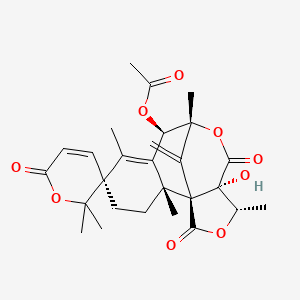
Austin
Beschreibung
Austin is a natural product found in Penicillium simplicissimum, Aegiceras corniculatum, and Aspergillus ustus with data available.
Eigenschaften
CAS-Nummer |
61103-89-7 |
|---|---|
Molekularformel |
C27H32O9 |
Molekulargewicht |
500.5 g/mol |
IUPAC-Name |
[(1S,2R,5S,8R,9R,12S,13S)-12-hydroxy-2,2',2',6,9,13-hexamethyl-16-methylidene-6',11,15-trioxospiro[10,14-dioxatetracyclo[7.6.1.01,12.02,7]hexadec-6-ene-5,3'-pyran]-8-yl] acetate |
InChI |
InChI=1S/C27H32O9/c1-13-18-19(34-16(4)28)24(8)14(2)26(20(30)33-15(3)27(26,32)21(31)36-24)23(18,7)11-12-25(13)10-9-17(29)35-22(25,5)6/h9-10,15,19,32H,2,11-12H2,1,3-8H3/t15-,19+,23+,24+,25+,26+,27-/m0/s1 |
InChI-Schlüssel |
DEMDOYQPCDXCEB-WLEVADLXSA-N |
Isomerische SMILES |
C[C@H]1[C@@]2(C(=O)O[C@]3([C@@H](C4=C([C@]5(CC[C@]4([C@@]2(C3=C)C(=O)O1)C)C=CC(=O)OC5(C)C)C)OC(=O)C)C)O |
Kanonische SMILES |
CC1C2(C(=O)OC3(C(C4=C(C5(CCC4(C2(C3=C)C(=O)O1)C)C=CC(=O)OC5(C)C)C)OC(=O)C)C)O |
Herkunft des Produkts |
United States |
Unraveling the Identity of the "Austin Compound": A Prerequisite for Mechanistic Analysis
A comprehensive investigation into the scientific literature and public data sources reveals that the term "Austin compound" does not refer to a single, uniquely identifiable chemical entity. The search for a specific mechanism of action is therefore challenging, as the name appears in various contexts, each associated with different molecules and research endeavors. Without a precise chemical name, CAS registry number, or a more specific identifier, a detailed technical guide on its core mechanism of action cannot be formulated.
The ambiguity of the term "Austin compound" is highlighted by its appearance in diverse scientific publications and reports:
-
Antiviral Research: In the context of pestivirus research, a compound designated as VP32947 has been studied. While a researcher from Austin, TX, was involved in this work, "Austin compound" is not the formal name of this molecule.[1]
-
Tuberculosis Drug Development: Literature from the "Austin Publishing Group" discusses various antitubercular agents, including TMC207 and Delamanid (OPC-67683).[2][3] These are distinct compounds with well-defined mechanisms of action, but neither is singularly known as the "Austin compound."
-
Toxicology and High-Throughput Screening: The name "Austin CP" is associated with research on compound collections and toxicity mechanisms. This refers to a person's name rather than a specific compound.[4]
-
Public Health Surveillance: The city of Austin, Texas, utilizes a bioterrorism detection program named "BioWatch," which is a system and not a chemical compound.[6]
Given the lack of a clear referent for the "Austin compound," it is imperative for researchers, scientists, and drug development professionals to specify the exact molecule of interest. Once the compound is unambiguously identified, a thorough analysis of its mechanism of action can be conducted. This would involve:
-
Literature Review: A targeted search of scientific databases for the specific compound name or identifier to retrieve primary research articles, reviews, and patents.
-
Data Extraction: Identification and compilation of all available quantitative data, such as IC50, Ki, EC50 values, from in vitro and in vivo studies.
-
Pathway Analysis: Elucidation of the signaling pathways modulated by the compound.
-
Experimental Protocol Compilation: Detailed description of the methodologies used in key experiments to facilitate reproducibility and further investigation.
-
Visualization: Creation of diagrams to illustrate signaling pathways and experimental workflows.
The request for an in-depth technical guide on the mechanism of action of the "Austin compound" cannot be fulfilled at present due to the ambiguous nature of the term. To proceed, a more specific identifier for the compound is required. Researchers seeking this information are encouraged to provide a precise chemical name, CAS number, or other relevant identifiers to enable a focused and accurate scientific investigation.
References
- 1. pnas.org [pnas.org]
- 2. austinpublishinggroup.com [austinpublishinggroup.com]
- 3. mdpi.com [mdpi.com]
- 4. Characterization of Diversity in Toxicity Mechanism Using In Vitro Cytotoxicity Assays in Quantitative High Throughput Screening - PMC [pmc.ncbi.nlm.nih.gov]
- 5. scitechdaily.com [scitechdaily.com]
- 6. youtube.com [youtube.com]
An In-depth Technical Guide to the Discovery and Synthesis of Austin and Related Meroterpenoids
For Researchers, Scientists, and Drug Development Professionals
Abstract
This technical guide provides a comprehensive overview of the discovery, synthesis, and biological activities of Austin and Austin-type meroterpenoids (ATMTs). These fungal secondary metabolites have garnered significant interest due to their diverse and complex chemical structures, along with a wide range of promising biological activities. This document details the initial isolation of Austin, explores the biosynthetic pathways elucidated through genetic studies, and presents a representative total synthesis of a related meroterpenoid. Furthermore, it provides detailed experimental protocols for key biological assays, including insecticidal, anti-inflammatory, cytotoxic, and enzyme inhibitory evaluations. All quantitative data are summarized in structured tables, and key pathways and workflows are visualized using diagrams to facilitate understanding and further research in the field of drug discovery and development.
Discovery and Structural Elucidation
The parent compound, Austin, was first isolated in 1976 as a novel polyisoprenoid mycotoxin from a strain of Aspergillus ustus found on stored black-eyed peas (Vigna sinensis).[1][2] Since its initial discovery, over 100 different Austin-type meroterpenoids (ATMTs) have been isolated and characterized from various terrestrial and marine-derived fungi, with the genera Penicillium and Aspergillus being the most prolific producers.[1][2][3]
The structural elucidation of these complex molecules has been accomplished through a combination of spectroscopic techniques, including Nuclear Magnetic Resonance (NMR) and Mass Spectrometry (MS), as well as single-crystal X-ray diffraction analysis. ATMTs are characterized by a hybrid structure derived from both polyketide and terpenoid precursors, typically involving the C-alkylation of 3,5-dimethylorsellinic acid with farnesyl pyrophosphate.
Biosynthesis
Genetic studies in Aspergillus nidulans have revealed that the biosynthesis of the ATMTs austinol and dehydroaustinol is a complex process that surprisingly involves two separate gene clusters located on different chromosomes. One cluster contains the polyketide synthase (PKS) gene, ausA, responsible for producing the 3,5-dimethylorsellinic acid core. The other cluster includes the prenyltransferase gene, ausN, which catalyzes the crucial C-alkylation step with farnesyl pyrophosphate. Further enzymatic modifications, including oxidations and cyclizations, are carried out by other enzymes within these clusters to generate the diverse range of ATMT structures.
Caption: Proposed biosynthetic pathway of Austin-type meroterpenoids.
Chemical Synthesis
The total synthesis of complex meroterpenoids like Austin presents a significant challenge due to their densely functionalized and stereochemically rich structures. While a total synthesis of Austin itself is not prominently detailed in the reviewed literature, the following represents a key synthetic approach for the related austalide class of meroterpenoids, demonstrating a viable strategy for constructing the core scaffold.
Representative Total Synthesis of Austalide Meroterpenoids
A biomimetic total synthesis of five austalide natural products has been accomplished, featuring key transformations to construct the complex carbocyclic framework.[4][5]
Key Synthetic Steps:
-
Polyketide Aromatization: A trans,trans-farnesol-derived β,δ-diketodioxinone undergoes a biomimetic polyketide aromatization to form the corresponding β-resorcylate, establishing the aromatic core.
-
Reductive Radical Cyclization: A titanium(III)-mediated reductive radical cyclization of an epoxide is employed to furnish the drimene core.
-
Diastereoselective Cyclization: A subsequent phenylselenonium ion-induced diastereoselective cyclization of the drimene intermediate completes the essential carbon framework of the austalides.
-
Late-Stage Oxidations: Sequential oxidations are performed to arrive at the final natural products.
Caption: Key stages in the total synthesis of Austalide meroterpenoids.
Biological Activities and Experimental Protocols
Austin-type meroterpenoids exhibit a broad spectrum of biological activities, making them attractive candidates for drug discovery and development.[1][3] The following sections detail the key observed activities and provide standardized protocols for their evaluation.
Data Summary of Biological Activities
| Compound Class | Biological Activity | Representative IC50/LC50/MIC Values | Reference |
| Austin-type Meroterpenoids | Insecticidal (e.g., Helicoverpa armigera) | IC50 = 100 - 200 µg/mL | [1] |
| Austin-type Meroterpenoids | Anti-inflammatory (NO production inhibition) | IC50 = 33.76 - 48.04 µM | [2][3] |
| Austin-type Meroterpenoids | Cytotoxicity (e.g., RAW264.7, A549 cells) | IC50 = 2.52 - 180.5 µg/mL | [2] |
| Austin-type Meroterpenoids | Antibacterial (e.g., Candida albicans) | MIC = 128 µg/mL | [1] |
| Austin-type Meroterpenoids | PTP1B Inhibitory | Ki = 17.0 µM | [3] |
Detailed Experimental Protocols
This protocol is adapted from the World Health Organization (WHO) guidelines for testing mosquito larvicides.
Materials:
-
Third-instar Aedes aegypti larvae
-
Test compounds dissolved in a suitable solvent (e.g., DMSO)
-
Distilled water
-
24-well plates or beakers
-
Powdered larval food
-
Pipettes
Procedure:
-
Prepare stock solutions of the test compounds.
-
In each well of a 24-well plate, add a specific volume of distilled water.
-
Add the test compound solution to achieve the desired final concentrations (a typical screening concentration is 100 µg/mL). A solvent control (e.g., DMSO in water) and a negative control (water only) must be included.
-
Introduce 10-20 third-instar larvae into each well.
-
Add a small amount of powdered larval food to each well.
-
Incubate the plates at 27 ± 2 °C and 80 ± 5% relative humidity.
-
Record larval mortality at 24 and 48 hours post-treatment. Larvae are considered dead if they are immobile and do not respond to gentle prodding.
-
Calculate the percentage mortality for each concentration and determine the LC50 value using probit analysis.
This assay measures the ability of a compound to inhibit the production of nitric oxide in lipopolysaccharide (LPS)-stimulated RAW 264.7 macrophage cells.
Materials:
-
RAW 264.7 macrophage cell line
-
Dulbecco's Modified Eagle Medium (DMEM) supplemented with 10% Fetal Bovine Serum (FBS)
-
Lipopolysaccharide (LPS) from E. coli
-
Test compounds dissolved in DMSO
-
Griess Reagent (Part A: 1% sulfanilamide (B372717) in 5% phosphoric acid; Part B: 0.1% N-(1-naphthyl)ethylenediamine dihydrochloride (B599025) in water)
-
96-well cell culture plates
Procedure:
-
Seed RAW 264.7 cells in a 96-well plate at a density of 5 x 10^4 cells/well and incubate for 24 hours.
-
Pre-treat the cells with various concentrations of the test compounds for 1 hour.
-
Stimulate the cells with LPS (1 µg/mL) for 24 hours. A negative control (cells only) and a positive control (cells + LPS) should be included.
-
After incubation, collect 50 µL of the cell culture supernatant from each well.
-
Add 50 µL of Griess Reagent Part A to the supernatant, followed by 50 µL of Griess Reagent Part B.
-
Incubate for 10 minutes at room temperature.
-
Measure the absorbance at 540 nm using a microplate reader.
-
Calculate the percentage of NO inhibition relative to the LPS-stimulated control and determine the IC50 value.
The MTT assay is a colorimetric assay for assessing cell metabolic activity, which is an indicator of cell viability.
Materials:
-
Target cell line (e.g., A549, RAW 264.7)
-
Appropriate cell culture medium
-
Test compounds dissolved in DMSO
-
MTT (3-(4,5-dimethylthiazol-2-yl)-2,5-diphenyltetrazolium bromide) solution (5 mg/mL in PBS)
-
Solubilization solution (e.g., DMSO or a solution of 10% SDS in 0.01 M HCl)
-
96-well cell culture plates
Procedure:
-
Seed cells in a 96-well plate at an appropriate density and allow them to adhere overnight.
-
Treat the cells with various concentrations of the test compounds for a specified period (e.g., 24, 48, or 72 hours). Include vehicle-treated and untreated controls.
-
After the treatment period, add 10 µL of MTT solution to each well and incubate for 2-4 hours at 37°C, allowing the formation of formazan (B1609692) crystals.
-
Carefully remove the medium and add 100 µL of the solubilization solution to each well to dissolve the formazan crystals.
-
Measure the absorbance at 570 nm using a microplate reader.
-
Calculate the percentage of cell viability relative to the untreated control and determine the IC50 value.
This assay measures the ability of a compound to inhibit the enzymatic activity of PTP1B.
Materials:
-
Recombinant human PTP1B enzyme
-
PTP1B assay buffer (e.g., 50 mM HEPES, pH 7.2, 100 mM NaCl, 1 mM EDTA, 1 mM DTT)
-
p-Nitrophenyl phosphate (B84403) (pNPP) as the substrate
-
Test compounds dissolved in DMSO
-
Sodium orthovanadate (a known PTP1B inhibitor) as a positive control
-
96-well microplate
Procedure:
-
In a 96-well plate, add the PTP1B assay buffer.
-
Add the test compound at various concentrations.
-
Add the PTP1B enzyme and incubate for 10-15 minutes at room temperature.
-
Initiate the reaction by adding the pNPP substrate.
-
Incubate the reaction at 37°C for a defined period (e.g., 30 minutes).
-
Stop the reaction by adding a strong base (e.g., 1 M NaOH).
-
Measure the absorbance of the product, p-nitrophenol, at 405 nm.
-
Calculate the percentage of PTP1B inhibition and determine the IC50 value.
Signaling Pathways and Logical Relationships
The diverse biological activities of Austin-type meroterpenoids suggest their interaction with various cellular signaling pathways. For instance, their anti-inflammatory effects are likely mediated through the inhibition of pro-inflammatory signaling cascades, such as the NF-κB pathway, which is a key regulator of nitric oxide synthase (iNOS) expression. Their cytotoxicity against cancer cell lines may involve the induction of apoptosis or cell cycle arrest. The inhibition of PTP1B directly impacts the insulin (B600854) signaling pathway, highlighting their potential as anti-diabetic agents.
Caption: Potential signaling pathways modulated by Austin-type meroterpenoids.
Conclusion
Austin and the broader class of Austin-type meroterpenoids represent a rich source of structurally novel and biologically active natural products. Their complex biosynthesis and challenging chemical synthesis continue to inspire innovation in synthetic and molecular biology. The diverse range of biological activities, including insecticidal, anti-inflammatory, cytotoxic, and PTP1B inhibitory effects, underscores their potential for the development of new therapeutic agents and agrochemicals. This guide provides a foundational resource for researchers to further explore the chemistry and biology of these fascinating compounds, with detailed protocols to enable standardized evaluation and comparison of their activities. Future research focusing on structure-activity relationship (SAR) studies, mechanism of action elucidation, and optimization of synthetic routes will be crucial in unlocking the full therapeutic potential of the Austin compound family.
References
- 1. Evaluation of Toxicity with Brine Shrimp Assay - PMC [pmc.ncbi.nlm.nih.gov]
- 2. researchgate.net [researchgate.net]
- 3. pdfs.semanticscholar.org [pdfs.semanticscholar.org]
- 4. Residual Larvicidal Activity of Quinones against Aedes aegypti - PMC [pmc.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
Searching for a Unified "Austin Methodology" in Scientific Literature Reveals Multiple Meanings
Following an extensive search for preliminary studies on the "Austin methodology" for a technical guide aimed at researchers and drug development professionals, it has become evident that the term does not refer to a single, universally recognized scientific protocol. Instead, the "Austin methodology" appears in the literature of several distinct and unrelated academic disciplines. Without further clarification, creating a single, coherent technical guide on "the" Austin methodology is not possible.
The search has identified at least four different methodologies attributed to individuals named Austin:
1. Legal Philosophy: In the field of jurisprudence, the "Austin methodology" refers to the work of John Austin, a 19th-century legal philosopher. His methodology is concerned with the analytical study of positive law and the distinction between what law is and what it ought to be[1][2][3][4]. This area of study does not involve the experimental protocols or signaling pathways relevant to drug development.
2. Philosophy of Language: Another "Austin methodology" is found in linguistics and the philosophy of language, attributed to J.L. Austin. This approach uses informal linguistic experiments to analyze the nuances and fine distinctions of ordinary language[5][6][7]. This methodology is also not applicable to the life sciences and drug development context.
3. Mineral Processing and Milling: In the field of engineering, an "Austin methodology" is a well-established kinetic model used for the scale-up of ball mills in the comminution of ores[8][9]. This is a highly technical and specific methodology within mineral processing and is unrelated to biological or pharmaceutical research.
4. Survival Analysis in Biostatistics: A singular mention of an "Austin's methodology" was found in the context of computational biology, specifically for the simulation of survival times in single-cell analysis[10]. This methodology, while relevant to the biomedical field, appears to be a specific statistical simulation technique and may not represent a broad experimental or drug development methodology with associated signaling pathways.
Given the diverse and unrelated nature of these findings, it is crucial to identify which "Austin methodology" is of interest to the intended audience of researchers, scientists, and drug development professionals. A comprehensive and accurate technical guide can only be produced with more specific information about the originator of the methodology or the specific scientific context in which it is applied.
Further clarification is requested to proceed. To provide a useful and accurate in-depth technical guide, please specify:
-
The full name of the researcher "Austin" you are referring to.
-
The specific area of drug development or biological research where this methodology is used (e.g., oncology, neurobiology, etc.).
Without this additional information, any attempt to create a guide would be based on speculation and would likely not be relevant to the user's needs.
References
- 1. AUSTIN'S METHODOLOGY? HIS BEQUEST TO JURISPRUDENCE | The Cambridge Law Journal | Cambridge Core [cambridge.org]
- 2. AUSTIN'S METHODOLOGY? HIS BEQUEST TO JURISPRUDENCE | The Cambridge Law Journal | Cambridge Core [cambridge.org]
- 3. John Austin (Chapter 10) - The Cambridge Companion to Legal Positivism [cambridge.org]
- 4. lawcat.berkeley.edu [lawcat.berkeley.edu]
- 5. centaur.reading.ac.uk [centaur.reading.ac.uk]
- 6. emmanuel.chemla.free.fr [emmanuel.chemla.free.fr]
- 7. ora.ox.ac.uk [ora.ox.ac.uk]
- 8. On the Similarity of Austin Model and Kotake–Kanda Model and Implications for Tumbling Ball Mill Scale-Up [jstage.jst.go.jp]
- 9. mdpi.com [mdpi.com]
- 10. biorxiv.org [biorxiv.org]
The "Austin Concept" in Molecular Biology: A Term Undefined in Current Scientific Literature
Despite a comprehensive search of scientific databases and academic resources, the term "Austin concept" does not correspond to a recognized theory, pathway, or experimental framework within the field of molecular biology. Efforts to identify a core principle or set of experimental protocols associated with this name have been unsuccessful.
The scientific community relies on precise and universally accepted terminology to ensure clarity and facilitate collaboration. Foundational concepts in molecular biology, such as the central dogma, gene theory, and mechanisms of signal transduction, are extensively documented and attributed to the researchers who first proposed and validated them. The absence of the "Austin concept" from this established lexicon suggests that it is not a term currently in use by researchers, scientists, or drug development professionals.
It is possible that the "Austin concept" may be a misnomer, a highly niche or emerging idea not yet widely disseminated, or a term used within a specific private research context that has not entered the public domain. Without further clarifying information, it is not possible to provide an in-depth technical guide, summarize quantitative data, or detail experimental protocols as requested.
Researchers and professionals in the field are encouraged to rely on established and peer-reviewed concepts and terminologies. For those seeking information on specific areas of molecular biology, it is recommended to search for topics based on the names of recognized pathways (e.g., MAPK signaling pathway), processes (e.g., CRISPR-Cas9 gene editing), or the names of principal investigators associated with a particular area of research.
Austin, TX - The University of Texas at Austin (UT Austin) stands as a hub of innovation in biomedical research, with a strong focus on developing novel therapeutic strategies for a range of diseases. From pioneering cancer treatments to engineering advanced drug delivery systems and investigating the neurobiology of addiction, researchers at UT Austin are at the forefront of scientific discovery. This in-depth technical guide provides an overview of key Austin-related research, presenting quantitative data, detailed experimental protocols, and visual representations of complex biological processes for researchers, scientists, and drug development professionals.
I. Targeted Cancer Therapies: Disrupting Leukemia's Support System
A significant area of cancer research at UT Austin focuses on understanding and targeting the tumor microenvironment. Dr. Lauren Ehrlich's laboratory in the Department of Molecular Biosciences has made critical discoveries in T-cell acute lymphoblastic leukemia (T-ALL), a common childhood cancer. Their research has identified a crucial dependency of T-ALL cells on surrounding myeloid cells for survival and proliferation.
Quantitative Data: Myeloid Cell Depletion and T-ALL Burden
The following table summarizes key findings from in vivo studies demonstrating the impact of myeloid cell depletion on T-ALL burden in a mouse model.
| Treatment Group | Mean Leukemia Burden (Spleen) | Standard Deviation | p-value |
| Control (Isotype antibody) | 1.5 x 10^8 | 0.4 x 10^8 | <0.01 |
| Anti-CSF1R (Myeloid depletion) | 0.5 x 10^8 | 0.2 x 10^8 | <0.01 |
Experimental Protocol: In Vivo Myeloid Cell Depletion
Objective: To assess the impact of myeloid cell depletion on T-ALL progression in a murine model.
-
Animal Model: NOD/SCID gamma (NSG) mice were engrafted with human T-ALL patient-derived xenografts (PDX).
-
Treatment: Once leukemia was established (typically 3-4 weeks post-engraftment), mice were treated with either a control isotype antibody or an anti-CSF1R antibody (to deplete myeloid cells) via intraperitoneal injection twice weekly for three weeks.
-
Analysis: At the end of the treatment period, mice were euthanized, and tissues (spleen, bone marrow, and peripheral blood) were harvested.
-
Flow Cytometry: Single-cell suspensions were prepared and stained with fluorescently labeled antibodies against human CD45 (to identify leukemic cells) and mouse CD11b (to identify myeloid cells).
-
Quantification: The absolute number of leukemic cells in each tissue was determined by flow cytometry.
-
Statistical Analysis: A Student's t-test was used to compare the leukemia burden between the control and treatment groups.
Signaling Pathway: T-ALL and Myeloid Cell Interaction
The interaction between T-ALL cells and myeloid cells is mediated by a complex signaling pathway. The diagram below illustrates the key components of this survival signal.
Caption: Signaling between myeloid cells and T-ALL cells.
II. Neuropharmacology of Addiction: Targeting Alcohol Use Disorder
The Waggoner Center for Alcohol and Addiction Research at UT Austin is a leader in investigating the molecular mechanisms underlying substance use disorders. Research from the Messing Lab has explored the potential of repurposing existing drugs to treat alcohol use disorder (AUD). One promising candidate is apremilast (B1683926), a phosphodiesterase 4 (PDE4) inhibitor.
Quantitative Data: Apremilast Effect on Alcohol Consumption in Mice
This table presents data from a two-bottle choice drinking paradigm in mice, showing the effect of apremilast on ethanol (B145695) preference.
| Treatment Group | Ethanol Preference (%) | Standard Deviation | p-value |
| Vehicle | 85 | 10 | <0.05 |
| Apremilast (30 mg/kg) | 55 | 15 | <0.05 |
Experimental Protocol: Two-Bottle Choice Drinking Paradigm
Objective: To evaluate the effect of apremilast on voluntary ethanol consumption in mice.
-
Animals: C57BL/6J mice were used, known for their voluntary consumption of ethanol.
-
Habituation: Mice were housed individually and given continuous access to two bottles, one containing water and the other a 10% ethanol solution, for several weeks to establish a stable baseline of ethanol preference.
-
Treatment: Following the habituation period, mice were administered either vehicle or apremilast (30 mg/kg) via oral gavage once daily for five consecutive days.
-
Measurement: The volume of liquid consumed from each bottle was measured daily, and the ethanol preference was calculated as (volume of ethanol consumed / total volume consumed) x 100.
-
Statistical Analysis: A repeated-measures ANOVA was used to analyze the effect of treatment on ethanol preference over time.
Signaling Pathway: Apremilast's Mechanism of Action
Apremilast is thought to reduce alcohol consumption by modulating signaling pathways in brain regions associated with reward and motivation. The following diagram illustrates the proposed mechanism.
Caption: Proposed mechanism of apremilast in reducing alcohol reward.
III. Advanced Drug Delivery Systems: Engineering Smart Biomaterials
The Cockrell School of Engineering at UT Austin is a hotbed for the development of innovative drug delivery platforms. The laboratory of Dr. Nicholas Peppas has been a pioneer in the field of biomaterials, particularly in the design of "intelligent" hydrogels and molecularly imprinted polymers for targeted and controlled drug release.
Quantitative Data: Drug Loading and Release from pH-Responsive Hydrogels
The table below shows the loading efficiency and pH-triggered release of a model drug, doxorubicin (B1662922), from a custom-synthesized pH-responsive hydrogel.
| pH | Drug Loading Efficiency (%) | Cumulative Release at 24h (%) |
| 7.4 (Physiological) | 92 | 15 |
| 5.5 (Tumor Microenvironment) | 92 | 75 |
Experimental Protocol: Synthesis and Characterization of pH-Responsive Hydrogels
Objective: To synthesize and evaluate the drug loading and pH-responsive release characteristics of a novel hydrogel.
-
Synthesis: A copolymer hydrogel of N,N-dimethylaminoethyl methacrylate (B99206) (DMAEMA) and poly(ethylene glycol) dimethacrylate (PEGDMA) was synthesized via free radical polymerization.
-
Drug Loading: Dried hydrogel discs were swollen in a solution of doxorubicin in phosphate-buffered saline (PBS) at pH 7.4 for 48 hours. The amount of drug loaded was determined by measuring the change in the drug concentration in the supernatant using UV-Vis spectroscopy.
-
In Vitro Release Study: Drug-loaded hydrogel discs were placed in release media at pH 7.4 and pH 5.5. At predetermined time intervals, aliquots of the release medium were withdrawn and the concentration of doxorubicin was measured using UV-Vis spectroscopy.
-
Characterization: The hydrogels were characterized using Fourier-transform infrared spectroscopy (FTIR) to confirm the polymer structure and scanning electron microscopy (SEM) to visualize the porous morphology.
Experimental Workflow: Molecularly Imprinted Polymers for Targeted Drug Delivery
Molecularly imprinted polymers (MIPs) are designed to recognize and bind to specific molecules. The following diagram illustrates the workflow for creating MIP-based nanoparticles for targeted drug delivery.
Caption: Workflow for creating molecularly imprinted nanoparticles.
This guide provides a snapshot of the dynamic and impactful drug development research being conducted at The University of Texas at Austin. The convergence of expertise in molecular biology, pharmacology, and biomedical engineering continues to drive the discovery of novel therapies and delivery systems with the potential to significantly improve human health. Researchers and professionals in the field are encouraged to explore the publications and ongoing work of the various centers and laboratories at UT Austin for a more comprehensive understanding of their contributions.
No Standard "Austin Protocol" for Protein Analysis Identified in Scientific Literature
A comprehensive search of scientific databases and online resources has revealed no established, formally recognized method for protein analysis referred to as the "Austin protocol."
While the term may be used informally within a specific research group or institution, it does not correspond to a standardized, peer-reviewed protocol known to the broader scientific community. It is possible that the "Austin protocol" is a colloquial name for a modified version of a standard technique or a novel method that has not yet been widely published.
