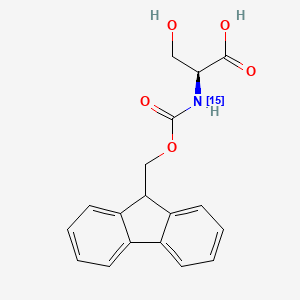
Fmoc-Ser-OH-15N
Beschreibung
BenchChem offers high-quality this compound suitable for many research applications. Different packaging options are available to accommodate customers' requirements. Please inquire for more information about this compound including the price, delivery time, and more detailed information at info@benchchem.com.
Structure
3D Structure
Eigenschaften
Molekularformel |
C18H17NO5 |
|---|---|
Molekulargewicht |
328.3 g/mol |
IUPAC-Name |
(2S)-2-(9H-fluoren-9-ylmethoxycarbonyl(15N)amino)-3-hydroxypropanoic acid |
InChI |
InChI=1S/C18H17NO5/c20-9-16(17(21)22)19-18(23)24-10-15-13-7-3-1-5-11(13)12-6-2-4-8-14(12)15/h1-8,15-16,20H,9-10H2,(H,19,23)(H,21,22)/t16-/m0/s1/i19+1 |
InChI-Schlüssel |
JZTKZVJMSCONAK-BTEQYEEISA-N |
Isomerische SMILES |
C1=CC=C2C(=C1)C(C3=CC=CC=C32)COC(=O)[15NH][C@@H](CO)C(=O)O |
Kanonische SMILES |
C1=CC=C2C(=C1)C(C3=CC=CC=C32)COC(=O)NC(CO)C(=O)O |
Herkunft des Produkts |
United States |
Foundational & Exploratory
Fmoc-Ser-OH-15N: A Technical Guide for Researchers and Drug Development Professionals
Fmoc-Ser-OH-15N is a stable isotope-labeled amino acid derivative that serves as a critical building block in modern biochemical and pharmaceutical research. Its strategic incorporation of a nitrogen-15 (¹⁵N) isotope allows for the precise tracking and quantification of serine-containing peptides and proteins. This technical guide provides an in-depth exploration of the properties, synthesis, and applications of this compound, with a focus on its utility in solid-phase peptide synthesis (SPPS), nuclear magnetic resonance (NMR) spectroscopy, and mass spectrometry (MS).
Core Properties and Specifications
This compound, chemically known as N-α-(9-Fluorenylmethoxycarbonyl)-L-serine-¹⁵N, is a white to off-white solid. The fluorenylmethyloxycarbonyl (Fmoc) group provides a temporary, base-labile protecting group for the α-amino group, a cornerstone of modern peptide synthesis. The incorporation of the stable, non-radioactive ¹⁵N isotope provides a distinct mass signature for analytical applications without altering the chemical reactivity of the amino acid.
| Property | Value |
| Chemical Formula | C₁₈H₁₇¹⁵NO₅ |
| Molecular Weight | 328.32 g/mol |
| CAS Number | 2137490-19-6 |
| Unlabeled CAS Number | 73724-45-5 |
| Appearance | White to off-white solid |
| Purity | Typically ≥98% |
| Isotopic Enrichment | Typically ≥98 atom % ¹⁵N |
| Solubility | Soluble in organic solvents like DMF, DMSO |
| Storage | Store at -20°C for long-term stability |
Synthesis and Purification
The synthesis of this compound involves the reaction of ¹⁵N-labeled L-serine with a fluorenylmethyloxycarbonylating agent, such as Fmoc-chloride (Fmoc-Cl) or 9-fluorenylmethylsuccinimidyl carbonate (Fmoc-OSu), under basic conditions. The reaction is typically carried out in a mixed aqueous-organic solvent system.
Experimental Protocol: Synthesis of this compound
-
Dissolution: L-serine-¹⁵N is dissolved in an aqueous solution of a mild base, such as sodium bicarbonate or sodium carbonate.
-
Fmoc-Reagent Addition: An equimolar or slight excess of Fmoc-OSu or Fmoc-Cl, dissolved in an organic solvent like dioxane or acetone, is added dropwise to the stirring serine solution at a controlled temperature, often between 0-5°C.
-
Reaction: The reaction mixture is allowed to warm to room temperature and stirred for several hours to ensure complete reaction.
-
Work-up: The reaction mixture is then acidified to a pH of approximately 2 using a dilute acid like HCl, causing the this compound product to precipitate.
-
Purification: The crude product is collected by filtration and can be further purified by recrystallization from a suitable solvent system, such as ethyl acetate/hexane, to yield the final high-purity product.
Synthesis workflow for this compound.
Applications in Research and Drug Development
Solid-Phase Peptide Synthesis (SPPS)
The primary application of this compound is as a building block in Fmoc-based solid-phase peptide synthesis.[1] This methodology allows for the controlled, stepwise assembly of amino acids to create custom peptides. The ¹⁵N label is introduced at a specific serine residue within the peptide sequence.
-
Resin Preparation: A suitable solid support resin (e.g., Wang or Rink Amide resin) is swelled in a solvent like N,N-dimethylformamide (DMF).
-
Fmoc Deprotection: The Fmoc protecting group on the resin-bound amino acid is removed using a solution of 20% piperidine in DMF.
-
Washing: The resin is thoroughly washed with DMF to remove the piperidine and the Fmoc-adduct.
-
Amino Acid Activation: In a separate vessel, this compound is activated by a coupling reagent (e.g., HBTU, HATU) in the presence of a base (e.g., DIPEA).
-
Coupling: The activated this compound solution is added to the resin, and the mixture is agitated to facilitate the formation of a peptide bond.
-
Washing: The resin is washed again with DMF to remove any unreacted reagents.
-
Cycle Repetition: Steps 2-6 are repeated for each subsequent amino acid in the desired peptide sequence.
-
Cleavage and Deprotection: Once the synthesis is complete, the peptide is cleaved from the resin, and all side-chain protecting groups are removed using a strong acid cocktail, typically containing trifluoroacetic acid (TFA).
-
Purification: The crude peptide is then purified using techniques like reverse-phase high-performance liquid chromatography (RP-HPLC).
Workflow for SPPS using this compound.
Nuclear Magnetic Resonance (NMR) Spectroscopy
¹⁵N-labeled peptides and proteins are invaluable tools in NMR spectroscopy for elucidating three-dimensional structures and studying molecular dynamics. The ¹⁵N nucleus has a spin of 1/2, making it NMR-active. The incorporation of ¹⁵N allows for the use of heteronuclear correlation experiments, such as ¹H-¹⁵N HSQC (Heteronuclear Single Quantum Coherence), which provides a unique signal for each N-H bond in the protein backbone. This greatly aids in the assignment of resonances and the determination of protein structure and dynamics in solution.
Quantitative Mass Spectrometry (MS)
In the field of proteomics, ¹⁵N-labeled peptides synthesized using this compound serve as ideal internal standards for the accurate quantification of their unlabeled counterparts in complex biological samples. This technique, often referred to as Stable Isotope Labeling with Amino acids in cell culture (SILAC) when performed metabolically, or by spiking in a labeled synthetic peptide standard, allows for precise ratiometric analysis. The mass spectrometer can distinguish between the 'light' (¹⁴N) and 'heavy' (¹⁵N) versions of the peptide, and the ratio of their signal intensities directly corresponds to their relative abundance.
Workflow for quantitative mass spectrometry.
Conclusion
This compound is a versatile and indispensable reagent for researchers in structural biology, proteomics, and drug development. Its application in the synthesis of isotopically labeled peptides enables detailed investigations into the structure, function, and quantity of proteins, thereby advancing our understanding of complex biological systems and facilitating the development of new therapeutic agents.
References
In-Depth Technical Guide to Fmoc-Ser-OH-15N
For Researchers, Scientists, and Drug Development Professionals
This guide provides a comprehensive overview of Fmoc-Ser-OH-15N, a crucial isotopically labeled amino acid derivative for advanced research applications. We will delve into its fundamental properties, synthesis, and applications, with a focus on providing practical information for laboratory settings.
Core Data at a Glance
For clarity and rapid comparison, the molecular weights of both the standard and the nitrogen-15 labeled Fmoc-L-Serine are presented below.
| Compound | Molecular Formula | Molecular Weight ( g/mol ) |
| Fmoc-Ser-OH | C₁₈H₁₇NO₅ | 327.33[1][2] |
| This compound | C₁₈H₁₇¹⁵NO₅ | 328.32[3] |
Synthesis and Isotopic Labeling: A Methodological Overview
The synthesis of this compound is a critical process for its use in various research applications. The following protocol outlines a generalizable approach to the N-protection of 15N-labeled L-serine.
Objective: To synthesize this compound by reacting 15N-labeled L-serine with 9-fluorenylmethyl chloroformate (Fmoc-Cl).
Materials:
-
L-Serine-15N
-
9-fluorenylmethyl chloroformate (Fmoc-Cl)
-
Sodium carbonate (Na₂CO₃)
-
Dioxane
-
Water (deionized)
-
Ethyl acetate
-
Hexane
-
Hydrochloric acid (HCl), 1M
-
Brine solution
-
Magnesium sulfate (MgSO₄), anhydrous
-
Rotary evaporator
-
Magnetic stirrer and stir bar
-
Separatory funnel
-
Standard laboratory glassware
Procedure:
-
Dissolution of L-Serine-15N: Dissolve L-Serine-15N in a 10% aqueous solution of sodium carbonate in a round-bottom flask equipped with a magnetic stir bar. The basic solution deprotonates the amino group, making it nucleophilic.
-
Addition of Fmoc-Cl: While stirring vigorously, slowly add a solution of Fmoc-Cl dissolved in dioxane to the L-Serine-15N solution at room temperature. The reaction is typically allowed to proceed for several hours.
-
Work-up:
-
Once the reaction is complete (monitored by TLC), transfer the reaction mixture to a separatory funnel.
-
Wash the mixture with ethyl acetate to remove unreacted Fmoc-Cl and other nonpolar impurities.
-
Acidify the aqueous layer to a pH of approximately 2 by adding 1M HCl. This protonates the carboxylic acid, making the product extractable into an organic solvent.
-
Extract the product into ethyl acetate. Repeat the extraction multiple times to ensure complete recovery.
-
-
Drying and Evaporation:
-
Combine the organic extracts and wash them with a brine solution to remove any remaining water-soluble impurities.
-
Dry the organic layer over anhydrous magnesium sulfate.
-
Filter the drying agent and concentrate the filtrate under reduced pressure using a rotary evaporator.
-
-
Purification:
-
The crude product can be further purified by recrystallization from a suitable solvent system, such as ethyl acetate/hexane, to yield pure this compound.
-
-
Characterization: Confirm the identity and purity of the final product using techniques such as Nuclear Magnetic Resonance (NMR) spectroscopy and Mass Spectrometry (MS).
Applications in Research and Development
The primary utility of this compound lies in its application as a tracer in various biochemical and biomedical studies. The incorporation of the stable ¹⁵N isotope allows for the precise tracking and quantification of serine metabolism and its incorporation into proteins and other biomolecules.
Experimental Workflow: Peptide Synthesis and Analysis
The following diagram illustrates a typical workflow for the use of this compound in solid-phase peptide synthesis (SPPS) and subsequent analysis.
Caption: Workflow for SPPS using this compound and subsequent analysis.
Role in Signaling Pathways
Serine is a pivotal amino acid in numerous cellular signaling pathways, primarily through its phosphorylation by serine/threonine kinases. The diagram below depicts a simplified representation of a generic serine phosphorylation-mediated signaling cascade. The use of this compound in cell culture or in vitro kinase assays allows for the tracing of serine incorporation into phosphoproteins.
Caption: A generic serine phosphorylation signaling pathway.
References
An In-depth Technical Guide to Fmoc-Ser-OH-15N
This technical guide provides a comprehensive overview of Fmoc-Ser-OH-15N, a stable isotope-labeled amino acid derivative crucial for advanced research in proteomics, structural biology, and drug development. The incorporation of the heavy nitrogen isotope (¹⁵N) allows for precise tracking and quantification of serine-containing peptides and proteins in complex biological systems.
Molecular Structure and Properties
This compound is an N-terminally protected L-serine with a ¹⁵N isotope in the amine group. The fluorenylmethyloxycarbonyl (Fmoc) group is a base-labile protecting group that is stable under acidic conditions, making it ideal for solid-phase peptide synthesis (SPPS).
Chemical Structure
Below is a two-dimensional representation of the this compound structure.
Caption: Chemical structure of this compound.
The Use of ¹⁵N Labeled Serine in NMR Studies: A Technical Guide
For Researchers, Scientists, and Drug Development Professionals
This guide provides an in-depth overview of the application of ¹⁵N labeled serine in Nuclear Magnetic Resonance (NMR) spectroscopy for the study of biomolecules. We will cover the synthesis of ¹⁵N labeled serine, its incorporation into proteins, and the NMR experimental techniques used to probe molecular structure, dynamics, and interactions.
Introduction to ¹⁵N Labeled Serine in NMR
Nitrogen-15 (¹⁵N) is a stable isotope of nitrogen that is frequently utilized in NMR spectroscopy. Unlike the more abundant ¹⁴N isotope, which has a nuclear spin of 1 and a quadrupole moment that leads to broad NMR signals, ¹⁵N has a nuclear spin of 1/2. This property results in sharp, well-resolved peaks in NMR spectra, making it ideal for detailed molecular structure analysis.[1] The incorporation of ¹⁵N labeled serine into proteins and other biomolecules allows researchers to specifically monitor the environment and behavior of these residues, providing invaluable insights into protein folding, enzyme mechanisms, and drug-binding interactions.
Synthesis and Incorporation of ¹⁵N Labeled Serine
The journey of a ¹⁵N labeled serine from a simple nitrogen source to its place within a protein involves several key steps, from the synthesis of the amino acid itself to its incorporation during protein expression.
Enzymatic Synthesis of L-[¹⁵N]Serine
A highly efficient and stereospecific method for synthesizing L-[¹⁵N]serine involves an enzymatic approach. This method utilizes NAD-dependent amino acid dehydrogenases to catalyze the formation of the amino acid from its corresponding α-keto acid precursor.[2][3][4]
The overall workflow for the enzymatic synthesis of L-[¹⁵N]serine is depicted below:
References
Applications of Fmoc-Protected Amino Acids: A Technical Guide
For Researchers, Scientists, and Drug Development Professionals
This in-depth technical guide explores the core applications of 9-fluorenylmethyloxycarbonyl (Fmoc)-protected amino acids, pivotal building blocks in modern peptide science. This document provides a comprehensive overview of their primary use in Solid-Phase Peptide Synthesis (SPPS), their role in the development of advanced biomaterials, and their impact on drug discovery and development. Detailed experimental protocols, quantitative data for reaction optimization, and visual representations of key workflows and biological pathways are presented to equip researchers with the practical knowledge for successful application.
Core Application: Solid-Phase Peptide Synthesis (SPPS)
The introduction of the Fmoc protecting group revolutionized peptide synthesis, offering a milder and more versatile alternative to the traditional tert-butyloxycarbonyl (Boc) strategy.[1][2] The Fmoc group's key advantage lies in its lability to mild basic conditions, typically a solution of piperidine in a polar aprotic solvent like N,N-dimethylformamide (DMF), while remaining stable to the acidic conditions used for final cleavage of the peptide from the resin and removal of side-chain protecting groups.[3][4] This orthogonality forms the foundation of the widely adopted Fmoc/tBu (tert-butyl) strategy, enabling the synthesis of a vast array of peptides with high purity and yield.[5]
The cyclical nature of Fmoc-SPPS, involving repetitive steps of deprotection, washing, coupling, and washing, is highly amenable to automation, which has significantly accelerated peptide synthesis for research and pharmaceutical production.[6][7]
The Fmoc-SPPS Workflow
The synthesis of a peptide using Fmoc chemistry follows a well-defined cyclical process. Each cycle results in the addition of one amino acid to the growing peptide chain anchored to a solid support.
Quantitative Data for Reaction Optimization
The efficiency of both the deprotection and coupling steps is critical for the successful synthesis of long and complex peptides. The choice of reagents and reaction times significantly impacts the overall yield and purity of the final product.
Table 1: Comparison of Fmoc Deprotection Reagents and Conditions
| Reagent(s) | Concentration | Deprotection Time | Peptide Purity (%) | Aspartimide Formation (%) | Diketopiperazine (DKP) Formation (%) | Racemization (%) | Reference(s) |
| Piperidine | 20% in DMF | 5-20 min | Variable | Can be significant, especially with Asp-Xxx sequences | Prone to occur, especially with Pro-containing dipeptides | Can occur, particularly at the C-terminus and with sensitive residues like Cys and His | [8] |
| 4-Methylpiperidine (4MP) | 20% in DMF | 10 min (for Arginine) | Similar to Piperidine | - | - | - | [9][10] |
| Piperazine (PZ) | 10% w/v in 9:1 DMF/ethanol | >10 min (for Arginine) | Similar to Piperidine | Reduced compared to Piperidine | - | - | [9][10] |
| Piperazine/DBU | 5% (w/v) Piperazine, 2% (v/v) DBU in DMF | 2-5 min | Generally high | Significantly reduced, especially with the addition of 1% formic acid | Reduced | Low | [8] |
Note: The efficiency and side reactions are highly sequence-dependent. The values presented are indicative and may vary.
Table 2: Performance of Common Coupling Reagents in Fmoc-SPPS
| Coupling Reagent | Reagent Type | Typical Coupling Time | Representative Yield (%) | Representative Purity (%) | Level of Racemization | Reference(s) |
| HATU | Aminium/Uronium Salt | 15-45 minutes | >99 | >95 | Very Low | [3] |
| HBTU | Aminium/Uronium Salt | 20-60 minutes | >98 | >95 | Low | [3] |
| HCTU | Aminium/Uronium Salt | 15-45 minutes | >99 | >95 | Very Low | [3] |
| PyBOP | Phosphonium Salt | 30-120 minutes | >98 | >95 | Low | [3] |
| DIC/HOBt | Carbodiimide/Additive | 60-180 minutes | 95-98 | >95 | Low | [3][6] |
| COMU | Aminium/Uronium Salt | 20-45 minutes | >99.5 | >95 | Very Low | [6] |
Disclaimer: The data presented in this table is a compilation of representative values from various studies and application notes. Actual results may vary depending on the specific peptide sequence, solid support, solvent, base, and other reaction conditions.
Experimental Protocols
Protocol 1: Standard Fmoc-SPPS Cycle (Manual Synthesis)
This protocol outlines the manual synthesis of a peptide on a 0.1 mmol scale.
1. Resin Swelling:
-
Place the appropriate amount of resin (e.g., 200 mg of 0.5 mmol/g loading Rink Amide resin) in a fritted reaction vessel.
-
Add 5 mL of DMF and allow the resin to swell for at least 30 minutes with occasional agitation.[11]
-
Drain the DMF.
2. Fmoc Deprotection:
-
Add 5 mL of 20% (v/v) piperidine in DMF to the swollen resin.[11]
-
Agitate the mixture for 3 minutes at room temperature.[12]
-
Drain the solution.
-
Add a fresh 5 mL of 20% piperidine in DMF and agitate for 10-15 minutes.[4]
-
Drain the solution.
3. Washing:
-
Wash the resin thoroughly with DMF (5 x 5 mL) to remove all traces of piperidine and the dibenzofulvene-piperidine adduct.[8]
4. Amino Acid Coupling (using HATU):
-
In a separate vial, dissolve the Fmoc-amino acid (0.5 mmol, 5 equivalents) and HATU (0.49 mmol, 4.9 equivalents) in 2 mL of DMF.
-
Add N,N-Diisopropylethylamine (DIPEA) (1.0 mmol, 10 equivalents) to the amino acid solution and vortex briefly.
-
Immediately add the activated amino acid solution to the deprotected resin.
-
Agitate the reaction mixture for 30-60 minutes at room temperature.[5]
-
To monitor the completion of the reaction, a small sample of the resin can be taken for a Kaiser test (a positive test for primary amines will give a blue color, indicating incomplete coupling).[13]
5. Washing:
-
Drain the coupling solution.
-
Wash the resin with DMF (3 x 5 mL).
This cycle is repeated for each amino acid in the peptide sequence.
Protocol 2: Cleavage and Deprotection
-
After the final amino acid has been coupled and the N-terminal Fmoc group removed, wash the peptide-resin with dichloromethane (DCM) (3 x 5 mL) and dry it under vacuum.
-
Prepare a cleavage cocktail. A common cocktail is 95% trifluoroacetic acid (TFA), 2.5% water, and 2.5% triisopropylsilane (TIS).[14] TIS acts as a scavenger to trap reactive cationic species.
-
Add the cleavage cocktail (e.g., 5 mL) to the resin and agitate for 2-3 hours at room temperature.[14]
-
Filter the solution to separate the resin and collect the filtrate containing the peptide.
-
Precipitate the peptide by adding the filtrate to a 10-fold volume of cold diethyl ether.
-
Centrifuge the mixture to pellet the peptide, decant the ether, and wash the peptide pellet with cold ether twice more.
-
Dry the crude peptide under vacuum. The peptide can then be purified by reverse-phase high-performance liquid chromatography (RP-HPLC).
Application in Biomaterials: Self-Assembling Hydrogels
Beyond their role in peptide synthesis, Fmoc-protected amino acids are increasingly utilized as building blocks for functional biomaterials.[10] The aromatic Fmoc group can drive the self-assembly of these molecules in aqueous solution through π-π stacking interactions, while the amino acid component provides sites for hydrogen bonding.[7] This leads to the formation of nanofibrous networks that can entrap large amounts of water, forming hydrogels.
These hydrogels are biocompatible and biodegradable, making them attractive for a range of biomedical applications, including:
-
3D Cell Culture: The hydrogel scaffold mimics the extracellular matrix, providing a suitable environment for cell growth and proliferation.[7]
-
Drug Delivery: The porous network of the hydrogel can encapsulate therapeutic molecules for sustained and controlled release.[7]
-
Tissue Engineering: These hydrogels can be used as scaffolds to support the growth of new tissue.[7]
Experimental Protocol for Hydrogel Formation
Protocol 3: pH-Triggered Hydrogelation of Fmoc-Amino Acid
This protocol describes the formation of a hydrogel from an Fmoc-amino acid by adjusting the pH.
1. Solubilization:
-
Weigh the desired amount of the Fmoc-amino acid (e.g., 10 mg for a 1% w/v hydrogel) and place it in a vial.
-
Add a small volume of 0.1 M NaOH solution (e.g., 100 µL) to deprotonate the carboxylic acid and dissolve the Fmoc-amino acid, forming a clear solution.[7]
2. Dilution:
-
Dilute the solution with sterile deionized water or a buffer such as phosphate-buffered saline (PBS) to the desired final concentration (e.g., add 900 µL for a final volume of 1 mL).[7]
3. Gelation Trigger:
-
Rapid Gelation: Slowly add 0.1 M HCl dropwise while gently mixing until the pH reaches approximately 7.0-7.4. Gelation should occur quickly.[7]
-
Slow Gelation: For a more homogenous gel, add a calculated amount of glucono-δ-lactone (GdL). GdL will slowly hydrolyze to gluconic acid, gradually lowering the pH and inducing gelation over several hours.[7]
4. Equilibration:
-
Allow the hydrogel to stand at room temperature or 37°C for at least 30 minutes (for rapid gelation) or several hours (for slow gelation) to allow the fibrous network to fully form and equilibrate.[7]
Protocol 4: Characterization of Hydrogels - Rheology
Rheological measurements are essential for quantifying the mechanical properties (e.g., stiffness) of the hydrogel.
-
Sample Loading: Carefully place the formed hydrogel onto the lower plate of a rheometer.
-
Geometry: Lower the upper plate (cone-plate or parallel-plate) to the desired gap, ensuring the hydrogel fills the gap without overflowing.
-
Oscillatory Measurements: Perform a frequency sweep at a constant strain within the linear viscoelastic region to determine the storage modulus (G') and loss modulus (G''). A solid-like hydrogel will have a G' value significantly higher than G''.
Impact on Drug Development
The robustness and efficiency of Fmoc-SPPS have been instrumental in the development of numerous peptide-based therapeutics.[11] This technology allows for the precise synthesis of complex peptide drugs, including those with modified or unnatural amino acids to enhance their therapeutic properties.[2]
A prominent example is the synthesis of Glucagon-Like Peptide-1 (GLP-1) receptor agonists, such as liraglutide and semaglutide, which are used in the treatment of type 2 diabetes and obesity. These synthetic peptides are designed to mimic the action of the endogenous GLP-1 hormone.
GLP-1 Receptor Signaling Pathway
GLP-1 receptor agonists exert their therapeutic effects by activating the GLP-1 receptor, a G protein-coupled receptor (GPCR) located on pancreatic β-cells and other tissues. Activation of this receptor triggers a downstream signaling cascade that ultimately leads to enhanced glucose-dependent insulin secretion.
References
- 1. researchgate.net [researchgate.net]
- 2. Frontiers | Pleiotropic Effects of GLP-1 and Analogs on Cell Signaling, Metabolism, and Function [frontiersin.org]
- 3. The Identification of Novel Proteins That Interact With the GLP-1 Receptor and Restrain its Activity - PMC [pmc.ncbi.nlm.nih.gov]
- 4. researchgate.net [researchgate.net]
- 5. researchgate.net [researchgate.net]
- 6. researchgate.net [researchgate.net]
- 7. researchgate.net [researchgate.net]
- 8. vectormine.com [vectormine.com]
- 9. researchgate.net [researchgate.net]
- 10. Frontiers | The Interplay of Glucagon-Like Peptide-1 Receptor Trafficking and Signalling in Pancreatic Beta Cells [frontiersin.org]
- 11. GLP-1 receptor activated insulin secretion from pancreatic β-cells: mechanism and glucose dependence - PMC [pmc.ncbi.nlm.nih.gov]
- 12. GLP-1 receptor signaling: effects on pancreatic beta-cell proliferation and survival - PubMed [pubmed.ncbi.nlm.nih.gov]
- 13. Glucagon-like peptide-1 receptor - Wikipedia [en.wikipedia.org]
- 14. droracle.ai [droracle.ai]
The Role of 15N Isotopes in Proteomics: A Technical Guide
For Researchers, Scientists, and Drug Development Professionals
This guide provides a comprehensive overview of the principles, applications, and methodologies of using the stable isotope Nitrogen-15 (¹⁵N) in quantitative proteomics. Metabolic labeling with ¹⁵N is a powerful strategy for accurately determining relative protein abundance, offering critical insights into cellular processes, disease mechanisms, and drug action.
Core Principles of ¹⁵N Metabolic Labeling
Metabolic labeling with ¹⁵N is an in vivo technique where cells or organisms are cultured in a medium containing a ¹⁵N-enriched nitrogen source, such as ¹⁵N-labeled amino acids or ammonium salts.[1] During de novo protein synthesis, these heavy isotopes are incorporated into the entire proteome.[1]
The fundamental principle lies in the mass difference between the heavy (¹⁵N) and light (¹⁴N) nitrogen isotopes, which is approximately 1 Dalton.[] This mass difference is detectable by a mass spectrometer. By mixing a "heavy" ¹⁵N-labeled proteome with a "light" ¹⁴N proteome (the control sample), a direct comparison of peptide and protein abundance can be made.[1] Since the samples are combined at a very early stage, typically at the cell or tissue level, this method significantly minimizes experimental variations that can be introduced during sample preparation, leading to high accuracy and precision.[1][3]
A key characteristic of ¹⁵N labeling is that the mass shift for each peptide is variable, depending on the number of nitrogen atoms in its amino acid sequence.[4][5][6] This contrasts with other methods like SILAC (Stable Isotope Labeling with Amino acids in Cell culture), which uses labeled arginine and lysine, resulting in a predictable mass shift for tryptic peptides.[1] While this variability adds complexity to data analysis, it also provides an additional layer of validation for peptide identification.[7]
Experimental Workflow and Protocols
A successful ¹⁵N labeling experiment involves careful planning and execution, from cell culture to data analysis. The general workflow is depicted below.
References
- 1. benchchem.com [benchchem.com]
- 3. Quantitative Comparison of Proteomes Using SILAC - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Frontiers | 15N Metabolic Labeling Quantification Workflow in Arabidopsis Using Protein Prospector [frontiersin.org]
- 5. biorxiv.org [biorxiv.org]
- 6. 15N Metabolic Labeling Quantification Workflow in Arabidopsis Using Protein Prospector - PMC [pmc.ncbi.nlm.nih.gov]
- 7. patofyziologie.lf1.cuni.cz [patofyziologie.lf1.cuni.cz]
A Technical Guide to Fmoc-Ser-OH-15N: Sourcing, Synthesis, and Application in Advanced Research
For Researchers, Scientists, and Drug Development Professionals
This technical guide provides an in-depth overview of Fmoc-Ser-OH-15N, a stable isotope-labeled amino acid crucial for modern biochemical and pharmaceutical research. The document details commercially available sources and pricing, provides comprehensive experimental protocols for its use in solid-phase peptide synthesis (SPPS), and explores its applications in quantitative proteomics and the study of cellular signaling pathways.
Sourcing and Procurement of this compound
The availability and cost of this compound and its protected derivatives are critical considerations for research planning. The following table summarizes information from various suppliers. Please note that pricing is subject to change and may vary based on institutional contracts and bulk purchasing. It is recommended to contact the suppliers directly for the most current information.
| Supplier | Product Name | Catalog Number | Purity | Quantity | Price (USD) |
| Sigma-Aldrich | Fmoc-Ser(tBu)-OH-15N | 609145 | 98 atom % 15N | 100 mg | $1,330.00 |
| Alfa Chemistry | Fmoc-Ser(tBu)-OH-15N | ACMA00051130 | Not Specified | N/A | Inquiry |
| MedchemExpress | This compound | HY-W007720S1 | 98.0% | N/A | Inquiry |
| BOC Sciences | L-Serine-15N-N-FMOC | Not Specified | 95% by HPLC; 98% atom 15N | N/A | Inquiry |
Experimental Protocol: Solid-Phase Peptide Synthesis (SPPS) of a 15N-Serine Containing Peptide
This protocol outlines the manual synthesis of a model peptide containing a ¹⁵N-labeled serine residue using Fmoc-SPPS methodology. Thetert-butyl (tBu) protecting group is recommended for the serine side chain to prevent side reactions.
Materials and Reagents
-
Fmoc-Ser(tBu)-OH-15N
-
Rink Amide resin
-
Other Fmoc-protected amino acids
-
Coupling reagents: HBTU (2-(1H-benzotriazol-1-yl)-1,1,3,3-tetramethyluronium hexafluorophosphate)
-
Base: DIPEA (N,N-Diisopropylethylamine)
-
Fmoc deprotection solution: 20% piperidine in DMF (N,N-Dimethylformamide)
-
Solvents: DMF, DCM (Dichloromethane), Methanol
-
Washing solvent: DMF
-
Cleavage cocktail: 95% TFA (Trifluoroacetic acid), 2.5% TIS (Triisopropylsilane), 2.5% H₂O
-
Diethyl ether
Synthesis Workflow
The synthesis follows a cyclical process of deprotection, activation, and coupling.
Technical Guide: Fmoc-Ser-OH-15N for Research and Development
This technical guide provides comprehensive safety information, experimental protocols, and workflow diagrams for the use of Fmoc-Ser-OH-15N in research and drug development. The content is intended for researchers, scientists, and professionals familiar with peptide synthesis and laboratory safety procedures.
Safety and Physicochemical Data
While this compound is not classified as a hazardous substance according to the Globally Harmonized System (GHS), standard laboratory safety precautions should always be observed.[1] The following tables summarize the known safety and physicochemical properties.
Safety Data Summary
| Hazard Identification | GHS Classification: Not a hazardous substance.[1] |
| Signal Word | None[1] |
| Hazard Statements | None[1] |
| Precautionary Statements | None[1] |
| Routes of Exposure | Inhalation, Ingestion, Skin and Eyes.[1] |
| Potential Health Effects | Eye Contact: May cause eye irritation.[1] Skin Contact: May be harmful if absorbed through the skin. May cause skin irritation.[1] Inhalation: May be harmful if inhaled. May cause respiratory tract irritation.[1] Ingestion: May be harmful if swallowed.[1] |
| Toxicological Data | Carcinogenic, Mutagenic, and Teratogenic Effects: No data available.[1] |
| First Aid Measures | Eye Contact: Flush eyes with water as a precaution.[1] Skin Contact: Wash off with soap and plenty of water. Consult a physician.[1] Inhalation: Move person into fresh air. If not breathing, give artificial respiration. Consult a physician.[1] Ingestion: Rinse mouth with water. Never give anything by mouth to an unconscious person. Consult a physician.[1] |
Physical and Chemical Properties
| Property | Value | Source |
| Chemical Formula | C18H17¹⁵NO5 | [1] |
| Molecular Weight | 328.32 g/mol | [2] |
| Appearance | Solid | [1] |
| CAS Number | 2137490-19-6 | [1] |
| Unlabeled CAS Number | 73724-45-5 | [1] |
| Synonyms | FMOC-L-Serine-15N, FMOC-L-Ser-OH-15N | [1] |
| Purity | > 98% | [1] |
| Storage Temperature | Room temperature | [1] |
| Solubility | Soluble in DMSO, Chloroform, Dichloromethane, Ethyl Acetate, Acetone.[3][4] | |
| InChI Key | JZTKZVJMSCONAK-INIZCTEOSA-M | [5] |
Experimental Protocols
This compound is primarily used in solid-phase peptide synthesis (SPPS). The following is a generalized protocol for the manual Fmoc-SPPS of a peptide chain.
Materials and Reagents
-
This compound
-
Appropriate resin (e.g., Wang resin for C-terminal acid, Rink amide resin for C-terminal amide)[6]
-
Other Fmoc-protected amino acids
-
Coupling Reagents: e.g., HBTU (2-(1H-benzotriazol-1-yl)-1,1,3,3-tetramethyluronium hexafluorophosphate), HATU (1-[Bis(dimethylamino)methylene]-1H-1,2,3-triazolo[4,5-b]pyridinium 3-oxide hexafluorophosphate), or DIC (N,N'-Diisopropylcarbodiimide) with an additive like HOBt (Hydroxybenzotriazole).[7][8][9][10]
-
Fmoc Deprotection Solution: 20% piperidine in N,N-Dimethylformamide (DMF)[6]
-
Solvents: DMF, Dichloromethane (DCM), Methanol (MeOH)
-
Washing Solvents: DMF, DCM
-
Cleavage Cocktail: e.g., 95% Trifluoroacetic acid (TFA), 2.5% Triisopropylsilane (TIS), 2.5% Water. (Composition may vary based on peptide sequence and protecting groups).
-
Cold diethyl ether
-
Reaction vessel with a frit
-
Shaker or bubbler (for mixing)
Procedure
-
Resin Swelling: Swell the resin in DMF for at least 30 minutes in the reaction vessel.[6]
-
First Amino Acid Loading (if not using pre-loaded resin):
-
Dissolve the first Fmoc-amino acid (e.g., this compound) and a coupling agent in DMF.
-
Add the activation mixture to the swelled resin and shake for 2-4 hours.
-
Wash the resin thoroughly with DMF and DCM.
-
-
Fmoc Deprotection:
-
Amino Acid Coupling:
-
In a separate vial, pre-activate the next Fmoc-amino acid by dissolving it with the coupling reagent and DIPEA in DMF.
-
Add the activated amino acid solution to the deprotected resin.
-
Shake for 1-2 hours.
-
Wash the resin with DMF.
-
-
Repeat Deprotection and Coupling: Repeat steps 3 and 4 for each subsequent amino acid in the peptide sequence.
-
Final Fmoc Deprotection: After the last amino acid coupling, perform a final deprotection step (step 3).
-
Resin Washing and Drying: Wash the resin with DMF, followed by DCM, and then dry the resin under vacuum.
-
Cleavage and Side-Chain Deprotection:
-
Add the cleavage cocktail to the dry resin.
-
Gently mix for 2-3 hours at room temperature.
-
Filter the resin and collect the filtrate containing the cleaved peptide.
-
Wash the resin with a small amount of TFA.
-
-
Peptide Precipitation and Purification:
-
Precipitate the crude peptide by adding the TFA solution to cold diethyl ether.
-
Centrifuge to pellet the peptide.
-
Wash the peptide pellet with cold ether.
-
Dry the crude peptide.
-
Purify the peptide using techniques such as reverse-phase high-performance liquid chromatography (RP-HPLC).
-
Visualized Workflows
The following diagrams illustrate key processes involving this compound.
References
- 1. Fmoc Solid Phase Peptide Synthesis: Mechanism and Protocol - Creative Peptides [creative-peptides.com]
- 2. medchemexpress.com [medchemexpress.com]
- 3. chemistry.du.ac.in [chemistry.du.ac.in]
- 4. Fmoc-Ser-OH | CAS:73724-45-5 | High Purity | Manufacturer BioCrick [biocrick.com]
- 5. Fmoc-Ser-OH Novabiochem 73724-45-5 [sigmaaldrich.com]
- 6. chem.uci.edu [chem.uci.edu]
- 7. jpt.com [jpt.com]
- 8. youtube.com [youtube.com]
- 9. youtube.com [youtube.com]
- 10. youtube.com [youtube.com]
- 11. chempep.com [chempep.com]
An In-depth Technical Guide on the Solubility of Fmoc-Ser-OH-15N in Dimethylformamide (DMF)
For Researchers, Scientists, and Drug Development Professionals
This technical guide provides a comprehensive overview of the solubility of N-α-(9-Fluorenylmethoxycarbonyl)-L-serine-15N (Fmoc-Ser-OH-15N) in the polar aprotic solvent, N,N-Dimethylformamide (DMF). Understanding the solubility of this isotopically labeled amino acid derivative is critical for its effective use in various applications, particularly in solid-phase peptide synthesis (SPPS) and mass spectrometry-based proteomics. This document outlines available solubility data for the unlabeled analogue, provides a detailed experimental protocol for determining precise solubility, and presents a logical workflow for solubility testing.
Core Concepts in Solubility for Peptide Synthesis
The solubility of Fmoc-protected amino acids in solvents like DMF is a critical parameter for successful solid-phase peptide synthesis.[2][3] Poor solubility can lead to several challenges, including:
-
Incomplete Coupling Reactions: Undissolved Fmoc-amino acid is unavailable to react with the free N-terminus of the growing peptide chain, leading to deletion sequences in the final peptide.
-
Slow Reaction Kinetics: Low concentrations of the dissolved amino acid can slow down the coupling reaction, potentially requiring longer reaction times or resulting in incomplete incorporation.
-
Aggregation: Some Fmoc-amino acids have a tendency to aggregate in solution, which can reduce their effective concentration and hinder reactivity.[3]
DMF is a widely used solvent in SPPS due to its excellent ability to solvate a broad range of organic molecules, including protected amino acids and growing peptide chains.[4][5]
Data Presentation: Solubility of Fmoc-Serine Derivatives in DMF
The following table summarizes the available solubility data for Fmoc-L-serine and its tert-butyl protected analogue in DMF. This data serves as a strong proxy for the expected solubility of this compound.
| Compound | Solvent | Concentration | Molar Concentration (Approx.) | Observation | Source Citation |
| Fmoc-Ser-OH | DMF | 1 mmole in 2 ml | 0.5 M | Clearly soluble | |
| Fmoc-Ser-OH | DMF | 1% (w/v) | ~30.5 mM | Soluble (for optical activity measurement) | [6] |
| Fmoc-Ser(tBu)-OH | DMF | 25 mmole in 50 ml | 0.5 M | Clearly soluble | [2] |
| Fmoc-Ser(tBu)-OH | DMF | 1 mmole in 2 ml | 0.5 M | Clearly soluble | [2] |
It is important to note that factors such as the purity of the solvent, temperature, and the specific crystalline form of the amino acid derivative can influence solubility.[7] For applications requiring precise concentrations, it is highly recommended to determine the solubility experimentally under the specific laboratory conditions.
Experimental Protocol: Determining the Solubility of this compound in DMF
This protocol outlines a general method for determining the solubility of an Fmoc-amino acid in an organic solvent using the saturation shake-flask method.
1. Materials and Equipment:
-
This compound
-
High-purity, anhydrous DMF
-
Analytical balance
-
Several small, sealable glass vials
-
Constant temperature bath or incubator with shaker
-
Magnetic stirrer and stir bars (optional)
-
Syringes and syringe filters (e.g., 0.22 µm PTFE)
-
High-Performance Liquid Chromatography (HPLC) system with a UV detector
-
Volumetric flasks and pipettes
2. Procedure:
-
Preparation of Saturated Solutions:
-
Accurately weigh an excess amount of this compound into several vials. The amount should be more than what is expected to dissolve.
-
Precisely add a known volume of anhydrous DMF to each vial.
-
Seal the vials tightly to prevent solvent evaporation.
-
-
Equilibration:
-
Place the vials in a constant temperature bath set to the desired temperature (e.g., 25 °C).
-
Agitate the solutions vigorously using a shaker or magnetic stirrer for a predetermined period (e.g., 24-48 hours) to ensure equilibrium is reached.[2]
-
-
Sample Collection and Preparation:
-
After equilibration, cease agitation and allow the undissolved solid to settle.
-
Carefully withdraw a known volume of the supernatant (the clear, saturated solution) using a syringe.
-
Immediately filter the supernatant through a syringe filter into a clean vial to remove any suspended microcrystals.
-
Accurately dilute the filtered, saturated solution with a known volume of DMF to a concentration suitable for HPLC analysis.
-
-
Analysis:
-
Prepare a series of standard solutions of this compound in DMF with known concentrations.
-
Generate a calibration curve by injecting the standard solutions into the HPLC and plotting the peak area against concentration.
-
Inject the diluted sample of the saturated solution into the HPLC and determine its concentration from the calibration curve.
-
-
Calculation of Solubility:
-
Calculate the concentration of the original saturated solution by multiplying the concentration of the diluted sample by the dilution factor.
-
Express the solubility in the desired units (e.g., mg/mL or mol/L).
-
Mandatory Visualizations
The following diagrams illustrate the logical workflow for the experimental solubility determination and the general signaling pathway of utilizing Fmoc-protected amino acids in SPPS.
Caption: Experimental workflow for determining the solubility of this compound.
Caption: Logical workflow of Fmoc-amino acid dissolution for SPPS.
References
Isotopic Purity of Fmoc-Ser-OH-15N: An In-depth Technical Guide
For Researchers, Scientists, and Drug Development Professionals
This technical guide provides a comprehensive overview of the synthesis and determination of the isotopic purity of N-α-(9-Fluorenylmethoxycarbonyl)-L-serine-¹⁵N (Fmoc-Ser-OH-¹⁵N), a critical reagent in peptide synthesis and various research applications. This document outlines the synthetic pathway, details experimental protocols for assessing isotopic enrichment, and presents quantitative data in a clear, structured format.
Introduction
Fmoc-Ser-OH-¹⁵N is a stable isotope-labeled amino acid derivative widely used in solid-phase peptide synthesis (SPPS). The incorporation of the ¹⁵N isotope allows for the sensitive and specific tracking of the serine residue in various analytical techniques, including mass spectrometry (MS) and nuclear magnetic resonance (NMR) spectroscopy. The precise knowledge of its isotopic purity is paramount for the accuracy and reliability of quantitative proteomics, metabolic flux analysis, and structural biology studies. This guide serves as a technical resource for researchers utilizing Fmoc-Ser-OH-¹⁵N, providing essential information on its synthesis and quality control.
Synthesis of Fmoc-Ser-OH-¹⁵N
The synthesis of Fmoc-Ser-OH-¹⁵N is a two-step process that begins with the preparation of ¹⁵N-labeled L-serine, followed by the protection of the α-amino group with the Fmoc moiety.
Synthesis of L-Serine-¹⁵N
A common method for the synthesis of ¹⁵N-labeled L-serine is the enzymatic conversion of a corresponding α-keto acid using a dehydrogenase.
Experimental Protocol: Enzymatic Synthesis of L-Serine-¹⁵N
-
Materials:
-
β-Hydroxypyruvate
-
¹⁵NH₄Cl (99 atom % ¹⁵N)
-
Serine dehydrogenase
-
NADH (β-Nicotinamide adenine dinucleotide, reduced form)
-
Phosphate buffer (pH 7.5)
-
Cation exchange resin (e.g., Dowex 50W)
-
Ammonia solution
-
-
Procedure:
-
Dissolve β-hydroxypyruvate and ¹⁵NH₄Cl in phosphate buffer.
-
Add serine dehydrogenase and NADH to the solution.
-
Incubate the reaction mixture at a controlled temperature (e.g., 37°C) and monitor the reaction progress by HPLC.
-
Upon completion, acidify the reaction mixture and apply it to a cation exchange resin column to remove unreacted components and the enzyme.
-
Wash the column with deionized water.
-
Elute the ¹⁵N-labeled L-serine from the resin using an ammonia solution.
-
Lyophilize the eluate to obtain solid L-Serine-¹⁵N.
-
Fmoc Protection of L-Serine-¹⁵N
The α-amino group of the newly synthesized L-Serine-¹⁵N is then protected using 9-fluorenylmethoxycarbonyl chloride (Fmoc-Cl) or a similar Fmoc-donating reagent.
Experimental Protocol: Fmoc Protection
-
Materials:
-
L-Serine-¹⁵N
-
Fmoc-Cl (9-fluorenylmethoxycarbonyl chloride)
-
Sodium carbonate
-
Dioxane
-
Water
-
Ethyl acetate
-
Hexane
-
Hydrochloric acid (1 M)
-
-
Procedure:
-
Dissolve L-Serine-¹⁵N in an aqueous solution of sodium carbonate.
-
Add a solution of Fmoc-Cl in dioxane dropwise to the stirring serine solution at room temperature.
-
Allow the reaction to proceed for several hours. Monitor the reaction by thin-layer chromatography (TLC).
-
Once the reaction is complete, wash the mixture with ethyl acetate to remove unreacted Fmoc-Cl.
-
Acidify the aqueous layer with 1 M HCl to a pH of ~2, which will precipitate the Fmoc-Ser-OH-¹⁵N.
-
Extract the product into ethyl acetate.
-
Wash the organic layer with brine, dry over anhydrous sodium sulfate, and evaporate the solvent under reduced pressure.
-
Recrystallize the crude product from an ethyl acetate/hexane mixture to yield pure Fmoc-Ser-OH-¹⁵N.
-
Isotopic Purity Determination
The isotopic purity of the synthesized Fmoc-Ser-OH-¹⁵N is a critical parameter and is typically determined by mass spectrometry or NMR spectroscopy.
Quantitative Data Summary
Commercially available Fmoc-Ser-OH-¹⁵N and its protected form, Fmoc-Ser(tBu)-OH-¹⁵N, generally exhibit high isotopic purity. The following table summarizes typical specifications.
| Compound | Supplier | Stated Isotopic Purity (atom % ¹⁵N) |
| Fmoc-Ser(tBu)-OH-¹⁵N | Sigma-Aldrich | 98% |
| Fmoc-Ser-OH-¹⁵N | MedChemExpress | 98.0% |
| L-Serine-¹³C₃, ¹⁵N | Cambridge Isotope Laboratories | 99% ¹⁵N |
Mass Spectrometry Analysis
High-resolution mass spectrometry (HRMS) is the most common and accurate method for determining the isotopic enrichment of labeled compounds.
Experimental Protocol: Isotopic Purity Determination by LC-HRMS
-
Sample Preparation:
-
Accurately weigh and dissolve a small amount (e.g., 1 mg) of Fmoc-Ser-OH-¹⁵N in a suitable solvent (e.g., acetonitrile/water mixture) to a concentration of 1 mg/mL.
-
Perform serial dilutions to achieve a final concentration appropriate for the mass spectrometer (typically in the low µg/mL to ng/mL range).
-
-
Instrumentation and Parameters (Representative):
-
Liquid Chromatograph: UHPLC system
-
Column: C18 reversed-phase column (e.g., 2.1 x 50 mm, 1.7 µm)
-
Mobile Phase A: 0.1% formic acid in water
-
Mobile Phase B: 0.1% formic acid in acetonitrile
-
Gradient: A suitable gradient to elute the compound.
-
Mass Spectrometer: High-resolution mass spectrometer (e.g., Orbitrap or TOF)
-
Ionization Mode: Electrospray Ionization (ESI), positive or negative ion mode.
-
Scan Mode: Full scan in a mass range that includes the molecular ions of the labeled and unlabeled species.
-
Resolution: > 60,000
-
-
Data Analysis:
-
Identify the molecular ion peak for Fmoc-Ser-OH-¹⁵N ([M+H]⁺ or [M-H]⁻). The expected monoisotopic mass for the ¹⁵N-labeled compound is approximately 328.1165 Da, while the unlabeled counterpart is approximately 327.1192 Da.
-
Examine the isotopic distribution of the molecular ion peak.
-
Calculate the isotopic purity by determining the relative abundance of the ¹⁵N-labeled isotopologue compared to the unlabeled (¹⁴N) isotopologue. The formula for atom percent enrichment is:
Atom % ¹⁵N = [Intensity(¹⁵N) / (Intensity(¹⁵N) + Intensity(¹⁴N))] x 100
Note: Corrections for the natural abundance of other isotopes (e.g., ¹³C) should be applied for high accuracy.
-
NMR Spectroscopy Analysis
¹⁵N NMR spectroscopy can also be used to determine isotopic enrichment, although it is less common for routine purity checks than mass spectrometry.
Methodology Overview: ¹⁵N NMR Spectroscopy
-
Principle: The presence of the ¹⁵N nucleus gives rise to specific signals in the ¹⁵N NMR spectrum and introduces characteristic couplings in ¹H and ¹³C NMR spectra.
-
Procedure:
-
Dissolve a sufficient amount of the ¹⁵N-enriched sample in a suitable deuterated solvent.
-
Acquire a ¹⁵N NMR spectrum. The presence and intensity of the signal corresponding to the Fmoc-Ser-OH-¹⁵N nitrogen confirms enrichment.
-
Alternatively, in a high-resolution ¹H NMR spectrum, the signal of the proton attached to the ¹⁵N atom will appear as a doublet due to ¹J(¹⁵N-¹H) coupling, whereas the proton attached to a ¹⁴N atom will appear as a singlet (or a broad triplet). The ratio of the integrals of the doublet to the singlet can be used to estimate the isotopic enrichment.
-
-
Considerations: This method requires a higher sample concentration compared to mass spectrometry and a spectrometer equipped for ¹⁵N detection.
Visualizations
Signaling Pathways and Experimental Workflows
Caption: Workflow for the synthesis and isotopic purity analysis of this compound.
Commercial Availability and Application of 15N Labeled Serine: An In-depth Technical Guide
For Researchers, Scientists, and Drug Development Professionals
This guide provides a comprehensive overview of the commercial availability of 15N labeled serine, a critical tool for researchers in metabolomics, proteomics, and drug development. This document details the various forms of 15N serine, their specifications from key suppliers, and in-depth experimental protocols for its application in metabolic tracing and flux analysis.
Commercial Availability of 15N Labeled Serine
The commercial availability of 15N labeled serine is robust, with several major suppliers offering a range of products to suit diverse research needs. These products vary in their stereochemistry (L-form or DL-racemic mixture), isotopic enrichment, chemical purity, and the presence of protecting groups for specific synthetic applications. Below are tables summarizing the offerings from prominent vendors.
Table 1: Commercial Suppliers of L-Serine-15N
| Supplier | Product Name | Catalog Number (Example) | Isotopic Purity (atom % 15N) | Chemical Purity | Available Quantities |
| Sigma-Aldrich | L-Serine-15N | 609005 | 98% | ≥98% (CP) | 500 mg |
| Cambridge Isotope Laboratories, Inc. | L-Serine (¹⁵N, 98%) | NLM-2036 | 98% | ≥98% | 0.5 g, 1 g |
| MedChemExpress | L-Serine-15N | HY-112373S | Not Specified | >98% | 5 mg, 10 mg |
| BLD Pharm | L-Serine-15N | BD138435 | Not Specified | ≥98% | 50 mg, 100 mg, 250 mg |
| DC Chemicals | L-Serine-15N | DC49204 | Not Specified | >98% | Inquire |
Table 2: Commercial Suppliers of DL-Serine-15N
| Supplier | Product Name | Catalog Number (Example) | Isotopic Purity (atom % 15N) | Chemical Purity | Available Quantities |
| Sigma-Aldrich | DL-Serine-15N | 608998 | 98% | ≥98% (CP) | 250 mg, 1 g |
| Cambridge Isotope Laboratories, Inc. | DL-Serine (¹⁵N, 98%) | NLM-1531 | 98% | ≥98% | 250 mg, 1 g |
| Clearsynth | DL-Serine-15N | CS-T-99838 | Not Specified | Not Specified | Inquire |
Table 3: Commercial Suppliers of Fmoc-Protected L-Serine-15N
| Supplier | Product Name | Catalog Number (Example) | Isotopic Purity (atom % 15N) | Chemical Purity | Available Quantities |
| BOC Sciences | L-Serine-15N-N-FMOC | Not Specified | 98% | >95% (HPLC) | Inquire |
Key Applications of 15N Labeled Serine
15N labeled serine is a versatile tool in biological research. Its primary applications include:
-
Metabolic Flux Analysis (MFA): Tracing the nitrogen atom from serine allows for the quantification of its contribution to various metabolic pathways, including one-carbon metabolism and the biosynthesis of nucleotides and other amino acids.
-
Stable Isotope Labeling by Amino Acids in Cell Culture (SILAC): As a component of SILAC media, 15N serine enables the quantitative analysis of protein expression and turnover.
-
Mass Spectrometry Internal Standard: 15N labeled serine serves as an excellent internal standard for the accurate quantification of unlabeled serine in complex biological samples.[1]
-
Elucidation of Signaling Pathways: By tracking the metabolic fate of serine, researchers can gain insights into the regulation of signaling pathways involved in cell proliferation, cancer metabolism, and neurobiology.[1]
Signaling Pathways and Metabolic Networks Involving Serine
Serine is a central node in cellular metabolism, connecting glycolysis to several critical biosynthetic pathways. The diagrams below illustrate these connections.
The de novo synthesis of serine from the glycolytic intermediate 3-phosphoglycerate is a critical pathway, particularly in proliferating cells.[2] This pathway is often upregulated in cancer.[3]
Serine is a major source of one-carbon units for the folate and methionine cycles, which are essential for nucleotide synthesis and methylation reactions.[4][5]
Experimental Protocols
Metabolic Labeling of Adherent Mammalian Cells with 15N-Serine
This protocol provides a general procedure for labeling adherent mammalian cells with 15N-serine for metabolic flux analysis.
Materials:
-
Adherent mammalian cells of interest
-
Complete growth medium (e.g., DMEM)
-
Serine-free DMEM
-
Dialyzed Fetal Bovine Serum (dFBS)
-
15N-L-Serine
-
Phosphate-Buffered Saline (PBS), ice-cold
-
80% Methanol, pre-chilled to -80°C
-
6-well cell culture plates
-
Cell scraper
-
Microcentrifuge tubes
Procedure:
-
Cell Seeding: Seed cells in 6-well plates at a density that will result in approximately 80% confluency at the time of harvest. Culture cells in complete growth medium.
-
Media Preparation: Prepare the 15N-labeling medium by supplementing serine-free DMEM with the desired concentration of 15N-L-Serine and dFBS.
-
Labeling: When cells reach the desired confluency, aspirate the growth medium, wash the cells once with pre-warmed PBS, and then add the pre-warmed 15N-labeling medium.
-
Incubation: Incubate the cells for the desired period. The incubation time will depend on the specific metabolic pathway and the turnover rate of the metabolites of interest.
-
Metabolite Extraction:
-
Place the 6-well plates on ice.
-
Aspirate the labeling medium and wash the cells twice with ice-cold PBS.
-
Add 1 mL of pre-chilled (-80°C) 80% methanol to each well.
-
Scrape the cells and transfer the cell suspension to a microcentrifuge tube.
-
Vortex the tubes and incubate at -80°C for at least 20 minutes to precipitate proteins.
-
-
Sample Preparation for Analysis:
-
Centrifuge the tubes at maximum speed for 10 minutes at 4°C.
-
Carefully transfer the supernatant containing the metabolites to a new tube.
-
Dry the metabolite extract under a stream of nitrogen or using a vacuum concentrator.
-
The dried metabolites can be stored at -80°C until analysis by mass spectrometry.
-
Experimental Workflow for 15N-Serine Tracing and Mass Spectrometry Analysis
The following diagram outlines a typical workflow for a stable isotope tracing experiment using 15N-serine.
