dot blot or ELISA to validate its specificity against other modifications like m6A and unmodified adenosine.[9] Include a mock IP with a non-specific IgG antibody as a negative control. |
| Insufficient Washing during IP | Increase the number and stringency of washes after the immunoprecipitation step to remove non-specifically bound RNA fragments. |
| Suboptimal Blocking | Ensure proper blocking of the protein A/G beads before adding the antibody-RNA complex to reduce non-specific binding. |
| High Abundance of Ribosomal RNA (rRNA) | If not targeting m1A in rRNA, consider performing rRNA depletion before fragmentation and immunoprecipitation to reduce background from abundant rRNA species. |
| Cross-reactivity with m7G-cap | Some m1A antibodies have been reported to cross-react with the 7-methylguanosine (m7G) cap at the 5' end of mRNAs.[15] Validate your antibody for this potential cross-reactivity. |
Quantitative Data Summaries
The following tables provide a summary of expected outcomes and parameters for key steps in the m1A-seq protocol. Note: These values are illustrative and may vary depending on the specific protocol, reagents, and sample type.
Table 1: RNA Quality Control Recommendations
| Parameter | Recommended Value | Method of Assessment |
| RNA Integrity Number (RIN) | ≥ 7.0 | Agilent Bioanalyzer / TapeStation |
| A260/A280 Ratio | 1.8 - 2.1 | UV-Vis Spectrophotometer (e.g., NanoDrop) |
| A260/A230 Ratio | > 1.8 | UV-Vis Spectrophotometer (e.g., NanoDrop) |
Table 2: Example of RNA Fragmentation Optimization
| Fragmentation Time (minutes) | Average Fragment Size (nt) | Library Yield (ng) | Comments |
| 5 | ~500 | 15 | Under-fragmented, may lead to lower cluster density. |
| 10 | ~150 | 25 | Optimal for many protocols. |
| 15 | <100 | 10 | Over-fragmented, may result in loss of smaller fragments during cleanup. |
Table 3: m1A Antibody Validation by Dot Blot (Hypothetical Data)
| Antigen Spotted | Signal Intensity (Arbitrary Units) | Specificity Assessment |
| m1A-containing oligo | 950 | Strong signal indicates binding to the target. |
| m6A-containing oligo | 50 | Low signal indicates minimal cross-reactivity. |
| Unmodified Adenosine oligo | 25 | Low signal indicates high specificity for the modification. |
Experimental Protocols
This section provides a detailed methodology for a standard m1A MeRIP-seq experiment.
Detailed m1A MeRIP-seq Protocol
1. RNA Preparation and Fragmentation
-
Start with 15-30 µg of high-quality total RNA in nuclease-free water.
-
Perform rRNA depletion if necessary, following the manufacturer's protocol.
-
Fragment the RNA to an average size of ~100-200 nucleotides. This can be achieved using a metal-ion-based fragmentation buffer at elevated temperatures (e.g., 94°C for 5-15 minutes), followed by immediate chilling on ice.[5] The optimal fragmentation time should be determined empirically.[5]
-
Purify the fragmented RNA using a suitable RNA cleanup kit and elute in nuclease-free water.
-
Assess the fragment size distribution using an Agilent Bioanalyzer or TapeStation.
-
Set aside 5-10% of the fragmented RNA to serve as the "input" control library.
2. m1A Immunoprecipitation (IP)
-
For each IP reaction, prepare protein A/G magnetic beads by washing them with IP buffer (e.g., 150 mM NaCl, 10 mM Tris-HCl pH 7.5, 0.1% NP-40).
-
Incubate the beads with 5-10 µg of a validated anti-m1A antibody for 1-2 hours at 4°C with rotation.
-
Add the fragmented RNA to the antibody-bead mixture and incubate overnight at 4°C with rotation.
-
Wash the beads multiple times with IP buffer of increasing stringency (e.g., by increasing the salt concentration) to remove non-specifically bound RNA.
-
Elute the m1A-enriched RNA from the beads using an appropriate elution buffer (e.g., containing a competitive agent or by proteinase K treatment).
-
Purify the eluted RNA using an RNA cleanup kit.
3. Library Construction and Sequencing
-
Construct sequencing libraries from the m1A-enriched RNA (IP sample) and the fragmented RNA set aside earlier (input sample) using a strand-specific library preparation kit compatible with your sequencing platform (e.g., Illumina).
-
This process typically involves:
-
End repair and A-tailing
-
Adapter ligation
-
Reverse transcription to generate cDNA
-
PCR amplification to enrich the library
-
-
Perform size selection of the final library to remove adapter-dimers and select the desired fragment size range.
-
Quantify the final libraries and assess their quality using a Bioanalyzer/TapeStation and qPCR.
-
Pool the libraries and perform high-throughput sequencing according to the manufacturer's instructions.
Visualizations
m1A-Seq Experimental Workflow
Caption: Overview of the m1A-seq (MeRIP-seq) experimental workflow.
Troubleshooting Logic for Low Library Yield
Caption: Decision tree for troubleshooting low library yield in m1A-seq.
References
- 1. m1A RNA Methylation Analysis - CD Genomics [cd-genomics.com]
- 2. m1A (N1-methyladenosine) Dot Blot Assay Kit_RayBiotech [new.raybiotech.cn]
- 3. epigenie.com [epigenie.com]
- 4. MeRIP-seq for Detecting RNA methylation: An Overview - CD Genomics [cd-genomics.com]
- 5. MeRIP-seq Protocol - CD Genomics [rna.cd-genomics.com]
- 6. Comparative analysis of improved m6A sequencing based on antibody optimization for low-input samples - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Refined RIP-seq protocol for epitranscriptome analysis with low input materials - PMC [pmc.ncbi.nlm.nih.gov]
- 8. mRNA-seq library prep for low input samples | CHMI services [chmi-sops.github.io]
- 9. N1-Methyladenosine (m1A) (E8S7H) Rabbit Monoclonal Antibody | Cell Signaling Technology [cellsignal.com]
- 10. raybiotech.com [raybiotech.com]
- 11. biocat.com [biocat.com]
- 12. Low-cost, low-input RNA-seq protocols perform nearly as well as high-input protocols - PMC [pmc.ncbi.nlm.nih.gov]
- 13. stackwave.com [stackwave.com]
- 14. How to Troubleshoot Sequencing Preparation Errors (NGS Guide) - CD Genomics [cd-genomics.com]
- 15. Improving MeRIP with CUT&RUN Technology | EpigenTek [epigentek.com]
Technical Support Center: Dimroth Rearrangement of 1-Methyladenine
Welcome to the technical support center for the Dimroth rearrangement of 1-methyladenine. This guide is designed for researchers, scientists, and drug development professionals to provide troubleshooting assistance and answers to frequently asked questions (FAQs) related to this important chemical transformation.
Frequently Asked Questions (FAQs)
Q1: What is the Dimroth rearrangement of 1-methyladenine?
The Dimroth rearrangement is an isomerization reaction where the endocyclic N1 nitrogen and the exocyclic N6 nitrogen of the adenine ring, along with the methyl group, effectively switch places.[1] This converts 1-methyladenine into the more thermodynamically stable N6-methyladenine. The reaction is typically facilitated by heat and alkaline conditions.[1]
Q2: Why is the Dimroth rearrangement of 1-methyladenine important?
This rearrangement is significant in several fields. In RNA biology, 1-methyladenosine (the ribonucleoside of 1-methyladenine) is a common modification that can affect RNA structure and function. The Dimroth rearrangement can occur as an undesired side reaction during sample preparation under alkaline conditions, potentially leading to the misidentification of N6-methyladenosine.[1] Conversely, it can be used intentionally to study the effects of these modifications. In synthetic and medicinal chemistry, the Dimroth rearrangement is a useful tool for the synthesis of various biologically active compounds.
Q3: What are the typical conditions for performing the Dimroth rearrangement?
The traditional method involves heating 1-methyladenine in an alkaline solution. A common protocol uses a sodium carbonate/bicarbonate buffer at a pH of around 10.4, with heating at 60°C for one hour.[1] However, these conditions can be harsh, especially for sensitive molecules like RNA. Milder methods have been developed, such as using a thiol catalyst like 4-nitrothiophenol at a near-neutral pH.[1]
Q4: What are the main challenges or side reactions to be aware of?
The primary challenge, particularly when working with RNA, is degradation of the phosphodiester backbone under the required alkaline conditions.[1] For the rearrangement of the 1-methyladenine base itself, incomplete reaction and the formation of side products can be concerns. Under certain conditions, an acyclic intermediate, N-(2-cyano-2-formylvinyl)-N'-methylguanidine, can be formed, which can then cyclize to different products depending on the reaction conditions.
Troubleshooting Guide
This section addresses common issues encountered during the Dimroth rearrangement of 1-methyladenine.
Issue 1: Low or No Conversion to N6-Methyladenine
| Possible Cause | Suggestion |
| Insufficiently Alkaline pH | The rate of the Dimroth rearrangement is highly dependent on pH.[2] Ensure the pH of your reaction mixture is in the optimal range. For the traditional method, a pH of 10.4 or higher is recommended.[1] Carefully check the pH of your buffer before starting the reaction. |
| Low Reaction Temperature | The rearrangement is accelerated by heat.[2] If you are seeing low conversion at a certain temperature, consider increasing it. However, be mindful of the stability of your starting material and product at higher temperatures. |
| Short Reaction Time | The reaction may not have had enough time to go to completion. Monitor the reaction progress over time using an appropriate analytical method such as TLC, HPLC, or NMR. |
| Inhibitory Substituents | Electron-releasing groups on the adenine ring can slow down the reaction.[3] If your substrate has such groups, you may need to use more forcing conditions (higher pH, higher temperature, or longer reaction time). |
Issue 2: Degradation of Starting Material or Product
| Possible Cause | Suggestion |
| Harsh Alkaline Conditions | This is a major concern, especially for RNA.[1] If you are observing significant degradation, consider using milder reaction conditions. The thiol-catalyzed method at a near-neutral pH is a good alternative.[1] |
| High Reaction Temperature | Excessive heat can lead to the decomposition of your compounds. Try running the reaction at a lower temperature for a longer period. |
| Prolonged Reaction Time | While sufficient time is needed for the reaction to complete, extended reaction times, especially under harsh conditions, can increase the likelihood of degradation. Optimize the reaction time by monitoring its progress. |
Issue 3: Formation of Unexpected Side Products
| Possible Cause | Suggestion |
| Reaction Conditions Favoring Side Reactions | The nature of the solvent and base can influence the reaction pathway. In some cases, acyclic intermediates can form and cyclize to undesired products. If you suspect side product formation, try altering the solvent or using a different base. |
| Presence of Reactive Functional Groups | If your 1-methyladenine derivative contains other reactive functional groups, they may participate in side reactions under the reaction conditions. Consider protecting these groups before performing the Dimroth rearrangement. |
Data Presentation: Reaction Parameters
The following table summarizes the influence of key parameters on the Dimroth rearrangement of 1-methyladenine. Please note that optimal conditions can vary depending on the specific substrate and experimental setup.
| Parameter | Condition | Effect on Reaction Rate | Potential Issues |
| pH | Low (e.g., pH 7-8) | Slow | Incomplete reaction |
| High (e.g., pH > 10) | Fast | Increased risk of degradation, especially for RNA | |
| Temperature | Low (e.g., Room Temp - 40°C) | Very Slow | Incomplete reaction |
| Moderate (e.g., 50-60°C) | Moderate to Fast | Generally a good starting point | |
| High (e.g., > 80°C) | Very Fast | Increased risk of degradation and side products | |
| Catalyst | None (Hydroxide promoted) | Dependent on pH and temperature | Can require harsh conditions |
| Thiol (e.g., 4-nitrothiophenol) | Can be fast even at near-neutral pH | Potential for catalyst-related side reactions (though generally clean) |
Experimental Protocols
Protocol 1: Traditional Hydroxide-Promoted Dimroth Rearrangement
This protocol is adapted from methods used for the rearrangement of 1-methyladenosine in RNA.[1]
-
Preparation of Reaction Mixture:
-
Dissolve 1-methyladenine in a 50 mM sodium carbonate and sodium bicarbonate buffer to achieve a final pH of 10.4.
-
Add EDTA to a final concentration of 2 mM.
-
-
Reaction:
-
Incubate the reaction mixture at 60°C for 1 hour.
-
-
Monitoring the Reaction:
-
Periodically take aliquots from the reaction mixture and analyze by thin-layer chromatography (TLC) or high-performance liquid chromatography (HPLC) to monitor the disappearance of the starting material and the appearance of the product.
-
-
Work-up and Purification:
-
After the reaction is complete (as determined by the monitoring method), cool the reaction mixture to room temperature.
-
Neutralize the solution with a suitable acid (e.g., HCl).
-
The product, N6-methyladenine, can be purified from the reaction mixture using reversed-phase HPLC.
-
Protocol 2: Thiol-Catalyzed Dimroth Rearrangement
This protocol provides a milder alternative to the traditional method.[1]
-
Preparation of Reagents:
-
Prepare a 2x treatment solution containing 50 mM 4-nitrothiophenol and 10 mM tris(hydroxypropyl)phosphine (THP) in 10% (v/v) DMF in water.
-
Adjust the pH of the 2x solution to 6 with concentrated NaOH and HCl.
-
-
Reaction:
-
Mix the 1-methyladenine solution (in water) with an equal volume of the 2x treatment solution.
-
Incubate the reaction mixture at 50°C. The reaction time may need to be optimized (e.g., several hours).
-
-
Monitoring the Reaction:
-
Monitor the progress of the reaction using TLC or HPLC.
-
-
Work-up and Purification:
-
Once the reaction is complete, the product can be purified by reversed-phase HPLC.
-
Visualizations
References
- 1. Development of mild chemical catalysis conditions for m1A-to-m6A rearrangement on RNA - PMC [pmc.ncbi.nlm.nih.gov]
- 2. The Dimroth Rearrangement in the Synthesis of Condensed Pyrimidines – Structural Analogs of Antiviral Compounds - PMC [pmc.ncbi.nlm.nih.gov]
- 3. starchemistry888.com [starchemistry888.com]
Technical Support Center: 1-Methyladenine (m1A) Antibodies
This technical support center provides researchers, scientists, and drug development professionals with comprehensive troubleshooting guides and FAQs for improving the specificity of 1-Methyladenine (m1A) antibodies in various applications.
Frequently Asked Questions (FAQs)
Q1: My MeRIP-seq/m1A-seq results show a high number of peaks in the 5' UTR of mRNAs. Is this expected?
A1: Not necessarily. While m1A is known to be enriched around the start codon, some commercial anti-m1A antibodies have been shown to cross-react with the N7-methylguanosine (m7G) cap at the 5' end of mRNAs. This can lead to a widespread appearance of false-positive peaks in the 5' UTR. It is crucial to use a highly specific antibody that has been validated to lack cap-binding cross-reactivity.[1]
Q2: I am observing high background in my immunoprecipitation (IP) or dot blot experiments. What are the common causes and solutions?
A2: High background can be caused by several factors:
-
Non-specific antibody binding: The primary or secondary antibody may bind to non-target molecules.
-
Insufficient blocking: The blocking step may not be adequate to cover all non-specific binding sites.
-
Inadequate washing: Washing steps may not be stringent enough to remove unbound antibodies.
-
Antibody concentration is too high: Using an excessive amount of primary antibody can lead to non-specific binding.
To address these issues, consider the troubleshooting guide below for specific recommendations on optimizing your blocking, washing, and antibody concentrations.[2][3]
Q3: What is the best way to validate the specificity of a new lot of anti-m1A antibody?
A3: It is highly recommended to validate each new antibody or lot. A dot blot is a straightforward method for this. You can spot synthetic RNA oligonucleotides containing m1A, as well as unmodified adenosine (A) and other methylated bases (like m6A), onto a membrane and probe it with your antibody. A specific antibody should only show a strong signal for the m1A-containing oligo.[4][5][6] Competition ELISA can also be performed where the binding of the antibody to immobilized m1A-containing oligos is competed with free m1A, m6A, or A nucleosides.[5]
Q4: Can I use the same anti-m1A antibody for different applications like dot blot, IP, and immunofluorescence?
A4: Not always. An antibody that works well for one application may not be suitable for another. For instance, an antibody that recognizes m1A in a denatured RNA context (like in a dot blot) might not efficiently bind to it in the context of a folded RNA-protein complex (as in IP). Always refer to the manufacturer's datasheet for validated applications. If you are adapting an antibody to a new application, it will require thorough in-house validation.
Troubleshooting Guides
High Background in Immunoprecipitation (IP) / MeRIP-seq
| Possible Cause | Recommended Solution |
| Insufficient Blocking | Pre-block beads with 1% BSA in PBS for 1 hour before use.[2] Use a blocking buffer containing normal serum from the same species as the secondary antibody (1-5% w/v).[7] |
| Non-specific Antibody Binding | Titrate the primary antibody to determine the optimal concentration that gives the best signal-to-noise ratio.[8] Include an isotype control to check for non-specific binding of the antibody.[8] Pre-clear the lysate by incubating it with beads alone before adding the primary antibody.[2][3] |
| Inadequate Washing | Increase the number and duration of wash steps. Increase the salt concentration or include a mild non-ionic detergent (e.g., 0.01-0.1% Tween-20 or Triton X-100) in the wash buffer. |
| Too Much Input Material | Reduce the amount of total RNA or cell lysate used for the IP.[2] |
Low or No Signal in Immunoprecipitation (IP) / MeRIP-seq
| Possible Cause | Recommended Solution |
| Poor Antibody Performance in IP | Ensure the antibody is validated for immunoprecipitation. Polyclonal antibodies sometimes perform better in IP than monoclonals.[2] Verify the antibody's ability to bind the target via a dot blot before proceeding with IP. |
| Low Abundance of m1A | Increase the amount of input RNA. MeRIP-seq efficiency can decrease with lower starting amounts of RNA. Ensure that your cell type or condition of interest is expected to have detectable levels of m1A. |
| Inefficient Elution | Check that the elution buffer is appropriate for your antibody and downstream application. Some antigens are sensitive to low pH elution; a neutral pH, high-salt elution buffer may be an alternative. |
| Protein-Protein Interactions Disrupted (for Co-IP) | Use a milder lysis buffer. Buffers containing ionic detergents like SDS can disrupt protein-protein interactions. A non-ionic detergent-based buffer is often preferred for Co-IP.[3] |
Experimental Protocols
Protocol: Dot Blot for Anti-m1A Antibody Specificity
This protocol is adapted from procedures for validating modified nucleotide antibodies.[4][5][6]
Materials:
-
Nitrocellulose or nylon membrane
-
Synthetic RNA oligonucleotides (e.g., 30-mer) containing a single m1A, m6A, or unmodified A.
-
UV cross-linker
-
Blocking buffer (e.g., 5% non-fat milk or 1-3% BSA in TBST)
-
Anti-m1A primary antibody
-
HRP-conjugated secondary antibody
-
ECL substrate
Procedure:
-
Spot serial dilutions of the synthetic RNA oligos (e.g., starting from 300 pmol down to 3 pmol) onto the membrane.
-
Allow the spots to air dry completely.
-
UV cross-link the RNA to the membrane (e.g., at 120 mJ/cm²).
-
Block the membrane with blocking buffer for 1 hour at room temperature.
-
Incubate the membrane with the anti-m1A primary antibody (e.g., at a 1:1000 to 1:5000 dilution in blocking buffer) overnight at 4°C.
-
Wash the membrane three times for 10 minutes each with TBST.
-
Incubate with the HRP-conjugated secondary antibody (at the manufacturer's recommended dilution) for 1 hour at room temperature.
-
Wash the membrane three times for 10 minutes each with TBST.
-
Develop the blot using an ECL substrate and image the results. A specific antibody will only show a signal for the m1A-containing oligo.
Protocol: Methylated RNA Immunoprecipitation (MeRIP-seq)
This is a generalized protocol; optimization of antibody and RNA amounts is recommended.
Materials:
-
Total RNA from cells or tissues
-
RNA fragmentation buffer
-
Anti-m1A antibody
-
Protein A/G magnetic beads
-
IP buffer (e.g., 50 mM Tris-HCl pH 7.4, 150 mM NaCl, 0.1% NP-40, with protease and RNase inhibitors)
-
Wash buffers (low and high salt)
-
Elution buffer
-
RNA purification kit
Procedure:
-
RNA Fragmentation: Fragment 5-10 µg of total RNA to ~100-200 nucleotide fragments using fragmentation buffer or enzymatic methods. Purify the fragmented RNA.
-
Immunoprecipitation: a. Pre-clear the fragmented RNA by incubating with protein A/G beads for 1 hour at 4°C. b. In a new tube, incubate the pre-cleared RNA with the anti-m1A antibody (typically 1-5 µg) in IP buffer for 2-4 hours at 4°C with rotation. c. Add pre-blocked protein A/G beads and incubate for another 2 hours at 4°C with rotation.
-
Washing: a. Pellet the beads and discard the supernatant. b. Perform a series of washes to remove non-specific binding. This typically includes washes with low-salt buffer, high-salt buffer, and finally a wash with IP buffer.
-
Elution: Elute the methylated RNA from the beads using an appropriate elution buffer.
-
RNA Purification: Purify the eluted RNA using an RNA purification kit.
-
Library Preparation and Sequencing: Proceed with library construction for high-throughput sequencing. An input control (fragmented RNA that did not undergo IP) should be prepared in parallel.
Quantitative Data Summary
Table 1: Recommended Antibody Dilutions for Various Applications
| Application | Antibody Type | Starting Dilution | Reference |
| Dot Blot | Monoclonal | 1:2000 | [4] |
| Dot Blot | Polyclonal | 1:1000 | |
| ELISA | Monoclonal | 1:1000 | |
| MeRIP | Polyclonal/Monoclonal | 1-5 µg per IP | [5] |
Table 2: MeRIP-seq Optimization Parameters
| Parameter | Condition 1 | Condition 2 | Outcome | Reference |
| Starting RNA Amount | 2 µg total RNA | 32 µg total RNA | Higher input RNA yields more unique m6A peaks, particularly for lower abundance transcripts. | |
| Washing Conditions | Standard Salt | High/Low Salt Washes | Extensive high/low salt washes can improve the signal-to-noise ratio. |
Visualizations
Signaling Pathway: Role of m1A in Cellular Stress Response
References
- 1. DSpace [repositori.upf.edu]
- 2. researchgate.net [researchgate.net]
- 3. researchgate.net [researchgate.net]
- 4. elifesciences.org [elifesciences.org]
- 5. m1A RNA Modification in Gene Expression Regulation [mdpi.com]
- 6. Granulation of m1A-modified mRNAs protects their functionality through cellular stress - PMC [pmc.ncbi.nlm.nih.gov]
- 7. The m1A modification of tRNAs: a translational accelerator of T-cell activation - PMC [pmc.ncbi.nlm.nih.gov]
- 8. The landscape of m1A modification and its posttranscriptional regulatory functions in primary neurons - PMC [pmc.ncbi.nlm.nih.gov]
Technical Support Center: Overcoming 1-methyladenine Replication Blockage in E. coli
This technical support center provides troubleshooting guidance and answers to frequently asked questions for researchers, scientists, and drug development professionals working with 1-methyladenine (1-meA) induced DNA replication blockage in Escherichia coli.
Frequently Asked Questions (FAQs)
Q1: What is 1-methyladenine (1-meA) and why does it block DNA replication?
A1: 1-methyladenine (1-meA) is a DNA lesion formed when an adenine base is methylated at the N1 position, often by SN2 alkylating agents. This modification disrupts the Watson-Crick base pairing face of the adenine, preventing standard DNA polymerases from correctly reading the template strand and thereby stalling the replication fork.[1] All lesions that block replication are considered genotoxic.[2]
Q2: What is the primary mechanism for repairing 1-meA in E. coli?
A2: The primary repair mechanism is direct reversal by the AlkB protein.[2][3] AlkB is an Fe(II) and 2-oxoglutarate-dependent dioxygenase that oxidatively removes the methyl group from 1-meA.[3][4] This process restores the original adenine base without excising it, directly removing the replication block.[2][3]
Q3: Is 1-meA a mutagenic lesion in E. coli?
A3: 1-meA itself is only weakly mutagenic. In E. coli cells deficient in both AlkB and the SOS response, 1-meA lesions result in mutations only about 1% of the time.[2][5] The primary challenge it presents is its toxicity due to the blockage of DNA replication.[2]
Q4: What happens if the AlkB repair pathway is absent or overwhelmed?
A4: If AlkB is not available, E. coli can employ a damage tolerance mechanism called translesion synthesis (TLS).[6][7] This process involves specialized, low-fidelity DNA polymerases (such as Pol II, IV, and V) that can synthesize DNA across the lesion.[6][8] While TLS allows bypass of the block, it can be error-prone.[9] The induction of these TLS polymerases is often part of the SOS response to DNA damage.[2]
Q5: What are the key substrates for the AlkB protein?
A5: The AlkB protein has a range of substrates. Its primary targets are 1-methyladenine (1-meA) and 3-methylcytosine (3-meC) in single-stranded DNA.[1][10] It can also repair other lesions such as 1-methylguanine (1-meG) and 3-methylthymine (3-meT).[2][4]
Troubleshooting Guide
Problem 1: I've treated my E. coli culture with a methylating agent and observe high levels of cell death, even at low concentrations. What is the likely cause?
-
Answer: This is a classic sign of genotoxicity resulting from replication blockage. The likely cause is the formation of lesions like 1-meA and 3-meC, which are potent blockers of DNA replication.[1][2] Your E. coli strain may have a compromised or saturated AlkB repair pathway.
-
Check Strain Genotype: Ensure you are not using a strain with a knockout of the alkB gene (i.e., alkB-), as these strains are hypersensitive to alkylating agents.
-
Assess Agent Concentration: The concentration of your methylating agent may be too high, overwhelming the cell's natural repair capacity. Perform a dose-response curve to find a sublethal concentration for your experiments.
-
Consider Growth Phase: Cells in the exponential growth phase, with active DNA replication, are more susceptible to replication-blocking lesions.
-
Problem 2: My plasmid-based mutagenesis assay shows very low transformation efficiency after treating the plasmid with a methylating agent and transforming it into an alkB- strain.
-
Answer: This result indicates that the lesions on your plasmid are highly toxic and are preventing its successful replication in the host cell.
-
Confirm Lesion Type: The high toxicity in an alkB- background strongly suggests the presence of AlkB substrates like 1-meA or 3-meC, which become potent replication blocks in the absence of repair.[2]
-
Use a Wild-Type (AlkB+) Control: As a control, transform the same treated plasmid into a wild-type (alkB+) E. coli strain. You should observe a significant increase in transformation efficiency, as the AlkB protein will repair the lesions and allow replication to proceed.[2]
-
Induce the SOS Response: In the alkB- strain, inducing the SOS response (e.g., with a low dose of UV radiation) before transformation may slightly increase plasmid survival by activating translesion synthesis (TLS) polymerases, which can bypass the lesions.[2][6]
-
Problem 3: I am studying the mutagenicity of 1-meA using a site-specifically modified oligonucleotide inserted into a vector, but I am not seeing the expected mutation frequency.
-
Answer: This can be due to several factors related to the repair or bypass of the lesion.
-
Host Strain is Repair-Proficient: If you are using a wild-type (alkB+) strain, the AlkB protein is likely repairing the 1-meA lesion with high fidelity, which would abrogate any mutagenic potential.[2][5] To study mutagenicity, you must use an alkB- strain.
-
1-meA is Not Highly Mutagenic: As noted in the FAQs, 1-meA is not a highly mutagenic lesion. Its mutation frequency is only around 1% in alkB-, SOS- cells.[5] Do not expect high mutation rates like those seen with other lesions such as 1-methylguanine.
-
Check Sequencing Data: Ensure you are analyzing the correct site and that your sequencing coverage is deep enough to detect low-frequency mutation events. The predominant mutation, if any, should be an A→T or A→G transversion.
-
Data Presentation
Table 1: Genotoxicity and Mutagenicity of Alkyl Lesions in E. coli
This table summarizes the cellular response to various DNA lesions introduced on a single-stranded vector and passaged through E. coli strains with different DNA repair capacities. Genotoxicity is represented by the percentage of plasmids that successfully replicate (bypass efficiency), while mutagenicity is the percentage of replicated plasmids that contain a mutation at the lesion site.
| Lesion | E. coli Genotype | Bypass Efficiency (Survival) | Mutagenicity (%) | Predominant Mutations |
| 1-methyladenine (1-meA) | AlkB- / SOS- | ~20% | ~1% | A→T, A→G |
| AlkB+ / SOS- | ~100% | 0% | - | |
| 3-methylcytosine (3-meC) | AlkB- / SOS- | ~15% | ~30% | C→T, C→A |
| AlkB+ / SOS- | ~100% | 0% | - | |
| AlkB- / SOS+ | ~40% | ~70% | C→T, C→A | |
| 1-methylguanine (1-meG) | AlkB- / SOS- | ~5% | ~80% | G→T, G→A |
| AlkB+ / SOS- | ~20% | ~4% | - | |
| 3-methylthymine (3-meT) | AlkB- / SOS- | ~30% | ~60% | T→C, T→A |
| AlkB+ / SOS- | ~30% | ~35% | - |
Data summarized from Delaney and Essigmann (2004).[2][5]
Experimental Protocols
Protocol 1: In Vivo Assay for Lesion Genotoxicity and Mutagenicity
This protocol describes a common method for assessing how E. coli overcomes a specific DNA lesion using a plasmid-based system.
-
Vector Preparation:
-
Synthesize a short single-stranded DNA oligonucleotide containing a single, site-specific 1-methyladenine lesion.