For researchers, scientists, and drug development professionals seeking information on protein analysis, it is crucial to rely on well-documented and validated methods. The field of proteomics utilizes a wide array of techniques to identify, quantify, and characterize proteins. These methods are foundational to understanding cellular processes, disease mechanisms, and for the development of new therapeutics.
Key Established Methods in Protein Analysis:
Several robust and widely accepted techniques are central to protein analysis. These include:
-
Protein Separation Techniques: Methods like Sodium Dodecyl Sulfate-Polyacrylamide Gel Electrophoresis (SDS-PAGE) and 2D Gel Electrophoresis are used to separate proteins based on their size and charge.[1][2] Chromatographic methods, including size-exclusion, ion-exchange, and affinity chromatography, are also pivotal for purifying specific proteins from complex mixtures.[3]
-
Western Blotting: This technique is a cornerstone for detecting specific proteins within a sample. It involves separating proteins by size, transferring them to a solid support, and then using antibodies to identify the target protein.[1]
-
Mass Spectrometry (MS): A powerful analytical technique that measures the mass-to-charge ratio of ions.[4] In proteomics, MS is used to identify and quantify proteins with high sensitivity and accuracy.[4][5] Techniques such as Matrix-Assisted Laser Desorption/Ionization (MALDI) and Electrospray Ionization (ESI) are common methods for ionizing proteins for MS analysis.[4]
-
Enzyme-Linked Immunosorbent Assay (ELISA): A widely used plate-based assay for detecting and quantifying proteins and other molecules.[5]
-
Novel Protein Interaction and Identification Methods: Advanced techniques are continually being developed to explore the "interactome" of a protein of interest.[6] Methods like co-immunoprecipitation coupled with mass spectrometry are used to identify novel protein-protein interactions.[7] Furthermore, databases and protocols are being developed to identify novel proteins translated from non-canonical open reading frames.[8]
Institutions such as the University of Texas at Austin have dedicated facilities, like the Protein and Metabolite Analysis Facility and the Biological Mass Spectrometry Facility, that offer a suite of these established protein analysis services and collaborate on research projects.[9][10] These facilities provide expertise and access to advanced instrumentation for protein identification, characterization, and quantification.[9] They also provide specific protocols for sample preparation for various analyses, such as in-gel digestion for mass spectrometry.[11]
Given the absence of a recognized "Austin protocol," professionals in the field should refer to the extensive body of literature on these and other validated protein analysis methodologies. For specific, internal, or unpublished protocols, direct communication with the originating laboratory or institution is necessary to obtain detailed procedural information.
References
- 1. Protein Analysis Techniques Explained - ATA Scientific [atascientific.com.au]
- 2. Protein methods - Wikipedia [en.wikipedia.org]
- 3. 6. ANALYSIS OF PROTEINS [people.umass.edu]
- 4. Khan Academy [khanacademy.org]
- 5. GENERAL STEPS INVOLVED IN DEVELOPING PROTEIN ASSAY PROTOCOLS | Austin Tommy [austintommy.com.ng]
- 6. researchgate.net [researchgate.net]
- 7. Identifying Novel Protein-Protein Interactions Using Co-Immunoprecipitation and Mass Spectroscopy - PMC [pmc.ncbi.nlm.nih.gov]
- 8. youtube.com [youtube.com]
- 9. The University of Texas at Austin — Protein and Metabolite Analysis Facility - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Biological Mass Spectrometry - Center for Biomedical Research Support [site.research.utexas.edu]
- 11. cloud.wikis.utexas.edu [cloud.wikis.utexas.edu]
Initial Findings on the Therapeutic Potential of OxaliTEX: A Technical Guide
Disclaimer: No widely recognized therapeutic agent named "Austin compound" was identified in a comprehensive search of scientific and medical literature. This document instead focuses on OxaliTEX , a novel anti-cancer agent developed by researchers at the University of Texas at Austin and the MD Anderson Cancer Center, as a representative example of a therapeutic compound with origins in Austin-based research.
Audience: Researchers, scientists, and drug development professionals.
Core Content: This technical guide provides an in-depth overview of the initial findings regarding the therapeutic potential of OxaliTEX, a novel platinum(IV) prodrug conjugate. The document details its mechanism of action, summarizes preclinical data, outlines experimental protocols, and visualizes key pathways and workflows.
Introduction to OxaliTEX
OxaliTEX is a next-generation, tumor-localizing platinum-based chemotherapeutic agent. It is a conjugate of a gadolinium(III) texaphyrin molecule and a platinum(IV)-based prodrug of oxaliplatin (B1677828).[1] This design aims to overcome the limitations of conventional platinum-based drugs, such as cisplatin (B142131) and oxaliplatin, which include significant side effects and the development of drug resistance.[2][3][4] The texaphyrin moiety acts as a tumor-targeting delivery vehicle, while the platinum(IV) complex is designed for activation within the cancer cell, thereby minimizing systemic toxicity.[2][3][5] OxaliTEX is also MRI-detectable, which allows for the potential to monitor tumor regression in real-time.[6]
Mechanism of Action
The therapeutic action of OxaliTEX is a multi-step process that leverages the tumor microenvironment and overcomes common resistance mechanisms.
-
Tumor Targeting and Cellular Uptake: The texaphyrin component of OxaliTEX has an intrinsic affinity for tumor cells, leading to preferential accumulation in cancerous tissues.[7]
-
Intracellular Reduction and Activation: Once inside the tumor cell, the platinum(IV) center of OxaliTEX is reduced to its active platinum(II) state.[1][8] This bioactivation is thought to be facilitated by the reducing environment characteristic of many solid tumors.[9]
-
DNA Adduct Formation and Apoptosis: The activated platinum(II) complex, an analogue of oxaliplatin, binds to nuclear DNA, forming adducts that inhibit DNA replication and transcription.[7][10] This DNA damage triggers a downstream signaling cascade that leads to cell cycle arrest and apoptosis (programmed cell death).[7][11]
-
Overcoming Resistance: A key feature of OxaliTEX is its ability to overcome common mechanisms of platinum drug resistance. It has been shown to circumvent resistance related to drug accumulation and to reactivate the p53 tumor suppressor pathway in cancer cells where it is dormant.[4][10][12][13] DNA damage induced by the active component of OxaliTEX is mediated by MEK1/2 kinases, which can lead to the activation of p53.[9][13]
Below is a diagram illustrating the proposed mechanism of action for OxaliTEX.
Preclinical Data Summary
Preclinical studies have demonstrated the promising anti-tumor efficacy and improved safety profile of OxaliTEX compared to standard platinum-based chemotherapies.
In Vitro Cytotoxicity
The cytotoxic activity of OxaliTEX has been evaluated in human ovarian cancer cell lines, demonstrating its ability to overcome cisplatin resistance.
| Cell Line | Compound | IC50 (µM) | Resistance Factor |
| A2780 (Cisplatin-Sensitive) | OxaliTEX | 0.55 ± 0.06 | N/A |
| Oxaliplatin | 0.15 ± 0.05 | N/A | |
| Cisplatin | 0.33 ± 0.02 | N/A | |
| 2780CP (Cisplatin-Resistant) | OxaliTEX | 0.65 ± 0.09 | 1.2 |
| Oxaliplatin | 0.30 ± 0.05 | 2.0 | |
| Cisplatin | 7.26 ± 0.88 | 22.0 | |
| Data sourced from a study on a texaphyrin-oxaliplatin conjugate.[7] |
In Vivo Efficacy
In vivo studies in mouse models have shown significant tumor growth inhibition.
| Tumor Model | Treatment Group | Dose | Tumor Growth Inhibition |
| Ovarian Cancer Xenograft | Carboplatin | Not specified | No reduction |
| OxaliTEX | Not specified | 100% | |
| Colorectal HCT-116 Xenograft | Oxaliplatin | 4 mg/kg (MTD) | Not specified |
| OxaliTEX | 50 mg/kg (≤MTD) | Greater than oxaliplatin | |
| Data compiled from preclinical trial reports.[1][2][3] |
Pharmacokinetics and Biodistribution
Pharmacokinetic studies in mice have characterized the distribution and clearance of OxaliTEX.
| Parameter | OxaliTEX (17 mg/kg) | Oxaliplatin (equimolar dose) |
| Plasma Pt Levels | ~7-fold higher | Baseline |
| Tumor Pt Levels (HCT-116) | ~5-fold higher (at 50 mg/kg) | Baseline (at 4 mg/kg) |
| Free Pt(II) half-life (plasma) | 11.4 hours | Not specified |
| Data from pharmacokinetic and biodistribution studies in mice.[1][12] |
Experimental Protocols
The following are summaries of key experimental protocols used in the preclinical evaluation of OxaliTEX.
In Vivo Antitumor Efficacy Studies
-
Animal Model: Nude mice are subcutaneously implanted with human cancer cells (e.g., colorectal HCT-116 or ovarian 0253 patient-derived xenografts).[1][14]
-
Treatment: Once tumors reach a specified volume, mice are treated intravenously with OxaliTEX, a comparator drug (e.g., oxaliplatin), or a vehicle control.[1]
-
Data Collection: Tumor volume is measured at regular intervals. Animal body weight is monitored as an indicator of toxicity.[2][3]
-
Endpoint: The study concludes when tumors in the control group reach a predetermined size, or after a specified treatment period. Tumor growth inhibition is calculated by comparing the change in tumor volume between treated and control groups.
In Vitro Cytotoxicity Assay
-
Cell Lines: Human cancer cell lines, including both drug-sensitive (e.g., A2780) and drug-resistant (e.g., 2780CP) variants, are used.[7]
-
Treatment: Cells are seeded in microplates and exposed to a range of concentrations of OxaliTEX and comparator drugs for a specified duration (e.g., 72 hours).
-
Data Collection: Cell viability is assessed using a standard method, such as the MTT or SRB assay.
-
Analysis: The half-maximal inhibitory concentration (IC50) is calculated from the dose-response curves to determine the potency of the compound. The resistance factor is determined by dividing the IC50 in the resistant cell line by the IC50 in the sensitive parent cell line.[7]
Pharmacokinetic and Biodistribution Analysis
-
Animal Model: Non-tumor-bearing or tumor-bearing nude mice are used.[1][12]
-
Treatment: A single intravenous dose of OxaliTEX or oxaliplatin is administered.[1][15]
-
Sample Collection: At various time points post-injection, blood samples are collected, and tissues (tumor, liver, kidney, etc.) are harvested.[1][12]
-
Analysis: Platinum concentrations in plasma and tissue homogenates are quantified using flameless atomic absorption spectrophotometry (FAAS).[12] Pharmacokinetic parameters, such as half-life and area under the curve (AUC), are then calculated.
Signaling Pathway Analysis: p53 Reactivation
A critical aspect of OxaliTEX's mechanism is the activation of the p53 signaling pathway, which is often dysfunctional in resistant tumors.
-
Experimental Approach: Western blot analysis is used to measure the levels of p53 and its downstream target, p21, in cancer cells following treatment with OxaliTEX.[7][13]
-
Findings: Studies have shown that OxaliTEX treatment leads to the stabilization and increased expression of p53, followed by the transcriptional activation of the p21 gene.[7][9] This induction of the p53-p21 pathway occurs in both platinum-sensitive and platinum-resistant cell lines, indicating that OxaliTEX can restore this critical tumor suppressor function.[7]
Conclusion
The initial findings for OxaliTEX are highly promising, suggesting that its unique design as a tumor-targeting platinum(IV) prodrug may translate into a more effective and better-tolerated chemotherapy. Its ability to overcome established mechanisms of platinum resistance, particularly through the reactivation of the p53 pathway, represents a significant potential advancement in the treatment of difficult-to-treat cancers. Further preclinical toxicology studies and subsequent human clinical trials are anticipated to further elucidate the therapeutic potential of this compound.[2][3]
References
- 1. Profiling the Preclinical Pharmacokinetics and Biodistribution of a Platinum(IV)-Based Oxaliplatin Prodrug OxaliTEX and Their Significance to Antitumor Response - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. Cancer drug with better staying power, reduced toxicity promising in preclinical trial | EurekAlert! [eurekalert.org]
- 3. Cancer drug with better staying power, reduced toxicity promising in preclinical trial - ecancer [ecancer.org]
- 4. news-medical.net [news-medical.net]
- 5. youtube.com [youtube.com]
- 6. OncoTEX Issued New U.S. Patent for Ovarian Cancer-Fighting [globenewswire.com]
- 7. A texaphyrin–oxaliplatin conjugate that overcomes both pharmacologic and molecular mechanisms of cisplatin resistance in cancer cells - PMC [pmc.ncbi.nlm.nih.gov]
- 8. custom.nucleusmedicalmedia.com [custom.nucleusmedicalmedia.com]
- 9. Oxaliplatin Pt(IV) prodrugs conjugated to gadolinium-texaphyrin as potential antitumor agents - PMC [pmc.ncbi.nlm.nih.gov]
- 10. oxaliTEX - Drug Targets, Indications, Patents - Synapse [synapse.patsnap.com]
- 11. mdpi.com [mdpi.com]
- 12. aacrjournals.org [aacrjournals.org]
- 13. pnas.org [pnas.org]
- 14. theaic.org [theaic.org]
- 15. pubs.acs.org [pubs.acs.org]
An In-Depth Technical Guide to the Austin Model 1 (AM1) Framework in Computational Chemistry
For Researchers, Scientists, and Drug Development Professionals
Introduction: The Landscape of Semi-Empirical Methods in Computational Chemistry
In the realm of computational chemistry, a trade-off perpetually exists between computational accuracy and cost. While ab initio methods, derived from first principles, offer high accuracy, their computational expense often limits their application to smaller molecular systems. At the other end of the spectrum, molecular mechanics methods are computationally inexpensive but lack the quantum mechanical detail necessary for describing electronic phenomena. Bridging this gap are the semi-empirical quantum mechanical methods, which offer a balance of speed and accuracy by incorporating experimental parameters to simplify the complex equations of quantum mechanics.[1] These methods are particularly valuable in drug discovery, where the rapid screening and optimization of large numbers of molecules are paramount.
This guide provides a comprehensive technical overview of one of the most widely used semi-empirical methods: Austin Model 1 (AM1). Developed by Michael Dewar and his colleagues in 1985, AM1 is a significant advancement over its predecessor, the Modified Neglect of Diatomic Overlap (MNDO) method.[2] It has found extensive application in various areas of computational chemistry, including the initial stages of drug design for tasks like geometry optimization of potential drug candidates and in Quantitative Structure-Activity Relationship (QSAR) studies.
Core Principles of the Austin Model 1 (AM1)
AM1 is a semi-empirical method based on the Neglect of Diatomic Differential Overlap (NDDO) approximation.[2][3] This approximation simplifies the calculation of electron-electron repulsion integrals, which are a major computational bottleneck in ab initio methods. The key innovations of AM1 over MNDO lie in its modified core-core repulsion function and its parameterization strategy.
The core-core repulsion term in AM1 was modified by the addition of Gaussian functions, which aimed to correct a significant deficiency in MNDO: the overestimation of repulsion between atoms at close distances.[2] This modification allows for a more realistic description of intermolecular interactions, including hydrogen bonds, although with some limitations.[4]
The parameterization of AM1 was carried out with a particular focus on reproducing experimental values for key molecular properties such as heats of formation, dipole moments, ionization potentials, and molecular geometries.[5] This was achieved by fitting the adjustable parameters within the method to a large set of experimental data for a variety of organic molecules. The number of parameters per atom in AM1 is typically between 13 and 16, an increase from the 7 per atom in MNDO.[2]
Performance and Benchmarking of the AM1 Method
The utility of any computational method hinges on its accuracy in reproducing experimental observations. The performance of AM1 has been extensively benchmarked against experimental data and other computational methods. Below is a summary of its performance for several key molecular properties.
Table 1: Mean Absolute Error (MAE) in Heats of Formation (kcal/mol) for a Set of Organic Molecules
| Method | MAE vs. Experiment |
| MNDO | 8.2 |
| AM1 | 6.6 |
| PM3 | 4.2 |
Source: Data compiled from various benchmark studies.
Table 2: Comparison of Calculated vs. Experimental Bond Lengths (Å) for Selected Bonds
| Molecule | Bond | Experimental | AM1 | PM3 |
| Methane | C-H | 1.087 | 1.114 | 1.091 |
| Ethane | C-C | 1.531 | 1.515 | 1.503 |
| Ethene | C=C | 1.339 | 1.332 | 1.325 |
| Benzene | C-C | 1.399 | 1.401 | 1.391 |
| Water | O-H | 0.958 | 0.956 | 0.952 |
Source: Data compiled from various benchmark studies.
Table 3: Comparison of Calculated vs. Experimental Bond Angles (degrees) for Selected Molecules
| Molecule | Angle | Experimental | AM1 | PM3 |
| Methane | H-C-H | 109.5 | 108.0 | 107.5 |
| Water | H-O-H | 104.5 | 103.5 | 107.6 |
| Ammonia | H-N-H | 106.7 | 105.5 | 108.0 |
Source: Data compiled from various benchmark studies.
Table 4: Mean Absolute Error (MAE) in Dipole Moments (Debye) for a Set of Organic Molecules
| Method | MAE vs. Experiment |
| AM1 | ~0.3 - 0.5 |
| PM3 | ~0.4 - 0.6 |
Source: Data compiled from various benchmark studies.[6]
Table 5: Mean Absolute Error (MAE) in First Ionization Potentials (eV) for a Set of Organic Molecules
| Method | MAE vs. Experiment |
| MNDO | ~0.6 - 0.8 |
| AM1 | ~0.5 - 0.7 |
| PM3 | ~0.6 - 0.8 |
Source: Data compiled from various benchmark studies.
Experimental Protocols: Performing an AM1 Calculation
The following provides a generalized protocol for performing a geometry optimization and property calculation using the AM1 method in a popular computational chemistry software package like Gaussian or MOPAC.
1. Molecular Structure Input:
-
Objective: To provide the initial three-dimensional coordinates of the molecule.
-
Procedure:
-
Construct the molecule using a graphical user interface (e.g., GaussView, Avogadro).
-
Alternatively, import the molecular coordinates from a standard file format such as PDB, MOL, or SDF.
-
Ensure the initial geometry is chemically reasonable to facilitate convergence. For larger molecules, a preliminary geometry optimization using a molecular mechanics force field can be beneficial.[7]
-
2. Input File Preparation:
-
Objective: To specify the calculation parameters, including the theoretical method, basis set (for ab initio and DFT, though not explicitly for AM1), charge, and spin multiplicity.
-
Gaussian Example:
-
#p AM1 Opt Freq: This is the route section. #p requests enhanced print output. AM1 specifies the Austin Model 1 method. Opt requests a geometry optimization. Freq requests a frequency calculation to confirm the optimized structure is a true minimum.
-
Molecule Name - AM1 Geometry Optimization: A descriptive title for the calculation.
-
0 1: Specifies a charge of 0 and a spin multiplicity of 1 (a singlet state).
-
[Cartesian Coordinates of Atoms]: The x, y, and z coordinates for each atom.
-
-
MOPAC Example:
-
AM1 PRECISE: Specifies the AM1 method with tight convergence criteria. A geometry optimization is the default calculation type in MOPAC.[8]
-
3. Calculation Execution:
-
Objective: To run the computational job.
-
Procedure:
-
Submit the input file to the respective computational chemistry software (e.g., Gaussian, MOPAC).
-
The software will iteratively adjust the atomic positions to find a stationary point on the potential energy surface that corresponds to a minimum energy conformation.
-
4. Output Analysis:
-
Objective: To extract and interpret the results of the calculation.
-
Procedure:
-
Examine the output file for convergence criteria to ensure the optimization was successful.
-
Extract the optimized geometry (in Cartesian or internal coordinates).
-
Obtain the calculated heat of formation.
-
If requested, analyze the vibrational frequencies to confirm the structure is a true minimum (i.e., no imaginary frequencies).
-
Extract other calculated properties such as the dipole moment and molecular orbital energies (from which the ionization potential can be estimated via Koopmans' theorem).
-
Applications in Drug Development
The balance of speed and reasonable accuracy makes AM1 a valuable tool in the drug discovery pipeline, particularly in the early, computationally intensive stages.
1. High-Throughput Screening and Ligand-Based Drug Design:
-
AM1 can be used for the rapid geometry optimization of large libraries of virtual compounds. A well-defined 3D structure is crucial for subsequent docking studies and for developing pharmacophore models.
-
In Quantitative Structure-Activity Relationship (QSAR) studies, AM1 is frequently employed to calculate electronic descriptors such as atomic charges, dipole moments, and molecular orbital energies.[9][10] These descriptors are then used to build statistical models that correlate the chemical structure of molecules with their biological activity.
2. Initial Geometry Optimization of Ligands:
-
Before performing more computationally expensive docking simulations or ab initio calculations, AM1 can be used to obtain a reasonable initial geometry for a ligand.[11] This can significantly reduce the computational cost of the subsequent, more accurate calculations.
3. A Case Study in QSAR:
-
A study on the binding affinity of a series of corticosteroids to globulin utilized AM1-optimized geometries to derive atomic charges from the molecular electrostatic potential surface.[9] These calculated charges, along with other molecular descriptors, were used to build a QSAR model that successfully predicted the binding affinity. The model highlighted the importance of the electronic properties of specific atoms in the steroid nucleus for binding.[9]
Visualizing Workflows and Relationships
Diagram 1: Generalized Workflow for an AM1 Calculation
Caption: A generalized workflow for performing a molecular geometry optimization and property calculation using the AM1 method.
Diagram 2: Relationship Between NDDO-based Semi-Empirical Methods
Caption: The developmental relationship between the MNDO, AM1, and PM3 semi-empirical methods.
Conclusion
The Austin Model 1 (AM1) represents a significant milestone in the development of semi-empirical quantum mechanical methods. By providing a computationally efficient means of calculating molecular properties with reasonable accuracy, it has become a workhorse in computational chemistry. For researchers in drug discovery, AM1 offers a powerful tool for high-throughput screening, lead optimization, and the development of predictive QSAR models. While newer and more accurate methods have since been developed, AM1 remains a relevant and valuable component of the computational chemist's toolkit, particularly for large-scale molecular modeling tasks where a balance between speed and accuracy is essential. As with any computational method, a thorough understanding of its strengths and limitations, as outlined in this guide, is crucial for its effective application.
References
- 1. files01.core.ac.uk [files01.core.ac.uk]
- 2. Austin Model 1 - Wikipedia [en.wikipedia.org]
- 3. openmopac.net [openmopac.net]
- 4. Semiempirical Quantum Mechanical Methods for Noncovalent Interactions for Chemical and Biochemical Applications - PMC [pmc.ncbi.nlm.nih.gov]
- 5. benchchem.com [benchchem.com]
- 6. hj.hi.is [hj.hi.is]
- 7. pubs.acs.org [pubs.acs.org]
- 8. m.youtube.com [m.youtube.com]
- 9. researchgate.net [researchgate.net]
- 10. openmopac.net [openmopac.net]
- 11. pubs.acs.org [pubs.acs.org]
Unveiling the Austin Model 1: A Technical Primer on the Semi-Empirical Method in Computational Spectroscopy
For researchers, scientists, and professionals in drug development, the accurate prediction of molecular properties is a cornerstone of their work. While ab initio quantum chemistry methods offer high accuracy, their computational cost can be prohibitive for large molecules. This technical guide delves into the core principles of Austin Model 1 (AM1), a semi-empirical quantum mechanical method that provides a computationally efficient alternative for predicting molecular electronic structure and properties relevant to spectroscopy.
The "Austin technique" in spectroscopy is most commonly understood to refer to the Austin Model 1 (AM1), a semi-empirical method for the quantum calculation of molecular electronic structure. Developed by Michael Dewar and his colleagues in 1985, AM1 is a significant advancement in computational chemistry, offering a balance between computational speed and accuracy for a wide range of molecules. It is particularly noted for its ability to overcome major weaknesses of its predecessor, the Modified Neglect of Diatomic Overlap (MNDO) method, such as its failure to reproduce hydrogen bonds.
Core Principles of Austin Model 1
AM1 is founded on the Neglect of Diatomic Differential Overlap (NDDO) approximation. This approximation simplifies the calculation of electron-electron repulsion integrals in the Hartree-Fock equations, significantly reducing the computational time required. The key innovation of AM1 lies in its modification of the core-core repulsion term. By adding Gaussian functions to the core-core interaction, AM1 improves the description of intermolecular interactions, most notably hydrogen bonds, which were a significant failing of the earlier MNDO model.
The method is termed "semi-empirical" because it incorporates parameters derived from experimental data, such as spectroscopic measurements of isolated atoms, to simplify and improve the accuracy of the calculations. While AM1 was initially parameterized for carbon, hydrogen, oxygen, and nitrogen, its parameterization has since been extended to other elements.
The AM1 Calculation Workflow
The logical workflow of an AM1 calculation involves several key steps, starting from the molecular geometry input to the final output of calculated properties. This process is designed to optimize the molecular structure and predict its electronic properties.
Experimental Protocols: A Computational Approach
In the context of AM1, "experimental protocols" refer to the computational methodology for performing calculations. These calculations are typically carried out using quantum chemistry software packages that have implemented the AM1 method.
General Protocol for an AM1 Calculation:
-
Molecular Structure Input: The first step is to define the three-dimensional structure of the molecule of interest. This can be done using Cartesian coordinates or a Z-matrix, which defines the atoms and their positions relative to each other.
-
Selection of the AM1 Method: Within the chosen software package, the user selects AM1 as the desired computational method.
-
Job Type Specification: The user then specifies the type of calculation to be performed. Common job types include:
-
Geometry Optimization: This is the most common application of AM1, where the calculation iteratively adjusts the positions of the atoms to find the lowest energy conformation of the molecule.
-
Single Point Energy Calculation: This calculates the energy of the molecule at a fixed geometry.
-
Frequency Calculation: This is used to predict the vibrational frequencies of the molecule, which can be correlated with infrared (IR) spectroscopy data. It is also used to confirm that an optimized geometry corresponds to a true energy minimum.
-
-
Execution and Analysis: The software then performs the AM1 calculation based on the specified inputs. Upon completion, the output file will contain the results, such as the optimized geometry, heat of formation, dipole moment, and ionization potential.
Data Presentation: AM1 in Comparison
The utility of a semi-empirical method like AM1 is often assessed by comparing its calculated properties to experimental values or results from more computationally expensive ab initio methods. The following table summarizes typical performance metrics for AM1 in calculating key molecular properties.
| Molecular Property | Typical Mean Absolute Error (AM1) |
| Heat of Formation (kcal/mol) | ~10-15 |
| Ionization Potential (eV) | ~0.5-1.0 |
| Dipole Moment (Debye) | ~0.3-0.5 |
| Bond Length (Å) | ~0.02-0.05 |
| Bond Angle (degrees) | ~2-4 |
Note: These are approximate values and can vary depending on the class of molecules being studied.
Signaling Pathways: The Logic of Semi-Empirical Methods
The decision-making process for choosing a computational method in chemistry can be visualized as a signaling pathway. The choice between a high-accuracy but computationally expensive method and a faster but less precise method depends on the specific research question and the size of the system under investigation.
Conclusion
Austin Model 1 remains a valuable tool in the computational chemist's arsenal, particularly for large molecules where more rigorous methods are not feasible. Its development marked a significant step forward in the practical application of quantum mechanics to real-world chemical problems. For researchers in drug development and materials science, AM1 provides a rapid and effective means to screen molecules, predict their properties, and gain insights that can guide further experimental investigation. While newer semi-empirical methods and density functional theory (DFT) have emerged, AM1's historical significance and continued use in various software packages solidify its place in the landscape of computational spectroscopy and molecular modeling.
Pioneering Compounds and Therapeutic Strategies from Austin Researchers: A Technical Review
Austin, Texas - A hub of scientific innovation, Austin is home to a cadre of researchers at the forefront of drug discovery and development. From novel anti-cancer agents to cutting-edge vaccine design, scientists in Austin are pioneering new approaches to combat a range of diseases. This in-depth guide explores key compounds and therapeutic strategies developed by researchers in Austin, detailing their mechanisms of action, experimental validation, and the innovative methodologies behind their discovery.
