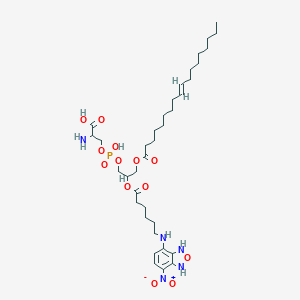
Nbdps
Beschreibung
Eigenschaften
CAS-Nummer |
132880-14-9 |
|---|---|
Molekularformel |
C36H60N5O13P |
Molekulargewicht |
801.9 g/mol |
IUPAC-Name |
2-amino-3-[hydroxy-[2-[6-[(4-nitro-1,3-dihydro-2,1,3-benzoxadiazol-7-yl)amino]hexanoyloxy]-3-[(E)-octadec-9-enoyl]oxypropoxy]phosphoryl]oxypropanoic acid |
InChI |
InChI=1S/C36H60N5O13P/c1-2-3-4-5-6-7-8-9-10-11-12-13-14-15-17-20-32(42)50-25-28(26-51-55(48,49)52-27-29(37)36(44)45)53-33(43)21-18-16-19-24-38-30-22-23-31(41(46)47)35-34(30)39-54-40-35/h9-10,22-23,28-29,38-40H,2-8,11-21,24-27,37H2,1H3,(H,44,45)(H,48,49)/b10-9+ |
InChI-Schlüssel |
MPEALQZPJOTEJL-MDZDMXLPSA-N |
SMILES |
CCCCCCCCC=CCCCCCCCC(=O)OCC(COP(=O)(O)OCC(C(=O)O)N)OC(=O)CCCCCNC1=C2C(=C(C=C1)[N+](=O)[O-])NON2 |
Isomerische SMILES |
CCCCCCCC/C=C/CCCCCCCC(=O)OCC(COP(=O)(O)OCC(C(=O)O)N)OC(=O)CCCCCNC1=C2C(=C(C=C1)[N+](=O)[O-])NON2 |
Kanonische SMILES |
CCCCCCCCC=CCCCCCCCC(=O)OCC(COP(=O)(O)OCC(C(=O)O)N)OC(=O)CCCCCNC1=C2C(=C(C=C1)[N+](=O)[O-])NON2 |
Synonyme |
1-oleoyl-2-((N-(7-nitro-2,1,3-benzoxadiazol-4-yl)amino)caproyl)phosphatidylserine |
Herkunft des Produkts |
United States |
Foundational & Exploratory
A Technical Guide to the National Birth Defects Prevention Study (NBDPS)
Abstract: The National Birth Defects Prevention Study (NBDPS) represents one of the most significant undertakings in the United States to investigate the etiologies of major structural birth defects. Operating from 1997 to 2011, this multi-center, population-based case-control study was designed to explore the complex interplay of genetic and environmental factors contributing to congenital anomalies. This document provides a comprehensive technical overview of the this compound, detailing its study design, participant selection, data collection protocols, and analytical framework. It is intended for researchers, epidemiologists, clinicians, and professionals in drug development who require a deep understanding of the study's robust methodology and its vast repository of data, which continues to yield critical insights into the prevention of birth defects.
Introduction and Core Objectives
The National Birth Defects Prevention Study (this compound) was initiated in 1996 following a congressional directive to the Centers for Disease Control and Prevention (CDC) to establish the Centers for Birth Defects Research and Prevention (CBDRP).[1] The primary objective of the this compound was to identify environmental and genetic risk factors for more than 30 different types of major structural birth defects.[2][3] By combining data from multiple centers across the United States, the study aimed to achieve the statistical power necessary to investigate even rare defects and to explore potential gene-environment interactions.[4][5] The this compound was designed as an observational, population-based, case-control study, meaning researchers analyzed existing conditions and historical exposures without introducing interventions or treatments.[6][7]
The study's core goals were:
-
To identify maternal and paternal exposures (e.g., medications, diet, lifestyle, occupation) that may alter the risk of specific birth defects.
-
To investigate the role of genetic factors, both independently and as modifiers of environmental exposures.
-
To create a comprehensive and invaluable data and DNA repository for future research into the causes of birth defects.[5][8]
Study Design and Population
The this compound employed a rigorous population-based case-control methodology.[1] Data collection ran from 1998 to 2013, covering pregnancies that ended between October 1997 and December 2011.[3][9] The study was conducted across ten state-based centers in Arkansas, California, Georgia, Iowa, Massachusetts, New Jersey, New York, North Carolina, Texas, and Utah.[1][4]
Quantitative Summary of the this compound
The following tables summarize the key quantitative aspects of the study's scope and participation rates.
Table 1: this compound Operational and Population Metrics
| Metric | Value | Source(s) |
| Study Period (Deliveries) | 1997 - 2011 | [1][10] |
| Data Collection Period | 1998 - 2013 | [3][9] |
| Participating State Centers | 10 | [4] |
| Approximate Annual Births Covered | 482,000 (~10% of U.S. births) | [11] |
| Total Births in Catchment Areas | ~6,000,000 | [9] |
| Number of Birth Defects Studied | Approximately 35 | [4][5] |
Table 2: this compound Participant Enrollment and Data Collection Summary
| Participant Group | Eligible Individuals | Interviewed Participants | Interview Participation Rate | Buccal Swab Kits Returned (Families) | Swab Return Rate | Source(s) |
| Cases | 47,832 | 32,187 | 67% | 19,065 | 65% | [3][9][12] |
| Controls | 18,272 | 11,814 | 65% | 6,211 | 59% | [3][9][12] |
| Total Women Interviewed | > 45,000 | > 44,000 | ~66% | - | - | [1][9] |
Experimental Protocols and Methodologies
The this compound methodology was standardized across all participating centers to ensure data consistency and validity. The core components included case and control ascertainment, a detailed maternal interview, and the collection of biological specimens for genetic analysis.[6]
Case Ascertainment and Classification
Protocol for Case Identification:
-
Surveillance: Cases, including live births, stillbirths, and induced terminations, were identified through existing, active birth defects surveillance programs in each of the ten participating states.[2][9]
-
Eligibility Screening: To be included, an infant or fetus had to present with at least one of over 30 eligible major structural birth defects.[2] Cases with known etiologies, such as single-gene disorders or chromosomal abnormalities, were excluded to focus the research on identifying unknown causes.[9][11]
-
Clinical Review: All potential cases underwent a thorough review of clinical information and diagnostic tests by a clinical geneticist to confirm eligibility based on standardized, detailed case definitions.[9][13] This step was crucial for ensuring diagnostic accuracy and consistency across sites.
-
Classification: Following confirmation, each case was classified into one of three categories:
-
Isolated: The infant has a single major defect, or multiple defects known to be part of a pathogenic sequence.[14][15]
-
Multiple: The infant has two or more major defects that are not recognized as a sequence or syndrome.[14]
-
Syndromic: The infant has a recognized pattern of defects constituting a syndrome.[14]
-
This classification schema was developed to create more etiologically homogeneous groups for analysis, a critical factor in the success of epidemiologic studies of birth defects.[13][14]
Control Selection
Protocol for Control Identification:
-
Source Population: Control infants were randomly selected from the same geographic regions and time periods as the cases to ensure they arose from the same base population.[2][9]
-
Selection Method: Controls were identified either from vital records (birth certificates) or from birth hospital records.[2][9] They were live-born infants without any major birth defects.[2]
-
Sampling Strategy: The number of controls selected each month was proportional to the number of births in that same month of the previous year, ensuring a representative sample over time.[9] Controls were not matched to individual cases.[2]
Data Collection
The this compound utilized two primary methods for data collection: a comprehensive maternal interview and the collection of buccal cells from the family triad (B1167595) (mother, father, and infant).[6][16]
Protocol for Maternal Interview:
-
Timing: Mothers were contacted for a computer-assisted telephone interview (CATI) between six weeks and 24 months after their estimated delivery date.[9][12]
-
Standardization: The CATI system ensured that every woman was asked the same questions in the same order, minimizing interviewer bias.[16][17]
-
Content: The detailed, hour-long interview collected information on a wide range of potential exposures during the critical periconceptional period (three months before pregnancy through the first trimester).[13][16] Topics included:
Protocol for Genetic Sample Collection:
-
Kit Distribution: After the interview was completed, families were mailed a kit containing cytobrushes for the collection of buccal (cheek) cells.[6][9]
-
Sample Collection: The kit included instructions for collecting samples from the mother, father, and the infant (if living).[4][16]
-
Sample Return and Processing: Families returned the samples in a postage-paid mailer. Upon receipt at the laboratory, DNA was extracted from the cells for genetic analysis and securely stored without personal identifiers.[11][16] This repository allows for the investigation of genetic markers, gene-environment interactions, and other molecular analyses.[4][8]
Study Workflow and Logical Relationships
The operational flow of the this compound, from participant identification through data analysis, followed a highly structured and systematic process.
Caption: this compound Experimental Workflow from Population Surveillance to Analysis.
Significance and Key Contributions
The this compound has made substantial and lasting contributions to the field of birth defects epidemiology.[9] Its large scale and rigorous design have provided unprecedented statistical power to study rare defects and identify modest risk associations that smaller studies could not detect.[5]
Key findings and contributions from the this compound data include a better understanding of risks associated with:
-
Maternal medication use during pregnancy, such as certain antidepressants and anti-epileptic drugs.[4][10]
-
Maternal health conditions like diabetes and obesity.[10]
-
Lifestyle factors, including maternal smoking, which has been linked to a higher risk of several congenital heart defects.[10][18]
The vast repository of interview data and biological samples continues to be an invaluable resource for researchers worldwide, enabling ongoing investigations into the complex causes of birth defects.[1][19] Although data collection has concluded, analysis of this rich dataset persists, promising further insights that can inform clinical guidance and public health strategies aimed at prevention.[1]
References
- 1. National Birth Defects Prevention Study – Iowa Registry for Congenital and Inherited Disorders [ircid.public-health.uiowa.edu]
- 2. academic.oup.com [academic.oup.com]
- 3. researchgate.net [researchgate.net]
- 4. National Birth Defects Prevention Study | Mass.gov [mass.gov]
- 5. researchgate.net [researchgate.net]
- 6. This compound.org [this compound.org]
- 7. This compound.org [this compound.org]
- 8. The National Birth Defects Prevention Study - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. The National Birth Defects Prevention Study: a review of the methods - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Birth Defects Research | Birth Defects | CDC [cdc.gov]
- 11. 2.2. Study population [bio-protocol.org]
- 12. The National Birth Defects Prevention Study: A review of the methods - PubMed [pubmed.ncbi.nlm.nih.gov]
- 13. researchgate.net [researchgate.net]
- 14. [PDF] Guidelines for case classification for the National Birth Defects Prevention Study. | Semantic Scholar [semanticscholar.org]
- 15. stacks.cdc.gov [stacks.cdc.gov]
- 16. This compound.org [this compound.org]
- 17. bdsteps.org [bdsteps.org]
- 18. This compound.org [this compound.org]
- 19. Methods for Accessing this compound and BD-STEPS Data | Birth Defects | CDC [cdc.gov]
The National Birth Defects Prevention Study (NBDPS): A Technical Overview of Study Design and Core Objectives
The National Birth Defects Prevention Study (NBDPS) represents one of the largest and most comprehensive population-based case-control studies on birth defects in the United States. This technical guide provides an in-depth overview of the this compound study design, its primary objectives, and the methodologies employed, with a focus on data collection and experimental protocols for genetic analysis. This document is intended for researchers, scientists, and professionals in the field of drug development who are interested in understanding the intricacies of this landmark epidemiological study.
Core Study Design
The this compound was designed as an observational, population-based, case-control study to investigate the potential genetic and environmental risk factors for a wide range of major structural birth defects. Data collection for the study spanned from 1998 to 2013, covering pregnancies with estimated delivery dates between October 1997 and December 2011. The study was a collaborative effort across ten participating centers in the United States: Arkansas, California, Georgia, Iowa, Massachusetts, New Jersey, New York, North Carolina, Texas, and Utah.
The core tenets of the this compound study design include:
-
Population-Based Ascertainment: Cases, including live births, stillbirths, and induced terminations with major birth defects, were identified through established birth defects surveillance programs in the participating states. This approach aimed to capture a comprehensive sample of birth defect occurrences within defined geographical areas.
-
Case-Control Methodology: The study compared exposures and genetic markers between "cases" (infants or fetuses with a specific birth defect) and "controls" (infants born without major birth defects). Controls were randomly selected from the same geographic regions and time periods as the cases, typically from birth certificate records or birth hospitals.
-
Maternal Interviews: A key component of the data collection was a detailed computer-assisted telephone interview with the mothers of both cases and controls. These interviews were conducted between six weeks and 24 months after the estimated date of delivery.
-
Biological Sample Collection: Following the interview, families were sent kits to collect buccal (cheek) cells from the mother, father, and infant (if living). These samples provided the genetic material for subsequent analysis.
Primary Objectives
The overarching goal of the this compound was to identify preventable causes of birth defects. The primary objectives of the study were:
-
To investigate the association between a wide range of environmental exposures during the periconceptional period (three months before and during pregnancy) and the risk of specific birth defects.
-
To identify genetic factors, such as single nucleotide polymorphisms (SNPs), that may be associated with an increased risk for specific birth defects.
-
To explore the interplay between genetic and environmental factors (gene-environment interactions) in the etiology of birth defects.
-
To create a robust and comprehensive dataset and biorepository that could be used for numerous future research studies on the causes of birth defects.
Quantitative Data Summary
The this compound amassed a significant amount of data from a large and diverse population. The following tables summarize the key quantitative aspects of the study.
| Participant Enrollment | Number |
| Eligible Cases | 47,832 |
| Eligible Controls | 18,272 |
| Data Source | Collection Period |
| Pregnancies Included | October 1997 - December 2011 |
| Data Collection | 1998 - 2013 |
| Interview Participation | Cases | Controls |
| Number of Completed Interviews | 32,187 | 11,814 |
| Participation Rate | 67% | 65% |
| Buccal Cell Kit Return | Cases | Controls |
| Number of Families Returning at Least One Kit | 19,065 | 6,211 |
| Return Rate (of those sent a kit) | 65% | 59% |
Experimental Protocols
The this compound employed a multi-stage process for data and biological sample collection and analysis. The following sections detail the methodologies for the key components of the study.
Maternal Interview
The maternal interview was a critical component of the this compound, designed to collect detailed information on a wide array of potential exposures.
Methodology:
-
Standardized Questionnaire: A computer-assisted telephone interview (CATI) system was used to administer a standardized, structured questionnaire to all participants. This ensured consistency in the questions asked and the manner in which they were presented.
-
Recall Period: The interview focused on the periconceptional period, defined as the three months prior to conception through the end of pregnancy.
-
Exposure Domains: The questionnaire covered a broad range of topics, including:
-
Maternal health and diet
-
Prescription and over-the-counter medication use
-
Maternal illnesses and infections
-
Occupational and environmental exposures
-
Lifestyle factors (e.g., smoking, alcohol use)
-
Family history of birth defects
-
Father's work and lifestyle
-
Genetic Analysis
The collection of buccal cells from the infant, mother, and father (creating a "trio") was a unique and powerful aspect of the this compound, enabling a wide range of genetic studies.
1. Buccal Cell Collection and DNA Extraction:
-
Collection: Families were mailed a kit containing cytobrushes for the collection of cheek cells from the inside of the mouth of the infant, mother, and father.
-
DNA Extraction: While specific laboratory protocols varied slightly between participating centers and over the long duration of the study, a common approach for DNA extraction from buccal cells involves the following steps:
-
Lysis: The buccal cells are suspended in a lysis buffer containing detergents and enzymes (such as Proteinase K) to break open the cell and nuclear membranes, releasing the DNA.
-
Purification: The DNA is then purified from other cellular components, such as proteins and RNA. This is often achieved through methods like phenol-chloroform extraction or by using commercially available DNA extraction kits with silica-based spin columns.
-
Quantification and Quality Control: The concentration and purity of the extracted DNA are assessed using spectrophotometry (e.g., measuring the A260/A280 ratio) or fluorometry.
-
2. Genotyping:
The this compound employed various genotyping technologies to analyze the genetic variation in the collected DNA samples. The choice of platform often depended on the specific research question and the technology available at the time of the analysis.
-
Candidate Gene Approaches: Early studies often focused on specific genes or genetic pathways hypothesized to be involved in embryonic development. Common techniques included:
-
TaqMan Assays: A real-time PCR-based method for SNP genotyping.
-
PCR-RFLP (Restriction Fragment Length Polymorphism): Involves amplifying a DNA segment and then digesting it with a restriction enzyme to identify sequence variations.
-
-
Genome-Wide Association Studies (GWAS): As technology advanced, the this compound utilized high-throughput SNP genotyping arrays, such as those from Illumina (e.g., GoldenGate, BeadChip arrays). These platforms allow for the simultaneous genotyping of hundreds of thousands to millions of SNPs across the entire genome. The general workflow for Illumina SNP genotyping is as follows:
-
Whole-Genome Amplification: The genomic DNA is uniformly amplified to increase the amount of starting material.
-
Fragmentation: The amplified DNA is then fragmented into smaller pieces.
-
Hybridization: The fragmented DNA is hybridized to a microarray chip that contains hundreds of thousands of microscopic beads, each coated with a specific DNA probe corresponding to a particular SNP.
-
Single-Base Extension and Staining: A single fluorescently labeled nucleotide is added to the probe, which is complementary to the base on the sample DNA.
-
Imaging: The microarray is scanned, and the fluorescent signals are detected to determine the genotype at each SNP locus.
-
3. Data Analysis:
The genetic and exposure data were analyzed using a variety of statistical methods to identify associations with birth defects. These included:
-
Case-Control Analyses: Comparing the frequency of specific alleles or genotypes between cases and controls.
-
Trio-Based Analyses: Utilizing the genetic information from the infant and both parents to study patterns of inheritance and identify de novo mutations.
-
Gene-Environment Interaction Analyses: Statistical models were used to assess whether the effect of an environmental exposure on birth defect risk was modified by an individual's genetic makeup.
Visualizations
This compound Study Workflow
The following diagram illustrates the overall workflow of the National Birth Defects Prevention Study, from participant identification to data analysis.
Caption: Overall workflow of the National Birth Defects Prevention Study (this compound).
This comprehensive approach, integrating detailed exposure data with robust genetic analysis, has made the this compound an invaluable resource for the scientific community. The findings from this study have significantly contributed to our understanding of the complex etiology of birth defects and continue to inform public health strategies for prevention. The wealth of data generated by the this compound will undoubtedly continue to be a source of important discoveries for years to come.
National Birth Defects Prevention Study: A Technical Guide to Core Findings
For Researchers, Scientists, and Drug Development Professionals
This in-depth technical guide synthesizes the pivotal findings and methodologies of the National Birth Defects Prevention Study (NBDPS), one of the largest population-based case-control studies on birth defects in the United States. The study, conducted by the Centers for Disease Control and Prevention (CDC) and several collaborating centers, aimed to identify environmental and genetic risk factors for a range of major structural birth defects. This document provides a comprehensive overview of the study's design, experimental protocols, and key quantitative outcomes to support further research and inform drug development processes.
Study Methodology
The National Birth Defects Prevention Study was a multi-center, population-based case-control study that collected data on pregnancies with estimated dates of delivery from October 1997 through December 2011.[1] The study was conducted across ten participating centers in the United States: Arkansas, California, Georgia, Iowa, Massachusetts, New Jersey, New York, North Carolina, Texas, and Utah.[1]
Case and Control Selection
-
Cases: Infants or fetuses with one or more major structural birth defects were identified through existing birth defects surveillance programs at each study center.[1] Cases included live births, stillbirths, and elective terminations.[1] Clinical geneticists reviewed all potential cases to confirm eligibility and classify the defects. Cases with known single-gene or chromosomal abnormalities were excluded to focus on identifying unknown causes.[1]
-
Controls: A random sample of live-born infants without any major birth defects were selected from the same geographic areas and time periods as the cases.[1] Controls were identified through vital records or birth hospital logs.[1]
Data Collection
The this compound employed two primary methods for data collection: a computer-assisted telephone interview (CATI) with the mothers and the collection of buccal (cheek) cells from the infant and both parents for genetic analysis.[2][3]
1.2.1. Computer-Assisted Telephone Interview (CATI)
Mothers of both case and control infants were interviewed between six weeks and two years after their estimated delivery date. The standardized, hour-long interview collected extensive information on a wide range of topics, including:
-
Maternal Health and Demographics: Age, race/ethnicity, education, pre-pregnancy weight, and height.
-
Reproductive History: Previous pregnancies and their outcomes.
-
Lifestyle Factors: Periconceptional (one month before to three months after conception) smoking, alcohol consumption, and illicit drug use.
-
Medication Use: Detailed information on prescription and over-the-counter medications taken during the periconceptional period.
-
Maternal Illnesses and Infections: Any acute or chronic illnesses during pregnancy.
-
Occupational and Environmental Exposures: Potential exposures at work and in the home environment.
-
Folic Acid Intake: Use of folic acid supplements before and during early pregnancy.
1.2.2. Buccal Cell Collection and Genetic Analysis
Following the interview, families were mailed kits to collect buccal cells from the infant and both parents using a cytobrush.[1] This non-invasive method provided a source of genomic DNA for investigating genetic contributions to birth defects.
The general protocol for DNA extraction from buccal swabs involves the following steps:
-
Cell Lysis: The collected buccal cells are suspended in a lysis buffer containing detergents and proteinase K to break open the cell and nuclear membranes, releasing the DNA.
-
Protein Precipitation: Proteins are precipitated from the cell lysate, often by adding a high-concentration salt solution.
-
DNA Precipitation: The DNA is then precipitated from the remaining solution, typically using isopropanol (B130326) or ethanol (B145695).
-
DNA Washing and Rehydration: The precipitated DNA is washed with ethanol to remove any remaining contaminants and then rehydrated in a buffer solution for storage and analysis.
Genotyping was performed to identify specific genetic variants in both cases and controls to assess for associations with birth defects, both independently and in conjunction with environmental exposures (gene-environment interactions).
Experimental Workflows
The following diagrams illustrate the key workflows of the National Birth Defects Prevention Study.
References
A Landmark Investigation into the Causes of Birth Defects: The National Birth Defects Prevention Study
An In-depth Technical Guide for Researchers, Scientists, and Drug Development Professionals
The National Birth Defects Prevention Study (NBDPS) stands as one of the largest and most significant population-based case-control studies ever conducted to investigate the potential genetic and environmental causes of major birth defects in the United States. Initiated in 1996 by the Centers for Disease Control and Prevention (CDC), this multi-center collaborative effort has provided a wealth of data that continues to be analyzed, yielding crucial insights into the etiology of these conditions and informing public health recommendations for prevention. This technical guide provides a comprehensive overview of the history, methodology, and key quantitative findings of the this compound, tailored for professionals in research and drug development.
Study Inception and Design
The this compound was established in response to a congressional directive to the CDC to create Centers for Birth Defects Research and Prevention (CBDRP).[1] The study was designed as a population-based, case-control investigation to explore the independent and interactive roles of genetic and environmental factors in the causation of a wide array of major structural birth defects.[2] Data collection for the this compound ran from 1997 to 2013, encompassing births from October 1997 through December 2011.[2]
The study was conducted across ten participating centers located in Arkansas, California, Georgia, Iowa, Massachusetts, New Jersey, New York, North Carolina, Texas, and Utah.[2] These locations were selected due to their established birth defects surveillance programs and expertise in the field.[1]
The core of the this compound is its case-control methodology. "Cases" were infants or fetuses with one or more of over 30 major structural birth defects, identified through the state-based surveillance systems. "Controls" were live-born infants without any major birth defects, randomly selected from the same geographic areas and time periods as the cases.[2][3]
Participant Recruitment and Data Collection
The this compound employed a rigorous and multi-faceted approach to participant recruitment and data collection, which involved two primary components: a detailed maternal interview and the collection of biological samples for genetic analysis.
Case and Control Selection
Case infants and fetuses were identified through active surveillance systems at each participating center. To ensure etiological homogeneity, cases with known single-gene or chromosomal abnormalities were excluded.[2] A clinical geneticist at each center reviewed all potential cases to confirm eligibility based on detailed, study-specific case definitions.[2]
Control infants were randomly selected from birth hospital records or vital records within the same geographic catchment area and time frame as the cases.[2][3] This population-based approach aimed to select a control group that was representative of the base population from which the cases arose.
Maternal Interview
A key component of the this compound was a comprehensive, computer-assisted telephone interview (CATI) administered to the mothers of both case and control infants.[2] The interview was designed to be approximately one hour in length and was conducted between six weeks and two years after the infant's estimated date of delivery.[2]
The interview collected a wide range of information on maternal exposures and characteristics during the periconceptional period (three months before pregnancy through the end of pregnancy). Key domains of the questionnaire included:
-
Maternal Health and Demographics: Age, race/ethnicity, education, and pre-existing health conditions.
-
Reproductive History: Previous pregnancies and their outcomes.
-
Lifestyle Factors: Smoking, alcohol consumption, and recreational drug use.
-
Medication Use: Detailed information on prescription and over-the-counter medications.
-
Dietary Intake: Use of a food frequency questionnaire to assess nutritional exposures.
-
Occupational and Environmental Exposures: Information on parental occupations and potential exposures to chemicals or other agents.
-
Folic Acid Supplementation: Detailed questions on the timing and dosage of folic acid intake.
Biological Sample Collection
Following the maternal interview, families were asked to provide biological samples for genetic analysis. This was primarily done through the collection of buccal (cheek) cells from the infant, mother, and father using a cytobrush kit that was mailed to the family.[2][3] The collected samples were sent to a central repository for DNA extraction, storage, and analysis.
Laboratory Protocols
The genetic component of the this compound was integral to its mission of investigating gene-environment interactions. Rigorous laboratory protocols were established for DNA extraction, quality control, and genotyping.
DNA Extraction and Quality Control
DNA was extracted from the buccal cell samples using standardized laboratory procedures. To ensure the quality and integrity of the genetic data, a series of quality control (QC) measures were implemented. These included quantification of the extracted DNA and assessment of its purity. DNA specimens that met the established QC criteria were then sent to a central biorepository for long-term storage and use in subsequent genetic analyses.[2]
Genotyping
A variety of genotyping methods were employed throughout the course of the this compound and in subsequent analyses of the collected DNA samples. To ensure consistency and accuracy across different genotyping laboratories, the this compound implemented an external quality assessment program. This involved the annual genotyping of a standard set of single nucleotide polymorphisms (SNPs) on a blinded set of reference DNA samples.[2]
For specific genetic association studies, various platforms were utilized. For instance, some of the later genetic analyses on this compound samples used Illumina's GoldenGate™ and targeted sequencing technologies.[4]
Quantitative Overview of the this compound Cohort
The this compound amassed a large and diverse dataset, providing unprecedented statistical power for studying a wide range of birth defects.
Study Participants
The following table summarizes the overall participation in the this compound:
| Participant Group | Eligible | Interviewed | Participation Rate | Buccal Cell Kits Returned |
| Cases | 47,832 | 32,187 | 67% | 19,065 (65% of those sent a kit) |
| Controls | 18,272 | 11,814 | 65% | 6,211 (59% of those sent a kit) |
Source: Reefhuis et al., 2015[2]
Maternal Sociodemographic Characteristics
The following table presents a selection of maternal sociodemographic characteristics of study participants from a publication utilizing this compound data. It is important to note that these figures may vary across different analyses and subpopulations within the this compound.
| Characteristic | Cases (n=126) % | Controls (n=126) % |
| Maternal Age (years) | ||
| < 20 | 16.7 | 13.5 |
| 20–29 | 55.6 | 65.1 |
| ≥ 30 | 27.8 | 21.4 |
| Educational Level | ||
| Did not complete basic education | 53.2 | 46.0 |
| Completed basic education and more | 46.8 | 54.0 |
| Smoking | ||
| Yes | 32.5 | 13.5 |
| No | 67.5 | 86.5 |
Source: Adapted from a study on low birth weight, which may not be fully representative of the entire this compound cohort.[1]
Prevalence of Selected Birth Defects
The this compound has been instrumental in providing more precise estimates of the prevalence of various birth defects. The following table provides national prevalence estimates for selected birth defects, informed by data from state surveillance systems, including those participating in the this compound.
| Birth Defect Category | Specific Defect | Prevalence per 10,000 Births |
| Brain/Spine Defects | Anencephaly | 1 in 5,246 |
| Spina bifida without anencephaly | 1 in 2,875 | |
| Heart Defects | Atrioventricular septal defect | 1 in 1,712 |
| Coarctation of the aorta | 1 in 1,712 | |
| Hypoplastic left heart syndrome | 1 in 3,955 | |
| Orofacial Clefts | Cleft lip with or without cleft palate | 1 in 1,598 |
| Cleft palate alone | 1 in 2,651 | |
| Gastrointestinal Defects | Gastroschisis | 1 in 2,134 |
| Omphalocele | 1 in 4,163 |
Source: Centers for Disease Control and Prevention[5]
Experimental Workflow and Logical Relationships
The following diagrams illustrate the overall workflow of the National Birth Defects Prevention Study.
Caption: Overall workflow of the National Birth Defects Prevention Study.
Caption: Detailed data collection workflow in the this compound.
Conclusion and Future Directions
The National Birth Defects Prevention Study has made invaluable contributions to our understanding of the complex etiology of birth defects. Its robust design, large sample size, and rich dataset have enabled the identification of novel risk factors and the confirmation of previously suspected associations. The wealth of data collected by the this compound continues to be a vital resource for researchers, and the ongoing analysis of these data, along with the follow-up study, the Birth Defects Study To Evaluate Pregnancy exposureS (BD-STEPS), promises to yield further critical insights into the prevention of birth defects. For professionals in drug development, the findings from the this compound underscore the importance of considering potential teratogenic effects and provide a valuable knowledge base for preclinical and clinical safety assessments.
References
In-Depth Technical Guide: National Birth Defects Prevention Study (NBDPS) Data Collection Period and Scope
For Researchers, Scientists, and Drug Development Professionals
This technical guide provides a comprehensive overview of the data collection period, scope, and methodologies of the National Birth Defects Prevention Study (NBDPS), a major population-based case-control study of major birth defects in the United States.
Data Collection Period and Scope
The National Birth Defects Prevention Study (this compound) was a large-scale epidemiological study aimed at identifying genetic and non-genetic risk factors for a range of major birth defects.
Data Collection Timeline
The this compound collected data on pregnancies with estimated dates of delivery from October 1, 1997, to December 31, 2011 .[1] The active data collection, including interviews with mothers, took place from 1998 through 2013 .[1][2][3] This long-term data collection effort has resulted in a rich and extensive dataset for research.
Study Population and Scope
The this compound was a multi-center study that included participants from ten states: Arkansas, California, Georgia, Iowa, Massachusetts, New Jersey, New York, North Carolina, Texas, and Utah.[1][4] The study population consisted of two main groups:
-
Cases: Mothers of more than 30,000 babies with one or more of over 30 different major birth defects.[5] Cases included live births, stillbirths, and induced terminations.[1]
-
Controls: Mothers of over 10,000 babies without any major birth defects, who were randomly selected from the same geographic areas and time periods as the cases.[1][5]
The comprehensive scope of the this compound allowed for the investigation of a wide array of potential risk factors and their interactions.
Data Presentation: Quantitative Summary
The following tables summarize the key quantitative aspects of the this compound data collection.
Table 1: this compound Participant Enrollment Summary
| Participant Group | Number of Participants |
| Eligible Cases | 47,832 |
| Eligible Controls | 18,272 |
| Mothers of Cases Interviewed | 32,187 (67% of eligible) |
| Mothers of Controls Interviewed | 11,814 (65% of eligible) |
| Case Families Returning Buccal Cell Kits | 19,065 (65% of those sent a kit) |
| Control Families Returning Buccal Cell Kits | 6,211 (59% of those sent a kit) |
Source: The National Birth Defects Prevention Study: a review of the methods[1]
Table 2: this compound Data Collection Timeline
| Milestone | Date Range |
| Study Eligibility Period (Deliveries) | October 1997 – December 2011 |
| Data Collection Period (Interviews) | 1998 – 2013 |
Source: The National Birth Defects Prevention Study: a review of the methods; Agency Forms Undergoing Paperwork Reduction Act Review[1][2]
Experimental Protocols
The this compound employed a rigorous case-control study design involving two primary data collection methods: computer-assisted telephone interviews and the collection of biological specimens for genetic analysis.
Case and Control Ascertainment
Cases were identified through existing birth defects surveillance programs in the participating states.[1] A clinical geneticist reviewed all clinical information to confirm eligibility and to exclude cases with known single-gene or chromosomal etiologies.[1] Controls were live-born infants without major birth defects, randomly selected from either vital records or birth hospital records from the same geographic regions and time periods as the cases.[1]
Interview Data Collection
Trained interviewers conducted computer-assisted telephone interviews with the mothers of both cases and controls.[1] The interviews were typically conducted between six weeks and 24 months after the estimated date of delivery.[1] The comprehensive questionnaire covered a wide range of topics, including:
-
Maternal Health: Pre-existing conditions, illnesses during pregnancy.
-
Medication Use: Prescription and over-the-counter medications taken before and during pregnancy.
-
Lifestyle Factors: Diet, vitamin and supplement use, smoking, and alcohol consumption.
-
Occupational and Environmental Exposures: Workplace exposures and residential history.
-
Paternal Information: Father's work and lifestyle.[6]
Biological Specimen Collection and Genetic Analysis
A crucial component of the this compound was the collection of biological samples for genetic research to investigate gene-environment interactions.[7]
3.3.1. Buccal Cell Collection
After the interview, families were mailed kits to collect buccal (cheek) cells from the mother, father, and infant (if living).[1] These kits contained cytobrushes for sample collection.[1]
3.3.2. DNA Extraction
While a specific, universally applied DNA extraction protocol for the entire this compound is not detailed in a single public document, a common and representative method for extracting high-quality genomic DNA from buccal cells collected with brushes involves the following general steps, often utilizing commercially available kits like the Gentra Puregene Buccal Cell Kit:
-
Cell Lysis: The brush head containing the buccal cells is placed in a tube with a cell lysis solution. This solution breaks open the cell and nuclear membranes to release the DNA.
-
Protein Precipitation: A protein precipitation solution is added to the lysate, causing proteins to clump together.
-
DNA Precipitation: The sample is centrifuged to pellet the precipitated proteins, and the supernatant containing the DNA is transferred to a new tube. Isopropanol or ethanol (B145695) is then added to precipitate the DNA out of the solution.
-
DNA Wash: The DNA pellet is washed with 70% ethanol to remove any remaining salts and other impurities.
-
DNA Hydration: The air-dried DNA pellet is re-dissolved in a DNA hydration solution or TE buffer for storage and subsequent analysis.
3.3.3. Genotyping
The this compound utilized the collected DNA to investigate the association of specific genetic variants, particularly single nucleotide polymorphisms (SNPs), with the risk of birth defects. While the exact genotyping platforms evolved over the course of the long study, SNP arrays were a key technology employed.[8] These microarrays allow for the simultaneous genotyping of hundreds of thousands to over a million SNPs across the genome.[8]
3.3.4. Quality Control for Genetic Data
To ensure the high quality of the genetic data, the this compound implemented rigorous quality control (QC) procedures.[6] These included:
-
DNA Quantification: Assessing the concentration of the extracted DNA.
-
PCR Amplification Success: Ensuring the DNA was of sufficient quality for amplification using techniques like quantitative real-time PCR.
-
Allele Consistency: Using short tandem repeat (STR) markers to verify family relationships (e.g., paternity).[6]
-
External Genotyping Quality Assessment: Participating genotyping laboratories annually genotyped a standard set of SNPs on reference DNA samples from the Coriell Institute for Medical Research's Polymorphism Discovery Resource to ensure inter-laboratory consistency and accuracy.[6]
Mandatory Visualization: Signaling Pathways and Workflows
The following diagrams illustrate key aspects of the this compound methodology and a significant area of its research focus.
A significant focus of this compound genetic research has been on the folate pathway, particularly in relation to neural tube defects (NTDs). Folic acid supplementation is known to reduce the risk of NTDs, and genetic variations in the enzymes involved in folate metabolism can impact this risk.
This whitepaper provides a foundational understanding of the this compound data collection and methodologies. For researchers interested in utilizing this compound data, it is important to note that the data are not publicly available but can be accessed by qualified researchers through collaboration with the Centers for Birth Defects Research and Prevention (CBDRP).[5]
References
- 1. Neural Tube Defects and Folate Pathway Genes: Family-Based Association Tests of Gene–Gene and Gene–Environment Interactions - PMC [pmc.ncbi.nlm.nih.gov]
- 2. mdpi.com [mdpi.com]
- 3. Buccal cells DNA extraction to obtain high quality human genomic DNA suitable for polymorphism genotyping by PCR-RFLP and Real-Time PCR - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Neural Tube Defects and Maternal Biomarkers of Folate, Homocysteine, and Glutathione Metabolism - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Detecting gene-environment interactions in human birth defects: Study designs and statistical methods - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. The National Birth Defects Prevention Study: a review of the methods - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Folate Pathway Gene Single Nucleotide Polymorphisms and Neural Tube Defects: A Systematic Review and Meta-Analysis [ouci.dntb.gov.ua]
- 8. Single nucleotide polymorphism arrays: a decade of biological, computational and technological advances - PMC [pmc.ncbi.nlm.nih.gov]
An In-depth Technical Guide to the Major Birth Defects Investigated in the National Birth Defects Prevention Study (NBDPS)
For Researchers, Scientists, and Drug Development Professionals
This technical guide provides a comprehensive overview of the major birth defects investigated in the National Birth Defects Prevention Study (NBDPS), a landmark population-based case-control study conducted in the United States. This document is intended to serve as a resource for researchers, scientists, and professionals in drug development by detailing the study's methodologies, presenting key quantitative findings in a structured format, and illustrating the biological pathways implicated in the etiology of these conditions.
Introduction to the National Birth Defects Prevention Study (this compound)
The National Birth Defects Prevention Study (this compound) was a multi-site case-control study designed to identify environmental and genetic risk factors for a wide range of major structural birth defects.[1][2] Data was collected on pregnancies with estimated delivery dates between October 1997 and December 2011.[1][2][3] The study's robust design and large sample size have made it a critical resource for understanding the causes of birth defects.[1]
The core components of the this compound included:
-
Case and Control Ascertainment: Cases with major birth defects were identified through existing birth defect surveillance systems in participating states.[1][2][3] Controls were randomly selected from live-born infants without major birth defects from the same geographic areas and time periods.[1][2][3]
-
Maternal Interviews: Detailed information on a wide array of potential exposures was collected through computer-assisted telephone interviews with the mothers of both cases and controls.[4][5] These interviews covered topics such as medication use, maternal health conditions, lifestyle factors, and occupational exposures.[5]
-
Genetic Specimen Collection: Buccal (cheek) cells were collected from the infant, mother, and father to obtain DNA for genetic analysis.[4][5] This allowed for the investigation of genetic risk factors and gene-environment interactions.
Major Birth Defects Investigated in the this compound
The this compound investigated over 30 different types of major birth defects. These can be broadly categorized as follows:
-
Congenital Heart Defects (CHDs): A wide range of structural heart abnormalities were included, such as conotruncal defects, septal defects, and single ventricle defects.[6]
-
Neural Tube Defects (NTDs): This category includes serious birth defects of the brain and spine, such as anencephaly and spina bifida.
-
Orofacial Clefts: The study examined both cleft lip with or without cleft palate and cleft palate alone.
-
Gastrointestinal Defects: This group includes conditions like gastroschisis and esophageal atresia.[6]
-
Musculoskeletal Defects: Limb deficiencies and other skeletal abnormalities were part of the investigation.
-
Other Structural Defects: A variety of other birth defects, including biliary atresia and choanal atresia, were also studied.[6]
Quantitative Data Summary
The extensive data collected by the this compound has been used to quantify the association between various risk factors and specific birth defects. The following tables summarize some of the key findings from this compound publications, presenting adjusted odds ratios (aORs) which estimate the increased risk of a specific birth defect associated with a particular exposure or maternal characteristic.
Table 1: Maternal Health Conditions and Risk of Specific Birth Defects
| Maternal Condition | Birth Defect | Adjusted Odds Ratio (aOR) | 95% Confidence Interval (CI) |
| Pre-existing Diabetes | Congenital Heart Defects (various) | 2.0 - 5.0 | Varies by specific defect |
| Pre-existing Diabetes | Neural Tube Defects | ~3.0 | Varies by specific study |
| Obesity (BMI ≥30) | Neural Tube Defects | ~2.0 | Varies by specific study |
| Obesity (BMI ≥30) | Congenital Heart Defects (various) | 1.5 - 2.0 | Varies by specific defect |
| Fever during Pregnancy | Congenital Heart Defects (some types) | Elevated | Varies by specific study |
Table 2: Medication Use During Pregnancy and Risk of Specific Birth Defects
| Medication Class/Specific Drug | Birth Defect | Adjusted Odds Ratio (aOR) | 95% Confidence Interval (CI) |
| Certain Antidepressants (SSRIs) | Some Congenital Heart Defects | Modestly Increased | Varies by specific drug and defect |
| Opioid Analgesics | Congenital Heart Defects (some types) | ~2.0 | Varies by specific drug and defect |
| Certain Antifungal Medications | Varies | Elevated | Varies by specific drug and defect |
Table 3: Lifestyle and Environmental Factors and Risk of Specific Birth Defects
| Factor | Birth Defect | Adjusted Odds Ratio (aOR) | 95% Confidence Interval (CI) |
| Maternal Smoking | Orofacial Clefts | 1.5 - 2.0 | Varies by intensity of smoking |
| Maternal Smoking | Congenital Heart Defects (some types) | Modestly Increased | Varies by intensity of smoking |
| High Caffeine Intake | Choanal Atresia | Elevated | Varies by specific study |
Note: The odds ratios presented in these tables are approximate and are intended to provide a general indication of the strength of the association. For precise values and detailed information on the specific exposures and birth defect subtypes, readers are encouraged to consult the original this compound publications.
Experimental Protocols
Data Collection
Maternal Interview: A standardized, computer-assisted telephone interview was administered to mothers of cases and controls. The interview was designed to collect detailed information on demographics, reproductive history, lifestyle, occupation, and a wide range of exposures during the periconceptional period (three months before conception through the first trimester of pregnancy).
Buccal Cell Collection: Families were mailed a kit containing cytobrushes for the collection of buccal cells from the infant, mother, and father. The brushes were rubbed against the inside of the cheek to collect epithelial cells containing DNA. The collected samples were then mailed back to a central repository for processing and storage.[4][5]
Genetic Analysis
DNA Extraction: Genomic DNA was extracted from the collected buccal cells. While specific protocols may have varied slightly over the long course of the study, standard methods for DNA extraction from buccal swabs were employed. These generally involve cell lysis, proteinase K digestion to remove proteins, and subsequent purification of the DNA.
Genotyping and Sequencing: A variety of genetic analysis techniques have been applied to the this compound DNA samples over the years, reflecting the evolution of genetic technologies.
-
Candidate Gene Analysis: Early studies often focused on genotyping specific single nucleotide polymorphisms (SNPs) in candidate genes that were hypothesized to be involved in the development of a particular birth defect.
-
Whole Exome Sequencing (WES): With the advent of next-generation sequencing, the this compound initiated whole exome sequencing on a subset of its samples.[7][8] The general workflow for WES includes:
-
Library Preparation: The extracted genomic DNA is fragmented, and adapters are ligated to the ends of the fragments.
-
Exome Capture: The DNA library is hybridized to probes that are specific to the exonic (protein-coding) regions of the genome, thereby enriching for these regions.
-
Sequencing: The captured exome fragments are then sequenced using high-throughput sequencing platforms.
-
Data Analysis: The sequencing data is analyzed to identify genetic variants, such as single nucleotide variants (SNVs) and small insertions and deletions (indels), that may be associated with the birth defect of interest.
-
Signaling Pathways and Logical Relationships
The genetic data from the this compound has provided valuable insights into the biological pathways that, when disrupted, can lead to birth defects. The following diagrams, generated using the DOT language, illustrate some of the key signaling pathways that have been investigated in the context of the this compound.
Conclusion
The National Birth Defects Prevention Study has been instrumental in advancing our understanding of the etiologies of major birth defects. By combining detailed exposure data with genetic information from a large, population-based sample, the this compound has identified numerous risk factors and provided critical insights into the complex interplay between genes and the environment in the causation of these conditions. The findings from this study continue to inform public health recommendations and guide future research aimed at preventing birth defects. This technical guide serves as a foundational resource for professionals dedicated to this important field, offering a structured overview of the study's key contributions.
References
- 1. The National Birth Defects Prevention Study: a review of the methods - PMC [pmc.ncbi.nlm.nih.gov]
- 2. researchgate.net [researchgate.net]
- 3. The National Birth Defects Prevention Study: A review of the methods - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. This compound.org [this compound.org]
- 5. This compound.org [this compound.org]
- 6. This compound.org [this compound.org]
- 7. cdr.lib.unc.edu [cdr.lib.unc.edu]
- 8. Exome sequencing of family trios from the National Birth Defects Prevention Study: Tapping into a rich resource of genetic and environmental data - PubMed [pubmed.ncbi.nlm.nih.gov]
Unveiling the Origins of Birth Defects: A Technical Guide to the Findings of the National Birth Defects Prevention Study
For Immediate Release
This technical guide provides an in-depth analysis of the key risk factors for birth defects as identified by the National Birth Defects Prevention Study (NBDPS). Designed for researchers, scientists, and drug development professionals, this document synthesizes the extensive epidemiological and genetic data from one of the largest case-control studies on this critical public health issue. The guide details the study's methodologies, presents quantitative findings in structured tables for clear comparison, and visualizes relevant biological pathways and experimental workflows.
The this compound, a multi-center case-control study, has made significant contributions to our understanding of the complex etiology of birth defects.[1][2][3][4][5] By collecting extensive data on maternal health, lifestyle, medication use, and genetics, the this compound has identified several key modifiable and non-modifiable risk factors, paving the way for targeted prevention strategies.
Core Findings: A Quantitative Overview
The this compound has produced a wealth of data quantifying the association between various exposures and the risk of specific birth defects. The following tables summarize the key statistically significant findings, presenting adjusted odds ratios (aORs) and 95% confidence intervals (CIs) where available.
Table 1: Maternal Smoking and Congenital Heart Defects
Maternal periconceptional smoking has been identified as a significant risk factor for several congenital heart defects (CHDs).[6] The this compound data show a clear dose-response relationship for certain defects.
| Congenital Heart Defect | Any Smoking aOR (95% CI) | Heavy Smoking (≥15 cigarettes/day) aOR (95% CI) |
| Atrial Septal Defect, Secundum | 1.7 (1.5–2.0) | - |
| Tricuspid Atresia | 1.7 (1.0–2.7) | 3.0 (1.5–6.1) |
| Double Outlet Right Ventricle | 1.5 (1.1–2.2) | 1.5 (1.1–2.2) |
| Any Septal Defect | 1.5 (1.3–1.7) | - |
| Atrioventricular Septal Defect | 1.3 (1.0–1.9) | - |
| Perimembranous Ventricular Septal Defect | 1.3 (1.1–1.5) | - |
| Right-sided Obstructive Lesion | 1.2 (1.0–1.4) | - |
| Pulmonary Valve Stenosis | 1.2 (1.0–1.4) | - |
| Truncus Arteriosus | 1.2 (0.7–2.1) | - |
Data sourced from a retrospective case-control study using this compound data from 1997–2011.[6]
Table 2: Pregestational Diabetes and Various Birth Defects
The this compound has provided robust evidence linking pregestational diabetes (both Type 1 and Type 2) to a wide range of structural birth defects. The associations are notably strong for certain conditions.
| Birth Defect | Pregestational Type 1 Diabetes aOR (95% CI) | Pregestational Type 2 Diabetes aOR (95% CI) |
| Sacral Agenesis | 70.4 (32.3–147) | 59.9 (25.4–135) |
| Heterotaxy | 13.5 (5.7–29.3) | - |
| Holoprosencephaly | - | 13.1 (7.0-24.5) |
| Longitudinal Limb Deficiency | - | 10.1 (6.2-16.5) |
| Atrioventricular Septal Defect | - | 10.5 (6.2-17.9) |
| Single Ventricle Complex | - | 14.7 (8.9-24.3) |
| Truncus Arteriosus | - | 14.9 (7.6-29.3) |
Data from an analysis of this compound data from 1997-2011.
Table 3: Selective Serotonin Reuptake Inhibitor (SSRI) Use and Specific Birth Defects
The use of certain SSRIs during early pregnancy has been associated with an increased risk for specific birth defects. The findings underscore the need for careful consideration of medication use during pregnancy.
| Birth Defect | Paroxetine Use aOR (95% CI) | Fluoxetine Use aOR (95% CI) |
| Anencephaly | 3.2 (1.6–6.2) | - |
| Atrial Septal Defects | 1.8 (1.1–3.0) | - |
| Right Ventricular Outflow Tract Obstruction Defects | 2.4 (1.4–3.9) | 2.0 (1.4–3.1) |
| Gastroschisis | 2.5 (1.2–4.8) | - |
| Omphalocele | 3.5 (1.3–8.0) | - |
| Craniosynostosis | - | 1.9 (1.1–3.0) |
Findings from a Bayesian analysis of this compound data from 1997-2009.