-
Ligate this oligonucleotide into a single-stranded phagemid vector (e.g., M13-based). This creates a heteroduplex vector with the lesion on one strand.
-
-
Bacterial Transformation:
-
Prepare competent cells from the desired E. coli strains (e.g., wild-type, alkB-, alkB-umuC- for an SOS-deficient background).
-
Transform the lesion-containing vector into each strain. Also, transform a control vector (containing a normal 'A' at the same position) to establish a baseline transformation efficiency.
-
-
Assessing Genotoxicity (Bypass Efficiency):
-
Plate serial dilutions of the transformation mixtures onto agar plates with the appropriate antibiotic.
-
After overnight incubation, count the number of colonies.
-
Calculate the bypass efficiency as: (CFU from lesion vector / CFU from control vector) * 100%. A low percentage indicates high genotoxicity.[2]
-
-
Assessing Mutagenicity:
-
Isolate progeny plasmids from individual colonies grown from the lesion-vector transformation.
-
Sequence the region of the plasmid that originally contained the 1-meA lesion.
-
The mutagenicity is the percentage of sequenced plasmids that show a base change at the target site.[5]
-
Mandatory Visualizations
Signaling Pathways and Workflows
Caption: AlkB-mediated direct repair of 1-methyladenine.
Caption: Workflow for in vivo lesion bypass and mutagenesis assay.
Caption: Translesion Synthesis (TLS) as a bypass mechanism.
References
- 1. Reversal of DNA alkylation damage by two human dioxygenases - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Mutagenesis, genotoxicity, and repair of 1-methyladenine, 3-alkylcytosines, 1-methylguanine, and 3-methylthymine in alkB Escherichia coli - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. AlkB-mediated oxidative demethylation reverses DNA damage in Escherichia coli - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. academic.oup.com [academic.oup.com]
- 5. Mutagenesis, genotoxicity, and repair of 1-methyladenine, 3-alkylcytosines, 1-methylguanine, and 3-methylthymine in alkB Escherichia coli - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Translesion DNA synthesis - PMC [pmc.ncbi.nlm.nih.gov]
- 7. A Comprehensive View of Translesion Synthesis in Escherichia coli - PMC [pmc.ncbi.nlm.nih.gov]
- 8. A Comprehensive View of Translesion Synthesis in Escherichia coli - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. Translesion synthesis by the UmuC family of DNA polymerases - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. AlkB - Wikipedia [en.wikipedia.org]
Technical Support Center: Minimizing RNA Degradation During m1A Analysis
This technical support center provides researchers, scientists, and drug development professionals with comprehensive guidance on preventing, troubleshooting, and resolving issues related to RNA degradation during N1-methyladenosine (m1A) analysis.
Frequently Asked Questions (FAQs)
Q1: What are the primary sources of RNA degradation during m1A analysis?
A1: RNA is highly susceptible to degradation by ribonucleases (RNases), which are ubiquitous enzymes found in virtually all environments. The primary sources of RNase contamination include:
-
Endogenous RNases: Released from cellular compartments during sample lysis.
-
Environmental Contamination: Introduced from the researcher's skin, breath, and non-certified RNase-free lab equipment such as pipette tips, tubes, and reagents.[1][2]
-
Cross-contamination: From other samples or reagents in the laboratory.
Q2: How can I prevent RNA degradation during sample collection and storage?
A2: Proper sample handling from the outset is critical. Effective methods include:
-
Immediate Processing: Homogenize samples immediately after collection in a lysis buffer containing a chaotropic agent like guanidinium.[3][4]
-
Flash Freezing: For tissue samples, rapidly freeze them in liquid nitrogen. Ensure the tissue pieces are small enough to freeze almost instantly to halt RNase activity.[3][4]
-
RNA Stabilization Reagents: Submerge samples in a commercial RNA stabilization solution, which protects cellular RNA in unfrozen samples.[3][4]
-
Proper Storage: For short-term storage, keep purified RNA at -20°C. For long-term preservation, store it at -80°C in single-use aliquots to minimize freeze-thaw cycles.[3][5]
Q3: What are RNase inhibitors and when should I use them?
A3: RNase inhibitors are proteins that bind to and inactivate a broad spectrum of RNases, including RNases A, B, and C.[1][6] They are essential for protecting RNA integrity during enzymatic manipulations. It is highly recommended to use RNase inhibitors when working with samples known to have high levels of RNases or during sensitive downstream applications like reverse transcription and library preparation for m1A-seq.[7][8] For optimal protection, add the inhibitor to your reaction before other components that could be potential sources of RNase contamination.[6]
Q4: Are there specific steps in m1A analysis protocols that are particularly prone to causing RNA degradation?
A4: Yes, some m1A analysis techniques involve harsh chemical or enzymatic steps that can compromise RNA integrity. For example, methods that utilize Dimroth rearrangement to convert m1A to m6A for detection often require incubation at high temperatures under alkaline conditions, which can lead to significant RNA degradation.[9][10][11] Newer methods often employ enzymatic demethylation, which is generally gentler on the RNA.[9]
Q5: How do I assess the quality of my RNA before proceeding with m1A analysis?
A5: It is crucial to perform quality control checks on your purified RNA. The most common metrics are:
-
A260/A280 Ratio: This spectrophotometric measurement indicates the purity of the RNA from protein contamination. A ratio between 1.8 and 2.0 is generally considered acceptable.[3]
-
RNA Integrity Number (RIN): Determined by capillary electrophoresis, the RIN provides a score from 1 to 10, indicating the intactness of the RNA. For most high-throughput sequencing applications, including m1A-seq, a minimum RIN value of 7 is recommended.[3][12]
Troubleshooting Guides
Table 1: Common Issues in m1A Analysis Related to RNA Degradation
| Problem | Potential Cause | Recommended Solution |
| Low RNA Yield | Incomplete cell or tissue lysis. | Use a lysis method appropriate for your sample type. Consider combining chemical lysis with mechanical disruption (e.g., bead beating).[4] |
| RNA degradation during extraction. | Ensure an RNase-free work environment. Use an optimized RNA extraction kit and consider adding RNase inhibitors to the lysis buffer. | |
| Low RIN Score (<7) | Improper sample handling and storage. | Immediately stabilize samples upon collection using flash freezing or an RNA stabilization reagent.[3][4] Store purified RNA at -80°C in aliquots.[3] |
| RNase contamination during the procedure. | Decontaminate work surfaces and equipment with RNase-inactivating solutions. Use certified RNase-free tips, tubes, and reagents.[13] Wear gloves and a mask.[2] | |
| Smeared Bands on an Agarose Gel | Widespread RNA degradation. | Review and optimize the entire workflow, from sample collection to RNA purification, to eliminate all potential sources of RNase contamination. |
| Inconsistent or Low m1A Signal | Degradation of m1A-containing RNA fragments during library preparation. | If using a method involving Dimroth rearrangement, optimize the reaction conditions to minimize RNA fragmentation.[9][10] Consider using an alternative, gentler m1A mapping technique. |
| Poor enrichment of m1A-containing fragments. | Ensure the antibody used for immunoprecipitation is specific and of high quality. Optimize antibody-to-RNA ratio and incubation times. |
Experimental Protocols
Detailed Protocol: RNase-Free RNA Extraction for m1A Analysis
This protocol outlines a generalized procedure for extracting high-quality total RNA from mammalian cells, suitable for downstream m1A analysis.
1. Preparation:
-
Designate a specific laboratory area for RNA work.
-
Clean the bench, pipettes, and other equipment with an RNase decontamination solution.
-
Use certified RNase-free pipette tips, microcentrifuge tubes, and reagents.
-
Always wear gloves and change them frequently.
2. Sample Collection and Lysis:
-
For adherent cells, aspirate the culture medium and wash the cells with ice-cold, RNase-free PBS.
-
Add 1 mL of a guanidinium-based lysis buffer (e.g., TRIzol) directly to the culture dish and scrape the cells.
-
For suspension cells, pellet the cells by centrifugation, remove the supernatant, and add 1 mL of lysis buffer to the cell pellet.
-
Homogenize the sample by passing the lysate several times through a pipette.
3. Phase Separation:
-
Incubate the homogenate for 5 minutes at room temperature to permit the complete dissociation of nucleoprotein complexes.
-
Add 0.2 mL of chloroform per 1 mL of lysis buffer.
-
Cap the tube securely and shake vigorously for 15 seconds.
-
Incubate at room temperature for 2-3 minutes.
-
Centrifuge the sample at 12,000 x g for 15 minutes at 4°C. The mixture will separate into a lower red, phenol-chloroform phase, an interphase, and a colorless upper aqueous phase. RNA remains exclusively in the aqueous phase.
4. RNA Precipitation:
-
Carefully transfer the upper aqueous phase to a fresh RNase-free tube.
-
Precipitate the RNA by adding 0.5 mL of isopropanol per 1 mL of lysis buffer used for the initial homogenization.
-
Incubate at room temperature for 10 minutes.
-
Centrifuge at 12,000 x g for 10 minutes at 4°C. The RNA will form a gel-like pellet on the side and bottom of the tube.
5. RNA Wash and Resuspension:
-
Remove the supernatant completely.
-
Wash the RNA pellet once with 1 mL of 75% ethanol (prepared with RNase-free water).
-
Mix by vortexing and centrifuge at 7,500 x g for 5 minutes at 4°C.
-
Carefully remove the ethanol wash. Briefly air-dry the pellet for 5-10 minutes. Do not over-dry the pellet as this will decrease its solubility.
-
Resuspend the RNA in an appropriate volume of RNase-free water or a storage solution.
-
Incubate for 10 minutes at 55-60°C to aid dissolution.
6. Quality Control:
-
Determine the RNA concentration and purity (A260/A280 ratio) using a spectrophotometer.
-
Assess RNA integrity (RIN) using an automated electrophoresis system.
Visualizations
Diagram 1: Experimental Workflow for Minimizing RNA Degradation
Caption: Workflow for preserving RNA integrity during m1A analysis.
Diagram 2: Logical Flow for Troubleshooting Low RNA Quality
Caption: Decision tree for troubleshooting poor RNA quality.
References
- 1. meridianbioscience.com [meridianbioscience.com]
- 2. reddit.com [reddit.com]
- 3. Top Ten Ways to Improve Your RNA Isolation | Thermo Fisher Scientific - TR [thermofisher.com]
- 4. zymoresearch.com [zymoresearch.com]
- 5. biostate.ai [biostate.ai]
- 6. neb.com [neb.com]
- 7. Help Center [kb.10xgenomics.com]
- 8. Ribonuclease Inhibitors (RNase Inhibitors) | Thermo Fisher Scientific - FR [thermofisher.com]
- 9. Base-resolution mapping reveals distinct m1A methylome in nuclear- and mitochondrial-encoded transcripts - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Chemical manipulation of m1A mediates its detection in human tRNA - PMC [pmc.ncbi.nlm.nih.gov]
- 11. academic.oup.com [academic.oup.com]
- 12. m1A Sequencing - CD Genomics [rna.cd-genomics.com]
- 13. biocompare.com [biocompare.com]
Technical Support Center: Artifact Identification in 1-Methyladenine (m1A) Mapping Data
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to help researchers, scientists, and drug development professionals identify and mitigate artifacts in 1-Methyladenine (m1A) mapping data.
Frequently Asked Questions (FAQs)
Q1: What are the common sources of artifacts in m1A mapping experiments?
A1: Artifacts in m1A mapping data can arise from several sources throughout the experimental and bioinformatic workflow. Key sources include:
-
Reverse Transcription (RT) Errors: Reverse transcriptases can introduce errors such as misincorporations and truncations that are not dependent on m1A modifications. This can be influenced by the specific enzyme used and the sequence context.[1][2][3][4] Non-templated nucleotide additions by some reverse transcriptases can also be a source of false signals, particularly at the 5' end of transcripts.[5][6]
-
Sequencing and Alignment Artifacts: Mismapping of sequencing reads, especially when aligning to a transcriptome reference alone, can lead to false positives.[6] Other issues include sequencing errors, single nucleotide polymorphisms (SNPs), and gene duplications being misinterpreted as m1A sites.[6]
-
Other RNA Modifications: Some m1A mapping methods may not be able to distinguish m1A from other modifications. For instance, it can be challenging to differentiate m1A from N1-methyladenosine with a 2'-O-methylation (m1Am) at the mRNA cap.[1]
-
Experimental Conditions: RNA degradation during sample preparation, for example, due to extended alkaline treatment in methods like Dimroth rearrangement, can lead to loss of material and potentially biased results.[1]
-
Contamination: Contamination with bacterial DNA can be a source of artifacts, as bacteria have their own repertoire of DNA modifications that could be misinterpreted in eukaryotic samples.[7]
Q2: My m1A mapping data shows a high number of mismatches that are not sensitive to demethylase treatment. What could be the cause?
A2: If observed mismatches are not reduced after treatment with a demethylase like AlkB, it strongly suggests they are not bona fide m1A modifications.[1][2][3] Potential causes include:
-
Other RNA Modifications: The mismatches could be induced by other RNA modifications that are not substrates for the demethylase used.[1]
-
Single Nucleotide Polymorphisms (SNPs): Genetic variants in the sequenced sample will appear as consistent mismatches against the reference genome.
-
Reverse Transcriptase Errors: Certain reverse transcriptases have inherent error rates and sequence-specific misincorporation patterns that are independent of RNA modifications.[4][8]
-
Sequencing Errors: Although less frequent with modern sequencers, systematic sequencing errors can lead to consistent mismatches at specific positions.
To troubleshoot this, it is recommended to:
-
Sequence a "no-demethylase" control to establish a baseline mismatch rate.
-
Compare your mismatch sites against known SNP databases.
-
Analyze the sequence context around the mismatch sites to identify any potential motifs that might induce RT errors.
Q3: Why do I see a high rate of RT truncation in my data, and how can I be sure it's due to m1A?
A3: 1-Methyladenine can cause both truncation and misincorporation during reverse transcription.[1][2][3] However, RT truncation can also be caused by other factors such as stable RNA secondary structures, other RNA modifications, or simply poor RNA quality. To increase confidence that the observed truncation is m1A-dependent:
-
Use a Demethylase Control: Treatment with a demethylase should reduce the truncation signal at true m1A sites.
-
Optimize RT Conditions: Different reverse transcriptases have varying propensities for truncation versus misincorporation at m1A sites.[1][2][3] For example, some studies have found that TGIRT can lead to a higher misincorporation rate, while enzymes like SuperScript may have a higher termination rate.[5][9]
-
Compare with Misincorporation Data: True m1A sites often exhibit both truncation and misincorporation signals. Analyzing both can provide stronger evidence.
Troubleshooting Guides
Guide 1: Distinguishing True m1A Sites from RT-induced Artifacts
This guide provides a systematic approach to differentiate genuine m1A signals from artifacts introduced during reverse transcription.
| Symptom | Potential Cause | Troubleshooting Steps | Expected Outcome |
| High mismatch rate at A residues in input/control samples. | Inherent reverse transcriptase error rate or other RNA modifications. | 1. Compare mismatch rates between different reverse transcriptases (e.g., SuperScript III vs. TGIRT).[1][2][3]2. Treat RNA with a demethylase (e.g., AlkB) and compare mismatch rates to an untreated sample.[1][2][3]3. Analyze the sequence context of high-mismatch sites for known RT error-prone motifs.[4] | Mismatch rates at true m1A sites should be significantly reduced after demethylase treatment. Different RT enzymes will show different background error profiles. |
| Mismatches observed at the very first transcribed base. | Non-templated nucleotide addition by the reverse transcriptase.[5][6] | 1. Analyze the mismatch patterns at transcription start sites (TSSs) across many genes.2. Compare results from IP (immunoprecipitation) and IP + Demethylase treated samples.[5] | Artifactual mismatches at the TSS will be present in both the IP and the demethylase-treated samples, indicating they are not true m1A modifications.[5] |
| RT stops (truncation) are not consistently at 'A' residues. | RNA secondary structure, RNA degradation, or other modifications causing RT to stall. | 1. Ensure high-quality, intact RNA is used for the experiment.2. Perform RNA structure probing experiments or use software to predict if truncation sites fall within highly structured regions.3. Use a demethylase control; truncation at true m1A sites should be reduced. | A reduction in truncation after demethylase treatment points towards m1A. Truncations aligning with predicted stable secondary structures are likely artifacts. |
Guide 2: Addressing Bioinformatic Artifacts
This guide focuses on identifying and removing artifacts during the data analysis stage.
| Symptom | Potential Cause | Troubleshooting Steps | Expected Outcome |
| High confidence "m1A" sites are identified in knockout models for m1A methyltransferases. | Mismapping of reads, SNPs, or other modifications not dependent on the knocked-out enzyme. | 1. Re-align sequencing reads to the genome instead of just the transcriptome to identify mismapped reads.[6]2. Filter identified sites against a database of known SNPs for the organism and cell line.3. Use more stringent statistical cutoffs for calling m1A sites. | Removal of false positives that are due to alignment errors or genetic variation. True m1A sites dependent on the specific methyltransferase should disappear in the knockout.[4] |
| Identified m1A sites are located in duplicated or misannotated genomic regions. | Reads from multiple genomic locations are incorrectly mapped to a single site.[6] | 1. Analyze the mapping quality of reads at putative m1A sites. Uniquely mapping reads should be prioritized.2. Visually inspect the alignment data in a genome browser to identify regions with ambiguous read alignments.3. Filter out sites that fall within known duplicated or poorly annotated regions of the genome. | Increased confidence in the identified m1A sites by removing those arising from ambiguous alignments. |
Experimental Protocols
Key Experiment: m1A-MAP (m1A-misincorporation assisted profiling)
This protocol is a summary of the key steps for m1A-MAP, a method that utilizes m1A-induced misincorporation during reverse transcription to identify m1A sites at single-nucleotide resolution.[1][2][3]
-
RNA Fragmentation and Immunoprecipitation (IP):
-
Isolate total RNA or poly(A) RNA from the sample of interest.
-
Fragment the RNA to a desired size range (e.g., ~100-200 nucleotides).
-
Perform immunoprecipitation using an anti-m1A antibody to enrich for RNA fragments containing the m1A modification.
-
-
Demethylase Treatment (Control):
-
Divide the enriched RNA into two aliquots.
-
Treat one aliquot with a demethylase enzyme (e.g., AlkB) to remove the m1A modification (+ demethylase sample).
-
Leave the other aliquot untreated (- demethylase sample).
-
-
Reverse Transcription (RT):
-
Perform reverse transcription on both the + and - demethylase samples.
-
Use a reverse transcriptase that efficiently causes misincorporation at m1A sites (e.g., TGIRT) under optimized conditions.
-
-
Library Preparation and Sequencing:
-
Prepare strand-specific sequencing libraries from the resulting cDNA.
-
Perform high-throughput sequencing.
-
-
Data Analysis:
-
Align sequencing reads to the reference genome/transcriptome.
-
Calculate the mismatch (misincorporation) rate at each adenine residue for both the + and - demethylase samples.
-
A bona fide m1A site is identified by a significantly higher mismatch rate in the - demethylase sample compared to the + demethylase sample.
-
Visualizations
Caption: Workflow for m1A-MAP, from RNA preparation to data analysis.
Caption: Decision tree for validating a putative m1A site and ruling out common artifacts.
References
- 1. Base-resolution mapping reveals distinct m1A methylome in nuclear- and mitochondrial-encoded transcripts - PMC [pmc.ncbi.nlm.nih.gov]
- 2. biorxiv.org [biorxiv.org]
- 3. qian.human.cornell.edu [qian.human.cornell.edu]
- 4. researchgate.net [researchgate.net]
- 5. biorxiv.org [biorxiv.org]
- 6. m1A within cytoplasmic mRNAs at single nucleotide resolution: a reconciled transcriptome-wide map - PMC [pmc.ncbi.nlm.nih.gov]
- 7. researchgate.net [researchgate.net]
- 8. Artifacts and biases of the reverse transcription reaction in RNA sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Research progress of N1-methyladenosine RNA modification in cancer - PMC [pmc.ncbi.nlm.nih.gov]
Technical Support Center: Enhancing Ligation Efficiency for m1A Detection
Welcome to the technical support center for enhancing ligation efficiency in N1-methyladenosine (m1A) detection methods. This resource provides researchers, scientists, and drug development professionals with troubleshooting guides and frequently asked questions (FAQs) to address common issues encountered during experimentation.
Troubleshooting Guide
This guide is designed to help you identify and resolve common problems that can lead to low ligation efficiency in m1A detection protocols.
Q1: I am observing very low or no ligation product. What are the potential causes and how can I troubleshoot this?
A1: Low or no ligation product is a common issue. Several factors related to your reagents, RNA, and reaction conditions could be the cause. Here’s a step-by-step troubleshooting approach:
-
Verify Reagent Integrity:
-
Ligase and Buffer: Ensure your T4 DNA ligase is active and the ligation buffer is fresh. The ATP in the buffer is sensitive to freeze-thaw cycles.[1][2][3] Aliquot the buffer upon arrival to minimize degradation.[2] You can test ligase activity with a control ligation, such as ligating a known DNA ladder and observing a shift to higher molecular weight bands on a gel.[2]
-
Adapters/Oligonucleotides: Check the integrity and concentration of your adapters or oligonucleotides. Ensure they have the required 5' phosphate group for ligation.
-
-
Assess RNA Quality and Structure:
-
RNA Integrity: Run an aliquot of your RNA on a denaturing gel to check for degradation. Degraded RNA will result in poor ligation efficiency.
-
RNA Purity: Contaminants from RNA purification, such as salts or phenol, can inhibit the ligation reaction.[4][5] Re-purify your RNA if you suspect contamination.
-
Secondary Structures: Complex RNA secondary structures can hinder adapter ligation by making the ligation site inaccessible.[4][6][7]
-
-
Optimize Reaction Conditions:
-
Temperature: The optimal temperature for T4 DNA ligase is around 25°C, but a compromise is often needed to maintain the annealing of adapters to the RNA template.[1] A common incubation temperature is 16°C overnight to balance enzyme activity and annealing stability.[1][8]
-
Molar Ratios: The molar ratio of adapter to RNA is critical. An excess of adapter is generally recommended, with ratios from 10:1 to 100:1 being common starting points.[1]
-
The following workflow can help you systematically troubleshoot low ligation efficiency:
Q2: My ligation efficiency is inconsistent across different m1A sites. Why is this happening?
A2: Site-specific variation in ligation efficiency is a known challenge in m1A detection. The primary reasons for this are:
-
Inherent Inhibition by m1A: The N1-methyladenosine modification itself can sterically hinder the ligation process. The efficiency of ligation is sensitive to the presence and type of modification at or near the ligation junction.[6]
-
Local Sequence Context and Secondary Structure: The sequence and secondary structure of the RNA surrounding the m1A site can significantly influence the accessibility of the termini for ligation.[6][7] Highly structured regions can prevent the efficient binding of ligase and adapters.
-
Ligase Bias: T4 RNA ligase, commonly used in these protocols, is known to have sequence-dependent biases, which can lead to different efficiencies at different sites.[9]
To address this, consider using methods that are less sensitive to RNA structure or employ enzymes with higher efficiency on structured templates. For example, SplintR ligase, when used in templated ligation assays, has shown high efficiency.[10]
Q3: How can I mitigate the impact of RNA secondary structure on ligation efficiency?
A3: Overcoming the inhibitory effects of RNA secondary structure is crucial for uniform ligation. Here are several strategies:
-
Denaturing Agents: Including a low concentration of denaturing agents like dimethyl sulfoxide (DMSO) or formamide in your ligation reaction can help to disrupt secondary structures.[4][9]
-
Temperature Optimization: Increasing the reaction temperature can help to melt secondary structures. However, this must be balanced with the optimal temperature for ligase activity.[1][4] Some protocols use thermostable ligases that can function at higher temperatures.[9]
-
RNA Fragmentation: Fragmenting the RNA before ligation can reduce the complexity of secondary structures.
-
Template-Directed Ligation: Using a bridging DNA or RNA oligonucleotide that is complementary to the ends of the RNA molecules to be ligated can bring them into close proximity and in the correct orientation for ligation.[4]
Frequently Asked Questions (FAQs)
Q1: Which ligase is best for m1A detection methods?
A1: T4 DNA ligase is commonly used for templated ligation on an RNA strand.[6] However, for methods that rely on the ligation of adapters to RNA, T4 RNA ligase 1 (RNL1) is often employed. For applications requiring high efficiency and specificity, especially in the presence of RNA modifications, SplintR ligase has emerged as a powerful alternative in templated ligation assays.[10][11]
Q2: What is the role of polyethylene glycol (PEG) in ligation reactions?
A2: Polyethylene glycol (PEG) is often included in ligation buffers to increase the effective concentration of macromolecules in the solution, a phenomenon known as molecular crowding.[1] This promotes the association of the ligase with the DNA/RNA substrate and the joining of ends, thereby increasing the ligation efficiency.[1][9][12] Studies have shown that high concentrations of PEG can be critical in suppressing ligation bias.[12][13]
Q3: Can the m1A modification be removed or altered to improve downstream enzymatic steps?
A3: Yes, chemical or enzymatic treatment to alter the m1A modification is a key strategy in many m1A detection methods.
-
Enzymatic Demethylation: The AlkB family of enzymes can demethylate m1A to adenosine.[14] This is often used as a control to confirm that the observed ligation inhibition or reverse transcription signature is indeed due to m1A.
-
Chemical Conversion (Dimroth Rearrangement): Under alkaline conditions, m1A can be chemically converted to N6-methyladenosine (m6A).[15][16] This rearrangement can be more efficient and robust than enzymatic demethylation for generating control libraries.[15] However, alkaline conditions can also lead to RNA degradation.[17][18]
The following diagram illustrates the logical relationship in using these treatments for m1A detection:
Quantitative Data Summary
The following tables summarize quantitative data on factors influencing ligation efficiency from various studies.
Table 1: Effect of Additives on Ligation Efficiency
| Additive | Concentration | Observed Effect on Ligation Efficiency | Reference |
| PEG 8000 | 10% | Approached 100% for a poor substrate | [9] |
| PEG 8000 | 20% | Optimized 5' ligation to ~97% | [9] |
| DMSO | Not specified | Stimulates ligation to highly structured tRNAs | [9] |
Table 2: Ligation Efficiency of Different Ligases
| Ligase | Substrate/Method | Reported Efficiency | Reference |
| T4 RNA Ligase 1 | Mixed synthetic miRNAs | 9% (unoptimized) | [9] |
| Thermostable RNA Ligase | Mixed synthetic miRNAs | 7% | [9] |
| SplintR Ligase | Templated ligation | High efficiency | [10] |
Experimental Protocols
Protocol 1: General T4 RNA Ligase 1 Reaction for Adapter Ligation
-
Reaction Setup: In a nuclease-free microfuge tube, combine the following on ice:
-
Total RNA or purified small RNA (1-2 µg)
-
3' adapter (e.g., 20 µM final concentration)
-
Nuclease-free water to a final volume of 10 µL
-
-
Denaturation and Annealing: Heat the mixture to 70°C for 2 minutes and then place immediately on ice.
-
Ligation Master Mix: Prepare a master mix containing:
-
10X T4 RNA Ligase Buffer
-
T4 RNA Ligase 1 (e.g., 10 U/µL)
-
RNase Inhibitor (optional)
-
PEG 8000 (to a final concentration of 10-20%)
-
-
Ligation Reaction: Add the master mix to the RNA/adapter mixture. The final reaction volume is typically 20 µL.
-
Incubation: Incubate at 16°C overnight or at 25°C for 1-2 hours.
-
Purification: Purify the ligated product using silica-based columns or by gel electrophoresis to remove unligated adapters.
Protocol 2: Template-Directed Ligation using SplintR Ligase for m1A Quantification
This protocol is adapted from methods for quantifying tRNA m1A modifications.[10]
-
Reaction Components:
-
Total RNA (sub-nanogram amounts)
-
Two DNA oligonucleotides complementary to the target tRNA, flanking the m1A site.
-
SplintR Ligase
-
10X SplintR Ligase Reaction Buffer
-
-
Reaction Assembly: Combine the RNA template and DNA oligonucleotides in the reaction buffer.
-
Ligation: Add SplintR ligase and incubate according to the manufacturer's recommendations. The m1A modification will interfere with the ligation of the DNA oligos templated by the tRNA.
-
Quantification: The ligation product is then used as a template for qPCR. The level of m1A is quantified by comparing the ligation efficiency (and subsequent qPCR signal) between a sample and a control (e.g., an unmodified in vitro transcribed RNA or a sample treated with a demethylase).
The workflow for this templated ligation qPCR method is as follows:
References
- 1. Troubleshooting DNA ligation in NGS library prep - Enseqlopedia [enseqlopedia.com]
- 2. researchgate.net [researchgate.net]
- 3. neb.com [neb.com]
- 4. benchchem.com [benchchem.com]
- 5. How to Troubleshoot Sequencing Preparation Errors (NGS Guide) - CD Genomics [cd-genomics.com]
- 6. A systematic, ligation-based approach to study RNA modifications - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Navigating the pitfalls of mapping DNA and RNA modifications - PMC [pmc.ncbi.nlm.nih.gov]
- 8. bitesizebio.com [bitesizebio.com]
- 9. researchgate.net [researchgate.net]
- 10. Quantification of tRNA m1A modification by templated-ligation qPCR - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Quantification of tRNA m1A modification by templated-ligation qPCR - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. pure.johnshopkins.edu [pure.johnshopkins.edu]
- 13. researchgate.net [researchgate.net]
- 14. m1A RNA Modification in Gene Expression Regulation - PMC [pmc.ncbi.nlm.nih.gov]
- 15. Chemical manipulation of m1A mediates its detection in human tRNA - PMC [pmc.ncbi.nlm.nih.gov]
- 16. Development of mild chemical catalysis conditions for m1A-to-m6A rearrangement on RNA - PMC [pmc.ncbi.nlm.nih.gov]
- 17. Base-resolution mapping reveals distinct m1A methylome in nuclear- and mitochondrial-encoded transcripts - PMC [pmc.ncbi.nlm.nih.gov]
- 18. qian.human.cornell.edu [qian.human.cornell.edu]
Technical Support Center: Synthesis of 1-Methyladenine Analogs
Welcome to the technical support center for the synthesis of 1-methyladenine analogs. This resource is designed for researchers, scientists, and drug development professionals to provide troubleshooting guidance and frequently asked questions (FAQs) to improve experimental outcomes.