Conclusion
15N labeled serine is an indispensable tool for dissecting the complexities of cellular metabolism. Its commercial availability from a variety of suppliers ensures that researchers can select the appropriate product for their specific experimental needs. The protocols and pathway diagrams provided in this guide offer a solid foundation for designing and executing robust stable isotope tracing experiments to advance our understanding of the critical roles of serine in health and disease.
References
- 1. Overview of Serine Metabolism - Creative Proteomics [creative-proteomics.com]
- 2. Serine and Metabolism Regulation: A Novel Mechanism in Antitumor Immunity and Senescence - PMC [pmc.ncbi.nlm.nih.gov]
- 3. aacrjournals.org [aacrjournals.org]
- 4. researchgate.net [researchgate.net]
- 5. proteopedia.org [proteopedia.org]
Safeguarding Synthesis: A Technical Guide to the Optimal Storage of Fmoc-Amino Acids
For Researchers, Scientists, and Drug Development Professionals
This in-depth technical guide provides a comprehensive overview of the core principles and practices for the proper storage of 9-fluorenylmethyloxycarbonyl (Fmoc) protected amino acids. Adherence to these guidelines is critical for maintaining the chemical integrity, purity, and reactivity of these essential reagents, thereby ensuring the successful and reproducible synthesis of high-quality peptides for research and therapeutic development.
Core Principles of Fmoc-Amino Acid Stability
The stability of Fmoc-amino acids is primarily influenced by three environmental factors: temperature, moisture, and light . The Fmoc protecting group, while robust under the acidic conditions of side-chain deprotection, is susceptible to degradation under certain environmental stresses, leading to compromised purity and performance in solid-phase peptide synthesis (SPPS).
Temperature plays a crucial role in the long-term preservation of Fmoc-amino acids. While they can be temporarily stored at room temperature, prolonged exposure to elevated temperatures can accelerate degradation.[1] For extended storage, refrigeration or freezing is strongly recommended.
Moisture is a significant threat to the stability of Fmoc-amino acids. The presence of water can lead to the hydrolysis of the Fmoc group, resulting in the formation of the free amino acid and other impurities.[2] Therefore, it is imperative to store these compounds in a dry environment.
Light , particularly in solution, can cause the degradation of the Fmoc group.[2] While the solid powder form is more stable, it is a good laboratory practice to minimize exposure to light as a general precaution.
Recommended Storage Conditions
To ensure the long-term stability and integrity of Fmoc-amino acids, the following storage conditions are recommended. These recommendations are a synthesis of best practices from leading chemical suppliers and scientific literature.
| Parameter | Condition | Rationale |
| Temperature | ||
| Long-Term Storage (> 1 month): -20°C[1] | Minimizes the rate of all potential degradation pathways, ensuring maximum shelf-life. | |
| Short-Term Storage (< 1 month): 2°C to 8°C[2] | Suitable for working stock that is frequently accessed, balancing stability with convenience. | |
| Temporary Storage/Shipping: Ambient Temperature | Generally acceptable for short durations, though exposure to extreme heat should be avoided.[3] | |
| Moisture | Store in a tightly sealed container in a desiccator or a dry, inert atmosphere.[2] | Prevents hydrolysis of the Fmoc group and clumping of the powder. |
| Light | Store in an opaque container or in a dark location.[2] | Protects the light-sensitive Fmoc group from degradation. |
Handling Procedures for Maintaining Purity
Proper handling techniques are as crucial as storage conditions for preserving the quality of Fmoc-amino acids.
Acclimatization to Room Temperature
Before opening a refrigerated or frozen container of Fmoc-amino acid, it is essential to allow it to equilibrate to room temperature in a desiccator.[1] This prevents the condensation of atmospheric moisture onto the cold powder, which could compromise its stability.
Dispensing and Storage of Unused Material
When weighing out the required amount of Fmoc-amino acid, it is advisable to do so in a controlled environment with low humidity.[4] After dispensing, the container should be purged with an inert gas like nitrogen or argon, tightly resealed, and returned to the recommended storage conditions.
Impact of Impurities on Stability and Synthesis
The presence of certain impurities in Fmoc-amino acids can negatively impact their stability and the outcome of peptide synthesis.
| Impurity | Source | Impact on Stability and Synthesis |
| Free Amino Acid | Incomplete Fmoc protection during synthesis or degradation during storage. | Can promote the autocatalytic cleavage of the Fmoc group during storage.[5] In SPPS, it can lead to the double insertion of the amino acid. |
| Acetate/Acetic Acid | Residual solvent (ethyl acetate) from the manufacturing process.[5] | Can act as a capping agent during SPPS, leading to truncated peptide sequences.[5] |
| Ethyl Acetate | Residual solvent from the manufacturing process.[5] | Can slowly hydrolyze to form acetic acid during long-term storage, thereby increasing the risk of capping.[5] |
| Water | Absorption from the atmosphere due to improper storage or handling. | Promotes the hydrolysis of the Fmoc group, reducing the purity of the starting material.[2] |
Experimental Protocol: Long-Term Stability Study of Fmoc-Amino Acids
This protocol outlines a comprehensive methodology for conducting a long-term stability study of Fmoc-amino acids to determine their shelf-life under defined storage conditions.
Objective
To evaluate the stability of a solid Fmoc-amino acid over an extended period under controlled temperature and humidity conditions.
Materials
-
Fmoc-amino acid (e.g., Fmoc-L-Phenylalanine) of high purity (≥99%)
-
Stability chambers or incubators capable of maintaining constant temperature and humidity
-
Amber glass vials with airtight seals
-
Desiccator
-
Analytical balance
-
HPLC system with a UV detector
-
C18 reverse-phase HPLC column (e.g., 4.6 x 150 mm, 5 µm)
-
HPLC grade acetonitrile, water, and trifluoroacetic acid (TFA)
-
Volumetric flasks and pipettes
-
Syringe filters (0.45 µm)
Experimental Procedure
-
Initial Characterization (Time Zero):
-
Perform a complete analysis of the initial batch of the Fmoc-amino acid.
-
Appearance: Record the physical state (e.g., white crystalline powder).
-
Purity by HPLC: Determine the initial purity of the material using the HPLC method described in section 5.5. This will serve as the baseline.
-
Moisture Content: Determine the initial water content using Karl Fischer titration (if available).
-
-
Sample Preparation and Storage:
-
Aliquot approximately 100 mg of the Fmoc-amino acid into several amber glass vials.
-
Tightly seal the vials.
-
Place the vials into stability chambers set to the desired storage conditions. Recommended conditions to test include:
-
Long-Term: 2-8°C / ambient humidity
-
Accelerated: 25°C / 60% RH and 40°C / 75% RH
-
-
-
Stability Testing Schedule:
-
Withdraw one vial from each storage condition at predetermined time points.
-
Suggested time points for a long-term study: 0, 3, 6, 9, 12, 18, 24, and 36 months.
-
Suggested time points for an accelerated study: 0, 1, 2, 3, and 6 months.
-
-
Analysis of Stability Samples:
-
At each time point, allow the withdrawn vial to equilibrate to room temperature in a desiccator before opening.
-
Perform the same set of analyses as in the initial characterization (Appearance and Purity by HPLC).
-
HPLC Method for Purity Assessment
-
Mobile Phase A: 0.1% TFA in water
-
Mobile Phase B: 0.1% TFA in acetonitrile
-
Gradient: A linear gradient from 30% to 90% B over 15 minutes.
-
Flow Rate: 1.0 mL/min
-
Column Temperature: 25°C
-
Detection: UV at 265 nm
-
Injection Volume: 10 µL
-
Sample Preparation: Prepare a stock solution of the Fmoc-amino acid in a 1:1 mixture of acetonitrile and water to a final concentration of 1 mg/mL. Filter the solution through a 0.45 µm syringe filter before injection.[1]
Data Analysis and Interpretation
-
Calculate the percentage purity of the Fmoc-amino acid at each time point.
-
Record any changes in physical appearance.
-
Identify and quantify any significant degradation products.
-
Plot the percentage purity versus time for each storage condition to determine the degradation rate.
-
The shelf-life can be defined as the time at which the purity drops below a predetermined specification (e.g., 98%).
Visualizing Key Processes
Recommended Workflow for Handling and Storage
Caption: Recommended workflow for handling and storage.
Potential Degradation Pathways
Caption: Potential degradation pathways for Fmoc-amino acids.
Conclusion
The chemical integrity of Fmoc-amino acids is a cornerstone of successful solid-phase peptide synthesis. By implementing stringent storage and handling protocols, researchers and drug development professionals can significantly mitigate the risk of reagent degradation. The core principles of maintaining a cold, dry, and dark environment are paramount. Furthermore, a thorough understanding of potential impurities and the implementation of robust analytical methods for quality control are essential for ensuring the reliability and reproducibility of synthetic outcomes. This guide provides the foundational knowledge and practical protocols to safeguard these critical reagents, ultimately contributing to the successful synthesis of high-purity peptides for a wide range of scientific applications.
References
- 1. (Fluoren-9-ylmethoxy)carbonyl (Fmoc) amino acid azides: Synthesis, isolation, characterisation, stability and application to synthesis of peptides - Journal of the Chemical Society, Perkin Transactions 1 (RSC Publishing) [pubs.rsc.org]
- 2. benchchem.com [benchchem.com]
- 3. researchgate.net [researchgate.net]
- 4. benchchem.com [benchchem.com]
- 5. merckmillipore.com [merckmillipore.com]
The Cornerstone of Peptide Science: A Technical Guide to Solid-Phase Peptide Synthesis
For Researchers, Scientists, and Drug Development Professionals
Solid-Phase Peptide Synthesis (SPPS) has revolutionized the landscape of peptide chemistry, providing a robust and efficient methodology for the synthesis of peptides. Developed by R. Bruce Merrifield, who was awarded the 1984 Nobel Prize in Chemistry for this work, SPPS has become an indispensable tool in both academic research and the pharmaceutical industry. This guide provides an in-depth exploration of the core principles of SPPS, detailing the chemical strategies, experimental protocols, and critical considerations for the successful synthesis of peptides.
Core Principles of Solid-Phase Peptide Synthesis
The fundamental concept of SPPS involves the stepwise addition of amino acids to a growing peptide chain that is covalently anchored to an insoluble solid support, typically a polymeric resin.[1][2] This approach offers several key advantages over traditional solution-phase synthesis:
-
Simplified Purification: Excess reagents and soluble by-products are easily removed by simple filtration and washing of the resin-bound peptide, eliminating the need for complex purification of intermediates.[3][4]
-
Use of Excess Reagents: High concentrations of reagents can be used to drive reactions to completion, maximizing the yield of each coupling step.[5]
-
Automation: The repetitive nature of the synthesis cycle is highly amenable to automation, enabling the efficient production of long and complex peptide sequences.[4]
The SPPS process is cyclical, with each cycle consisting of two main chemical steps: Nα-deprotection and coupling. This cycle is repeated until the desired peptide sequence is assembled. The final step involves the cleavage of the completed peptide from the solid support and the simultaneous removal of any side-chain protecting groups.[2][4]
Two primary orthogonal protection strategies are predominantly used in SPPS: the Fmoc/tBu strategy and the Boc/Bzl strategy. The choice of strategy dictates the types of protecting groups, deprotection reagents, and cleavage conditions used throughout the synthesis.
The Fmoc/tBu Strategy
The 9-fluorenylmethyloxycarbonyl (Fmoc)/tert-butyl (tBu) strategy is the most widely used approach in modern SPPS. It is characterized by the use of the base-labile Fmoc group for the temporary protection of the Nα-amino group and acid-labile tBu-based groups for the protection of amino acid side chains.[6][7] This orthogonality allows for the selective removal of the Fmoc group at each cycle without affecting the side-chain protecting groups.
The Boc/Bzl Strategy
The tert-butyloxycarbonyl (Boc)/benzyl (Bzl) strategy, pioneered by Merrifield, utilizes the acid-labile Boc group for Nα-protection and more acid-stable benzyl-based groups for side-chain protection.[1][8] The Boc group is removed with a moderately strong acid, such as trifluoroacetic acid (TFA), while the side-chain protecting groups and the peptide-resin linkage are cleaved with a much stronger acid, typically anhydrous hydrogen fluoride (HF).[8][9]
The Solid Support: Resins and Linkers
The choice of resin is a critical parameter in SPPS, as it serves as the insoluble support for peptide chain assembly. The resin must be chemically inert to the reaction conditions and possess good swelling properties in the solvents used for synthesis.[6] The most common resins are based on cross-linked polystyrene.[6]
A linker molecule is covalently attached to the resin and serves as the anchoring point for the first amino acid. The nature of the linker determines the C-terminal functionality of the cleaved peptide (e.g., carboxylic acid or amide) and the conditions required for the final cleavage.[10]
Table 1: Common Resins Used in Solid-Phase Peptide Synthesis
| Resin Name | Linker Type | C-Terminal Functionality | Cleavage Conditions | Typical Loading Capacity (mmol/g) |
| Wang Resin | p-Alkoxybenzyl alcohol | Carboxylic Acid | Moderate to strong acid (e.g., 50-95% TFA)[5] | 0.5 - 1.2[6] |
| 2-Chlorotrityl Chloride (2-CTC) Resin | Chlorotrityl | Carboxylic Acid | Very mild acid (e.g., 1-2% TFA, acetic acid)[10] | 1.0 - 2.0[6] |
| Rink Amide Resin | Knorr/Rink linker | Amide | Moderate acid (e.g., 20-50% TFA)[1][11] | 0.4 - 0.8[6] |
| Merrifield Resin | Chloromethyl | Carboxylic Acid | Strong acid (e.g., anhydrous HF) | 0.5 - 2.0 |
The SPPS Cycle: A Step-by-Step Workflow
The synthesis of a peptide on a solid support follows a repetitive cycle of deprotection, washing, coupling, and washing. The following sections detail the key steps in the context of the widely used Fmoc/tBu strategy.
Resin Swelling
Prior to the commencement of synthesis, the resin must be swollen in a suitable solvent to allow for the penetration of reagents and to make the reactive sites accessible.[6]
Nα-Fmoc Deprotection
The first step in each cycle is the removal of the Nα-Fmoc protecting group to expose a free amine for the subsequent coupling reaction. This is typically achieved by treating the resin with a solution of a secondary amine, most commonly piperidine, in a polar aprotic solvent like N,N-dimethylformamide (DMF).[12][13]
Table 2: Comparison of Common Fmoc Deprotection Reagents
| Reagent | Typical Concentration | Deprotection Time | Advantages | Disadvantages |
| Piperidine | 20% in DMF | 5-20 minutes[9] | Highly effective, well-established | Can cause side reactions with sensitive residues |
| DBU (1,8-Diazabicyclo[5.4.0]undec-7-ene) | 2% DBU / 2% Piperidine in DMF | 2-10 minutes | Faster than piperidine, useful for difficult sequences[12] | Stronger base, increased risk of side reactions |
| Morpholine | 50% in DMF | 30-60 minutes | Milder, suitable for base-sensitive peptides[12] | Slower deprotection |
Amino Acid Coupling
Following deprotection and thorough washing, the next Fmoc-protected amino acid is coupled to the newly exposed N-terminal amine of the growing peptide chain. This reaction requires the activation of the carboxylic acid of the incoming amino acid, which is facilitated by a coupling reagent.
Table 3: Comparison of Common Coupling Reagents for Fmoc-SPPS
| Reagent | Class | Advantages | Disadvantages |
| HBTU / HATU | Aminium/Uronium Salt | High coupling efficiency, fast reaction times[14][15] | Potential for side reactions (guanidinylation with HBTU)[14] |
| COMU | Aminium/Uronium Salt | High efficiency, safer alternative to HBTU/HATU[15][16] | Higher cost |
| DIC / HOBt (or Oxyma) | Carbodiimide / Additive | Cost-effective, low racemization[2][15] | Slower reaction times compared to aminium salts |
Monitoring the Reaction
To ensure the completeness of the coupling reaction, a qualitative colorimetric test, such as the Kaiser test, is often employed. The Kaiser test detects the presence of primary amines on the resin. A positive result (blue color) indicates incomplete coupling, while a negative result (yellow/colorless) signifies a successful coupling.[17][18]
Final Cleavage and Deprotection
Once the desired peptide sequence has been assembled, the final step is to cleave the peptide from the resin and remove the side-chain protecting groups. In the Fmoc/tBu strategy, this is typically achieved in a single step using a strong acid, most commonly trifluoroacetic acid (TFA), in the presence of scavengers.[19][20] Scavengers are nucleophilic compounds that "trap" the reactive carbocations generated from the cleavage of the side-chain protecting groups, thereby preventing unwanted side reactions with sensitive amino acid residues.[9][21]
Table 4: Common Cleavage Cocktails for Fmoc-SPPS
| Cleavage Cocktail | Composition (v/v/v) | Application |
| Standard Cocktail | 95% TFA / 2.5% H₂O / 2.5% TIS | General purpose for peptides without highly sensitive residues.[21] |
| Reagent K | 82.5% TFA / 5% Phenol / 5% H₂O / 5% Thioanisole / 2.5% EDT | Recommended for peptides containing Cys, Met, or Trp.[20] |
| Reagent R | 90% TFA / 5% Thioanisole / 3% EDT / 2% Anisole | For peptides containing Arg(Pbf/Pmc) and other sensitive residues.[20] |
Experimental Protocols
The following section provides detailed, step-by-step protocols for the key experimental procedures in manual Fmoc-based SPPS.
Resin Swelling
-
Place the desired amount of resin in a suitable reaction vessel.
-
Add the primary synthesis solvent (e.g., DMF or DCM) to the resin (approximately 10-15 mL per gram of resin).[22]
-
Gently agitate the resin suspension for 30-60 minutes at room temperature to allow for complete swelling.[5]
-
Drain the solvent by filtration.
Nα-Fmoc Deprotection with Piperidine
-
Wash the swollen resin with DMF (3 x resin volume).
-
Add a solution of 20% piperidine in DMF (v/v) to the resin.
-
Agitate the mixture for 3 minutes at room temperature.[12]
-
Drain the deprotection solution.
-
Add a fresh portion of 20% piperidine in DMF and agitate for an additional 10-15 minutes.[12]
-
Drain the deprotection solution and wash the resin thoroughly with DMF (5-7 times) to remove all traces of piperidine and the dibenzofulvene-piperidine adduct.[12]
Amino Acid Coupling with HBTU/DIEA
-
In a separate vessel, dissolve the Fmoc-amino acid (3-4 equivalents relative to resin loading) and HBTU (3-4 equivalents) in DMF.
-
Add N,N-Diisopropylethylamine (DIEA) (6-8 equivalents) to the amino acid solution and allow the mixture to pre-activate for 1-2 minutes.
-
Add the activated amino acid solution to the deprotected peptide-resin.
-
Agitate the mixture at room temperature for 1-2 hours.
-
Monitor the completion of the coupling reaction using the Kaiser test.
-
Once the coupling is complete, drain the reaction solution and wash the resin with DMF (3-5 times) and DCM (3-5 times).
Kaiser Test for Monitoring Coupling Completion
-
Carefully remove a small sample of the peptide-resin (approximately 10-15 beads) from the reaction vessel.[23]
-
Wash the resin beads thoroughly with a solvent such as DCM or DMF to remove any residual reagents.
-
Add 2-3 drops of each of the three Kaiser test reagents (Reagent A: KCN in pyridine, Reagent B: ninhydrin in n-butanol, Reagent C: phenol in n-butanol) to the resin beads in a small test tube.[23]
-
Heat the test tube at 100-110°C for 5 minutes.[23]
-
Observe the color of the beads and the solution.
-
Blue beads/solution: Incomplete coupling (free primary amine present).
-
Yellow/Colorless beads/solution: Complete coupling.
-
Peptide Cleavage from Wang Resin
-
Ensure the N-terminal Fmoc group has been removed.
-
Wash the peptide-resin thoroughly with DCM and dry under vacuum for at least 1 hour.[21]
-
In a fume hood, prepare the appropriate cleavage cocktail based on the peptide's amino acid composition (see Table 4).
-
Add the freshly prepared cleavage cocktail to the dried resin (approximately 10-20 mL per gram of resin).[21]
-
Gently agitate the mixture at room temperature for 2-4 hours.[21]
-
Filter the cleavage mixture to separate the resin and collect the filtrate.
-
Add the filtrate dropwise to a 10-fold volume of cold diethyl ether to precipitate the peptide.[6]
-
Collect the precipitated peptide by centrifugation and wash the pellet with cold diethyl ether.[24]
-
Dry the crude peptide pellet under vacuum.
Conclusion
Solid-phase peptide synthesis remains a powerful and versatile technique for the chemical synthesis of peptides. A thorough understanding of the fundamental principles, including the choice of chemical strategy, resin, coupling reagents, and cleavage conditions, is paramount for the successful synthesis of high-purity peptides. This guide provides a comprehensive overview of these core concepts and detailed experimental protocols to serve as a valuable resource for researchers, scientists, and professionals in the field of drug development. By carefully considering the factors outlined herein, practitioners can optimize their synthetic strategies to achieve their desired peptide targets with high efficiency and purity.
References
- 1. peptide.com [peptide.com]
- 2. benchchem.com [benchchem.com]
- 3. benchchem.com [benchchem.com]
- 4. datapott.com [datapott.com]
- 5. chem.uci.edu [chem.uci.edu]
- 6. chemistry.du.ac.in [chemistry.du.ac.in]
- 7. benchchem.com [benchchem.com]
- 8. Boc Deprotection - TFA [commonorganicchemistry.com]
- 9. benchchem.com [benchchem.com]
- 10. peptide.com [peptide.com]
- 11. benchchem.com [benchchem.com]
- 12. benchchem.com [benchchem.com]
- 13. peptide.com [peptide.com]
- 14. benchchem.com [benchchem.com]
- 15. bachem.com [bachem.com]
- 16. pubs.acs.org [pubs.acs.org]
- 17. americanpeptidesociety.org [americanpeptidesociety.org]
- 18. peptide.com [peptide.com]
- 19. Fmoc Resin Cleavage and Deprotection [sigmaaldrich.com]
- 20. benchchem.com [benchchem.com]
- 21. benchchem.com [benchchem.com]
- 22. eprints.whiterose.ac.uk [eprints.whiterose.ac.uk]
- 23. benchchem.com [benchchem.com]
- 24. benchchem.com [benchchem.com]
Methodological & Application
Application Notes and Protocols for Solid-Phase Peptide Synthesis (SPPS) using Fmoc-Ser-OH-¹⁵N
For Researchers, Scientists, and Drug Development Professionals
This document provides a detailed protocol for the solid-phase peptide synthesis (SPPS) of peptides containing ¹⁵N-labeled serine using Fmoc-Ser(tBu)-OH-¹⁵N. The site-specific incorporation of stable isotopes like ¹⁵N into peptides is a powerful technique for quantitative proteomics, structural biology studies using nuclear magnetic resonance (NMR), and metabolic labeling.[1][2][3] The Fmoc/tBu strategy is widely employed due to its mild deprotection conditions, making it compatible with a wide range of peptide modifications.[4][5][6]
Introduction
Solid-phase peptide synthesis (SPPS) is the cornerstone of modern peptide chemistry, allowing for the efficient and stepwise assembly of amino acids into a desired peptide sequence on an insoluble resin support. The 9-fluorenylmethyloxycarbonyl (Fmoc) protecting group for the α-amino group is central to this strategy. It is base-labile and can be removed under gentle conditions, leaving acid-labile side-chain protecting groups intact.[4][5][7]
The serine side-chain hydroxyl group is reactive and must be protected during synthesis to prevent side reactions. A common protecting group is the tert-Butyl (tBu) group, which is removed during the final cleavage from the resin with a strong acid like trifluoroacetic acid (TFA).[5] Therefore, the building block used in this protocol is Fmoc-Ser(tBu)-OH-¹⁵N. The ¹⁵N label provides a specific probe for downstream applications without altering the chemical properties of the resulting peptide.
Key Applications:
-
NMR Spectroscopy: ¹⁵N-labeled peptides are essential for a variety of NMR experiments to determine three-dimensional structures, study protein-ligand interactions, and probe peptide dynamics.[3]
-
Quantitative Proteomics: Peptides containing ¹⁵N-labeled amino acids can serve as internal standards for accurate quantification of proteins in complex biological samples by mass spectrometry.[2][3]
-
Metabolic Labeling: Labeled peptides can be used to trace metabolic pathways and study the fate of peptides and proteins in biological systems.[2][3]
Experimental Protocols
This section details the step-by-step procedure for manual solid-phase peptide synthesis using Fmoc-Ser(tBu)-OH-¹⁵N. The protocol covers resin selection and preparation, and the iterative cycles of deprotection, washing, coupling, and capping, followed by final cleavage and deprotection.
Materials and Reagents
| Reagent/Material | Grade | Supplier | Notes |
| Fmoc-Ser(tBu)-OH-¹⁵N | Peptide synthesis grade | e.g., Sigma-Aldrich[8] | Isotopic purity >98% |
| Other Fmoc-amino acids | Peptide synthesis grade | Various | |
| Rink Amide Resin | 100-200 mesh | Various | For C-terminal amide peptides. |
| Dichloromethane (DCM) | Anhydrous | Various | |
| N,N-Dimethylformamide (DMF) | Peptide synthesis grade | Various | |
| Piperidine | Reagent grade | Various | |
| Diisopropylethylamine (DIPEA) | Reagent grade | Various | |
| HBTU (or other coupling agent) | Peptide synthesis grade | Various | |
| Trifluoroacetic acid (TFA) | Reagent grade | Various | Corrosive, handle in fume hood. |
| Triisopropylsilane (TIS) | Reagent grade | Various | Scavenger |
| Water | HPLC grade | Various | Scavenger |
Workflow Overview
The overall workflow for the solid-phase synthesis of a peptide containing ¹⁵N-labeled serine is depicted below.
Caption: General workflow for Fmoc solid-phase peptide synthesis.
Detailed Synthesis Steps (0.1 mmol scale)
Step 1: Resin Preparation
-
Place 0.1 mmol of Rink Amide resin in a reaction vessel.
-
Swell the resin in DMF (5-10 mL) for 1-2 hours at room temperature with gentle agitation.[9]
-
Drain the DMF.
Step 2: Fmoc Deprotection
-
Add a solution of 20% piperidine in DMF (5 mL) to the resin.
-
Agitate for 5-10 minutes at room temperature.
-
Drain the solution.
-
Repeat the piperidine treatment for another 10-15 minutes.
-
Drain the solution and wash the resin thoroughly with DMF (5 x 10 mL).
Step 3: Amino Acid Coupling (Incorporation of Fmoc-Ser(tBu)-OH-¹⁵N)
-
In a separate vial, dissolve Fmoc-Ser(tBu)-OH-¹⁵N (0.4 mmol, 4 eq.) and HBTU (0.38 mmol, 3.8 eq.) in DMF (2 mL).
-
Add DIPEA (0.8 mmol, 8 eq.) to the amino acid solution and mix for 1-2 minutes to activate.
-
Immediately add the activated amino acid solution to the deprotected resin.
-
Agitate the reaction mixture for 1-2 hours at room temperature.
-
To monitor coupling completion, perform a Kaiser test. A negative result (beads remain colorless) indicates a complete reaction.
-
Drain the coupling solution and wash the resin with DMF (5 x 10 mL).
Step 4: Peptide Chain Elongation
-
Repeat steps 2 (Fmoc Deprotection) and 3 (Amino Acid Coupling) for each subsequent amino acid in the peptide sequence.
Step 5: Final Cleavage and Deprotection
-
After the final amino acid has been coupled and the N-terminal Fmoc group has been removed, wash the resin with DMF (3 x 10 mL) followed by DCM (3 x 10 mL).
-
Dry the resin under a stream of nitrogen.
-
Prepare a cleavage cocktail. A common cocktail is Reagent K: TFA/Water/TIS (95:2.5:2.5 v/v/v).[10] Caution: TFA is highly corrosive and must be handled in a fume hood.
-
Add the cleavage cocktail (5-10 mL) to the dried resin.
-
Agitate gently for 2-3 hours at room temperature.
-
Filter the resin and collect the filtrate containing the cleaved peptide into a centrifuge tube.
-
Wash the resin with a small amount of fresh TFA and combine the filtrates.
Step 6: Peptide Precipitation and Purification
-
Precipitate the crude peptide by adding the TFA filtrate to cold diethyl ether (40-50 mL).
-
Centrifuge the mixture to pellet the peptide, and decant the ether.
-
Wash the peptide pellet with cold diethyl ether two more times.
-
Dry the crude peptide pellet under vacuum.
-
Purify the peptide using reverse-phase high-performance liquid chromatography (RP-HPLC).
-
Confirm the identity and isotopic incorporation of the final peptide by mass spectrometry.
Quantitative Data Summary
The following tables provide typical quantitative parameters for the synthesis protocol.
Table 1: Reagent Equivalents and Reaction Times
| Step | Reagent | Equivalents (relative to resin loading) | Typical Reaction Time |
| Deprotection | 20% Piperidine in DMF | - | 2 x 10-15 min |
| Coupling | Fmoc-Amino Acid | 3-5 | 1-2 hours |
| Coupling Agent (e.g., HBTU) | 3-5 | 1-2 hours | |
| Base (e.g., DIPEA) | 6-10 | 1-2 hours | |
| Cleavage | Cleavage Cocktail | - | 2-3 hours |
Table 2: Standard Cleavage Cocktail Composition
| Component | Percentage (v/v) | Purpose |
| Trifluoroacetic acid (TFA) | 95% | Cleaves peptide from resin and removes side-chain protecting groups. |
| Water | 2.5% | Cation scavenger. |
| Triisopropylsilane (TIS) | 2.5% | Cation scavenger, prevents side reactions. |
Signaling Pathways and Logical Relationships
The logical relationship between the key chemical groups during one cycle of Fmoc-SPPS is illustrated below.
References
- 1. Determination of multiply labeled serine and glycine isotopomers in human plasma by isotope dilution negative-ion chemical ionization mass spectrometry - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. benchchem.com [benchchem.com]
- 3. benchchem.com [benchchem.com]
- 4. Advances in Fmoc solid‐phase peptide synthesis - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Fmoc / t-Bu Solid Phase Synthesis - Sunresin [seplite.com]
- 6. luxembourg-bio.com [luxembourg-bio.com]
- 7. Fmoc Solid-Phase Peptide Synthesis | Springer Nature Experiments [experiments.springernature.com]
- 8. Fmoc-Ser(tBu)-OH-15N 98 atom % 15N | Sigma-Aldrich [sigmaaldrich.com]
- 9. chem.uci.edu [chem.uci.edu]
- 10. Fmoc Solid Phase Peptide Synthesis: Mechanism and Protocol - Creative Peptides [creative-peptides.com]
Application Notes and Protocols for the Incorporation of Fmoc-Ser-OH-15N into Peptide Sequences
For Researchers, Scientists, and Drug Development Professionals
Introduction
Stable isotope labeling of peptides with ¹⁵N is a powerful technique for a variety of applications in proteomics, structural biology, and drug development. The incorporation of ¹⁵N-labeled amino acids, such as Fmoc-Ser-OH-¹⁵N, into a peptide sequence enables quantitative analysis by mass spectrometry (MS) and detailed structural and dynamic studies by nuclear magnetic resonance (NMR) spectroscopy.[1][2][3] This document provides detailed application notes and protocols for the successful incorporation of Fmoc-Ser-OH-¹⁵N into a peptide sequence using solid-phase peptide synthesis (SPPS). The commercially available and widely used tert-butyl protected form, Fmoc-Ser(tBu)-OH-¹⁵N, will be the focus of these protocols.[4][5][6]
Chemical Properties of Fmoc-Ser(tBu)-OH-¹⁵N
A thorough understanding of the chemical properties of the labeled amino acid is crucial for its effective use.
| Property | Value | Reference |
| Molecular Formula | C₂₂H₂₅¹⁵NO₅ | [6] |
| Molecular Weight | 384.43 g/mol | [6] |
| Isotopic Purity | Typically ≥98 atom % ¹⁵N | [5] |
| Appearance | White to off-white solid | --- |
| Solubility | Soluble in common SPPS solvents such as N,N-dimethylformamide (DMF) and N-methyl-2-pyrrolidone (NMP). | --- |
| Storage | Store at 2-8°C, desiccated. | [6] |
Experimental Protocols
The following protocols are based on the well-established Fmoc/tBu strategy for solid-phase peptide synthesis.[4]
Solid-Phase Peptide Synthesis (SPPS) Protocol
This protocol outlines the manual incorporation of a single Fmoc-Ser(tBu)-OH-¹⁵N residue. The steps can be adapted for automated peptide synthesizers.
Materials and Reagents:
-
Fmoc-Ser(tBu)-OH-¹⁵N
-
SPPS resin (e.g., Rink Amide resin for C-terminal amides, Wang resin for C-terminal acids)
-
N,N-Dimethylformamide (DMF), peptide synthesis grade
-
Dichloromethane (DCM), peptide synthesis grade
-
Piperidine, peptide synthesis grade
-
Coupling reagents: e.g., HBTU/HOBt or HATU
-
N,N-Diisopropylethylamine (DIPEA)
-
Cleavage cocktail (e.g., 95% Trifluoroacetic acid (TFA), 2.5% water, 2.5% triisopropylsilane (TIS))
-
Cold diethyl ether
-
Kaiser test kit
Procedure:
-
Resin Swelling: Swell the resin in DMF for at least 30 minutes in a reaction vessel.
-
Fmoc Deprotection: Remove the Fmoc group from the N-terminal amino acid of the growing peptide chain by treating the resin with 20% piperidine in DMF (v/v) for 5 minutes, followed by a second treatment for 15 minutes.
-
Washing: Thoroughly wash the resin with DMF (5 times) and DCM (3 times) to remove residual piperidine and byproducts.
-
Kaiser Test: Perform a Kaiser test to confirm the presence of a free primary amine. A positive result (blue color) indicates successful Fmoc deprotection.
-
Amino Acid Coupling:
-
In a separate vial, dissolve Fmoc-Ser(tBu)-OH-¹⁵N (3-5 equivalents relative to the resin loading) and a suitable coupling reagent (e.g., HBTU/HOBt or HATU, 3-5 equivalents) in DMF.
-
Add DIPEA (6-10 equivalents) to the amino acid solution and pre-activate for 1-2 minutes.
-
Add the activated Fmoc-Ser(tBu)-OH-¹⁵N solution to the resin.
-
Agitate the reaction mixture for 1-2 hours at room temperature.
-
-
Washing: Wash the resin with DMF (5 times) and DCM (3 times).
-
Kaiser Test: Perform a Kaiser test to confirm the completion of the coupling reaction. A negative result (yellow color) indicates a successful coupling. If the test is positive, a second coupling may be necessary.
-
Chain Elongation: Repeat steps 2-7 for each subsequent amino acid in the peptide sequence.
-
Final Deprotection and Cleavage: Once the peptide synthesis is complete, wash the resin with DCM and dry it under vacuum. Treat the resin with a cleavage cocktail for 2-3 hours to cleave the peptide from the resin and remove the side-chain protecting groups.
-
Peptide Precipitation and Purification: Precipitate the crude peptide by adding the cleavage mixture to cold diethyl ether. Centrifuge to pellet the peptide, decant the ether, and wash the pellet with cold ether. The crude peptide can then be purified by reverse-phase high-performance liquid chromatography (RP-HPLC).
Characterization and Verification of ¹⁵N Incorporation
Confirmation of the successful incorporation and quantification of the isotopic label is a critical step.
a) Mass Spectrometry (MS)
-
Principle: The incorporation of a ¹⁵N atom results in a mass increase of approximately 1 Dalton compared to the corresponding unlabeled peptide.
-
Procedure:
-
Analyze the purified peptide by electrospray ionization (ESI) or matrix-assisted laser desorption/ionization (MALDI) mass spectrometry.
-
Compare the observed molecular weight of the synthesized peptide with the theoretical molecular weight of the ¹⁵N-labeled peptide.
-
For quantitative assessment, analyze the isotopic distribution of the peptide. The relative intensities of the isotopic peaks can be used to determine the percentage of ¹⁵N incorporation.[7][8]
-
-
Data Interpretation: A successful incorporation will show a mass shift corresponding to the number of ¹⁵N labels introduced. High-resolution mass spectrometry can resolve the isotopic peaks and allow for accurate quantification of the enrichment level.
b) Nuclear Magnetic Resonance (NMR) Spectroscopy
-
Principle: ¹⁵N is a spin-½ nucleus and is NMR active. Two-dimensional ¹H-¹⁵N heteronuclear single quantum coherence (HSQC) spectroscopy is a powerful method to directly observe the ¹⁵N-labeled amide groups.[2]
-
Procedure:
-
Dissolve the purified ¹⁵N-labeled peptide in a suitable NMR buffer (e.g., H₂O/D₂O 90/10).
-
Acquire a 2D ¹H-¹⁵N HSQC spectrum.
-
-
Data Interpretation: Each amide group in the peptide will give rise to a cross-peak in the HSQC spectrum, with coordinates corresponding to the chemical shifts of the amide proton (¹H) and the amide nitrogen (¹⁵N). The presence of a peak corresponding to the ¹⁵N-labeled serine residue confirms its incorporation.
Quantitative Data Summary
The following table provides representative data for the incorporation of Fmoc-Ser(tBu)-OH-¹⁵N. Actual results may vary depending on the peptide sequence, synthesis scale, and instrumentation.
| Parameter | Representative Value | Method of Determination |
| Coupling Efficiency | >99% | Kaiser Test / HPLC analysis of a cleaved aliquot |
| Isotopic Enrichment | >98% | Mass Spectrometry (Isotopic distribution analysis) |
| Final Purity (after HPLC) | >95% | Analytical RP-HPLC |
| Overall Yield | 15-40% (sequence dependent) | Gravimetric analysis |
Visualizations
Caption: Workflow for SPPS incorporation of Fmoc-Ser-OH-15N.
Caption: Applications of ¹⁵N-labeled peptides.
References
- 1. Frontiers | Application of Parallel Reaction Monitoring in 15N Labeled Samples for Quantification [frontiersin.org]
- 2. protein-nmr.org.uk [protein-nmr.org.uk]
- 3. Cell-free synthesis of 15N-labeled proteins for NMR studies - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. benchchem.com [benchchem.com]
- 5. Fmoc-Ser(tBu)-OH-15N 98 atom % 15N | Sigma-Aldrich [sigmaaldrich.com]
- 6. alfa-chemistry.com [alfa-chemistry.com]
- 7. benchchem.com [benchchem.com]
- 8. Method for the Determination of ¹⁵N Incorporation Percentage in Labeled Peptides and Proteins - PubMed [pubmed.ncbi.nlm.nih.gov]
Application Notes and Protocols for 15N Metabolic Labeling of Proteins Using Labeled Serine
For Researchers, Scientists, and Drug Development Professionals
Introduction
Stable isotope labeling with amino acids in cell culture (SILAC) is a powerful technique for quantitative mass spectrometry-based proteomics. While traditionally reliant on labeled arginine and lysine, the use of other labeled amino acids, such as ¹⁵N-Serine, offers unique advantages for studying specific metabolic pathways and protein dynamics. Serine is a central node in cellular metabolism, serving not only as a building block for proteins but also as a major source of one-carbon units for the synthesis of nucleotides, lipids, and other amino acids like glycine. Metabolic labeling with ¹⁵N-Serine allows for the tracing of nitrogen through these critical pathways, providing insights into protein synthesis, turnover, and the metabolic state of the cell.
These application notes provide a comprehensive overview and detailed protocols for the use of ¹⁵N-Serine in metabolic labeling experiments for quantitative proteomics.
Core Principles
The fundamental principle of metabolic labeling with ¹⁵N-Serine is to replace the natural ¹⁴N-Serine in the cell culture medium with its heavy isotope counterpart, ¹⁵N-Serine. As cells proliferate, they incorporate this heavy serine into newly synthesized proteins. By comparing the mass spectra of "heavy" proteins (from the ¹⁵N-Serine labeled state) with "light" proteins (from an unlabeled or ¹⁴N-Serine state), one can accurately quantify differences in protein abundance. This method allows for the mixing of cell populations from different experimental conditions at an early stage, minimizing experimental variability.
A key consideration in using ¹⁵N-Serine is its metabolic conversion to other amino acids, most notably glycine. This conversion, catalyzed by serine hydroxymethyltransferase (SHMT), means that the ¹⁵N label will also be incorporated into glycine residues of newly synthesized proteins. This metabolic scrambling must be accounted for during mass spectrometry data analysis.
Applications
The use of ¹⁵N-Serine for metabolic labeling is particularly suited for:
-
Quantitative Analysis of Protein Expression: Determining relative changes in protein abundance in response to drug treatment, genetic modification, or changes in cellular state.
-
Protein Turnover Studies: Measuring the rates of protein synthesis and degradation by performing pulse-chase experiments with ¹⁵N-Serine.
-
Tracing One-Carbon Metabolism: Investigating the flux through serine-dependent biosynthetic pathways, which are often dysregulated in diseases like cancer. The connection between serine metabolism and signaling pathways such as mTOR makes this a valuable tool for studying cellular growth and proliferation.[1][2][3][4]
Data Presentation
Table 1: Typical Labeling Efficiency with ¹⁵N-Labeled Amino Acids
| Cell Line | Labeled Amino Acid | Duration of Labeling | Labeling Efficiency (%) | Reference |
| HEK293 | ¹⁵N-Lys, ¹⁵N-Gly, ¹⁵N-Ser | Not Specified | 52 ± 4 | [5] |
| HEK293 | ¹⁵N-Val, ¹⁵N-Ile, ¹⁵N-Leu | Not Specified | 30 ± 14 | [5] |
| Arabidopsis | ¹⁵N (from K¹⁵NO₃) | 14 days | 93-99 | [6] |
| Mammalian Tissue (in vivo) | ¹⁵N-enriched diet | Extended | >94 | [7] |
Table 2: Fractional Synthesis Rates (FSR) of Proteins in Pancreatic Cancer Cells using a ¹⁵N Amino Acid Mixture
| Protein Spot | Protein Identity | FSR (%) in 50% ¹⁵N Medium | FSR (%) in 33% ¹⁵N Medium |
| 1 | Not specified | 65 | 68 |
| 2 | Not specified | 76 | 75 |
| 3 | Not specified | 44 | 45 |
| 4 | Not specified | 58 | 59 |
| 5 | Not specified | 72 | 70 |
| 6 | 40S ribosomal protein SA | 55 | 53 |
| Data adapted from a study using a mixture of ¹⁵N-labeled amino acids, demonstrating the principle of measuring protein synthesis rates.[8] |
Experimental Protocols
Protocol 1: Preparation of ¹⁵N-Serine Labeling Medium
This protocol outlines the preparation of a custom cell culture medium for labeling with ¹⁵N-Serine, based on a serine-free formulation. DMEM/F-12 is a common basal medium that can be customized for this purpose.[9][10][11]
Materials:
-
Serine-free DMEM/F-12 powder
-
Cell culture-grade water
-
Sodium bicarbonate
-
Dialyzed Fetal Bovine Serum (dFBS)
-
¹⁵N-L-Serine (≥98% isotopic purity)
-
Unlabeled L-Serine
-
Penicillin-Streptomycin solution
-
Sterile filtration unit (0.22 µm)
Procedure:
-
Prepare Basal Medium: Dissolve the serine-free DMEM/F-12 powder in cell culture-grade water according to the manufacturer's instructions. Add sodium bicarbonate as required by the formulation.
-
Sterilize: Filter the basal medium through a 0.22 µm sterile filtration unit.
-
Prepare "Heavy" Labeling Medium:
-
To the sterile, serine-free basal medium, add ¹⁵N-L-Serine to a final concentration that matches the physiological concentration in standard DMEM/F-12 (typically around 0.2-0.4 mM).
-
Add dFBS to the desired final concentration (e.g., 10%). The use of dialyzed FBS is critical to avoid the introduction of unlabeled serine from the serum.
-
Add Penicillin-Streptomycin to a 1x final concentration.
-
-
Prepare "Light" Control Medium:
-
To a separate aliquot of the sterile, serine-free basal medium, add unlabeled L-Serine to the same final concentration as the heavy medium.
-
Add dFBS and Penicillin-Streptomycin as in the heavy medium.
-
-
Storage: Store the prepared media at 4°C for up to 2-4 weeks.
Protocol 2: ¹⁵N-Serine Metabolic Labeling of Adherent Mammalian Cells
Materials:
-
Adherent mammalian cell line of interest
-
"Heavy" and "Light" ¹⁵N-Serine labeling media (from Protocol 1)
-
Standard cell culture reagents and equipment
-
Phosphate-Buffered Saline (PBS)
-
Lysis buffer (e.g., RIPA buffer with protease and phosphatase inhibitors)
-
BCA Protein Assay Kit
Procedure:
-
Cell Culture Adaptation:
-
Culture the cells in the "Light" medium for at least two passages to adapt them to the custom medium formulation.
-
Monitor cell morphology and doubling time to ensure they are not adversely affected by the custom medium.
-
-
Labeling:
-
For the "heavy" labeled sample, seed the cells and culture them in the "Heavy" medium.
-
For the "light" control sample, seed and culture the cells in the "Light" medium.
-
Culture the cells for at least 5-6 cell doublings to achieve near-complete incorporation (>95%) of the ¹⁵N-Serine.
-
-
Experimental Treatment:
-
Once labeling is complete, apply the desired experimental treatment (e.g., drug administration, growth factor stimulation) to the "heavy" labeled cells. The "light" labeled cells can serve as the control.
-
-
Cell Harvest and Lysis:
-
Wash the cells with ice-cold PBS.
-
Lyse the "heavy" and "light" cell populations separately using an appropriate lysis buffer.
-
-
Protein Quantification and Mixing:
-
Determine the protein concentration of each lysate using a BCA protein assay.
-
Mix equal amounts of protein from the "heavy" and "light" lysates. This mixed sample is now ready for downstream processing.
-
Protocol 3: Protein Digestion and Mass Spectrometry Analysis
This is a general protocol for the preparation of the mixed protein sample for mass spectrometry analysis.
Materials:
-
Dithiothreitol (DTT)
-
Iodoacetamide (IAA)
-
Trypsin (mass spectrometry grade)
-
Ammonium bicarbonate
-
Formic acid
-
C18 desalting columns
-
High-resolution mass spectrometer
Procedure:
-
Reduction and Alkylation:
-
Reduce the disulfide bonds in the mixed protein sample by adding DTT to a final concentration of 10 mM and incubating at 56°C for 30 minutes.
-
Alkylate the free cysteine residues by adding IAA to a final concentration of 55 mM and incubating in the dark at room temperature for 20 minutes.
-
-
Proteolytic Digestion:
-
Dilute the sample with ammonium bicarbonate buffer to reduce the concentration of denaturants.
-
Add trypsin at a 1:50 (trypsin:protein) ratio and incubate overnight at 37°C.
-
-
Desalting:
-
Acidify the peptide mixture with formic acid.
-
Desalt the peptides using a C18 column according to the manufacturer's protocol.
-
-
LC-MS/MS Analysis:
-
Analyze the desalted peptide mixture using a high-resolution Orbitrap mass spectrometer.
-
Acquire data in a data-dependent acquisition mode, collecting high-resolution MS1 scans followed by MS/MS scans of the most abundant precursor ions.
-
Protocol 4: Data Analysis Workflow
Software:
-
MaxQuant, Proteome Discoverer, or similar proteomics data analysis software.
Procedure:
-
Database Search:
-
Search the raw mass spectrometry data against a relevant protein database (e.g., UniProt).
-
Specify ¹⁵N-Serine as a variable modification. Crucially, also specify ¹⁵N-Glycine as a variable modification to account for the metabolic conversion of serine to glycine.
-
-
Quantification:
-
The software will identify peptide pairs (heavy and light) and calculate the heavy/light (H/L) ratios based on the extracted ion chromatograms of the precursor ions.
-
-
Data Interpretation:
-
The H/L ratios for multiple peptides are combined to determine the relative abundance of each protein between the two experimental conditions.
-
For protein turnover studies (pulse-chase), the rate of decrease in the H/L ratio over time is used to calculate the protein's half-life.
-
Visualizations
References
- 1. Targeting one-carbon metabolism requires mTOR inhibition: a new therapeutic approach in osteosarcoma - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Serine and one-carbon metabolism, a bridge that links mTOR signaling and DNA methylation in cancer - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. researchgate.net [researchgate.net]
- 4. researchgate.net [researchgate.net]
- 5. A comprehensive assessment of selective amino acid 15N-labeling in human embryonic kidney 293 cells for NMR spectroscopy - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Frontiers | 15N Metabolic Labeling Quantification Workflow in Arabidopsis Using Protein Prospector [frontiersin.org]
- 7. 15N Metabolic Labeling of Mammalian Tissue with Slow Protein Turnover - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Quantitative Proteomics: Measuring Protein Synthesis Using 15N Amino Acids Labeling in Pancreas Cancer Cells - PMC [pmc.ncbi.nlm.nih.gov]
- 9. DMEM-F-12 Cell Culture Media | Fisher Scientific [fishersci.com]
- 10. DMEM/F12 Cell Culture Media | Classical Media | Captivate Bio [captivatebio.com]
- 11. definedbioscience.com [definedbioscience.com]
Application of Fmoc-Ser-OH-¹⁵N in Protein Structure Determination by NMR: A Detailed Guide for Researchers
Introduction: The site-specific incorporation of stable isotopes, such as ¹⁵N, into proteins and peptides is a cornerstone of modern biomolecular Nuclear Magnetic Resonance (NMR) spectroscopy. Fmoc-Ser-OH-¹⁵N, a serine amino acid with its alpha-amino group protected by a fluorenylmethyloxycarbonyl (Fmoc) group and its backbone nitrogen atom enriched with the ¹⁵N isotope, is a critical reagent for these studies. This application note provides detailed protocols and data for researchers, scientists, and drug development professionals on the use of Fmoc-Ser-OH-¹⁵N in the synthesis of labeled peptides and proteins for structural analysis by NMR. The focus is on providing practical experimental details, presenting quantitative data in a clear format, and illustrating relevant biological and experimental workflows.
Synthetic Incorporation of Fmoc-Ser-OH-¹⁵N via Solid-Phase Peptide Synthesis (SPPS)
The primary method for incorporating Fmoc-Ser-OH-¹⁵N into a specific site within a peptide or small protein is Fmoc-based Solid-Phase Peptide Synthesis (SPPS). Due to the reactive hydroxyl group on the serine side chain, it is crucial to use a protected version, typically Fmoc-Ser(tBu)-OH-¹⁵N, where the side chain is protected with a tert-butyl (tBu) group. This protecting group is stable under the basic conditions used for Fmoc removal but is readily cleaved by acid during the final cleavage step.
Quantitative Data in Fmoc-SPPS
The efficiency of each step in SPPS is critical for the overall yield and purity of the final peptide. While specific data for Fmoc-Ser-OH-¹⁵N is not always published independently, the values are comparable to its unlabeled counterpart and other standard Fmoc-amino acids. The following tables provide representative data on the impact of amino acid purity on the final peptide and the typical yields and purities achievable in Fmoc-SPPS.
Table 1: Impact of Fmoc-Amino Acid Purity on Final Peptide Purity
| Parameter | Standard Grade Fmoc-Amino Acids | High-Purity Fmoc-Amino Acids |
| Initial Impurity Level | ~1-5% | <0.5% |
| Resulting Crude Peptide Purity | 50-70% | >80% |
| Final Peptide Purity (Post-HPLC) | >95% | >98% |
Note: Data is generalized from typical SPPS outcomes. High-purity starting materials are essential for successful synthesis.
Table 2: Typical Yields and Purity for a Model Peptide (e.g., 10-15 amino acids) Synthesized via Fmoc-SPPS
| Parameter | Expected Range | Notes |
| Coupling Efficiency per Step | >99% | Monitored by qualitative tests like the Kaiser test. |
| Overall Crude Peptide Yield | 60-80% | Dependent on peptide length and sequence. |
| Purity of Crude Peptide | 50-85% | Major impurities are often deletion sequences. |
| Final Yield after Purification | 20-40% | Highly dependent on the efficiency of HPLC purification. |
| Final Purity | >98% | Required for high-resolution NMR studies.[1] |
Experimental Protocol: Manual Fmoc-SPPS of a ¹⁵N-Serine Containing Peptide
This protocol outlines the manual synthesis of a peptide with a site-specifically incorporated ¹⁵N-labeled serine.
Materials:
-
Fmoc-Ser(tBu)-OH-¹⁵N
-
Other required Fmoc-amino acids
-
Rink Amide resin (or other suitable solid support)
-
N,N-Dimethylformamide (DMF), peptide synthesis grade
-
Piperidine
-
Coupling reagents: HBTU (2-(1H-benzotriazol-1-yl)-1,1,3,3-tetramethyluronium hexafluorophosphate)
-
Base: N,N-Diisopropylethylamine (DIPEA)
-
Dichloromethane (DCM)
-
Cleavage cocktail (e.g., 95% Trifluoroacetic acid (TFA), 2.5% water, 2.5% triisopropylsilane (TIS))
-
Cold diethyl ether
-
SPPS reaction vessel
Procedure:
-
Resin Swelling:
-
Place the resin in the reaction vessel.
-
Add DMF and allow the resin to swell for at least 30 minutes with gentle agitation.
-
Drain the DMF.
-
-
Fmoc Deprotection:
-
Add a 20% piperidine in DMF solution to the resin.
-
Agitate for 5 minutes and drain.
-
Repeat the piperidine treatment for another 15 minutes.
-
Wash the resin thoroughly with DMF (5-7 times) to remove all traces of piperidine.
-
-
Amino Acid Coupling (Incorporation of Fmoc-Ser(tBu)-OH-¹⁵N):
-
In a separate vial, dissolve Fmoc-Ser(tBu)-OH-¹⁵N (3-5 equivalents relative to the resin loading) and HBTU (3-5 equivalents) in DMF.
-
Add DIPEA (6-10 equivalents) to the solution to activate the amino acid.
-
Immediately add the activated amino acid solution to the deprotected resin.
-
Agitate the mixture for 1-2 hours at room temperature.
-
Monitoring: Perform a Kaiser test to check for the presence of free primary amines. A negative result (yellow beads) indicates complete coupling. If the test is positive (blue/purple beads), the coupling step should be repeated ("double coupling").
-
-
Washing:
-
Drain the coupling solution and wash the resin with DMF (3-5 times).
-
-
Chain Elongation:
-
Repeat steps 2-4 for each subsequent amino acid in the peptide sequence.
-
-
Final Deprotection and Cleavage:
-
After the final amino acid has been coupled, perform a final Fmoc deprotection (step 2).
-
Wash the peptide-resin with DMF, followed by DCM, and dry under vacuum.
-
Add the cleavage cocktail to the resin and agitate for 2-3 hours at room temperature.
-
Filter the resin and collect the filtrate containing the cleaved peptide.
-
-
Peptide Precipitation and Purification:
-
Precipitate the crude peptide by adding the TFA filtrate to a 10-fold volume of cold diethyl ether.
-
Centrifuge to pellet the peptide and decant the ether.
-
Wash the peptide pellet with cold ether twice more.
-
Dry the crude peptide under vacuum.
-
Purify the peptide using reverse-phase high-performance liquid chromatography (RP-HPLC).
-
Lyophilize the pure fractions to obtain the final product.
-
Protein Expression and Labeling
For larger proteins, recombinant expression is the method of choice. While uniform ¹⁵N labeling is commonly achieved by growing bacteria in a minimal medium containing ¹⁵NH₄Cl as the sole nitrogen source, selective labeling with ¹⁵N-serine is more complex. It requires either specialized bacterial strains auxotrophic for serine or cell-free protein synthesis systems where the amino acid mixture can be precisely controlled.[2]
Protocol: Uniform ¹⁵N Labeling of a Recombinantly Expressed Protein
This protocol is for uniform labeling but serves as a basis for developing selective labeling strategies.
Materials:
-
E. coli expression strain (e.g., BL21(DE3)) transformed with the plasmid encoding the protein of interest.
-
M9 minimal medium components.
-
¹⁵NH₄Cl (isotopic purity >98%).
-
Glucose (or ¹³C-glucose for double labeling).
-
IPTG (Isopropyl β-D-1-thiogalactopyranoside).
Procedure:
-
Starter Culture: Inoculate a small volume of LB medium with a single colony of the expression strain and grow overnight at 37°C.
-
Adaptation: The next day, inoculate a larger volume of M9 medium containing standard ¹⁴NH₄Cl with the overnight culture and grow to mid-log phase. This step helps the cells adapt to the minimal medium.
-
Main Culture: Pellet the adapted cells and resuspend them in M9 medium where the sole nitrogen source is ¹⁵NH₄Cl.