Experimental Protocols
The this compound employed a rigorous, population-based case-control study design. A detailed overview of the study's methodology is provided below, followed by a generalized protocol for the genetic analysis component.
This compound Study Methodology
The core methodology of the this compound involved the following key steps:
-
Case Ascertainment: Infants and fetuses with major structural birth defects (cases) were identified through existing state-based birth defects surveillance systems in ten participating centers.[1]
-
Control Selection: A random sample of live-born infants without major birth defects (controls) were selected from the same geographic areas and time periods as the cases.[1]
-
Data Collection: Mothers of both cases and controls participated in a detailed computer-assisted telephone interview.[1] The interview collected information on a wide range of potential risk factors, including:
-
Demographics
-
Maternal health conditions (e.g., diabetes, obesity)
-
Medication use before and during pregnancy
-
Lifestyle factors (e.g., smoking, alcohol use)
-
Occupational and environmental exposures
-
-
Genetic Sample Collection: Families were asked to provide buccal (cheek) cell samples from the mother, father, and infant for genetic analysis.[1][7][8]
Generalized Protocol for DNA Extraction from Buccal Cells
While the specific, proprietary protocols used by the this compound laboratories are not publicly available, the following represents a standard method for DNA extraction from buccal cells collected via cytobrushes, a method consistent with the this compound sample collection.
-
Sample Lysis: The buccal brush head is placed in a microcentrifuge tube containing a cell lysis solution. The sample is incubated to break open the cells and release the DNA.
-
Protein Precipitation: A protein precipitation solution is added to the lysate, which causes proteins to clump together.
-
Centrifugation: The tube is centrifuged to pellet the precipitated proteins, leaving the DNA in the supernatant.
-
DNA Precipitation: The supernatant is transferred to a new tube, and isopropanol (B130326) is added to precipitate the DNA out of the solution.
-
DNA Pellet Washing: The DNA pellet is washed with ethanol (B145695) to remove any remaining contaminants.
-
DNA Rehydration: The final, purified DNA pellet is air-dried and then resuspended in a hydration solution for storage and downstream analysis.
Potential Signaling Pathways Implicated by this compound Findings
While the this compound was primarily an epidemiological study and did not directly investigate molecular mechanisms, its findings point towards the disruption of critical developmental signaling pathways by the identified risk factors. The following diagrams illustrate putative pathways that may be affected.
Maternal Diabetes and Embryonic Development
Maternal hyperglycemia is a known teratogen that can disrupt several signaling pathways crucial for normal embryonic development.[9][10] One of the key mechanisms is the induction of oxidative stress, which can lead to apoptosis (programmed cell death) in developing tissues.[9] This can interfere with pathways such as the Wnt and Notch signaling pathways, which are essential for cardiac and neural tube development.[10]
Maternal Smoking and Fetal Development
The constituents of tobacco smoke are known to have wide-ranging effects on fetal development. One proposed mechanism involves the generation of reactive oxygen species (ROS), leading to oxidative stress. This can result in DNA damage and cellular dysfunction. Furthermore, components of tobacco smoke can interfere with crucial signaling pathways, such as the Sonic hedgehog (Shh) pathway, which plays a vital role in craniofacial and limb development, and the vascular endothelial growth factor (VEGF) pathway, which is critical for proper cardiovascular development.
Conclusion
The National Birth Defects Prevention Study has been instrumental in identifying and quantifying numerous risk factors for birth defects. The findings summarized in this guide highlight the significant impact of maternal health conditions, lifestyle choices, and medication use on fetal development. For researchers and drug development professionals, this information is critical for designing preclinical safety studies, identifying susceptible populations, and developing targeted prevention strategies. Further research building upon the foundation of the this compound is essential to elucidate the precise molecular mechanisms underlying these associations and to develop novel interventions to reduce the burden of birth defects.
References
- 1. The National Birth Defects Prevention Study: a review of the methods - PMC [pmc.ncbi.nlm.nih.gov]
- 2. pure.johnshopkins.edu [pure.johnshopkins.edu]
- 3. researchgate.net [researchgate.net]
- 4. Research Portal [iro.uiowa.edu]
- 5. The National Birth Defects Prevention Study: A review of the methods - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. Diabetic Embryopathy - StatPearls - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 7. This compound.org [this compound.org]
- 8. This compound.org [this compound.org]
- 9. Birth defects in pregestational diabetes: Defect range, glycemic threshold and pathogenesis - PMC [pmc.ncbi.nlm.nih.gov]
- 10. sciencedaily.com [sciencedaily.com]
Genetic and Environmental Factors in the National Birth Defects Prevention Study (NBDPS): A Technical Guide
Introduction to the National Birth Defects Prevention Study (NBDPS)
The National Birth Defects Prevention Study (this compound) was one of the largest population-based case-control studies in the United States, designed to identify environmental and genetic risk factors for major structural birth defects.[1][2][3][4] Initiated in 1996 by the Centers for Disease Control and Prevention (CDC), the study collected data from 10 participating state centers on pregnancies ending between October 1997 and December 2011.[2] The this compound has provided an invaluable resource for investigating the complex etiology of birth defects, leading to over 200 published manuscripts.[2]
The study's design involved two primary components: a detailed computer-assisted telephone interview with mothers and the collection of genetic material via buccal (cheek) cell swabs from the infant, mother, and father.[5][6][7] This dual approach allowed researchers to rigorously analyze the independent effects of genetic and environmental factors and, crucially, to explore their interactions.[8] Cases included live births, stillbirths, and induced terminations with major structural birth defects, identified through population-based surveillance systems.[2] Controls were live-born infants without major birth defects, selected randomly from the same geographical areas.[5]
This guide provides a technical overview of the methodologies employed in the this compound and summarizes key findings related to gene-environment interactions, with a focus on quantitative data, experimental protocols, and the illustration of key biological and procedural pathways.
Data Presentation: Key Gene-Environment Interaction Findings
The this compound dataset has been instrumental in identifying and quantifying the risks associated with specific gene-environment interactions. The following tables summarize notable findings.
Table 2.1: Interaction of Maternal Smoking and Congenital Heart Defects (CHDs)
Maternal periconceptional smoking (one month before to three months after conception) has been identified as a significant risk factor for several CHDs. The risk is often dose-dependent.
| Congenital Heart Defect Subtype | Maternal Smoking Exposure | Adjusted Odds Ratio (aOR) | 95% Confidence Interval (CI) |
| Septal Defects (Aggregated) | Any Smoking | 1.5 | 1.3 - 1.7 |
| Heavy Smoking (≥15 cigarettes/day) | - | - | |
| Tricuspid Atresia (TA) | Any Smoking | 1.7 | 1.0 - 2.7 |
| Heavy Smoking (≥15 cigarettes/day) | 3.0 | 1.5 - 6.1 | |
| Double Outlet Right Ventricle (DORV) | Any Smoking | 1.5 | 1.1 - 2.1 |
| Heavy Smoking (≥15 cigarettes/day) | 1.5 | 1.1 - 2.2 | |
| Right-Sided Obstructive Defects | Heavy Smoking (≥25 cigarettes/day) | >1.0 (Increased Risk) | - |
| Data synthesized from this compound publications. Adjusted for potential confounders such as maternal age, race/ethnicity, and BMI.[1][9][10] |
Table 2.2: Interaction of Folate Pathway Genes and Maternal Folic Acid Supplementation in Conotruncal Heart Defects (CTDs)
Genetic variants in both maternal and fetal folate pathway genes can increase the risk of CTDs, particularly in the absence of periconceptional folic acid supplementation.
| Gene (Individual with Variant) | Maternal Folic Acid Status | Adjusted Odds Ratio (aOR) | 95% Confidence Interval (CI) |
| MTHFS (Maternal) | No Supplementation | 1.34 | 1.07 - 1.67 |
| NOS2 (Maternal) | No Supplementation | 1.34 | 1.05 - 1.72 |
| MTHFS (Fetal) | No Supplementation | 1.35 | 1.09 - 1.66 |
| TCN2 (Fetal) | No Supplementation | 1.38 | 1.12 - 1.70 |
| Data from a targeted sequencing study within the this compound cohort, highlighting increased risk when susceptible genotypes are present without folic acid supplementation. |
Experimental Protocols and Methodologies
The rigor of the this compound findings is grounded in its standardized and carefully controlled methodologies for data and sample collection.
Environmental Exposure Assessment
Environmental and lifestyle data were collected via a standardized, computer-assisted telephone interview (CATI) administered to mothers of cases and controls.[6]
-
Timing: The interview was conducted between 6 weeks and 24 months post-delivery.[2]
-
Exposure Window: The questionnaire focused on the periconceptional period, defined as the three months prior to conception through the end of the pregnancy.[6]
-
Content Areas: The interview covered a broad range of topics, including:
-
Maternal and paternal demographics
-
Maternal health conditions and illnesses
-
Use of prescription and over-the-counter medications
-
Vitamin and supplement use (including folic acid)
-
Maternal diet
-
Lifestyle factors such as smoking, alcohol, and illicit drug use[6]
-
Occupational and residential history to inform potential chemical exposures[2]
-
-
Standardization: The CATI system ensured that all questions were asked in a consistent manner across all participants and study sites.[6]
-
Definition of Smoking Exposure: In analyses of congenital heart defects, smoking levels were often categorized based on maternal self-report for the periconceptional period:
-
Light Smoking: 1-4 cigarettes per day
-
Medium Smoking: 5-14 cigarettes per day
-
Heavy Smoking: ≥15 cigarettes per day[1]
-
Genetic Sample Collection and Analysis
Genetic material was collected non-invasively to facilitate high participation rates.
-
Sample Collection: Following the maternal interview, families were mailed kits to collect buccal (cheek) cells from the mother, father, and infant (if living) using a cytobrush.[2][5]
-
DNA Extraction: A standardized laboratory protocol was used for DNA extraction from buccal cells. A typical procedure involves:
-
Cell Lysis: The brush head is placed in a Cell Lysis Solution.
-
Protein Digestion: Proteinase K is added to digest cellular proteins, followed by incubation.
-
Protein Precipitation: A salt-based solution (e.g., ammonium (B1175870) acetate) is used to precipitate proteins, which are then pelleted by centrifugation.
-
DNA Precipitation: The supernatant containing the DNA is transferred to a new tube, and isopropanol (B130326) or ethanol (B145695) is added to precipitate the genomic DNA.
-
Washing and Hydration: The DNA pellet is washed with 70% ethanol, air-dried, and rehydrated in a hydration solution for storage and analysis.
-
-
Genotyping and Quality Control:
-
A variety of genotyping methods were used across different this compound projects, from single nucleotide polymorphism (SNP) analysis to higher-throughput arrays.
-
To ensure cross-laboratory proficiency, genotyping laboratories participated in an annual external quality assessment (EQA).[2] This involved genotyping a standard, blinded set of DNA specimens from the Coriell Institute for Medical Research.[2]
-
Laboratories consistently achieved call rates of 97-100% and concordance rates of 99-100% in these EQA tests, ensuring high data quality and comparability across studies.[2]
-
Visualizations: Workflows and Pathways
Diagrams are provided to illustrate the logical flow of the this compound protocol and the biological context of key findings.
This compound Gene-Environment Study Workflow
The following diagram outlines the sequential process of an this compound investigation, from participant identification to data analysis.
Simplified Folate Metabolism Pathway and Neural Tube Defects (NTDs)
This diagram illustrates the critical role of folate metabolism in providing methyl groups for DNA synthesis and methylation, a process vital for neural tube closure. Genetic variations in key enzymes can impair this pathway, increasing the risk of NTDs, a risk that can often be mitigated by maternal folic acid supplementation.
Conceptual Model of Gene-Environment Interaction
This diagram illustrates the statistical concept of interaction, where the combined risk of a genetic factor and an environmental exposure is greater than the sum of their individual risks.
References
- 1. Maternal Smoking and Congenital Heart Defects, National Birth Defects Prevention Study, 1997–2011 - PMC [pmc.ncbi.nlm.nih.gov]
- 2. The National Birth Defects Prevention Study: a review of the methods - PMC [pmc.ncbi.nlm.nih.gov]
- 3. researchgate.net [researchgate.net]
- 4. pure.johnshopkins.edu [pure.johnshopkins.edu]
- 5. This compound.org [this compound.org]
- 6. This compound.org [this compound.org]
- 7. This compound.org [this compound.org]
- 8. The National Birth Defects Prevention Study - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. publications.aap.org [publications.aap.org]
- 10. Maternal smoking and congenital heart defects - PubMed [pubmed.ncbi.nlm.nih.gov]
Maternal Medication Use and Birth Defects: A Technical Analysis of Findings from the National Birth Defects Prevention Study
For Researchers, Scientists, and Drug Development Professionals
This in-depth technical guide synthesizes the extensive findings from the National Birth Defects Prevention Study (NBDPS) on the association between maternal medication use during pregnancy and the risk of birth defects. The this compound, a large-scale, population-based case-control study, has provided critical data for understanding the potential teratogenic effects of various pharmaceuticals. This document presents a comprehensive overview of the study's methodology, quantitative findings for key medication classes, and visualizations of the experimental workflow.
Executive Summary
The National Birth Defects Prevention Study (this compound) was a multi-center case-control study designed to identify risk factors for major birth defects in the United States.[1][2] Running from 1997 to 2011, the study collected extensive data from mothers of more than 30,000 babies with birth defects and 10,000 babies without birth defects.[3][4] This guide focuses on the this compound findings related to maternal medication use, providing a valuable resource for researchers and professionals in the fields of drug development, clinical research, and pediatric medicine. The data presented herein are crucial for informing preclinical and clinical safety assessments of drugs intended for use by women of childbearing potential.
The National Birth Defects Prevention Study (this compound): Core Methodology
The this compound employed a robust, population-based case-control design to investigate the potential causes of dozens of major birth defects.[1][5][6]
Study Design and Population
Cases, defined as live births, stillbirths, or elective terminations with at least one of over 30 eligible major birth defects, were identified through state-based birth defect surveillance systems across ten participating centers in the United States.[1][7][8] Controls were live-born infants without any major birth defects, randomly selected from the same geographic areas and time periods as the cases.[1][5][6]
Data Collection
The primary method of data collection was a standardized, computer-assisted telephone interview with the mothers of both cases and controls, conducted between six weeks and two years after the estimated date of delivery.[1][3] The interview gathered comprehensive information on a wide range of potential exposures during the periconceptional period (three months before conception through the end of pregnancy), including:
-
Prescription and over-the-counter medication use: Mothers were asked about specific medications and the timing of their use.[9]
-
Maternal health and diet[9]
-
Lifestyle factors, including smoking and alcohol consumption
-
Occupational and environmental exposures[9]
-
Family history of birth defects
In addition to the interview, the this compound also collected buccal (cheek) cells from the mother, father, and infant (when possible) for genetic analysis, allowing for the investigation of gene-environment interactions.[5][6][9]
Data Analysis
The this compound utilized sophisticated statistical methods to analyze the vast amount of data collected. For studies on medication use, the primary analytical approach involved calculating odds ratios (ORs) and their 95% confidence intervals (CIs) to estimate the association between exposure to a specific medication and the occurrence of a particular birth defect. These analyses typically controlled for various potential confounding factors, such as maternal age, race/ethnicity, education level, and other co-exposures.
Quantitative Findings: Maternal Medication Use and Birth Defect Associations
The following tables summarize the key quantitative findings from the this compound for several classes of medications. It is important to note that an association does not prove causation, and these findings often warrant further investigation.
Selective Serotonin Reuptake Inhibitors (SSRIs)
SSRIs are a class of antidepressants commonly prescribed to women of childbearing age. The this compound investigated the potential risks associated with their use during early pregnancy. While the use of SSRIs as a class was not associated with most of the birth defects studied, some associations were observed with specific SSRIs and certain defects.[10]
| Medication | Birth Defect | Adjusted Odds Ratio (aOR) / Posterior Odds Ratio (pOR) | 95% Confidence/Credible Interval |
| Paroxetine | Anencephaly | 3.2 (pOR) | 1.6 - 6.2 |
| Atrial septal defects | 1.8 (pOR) | 1.1 - 3.0 | |
| Right ventricular outflow tract obstruction defects | 2.4 (pOR) | 1.4 - 3.9 | |
| Gastroschisis | 2.5 (pOR) | 1.2 - 4.8 | |
| Omphalocele | 3.5 (pOR) | 1.3 - 8.0 | |
| Fluoxetine | Right ventricular outflow tract obstruction cardiac defects | 2.0 (pOR) | 1.4 - 3.1 |
| Craniosynostosis | 1.9 (pOR) | 1.1 - 3.0 | |
| Sertraline | No confirmed associations with five previously reported birth defects | - | - |
| Any SSRI | Anencephaly | Significant Association Reported | - |
| Craniosynostosis | Significant Association Reported | - | |
| Omphalocele | Significant Association Reported | - |
Data from a Bayesian analysis of this compound data.[1][11]
Opioid Analgesics
The this compound found that maternal use of prescription opioid analgesics, such as codeine and hydrocodone, in the periconceptional period was associated with an increased risk for several types of birth defects, particularly congenital heart defects.[3][12] Women who took these medications were found to have approximately twice the risk of having a baby with hypoplastic left heart syndrome.[12]
| Medication Class | Birth Defect Category | Reported Risk |
| Opioid Analgesics | Congenital Heart Defects (e.g., atrioventricular septal defects, hypoplastic left heart syndrome) | Increased Risk |
| Spina Bifida | Increased Risk | |
| Gastroschisis | Increased Risk |
Nonsteroidal Anti-inflammatory Drugs (NSAIDs)
NSAIDs, including ibuprofen, aspirin, and naproxen, are commonly used over-the-counter medications. The this compound found that while the overall risk of birth defects associated with first-trimester NSAID use was not substantially elevated, some small-to-moderate increased risks were observed for specific defects.[7][8][13][14]
| Medication Class/Medication | Birth Defect | Finding |
| NSAIDs (Ibuprofen, Aspirin, Naproxen) | Some oral clefts | Small-to-moderate increased risk |
| Some neural tube defects | Small-to-moderate increased risk | |
| Anophthalmia/microphthalmia | Small-to-moderate increased risk | |
| Pulmonary valve stenosis | Small-to-moderate increased risk | |
| Amniotic bands/limb body wall defects | Small-to-moderate increased risk | |
| Transverse limb deficiencies | Small-to-moderate increased risk |
Other Medications
The this compound has investigated a wide array of other medications. The following table highlights some of these findings.
| Medication/Class | Birth Defect | Adjusted Odds Ratio (aOR) | 95% Confidence Interval |
| Antiherpetic Medications (Acyclovir, Valacyclovir, Famciclovir) | Gastroschisis | 4.7 | 1.7 - 13.3 (among women with self-reported genital herpes) |
| 4.7 | 1.2 - 19.0 (among women without self-reported genital herpes) | ||
| Butalbital | Tetralogy of Fallot | 3.04 | 1.07 - 8.62 |
| Pulmonary valve stenosis | 5.73 | 2.25 - 14.62 | |
| Secundum-type atrial septal defect | 3.06 | 1.07 - 8.79 |
Antiherpetic medication data from Ahrens et al.[13][15] Butalbital data from a this compound study.[16]
Experimental Protocols and Workflows
The following section details the generalized experimental protocol of the this compound and provides a visual representation of the study's workflow.
Detailed this compound Methodology
-
Case Ascertainment: State-based birth defect surveillance systems identified infants and fetuses with major structural birth defects. Clinical geneticists reviewed all cases to confirm eligibility and exclude those with known genetic syndromes or chromosomal abnormalities.[2]
-
Control Selection: A random sample of live-born infants without major birth defects was selected from the same geographic regions and birth periods as the cases, using birth certificates or hospital records.[5][6]
-
Maternal Interview: Mothers of both cases and controls were contacted for a computer-assisted telephone interview.[1] The interview was designed to be comprehensive, covering a wide range of exposures. For medication exposures, mothers were asked about the specific name of the medication, the reason for use, the start and end dates of use, and the frequency of use.
-
Exposure and Covariate Data Collection: Detailed information on potential confounding variables was also collected during the interview, including maternal demographics, reproductive history, lifestyle factors (smoking, alcohol use), and other medical conditions.
-
Biological Sample Collection: Families were mailed kits to collect buccal cells from the mother, father, and infant.[5][6][9] These samples were stored for future genetic analyses.
-
Statistical Analysis:
-
Descriptive Statistics: The prevalence of medication use and other characteristics were calculated for both case and control groups.
-
Logistic Regression: Unconditional logistic regression was the primary statistical method used to calculate odds ratios (ORs) and 95% confidence intervals (CIs).
-
Confounder Adjustment: The regression models were adjusted for a range of potential confounders to isolate the effect of the medication of interest. Common confounders included maternal age, race/ethnicity, education, smoking status, and study center.
-
Subgroup Analyses: In some studies, analyses were stratified by factors such as the specific type of medication within a class or by the presence of other maternal conditions.
-
Visualizations
The following diagrams illustrate the overall workflow of the National Birth Defects Prevention Study.
Signaling Pathways and Future Directions
While the this compound was primarily an epidemiological study designed to identify associations, its findings provide a critical foundation for mechanistic research. The specific birth defects associated with certain medications can offer clues about the underlying biological pathways that may be disrupted. For example, the association of some medications with congenital heart defects suggests potential interference with critical signaling pathways involved in cardiac development, such as the Wnt, Notch, or Hedgehog pathways.
Future research, including in vitro and in vivo toxicological studies, is needed to elucidate the precise molecular mechanisms by which these medications may exert teratogenic effects. Integrating data from the this compound with findings from these mechanistic studies will be essential for developing a more complete understanding of medication-induced birth defects and for improving the safety of pharmacotherapy during pregnancy. The development of knowledge graphs, such as the ReproTox-KG, which connect drug data with genetic and pathway information, represents a promising approach to predicting and understanding these adverse developmental outcomes.[17]
Conclusion
The National Birth Defects Prevention Study has been a landmark endeavor in the field of birth defects epidemiology. Its comprehensive data have provided invaluable insights into the potential risks associated with maternal medication use during pregnancy. This technical guide has summarized the core methodologies and key quantitative findings of the this compound, offering a valuable resource for researchers, scientists, and drug development professionals. The continued analysis of this compound data, coupled with mechanistic research into the identified associations, will be crucial for advancing our understanding of the causes of birth defects and for ensuring the safety of medications for pregnant women and their children.
References
- 1. Analysis shows link between certain SSRIs and birth defect risk | MDedge [mdedge.com]
- 2. The National Birth Defects Prevention Study: a review of the methods - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Maternal exposures in the National Birth Defects Prevention Study: time trends of selected exposures - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Methods for Accessing this compound and BD-STEPS Data | Birth Defects | CDC [cdc.gov]
- 5. National Birth Defects Prevention Study (this compound) | Birth Defects | NCBDDD | CDC [medbox.iiab.me]
- 6. This compound.org [this compound.org]
- 7. Nonsteroidal antiinflammatory drug use among women and the risk of birth defects - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Nonsteroidal antiinflammatory drug use among women and the risk of birth defects | Obgyn Key [obgynkey.com]
- 9. This compound.org [this compound.org]
- 10. This compound.org [this compound.org]
- 11. Specific SSRIs and birth defects: bayesian analysis to interpret new data in the context of previous reports - PMC [pmc.ncbi.nlm.nih.gov]
- 12. hcplive.com [hcplive.com]
- 13. Antiherpetic medication use and the risk of gastroschisis: findings from the National Birth Defects Prevention Study, 1997-2007 - PubMed [pubmed.ncbi.nlm.nih.gov]
- 14. Nonsteroidal antiinflammatory drug use among women and the risk of birth defects - PubMed [pubmed.ncbi.nlm.nih.gov]
- 15. researchgate.net [researchgate.net]
- 16. researchgate.net [researchgate.net]
- 17. Mapping Connections Between Drugs, Genes, and Birth Defects | NIH Common Fund [commonfund.nih.gov]
An In-depth Technical Guide to the Centers for Birth Defects Research and Prevention (CBDRP)
For Researchers, Scientists, and Drug Development Professionals
This guide provides a comprehensive overview of the Centers for Birth Defects Research and Prevention (CBDRP), a collaborative network of research centers in the United States dedicated to understanding the causes of birth defects. Funded by the Centers for Disease Control and Prevention (CDC), the CBDRP conducts large-scale epidemiological studies to identify risk factors for birth defects, with the ultimate goal of developing prevention strategies. This document details the core methodologies of the CBDRP's key studies, presents significant quantitative findings in a structured format, and visualizes the molecular pathways implicated in the etiology of various birth defects.
Overview of the CBDRP
The Centers for Birth Defects Research and Prevention (CBDRP) were established by the CDC to investigate the causes of birth defects. The CBDRP conducts its research through a network of centers located in several states, including Arkansas, California, Georgia, Iowa, Massachusetts, New York, North Carolina, Texas, and Utah. This collaborative effort has led to two landmark studies: the National Birth Defects Prevention Study (NBDPS) and its successor, the Birth Defects Study to Evaluate Pregnancy Exposures (BD-STEPS).
These studies are critical in identifying potential risk factors for birth defects, which are a leading cause of infant mortality and contribute significantly to childhood morbidity. The research conducted by the CBDRP provides crucial data for public health recommendations, clinical guidance, and the development of safer therapeutic alternatives for use during pregnancy.
Experimental Protocols and Methodologies
The primary research initiatives of the CBDRP are the National Birth Defects Prevention Study (this compound) and the Birth Defects Study to Evaluate Pregnancy Exposures (BD-STEPS). Both are observational, population-based, case-control studies.
Study Design
-
Observational: Researchers observe and collect data on exposures and outcomes without intervening.
-
Population-Based: The studies aim to include all cases of specific birth defects within a defined geographic area, making the findings more generalizable to the broader population.
-
Case-Control: Mothers of infants with specific birth defects (cases) are compared to mothers of infants without birth defects (controls) from the same population.
Data Collection
A multi-faceted approach to data collection is employed to gather comprehensive information on potential risk factors.
-
Computer-Assisted Telephone Interviews: Detailed interviews are conducted with mothers of both cases and controls. These interviews cover a wide range of topics, including:
-
Maternal and paternal demographics
-
Maternal health conditions before and during pregnancy
-
Use of prescription and over-the-counter medications
-
Lifestyle factors (e.g., diet, smoking, alcohol use)
-
Occupational and environmental exposures
-
-
Biological Sample Collection:
-
This compound: Cheek cells were collected from the mother, father, and infant to obtain DNA for genetic analysis.
-
BD-STEPS: The study requests permission to use residual newborn screening blood spots for genetic analyses.[1]
-
Case and Control Selection
-
Cases: Infants and fetuses with major structural birth defects are identified through state-based birth defects surveillance systems.
-
Controls: A random sample of live-born infants without major birth defects is selected from the same geographic areas and time periods as the cases.
The rigorous and standardized methodologies employed by the this compound and BD-STEPS ensure the collection of high-quality data, which is essential for identifying potential causal links between exposures and birth defects.
Quantitative Data Summary
The this compound and BD-STEPS have generated a wealth of data on the association between various maternal exposures and the risk of specific birth defects. The following tables summarize some of the key quantitative findings from these studies. The data are presented as adjusted odds ratios (aOR) with 95% confidence intervals (CI). An odds ratio greater than 1.0 suggests an increased risk of the birth defect associated with the exposure.
Maternal Medication Use and Birth Defects
Table 1: Association Between Maternal Opioid Use During Early Pregnancy and Specific Birth Defects
| Birth Defect Category | Adjusted Odds Ratio (95% Confidence Interval) |
| Congenital Heart Defects | |
| Conoventricular Septal Defects | 2.7 (1.1 - 6.3)[2] |
| Atrioventricular Septal Defects | 2.0 (1.2 - 3.6)[2] |
| Hypoplastic Left Heart Syndrome | 2.4 (1.4 - 4.1)[2] |
| Neural Tube Defects | |
| Spina Bifida | 2.0 (1.3 - 3.2)[2] |
| Other Defects | |
| Gastroschisis | 1.8 (1.1 - 2.9)[2] |
Table 2: Association Between Maternal Selective Serotonin Reuptake Inhibitor (SSRI) Use During Early Pregnancy and Specific Birth Defects
| SSRI Medication | Birth Defect Category | Posterior Odds Ratio (95% Credible Interval) |
| Paroxetine | Anencephaly | 3.2 (1.6 - 6.2)[3] |
| Atrial Septal Defects | 1.8 (1.1 - 3.0)[3] | |
| Right Ventricular Outflow Tract Obstruction Defects | 2.4 (1.4 - 3.9)[3] | |
| Gastroschisis | 2.5 (1.2 - 4.8)[3] | |
| Omphalocele | 3.5 (1.3 - 8.0)[3] | |
| Fluoxetine | Right Ventricular Outflow Tract Obstruction Defects | 2.0 (1.4 - 3.1)[3] |
| Craniosynostosis | 1.9 (1.1 - 3.0)[3] |
Table 3: Association Between Maternal Antihypertensive Medication Use During Early Pregnancy and Congenital Heart Defects
| Birth Defect Category | Adjusted Odds Ratio (95% Confidence Interval) |
| Coarctation of the Aorta | 2.50 (1.52 - 4.11)[4] |
| Pulmonary Valve Stenosis | 2.19 (1.44 - 3.34)[4] |
| Perimembranous Ventricular Septal Defect | 1.90 (1.09 - 3.31)[4] |
| Secundum Atrial Septal Defect | 1.94 (1.36 - 2.79)[4] |
Maternal Health Conditions and Birth Defects
Table 4: Association Between Maternal Pre-pregnancy Obesity (BMI ≥ 30) and Specific Birth Defects
| Birth Defect Category | Unadjusted Odds Ratio (95% Confidence Interval) |
| Spina Bifida | 3.5 (1.2 - 10.3)[5] |
| Omphalocele | 3.3 (1.0 - 10.3)[5] |
| Heart Defects | 2.0 (1.2 - 3.4)[5] |
| Multiple Anomalies | 2.0 (1.0 - 3.8)[5] |
Signaling Pathways and Molecular Mechanisms
Understanding the molecular pathways disrupted by various exposures is crucial for developing targeted prevention and intervention strategies. The following diagrams illustrate some of the key signaling pathways implicated in the etiology of birth defects.
Folate Metabolism and Neural Tube Defects
Folic acid supplementation is a well-established preventive measure for neural tube defects (NTDs). Folate is a crucial cofactor in one-carbon metabolism, which is essential for DNA synthesis and methylation.[6] Disruptions in this pathway can lead to impaired cell proliferation and differentiation during the critical period of neural tube closure.[7]
Maternal Obesity and Oxidative Stress-Induced Birth Defects
Maternal obesity is associated with a state of chronic low-grade inflammation and increased oxidative stress.[8] This can lead to an imbalance between reactive oxygen species (ROS) and the antioxidant defense system in the developing embryo, resulting in damage to cellular macromolecules and disruption of critical signaling pathways involved in organogenesis.
Opioid Use and Disruption of Neuronal Development
Opioids exert their effects by binding to opioid receptors, which are G-protein coupled receptors. During embryonic development, the endogenous opioid system plays a role in cell proliferation, differentiation, and migration.[9] Exogenous opioids can interfere with these processes, particularly in the developing central nervous system, potentially leading to structural and functional abnormalities.[10]
Conclusion
The Centers for Birth Defects Research and Prevention, through the this compound and BD-STEPS studies, have made significant contributions to our understanding of the causes of birth defects. The extensive data collected have allowed researchers to identify several modifiable risk factors, including medication use and maternal health conditions. The continued analysis of this rich dataset, combined with research into the underlying molecular mechanisms, holds the promise of developing new strategies to prevent birth defects and improve the health of mothers and their children. For researchers and professionals in drug development, the findings from the CBDRP underscore the critical importance of considering the potential teratogenic effects of new compounds and the need for robust preclinical and post-market surveillance.
References
- 1. Next steps for birth defects research and prevention: The birth defects study to evaluate pregnancy exposures (BD-STEPS) - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. managedhealthcareexecutive.com [managedhealthcareexecutive.com]
- 3. Specific SSRIs and birth defects: bayesian analysis to interpret new data in the context of previous reports - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Maternal Antihypertensive Medication Use and Congenital Heart Defects: Updated Results From the National Birth Defects Prevention Study - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. Maternal obesity and risk for birth defects - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. Neural Tube Defects and Folate Pathway Genes: Family-Based Association Tests of Gene–Gene and Gene–Environment Interactions - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Neural tube defects between folate metabolism and genetics - PMC [pmc.ncbi.nlm.nih.gov]
- 8. ahajournals.org [ahajournals.org]
- 9. gmr.scholasticahq.com [gmr.scholasticahq.com]
- 10. Reviewing the Impact of Maternal Opioid Use Disorder on Fetal Development and Long-Term Pediatric Health Outcomes - PMC [pmc.ncbi.nlm.nih.gov]
A Technical Guide to the National Birth Defects Prevention Study (NBDPS) and the Birth Defects Study To Evaluate Pregnancy Exposures (BD-STEPS) for Researchers and Drug Development Professionals
An In-Depth Examination of Two Landmark Epidemiological Studies and Their Relevance to Understanding the Etiology of Birth Defects
This technical guide provides a comprehensive overview of the National Birth Defects Prevention Study (NBDPS) and its successor, the Birth Defects Study To Evaluate Pregnancy Exposures (BD-STEPS). While not studies of specific molecular signaling pathways in a laboratory setting, these large-scale, population-based case-control studies offer a wealth of data on genetic and environmental risk factors for birth defects. This information is invaluable for researchers and professionals in drug development, as it helps to identify potential teratogenic exposures and informs hypotheses for mechanistic studies, including the investigation of underlying signaling pathways.
Executive Summary: The Relationship between this compound and BD-STEPS
The National Birth Defects Prevention Study (this compound) was a landmark case-control study conducted in the United States to investigate the causes of birth defects.[1] Its successor, the Birth Defects Study To Evaluate Pregnancy Exposures (BD-STEPS), builds upon the foundation of this compound by extending and expanding its research efforts.[2][3] BD-STEPS continues to collect data on many of the same exposures as this compound, allowing for combined analysis and providing a larger sample size to study rare exposures.[2][3] Additionally, BD-STEPS gathers more detailed information on existing exposures and investigates new ones.[2][3] A significant addition to the research scope of BD-STEPS is the inclusion of stillbirths as a focus of investigation.[4][5]
Quantitative Data Summary
The extensive data collected by this compound and BD-STEPS provide a powerful resource for researchers. The following tables summarize the key quantitative aspects of these studies.
Table 1: Overview of this compound and BD-STEPS
| Feature | National Birth Defects Prevention Study (this compound) | Birth Defects Study To Evaluate Pregnancy Exposures (BD-STEPS) |
| Study Period | Deliveries from 1997 to 2011[4][5] | Deliveries from 2014 to present[4][5] |
| Study Type | Observational, population-based, case-control study[6] | Observational, population-based, case-control study[7] |
| Primary Focus | Genetic and environmental risk factors for major structural birth defects[8] | Modifiable risk factors for selected structural birth defects and stillbirths[2][4] |
| Participating Centers | 10 U.S. states[9] | 7 U.S. states[9][10] |
Table 2: Participant Enrollment and Data Collection in this compound
| Participant Group | Number of Participants | Data Collection Methods |
| Mothers of babies with birth defects (Cases) | Over 30,000[11] | Computer-assisted telephone interviews, cheek cell samples for DNA analysis[12] |
| Mothers of babies without birth defects (Controls) | Over 10,000[11] | Computer-assisted telephone interviews, cheek cell samples for DNA analysis[12] |
| Total Interviews Conducted | Over 43,000[9] | N/A |
| Families Providing Cheek Cell Samples | Over 23,000[9] | N/A |
Experimental Protocols: Study Methodologies
The "experimental protocols" for this compound and BD-STEPS are the detailed methodologies used for these large-scale epidemiological studies. Both studies employ a case-control design.[6][7]
Case and Control Selection
-
Cases: Infants with major birth defects are identified through existing birth defects surveillance programs in the participating states.[2]
-
Controls: Infants without major birth defects are randomly selected from the same geographic areas and time periods as the cases, using vital records or birth hospital logs.[2][6]
Data Collection Procedures
The primary methods of data collection for both studies include:
-
Computer-Assisted Telephone Interviews: Mothers of both case and control infants participate in a standardized telephone interview.[2][12] This interview gathers information on a wide range of topics, including:
-
Demographics
-
Maternal health conditions
-
Medication use before and during pregnancy
-
Lifestyle factors (e.g., diet, smoking, alcohol use)
-
Occupational exposures
-
Family history of birth defects
-
-
Biological Sample Collection:
Expansion of Data Collection in BD-STEPS
BD-STEPS has expanded its data collection to include:[2]
-
Linkages with external datasets.
-
Use of online questionnaires for more in-depth information on specific exposures.
Logical and Workflow Relationships
The following diagram illustrates the progression from this compound to BD-STEPS, highlighting the flow of research focus and data utilization.
From Population-Level Data to Molecular Mechanisms: The Role of this compound and BD-STEPS in Informing Signaling Pathway Research
While this compound and BD-STEPS do not directly investigate molecular signaling pathways, their findings are critical for generating hypotheses that can be tested in a laboratory setting. By identifying associations between specific exposures (e.g., medications, environmental factors) and birth defects, these studies provide crucial leads for molecular biologists and toxicologists.
For example, if a study finds an association between a particular medication and a specific type of congenital heart defect, researchers can then investigate the drug's mechanism of action and its potential impact on signaling pathways known to be critical for cardiac development (e.g., Wnt, Notch, or TGF-β signaling). The genetic data collected in these studies also allow for the investigation of gene-environment interactions, potentially identifying genetic susceptibilities that may be linked to alterations in key developmental pathways.
In essence, this compound and BD-STEPS provide the "what" (the association between an exposure and an outcome) that guides laboratory-based research to uncover the "how" (the underlying molecular mechanisms and signaling pathways). The publications resulting from these studies are a valuable resource for drug development professionals seeking to understand the potential teratogenic effects of compounds and for researchers aiming to elucidate the complex interplay of genetics and environment in congenital anomalies. Over 300 scientific papers have been published using data from this compound alone.[13]
References
- 1. researchgate.net [researchgate.net]
- 2. Next steps for birth defects research and prevention: The birth defects study to evaluate pregnancy exposures (BD-STEPS) - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. Next steps for birth defects research and prevention: The Birth Defects Study To Evaluate Pregnancy exposureS (BD-STEPS) - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Checking your connection... [researchfunding.duke.edu]
- 5. Birth Defects Research | Birth Defects | CDC [cdc.gov]
- 6. This compound.org [this compound.org]
- 7. bdsteps.org [bdsteps.org]
- 8. The National Birth Defects Prevention Study - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. publichealth.uams.edu [publichealth.uams.edu]
- 10. bdsteps.org [bdsteps.org]
- 11. Methods for Accessing this compound and BD-STEPS Data | Birth Defects | CDC [cdc.gov]
- 12. This compound.org [this compound.org]
- 13. bdsteps.org [bdsteps.org]
Methodological & Application
Navigating a Complex Data Landscape: Application Protocols for NBDPS and NBS Data
For researchers, scientists, and drug development professionals, accessing large-scale national health and statistical data is crucial for advancing scientific discovery and improving public health. This document provides a detailed guide to the data request and application processes for two significant data sources: the National Birth Defects Prevention Study (NBDPS) in the United States and the National Bureau of Statistics (NBS) of China. While both entities offer valuable data, their accessibility and application procedures differ significantly. This guide aims to provide clear, actionable protocols and to set realistic expectations for researchers seeking to utilize these datasets.
Section 1: The National Birth Defects Prevention Study (this compound) - A Collaborative Approach to Data Access
The National Birth Defects Prevention Study (this compound) is a large-scale, population-based case-control study conducted by the Centers for Disease Control and Prevention (CDC) in the United States. It investigated the potential causes of birth defects.[1][2] While the raw data is not publicly available to protect participant confidentiality, qualified researchers can gain access through a collaborative process.[1][2][3]
Data Availability
The this compound collected extensive data from mothers of babies born with and without birth defects between 1997 and 2011.[1][2] The data collected includes:
-
Interview Data: Information gathered through computer-guided telephone interviews with mothers, covering topics such as:
-
Genetic Data: DNA samples were collected from cheek cells of the mother, father, and baby (when possible) to study genetic factors related to birth defects.[4][5]
Application Process and Protocols
Access to this compound data is granted through collaboration with one of the Centers for Birth Defects Research and Prevention (CBDRP). The application process is structured and transparent, with clear review criteria.
Table 1: this compound Data Application and Review Process
| Stage | Key Actions and Protocols |
| 1. Preliminary Research | Researchers must thoroughly review existing this compound publications to ensure their proposed analysis does not overlap with previously published work.[1][2] Proposals with significant overlap will be denied.[1][2] |
| 2. Identify Collaborating Center | Applicants must identify a CBDRP center to sponsor their research project. A list of centers is available on the CDC's website. If no center is specified, the request is routed to the Georgia Center at the CDC.[2] |
| 3. Complete Collaboration Request Form | Download and complete the official Collaboration Request Form. This form requires a detailed description of the proposed research, including the study's public health significance.[1] |
| 4. Submission | The completed form should be emailed to the Principal Investigator of the identified collaborating center.[1][2] |
| 5. Review by CBDRP Data Sharing Committee | The committee reviews requests based on several criteria: scientific merit, benefit to public health, lack of conflict of interest, and the researcher's qualifications and resources.[1][2] |
| 6. Data Use Agreement and Confidentiality | If approved, researchers must adhere to strict confidentiality and data use agreements to protect participant privacy.[1][3] |
Experimental Protocols: A Methodological Overview
The this compound employed a robust case-control study design.
-
Observational Study: Researchers observed existing health outcomes and exposures without intervening.[5]
-
Population-Based: The study included all individuals with a specific birth defect within a defined geographic area.[5]
-
Case-Control Design: Information was collected from "cases" (mothers of babies with birth defects) and "controls" (mothers of babies without birth defects).[5] Controls were randomly selected from birth certificate records.[5]
Diagram 1: this compound Data Request Workflow
Caption: Workflow for requesting access to this compound data.
Section 2: The National Bureau of Statistics (NBS) of China - A More Complex Terrain
The National Bureau of Statistics (NBS) of China is the primary government agency responsible for statistical work and economic accounting.[6] It manages the National Statistical Data Repository, which provides a wealth of data on China's economy and society.[2] Since December 2018, the NBS has made detailed microdata available to authorized researchers and universities within China through an application-based system.[2]
Data Availability
The NBS offers a vast array of statistical data, including:
-
Macroeconomic Data: Monthly, quarterly, and annual data on indicators such as GDP, CPI, and industrial production.[2][7]
-
Census Data: Data from national censuses on population, economy, and agriculture.[2][7]
-
Microdata: Since 2018, the NBS has been piloting the release of microdata from various surveys to authorized institutions.[2][8]
Application Process and Protocols: A Less Defined Path
Known Access Points:
-
National Statistical Data Repository: Publicly available aggregated data can be accessed and downloaded directly from the NBS website.[9][10]
-
Data Request Form: A general form is available on the NBS website for inquiries. The specificity of data that can be requested and the likelihood of fulfillment for international researchers are unclear.
-
Tsinghua China Data Center (CDC): A joint initiative between the NBS and Tsinghua University, the CDC serves as a pilot for the development and application of government microdata.[8] Access appears to be primarily for researchers affiliated with Tsinghua University and the University of Chicago.[8]
Table 2: Comparison of this compound and NBS Data Access
| Feature | This compound (US) | NBS (China) |
| Data Access Model | Collaborative, project-based | Direct access to public data; limited, application-based access to microdata |
| Application Process | Clearly defined, multi-step process | Less defined; a general data request form is available |
| Eligibility | Qualified researchers, subject to review | Primarily researchers and universities within China for microdata |
| Transparency | High - clear review criteria and procedures | Low - limited information on microdata access protocols for international researchers |
| Data Use Agreements | Strict confidentiality and data use agreements | Likely required for microdata, but specific terms are not readily available |
Navigating the Challenges of Accessing NBS Data
For drug development professionals and international researchers, accessing detailed NBS microdata presents significant hurdles. The primary route for most will be through the publicly available aggregated data on the NBS website. For those seeking microdata, collaboration with a Chinese academic institution, such as Tsinghua University, may be a potential, though likely challenging, pathway.
Diagram 2: Logical Flow for Accessing NBS Data
Caption: Decision flow for researchers seeking data from the NBS of China.
Conclusion
The this compound and the NBS of China represent two vastly different landscapes for data access. The this compound provides a clear, albeit rigorous, collaborative pathway for researchers to access rich public health data. In contrast, while the NBS offers a wealth of publicly available aggregated statistics, the process for accessing more granular microdata is opaque and appears to be increasingly challenging for international researchers. Professionals in the field of drug development and scientific research should be aware of these differences to effectively plan their research strategies and manage their expectations when seeking to utilize these valuable data resources.
References
- 1. Chinese government to enhance interdepartmental data sharing, improve data quality: NBS - Global Times [globaltimes.cn]
- 2. National Bureau of Statistics of China - Wikipedia [en.wikipedia.org]
- 3. Statistics Law of the People's Republic of China [stats.gov.cn]
- 4. National Data [data.stats.gov.cn]
- 5. unstats.un.org [unstats.un.org]
- 6. About NBS [stats.gov.cn]
- 7. National Bureau of Statistics of China [stats.gov.cn]
- 8. jrcef.cn [jrcef.cn]
- 9. National Data [data.stats.gov.cn]
- 10. National Data [data.stats.gov.cn]
Navigating the National Birth Defects Prevention Study (NBDPS) Data: A Guide for Researchers
Application Notes and Protocols for Utilizing the National Birth Defects Prevention Study (NBDPS) Data Set
For researchers, scientists, and professionals in drug development, the National Birth Defects Prevention Study (this compound) represents a significant resource for investigating the causes of birth defects. This document provides a comprehensive overview of the this compound public use data set, including its availability, the scope of collected data, and protocols for its use. Due to the sensitive nature of the data, direct public access is restricted to protect participant confidentiality. However, qualified researchers can gain access through a collaborative agreement with the Centers for Birth Defects Research and Prevention (CBDRP).
Data Set Availability and Access Protocol
The this compound dataset is not available for public download because it contains personally identifiable information (PII).[1] Researchers seeking to use this valuable resource must engage in a formal collaboration with one of the CBDRP centers.
The process for obtaining access to the this compound data is a structured procedure designed to ensure the responsible and ethical use of the information. The key steps are outlined below.
References
Methodological Insights for Utilizing National Birth Defects Prevention Study (NBDPS) Data
Application Notes and Protocols for Researchers, Scientists, and Drug Development Professionals
The National Birth Defects Prevention Study (NBDPS) is a robust, population-based case-control study that offers a valuable resource for investigating the potential causes of birth defects. This document provides detailed methodological considerations, data presentation guidelines, and experimental protocols for researchers interested in leveraging this significant dataset. The this compound collected extensive data on maternal health, lifestyle, environmental exposures, and genetics, providing a powerful platform for identifying risk factors for a range of congenital anomalies.
Data Presentation: Quantitative Findings from this compound
Table 1: Association Between Maternal Periconceptional Smoking and Congenital Heart Defects (CHDs)
| Congenital Heart Defect Subtype | Maternal Smoking Status | Adjusted Odds Ratio (aOR) | 95% Confidence Interval (CI) |
| Septal Defects (Aggregated) | Any Smoking | 1.5 | 1.3 - 1.7 |
| Heavy Smoking (≥15 cigarettes/day) | - | - | |
| Heavy Smoking (Maternal Age ≥35) | 2.3 | 1.4 - 3.9 | |
| Tricuspid Atresia | Any Smoking | 1.7 | 1.0 - 2.7 |
| Heavy Smoking (≥15 cigarettes/day) | 3.0 | 1.5 - 6.1 | |
| Double Outlet Right Ventricle (DORV) | Any Smoking | 1.5 | 1.1 - 2.1 |
| Heavy Smoking (≥15 cigarettes/day) | 1.5 | 1.1 - 2.2 | |
| Secundum Atrial Septal Defect (ASD) | Any Smoking | 1.7 | 1.5 - 2.0 |
| Perimembranous Ventricular Septal Defect (VSD) | Any Smoking | 1.3 | 1.1 - 1.5 |
| Atrioventricular Septal Defect (AVSD) | Any Smoking | 1.3 | 1.0 - 1.9 |
| Pulmonary Valve Stenosis | Any Smoking | 1.2 | 1.0 - 1.4 |
Data extracted from a retrospective case-control study using this compound data from 1997-2011.[1][2]
Table 2: Association Between Maternal Antihypertensive Medication Use in Early Pregnancy and Congenital Heart Defects (CHDs)
| Congenital Heart Defect Phenotype | Maternal Antihypertensive Use | Adjusted Odds Ratio (aOR) | 95% Confidence Interval (CI) |
| Coarctation of the Aorta | Any Antihypertensive Use | 2.50 | 1.52 - 4.11 |
| Pulmonary Valve Stenosis | Any Antihypertensive Use | 2.19 | 1.44 - 3.34 |
| Perimembranous Ventricular Septal Defect | Any Antihypertensive Use | 1.90 | 1.09 - 3.31 |
| Secundum Atrial Septal Defect | Any Antihypertensive Use | 1.94 | 1.36 - 2.79 |
Data from an analysis of this compound data from 1997 to 2011.[3]
Experimental Protocols: A Guide to Analyzing this compound Data
The this compound is an observational study, and as such, "experimental protocols" primarily refer to the detailed epidemiological and statistical methods used for data analysis. Access to this compound data is restricted and requires collaboration with one of the Centers for Birth Defects Research and Prevention (CBDRP).[4]
Protocol 1: Case-Control Study Design and Data Collection
The this compound employed a population-based case-control study design.[5]
1. Case and Control Selection:
- Cases: Infants or fetuses with major structural birth defects were identified through population-based birth defects surveillance systems in participating states. Cases with known single-gene or chromosomal abnormalities were typically excluded to focus on identifying unknown causes of birth defects.