Troubleshooting Guides and FAQs
This section addresses common issues encountered during the synthesis and purification of 1-methyladenine analogs.
FAQs: Synthesis and Yield Optimization
Q1: My reaction yield for N1-methylation of adenine is consistently low. What are the potential causes and how can I improve it?
A1: Low yields in N1-methylation of adenine can stem from several factors. Here are some common causes and solutions:
-
Poor solubility of adenine: Adenine has low solubility in many organic solvents.
-
Suboptimal reaction temperature: The reaction temperature can significantly impact the rate and yield.
-
Solution: While heating can increase the reaction rate, it can also lead to side products. Empirically test a range of temperatures (e.g., room temperature to 80°C) to find the optimal balance for your specific analog.
-
-
Inefficient methylating agent: The choice of methylating agent is crucial.
-
Solution: Methyl iodide and methyl-p-toluenesulfonate are commonly used.[3] Ensure the agent is fresh and used in an appropriate molar excess.
-
-
Presence of moisture: Water can react with the methylating agent and interfere with the reaction.
-
Solution: Use anhydrous solvents and perform the reaction under an inert atmosphere (e.g., nitrogen or argon).
-
-
Incomplete deprotonation of adenine: For the N1 position to be alkylated, the adenine must be deprotonated.
-
Solution: Use a suitable base, such as sodium hydride (NaH), in an appropriate solvent to ensure complete deprotonation of the adenine starting material.
-
Q2: I am observing the formation of multiple isomers (N3, N7, N9-methyladenine) in my reaction. How can I improve the regioselectivity for the N1 position?
A2: Controlling the regioselectivity of adenine alkylation is a significant challenge. The N1, N3, N7, and N9 positions are all potential sites for alkylation.[1][2]
-
Solvent Choice: The solvent system plays a critical role in directing the site of alkylation.
-
Protecting Groups: While direct alkylation is often attempted, the use of protecting groups on the adenine ring can direct methylation to the desired position. However, this adds extra steps to the synthesis.
-
Reaction Conditions:
-
Kinetic vs. Thermodynamic Control: The reaction conditions can favor either the kinetically or thermodynamically preferred product. N9-alkylation is often the thermodynamically favored product. Running the reaction for a longer time at a moderate temperature may increase the proportion of the N9 isomer.
-
Nature of the Alkylating Agent: The steric bulk of the alkylating agent can influence the site of attack.
-
Q3: My final product appears to be N6-methyladenine instead of the desired 1-methyladenine. What is happening and how can I prevent it?
A3: You are likely observing the result of a Dimroth rearrangement . This is a common isomerization where the N1-alkylated adenine rearranges to the more stable N6-alkylated isomer, especially under basic or heated conditions.[3]
-
Deprotection Conditions: Harsh deprotection conditions are a primary cause of the Dimroth rearrangement.
-
Solution: Use milder deprotection strategies. For example, when removing protecting groups from a synthesized oligonucleotide containing 1-methyladenosine, use 2M methanolic ammonia at room temperature instead of concentrated aqueous ammonia.
-
-
pH Control: The rearrangement is often base-catalyzed.
-
Solution: Maintain careful control of pH during workup and purification steps. Avoid prolonged exposure to basic conditions.
-
-
Temperature: Elevated temperatures can accelerate the rearrangement.
-
Solution: Perform deprotection and purification steps at room temperature or below whenever possible.
-
FAQs: Purification and Analysis
Q1: I am having difficulty separating the different methylated adenine isomers by HPLC. What can I do to improve the separation?
A1: HPLC is a powerful tool for separating nucleoside isomers, but optimization is often necessary.
-
Column Choice: The type of stationary phase is critical.
-
Recommendation: A C18 reverse-phase column is a good starting point.
-
-
Mobile Phase Composition: The mobile phase composition will have the largest impact on your separation.
-
Gradient Elution: A gradient of an aqueous buffer (e.g., ammonium acetate or triethylammonium acetate) and an organic solvent (e.g., acetonitrile or methanol) is typically required to resolve these closely related compounds.
-
pH Adjustment: The pH of the aqueous buffer can alter the ionization state of the adenine analogs, which can significantly affect their retention times. Experiment with a pH range around the pKa of the compounds.
-
-
Flow Rate and Temperature:
-
Flow Rate: A lower flow rate can improve resolution but will increase the run time.
-
Temperature: Operating the column at a slightly elevated and controlled temperature (e.g., 30-40°C) can improve peak shape and reproducibility.
-
For a general HPLC troubleshooting guide, refer to established resources on common issues like pressure fluctuations, peak tailing, and ghost peaks.
Quantitative Data on Synthetic Yields
The following table summarizes reported yields for different steps in the synthesis of 1-methyladenosine, providing a comparative overview.
| Step | Starting Material | Reagents | Solvent | Yield (%) | Reference |
| Acetylation of Adenosine | Adenosine | Acetic Anhydride, Pyridine | - | 81 | [3] |
| N1-Methylation | Acetylated Adenosine | Methyl Iodide | DMF | 61 | [3] |
| Deprotection | Acetylated 1-Methyladenosine | Ammonia in Methanol | Methanol | 57 | [3] |
Note: Yields are highly dependent on specific reaction conditions and scale.
Experimental Protocols
Protocol 1: Synthesis of 1-Methyladenosine
This protocol is adapted from the work of Matuszewski and Sochacka, and Oslovsky, et al.[3]
Step 1: Acetylation of Adenosine
-
Suspend adenosine in a suitable solvent such as pyridine.
-
Add acetic anhydride to the suspension.
-
Stir the reaction mixture at room temperature until the reaction is complete (monitor by TLC).
-
Quench the reaction by adding methanol.
-
Remove the solvent under reduced pressure.
-
Recrystallize the resulting solid from hot ethanol to yield 2',3',5'-tri-O-acetyladenosine.
Step 2: N1-Methylation
-
Dissolve the acetylated adenosine in an anhydrous polar aprotic solvent like DMF.
-
Add methyl iodide to the solution.
-
Stir the reaction at room temperature for 24-48 hours (monitor by TLC).
-
Concentrate the reaction mixture in vacuo.
Step 3: Deprotection
-
Dissolve the crude methylated product in methanolic ammonia.
-
Stir the solution at room temperature until deprotection is complete (monitor by TLC).
-
Remove the solvent under reduced pressure.
-
Purify the final product, 1-methyladenosine, by a suitable method such as column chromatography or recrystallization.
Signaling Pathways and Experimental Workflows
Signaling Pathways
The biological activity of 1-methyladenine and its analogs is often linked to their role as epigenetic modifiers, particularly in the context of RNA methylation (m1A). The m1A modification is dynamically regulated by "writer," "eraser," and "reader" proteins and has been shown to influence signaling pathways such as the PI3K/AKT/mTOR pathway, which is crucial for cell growth, proliferation, and survival.[4][5]
Caption: The m1A RNA methylation cycle.
References
- 1. researchgate.net [researchgate.net]
- 2. Reaction Kinetics of the Benzylation of Adenine in DMSO: Regio‐Selectivity Guided by Entropy - PMC [pmc.ncbi.nlm.nih.gov]
- 3. researchgate.net [researchgate.net]
- 4. m1A Regulated Genes Modulate PI3K/AKT/mTOR and ErbB Pathways in Gastrointestinal Cancer - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. m1A Regulated Genes Modulate PI3K/AKT/mTOR and ErbB Pathways in Gastrointestinal Cancer - PMC [pmc.ncbi.nlm.nih.gov]
troubleshooting off-target effects of m1A editing tools
Welcome to the technical support center for N1-methyladenosine (m1A) RNA editing technologies. This resource is designed for researchers, scientists, and drug development professionals to provide guidance on troubleshooting off-target effects and ensuring the specificity of your m1A editing experiments.
Frequently Asked Questions (FAQs)
Q1: What are the primary sources of off-target effects in m1A RNA editing?
Off-target effects in m1A RNA editing can arise from two main sources, depending on the editing tool used:
-
Endogenous Enzyme-Based Editing (Overexpression of Writers/Erasers): When overexpressing m1A methyltransferases ("writers") like TRMT6/TRMT61A or demethylases ("erasers") like ALKBH3, off-target effects can occur due to the promiscuous substrate specificity of these enzymes. This can lead to the modification of unintended RNA molecules, potentially altering their stability and function.[1]
-
CRISPR-dCas13-Based Editing: For targeted m1A editing using dCas13 fused to an m1A writer or eraser, off-target effects are primarily driven by the guide RNA (gRNA). The dCas13/gRNA complex may bind to unintended RNA transcripts that share sequence homology with the target, leading to m1A modifications at undesired locations.[2] Mismatches between the gRNA and the RNA are tolerated to some extent, which can lead to non-specific binding.[2]
Q2: How can I predict potential off-target sites for my m1A editing experiment?
Predicting off-target sites is a crucial first step in mitigating their impact. The approach depends on your editing system:
-
For CRISPR-dCas13-Based Systems: Several computational tools are available for designing gRNAs with minimal predicted off-target effects. These tools work by searching the transcriptome for sequences with similarity to your target and providing on- and off-target scores.[3][4] It is highly recommended to use these tools during the gRNA design phase.
-
For Endogenous Enzyme-Based Systems: Predicting off-target sites is more challenging due to the complex substrate recognition motifs of the enzymes. However, computational models like m1A-Pred can be used to predict potential m1A sites across the transcriptome based on sequence and structural features.[5][6][7] This can help identify RNAs that might be susceptible to off-target modification when a writer or eraser is overexpressed.
Q3: What are the recommended methods for detecting off-target m1A editing events transcriptome-wide?
Transcriptome-wide analysis is essential for a comprehensive assessment of off-target effects. The primary method for this is m1A-seq , which is a variation of methylated RNA immunoprecipitation sequencing (MeRIP-seq).[8][9] This technique involves using an m1A-specific antibody to enrich for RNA fragments containing the m1A modification, followed by high-throughput sequencing.[8][10] By comparing the m1A profiles of edited cells to control cells, you can identify both on-target and off-target modifications. For single-base resolution, m1A-seq can be combined with techniques that induce mutations or deletions at m1A sites during reverse transcription.[11]
Q4: How do I validate a suspected off-target m1A modification on a specific RNA?
Once you have identified a potential off-target RNA from transcriptome-wide analysis, you need to validate this finding using a targeted approach. m1A-specific RNA immunoprecipitation followed by quantitative PCR (m1A-RIP-qPCR) is a reliable method. This involves immunoprecipitating the m1A-modified RNA from your experimental and control samples and then using qPCR to quantify the enrichment of the specific off-target transcript. A significant increase in enrichment in the edited sample compared to the control validates the off-target event.
Troubleshooting Guides
Problem 1: High background or false positives in my off-target analysis.
| Possible Cause | Recommended Solution |
| Non-specific antibody binding in m1A-seq | Ensure the specificity of your m1A antibody. Perform dot blot analysis with known m1A-containing and non-m1A-containing RNA oligonucleotides to validate antibody specificity. Include an isotype control immunoprecipitation in your m1A-seq experiment to identify non-specifically bound RNAs. |
| Suboptimal gRNA design (for dCas13 systems) | Redesign your gRNA using at least two different computational tools to ensure a comprehensive off-target prediction.[3][12][13] Test multiple gRNAs for your target to find the one with the highest on-target and lowest off-target activity. |
| Overexpression of editing components | Titrate the amount of transfected plasmid or viral vector to use the lowest effective concentration of your m1A editing tool. High concentrations of the editing machinery can increase the likelihood of off-target events. |
Problem 2: Low or no detectable on-target editing efficiency.
| Possible Cause | Recommended Solution |
| Inefficient gRNA (for dCas13 systems) | The secondary structure of the gRNA can impact its effectiveness.[12] Use gRNA design tools that predict secondary structure and select a gRNA with a more open and accessible conformation. Test at least 2-3 different gRNAs for your target RNA. |
| Target site accessibility | The secondary structure of the target RNA can block access for the editing machinery. Use RNA structure prediction tools to identify accessible regions in your target transcript and design gRNAs accordingly. |
| Low expression of the target RNA | Confirm the expression level of your target RNA in your experimental system using RT-qPCR. If the target is lowly expressed, you may need to increase the sensitivity of your detection method or consider a different experimental model. |
| Modification interferes with gRNA binding (for dCas13 systems) | If an existing RNA modification is within the gRNA binding site, it may prevent stable binding.[2] Design gRNAs that flank the modification site rather than directly overlapping it. |
Quantitative Data Summary
The following table summarizes hypothetical quantitative data for off-target analysis of two different m1A editing tools. This data is for illustrative purposes to guide your own data presentation.
| Editing Tool | Target Gene | On-Target Editing Efficiency (%) | Number of Off-Target Sites Detected (m1A-seq) | Off-Target Frequency (Off-targets / Total Reads) |
| Overexpressed ALKBH3 | Transcript A | 85 | 152 | 1 in 10,000 |
| dCas13b-TRMT6 | Transcript B | 78 | 23 | 1 in 75,000 |
Key Experimental Protocols
m1A-seq (Methylated RNA Immunoprecipitation Sequencing)
-
RNA Isolation and Fragmentation: Isolate total RNA from your control and experimental cells. Fragment the RNA to an average size of 100-200 nucleotides using enzymatic or chemical methods.
-
Immunoprecipitation: Incubate the fragmented RNA with an m1A-specific antibody. Use magnetic beads conjugated with Protein A/G to capture the antibody-RNA complexes.
-
Washing: Perform stringent washes to remove non-specifically bound RNA.
-
Elution and RNA Purification: Elute the m1A-containing RNA fragments from the antibody-bead complexes and purify the RNA.
-
Library Preparation and Sequencing: Prepare a sequencing library from the enriched RNA fragments and a corresponding input control library (from the fragmented RNA before immunoprecipitation). Perform high-throughput sequencing.
-
Data Analysis: Align the sequencing reads to the reference transcriptome. Use peak-calling algorithms to identify enriched regions in the m1A-IP sample compared to the input control. Differential peak analysis between experimental and control samples will reveal on-target and off-target editing events.
Visualizations
Caption: Workflow for transcriptome-wide detection of off-target m1A modifications using m1A-seq.
Caption: Troubleshooting flowchart for excessive off-target m1A modifications.
Signaling Pathway Considerations
Unintended m1A modifications can have significant downstream consequences. For example, the m1A status of certain transcripts is known to be read by YTHDF proteins, which can influence mRNA stability and translation.[1] Off-target modification of a key signaling molecule's mRNA could therefore lead to its unintended degradation or enhanced translation, ultimately perturbing cellular pathways. When analyzing off-target effects, it is crucial to consider the functional categories of the affected transcripts to understand the potential biological impact.
Caption: Potential impact of an off-target m1A modification on a signaling pathway.
References
- 1. Harnessing m1A modification: a new frontier in cancer immunotherapy - PMC [pmc.ncbi.nlm.nih.gov]
- 2. benchchem.com [benchchem.com]
- 3. benchling.com [benchling.com]
- 4. stemcell.com [stemcell.com]
- 5. m1A-pred: Prediction of Modified 1-methyladenosine Sites in RNA Sequences through Artificial Intelligence - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. researchgate.net [researchgate.net]
- 7. benthamdirect.com [benthamdirect.com]
- 8. m1A RNA Methylation Analysis - CD Genomics [cd-genomics.com]
- 9. epigenie.com [epigenie.com]
- 10. Sequencing Technologies of m1A RNA Modification - CD Genomics [rna.cd-genomics.com]
- 11. pnas.org [pnas.org]
- 12. jkip.kit.edu [jkip.kit.edu]
- 13. CRISPR: Guide to gRNA design - Snapgene [snapgene.com]
Technical Support Center: Optimizing Cell Lysis for m1A Preservation
This technical support center provides researchers, scientists, and drug development professionals with comprehensive troubleshooting guides and frequently asked questions (FAQs) for optimizing cell lysis conditions to preserve N1-methyladenosine (m1A) RNA modifications.
Troubleshooting Guide
This guide addresses specific issues that may arise during cell lysis for m1A analysis, offering potential causes and solutions.
| Issue | Potential Cause(s) | Recommended Solution(s) |
| Low m1A Signal or Loss of Modification | 1. Endogenous Demethylase Activity: m1A can be actively removed by demethylases such as ALKBH1 and ALKBH3, which may be active during the lysis procedure.[1] | a. Work Quickly and at Low Temperatures: Perform all lysis steps on ice or at 4°C to minimize enzymatic activity.[2] b. Use Demethylase Inhibitors: Add specific inhibitors for m1A demethylases to your lysis buffer. For example, Methylstat is a competitive inhibitor of ALKBH3.[3] For ALKBH1, specific inhibitors are also commercially available. Always prepare lysis buffer with freshly added inhibitors. |
| 2. Chemical Instability of m1A: The m1A modification can be susceptible to degradation under certain chemical conditions (e.g., extreme pH). | a. Maintain Optimal pH: Use a lysis buffer with a pH around 7.4, as this is a common component of protocols for m1A analysis.[1] b. Avoid Harsh Chemical Lysis: If possible, avoid harsh chemical lysis methods that involve strong acids or bases. | |
| 3. Inefficient Lysis: Incomplete cell disruption can lead to a low yield of total RNA, which in turn results in a low m1A signal.[4] | a. Optimize Lysis Method for Cell Type: Choose a lysis method appropriate for your cells. For example, mammalian cells are often lysed efficiently with detergent-based buffers, while yeast may require mechanical disruption like bead beating.[4] b. Verify Lysis Efficiency: After lysis, check for cell debris under a microscope to ensure complete disruption. | |
| RNA Degradation (Low RIN Score) | 1. RNase Contamination: RNases are ubiquitous and can rapidly degrade RNA, leading to the loss of all RNA species, including those with m1A modifications. | a. Use RNase-Free Reagents and Consumables: Ensure all buffers, water, pipette tips, and tubes are certified RNase-free. b. Wear Gloves: Always wear gloves and change them frequently to prevent RNase contamination from your skin. c. Add RNase Inhibitors: Include a potent RNase inhibitor cocktail in your lysis buffer.[5] |
| 2. Mechanical Shearing: Excessive mechanical force during lysis (e.g., prolonged sonication or vortexing) can shear RNA into smaller fragments. | a. Optimize Mechanical Lysis Parameters: If using sonication or bead beating, optimize the duration and intensity to be sufficient for lysis without causing excessive RNA degradation. Perform these steps in short bursts with cooling periods in between.[6] | |
| Inconsistent m1A Levels Between Replicates | 1. Variable Lysis Efficiency: Inconsistent application of the lysis procedure can lead to variable RNA yields and, consequently, variable m1A levels. | a. Standardize the Protocol: Ensure that all samples are treated identically, including cell number, buffer volumes, and incubation times. b. Homogenize Thoroughly: For tissue samples, ensure complete homogenization to achieve a uniform lysate. |
| 2. Incomplete Inhibition of Demethylases: Inconsistent addition or potency of demethylase inhibitors can lead to variable m1A preservation. | a. Prepare Fresh Lysis Buffer: Always use freshly prepared lysis buffer with inhibitors for each experiment. b. Ensure Proper Inhibitor Concentration: Use the recommended concentration of demethylase inhibitors. |
Frequently Asked Questions (FAQs)
Q1: Which lysis method is best for preserving m1A?
The optimal lysis method depends on the cell or tissue type. For cultured mammalian cells, a detergent-based chemical lysis is often sufficient and gentle. A validated protocol for m1A analysis uses a lysis buffer containing Triton X-100.[1] For tougher tissues or cells with resilient cell walls (e.g., yeast), mechanical disruption methods like bead beating or cryogenic grinding may be necessary.[4] When using mechanical methods, it is crucial to optimize the conditions to minimize RNA degradation.
Q2: What are the key components of a lysis buffer for m1A preservation?
A recommended lysis buffer for m1A preservation should contain:
-
A non-ionic detergent: To solubilize cell membranes (e.g., Triton X-100).[1]
-
Salts: To maintain osmolarity and ionic strength (e.g., KCl).[1]
-
A buffering agent: To maintain a stable pH (e.g., Tris-HCl at pH 7.4).[1]
-
Dithiothreitol (DTT): A reducing agent that can help inactivate RNases.[1]
-
RNase inhibitors: To protect RNA from degradation.[1]
-
Protease inhibitors: To prevent protein degradation, which can be important for downstream applications.[1]
-
m1A demethylase inhibitors: To prevent the enzymatic removal of the m1A modification (e.g., specific inhibitors for ALKBH1 and ALKBH3).
Q3: Can I use TRIzol for RNA extraction when I want to study m1A?
TRIzol is a common and effective reagent for RNA extraction that denatures proteins, including RNases, which is beneficial for RNA integrity.[7][8] While there is no direct evidence to suggest that TRIzol adversely affects the m1A modification itself, it is a harsh denaturant. For sensitive applications, it is always recommended to validate your extraction method. A study comparing different RNA preservation techniques found no significant difference in RNA concentration and purity between TRIzol and other reagents.[9] However, for m1A analysis, the inclusion of demethylase inhibitors is a critical consideration that is not a standard component of the TRIzol protocol.
Q4: How important is temperature control during cell lysis for m1A preservation?
Temperature control is critical. Low temperatures (on ice or 4°C) should be maintained throughout the lysis procedure to minimize the activity of endogenous enzymes like RNases and m1A demethylases.[2] Some studies have noted that certain RNA modifications can be induced at high temperatures, highlighting the importance of maintaining a stable and low-temperature environment to preserve the native modification state.[10]
Q5: Are there commercial kits available for m1A analysis that include optimized lysis buffers?
Yes, there are commercial kits available for m1A enrichment and quantification.[3] These kits often include optimized buffers and reagents, though the exact composition of the lysis buffer may be proprietary. When using a kit, it is still advisable to follow best practices for RNA handling, such as working in an RNase-free environment.
Experimental Protocols
Protocol 1: Detergent-Based Lysis for Cultured Mammalian Cells (Adapted from m1A-MAP Protocol)[1]
This protocol is suitable for the lysis of cultured mammalian cells for the preservation of m1A modifications.
Materials:
-
Lysis Buffer: 10 mM Tris-HCl (pH 7.4), 5 mM MgCl2, 100 mM KCl, 1% Triton X-100
-
Dithiothreitol (DTT)
-
RNase Inhibitor Cocktail
-
Protease Inhibitor Cocktail
-
m1A Demethylase Inhibitors (e.g., ALKBH1 and ALKBH3 inhibitors)
-
Ice-cold Phosphate-Buffered Saline (PBS)
-
Cell scraper (for adherent cells)
-
Microcentrifuge tubes
Procedure:
-
Cell Harvesting:
-
Adherent cells: Wash the cell monolayer once with ice-cold PBS. Add a small volume of ice-cold PBS and gently scrape the cells. Transfer the cell suspension to a pre-chilled microcentrifuge tube.
-
Suspension cells: Pellet the cells by centrifugation at 500 x g for 5 minutes at 4°C. Discard the supernatant and wash the cell pellet once with ice-cold PBS.
-
-
Cell Lysis:
-
Centrifuge the cell suspension at 500 x g for 5 minutes at 4°C to pellet the cells.
-
Carefully remove all of the supernatant.
-
Prepare the complete lysis buffer immediately before use by adding DTT to a final concentration of 2 mM, along with RNase inhibitors, protease inhibitors, and m1A demethylase inhibitors at their recommended concentrations.
-
Resuspend the cell pellet in 1 mL of complete lysis buffer.
-
-
Incubation and Clarification:
-
Incubate the lysate on ice for 15 minutes to ensure complete lysis.
-
Centrifuge the lysate at 15,000 x g for 15 minutes at 4°C to pellet cell debris.
-
-
RNA Extraction:
-
Carefully transfer the supernatant to a new pre-chilled, RNase-free microcentrifuge tube.
-
Proceed immediately with your chosen RNA extraction protocol (e.g., phenol-chloroform extraction or a column-based method).
-
Visualizations
Experimental Workflow for m1A Preservation during Cell Lysis
Caption: Workflow for optimal cell lysis and RNA extraction for m1A preservation.
Hypothetical Signaling Pathway Influencing m1A Levels
References
- 1. N1-methyladenosine formation, gene regulation, biological functions, and clinical relevance - PMC [pmc.ncbi.nlm.nih.gov]
- 2. mdpi.com [mdpi.com]
- 3. scbt.com [scbt.com]
- 4. Cell Disruption: Getting the RNA Out | Thermo Fisher Scientific - US [thermofisher.com]
- 5. Effects of Adenine Methylation on the Structure and Thermodynamic Stability of a DNA Minidumbbell - PMC [pmc.ncbi.nlm.nih.gov]
- 6. researchgate.net [researchgate.net]
- 7. researchgate.net [researchgate.net]
- 8. Comparison of RNA Extraction Methods for Molecular Analysis of Oral Cytology - PMC [pmc.ncbi.nlm.nih.gov]
- 9. repository.arizona.edu [repository.arizona.edu]
- 10. researchgate.net [researchgate.net]
Technical Support Center: Data Normalization for Comparative m1A Studies
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to assist researchers, scientists, and drug development professionals in navigating the complexities of data normalization for comparative N1-methyladenosine (m1A) studies.
Troubleshooting Guides
This section addresses specific issues that may arise during the normalization of m1A sequencing data.
Issue 1: High variability in m1A enrichment between replicate samples.
-
Question: My IP replicates show high variability in the number of enriched fragments. How can I normalize for this?
-
Answer: High variability between immunoprecipitation (IP) replicates can stem from minor differences in experimental conditions, such as antibody-to-RNA ratio or incubation times. It is crucial to normalize the data to an appropriate reference.
-
Recommendation: Utilize an "Input" control for each sample. The Input sample consists of fragmented RNA that has not undergone immunoprecipitation.[1] Normalizing the IP signal to the corresponding Input signal for each sample can account for variations in starting material and fragmentation. The enrichment (m1A level) for a given peak can be calculated as the ratio of read counts in the IP sample to the read counts in the Input sample for that specific region.
-
Issue 2: Suspected global changes in m1A methylation across experimental conditions.
-
Question: I am comparing a treatment group to a control group, and I suspect my treatment induces a global increase in m1A methylation. Which normalization strategy is appropriate?
-
Answer: When global changes in m1A methylation are expected, standard global normalization methods that assume the majority of methylation sites are unchanged can be misleading.
-
Recommendation: Avoid normalization methods that force the distributions of the datasets to be identical, such as quantile normalization, as this can obscure true global changes.[2] Instead, consider using a set of spike-in controls with known m1A modifications. These synthetic RNA molecules can be added to each sample at a constant amount and used as an external reference for normalization. Alternatively, methods that rely on a subset of presumably invariant genes (housekeeping genes) for normalization can be cautiously applied, though the stability of m1A on these genes should be validated.
-
Issue 3: Low signal-to-noise ratio in m1A-seq data.
-
Question: My m1A-seq data has a low signal-to-noise ratio, with high background in the IP samples. How can this be addressed during normalization?
-
Answer: A low signal-to-noise ratio can be due to inefficient IP or non-specific antibody binding.
-
Recommendation: Proper normalization using an Input control is the first step to mitigate this issue, as it helps to account for background non-specific binding.[1] During peak calling, use a stringent statistical cutoff (e.g., a low false discovery rate) to distinguish true m1A peaks from background noise. Additionally, ensure that the sequencing depth is sufficient for both IP and Input samples to provide the statistical power needed to differentiate signal from noise.[3]
-
Frequently Asked Questions (FAQs)
This section provides answers to common questions regarding data normalization in comparative m1A studies.
1. Why is data normalization necessary for comparative m1A studies?
Data normalization is a critical step to remove technical variations and systematic biases from experimental data, ensuring that any observed differences in m1A levels between samples are due to biological changes and not experimental artifacts.[4][5] Sources of technical variation in m1A-seq experiments include differences in sequencing depth, library preparation efficiency, and immunoprecipitation efficiency.[5][6]
2. What are the most common normalization strategies for m1A-seq data?
The choice of normalization strategy depends on the specific experimental design and biological question. Common approaches include:
-
Input Normalization: This is the most fundamental normalization step for m1A-meRIP-seq. It involves normalizing the read counts in the IP sample to the read counts in the corresponding non-immunoprecipitated Input sample.[1] This accounts for local variations in gene expression and chromatin accessibility.
-
Sequencing Depth Normalization: Methods like Reads Per Kilobase of transcript per Million mapped reads (RPKM), Fragments Per Kilobase of transcript per Million mapped reads (FPKM), and Transcripts Per Million (TPM) account for differences in sequencing depth and gene length.[5]
-
Between-Sample Normalization: Methods like Trimmed Mean of M-values (TMM) and Relative Log Expression (RLE) are designed to account for compositional biases in RNA populations between samples.[6]
-
Quantile Normalization: This method aligns the distributions of read counts across all samples. It is a stringent normalization method that should be used with caution, especially if global changes in m1A methylation are anticipated.[2][7]
3. What is the role of an "Input" control in m1A-seq normalization?
The Input control is a crucial component of m1A-meRIP-seq experiments. It is a sample of the initial fragmented RNA that does not undergo immunoprecipitation.[1] By sequencing the Input alongside the IP samples, it serves as a baseline for:
-
Local transcript abundance: The read density in the Input reflects the expression level of the corresponding transcripts.