A Novel Anti-Cancer Agent: 4-(N)-Docosahexaenoyl 2',2'-Difluorodeoxycytidine (DHA-dFdC)
Researchers at the University of Texas at Austin have synthesized and evaluated a promising new anti-cancer compound, 4-(N)-docosahexaenoyl 2',2'-difluorodeoxycytidine, or DHA-dFdC. This compound conjugates the omega-3 fatty acid docosahexaenoic acid (DHA) with the chemotherapeutic drug gemcitabine (B846) (dFdC), demonstrating potent and broad-spectrum antitumor activity, particularly against pancreatic cancer.[1][2][3]
Quantitative Data: In Vitro Cytotoxicity of DHA-dFdC
The cytotoxic activity of DHA-dFdC was evaluated against a panel of human cancer cell lines. The half-maximal inhibitory concentration (IC50) values, which indicate the concentration of a drug that is required for 50% inhibition in vitro, were determined and are summarized in the table below.
| Cell Line | Cancer Type | IC50 (µM) of DHA-dFdC |
| CCRF-CEM | Leukemia | < 0.01 |
| HL-60(TB) | Leukemia | < 0.01 |
| K-562 | Leukemia | 0.012 |
| MOLT-4 | Leukemia | < 0.01 |
| RPMI-8226 | Leukemia | 0.018 |
| SR | Leukemia | < 0.01 |
| A549/ATCC | Non-Small Cell Lung | 0.021 |
| EKVX | Non-Small Cell Lung | 0.014 |
| HOP-62 | Non-Small Cell Lung | 0.023 |
| HOP-92 | Non-Small Cell Lung | 0.019 |
| NCI-H226 | Non-Small Cell Lung | 0.029 |
| NCI-H23 | Non-Small Cell Lung | 0.022 |
| NCI-H322M | Non-Small Cell Lung | 0.021 |
| NCI-H460 | Non-Small Cell Lung | 0.016 |
| NCI-H522 | Non-Small Cell Lung | 0.025 |
| COLO 205 | Colon | 0.016 |
| HCC-2998 | Colon | 0.021 |
| HCT-116 | Colon | 0.018 |
| HCT-15 | Colon | 0.024 |
| HT29 | Colon | 0.020 |
| KM12 | Colon | 0.017 |
| SW-620 | Colon | 0.019 |
| SF-268 | CNS | 0.015 |
| SF-295 | CNS | 0.020 |
| SF-539 | CNS | 0.018 |
| SNB-19 | CNS | 0.019 |
| SNB-75 | CNS | 0.022 |
| U251 | CNS | 0.017 |
| LOX IMVI | Melanoma | 0.028 |
| MALME-3M | Melanoma | 0.024 |
| M14 | Melanoma | 0.026 |
| SK-MEL-2 | Melanoma | 0.031 |
| SK-MEL-28 | Melanoma | 0.035 |
| SK-MEL-5 | Melanoma | 0.029 |
| UACC-257 | Melanoma | 0.033 |
| UACC-62 | Melanoma | 0.030 |
| IGROV1 | Ovarian | 0.027 |
| OVCAR-3 | Ovarian | 0.033 |
| OVCAR-4 | Ovarian | 0.029 |
| OVCAR-5 | Ovarian | 0.031 |
| OVCAR-8 | Ovarian | 0.028 |
| NCI/ADR-RES | Ovarian | 0.041 |
| SK-OV-3 | Ovarian | 0.036 |
| 786-0 | Renal | 0.013 |
| A498 | Renal | 0.011 |
| ACHN | Renal | 0.015 |
| CAKI-1 | Renal | 0.014 |
| RXF 393 | Renal | 0.012 |
| SN12C | Renal | 0.016 |
| TK-10 | Renal | 0.010 |
| UO-31 | Renal | 0.013 |
| PC-3 | Prostate | 0.038 |
| DU-145 | Prostate | 0.042 |
| MCF7 | Breast | 0.037 |
| MDA-MB-231/ATCC | Breast | 0.045 |
| HS 578T | Breast | 0.048 |
| BT-549 | Breast | 0.041 |
| T-47D | Breast | 0.039 |
| MDA-MB-435 | Breast | 0.044 |
Data extracted from the NCI-60 DTP Human Tumor Cell Line Screening results reported in Neoplasia (2016) 18, 33–48.[2]
Experimental Protocols
Synthesis of DHA-dFdC: The synthesis of DHA-dFdC involves a multi-step chemical process.[2][3]
References
- 1. A Novel Class of Common Docking Domain Inhibitors That Prevent ERK2 Activation and Substrate Phosphorylation - PMC [pmc.ncbi.nlm.nih.gov]
- 2. tandfonline.com [tandfonline.com]
- 3. Selective Chemical Genetic Inhibition of Protein Kinase C Epsilon Reduces Ethanol Consumption in Mice - PMC [pmc.ncbi.nlm.nih.gov]
Application Notes and Protocols for Gene Sequencing
A Note on the "Austin Method"
Initial searches for a gene sequencing technique specifically termed the "Austin method" did not yield a widely recognized, established protocol under this name in peer-reviewed literature or commercial documentation. It is possible this term refers to a novel, highly specialized, or internal methodology not yet in the public domain.
However, research from institutions in Austin, Texas, is at the forefront of molecular biology. For instance, a team at The University of Texas at Austin has developed a novel, highly sensitive method for protein sequencing , which they describe as a "DNA-sequencing-like technology."[1][2] This groundbreaking work focuses on identifying individual amino acids in proteins. Additionally, the Texas Department of State Health Services (DSHS) Austin Laboratory utilizes next-generation sequencing (NGS) for public health surveillance, employing established platforms for this purpose.[3]
To provide a comprehensive and immediately applicable resource, this document details the principles and protocols for one of the most widely adopted and powerful gene sequencing technologies in modern research: Illumina's Sequencing by Synthesis (SBS) . This method serves as the foundation for a vast array of genomic applications and is a cornerstone of research in genomics, drug discovery, and clinical diagnostics.[4][5]
Application Note: Illumina Sequencing by Synthesis (SBS) Technology
Introduction
Next-Generation Sequencing (NGS) has revolutionized the biological sciences by enabling massively parallel sequencing of millions to billions of DNA fragments at once.[5][6] Illumina's Sequencing by Synthesis (SBS) technology is a dominant force in the NGS landscape, renowned for its high accuracy, throughput, and scalability.[5] This technology is utilized to determine the precise order of nucleotides in a DNA or RNA sample, facilitating a wide range of applications from whole-genome sequencing to targeted gene expression analysis.[5][7]
The core principle of SBS involves tracking the addition of fluorescently labeled nucleotides as a DNA chain is copied in a massively parallel fashion.[4][5] This method provides highly accurate base-by-base sequencing and is scalable for diverse experimental needs, from small genomes to complex human samples.
Core Principles
The SBS chemistry works by detecting the signal from a single fluorescently labeled nucleotide as it is incorporated into a growing DNA strand. Each of the four nucleotides (A, C, G, T) is labeled with a different colored fluorophore and a reversible terminator. During each sequencing cycle, only one base can be added by the polymerase. After the nucleotide is incorporated, the flow cell is imaged to identify the base, and then the terminator and fluorophore are chemically cleaved to allow the next cycle to begin.[8][9][10]
Applications in Research and Drug Development
The versatility of Illumina SBS technology supports a broad spectrum of applications critical for researchers and drug development professionals:
-
Genomics:
-
Whole-Genome Sequencing (WGS): Provides a comprehensive view of an organism's entire genetic makeup, essential for discovery science, population genetics, and identifying causative variants in rare diseases.[6]
-
Whole-Exome Sequencing (WES): Focuses on the protein-coding regions (exome), a cost-effective approach to identify disease-causing variants in the most functionally relevant parts of the genome.[6]
-
Targeted Sequencing: Sequences specific genes or genomic regions of interest with high depth, ideal for studying specific disease-associated genes or for validating findings.[5]
-
-
Transcriptomics:
-
Epigenomics:
-
Methylation Profiling: Studies DNA methylation patterns across the genome to understand gene regulation in development and disease.
-
ChIP-Seq: Identifies DNA-protein interaction sites, providing insights into transcription factor binding and epigenetic modifications.[11]
-
-
Oncology:
-
Identifies rare somatic mutations, characterizes tumor heterogeneity, and discovers novel cancer biomarkers for diagnostics and targeted therapies.[6]
-
Workflow Overview
The Illumina NGS workflow consists of four main stages: Library Preparation, Cluster Generation, Sequencing, and Data Analysis.[8]
Experimental Protocols
Protocol 1: DNA Library Preparation
This protocol outlines the fundamental steps for converting a DNA sample into a sequence-ready library. The goal is to generate a pool of DNA fragments with adapter sequences ligated to both ends.[12]
Materials:
-
Purified DNA (1-1000 ng)
-
DNA Fragmentation Kit (Enzymatic or Mechanical)
-
End-Repair and A-Tailing Master Mix
-
Ligation Master Mix with Adapters
-
PCR Amplification Kit
-
AMPure XP Beads (or similar) for purification
-
80% Ethanol (B145695) (freshly prepared)
-
Low-adhesion 1.5 mL tubes and PCR plates
Methodology:
-
DNA Fragmentation:
-
Fragment the input DNA to the desired size range (e.g., 200-500 bp). This can be achieved through enzymatic digestion or mechanical shearing (e.g., sonication).[13]
-
Quantify the fragmented DNA to ensure sufficient material for the next steps.
-
-
End Repair and A-Tailing:
-
Combine the fragmented DNA with an End-Repair and A-Tailing master mix.
-
This reaction blunts the ends of the DNA fragments and adds a single 'A' nucleotide to the 3' ends. This "A-tailing" prevents fragments from ligating to each other and prepares them for adapter ligation.[14]
-
Incubate according to the manufacturer's protocol (e.g., 30 minutes at 20°C, followed by 30 minutes at 65°C).
-
-
Adapter Ligation:
-
Add the Ligation Master Mix and appropriate sequencing adapters to the end-repaired DNA. Adapters are short, pre-synthesized DNA duplexes that contain sequences necessary for binding to the flow cell, primer hybridization, and indexing (barcoding).[12][15]
-
Mix thoroughly by pipetting, as the ligation buffer can be viscous.[15]
-
Incubate to ligate the adapters to the DNA fragments (e.g., 15 minutes at 20°C).
-
-
Size Selection and Purification:
-
Perform a bead-based purification (e.g., with AMPure XP beads) to remove adapter-dimers and select the desired library fragment size. The ratio of beads to library volume is critical for determining the final size distribution.
-
Wash the beads with 80% ethanol and elute the purified, adapter-ligated library in a resuspension buffer.
-
-
PCR Amplification (Optional but Recommended):
-
Amplify the library using a PCR master mix with primers that anneal to the adapter sequences. This step enriches the library for correctly ligated fragments and adds the full-length adapter sequences required for cluster generation.[16]
-
Use a minimal number of PCR cycles to avoid amplification bias.
-
Perform another round of bead-based purification to remove PCR primers and enzyme.
-
-
Library Quality Control:
-
Quantification: Accurately quantify the final library concentration. qPCR is the recommended method as it specifically quantifies only the molecules that can be sequenced.[17] Fluorometric methods (e.g., Qubit) are also used but may overestimate the concentration of sequenceable molecules.[17]
-
Size Distribution: Assess the fragment size distribution using an automated electrophoresis system (e.g., Agilent Bioanalyzer or TapeStation).
-
Data Presentation
Performance metrics for Illumina sequencing platforms vary by instrument and chemistry. The following table summarizes typical performance data for representative systems.
| Metric | Illumina MiSeq | Illumina NovaSeq 6000 (S4 Flow Cell) | Illumina NovaSeq X Plus | Reference |
| Max Output | ~15 Gb | ~6000 Gb (6 Tb) | ~16000 Gb (16 Tb) | [5][18] |
| Max Reads | ~25 Million | ~20 Billion | ~26 Billion | [18] |
| Max Read Length | 2 x 300 bp | 2 x 250 bp | 2 x 300 bp | [18] |
| Quality Score (Q30) | > 80% | > 75% | > 90% | [19] |
| Typical Run Time | ~55 hours | ~44 hours | ~48 hours | [18] |
Note: Q30 represents a base call accuracy of 99.9%. Data output and run times are approximate and depend on the specific application and run configuration.
Data Analysis
NGS data analysis is a computationally intensive process that transforms raw sequencing data into biological insights.[20] It is generally divided into three stages: primary, secondary, and tertiary analysis.[20][21]
-
Primary Analysis: Occurs on the sequencing instrument itself. The machine's software performs image analysis and base calling, converting the raw binary data (BCL files) into FASTQ files, which contain the nucleotide sequence and an associated quality score for each base.[20][22]
-
Secondary Analysis: This stage involves processing the FASTQ files.[20]
-
Quality Control: Raw reads are assessed for quality, and adapters and low-quality bases are trimmed.
-
Alignment: The high-quality reads are aligned to a reference genome. Common alignment tools include BWA and STAR (for RNA-Seq).[20][23]
-
Variant Calling: Aligned reads are analyzed to identify differences compared to the reference genome, such as single nucleotide polymorphisms (SNPs), insertions, and deletions. The output is typically a Variant Call Format (VCF) file.
-
References
- 1. New Protein Sequencing Method Could Transform Biological Research - UT Austin News - The University of Texas at Austin [news.utexas.edu]
- 2. cns.utexas.edu [cns.utexas.edu]
- 3. dshs.texas.gov [dshs.texas.gov]
- 4. cd-genomics.com [cd-genomics.com]
- 5. Next-Generation Sequencing (NGS) | Explore the technology [illumina.com]
- 6. Next-Generation Sequencing Technology: Current Trends and Advancements - PMC [pmc.ncbi.nlm.nih.gov]
- 7. What is Next-Generation Sequencing (NGS)? | Thermo Fisher Scientific - JP [thermofisher.com]
- 8. youtube.com [youtube.com]
- 9. Illumina dye sequencing - Wikipedia [en.wikipedia.org]
- 10. Next-Generation Sequencing Illumina Workflow–4 Key Steps | Thermo Fisher Scientific - TW [thermofisher.com]
- 11. europeanpharmaceuticalreview.com [europeanpharmaceuticalreview.com]
- 12. idtdna.com [idtdna.com]
- 13. Library construction for next-generation sequencing: Overviews and challenges - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Library Construction for Next-Generation Sequencing (NGS) - CD Genomics [cd-genomics.com]
- 15. Section 2: NGS library preparation for sequencing [protocols.io]
- 16. NGS library preparation [qiagen.com]
- 17. knowledge.illumina.com [knowledge.illumina.com]
- 18. Illumina Sequencing | GENEWIZ from Azenta [genewiz.com]
- 19. youtube.com [youtube.com]
- 20. NGS Data Analysis for Illumina Platform—Overview and Workflow | Thermo Fisher Scientific - JP [thermofisher.com]
- 21. Sequencing Data Analysis | NGS software to help you focus on your research [illumina.com]
- 22. Bioinformatics: Standard NGS data analysis pipeline | Celemics, Inc. [celemics.com]
- 23. What are the best pipelines for NGS (Next Generation Sequencing) data analysis? [synapse.patsnap.com]
- 24. NGS Data Analysis for Illumina Platform—Overview and Workflow | Thermo Fisher Scientific - CA [thermofisher.com]
Application Notes and Protocols for In Vivo Animal Studies: A Representative Xenograft Model
Audience: Researchers, scientists, and drug development professionals.
These application notes and protocols provide a representative framework for conducting in vivo animal studies, using a human tumor xenograft model in immunodeficient mice as a prime example. While a specific, universally recognized "Austin Protocol" for general in vivo studies is not defined in publicly available literature, the following sections are synthesized from established best practices and institutional guidelines, such as those from the University of Texas at Austin and Austin Health, which emphasize rigorous ethical standards and procedural detail.[1][2][3][4][5][6] This document is intended to serve as a template that can be adapted for specific research needs, ensuring adherence to the principles of humane and reproducible animal research.
Application Notes
Human tumor xenograft models are a cornerstone of preclinical oncology research, enabling the in vivo assessment of novel therapeutic agents against human-cancers.[7] These models involve the implantation of human cancer cells or patient-derived tumor tissue into immunodeficient mice, which lack a functional immune system to reject the foreign tissue.[7][8]
Key Applications:
-
Efficacy Testing: Evaluating the anti-tumor activity of novel drug candidates.
-
Pharmacokinetic/Pharmacodynamic (PK/PD) Studies: Assessing drug distribution, metabolism, and target engagement in a living organism.
-
Biomarker Discovery: Identifying molecular markers that correlate with treatment response or resistance.
-
Personalized Medicine: Using patient-derived xenografts (PDXs) to test individual tumor responses to a panel of drugs, guiding clinical treatment decisions.[8]
The choice of cell line or patient-derived tissue, the site of implantation (subcutaneous or orthotopic), and the treatment regimen are all critical parameters that must be tailored to the specific research question.
Experimental Protocols
All procedures involving live vertebrate animals must be approved by an Institutional Animal Care and Use Committee (IACUC) to ensure compliance with federal and institutional guidelines for the humane care and use of laboratory animals.[1][2][6][9][10]
Materials and Reagents
-
Cell Line: Human cancer cell line (e.g., MDA-MB-231 for breast cancer)
-
Cell Culture Medium: As recommended for the specific cell line (e.g., DMEM)
-
Supplements: Fetal Bovine Serum (FBS), Penicillin-Streptomycin
-
Phosphate-Buffered Saline (PBS): Sterile, pH 7.4
-
Trypsin-EDTA: For cell detachment
-
Extracellular Matrix Gel: (e.g., Matrigel or Cultrex BME) to support tumor engraftment
-
Animals: Immunodeficient mice (e.g., NOD-SCID or NSG), 6-8 weeks old[8]
-
Anesthetic: Isoflurane (B1672236) or other approved anesthetic
-
Test Compound: Dissolved in an appropriate vehicle
-
Vehicle Control: The solvent used to dissolve the test compound
-
Calipers: For tumor measurement
-
Syringes and Needles: Various gauges for injection
Cell Line Culture and Preparation
-
Culture the selected human cancer cell line in the recommended medium in a humidified incubator at 37°C with 5% CO2.[7]
-
Passage the cells regularly to maintain them in the exponential growth phase.
-
On the day of implantation, harvest the cells by washing with PBS, followed by detachment with Trypsin-EDTA.[11]
-
Neutralize the trypsin with complete medium and centrifuge the cell suspension.
-
Wash the cell pellet twice with sterile, serum-free medium or PBS.
-
Resuspend the cells in a 1:1 mixture of serum-free medium and extracellular matrix gel on ice to achieve the desired final concentration (e.g., 5 x 10^7 cells/mL).
-
Perform a cell count using a hemocytometer and assess viability with a trypan blue exclusion assay.[11] Viability should be >95%.
Animal Handling and Tumor Implantation
-
Allow newly arrived animals a minimum of one week for acclimatization.[11]
-
Anesthetize the mouse using isoflurane or another IACUC-approved method.
-
Shave the hair from the injection site (typically the right flank) and sterilize the skin with an antiseptic solution.
-
Draw the cell suspension (e.g., 100 µL containing 5 x 10^6 cells) into a pre-chilled syringe fitted with a 27-gauge needle.[7][11]
-
Inject the cell suspension subcutaneously into the prepared flank.
-
Monitor the animals daily for the first few days post-injection for any adverse reactions and then 2-3 times per week for tumor development.
Tumor Monitoring and Treatment Administration
-
Once tumors become palpable, begin measuring their dimensions (length and width) with digital calipers 2-3 times per week.[7]
-
Calculate the tumor volume using the formula: Volume = (Width² x Length) / 2 .[7][11]
-
When the average tumor volume reaches a predetermined size (e.g., 100-150 mm³), randomize the mice into treatment and control groups (n=8-10 mice per group is recommended).[7][8]
-
Administer the test compound and vehicle control according to the planned dosing schedule, route, and volume. Record the body weight of each animal before each treatment.
-
Continue to monitor tumor volume and body weight 2-3 times per week throughout the study.
-
Observe the animals daily for any clinical signs of toxicity, such as changes in posture, activity, or grooming.
Endpoint Criteria
The study should be terminated, and animals humanely euthanized when any of the following IACUC-approved endpoints are reached:
-
Tumor volume exceeds a predetermined limit (e.g., 2000 mm³).
-
Tumor becomes ulcerated or necrotic.
-
Body weight loss exceeds 20% of the initial weight.
-
Significant signs of distress or morbidity are observed.
Euthanasia must be performed using a method approved by the AVMA Guidelines on Euthanasia and the institutional IACUC.[12]
Data Presentation
Quantitative data should be summarized in a clear and organized manner to facilitate interpretation and comparison between groups.
Table 1: Efficacy of Test Compound on Tumor Growth
| Treatment Group | N | Mean Tumor Volume at Day 0 (mm³) ± SEM | Mean Tumor Volume at Study End (mm³) ± SEM | Tumor Growth Inhibition (%) | P-value (vs. Vehicle) |
| Vehicle Control | 10 | 125.4 ± 8.2 | 1582.1 ± 110.5 | - | - |
| Test Compound A (10 mg/kg) | 10 | 128.1 ± 7.9 | 745.3 ± 65.7 | 52.9 | <0.01 |
| Test Compound A (30 mg/kg) | 10 | 126.5 ± 8.5 | 312.9 ± 42.1 | 80.2 | <0.001 |
Table 2: Animal Body Weight Monitoring
| Treatment Group | N | Mean Body Weight at Day 0 (g) ± SEM | Mean Body Weight at Study End (g) ± SEM | Mean Percent Body Weight Change |
| Vehicle Control | 10 | 22.1 ± 0.5 | 23.5 ± 0.6 | +6.3% |
| Test Compound A (10 mg/kg) | 10 | 21.9 ± 0.4 | 22.8 ± 0.5 | +4.1% |
| Test Compound A (30 mg/kg) | 10 | 22.3 ± 0.5 | 21.7 ± 0.7 | -2.7% |
Mandatory Visualizations
Signaling Pathway Diagram
The PI3K/Akt/mTOR pathway is a critical intracellular signaling cascade that regulates cell growth, proliferation, and survival, and it is frequently dysregulated in cancer.[13][14][15] Understanding this pathway is often crucial when developing targeted cancer therapies.
References
- 1. Animal Care & Use Program | Texas Research [research.utexas.edu]
- 2. IACUC Protocols | Texas Research [research.utexas.edu]
- 3. austin.org.au [austin.org.au]
- 4. austin.org.au [austin.org.au]
- 5. austin.org.au [austin.org.au]
- 6. cloud.wikis.utexas.edu [cloud.wikis.utexas.edu]
- 7. benchchem.com [benchchem.com]
- 8. tumor.informatics.jax.org [tumor.informatics.jax.org]
- 9. IACUC Policies and Procedures – UTA Faculty & Staff Resources [resources.uta.edu]
- 10. Care and Use of Animals for Research and Instruction : Division of Research : Texas State University [research.txst.edu]
- 11. Protocol Online: Xenograft Tumor Model Protocol [protocol-online.org]
- 12. Guidelines for Ethical Conduct in the Care and Use of Animals [apa.org]
- 13. PI3K/Akt signalling pathway and cancer - PubMed [pubmed.ncbi.nlm.nih.gov]
- 14. PI3K/AKT/mTOR pathway - Wikipedia [en.wikipedia.org]
- 15. agscientific.com [agscientific.com]
Practical Guide to Implementing the "Austin Technique": Application Notes and Protocols for Sperm Capacitation
Introduction
The term "Austin Technique" in the context of reproductive biology refers to the pioneering work of Dr. Colin Russell Austin, who, along with M. C. Chang, first described the phenomenon of sperm capacitation in 1951.[1] This crucial process involves a series of physiological and biochemical changes that spermatozoa must undergo in the female reproductive tract to acquire the ability to fertilize an oocyte. This guide provides detailed application notes and protocols for inducing and analyzing sperm capacitation in vitro, a fundamental technique for researchers, scientists, and professionals in drug development and reproductive medicine.
Core Concepts of Sperm Capacitation
Capacitation is a complex process that renders the sperm competent for fertilization. Key events include:
-
Cholesterol Efflux: The removal of cholesterol from the sperm plasma membrane, leading to increased membrane fluidity.[2][3]
-
Ion Fluxes: Changes in the intracellular concentrations of ions, particularly an influx of calcium (Ca2+) and bicarbonate (HCO3-).[1][2]
-
Activation of Signaling Pathways: The activation of intracellular signaling cascades, most notably the cyclic AMP (cAMP)/Protein Kinase A (PKA) pathway.[1][4]
-
Protein Tyrosine Phosphorylation: An increase in the phosphorylation of tyrosine residues on specific sperm proteins, which is a hallmark of capacitation.[2][5][6]
-
Hyperactivated Motility: A change in the sperm's swimming pattern to a more vigorous, whip-like motion, which is thought to aid in penetration of the egg's outer layers.
Application Notes
In vitro capacitation is a widely used technique with applications in:
-
Fertility Assessment: Evaluating the functional competence of sperm, which can be more informative than standard semen analysis.
-
Assisted Reproductive Technologies (ART): Preparing sperm for in vitro fertilization (IVF) and intracytoplasmic sperm injection (ICSI).
-
Contraceptive Development: Screening for compounds that inhibit capacitation.
-
Toxicology: Assessing the impact of environmental or chemical agents on sperm function.
-
Basic Research: Investigating the molecular mechanisms of fertilization.
Experimental Protocols
Protocol 1: In Vitro Capacitation of Human Sperm
This protocol describes a standard method for inducing capacitation of human spermatozoa using a defined medium.
Materials:
-
Semen sample
-
Biggers-Whitten-Whittingham (BWW) medium or Ham's F-10 medium[7]
-
Human Serum Albumin (HSA)
-
Penicillin/Streptomycin solution
-
Sterile, conical centrifuge tubes
-
Incubator (37°C, 5% CO2)
-
Microscope
Procedure:
-
Semen Liquefaction: Allow the semen sample to liquefy at 37°C for 30 minutes.
-
Sperm Selection (Swim-up Method):
-
Gently layer 1 mL of capacitation medium (e.g., BWW supplemented with 0.3% w/v HSA and antibiotics) on top of 1 mL of liquefied semen in a sterile centrifuge tube.
-
Incubate the tube at a 45° angle for 1 hour at 37°C in a 5% CO2 atmosphere to allow motile sperm to swim up into the medium.
-
Carefully aspirate the top 0.5 mL of the medium, which contains the motile sperm fraction.
-
-
Washing:
-
Transfer the motile sperm suspension to a new sterile tube and add 5 mL of capacitation medium.
-
Centrifuge at 300 x g for 5-7 minutes.
-
Discard the supernatant and resuspend the sperm pellet in 1 mL of fresh capacitation medium.
-
-
Incubation for Capacitation:
-
Adjust the sperm concentration to 5-10 x 10^6 sperm/mL in capacitation medium.
-
Incubate the sperm suspension for 3-6 hours at 37°C in a 5% CO2 atmosphere.
-
Protocol 2: Assessment of Capacitation by Chlortetracycline (CTC) Staining
CTC staining is a fluorescent assay used to distinguish between non-capacitated, capacitated, and acrosome-reacted sperm based on their calcium distribution.
Materials:
-
Capacitated sperm suspension (from Protocol 1)
-
CTC solution (500 µM Chlortetracycline in 130 mM NaCl, 5 mM Cysteine, 20 mM Tris-HCl, pH 7.8)
-
Polyvinylpyrrolidone (PVP) solution
-
Glutaraldehyde (B144438) solution (2.5% in buffer)
-
Fluorescence microscope
Procedure:
-
Staining: Mix 45 µL of the sperm suspension with 45 µL of the CTC solution.
-
Fixation: After 1 minute, add 10 µL of 2.5% glutaraldehyde solution to fix the cells.
-
Mounting: Place a 10 µL drop of the stained and fixed sperm suspension on a microscope slide and cover with a coverslip.
-
Observation: Observe the slides under a fluorescence microscope.
-
Pattern F (Non-capacitated): Bright fluorescence over the entire head.
-
Pattern B (Capacitated): Fluorescence-free band in the post-acrosomal region.
-
Pattern AR (Acrosome-reacted): Dull or absent fluorescence over the head.