- Controls: Live-born infants without major birth defects were randomly selected from the same geographic regions and time periods as the cases, using birth certificates or hospital birth records.[5]
2. Data Collection Methods:
- Maternal Interview: Mothers of both cases and controls participated in a standardized, computer-assisted telephone interview. The interview collected comprehensive information on a wide range of topics, including:
- Demographics
- Maternal health conditions and illnesses during pregnancy
- Prescription and over-the-counter medication use
- Lifestyle factors (e.g., smoking, alcohol consumption, diet)
- Occupational and environmental exposures
- Family history of birth defects
- Genetic Specimen Collection: Families were asked to provide buccal (cheek) cell samples from the mother, father, and infant (if possible). These samples allow for the investigation of genetic factors and gene-environment interactions.
Protocol 2: Statistical Analysis of this compound Data
The following protocol outlines a typical approach for analyzing this compound data to investigate the association between a maternal exposure and a specific birth defect.
1. Definition of Exposure and Outcome:
- Exposure: Clearly define the maternal exposure of interest based on the information collected in the maternal interviews. For example, for maternal smoking, this could be categorized as "any smoking during the periconceptional period (one month before to three months after conception)" versus "no smoking." Further categorization by the number of cigarettes smoked per day (e.g., light, medium, heavy) can be used to assess dose-response relationships.[1][2]
- Outcome: Define the specific birth defect or category of birth defects being studied based on the detailed clinical classifications within the this compound data.
2. Statistical Modeling:
- Logistic Regression: Use multivariable logistic regression to estimate the association between the maternal exposure and the birth defect of interest. This method calculates the odds ratio (OR) and its 95% confidence interval (CI).
- Model Specification:
- The dependent variable is the case-control status (1 for cases, 0 for controls).
- The primary independent variable is the maternal exposure of interest.
- Covariate Adjustment: It is crucial to adjust for potential confounding variables to isolate the effect of the exposure. Common covariates to include in the logistic regression model are:
- Maternal age
- Maternal race/ethnicity
- Maternal education level
- Pre-pregnancy body mass index (BMI)
- Folic acid supplementation
- Maternal alcohol use
- Study site (to account for geographic variations)[3]
- The selection of covariates should be based on prior knowledge of risk factors for the specific birth defect being studied and should be pre-specified in the analysis plan.
3. Assessment of Gene-Environment Interactions:
- For studies investigating genetic factors, statistical models can be extended to include genetic data (e.g., single nucleotide polymorphisms or SNPs) and interaction terms between genetic variants and environmental exposures. This allows researchers to explore whether the effect of an environmental exposure on the risk of a birth defect is modified by an individual's genetic makeup.
4. Software:
- Statistical software packages such as SAS, Stata, or R are commonly used for these analyses.
Visualizing Methodological and Biological Frameworks
Diagrams created using Graphviz (DOT language) can effectively illustrate complex workflows and biological pathways relevant to this compound research.
Signaling Pathways Implicated in Birth Defects
Understanding the biological mechanisms by which environmental exposures may lead to birth defects is a key area of research. Several critical signaling pathways are involved in embryonic development, and their disruption has been linked to congenital anomalies.
WNT Signaling Pathway and Neural Tube Defects:
The WNT signaling pathway plays a crucial role in the development of the neural tube. Disruptions in this pathway, potentially influenced by environmental factors, can lead to neural tube defects such as spina bifida and anencephaly.
BMP Signaling Pathway and Congenital Heart Defects:
The Bone Morphogenetic Protein (BMP) signaling pathway is essential for proper heart development. Studies suggest that maternal exposures, such as smoking, may interfere with this pathway, contributing to congenital heart defects.
SHH Signaling Pathway and Holoprosencephaly:
The Sonic Hedgehog (SHH) signaling pathway is critical for the development of the forebrain and midline facial structures. Disruptions in this pathway are a major cause of holoprosencephaly. While direct links between many common maternal exposures in the this compound and SHH pathway disruption are still under investigation, this pathway is of high interest in birth defects research.
References
- 1. Introduction to DOT Plot Analysis in Bioinformatics - Omics tutorials [omicstutorials.com]
- 2. medium.com [medium.com]
- 3. Maternal Antihypertensive Medication Use and Congenital Heart Defects: Updated Results From the National Birth Defects Prevention Study - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. Covariate imbalance and adjustment for logistic regression analysis of clinical trial data - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. Maternal smoking and congenital heart defects - PubMed [pubmed.ncbi.nlm.nih.gov]
Application Notes and Protocols: National Birth Defects Prevention Study (NBDPS) Case-Control Methodology
For Researchers, Scientists, and Drug Development Professionals
These application notes provide a detailed overview of the methodology employed in the National Birth Defects Prevention Study (NBDPS), a large-scale, population-based case-control study designed to investigate the genetic and environmental risk factors for major structural birth defects in the United States.
Study Overview and Design
The National Birth Defects Prevention Study (this compound) was an observational, population-based, case-control study that collected data on pregnancies ending between October 1997 and December 2011.[1][2] The primary objective of the this compound was to identify preventable causes of birth defects. To achieve this, researchers collected information from mothers of babies with birth defects (cases) and mothers of babies without birth defects (controls).[3][4] The study was a collaborative effort among the Centers for Disease Control and Prevention (CDC) and several state-based birth defects surveillance programs.[5]
The case-control design is a powerful epidemiological tool for studying rare outcomes like specific birth defects. By comparing exposures between cases and controls, researchers can identify potential risk factors associated with the development of these conditions. The this compound was designed to have sufficient statistical power to investigate a wide range of potential risk factors, including medication use, parental occupation, and lifestyle factors.[4][6]
Quantitative Summary of the this compound
| Parameter | Description |
| Study Period | Data collection from 1998 to 2013 for pregnancies ending between October 1997 and December 2011.[1][2] |
| Study Population | Multicenter study conducted in ten US states: Arkansas, California, Georgia, Iowa, Massachusetts, New Jersey, New York, North Carolina, Texas, and Utah. |
| Eligible Cases | 47,832 infants or fetuses with one or more of over 30 major structural birth defects. Cases included live births, stillbirths, and elective terminations.[1] |
| Eligible Controls | 18,272 live-born infants without any major birth defects, randomly selected from the same geographic areas and time periods as the cases.[1][2] |
| Interview Participation | Interviews were completed for 32,187 (67%) of eligible cases and 11,814 (65%) of eligible controls.[1][2] |
| Buccal Cell Collection | Buccal cell collection kits were returned by 19,065 case families and 6,211 control families.[1] |
Experimental Protocols
The this compound employed a multi-faceted approach to data collection, combining detailed maternal interviews with the collection of biological specimens for genetic analysis.
Participant Recruitment and Consent
Case Ascertainment: Cases were identified through existing state-based birth defects surveillance systems.[1] These programs actively search for infants and fetuses with major structural birth defects. To be included in the this compound, cases with known causes, such as single-gene disorders or chromosomal abnormalities, were excluded.[1]
Control Selection: Controls were randomly selected from the same population base as the cases.[4] This was typically done using birth certificates or hospital birth logs to identify live-born infants without major birth defects.[1]
Informed Consent: The informed consent process was a critical component of the study.[7] Potential participants were first contacted by mail with information about the study. This was followed by a telephone call from trained interviewers who provided a detailed explanation of the study's purpose, procedures, potential risks, and benefits.[7] Verbal consent was obtained before the start of the telephone interview.[7] For the collection of biological samples, participants received a written consent form with the buccal cell collection kit, which they signed and returned with the samples.[7] Confidentiality of all participant information was strictly maintained.[7]
Data Collection: Maternal Interview
A standardized, computer-assisted telephone interview was administered to the mothers of both cases and controls.[8] The interview was designed to be approximately one hour long and was conducted between six weeks and 24 months after the estimated date of delivery.[1]
The comprehensive questionnaire covered a wide range of topics, focusing on the three months prior to conception and the duration of the pregnancy. Key areas of inquiry included:
-
Demographics and Health History: Maternal age, race/ethnicity, education, and previous pregnancy outcomes.
-
Lifestyle Factors: Maternal smoking, alcohol consumption, and diet.
-
Medication Use: Detailed information on prescription and over-the-counter medications.
-
Occupational Exposures: Information on the mother's and father's jobs and potential workplace exposures.[8]
-
Residential History: To assess potential environmental exposures.[1]
Biological Sample Collection and Genetic Analysis
To investigate the role of genetic factors in birth defects, the this compound collected biological samples from the infant, mother, and father when possible.[3]
Buccal Cell Collection: The primary method for obtaining DNA was through buccal (cheek) cell collection.[8] Families were mailed kits containing small brushes and instructions for collecting the cells.[3] These kits were then mailed back to a central laboratory for processing and storage.[8]
DNA Extraction and Quality Control: Upon receipt, DNA was extracted from the buccal cells. To ensure the quality and integrity of the genetic data, several quality control measures were implemented. This included checks for DNA quantity and purity. Furthermore, external quality assessments were conducted annually, where genotyping laboratories processed a standard set of DNA samples to ensure consistency and accuracy across different sites.[1]
Signaling Pathway of Interest: N-acetyltransferase (NAT) 1 and 2
The N-acetyltransferase (NAT) enzymes, specifically NAT1 and NAT2, play a crucial role in the metabolism of a wide range of environmental chemicals and drugs, including many known or suspected teratogens.[9] These enzymes catalyze the acetylation of aromatic and heterocyclic amines, a process that can either detoxify these compounds or, in some cases, activate them into more potent mutagens.[10]
Genetic variations (polymorphisms) in the NAT1 and NAT2 genes can lead to differences in enzyme activity, resulting in "fast," "intermediate," or "slow" acetylator phenotypes.[11] These variations in metabolic capacity are hypothesized to influence an individual's susceptibility to the adverse effects of certain environmental exposures during pregnancy, potentially increasing the risk of birth defects.[12] For instance, some studies have suggested an association between certain NAT1 and NAT2 genotypes and an increased risk of nonsyndromic cleft lip and palate and limb deficiency defects.[9][12]
Caption: N-acetyltransferase (NAT) 1 and 2 metabolic pathway.
Experimental Workflow
The this compound followed a systematic workflow from the identification of potential participants to the final analysis of the collected data.
Caption: this compound case-control study experimental workflow.
References
- 1. The National Birth Defects Prevention Study: a review of the methods - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Research Portal [iro.uiowa.edu]
- 3. This compound.org [this compound.org]
- 4. This compound.org [this compound.org]
- 5. Birth Defects Research | Birth Defects | CDC [cdc.gov]
- 6. Preventing birth defects: The value of the this compound case-control approach - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. This compound.org [this compound.org]
- 8. This compound.org [this compound.org]
- 9. Association of NAT1 and NAT2 genes with nonsyndromic cleft lip and palate - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. Molecular genetics and epidemiology of the NAT1 and NAT2 acetylation polymorphisms - PubMed [pubmed.ncbi.nlm.nih.gov]
- 11. researchgate.net [researchgate.net]
- 12. Risk of limb deficiency defects associated with NAT1, NAT2, GSTT1, GSTM1, and NOS3 genetic variants, maternal smoking, and vitamin supplement intake - PubMed [pubmed.ncbi.nlm.nih.gov]
Application Note: A Beginner's Guide to the Statistical Analysis of National Birth Defects Prevention Study (NBDPS) Data
Introduction
The National Birth Defects Prevention Study (NBDPS) is a large-scale, population-based case-control study designed to investigate the genetic and environmental risk factors for a range of major birth defects.[1][2][3] This application note provides a detailed protocol for researchers, scientists, and drug development professionals who are new to working with this compound data. It outlines the study's design, data structure, and a step-by-step guide to performing fundamental statistical analyses.
Target Audience: Researchers, scientists, and drug development professionals.
Understanding the this compound Data
The this compound collected two primary types of data: comprehensive maternal interviews and genetic samples from cheek cells of the infant and parents.[1][4] It is crucial to understand that this compound data is not publicly available due to the presence of personally identifiable information. Researchers must apply for access through a collaborative agreement with one of the Centers for Birth Defects Research and Prevention (CBDRP).[5]
1.1 Study Design
The this compound employed an observational, population-based, case-control study design.[1]
-
Cases: Infants or fetuses with major birth defects identified through surveillance systems.[2][6]
-
Controls: Live-born infants without major birth defects, randomly selected from the same geographic areas and time periods as the cases.[1][2]
1.2 Data Structure
The data from the this compound is extensive and typically provided to researchers in a format suitable for statistical analysis (e.g., SAS, Stata, or CSV files). The dataset includes a wide range of variables from maternal interviews covering the periconceptional period (three months before pregnancy through to the end of pregnancy).[4]
Data Presentation: Hypothetical this compound Data Summary
The following table provides a hypothetical summary of the types of quantitative data a researcher might encounter in a subset of the this compound data. This is for illustrative purposes to facilitate understanding of the data structure.
| Variable Category | Variable Name | Description | Data Type | Example Values (Cases) | Example Values (Controls) |
| Demographics | maternal_age | Mother's age at delivery. | Continuous | Mean: 28.5 (SD: 5.2) | Mean: 29.1 (SD: 4.8) |
| maternal_education | Highest level of education attained by the mother. | Categorical | <12 yrs: 15%, 12 yrs: 30%, >12 yrs: 55% | <12 yrs: 12%, 12 yrs: 28%, >12 yrs: 60% | |
| Maternal Health | pre_pregnancy_bmi | Mother's Body Mass Index before pregnancy. | Continuous | Mean: 25.8 (SD: 6.1) | Mean: 24.9 (SD: 5.5) |
| pregestational_diabetes | Presence of diabetes in the mother before pregnancy. | Binary | 5% Yes | 2% Yes | |
| Exposures | smoking_first_trimester | Maternal smoking during the first trimester of pregnancy. | Binary | 12% Yes | 9% Yes |
| folic_acid_supplementation | Use of folic acid supplements in the periconceptional period. | Binary | 65% Yes | 75% Yes | |
| specific_medication_use | Use of a specific medication of interest during the first trimester. | Binary | 8% Yes | 4% Yes | |
| Genetic Data | gene_variant_x | Presence of a specific genetic variant of interest. | Categorical | AA: 10%, AG: 40%, GG: 50% | AA: 15%, AG: 35%, GG: 50% |
Experimental Protocols: Statistical Analysis of this compound Data
This section details the methodology for conducting a basic statistical analysis of this compound data to investigate the association between a potential risk factor and a specific birth defect.
2.1 Protocol Overview
The primary analytical approach for case-control studies like the this compound is logistic regression.[7][8][9] This method allows for the calculation of odds ratios (ORs), which estimate the odds of an outcome (in this case, a birth defect) occurring given a particular exposure, compared to the odds of the outcome occurring in the absence of that exposure.
2.2 Step-by-Step Experimental Protocol
-
Define the Research Question: Clearly articulate the hypothesis to be tested. For example: "Is maternal use of a specific antidepressant during the first trimester associated with an increased risk of congenital heart defects?"
-
Data Preparation and Cleaning:
-
Obtain the this compound dataset through the official application process.[5]
-
Familiarize yourself with the data dictionary provided with the dataset to understand the variable names, coding, and definitions.
-
Identify the case group (e.g., infants with the specific birth defect of interest) and the control group.
-
Identify the primary exposure variable (e.g., use of the specific antidepressant).
-
Identify potential confounding variables (e.g., maternal age, pre-pregnancy BMI, smoking status, etc.).
-
Handle missing data appropriately. This may involve imputation or exclusion of participants with missing data on key variables, with clear justification.
-
-
Descriptive Statistical Analysis:
-
Summarize the characteristics of the case and control groups using descriptive statistics.
-
For continuous variables (e.g., maternal age, BMI), calculate means and standard deviations.
-
For categorical variables (e.g., maternal education, smoking status), calculate frequencies and percentages.
-
Compare the distribution of characteristics between cases and controls to identify potential confounding factors.
-
-
Univariate Logistic Regression:
-
Perform a univariate logistic regression for the primary exposure variable to obtain a crude odds ratio. This will provide an initial estimate of the association without accounting for other factors.
-
-
Multivariable Logistic Regression:
-
Construct a multivariable logistic regression model to calculate the adjusted odds ratio (aOR). This model should include the primary exposure variable and the potential confounding variables identified in the descriptive analysis.
-
The general form of the model is: logit(P(Y=1)) = β₀ + β₁X₁ + β₂X₂ + ... + βₚXₚ, where Y is the case/control status, X₁ is the primary exposure, and X₂...Xₚ are the confounding variables.
-
The aOR for the primary exposure is calculated as exp(β₁).
-
-
Interpretation of Results:
-
The odds ratio indicates the strength of the association:
-
OR = 1: No association.
-
OR > 1: Increased odds of the outcome with exposure.
-
OR < 1: Decreased odds of the outcome with exposure.
-
-
The 95% confidence interval (CI) for the OR provides a measure of the precision of the estimate. If the CI does not include 1.0, the result is considered statistically significant at the p < 0.05 level.
-
Report the aOR, 95% CI, and p-value for the primary exposure.
-
-
Sensitivity Analyses:
-
Conduct sensitivity analyses to assess the robustness of the findings. This may include altering the inclusion/exclusion criteria or the handling of missing data.
-
Mandatory Visualizations
This compound Case-Control Study Workflow
References
- 1. This compound.org [this compound.org]
- 2. The National Birth Defects Prevention Study: a review of the methods - PMC [pmc.ncbi.nlm.nih.gov]
- 3. The National Birth Defects Prevention Study - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. This compound.org [this compound.org]
- 5. Methods for Accessing this compound and BD-STEPS Data | Birth Defects | CDC [cdc.gov]
- 6. researchgate.net [researchgate.net]
- 7. Multiple bias analysis using logistic regression: an example from the National Birth Defects Prevention Study - PMC [pmc.ncbi.nlm.nih.gov]
- 8. stacks.cdc.gov [stacks.cdc.gov]
- 9. Multiple bias analysis using logistic regression: an example from the National Birth Defects Prevention Study - PubMed [pubmed.ncbi.nlm.nih.gov]
Harnessing the Power of Thai Genomics: A Guide to Utilizing National Biobank of Thailand Data for Genetic Association Studies
For Immediate Release
BANGKOK, Thailand – The National Biobank of Thailand (NBT), in collaboration with the Genomics Thailand initiative, offers an unparalleled resource for researchers, scientists, and drug development professionals seeking to conduct cutting-edge genetic association studies. This document provides detailed application notes and protocols for accessing and utilizing the extensive genomic and phenotypic data from the Thai population.
The Genomics Thailand project is a government-backed initiative aiming to create a comprehensive genetic database of 50,000 Thai individuals to advance precision medicine.[1][2][3] This ambitious project focuses on five key disease areas: cancer, rare diseases, non-communicable diseases, infectious diseases, and pharmacogenomics.[1][2][4][5] The National Biobank of Thailand is the central body responsible for managing this invaluable data resource.[1][2][6]
Available Data: A Rich Resource for Discovery
The Genomics Thailand initiative provides researchers with access to whole-genome sequencing (WGS) data, offering a high-resolution view of the genetic landscape of the Thai population.[1] As of March 2024, significant progress has been made in participant recruitment and data generation across the five main disease cohorts.
Quantitative Data Summary
| Disease Cohort | Number of Participants Recruited (Approx.) |
| Rare and Undiagnosed Diseases | 10,000[4] |
| Cancer | 7,000[4] |
| Non-Communicable Diseases (NCDs) | 6,700[4] |
| Infectious Diseases | 2,000[4] |
| Pharmacogenomics | 2,100[4] |
| Total | >25,000 [4] |
Table 1: Approximate participant recruitment numbers for the Genomics Thailand initiative as of June 2023.[4]
It is important to note that while these are the target recruitment areas, specific phenotypic data available for each participant will vary. Researchers are encouraged to inquire about the availability of specific data relevant to their research questions during the application process.
Experimental Protocols: A Roadmap for Your Research
Conducting a successful genetic association study requires a robust and well-defined protocol. The following sections outline the key experimental and analytical methodologies, from data access to analysis.
Data Access Protocol
-
Initial Inquiry: Researchers should begin by contacting the National Biobank of Thailand to express their interest in accessing the data and to inquire about the formal application process. Contact can be made via email at --INVALID-LINK--.[2]
-
Submission of a Research Proposal: A detailed research proposal is a standard requirement for accessing biobank data. The proposal should clearly outline the study's objectives, scientific rationale, methodology, data analysis plan, and the specific data requested (both genomic and phenotypic).
-
Review by a Data Access Committee: The research proposal will be reviewed by a Data Access Committee (DAC) to ensure scientific merit, ethical soundness, and feasibility. The DAC will also verify that the proposed research aligns with the consent provided by the study participants.
-
Data Access Agreement: Upon approval, researchers will be required to sign a Data Access Agreement (DAA). This legal document outlines the terms and conditions of data use, including data security, confidentiality, and publication policies.
Data Access Workflow
A flowchart illustrating the general workflow for accessing data from the National Biobank of Thailand.
Genomic Data Quality Control and Processing
The Genomics Thailand project employs state-of-the-art sequencing technologies, including MGI's DNBSEQ-T7RS platform, to generate high-quality whole-genome sequencing data.[7] A standardized quality control (QC) pipeline is applied to ensure the reliability of the data. While the specific parameters may evolve, a typical WGS QC pipeline involves the following steps:
-
Raw Read Quality Assessment: Tools like FastQC are used to assess the quality of the raw sequencing reads.
-
Adapter Trimming and Quality Filtering: Adapters and low-quality bases are removed from the reads.
-
Alignment to a Reference Genome: The cleaned reads are aligned to a human reference genome (e.g., GRCh38).
-
Duplicate Removal: PCR duplicates are identified and removed to avoid biases in variant calling.
-
Variant Calling: Variants (SNPs and indels) are identified using standard tools like GATK.
-
Variant Quality Score Recalibration (VQSR): Machine learning is used to filter out low-quality variant calls.
-
Sample- and Variant-level QC: Further QC steps are applied, such as removing samples with low call rates and variants with high missingness, low minor allele frequency (MAF), or deviation from Hardy-Weinberg equilibrium (HWE).
Genomic Data Processing Workflow
References
- 1. nstda.or.th [nstda.or.th]
- 2. nationalbiobank.in.th [nationalbiobank.in.th]
- 3. Decoding the Genes - Chula Applies Genomic Medicine to Diagnosing Rare Genetic Diseases in Thailand – Chulalongkorn University [chula.ac.th]
- 4. frontlinegenomics.com [frontlinegenomics.com]
- 5. Genomics Thailand [genomicsthailand.com]
- 6. nationalbiobank.in.th [nationalbiobank.in.th]
- 7. global-mgitech.com [global-mgitech.com]
Application Notes and Protocols for the National Birth Defects Prevention Study (NBDPS) Questionnaire and Interview Data
For Researchers, Scientists, and Drug Development Professionals
These application notes provide a detailed overview of the data variables collected through the National Birth Defects Prevention Study (NBDPS) questionnaire and interviews. The this compound was a major population-based case-control study conducted to investigate the potential causes of birth defects.[1][2][3] While direct access to the study's raw data and data dictionary is restricted to protect participant confidentiality, this document summarizes the key data categories and variables to aid researchers in understanding the scope of the available information and to facilitate the process of applying for data access.[4][5][6][7]
Data Presentation: Quantitative Data Variables
The this compound collected extensive quantitative data through a standardized computer-assisted telephone interview (CATI) with mothers of infants with (cases) and without (controls) birth defects.[8][9][10] The interview covered a wide range of topics pertaining to the three months prior to conception and the duration of the pregnancy.[8] The following tables summarize the key categories of quantitative data variables collected.
Table 1: Maternal Demographics and Socioeconomic Status
| Variable Category | Description of Data Collected |
| Maternal Age | Mother's age at the time of delivery.[11] |
| Race/Ethnicity | Maternal self-reported race and ethnicity.[12] |
| Education Level | Highest level of education completed by the mother.[6] |
| Marital Status | Marital status at the time of pregnancy. |
| Household Income | Categorical data on total household income. |
| Insurance Status | Type of health insurance coverage during pregnancy.[13] |
| Acculturation | For Hispanic mothers, questions related to acculturation were included.[13] |
Table 2: Maternal Health and Reproductive History
| Variable Category | Description of Data Collected |
| Gravidity & Parity | Total number of pregnancies and live births. |
| Previous Pregnancy Outcomes | History of prior live births, stillbirths, miscarriages, and induced abortions.[8][11] |
| History of Birth Defects | Information on birth defects in previous pregnancies. |
| Pre-pregnancy Body Mass Index (BMI) | Calculated from self-reported height and weight.[6][11] |
| Chronic Diseases | History and treatment of conditions such as diabetes, obesity, hypertension, thyroid disease, asthma, cancer, migraines, and autoimmune diseases.[9][13][14][15] |
| Infections during Pregnancy | Occurrence of infections during the periconceptional period and pregnancy.[14] |
| Maternal Illnesses | Self-reported illnesses during pregnancy, such as morning sickness, respiratory illness, and urinary tract infections.[10] |
| Mental Health | Information on conditions like depression and anxiety, including symptoms and duration.[13] |
Table 3: Lifestyle and Environmental Exposures
| Variable Category | Description of Data Collected |
| Smoking | Tobacco use (cigarettes per day) before and during pregnancy.[11][14][15] |
| Alcohol Consumption | Frequency and quantity of alcoholic beverage consumption before and during pregnancy.[11] |
| Illicit Drug Use | Use of recreational drugs before and during pregnancy. |
| Folic Acid Supplementation | Use of folic acid-containing multivitamins in the periconceptional period.[11][12] |
| Dietary Habits | General information on diet was collected.[8] |
| Physical Activity | Questions regarding physical activity levels were included in later stages of the study.[13] |
| Stress and Social Support | Information on maternal stress and social support systems was gathered in later study years.[13] |
| Occupational Exposures | Detailed information on maternal and paternal occupation and potential workplace exposures.[8][16] |
| Residential History | Geocoded residential addresses before and during pregnancy to assess environmental exposures.[6] |
| Water Consumption | Self-reported water consumption habits and use of filtration methods.[6] |
| Hobbies | Information on hobbies that might involve chemical exposures.[8][16] |
| Travel | Details on travel during the periconceptional period and pregnancy.[9] |
Table 4: Medication and Treatment Exposures
| Variable Category | Description of Data Collected |
| Prescription Medications | Use of a wide range of prescription drugs, including but not limited to, opioid analgesics, selective serotonin (B10506) reuptake inhibitors (SSRIs), and medications for chronic conditions.[8][12] |
| Over-the-Counter (OTC) Medications | Use of non-prescription medications such as acetaminophen (B1664979) and ibuprofen.[8][10] |
| Fertility Treatments | Information on the use of assisted reproductive technologies.[9][13] |
| Dental Procedures | Details on any dental procedures performed during the periconceptional period and pregnancy.[13] |
Table 5: Infant Data
| Variable Category | Description of Data Collected |
| Birth Defect Diagnosis | Detailed classification of major structural birth defects for case infants.[11] |
| Gestational Age | Gestational age at birth. |
| Birth Weight | Infant's weight at birth. |
| Sex | Infant's sex. |
| Plurality | Singleton, twin, or higher-order multiple gestation.[13] |
Experimental Protocols
The this compound employed a rigorous set of protocols for participant recruitment, data collection, and biological sample handling to ensure data quality and consistency across its multiple study centers.
Participant Recruitment and Study Design
The this compound was a population-based, case-control study conducted across ten states in the U.S.[1][11]
-
Case Ascertainment : Infants with major structural birth defects (cases) were identified through existing birth defects surveillance systems at each study center.[11] Cases could be live births, stillbirths, or induced terminations.[11]
-
Control Selection : A random sample of live-born infants without major birth defects (controls) were selected from the same geographical areas and time periods as the cases, typically from birth certificates or hospital birth logs.[3][9]
-
Eligibility : Mothers of eligible case and control infants were contacted for participation. The study aimed to interview mothers between six weeks and 24 months after the estimated date of delivery.[11]
Maternal Interview Protocol
The primary method of data collection was a structured, computer-assisted telephone interview (CATI) administered to the mothers.[8][10]
-
Informed Consent : Verbal informed consent was obtained from all participating mothers before the interview commenced.[10]
-
Standardized Questionnaire : A standardized questionnaire was used across all study sites to ensure consistency in data collection. The interview was conducted in either English or Spanish.[10]
-
Interviewer Training : Interviewers received extensive training to administer the questionnaire in a neutral and consistent manner. The computer-guided format ensured that questions were asked in the same order for every participant.[4][8]
-
Interview Content : The interview, lasting approximately one hour, collected detailed information on the various domains outlined in the data tables above, with a focus on the three months prior to conception and the entire pregnancy period.[8][10]
-
Data Quality : Follow-up calls were sometimes made to clarify responses or obtain missing information.[4][8]
Biological Sample Collection and Analysis
In addition to the interview data, the this compound collected biological samples for genetic analysis.
-
Sample Collection Kits : Following the interview, families were mailed kits to collect buccal (cheek) cells from the biological mother, father, and the infant (when possible).[8][9]
-
Sample Return : Participants returned the collection kits to a central laboratory.
-
DNA Extraction and Storage : DNA was extracted from the cheek cells and stored securely without personal identifiers to protect participant confidentiality.[8]
-
Genetic Analysis : The collected DNA was used to investigate genetic factors and gene-environment interactions that may contribute to the risk of birth defects.[8][9]
Mandatory Visualizations
This compound Data Collection and Analysis Workflow
Caption: Workflow of the this compound from participant recruitment to data analysis.
Interrelationship of this compound Data Variable Categories
Caption: Relationships between key data categories collected in the this compound.
Access to this compound Data
Data from the this compound are not publicly available due to the sensitive and personally identifiable nature of the information.[4][5][6][7] However, qualified researchers can apply for access to the data for analysis through a collaborative agreement with one of the Centers for Birth Defects Research and Prevention (CBDRP).[4][5] The process typically involves:
-
Reviewing Existing Publications : To avoid duplication of research, applicants are required to review the extensive list of publications that have already utilized this compound data.[4][5]
-
Identifying a Collaborating Center : Researchers must identify and partner with one of the CBDRP centers to sponsor their proposed analysis.[4][5]
-
Submitting a Proposal : A formal proposal outlining the research questions, study design, and data requirements must be submitted.
-
Review and Approval : Proposals are reviewed based on scientific merit, public health significance, and lack of overlap with existing projects.[5]
For the most current and detailed information on accessing this compound data, researchers should consult the official CDC website for the this compound Public Access Procedures.[4][6]
References
- 1. mass.gov [mass.gov]
- 2. researchgate.net [researchgate.net]
- 3. This compound.org [this compound.org]
- 4. This compound Public Access Procedures | Birth Defects | NCBDDD | CDC [medbox.iiab.me]
- 5. Methods for Accessing this compound and BD-STEPS Data | Birth Defects | CDC [cdc.gov]
- 6. catalog.data.gov [catalog.data.gov]
- 7. catalog.data.gov [catalog.data.gov]
- 8. This compound.org [this compound.org]
- 9. This compound.org [this compound.org]
- 10. academic.oup.com [academic.oup.com]
- 11. The National Birth Defects Prevention Study: a review of the methods - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Maternal exposures in the National Birth Defects Prevention Study: time trends of selected exposures - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Next steps for birth defects research and prevention: The Birth Defects Study To Evaluate Pregnancy exposureS (BD-STEPS) - PMC [pmc.ncbi.nlm.nih.gov]
- 14. The National Birth Defects Prevention Study - PubMed [pubmed.ncbi.nlm.nih.gov]
- 15. Birth Defects Research | Birth Defects | CDC [cdc.gov]
- 16. catalog.data.gov [catalog.data.gov]
Application Notes and Protocols for Analyzing Environmental Exposures in the NBDPS Dataset
FOR RESEARCHERS, SCIENTISTS, AND DRUG DEVELOPMENT PROFESSIONALS
These application notes provide a detailed overview of the methodologies and findings from analyses of environmental exposures within the National Birth Defects Prevention Study (NBDPS) dataset. The this compound is a large population-based case-control study that has been instrumental in identifying potential environmental risk factors for a range of birth defects.[1][2] This document summarizes key quantitative data, outlines experimental protocols for exposure assessment, and visualizes relevant biological pathways and workflows.
Overview of the this compound and Environmental Exposure Assessment
The National Birth Defects Prevention Study (this compound) was a multi-site case-control study that collected data on major birth defects in the United States.[2] The study gathered extensive information through computer-assisted telephone interviews with mothers of infants with and without birth defects.[1][3] These interviews covered a wide range of topics, including maternal health, diet, medication use, lifestyle, and occupational history.[3][4] Additionally, the this compound collected biological samples (cheek cells) from mothers, fathers, and infants for genetic analyses, allowing for the investigation of gene-environment interactions.[1][3][4][5]
Environmental exposures in the this compound were assessed through several methods:
-
Maternal Interviews: Self-reported data on a wide variety of exposures, including medication use, diet, smoking, and alcohol consumption.[3][4]
-
Geocoding of Maternal Residences: Linking maternal addresses to environmental databases to estimate exposures to air and water pollutants.[2][6][7]
-
Occupational Exposure Assessment: Using maternal job history information in conjunction with expert assessment and job-exposure matrices to estimate workplace exposures to specific agents.
Quantitative Data Summary
The following tables summarize the quantitative findings from several key studies that have utilized the this compound dataset to investigate the association between environmental exposures and specific birth defects.
Table 1: Association between Maternal Periconceptional Caffeine (B1668208) Consumption and Neural Tube Defects (NTDs) [5][6][7][8]
| Exposure Category | Odds Ratio (OR) | 95% Confidence Interval (CI) | Birth Defect |
| Total Caffeine Consumption | 1.4 | 1.1 - 1.9 | Spina Bifida |
| Caffeinated Tea Consumption | 0.7 | 0.6 - 0.9 | Spina Bifida |
Data from Schmidt RJ, et al. (2009). Birth Defects Res A Clin Mol Teratol.
Table 2: Association between Maternal Occupational Exposure to Polycyclic Aromatic Hydrocarbons (PAHs) and Oral Clefts [9][10]
| Exposure Category | Odds Ratio (OR) | 95% Confidence Interval (CI) | Birth Defect |
| Any Occupational PAH Exposure | 1.69 | 1.18 - 2.40 | Cleft Lip with or without Cleft Palate |
| Adjusted for Maternal Education | 1.47 | 1.02 - 2.12 | Cleft Lip with or without Cleft Palate |
Data from Langlois PH, et al. (2012). Cleft Palate Craniofac J.
Table 3: Association between Maternal Exposure to Drinking Water Disinfection By-products (DBPs) and Neural Tube Defects (NTDs) [11][12][13]
| Exposure Category | Adjusted Odds Ratio (aOR) Range | Birth Defect |
| Maternal Exposure to DBPs in Public Water Systems | 0.8 - 1.5 | All NTDs Combined |
| 0.6 - 2.0 | Spina Bifida | |
| 0.7 - 1.9 | Anencephaly | |
| Average Daily Maternal Ingestion of DBPs | 0.7 - 1.1 | All NTDs Combined |
| 0.5 - 1.5 | Spina Bifida | |
| 0.6 - 1.8 | Anencephaly |
Data from Kancherla V, et al. (2024). Birth Defects Res. All confidence intervals included the null.
Table 4: Association between Maternal Exposure to Particulate Matter (PM2.5) and Extreme Heat with Congenital Heart Defects (CHDs) [14][15]
| Exposure Scenario | Odds Ratio (OR) | 95% Confidence Interval (CI) | Birth Defect |
| Each 5 μg/m³ increase in average PM2.5 exposure (conditional on highest observed Extreme Heat Day count of 15) | 1.54 | 1.01 - 2.41 | Perimembranous Ventricular Septal Defects (VSDpm) |
Data from Simmons W, et al. (2021). Sci Total Environ.
Table 5: Pre-Pregnancy Dietary Arsenic Consumption in the this compound Control Population [2][8][16]
| Arsenic Type | Mean Daily Consumption |
| Total Dietary Arsenic | 14.9 µ g/day |
| Inorganic Dietary Arsenic | 5.2 µ g/day |
Data from Suhl J, et al. (2020). Birth Defects Res.
Experimental Protocols
This section details the methodologies employed in the cited this compound studies for assessing environmental exposures.
Protocol for Assessing Maternal Caffeine Consumption
-
Data Collection: A standardized, computer-assisted telephone interview was administered to mothers of cases and controls.
-
Exposure Window: The interview collected information on the frequency and type of caffeinated beverages (coffee, tea, soda) and chocolate consumed during the year before pregnancy.
-
Quantification: The average daily caffeine intake was estimated based on the reported consumption patterns and standard caffeine content values for each beverage and food item.
-
Statistical Analysis: Logistic regression models were used to calculate odds ratios (ORs) and 95% confidence intervals (CIs) for the association between caffeine intake and the risk of neural tube defects, adjusting for potential confounders.[6][8]
Protocol for Assessing Occupational Exposure to Polycyclic Aromatic Hydrocarbons (PAHs)
-
Data Collection: During the maternal interview, detailed information was collected on all jobs held from three months prior to conception through the end of pregnancy. This included job title, employer's name, industry, and a description of job duties.
-
Exposure Assessment: An industrial hygienist reviewed the job descriptions to assess the potential for occupational exposure to PAHs.
-
Exposure Classification: Jobs were classified as having no exposure, potential low exposure, or potential high exposure to PAHs.
-
Statistical Analysis: The association between any and level-specific occupational PAH exposure and the risk of oral clefts was evaluated using logistic regression, adjusting for covariates such as maternal education.[9][10]
Protocol for Assessing Exposure to Drinking Water Disinfection By-products (DBPs)
-
Data Collection: Maternal residential addresses from one month before conception through the first trimester were collected during the interview.
-
Geocoding: These addresses were geocoded to link them to specific public water systems.
-
Exposure Estimation: Data on DBP concentrations (e.g., trihalomethanes and haloacetic acids) were obtained from public water system monitoring data.
-
Individual Intake Estimation: Maternal self-reports of water consumption from the interview were used to estimate individual daily ingestion of DBPs.
-
Statistical Analysis: Logistic regression models were used to estimate adjusted odds ratios (aORs) for the association between DBP exposure levels and ingestion with the risk of neural tube defects.[11][12]
Protocol for Assessing Exposure to Particulate Matter (PM2.5) and Extreme Heat
-
Data Collection: Maternal residential history from three months prior to conception until delivery was collected.
-
Geocoding: Maternal residences were geocoded.
-
PM2.5 Exposure Assignment: Geocoded residences were mapped to the nearest U.S. Environmental Protection Agency (EPA) PM2.5 monitor within 50 km. The average 24-hour PM2.5 measurements during the critical window of cardiac development (post-conceptional weeks 3 to 8) were calculated.
-
Extreme Heat Exposure Assignment: Geocoded residences were mapped to the closest weather station with data from the National Oceanic and Atmospheric Administration (NOAA). The number of days exceeding the 90th percentile for daily maximum temperature during the critical exposure window was calculated.
-
Statistical Analysis: The study investigated the interaction between PM2.5 exposure and the duration of extreme heat exposure on the risk of congenital heart defects using appropriate statistical models.[14]
Visualizations
Experimental and Analytical Workflows
Caption: Workflow for environmental exposure analysis in the this compound.
Signaling Pathways Potentially Disrupted by Environmental Exposures
The following diagrams illustrate signaling pathways that are hypothesized to be disrupted by environmental exposures, potentially leading to birth defects. While direct evidence from the this compound is often observational, these pathways are supported by experimental studies.
Aryl Hydrocarbon Receptor (AhR) Signaling Pathway and PAHs
Polycyclic Aromatic Hydrocarbons (PAHs) are known activators of the Aryl Hydrocarbon Receptor (AhR), a ligand-activated transcription factor.[4][15][17][18] Dysregulation of the AhR signaling pathway during development has been linked to various adverse outcomes, including birth defects.[1][17][18]
Caption: PAH-mediated activation of the AhR signaling pathway.
Oxidative Stress as a Common Pathway in Teratogenesis
Many environmental toxicants, including arsenic and particulate matter, are thought to exert their teratogenic effects, at least in part, by inducing oxidative stress.[1][3][19][20] This occurs when the production of reactive oxygen species (ROS) overwhelms the cell's antioxidant defenses, leading to damage to DNA, proteins, and lipids, and disrupting critical signaling pathways involved in development.
Caption: Oxidative stress as a mechanism for birth defects.
Potential Mechanisms of Caffeine-Associated Neural Tube Defects
Studies using this compound data have suggested an association between maternal caffeine intake and NTDs.[8][16] Proposed mechanisms, primarily from experimental studies, involve the disruption of inositol (B14025) metabolism and calcium signaling, which are crucial for neural tube closure.[6][14]
Caption: Potential pathways of caffeine-induced neural tube defects.
References
- 1. [Polycyclic aromatic hydrocarbons exposure and birth defects] - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. Prenatal arsenic exposure alters the programming of the glucocorticoid signaling system during embryonic development - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Redox stress and signaling during vertebrate embryonic development: regulation and responses - PMC [pmc.ncbi.nlm.nih.gov]
- 4. A Functional Aryl Hydrocarbon Receptor Genetic Variant, Alone and in Combination with Parental Exposure, is a Risk Factor for Congenital Heart Disease - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
- 6. CAFFEINE INTAKE AND RISK OF NEURAL TUBE DEFECTS: AUTHOR RESPONSE TO CORRESPONDENCE - PMC [pmc.ncbi.nlm.nih.gov]
- 7. researchgate.net [researchgate.net]
- 8. Maternal Caffeine Consumption and Risk of Neural Tube Defects - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Health Effects Associated With Pre- and Perinatal Exposure to Arsenic - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Effects of polycyclic aromatic hydrocarbons (PAHs) on pregnancy, placenta, and placental trophoblasts - PubMed [pubmed.ncbi.nlm.nih.gov]
- 11. Maternal Exposure to Arsenic and Its Impact on Maternal and Fetal Health: A Review - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Maternal periconceptional exposure to drinking water disinfection by-products and neural tube defects in offspring - PMC [pmc.ncbi.nlm.nih.gov]
- 13. A comprehensive understanding of ambient particulate matter and its components on the adverse health effects based from epidemiological and laboratory evidence - PMC [pmc.ncbi.nlm.nih.gov]
- 14. researchgate.net [researchgate.net]
- 15. Influence of the Aryl Hydrocarbon Receptor Activating Environmental Pollutants on Autism Spectrum Disorder - PMC [pmc.ncbi.nlm.nih.gov]
- 16. Caffeine, Selected Metabolic Gene Variants, and Risk for Neural Tube Defects - PMC [pmc.ncbi.nlm.nih.gov]
- 17. mdpi.com [mdpi.com]
- 18. Gene Environment Interactions in the Etiology of Neural Tube Defects - PMC [pmc.ncbi.nlm.nih.gov]
- 19. Oxidative Stress as a Common Key Event in Developmental Neurotoxicity - PMC [pmc.ncbi.nlm.nih.gov]
- 20. academic.oup.com [academic.oup.com]
Application Notes and Protocols for Accessing National Birth Defects Prevention Study (NBDPS) Data
These notes provide a comprehensive guide for researchers, scientists, and drug development professionals on the process of applying for and accessing data from the National Birth Defects Prevention Study (NBDPS) for research proposals. Adherence to these protocols is essential to ensure a successful application.
Overview of this compound and Successor Study
The National Birth Defects Prevention Study (this compound) is a significant population-based, case-control study that investigated the potential genetic and non-genetic risk factors for a range of birth defects in the United States.[1][2] The study collected data on deliveries from 1997 to 2011, encompassing information from over 30,000 mothers of babies with birth defects and 10,000 mothers of babies without birth defects.[1]
It is crucial for researchers to understand that this compound and BD-STEPS data are not publicly available due to the inclusion of Personally Identifiable Information (PII).[6][7] Access is granted to qualified researchers through a collaborative agreement with one of the Centers for Birth Defects Research and Prevention (CBDRP).[1][7]
Pre-Application Requirements
Before initiating a formal data request, researchers must undertake the following preparatory steps to ensure their proposal is novel and scientifically sound.
2.1 Literature Review of Existing Publications
A thorough review of existing publications from both the this compound and BD-STEPS is mandatory.[1] Over 400 papers have been published to date, and proposals that substantially overlap with previously published analyses will be denied.[1][3] This step is critical to ensure the novelty and impact of the proposed research.
2.2 Identification of a Collaborating Center
All research proposals for this compound/BD-STEPS data analysis must be sponsored by a CBDRP center.[1] Researchers should identify a center with expertise aligning with their research interests. If a specific center is not designated by the applicant, the request will be routed to the Georgia Center at the Centers for Disease Control and Prevention (CDC).[1]
The table below summarizes the participating CBDRP centers and their primary research focuses.
| Collaborating Center | Principal Investigator | Contact Email | Research Focus |
| Arkansas | Wendy Nembhard, PhD, MPH, FACE | --INVALID-LINK-- or --INVALID-LINK-- | General this compound and/or BD-STEPS analyses |
| Georgia (CDC) | Elizabeth Ailes, PhD | --INVALID-LINK-- or --INVALID-LINK-- | Medication use during pregnancy, fertility treatments, novel statistical methods[1] |
| Massachusetts | Mahsa Yazdy, PhD | --INVALID-LINK-- or --INVALID-LINK-- | Medication use during pregnancy[1] |
Note: The list of participating centers and their research focuses may be subject to change. Applicants should verify the latest information on the official CDC website.
Application Protocol
The application process for accessing this compound data is a structured, multi-step procedure designed to ensure the scientific merit and ethical conduct of the proposed research.
3.1 Completion of the Collaboration Request Form
Applicants must download and complete the official Collaboration Request Form. This form requires detailed information about the proposed research project, including the scientific background, specific aims, and a preliminary analysis plan.
3.2 Submission of the Application Package
The completed Collaboration Request Form should be submitted via email to the Principal Investigator of the selected collaborating CBDRP center.[1]
3.3 Review Process
The CBDRP Data Sharing Committee reviews all collaboration requests.[8] The review is based on a set of stringent criteria to ensure the responsible use of the data.
3.3.1 Initial Letter of Intent
The initial application is treated as a two-page letter of intent. This document should provide a concise summary of the scientific background and justification for the study, a brief overview of the analytical plan, and a declaration of any potential conflicts with existing this compound analytic projects.[8]
3.3.2 Detailed Research Proposal
Upon approval of the letter of intent, the lead investigator will be invited to submit a more detailed research proposal. This comprehensive document must include a thorough analytical plan, complete with power calculations to justify the feasibility of the proposed study.[8]
The diagram below illustrates the workflow for the this compound data application and review process.
Data and Experimental Protocols
The this compound collected a rich dataset through two primary methods: comprehensive maternal interviews and the collection of genetic material.
4.1 Data Collection Methods
The table below outlines the types of data collected in the this compound.
| Data Type | Collection Method | Description |
| Interview Data | Computer-assisted telephone interviews | Information was gathered from mothers on a wide range of topics, including past pregnancies, health and diet, medication use, occupation and hobbies, lifestyle, and paternal work and lifestyle.[9] The interview covered the three months prior to and the duration of the pregnancy.[9] |
| Genetic Data | Cheek cell samples | Small brushes were sent to families to collect cheek cells from the biological mother, father, and baby, when possible.[2][9] These samples provide DNA for investigating genetic factors related to birth defects.[9] |
4.2 Case and Control Selection
The this compound employed a case-control study design.[2]
-
Cases: Infants with major structural birth defects were identified through active case-finding at birth and children's hospitals by participating birth defects surveillance programs.[8] Clinical geneticists reviewed all clinical information to confirm eligibility, excluding cases with known etiologies such as single-gene conditions or chromosomal abnormalities.[8]
-
Controls: Unaffected infants were randomly selected from birth certificate records or birth hospital logs from the same catchment areas as the cases.[2]
The following diagram illustrates the logical relationship in the this compound case-control study design.