-
Growth and Induction: Grow the main culture at 37°C to an OD₆₀₀ of 0.6-0.8. Induce protein expression by adding IPTG to a final concentration of 0.5-1 mM.
-
Expression: Continue to grow the culture for 3-5 hours at 30°C or overnight at a lower temperature (e.g., 18-25°C) to improve protein solubility.
-
Harvesting and Purification: Harvest the cells by centrifugation. Purify the ¹⁵N-labeled protein using standard chromatography techniques (e.g., affinity, ion exchange, size exclusion).
NMR Spectroscopy for Structure Determination
The key advantage of ¹⁵N labeling is the ability to perform heteronuclear NMR experiments, which resolve the spectral overlap inherent in the ¹H NMR spectra of proteins. The ¹H-¹⁵N Heteronuclear Single Quantum Coherence (HSQC) experiment is the cornerstone of this approach, providing a unique signal for each backbone N-H group.
Case Study: Phospholamban (PLN)
Phospholamban is a 52-amino acid membrane protein crucial for regulating cardiac muscle contractility.[3] Its function is modulated by phosphorylation at Serine-16. NMR studies using site-specifically ¹⁵N-labeled PLN, including at serine residues, have been instrumental in understanding the structural changes that occur upon phosphorylation.[4][5]
Table 3: ¹⁵N Chemical Shift Changes in Phospholamban upon Phosphorylation at Ser-16
| Labeled Residue | State | ¹⁵N Chemical Shift (ppm) |
| Ala-11 | Unphosphorylated | ~71 |
| Ala-11 | Phosphorylated | ~92 |
| Leu-7 | Unphosphorylated | ~75 |
| Leu-7 | Phosphorylated | ~99 |
Data from solid-state NMR studies on aligned lipid bilayers. The significant downfield shift upon phosphorylation indicates a major conformational change in the cytoplasmic domain.[4][5]
Signaling Pathway of Phospholamban in Cardiac Muscle
PLN is a key player in the β-adrenergic signaling pathway that controls heart rate and contractility.
Experimental Protocol: ¹H-¹⁵N HSQC Experiment
This protocol provides a general framework for acquiring a ¹H-¹⁵N HSQC spectrum.
1. Sample Preparation:
-
The ¹⁵N-labeled protein should be in a buffered solution (e.g., 20 mM sodium phosphate, 50 mM NaCl, pH 6.0-7.0).
-
The protein concentration should be between 0.1 and 1 mM.
-
Add 5-10% D₂O to the sample for the spectrometer's lock system.
-
Transfer ~500-600 µL of the sample to a high-quality NMR tube.
2. NMR Spectrometer Setup:
-
Tune and match the probe for both ¹H and ¹⁵N frequencies.
-
Lock onto the D₂O signal and shim the magnetic field to achieve high homogeneity.
-
Calibrate the ¹H and ¹⁵N pulse widths (90° pulses).
3. Data Acquisition:
-
Load a standard ¹H-¹⁵N HSQC pulse sequence (e.g., hsqcetf3gpsi on Bruker spectrometers).
-
Set the spectral widths: ~12-16 ppm for the ¹H dimension and ~30-40 ppm for the ¹⁵N dimension, centered around the amide region.
-
Set the number of complex points in the direct (¹H) and indirect (¹⁵N) dimensions (e.g., 2048 in t₂ and 256 in t₁).
-
Set the number of scans per increment (e.g., 8, 16, or 32) depending on the sample concentration and desired signal-to-noise ratio.
-
The total experimental time will depend on these parameters.
4. Data Processing:
-
Apply a squared sine-bell window function to both dimensions.
-
Zero-fill the data to at least double the number of acquired points in each dimension.
-
Perform a Fourier transform.
-
Phase correct the spectrum in both dimensions.
-
Reference the spectrum using an internal standard or by referencing the water signal.
Conclusion
Fmoc-Ser-OH-¹⁵N is an invaluable tool for elucidating the structure and function of proteins and peptides by NMR. Through site-specific incorporation via SPPS or selective labeling in expression systems, researchers can gain detailed insights into protein conformation, dynamics, and interactions. The case of Phospholamban highlights how ¹⁵N labeling at serine residues can reveal the molecular mechanisms of crucial biological regulatory processes. The protocols and data presented here provide a comprehensive guide for the effective application of this powerful isotopic labeling strategy in biomolecular NMR.
References
- 1. gyrosproteintechnologies.com [gyrosproteintechnologies.com]
- 2. Fmoc Amino Acids for SPPS - AltaBioscience [altabioscience.com]
- 3. ahajournals.org [ahajournals.org]
- 4. 15N Solid-state NMR Spectroscopic Studies on Phospholamban at its Phosphorylated form at Ser-16 in Aligned Phospholipid Bilayers - PMC [pmc.ncbi.nlm.nih.gov]
- 5. (15)N Solid-state NMR spectroscopic studies on phospholamban at its phosphorylated form at ser-16 in aligned phospholipid bilayers - PubMed [pubmed.ncbi.nlm.nih.gov]
Application Notes and Protocols for Quantitative Mass Spectrometry using Fmoc-Ser-OH-15N
For Researchers, Scientists, and Drug Development Professionals
Introduction
Stable isotope labeling coupled with mass spectrometry has become an indispensable tool for accurate and robust quantification of proteins and their post-translational modifications (PTMs) in complex biological samples. The use of stable isotope-labeled (SIL) peptides as internal standards is a cornerstone of targeted proteomics, enabling precise measurement by correcting for variability during sample preparation and analysis. Fmoc-Ser-OH-15N is a key reagent for the synthesis of 15N-labeled peptides, allowing for the site-specific incorporation of a heavy isotope into a peptide sequence. This document provides detailed application notes and protocols for the use of this compound in the synthesis of SIL peptides for quantitative mass spectrometry, with a particular focus on the analysis of protein phosphorylation.
Core Applications
The primary application of this compound in quantitative proteomics is the synthesis of 15N-labeled peptide standards for targeted protein and PTM quantification. These standards are essential for:
-
Biomarker Discovery and Validation: Accurately quantifying potential protein biomarkers in clinical samples.
-
Pharmacokinetic/Pharmacodynamic (PK/PD) Studies: Measuring the concentration of protein therapeutics or their targets over time.
-
Cell Signaling Pathway Analysis: Quantifying changes in the abundance of key signaling proteins and their phosphorylation status.[1]
-
Systems Biology Research: Precisely measuring protein expression levels for building and validating biological models.
Principle of Quantitative Analysis using 15N-Labeled Peptide Standards
The fundamental principle behind using a 15N-labeled peptide as an internal standard is stable isotope dilution mass spectrometry. A known quantity of the "heavy" synthetic peptide, which is chemically identical to the endogenous "light" target peptide but differs in mass due to the 15N label, is spiked into a biological sample. The "heavy" and "light" peptides co-elute during liquid chromatography and are detected by the mass spectrometer. The ratio of the signal intensities of the heavy and light peptides is then used to accurately determine the concentration of the endogenous peptide.
Experimental Protocols
Protocol 1: Synthesis of a 15N-Serine Labeled Peptide Standard via Fmoc-Based Solid-Phase Peptide Synthesis (SPPS)
This protocol describes the manual synthesis of a hypothetical peptide containing a 15N-labeled serine residue. For this example, we will synthesize a peptide derived from the activation loop of ERK1, a key protein in the MAPK signaling pathway. The target peptide sequence is DHTGFLTEYVATR, with the serine residue being 15N-labeled.
Materials:
-
Fmoc-Rink Amide MBHA resin
-
Fmoc-amino acids (including Fmoc-Ser(tBu)-OH-15N and other required amino acids with appropriate side-chain protection, e.g., Fmoc-Thr(tBu)-OH, Fmoc-Tyr(tBu)-OH)
-
N,N-Dimethylformamide (DMF)
-
Dichloromethane (DCM)
-
Piperidine solution (20% in DMF)
-
Coupling reagents: HBTU (2-(1H-benzotriazol-1-yl)-1,1,3,3-tetramethyluronium hexafluorophosphate), HOBt (Hydroxybenzotriazole)
-
N,N-Diisopropylethylamine (DIPEA)
-
Cleavage cocktail: Trifluoroacetic acid (TFA, 95%), Triisopropylsilane (TIS, 2.5%), Water (2.5%)
-
Cold diethyl ether
-
Solid-phase peptide synthesis reaction vessel
Procedure:
-
Resin Swelling: Swell the Fmoc-Rink Amide MBHA resin in DMF for 30 minutes in the reaction vessel.
-
Fmoc Deprotection:
-
Drain the DMF.
-
Add 20% piperidine in DMF to the resin and agitate for 5 minutes.
-
Drain the solution and repeat the piperidine treatment for an additional 15 minutes.
-
Wash the resin thoroughly with DMF (5 times) and DCM (3 times).
-
-
Amino Acid Coupling (Iterative Process):
-
Activation: In a separate vial, dissolve the Fmoc-amino acid (3 equivalents to the resin loading capacity) and HOBt (3 equivalents) in DMF. Add HBTU (3 equivalents) and DIPEA (6 equivalents). Allow the mixture to pre-activate for 1-2 minutes.
-
Coupling: Add the activated amino acid solution to the deprotected resin. Agitate the reaction vessel for 1-2 hours at room temperature.
-
Washing: Drain the coupling solution and wash the resin with DMF (3 times) and DCM (3 times).
-
Confirmation: Perform a Kaiser test to ensure complete coupling (a negative result indicates completion). If the test is positive, repeat the coupling step.
-
Repeat: Repeat the deprotection and coupling steps for each amino acid in the sequence, using Fmoc-Ser(tBu)-OH-15N at the desired position.
-
-
Final Fmoc Deprotection: After coupling the last amino acid, perform a final deprotection step as described in step 2.
-
Cleavage and Deprotection:
-
Wash the resin with DCM and dry under vacuum.
-
Add the cleavage cocktail to the resin and incubate for 2-3 hours at room temperature with occasional agitation.
-
Filter the resin and collect the filtrate containing the cleaved peptide.
-
-
Peptide Precipitation and Purification:
-
Precipitate the peptide by adding the TFA filtrate to a 10-fold volume of cold diethyl ether.
-
Centrifuge to pellet the peptide, decant the ether, and wash the pellet with cold ether.
-
Air-dry the crude peptide.
-
Purify the 15N-labeled peptide by reverse-phase high-performance liquid chromatography (RP-HPLC).
-
-
Verification: Confirm the mass of the purified 15N-labeled peptide using mass spectrometry to verify the incorporation of the 15N-serine.
Protocol 2: Sample Preparation for Quantitative Phosphoproteomics
This protocol outlines the preparation of a cell lysate for the quantification of a target phosphoprotein using the synthesized 15N-labeled peptide standard.
Materials:
-
Cell culture plates with treated and untreated cells
-
Phosphate-buffered saline (PBS), ice-cold
-
Lysis buffer (e.g., RIPA buffer) supplemented with protease and phosphatase inhibitors
-
15N-labeled peptide internal standard (from Protocol 1)
-
Dithiothreitol (DTT)
-
Iodoacetamide (IAA)
-
Trypsin (mass spectrometry grade)
-
Ammonium bicarbonate buffer
-
Formic acid
-
Solid-phase extraction (SPE) C18 cartridges
Procedure:
-
Cell Lysis:
-
Wash cultured cells with ice-cold PBS.
-
Add lysis buffer to the cells and scrape to collect the lysate.
-
Incubate on ice for 30 minutes with occasional vortexing.
-
Centrifuge at high speed to pellet cell debris and collect the supernatant.
-
-
Protein Quantification: Determine the protein concentration of the lysate using a standard protein assay (e.g., BCA assay).
-
Internal Standard Spiking: Add a known amount of the purified 15N-labeled peptide standard to the protein lysate.
-
Reduction and Alkylation:
-
Add DTT to a final concentration of 10 mM and incubate at 56°C for 30 minutes.
-
Cool to room temperature and add IAA to a final concentration of 55 mM. Incubate in the dark for 30 minutes.
-
-
Proteolytic Digestion:
-
Dilute the sample with ammonium bicarbonate buffer to reduce the denaturant concentration.
-
Add trypsin at a 1:50 (w/w) enzyme-to-protein ratio.
-
Incubate overnight at 37°C.
-
-
Sample Cleanup:
-
Acidify the digest with formic acid.
-
Desalt the peptide mixture using SPE C18 cartridges.
-
Elute the peptides and dry them under vacuum.
-
Protocol 3: LC-MS/MS Analysis for Targeted Quantification
This protocol describes the liquid chromatography-tandem mass spectrometry (LC-MS/MS) analysis of the prepared peptide samples.
Materials:
-
Dried peptide sample from Protocol 2
-
LC-MS/MS system (e.g., a quadrupole-Orbitrap or triple quadrupole mass spectrometer)
-
C18 reverse-phase LC column
-
Mobile phases:
-
Solvent A: 0.1% formic acid in water
-
Solvent B: 0.1% formic acid in acetonitrile
-
Procedure:
-
Sample Reconstitution: Reconstitute the dried peptides in a suitable volume of Solvent A.
-
LC Separation:
-
Inject the sample onto the C18 column.
-
Elute the peptides using a gradient of Solvent B. A typical gradient might be 2-40% Solvent B over 60 minutes.
-
-
MS/MS Analysis (Targeted Mode):
-
Operate the mass spectrometer in a targeted mode, such as Selected Reaction Monitoring (SRM) or Parallel Reaction Monitoring (PRM).
-
Define the precursor ion m/z values for both the "light" (endogenous) and "heavy" (15N-labeled) target peptides.
-
Define the fragment ion m/z values to be monitored for each precursor.
-
-
Data Analysis:
-
Integrate the peak areas for the selected fragment ion transitions for both the light and heavy peptides.
-
Calculate the ratio of the peak area of the light peptide to the heavy peptide.
-
Determine the absolute quantity of the endogenous peptide based on the known concentration of the spiked-in heavy standard.
-
Data Presentation
Quantitative data from targeted mass spectrometry experiments should be summarized in a clear and structured format. The following table provides an example of how to present the quantification of ERK1 phosphorylation at a specific serine site in response to a stimulus.
| Sample Condition | Target Peptide | Light Peptide Peak Area | Heavy Peptide Peak Area | Light/Heavy Ratio | Calculated Amount (fmol) |
| Control | DHTGFLpTEYVATR | 1.5 x 10^6 | 5.0 x 10^7 | 0.03 | 15 |
| Stimulated (5 min) | DHTGFLpTEYVATR | 7.5 x 10^6 | 5.0 x 10^7 | 0.15 | 75 |
| Stimulated (30 min) | DHTGFLpTEYVATR | 3.0 x 10^7 | 5.0 x 10^7 | 0.60 | 300 |
Visualization of Workflows and Pathways
Experimental Workflow
Caption: Experimental workflow for quantitative proteomics using a 15N-labeled peptide standard.
ERK1/2 Signaling Pathway
Caption: Simplified ERK1/2 signaling pathway highlighting key phosphorylation events.
References
Application Notes and Protocols for the Solid-Phase Peptide Synthesis (SPPS) Coupling of Fmoc-Ser-OH-15N
Abstract
This document provides detailed application notes and protocols for the incorporation of ¹⁵N-labeled serine, Fmoc-Ser-OH-¹⁵N, into peptide sequences using solid-phase peptide synthesis (SPPS) with the Fmoc/tBu strategy. The site-specific incorporation of stable isotopes like ¹⁵N is invaluable for nuclear magnetic resonance (NMR) spectroscopy and mass spectrometry (MS) to study peptide structure, dynamics, and interactions. Due to the reactive nature of the serine hydroxyl group, this document strongly recommends the use of its side-chain protected form, Fmoc-Ser(tBu)-OH-¹⁵N , to prevent side reactions and ensure high peptide purity. Protocols for both the recommended protected and the higher-risk unprotected amino acid are provided, along with a discussion of potential side reactions and mitigation strategies.
Introduction and Key Considerations
The synthesis of peptides using the Fmoc (9-fluorenylmethyloxycarbonyl) strategy is a robust and widely adopted methodology.[1] The Fmoc group provides temporary protection of the α-amino group, which is removed with a mild base like piperidine, while side-chain protecting groups are typically stable to these conditions but are cleaved with strong acid (e.g., trifluoroacetic acid, TFA) during the final step.[1]
When incorporating serine, two primary challenges must be addressed:
-
O-Acylation of the Hydroxyl Side-Chain: Using Fmoc-Ser-OH (unprotected side-chain) creates a risk of O-acylation, where a second serine molecule attaches to the hydroxyl group of the first. This can lead to a side-chain serinyl moiety migrating to the peptide backbone, resulting in an "endo-Ser" impurity with an 87 Da mass increase.[2] To prevent this, the use of a side-chain protecting group, such as the tert-butyl (tBu) ether in Fmoc-Ser(tBu)-OH-¹⁵N , is the standard and highly recommended approach.[1]
-
Racemization: Serine is susceptible to racemization (epimerization) at its α-carbon during the carboxyl group activation step. This is particularly problematic when using certain amine bases like N,N-diisopropylethylamine (DIPEA).[1][3] The use of alternative bases like 2,4,6-collidine or base-free coupling conditions can significantly reduce this side reaction.[3]
The presence of the ¹⁵N isotope does not alter the chemical reactivity of the amino acid; therefore, standard coupling protocols can be adapted with the above considerations in mind.[4][5]
Data Presentation: Comparative Performance of Coupling Reagents
The choice of coupling reagent is critical for efficient and high-fidelity peptide synthesis. For serine, the goal is to achieve a balance between high reactivity and minimal risk of racemization.
| Coupling Reagent/Method | Activating Agent(s) | Relative Reactivity | Key Advantages | Potential Disadvantages |
| Uronium/Aminium Salts | ||||
| HATU / Collidine or DIPEA | 1-[Bis(dimethylamino)methylene]-1H-1,2,3-triazolo[4,5-b]pyridinium 3-oxid hexafluorophosphate | Very High | Fast reaction kinetics; highly effective for standard and hindered couplings.[6] | Higher cost. Potential for racemization with DIPEA, use of collidine is recommended for serine.[3] |
| HBTU / Collidine or DIPEA | O-Benzotriazole-N,N,N',N'-tetramethyl-uronium-hexafluoro-phosphate | High | Effective and widely used. | Can cause racemization, especially with DIPEA.[1][3] |
| Carbodiimide Method | ||||
| DIC / Oxyma or HOBt | N,N'-Diisopropylcarbodiimide / Ethyl cyano(hydroxyimino)acetate or Hydroxybenzotriazole | Moderate | Cost-effective; low risk of racemization when used with an additive like HOBt or Oxyma.[6] | Slower reaction times compared to uronium salts; formation of insoluble DCU byproduct if DCC is used.[6] |
Experimental Protocols
These protocols are designed for manual SPPS on a 0.1 mmol scale. Reagent quantities should be adjusted based on the specific resin loading.
Materials and Reagents
-
Resin (e.g., Rink Amide, Wang resin)
-
Fmoc-Ser(tBu)-OH-¹⁵N (Recommended) or Fmoc-Ser-OH-¹⁵N
-
N,N-Dimethylformamide (DMF), peptide synthesis grade
-
Dichloromethane (DCM)
-
Deprotection Solution: 20% (v/v) piperidine in DMF
-
Coupling Reagents (see Table above)
-
Base: 2,4,6-Collidine or N,N-Diisopropylethylamine (DIPEA)
-
Washing Solvents: DMF, Isopropanol (IPA)
-
Kaiser Test Kit
-
Capping Solution (Optional): Acetic anhydride/Pyridine/DMF
Protocol 1: Resin Preparation and Swelling
-
Place the resin (0.1 mmol) in a reaction vessel equipped with a sintered frit.
-
Add DMF (approx. 10 mL/g of resin) and allow the resin to swell for 30-60 minutes with gentle agitation.
-
Drain the DMF.
Protocol 2: N-Terminal Fmoc Deprotection
-
Add the deprotection solution (20% piperidine in DMF) to the swollen resin.
-
Agitate the mixture for 5 minutes at room temperature.
-
Drain the solution.
-
Repeat the treatment with fresh deprotection solution for an additional 15 minutes.
-
Drain the solution and wash the resin thoroughly with DMF (5 x 10 mL) to remove all traces of piperidine.
Protocol 3A: Coupling of Fmoc-Ser(tBu)-OH-¹⁵N (Recommended)
This method utilizes DIC/Oxyma to minimize the risk of racemization.
-
Activation: In a separate vial, dissolve Fmoc-Ser(tBu)-OH-¹⁵N (3-5 eq.), Oxyma (3-5 eq.) in DMF.
-
Add the solution to the deprotected resin.
-
Add DIC (3-5 eq.) to the reaction vessel.
-
Coupling: Agitate the mixture for 1-4 hours at room temperature.
-
Washing: Drain the coupling solution and wash the resin with DMF (3 x 10 mL) and IPA (2 x 10 mL).
-
Monitoring: Perform a Kaiser test to confirm the absence of free primary amines (a negative test results in yellow beads). If the test is positive (blue beads), a second coupling may be required.[1]
Protocol 3B: Coupling of Fmoc-Ser-OH-¹⁵N (High-Risk Alternative)
Caution: This protocol carries a significant risk of O-acylation side reactions.[2] Use with caution and thorough analysis of the final product.
-
Activation: In a separate vial, dissolve Fmoc-Ser-OH-¹⁵N (3 eq.) and HOBt (3 eq.) in DMF. Add DIC (3 eq.) and allow to pre-activate for 5-10 minutes.
-
Coupling: Add the activated amino acid solution to the deprotected resin. Agitate for 1 hour. Avoid extended coupling times to minimize side reactions.
-
Washing & Monitoring: Proceed as described in Protocol 3A.
Overall SPPS Workflow Visualization
The entire SPPS process is a cycle of deprotection and coupling steps, repeated until the desired peptide sequence is assembled.
Potential Side Reactions and Mitigation
| Side Reaction | Description | Mitigation Strategies |
| Racemization | Loss of stereochemical integrity at the α-carbon during activation, leading to the incorporation of D-Serine. Often exacerbated by strong, sterically hindered bases.[3] | - Use a less hindered base like 2,4,6-collidine instead of DIPEA. - Employ base-free activation methods such as DIC/HOBt or DIC/Oxyma.[6] - Avoid prolonged pre-activation times. |
| O-Acylation / Double Insertion | The hydroxyl group of an unprotected serine is acylated by a second activated serine molecule. This can lead to chain branching or rearrangement to form an endo-Ser impurity.[2] | - Primary Method: Use a side-chain protected derivative, Fmoc-Ser(tBu)-OH-¹⁵N . The tBu group is stable to piperidine but is removed during final TFA cleavage.[1] - If using the unprotected form, use milder activation conditions and shorter coupling times. |
Final Cleavage and Deprotection
After the final amino acid has been coupled and its N-terminal Fmoc group removed, the peptide is cleaved from the resin. This step also removes the side-chain protecting groups (like tBu).
-
Wash the final peptidyl-resin with DCM and dry it under vacuum.
-
Prepare a cleavage cocktail suitable for the peptide sequence (e.g., Reagent K: 82.5% TFA, 5% phenol, 5% water, 5% thioanisole, 2.5% 1,2-ethanedithiol).[4]
-
Add the cleavage cocktail to the resin and agitate for 2-3 hours at room temperature.
-
Filter the resin and collect the filtrate.
-
Precipitate the crude peptide by adding the filtrate to a 10-fold volume of cold diethyl ether.
-
Collect the peptide pellet via centrifugation and purify by reverse-phase HPLC.
References
Application Notes and Protocols: Efficient Cleavage of Peptides Containing 15N-Serine from Solid-Phase Synthesis Resins
For Researchers, Scientists, and Drug Development Professionals
Introduction
Solid-Phase Peptide Synthesis (SPPS) is a cornerstone technique for the creation of synthetic peptides for a wide range of applications, including drug discovery, proteomics, and structural biology. The incorporation of stable isotopes, such as 15N-labeled amino acids, provides a powerful tool for quantitative analysis and structural studies of peptides and proteins by mass spectrometry and NMR. The final and critical step in SPPS is the cleavage of the synthesized peptide from the solid support and the simultaneous removal of side-chain protecting groups.
This application note provides detailed protocols for the efficient cleavage of peptides containing 15N-serine from two commonly used resins in Fmoc-based SPPS: Wang resin (for C-terminal acids) and Rink Amide resin (for C-terminal amides). The presence of the 15N isotope in the serine residue does not alter the chemical principles of the cleavage process; therefore, standard, well-established protocols are applicable.[1][2] The key to successful cleavage is the selection of an appropriate cleavage cocktail, which typically consists of a strong acid, most commonly trifluoroacetic acid (TFA), and a mixture of "scavengers" to prevent side reactions.[1][3]
Reactive carbocations generated from the cleavage of protecting groups and the resin linker can lead to unwanted modifications of sensitive amino acid residues.[1][3] Scavengers are crucial for trapping these reactive species.[3] This document outlines standard and optimized cleavage cocktails and provides step-by-step procedures to maximize peptide yield and purity.
Experimental Workflow
The general workflow for the cleavage of peptides from the resin is depicted below. The process begins with the dried peptide-resin and culminates in the isolation of the crude peptide, which can then be purified and analyzed.
Caption: General experimental workflow for peptide cleavage from solid-phase resin.
Materials and Reagents
-
Peptide-resin containing 15N-serine (synthesized on Wang or Rink Amide resin)
-
Trifluoroacetic acid (TFA), reagent grade (≥99%)
-
Triisopropylsilane (TIS)
-
Deionized water (H₂O)
-
1,2-Ethanedithiol (EDT)
-
Thioanisole
-
Phenol
-
Dichloromethane (DCM), HPLC grade
-
Diethyl ether, cold (stored at -20°C)
-
Reaction vessel (scintillation vial or small flask with a screw cap)
-
Sintered glass funnel
-
Centrifuge tubes
-
Nitrogen or argon gas source
-
Vacuum desiccator
-
HPLC system for analysis
Experimental Protocols
Protocol 1: Standard Cleavage from Wang or Rink Amide Resin
This protocol is suitable for peptides that do not contain sensitive residues like Cysteine (Cys), Methionine (Met), or Tryptophan (Trp).
-
Resin Preparation:
-
Place the dried peptide-resin (e.g., 100 mg) into a suitable reaction vessel.
-
Wash the resin thoroughly with dichloromethane (DCM) (3 x 5 mL) to remove any residual dimethylformamide (DMF) and to swell the resin.[2]
-
Dry the resin under a stream of nitrogen or in a vacuum desiccator for at least 1 hour.[1]
-
-
Cleavage Cocktail Preparation (Standard):
-
Cleavage Reaction:
-
Peptide Precipitation and Isolation:
-
Filter the cleavage mixture through a sintered glass funnel to separate the resin. Collect the filtrate.[4]
-
Wash the resin with a small amount of fresh TFA (2 x 0.5 mL) and combine the filtrates.[6]
-
In a larger centrifuge tube, add cold diethyl ether (approximately 10 times the volume of the TFA filtrate).[1][4]
-
Add the TFA filtrate dropwise to the cold ether with gentle swirling to precipitate the peptide as a white solid.
-
Incubate the ether-peptide mixture at -20°C for at least 1 hour to maximize precipitation.[1]
-
-
Peptide Washing and Drying:
-
Centrifuge the peptide suspension to pellet the precipitated peptide.[1]
-
Carefully decant the ether.
-
Wash the peptide pellet with cold diethyl ether (2-3 times) to remove residual scavengers and cleaved protecting groups.[1][2]
-
After the final wash, dry the peptide pellet under a stream of nitrogen or in a vacuum desiccator to obtain the crude peptide.[1]
-
Protocol 2: Cleavage for Peptides with Sensitive Residues
This protocol is recommended for peptides containing sensitive amino acids such as Cys, Met, or Trp, which are prone to alkylation or oxidation.[3]
-
Resin Preparation:
-
Follow steps 1a-1c from Protocol 1.
-
-
Cleavage Cocktail Preparation (Reagent K):
-
Cleavage Reaction:
-
Peptide Precipitation, Isolation, and Drying:
-
Follow steps 4a-5d from Protocol 1.
-
Data Presentation
The choice of cleavage cocktail significantly impacts the yield and purity of the final peptide product. The following tables provide a summary of expected outcomes based on the chosen protocol.
Table 1: Comparison of Cleavage Cocktails for a Model 15N-Serine Peptide
| Cleavage Cocktail | Target Peptide | Key Scavengers | Cleavage Time (hr) | Crude Purity (%) | Yield (%) | Notes |
| Reagent B (TFA/H₂O/TIS, 95:2.5:2.5) | Peptides without sensitive residues | TIS | 2-3 | > 85% | 70-90% | A good general-purpose cocktail for robust sequences.[2][4] |
| Reagent K (TFA/Phenol/H₂O/Thioanisole/EDT, 82.5:5:5:5:2.5) | Peptides with Trp, Met, Cys | Phenol, Thioanisole, EDT | 2-4 | > 90% | 75-95% | Recommended for peptides with multiple sensitive residues to minimize side reactions.[2][3] |
*Crude purity and yield are dependent on the peptide sequence and the efficiency of the synthesis. Values are representative.
Table 2: Troubleshooting Common Cleavage Problems
| Observation | Potential Cause(s) | Recommended Solution(s) |
| Low Peptide Yield | Incomplete cleavage. | Increase cleavage time to 3-4 hours; ensure sufficient volume of cleavage cocktail.[2] |
| Peptide precipitation is incomplete. | Ensure ether is sufficiently cold (-20°C); increase precipitation time.[1] | |
| Extra Peaks in HPLC/MS (+57, +73 Da) | Alkylation of sensitive residues (e.g., Trp, Cys, Met) by carbocations. | Use a cocktail with appropriate scavengers (e.g., Reagent K).[2][3] |
| Oxidation of Methionine (+16 Da) | Exposure to oxygen during cleavage. | Degas the cleavage cocktail; perform cleavage under a nitrogen or argon atmosphere.[2] |
| Incomplete Deprotection | Insufficient cleavage time or TFA concentration, especially for Arg(Pbf). | Increase cleavage time; for multiple Arg(Pbf) residues, a stronger cocktail may be needed.[7] |
Signaling Pathways and Logical Relationships
The following diagram illustrates the logic behind choosing a cleavage cocktail and troubleshooting common issues that arise during the cleavage of peptides from the resin.
Caption: Decision tree for cleavage cocktail selection and troubleshooting.
Conclusion
The successful cleavage of peptides containing 15N-serine from solid-phase supports is readily achievable with careful selection of the cleavage cocktail and adherence to established protocols. For peptides lacking sensitive residues, a standard TFA/TIS/H₂O cocktail is generally sufficient. However, for sequences containing amino acids prone to modification, a more robust scavenger mixture, such as Reagent K, is highly recommended to ensure high purity and yield of the desired isotopically labeled peptide. The protocols and data presented herein serve as a comprehensive guide for researchers to effectively cleave and isolate their target peptides for downstream applications.
References
Synthesis of Phosphoserine-Containing Peptides with Fmoc-Chemistry: Application Notes and Protocols
For Researchers, Scientists, and Drug Development Professionals
Introduction
Protein phosphorylation is a critical post-translational modification that regulates a vast array of cellular processes, including signal transduction, cell cycle progression, and apoptosis. The ability to synthesize peptides containing phosphoserine (pSer) is therefore essential for studying the roles of protein kinases and phosphatases, developing kinase inhibitors, and creating tools for phosphoproteomics research.[1][2] This document provides detailed application notes and protocols for the synthesis of phosphoserine-containing peptides using Fmoc-based solid-phase peptide synthesis (SPPS), the most common and versatile method for this purpose.[2][3]
Two primary strategies are employed for the synthesis of phosphopeptides using Fmoc chemistry: the "building block" approach and the "global phosphorylation" approach .[4][5] The building block method involves the direct incorporation of a pre-phosphorylated and protected Fmoc-L-phosphoserine derivative during peptide chain elongation.[2] In contrast, the global phosphorylation strategy involves the synthesis of a serine-containing peptide followed by a post-synthetic phosphorylation of the serine residue while the peptide is still attached to the solid support.[2][4] This document will detail both methodologies, offering insights into their advantages, challenges, and specific protocols.
Key Challenges in Phosphopeptide Synthesis
The synthesis of phosphopeptides presents unique challenges that must be carefully managed to ensure high yield and purity. The primary obstacle is the base-lability of the phosphate protecting groups and the phosphorylated serine residue itself.
β-Elimination: A significant side reaction, particularly for phosphoserine, is β-elimination, which is promoted by the basic conditions used for Fmoc deprotection (e.g., piperidine).[1][6] This reaction leads to the formation of a dehydroalanine residue, which can subsequently react with piperidine to form a piperidinyl-alanine adduct, resulting in a difficult-to-remove impurity.[6]
Reduced Coupling Efficiency: The bulky and negatively charged nature of the phosphate group can sterically hinder the coupling of the subsequent amino acid, leading to incomplete reactions and deletion sequences.[1] Careful selection of coupling reagents and optimization of reaction conditions are crucial to overcome this.
The "Building Block" Approach: Utilizing Pre-Phosphorylated Amino Acids
The building block approach is the most widely used and generally more reliable method for synthesizing phosphoserine-containing peptides.[2] This strategy relies on the use of Fmoc-Ser(PO(OR)OH)-OH derivatives, where 'R' is a protecting group for the phosphate moiety. The most common derivative is Fmoc-Ser(PO(OBzl)OH)-OH , which utilizes a benzyl protecting group.
Diagram of the "Building Block" Approach Workflow
Caption: A schematic of the solid-phase synthesis of a phosphoserine-containing peptide using a pre-phosphorylated building block.
Experimental Protocol: "Building Block" Approach with Fmoc-Ser(PO(OBzl)OH)-OH
This protocol is a general guideline and may require optimization based on the specific peptide sequence.
1. Resin Swelling and Initial Deprotection:
-
Swell the resin (e.g., Rink Amide MBHA resin, 0.1 mmol scale) in dimethylformamide (DMF) for 30 minutes.
-
Treat the resin with 20% piperidine in DMF (v/v) for 5 minutes, drain, and repeat for 15 minutes to remove the Fmoc group from the first amino acid.
-
Wash the resin thoroughly with DMF (5 x 1 min).
2. Standard Amino Acid Coupling:
-
In a separate vessel, pre-activate the Fmoc-amino acid (3 equivalents relative to resin loading) with a coupling reagent such as HATU (2.9 equivalents) and a base like diisopropylethylamine (DIPEA) (6 equivalents) in DMF for 5 minutes.[1][7]
-
Add the activated amino acid solution to the resin and shake for 1-2 hours at room temperature.
-
Monitor the coupling reaction using a ninhydrin (Kaiser) test. If the test is positive (blue), indicating incomplete coupling, repeat the coupling step.
-
Wash the resin with DMF (5 x 1 min).
3. Incorporation of Fmoc-Ser(PO(OBzl)OH)-OH:
-
Pre-activate Fmoc-Ser(PO(OBzl)OH)-OH (3 equivalents) with HATU (2.9 equivalents) and DIPEA (6 equivalents) in DMF.[1][7]
-
Couple the activated phosphoserine derivative to the deprotected peptide-resin for 2 hours at room temperature.
-
Wash the resin thoroughly with DMF (5 x 1 min).
4. Fmoc Deprotection of the Phosphoserine Residue (Mitigating β-Elimination):
-
To minimize β-elimination, use a milder deprotection cocktail. A recommended solution is 2% 1,8-diazabicyclo[5.4.0]undec-7-ene (DBU) and 2% piperidine in DMF (v/v).[6]
-
Treat the resin with this solution for 10-15 minutes at room temperature.
-
Alternatively, for N-terminal phosphoserine residues, 50% cyclohexylamine in dichloromethane (DCM) can be used.[8]
-
Wash the resin thoroughly with DMF (5 x 1 min).
5. Continuation of Peptide Synthesis:
-
Continue the peptide chain elongation by repeating the standard coupling and deprotection steps. For subsequent deprotections after the phosphoserine residue, it is advisable to continue using the milder DBU/piperidine cocktail to prevent further risk of β-elimination.[6]
6. Cleavage and Deprotection:
-
After the final Fmoc deprotection, wash the peptide-resin with DMF, followed by DCM, and dry under vacuum.
-
Treat the resin with a cleavage cocktail such as TFA/triisopropylsilane (TIS)/water (95:2.5:2.5, v/v/v) for 2-4 hours at room temperature.[1] The benzyl protecting group on the phosphate is removed simultaneously during this step.
-
Filter the resin and collect the filtrate.
-
Precipitate the crude peptide by adding cold diethyl ether.
-
Centrifuge to pellet the peptide, decant the ether, and repeat the ether wash twice.
-
Dry the crude peptide pellet under vacuum.
7. Purification and Analysis:
-
Purify the crude peptide by reverse-phase high-performance liquid chromatography (RP-HPLC).
-
Confirm the identity and purity of the final product by mass spectrometry.
Quantitative Data Summary for the "Building Block" Approach
| Parameter | Recommended Conditions | Reference(s) |
| Phosphoserine Building Block | Fmoc-Ser(PO(OBzl)OH)-OH | |
| Coupling Reagents | HATU, HBTU, PyBOP | [1][7][9] |
| Activator Base | DIPEA (N,N-Diisopropylethylamine) | [1][7] |
| Reagent Equivalents (AA:Coupling Reagent:Base) | 3:2.9:6 | [1][7] |
| Coupling Time | 1-2 hours | [8][10] |
| Fmoc Deprotection (Standard) | 20% piperidine in DMF | [6][] |
| Fmoc Deprotection (for pSer to mitigate β-elimination) | 2% DBU / 2% piperidine in DMF | [6] |
| Cleavage Cocktail | TFA/TIS/H₂O (95:2.5:2.5) | [1] |
| Cleavage Time | 2-4 hours | [1] |
| Typical Crude Purity | 50-80% (sequence dependent) | General SPPS knowledge |
| Typical Final Purity (after HPLC) | >95% | [12] |
The "Global Phosphorylation" Approach
This method involves synthesizing the full-length peptide with an unprotected serine residue, which is then phosphorylated on the solid support before cleavage.[2][4] This approach can be more cost-effective if large quantities of a single phosphopeptide are required, as it avoids the use of the more expensive phosphoserine building block. However, it requires an additional on-resin reaction step and can be less efficient, with a higher risk of side reactions. The most common method for global phosphorylation utilizes phosphoramidite chemistry.[2]
Diagram of the "Global Phosphorylation" Approach Workflow
Caption: A schematic of the post-synthetic, on-resin phosphorylation of a serine-containing peptide.
Experimental Protocol: "Global Phosphorylation" using Phosphoramidite Chemistry
1. Peptide Synthesis:
-
Synthesize the desired peptide sequence on a solid support using standard Fmoc-SPPS protocols, incorporating a standard Fmoc-Ser-OH building block at the desired phosphorylation site.
-
Ensure all other hydroxyl-containing amino acids (e.g., Thr, Tyr) are appropriately protected if they are not intended for phosphorylation.
2. On-Resin Phosphorylation:
-
After synthesis, ensure the peptide-resin is thoroughly dried and kept under an inert atmosphere (e.g., argon or nitrogen) as phosphoramidite reagents are sensitive to moisture.
-
Swell the resin in anhydrous acetonitrile or dichloromethane.
-
In a separate flask, dissolve the phosphoramidite reagent (e.g., dibenzyl N,N-diethylphosphoramidite, 5-10 equivalents) and an activator (e.g., 1H-tetrazole, 10-20 equivalents) in anhydrous acetonitrile.[13]
-
Add this solution to the peptide-resin and react for 1-2 hours at room temperature.
-
Wash the resin with anhydrous acetonitrile.
3. Oxidation:
-
Prepare a solution of an oxidizing agent, such as tert-butyl hydroperoxide (t-BuOOH) in decane or m-chloroperoxybenzoic acid (m-CPBA) in DCM.
-
Add the oxidizing solution to the resin and react for 30-60 minutes.
-
Wash the resin thoroughly with DCM and DMF.
4. Cleavage and Deprotection:
-
Proceed with the standard cleavage and deprotection protocol as described for the "building block" approach using a TFA-based cocktail. The phosphate protecting groups will be removed simultaneously.
5. Purification and Analysis:
-
Purify and characterize the final phosphopeptide using RP-HPLC and mass spectrometry.
Quantitative Data Summary for the "Global Phosphorylation" Approach
| Parameter | Recommended Conditions | Reference(s) |
| Phosphitylating Reagent | Dibenzyl N,N-diethylphosphoramidite | [2][13] |
| Activator | 1H-Tetrazole | [13] |
| Reagent Equivalents (Phosphoramidite:Activator) | 5-10 : 10-20 | [13] |
| Phosphitylation Time | 1-2 hours | General knowledge |
| Oxidizing Agent | t-Butyl hydroperoxide or m-CPBA | [2][13] |
| Oxidation Time | 30-60 minutes | General knowledge |
| Cleavage Cocktail | TFA/TIS/H₂O (95:2.5:2.5) | [1] |
| Typical Yield | Generally lower and more variable than the building block approach | [2] |
Case Studies: Synthesis of Biologically Active Phosphopeptides
The synthesis of phosphopeptides has been instrumental in studying the function of proteins like phospholamban and statherin.
-
Phospholamban (PLB): A 52-amino acid transmembrane protein that regulates the Ca²⁺-ATPase in cardiac muscle. Its phosphorylation at Ser16 and Thr17 is crucial for cardiac function. Synthetic PLB and its phosphorylated variants have been produced using Fmoc-SPPS with pseudoproline dipeptides to improve synthesis efficiency and yield.[14][15]
-
Human Salivary Statherin: A 43-residue phosphoprotein that inhibits the precipitation of calcium phosphate salts in saliva. It has been successfully synthesized using Fmoc chemistry and preformed phosphoserine building blocks.[16][17]
Application in Signaling Pathway Research: The ERK/MAPK Pathway
Phosphoserine-containing peptides are invaluable tools for studying signaling cascades like the ERK/MAPK pathway, which is central to cell proliferation, differentiation, and survival.[18][19] This pathway involves a cascade of protein kinases that sequentially phosphorylate and activate each other, with many of the key phosphorylation events occurring on serine and threonine residues.
Diagram of the ERK/MAPK Signaling Pathway
Caption: A simplified representation of the ERK/MAPK signaling cascade, highlighting key phosphorylation events.
Synthetic phosphopeptides corresponding to the phosphorylation sites on MEK and ERK substrates can be used to:
-
Develop specific antibodies that recognize the phosphorylated form of the protein.
-
Act as competitive inhibitors for kinase activity assays.
-
Study the binding interactions with downstream effector proteins.
Conclusion
The Fmoc-based solid-phase synthesis of phosphoserine-containing peptides is a powerful technique for advancing our understanding of cellular signaling and for the development of new therapeutic agents. While challenges such as β-elimination and reduced coupling efficiency exist, they can be effectively managed through the careful selection of synthesis strategy, protected amino acid building blocks, and optimized reaction conditions. The "building block" approach using Fmoc-Ser(PO(OBzl)OH)-OH is generally the most robust and reliable method, while the "global phosphorylation" strategy offers a cost-effective alternative for specific applications. The detailed protocols and data presented in these application notes provide a solid foundation for researchers to successfully synthesize these critical biomolecules.
References
- 1. Accelerated Multiphosphorylated Peptide Synthesis - PMC [pmc.ncbi.nlm.nih.gov]
- 2. pdfs.semanticscholar.org [pdfs.semanticscholar.org]
- 3. Advances in Fmoc solid‐phase peptide synthesis - PMC [pmc.ncbi.nlm.nih.gov]
- 4. luxembourg-bio.com [luxembourg-bio.com]
- 5. Thieme E-Books & E-Journals [thieme-connect.de]
- 6. benchchem.com [benchchem.com]
- 7. rsc.org [rsc.org]
- 8. researchgate.net [researchgate.net]
- 9. bachem.com [bachem.com]
- 10. peptide.com [peptide.com]
- 12. A statherin-derived peptide promotes hydroxyapatite crystallization and in situ remineralization of artificial enamel caries - RSC Advances (RSC Publishing) DOI:10.1039/C7RA12032J [pubs.rsc.org]
- 13. researchgate.net [researchgate.net]
- 14. Improved Solid-Phase Peptide Synthesis of Wild-Type and Phosphorylated Phospholamban Using a Pseudoproline Dipeptide [scirp.org]
- 15. Synthetic phosphopeptides enable quantitation of the content and function of the four phosphorylation states of phospholamban in cardiac muscle - PubMed [pubmed.ncbi.nlm.nih.gov]
- 16. Solid-phase synthesis and characterization of human salivary statherin: a tyrosine-rich phosphoprotein inhibitor of calcium phosphate precipitation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 17. Molecular basis of salivary proline-rich protein and peptide synthesis: cell-free translations and processing of human and macaque statherin mRNAs and partial amino acid sequence of their signal peptides - PubMed [pubmed.ncbi.nlm.nih.gov]
- 18. MAPK/ERK pathway - Wikipedia [en.wikipedia.org]
- 19. creative-diagnostics.com [creative-diagnostics.com]
Application Notes: Probing Protein-Protein Interactions with Fmoc-Ser-OH-15N
For Researchers, Scientists, and Drug Development Professionals
Introduction
The study of protein-protein interactions (PPIs) is fundamental to understanding cellular signaling, disease pathogenesis, and for the development of novel therapeutics. A key method for elucidating these interactions at atomic resolution is Nuclear Magnetic Resonance (NMR) spectroscopy. The incorporation of stable isotopes, such as ¹⁵N, into one of the interacting partners allows for the sensitive detection of binding events. Fmoc-Ser-OH-¹⁵N is a valuable reagent for these studies, enabling the site-specific labeling of serine residues within a peptide or protein. This is particularly relevant for investigating interactions involving serine phosphorylation, a critical post-translational modification in many signaling pathways.
These application notes provide a detailed overview and protocols for the use of Fmoc-Ser-OH-¹⁵N in studying PPIs, with a focus on the interaction between an SH2 domain-containing protein and a serine-phosphorylated peptide.
Key Applications
-
Binding Site Mapping: Identify the specific amino acid residues at the interface of a protein-protein interaction using Chemical Shift Perturbation (CSP) analysis.
-
Quantitative Analysis of Binding Affinity: Determine the dissociation constant (Kd) to quantify the strength of the interaction.
-
Structural Elucidation: Provide distance restraints for the determination of the three-dimensional structure of protein-peptide complexes.
-
Fragment-Based Drug Discovery: Screen and characterize small molecule inhibitors that disrupt protein-protein interactions.
Featured Application: Grb2-SH2 Domain Interaction with a Phosphoserine-Containing Peptide
Growth factor receptor-bound protein 2 (Grb2) is an adaptor protein that plays a crucial role in signal transduction pathways, such as the Ras/MAPK pathway. Its SH2 domain specifically recognizes and binds to phosphorylated tyrosine or serine residues on activated receptor tyrosine kinases and other signaling proteins. By synthesizing a peptide with a ¹⁵N-labeled phosphoserine, we can use NMR to monitor its interaction with the Grb2-SH2 domain.
Signaling Pathway Context:
Caption: Grb2-mediated signal transduction pathway.
Data Presentation
The binding of a ¹⁵N-labeled phosphoserine-containing peptide to the Grb2-SH2 domain can be quantified by monitoring the chemical shift perturbations in the ¹H-¹⁵N HSQC spectrum of the peptide upon titration with the SH2 domain.
| Residue | δ¹⁵N (ppm) Free | δ¹⁵N (ppm) Bound | Δδ¹⁵N (ppm) | δ¹H (ppm) Free | δ¹H (ppm) Bound | Δδ¹H (ppm) | Combined CSP¹ |
| Gly-1 | 108.5 | 108.6 | 0.1 | 8.30 | 8.32 | 0.02 | 0.03 |
| Ala-2 | 121.2 | 121.3 | 0.1 | 8.15 | 8.16 | 0.01 | 0.02 |
| Val-3 | 119.8 | 120.1 | 0.3 | 8.42 | 8.48 | 0.06 | 0.08 |
| pSer-4-¹⁵N | 115.2 | 117.5 | 2.3 | 8.55 | 9.15 | 0.60 | 0.70 |
| Asn-5 | 118.9 | 119.8 | 0.9 | 8.21 | 8.45 | 0.24 | 0.30 |
| Leu-6 | 122.5 | 122.8 | 0.3 | 8.05 | 8.10 | 0.05 | 0.07 |
| Gln-7 | 114.7 | 114.8 | 0.1 | 8.33 | 8.34 | 0.01 | 0.02 |
¹Combined CSP (ppm) = [ (Δδ¹H)² + (α * Δδ¹⁵N)² ]^½, where α is a weighting factor (typically ~0.14-0.2).
Dissociation Constant (Kd):
By fitting the chemical shift perturbation data to a binding isotherm, the dissociation constant (Kd) for this interaction was determined.
| Interacting Partners | Method | Dissociation Constant (Kd) |
| Grb2-SH2 & pSer-Peptide-¹⁵N | NMR Titration | 2.5 µM |
Experimental Protocols
Protocol 1: Synthesis of ¹⁵N-labeled Phosphoserine Peptide via SPPS
This protocol describes the manual solid-phase peptide synthesis of a model phosphoserine-containing peptide (e.g., Ac-GAV-pSer-NLQ-NH₂) with a ¹⁵N-labeled serine residue.
Materials:
-
Rink Amide MBHA resin
-
Fmoc-amino acids (including Fmoc-Ser-OH-¹⁵N)
-
O-(dibenzyl-N,N-diisopropylisourea)-L-serine (for phosphoserine incorporation)
-
Coupling reagents: HBTU, HOBt
-
Base: N,N-Diisopropylethylamine (DIPEA)
-
Fmoc deprotection solution: 20% piperidine in DMF
-
Solvents: N,N-Dimethylformamide (DMF), Dichloromethane (DCM)
-
Cleavage cocktail: 95% TFA, 2.5% TIS, 2.5% H₂O
-
Diethyl ether
Procedure:
-
Resin Swelling: Swell the Rink Amide resin in DMF for 1 hour in a reaction vessel.
-
Fmoc Deprotection: Remove the Fmoc group with 20% piperidine in DMF (2 x 10 min).
-
Washing: Wash the resin with DMF (5x) and DCM (5x).
-
Amino Acid Coupling:
-
For standard amino acids: Dissolve Fmoc-amino acid (3 eq), HBTU (3 eq), HOBt (3 eq), and DIPEA (6 eq) in DMF. Add to the resin and agitate for 2 hours.
-
For ¹⁵N-Serine: Use Fmoc-Ser-OH-¹⁵N in the corresponding cycle.
-
-
Wash: Wash the resin with DMF (3x) and DCM (3x).
-
Repeat: Repeat steps 2-5 for each amino acid in the sequence.
-
Phosphorylation: Couple O-(dibenzyl-N,N-diisopropylisourea)-L-serine.
-
Final Deprotection: Remove the N-terminal Fmoc group.
-
Cleavage and Deprotection: Treat the resin with the cleavage cocktail for 3 hours.
-
Precipitation and Purification: Precipitate the peptide in cold diethyl ether, centrifuge, and purify by reverse-phase HPLC.
Protocol 2: NMR Titration for PPI Analysis
Materials:
-
¹⁵N-labeled phosphoserine peptide
-
Unlabeled Grb2-SH2 domain protein
-
NMR buffer (e.g., 20 mM Phosphate, 50 mM NaCl, pH 6.8)
-
D₂O
Procedure:
-
Sample Preparation: Prepare a ~100 µM solution of the ¹⁵N-labeled phosphoserine peptide in NMR buffer with 10% D₂O. Prepare a concentrated stock (~2 mM) of the unlabeled Grb2-SH2 domain in the same buffer.
-
Initial Spectrum: Acquire a ¹H-¹⁵N HSQC spectrum of the free ¹⁵N-labeled peptide.
-
Titration: Add small aliquots of the concentrated Grb2-SH2 domain solution to the peptide sample.
-
Acquire Spectra: After each addition, gently mix and acquire a ¹H-¹⁵N HSQC spectrum.
-
Data Analysis:
-
Process the spectra using appropriate software (e.g., NMRPipe).
-
Overlay the spectra and track the chemical shift changes for each assigned peak.
-
Calculate the combined chemical shift perturbations.
-
Plot the chemical shift changes against the molar ratio of protein to peptide and fit the data to a one-site binding model to determine the Kd.
-
Visualizations
Experimental Workflow for PPI Analysis
Caption: Workflow for studying PPIs using a ¹⁵N-labeled peptide.
Logical Relationship for CSP Analysis
Caption: Logic diagram for Chemical Shift Perturbation analysis.
Application Notes and Protocols for Mass Spectrometry Analysis of Fmoc-Ser-OH-15N
For Researchers, Scientists, and Drug Development Professionals
Introduction
Stable isotope labeling is a powerful technique in mass spectrometry for quantitative analysis, enabling precise differentiation and quantification of molecules in complex mixtures.[1][2] The use of amino acids labeled with heavy isotopes, such as ¹⁵N, provides an internal standard that is chemically identical to the analyte of interest but mass-shifted, allowing for accurate quantification by correcting for variations in sample preparation and instrument response.[1][3] Fmoc-Ser-OH-¹⁵N is a ¹⁵N-labeled version of N-(9-Fluorenylmethoxycarbonyl)-L-serine, a derivative commonly used in peptide synthesis and as a standalone analyte for various analytical purposes.[4][5]
This application note provides detailed protocols for the sample preparation of Fmoc-Ser-OH-¹⁵N for mass spectrometry analysis. The derivatization of serine with 9-fluorenylmethoxycarbonyl chloride (Fmoc-Cl) enhances its chromatographic retention on reversed-phase columns and improves its ionization efficiency, leading to sensitive and selective detection.[6][7][8]
Data Presentation
The following table summarizes key quantitative data for the analysis of Fmoc-Ser-OH and its ¹⁵N-labeled counterpart.
| Parameter | Value (Fmoc-Ser-OH) | Value (Fmoc-Ser-OH-¹⁵N) | Reference |
| Molecular Formula | C₁₈H₁₇NO₅ | C₁₈H₁₇¹⁵NO₅ | [4] |
| Molecular Weight | 327.33 g/mol | 328.32 g/mol | [4] |
| [M+H]⁺ (protonated) | m/z 328.1 | m/z 329.1 | [3] |
| [M+Na]⁺ (sodiated) | m/z 350.1 | m/z 351.1 | [3] |
| [M-H]⁻ (deprotonated) | m/z 326.1 | m/z 327.1 | N/A |
| Key MS/MS Fragments | m/z 179.1, 222.1 | m/z 179.1, 222.1 | [3] |
| Typical LOQ | 1 - 5 pmol | 1 - 5 pmol | [9] |
Experimental Protocols
Protocol 1: Derivatization of Serine with Fmoc-Cl
This protocol details the derivatization of serine (or a sample containing serine) with 9-fluorenylmethoxycarbonyl chloride for subsequent LC-MS analysis.
Materials:
-
Serine standard or sample
-
Fmoc-Ser-OH-¹⁵N (as internal standard)
-
Borate Buffer (0.5 M, pH 9.0)
-
Fmoc-Cl solution (3 mM in acetone or acetonitrile)
-
Formic acid (for quenching)
-
Acetonitrile (ACN), HPLC grade
-
Water, HPLC grade
-
Solid-Phase Extraction (SPE) cartridges (e.g., C18)
Procedure:
-
Sample Preparation:
-
Dissolve the serine standard or sample in an appropriate solvent.
-
For quantitative analysis, spike the sample with a known concentration of Fmoc-Ser-OH-¹⁵N internal standard.
-
-
Derivatization Reaction:
-
Quenching the Reaction:
-
Add 10 µL of 1% formic acid to the reaction mixture to lower the pH and stop the derivatization process.[10]
-
Vortex briefly.
-
-
Sample Cleanup (SPE):
-
Condition a C18 SPE cartridge by washing with 1 mL of acetonitrile followed by 1 mL of water.
-
Load the reaction mixture onto the conditioned SPE cartridge.
-
Wash the cartridge with 1 mL of 5% acetonitrile in water to remove salts and other polar impurities.
-
Elute the Fmoc-derivatized serine with 1 mL of 80% acetonitrile in water.
-
Dry the eluate under a stream of nitrogen or in a vacuum centrifuge.
-
-
Final Sample Preparation:
-
Reconstitute the dried sample in a suitable volume (e.g., 100 µL) of the initial mobile phase for LC-MS analysis (e.g., 10% acetonitrile in water with 0.1% formic acid).
-
Protocol 2: LC-MS/MS Analysis
This protocol provides general parameters for the analysis of Fmoc-derivatized serine by liquid chromatography-tandem mass spectrometry.