-
Background estimation: It helps to distinguish true m1A-enriched regions from background noise and non-specific antibody binding.[1]
4. How does m1A stoichiometry affect data normalization and interpretation?
m1A modifications can have low stoichiometry, meaning only a small fraction of a specific transcript may be modified at a given site. This can result in a low signal in the IP sample. Normalization using Input controls is essential to accurately quantify the enrichment of these low-stoichiometry sites. It is also important to use sensitive peak-calling algorithms that can detect these subtle enrichments.
5. Can I use normalization methods developed for ChIP-seq for my m1A-seq data?
While m1A-seq and ChIP-seq are both based on immunoprecipitation, there are key differences. However, some normalization principles from ChIP-seq can be adapted. For instance, the concept of using a control sample (Input) to normalize for background and local biases is central to both techniques.[8] Normalization methods that account for differences in IP efficiency by scaling to background regions can also be applicable.[8]
Quantitative Data Summary
The following table summarizes common normalization methods and their applicability to comparative m1A studies.
| Normalization Method | Principle | Advantages | Disadvantages | Best For |
| Input Normalization | Normalizes IP signal to the corresponding Input sample's read count.[1] | Accounts for local transcript abundance and background noise.[1] | Requires sequencing of an additional Input library for each sample. | All m1A-meRIP-seq experiments. |
| TPM / RPKM / FPKM | Normalizes for sequencing depth and gene length.[5] | Allows for comparison of m1A levels within and between samples. | Can be sensitive to highly expressed genes. | General comparison of m1A enrichment across different genes and samples. |
| TMM / RLE | Adjusts library sizes based on the assumption that most genes are not differentially methylated.[6] | Robust to the presence of a small number of highly differentially methylated regions. | Assumes that the overall m1A levels are relatively constant across samples. | Comparative studies where global changes in m1A are not expected. |
| Quantile Normalization | Forces the distribution of read counts to be the same across all samples.[2][7] | Can effectively remove technical variation. | Can mask true biological differences if there are global shifts in m1A methylation.[2] | Datasets with high technical variability where no global changes in m1A are hypothesized. |
| Spike-in Normalization | Uses synthetic RNA with known m1A modifications added to each sample in a constant amount. | Provides an external reference for absolute quantification and is not affected by global changes in endogenous m1A. | Requires the synthesis and validation of appropriate spike-in controls. | Studies where global changes in m1A are expected or when absolute quantification is desired. |
Experimental Protocols
Methodology for m1A-meRIP-seq
-
RNA Isolation and Fragmentation: Isolate total RNA from the samples of interest. Purify mRNA and fragment it into ~100 nucleotide-long fragments.
-
Immunoprecipitation: For each sample, take an aliquot of the fragmented RNA as the "Input" control and set it aside. Incubate the remaining fragmented RNA with an anti-m1A antibody to enrich for m1A-containing fragments.[1]
-
Washing and Elution: Wash the antibody-RNA complexes to remove non-specifically bound fragments. Elute the m1A-enriched RNA fragments.
-
Library Preparation: Prepare sequencing libraries from both the IP and Input RNA fragments. This typically involves reverse transcription, second-strand synthesis, adapter ligation, and PCR amplification.
-
Sequencing: Sequence the prepared libraries using a high-throughput sequencing platform.
Methodology for Data Normalization and Analysis
-
Read Alignment: Align the sequencing reads from both IP and Input samples to a reference genome or transcriptome.
-
Peak Calling: Use a peak calling algorithm (e.g., MACS2) to identify regions of significant m1A enrichment in the IP samples compared to the Input samples.
-
Normalization:
-
Within-Sample Normalization (Input Normalization): For each identified peak, calculate the enrichment over Input by dividing the normalized read counts (e.g., in TPM) in the IP sample by the normalized read counts in the Input sample.
-
Between-Sample Normalization: Apply a between-sample normalization method (e.g., TMM, RLE) to the enrichment values to account for compositional differences between the samples.
-
-
Differential m1A Analysis: Use statistical methods to identify significant differences in m1A enrichment between experimental conditions.
Visualizations
Caption: Workflow for m1A-meRIP-seq experiment and data analysis.
Caption: Decision tree for selecting a data normalization strategy.
References
- 1. m1A RNA Methylation Analysis - CD Genomics [cd-genomics.com]
- 2. biorxiv.org [biorxiv.org]
- 3. biorxiv.org [biorxiv.org]
- 4. Chapter 7 - Data Normalization — Bioinforomics- Introduction to Systems Bioinformatics [introduction-to-bioinformatics.dev.maayanlab.cloud]
- 5. pluto.bio [pluto.bio]
- 6. Comparison of normalization methods for differential gene expression analysis in RNA-Seq experiments: A matter of relative size of studied transcriptomes - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Evaluation of normalization methods in mammalian microRNA-Seq data - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Normalization, bias correction, and peak calling for ChIP-seq - PMC [pmc.ncbi.nlm.nih.gov]
Technical Support Center: Refining Bioinformatics Pipelines for m1A Peak Calling
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to assist researchers, scientists, and drug development professionals in refining their bioinformatics pipelines for N1-methyladenosine (m1A) peak calling.
Frequently Asked Questions (FAQs)
Q1: What is m1A peak calling and why is it important?
A1: N1-methyladenosine (m1A) is a post-transcriptional RNA modification implicated in various cellular processes, including the regulation of mRNA translation.[1][2] m1A peak calling is the computational process of identifying regions in the transcriptome that are enriched for m1A modifications from high-throughput sequencing data, typically generated by m1A-specific methylated RNA immunoprecipitation sequencing (m1A-seq or MeRIP-seq).[2][3] Accurate peak calling is crucial for mapping the m1A methylome, understanding its regulatory functions, and identifying potential therapeutic targets.
Q2: What are the key steps in a typical m1A peak calling bioinformatics workflow?
A2: A standard m1A-seq bioinformatics workflow involves several key stages:
-
Raw Data Quality Control: Assessing the quality of raw sequencing reads using tools like FastQC.
-
Adapter and Quality Trimming: Removing low-quality bases and adapter sequences.
-
Alignment to Reference Genome/Transcriptome: Mapping the cleaned reads to a reference genome or transcriptome.
-
Peak Calling: Identifying regions of m1A enrichment (peaks) in the immunoprecipitation (IP) sample relative to a control (input) sample.
-
Peak Annotation and Visualization: Annotating peaks to genomic features and visualizing them in a genome browser.
-
Downstream Analysis: Including differential methylation analysis, motif discovery, and functional enrichment analysis.[2][4]
Q3: Which peak calling software is recommended for m1A-seq data?
A3: While there are no peak callers designed exclusively for m1A-seq, tools developed for ChIP-seq and m6A-MeRIP-seq are commonly used and have shown to be effective. The choice of software can impact the results, so it's important to understand their underlying algorithms.[5]
-
MACS2 (Model-based Analysis of ChIP-Seq): A widely used tool for identifying transcription factor binding sites, it can be adapted for m1A-seq data. It models the shift size of reads to improve spatial resolution.[6][7]
-
exomePeak2: An R/Bioconductor package specifically designed for MeRIP-seq data, which can account for biases such as GC content and immunoprecipitation efficiency.[8][9]
A comparative overview of commonly used peak callers is provided in the table below.
Troubleshooting Guides
Section 1: Experimental & Library Preparation Issues Affecting Peak Calling
Problem: Low yield of immunoprecipitated RNA.
| Possible Cause | Recommended Solution |
| Inefficient Antibody Binding | Ensure the m1A antibody has been validated for immunoprecipitation. Use a sufficient amount of antibody as recommended by the manufacturer or determined through titration experiments. |
| RNA Degradation | Maintain a sterile, RNase-free environment. Use RNase inhibitors throughout the procedure. Assess RNA integrity (e.g., using a Bioanalyzer) before and after fragmentation.[2] |
| Suboptimal Fragmentation | Optimize RNA fragmentation time to ensure fragments are in the desired size range (typically 100-200 nucleotides).[10] |
Problem: High background signal in the input control.
| Possible Cause | Recommended Solution |
| Non-specific Binding to Beads | Pre-clear the RNA fragments by incubating them with beads before adding the antibody. Use a blocking agent like BSA to reduce non-specific binding. |
| Contamination | Ensure that the input sample is a true representation of the pre-IP RNA and has not been contaminated. |
Section 2: Bioinformatics Pipeline Troubleshooting
Problem: Low number of called peaks.
| Possible Cause | Recommended Solution |
| Low Sequencing Depth | Ensure sufficient sequencing depth for both IP and input samples. A lack of saturation in peak detection with increasing read depth may indicate insufficient sequencing.[5] |
| Stringent Peak Calling Parameters | The p-value or q-value (FDR) cutoff may be too stringent. Try relaxing the threshold (e.g., from q < 0.01 to q < 0.05) to identify more potential peaks.[6] |
| Inefficient Immunoprecipitation | If the IP efficiency was low, the signal-to-noise ratio will be poor, leading to fewer significant peaks. Review the experimental protocol for potential improvements. |
| Inappropriate Peak Caller for Data Type | Some peak callers are better suited for broad peaks, while others excel at narrow peaks. m1A peaks are typically narrow. Ensure you are using a peak caller and parameters appropriate for narrow peak detection.[7] |
Problem: Peaks are too broad or poorly defined.
| Possible Cause | Recommended Solution |
| Inefficient RNA Fragmentation | Over-fragmentation can lead to a diffuse signal, while under-fragmentation can result in broad, poorly resolved peaks. Optimize the fragmentation step. |
| Incorrect Peak Calling Parameters | If using MACS2, ensure the --broad option is not used for m1A-seq, as it is intended for diffuse histone marks.[6] |
| PCR Duplicates | High levels of PCR duplicates can create artificial peaks. Use tools to mark or remove duplicates before peak calling. |
Problem: High number of false-positive peaks.
| Possible Cause | Recommended Solution |
| Insufficiently Complex Library | Low library complexity can lead to PCR artifacts that are incorrectly called as peaks. Assess library complexity before sequencing. |
| Inadequate Input Control | The input control is crucial for distinguishing true enrichment from background noise. Ensure the input and IP libraries are sequenced to comparable depths. |
| Repetitive Regions | Reads mapping to repetitive regions can cause false-positive peaks. Filter out multi-mapping reads and consider using a blacklist of problematic genomic regions. |
Data Presentation
Table 1: Comparison of Commonly Used Peak Calling Software for m1A-Seq
| Feature | MACS2 (Model-based Analysis of ChIP-Seq) | exomePeak2 |
| Primary Application | ChIP-seq, adaptable for MeRIP-seq[6] | MeRIP-seq[8] |
| Input Files | Aligned reads in BAM or SAM format for IP and input samples.[7] | Aligned reads in BAM format for IP and input samples.[9] |
| Key Algorithm | Uses a dynamic Poisson distribution to model read counts and identifies enriched regions.[7] | Employs a generalized linear model (GLM) to account for biases and quantify methylation.[8] |
| Bias Correction | Models local background noise. | Corrects for GC content bias and immunoprecipitation efficiency.[9] |
| Output Files | BED file of peak locations, peak summit information, and fold-enrichment values.[11] | BED and CSV files with peak locations and statistics.[9] |
| Strengths | Widely used and well-documented, good for identifying narrow peaks.[6] | Specifically designed for MeRIP-seq, robust against common biases.[8] |
| Limitations | Does not explicitly correct for GC content or IP efficiency biases. | Less widely used than MACS2. |
Experimental Protocols
Protocol 1: m1A RNA Immunoprecipitation (m1A-IP)
This protocol is a generalized procedure for the immunoprecipitation of m1A-containing RNA fragments.
-
RNA Preparation and Fragmentation:
-
Isolate total RNA from cells or tissues of interest.
-
Assess RNA quality and quantity.
-
Fragment the RNA to an average size of 100-200 nucleotides using appropriate methods (e.g., enzymatic or chemical fragmentation).
-
Purify the fragmented RNA.
-
-
Antibody-Bead Conjugation:
-
Wash magnetic beads (e.g., Protein A/G) with IP buffer.
-
Incubate the beads with an anti-m1A antibody to allow for conjugation.
-
-
Immunoprecipitation:
-
Add the fragmented RNA to the antibody-conjugated beads.
-
Incubate to allow the antibody to bind to m1A-containing RNA fragments.
-
A portion of the fragmented RNA should be saved as the "input" control.
-
-
Washing:
-
Wash the beads multiple times with wash buffer to remove non-specifically bound RNA.
-
-
Elution and Purification:
-
Elute the m1A-enriched RNA from the beads.
-
Purify the eluted RNA.
-
-
Library Preparation and Sequencing:
-
Prepare sequencing libraries from both the m1A-enriched (IP) and input RNA samples.
-
Perform high-throughput sequencing.
-
Mandatory Visualization
Caption: Overview of the m1A-seq experimental and bioinformatics workflow.
Caption: Troubleshooting flowchart for a low number of m1A peaks.
References
- 1. epigenie.com [epigenie.com]
- 2. m1A Sequencing - CD Genomics [rna.cd-genomics.com]
- 3. Sequencing Technologies of m1A RNA Modification - CD Genomics [rna.cd-genomics.com]
- 4. Master MeRIP-seq Data Analysis: Step-by-Step Process for RNA Methylation Studies - CD Genomics [rna.cd-genomics.com]
- 5. Comparative analysis of commonly used peak calling programs for ChIP-Seq analysis - PMC [pmc.ncbi.nlm.nih.gov]
- 6. How To Analyze ChIP-seq Data For Absolute Beginners Part 4: From FASTQ To Peaks With MACS2 - NGS Learning Hub [ngs101.com]
- 7. Peak calling with MACS2 | Introduction to ChIP-Seq using high-performance computing [hbctraining.github.io]
- 8. s3.jcloud.sjtu.edu.cn [s3.jcloud.sjtu.edu.cn]
- 9. bioconductor.statistik.tu-dortmund.de [bioconductor.statistik.tu-dortmund.de]
- 10. MeRIP Sequencing Q&A - CD Genomics [cd-genomics.com]
- 11. Peak - ChIP-seq tutorials [chip-seq.readthedocs.io]
Technical Support Center: Addressing Biases in PCR Amplification of N1-methyladenosine (m1A)-Containing Fragments
Welcome to the technical support center for researchers, scientists, and drug development professionals encountering challenges with PCR amplification of RNA fragments containing N1-methyladenosine (m1A). This resource provides troubleshooting guides and frequently asked questions (FAQs) to help you overcome biases in your experiments.
Understanding the Challenge: The Impact of m1A on Reverse Transcription and PCR
N1-methyladenosine (m1A) is a post-transcriptional RNA modification that plays a crucial role in regulating various biological processes. However, its presence can introduce significant bias during reverse transcription (RT) and subsequent PCR amplification. The methyl group on the N1 position of adenosine blocks the Watson-Crick base-pairing face, which is essential for standard reverse transcriptases. This blockage leads to two primary issues:
-
Reverse Transcriptase Stalling: The reverse transcriptase enzyme often halts at the m1A site, resulting in truncated complementary DNA (cDNA) fragments. These truncated fragments are not efficiently amplified in the subsequent PCR step, leading to an underrepresentation of m1A-containing transcripts in the final sequencing library.[1][2][3]
-
Misincorporation: Some reverse transcriptases can read through the m1A modification but may incorporate an incorrect nucleotide opposite the m1A base. This leads to mutations in the cDNA sequence, which can be misinterpreted in downstream analyses.[2][4]
This guide provides solutions to mitigate these biases and achieve more accurate quantification and analysis of m1A-containing RNA molecules.
Troubleshooting Guide
This section addresses specific issues you might encounter during your experiments in a question-and-answer format.
Issue 1: Low or No cDNA Yield After Reverse Transcription
Question: I am getting very low or no full-length cDNA product after reverse transcription of my RNA sample, which I suspect contains m1A. What could be the cause and how can I fix it?
Answer:
This is a classic sign of reverse transcriptase stalling at m1A sites. Here are the potential causes and solutions:
-
Cause: Your reverse transcriptase is being blocked by the m1A modification.
-
Solution 1: Enzymatic Demethylation with AlkB. Treat your RNA with an AlkB family demethylase (e.g., E. coli AlkB or human ALKBH3) prior to reverse transcription.[5][6] AlkB removes the methyl group from m1A, converting it back to a standard adenosine that can be easily read by the reverse transcriptase. See the detailed protocol for AlkB treatment below.
-
Solution 2: Use an Engineered Reverse Transcriptase. Employ a reverse transcriptase specifically engineered to read through m1A modifications, such as RT-1306. This evolved enzyme can bypass the m1A site, often introducing a specific mutation that can be used for mapping purposes.[2][7]
-
Solution 3: Optimize Your Choice of Reverse Transcriptase. If you are not using an engineered enzyme, some commercially available reverse transcriptases may have better read-through capabilities than others on modified templates. While not specifically designed for m1A, enzymes with high processivity and thermostability, such as SuperScript IV or Maxima H Minus, may offer some improvement over older enzymes.[8][9][10][11] However, for significant bias reduction, AlkB treatment or an engineered RT is recommended.
Question: I treated my RNA with AlkB, but I am still observing low cDNA yield. What should I do?
Answer:
If AlkB treatment does not resolve the low yield, consider the following troubleshooting steps:
-
Incomplete Demethylation:
-
Enzyme Activity: Ensure your AlkB enzyme is active and has been stored correctly. Consider running a positive control with a known m1A-containing synthetic oligo to verify enzyme activity.
-
Reaction Conditions: Optimize the AlkB reaction conditions, including buffer components, co-factors (Fe(II) and α-ketoglutarate), and incubation time and temperature.[5] Refer to the detailed protocol for recommended conditions.
-
RNA Secondary Structure: Complex RNA secondary structures can sometimes hinder enzyme access to the m1A site.[6] You can try a brief denaturation step (e.g., 70°C for 2 minutes followed by snap-cooling on ice) before adding the AlkB enzyme.
-
-
RNA Quality:
-
RNA Degradation: Assess the integrity of your RNA sample using a Bioanalyzer or gel electrophoresis. Degraded RNA will result in low yields of full-length cDNA regardless of m1A presence.
-
Inhibitors: Your RNA sample may contain inhibitors from the extraction process that affect either the AlkB enzyme or the reverse transcriptase. Consider re-purifying your RNA.
-
-
Reverse Transcription Issues:
-
Suboptimal RT Conditions: Ensure your reverse transcription reaction is set up correctly with optimal primer concentrations, dNTPs, and buffer.
-
RNase Contamination: Use RNase inhibitors in your reactions to prevent RNA degradation.
-
Issue 2: Unexpected Mutations or Sequence Ambiguities
Question: I used the engineered reverse transcriptase RT-1306 and see mutations in my sequencing data, but the pattern is not what I expected. How do I interpret these results?
Answer:
Ambiguous mutation signatures when using RT-1306 can arise from several factors:
-
Background Mutations: RT-1306 has a low background mutation rate on unmodified adenosine residues.[2] To distinguish true m1A-induced mutations from background noise, it is crucial to have a control sample.
-
AlkB Treatment Control: The gold standard is to treat an aliquot of your RNA with AlkB demethylase before performing reverse transcription with RT-1306.[2] A true m1A site will show a significantly reduced mutation rate in the AlkB-treated sample compared to the untreated sample.
-
-
Other RNA Modifications: Other RNA modifications can also induce mutations during reverse transcription. Comparing your data to existing databases of RNA modifications can help to identify if other modifications are present at the site of interest.
-
Single Nucleotide Polymorphisms (SNPs): If you are working with samples from different individuals or cell lines, apparent mutations could be due to genetic variation. Sequencing a genomic DNA control can help to rule out SNPs.
-
Suboptimal Sequencing Quality: Low-quality sequencing reads can contain errors that may be misinterpreted as mutations. Ensure your sequencing data meets quality control standards.
Frequently Asked Questions (FAQs)
Q1: What is the primary cause of PCR bias when working with m1A-containing RNA?
A1: The primary cause is the N1-methyladenosine (m1A) modification itself, which blocks the Watson-Crick base-pairing face of the adenosine. This hinders the progression of most standard reverse transcriptases, leading to truncated cDNA synthesis (stalling) and an underrepresentation of these RNA molecules in the final amplified product.[1][3]
Q2: How can I remove the m1A modification before PCR?
A2: The most effective way to remove the m1A modification is through enzymatic demethylation using an AlkB family protein, such as E. coli AlkB or human ALKBH3.[5][6] These enzymes convert m1A back to adenosine, allowing for efficient and accurate reverse transcription.
Q3: Are there any reverse transcriptases that can read through m1A?
A3: Yes, the engineered reverse transcriptase RT-1306 has been specifically developed to read through m1A sites with high efficiency.[2][7] It's important to note that RT-1306 introduces specific mutations (predominantly A-to-T) at the m1A site, which can be used to map the location of the modification.[2] Some thermostable group II intron reverse transcriptases (TGIRTs) also show a higher read-through rate compared to standard retroviral RTs, but RT-1306 generally demonstrates superior performance for m1A.[1][12]
Q4: Can I just use a more processive reverse transcriptase like SuperScript IV to overcome the bias?
A4: While highly processive enzymes like SuperScript IV and Maxima H Minus may show some improvement in reading through structured or modified RNA compared to older enzymes, they are not specifically designed to overcome the block posed by m1A.[8][9][10][11] For a significant reduction in bias, it is recommended to either remove the m1A modification with AlkB or use an engineered enzyme like RT-1306.
Q5: How do I know if my AlkB demethylation reaction was successful?
A5: You can assess the success of your AlkB treatment in a few ways:
-
Increased cDNA Yield: A successful demethylation should result in a noticeable increase in the yield of full-length cDNA, which can be visualized on a gel or quantified by qPCR.
-
Reduced Mutation Rate (if using RT-1306): If you are using RT-1306 for reverse transcription, a successful AlkB treatment will lead to a significant reduction in the mutation rate at known or suspected m1A sites in your sequencing data.
-
Control Reactions: Including a positive control (a synthetic RNA with a known m1A site) and a no-enzyme control in your experiment will help you validate the effectiveness of the treatment.
Q6: Are there commercial kits available to help with this issue?
A6: Several companies offer kits for RNA library preparation for next-generation sequencing that include modules or recommendations for handling RNA modifications. For example, some kits for tRNA and tRF sequencing include an enzymatic demethylation step.[13] Additionally, individual enzymes like Maxima H Minus Reverse Transcriptase and SuperScript IV Reverse Transcriptase are commercially available.[11][14] For specific m1A-seq library preparation, you may need to purchase the components, such as the RT-1306 enzyme and AlkB demethylase, separately and follow published protocols.[1][2]
Data Presentation
Table 1: Comparison of Reverse Transcriptase Performance on m1A-Containing RNA
| Reverse Transcriptase | Type | Read-through Efficiency at m1A | Mutation Rate at m1A | Recommended Use for m1A-RNA |
| Standard M-MuLV RTs | Wild-Type Retroviral | Very Low | Low (if read-through occurs) | Not Recommended |
| SuperScript II/III | Engineered Retroviral | Low | Low | Not Recommended |
| SuperScript IV | Engineered Retroviral | Moderate | Low | Better than older versions, but not ideal |
| Maxima H Minus | Engineered Retroviral | Moderate | Low | Better than older versions, but not ideal |
| TGIRT | Group II Intron | High | Moderate | Good for read-through, but lower cDNA yield than RT-1306 |
| RT-1306 | Engineered HIV-1 RT | Very High (~80%) | High (~84%, predominantly A-to-T) | Recommended for m1A mapping via mutation signature |
Note: Performance can be sequence context-dependent. Data for RT-1306 and its comparison to TGIRT are from Zhou et al., 2019.[1] Performance of other RTs on m1A is inferred from their general properties and comparative studies on other difficult templates.
Experimental Protocols
Protocol 1: AlkB Demethylation of m1A-Containing RNA
This protocol is adapted from published methods for the enzymatic removal of m1A from RNA.[5]
Materials:
-
Total RNA or poly(A)-selected RNA
-
AlkB enzyme (e.g., recombinant E. coli AlkB)
-
10x AlkB Reaction Buffer (e.g., 500 mM MES, pH 6.5)
-
Cofactors: (NH₄)₂Fe(SO₄)₂·6H₂O, α-ketoglutarate, L-ascorbic acid
-
RNase Inhibitor
-
Nuclease-free water
Procedure:
-
Prepare the Reaction Mix: In a nuclease-free tube on ice, prepare the following reaction mixture:
Component Final Concentration RNA 1-5 µg 10x AlkB Reaction Buffer 1x (NH₄)₂Fe(SO₄)₂·6H₂O 50 µM α-ketoglutarate 1 mM L-ascorbic acid 2 mM RNase Inhibitor 20 units AlkB Enzyme 1-2 µM | Nuclease-free water | to final volume |
-
Incubation: Incubate the reaction at 37°C for 1-2 hours.
-
RNA Cleanup: Purify the RNA using an RNA cleanup kit (e.g., Zymo RNA Clean & Concentrator) or by ethanol precipitation.
-
Proceed to Reverse Transcription: The demethylated RNA is now ready for use in your standard reverse transcription protocol.
Protocol 2: Reverse Transcription of m1A-Containing RNA using RT-1306
This protocol is based on the methodology described for m1A mapping using the engineered RT-1306.[1]
Materials:
-
AlkB-treated (control) or untreated RNA
-
RT-1306 Reverse Transcriptase
-
Gene-specific primers or oligo(dT) primers
-
dNTPs
-
5x RT Buffer
-
DTT
-
RNase Inhibitor
-
Nuclease-free water
Procedure:
-
Primer Annealing: In a PCR tube, combine:
-
RNA (up to 1 µg)
-
Primer (10 µM) - 1 µL
-
dNTPs (10 mM) - 1 µL
-
Nuclease-free water to 13 µL Incubate at 65°C for 5 minutes, then place on ice for at least 1 minute.
-
-
Prepare RT Master Mix: On ice, prepare the following master mix for each reaction:
-
5x RT Buffer - 4 µL
-
100 mM DTT - 1 µL
-
RNase Inhibitor (40 U/µL) - 1 µL
-
RT-1306 Enzyme - 1 µL
-
-
Reverse Transcription: Add 7 µL of the RT master mix to the annealed primer/RNA mix. Mix gently and incubate at 50°C for 60 minutes.
-
Enzyme Inactivation: Heat the reaction at 70°C for 15 minutes to inactivate the RT-1306 enzyme.
-
Proceed to PCR: The resulting cDNA can now be used as a template for PCR amplification.
Mandatory Visualizations
Caption: Workflow for addressing m1A-induced PCR bias.
Caption: Troubleshooting logic for low cDNA yield.
References
- 1. Evolution of a Reverse Transcriptase to Map N1-Methyladenosine in Human mRNA - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Chemical manipulation of m1A mediates its detection in human tRNA - PMC [pmc.ncbi.nlm.nih.gov]
- 3. m1A RNA Modification in Gene Expression Regulation - PMC [pmc.ncbi.nlm.nih.gov]
- 4. idtdna.com [idtdna.com]
- 5. researchgate.net [researchgate.net]
- 6. Quantification of tRNA m1A modification by templated-ligation qPCR - PMC [pmc.ncbi.nlm.nih.gov]
- 7. biorxiv.org [biorxiv.org]
- 8. Direct tracking of reverse-transcriptase speed and template sensitivity: implications for sequencing and analysis of long RNA molecules - PMC [pmc.ncbi.nlm.nih.gov]
- 9. biorxiv.org [biorxiv.org]
- 10. How to Troubleshoot Sequencing Preparation Errors (NGS Guide) - CD Genomics [cd-genomics.com]
- 11. Performance Comparison of Reverse Transcriptases for Single-Cell Studies - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. TGIRT-seq to profile tRNA-derived RNAs and associated RNA modifications - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Development of mild chemical catalysis conditions for m1A-to-m6A rearrangement on RNA - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Maxima H Minus Reverse Transcriptase (200 U/μL), 4 x 10,000 Units - FAQs [thermofisher.com]
Validation & Comparative
Validating m1A-Seq Results with Targeted qPCR: A Comparative Guide
Introduction
N1-methyladenosine (m1A) is a widespread post-transcriptional RNA modification that plays a crucial role in regulating various biological processes, including mRNA translation and stability.[1][2][3] The development of high-throughput sequencing techniques, such as m1A-seq, has enabled transcriptome-wide mapping of m1A sites.[2][4] However, like other sequencing-based methods, results from m1A-seq require rigorous validation to confirm the identified methylation sites. Targeted quantitative PCR (qPCR) is a widely accepted and robust method for validating such findings, offering a quantitative measure of the enrichment of specific RNA modifications.[5][6]
This guide provides a comprehensive comparison of m1A-seq and targeted qPCR for the validation of m1A methylation, complete with experimental protocols and data presentation formats tailored for researchers, scientists, and drug development professionals.
Comparative Data Analysis
The primary goal of the validation experiment is to determine if the fold enrichment of a specific transcript in the m1A immunoprecipitation (IP) sample, as suggested by m1A-seq, can be confirmed by targeted qPCR. The table below presents a hypothetical dataset comparing the results from both methods for several target genes.
| Gene | m1A-Seq Peak Score | m1A-Seq Fold Enrichment | qPCR % Input (m1A IP) | qPCR Fold Enrichment | Validation Status |
| GENE-A | 250.7 | 8.2 | 1.5% | 7.5 | Validated |
| GENE-B | 180.4 | 6.1 | 1.1% | 5.5 | Validated |
| GENE-C | 95.2 | 3.3 | 0.3% | 1.5 | Weakly Validated |
| GENE-D | 210.1 | 7.5 | 0.2% | 1.1 | Not Validated |
| GENE-E | 45.8 | 1.8 | 0.1% | 0.9 | Not Validated |
-
m1A-Seq Peak Score: A value assigned by the sequencing data analysis pipeline, indicating the confidence of the m1A peak.