Conclusion
Accessing this compound data for research requires a well-prepared and scientifically rigorous proposal that aligns with the collaborative framework established by the CDC and the CBDRP. By following the detailed protocols outlined in these notes, researchers can navigate the application process effectively and contribute to the ongoing efforts to understand and prevent birth defects.
References
- 1. Methods for Accessing this compound and BD-STEPS Data | Birth Defects | CDC [cdc.gov]
- 2. This compound.org [this compound.org]
- 3. Birth Defects Research | Birth Defects | CDC [cdc.gov]
- 4. bdsteps.org [bdsteps.org]
- 5. pmc.ncbi.nlm.nih.gov [pmc.ncbi.nlm.nih.gov]
- 6. catalog.data.gov [catalog.data.gov]
- 7. catalog.data.gov [catalog.data.gov]
- 8. pmc.ncbi.nlm.nih.gov [pmc.ncbi.nlm.nih.gov]
- 9. This compound.org [this compound.org]
Application Notes and Protocols for NBDPS Data Linkage
Topic: NBDPS Data Linkage with Other Databases Content Type: Detailed Application Notes and Protocols Audience: Researchers, scientists, and drug development professionals
These notes provide a comprehensive guide for researchers interested in accessing and linking data from the National Birth Defects Prevention Study (this compound) with other databases. Due to the sensitive nature of the data, direct public access is not available. However, linkage is possible through a structured collaboration with the Centers for Birth Defects Research and Prevention (CBDRP).
Overview of the National Birth Defects Prevention Study (this compound)
The this compound is a significant population-based, case-control study that investigated the potential causes of birth defects.[1][2] Data was collected on babies born between 1997 and 2011.[1][2] The study includes interviews with over 30,000 mothers of babies with birth defects and 10,000 mothers of babies without birth defects.[3] While data collection for this compound concluded in 2013, this rich dataset continues to be a valuable resource for researchers.[1][2] Its successor, the Birth Defects Study To Evaluate Pregnancy exposureS (BD-STEPS), began in 2014 and is ongoing.[4]
This compound Data Characteristics
The this compound dataset is extensive and contains a wide range of information. Understanding the data is crucial for proposing a relevant data linkage project.
Table 1: Summary of this compound Data
| Data Category | Description |
| Study Design | Population-based case-control study.[1][2] |
| Study Period | 1997 - 2011 (deliveries).[1][3] |
| Participants | Mothers of over 30,000 babies with birth defects and 10,000 mothers of babies without birth defects.[3] |
| Data Sources | - Computer-assisted telephone interviews (CATI) with mothers.[5] - Abstracted clinical data.[6] - Biologic samples (cheek cells) from mother, father, and baby for genetic analysis.[1][7] |
| Key Variables | - Demographics - Maternal health conditions - Medication use before and during pregnancy[4] - Lifestyle factors (e.g., smoking, diet)[4] - Occupational history[5] - Residential history (geocoded)[8] - Genetic data from biologic samples.[1][9] |
Protocol for Accessing and Linking this compound Data
Direct access to this compound data is restricted to protect participant confidentiality.[1][3][9][10] Researchers must collaborate with one of the CBDRP centers to gain access.[3] The following protocol outlines the necessary steps.
Experimental Protocol: this compound Data Access and Linkage Application
-
Conceptualize Research Project:
-
Develop a clear research question and hypothesis that necessitates the use of this compound data and linkage to an external database.
-
Ensure the proposed research does not overlap with previously published studies by reviewing the extensive list of this compound and BD-STEPS publications.[3] Overlapping proposals will be denied.[3]
-
-
Identify a Collaborating Center:
-
All research proposals must be sponsored by a CBDRP center.[3]
-
Centers are located in Arkansas, California, Georgia (CDC), Iowa, Massachusetts, New Jersey, New York, North Carolina, Texas, and Utah.[1][4]
-
Researchers should identify a center whose research focus aligns with their proposal. For example, the Georgia Center focuses on medication use, fertility treatments, and novel statistical methods.[3]
-
-
Submit a Collaboration Request Form:
-
Complete the official Collaboration Request Form available on the CDC's this compound/BD-STEPS public access procedures website.
-
The form requires details about the principal investigator, research objectives, proposed data analysis plan, and the specific this compound variables and external data sources required.
-
-
Review Process by the CBDRP Data Sharing Committee:
-
Data Use Agreement and Data Access:
-
Upon approval, a formal data use agreement is established.
-
Researchers will be granted access to a de-identified this compound dataset for their specific project. The data linkage with external databases will be performed in a secure environment, often facilitated by the collaborating CBDRP center or the CDC.
-
References
- 1. National Birth Defects Prevention Study – Iowa Registry for Congenital and Inherited Disorders [ircid.public-health.uiowa.edu]
- 2. This compound.org [this compound.org]
- 3. Methods for Accessing this compound and BD-STEPS Data | Birth Defects | CDC [cdc.gov]
- 4. Birth Defects Research | Birth Defects | CDC [cdc.gov]
- 5. Data Linkage Between the National Birth Defects Prevention Study and the Occupational Information Network (O*NET) to Assess Workplace Physical Activity, Sedentary Behaviors, and Emotional Stressors During Pregnancy - PMC [pmc.ncbi.nlm.nih.gov]
- 6. The National Birth Defects Prevention Study: a review of the methods - PMC [pmc.ncbi.nlm.nih.gov]
- 7. This compound.org [this compound.org]
- 8. catalog.data.gov [catalog.data.gov]
- 9. This compound.org [this compound.org]
- 10. bdsteps.org [bdsteps.org]
Unlocking Insights into Birth Defects: A Guide to Accessing NBDPS Biospecimens for Research
Application Note & Protocol
For researchers, scientists, and professionals in drug development, the National Birth Defects Prevention Study (NBDPS) offers a valuable repository of biological specimens. This extensive, population-based case-control study, conducted from 1997 to 2011, has amassed a significant collection of biospecimens from infants with and without major birth defects, as well as their parents.[1][2][3][4] These samples, coupled with detailed maternal interview data, provide an unparalleled resource for investigating the complex interplay of genetic and environmental factors in the etiology of birth defects.[4][5]
This document provides a comprehensive overview of the available this compound biospecimens, the associated data, and the detailed protocols for accessing and utilizing these resources for your research endeavors.
Available Biospecimens and Associated Data
The primary biological samples available through the this compound are buccal cells, collected from the infant, mother, and father, which serve as a rich source of DNA for genetic and genomic analyses.[4][5] In some instances, residual dried blood spots (DBS) from newborn screening programs may also be accessible.
The biospecimens are linked to a wealth of data collected through comprehensive maternal telephone interviews. This information encompasses a wide range of potential exposures and risk factors, including:
-
Maternal Health: Pre-existing conditions, illnesses during pregnancy.
-
Medication Use: Prescription and over-the-counter medications.
-
Lifestyle Factors: Diet, vitamin use, smoking, and alcohol consumption.
-
Environmental and Occupational Exposures: Exposure to chemicals and other potential teratogens.
-
Demographics and Reproductive History.
It is important to note that all data and biospecimens are de-identified to protect participant confidentiality.[6]
Summary of this compound Participants and Biospecimen Collection
| Participant Group | Total Number of Participants | Number of Families Returning Buccal Cell Kits |
| Cases (Infants with Birth Defects) | 32,187 | 19,065 |
| Controls (Infants without Birth Defects) | 11,814 | 6,211 |
Source: The National Birth Defects Prevention Study: a review of the methods[3]
Birth Defects Investigated in the this compound
The this compound included a broad range of major structural birth defects. Researchers interested in specific conditions should inquire about the availability of samples for their particular area of interest during the collaboration process. The categories of birth defects studied include, but are not limited to:
-
Cardiovascular Defects: (e.g., conotruncal defects, hypoplastic left heart syndrome)
-
Central Nervous System Defects: (e.g., spina bifida, anencephaly)
-
Orofacial Clefts: (e.g., cleft lip, cleft palate)
-
Gastrointestinal Defects: (e.g., gastroschisis, esophageal atresia)
-
Musculoskeletal Defects: (e.g., limb deficiencies, craniosynostosis)
-
And many others.
Protocol for Accessing this compound Biospecimens
Direct public access to this compound data and biospecimens is not available to safeguard participant privacy.[1][2] Instead, a collaborative approach is required, where external researchers partner with one of the Centers for Birth Defects Research and Prevention (CBDRP).[1][2]
The process for initiating a research collaboration is outlined below:
Step-by-Step Application Protocol:
-
Review Existing Publications: Before submitting a proposal, researchers must thoroughly review the extensive list of publications from the this compound.[1][2] This is to ensure that the proposed research does not overlap with completed or ongoing studies.[1] A list of publications can be found on the CDC's this compound website.
-
Develop a Research Proposal: The proposal should clearly outline the research questions, study design, analytical plan, and the specific data and biospecimens required. It must demonstrate scientific merit and have the potential to contribute to public health.[1]
-
Identify a Collaborating Center: Researchers must identify a CBDRP center to sponsor their project. A list of centers and their research interests is available on the CDC's website. If a center is not specified, the request will be routed to the CDC.[2]
-
Submit a Collaboration Request Form: The formal request is submitted via the "National Birth Defects Prevention Study (this compound) and Birth Defects Study To Evaluate Pregnancy exposureS (BD-STEPS) Collaboration Request Form".[7] This form requires details about the proposed project, the investigators' qualifications, and any potential conflicts of interest.[7]
-
Review Process: The CBDRP Data Sharing Committee reviews all proposals. The review criteria include scientific merit, lack of overlap with existing research, and the project's potential public health impact.[1][2]
-
Collaboration Agreement: If the proposal is approved, a formal collaboration agreement will be established. This will outline the terms of the collaboration, data and specimen use policies, and publication guidelines.
Experimental Protocols
While the specific, detailed laboratory protocols used by the this compound for every sample are not publicly available, the methods employed are based on standard, validated techniques for DNA extraction and analysis from buccal cells and dried blood spots. Researchers should confirm the exact protocols with their collaborating CBDRP center.
General Protocol for DNA Extraction from Buccal Swabs
Buccal swabs collected from participants are a primary source of genomic DNA. The general steps for DNA extraction from these samples typically involve:
-
Lysis: The buccal cells are lysed to release the DNA. This is often achieved using a lysis buffer containing detergents and proteinase K to break down cellular and nuclear membranes and digest proteins.
-
Purification: The DNA is then purified from other cellular components. This can be accomplished through various methods, including:
-
Phenol-chloroform extraction: A traditional method for separating nucleic acids from proteins and lipids.
-
Silica-based spin columns: A more modern and rapid method where DNA binds to a silica (B1680970) membrane in the presence of high salt concentrations, while other contaminants are washed away.
-
-
Elution: The purified DNA is eluted in a low-salt buffer or sterile water, making it ready for downstream applications.
General Protocol for DNA Extraction from Dried Blood Spots (DBS)
Residual newborn screening cards can be a source of infant DNA. The extraction process from DBS generally follows these steps:
-
Punching: A small disc is punched from the blood spot on the filter paper.
-
Washing and Lysis: The disc is washed to remove inhibitors of downstream enzymatic reactions. The blood cells are then lysed to release the DNA.
-
Purification and Elution: Similar to buccal swab DNA extraction, the DNA is purified and then eluted. Commercial kits are widely available and commonly used for this purpose.
Illustrative DNA Analysis Workflow
The DNA obtained from this compound biospecimens can be used in a variety of genetic and genomic analyses to investigate the genetic underpinnings of birth defects.
Conclusion
The National Birth Defects Prevention Study provides an invaluable resource for researchers dedicated to understanding the causes of birth defects. The extensive collection of biospecimens, linked to comprehensive exposure data, offers a unique opportunity for groundbreaking research in genetics, epidemiology, and toxicology. By following the established collaborative research framework, scientists and drug development professionals can gain access to these critical resources and contribute to the ultimate goal of preventing birth defects and improving the health of future generations.
References
- 1. This compound Public Access Procedures | Birth Defects | NCBDDD | CDC [medbox.iiab.me]
- 2. Methods for Accessing this compound and BD-STEPS Data | Birth Defects | CDC [cdc.gov]
- 3. The National Birth Defects Prevention Study: a review of the methods - PMC [pmc.ncbi.nlm.nih.gov]
- 4. The National Birth Defects Prevention Study - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. This compound.org [this compound.org]
- 6. This compound.org [this compound.org]
- 7. cdc.gov [cdc.gov]
Application Notes and Protocols for Publishing Research Utilizing NBDPS Data
For Researchers, Scientists, and Drug Development Professionals
These application notes provide a comprehensive guide for researchers intending to publish studies using data from the National Birth Defects Prevention Study (NBDPS). Adherence to these guidelines will facilitate clear, transparent, and reproducible research findings.
Data Presentation: Standardized Tables for Quantitative Data
To ensure consistency and comparability across studies using this compound data, all quantitative data should be presented in clearly structured tables. Below are templates for presenting demographic data and the results of statistical analyses, such as logistic regression.
Table 1: Characteristics of Case and Control Participants in the this compound
This table should be used to present the demographic and baseline characteristics of the case and control groups.
| Characteristic | Cases (n=XXXX) | Controls (n=XXXX) | p-value |
| Maternal Age (years) | |||
| <25 | XX (XX%) | XX (XX%) | |
| 25-29 | XX (XX%) | XX (XX%) | |
| 30-34 | XX (XX%) | XX (XX%) | |
| ≥35 | XX (XX%) | XX (XX%) | |
| Maternal Race/Ethnicity | |||
| Non-Hispanic White | XX (XX%) | XX (XX%) | |
| Non-Hispanic Black | XX (XX%) | XX (XX%) | |
| Hispanic | XX (XX%) | XX (XX%) | |
| Other | XX (XX%) | XX (XX%) | |
| Maternal Education | |||
| < High School | XX (XX%) | XX (XX%) | |
| High School Graduate | XX (XX%) | XX (XX%) | |
| Some College | XX (XX%) | XX (XX%) | |
| College Graduate | XX (XX%) | XX (XX%) | |
| Pre-pregnancy BMI | |||
| Underweight (<18.5) | XX (XX%) | XX (XX%) | |
| Normal (18.5-24.9) | XX (XX%) | XX (XX%) | |
| Overweight (25.0-29.9) | XX (XX%) | XX (XX%) | |
| Obese (≥30.0) | XX (XX%) | XX (XX%) | |
| Periconceptional Smoking | |||
| No | XX (XX%) | XX (XX%) | |
| Yes | XX (XX%) | XX (XX%) | |
| Periconceptional Alcohol Use | |||
| No | XX (XX%) | XX (XX%) | |
| Yes | XX (XX%) | XX (XX%) |
Table 2: Association Between Maternal Exposure and a Specific Birth Defect
This table is designed to present the results of a logistic regression analysis, showing the association between a particular exposure (e.g., a medication, a lifestyle factor) and a specific birth defect.
| Exposure Category | Cases (n) | Controls (n) | Crude Odds Ratio (95% CI) | Adjusted Odds Ratio (95% CI)¹ |
| No Exposure | XXX | XXX | 1.0 (Reference) | 1.0 (Reference) |
| Any Exposure | XXX | XXX | X.X (X.X-X.X) | X.X (X.X-X.X) |
| Dose/Frequency (if applicable) | ||||
| Low | XXX | XXX | X.X (X.X-X.X) | X.X (X.X-X.X) |
| Medium | XXX | XXX | X.X (X.X-X.X) | X.X (X.X-X.X) |
| High | XXX | XXX | X.X (X.X-X.X) | X.X (X.X-X.X) |
¹Adjusted for maternal age, race/ethnicity, education, pre-pregnancy BMI, and other relevant confounders.
Experimental Protocols
Detailed and transparent methodologies are crucial for the replication and validation of research findings. The following protocols outline the standard procedures for working with this compound data.
Protocol 1: Data Access and Study Population
The this compound is a large population-based case-control study of major birth defects in the United States.[1][2][3] Data from the this compound are not publicly available due to the sensitive nature of the information and the presence of personally identifiable information.[4] Qualified researchers can gain access to the data through a formal collaboration with one of the Centers for Birth Defects Research and Prevention (CBDRP).[4]
Procedure:
-
Review Existing Publications: Before proposing a new study, researchers must thoroughly review the extensive list of existing this compound publications to ensure their proposed analysis does not overlap with completed or ongoing projects.[4]
-
Identify a Collaborating Center: Researchers must identify and contact a CBDRP center to sponsor their proposed analysis.[4]
-
Submit a Collaboration Request: A formal request must be submitted to the chosen center, detailing the research question, study design, and analytical plan.
-
Data Sharing Committee Review: The CBDRP Data Sharing Committee reviews all proposals based on scientific merit, public health impact, and lack of overlap with other studies.[4]
-
Data Use Agreement: Upon approval, researchers must sign a data use agreement that outlines the terms of data access and confidentiality requirements.
Protocol 2: Case and Control Ascertainment
The this compound employed a rigorous case-ascertainment methodology.
Procedure:
-
Case Identification: Cases with major structural birth defects were identified through population-based birth defects surveillance systems in participating states.[1][3]
-
Clinical Review: A clinical geneticist reviewed all potential cases to confirm the diagnosis and ensure they met the study's case definition.[1] Cases with known single-gene or chromosomal abnormalities were excluded to focus on idiopathic birth defects.[1]
-
Control Selection: Controls were live-born infants without any major birth defects, randomly selected from the same geographic areas and time periods as the cases.[2]
Protocol 3: Exposure Assessment
Exposure information in the this compound was primarily collected through maternal interviews.
Procedure:
-
Maternal Interviews: Trained interviewers conducted computer-assisted telephone interviews with mothers of both cases and controls.[2][3]
-
Recall Period: The interviews covered a wide range of topics, including demographics, lifestyle factors, medication use, and occupational exposures during the periconceptional period (one month before conception through the first trimester).
-
Data Linkage: For certain environmental exposures, maternal address information was linked to external databases (e.g., air pollution data) to estimate exposure levels.
Protocol 4: Genetic Analysis
The this compound collected biological samples for genetic research.
Procedure:
-
Sample Collection: Buccal (cheek) cell samples were collected from the infant, mother, and father using cytobrushes mailed to the participants.[2]
-
DNA Extraction: Genomic DNA is extracted from the buccal cells using standard laboratory protocols (e.g., QIAamp DNA Blood Mini Kit).
-
Genotyping: DNA samples can be used for a variety of genetic analyses, including candidate gene studies, genome-wide association studies (GWAS), and next-generation sequencing.
-
Quality Control: Rigorous quality control measures should be applied at each step of the genetic analysis, including checks for DNA quantity and quality, and genotype call rates.
Protocol 5: Statistical Analysis
The case-control design of the this compound lends itself to specific statistical approaches.
Procedure:
-
Descriptive Statistics: Frequencies and percentages are used to describe the characteristics of the case and control groups. Chi-square tests or Fisher's exact tests are used to compare categorical variables, and t-tests or Wilcoxon rank-sum tests are used for continuous variables.
-
Logistic Regression: Unconditional logistic regression is the primary statistical method used to estimate the association between exposures and birth defects.[5]
-
Odds Ratios: Results are typically presented as odds ratios (ORs) with 95% confidence intervals (CIs).
-
Confounder Adjustment: Multivariable logistic regression models are used to adjust for potential confounding factors, such as maternal age, race/ethnicity, education, and pre-pregnancy body mass index (BMI).[5][6]
-
Stratified Analyses: To investigate potential effect modification, stratified analyses can be performed based on factors like maternal age or smoking status.[5]
Mandatory Visualizations
The following diagrams, created using the DOT language, illustrate key workflows and concepts in this compound research.
References
- 1. The National Birth Defects Prevention Study: a review of the methods - PMC [pmc.ncbi.nlm.nih.gov]
- 2. This compound.org [this compound.org]
- 3. researchgate.net [researchgate.net]
- 4. Methods for Accessing this compound and BD-STEPS Data | Birth Defects | CDC [cdc.gov]
- 5. Maternal Smoking and Congenital Heart Defects, National Birth Defects Prevention Study, 1997-2011 - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. Maternal smoking and congenital heart defects - PubMed [pubmed.ncbi.nlm.nih.gov]
Navigating the National Birth Defects Prevention Study (NBDPS) Data: A Guide for Researchers
Application Notes and Protocols for Utilizing NBDPS Data in Drug Development and Scientific Research
The National Birth Defects Prevention Study (this compound) represents a cornerstone of birth defects research in the United States, offering a vast repository of data for investigating the genetic and non-genetic causes of major birth defects.[1] This document provides researchers, scientists, and drug development professionals with a comprehensive overview of the this compound data structure, the protocols for data access and utilization, and the experimental methodologies employed in the study.
Understanding the this compound Data Landscape
The this compound is a large-scale, population-based case-control study that collected data on deliveries from 1997 to 2011.[2][1] The study includes information from over 30,000 mothers of babies with birth defects and 10,000 mothers of babies without birth defects.[2] It is important to note that direct public access to the this compound dataset is restricted to protect participant confidentiality.[2][3] However, qualified researchers can gain access to the data through a formal collaboration with one of the Centers for Birth Defects Research and Prevention (CBDRP).[2]
Data Presentation: A Glimpse into the Variables
While a direct data dictionary is not publicly available, the this compound collected a rich array of quantitative and qualitative data through structured interviews and the collection of biological specimens.[4] The table below summarizes the key categories of variables researchers can expect to find within the dataset.
| Variable Category | Description of Data Collected |
| Maternal Demographics | Age, race/ethnicity, education level, marital status. |
| Reproductive History | Previous pregnancies, history of birth defects, use of assisted reproductive technology. |
| Maternal Health | Pre-existing medical conditions (e.g., diabetes, obesity), infections during pregnancy.[1] |
| Medication Use | Prescription and over-the-counter medications taken before and during pregnancy.[1][4] |
| Lifestyle Factors | Smoking, alcohol consumption, diet and nutrition.[1][4] |
| Occupational & Environmental Exposures | Mother's and father's occupation, exposure to chemicals or other potential teratogens.[4] |
| Infant Demographics | Sex, gestational age, birth weight. |
| Birth Defect Diagnosis | Specific major structural birth defects, classified as isolated, multiple, or complex.[5] |
| Genetic Data | DNA from cheek cells of the mother, father, and infant (when possible).[4] |
Experimental Protocols: A Methodological Deep Dive
The this compound employed a rigorous and standardized methodology to ensure data quality and comparability across its multiple research centers.[5]
Case and Control Ascertainment
-
Cases: Infants with major structural birth defects were identified through active case-finding by birth defects surveillance programs in participating states.[5] Cases could be live births, stillbirths, or induced terminations.[5] A clinical geneticist reviewed all clinical information to confirm eligibility and exclude cases with known genetic or chromosomal etiologies.[5]
-
Controls: Live-born infants without major birth defects were randomly selected from the same geographical regions and time periods as the cases.[5] This selection was typically done using vital records or birth hospital records.[6][7]
Data Collection: The Interview and Biologic Sampling
The study utilized a two-pronged approach for data collection:
-
Computer-Assisted Telephone Interview (CATI): Mothers of both cases and controls were interviewed between six weeks and 24 months after their estimated delivery date.[5] A standardized, computer-guided questionnaire was used to ensure consistency in the questions asked and the manner in which they were posed.[4] The interview covered a wide range of topics, including the mother's health, lifestyle, and exposures during the three months prior to and throughout pregnancy.[4]
-
Buccal Cell Collection: Following the interview, families were mailed kits to collect cheek cells from the biological mother, father, and infant.[4] These samples serve as a valuable source of DNA for genetic analyses, allowing researchers to investigate the role of specific genes in the development of birth defects.[4]
Visualizing the Path to Discovery
The following diagrams illustrate key workflows and logical relationships within the this compound, providing a visual guide for researchers.
Caption: this compound Data Collection and Case-Control Workflow.
Caption: Protocol for Researchers to Access this compound Data.
Caption: Example Signaling Pathway for Hypothesis Generation.
References
- 1. Birth Defects Research | Birth Defects | CDC [cdc.gov]
- 2. Methods for Accessing this compound and BD-STEPS Data | Birth Defects | CDC [cdc.gov]
- 3. catalog.data.gov [catalog.data.gov]
- 4. This compound.org [this compound.org]
- 5. The National Birth Defects Prevention Study: a review of the methods - PMC [pmc.ncbi.nlm.nih.gov]
- 6. bdsteps.org [bdsteps.org]
- 7. This compound.org [this compound.org]
Troubleshooting & Optimization
Navigating the Complexities of Large-Scale Epidemiological Data: A Technical Support Guide for NBDPS Analysts
For Immediate Release
Researchers, scientists, and drug development professionals working with large-scale epidemiological data, such as the National Birth Defects Prevention Study (NBDPS), now have a dedicated resource to navigate the unique challenges of their analyses. This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to address common issues encountered during experimental design and data interpretation.
The this compound, a significant population-based case-control study, has been instrumental in identifying potential risk factors for birth defects.[1][2] However, its large and complex dataset presents considerable analytical hurdles.[3][4] This guide aims to equip researchers with the knowledge and tools to conduct robust and reliable analyses.
Frequently Asked Questions (FAQs)
1. What are the primary challenges I should be aware of when analyzing this compound data?
Analyzing the this compound dataset presents a unique set of challenges stemming from its scale and design. Key issues include:
-
Data Volume and Complexity: The sheer size of the dataset, encompassing numerous variables per participant, requires significant computational resources for storage, processing, and analysis.[5][6]
-
Potential for Bias: As a case-control study relying on retrospective data collection, this compound is susceptible to several types of bias:
-
Selection Bias: Differences between individuals who participate in the study and those who do not can skew results.[4][7][8] For instance, this compound control participants were generally older, more often non-Hispanic white, and had higher education levels than non-participants.[1]
-
Recall Bias: Mothers of children with birth defects may recall past exposures differently than mothers of children without birth defects.[4][9]
-
Incomplete Ascertainment: The study may not capture all pregnancy outcomes, such as terminations of pregnancy for fetal anomalies, which can introduce bias.[4]
-
-
Confounding: The vast number of variables makes it challenging to control for all potential confounding factors that could influence the relationship between an exposure and an outcome.[10]
-
Multiple Testing: Analyzing numerous exposures and outcomes increases the likelihood of finding statistically significant associations by chance alone.[4]
2. How can I address the issue of selection bias in my analysis?
Several strategies can be employed to mitigate selection bias:
-
Bias Analysis: Conduct quantitative bias analyses to estimate the potential magnitude and direction of bias. This involves making assumptions about the differences between participants and non-participants and assessing how these differences might affect the observed associations.[7][8]
-
Sensitivity Analysis: Perform sensitivity analyses to explore how robust the findings are to different assumptions about selection bias.[12]
-
Careful Interpretation: Acknowledge the potential for selection bias when interpreting and reporting results, discussing its potential impact on the findings.
3. What are the best practices for handling missing data in the this compound dataset?
Simply deleting records with missing data (listwise deletion) can introduce bias and reduce statistical power.[11] More sophisticated and principled methods are recommended:
-
Multiple Imputation (MI): This is a flexible and widely used method where missing values are replaced with multiple simulated values, creating several complete datasets.[11][12] Analyses are then performed on each dataset and the results are pooled.
-
Inverse Probability Weighting (IPW): This method involves creating weights to up-weight individuals who are similar to those with missing data, effectively accounting for the missing information.[13][14]
The choice of method depends on the pattern of missing data and the underlying assumptions. It is crucial to understand the mechanisms of missing data (Missing Completely at Random, Missing at Random, Missing Not at Random) to select the most appropriate approach.[11][13]
Troubleshooting Guides
Problem: Unexpected or conflicting results compared to previous studies.
Possible Causes & Solutions:
| Potential Cause | Troubleshooting Steps |
| Selection Bias | As noted in studies on this compound data, differential participation can lead to unexpected findings.[7][8] Conduct a bias analysis to assess the potential impact of this on your results. |
| Recall Bias | The retrospective nature of exposure ascertainment in this compound is a known limitation.[4] Compare your findings with studies that used prospective data collection methods, if available. |
| Confounding Variables | A previously unconsidered variable may be confounding your results. Utilize advanced statistical methods to adjust for a large number of potential confounders.[10] |
| Differences in Case/Control Definitions | Ensure your case and control definitions are consistent with those used in the studies you are comparing against. The this compound has rigorous case classification methods.[1] |
| Methodological Differences | The statistical methods used in your analysis may differ from those in other studies. Carefully review and compare the analytical approaches. |
Problem: Difficulty managing and processing the large this compound dataset.
Possible Causes & Solutions:
| Potential Cause | Troubleshooting Steps |
| Insufficient Computational Resources | Traditional epidemiological methods may struggle with the scale of the data.[5] Consider leveraging cloud computing or distributed computing frameworks for more efficient data management and analysis.[5] |
| Inefficient Data Handling | Optimize your code for handling large datasets. Utilize data formats that are efficient for storage and retrieval. |
| Lack of Expertise | Analyzing large datasets requires specialized skills.[15][16] Collaborate with bioinformaticians or data scientists with experience in big data analytics. |
Experimental Protocols & Methodologies
A crucial aspect of robust analysis is a well-defined methodology. The following diagram illustrates a generalized workflow for analyzing data from a large-scale case-control study like this compound.
Caption: A generalized workflow for analyzing this compound data.
Logical Relationships in Addressing Bias
The interplay between different types of bias and the methods to address them can be complex. The following diagram illustrates these relationships.
Caption: Logical relationships between sources of bias and mitigation strategies.
By understanding and proactively addressing these challenges, researchers can enhance the validity and impact of their findings, ultimately contributing to the prevention of birth defects and the development of safer therapeutic interventions.
References
- 1. The National Birth Defects Prevention Study: a review of the methods - PMC [pmc.ncbi.nlm.nih.gov]
- 2. This compound.org [this compound.org]
- 3. researchgate.net [researchgate.net]
- 4. Preventing birth defects: The value of the this compound case-control approach - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. Epidemiology in the Age of Big Data: Challenges and Opportunities [falconediting.com]
- 6. Challenges of Big Data Analysis - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Bias analyses to investigate the impact of differential participation: Application to a birth defects case-control study - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Scholars@Duke publication: Bias analyses to investigate the impact of differential participation: Application to a birth defects case-control study. [scholars.duke.edu]
- 9. Case-control studies for identifying novel teratogens - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Big data: Some statistical issues - PMC [pmc.ncbi.nlm.nih.gov]
- 11. The prevention and handling of the missing data - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Framework for the treatment and reporting of missing data in observational studies: The Treatment And Reporting of Missing data in Observational Studies framework - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Principled Approaches to Missing Data in Epidemiologic Studies - PMC [pmc.ncbi.nlm.nih.gov]
- 14. m.youtube.com [m.youtube.com]
- 15. medium.com [medium.com]
- 16. Challenges Associated With Using Large Data Sets for Quality Assessment and Research in Clinical Settings - PMC [pmc.ncbi.nlm.nih.gov]
Addressing confounding variables in NBDPS data analysis
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) for researchers, scientists, and drug development professionals working with the National Birth Defects Prevention Study (NBDPS) data. The focus is on addressing confounding variables to ensure the validity and accuracy of your research findings.
Frequently Asked Questions (FAQs)
Q1: What is the National Birth Defects Prevention Study (this compound)?
A1: The this compound is a large, population-based case-control study that investigated the risk factors for major birth defects in the United States.[1][2] Data collection ran from 1997 to 2011 and included interviews with mothers of infants with and without birth defects, as well as genetic samples (buccal cells) from the infant and both parents.[3][4] The study's primary goal was to identify environmental and genetic factors associated with a wide range of birth defects.[4]
Q2: What are the most common confounding variables I should consider in my this compound data analysis?
A2: Based on numerous publications using this compound data, the following are common potential confounding variables that should be considered for adjustment in your statistical models:
-
Maternal Demographics:
-
Maternal age
-
Maternal race/ethnicity
-
Maternal education level
-
-
Maternal Health and Lifestyle:
-
Maternal body mass index (BMI)
-
Maternal smoking
-
Maternal alcohol consumption
-
Periconceptional folic acid or multivitamin use
-
Maternal fever or illness during pregnancy
-
-
Pregnancy History:
-
Gravidity (number of pregnancies)
-
-
Socioeconomic Status (SES):
Q3: What is "confounding by indication" and why is it a concern in this compound data?
A3: Confounding by indication is a specific type of confounding that occurs when a health condition (the "indication") for which a medication is prescribed is itself a risk factor for the outcome being studied (the birth defect).[9][10] For example, if a study finds an association between an antidepressant and a specific birth defect, it can be difficult to determine if the risk is due to the medication itself or the underlying depression, which may independently increase the risk for certain birth defects. This is a significant challenge in observational studies like the this compound where medication use is not randomized.[9][11]
Troubleshooting Guides
Problem: My initial analysis shows a strong association between an exposure and a birth defect, but I suspect it might be due to confounding.
Solution:
-
Identify Potential Confounders: Create a list of all theoretically possible confounders based on existing literature and biological plausibility. The common confounders listed in the FAQ section are a good starting point.
-
Examine the Distribution of Potential Confounders: In your this compound dataset, compare the distribution of each potential confounder between the case and control groups. Significant differences in the distribution of a variable between cases and controls suggest it may be a confounder.
-
Perform Stratified Analysis: Stratify your data by the potential confounder and calculate the measure of association (e.g., odds ratio) within each stratum. If the stratum-specific odds ratios are similar to each other but different from the crude (unadjusted) odds ratio, confounding is likely present.
-
Use Multivariable Regression Models: The most common approach to control for multiple confounders simultaneously is to use multivariable logistic regression.[5][6][12] Include the exposure of interest and all potential confounders as independent variables in your model. The adjusted odds ratio for the exposure will provide an estimate of the association, holding the other variables in the model constant.
Problem: I am studying the effect of a medication on birth defect risk and am concerned about confounding by indication.
Solution:
-
Collect Detailed Information on the Indication: The this compound interviews often collected information on maternal health conditions.[3] Whenever possible, use this data to characterize the severity and nature of the underlying illness for which a medication was taken.
-
Stratify by Indication: If there is sufficient sample size, you can conduct separate analyses for individuals with and without the indication for the medication.
-
Use Propensity Score Methods: Propensity score matching or inverse probability of treatment weighting (IPTW) can be used to balance the distribution of measured confounders (including proxies for the indication) between the exposed and unexposed groups.
-
Consider Advanced Methods: For complex situations, methods like instrumental variable analysis or prior event rate ratio adjustment may be considered, although these have their own assumptions and limitations.[13][14]
Quantitative Data Summary
The following tables summarize adjusted odds ratios (aORs) from published studies using this compound data, demonstrating the impact of adjusting for confounding variables.
Table 1: Association between Maternal Smoking and Gastroschisis, Adjusted for Maternal Age and Race/Ethnicity
| Maternal Smoking Status | Adjusted Odds Ratio (aOR) | 95% Confidence Interval (CI) |
| Non-Smoker | 1.00 (Reference) | - |
| Smoker | 2.82 | 2.62 - 3.04 |
Source: Adapted from a study on maternal smoking and gastroschisis.[15]
Table 2: Association between Lower Socioeconomic Status (SES) Indicators and Neural Tube Defects (NTDs), Adjusted for Vitamin Use, Race/Ethnicity, Age, BMI, and Fever
| Number of Lower SES Indicators | Adjusted Odds Ratio (aOR) | 95% Confidence Interval (CI) |
| 0 (Highest SES) | 1.0 (Reference) | - |
| 1 to 3 | 1.6 | 1.1 - 2.2 |
| 4 to 6 (Lowest SES) | 3.2 | 1.9 - 5.4 |
Source: Adapted from a study on socioeconomic status and neural tube defects.[5][7]
Experimental Protocols
Protocol 1: General Workflow for Confounding Adjustment in this compound Data Analysis
This protocol outlines a generalized workflow for addressing confounding variables when analyzing this compound data.
Methodology:
-
Variable Definition: Clearly define your primary exposure, the specific birth defect outcome, and a comprehensive list of potential confounders based on prior research.
-
Descriptive Analysis: Use appropriate statistical tests (e.g., chi-square for categorical variables, t-tests or Wilcoxon rank-sum tests for continuous variables) to compare the distribution of potential confounders between the case and control groups.
-
Crude Association: Calculate the unadjusted odds ratio to understand the association between the exposure and outcome before accounting for confounders.
-
Stratification: For key potential confounders, stratify the data and calculate stratum-specific odds ratios. This can help identify effect modification.
-
Multivariable Modeling: Construct a multivariable logistic regression model. Include the primary exposure and all pre-specified potential confounders. The selection of confounders should be based on a priori knowledge, not solely on statistical significance in bivariate analyses.
-
Model Evaluation: Assess the goodness-of-fit of your final model and check for issues like multicollinearity among the independent variables.
-
Interpretation: Interpret the adjusted odds ratio for your primary exposure as the association between the exposure and the outcome, having controlled for the effects of the other variables in the model.
Signaling Pathway and Logic Diagrams
Diagram 1: The Concept of Confounding
This diagram illustrates the relationship between an exposure, an outcome, and a confounding variable.
Diagram 2: Key Signaling Pathways in Neural Tube Development
This diagram depicts some of the critical signaling pathways involved in the closure of the neural tube, disruptions of which can lead to neural tube defects (NTDs).
Diagram 3: Signaling Pathways in Congenital Heart Development
This diagram illustrates key signaling pathways that regulate the complex process of heart development. Perturbations in these pathways are associated with congenital heart defects (CHDs).
References
- 1. Planar Cell Polarity Signaling Pathway in Congenital Heart Diseases - PMC [pmc.ncbi.nlm.nih.gov]
- 2. mdpi.com [mdpi.com]
- 3. sciencedaily.com [sciencedaily.com]
- 4. Frontiers | A quest for genetic causes underlying signaling pathways associated with neural tube defects [frontiersin.org]
- 5. researchgate.net [researchgate.net]
- 6. academic.oup.com [academic.oup.com]
- 7. Socioeconomic status, neighborhood social conditions, and neural tube defects - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Neighborhood Deprivation and Neural Tube Defects - PMC [pmc.ncbi.nlm.nih.gov]
- 9. A most stubborn bias: no adjustment method fully resolves confounding by indication in observational studies - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. Confounding by indication | Catalog of Bias [catalogofbias.org]
- 11. researchgate.net [researchgate.net]
- 12. stacks.cdc.gov [stacks.cdc.gov]
- 13. Chapter 6: Methods to address bias and confounding - European Network of Centres for Pharmacoepidemiology and Pharmacovigilance [encepp.europa.eu]
- 14. Adjusting for confounding by indication in observational studies: a case study in traumatic brain injury - PMC [pmc.ncbi.nlm.nih.gov]
- 15. aap.org [aap.org]
Technical Support Center: Statistical Power in Rare Birth Defect Research using NBDPS Data
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) for researchers, scientists, and drug development professionals working with the National Birth Defects Prevention Study (NBDPS) data, focusing on the critical issue of statistical power when studying rare birth defects.
Frequently Asked Questions (FAQs)
Q1: Why is statistical power a major concern when studying rare birth defects in the this compound?
A1: Statistical power is the probability of detecting a true association between an exposure and an outcome. When studying rare birth defects, the number of affected individuals (cases) is inherently small. Similarly, exposures of interest, such as the use of a specific medication, may also be uncommon. This combination of a rare outcome and potentially rare exposure significantly reduces statistical power, making it difficult to distinguish a true, modest association from random chance. Low statistical power can lead to false-negative findings, where a genuine risk factor is missed.
Q2: How does the case-control design of the this compound help address the issue of rarity?
A2: The this compound employs a case-control study design, which is particularly well-suited for studying rare diseases.[1] Instead of following a large cohort of pregnant women to observe the rare occurrence of a birth defect, this design starts with a group of individuals who have the birth defect (cases) and a group of individuals without the birth defect (controls). Researchers then look back in time to compare the frequency of exposures between the two groups. This approach is more efficient than a cohort study for rare outcomes because it enriches the study population with the rare events of interest, thereby increasing the statistical power to detect associations.[1]
Q3: What are the key parameters I need to consider for a power calculation in a case-control study using this compound data?
A3: To perform a power calculation for a case-control study, you will need to estimate the following four key parameters:
-
Alpha (α) or the Significance Level: This is the probability of making a Type I error (false positive), which is typically set at 0.05.
-
Beta (β) or the Type II Error Rate: Power is calculated as 1 - β. A common target for power is 80% (β = 0.20).
-
Prevalence of Exposure in the Control Group (P₀): This is the estimated proportion of individuals in the control group who were exposed to the risk factor of interest. This information can often be estimated from existing this compound publications or other population-based data.
-
Odds Ratio (OR): This is the measure of association between the exposure and the birth defect that you want to be able to detect. You need to specify the minimum odds ratio that you would consider clinically or scientifically important.
Q4: Where can I find the necessary information to estimate these parameters for my power calculation?
A4: Existing this compound publications are a valuable resource. For instance, a study on maternal SSRI use and birth defects can provide estimates for the prevalence of specific SSRI use among control mothers (P₀) and the magnitude of odds ratios observed for various birth defects.[2][3] For novel exposures, you may need to consult other epidemiological literature or conduct a pilot study to get a preliminary estimate of exposure prevalence.
Troubleshooting Guides
Issue: My planned analysis for a very rare birth defect has low statistical power. What are my options?
Solution:
When faced with low statistical power for a very rare birth defect, consider the following strategies:
-
Increase the Sample Size:
-
Collaborate and Pool Data: The this compound is a multi-center study, and its strength lies in the large number of participants.[4] For extremely rare defects, consider collaborating with other researchers or consortia to pool data from multiple studies, if available. The successor to the this compound, the Birth Defects Study To Evaluate Pregnancy exposureS (BD-STEPS), was designed to allow for combined analyses with this compound data, providing an even larger sample size for studying rare exposures.
-
Increase the Control-to-Case Ratio: While the this compound has a fixed number of cases and controls, for future studies, increasing the number of controls per case (e.g., up to a 4:1 ratio) can modestly increase statistical power, especially when the cost of recruiting controls is lower than recruiting cases.
-
-
Modify the Study Design:
-
Group Similar Birth Defects: If biologically plausible, you can increase your case number by grouping together etiologically related birth defects. However, this must be done cautiously to avoid masking defect-specific associations. The this compound provides detailed guidelines for case classification to assist in this process.
-
Focus on a More Common, Related Outcome: If the primary defect is too rare, consider analyzing a broader, more common category of defects that includes the defect of interest as a secondary analysis.
-
-
Adjust the Analytical Approach:
-
Use a Higher Alpha Level: While the standard is 0.05, for exploratory analyses of very rare defects, you might consider a higher alpha level (e.g., 0.10) to increase the probability of detecting a potential signal, with the understanding that this also increases the risk of a false positive. This approach should be clearly justified.
-
Employ Bayesian Methods: As demonstrated in some this compound analyses, Bayesian statistical methods can be used to incorporate prior knowledge and provide probabilistic statements about the likelihood of an association, which can be particularly useful when power is low.[2][3]
-
Issue: How do I handle multiple comparisons when analyzing the association between an exposure and several different birth defects?
Solution:
Analyzing the association between an exposure and multiple birth defect outcomes increases the probability of finding a statistically significant result by chance alone (a Type I error). Here are some approaches to address this:
-
Bonferroni Correction: This is a conservative method where you divide your significance level (α) by the number of comparisons you are making. For example, if you are testing for associations with 10 different birth defects, the new significance level for each test would be 0.05 / 10 = 0.005. While this method effectively controls the family-wise error rate, it can be overly stringent and increase the risk of missing a true association (a Type II error).
-
False Discovery Rate (FDR) Control: Methods like the Benjamini-Hochberg procedure control the expected proportion of false positives among all significant findings. This approach is generally less conservative than the Bonferroni correction and is often preferred when a large number of comparisons are made.
-
Prioritize Hypotheses: Before conducting your analysis, clearly define your primary and secondary hypotheses. You can apply a stricter significance level to your primary hypotheses and a more lenient one to your exploratory, secondary hypotheses.
-
Bayesian Approach: A Bayesian framework can naturally account for multiple comparisons by using hierarchical models that can "borrow strength" across different outcomes.
Data Presentation
Table 1: Illustrative Power Calculations for a Case-Control Study
This table demonstrates how statistical power changes based on the odds ratio and the prevalence of exposure in the control group, assuming a 1:1 case-to-control ratio, a significance level (α) of 0.05, and a sample size of 500 cases and 500 controls.
| Prevalence of Exposure in Controls (P₀) | Odds Ratio (OR) to Detect | Statistical Power (1-β) |
| 5% | 1.5 | 39% |
| 5% | 2.0 | 78% |
| 5% | 2.5 | 96% |
| 10% | 1.5 | 56% |
| 10% | 2.0 | 94% |
| 10% | 2.5 | >99% |
| 20% | 1.5 | 78% |
| 20% | 2.0 | >99% |
| 20% | 2.5 | >99% |
Table 2: Sample Size Requirements for 80% Power
This table shows the required number of cases and controls (assuming a 1:1 ratio) to achieve 80% power at a significance level of 0.05 for different odds ratios and exposure prevalences in the control group.
| Prevalence of Exposure in Controls (P₀) | Odds Ratio (OR) to Detect | Required Number of Cases | Required Number of Controls | Total Sample Size |
| 1% | 2.0 | 2,334 | 2,334 | 4,668 |
| 1% | 3.0 | 651 | 651 | 1,302 |
| 5% | 1.5 | 1,078 | 1,078 | 2,156 |
| 5% | 2.0 | 384 | 384 | 768 |
| 10% | 1.5 | 586 | 586 | 1,172 |
| 10% | 2.0 | 210 | 210 | 420 |
Experimental Protocols
Protocol: Statistical Analysis of a Putative Teratogen using this compound Data
This protocol outlines the typical steps for analyzing the association between a specific maternal exposure (e.g., a medication) and a rare birth defect using the this compound dataset. This is a generalized protocol, and specific details may vary based on the research question.
-
Case and Control Definition:
-
Define the specific birth defect(s) of interest based on the this compound case classification guidelines.
-
Select the appropriate control group from the this compound data (live-born infants without major birth defects).
-
-
Exposure Definition:
-
Define the exposure of interest, including the timing of exposure relevant to the critical window of development for the birth defect (typically the first trimester of pregnancy).
-
The this compound collects detailed information on maternal medication use, illnesses, and other lifestyle factors through a standardized computer-assisted telephone interview.[5]
-
-
Data Extraction and Management:
-
Request access to the this compound dataset through the appropriate channels, which typically involves collaboration with one of the Centers for Birth Defects Research and Prevention (CBDRP).[6]
-
Extract the relevant variables for cases and controls, including the exposure of interest and potential confounding factors.
-
-
Statistical Analysis:
-
Descriptive Statistics: Calculate the frequency of the exposure among cases and controls. Calculate the demographic and clinical characteristics of the study population.
-
Bivariate Analysis: Use logistic regression to calculate the crude odds ratio (OR) and its 95% confidence interval (CI) to assess the unadjusted association between the exposure and the birth defect.
-
Multivariable Analysis: Use multiple logistic regression to calculate the adjusted odds ratio (aOR) and its 95% CI, controlling for potential confounding factors. Common confounders in this compound analyses include maternal age, race/ethnicity, education, smoking, and pre-pregnancy BMI.
-
Addressing Multiple Comparisons: If analyzing multiple exposures or multiple birth defects, apply a method to adjust for multiple comparisons, such as the Bonferroni correction or a false discovery rate controlling procedure.
-
-
Sensitivity Analyses:
-
Conduct sensitivity analyses to assess the robustness of the findings. This may include:
-
Restricting the analysis to cases with isolated birth defects.
-
Varying the definition of the exposure window.
-
Using different methods to handle missing data.
-
-
-
Interpretation and Reporting:
-
Interpret the findings in the context of the study's statistical power. If the results are null, consider whether the study was underpowered to detect a small but clinically meaningful effect.
-
Report the aOR, 95% CI, and p-value. Clearly describe the methods used, including the definition of cases, controls, exposure, and the statistical models employed.
-
Mandatory Visualization
Caption: Workflow of a typical study using this compound data, from data collection to analysis and key challenges.
References
- 1. This compound.org [this compound.org]
- 2. Specific SSRIs and birth defects: bayesian analysis to interpret new data in the context of previous reports - PMC [pmc.ncbi.nlm.nih.gov]
- 3. researchgate.net [researchgate.net]
- 4. The National Birth Defects Prevention Study: a review of the methods - PMC [pmc.ncbi.nlm.nih.gov]
- 5. This compound.org [this compound.org]
- 6. Methods for Accessing this compound and BD-STEPS Data | Birth Defects | CDC [cdc.gov]
Best practices for handling missing data in the NBDPS dataset
Technical Support Center: NBDPS Dataset
This guide provides researchers, scientists, and drug development professionals with best practices for identifying, characterizing, and handling missing data within the National Birth Defects Prevention Study (this compound) dataset.
Frequently Asked Questions (FAQs)
Q1: What is the this compound dataset and why might it contain missing data?