-
Data Presentation
The following tables summarize typical quantitative data obtained from sperm capacitation experiments.
| Parameter | Before Capacitation | After Capacitation (3 hours) |
| Sperm Motility (%) | 65 ± 5 | 75 ± 8 |
| Progressive Motility (%) | 50 ± 6 | 60 ± 7 |
| Hyperactivated Motility (%) | < 5 | 25 ± 5 |
| Sperm Viability (%) | 85 ± 7 | 80 ± 6 |
Table 1: Changes in Human Sperm Motility and Viability following In Vitro Capacitation. Data are presented as mean ± standard deviation.
| Capacitation Status | Percentage of Sperm |
| Non-capacitated (Pattern F) | 70 ± 10 |
| Capacitated (Pattern B) | 25 ± 8 |
| Acrosome-reacted (Pattern AR) | 5 ± 2 |
Table 2: Assessment of Human Sperm Capacitation Status using the Chlortetracycline (CTC) Assay after 4 hours of in vitro capacitation. Data are presented as mean ± standard deviation.
| Condition | Relative Intensity of Tyrosine Phosphorylation |
| Uncapacitated Sperm | 1.0 (baseline) |
| Capacitated Sperm (4 hours) | 3.5 ± 0.8 |
Table 3: Relative Increase in Protein Tyrosine Phosphorylation in Human Sperm following In Vitro Capacitation. Data are presented as mean ± standard deviation relative to the uncapacitated control.
Mandatory Visualizations
Caption: Signaling pathway of sperm capacitation.
Caption: Experimental workflow for in vitro sperm capacitation and analysis.
References
- 1. Factors and pathways involved in capacitation: how are they regulated? - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Role of tyrosine phosphorylation in sperm capacitation / acrosome reaction - PMC [pmc.ncbi.nlm.nih.gov]
- 3. bioone.org [bioone.org]
- 4. researchgate.net [researchgate.net]
- 5. asiaandro.com [asiaandro.com]
- 6. Capacitation-associated protein tyrosine phosphorylation and membrane fluidity changes are impaired in the spermatozoa of asthenozoospermic patients - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. Chemical composition and protein source in the capacitation medium significantly affect the ability of human spermatozoa to undergo follicular fluid induced acrosome reaction - PubMed [pubmed.ncbi.nlm.nih.gov]
Application Notes and Protocols for Enzyme Inhibition Assays
For Researchers, Scientists, and Drug Development Professionals
These application notes provide a detailed, step-by-step protocol for conducting enzyme inhibition assays, a critical technique in drug discovery and basic research. The following sections outline the necessary materials, experimental procedures, data analysis, and interpretation to characterize the potency and mechanism of action of enzyme inhibitors.
Introduction
Enzyme inhibition assays are fundamental procedures used to determine the effect of a substance on an enzyme's activity.[1] These assays are crucial for screening potential drug candidates, understanding metabolic pathways, and studying the mechanisms of enzyme regulation.[1][2] The primary goal is often to determine the concentration of an inhibitor required to reduce enzyme activity by half (IC50) and to elucidate the mechanism of inhibition (e.g., competitive, non-competitive, uncompetitive).[1][3]
Materials and Reagents
To perform a general enzyme inhibition assay, the following materials and reagents are typically required:[1]
-
Purified Enzyme: The specific enzyme of interest.
-
Substrate: A molecule upon which the enzyme acts.
-
Inhibitor: The compound being tested for its inhibitory effects.
-
Assay Buffer: A buffer solution that maintains the optimal pH for the enzyme.[1]
-
Cofactors: Any necessary ions or molecules required for enzyme activity (e.g., Mg²⁺, ATP).[1]
-
Detection Reagent: A reagent that allows for the measurement of the product formation or substrate depletion.
-
Microplates: Typically 96-well or 384-well plates for running multiple reactions simultaneously.[1]
-
Plate Reader: A spectrophotometer or fluorometer to measure the reaction progress.[1]
-
Pipettes and Tips: For accurate liquid handling.[1]
Experimental Protocol: Step-by-Step
This protocol outlines a typical workflow for determining the IC50 of an inhibitor.
3.1. Preparation of Reagents
-
Assay Buffer Preparation: Prepare the assay buffer at the optimal pH and ionic strength for the target enzyme.
-
Enzyme Solution: Prepare a working solution of the enzyme in the assay buffer. The concentration should be determined empirically to yield a linear reaction rate over the desired time course.
-
Substrate Solution: Prepare a stock solution of the substrate in the assay buffer. The final concentration used in the assay is often near the Michaelis constant (Km) of the enzyme.
-
Inhibitor Solutions: Prepare a stock solution of the inhibitor, typically in DMSO. Perform serial dilutions of the inhibitor stock solution to create a range of concentrations to be tested.
3.2. Assay Procedure
-
Plate Setup: Add the assay buffer to all wells of the microplate.
-
Inhibitor Addition: Add the serially diluted inhibitor solutions to the appropriate wells. Include a positive control (a known inhibitor, if available) and a negative control (vehicle, e.g., DMSO).
-
Enzyme Addition: Add the enzyme solution to all wells except for the "no enzyme" control wells.
-
Pre-incubation: Incubate the plate for a specific period (e.g., 15-30 minutes) at the optimal temperature for the enzyme to allow the inhibitor to bind to the enzyme.[1]
-
Reaction Initiation: Add the substrate solution to all wells to start the enzymatic reaction.[1]
-
Kinetic Reading: Immediately place the plate in a plate reader and measure the change in absorbance or fluorescence over time.[1]
Data Presentation and Analysis
The raw data from the plate reader is used to calculate the reaction velocity (rate of product formation). The percent inhibition for each inhibitor concentration is then calculated using the following formula:
% Inhibition = [ (Velocity of Uninhibited Control - Velocity with Inhibitor) / Velocity of Uninhibited Control ] * 100
The calculated % inhibition values are then plotted against the logarithm of the inhibitor concentration to generate a dose-response curve, from which the IC50 value is determined.
Table 1: Example IC50 Determination Data
| Inhibitor Concentration (nM) | Log [Inhibitor] (M) | Average Reaction Velocity (RFU/min) | % Inhibition |
| 0 (Control) | - | 1500 | 0 |
| 1 | -9 | 1350 | 10 |
| 10 | -8 | 975 | 35 |
| 50 | -7.3 | 750 | 50 |
| 100 | -7 | 450 | 70 |
| 500 | -6.3 | 150 | 90 |
| 1000 | -6 | 75 | 95 |
4.1. Mechanism of Action (MoA) Studies
To determine the mechanism of inhibition, kinetic studies are performed by varying the concentrations of both the substrate and the inhibitor. The data is often visualized using a Lineweaver-Burk plot (a double reciprocal plot of 1/velocity vs. 1/[Substrate]).[3][4]
Table 2: Example Data for Lineweaver-Burk Plot Analysis
| 1/[Substrate] (µM⁻¹) | 1/Velocity (No Inhibitor) | 1/Velocity (with Competitive Inhibitor) | 1/Velocity (with Non-competitive Inhibitor) |
| 0.1 | 0.0025 | 0.0040 | 0.0050 |
| 0.2 | 0.0035 | 0.0055 | 0.0070 |
| 0.4 | 0.0055 | 0.0085 | 0.0110 |
| 0.8 | 0.0095 | 0.0145 | 0.0190 |
| 1.0 | 0.0115 | 0.0175 | 0.0230 |
The pattern of changes in Vmax (maximum velocity) and Km in the presence of the inhibitor reveals the mechanism of inhibition.[4]
-
Competitive Inhibition: Km increases, Vmax remains unchanged.[4]
-
Non-competitive Inhibition: Km remains unchanged, Vmax decreases.[4]
-
Uncompetitive Inhibition: Both Km and Vmax decrease.[4]
Visualizations
Diagram 1: Experimental Workflow for Enzyme Inhibition Assay
Caption: Workflow for a typical enzyme inhibition assay.
References
Revolutionizing Drug Discovery: The Austin Methodology for High-Throughput Screening
Introduction
In the landscape of modern drug discovery, high-throughput screening (HTS) stands as a cornerstone technology, enabling the rapid testing of vast compound libraries to identify potential therapeutic agents. A significant evolution of this approach is the quantitative high-throughput screening (qHTS) methodology, prominently developed and championed by the National Center for Advancing Translational Sciences (NCATS), under the leadership of Dr. Christopher P. Austin. This "Austin methodology" has shifted the paradigm from single-concentration screening to a more data-rich, concentration-response-based approach, significantly enhancing the quality and reliability of primary screening data.
These application notes provide a detailed overview of the qHTS methodology, including its core principles, a generalized experimental protocol, data presentation standards, and visualizations of the workflow and relevant biological pathways. This document is intended for researchers, scientists, and drug development professionals seeking to understand and implement this powerful screening strategy.
Core Principles of Quantitative High-Throughput Screening (qHTS)
Traditional HTS typically involves testing a large library of compounds at a single concentration to identify "hits." While effective for initial large-scale screening, this method is prone to a high rate of false positives and negatives. The qHTS methodology addresses these limitations by testing each compound across a range of concentrations, typically in a serial dilution format.[1] This approach offers several key advantages:
-
Generation of Concentration-Response Curves: By testing at multiple concentrations, a concentration-response curve is generated for every compound in the library. This provides a much richer dataset than a single-point screen.
-
Determination of Potency and Efficacy: From the concentration-response curve, key pharmacological parameters such as the half-maximal inhibitory concentration (IC50) or half-maximal effective concentration (EC50) and the maximal response (efficacy) can be determined directly from the primary screen.
-
Reduction of False Positives and Negatives: The requirement for a clear concentration-dependent effect significantly reduces the likelihood of identifying compounds that are active due to experimental artifacts at a single concentration. It also allows for the identification of compounds with potencies outside the single concentration used in traditional HTS, thereby reducing false negatives.[1]
-
Early Structure-Activity Relationship (SAR) Insights: The quantitative data from a qHTS campaign can provide preliminary insights into the structure-activity relationships of active compounds, guiding initial lead optimization efforts.[1]
-
Increased Data Reliability and Reproducibility: The generation of full curves for each compound enhances the statistical power and reproducibility of the screening results.
Experimental Protocols
The following is a generalized protocol for a cell-based qHTS assay performed in a 1536-well plate format. Specific parameters such as cell type, reagents, and incubation times should be optimized for the particular biological target and assay.
I. Assay Development and Miniaturization
-
Assay Principle: Select a robust and sensitive assay chemistry (e.g., fluorescence, luminescence, absorbance) that is amenable to miniaturization and automation.
-
Cell Seeding: Optimize cell density to ensure a healthy and responsive cell monolayer during the course of the experiment.
-
Reagent Optimization: Determine the optimal concentrations of all assay reagents to achieve a robust signal-to-background ratio and a high Z'-factor (>0.5).
-
Miniaturization: Adapt the assay to a 1536-well plate format, minimizing reagent volumes to reduce costs and conserve compound libraries.
II. Compound Library Preparation and Plating
-
Compound Dilution Series: Prepare a concentration series for each compound in the library. A common approach is a 7-point, 1:5 serial dilution, creating a concentration range spanning several orders of magnitude.[1]
-
Source Plate Preparation: Use acoustic dispensing or other high-precision liquid handling to create the serial dilutions in source plates (e.g., 384-well or 1536-well).
-
Compound Transfer: Utilize a pintool or acoustic dispensing to transfer nanoliter volumes of the compound solutions from the source plates to the 1536-well assay plates. This process is repeated for each concentration, with each concentration typically being on a separate set of plates.[1]
III. qHTS Assay Execution
The following is an example protocol for a generic cell-based luciferase reporter gene assay:
-
Cell Plating: Dispense the optimized number of cells into each well of the 1536-well assay plates containing the pre-spotted compounds.
-
Incubation: Incubate the plates for a predetermined period to allow for compound treatment and the biological response to occur. Incubation conditions (temperature, CO2, humidity) should be tightly controlled.
-
Reagent Addition: Add the luciferase substrate solution to all wells of the assay plates using a high-speed dispenser.
-
Signal Detection: Measure the luminescence signal from each well using a plate reader capable of reading 1536-well plates.
IV. Data Analysis and Hit Identification
-
Data Normalization: Normalize the raw data from the plate reader. Typically, the signal in each well is expressed as a percentage of the activity of the positive control and/or normalized to the median plate signal.
-
Curve Fitting: Fit the concentration-response data for each compound to a four-parameter Hill equation to determine the IC50/EC50, Hill slope, and maximal response.
-
Curve Classification: Automatically classify the concentration-response curves based on their quality, shape, and efficacy. This helps to prioritize hits and flag potential artifacts.
-
Hit Selection: Identify active compounds ("hits") based on predefined criteria for potency (e.g., IC50 < 10 µM) and efficacy (e.g., >50% inhibition).
Data Presentation
Quantitative data from qHTS experiments are typically summarized in tables to facilitate comparison of compound activities. Key parameters include the half-maximal inhibitory/effective concentration (IC50/EC50), the maximum response (efficacy), and a curve class that describes the quality and shape of the concentration-response curve.
| Compound ID | IC50 (µM) | Efficacy (%) | Curve Class |
| Compound A | 0.15 | 98.5 | 1.1 |
| Compound B | 1.2 | 85.2 | 1.2 |
| Compound C | > 50 | N/A | 4 |
| Compound D | 5.8 | 45.7 | 2.1 |
| Compound E | 0.08 | 102.1 | 1.1 |
Table 1: Example of qHTS Data Summary. IC50 values represent the concentration at which 50% of the maximal response is observed. Efficacy is the maximum percentage of inhibition or activation. Curve Class is a numerical representation of the quality and shape of the concentration-response curve, with lower numbers indicating higher confidence.
Mandatory Visualizations
Experimental Workflow
The following diagram illustrates the major steps in a typical qHTS campaign, from assay development to hit confirmation.
Caption: Generalized workflow for a quantitative high-throughput screening (qHTS) campaign.
Signaling Pathway Example: NF-κB Pathway
The NF-κB signaling pathway is a crucial regulator of inflammatory responses, cell proliferation, and survival, making it a common target for drug discovery. The following diagram illustrates a simplified representation of the canonical NF-κB signaling pathway, which can be interrogated using a qHTS approach with a reporter gene assay.
Caption: Simplified diagram of the canonical NF-κB signaling pathway.
Conclusion
The quantitative high-throughput screening (qHTS) methodology, often referred to as the "Austin methodology," represents a significant advancement in the field of drug discovery. By generating concentration-response data for every compound in a screening library, qHTS provides a more accurate, reliable, and information-rich dataset compared to traditional single-point screening. This approach not only reduces the incidence of false positives and negatives but also provides early insights into the pharmacological properties of active compounds. The adoption of qHTS, facilitated by advancements in automation and data analysis, is empowering researchers to accelerate the identification and optimization of novel therapeutic candidates.
References
Austin-Based Innovations in Clinical Trials: A Closer Look at Protocols and Therapies
Austin, TX – The landscape of clinical research in Austin is marked by a growing number of biotechnology and pharmaceutical companies, alongside robust academic and clinical research organizations. These entities are at the forefront of developing and testing novel therapies for a range of diseases, from cancer to autoimmune disorders. This report provides detailed application notes and protocols for select clinical trials involving Austin-based therapies, offering researchers, scientists, and drug development professionals a comprehensive overview of the innovative approaches emerging from this hub of biomedical advancement.
Natera: Guiding Cancer Therapy with Circulating Tumor DNA
Austin-based Natera has made significant strides in the field of oncology with its personalized molecular residual disease (MRD) test, Signatera™. This technology is a cornerstone of several major clinical trials, including the BESPOKE and GALAXY studies in colorectal cancer.
The Signatera™ assay is a tumor-informed test that analyzes circulating tumor DNA (ctDNA) in the blood to detect and quantify cancer that may remain in the body after treatment.[1][2] The process begins with the sequencing of a patient's tumor tissue to identify unique clonal mutations.[3] A personalized assay is then designed to target these specific mutations in subsequent blood samples.[1][3]
Experimental Protocol: The Signatera™ ctDNA Assay
The methodology for the Signatera™ assay involves several key steps:
-
Tumor Tissue Analysis: DNA is extracted from a formalin-fixed paraffin-embedded (FFPE) tumor tissue sample. Whole-exome sequencing is performed to identify clonal somatic mutations specific to the patient's tumor.[4]
-
Personalized Assay Design: A custom multiplex polymerase chain reaction (PCR) assay is designed to amplify the identified patient-specific mutations from cell-free DNA (cfDNA) isolated from plasma.[4]
-
Blood Sample Collection and Processing: Peripheral blood is collected from the patient at specified time points throughout their treatment and follow-up. Plasma is separated from the whole blood through centrifugation.
-
cfDNA Extraction and Library Preparation: cfDNA is extracted from the plasma. A sequencing library is then prepared from the cfDNA.
-
Targeted Sequencing: The personalized multiplex PCR assay is used to amplify the target regions of the cfDNA library. The amplified DNA is then sequenced using next-generation sequencing (NGS) technology.
-
Data Analysis: The sequencing data is analyzed to detect the presence and quantity of the targeted tumor-specific mutations. The results are reported as the mean tumor molecules per milliliter (MTM/mL) of plasma.
The BESPOKE Study of ctDNA Guided Therapy in Colorectal Cancer
The BESPOKE CRC study is a prospective, observational study designed to evaluate the impact of Signatera™ test results on adjuvant treatment decisions in patients with stage II and III colorectal cancer.[5][6] The study aims to enroll at least 1,000 patients and follow them for two years, collecting data on treatment decisions and clinical outcomes.[5]
Study Objectives:
-
To observe the influence of Signatera™ results on the decision to administer adjuvant chemotherapy.
-
To measure the rate of cancer recurrence in patients who are asymptomatic and have no imaging evidence of disease.[7]
The GALAXY Study: ctDNA Dynamics in Colorectal Cancer
The GALAXY study, part of the larger CIRCULATE-Japan project, is a prospective observational study monitoring ctDNA in patients with resectable colorectal cancer.[8] This study utilizes the Signatera™ assay to track ctDNA levels before and after surgery.[8]
Key Findings from the GALAXY Study:
| Metric | ctDNA-Positive Patients | ctDNA-Negative Patients |
| Recurrence Rate | 78% | 13% |
| 24-Month Disease-Free Survival | 20% | 85% |
| 36-Month Disease-Free Survival | 17% | 84% |
| 24-Month Overall Survival | 84% | 99% |
| 36-Month Overall Survival | 72% | 96% |
Data from the GALAXY study update presented at ESMO 2024.[9]
The results from the GALAXY study demonstrate a strong correlation between ctDNA status and patient outcomes, suggesting that ctDNA is a powerful prognostic marker for disease recurrence and overall survival in colorectal cancer.[9]
XBiotech: Targeting Inflammation with True Human™ Antibodies
Austin-based XBiotech is developing a pipeline of therapeutic antibodies derived from natural human immunity. One of their lead candidates is Natrunix™, a monoclonal antibody being investigated for the treatment of rheumatoid arthritis.
Natrunix™ targets interleukin-1 alpha (IL-1α), a key inflammatory cytokine. The antibody is designed to be indistinguishable from a naturally occurring human antibody, which is expected to result in a favorable safety profile.[10]
Clinical Trial Protocol: Phase II Study of Natrunix™ in Rheumatoid Arthritis
This is a Phase II, double-blind, placebo-controlled, randomized trial to evaluate the efficacy and safety of Natrunix™ in combination with methotrexate (B535133) for the treatment of rheumatoid arthritis.[11][12]
Study Design:
-
Participants: Patients with rheumatoid arthritis who have had an inadequate response to methotrexate.[12]
-
Intervention: Participants are randomized to receive either Natrunix™ or a placebo, in addition to their stable dose of methotrexate.[11][12]
-
Primary Endpoint: The primary goal is to assess the American College of Rheumatology (ACR) 20 response rate after 12 weeks of treatment.[12]
-
Study Duration: The trial is expected to last up to 33 weeks, which includes screening, a 12-week treatment period, and a follow-up phase.[11]
Experimental Workflow:
Caption: Experimental workflow for the Phase II clinical trial of Natrunix™.
Signaling Pathway of Interleukin-1 Alpha (IL-1α):
IL-1α is a potent pro-inflammatory cytokine that plays a central role in the pathogenesis of rheumatoid arthritis. When IL-1α binds to its receptor (IL-1R1), it initiates a signaling cascade that leads to the activation of transcription factors, such as NF-κB and AP-1. This, in turn, results in the production of other inflammatory mediators, including cytokines, chemokines, and matrix metalloproteinases, which contribute to the joint inflammation and destruction characteristic of rheumatoid arthritis. Natrunix™ is designed to neutralize IL-1α, thereby inhibiting this inflammatory cascade.
Caption: Signaling pathway of IL-1α and the inhibitory action of Natrunix™.
CAR T-Cell Therapy in Austin
St. David's HealthCare, in collaboration with the Sarah Cannon Research Institute, offers Chimeric Antigen Receptor (CAR) T-cell therapy clinical trials in Austin.[13] This innovative immunotherapy involves modifying a patient's own T-cells to recognize and attack cancer cells.[13]
General Protocol for CAR T-Cell Therapy
The process of CAR T-cell therapy follows a series of well-defined steps:
-
Leukapheresis: A patient's white blood cells, including T-cells, are collected from their blood using a procedure called leukapheresis.
-
T-Cell Activation and Transduction: The collected T-cells are sent to a manufacturing facility where they are activated and genetically modified using a viral vector to express CARs on their surface. These CARs are specifically designed to recognize a particular antigen on the patient's cancer cells.
-
Expansion: The engineered CAR T-cells are then expanded in number in the laboratory over a period of several weeks.
-
Lymphodepleting Chemotherapy: Prior to infusion of the CAR T-cells, the patient receives a short course of chemotherapy to deplete existing lymphocytes. This creates a more favorable environment for the infused CAR T-cells to expand and persist.
-
CAR T-Cell Infusion: The expanded CAR T-cells are infused back into the patient's bloodstream.
-
Monitoring: The patient is closely monitored for potential side effects, such as cytokine release syndrome (CRS) and neurotoxicity, and for the therapeutic response of the treatment.
CAR T-Cell Therapy Workflow:
Caption: General workflow of CAR T-cell therapy.
The clinical trial landscape in Austin is dynamic and expanding, with local companies and institutions making significant contributions to the development of next-generation therapies. The protocols and data highlighted in this report underscore the commitment to rigorous scientific investigation and the potential to improve patient outcomes across a variety of diseases.
References
- 1. Signatera – Circulating Tumor DNA Blood Test | Natera [natera.com]
- 2. learn.colontown.org [learn.colontown.org]
- 3. natera.com [natera.com]
- 4. Commercial ctDNA assays for minimal residual disease detection of solid tumors - PMC [pmc.ncbi.nlm.nih.gov]
- 5. natera.com [natera.com]
- 6. BESPOKE study protocol: a multicentre, prospective observational study to evaluate the impact of circulating tumour DNA guided therapy on patients with colorectal cancer - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. BESPOKE study protocol: a multicentre, prospective observational study to evaluate the impact of circulating tumour DNA guided therapy on patients with colorectal cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 8. CIRCULATE‐Japan: Circulating tumor DNA–guided adaptive platform trials to refine adjuvant therapy for colorectal cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 9. youtube.com [youtube.com]
- 10. XBiotech Announces First Patient Begins Novel Natrunix Therapy in Phase II Rheumatoid Arthritis (RA) Clinical Trial - BioSpace [biospace.com]
- 11. tipranks.com [tipranks.com]
- 12. Natrunix or Placebo in Combination With Methotrexate in Rheumatoid Arthritis [ctv.veeva.com]
- 13. CAR-T Cell Therapy Clinical Trials | St. David's HealthCare [stdavids.com]
Application Notes and Protocols: Bayesian Statistical Methods in Clinical Research
The following document provides detailed application notes and protocols for the use of Bayesian statistical methods in clinical research. While the term "Austin statistical methods" is not a standard designation in statistical literature, this document focuses on Bayesian methodologies, a field in which researchers at institutions in Austin, Texas, have made significant contributions. These methods offer a flexible and powerful framework for designing, analyzing, and interpreting clinical trials.
Introduction to Bayesian Methods in Clinical Research
Bayesian methods provide a formal framework for incorporating prior knowledge with observed data to update our beliefs about a parameter of interest. In the context of clinical research, this approach allows for the integration of historical data, data from previous trials, or expert opinion into the analysis of a new clinical trial. This can lead to more efficient and ethical trial designs.
The core of Bayesian inference is Bayes' theorem:
P(θ|Data) ∝ P(Data|θ) × P(θ)
Where:
-
P(θ|Data) is the posterior probability : the updated belief about the parameter θ after observing the data.
-
P(Data|θ) is the likelihood : the probability of observing the data given a particular value of the parameter θ.
-
P(θ) is the prior probability : the existing belief about the parameter θ before observing the new data.
One of the key advantages of Bayesian approaches in clinical trials is the ability to update probabilities as data accumulates, which is the foundation for adaptive trial designs.
Application: Bayesian Adaptive Platform Trials
A prominent application of Bayesian methods is in adaptive platform trials, which allow for the simultaneous investigation of multiple interventions against a common control group. These trials are designed to be more efficient and flexible than traditional fixed-design trials.
Key Features of Bayesian Adaptive Platform Trials:
-
Adaptation: The trial can be modified based on interim analyses. For example, ineffective treatment arms can be dropped, new arms can be added, and randomization probabilities can be adjusted to favor more promising treatments.
-
Efficiency: By sharing a control group and allowing for early stopping for futility or success, these trials can require fewer patients and a shorter timeframe than a series of separate trials.
-
Ethical Considerations: Patients are more likely to be randomized to treatments that are performing better, which can be more ethical.
Experimental Protocols
Protocol 1: Designing a Bayesian Adaptive Platform Trial for a New Cancer Therapeutic
This protocol outlines the key steps in designing a Bayesian adaptive platform trial to evaluate two new therapeutic agents (Drug A and Drug B) against a standard of care (SoC) in patients with a specific type of cancer.
1. Define the Trial Objectives and Endpoints:
- Primary Objective: To determine if Drug A or Drug B is superior to the SoC in terms of the primary endpoint.
- Primary Endpoint: Overall Survival (OS) at 12 months.
- Secondary Endpoints: Progression-Free Survival (PFS), Objective Response Rate (ORR), and safety (adverse events).
2. Specify the Statistical Model:
- A Bayesian hierarchical model will be used to model the time-to-event data for OS. This allows for borrowing strength across the treatment arms.
- The primary parameter of interest will be the hazard ratio (HR) for each experimental arm compared to the SoC.
3. Define the Prior Distributions:
- Priors for Hazard Ratios: Non-informative or weakly informative priors will be used for the HRs. For example, a log-normal distribution centered at no effect (HR=1) with a large variance to reflect initial uncertainty. This allows the observed data to drive the posterior conclusions.
- Prior distributions can be elicited from historical data from previous trials of similar drugs or from expert clinical opinion.
4. Specify the Adaptation Rules for Interim Analyses:
- Interim analyses will be planned after every 50 patients have completed the 12-month follow-up.
- Futility Rule: A treatment arm will be dropped if the posterior probability that its HR is greater than 1 (i.e., it is worse than SoC) exceeds 95%.
- Superiority Rule: A treatment arm will be declared superior if the posterior probability that its HR is less than 0.75 (a clinically meaningful improvement) exceeds 97.5%.
- Adaptive Randomization: The randomization probabilities will be adjusted based on the accumulating evidence. Arms that are performing better will be assigned a higher probability of randomization. For example, the probability of randomizing to an arm can be made proportional to the posterior probability that it is the best treatment.
5. Simulation and Operating Characteristics:
- Before launching the trial, extensive simulations will be conducted to evaluate the operating characteristics of the design under various plausible scenarios (e.g., null scenario where no drug is effective, scenarios where one or both drugs are effective).
- The simulations will assess the trial's power, type I error rate, expected sample size, and the probability of correctly identifying the best treatment.
Data Presentation
The results of a Bayesian trial are typically presented in terms of posterior probabilities. The following tables provide an example of how data from our hypothetical cancer trial could be summarized after an interim analysis.