-
m1A-Seq Fold Enrichment: The ratio of normalized read counts in the IP sample to the input sample from the sequencing data.
-
qPCR % Input (m1A IP): The amount of a specific transcript in the IP sample, calculated as a percentage of the starting material ("input").
-
qPCR Fold Enrichment: The enrichment of a specific transcript in the m1A IP sample compared to a negative control IP (e.g., IgG), calculated using the ΔΔCt method.
Experimental Workflow
The overall process of validating m1A-seq data with qPCR involves several key stages, from the initial high-throughput experiment to the targeted validation of individual "hits." The workflow ensures a logical progression from discovery to confirmation.
Figure 1. Workflow for m1A-seq and subsequent qPCR validation.
Experimental Protocols
Methylated RNA Immunoprecipitation (MeRIP)
This protocol is adapted for m1A and is based on established methods for methylated RNA immunoprecipitation.[7][8][9]
-
RNA Preparation:
-
Isolate total RNA from cells or tissues using a standard method like TRIzol.
-
Purify mRNA using oligo(dT) magnetic beads.
-
Chemically fragment the mRNA to an average size of 100-200 nucleotides by incubating with an RNA fragmentation buffer at 90°C for a short duration.[10][11]
-
Precipitate the fragmented RNA using ethanol and resuspend in nuclease-free water.
-
-
Immunoprecipitation:
-
Prepare Protein A/G magnetic beads by washing them three times in IP buffer.
-
Incubate the beads with an anti-m1A antibody (or a negative control IgG) for 1 hour at room temperature with gentle rotation.
-
Add the fragmented mRNA to the antibody-bead mixture along with RNase inhibitors.
-
Incubate overnight at 4°C with gentle rotation to allow the antibody to capture m1A-containing RNA fragments.
-
Save a small fraction (e.g., 10%) of the fragmented RNA before this step to serve as the "input" control.[9][11]
-
-
Washing and Elution:
-
Wash the beads multiple times with low and high salt IP buffers to remove non-specifically bound RNA.
-
Elute the captured RNA from the beads using an appropriate elution buffer.
-
Purify the eluted RNA and the input RNA using an RNA cleanup kit or ethanol precipitation.
-
Targeted qPCR Validation
-
Reverse Transcription:
-
Convert the eluted RNA from the IP and input samples into cDNA using a reverse transcription kit with random primers.
-
-
Primer Design:
-
Design qPCR primers to amplify a 70-200 bp region that flanks the putative m1A site identified from the m1A-seq data.[12][13]
-
Ensure primers have a GC content between 40-60% and a melting temperature (Tm) of 60-63°C.[13]
-
Verify primer specificity in silico using tools like NCBI Primer-BLAST and experimentally via a melt curve analysis to ensure a single product is amplified.[12][14]
-
-
qPCR Reaction:
-
Set up qPCR reactions in triplicate for each target gene using SYBR Green chemistry.
-
Include reactions for the IP sample, the input sample, and a no-template control.
-
Run the qPCR on a real-time PCR instrument.
-
-
Data Analysis:
-
Determine the Ct (cycle threshold) value for each reaction.
-
Calculate the amount of target transcript in the IP sample as a percentage of the input using the formula: % Input = 2^(-ΔCt) * 100, where ΔCt = Ct(IP) - Ct(Input).
-
To determine fold enrichment over a negative control (IgG), use the ΔΔCt method.
-
Application in Signaling Pathway Analysis
The regulation of mRNA by m1A modification can have significant downstream effects on cellular signaling pathways. For instance, if m1A modification enhances the stability or translation of an mRNA encoding a key kinase, it could lead to the upregulation of that pathway. Validating such m1A modifications is the first step in elucidating these regulatory mechanisms.
Figure 2. Hypothetical impact of m1A on the MAPK signaling pathway.
In the example above, an m1A modification on the mRNA of the RAF kinase could enhance its translation, leading to increased protein levels and hyperactivation of the downstream MAPK/ERK pathway. Validating the m1A status of RAF mRNA using qPCR would be a critical experiment to support this hypothesis.
References
- 1. Quantification of tRNA m1A modification by templated-ligation qPCR - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. m1A RNA Methylation Analysis - CD Genomics [cd-genomics.com]
- 3. Research progress of N1-methyladenosine RNA modification in cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Base-resolution mapping reveals distinct m1A methylome in nuclear- and mitochondrial-encoded transcripts - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Quantification of tRNA m1A modification by templated-ligation qPCR - PMC [pmc.ncbi.nlm.nih.gov]
- 6. rna-seqblog.com [rna-seqblog.com]
- 7. Methylated RNA Immunoprecipitation (meRIP) and RT-qPCR [bio-protocol.org]
- 8. pubcompare.ai [pubcompare.ai]
- 9. sigmaaldrich.com [sigmaaldrich.com]
- 10. An experimental workflow for identifying RNA m6A alterations in cellular senescence by methylated RNA immunoprecipitation sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Detection of N6-methyladenosine in SARS-CoV-2 RNA by methylated RNA immunoprecipitation sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 12. bio-rad.com [bio-rad.com]
- 13. m.youtube.com [m.youtube.com]
- 14. researchhub.com [researchhub.com]
A Comparative Guide to 1-Methyladenine (m1A) and N6-methyladenosine (m6A) Distribution in RNA
For Researchers, Scientists, and Drug Development Professionals
This guide provides an objective comparison of the distribution and biological significance of two key RNA modifications: 1-Methyladenine (m1A) and N6-methyladenosine (m6A). The information presented is supported by experimental data to facilitate a comprehensive understanding of these epitranscriptomic marks.
Introduction to m1A and m6A
Post-transcriptional modifications of RNA add a critical layer of regulatory complexity to gene expression. Among the more than 170 known RNA modifications, N6-methyladenosine (m6A) is the most abundant internal modification in eukaryotic mRNA, while 1-Methyladenine (m1A) is a more recently appreciated, dynamic modification found across various RNA species. Both play pivotal roles in numerous biological processes, and their dysregulation has been implicated in various diseases, including cancer.
1-Methyladenine (m1A): This modification involves the methylation of the N1 position of adenine. The addition of a methyl group to this position disrupts the canonical Watson-Crick base pairing, thereby impacting RNA structure and its interactions with proteins.
N6-methyladenosine (m6A): This modification occurs at the N6 position of adenine. Unlike m1A, m6A does not directly inhibit Watson-Crick base pairing but can influence RNA structure and is recognized by a specific set of binding proteins known as "readers."
Quantitative Distribution of m1A and m6A
The distribution of m1A and m6A is not random and exhibits distinct patterns across different RNA types and within specific transcript regions. The following table summarizes their quantitative distribution based on current research.
| Feature | 1-Methyladenine (m1A) | N6-methyladenosine (m6A) |
| Abundance in total RNA | Less abundant than m6A. | Most abundant internal mRNA modification, accounting for 0.15-0.6% of all adenosines in mammalian mRNA.[1] |
| Distribution in mRNA | Predominantly enriched in the 5' untranslated region (5' UTR), particularly near the translation initiation site (TIS).[2] Also found in coding sequences (CDS). | Enriched near stop codons, in 3' untranslated regions (3' UTRs), and within long internal exons.[1] |
| Distribution in tRNA | Highly abundant and evolutionarily conserved, found at specific positions such as T54 and T58.[3] | Present, but less studied than in mRNA. |
| Distribution in rRNA | Present in both small and large ribosomal subunits. | Found in 18S and 28S rRNA at specific, functionally important sites.[4] |
| Cellular Localization | Found in both the nucleus and cytoplasm, as well as in mitochondrial RNA. | Primarily deposited in the nucleus and functions in both the nucleus and cytoplasm. |
| Consensus Motif | A "GUUCRA" tRNA-like motif has been identified for a subset of m1A sites in mRNA.[5] | Primarily occurs within a "RRACH" (R=G or A; H=A, C, or U) sequence motif. |
Biological Functions and Signaling Pathways
Both m1A and m6A are dynamically regulated by a set of "writer" (methyltransferases), "eraser" (demethylases), and "reader" (binding) proteins. These modifications influence various aspects of RNA metabolism, from processing and export to translation and decay.
1-Methyladenine (m1A):
-
Translation Regulation: m1A in the 5' UTR is generally associated with enhanced translation initiation.[2] Conversely, m1A within the coding sequence can inhibit translation.
-
RNA Stability: The impact of m1A on mRNA stability is context-dependent. It can either promote or inhibit RNA decay.
-
tRNA Function: m1A is crucial for maintaining the structural integrity and stability of tRNAs, which is essential for efficient protein synthesis.[3]
N6-methyladenosine (m6A):
-
RNA Splicing: m6A can influence pre-mRNA splicing by recruiting splicing factors.
-
RNA Export: It facilitates the nuclear export of mRNAs.
-
RNA Stability and Decay: m6A is a key regulator of mRNA stability. The binding of reader proteins like YTHDF2 to m6A-modified transcripts can target them for degradation.[6]
-
Translation Regulation: m6A can either promote or inhibit translation depending on its location within the mRNA and the specific reader proteins involved.
Recent evidence suggests a functional interplay between m1A and m6A. For instance, the presence of both modifications on an mRNA can cooperatively facilitate its rapid degradation.[6][7]
Signaling Pathway Example: m1A-mediated T-cell Expansion
The diagram below illustrates the role of m1A modification in promoting T-cell expansion through the efficient synthesis of the MYC protein, a key regulator of cell proliferation.
Experimental Protocols for m1A and m6A Detection
The transcriptome-wide mapping of m1A and m6A is primarily achieved through antibody-based enrichment coupled with high-throughput sequencing.
m6A-Seq / MeRIP-Seq (Methylated RNA Immunoprecipitation Sequencing)
This is the most widely used method for mapping m6A.
1. RNA Preparation and Fragmentation:
-
Isolate total RNA from cells or tissues of interest.
-
Purify mRNA using oligo(dT) magnetic beads.
-
Fragment the mRNA into ~100-nucleotide fragments using chemical or enzymatic methods.
2. Immunoprecipitation (IP):
-
Incubate the fragmented RNA with an anti-m6A antibody.
-
Capture the antibody-RNA complexes using protein A/G magnetic beads.
-
Wash the beads to remove non-specifically bound RNA.
3. Elution and Library Preparation:
-
Elute the m6A-containing RNA fragments from the beads.
-
Prepare a sequencing library from the eluted RNA fragments. An "input" library should also be prepared from a small fraction of the fragmented RNA before the IP step to serve as a control.
4. Sequencing and Data Analysis:
-
Sequence both the IP and input libraries using a high-throughput sequencing platform.
-
Align the sequencing reads to the reference genome/transcriptome.
-
Identify m6A peaks by comparing the read enrichment in the IP sample to the input control.
m1A-Seq
Mapping m1A is more complex due to the modification's impact on reverse transcription. Several methods have been developed.
Method 1: Antibody-based (similar to MeRIP-Seq)
-
This method follows a similar protocol to MeRIP-Seq but utilizes a specific anti-m1A antibody for the immunoprecipitation step.[8]
Method 2: Exploiting Reverse Transcriptase Signatures
-
This approach leverages the fact that m1A can cause misincorporations or truncations during reverse transcription.
-
m1A-MAP (m1A-sensitive Mutation Analysis upon sequencing): This method identifies m1A sites by detecting specific mutation patterns in the sequencing data.[9] Demethylase treatment can be used as a control to confirm the m1A-dependent nature of the mutations.
Experimental Workflow: MeRIP-Seq
The following diagram outlines the key steps in a typical MeRIP-Seq experiment.
Conclusion
Both 1-Methyladenine and N6-methyladenosine are critical epitranscriptomic modifications with distinct distributions and diverse regulatory functions. While m6A is more abundant and its roles in mRNA metabolism are well-characterized, the importance of m1A in regulating translation and tRNA function is increasingly being recognized. The continued development of high-resolution mapping techniques will further elucidate the specific roles of these modifications in health and disease, paving the way for novel therapeutic strategies targeting the epitranscriptome.
References
- 1. m6A RNA methylation: from mechanisms to therapeutic potential - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Quantitative profiling of m6A at single base resolution across the life cycle of rice and Arabidopsis - PMC [pmc.ncbi.nlm.nih.gov]
- 3. academic.oup.com [academic.oup.com]
- 4. The rRNA m6A methyltransferase METTL5 is involved in pluripotency and developmental programs - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Base-resolution mapping reveals distinct m1A methylome in nuclear- and mitochondrial-encoded transcripts - PMC [pmc.ncbi.nlm.nih.gov]
- 6. researchgate.net [researchgate.net]
- 7. m1A and m6A modifications function cooperatively to facilitate rapid mRNA degradation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. m1A RNA Methylation Analysis - CD Genomics [cd-genomics.com]
- 9. qian.human.cornell.edu [qian.human.cornell.edu]
A Functional Showdown: Dissecting the Roles of m1A RNA Methylation Writers and Erasers
For researchers, scientists, and drug development professionals, understanding the intricate dance of post-transcriptional modifications is paramount. Among these, N1-methyladenosine (m1A) has emerged as a critical regulator of RNA fate and function. This guide provides an in-depth functional comparison of the key enzymes that install (writers) and remove (erasers) this vital mark, supported by experimental data and detailed protocols to empower further research in this burgeoning field.
The reversibility of m1A methylation, orchestrated by a dedicated set of writers and erasers, allows for dynamic control over gene expression. This dynamic interplay governs a multitude of cellular processes, from tRNA stability and mRNA translation to cellular stress responses and disease progression, including cancer.[1][2]
The Architects of m1A: A Comparative Look at Writer Enzymes
The primary writers of m1A methylation in mammalian cells are the TRMT6/TRMT61A complex for cytoplasmic RNAs, and TRMT61B and TRMT10C within the mitochondria.
The TRMT6/TRMT61A complex is the principal methyltransferase for m1A at position 58 (m1A58) of cytoplasmic tRNAs and also targets a subset of mRNAs.[3][4] TRMT61A serves as the catalytic subunit, while TRMT6 is crucial for tRNA binding.[3] This complex exhibits a notable substrate specificity, recognizing a "GUUCRA" motif within a T-loop-like structure.[4] Dysregulation of the TRMT6/TRMT61A complex has been implicated in various cancers, where its overexpression often promotes proliferation and malignant transformation.[3][5]
Mitochondrial m1A methylation is handled by TRMT61B and TRMT10C . While both function within the mitochondria, they target different positions and substrates, highlighting the compartmentalized regulation of m1A.
Table 1: Functional Comparison of m1A Writer Enzymes
| Enzyme Complex/Subunit | Cellular Location | Primary Substrates | Recognition Motif/Structural Feature | Known Biological Roles |
| TRMT6/TRMT61A | Cytoplasm, Nucleus | tRNAs (at A58), subset of mRNAs | GUUCRA motif in a T-loop-like structure | tRNA stability, mRNA translation, cell proliferation, cancer progression |
| TRMT61B | Mitochondria | Mitochondrial tRNAs, some mitochondrial mRNAs | - | Mitochondrial translation |
| TRMT10C | Mitochondria | Mitochondrial tRNAs (at A9) | - | Mitochondrial tRNA processing |
The Erasers: Unraveling the Demethylase Machinery
The removal of m1A is primarily carried out by members of the AlkB family of dioxygenases, namely ALKBH1 and ALKBH3 , with FTO also implicated in this process. These enzymes facilitate the oxidative demethylation of m1A, rendering the modification reversible.
ALKBH1 and ALKBH3 are the most prominent m1A erasers.[6] Both enzymes can demethylate m1A in tRNA and mRNA.[6][7] In vitro studies have shown that the demethylation activity of ALKBH3 on tRNA is comparable to that of ALKBH1. ALKBH1-mediated demethylation of tRNA has been shown to regulate translation initiation and elongation.[6][7]
The fat mass and obesity-associated protein, FTO , is another enzyme capable of erasing m1A modifications, in addition to its well-known role as an m6A demethylase.[8]
Table 2: Functional Comparison of m1A Eraser Enzymes
| Enzyme | Cellular Location | Primary Substrates | Substrate Preference | Known Biological Roles |
| ALKBH1 | Nucleus, Cytoplasm, Mitochondria | tRNAs, mRNAs | Prefers m1A in stem-loop structures | Regulation of translation, response to glucose deprivation |
| ALKBH3 | Nucleus, Cytoplasm | tRNAs, mRNAs | Comparable activity to ALKBH1 on tRNA | Cell cycle regulation, cancer progression, DNA repair |
| FTO | Nucleus, Cytoplasm | mRNAs, tRNAs | Also demethylates m6A and m6Am | Metabolic regulation, cancer |
Signaling Pathways Under m1A Control
The functional consequences of m1A modification are evident in its influence on key cellular signaling pathways. Dysregulation of m1A writers and erasers has been shown to impact the PI3K/AKT/mTOR and ErbB signaling pathways, both of which are central to cell growth, proliferation, and survival.[1][9][10] For instance, alterations in the expression of m1A regulatory genes are associated with changes in the activity of these pathways in gastrointestinal cancers.[9]
Furthermore, there is significant crosstalk between m1A and N6-methyladenosine (m6A) , another prevalent mRNA modification.[11][12] This interplay adds another layer of complexity to post-transcriptional gene regulation, where the presence of one modification can influence the recognition and function of the other.
Caption: Interplay of m1A writers and erasers in regulating cellular signaling.
Experimental Corner: Protocols for m1A Analysis
To facilitate further investigation into the functional roles of m1A writers and erasers, we provide detailed methodologies for key experiments.
In Vitro Demethylase Assay for ALKBH1/ALKBH3
This assay measures the ability of recombinant ALKBH1 or ALKBH3 to remove the methyl group from an m1A-containing RNA substrate.
Methodology:
-
Reaction Setup: Prepare a reaction mixture containing the m1A-modified RNA substrate, recombinant ALKBH1 or ALKBH3 enzyme, and a buffer containing cofactors such as Fe(II), α-ketoglutarate, and ascorbate.
-
Incubation: Incubate the reaction mixture at 37°C for a specified time course.
-
Quenching: Stop the reaction by adding a chelating agent like EDTA.
-
Analysis: Analyze the reaction products using liquid chromatography-tandem mass spectrometry (LC-MS/MS) to quantify the levels of m1A and adenosine. The decrease in the m1A/adenosine ratio over time indicates demethylase activity.
m1A MeRIP-Seq (Methylated RNA Immunoprecipitation Sequencing)
This technique allows for the transcriptome-wide identification of m1A-modified RNAs.
Methodology:
-
RNA Fragmentation: Isolate total RNA and fragment it into smaller pieces (typically ~100 nucleotides).
-
Immunoprecipitation: Incubate the fragmented RNA with an antibody specific to m1A. This will enrich for RNA fragments containing the m1A modification.
-
Library Preparation: Prepare a sequencing library from the immunoprecipitated RNA fragments. A parallel library should be prepared from an input control (fragmented RNA that has not been immunoprecipitated).
-
Sequencing: Perform high-throughput sequencing of both the immunoprecipitated and input libraries.
-
Data Analysis: Align the sequencing reads to a reference genome/transcriptome and identify regions that are significantly enriched in the immunoprecipitated sample compared to the input. These enriched regions correspond to m1A peaks.
Caption: Key experimental workflows for studying m1A demethylases and mapping m1A sites.
Concluding Remarks
The dynamic regulation of m1A methylation by its dedicated writers and erasers represents a critical layer of post-transcriptional gene control. A deeper understanding of the functional nuances of these enzymes, their substrate specificities, and their impact on cellular signaling is essential for developing novel therapeutic strategies targeting diseases driven by aberrant RNA methylation. The data and protocols presented in this guide offer a foundational resource for researchers poised to unravel the complexities of the m1A epitranscriptome.
References
- 1. m1A methylation modification patterns and metabolic characteristics in hepatocellular carcinoma - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Frontiers | Harnessing m1A modification: a new frontier in cancer immunotherapy [frontiersin.org]
- 3. Frontiers | Depletion of the m1A writer TRMT6/TRMT61A reduces proliferation and resistance against cellular stress in bladder cancer [frontiersin.org]
- 4. Base-resolution mapping reveals distinct m1A methylome in nuclear- and mitochondrial-encoded transcripts - PMC [pmc.ncbi.nlm.nih.gov]
- 5. TRMT6/61A-dependent base methylation of tRNA-derived fragments regulates gene-silencing activity and the unfolded protein response in bladder cancer - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. ALKBH1-Mediated tRNA Demethylation Regulates Translation - PMC [pmc.ncbi.nlm.nih.gov]
- 7. ALKBH1-Mediated tRNA Demethylation Regulates Translation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. researchgate.net [researchgate.net]
- 9. m1A Regulated Genes Modulate PI3K/AKT/mTOR and ErbB Pathways in Gastrointestinal Cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Modomics - A Database of RNA Modifications [genesilico.pl]
- 11. m1A and m6A modifications function cooperatively to facilitate rapid mRNA degradation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. The crosstalk between m6A RNA methylation and other epigenetic regulators: a novel perspective in epigenetic remodeling - PMC [pmc.ncbi.nlm.nih.gov]
Comparative Analysis of 1-Methyladenine Across Diverse Cell Lines: A Guide for Researchers
For researchers, scientists, and drug development professionals, this guide provides a comprehensive overview of 1-Methyladenine (1-mA), focusing on its role as an epigenetic modulator and its potential effects on various cell lines. While direct comparative studies on the exogenous application of 1-Methyladenine are limited, this document synthesizes the current understanding of its biological significance, details relevant experimental protocols, and presents data in a comparative framework.
Introduction to 1-Methyladenine
1-Methyladenine is a modified purine nucleobase. In the context of cell biology, it is primarily known as N1-methyladenosine (m1A), a post-transcriptional modification of RNA. This modification is a crucial regulator of gene expression, impacting RNA stability, translation, and splicing.[1] The cellular machinery responsible for m1A includes "writer" enzymes that add the methyl group, "eraser" enzymes that remove it, and "reader" proteins that recognize the modification and elicit downstream effects.[1] Dysregulation of m1A has been implicated in various diseases, including cancer, making it a molecule of significant interest in biomedical research.[1][2]
Comparative Effects of 1-Methyladenine on Cell Lines
Direct, quantitative comparative data on the effects of exogenously administered 1-Methyladenine across a wide range of cell lines is not extensively available in current literature. Most research has focused on the role of the endogenous m1A RNA modification. However, based on the known functions of m1A regulators in different cancer types, we can infer potential differential effects.
| Cell Line | Cancer Type | Key m1A Regulator(s) | Reported Effect of m1A Dysregulation | Hypothetical IC50 of 1-mA |
| HeLa | Cervical Cancer | ALKBH1 | Knockdown of ALKBH1 increases m1A levels in tRNAs, promoting translation and protein synthesis.[1] | Not Available |
| MCF-7 | Breast Cancer | FTO, ALKBH3 | The FTO inhibitor MO-I-500 inhibits cell survival.[2] | Not Available |
| A549 | Lung Cancer | ALKBH3 | ALKBH3 knockdown may inhibit proliferation through p21/p27-mediated cell-cycle arrest.[1] | Not Available |
| HepG2 | Liver Cancer | TRMT6, TRMT61A | m1A regulators can modulate the PI3K/AKT pathway to promote proliferation.[2] | Not Available |
| HCT116 | Colon Cancer | ALKBH3 | m1A regulators have been found to promote the proliferation of colorectal cancer cells.[2] | Not Available |
Key Experimental Protocols
To facilitate further research into the comparative effects of 1-Methyladenine, detailed protocols for essential assays are provided below.
Cell Viability Assessment: MTT Assay
The MTT assay is a colorimetric assay for assessing cell metabolic activity. NAD(P)H-dependent cellular oxidoreductase enzymes may, under defined conditions, reflect the number of viable cells present.
Materials:
-
1-Methyladenine
-
MTT (3-(4,5-dimethylthiazol-2-yl)-2,5-diphenyltetrazolium bromide) solution (5 mg/mL in PBS)
-
Cell culture medium
-
DMSO (Dimethyl sulfoxide)
-
96-well plates
-
Microplate reader
Procedure:
-
Seed cells in a 96-well plate at a density of 5,000-10,000 cells/well and incubate for 24 hours.
-
Treat the cells with various concentrations of 1-Methyladenine and incubate for the desired period (e.g., 24, 48, 72 hours).
-
Add 10 µL of MTT solution to each well and incubate for 4 hours at 37°C.
-
Remove the medium and add 100 µL of DMSO to each well to dissolve the formazan crystals.
-
Measure the absorbance at 570 nm using a microplate reader.
Apoptosis Detection: Annexin V/Propidium Iodide Staining
This flow cytometry-based assay distinguishes between viable, early apoptotic, late apoptotic, and necrotic cells.
Materials:
-
Annexin V-FITC Apoptosis Detection Kit
-
Binding Buffer
-
Propidium Iodide (PI) solution
-
Flow cytometer
Procedure:
-
Seed cells and treat with 1-Methyladenine as described for the MTT assay.
-
Harvest the cells (including floating cells) and wash with cold PBS.
-
Resuspend the cells in 1X Binding Buffer at a concentration of 1 x 10^6 cells/mL.
-
Add 5 µL of Annexin V-FITC and 5 µL of PI to 100 µL of the cell suspension.
-
Incubate for 15 minutes at room temperature in the dark.
-
Add 400 µL of 1X Binding Buffer to each tube.
-
Analyze the cells by flow cytometry within one hour.
Cell Cycle Analysis: Propidium Iodide Staining
This method uses propidium iodide to stain DNA and allows for the analysis of cell cycle distribution by flow cytometry.
Materials:
-
Propidium Iodide (PI) staining solution (containing RNase A)
-
70% Ethanol
-
PBS
-
Flow cytometer
Procedure:
-
Seed and treat cells with 1-Methyladenine.
-
Harvest cells and wash with PBS.
-
Fix the cells by adding them dropwise to ice-cold 70% ethanol while vortexing, and store at -20°C for at least 2 hours.
-
Wash the fixed cells with PBS.
-
Resuspend the cell pellet in PI staining solution and incubate for 30 minutes at room temperature in the dark.
-
Analyze the DNA content by flow cytometry.
Signaling Pathways and Experimental Workflows
Visual representations of the key signaling pathways involving m1A modification and the experimental workflows for its analysis are provided below.
Caption: Workflow for comparative analysis of 1-Methyladenine.
Caption: Key regulators and effects of m1A RNA modification.
Conclusion and Future Directions
The study of 1-Methyladenine and its role in cellular processes is a rapidly evolving field. While the current body of research predominantly focuses on the epitranscriptomic aspects of m1A, the potential for exogenous 1-Methyladenine to modulate cellular behavior remains an intriguing and underexplored area. The provided experimental frameworks can serve as a foundation for researchers to conduct direct comparative studies across various cell lines. Such research is crucial to unlock the therapeutic potential of targeting 1-Methyladenine signaling in diseases like cancer. Future investigations should aim to generate comprehensive datasets, including IC50 values and detailed mechanistic studies, to elucidate the cell-type-specific responses to 1-Methyladenine.
References
A Comparative Guide to 1-Methyladenine (m1A) Methylomes Across Species
For Researchers, Scientists, and Drug Development Professionals
The epitranscriptomic mark 1-methyladenine (m1A) is a post-transcriptional modification that plays a critical role in regulating the fate of RNA molecules. This guide provides a cross-species comparison of m1A methylomes, summarizing key quantitative data, detailing experimental methodologies, and illustrating the conserved regulatory pathways influenced by this modification.
Data Presentation: A Quantitative Overview of m1A Methylomes
The prevalence and distribution of m1A vary across different RNA types and species. While m1A is a highly conserved and abundant modification in transfer RNAs (tRNAs) across all domains of life, its presence in messenger RNA (mRNA) is more dynamically regulated and has been a subject of evolving research.
| Feature | Human | Mouse | Yeast (S. cerevisiae) | Key Insights |
| m1A abundance in mRNA (m1A/A ratio) | 0.015% - 0.054% in cell lines; up to 0.16% in tissues[1] | Similar low abundance to humans is generally accepted, though specific comparative quantification is less documented. | N6-methyladenosine (m6A) is more prevalent during sporulation; m1A in mRNA is less characterized. | m1A is a low-abundance modification in mammalian mRNA compared to its prevalence in tRNA.[1] |
| Number of identified mRNA m1A sites | Highly debated; early studies reported hundreds of sites, while more recent, high-resolution methods suggest a much smaller number of bona fide internal sites (e.g., ~10-50)[2][3]. | Fewer comprehensive studies compared to human, but the number of conserved sites is expected to be low. | Not well-established. | The number of genuine internal m1A sites in mRNA is likely much lower than initially thought, with many previously identified sites being artifacts or located at the 5' cap[3][4]. |
| Distribution of m1A in mRNA | Enriched in the 5' untranslated region (5' UTR) and at the translation start site. A small, conserved subset of sites with a GUUCRA motif is found in various transcript regions[5]. | Conserved enrichment patterns around the translation start site have been observed, suggesting a conserved function in translation regulation. | Not well-established. | The location of m1A in mRNA suggests a primary role in regulating translation initiation. |
| m1A in tRNA | Highly prevalent, found at conserved positions such as 9, 14, and 58[1][4][6]. | Highly prevalent and conserved, similar to humans. | The TRMT6/61A homolog (GDC10/GDC14) is responsible for m1A58 in tRNA[7][8]. | m1A is a fundamental modification for tRNA structure and function across eukaryotes.[1] |
| m1A in rRNA | Present at conserved sites, for example, position 1322 of the 28S rRNA[9]. | Conserved sites in rRNA are expected. | Conserved sites in rRNA are present. | m1A in rRNA contributes to ribosome structure and function. |
Key Enzymes in m1A Methylation: A Cross-Species Perspective
The deposition and removal of m1A are managed by specific enzymes that are highly conserved across species.
| Enzyme Family | Human Ortholog(s) | Mouse Ortholog(s) | Yeast Ortholog(s) | Primary Substrate(s) and Location |
| Writers (Methyltransferases) | TRMT6/TRMT61A | Trmt6/Trmt61a | Gcd10/Gcd14 | tRNA (cytosolic, position 58), subset of mRNAs with T-loop like structures[7][8][10][11] |
| TRMT61B | Trmt61b | Not present | Mitochondrial tRNA (position 58) and mitochondrial mRNA[5][9] | |
| TRMT10C | Trmt10c | Not present | Mitochondrial tRNA (position 9) and a specific site in mitochondrial ND5 mRNA[9][12] | |
| Erasers (Demethylases) | ALKBH1, ALKBH3 | Alkbh1, Alkbh3 | Not well-established | tRNA, mRNA[2] |
Experimental Protocols: Mapping m1A at Single-Nucleotide Resolution
Several high-throughput sequencing methods have been developed to map m1A across the transcriptome. m1A-MAP (misincorporation-assisted profiling of m1A) is a technique that provides single-base resolution by identifying the characteristic misincorporations and truncations induced by m1A during reverse transcription.