Instrumentation:
-
HPLC system coupled to a tandem mass spectrometer (e.g., Q-TOF or triple quadrupole) with an electrospray ionization (ESI) source.[3]
LC Conditions:
-
Column: C18 reversed-phase column (e.g., 2.1 x 100 mm, 2.6 µm particle size).[4]
-
Mobile Phase A: 0.1% Formic Acid in Water.[7]
-
Mobile Phase B: 0.1% Formic Acid in Acetonitrile.[7]
-
Gradient: A linear gradient from 10% to 90% B over 10-15 minutes.
-
Flow Rate: 0.2 - 0.4 mL/min.
-
Column Temperature: 30-40 °C.
-
Injection Volume: 5 - 10 µL.
MS Conditions:
-
Ionization Mode: Positive ESI.[3]
-
Capillary Voltage: 3-4 kV.[3]
-
Cone Voltage: 20-40 V.[3]
-
Desolvation Gas Temperature: 250-350 °C.[3]
-
MS1 Scan Range: m/z 100-500.
-
MS/MS Analysis: Use Multiple Reaction Monitoring (MRM) for quantitative analysis.
-
MRM Transition for Fmoc-Ser-OH: Precursor ion m/z 328.1 → Product ions (e.g., m/z 179.1).
-
MRM Transition for Fmoc-Ser-OH-¹⁵N: Precursor ion m/z 329.1 → Product ions (e.g., m/z 179.1).
-
Signaling Pathways and Experimental Workflows
Mass Spectrometry Analysis Workflow
The following diagram illustrates the experimental workflow for the sample preparation and analysis of Fmoc-Ser-OH-¹⁵N.
Caption: Experimental workflow from sample preparation to MS analysis.
Expected MS/MS Fragmentation
In positive ion mode ESI-MS/MS, Fmoc-protected amino acids typically exhibit characteristic fragmentation patterns. The protonated molecule [M+H]⁺ will undergo collision-induced dissociation (CID). The most common fragmentation involves the cleavage of the carbamate bond, leading to the formation of the stable fluorenylmethyl cation.
-
Loss of the Fmoc group: A significant neutral loss of the Fmoc group (222.1 Da) can be observed.
-
Formation of the fluorenylmethyl cation: A prominent fragment ion at m/z 179.1, corresponding to the fluorenylmethyl cation ([C₁₄H₁₁]⁺), is expected.[3]
-
Formation of [Fmoc-CH₂]⁺: A fragment at m/z 222.1 corresponding to the Fmoc-methylene cation may also be observed.[3]
For quantitative analysis using MRM, the transition from the precursor ion ([M+H]⁺) to a stable and abundant product ion is monitored. For Fmoc-Ser-OH, a suitable transition would be m/z 328.1 → 179.1. For the ¹⁵N-labeled internal standard, the transition would be m/z 329.1 → 179.1. The product ion does not contain the nitrogen atom from serine, and therefore its mass is the same for both the labeled and unlabeled species.
References
- 1. researchgate.net [researchgate.net]
- 2. Optimization and validation of a liquid chromatography-tandem mass spectrometry method for the determination of glyphosate in human urine after pre-column derivatization with 9-fluorenylmethoxycarbonyl chloride - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. benchchem.com [benchchem.com]
- 4. researchgate.net [researchgate.net]
- 5. Separation of 9-Fluorenylmethyloxycarbonyl Amino Acid Derivatives in Micellar Systems of High-Performance Thin-Layer Chromatography and Pressurized Planar Electrochromatography - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Sensitive and Selective Amino Acid Profiling of Minute Tissue Amounts by HPLC/Electrospray Negative Tandem Mass Spectrometry Using 9-Fluorenylmethoxycarbonyl (Fmoc-Cl) Derivatization | Springer Nature Experiments [experiments.springernature.com]
- 7. A Practical Method for Amino Acid Analysis by LC-MS Using Precolumn Derivatization with Urea - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Sensitive and Selective Amino Acid Profiling of Minute Tissue Amounts by HPLC/Electrospray Negative Tandem Mass Spectrometry Using 9-Fluorenylmethoxycarbonyl (Fmoc-Cl) Derivatization - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. Amino acid analysis by high-performance liquid chromatography after derivatization with 9-fluorenylmethyloxycarbonyl chloride Literature overview and further study - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. ikm.org.my [ikm.org.my]
A Comparative Guide to Manual and Automated Synthesis of Peptides with Fmoc-Ser-OH-¹⁵N
Application Note and Protocol Guide
For researchers, scientists, and drug development professionals, the incorporation of isotopically labeled amino acids is crucial for a variety of applications, from NMR-based structural biology to quantitative proteomics.[1][2] This document provides a detailed comparison of manual and automated solid-phase peptide synthesis (SPPS) for peptides containing ¹⁵N-labeled serine (Fmoc-Ser-OH-¹⁵N). We offer comprehensive experimental protocols, a summary of expected quantitative outcomes, and visual workflows to guide the synthesis strategy.
The primary challenge in synthesizing serine-containing peptides is the potential for side reactions related to the hydroxyl group. While the isotopic ¹⁵N label is not expected to alter the chemical reactivity of the serine, careful control of the synthesis conditions is paramount to ensure high purity and yield. Potential side reactions include O-sulfonation during the final cleavage if appropriate scavengers are not used and the formation of endo-Ser impurities.
Data Presentation: A Quantitative Comparison
| Parameter | Manual Synthesis | Automated Synthesis (Standard) |
| Crude Purity | Can be higher with optimized, hands-on control. One study reported an average crude purity of 70% with a rapid manual method.[3] | Typically consistent and high for standard sequences. A comparative study showed an average purity of 50% for microwave-assisted automated synthesis of the same peptides.[3] |
| Overall Yield | Highly dependent on operator skill and sequence complexity. | Generally reproducible and can be higher due to optimized and consistent protocols. |
| Synthesis Time per Cycle | Slower due to manual interventions, typically 80-150 minutes per amino acid.[3] | Significantly faster, with cycles often under an hour. Microwave-assisted synthesis can reduce cycle times to minutes. |
| Reagent Consumption | Can be optimized for single syntheses, but may be higher due to less precise dispensing. | Optimized protocols can reduce reagent and solvent waste. |
| Reproducibility | Lower, prone to operator-to-operator variability. | High, with precise robotic control leading to consistent results between runs. |
| Initial Cost | Lower equipment cost. | Higher initial investment for the synthesizer. |
Experimental Protocols
The following are detailed protocols for the manual and automated synthesis of a peptide incorporating Fmoc-Ser-OH-¹⁵N. These protocols are based on a 0.1 mmol synthesis scale using a Rink Amide resin for a C-terminally amidated peptide. The side chain of serine is protected with a tert-butyl (tBu) group, which is standard practice in Fmoc-SPPS.
Protocol 1: Manual Solid-Phase Peptide Synthesis
1. Resin Swelling:
-
Place 135 mg of Rink Amide resin (0.74 mmol/g loading) in a fritted glass reaction vessel.
-
Add 5 mL of N,N-dimethylformamide (DMF) and gently agitate for 30-60 minutes.
-
Drain the DMF.
2. Fmoc Deprotection:
-
Add 5 mL of 20% (v/v) piperidine in DMF to the resin.
-
Agitate for 5 minutes and drain.
-
Repeat the piperidine treatment for an additional 10-15 minutes.
-
Wash the resin thoroughly with DMF (5 x 5 mL).
3. Amino Acid Coupling (Fmoc-Ser(tBu)-OH-¹⁵N):
-
In a separate vial, dissolve Fmoc-Ser(tBu)-OH-¹⁵N (3-5 equivalents), a coupling agent like HBTU (3-5 equivalents), and an activation base such as DIPEA (6-10 equivalents) in DMF.
-
Add the activated amino acid solution to the deprotected resin.
-
Agitate the mixture for 1-2 hours at room temperature.
-
To confirm coupling completion, perform a Kaiser test. If the test is positive (blue beads), repeat the coupling step.
-
Wash the resin with DMF (3 x 5 mL).
4. Subsequent Amino Acid Couplings:
-
Repeat steps 2 and 3 for each subsequent amino acid in the peptide sequence.
5. Final Fmoc Deprotection:
-
After the final amino acid coupling, repeat step 2 to remove the N-terminal Fmoc group.
6. Cleavage and Deprotection:
-
Wash the peptide-resin with dichloromethane (DCM) (3 x 5 mL) and dry under vacuum.
-
Prepare a cleavage cocktail, typically trifluoroacetic acid (TFA)/water/triisopropylsilane (TIS) in a ratio of 95:2.5:2.5.
-
Add the cleavage cocktail to the resin and agitate for 2-3 hours at room temperature.
-
Filter the resin and collect the filtrate containing the cleaved peptide.
7. Peptide Precipitation and Purification:
-
Precipitate the crude peptide by adding the TFA filtrate to a 10-fold volume of cold diethyl ether.
-
Centrifuge the mixture to pellet the peptide.
-
Wash the peptide pellet with cold diethyl ether twice.
-
Dry the crude peptide under vacuum.
-
Purify the peptide using reverse-phase high-performance liquid chromatography (RP-HPLC).
Protocol 2: Automated Solid-Phase Peptide Synthesis
1. Instrument Setup:
-
Load vials with Fmoc-amino acids (including Fmoc-Ser(tBu)-OH-¹⁵N), activator (e.g., HBTU/HOBt), base (e.g., DIPEA), 20% piperidine in DMF, and washing solvents (DMF, DCM) into the designated positions on the automated synthesizer.
-
Place the reaction vessel containing the Rink Amide resin in the synthesizer.
2. Synthesis Program:
-
Program the synthesizer with the desired peptide sequence and synthesis parameters. A typical cycle for a 0.1 mmol scale synthesis is as follows:
-
Resin Swelling: Swell the resin in DMF for 30 minutes.
-
Fmoc Deprotection: Treat the resin with 20% piperidine in DMF (2 x 7 minutes).
-
Washing: Wash the resin with DMF (5-7 times).
-
Coupling: Deliver the pre-activated Fmoc-amino acid solution to the reaction vessel and allow it to react for the programmed time (e.g., 30-60 minutes).
-
Washing: Wash the resin with DMF (5-7 times).
-
3. Post-Synthesis Processing:
-
Once the automated synthesis is complete, the peptide-resin is removed from the synthesizer.
-
The cleavage, deprotection, precipitation, and purification steps are performed manually as described in the manual synthesis protocol (steps 6 and 7).
Visualizing the Workflow and Application
To better understand the synthesis process and the application of the resulting ¹⁵N-labeled peptide, the following diagrams illustrate the experimental workflows and a key signaling pathway where such a peptide would be utilized.
Caption: Manual Solid-Phase Peptide Synthesis Workflow.
Caption: Automated Solid-Phase Peptide Synthesis Workflow.
A primary application for peptides containing ¹⁵N-labeled serine is in the study of protein phosphorylation by techniques like NMR and mass spectrometry.[4][5] Serine phosphorylation is a key event in many signaling pathways, such as those mediated by kinases.
Caption: Serine Phosphorylation in a Kinase Signaling Pathway.
Conclusion
The choice between manual and automated synthesis for incorporating Fmoc-Ser-OH-¹⁵N depends on the specific needs of the research. Manual synthesis offers greater flexibility and potentially higher purity for complex sequences with careful optimization, making it suitable for methods development and small-scale synthesis.[3] Automated synthesis, on the other hand, provides high throughput and reproducibility, which is advantageous for synthesizing multiple peptides or for routine production. Regardless of the method, the use of high-purity reagents and careful monitoring of the coupling steps are essential for the successful synthesis of ¹⁵N-labeled serine-containing peptides for downstream applications in biological research and drug development.
References
- 1. Cell-free synthesis of 15N-labeled proteins for NMR studies - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. pharmacy.nmims.edu [pharmacy.nmims.edu]
- 3. A Rapid Manual Solid Phase Peptide Synthesis Method for High-Throughput Peptide Production - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. researchgate.net [researchgate.net]
- 5. ba333.free.fr [ba333.free.fr]
Monitoring ¹⁵N Incorporation in Protein Expression: Application Notes and Protocols
For Researchers, Scientists, and Drug Development Professionals
Introduction
Stable isotope labeling with ¹⁵N has become an indispensable tool in proteomics and drug development. By replacing the naturally abundant ¹⁴N with the heavier, non-radioactive ¹⁵N isotope, researchers can accurately trace, identify, and quantify proteins in complex biological systems. This technique is foundational for a wide range of applications, from determining protein structure and function to elucidating metabolic pathways and identifying drug targets.[1][2][3] This document provides detailed application notes and protocols for monitoring ¹⁵N incorporation in protein expression, tailored for researchers, scientists, and professionals in drug development.
Metabolic labeling with ¹⁵N involves culturing cells or organisms in a medium where the standard nitrogen sources are replaced with ¹⁵N-labeled counterparts, typically ¹⁵N-labeled amino acids or ammonium salts.[4] As proteins are synthesized, the ¹⁵N isotope is incorporated into the proteome. This mass shift allows for the differentiation and relative quantification of proteins from different samples when analyzed by mass spectrometry (MS) or nuclear magnetic resonance (NMR) spectroscopy.[1][2] A key advantage of this in vivo labeling approach is the early combination of samples, which significantly minimizes experimental variability that can arise during sample preparation.[4]
One of the most powerful applications of this technique is Stable Isotope Labeling by Amino Acids in Cell Culture (SILAC), a method developed to monitor the relative abundance of proteins.[5][6] In a typical SILAC experiment, two cell populations are grown in media containing either "light" (natural) or "heavy" (stable isotope-labeled) amino acids.[6] This results in two proteomes that are chemically identical but differ in mass, allowing for precise quantification by mass spectrometry.[5][6]
The applications of ¹⁵N-labeled proteins are vast and impactful. In quantitative proteomics, it enables the global analysis of protein expression changes in response to various stimuli.[4][7] For drug development, ¹⁵N labeling is crucial for identifying the protein targets of new drug candidates, understanding their mechanisms of action, and discovering biomarkers for disease.[4] Furthermore, by tracking the rate of ¹⁵N incorporation, researchers can study protein synthesis and degradation, providing critical insights into protein dynamics.[4][6]
Experimental Workflow Overview
The general workflow for a ¹⁵N labeling experiment involves several key stages, from cell culture and protein expression to sample analysis and data interpretation. The following diagram illustrates the typical steps involved.
Caption: A generalized workflow for monitoring 15N incorporation in protein expression.
Detailed Experimental Protocols
Protocol 1: ¹⁵N Labeling of Proteins in E. coli
This protocol is adapted for the expression of ¹⁵N-labeled proteins in the E. coli strain KRX.[8]
Materials:
-
E. coli KRX strain containing the plasmid for the target protein.
-
¹⁵NH₄Cl (Isotope-labeled ammonium chloride).
-
Glucose (or ¹³C-glucose for double labeling).
-
Trace elements solution.[10]
-
1M MgSO₄.
-
1M CaCl₂.
-
Thiamin and Biotin solutions.
-
Appropriate antibiotics.
-
Isopropyl β-D-1-thiogalactopyranoside (IPTG) for induction.
Procedure:
-
Starter Culture: Inoculate a single colony of transformed E. coli into 5 mL of rich medium (e.g., LB or 2xTY) with the appropriate antibiotic.[9] Grow overnight at 37°C with shaking.
-
Pre-culture: Inoculate 10 mL of M9 minimal medium (containing standard ¹⁴NH₄Cl) with the overnight starter culture (1:100 dilution).[9] Grow until the culture is visibly turbid.
-
Main Culture: Prepare 1 L of M9 minimal medium, substituting ¹⁴NH₄Cl with 1 g of ¹⁵NH₄Cl.[9] Supplement the medium with glucose, trace elements, MgSO₄, CaCl₂, vitamins, and the appropriate antibiotic.[10]
-
Inoculation: Inoculate the 1 L ¹⁵N-labeled M9 medium with the pre-culture (1:100 dilution).[9]
-
Growth and Induction: Grow the main culture at the optimal temperature for your protein (e.g., 37°C) with vigorous shaking until the OD₆₀₀ reaches 0.6-0.8.[10] Induce protein expression by adding IPTG to a final concentration of 1 mM.[11] Reduce the temperature if necessary (e.g., 18-20°C) and continue to shake for 16-18 hours.[11][12]
-
Harvesting: Harvest the cells by centrifugation at 4,000 x g for 20 minutes at 4°C.[10] The cell pellet can be stored at -80°C until purification.
Protocol 2: Analysis of ¹⁵N Incorporation by Mass Spectrometry
This protocol outlines the general steps for determining the percentage of ¹⁵N incorporation using mass spectrometry.
Materials:
-
¹⁵N-labeled protein sample.
-
Denaturation and reduction buffers (e.g., DTT, urea).
-
Alkylation reagent (e.g., iodoacetamide).
-
Trypsin (or other suitable protease).
-
LC-MS/MS system (e.g., Orbitrap or TOF).
Procedure:
-
Protein Denaturation, Reduction, and Alkylation: Resuspend the protein pellet in a denaturation buffer. Reduce disulfide bonds with DTT and then alkylate cysteine residues with iodoacetamide.
-
Proteolytic Digestion: Dilute the sample to reduce the denaturant concentration and add trypsin. Incubate overnight at 37°C to digest the protein into peptides.
-
LC-MS/MS Analysis: Analyze the resulting peptide mixture using an LC-MS/MS system. The mass spectrometer will measure the mass-to-charge ratio of the peptides.
-
Data Analysis:
-
Identify the peptide sequences from the MS/MS spectra using a database search algorithm (e.g., Mascot, Sequest).
-
For identified peptides, compare the experimental isotopic distribution of the ¹⁵N-labeled peptide with the theoretical distribution for varying levels of ¹⁵N incorporation.[13][14]
-
The percentage of incorporation can be calculated by finding the best fit between the experimental and theoretical isotopic profiles.[13] Software tools can automate this process by comparing profiles using correlation coefficients.[13]
-
For SILAC experiments, the relative quantification is determined by the ratio of the peak intensities for the "heavy" and "light" peptide pairs.[15]
-
Data Presentation and Interpretation
The primary output for monitoring ¹⁵N incorporation is the percentage of enrichment. This data is critical for ensuring the quality of labeled protein standards and for accurate quantification in proteomics studies.
Table 1: Example of ¹⁵N Incorporation Efficiency for a Recombinant Protein
| Peptide Sequence | Theoretical Mass (¹⁴N) (Da) | Observed Mass (¹⁵N) (Da) | Number of Nitrogen Atoms | Calculated ¹⁵N Incorporation (%) |
| VGYVSGWGR | 977.48 | 991.52 | 14 | 99.6 |
| YLYEIAR | 909.50 | 920.53 | 11 | 99.2 |
| FESNFNTQATNR | 1421.64 | 1438.70 | 17 | 99.5 |
| KVPQVSTPTLVEVSR | 1653.93 | 1675.01 | 22 | 99.3 |
Note: The calculated incorporation percentage is determined by the mass shift observed in the mass spectrometer. The expected mass shift is approximately 1 Da for each nitrogen atom at 100% incorporation.
Table 2: SILAC Data for Relative Protein Quantification
| Protein ID | Peptide Sequence | Light (¹⁴N) Intensity | Heavy (¹⁵N) Intensity | Ratio (Heavy/Light) | Fold Change |
| P12345 | AGFAGDDAPR | 1.2E+07 | 1.1E+07 | 0.92 | ~1.0 |
| Q67890 | VAPEEHPVLLTEAPLNPK | 5.4E+06 | 1.3E+07 | 2.41 | ↑ 2.4 |
| R54321 | LTILEELR | 8.9E+07 | 2.2E+07 | 0.25 | ↓ 4.0 |
This table illustrates how SILAC data can be used to determine the relative abundance of proteins between two conditions. A ratio of ~1 indicates no change, while ratios greater or less than 1 indicate up- or down-regulation, respectively.
Advanced Applications and Considerations
NMR Spectroscopy: For structural biology applications, uniform ¹⁵N labeling is essential for a variety of NMR experiments that provide information on protein structure and dynamics.[3][16][17] The success of these experiments is highly dependent on achieving a high level of isotope enrichment.
In-Vivo Labeling in Complex Organisms: ¹⁵N metabolic labeling can also be applied to whole organisms, such as mice, to study protein turnover and dynamics in different tissues.[18][7] This approach provides valuable insights into physiological and pathological processes.
Potential for Isotope Effects: Researchers should be aware that the introduction of heavy isotopes can sometimes have a minor effect on biological processes, such as protein expression levels and chromatographic retention times.[19] These effects are generally small but should be considered when interpreting results.
Scrambling of Labels: In some cases, metabolic pathways can lead to the "scrambling" of isotopes, where the ¹⁵N from a labeled amino acid is incorporated into other amino acids.[12] This can be monitored by MS/MS analysis and often mitigated by adjusting the composition of the culture medium.[12]
Logical Relationship of Key Analytical Steps
The following diagram illustrates the logical flow from a labeled protein sample to the final determination of incorporation efficiency.
References
- 1. Nitrogen-15 Labeling: A Game-Changer in Protein Metabolism and Drug Development - China Isotope Development [asiaisotopeintl.com]
- 2. benchchem.com [benchchem.com]
- 3. isotope-science.alfa-chemistry.com [isotope-science.alfa-chemistry.com]
- 4. benchchem.com [benchchem.com]
- 5. sigmaaldrich.com [sigmaaldrich.com]
- 6. chempep.com [chempep.com]
- 7. Using 15N-Metabolic Labeling for Quantitative Proteomic Analyses | Springer Nature Experiments [experiments.springernature.com]
- 8. 15N Labeling of Proteins Overexpressed in the Escherichia coli Strain KRX [promega.sg]
- 9. www2.mrc-lmb.cam.ac.uk [www2.mrc-lmb.cam.ac.uk]
- 10. 15N labeling of proteins in E. coli – Protein Expression and Purification Core Facility [embl.org]
- 11. antibodies.cancer.gov [antibodies.cancer.gov]
- 12. Rapid mass spectrometric analysis of 15N-Leu incorporation fidelity during preparation of specifically labeled NMR samples - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Method for the Determination of ¹⁵N Incorporation Percentage in Labeled Peptides and Proteins - PubMed [pubmed.ncbi.nlm.nih.gov]
- 14. researchgate.net [researchgate.net]
- 15. Stable isotope labeling by amino acids in cell culture - Wikipedia [en.wikipedia.org]
- 16. researchgate.net [researchgate.net]
- 17. eprints.whiterose.ac.uk [eprints.whiterose.ac.uk]
- 18. Using 15N-Metabolic Labeling for Quantitative Proteomic Analyses - PubMed [pubmed.ncbi.nlm.nih.gov]
- 19. ¹⁵N metabolic labeling: evidence for a stable isotope effect on plasma protein levels and peptide chromatographic retention times - PubMed [pubmed.ncbi.nlm.nih.gov]
Application Notes and Protocols: Fmoc-Ser-OH-15N in Cell-Free Protein Synthesis Systems
For Researchers, Scientists, and Drug Development Professionals
Introduction
Cell-free protein synthesis (CFPS) has emerged as a powerful platform for the rapid production of proteins, offering significant advantages over traditional in vivo expression systems.[1] One of the key benefits of CFPS is the ability to easily incorporate isotopically labeled amino acids for structural and functional studies, particularly for Nuclear Magnetic Resonance (NMR) spectroscopy.[2] This document provides detailed application notes and protocols for the use of ¹⁵N-labeled serine, derived from Fmoc-Ser-OH-¹⁵N, in E. coli-based cell-free protein synthesis systems.
While Fmoc-Ser-OH-¹⁵N is a protected amino acid primarily utilized in Solid-Phase Peptide Synthesis (SPPS)[3], it serves as a high-purity source for ¹⁵N-L-Serine for CFPS applications. In SPPS, the 9-fluorenylmethyloxycarbonyl (Fmoc) group is a temporary protecting group for the α-amino group, which is removed at each step of peptide elongation.[4] For protein synthesis in CFPS, the N-terminal amino group must be free for ribosomal peptide bond formation. Therefore, the Fmoc group must be removed from Fmoc-Ser-OH-¹⁵N prior to its use in a standard CFPS reaction.
An emerging, advanced application involves the direct incorporation of an Fmoc-labeled amino acid as a bulky, hydrophobic label to study protein folding and interactions.[5] This specialized technique requires non-natural amino acid incorporation methods, such as nonsense codon suppression with a pre-charged suppressor tRNA, and is distinct from the uniform labeling protocols detailed below.[5][6]
The primary application detailed here is the use of ¹⁵N-L-Serine in CFPS to produce uniformly ¹⁵N-labeled proteins for downstream analysis, such as NMR spectroscopy, which allows for the elucidation of protein structure, dynamics, and interactions.[2]
Data Presentation
Table 1: Representative Quantitative Data for ¹⁵N-Labeling in a Commercial E. coli CFPS System
| Parameter | Value | Notes |
| Protein Yield (Uniform ¹⁵N-Labeling) | 0.5 - 1.5 mg/mL | Yield is protein-dependent and can be optimized by adjusting reaction conditions. |
| ¹⁵N Incorporation Efficiency | > 95% | The open nature of CFPS allows for precise control of the amino acid pool, leading to high labeling efficiency.[2] |
| Reaction Time | 4 - 8 hours | CFPS allows for rapid protein production compared to in vivo methods.[1] |
| Concentration of ¹⁵N-L-Serine | 1 - 2 mM | Optimal concentration may vary depending on the specific CFPS kit and target protein. |
Note: The values presented are typical and may require optimization for specific proteins and CFPS systems.
Experimental Protocols
Protocol 1: Deprotection of Fmoc-Ser-OH-¹⁵N to Yield ¹⁵N-L-Serine
This protocol describes the removal of the Fmoc protecting group from Fmoc-Ser-OH-¹⁵N to generate ¹⁵N-L-Serine suitable for use in CFPS.
Materials:
-
Fmoc-Ser-OH-¹⁵N
-
20% Piperidine in Dimethylformamide (DMF)
-
Diethyl ether
-
0.1 M Hydrochloric acid (HCl)
-
Lyophilizer
Procedure:
-
Dissolve Fmoc-Ser-OH-¹⁵N in a minimal amount of DMF.
-
Add 20% piperidine in DMF to the solution. A typical ratio is 2-3 mL of the piperidine solution per 0.1 mmol of the Fmoc-amino acid.
-
Allow the reaction to proceed at room temperature for 1-2 hours with gentle stirring.
-
Monitor the deprotection by TLC or HPLC.
-
Once the reaction is complete, precipitate the deprotected ¹⁵N-L-Serine by adding a large excess of cold diethyl ether.
-
Collect the precipitate by centrifugation or filtration.
-
Wash the precipitate several times with diethyl ether to remove the fluorenyl-piperidine adduct.
-
Dissolve the crude product in water and acidify to a pH of approximately 6.0 with 0.1 M HCl.
-
Lyophilize the aqueous solution to obtain the purified ¹⁵N-L-Serine as a white powder.
-
Confirm the purity and identity of the product by NMR or mass spectrometry.
Protocol 2: Uniform ¹⁵N-Labeling of a Target Protein using an E. coli CFPS System
This protocol outlines the expression of a target protein with uniform ¹⁵N-labeling using a commercially available E. coli CFPS kit and the prepared ¹⁵N-L-Serine.
Materials:
-
E. coli CFPS Kit (containing E. coli lysate, reaction mix, and positive control plasmid)
-
Plasmid DNA encoding the target protein with a T7 promoter (concentration ≥ 500 ng/µL)
-
Amino acid mixture lacking serine
-
¹⁵N-L-Serine (prepared from Protocol 1 or commercially sourced)
-
Nuclease-free water
Procedure:
-
Thaw all CFPS components on ice.
-
Prepare a master mix of the CFPS reaction components according to the manufacturer's instructions, substituting the provided amino acid mix with the serine-deficient mixture.
-
Add the ¹⁵N-L-Serine to the master mix to a final concentration of 1-2 mM.
-
Add the plasmid DNA encoding the target protein to the reaction tube. A typical concentration is 10-20 nM of the final reaction volume.
-
Gently mix the reaction by pipetting and incubate at 30-37°C for 4-8 hours. For larger proteins or higher yields, a dialysis-based reaction setup can be used.[7]
-
After the incubation, the expressed protein can be analyzed directly or purified.
-
To confirm expression and labeling, a small aliquot of the reaction can be analyzed by SDS-PAGE and autoradiography (if a radiolabeled amino acid is also included) or by mass spectrometry to confirm the mass shift corresponding to ¹⁵N incorporation.
Visualizations
Experimental Workflow for ¹⁵N-Labeled Protein Production and NMR Analysis
Caption: Workflow for the production of ¹⁵N-labeled protein for NMR analysis.
Logical Relationship of Components in CFPS
Caption: Core components and outputs of a CFPS reaction for labeled protein production.
References
- 1. Cell-free protein synthesis - Wikipedia [en.wikipedia.org]
- 2. CFPS Isotope Labeling for NMR/Structure Service - CD Biosynsis [biosynsis.com]
- 3. Fmoc Amino Acids for SPPS - AltaBioscience [altabioscience.com]
- 4. genscript.com [genscript.com]
- 5. benchchem.com [benchchem.com]
- 6. Cell-Free Synthesis of Defined Protein Conjugates by Site-directed Cotranslational Labeling - Madame Curie Bioscience Database - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 7. researchgate.net [researchgate.net]
Application Notes and Protocols for Selective 15N Labeling of Serine Residues in Proteins
For Researchers, Scientists, and Drug Development Professionals
Introduction
Selective isotopic labeling of amino acids within a protein is a powerful technique for elucidating protein structure, dynamics, and interactions. Specifically, the incorporation of ¹⁵N at serine residues provides a targeted probe for nuclear magnetic resonance (NMR) spectroscopy and mass spectrometry (MS), enabling the study of specific regions within a protein without the spectral complexity of uniform labeling.[1][2] This approach is particularly valuable in drug discovery for mapping binding sites and understanding the conformational changes upon ligand binding.[3]
Serine is a non-essential amino acid central to cellular metabolism, serving as a precursor for the synthesis of other amino acids like glycine and cysteine, as well as being involved in nucleotide biosynthesis.[4][5] This metabolic activity presents a challenge for selective labeling, as the ¹⁵N isotope from serine can be transferred to other amino acids, a phenomenon known as "scrambling."[2][6] Understanding and minimizing this scrambling is crucial for the accurate interpretation of experimental data.
These application notes provide a detailed overview of the principles, protocols, and analytical methods for the selective ¹⁵N labeling of serine residues in recombinant proteins.
Principle of Selective ¹⁵N-Serine Labeling
The fundamental principle of selective ¹⁵N-serine labeling involves expressing a protein of interest in a host organism (e.g., E. coli) using a minimal medium that lacks nitrogen sources. This medium is then supplemented with ¹⁵N-labeled serine and an excess of all other 19 unlabeled amino acids.[2][7] The host cells will uptake and incorporate the provided amino acids into the expressed protein. The excess of unlabeled amino acids helps to suppress the host's own amino acid biosynthesis pathways and minimize the metabolic scrambling of the ¹⁵N label from serine to other amino acids.[2]
However, due to the central role of serine in metabolism, some degree of scrambling is often unavoidable, primarily to glycine. The primary pathway for this is the conversion of serine to glycine by the enzyme serine hydroxymethyltransferase (SHMT), which is a key step in one-carbon metabolism.
Key Applications in Research and Drug Development
-
NMR Spectroscopy: Simplifies crowded ¹H-¹⁵N HSQC spectra, allowing for the unambiguous assignment and analysis of signals from serine residues.[3][8] This is critical for studying post-translational modifications like phosphorylation at serine sites and for mapping protein-ligand interaction interfaces.[8]
-
Mass Spectrometry: Enables the precise quantification of serine incorporation and the extent of metabolic scrambling.[2][9] This information is vital for validating the labeling strategy and for quantitative proteomics studies.
-
Drug Discovery: Facilitates fragment-based drug discovery (FBDD) by monitoring chemical shift perturbations of serine residues in the presence of small molecule fragments.[3] It also aids in characterizing the binding kinetics and affinities of drug candidates.[10]
-
Metabolic Flux Analysis: Tracing the fate of the ¹⁵N label from serine can provide insights into cellular metabolic pathways.[4]
Experimental Protocols
Protocol 1: Expression of Selectively ¹⁵N-Serine Labeled Protein in E. coli
This protocol is adapted for a standard T7 promoter-based expression system in E. coli.
1. Preparation of Media and Solutions:
-
M9 Minimal Medium (10x Stock, 1 L):
-
68 g Na₂HPO₄
-
30 g KH₂PO₄
-
5 g NaCl
-
Dissolve in deionized water to 1 L and autoclave.
-
-
¹⁵NH₄Cl Stock (1 g/L): Prepare a sterile stock of ¹⁵N ammonium chloride (if needed for initial growth before addition of amino acids).
-
Amino Acid Stocks (100x): Prepare sterile-filtered stocks of all 20 amino acids. For selective labeling, the serine stock will be ¹⁵N-labeled, while the others will be unlabeled.
-
Other Components (Sterile):
-
20% (w/v) Glucose
-
1 M MgSO₄
-
1 M CaCl₂
-
Trace Elements Solution (100x)[11]
-
2. Expression Procedure:
-
Transform the expression plasmid into a suitable E. coli strain (e.g., BL21(DE3)).
-
Inoculate a single colony into 5 mL of LB medium and grow overnight at 37°C.
-
The next day, inoculate 1 L of M9 minimal medium (supplemented with MgSO₄, CaCl₂, glucose, and trace elements) with the overnight culture. For initial growth, a small amount of ¹⁴NH₄Cl can be used as the sole nitrogen source.
-
Grow the culture at 37°C with vigorous shaking until the OD₆₀₀ reaches 0.6-0.8.
-
Harvest the cells by centrifugation (e.g., 5000 x g for 10 minutes at 4°C).
-
Wash the cell pellet twice with M9 salts (M9 medium base without any nitrogen source or carbon source) to remove any residual rich media.
-
Resuspend the cell pellet in 1 L of fresh M9 minimal medium containing:
-
20% (w/v) Glucose
-
1 M MgSO₄
-
1 M CaCl₂
-
Trace Elements
-
100 mg/L ¹⁵N-Serine
-
100 mg/L of each of the other 19 unlabeled amino acids.
-
-
Incubate the culture for 1 hour at the desired expression temperature to allow the cells to adapt and start consuming the provided amino acids.
-
Induce protein expression with an appropriate concentration of IPTG (e.g., 0.1-1 mM).
-
Continue to grow the culture for the desired expression time (typically 4-16 hours) at the optimal temperature.
-
Harvest the cells by centrifugation and store the pellet at -80°C until purification.
3. Protein Purification:
Purify the labeled protein using standard chromatography techniques (e.g., affinity, ion exchange, size exclusion) as you would for an unlabeled protein.
Protocol 2: Verification of Labeling by Mass Spectrometry
-
Run a small sample of the purified protein on an SDS-PAGE gel and excise the corresponding band.
-
Perform in-gel tryptic digestion of the protein.
-
Analyze the resulting peptides by MALDI-TOF or LC-MS/MS.
-
Search the mass spectra for peptides containing serine. The mass of these peptides will be shifted by +1 Da for each incorporated ¹⁵N atom.
-
Analyze the isotopic distribution of serine-containing peptides to quantify the percentage of ¹⁵N incorporation.[9] Also, analyze peptides containing other amino acids (especially glycine) to assess the degree of scrambling.[2]
Data Presentation
Table 1: Expected Mass Shifts for Amino Acids due to ¹⁵N Labeling
| Amino Acid | Number of Nitrogen Atoms | Expected Mass Shift (Da) with ¹⁵N Labeling |
| Alanine | 1 | +1 |
| Arginine | 4 | +4 |
| Asparagine | 2 | +2 |
| Aspartic Acid | 1 | +1 |
| Cysteine | 1 | +1 |
| Glutamic Acid | 1 | +1 |
| Glutamine | 2 | +2 |
| Glycine | 1 | +1 |
| Histidine | 3 | +3 |
| Isoleucine | 1 | +1 |
| Leucine | 1 | +1 |
| Lysine | 2 | +2 |
| Methionine | 1 | +1 |
| Phenylalanine | 1 | +1 |
| Proline | 1 | +1 |
| Serine | 1 | +1 |
| Threonine | 1 | +1 |
| Tryptophan | 2 | +2 |
| Tyrosine | 1 | +1 |
| Valine | 1 | +1 |
Table 2: Representative Quantitative Data for Selective ¹⁵N-Serine Labeling
| Parameter | Typical Value | Method of Determination |
| Protein Yield | 1-10 mg/L of culture | UV-Vis Spectroscopy (A₂₈₀) |
| ¹⁵N-Serine Incorporation Efficiency | >95% | Mass Spectrometry[12] |
| Scrambling to Glycine | 5-20% | Mass Spectrometry / NMR Spectroscopy |
| Scrambling to other Amino Acids | <5% | Mass Spectrometry / NMR Spectroscopy |
Note: These values are representative and can vary depending on the expression host, protein, and specific experimental conditions.
Visualization of Pathways and Workflows
Caption: Serine biosynthesis and potential ¹⁵N scrambling pathway.
References
- 1. NMR resonance assignments for sparsely 15N labeled proteins - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. Rapid mass spectrometric analysis of 15N-Leu incorporation fidelity during preparation of specifically labeled NMR samples - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Recent applications of isotopic labeling for protein NMR in drug discovery | Semantic Scholar [semanticscholar.org]
- 4. benchchem.com [benchchem.com]
- 5. The phosphorylated pathway of serine biosynthesis links plant growth with nitrogen metabolism - PMC [pmc.ncbi.nlm.nih.gov]
- 6. A comprehensive assessment of selective amino acid 15N-labeling in human embryonic kidney 293 cells for NMR spectroscopy - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Selective labeling of a membrane peptide with 15N-amino acids using cells grown in rich medium - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. researchgate.net [researchgate.net]
- 9. pubs.acs.org [pubs.acs.org]
- 10. Applications of Stable Isotope-Labeled Molecules | Silantes [silantes.com]
- 11. 15N labeling of proteins in E. coli – Protein Expression and Purification Core Facility [embl.org]
- 12. Frontiers | 15N Metabolic Labeling Quantification Workflow in Arabidopsis Using Protein Prospector [frontiersin.org]
Probing Molecular Interactions: The Use of Fmoc-Ser-OH-15N in Structural Biology
Introduction
The site-specific incorporation of stable isotopes into peptides and proteins is a cornerstone of modern structural biology, providing an unparalleled window into molecular structure, dynamics, and interactions.[1] Among the array of available isotopic labels, ¹⁵N-labeled amino acids are particularly valuable for Nuclear Magnetic Resonance (NMR) spectroscopy.[2][3][4] Fmoc-Ser-OH-¹⁵N, a derivative of the amino acid serine, is a critical reagent for introducing a ¹⁵N label at a specific serine residue within a synthetically produced peptide. This allows researchers to probe the local environment of that serine, making it an invaluable tool for studying protein-protein interactions, enzyme mechanisms, and the effects of post-translational modifications such as phosphorylation.[2][3]
Serine residues are frequently involved in critical biological processes, including acting as phosphorylation sites in signaling cascades and participating in the active sites of enzymes.[5] The ability to specifically label serine with ¹⁵N enables high-resolution studies of these phenomena. This application note provides detailed protocols for the use of Fmoc-Ser-OH-¹⁵N in solid-phase peptide synthesis (SPPS) and the subsequent analysis of the labeled peptide by NMR spectroscopy to study protein-ligand interactions.
Key Applications
The site-specific incorporation of Fmoc-Ser-OH-¹⁵N into peptides enables a variety of powerful analytical techniques:
-
Structural Biology (NMR Spectroscopy): The ¹⁵N nucleus is NMR-active, and its incorporation at a specific serine residue simplifies complex NMR spectra. This allows for the precise determination of local conformation, dynamics, and hydrogen bonding patterns around the labeled site, which is critical for understanding peptide folding and stability.[6]
-
Protein-Ligand Interaction Studies: By monitoring the chemical environment of the ¹⁵N-labeled serine, researchers can map binding interfaces and determine the affinity of interactions with proteins, nucleic acids, or small molecules.[7] The most common technique for this is the ¹H-¹⁵N Heteronuclear Single Quantum Coherence (HSQC) experiment, which provides a fingerprint of the protein's structure.[4][7]
-
Enzyme Mechanism and Inhibition Studies: For enzymes where serine is in the active site (e.g., serine proteases), a ¹⁵N label can provide detailed information about the catalytic mechanism.[5] It can also be used to study the binding of inhibitors to the active site.
-
Analysis of Post-Translational Modifications: Serine phosphorylation is a key regulatory mechanism in many cellular processes.[2][3] Incorporating a ¹⁵N label at a specific serine allows for detailed NMR studies of the structural and dynamic consequences of phosphorylation.[2][3]
Data Presentation
The success of incorporating Fmoc-Ser-OH-¹⁵N and its utility in subsequent experiments can be quantified. The following tables provide examples of the types of quantitative data that can be obtained.
Table 1: Isotopic Incorporation Efficiency
This table illustrates the expected mass shift and methods for quantifying the efficiency of ¹⁵N incorporation into a synthetic peptide. Mass spectrometry is the primary method for this analysis.[3][8][9]
| Parameter | Unlabeled Peptide | ¹⁵N-Serine Labeled Peptide | Method of Analysis |
| Theoretical Monoisotopic Mass | Varies | Mass of Unlabeled Peptide + 0.997 Da | Mass Spectrometry (e.g., MALDI-TOF, ESI) |
| Observed Monoisotopic Mass | Varies | Varies (dependent on incorporation) | Mass Spectrometry (e.g., MALDI-TOF, ESI) |
| Incorporation Efficiency | N/A | Typically >98% | Comparison of isotopic peak intensities in mass spectra[8][9] |
Table 2: NMR Chemical Shift Perturbation Data for a ¹⁵N-Serine Labeled Peptide Binding to a Kinase
This table presents hypothetical data from an NMR titration experiment, where a ¹⁵N-serine labeled peptide substrate is titrated with a protein kinase. The changes in the ¹H and ¹⁵N chemical shifts of the labeled serine residue are monitored to determine the binding affinity (Kd).[10]
| Ligand:Protein Ratio | ¹H Chemical Shift (ppm) | ¹⁵N Chemical Shift (ppm) | Combined Chemical Shift Perturbation (CSP) (ppm)¹ |
| 0:1 | 8.50 | 118.0 | 0.000 |
| 0.5:1 | 8.55 | 118.4 | 0.100 |
| 1:1 | 8.60 | 118.8 | 0.200 |
| 2:1 | 8.68 | 119.5 | 0.322 |
| 5:1 | 8.75 | 120.0 | 0.472 |
| Binding Affinity (Kd) | Calculated from fitting CSP data |
¹Combined Chemical Shift Perturbation (CSP) is calculated using the formula: Δδ = [ (ΔδH)² + (α * ΔδN)² ]^½, where ΔδH and ΔδN are the changes in the proton and nitrogen chemical shifts, respectively, and α is a weighting factor (typically ~0.2).[10]
Experimental Protocols
Protocol 1: Solid-Phase Peptide Synthesis (SPPS) with Fmoc-Ser-OH-15N
This protocol outlines the manual synthesis of a peptide with a site-specifically incorporated ¹⁵N-labeled serine residue using Fmoc chemistry. The tert-butyl (tBu) group is a common side-chain protecting group for serine.
Materials:
-
Rink Amide resin
-
Fmoc-protected amino acids
-
Fmoc-Ser(tBu)-OH-¹⁵N
-
N,N-Dimethylformamide (DMF)
-
Dichloromethane (DCM)
-
20% (v/v) piperidine in DMF
-
HBTU (2-(1H-benzotriazol-1-yl)-1,1,3,3-tetramethyluronium hexafluorophosphate)
-
N,N-Diisopropylethylamine (DIPEA)
-
Cleavage cocktail (e.g., 95% Trifluoroacetic acid (TFA), 2.5% water, 2.5% triisopropylsilane)
-
Cold diethyl ether
Procedure:
-
Resin Swelling: Swell the Rink Amide resin in DMF for 30 minutes in a synthesis vessel.
-
Fmoc Deprotection:
-
Drain the DMF.
-
Add the 20% piperidine/DMF solution to the resin and agitate for 5 minutes.
-
Drain the solution.
-
Add fresh 20% piperidine/DMF solution and agitate for another 15 minutes.
-
Drain and wash the resin thoroughly with DMF (5x) and DCM (3x).
-
-
Amino Acid Coupling (for non-labeled amino acids):
-
Dissolve the Fmoc-amino acid (3 eq.), HBTU (3 eq.), and DIPEA (6 eq.) in DMF.
-
Add the activated amino acid solution to the deprotected resin.
-
Agitate for 1-2 hours.
-
Drain and wash the resin with DMF (3x) and DCM (3x).
-
-
Incorporation of Fmoc-Ser(tBu)-OH-¹⁵N:
-
Repeat the deprotection step (Step 2).
-
In a separate vial, dissolve Fmoc-Ser(tBu)-OH-¹⁵N (3 eq.), HBTU (3 eq.), and DIPEA (6 eq.) in DMF.
-
Add the activated ¹⁵N-serine solution to the resin and agitate for 1-2 hours.
-
Drain and wash the resin with DMF (3x) and DCM (3x).
-
-
Chain Elongation: Repeat the deprotection and coupling steps for all subsequent amino acids in the sequence.
-
Final Deprotection: After the final amino acid coupling, remove the N-terminal Fmoc group as described in Step 2.
-
Cleavage and Deprotection:
-
Wash the resin with DCM and dry under vacuum.
-
Treat the resin with the cleavage cocktail for 2-3 hours to cleave the peptide from the resin and remove side-chain protecting groups.
-
-
Peptide Precipitation and Purification:
-
Precipitate the crude peptide in cold diethyl ether.
-
Centrifuge to pellet the peptide and decant the ether.
-
Wash the peptide pellet with cold diethyl ether twice.
-
Dry the crude peptide and purify by reverse-phase high-performance liquid chromatography (RP-HPLC).
-
Lyophilize the pure fractions to obtain the final peptide product.
-
Protocol 2: NMR Analysis of Protein-Peptide Interaction
This protocol describes a typical ¹H-¹⁵N HSQC titration experiment to study the interaction between a ¹⁵N-serine labeled peptide and a target protein (e.g., a kinase).
Materials:
-
Lyophilized ¹⁵N-serine labeled peptide
-
Purified target protein
-
NMR buffer (e.g., 20 mM Phosphate, 50 mM NaCl, pH 6.5 in 90% H₂O/10% D₂O)
-
NMR spectrometer equipped with a cryoprobe
Procedure:
-
Sample Preparation:
-
Dissolve the lyophilized ¹⁵N-serine labeled peptide in the NMR buffer to a final concentration of 50-100 µM.
-
Prepare a concentrated stock solution of the unlabeled target protein in the same NMR buffer.
-
-
Initial NMR Spectrum (Apo state):
-
Transfer the peptide solution to an NMR tube.
-
Acquire a 2D ¹H-¹⁵N HSQC spectrum. This spectrum represents the "free" or "apo" state of the peptide. The single cross-peak from the ¹⁵N-labeled serine should be well-resolved.
-
-
Titration:
-
Add a small aliquot of the concentrated target protein solution to the NMR tube to achieve a specific molar ratio (e.g., 0.25:1 protein to peptide).
-
Gently mix the sample.
-
Acquire another 2D ¹H-¹⁵N HSQC spectrum.
-
Repeat the addition of the target protein to obtain a series of spectra at different molar ratios (e.g., 0.5:1, 1:1, 2:1, 5:1).
-
-
Data Processing and Analysis:
-
Process all HSQC spectra identically using NMR processing software (e.g., TopSpin, NMRPipe).
-
Overlay the spectra to visualize the chemical shift perturbations (CSPs) of the ¹⁵N-serine peak as a function of target protein concentration.
-
For each titration point, measure the ¹H and ¹⁵N chemical shifts of the serine amide cross-peak.
-
Calculate the combined CSP for each titration point.
-
Plot the CSP values against the molar ratio of the target protein.
-
Fit the resulting binding isotherm to a suitable binding model to determine the dissociation constant (Kd).
-
Visualizations
Case Study: Probing a Kinase-Substrate Interaction
A common application for a ¹⁵N-serine labeled peptide is to study its interaction with a protein kinase. The peptide is designed to be a substrate for the kinase, and the ¹⁵N label at the serine phosphorylation site allows for the direct observation of binding.
Caption: Workflow for studying kinase-substrate interactions using a ¹⁵N-serine labeled peptide.
Signaling Pathway Context: Grb2-SH2 Domain Interaction
The adaptor protein Grb2 plays a crucial role in receptor tyrosine kinase (RTK) signaling pathways. The SH2 domain of Grb2 binds to phosphotyrosine residues on activated receptors or docking proteins. A synthetic peptide with a ¹⁵N-labeled serine adjacent to a phosphotyrosine can be used to study the structural details of this interaction.
Caption: Simplified RTK signaling pathway involving Grb2, a target for interaction studies.
Conclusion
Fmoc-Ser-OH-¹⁵N is a versatile and powerful tool for researchers in structural biology, drug discovery, and chemical biology. Its use in solid-phase peptide synthesis allows for the precise, site-specific incorporation of a ¹⁵N label. This enables detailed investigation of peptide and protein structure, dynamics, and interactions using NMR spectroscopy. The protocols and applications described herein provide a framework for leveraging this technology to gain critical insights into fundamental biological processes at the atomic level. The ability to probe the local environment of serine residues—which are central to many biological functions—ensures that Fmoc-Ser-OH-¹⁵N will remain an indispensable reagent for advancing our understanding of complex biological systems.
References
- 1. benchchem.com [benchchem.com]
- 2. Accessing isotopically labeled proteins containing genetically encoded phosphoserine for NMR with optimized expression conditions - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Site-specific NMR mapping and time-resolved monitoring of serine and threonine phosphorylation in reconstituted kinase reactions and mammalian cell extracts - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. researchgate.net [researchgate.net]
- 5. Cell-free synthesis of 15N-labeled proteins for NMR studies - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. semanticscholar.org [semanticscholar.org]
- 7. Novel peptide inhibitors for Grb2 SH2 domain and their detection by surface plasmon resonance - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. 15N-1H Scalar Coupling Perturbation: An Additional Probe for Measuring Structural Changes Due to Ligand Binding - PMC [pmc.ncbi.nlm.nih.gov]
- 9. protein-nmr.org.uk [protein-nmr.org.uk]
- 10. researchgate.net [researchgate.net]
Troubleshooting & Optimization
Technical Support Center: Fmoc-Ser-OH Coupling Efficiency
This technical support center provides troubleshooting guidance and frequently asked questions (FAQs) for researchers, scientists, and drug development professionals encountering low coupling efficiency with Fmoc-Ser-OH and its derivatives during solid-phase peptide synthesis (SPPS).
Troubleshooting Guide
Low coupling efficiency of Fmoc-Ser-OH is a common challenge in SPPS. This guide provides a systematic approach to diagnosing and resolving these issues.
Initial Assessment: Confirming Incomplete Coupling
Before extensive troubleshooting, it is crucial to confirm that the coupling reaction is indeed incomplete. The Kaiser test is a reliable qualitative method for detecting free primary amines on the resin. A positive result (blue or purple beads) indicates the presence of unreacted amino groups and an incomplete coupling reaction.
Frequently Asked Questions (FAQs)
Q1: What are the primary causes of low coupling efficiency with Fmoc-Serine derivatives?
Low coupling efficiency with Fmoc-Serine derivatives in SPPS can be attributed to several factors:
-
Steric Hindrance: The bulky Fmoc protecting group, combined with the side-chain protecting group (e.g., tert-butyl), can physically obstruct the activated carboxyl group from efficiently reaching the N-terminus of the growing peptide chain.
-
Peptide Aggregation: As the peptide chain elongates, it can form secondary structures or aggregate on the solid support. This aggregation can make the N-terminal amine less accessible for the incoming amino acid. This is particularly problematic in sequences with multiple serine residues.
-
Side Reactions: Several side reactions can compete with the desired coupling reaction, consuming the activated amino acid or modifying the peptide chain. Key side reactions for serine include:
-
Racemization: Loss of stereochemical integrity at the α-carbon can be induced by the activating base.
-
β-elimination: This reaction, which forms a dehydroalanine residue, is promoted by basic conditions.
-
O-acylation: If the serine's hydroxyl group is unprotected, a second Fmoc-Ser-OH molecule can attach to the side chain, leading to a double insertion impurity. To prevent this, using a side-chain protected derivative like Fmoc-Ser(tBu)-OH is standard practice.
-
-
Incomplete Deprotection: If the Fmoc group from the previously coupled amino acid is not completely removed, the N-terminal amine will be unavailable for the subsequent coupling reaction, resulting in a deletion sequence.
Q2: My Kaiser test is positive after coupling with Fmoc-Ser(tBu)-OH. What is the most straightforward first step to resolve this?
A positive Kaiser test indicates an incomplete coupling reaction. The simplest and often most effective initial step is to perform a double coupling . This involves repeating the coupling step with a fresh solution of the activated amino acid to drive the reaction to completion.
Q3: Which coupling reagents are most effective for a difficult Fmoc-Serine coupling?
For sterically hindered amino acids like serine, standard coupling reagents such as DIC/HOBt may not be sufficient. More potent onium salt-based reagents are highly recommended:
-
Uronium/Aminium Reagents: HATU, HCTU, and COMU are highly effective for hindered couplings. HATU is frequently cited for its high reactivity and ability to suppress racemization.
-
Phosphonium Reagents: PyBOP and PyAOP are excellent choices for difficult couplings. A key advantage is that they can be used in excess to drive the reaction to completion without the risk of guanidinylation of the N-terminus, a side reaction associated with uronium/aminium reagents.
Q4: How can I minimize side reactions associated with Fmoc-Serine coupling?
-
Racemization: This can be minimized by using additives like HOBt or HOAt and choosing coupling reagents known to suppress racemization, such as HATU. The choice of base is also critical; using a bulkier, less nucleophilic base like 2,4,6-collidine instead of DIPEA can reduce racemization.
-
β-elimination: Minimize the exposure time to piperidine during the Fmoc deprotection step and use a milder base for coupling activation.
-
O-Acylation: This is effectively prevented by using a side-chain protected serine derivative, such as Fmoc-Ser(tBu)-OH.
Q5: When should I consider using an alternative side-chain protecting group for Serine?
For sequences prone to aggregation, such as those containing multiple serine residues (e.g., poly-serine tracts), the standard Fmoc-Ser(tBu)-OH may still present challenges. In such cases, using Fmoc-Ser(Trt)-OH is a highly effective strategy. The bulky trityl (Trt) group acts as a steric shield, disrupting the interchain hydrogen bonding that leads to aggregation and significantly improving the synthesis outcome.
Data Presentation
Table 1: Qualitative Comparison of Common Coupling Reagents for Fmoc-Ser(tBu)-OH
| Coupling Reagent | Reagent Type | Relative Reactivity | Key Advantages | Potential Disadvantages |
| DIC/HOBt | Carbodiimide | Standard | Cost-effective. | Can be insufficient for hindered couplings. |
| HBTU/HOBt | Aminium | High | A common and effective choice for most couplings. | Can cause guanidinylation of the N-terminus. |
| HATU/HOAt | Aminium | Very High | Highly effective, especially for difficult couplings.[1] | More expensive; based on potentially explosive HOAt. |
| PyBOP | Phosphonium | High | Effective for sterically demanding couplings; no risk of guanidinylation. | Byproducts can be difficult to remove. |
Experimental Protocols
Protocol 1: High-Efficiency Coupling of Fmoc-Ser(tBu)-OH using HATU
This protocol is designed to maximize the coupling efficiency for a sterically hindered serine residue.
-
Resin Preparation: Swell the peptide-resin in DMF for 30 minutes.
-
Fmoc Deprotection: Perform Fmoc deprotection using 20% piperidine in DMF (1 x 5 min, followed by 1 x 15 min).
-
Washing: Wash the resin thoroughly with DMF (5-7 times).
-
Activation Mixture: In a separate vessel, dissolve Fmoc-Ser(tBu)-OH (4 eq.), HATU (3.9 eq.), and HOAt (4 eq.) in DMF. Add DIPEA (8 eq.) and allow the mixture to pre-activate for 2-5 minutes.
-
Coupling: Add the activation mixture to the deprotected resin and agitate at room temperature for 2 hours.
-
Washing: Drain the reaction vessel and wash the resin thoroughly with DMF (3-5 times).
-
Monitoring: Perform a Kaiser test (Protocol 4) to check for the presence of free primary amines. If the test is positive, proceed to Protocol 2 (Double Coupling).