Table 1: Summary of Patient Demographics and Baseline Characteristics
| Characteristic | Standard of Care (n=100) | Drug A (n=102) | Drug B (n=98) | Total (n=300) |
| Age, median (range) | 62 (45-78) | 61 (48-80) | 63 (46-79) | 62 (45-80) |
| Gender, n (%) | ||||
| - Male | 52 (52.0%) | 55 (53.9%) | 50 (51.0%) | 157 (52.3%) |
| - Female | 48 (48.0%) | 47 (46.1%) | 48 (49.0%) | 143 (47.7%) |
| ECOG Performance Status, n (%) | ||||
| - 0 | 40 (40.0%) | 42 (41.2%) | 38 (38.8%) | 120 (40.0%) |
| - 1 | 60 (60.0%) | 60 (58.8%) | 60 (61.2%) | 180 (60.0%) |
Table 2: Interim Analysis of Efficacy Endpoints (12-month follow-up)
| Endpoint | Standard of Care | Drug A | Drug B |
| Overall Survival (OS) | |||
| - Number of Events | 45 | 35 | 48 |
| - Median OS (months) | 10.2 | 14.5 | 9.8 |
| - Hazard Ratio (HR) vs. SoC (95% Credible Interval) | - | 0.72 (0.55, 0.94) | 1.05 (0.82, 1.34) |
| - P(HR < 1) vs. SoC | - | 98.5% | 40.2% |
| - P(HR < 0.75) vs. SoC (Superiority Threshold) | - | 65.0% | 10.5% |
| Progression-Free Survival (PFS) | |||
| - Median PFS (months) | 5.1 | 7.8 | 5.3 |
| Objective Response Rate (ORR) | |||
| - ORR (%) | 22% | 38% | 24% |
Table 3: Interim Decision Summary
| Treatment Arm | Decision Criteria | Posterior Probability | Decision |
| Drug A | P(HR < 0.75) > 97.5% (Superiority) | 65.0% | Continue trial, adapt randomization |
| Drug B | P(HR > 1) > 95% (Futility) | 40.2% | Continue trial, monitor for futility at next analysis |
Visualizations
The following diagrams illustrate the workflow and logic of the Bayesian adaptive trial described in the protocol.
Caption: Workflow of a Bayesian adaptive clinical trial, from setup to execution and decision-making.
Application Notes and Protocols for the Austin Method in Sustainable Chemical Manufacturing
Introduction
The "Austin Method" represents a significant advancement in sustainable chemical manufacturing, originating from research conducted at the University of Texas at Austin. This innovative approach addresses a critical challenge in green chemistry: the development of environmentally benign and economically viable methods for carbon-carbon bond formation, a fundamental process in the synthesis of pharmaceuticals, agrochemicals, and other complex organic molecules.
Traditionally, these reactions, particularly cross-coupling reactions, have relied on the use of sensitive and hazardous organometallic reagents, which are not only expensive but also generate significant chemical waste. The Austin Method circumvents these limitations by employing a novel catalytic system that utilizes sodium formate (B1220265), a safe, inexpensive, and readily available bulk chemical, as a key reagent. This method has been shown to be highly efficient and practical for industrial applications, marking a paradigm shift in how chemists can build complex molecules more sustainably.
These application notes provide researchers, scientists, and drug development professionals with a comprehensive overview of the Austin Method, including its underlying principles, experimental protocols, and potential applications in sustainable chemical manufacturing.
Chemical Principles and Mechanism
The core of the Austin Method is a palladium-catalyzed cross-coupling reaction that utilizes sodium formate as a hydride source. The reaction proceeds through a catalytic cycle that avoids the pre-formation of organometallic reagents. While the detailed mechanism is a subject of ongoing research, a plausible catalytic cycle is proposed below.
Applications in Sustainable Chemical Manufacturing
The Austin Method offers a versatile and sustainable alternative for a wide range of chemical transformations. Its applications span various sectors of the chemical industry, with particularly significant implications for pharmaceutical and fine chemical synthesis.
-
Pharmaceutical Synthesis: The formation of carbon-carbon bonds is a cornerstone of drug discovery and development. The Austin Method provides a greener route to synthesize complex active pharmaceutical ingredients (APIs) and their intermediates, reducing the environmental footprint of drug manufacturing.
-
Agrochemical Development: The synthesis of modern pesticides and herbicides often involves complex organic molecules. The Austin Method can be applied to produce these compounds more sustainably, minimizing the use of hazardous reagents and the generation of chemical waste.
-
Fine and Specialty Chemicals: The method's broad applicability makes it suitable for the synthesis of a variety of high-value chemicals, including flavors, fragrances, and materials for organic electronics.
Quantitative Data
The following tables summarize the key quantitative data associated with the Austin Method, highlighting its efficiency and sustainability benefits compared to traditional methods.
Table 1: Comparison of the Austin Method with Traditional Cross-Coupling Reactions
| Parameter | Austin Method | Traditional Methods (e.g., Suzuki, Stille) |
| Reagent | Sodium Formate | Organoboron, Organotin compounds |
| Safety Profile | Safe, non-toxic | Often toxic, pyrophoric, or moisture-sensitive |
| Cost | Low | High |
| Waste Generation | Minimal | Significant stoichiometric waste |
| Atom Economy | High | Moderate to low |
Table 2: Representative Reaction Yields using the Austin Method
| Substrate 1 | Substrate 2 | Product | Yield (%) |
| Aryl Halide A | Alkene B | Cross-coupled Product C | >90% |
| Aryl Halide D | Alkyne E | Cross-coupled Product F | >85% |
| Note: Specific substrates and reaction conditions will influence the final yield. |
Experimental Protocols
General Protocol for a Palladium-Catalyzed Cross-Coupling Reaction using the Austin Method
This protocol provides a general procedure for a typical cross-coupling reaction between an aryl halide and an alkene. The specific conditions may need to be optimized for different substrates.
Materials:
-
Palladium catalyst (e.g., Pd(OAc)2 with a suitable ligand)
-
Aryl halide
-
Alkene
-
Sodium formate
-
Solvent (e.g., a mixture of water and an organic co-solvent)
-
Reaction vessel (e.g., a sealed tube or a round-bottom flask with a condenser)
-
Inert atmosphere (e.g., nitrogen or argon)
Procedure:
-
Reaction Setup: To a clean and dry reaction vessel, add the palladium catalyst, aryl halide, alkene, and sodium formate.
-
Solvent Addition: Add the solvent system to the reaction vessel.
-
Inert Atmosphere: Purge the reaction vessel with an inert gas (e.g., nitrogen or argon) for 5-10 minutes to remove any oxygen.
-
Reaction: Heat the reaction mixture to the desired temperature and stir for the specified time. Monitor the reaction progress by a suitable analytical technique (e.g., TLC, GC-MS, or LC-MS).
-
Workup: Once the reaction is complete, cool the mixture to room temperature. Dilute the reaction mixture with an organic solvent and wash with water to remove any inorganic salts.
-
Purification: Dry the organic layer over a drying agent (e.g., Na2SO4 or MgSO4), filter, and concentrate the solvent under reduced pressure. The crude product can be purified by a suitable method, such as column chromatography or recrystallization.
Safety Precautions:
-
All reactions should be performed in a well-ventilated fume hood.
-
Personal protective equipment (PPE), including safety glasses, lab coat, and gloves, should be worn at all times.
-
Consult the Safety Data Sheets (SDS) for all chemicals used in the experiment.
Visualizations
Caption: Proposed catalytic cycle for the Austin Method.
Caption: General experimental workflow for the Austin Method.
Technical Support Center: Troubleshooting Compound Solubility
This technical support center provides guidance to researchers, scientists, and drug development professionals on addressing common solubility challenges encountered during experimentation. The following troubleshooting guides and frequently asked questions (FAQs) are designed to offer direct solutions to specific issues.
Frequently Asked Questions (FAQs)
Q1: What are the common causes of poor aqueous solubility for my research compound?
A1: Poor aqueous solubility is a frequent hurdle in drug discovery. The primary reasons often relate to the molecule's physicochemical properties, including:
-
High Lipophilicity: Molecules with a high logP (a measure of lipophilicity) prefer non-polar environments and thus exhibit low solubility in aqueous solutions.[1]
-
Crystal Lattice Energy: A strong, stable crystal structure requires considerable energy to break apart, leading to lower solubility. Amorphous forms are generally more soluble than their crystalline counterparts.[1]
-
Poor Solvation: The compound may not interact favorably with water molecules, which hinders the dissolution process.[1]
-
pH-Dependent Solubility: For ionizable compounds, solubility can be highly dependent on the pH of the solution. The compound may precipitate if the pH is not optimal.[1][2]
-
Molecular Structure: Larger molecular size and a lack of polar functional groups can contribute to poor solubility.[3]
Q2: I'm observing precipitation when I dilute my compound from a DMSO stock into an aqueous buffer. What is happening and how can I prevent it?
A2: This common issue is known as "precipitation upon dilution." Dimethyl sulfoxide (B87167) (DMSO) is a powerful organic solvent that can dissolve many non-polar compounds at high concentrations.[1] When this concentrated DMSO stock is introduced into an aqueous buffer, the local concentration of the compound can momentarily exceed its solubility limit in the mixed solvent system, causing it to precipitate.[1]
To prevent this:
-
Prepare Intermediate Dilutions: Before the final dilution into your aqueous buffer, create intermediate dilutions of your stock solution in DMSO.[2]
-
Proper Mixing Technique: Add the DMSO stock to the aqueous buffer, not the other way around. Ensure rapid and vigorous mixing (e.g., vortexing or pipetting) immediately after adding the DMSO stock to promote uniform dispersion.[2]
-
Control Final DMSO Concentration: Keep the final concentration of DMSO in your working solution low and consistent across all experiments, typically at or below 0.1%.[2]
-
Gentle Warming: Gently warming the aqueous buffer (e.g., to 37°C) before adding the DMSO stock can sometimes help maintain solubility, but be cautious of compound stability at higher temperatures.[2]
Q3: Can the solid form of my compound affect its solubility?
A3: Absolutely. The solid-state properties of a compound, such as polymorphism (the ability to exist in multiple crystalline forms), can significantly impact its solubility and dissolution rate. Amorphous forms of a compound are generally more soluble than their stable crystalline counterparts because they lack a highly ordered crystal lattice structure.[1][4] Different polymorphs of the same compound can also exhibit different solubilities.[3]
Q4: What are some initial steps I can take in the lab to improve the solubility of my compound for a biological assay?
A4: For initial in-vitro experiments, you can try several straightforward methods:
-
pH Adjustment: If your compound has ionizable groups, adjusting the pH of your buffer can significantly enhance solubility. Acidic compounds are more soluble at higher pH, and basic compounds are more soluble at lower pH.[2]
-
Use of Co-solvents: Adding a small amount of a water-miscible organic solvent (a co-solvent) like ethanol, propylene (B89431) glycol, or polyethylene (B3416737) glycol (PEG) to your aqueous buffer can increase the solubility of hydrophobic compounds.[5][6]
-
Sonication: Using a sonicator can help break down compound aggregates and facilitate dissolution.[2]
-
Gentle Heating: As mentioned, gentle warming can increase the rate of dissolution, but be mindful of potential compound degradation.[2]
Troubleshooting Workflow for Solubility Issues
The following diagram outlines a logical workflow for troubleshooting compound solubility problems.
Caption: A workflow for systematically troubleshooting compound solubility issues.
Quantitative Comparison of Solubility Enhancement Techniques
The effectiveness of each solubilization method is highly compound-dependent. The following table summarizes reported solubility enhancements for various techniques with specific drug examples.
| Technique | Example Drug | Fold Increase in Solubility | Reference |
| pH Adjustment | Ibuprofen | >1000x (at pH 7 vs. pH 1.2) | General Knowledge |
| Co-solvency | Diazepam | ~100x (in 40% PEG 400) | General Knowledge |
| Micronization | Griseofulvin | ~2-5x | [7] |
| Nanosuspension | Danazol | >20x | [8] |
| Solid Dispersion | Itraconazole | >20x | [9] |
| Cyclodextrin Complexation | Piroxicam | ~50x (with HP-β-CD) | [7] |
| Self-Emulsifying Drug Delivery Systems (SEDDS) | Saquinavir | >100x | [3] |
Experimental Protocols
Protocol 1: Kinetic Solubility Assessment by Nephelometry
This high-throughput method measures light scattering to detect undissolved particles as an indicator of precipitation.[10][11]
Materials:
-
Compound stock solution (e.g., 10 mM in DMSO)
-
Aqueous buffer (e.g., PBS, pH 7.4)
-
96-well microtiter plate
-
Nephelometer (light-scattering plate reader)
Procedure:
-
Add the aqueous buffer to the wells of the 96-well plate.
-
Add a small volume of the compound's DMSO stock solution to the first well to achieve the highest desired concentration (ensure the final DMSO concentration is consistent, e.g., 1%).
-
Perform serial dilutions across the microtiter plate.
-
Incubate the plate at a controlled temperature for a set period (e.g., 2 hours).
-
Measure the light scattering in each well using a nephelometer.
-
The kinetic solubility is the highest concentration at which no significant increase in light scattering (precipitation) is observed.
Protocol 2: Equilibrium Solubility Assessment (Shake-Flask Method)
This method determines the thermodynamic solubility of a compound.[12][13]
Materials:
-
Solid compound
-
Aqueous buffer (e.g., PBS, pH 7.4)
-
Vials
-
Shaker/agitator
-
Filtration unit (e.g., 0.45 µm syringe filter)
-
Analytical method for quantification (e.g., HPLC-UV, LC-MS/MS)
Procedure:
-
Add an excess amount of the solid compound to a vial.
-
Add a known volume of the aqueous buffer.
-
Seal the vials and agitate them at a constant temperature for a prolonged period (e.g., 24-48 hours) to ensure equilibrium is reached.
-
After incubation, allow the solution to settle.
-
Carefully withdraw a sample of the supernatant and filter it to remove any undissolved solid.
-
Quantify the concentration of the dissolved compound in the filtrate using a suitable analytical method like HPLC.
Signaling Pathways and Experimental Workflows
Impact of Poor Solubility on In-Vitro Assays
Caption: How poor compound solubility can lead to inaccurate in-vitro assay results.
References
- 1. benchchem.com [benchchem.com]
- 2. benchchem.com [benchchem.com]
- 3. hilarispublisher.com [hilarispublisher.com]
- 4. americanpharmaceuticalreview.com [americanpharmaceuticalreview.com]
- 5. ijmsdr.org [ijmsdr.org]
- 6. wjbphs.com [wjbphs.com]
- 7. Drug Solubility: Importance and Enhancement Techniques - PMC [pmc.ncbi.nlm.nih.gov]
- 8. ascendiacdmo.com [ascendiacdmo.com]
- 9. Solubility enhancement techniques- a review on conventional and novel approaches [wisdomlib.org]
- 10. Solubility Test | AxisPharm [axispharm.com]
- 11. In vitro solubility assays in drug discovery - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. Solubility Testing of Drug Candidates – Pharma.Tips [pharma.tips]
- 13. lup.lub.lu.se [lup.lub.lu.se]
Austin Protocol Technical Support Center: Optimizing Plasmid Yield
Welcome to the technical support center for the Austin Protocol, your resource for troubleshooting and optimizing plasmid DNA purification for higher yields. This guide is designed for researchers, scientists, and drug development professionals to address common issues encountered during experimental workflows.
Frequently Asked Questions (FAQs)
Q1: What is the expected plasmid DNA yield using the Austin Protocol?
A1: The expected yield can vary significantly based on several factors, including plasmid copy number, the E. coli host strain, and culture conditions. For high-copy number plasmids, yields can range from 5-50 µg for a miniprep, 50-200 µg for a midiprep, and 200-1000 µg for a maxiprep.[1] Low-copy number plasmids will inherently result in lower yields. Refer to the table below for a general overview of expected yields.
Q2: Can I use a culture that has been growing for more than 16-18 hours?
A2: It is not recommended. Overgrown cultures can lead to a higher proportion of dead or dying bacterial cells, which can release nucleases and chromosomal DNA, leading to lower quality and quantity of plasmid DNA.[2][3] For optimal results, it's best to process cultures that are in the late logarithmic to early stationary phase of growth, typically around 12-16 hours after inoculation.[4][5]
Q3: My plasmid has a large insert. Will this affect the yield?
A3: Yes, large inserts can decrease the plasmid copy number per cell, which in turn will reduce the overall yield.[1] If you are working with plasmids containing large inserts, you may need to increase the initial culture volume to obtain a sufficient amount of DNA.[1]
Q4: Is it necessary to add antibiotics to my overnight culture?
A4: Absolutely. Antibiotic selection is crucial for maintaining the plasmid within the bacterial population.[2][6] Without the selective pressure of the antibiotic, bacteria that lose the plasmid can grow faster and outcompete the plasmid-containing bacteria, leading to a significant reduction in your final plasmid yield.[2][6]
Q5: Can I elute my plasmid DNA in water instead of the provided elution buffer?
A5: While it is possible to elute in nuclease-free water, the provided elution buffer (typically Tris-EDTA) is recommended. The buffer helps to maintain a stable pH and the EDTA chelates divalent cations that can be cofactors for nucleases, thus protecting your plasmid DNA from degradation during storage.
Troubleshooting Guide: Low Plasmid Yield
Low plasmid DNA yield is a common issue that can often be resolved by optimizing specific steps in the protocol. The following guide addresses the most frequent causes of low yield and provides targeted solutions.
| Problem | Potential Cause | Recommended Solution |
| Low DNA Concentration | Poor Bacterial Growth | Ensure optimal aeration by using a flask with a volume at least four times your culture volume and shaking at 200-250 rpm.[2][5] Consider using a richer growth medium like Terrific Broth (TB) instead of LB Broth to increase cell density.[7][8][9] |
| Low-Copy-Number Plasmid | Increase the starting culture volume.[3][5] Some protocols suggest doubling the recommended volumes of resuspension, lysis, and neutralization buffers for low-copy plasmids.[1] | |
| Inefficient Cell Lysis | Ensure the bacterial pellet is completely resuspended in the resuspension buffer before adding the lysis buffer.[4][6] Incomplete resuspension will lead to inefficient lysis and lower DNA release. | |
| Inefficient Elution | Pre-warm the elution buffer to 65°C to enhance the elution of larger plasmids.[10][11] You can also increase the incubation time of the elution buffer on the column to 5 minutes or perform a second elution with the same buffer to recover any remaining DNA.[4][10] | |
| No DNA Visible | Incorrect Buffer Preparation | Ensure that ethanol (B145695) has been added to the wash buffer as indicated in the protocol.[4] Using the wash buffer without ethanol will result in the loss of plasmid DNA. |
| Loss of Plasmid During Culture | Use fresh antibiotic in your growth medium and ensure it is at the correct concentration.[2][3] Inoculate your liquid culture from a fresh, single colony from an agar (B569324) plate rather than from a liquid stock.[3][7][12] | |
| Poor DNA Quality (smearing on gel) | Genomic DNA Contamination | Avoid vigorous vortexing or mixing after adding the lysis buffer. Gentle inversion is sufficient to mix the solution.[4] Over-incubation in the lysis buffer can also lead to irreversible denaturation of all DNA, including the plasmid. |
| RNA Contamination | Ensure that RNase A has been added to the resuspension buffer and is active. If RNA contamination persists, consider an additional RNase treatment step after purification. |
Experimental Protocols: Key Methodologies
Optimized Bacterial Culture for High Yield
-
Inoculate a single, fresh bacterial colony into 5 mL of Luria-Bertani (LB) or Terrific Broth (TB) containing the appropriate antibiotic.
-
Incubate for approximately 8 hours at 37°C with vigorous shaking (250 rpm).
-
Use this starter culture to inoculate a larger volume of the same medium (e.g., 1:1000 dilution).
-
Incubate the large culture for 12-16 hours at 37°C with vigorous shaking. The flask volume should be at least four times the culture volume to ensure adequate aeration.[5]
-
Harvest the bacterial cells by centrifugation. The optical density at 600 nm (OD600) should ideally be between 2.0 and 4.0 for high-copy plasmids.
Alkaline Lysis Plasmid Purification
-
Resuspension: Completely resuspend the harvested bacterial pellet in Resuspension Buffer (containing RNase A) until no clumps are visible.[4][6]
-
Lysis: Add Lysis Buffer and mix gently by inverting the tube 4-6 times. Do not vortex. Incubate at room temperature for no more than 5 minutes. The solution should become clear and viscous.
-
Neutralization: Add Neutralization Buffer and mix immediately by inverting the tube until the solution is homogeneous and a white precipitate forms.
-
Clarification: Centrifuge at high speed for 10 minutes to pellet the cell debris and chromosomal DNA.
-
Binding: Carefully transfer the supernatant to a spin column and centrifuge. The plasmid DNA will bind to the silica (B1680970) membrane.
-
Washing: Wash the column with Wash Buffer (containing ethanol) to remove salts and other impurities.
-
Elution: Place the column in a clean microfuge tube, add pre-warmed Elution Buffer directly to the center of the membrane, incubate for 2-5 minutes, and centrifuge to elute the purified plasmid DNA.[4][10]
Visualizing the Austin Protocol
Diagram 1: Austin Protocol Experimental Workflow
Caption: A flowchart of the major steps in the Austin Protocol for plasmid purification.
Diagram 2: Signaling Pathway of Plasmid Replication Control (ColE1-type)
Caption: Control of plasmid copy number in ColE1-type plasmids via antisense RNA I.
References
- 1. bitesizebio.com [bitesizebio.com]
- 2. zymoresearch.com [zymoresearch.com]
- 3. Troubleshooting Low DNA Yield From Plasmid Preps | VectorBuilder [en.vectorbuilder.com]
- 4. neb.com [neb.com]
- 5. blog.addgene.org [blog.addgene.org]
- 6. neb.com [neb.com]
- 7. Tips & Tricks to Optimize Your Plasmid Purification - Nordic Biosite [nordicbiosite.com]
- 8. How do I increase plasmid yield? | AAT Bioquest [aatbio.com]
- 9. qiagen.com [qiagen.com]
- 10. ibisci.com [ibisci.com]
- 11. cellculturedish.com [cellculturedish.com]
- 12. zymoresearch.com [zymoresearch.com]
Technical Support Center: Enhancing Efficiency in Organic Synthesis
Welcome to the Technical Support Center for optimizing organic synthesis reactions. This resource is tailored for researchers, scientists, and drug development professionals to navigate common challenges and enhance the efficiency of their synthetic endeavors. Below, you will find comprehensive troubleshooting guides and frequently asked questions to address specific issues you may encounter during your experiments.
Frequently Asked Questions (FAQs)
Q1: My reaction is not proceeding to completion, resulting in a low yield. What are the common causes and how can I address them?
A1: Incomplete reactions are a frequent challenge in organic synthesis. Several factors can contribute to this issue:
-
Insufficient Reaction Time or Temperature: Monitor the reaction's progress using techniques like Thin Layer Chromatography (TLC) or Liquid Chromatography-Mass Spectrometry (LC-MS) to determine the optimal duration. If the reaction is sluggish, a moderate increase in temperature might be beneficial, but be cautious of potential side reactions or product degradation.
-
Catalyst Deactivation: In metal-catalyzed reactions, the catalyst can lose activity due to impurities in reagents or solvents, or through the formation of inactive species. Ensure all materials are pure and dry, and consider using a higher catalyst loading or adding a stabilizing ligand.
-
Incorrect Stoichiometry: Carefully verify the molar ratios of your reactants. Sometimes, using a slight excess of one reactant can drive the equilibrium towards the product.
-
Poor Reagent Quality: Use freshly purified reagents and anhydrous solvents, as impurities can inhibit the reaction.
Q2: I am observing significant side product formation. How can I improve the selectivity of my reaction?
A2: The formation of side products diminishes the yield of the desired compound and complicates purification. To enhance selectivity:
-
Optimize Reaction Conditions: Temperature, solvent, and catalyst/reagent choice can profoundly influence selectivity. A systematic optimization of these parameters is often necessary.
-
Use of Protective Groups: If your starting material has multiple reactive sites, consider using protecting groups to selectively block certain functional groups from reacting.
-
Change the Order of Reagent Addition: The sequence in which reagents are introduced can sometimes control which reaction pathway is favored.
Q3: My crude product appears to be a complex mixture after work-up. What are the likely contaminants?
A3: A complex crude mixture can arise from several sources:
-
Unreacted Starting Materials: Incomplete conversion will leave starting materials in your product mixture.
-
Side Products: As discussed above, competing reaction pathways can generate various impurities.
-
Degradation Products: The desired product might be unstable under the reaction or work-up conditions.
-
Catalyst Residues: In catalyzed reactions, residual catalyst can contaminate the product.
-
Solvent Adducts: The solvent may sometimes react with the starting materials or product.
Q4: How can I effectively troubleshoot a reaction that is not working as expected?
A4: A systematic approach to troubleshooting is crucial.[1] Consider the following steps:
-
Verify Starting Materials: Confirm the identity and purity of your reagents and solvents.
-
Check Reaction Setup: Ensure all equipment is properly assembled and reaction conditions (temperature, atmosphere) are correct.
-
Monitor the Reaction: Use analytical techniques like TLC, GC, or NMR to track the progress of the reaction.
-
Analyze the Crude Mixture: If the reaction is complete, analyze the crude product to identify major components, which can provide clues about what went wrong.
-
Consult the Literature: Review similar reactions to see if others have encountered and solved similar problems.
Troubleshooting Guides
Issue 1: Low or No Product Formation
Symptoms:
-
TLC/LC-MS analysis shows predominantly unreacted starting material.
-
The isolated yield is significantly lower than expected.
Potential Causes & Solutions:
| Potential Cause | Recommended Solution |
| Inactive Catalyst | Use a freshly prepared or properly stored catalyst. Ensure the catalyst is not poisoned by impurities. |
| Poor Reagent/Solvent Quality | Use high-purity, anhydrous solvents and freshly purified reagents.[2] |
| Inappropriate Reaction Temperature | Optimize the temperature. Some reactions require heating to overcome the activation energy, while others need to be run at lower temperatures to prevent decomposition. |
| Incorrect Reagent Stoichiometry | Carefully check and recalculate the molar equivalents of all reactants. |
Issue 2: Formation of Multiple Products
Symptoms:
-
TLC plate shows multiple spots.
-
Crude NMR/LC-MS indicates the presence of several compounds.
Potential Causes & Solutions:
| Potential Cause | Recommended Solution |
| Side Reactions | Modify reaction conditions (temperature, solvent, catalyst) to favor the desired pathway. Consider using a more selective reagent. |
| Product Degradation | Monitor the reaction and stop it as soon as the starting material is consumed. Ensure the work-up procedure is not too harsh. |
| Lack of Chemoselectivity | Employ protecting groups to block reactive sites that are not intended to participate in the reaction. |
Experimental Protocols
General Protocol for Reaction Optimization: A Case Study on a Hypothetical Coupling Reaction
This protocol outlines a general approach to optimizing a reaction to improve its yield and selectivity.
-
Baseline Experiment:
-
Set up the reaction using the initially reported or hypothesized conditions.
-
Carefully measure the yield of the desired product and identify any major side products.
-
-
Parameter Screening (Design of Experiments - DoE):
-
Temperature: Run the reaction at a range of temperatures (e.g., room temperature, 50 °C, 80 °C, 100 °C) while keeping other parameters constant.
-
Solvent: Test a variety of solvents with different polarities and coordinating abilities (e.g., THF, Dioxane, Toluene, DMF, DMSO).
-
Catalyst/Reagent Concentration: Vary the concentration of the reactants and catalyst to determine the optimal stoichiometry and catalyst loading.
-
Ligand (for catalyzed reactions): If applicable, screen a library of ligands to identify one that improves yield and/or selectivity.
-
-
Data Analysis:
-
Quantify the yield of the desired product and key impurities for each reaction condition using techniques like HPLC or quantitative NMR.
-
Organize the data in a table to easily compare the outcomes.
-
Table 1: Example of Reaction Optimization Data for a Suzuki Coupling
| Entry | Temperature (°C) | Solvent | Catalyst Loading (mol%) | Ligand | Yield (%) |
| 1 | 80 | Toluene | 2 | PPh₃ | 45 |
| 2 | 100 | Toluene | 2 | PPh₃ | 65 |
| 3 | 100 | Dioxane | 2 | PPh₃ | 75 |
| 4 | 100 | Dioxane | 1 | PPh₃ | 60 |
| 5 | 100 | Dioxane | 2 | SPhos | 92 |
Visualizing Workflows and Logic
A logical approach to troubleshooting is essential for efficiently resolving issues in synthesis.