Detailed Methodology for m1A-MAP
-
RNA Isolation and Fragmentation:
-
Isolate total RNA from the species and cell type of interest.
-
Purify poly(A) RNA to enrich for mRNA.
-
Fragment the RNA to an appropriate size (e.g., ~100 nucleotides) using chemical or enzymatic methods.
-
-
m1A Immunoprecipitation (IP):
-
Incubate the fragmented RNA with an antibody specific to m1A.
-
Capture the antibody-RNA complexes using magnetic beads.
-
Wash the beads to remove non-specifically bound RNA fragments.
-
Elute the m1A-containing RNA fragments. An "input" sample (without IP) should be processed in parallel as a control.
-
-
Optional Demethylation Control:
-
Treat a portion of the IP sample with a demethylase enzyme, such as E. coli AlkB, to convert m1A back to adenosine. This serves as a negative control to confirm that the reverse transcription signatures are specific to m1A.
-
-
Library Preparation and Sequencing:
-
Prepare sequencing libraries from the IP, input, and demethylated control samples.
-
During the reverse transcription step, the presence of m1A will cause the reverse transcriptase to stall (leading to truncations) or misincorporate a different nucleotide into the cDNA.
-
Perform high-throughput sequencing of the prepared libraries.
-
-
Data Analysis:
-
Align the sequencing reads to the reference genome/transcriptome.
-
Identify potential m1A sites by looking for an enrichment of reverse transcription stop sites and a high frequency of mismatches at specific adenosine residues in the IP sample compared to the input and demethylated controls.
-
Use bioinformatics tools to call m1A peaks and identify specific m1A-modified transcripts.
-
Mandatory Visualizations
Logical Diagram: Key Features of m1A Methylomes
Caption: Comparative features of m1A methylomes in different RNA species.
Experimental Workflow: m1A-MAP Sequencing
Caption: Experimental workflow for m1A-MAP sequencing.
Signaling Pathway: Conserved Regulation of mTORC1 by tRNA m1A Modification
Caption: Regulation of mTORC1 signaling by tRNA m1A modification.
References
- 1. Reversible RNA Modification N1-methyladenosine (m1A) in mRNA and tRNA - PMC [pmc.ncbi.nlm.nih.gov]
- 2. New directions for Ψ and m1A decoding in mRNA: deciphering the stoichiometry and function - PMC [pmc.ncbi.nlm.nih.gov]
- 3. m1A within cytoplasmic mRNAs at single nucleotide resolution: a reconciled transcriptome-wide map - PMC [pmc.ncbi.nlm.nih.gov]
- 4. pubs.acs.org [pubs.acs.org]
- 5. Base-resolution mapping reveals distinct m1A methylome in nuclear- and mitochondrial-encoded transcripts - PMC [pmc.ncbi.nlm.nih.gov]
- 6. qian.human.cornell.edu [qian.human.cornell.edu]
- 7. scispace.com [scispace.com]
- 8. TRMT6/61A-dependent base methylation of tRNA-derived fragments regulates gene-silencing activity and the unfolded protein response in bladder cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Chemical manipulation of m1A mediates its detection in human tRNA - PMC [pmc.ncbi.nlm.nih.gov]
- 10. TRMT61A tRNA methyltransferase 61A [Homo sapiens (human)] - Gene - NCBI [ncbi.nlm.nih.gov]
- 11. GeneCards Commercial Trial - LifeMap Sciences [lifemapsc.com]
- 12. weizmann.elsevierpure.com [weizmann.elsevierpure.com]
The Mutagenic Landscape of DNA Alkylation: A Comparative Analysis of 1-Methyladenine and Other Alkylated Bases
For researchers, scientists, and drug development professionals navigating the complex world of DNA damage and repair, understanding the mutagenic potential of various DNA lesions is paramount. Alkylating agents, a ubiquitous class of compounds encountered both endogenously and exogenously, can modify DNA bases, leading to a spectrum of mutagenic outcomes. This guide provides a comprehensive comparison of the mutagenic potential of 1-methyladenine (1-meA) against other significant alkylated bases, supported by experimental data, detailed methodologies, and a visual representation of the key repair pathways.
Quantitative Comparison of Mutagenic Potential
The mutagenic potential of an alkylated base is not uniform; it is highly dependent on the specific base, the position of the alkyl group, the surrounding DNA sequence, and the DNA repair capacity of the cell. Site-directed mutagenesis studies, where a specific alkylated base is incorporated into a known position in a vector and then replicated in a host organism (typically E. coli), have provided invaluable quantitative data on the mutagenicity of these lesions. The following table summarizes key findings from such studies.
| Alkylated Base | Abbreviation | Mutation Frequency (%) (in E. coli) | Predominant Mutation | Reference(s) |
| 1-Methyladenine | 1-meA | ~1 | A → G | [1] |
| O⁶-Methylguanine | O⁶-meG | 0.4 - 20 | G → A | [2] |
| 3-Methyladenine | 3-meA | SOS-dependent, up to 5-fold increase in TagI-deficient strains | A → G, A → T | [3] |
| 1-Methylguanine | 1-meG | 66 - 80 | G → T, G → A | [1] |
| 3-Methylcytosine | 3-meC | 30 - 70 | C → T, C → A | [1] |
| 3-Methylthymine | 3-meT | 53 - 60 | T → C, T → A | [4] |
| 7-Methylguanine | 7-meG | < 0.5 | G → A (minor) | [5] |
Note: Mutation frequencies can vary significantly depending on the experimental conditions, including the specific E. coli strain (and its DNA repair capabilities) and the induction of the SOS response.
Experimental Protocols
A fundamental technique to quantitatively assess the mutagenic potential of a specific DNA lesion is site-directed mutagenesis . This method allows researchers to study the consequences of a single, defined DNA adduct.
Protocol: Site-Directed Mutagenesis to Determine the Mutagenic Potential of an Alkylated Base
This protocol is a generalized representation based on established methodologies.
1. Oligonucleotide Synthesis and Vector Preparation:
-
Synthesize a short single-stranded DNA oligonucleotide containing the desired alkylated base at a specific position.
-
Prepare a single-stranded M13 bacteriophage vector or a phagemid vector. This vector contains a selectable marker and a known DNA sequence where the mutagenic potential will be assessed.
2. Annealing and Ligation:
-
Anneal the alkylated oligonucleotide to the complementary region of the single-stranded vector.
-
Use DNA polymerase and DNA ligase to synthesize the complementary strand, creating a double-stranded, covalently closed circular DNA molecule containing the site-specific lesion.
3. Transformation and Replication:
-
Transform competent E. coli cells with the modified vector. Different strains can be used, including wild-type and strains deficient in specific DNA repair pathways (e.g., alkB⁻, tag⁻, uvrA⁻) to investigate the role of these pathways in repairing the lesion.
-
Allow the bacteria to replicate the vector for a defined number of generations. During replication, the DNA polymerase will encounter the alkylated base. If the lesion is not repaired, the polymerase may stall or insert an incorrect nucleotide opposite the adduct.
4. Progeny Phage/Plasmid Isolation and Analysis:
-
Isolate the progeny phage particles or plasmids from the bacterial culture.
-
Determine the DNA sequence of the region surrounding the original site of the lesion in the progeny vectors. This is typically done by Sanger sequencing of a sufficient number of individual clones.
5. Calculation of Mutation Frequency:
-
The mutation frequency is calculated as the number of progeny vectors containing a mutation at the site of the original lesion divided by the total number of progeny vectors sequenced.
-
The type of mutation (e.g., transition, transversion, frameshift) provides insight into the miscoding properties of the alkylated base.
DNA Repair Pathways for Alkylated Bases
Cells have evolved sophisticated DNA repair mechanisms to counteract the deleterious effects of DNA alkylation. The two primary pathways involved in the repair of the alkylated bases discussed in this guide are Base Excision Repair (BER) and Direct Reversal of Damage by enzymes such as the AlkB family of dioxygenases.
Base Excision Repair (BER) Pathway for N-Alkylated Purines
The BER pathway is a major route for the removal of N-alkylated purines like 3-methyladenine and 7-methylguanine.[3][6][7][8][9]
Caption: Base Excision Repair pathway for N-alkylated purines.
AlkB-Mediated Direct Reversal of 1-methyladenine
The AlkB family of Fe(II)/α-ketoglutarate-dependent dioxygenases directly reverses methylation damage on certain bases, including 1-methyladenine and 3-methylcytosine, by oxidative demethylation.[10][11][12]
Caption: AlkB-mediated direct reversal of 1-methyladenine.
References
- 1. Multi-substrate selectivity based on key loops and non-homologous domains: new insight into ALKBH family - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. Mutagenic specificity of alkylated and oxidized DNA bases as determined by site-specific mutagenesis - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. Repair of 3-methyladenine and abasic sites by base excision repair mediates glioblastoma resistance to temozolomide - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Genotoxic and mutagenic potential of 7-methylxanthine: an investigational drug molecule for the treatment of myopia - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. pubs.acs.org [pubs.acs.org]
- 6. Base excision repair and nucleotide excision repair contribute to the removal of N-methylpurines from active genes - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. Repair of 3-methyladenine and abasic sites by base excision repair mediates glioblastoma resistance to temozolomide - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. Base excision repair - Wikipedia [en.wikipedia.org]
- 9. Overview of Base Excision Repair Biochemistry - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Multi-substrate selectivity based on key loops and non-homologous domains: new insight into ALKBH family - PMC [pmc.ncbi.nlm.nih.gov]
- 11. The AlkB Family of Fe(II)/α-Ketoglutarate-dependent Dioxygenases: Repairing Nucleic Acid Alkylation Damage and Beyond - PMC [pmc.ncbi.nlm.nih.gov]
- 12. books.rsc.org [books.rsc.org]
A Comparative Guide to Validating m1A's Role in tRNA Stability via Mutation Analysis
For Researchers, Scientists, and Drug Development Professionals
This guide provides an objective comparison of experimental strategies used to validate the crucial role of N1-methyladenosine (m1A) in transfer RNA (tRNA) stability. We will delve into mutation analysis techniques, compare them with alternative approaches, and provide the supporting experimental data and detailed protocols necessary for replication and further investigation.
Post-transcriptional modifications are essential for the structure and function of tRNA.[1][2] Among the most prevalent is methylation, with N1-methyladenosine (m1A) being a critical modification that influences tRNA folding, stability, and the accurate decoding of genetic information.[2][3][4] The m1A modification is found at several positions within tRNA, such as 9, 14, 22, 57, and 58, and is catalyzed by specific methyltransferase enzymes.[2][5][6][7] The modification at position 58 (m1A58), in particular, is highly conserved and critical for tRNA stability.[5][6] The absence of such modifications can lead to tRNA degradation through pathways like the Rapid tRNA Decay (RTD) pathway, highlighting the importance of these chemical marks in tRNA quality control.[8][9][10][11]
Mutation analysis serves as a powerful tool to dissect the functional significance of m1A. By disrupting the elements required for this modification—either the methyltransferase "writer" enzymes or the target adenosine nucleoside itself—researchers can directly observe the consequences on tRNA integrity and cellular function.
Comparative Analysis of Mutation Strategies
The validation of m1A's role in tRNA stability primarily relies on two complementary mutation strategies: inactivation of the methyltransferase enzymes responsible for writing the m1A mark, and site-directed mutagenesis of the target adenosine within the tRNA gene.
1. Inactivation of m1A Methyltransferases ("Writers")
This top-down approach involves eliminating the enzyme responsible for adding the m1A modification. In eukaryotes, the primary enzyme for cytoplasmic m1A58 is a heterodimeric complex of TRMT6 and TRMT61A.[5][12][13]
-
Principle: By knocking out or knocking down the gene(s) for the methyltransferase (e.g., TRMT61A), the synthesis of m1A is prevented across all its tRNA substrates. The resulting phenotype, particularly the stability of specific tRNAs, is then assessed.
-
Advantages: This method allows for the systemic study of the m1A modification's importance across the entire pool of its target tRNAs.
-
Limitations: A potential for pleiotropic effects exists, as the enzyme may have other unknown functions or substrates.
2. Site-Directed Mutagenesis of tRNA
This bottom-up approach targets the specific site of modification within a single tRNA species.
-
Principle: The adenosine at the target position (e.g., A58) in a specific tRNA gene is mutated to another nucleotide (G, C, or U). This prevents methylation at that site and allows for the study of both the importance of the adenosine itself and the subsequent methyl group addition.
-
Advantages: This is a highly specific method to probe the importance of m1A at a precise location in a single tRNA species, minimizing off-target effects.
-
Limitations: This approach is labor-intensive if a broad understanding across many different tRNA species is desired.
Alternative Validation: Targeting Demethylases ("Erasers")
A complementary strategy involves the knockdown of m1A "eraser" enzymes, such as ALKBH1.[5] In contrast to "writer" knockouts, eliminating a demethylase is expected to increase m1A levels. Observing enhanced tRNA stability upon "eraser" knockdown provides converging evidence for m1A's stabilizing role.[5]
Quantitative Data Summary
The following tables summarize the expected outcomes and comparative data from mutation analysis studies.
Table 1: Effect of Mutations on tRNA Stability
| Experimental Approach | Target Gene/Sequence | Model Organism | Affected tRNA Species | Observed Effect on tRNA Level/Stability | Reference |
| Methyltransferase Knockout | trm6Δ trm61Δ | S. cerevisiae | tRNAiMet | Decreased stability, leading to degradation | [5] |
| Methyltransferase Knockdown | TRMT61A shRNA | Mouse CD4+ T cells | Subset of early expressed tRNAs | Reduced levels, leading to impaired T cell expansion | [13] |
| Site-Directed Mutagenesis | tRNAAsp (G57A) | T. thermophilus (in vitro) | Mutant tRNAAsp | Allowed for m1A formation at position 57, demonstrating enzyme-substrate recognition | [14] |
| Demethylase Knockdown | ALKBH1 shRNA | Human cell lines | tRNAiMet | Increased m1A levels and increased tRNA stability | [5] |
Table 2: Comparison of Methods for m1A Detection and tRNA Quantification
| Method | Principle | Measures | Advantages | Limitations |
| Northern Blotting | Hybridization of a labeled probe to RNA separated by size. | Abundance and integrity of a specific tRNA. | Gold standard for size and abundance validation. | Lower throughput, requires specific probes. |
| Quantitative RT-PCR (qRT-PCR) | Reverse transcription followed by PCR amplification. | Relative abundance of a specific tRNA. | High sensitivity and throughput. | Indirect measurement; can be affected by modifications that block reverse transcriptase. |
| Liquid Chromatography-Mass Spectrometry (LC-MS) | Separation and mass analysis of digested nucleosides. | Absolute quantification of specific modifications (e.g., m1A). | Highly accurate and quantitative for modifications.[15][16][] | Does not identify the specific tRNA isoacceptor containing the modification.[15] |
| m1A-Specific Sequencing (e.g., red-m1A-seq) | Chemical treatment and deep sequencing to identify m1A sites by mutational signatures.[4] | Genome-wide location and relative abundance of m1A. | Single-nucleotide resolution, high throughput. | Can be complex; relies on indirect detection via reverse transcription errors.[4] |
Visualizations: Workflows and Pathways
The following diagrams, generated using Graphviz, illustrate the key experimental workflows and biological pathways discussed.
Caption: Experimental workflow for validating m1A's role by 'writer' enzyme knockout.
Caption: Logical relationship between m1A modification, tRNA structure, and stability.
Caption: Simplified Rapid tRNA Decay (RTD) pathway for hypomodified tRNAs.
Detailed Experimental Protocols
Here we provide methodologies for key experiments cited in the validation of m1A's role in tRNA stability.
Protocol 1: Analysis of tRNA Stability in a Yeast Mutant Strain by Northern Blot
This protocol is adapted from studies analyzing tRNA decay in Saccharomyces cerevisiae strains with mutations in tRNA modification enzymes.[11]
Objective: To determine if the absence of a specific modification (due to an enzyme knockout, e.g., trm6Δ) leads to decreased levels of a target tRNA, indicating instability.
Materials:
-
Wild-type (WT) and mutant (trm6Δ) yeast strains.
-
YPD liquid media.
-
Total RNA extraction kit (e.g., hot acid phenol method).
-
Agarose gel, MOPS buffer, formaldehyde.
-
Nylon membrane for blotting.
-
UV crosslinker.
-
Hybridization buffer (e.g., ULTRAhyb).
-
DNA oligonucleotide probe complementary to the target tRNA (e.g., tRNAiMet), end-labeled with ³²P-ATP.
-
Phosphorimager screen and scanner.
-
Loading control probe (e.g., U4 snRNA).
Methodology:
-
Cell Culture and Harvest:
-
Inoculate 50 mL of YPD with WT and trm6Δ strains. Grow overnight at 30°C to mid-log phase (OD₆₀₀ ≈ 0.5).
-
(Optional, for temperature-sensitive mutants): Shift cultures to a non-permissive temperature (e.g., 37°C) for a specified time (e.g., 0, 30, 60, 120 minutes) before harvesting.
-
Harvest cells by centrifugation at 3,000 x g for 5 minutes.
-
-
RNA Extraction:
-
Extract total RNA from cell pellets using a hot acid phenol-chloroform extraction method to ensure high-quality RNA.
-
Quantify RNA concentration using a spectrophotometer (e.g., NanoDrop).
-
-
Northern Blotting:
-
Prepare a 1.2% agarose gel containing 1.2% formaldehyde in 1X MOPS buffer.
-
Denature 10 µg of total RNA from each sample by heating at 65°C for 15 minutes in formaldehyde-containing loading buffer.
-
Separate the RNA by electrophoresis.
-
Transfer the RNA from the gel to a nylon membrane via capillary action overnight.
-
UV-crosslink the RNA to the membrane.
-
-
Hybridization:
-
Pre-hybridize the membrane in hybridization buffer for 1 hour at 42°C.
-
Add the ³²P-labeled tRNA-specific oligonucleotide probe and hybridize overnight at 42°C.
-
Wash the membrane with low and high stringency SSC buffers to remove non-specific binding.
-
-
Detection and Quantification:
-
Expose the membrane to a phosphorimager screen.
-
Scan the screen and quantify the band intensity for the target tRNA using appropriate software (e.g., ImageJ).
-
Strip the membrane and re-probe with a loading control probe (e.g., U4 snRNA) to normalize the data.
-
Compare the normalized intensity of the target tRNA band in the trm6Δ strain to the WT strain. A significant decrease in the mutant indicates tRNA instability.
-
Protocol 2: Site-Directed Mutagenesis of a tRNA Gene
Objective: To create a specific point mutation in a tRNA gene (e.g., A58G) to study the effect of preventing m1A modification at that site.
Materials:
-
Plasmid containing the wild-type tRNA gene of interest.
-
Site-directed mutagenesis kit (e.g., QuikChange II, Agilent).
-
Custom mutagenic primers (forward and reverse) containing the desired mutation (e.g., changing the A58 codon to a G58 codon).
-
High-fidelity DNA polymerase.
-
DpnI restriction enzyme.
-
Competent E. coli cells for transformation.
-
DNA sequencing services for verification.
Methodology:
-
Primer Design: Design a pair of complementary primers, typically 25-45 bases in length, containing the desired mutation in the middle. The primers should have a melting temperature (Tm) ≥ 78°C.
-
Mutagenesis PCR:
-
Set up the PCR reaction containing the template plasmid DNA, mutagenic primers, dNTPs, reaction buffer, and high-fidelity DNA polymerase.
-
Perform thermal cycling, typically for 12-18 cycles. This process amplifies the entire plasmid, incorporating the mutation.
-
-
Digestion of Template DNA:
-
Add DpnI restriction enzyme directly to the amplification product. Incubate at 37°C for 1 hour.
-
DpnI specifically digests the parental, methylated (dam-methylated) template DNA, leaving the newly synthesized, mutated plasmid intact.
-
-
Transformation:
-
Transform the DpnI-treated DNA into high-efficiency competent E. coli cells.
-
Plate the transformation mix on an appropriate antibiotic selection plate and incubate overnight.
-
-
Verification:
-
Select several colonies and grow them in liquid culture to isolate plasmid DNA (miniprep).
-
Send the purified plasmid DNA for Sanger sequencing using a primer flanking the tRNA gene to confirm the presence of the desired mutation and the absence of any other unintended mutations.
-
-
Functional Analysis: The verified mutant plasmid can then be transformed into the appropriate host organism (e.g., yeast) to study the expression and stability of the mutant tRNA using methods described in Protocol 1.
References
- 1. researchgate.net [researchgate.net]
- 2. m1A Post-Transcriptional Modification in tRNAs - PMC [pmc.ncbi.nlm.nih.gov]
- 3. creative-diagnostics.com [creative-diagnostics.com]
- 4. Chemical manipulation of m1A mediates its detection in human tRNA - PMC [pmc.ncbi.nlm.nih.gov]
- 5. academic.oup.com [academic.oup.com]
- 6. academic.oup.com [academic.oup.com]
- 7. pubs.acs.org [pubs.acs.org]
- 8. bibliotekanauki.pl [bibliotekanauki.pl]
- 9. The yeast rapid tRNA decay pathway competes with elongation factor 1A for substrate tRNAs and acts on tRNAs lacking one or more of several modifications - PMC [pmc.ncbi.nlm.nih.gov]
- 10. researchgate.net [researchgate.net]
- 11. The yeast rapid tRNA decay pathway primarily monitors the structural integrity of the acceptor and T-stems of mature tRNA - PMC [pmc.ncbi.nlm.nih.gov]
- 12. researchgate.net [researchgate.net]
- 13. tRNA-m1A modification promotes T cell expansion via efficient MYC protein synthesis - PubMed [pubmed.ncbi.nlm.nih.gov]
- 14. academic.oup.com [academic.oup.com]
- 15. Quantitative analysis of tRNA abundance and modifications by nanopore RNA sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 16. tRNA Modification Analysis by MS - CD Genomics [rna.cd-genomics.com]
comparing the efficiency of different m1A detection techniques
A Comprehensive Guide to Comparing the Efficiency of m1A Detection Techniques
The reversible RNA modification, N1-methyladenosine (m1A), has emerged as a critical regulator of RNA metabolism and function. Its presence in various RNA species, including messenger RNA (mRNA), transfer RNA (tRNA), and ribosomal RNA (rRNA), influences processes such as translation, RNA stability, and structure.[1][2] Consequently, the accurate and efficient detection of m1A is paramount for elucidating its biological roles in health and disease. A variety of techniques have been developed to map m1A modifications, each with its own set of advantages and limitations.
This guide provides a comprehensive comparison of the most prominent m1A detection methods, offering researchers, scientists, and drug development professionals the necessary information to select the most appropriate technique for their experimental needs. We will delve into the principles of each method, present a quantitative comparison of their performance, provide detailed experimental protocols, and visualize their workflows.
Quantitative Comparison of m1A Detection Techniques
The efficiency of m1A detection techniques can be evaluated based on several key parameters, including resolution, sensitivity, specificity, and the required amount of input RNA. The following table summarizes the performance of four major m1A detection methods: m1A-seq (and its variant MeRIP-seq), m1A-ID-seq, m1A-MAP, and red-m1A-seq.
| Feature | m1A-seq / MeRIP-seq | m1A-ID-seq | m1A-MAP | red-m1A-seq |
| Principle | Antibody-based enrichment of m1A-containing RNA fragments followed by high-throughput sequencing.[3][4] | Antibody-based enrichment coupled with demethylation by an AlkB enzyme to identify m1A sites by comparing read pileups.[3] | Antibody-based enrichment combined with a specific reverse transcriptase (TGIRT) that induces misincorporations at m1A sites.[5][6] | Chemical reduction of m1A followed by reverse transcription, which enhances misincorporation and read-through rates. |
| Resolution | Low (~100-200 nucleotides)[3] | Single nucleotide | Single nucleotide[5][6] | Single nucleotide |
| Sensitivity | Moderate; dependent on antibody efficiency. | High; antibody enrichment enhances detection. | High; antibody enrichment and specific RT increase sensitivity.[5] | Potentially very high; chemical treatment improves signal. |
| Specificity | Variable; potential for antibody cross-reactivity. | High; comparison with demethylated control reduces false positives.[3] | High; comparison with a demethylated control and the specific signature of TGIRT improve specificity.[5][6] | High; comparison with a control treatment (Dimroth rearrangement) provides a robust baseline. |
| RNA Input | High (micrograms of total RNA) | High (micrograms of total RNA) | Moderate to high (micrograms of total RNA) | Moderate (nanograms to micrograms of total RNA) |
| Quantitative | Semi-quantitative | Semi-quantitative | Semi-quantitative; can be adapted for better quantification.[5] | Potentially quantitative with appropriate controls. |
| Key Advantage | Relatively straightforward for transcriptome-wide screening. | High specificity due to enzymatic removal of m1A.[3] | High sensitivity and single-nucleotide resolution.[5][6] | High sensitivity and does not rely on specific enzymes that may not be commercially available. |
| Key Limitation | Low resolution and potential for antibody-related artifacts.[3] | Requires a specific demethylase enzyme which may have its own biases. | Requires a specific reverse transcriptase (TGIRT).[7] | Involves chemical treatments that need careful optimization. |
Experimental Workflows and Methodologies
A detailed understanding of the experimental procedures is crucial for the successful implementation of these techniques. Below are the detailed protocols and workflow diagrams for m1A-seq, m1A-ID-seq, and m1A-MAP.
m1A-seq (Methylated RNA Immunoprecipitation Sequencing)
Principle: This technique relies on the use of an antibody that specifically recognizes and binds to m1A-modified RNA fragments. These enriched fragments are then sequenced to identify the m1A-containing regions of the transcriptome.[3][4]
Experimental Protocol:
-
RNA Extraction and Fragmentation: Isolate total RNA from the sample of interest and fragment it into smaller pieces (typically around 100-200 nucleotides) using enzymatic or chemical methods.
-
Immunoprecipitation (IP):
-
Incubate the fragmented RNA with an anti-m1A antibody.
-
Add protein A/G magnetic beads to the mixture to capture the antibody-RNA complexes.
-
Wash the beads several times to remove non-specifically bound RNA fragments.
-
Elute the m1A-enriched RNA fragments from the beads.
-
-
Library Preparation:
-
Prepare a sequencing library from the eluted m1A-enriched RNA fragments. This typically involves reverse transcription, second-strand synthesis, adapter ligation, and PCR amplification.
-
Prepare a control "input" library from a small fraction of the fragmented RNA before the immunoprecipitation step.
-
-
Sequencing and Data Analysis:
-
Sequence both the IP and input libraries using a high-throughput sequencing platform.
-
Align the sequencing reads to a reference genome or transcriptome.
-
Identify m1A-enriched regions (peaks) by comparing the read coverage in the IP sample to the input sample.
-
Workflow Diagram:
m1A-seq Experimental Workflow
m1A-ID-seq (m1A-Immunoprecipitation with Demethylase Treatment followed by Sequencing)
Principle: m1A-ID-seq is an advancement of m1A-seq that incorporates an enzymatic demethylation step to improve specificity. By comparing the sequencing results of an antibody-enriched sample with and without demethylase treatment, true m1A sites can be more confidently identified.[3]
Experimental Protocol:
-
RNA Extraction and Fragmentation: Isolate and fragment total RNA as described for m1A-seq.
-
Immunoprecipitation (IP): Perform immunoprecipitation using an anti-m1A antibody to enrich for m1A-containing RNA fragments.
-
Sample Splitting and Demethylation:
-
Split the eluted m1A-enriched RNA into two aliquots.
-
Treat one aliquot with a demethylase enzyme (e.g., AlkB) that specifically removes the methyl group from m1A, converting it back to adenosine.
-
Leave the other aliquot untreated as a control.
-
-
Library Preparation: Prepare sequencing libraries from both the demethylase-treated and untreated samples, as well as an input control.
-
Sequencing and Data Analysis:
-
Sequence all three libraries.
-
Align reads to the reference genome/transcriptome.
-
Identify m1A sites by comparing the read coverage between the untreated and demethylase-treated samples. A significant reduction in read enrichment after demethylation indicates a true m1A site.