The National Birth Defects Prevention Study (this compound) is a large, population-based case-control study that collected data on babies born between 1997 and 2011 to understand potential causes of birth defects.[1][2] The data includes detailed maternal interviews on topics like health, diet, lifestyle, and prescription drug use, as well as genetic information from cheek swabs.[3][4] Missing data is a common issue in such extensive studies and can arise for several reasons:
-
Participant Refusal: A participant may decline to answer sensitive questions.
-
Recall Bias: A participant may not remember specific details, such as the exact timing of a medication or a specific dietary item.
-
Data Entry Errors: Clerical errors during the data recording process.
-
Loss to Follow-up: In some cases, complete information could not be collected from a participant.
-
Technical Failures: Equipment malfunction during sample processing or data transfer.[5]
Q2: What are the main types of missing data I should be aware of?
Understanding the mechanism of missingness is critical for choosing the correct handling strategy. There are three main types:[5][6]
-
Missing Completely at Random (MCAR): The reason for the missing value is unrelated to any data, either observed or missing. For example, a data entry was accidentally skipped, or a blood sample was dropped. This is the simplest scenario to handle.
-
Missing at Random (MAR): The probability of a value being missing is related to other observed information in the dataset, but not the missing value itself. For instance, if male participants are less likely to answer a question about dietary habits, the "missingness" in the diet variable is conditional on the "sex" variable.
-
Missing Not at Random (MNAR): The probability of a value being missing is related to the value itself. For example, if participants with very high or very low income are less likely to report it, the missingness is dependent on the unobserved income level. This is the most challenging type of missing data to handle as it can introduce significant bias.[6]
Q3: Should I just delete participants with any missing data?
This approach, known as listwise deletion or complete-case analysis, is generally not recommended unless the amount of missing data is very small (e.g., <5%) and you have strong evidence that the data is Missing Completely at Random (MCAR).[5] Deleting cases can significantly reduce your sample size, leading to a loss of statistical power, and more importantly, it can introduce substantial bias if the data is not MCAR.[5]
Q4: What is imputation and when should I use it?
Imputation is the process of replacing missing values with plausible estimates.[5] It is generally preferred over deletion when data is not MCAR or when the proportion of missing data is significant. The goal is to create a complete dataset that can be analyzed with standard statistical methods while preserving the natural structure of the data. There are two main categories: single imputation (e.g., replacing with the mean/median) and multiple imputation (e.g., MICE), with the latter being more robust.[7]
Q5: Which imputation method is best for the this compound dataset?
There is no single "best" method; the choice depends on the type of variable (categorical vs. continuous), the presumed missingness mechanism, and the percentage of missing values.
-
For MCAR/MAR data: Methods like Multiple Imputation by Chained Equations (MICE) or k-Nearest Neighbors (k-NN) are often superior to simple mean/median imputation because they use information from other variables to inform the imputed values.[8][9]
-
For MNAR data: This is more complex and may require specialized modeling techniques that explicitly account for the reason data is missing.[6] For example, if values are missing because they fall below an instrument's limit of detection (a common issue in metabolomics or exposure data), specific methods like Quantile Regression Imputation of Left-Censored data (QRILC) might be appropriate.[9][10]
Troubleshooting Guide
Problem: My statistical analysis fails or gives strange results after handling missing data.
-
Possible Cause: The chosen method may have distorted the data's natural distribution or variance. Simple mean/median imputation, for example, artificially reduces the variability of the data, which can bias results like standard errors and p-values.[9]
-
Solution:
-
Visualize your data before and after imputation to check for distributional changes.
-
Avoid single imputation for large amounts of missing data. Instead, use a more sophisticated method like Multiple Imputation (MI). MI generates several complete datasets, analyzes each one, and then pools the results, which accounts for the uncertainty of the imputation process itself.[7]
-
Ensure your imputation model includes all variables that are in your final analysis model, including the outcome variable.[7]
-
Problem: I'm not sure if my data is MCAR, MAR, or MNAR.
-
Possible Cause: Determining the missingness mechanism is often a detective-like process that requires subject matter expertise.
-
Solution:
-
Perform statistical tests: Little's MCAR test can be used to formally test the null hypothesis that data is MCAR.
-
Create dummy variables: Create a new binary variable where 1 = missing and 0 = observed for a variable of interest. Run t-tests or chi-square tests to see if this "missingness indicator" is associated with other variables in your dataset. If it is, your data is likely not MCAR.
-
Consult study documentation: Review the this compound data collection protocols to understand why data might be missing.[3][4] For example, if a question was only asked to participants who answered "yes" to a previous question, the resulting missing data is systematic (a form of MAR).
-
Comparison of Common Imputation Methods
| Method | Best For | Assumptions / Requirements | Computational Cost | Potential for Bias |
| Mean/Median/Mode Imputation | Continuous or categorical data with a small percentage of MCAR values. | Data is MCAR. | Very Low | High. Reduces variance, weakens correlations, and biases estimates towards the mean.[8] |
| k-Nearest Neighbors (k-NN) | Continuous and categorical data. Works well with MAR mechanisms. | Assumes that similar data points (neighbors) can predict the missing value. | Moderate | Lower than mean imputation, but can be biased if the number of predictors is low or k is chosen poorly. |
| Multiple Imputation (MICE) | Complex datasets with multiple variables having missing data under MAR. | The imputation model must be correctly specified. Assumes MAR. | High | Low, if implemented correctly. Considered a gold standard for handling MAR data.[7] |
| Random Forest Imputation | Mixed data types (continuous, categorical) with complex, non-linear relationships. Handles MAR. | Few assumptions about data distribution. | High | Generally low and robust. Outperforms many other methods in complex scenarios.[8][10] |
Experimental Protocol: Handling Missing Data with MICE
This protocol outlines a standard workflow for implementing Multiple Imputation by Chained Equations (MICE) using the R programming language, a common tool in academic research.
Objective: To impute missing values in a subset of the this compound dataset to prepare for a regression analysis.
Methodology:
-
Load Data & Libraries:
-
Load your this compound data subset into your R environment.
-
Install and load the mice package: install.packages("mice") and library(mice).
-
-
Initial Exploration:
-
Use the md.pattern() function from the mice package to visualize the missing data patterns. This helps in understanding the scope and location of missingness.
-
-
Define the Imputation Model:
-
The MICE algorithm works by creating a model for each variable with missing data, using the other variables as predictors.
-
By default, mice chooses a suitable regression model based on the variable type (e.g., logistic regression for binary data, predictive mean matching for continuous data).
-
Crucially, ensure all variables from your planned final analysis (including your outcome variable) are included in the data frame passed to the mice function. This prevents biased estimates.[7]
-
-
Perform Imputation:
-
Run the main mice function. A standard starting point is to generate 5 to 10 imputed datasets (m=10).
-
imputed_data <- mice(your_data, m=10, maxit=5, seed=123)
-
The maxit argument specifies the number of iterations for the algorithm to converge.
-
-
Assess Imputation Quality (Diagnostics):
-
After imputation, it is essential to check the plausibility of the imputed values.
-
Use plot(imputed_data) to generate diagnostic plots. These plots show the imputed values for each iteration, allowing you to check for convergence.
-
Use stripplot(imputed_data, pch=20) to compare the distributions of observed (blue) and imputed (red) data. The distributions should be similar.
-
-
Perform Analysis and Pool Results:
-
Fit your statistical model (e.g., a logistic regression) to each of the m imputed datasets using the with() function: model_fit <- with(imputed_data, glm(outcome ~ predictor1 + predictor2, family="binomial"))
-
Combine the results from each model into a single set of estimates, confidence intervals, and p-values using the pool() function: pooled_results <- pool(model_fit)
-
Use summary(pooled_results) to view the final results, which properly account for the uncertainty introduced by the imputation process.
-
Visual Workflow
The following diagram illustrates a logical workflow for deciding how to handle missing data in your this compound experiment.
Caption: A decision tree for selecting an appropriate missing data handling strategy.
References
- 1. National Birth Defects Prevention Study – Iowa Registry for Congenital and Inherited Disorders [ircid.public-health.uiowa.edu]
- 2. This compound.org [this compound.org]
- 3. This compound.org [this compound.org]
- 4. This compound.org [this compound.org]
- 5. Handling missing data in research - PMC [pmc.ncbi.nlm.nih.gov]
- 6. A Comprehensive Review of Handling Missing Data: Exploring Special Missing Mechanisms [arxiv.org]
- 7. Missing Data in Clinical Research: A Tutorial on Multiple Imputation - PMC [pmc.ncbi.nlm.nih.gov]
- 8. bmjopen.bmj.com [bmjopen.bmj.com]
- 9. researchgate.net [researchgate.net]
- 10. pubs.acs.org [pubs.acs.org]
Technical Support Center: Overcoming Selection Bias in NBDPS Case-Control Studies
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) for researchers, scientists, and drug development professionals working with data from the National Birth Defects Prevention Study (NBDPS) or similar case-control studies. The focus is on identifying and mitigating selection bias to ensure the validity of research findings.
Frequently Asked Questions (FAQs)
Q1: What is selection bias in the context of the this compound?
A1: In the this compound, a population-based case-control study, selection bias can occur when the selection of cases or controls is related to the exposure of interest, leading to a distorted measure of association between the exposure and the birth defect.[1][2][3][4] The this compound recruited cases (infants with birth defects) from birth defects surveillance programs and controls (infants without major birth defects) from birth certificate records or birth hospitals.[5][6][7] Two primary types of selection bias are of concern:
-
Participation Bias: This occurs when the likelihood of participating in the study differs between cases and controls and is also related to the exposure. For example, if mothers of infants with a specific birth defect who were exposed to a certain medication are more likely to participate than mothers of healthy infants with the same exposure, the odds ratio will be biased. The overall participation rate in the this compound for the interview component was approximately 65% for both cases and controls.[7][8]
-
Live-Birth Bias (a form of survival bias): This can occur when studying birth defects with high rates of fetal loss. If an exposure is associated with both the birth defect and fetal death, restricting the study to live births can lead to a biased association. For instance, if an exposure increases the risk of both a severe birth defect and fetal demise, the association between the exposure and the birth defect might be underestimated among live births because the most severely affected fetuses did not survive.
Q2: How can I assess the potential for participation bias in my this compound analysis?
A2: To assess the potential for participation bias, you should compare the characteristics of participants and non-participants, if data are available. In the this compound, participation in the interview and buccal cell collection varied by several factors. Researchers can examine whether these factors are also associated with the exposure of interest in their study.
Data Presentation: this compound Interview and Buccal Cell Participation Rates
The following table summarizes participation rates in the this compound, highlighting factors that may be associated with selection bias.
| Characteristic | Interview Participation Rate (Cases) | Interview Participation Rate (Controls) | Buccal Cell Collection Participation Rate (Interviewed Mothers) |
| Overall | 64.8%[8] | 64.7%[8] | 62.9%[8] |
| Maternal Race/Ethnicity | |||
| Non-Hispanic White | 68.9%[8] | 67.2%[8] | |
| Non-Hispanic Black | 59.2%[8] | 46.6%[8] | |
| Hispanic | 60.3%[8] | 60.2%[8] | |
| Maternal Education | Higher education associated with increased participation[8] | Higher education associated with increased participation[8] | Higher education associated with increased participation among non-Hispanic whites and Hispanics[8] |
| Infant Status | Case mothers were more likely to participate in buccal cell collection than control mothers[8] | ||
| Study Site | Varied significantly[8] | Varied significantly[8] | 50.2% - 74.2%[8] |
Q3: What are the primary methods to address selection bias in my analysis?
A3: Two common and robust methods to address selection bias are Inverse Probability Weighting (IPW) and Quantitative Bias Analysis (QBA).
-
Inverse Probability Weighting (IPW): This method attempts to create a "pseudo-population" where the selection of participants is independent of the exposure and outcome. It involves calculating the probability of participation (the selection probability) for each individual and then weighting each participant by the inverse of this probability.[2][9][10][11][12][13]
-
Quantitative Bias Analysis (QBA): QBA is a sensitivity analysis that allows you to estimate the potential magnitude and direction of bias due to unmeasured factors, including selection bias. It involves making assumptions about the relationships between the unmeasured factors (e.g., participation), the exposure, and the outcome.[1][14][15][16][17][18][19]
Troubleshooting Guides
Guide 1: Implementing Inverse Probability Weighting (IPW) for Participation Bias
Issue: I am concerned that participation in my this compound study is related to both the exposure and the birth defect I am studying, and I want to use IPW to adjust for this.
Experimental Protocol: Step-by-Step IPW for Participation Bias
-
Identify Covariates Associated with Participation: From the this compound data, identify variables that are predictive of participation. These can include maternal age, race/ethnicity, education level, socioeconomic status, study site, and infant's case/control status.[8]
-
Model the Probability of Participation:
-
Create a binary variable for participation (1 = participated, 0 = did not participate).
-
Use logistic regression to model the probability of participation based on the covariates identified in Step 1. The model will be of the form: logit(P(Participation=1)) = β₀ + β₁X₁ + ... + βₚXₚ, where X₁...Xₚ are the covariates.
-
-
Calculate Inverse Probability Weights:
-
For each participant, predict their probability of participation (p) using the logistic regression model from Step 2.
-
The inverse probability weight (IPW) for each participant is 1/p.
-
-
Apply the Weights in Your Analysis:
-
Use these weights in your final logistic regression model that examines the association between the exposure and the birth defect. Most statistical software (e.g., R, SAS) allows for weighted analyses.
-
Troubleshooting IPW:
-
Problem: I have very large weights for some individuals.
-
Solution: Extreme weights can inflate the variance of your estimates. Consider "trimming" or "truncating" the weights by setting a maximum value (e.g., the 99th percentile of the weight distribution).[2]
-
-
Problem: I don't have data on non-participants to model the probability of participation.
Guide 2: Conducting a Quantitative Bias Analysis (QBA) for Selection Bias
Issue: I suspect selection bias in my study but cannot directly adjust for it using methods like IPW because I lack the necessary data. I want to perform a QBA to assess the potential impact of this bias.
Experimental Protocol: Step-by-Step QBA for Participation Bias
-
Define the Bias Model: Specify the relationship between participation, the exposure, and the outcome. This is often represented using a Directed Acyclic Graph (DAG).
-
Specify Bias Parameters: You will need to make assumptions about the strength of the association between:
-
The exposure and participation, stratified by case/control status.
-
The outcome (birth defect) and participation, stratified by exposure status. These parameters are often expressed as odds ratios. For example, you might assume that exposed cases are 1.5 times more likely to participate than unexposed cases. These assumptions should be based on literature, expert opinion, or internal data if available.[15]
-
-
Calculate the Adjusted Odds Ratio: Use a bias formula or a probabilistic bias analysis software to calculate the adjusted odds ratio based on your observed data and the specified bias parameters.
-
Perform a Sensitivity Analysis: Vary the bias parameters across a plausible range of values to see how the adjusted odds ratio changes. This will give you a sense of how robust your findings are to different assumptions about selection bias.[14]
Troubleshooting QBA:
-
Problem: I don't know what values to choose for my bias parameters.
-
Solution: This is the most challenging aspect of QBA. Start by reviewing the literature for studies that have examined participation in similar populations.[17] If no data are available, you can present a range of plausible scenarios. The goal is not to find the "true" answer but to understand the potential magnitude of the bias.
-
-
Problem: The QBA results suggest that my findings could be entirely due to bias.
-
Solution: This is a possible and important outcome of a QBA. It indicates that your results should be interpreted with extreme caution. In your discussion, you should transparently report the QBA findings and acknowledge the uncertainty in your results.
-
Mandatory Visualizations
Signaling Pathway Diagrams
The following diagrams illustrate key signaling pathways potentially involved in the development of birth defects frequently studied in the this compound.
Caption: Simplified Folic Acid Metabolism Pathway and its role in Neural Tube Closure.
Caption: The Sonic Hedgehog (Shh) signaling pathway's role in craniofacial development.
Caption: The canonical Wnt/β-catenin signaling pathway in heart development.
Experimental Workflow Diagram
References
- 1. youtube.com [youtube.com]
- 2. An introduction to inverse probability of treatment weighting in observational research - PMC [pmc.ncbi.nlm.nih.gov]
- 3. researchgate.net [researchgate.net]
- 4. This compound.org [this compound.org]
- 5. academic.oup.com [academic.oup.com]
- 6. This compound.org [this compound.org]
- 7. The National Birth Defects Prevention Study: a review of the methods - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Factors affecting maternal participation in the genetic component of the National Birth Defects Prevention Study—United States, 1997–2007 - PMC [pmc.ncbi.nlm.nih.gov]
- 9. rama.mahidol.ac.th [rama.mahidol.ac.th]
- 10. Inverse Probability Weighting | Columbia University Mailman School of Public Health [publichealth.columbia.edu]
- 11. Adjusting for selection bias due to missing data in electronic health records-based research - PMC [pmc.ncbi.nlm.nih.gov]
- 12. towardsdatascience.com [towardsdatascience.com]
- 13. biostats.bepress.com [biostats.bepress.com]
- 14. academic.oup.com [academic.oup.com]
- 15. Quantitative Assessment of Systematic Bias: A Guide for Researchers - PMC [pmc.ncbi.nlm.nih.gov]
- 16. Bias Analysis Gone Bad - PMC [pmc.ncbi.nlm.nih.gov]
- 17. researchgate.net [researchgate.net]
- 18. Quantitative Bias Analysis for Epidemiologic Data [cran.r-project.org]
- 19. Monte Carlo Simulation Approaches for Quantitative Bias Analysis: A Tutorial - PMC [pmc.ncbi.nlm.nih.gov]
- 20. amerispeak.norc.org [amerispeak.norc.org]
- 21. Handling non-probability samples through inverse probability weighting with an application to Statistics Canada’s crowdsourcing data [www150.statcan.gc.ca]
- 22. m.youtube.com [m.youtube.com]
- 23. researchgate.net [researchgate.net]
Technical Support Center: Advanced Statistical Models for NBDPS Data Analysis
Welcome to the technical support center for the analysis of National Birth Defects Prevention Study (NBDPS) data. This resource is designed for researchers, scientists, and drug development professionals to provide guidance on the application of advanced statistical models to this unique dataset. Here you will find troubleshooting guides and frequently asked questions (FAQs) to address specific issues you may encounter during your experiments.
Frequently Asked Questions (FAQs)
Q1: What are the primary characteristics of the this compound data that I need to consider before selecting a statistical model?
A1: The this compound is a large, population-based case-control study. Key characteristics to consider are:
-
Case-Control Design: You are comparing individuals with a specific birth defect (cases) to individuals without that birth defect (controls). This design is optimal for studying rare diseases.[1]
-
Observational Data: The data is collected from interviews and biological samples without experimental intervention. This means establishing causality requires careful consideration of confounding factors.[1]
-
Rich Data on Exposures: The study includes detailed information on a wide range of potential risk factors, including maternal health, diet, medication use, and environmental exposures.[2]
-
Genetic Data: DNA samples from cheek cells were collected from cases, controls, and their parents, allowing for the investigation of genetic factors and gene-environment interactions.[1][2]
Q2: What are the most common statistical models used for analyzing this compound data?
A2: The foundational model for case-control studies like the this compound is logistic regression . It is used to estimate the odds ratio (OR) for the association between an exposure and a birth defect, while adjusting for potential confounding variables.[3] More advanced models are often employed to investigate complex relationships, such as:
-
Models for Gene-Environment (GxE) Interactions: These assess whether the effect of an environmental exposure on the risk of a birth defect differs by an individual's genetic makeup.
-
Bayesian Hierarchical Models: These models are useful for handling complex data structures, such as data from multiple geographic locations or different types of birth defects, and can incorporate prior knowledge into the analysis.[4][5][6]
-
Machine Learning Models: Techniques like Random Forest and Gradient Boosting can be used for predictive modeling to identify key risk factors from a large number of variables.[7][8][9][10]
Q3: How can I investigate the interaction between a specific gene and an environmental exposure in the this compound data?
A3: To investigate gene-environment (GxE) interactions, you can use several approaches:
-
Stratified Analysis: You can stratify your data by genotype and perform separate analyses of the exposure-disease relationship within each genetic group.
-
Logistic Regression with an Interaction Term: This is a common and powerful method where you include the genetic factor, the environmental factor, and their product (the interaction term) in the logistic regression model.[11] A statistically significant interaction term suggests that the effect of the environmental exposure on the odds of the birth defect depends on the genotype.
-
Case-Only Design: This design uses only the case group to assess the association between the gene and the exposure. It is more statistically powerful than the case-control design for detecting interactions but relies on the assumption that the genetic and environmental factors are independent in the control population.[12]
-
Bayesian Models: Bayesian approaches can be used to model GxE interactions, which can be particularly useful when dealing with uncertainty in the assumption of gene-environment independence.[13]
Troubleshooting Guides
Issue 1: My logistic regression model for a specific exposure shows a significant association, but I'm concerned about confounding.
Troubleshooting Steps:
-
Identify Potential Confounders: Brainstorm variables that could be associated with both the exposure and the birth defect. Common confounders in this compound data include maternal age, education, race/ethnicity, and socioeconomic status.
-
Perform Stratified Analysis: Stratify your data by the potential confounder and examine the exposure-disease association within each stratum. If the odds ratios are substantially different across strata, confounding may be present.
-
Use Multivariable Logistic Regression: Include the potential confounders as covariates in your logistic regression model. If the odds ratio for the exposure of interest changes substantially after adjusting for the confounder, this indicates that confounding was present.
-
Check for Multicollinearity: If you include multiple highly correlated variables in your model, it can lead to unstable estimates. Assess the variance inflation factor (VIF) for each variable; a VIF greater than 10 may indicate a problem.
Issue 2: I am performing a genome-wide association study (GWAS) and am concerned about population stratification.
Troubleshooting Steps:
-
Principal Component Analysis (PCA): Use PCA on the genetic data to identify the major axes of genetic variation in your sample. You can then include the top principal components as covariates in your association model to adjust for population structure.
-
Genomic Control: This method adjusts the test statistics from your association analysis to account for inflation due to population stratification.
-
Linear Mixed Models: These models can account for subtle family relationships and population structure in your sample, providing more robust association results.
Issue 3: I am trying to build a predictive model using machine learning, but the performance is poor.
Troubleshooting Steps:
-
Feature Engineering: The way you represent your variables can have a significant impact on model performance. Consider creating new features from existing ones, such as interaction terms or composite scores.
-
Address Class Imbalance: In this compound data, the number of controls is often much larger than the number of cases for a specific birth defect. This class imbalance can bias your model. Techniques to address this include:
-
Oversampling: Increase the number of cases in your training data.
-
Undersampling: Decrease the number of controls in your training data.
-
Using appropriate evaluation metrics: Instead of accuracy, use metrics like the area under the ROC curve (AUC), precision, recall, and F1-score, which are less sensitive to class imbalance.
-
-
Hyperparameter Tuning: Machine learning models have several parameters that need to be set before training. Use techniques like grid search or random search to find the optimal combination of hyperparameters for your model.
-
Cross-Validation: Use k-fold cross-validation to get a more robust estimate of your model's performance and to avoid overfitting.
Quantitative Data Summary
The following tables provide examples of how to present quantitative data from analyses of this compound data.
Table 1: Association between Maternal Smoking and Congenital Heart Defects (CHDs) using Logistic Regression
| Variable | Odds Ratio (OR) | 95% Confidence Interval (CI) | p-value |
| Maternal Smoking (Yes vs. No) | 1.5 | 1.2 - 1.9 | <0.001 |
| Maternal Age (per year) | 1.02 | 1.01 - 1.03 | <0.05 |
| Maternal Education (College vs. High School) | 0.8 | 0.6 - 1.0 | 0.06 |
Table 2: Gene-Environment Interaction between a SNP and Pesticide Exposure on Spina Bifida Risk
| Genotype | Pesticide Exposure | Odds Ratio (OR) | 95% Confidence Interval (CI) | p-value for interaction |
| GG | No | 1.0 (Reference) | - | <0.01 |
| GG | Yes | 1.8 | 1.3 - 2.5 | |
| GA/AA | No | 1.2 | 0.9 - 1.6 | |
| GA/AA | Yes | 3.5 | 2.5 - 4.9 |
Experimental Protocols
Protocol 1: Logistic Regression Analysis of a Single Exposure
Objective: To assess the association between a specific maternal exposure (e.g., a medication) and a particular birth defect.
Methodology:
-
Data Preparation:
-
Select cases with the birth defect of interest and a random sample of controls from the this compound dataset.
-
Define the exposure variable (e.g., binary: yes/no for medication use).
-
Identify potential confounding variables (e.g., maternal age, race, education).
-
-
Statistical Analysis:
-
Perform univariate logistic regression to assess the crude association between the exposure and the birth defect.
-
Perform multivariable logistic regression, including the exposure and potential confounders in the model.
-
The model is specified as: logit(P(Disease)) = β₀ + β₁(Exposure) + β₂(Confounder₁) + ... + βₙ(Confounderₙ)
-
-
Interpretation:
-
The odds ratio for the exposure is calculated as exp(β₁).
-
A 95% confidence interval for the odds ratio that does not include 1.0 indicates a statistically significant association.
-
Protocol 2: Analysis of Gene-Environment Interaction using a Case-Only Design
Objective: To efficiently screen for potential interactions between a large number of genetic variants and an environmental exposure.
Methodology:
-
Data Preparation:
-
Select only the cases with the birth defect of interest from the this compound dataset.
-
Define the genetic variables (e.g., genotypes for a set of SNPs).
-
Define the environmental exposure variable.
-
-
Statistical Analysis:
-
For each genetic variant, perform a logistic regression with the genotype as the outcome and the environmental exposure as the predictor.
-
The model is specified as: logit(P(Genotype)) = α₀ + α₁(Exposure)
-
-
Interpretation:
-
A statistically significant association between the exposure and the genotype among cases suggests a potential gene-environment interaction.
-
Caution: This method assumes that the genetic and environmental factors are independent in the general population. Any significant findings should be validated using a case-control analysis with an interaction term.
-
Visualizations
Below are diagrams illustrating common workflows and logical relationships in the analysis of this compound data.
Caption: Workflow for Logistic Regression Analysis.
Caption: Logical Model of Gene-Environment Interaction.
References
- 1. This compound.org [this compound.org]
- 2. This compound.org [this compound.org]
- 3. catalog.data.gov [catalog.data.gov]
- 4. routledge.com [routledge.com]
- 5. Bayesian hierarchical models for disease mapping applied to contagious pathologies - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Bayesian hierarchical modeling - Wikipedia [en.wikipedia.org]
- 7. researchgate.net [researchgate.net]
- 8. Machine Learning Approaches for Early Diagnosis and Prediction of Fetal Abnormalities | IEEE Conference Publication | IEEE Xplore [ieeexplore.ieee.org]
- 9. scholarworks.aub.edu.lb [scholarworks.aub.edu.lb]
- 10. New Study Using Machine Learning Shows Promise in Predicting Birth Defects Cases - BioSpace [biospace.com]
- 11. Joint modeling of gene-environment correlations and interactions using polygenic risk scores in case-control studies - PMC [pmc.ncbi.nlm.nih.gov]
- 12. academic.oup.com [academic.oup.com]
- 13. academic.oup.com [academic.oup.com]
Technical Support Center: Adjusting for Multiple Comparisons in NBDPS Genetic Studies
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to assist researchers, scientists, and drug development professionals in addressing the challenges of multiple comparisons in National Birth Defects Prevention Study (NBDPS) genetic studies.
Frequently Asked Questions (FAQs)
Q1: Why is it critical to adjust for multiple comparisons in this compound genetic studies?
In genetic association studies like the this compound, researchers often test hundreds of thousands to millions of genetic markers (e.g., SNPs) for association with a particular birth defect.[1] When performing a large number of statistical tests, some tests will yield statistically significant results purely by chance, even if there is no true association. This is known as the multiple comparisons problem.[2]
For instance, if you perform 100,000 independent tests at a significance level (alpha) of 0.05, you would expect to find 5,000 false positives (Type I errors) by chance alone.[1] Adjusting for multiple comparisons is essential to control for this inflated false positive rate and to ensure that the identified associations are genuinely linked to the phenotype and not just random noise.[1][3]
Q2: What are the most common methods for multiple comparison correction in genetic studies?
There are several methods to control for multiple comparisons, each with its own strengths and weaknesses. The most common approaches include:
-
Bonferroni Correction: This is a traditional and straightforward method that adjusts the significance threshold by dividing the desired alpha level (e.g., 0.05) by the number of tests performed.[1][4]
-
False Discovery Rate (FDR) Control: Methods like the Benjamini-Hochberg procedure control the expected proportion of false positives among the significant results.[4][5] This approach is generally less stringent than the Bonferroni correction.[6]
-
Permutation Testing: Considered a gold standard by many, this non-parametric method empirically determines the significance threshold by randomly shuffling the phenotype data and re-running the association tests thousands of times to create a null distribution of the test statistic.[7][8][9]
Q3: How does Linkage Disequilibrium (LD) impact the choice of a multiple comparison correction method?
Linkage Disequilibrium (LD) is the non-random association of alleles at different loci. In genetic studies, SNPs in close proximity on a chromosome are often correlated, meaning they are not independent tests.[10][11]
The Bonferroni correction assumes that all tests are independent. When tests are correlated due to LD, the Bonferroni correction becomes overly conservative, leading to a high rate of false negatives (failing to detect true associations).[1][10][11] Methods that account for the correlation structure of the data, such as permutation testing or those that estimate the "effective" number of independent tests, are often more powerful in the presence of LD.[4][12]
Troubleshooting Guides
Issue: My Bonferroni-corrected p-values are too stringent, and I'm not detecting any significant associations.
This is a common issue, especially in genome-wide association studies (GWAS) with high LD.[1] The Bonferroni correction is known to be conservative and can lead to a substantial loss of statistical power.[1][10]
Solutions:
-
Consider a less stringent method: Instead of controlling the Family-Wise Error Rate (FWER) with Bonferroni, consider controlling the False Discovery Rate (FDR).[5] The Benjamini-Hochberg procedure, for example, offers a better balance between discovering true associations and limiting false positives.[6]
-
Use a method that accounts for LD:
-
Permutation Testing: This is a robust method that implicitly accounts for the correlation between markers.[7][8] However, it can be computationally intensive.[8][12]
-
Effective Number of Tests: Some methods estimate the "effective" number of independent tests based on the LD structure of your data and use this smaller number in a Bonferroni-style correction.[4][12]
-
Issue: Permutation testing is too computationally intensive for my dataset.
While powerful, permutation testing can be time-consuming, especially for large datasets.[8]
Solutions:
-
Optimized Permutation Algorithms: Several software packages have implemented optimized algorithms to speed up permutation testing.[13]
-
Parametric Bootstrap: As an alternative, the parametric bootstrap approach can be used, which may be less computationally demanding in some scenarios.[14]
-
Alternative Methods: Consider methods like SLIDE (Sliding-window method for Locally Inter-correlated markers with asymptotic Distribution Errors corrected) or simpleM, which are designed to be faster alternatives to permutation testing while still accounting for LD.[10][11][13]
Data Presentation
The following table summarizes the key characteristics of the most common multiple comparison correction methods.
| Method | Controls | Stringency | Assumption of Independence | Impact of LD | Computational Intensity |
| Bonferroni Correction | Family-Wise Error Rate (FWER) | High | Assumes independence | Overly conservative | Low |
| False Discovery Rate (FDR) | Proportion of false positives | Moderate | Less sensitive to dependence | Less conservative than Bonferroni | Low |
| Permutation Testing | Family-Wise Error Rate (FWER) | Moderate to High | Does not assume independence | Accounts for LD structure | High |
Experimental Protocols
Protocol 1: Bonferroni Correction
-
Determine the number of tests (m): This is the total number of SNPs or genetic markers you are testing.
-
Set your desired family-wise error rate (α): This is typically 0.05.
-
Calculate the corrected significance threshold (α'): α' = α / m.[15]
-
Compare each p-value to the corrected threshold: A p-value is considered significant only if it is less than or equal to α'.
Protocol 2: False Discovery Rate (FDR) Control using Benjamini-Hochberg
-
Rank your p-values: Order your p-values from smallest to largest: p(1) ≤ p(2) ≤ ... ≤ p(m).
-
Calculate the Benjamini-Hochberg critical value for each p-value: For each p-value p(i), the critical value is (i/m) * Q, where 'i' is the rank of the p-value, 'm' is the total number of tests, and 'Q' is your desired false discovery rate (e.g., 0.05).
-
Identify the largest p-value that is smaller than its critical value: Find the largest 'i' for which p(i) ≤ (i/m) * Q.
-
Declare significance: All p-values with a rank less than or equal to this 'i' are considered significant.
Protocol 3: Permutation Testing
-
Record the observed test statistic: For each SNP, calculate and record the test statistic (e.g., chi-squared value) from your original data. Identify the maximum test statistic across all SNPs.
-
Permute the data: Randomly shuffle the phenotype labels (e.g., case/control status) among your subjects.
-
Recalculate the test statistic: Perform the association tests on the permuted data and record the maximum test statistic.
-
Repeat: Repeat steps 2 and 3 a large number of times (e.g., 10,000 or more) to generate a null distribution of the maximum test statistic.[9]
-
Calculate the empirical p-value: The empirical p-value for your observed maximum test statistic is the proportion of times the maximum test statistic from the permuted data was greater than or equal to your observed maximum test statistic.
Visualizations
Caption: Workflow for a typical genetic association study.
Caption: Decision tree for choosing a correction method.
Caption: Relationship between different error types.
References
- 1. The multiple comparison problem in GWAS: Bonferroni correction, FDR control, and permutation testing [lybird300.github.io]
- 2. stats.libretexts.org [stats.libretexts.org]
- 3. pnas.org [pnas.org]
- 4. Multiple Comparisons in Genetic Association Studies: A Hierarchical Modeling Approach - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Improving Power of Genome-Wide Association Studies with Weighted False Discovery Rate Control and Prioritized Subset Analysis | PLOS One [journals.plos.org]
- 6. physiology.med.cornell.edu [physiology.med.cornell.edu]
- 7. BRASS: Permutation methods for binary traits in genetic association studies with structured samples | PLOS Genetics [journals.plos.org]
- 8. Permutation tests in genome-wide asscociation studies [lybird300.github.io]
- 9. faculty.washington.edu [faculty.washington.edu]
- 10. "Accounting for Multiple Comparisons in a Genome-Wide Association Study" by Randall C. Johnson, George W. Nelson et al. [nsuworks.nova.edu]
- 11. Accounting for multiple comparisons in a genome-wide association study (GWAS) - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. Correction for multiple testing in a gene region - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Accounting for multiple comparisons in a genome-wide association study (GWAS) - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Permutation and parametric bootstrap tests for gene—gene and gene—environment interactions - PMC [pmc.ncbi.nlm.nih.gov]
- 15. A general introduction to adjustment for multiple comparisons - PMC [pmc.ncbi.nlm.nih.gov]
Technical Support Center: Improving Exposure Assessment Accuracy in NBDPS Data
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) for researchers, scientists, and drug development professionals working with the National Birth Defects Prevention Study (NBDPS) data. The focus is on enhancing the accuracy of exposure assessment, a critical component of identifying potential risk factors for birth defects.
Frequently Asked Questions (FAQs)
Q1: What are the primary limitations of exposure assessment in the this compound data?
The primary limitation of exposure assessment in the this compound is its heavy reliance on maternal self-report through computer-assisted telephone interviews (CATI).[1] This method is susceptible to several forms of bias:
-
Recall Bias: Mothers of children with birth defects may recall and report exposures differently than mothers of children without birth defects. This differential recall can artificially inflate or deflate the association between an exposure and an outcome.
-
Exposure Misclassification: Participants may not accurately remember the timing, duration, or frequency of certain exposures, leading to misclassification. This can be non-differential (occurring equally in cases and controls) or differential.
-
Social Desirability Bias: Participants may underreport socially undesirable behaviors (e.g., smoking, alcohol use) or over-report socially desirable ones (e.g., vitamin use).
Q2: How can I address recall bias in my analysis of this compound data?
Several strategies can be employed to mitigate the impact of recall bias:
-
Use of a Control Group: The case-control design of the this compound itself is a fundamental strategy to assess recall bias by comparing the reporting patterns of case and control mothers.[1]
-
Validation Sub-studies: Compare self-reported data with more objective sources for a subset of your study population. For example, self-reported smoking can be compared with cotinine (B1669453) levels in stored biological samples.[2]
-
Statistical Adjustments: Employ statistical techniques like probabilistic bias analysis (PBA) to model the uncertainty due to misclassification and adjust the observed associations.[3][4][5]
Q3: Are there ways to validate self-reported medication use in the this compound?
Yes, researchers can attempt to validate self-reported medication use by linking this compound data with external databases. This process, however, is complex and requires appropriate approvals.
-
Linkage to Prescription Databases: If available for the study population, prescription databases can provide a more objective measure of medication dispensing.
-
Linkage to Electronic Health Records (EHRs): EHRs may contain physician-recorded medication lists and prescriptions.
-
Challenges: Access to these databases is often restricted due to privacy regulations. Furthermore, prescription data does not confirm that the medication was actually taken by the individual.
Q4: How was occupational exposure assessed in the this compound, and how can I refine this in my study?
The this compound collected information on maternal occupations.[6] This self-reported job information was then used by industrial hygienists to estimate exposures to various workplace agents.[7][8][9] To refine occupational exposure assessment, you can:
-
Utilize the this compound Occupational Exposure Database: An occupational exposure database was created for the this compound, which includes estimates of frequency, intensity, and duration of exposure to various chemicals for over 10,000 respondents.
-
Expert Review: For specific occupations or exposures of interest, consider a more detailed review of the job descriptions by an industrial hygienist to refine exposure estimates.
-
Job-Exposure Matrices (JEMs): Apply JEMs to link job titles with potential exposures. However, be aware that JEMs provide a general estimation and may not capture the variability in exposure within a specific job title.
Q5: Can I link this compound data to environmental databases to improve exposure assessment?
Yes, linking this compound data with environmental databases is a key strategy for improving the accuracy of exposure to environmental contaminants.[10][11]
-
Geocoding: Maternal residential addresses from the this compound have been geocoded, allowing for linkage with spatial environmental data.[12]
-
Available Data: This approach has been used to assess exposure to air pollution, contaminants in drinking water, and proximity to hazardous waste sites.[10][12][13]
-
Access: Accessing geocoded data is restricted and requires special permission through the this compound public access protocol to protect participant confidentiality.[14][15]
Troubleshooting Guides
Problem: My analysis shows a strong association between a self-reported exposure and a birth defect, but I am concerned about recall bias.
Solution Workflow:
-
Assess Plausibility: Critically evaluate the biological plausibility of the association.
-
Internal Validation: If available, analyze data from any internal validation components of the this compound for the exposure of interest.
-
Sensitivity Analysis: Conduct a sensitivity analysis to assess how the association changes under different assumptions about recall bias.
-
Probabilistic Bias Analysis (PBA): Implement a PBA to quantify the potential impact of misclassification on your results. This involves specifying prior distributions for sensitivity and specificity of exposure reporting in cases and controls.
Logical Workflow for Addressing Potential Recall Bias
Caption: A stepwise approach to addressing potential recall bias.
Problem: I want to assess exposure to a specific environmental contaminant not directly measured in the this compound.
Solution Workflow:
-
Identify Relevant Environmental Databases: Research publicly available or restricted-access environmental databases that contain data on the contaminant of interest for the relevant time period and geographic locations covered by the this compound.
-
Request Geocoded this compound Data: Follow the official this compound protocol to request access to the geocoded residential data for your study population.[14][15]
-
Data Linkage: Once you have the necessary approvals and data, link the this compound participant residences to the environmental data using geographic information systems (GIS).
-
Exposure Modeling: Develop an exposure model to estimate individual-level exposures based on the linked data. This may involve considering factors like distance to the source, prevailing winds, and water distribution networks.
-
Statistical Analysis: Incorporate the modeled exposure estimates into your statistical analysis.
Experimental Workflow for Environmental Data Linkage
Caption: Workflow for linking this compound data with environmental databases.
Data Presentation
Table 1: Comparison of Exposure Assessment Methods
| Method | Description | Advantages | Disadvantages |
| Maternal Interview (CATI) | Structured questionnaire administered over the phone to collect self-reported data on a wide range of exposures.[1] | - Cost-effective for large populations.- Can collect data on a wide variety of exposures.- Captures information on timing and duration of exposure. | - Prone to recall bias and misclassification.- May be influenced by social desirability bias. |
| Biomarkers | Measurement of a substance or its metabolite in biological samples (e.g., blood, urine) to indicate exposure.[2][16] | - Objective measure of internal dose.- Can validate self-reported data. | - Can be expensive and invasive.- Short half-life of some biomarkers may not reflect chronic exposure.- Samples may not be available for all participants or time periods. |
| Environmental Data Linkage | Linking geocoded residential addresses to external databases on environmental quality (e.g., air and water pollution).[10][11] | - Provides objective, geographically-based exposure estimates.- Can assess exposures not easily recalled by individuals. | - Exposure at residence may not reflect total personal exposure.- Accuracy depends on the quality and resolution of the environmental data. |
| Occupational Exposure Assessment | Use of job titles, industry codes, and expert review by industrial hygienists to estimate workplace exposures.[7][8] | - More specific than relying on job titles alone.- Can estimate exposure to specific chemicals and their intensity. | - Can be resource-intensive.- Relies on the accuracy of self-reported job descriptions.- Exposure can vary significantly within the same job title. |
Experimental Protocols
Protocol 1: Probabilistic Bias Analysis (PBA) for Misclassified Self-Reported Exposure
Objective: To adjust the odds ratio for the association between a self-reported binary exposure and a birth defect for potential misclassification.
Methodology:
-
Define Bias Parameters:
-
Sensitivity of exposure reporting among cases (SeC)
-
Specificity of exposure reporting among cases (SpC)
-
Sensitivity of exposure reporting among controls (SeT)
-
Specificity of exposure reporting among controls (SpT)
-
-
Specify Prior Distributions: Based on literature, validation data, or expert opinion, specify probability distributions for each bias parameter (e.g., Beta, triangular).[4][5]
-
Monte Carlo Simulation:
-
Run a large number of iterations (e.g., 10,000).
-
In each iteration, randomly draw a value for each bias parameter from its specified distribution.
-
Use these drawn values to calculate an adjusted odds ratio.
-
-
Summarize Results:
-
Create a frequency distribution of the adjusted odds ratios.
-
Report the median and the 95% simulation interval (2.5th and 97.5th percentiles) of the adjusted odds ratios.
-
Protocol 2: Industrial Hygienist Review for Occupational Exposure Assessment
Objective: To systematically estimate maternal occupational exposure to specific agents based on interview data.
Methodology:
-
Data Collection: Gather all relevant information from the maternal interview, including:
-
Job title and industry.
-
Description of job duties and tasks.
-
Materials and chemicals used.
-
Use of personal protective equipment (PPE).
-
-
Development of an Exposure Assessment Protocol: Create a standardized protocol for the industrial hygienist to follow, including a list of specific agents of interest and a rating scale for exposure probability, intensity, and frequency.[9]
-
Expert Review: A trained industrial hygienist reviews each job description without knowledge of the case or control status of the participant.
-
Exposure Rating: The hygienist assigns ratings for the likelihood, intensity, and frequency of exposure to the agents of interest for each job.
-
Data Analysis: Use the assigned exposure ratings as the exposure variable in the statistical analysis.
Signaling Pathways
Environmental Exposures and Developmental Signaling Pathways
Certain environmental exposures have been hypothesized to interfere with key signaling pathways crucial for normal embryonic development.[17][18][19][20] For example, exposure to endocrine-disrupting chemicals (EDCs) can interfere with hormone signaling pathways that are essential for the development of the reproductive, nervous, and immune systems.
Hypothesized Impact of Endocrine Disruptors on Fetal Development
Caption: A simplified signaling pathway illustrating how EDCs may lead to birth defects.
References
- 1. This compound.org [this compound.org]
- 2. Association between Self-Reported Survey Measures and Biomarkers of Second-Hand Tobacco Smoke Exposure in Non-Smoking Pregnant Women - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. Assessing the Impact of Exposure Misclassification in Case-Control Studies of Self-Reported Medication Use - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. Probabilistic Sensitivity Analysis of Misclassification | Columbia University Mailman School of Public Health [publichealth.columbia.edu]
- 5. Probabilistic bias analysis in pharmacoepidemiology and comparative effectiveness research: a systematic review - PMC [pmc.ncbi.nlm.nih.gov]
- 6. The National Birth Defects Prevention Study: a review of the methods - PMC [pmc.ncbi.nlm.nih.gov]
- 7. tandfonline.com [tandfonline.com]
- 8. Exposure Assessment in Epidemiologic Carcinogenicity Studies - Review of the Formaldehyde Assessment in the National Toxicology Program 12th Report on Carcinogens - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 9. ishn.com [ishn.com]
- 10. Next steps for birth defects research and prevention: The Birth Defects Study To Evaluate Pregnancy exposureS (BD-STEPS) - PMC [pmc.ncbi.nlm.nih.gov]
- 11. researchgate.net [researchgate.net]
- 12. catalog.data.gov [catalog.data.gov]
- 13. Air pollutants linked to higher risk of birth defects, researchers find [med.stanford.edu]
- 14. catalog.data.gov [catalog.data.gov]
- 15. Methods for Accessing this compound and BD-STEPS Data | Birth Defects | CDC [cdc.gov]
- 16. The relationship between self-report and biomarkers of stress in low-income, reproductive age women - PMC [pmc.ncbi.nlm.nih.gov]
- 17. Environmental chemicals and preterm birth: Biological mechanisms and the state of the science - PMC [pmc.ncbi.nlm.nih.gov]
- 18. Effects of environmental exposures on fetal and childhood growth trajectories - PMC [pmc.ncbi.nlm.nih.gov]
- 19. Environmental birth defects | Research Starters | EBSCO Research [ebsco.com]
- 20. ephtn.dhss.mo.gov [ephtn.dhss.mo.gov]
Technical Support Center: NBDPS Cohort Subgroup Analysis
This technical support center provides researchers, scientists, and drug development professionals with troubleshooting guides and frequently asked questions (FAQs) for conducting subgroup analysis within the National Birth Defects Prevention Study (NBDPS) cohort.
Frequently Asked Questions (FAQs)
Q1: What is the primary goal of subgroup analysis in the this compound?
The main objective is to assess "effect modification," which is to determine if the association between a specific exposure (e.g., medication, environmental factor) and a birth defect outcome differs across various strata or subgroups of the study population (e.g., by maternal age, genetic variants, or co-exposures). This helps in identifying populations that may be more susceptible to certain risk factors.
Q2: How should I pre-specify my subgroup analyses to avoid spurious findings?
To ensure the credibility of your findings, subgroup analyses should be based on strong biological or theoretical rationale and specified a priori in your statistical analysis plan.[1][2] Exploratory, or post hoc, analyses can be useful for generating new hypotheses but should be clearly labeled as such and interpreted with caution due to the risk of false positives from multiple testing.[1][3]
Q3: My subgroup of interest is very small. How does this affect my analysis?
Analyses of small subgroups are often underpowered, meaning they lack the statistical ability to detect a true effect or interaction, leading to false-negative results.[4] For a subgroup analysis to be reliable, the initial study's power calculation should ideally account for the planned subgroups. When sample sizes are small, confidence intervals around your effect estimates will be wide, reflecting greater uncertainty. It is crucial to report these confidence intervals to convey the precision of the estimate.[3]
Q4: How do I statistically test for an interaction between an exposure and a subgroup characteristic?
The standard method is to use a multivariable logistic regression model that includes the main exposure variable, the subgrouping variable, and an "interaction term."[5] The interaction term is typically the product of the exposure and subgroup variables. A statistically significant coefficient for this interaction term (evaluated using a p-value) suggests that the effect of the exposure on the outcome differs depending on the subgroup.
Q5: What are the common challenges and biases I should be aware of when analyzing this compound data?
The this compound, like any large case-control study, has specific challenges:
-
Recall Bias: Maternal self-report of exposures after the birth of a child can be differential between mothers of cases and controls.[6]
-
Confounding: It is critical to adjust for potential confounders in your statistical models. For example, when studying the effect of an antidepressant, one must consider confounding by the underlying indication (i.e., depression itself).[6]
-
Multiple Testing: Analyzing multiple exposures, multiple outcomes, and multiple subgroups increases the probability of finding a statistically significant result by chance alone.[7][8] Methods like the Bonferroni correction can be used to adjust p-values, though they can be overly conservative.[4]
-
Population Stratification: In gene-environment interaction studies, it's important to account for potential confounding by genetic ancestry, as the frequency of genetic variants can differ across populations.[9]
Troubleshooting Guides
Guide: Testing for Effect Modification with Logistic Regression
This guide outlines the protocol for assessing whether the effect of a primary exposure on a birth defect is modified by a third variable (the subgroup characteristic). We will use the example of assessing if the effect of maternal smoking is modified by maternal age.
Objective: To determine if the odds ratio for the association between maternal smoking and a specific congenital heart defect (CHD) is different for mothers aged ≥35 compared to mothers <35.