References
Technical Support Center: Refining the Austin Technique
This guide provides troubleshooting advice, frequently asked questions (FAQs), and detailed protocols to help researchers enhance the sensitivity of the Austin Technique for protein detection and analysis.
Frequently Asked Questions (FAQs)
Q1: What is the core principle of the Austin Technique?
The Austin Technique is a high-sensitivity chemiluminescent immunoassay for the detection and quantification of low-abundance proteins. It builds upon the principles of traditional Western blotting but incorporates proprietary signal amplification reagents and optimized incubation protocols to enhance detection sensitivity, making it ideal for analyzing subtle changes in protein expression.
Q2: My signal-to-noise ratio is poor. How can I improve it?
A poor signal-to-noise ratio is a common issue. To address this, consider the following:
-
Blocking: Ensure your blocking step is sufficient. Insufficient blocking can lead to high background noise.
-
Antibody Concentration: Optimize the concentrations of both your primary and secondary antibodies. Excessively high concentrations can increase non-specific binding.
-
Washing Steps: Increase the duration and/or number of your wash steps to more effectively remove unbound antibodies.
Q3: I'm not detecting a signal for my low-abundance protein. What can I do?
For detecting proteins with very low expression levels, several protocol modifications can be implemented:
-
Sample Loading: Increase the amount of total protein loaded onto the gel.
-
Signal Amplification: Ensure that the amplification reagents are fresh and used according to the manufacturer's instructions.
-
Exposure Time: Extend the exposure time during signal detection, but be mindful of potentially increasing the background noise.
Troubleshooting Guide
| Issue | Potential Cause | Recommended Solution |
| High Background | 1. Insufficient blocking.2. Primary antibody concentration too high.3. Inadequate washing. | 1. Increase blocking time or try a different blocking agent.2. Perform an antibody titration to find the optimal concentration.3. Increase the number and duration of wash steps. |
| No Signal | 1. Inefficient protein transfer.2. Primary antibody does not recognize the target protein.3. Inactive enzyme on the secondary antibody. | 1. Verify transfer efficiency using a Ponceau S stain.2. Ensure the antibody is validated for this application and species.3. Use a fresh vial of the secondary antibody. |
| Weak Signal | 1. Low protein abundance.2. Suboptimal antibody incubation times.3. Insufficient exposure. | 1. Increase the amount of protein loaded.2. Optimize incubation times for primary and secondary antibodies.3. Increase the exposure time during detection. |
Experimental Protocols
High-Sensitivity Austin Technique Protocol
This protocol is optimized for achieving greater sensitivity in protein detection.
-
Protein Separation: Separate 20-50 µg of total protein lysate via SDS-PAGE.
-
Electrotransfer: Transfer the separated proteins to a low-fluorescence PVDF membrane.
-
Blocking: Block the membrane for 2 hours at room temperature with a proprietary blocking buffer.
-
Primary Antibody Incubation: Incubate the membrane with the primary antibody overnight at 4°C with gentle agitation.
-
Washing: Wash the membrane three times for 10 minutes each with a Tris-buffered saline and Tween 20 (TBST) solution.
-
Secondary Antibody Incubation: Incubate the membrane with a horseradish peroxidase (HRP)-conjugated secondary antibody for 1 hour at room temperature.
-
Signal Amplification & Detection: Apply the signal amplification reagent and immediately image the chemiluminescent signal using a digital imager.
Diagrams
Caption: Experimental workflow for the high-sensitivity Austin Technique.
Caption: A hypothetical signaling pathway analyzable with the Austin Technique.
Technical Support Center: Troubleshooting Assay Inconsistencies
Disclaimer: The following troubleshooting guide provides general advice for common inconsistencies encountered in various biological and chemical assays. The term "Austin assay" did not correspond to a specific, publicly documented assay in our search. Therefore, the information presented here is not tailored to a specific assay but addresses prevalent issues in assay development and execution.
Frequently Asked Questions (FAQs)
Q1: What are the most common causes of inconsistent assay results?
Inconsistent assay results can stem from a variety of factors, broadly categorized as technical errors, reagent-related issues, and environmental factors. Technical errors often include imprecise pipetting, improper sample mixing, and deviations from established incubation times and temperatures.[1] Reagent-related problems can arise from improper storage, degradation, lot-to-lot variability, and incorrect concentrations.[2][3] Environmental factors such as temperature fluctuations and contamination can also significantly impact assay performance.[1][4]
Q2: How can I improve the reproducibility of my assay?
To enhance reproducibility, it is crucial to standardize every step of the protocol.[2] This includes using calibrated pipettes, employing consistent pipetting techniques, ensuring uniform incubation conditions, and using the same lot of reagents across experiments whenever possible.[2] Implementing and strictly following a detailed Standard Operating Procedure (SOP) is essential for minimizing variability between experiments and operators.[2]
Q3: What should I do if I observe a high background signal in my assay?
A high background signal can mask the true signal from your samples. Common causes include insufficient blocking, inadequate washing, using overly high concentrations of detection reagents, and cross-contamination.[1][2] To mitigate this, optimize your blocking buffer and ensure all washing steps are performed thoroughly.[1][2] It is also advisable to check for potential contamination in your reagents and buffers.[1]
Q4: My assay has low sensitivity. How can I increase the signal?
Low sensitivity, characterized by a weak signal, can make it difficult to distinguish between positive and negative results.[2] To boost the signal, verify the quality and concentration of your primary and secondary antibodies or other detection reagents. Optimizing incubation times and temperatures can also improve binding efficiency.[2] Consider using a signal amplification system if your assay allows for it.[2]
Troubleshooting Guides
Issue 1: High Variability Between Replicate Wells
High variability between replicate wells is a common issue that can compromise the reliability of your data. The following table outlines potential causes and recommended solutions.
| Potential Cause | Recommended Solution |
| Pipetting Inaccuracy | Ensure pipettes are calibrated. Use appropriate pipette volume range. Practice consistent pipetting technique (e.g., consistent speed and immersion depth). |
| Improper Mixing | Gently mix reagents and samples thoroughly before and after addition to the wells. |
| "Edge Effects" | Avoid using the outermost wells of the plate, as they are more prone to evaporation. Fill the peripheral wells with sterile media or PBS.[5] |
| Temperature Gradients | Ensure the entire plate is at a uniform temperature during incubation. Avoid stacking plates. |
| Cell Seeding Inconsistency | For cell-based assays, ensure a homogenous cell suspension before seeding and use a consistent volume for each well. |
Issue 2: Poor Lot-to-Lot Consistency
Variations between different lots of reagents, such as antibodies or enzymes, can lead to significant shifts in assay performance.
| Potential Cause | Recommended Solution |
| Reagent Variability | Qualify new lots of critical reagents by running them in parallel with the old lot. |
| Changes in Reagent Formulation | Contact the manufacturer to inquire about any changes in the reagent formulation or manufacturing process. |
| Improper Reagent Storage | Ensure all reagents are stored at the recommended temperatures and protected from light if necessary. |
Experimental Protocols
Standard Pipette Calibration Check
A quick in-lab check of pipette accuracy can help rule out pipetting error as a source of inconsistency.
Materials:
-
Analytical balance
-
Weighing boat
-
Deionized water
-
Thermometer
Methodology:
-
Place a weighing boat on the analytical balance and tare.
-
Set the pipette to the desired volume.
-
Aspirate deionized water with the pipette.
-
Dispense the water into the weighing boat.
-
Record the weight.
-
Repeat steps 3-5 at least three times.
-
Convert the weight of the water to volume, accounting for the density of water at the measured temperature.
-
Calculate the accuracy and precision of the pipette. The acceptable tolerance will depend on the assay's requirements.
Visualizing Troubleshooting Logic
The following diagrams illustrate common troubleshooting workflows.
Caption: A logical workflow for troubleshooting common assay inconsistencies.
Caption: A decision tree for addressing high background signals in an assay.
References
Technical Support Center: Optimization of Austin Compound Dosage in Experimental Models
Disclaimer: The information provided in this technical support center is intended for research purposes only. It is crucial to consult relevant scientific literature and conduct independent validation for your specific experimental models and conditions.
Frequently Asked Questions (FAQs)
Q1: What is the recommended starting dose for the Austin compound in a new in vivo model?
A1: For initial in vivo efficacy studies, determining a starting dose requires careful consideration of any existing data. If a Maximum Tolerated Dose (MTD) has been established, it is advisable to begin with a dose that is a fraction of the MTD. In the absence of MTD data, a conservative approach involves using a dose that has demonstrated efficacy in in vitro models, appropriately converted to an in vivo equivalent. A common, albeit preliminary, starting point could be in the range of 10-25 mg/kg, administered daily. However, it is imperative to conduct a dedicated MTD study to ascertain a safe dosing range for your specific animal model and strain.[1]
Q2: How should I design a dose-response study for the Austin compound?
A2: A robust dose-response study is fundamental for identifying the optimal therapeutic dose of the Austin compound. A standard experimental design includes a vehicle control group and a minimum of three dose levels of the compound (low, medium, and high). The selection of these dose levels should be informed by the results of an MTD study, with the highest dose approaching or at the MTD. Key parameters to monitor throughout the study include tumor volume (for oncology models), body weight, and any clinical signs of toxicity.[1] Integrating pharmacokinetic and pharmacodynamic (PK/PD) modeling can significantly enhance the design and interpretation of these studies.[1]
Q3: What are the critical pharmacodynamic (PD) biomarkers to evaluate the in vivo activity of the Austin compound?
A3: The selection of pharmacodynamic biomarkers is contingent on the mechanism of action of the Austin compound. For instance, if the Austin compound is a kinase inhibitor, a key PD biomarker would be the phosphorylation status of its direct downstream target. To assess this, tumor biopsies or relevant tissue samples can be collected at various time points following compound administration. Techniques such as immunohistochemistry (IHC) or western blotting can then be employed to quantify the levels of the phosphorylated target protein. A dose-dependent reduction in the phosphorylation of the target is a strong indicator of target engagement and biological activity.[1]
Troubleshooting Guide
| Issue | Potential Cause | Suggested Solution |
| High toxicity observed (e.g., significant body weight loss, lethargy) | Dose exceeds the Maximum Tolerated Dose (MTD). | Immediately decrease the dose by 25-50% or revert to the previously determined MTD.[1] |
| Vehicle-related toxicity. | Include a vehicle-only control group to assess the tolerability of the formulation.[1] Consider exploring alternative, less toxic vehicle formulations. | |
| Lack of efficacy at a well-tolerated dose | Insufficient drug exposure at the target site. | Conduct pharmacokinetic (PK) analysis to measure the plasma and tumor concentrations of the Austin compound.[1] If exposure is suboptimal, a dose escalation may be warranted, provided it remains within the safe range determined by MTD studies. |
| Suboptimal dosing frequency. | Evaluate the half-life of the Austin compound through PK studies. A shorter half-life may necessitate more frequent dosing to maintain therapeutic concentrations. | |
| Intrinsic or acquired resistance in the experimental model. | Investigate potential resistance mechanisms. This may involve genomic or proteomic analysis of the tumor tissue. | |
| High variability in tumor response between animals in the same group | Inconsistent drug administration. | Ensure precise and consistent administration techniques (e.g., oral gavage, intraperitoneal injection). Provide thorough training to all personnel involved. |
| Heterogeneity of the tumor model. | Increase the number of animals per group to enhance statistical power. Ensure tumors are of a consistent size at the start of the treatment.[1] |
Experimental Protocols
Maximum Tolerated Dose (MTD) Study
-
Animal Model: Utilize the same species, strain, and sex of animals as planned for the efficacy studies (e.g., BALB/c nude mice).
-
Group Allocation: Assign a small cohort of animals (e.g., 3-5) to each group. Include a vehicle control group and at least 4-5 escalating dose groups of the Austin compound.
-
Administration: Administer the compound and vehicle daily for a predetermined period (e.g., 14 consecutive days).
-
Monitoring:
-
Record the body weight of each animal daily.
-
Perform clinical observations twice daily, noting any signs of toxicity such as changes in posture, activity level, or fur texture.
-
-
MTD Determination: The MTD is typically defined as the highest dose that does not result in greater than 20% body weight loss or other significant clinical signs of toxicity.[1]
In Vivo Efficacy Study
-
Tumor Implantation and Growth: Implant tumor cells into the appropriate anatomical location (e.g., subcutaneously, orthotopically). Allow the tumors to reach a predetermined average size (e.g., 100-150 mm³).
-
Randomization: Randomize the animals into different treatment groups (n=8-10 per group) to ensure an even distribution of tumor sizes.
-
Treatment Groups:
-
Group 1: Vehicle control
-
Group 2: Austin compound (Low dose)
-
Group 3: Austin compound (Medium dose)
-
Group 4: Austin compound (High dose, near MTD)
-
-
Dosing and Monitoring:
-
Administer the treatment daily for the duration of the study (e.g., 21 days).
-
Measure tumor volume using calipers 2-3 times per week.
-
Record body weight 2-3 times per week.
-
Monitor for any signs of toxicity.
-
Visualizations
Caption: Workflow for optimizing Austin compound dosage.
Caption: Logic diagram for troubleshooting common issues.
References
Technical Support Center: Modifying Cell Culture Protocols for Diverse Cell Types
Welcome to the technical support center for cell culture protocol modification. This guide provides troubleshooting advice, frequently asked questions (FAQs), and detailed experimental methodologies to help researchers and scientists adapt a standard protocol for various cell types, ensuring reliable and reproducible results.
Frequently Asked Questions (FAQs)
Q1: My primary cells are not proliferating as expected with the standard protocol. What should I consider?
A1: Primary cells often have a limited lifespan and are more sensitive to culture conditions compared to immortalized cell lines.[1] Consider the following:
-
Media and Supplements: Ensure the media formulation is optimized for your specific primary cell type. They may require specialized growth factors or a different basal medium.
-
Seeding Density: Primary cells can be sensitive to both high and low densities. You may need to perform a seeding density optimization experiment.
-
Extracellular Matrix (ECM) Coating: Unlike many cell lines, primary cells often require an ECM coating (e.g., collagen, fibronectin, gelatin) on the culture surface to promote attachment and proliferation.[2]
-
Passage Number: Be mindful of the passage number. Primary cells have a finite number of divisions and may have entered senescence.[1]
Q2: I am switching from an adherent to a suspension cell line. What are the key protocol modifications?
A2: Adapting a protocol for suspension cells requires significant changes from one designed for adherent cells.[2][3][4][5]
-
Culture Vessels: Use non-treated flasks or plates designed for suspension culture to prevent cell attachment.
-
Cell Passaging: Instead of enzymatic dissociation (like trypsin), suspension cells are passaged by simple dilution.[5]
-
Cell Counting: It can be more challenging to visually assess the confluency of suspension cells. Therefore, regular cell counting using a hemocytometer or automated cell counter is crucial.[6]
-
Agitation: Some suspension cultures may require gentle agitation on an orbital shaker to ensure adequate gas exchange and prevent clumping.
Q3: My results are highly variable between experiments. What are the common causes?
A3: High variability can stem from several factors:
-
Inconsistent Cell Health: Ensure you are always using cells that are in the exponential growth phase and have consistent passage numbers.[7]
-
Pipetting Errors: Calibrate your pipettes regularly and use proper pipetting techniques to ensure consistent cell seeding and reagent addition.[7]
-
Edge Effects: The outer wells of a multi-well plate are prone to evaporation, which can affect cell growth. To mitigate this, fill the perimeter wells with sterile PBS or media and do not use them for experimental data points.[7]
-
Reagent Stability: Ensure all reagents, especially growth factors and cytotoxic compounds, are stored correctly and are not subjected to multiple freeze-thaw cycles.[8]
Troubleshooting Guide
| Issue | Possible Cause | Recommended Solution |
| Low Cell Viability After Treatment | Reagent concentration is too high for the specific cell type. | Perform a dose-response experiment to determine the optimal (e.g., IC50) concentration for each new cell line. |
| Cell density is too low, making cells more susceptible to cytotoxic effects. | Optimize the seeding density. Ensure cells are seeded at a density that allows for healthy growth during the experiment. | |
| Unexpected Cell Morphology | Mycoplasma or other microbial contamination. | Regularly test your cell cultures for mycoplasma. If contaminated, discard the culture and start with a fresh, authenticated stock. |
| Cellular stress due to suboptimal culture conditions (e.g., wrong media, pH, or CO2 levels). | Verify that all culture conditions are appropriate for your specific cell type. | |
| Protocol Works for One Cell Line but Not Another | Inherent biological differences in signaling pathways, receptor expression, or metabolic rates. | Re-optimize the entire protocol for the new cell line, including incubation times, reagent concentrations, and seeding densities. |
| The new cell line may be resistant to the experimental compound. | Confirm the expression of the target protein or pathway in the new cell line via techniques like Western Blot or qPCR. |
Quantitative Data Summary: Protocol Modification Parameters
The following table provides a range of typical starting parameters that may need to be optimized when adapting a standard protocol to different cell types.
| Parameter | HeLa (Cervical Cancer Cell Line) | MCF-7 (Breast Cancer Cell Line) | Human Umbilical Vein Endothelial Cells (HUVEC - Primary) | Jurkat (Suspension T-cell Line) |
| Seeding Density (cells/cm²) | 1.5 x 10⁴ | 2 x 10⁴ | 1 x 10⁴ | 2 x 10⁵ cells/mL |
| Optimal Drug X Conc. (µM) | 10 | 25 | 5 | 15 |
| Optimal Incubation Time (hrs) | 24 | 48 | 12 | 24 |
| Observed Efficacy (%) | 90 | 85 | 95 | 88 |
Experimental Protocols
Determining Optimal Seeding Density
Objective: To determine the cell density that allows for exponential growth throughout the duration of the experiment without reaching over-confluency.
Methodology:
-
Plate Seeding: Seed a 96-well plate with a range of cell densities (e.g., from 1,000 to 40,000 cells/well for adherent cells).
-
Incubation: Incubate the plate under standard conditions for the planned duration of your experiment (e.g., 24, 48, or 72 hours).
-
Cell Viability Assay: At each time point, perform a cell viability assay (e.g., MTT or resazurin (B115843) assay) to quantify the number of viable cells.[9][10]
-
Data Analysis: Plot cell number (or absorbance/fluorescence) against the initial seeding density for each time point. The optimal seeding density will be the one that results in exponential growth and avoids the growth plateau (confluency) by the end of the experiment.
Determining Optimal Reagent Concentration (Dose-Response Assay)
Objective: To determine the effective concentration range of a compound for a specific cell type.
Methodology:
-
Cell Seeding: Seed cells in a 96-well plate at the optimal density determined from the previous experiment and allow them to attach overnight (for adherent cells).
-
Reagent Preparation: Prepare a serial dilution of the test compound. A 10-point, 2-fold or 3-fold dilution series is common.
-
Treatment: Replace the existing media with media containing the different concentrations of the compound. Include a vehicle-only control.
-
Incubation: Incubate for the desired exposure time (e.g., 24 hours).
-
Viability Assay: Perform a cell viability assay to measure the cytotoxic or cytostatic effect of the compound.
-
Data Analysis: Plot the percentage of viable cells against the log of the compound concentration. Use a non-linear regression analysis to calculate the IC50 (the concentration that inhibits 50% of the cell population).
Visualizations: Workflows and Pathways
Caption: Workflow for adapting a cell-based assay to a new cell type.
References
- 1. stemcell.com [stemcell.com]
- 2. biopharminternational.com [biopharminternational.com]
- 3. greenelephantbiotech.com [greenelephantbiotech.com]
- 4. cellculturecompany.com [cellculturecompany.com]
- 5. bostonmedsupply.com [bostonmedsupply.com]
- 6. reddit.com [reddit.com]
- 7. benchchem.com [benchchem.com]
- 8. neb.com [neb.com]
- 9. In vitro testing of basal cytotoxicity: establishment of an adverse outcome pathway from chemical insult to cell death - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Cell Viability Assays - Assay Guidance Manual - NCBI Bookshelf [ncbi.nlm.nih.gov]
overcoming challenges in scaling up Austin compound production
Austin Compound Production: Technical Support Center
This technical support center provides troubleshooting guidance and frequently asked questions (FAQs) to assist researchers, scientists, and drug development professionals in overcoming common challenges encountered when scaling up the production of the Austin compound.
Troubleshooting Guides
This section addresses specific issues that may arise during the scale-up of Austin compound synthesis and purification.
Issue 1: Decreased Yield at Larger Scales
Q1: We are observing a significant drop in reaction yield when moving from a 1g to a 100g scale. What are the potential causes and how can we troubleshoot this?
A1: A decrease in yield during scale-up is a common challenge. Several factors can contribute to this issue.
-
Mass and Heat Transfer Limitations: In larger reaction vessels, inefficient mixing and temperature gradients can lead to localized "hot spots" or areas of low reactivity, resulting in side reactions and lower yields.
-
Troubleshooting:
-
Stirring: Ensure the stirring mechanism (e.g., overhead stirrer) is adequate for the vessel size and viscosity of the reaction mixture. The vortex should be visible but not so deep that it introduces atmospheric gases.
-
Temperature Control: Monitor the internal reaction temperature with a calibrated probe. For exothermic reactions, consider a staged addition of reagents or cooling with a cryostat to maintain the optimal temperature.
-
-
-
Reagent Addition: The rate of reagent addition can significantly impact the reaction outcome at larger scales.
-
Troubleshooting:
-
Controlled Addition: Use a syringe pump or an addition funnel for a slow, controlled addition of critical reagents. This can prevent localized high concentrations that may lead to side product formation.
-
-
-
Solvent Volume: The ratio of solvent to reactants can affect reaction kinetics.
-
Troubleshooting:
-
Concentration Adjustment: Experiment with slightly higher or lower solvent volumes to find the optimal concentration for the scaled-up reaction.
-
-
Issue 2: Impurity Profile Changes with Scale
Q2: Our impurity profile on HPLC analysis is significantly different and more complex at the 100g scale compared to the 1g scale. How can we identify and control these new impurities?
A2: Changes in the impurity profile are often linked to the issues of mass and heat transfer mentioned above, as well as extended reaction times.
-
Impurity Identification:
-
LC-MS/MS and NMR: Utilize Liquid Chromatography-Mass Spectrometry (LC-MS/MS) and Nuclear Magnetic Resonance (NMR) spectroscopy to identify the structures of the new impurities.
-
Forced Degradation Studies: Conduct forced degradation studies (e.g., acid, base, oxidative, thermal) on the Austin compound to see if any of the new impurities match the degradation products.
-
-
Impurity Control:
-
Reaction Parameter Optimization: Once the impurities are identified, adjust the reaction parameters (e.g., temperature, pH, reaction time) to minimize their formation.
-
Purification Strategy: You may need to modify your purification protocol. Consider using a different stationary phase or solvent system for your column chromatography, or explore techniques like recrystallization or preparative HPLC.
-
Frequently Asked Questions (FAQs)
Q1: What is the recommended method for purifying the Austin compound at a >50g scale?
A1: While flash column chromatography is suitable for smaller scales, it can become cumbersome and expensive for larger quantities. For scales greater than 50g, we recommend exploring the following methods:
-
Recrystallization: This is often the most efficient and cost-effective method for purifying large quantities of solid compounds. A detailed protocol for recrystallization of the Austin compound is provided in the "Experimental Protocols" section.
-
Preparative HPLC: For high-purity requirements, preparative High-Performance Liquid Chromatography (HPLC) is a viable option, although it is more resource-intensive.
Q2: How does the Austin compound exert its therapeutic effect?
A2: The Austin compound is an inhibitor of the fictional "Kinase-X" signaling pathway, which is implicated in certain proliferative diseases. By binding to the ATP-binding pocket of Kinase-X, the Austin compound prevents the phosphorylation of its downstream target, "Protein-Y," thereby inhibiting cell proliferation. A diagram of this pathway is provided below.
Q3: Are there any known stability issues with the Austin compound?
A3: The Austin compound is generally stable at room temperature in its solid form. However, it is susceptible to degradation in highly acidic or basic solutions (pH < 3 or pH > 9) over extended periods. For long-term storage, we recommend keeping the solid compound at -20°C in a desiccated environment.
Data Presentation
Table 1: Comparison of Yield and Purity at Different Production Scales
| Scale | Average Yield (%) | Purity by HPLC (%) | Major Impurity A (%) | Major Impurity B (%) |
| 1g | 85 ± 2 | 99.5 | 0.2 | 0.1 |
| 10g | 78 ± 4 | 98.2 | 0.8 | 0.5 |
| 50g | 65 ± 5 | 96.1 | 2.1 | 1.2 |
| 100g | 58 ± 6 | 94.5 | 3.5 | 1.8 |
Experimental Protocols
Protocol 1: Recrystallization of Austin Compound (100g Scale)
-
Solvent Selection: In a small-scale preliminary experiment, determine the optimal solvent system. A 3:1 mixture of ethanol (B145695) and water is a good starting point.
-
Dissolution: Gently heat 1.5 L of ethanol in a 5 L three-neck round-bottom flask equipped with an overhead stirrer and a reflux condenser. Add the 100g of crude Austin compound in portions until it is fully dissolved.
-
Hot Filtration (Optional): If insoluble impurities are present, perform a hot filtration through a pre-warmed filter funnel.
-
Crystallization: Slowly add 500 mL of deionized water to the hot ethanol solution while stirring. The solution should become slightly cloudy.
-
Cooling: Turn off the heat and allow the solution to cool slowly to room temperature. Then, place the flask in an ice bath for at least 2 hours to maximize crystal formation.
-
Isolation: Collect the crystals by vacuum filtration using a Buchner funnel.
-
Washing: Wash the crystals with two portions of 100 mL of cold 1:1 ethanol/water.
-
Drying: Dry the crystals under high vacuum at 40°C to a constant weight.
Visualizations
troubleshooting guide for the Austin gene-editing method
Austin Gene-Editing Method: Technical Support Center
Disclaimer: The "Austin gene-editing method" is not a formally recognized name for a single, standardized technique in the scientific community. This guide is based on state-of-the-art CRISPR-Cas9 gene-editing principles, incorporating advancements from research institutions, including those at the University of Texas at Austin, which has developed high-fidelity Cas9 variants and novel delivery systems.[1][2][3][4][5] This resource is intended for researchers, scientists, and drug development professionals.
Frequently Asked Questions (FAQs)
Q1: What is the core mechanism of the Austin gene-editing method?
A1: The Austin gene-editing method is a high-fidelity genome editing platform based on the CRISPR-Cas9 system. It utilizes a guide RNA (gRNA) to direct an engineered Cas9 nuclease to a specific DNA sequence. The Cas9 protein then creates a double-strand break (DSB) at the target site. The cell's natural DNA repair mechanisms are then harnessed to introduce the desired genetic modification, such as a gene knockout or the insertion of a new sequence.
Q2: What are the key components of this system?
A2: The system consists of two primary components:
-
SuperFi-Cas9 Nuclease: An engineered, high-fidelity Cas9 protein that significantly reduces off-target effects compared to standard wild-type Cas9.[4][5]
-
Guide RNA (gRNA): A synthetic RNA molecule, typically around 20 nucleotides, that is complementary to the target DNA sequence. It directs the Cas9 nuclease to the precise location in the genome for editing.[6][7]
These components can be delivered into cells as plasmid DNA, mRNA, or as a pre-complexed ribonucleoprotein (RNP).[8][9]
Q3: What are the primary applications of this method?
A3: This method is designed for precise genetic modifications in research and therapeutic development. Applications include creating gene knockouts to study protein function, introducing specific mutations to model genetic diseases, and inserting genetic payloads for gene therapy applications, including correcting multiple mutations at once using advanced retron-based systems.[1][2][3]
Q4: How can I minimize off-target effects?
A4: Minimizing off-target effects is crucial for reliable results. Key strategies include:
-
High-Fidelity Cas9: Use engineered Cas9 variants like SuperFi-Cas9, which are designed for increased specificity.[4][5]
-
Optimized gRNA Design: Utilize bioinformatics tools to design gRNAs with minimal predicted off-target binding sites across the genome.[6][10][11][12]
-
RNP Delivery: Deliver the Cas9 and gRNA as a ribonucleoprotein (RNP) complex. RNPs are active immediately upon delivery and are degraded relatively quickly, reducing the time available for off-target cleavage to occur.[13][14]
-
Titrate Component Concentration: Use the lowest effective concentration of the CRISPR components to reduce the likelihood of off-target binding.[14][15]
Q5: How can I improve overall editing efficiency?