Protocol 2: Double Coupling for a Hindered Amino Acid
-
First Coupling: Perform the initial coupling as described in Protocol 1.
-
Washing: After the first coupling, drain the reaction vessel and wash the resin thoroughly with DMF (3-5 times) to remove all soluble reagents and byproducts.
-
Second Coupling: Prepare a fresh activation mixture (Step 4 in Protocol 1) and add it to the resin. Agitate for an additional 1-2 hours.
-
Final Wash and Monitoring: Wash the resin thoroughly with DMF. Perform a final Kaiser test to confirm completion.
Protocol 3: Capping of Unreacted Amines
If coupling remains incomplete after a double coupling, it is advisable to cap the unreacted amino groups to prevent the formation of deletion sequences.
-
Washing: Wash the resin several times with DMF.
-
Capping Solution: Prepare a capping solution of acetic anhydride and pyridine in a 3:2 ratio in DMF.
-
Capping Reaction: Add the capping solution to the resin and agitate for 30 minutes at room temperature.
-
Washing: Drain the capping solution and wash the resin thoroughly with DMF (3-5 times).
-
Confirmation: A negative Kaiser test should be obtained.
Protocol 4: Kaiser Test for Monitoring Coupling Completion
This test qualitatively detects free primary amines on the resin.
-
Reagent Preparation:
-
Reagent A: Dissolve 16.5 mg of KCN in 25 mL of distilled water. Dilute 1.0 mL of this solution with 49 mL of pyridine.
-
Reagent B: Dissolve 1.0 g of ninhydrin in 20 mL of n-butanol.
-
Reagent C: Dissolve 40 g of phenol in 20 mL of n-butanol.
-
-
Procedure:
-
Place a small sample of resin beads (approx. 10-15) in a small test tube.
-
Add 2-3 drops of each Reagent A, B, and C to the test tube.
-
Heat the tube at 110°C for 5 minutes.
-
-
Interpretation of Results:
-
Intense blue solution and blue beads: Incomplete coupling.
-
Colorless or faint yellow solution and beads: Complete coupling.
-
Mandatory Visualizations
Caption: Troubleshooting workflow for low Fmoc-Ser-OH coupling efficiency.
Caption: Side reactions in Fmoc-Ser-OH coupling and their mitigation.
References
Technical Support Center: Preventing Racemization of Serine during Peptide Synthesis
This technical support center provides researchers, scientists, and drug development professionals with comprehensive troubleshooting guides and frequently asked questions (FAQs) to address the challenge of serine racemization during peptide synthesis.
Frequently Asked Questions (FAQs)
Q1: What is racemization in the context of peptide synthesis?
A1: Racemization is the process in which a chiral molecule, such as an L-amino acid, converts into an equal mixture of both its L- and D-enantiomers. During peptide synthesis, the stereochemical integrity of the α-carbon of an amino acid can be compromised, leading to the incorporation of D-amino acids into the peptide chain where only L-amino acids are intended. This loss of chirality can significantly impact the peptide's structure, biological activity, and therapeutic efficacy.
Q2: Why is serine particularly susceptible to racemization?
A2: Serine, like other amino acids, is susceptible to racemization primarily through the formation of a planar oxazolone intermediate during the activation of its carboxyl group for coupling.[1] The electron-withdrawing nature of the protected hydroxyl group in the side chain can influence the acidity of the α-proton, making it more susceptible to abstraction under basic conditions, which facilitates the formation of the planar, achiral enolate intermediate that leads to racemization.[2]
Q3: What are the main factors that contribute to serine racemization?
A3: Several factors during the coupling step can promote the racemization of serine:
-
Coupling Reagents: The type of coupling reagent and its activation mechanism play a crucial role. Some highly reactive reagents can accelerate oxazolone formation.
-
Base: The presence, strength, and concentration of the base used can significantly increase the rate of racemization by promoting the abstraction of the α-proton.[3]
-
Temperature: Higher reaction temperatures can increase the rate of racemization.[4]
-
Protecting Groups: The choice of N-terminal and side-chain protecting groups can influence the susceptibility of serine to racemization.
Troubleshooting Guide
Issue: Significant level of D-Serine detected in the final peptide.
This troubleshooting guide will help you identify the potential causes of serine racemization and provide solutions to minimize it in your solid-phase peptide synthesis (SPPS) protocols.
Step 1: Evaluate Your Coupling Reagent and Additives
Certain coupling reagents are more prone to causing racemization. The use of additives is a common strategy to suppress this side reaction.
Possible Cause: The coupling reagent used promotes oxazolone formation.
Solution:
-
Use Carbodiimides with Additives: When using carbodiimides like Dicyclohexylcarbodiimide (DCC) or Diisopropylcarbodiimide (DIC), always include a racemization-suppressing additive such as 1-hydroxybenzotriazole (HOBt) or ethyl 2-cyano-2-(hydroxyimino)acetate (Oxyma).[5][6] These additives react with the activated amino acid to form an active ester that is less prone to racemization.
-
Consider Modern Onium Salts: Uronium/aminium salt-based reagents like HATU and HCTU are generally very efficient and can lead to less racemization due to their high reactivity, which promotes rapid peptide bond formation over the competing racemization pathway.[6][7]
Step 2: Assess the Base in Your Coupling Reaction
The choice and amount of base are critical in controlling racemization.
Possible Cause: The base used is too strong or is present in excess.
Solution:
-
Choose a Weaker or Sterically Hindered Base: Opt for weaker or sterically hindered bases like N-methylmorpholine (NMM) or 2,4,6-collidine instead of stronger, less hindered bases like N,N-diisopropylethylamine (DIEA).[3]
-
Minimize Base Concentration: Use the minimum amount of base necessary for the coupling reaction. Often, one equivalent is sufficient, especially when using amino acid salts.
Step 3: Control the Reaction Temperature
Elevated temperatures can accelerate the rate of racemization.
Possible Cause: The coupling reaction is performed at an elevated temperature.
Solution:
-
Perform Coupling at Room Temperature or Below: Conduct coupling reactions at room temperature (around 25°C) or lower (e.g., 0°C), especially for sensitive amino acids like serine.
-
Optimize Microwave Protocols: If using microwave-assisted peptide synthesis, lowering the coupling temperature can significantly reduce racemization.[4]
Step 4: Review Your Protecting Group Strategy
The protecting groups on both the N-terminus and the side chain can influence racemization.
Possible Cause: The protecting groups used are not optimal for preventing racemization.
Solution:
-
Side-Chain Protection: For serine, the tert-butyl (tBu) protecting group is commonly used and is generally effective.[8]
-
N-Terminal Protecting Group: While the standard Fmoc group is widely used, some studies suggest that alternative protecting groups can reduce racemization. For instance, the 2,4-dinitro-6-phenyl-benzene sulfenyl (DNPBS) protecting group has been shown to decrease α-C racemization compared to Fmoc-protected amino acids.[9]
Data Presentation
The following table summarizes the percentage of D-serine formation observed when coupling Fmoc-L-Ser(tBu)-OH using various coupling reagents and bases. This data is crucial for selecting the optimal conditions to minimize racemization.
| Coupling Reagent/Additive | Base | Temperature (°C) | % D-Serine Formed |
| DIC/HOBt | DIPEA | Room Temp | 1.8 |
| HBTU/HOBt | DIPEA | Room Temp | 2.2 |
| EDCI/HOBt | NMM | Room Temp | 2.4 |
| DIC/Oxyma | DIPEA | Room Temp | 1.7 |
| HATU/DIPEA | DIPEA | Room Temp | High |
| HBTU/HOAt | DIPEA | 55 | 31.0 |
Data adapted from studies investigating the effect of coupling reagents on the α-C racemization of amino acids.[10][11]
Experimental Protocols
Protocol 1: Low-Racemization Coupling of Fmoc-Ser(tBu)-OH using DIC/Oxyma
This protocol describes a standard method for the manual solid-phase synthesis coupling of Fmoc-protected serine with minimal racemization.
Materials:
-
Fmoc-Ser(tBu)-OH
-
Peptide-resin with a free N-terminal amine
-
Diisopropylcarbodiimide (DIC)
-
Ethyl 2-cyano-2-(hydroxyimino)acetate (Oxyma)
-
N,N-Dimethylformamide (DMF)
-
Piperidine solution (20% in DMF)
-
Dichloromethane (DCM)
Procedure:
-
Resin Swelling: Swell the peptide-resin in DMF for 30-60 minutes in a reaction vessel.
-
Fmoc Deprotection:
-
Drain the DMF.
-
Add the 20% piperidine in DMF solution to the resin.
-
Agitate the mixture for 5-10 minutes.
-
Drain the solution.
-
Repeat the piperidine treatment for another 10-15 minutes to ensure complete Fmoc removal.
-
Wash the resin thoroughly with DMF (5 times) and then with DCM (3 times) to remove residual piperidine.
-
-
Amino Acid Activation:
-
In a separate vessel, dissolve Fmoc-Ser(tBu)-OH (3 equivalents relative to resin loading) and Oxyma (3 equivalents) in a minimal amount of DMF.
-
Add DIC (3 equivalents) to the solution.
-
Allow the activation to proceed for 1-5 minutes at room temperature. Do not exceed this pre-activation time to minimize potential side reactions.
-
-
Coupling:
-
Add the activated amino acid solution to the deprotected peptide-resin.
-
Agitate the mixture for 1-2 hours at room temperature.
-
-
Washing: Drain the coupling solution and wash the resin thoroughly with DMF (3 times) to remove excess reagents and byproducts.
-
Confirmation: Perform a qualitative test (e.g., Kaiser test) on a small sample of resin beads to confirm the completion of the coupling reaction. A negative test (beads remain yellow) indicates a successful coupling.
Protocol 2: Quantification of Serine Racemization by Chiral HPLC
This protocol outlines the general steps to quantify the extent of serine racemization in a synthetic peptide.
Procedure:
-
Peptide Cleavage and Deprotection: Cleave the synthesized peptide from the solid support and remove all protecting groups using a standard cleavage cocktail (e.g., 95% Trifluoroacetic acid (TFA), 2.5% water, 2.5% triisopropylsilane (TIS)).
-
Peptide Purification: Purify the crude peptide using reverse-phase high-performance liquid chromatography (RP-HPLC) to isolate the desired peptide from deletion sequences and other impurities.
-
Peptide Hydrolysis:
-
Lyophilize the purified peptide.
-
Hydrolyze the peptide into its constituent amino acids by treating it with 6 M HCl at 110°C for 24 hours in a sealed, evacuated tube.
-
Evaporate the HCl to dryness.
-
-
Derivatization:
-
React the amino acid hydrolysate with a chiral derivatizing agent, such as Marfey's reagent (1-fluoro-2,4-dinitrophenyl-5-L-alanine amide, L-FDAA) or by reacting with ortho-phthalaldehyde (OPA) and a chiral thiol like N-acetyl-L-cysteine (NAC) to form diastereomeric derivatives.[12]
-
-
Chiral HPLC Analysis:
-
Separate the resulting diastereomers on a standard C18 RP-HPLC column.
-
The L- and D-amino acid derivatives will have different retention times, allowing for their separation and quantification.
-
Calculate the percentage of racemization by integrating the peak areas of the D- and L-serine derivatives: % Racemization = [Area(D-Ser) / (Area(L-Ser) + Area(D-Ser))] x 100
-
Visualizations
The following diagrams illustrate key pathways and logical relationships relevant to understanding and troubleshooting serine racemization.
Caption: Mechanism of serine racemization via oxazolone formation.
Caption: Troubleshooting workflow for high serine racemization.
References
- 1. benchchem.com [benchchem.com]
- 2. researchgate.net [researchgate.net]
- 3. DOT Language | Graphviz [graphviz.org]
- 4. pubs.acs.org [pubs.acs.org]
- 5. peptide.com [peptide.com]
- 6. peptide.com [peptide.com]
- 7. benchchem.com [benchchem.com]
- 8. benchchem.com [benchchem.com]
- 9. benchchem.com [benchchem.com]
- 10. benchchem.com [benchchem.com]
- 11. researchgate.net [researchgate.net]
- 12. Separation and detection of D-/L-serine by conventional HPLC - PMC [pmc.ncbi.nlm.nih.gov]
Technical Support Center: Solid-Phase Peptide Synthesis
Topic: Troubleshooting Incomplete Fmoc Deprotection
This guide provides researchers, scientists, and drug development professionals with a comprehensive resource for troubleshooting issues related to incomplete N-α-Fmoc group removal during solid-phase peptide synthesis (SPPS).
Frequently Asked Questions (FAQs)
Q1: What is incomplete Fmoc deprotection and what are its consequences?
Incomplete Fmoc deprotection is the failure to completely remove the fluorenylmethyloxycarbonyl (Fmoc) protecting group from the N-terminal amine of the growing peptide chain.[1][2] This critical failure prevents the next amino acid from being coupled to the peptide. The primary consequence is the formation of deletion sequences, which are peptides missing one or more amino acid residues.[1][2] These impurities can be very difficult to separate from the target peptide during purification, leading to a significant reduction in the overall yield and purity of the final product.[1][2]
Q2: What are the primary causes of incomplete Fmoc deprotection?
Several factors, often inter-related, can contribute to inefficient Fmoc removal:
-
Peptide Sequence and Structure: Certain peptide sequences are inherently "difficult." This can be due to:
-
Steric Hindrance: Amino acids with bulky side chains (e.g., Valine, Isoleucine) can physically block the deprotection reagent from accessing the N-terminal Fmoc group.[2]
-
Peptide Aggregation: As the peptide chain elongates, it can fold and form secondary structures, such as β-sheets.[2][3] This aggregation, common in sequences with repeating hydrophobic residues, can prevent reagents from penetrating the resin and reaching the reaction sites.[2][3]
-
-
Suboptimal Reagents or Protocols: The quality and application of your reagents are critical.
-
Degraded Reagents: Using old or improperly stored piperidine can reduce its efficacy.[1]
-
Incorrect Concentrations or Time: Standard protocols (e.g., 20% piperidine in DMF) may be insufficient for difficult sequences.[2] Inadequate reaction times or temperatures can also lead to incomplete removal.[1]
-
-
Physical Resin Properties:
-
Poor Resin Swelling: If the solid support (resin) is not properly swelled before synthesis begins, the peptide chains can remain too close together, hindering the diffusion of reagents.[1][2]
-
High Resin Loading: Overloading the resin with the first amino acid can cause steric hindrance between the growing peptide chains, impeding reagent access.[1]
-
Q3: How can I detect if Fmoc deprotection is incomplete during my synthesis?
Several qualitative and quantitative methods can be used to monitor the completeness of the deprotection step in real-time or on a sample of resin beads.
-
Kaiser (Ninhydrin) Test: This is a rapid, qualitative colorimetric test performed on a small sample of the peptide-resin.[1] A positive result (dark blue beads/solution) indicates the presence of free primary amines, signifying a successful deprotection.[1] A negative result (yellow or no color change) suggests the Fmoc group is still attached.[1] Note: This test does not work for N-terminal proline (a secondary amine), which typically gives a reddish-brown color.[1]
-
UV-Vis Spectrophotometry: This quantitative method monitors the release of the dibenzofulvene (DBF)-piperidine adduct, which has a strong UV absorbance around 301-312 nm.[1][4] By collecting the filtrate during the deprotection step and measuring its absorbance, you can quantify the amount of Fmoc group removed.[1] A plateau in absorbance over consecutive deprotection cycles indicates consistent and complete removal, while a drop in absorbance can signal an incomplete reaction.
Troubleshooting Guide
If you suspect incomplete Fmoc deprotection based on analytical data (e.g., HPLC showing deletion sequences) or monitoring tests, follow this workflow to diagnose and resolve the issue.
Diagram: Troubleshooting Workflow for Incomplete Fmoc Deprotection
Caption: A stepwise workflow for troubleshooting incomplete Fmoc deprotection.
Data Presentation: Deprotection Cocktails
For particularly stubborn sequences, altering the chemical composition of the deprotection solution can overcome the problem. The following table summarizes common and alternative deprotection cocktails.
| Reagent Cocktail | Typical Concentration | Recommended Treatment | Use Case & Considerations |
| Piperidine | 20% in DMF or NMP | 1 x 3 min, then 1 x 10-15 min | Standard Protocol. Generally effective but may be insufficient for aggregated or sterically hindered sequences.[5] |
| 4-Methylpiperidine (4MP) | 20% v/v in DMF | Similar to Piperidine | Shows similar efficacy to piperidine and can be a direct replacement.[6][7] |
| Piperazine (PZ) | 5-10% w/v in DMF or NMP | 2 x 8 min | A weaker base that can reduce the rate of some side reactions like diketopiperazine (DKP) formation.[5][8] |
| DBU / Piperidine | 2% DBU, 2-5% Piperidine in DMF/NMP | 2 x 5-10 min | For Difficult Sequences. DBU is a strong, non-nucleophilic base that accelerates deprotection. Effective for hindered sequences.[9] |
| DBU / Piperazine | 2% DBU, 5% Piperazine in NMP | 2 x 2 min | Very Rapid Deprotection. Highly effective for difficult and aggregation-prone sequences. May require optimization to minimize side reactions.[9][10] |
Experimental Protocols
Protocol 1: Standard Fmoc Deprotection
This protocol describes a typical manual Fmoc deprotection step in SPPS.
-
Resin Swelling: Ensure the peptide-resin is adequately swelled in DMF for at least 30-60 minutes before the first deprotection.[2][9]
-
Solvent Wash: Wash the peptide-resin thoroughly with DMF (3 times) to remove residual reagents from the previous coupling step.[1]
-
First Deprotection: Add the deprotection solution (e.g., 20% piperidine in DMF) to the resin-containing vessel, ensuring the resin is fully submerged. Agitate gently for 3 minutes.[9]
-
Drain: Remove the deprotection solution by filtration.[1]
-
Second Deprotection: Add a fresh portion of the deprotection solution and agitate for an additional 10-20 minutes. For difficult sequences, this time can be extended.[1][2]
-
Final Wash: Drain the solution and wash the resin thoroughly with DMF (at least 5-6 times) to completely remove residual piperidine and the DBF-adduct.[2] The resin is now ready for monitoring (e.g., Kaiser test) or the next amino acid coupling step.
Protocol 2: Kaiser (Ninhydrin) Test
This test confirms the presence of free primary amines after deprotection.[1][2]
-
Prepare Reagents:
-
Sample Collection: Take a small sample of the peptide-resin (a few beads) and place it in a small glass test tube.[1]
-
Add Reagents: Add 2-3 drops of each reagent (A, B, and C) to the test tube.[1][2]
-
Observe Color:
Mechanism Visualization
Understanding the chemical mechanism of Fmoc removal is key to effective troubleshooting.
Diagram: Mechanism of Fmoc Deprotection by Piperidine
Caption: The E1cB mechanism of Fmoc group removal by a base (piperidine).
References
- 1. benchchem.com [benchchem.com]
- 2. benchchem.com [benchchem.com]
- 3. Incomplete Fmoc deprotection in solid-phase synthesis of peptides - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. researchgate.net [researchgate.net]
- 5. benchchem.com [benchchem.com]
- 6. Deprotection Reagents in Fmoc Solid Phase Peptide Synthesis: Moving Away from Piperidine? - PMC [pmc.ncbi.nlm.nih.gov]
- 7. mdpi.com [mdpi.com]
- 8. pubs.acs.org [pubs.acs.org]
- 9. benchchem.com [benchchem.com]
- 10. Optimized Fmoc-Removal Strategy to Suppress the Traceless and Conventional Diketopiperazine Formation in Solid-Phase Peptide Synthesis - PMC [pmc.ncbi.nlm.nih.gov]
Technical Support Center: Aggregation of Peptides Containing Serine Residues
This technical support center provides troubleshooting guidance and frequently asked questions (FAQs) for researchers, scientists, and drug development professionals encountering challenges with the aggregation of peptides containing serine residues.
Frequently Asked Questions (FAQs) & Troubleshooting Guides
Q1: My serine-containing peptide is showing poor solubility and forming visible precipitates. What are the likely causes and how can I solubilize it?
A1: Poor solubility and precipitation of serine-containing peptides are common issues stemming from intermolecular hydrogen bonding, leading to the formation of β-sheet structures and subsequent aggregation.[1][2] The hydroxyl group (-OH) of serine can participate in these hydrogen bonds, contributing to self-association.
Troubleshooting Steps:
-
Optimize Dissolution Protocol:
-
Solvent Choice: For hydrophobic peptides, start by dissolving the peptide in a small volume of an organic solvent such as dimethyl sulfoxide (DMSO) or N,N-dimethylformamide (DMF) before slowly adding the aqueous buffer.[3] Be mindful that high concentrations of organic solvents may interfere with downstream biological assays.
-
pH Adjustment: The net charge of the peptide influences its solubility. Adjust the pH of the buffer to be at least one unit away from the peptide's isoelectric point (pI) to increase electrostatic repulsion between peptide molecules.[4]
-
Sonication: Brief sonication can help break up small aggregates and facilitate dissolution.[1][3]
-
-
Use of Chaotropic Agents:
-
Agents like 6 M guanidine hydrochloride (GdnHCl) or 8 M urea can disrupt non-covalent interactions and solubilize aggregated peptides.[3] Note that subsequent removal of these agents through dialysis or chromatography might be necessary for functional assays.
-
Q2: I am observing low yield and purity during the solid-phase peptide synthesis (SPPS) of a serine-rich peptide. What could be the problem and how can I improve the synthesis?
A2: Low yield and purity during the SPPS of serine-rich peptides are often due to on-resin aggregation of the growing peptide chain.[1][3] This aggregation can block the N-terminus, leading to incomplete coupling and deprotection steps, resulting in deletion sequences.[3]
Troubleshooting and Optimization Strategies:
-
Incorporate Pseudoproline Dipeptides: Introducing pseudoproline dipeptides, which are derivatives of serine or threonine, can disrupt the formation of secondary structures like β-sheets in the growing peptide chain.[3][5] These are temporary modifications that revert to the native serine or threonine residue during final cleavage.[1][5]
-
Utilize Backbone-Protecting Groups: Attaching protecting groups like 2-hydroxy-4-methoxybenzyl (Hmb) or 2,4-dimethoxybenzyl (Dmb) to the backbone nitrogen of an amino acid can prevent hydrogen bonding and reduce aggregation.[1][3]
-
Optimize Synthesis Conditions:
-
Solvent Choice: Switching to N-methylpyrrolidone (NMP) or adding DMSO to the solvent can improve solvation and reduce aggregation.[1][6]
-
Elevated Temperature: Performing couplings at a higher temperature can help disrupt secondary structures.[1]
-
Chaotropic Salts: Adding chaotropic salts like LiCl or KSCN to the coupling mixture can disrupt hydrogen bonding.[1][7]
-
-
Microwave-Assisted Synthesis: The use of microwave irradiation can accelerate coupling reactions and help overcome aggregation-related difficulties.[1][8]
Q3: How does phosphorylation of serine residues affect peptide aggregation?
A3: Serine phosphorylation can significantly modulate peptide aggregation, often by inhibiting it. The introduction of a negatively charged phosphate group can increase electrostatic repulsion between peptide molecules, disrupting the formation of aggregates.[9] However, the effect is position-dependent and can also alter the aggregation mechanism and the morphology of the resulting fibrils.[10][11][12] For instance, in the case of amyloid-β peptide, phosphomimetic mutations at serine residues were found to alter the aggregation mechanism.[10]
Q4: What methods can I use to detect and quantify the aggregation of my serine-containing peptide?
A4: Several biophysical techniques can be employed to monitor and quantify peptide aggregation.
-
Thioflavin T (ThT) Fluorescence Assay: This is a widely used method to detect the formation of amyloid-like fibrils. ThT dye exhibits enhanced fluorescence upon binding to the β-sheet structures characteristic of these aggregates.[13]
-
Size Exclusion Chromatography (SEC-HPLC): SEC-HPLC separates molecules based on their size, allowing for the detection and quantification of monomers, oligomers, and higher-order aggregates.[14]
-
Circular Dichroism (CD) Spectroscopy: CD spectroscopy is used to monitor changes in the secondary structure of the peptide, such as the transition from a random coil to a β-sheet conformation, which is a hallmark of aggregation.[3]
-
Transmission Electron Microscopy (TEM) or Atomic Force Microscopy (AFM): These imaging techniques provide direct visualization of the morphology of peptide aggregates, allowing for the differentiation between amorphous aggregates and ordered fibrils.[3][13]
Quantitative Data on Factors Influencing Serine Peptide Aggregation
The following table summarizes findings from various studies on factors affecting the aggregation of peptides, including those containing serine.
| Factor | Peptide/Protein System | Observation | Reference |
| pH | 13-residue synthetic peptide | Fibril formation inhibited at pH 7.5 (phosphate group fully charged), rapid formation at pH 1.1 (phosphate group protonated). | [9] |
| Phosphorylation | Huntingtin (htt) protein fragments | Ser-to-Asp mutations (phosphomimics) dramatically reduced aggregation rates and altered aggregate morphology. | [11][12] |
| Phosphorylation | Amyloid-β (Aβ) 42 | Mutations mimicking serine phosphorylation (S8E, S26E) altered the aggregation mechanism. | [10] |
| Concentration | General peptides | Aggregation kinetics are highly dependent on peptide concentration, often following a nucleation-polymerization mechanism. | [15] |
| Ionic Strength | Islet amyloid polypeptide, human glucagon, Aβ peptide | Ions can influence both the kinetics of aggregation and the structure of the fibrils formed. | [15] |
Key Experimental Protocols
Thioflavin T (ThT) Fluorescence Assay for Aggregation Kinetics
Objective: To monitor the formation of amyloid-like fibrils over time.
Materials:
-
Peptide stock solution
-
Thioflavin T (ThT) stock solution (e.g., 1 mM in water)
-
Assay buffer (e.g., phosphate-buffered saline, pH 7.4)
-
96-well black, clear-bottom microplate
-
Plate reader with fluorescence capabilities (Excitation ~440 nm, Emission ~485 nm)
Procedure:
-
Prepare the peptide solution at the desired concentration in the assay buffer.
-
Add ThT from the stock solution to the peptide solution to a final concentration of 10-20 µM.
-
Pipette replicates of the peptide-ThT mixture into the wells of the 96-well plate.
-
Include control wells containing only the buffer and ThT.
-
Place the plate in the plate reader, set the temperature to 37°C, and configure the instrument for kinetic reads at set intervals (e.g., every 15 minutes) for the desired duration (e.g., 50 hours).[16] Enable orbital shaking between reads to promote aggregation.[16]
-
Monitor the increase in fluorescence intensity over time. The lag time, elongation rate, and final fluorescence intensity provide information about the aggregation kinetics.
Size Exclusion Chromatography (SEC-HPLC) for Aggregate Quantification
Objective: To separate and quantify monomeric, oligomeric, and aggregated peptide species.
Materials:
-
Peptide sample
-
HPLC system with a UV detector
-
Size exclusion column appropriate for the molecular weight range of the peptide and its aggregates.
-
Mobile phase (e.g., phosphate buffer with a specific salt concentration)
Procedure:
-
Equilibrate the SEC column with the mobile phase until a stable baseline is achieved.
-
Prepare the peptide sample in the mobile phase.
-
Inject a defined volume of the peptide sample onto the column.
-
Run the separation isocratically.
-
Monitor the elution profile using the UV detector at a suitable wavelength (e.g., 214 nm or 280 nm).
-
Larger aggregates will elute first, followed by smaller oligomers and the monomeric peptide.
-
Quantify the different species by integrating the peak areas in the chromatogram.
Visualizations
Caption: A simplified pathway of peptide aggregation from monomers to mature fibrils.
Caption: A troubleshooting guide for addressing on-resin aggregation during SPPS.
Caption: The role of serine phosphorylation in inhibiting peptide aggregation.
References
- 1. peptide.com [peptide.com]
- 2. researchgate.net [researchgate.net]
- 3. benchchem.com [benchchem.com]
- 4. Reddit - The heart of the internet [reddit.com]
- 5. chempep.com [chempep.com]
- 6. biotage.com [biotage.com]
- 7. Overcoming Aggregation in Solid-phase Peptide Synthesis [sigmaaldrich.com]
- 8. blog.mblintl.com [blog.mblintl.com]
- 9. Phosphorylation as a Tool To Modulate Aggregation Propensity and To Predict Fibril Architecture - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Serine phosphorylation mimics of Aβ form distinct, non-cross-seeding fibril morphs - Chemical Science (RSC Publishing) [pubs.rsc.org]
- 11. Serine phosphorylation suppresses huntingtin amyloid accumulation by altering protein aggregation properties - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. researchgate.net [researchgate.net]
- 13. Protein Aggregation Analysis - Creative Proteomics [creative-proteomics.com]
- 14. researchgate.net [researchgate.net]
- 15. Factors affecting the physical stability (aggregation) of peptide therapeutics - PMC [pmc.ncbi.nlm.nih.gov]
- 16. m.youtube.com [m.youtube.com]
Technical Support Center: Optimizing Cleavage Cocktails for Serine-Containing Peptides
Welcome to the Technical Support Center for optimizing cleavage cocktails for serine-containing peptides. This guide is designed for researchers, scientists, and drug development professionals to provide troubleshooting assistance and frequently asked questions (FAQs) to address common challenges during the cleavage and deprotection of synthetic peptides containing serine residues.
Frequently Asked Questions (FAQs)
Q1: What is the primary role of a cleavage cocktail in solid-phase peptide synthesis (SPPS)?
A1: In SPPS, the cleavage cocktail serves two main purposes: it cleaves the synthesized peptide from the solid resin support and removes the side-chain protecting groups from the amino acid residues in a process known as global deprotection.[1] The most common method utilizes a strong acid, typically trifluoroacetic acid (TFA), as the primary cleavage reagent.[1][2]
Q2: Why are scavengers essential when cleaving peptides, especially those containing serine?
A2: During the acid-mediated cleavage process, reactive carbocations are generated from the removal of protecting groups (e.g., tert-butyl from serine) and from the resin linker.[1][2] These electrophilic species can cause unwanted side reactions by modifying nucleophilic amino acid side chains.[2] For serine, this can result in O-alkylation of the hydroxyl group.[3] Scavengers are nucleophilic reagents added to the cleavage cocktail to "trap" these reactive carbocations, thereby preventing these side reactions and protecting the integrity of the final peptide.[1][4]
Q3: What are some common scavengers and their functions in a cleavage cocktail?
A3: The selection of scavengers is critical and depends on the peptide's amino acid composition.[1][2] Common scavengers include:
-
Triisopropylsilane (TIS): An effective scavenger for t-butyl and trityl cations, which helps prevent alkylation of tryptophan and cysteine residues.[1]
-
Water: Acts as a proton source and helps to suppress the t-butylation of tryptophan and other sensitive residues.[1]
-
1,2-Ethanedithiol (EDT): A reducing agent that is particularly effective at preventing the oxidation of cysteine and methionine residues and also scavenges trityl groups.[1]
-
Thioanisole: Often used to accelerate the deprotection of arginine's Pmc group and to scavenge various carbocations.[1]
-
Phenol: A general scavenger for various carbocations.[1]
Q4: What specific side reactions can occur with serine during cleavage, and how can they be minimized?
A4: The primary side reaction involving serine during TFA cleavage is O-alkylation of its hydroxyl group by carbocations generated from protecting groups.[3] Another potential, though less common, side reaction is O-sulfonation , which can occur during the removal of Pmc or Mtr protecting groups from arginine residues in the absence of suitable scavengers.[5]
To minimize these side reactions:
-
Always use a well-defined cleavage cocktail containing appropriate scavengers. A standard and effective cocktail for most peptides, including those with serine, is a mixture of TFA/TIS/H₂O (95:2.5:2.5, v/v/v).[6][7]
-
For peptides also containing sensitive residues like Cys, Met, or Trp, a more robust cocktail such as Reagent K (TFA/water/phenol/thioanisole/EDT; 82.5:5:5:5:2.5, v/v/v/v/v) may be necessary.
Troubleshooting Guide
This section addresses specific issues that may arise during the cleavage of serine-containing peptides.
Issue 1: Low peptide yield after cleavage and precipitation.
-
Possible Cause: Incomplete Cleavage from the Resin.
-
Troubleshooting Steps:
-
Perform a Post-Cleavage Kaiser Test: A positive Kaiser test (blue or purple beads) on the resin after cleavage indicates the presence of remaining peptide attached to the resin.[8]
-
Extend Cleavage Time: Standard cleavage times are 2-4 hours.[9] For peptides with more stable protecting groups or complex sequences, extending the cleavage time may be necessary.[4]
-
Optimize Cleavage Cocktail: Ensure the TFA concentration is not diluted by residual solvent from washing steps.[9] If incomplete cleavage is confirmed, re-cleaving the resin with a fresh, optimized cocktail is recommended.[10]
-
Check Reagents: Ensure that the TFA and scavengers are fresh, as degraded reagents can lead to lower cleavage efficiency.[8]
-
-
-
Possible Cause: Poor Peptide Precipitation.
-
Troubleshooting Steps:
-
Optimize Precipitation Conditions: Ensure the diethyl ether used for precipitation is ice-cold.[4] You can also try concentrating the TFA filtrate before adding it to the ether.[4]
-
Check Supernatant: After centrifugation, check the ether supernatant for any dissolved peptide. If present, it can be recovered by evaporating the ether.[1]
-
-
Issue 2: Unexpected peaks in the HPLC chromatogram of the crude peptide.
-
Possible Cause: Side-Chain Modifications.
-
Troubleshooting Steps:
-
Analyze by Mass Spectrometry: Determine the mass of the unexpected peaks to identify potential modifications. For instance, a +56 Da shift could indicate t-butylation.[4]
-
Optimize Scavenger Composition: If side-chain modifications are confirmed, adjust the scavenger composition in your cleavage cocktail. For serine-containing peptides, ensuring an adequate concentration of TIS and water is crucial to prevent O-alkylation.[1][6] For peptides also containing arginine protected with Pmc or Mtr groups, the addition of thioanisole can help prevent O-sulfonation of serine.[5][11]
-
-
-
Possible Cause: Deletion Sequences from Synthesis.
-
Troubleshooting Steps:
-
Review Synthesis Protocol: If mass spectrometry indicates deletion sequences, review the solid-phase peptide synthesis (SPPS) protocol for potential issues with coupling efficiency during synthesis.[4]
-
-
Issue 3: The peptide is difficult to dissolve after precipitation.
-
Possible Cause: Hydrophobicity or Aggregation.
-
Troubleshooting Steps:
-
Lyophilize from an Aqueous/Organic Mixture: After the final ether wash, dissolve the peptide pellet in a mixture of water and an organic solvent like acetonitrile, then lyophilize.[4]
-
Use a Different Solvent System: For highly hydrophobic peptides, dissolving in a small amount of DMSO or DMF before adding water for lyophilization can be effective.[4]
-
-
Data Presentation: Comparison of Common Cleavage Cocktails
The following table summarizes common cleavage cocktails and their applications, particularly for peptides containing serine and other sensitive amino acids.
| Cleavage Cocktail | Composition (v/v) | Target Peptides & Remarks | Reference(s) |
| Standard Cocktail | 95% TFA, 2.5% TIS, 2.5% H₂O | Effective for most peptides, including those with serine, that lack other highly sensitive residues like unprotected Trp, Met, or Cys.[6][7] | [6][7] |
| Reagent K | 82.5% TFA, 5% H₂O, 5% Phenol, 5% Thioanisole, 2.5% EDT | A universal and highly effective cocktail for complex peptides, especially those containing multiple sensitive residues such as Cys, Met, and Trp.[6] | [6] |
| Reagent B ("Odorless") | 88% TFA, 5% Phenol, 5% H₂O, 2% TIS | Useful when the peptide contains trityl-based protecting groups. It will not, however, prevent the oxidation of methionine.[12] | [12] |
Experimental Protocols
Protocol 1: General TFA Cleavage and Peptide Precipitation
This protocol is suitable for serine-containing peptides without other highly sensitive residues.[6]
-
Resin Preparation: Place the dried peptide-resin (e.g., 100 mg) in a reaction vessel.
-
Prepare Cleavage Cocktail: In a fume hood, freshly prepare the cleavage cocktail: 95% TFA, 2.5% H₂O, and 2.5% TIS. For 2 mL of cocktail, this corresponds to 1.9 mL of TFA, 50 µL of H₂O, and 50 µL of TIS.
-
Cleavage Reaction: Add the cleavage cocktail (e.g., 2 mL per 100 mg of resin) to the reaction vessel.
-
Reaction Time: Gently agitate the mixture at room temperature for 2-3 hours.
-
Peptide Filtration: Filter the resin using a sintered glass funnel and collect the filtrate, which contains the peptide.
-
Resin Wash: Wash the resin with a small amount of fresh TFA (e.g., 2 x 0.5 mL) and combine the filtrates.
-
Precipitation: Slowly add the combined filtrate dropwise into a 10-fold volume of ice-cold diethyl ether. A white precipitate of the crude peptide should form.
-
Incubation: To maximize precipitation, incubate the mixture at a low temperature (e.g., -20°C or 4°C).
-
Isolation: Centrifuge the mixture to pellet the crude peptide. Carefully decant the ether supernatant.
-
Washing and Drying: Wash the peptide pellet with cold ether multiple times to remove residual scavengers and TFA. Dry the final peptide pellet under a stream of nitrogen or in a vacuum desiccator.
Protocol 2: Cleavage of Peptides with Multiple Sensitive Residues (using Reagent K)
This protocol is recommended for serine-containing peptides that also have other sensitive residues like Cys, Met, or Trp.[6]
-
Resin Preparation: Place the dried peptide-resin (e.g., 100 mg) in a reaction vessel.
-
Prepare Cleavage Cocktail (Reagent K): In a fume hood, freshly prepare Reagent K: 82.5% TFA, 5% H₂O, 5% Phenol, 5% Thioanisole, and 2.5% EDT. For 2 mL of cocktail, this corresponds to 1.65 mL of TFA, 0.1 mL of H₂O, 0.1 mL of Phenol, 0.1 mL of Thioanisole, and 0.05 mL of EDT.
-
Cleavage Reaction: Add Reagent K (e.g., 2 mL per 100 mg of resin) to the reaction vessel.
-
Reaction Time: Gently agitate the mixture at room temperature for 2 to 4 hours.
-
Work-up: Follow steps 5-10 from the "General TFA Cleavage and Peptide Precipitation" protocol above.
Visualizations
References
- 1. benchchem.com [benchchem.com]
- 2. benchchem.com [benchchem.com]
- 3. benchchem.com [benchchem.com]
- 4. benchchem.com [benchchem.com]
- 5. [Side reactions in peptide synthesis. V. O-sulfonation of serine and threonine during removal of pmc- and mtr-protecting groups from arginine residues in fmoc-solid phase synthesis] - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. benchchem.com [benchchem.com]
- 7. WO2015028599A1 - Cleavage of synthetic peptides - Google Patents [patents.google.com]
- 8. benchchem.com [benchchem.com]
- 9. benchchem.com [benchchem.com]
- 10. researchgate.net [researchgate.net]
- 11. peptide.com [peptide.com]
- 12. peptide.com [peptide.com]
Technical Support Center: Fmoc-Ser-OH vs. Fmoc-Ser(tBu)-OH in Peptide Synthesis
This guide provides researchers, scientists, and drug development professionals with comprehensive troubleshooting advice and frequently asked questions (FAQs) regarding the use of Fmoc-Ser-OH and Fmoc-Ser(tBu)-OH in solid-phase peptide synthesis (SPPS).
Frequently Asked Questions (FAQs)
Q1: What is the primary difference between using Fmoc-Ser-OH and Fmoc-Ser(tBu)-OH in SPPS?
The fundamental difference lies in the protection of the serine side-chain hydroxyl group. In Fmoc-Ser(tBu)-OH, the hydroxyl group is protected by a tert-butyl (tBu) ether.[1] This protection is stable to the basic conditions used for Fmoc group removal (e.g., piperidine) but is readily cleaved by strong acids like trifluoroacetic acid (TFA) during the final cleavage step.[1][2] This "orthogonal" protection strategy prevents side reactions at the hydroxyl group during synthesis.[3][] In contrast, Fmoc-Ser-OH has an unprotected hydroxyl group, which can lead to undesired side reactions.
Q2: What are the most common side reactions when using Fmoc-Ser-OH with its unprotected side-chain?
The primary side reactions associated with the unprotected hydroxyl group of Fmoc-Ser-OH are:
-
β-elimination (Dehydration): Under basic conditions, the serine residue can undergo dehydration to form a dehydroalanine (Dha) residue.[5][6] This results in a mass loss of 18 Da in the final peptide.
-
O-acylation: The free hydroxyl group can be acylated by the activated carboxyl group of the incoming amino acid, leading to the formation of branched peptides or other impurities.
-
endo-Ser Impurity Formation: A double insertion of serine can occur where a second Fmoc-Ser-OH molecule acylates the hydroxyl group of a resin-bound serine. Subsequent migration of this side-chain serine into the peptide backbone can occur, resulting in an "endo-Ser" impurity with a mass increase of 87 Da.[7]
Q3: What are the potential side reactions when using Fmoc-Ser(tBu)-OH?
While the tBu group effectively prevents side reactions at the hydroxyl group, other issues can arise:
-
Racemization: The chiral integrity of the serine residue can be compromised during the activation and coupling steps, leading to the formation of the D-isomer.[8] This is a particular concern for serine, cysteine, and histidine.[9] The choice of base and coupling reagent significantly influences the extent of racemization.[8][10] For instance, the use of N,N-diisopropylethylamine (DIPEA) has been shown to induce racemization with Fmoc-Ser(tBu)-OH.[1][11]
-
N -> O Acyl Shift: During the final acid-catalyzed cleavage with TFA, a migration of a peptide bond from the amide nitrogen to the serine hydroxyl group can occur.[1] This is generally a minor side reaction under standard conditions.[1]
Q4: How can I minimize or prevent these side reactions?
For Fmoc-Ser-OH :
-
Preventing Dehydration: The most effective way to prevent dehydration and other side-chain reactions is to use the side-chain protected derivative, Fmoc-Ser(tBu)-OH. If Fmoc-Ser-OH must be used, careful control of base exposure time and temperature is critical.
For Fmoc-Ser(tBu)-OH :
-
Minimizing Racemization:
-
Base Selection: Use a weaker, sterically hindered base like 2,4,6-collidine or N-methylmorpholine (NMM) instead of DIPEA.[10][11]
-
Coupling Reagents: Employ coupling reagents in combination with racemization-suppressing additives like 1-hydroxybenzotriazole (HOBt) or Oxyma.[10]
-
Temperature Control: Perform coupling reactions at room temperature or below, as elevated temperatures can increase the rate of racemization.[10]
-
Troubleshooting Guides
Problem 1: An unexpected mass loss of 18 Da is observed in my serine-containing peptide.
-
Probable Cause: This mass loss corresponds to the dehydration of a serine residue to dehydroalanine (Dha).[12] This is a classic β-elimination side reaction, most common when using Fmoc-Ser-OH with its unprotected side chain.[6]
-
Troubleshooting Steps:
-
Confirm the Side Product: Use tandem mass spectrometry (MS/MS) to identify the location of the modification. Dehydroalanine residues are known to induce characteristic fragmentation patterns.[5]
-
Review Synthesis Protocol: Check if Fmoc-Ser-OH was used instead of Fmoc-Ser(tBu)-OH.
-
Solution: Re-synthesize the peptide using Fmoc-Ser(tBu)-OH to protect the serine side-chain hydroxyl group during synthesis.[2]
-
Problem 2: My peptide has an unexpected mass increase of 87 Da.
-
Probable Cause: This mass increase is characteristic of the formation of an "endo-Ser" impurity, which results from the double insertion of a serine residue.[7] This occurs when using Fmoc-Ser-OH, where the unprotected hydroxyl group of one serine is acylated by a second incoming Fmoc-Ser-OH.[7]
-
Troubleshooting Steps:
-
Verify Mass: Ensure the observed mass corresponds exactly to the addition of a serine residue (87.08 Da).
-
Analyze Synthesis Conditions: This side reaction is specific to the use of Fmoc-Ser-OH.
-
Solution: The most effective solution is to re-synthesize the peptide using Fmoc-Ser(tBu)-OH to prevent acylation of the side-chain hydroxyl group.[1]
-
Problem 3: HPLC analysis shows a diastereomeric impurity for my serine-containing peptide.
-
Probable Cause: This indicates racemization of the serine residue during the coupling step, where the L-serine has been partially converted to D-serine.[8]
-
Troubleshooting Steps:
-
Review Coupling Conditions:
-
Optimize Protocol:
-
Data Presentation
| Side Reaction | Amino Acid Derivative | Mass Change | Primary Cause | Prevention / Mitigation Strategy |
| β-Elimination (Dehydration) | Fmoc-Ser-OH | -18 Da | Base-catalyzed elimination from the unprotected hydroxyl group.[6] | Use Fmoc-Ser(tBu)-OH. |
| endo-Ser Formation | Fmoc-Ser-OH | +87 Da | O-acylation of the unprotected hydroxyl group by a second Ser residue, followed by an O-to-N acyl shift.[7] | Use Fmoc-Ser(tBu)-OH. |
| Racemization | Fmoc-Ser(tBu)-OH | No Change | Abstraction of the alpha-proton during activation/coupling, often promoted by strong bases like DIPEA.[10][11] | Use weaker bases (e.g., collidine), add racemization suppressants (e.g., HOBt, Oxyma), control temperature.[10][11] |
| N -> O Acyl Shift | Fmoc-Ser(tBu)-OH | No Change | Acid-catalyzed migration of the peptide backbone during final TFA cleavage.[1] | Minimize cleavage time and temperature. Generally a minor issue.[1] |
Experimental Protocols
Protocol 1: Standard Coupling of Fmoc-Ser(tBu)-OH
This protocol is for a standard 0.1 mmol synthesis scale.
-
Resin Preparation: Swell the resin (e.g., Rink Amide for a C-terminal amide) in dimethylformamide (DMF) for 30-60 minutes.[1]
-
Fmoc Deprotection: Treat the resin with 20% piperidine in DMF (v/v). Perform two treatments: one for 5 minutes and a second for 15 minutes.[13] Wash the resin thoroughly with DMF.
-
Amino Acid Activation: In a separate vial, dissolve Fmoc-Ser(tBu)-OH (3-5 equivalents) and a coupling reagent (e.g., HBTU, 3-5 equivalents) in DMF. Add a suitable base (e.g., collidine, 6-10 equivalents) and allow the mixture to pre-activate for 1-2 minutes.[1]
-
Coupling: Add the activated amino acid solution to the deprotected resin. Agitate the mixture for 1-2 hours at room temperature.[1]
-
Washing: Drain the coupling solution and wash the resin extensively with DMF.
-
Confirmation (Optional): Perform a Kaiser test to confirm the completion of the coupling. A negative result (yellow beads) indicates a complete reaction. If the test is positive (blue beads), a second coupling may be required.[1]
Protocol 2: Final Cleavage and Deprotection
-
Resin Preparation: After the final Fmoc deprotection, wash the peptide-resin with DMF, followed by dichloromethane (DCM), and dry it under vacuum.[1]
-
Cleavage Cocktail Preparation: Prepare a suitable cleavage cocktail. A common option is "Reagent K": 82.5% TFA, 5% phenol, 5% water, 5% thioanisole, 2.5% 1,2-ethanedithiol.[1]
-
Cleavage Reaction: Add the cleavage cocktail to the dried resin and allow the reaction to proceed for 2-3 hours at room temperature with occasional agitation.[1]
-
Peptide Precipitation: Filter the resin and collect the filtrate. Precipitate the crude peptide by adding the filtrate to cold diethyl ether.
-
Peptide Isolation: Centrifuge the mixture to pellet the peptide, decant the ether, and dry the peptide pellet under vacuum.
Protocol 3: Detection of Dehydroalanine (Dha) by Chemical Labeling
This method allows for the confirmation of Dha in a peptide sample.
-
Principle: The α,β-unsaturated bond in Dha is a Michael acceptor and can react specifically with thiol-containing molecules. A biotin-conjugated thiol can be used to label the Dha residue.[14]
-
Labeling: Incubate the crude peptide (containing the suspected Dha) with a biotin-conjugated cysteamine derivative.
-
Detection: The now biotinylated peptide can be detected using standard methods such as Western blot or dot blot with streptavidin-HRP conjugate, or analyzed by mass spectrometry to confirm the mass addition of the label.[14]
Visualizations
Caption: Orthogonal protection scheme in Fmoc-SPPS.
Caption: Mechanism of dehydroalanine formation.
Caption: Racemization pathway for activated serine.
Caption: Troubleshooting logic for serine side reactions.
References
- 1. benchchem.com [benchchem.com]
- 2. benchchem.com [benchchem.com]
- 3. benchchem.com [benchchem.com]
- 5. The dehydroalanine effect in the fragmentation of ions derived from polypeptides - PMC [pmc.ncbi.nlm.nih.gov]
- 6. researchgate.net [researchgate.net]
- 7. researchgate.net [researchgate.net]
- 8. Suppression of alpha-carbon racemization in peptide synthesis based on a thiol-labile amino protecting group - PMC [pmc.ncbi.nlm.nih.gov]
- 9. A Brief Introduction to the Racemization of Amino Acids in Polypeptide Synthesis [en.highfine.com]
- 10. benchchem.com [benchchem.com]
- 11. chempep.com [chempep.com]
- 12. researchgate.net [researchgate.net]
- 13. benchchem.com [benchchem.com]
- 14. Blot-based detection of dehydroalanine-containing glutathione peroxidase with the use of biotin-conjugated cysteamine - PubMed [pubmed.ncbi.nlm.nih.gov]
troubleshooting 15N labeled peptide fragmentation in MS/MS
Welcome to the Technical Support Center for 15N Labeled Peptide Fragmentation in Mass Spectrometry. This guide provides detailed troubleshooting advice and answers to frequently asked questions to assist researchers, scientists, and drug development professionals in their MS/MS experiments.
Category 1: Fragmentation & Spectra Quality
Q1: Why are my 15N-labeled peptides showing poor or no fragmentation?
A: Poor fragmentation of 15N-labeled peptides can stem from several factors. A primary cause is suboptimal collision energy. The energy required for optimal fragmentation can differ from that of unlabeled peptides.[1] Additionally, issues with the mass spectrometer, such as a contaminated collision cell, can universally affect fragmentation. For certain peptides, their intrinsic properties, like a lack of mobile protons, can also lead to poor fragmentation.
Q2: My sequence coverage for 15N-labeled peptides is low. How can I improve it?
A: Low sequence coverage is a common challenge. To improve it, consider the following:
-
Optimize Collision Energy: The fragmentation pattern is highly dependent on the collision energy applied.[2][3] A systematic optimization can significantly increase the number and intensity of fragment ions. Using a stepped normalized collision energy (NCE) scheme can also be beneficial, as it allows for the fragmentation of precursors with varying characteristics.[4]
-
Choose the Right Fragmentation Method: While Collision-Induced Dissociation (CID) is common, Higher-Energy Collisional Dissociation (HCD) can provide more complete fragmentation and is less prone to biases in isotopic distribution.[5]
-
Improve Upstream Sample Handling: Ensure efficient protein digestion and clean peptide desalting. Poor sample quality can lead to a complex mixture where the target peptides are of low abundance, resulting in poor quality MS/MS spectra.[6]
Q3: How can I effectively differentiate between b- and y-ions in my 15N-labeled peptide spectra?
A: The incorporation of 15N provides a unique way to distinguish N-terminal (b-ions) from C-terminal (y-ions) fragments. By comparing the MS/MS spectra of the 14N (unlabeled) and 15N (labeled) versions of a peptide, you can identify the b-ions based on their characteristic mass shift.[7][8] Each nitrogen atom in a b-ion will be a 15N isotope, resulting in a predictable mass increase. In contrast, y-ions will only show a mass shift if they contain amino acids with nitrogen in their side chains (e.g., Lys, Arg, His, Asn, Gln, Trp). This differential labeling strategy greatly simplifies de novo peptide sequencing.[7][9]
Category 2: Labeling & Quantification Issues
Q4: What causes incomplete 15N labeling, and how does it affect my MS/MS analysis?
A: Incomplete metabolic labeling is a frequent issue that can complicate data analysis.[10]
-
Causes: The primary causes include insufficient labeling duration (not enough cell divisions), low purity of the 15N-labeled nutrients, or the presence of contaminating 14N sources.[10][11] For optimal labeling, ensure cells undergo at least 5-6 divisions and use high-purity (>99%) 15N salts.[10][11]
-
Effects on MS/MS: Incomplete labeling broadens the isotopic clusters of precursor ions, which can make it difficult for the instrument's software to correctly assign the monoisotopic peak for MS/MS selection.[11][12] This can lead to a lower identification rate for heavy-labeled peptides and introduce inaccuracies in quantification.[13][14]
Q5: My quantification of 15N-labeled peptides is inaccurate. What are the common pitfalls?
A: Inaccurate quantification can arise from both experimental and data analysis issues.
-
Co-eluting Peptides: Contamination from co-eluting peptides or chemical noise in the MS1 survey scan can interfere with the accurate measurement of the peak intensity for your target peptide.[13][14]
-
Incomplete Labeling: If not corrected for, incomplete labeling will skew the calculated heavy/light ratios.[11] It's crucial to determine the labeling efficiency and adjust the quantification ratios accordingly.[10]
-
MS1 vs. MS2 Quantification: While MS1-level quantification is common, it can be prone to interference.[13] Targeted methods like Parallel Reaction Monitoring (PRM), which quantify at the MS2 level using fragment ions, can provide more accurate and reliable results, especially for low-abundance proteins.[13][14] The heavy-labeled peptides in a 15N experiment can serve as natural internal standards, enhancing the reliability of PRM quantification.[13]
Data & Tables
Table 1: Expected Mass Shifts in 15N-Labeled Fragment Ions
This table summarizes the theoretical monoisotopic mass increase for a fragment ion based on the number of nitrogen atoms it contains. The mass of ¹⁴N is 14.003074 u and ¹⁵N is 15.000109 u, giving a mass difference of 0.997035 u per nitrogen atom.
| Number of Nitrogen Atoms (N) in Fragment | Monoisotopic Mass Increase (Da) |
| 1 | 0.997035 |
| 2 | 1.994070 |
| 3 | 2.991105 |
| 4 | 3.988140 |
| 5 | 4.985175 |
| 10 | 9.970350 |
| 15 | 14.955525 |
| 20 | 19.940700 |
Table 2: Troubleshooting Summary for 15N Labeled Peptide Fragmentation
| Issue | Probable Cause(s) | Recommended Action(s) |
| Low Identification Rate of Heavy Peptides | Incomplete labeling leading to broad isotopic clusters and incorrect monoisotopic peak selection.[11][12] | Ensure high-purity (>99%) 15N source and sufficient labeling time (e.g., >14 days for Arabidopsis).[11] Use software tools that can correctly identify the monoisotopic peak in complex isotopic patterns.[11] |
| Inaccurate Quantification Ratios | Co-eluting interference in MS1 scans.[13] Failure to correct for incomplete labeling.[11] | Use targeted proteomics (e.g., PRM) to quantify using MS2 fragment ions.[13][14] Calculate the labeling efficiency and apply a correction factor to the final ratios.[10] |
| Poor Sequence Coverage | Suboptimal collision energy; Inappropriate fragmentation method.[1][2] | Perform a collision energy optimization experiment for representative peptides.[2] Consider using HCD instead of CID for more thorough fragmentation.[5] |
| Ambiguous b- and y-ion Assignment | Complex fragmentation patterns in a single spectrum.[7] | Analyze both 14N and 15N versions of the peptide. Identify b-ions by their predictable mass shift based on the number of nitrogen atoms in their sequence.[8][9] |
| Skewed Isotopic Patterns in Fragments | Low-energy CID can preferentially fragment lighter isotopologues.[5] | Use a higher-energy fragmentation method like HCD, which provides more uniform fragmentation across the isotopic envelope.[5] |
Diagrams and Workflows
Troubleshooting Workflow for Poor Fragmentation
Caption: A logical workflow for troubleshooting poor MS/MS fragmentation.
Logic of Fragment Ion Mass Shifts in 15N Labeling
Caption: Mass shifts of b- and y-ions depend on nitrogen content.
Experimental Protocols
Protocol: Optimizing Collision Energy for 15N-Labeled Peptides
This protocol provides a general framework for optimizing collision energy (CE) or normalized collision energy (NCE) to improve MS/MS spectral quality.
Objective: To determine the optimal CE/NCE value that maximizes fragment ion intensity and sequence coverage for a set of target 15N-labeled peptides.