Methodology: Unconditional multivariable logistic regression.[3]
Protocol Steps:
-
Variable Coding:
-
Outcome (Y): Case status (e.g., 1 = Septal Heart Defect, 0 = Control).
-
Primary Exposure (X1): Maternal Smoking (e.g., 1 = Smoker, 0 = Non-smoker).
-
Subgroup/Moderator (X2): Maternal Age (e.g., 1 = ≥35 years, 0 = <35 years).
-
Covariates (C1, C2,...Cn): Include other known confounders such as maternal race-ethnicity, education, and pre-pregnancy BMI.
-
-
Model Building:
-
Construct a logistic regression model in your statistical software (e.g., R, SAS).
-
The model should include the main effects of the exposure and the moderator, any confounders, and the interaction term.
-
The interaction term is created by multiplying the exposure variable by the moderator variable (X1 * X2).
-
-
Regression Equation: logit(P(Y=1)) = β0 + β1(Smoking) + β2(Age≥35) + β3(Smoking * Age≥35) + ... + βn(Cn)
-
Interpretation of Coefficients:
-
exp(β1): The odds ratio for the effect of smoking among the reference group for age (Mothers <35).
-
exp(β2): The odds ratio for having the outcome for older mothers (≥35) who are non-smokers, compared to younger mothers (<35) who are non-smokers.
-
exp(β3): The key term for effect modification. This is the ratio of the odds ratios. If β3 is statistically significant (e.g., p < 0.05), it indicates that the effect of smoking on the outcome is different for mothers aged ≥35 compared to those <35.
-
-
Reporting Results:
-
Present the adjusted odds ratio (aOR) and 95% confidence interval for the interaction term.
-
Report the stratum-specific odds ratios (i.e., the OR for smoking in the <35 age group and the OR for smoking in the ≥35 age group) to make the nature of the interaction clear.
-
Data Presentation
The following table summarizes data from a study on maternal smoking and septal defects within the this compound cohort, demonstrating how to present results from a subgroup analysis.
Table 1: Subgroup Analysis of the Association Between Periconceptional Smoking and Septal Defects
| Subgroup Characteristic | Subgroup Levels | Cases/Controls (Smokers) | Adjusted Odds Ratio (95% CI) |
| Maternal Age | < 20 years | 215 / 277 | 1.8 (1.4 - 2.3) |
| 20-34 years | 1201 / 1572 | 1.4 (1.3 - 1.6) | |
| ≥ 35 years | 179 / 188 | 1.7 (1.3 - 2.3) | |
| Maternal Race/Ethnicity | Non-Hispanic White | 1259 / 1476 | 1.5 (1.4 - 1.7) |
| Non-Hispanic Black | 100 / 142 | 1.4 (1.0 - 1.9) | |
| Hispanic | 174 / 321 | 1.2 (0.9 - 1.5) | |
| Data derived from Al-Ani et al., "Maternal Smoking and Congenital Heart Defects, National Birth Defects Prevention Study, 1997–2011". The table presents adjusted odds ratios for any maternal smoking versus no smoking for the outcome of aggregated septal defects.[3] |
Experimental Protocols & Visualizations
General Workflow for Subgroup Analysis
This workflow outlines the key stages of a well-designed subgroup analysis project using this compound data.
References
- 1. researchgate.net [researchgate.net]
- 2. pmc.ncbi.nlm.nih.gov [pmc.ncbi.nlm.nih.gov]
- 3. pmc.ncbi.nlm.nih.gov [pmc.ncbi.nlm.nih.gov]
- 4. m.youtube.com [m.youtube.com]
- 5. web.pdx.edu [web.pdx.edu]
- 6. pmc.ncbi.nlm.nih.gov [pmc.ncbi.nlm.nih.gov]
- 7. pmc.ncbi.nlm.nih.gov [pmc.ncbi.nlm.nih.gov]
- 8. Neural Tube Defects (NTD): Folic Acid and Pregnancy | Embryo Project Encyclopedia [embryo.asu.edu]
- 9. ncbi.nlm.nih.gov [ncbi.nlm.nih.gov]
Technical Support Center: Software and Tools for Protein Stability and Characterization Analysis
A Note on Terminology: The term "NBDPS data" most commonly refers to the National Birth Defects Prevention Study, a large-scale public health research project.[1][2][3][4][5][6][7] For researchers, scientists, and drug development professionals in the biophysical and pharmaceutical fields, a more frequent area of focus is the analysis of protein characteristics. This guide will focus on the software, tools, and workflows for analyzing protein stability, a critical aspect of drug development and protein engineering. We will also touch upon the emerging field of Next-Generation Protein Sequencing (NGPS).[8][9][10][11][12]
This technical support center provides troubleshooting guides and FAQs for common software and experimental procedures related to protein stability analysis, particularly focusing on thermal shift assays (also known as Differential Scanning Fluorimetry or DSF).
Frequently Asked Questions (FAQs)
Q1: What is a thermal shift assay and why is it important?
A thermal shift assay is a technique used to determine the thermal stability of a protein. It measures the change in the melting temperature (Tm) of a protein under different conditions, such as the presence of various ligands, buffer compositions, or mutations. An increase in Tm typically indicates that the ligand or condition has a stabilizing effect on the protein, which is crucial information for drug discovery (e.g., identifying compounds that bind to a target protein) and protein engineering.
Q2: What are the key software tools for analyzing thermal shift assay data?
Several software tools are available for analyzing data from thermal shift experiments, which are often generated by real-time PCR instruments.[13][14][15][16] Key software includes:
-
TSA-CRAFT: A free, web-based tool for automatic and robust analysis of thermal shift assay data. It can directly read data files from real-time PCR instruments and provides accurate Tm and ΔTm results.[13]
-
Applied Biosystems™ Protein Thermal Shift™ Software: This software is designed to analyze protein melt fluorescent readings directly from Applied Biosystems real-time PCR instrument files.[14][15][16]
-
CalFitter 2.0: A web server that allows for the analysis of thermal shift data without requiring deep knowledge of the underlying mathematical principles.[17]
-
MoltenProt: An online tool for determining the melting temperature (Tm) and the slope of the thermal unfolding curve, which is also important for understanding protein stability.[17]
Q3: What is the difference between the Boltzmann and derivative methods for Tm determination?
The Protein Thermal Shift™ Software and other tools often provide two methods for calculating the melting temperature (Tm):[14][15]
-
Boltzmann Method: This method fits the unfolding data to the two-state Boltzmann model to generate the Tm. It is typically used for proteins that exhibit a single, well-defined melting transition.[14]
-
Derivative Curve Method: This method calculates the first derivative of the melting curve, and the peak of the derivative curve corresponds to the Tm.
The Boltzmann method is often considered more accurate for proteins with a clear two-state unfolding process.[13]
Q4: Can I predict protein stability computationally?
Yes, several computational tools can predict changes in protein stability upon mutation, which is valuable for protein engineering and understanding the impact of genetic variations. Some widely used tools include:
-
FoldX: A powerful tool for predicting changes in protein stability by estimating the contribution of individual amino acid residues.[18]
-
Rosetta: A comprehensive suite of tools for protein structure prediction and design that includes protocols for predicting the stability effects of mutations.[18]
-
PoPMuSiC (Prediction of Mutations in Stability of Proteins with Internal Contacts): A web server that predicts the effects of mutations on protein stability.[18]
-
I-Mutant Suite: A web server with tools to predict protein stability changes upon single-point mutations.[18]
Troubleshooting Guides
Issue 1: High variability in melting temperature (Tm) replicates.
-
Possible Cause: Inaccurate pipetting, leading to variations in protein or ligand concentration.
-
Solution: Ensure pipettes are calibrated. Use low-retention pipette tips. Prepare a master mix of the protein and buffer to minimize pipetting errors between wells.
-
-
Possible Cause: Air bubbles in the wells of the PCR plate.
-
Solution: Centrifuge the plate briefly after sealing to remove any air bubbles.
-
-
Possible Cause: Poor quality or improperly sealed plate.
-
Solution: Use high-quality PCR plates and ensure they are sealed properly to prevent evaporation during the experiment.
-
Issue 2: No clear melting transition observed.
-
Possible Cause: The protein may be unfolded or aggregated at the starting temperature.
-
Solution: Check the initial stability of your protein sample using other techniques like size-exclusion chromatography. Optimize the buffer conditions (pH, salt concentration) to ensure the protein is properly folded.
-
-
Possible Cause: The fluorescent dye is incompatible with the protein or buffer.
-
Solution: Try a different fluorescent dye. Some proteins may have intrinsic fluorescence that can be used instead of an extrinsic dye.
-
-
Possible Cause: The protein concentration is too low or too high.
-
Solution: Optimize the protein concentration. A typical starting point is between 2-10 µM.
-
Issue 3: Software fails to fit the melting curve.
-
Possible Cause: The data is too noisy.
-
Solution: Repeat the experiment with careful attention to pipetting and plate setup. Ensure the instrument is functioning correctly.
-
-
Possible Cause: The melting transition is not a simple two-state process.
-
Solution: Manually inspect the melt curve. Some proteins may have multiple unfolding domains, leading to complex curves. The derivative method might be more suitable for identifying multiple transitions.
-
-
Possible Cause: Incorrect data import format.
Data Presentation
Table 1: Comparison of Thermal Shift Analysis Software
| Feature | TSA-CRAFT[13] | Applied Biosystems™ Protein Thermal Shift™ Software[14][15] |
| Cost | Free | Commercial |
| Platform | Web-based | Standalone software |
| Input File Format | Supports various real-time PCR instrument files | Primarily for Applied Biosystems™ instruments |
| Analysis Methods | Boltzmann equation fitting | Boltzmann and Derivative Curve methods |
| Throughput | High-throughput analysis | Medium to high-throughput analysis |
| User Interface | Web browser-based | Graphical User Interface |
Experimental Protocols
Detailed Methodology: Protein Thermal Shift Assay
-
Protein and Ligand Preparation:
-
Prepare a stock solution of the purified protein in a suitable buffer (e.g., 100 mM HEPES pH 7.5, 150 mM NaCl). The final protein concentration in the assay is typically 2-10 µM.
-
Prepare stock solutions of the ligands (e.g., small molecules, peptides) to be tested. It is recommended to have a final DMSO concentration below 1% if ligands are dissolved in DMSO.
-
-
Assay Plate Setup:
-
On a 96-well or 384-well PCR plate, add the protein solution to each well.
-
Add the test ligands to the appropriate wells. Include control wells with no ligand and wells with a known stabilizing ligand if available.
-
Add the fluorescent dye (e.g., SYPRO Orange) to each well. The final concentration of the dye needs to be optimized, but a 5X final concentration is a common starting point.
-
The final reaction volume is typically 20-25 µL.
-
-
Data Acquisition:
-
Seal the PCR plate securely.
-
Centrifuge the plate briefly to remove air bubbles.
-
Place the plate in a real-time PCR instrument.
-
Set up the instrument to ramp the temperature from a starting temperature (e.g., 25°C) to a final temperature (e.g., 95°C) with a slow ramp rate (e.g., 0.05°C/sec).
-
Configure the instrument to collect fluorescence data at each temperature increment.
-
-
Data Analysis:
-
Export the fluorescence data from the real-time PCR instrument.
-
Import the data into your chosen analysis software (e.g., TSA-CRAFT, Protein Thermal Shift™ Software).
-
The software will generate melting curves by plotting fluorescence intensity versus temperature.
-
Calculate the melting temperature (Tm) for each well using either the Boltzmann fitting or the derivative method.
-
Determine the change in melting temperature (ΔTm) by subtracting the Tm of the control (protein + dye) from the Tm of the protein with a ligand. A positive ΔTm indicates stabilization.
-
Visualizations
Experimental and Computational Workflow for Protein Stability Analysis
Caption: Workflow for experimental and computational protein stability analysis.
Signaling Pathway Example: Kinase Inhibition and Stability
References
- 1. Methods for Accessing this compound and BD-STEPS Data | Birth Defects | CDC [cdc.gov]
- 2. This compound.org [this compound.org]
- 3. Research Portal [iro.uiowa.edu]
- 4. This compound.org [this compound.org]
- 5. The National Birth Defects Prevention Study: a review of the methods - PMC [pmc.ncbi.nlm.nih.gov]
- 6. This compound.org [this compound.org]
- 7. National Birth Defects Prevention Study – Iowa Registry for Congenital and Inherited Disorders [ircid.public-health.uiowa.edu]
- 8. Strategies for Development of a Next-Generation Protein Sequencing Platform - PMC [pmc.ncbi.nlm.nih.gov]
- 9. A New Era of Protein Sequencing | Lab Manager [labmanager.com]
- 10. Towards Next Generation Protein Sequencing - PubMed [pubmed.ncbi.nlm.nih.gov]
- 11. discovery.researcher.life [discovery.researcher.life]
- 12. quantum-si.com [quantum-si.com]
- 13. TSA-CRAFT: A Free Software for Automatic and Robust Thermal Shift Assay Data Analysis - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Applied Biosystems™ Protein Thermal Shift™ Software v1.4 | Fisher Scientific [fishersci.ca]
- 15. Protein Thermal Shift™ Software v1.4 | Request for Quote | Applied Biosystems™ [thermofisher.com]
- 16. m.youtube.com [m.youtube.com]
- 17. academic.oup.com [academic.oup.com]
- 18. researchgate.net [researchgate.net]
Navigating the National Birth Defects Prevention Study (NBDPS) Data: A Guide for Researchers
The National Birth Defects Prevention Study (NBDPS) is a valuable resource for investigating the potential causes of birth defects. As a large, population-based case-control study, it provides a wealth of data for researchers, scientists, and drug development professionals. However, like any complex dataset, it has inherent limitations and potential pitfalls that users must consider to ensure the validity of their findings. This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to help you navigate common challenges when using this compound data.
Frequently Asked Questions (FAQs)
Q1: What is the basic study design of the this compound, and what are its primary strengths?
The this compound is a case-control study that collected data on babies with and without major birth defects from ten U.S. states between 1997 and 2011.[1][2] Information was gathered through computer-assisted telephone interviews with mothers and through the collection of buccal (cheek) cells from the mother, father, and infant for genetic analysis.[1][3][4]
The primary strengths of the this compound lie in its large sample size, population-based design, and detailed classification of birth defects by clinical geneticists.[1][5] This allows for the study of a wide range of birth defects and potential risk factors.
Q2: What are the main sources of bias I should be aware of when using this compound data?
The main sources of bias in the this compound data are related to its case-control design and retrospective data collection. These include:
-
Recall Bias: Since mothers were interviewed after their baby was born, their recollection of exposures during pregnancy may be inaccurate. Mothers of babies with birth defects (cases) might recall exposures differently than mothers of babies without birth defects (controls).
-
Selection Bias: Only about two-thirds of eligible women participated in the study, which could introduce selection bias if the non-participants had different risk profiles from those who participated.[1] For instance, this compound control participants were generally older, more often non-Hispanic white, and had higher education levels than non-participants.[1] There is also potential bias in case selection, particularly regarding the incomplete inclusion of pregnancies that ended in termination.[5]
-
Confounding by Indication: When studying the effects of medications, it can be challenging to separate the effect of the drug from the effect of the underlying medical condition for which the drug was taken.[5][6]
Q3: How was the information on exposures during pregnancy collected, and what are the limitations?
Information on a wide range of exposures, including maternal health, diet, medication use, occupation, and lifestyle, was collected through a standardized computer-assisted telephone interview.[4] The interview covered the three months before pregnancy and the pregnancy period itself.[4]
A significant limitation is the retrospective nature of this data collection, which can lead to recall bias.[5] The accuracy of self-reported information on exposures, such as the specific timing and dosage of medications, can be a challenge.[5]
Q4: How were the cases and controls defined and selected in the this compound?
-
Cases: Cases were infants or fetuses with one or more of over 30 eligible major structural birth defects.[7] They were identified through existing birth defects surveillance programs in the participating states and included live births, stillbirths, and elective terminations.[1][7] A clinical geneticist reviewed all clinical information to confirm eligibility.[1]
-
Controls: Controls were live-born infants without any major birth defects.[1] They were randomly selected from the same geographic areas and time periods as the cases, using either vital records or birth hospital logs.[1][7]
Q5: Is genetic data available from the this compound, and how was it collected?
Yes, the this compound collected biological samples for genetic analysis. After the interview, families were sent kits to collect buccal (cheek) cells from the mother, father, and infant (if living).[1][4] DNA was extracted from these cells for genetic studies.[1]
Troubleshooting Guides
Issue 1: My analysis shows an association between a medication and a birth defect. How can I be more confident this is not due to confounding by indication?
Troubleshooting Steps:
-
Carefully define the underlying condition: Use the maternal health information collected in the this compound to identify women with the medical condition for which the drug is prescribed.
-
Stratify your analysis: Analyze the association between the medication and the birth defect separately for women with and without the underlying condition.
-
Use propensity score matching: This statistical method can help to balance the distribution of the underlying condition and other potential confounders between the exposed and unexposed groups.
-
Consider the severity of the indication: If possible, use available data to stratify by the severity of the maternal illness, as this may be associated with both the likelihood of taking the medication and the risk of a birth defect.[6]
Logical Relationship: Addressing Confounding by Indication
Caption: A diagram illustrating the challenge of confounding by indication and analytical approaches to mitigate it.
Issue 2: I am concerned about the potential for recall bias in my analysis of a self-reported exposure. What can I do?
Troubleshooting Steps:
-
Analyze exposures with high salience: Exposures that are more memorable and significant to the mother (e.g., a major illness during pregnancy) are less likely to be affected by recall bias than less memorable exposures (e.g., short-term use of an over-the-counter medication).
-
Use a control group with a different, but also stressful, outcome: While not possible with the existing this compound data, for future studies, comparing to a control group with a different adverse outcome can help to balance the recall process.
-
Conduct a sensitivity analysis: Perform a bias analysis to estimate how strong the recall bias would need to be to explain your observed association. This involves making assumptions about the sensitivity and specificity of exposure recall in cases and controls.
-
Look for consistency with other data sources: If possible, compare your findings with studies that used different methods for exposure ascertainment, such as prescription databases or medical records.
Experimental Workflow: Investigating and Mitigating Recall Bias
Caption: A workflow diagram for addressing potential recall bias in this compound data analysis.
Data Presentation
Due to the qualitative nature of the common pitfalls, a quantitative summary table is not applicable. Instead, the following table summarizes the key methodological considerations and potential biases in the this compound.
| Methodological Aspect | Description | Potential Pitfalls/Biases | Mitigation Strategies |
| Study Design | Population-based case-control study.[3] | Selection bias, recall bias.[5] | Careful selection of controls, sensitivity analyses for bias. |
| Data Collection | Computer-assisted telephone interviews with mothers.[1][4] | Inaccurate recall of timing, dose, and duration of exposures.[5] | Focus on salient exposures, use of standardized questionnaires. |
| Case Ascertainment | Identification through state-based birth defects surveillance systems.[1] | Incomplete ascertainment of terminated pregnancies, potential for misclassification.[5] | Review of clinical data by geneticists to confirm diagnoses.[1] |
| Control Selection | Random selection of live births without major birth defects from the same population.[7] | Non-participation bias, potential for controls to not be fully representative of the base population.[1][7] | Comparison of participant characteristics to the source population. |
| Genetic Data | Collection of buccal cells from mother, father, and infant.[1][4] | Potential for lower participation rates in genetic component, quality control of DNA samples.[1] | Standardized protocols for sample collection and processing.[1] |
Experimental Protocols
While specific laboratory protocols for the genetic analyses performed on this compound samples are not publicly detailed, the general methodology for data collection is as follows:
Protocol for this compound Data Collection:
-
Case and Control Identification: Eligible cases (infants/fetuses with major birth defects) and controls (live-born infants without major birth defects) were identified through participating state surveillance systems and vital records/hospital logs, respectively.[1][7]
-
Maternal Interview: Mothers of eligible cases and controls were contacted for a computer-assisted telephone interview between 6 weeks and 24 months after the estimated date of delivery.[2] The standardized interview collected detailed information on demographics, health conditions, medication use, and other potential exposures.[4]
-
Buccal Cell Collection: Following the interview, families were mailed a kit containing cytobrushes for the collection of cheek cells from the biological mother, father, and infant (if living).[1][4]
-
Data and Sample Processing: Interview data were entered into a central database. Buccal cell samples were sent to a laboratory for DNA extraction and quality control checks.[1]
Researchers seeking to use this compound data must typically collaborate with one of the Centers for Birth Defects Research and Prevention and are not granted direct public access to the raw data to protect participant confidentiality.[8] Proposed analyses are reviewed to ensure they do not overlap with existing projects.[8]
References
- 1. The National Birth Defects Prevention Study: a review of the methods - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Research Portal [iro.uiowa.edu]
- 3. This compound.org [this compound.org]
- 4. Next steps for birth defects research and prevention: The Birth Defects Study To Evaluate Pregnancy exposureS (BD-STEPS) - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Preventing birth defects: The value of the this compound case-control approach - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. The Problem of Confounding in Studies of the Effect of Maternal Drug Use on Pregnancy Outcome - PMC [pmc.ncbi.nlm.nih.gov]
- 7. academic.oup.com [academic.oup.com]
- 8. Methods for Accessing this compound and BD-STEPS Data | Birth Defects | CDC [cdc.gov]
Technical Support Center: Enhancing the Reproducibility of NBDPS Research Findings
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to assist researchers, scientists, and drug development professionals in utilizing the National Birth Defects Prevention Study (NBDPS) data and applying similar case-control study designs. Our goal is to promote the reproducibility of research findings in the field of birth defects epidemiology.
Frequently Asked Questions (FAQs)
Q1: What is the basic study design of the this compound?
A1: The this compound is a large, population-based case-control study that investigated potential risk factors for major birth defects in the United States.[1][2][3][4] It collected data from mothers of babies with and without birth defects.[4][5] Cases (infants with major birth defects) were identified through birth defects surveillance systems in ten states.[1][2][3] Controls (infants without major birth defects) were randomly selected from the same geographic areas and time periods.[1][4] Data were collected through computer-assisted telephone interviews with mothers and through the collection of buccal (cheek) cells from the mother, father, and infant for genetic analysis.[1][3][5]
Q2: How are cases and controls defined and selected in the this compound to ensure comparability?
A2: Case eligibility was determined by a clinical geneticist review of all clinical information to confirm a major structural birth defect.[1] Cases with known genetic or chromosomal causes were excluded to focus on identifying unknown etiologies.[1] Controls were live-born infants without any major birth defects, randomly selected from either vital records or birth hospital records within the same geographical catchment areas as the cases.[1][3] This population-based approach aimed to ensure that controls were representative of the population from which the cases arose.[5]
Q3: What are the main sources of potential bias in a study like the this compound, and how can they be addressed?
A3: A primary challenge is recall bias, as mothers are interviewed retrospectively about their exposures during pregnancy.[6] This can be addressed by using standardized, detailed questionnaires and, where possible, validating self-reported data with medical records or other objective measures. Another potential bias is selection bias, particularly concerning the inclusion of terminated pregnancies, which may be under-ascertained.[6][7] To mitigate this, this compound made efforts to include cases from live births, stillbirths, and induced terminations.[1][3]
Q4: How can I access and use this compound data for my own research?
A4: this compound data are not publicly available to protect participant confidentiality.[8][9] However, qualified researchers can apply for access to the data for collaborative research projects with one of the Centers for Birth Defects Research and Prevention (CBDRP).[8] Proposals for analyses that overlap with previously published research will be denied.[8]
Troubleshooting Guides
Issue 1: Difficulty in replicating findings related to a specific exposure.
-
Possible Cause: Inconsistent definition of the exposure.
-
Troubleshooting Step: Carefully review the original this compound publication for the precise definition of the exposure, including timing, duration, and dose if available. Ensure your replication study uses the exact same criteria.
-
-
Possible Cause: Differences in the study population.
-
Troubleshooting Step: Compare the demographic and clinical characteristics of your study population with the this compound cohort. Significant differences could explain divergent findings.
-
-
Possible Cause: Insufficient statistical power in the replication study.
-
Troubleshooting Step: Conduct a power analysis to determine if your sample size is adequate to detect the effect size reported in the original study.
-
Issue 2: My analysis of this compound data yields unexpected or null findings.
-
Possible Cause: Inappropriate statistical model.
-
Troubleshooting Step: Consult with a biostatistician to ensure your analytical approach is appropriate for the case-control design and the specific variables you are investigating. Consider potential confounding variables that may need to be included in the model.
-
-
Possible Cause: Misinterpretation of variable coding.
-
Troubleshooting Step: Thoroughly review the this compound data dictionary and any accompanying documentation to ensure a correct understanding of how variables are coded and categorized.[4]
-
-
Possible Cause: The association is truly null.
-
Troubleshooting Step: While it is important to troubleshoot methodological issues, it is also crucial to consider the possibility that there is no true association between the exposure and the outcome in the population studied.
-
Quantitative Data Summary
The following tables summarize key quantitative data from the National Birth Defects Prevention Study.
Table 1: this compound Participant Enrollment Summary
| Participant Group | Eligible | Interviewed | Buccal Cell Kit Returned |
| Cases | 47,832 | 32,187 (67%) | 19,065 (65% of kits sent) |
| Controls | 18,272 | 11,814 (65%) | 6,211 (59% of kits sent) |
Experimental Protocols
The core "experiment" in the this compound is the observational case-control study design. The key methodologies are outlined below.
Methodology 1: Case and Control Ascertainment and Enrollment
-
Case Identification: Cases with major structural birth defects were identified through active surveillance systems in ten participating states.[1]
-
Clinical Review: A clinical geneticist reviewed medical records to confirm the diagnosis and determine eligibility. Cases with known genetic syndromes were excluded.[1]
-
Control Selection: A random sample of live-born infants without major birth defects was selected from the same geographic areas and time periods using vital records or birth hospital logs.[1][4]
-
Recruitment: Mothers of eligible cases and controls were contacted and invited to participate in a telephone interview.
Methodology 2: Data Collection
-
Computer-Assisted Telephone Interview: Trained interviewers administered a standardized, computer-assisted telephone interview to mothers between 6 weeks and 24 months after their estimated delivery date.[1][3] The interview collected information on a wide range of potential exposures, including demographics, health history, medication use, and lifestyle factors.
-
Buccal Cell Collection: After the interview, families were mailed kits to collect buccal (cheek) cells from the mother, father, and infant.[1][3][5] These samples were used for genetic analyses.
Visualizations
Caption: Workflow of the National Birth Defects Prevention Study (this compound).
Caption: Logical framework for a case-control study design like the this compound.
References
- 1. The National Birth Defects Prevention Study: a review of the methods - PMC [pmc.ncbi.nlm.nih.gov]
- 2. researchgate.net [researchgate.net]
- 3. The National Birth Defects Prevention Study: A review of the methods - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. This compound.org [this compound.org]
- 5. This compound.org [this compound.org]
- 6. Preventing birth defects: The value of the this compound case-control approach - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. Challenges in Studying Modifiable Risk Factors for Birth Defects - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Methods for Accessing this compound and BD-STEPS Data | Birth Defects | CDC [cdc.gov]
- 9. catalog.data.gov [catalog.data.gov]
Navigating the Ethical Landscape of NBDPS Data Research: A Technical Support Guide
For Researchers, Scientists, and Drug Development Professionals
This technical support center provides essential guidance on the ethical considerations for researchers utilizing data from the National Birth Defects Prevention Study (NBDPS). Below you will find frequently asked questions (FAQs), a summary of key study data, a detailed experimental protocol outline, and a visualization of the data access workflow to assist you in your research endeavors.
Frequently Asked Questions (FAQs)
Our FAQs are designed to address common queries and potential hurdles you may encounter when planning and conducting your research with this compound data.
Q1: What are the primary ethical considerations I need to be aware of when using this compound data?
A: The primary ethical considerations revolve around the secondary analysis of existing data.[1] This includes respecting the informed consent provided by the original participants, ensuring data confidentiality and privacy, and preventing potential harm to individuals or groups.[1][2] It is crucial to remember that while the data is de-identified for researchers, it contains sensitive information about mothers and children.[3][4][5]
Q2: How is the confidentiality of this compound participants protected?
A: The this compound has robust measures in place to protect participant confidentiality. All identifying information is removed from the data files provided to researchers.[6] Names of participants are never used in any reports or publications.[6] The data is stored on password-protected computer systems, and physical records are kept under lock and key.[6][7]
Q3: Was informed consent obtained from the original this compound participants?
A: Yes, the this compound obtained informed consent from all participants.[6] Verbal consent was acquired for the telephone interviews, and written consent was obtained for the collection of cheek cell samples for DNA analysis.[6]
Q4: Do I need to obtain separate informed consent from the original participants for my specific research project?
A: Generally, you do not need to re-consent participants for secondary data analysis, provided your research aligns with the scope of the original consent.[1] However, your research proposal must be reviewed and approved by the Centers for Birth Defects Research and Prevention (CBDRP) Data Sharing Committee to ensure it is in accordance with the purposes for which the parents signed consent.[8]
Q5: What is the role of the Institutional Review Board (IRB) when using this compound data?
A: Your institution's IRB will need to review and approve your research plan. The IRB's role is to ensure that you have adequate procedures in place to protect the confidentiality of the data and that your research design is ethical.[9][10] Even if your research is considered exempt, you will likely still need to submit documentation to your IRB for a formal determination.[9]
Q6: What are the key requirements for gaining access to this compound data?
A: Access to this compound data is not public.[3][8] To gain access, qualified researchers must collaborate with one of the Centers for Birth Defects Research and Prevention (CBDRP).[8] You will need to submit a collaboration request form that outlines your proposed research.
Q7: What are the criteria for the approval of a research proposal by the CBDRP Data Sharing Committee?
A: The CBDRP Data Sharing Committee reviews proposals based on several criteria, including:
-
No overlap with an existing this compound or BD-STEPS research project.[6][8]
-
The research project is designed to benefit public health.[6][8]
-
No identified conflicts of interest (financial, social, or personal).[6][8]
-
The researcher is qualified to conduct the proposed research.[6][8]
Data Presentation
The following table summarizes key quantitative data about the National Birth Defects Prevention Study.
| Metric | Value | Source |
| Study Period | 1997 - 2011 | [8] |
| Number of Participating States | 10 | |
| Total Participants (Women) | Over 35,000 | |
| Case Mothers Interviewed | 32,187 | [3][8] |
| Control Mothers Interviewed | 11,814 | [3][8] |
| Families Returning Buccal Cell Kits (Cases) | 19,065 | [3][8] |
| Families Returning Buccal Cell Kits (Controls) | 6,211 | [3][8] |
| Proposed Projects (as of Dec 2014) | Over 500 | [3][8] |
| Published Manuscripts (as of Dec 2014) | Over 200 | [3][8] |
Experimental Protocols
While specific protocols will vary depending on the research question, the following provides a detailed methodology for a typical case-control study using this compound data to investigate the association between a specific exposure and a birth defect.
1. Study Design:
-
Case-Control Design: The this compound is a population-based case-control study. Cases are infants with major birth defects, and controls are infants without major birth defects.
2. Data and Sample Collection (as performed in the original this compound):
-
Maternal Interviews: Computer-assisted telephone interviews were conducted with mothers of cases and controls. These interviews collected information on a wide range of topics, including demographics, health history, lifestyle, and environmental exposures during the periconceptional period.
-
Buccal Cell Collection: Families were mailed kits to collect cheek cells from the mother, father, and infant. These samples provide the DNA for genetic analyses.
3. Laboratory Analysis (for genetic studies):
-
DNA Extraction: DNA is extracted from the buccal cell samples.
-
Genotyping: Specific genetic variants of interest are identified using methods such as polymerase chain reaction (PCR) or microarray analysis.
4. Statistical Analysis:
-
Descriptive Statistics: Calculate frequencies and distributions of demographic characteristics and exposures for both cases and controls.
-
Logistic Regression: Use logistic regression to calculate odds ratios (ORs) and 95% confidence intervals (CIs) to assess the association between the exposure of interest and the birth defect, while adjusting for potential confounding factors (e.g., maternal age, education, race/ethnicity).
-
Gene-Environment Interaction Analysis: If genetic data is being used, statistical models can be employed to assess whether the effect of the environmental exposure on the risk of the birth defect differs by genetic variants.
Mandatory Visualization
The following diagram illustrates the workflow for accessing and conducting research with this compound data, highlighting the key ethical review stages.
References
- 1. This compound.org [this compound.org]
- 2. The National Birth Defects Prevention Study: A review of the methods - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. Common Reasons Grant Proposals Are Rejected | SUNY Geneseo [geneseo.edu]
- 4. catalog.data.gov [catalog.data.gov]
- 5. Methods for Accessing this compound and BD-STEPS Data | Birth Defects | CDC [cdc.gov]
- 6. Detecting gene–environment interactions in human birth defects: Study designs and statistical methods [escholarship.org]
- 7. The National Birth Defects Prevention Study: a review of the methods - PMC [pmc.ncbi.nlm.nih.gov]
- 8. cdc.gov [cdc.gov]
- 9. This compound.org [this compound.org]
- 10. This compound.org [this compound.org]
Validation & Comparative
A Guide to Validating NBDPS Findings with Other Birth Defect Registries
For Researchers, Scientists, and Drug Development Professionals
This guide provides a framework for comparing and validating findings from the National Birth Defects Prevention Study (NBDPS) with data from other major birth defect registries. Understanding the consistency of findings across different populations and surveillance systems is crucial for confirming potential risk factors and informing public health interventions. This document outlines key methodological comparisons, presents available data for selected birth defects and risk factors, and details the necessary protocols for conducting such comparative analyses.
Methodological Comparison of Major Birth Defect Registries
A direct comparison of findings between birth defect registries requires a thorough understanding of their respective methodologies. The this compound was a large, population-based case-control study in the United States, while other significant registries like the European Surveillance of Congenital Anomalies (EUROCAT) and the International Clearinghouse for Birth Defects Surveillance and Research (ICBDSR) represent networks of regional registries with varying methodologies. Key differences in case ascertainment, exposure data collection, and inclusion criteria can influence prevalence estimates and risk factor associations.
| Feature | National Birth Defects Prevention Study (this compound) | European Surveillance of Congenital Anomalies (EUROCAT) | International Clearinghouse for Birth Defects Surveillance and Research (ICBDSR) |
| Study Design | Population-based case-control study.[1] | Network of population-based registries.[2][3] | Global network of birth defect surveillance programs.[4] |
| Geographic Coverage | 10 U.S. states (Arkansas, California, Georgia, Iowa, Massachusetts, New Jersey, New York, North Carolina, Texas, Utah). | Multiple regions across Europe.[5][6] | Worldwide member registries.[4] |
| Case Ascertainment | Active case ascertainment through review of medical records from multiple sources (e.g., hospitals, genetic centers). | Primarily active case ascertainment, though methods can vary by member registry. | Methods vary by member program, including both active and passive surveillance.[4] |
| Data Collection | Detailed maternal interviews via telephone, and collection of buccal cells for genetic analysis. | Standardized data collection from multiple sources including medical records and prenatal screening information.[2][7][8] | Data submitted by member registries; collection methods vary. |
| Inclusion Criteria | Included major structural birth defects; excluded cases with known chromosomal abnormalities or single-gene disorders. | Includes a wide range of congenital anomalies, with standardized coding and classification.[2][3] | Varies by member program.[4] |
| Exposure Information | Self-reported maternal exposures during the periconceptional period (one month before to three months after conception).[1][9][10] | Varies by registry; can include maternal interviews, medical records, and prescription databases. | Varies by member program. |
Experimental Protocols for Comparative Analysis
Validating findings across different registries is a complex process that requires careful planning and execution. The following experimental workflow outlines the key steps involved in such a comparative analysis.
A critical step in this process is data harmonization, which involves creating a common data model and standardizing definitions for birth defects and exposures across registries. This often requires recoding data to a common classification system, such as the International Classification of Diseases (ICD).
Comparative Findings: Prevalence and Risk Factor Associations
Prevalence of Selected Birth Defects
The reported prevalence of birth defects can vary between registries due to differences in case ascertainment and population demographics. The following table presents prevalence estimates for spina bifida from this compound-related data and EUROCAT.
| Birth Defect | Registry/Study | Prevalence (per 10,000 births) | Years of Data |
| Spina Bifida | This compound (U.S., 1991-2006) | 5.6 (post-fortification) | 1991-2006[6] |
| EUROCAT (Europe, 1991-2011) | ~9.1 (for all NTDs) | 1991-2011[11] | |
| EUROCAT (Europe, 2000-2008) | 9.43 (for all NTDs) | 2000-2008[12] |
Note: Direct comparison is challenging as the this compound estimate is specific to spina bifida post-folic acid fortification, while the EUROCAT estimates are for all neural tube defects (NTDs) over a broader time frame.
Risk Factor Association: Maternal Smoking and Congenital Heart Defects
The association between maternal smoking and congenital heart defects (CHDs) has been investigated in multiple studies using data from different registries. While the specific odds ratios may differ, the general finding of a modest association is consistent.
| Study Population (Registry) | Defect Category | Odds Ratio (OR) / Adjusted OR (aOR) | 95% Confidence Interval (CI) |
| This compound | Septal Defects | aOR: 1.5 | 1.3 - 1.7[1][9] |
| Tricuspid Atresia | aOR: 1.7 | 1.0 - 2.7[1][9] | |
| Double Outlet Right Ventricle | aOR: 1.5 | 1.1 - 2.1[1][9] | |
| Baltimore-Washington Infant Study | Secundum-type Atrial Septal Defects | OR: 1.36 | 1.04 - 1.78[13] |
| Right Ventricular Outflow Tract Defects | OR: 1.32 | 1.06 - 1.65[13] | |
| Swedish Registries | All Heart Defects | OR: 1.09 | 1.01 - 1.19[14] |
| Atrial Septal Defects | OR: 1.63 | 1.04 - 2.57[14] |
This table demonstrates that while different studies report associations with slightly different sub-types of CHDs, there is a recurring theme of an elevated risk with maternal smoking.
Logical Relationship for Validating a Risk Factor Finding
The process of validating a risk factor finding from an initial study (like this compound) involves a logical progression of evidence from independent sources.
Conclusion
Validating findings from the this compound with other birth defect registries is a scientifically rigorous process that strengthens the evidence for potential causal relationships. While direct, comprehensive validation studies are not always available, comparing methodologies and findings from separate studies provides valuable insights. The key challenges lie in the harmonization of data and accounting for methodological differences between registries. Future collaborative efforts, such as those facilitated by the NBDPN and ICBDSR, are essential for conducting robust validation studies and advancing our understanding of the causes of birth defects.[4][15][16]
References
- 1. Maternal Smoking and Congenital Heart Defects, National Birth Defects Prevention Study, 1997–2011 - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Data quality indicators tool – ICBDSR [icbdsr.org]
- 3. icbdsr.org [icbdsr.org]
- 4. Value of sharing and networking among birth defects surveillance programs: an ICBDSR perspective - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Prevalence of neural tube defects in 16 regions of Europe, 1980-1983. The EUROCAT Working Group - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. Prevention of Neural Tube Defects in Europe: A Public Health Failure - PMC [pmc.ncbi.nlm.nih.gov]
- 7. scielosp.org [scielosp.org]
- 8. Maternal Smoking and Congenital Heart Defects, National Birth Defects Prevention Study, 1997-2011 - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. Maternal smoking and congenital heart defects - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. eu-rd-platform.jrc.ec.europa.eu [eu-rd-platform.jrc.ec.europa.eu]
- 11. Long term trends in prevalence of neural tube defects in Europe: population based study - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Maternal smoking and congenital heart defects in the Baltimore-Washington Infant Study - PubMed [pubmed.ncbi.nlm.nih.gov]
- 13. Maternal smoking and congenital heart defects - PubMed [pubmed.ncbi.nlm.nih.gov]
- 14. nbdpn.org [nbdpn.org]
- 15. nbdpn.org [nbdpn.org]
- 16. Birth Defects Tracking | Birth Defects | CDC [cdc.gov]
A Comparative Analysis of the National Birth Defects Prevention Study (NBDPS) and International Counterparts
For Researchers, Scientists, and Drug Development Professionals
This guide provides a comprehensive comparison of the National Birth Defects Prevention Study (NBDPS), a major U.S. initiative, with prominent international birth defect studies. By presenting quantitative data, detailed experimental protocols, and key signaling pathways, this document aims to offer researchers, scientists, and drug development professionals a clear understanding of the methodologies and findings of these crucial epidemiological resources.
Overview of Major Birth Defect Studies
The National Birth Defects Prevention Study (this compound) was a large-scale, population-based case-control study in the United States that operated from 1997 to 2011. Its primary objective was to identify environmental and genetic risk factors for a wide range of major birth defects.[1][2] The study was conducted by the Centers for Birth Defects Research and Prevention (CBDRP), a collaborative group of centers across the U.S.[3]
Internationally, two of the most significant counterparts are the European Surveillance of Congenital Anomalies (EUROCAT) and the International Clearinghouse for Birth Defects Surveillance and Research (ICBDSR) .
-
EUROCAT is a network of population-based registries for the epidemiological surveillance of congenital anomalies across Europe. Established in 1979, it collects standardized data to monitor trends, evaluate the impact of prenatal screening, and identify teratogenic exposures.[4][5]
-
ICBDSR is a global voluntary non-profit organization that brings together birth defect surveillance and research programs from around the world to investigate, prevent, and ameliorate birth defects.[5]
Comparative Data on Birth Defect Prevalence
The following tables present a comparison of prevalence rates for selected major birth defects as reported by the this compound and EUROCAT. It is important to note that direct comparisons should be made with caution due to potential differences in study design, case ascertainment, and population demographics.
Table 1: Prevalence of Neural Tube Defects (per 10,000 births)
| Birth Defect | This compound (1997-2011) | EUROCAT (2000-2010) |
| Spina Bifida | 3.06[6] | ~4.5 (estimated from combined data)[7] |
| Anencephaly | ~2.8 (estimated from combined data)[8] | 3.52[9] |
Table 2: Prevalence of Oral Clefts (per 10,000 births)
| Birth Defect | This compound (1997-2004) | EUROCAT (2000-2005) |
| Cleft Lip with or without Cleft Palate | 8.0 | 9.92 |
Note: Data for this table is derived from a collaborative study involving this compound, EUROCAT, and ICBDSR, providing a more direct comparison.
Table 3: Prevalence of Selected Congenital Heart Defects (per 10,000 births)
| Birth Defect | This compound (1997-2011) | EUROCAT (2002-2011) |
| Tetralogy of Fallot | Studied as a key outcome[10][11] | 3.32[12] |
This compound, as a case-control study, primarily focused on risk factor identification rather than generating national prevalence estimates for all defects. The provided this compound information indicates Tetralogy of Fallot was a key defect studied for risk factor associations.
Experimental Protocols: A Methodological Comparison
The fundamental difference between the this compound and EUROCAT lies in their study design.
National Birth Defects Prevention Study (this compound): Case-Control Methodology
The this compound employed a population-based case-control study design .[1]
-
Case Selection: Cases were infants or fetuses with one or more of over 30 major birth defects, identified through existing birth defects surveillance programs in ten U.S. states.[3] Clinical geneticists reviewed medical records to confirm diagnoses and ensure they met specific inclusion and exclusion criteria.[1][2] Cases with known single-gene or chromosomal disorders were typically excluded to focus on identifying unknown causes.[1][3]
-
Control Selection: Controls were live-born infants without any major birth defects, randomly selected from the same geographic areas and time periods as the cases.[1]
-
Data Collection: Data was primarily collected through computer-assisted telephone interviews with mothers between 6 weeks and 24 months after the estimated delivery date.[1] These interviews gathered extensive information on a wide range of potential exposures, including medications, diet, lifestyle factors, and parental occupation. Additionally, buccal (cheek) cell samples were collected from the mother, father, and infant for genetic analysis.[13]
European Surveillance of Congenital Anomalies (EUROCAT): Registry-Based Surveillance
EUROCAT operates as a network of population-based registries .[4]
-
Case Ascertainment: Each member registry systematically collects data on all congenital anomalies occurring within a defined geographic population. This includes live births, fetal deaths from 20 weeks gestation, and terminations of pregnancy for fetal anomaly.[14]
-
Data Standardization and Classification: To ensure comparability across registries, EUROCAT has established detailed guidelines for case registration, coding (using the International Classification of Diseases, ICD), and classification of anomalies.[4][15][16] Cases are classified as isolated, multiple, or associated with a syndrome.[4]
-
Data Analysis: The centralized database allows for the monitoring of trends in the prevalence of specific anomalies, the detection of clusters, and the evaluation of public health interventions, such as prenatal screening programs.[14]
Key Signaling Pathways in Birth Defect Etiology
Understanding the molecular mechanisms underlying birth defects is crucial for developing preventive strategies. The following diagrams, generated using the DOT language, illustrate key signaling pathways implicated in the etiology of specific congenital anomalies.
Folic Acid Metabolism and Neural Tube Closure
Periconceptional folic acid supplementation is a well-established preventive measure for neural tube defects (NTDs) like spina bifida and anencephaly.[17][18][19] Folate is a crucial B-vitamin that, in its active form (tetrahydrofolate), acts as a coenzyme in the transfer of one-carbon units. This process is essential for the synthesis of nucleotides (the building blocks of DNA) and for methylation reactions that regulate gene expression, both of which are critical for the rapidly proliferating cells of the closing neural tube during early embryonic development.[18]
Caption: Folic acid's role in one-carbon metabolism, crucial for preventing neural tube defects.
Sonic Hedgehog (SHH) Signaling in Forebrain Development
The Sonic Hedgehog (SHH) signaling pathway plays a critical role in the development of the central nervous system, including the patterning of the ventral forebrain.[20] Mutations in the SHH gene are the most common known genetic cause of holoprosencephaly (HPE), a severe birth defect characterized by the failure of the embryonic forebrain to divide into two hemispheres.[21][22][23] The SHH protein acts as a morphogen, and its signaling cascade through its receptor Patched (PTCH) and the transmembrane protein Smoothened (SMO) ultimately leads to the activation of Gli transcription factors, which regulate the expression of genes essential for proper brain development.[20]
Caption: The Sonic Hedgehog signaling pathway's crucial role in forebrain development.
Experimental Workflow Comparison
The distinct methodologies of the this compound and EUROCAT dictate their respective operational workflows. The following diagram illustrates a simplified comparison of these processes.
Caption: A comparative overview of the this compound and EUROCAT study workflows.
Conclusion
The this compound and international studies like EUROCAT represent complementary and invaluable resources in the global effort to understand and prevent birth defects. The case-control design of the this compound has been instrumental in identifying specific genetic and environmental risk factors, providing crucial insights for targeted prevention strategies.[1] In contrast, the registry-based approach of EUROCAT offers a powerful tool for monitoring population-wide trends, evaluating the effectiveness of public health interventions, and detecting potential new teratogens in a timely manner.[4]
For researchers, scientists, and professionals in drug development, a thorough understanding of the strengths and limitations of these different study designs is essential for accurately interpreting their findings and for designing future research. The quantitative data, methodological details, and pathway analyses presented in this guide are intended to facilitate this understanding and to support the ongoing work of preventing birth defects and improving the health of children worldwide.
References
- 1. The National Birth Defects Prevention Study: a review of the methods - PMC [pmc.ncbi.nlm.nih.gov]
- 2. researchgate.net [researchgate.net]
- 3. Next steps for birth defects research and prevention: The Birth Defects Study To Evaluate Pregnancy exposureS (BD-STEPS) - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Updated EUROCAT guidelines for classification of cases with congenital anomalies - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. eu-rd-platform.jrc.ec.europa.eu [eu-rd-platform.jrc.ec.europa.eu]
- 6. digitalcommons.library.tmc.edu [digitalcommons.library.tmc.edu]
- 7. Preventable spina bifida and anencephaly in Europe - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. Association between maternal periconceptional alcohol consumption and neural tube defects: Findings from the National Birth Defects Prevention Study, 1997–2011 - PMC [pmc.ncbi.nlm.nih.gov]
- 9. researchgate.net [researchgate.net]
- 10. Proportion of selected congenital heart defects attributable to recognized risk factors - PMC [pmc.ncbi.nlm.nih.gov]
- 11. This compound.org [this compound.org]
- 12. eu-rd-platform.jrc.ec.europa.eu [eu-rd-platform.jrc.ec.europa.eu]
- 13. This compound.org [this compound.org]
- 14. europeristat.com [europeristat.com]
- 15. Guidelines for data registration | European Platform on Rare Disease Registration [eu-rd-platform.jrc.ec.europa.eu]
- 16. Prevalence Guide | European Platform on Rare Disease Registration [eu-rd-platform.jrc.ec.europa.eu]
- 17. Neural Tube Defects, Folic Acid and Methylation - PMC [pmc.ncbi.nlm.nih.gov]
- 18. Neural tube defects and folate: case far from closed - PMC [pmc.ncbi.nlm.nih.gov]
- 19. researchgate.net [researchgate.net]
- 20. pnas.org [pnas.org]
- 21. The Role of Sonic Hedgehog in Human Holoprosencephaly and Short-Rib Polydactyly Syndromes - PMC [pmc.ncbi.nlm.nih.gov]
- 22. Sonic hedgehog protein - Wikipedia [en.wikipedia.org]
- 23. Sonic Hedgehog Mutations Identified in Holoprosencephaly Patients Can Act in a Dominant Negative Manner - PMC [pmc.ncbi.nlm.nih.gov]
Replication of National Birth Defects Prevention Study (NBDPS) Findings in Different Populations: A Comparative Guide
For Researchers, Scientists, and Drug Development Professionals
This guide provides a comparative analysis of key findings from the U.S. National Birth Defects Prevention Study (NBDPS) and their replication in different global populations. By examining data from various populations, researchers can assess the generalizability of initial findings and identify potential population-specific risk factors for congenital anomalies. This document summarizes quantitative data, details experimental protocols, and visualizes relevant biological pathways to offer a comprehensive resource for the scientific community.