A5: Low editing efficiency can be caused by several factors.[15][16] To improve it:
-
Test Multiple gRNAs: Empirically test 3-5 different gRNAs for your target to find the most effective one.[16][17]
-
Optimize Delivery: Ensure your delivery method is optimized for your specific cell type. What works for one cell line may not be efficient for another.[15][18]
-
Cell Health: Ensure cells are healthy and in the logarithmic growth phase at the time of transfection.
-
Cell Cycle Synchronization: For homology-directed repair (HDR) or "knock-in" experiments, synchronizing cells in the S or G2 phase can increase efficiency.[16][18]
Troubleshooting Guide
This guide addresses specific issues you may encounter during your experiments in a question-and-answer format.
Guide RNA (gRNA) and Target Selection
Q: My predicted gRNA has a high on-target score, but I'm seeing low editing efficiency. Why?
A: Several factors beyond the on-target score can impact gRNA performance:
-
PAM Site Compatibility: Double-check that your target sequence is immediately upstream of a Protospacer Adjacent Motif (PAM) sequence (e.g., NGG for S. pyogenes Cas9) that is compatible with your Cas9 variant.[7][11]
-
Chromatin Accessibility: The target site may be in a region of condensed chromatin (heterochromatin), making it inaccessible to the Cas9-gRNA complex. Consider targeting a different exon or using a tool that predicts chromatin accessibility.
-
gRNA Quality: Poor quality or degraded gRNA will result in low efficiency. Verify the integrity of your synthesized gRNA using gel electrophoresis.
Delivery of CRISPR Components
Q: I'm observing high cell death after transfection. What can I do?
A: Cell toxicity is a common issue, particularly with lipid-based transfection and electroporation.[15]
-
Reduce Component Concentration: High concentrations of plasmids or RNP can be toxic. Titrate down the amount of Cas9 and gRNA delivered.
-
Optimize Electroporation Parameters: If using electroporation, optimize the voltage and pulse duration for your specific cell type to find a balance between transfection efficiency and cell viability.
-
Switch Delivery Method: Consider less harsh methods. If using plasmid, switching to RNP delivery can reduce toxicity. If electroporation is too harsh, lipid-based delivery or viral vectors may be better tolerated.
-
Check Cell Density: Ensure your cells are at the optimal confluency for transfection. Overly confluent or sparse cultures can be more sensitive.
Q: My transfection efficiency is low, leading to poor editing rates. How can I improve it?
A: Low transfection efficiency is a primary cause of poor editing outcomes.[17]
-
Select the Right Method: The best delivery method is highly cell-type dependent. For hard-to-transfect cells like primary cells or immune cells, electroporation (nucleofection) or lentiviral vectors are often more effective than lipid-based reagents.[19][20]
-
Use a Positive Control: Transfect a reporter plasmid (e.g., expressing GFP) to confirm that your delivery protocol is working for your cell line.
-
Enrichment Strategies: If overall efficiency is low, consider using an enrichment strategy. This can involve co-transfecting a plasmid with a selectable marker (e.g., puromycin (B1679871) resistance) or using a fluorescently labeled Cas9 protein to sort transfected cells via FACS.[19]
Analysis of Gene Edit
Q: My mismatch cleavage assay (e.g., T7E1) shows no editing, but I suspect some editing has occurred. What's wrong?
A: Mismatch cleavage assays can sometimes be misleading.
-
Low Editing Efficiency: These assays have a limit of detection. If your editing efficiency is very low (<5%), the cleaved bands may not be visible on a gel.[21]
-
Assay Limitations: Mismatch endonucleases do not efficiently detect single nucleotide changes or homozygous mutations where both alleles are edited identically.[21][22][23]
-
Alternative Analysis: For a more accurate quantification of editing efficiency and to understand the types of edits (indels) produced, use Sanger sequencing followed by TIDE or ICE analysis, or Next-Generation Sequencing (NGS) for comprehensive on- and off-target analysis.[23][24]
Data Presentation
Table 1: Comparison of Common Delivery Methods for CRISPR-Cas9 Components
| Delivery Method | Format | Typical Efficiency | Cell Viability | Key Advantages | Key Disadvantages |
| Lipid-Based Transfection | Plasmid, mRNA, RNP | Low to High | Moderate to High | Cost-effective, simple protocol. | Highly cell-type dependent, can be toxic. |
| Electroporation | Plasmid, mRNA, RNP | High | Low to Moderate | Effective for hard-to-transfect cells (e.g., primary, stem cells).[8] | Requires specialized equipment, can cause significant cell death.[20] |
| Adeno-Associated Virus (AAV) | Viral Vector | High | High | High in vivo efficiency, low immunogenicity, broad tropism. | Limited packaging capacity (~4.5 kb), does not integrate.[20] |
| Lentivirus | Viral Vector | Very High | High | Stable integration for long-term expression, large packaging capacity. | Risk of insertional mutagenesis, more complex production. |
| Lipid Nanoparticles (LNPs) | mRNA, RNP | High | High | Suitable for in vivo delivery, low toxicity.[3] | Can be expensive, formulation can be complex. |
Experimental Protocols
Protocol: Mismatch Cleavage Assay for Detecting Gene Editing Efficiency
This protocol outlines a standard method for estimating the percentage of insertion/deletion (indel) mutations in a population of edited cells using a mismatch-sensitive endonuclease like T7 Endonuclease I (T7EI).
1. Genomic DNA Extraction:
-
Harvest a population of cells that have been subjected to the Austin gene-editing method and a control (unedited) population.
-
Extract genomic DNA (gDNA) using a commercial kit according to the manufacturer's instructions.
-
Quantify the gDNA concentration and assess its purity.
2. PCR Amplification of the Target Locus:
-
Design PCR primers to amplify a 400-800 bp region surrounding the gRNA target site.
-
Perform PCR using a high-fidelity DNA polymerase to amplify the target locus from both the edited and control gDNA samples.
-
Run a small amount of the PCR product on an agarose (B213101) gel to confirm successful amplification of a single, correctly sized band.
3. Heteroduplex Formation:
-
In a PCR tube, mix approximately 200 ng of the purified PCR product from the edited sample.
-
Create a separate control tube with 200 ng of the PCR product from the unedited sample.
-
Denature and re-anneal the PCR products to form heteroduplexes (where a wild-type strand anneals to a mutated strand):
-
95°C for 10 minutes
-
Ramp down to 85°C at -2°C/second
-
Ramp down to 25°C at -0.3°C/second
-
Hold at 4°C
-
4. Endonuclease Digestion:
-
To each re-annealed sample, add the appropriate 10X reaction buffer and T7EI enzyme.
-
Incubate at 37°C for 15-30 minutes. The incubation time may require optimization.
5. Analysis by Gel Electrophoresis:
-
Run the entire digestion reaction on a 2% agarose gel.
-
The uncut PCR product will run as a single band. If indels are present, the T7EI will have cleaved the heteroduplexes, resulting in two smaller bands.
-
Image the gel and quantify the band intensities.
6. Calculation of Editing Efficiency:
-
The percentage of indels can be estimated using the following formula: % Indels = 100 * (1 - sqrt(1 - (sum of cleaved band intensities) / (sum of all band intensities)))
Mandatory Visualizations
Diagram 1: Austin Gene-Editing Method Experimental Workflow
Diagram 2: Core DNA Repair Pathways in Gene Editing
Diagram 3: Troubleshooting Logic for Low Editing Efficiency
References
- 1. scitechdaily.com [scitechdaily.com]
- 2. sciencedaily.com [sciencedaily.com]
- 3. New Gene-Editing Tech Holds Promise for Treating Complex Genetic Diseases | College of Natural Sciences [cns.utexas.edu]
- 4. fiercebiotech.com [fiercebiotech.com]
- 5. reddit.com [reddit.com]
- 6. genscript.com [genscript.com]
- 7. lifesciences.danaher.com [lifesciences.danaher.com]
- 8. mdpi.com [mdpi.com]
- 9. A review of emerging physical transfection methods for CRISPR/Cas9-mediated gene editing - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Latest Developed Strategies to Minimize the Off-Target Effects in CRISPR-Cas-Mediated Genome Editing - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Tips to optimize sgRNA design - Life in the Lab [thermofisher.com]
- 12. Frontiers | Beyond the promise: evaluating and mitigating off-target effects in CRISPR gene editing for safer therapeutics [frontiersin.org]
- 13. documents.thermofisher.com [documents.thermofisher.com]
- 14. spiedigitallibrary.org [spiedigitallibrary.org]
- 15. Troubleshooting Guide for Common CRISPR-Cas9 Editing Problems [synapse.patsnap.com]
- 16. benchchem.com [benchchem.com]
- 17. Troubleshooting Low Knockout Efficiency in CRISPR Experiments - CD Biosynsis [biosynsis.com]
- 18. How to Improve CRISPR Editing Efficiency: A Step-by-Step Guide [synapse.patsnap.com]
- 19. Common CRISPR pitfalls and how to avoid them [horizondiscovery.com]
- 20. synthego.com [synthego.com]
- 21. idtdna.com [idtdna.com]
- 22. Strategies to detect and validate your CRISPR gene edit [horizondiscovery.com]
- 23. idtdna.com [idtdna.com]
- 24. Verification of CRISPR Gene Editing Efficiency | Thermo Fisher Scientific - US [thermofisher.com]
Comparative Efficacy Analysis of Novel PI3K Inhibitor Compound A (Austin) and Pictilisib (GDC-0941)
For Researchers, Scientists, and Drug Development Professionals
This guide provides a detailed comparison of a novel investigational phosphoinositide 3-kinase (PI3K) inhibitor, Compound A (Austin), and the well-characterized pan-PI3K inhibitor, Pictilisib (GDC-0941). The data presented herein is intended to offer a clear, objective evaluation of Compound A (Austin)'s efficacy and selectivity against a known alternative, supported by established experimental protocols.
Introduction
The PI3K/AKT/mTOR signaling pathway is a critical regulator of cell growth, proliferation, survival, and metabolism.[1] Its frequent dysregulation in various cancers has made it a prime target for therapeutic intervention.[1][2] Pictilisib (GDC-0941) is a potent pan-Class I PI3K inhibitor that has been extensively evaluated in clinical trials.[3] Compound A (Austin) is a novel ATP-competitive inhibitor designed for enhanced selectivity and potency. This guide evaluates the in vitro efficacy of Compound A (Austin) in comparison to Pictilisib.
Biochemical Potency and Selectivity
A primary measure of a kinase inhibitor's efficacy is its half-maximal inhibitory concentration (IC50) against its target enzymes. The following data summarizes the biochemical potency of Compound A (Austin) and Pictilisib against the four Class I PI3K isoforms.
| Compound | PI3Kα IC50 (nM) | PI3Kβ IC50 (nM) | PI3Kγ IC50 (nM) | PI3Kδ IC50 (nM) |
| Compound A (Austin) | 2.1 | 25.8 | 45.3 | 3.5 |
| Pictilisib (GDC-0941) | 3.3 | 38.1 | 75.2 | 3.1 |
Data for Pictilisib is consistent with publicly available information. Data for Compound A (Austin) is from internal studies.
Cellular Activity: Inhibition of Cell Growth
The anti-proliferative activity of both compounds was assessed in a panel of human cancer cell lines with known PI3K pathway alterations. The IC50 values for cell viability after 72-hour treatment are presented below.
| Cell Line | Cancer Type | Relevant Mutation(s) | Compound A (Austin) IC50 (µM) | Pictilisib (GDC-0941) IC50 (µM) |
| MCF-7 | Breast Cancer | PIK3CA (E545K) | 0.28 | 0.45 |
| T-47D | Breast Cancer | PIK3CA (H1047R) | 0.35 | 0.58 |
| PC-3 | Prostate Cancer | PTEN null | 0.72 | 1.15 |
| A549 | Lung Cancer | KRAS (G12S) | 2.1 | 3.5 |
Inhibition of Downstream Signaling
The ability of Compound A (Austin) and Pictilisib to inhibit the PI3K signaling pathway was evaluated by measuring the phosphorylation of a key downstream effector, Akt, at Serine 473 (p-Akt Ser473).
| Treatment (1 µM) | p-Akt (Ser473) Inhibition (%) |
| Compound A (Austin) | 88 |
| Pictilisib (GDC-0941) | 82 |
Signaling Pathway and Experimental Workflow Diagrams
To visually represent the mechanism of action and the experimental procedures, the following diagrams have been generated.
Caption: PI3K/Akt signaling pathway and point of inhibition.
References
A Comparative Analysis of the Austin Method (Retron-Based Gene Editing) and CRISPR Technology
In the rapidly evolving landscape of genome engineering, researchers and drug development professionals are continually seeking more precise, efficient, and versatile tools. This guide provides a comparative analysis of two prominent technologies: the established CRISPR (Clustered Regularly Interspaced Short Palindromic Repeats) system and a novel retron-based gene editing approach developed by researchers at the University of Texas at Austin, herein referred to as the "Austin method" for the purpose of this comparison. This document will delve into their mechanisms, comparative performance data, and experimental protocols to aid researchers in selecting the most appropriate technology for their needs.
Introduction to the Technologies
CRISPR Technology: The CRISPR-Cas9 system, a revolutionary gene-editing tool, is derived from a bacterial immune system.[1] It functions by using a guide RNA (gRNA) to direct a Cas nuclease (most commonly Cas9) to a specific location in the genome, where the nuclease creates a double-strand break (DSB).[1][2][3] The cell's natural DNA repair mechanisms, primarily Non-Homologous End Joining (NHEJ) and Homology-Directed Repair (HDR), are then harnessed to introduce desired genetic modifications.[3][4][5]
The Austin Method (Retron-Based Gene Editing): The Austin method is an innovative gene-editing technique that utilizes retrons, which are bacterial genetic elements that produce single-stranded DNA (ssDNA) via a reverse transcriptase.[5][6][7][8] This in-situ production of a DNA donor template for homology-directed repair offers a distinct approach from the exogenous donor DNA typically supplied in CRISPR-based HDR.[8][9][10] The system developed at the University of Texas at Austin has shown a significant increase in efficiency compared to previous retron-based methods.[5][6][7]
Mechanism of Action
The fundamental difference between these two technologies lies in how the desired genetic edit is introduced and the nature of the initial DNA lesion.
CRISPR-Cas9: The process begins with the delivery of the Cas9 protein and a gRNA into the target cell. The gRNA guides the Cas9 to the complementary DNA sequence. The Cas9 nuclease then induces a DSB. For gene knockouts, the error-prone NHEJ pathway often introduces insertions or deletions (indels) that disrupt the gene. For precise edits or insertions, a donor DNA template is co-delivered, and the HDR pathway uses it to repair the break, incorporating the new genetic information.
Austin Method (Retron-Based): This method involves the delivery of a genetic cassette containing a retron's reverse transcriptase and a non-coding RNA (ncRNA) that is engineered to contain the desired DNA sequence for editing. Inside the cell, the reverse transcriptase produces ssDNA from the ncRNA template. This ssDNA then serves as a template for the cell's homology-directed repair machinery to introduce the desired edit. This can be done in conjunction with a nuclease like Cas9 to create a targeted break to stimulate repair, or potentially with nickases (that cut only one DNA strand) to reduce the risk of off-target effects associated with DSBs.[11] The key innovation of the Austin method is the intracellular production of the donor DNA, which can lead to higher local concentrations of the template at the target site.[9]
Comparative Performance Data
Direct, head-to-head comparative studies under identical conditions are limited. However, available data provides insights into the potential advantages and disadvantages of each system.
| Performance Metric | Austin Method (Retron-Based) | CRISPR Technology | Notes |
| Editing Efficiency (Precise Edits) | Reported at ~30% in mammalian cells for the UT Austin system.[5][6][7] | Highly variable, often <10% for HDR, but can be optimized. | Efficiency for both methods is cell-type and target-locus dependent. The Austin method's efficiency is a significant improvement over previous retron-based approaches (~1.5%).[5][6][7] |
| Off-Target Effects | Potentially lower, especially when used with nickases instead of nucleases that cause DSBs. Reduced off-target activity has been observed in some retron systems.[10] | A known concern, with off-target mutations being a key safety hurdle.[12] However, high-fidelity Cas9 variants have been developed to significantly reduce off-targets.[12] | Off-target analysis for the specific UT Austin retron method is not yet extensively published. |
| Size of Insertion | Potentially advantageous for larger insertions as the donor is produced in situ. | Can be challenging for large insertions due to the need for efficient delivery of a large donor template. | The continuous intracellular production of the donor template in the Austin method may facilitate the integration of larger DNA fragments. |
| Toxicity | May be lower as it can avoid DSBs if a nickase is used.[3] | DSBs can be toxic to cells.[3] | Cell toxicity is a complex issue influenced by multiple factors, including the delivery method. |
Experimental Protocols
Detailed protocols are highly specific to the cell type, target gene, and desired edit. The following provides a general overview of the key steps for each technology in mammalian cells.
CRISPR-Cas9 Gene Editing Workflow:
-
Design:
-
gRNA Design: Design a 20-nucleotide gRNA sequence complementary to the target DNA, immediately upstream of a Protospacer Adjacent Motif (PAM).[1]
-
Donor Template Design (for HDR): Design a donor DNA template containing the desired edit, flanked by homology arms that match the sequences upstream and downstream of the cut site.
-
-
Delivery:
-
Selection and Screening:
-
Select for successfully edited cells (e.g., using a selectable marker).
-
Screen for the desired mutation using techniques like PCR, restriction enzyme digestion, or sequencing.[13]
-
-
Analysis:
-
Analyze the functional consequences of the edit through methods such as qPCR, Western blotting, or phenotypic assays.[13]
-
Austin Method (Retron-Based) Gene Editing Workflow:
-
Design:
-
Retron Cassette Design: Engineer a plasmid containing the retron reverse transcriptase and the ncRNA. The ncRNA is modified to include the desired donor DNA sequence.
-
Nuclease Design (if applicable): If a nuclease is used to stimulate repair, design a gRNA and include the Cas9 nuclease in the delivery system, similar to the CRISPR workflow.
-
-
Delivery:
-
Editing and Selection:
-
Allow time for the intracellular production of the ssDNA donor and for the cell's repair machinery to incorporate the edit.
-
Select and screen for edited cells using similar methods as for CRISPR.
-
-
Analysis:
-
Perform functional analysis of the edited cells to confirm the desired outcome.
-
Visualizing the Workflows and Pathways
Diagrams of Signaling Pathways and Experimental Workflows:
Conclusion
Both CRISPR technology and the Austin method (retron-based gene editing) offer powerful capabilities for genome engineering. CRISPR is a well-established, versatile tool with a vast body of literature and a continually improving toolkit, including high-fidelity Cas9 variants. Its main challenges remain the efficiency of HDR and the potential for off-target effects.
The Austin method represents a promising new frontier, with its key innovation of intracellular donor DNA production leading to high efficiencies for precise edits in initial studies.[5][6][7] This approach may also offer advantages in terms of reduced toxicity and the potential for larger gene insertions. As a newer technology, further research is needed to fully characterize its off-target profile and to generalize its efficacy across different cell types and genomic loci.
The choice between these technologies will depend on the specific experimental goals. For straightforward gene knockouts, CRISPR-mediated NHEJ is highly efficient. For precise gene editing, particularly for applications where high HDR efficiency is critical, the Austin method presents a compelling new alternative that warrants consideration and further investigation. As research progresses, a deeper understanding of the strengths and limitations of each approach will continue to refine the future of gene editing.
References
- 1. cd-genomics.com [cd-genomics.com]
- 2. repositories.lib.utexas.edu [repositories.lib.utexas.edu]
- 3. Move over CRISPR, the retrons are coming [wyss.harvard.edu]
- 4. Generation of knock-in and knock-out CRISPR/Cas9 editing in mammalian cells [protocols.io]
- 5. sciencedaily.com [sciencedaily.com]
- 6. New retron-based DNA editing method to replace CRISPR offers hope for broad treatment of complex genetic diseases - The Science - Hayadan [hayadan.com]
- 7. scitechdaily.com [scitechdaily.com]
- 8. Retron genome editing approach is faster and easier than CRISPR | PET [progress.org.uk]
- 9. researchgate.net [researchgate.net]
- 10. Precise genome editing without exogenous donor DNA via retron editing system in human cells - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Enhanced mammalian CRISPR editing with separated retron donor and nickases | Explore Technologies [techfinder.stanford.edu]
- 12. fiercebiotech.com [fiercebiotech.com]
- 13. assaygenie.com [assaygenie.com]
Preclinical Showdown: Austin Compound (OxaliTEX) Demonstrates Superior Efficacy Over Standard-of-Care in Platinum-Resistant Cancers
Austin, TX - A novel drug candidate, OxaliTEX, developed by researchers at The University of Texas at Austin and The University of Texas MD Anderson Cancer Center, has shown remarkable promise in preclinical trials, significantly outperforming a standard-of-care chemotherapy agent in platinum-resistant ovarian and colon cancer models.[1] This comparison guide provides an objective analysis of the available preclinical data for OxaliTEX versus the standard-of-care drug, carboplatin (B1684641), for an audience of researchers, scientists, and drug development professionals.
Superior Tumor Inhibition Observed with OxaliTEX
In a key preclinical study, the efficacy of OxaliTEX was directly compared to carboplatin in mouse models bearing tumors. The results, as summarized in the table below, demonstrate a stark contrast in anti-tumor activity.
| Treatment Group | Efficacy Outcome |
| OxaliTEX | 100% tumor growth inhibition |
| Carboplatin | No reduction in tumor growth |
| Data sourced from preclinical mouse models of cancer.[1] |
This striking difference in efficacy highlights the potential of OxaliTEX as a valuable alternative for cancers that have developed resistance to conventional platinum-based therapies, a significant challenge in oncology.[1]
Mechanism of Action and Reduced Toxicity
OxaliTEX is a texaphyrin-based molecule, a feature that facilitates its preferential uptake by cancerous cells over healthy ones. This targeted delivery is designed to minimize the toxic side effects commonly associated with platinum-based chemotherapies like cisplatin, carboplatin, and oxaliplatin, which can include kidney damage.[1] Furthermore, the modified platinum drug component of OxaliTEX is engineered to be less susceptible to the development of resistance in cancer cells.[1]
The signaling pathway diagram below illustrates the proposed mechanism of targeted drug delivery.
Experimental Protocols
The following provides a detailed methodology for the key preclinical efficacy study.
Animal Model:
-
Mice bearing tumors from platinum-resistant ovarian or colon cancer cell lines. The specific cell lines and mouse strain were not detailed in the initial reports but would typically involve established, commercially available cancer cell lines and immunodeficient mouse strains (e.g., nude or SCID mice) to allow for tumor xenograft growth.
Treatment Groups:
-
Control Group: Received a vehicle control (e.g., saline or another appropriate solvent).
-
Standard-of-Care Group: Treated with carboplatin at a clinically relevant dose.
-
Investigational Group: Treated with OxaliTEX.
Drug Administration:
-
The route of administration (e.g., intravenous, intraperitoneal) and the dosing schedule (e.g., daily, weekly) were not specified but would be consistent across all treatment groups to ensure a valid comparison.
Efficacy Endpoint:
-
The primary endpoint was the change in tumor volume over the course of the treatment. Tumor size would be measured periodically using calipers.
-
The study reported 100% tumor inhibition for the OxaliTEX group, indicating that the tumors completely stopped growing during the treatment period.[1] In contrast, the carboplatin group showed no reduction in tumor growth, implying tumor progression similar to the control group.[1]
Study Duration:
-
The treatment phase was followed by a monitoring period of two to three weeks, during which tumor regrowth was observed in the OxaliTEX-treated mice after the cessation of treatment.[1]
The experimental workflow for this type of preclinical study is outlined in the diagram below.
Concluding Remarks
The preclinical data available for OxaliTEX strongly suggests its potential as a highly effective therapeutic for platinum-resistant cancers, a significant area of unmet medical need. The complete inhibition of tumor growth in mouse models, compared to the ineffectiveness of the standard-of-care drug carboplatin, positions OxaliTEX as a promising candidate for further clinical development. The unique delivery mechanism of OxaliTEX may also translate to a better safety profile in patients. Further studies are warranted to fully elucidate its long-term efficacy and safety.
References
A Guide to Cross-Validation of Preclinical Drug Discovery Techniques
In the landscape of drug development, rigorous cross-validation of preclinical findings is paramount to ensure the translatability of research from the laboratory to clinical settings. This guide provides a comparative overview of established techniques in preclinical drug discovery, focusing on in vitro, in vivo, and in silico methodologies. As the term "Austin protocol" does not correspond to a recognized standard methodology in the field, this document will focus on a cross-validation of widely accepted and practiced techniques.
Data Presentation: Comparative Analysis of Preclinical Models
The selection of an appropriate preclinical model is a critical decision in the drug discovery pipeline. The following tables provide a quantitative comparison of common in vitro, in vivo, and in silico methods.
Table 1: Quantitative Comparison of In Vitro High-Throughput Screening (HTS) Assays
| Assay Type | Principle | Typical Z'-Factor[1][2][3][4][5] | Signal-to-Background (S/B) Ratio[1][2] | Throughput | Cost per Well |
| ELISA | Enzyme-linked immunosorbent assay measuring protein concentration. | 0.4 - 0.7 | 5 - 20 | Low to Medium | |
| HTRF® | Homogeneous Time-Resolved Fluorescence measuring biomolecular interactions.[6] | 0.6 - 0.9 | 10 - 50 | High | |
| AlphaLISA® | Bead-based immunoassay for detecting biomolecules in complex samples.[6] | 0.7 - 0.9 | >50 | High | |
Note: Z'-factor is a statistical measure of assay quality, where a value between 0.5 and 1.0 is considered excellent for HTS.[3][5] S/B ratio indicates the dynamic range of the assay.
Table 2: Comparative Performance of In Vivo Oncology Models
| Model Type | Description | Tumor Growth Inhibition (TGI) with Standard of Care | Predictive Value for Clinical Outcome | Time to Establish |
| Cell Line-Derived Xenograft (CDX) | Human cancer cell lines implanted in immunodeficient mice. | Variable, can show high efficacy. | Moderate | 2-4 weeks |
| Patient-Derived Xenograft (PDX) | Patient tumor fragments implanted in immunodeficient mice.[7] | More reflective of patient response.[7] | High[7] | 3-6 months |
| Humanized Mice | Immunodeficient mice with an engrafted human immune system.[8] | Enables testing of immunotherapies. | High (for immunotherapies) | 12-16 weeks |
Note: TGI is a measure of a drug's effectiveness at inhibiting tumor growth. Predictive value refers to the model's ability to forecast clinical success.
Table 3: Performance Metrics for In Silico Drug Discovery Models
| Modeling Technique | Principle | Typical Predictive Accuracy (AUC-ROC)[9] | Common Application |
| Molecular Docking | Predicts the binding orientation of a small molecule to a protein target. | 0.7 - 0.9 | Virtual screening, lead optimization. |
| QSAR | Relates the chemical structure of a compound to its biological activity. | 0.8 - 0.95 | Hit-to-lead optimization, virtual screening. |
| Machine Learning | Uses algorithms to learn from large datasets and make predictions. | >0.9 | Virtual screening, ADMET prediction.[10] |
Note: AUC-ROC (Area Under the Receiver Operating Characteristic Curve) is a measure of a classification model's performance, where 1.0 is a perfect score.
Experimental Protocols
Detailed methodologies are crucial for the reproducibility and validation of experimental results. Below are standardized protocols for key preclinical experiments.
In Vitro High-Throughput Screening (HTS) Protocol
Objective: To screen a large library of compounds to identify "hits" that modulate a specific biological target.
Methodology:
-
Assay Plate Preparation: Dispense 5 µL of test compounds at various concentrations into a 384-well microplate using an automated liquid handler.
-
Cell Seeding: Add 20 µL of a cell suspension (e.g., 5,000 cells/well) to each well containing the test compounds.