Methodology:
-
Peptide Selection:
-
Choose a representative set of 5-10 identified 15N-labeled peptides from your sample. Select peptides that span a range of m/z values, charge states (2+ and 3+), and general hydrophobicity.
-
-
Instrument Setup:
-
Prepare a dilution of your digested sample that provides a stable and moderately intense signal for the selected precursor ions.
-
Create a targeted inclusion list in the mass spectrometer's acquisition software containing the m/z and charge state of your selected precursor peptides.
-
-
Collision Energy Stepping:
-
Set up a series of acquisition methods. Each method will be identical except for the collision energy setting.
-
For Normalized Collision Energy (NCE) : Create methods with NCE values stepped in increments. For example, for a peptide typically fragmented at 25%, test a range from 15% to 35% in steps of 2-3% (e.g., 15, 18, 21, 25, 28, 32, 35).[4]
-
For Collision Energy (CE) in volts : If your instrument uses absolute CE, the optimal value is dependent on the precursor's m/z and charge state.[2] You can test a range of +/- 10V around the instrument's default calculated value in steps of 2V.
-
-
Data Acquisition:
-
Inject the sample and acquire data using each of the defined methods. Ensure enough MS/MS scans are collected for each precursor at each CE level to allow for robust analysis.
-
-
Data Analysis:
-
Manually inspect the MS/MS spectra for each peptide at each CE level.
-
Evaluate the following metrics:
-
Total Ion Current (TIC) of the MS/MS Scan: Higher TIC can indicate more efficient fragmentation.
-
Number of Fragment Ions: Count the number of significant b- and y-ions identified.
-
Fragment Ion Intensity: Assess the intensity of the most abundant fragment ions.
-
Sequence Coverage: Determine the percentage of the peptide sequence that is confirmed by the observed fragment ions.
-
-
Plot the desired metric (e.g., number of identified fragment ions) against the CE/NCE value for each peptide. The peak of this curve represents the optimal energy for that specific peptide.
-
-
Implementation:
-
Based on the analysis, determine if a single, globally optimized CE/NCE value is sufficient for your entire run, or if different values are needed for peptides of different charge states. Some acquisition strategies allow for the use of CE equations that calculate the optimal energy on-the-fly based on precursor m/z and charge.[2]
-
References
- 1. researchgate.net [researchgate.net]
- 2. Effect of Collision Energy Optimization on the Measurement of Peptides by Selected Reaction Monitoring (SRM) Mass Spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 3. researchgate.net [researchgate.net]
- 4. Optimization of Higher-Energy Collisional Dissociation Fragmentation Energy for Intact Protein-Level Tandem Mass Tag Labeling - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. benchchem.com [benchchem.com]
- 6. researchgate.net [researchgate.net]
- 7. Differential 14N/15N-Labeling of Peptides Using N-Terminal Charge Derivatization with a High-Proton Affinity for Straightforward de novo Peptide Sequencing - PMC [pmc.ncbi.nlm.nih.gov]
- 8. jstage.jst.go.jp [jstage.jst.go.jp]
- 9. Two-dimensional mass spectra generated from the analysis of 15N-labeled and unlabeled peptides for efficient protein identification and de novo peptide sequencing - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. benchchem.com [benchchem.com]
- 11. Frontiers | 15N Metabolic Labeling Quantification Workflow in Arabidopsis Using Protein Prospector [frontiersin.org]
- 12. biorxiv.org [biorxiv.org]
- 13. Application of Parallel Reaction Monitoring in 15N Labeled Samples for Quantification - PMC [pmc.ncbi.nlm.nih.gov]
- 14. escholarship.org [escholarship.org]
Technical Support Center: Minimizing 15N Label Scrambling in Metabolic Labeling
Welcome to the technical support center for researchers, scientists, and drug development professionals. This resource provides in-depth troubleshooting guides and frequently asked questions (FAQs) to help you minimize the scrambling of ¹⁵N labels during your metabolic labeling experiments.
Frequently Asked Questions (FAQs)
Q1: What is ¹⁵N label scrambling?
A1: Isotopic scrambling, in the context of ¹⁵N metabolic labeling, refers to the undesired redistribution of the ¹⁵N isotope from its intended molecular position to other positions within the same or different molecules. This occurs through various metabolic reactions within the cell, leading to the incorporation of ¹⁵N into amino acids that were not the intended target. This can complicate data analysis and lead to inaccuracies in protein quantification and turnover studies.
Q2: What are the primary causes of ¹⁵N scrambling?
A2: The main drivers of ¹⁵N scrambling are enzymatic reactions that involve the transfer of amino groups. Key causes include:
-
Transaminase Activity: Transaminases (or aminotransferases) are enzymes that catalyze the transfer of an amino group from an amino acid to an α-keto acid. This is a major route for the interconversion of amino acids and a primary cause of ¹⁵N scrambling. For example, alanine transaminase can convert ¹⁵N-alanine to ¹⁵N-pyruvate, which can then be used to synthesize other ¹⁵N-labeled amino acids.[1]
-
Metabolic Branch Points: Amino acid biosynthesis and degradation pathways are highly interconnected. Labeled nitrogen from one amino acid can be channeled into various metabolic pathways, leading to its incorporation into other amino acids.[1]
-
Reversible Enzymatic Reactions: Many reactions in amino acid metabolism are reversible, allowing the ¹⁵N label to be passed back and forth between different molecules, further contributing to scrambling.[1]
Q3: How can I detect and quantify the extent of ¹⁵N scrambling in my experiment?
A3: The extent of ¹⁵N scrambling is typically assessed using mass spectrometry (MS). By analyzing the isotopic distribution of peptides from your labeled protein, you can determine the degree of ¹⁵N enrichment and identify its presence in unexpected amino acid residues. High-resolution mass spectrometry is particularly useful for resolving the isotopic patterns of labeled and unlabeled peptides.[2] Tandem mass spectrometry (MS/MS) can be used to fragment peptides and pinpoint the location of the ¹⁵N label on specific amino acid residues. Software tools can then be used to compare the experimental isotopic patterns to theoretical distributions to quantify the percentage of scrambling.
Q4: Which amino acids are more prone to ¹⁵N scrambling?
A4: Amino acids that are central to nitrogen metabolism are more susceptible to scrambling. In HEK293 cells, for instance, significant scrambling has been observed for Alanine (A), Aspartate (D), Glutamate (E), Isoleucine (I), Leucine (L), and Valine (V). Glycine (G) and Serine (S) are often interconverted. Conversely, amino acids with more isolated biosynthetic pathways, such as Cysteine (C), Phenylalanine (F), Histidine (H), Lysine (K), Methionine (M), Asparagine (N), Arginine (R), Threonine (T), Tryptophan (W), and Tyrosine (Y), tend to exhibit minimal scrambling.[3]
Q5: Can the choice of cell line or organism affect the degree of scrambling?
A5: Yes, the metabolic wiring and enzyme expression levels can vary significantly between different cell lines and organisms, which in turn affects the extent of ¹⁵N scrambling. For example, certain mammalian cell lines may have higher transaminase activity compared to others, leading to more pronounced scrambling. It is therefore important to characterize the scrambling profile for your specific experimental system.
Troubleshooting Guide
Issue: High levels of ¹⁵N scrambling detected in my mass spectrometry data.
This is a common issue that can compromise the accuracy of quantitative proteomics experiments. The following troubleshooting steps can help identify the cause and minimize its impact.
Diagram: Troubleshooting Logic for High ¹⁵N Scrambling
Caption: A decision tree to guide troubleshooting of high ¹⁵N scrambling.
Possible Cause 1: High Transaminase Activity
-
Solution:
-
Use Transaminase-Deficient E. coli Strains: For protein expression in E. coli, consider using strains deficient in key transaminases, such as those with knockouts of aspC (aspartate aminotransferase) and tyrB (aromatic amino acid aminotransferase).
-
Enzyme Inhibitors: The addition of transaminase inhibitors to the culture medium can reduce scrambling. Aminooxyacetate is a broad-spectrum transaminase inhibitor that has been shown to be effective.[4]
-
Possible Cause 2: Interconnected Metabolic Pathways
-
Solution:
-
Optimize Media Composition: Supplementing the medium with a mixture of unlabeled amino acids can help to dilute the labeled pool and reduce the flux of the ¹⁵N label into other amino acid biosynthesis pathways.
-
Choose a Different Labeled Amino Acid: If using a single labeled amino acid (as in SILAC), select one that is less central to metabolism, such as lysine or arginine.
-
Possible Cause 3: Inappropriate Cell Culture Conditions
-
Solution:
-
Optimize Labeling Time: Ensure that the cells have reached an isotopic steady state. This may require passaging the cells for several generations in the ¹⁵N-labeled medium.
-
Control Cell Density: High cell densities can lead to nutrient depletion and changes in metabolism that may increase scrambling. Maintain cells in the exponential growth phase during labeling.
-
Possible Cause 4: Inherent Metabolic Activity of the Expression System
-
Solution:
-
Use a Cell-Free Protein Synthesis System: Cell-free systems have significantly lower metabolic activity compared to in-vivo systems, which greatly reduces the extent of ¹⁵N scrambling. Further reduction can be achieved by treating the cell extract with sodium borohydride (NaBH₄) to inactivate pyridoxal-phosphate (PLP)-dependent enzymes, which include many transaminases.
-
Quantitative Data on ¹⁵N Scrambling
The degree of ¹⁵N scrambling can vary depending on the amino acid and the experimental system. The following tables provide some representative data.
Table 1: ¹⁵N Scrambling of Different Amino Acids in HEK293 Cells
| Labeled Amino Acid | Scrambling Observed | Notes |
| Alanine (A) | Significant | The ¹⁵N label is readily transferred to other amino acids. |
| Aspartate (D) | Significant | A central metabolite in amino acid biosynthesis. |
| Glutamate (E) | Significant | Acts as a primary amino group donor in many reactions. |
| Isoleucine (I) | Significant | Can be interconverted with other branched-chain amino acids. |
| Leucine (L) | Significant | Shares metabolic pathways with other branched-chain amino acids. |
| Valine (V) | Significant | Prone to interconversion with other branched-chain amino acids. |
| Glycine (G) | Interconversion with Serine | The ¹⁵N label is often exchanged between glycine and serine.[3] |
| Serine (S) | Interconversion with Glycine | The ¹⁵N label is often exchanged between serine and glycine.[3] |
| C, F, H, K, M, N, R, T, W, Y | Minimal | These amino acids have more isolated biosynthetic pathways.[3] |
Table 2: Typical ¹⁵N Labeling Efficiencies in Various Organisms
| Organism | Typical Labeling Efficiency (%) | Notes |
| E. coli | >99% | Achieved relatively quickly in minimal media.[1] |
| S. cerevisiae | >98% | Efficient labeling in defined media. |
| Mammalian Cells (e.g., HEK293) | 95-99% | Dependent on cell line, media, and duration of labeling.[1] |
| Arabidopsis thaliana | 93-99% | Efficiency depends on the duration of labeling and the specific ¹⁵N source used.[1] |
Experimental Protocols
Protocol 1: Uniform ¹⁵N Labeling of Proteins in E. coli
This protocol is for expressing a uniformly ¹⁵N-labeled protein in E. coli using a minimal medium.
Materials:
-
M9 minimal medium components
-
¹⁵NH₄Cl (as the sole nitrogen source)
-
Glucose (or other carbon source)
-
MgSO₄, CaCl₂, and trace elements solution
-
Appropriate antibiotics
-
E. coli expression strain (e.g., BL21(DE3)) transformed with the plasmid of interest
Procedure:
-
Prepare Pre-culture: Inoculate a single colony of the transformed E. coli into 5 mL of LB medium containing the appropriate antibiotic. Grow overnight at 37°C with shaking.
-
Adapt to Minimal Medium: Inoculate 1 mL of the overnight culture into 100 mL of M9 minimal medium containing ¹⁴NH₄Cl and the appropriate antibiotic. Grow until the culture reaches an OD₆₀₀ of 0.6-0.8. This step helps the cells adapt to the minimal medium.[1]
-
Inoculate Main Culture: Prepare 1 L of M9 minimal medium containing 1 g of ¹⁵NH₄Cl as the sole nitrogen source, along with other necessary components (glucose, MgSO₄, CaCl₂, trace elements, and antibiotic). Inoculate this medium with the adapted pre-culture to a starting OD₆₀₀ of approximately 0.05.[1]
-
Growth and Induction: Grow the main culture at the optimal temperature for your protein expression (e.g., 37°C) with vigorous shaking. Monitor the OD₆₀₀. When the OD₆₀₀ reaches 0.6-0.8, induce protein expression with the appropriate inducer (e.g., IPTG).[1]
-
Expression: Continue to grow the culture for the desired period post-induction (typically 3-16 hours, depending on the protein and expression temperature).[1]
-
Harvest Cells: Harvest the cells by centrifugation (e.g., 6,000 x g for 15 minutes at 4°C).
-
Protein Purification: Resuspend the cell pellet in a suitable lysis buffer and proceed with your standard protein purification protocol.
Diagram: Workflow for Uniform ¹⁵N Labeling in E. coli
Caption: A typical workflow for producing uniformly ¹⁵N-labeled proteins in E. coli.
Protocol 2: Minimizing Scrambling with a Cell-Free Protein Synthesis System
This protocol describes the preparation of a metabolically "quenched" E. coli S30 extract to minimize ¹⁵N scrambling during cell-free protein synthesis.
Materials:
-
E. coli S30 extract
-
Sodium borohydride (NaBH₄) solution, freshly prepared
-
Dialysis buffer (e.g., 10 mM Tris-acetate pH 8.2, 14 mM magnesium acetate, 60 mM potassium acetate, 1 mM DTT)
-
Cell-free protein synthesis reaction components (amino acids, energy source, etc.)
Procedure:
-
Prepare S30 Extract: Prepare the E. coli S30 extract according to standard protocols.
-
NaBH₄ Treatment: On ice, add a freshly prepared solution of NaBH₄ to the S30 extract to a final concentration of 1 mM.
-
Incubation: Gently mix and incubate the mixture on ice for 30 minutes. This step inactivates PLP-dependent enzymes.
-
Removal of Excess NaBH₄: Dialyze the treated S30 extract against a suitable buffer to remove excess NaBH₄ and reaction byproducts.
-
Cell-Free Protein Synthesis: Use the treated S30 extract in your standard cell-free protein synthesis reaction with the desired ¹⁵N-labeled amino acids.
Diagram: Key Amino Acid Interconversion Pathways
Caption: Simplified overview of amino acid biosynthetic families.
This technical support guide provides a starting point for addressing ¹⁵N label scrambling in your experiments. For more specific issues, consulting detailed literature on the metabolism of your particular organism or cell line is recommended.
References
- 1. 15N labeling of proteins in E. coli – Protein Expression and Purification Core Facility [embl.org]
- 2. Quantitative Proteomics: Measuring Protein Synthesis Using 15N Amino Acids Labeling in Pancreas Cancer Cells - PMC [pmc.ncbi.nlm.nih.gov]
- 3. A comprehensive assessment of selective amino acid 15N-labeling in human embryonic kidney 293 cells for NMR spectroscopy - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Using 15N-Metabolic Labeling for Quantitative Proteomic Analyses | Springer Nature Experiments [experiments.springernature.com]
Technical Support Center: Purification of Peptides with Unprotected Serine
Welcome to the technical support center for researchers, scientists, and drug development professionals. This resource provides comprehensive troubleshooting guides and frequently asked questions (FAQs) to address the challenges encountered during the purification of synthetic peptides containing unprotected serine residues.
Frequently Asked Questions (FAQs)
Q1: What are the primary challenges when purifying peptides with unprotected serine?
A1: The primary challenges stem from the nucleophilic nature of the serine hydroxyl group (-OH), which can lead to several side reactions during peptide synthesis and purification. These include:
-
O-Acylation (N-O Acyl Shift): The serine hydroxyl group can be acylated by activated amino acids during coupling, leading to the formation of ester linkages and branched peptides. This can also occur during the final cleavage from the resin under acidic conditions, resulting in an N-O acyl shift.[1]
-
β-Elimination (Dehydration): Under basic conditions, the serine residue can undergo β-elimination to form a dehydroalanine (Dha) residue.[2] This is particularly problematic during the removal of the Fmoc protecting group with piperidine.[2] The resulting Dha is reactive and can form adducts, further complicating the purification process.[1][2]
-
Racemization: The stereochemical integrity of the serine residue can be compromised, leading to a mixture of D- and L-isomers, which can be difficult to separate and can significantly impact the peptide's biological activity.[1]
Q2: Is it always necessary to protect the serine side chain during synthesis?
A2: While it is highly recommended to protect the serine side chain to prevent the side reactions mentioned above, it is possible to synthesize short peptides or peptides where serine is at the N-terminus without protection.[3] However, for longer or more complex peptides, the use of a protecting group like tert-butyl (tBu) is the most effective strategy to ensure high purity and yield of the target peptide.[1][4]
Q3: Which analytical technique is best for identifying impurities from unprotected serine side reactions?
A3: A combination of High-Performance Liquid Chromatography (HPLC) and Mass Spectrometry (MS) is the most powerful approach.
-
RP-HPLC: Can separate the desired peptide from various impurities. Side products like O-acylated peptides or Dha-containing peptides will typically have different retention times.[1][2]
-
Mass Spectrometry (MS): Is crucial for identifying the nature of the impurities by their mass. For instance, O-acylation will result in a mass increase corresponding to the added amino acid, while β-elimination leads to a mass loss of 18 Da (water).[1][2]
Q4: Can alternative purification methods be used for peptides with unprotected serine?
A4: Yes, while RP-HPLC is the standard, other methods can be effective, especially for resolving challenging separations. Mixed-mode hydrophilic interaction/cation-exchange chromatography (HILIC/CEC) has shown excellent potential for separating peptides from closely related impurities, such as side-chain acetylated peptides.[5]
Troubleshooting Guides
Issue 1: Low Purity of Target Peptide with Multiple Unresolved Peaks in HPLC
Possible Cause: Presence of side-reaction products due to the unprotected serine.
Troubleshooting Workflow:
Caption: Troubleshooting workflow for low purity peptides.
Issue 2: Poor Peak Shape and Tailing in RP-HPLC
Possible Cause: On-column interactions or degradation, or issues with the mobile phase.
Troubleshooting Steps:
-
Optimize Mobile Phase pH: The pH of the mobile phase can affect the ionization state of the peptide and its interaction with the stationary phase. Experiment with small adjustments to the trifluoroacetic acid (TFA) concentration.
-
Check for On-Column Degradation: The acidic environment of the RP-HPLC mobile phase can sometimes exacerbate side reactions. Try a faster gradient to minimize the time the peptide spends on the column.
-
Use a High-Purity Column: Residual silanols on lower-quality silica-based columns can cause peak tailing. Use a high-purity, end-capped C18 column.
-
Sample Solubility: Ensure the peptide is fully dissolved in the injection solvent. Poor solubility can lead to broad and tailing peaks.
Data Presentation
Table 1: Impact of Serine Protection on Peptide Purity and Yield (Illustrative Data)
| Protection Strategy | Crude Purity (%) | Final Purity after RP-HPLC (%) | Overall Yield (%) | Common Impurities |
| Unprotected Serine | 40-60 | 85-90 | 10-20 | O-acylated peptides, β-elimination products, diastereomers |
| Fmoc-Ser(tBu)-OH | 70-85 | >98 | 40-60 | Deletion sequences, incomplete deprotection |
Table 2: Comparison of Coupling Reagents for Peptides with Unprotected Serine (Illustrative Data)
| Coupling Reagent | O-Acylation Side Product (%) | Desired Peptide Yield (%) |
| HBTU/HATU | 15-25 | 50-60 |
| DIC/HOBt | 5-10 | 70-80 |
Experimental Protocols
Protocol 1: Analytical RP-HPLC for Purity Assessment
This protocol outlines a standard method for analyzing the purity of a crude peptide containing an unprotected serine.
-
System Preparation:
-
Chromatography System: HPLC system with UV detector.
-
Column: C18 stationary phase (e.g., 5 µm particle size, 100 Å pore size, 4.6 x 250 mm).
-
Mobile Phase A: 0.1% Trifluoroacetic Acid (TFA) in water.
-
Mobile Phase B: 0.1% TFA in acetonitrile.
-
-
Sample Preparation:
-
Dissolve the crude peptide in a minimal amount of Mobile Phase A.
-
Filter the sample through a 0.22 µm syringe filter before injection.
-
-
Chromatographic Conditions:
-
Flow Rate: 1.0 mL/min.
-
Detection: 220 nm.
-
Gradient:
-
0-5 min: 5% B
-
5-35 min: 5% to 65% B (linear gradient)
-
35-40 min: 65% to 95% B (linear gradient)
-
40-45 min: 95% B
-
45-50 min: 95% to 5% B (linear gradient)
-
50-60 min: 5% B (equilibration)
-
-
-
Data Analysis:
-
Integrate the peak areas in the chromatogram.
-
Calculate the percentage purity by dividing the area of the main peak by the total area of all peaks.
-
Protocol 2: Preparative RP-HPLC for Purification
This protocol provides a general method for purifying a peptide with an unprotected serine.
-
System Preparation:
-
Chromatography System: Preparative HPLC system with a fraction collector.
-
Column: C18 stationary phase with a larger diameter (e.g., 21.2 x 250 mm).
-
Mobile Phase A: 0.1% TFA in water.
-
Mobile Phase B: 0.1% TFA in acetonitrile.
-
-
Sample Preparation:
-
Dissolve the crude peptide in a minimal volume of a strong solvent (e.g., DMSO) and then dilute with Mobile Phase A.
-
Filter the sample to remove any particulates.
-
-
Chromatographic Conditions:
-
Optimize the gradient based on the analytical HPLC run to ensure good separation of the target peptide from impurities. A shallower gradient around the elution time of the target peptide is recommended.
-
Adjust the flow rate according to the column dimensions.
-
-
Fraction Collection and Analysis:
-
Collect fractions throughout the elution of the main peak.
-
Analyze the purity of each fraction using analytical RP-HPLC.
-
Pool the fractions that meet the desired purity level.
-
-
Lyophilization:
-
Freeze the pooled fractions and lyophilize to obtain the purified peptide as a powder.
-
Mandatory Visualization
Caption: General workflow for peptide purification.
References
Technical Support Center: Strategies for High-Yield Serine-Rich Peptide Synthesis
Welcome to the technical support center for researchers, scientists, and drug development professionals. This resource provides comprehensive troubleshooting guides and frequently asked questions (FAQs) to enhance the synthesis yield of serine-rich peptides.
Troubleshooting Guide
This guide addresses common issues encountered during the synthesis of serine-rich peptides, offering potential causes and recommended solutions in a direct question-and-answer format.
| Issue | Potential Cause(s) | Recommended Solution(s) |
| Low Peptide Yield | - Incomplete Coupling: Steric hindrance from serine residues or aggregation of the growing peptide chain can lead to inefficient coupling.[1][2] - Premature Cleavage: The linkage to the solid support may be unstable under the reaction conditions. - Side Reactions: Unwanted chemical modifications of the amino acid residues can reduce the amount of the desired product.[3] | - Optimize Coupling Strategy: Use a more efficient coupling reagent such as HATU, HCTU, or COMU. Consider a double coupling strategy for difficult residues.[2][4] - Select Appropriate Resin: Utilize a resin with a suitable linker that is stable throughout the synthesis and allows for efficient cleavage at the final step.[5] Consider low-substitution resins to reduce aggregation.[5] |
| Peptide Aggregation | - Interchain Hydrogen Bonding: Serine-rich sequences are prone to forming secondary structures (β-sheets) on the solid support, which hinders reagent access.[1][6] - Hydrophobicity: Although serine is polar, long sequences can exhibit hydrophobic collapse. | - Incorporate Pseudoproline Dipeptides: These derivatives introduce a "kink" in the peptide backbone, disrupting secondary structure formation.[6] - Use Backbone Protection: Employ Hmb or Dmb protecting groups on the alpha-nitrogen of amino acids to prevent hydrogen bonding.[1] - Modify Synthesis Conditions: Switch to solvents like N-methylpyrrolidone (NMP) or add chaotropic agents. Microwave-assisted synthesis can also help reduce aggregation.[1][7] |
| Presence of Deletion Sequences | - Incomplete Fmoc Deprotection or Coupling: Aggregation can prevent complete removal of the Fmoc group or hinder the coupling of the next amino acid.[1] | - Optimize Deprotection: If Fmoc deprotection is slow, consider switching to a DBU-containing deprotection reagent.[1] - Monitor Coupling Reactions: Use a qualitative test (e.g., Kaiser test) to ensure complete coupling before proceeding to the next step. - Implement Double Coupling: For notoriously difficult couplings, performing the reaction twice can improve the incorporation of the amino acid.[8] |
| Side Product Formation (e.g., β-elimination) | - Basic Conditions: The piperidine used for Fmoc deprotection can promote β-elimination of the serine side chain, leading to dehydroalanine (Dha) formation.[9] - Elevated Temperatures: Microwave synthesis, while beneficial for coupling, can increase the rate of β-elimination.[9] | - Use Milder Deprotection Conditions: Consider using a less basic deprotection solution if β-elimination is a significant problem. - Optimize Microwave Parameters: If using a microwave synthesizer, carefully control the temperature to minimize side reactions.[9] - Appropriate Side-Chain Protection: The standard tert-butyl (tBu) protecting group for serine is generally effective at minimizing this side reaction under normal conditions.[3][9][10] |
Frequently Asked Questions (FAQs)
Q1: What is the best side-chain protecting group for serine in Fmoc-SPPS?
A1: The tert-butyl (tBu) group is considered the gold standard for serine side-chain protection in routine Fmoc-based solid-phase peptide synthesis (SPPS).[3][10] Its stability to the basic conditions of Fmoc removal and its clean cleavage with trifluoroacetic acid (TFA) make it a key component of the orthogonal Fmoc/tBu strategy.[3][10] For syntheses requiring milder cleavage conditions, the trityl (Trt) group is a viable alternative.[3]
Q2: How do pseudoproline dipeptides improve the synthesis of serine-rich peptides?
A2: Pseudoproline dipeptides are derived from serine or threonine and contain a temporary oxazolidine ring structure.[6] This cyclic structure mimics proline and introduces a "kink" into the peptide backbone. This disruption of the linear structure effectively breaks up the interchain hydrogen bonding that leads to aggregation and β-sheet formation.[6] By preventing aggregation, pseudoprolines enhance the solvation of the growing peptide chain, leading to improved coupling and deprotection efficiency, and ultimately higher yields.[6]
Q3: Can I use microwave synthesis for serine-rich peptides?
A3: Yes, microwave-assisted synthesis can be beneficial for serine-rich peptides as the increased temperature can help disrupt aggregation and accelerate coupling reactions.[1][7] However, it is crucial to carefully control the temperature, as elevated temperatures can increase the rate of side reactions, particularly the β-elimination of serine.[9]
Q4: What are the signs of peptide aggregation during synthesis?
A4: A key indicator of aggregation is the failure of the peptide-resin to swell properly.[1] You may also observe slow or incomplete deprotection and coupling reactions, which can be monitored using methods like the Kaiser test.[1]
Q5: What analytical techniques are recommended for identifying side products in serine-rich peptide synthesis?
A5: High-Performance Liquid Chromatography (HPLC) and Mass Spectrometry (MS) are essential for analyzing the crude peptide product.[9] RP-HPLC can separate the desired peptide from byproducts, with side products like dehydroalanine derivatives typically having different retention times.[9] Mass spectrometry can then be used to identify the masses of these impurities, confirming the occurrence of side reactions such as β-elimination (a mass loss of 18 Da) or the formation of adducts.[9]
Experimental Protocols
Protocol 1: Incorporation of a Pseudoproline Dipeptide
This protocol describes the general steps for incorporating a pseudoproline dipeptide into a peptide sequence during Fmoc-SPPS.
-
Resin Preparation: Swell the appropriate resin (e.g., Rink Amide) in dimethylformamide (DMF) for 1-2 hours.
-
Fmoc Deprotection: Treat the resin with 20% piperidine in DMF (v/v) for 5 minutes, followed by a second treatment for 15 minutes to remove the Fmoc group from the N-terminus of the growing peptide chain.
-
Washing: Thoroughly wash the resin with DMF (5-7 times) to remove all traces of piperidine.
-
Coupling of Pseudoproline Dipeptide:
-
Dissolve the Fmoc-Xaa-Ser(ψMe,MePro)-OH or Fmoc-Xaa-Thr(ψMe,MePro)-OH dipeptide (3-5 equivalents relative to resin loading) and a coupling agent (e.g., HBTU, 3-5 equivalents) in DMF.
-
Add a base (e.g., DIPEA, 6-10 equivalents) to the activation mixture.
-
Add the activated mixture to the resin and shake at room temperature for 1-2 hours. Coupling reactions are generally complete within 1 hour when using a 5-fold excess of the dipeptide.
-
-
Monitoring: Perform a Kaiser test to confirm the completion of the coupling reaction.
-
Washing: Wash the resin with DMF (3-5 times) and dichloromethane (DCM) (3-5 times) to remove excess reagents.
-
Chain Elongation: Continue with the standard Fmoc-SPPS cycles for the subsequent amino acids.
-
Cleavage and Deprotection: The pseudoproline moiety is cleaved, and the native serine or threonine residue is regenerated during the final TFA-based cleavage from the resin.
Protocol 2: Optimized Cleavage of Serine-Rich Peptides
This protocol provides a standard procedure for the cleavage and deprotection of a synthesized peptide from the resin, with considerations for serine-rich sequences.
-
Resin Preparation: After the final Fmoc deprotection and washing steps, dry the peptide-resin under vacuum.
-
Cleavage Cocktail Preparation: Prepare a cleavage cocktail appropriate for the peptide's amino acid composition. A common cocktail is TFA/water/triisopropylsilane (TIS) (95:2.5:2.5, v/v/v). TIS is a scavenger used to prevent the reattachment of protecting groups to sensitive residues.
-
Cleavage Reaction: Add the cleavage cocktail to the dried resin (typically 10 mL per gram of resin) and shake at room temperature for 2-3 hours.
-
Peptide Precipitation:
-
Filter the resin and collect the TFA solution containing the cleaved peptide.
-
Reduce the volume of the TFA solution under a stream of nitrogen.
-
Precipitate the peptide by adding the concentrated TFA solution to cold diethyl ether.
-
-
Peptide Collection: Centrifuge the ether suspension to pellet the peptide. Decant the ether and repeat the ether wash 2-3 times to remove residual scavengers and dissolved protecting groups.
-
Drying: Dry the peptide pellet under vacuum to obtain the crude product.
-
Analysis: Analyze the crude peptide using HPLC and Mass Spectrometry to determine purity and confirm the molecular weight.
Visualizations
Caption: A flowchart of the solid-phase peptide synthesis (SPPS) process.
Caption: A decision tree for troubleshooting low peptide yield.
References
- 1. peptide.com [peptide.com]
- 2. benchchem.com [benchchem.com]
- 3. benchchem.com [benchchem.com]
- 4. nbinno.com [nbinno.com]
- 5. researchgate.net [researchgate.net]
- 6. chempep.com [chempep.com]
- 7. blog.mblintl.com [blog.mblintl.com]
- 8. biotage.com [biotage.com]
- 9. benchchem.com [benchchem.com]
- 10. benchchem.com [benchchem.com]
Technical Support Center: Troubleshooting Unexpected Mass Shifts in 15N Labeled Protein Analysis
This technical support center is designed for researchers, scientists, and drug development professionals to troubleshoot and understand unexpected mass shifts encountered during the analysis of 15N labeled proteins.
Frequently Asked Questions (FAQs)
Q1: Why am I not seeing the expected mass shift for my 15N labeled protein?
An unexpected or lower-than-expected mass shift in 15N labeled proteins can stem from several factors. The most common cause is incomplete incorporation of the 15N isotope during protein expression. For accurate quantification, a labeling efficiency of over 95% is recommended.[1][2] You may be observing a mixture of fully and partially labeled peptides, which can lead to broader isotopic clusters in the mass spectrum, making it difficult to correctly identify the monoisotopic peak.[3][4]
Q2: My mass spectrum shows additional peaks that do not correspond to the light (14N) or heavy (15N) forms of my peptide. What could be the cause?
These additional peaks are often the result of post-translational modifications (PTMs) or chemical modifications that occur either in vivo or during sample preparation. Common modifications include:
-
Oxidation: Particularly of methionine residues, which adds approximately 16 Da to the peptide mass.[5][6]
-
Deamidation: The conversion of asparagine or glutamine to aspartic or glutamic acid, respectively, results in a mass increase of about 0.98 Da.[7][8]
-
Carbamylation: This can be caused by the breakdown of urea in your sample preparation buffers and adds about 43 Da to the N-terminus or lysine residues.[9][10][11] Contaminants from labware or reagents, such as polymers or detergents, can also appear as unexpected peaks.[2]
Q3: What is isotopic scrambling and how can it affect my results?
Isotopic scrambling occurs when the 15N label from a specific amino acid is metabolically transferred to other amino acids.[12][13] This can happen through the action of transaminases in the expression host.[13] The result is the unexpected incorporation of 15N into amino acids that were not intended to be labeled, leading to complex and difficult-to-interpret mass spectra.[12][14] Using E. coli strains deficient in key transaminases or supplementing the media with an excess of unlabeled amino acids can help minimize scrambling.[12][13]
Q4: How can I differentiate between a post-translational modification and incomplete labeling?
High-resolution mass spectrometry is crucial for distinguishing between different sources of mass shifts. Incomplete labeling will result in a distribution of isotopic peaks between the fully light (all 14N) and fully heavy (all 15N) forms of the peptide. A post-translational modification, on the other hand, will cause a discrete mass shift for both the light and heavy isotopic envelopes. For example, an oxidation event will create a +16 Da shift for both the 14N and 15N peptide clusters.
Q5: Can the sample preparation process introduce mass shifts?
Yes, sample preparation is a common source of artificial modifications. For instance:
-
Deamidation of asparagine and glutamine residues can be induced by basic pH conditions, which are often used during tryptic digestion.[7][15]
-
Oxidation of methionine can occur spontaneously during sample handling and analysis.[6][16]
-
If urea is used for denaturation, it can decompose to isocyanic acid, leading to carbamylation of primary amines on the protein.[9]
Troubleshooting Guide
If you observe an unexpected mass shift, follow this systematic approach to identify the root cause.
Common Mass Shifts Summary
The following tables summarize the mass shifts associated with common biological and chemical modifications.
Table 1: Common Post-Translational Modifications (PTMs)
| Modification | Monoisotopic Mass Change (Da) | Average Mass Change (Da) | Commonly Modified Residues |
| Acetylation | +42.01057 | +42.0367 | Lysine, N-terminus |
| Phosphorylation | +79.96633 | +79.9799 | Serine, Threonine, Tyrosine |
| Methylation | +14.01565 | +14.0266 | Lysine, Arginine |
| Dimethylation | +28.03130 | +28.0532 | Lysine, Arginine |
| Trimethylation | +42.04695 | +42.0798 | Lysine |
| Glycosylation (HexNAc) | +203.07937 | +203.1950 | Asparagine, Serine, Threonine |
Table 2: Common Chemical Modifications and Artifacts
| Modification | Monoisotopic Mass Change (Da) | Average Mass Change (Da) | Cause / Commonly Modified Residues |
| Oxidation | +15.99491 | +15.9994 | Methionine, Tryptophan |
| Dioxidation | +31.98982 | +31.9988 | Methionine, Tryptophan |
| Deamidation | +0.98402 | +0.9848 | Asparagine, Glutamine |
| Carbamylation | +43.00581 | +43.0247 | Lysine, N-terminus (from urea) |
| Formylation | +27.99491 | +28.0104 | N-terminus, Serine, Threonine |
Key Experimental Protocols
Protocol 1: Determination of 15N Labeling Efficiency
This protocol outlines the steps to calculate the percentage of 15N incorporation in your protein sample.
-
Protein Digestion: Digest your 14N (control) and 15N-labeled proteins into peptides using a standard in-solution or in-gel trypsin digestion protocol.
-
LC-MS/MS Analysis: Analyze the resulting peptide mixtures using a high-resolution mass spectrometer (e.g., Orbitrap or FT-ICR).
-
Data Analysis:
-
Identify peptides in both the 14N and 15N samples using a database search algorithm (e.g., Mascot, Sequest).
-
For several high-intensity, unambiguously identified peptides, extract the ion chromatograms for both the light (14N) and heavy (15N) isotopic envelopes.
-
Calculate the peak area for both the light (Area_light) and heavy (Area_heavy) forms of each peptide.
-
The labeling efficiency can be calculated using the following formula: Efficiency (%) = (Area_heavy / (Area_heavy + Area_light)) * 100%
-
Average the efficiency across multiple peptides to get a global estimate for the protein.
-
Protocol 2: Identification of Post-Translational Modifications
-
Data Acquisition: Acquire high-resolution MS and MS/MS data for your 15N-labeled protein digest.
-
Database Search with Variable Modifications:
-
Perform a database search of your MS/MS data.
-
In the search parameters, specify potential PTMs as variable modifications. Include common modifications such as oxidation of methionine (+15.995 Da) and deamidation of asparagine and glutamine (+0.984 Da).
-
Also include the 15N label as a fixed or variable modification on all nitrogen-containing residues.
-
-
Manual Validation:
-
Carefully inspect the MS/MS spectra of peptides identified with modifications.
-
Confirm that the major fragment ions (b- and y-ions) are consistent with the assigned sequence and modification site. High mass accuracy in your fragment ion data is essential for confident assignment.
-
Visual Guides
References
- 1. benchchem.com [benchchem.com]
- 2. benchchem.com [benchchem.com]
- 3. 15N Metabolic Labeling Quantification Workflow in Arabidopsis Using Protein Prospector - PMC [pmc.ncbi.nlm.nih.gov]
- 4. biorxiv.org [biorxiv.org]
- 5. researchgate.net [researchgate.net]
- 6. researchgate.net [researchgate.net]
- 7. Accurate Identification of Deamidated Peptides in Global Proteomics using a Quadrupole Orbitrap Mass Spectrometer - PMC [pmc.ncbi.nlm.nih.gov]
- 8. ionsource.com [ionsource.com]
- 9. Site-specific detection and characterization of ubiquitin carbamylation - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Mass spectrometric identification of in vivo carbamylation of the amino terminus of Ectothiorhodospira mobilis high-potential iron-sulfur protein, isozyme 1 - PubMed [pubmed.ncbi.nlm.nih.gov]
- 11. ionsource.com [ionsource.com]
- 12. Rapid mass spectrometric analysis of 15N-Leu incorporation fidelity during preparation of specifically labeled NMR samples - PMC [pmc.ncbi.nlm.nih.gov]
- 13. benchchem.com [benchchem.com]
- 14. Measuring 15N and 13C Enrichment Levels in Sparsely Labeled Proteins Using High-Resolution and Tandem Mass Spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 15. Quadrupole Orbitrap Accurately Identifies Deamidated Peptides [thermofisher.com]
- 16. Quantitative Analysis of in Vivo Methionine Oxidation of the Human Proteome - PMC [pmc.ncbi.nlm.nih.gov]
Technical Support Center: Optimizing NMR Experiments for 15N Labeled Serine
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to assist researchers, scientists, and drug development professionals in optimizing Nuclear Magnetic Resonance (NMR) experiments for proteins containing 15N labeled serine residues.
Frequently Asked Questions (FAQs)
Q1: What are the optimal sample conditions for 15N labeled protein NMR studies?
A1: Achieving high-quality NMR spectra is critically dependent on sample preparation. Key parameters to control include protein concentration, buffer composition, pH, and sample purity.
Table 1: Recommended Sample Conditions for 15N Labeled Protein NMR
| Parameter | Recommendation | Rationale |
| Protein Concentration | 0.3-0.5 mM for larger proteins; 2-5 mM for peptides.[1] | Signal intensity is directly proportional to concentration. Higher concentrations yield better data quality.[1] |
| Buffer | Phosphate buffer (e.g., 25 mM sodium phosphate).[2] Use buffers with no detectable protons if possible. | Minimizes interference from buffer signals which are at a much higher concentration than the protein.[2] |
| pH | Below 6.5.[2] | The exchange of backbone amide protons is base-catalyzed. At higher pH, rapid exchange can lead to signal loss.[2] |
| Ionic Strength | Keep as low as possible (e.g., 25 mM NaCl).[2] | High salt concentrations (>100 mM) can degrade spectral quality and spectrometer performance.[2] |
| D₂O Content | 5-10%.[2] | Required for the NMR spectrometer's lock system to maintain field stability.[2] |
| Additives | 0.1% sodium azide to inhibit bacterial growth.[2] | Ensures sample stability over the course of long experiments. |
| Purity | Free of suspended material (precipitates, dust). | Suspended particles broaden spectral lines, reducing resolution.[3] Filtration is crucial.[3][4] |
| Volume | ~400-700 µL.[2][3] | Ensures the sample fills the active volume of the NMR coil for optimal sensitivity. |
Q2: Which NMR experiment is best to start with for a 15N labeled protein?
A2: The 2D ¹H-¹⁵N Heteronuclear Single Quantum Coherence (HSQC) experiment is the standard starting point.[5][6] It provides a "fingerprint" of the protein, with one peak for each backbone and sidechain amide group.[5][6] This allows for an initial assessment of sample quality, protein folding, and spectral dispersion.
Q3: How can I identify all the serine residues in my protein using NMR?
A3: For 13C/15N labeled proteins, 3D experiments like HNCACB or HN(CO)CACB are highly effective.[7] These experiments correlate the backbone amide ¹H and ¹⁵N chemical shifts with the Cα and Cβ chemical shifts of the same and preceding residues. Serine residues have a characteristic Cβ chemical shift that aids in their identification.[7]
Q4: How does phosphorylation of a serine residue affect the ¹H-¹⁵N HSQC spectrum?
A4: Phosphorylation of a serine residue induces characteristic chemical shift perturbations in the ¹H-¹⁵N HSQC spectrum. The amide proton (HN) of the phosphorylated serine typically shifts downfield by approximately 0.3 ppm.[8] Neighboring residues may also exhibit smaller chemical shift changes.
Q5: What is "pure shift" NMR and how can it help my experiments on 15N labeled serine?
A5: "Pure shift" NMR is a technique that simplifies spectra by collapsing proton-proton J-coupling multiplets into single peaks.[9][10][11] This leads to a significant improvement in both spectral resolution and sensitivity, making it easier to resolve overlapping peaks, which can be a common issue in crowded spectral regions.[9][12][13] This is particularly beneficial for analyzing complex spectra of proteins.[10]
Troubleshooting Guides
Problem 1: Low Signal-to-Noise in ¹H-¹⁵N HSQC Spectrum
Low signal-to-noise can arise from several factors, from sample preparation to experimental setup. Follow this workflow to diagnose and address the issue.
Caption: Troubleshooting workflow for low signal-to-noise.
Problem 2: Missing Serine Peaks or Broad Lines
Missing or broadened peaks, particularly for serine residues, can be due to conformational exchange or rapid exchange with the solvent.
Caption: Troubleshooting workflow for missing or broad peaks.
Problem 3: Spectral Overlap Involving Serine Resonances
Spectral overlap can make assignment and analysis difficult. Several strategies can be employed to improve resolution.
Caption: Strategies to resolve spectral overlap.
Experimental Protocols
Protocol 1: Standard ¹H-¹⁵N HSQC
This experiment is fundamental for any protein NMR study.
-
Sample Preparation: Prepare 500 µL of 0.3-0.5 mM ¹⁵N-labeled protein in a suitable buffer (e.g., 25 mM Sodium Phosphate, 25 mM NaCl, pH 6.0, 10% D₂O).[2] Filter the sample into a clean NMR tube.[3]
-
Spectrometer Setup:
-
Tune and match the probe for ¹H and ¹⁵N frequencies.
-
Lock on the D₂O signal.
-
Shim the magnetic field to achieve good homogeneity.
-
-
Acquisition Parameters (Example for a 600 MHz spectrometer):
-
Pulse Sequence: hsqcetf3gpsi (or equivalent sensitivity-enhanced, gradient-selected HSQC).
-
¹H Spectral Width: 12-16 ppm.
-
¹⁵N Spectral Width: 30-35 ppm.
-
Number of Scans: 8-16 (adjust based on concentration).
-
Recycle Delay (d1): 1.5 seconds.
-
¹J(NH) Coupling Constant: Set to ~92 Hz.
-
Acquisition Time (¹H): ~0.1 seconds.
-
Number of Increments (¹⁵N): 128-256.
-
-
Processing:
Protocol 2: Time-Resolved Monitoring of Serine Phosphorylation using SOFAST-HMQC
This protocol is designed for real-time observation of kinase activity.[16]
-
Sample Preparation:
-
Prepare the ¹⁵N-labeled substrate protein (e.g., 50 µM) in kinase buffer.
-
Prepare a concentrated stock of the kinase and ATP.
-
-
Experiment Setup:
-
Acquire an initial 2D ¹H-¹⁵N SOFAST-HMQC spectrum of the substrate alone.
-
Initiate the reaction by adding the kinase and ATP to the NMR tube.
-
-
Acquisition:
-
Immediately start acquiring a series of 2D ¹H-¹⁵N SOFAST-HMQC spectra over time. The short transient time of this experiment allows for rapid data collection.[16]
-
The short recycle delay in SOFAST-HMQC is key to its high temporal resolution.
-
-
Analysis:
-
Process each spectrum in the time series.
-
Monitor the decrease in intensity of the peaks corresponding to the unphosphorylated serine and the concomitant appearance and increase in intensity of new peaks for the phosphoserine.
-
The rate of phosphorylation can be quantified by plotting the peak intensities as a function of time.[16]
-
References
- 1. nmr-bio.com [nmr-bio.com]
- 2. www2.mrc-lmb.cam.ac.uk [www2.mrc-lmb.cam.ac.uk]
- 3. Sample Preparation [nmr.chem.ualberta.ca]
- 4. sites.bu.edu [sites.bu.edu]
- 5. protein-nmr.org.uk [protein-nmr.org.uk]
- 6. 1H-15N HSQC - Iowa State University Biological NMR Facility [bnmrf.bbmb.iastate.edu]
- 7. researchgate.net [researchgate.net]
- 8. researchgate.net [researchgate.net]
- 9. Real-time pure shift 15N HSQC of proteins: a real improvement in resolution and sensitivity - PMC [pmc.ncbi.nlm.nih.gov]
- 10. researchgate.net [researchgate.net]
- 11. Real-time pure shift 15N HSQC of proteins: a real improvement in resolution and sensitivity - White Rose Research Online [eprints.whiterose.ac.uk]
- 12. nmr.chemistry.manchester.ac.uk [nmr.chemistry.manchester.ac.uk]
- 13. files01.core.ac.uk [files01.core.ac.uk]
- 14. Chemical Shift Referencing [nmr.chem.ucsb.edu]
- 15. researchgate.net [researchgate.net]
- 16. Site-specific NMR mapping and time-resolved monitoring of serine and threonine phosphorylation in reconstituted kinase reactions and mammalian cell extracts - PubMed [pubmed.ncbi.nlm.nih.gov]
Validation & Comparative
A Comparative Guide to Fmoc-Ser-OH-¹⁵N and Fmoc-Ser(tBu)-OH-¹⁵N in Peptide Synthesis
For Researchers, Scientists, and Drug Development Professionals
In the precise world of solid-phase peptide synthesis (SPPS), the selection of building blocks is paramount to achieving high yield and purity. For the incorporation of serine, a trifunctional amino acid, the strategy for protecting its reactive hydroxyl side-chain is a critical decision. This guide provides an objective, data-supported comparison between using unprotected Fmoc-Ser-OH-¹⁵N and side-chain protected Fmoc-Ser(tBu)-OH-¹⁵N. The inclusion of the stable isotope ¹⁵N in these reagents provides a powerful tool for quantitative proteomics and structural analysis via mass spectrometry (MS) and nuclear magnetic resonance (NMR) spectroscopy.[1][2][3][4]
The fundamental difference lies in the tert-butyl (tBu) protecting group on the serine side-chain. The Fmoc/tBu orthogonal protection strategy is the cornerstone of modern SPPS. In this strategy, the N-α-Fmoc group is labile to mild base (e.g., piperidine), while the tBu side-chain protection is stable to this base but is readily cleaved by strong acid (e.g., trifluoroacetic acid, TFA) during the final step.[5] This orthogonality is essential for the stepwise, controlled assembly of the peptide chain.
Using Fmoc-Ser-OH-¹⁵N, which lacks side-chain protection, introduces significant risks of deleterious side reactions that compromise the synthesis. The unprotected hydroxyl group is nucleophilic and can be acylated during the coupling step, leading to chain branching and the formation of impurities.[6][7] Therefore, Fmoc-Ser(tBu)-OH-¹⁵N is established as the industry standard for incorporating serine residues in Fmoc-based SPPS.[6][8]
Performance Comparison: Key Characteristics
The choice between these two derivatives profoundly impacts the success of peptide synthesis. The following table summarizes their key characteristics and performance aspects.
| Feature | Fmoc-Ser(tBu)-OH-¹⁵N | Fmoc-Ser-OH-¹⁵N |
| Side-Chain Protection | tert-Butyl (tBu) ether | None |
| Orthogonality in Fmoc SPPS | High. The tBu group is stable to piperidine treatment used for Fmoc deprotection and cleaved by TFA.[8] | None. The unprotected hydroxyl group is reactive under standard coupling conditions. |
| Coupling Efficiency | Generally high, though steric hindrance can be a factor in some sequences.[8][9] | Deceptively high initial coupling to the N-terminus, but prone to simultaneous side-chain acylation. |
| Risk of Side Reactions | Low. The tBu group effectively prevents side-chain reactions. Minor risk of racemization can be induced by certain bases like DIPEA.[8][10] | Very High. Prone to O-acylation, leading to double insertion and formation of "endo-Ser" impurities.[7] Subsequent N→O acyl shift is also possible.[7][8] |
| Expected Crude Purity | High | Low, with significant, difficult-to-remove impurities. |
| Primary Application | Standard for incorporating ¹⁵N-labeled serine into peptides for NMR, MS, and metabolic studies.[1][3] | Not recommended for standard SPPS. Its use is generally avoided due to predictable and significant side reactions. |
Visualizing the Synthesis Strategy and Side Reactions
Diagrams are crucial for understanding the chemical principles governing the choice of serine derivative.
Caption: Orthogonal protection in Fmoc/tBu strategy.
The diagram above illustrates the core principle of the Fmoc/tBu strategy. The Fmoc group is removed by a base to allow chain elongation, while the tBu group remains to protect the side chain. The tBu group is only removed during the final acid-mediated cleavage from the resin.
Caption: Standard Fmoc-SPPS workflow using Fmoc-Ser(tBu)-OH-¹⁵N.
In contrast, using an unprotected serine leads to a critical side reaction, as detailed below.
Caption: O-acylation side reaction with unprotected Fmoc-Ser-OH.
This O-acylation leads to the formation of a branched peptide, which can undergo further rearrangement upon Fmoc removal to form an "endo-Ser" impurity, adding 87 Da to the mass of the desired peptide.[7] This side product is often difficult to separate during purification, leading to a significant reduction in the final yield of the target peptide.
Experimental Protocols
The following protocols outline the standard procedure for incorporating the protected serine derivative and highlight why a similar protocol is unsuitable for the unprotected version.
Protocol 1: Manual SPPS using Fmoc-Ser(tBu)-OH-¹⁵N
This protocol describes a single coupling cycle for adding Fmoc-Ser(tBu)-OH-¹⁵N to a growing peptide chain on a solid support (e.g., Rink Amide resin).
1. Resin Preparation:
-
Swell the resin (e.g., 0.1 mmol scale) in N,N-Dimethylformamide (DMF) for 30 minutes in a reaction vessel.[1]
-
Drain the DMF.
2. Fmoc Deprotection:
-
Add a solution of 20% piperidine in DMF to the resin.
-
Agitate for 5 minutes, then drain.
-
Repeat the piperidine treatment for an additional 15 minutes to ensure complete Fmoc removal.[1]
-
Wash the resin thoroughly with DMF (5-7 times) to remove all traces of piperidine.[2]
3. Amino Acid Activation and Coupling:
-
In a separate vial, dissolve Fmoc-Ser(tBu)-OH-¹⁵N (3-5 equivalents) and an activating agent like HBTU (3-5 equivalents) in DMF.
-
Add an activation base such as N,N-Diisopropylethylamine (DIPEA) (6-10 equivalents).
-
Immediately add the activated amino acid solution to the deprotected resin.[2]
-
Agitate the mixture for 1-2 hours at room temperature.
-
Perform a qualitative test (e.g., Kaiser test) to confirm the absence of free primary amines, indicating complete coupling.[9] If the test is positive, a second coupling may be required.[9]
-
Drain the coupling solution and wash the resin with DMF (3 times) and Dichloromethane (DCM) (3 times).
4. Chain Elongation:
-
Repeat steps 2 and 3 for each subsequent amino acid in the sequence.
5. Final Cleavage and Deprotection:
-
After the final amino acid is coupled and deprotected, wash the resin with DCM and dry it under vacuum.
-
Prepare a cleavage cocktail (e.g., 95% TFA, 2.5% Triisopropylsilane (TIS), 2.5% water).[1]
-
Add the cleavage cocktail to the resin and incubate for 2-3 hours. This step cleaves the peptide from the resin and removes the tBu side-chain protecting group.[2]
-
Filter to collect the peptide solution and precipitate the crude peptide using cold diethyl ether.[2]
Protocol 2: Considerations for Fmoc-Ser-OH-¹⁵N
A standard protocol for Fmoc-Ser-OH-¹⁵N is not provided because its use in SPPS is strongly discouraged. Attempting to use the above protocol with the unprotected derivative would lead to:
-
During Step 3 (Coupling): The activated incoming amino acid would react with both the N-terminal amine and the side-chain hydroxyl group of the previously incorporated unprotected serine, leading to the side reactions illustrated in the diagram above.[6][7]
-
Result: The final crude product would be a complex mixture of the desired peptide, branched peptides, and deletion sequences, resulting in extremely low yield and a challenging purification process.
Conclusion
References
- 1. benchchem.com [benchchem.com]
- 2. benchchem.com [benchchem.com]
- 3. Solid Phase Peptide Synthesis with Isotope Labeling | Silantes [silantes.com]
- 4. Quantitative Proteomics: Measuring Protein Synthesis Using 15N Amino Acids Labeling in Pancreas Cancer Cells - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Introduction to Peptide Synthesis - PMC [pmc.ncbi.nlm.nih.gov]
- 6. nbinno.com [nbinno.com]
- 7. researchgate.net [researchgate.net]
- 8. benchchem.com [benchchem.com]
- 9. benchchem.com [benchchem.com]
- 10. chempep.com [chempep.com]
A Comparative Guide to Isotopic Labeling in Proteomics: 15N Labeling vs. Other Key Techniques
For researchers, scientists, and drug development professionals navigating the complex landscape of quantitative proteomics, selecting the appropriate isotopic labeling strategy is a critical decision that profoundly impacts experimental outcomes. This guide provides an objective comparison of 15N metabolic labeling with other widely used techniques, including Stable Isotope Labeling by Amino acids in Cell culture (SILAC), Isobaric Tags for Relative and Absolute Quantitation (iTRAQ), and Tandem Mass Tags (TMT). By presenting supporting experimental data, detailed methodologies, and clear visual workflows, this guide aims to equip researchers with the knowledge to make informed decisions for their specific research needs.
Introduction to Isotopic Labeling in Proteomics
Quantitative proteomics is essential for understanding the dynamic changes in protein expression that underlie various biological processes, from disease pathogenesis to drug response.[1][2][3][4] Isotopic labeling techniques have become a cornerstone of quantitative proteomics, offering high accuracy and reproducibility by introducing stable isotopes into proteins or peptides.[5][6] These labels act as internal standards, allowing for the precise relative or absolute quantification of thousands of proteins in a single experiment.[3][7]
The major isotopic labeling strategies can be broadly categorized into two types: metabolic labeling and chemical labeling.
-
Metabolic labeling , such as 15N labeling and SILAC, incorporates isotopes into proteins in vivo during cell growth and protein synthesis.[8][9][10] This approach allows for the mixing of samples at a very early stage, minimizing experimental variability.[11][12][13]
-
Chemical labeling , including iTRAQ and TMT, involves the covalent attachment of isotope-coded tags to proteins or peptides in vitro after extraction and digestion.[14][15][16] These methods offer greater flexibility in sample types and higher multiplexing capabilities.
This guide will delve into a detailed comparison of these methods, with a particular focus on how 15N labeling performs against its alternatives.