Data Presentation: Comparative Analysis of Key Findings
The following tables summarize the associations between selected maternal exposures and the risk of specific birth defects as reported by the this compound and comparable studies in other populations, primarily from European countries through the European Surveillance of Congenital Anomalies (EUROCAT) network and various meta-analyses.
Table 1: Maternal Smoking and Congenital Heart Defects (CHDs)
| Congenital Heart Defect | This compound (USA) - Adjusted Odds Ratio (aOR) [95% CI] | European Studies/Meta-Analyses - Relative Risk (RR) or Odds Ratio (OR) [95% CI] |
| Septal Defects (Overall) | 1.5 [1.3-1.7][1][2] | 1.44 [1.16-1.79] (Meta-analysis)[3] |
| Atrial Septal Defect (ASD) | - | 1.27 [1.02-1.59] (Meta-analysis) |
| Tricuspid Atresia | 1.7 [1.0-2.7][1][2] | Data not consistently reported for direct comparison |
| Double Outlet Right Ventricle (DORV) | 1.5 [1.1-2.1][1][2] | Data not consistently reported for direct comparison |
| Right Ventricular Outflow Tract Obstruction (RVOTO) | - | 1.43 [1.04-1.97] (Meta-analysis) |
Table 2: Maternal SSRI Use and Congenital Anomalies
| Congenital Anomaly | This compound (USA) - Adjusted Odds Ratio (aOR) [95% CI] | EUROCAT & Other European Studies - Odds Ratio (OR) [95% CI] |
| Congenital Heart Defects (Overall) | No significant increased risk for most CHDs[4] | 1.41 [1.07-1.86][5][6] |
| Severe Congenital Heart Defects | - | 1.50 [1.06-2.11][7][8] |
| Atrial Septal Defects | 1.8 [1.1-3.0] (for Paroxetine)[9] | 1.71 [1.09-2.68][5] |
| Right Ventricular Outflow Tract Obstruction Defects | 2.4 [1.4-3.9] (for Paroxetine); 2.0 [1.4-3.1] (for Fluoxetine)[9] | - |
| Anencephaly | Small increased risk linked to SSRIs[4] | - |
| Craniosynostosis | Small increased risk linked to SSRIs[4] | 2.48 [0.99-6.22] (borderline significance)[5] |
| Omphalocele | Small increased risk linked to SSRIs[4] | - |
| Gastroschisis | - | 2.42 [1.10-5.29][5][6] |
| Anorectal Atresia/Stenosis | - | 2.46 [1.06-5.68][5][6] |
| Renal Dysplasia | - | 3.01 [1.61-5.61][5][6] |
| Clubfoot | - | 2.41 [1.59-3.65][5][6] |
Experimental Protocols
National Birth Defects Prevention Study (this compound)
The this compound was a large-scale, population-based case-control study conducted across 10 centers in the United States.[10]
-
Study Design: Case-control.
-
Population: Mothers of infants with major birth defects (cases) and mothers of infants without major birth defects (controls) were enrolled. The study included deliveries from 1997 to 2011.[11]
-
Data Collection: Information on a wide range of exposures, including medication use and lifestyle factors, was collected through computer-assisted telephone interviews with mothers from 6 weeks to 2 years after the estimated date of delivery.[5] For genetic research, buccal cell samples were collected from the mother, father, and infant.[5]
-
Case Ascertainment and Classification: Cases were identified through existing birth defects surveillance systems at each study center.[10] A standardized and detailed case classification system was used to ensure homogeneity of the case groups.[12]
European Surveillance of Congenital Anomalies (EUROCAT)
EUROCAT is a European network of population-based registries for the epidemiological surveillance of congenital anomalies.[13]
-
Study Design: Network of population-based registries.
-
Population: The registries cover a significant portion of the European birth population and include live births, fetal deaths from 20 weeks gestation, and terminations of pregnancy for fetal anomaly.[13]
-
Data Collection: Data is collected from multiple sources, including hospital records, pediatricians, and midwives.[14] Some registries supplement this with parental questionnaires and pharmacy records.[14] Standardized coding and classification systems are used across registries to ensure data comparability.[15]
-
Data Analysis: EUROCAT conducts statistical monitoring to detect clusters and trends in congenital anomalies over time and across different European regions.[13]
Mandatory Visualization
The following diagrams illustrate potential signaling pathways and biological mechanisms that may be disrupted by maternal smoking and SSRI use during embryonic development, leading to congenital anomalies.
Caption: Putative pathways of maternal smoking-induced congenital heart defects.
Caption: Proposed mechanisms of SSRI-associated congenital anomalies.
References
- 1. Parental smoking and congenital heart defects: An update on evidence and current trends [tobaccopreventioncessation.com]
- 2. researchgate.net [researchgate.net]
- 3. Cardiovascular and metabolic influences of fetal smoke exposure - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Maternal nicotine exposure induces congenital heart defects in the offspring of mice - PMC [pmc.ncbi.nlm.nih.gov]
- 5. This compound.org [this compound.org]
- 6. Smoking and congenital heart disease: the epidemiological and biological link - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. Selective Serotonin Reuptake Inhibitor Use During Pregnancy and Major Malformations: The Importance of Serotonin for Embryonic Development and the Effect of Serotonin Inhibition on the Occurrence of Malformations - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Selective Serotonin Reuptake Inhibitor Use During Pregnancy and Major Malformations: The Importance of Serotonin for Embryonic Development and the Effect of Serotonin Inhibition on the Occurrence of Malformations - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. Maternal and infant genetic variants, maternal periconceptional use of selective serotonin reuptake inhibitors, and risk of congenital heart defects in offspring: population based study - PMC [pmc.ncbi.nlm.nih.gov]
- 10. The National Birth Defects Prevention Study: a review of the methods - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Methods for Accessing this compound and BD-STEPS Data | Birth Defects | CDC [cdc.gov]
- 12. pure.johnshopkins.edu [pure.johnshopkins.edu]
- 13. Detection and investigation of temporal clusters of congenital anomaly in Europe: seven years of experience of the EUROCAT surveillance system - PMC [pmc.ncbi.nlm.nih.gov]
- 14. umcgresearch.org [umcgresearch.org]
- 15. Data Collection | European Platform on Rare Disease Registration [eu-rd-platform.jrc.ec.europa.eu]
A Tale of Two Studies: A Comparative Meta-Analysis of NBDPS and Other Case-Control Studies in Birth Defect Research
A deep dive into the methodologies and findings of large-scale case-control studies is crucial for advancing our understanding of the potential causes of birth defects. This guide provides a comparative analysis of two prominent studies: the National Birth Defects Prevention Study (NBDPS) and the Slone Epidemiology Center Birth Defects Study (BDS). By examining a meta-analysis that combines data from both, we can gain a clearer picture of their respective strengths and how they contribute to the broader field of birth defects research.
This guide is intended for researchers, scientists, and drug development professionals, offering a detailed comparison of the experimental protocols, data presentation, and logical frameworks of these influential studies.
Unpacking the Methodologies: this compound vs. BDS
The National Birth Defects Prevention Study (this compound) and the Slone Epidemiology Center Birth Defects Study (BDS) are both large, long-running case-control studies designed to identify risk factors for major birth defects. While their goals are similar, their methodologies exhibit key differences that are important to consider when interpreting their findings, especially in the context of a meta-analysis.
| Feature | National Birth Defects Prevention Study (this compound) | Slone Epidemiology Center Birth Defects Study (BDS) |
| Study Design | Population-based case-control study.[1] | Multicenter case-control study. |
| Recruitment of Cases | Cases with major birth defects were identified through existing birth defects surveillance programs in ten U.S. states (Arkansas, California, Georgia, Iowa, Massachusetts, New Jersey, New York, North Carolina, Texas, and Utah). | Infants with birth defects were identified through arrangements with state birth defect registries and direct contact with approximately 28 participating institutions in areas surrounding Philadelphia, Nashville, San Diego, and parts of the Northeastern U.S.[2] |
| Recruitment of Controls | Controls were live-born infants without major birth defects, randomly selected from the same geographic areas and time periods as the cases, using vital records or birth hospital logs.[1] | A sample of healthy infants without birth defects were identified from the same participating institutions and state registries as the cases.[2] |
| Data Collection | Standardized, computer-assisted telephone interviews with mothers were conducted between 6 weeks and 24 months after the estimated date of delivery. Information on a wide range of exposures was collected.[3] Buccal (cheek) cell samples were also collected from the infant and both parents for genetic analysis.[3] | Trained nurse-interviewers conducted telephone interviews with mothers, gathering information on medical history, pregnancies, nutrition, occupation, health behaviors, smoking, and detailed medication use.[2] |
| Exposure Window of Interest | Primarily the periconceptional period (one month before conception through the first trimester of pregnancy). | The period prior to conception through the entire pregnancy.[2] |
A Case Study in Collaboration: Hydroxychloroquine (B89500) and Birth Defects
A prime example of combining data from these two major studies is the investigation into the potential link between maternal use of hydroxychloroquine (HCQ) and the risk of birth defects. HCQ is a medication used to treat autoimmune diseases and has been a subject of interest regarding its safety during pregnancy.
A study published in Birth Defects Research utilized data from both the this compound and the BDS to assess this risk.[4] This collaborative approach is particularly valuable for studying rare exposures and specific birth defects, as it increases the statistical power of the analysis.
Combined Study Population and Findings
In this combined analysis, the researchers identified a small number of women in each study who had used HCQ during pregnancy. The key findings from this pooled analysis were:
-
Low Prevalence of Use: The use of HCQ during pregnancy was infrequent in both study populations. In the this compound, 0.06% of case mothers and 0.04% of control mothers reported using HCQ. In the BDS, 0.04% of case mothers and 0.05% of control mothers reported its use.
-
No Clear Pattern of Defects: While a variety of birth defects were observed among the offspring of women who took HCQ, there was no consistent pattern to suggest a causal link with the medication.[4] The types of birth defects were varied and did not point to a specific teratogenic effect.
Experimental Protocols in Detail
To understand the rigor of these studies, it is essential to examine their experimental protocols.
National Birth Defects Prevention Study (this compound) Protocol
-
Case Ascertainment: Cases of major structural birth defects were identified through active, population-based surveillance systems in participating states.[1] Clinical geneticists reviewed all potential cases to confirm the diagnosis and ensure they met the study's eligibility criteria.
-
Control Selection: A random sample of live-born infants without any major birth defects was selected from the same geographical regions and birth years as the cases. This was done using birth certificates or hospital birth logs.[1]
-
Maternal Interview: Mothers of both cases and controls were contacted for a comprehensive telephone interview. The interview was computer-assisted to ensure standardization and covered a wide range of topics, including maternal health, lifestyle, diet, medication use, and occupational exposures during the periconceptional period.
-
Genetic Sample Collection: After the interview, families were mailed kits to collect buccal (cheek) cells from the mother, father, and infant. These samples provided DNA for genetic analyses to investigate gene-environment interactions.
Slone Epidemiology Center Birth Defects Study (BDS) Protocol
-
Case and Control Identification: Infants with and without major birth defects were identified through a network of collaborating hospitals and state birth defect registries.
-
Maternal Interview: Trained nurse-interviewers conducted detailed telephone interviews with the mothers of enrolled infants. The interview focused on a comprehensive medical and exposure history, with a particular emphasis on medication use throughout the entire pregnancy.[2]
-
Data Abstraction: In addition to the maternal interview, relevant medical records were often reviewed to confirm diagnoses and gather additional clinical information.
Visualizing the Research Workflow
The following diagram illustrates the general workflow for a meta-analysis combining data from case-control studies like the this compound and BDS.
Caption: Workflow of a meta-analysis combining this compound and BDS data.
By integrating data from well-designed studies like the this compound and BDS, researchers can conduct more powerful and comprehensive analyses. This comparative guide highlights the distinct yet complementary nature of these studies, underscoring the value of collaborative research in the ongoing effort to understand and prevent birth defects.
References
A Comparative Analysis of the National Birth Defects Prevention Study (NBDPS) and the Birth Defects Study To Evaluate Pregnancy Exposures (BD-STEPS)
A comprehensive understanding of the etiological factors contributing to birth defects is paramount for the development of effective prevention strategies and therapeutic interventions. Two landmark epidemiological studies in the United States, the National Birth Defects Prevention Study (NBDPS) and its successor, the Birth Defects Study To Evaluate Pregnancy Exposures (BD-STEPS), have been instrumental in advancing this field of research. This guide provides a detailed comparison of the methodologies and key findings of these two pivotal studies, tailored for researchers, scientists, and drug development professionals.
Overview of the Studies
The this compound was a population-based case-control study that collected data from 1997 to 2011, making significant contributions to our understanding of the genetic and environmental risk factors for a wide range of birth defects.[1][2] Building upon the foundation of the this compound, BD-STEPS was launched in 2014 as an ongoing study to extend and expand upon the research of its predecessor.[1][3][4] A key feature of this succession is the ability to combine data from both studies, creating a powerful resource for investigating rare exposures and their potential associations with birth defects.[3][5]
Data Presentation: A Comparative Look at Study Design and Scope
The following tables provide a structured comparison of the key quantitative aspects of the this compound and BD-STEPS, offering a clear overview of their respective scales and focus areas.
| Feature | National Birth Defects Prevention Study (this compound) | Birth Defects Study To Evaluate Pregnancy Exposures (BD-STEPS) |
| Study Period | Deliveries from 1997 to 2011[1][2] | Deliveries from 2014 to present[1][6] |
| Participant Enrollment | Over 30,000 mothers of babies with birth defects and over 10,000 mothers of babies without birth defects[6][7] | Estimated 1,000 cases and 500 controls per year[3] |
| Study Centers | 10 U.S. states: Arkansas, California, Georgia, Iowa, Massachusetts, New Jersey, New York, North Carolina, Texas, and Utah[1][6] | 7 U.S. states: Arkansas, California, Georgia, Iowa, Massachusetts, New York, and North Carolina[8] |
| Primary Focus | Investigating genetic and non-genetic risk factors and potential causes of a broad range of major birth defects[7] | Extends and focuses the efforts of this compound, with an added emphasis on stillbirths and more detailed data on specific exposures[1][3][7] |
Key Methodological Differences and Evolutions
While both studies employ a population-based case-control design, BD-STEPS introduced several methodological refinements based on the experience gained from the this compound.
| Methodology | National Birth Defects Prevention Study (this compound) | Birth Defects Study To Evaluate Pregnancy Exposures (BD-STEPS) |
| Data Collection | Computer-assisted telephone interviews with mothers of cases and controls.[9][10] | Standardized computer-assisted telephone interviews with mothers, with the addition of supplemental online questionnaires for in-depth information on selected exposures.[3][5] |
| Exposure Window | Focused on the period three months before pregnancy through the end of pregnancy.[10] | Shortened to the one month before through the third month of pregnancy, as this is the critical period for the development of most structural birth defects.[3] |
| Biological Sample Collection | Collection of buccal (cheek) cells from the mother, father, and infant for genetic analysis.[9] | Utilization of residual newborn screening blood spots for genetic and biomarker analysis.[3] |
| Birth Defects Studied | A comprehensive range of major structural birth defects. | A focused set of 17 categories of structural birth defects selected based on severity, prevalence, and the need for further research.[3][5] |
Experimental Protocols
A detailed understanding of the experimental protocols is crucial for evaluating and replicating research findings. Below are summaries of the key methodologies employed in both studies.
Participant Recruitment and Interview
In both the this compound and BD-STEPS, cases (infants with major birth defects) are identified through population-based birth defects surveillance systems in participating states.[3][11] Controls (infants without major birth defects) are randomly selected from the same geographic areas and time periods.[3][9]
Mothers of both cases and controls are invited to participate in a detailed telephone interview.[9][12] The this compound interview covered a wide range of topics including demographics, health history, diet, medication use, and lifestyle factors.[10] The BD-STEPS interview builds on this by including more detailed questions on chronic maternal health conditions and has the capability to be supplemented with online questionnaires for specific topics like occupational exposures.[3][13][14]
Biological Specimen Collection and Analysis
A significant evolution from this compound to BD-STEPS was the method of collecting biological samples for genetic research.
-
This compound - Buccal Cell Collection: The this compound collected buccal cells from the infant and both parents using small brushes.[9] These samples provided a source of DNA to investigate the role of genetic factors in birth defects. The collected cheek cells were sent to a laboratory for secure storage and DNA extraction.[10]
-
BD-STEPS - Newborn Blood Spot Utilization: BD-STEPS transitioned to using residual dried blood spots collected for routine newborn screening.[3] This method is less invasive for participants and leverages an existing resource. After obtaining maternal consent, researchers can access these blood spots for genetic and other biomarker analyses.[3][12]
Quantitative Findings: A Comparative Overview
The extensive data collected through the this compound has led to numerous publications identifying associations between maternal exposures and specific birth defects. As an ongoing study, detailed quantitative findings from BD-STEPS are continually emerging. Below is a sample of key findings from the this compound, which provides a baseline for future comparative analyses with BD-STEPS data.
| Exposure | Birth Defect Category | This compound Finding (Odds Ratio, 95% Confidence Interval) |
| Maternal Periconceptional Smoking | Septal Defects | 1.5 (1.3-1.7)[15][16] |
| Tricuspid Atresia | 1.7 (1.0-2.7)[15][16] | |
| Double Outlet Right Ventricle | 1.5 (1.1-2.1)[15][16] | |
| Heavy Maternal Smoking (≥25 cigarettes/day) | Right-sided Obstructive Defects | Increased likelihood compared to non-smoking mothers[17][18] |
Mandatory Visualizations
Experimental Workflow
The following diagram illustrates the general experimental workflow for both the this compound and BD-STEPS, highlighting the key stages from participant identification to data analysis.
Caption: General experimental workflow for this compound and BD-STEPS.
Logical Relationship of Study Evolution
This diagram illustrates the evolution from the this compound to the BD-STEPS, emphasizing how the latter builds upon and expands the former.
Caption: Evolution from this compound to BD-STEPS and data integration.
References
- 1. ncbi.nlm.nih.gov [ncbi.nlm.nih.gov]
- 2. This compound.org [this compound.org]
- 3. Next steps for birth defects research and prevention: The Birth Defects Study To Evaluate Pregnancy exposureS (BD-STEPS) - PMC [pmc.ncbi.nlm.nih.gov]
- 4. bdsteps.org [bdsteps.org]
- 5. Next steps for birth defects research and prevention: The birth defects study to evaluate pregnancy exposures (BD-STEPS) - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. Birth Defects Research | Birth Defects | CDC [cdc.gov]
- 7. This compound.org [this compound.org]
- 8. publichealth.uams.edu [publichealth.uams.edu]
- 9. This compound.org [this compound.org]
- 10. This compound.org [this compound.org]
- 11. The National Birth Defects Prevention Study: a review of the methods - PMC [pmc.ncbi.nlm.nih.gov]
- 12. bdsteps.org [bdsteps.org]
- 13. reginfo.gov [reginfo.gov]
- 14. bdsteps.org [bdsteps.org]
- 15. Maternal Smoking and Congenital Heart Defects, National Birth Defects Prevention Study, 1997-2011 - PubMed [pubmed.ncbi.nlm.nih.gov]
- 16. Maternal Smoking and Congenital Heart Defects, National Birth Defects Prevention Study, 1997–2011 - PMC [pmc.ncbi.nlm.nih.gov]
- 17. publications.aap.org [publications.aap.org]
- 18. Maternal smoking and congenital heart defects - PubMed [pubmed.ncbi.nlm.nih.gov]
Unraveling the Genetic Blueprint of Birth Defects: A Comparative Guide to Risk Factors
For Immediate Release
A comprehensive analysis of recent genome-wide association studies (GWAS) provides a clearer, comparative view of the genetic risk factors underlying common structural birth defects, including congenital heart defects (CHDs), orofacial clefts, and neural tube defects (NTDs). This guide synthesizes key findings, offering researchers, scientists, and drug development professionals a consolidated resource for understanding the genetic architecture of these complex conditions.
Birth defects represent a significant global health challenge, with complex etiologies that intertwine genetic predispositions and environmental influences. Genome-wide association studies have been instrumental in identifying common genetic variants that contribute to the risk of developing these conditions. This guide provides a comparative overview of key genetic risk factors identified across multiple studies, details the experimental methodologies employed, and visualizes associated biological pathways and research workflows.
Comparative Analysis of Genetic Risk Factors
The following table summarizes significant genetic loci associated with an increased risk for congenital heart defects, orofacial clefts, and neural tube defects as identified in various genome-wide association studies. It is important to note that the etiology of these conditions is multifactorial, and the presence of these genetic variants does not definitively predict the occurrence of a birth defect but rather indicates an increased susceptibility.
| Birth Defect Category | Locus/Gene | Risk Allele (SNP) | Odds Ratio (OR) [95% CI] | p-value | Study Population |
| Congenital Heart Defects | |||||
| Atrial Septal Defect | 4p16 | rs870142 | 1.40 [1.19-1.65] | 2.6 x 10⁻¹⁰ | European |
| Left-Sided Lesions | 1p21.2 (near PALMD) | rs35046143 | 1.15 [1.09-1.21] | 7.1 x 10⁻⁹ | Finnish |
| Septal Defects | 17q25.3 (near BAHCC1) | rs1293973611 | 4.48 [2.80-7.17] | 7.0 x 10⁻¹⁰ | Finnish |
| General CHD | 17q21.32 (LRRC37A2) | rs2316327 | 1.17 [1.12-1.23] | 1.5 x 10⁻⁹ | Finnish |
| Orofacial Clefts | |||||
| Cleft Lip with/without Palate | 8q24 | rs987525 | 2.57 (for heterozygotes) | < 5 x 10⁻⁸ | European |
| Cleft Lip with/without Palate | 1q32.2 (IRF6) | rs2235371 | 1.62 [1.48-1.77] | 1.2 x 10⁻⁴² | European, Asian |
| Cleft Lip with/without Palate | 3q28 (TP63) | rs76479869 | Not Reported | 1.16 x 10⁻⁸ | Multi-ethnic |
| Cleft Palate Only | 2p21 (near CTNNA2) | rs1884800 | 1.54 [1.34-1.76] | 1.2 x 10⁻⁹ | African |
| Neural Tube Defects | |||||
| Spina Bifida | MTHFR | C677T | 2.03 [1.09-3.79] | < 0.05 | UK |
| Spina Bifida & Anencephaly | VANGL1 | Multiple variants | Not Reported | Not Reported | Mixed |
| Spina Bifida | SLC19A1 (Folate transporter) | Multiple novel variants | Not Reported | Not Reported | Mixed |
Experimental Protocols: A Methodological Overview
The identification of the genetic risk factors detailed above largely relies on the robust methodology of Genome-Wide Association Studies (GWAS). While specific protocols vary between studies, a generalized experimental workflow is outlined below.
Study Design
The majority of genetic association studies for birth defects utilize a case-control design [1][2][3]. This involves comparing the frequency of genetic variants in a group of individuals with a specific birth defect (cases) to a group of individuals without the birth defect (controls)[1][2][3]. An alternative and powerful design, particularly for early-onset conditions, is the case-parent trio design , which includes the affected individual and their biological parents[1][4]. This design is effective in controlling for population stratification and allows for the investigation of parental genetic effects[1][2][4].
Subject Recruitment and Phenotyping
Case subjects are typically identified through birth defect registries or clinical centers. Detailed clinical information, including medical records and imaging, is reviewed by clinical geneticists to ensure accurate and specific phenotyping of the birth defect. Control subjects are selected from the same population base as the cases and are confirmed to be free of major birth defects. For all participants, informed consent is obtained, and biological samples, usually blood or saliva, are collected for DNA extraction.
Genotyping and Quality Control
DNA samples are genotyped using high-density single nucleotide polymorphism (SNP) arrays, such as those from Illumina or Affymetrix. Rigorous quality control measures are applied to the genotyping data. These typically include:
-
Sample-level filtering: Exclusion of samples with low call rates (e.g., < 95%) or sex discrepancies.
-
SNP-level filtering: Removal of SNPs with low genotyping call rates (e.g., < 95%), low minor allele frequency (e.g., < 1-5%), and significant deviation from Hardy-Weinberg equilibrium in controls (e.g., p < 1 x 10⁻⁵)[4].
-
Mendelian error checks: In trio studies, SNPs with a high rate of Mendelian inconsistency are excluded[4].
Statistical Analysis
The core of a GWAS is the statistical analysis to identify associations between genetic variants and the birth defect. For case-control studies, a logistic regression model is commonly employed, with the presence or absence of the birth defect as the outcome and the genotype as the predictor. The analysis is adjusted for potential confounders such as sex and population stratification (typically addressed by including principal components of ancestry as covariates)[5]. The strength of the association is quantified by the odds ratio (OR) and its statistical significance is determined by the p-value. A genome-wide significance threshold is typically set at p < 5 x 10⁻⁸ to correct for multiple testing. For trio studies, log-linear models or transmission disequilibrium tests (TDT) are often used[4].
Visualizing the Molecular Landscape
To better understand the biological context of the identified genetic risk factors, it is crucial to visualize the signaling pathways involved in embryonic development. Below are diagrams of two key pathways implicated in congenital heart defects and neural tube defects, respectively, as well as a generalized workflow for a typical GWAS.
References
- 1. Genome-wide association studies of structural birth defects: A review and commentary - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Genetic Epidemiology of Neural Tube Defects - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Case-control studies for identifying novel teratogens - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Genome-wide association study of maternal and inherited effects on left-sided cardiac malformations - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Genome-wide association studies of Down syndrome associated congenital heart defects - PMC [pmc.ncbi.nlm.nih.gov]
Consistency of Birth Defect Findings: A Comparative Analysis of the National Birth Defects Prevention Study (NBDPS) and Animal Models
For Researchers, Scientists, and Drug Development Professionals: An objective comparison of human epidemiological data and animal model studies on the teratogenic potential of select medications.
The National Birth Defects Prevention Study (NBDPS), a large-scale population-based case-control study, has been instrumental in identifying potential risk factors for birth defects.[1] Concurrently, animal models provide a crucial platform for investigating the biological mechanisms underlying these associations. This guide offers a comparative overview of the consistency of findings between the this compound and animal model studies for three commonly prescribed medications: Selective Serotonin (B10506) Reuptake Inhibitors (SSRIs), Ondansetron (B39145), and Topiramate (B1683207).
Selective Serotonin Reuptake Inhibitors (SSRIs)
The this compound has suggested a potential link between first-trimester use of certain SSRIs and a small increased risk for specific birth defects.[2][3] Animal studies have explored the impact of prenatal SSRI exposure, with some findings corroborating the potential for developmental toxicity.
Data Presentation: this compound Findings vs. Animal Model Outcomes
| Birth Defect Category | This compound Findings (Odds Ratio) | Animal Model Findings (Species) | Relevant SSRIs (in Animal Models) |
| Anencephaly | Small increased risk[2] | Not consistently reported | Paroxetine |
| Craniosynostosis | Small increased risk[2] | Observed in some rodent models | Fluoxetine |
| Omphalocele | Small increased risk[2] | Can be induced in mouse models through genetic manipulation that may be influenced by serotonin signaling | Paroxetine |
| Cardiac Defects | Mixed findings, some studies suggest a small increased risk with paroxetine[4] | Cardiac malformations and functional changes observed in rodent models[5] | Paroxetine, Sertraline |
Experimental Protocols
Rodent Model for SSRI-Induced Craniofacial and Cardiac Defects:
-
Animal Model: C57BL/6 mice.
-
Drug Administration: Pregnant dams are administered a specific SSRI (e.g., fluoxetine, paroxetine) via oral gavage or subcutaneous injection daily during the period of organogenesis (gestational days 6-15). Doses are typically calculated based on human therapeutic doses, adjusted for the animal's body weight.
-
Fetal Examination: On gestational day 18, fetuses are collected and examined for gross external malformations. A subset of fetuses is fixed for visceral examination to assess internal organ development, including the heart. Another subset is stained with Alizarin red and Alcian blue to visualize the skeleton and identify any craniofacial abnormalities, such as craniosynostosis.
-
Data Analysis: The incidence of specific birth defects in the SSRI-exposed groups is compared to a control group receiving a vehicle solution. Statistical significance is determined using appropriate statistical tests, such as the Chi-squared or Fisher's exact test.
Signaling Pathway
Serotonin (5-HT) plays a crucial role in early embryonic development, influencing cell proliferation, migration, and differentiation.[6][7][8] SSRIs, by blocking the serotonin transporter (SERT), increase the extracellular levels of serotonin. This disruption of normal serotonin signaling is hypothesized to interfere with developmental processes. For instance, altered 5-HT signaling can impact neural crest cell migration, which is critical for the development of craniofacial structures and the heart.
Caption: SSRI-mediated inhibition of serotonin reuptake and its potential downstream effects on embryonic development.
Ondansetron
Ondansetron, a 5-HT3 receptor antagonist, is commonly used to treat nausea and vomiting during pregnancy. This compound data have raised concerns about a possible association with a small increased risk of cardiovascular defects and orofacial clefts.[9][10] Animal studies have explored these potential risks, with a focus on the drug's known pharmacological effects.
Data Presentation: this compound Findings vs. Animal Model Outcomes
| Birth Defect Category | This compound Findings (Odds Ratio) | Animal Model Findings (Species) |
| Cardiovascular Defects | Possible small increased risk[9][11] | Cardiovascular malformations and embryonic heart rhythm disturbances observed in rats[12][13] |
| Orofacial Clefts | Possible small increased risk[9][10] | Can be induced in animal models secondary to hypoxia caused by cardiac dysfunction[13] |
Experimental Protocols
Rat Embryo Culture Model for Ondansetron-Induced Cardiac Effects:
-
Animal Model: Sprague-Dawley rats.
-
Embryo Culture: On gestational day 13, embryos are explanted and cultured in rotating bottles containing rat serum. This in vitro system allows for direct observation of the embryonic heart.
-
Drug Exposure: Ondansetron is added to the culture medium at various concentrations.
-
Cardiovascular Assessment: The embryonic heart rate and rhythm are continuously monitored and recorded. At the end of the culture period, embryos are examined for morphological abnormalities of the heart and great vessels.
-
Data Analysis: The incidence of arrhythmias and structural cardiac defects in ondansetron-exposed embryos is compared to control embryos cultured in the absence of the drug.
Signaling Pathway
The leading hypothesis for ondansetron's potential teratogenicity involves its ability to block the human Ether-à-go-go-Related Gene (hERG) potassium channel.[12][13] Blockade of this channel in the embryonic heart can disrupt normal cardiac repolarization, leading to arrhythmias such as bradycardia.[12] Severe or prolonged embryonic arrhythmias can alter blood flow dynamics, leading to structural heart defects. Furthermore, the resulting hypoxia may also contribute to other malformations, such as orofacial clefts.[13]
Caption: Proposed mechanism of ondansetron-induced birth defects via hERG channel blockade.
Topiramate
Topiramate is an antiepileptic drug also prescribed for migraine prevention. Data from the this compound and other studies have consistently shown an association between first-trimester topiramate exposure and an increased risk of oral clefts.[2][7][14] This association is supported by findings from various animal models.
Data Presentation: this compound Findings vs. Animal Model Outcomes
| Birth Defect Category | This compound Findings (Odds Ratio) | Animal Model Findings (Species) | Incidence in Animal Models |
| Oral Clefts | Increased risk (pooled OR ~5.4)[2][7][14] | Craniofacial malformations, including oral clefts, observed in mice, rats, and zebrafish[15][16] | ~23% with cartilage malformation in zebrafish offspring[15] |
Experimental Protocols
Zebrafish Model for Topiramate-Induced Craniofacial Defects:
-
Animal Model: Zebrafish (Danio rerio).
-
Drug Administration: Adult female zebrafish are exposed to topiramate in their tank water for a specified period. Following exposure, they are bred with unexposed males.
-
Embryo and Larval Development: Fertilized eggs are collected and raised in a topiramate-free environment. Embryonic and larval development is monitored.
-
Craniofacial Analysis: At specific developmental stages (e.g., 5 days post-fertilization), larvae are fixed and stained with Alcian blue to visualize the craniofacial cartilage. The morphology of the pharyngeal arches and other craniofacial structures is examined under a microscope.
-
Data Analysis: The prevalence of craniofacial malformations in the offspring of topiramate-exposed females is compared to the offspring of control females.
Signaling Pathway
The mechanism by which topiramate may induce oral clefts is thought to involve its effects on neurotransmitter signaling, particularly the enhancement of GABAergic activity.[8] Gamma-aminobutyric acid (GABA) is an important signaling molecule in embryonic development. Altered GABA signaling can disrupt the expression of key developmental genes, such as Transforming Growth Factor Beta 1 (TGFβ1) and SRY-Box Transcription Factor 9 (SOX9), which are crucial for the proper formation of the palate.[3][17]
Caption: Postulated pathway for topiramate-induced oral clefts through altered GABAergic signaling.
References
- 1. hyperemesis.org [hyperemesis.org]
- 2. Use of topiramate in pregnancy and risk of oral clefts - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. Anti-epileptic drug topiramate upregulates TGFβ1 and SOX9 expression in primary embryonic palatal mesenchyme cells: Implications for teratogenicity - PMC [pmc.ncbi.nlm.nih.gov]
- 4. First trimester ondansetron exposure and risk of structural birth defects - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
- 6. womensmentalhealth.org [womensmentalhealth.org]
- 7. Use of topiramate in pregnancy and risk of oral clefts | RTI [rti.org]
- 8. Mechanisms of neurodevelopmental toxicity of topiramate - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Medications used to treat nausea and vomiting of pregnancy and the risk of selected birth defects - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. Association of maternal first trimester ondansetron use with cardiac malformations and oral clefts in offspring - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Ondansetron Use in Pregnancy and Birth Defects: A Systematic Review - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. Ondansetron and teratogenicity in rats: Evidence for a mechanism mediated via embryonic hERG blockade - PubMed [pubmed.ncbi.nlm.nih.gov]
- 13. downloads.regulations.gov [downloads.regulations.gov]
- 14. Use of topiramate in pregnancy and risk of oral clefts | Obgyn Key [obgynkey.com]
- 15. Teratogenic Effects of Topiramate in a Zebrafish Model - PMC [pmc.ncbi.nlm.nih.gov]
- 16. Use of topiramate in pregnancy and risk of oral clefts - PMC [pmc.ncbi.nlm.nih.gov]
- 17. researchgate.net [researchgate.net]
Paving the Way for Collaborative Research: A Guide to Harmonizing NBDPS Data with Other Epidemiological Cohorts
For researchers, scientists, and drug development professionals, the ability to combine and compare data from multiple large-scale studies is paramount to advancing our understanding of birth defects. This guide provides a framework for harmonizing data from the National Birth Defects Prevention Study (NBDPS) with other major epidemiological cohorts, offering a roadmap to enhanced statistical power and novel research opportunities.
The National Birth defects Prevention Study (this compound) is one of the largest population-based case-control studies of birth defects ever conducted in the United States, gathering extensive data on genetic and non-genetic risk factors.[1][2] While the this compound itself is a rich resource, harmonizing its data with other epidemiological cohorts, such as the European Concerted Action on Congenital Anomalies and Twins (EUROCAT) and the Slone Epidemiology Center Birth Defects Study, can unlock even greater potential for discovery. This guide outlines the key considerations, methodologies, and challenges in undertaking such data harmonization projects.
Comparing the Cohorts: A High-Level Overview
Effective data harmonization begins with a thorough understanding of the individual cohorts. The table below summarizes the key characteristics of the this compound, EUROCAT, and the Slone Epidemiology Center Birth Defects Study.
| Feature | National Birth Defects Prevention Study (this compound) | European Concerted Action on Congenital Anomalies and Twins (EUROCAT) | Slone Epidemiology Center Birth Defects Study (PHIS) |
| Study Design | Population-based case-control study.[1][3][4] | Network of population-based registries for the epidemiological surveillance of congenital anomalies.[5] | Multicenter case-control study.[6] |
| Geographic Scope | 10 U.S. states.[7] | Multiple registries across Europe. | Areas surrounding Philadelphia, Nashville, and San Diego; Massachusetts, Rhode Island, Southern New Hampshire, and parts of New York State.[6] |
| Data Collection Period | Births from 1997 to 2011.[2][3] | Ongoing, with data from registries spanning several decades. | 1976 to 2015. |
| Primary Data Sources | Maternal telephone interviews, medical records, and collection of cheek cells for genetic analysis.[7][8] | Data from multiple sources including hospital records, birth and death certificates, and specialized clinics. | Telephone interviews with mothers conducted by trained nurse-interviewers.[6] |
| Key Data Domains | Demographics, maternal health, pregnancy history, medication and supplement use, occupational exposures, lifestyle factors, and paternal information.[8] | Standardized set of core and recommended variables including infant and maternal demographics, diagnostic information, and pregnancy outcomes.[9] | Medical history, previous pregnancies, nutrition, occupation, health behaviors, smoking, and detailed medication use.[6] |
A Framework for Retrospective Data Harmonization
Harmonizing data from disparate studies is a complex but manageable process. The following protocol, adapted from the Maelstrom Research guidelines for retrospective data harmonization, provides a structured approach.[10][11][12]
Phase 1: Feasibility and Planning
-
Define Research Objectives: Clearly articulate the specific research questions that will be addressed by the harmonized dataset.
-
Identify and Characterize Cohorts: Select relevant cohorts and thoroughly document their study design, data collection methods, and available variables.
-
Assess Harmonization Potential: Evaluate the comparability of variables across studies, considering differences in definitions, measurement techniques, and coding schemes.
Phase 2: Harmonization Process
-
Develop a Data Dictionary: Create a comprehensive data dictionary for the target harmonized dataset, defining each variable, its format, and permissible values.
-
Map and Transform Variables: For each cohort, map the original variables to the harmonized variables. This may involve recoding, rescaling, or combining variables.
-
Implement Data Processing: Write and execute scripts to transform the data from each cohort into the harmonized format.
-
Quality Control: Perform rigorous quality control checks to ensure the accuracy and consistency of the harmonized data. This includes checking for missing data, outliers, and logical inconsistencies.
Phase 3: Analysis and Dissemination
-
Statistical Analysis: Employ appropriate statistical methods to analyze the pooled data, accounting for potential heterogeneity between studies. This may involve using random-effects models or other advanced statistical techniques.[13]
-
Document and Disseminate: Thoroughly document the entire harmonization process, including all decisions made and any challenges encountered. Publish the findings in peer-reviewed journals to ensure transparency and reproducibility.
Key Experimental Protocols
Protocol 1: Variable Mapping and Transformation
Objective: To create a harmonized dataset of maternal demographics and exposures from this compound and another case-control study.
Methodology:
-
Variable Selection: Identify key maternal demographic variables (e.g., age, race/ethnicity, education) and exposure variables (e.g., smoking, alcohol use, pre-gestational diabetes) present in both datasets.
-
Definition Comparison: Carefully compare the definitions and coding of each selected variable. For example, how is "maternal smoking" defined in each study (e.g., any smoking during pregnancy, smoking in the three months before pregnancy)?
-
Mapping Strategy:
-
Direct Match: If variables are identical in definition and coding, they can be directly mapped.
-
Recoding: If coding differs but the underlying definition is the same, recode one or both variables to a common format. For instance, educational attainment might be categorized differently and require re-grouping.
-
Algorithmic Transformation: For more complex differences, develop an algorithm to transform the data. For example, if one study collects the number of cigarettes smoked per day and the other collects smoking status as "yes/no," the continuous variable can be dichotomized.
-
-
Documentation: Meticulously document all mapping and transformation rules in a data dictionary.
Protocol 2: Statistical Harmonization
Objective: To pool data from a case-control study (this compound) and a registry-based cohort (EUROCAT) to increase statistical power for studying a rare birth defect.
Methodology:
-
Data Preparation: Harmonize the case and control definitions as much as possible. Ensure the birth defect phenotype is defined consistently across both data sources.
-
Assessment of Heterogeneity: Before pooling, assess the degree of heterogeneity between the studies. This can be done by comparing the distribution of key demographic and exposure variables and by looking for differences in the effect estimates of known risk factors.
-
Statistical Modeling:
-
Meta-analysis: If significant heterogeneity exists that cannot be fully resolved through variable harmonization, a meta-analytic approach may be most appropriate. This involves analyzing each dataset separately and then combining the summary statistics.
-
Pooled Analysis with Study as a Covariate: If heterogeneity is manageable, the datasets can be pooled, and "study" can be included as a covariate in the statistical model to adjust for potential systematic differences.
-
Hierarchical/Multilevel Models: These models can also be used to account for the clustering of data within studies.
-
Challenges in Data Harmonization
Researchers should be aware of several potential challenges when harmonizing data from different epidemiological cohorts:
-
Differences in Study Design: Combining data from case-control studies and registries requires careful consideration of potential biases inherent in each design.[6]
-
Variable Definitions and Coding: As highlighted in the protocols, inconsistencies in how data were defined and collected are a primary challenge.
-
Data Quality: The quality and completeness of data may vary significantly between studies.
-
Confidentiality and Data Sharing: Access to individual-level data from multiple studies often requires navigating complex data sharing agreements and ensuring patient confidentiality.[14]
By carefully planning and executing a data harmonization project, researchers can overcome these challenges and leverage the wealth of information contained within the this compound and other valuable epidemiological cohorts to accelerate the pace of discovery in birth defects research.
References
- 1. The National Birth Defects Prevention Study: a review of the methods - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Methods for Accessing this compound and BD-STEPS Data | Birth Defects | CDC [cdc.gov]
- 3. This compound.org [this compound.org]
- 4. This compound.org [this compound.org]
- 5. eu-rd-platform.jrc.ec.europa.eu [eu-rd-platform.jrc.ec.europa.eu]
- 6. Pregnancy Health Interview Study (Birth Defects Study) | Slone Epidemiology Center [bu.edu]
- 7. mass.gov [mass.gov]
- 8. This compound.org [this compound.org]
- 9. eu-rd-platform.jrc.ec.europa.eu [eu-rd-platform.jrc.ec.europa.eu]
- 10. Maelstrom Guidelines - Maelstrom Research [maelstrom-research.org]
- 11. Maelstrom Research guidelines for rigorous retrospective data harmonization - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Maelstrom Research guidelines for rigorous retrospective data harmonization - PubMed [pubmed.ncbi.nlm.nih.gov]
- 13. Statistical methodologies to pool across multiple intervention studies - PMC [pmc.ncbi.nlm.nih.gov]
- 14. catalog.data.gov [catalog.data.gov]
Assessing the Generalizability of the National Birth Defects Prevention Study (NBDPS) Findings: A Comparative Guide
The National Birth Defects Prevention Study (NBDPS) stands as a landmark population-based case-control study in the United States, offering a wealth of data on potential risk factors for a range of birth defects.[1][2] Its findings have been instrumental in shaping clinical guidance and public health recommendations. This guide provides an objective assessment of the generalizability of this compound findings by comparing key results with other research, presenting the underlying data, and detailing the study's robust methodology.
Core Strengths of the this compound and Generalizability
The generalizability of findings from an epidemiological study hinges on the characteristics of the study population and the rigor of its design. The this compound was designed to maximize the applicability of its results.[3]
Key features contributing to the generalizability of this compound findings include:
-
Large, Multi-Center Population: The study encompassed a large and diverse population across 10 states (Arkansas, California, Georgia, Iowa, Massachusetts, New Jersey, New York, North Carolina, Texas, and Utah), enhancing its racial, ethnic, and geographic representativeness.[3][4] This multi-center approach helps to minimize selection bias and improve the likelihood that the findings are applicable to the broader U.S. population.[3]
-
Population-Based Case Ascertainment: Cases were identified through active surveillance programs in each participating state, aiming to capture all eligible birth defects within a defined geographic area.[2]
-
Standardized Data Collection: A standardized computer-assisted telephone interview was used for all participants, ensuring consistency in data collection across all study sites.[5]
Comparative Analysis of Key this compound Findings
This section examines key findings from the this compound and compares them with other relevant studies, presenting the quantitative data in structured tables.
Maternal Smoking and Congenital Heart Defects
One of the significant findings from the this compound is the association between maternal smoking during the periconceptional period and an increased risk of specific congenital heart defects (CHDs).[6] The study's large sample size allowed for the examination of various CHD subtypes.
Table 1: this compound Findings on Maternal Smoking and Congenital Heart Defects [4]
| Congenital Heart Defect Subtype | Any Periconceptional Smoking (Adjusted Odds Ratio [aOR]) | 95% Confidence Interval (CI) | Heavy Smoking (≥25 cigarettes/day) (aOR) | 95% Confidence Interval (CI) |
| Septal Defects (any) | 1.5 | 1.3 - 1.7 | - | - |
| Atrial Septal Defect (secundum) | 1.7 | 1.5 - 2.0 | - | - |
| Tricuspid Atresia | 1.7 | 1.0 - 2.7 | 3.0 | 1.5 - 6.1 |
| Double Outlet Right Ventricle | 1.5 | 1.1 - 2.2 | 1.5 | 1.1 - 2.2 |
| Perimembranous Ventricular Septal Defect | 1.3 | 1.1 - 1.5 | - | - |
| Atrioventricular Septal Defect | 1.3 | 1.0 - 1.9 | - | - |
| Right-sided Obstructive Lesions | 1.2 | 1.0 - 1.4 | - | - |
| Pulmonary Valve Stenosis | 1.2 | 1.0 - 1.4 | - | - |
These findings are consistent with other research, such as the Baltimore-Washington Infant Study, which also reported a modest increase in the risk for certain CHDs with first-trimester maternal smoking.[7] A systematic review of multiple studies also concluded that maternal smoking during pregnancy is associated with an increased risk of CHDs, particularly septal and right-sided obstructive defects.
Influenza Vaccination During Pregnancy and Birth Defects
The this compound investigated the safety of inactivated influenza vaccination during early pregnancy and found no association with an increased risk for 19 non-cardiac birth defects studied.[1] This finding provides crucial evidence to support public health recommendations for influenza vaccination during pregnancy.
Table 2: this compound Findings on Influenza Vaccination (1 Month Before to 3rd Month of Pregnancy) and Selected Non-Cardiac Birth Defects [8]
| Birth Defect | Adjusted Odds Ratio (aOR) | 95% Confidence Interval (CI) |
| Duodenal Atresia/Stenosis | 1.74 | - |
| Craniosynostosis | 1.23 | 0.88 - 1.74 |
| Hypospadias | 1.25 | 0.89 - 1.76 |
| Omphalocele | 0.53 | - |
Note: For most of the 19 defects studied, the adjusted odds ratios were less than or equal to 1, and all confidence intervals included the null value, indicating no statistically significant association.
Subsequent research, including data from the Birth Defects Study To Evaluate Pregnancy exposureS (BD-STEPS), which succeeded the this compound, has further supported these findings, showing no statistically significant positive associations between influenza vaccination and a range of selected birth defects.[9][10]
Hydroxychloroquine (B89500) Use During Pregnancy and Birth Defects
The this compound, in conjunction with the Slone Epidemiology Center Birth Defects Study, examined the use of hydroxychloroquine (HCQ) during pregnancy. The study found no clear pattern of birth defects among women who used HCQ, suggesting no meaningful evidence for an increased risk of specific defects.[11] However, the number of exposed cases was small, warranting cautious interpretation.[11]
Table 3: Hydroxychloroquine (HCQ) Use in Pregnancy and Birth Defects (Combined this compound and Slone Epidemiology Center BDS Data) [11][12]
| Study Population | HCQ Use in Case Mothers | HCQ Use in Control Mothers |
| This compound | 0.06% (19/31,468) | 0.04% (5/11,614) |
| Slone BDS | 0.04% (11/29,838) | 0.05% (7/12,868) |
Experimental Protocols
The robust methodology of the this compound is a cornerstone of its contribution to the field.