-
Workflow Diagram:
m1A-ID-seq Experimental Workflow
m1A-MAP (m1A-Misincorporation-Assisted Profiling)
Principle: m1A-MAP achieves single-nucleotide resolution by exploiting the property of certain reverse transcriptase enzymes, such as Thermostable Group II Intron Reverse Transcriptase (TGIRT), to misincorporate nucleotides when encountering an m1A-modified base. This method combines antibody enrichment with this specific enzymatic signature.[5][6]
Experimental Protocol:
-
RNA Extraction and Fragmentation: Isolate and fragment total RNA.
-
Immunoprecipitation (IP): Enrich for m1A-containing RNA fragments using an anti-m1A antibody.
-
Sample Splitting and Demethylation: Split the enriched RNA into two aliquots, one treated with a demethylase and one left untreated, similar to m1A-ID-seq.
-
Reverse Transcription with TGIRT: Perform reverse transcription on both aliquots using the TGIRT enzyme. The m1A sites in the untreated sample will cause misincorporations in the resulting cDNA.
-
Library Preparation and Sequencing: Prepare and sequence libraries from both the treated and untreated samples.
-
Data Analysis:
-
Align sequencing reads to the reference.
-
Identify positions with a high rate of single nucleotide variants (SNVs) or "mutations" in the untreated sample compared to the demethylase-treated sample. These positions correspond to m1A sites.
-
Workflow Diagram:
m1A-MAP Experimental Workflow
Conclusion
The choice of an m1A detection technique depends on the specific research question, available resources, and desired resolution. For initial transcriptome-wide screening where high resolution is not a primary concern, m1A-seq offers a relatively straightforward approach. For studies requiring higher confidence and single-nucleotide resolution, m1A-ID-seq and m1A-MAP are superior choices, with m1A-MAP often providing higher sensitivity. The newer red-m1A-seq method holds promise for even greater sensitivity and may become more widely adopted as the protocol is further refined and validated. By carefully considering the trade-offs between resolution, sensitivity, specificity, and experimental complexity, researchers can select the optimal method to advance our understanding of the epitranscriptome.
References
- 1. researchgate.net [researchgate.net]
- 2. m1A Sequencing - CD Genomics [rna.cd-genomics.com]
- 3. researchgate.net [researchgate.net]
- 4. m1A RNA Methylation Analysis - CD Genomics [cd-genomics.com]
- 5. Clinician’s Guide to Epitranscriptomics: An Example of N1-Methyladenosine (m1A) RNA Modification and Cancer [mdpi.com]
- 6. Chemical manipulation of m1A mediates its detection in human tRNA - PMC [pmc.ncbi.nlm.nih.gov]
- 7. m1A-Ensem: accurate identification of 1-methyladenosine sites through ensemble models - PMC [pmc.ncbi.nlm.nih.gov]
A Researcher's Guide to the Functional Validation of Novel m1A Reader Proteins
For researchers, scientists, and drug development professionals, this guide provides a comprehensive comparison of methodologies for the functional validation of novel N1-methyladenosine (m1A) reader proteins. It includes supporting experimental data, detailed protocols, and visual workflows to facilitate experimental design and interpretation.
The discovery of N1-methyladenosine (m1A) as a reversible modification on mRNA has opened a new frontier in epitranscriptomics. This modification plays a crucial role in regulating mRNA stability, translation, and other cellular processes. Central to these functions are "reader" proteins that specifically recognize and bind to m1A-modified RNA, thereby dictating the downstream fate of the transcript. The YTH domain-containing family of proteins (YTHDF1, YTHDF2, and YTHDF3), initially characterized as m6A readers, have been identified as prominent m1A readers.[1][2][3][4] Functional validation of these and other novel m1A reader proteins is critical for understanding their biological roles and for the development of targeted therapeutics.
This guide compares key experimental approaches for validating novel m1A reader proteins, presenting quantitative data for established readers and outlining detailed experimental protocols.
Comparative Analysis of m1A Reader Proteins
The YTHDF protein family has been the most extensively studied class of m1A readers. Quantitative proteomics and binding assays have provided insights into their binding preferences and affinities.
| Reader Protein | Method of Identification | Quantitative Measurement | Cell Line | Key Finding |
| YTHDF1 | SILAC-based quantitative proteomics | 2.3 ± 0.7 (m1A/rA SILAC ratio)[2][4] | HeLa | Preferentially binds to m1A-modified RNA over unmodified RNA. |
| Electrophoretic Mobility Shift Assay (EMSA) | Kd = 0.13 ± 0.047 µM (for m1A-probe 3); Kd = 0.15 ± 0.044 µM (for m1A-probe 5)[1] | Recombinant Protein | Exhibits tight binding to m1A-modified oligonucleotides in a sequence-independent manner. | |
| YTHDF2 | SILAC-based quantitative proteomics | 4.1 ± 2.7 (m1A/rA SILAC ratio)[2][5] | HEK293T | Shows strong preferential binding to m1A-modified RNA. |
| Electrophoretic Mobility Shift Assay (EMSA) | Kd = 0.39 ± 0.030 µM (for m1A-probe 3); Kd = 0.35 ± 0.048 µM (for m1A-probe 5)[1] | Recombinant Protein | Binds with high affinity to m1A-modified RNA, and this interaction is crucial for its function. | |
| YTHDF3 | SILAC-based quantitative proteomics | 6.9 ± 1.7 (m1A/rA SILAC ratio)[2][5] | HEK293T | Demonstrates the highest preferential binding to m1A-modified RNA among the YTHDF family in this study. |
Table 1: Quantitative Comparison of Known m1A Reader Proteins. This table summarizes key quantitative data from studies identifying and characterizing the binding of YTHDF proteins to m1A-modified RNA. SILAC (Stable Isotope Labeling by Amino acids in Cell culture) ratios indicate the relative enrichment of the protein on m1A-containing RNA versus unmodified RNA. The dissociation constant (Kd) measures the binding affinity, with lower values indicating stronger binding.
Beyond the well-established YTHDF family, other proteins have been suggested as potential m1A binders, although their roles as direct "readers" are still under investigation. These include the stress granule-associated protein G3BP1 , which has been shown to be repelled by m6A modifications, and the translation initiation factor eIF3 , which can be recruited to m6A-modified 5'UTRs.[6][7] Further research is needed to validate their direct and functional interactions with m1A.
Key Experimental Methodologies for Validation
A multi-faceted approach employing both in vitro and in vivo techniques is essential for the robust functional validation of a novel m1A reader protein.
Identification of Candidate m1A Readers: RNA Pull-down Coupled with Mass Spectrometry
This is a primary discovery method to identify proteins that interact with m1A-modified RNA.
Experimental Protocol: Biotinylated RNA Pull-down Assay
-
Probe Preparation: Synthesize biotinylated RNA oligonucleotides with and without the m1A modification at a specific position. A typical probe length is 20-50 nucleotides.
-
Cell Lysate Preparation: Prepare whole-cell or nuclear extracts from the cell line of interest under RNase-free conditions.
-
Binding Reaction: Incubate the biotinylated RNA probes with the cell lysate to allow the formation of RNA-protein complexes.
-
Capture of Complexes: Add streptavidin-coated magnetic beads to the binding reaction to capture the biotinylated RNA and any interacting proteins.
-
Washing: Wash the beads extensively to remove non-specific binding proteins.
-
Elution and Protein Identification: Elute the bound proteins from the beads and identify them using mass spectrometry (e.g., LC-MS/MS). For quantitative analysis, SILAC can be employed to compare the abundance of proteins pulled down with the m1A-modified probe versus the unmodified control.
Caption: Workflow for RNA pull-down assay.
In Vitro Validation of Direct Binding: Electrophoretic Mobility Shift Assay (EMSA)
EMSA is a classic technique to confirm a direct interaction between a purified protein and an RNA probe and to determine binding affinity (Kd).
Experimental Protocol: Electrophoretic Mobility Shift Assay (EMSA)
-
Probe Labeling: Label a short RNA oligonucleotide (with or without m1A) with a radioactive isotope (e.g., ³²P) or a non-radioactive tag (e.g., biotin).
-
Protein Purification: Purify the candidate reader protein using recombinant expression systems.
-
Binding Reaction: Incubate the labeled RNA probe with increasing concentrations of the purified protein in a binding buffer.
-
Electrophoresis: Separate the binding reactions on a non-denaturing polyacrylamide gel.
-
Detection: Visualize the RNA probe. A slower migrating band compared to the free probe indicates the formation of an RNA-protein complex.
-
Quantitative Analysis: Quantify the shifted and free probe bands to calculate the dissociation constant (Kd), a measure of binding affinity.
Caption: EMSA workflow.
In Vivo Validation of Interaction and Functional Consequences
To understand the biological relevance of the interaction, it is crucial to validate it within a cellular context and assess its functional impact.
Experimental Protocol: RNA Immunoprecipitation (RIP) followed by RT-qPCR
-
Cell Lysis: Lyse cells under conditions that preserve RNA-protein interactions.
-
Immunoprecipitation: Use an antibody specific to the candidate reader protein to immunoprecipitate the protein and any associated RNAs.
-
RNA Isolation: Isolate the RNA from the immunoprecipitated complexes.
-
RT-qPCR: Use reverse transcription followed by quantitative PCR (RT-qPCR) to quantify the enrichment of specific m1A-containing transcripts in the immunoprecipitate compared to a negative control (e.g., IgG immunoprecipitation).
Functional Analysis: Gene Expression and Stability Assays
-
Knockdown/Knockout Studies: Deplete the candidate reader protein using siRNA, shRNA, or CRISPR/Cas9.
-
Gene Expression Analysis: Measure the expression levels of known or suspected m1A-modified target transcripts using RT-qPCR or RNA sequencing. An increase in transcript levels upon reader depletion may suggest a role in promoting RNA decay.
-
RNA Stability Assay: Treat cells with a transcription inhibitor (e.g., Actinomycin D) and measure the decay rate of target transcripts over time in the presence and absence of the reader protein.
Signaling Pathways Modulated by m1A Reader Proteins
The functional consequences of m1A reader protein binding are often linked to the regulation of key cellular signaling pathways. Dysregulation of these pathways is frequently implicated in diseases such as cancer.
PI3K/AKT/mTOR Pathway
This pathway is a central regulator of cell growth, proliferation, and survival. Studies have shown a correlation between the expression of m1A regulators and the activity of the PI3K/AKT/mTOR pathway.[8][9] For instance, the m1A reader YTHDF2 can influence the stability of mRNAs encoding key components of this pathway.
Caption: m1A readers and the PI3K/AKT/mTOR pathway.
ErbB Signaling Pathway
The ErbB family of receptor tyrosine kinases, including EGFR, plays a critical role in cell proliferation and differentiation. YTHDF2 has been shown to destabilize the mRNA of EGFR, thereby suppressing cell proliferation and growth in certain cancers.[10][11]
Caption: YTHDF2-mediated regulation of ErbB signaling.
Comparison of Validation Methods
| Method | Principle | Advantages | Disadvantages |
| RNA Pull-down + MS | Affinity capture of RNA-protein complexes. | Unbiased discovery of interacting proteins. Can be quantitative with SILAC. | Prone to identifying indirect interactions. May be biased towards abundant proteins. |
| EMSA | Separation of RNA-protein complexes by native gel electrophoresis. | Confirms direct interaction. Allows for determination of binding affinity (Kd). | Requires purified protein. In vitro conditions may not reflect the cellular environment. |
| RIP-qPCR | Immunoprecipitation of an RBP and its associated RNAs. | Validates interaction in vivo. Can be used to assess changes in binding under different conditions. | Depends on antibody quality. Does not prove direct interaction. |
| CLIP-seq | UV crosslinking followed by immunoprecipitation and sequencing. | Identifies direct binding sites with high resolution in vivo. | Can be technically challenging. UV crosslinking has sequence biases. |
Table 2: Comparison of Key Validation Techniques. This table provides a summary of the principles, advantages, and disadvantages of the primary methods used to validate novel m1A reader proteins.
Conclusion
The functional validation of novel m1A reader proteins requires a rigorous and multi-pronged experimental approach. By combining proteomic discovery methods with in vitro binding assays and in vivo functional studies, researchers can confidently identify and characterize new players in the expanding field of epitranscriptomics. This guide provides a framework for designing and interpreting these crucial experiments, ultimately paving the way for a deeper understanding of m1A-mediated gene regulation in health and disease.
References
- 1. YTHDF2 recognition of N1-methyladenosine (m1A)-modified RNA is associated with transcript destabilization - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Identification of YTH Domain-Containing Proteins as the Readers for N1-Methyladenosine in RNA - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Identification of YTH Domain-Containing Proteins as the Readers for N1-Methyladenosine in RNA - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. pubs.acs.org [pubs.acs.org]
- 5. escholarship.org [escholarship.org]
- 6. Embraced by eIF3: structural and functional insights into the roles of eIF3 across the translation cycle - PMC [pmc.ncbi.nlm.nih.gov]
- 7. N6-methyladenosine (m6A) recruits and repels proteins to regulate mRNA homeostasis - PMC [pmc.ncbi.nlm.nih.gov]
- 8. m1A Regulated Genes Modulate PI3K/AKT/mTOR and ErbB Pathways in Gastrointestinal Cancer - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. m1A Regulated Genes Modulate PI3K/AKT/mTOR and ErbB Pathways in Gastrointestinal Cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 10. The biological function of m6A reader YTHDF2 and its role in human disease - PMC [pmc.ncbi.nlm.nih.gov]
- 11. researchgate.net [researchgate.net]
Validating the Role of N1-methyladenosine (m1A) in Biological Processes Using Knockout Models: A Comparative Guide
N1-methyladenosine (m1A) is a dynamic and reversible post-transcriptional RNA modification that plays a critical role in regulating gene expression.[1][2] This modification, installed by "writer" enzymes, removed by "erasers," and interpreted by "readers," influences numerous biological processes, from cancer progression to immune regulation.[3][4] Establishing a definitive causal link between m1A and these processes requires robust validation tools. This guide compares the use of knockout (KO) models with other alternatives, providing experimental data and detailed protocols for researchers, scientists, and drug development professionals.
Comparison of Validation Methodologies
Validating the function of m1A regulators relies on perturbing their expression or activity. Gene knockout provides a permanent and complete loss of function, offering clear insights into a protein's essential roles. However, alternative methods like transient knockdown or targeted enzymatic manipulation offer different advantages, such as temporal control and the ability to study essential genes where a full knockout would be lethal.
| Methodology | Principle | Advantages | Disadvantages |
| Knockout (KO) | Permanent gene deletion, typically using CRISPR/Cas9, resulting in complete loss of protein function.[5] | Definitive loss-of-function; stable and heritable modification; ideal for studying non-essential gene roles. | Can be lethal if the gene is essential for survival; potential for off-target effects; compensatory mechanisms may arise.[6] |
| Knockdown (KD) | Transient reduction of gene expression, typically using siRNA or shRNA to target mRNA for degradation.[7] | Allows study of essential genes; temporal control of gene silencing; relatively rapid and cost-effective. | Incomplete suppression of protein expression; off-target effects are common; transient effect may not be suitable for long-term studies. |
| Chemical Inhibition | Small molecules that bind to and inhibit the enzymatic activity of a target protein. | High temporal control (rapid on/off); dose-dependent effects; potential for therapeutic development.[8] | Potential for lack of specificity and off-target effects; requires extensive screening and development; not available for all m1A regulators. |
| Targeted Editing | CRISPR-based tools (e.g., dCas13b fused to a demethylase) to add or remove m1A at specific sites without altering the gene sequence.[4] | High specificity for individual m1A sites; allows for studying the function of specific RNA modifications; reversible.[4] | Technically complex to design and validate; delivery can be challenging in vivo; potential for off-target RNA binding. |
The Role of m1A in Key Biological Processes: Insights from Knockout and Knockdown Models
Genetic perturbation models have been instrumental in elucidating the function of m1A regulators in diverse biological contexts.
Cancer Progression
Dysregulation of m1A modification is frequently linked to cancer.[9][10] Knockout and knockdown studies of m1A "erasers" like ALKBH1 and ALKBH3 have revealed their significant roles in tumor cell migration, invasion, and gene expression.
ALKBH1 in Colorectal Cancer (CRC) Metastasis: Studies have shown that the m1A demethylase ALKBH1 promotes CRC metastasis.[11] Knockdown of ALKBH1 in CRC cell lines HCT116 and RKO suppressed their ability to migrate and invade. Mechanistically, ALKBH1 depletion was found to decrease the expression of METTL3 (an m6A writer) by affecting the m1A modification of its mRNA. This, in turn, led to reduced m6A demethylation of SMAD7 mRNA, an inhibitor of metastasis.[11]
Table 1: Effect of ALKBH1 Knockdown on Colorectal Cancer Cell Invasion
| Cell Line | Condition | Relative Invasion (%) | Data Source |
| HCT116 | Control siRNA | 100 | [11][12] |
| HCT116 | ALKBH1 siRNA | ~45 | [11][12] |
| RKO | Control siRNA | 100 | [11][12] |
| RKO | ALKBH1 siRNA | ~55 | [11][12] |
Data are approximated from published figures.
Figure 1. ALKBH1-mediated regulation of CRC metastasis.
ALKBH3 in Hodgkin Lymphoma: In Hodgkin lymphoma, epigenetic silencing of the m1A demethylase ALKBH3 is associated with a poor clinical outcome.[7] Using an shRNA-mediated knockdown of ALKBH3 in lymphoma cells, researchers observed an increase in m1A peaks on the transcripts for collagens COL1A1 and COL1A2. This led to a corresponding increase in collagen protein expression, highlighting a role for ALKBH3 in remodeling the tumor microenvironment.[7]
Ciliogenesis and Development
The formation of primary cilia, crucial sensory organelles, is tightly regulated. Studies using knockdown models in zebrafish have implicated the m1A eraser ALKBH3 as a key player in this process.
Depletion of ALKBH3 in zebrafish embryos using morpholinos resulted in classic ciliary defects, including a curved body and pericardial edema.[13] The underlying mechanism involves ALKBH3-mediated m1A demethylation of the mRNA for Aurora A, a known suppressor of ciliogenesis. Loss of ALKBH3 enhances the decay and inhibits the translation of Aurora A mRNA, thereby disrupting normal cilia formation.[13]
Figure 2. ALKBH3-dependent regulation of ciliogenesis.
Immune Cell Function
The adaptive immune response requires precise regulation of T-cell activation and proliferation. Conditional knockout models have demonstrated that m1A modification is a critical checkpoint in this process.
Using a conditional knockout mouse model, researchers found that deleting the m1A "writer" TRMT61A in T-cells impaired their activation and proliferation.[4] Loss of TRMT61A-mediated m1A modification on tRNAs hindered the translation of key proteins required for T-cell function, most notably the transcription factor MYC. This positions tRNA m1A modification as a novel "translational checkpoint" in the immune response.[4]
Table 2: Effect of TRMT61A Knockout on CD4+ T-Cell Proliferation
| Genotype | Condition | Proliferation Index | Data Source |
| Wild-Type | Activated | High | [4] |
| TRMT61A cKO | Activated | Significantly Reduced | [4] |
Data are qualitative based on published findings.
Figure 3. Role of TRMT61A in T-cell proliferation.
Experimental Protocols
Detailed and reproducible protocols are essential for validating experimental findings. Below are methodologies for key experiments cited in m1A research.
Protocol 1: Generation of a Knockout Cell Line via CRISPR/Cas9
This protocol provides a general workflow for creating a gene knockout in a mammalian cell line.[5][14]
Figure 4. CRISPR/Cas9 knockout experimental workflow.
-
sgRNA Design and Cloning:
-
Design 2-3 single guide RNAs (sgRNAs) targeting an early exon of the gene of interest using a web-based tool (e.g., CHOPCHOP, CRISPOR). Select sgRNAs with high predicted on-target efficiency and low off-target scores.
-
Synthesize and anneal complementary oligonucleotides for the chosen sgRNA sequence.
-
Clone the annealed oligos into a suitable sgRNA expression vector (e.g., one containing a U6 promoter).
-
-
Cell Transfection:
-
Culture the target cells (e.g., HCT116) to 70-80% confluency.
-
Co-transfect the cells with a plasmid expressing Cas9 nuclease and the validated sgRNA expression plasmid using a suitable transfection reagent (e.g., Lipofectamine). A plasmid containing both Cas9 and the sgRNA can also be used.
-
-
Selection and Single-Cell Cloning:
-
48 hours post-transfection, begin selection by adding the appropriate antibiotic (e.g., puromycin) if the Cas9/sgRNA plasmids contain a resistance marker.
-
After selection, dilute the surviving cells to a concentration of a single cell per well in 96-well plates to isolate individual clones.
-
-
Clonal Expansion and Screening:
-
Culture the single-cell clones until sufficient cell numbers are available for screening.
-
Screen for successful knockout by extracting genomic DNA and performing PCR followed by Sanger sequencing to identify clones with frameshift-inducing insertions or deletions (indels).
-
Confirm the absence of the target protein in candidate clones using Western blotting.
-
Protocol 2: Transwell Migration Assay
This assay quantifies the migratory capacity of cells in response to a chemoattractant.[12]
-
Cell Preparation:
-
Culture control and knockout/knockdown cells. 24 hours before the assay, starve the cells in a serum-free medium.
-
On the day of the assay, detach the cells using trypsin, wash with PBS, and resuspend them in a serum-free medium at a concentration of 1x10^5 cells/mL.
-
-
Assay Setup:
-
Place Transwell inserts (typically 8 µm pore size) into the wells of a 24-well plate.
-
Add 600 µL of complete medium (containing serum as a chemoattractant) to the lower chamber of each well.
-
Add 200 µL of the cell suspension (20,000 cells) to the upper chamber of each Transwell insert.
-
-
Incubation:
-
Incubate the plate at 37°C in a CO2 incubator for a period determined by the cell type's migration rate (e.g., 24-48 hours).
-
-
Staining and Quantification:
-
After incubation, carefully remove the medium from the upper chamber.
-
Use a cotton swab to gently wipe away the non-migrated cells from the top surface of the membrane.
-
Fix the migrated cells on the bottom surface of the membrane with 4% paraformaldehyde for 15 minutes.
-
Stain the cells with 0.1% crystal violet for 20 minutes.
-
Wash the inserts with water and allow them to air dry.
-
Image the migrated cells under a microscope and count the cells in several random fields to determine the average number of migrated cells per condition.
-
Protocol 3: m1A MeRIP-Seq (Methylated RNA Immunoprecipitation Sequencing)
This protocol enables the transcriptome-wide mapping of m1A sites.[15]
-
RNA Extraction and Fragmentation:
-
Extract total RNA from cells or tissues using a standard method (e.g., TRIzol). Ensure high quality and integrity of the RNA.
-
Fragment the RNA into ~100-nucleotide fragments using RNA fragmentation buffer or enzymatic methods.
-
-
Immunoprecipitation (IP):
-
Take an aliquot of the fragmented RNA to serve as the "Input" control.
-
Incubate the remaining fragmented RNA with an m1A-specific antibody that has been pre-bound to protein A/G magnetic beads.
-
Incubate overnight at 4°C with rotation to allow the antibody to capture m1A-containing RNA fragments.
-
Wash the beads multiple times to remove non-specifically bound RNA.
-
Elute the m1A-enriched RNA from the beads.
-
-
Library Preparation and Sequencing:
-
Prepare sequencing libraries from both the eluted (IP) and the Input RNA samples using a strand-specific library preparation kit.
-
Perform high-throughput sequencing on a platform like Illumina.
-
-
Data Analysis:
-
Align the sequencing reads from both IP and Input samples to the reference genome/transcriptome.
-
Use a peak-calling algorithm (e.g., MACS2) to identify regions significantly enriched for m1A in the IP sample compared to the Input control. These enriched regions represent m1A peaks.
-
Perform motif analysis on the identified peaks to find consensus sequences for m1A modification.
-
References
- 1. m1A RNA Modification in Gene Expression Regulation - PMC [pmc.ncbi.nlm.nih.gov]
- 2. m1A RNA Modification in Gene Expression Regulation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. N1-methyladenosine formation, gene regulation, biological functions, and clinical relevance - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Frontiers | Harnessing m1A modification: a new frontier in cancer immunotherapy [frontiersin.org]
- 5. Guidelines for optimized gene knockout using CRISPR/Cas9 - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. Context-dependent functional compensation between Ythdf m6A reader proteins - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Epigenetic loss of m1A RNA demethylase ALKBH3 in Hodgkin lymphoma targets collagen, conferring poor clinical outcome - PMC [pmc.ncbi.nlm.nih.gov]
- 8. researchgate.net [researchgate.net]
- 9. N1-methyladenosine modification in cancer biology: Current status and future perspectives - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Research progress of N1-methyladenosine RNA modification in cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 11. ALKBH1‐mediated m1A demethylation of METTL3 mRNA promotes the metastasis of colorectal cancer by downregulating SMAD7 expression - PMC [pmc.ncbi.nlm.nih.gov]
- 12. researchgate.net [researchgate.net]
- 13. researchgate.net [researchgate.net]
- 14. CRISPR Cas9 - Gene Knockout/Knock-in Case Studies | abm Inc. [info.abmgood.com]
- 15. m1A RNA Methylation Analysis - CD Genomics [cd-genomics.com]
A Comparative Guide to the Substrate Specificity of ALKBH1 and ALKBH3
For Researchers, Scientists, and Drug Development Professionals
The AlkB homolog (ALKBH) family of Fe(II)/α-ketoglutarate-dependent dioxygenases plays a crucial role in the demethylation of nucleic acids and proteins, influencing a wide range of cellular processes. Among the nine members of this family, ALKBH1 and ALKBH3 are of particular interest due to their distinct yet sometimes overlapping substrate specificities and their implications in various diseases, including cancer. This guide provides an objective comparison of the substrate specificities of ALKBH1 and ALKBH3, supported by experimental data, detailed methodologies, and visual diagrams to facilitate a deeper understanding of their functions.
Core Substrate Preferences and Enzymatic Activity
ALKBH1 and ALKBH3 exhibit both shared and unique substrate preferences, primarily targeting methylated bases in DNA and RNA. Their catalytic activity, however, is often dictated by the structural context of the substrate.
ALKBH1 is a versatile enzyme with a demonstrated preference for structured nucleic acids. Its primary substrates include:
-
N1-methyladenosine (m1A) in transfer RNA (tRNA) : ALKBH1 preferentially demethylates m1A at position 58 (m1A58) located within the T-loop of tRNAs.[1][2] This activity is crucial for tRNA stability and proper translation initiation.[1]
-
Modified cytidines in tRNA : ALKBH1 is involved in the biogenesis of 5-hydroxymethyl-2'-O-methylcytidine (hm⁵Cm34) and 5-formyl-2'-O-methylcytidine (f⁵Cm34) in cytoplasmic tRNA, as well as 5-formylcytidine (f⁵C34) in mitochondrial tRNA.[2][3]
-
N6-methyladenosine (N6-mA) in DNA : ALKBH1 has been shown to demethylate N6-mA in DNA, particularly in bulged or bubbled DNA structures, suggesting a role in transcriptional regulation.[3][4]
-
Other potential substrates : While some studies have reported ALKBH1 activity on N6-methyladenosine (m6A) in mRNA, N3-methylcytidine (m3C), and even histone H2A, these findings are still under investigation and subject to some debate.[1][3][5][6]
ALKBH3 , in contrast, displays a strong preference for single-stranded nucleic acids. It is recognized as the primary demethylase for:
-
N1-methyladenosine (m1A) in messenger RNA (mRNA) : ALKBH3 is the only known enzyme to demethylate m1A in mRNA, a modification that plays a role in mRNA stability and translation.[7]
-
N1-methyladenosine (m1A) and N3-methylcytidine (m3C) in single-stranded DNA (ssDNA) and RNA : ALKBH3 efficiently repairs these lesions in single-stranded contexts, highlighting its role in DNA repair and RNA quality control.[7][8][9][10][11]
-
m1A and m3C in tRNA : ALKBH3 can also demethylate m1A and m3C in tRNA, indicating some overlap with ALKBH1's function, though the structural preference differs.[12]
-
Exocyclic DNA adducts : ALKBH3 has been shown to repair other forms of DNA damage, such as 3,N4-ethenocytosine.[10][13]
Quantitative Comparison of Substrate Specificity
The following table summarizes the key differences in substrate preference between ALKBH1 and ALKBH3 based on available experimental data.
| Substrate | ALKBH1 Preference | ALKBH3 Preference | Key References |
| N1-methyladenosine (m1A) | High in structured tRNA (stem-loop) | High in single-stranded RNA (mRNA) and ssDNA | [1][7] |
| N3-methylcytidine (m3C) | Lower activity reported | High in single-stranded DNA and RNA | [4][7][12] |
| N6-methyladenosine (m6A) in RNA | Debated, likely low activity | No significant activity reported | [1] |
| N6-methyladenine (6mA) in DNA | Prefers bulged/bubbled structures | Low to no activity | [1][4] |
| Substrate Structure | Prefers structured RNA (tRNA) and non-canonical DNA structures | Strong preference for single-stranded DNA and RNA | [1][4][8] |
Experimental Protocols
Understanding the methodologies used to determine substrate specificity is critical for interpreting the data. Below are detailed protocols for key experiments.
In Vitro Demethylation Assay (Fluorescence-based)
This continuous and rapid assay measures the formaldehyde produced during the demethylation reaction.