Comparison of Key Performance Metrics
The choice of a quantitative proteomics method is often dictated by a trade-off between several key performance indicators. The following tables summarize the quantitative data and qualitative characteristics of 15N labeling, SILAC, iTRAQ, and TMT.
| Parameter | 15N Labeling | SILAC | iTRAQ | TMT |
| Principle | Metabolic | Metabolic | Chemical (Isobaric) | Chemical (Isobaric) |
| Labeling Agent | 15N-enriched media (e.g., 15NH4Cl) | Isotope-labeled amino acids (e.g., 13C6-Arg, 13C6,15N2-Lys) | Amine-reactive isobaric tags | Amine-reactive isobaric tags |
| Sample Mixing Point | Early (cell/tissue level) | Early (cell level) | Late (peptide level) | Late (peptide level) |
| Multiplexing Capacity | 2-plex | 2-plex or 3-plex (up to 5-plex with specific amino acids)[17] | 4-plex or 8-plex[15] | 2-plex to 18-plex[18] |
| Quantification Level | MS1 | MS1 | MS2/MS3 | MS2/MS3 |
Table 1: General Characteristics of Isotopic Labeling Methods
| Performance Metric | 15N Labeling | SILAC | iTRAQ | TMT |
| Proteome Coverage | Good to High | Good to High | High | High |
| Quantification Accuracy | High | Very High | Good to High (subject to ratio compression)[19] | Good to High (subject to ratio compression)[19] |
| Quantification Precision | High | Very High | High | High |
| Reproducibility | High | Very High[13][20] | Good | Good |
| Cost | Relatively Low | High | High | Very High |
| Applicability | Whole organisms (plants, bacteria, yeast, rodents), cell culture | Primarily cell culture, limited in non-dividing cells and whole organisms[13][21] | Any protein sample | Any protein sample |
Table 2: Performance Comparison of Isotopic Labeling Methods
In-depth Analysis of Labeling Methods
15N Metabolic Labeling
15N labeling is a powerful metabolic labeling technique where organisms are grown in a medium containing a 15N-labeled nitrogen source, leading to the incorporation of the heavy isotope into all nitrogen-containing molecules, including all amino acids in proteins.[9]
Advantages:
-
Cost-effective for whole organisms: It is a more economical option for labeling entire organisms like plants, yeast, and bacteria compared to SILAC.[11][12]
-
Early sample mixing: Samples can be mixed at the very beginning of the experimental workflow, minimizing sample handling variations and improving quantification accuracy.[11][12]
-
Universal labeling: All proteins are labeled, providing comprehensive proteome coverage.
Disadvantages:
-
Complex data analysis: The variable number of nitrogen atoms in different peptides leads to complex isotopic patterns in the mass spectra, which can complicate data analysis.[6][11][12]
-
Incomplete labeling: Achieving 100% labeling efficiency can be challenging and may vary between experiments, potentially affecting quantification accuracy if not properly accounted for.[11][12] Labeling efficiency in organisms like Arabidopsis plants can range from 93-99%.[11][12]
-
Broader isotope clusters: The incorporation of multiple 15N atoms can result in broader isotopic envelopes, which may make it more difficult to identify the monoisotopic peak and can reduce the number of identified heavy-labeled peptides.[11][12]
Stable Isotope Labeling by Amino acids in Cell culture (SILAC)
SILAC is considered a "gold standard" in quantitative proteomics for cell culture-based experiments.[11][12] It involves growing cells in media where specific essential amino acids (typically arginine and lysine) are replaced with their heavy isotope-containing counterparts.[8][22]
Advantages:
-
High accuracy and precision: The defined mass shift for each labeled peptide simplifies data analysis and leads to highly accurate and reproducible quantification.[13]
-
Early sample mixing: Similar to 15N labeling, SILAC allows for early mixing of cell populations, reducing experimental error.[8]
-
Robust and well-established: The methodology and data analysis workflows for SILAC are well-established and supported by various software platforms.[23]
Disadvantages:
-
Limited to cell culture: SILAC is primarily applicable to actively dividing cells in culture and is difficult and expensive to apply to whole organisms or non-dividing primary cells.[8][13][21]
-
High cost: The use of isotope-labeled amino acids makes SILAC a more expensive option compared to 15N labeling.[1]
-
Requirement for complete incorporation: Cells need to undergo several doublings to ensure near-complete incorporation of the labeled amino acids, which can be time-consuming.[8]
Isobaric Tags for Relative and Absolute Quantitation (iTRAQ) and Tandem Mass Tags (TMT)
iTRAQ and TMT are chemical labeling methods that use isobaric tags.[16] This means that the different isotopic labels have the same total mass, and peptides labeled with different tags are indistinguishable in the MS1 scan. Upon fragmentation in the mass spectrometer (MS/MS or MS3), reporter ions with different masses are generated, and the relative intensities of these reporter ions are used for quantification.[15][24]
Advantages:
-
High multiplexing capability: TMT, in particular, allows for the simultaneous comparison of up to 18 samples, significantly increasing throughput.[18]
-
Wide applicability: These methods can be used on virtually any protein sample, including tissues and clinical specimens, as the labeling is performed in vitro.[14]
-
Increased proteome coverage with fractionation: When combined with fractionation techniques, iTRAQ and TMT can provide deep proteome coverage.[15]
Disadvantages:
-
Ratio compression: A significant drawback of isobaric labeling is the phenomenon of "ratio compression," where co-isolation and co-fragmentation of peptides can lead to an underestimation of the true quantitative differences between samples.[19]
-
Late sample mixing: Samples are mixed at the peptide level, which means that any variability introduced during protein extraction, digestion, and labeling will be carried through to the final quantification.[13]
-
Complex fragmentation spectra: The presence of reporter ions can complicate the MS/MS spectra, potentially reducing the number of peptide identifications compared to label-free or metabolic labeling approaches.[25]
Experimental Workflows and Signaling Pathways
To visualize the differences in experimental procedures, the following diagrams illustrate the general workflows for metabolic and chemical labeling, as well as a comparison of the key features of each method.
References
- 1. medium.com [medium.com]
- 2. Comparative and Quantitative Global Proteomics Approaches: An Overview - PMC [pmc.ncbi.nlm.nih.gov]
- 3. A Guide to Quantitative Proteomics | Silantes [silantes.com]
- 4. benchchem.com [benchchem.com]
- 5. benchchem.com [benchchem.com]
- 6. A Tutorial Review of Labeling Methods in Mass Spectrometry-Based Quantitative Proteomics - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Using 15N-Metabolic Labeling for Quantitative Proteomic Analyses - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. Quantitative Comparison of Proteomes Using SILAC - PMC [pmc.ncbi.nlm.nih.gov]
- 9. benchchem.com [benchchem.com]
- 10. liverpool.ac.uk [liverpool.ac.uk]
- 11. 15N Metabolic Labeling Quantification Workflow in Arabidopsis Using Protein Prospector - PMC [pmc.ncbi.nlm.nih.gov]
- 12. biorxiv.org [biorxiv.org]
- 13. Comparing SILAC- and Stable Isotope Dimethyl-Labeling Approaches for Quantitative Proteomics - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Omics Technologies - The Leader in Omics Services [proteomics.omicstech.com]
- 15. iTRAQ and TMT | Proteomics [medicine.yale.edu]
- 16. Principles of iTRAQ, TMT, and SILAC in Protein Quantification | MtoZ Biolabs [mtoz-biolabs.com]
- 17. info.gbiosciences.com [info.gbiosciences.com]
- 18. Label-based Proteomics: iTRAQ, TMT, SILAC Explained - MetwareBio [metwarebio.com]
- 19. Comparing iTRAQ, TMT and SILAC | Silantes [silantes.com]
- 20. researchgate.net [researchgate.net]
- 21. pubs.acs.org [pubs.acs.org]
- 22. Stable isotope labeling by amino acids in cell culture - Wikipedia [en.wikipedia.org]
- 23. info.gbiosciences.com [info.gbiosciences.com]
- 24. Relative Quantification: iTRAQ & TMT [bpmsf.ucsd.edu]
- 25. pubs.acs.org [pubs.acs.org]
Validating 15N Incorporation: A Comparative Guide to Mass Spectrometry-Based Methods
For researchers, scientists, and drug development professionals engaged in quantitative proteomics, accurate determination of 15N incorporation is paramount for reliable experimental outcomes. This guide provides an objective comparison of mass spectrometry-based methods for validating 15N incorporation efficiency, supported by experimental data and detailed protocols.
Stable isotope labeling with heavy nitrogen (15N) has become a cornerstone of quantitative proteomics, enabling precise measurement of protein turnover, flux analysis, and differential expression. The success of these experiments hinges on the accurate assessment of 15N incorporation into the proteome. Mass spectrometry (MS) stands as the gold standard for this validation, offering a suite of techniques with distinct advantages and considerations. This guide delves into the primary MS-based methodologies, providing a framework for selecting the optimal approach for your research needs.
Comparing the Platforms: Performance Metrics
The choice of mass spectrometry platform significantly impacts the precision, sensitivity, and depth of 15N incorporation analysis. The two most prominent techniques are Liquid Chromatography-Mass Spectrometry (LC-MS), particularly with high-resolution analyzers like the Orbitrap, and Matrix-Assisted Laser Desorption/Ionization-Time of Flight (MALDI-TOF) mass spectrometry.
| Feature | LC-MS (Orbitrap/FT-ICR) | MALDI-TOF MS |
| Primary Measurement | Mass-to-charge ratio of ions in solution | Mass-to-charge ratio of ions from a solid matrix |
| Resolution | Very High (>100,000)[1] | Moderate to High (up to 60,000)[1] |
| Mass Accuracy | Very High (< 5 ppm)[1][2] | High (< 10 ppm) |
| Sensitivity | High (nanogram to picogram range) | Moderate (picogram to femtomole range) |
| Dynamic Range | Wide (3-5 orders of magnitude)[3] | Moderate (2-3 orders of magnitude) |
| Throughput | Lower (due to chromatography) | Higher (rapid sample spotting and analysis)[4] |
| Sample Complexity | Ideal for complex protein digests | Better suited for simpler mixtures or purified proteins |
| Quantification Precision | High, especially with stable isotope labeling | Moderate, can be affected by shot-to-shot variability |
| Typical 15N Incorporation Efficiency Range Reported | 93-99%[5][6] | 88-99%[7] |
Methodologies for 15N Incorporation Validation
The two primary strategies for introducing 15N labels into proteins are metabolic labeling using 15N-containing salts and Stable Isotope Labeling by Amino Acids in Cell Culture (SILAC).
Metabolic Labeling with 15N Salts
This approach involves growing cells or organisms in a medium where the sole nitrogen source is a 15N-labeled salt (e.g., 15NH4Cl or K15NO3). This results in the incorporation of 15N into all nitrogen-containing biomolecules, including all amino acids in proteins.
Advantages:
-
Cost-effective: Generally less expensive than using 15N-labeled amino acids.
-
Comprehensive Labeling: Labels all proteins within the organism or cell culture.[8]
Disadvantages:
-
Incomplete Labeling: Achieving >98% incorporation can be challenging and time-consuming, especially in organisms with slow turnover rates.[9]
-
Complex Spectra: The variable number of nitrogen atoms in different peptides leads to complex isotopic patterns, which can complicate data analysis.[5][6]
Stable Isotope Labeling by Amino Acids in Cell Culture (SILAC)
SILAC involves the metabolic incorporation of specific essential amino acids labeled with heavy isotopes (e.g., 13C and/or 15N) into proteins.[10] For 15N incorporation validation, specific amino acids containing 15N are used.
Advantages:
-
High Incorporation Efficiency: Can achieve near-complete (>99%) incorporation of the labeled amino acids.
-
Simpler Spectra: Results in a predictable mass shift for peptides containing the labeled amino acid, simplifying data analysis.
-
Multiplexing Capability: Allows for the comparison of multiple experimental conditions simultaneously.[10]
Disadvantages:
-
Higher Cost: Labeled amino acids are more expensive than 15N salts.
-
Limited to Cell Culture: Primarily applicable to in vitro cell culture systems.
-
Potential for Amino Acid Conversion: Cells may metabolically convert the labeled amino acid into other amino acids, which requires careful consideration during data analysis.
Experimental Protocols
Protocol 1: 15N Metabolic Labeling and LC-MS/MS Analysis
This protocol outlines the general steps for determining 15N incorporation efficiency using 15N salts and a high-resolution LC-MS/MS system like an Orbitrap.
1. Cell Culture and Labeling:
- Culture cells in a standard medium.
- For the "heavy" sample, replace the standard nitrogen source with a 15N-labeled salt (e.g., 1 g/L K15NO3).
- Grow cells for a sufficient number of passages (typically 5-6 doublings) to ensure maximal incorporation.
2. Sample Preparation:
- Harvest and lyse both unlabeled ("light") and 15N-labeled ("heavy") cells.
- Combine equal amounts of protein from the light and heavy lysates.
- Perform in-solution or in-gel tryptic digestion of the combined protein mixture.
- Desalt the resulting peptide mixture using a C18 column.
3. LC-MS/MS Analysis:
- Analyze the peptide mixture using a high-resolution mass spectrometer (e.g., Q-Exactive HF).
- Acquire data in a data-dependent acquisition (DDA) mode, with high-resolution MS1 scans (e.g., 60,000 resolution) and MS2 scans (e.g., 15,000 resolution).
4. Data Analysis:
- Use software such as Protein Prospector or MaxQuant to identify peptides and determine the isotopic distribution.[5]
- Calculate the 15N incorporation efficiency by comparing the experimental isotopic pattern of peptides to their theoretical patterns at different incorporation levels.[5][7] The relative abundance of the M-1 peak (one mass unit lighter than the monoisotopic peak of the heavy peptide) is indicative of lower labeling efficiency.[5]
Protocol 2: SILAC Labeling and MALDI-TOF MS Analysis
This protocol describes the validation of 15N incorporation using SILAC and MALDI-TOF MS.
1. Cell Culture and Labeling:
- Culture cells in SILAC-specific media, one containing the "light" (e.g., 14N-Arginine) and the other the "heavy" (e.g., 15N4-Arginine) amino acid.
- Ensure complete incorporation by growing cells for at least five doublings.
2. Sample Preparation:
- Harvest and lyse the "light" and "heavy" labeled cells.
- Combine the lysates in a 1:1 ratio based on protein concentration.
- Perform SDS-PAGE to separate the protein mixture.
- Excise the protein bands of interest and perform in-gel tryptic digestion.
- Extract the peptides from the gel.
3. MALDI-TOF MS Analysis:
- Co-crystallize the extracted peptides with a suitable matrix (e.g., α-cyano-4-hydroxycinnamic acid) on a MALDI target plate.[4]
- Acquire mass spectra in reflectron mode for high mass accuracy.
4. Data Analysis:
- Analyze the mass spectra to identify the "light" and "heavy" peptide pairs.
- The mass difference between the pairs should correspond to the number of incorporated 15N atoms.
- Calculate the incorporation efficiency by comparing the peak intensities of the heavy and light isotopic envelopes. Software like QuantiSpec can be used for automated analysis.[11]
Visualizing Workflows and Pathways
Diagrams are crucial for understanding the complex workflows in quantitative proteomics and the signaling pathways under investigation.
Experimental Workflow for 15N Incorporation Validation
References
- 1. biocompare.com [biocompare.com]
- 2. Comparison of High-Resolution Fourier Transform Mass Spectrometry Platforms for Putative Metabolite Annotation - PMC [pmc.ncbi.nlm.nih.gov]
- 3. researchgate.net [researchgate.net]
- 4. aims.chem.utoronto.ca [aims.chem.utoronto.ca]
- 5. 15N Metabolic Labeling Quantification Workflow in Arabidopsis Using Protein Prospector - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Frontiers | 15N Metabolic Labeling Quantification Workflow in Arabidopsis Using Protein Prospector [frontiersin.org]
- 7. researchgate.net [researchgate.net]
- 8. researchgate.net [researchgate.net]
- 9. researchgate.net [researchgate.net]
- 10. UWPR [proteomicsresource.washington.edu]
- 11. 2024.sci-hub.se [2024.sci-hub.se]
A Comparative Guide to Alternative Protecting Groups for Serine in Fmoc-SPPS
For researchers, scientists, and drug development professionals engaged in solid-phase peptide synthesis (SPPS), the judicious selection of protecting groups for trifunctional amino acids like serine is critical for maximizing yield, purity, and overall synthetic success. While the tert-butyl (tBu) group is the established standard for protecting the hydroxyl function of serine in Fmoc-based protocols, several alternatives offer distinct advantages in specific contexts, particularly for the synthesis of "difficult" or aggregation-prone peptide sequences.
This guide provides an objective comparison of the performance of common and alternative protecting groups for serine in Fmoc-SPPS, supported by available experimental data. We will delve into the strengths and weaknesses of each, offering insights to aid in the selection of the optimal protecting group for your specific synthetic challenge.
The Standard Choice: Tert-Butyl (tBu)
Fmoc-Ser(tBu)-OH is the most widely used derivative for incorporating serine residues in Fmoc-SPPS.[1][2] Its popularity stems from a combination of factors including its cost-effectiveness, stability to the basic conditions required for Fmoc-group removal (typically 20% piperidine in DMF), and its straightforward cleavage under standard final trifluoroacetic acid (TFA) treatment.[3] This makes it a reliable choice for routine peptide synthesis.
However, the tBu group is not without its drawbacks. During the synthesis of sequences prone to aggregation, particularly those containing multiple serine residues (e.g., poly-serine tracts), the tBu group can contribute to interchain hydrogen bonding, leading to incomplete reactions and challenging purifications.[1]
The Bulky Alternative: Trityl (Trt)
Fmoc-Ser(Trt)-OH has emerged as the leading alternative to its tBu-protected counterpart, especially for the synthesis of "difficult" peptides.[1][4] The bulky trityl (Trt) group acts as a steric shield, effectively disrupting the formation of secondary structures like β-sheets that are responsible for peptide aggregation.[1] This disruption of interchain hydrogen bonding facilitates more efficient deprotection and coupling steps, resulting in higher purity and yield of the final peptide.[4][5]
A notable study by Barlos et al. demonstrated that the use of Fmoc/Trt-protected amino acids, including serine, resulted in crude peptides of higher purity compared to their Fmoc/tBu counterparts when synthesizing model peptides.[5] The Trt group is also significantly more acid-labile than the tBu group, allowing for the use of milder acidic conditions for its removal, which can be advantageous for peptides containing sensitive residues.[6]
While Fmoc-Ser(Trt)-OH offers significant advantages for challenging sequences, its higher cost is a key consideration for routine synthesis of non-aggregating peptides.[1]
Performance Comparison: tBu vs. Trt
| Feature | Fmoc-Ser(tBu)-OH | Fmoc-Ser(Trt)-OH |
| Primary Application | Routine peptide synthesis | "Difficult" or aggregation-prone sequences (e.g., poly-serine) |
| Prevention of Aggregation | Less effective | Highly effective due to steric bulk |
| Purity in Difficult Sequences | Lower | Higher[5] |
| Yield in Difficult Sequences | Lower | Higher[1] |
| Acid Lability | Requires strong acid (e.g., >90% TFA) for efficient removal[6] | High; cleavable with very mild acid (e.g., 1% TFA)[6] |
| Side Reactions | Can lead to incomplete Fmoc deprotection in aggregated sequences.[4] | Minimizes side reactions associated with aggregation. |
| Cost | Lower | Higher |
Other Alternative Protecting Groups
Beyond the well-established tBu and Trt groups, other protecting groups for serine have been explored, each with its own set of characteristics.
Benzyl (Bzl) Group
The benzyl (Bzl) group is a classical protecting group for hydroxyl functions. However, its application in standard Fmoc-SPPS is limited due to its partial lability to the piperidine solutions used for Fmoc deprotection. This can lead to undesired side reactions and impurities. The Bzl group is typically removed by strong acids like HF or by catalytic hydrogenolysis, conditions that are often not compatible with the overall Fmoc-SPPS strategy.
Cyclohexyl (Chx) Group
The cyclohexyl (Chx) ether has been investigated as a protecting group for serine and has been shown to be stable to 20% piperidine in DMF.[7] This stability makes it theoretically compatible with the Fmoc-SPPS workflow. The Chx group is removed by strong acid treatment, such as with trifluoromethanesulfonic acid.[7] However, its practical application and a direct performance comparison with tBu and Trt in Fmoc-SPPS for serine are not extensively documented.
Photolabile Protecting Groups (e.g., o-Nitrobenzyl)
Photolabile protecting groups (PPGs), such as the o-nitrobenzyl (ONB) group, offer a "green" alternative for peptide synthesis, as their removal is achieved using light, avoiding the use of harsh chemical reagents.[8][9] This orthogonality is particularly valuable for the synthesis of sensitive or modified peptides. The use of PPGs can lead to high-purity peptides, but factors such as the efficiency of photolysis and potential side reactions need to be carefully considered. While the concept is promising, comprehensive comparative data on the performance of photolabile-protected serine in Fmoc-SPPS versus traditional methods are still emerging.
Experimental Protocols
Standard Fmoc-SPPS Coupling Protocol for Fmoc-Ser(tBu)-OH
This protocol outlines a general procedure for the manual coupling of Fmoc-Ser(tBu)-OH. Automated synthesizers will follow a similar sequence of steps.
Materials:
-
Fmoc-Ser(tBu)-OH
-
Peptide-resin with a free N-terminal amine
-
Coupling reagent (e.g., HBTU, HATU)
-
Base (e.g., DIPEA or 2,4,6-collidine)
-
DMF (peptide synthesis grade)
-
20% Piperidine in DMF
-
DCM
Procedure:
-
Resin Swelling: Swell the peptide-resin in DMF for at least 30 minutes.
-
Fmoc Deprotection: Treat the resin with 20% piperidine in DMF for 5-10 minutes. Repeat this step once.
-
Washing: Wash the resin thoroughly with DMF (5-7 times) to remove piperidine and the dibenzofulvene-piperidine adduct.
-
Coupling Cocktail Preparation: In a separate vessel, dissolve Fmoc-Ser(tBu)-OH (3-5 equivalents relative to resin loading) and the coupling reagent (e.g., HBTU) in DMF. Add the base (e.g., DIPEA).
-
Coupling Reaction: Add the activated Fmoc-Ser(tBu)-OH solution to the resin and allow the reaction to proceed for 30-60 minutes.
-
Washing: Wash the resin with DMF to remove excess reagents.
-
Confirmation of Coupling: Perform a Kaiser test to ensure the coupling reaction is complete (a negative result indicates completion). If the test is positive, a second coupling may be necessary.
Recommended Coupling Protocol for Fmoc-Ser(Trt)-OH in Difficult Sequences
For aggregation-prone sequences, the use of Fmoc-Ser(Trt)-OH is recommended. The coupling protocol is similar to that of Fmoc-Ser(tBu)-OH, but the following considerations may improve results:
-
Double Coupling: For particularly difficult couplings, performing the coupling step twice can improve efficiency.
-
Choice of Coupling Reagent: More potent coupling reagents like HATU may be beneficial.
-
Monitoring: Careful monitoring of both deprotection and coupling steps is crucial to ensure the synthesis proceeds efficiently.
Visualizing the Workflow and Structures
To better understand the concepts discussed, the following diagrams illustrate the chemical structures of the protected serine derivatives and the general workflow of Fmoc-SPPS.
References
- 1. benchchem.com [benchchem.com]
- 2. chemia.ug.edu.pl [chemia.ug.edu.pl]
- 3. Fmoc Amino Acids for SPPS - AltaBioscience [altabioscience.com]
- 4. cblpatras.gr [cblpatras.gr]
- 5. Fmoc/Trt-amino acids: comparison to Fmoc/tBu-amino acids in peptide synthesis - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. benchchem.com [benchchem.com]
- 7. Cyclohexyl ether as a new hydroxy-protecting group for serine and threonine in peptide synthesis [ ] 1 - Journal of the Chemical Society, Perkin Transactions 1 (RSC Publishing) [pubs.rsc.org]
- 8. pubs.acs.org [pubs.acs.org]
- 9. A Photolabile Carboxyl Protecting Group for Solid Phase Peptide Synthesis - PMC [pmc.ncbi.nlm.nih.gov]
A Researcher's Guide to Quantitative Proteomics: Comparing 15N Labeling, SILAC, TMT, and iTRAQ
For researchers, scientists, and drug development professionals, the precise quantification of proteins is paramount to unraveling complex biological processes and identifying potential therapeutic targets. This guide provides an objective comparison of four leading labeling techniques in quantitative mass spectrometry-based proteomics: 15N metabolic labeling, Stable Isotope Labeling by Amino acids in Cell culture (SILAC), Tandem Mass Tags (TMT), and isobaric Tags for Relative and Absolute Quantitation (iTRAQ). We delve into their respective experimental protocols, present comparative performance data, and offer insights to help you select the optimal method for your research needs.
Introduction to Quantitative Proteomics Labeling
Quantitative proteomics aims to determine the relative or absolute abundance of proteins in a sample. Label-based quantification methods introduce a mass-differentiated tag to proteins or peptides, allowing for the direct comparison of multiple samples within the same mass spectrometry run. This approach significantly enhances accuracy and reproducibility by minimizing experimental variability.[1][2] The choice of labeling strategy depends on the biological system under investigation, the desired level of multiplexing, and the specific scientific question being addressed.
Comparing the Titans: 15N, SILAC, TMT, and iTRAQ
Metabolic labeling methods, such as 15N and SILAC, integrate stable isotopes into proteins in vivo or in cellulo.[3][4] This early-stage labeling allows for the mixing of samples at the cellular or protein level, which drastically reduces downstream processing errors.[5] In contrast, chemical labeling with isobaric tags like TMT and iTRAQ occurs at the peptide level after protein extraction and digestion.[6][7] This approach offers higher multiplexing capabilities, enabling the simultaneous analysis of a larger number of samples.[8]
Key Differences at a Glance
| Feature | 15N Metabolic Labeling | SILAC | TMT | iTRAQ |
| Labeling Type | Metabolic (in vivo/in-cell) | Metabolic (in cellulo) | Chemical (peptide-level) | Chemical (peptide-level) |
| Principle | Incorporation of 15N-containing nutrients into all nitrogen-containing amino acids. | Incorporation of "heavy" amino acids (e.g., 13C, 15N-labeled Arg/Lys). | Isobaric tags with different reporter ions released upon fragmentation. | Isobaric tags with different reporter ions released upon fragmentation. |
| Multiplexing | Typically 2-plex | Up to 3-plex (or more with specialized reagents) | Up to 18-plex (TMTpro) | 4-plex or 8-plex |
| Applicability | Whole organisms, cells, tissues.[3][9] | Proliferating cells in culture.[4][10] | Any protein sample (cells, tissues, biofluids).[2][6] | Any protein sample (cells, tissues, biofluids).[7][11] |
| Mixing Point | Early (cells/tissue) | Early (cells/lysate) | Late (peptides) | Late (peptides) |
| Data Analysis | Complex due to variable mass shifts. | Relatively straightforward, fixed mass shifts. | Requires specialized software for reporter ion quantification. | Requires specialized software for reporter ion quantification. |
Visualizing the 15N Metabolic Labeling Workflow
The following diagram illustrates the key steps involved in a typical 15N metabolic labeling experiment.
Caption: Workflow of a 15N metabolic labeling experiment.
Detailed Experimental Protocols
Accurate and reproducible results in quantitative proteomics are highly dependent on meticulous experimental execution. Below are detailed protocols for the key labeling methods.
15N Metabolic Labeling Protocol
This protocol is adapted for cell culture but can be modified for whole organisms.[3][12]
-
Adaptation Phase: Culture cells in a "heavy" medium where the standard nitrogen source is replaced with a 15N-labeled equivalent (e.g., 15N ammonium chloride or 15N-labeled amino acids). A parallel culture is maintained in a "light" medium with the natural 14N nitrogen source. Cells should be cultured for a sufficient number of doublings to ensure near-complete incorporation of the 15N isotope (typically >95%).[13]
-
Experimental Phase: Apply the experimental treatment to one of the cell populations.
-
Harvesting and Mixing: Harvest the "light" and "heavy" cell populations and mix them in a 1:1 ratio based on cell count or total protein concentration.
-
Protein Extraction: Lyse the mixed cells using a suitable lysis buffer (e.g., RIPA buffer) containing protease and phosphatase inhibitors.
-
Protein Digestion: Reduce and alkylate the protein extract, followed by digestion with a sequence-specific protease, most commonly trypsin, overnight at 37°C.
-
Peptide Cleanup: Desalt the resulting peptide mixture using a C18 solid-phase extraction column to remove contaminants that could interfere with mass spectrometry analysis.
-
LC-MS/MS Analysis: Analyze the cleaned peptide mixture using a high-resolution mass spectrometer.
-
Data Analysis: Use specialized software (e.g., MaxQuant, Protein Prospector) to identify peptides and quantify the area ratios of the "heavy" and "light" peptide pairs.[3] The software must be able to handle the variable mass shifts characteristic of 15N labeling.
SILAC Protocol
This protocol outlines the general steps for a SILAC experiment in cell culture.[4][14]
-
Adaptation Phase: Culture two populations of cells in specialized SILAC media. One medium contains "light" (natural abundance) arginine and lysine, while the other contains "heavy" (e.g., 13C6- or 13C6,15N2-) versions of these amino acids. A third medium with "medium-heavy" amino acids can be used for 3-plex experiments. Cells should be cultured for at least five to six doublings to achieve complete labeling.[15]
-
Experimental Phase: Apply different treatments to the distinct cell populations.
-
Cell Lysis and Mixing: Lyse the cells from each condition separately and determine the protein concentration. Combine equal amounts of protein from the "light" and "heavy" (and "medium") lysates.
-
Protein Digestion: The combined protein lysate is then subjected to reduction, alkylation, and tryptic digestion.
-
Peptide Cleanup: Desalt the peptide mixture using C18 chromatography.
-
LC-MS/MS Analysis: Analyze the peptides by LC-MS/MS.
-
Data Analysis: Use software like MaxQuant to identify peptides and calculate the intensity ratios of the "light," "medium," and "heavy" peptide pairs.
TMT Protocol
The following is a generalized protocol for TMT labeling.[16][17]
-
Protein Extraction and Digestion: Extract proteins from each sample and quantify the protein concentration. Reduce, alkylate, and digest 10-100 µg of protein per sample with trypsin.
-
Peptide Cleanup: Desalt the resulting peptides for each sample individually.
-
TMT Labeling: Label each peptide sample with a different isobaric TMT reagent according to the manufacturer's instructions. This is typically done for 1 hour at room temperature.
-
Quenching and Mixing: Quench the labeling reaction with hydroxylamine. Combine all labeled samples into a single tube.
-
Fractionation and Cleanup: To reduce sample complexity and improve proteome coverage, the mixed peptide sample is often fractionated using techniques like high-pH reversed-phase chromatography. The fractions are then desalted.
-
LC-MS/MS Analysis: Analyze each fraction by LC-MS/MS. The mass spectrometer is programmed to isolate and fragment the precursor ions (MS2), where the reporter ions are released and their intensities measured.
-
Data Analysis: Use software such as Proteome Discoverer to identify peptides and quantify the relative abundance of each protein based on the reporter ion intensities.
iTRAQ Protocol
This protocol provides a general workflow for iTRAQ labeling.[7][18]
-
Protein Extraction and Digestion: Extract and quantify proteins from each sample. Take an equal amount of protein from each sample and perform reduction, alkylation, and tryptic digestion.
-
iTRAQ Labeling: Label each peptide digest with a specific iTRAQ reagent (4-plex or 8-plex) following the manufacturer's protocol.
-
Sample Pooling: Combine the labeled peptide samples into a single mixture.
-
Fractionation and Desalting: Fractionate the pooled peptide mixture to reduce complexity, followed by desalting.
-
LC-MS/MS Analysis: Analyze the fractions by LC-MS/MS. During MS2 fragmentation, the reporter ions are generated and their intensities are measured.
-
Data Analysis: Utilize appropriate software to identify peptides and quantify proteins based on the relative intensities of the iTRAQ reporter ions.
Quantitative Performance Comparison
The quantitative accuracy and precision are critical metrics for evaluating the performance of these labeling techniques. The following tables summarize key performance indicators based on available literature.
Table 1: General Quantitative Performance
| Metric | 15N Metabolic Labeling | SILAC | TMT | iTRAQ |
| Quantitative Accuracy | High, but can be affected by incomplete labeling.[3] | Very High. Considered a gold standard for accuracy.[5] | Good, but can be affected by ratio compression.[1] | Good, but can be affected by ratio compression.[19] |
| Quantitative Precision (CV) | Generally low, benefits from early mixing. | Very low, highly reproducible.[20] | Low within a multiplexed set. | Low within a multiplexed set. |
| Number of Proteins Quantified | High, provides global proteome coverage.[3] | High, comparable to other methods. | High, multiplexing can increase depth of coverage.[6] | High, comparable to TMT.[19] |
| Dynamic Range | Wide | Wide | Can be limited by ratio compression. | Can be limited by ratio compression. |
Table 2: Advantages and Limitations
| Method | Advantages | Limitations |
| 15N Metabolic Labeling | - Applicable to whole organisms.[3] - Complete proteome labeling. - Early sample mixing minimizes error. | - Incomplete labeling can affect accuracy.[13] - Complex data analysis. - Not suitable for all organisms. |
| SILAC | - Highly accurate and precise.[5][15] - Early sample mixing. - Straightforward data analysis. | - Limited to proliferating cells in culture.[20] - Can be expensive. - Requires complete metabolic incorporation. |
| TMT | - High multiplexing capability (up to 18-plex).[2] - Suitable for all sample types. - Increased sample throughput. | - Ratio compression can underestimate fold changes.[2] - Labeling occurs at the peptide level. - Reagent cost can be high. |
| iTRAQ | - Good multiplexing (4 or 8-plex).[8] - Broad sample applicability. - Well-established methodology. | - Ratio compression is a known issue.[19] - Labeling at the peptide level. - Lower multiplexing than TMT. |
Conclusion: Selecting the Right Tool for the Job
The choice between 15N, SILAC, TMT, and iTRAQ depends heavily on the specific research goals and the nature of the biological samples.
-
For studies involving whole organisms or when a complete, unbiased labeling of the entire proteome is desired, 15N metabolic labeling is a powerful, albeit analytically challenging, option.
-
When working with cell cultures and requiring the highest degree of quantitative accuracy and precision, SILAC is often the preferred method. [5]
-
For studies requiring the comparison of multiple conditions or patient samples (up to 18), TMT offers the highest multiplexing capacity, which can increase throughput and reduce instrument time. [2]
-
iTRAQ remains a robust and widely used technique for multiplexed quantitative proteomics, particularly for 4-plex and 8-plex experiments.
Ultimately, a thorough understanding of the principles, advantages, and limitations of each technique, as outlined in this guide, will enable researchers to design more effective quantitative proteomics experiments and generate high-quality, reliable data to drive their scientific discoveries.
References
- 1. Comparing SILAC- and Stable Isotope Dimethyl-Labeling Approaches for Quantitative Proteomics - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Label-based Proteomics: iTRAQ, TMT, SILAC Explained - MetwareBio [metwarebio.com]
- 3. benchchem.com [benchchem.com]
- 4. SILAC: Principles, Workflow & Applications in Proteomics - Creative Proteomics Blog [creative-proteomics.com]
- 5. biocev.lf1.cuni.cz [biocev.lf1.cuni.cz]
- 6. TMT Quantitative Proteomics: A Comprehensive Guide to Labeled Protein Analysis - MetwareBio [metwarebio.com]
- 7. iTRAQ-based Proteomics Analysis - Creative Proteomics [creative-proteomics.com]
- 8. researchgate.net [researchgate.net]
- 9. 15N Metabolic Labeling of Mammalian Tissue with Slow Protein Turnover - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Comparing iTRAQ, TMT and SILAC | Silantes [silantes.com]
- 11. iTRAQ Quantification Technology: Principles, Advantages, and Applications | MtoZ Biolabs [mtoz-biolabs.com]
- 12. Using 15N-Metabolic Labeling for Quantitative Proteomic Analyses | Springer Nature Experiments [experiments.springernature.com]
- 13. 15N Metabolic Labeling Quantification Workflow in Arabidopsis Using Protein Prospector - PMC [pmc.ncbi.nlm.nih.gov]
- 14. benchchem.com [benchchem.com]
- 15. Quantitative Comparison of Proteomes Using SILAC - PMC [pmc.ncbi.nlm.nih.gov]
- 16. TMT Sample Preparation for Proteomics Facility Submission and Subsequent Data Analysis - PMC [pmc.ncbi.nlm.nih.gov]
- 17. aragen.com [aragen.com]
- 18. biotech.cornell.edu [biotech.cornell.edu]
- 19. iTRAQ Labeling is Superior to mTRAQ for Quantitative Global Proteomics and Phosphoproteomics - PMC [pmc.ncbi.nlm.nih.gov]
- 20. pubs.acs.org [pubs.acs.org]
A Comparative Guide to Solid-Phase versus Solution-Phase Synthesis of ¹⁵N-Labeled Peptides
For researchers, scientists, and drug development professionals, the incorporation of stable isotopes like ¹⁵N into peptides is a critical tool for a range of applications, from structural biology studies using Nuclear Magnetic Resonance (NMR) to quantitative proteomics via mass spectrometry. The choice of synthetic methodology, either solid-phase peptide synthesis (SPPS) or solution-phase peptide synthesis (LPPS), can significantly impact the yield, purity, and overall efficiency of producing these invaluable research tools. This guide provides an objective comparison of these two synthetic strategies for ¹⁵N-labeled peptides, supported by experimental data and detailed protocols.
At a Glance: Key Differences Between SPPS and LPPS
Solid-phase and solution-phase synthesis represent two fundamentally different approaches to peptide assembly. In SPPS, the peptide chain is incrementally constructed on an insoluble resin support, which simplifies the purification process at each step to simple washing and filtration.[1][2] Conversely, LPPS involves the synthesis of the peptide entirely in a homogenous solution, necessitating purification of the intermediate peptide after each coupling step, often by crystallization or chromatography.[1][3]
The decision between these two methods hinges on several factors, including the desired peptide length, the scale of synthesis, and the specific sequence. For the synthesis of long peptides, SPPS is generally the method of choice due to its speed and amenability to automation.[3][4] LPPS, while more labor-intensive, can be more cost-effective for the large-scale production of shorter peptides and offers greater flexibility in reaction conditions for complex sequences.[2][5]
Quantitative Performance Comparison
A case study on the solid-phase synthesis of [Ala3-¹⁵N][Val1]gramicidin A, a 15-amino acid peptide, reported an overall yield of 30% after purification.[6] For solution-phase synthesis, data for a short peptide, Leu-Enkephalin (a 5-mer), shows an overall yield of 62% with a purity of 93%.[3] Another example for a tetrapeptide (H-Val-Ala-Ala-Phe-OH) synthesized via both methods showed an overall yield of approximately 75% for SPPS and 60% for LPPS, with both achieving a final purity of ≥98% after purification.[1]
The following table summarizes these representative quantitative data points:
| Metric | Solid-Phase Synthesis (SPPS) | Solution-Phase Synthesis (LPPS) |
| Overall Yield | ~30% - 75% | ~60% - 62% (for short peptides) |
| Crude Purity | >90% | ~85% |
| Final Purity (after purification) | ≥98% | ≥98% |
Note: The data presented is from different studies and for different peptides, serving as illustrative examples of typical outcomes for each method.
Experimental Protocols
Detailed methodologies for both solid-phase and solution-phase synthesis are crucial for reproducibility and for understanding the practical differences between the two techniques.
Solid-Phase Synthesis Protocol for a ¹⁵N-Labeled Peptide
This protocol describes the manual solid-phase synthesis of a peptide incorporating a ¹⁵N-labeled amino acid using Fmoc (9-fluorenylmethyloxycarbonyl) chemistry.
1. Resin Preparation and Swelling:
-
Place the appropriate resin (e.g., Rink Amide resin for a C-terminal amide) in a reaction vessel.
-
Swell the resin in N,N-Dimethylformamide (DMF) for at least 30 minutes.
2. Fmoc Deprotection:
-
Drain the DMF from the swollen resin.
-
Add a 20% (v/v) solution of piperidine in DMF to the resin and agitate for 5-10 minutes.
-
Drain the solution and repeat the piperidine treatment for another 10-15 minutes to ensure complete deprotection.
-
Thoroughly wash the resin with DMF to remove all traces of piperidine.
3. ¹⁵N-Amino Acid Coupling:
-
In a separate vial, dissolve the ¹⁵N-labeled Fmoc-amino acid (3-5 equivalents) and a coupling reagent such as HBTU (3-5 equivalents) in DMF.
-
Add Diisopropylethylamine (DIPEA) (6-10 equivalents) to activate the amino acid.
-
Immediately add the activated ¹⁵N-amino acid solution to the deprotected peptide-resin.
-
Agitate the mixture for 1-2 hours at room temperature. A Kaiser test can be performed to monitor the reaction for completion (a negative result indicates a complete coupling).
-
Drain the coupling solution and wash the resin thoroughly with DMF.
4. Chain Elongation:
-
Repeat the Fmoc deprotection (Step 2) and amino acid coupling (Step 3) steps for each subsequent amino acid in the peptide sequence.
5. Cleavage and Deprotection:
-
Once the peptide synthesis is complete, wash the resin with Dichloromethane (DCM) and dry it under vacuum.
-
Treat the resin with a cleavage cocktail (e.g., a mixture of Trifluoroacetic acid (TFA), water, and scavengers) for 2-3 hours to cleave the peptide from the resin and remove side-chain protecting groups.
6. Peptide Precipitation and Purification:
-
Filter the resin and collect the filtrate containing the cleaved peptide.
-
Precipitate the crude peptide by adding the TFA filtrate to a 10-fold volume of cold diethyl ether.
-
Centrifuge the mixture to pellet the peptide and wash the pellet with cold diethyl ether.
-
Dry the crude peptide under vacuum.
-
Purify the peptide by reverse-phase high-performance liquid chromatography (RP-HPLC).
-
Lyophilize the pure fractions to obtain the final ¹⁵N-labeled peptide.
Solution-Phase Synthesis Protocol for a Dipeptide
This protocol outlines a general procedure for the solution-phase synthesis of a dipeptide, which can be adapted for the incorporation of a ¹⁵N-labeled amino acid.
1. N-terminal and C-terminal Protection:
-
Protect the N-terminus of the first amino acid (e.g., with a Boc group) to prevent self-coupling.
-
Protect the C-terminus of the second amino acid (e.g., as a methyl ester) to prevent its carboxyl group from reacting.
2. Amino Acid Coupling:
-
In a dry reaction vessel under an inert atmosphere, dissolve the N-protected amino acid (1.0 equivalent) and a coupling agent like HOBt (1.1 equivalents) in an anhydrous solvent such as DCM or DMF.
-
Add the C-terminally protected amino acid (1.0 equivalent) and a base such as NMM or DIPEA (1.0-1.2 equivalents) to the solution.
-
Cool the reaction mixture to 0 °C.
-
Add a solution of a coupling reagent like DCC (1.1 equivalents) in anhydrous DCM dropwise.
-
Allow the reaction to warm to room temperature and stir for 12-24 hours. The reaction progress can be monitored by Thin Layer Chromatography (TLC).
3. Work-up and Purification of Protected Dipeptide:
-
Once the reaction is complete, filter the reaction mixture to remove by-products (e.g., dicyclohexylurea if DCC is used).
-
The filtrate is then typically washed with an acidic solution (e.g., 1N HCl), a basic solution (e.g., saturated NaHCO₃), and brine.
-
The organic layer is dried over an anhydrous salt (e.g., Na₂SO₄), filtered, and the solvent is removed under reduced pressure.
-
The crude protected dipeptide is purified by column chromatography on silica gel.
4. Deprotection:
-
The protecting groups are removed to yield the final dipeptide. For example, a Boc group can be removed by treatment with TFA.
-
The deprotected dipeptide is then purified, often by recrystallization or chromatography.
For the synthesis of longer peptides in solution, a fragment condensation approach is often employed. This involves synthesizing smaller peptide fragments (2-10 amino acids) using the stepwise method described above, and then coupling these purified fragments together in solution.[2]
Visualizing the Synthesis Workflows
To further clarify the procedural differences between solid-phase and solution-phase synthesis, the following diagrams illustrate the general workflows for each methodology.
Choosing the Right Method: A Decision Framework
The selection of the optimal synthesis strategy depends on the specific requirements of the research project. The following decision-making framework can guide researchers in choosing between SPPS and LPPS for the synthesis of ¹⁵N-labeled peptides.
References
- 1. benchchem.com [benchchem.com]
- 2. Solid-Phase vs Liquid-Phase Peptide Synthesis | Adesis [adesisinc.com]
- 3. benchchem.com [benchchem.com]
- 4. Solid-Phase or Liquid-Phase? How Has Peptide Synthesis Revolutionized Drug Discovery?-BioDuro-Global CRDMO, Rooted in Science [bioduro.com]
- 5. benchchem.com [benchchem.com]
- 6. Solid-phase peptide synthesis and solid-state NMR spectroscopy of [Ala3-15N][Val1]gramicidin A - PubMed [pubmed.ncbi.nlm.nih.gov]
A Comparative Guide to Alternative Methods for Synthesizing Phosphoserine Peptides
For Researchers, Scientists, and Drug Development Professionals
The synthesis of phosphoserine-containing peptides is a critical tool in biochemical and pharmacological research, enabling the study of protein phosphorylation, a key post-translational modification that governs a vast array of cellular processes. This guide provides an objective comparison of the three primary methods for synthesizing phosphoserine peptides: the 'Building Block' approach, the 'Global Phosphorylation' approach, and the Enzymatic method. We present a summary of their performance based on available experimental data, detailed experimental protocols, and visual workflows to aid in the selection of the most suitable method for your research needs.
Performance Comparison
The choice of a synthetic strategy for phosphoserine peptides depends on several factors, including the desired peptide sequence, the scale of the synthesis, the required purity, and the available resources. The following table summarizes the key performance indicators for each method based on published data.
| Method | Key Reagent/Enzyme | Typical Crude Purity (%) | Isolated Yield (%) | Key Advantages | Key Disadvantages |
| Building Block Approach (Fmoc-SPPS) | Fmoc-Ser(PO(OBzl)OH)-OH | 7.7 - 37.2 (for multi-phosphorylated peptides)[1] | 3.6 - 33.6 (for multi-phosphorylated peptides)[1] | Site-specific phosphorylation, high reliability, suitable for complex peptides.[2] | Higher cost of protected amino acid, potential for β-elimination.[1] |
| Global Phosphorylation Approach | Benzyl H-phosphonate | Not explicitly reported, but method is described as "highly efficient". | ~83 (for a specific peptide)[3] | Cost-effective for single phosphorylation, can produce both phosphorylated and non-phosphorylated peptides from one synthesis. | Risk of incomplete phosphorylation and side reactions, less suitable for multiple phosphorylation sites. |
| Enzymatic Approach | Protein Kinase A (PKA) | High (due to enzyme specificity) | Dependent on kinase activity and substrate specificity; quantitative data on isolated yields are limited in a preparative context. | High specificity, mild reaction conditions, no need for protecting groups. | Limited to kinase recognition sequence, potential for incomplete phosphorylation, enzyme cost and stability. |
Methodologies and Experimental Protocols
This section provides detailed experimental protocols for the three main phosphoserine peptide synthesis methods.
The 'Building Block' Approach using Fmoc-SPPS
This method involves the incorporation of a pre-phosphorylated and protected serine residue during solid-phase peptide synthesis (SPPS). The most commonly used building block is N-α-Fmoc-O-(monobenzylphospho)-L-serine (Fmoc-Ser(PO(OBzl)OH)-OH).
Experimental Protocol:
-
Resin Swelling and Fmoc Deprotection: Swell the resin (e.g., Rink Amide resin) in N,N-dimethylformamide (DMF) for 30 minutes. Remove the Fmoc protecting group by treating the resin with 20% piperidine in DMF (2 x 10 min). Wash the resin with DMF.
-
Amino Acid Coupling: For non-phosphorylated amino acids, activate the Fmoc-protected amino acid (4 equivalents) with a coupling reagent like HATU (3.95 equivalents) and a base such as N,N-diisopropylethylamine (DIPEA) (8 equivalents) in DMF. Add the activated amino acid to the resin and couple for 1-2 hours. Monitor the reaction using a ninhydrin test.
-
Phosphoserine Incorporation: Dissolve Fmoc-Ser(PO(OBzl)OH)-OH (3-5 equivalents) and a coupling agent (e.g., HATU, 3-5 equivalents) in DMF. Add a base (e.g., DIPEA, 6-10 equivalents) to the solution to pre-activate for 1-5 minutes before adding to the resin.[2] The coupling time may need to be extended for the bulky phosphorylated residue.
-
Chain Elongation: Repeat the deprotection and coupling steps for each amino acid in the peptide sequence.
-
Cleavage and Deprotection: After synthesis is complete, wash the resin with dichloromethane (DCM). Treat the resin with a cleavage cocktail, typically trifluoroacetic acid (TFA) with scavengers (e.g., 95% TFA, 2.5% water, 2.5% triisopropylsilane) for 2-3 hours to cleave the peptide from the resin and remove the side-chain protecting groups, including the benzyl group on the phosphate.[1]
-
Purification: Precipitate the crude peptide in cold diethyl ether. Purify the peptide by reverse-phase high-performance liquid chromatography (RP-HPLC).
-
Analysis: Confirm the identity and purity of the phosphopeptide by mass spectrometry and analytical HPLC.
Accelerated Microwave-Assisted Protocol (AMPS):
For the synthesis of multi-phosphorylated peptides, an accelerated microwave-assisted protocol can be employed. This involves performing the coupling and deprotection steps at elevated temperatures (e.g., 90°C) with very short reaction times (e.g., 1-minute couplings, 10-second deprotections with 0.5% DBU in DMF).[1]
The 'Global Phosphorylation' Approach
In this strategy, the peptide is first synthesized with an unprotected serine residue, which is then phosphorylated on the solid support before cleavage.
Experimental Protocol using H-phosphonate:
-
Peptide Synthesis: Synthesize the peptide on a solid support using standard Fmoc-SPPS, incorporating a serine residue with its hydroxyl group unprotected.
-
On-Resin Phosphorylation:
-
Swell the peptide-resin in a mixture of pyridine and dichloromethane.
-
Add a solution of benzyl H-phosphonate (5 equivalents) and pivaloyl chloride (5 equivalents) in pyridine/DCM.[3]
-
Allow the reaction to proceed for 1-2 hours at room temperature.
-
Oxidize the resulting H-phosphonate diester to the phosphate triester using a solution of iodine in pyridine/water.[3]
-
-
Cleavage and Deprotection: Cleave the peptide from the resin and remove the protecting groups using a TFA cleavage cocktail as described in the building block approach. The benzyl protecting group on the phosphate will be removed simultaneously.
-
Purification and Analysis: Purify and analyze the phosphopeptide using RP-HPLC and mass spectrometry.
Experimental Protocol using Dibenzyl Phosphochloridate:
-
Peptide Synthesis: Assemble the peptide on the resin using standard Fmoc-SPPS, leaving the serine residue to be phosphorylated with its side chain unprotected.
-
On-Resin Phosphorylation:
-
Swell the peptide-resin in an appropriate solvent.
-
Treat the resin with a solution of dibenzylphosphochloridate in the presence of a base (e.g., pyridine or N-methylimidazole) to phosphorylate the serine hydroxyl group.
-
-
Cleavage and Deprotection: Cleave the peptide from the resin and remove all protecting groups, including the benzyl groups on the phosphate, using a strong acid cocktail (e.g., TFA with scavengers).
-
Purification and Analysis: Purify the phosphopeptide by RP-HPLC and characterize it by mass spectrometry.
The Enzymatic Approach
This method utilizes a specific protein kinase to phosphorylate a serine residue within a synthesized peptide that contains the kinase's recognition motif.
Experimental Protocol using Protein Kinase A (PKA):
-
Peptide Synthesis: Synthesize the substrate peptide containing the PKA recognition sequence (e.g., Arg-Arg-X-Ser-Y, where X is a small amino acid and Y is a large hydrophobic amino acid) using standard SPPS. Purify the peptide to a high degree.
-
Enzymatic Phosphorylation Reaction:
-
Prepare a reaction buffer (e.g., 40 mM Tris-HCl, pH 7.5, 10 mM MgCl₂, 0.1 mg/mL BSA).
-
Dissolve the purified peptide in the reaction buffer.
-
Add ATP (as the phosphate donor) to the reaction mixture.
-
Initiate the reaction by adding the catalytic subunit of PKA.
-
Incubate the reaction mixture at 30°C for a sufficient time (e.g., 2-4 hours) to ensure complete phosphorylation.
-
-
Reaction Quenching and Purification:
-
Stop the reaction by adding a solution that denatures the enzyme (e.g., a small volume of TFA or by heating).
-
Purify the phosphopeptide from the reaction mixture, separating it from the unphosphorylated peptide, ATP, ADP, and the kinase, using RP-HPLC.
-
-
Analysis: Confirm the identity and purity of the phosphopeptide by mass spectrometry and analytical HPLC. The extent of phosphorylation can be quantified by comparing the peak areas of the phosphorylated and unphosphorylated peptides in the HPLC chromatogram.
Visualizing the Synthetic Workflows
The following diagrams illustrate the workflows for each of the described phosphoserine peptide synthesis methods.
References
A Researcher's Guide to Validating Protein Structure with 15N NMR Data
For researchers, scientists, and drug development professionals, the accurate determination of a protein's three-dimensional structure is a cornerstone of modern molecular biology and rational drug design. While various techniques exist for structure elucidation, Nuclear Magnetic Resonance (NMR) spectroscopy, particularly utilizing 15N isotopic labeling, offers a powerful approach to determine and validate protein structures in a solution state that mimics their native physiological environment.
This guide provides an objective comparison of 15N NMR-based protein structure validation with other prominent methods, supported by experimental data and detailed protocols. We will delve into the key experiments, data analysis workflows, and the quantitative metrics used to assess the quality and accuracy of a protein structure.
Core Principles of Protein Structure Validation using 15N NMR
The fundamental principle behind using 15N NMR for protein structure validation lies in the ability to probe the local chemical environment of individual atoms within the protein. By enriching the protein with the 15N isotope, we can specifically observe signals from the backbone amide nitrogens, providing a wealth of structural information.