1. Study Design: The this compound employed a population-based case-control study design.[3][5]
2. Case and Control Selection:
-
Cases: Infants or fetuses with major structural birth defects were identified through population-based birth defects surveillance systems in the participating states.[2] Cases with known chromosomal or single-gene disorders were excluded.[2]
-
Controls: Live-born infants without any major birth defects were randomly selected from the same geographic areas and time periods as the cases, using birth certificates or hospital birth logs.[2]
3. Data Collection:
-
Computer-Assisted Telephone Interview: Mothers of both cases and controls participated in a detailed, standardized telephone interview conducted between 6 weeks and 24 months after the estimated delivery date.[2][5] The interview gathered information on a wide range of topics, including:
-
Maternal health and medical history
-
Medication use (prescription and over-the-counter)
-
Lifestyle factors (e.g., smoking, alcohol use)
-
Dietary intake
-
Occupational exposures
-
Demographic information
-
-
Buccal Cell Collection: Families were asked to provide buccal (cheek) cell samples from the mother, father, and infant for genetic analysis.[5][14]
Visualizing Key Pathways and Processes
To further elucidate the context of the this compound findings, the following diagrams illustrate relevant biological pathways and the study's workflow.
This compound Experimental Workflow
Case-Control Study Design
Folate Metabolism Pathway
Note on the Folate Metabolism Pathway: The this compound has contributed to understanding the role of periconceptional folic acid in preventing neural tube defects (NTDs).[15] This pathway illustrates the critical role of folate in DNA synthesis and methylation, processes essential for normal embryonic development.[11][16] Genetic variations in enzymes like MTHFR can impact this pathway and have been studied in relation to NTD risk.[11]
Conclusion
The National Birth Defects Prevention Study has made substantial contributions to our understanding of the potential causes of birth defects. The study's large, diverse, and population-based design provides a strong foundation for the generalizability of its findings. While some associations, such as that between maternal smoking and congenital heart defects, are well-supported by other research, others, like the impact of hydroxychloroquine, require further investigation due to the rarity of exposure. The detailed methodologies and extensive data collected by the this compound continue to be a valuable resource for researchers, clinicians, and public health professionals working to prevent birth defects.
References
- 1. academic.oup.com [academic.oup.com]
- 2. Insights into Metabolic Mechanisms Underlying Folate-Responsive Neural Tube Defects: A Minireview - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Neural Tube Defects and Folate Pathway Genes: Family-Based Association Tests of Gene–Gene and Gene–Environment Interactions - PMC [pmc.ncbi.nlm.nih.gov]
- 4. researchgate.net [researchgate.net]
- 5. researchgate.net [researchgate.net]
- 6. Maternal smoking and congenital heart defects - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. scribd.com [scribd.com]
- 8. Methodology Series Module 2: Case-control Studies - PMC [pmc.ncbi.nlm.nih.gov]
- 9. This compound.org [this compound.org]
- 10. genomeweb.com [genomeweb.com]
- 11. Neural tube defects between folate metabolism and genetics - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Maternal Cigarette Smoking and Congenital Heart Defects - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Methods for Accessing this compound and BD-STEPS Data | Birth Defects | CDC [cdc.gov]
- 14. researchgate.net [researchgate.net]
- 15. The National Birth Defects Prevention Study: a review of the methods - PMC [pmc.ncbi.nlm.nih.gov]
- 16. mdpi.com [mdpi.com]
A Comparative Analysis of Large-Scale Epidemiological Studies on Birth Defects: NBDPS and its Successor
In the landscape of public health research, understanding the etiology of birth defects is a critical endeavor. For years, the National Birth Defects Prevention Study (NBDPS) has been a cornerstone of this research in the United States. This guide provides a detailed comparison of the this compound with its successor, the Birth Defects Study To Evaluate Pregnancy exposureS (BD-STEPS), offering researchers, scientists, and drug development professionals a clear overview of their methodologies and evolution. While not a direct cross-validation of a single analytical product, this comparison serves to validate the overarching approach to birth defects research through an examination of two major, sequential studies.
The this compound was a landmark population-based case-control study that gathered extensive data to investigate the genetic and non-genetic risk factors for a wide range of birth defects.[1][2][3] Its successor, BD-STEPS, was designed to build upon and enhance the work of the this compound, continuing the critical mission of identifying preventable causes of birth defects and expanding the scope to include stillbirths.[4][5][6]
Methodological Comparison of this compound and BD-STEPS
The core analytical approach for both this compound and BD-STEPS is an observational, population-based, case-control study design.[7][8] This methodology involves identifying individuals with the outcome of interest (cases) and a comparable group without the outcome (controls) and retrospectively assessing exposures.[9][10] The table below summarizes the key methodological aspects of each study for easy comparison.
| Feature | National Birth Defects Prevention Study (this compound) | Birth Defects Study To Evaluate Pregnancy exposureS (BD-STEPS) |
| Study Period | Deliveries from October 1997 - December 2011[1][2][3] | Deliveries from January 2014 - Ongoing[3][5][6] |
| Primary Focus | Genetic and non-genetic risk factors for over 30 major structural birth defects.[11][12] | Modifiable risk factors for 17 selected categories of severe structural birth defects; also investigates potential causes of stillbirths.[4][13][14] |
| Study Population | Mothers of over 30,000 babies with birth defects and over 10,000 babies without birth defects from 10 U.S. states.[3] | Ongoing recruitment in 7 U.S. states, aiming for approximately 1,000 cases and 500 controls per year.[4][6] |
| Data Collection | Computer-assisted telephone interviews with mothers; collection of buccal (cheek) cells from mother, father, and infant for DNA analysis.[2][11][15] | Computer-assisted telephone interviews with mothers; use of residual newborn screening blood spots for genetic analyses; planned use of online questionnaires and data linkages.[4][7][13] |
| Case Identification | Cases (live births, stillbirths, or terminations) identified from birth defects surveillance programs in participating states.[2] | Cases identified through existing birth defects surveillance programs in participating states.[4][13] |
| Control Selection | Randomly selected live born infants without major birth defects from the same geographical regions and time periods as cases, identified via vital records or birth hospital logs.[2][8] | Randomly selected live born infants without major birth defects from the same catchment area, identified via vital records or birth hospital logs.[4][7] |
Study Protocols and Workflows
The integrity of epidemiological findings relies heavily on robust and consistent study protocols. Both this compound and BD-STEPS have employed rigorous methodologies for participant recruitment, data collection, and analysis.
Experimental Protocol: Case-Control Study Design
-
Case Ascertainment: Cases (infants with specific birth defects) are identified through established, population-based state surveillance systems. Clinical geneticists at each study center review medical records to confirm diagnoses and ensure they meet the study's specific inclusion criteria.[4] Infants with known chromosomal or single-gene disorders are typically excluded to focus on identifying unknown risk factors.[4]
-
Control Selection: A comparison group of control infants (without major birth defects) is randomly selected from the same population base (e.g., from the same states and birth periods) as the cases.[2][4] This is crucial for ensuring that the control group is representative of the population from which the cases arose.
-
Exposure Data Collection: Mothers of both cases and controls are contacted for a detailed, computer-assisted telephone interview.[2][13] The interview covers a wide range of topics, including demographics, maternal health conditions, lifestyle factors, and exposures during pregnancy such as medications and environmental factors.
-
Biological Sample Collection: A key component for genetic research involves the collection of biological samples. The this compound requested buccal (cheek) cell swabs from the infant and both parents.[15] BD-STEPS has adapted this to request permission to use residual dried blood spots collected for routine newborn screening.[4]
-
Data Analysis: The frequency of various exposures is compared between the case and control groups. Statistical methods, primarily logistic regression, are used to calculate the odds ratio (OR).[9][16] The OR estimates the strength of the association between an exposure and the risk of a specific birth defect.[9][10]
Visualizing the Research Workflow
The following diagrams illustrate the general workflow of these large-scale case-control studies and their programmatic relationship.
Conclusion: An Evolving Approach to Cross-Validation
Direct cross-validation of the "results" of an epidemiological study like the this compound is achieved not by running a sample on a different machine, but by conducting subsequent, improved studies that can confirm, refine, or build upon previous findings. The transition from this compound to BD-STEPS is a prime example of this scientific progression. BD-STEPS extends the work of this compound by continuing to collect data on many of the same exposures, which allows for the pooling of data to achieve unprecedented statistical power for analyzing rare events.[4][13] Furthermore, BD-STEPS expands upon its predecessor by incorporating new methodologies, such as using newborn blood spots and planning for linkages to external datasets, and by adding a focus on stillbirths.[4][13]
For researchers and drug development professionals, understanding the methodologies of these large-scale studies is crucial for interpreting their findings. The data generated from this compound and BD-STEPS have been instrumental in identifying potential risk factors for birth defects and informing public health prevention strategies. The consistency in the core case-control design, coupled with the methodical evolution seen in BD-STEPS, provides a strong foundation for the validity and reliability of the collective body of research.
References
- 1. The National Birth Defects Prevention Study: a review of the methods - PMC [pmc.ncbi.nlm.nih.gov]
- 2. The National Birth Defects Prevention Study: A review of the methods - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. Methods for Accessing this compound and BD-STEPS Data | Birth Defects | CDC [cdc.gov]
- 4. Next steps for birth defects research and prevention: The Birth Defects Study To Evaluate Pregnancy exposureS (BD-STEPS) - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Birth Defects Research | Birth Defects | CDC [cdc.gov]
- 6. Birth Defects Study to Evaluate Pregnancy Exposures – Iowa Registry for Congenital and Inherited Disorders [ircid.public-health.uiowa.edu]
- 7. bdsteps.org [bdsteps.org]
- 8. This compound.org [this compound.org]
- 9. Case Control Studies - StatPearls - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 10. Introduction to study designs - case-control studies | Health Knowledge [healthknowledge.org.uk]
- 11. The National Birth Defects Prevention Study - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. researchgate.net [researchgate.net]
- 13. Next steps for birth defects research and prevention: The birth defects study to evaluate pregnancy exposures (BD-STEPS) - PubMed [pubmed.ncbi.nlm.nih.gov]
- 14. publichealth.uams.edu [publichealth.uams.edu]
- 15. mass.gov [mass.gov]
- 16. Statistical analysis of case-control studies - PubMed [pubmed.ncbi.nlm.nih.gov]
A Comparative Analysis of Methodologies in Large-Scale Birth Defect Studies
An in-depth guide for researchers, scientists, and drug development professionals on the methodological approaches of the National Birth Defects Prevention Study (NBDPS) and other prominent large-scale birth defect investigations.
This guide provides a comprehensive comparison of the methodologies employed by the National Birth Defects Prevention Study (this compound) with other major birth defect studies, including the European Surveillance of Congenital Anomalies (EUROCAT), the Slone Epidemiology Center Birth Defects Study, and the National Down Syndrome Project (NDSP). Understanding the nuances of these study designs, data collection protocols, and analytical approaches is crucial for interpreting their findings and advancing research in birth defects etiology and prevention.
Quantitative Comparison of Major Birth Defect Studies
The following table summarizes key quantitative aspects of the this compound and selected comparative studies, offering a clear overview of their scale and scope.
| Feature | National Birth Defects Prevention Study (this compound) | European Surveillance of Congenital Anomalies (EUROCAT) | Slone Epidemiology Center Birth Defects Study | National Down Syndrome Project (NDSP) |
| Study Design | Population-based, multi-center case-control study.[1][2][3] | Network of population-based congenital anomaly registries.[4][5] | Multicenter case-control study.[6] | Population-based, multi-site case-control study.[7][8] |
| Study Period | Pregnancies ending between October 1997 and December 2011.[2][9] | Ongoing since 1979.[4] | 1976 to 2015.[6] | Data collection for the initial phase is complete. |
| Number of Cases | 47,832 eligible cases.[2] | Data on over 155,000 children with congenital anomalies from 1995-2014 in the EUROlinkCAT project.[4][5] | Over 1,100 spina bifida cases included in specific analyses.[10] | 907 infants with Down syndrome.[7][8] |
| Number of Controls | 18,272 eligible controls.[2] | Varies by individual registry and study; some registries collect data on non-malformed controls.[11] | Over 9,000 controls for spina bifida analyses.[10] | 977 infants without major birth defects.[7][8] |
| Geographic Scope | 10 U.S. states.[2] | 22 registries in 14 European countries participating in EUROlinkCAT.[4][5] | Areas in the United States and Canada.[6] | Six national sites in the U.S., representing approximately 11% of U.S. births.[7][8] |
| Primary Focus | Genetic and environmental risk factors for a wide range of major structural birth defects.[9] | Epidemiological surveillance of congenital anomalies, identification of teratogenic exposures, and evaluation of prevention policies.[12] | Safety and risks of a wide range of environmental exposures, primarily medications, in pregnancy.[6] | Molecular and epidemiological factors contributing to chromosome 21 nondisjunction and risk factors for Down syndrome-associated birth defects.[7][8] |
Detailed Methodologies and Experimental Protocols
A thorough understanding of the experimental protocols is essential for evaluating the strengths and limitations of each study.
National Birth Defects Prevention Study (this compound)
The this compound employed a rigorous, population-based case-control design to investigate the causes of major birth defects.[1][2][3]
Case and Control Selection:
-
Cases: Infants or fetuses with major structural birth defects were identified through active case ascertainment by birth defects surveillance programs in participating states.[2] Cases with known chromosomal or single-gene disorders were excluded to focus on identifying unknown causes.[2]
-
Controls: Live-born infants without major birth defects were randomly selected from the same geographic areas and time periods as the cases, using birth certificates or hospital birth logs.[1][2][3]
Data Collection:
-
Maternal Interviews: Trained interviewers conducted computer-assisted telephone interviews with mothers of cases and controls between six weeks and two years after the estimated delivery date.[2] These interviews gathered detailed information on a wide range of potential exposures, including demographics, health conditions, medication use, diet, and occupational exposures.
-
Biological Sample Collection: After the interview, families were asked to provide buccal (cheek) cell samples from the mother, father, and infant.[1] These samples were used for genetic analyses to investigate the role of gene-environment interactions.
Exposure Assessment: The this compound utilized a multi-faceted approach to exposure assessment. For occupational exposures, an industrial hygienist systematically reviewed maternal interview data to impute exposures to various chemical and non-chemical agents.[13] This method aimed to improve upon the use of job titles as a proxy for exposure.
European Surveillance of Congenital Anomalies (EUROCAT)
EUROCAT operates as a network of population-based registries, providing a standardized framework for the surveillance and research of congenital anomalies across Europe.[4][5]
Data Collection and Standardization:
-
Registries collect data on all live births, fetal deaths from 20 weeks gestation, and terminations of pregnancy for fetal anomaly.
-
A standardized methodology is used for the classification and coding of congenital anomalies, primarily using the International Classification of Diseases (ICD) codes with British Paediatric Association (BPA) extensions.[12][14] This ensures comparability of data across different European regions.
-
The EUROCAT subgroups and a Multiple Congenital Anomaly (MCA) algorithm are used to create homogeneous groups for surveillance and research.[12][14]
Data Linkage and Analysis: The EUROlinkCAT project links data from EUROCAT registries with mortality, hospital discharge, prescription, and educational databases.[4][5] This allows for long-term follow-up of children with congenital anomalies to study survival, morbidity, and educational outcomes. Each registry transforms its data into a common data model, and standardized scripts are used for analysis, with results pooled for meta-analyses.[4][5]
Slone Epidemiology Center Birth Defects Study
This long-running case-control study has been a significant contributor to understanding the effects of medications and other environmental exposures during pregnancy.[6]
Case and Control Identification:
-
Infants with birth defects (cases) and a sample of healthy infants (controls) were identified through collaborations with state birth defect registries and participating medical institutions.[6]
Data Collection:
-
Trained nurse-interviewers conducted telephone interviews with mothers, gathering comprehensive information on medical history, previous pregnancies, nutrition, occupation, health behaviors, and detailed medication use throughout pregnancy.[6] Over 51,000 women were interviewed during the study period.[6]
National Down Syndrome Project (NDSP)
The NDSP is a specialized, population-based case-control study focused on understanding the etiology of Down syndrome.[7][8]
Case and Control Selection:
-
Cases: Newborns with a confirmed diagnosis of trisomy 21 were enrolled.[7][8]
-
Controls: Infants without major birth defects were randomly selected from the same birth populations.[7][8]
Data Collection:
-
Parental Interviews: Parents of both cases and controls were interviewed about their pregnancy, medical and family history, occupation, and various exposures.[7][8]
-
Biological Samples: Biological samples were collected from the infants with Down syndrome and their parents.[7][8] These samples were crucial for genetic analyses to determine the parental origin of the chromosome 21 nondisjunction.[7][8]
Visualizing Methodological Workflows
The following diagrams, generated using Graphviz, illustrate the logical flow of the this compound and a generalized registry-based surveillance and research workflow, representative of the EUROCAT model.
References
- 1. This compound.org [this compound.org]
- 2. The National Birth Defects Prevention Study: a review of the methods - PMC [pmc.ncbi.nlm.nih.gov]
- 3. This compound.org [this compound.org]
- 4. bmjopen.bmj.com [bmjopen.bmj.com]
- 5. researchgate.net [researchgate.net]
- 6. Pregnancy Health Interview Study (Birth Defects Study) | Slone Epidemiology Center [bu.edu]
- 7. The National Down Syndrome Project: design and implementation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. The National Down Syndrome Project: Design and Implementation - PMC [pmc.ncbi.nlm.nih.gov]
- 9. researchgate.net [researchgate.net]
- 10. RePORT ⟩ RePORTER [reporter.nih.gov]
- 11. Evaluation of the representativeness of a Dutch non-malformed control group for the general pregnant population: are these controls useful for EUROCAT? - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. Updated EUROCAT guidelines for classification of cases with congenital anomalies - PubMed [pubmed.ncbi.nlm.nih.gov]
- 13. Exposure assessment in epidemiologic studies of birth defects by industrial hygiene review of maternal interviews - PubMed [pubmed.ncbi.nlm.nih.gov]
- 14. findresearcher.sdu.dk [findresearcher.sdu.dk]
NBDPS Findings: A Catalyst for Evolving Clinical Practice Guidelines in Prenatal Care
For Immediate Release
A comprehensive review of the National Birth Defects Prevention Study (NBDPS) reveals its significant, albeit often indirect, influence on the evolution of clinical practice guidelines for prenatal care. This extensive, population-based case-control study, which ran from 1997 to 2013, has provided crucial data on the associations between various maternal exposures and the risk of birth defects. While a direct, one-to-one causal link between a single this compound finding and a specific guideline change is not always explicit, the study's robust evidence has demonstrably reinforced, informed, and supported key recommendations from professional bodies such as the American College of Obstetricians and Gynecologists (ACOG) and the Centers for Disease Control and Prevention (CDC).
This guide examines the impact of this compound findings in four key areas: maternal smoking, maternal obesity, influenza vaccination during pregnancy, and prenatal opioid exposure, comparing the landscape of clinical guidance before and after the dissemination of significant this compound research.
I. Maternal Smoking and Congenital Heart Defects
This compound research provided compelling quantitative evidence solidifying the link between maternal smoking and an increased risk of specific congenital heart defects (CHDs). These findings have bolstered the stringency of anti-smoking recommendations in prenatal care guidelines.
Data Presentation: this compound Findings on Maternal Smoking and CHDs
| Congenital Heart Defect | Association with Any Periconceptional Smoking (Adjusted Odds Ratio) | 95% Confidence Interval |
| Septal Defects (Aggregated) | 1.5 | 1.3 - 1.7 |
| Tricuspid Atresia | 1.7 | 1.0 - 2.7 |
| Double Outlet Right Ventricle (DORV) | 1.5 | 1.1 - 2.1 |
Source: Bolin et al., The Journal of Pediatrics, 2022.[1][2]
Experimental Protocols: this compound Case-Control Study on Maternal Smoking
The this compound employed a population-based case-control study design.[3][4] Cases were infants or fetuses with major structural birth defects identified through surveillance systems in ten US states. Controls were live-born infants without major birth defects, randomly selected from the same geographic areas and time periods.[3] Mothers of both cases and controls participated in a detailed telephone interview about their health and exposures, including smoking habits, during the periconceptional period (one month before to three months after conception).[2] The collected data were then analyzed to calculate odds ratios, adjusting for potential confounding factors.
Impact on Clinical Practice Guidelines:
While guidelines have long advised against smoking during pregnancy, this compound findings provided more specific and statistically significant evidence of the cardiac risks. This has empowered healthcare providers with stronger data to counsel patients on smoking cessation. ACOG and CDC guidelines continue to strongly recommend complete smoking cessation before and during pregnancy, with this compound data serving as a key evidence pillar supporting these recommendations.
Logical Relationship: this compound Findings to Guideline Reinforcement
References
- 1. stacks.cdc.gov [stacks.cdc.gov]
- 2. Maternal Smoking and Congenital Heart Defects, National Birth Defects Prevention Study, 1997-2011 - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. The National Birth Defects Prevention Study: A review of the methods - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. The National Birth Defects Prevention Study: a review of the methods - PMC [pmc.ncbi.nlm.nih.gov]
NBDPS Findings in the Context of Broader Scientific Literature: A Comparative Guide
The National Birth Defects Prevention Study (NBDPS) has been a landmark undertaking in the effort to understand the causes of congenital anomalies. This guide provides a comparative analysis of key this compound findings alongside the broader scientific literature, including other observational studies and alternative research methodologies such as animal studies. It is intended for researchers, scientists, and drug development professionals to offer a comprehensive perspective on the current understanding of birth defects etiology.
Key this compound Findings and Comparative Literature
The this compound, a large-scale, population-based case-control study, has investigated a wide range of potential risk factors for birth defects.[1] This section will compare its findings on three major exposures—Selective Serotonin (B10506) Reuptake Inhibitors (SSRIs), maternal smoking, and maternal obesity—with evidence from other human studies and experimental animal models.
Selective Serotonin Reuptake Inhibitors (SSRIs) and Congenital Heart Defects
The use of SSRIs during pregnancy and the potential risk of birth defects has been a subject of considerable debate and research.
This compound Findings: An early analysis of this compound data did not find a significant increase in the risk for most birth defects, including congenital heart defects, when SSRIs were studied as a group.[2] However, subsequent analyses and re-evaluations have suggested potential associations between specific SSRIs and certain heart defects. For instance, some this compound findings pointed to a small increased risk for three specific birth defects: anencephaly, craniosynostosis, and omphalocele with SSRI use, though these have not been consistently confirmed by other studies.[3] A 2015 study using this compound data suggested that some birth defects may occur 2-3.5 times more frequently in infants of women treated with paroxetine (B1678475) or fluoxetine (B1211875) early in pregnancy.[4]
Broader Scientific Literature: The broader literature on SSRIs and birth defects presents a complex and sometimes conflicting picture. Systematic reviews and meta-analyses of observational studies have reported a small but statistically significant association between first-trimester SSRI exposure and an increased risk of cardiovascular malformations.[3][5][6][7] One meta-analysis found that while antidepressant exposure overall was not associated with congenital malformations in general, there was an increased risk for cardiovascular malformations.[3][5] Another systematic review and meta-analysis confirmed an increased likelihood of congenital heart defects with maternal SNRI and SSRI use during the first trimester.[6] Specifically, paroxetine and fluoxetine have been linked to an elevated risk of certain heart defects.[4][8] However, some large cohort studies have suggested that after adjusting for confounding factors like maternal depression, the increased risk of cardiac malformations attributable to SSRIs is not substantial.[9] The inconsistency in findings across studies may be due to differences in study design, sample size, control for confounding variables, and the specific SSRIs and birth defects examined.[10]
Alternative Methodologies (Animal Studies): Animal studies provide a controlled environment to investigate the potential teratogenic effects of SSRIs. Studies in rodents have shown that SSRI administration during critical developmental windows can lead to changes in brain circuitry and behavior that persist into adulthood.[11] Some animal studies have demonstrated that in utero exposure to sertraline (B1200038) can be embryotoxic, teratogenic, and fetotoxic in mice, leading to an increased incidence of cleft palate.[12] Animal models have also been crucial in exploring the biological mechanisms, showing that SSRIs can impact placental development and fetal growth, potentially leading to adverse pregnancy outcomes observed in both humans and animals, such as decreased birthweight and preterm birth.[13][14][15]
Table 1: Comparison of Findings on SSRI Use and Congenital Heart Defects
| Study Type | Key Findings | Odds Ratio (OR) / Relative Risk (RR) and 95% Confidence Interval (CI) |
| This compound | Initial findings showed no significant increased risk for most heart defects with SSRIs as a class.[2] Later studies suggested a 2-3.5 times more frequent occurrence of some defects with paroxetine or fluoxetine.[4] | Not consistently reported as a single value across all this compound publications. |
| Systematic Reviews/Meta-Analyses | Increased risk for cardiovascular malformations.[3][5] Pooled OR for cardiovascular abnormalities with SSRIs: 1.25 (95% CI: 1.20, 1.30).[16] Pooled OR for congenital heart defects with any antidepressant: 1.22 (95% CI: 1.11 to 1.33).[6] | OR: 1.25 (95% CI: 1.20-1.30) for cardiovascular abnormalities with SSRIs.[16] |
| Animal Studies | Sertraline exposure in mice led to increased cleft palate.[12] SSRIs can alter brain development and function in rodents.[11] | Not applicable (focus on mechanisms and identifying hazards). |
Maternal Smoking and Orofacial Clefts
Maternal smoking during pregnancy is a known risk factor for various adverse birth outcomes.
This compound Findings: this compound data have shown an association between maternal cigarette smoking and an increased risk of having a baby with several types of congenital heart defects, including septal defects, tricuspid atresia, and double outlet right ventricle.[8][17] The study also found a dose-response relationship, with heavier smoking associated with a higher risk.[17]
Broader Scientific Literature: The link between maternal smoking and orofacial clefts has been investigated in numerous studies with largely consistent findings. A UK-based case-control study found a positive association between maternal smoking during the first trimester and both cleft lip with or without cleft palate (OR 1.9, 95% CI 1.1 to 3.1) and cleft palate alone (OR 2.3, 95% CI 1.3 to 4.1).[1][18][19] A study using the Swedish Medical Birth Registry also supported an association between smoking and cleft palate.[20] However, one older, large case-control study did not find a significant increase in the risk of oral clefts with maternal smoking.[21]
Alternative Methodologies (Animal Studies): Animal studies have been instrumental in elucidating the biological mechanisms through which nicotine (B1678760), a major component of tobacco smoke, can be teratogenic. Nicotine has been shown to produce birth defects in some animal species and is considered a possible human teratogen.[22] Studies in animals have demonstrated that nicotine can negatively impact fetal brain development and pregnancy outcomes.[22][23] Research in chicken embryos has shown that nicotine exposure can lead to various malformations, including neural tube defects and affects angiogenesis and cell proliferation.[24] Preclinical rodent models have established that developmental nicotine exposure can have lasting effects on brain structure and behavior.[25] These studies provide biological plausibility for the associations observed in human epidemiological studies.
Table 2: Comparison of Findings on Maternal Smoking and Orofacial Clefts
| Study Type | Key Findings | Odds Ratio (OR) and 95% Confidence Interval (CI) |
| This compound | Primarily focused on congenital heart defects, showing an increased risk.[8][17] | For septal defects: OR 1.5 (1.3–1.7).[17] |
| Case-Control Studies (non-NBDPS) | Positive association between maternal smoking and both cleft lip with or without cleft palate and cleft palate alone.[1][18][19] | Cleft lip ± palate: OR 1.9 (1.1-3.1); Cleft palate: OR 2.3 (1.3-4.1).[19] |
| Animal Studies | Nicotine exposure in animal models leads to birth defects and impacts fetal development.[22][23] | Not applicable. |
Maternal Obesity and Neural Tube Defects
Maternal pre-pregnancy obesity is an increasingly recognized risk factor for a number of birth defects.
This compound Findings: The this compound has not been the primary source of initial findings on this topic, but its data would be used in broader analyses.
Broader Scientific Literature: A substantial body of evidence from observational studies has established a link between maternal obesity and an increased risk of neural tube defects (NTDs). A systematic review and meta-analysis of ten studies found that obese mothers had a significantly higher risk of fetal NTDs compared to women with a normal BMI (OR 1.62, 95% CI 1.32–1.99).[26][27] Another meta-analysis reported unadjusted odds ratios for an NTD-affected pregnancy of 1.70 for obese women and 3.11 for severely obese women compared with normal-weight women.[28] A case-control study in China also found that maternal obesity before pregnancy was associated with an increased risk of NTDs.[29] Higher intake of dietary folate was associated with a decreased NTD risk, and this protective effect was stronger in overweight and obese women.[30]
Alternative Methodologies (Animal Studies): Animal models of maternal obesity have been developed to investigate the underlying mechanisms.[31] These studies have shown that maternal overnutrition can lead to metabolic disorders in the offspring.[31] Murine models of diet-induced maternal obesity have demonstrated that maternal obesity alone, even without diabetes, can result in cardiac defects in offspring through mechanisms involving oxidative stress and altered cell signaling.[32][33] These models are crucial for understanding the complex interplay between maternal metabolism and fetal development and for testing potential intervention strategies.[34]
Table 3: Comparison of Findings on Maternal Obesity and Neural Tube Defects
| Study Type | Key Findings | Odds Ratio (OR) and 95% Confidence Interval (CI) |
| This compound | Data contributed to broader analyses confirming the association. | Not a primary source of standalone published odds ratios on this specific link. |
| Systematic Reviews/Meta-Analyses | Significantly higher risk of NTDs in obese mothers.[26][27][28] | OR 1.62 (1.32–1.99) for obese vs. normal BMI.[26][27] |
| Animal Studies | Maternal obesity in animal models leads to metabolic and cardiovascular defects in offspring.[31][32][33] | Not applicable. |
Experimental Protocols
This section provides an overview of the methodologies employed in the this compound and other comparative studies.
National Birth Defects Prevention Study (this compound)
-
Study Design: Population-based, multicenter case-control study.[1]
-
Participants: Mothers of infants with major birth defects (cases) and mothers of infants without major birth defects (controls).[1]
-
Data Collection: Computer-assisted telephone interviews with mothers between 6 weeks and 2 years after the estimated delivery date.[1] The interview collected information on demographics, health conditions, lifestyle factors, and medication use before and during pregnancy.[35]
-
Genetic Component: Collection of buccal cells from the mother, father, and infant for genetic analysis.[1]
-
Case Ascertainment: Cases were identified through birth defects surveillance programs in participating states.[1]
-
Control Selection: Controls were randomly selected from birth certificates or hospital birth logs from the same geographic areas and time periods as the cases.[1]
Alternative Human Study Designs
-
Systematic Reviews and Meta-Analyses: These studies synthesize data from multiple individual studies to provide a more robust estimate of an association. They involve a systematic search of the literature, predefined inclusion and exclusion criteria, and statistical methods to pool the results of the included studies.[3][5][6][7][16][26][27][28]
-
Cohort Studies: These studies follow a group of individuals (a cohort) over time to observe the development of an outcome. In the context of birth defects, a cohort of pregnant women would be followed to see who gives birth to a child with a birth defect. This design can establish a temporal relationship between an exposure and an outcome.
-
Other Case-Control Studies: Similar in design to the this compound but may vary in size, geographic location, and specific methodologies for data collection and control selection.[1][18][19][20][21][29]
Animal Studies (General Protocol)
-
Species: Rodents (mice, rats) are commonly used due to their short gestation period and well-understood genetics.[11][12][25][32][33] Other models like chicken embryos are also utilized.[24]
-
Exposure: Administration of the substance of interest (e.g., SSRI, nicotine) at specific doses during critical periods of gestation (organogenesis).[12][23] For obesity studies, dams are often fed a high-fat diet before and during pregnancy.[32][33]
-
Outcome Assessment: Examination of fetuses for structural abnormalities (e.g., skeletal and visceral malformations), growth retardation, and embryonic death.[12] Postnatal assessments may include neurobehavioral tests and evaluation of long-term health outcomes in the offspring.[11][25]
-
Mechanism Investigation: Molecular and cellular analyses to understand the pathways through which the exposure leads to adverse developmental outcomes.[32][33]
Visualizations
The following diagrams illustrate key concepts and workflows discussed in this guide.
Caption: this compound Experimental Workflow.
Caption: Methodologies in Birth Defects Research.
Caption: Gene-Environment Interaction Model.
Conclusion
The this compound has made invaluable contributions to our understanding of the potential causes of birth defects. However, as this guide illustrates, its findings are best interpreted within the broader context of the scientific literature, which includes a variety of study designs and methodologies. While observational studies like the this compound are essential for identifying potential associations in human populations, the evidence is strengthened when supported by findings from other epidemiological studies and when biological plausibility is established through experimental models. The inconsistencies in findings, particularly for exposures like SSRIs, highlight the challenges of confounding and bias in observational research and underscore the need for continued investigation using diverse and rigorous methodologies. For drug development professionals, this comparative perspective is crucial for a comprehensive risk assessment of new therapeutic agents. Future research, including the ongoing Birth Defects Study to Evaluate Pregnancy exposureS (BD-STEPS), will continue to build upon the foundation laid by the this compound, further refining our understanding and ultimately aiding in the prevention of birth defects.[2][36][37][38][39][40]
References
- 1. Smoking and Orofacial Clefts: A United Kingdom–Based Case-Control Study | Semantic Scholar [semanticscholar.org]
- 2. Next steps for birth defects research and prevention: The Birth Defects Study To Evaluate Pregnancy exposureS (BD-STEPS) - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Antidepressant exposure during pregnancy and congenital malformations: is there an association? A systematic review and meta-analysis of the best evidence - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. reichandbinstock.com [reichandbinstock.com]
- 5. psychiatrist.com [psychiatrist.com]
- 6. medrxiv.org [medrxiv.org]
- 7. researchgate.net [researchgate.net]
- 8. This compound.org [this compound.org]
- 9. Antidepressant Use in Pregnancy and the Risk of Cardiac Defects - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Selective serotonin reuptake inhibitors and the risk of congenital anomalies: a systematic review of current meta-analyses: Abstract, Citation (BibTeX) & Reference | Bohrium [bohrium.com]
- 11. Developmental effects of SSRIs: lessons learned from animal studies - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. The teratogenic effects of sertraline in mice - PubMed [pubmed.ncbi.nlm.nih.gov]
- 13. asset.library.wisc.edu [asset.library.wisc.edu]
- 14. Maternal serotonin: implications for the use of selective serotonin reuptake inhibitors during gestation - PMC [pmc.ncbi.nlm.nih.gov]
- 15. Long term impact of prenatal exposure to SSRIs on growth and body weight in childhood: evidence from animal and human studies - PubMed [pubmed.ncbi.nlm.nih.gov]
- 16. Maternal exposure to SSRIs or SNRIs and the risk of congenital abnormalities in offspring: A systematic review and meta-analysis - PMC [pmc.ncbi.nlm.nih.gov]
- 17. Maternal Smoking and Congenital Heart Defects, National Birth Defects Prevention Study, 1997–2011 - PMC [pmc.ncbi.nlm.nih.gov]
- 18. researchgate.net [researchgate.net]
- 19. Smoking and orofacial clefts: a United Kingdom-based case-control study - PubMed [pubmed.ncbi.nlm.nih.gov]
- 20. Smoking and the risk of oral clefts: exploring the impact of study designs - PubMed [pubmed.ncbi.nlm.nih.gov]
- 21. Maternal cigarette smoking during pregnancy in relation to oral clefts - PubMed [pubmed.ncbi.nlm.nih.gov]
- 22. Nicotine - Wikipedia [en.wikipedia.org]
- 23. The Effects of Nicotine on Development - PMC [pmc.ncbi.nlm.nih.gov]
- 24. Effects of Nicotine on Chicken Embryo Development: A Review , American Journal of Zoology, Science Publishing Group [sciencepublishinggroup.com]
- 25. Nicotine and the developing brain: Insights from preclinical models - PMC [pmc.ncbi.nlm.nih.gov]
- 26. tandfonline.com [tandfonline.com]
- 27. Risk of neural tube defects according to maternal body mass index: a systematic review and meta-analysis - PubMed [pubmed.ncbi.nlm.nih.gov]
- 28. researchgate.net [researchgate.net]
- 29. Maternal overweight and obesity and the risk of neural tube defects: a case-control study in China - PubMed [pubmed.ncbi.nlm.nih.gov]
- 30. Maternal obesity, folate intake, and neural tube defects in offspring - PubMed [pubmed.ncbi.nlm.nih.gov]
- 31. Maternal obesity and developmental programming of metabolic disorders in offspring: evidence from animal models - PubMed [pubmed.ncbi.nlm.nih.gov]
- 32. researchgate.net [researchgate.net]
- 33. ahajournals.org [ahajournals.org]
- 34. Persistent influence of maternal obesity on offspring health: Mechanisms from animal models and clinical studies - PubMed [pubmed.ncbi.nlm.nih.gov]
- 35. Pregnancy Health Interview Study (Birth Defects Study) | Slone Epidemiology Center [bu.edu]
- 36. Next steps for birth defects research and prevention: The birth defects study to evaluate pregnancy exposures (BD-STEPS) - PubMed [pubmed.ncbi.nlm.nih.gov]
- 37. bdsteps.org [bdsteps.org]
- 38. omb.report [omb.report]
- 39. Checking your connection... [researchfunding.duke.edu]
- 40. Centers for Excellence in Birth Defects Research and Prevention | Slone Epidemiology Center [bu.edu]
A Comparative Analysis of Study Designs: The Case-Control Method of the National Birth Defects Prevention Study (NBDPS) Versus Other Approaches
In the landscape of epidemiological research and drug development, the selection of an appropriate study design is paramount to generating robust and reliable evidence. While a multitude of designs exist, this guide focuses on a comparative analysis of the case-control study design, as exemplified by the large-scale National Birth Defects Prevention Study (NBDPS), against other prominent study designs such as cohort studies and randomized controlled trials (RCTs). This comparison aims to provide researchers, scientists, and drug development professionals with a clear understanding of the relative strengths and weaknesses of each approach, thereby facilitating more informed decisions in future research endeavors.
The this compound was a multi-center population-based case-control study designed to identify risk factors for major birth defects. Its design is particularly well-suited for studying rare outcomes, a common challenge in the field of teratology. However, like all study designs, the case-control approach has inherent limitations. This guide will objectively compare the case-control design with other methodologies, supported by data and experimental considerations.
Quantitative Comparison of Study Designs
| Parameter | Case-Control Study (e.g., this compound) | Cohort Study | Randomized Controlled Trial (RCT) |
| Best For | Rare diseases or outcomes | Rare exposures | Evaluating interventions |
| Sample Size | Generally smaller | Often large | Varies, can be large |
| Cost | Relatively inexpensive | Expensive | Very expensive |
| Time to Completion | Shorter | Long, requires follow-up | Can be long, depends on follow-up |
| Major Bias | Recall bias, selection bias | Selection bias, loss to follow-up | Selection bias (if not properly randomized) |
| Causality | Suggests association | Can establish temporality | Strongest evidence for causality |
| Incidence Calculation | Cannot directly calculate incidence | Can calculate incidence | Can calculate incidence |
Methodological Overviews
Understanding the experimental workflow of each study design is crucial for appreciating their respective strengths and weaknesses.
Case-Control Study Protocol (this compound-based Example)
-
Case Ascertainment: Identify infants with major birth defects (cases) from a defined population (e.g., through birth defect registries).
-
Control Selection: Select a comparable group of infants without birth defects (controls) from the same population.
-
Exposure Assessment: Collect data on maternal exposures (e.g., medication use, diet, environmental factors) during the periconceptional period for both cases and controls. This is often done retrospectively through interviews or questionnaires.
-
Data Analysis: Calculate the odds ratio to estimate the association between a specific exposure and the birth defect.
Cohort Study Protocol
-
Cohort Selection: Recruit a group of individuals (the cohort) who are initially free of the outcome of interest.
-
Exposure Assessment: Classify individuals in the cohort based on their exposure status (e.g., exposed or unexposed to a certain medication).
-
Follow-up: Follow the cohort over time to determine the incidence of the outcome (e.g., a specific health condition) in both the exposed and unexposed groups.
-
Data Analysis: Calculate the relative risk or risk ratio to compare the incidence of the outcome in the exposed group to the unexposed group.
Randomized Controlled Trial (RCT) Protocol
-
Participant Recruitment: Recruit a sample of individuals who meet specific eligibility criteria.
-
Randomization: Randomly assign participants to either the intervention group (receiving the new drug) or the control group (receiving a placebo or standard treatment).
-
Intervention and Follow-up: Administer the intervention and follow both groups over a pre-defined period, monitoring for the outcome of interest.
-
Data Analysis: Compare the rates of the outcome between the intervention and control groups to determine the efficacy of the intervention.
Visualizing Study Design Workflows and Logical Relationships
The following diagrams illustrate the fundamental differences in the workflow and logic of case-control, cohort, and randomized controlled studies.
Caption: Workflow of a case-control study design.
Caption: Workflow of a cohort study design.
Caption: Workflow of a randomized controlled trial.
Strengths and Weaknesses in Detail
Case-Control Studies (as in this compound)
-
Strengths:
-
Efficiency for Rare Outcomes: This design is highly efficient for studying conditions that occur infrequently, such as many major birth defects.
-
Cost-Effectiveness: They are generally less expensive and time-consuming than cohort studies.
-
Multiple Exposures: Allows for the investigation of multiple potential risk factors for a single outcome.
-
-
Weaknesses:
-
Recall Bias: The retrospective nature of exposure assessment can lead to recall bias, where cases may remember past exposures differently than controls.
-
Selection of Controls: The selection of an appropriate control group can be challenging and is a potential source of bias.
-
Causality: It can be difficult to establish a clear temporal relationship between exposure and outcome, which limits the ability to infer causality.
-
Cohort Studies
-
Strengths:
-
Temporal Relationship: The prospective nature of cohort studies allows for the clear establishment of a temporal relationship between exposure and outcome.
-
Multiple Outcomes: Can be used to study multiple outcomes associated with a single exposure.
-
Incidence Rates: Allows for the direct calculation of incidence rates and relative risk.
-
-
Weaknesses:
-
Inefficient for Rare Outcomes: Not practical for studying rare diseases as a very large cohort would be needed.
-
Time and Cost: These studies are often long, expensive, and resource-intensive.
-
Loss to Follow-up: Participants may drop out over time, which can introduce bias.
-
Randomized Controlled Trials (RCTs)
-
Strengths:
-
Gold Standard for Causality: Randomization minimizes confounding, providing the strongest evidence for a causal relationship between an intervention and an outcome.
-
Bias Reduction: Blinding of participants and investigators can reduce bias in outcome assessment.
-
-
Weaknesses:
-
Ethical Concerns: It is not always ethical to randomize participants to a potentially harmful exposure. This is a major limitation in the study of birth defects.
-
High Cost and Complexity: RCTs are typically very expensive and complex to conduct.
-
Generalizability: The strict inclusion and exclusion criteria may limit the generalizability of the findings to a broader population.
-
Safety Operating Guide
Information Not Found and Clarification Required
Extensive searches for "NBDPS" have not yielded any information regarding a chemical substance with this abbreviation. All search results exclusively refer to the National Birth Defects Prevention Study (this compound) , a significant population-based, case-control study in the United States investigating the potential causes of birth defects.[1][2][3][4]
The National Birth Defects Prevention Study was a research initiative that collected data from 1997 to 2011 to identify risk factors for birth defects.[4][5] The study involved interviews with mothers and the collection of biological specimens, such as cheek cells, for genetic analysis.[1][2] Data from the this compound has been used in over 500 research projects and has contributed to more than 200 published scientific manuscripts.[1][5]
Given that the provided query focuses on the proper disposal procedures for a chemical substance, and no such information exists for a compound abbreviated as "this compound," it is highly probable that "this compound" is either a typographical error or a lesser-known acronym.
To provide the requested safety and logistical information, including operational and disposal plans, clarification on the correct chemical name or its full, unabbreviated name is required. Without the correct identification of the substance, it is not possible to provide accurate and safe disposal procedures, quantitative data, experimental protocols, or relevant diagrams.
For general guidance on the proper disposal of laboratory chemicals, it is always recommended to consult the substance's Safety Data Sheet (SDS) and follow all local, state, and federal regulations. General best practices for biohazardous waste management include proper segregation, labeling, and the use of licensed biomedical waste disposal companies.[6][7][8]
References
- 1. The National Birth Defects Prevention Study: a review of the methods - PMC [pmc.ncbi.nlm.nih.gov]
- 2. This compound.org [this compound.org]
- 3. This compound.org [this compound.org]
- 4. Birth Defects Research | Birth Defects | CDC [cdc.gov]
- 5. The National Birth Defects Prevention Study: A review of the methods - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. needle.tube [needle.tube]
- 7. needle.tube [needle.tube]
- 8. m.youtube.com [m.youtube.com]
Navigating the Safe Handling of NBD-PS: A Guide for Laboratory Professionals
For researchers, scientists, and drug development professionals working with NBD-PS (N-(7-nitrobenz-2-oxa-1,3-diazol-4-yl)phosphatidylserine), a fluorescently labeled phosphatidylserine (B164497) analog, ensuring laboratory safety and proper handling is paramount. This guide provides essential, immediate safety and logistical information, including operational and disposal plans, to foster a secure and efficient research environment.
Immediate Safety and Handling Protocols
NBD-PS and its analogs are light-sensitive and hygroscopic materials that require careful handling to maintain their integrity and ensure the safety of laboratory personnel.[1][2] Adherence to the following procedures is critical.
Personal Protective Equipment (PPE): When handling NBD-PS compounds, a comprehensive suite of personal protective equipment is necessary. This includes, but is not limited to:
-
Eye Protection: Safety glasses or goggles should be worn at all times to prevent accidental splashes or contact with the eyes.
-
Hand Protection: Chemical-resistant gloves are mandatory to avoid skin contact.
-
Body Protection: A lab coat or other protective clothing is required to shield the body from potential exposure.[3]
-
Respiratory Protection: Work should be conducted in a well-ventilated area, and for procedures that may generate aerosols, a fume hood is essential.[3][4]
Storage and Stability: Proper storage is crucial for maintaining the chemical's efficacy. NBD-PS compounds should be stored at -20°C in a tightly sealed container, protected from light to prevent degradation.[1][2][5] The stability of the product is typically guaranteed for at least one year under these conditions.[1][2]
Quantitative Data Summary
For quick reference, the following table summarizes key quantitative data for common NBD-PS variants.
| Property | 18:1-12:0 NBD PS | 16:0-12:0 NBD PS | 16:0-06:0 NBD PS |
| Molecular Formula | C42H73N6O13P | C40H71N6O13P | C34H59N6O13P |
| Formula Weight | 901.035 | 874.998 | 790.84 |
| Purity | >99% | >99% | >99% (TLC) |
| Storage Temperature | -20°C | -20°C | -20°C |
| CAS Number | 474943-00-5 | 384833-07-2 | 384833-06-1 |
Hazard Identification and Disposal
NBD-PS is classified with several hazards that necessitate careful handling and disposal. It is considered an acute toxin if inhaled and harmful if swallowed. It can cause skin and eye irritation and may have carcinogenic and reproductive toxicity effects. The target organs for toxicity include the central nervous system, liver, and kidneys.
Disposal Plan: Unused or waste NBD-PS must be disposed of as hazardous chemical waste in accordance with local, state, and federal regulations. Consult your institution's environmental health and safety office for specific guidelines on chemical waste disposal.
Experimental Workflow for Handling NBD-PS
The following diagram outlines the standard operational workflow for handling NBD-PS in a laboratory setting, from preparation to disposal.
Caption: Standard workflow for safe handling of NBD-PS.
References
- 1. avantiresearch.com [avantiresearch.com]
- 2. avantiresearch.com [avantiresearch.com]
- 3. Visualizing NBD-lipid Uptake in Mammalian Cells by Confocal Microscopy - PMC [pmc.ncbi.nlm.nih.gov]
- 4. NBD-lipid Uptake Assay for Mammalian Cell Lines - PMC [pmc.ncbi.nlm.nih.gov]
- 5. 16:0-06:0 NBD PS powder 99 (TLC) Avanti Polar Lipids [sigmaaldrich.com]
Featured Recommendations
| Most viewed |


|
|
|---|---|---|
| Most popular with customers |
|
Haftungsausschluss und Informationen zu In-Vitro-Forschungsprodukten
Bitte beachten Sie, dass alle Artikel und Produktinformationen, die auf BenchChem präsentiert werden, ausschließlich zu Informationszwecken bestimmt sind. Die auf BenchChem zum Kauf angebotenen Produkte sind speziell für In-vitro-Studien konzipiert, die außerhalb lebender Organismen durchgeführt werden. In-vitro-Studien, abgeleitet von dem lateinischen Begriff "in Glas", beinhalten Experimente, die in kontrollierten Laborumgebungen unter Verwendung von Zellen oder Geweben durchgeführt werden. Es ist wichtig zu beachten, dass diese Produkte nicht als Arzneimittel oder Medikamente eingestuft sind und keine Zulassung der FDA für die Vorbeugung, Behandlung oder Heilung von medizinischen Zuständen, Beschwerden oder Krankheiten erhalten haben. Wir müssen betonen, dass jede Form der körperlichen Einführung dieser Produkte in Menschen oder Tiere gesetzlich strikt untersagt ist. Es ist unerlässlich, sich an diese Richtlinien zu halten, um die Einhaltung rechtlicher und ethischer Standards in Forschung und Experiment zu gewährleisten.