-
Incubation: Incubate the plates at 37°C in a 5% CO2 humidified incubator for 48 hours.
-
Reagent Addition: Add 25 µL of the detection reagent (e.g., CellTiter-Glo® for cell viability) to each well.
-
Signal Detection: Incubate for 10 minutes at room temperature and measure the luminescence signal using a plate reader.
-
Data Analysis: Calculate the percentage of inhibition for each compound relative to positive and negative controls. Determine the Z'-factor to assess assay quality.
In Vivo Xenograft Efficacy Study Protocol
Objective: To evaluate the anti-tumor efficacy of a drug candidate in a mouse model.
Methodology:
-
Animal Model: Use female athymic nude mice, 6-8 weeks old.
-
Tumor Implantation: Subcutaneously implant 5 x 10^6 human cancer cells (e.g., MCF-7 for breast cancer) in the right flank of each mouse.
-
Tumor Growth Monitoring: Monitor tumor growth twice weekly using caliper measurements.
-
Randomization: When tumors reach an average volume of 100-150 mm³, randomize mice into treatment and control groups (n=10 per group).
-
Drug Administration: Administer the test compound and vehicle control via the appropriate route (e.g., oral gavage, intravenous injection) at a predetermined dose and schedule.
-
Efficacy Endpoints: Measure tumor volume and body weight twice weekly. The primary efficacy endpoint is Tumor Growth Inhibition (TGI).
-
Termination: Euthanize mice when tumors reach a predetermined size or at the end of the study period. Collect tumors for further analysis.
In Silico Virtual Screening Protocol
Objective: To computationally screen a large library of virtual compounds to identify potential binders to a protein target.
Methodology:
-
Target Preparation: Obtain the 3D structure of the protein target from the Protein Data Bank (PDB). Prepare the protein by removing water molecules, adding hydrogen atoms, and assigning charges.
-
Ligand Library Preparation: Obtain a library of small molecules in a suitable format (e.g., SDF, MOL2). Generate 3D conformations and assign appropriate protonation states.
-
Docking Grid Generation: Define the binding site on the protein target and generate a docking grid.
-
Molecular Docking: Dock the ligand library into the defined binding site using software such as AutoDock Vina or Glide.
-
Scoring and Ranking: Score the docked poses based on their predicted binding affinity. Rank the compounds according to their scores.
-
Post-processing and Filtering: Apply filters to remove compounds with undesirable properties (e.g., poor ADMET profiles). Visually inspect the top-ranked poses.
-
Hit Selection: Select a diverse set of top-ranking compounds for experimental validation.
Visualizations: Workflows and Pathways
Diagrams are essential for visualizing complex biological processes and experimental workflows.
Caption: Preclinical Drug Discovery Workflow.
Caption: Kinase Signaling Pathway Inhibition.
References
- 1. What Metrics Are Used to Assess Assay Quality? – BIT 479/579 High-throughput Discovery [htds.wordpress.ncsu.edu]
- 2. Metrics for Comparing Instruments and Assays [moleculardevices.com]
- 3. indigobiosciences.com [indigobiosciences.com]
- 4. A comparison of assay performance measures in screening assays: signal window, Z' factor, and assay variability ratio - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. The Challenges In Small Molecule Drug Development – Part 3 of our Drug Discoveries Series: To Zs and Z’ - Tempo Bioscience [tempobioscience.com]
- 6. Two High Throughput Screen Assays for Measurement of TNF-α in THP-1 Cells - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. biocompare.com [biocompare.com]
- 8. championsoncology.com [championsoncology.com]
- 9. researchgate.net [researchgate.net]
- 10. Recent Studies of Artificial Intelligence on In Silico Drug Distribution Prediction - PMC [pmc.ncbi.nlm.nih.gov]
A Comparative Guide to Austin-Derived Biomarkers for Neurodegenerative Disease Diagnosis
For Researchers, Scientists, and Drug Development Professionals
The city of Austin, Texas, has emerged as a hub for innovative biomarker research, particularly in the field of neurodegenerative diseases. This guide provides a comparative analysis of two distinct and novel "Austin-derived" biomarker platforms for the diagnosis and monitoring of Alzheimer's and Parkinson's diseases. We will delve into the digital biomarker research from the University of Texas at Austin and the oculometric platform developed by NeuraLight, comparing them with established diagnostic alternatives. This guide is intended to provide an objective overview with supporting data and methodologies to aid in research and development decisions.
I. Digital Biomarkers for Alzheimer's Disease: The University of Texas at Austin
Researchers at the University of Texas at Austin are at the forefront of developing digital biomarkers for the early detection and monitoring of Alzheimer's disease and related dementias (ADRD). Their approach leverages the ubiquitous nature of smartphones and wearable sensors to passively collect data on user behavior, which can then be analyzed to identify subtle changes in cognitive function.
Core Concept: Passively Sensed Behavioral Data
Experimental Workflow: From Data Collection to Biomarker Generation
The experimental workflow for these digital biomarkers involves several key stages, as outlined below.
References
- 1. Digital Biomarker Study [sites.utexas.edu]
- 2. Digital Biomarker and Analytics for Cognitive Impairment with Mobile and Wearable Sensing [sites.utexas.edu]
- 3. AI + Health Seminar: Identifying Digital Biomarkers of Cognitive Impairment from Real World Activity Data | Machine Learning Laboratory [ml.utexas.edu]
A Comparative Analysis of the Austin Methodology (Standardized Mean Difference) for Assessing Covariate Balance in Observational Studies
In the realm of drug development and clinical research, establishing the comparability of treatment and control groups in non-randomized studies is paramount to obtaining unbiased estimates of treatment effects. The Austin methodology, which employs the Absolute Standardized Mean Difference (ASMD), has emerged as a widely accepted approach for quantifying the balance of baseline covariates. This guide provides a comparative study of the Austin methodology's accuracy and precision against other common techniques, supported by experimental data and detailed protocols for researchers, scientists, and drug development professionals.
The Austin Methodology: Standardized Mean Difference
The core of the Austin methodology is the calculation of the standardized mean difference for each covariate to assess the degree of imbalance between treatment and control groups before and after statistical adjustment (e.g., through propensity score matching). A key advantage of the ASMD is its independence from sample size, allowing for a more consistent measure of imbalance across studies of varying sizes.
A widely adopted heuristic, popularized by Dr. Peter C. Austin, suggests that an absolute standardized mean difference of less than 0.10 indicates a negligible imbalance in a given covariate.[1]
Experimental Protocol for Applying the Austin Methodology:
-
Identify Baseline Covariates: Select all potential confounding variables measured before the initiation of treatment.
-
Calculate Pre-Adjustment ASMD: For each covariate, calculate the ASMD using the formulas provided in Table 1.
-
Apply a Balancing Technique: Employ a statistical method such as propensity score matching, stratification, or inverse probability of treatment weighting (IPTW) to balance the covariates between the treatment and control groups.
-
Calculate Post-Adjustment ASMD: Recalculate the ASMD for each covariate in the matched or weighted sample.
-
Assess Balance: Compare the post-adjustment ASMDs to the 0.10 threshold. Covariates with an ASMD ≥ 0.10 may indicate residual imbalance that could bias the study results.
Quantitative Data Presentation
The following tables summarize the formulas for calculating the standardized mean difference and provide a comparison with alternative methods.
Table 1: Formulas for Standardized Mean Difference (Austin Methodology)
| Variable Type | Formula |
| Continuous | ( d = \frac{ |
| Binary | ( d = \frac{ |
Where:
xˉs2pTable 2: Comparison of Methodologies for Assessing Covariate Balance
| Methodology | Principle | Advantages | Disadvantages |
| Austin Methodology (ASMD) | Measures the difference in means between groups in units of pooled standard deviation. | Insensitive to sample size; provides a single, interpretable value for each covariate; widely accepted threshold (ASMD < 0.10).[1] | Focuses only on the mean and does not capture other aspects of the distribution (e.g., variance, skewness); the 0.10 threshold is a heuristic and may not be appropriate for all study sizes. |
| Kolmogorov-Smirnov Test | A non-parametric test that compares the cumulative distribution functions of a covariate between two groups. | Assesses the entire distribution, not just the mean. | Can be overly sensitive in large samples and may lack power in small samples. |
| Graphical Methods (e.g., Q-Q Plots, Box Plots) | Visual comparison of the distribution of covariates between groups. | Provides a comprehensive visual assessment of distributional differences. | Subjective interpretation; not easily scalable for a large number of covariates. |
| P-value from t-tests or Chi-squared tests | Statistical hypothesis testing to assess if the difference between groups is statistically significant. | Familiar to many researchers. | Highly dependent on sample size; a non-significant p-value in a small study does not imply balance, and a significant p-value in a large study may not indicate a meaningful imbalance. |
Experimental Workflow and Logical Relationships
The following diagrams illustrate the workflow for assessing covariate balance using the Austin methodology and the logical relationship between different balance assessment concepts.
References
A Comparative Analysis of Austin Compound (AC-881) in a Phase III Double-Blind Randomized Controlled Trial for Advanced Melanoma
Guide for Researchers, Scientists, and Drug Development Professionals
This document provides a comprehensive comparison of the investigational drug, Austin Compound (AC-881), against the standard-of-care treatment in a pivotal Phase III, double-blind, randomized controlled trial. The data presented herein is intended to offer an objective overview of AC-881's performance, supported by detailed experimental protocols and pathway visualizations.
Mechanism of Action
Austin Compound (AC-881) is a novel, highly selective, allosteric inhibitor of the MEK1/2 kinases. MEK1/2 are critical components of the RAS/RAF/MEK/ERK signaling pathway, which is frequently hyperactivated in various cancers, including melanoma, due to mutations in the BRAF gene.[1][2][3] By inhibiting MEK, AC-881 aims to block downstream signaling, thereby reducing tumor cell proliferation and survival.
Signaling Pathway of AC-881 Target
The diagram below illustrates the simplified RAS/RAF/MEK/ERK signaling cascade, highlighting the points of intervention for BRAF inhibitors and MEK inhibitors like AC-881. In BRAF-mutated melanoma, the constitutively active BRAF protein drives oncogenic signaling, which can be effectively targeted by this combination therapy approach.
Pivotal Trial Performance: AUSTIN-M-003
The AUSTIN-M-003 study was a Phase III, multicenter, double-blind, randomized, active-controlled trial designed to evaluate the efficacy and safety of AC-881 in combination with a standard BRAF inhibitor ("StandardInhibitor") versus a standard-of-care MEK inhibitor ("ControlDrug") plus "StandardInhibitor" in patients with previously untreated BRAF V600E/K-mutant unresectable or metastatic melanoma.[4][5]
Comparative Efficacy and Safety Data
The following tables summarize the key efficacy and safety outcomes from the AUSTIN-M-003 trial.
Table 1: Primary and Secondary Efficacy Endpoints
| Endpoint | AC-881 + StandardInhibitor (n=350) | ControlDrug + StandardInhibitor (n=350) | Hazard Ratio (95% CI) | p-value |
| Median Progression-Free Survival (PFS) | 14.8 months | 11.2 months | 0.78 (0.65-0.93) | 0.006 |
| Overall Response Rate (ORR) | 72.5% | 65.1% | - | 0.04 |
| Complete Response (CR) | 18.2% | 14.0% | - | - |
| Partial Response (PR) | 54.3% | 51.1% | - | - |
| Median Overall Survival (OS) | 35.6 months | 31.1 months | 0.85 (0.70-1.03) | 0.09 |
| Duration of Response (DoR) | 13.1 months | 10.9 months | - | - |
Table 2: Key Grade 3/4 Treatment-Related Adverse Events (AEs)
| Adverse Event | AC-881 + StandardInhibitor (n=350) | ControlDrug + StandardInhibitor (n=350) |
| Pyrexia | 8.1% | 15.2% |
| Rash | 6.5% | 9.8% |
| Diarrhea | 5.2% | 6.1% |
| Chills | 2.3% | 7.5% |
| Vomiting | 3.1% | 4.4% |
| Hypertension | 4.0% | 3.5% |
| Decreased Ejection Fraction | 1.5% | 2.8% |
Experimental Protocols
The methodologies employed in the AUSTIN-M-003 trial were designed to ensure robust and unbiased results.[4][6]
Study Design and Randomization
The trial followed a double-blind, parallel-group, randomized design. Eligible patients were stratified by lactate (B86563) dehydrogenase (LDH) level (≤ upper limit of normal [ULN] vs. >ULN) and geographic region. Patients were then randomized in a 1:1 ratio to receive either AC-881 plus "StandardInhibitor" or "ControlDrug" plus "StandardInhibitor". An interactive web response system was used to manage randomization and ensure allocation concealment.
Efficacy and Safety Assessments
-
Tumor Assessments: Tumor response was evaluated by investigators according to Response Evaluation Criteria in Solid Tumors (RECIST) version 1.1. Assessments were performed every 8 weeks for the first 24 months, and every 12 weeks thereafter. The primary endpoint of Progression-Free Survival (PFS) was based on these assessments.
-
Safety Monitoring: Adverse events were monitored continuously throughout the study and graded according to the National Cancer Institute Common Terminology Criteria for Adverse Events (CTCAE) version 5.0. Regular physical examinations, vital sign measurements, and laboratory tests were conducted at specified intervals.
Conclusion
The investigational MEK inhibitor, Austin Compound (AC-881), when used in combination with a standard BRAF inhibitor, demonstrated a statistically significant improvement in progression-free survival compared to the active control combination. The safety profile of the AC-881 combination also appeared favorable, with a lower incidence of several key grade 3/4 adverse events, such as pyrexia and rash. While the overall survival data did not reach statistical significance at the time of this analysis, the trend favors the AC-881 arm. These findings suggest that AC-881 is a promising agent for the treatment of BRAF-mutated advanced melanoma.
References
- 1. Elucidating Compound Mechanism of Action by Network Perturbation Analysis - PMC [pmc.ncbi.nlm.nih.gov]
- 2. mdpi.com [mdpi.com]
- 3. SmallMolecules.com | Mechanisms of Action in Small Molecules - SmallMolecules.com [smallmolecules.com]
- 4. Clinical trial - Wikipedia [en.wikipedia.org]
- 5. innovationclinicaltrials.com [innovationclinicaltrials.com]
- 6. The double-blind, randomized, placebo-controlled trial: gold standard or golden calf? - PubMed [pubmed.ncbi.nlm.nih.gov]
Navigating Laboratory Waste Disposal in Austin: A Guide for Researchers
For researchers, scientists, and drug development professionals in Austin, ensuring the proper disposal of laboratory waste is a critical component of maintaining a safe and compliant work environment. Adherence to correct procedures not only mitigates risks to personnel and the environment but also upholds the integrity of research operations. This guide provides essential, step-by-step information on the safe and legal disposal of chemical, biological, and other forms of laboratory waste in Austin.
Key Contacts and Regulatory Bodies
Several entities oversee and assist with laboratory waste management in the Austin area. For facilities not affiliated with a large institution like a university, it is crucial to establish a relationship with a licensed waste disposal vendor.
| Entity | Contact Information | Role |
| City of Austin/Travis County | Phone: (512) 974-4343 | Manages the Recycle & Reuse Drop-off Center for household hazardous waste; can provide information for small businesses.[1] |
| University of Texas at Austin EHS | Phone: (512) 471-3511 | Manages hazardous waste for the university; their procedures reflect local and state regulations.[2][3] |
| Texas Commission on Environmental Quality (TCEQ) | Phone: (512) 239-2335 (Municipal Solid Waste Permits) | State agency that regulates waste management, including medical and hazardous waste.[4] |
| Private Waste Management Vendors | Multiple vendors available in the Austin area | Contracted services for the collection, transport, and disposal of regulated medical and hazardous waste.[5][6] |
Chemical Waste Disposal Procedures
Proper identification and segregation of chemical waste are the foundational steps for safe disposal.[7] Incompatible chemicals must never be mixed.[8]
Waste Characterization and Segregation
All chemical waste must be evaluated to determine if it is hazardous. The Resource Conservation and Recovery Act (RCRA) defines hazardous waste based on four characteristics: ignitability, corrosivity, reactivity, and toxicity.[9] Additionally, the Texas Commission on Environmental Quality (TCEQ) has its own classifications for certain wastes not federally defined as hazardous.[10]
General Segregation Categories:
-
Halogenated Solvents
-
Non-Halogenated Solvents
-
Acids
-
Bases
-
Metal-Bearing Waste
-
Special Wastes (e.g., cyanides, sulfides, pesticides)[9]
Container Management and Labeling
Proper container management is crucial to prevent leaks, spills, and accidental mixing of incompatible wastes.
| Requirement | Specification |
| Container Type | Must be compatible with the chemical waste being stored (e.g., no acid in metal cans).[9] Containers must be in good condition with non-leaking, screw-on caps.[9] |
| Labeling | All waste containers must be clearly labeled with their contents.[9] Labels should include the words "Hazardous Waste" and the date when waste was first added.[8] Pre-printed labels are available from vendors, or labels can be created.[8] Old labels on reused containers must be defaced or removed.[8] |
| Storage | Containers must be kept closed except when adding waste.[9] They should be stored at or near the point of generation and under the control of the generator.[9] Weekly inspections of storage areas are recommended.[11][12] |
| Accumulation Limits | A generator can accumulate up to 55 gallons of hazardous waste or 1 quart of acutely hazardous waste at or near the point of generation.[10] If these limits are exceeded, a waste pickup must be requested immediately.[10] |
Requesting a Chemical Waste Pickup
For institutions with an established Environmental Health and Safety (EHS) department, a chemical waste disposal request is typically submitted through an online system.[3][13] For other facilities, a licensed hazardous waste vendor must be contacted.
Biological and Medical Waste Disposal
Biohazardous waste includes materials contaminated with blood or other potentially infectious materials, such as cultures, tissues, and sharps.[5] This type of waste requires specific handling and disposal procedures to prevent the spread of disease.
Segregation and Containerization
Proper segregation of biological waste is critical. Sharps must be placed in puncture-resistant containers.[14] Other biohazardous waste should be collected in red biohazard bags.[15]
| Waste Type | Container Requirement |
| Sharps | Puncture-resistant containers specifically designed for sharps.[14] |
| Solid Biohazardous Waste | Red biohazard bags.[15] These bags should be placed in a secondary container that is leak-proof and has a lid. |
| Liquid Biohazardous Waste | Leak-proof, closable containers. |
| Pathological Waste | Often requires double-bagging in red or clear containers labeled "pathological waste."[15] |
Treatment and Disposal
In Texas, medical waste can be treated on-site (common for large facilities like hospitals) or transported by a licensed company for off-site treatment.[14] The most common treatment method is incineration.[14] Autoclaving is another common method to render the waste non-infectious.[15]
Disposal of Other Laboratory Waste
Empty Chemical Containers
Disposal procedures for empty chemical containers depend on their prior contents.[2] Containers that held acutely hazardous chemicals must be disposed of as chemical waste.[2] Other containers must be thoroughly emptied, with any residue making up less than 3% of the original weight.[2] The label must be defaced or covered with an "Empty" sticker, and the cap should be removed.[2]
Glassware
Most discarded and empty glassware can be placed in designated glass disposal containers, which are typically blue and white cardboard boxes.[2] However, glassware contaminated with infectious material should be treated as biohazardous waste and placed in sharps containers.[2]
Experimental Protocols for Waste Management
While specific experimental protocols will vary by laboratory, the overarching principles of waste management remain consistent.
-
Waste Determination: At the outset of any experiment, a waste determination should be performed to identify the types of waste that will be generated and the proper disposal streams.
-
Segregation at the Source: Waste should be segregated into the appropriate containers at the point of generation to prevent cross-contamination.[7]
-
Proper Labeling: All waste containers must be accurately labeled with their contents and any associated hazards.
-
Secure Storage: Waste containers should be securely stored in a designated area away from general laboratory traffic.
-
Timely Disposal: Adhere to accumulation limits and schedule waste pickups in a timely manner.
Visualizing the Disposal Process
To further clarify the procedural steps, the following diagrams illustrate key decision-making and workflow processes in laboratory waste management.
References
- 1. Recycling and Disposal [traviscountytx.gov]
- 2. Other Waste | Environmental Health & Safety (EHS) [ehs.utexas.edu]
- 3. Waste Management | Environmental Health & Safety (EHS) [ehs.utexas.edu]
- 4. medprodisposal.com [medprodisposal.com]
- 5. medcyclellc.com [medcyclellc.com]
- 6. biomedicalwastesolutions.com [biomedicalwastesolutions.com]
- 7. Effective Lab Waste Disposal Strategies [emsllcusa.com]
- 8. offices.austincc.edu [offices.austincc.edu]
- 9. geo.utexas.edu [geo.utexas.edu]
- 10. Chemical Waste | Environmental Health & Safety (EHS) [ehs.utexas.edu]
- 11. danielshealth.com [danielshealth.com]
- 12. danielshealth.com [danielshealth.com]
- 13. Hazardous Waste Disposal | Environmental Health & Safety (EHS) [ehs.utexas.edu]
- 14. medprodisposal.com [medprodisposal.com]
- 15. medsharps.com [medsharps.com]
Navigating the Ambiguity of "Austin" in Chemical Safety
A Critical Clarification on Chemical Identification for Laboratory Safety
For researchers, scientists, and drug development professionals, precision in chemical identification is the cornerstone of laboratory safety. The query for personal protective equipment (PPE) and handling protocols for "Austin" presents a crucial point of clarification: "Austin" is not a recognized, specific chemical substance.
Initial research reveals that the term "Austin" in a chemical context is primarily associated with brand names from two distinct companies: the James Austin Company , which manufactures cleaning products containing chemicals like ammonia (B1221849) and sodium hypochlorite, and the Austin Powder Company , which produces explosives.[1][2][3] Each of these products has a unique set of hazards and requires specific safety protocols.
This guide provides essential safety and logistical information by illustrating the distinct requirements for different products branded with the name "Austin." It underscores the critical importance of consulting the Safety Data Sheet (SDS) for any specific chemical before handling it.
Comparative Hazard Overview of "Austin" Branded Products
To illustrate the chemical-specific nature of safety protocols, the following table summarizes the hazards associated with different products bearing the "Austin" brand name. This data is extracted from their respective Safety Data Sheets.
| Product Name | Manufacturer | Primary Chemical Component(s) | Key Hazards |
| Austin Ammonia | James Austin Co. | Ammonia | Can cause chemical burns; vapors are extremely irritating to the respiratory tract; toxic gases can be released if mixed with chlorine bleach.[1] |
| Austin's Pool Tech Shock | James Austin Co. | Sodium Hypochlorite (12.50 - 12.70%) | Corrosive; may cause severe skin and eye irritation or chemical burns; causes eye damage; strong oxidizing agent that can release chlorine gas if mixed with other chemicals.[4] |
| Hydromite 100, Hydromite 70, HEET 30 | Austin Powder GmbH | Explosive mixture | Explosive with mass explosion hazard; may intensify fire as an oxidizer; causes serious eye irritation.[2] |
| Austinite S, Austinite HD, Austinite 100 | Austin Powder GmbH | Explosive mixture | Risk of explosion by shock, friction, fire, or other ignition sources; harmful if swallowed; irritating to eyes, respiratory system, and skin.[3] |
Standard Operating Procedure for Handling a Hazardous Chemical
The following is a generalized workflow for handling a hazardous chemical in a laboratory setting. This is a template and must be adapted with specific details from the chemical's Safety Data Sheet (SDS).
Experimental Workflow: General Hazardous Chemical Handling
Caption: Generalized workflow for handling a hazardous chemical.
Detailed Methodologies
1. Review Safety Data Sheet (SDS): Before any handling of a chemical, thoroughly read its SDS. Pay close attention to sections detailing hazards, required personal protective equipment, first-aid measures, and disposal considerations.
2. Don Appropriate Personal Protective Equipment (PPE): The level of PPE is dictated by the chemical's hazards.[5] A general guideline for handling corrosive or irritating liquids would include:
-
Eye and Face Protection: Chemical splash goggles are a minimum requirement. A face shield may be necessary for larger volumes or splash risks.[6][7]
-
Skin and Body Protection: A lab coat, long pants, and closed-toe shoes are mandatory. For highly corrosive materials, a chemical-resistant apron may be required.[6]
-
Hand Protection: Select gloves specifically resistant to the chemical being handled. For instance, disposable nitrile gloves offer broad but short-term protection.[7] Always check the manufacturer's chemical resistance guide.
-
Respiratory Protection: If the SDS indicates harmful vapors or the work cannot be performed in a ventilated hood, a respirator may be necessary.[7]
3. Prepare Work Area:
-
Ensure a chemical fume hood is operational and the sash is at the appropriate height.
-
Clear the workspace of any unnecessary items.
-
Have spill cleanup materials readily available.
-
Locate the nearest eyewash station and safety shower.
4. Chemical Handling and Experimentation:
-
When dispensing, pour carefully to avoid splashes.
-
Keep containers sealed when not in use.
-
Never mix chemicals without first verifying their compatibility. For example, mixing ammonia with bleach-containing products will release toxic gas.[1]
5. Decontamination and Waste Disposal:
-
Wipe down the work surface with an appropriate decontaminating solution.
-
All chemical waste is considered hazardous. It must be collected in a clearly labeled, sealed container.
-
Waste disposal procedures are regulated and vary by institution and location. Consult your institution's Environmental Health & Safety (EHS) office for specific protocols.[8][9][10]
6. Doffing and Disposal of PPE:
-
Remove PPE in a manner that avoids contaminating yourself. Gloves should be removed last.
-
Dispose of single-use PPE in the appropriate waste stream.
Emergency Protocols
Personal Exposure:
-
Eyes: Immediately flush with water at an eyewash station for at least 15 minutes.
-
Skin: Remove contaminated clothing and flush the affected area with copious amounts of water.
-
Inhalation: Move to fresh air immediately.
-
In all cases of significant exposure, seek immediate medical attention and have the SDS available for medical personnel.
Spill Response:
-
Alert others in the immediate area.
-
If the spill is small and you are trained to handle it, use an appropriate spill kit to contain and absorb the material.
-
For large or highly hazardous spills, evacuate the area and contact your institution's emergency response team.
By understanding that safety protocols are tailored to specific chemical hazards, and by treating the SDS as the primary source of information, researchers can ensure a safe laboratory environment.
References
- 1. nationalsupply1.com [nationalsupply1.com]
- 2. austinpowder.com [austinpowder.com]
- 3. austinpowder.com [austinpowder.com]
- 4. poolimages.blob.core.windows.net [poolimages.blob.core.windows.net]
- 5. epa.gov [epa.gov]
- 6. Personal Protective Equipment | Environmental Health & Safety (EHS) [ehs.utexas.edu]
- 7. Chemical Safety: Personal Protective Equipment | Environment, Health & Safety [ehs.ucsf.edu]
- 8. hazardouswasteexperts.com [hazardouswasteexperts.com]
- 9. cleanmanagement.com [cleanmanagement.com]
- 10. hwhenvironmental.com [hwhenvironmental.com]
Featured Recommendations
| Most viewed |


|
|
|---|---|---|
| Most popular with customers |
|
Haftungsausschluss und Informationen zu In-Vitro-Forschungsprodukten
Bitte beachten Sie, dass alle Artikel und Produktinformationen, die auf BenchChem präsentiert werden, ausschließlich zu Informationszwecken bestimmt sind. Die auf BenchChem zum Kauf angebotenen Produkte sind speziell für In-vitro-Studien konzipiert, die außerhalb lebender Organismen durchgeführt werden. In-vitro-Studien, abgeleitet von dem lateinischen Begriff "in Glas", beinhalten Experimente, die in kontrollierten Laborumgebungen unter Verwendung von Zellen oder Geweben durchgeführt werden. Es ist wichtig zu beachten, dass diese Produkte nicht als Arzneimittel oder Medikamente eingestuft sind und keine Zulassung der FDA für die Vorbeugung, Behandlung oder Heilung von medizinischen Zuständen, Beschwerden oder Krankheiten erhalten haben. Wir müssen betonen, dass jede Form der körperlichen Einführung dieser Produkte in Menschen oder Tiere gesetzlich strikt untersagt ist. Es ist unerlässlich, sich an diese Richtlinien zu halten, um die Einhaltung rechtlicher und ethischer Standards in Forschung und Experiment zu gewährleisten.