Two primary NMR experiments form the bedrock of this approach:
-
15N-HSQC (Heteronuclear Single Quantum Coherence): This two-dimensional experiment correlates the chemical shifts of the backbone amide proton (¹H) with its directly bonded nitrogen (¹⁵N). The resulting spectrum is often referred to as a "fingerprint" of the protein, as each non-proline residue gives rise to a unique peak.[1][2] The dispersion of these peaks is a primary indicator of whether a protein is well-folded.[2][3]
-
15N-NOESY-HSQC (Nuclear Overhauser Effect Spectroscopy-HSQC): This three-dimensional experiment extends the 15N-HSQC by incorporating the Nuclear Overhauser Effect (NOE). The NOE is a through-space interaction between protons that are close to each other (typically within 5 Å), regardless of their position in the primary sequence.[4][5] By analyzing the cross-peaks in a 15N-NOESY-HSQC spectrum, we can derive distance restraints between specific protons, which are crucial for calculating and validating the three-dimensional fold of the protein.[4][6][7]
Comparative Analysis of Structure Validation Methods
While 15N NMR provides invaluable data for structure validation, it is often used in conjunction with, or compared against, other methods. The following table summarizes the key performance metrics and characteristics of 15N NMR, X-ray crystallography, and computational modeling with AlphaFold2.
| Feature | 15N NMR Spectroscopy | X-ray Crystallography | AlphaFold2 (Computational Modeling) |
| Principle | Measures nuclear spin properties in solution to derive distance and dihedral angle restraints. | Scatters X-rays from a protein crystal to determine electron density and infer atomic positions. | Predicts protein structure from amino acid sequence using deep learning algorithms trained on known structures. |
| Sample Phase | Solution | Crystalline Solid | In silico |
| Dynamic Information | Provides information on conformational flexibility and dynamics. | Primarily provides a static, time-averaged structure. | Can predict a single, static model; ensemble predictions can offer some insight into flexibility. |
| Key Validation Metrics | NOE violations, Dihedral angle restraints, Residual Dipolar Couplings (RDCs), Ramachandran plot analysis, ANSURR score, DP score. | R-factor, R-free, Resolution, Ramachandran plot analysis, Clashscore. | pLDDT score (predicted local distance difference test), PAE (predicted aligned error). |
| Strengths | - Structure in a physiologically relevant solution state.- Can study protein dynamics.- Can characterize partially or wholly unstructured proteins. | - Can achieve very high atomic resolution.- Well-established and widely used. | - Extremely fast and cost-effective.- High accuracy for many proteins, often comparable to experimental methods.[8][9][10] |
| Limitations | - Generally limited to smaller proteins (<~30 kDa).- Structure calculation can be complex and time-consuming.- Sparsity of experimental restraints can sometimes lead to lower precision. | - Requires protein crystallization, which can be a major bottleneck.- Crystal packing forces can sometimes influence the protein conformation.- Provides limited information about dynamics. | - Accuracy can be lower for novel folds, disordered regions, and protein complexes.- Predictions are not based on direct experimental data for the specific protein.[11] |
Quantitative Assessment of Protein Structure Quality
Several software suites and metrics are employed to quantitatively assess the quality of a protein structure derived from 15N NMR data. These tools analyze the agreement of the structural model with the experimental data and its overall stereochemical quality.
| Validation Parameter | Description | Software/Method | Interpretation of "Good" Quality |
| Ramachandran Plot Analysis | Examines the distribution of backbone dihedral angles (phi, ψ) to identify sterically allowed and disallowed conformations.[12][13][14][15] | PROCHECK, MolProbity, PSVS | >90% of residues in "most favored" regions, <2% in "disallowed" regions.[12] |
| NOE Restraint Violations | Measures the number and magnitude of distances in the calculated structure that violate the experimentally derived NOE distance restraints.[16] | CYANA, Xplor-NIH, CNS | Minimal number of significant and persistent violations across the structural ensemble. |
| Residual Dipolar Coupling (RDC) Q-factor | Assesses the agreement between experimentally measured RDCs and those back-calculated from the structural model. RDCs provide long-range orientational information.[17][18] | PALES, MODULE | A lower Q-factor indicates better agreement. |
| ANSURR Score | Compares the predicted rigidity from the structure with that derived from chemical shift data.[8][9][10] | ANSURR | Higher scores indicate better agreement and a more accurate structure. |
| DP (Discriminating Power) Score | Quantifies the agreement between the NOESY peak list and the structural model.[8] | RPF | Higher DP scores indicate better consistency between the data and the structure. |
| Clashscore | Identifies the number of serious steric clashes per 1000 atoms.[19] | MolProbity, PSVS | Lower clashscores are better, indicating fewer steric overlaps. |
Experimental Protocols
Detailed methodologies are crucial for obtaining high-quality data for protein structure validation. Below are summarized protocols for the key 15N NMR experiments.
Protocol 1: 2D ¹⁵N-¹H HSQC Experiment
This experiment serves as the initial screen for sample quality and as the foundation for more complex experiments.[1][20][21]
-
Sample Preparation: Prepare a 0.1 - 1.0 mM sample of uniformly ¹⁵N-labeled protein in a suitable buffer (e.g., 20 mM phosphate, 50 mM NaCl, pH 6.5) containing 5-10% D₂O for the lock signal.
-
Spectrometer Setup:
-
Insert the sample into the magnet and lock the spectrometer on the D₂O signal.
-
Tune and match the ¹H and ¹⁵N channels of the probe.
-
Optimize the shims to achieve a narrow and symmetrical water signal.
-
Calibrate the 90° pulse widths for both ¹H and ¹⁵N.
-
-
Acquisition Parameters (Typical for a 600 MHz spectrometer):
-
Use a sensitivity-enhanced gradient-selected HSQC pulse sequence.
-
Set the ¹H spectral width to ~12 ppm centered at the water resonance (~4.7 ppm).
-
Set the ¹⁵N spectral width to ~35 ppm centered at ~118 ppm.
-
Acquire 1024 complex points in the direct ¹H dimension and 256 increments in the indirect ¹⁵N dimension.
-
Set the number of scans per increment based on the sample concentration (e.g., 8-16 scans for a ~0.5 mM sample).
-
-
Processing and Analysis:
-
Process the data using software such as NMRPipe or TopSpin.
-
Apply a squared sine-bell window function in both dimensions.
-
Perform Fourier transformation and phase correction.
-
Analyze the spectrum for peak dispersion and the expected number of peaks.[2]
-
Protocol 2: 3D ¹⁵N-edited NOESY-HSQC Experiment
This experiment is critical for obtaining the distance restraints necessary for structure calculation and validation.[4][6][7][22][23]
-
Sample Preparation: Use the same ¹⁵N-labeled protein sample as for the HSQC experiment.
-
Spectrometer Setup: The initial setup is identical to the ¹⁵N-HSQC experiment.
-
Acquisition Parameters (Typical for a 600 MHz spectrometer):
-
Use a 3D ¹⁵N-edited NOESY-HSQC pulse sequence.
-
Set the ¹H and ¹⁵N spectral widths and centers as in the HSQC experiment.
-
Set the NOESY mixing time to a value appropriate for the size of the protein (e.g., 80-150 ms).[4]
-
Acquire 1024 complex points in the direct ¹H dimension, and a suitable number of increments in the two indirect dimensions (e.g., 128 in ¹H and 64 in ¹⁵N).
-
The number of scans will depend on the desired signal-to-noise ratio and the total experiment time.
-
-
Processing and Analysis:
-
Process the 3D data using appropriate software.
-
Pick peaks corresponding to through-space correlations.
-
Assign the NOE cross-peaks to specific pairs of protons.
-
Convert the volumes or intensities of the NOE cross-peaks into distance restraints (e.g., strong, medium, weak corresponding to <2.8 Å, <3.5 Å, <5.0 Å).
-
Visualizing the Validation Workflow
The process of validating a protein structure using 15N NMR data can be visualized as a logical workflow, from initial data acquisition to the final assessment of the structural model.
Caption: Workflow for protein structure validation using 15N NMR data.
This diagram illustrates the progression from acquiring raw NMR data to generating a validated three-dimensional protein structure.
Signaling Pathways in Data Interpretation
The interpretation of NMR data to yield structural insights involves a cascade of logical steps. The following diagram illustrates the relationship between different types of NMR data and the structural information they provide.
Caption: Relationship between NMR data and derived structural information.
This diagram shows how different types of NMR observables are translated into specific structural restraints that collectively define the three-dimensional architecture of the protein.
References
- 1. protein-nmr.org.uk [protein-nmr.org.uk]
- 2. aheyam.science [aheyam.science]
- 3. renafobis.fr [renafobis.fr]
- 4. protein-nmr.org.uk [protein-nmr.org.uk]
- 5. chem.libretexts.org [chem.libretexts.org]
- 6. NOESYHSQC_15N_3D.nan [protocols.io]
- 7. NMRGenerator - [1H, 15N]-NOESY-HSQC [sites.google.com]
- 8. Frontiers | AlphaFold Models of Small Proteins Rival the Accuracy of Solution NMR Structures [frontiersin.org]
- 9. The accuracy of protein structures in solution determined by AlphaFold and NMR - PMC [pmc.ncbi.nlm.nih.gov]
- 10. biorxiv.org [biorxiv.org]
- 11. NMR Spectroscopy for the Validation of AlphaFold2 Structures - PMC [pmc.ncbi.nlm.nih.gov]
- 12. binf.gmu.edu [binf.gmu.edu]
- 13. A global Ramachandran score identifies protein structures with unlikely stereochemistry - PMC [pmc.ncbi.nlm.nih.gov]
- 14. worldscientific.com [worldscientific.com]
- 15. Stereochemistry and Validation of Macromolecular Structures - PMC [pmc.ncbi.nlm.nih.gov]
- 16. Biomolecular NMR Wiki - Violation analysis and structure validation [sites.google.com]
- 17. Quality Assessment of Protein NMR Structures - PMC [pmc.ncbi.nlm.nih.gov]
- 18. Determination of Protein Backbone Structures from Residual Dipolar Couplings - PMC [pmc.ncbi.nlm.nih.gov]
- 19. researchgate.net [researchgate.net]
- 20. HSQC_15N.nan [protocols.io]
- 21. Collecting a 15N Edited HSQC - Powers Wiki [bionmr.unl.edu]
- 22. benchchem.com [benchchem.com]
- 23. TUTORIAL:3D 1H-15N NOESY-HSQC EXPERIMENT [imserc.northwestern.edu]
A Comparative Guide to Coupling Reagents for Fmoc-Ser(tBu)-OH in Solid-Phase Peptide Synthesis
For researchers, scientists, and drug development professionals engaged in solid-phase peptide synthesis (SPPS), the selection of an appropriate coupling reagent is a critical determinant of success, particularly when incorporating sterically hindered or racemization-prone amino acids like O-tert-butyl-protected serine (Fmoc-Ser(tBu)-OH). The choice of coupling reagent directly impacts coupling efficiency, reaction time, and the stereochemical integrity of the final peptide. This guide provides an objective comparison of commonly used coupling reagents for the incorporation of Fmoc-Ser(tBu)-OH, supported by experimental data.
The tert-butyl (tBu) protecting group on the serine side chain, while effective, can present steric challenges during peptide bond formation. Furthermore, serine derivatives are known to be susceptible to racemization, a side reaction that can lead to the formation of diastereomeric impurities that are often difficult to separate from the desired product. Therefore, a careful selection of the coupling methodology is paramount to ensure high yield and purity.
Performance Comparison of Coupling Reagents
The performance of a coupling reagent is primarily evaluated based on its efficiency in driving the acylation reaction to completion and its ability to suppress side reactions, most notably racemization. The following table summarizes the performance of several widely used coupling reagents for the incorporation of Fmoc-Ser(tBu)-OH.
| Coupling Reagent/Additive | Reagent Type | Coupling Efficiency/Purity | Racemization Potential | Key Advantages | Potential Disadvantages |
| HATU | Uronium/Aminium Salt | Very High | Low to Moderate | High reactivity, very effective for hindered amino acids. | Higher cost, potential for guanidinylation of the N-terminus if used in excess. |
| HBTU | Uronium/Aminium Salt | High | Low to Moderate | Good balance of reactivity and cost, widely used. | Can be less effective than HATU for highly challenging couplings. |
| HCTU | Uronium/Aminium Salt | Very High | Low | More reactive than HBTU, effective for difficult couplings. | Higher cost. |
| PyBOP | Phosphonium Salt | High | Low | Good for sterically demanding couplings, byproducts are generally not problematic. | Can be less effective than aminium salts for highly challenging couplings. |
| DIC/Oxyma | Carbodiimide/Additive | Good to High | Very Low | Excellent racemization suppression, cost-effective. | Slower reaction rates compared to uronium/phosphonium reagents. |
| DIC/HOBt | Carbodiimide/Additive | Good | Low | Cost-effective, widely used. | Slower reaction rates, potential for N-acylurea formation. |
Quantitative Racemization Data
Racemization is a critical concern when coupling Fmoc-Ser(tBu)-OH. The choice of coupling reagent and base plays a significant role in maintaining the stereochemical integrity of the amino acid. A study comparing various coupling reagents for the reaction of Fmoc-L-Ser(tBu)-OH with L-Leu-OtBu provides valuable quantitative data on the formation of the D-Ser isomer.[1][2]
| Coupling Reagent/Additive | Base | Temperature (°C) | % D-Serine Formed |
| DIC/Oxyma | DIPEA | Room Temp. | 0.5 |
| EDCI/HOBt | DIPEA | Room Temp. | 1.5 |
| DIC/HOBt | DIPEA | Room Temp. | 1.8[1] |
| HATU | DIPEA | Room Temp. | 2.1 |
| HBTU | DIPEA | Room Temp. | 2.3 |
| PyBop | DIPEA | Room Temp. | 2.5 |
Note: The data presented is from a specific study and may vary depending on the exact reaction conditions, peptide sequence, and analytical method used.
Experimental Protocols
Detailed methodologies are crucial for reproducing and comparing experimental outcomes. Below are generalized protocols for the manual coupling of Fmoc-Ser(tBu)-OH using different classes of coupling reagents in SPPS. These protocols are intended as a starting point and may require optimization based on the specific peptide sequence and resin.
General Deprotection Step (Prior to each coupling)
-
Treat the resin-bound peptide with a 20% solution of piperidine in N,N-dimethylformamide (DMF) for 5-10 minutes.
-
Drain the solution.
-
Repeat the treatment with 20% piperidine in DMF for another 15-20 minutes.
-
Wash the resin thoroughly with DMF (5-7 times) to remove residual piperidine.
Protocol 1: Coupling with Uronium/Aminium Salt Reagents (e.g., HATU, HBTU, HCTU)
-
Amino Acid Activation (Pre-activation): In a separate vessel, dissolve Fmoc-Ser(tBu)-OH (3-5 equivalents relative to the resin loading) and the uronium/aminium salt reagent (2.9-4.9 equivalents) in DMF. Add a tertiary amine base such as N,N-diisopropylethylamine (DIPEA) or collidine (6-10 equivalents) and allow the mixture to pre-activate for 2-5 minutes.[3][4]
-
Coupling Reaction: Add the pre-activated amino acid solution to the deprotected peptide-resin.
-
Incubation: Agitate the reaction mixture at room temperature for 20-60 minutes.
-
Monitoring: Monitor the completion of the coupling reaction using a qualitative method like the Kaiser test. A negative result (beads remain colorless or yellowish) indicates a complete reaction.
-
Washing: Upon completion, drain the coupling solution and wash the resin extensively with DMF (5-7 times) and dichloromethane (DCM) (3 times).
Protocol 2: Coupling with Phosphonium Salt Reagents (e.g., PyBOP)
-
Reagent Preparation: In a separate vessel, dissolve Fmoc-Ser(tBu)-OH (3-5 equivalents) and PyBOP (2.9-4.9 equivalents) in DMF.
-
Coupling Reaction: Add the amino acid/PyBOP solution to the deprotected peptide-resin, followed by the addition of a tertiary amine base (e.g., DIPEA, 6-10 equivalents).
-
Incubation: Agitate the reaction mixture at room temperature for 30-90 minutes.
-
Monitoring: Perform a Kaiser test to monitor the reaction progress.
-
Washing: Once the reaction is complete, drain the coupling solution and wash the resin thoroughly with DMF (5-7 times) and DCM (3 times).
Protocol 3: Coupling with Carbodiimide/Additive Combination (e.g., DIC/Oxyma or DIC/HOBt)
-
Reagent Preparation: In a separate vessel, dissolve Fmoc-Ser(tBu)-OH (3-5 equivalents) and the additive (Oxyma or HOBt, 3-5 equivalents) in a minimal amount of DMF.[1]
-
Coupling Reaction: Add the dissolved amino acid and additive solution to the deprotected peptide-resin. Then, add Diisopropylcarbodiimide (DIC) (3-5 equivalents) to the reaction vessel.
-
Incubation: Agitate the reaction mixture at room temperature for 60-120 minutes.
-
Monitoring: Perform a Kaiser test to monitor the reaction progress.
-
Washing: Once the reaction is complete, drain the coupling solution and wash the resin thoroughly with DMF (5-7 times) and DCM (3 times).
Visualizing the SPPS Coupling Workflow
The following diagrams illustrate the general workflow of a solid-phase peptide synthesis coupling cycle and the decision-making process for selecting a suitable coupling reagent.
Conclusion and Recommendations
The selection of an optimal coupling reagent for the incorporation of Fmoc-Ser(tBu)-OH is a critical step in ensuring the successful synthesis of serine-containing peptides. For routine couplings where speed and high efficiency are paramount, uronium/aminium salt-based reagents such as HATU and HCTU are excellent choices. For sequences where the risk of racemization is a primary concern, the use of DIC/Oxyma is highly recommended due to its superior ability to suppress this side reaction. HBTU and PyBOP offer a good balance of performance and cost for many applications. Ultimately, the choice of reagent should be guided by the specific requirements of the peptide sequence, the desired purity, and economic considerations. It is often beneficial to perform small-scale test couplings to determine the optimal conditions for a particularly challenging sequence.
References
A Researcher's Guide to Cross-Validation of Quantitative Proteomics Data with Western Blot
In the fields of molecular biology and drug development, the robust validation of large-scale quantitative proteomics data is paramount. While high-throughput techniques like mass spectrometry provide a broad overview of protein expression changes, orthogonal validation of key findings is crucial for data confidence. Western blotting remains a widely accepted method for confirming the results of quantitative proteomics studies. This guide provides a comparative framework for these two techniques, complete with experimental protocols and data visualization, to aid researchers in designing and interpreting cross-validation experiments.
Data Presentation: A Comparative Analysis
To illustrate the cross-validation process, we will draw upon data from a study by Kani et al. (2012) that investigated protein expression changes in A431 epidermoid carcinoma cells upon treatment with the EGFR inhibitor, gefitinib.[1] The researchers used Stable Isotope Labeling by Amino Acids in Cell Culture (SILAC), a mass spectrometry-based quantitative proteomics technique, and validated a subset of their findings using Western blot.
The following table summarizes the quantitative data for selected proteins that were significantly altered upon a 16-hour treatment with gefitinib, as identified by SILAC proteomics and subsequently validated by Western blot analysis.
| Protein Name | Gene Symbol | SILAC Fold Change (Treated/Control) | Western Blot Result (Treated vs. Control) | Function in EGFR Signaling & Cancer |
| 14-3-3 protein zeta/delta | YWHAZ | 1.8 | Increased | Involved in signal transduction, apoptosis, and cell cycle regulation. |
| Annexin A1 | ANXA1 | 2.1 | Increased | Plays a role in the regulation of cellular growth and in signal transduction pathways. |
| Calpain-1 catalytic subunit | CAPN1 | 1.9 | Increased | A calcium-dependent protease involved in cell motility and apoptosis. |
| Cathepsin D | CTSD | 2.5 | Increased | A lysosomal aspartyl protease implicated in tumor progression and metastasis. |
| Galectin-1 | LGALS1 | 2.2 | Increased | A beta-galactoside-binding protein that modulates cell-cell and cell-matrix interactions. |
| Vimentin | VIM | 1.7 | Increased | An intermediate filament protein involved in cell migration and adhesion. |
Note: The SILAC fold changes are derived from the supplementary data of Kani et al., 2012. The Western blot results are a qualitative interpretation of the immunoblot images presented in the publication, confirming the direction of change observed in the proteomics data.
Experimental Protocols
Detailed and consistent methodologies are critical for both quantitative proteomics and Western blot to ensure data accuracy and reproducibility. The following protocols are based on the methods described by Kani et al., 2012.[1][2]
Quantitative Proteomics: SILAC and Mass Spectrometry
1. Cell Culture and SILAC Labeling:
-
A431 cells were cultured in DMEM. For SILAC labeling, cells were grown in DMEM lacking lysine, supplemented with either "light" (normal isotopic abundance) or "heavy" (¹³C₆) L-lysine, and 10% dialyzed fetal bovine serum for at least five cell doublings to ensure complete incorporation of the labeled amino acid.
2. Gefitinib Treatment and Sample Preparation:
-
Cells grown in "heavy" lysine-containing medium were treated with 100 nmol/L gefitinib for 16 hours. Control cells were grown in "light" lysine-containing medium.
-
After treatment, cells were harvested, and equal numbers of cells from the "heavy" (treated) and "light" (control) populations were combined.
3. Protein Lysis and Digestion:
-
The combined cell pellet was lysed in a buffer containing 8 M urea, 50 mM Tris-HCl (pH 8.0), and protease and phosphatase inhibitors.
-
Protein concentration was determined, and proteins were reduced with DTT and alkylated with iodoacetamide.
-
Proteins were digested overnight with trypsin.
4. Mass Spectrometry Analysis:
-
The resulting peptide mixture was analyzed by liquid chromatography-tandem mass spectrometry (LC-MS/MS).
-
Data was acquired on a high-resolution mass spectrometer, such as an Orbitrap.
5. Data Analysis:
-
The raw mass spectrometry data was processed using software capable of identifying peptides and quantifying the relative abundance of "heavy" and "light" labeled peptides.[3][4] The ratio of the intensities of the heavy to light peptide pairs corresponds to the fold change in protein abundance between the treated and control samples.
Western Blot Validation
1. Cell Culture and Treatment:
-
A431 cells were cultured in standard DMEM with 10% FBS.
-
Cells were treated with 100 nmol/L gefitinib for 16 hours. Control cells were left untreated.
2. Protein Lysis and Quantification:
-
Cells were washed with ice-cold PBS and lysed in RIPA buffer (50 mM Tris-HCl, pH 8.0, 150 mM NaCl, 1% NP-40, 0.5% sodium deoxycholate, 0.1% SDS) supplemented with protease and phosphatase inhibitors.
-
Cell lysates were centrifuged to pellet cell debris, and the supernatant containing the protein extract was collected.
-
Protein concentration was determined using a BCA protein assay.
3. SDS-PAGE and Protein Transfer:
-
Equal amounts of protein from treated and control samples were mixed with Laemmli sample buffer, boiled, and loaded onto a polyacrylamide gel.
-
Proteins were separated by size using sodium dodecyl sulfate-polyacrylamide gel electrophoresis (SDS-PAGE).
-
The separated proteins were then transferred from the gel to a nitrocellulose or PVDF membrane.
4. Immunoblotting:
-
The membrane was blocked for 1 hour at room temperature in a blocking buffer (e.g., 5% non-fat dry milk or BSA in Tris-buffered saline with 0.1% Tween 20 - TBST) to prevent non-specific antibody binding.
-
The membrane was incubated with a primary antibody specific to the protein of interest overnight at 4°C with gentle agitation.
-
The membrane was washed three times with TBST.
-
The membrane was then incubated with a horseradish peroxidase (HRP)-conjugated secondary antibody for 1 hour at room temperature.
-
After another series of washes with TBST, the protein bands were visualized using an enhanced chemiluminescence (ECL) substrate and an imaging system.
Mandatory Visualization
Signaling Pathway Diagram
Caption: EGFR signaling pathway with validated proteins highlighted.
Experimental Workflow Diagram
Caption: Cross-validation workflow for proteomics and Western blot.
References
- 1. SILAC: Principles, Workflow & Applications in Proteomics - Creative Proteomics Blog [creative-proteomics.com]
- 2. s3-eu-west-1.amazonaws.com [s3-eu-west-1.amazonaws.com]
- 3. Benchmarking SILAC Proteomics Workflows and Data Analysis Platforms - PMC [pmc.ncbi.nlm.nih.gov]
- 4. info.gbiosciences.com [info.gbiosciences.com]
Assessing the Impact of 15N Labeling on Protein Function: A Comparative Guide
For researchers, scientists, and drug development professionals, stable isotope labeling is an indispensable tool for elucidating protein structure, dynamics, and function. Nitrogen-15 (¹⁵N) labeling, in particular, is a cornerstone technique for nuclear magnetic resonance (NMR) spectroscopy and mass spectrometry (MS)-based quantitative proteomics. A critical consideration for the accurate interpretation of experimental data is the assumption that isotopic labeling does not perturb the biological system. This guide provides a comprehensive comparison of ¹⁵N-labeled and unlabeled proteins, focusing on structural integrity and functional activity, and is supported by experimental data and detailed protocols for assessing these parameters.
Introduction to ¹⁵N Labeling and the Concept of Isotope Effects
Nitrogen-15 is a stable, non-radioactive isotope of nitrogen. Replacing the naturally abundant ¹⁴N with ¹⁵N in a protein allows researchers to track and differentiate molecules using analytical techniques like NMR and MS.[1] While generally considered a benign modification, the introduction of a heavier isotope can, in some instances, lead to "kinetic isotope effects" (KIEs). This phenomenon arises from the change in mass, which can affect the vibrational frequencies of chemical bonds and, consequently, the rate of chemical reactions.[2]
The prevailing view in the field is that the kinetic isotope effect for ¹⁵N is negligible for most enzymatic reactions.[3] However, some studies on "heavy enzymes," which are labeled with multiple heavy isotopes (e.g., ¹³C, ²H, and ¹⁵N), have reported measurable effects on enzyme kinetics, suggesting that protein dynamics can be subtly influenced.[4] These effects appear to be system-dependent and are not universally observed.[4]
Structural and Functional Comparison: ¹⁵N-Labeled vs. Unlabeled Proteins
Impact on Protein Structure
The three-dimensional structure of a protein is paramount to its function. Any significant alteration due to isotopic labeling would be a major concern. Techniques such as Circular Dichroism (CD) spectroscopy, which assesses the secondary structure of proteins, are invaluable for comparing labeled and unlabeled proteins.
A study on human Dihydrofolate Reductase (HsDHFR) provides a direct comparison. The CD spectra of the unlabeled ("light") enzyme and the isotopically labeled ("heavy") enzyme were found to be indistinguishable, indicating that the secondary structure was not altered by the isotopic substitution.[4]
| Secondary Structure Element | Unlabeled Protein (% Content) | ¹⁵N-Labeled Protein (% Content) | Expected Impact of ¹⁵N Labeling |
| α-Helix | Varies by protein | Expected to be highly similar | Negligible[3] |
| β-Sheet | Varies by protein | Expected to be highly similar | Negligible[3] |
| Random Coil | Varies by protein | Expected to be highly similar | Negligible[3] |
| Table 1: Comparison of Secondary Structure Content Determined by Circular Dichroism. This table presents the expected similarity in secondary structure between unlabeled and ¹⁵N-labeled proteins based on available literature. |
Impact on Protein Stability
Protein stability, often measured by its melting temperature (Tm), is another critical parameter. The Thermal Shift Assay (TSA), or Differential Scanning Fluorimetry (DSF), is a high-throughput method to assess protein stability. While direct comparative studies on a wide range of ¹⁵N-labeled proteins are not abundant, the extensive use of labeled proteins in structural and functional studies suggests no widespread, significant destabilization occurs.
| Stability Parameter | Unlabeled Protein | ¹⁵N-Labeled Protein | Expected Impact of ¹⁵N Labeling |
| Melting Temperature (Tm) | Varies by protein and buffer conditions | Expected to be highly similar | Negligible |
| Table 2: Comparison of Thermal Stability. This table illustrates the anticipated similarity in melting temperature between unlabeled and ¹⁵N-labeled proteins. |
Impact on Protein Function
For enzymes and binding proteins, functional equivalence between labeled and unlabeled forms is crucial. Key parameters include enzyme kinetic constants (Km and kcat) and binding affinities (Kd).
A study on human Dihydrofolate Reductase (HsDHFR) provides quantitative insight. At a physiological temperature of 20°C, the steady-state kinetic parameters for the unlabeled enzyme and a "heavy" enzyme (labeled with ¹³C, ¹⁵N, and ²H) were found to be identical within the margin of experimental error.[4] It is important to note that while this study provides strong evidence, the "heavy" enzyme included other isotopes in addition to ¹⁵N.
| Functional Parameter | Unlabeled Protein | ¹⁵N-Labeled Protein | Expected Impact of ¹⁵N Labeling |
| Michaelis Constant (Km) | Varies by enzyme-substrate pair | Expected to be highly similar | Generally considered negligible[3] |
| Catalytic Rate (kcat or Vmax) | Varies by enzyme | Expected to be highly similar | Generally considered negligible[3] |
| Dissociation Constant (Kd) | Varies by binding partners | Expected to be highly similar | Not a common concern[3] |
| Table 3: Comparison of Functional Parameters. This table summarizes the expected functional equivalence between unlabeled and ¹⁵N-labeled proteins based on the general consensus and available data. |
Experimental Protocols
To empirically assess the impact of ¹⁵N labeling on a specific protein of interest, the following experimental protocols are recommended.
Protein Expression and Labeling
A common method for producing ¹⁵N-labeled protein is through expression in E. coli grown in M9 minimal media.
Protocol for ¹⁵N Labeling in E. coli
-
Prepare M9 Minimal Media: Prepare a sterile M9 salt solution. Separately prepare sterile solutions of 20% glucose, 1 M MgSO₄, 1 M CaCl₂, and a ¹⁵N-labeled nitrogen source, typically ¹⁵NH₄Cl (1 g/L).
-
Starter Culture: Inoculate a small volume of LB media with a single colony of E. coli transformed with the expression plasmid for the protein of interest. Grow overnight at 37°C with shaking.
-
Adaptation to Minimal Media: The next day, inoculate a larger volume of M9 minimal media (containing standard ¹⁴NH₄Cl) with the overnight culture. Grow until the OD₆₀₀ reaches 0.6-0.8.
-
Expression Culture: Pellet the adapted cells by centrifugation and resuspend them in fresh M9 minimal media where the sole nitrogen source is ¹⁵NH₄Cl.
-
Induction: Grow the culture at the optimal temperature for your protein until the OD₆₀₀ reaches 0.6-0.8. Induce protein expression with an appropriate inducer (e.g., IPTG).
-
Harvesting and Purification: After the desired expression time, harvest the cells by centrifugation. Purify the ¹⁵N-labeled protein using the same protocol as for the unlabeled protein.
Circular Dichroism (CD) Spectroscopy
CD spectroscopy is used to assess the secondary structure of the protein.
Protocol for CD Spectroscopy
-
Sample Preparation: Prepare samples of both unlabeled and ¹⁵N-labeled protein at a concentration of 0.1-0.2 mg/mL in a suitable buffer (e.g., 10 mM sodium phosphate, pH 7.4). The buffer must be transparent in the far-UV region.[5][6]
-
Instrument Setup: Use a CD spectropolarimeter. Set the wavelength range to 190-260 nm for far-UV CD.[7]
-
Data Acquisition: Record the CD spectra for the buffer alone (baseline), the unlabeled protein, and the ¹⁵N-labeled protein.
-
Data Processing: Subtract the buffer baseline from the protein spectra. Convert the raw data (millidegrees) to molar ellipticity.[7]
-
Analysis: Compare the spectra of the labeled and unlabeled proteins. Deconvolution algorithms can be used to estimate the percentage of α-helix, β-sheet, and random coil.[4][7]
Thermal Shift Assay (TSA)
TSA is used to determine the melting temperature (Tm) of the protein, a measure of its thermal stability.
Protocol for Thermal Shift Assay
-
Reagent Preparation: Prepare a working solution of your protein (unlabeled and ¹⁵N-labeled separately) at approximately 2-5 µM in a suitable buffer. Prepare a stock solution of a fluorescent dye that binds to hydrophobic regions of unfolded proteins (e.g., SYPRO Orange).[8][9]
-
Assay Setup: In a 96-well PCR plate, mix the protein solution with the dye. Include a no-protein control.[10]
-
Thermal Denaturation: Place the plate in a real-time PCR instrument. Program a temperature ramp from 25°C to 95°C with a ramp rate of 1°C/minute.[8]
-
Data Acquisition: Monitor the fluorescence intensity at each temperature increment.
-
Data Analysis: Plot fluorescence intensity versus temperature. The melting temperature (Tm) is the midpoint of the unfolding transition, which can be determined from the peak of the first derivative of the melting curve.[8]
Enzyme Kinetics Assay (Spectrophotometric)
This protocol is for determining the Michaelis-Menten constant (Km) and maximum reaction velocity (Vmax).
Protocol for Spectrophotometric Enzyme Kinetics Assay
-
Assay Setup: Prepare a series of reaction mixtures with varying substrate concentrations. Each mixture should contain a constant concentration of the enzyme (either unlabeled or ¹⁵N-labeled) in an appropriate assay buffer.
-
Initiate Reaction: Start the reaction by adding the enzyme to the substrate solutions.[11]
-
Monitor Reaction Progress: Use a spectrophotometer to monitor the change in absorbance over time at a wavelength where either the substrate is consumed or the product is formed.[12][13]
-
Determine Initial Velocities: For each substrate concentration, calculate the initial reaction velocity (v₀) from the linear portion of the absorbance vs. time plot.
-
Data Analysis: Plot the initial velocities against the corresponding substrate concentrations. Fit the data to the Michaelis-Menten equation to determine the Km and Vmax values. Compare the kinetic parameters obtained for the unlabeled and ¹⁵N-labeled enzyme.
Conclusion
The incorporation of ¹⁵N for isotopic labeling is a powerful and widely used technique in protein science. While the potential for "heavy enzyme" isotope effects exists, the current body of evidence and the widespread success of this method suggest that for most proteins, ¹⁵N labeling has a negligible impact on their structure, stability, and function. However, for systems where subtle changes in protein dynamics may be critical, or when unexpected results arise, it is prudent for researchers to perform the comparative assessments outlined in this guide to validate the assumption of functional equivalence. By employing these straightforward biophysical and biochemical assays, researchers can ensure the robustness and accuracy of their findings.
References
- 1. M-CSA Mechanism and Catalytic Site Atlas [ebi.ac.uk]
- 2. Dihydrofolate reductase - Wikipedia [en.wikipedia.org]
- 3. Cryo‐kinetics Reveal Dynamic Effects on the Chemistry of Human Dihydrofolate Reductase - PMC [pmc.ncbi.nlm.nih.gov]
- 4. pubs.acs.org [pubs.acs.org]
- 5. Kinetic and Structural Characterization of Dihydrofolate Reductase from Streptococcus pneumoniae - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Protein conformational dynamics in the mechanism of HIV-1 protease catalysis - PMC [pmc.ncbi.nlm.nih.gov]
- 7. The denatured state of HIV‐1 protease under native conditions - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Top-Down Structural Characterization of Native Ubiquitin Combining Solution Stable Isotope Labelling, Trapped Ion Mobility Spectrometry and Tandem Electron Capture Dissociation Mass Spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Catalytic efficiency and vitality of HIV-1 proteases from African viral subtypes - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Affinity labeling of calmodulin-binding proteins in skeletal muscle sarcoplasmic reticulum - PubMed [pubmed.ncbi.nlm.nih.gov]
- 11. pubs.acs.org [pubs.acs.org]
- 12. pubs.acs.org [pubs.acs.org]
- 13. ubpbio.com [ubpbio.com]
A Head-to-Head Comparison: Metabolic Labeling vs. In Vitro Isotopic Labeling for Quantitative Proteomics
For researchers, scientists, and drug development professionals navigating the complex landscape of quantitative proteomics, the choice of labeling strategy is a critical decision that profoundly impacts experimental outcomes. This guide provides an objective comparison of two cornerstone methodologies: metabolic labeling and in vitro isotopic labeling. By delving into their principles, performance, and protocols, we aim to equip you with the knowledge to select the optimal approach for your research needs.
Metabolic labeling, exemplified by Stable Isotope Labeling by Amino Acids in Cell Culture (SILAC), integrates isotopic labels into proteins in vivo during cell growth. In contrast, in vitro isotopic labeling chemically attaches tags to proteins or peptides after extraction. This fundamental difference dictates their respective strengths and weaknesses, influencing factors such as accuracy, sample compatibility, and experimental workflow.
Quantitative Performance: A Data-Driven Comparison
The choice between metabolic and in vitro labeling often hinges on the desired level of quantitative accuracy and the nature of the biological sample. Metabolic labeling is widely regarded for its high precision, as samples are combined at the cellular level, minimizing downstream handling errors.[1][2] In vitro methods, such as dimethyl labeling and iTRAQ, offer greater flexibility for analyzing tissues and clinical samples where metabolic labeling is not feasible.[1][3]
| Feature | Metabolic Labeling (SILAC) | In Vitro Isotopic Labeling (Dimethyl Labeling) | In Vitro Isotopic Labeling (iTRAQ/TMT) |
| Point of Sample Mixing | Before cell lysis (at the cellular level)[1] | After protein/peptide extraction and digestion[1] | After protein/peptide extraction and digestion[4] |
| Reproducibility | Higher[1][3][5] | Lower than SILAC[1][3][5] | High, but susceptible to co-isolation interference[3] |
| Accuracy | Very high[6][7] | Comparable to SILAC[1][3] | High, but can be compromised by ratio compression[3] |
| Quantitative Dynamic Range | 1-2 orders of magnitude[8] | Comparable to SILAC[1][3] | ~2 orders of magnitude |
| Proteome Coverage | High[6] | Can be lower than SILAC (~20-23% fewer peptide IDs)[1][3] | High |
| Sample Compatibility | Proliferating cells in culture[1][9] | Cells, tissues, clinical samples[1][3] | Cells, tissues, clinical samples[4] |
| Multiplexing Capability | Up to 5-plex (can be combined)[6] | Up to 3-plex[10] | 4-plex, 8-plex, and higher[4] |
Experimental Workflows: Visualizing the Methodologies
The distinct workflows of metabolic and in vitro labeling are central to understanding their practical application.
Metabolic Labeling (SILAC) Workflow
In Vitro Isotopic Labeling Workflow
Key Experimental Protocols
Below are detailed methodologies for hallmark experiments using both metabolic and in vitro labeling techniques.
Metabolic Labeling: SILAC Protocol for Quantitative Proteomics
This protocol outlines the key steps for a typical SILAC experiment.
-
Cell Culture and Labeling:
-
Culture two populations of cells in parallel. One population is grown in "light" medium containing normal amino acids (e.g., L-arginine and L-lysine), while the other is grown in "heavy" medium containing stable isotope-labeled amino acids (e.g., 13C6-L-arginine and 13C6,15N2-L-lysine).[11]
-
Cells should be cultured for at least five passages to ensure complete incorporation of the labeled amino acids.[12]
-
-
Experimental Treatment:
-
Once labeling is complete, apply the experimental treatment to one cell population while the other serves as a control.
-
-
Cell Harvesting and Lysis:
-
Harvest both cell populations and combine them in a 1:1 ratio based on cell number or protein concentration.[11]
-
Lyse the combined cell pellet using a suitable lysis buffer containing protease and phosphatase inhibitors.
-
-
Protein Digestion:
-
LC-MS/MS Analysis:
-
Analyze the resulting peptide mixture by liquid chromatography-tandem mass spectrometry (LC-MS/MS).
-
-
Data Analysis:
-
Utilize specialized software (e.g., MaxQuant) to identify peptides and quantify the relative abundance of proteins by comparing the signal intensities of the "light" and "heavy" peptide pairs.[6]
-
In Vitro Isotopic Labeling: Dimethyl Labeling Protocol
This protocol details the steps for stable isotope dimethyl labeling of peptides.
-
Protein Extraction and Digestion:
-
Extract proteins from the samples of interest (e.g., cells or tissues).
-
Quantify the protein concentration in each sample.
-
Reduce, alkylate, and digest the proteins into peptides using trypsin.
-
-
Peptide Labeling:
-
For each sample, label the peptides with either "light" (CH2O) or "heavy" (CD2O or 13CD2O) formaldehyde in the presence of a reducing agent (sodium cyanoborohydride).[1][3] This reaction specifically labels the N-terminus of peptides and the ε-amino group of lysine residues.
-
The labeling can be performed in-solution or on-column using a StageTip.[1][3]
-
-
Sample Combination and Cleanup:
-
Combine the "light" and "heavy" labeled peptide samples in a 1:1 ratio.
-
Desalt the combined peptide mixture using a C18 StageTip or equivalent.[1]
-
-
LC-MS/MS Analysis:
-
Analyze the labeled peptide mixture by LC-MS/MS.
-
-
Data Analysis:
-
Identify peptides and quantify their relative abundance by comparing the signal intensities of the "light" and "heavy" peptide pairs in the mass spectra.
-
Application in Signaling Pathway Analysis: Protein Turnover
Both labeling strategies can be employed to study protein dynamics, such as protein turnover. The following diagram illustrates a typical workflow for a pulse-SILAC experiment to measure protein synthesis rates.
Pulse-SILAC Workflow
References
- 1. Comparing SILAC- and Stable Isotope Dimethyl-Labeling Approaches for Quantitative Proteomics - PMC [pmc.ncbi.nlm.nih.gov]
- 2. biocev.lf1.cuni.cz [biocev.lf1.cuni.cz]
- 3. pubs.acs.org [pubs.acs.org]
- 4. iTRAQ-based Proteomics Analysis - Creative Proteomics [creative-proteomics.com]
- 5. Benchmarking stable isotope labeling based quantitative proteomics. | Semantic Scholar [semanticscholar.org]
- 6. info.gbiosciences.com [info.gbiosciences.com]
- 7. SILAC/Dimethyl Quantitative Proteomics Analysis | Baitai Paike Biotechnology [en.biotech-pack.com]
- 8. Benchmarking SILAC Proteomics Workflows and Data Analysis Platforms - PMC [pmc.ncbi.nlm.nih.gov]
- 9. SILAC: Principles, Workflow & Applications in Proteomics - Creative Proteomics Blog [creative-proteomics.com]
- 10. researchgate.net [researchgate.net]
- 11. Quantitative Comparison of Proteomes Using SILAC - PMC [pmc.ncbi.nlm.nih.gov]
- 12. SILAC Protocol for Global Phosphoproteomics Analysis - Creative Proteomics [creative-proteomics.com]
A Comparative Guide to the Applications of Fmoc-Ser-OH-15N in Peptide-Based Research
For Researchers, Scientists, and Drug Development Professionals
The site-specific incorporation of stable isotopes into peptides is a cornerstone of modern biomedical research, providing invaluable insights into protein structure, function, and dynamics. Fmoc-Ser-OH-15N, a serine derivative with a Nitrogen-15 (¹⁵N) isotope at the alpha-amino group, is a key reagent in this field. This guide offers an objective comparison of this compound with its alternatives, supported by experimental data and detailed protocols for its primary applications in solid-phase peptide synthesis (SPPS), nuclear magnetic resonance (NMR) spectroscopy, and mass spectrometry (MS).
Performance Comparison: this compound and Its Alternatives
The choice of isotopic labeling strategy is dictated by the intended downstream application. While this compound is a powerful tool, alternatives such as ¹³C-labeled or dual-labeled (¹³C/¹⁵N) amino acids, as well as label-free approaches, offer distinct advantages for specific experimental goals.
The incorporation of a stable isotope like ¹⁵N is generally considered to have a minimal impact on the chemical reactivity of the amino acid during peptide synthesis.[1] Consequently, the performance of this compound in terms of coupling efficiency and the purity of the final peptide is expected to be comparable to its unlabeled counterpart under identical synthesis conditions.[2] The primary differences arise in the analytical capabilities the isotopic label imparts to the resulting peptide.
For serine residues, a common alternative in SPPS is the side-chain protected Fmoc-Ser(tBu)-OH. The tert-butyl (tBu) group prevents side reactions at the hydroxyl group and is readily removed during the final acid cleavage step.[3][4] For sequences prone to aggregation, Fmoc-Ser(Trt)-OH can be a superior, albeit more expensive, alternative due to the bulky trityl (Trt) group that disrupts interchain hydrogen bonding.[5]
Table 1: Comparison of Isotopic Labeling Strategies for Peptide-Based Research
| Feature | This compound | Fmoc-Ser-OH-13C | Dual (¹³C/¹⁵N) Labeling | Label-Free Quantification |
| Primary Application | NMR Structural Biology, Quantitative Proteomics (MS) | Metabolic Flux Analysis, Quantitative Proteomics (MS) | Advanced NMR, High-Precision Quantitative Proteomics (MS) | Large-Scale Proteome Profiling |
| Mass Shift in MS | +1 Da per nitrogen atom[1] | +1 Da per carbon atom | Larger, variable mass shift | N/A |
| NMR Spectroscopy | Enables ¹H-¹⁵N correlation experiments (e.g., HSQC) for backbone assignment and dynamics.[6] | Enables ¹³C-detection experiments for side-chain and backbone analysis. | Enables advanced multi-dimensional experiments for detailed structural elucidation.[] | Not directly applicable for structural studies. |
| Quantitative Proteomics (MS) | Good for relative quantification; simpler mass increment pattern.[] | Provides larger mass shifts, enhancing specificity.[] | Maximizes mass shift for highest quantification accuracy (e.g., SILAC).[] | Cost-effective for large sample sets; lower precision and accuracy.[8] |
| Natural Abundance | ~0.37%[] | ~1.1%[] | N/A | N/A |
| Background Signal in MS | Lower natural abundance provides a cleaner background.[] | Higher natural abundance can create more complex isotopic envelopes.[] | N/A | Subject to complex sample matrix effects. |
Experimental Protocols
Detailed methodologies are crucial for the successful application of this compound in research. Below are generalized protocols for its use in SPPS and subsequent analysis by NMR and MS.
Protocol 1: Solid-Phase Peptide Synthesis (SPPS) using this compound
This protocol outlines the manual synthesis of a peptide with a site-specifically incorporated ¹⁵N-labeled serine residue.
1. Resin Preparation:
-
Swell the appropriate resin (e.g., Rink Amide resin for C-terminal amides or Wang resin for C-terminal acids) in N,N-dimethylformamide (DMF) for 30-60 minutes in a peptide synthesis vessel.[9][10]
2. Fmoc Deprotection:
-
Drain the DMF and add a solution of 20% piperidine in DMF to the resin.
-
Agitate the mixture for 5-10 minutes at room temperature.[10]
-
Drain the deprotection solution and repeat the treatment with 20% piperidine in DMF for another 5-10 minutes.
-
Thoroughly wash the resin with DMF to remove all traces of piperidine.[10]
3. Amino Acid Coupling (this compound):
-
In a separate vial, dissolve this compound (3-5 equivalents relative to resin loading) and a coupling reagent such as HBTU (3-5 equivalents) in DMF.
-
Add N,N-diisopropylethylamine (DIPEA) (6-10 equivalents) to the amino acid solution to activate it.[10]
-
Immediately add the activated amino acid solution to the deprotected peptide-resin.
-
Agitate the reaction mixture for 1-2 hours at room temperature. Coupling times may be extended for difficult sequences.[9]
-
Drain the coupling solution and wash the resin with DMF.
4. Repeat Synthesis Cycle:
-
Repeat the deprotection (step 2) and coupling (step 3) steps for each subsequent amino acid in the peptide sequence.
5. Final Cleavage and Deprotection:
-
After the final amino acid has been coupled and the N-terminal Fmoc group is removed, wash the resin with dichloromethane (DCM) and dry it.
-
Add a cleavage cocktail (e.g., 95% trifluoroacetic acid (TFA), 2.5% water, 2.5% triisopropylsilane (TIS)) to the resin.[11]
-
Gently agitate the mixture for 2-3 hours at room temperature.[10]
-
Filter the resin and collect the filtrate containing the cleaved peptide.
-
Precipitate the crude peptide by adding the TFA filtrate to cold diethyl ether.
-
Centrifuge to pellet the peptide, wash with cold diethyl ether, and dry under vacuum.[10]
-
Purify the crude peptide by reverse-phase high-performance liquid chromatography (RP-HPLC).
Standard Fmoc Solid-Phase Peptide Synthesis (SPPS) Cycle.
Protocol 2: ¹H-¹⁵N HSQC NMR Spectroscopy of ¹⁵N-Labeled Peptides
The ¹H-¹⁵N Heteronuclear Single Quantum Coherence (HSQC) experiment is a fundamental NMR technique for analyzing ¹⁵N-labeled peptides, providing a unique signal for each backbone amide group.[6]
1. Sample Preparation:
-
Dissolve the lyophilized ¹⁵N-labeled peptide in a suitable NMR buffer (e.g., 20 mM phosphate buffer, pH 6.5) containing 5-10% D₂O for the lock signal.[1]
-
The final peptide concentration should typically be in the range of 0.5 – 1 mM.[1]
2. Data Acquisition:
-
Acquire a 2D ¹H-¹⁵N HSQC spectrum on an NMR spectrometer equipped with a cryoprobe for optimal sensitivity.
-
Typical pulse programs like hsqcetfpf3gp are used.[11]
-
Set the appropriate spectral widths in both the ¹H and ¹⁵N dimensions to cover all expected amide signals.
3. Data Processing and Analysis:
-
Process the raw data using NMR software (e.g., Topspin, NMRPipe). This involves Fourier transformation, phasing, and baseline correction.[12]
-
Analyze the resulting spectrum where each peak corresponds to a specific amide proton-nitrogen pair in the peptide backbone. The spectrum serves as a fingerprint of the peptide's folded state.[6][13]
Workflow for NMR analysis of a ¹⁵N-labeled peptide.
Protocol 3: Quantitative Mass Spectrometry using ¹⁵N-Labeled Peptides
¹⁵N-labeled peptides are excellent internal standards for the accurate quantification of their unlabeled counterparts in complex biological samples.[8]
1. Sample Preparation:
-
Combine a known amount of the purified ¹⁵N-labeled peptide (heavy) with the biological sample containing the unlabeled peptide (light).
-
Perform protein extraction, denaturation, reduction, alkylation, and enzymatic digestion (e.g., with trypsin) of the combined sample.[14]
2. LC-MS/MS Analysis:
-
Analyze the resulting peptide mixture using a high-resolution liquid chromatography-tandem mass spectrometry (LC-MS/MS) system.[15]
-
The mass spectrometer will detect both the light and heavy peptide pairs, which are separated by a mass difference corresponding to the number of nitrogen atoms in the peptide.[15]
3. Data Analysis:
-
Use specialized software (e.g., MaxQuant, Proteome Discoverer) to identify and quantify the peak areas or intensities of the light and heavy peptide pairs.[15]
-
The ratio of the light-to-heavy peptide intensity directly reflects the relative abundance of the target peptide in the experimental sample.[14][16]
Workflow for quantitative MS using a ¹⁵N-labeled peptide.
Conclusion
This compound is a versatile and indispensable tool for researchers in structural biology, proteomics, and drug development. Its primary value lies not in altering the performance of peptide synthesis, but in enabling powerful analytical techniques for the detailed investigation of peptide and protein structure, dynamics, and abundance. While alternatives like ¹³C-labeling and label-free methods have their own merits for specific applications, ¹⁵N-labeling remains the gold standard for a wide range of NMR and MS-based studies. The choice of the appropriate isotopically labeled amino acid should be carefully considered based on the specific research question and the analytical capabilities required.
References
- 1. benchchem.com [benchchem.com]
- 2. Fmoc Solid-Phase Peptide Synthesis | Springer Nature Experiments [experiments.springernature.com]
- 3. peptide.com [peptide.com]
- 4. benchchem.com [benchchem.com]
- 5. benchchem.com [benchchem.com]
- 6. protein-nmr.org.uk [protein-nmr.org.uk]
- 8. benchchem.com [benchchem.com]
- 9. Fmoc Solid Phase Peptide Synthesis: Mechanism and Protocol - Creative Peptides [creative-peptides.com]
- 10. benchchem.com [benchchem.com]
- 11. 1H-15N HSQC | Department of Chemistry and Biochemistry | University of Maryland [chem.umd.edu]
- 12. fbri.vtc.vt.edu [fbri.vtc.vt.edu]
- 13. renafobis.fr [renafobis.fr]
- 14. benchchem.com [benchchem.com]
- 15. benchchem.com [benchchem.com]
- 16. researchgate.net [researchgate.net]
Safety Operating Guide
Proper Disposal of Fmoc-Ser-OH-15N: A Guide for Laboratory Professionals
For researchers and scientists engaged in drug development and other laboratory research, the safe handling and disposal of chemical reagents are paramount for operational integrity and environmental protection. This guide provides detailed, step-by-step procedures for the proper disposal of Fmoc-Ser-OH-15N, a stable isotope-labeled amino acid derivative.
Immediate Safety and Handling
Before initiating any disposal procedures, it is crucial to don the appropriate Personal Protective Equipment (PPE), including chemical safety glasses, gloves, and a laboratory coat. All handling of solid this compound should occur in a well-ventilated area or a chemical fume hood to minimize inhalation risks. Although some safety data sheets (SDS) for similar, non-labeled compounds do not classify them as hazardous, others indicate potential for skin, eye, and respiratory irritation[1][2]. Therefore, a cautious approach is recommended.
The disposal protocol for this compound is determined by the chemical properties of the Fmoc-serine molecule itself. The presence of the stable, non-radioactive 15N isotope does not necessitate any special precautions for radiation safety[3][4].
Quantitative Safety Data
The following table summarizes key safety and hazard information applicable to this compound, based on data for similar Fmoc-protected amino acids.
| Property | Value | Source(s) |
| Chemical Formula | C₁₈H₁₇¹⁵NO₅ | |
| Appearance | White to off-white solid | [5] |
| Storage Temperature | 2-8°C | [1] |
| Potential Hazards | May be harmful if inhaled or swallowed. May cause skin, eye, and respiratory tract irritation. | [6][7][8] |
| GHS Hazard Statements | H315: Causes skin irritation. H319: Causes serious eye irritation. H335: May cause respiratory irritation. (Reported for similar compounds) | [2] |
| First Aid: Skin Contact | Immediately wash the affected area with soap and plenty of water. | [1][7] |
| First Aid: Eye Contact | Flush eyes with water for at least 15 minutes as a precaution. | [1][7] |
Experimental and Disposal Protocols
The disposal procedures outlined below cover solid waste, liquid waste streams typically generated during solid-phase peptide synthesis (SPPS), and contaminated labware.
Spill and Personal Contamination Protocol
-
Skin Contact: Immediately wash the affected area with soap and plenty of water[7].
-
Eye Contact: Flush eyes with water for at least 15 minutes as a precaution[7].
-
Solid Spill: Avoid generating dust. Carefully sweep or scoop the spilled solid material into a designated and labeled hazardous waste container[1][6][7]. Clean the spill area with a damp cloth and dispose of the cloth as hazardous waste.
-
Reporting: Report all spills and exposures to your laboratory supervisor and adhere to your institution's established protocols.
Step-by-Step Disposal Procedures
-
Step 1: Collection Collect any unused or expired solid this compound in its original container or a new, clearly labeled, and sealed container specifically for solid chemical waste[1].
-
Step 2: Segregation Do not mix with other solid wastes unless explicitly permitted by your institution's waste management guidelines[1].
-
Step 3: Storage Store the waste container in a designated, secure area for hazardous waste pickup[1].
-
Step 4: Disposal Arrange for disposal through your institution's environmental health and safety (EHS) office as chemical waste[1].
The primary liquid waste stream from the use of this compound is generated during the Fmoc-deprotection step of SPPS, which commonly uses a solution of a base like piperidine in a solvent such as dimethylformamide (DMF)[9][10][11][12].
-
Step 1: Collection Collect all liquid waste from the synthesis, including reaction filtrates and solvent washes, in a dedicated, properly labeled hazardous waste container[1].
-
Step 2: Labeling The label should clearly indicate the contents, for example, "Hazardous Waste: DMF, Piperidine, Fmoc-byproducts."
-
Step 3: Storage Keep the liquid waste container tightly sealed and stored in a secondary containment tray within a ventilated cabinet or a designated waste accumulation area[1].
-
Step 4: Disposal When the container is approximately 90% full, arrange for pickup and disposal through your institution's EHS office[1].
-
Step 1: Collection All disposable labware (e.g., pipette tips, gloves, weighing paper) contaminated with this compound should be collected in a designated solid hazardous waste container[1].
-
Step 2: Disposal This container should be sealed and disposed of through the institutional EHS office[1].
Disposal Workflow Diagram
The following diagram illustrates the decision-making process for the proper disposal of this compound and its associated waste streams.
References
- 1. benchchem.com [benchchem.com]
- 2. aksci.com [aksci.com]
- 3. benchchem.com [benchchem.com]
- 4. moravek.com [moravek.com]
- 5. medchemexpress.com [medchemexpress.com]
- 6. peptide.com [peptide.com]
- 7. peptide.com [peptide.com]
- 8. peptide.com [peptide.com]
- 9. genscript.com [genscript.com]
- 10. peptide.com [peptide.com]
- 11. mdpi.com [mdpi.com]
- 12. Fmoc Amino Acids for SPPS - AltaBioscience [altabioscience.com]
Featured Recommendations
| Most viewed |


|
|
|---|---|---|
| Most popular with customers |
|
Haftungsausschluss und Informationen zu In-Vitro-Forschungsprodukten
Bitte beachten Sie, dass alle Artikel und Produktinformationen, die auf BenchChem präsentiert werden, ausschließlich zu Informationszwecken bestimmt sind. Die auf BenchChem zum Kauf angebotenen Produkte sind speziell für In-vitro-Studien konzipiert, die außerhalb lebender Organismen durchgeführt werden. In-vitro-Studien, abgeleitet von dem lateinischen Begriff "in Glas", beinhalten Experimente, die in kontrollierten Laborumgebungen unter Verwendung von Zellen oder Geweben durchgeführt werden. Es ist wichtig zu beachten, dass diese Produkte nicht als Arzneimittel oder Medikamente eingestuft sind und keine Zulassung der FDA für die Vorbeugung, Behandlung oder Heilung von medizinischen Zuständen, Beschwerden oder Krankheiten erhalten haben. Wir müssen betonen, dass jede Form der körperlichen Einführung dieser Produkte in Menschen oder Tiere gesetzlich strikt untersagt ist. Es ist unerlässlich, sich an diese Richtlinien zu halten, um die Einhaltung rechtlicher und ethischer Standards in Forschung und Experiment zu gewährleisten.