Principle: The demethylation of a methyl-adduct by an ALKBH enzyme produces formaldehyde. This formaldehyde is then oxidized by formaldehyde dehydrogenase (FDH), which is coupled to the reduction of an NAD+ analog to a fluorescent NADH analog. The increase in fluorescence is proportional to the demethylase activity.[14][15][16]
Protocol:
-
Reaction Mixture Preparation: In a 96-well plate, prepare a reaction mixture containing reaction buffer (e.g., 50 mM HEPES pH 7.5, 50 µM (NH₄)₂Fe(SO₄)₂·6H₂O, 1 mM α-ketoglutarate, 2 mM L-ascorbic acid), formaldehyde dehydrogenase, and the NAD+ analog.
-
Enzyme and Substrate Addition: Add the purified ALKBH1 or ALKBH3 enzyme to the wells. Initiate the reaction by adding the methylated DNA or RNA substrate.
-
Fluorescence Measurement: Immediately place the plate in a fluorescence plate reader and monitor the increase in fluorescence over time at the appropriate excitation and emission wavelengths for the NADH analog.
-
Data Analysis: Calculate the initial reaction velocity from the linear phase of the fluorescence curve. Determine kinetic parameters (Km and kcat) by varying the substrate concentration.
Cross-Linking and Immunoprecipitation followed by Sequencing (CLIP-Seq)
CLIP-Seq is a powerful technique to identify the in vivo RNA targets of an RNA-binding protein like ALKBH1 or ALKBH3.
Principle: Cells are treated with UV light to cross-link proteins to the RNAs they are bound to. The protein of interest is then immunoprecipitated, and the associated RNA fragments are sequenced to identify the binding sites.[1][12]
Protocol:
-
UV Cross-linking: Expose cultured cells to UV light to induce covalent cross-links between proteins and RNA.
-
Cell Lysis and RNase Digestion: Lyse the cells and perform a limited digestion with RNase to fragment the RNA.
-
Immunoprecipitation: Incubate the cell lysate with antibodies specific to ALKBH1 or ALKBH3 conjugated to magnetic beads to pull down the protein-RNA complexes.
-
RNA Isolation and Library Preparation: After stringent washes, treat the immunoprecipitated material with proteinase K to digest the protein and isolate the cross-linked RNA fragments. Ligate adapters to the RNA fragments and perform reverse transcription to generate a cDNA library.
-
Sequencing and Data Analysis: Sequence the cDNA library using high-throughput sequencing. Align the sequencing reads to the genome to identify the specific RNA molecules and binding sites for the ALKBH enzyme.
Signaling Pathways and Functional Relationships
The distinct substrate specificities of ALKBH1 and ALKBH3 lead to their involvement in different cellular signaling pathways.
ALKBH1 is implicated in fundamental cellular processes such as the regulation of pluripotency and metabolism. In the nucleus, it can interact with core transcription factors like NANOG and SOX2.[6] It also regulates the expression of Hypoxia-Inducible Factor 1-alpha (HIF-1α) and Nuclear Respiratory Factor 1 (NRF1) through DNA demethylation, thereby influencing the AMPK signaling pathway and cellular metabolism.[17][18] In the cytoplasm and mitochondria, its activity on tRNA modulates protein synthesis.[2]
ALKBH3 is strongly associated with cancer progression. Its role in demethylating m1A in mRNA can affect the stability of transcripts for key signaling molecules like Colony-Stimulating Factor 1 (CSF-1).[19] Furthermore, ALKBH3-mediated demethylation of tRNA can lead to the generation of tRNA-derived small RNAs (tDRs), which have been shown to promote cancer cell proliferation and invasion.[12] ALKBH3 has also been linked to the Vascular Endothelial Growth Factor (VEGF) signaling pathway, a critical driver of angiogenesis in tumors.[8]
Experimental Workflow Visualization
The following diagram illustrates a typical workflow for comparing the demethylase activity of ALKBH1 and ALKBH3 on different substrates.
Conclusion
ALKBH1 and ALKBH3, while both members of the AlkB family, exhibit distinct substrate specificities that underscore their unique biological roles. ALKBH1 demonstrates a clear preference for structured nucleic acids, particularly tRNA, and is involved in fundamental processes like translation and metabolic regulation. In contrast, ALKBH3 is a specialist for single-stranded substrates, playing a critical role in mRNA demethylation and DNA repair, with significant implications for cancer biology. A thorough understanding of these differences is essential for researchers and drug development professionals aiming to target these enzymes for therapeutic intervention. The experimental approaches outlined in this guide provide a framework for further dissecting the nuanced functions of these important demethylases.
References
- 1. ALKBH1-Mediated tRNA Demethylation Regulates Translation - PMC [pmc.ncbi.nlm.nih.gov]
- 2. academic.oup.com [academic.oup.com]
- 3. The biological function of demethylase ALKBH1 and its role in human diseases - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Multi-substrate selectivity based on key loops and non-homologous domains: new insight into ALKBH family - PMC [pmc.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
- 6. karger.com [karger.com]
- 7. The Molecular Basis of Human ALKBH3 Mediated RNA N1-methyladenosine (m1A) Demethylation - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Frontiers | The role of demethylase AlkB homologs in cancer [frontiersin.org]
- 9. Alkb homolog 3, alpha-ketoglutaratedependent dioxygenase - Wikipedia [en.wikipedia.org]
- 10. uniprot.org [uniprot.org]
- 11. ALKBH3 protein expression summary - The Human Protein Atlas [proteinatlas.org]
- 12. Transfer RNA demethylase ALKBH3 promotes cancer progression via induction of tRNA-derived small RNAs - PMC [pmc.ncbi.nlm.nih.gov]
- 13. genecards.org [genecards.org]
- 14. Kinetic studies of Escherichia coli AlkB using a new fluorescence-based assay for DNA demethylation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 15. academic.oup.com [academic.oup.com]
- 16. researchgate.net [researchgate.net]
- 17. DNA demethylase ALKBH1 promotes adipogenic differentiation via regulation of HIF-1 signaling - PMC [pmc.ncbi.nlm.nih.gov]
- 18. Biological interpretation of DNA/RNA modification by ALKBH proteins and their role in human cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 19. The role of demethylase AlkB homologs in cancer - PMC [pmc.ncbi.nlm.nih.gov]
Validating m1A as a Therapeutic Target: A Comparative Guide for Preclinical Research
For researchers, scientists, and drug development professionals, the burgeoning field of epitranscriptomics offers a new frontier in therapeutic innovation. Among the numerous RNA modifications, N1-methyladenosine (m1A) has emerged as a critical regulator of gene expression, with its dysregulation implicated in the progression of various cancers. This guide provides a comparative analysis of preclinical studies that have validated m1A and its regulatory proteins as viable therapeutic targets, offering a comprehensive overview of current strategies, supporting experimental data, and detailed methodologies.
The dynamic and reversible nature of m1A modification is governed by a trio of protein families: "writers" (methyltransferases), "erasers" (demethylases), and "readers" (m1A-binding proteins). Key among these are the writer complex TRMT6/TRMT61A and the eraser enzymes ALKBH1 and ALKBH3. Preclinical research has increasingly focused on targeting these regulators to modulate m1A levels and consequently impact cancer cell proliferation, survival, and metastasis.
Comparative Efficacy of m1A Modulators in Preclinical Cancer Models
The development of small molecule inhibitors targeting m1A regulators has shown promise in various cancer models. Below is a summary of the quantitative data from key preclinical studies, providing a comparative look at their efficacy.
| Therapeutic Target | Inhibitor | Cancer Model | Cell Line | Administration Route & Dosage | Key Findings |
| TRMT6/TRMT61A | Thiram | Orthotopic Hepatocellular Carcinoma (HCC) | Patient-Derived Cells (PDCs) | Intraperitoneal, 1.6 mg/kg | Significantly reduced tumor volume and improved survival. Reduced m1A levels in HCC cells. |
| ALKBH3 | HUHS015 | Subcutaneous Prostate Cancer Xenograft | DU145 | Subcutaneous, 32 mg/kg | Showed a synergistic antitumor effect when combined with docetaxel (2.5 mg/kg). |
| ALKBH1 | 29E (prodrug) | Gastric Cancer | N/A | Oral administration | Exhibited high exposure in mice and inhibited gastric cancer cell viability by increasing 6mA abundance.[1] |
| TRMT61A | CMP1 | Subcutaneous Bladder Cancer Xenograft | 5637 | Intraperitoneal, 1 mg/kg for 10 days | Suppressed tumor growth. |
| TRMT61A | CMP9 | Subcutaneous Bladder Cancer Xenograft | 5637 | Intraperitoneal, 10 mg/kg for 10 days | Suppressed tumor growth. |
Experimental Protocols: A Guide to Preclinical Validation
Reproducibility and standardization are paramount in preclinical research. This section details the methodologies for key experiments cited in the validation of m1A as a therapeutic target.
Orthotopic Hepatocellular Carcinoma (HCC) Mouse Model
This model recapitulates the tumor microenvironment, providing a clinically relevant platform for evaluating therapeutic efficacy.
-
Cell Preparation: Patient-derived HCC cells are cultured and harvested.
-
Animal Model: Immunocompromised mice (e.g., NOD/SCID) are used.
-
Surgical Procedure:
-
Anesthetize the mouse.
-
Make a small incision in the left flank to expose the spleen.
-
Inject approximately 1 x 10^6 HCC cells in 50 µL of a 1:1 mixture of serum-free medium and Matrigel into the spleen.
-
Suture the incision.
-
-
Tumor Growth Monitoring: Tumor growth is monitored weekly using in vivo imaging systems (e.g., IVIS) for bioluminescently tagged cells or via ultrasound.
-
Treatment Administration: Once tumors are established (typically 1-2 weeks post-injection), treatment with the investigational drug (e.g., Thiram at 1.6 mg/kg, i.p.) is initiated.
-
Endpoint Analysis: At the end of the study, mice are euthanized, and tumors are excised, weighed, and processed for histological and molecular analysis, including quantification of m1A levels.
Subcutaneous Prostate Cancer Xenograft Model
This is a widely used model for initial in vivo screening of potential anticancer agents.
-
Cell Preparation: DU145 human prostate cancer cells are cultured and harvested.
-
Animal Model: Male athymic nude mice are typically used.
-
Implantation:
-
Resuspend approximately 2 x 10^6 DU145 cells in 100 µL of a 1:1 mixture of culture medium and Matrigel.
-
Inject the cell suspension subcutaneously into the flank of the mouse.
-
-
Tumor Growth Monitoring: Tumor volume is measured 2-3 times per week with calipers using the formula: (Length x Width^2)/2.
-
Treatment Administration: When tumors reach a palpable size (e.g., 100-200 mm³), mice are randomized into treatment groups. For combination studies, this could include a vehicle control, Docetaxel alone (e.g., 2.5 mg/kg, i.p.), HUHS015 alone (e.g., 32 mg/kg, s.c.), and the combination of both.
-
Endpoint Analysis: The study is terminated when tumors in the control group reach a predetermined size. Tumors are then excised and weighed.
Quantification of m1A Levels by LC-MS/MS
Liquid chromatography-tandem mass spectrometry (LC-MS/MS) is the gold standard for accurate quantification of RNA modifications.
-
RNA Isolation: Total RNA is extracted from tumor tissue or cells using standard methods (e.g., Trizol reagent).
-
RNA Digestion: The RNA is digested to single nucleosides using a mixture of nucleases (e.g., nuclease P1 and alkaline phosphatase).
-
LC-MS/MS Analysis: The nucleoside mixture is analyzed by LC-MS/MS. The amount of m1A is quantified by comparing its signal to that of a standard curve of known m1A concentrations and normalized to the amount of canonical adenosine (A).
Signaling Pathways and Experimental Workflows
Understanding the molecular mechanisms by which m1A modulation exerts its anti-cancer effects is crucial for rational drug design and patient selection. Preclinical studies have implicated the PI3K/AKT/mTOR and ErbB signaling pathways as key downstream effectors.
Caption: m1A regulatory pathways and their downstream effects on cancer cell signaling.
Caption: A typical workflow for the preclinical validation of an m1A-targeting therapeutic.
References
Comparative Transcriptomics: Unraveling the Impact of m1A RNA Demethylase Deficiency
A comprehensive guide for researchers, scientists, and drug development professionals on the transcriptomic landscapes of wild-type versus m1A-deficient organisms. This guide provides an objective comparison supported by experimental data, detailed methodologies, and visual representations of affected signaling pathways.
The reversible N1-methyladenosine (m1A) modification of RNA is a critical regulator of gene expression, influencing RNA stability, translation, and various cellular processes.[1] The enzymes responsible for removing this modification, primarily ALKBH1 and ALKBH3, play a pivotal role in maintaining transcriptomic integrity. Their deficiency leads to significant alterations in gene expression, impacting pathways crucial for development, cellular homeostasis, and disease progression, including cancer.[2][3] This guide delves into the comparative transcriptomics of wild-type organisms versus those deficient in m1A demethylases, providing a valuable resource for understanding the functional consequences of this vital RNA modification.
Quantitative Transcriptomic Analysis: A Comparative Overview
Studies employing high-throughput sequencing have begun to shed light on the widespread changes in the transcriptome following the depletion of m1A demethylases. Here, we summarize key findings from studies on ALKBH1 and ALKBH3 deficient models.
ALKBH1 Deficiency
ALKBH1 has been identified as a key tRNA demethylase, and its absence leads to significant perturbations in the translational machinery.[4][5] However, it also influences the mRNA methylome.[1] In a study on human mesenchymal stem cells (hMSCs), knockdown of ALKBH1 resulted in a total of 496 differentially expressed genes, with 330 genes being downregulated and 166 upregulated.[6]
| Organism/Cell Line | m1A Demethylase Deficiency | Number of Downregulated Genes | Number of Upregulated Genes | Key Affected Pathways | Reference |
| Human Mesenchymal Stem Cells (hMSCs) | ALKBH1 Knockdown | 330 | 166 | Adipogenesis, HIF-1 Signaling | [6] |
| Rice (Oryza sativa) | alkbh1 mutant | 1047 | 386 | Stress response, Development | [7] |
ALKBH3 Deficiency
ALKBH3 is a primary demethylase for m1A in mRNA and its deficiency has been strongly implicated in various cancers.[2][3] In Hodgkin lymphoma cells, depletion of ALKBH3 led to a significant gain of m1A marks on 141 transcripts.[8] A study on human dermal fibroblasts (HDFs) with ALKBH3 knockdown identified 1707 downregulated and 589 upregulated genes, highlighting the extensive regulatory role of ALKBH3.[9]
| Organism/Cell Line | m1A Demethylase Deficiency | Number of Downregulated Genes | Number of Upregulated Genes | Key Affected Pathways | Reference |
| Human Dermal Fibroblasts (HDFs) | ALKBH3 Knockdown | 1707 | 589 | Fibrosis-related pathways | [9] |
| Triple-Negative Breast Cancer Cells (MDA-MB-231/Dox) | ALKBH3 Knockdown | Not specified | Not specified | Glycolysis | [10] |
| Hodgkin Lymphoma Cells (HD-MY-Z) | ALKBH3 Depletion | Not specified | Not specified | Collagen-related pathways | [8] |
Experimental Protocols
Understanding the methodologies behind these comparative transcriptomic studies is crucial for interpreting the data and designing future experiments.
RNA-Sequencing (RNA-Seq)
A standard workflow for comparing the transcriptomes of wild-type and m1A-deficient organisms involves the following key steps:
-
RNA Isolation: Total RNA is extracted from cells or tissues using methods like TRIzol reagent, followed by purification to remove contaminants.[11] RNA quality and quantity are assessed using spectrophotometry and capillary electrophoresis.
-
Library Preparation:
-
rRNA Depletion: Ribosomal RNA, which constitutes a large portion of total RNA, is removed to enrich for messenger RNA (mRNA) and other non-coding RNAs.[11]
-
Fragmentation: The enriched RNA is fragmented into smaller pieces.
-
Reverse Transcription: Fragmented RNA is reverse transcribed into complementary DNA (cDNA).
-
Second Strand Synthesis & A-tailing: The single-stranded cDNA is converted into double-stranded cDNA, and an adenine base is added to the 3' end.
-
Adapter Ligation: Sequencing adapters are ligated to the ends of the cDNA fragments.
-
PCR Amplification: The adapter-ligated cDNA is amplified by PCR to create a library for sequencing.[5]
-
-
Sequencing: The prepared libraries are sequenced using a high-throughput sequencing platform (e.g., Illumina NextSeq 500).[11]
-
Data Analysis:
-
Quality Control: Raw sequencing reads are assessed for quality.
-
Mapping: Reads are aligned to a reference genome.
-
Quantification: The number of reads mapping to each gene is counted to determine its expression level.
-
Differential Expression Analysis: Statistical methods (e.g., DESeq2) are used to identify genes with significant expression changes between wild-type and deficient samples.[12]
-
m1A-Specific Sequencing (m1A-Seq / MeRIP-Seq)
To specifically map the locations of m1A modifications across the transcriptome, a technique involving immunoprecipitation of m1A-containing RNA fragments is employed.
-
RNA Fragmentation: Total RNA is fragmented into smaller pieces.
-
Immunoprecipitation (IP): The fragmented RNA is incubated with an antibody specific to m1A. This antibody binds to the RNA fragments containing the m1A modification.
-
Enrichment: The antibody-RNA complexes are captured, enriching for m1A-modified RNA fragments.
-
RNA Elution and Library Preparation: The enriched RNA is eluted and used to construct a sequencing library, similar to the RNA-seq protocol.
-
Sequencing and Data Analysis: The library is sequenced, and the resulting data is analyzed to identify peaks, which represent regions enriched for m1A modification. These peaks are then annotated to specific genes and transcript regions.[8]
Visualization of Affected Signaling Pathways
The transcriptomic changes resulting from m1A demethylase deficiency have profound effects on various signaling pathways. Here, we visualize some of the key pathways identified in the literature using the DOT language for Graphviz.
Caption: ALKBH1's role in HIF-1 signaling and adipogenesis.
In wild-type cells, ALKBH1 demethylates HIF-1α mRNA, promoting the expression of downstream targets like GYS1 and driving adipogenesis.[6] In ALKBH1-deficient cells, hypermethylation of HIF-1α and GYS1 mRNA leads to the inhibition of this pathway and impaired adipogenic differentiation.[6]
Caption: ALKBH3's role in pathological skin fibrosis.
In fibrotic conditions, upregulated ALKBH3 demethylates METTL3 mRNA, leading to increased METTL3 protein expression.[9] METTL3, in turn, adds m6A modifications to COL1A1 and FN1 mRNAs, which are then stabilized by YTHDF1, promoting fibroblast activation and fibrosis.[9] Deficiency of ALKBH3 disrupts this cascade, reducing fibrosis.[9]
Caption: General workflow for comparative transcriptomics.
This guide provides a foundational understanding of the transcriptomic consequences of m1A demethylase deficiency. The presented data and methodologies offer a valuable starting point for researchers investigating the epitranscriptome's role in health and disease, and for professionals in drug development seeking novel therapeutic targets within these pathways. Further exploration of publicly available datasets, such as those in the Gene Expression Omnibus (GEO), can provide deeper insights into the specific gene expression changes in various m1A-deficient models.
References
- 1. ALKBH1-Mediated tRNA Demethylation Regulates Translation - PMC [pmc.ncbi.nlm.nih.gov]
- 2. GEO Accession viewer [ncbi.nlm.nih.gov]
- 3. researchgate.net [researchgate.net]
- 4. researchgate.net [researchgate.net]
- 5. m.youtube.com [m.youtube.com]
- 6. DNA demethylase ALKBH1 promotes adipogenic differentiation via regulation of HIF-1 signaling - PMC [pmc.ncbi.nlm.nih.gov]
- 7. GEO Accession viewer [ncbi.nlm.nih.gov]
- 8. AlkB homolog 3-mediated tRNA demethylation promotes protein synthesis in cancer cells - PMC [pmc.ncbi.nlm.nih.gov]
- 9. ALKBH3‐Mediated M1A Demethylation of METTL3 Endows Pathological Fibrosis:Interplay Between M1A and M6A RNA Methylation - PMC [pmc.ncbi.nlm.nih.gov]
- 10. ALKBH3-regulated m1A of ALDOA potentiates glycolysis and doxorubicin resistance of triple negative breast cancer cells - PMC [pmc.ncbi.nlm.nih.gov]
- 11. researchgate.net [researchgate.net]
- 12. GEO Accession viewer [ncbi.nlm.nih.gov]
Safety Operating Guide
Proper Disposal of 1-Methyladenine: A Guide for Laboratory Professionals
An essential guide for researchers, scientists, and drug development professionals on the safe and compliant disposal of 1-Methyladenine, ensuring laboratory safety and environmental protection.
1-Methyladenine is a methylated purine base that requires careful handling and disposal due to its potential hazards. While its toxicological and ecological properties are not fully investigated, it is classified as harmful if swallowed.[1] Adherence to proper disposal protocols is crucial to mitigate risks to personnel and the environment. This guide provides detailed procedures for the safe disposal of 1-Methyladenine in solid form and as aqueous solutions.
Hazard and Safety Information
A thorough understanding of the hazard profile of 1-Methyladenine is the first step toward safe handling and disposal. The following table summarizes key safety data.
| Hazard Classification | Data and Remarks |
| Acute Oral Toxicity | Category 4: Harmful if swallowed.[1][2] |
| Skin Corrosion/Irritation | May cause skin irritation. |
| Eye Damage/Irritation | May cause eye irritation. |
| Respiratory Irritation | May cause respiratory tract irritation. |
| Carcinogenicity | Not listed by ACGIH, IARC, NTP, or CA Prop 65.[3] |
| RCRA Classification | Not listed as a hazardous waste under RCRA P-Series or U-Series.[3] |
| Environmental Hazards | No specific information is available. Should not be released into the environment.[1] |
Step-by-Step Disposal Protocol
The recommended procedure for the disposal of 1-Methyladenine is to treat it as a chemical waste. Do not dispose of 1-Methyladenine or its solutions down the drain.
1. Personal Protective Equipment (PPE): Before handling 1-Methyladenine waste, ensure you are wearing appropriate PPE:
-
Gloves: Chemical-resistant gloves.
-
Eye Protection: Safety glasses with side shields or goggles.
-
Lab Coat: A standard laboratory coat.
2. Solid Waste Disposal:
-
Collection: Carefully sweep up solid 1-Methyladenine, avoiding dust generation.[1]
-
Containerization: Place the solid waste into a designated, properly labeled, and leak-proof container. The container should be clearly marked with "Hazardous Waste" and the full chemical name "1-Methyladenine".
-
Storage: Store the waste container in a designated satellite accumulation area, segregated from incompatible materials.[4]
3. Aqueous Solution Disposal:
-
Collection: Collect all aqueous solutions containing 1-Methyladenine in a dedicated, leak-proof container.
-
Containerization: Use a container compatible with aqueous waste. Label the container clearly with "Hazardous Waste," "Aqueous 1-Methyladenine Waste," and the approximate concentration.
-
Segregation: Keep halogenated and non-halogenated solvent wastes in separate containers. While 1-Methyladenine solutions are aqueous, ensure they are not mixed with other chemical waste streams.
4. Waste Pickup and Disposal:
-
Contact EH&S: Contact your institution's Environmental Health and Safety (EH&S) department to schedule a pickup for the hazardous waste.
-
Documentation: Maintain detailed records of the waste generated, including the amount and date of accumulation.
5. Spill Cleanup:
-
Small Spills: For small spills of solid 1-Methyladenine, sweep up the material and place it in a suitable disposal container.[1]
-
Ventilation: Ensure adequate ventilation in the area of the spill.
-
Large Spills: For larger spills, or if you are unsure how to proceed, contact your institution's EH&S department for guidance.
Disposal Workflow Diagram
The following diagram illustrates the decision-making process for the proper disposal of 1-Methyladenine.
Caption: Disposal workflow for 1-Methyladenine waste.
By following these procedures, you can ensure the safe and compliant disposal of 1-Methyladenine, contributing to a secure laboratory environment. Always consult your institution's specific waste disposal guidelines and the Safety Data Sheet for the most accurate and up-to-date information.
References
Essential Safety and Operational Guidance for Handling 1-Methyladenine
For researchers, scientists, and drug development professionals, ensuring laboratory safety is paramount, especially when handling specialized chemical compounds like 1-Methyladenine. This document provides immediate, essential safety protocols, operational plans, and disposal guidelines to foster a secure research environment. Adherence to these procedures is critical to minimize exposure and mitigate potential hazards.
Hazard Identification and Personal Protective Equipment (PPE)
1-Methyladenine is a substance that may cause irritation to the eyes, skin, respiratory system, and digestive tract.[1] It is classified as harmful if swallowed.[2][3] The toxicological properties of this material have not been fully investigated, warranting cautious handling.[1]
The following table summarizes the mandatory personal protective equipment required to handle 1-Methyladenine safely.
| PPE Category | Item | Specifications |
| Eye and Face Protection | Safety Goggles | Wear appropriate protective eyeglasses or chemical safety goggles that comply with OSHA's eye and face protection regulations in 29 CFR 1910.133 or European Standard EN166.[1][2] |
| Skin Protection | Gloves | Wear compatible chemical-resistant gloves to prevent skin exposure.[1][4] |
| Protective Clothing | A lab coat or other appropriate protective clothing should be worn to minimize skin contact.[1][4] | |
| Respiratory Protection | Respirator | In situations where ventilation is inadequate or dust generation is likely, a NIOSH/MSHA or European Standard EN 149 approved respirator is required.[1][4] |
Operational Plan for Handling 1-Methyladenine
A systematic approach to handling 1-Methyladenine is essential to maintain a safe laboratory environment.
Step 1: Preparation
-
Ensure that an eyewash station and a safety shower are readily accessible.[1]
-
Verify that the work area, preferably a chemical fume hood, has adequate ventilation.[1][5]
-
Assemble all necessary materials and equipment before handling the compound.
-
Put on all required personal protective equipment as detailed in the table above.
Step 2: Handling
-
Avoid the generation and accumulation of dust.[1]
-
Do not breathe in dust.[5]
-
Wash hands and any exposed skin thoroughly after handling.[1][2]
Step 3: Storage
-
Store 1-Methyladenine in a cool, dry, and well-ventilated area.[1][4]
-
Keep the container tightly closed to prevent contamination and degradation.[1][5]
-
Store away from incompatible substances such as strong oxidizing agents.[2][5]
Disposal Plan
Proper disposal of 1-Methyladenine and any contaminated materials is crucial to prevent environmental contamination and ensure regulatory compliance.
Waste Collection:
-
Solid Waste: Spilled 1-Methyladenine should be carefully swept or vacuumed up and placed into a suitable, labeled container for disposal.[1][2] Avoid generating dust during cleanup.[1]
-
Contaminated Materials: Any materials, such as gloves, weigh papers, or disposable lab coats, that come into contact with 1-Methyladenine should be considered contaminated and placed in a designated hazardous waste container.
Labeling and Storage of Waste:
-
The waste container must be clearly labeled as "Hazardous Waste" and include the chemical name "1-Methyladenine."
-
Store the hazardous waste container in a designated, well-ventilated, and secure area, away from incompatible materials, pending disposal.
Final Disposal:
-
All waste must be disposed of in accordance with federal, state, and local environmental control regulations.[5]
-
Dispose of the contents and container at an approved waste disposal plant.[2]
Workflow for Safe Handling and Disposal
The following diagram illustrates the standard workflow for handling and disposing of 1-Methyladenine in a laboratory setting.
References
Retrosynthesis Analysis
AI-Powered Synthesis Planning: Our tool employs the Template_relevance Pistachio, Template_relevance Bkms_metabolic, Template_relevance Pistachio_ringbreaker, Template_relevance Reaxys, Template_relevance Reaxys_biocatalysis model, leveraging a vast database of chemical reactions to predict feasible synthetic routes.
One-Step Synthesis Focus: Specifically designed for one-step synthesis, it provides concise and direct routes for your target compounds, streamlining the synthesis process.
Accurate Predictions: Utilizing the extensive PISTACHIO, BKMS_METABOLIC, PISTACHIO_RINGBREAKER, REAXYS, REAXYS_BIOCATALYSIS database, our tool offers high-accuracy predictions, reflecting the latest in chemical research and data.
Strategy Settings
| Precursor scoring | Relevance Heuristic |
|---|---|
| Min. plausibility | 0.01 |
| Model | Template_relevance |
| Template Set | Pistachio/Bkms_metabolic/Pistachio_ringbreaker/Reaxys/Reaxys_biocatalysis |
| Top-N result to add to graph | 6 |
Feasible Synthetic Routes



Featured Recommendations
| Most viewed |
|
|
|---|---|---|
| Most popular with customers |
|
Haftungsausschluss und Informationen zu In-Vitro-Forschungsprodukten
Bitte beachten Sie, dass alle Artikel und Produktinformationen, die auf BenchChem präsentiert werden, ausschließlich zu Informationszwecken bestimmt sind. Die auf BenchChem zum Kauf angebotenen Produkte sind speziell für In-vitro-Studien konzipiert, die außerhalb lebender Organismen durchgeführt werden. In-vitro-Studien, abgeleitet von dem lateinischen Begriff "in Glas", beinhalten Experimente, die in kontrollierten Laborumgebungen unter Verwendung von Zellen oder Geweben durchgeführt werden. Es ist wichtig zu beachten, dass diese Produkte nicht als Arzneimittel oder Medikamente eingestuft sind und keine Zulassung der FDA für die Vorbeugung, Behandlung oder Heilung von medizinischen Zuständen, Beschwerden oder Krankheiten erhalten haben. Wir müssen betonen, dass jede Form der körperlichen Einführung dieser Produkte in Menschen oder Tiere gesetzlich strikt untersagt ist. Es ist unerlässlich, sich an diese Richtlinien zu halten, um die Einhaltung rechtlicher und ethischer Standards in Forschung und Experiment zu gewährleisten.
